Область техники
Настоящее изобретение относится к композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена и к способу ее применения. Более конкретно, настоящее изобретение относится к композиции для регуляции экспрессии, которая включает руководящую нуклеиновую кислоту, способную нацеливаться на область регуляции транскрипции дуплицированного гена и к способу регуляции экспрессии дуплицированного гена путем искусственного изменения и/или модификации области регуляции транскрипции дуплицированного гена с использованием композиции для регуляции экспрессии. Кроме того, настоящее изобретение относится к способу лечения или ослабления заболевания, вызываемого дупликацией гена, с использованием композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена.
Предпосылки создания изобретения
Дубликация гена представляет собой одну из ошибок, происходящих во время рекомбинации генов хромосомы, и феномен репликации, а именно, дупликацию неполной области хромосомы. Дупликация гена представляет собой тип мутации, которая передается следующему поколению. Дупликация гена, вместе с делецией гена, вызываемой отсутствием репликации неполной области хромосомы, влияют на экспрессию гена.
Дубликация гена также вызывает наследственное заболевание. Репрезентативным примером является болезнь Шарко-Мари-Туфа (СМТ) типа 1А, вызываемая дупликацией гена в определенной области хромосомы, и в результате такой дупликации гена происходит сверхэкспрессия гена, участвующего в развитии периферической нервной системы рук и ног, что вызывает порок развития рук и ног.
Так, например, важно, чтобы ген экспрессировался в соответствующем положении и в нужное время, что обеспечивало бы нормальное прохождение биологических процессов, таких как пролиферация клеток, их гибель, старение и дифференцировка. Если ген неправильно экспрессируется в несоответствующее время и в неправильном положении, то в частности, аномальная экспрессия генов, вызываемая дупликацией гена, может приводить к развитию заболевания, а поэтому необходимо понять молекулярный механизм регуляции экспрессии каждого гена и идентифицировать фактор регуляции транскрипции, ассоциированный с каждым геном. Существуют различные факторы регуляции транскрипции, которые позволяют точно регулировать экспрессию гена, например, промотор, дистальный регуляторный элемент и фактор транскрипции, активатор и коактиваторы, участвующие в регуляции экспрессии гена.
Экспрессия гена может регулироваться изменением фактора регуляции транскрипции, и аномальное изменение фактора регуляции транскрипции может приводить к аномальной экспрессии гена, и тем самым, вызывать заболевание. В соответствии с этим, изменение фактора регуляции транскрипции может вызывать различные заболевания, либо ослаблять или устранять заболевания.
Однако современный метод воздействия на фактор регуляции транскрипции позволяет регулировать только временную экспрессию гена, тогда как непрерывная регуляция экспрессии гена представляет определенные трудности. По этой причине, пока не был разработан фундаментальный способ лечения заболевания, вызываемого аномальной экспрессией гена или нарушением экспрессии гена. Следовательно, необходимо разработать способ, который давал бы более стабильный терапевтический эффект посредством редактирования гена или генетической модификации фактора регуляции транскрипции.
Документы предшествующего уровня техники
Непатентный документ
1. Hamdan, H., Kockara, N.T., Jolly, L.A., Haun, S., and Wight, P.A. (2015). Control of human PLP1 expression through transcriptional regulatory elements and alternatively spliced exons in intron 1. ASN Neuro 7.
2. Hamdan, H., Patyal, P., Kockara, N.T., and Wight, P.A. (2018). The wmN1 enhancer region in intron 1 is required for expression of human PLP1. Glia.
3. Meng, F., Zolova, O., Kokorina, N.A., Dobretsova, A., and Wight, P.A. (2005). Characterization of an intronic enhancer that regulates myelin proteolipid protein (Plp) gene expression in oligodendrocytes. J Neurosci Res 82, 346-356.
4. Tuason, M.C., Rastikerdar, A., Kuhlmann, T., Goujet-Zalc, C., Zalc, B., Dib, S., Friedman, H., and Peterson, A. (2008). Separate proteolipid protein/DM20 enhancers serve different lineages and stages of development. J Neurosci 28, 6895-6903.
5. Wight, P.A. (2017). Effects of Intron 1 Sequences on Human PLP1 Expression: Implications for PLP1-Related Disorders. ASN Neuro 9, 1759091417720583.
Раскрытие изобретения
Техническая проблема
Настоящее изобретение относится к получению композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена, присутствующего в геноме клетки.
Настоящее изобретение также относится к разработке способа регуляции экспрессии дуплицированного гена, присутствующего в геноме эукариотической клетки.
Настоящее изобретение также относится к разработке способа лечения заболевания, ассоциированного с дупликацией гена, с использованием композиции для регуляции экспрессии.
Техническое решение
Для достижения вышеупомянутых целей было разработано настоящее изобретение, которое относится к композиции для регуляции экспрессии, используемой для регуляции экспрессии дуплицированного гена, присутствующего в геноме клетки. Более конкретно, настоящее изобретение относится к композиции для регуляции экспрессии, включающей руководящую нуклеиновую кислоту, способную нацеливаться на область регуляции транскрипции дуплицированного гена, и к способу регуляции экспрессии дуплицированного гена путем искусственного изменения и/или модификации области регуляции транскрипции дуплицированного гена с использованием композиции для регуляции экспрессии. Кроме того, настоящее изобретение относится к композиции для регуляции экспрессии и к способу лечения или ослабления заболевания, вызываемого дупликацией гена, с использованием композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена.
Настоящее изобретение относится к композиции для регуляции экспрессии, используемой для регуляции экспрессии дуплицированного гена, присутствующего в геноме клетки.
В одном из аспектов изобретения, композиция для регуляции экспрессии может включать:
руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, присутствующую в области регуляции транскрипции дуплицированного гена, или нуклеиновую кислоту, кодирующую указанную нуклеиновую кислоту; и
один или более белков-редакторов или нуклеиновую кислоту, кодирующую эти белки. Руководящая нуклеиновая кислота может включать руководящий домен, способный нацеливаться на последовательность-мишень, присутствующую в области регуляции транскрипции дуплицированного гена.
В данном случае, руководящий домен может включать нуклеотидную последовательность, способную образовывать комплементарную связь с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции дуплицированного гена.
В данном случае, руководящий домен может образовывать комплементарную связь с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции дуплицированного гена.
В данном случае, комплементарное связывание может включать 0-5 ошибочных спариваний.
Руководящая нуклеиновая кислота может включать один или более доменов, выбранных из группы, состоящей из первого комплементарного домена, второго комплементарного домена, проксимального домена и хвостового домена.
Белок-редактор может представлять собой фермент CRISPR.
Руководящая нуклеиновая кислота и белок-редактор могут образовывать комплекс «руководящая нуклеиновая кислота - белок-редактор».
В данном случае, комплекс «руководящая нуклеиновая кислота - белок-редактор» может быть образован посредством взаимодействия части нуклеиновой кислоты руководящей нуклеиновой кислоты с частью аминокислотной последовательности белка-редактора.
Область регуляции транскрипции может представлять собой одну или более областей, выбранных из группы, состоящей из промоторной области, энхансерной области, сайленсерной области, области-изолятора и регуляторной области локуса (LCR).
Последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных в области регуляции транскрипции дуплицированного гена.
Последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных в промоторной области дуплицированного гена или рядом с ней.
Последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных в центральной промоторной области дуплицированного гена или рядом с ней.
В данном случае, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую область TATA-бокса в центральной промоторной области дуплицированного гена или непрерывную последовательность из 10-25 нуклеотидов, расположенную рядом с областью TATA-бокса.
В данном случае, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю или часть последовательности 5’-TATA-3’ (SEQ ID NO:261), присутствующей в центральной промоторной области дуплицированного гена.
В данном случае, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю или часть последовательности 5’-TATAWAW-3’ (W=A или T) (SEQ ID NO:262), присутствующей в центральной промоторной области дуплицированного гена.
В данном случае, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю или часть последовательности 5’-TATAWAWR-3’ (W=A или T, R=A или G) (SEQ ID NO:263), присутствующей в центральной промоторной области дуплицированного гена.
В данном случае, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю или часть последовательности, выбранной из группы, состоящей из последовательности 5’-CATAAAA-3’(SEQ ID NO:264), последовательности 5’-TATAA-3’(SEQ ID NO:265), последовательности 5’-TATAAAA-3’(SEQ ID NO:266), последовательности 5’-CATAAATA-3’(SEQ ID NO:267), последовательности 5’-TATATAA-3’(SEQ ID NO:268), последовательности 5’-TATATATATATATAA-3’(SEQ ID NO:269), последовательности 5’-TATATTATA-3’(SEQ ID NO:270), последовательности 5’-TATAAA-3’(SEQ ID NO:271), последовательности 5’-TATAAAATA-3’(SEQ ID NO:272), последовательности 5’-TATATA-3’(SEQ ID NO:273), последовательности 5’-GATTAAAAA-3’(SEQ ID NO:274), последовательности 5’-TATAAAAA-3’(SEQ ID NO:275), последовательности 5’-TTATAA-3’(SEQ ID NO:276), последовательности 5’-TTTTAAAA-3’(SEQ ID NO:277), последовательности 5’-TCTTTAAAA-3’(SEQ ID NO:278), последовательности 5’-GACATTTAA-3’(SEQ ID NO:279), последовательности 5’-TGATATCAA-3’(SEQ ID NO:280), последовательности 5’-TATAAATA-3’(SEQ ID NO:281), последовательности 5’-TATAAGA-3’(SEQ ID NO:282), последовательности 5’-AATAAA-3’(SEQ ID NO:283), последовательности 5’-TTTATA-3’(SEQ ID NO:284), последовательности 5’-CATAAAAA-3’(SEQ ID NO:285), последовательности 5’-TATACA-3’(SEQ ID NO:286), последовательности 5’-TTTAAGA-3’(SEQ ID NO:287), последовательности 5’-GATAAAG-3’(SEQ ID NO:288), последовательности 5’-TATAACA-3’(SEQ ID NO:289), последовательности 5’-TCTTATCTT-3’(SEQ ID NO:290), последовательности 5’-TTGTACTTT-3’(SEQ ID NO:291), последовательности 5’-CATATAA-3’(SEQ ID NO:292), последовательности 5’-TATAAAT-3’(SEQ ID NO:293), последовательности 5’-TATATATAAAAAAAA-3’(SEQ ID NO:294) и последовательности 5’-CATAAATAAAAAAAATTA-3’(SEQ ID NO:295).
В данном случае, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных у 5’-конца или 3’-конца последовательности, выбранной из группы, состоящей из последовательности 5’-TATA-3’(SEQ ID NO:261), последовательности 5’-CATAAAA-3’(SEQ ID NO:264), последовательности 5’-TATAA-3’(SEQ ID NO:265), последовательности 5’-TATAAAA-3’(SEQ ID NO:266), последовательности 5’-CATAAATA-3’(SEQ ID NO:267), последовательности 5’-TATATAA-3’(SEQ ID NO:268), последовательности 5’-TATATATATATATAA-3’(SEQ ID NO:269), последовательности 5’-TATATTATA-3’(SEQ ID NO:270), последовательности 5’-TATAAA-3’(SEQ ID NO:271), последовательности 5’-TATAAAATA-3’(SEQ ID NO:272), последовательности 5’-TATATA-3’(SEQ ID NO:273), последовательности 5’-GATTAAAAA-3’(SEQ ID NO:274), последовательности 5’-TATAAAAA-3’(SEQ ID NO:275), последовательности 5’-TTATAA-3’(SEQ ID NO:276), последовательности 5’-TTTTAAAA-3’(SEQ ID NO:277), последовательности 5’-TCTTTAAAA-3’(SEQ ID NO:278), последовательности 5’-GACATTTAA-3’(SEQ ID NO:279), последовательности 5’-TGATATCAA-3’(SEQ ID NO:280), последовательности 5’-TATAAATA-3’(SEQ ID NO:281), последовательности 5’-TATAAGA-3’(SEQ ID NO:282), последовательности 5’-AATAAA-3’(SEQ ID NO:283), последовательности 5’-TTTATA-3’(SEQ ID NO:284), последовательности 5’-CATAAAAA-3’(SEQ ID NO:285), последовательности 5’-TATACA-3’(SEQ ID NO:286), последовательности 5’-TTTAAGA-3’(SEQ ID NO:287), последовательности 5’-GATAAAG-3’(SEQ ID NO:288), последовательности 5’-TATAACA-3’(SEQ ID NO:289), последовательности 5’-TCTTATCTT-3’(SEQ ID NO:290), последовательности 5’-TTGTACTTT-3’(SEQ ID NO:291), последовательности 5’-CATATAA-3’(SEQ ID NO:292), последовательности 5’-TATAAAT-3’(SEQ ID NO:293), последовательности 5’-TATATATAAAAAAAA-3’(SEQ ID NO:294) и последовательности 5’-CATAAATAAAAAAAATTA-3’(SEQ ID NO:295).
Последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных в энхансерной области дуплицированного гена.
Последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных рядом с энхансерной областью дуплицированного гена.
Последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенных рядом с 5’-концом и/или 3’-концом последовательности PAM (протоспейсер-соседний мотив) в последовательности нуклеиновой кислоты области регуляции транскрипции дуплицированного гена.
В данном случае, последовательность PAM может быть определена в соответствии с ферментом CRISPR.
Фермент CRISPR может представлять собой белок Cas9 или белок Cpf1.
В данном случае, белок Cas9 представлять собой один или более белков Cas9, выбранных из группы, состоящей из белка Cas9, происходящего от Streptococcus pyogenes, белка Cas9, происходящего от Campylobacter jejuni, белка Cas9, происходящего от Streptococcus thermophilus, белка Cas9, происходящего от Staphylococcus aureus, и белка Cas9, происходящего от Neisseria meningitidis.
Дуплицированный ген представляет собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Дуплицированный ген может представлять собой онкоген.
В данном случае, онкоген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Клетка может быть эукариотической клеткой.
Эукариотическая клетка может представлять собой клетку млекопитающего.
Руководящая нуклеиновая кислота и белок-редактор могут присутствовать в одном или более векторах в форме последовательности нуклеиновой кислоты, соответственно.
В данном случае, вектор может представлять собой плазмиду или вирусный вектор.
В данном случае, вирусный вектор может представлять собой один или более вирусных векторов, выбранных из группы, состоящей из ретровируса, лентивируса, аденовируса, аденоассоциированного вируса (AAV), вируса осповакцины, поксвируса и вируса простого герпеса.
Композиция для регуляции экспрессии может включать руководящую нуклеиновую кислоту и белок-редактор в форме комплекса «руководящая нуклеиновая кислота - белок-редактор».
Композиция для регуляции экспрессии может также содержать донор.
Настоящее изобретение относится к способу регуляции экспрессии дуплицированного гена, присутствующего в геноме эукариотической клетки.
В одном аспекте изобретения, способ регуляции экспрессии дуплицированного гена, присутствующего в геноме эукариотической клетки, может включать введение композиции для регуляции экспрессии в эукариотическую клетку.
Композиция для регуляции экспрессии может включать:
руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, присутствующую в области регуляции транскрипции дуплицированного гена, или нуклеиновую кислоту, кодирующую указанную нуклеиновую кислоту; и
один или более белков-редакторов или нуклеиновую кислоту, кодирующую эти белки.
Эукариотическая клетка может представлять собой клетку млекопитающего.
Руководящая нуклеиновая кислота может включать руководящий домен, способный нацеливаться на последовательность-мишень, присутствующую в области регуляции транскрипции дуплицированного гена.
В данном случае, руководящий домен может включать нуклеотидную последовательность, способную образовывать комплементарную связь с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции дуплицированного гена.
В данном случае, руководящий домен может образовывать комплементарную связь с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции дуплицированного гена.
В данном случае, комплементарное связывание может включать 0-5 ошибочных спариваний.
Руководящая нуклеиновая кислота может включать один или более доменов, выбранных из группы, состоящей из первого комплементарного домена, второго комплементарного домена, проксимального домена и хвостового домена.
Белок-редактор может представлять собой фермент CRISPR.
Руководящая нуклеиновая кислота и белок-редактор могут образовывать комплекс «руководящая нуклеиновая кислота - белок-редактор».
В данном случае, комплекс «руководящая нуклеиновая кислота - белок-редактор» может быть образован посредством взаимодействия части нуклеиновой кислоты руководящей нуклеиновой кислоты с частью аминокислотной последовательности белка-редактора.
Композиция для регуляции экспрессии может включать руководящую нуклеиновую кислоту и белок-редактор в форме комплекса «руководящая нуклеиновая кислота - белок-редактор».
Композиция для регуляции экспрессии может включать один или более векторов, в которых руководящая нуклеиновая кислота и белок-редактор включены в форме нуклеиновой кислоты, соответственно.
Введение может быть осуществлено с применением одного или более методов, выбранных из метода электропорации, метода с использованием липосом, плазмид, вирусных векторов, наночастиц и гибридного белка «белок-домен транслокации» (PTD).
Настоящее изобретение относится к способу лечения заболевания, вызываемого дупликацией гена.
В одном аспекте изобретения, способ лечения заболевания, вызываемого дупликацией гена, может включать введение композиции для регуляции экспрессии индивидууму, нуждающемуся в таком лечении.
Композиция для регуляции экспрессии может включать:
руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, присутствующую в области регуляции транскрипции дуплицированного гена, или нуклеиновую кислоту, кодирующую указанную нуклеиновую кислоту; и
один или более белков-редакторов или нуклеиновую кислоту, кодирующую эти белки.
Руководящая нуклеиновая кислота может включать руководящий домен, способный нацеливаться на последовательность-мишень, присутствующую в области регуляции транскрипции дуплицированного гена.
В данном случае, руководящий домен может включать нуклеотидную последовательность, способную образовывать комплементарную связь с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции дуплицированного гена.
В данном случае, руководящий домен может образовывать комплементарную связь с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции дуплицированного гена.
В данном случае, комплементарное связывание может включать 0-5 ошибочных спариваний.
Руководящая нуклеиновая кислота может включать один или более доменов, выбранных из группы, состоящей из первого комплементарного домена, второго комплементарного домена, проксимального домена и хвостового домена.
Белок-редактор может представлять собой фермент CRISPR.
Руководящая нуклеиновая кислота и белок-редактор могут образовывать комплекс «руководящая нуклеиновая кислота - белок-редактор».
В данном случае, комплекс «руководящая нуклеиновая кислота - белок-редактор» может быть образован посредством взаимодействия части нуклеиновой кислоты руководящей нуклеиновой кислоты с частью аминокислотной последовательности белка-редактора.
Заболевание, вызываемое дупликацией гена, может представлять собой болезнь Шарко-Мари-Туфа 1A (CMT1A), болезнь Дежерина-Сотта (DSD), врожденную гипомиелинизирующую невропатию (CHN), синдром Русси-Леви (RLS), болезнь Пелициуса-Мерцбахера (PMD), синдром дупликации MECP2, X-сцепленный гипопитуитаризм (XLHP), синдром Потоцкого-Лупски (PTLS), синдром лицевого велокардита (VCFS), синдром Уильямса-Бейрена (WBS), синдром Аладжилля (AS), синдром замедления роста, преждевременное закрытие черепных швов, аутосомно-доминантную лейкодистрофию (ADLD), болезнь Паркинсона или болезнь Альцгеймера.
Болезнь, вызываемая дупликацией гена, может представлять собой рак, вызываемый дупликацией онкогена.
В данном случае, рак, вызываемый дупликацией онкогена, может представлять собой рак молочной железы, рак шейки матки, рак прямой и ободочной кишки, рак пищевода, рак желудка, глиобластому, рак головы и шеи, гепатоцеллюлярный рак, нейробластому, рак яичника, саркому или мелкоклеточный рак легких.
Индивидуумом, подвергаемым лечению, может быть млекопитающее, включая человека, обезьян, мышей и крыс.
Введение может быть осуществлено путем инъекци, переливания крови, имплантации или трансплантации.
Предпочтительные эффекты
Настоящее изобретение может быть использовано для регуляции экспрессии дуплицированного гена с помощью композиции для регуляции экспрессии. Более конкретно, экспрессия дуплицированного гена может регулироваться посредством искусственной манипуляции и/или модификации области регуляции транскрипции дуплицированного гена с использованием композиции для регуляции экспрессии, включающей руководящую нуклеиновую кислоту, способную нацеливаться на область регуляции транскрипции дуплицированного гена. Заболевание, вызываемое дупликацией гена, может быть также ослаблено или излечено с использованием композиции для регуляции экспрессии, а именно, экспрессии дуплицированного гена.
Описание чертежей
На фиг. 1 представлена серия результатов, иллюстрирующих частоту инсерции-делеции (%) после модификации гена, опосредуемой SpCas9-оцрРНК, и частоту инсерции-делеции каждого (a) TATA-бокса и (b) энхансера, в котором сайт-мишень оцрРНК является разделенным.
На фиг. 2 представлена серия результатов, иллюстрирующих частоту инсерции-делеции (%) после модификации гена, опосредуемой CjCas9-оцрРНК, и частоту инсерции-делеции каждого (a) TATA-бокса и (b) энхансера, в котором сайт-мишень оцрРНК является разделенным.
На фиг. 3 проиллюстрированы эффекты модификации гена с использованием SpCas9-оцрРНК, нацеленной на регуляторные элементы человеческого гена PMP22 в клетках, подобных шванновским клеткам.
На фиг. 4 проиллюстрированы отношения мутаций со сдвигом рамки считывания, индуцированных посредством нацеливания SpCas9-оцрРНК на CDS человеческого PMP22.
На фиг. 5 проиллюстрированы делеции небольшой части человеческого PMP22 после обработки двойными оцрРНК. Последовательность дикого типа, включающая последовательности для Sox10 и Egr2, представляет собой SEQ ID NO:330, а ее мутантная последовательность с делетированной частью представляет собой SEQ ID NO:331. Последовательности-мишени для Enh-Sp5 и Enh-Sp16 представляют собой SEQ ID NO:332 и 333. Кроме того, последовательность дикого типа, включающая ТАТА-боксы, представляет собой SEQ ID NO:334, а ее мутантная последовательность с делетированной частью представляет собой SEQ ID NO:335. Последовательности-мишени для TATA-Sp12 и TATA-Sp14, представляют собой SEQ ID NO:336 и 337.
На фиг. 6 представлен график, иллюстрирующий снижение уровня экспрессии мРНК человеческого PMP22 посредством SpCas9-оцрРНК в человеческих клетках, подобных шванновским клеткам.
На фиг. 7 представлен график, иллюстрирующий эффективное и специфическое снижение уровня экспрессии PMP22 посредством SpCas9-оцрРНК в каждом сайте-мишени человеческого гена PMP22 в человеческих первичных шванновских клетках и (а) проиллюстрированы результаты измерения частоты инсерций-делеций с использованием SpCas9-оцрРНК в каждом сайте-мишени. (b) проиллюстрированы результаты сравнения относительного уровня экспрессии мРНК PMP22, которые были получены с помощью кол.ОТ-ПЦР в отсутствии обработки или при обработке фактором сигнала миелинизации и комплексом RNP для каждого сайта-мишени (n=3, однофакторный ANOVA и post-hoc-критерий Тьюки: *p < 0,05), и (c) проиллюстрированы результаты измерения частоты инсерций-делеций с использованием SpCas9-оцрРНК, нацеленной на дистальные энхансерные сайты (дистальные энхансерные области) B и C.
На фиг. 8 представлен график, иллюстрирующий эффективное и специфическое снижение уровня экспрессии PMP22 посредством CRISPR-Cas9, нацеленной на сайт TATA-бокса человеческого гена PMP22 in vitro, и (а) проиллюстрировано нацеливание на промоторную область последовательности-мишени человеческого гена в положении PMP22 (последовательности части промоторной области представляют собой SEQ ID NO:338 (верхняя цепь) и 339 (нижняя цепь), а на самом крайнем левом графике, на среднем графике и на самом крайнем правом графике в (b) проиллюстрированы результаты измерения частоты инсерций-делеций посредством нацеленного глубокого секвенирования в первичных человеческих шванновских клетках, результаты измерения частоты мутаций TATA-бокса 1 (n=3) из всех частот инсерций-делеций и результаты сравнения относительного уровня экспрессии мРНК PMP22, которые были получены с помощью кол.ОТ-ПЦР в отсутствии обработки или при обработке фактором сигнала миелинизации и комплексом RNP в первичных человеческих шванновских клетках (n=3, однофакторный ANOVA и post-hoc-критерий Тьюки: *p < 0,05), соответственно.
На фиг. 9 проиллюстрирована частота инсерций-делеций в PMP22-TATA RNP в сайтах, не являющихся мишенями, и в сайтах-мишенях после проведения анализа на нежелательную мишень in silico с помощью нацеленного глубокого секвенирования в первичных человеческих шванновских клетках и (а) представлен график, иллюстрирующий частоты инсерций-делеций, (b) проиллюстрированы паттерны инсерций-делеций с высокой частотой (локальная последовательность дикого типа представляет собой SEQ ID NO: 340, а локальные последовательности, включающие indel, представляют собой SEQ ID NO: 341-345(Indel в порядке от -1 до -4)), и (с) показаны сайты, которые не являются мишенями, и которые были обнаружены в анализе на нежелательную мишень in silico (последовательность-мишень представляет собой SEQ ID NO:346, а последовательности, не являющиеся мишенью, представляют собой SEQ ID NO:347-364 (в порядке Off1-Off18)).
На фиг. 10 представлена серия результатов, где показаны сайты, расщепленные посредством PMP22-TATA RNP во всем человеческом геноме, и (а) представлен график Circos по всей ширине генома, (b) проиллюстрированы сайты, которые не являются мишенями, и которые были обнаружены с помощью секвенирования двойного генома среди сайтов, не являющихся мишенями и обнаруженных в анализе на нежелательную мишень in silico, и (с) представлен график, иллюстрирующий частоты инсерций-делеций в сайтах, не являющихся мишенями. В (b) и (с), последовательность-мишень представляет собой SEQ ID NO:346, а последовательности, не являющиеся мишенью, представляют собой SEQ ID NO:365-373 (в порядке Off1-Off9).
На фиг. 11 схематически проиллюстрирован терапевтический метод, проводимый посредством терапии с использованием РНК PMP22-TATA у мышей C22.
На фиг. 12 представлена серия результатов, иллюстрирующих ослабление фенотипа заболевания посредством ингибирования экспрессии PMP22 под действием CRISPR/Cas9 у мышей CMT1A и (а) представлен график, иллюстрирующий частоты инсерций-делеций посредством нацеленного глубокого секвенирования седалищного нерва, обработанного mRosa26 или комплексом PMP22-TATA RNP (n=3), (b) представлены результаты измерения частоты мутаций TATA-бокса 1 (n=3) из всех частот инсерций-делеций, и (с) представлен график для сравнения относительных величин мРНК, экспрессируемой в PMP22, где указанные величины были получены с помощью кол. ОТ-ПЦР седалищного нерва, обработанного mRosa26 или комплексом PMP22-TATA RNP.
На фиг. 13 представлена серия результатов, иллюстрирующих сайты, не являющиеся мишенями, и частоты инсерций-делеций оцрРНК PMP22-TATA в мышином геноме с помощью анализа in silico и (а) проиллюстрированы сайты, не являющиеся мишенями, и (b) представлен график, иллюстрирующий частоту инсерций-делеций в каждом сайте, не являющемся мишенью. В (a) и (b), последовательность-мишень представляет собой SEQ ID NO:346, а последовательности, не являющиеся мишенью, представляют собой SEQ ID NO:374-381 (в порядке Off1-Off8).
На фиг. 14 представлена серия результатов, иллюстрирующих ослабление фенотипа заболевания посредством ингибирования экспрессии PMP22 под действием CRISPR/Cas9 у мышей CMT1A и (а) представлена серия изображений полутонких срезов ткани седалищного нерва, обработанной mRosa26 или комплексом PMP22-TATA RNP, а на верхнем и на нижнем графике в (b) представлен график рассеяния, где показано, что g-отношение увеличивалось у мышей, обработанных PMP22-TATA RNP, и график, где показано, что диаметр миелинизированного аксона увеличивался у мышей, обработанных PMP22-TATA RNP, соответственно.
На фиг. 15 представлена серия результатов, иллюстрирующих электрофизиологические изменения в результате ингибирования экспрессии PMP22 под действием CRISPR/Cas9 у мышей CMT1A и (а) представлен график, иллюстрирующий изменение дистальной латентности (DL), (b) представлен график, иллюстрирующий изменение скорости проводимости двигательного нерва (NCV), и (c) представлен график, иллюстрирующий изменение потенциала действия соединения на мышцу (CMAP) (n=7 для mRosa26 RNP; n=10 для PMP22-TATA).
На фиг. 16 представлена серия результатов анализа на двигательную активность вследствие ингибирования экспрессии PMP22 под действием CRISPR/Cas9 у мышей CMT1A, а на верхнем и нижнем графике в (а) показан результат теста с использованием вращающегося стержня (n=7 для mRosa26 RNP, n=11 для PMP22-TATA) и результат теста с использованием вращающегося стержня, проводимого еженедельно до тех пор, пока возраст мышей не достигал 8-16 недель (n=7 для mRosa26 RNP, n=11 для PMP22-TATA), соответственно, и на верхнем графике и на нижнем изображении в (b) представлен график, иллюстрирующий отношение массы икроножной мышцы/массы тела мыши C22, обработанной mRosa26 или комплексом PMP22-TATA RNP, и серия изображений икроножных мышц мыши C22, обработанной mRosa26 или комплексом PMP22-TATA RNP, соответственно.
На фиг. 17 схематически представлена диаграмма, иллюстрирующая терапевтическую стратегию PMD, где были сконструированы оцрРНК, нацеленная на область TATA-бокса и энхансерную область гена PLP1. В случае оцрРНК, нацеленных на энхансерную область, была применена стратегия удаления энхансера с использованием двух оцрРНК. В данном случае, оцрРНК, нацеленная на область, расположенную выше энхансерной области, была представлена как верхняя, а оцрРНК, нацеленная на область, расположенную ниже энхансерной области, была представлена как нижняя, и эти верхние и нижние оцрРНК также представлены в соответствии с положениями в Таблицах 5 и 6.
На фиг. 18 проиллюстрирована плазмида CjCas9, используемая в репрезентативном варианте.
На фиг. 19 представлена серия графиков, где показаны результаты скрининга на SpCas9-оцрРНК, нацеленные на область TATA-бокса mPlp1. В (a) показана частота инсерций-делеций (%), подтвержденных в клетках NIH-3T3, а в (b) показана частота инсерций-делеций (%), подтвержденных в клетках N20.1. В данном случае, используемые оцрРНК представляют собой оцрРНК, нацеленные на mPlp1-TATA-Sp-01, и различаются номерами, представленными в последовательностях-мишенях на графиках.
На фиг. 20 представлена серия графиков, где показаны результаты скрининга на CjCas9-оцрРНК, нацеленные на область TATA-бокса mPlp1. В (a) показана частота инсерций-делеций (%), подтвержденных в клетках NIH-3T3, а в (b) показана частота инсерций-делеций (%), подтвержденных в клетках N20.1. В данном случае, используемые оцрРНК представляют собой mPlp1-TATA-Cj-01 - mPlp1-TATA-Cj-04, и различаются номерами, представленными в последовательностях-мишенях на графиках.
На фиг. 21 представлена серия графиков, где показаны результаты скрининга на SpCas9-оцрРНК, нацеленные на энхансерную область (энхансер wMN1) mPlp1. В (a) показана частота инсерций-делеций (%), подтвержденных в клетках NIH-3T3, а в (b) показана частота инсерций-делеций (%), подтвержденных в клетках N20.1. В данном случае, используемые оцрРНК представляют собой mPlp1-wMN1-Sp-01 - mPlp1-wMN1-Sp-36, и различаются номерами, представленными в последовательностях-мишенях на графиках.
На фиг. 22 представлена серия графиков, где показаны результаты скрининга на CjCas9-оцрРНК, нацеленные на энхансерную область (энхансер wMN1) mPlp1. В (a) показана частота инсерций-делеций (%), подтвержденных в клетках NIH-3T3, а в (b) показана частота инсерций-делеций (%), подтвержденных в клетках N20.1. В данном случае, используемые оцрРНК представляют собой mPlp1-wMN1-Cj-01 - mPlp1-wMN1-Cj-28 и различаются номерами, представленными в последовательностях-мишенях на графиках.
На фиг. 23 представлена серия графиков, где показаны уровни экспрессии мРНК Plp, соответствующие SpCas9-оцрРНК и CjCas9-оцрРНК, нацеленным на области TATA-бокса и энхансерные области (энхансер wMN1) mPlp1. В (а) показан уровень экспрессии мРНК Plp, соответствующий SpCas9-оцрРНК, а в данном случае, mPlp1-TATA-Sp-01, нацеленный на область TATA-бокса, и mPlp1-wMN1-Sp-07+mPlp1-wMN1-Sp-27 и mPlp1-wMN1-Sp-08+mPlp1-wMN1-Sp-27, нацеленные на энхансер, были использованы в качестве оцрРНК. В (b) показан уровень экспрессии мРНК Plp, соответствующий CjCas9-оцрРНК, а в данном случае, mPlp1-TATA-Cj-02 и mPlp1-TATA-Cj-03 были нацелены на область TATA-бокса, а mPlp1-wMN1-Cj-06+mPlp1-wMN1-Cj-09, mPlp1-wMN1-Cj-06+mPlp1-wMN1-Cj-10 и mPlp1-wMN1-Cj-06+mPlp1-wMN1-Cj-19, нацеленные на энхансер, были использованы в качестве оцрРНК. mRosa26 использовали в качестве контроля.
На фиг. 24 представлен график, где показан результат скрининга на SpCas9-оцрРНК, нацеленные на энхансерную область (энхансер wMN1) hPlP1, и показаны частоты инсерций-делеций (%), подтвержденных в клетках Jurkat, а используемые оцрРНК представляют собой hPLP1-wMN1-Sp-01 - hPLP1-wMN1-Sp-36, и различаются номерами, представленными в последовательностях-мишенях на графике.
На фиг. 25 представлен график, где показан результат скрининга на CjCas9-оцрРНК, нацеленные на энхансерную область (энхансер wMN1) hPlP1, и показаны частоты инсерций-делеций (%), подтвержденных в клетках 293T, а используемые оцрРНК представляют собой hPLP1-wMN1-Cj-01 - hPLP1-wMN1-Cj-36, и различаются номерами, представленными в последовательностях-мишенях на графике.
Способы осуществления изобретения
Если это не оговорено особо, то все используемые здесь техические и научные термины имеют общепринятые значения, понятные среднему специалисту в области, к которой относится настоящее изобретение. Хотя для практического осуществления настоящего изобретения или для проведения испытаний могут быть применены методы и материалы, аналогичные или идентичные описанным здесь методам и материалам, однако, подходящие методы и материалы описаны ниже. Все публикации, патентные заявки, патенты и другие упоминаемые здесь документы включены в настоящее описание посредством ссылки в полном объеме. Кроме того, материалы, методы и примеры носят лишь иллюстративный, но не ограничивающий характер.
Один из аспектов, раскрытых в настоящем описании, относится к композиции для регуляции экспрессии.
Композиция для регуляции экспрессии представляет собой композицию для регуляции экспрессии дуплицированного гена после дупликации гена.
Термин «дупликация гена» означает, что в геноме присутствуют два или более идентичных генов. Дупликация гена также включает наличие в геноме двух или более частей одного и того же гена. Так, например, дупликация гена может означать наличие в геноме двух или более полноразмерных генов А, или одного полноразмерного гена A или оной или более частей, например, экзона 1 гена А в геноме. Так, например, дупликация гена может означать наличие в геноме двух полноразмерных генов В и одной или более частей, например, экзона 1 и экзона 2 гена В. Типы дупликации гена могут варьироваться, и дупликация гена включает дупликации (то есть, наличие двух или более) полноразмерных генов и/или неполной последовательности гена в геноме.
Кроме того, дупликация гена включает феномен репликации, то есть, дупликации неполной области хромосомы, которая происходит в процессе генетической рекомбинации в хромосоме. Такая дупликация гена представляет собой один из типов мутации гена и передается последующему поколению. Дупликация гена влияет на экспрессию гена наряду с делецией гена, которая происходит из-за отсутствия репликации неполной области гена.
В данном случае, объект дупликации гена, то есть, гена, который присутствует в количестве 2 или более, называется «дуплицированным геном» (дупликацией гена).
Дуплицированный ген может представлять собой ген, в котором общее число копий в геноме увеличивается из-за дупликации гена.
Дуплицированный ген может представлять собой мутантный ген, в котором, в результате дупликации гена, дуплицированной является только часть области. В данном случае, мутантным геном может быть ген, в котором дуплицированными являются одна или более нуклеотидных последовательностей в полноразмерной последовательности гена. Альтернативно, мутантный ген может представлять собой ген, в котором, в результате дупликации гена, дуплицированным является только фрагмент нуклеиновой кислоты гена. В данном случае, фрагмент нуклеиновой кислоты может иметь нуклеотидную последовательность из 50 п.о. или более.
Дупликация гена включает дупликацию всего генома.
Дупликация гена включает дупликацию гена-мишени. В данном случае, дупликация гена-мишени представляет собой тип дупликации гена, где в случае дифференцировки и адаптации новых видов к изменениям окружающей среды, соответствующий ген амплифицируется или исчезает в зависимости от конкретного окружения, и большинство репликаций происходят посредством транспозонов.
Дупликация гена включает эктопическую рекомбинацию. В данном случае, эктопическая рекомбинация происходит в зависимости от степени встречаемости повторяющихся последовательностей между двумя хромосомами из-за репликации, которая происходит вследствие неравномерного кроссинговера в процессе мейоза в гомологичных хромосомах. Дупликация возникает на участке кроссинговера и в области реципрокной делеции. Эктопическая рекомбинация опосредуется типичным повторяющимся генетическим элементом, таким как генетический подвижный элемент, что приводит к репликации в результате рекомбинации.
Дупликация включает замедление репликации. В данном случае, замедление репликации представляет собой репликацию короткой генетической последовательности из-за ошибки в процессе репликации ДНК и наблюдается в том случае, когда ДНК-полимераза неправильно присоединяется к денатурированной цепи ДНК, и цепь ДНК реплицируется снова. Замедление репликации также часто опосредуется повторяющимся генетическим элементом.
Дупликация гена включает ретротранспозицию. В данном случае, ретротранспозиция представляет собой репликацию, опосредуемую внедрением в клетки ретровируса или ретроэлемента, после чего происходит обратная транскрипция гена с образованием ретрогена, и вследствие рекомбинации ретрогенов происходит репликация генов. Ретротранспозиция опосредуется генетическим элементом, таким как генетический подвижный ретроэлемент.
Дупликация гена может повышать уровень экспрессии мРНК, транскрибируемой из дуплицированного гена. В данном случае, экспрессия транскрибируемой мРНК может повышаться по сравнению с экспрессией в том случае, когда дупликации гена не происходит.
Дупликация гена может повышать уровень экспрессии белка, кодируемого дуплицированным геном. В данном случае, экспрессия белка может повышаться по сравнению с экспрессией в том случае, когда дупликации гена не происходит.
Дупликация гена может вызывать дисфункцию белка, кодируемого дуплицированным геном.
В данном случае, дисфункция может представлять собой избыточную функцию, ингибировнную функцию и какую-либо третью функцию белка.
Дупликация гена может вызывать заболевание, ассоциированное с дупликацией гена.
«Заболевание, ассоциированное с дупликацией гена» представляет собой заболевание, вызываемое дупликацией гена, и включает все заболевания и расстройства, приводящие к генетической аномалии в результате аномальной амплификации дуплицированного гена, и индуцирующие патологические признаки под действием белка, который был сверхэкспрессирован или аномально продуцирован. В данном случае, «патологический признаки» означают изменения на клеточном уровне в организме, в ткани и в органах и на индивидуальном уровне, вызываемые заболеванием.
Заболевание, вызываемое дупликацией гена, может представлять собой болезнь Шарко-Мари-Туфа 1A (CMT1A), болезнь Дежерина-Сотта (DSD), врожденную гипомиелинизирующую невропатию (CHN), синдром Русси-Леви (RLS), болезнь Пелициуса-Мерцбахера (PMD), синдром дупликации MECP2, X-сцепленный гипопитуитаризм (XLHP), синдром Потоцкого-Лупски (PTLS), синдром лицевого велокардита (VCFS), синдром Уильямса-Бейрена (WBS), синдром Аладжилля (AS), синдром замедления роста, преждевременное закрытие черепных швов, аутосомно-доминантную лейкодистрофию (ADLD), болезнь Паркинсона или болезнь Альцгеймера.
Заболевание, вызываемое дупликацией гена, может представлять собой рак, вызываемый дупликацией онкогена.
В данном случае, рак может представлять собой рак молочной железы, рак шейки матки, рак прямой и ободочной кишки, рак пищевода, рак желудка, глиобластому, рак головы и шеи, гепатоцеллюлярный рак, нейробластому, рак яичника, саркому или мелкоклеточный рак легких.
Заболевание, вызываемое дупликацией гена, может представлять собой заболевание, вызываемое дупликацией гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA или гена APP.
Заболевание, вызываемое дупликацией гена, может представлять собой заболевание, вызываемое дупликацией гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN или гена AKT2.
Заболевание, вызываемое дупликацией гена, может представлять собой заболевание, вызываемое аномальным увеличением уровня экспрессии транскрибированной мРНК дуплицированного гена.
Заболевание, вызываемое дупликацией гена, может представлять собой заболевание, вызываемое аномальным увеличением уровня экспрессии белка, кодируемого дуплицированным геном.
Композиция для регуляции экспрессии может быть использована для регуляции экспрессии мРНК, продуцируемой посредством транскрипции дуплицированного гена.
Композиция для регуляции экспрессии может быть использована для регуляции экспрессии белка, кодируемого дуплицированным геном.
Композиция для регуляции экспрессии может быть использована для искусственной модификации или обработки дуплицированного гена.
В данном случае, термин «искусственная модификация или обработка (искусственно модифицированный, обработанный или сконструированный)» относится к искусственно модифицированному, но не к природному состоянию. Далее, не-природный, искусственно модифицированный или обработанный дуплицированный ген может быть использован как синоним термина «искусственный дуплицированный ген».
Термин «система регуляции экспрессии» включает все случаи, обусловленные регуляцией экспрессии искусственно обработанного дуплицированного гена и все материалы, композиции, способы и применения, которые прямо или опосредованно участвуют в системе регуляции экспрессии.
Композиция для регуляции экспрессии может быть использована для искусственной обработки или модификации области регуляции транскрипции дуплицированного гена.
В данном случае, «регуляторная область транскрипции (область регуляции транскрипции)» представляет собой область, регулирующую весь процесс синтеза ДНК на основе ДНК гена, и включает все области, которые взаимодействуют с фактором транскрипции в последовательности ДНК гена и/или проксимальной последовательности ДНК гена. В данном случае, фактор транскрипции представляет собой белок, который, при его активации, связывается со специфической областью ДНК, то есть, с отвечающим элементом, расположенным поблизости от гена, что приводит к стимуляции или ингибированию экспрессии гена, и этот отвечающий элемент включен в область регуляции транскрипции. Типы и положения области регуляции транскрипции могут варьироваться в зависимости от гена, и даже у одних и тех же видов могут наблюдаться различия в последовательностях нуклеиновой кислоты между индивидуумами.
Область регуляции транскрипции может представлять собой промотор, энхансер, сайленсер, изолятор и регуляторную область локуса (LCR).
Промотор может представлять собой центральный промотор, проксимальный промотор и/или дистальный промотор.
В данном случае, центральный промотор может включать сайт инициации транскрипции (TSS), сайт связывания с РНК-полимеразой, сайт связывания с фактором транскрипции и/или TATA-бокс.
TATA-бокс может представлять собой область, расположенную на 25 пар оснований выше сайта инициации, используемого для инициации транскрипции Rpb4/Rbp7.
TATA-бокс может представлять собой область, расположенную на 30 пар оснований выше TSS.
TATA-бокс может представлять собой область, расположенную на 40-100 пар оснований выше TSS.
Так, например, TATA-бокс может представлять собой область, включающую последовательность 5’-TATA(A/T)A(A/T)-3’, присутствующую в промоторе и/или в центральном промоторе. Альтернативно, TATA-бокс может представлять собой область, включающую последовательность 5’-TATA(A/T)A(A/T)(A/G)-3’, присутствующую в промоторе и/или в центральном промоторе.
Так, например, TATA-бокс может представлять собой область, включающую одну или более последовательностей, выбранных из группы, состоящей из последовательности 5’-CATAAAA-3’(SEQ ID NO:264), последовательности 5’-TATAA-3’(SEQ ID NO:265), последовательности 5’-TATAAAA-3’(SEQ ID NO:266), последовательности 5’-CATAAATA-3’(SEQ ID NO:267), последовательности 5’-TATATAA-3’(SEQ ID NO:268), последовательности 5’-TATATATATATATAA-3’(SEQ ID NO:269), последовательности 5’-TATATTATA-3’(SEQ ID NO:270), последовательности 5’-TATAAA-3’(SEQ ID NO:271), последовательности 5’-TATAAAATA-3’(SEQ ID NO:272), последовательности 5’-TATATA-3’(SEQ ID NO:273), последовательности 5’-GATTAAAAA-3’(SEQ ID NO:274), последовательности 5’-TATAAAAA-3’(SEQ ID NO:275), последовательности 5’-TTATAA-3’(SEQ ID NO:276), последовательности 5’-TTTTAAAA-3’(SEQ ID NO:277), последовательности 5’-TCTTTAAAA-3’(SEQ ID NO:278), последовательности 5’-GACATTTAA-3’(SEQ ID NO:279), последовательности 5’-TGATATCAA-3’(SEQ ID NO:280), последовательности 5’-TATAAATA-3’(SEQ ID NO:281), последовательности 5’-TATAAGA-3’(SEQ ID NO:282), последовательности 5’-AATAAA-3’(SEQ ID NO:283), последовательности 5’-TTTATA-3’(SEQ ID NO:284), последовательности 5’-CATAAAAA-3’(SEQ ID NO:285), последовательности 5’-TATACA-3’(SEQ ID NO:286), последовательности 5’-TTTAAGA-3’(SEQ ID NO:287), последовательности 5’-GATAAAG-3’(SEQ ID NO:288), последовательности 5’-TATAACA-3’(SEQ ID NO:289), последовательности 5’-TCTTATCTT-3’(SEQ ID NO:290), последовательности 5’-TTGTACTTT-3’(SEQ ID NO:291), последовательности 5’-CATATAA-3’(SEQ ID NO:292), последовательности 5’-TATAAAT-3’(SEQ ID NO:293), последовательности 5’-TATATATAAAAAAAA-3’(SEQ ID NO:294) и последовательности 5’-CATAAATAAAAAAAATTA-3’(SEQ ID NO:295) которые присутствуют в промоторе и/или в центральном промоторе.
Так, например, TATA-бокс может представлять собой область, с которой связывается TATA-связывающий белок (TBP), присутствующий в промоторе и/или в центральном промоторе.
В данном случае, проксимальный промотор может включать область, расположенную на 1-300 п.о. выше TSS, сайта CpG и/или специфического сайта, связывающегося с фактором транскрипции.
Энхансер может включать энхансер-бокс (E-бокс).
Изолятор может представлять собой область, которая ингибирует взаимодействие между энхансером и промотором или предотвращает повышение уровня ингибированного хроматина.
Регуляторная область локуса (LCR) может представлять собой область, в которой присутствует множество цис-действующих факторов, таких как энхансер, сайленсер, изолятор, MAR и SAR.
В одном из аспектов, раскрытых в настоящем описании, композиция для регуляции экспрессии может включать руководящую нуклеиновую кислоту.
Композиция для регуляции экспрессии может включать руководящую нуклеиновую кислоту, нацеленную на дуплицированный ген, или последовательность нуклеиновой кислоты, кодирующую эту нуклеиновую кислоту.
«Руководящая нуклеиновая кислота» означает нуклеотидную последовательность, которая распознает нуклеиновую кислоту, ген или хромосому в качестве мишеней и взаимодействует с белком-редактором. В данном описании, руководящая нуклеиновая кислота может комплементарно связываться с неполной нуклеотидной последовательностью в нуклеиновой кислоте-, гене- или хромосоме-мишени. Кроме того, неполная нуклеотидная последовательность руководящей нуклеиновой кислоты может взаимодействовать с некоторыми аминокислотами белка-редактора с образованием комплекса «руководящая нуклеиновая кислота - белок-редактор».
Руководящая нуклеиновая кислота может выполнять функцию, заключающуюся в индуцировании образования комплекса «руководящая нуклеиновая кислота - белок-редактор», локализованного в области-мишени нуклеиновой кислоты-, гена- или хромосомы-мишени.
Руководящая нуклеиновая кислота может присутствовать в форме ДНК, РНК или гибрида ДНК/РНК и может иметь последовательность нуклеиновой кислоты из 5-150 нуклеотидов.
Руководящая нуклеиновая кислота может иметь одну непрерывную последовательность нуклеиновой кислоты.
Так, например, одна непрерывная последовательность нуклеиновой кислоты может представлять собой (N)m, где N представляет собой A, T, C или G, или A, U, C или G, а m равно целому числу от 1 до 150.
Руководящая нуклеиновая кислота может иметь две или более непрерывных последовательностей нуклеиновой кислоты.
Так, например, две или более непрерывных последовательностей нуклеиновой кислоты могут представлять собой (N)m и (N)o, где N представляет собой A, T, C или G или A, U, C или G, m и o равны целому числу от 1 до 150, и m и o могут быть одинаковыми или различными.
Руководящая нуклеиновая кислота может включать один или более доменов.
Доменами могут быть, но не ограничиваются ими, руководящий домен, первый комплементарный домен, линкерный домен, второй комплементарный домен, проксимальный домен или хвостовой домен.
В данном описании, одна руководящая нуклеиновая кислота может иметь два или более функциональных доменов. В данном случае, два или более функциональных доменов могут отличаться друг от друга. Так, например, одна руководящая нуклеиновая кислота может иметь руководящий домен и первый комплементарный домен. В другом примере, одна руководящая нуклеиновая кислота может иметь второй комплементарный домен, проксимальный домен и хвостовой домен. В другом примере, одна руководящая нуклеиновая кислота может иметь руководящий домен и первый комплементарный домен, второй комплементарный домен, проксимальный домен и хвостовой домен. Альтернативно, два или более функциональных доменов, включенных в одну руководящую нуклеиновую кислоту, могут быть одинаковыми. В одном примере, одна руководящая нуклеиновая кислота может иметь два или более проксимальных доменов. В другом примере, одна руководящая нуклеиновая кислота может иметь два или более хвостовых доменов. Однако, указание на то, что функциональные домены, включенные в одну руководящую нуклеиновую кислоту, являются одинаковыми, не означает, что последовательности двух функциональных доменов являются одинаковыми. Даже если последовательности являются различными, то два функциональных домена могут представлять собой одни и те же домены, если они выполняют одну и ту же функцию.
Функциональный домен более подробно описан ниже.
i) Руководящий домен
Термин «руководящий домен» означает домен, способный к комплементарному связыванию с неполной последовательностью любой одной цепи двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени, и способный к специфическому взаимодействию с нуклеиновой кислотой в области регуляции транскрипции гена-мишени. Так, например, руководящий домен может выполнять функцию, заключающуюся в индуцировании образования комплекса «руководящая нуклеиновая кислота - белок-редактор», локализованного в специфической нуклеотидной последовательности нуклеиновой кислоты области регуляции транскрипции гена-мишени.
Руководящий домен может представлять собой последовательность из 10-35 нуклеотидов.
В одном из примеров, руководящий домен может представлять собой последовательность из 10-35, 15-35, 20-35, 25-35 или 30-35 нуклеотидов.
В другом примере, руководящий домен может представлять собой последовательность из 10-15, 15-20, 20-25, 25-30 или 30-35 нуклеотидов.
Руководящий домен может иметь руководящую последовательность.
Термин «руководящая последовательность» означает нуклеотидную последовательность, комплементарную неполной последовательности любой цепи двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени. В данном описании, руководящая последовательность может представлять собой нуклеотидную последовательность, имеющую комплементарность по меньшей мере 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% или 95% или более или 100% комплементарность.
Руководящая последовательность может представлять собой последовательность из 10-25 нуклеотидов.
В одном из примеров, руководящая последовательность может представлять собой последовательность из 10-25, 15-25 или 20-25 нуклеотидов.
В другом примере, руководящая последовательность может представлять собой последовательность из 10-15, 15-20 или 20-25 нуклеотидов.
Кроме того, руководящий домен может также включать дополнительную нуклеотидную последовательность.
Дополнительная нуклеотидная последовательность может быть использована для улучшения или снижения функции руководящего домена.
Дополнительная нуклеотидная последовательность может быть использована для улучшения или снижения функции руководящей последовательности.
Дополнительная нуклеотидная последовательность может представлять собой последовательность из 1-10 нуклеотидов.
В одном из примеров, дополнительная нуклеотидная последовательность может представлять собой последовательность из 2-10, 4-10, 6-10 или 8-10 нуклеотидов.
В другом примере, дополнительная нуклеотидная последовательность может представлять собой последовательность из 1-3, 3-6 или 7-10 нуклеотидов.
В одном из вариантов осуществления изобретения, дополнительная нуклеотидная последовательность может представлять собой последовательность из 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 нуклеотидов.
Так, например, дополнительная нуклеотидная последовательность может представлять собой нуклеотидную последовательность из одного G (гуанина) или нуклеотидную последовательность из двух GG.
Дополнительная нуклеотидная последовательность может быть локализована у 5’-конца руководящей последовательности.
Дополнительная нуклеотидная последовательность может быть локализована у 3’-конца руководящей последовательности.
ii) Первый комплементарный домен
Термин «первый комплементарный домен» означает домен, включающий нуклеотидную последовательность, комплементарную второму комплементарному домену, описанному ниже, и имеющий комплементарность, достаточную для образования двойной цепи со вторым комплементарным доменом. Так, например, первый комплементарный домен может представлять собой нуклеотидную последовательность, которая меньшей мере на 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% или 95% или более комплементарна или полностью комплементарна второму комплементарному домену.
Первый комплементарный домен может образовывать двойную цепь со вторым комплементарным доменом посредством комплементарного связывания. В данном описании, образовавшаяся двойная цепь может образовывать комплекс «руководящая нуклеиновая кислота - белок-редактор» посредством взаимодействия с некоторыми аминокислотами белка-редактора.
Первый комплементарный домен может представлять собой последовательность из 5-35 нуклеотидов.
В одном примере, первый комплементарный домен может представлять собой последовательность из 5-35, 10-35, 15-35, 20-35, 25-35 или 30-35 нуклеотидов.
В другом примере, первый комплементарный домен может представлять собой последовательность из 1-5, 5-10, 10-15, 15-20, 20-25, 25-30 или 30-35 нуклеотидов.
iii) Линкерный домен
Термин «линкерный домен» означает нуклеотидную последовательность, соединяющую два или более доменов, которые представляют собой два или более идентичных или различных доменов. Линкерный домен может быть связан с двумя или более доменами посредством ковалентной или нековалентной связи, либо он может соединять два или более доменов посредством ковалентной или нековалентной связи.
Линкерный домен может представлять собой последовательность из 1-30 нуклеотидов.
В одном примере, линкерный домен может представлять собой последовательность из 1-5, 5-10, 10-15, 15-20, 20-25 или 25-30 нуклеотидов.
В другом примере, линкерный домен может представлять собой последовательность из 1-30, 5-30, 10-30, 15-30, 20-30 или 25-30 нуклеотидов.
iv) Второй комплементарный домен
Термин «второй комплементарный домен» означает домен, включающий нуклеотидную последовательность, комплементарную первому комплементарному домену, описанному выше, и имеющий комплементарность, достаточную для образования двойной цепи с первым комплементарным доменом. Так, например, второй комплементарный домен может представлять собой нуклеотидную последовательность, которая меньшей мере на 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% или 95% или более комплементарна или полностью комплементарна первому комплементарному домену.
Второй комплементарный домен может образовывать двойную цепь с первым комплементарным доменом посредством комплементарного связывания. В данном описании, образовавшаяся двойная цепь может образовывать комплекс «руководящая нуклеиновая кислота - белок-редактор» посредством взаимодействия с некоторыми аминокислотами белка-редактора. Второй комплементарный домен может иметь нуклеотидную последовательность, комплементарную первому комплементарному домену, и нуклеотидную последовательность, которая не является комплементарной первому комплементарному домену, например, нуклеотидную последовательность, которая не образует двойную цепь с первым комплементарным доменом и может иметь более длинную последовательность оснований, чем первый комплементарный домен.
Второй комплементарный домен может представлять собой последовательность из 5-35 нуклеотидов.
В одном примере, второй комплементарный домен может представлять собой последовательность из 5-35, 10-35, 15-35, 20-35, 25-35 или 30-35 нуклеотидов.
В другом примере, второй комплементарный домен может представлять собой последовательность из 1-5, 5-10, 10-15, 15-20, 20-25, 25-30 или 30-35 нуклеотидов.
v) Проксимальный домен
Термин «проксимальный домен» означает нуклеотидную последовательность, локализованную рядом со вторым комплементарным доменом.
Проксимальный домен может иметь комплементарную нуклеотидную последовательность, посредством которой может образовываться двойная цепь.
Проксимальный домен может представлять собой последовательность из 1-20 нуклеотидов.
В одном примере, проксимальный домен может представлять собой последовательность из 1-20, 5-20, 10-20 или 15-20 нуклеотидов.
В другом примере, проксимальный домен может представлять собой последовательность из 1-5, 5-10, 10-15 или 15-20 нуклеотидов.
vi) Хвостовой домен
Термин «хвостовой домен» означает нуклеотидную последовательность, локализованную у одного или более концов или у обоих концов руководящей нуклеиновой кислоты.
Хвостовой домен может иметь комплементарную нуклеотидную последовательность, посредством которой может образовываться двойная цепь.
Хвостовой домен может представлять собой последовательность из 1-50 нуклеотидов.
В одном примере, хвостовой домен может представлять собой последовательность из 5-50, 10-50, 15-50, 20-50, 25-50, 30-50, 35-50, 40-50 или 45-50 нуклеотидов.
В другом примере, хвостовой домен может представлять собой последовательность из 1-5, 5-10, 10-15, 15-20, 20-25, 25-30, 30-35, 35-40, 40-45 или 45-50 нуклеотидов.
Кроме того, часть или все последовательности нуклеиновой кислоты, включенные в домены, то есть, руководящий домен, первый комплементарный домен, линкерный домен, второй комплементарный домен, проксимальный домен и хвостовой домен могут выборочно или дополнительно включать химическую модификацию.
Такой химической модификацией могут быть, но не ограничиваются ими, метилирование, ацетилирование, фосфорилирование, фосфортиоатная связь, блокированная нуклеиновая кислота (LNA), 2’-O-метил-3’-фосфортиоат (MS) или 2’-O-метил-3’-тио-PACE (MSP).
Руководящая нуклеиновая кислота включает один или более доменов.
Руководящая нуклеиновая кислота может включать руководящий домен.
Руководящая нуклеиновая кислота может включать первый комплементарный домен.
Руководящая нуклеиновая кислота может включать линкерный домен.
Руководящая нуклеиновая кислота может включать второй комплементарный домен.
Руководящая нуклеиновая кислота может включать проксимальный домен.
Руководящая нуклеиновая кислота может включать хвостовой домен.
В данном описании могут присутствовать 1, 2, 3, 4, 5, 6 или более доменов.
Руководящая нуклеиновая кислота может включать 1, 2, 3, 4, 5, 6 или более руководящих доменов.
Руководящая нуклеиновая кислота может включать 1, 2, 3, 4, 5, 6 или более первых комплементарных доменов.
Руководящая нуклеиновая кислота может включать 1, 2, 3, 4, 5, 6 или более линкерных доменов.
Руководящая нуклеиновая кислота может включать 1, 2, 3, 4, 5, 6 или более вторых комплементарных доменов.
Руководящая нуклеиновая кислота может включать 1, 2, 3, 4, 5, 6 или более проксимальных доменов.
Руководящая нуклеиновая кислота может включать 1, 2, 3, 4, 5, 6 или более хвостовых доменов.
В данном описании, в руководящей нуклеиновой кислоте, домен одного типа может быть дуплицирован.
Руководящая нуклеиновая кислота может включать несколько доменов с дупликациями или без них.
Руководящая нуклеиновая кислота может включать домены одного типа. В данном описании, домены одного типа могут иметь одну и ту же последовательность нуклеиновой кислоты или различные последовательности нуклеиновой кислоты.
Руководящая нуклеиновая кислота может включать домены двух типов. В данном описании, домены двух различных типов могут иметь различные последовательности нуклеиновой кислоты или одинаковые последовательности нуклеиновой кислоты.
Руководящая нуклеиновая кислота может включать домены трех типов. В данном описании, домены трех различных типов могут иметь различные последовательности нуклеиновой кислоты или одинаковые последовательности нуклеиновой кислоты.
Руководящая нуклеиновая кислота может включать домены четырех типов. В данном описании, домены четырех различных типов могут иметь различные последовательности нуклеиновой кислоты или одинаковые последовательности нуклеиновой кислоты.
Руководящая нуклеиновая кислота может включать домены пяти типов. В данном описании, домены пяти различных типов могут иметь различные последовательности нуклеиновой кислоты или одинаковые последовательности нуклеиновой кислоты.
Руководящая нуклеиновая кислота может включать домены шести типов. В данном описании, домены шести различных типов могут иметь различные последовательности нуклеиновой кислоты или одинаковые последовательности нуклеиновой кислоты
Так, например, руководящая нуклеиновая кислота может состоять из [руководящего домена]-[первого комплементарного домена]-[линкерного домена]-[второго комплементарного домена]-[линкерного домена]-[руководящего домена]-[первого комплементарного домена]-[линкерного домена]-[второго комплементарного домена]. В данном описании, два руководящих домена могут включать руководящие последовательности для различных или одинаковых мишеней, где два первых комплементарных домена и два вторых комплементарных домена могут иметь одинаковые или различные последовательности нуклеиновой кислоты. Если руководящие домены включают руководящие последовательности для различных мишеней, то руководящие нуклеиновые кислоты могут специфически связываться с двумя различными мишенями, и в этом случае, специфическое связывание может осуществляться одновременно или последовательно. Кроме того, линкерные домены могут расщепляться специфическими ферментами, и руководящие нуклеиновые кислоты могут быть разделены на две или три части в присутствии специфических ферментов.
В одном репрезентативном варианте, раскрытом в настоящем описании, руководящая нуклеиновая кислота может представлять собой рРНК.
Термин «рРНК» означает РНК, способную специфически доставлять комплекс «рРНК-фермент CRISPR», то есть, комплекс CRISPR, к нуклеиновой кислоте в области регуляции транскрипции гена-мишени. Кроме того, рРНК представляет собой РНК, специфичную к нуклеиновой кислоте в области регуляции транскрипции гена-мишени, которая может связываться с ферментом CRISPR и доставлять этот фермент CRISPR к области регуляции транскрипции гена-мишени.
рРНК может включать множество доменов. Благодаря каждому из этих доменов могут происходить взаимодействия в трехмерной структуре или в активной форме цепи рРНК или между этими цепями.
рРНК может называться одноцепочечной рРНК (одной молекулой РНК, одной рРНК или оцрРНК) или двухцепочечной рРНК (включающей более, чем одну, а обычно две дискретных молекулы РНК).
В одном репрезентативном варианте осуществления изобретения, одноцепочечная рРНК может включать руководящий домен, то есть, домен, включающий руководящую последовательность, способную образовывать комплементарную связь с нуклеиновой кислотой в области регуляции транскрипции гена-мишени; первый комплементарный домен; линкерный домен; второй комплементарный домен, то есть, домен, имеющий последовательность, комплементарную последовательности первого комплементарного домена и образующую двухцепочечную нуклеиновую кислоту с первым комплементарным доменом; проксимальный домен и, необязательно, хвостовой домен в направлении 5’ → 3’.
В другом варианте осуществления изобретения, двухцепочечная рРНК может включать первую цепь, содержащую руководящий домен, то есть, домен, включающий руководящую последовательность, способную образовывать комплементарную связь с нуклеиновой кислотой в области регуляции транскрипции гена-мишени; и первый комплементарный домен; и вторую цепь, содержащую второй комплементарный домен, то есть, домен, имеющий последовательность, комплементарную последовательности первого комплементарного домена и образующую двухцепочечную нуклеиновую кислоту с первым комплементарным доменом; проксимальный домен и, необязательно, хвостовой домен в направлении 5’ → 3’.
В данном описании, первая цепь может обозначаться cr-РНК, а вторая цепь может обозначаться tracr-РНК. cr-РНК может включать руководящий домен и первый комплементарный домен, а tracr-РНК может включать второй комплементарный домен, проксимальный домен и, необязательно, хвостовой домен.
В другом варианте осуществления изобретения, одноцепочечная рРНК может включать руководящий домен, то есть, домен, включающий руководящую последовательность, способную образовывать комплементарную связь с нуклеиновой кислотой в области регуляции транскрипции гена-мишени; первый комплементарный домен; второй комплементарный домен, и домен, имеющий последовательность, комплементарную последовательности первого комплементарного домена и образующую двухцепочечную нуклеиновую кислоту с первым комплементарным доменом в направлении 5’ → 3’.
В данном описании, первый комплементарный домен может быть гомологичен первому природному комплементарному домену, либо он может происходить от этого домена. Кроме того, первый комплементарный домен может иметь нуклеотидную последовательность, отличающуюся от первого комплементарного домена в зависимости от вида, существующего в природе, или может происходить от первого комплементарного домена, присутствующего у вида, существующего в природе, или может быть частично или полностью гомологичным первому комплементарному домену, присутствующему у вида, существующего в природе.
В одном репрезентативном варианте осуществления изобретения, первый комплементарный домен может быть частично, то есть, по меньшей мере на 50% или более или полностью гомологичным первому комплементарному домену Streptococcus pyogenes, Campylobacter jejuni, Streptococcus thermophilus, Streptococcus aureus или Neisseria meningitides, или первому комплементарному домену, происходящему от этих видов.
Так, например, если первым комплементарным доменом является первый комплементарный домен Streptococcus pyogenes или первый комплементарный домен, происходящий от него, то первый комплементарный домен может представлять собой 5’-GUUUUAGAGCUA-3’ (SEQ ID NO:296) или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-GUUUUAGAGCUA-3’(SEQ ID NO:296). В данном описании, первый комплементарный домен может также включать (X)n, входящий в 5’-GUUUUAGAGCUA(X)n-3’ (SEQ ID NO:296). X может быть выбран из группы, состоящей из оснований A, T, U и G, а n может означать число нуклеотидов, которое равно 5-15. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G.
В другом варианте осуществления изобретения, если первым комплементарным доменом является первый комплементарный домен Campylobacter jejuni или первый комплементарный домен, происходящий от него, то первый комплементарный домен может представлять собой 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’ (SEQ ID NO:297), или последовательность оснований, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’(SEQ ID NO:297). В данном описании, первый комплементарный домен может также включать (X)n, входящий в 5’-GUUUUAGUCCCUUUUUAAAUUUCUU(X)n-3’(SEQ ID NO:297). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а n может означать число нуклеотидов, которое равно 5-15. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G.
В другом варианте осуществления изобретения, первый комплементарный домен может быть частично, то есть, по меньшей мере на 50% или более, или полностью гомологичным первому комплементарному домену Parcubacteria bacterium (GWC2011_GWC2_44_17), Lachnospiraceae bacterium (MC2017), Butyrivibrio proteoclasiicus, Peregrinibacteria bacterium (GW2011_GWA_33_10), Acidaminococcus sp. (BV3L6), Porphyromonas macacae, Lachnospiraceae bacterium (ND2006), Porphyromonas crevioricanis, Prevotella disiens, Moraxella bovoculi (237), Smiihella sp. (SC_KO8D17), Leptospira inadai, Lachnospiraceae bacterium (MA2020), Francisella novicida (U112), Candidatus Methanoplasma termitum или Eubacterium eligens, или первому комплементарному домену, происходящему от этих видов.
Так, например, если первым комплементарным доменом является первый комплементарный домен Parcubacteria bacterium или первый комплементарный домен, происходящий от него, то первый комплементарный домен может представлять собой 5’-UUUGUAGAU-3’(SEQ ID NO:298), или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-UUUGUAGAU-3’(SEQ ID NO:298). В данном описании, первый комплементарный домен может также включать (X)n, входящий в 5’-(X)nUUUGUAGAU-3’(SEQ ID NO:298). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а n может означать число нуклеотидов, которое равно целому числу 1-5. В данном описании, (X)n может означать n повторов одних и тех же оснований или смесь n нуклеотидов A, T, U и G.
В данном описании, линкерный домен может представлять собой нуклеотидную последовательность, соединяющую первый комплементарный домен со вторым комплементарным доменом.
Линкерный домен может образовывать ковалентную или нековалентную связь с первым комплементарным доменом и со вторым комплементарным доменом, соответственно.
Линкерный домен может соединять первый комплементарный домен со вторым комплементарным доменом посредством ковалентной или нековалентной связи.
Линкерный домен является подходящим для его использования в одноцепочечной молекуле рРНК и может быть использован для продуцирования одноцепочечной рРНК посредством присоединения к первой цепи и второй цепи двухцепочечной рРНК или посредством соединения первой цепи со второй цепью ковалентной или нековалентной связью.
Линкерный домен может быть использован для продуцирования одноцепочечной рРНК посредством присоединения к cr-РНК и tracr-РНК двухцепочечной рРНК или посредством присоединения cr-РНК к tracr-РНК посредством ковалентной или нековалентной связи.
В данном описании, второй комплементарный домен может быть гомологичен второму природному комплементарному домену, либо он может происходить от этого домена. Кроме того, второй комплементарный домен может иметь нуклеотидную последовательность, отличающуюся от второго комплементарного домена в зависимости от вида, существующего в природе, и может происходить от второго комплементарного домена, присутствующего у вида, существующего в природе, или может быть частично или полностью гомологичным второму комплементарному домену, присутствующему у вида, существующего в природе.
В репрезентативном варианте осуществления изобретения, второй комплементарный домен может быть частично, то есть, по меньшей мере на 50% или более, или полностью гомологичным второму комплементарному домену Streptococcus pyogenes, Campylobacter jejuni, Streptococcus thermophilus, Streptococcus aureus или Neisseria meningitides, или второму комплементарному домену, происходящему от этих видов.
Так, например, если вторым комплементарным доменом является второй комплементарный домен Streptococcus pyogenes или второй комплементарный домен, происходящий от него, то второй комплементарный домен может представлять собой 5’-UAGCAAGUUAAAAU-3’(SEQ ID NO:299), или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-UAGCAAGUUAAAAU-3’ (SEQ ID NO:299) (нуклеотидная последовательность, образующая двойную цепь с первым комплементарным доменом, подчеркнута). В данном описании, второй комплементарный домен может также включать (X)n и/или (X)m, входящие в 5’-(X)n UAGCAAGUUAAAAU(X)m-3’(SEQ ID NO:299). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а каждый n и m может означать число нуклеотидов, где n может быть равно целому числу 1-15, а m может быть равно целому числу 1-6. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G. Кроме того, (X)m может означать m повторов одних и тех же нуклеотидов или смесь m нуклеотидов A, T, U и G.
В другом примере, если вторым комплементарным доменом является второй комплементарный домен Campylobacter jejuni или второй комплементарный домен, происходящий от него, то второй комплементарный домен может представлять собой 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’(SEQ ID NO:300), или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’(SEQ ID NO:300) (нуклеотидная последовательность, образующая двойную цепь с первым комплементарным доменом, подчеркнута). В данном описании, второй комплементарный домен может также включать (X)n и/или (X)m, входящие в 5’-(X)nAAGAAAUUUAAAAAGGGACUAAAAU(X)m-3’(SEQ ID NO:300). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, каждый n и m может означать число нуклеотидов, где n может быть равно целому числу 1-15, а m может быть равно целому числу 1-6. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G. Кроме того, (X)m может означать m повторов одних и тех же нуклеотидов или смесь m нуклеотидов A, T, U и G.
В другом варианте осуществления изобретения, второй комплементарный домен может быть частично, то есть, по меньшей мере на 50% или более, или полностью гомологичным первому комплементарному домену Parcubacteria bacterium (GWC2011_GWC2_44_17), Lachnospiraceae bacterium (MC2017), Butyrivibrio proteoclasiicus, Peregrinibacteria bacterium (GW2011_GWA_33_10), Acidaminococcus sp. (BV3L6), Porphyromonas macacae, Lachnospiraceae bacterium (ND2006), Porphyromonas crevioricanis, Prevotella disiens, Moraxella bovoculi (237), Smiihella sp. (SC_KO8D17), Leptospira inadai, Lachnospiraceae bacterium (MA2020), Francisella novicida (U112), Candidatus Methanoplasma termitum или Eubacterium eligens, или второму комплементарному домену, происходящему от этих видов.
Так, например, если вторым комплементарным доменом является второй комплементарный домен Parcubacteria bacterium или второй комплементарный домен, происходящий от него, то второй комплементарный домен может представлять собой 5’-AAAUUUCUACU-3’(SEQ ID NO:301), или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-AAAUUUCUACU-3’(SEQ ID NO:301) (нуклеотидная последовательность, образующая двойную цепь с первым комплементарным доменом, подчеркнута). В данном описании, второй комплементарный домен может также включать (X)n и/или (X)m, входящие в 5’-(X)nAAAUUUCUACU(X)m-3’(SEQ ID NO:301). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, каждый n и m может означать число нуклеотидов, где n может быть равно целому числу 1-10, а m может быть равно целому числу 1-6. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G. Кроме того, (X)m может означать m повторов одних и тех же нуклеотидов или смесь m нуклеотидов A, T, U и G.
В данном описании, первый комплементарный домен и второй комплементарный домен могут комплементарно связываться друг с другом.
Первый комплементарный домен и второй комплементарный домен могут образовывать двойную цепь посредством комплементарного связывания.
Образовывавшаяся двойная цепь может взаимодействовать с ферментом CRISPR.
Первый комплементарный домен может включать, но необязательно, дополнительную нуклеотидную последовательность последовательность, которая комплементарно не связывается со вторым комплементарным доменом второй цепи.
В данном описании, дополнительная нуклеотидная последовательность может представлять собой последовательность из 1-15 нуклеотидов. Так, например, дополнительная нуклеотидная последовательность может представлять собой последовательность из 1-5, 5-10 или 10-15 нуклеотидов.
В данном описании, проксимальный домен может представлять собой домен, локализованный у 3’-конца второго комплементарного домена.
Проксимальный домен может быть гомологичен природному проксимальному домену, либо он может происходить от этого домена. Кроме того, проксимальный домен может иметь нуклеотидную последовательность, отличающуюся от проксимального домена вида, существующего в природе; может происходить от проксимального домена, присутствующего у вида, существующего в природе, или может быть частично или полностью гомологичным проксимальному домену, присутствующему у вида, существующего в природе.
В репрезентативном варианте осуществления изобретения, проксимальный домен может быть частично, то есть, по меньшей мере на 50% или более, или полностью гомологичным проксимальному домену Streptococcus pyogenes, Campylobacter jejuni, Streptococcus thermophilus, Streptococcus aureus или Neisseria meningitides, или проксимальному домену, происходящему от этих видов.
Так, например, если проксимальным доменом является проксимальный домен Streptococcus pyogenes или проксимальный домен, происходящий от него, то проксимальный домен может представлять собой 5’-AAGGCUAGUCCG-3’(SEQ ID NO:302) или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-AAGGCUAGUCCG-3’(SEQ ID NO:302). В данном описании, проксимальный домен может также включать (X)n, входящий в 5’-AAGGCUAGUCCG(X)n-3’(SEQ ID NO:302). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а n может означать число нуклеотидов, равное целому числу 1-15. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G.
В другом примере, если проксимальным доменом является проксимальный домен Campylobacter jejuni или проксимальный домен, происходящий от него, то проксимальный домен может представлять собой 5’-AAAGAGUUUGC-3’(SEQ ID NO:303) или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична последовательности 5’-AAAGAGUUUGC-3’(SEQ ID NO:303). В данном описании, проксимальный домен может также включать (X)n, входящий в 5’-AAAGAGUUUGC(X)n-3’(SEQ ID NO:303). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а n может означать число нуклеотидов, равное целому числу 1-40. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G.
В данном описании, хвостовой домен представляет собой домен, который может быть селективно присоединен к 3’-концу одноцепочечной рРНК или к первой или второй цепи двухцепочечной рРНК.
Хвостовой домен может быть гомологичен природному хвостовому домену, либо он может происходить от этого домена. Кроме того, хвостовой домен может иметь нуклеотидную последовательность, отличающуюся от хвостового домена вида, существующего в природе, может происходить от хвостового домена, присутствующего у вида, существующего в природе, или может быть частично или полностью гомологичным хвостовому домену, присутствующему у вида, существующего в природе.
В одном репрезентативном варианте осуществления изобретения, хвостовой домен может быть частично, то есть, по меньшей мере на 50% или более, или полностью гомологичным хвостовому домену Streptococcus pyogenes, Campylobacter jejuni, Streptococcus thermophilus, Streptococcus aureus или Neisseria meningitides, или хвостовому домену, происходящему от этих видов.
Так, например, если хвостовым доменом является хвостовой домен Streptococcus pyogenes или хвостовой домен, происходящий от него, то хвостовой домен может представлять собой 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’(SEQ ID NO:304) или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’(SEQ ID NO:304). В данном описании, хвостовой домен может также включать (X)n, входящий в 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC(X)n-3’(SEQ ID NO:304). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а n может означать число нуклеотидов, равное целому числу 1-15. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G.
В другом примере, если хвостовым доменом является хвостовой домен Campylobacter jejuni или хвостовой домен, происходящий от него, то хвостовой домен может представлять собой 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’(SEQ ID NO:305), или нуклеотидную последовательность, которая частично, то есть, по меньшей мере на 50% или более гомологична последовательности 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’(SEQ ID NO:305). В данном описании, хвостовой домен может также включать (X)n, входящий в GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU(X)n-3’(SEQ ID NO:305). X может быть выбран из группы, состоящей из нуклеотидов A, T, U и G, а n может означать число нуклеотидов, равное целому числу 1-15. В данном описании, (X)n может означать n повторов одних и тех же нуклеотидов или смесь n нуклеотидов A, T, U и G.
В другом варианте осуществления изобретения, хвостовой домен может включать последовательность из 1-10 нуклеотидов у 3’-конца, участвующую в транскрипции in vitro или in vivo.
Так, например, если промотор T7 используется для in vitro транскрипции рРНК, то хвостовой домен может представлять собой произвольную нуклеотидную последовательность, присутствующую у 3’-конца матричной ДНК. Кроме того, если для транскрипции in vivo используется промотор U6, то хвостовой домен может представлять собой UUUUUU, а если для транскрипции используется промотор H1, то хвостовой домен может представлять собой UUUU, и если используется промотор pol-III, то хвостовой домен может включать несколько урациловых нуклеотидов или альтернативных нуклеотидов.
рРНК может включать множество описанных выше доменов, а поэтому, длину последовательности нуклеиновой кислоты можно регулировать в зависимости от домена, содержащегося в рРНК, и взаимодействия могут происходить в цепях трехмерной структуры или в активной форме рРНК или между этими цепями посредством каждого домена.
рРНК может называться одноцепочечной рРНК (одной молекулой РНК); или двухцепочечной рРНК (включающей более, чем одну, а обычно две дискретных молекулы РНК).
Двухцепочечная рРНК
Двухцепочечная рРНК состоит из первой цепи и второй цепи.
В данном описании, первая цепь может состоять из:
5’-[руководящего домена]-[первого комплементарного домена]-3’, а
вторая цепь может состоять из:
5’-[второго комплементарного домена]-[проксимального домена]-3’ или
5’-[второго комплементарного домена]-[проксимального домена]-[хвостового домена]-3’.
В данном описании, первая цепь может быть обозначена cr-РНК, а вторая цепь может быть обозначена tracr-РНК.
В данном описании, первая цепь и вторая цепь могут включать, но необязательно, дополнительную нуклеотидную последовательность.
В одном примере, первая цепь может представлять собой:
5’-(Nмишень)-(Q)m-3’; или
5’-(X)a-(Nмишень)-(X)b-(Q)m-(X)c-3’.
В данном описании, Nмишень представляет собой нуклеотидную последовательность, комплементарную неполной последовательности любой цепи двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени, и области нуклеотидной последовательности, которая может быть изменена в соответствии с с последовательностью-мишенью нуклеиновой кислоты в области регуляции транскрипции гена-мишени.
В данном описании, (Q)m представляет собой нуклеотидную последовательность, включающую первый комплементарный домен, способный образовывать комплементарную связь со вторым комплементарным доменом второй цепи. (Q)m может представлять собой последовательность, частично или полностью гомологичную первому комплементарному домену вида, существующего в природе, а нуклеотидная последовательность первого комплементарного домена может быть изменена в соответствии с последовательностью вида-источника. Каждый Q может быть независимо выбран из группы, состоящей из A, U, C и G, а m может означать число нуклеотидов, равное целому числу 5-35.
Так, например, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Streptococcus pyogenes или первому комплементарному домену, происходящему от Streptococcus pyogenes, то (Q)m может представлять собой 5’-GUUUUAGAGCUA-3’(SEQ ID NO:296), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GUUUUAGAGCUA-3’(SEQ ID NO:296).
В другом примере, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Campylobacter jejuni или первому комплементарному домену, происходящему от Campylobacter jejuni, то (Q)m может представлять собой 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’(SEQ ID NO:297), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’(SEQ ID NO:297).
В другом примере, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Streptococcus thermophilus или первому комплементарному домену, происходящему от Streptococcus thermophilus, то (Q)m может представлять собой 5’-GUUUUAGAGCUGUGUUGUUUCG-3’(SEQ ID NO:306), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GUUUUAGAGCUGUGUUGUUUCG-3’(SEQ ID NO:306).
Кроме того, каждый из (X)a, (X)b и (X)c представляет собой соответственно выбранную дополнительную нуклеотидную последовательность, где каждый X может быть независимо выбран из группы, состоящей из A, U, C и G, а каждый из a, b и c может представлять собой число оснований, равное 0 или целому числу от 1 до 20.
В одном репрезентативном варианте осуществления изобретения, вторая цепь может представлять собой 5’-(Z)h-(P)k-3’; или 5’-(X)d-(Z)h-(X)e-(P)k-(X)f-3’.
В другом варианте осуществления изобретения, вторая цепь может представлять собой 5’-(Z)h-(P)k-(F)i-3’; или 5’-(X)d-(Z)h-(X)e-(P)k-(X)f-(F)i-3’.
В данном описании, (Z)h представляет собой нуклеотидную последовательность, включающую второй комплементарный домен, способный образовывать комплементарную связь с первым комплементарным доменом первой цепи. (Z)h может представлять собой последовательность, частично или полностью гомологичную второму комплементарному домену вида, существующего в природе, а нуклеотидная последовательность второго комплементарного домена может быть изменена в соответствии с последовательностью вида-источника. Каждый Z может быть независимо выбран из группы, состоящей из A, U, C и G, а h может означать число нуклеотидов, равное целому числу 5-50.
Так, например, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Streptococcus pyogenes или второму комплементарному домену, происходящему от Streptococcus pyogenes, то (Z)h может представлять собой 5’-UAGCAAGUUAAAAU-3’(SEQ ID NO:299), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UAGCAAGUUAAAAU-3’(SEQ ID NO:299).
В другом примере, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Campylobacter jejuni или второму комплементарному домену, происходящему от Campylobacter jejuni, то (Z)h может представлять собой 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’(SEQ ID NO:300), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’(SEQ ID NO:300).
В другом примере, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Streptococcus thermophilus или второму комплементарному домену, происходящему от Streptococcus thermophilus, то (Z)h может представлять собой 5’-CGAAACAACACAGCGAGUUAAAAU-3’(SEQ ID NO:307), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-CGAAACAACACAGCGAGUUAAAAU-3’(SEQ ID NO:307).
(P)k представляет собой нуклеотидную последовательность, включающую проксимальный домен, который может быть частично или полностью гомологичен проксимальному домену вида, существующего в природе, а нуклеотидная последовательность проксимального домена может быть модифицирована в соответствии с видом источника. Каждый P может быть независимо выбран из группы, состоящей из A, U, C и G, а k может означать число нуклеотидов, равное целому числу от 1 до 20.
Так, например, если проксимальный домен частично или полностью гомологичен проксимальному домену Streptococcus pyogenes или проксимальному домену, происходящему от Streptococcus pyogenes, то (P)k может представлять собой 5’-AAGGCUAGUCCG-3’(SEQ ID NO:302), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAGGCUAGUCCG-3’(SEQ ID NO:302).
В другом примере, если проксимальный домен частично или полностью гомологичен проксимальному домену Campylobacter jejuni или проксимальному домену, происходящему от Campylobacter jejuni, то (P)k может представлять собой 5’-AAAGAGUUUGC-3’(SEQ ID NO:303), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAAGAGUUUGC-3’(SEQ ID NO:303).
В другом примере, если проксимальный домен частично или полностью гомологичен проксимальному домену Streptococcus thermophilus или проксимальному домену, происходящему от Streptococcus thermophilus, то (P)k может представлять собой 5’-AAGGCUUAGUCCG-3’(SEQ ID NO:308), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAGGCUUAGUCCG-3’(SEQ ID NO:308).
(F)i может представлять собой нуклеотидную последовательность, включающую хвостовой домен, который может быть частично или полностью гомологичен хвостовому домену вида, существующего в природе, а нуклеотидная последовательность хвостового домена может быть модифицирована в соответствии с видом источника. Каждый F может быть независимо выбран из группы, состоящей из A, U, C и G, а i может означать число нуклеотидов, равное целому числу от 1 до 50.
Так, например, если хвостовой домен частично или полностью гомологичен хвостовому домену Streptococcus pyogenes или хвостовому домену, происходящему от Streptococcus pyogenes, то (F)i может представлять собой 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’(SEQ ID NO:304), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’(SEQ ID NO:304).
В другом примере, если хвостовой домен частично или полностью гомологичен хвостовому домену Campylobacter jejuni или хвостовому домену, происходящему от Campylobacter jejuni, то (F)i может представлять собой 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’(SEQ ID NO:305), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’(SEQ ID NO:305).
В другом примере, если хвостовой домен частично или полностью гомологичен хвостовому домену Streptococcus thermophilus или хвостовому домену, происходящему от Streptococcus thermophilus, то (F)i может представлять собой 5’-UACUCAACUUGAAAAGGUGGCACCGAUUCGGUGUUUUU-3’(SEQ ID NO:309), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UACUCAACUUGAAAAGGUGGCACCGAUUCGGUGUUUUU-3’(SEQ ID NO:309).
Кроме того, (F)i может включать последовательность из 1-10 нуклеотидов у 3’-конца, участвующую в транскрипции in vitro или in vivo.
Так, например, если промотор T7 используется для in vitro транскрипции рРНК, то хвостовой домен может представлять собой произвольную нуклеотидную последовательность, присутствующую у 3’-конца матричной ДНК. Кроме того, если для транскрипции in vivo используется промотор U6, то хвостовой домен может представлять собой UUUUUU, а если для транскрипции используется промотор H1, то хвостовой домен может представлять собой UUUU, и если используется промотор pol-III, то хвостовой домен может включать несколько урациловых оснований или альтернативных нуклеотидов.
Кроме того, (X)d, (X)e и (X)f могут представлять собой селективно добавленные нуклеотидные последовательности, где каждый X может быть независимо выбран из группы, состоящей из A, U, C и G, а каждый d, e и f может означать число нуклеотидов, равное 0 или целому числу от 1 до 20.
Одноцепочечная рРНК
Одноцепочечная рРНК может быть подразделена на первую одноцепочечную рРНК и вторую одноцепочечную рРНК.
Первая одноцепочечная рРНК
Первая одноцепочечная рРНК представляет собой одноцепочечную рРНК, в которой первая цепь или вторая цепь двухцепочечной рРНК связаны посредством линкерного домена.
В частности, одноцепочечная рРНК может состоять из:
5’-[руководящего домена]-[первого комплементарного домена]- [линкерного домена]-[второго комплементарного домена]-3’,
5’-[руководящего домена]-[первого комплементарного домена]- [линкерного домена]-[второго комплементарного домена]- [проксимального домена]-3’, или
5’-[руководящего домена]-[первого комплементарного домена]- [линкерного домена]-[второго комплементарного домена]- [проксимального домена]-[хвостового домена]-3’.
Первая одноцепочечная рРНК может селективно включать дополнительную нуклеотидную последовательность.
В одном репрезентативном варианте, первая одноцепочечная рРНК может представлять собой:
5’-(Nмишень)-(Q)m-(L)j-(Z)h-3’;
5’-(Nмишень)-(Q)m-(L)j-(Z)h-(P)k-3’; или
5’-(Nмишень)-(Q)m-(L)j-(Z)h-(P)k-(F)i-3’.
В другом варианте осуществления изобретения, одноцепочечная рРНК может представлять собой:
5’-(X)a-(Nмишень)-(X)b-(Q)m-(X)c-(L)j-(X)d-(Z)h-(X)e-3’;
5’-(X)a-(Nмишень)-(X)b-(Q)m-(X)c-(L)j-(X)d-(Z)h-(X)e-(P)k-(X)f-3’; или
5’-(X)a-(Nмишень)-(X)b-(Q)m-(X)c-(L)j-(X)d-(Z)h-(X)e-(P)k-(X)f-(F)i-3’.
В данном описании, Nмишень представляет собой нуклеотидную последовательность, комплементарную неполной последовательности любой цепи двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени и области нуклеотидной последовательности, способной модифицироваться в зависимости от последовательности-мишени в области регуляции транскрипции гена-мишени.
(Q)m представляет собой нуклеотидную последовательность, включающую первый комплементарный домен, способный образовывать комплементарную связь со вторым комплементарным доменом. (Q)m может представлять собой последовательность, частично или полностью гомологичную первому комплементарному домену вида, существующего в природе, а нуклеотидная последовательность первого комплементарного домена может быть изменена в соответствии с последовательностью вида-источника. Каждый Q может быть независимо выбран из группы, состоящей из A, U, C и G, а m может означать число оснований, равное целому числу 5-35.
Так, например, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Streptococcus pyogenes или первому комплементарному домену, происходящему от Streptococcus pyogenes, то (Q)m может представлять собой 5’-GUUUUAGAGCUA-3’(SEQ ID NO:296), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GUUUUAGAGCUA-3’(SEQ ID NO:296).
В другом примере, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Campylobacter jejuni или первому комплементарному домену, происходящему от Campylobacter jejuni, то (Q)m может представлять собой 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’(SEQ ID NO:297), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’(SEQ ID NO:297).
В другом примере, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Streptococcus thermophilus или первому комплементарному домену, происходящему от Streptococcus thermophilus, то (Q)m может представлять собой 5’-GUUUUAGAGCUGUGUUGUUUCG-3’(SEQ ID NO:306), или нуклеотидная последовательность, которая по меньшей мере на 50% или более гомологична 5’-GUUUUAGAGCUGUGUUGUUUCG-3’(SEQ ID NO:306).
Кроме того, (L)j представляет собой нуклеотидную последовательность, включающую линкерный домен и соединяющую первый комплементарный домен со вторым комплементарным доменом с образованием одноцепочечной рРНК. В данном описании, каждый L может быть независимо выбран из группы, состоящей из A, U, C и G, а j может означать число нуклеотидов, равное целому числу от 1 до 30.
(Z)h представляет собой нуклеотидную последовательность, включающую второй комплементарный домен, способный образовывать комплементарную связь с первым комплементарным доменом. (Z)h может представлять собой последовательность, частично или полностью гомологичную второму комплементарному домену вида, существующего в природе, а нуклеотидная последовательность второго комплементарного домена может быть изменена в соответствии с последовательностью вида-источника. Каждый Z может быть независимо выбран из группы, состоящей из A, U, C и G, а h может означать число нуклеотидов, равное целому числу 5-50.
Так, например, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Streptococcus pyogenes или второму комплементарному домену, происходящему от Streptococcus pyogenes, то (Z)h может представлять собой 5’-UAGCAAGUUAAAAU-3’(SEQ ID NO:299), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UAGCAAGUUAAAAU-3’(SEQ ID NO:299).
В другом примере, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Campylobacter jejuni или второму комплементарному домену, происходящему от Campylobacter jejuni, то (Z)h может представлять собой 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’(SEQ ID NO:300), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’(SEQ ID NO:300).
В другом примере, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Streptococcus thermophilus или второму комплементарному домену, происходящему от Streptococcus thermophilus, то (Z)h может представлять собой 5’-CGAAACAACACAGCGAGUUAAAAU-3’(SEQ ID NO:307), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-CGAAACAACACAGCGAGUUAAAAU-3’(SEQ ID NO:307).
(P)k представляет собой нуклеотидную последовательность, включающую проксимальный домен, который может быть частично или полностью гомологичен проксимальному домену вида, существующего в природе, а нуклеотидная последовательность проксимального домена может быть модифицирована в соответствии с видом источника. Каждый P может быть независимо выбран из группы, состоящей из A, U, C и G, а k может означать число нуклеотидов, равное целому числу от 1 до 20.
Так, например, если проксимальный домен частично или полностью гомологичен проксимальному домену Streptococcus pyogenes или проксимальному домену, происходящему от Streptococcus pyogenes, то (P)k может представлять собой 5’-AAGGCUAGUCCG-3’(SEQ ID NO:302), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAGGCUAGUCCG-3’(SEQ ID NO:302).
В другом примере, если проксимальный домен частично или полностью гомологичен проксимальному домену Campylobacter jejuni или проксимальному домену, происходящему от Campylobacter jejuni, то (P)k может представлять собой 5’-AAAGAGUUUGC-3’(SEQ ID NO:303), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAAGAGUUUGC-3’(SEQ ID NO:303).
В другом примере, если проксимальный домен частично или полностью гомологичен проксимальному домену Streptococcus thermophilus или проксимальному домену, происходящему от Streptococcus thermophilus, то (P)k может представлять собой 5’-AAGGCUUAGUCCG-3’(SEQ ID NO:308), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAGGCUUAGUCCG-3’(SEQ ID NO:308).
(F)i может представлять собой последовательность оснований, включающую хвостовой домен, который может быть частично или полностью гомологичен хвостовому домену вида, существующего в природе, а последовательность оснований хвостового домена может быть модифицирована в соответствии с видом источника. Каждый F может быть независимо выбран из группы, состоящей из A, U, C и G, а i может означать число нуклеотидов, равное целому числу от 1 до 50.
Так, например, если хвостовой домен частично или полностью гомологичен хвостовому домену Streptococcus pyogenes или хвостовому домену, происходящему от Streptococcus pyogenes, то (F)i может представлять собой 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’(SEQ ID NO:304), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’(SEQ ID NO:304).
В другом примере, если хвостовой домен частично или полностью гомологичен хвостовому домену Campylobacter jejuni или хвостовому домену, происходящему от Campylobacter jejuni, то (F)i может представлять собой 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’(SEQ ID NO:305), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’(SEQ ID NO:305).
В другом примере, если хвостовой домен частично или полностью гомологичен хвостовому домену Streptococcus thermophilus или хвостовому домену, происходящему от Streptococcus thermophilus, то (F)i может представлять собой 5’-UACUCAACUUGAAAAGGUGGCACCGAUUCGGUGUUUUU-3’(SEQ ID NO:309), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UACUCAACUUGAAAAGGUGGCACCGAUUCGGUGUUUUU-3’(SEQ ID NO:309).
Кроме того, (F)i может включать последовательность из 1-10 нуклеотидов у 3’-конца, участвующую в транскрипции in vitro или in vivo.
Так, например, если промотор T7 используется для in vitro транскрипции рРНК, то хвостовой домен может представлять собой произвольную нуклеотидную последовательность, присутствующую у 3’-конца матричной ДНК. Кроме того, если для транскрипции in vivo используется промотор U6, то хвостовой домен может представлять собой UUUUUU, а если для транскрипции используется промотор H1, то хвостовой домен может представлять собой UUUU, и если используется промотор pol-III, то хвостовой домен может включать несколько урациловых оснований или альтернативных нуклеотидов.
Кроме того, (X)a, (X)b, (X)c, (X)d, (X)e и (X)f могут представлять собой селективно добавленные нуклеотидные последовательности, где каждый X может быть независимо выбран из группы, состоящей из A, U, C и G, а каждый a, b, c, d, e и f может означать число нуклеотидов, равное 0 или целому числу от 1 до 20.
Вторая одноцепочечная рРНК
Вторая одноцепочечная рРНК может представлять собой одноцепочечную рРНК, состоящую из руководящего домена, первого комплементарного домена и второго комплементарного домена.
В данном описании, вторая одноцепочечная рРНК может состоять из:
5’-[второго комплементарного домена]-[первого комплементарного домена]- [руководящего домена]-3’,
5’-[второго комплементарного домена-[линкерного домена]-[первого комплементарного домена]-[руководящего домена]-3’.
Вторая одноцепочечная рРНК может селективно включать дополнительную нуклеотидную последовательность.
В одном репрезентативном варианте осуществления изобретения, вторая одноцепочечная рРНК может представлять собой:
5’-(Z)h-(Q)m-(Nмишень)-3’; или
5’-(X)a-(Z)h-(X)b-(Q)m-(X)c-(Nмишень)-3’.
В другом варианте осуществления изобретения, одноцепочечная рРНК может представлять собой:
5’-(Z)h-(L)j-(Q)m-(Nмишень)-3’; или
5’-(X)a-(Z)h-(L)j-(Q)m-(X)c-(Nмишень)-3’.
В данном описании, Nмишень представляет собой нуклеотидную последовательность, комплементарную неполной последовательности любой цепи двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени, и области нуклеотидной последовательности, которая может быть изменена в соответствии с с последовательностью-мишенью нуклеиновой кислоты в области регуляции транскрипции гена-мишени. (Q)m представляет собой нуклеотидную последовательность, включающую первый комплементарный домен, и нуклеотидную последовательность, способную образовывать комплементарную связь со вторым комплементарным доменом. (Q)m может представлять собой последовательность, частично или полностью гомологичную первому комплементарному домену вида, существующего в природе, а нуклеотидная последовательность первого комплементарного домена может быть изменена в соответствии с последовательностью вида-источника. Каждый Q может быть независимо выбран из группы, состоящей из A, U, C и G, а m может означать число нуклеотидов, равное целому числу 5-35.
Так, например, если первый комплементарный домен частично или полностью гомологичен первому комплементарному домену Parcubacteria bacterium или первому комплементарному домену, происходящему от Parcubacteria bacterium, то (Q)m может представлять собой 5’-UUUGUAGAU-3’(SEQ ID NO:298), или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-UUUGUAGAU-3’(SEQ ID NO:298).
(Z)h представляет собой нуклеотидную последовательность, включающую второй комплементарный домен, и нуклеотидную последовательность, способную образовывать комплементарную связь со вторым комплементарным доменом. (Z)h может представлять собой последовательность, частично или полностью гомологичную второму комплементарному домену вида, существующего в природе, а нуклеотидная последовательность второго комплементарного домена может быть изменена в соответствии с последовательностью вида-источника. Каждый Z может быть независимо выбран из группы, состоящей из A, U, C и G, а h может означать число нуклеотидов, равное целому числу 5-50.
Так, например, если второй комплементарный домен частично или полностью гомологичен второму комплементарному домену Parcubacteria bacterium или второму комплементарному домену, происходящему от Parcubacteria bacterium, то (Z)h может представлять собой 5’-AAAUUUCUACU-3’(SEQ ID NO:301) или нуклеотидную последовательность, которая по меньшей мере на 50% или более гомологична 5’-AAAUUUCUACU-3’(SEQ ID NO:301).
Кроме того, (L)j представляет собой нуклеотидную последовательность, включающую линкерный домен, который соединяет первый комплементарный домен со вторым комплементарным доменом. В данном описании, каждый L может быть независимо выбран из группы, состоящей из A, U, C и G, а j может означать число нуклеотидов, равное целому числу от 1 до 30.
Кроме того, каждый (X)a, (X)b и (X)c представляет собой селективно добавленную нуклеотидную последовательность, где каждый X может быть независимо выбран из группы, состоящей из A, U, C и G, и a, b и c могут означать число нуклеотидов, равное 0 или целому числу от 1 до 20.
В одном репрезентативном варианте данного описани, руководящая нуклеиновая кислота может представлять собой рРНК, комплементарно связывающуюся с последовательностью-мишенью в области регуляции транскрипции дуплицированного гена.
«Последовательность-мишень» представляет собой нуклеотидную последовательность, присутствующую в области регуляции транскрипции гена-мишени, а в частности, неполную нуклеотидную последовательность в области-мишени в области регуляции транскрипции гена-мишени, а в данном случае, «область-мишень» представляет собой область, которая может быть модифицирована комплексом «руководящая нуклеиновая кислота - белок-редактор» в области регуляции транскрипции гена-мишени.
Далее, последовательность-мишень может быть использована для сообщения информации о нуклеотидных последовательностях двух типов. Так, например, в случае гена-мишени, последовательность-мишень может означать информацию о нуклеотидной последовательности транскрибируемой цепи ДНК гена-мишени или информацию о нуклеотидной последовательности нетранскрибируемой цепи.
Так, например, последовательность-мишень может означать неполную нуклеотидную последовательность (транскрибируемую цепь), то есть, 5’-ATCATTGGCAGACTAGTTCG-3’(SEQ ID NO:310), в обласчти-мишени гена-мишени А, и нуклеотидную последовательность, комплементарную этой последовательности (нетранскрибируемую цепь), то есть, 5’-CGAACTAGTCTGCCAATGAT-3’(SEQ ID NO:311).
Последовательность-мишень может представлять собой последовательность из 5-50 нуклеотидов.
В одном репрезентативном варианте, последовательность-мишень может представлять собой последовательность из 16 нуклеотидов, последовательность из 17 нуклеотидов, последовательность из 18 нуклеотидов, последовательность из 19 нуклеотидов, последовательность из 20 нуклеотидов, последовательность из 21 нуклеотида, последовательность из 22 нуклеотидов, последовательность из 23 нуклеотидов, последовательность из 24 нуклеотидов или последовательность из 25 нуклеотидов.
Последовательность-мишень включает последовательность, связывающуюся с руководящей нуклеиновой кислотой, или последовательность, не связывающуюся с руководящей нуклеиновой кислотой.
«Последовательность, связывающаяся с руководящей нуклеиновой кислотой» представляет собой нуклеотидную последовательность, частично или полностью комплементарную руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты, и эта последовательность может быть комплементарно связана с руководящей последовательностью, включенной в руководящий домен руководящей нуклеиновой кислоты. Последовательность-мишень и последовательность, связывающаяся с руководящей нуклеиновой кислотой, могут представлять собой нуклеотидную последовательность, которая может варьироваться в соответствии с мишенью, которая была генетически сконструирована или отредактирована в зависимости от области регуляции транскрипции гена-мишени, и могут быть сконструированы различными способами в соответствии с последовательностью нуклеиновой кислоты в области регуляции транскрипции гена-мишени.
«Последовательность, не связывающаяся с руководящей нуклеиновой кислотой», представляет собой нуклеотидную последовательность, частично или полностью гомологичную руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты, и эта последовательность не может быть комплементарно связана с руководящей последовательностью, включенной в руководящий домен руководящей нуклеиновой кислоты. Кроме того, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, комплементарную последовательности, связывающейся с руководящей нуклеиновой кислотой, и может быть комплементарно связана с последовательностью, связывающейся с руководящей нуклеиновой кислотой.
Последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой неполную нуклеотидную последовательность последовательности-мишени и одну нуклеотидную последовательность из двух нуклеотидных последовательностей, каждая из которых отличается от другой последовательности, включенной в последовательность-мишень, то есть, одну из двух нуклеотидных последовательностей, способных комплементарно связываться друг с другом. В данном случае, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, отличающуюся от последовательности, связывающейся с руководящей нуклеиновой кислотой последовательности-мишени.
Так, например, если неполная нуклеотидная последовательность, то есть, 5’-ATCATTGGCAGACTAGTTCG-3’(SEQ ID NO:310) области-мишени в области регуляции транскрипции гена-мишени А, и нуклеотидная последовательность, то есть, 5’-CGAACTAGTCTGCCAATGAT-3’(SEQ ID NO:311), комплементарная этой последовательности, используются как последовательности-мишени, то последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой одну из двух последовательностей-мишеней, то есть, 5’-ATCATTGGCAGACTAGTTCG-3’(SEQ ID NO:310) или 5’-CGAACTAGTCTGCCAATGAT-3’(SEQ ID NO:311). В данном случае, если последовательность, связывающаяся с руководящей нуклеиновой кислотой, представляет собой 5’-ATCATTGGCAGACTAGTTCG-3’(SEQ ID NO:310), то последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой 5’-CGAACTAGTCTGCCAATGAT-3’(SEQ ID NO:311), или если последовательность, связывающаяся с руководящей нуклеиновой кислотой, представляет собой 5’-CGAACTAGTCTGCCAATGAT-3’(SEQ ID NO:311), то последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой 5’-ATCATTGGCAGACTAGTTCG-3’(SEQ ID NO:310).
Последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой одну из последовательностей-мишеней, то есть, нуклеотидную последовательность, которая являются такой же, как транскрибируемая цепь, и нуклеотидную последовательность, которая является такой же, как нетранскрибируемая цепь. В данном случае, последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, отличающуюся от последовательности, связывающейся с руководящей нуклеиновой кислотой последовательностей-мишеней, то есть, одну последовательность, выбранную из нуклеотидной последовательности, которая является такой же, как транскрибируемая цепь, и нуклеотидной последовательности, которая является такой же, как нетранскрибируемая цепь.
Последовательность, связывающаяся с руководящей нуклеиновой кислотой, может иметь такую же длину, как и последовательность-мишень.
Последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может иметь такую же длину, как и последовательность-мишень или последовательность, связывающаяся с руководящей нуклеиновой кислотой.
Последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой последовательность из 5-50 нуклеотидов.
В одном репрезентативном варианте, последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой последовательность из 16 нуклеотидов, последовательность из 17 нуклеотидов, последовательность из 18 нуклеотидов, последовательность из 19 нуклеотидов, последовательность из 20 нуклеотидов, последовательность из 21 нуклеотида, последовательность из 22 нуклеотидов, последовательность из 23 нуклеотидов, последовательность из 24 нуклеотидов или последовательность из 25 нуклеотидов.
Последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой последовательность из 5-50 нуклеотидов.
В одном репрезентативном варианте, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой последовательность из 16 нуклеотидов, последовательность из 17 нуклеотидов, последовательность из 18 нуклеотидов, последовательность из 19 нуклеотидов, последовательность из 20 нуклеотидов, последовательность из 21 нуклеотида, последовательность из 22 нуклеотидов, последовательность из 23 нуклеотидов, последовательность из 24 нуклеотидов или последовательность из 25 нуклеотидов.
Последовательность, связывающаяся с руководящей нуклеиновой кислотой, может частично или полностью комплементарно связываться к руководящей последовательностью, включенной в руководящий домен руководящей нуклеиновой кислоты, а длина последовательности, связывающейся с руководящей нуклеиновой кислотой, может быть такой же, как длина руководящей последовательности.
Последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, комплементарную руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты, и, например, нуклеотидную последовательность, которая являются комплементарной по меньшей мере на 70%, 75%, 80%, 85%, 90%, 95% или более, или на 100%.
Так, например, последовательность, связывающаяся с руководящей нуклеиновой кислотой, может иметь или включать последовательность из 1-8 нуклеотидов, которая не является комплементарной руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты.
Последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может быть частично или полностью гомологичной руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты, а длина последовательности, не связывающейся с руководящей нуклеиновой кислотой, может быть такой же, как длина руководящей последовательности.
Последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, гомологичную руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты, и, например, нуклеотидную последовательность, которая являются гомологичной по меньшей мере на 70%, 75%, 80%, 85%, 90%, 95% или более, или на 100%.
В одном примере, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может иметь или включать последовательность из 1-8 нуклеотидов, которая не является гомологичной руководящей последовательности, включенной в руководящий домен руководящей нуклеиновой кислоты.
Последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может комплементарно связываться с последовательностью, связывающейся с руководящей нуклеиновой кислотой, и последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может иметь такую же длину, как последовательность, связывающаяся с руководящей нуклеиновой кислотой.
Последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, комплементарную последовательности, связывающейся с руководящей нуклеиновой кислотой, и, например, нуклеотидную последовательность, которая является комплементарной по меньшей мере на 90%, 95% или более, или на 100%.
В одном примере, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может иметь или включать последовательность из 1-2 нуклеотидов, которая не является комплементарной последовательности, связывающейся с руководящей нуклеиновой кислотой.
Кроме того, последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, расположенную возле нуклеотидной последовательности, распознаваемой белком-редактором.
В одном примере, последовательность, связывающаяся с руководящей нуклеиновой кислотой, может представлять собой непрерывную последовательность из 5-50 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца нуклеотидной последовательности, распознаваемой белком-редактором.
Кроме того, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой нуклеотидную последовательность, расположенную возле нуклеотидной последовательности, распознаваемой белком-редактором.
В одном примере, последовательность, не связывающаяся с руководящей нуклеиновой кислотой, может представлять собой непрерывную последовательность из 5-50 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца нуклеотидной последовательности, распознаваемой белком-редактором.
«Таргетинг» означает комплементарное связывание с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции гена-мишени. В данном случае, комплементарное связывание может составлять 100% или 70% или более, и менее, чем 100%, то есть, неполное комплементарное связывание. Следовательно, «нацеливающая рРНК» означает рРНК, комплементарно связывающуюся с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой и присутствующей в области регуляции транскрипции гена-мишени.
Ген-мишень, раскрытый в настоящем описании, может представлять собой дуплицированный ген.
Ген-мишень, раскрытый в настоящем описании, может представлять собой ген PMP22, ген PLP1, ген MECP2, ген SOX3, ген RAI1, ген TBX1, ген ELN, ген JAGGED1, ген NSD1, ген MMP23, ген LMB1, ген SNCA и/или ген APP.
Ген-мишень, раскрытый в настоящем описании, может представлять собой онкоген.
В данном описании, онкоген может представлять собой ген MYC, ген ERBB2 (HER2), ген CCND1 (циклина D1), ген FGFR1, ген FGFR2, ген HRAS, ген KRAS, ген MYB, ген MDM2, ген CCNE (циклина E), ген MET, ген CDK4, ген ERBB1, ген MYCN и/или ген AKT2.
В репрезентативном варианте осуществления изобретения, последовательность-мишень, раскрытая в настоящем описании, может представлять собой непрерывную последовательность из 10-35 нуклеотидов, расположенную в промоторной области дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Последовательность-мишень может представлять собой последовательность из 10-35 нуклеотидов, последовательность из 15-35 нуклеотидов, последовательность из 20-35 нуклеотидов, последовательность из 25-35 нуклеотидов или последовательность из 30-35 нуклеотидов.
Альтернативно, последовательность-мишень может представлять собой последовательность из 10-15 нуклеотидов, последовательность из 15-20 нуклеотидов, последовательность из 20-25 нуклеотидов, последовательность из 25-30 нуклеотидов или последовательность из 30-35 нуклеотидов.
В одном примере, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в центральной промоторной области дуплицированного гена.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в области, включающей TTS или возле TTS дуплицированного гена.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в области, включающей область, связывающуюся с РНК-полимеразой дуплицированного гена или рядом с этой областью.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в области, включающей область, связывающуюся с фактором транскрипции дуплицированного гена или рядом с этой областью.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в области, включающей TATA-бокс дуплицированного гена или рядом с этой областью.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю последовательность или часть последовательности 5’-TATA(A/T)A(A/T)-3’, присутствующей в центральной промоторной области дуплицированного гена.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю последовательность или часть последовательности 5’-TATA(A/T)A(A/T)(A/G)-3’, присутствующей в центральной промоторной области дуплицированного гена.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю последовательность или часть одной или более последовательностей, выбранных из группы, состоящей из последовательности 5’-CATAAAA-3’(SEQ ID NO:264), последовательности 5’-TATAA-3’(SEQ ID NO:265), последовательности 5’-TATAAAA-3’(SEQ ID NO:266), последовательности 5’-CATAAATA-3’(SEQ ID NO:267), последовательности 5’-TATATAA-3’(SEQ ID NO:268), последовательности 5’-TATATATATATATAA-3’(SEQ ID NO:269), последовательности 5’-TATATTATA-3’(SEQ ID NO:270), последовательности 5’-TATAAA-3’(SEQ ID NO:271), последовательности 5’-TATAAAATA-3’(SEQ ID NO:272), последовательности 5’-TATATA-3’(SEQ ID NO:273), последовательности 5’-GATTAAAAA-3’(SEQ ID NO:274), последовательности 5’-TATAAAAA-3’(SEQ ID NO:275), последовательности 5’-TTATAA-3’(SEQ ID NO:276), последовательности 5’-TTTTAAAA-3’(SEQ ID NO:277), последовательности 5’-TCTTTAAAA-3’(SEQ ID NO:278), последовательности 5’-GACATTTAA-3’(SEQ ID NO:279), последовательности 5’-TGATATCAA-3’(SEQ ID NO:280), последовательности 5’-TATAAATA-3’(SEQ ID NO:281), последовательности 5’-TATAAGA-3’(SEQ ID NO:282), последовательности 5’-AATAAA-3’(SEQ ID NO:283), последовательности 5’-TTTATA-3’(SEQ ID NO:284), последовательности 5’-CATAAAAA-3’(SEQ ID NO:285), последовательности 5’-TATACA-3’(SEQ ID NO:286), последовательности 5’-TTTAAGA-3’(SEQ ID NO:287), последовательности 5’-GATAAAG-3’(SEQ ID NO:288), последовательности 5’-TATAACA-3’(SEQ ID NO:289), последовательности 5’-TCTTATCTT-3’(SEQ ID NO:290), последовательности 5’-TTGTACTTT-3’(SEQ ID NO:291), последовательности 5’-CATATAA-3’(SEQ ID NO:292), последовательности 5’-TATAAAT-3’(SEQ ID NO:293), последовательности 5’-TATATATAAAAAAAA-3’(SEQ ID NO:294) и последовательности 5’-CATAAATAAAAAAAATTA-3’(SEQ ID NO:295). которые присутствуют в центральной промоторной области дуплицированного гена.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, включающую всю последовательность или часть последовательности нуклеиновой кислоты, связывающейся с TATA-связывающим белком (TBP), и присутствующей в центральной промоторной области дуплицированного гена.
В другом примере, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в проксимальной промоторной области дуплицированного гена.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в области, которая на 1-300 п.о. выше TSS дуплицированного гена.
В другом примере, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в дистальной промоторной области дуплицированного гена.
Последовательность-мишень, раскрытая в настоящем описании, может представлять собой непрерывную последовательность из 10-35 нуклеотидов, расположенную в энхансерной области дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Последовательность-мишень может представлять собой последовательность из 10-35 нуклеотидов, последовательность из 15-35 нуклеотидов, последовательность из 20-35 нуклеотидов, последовательность из 25-35 нуклеотидов или последовательность из 30-35 нуклеотидов.
Альтернативно, последовательность-мишень может представлять собой последовательность из 10-15 нуклеотидов, последовательность из 15-20 нуклеотидов, последовательность из 20-25 нуклеотидов, последовательность из 25-30 нуклеотидов или последовательность из 30-35 нуклеотидов.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную в области, включающей энхансер-бокс (Е-бокс) дуплицированного гена или рядом с этой областью.
Так, например, последовательность-мишень может представлять собой непрерывную последовательность из 10-55 нуклеотидов, расположенную в энхансерной области, присутствующей в интроне дуплицированного гена.
Последовательность-мишень, раскрытая в настоящем описании, может представлять собой непрерывную последовательность из 10-35 нуклеотидов, расположенную в изоляторной области дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Последовательность-мишень может представлять собой последовательность из 10-35 нуклеотидов, последовательность из 15-35 нуклеотидов, последовательность из 20-35 нуклеотидов, последовательность из 25-35 нуклеотидов или последовательность из 30-35 нуклеотидов.
Альтернативно, последовательность-мишень может представлять собой последовательность из 10-15 нуклеотидов, последовательность из 15-20 нуклеотидов, последовательность из 20-25 нуклеотидов, последовательность из 25-30 нуклеотидов или последовательность из 30-35 нуклеотидов.
Последовательность-мишень, раскрытая в настоящем описании, может представлять собой непрерывную последовательность из 10-35 нуклеотидов, расположенную в сайленсерной области дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Последовательность-мишень может представлять собой последовательность из 10-35 нуклеотидов, последовательность из 15-35 нуклеотидов, последовательность из 20-35 нуклеотидов, последовательность из 25-35 нуклеотидов или последовательность из 30-35 нуклеотидов.
Альтернативно, последовательность-мишень может представлять собой последовательность из 10-15 нуклеотидов, последовательность из 15-20 нуклеотидов, последовательность из 20-25 нуклеотидов, последовательность из 25-30 нуклеотидов или последовательность из 30-35 нуклеотидов.
Последовательность-мишень, раскрытая в настоящем описании, может представлять собой непрерывную последовательность из 10-35 нуклеотидов, расположенную в регуляторной области локуса (LCR) дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Последовательность-мишень может представлять собой последовательность из 10-35 нуклеотидов, последовательность из 15-35 нуклеотидов, последовательность из 20-35 нуклеотидов, последовательность из 25-35 нуклеотидов или последовательность из 30-35 нуклеотидов.
Альтернативно, последовательность-мишень может представлять собой последовательность из 10-15 нуклеотидов, последовательность из 15-20 нуклеотидов, последовательность из 20-25 нуклеотидов, последовательность из 25-30 нуклеотидов или последовательность из 30-35 нуклеотидов.
Последовательность-мишень, раскрытая в настоящем описании, может представлять собой непрерывную последовательность из 10-35 нуклеотидов, которая находится рядом с 5’-концом и/или 3’-концом последовательности мотива, смежного с протоспейсером (PAM), где указанная последовательность расположена в области регуляции транскрипции дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
В данном случае, область регуляции транскрипции дуплицированного гена может представлять собой промотор, энхансер, сайленсер, изолятор или регуляторную область локуса (LCR) дуплицированного гена.
«Последовательности мотива, смежного с протоспейсером (PAM)» представляет собой нуклеотидную последовательность, которая может распознаваться белком-редактором. В данном случае, последовательности РАМ могут иметь различные нуклеотидные последовательности, в зависимости от типа белка-редактора и вида, от которого он происходит.
В данном случае, последовательность PAM может представлять собой, например, одну или более из нижеследующих последовательностей (записанных в направлении 5’ → 3’):
NGG (N представляет собой A, T, C или G);
NNNNRYAC (каждый N независимо представляет собой A, T, C или G, R представляет собой A или G, а Y представляет собой C или T);
NNAGAAW (каждый N независимо представляет собой A, T, C или G, а W представляет собой A или T);
NNNNGATT (каждый N независимо представляет собой A, T, C или G);
NNGRR(T) (каждый N независимо представляет собой A, T, C или G, R представляет собой A или G, а Y представляет собой C или T); и
TTN (N представляет собой A, T, C или G).
Последовательность-мишень может представлять собой последовательность из 10-35 нуклеотидов, последовательность из 15-35 нуклеотидов, последовательность из 20-35 нуклеотидов, последовательность из 25-35 нуклеотидов или последовательность из 30-35 нуклеотидов.
Альтернативно, последовательность-мишень может представлять собой последовательность из 10-15 нуклеотидов, последовательность из 15-20 нуклеотидов, последовательность из 20-25 нуклеотидов, последовательность из 25-30 нуклеотидов или последовательность из 30-35 нуклеотидов.
В репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-NGG-3’, 5’-NAG-3’ и/или 5’-NGA-3’ (N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-NGG-3’, 5’-NAG-3’ и/или 5’-NGA-3’ (N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
В другом репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-NGGNG-3’ и/или 5’-NNAGAAW-3’ (W=A или T, и N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-NGGNG-3’ и/или 5’-NNAGAAW-3’ (W=A или T, и N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
В другом репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-NNNNGATT-3’ и/или 5’-NNNGCTT-3’ (N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-NNNNGATT-3’ и/или 5’-NNNGCTT-3’ (N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
В одном репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-NNNVRYAC-3’ (V=G, C или A; R=A или G, Y=C или T, N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-NNNVRYAC-3’ (V=G, C или A; R=A или G, Y=C или T, N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
В другом репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-NAAR-3’(R=A или G, N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-NAAR-3’(R=A или G, N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
В другом репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-NNGRR-3’, 5’-NNGRRT-3’ и/или 5’-NNGRRV-3’ (R=A или G, V=G, C или A, N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-NNGRR-3’, 5’-NNGRRT-3’ и/или 5’-NNGRRV-3’ (R=A или G, V=G, C или A, N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
В одном репрезентативном варианте осуществления изобретения, если последовательность РАМ, распознаваемая белком-редактором, представляет собой 5’-TTN-3’ (N=A, T, G или C; или A, U, G или C), то последовательность-мишень может представлять собой непрерывную последовательность из 10-25 нуклеотидов, расположенную возле 5’-конца и/или 3’-конца последовательности 5’-TTN-3’ (N=A, T, G или C; или A, U, G или C) в области регуляции транскрипции дуплицированного гена.
Далее, примеры последовательностей-мишеней, которые могут быть использованы в репрезентативном варианте, раскрытом в настоящем описании, перечислены в Таблицах 1, 2, 3, 4, 5 и 6. Последовательности-мишени, перечисленные в Таблицах 1, 2, 3, 4, 5 и 6, представляют собой последовательности, не связывающиеся с руководящей нуклеиновой кислотой, и комплементарные им последовательности, то есть, последовательности, связывающиеся с руководящей нуклеиновой кислотой, могут быть предсказаны исходя из последовательностей, перечисленных в Таблицах. Кроме того, оцрРНК, представленные в Таблицах 1, 2, 3, 4, 5 и 6, были обозначены Sp для SpCas9 и Cj для CjCas9 в зависимости от белка-редактора.
Таблица 1
Последовательности-мишени человеческого гена РМР22 для SpCas9
Таблица 2
Последовательности-мишени человеческого гена РМР22 для CjCas9
Таблица 3
Последовательности-мишени человеческого гена PLP1 для SpCas9
спаривание 0
спаривание 1
спаривание 2
TGGGA
GCTAA
TATCT
TCATC
TTCCC
ATTCG
CATCT
TCCCA
TTCGT
GAATG
GGAAG
ATGAA
TCCCA
TTCGT
GGGCA
ACCTT
GCCCA
CGAAT
CACCT
TGCCC
ACGAA
TGCTT
GCACA
TAAAT
TTATG
TGCAA
GCATT
TTTAT
GTGCA
AGCAT
GCGTC
TGAAG
AGGAG
CGTCT
GAAGA
GGAGT
GTCTG
AAGAG
GAGTG
CAGAT
GCTGT
TGCCG
CACGG
CAACA
GCATC
GATTT
AGTAT
TACCA
TCGTG
TCCAA
AGAGG
TCTCA
GCCTC
CTCTT
CAAGG
TTAAC
TAAA
CAAAT
CATGT
GGAC
GATAG
TCAAA
TCATG
ATTTG
ACTAT
CCAGC
ACTAT
CCAGC
AGGCT
GAAGT
CTCTG
GGGCC
AGTCC
CGAAG
TCTCT
CAGTC
CCGAA
GTCTC
ACCAC
ATTCA
AGTGC
ATAAC
GAAGT
TGTGT
TATAA
CGAAG
TTGTG
TTTGT
TCACC
CCAAC
CTTGA
AATCC
TGTTG
ATTAG
GAGAA
ACAGA
AGTGA
CATAG
ACATT
CCTGA
CTTTG
ATGAA
AATGT
TATTA
CTATA
GCGAG
ATGAG
AGAGT
AGTCT
GTACT
TAGAC
CTCTT
GAGAG
AGCCA
Таблица 4
Последовательности-мишени человеческого гена PLP1 для CjCas9
спаривание 0
спаривание 1
спаривание 2
AAGAT
GAAAG
GGAAG
TA
GATTG
TTAAA
ACTTA
TC
TACCT
CAGCT
TCCCA
AT
CTTGC
ACATA
AATTG
GA
GAGAG
AGACA
GAATG
A
TTCAG
ACGCG
CACAC
AC
TCTTC
AGACG
CGCAC
AC
CCTCT
TCAGA
CGCGC
AC
CTCCT
CTTCA
GACGC
GC
CACTC
CTCTT
CAGAC
GC
CCCAC
TCCTC
TTCAG
AC
TCCCC
ACTCC
TCTTC
AG
ATCTG
GACTA
TCTTG
TT
CCAGA
TGCTG
TTGCC
GT
GAATC
TCAGC
CTCCT
CT
CTGCT
AGTGT
GCTTA
AT
AATTC
AGTAC
AAGAA
TT
TGAAT
TCAGT
ACAAG
AA
ATTTC
TGTTT
ATGTG
AA
CAGAA
ATGAA
AG
AACTC
TCTCA
TCTCG
CA
ATTCT
CACAT
TTCCA
GT
Таблица 5
Последовательности-мишени мишиного гена Plp1 для SpCas9
спаривание 0
спаривание 1
спаривание 2
GGTAG
TATAG
TAAGT
AGAAA
AGATC
AAGCC
GACTG
TGACC
TGATA
TTCAC
ACTTT
AACCA
TTGAG
ACAAT
GTTCC
TCATG
TGCAA
ACATT
CAGTT
TATAC
TTAGC
AGTTT
ATACT
TAGCT
ACCTC
AGGCT
CAACA
GTTTC
GGAAT
ACCTC
GACTA
CTTTG
ATGAA
CAAGA
TGATT
ATTTG
GGTTC
ATAGA
AATTT
TGCAT
GGCAG
AGCTT
TTAAC
CAAGG
AAAGA
GATCC
CCTCT
TTCCT
GGAGG
CCAAA
ATACA
TGTTT
GCACA
TGAAT
AGATG
CTGTC
CCTGA
GCCAT
TCAAA
CACAA
ACCCT
GTTGA
GCCTG
TACCT
CAGGC
TCAAC
AATGT
GAATT
CTAAC
TATTC
TATTA
GAGCT
GTAAT
GAAAT
GGACA
ACTGC
CTTAT
TAGGC
TCAAA
TGGGT
TCTAA
ATTCA
AGAGC
TCAAA
GATTG
GTTAC
ACTTG
TGCTG
CTACT
ACTTA
TGCCT
AATAA
GGCAG
GGAGA
GTCAG
TGGGA
GTGAG
TCTCA
GATTA
CAGAT
TGGTT
ACACT
AGATT
GGTTA
CACTT
ATTGG
TTACA
CTTGG
TTGGT
TACAC
TTGGG
Таблица 6
Последовательности-мишени мишиного гена Plp1 для CjCas9
спаривание 0
спаривание 1
спаривание 2
TACTA
TACTA
CCAAA
CA
CTACT
TACTA
TACTA
CC
GCCTA
CTTAC
TATAC
TA
TGAAT
CAAAA
GCCTA
CT
GGGAT
TCTAC
AAGTC
AC
GAGGG
GATCT
GGTAG
CA
CTGGT
AGCAT
AAAGT
AC
TCACT
AGCGA
CAAGT
GT
TGCAA
ACATT
TGGAG
GC
ACAGA
GAGGG
GGCGG
AG
GACGC
CATCA
CATCA
CA
CTATA
AGCTC
TCTGT
TTC
AAAGT
AGTCG
ACAGT
CA
TCTAA
CAGGA
AAACT
CA
TGCTA
CTACT
TATGG
TG
CCATA
AGTAG
TAGCA
GC
GTAGT
AGCAG
CAGTG
AT
TGGCT
TGCGA
ACAAA
GA
CTTTG
TTCGC
AAGCC
AT
GCATC
TCTAA
CGTGA
AC
GTTAG
AGATG
CAGCA
AA
GCAAC
TCTAA
ATCAC
CA
AAGTT
CTGTC
ACCCA
GT
GAGCT
CAAAT
GGGTT
CT
TGTGG
TATAA
GTGCT
AA
AGTGC
TAATA
TCATA
CA
TCCTG
TATGA
TATTA
GC
TGTGT
TTCCT
GTATG
AT
AATTA
TCAGG
CAGTG
AC
ATACT
AGAGT
AGCTG
TG
ATAGC
CATTC
AAATG
GC
ATCTC
CCTAA
GTCTC
GA
В одном из аспектов, раскрытых в настоящем описании, композиция для регуляции экспрессии может включать руководящую нуклеиновую кислоту и белок-редактор.
Композиция для регуляции экспрессии может включать:
(а) руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, локализованную в области регуляции транскрипции дуплицированного гена, или последовательность нуклеиновой кислоты, кодирующую эту последовательность; и
(b) одну или более последовательностей белков-редакторов или последовательностей нуклеиновой кислоты, кодирующих эти белки.
Описание дуплицированного гена приводится выше.
Описание области регуляции транскрипции приводится выше.
Описание последовательности-мишени приводится выше.
Композиция для регуляции экспрессии может включать комплекс «руководящая нуклеиновая кислота - белок-редактор».
Термин «комплекс «руководящая нуклеиновая кислота - белок-редактор» означает комплекс, образующийся в результате взаимодействия руководящей нуклеиновой кислоты и белка-редактора.
Описание руководящей нуклеиновой кислоты приводится выше.
Термин «белок-редактор» означает пептид, полипептид или белок, способные непосредственно связываться или взаимодействовать без непосредственного связывания с нуклеиновой кислотой.
В данном описании, нуклеиновая кислота может представлять собой нуклеиновую кислоту, включенную в нуклеиновую кислоту-, ген- или хромосому-мишень.
В данном описании, нуклеиновая кислота может представлять собой руководящую нуклеиновую кислоту,
Белком-редактором может быть фермент.
В данном описании, термин «фермент» означает полипептид или белок содержащий домен, способный расщеплять нуклеиновую кислоту, ген или хромосому.
Фермент может представлять собой нуклеазу или рестриктирующий фермент.
Белок-редактор может включать полностью активный фермент.
В данном описании, термин «полностью активный фермент» означает фермент, имеющий такую же функцию, как и фермент дикого типа, расщепляющий нуклеиновую кислоту, ген или хромосому. Так, например, фермент дикого типа, расщепляющий двухцепочечную ДНК, может представлять собой полностью активный фермент, способный полностью расщеплять двухцепочечную ДНК. В другом примере, если фермент дикого типа, расщепляющий двухцепочечную ДНК, имеет замену или делецию в неполной аминокислотной последовательности в результате искусственного конструирования, то такой искусственно сконструированный вариант фермента расщепляет двухцепочечную ДНК подобно ферменту дикого типа, то есть, искусственно сконструированный вариант фермента может представлять собой полностью активный фермент.
Кроме того, полностью активный фермент может включать фермент, обладающий улучшенной функцией по сравнению с ферментом дикого типа. Так, например, специфически модифицированный или измененный фермент дикого типа, расщепляющий двухцепочечную ДНК, может обладать полной ферментативной активностью, которая превышает активность фермента дикого типа, то есть, активность расщепления двухцепочечной ДНК.
Белок-редактор может включать не полностью или частично активный фермент.
Используемый здесь термин «не полностью или частично активный фермент» означает фермент, имеющий некоторые функции фермента дикого типа, а именно, способность расщеплять нуклеиновую кислоту, ген или хромосому. Так, например, специфически модифицированный или измененный фермент дикого типа, расщепляющий двухцепочечную ДНК, может представлять собой форму, обладающую первой функцией, или форму, обладающую второй функцией. В данном случае, первая функция заключется в расщеплении первой цепи двухцепочечной ДНК, а вторая функция может заключаться в расщеплении второй цепи двухцепочечной ДНК. В данном случае, фермент с первой функцией или фермент со второй функцией могут представлять собой не полностью или частично активные ферменты.
Белок-редактор может включать неактивный фермент.
Используемый здесь термин «неактивный фермент» означает фермент, в котором функция фермента дикого типа, заключающаяся в расщеплении нуклеиновой кислоты, гена или хромосомы, является полностью инактивированной. Так, например, специфически модифицированная или измененная форма фермента дикого типа может представлять собой форму, при которой первая и вторая функции теряются, то есть, теряется первая функция расщепления первой цепи двухцепочечной ДНК и вторая функция расщепления второй цепи этой ДНК. В данном случае, фермент, в котором отсутствуют первая и вторая функции, может представлять собой неактивный фермент.
Белок-редактор может представлять собой гибридный белок.
В данном описании, термин «гибридный белок» означает белок, полученный путем присоединения фермента к дополнительному домену, пептиду, полипептиду или белку.
Дополнительный домен, пептид, полипептид или белок могут представлять собой функциональный домен, пептид, полипептид или белок, функция которого является такой же, как функция фермента, или отличается от функции фермента.
Гибридный белок может представлять собой форму, при которой функциональный домен, пептид, полипептид или белок присоединен к одному или более амино-концу фермента или поблизости от него; к карбоксильному концу фермента или поблизости от него; к центральной части фермента; либо они присоединены в любых комбинациях.
В данном случае, функциональный домен, пептид, полипептид или белок могут представлять собой домен, пептид, полипептид или белок, обладающие метилазной активностью, демитилазной активностью, активностью в активации транскрипции, активностью в ингибировании транскрипции, активностью в высвобождении фактора транскрипции, активностью в модификации гистона, активностью в расщеплении РНК или связывании с нуклеиновой кислотой; или метку или репортерный ген для выделения и очистки белка (включая пептид), однако, настоящее изобретение не ограничивается ими.
Функциональный домен, пептид, полипептид или белок могут представлять собой дезаминазу. Метка включает гистидиновую (His) метку, V5-метку, FLAG-метку, метку гемаглютинина вируса гриппа (HA), Myc-метку, VSV-G-метку и тиоредоксиновую метку (Trx), а ген-репортер включает ген глутатион-S-трансферазы (GST), пероксидазы хрена (ПХ), хлорамфеникол-ацетилтрансферазы (CAT), β-галактозидазы, β-глюкуронидазы, люциферазы, аутофлуоресцентных белков, включая белок, флуоресцирующий в зеленом диапазоне спектра (GFP), HcRed, DsRed, белок, флуоресцирующий в голубом диапазоне спектра (CFP), белок, флуоресцирующий в желтом диапазоне спектра (YFP), и белок, флуоресцирующий в синем диапазоне спектра (BFP), однако, настоящее изобретение не ограничивается ими.
Кроме того, функциональный домен, пептид, полипептид или белок могут представлять собой последовательность или сигнал локализации в ядре (NLS) или последовательность или сигнал экспорта из ядра (NES).
NLS может представлять собой NLS крупного Т-антигена вируса SV40 с аминокислотной последовательностью PKKKRKV(SEQ ID NO:312); NLS, происходящий от нуклеоплазмина (например, двухкомпонентного NLS нуклеоплазмина с последовательностью KRPAATKKAGQAKKKK(SEQ ID NO:313)); NLS c-myc с аминокислотной последовательностью PAAKRVKLD(SEQ ID NO:314) или RQRRNELKRSP(SEQ ID NO:315); NLS hRNPA1 M9 с последовательностью NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY(SEQ ID NO:316); последовательность домена IBB, происходящего от импортина-α, RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV(SEQ ID NO:317); последовательность T-белка миомы VSRKRPRP(SEQ ID NO:318) и PPKKARED(SEQ ID NO:319); последовательность человеческого p53,PQPKKKPL (SEQ ID NO:320); последовательность мышиного c-abl IV, SALIKKKKKMAP (SEQ ID NO:321); последовательность вируса гриппа NS1, DRLRR (SEQ ID NO:322) и PKQKKRK (SEQ ID NO:323); последовательность антигена вируса гепатита дельта, RKLKKKIKKL (SEQ ID NO:324); последовательность мышиного белка Mx1, REKKKFLKRR (SEQ ID NO:325); последовательность человеческой поли(АДФ-рибозо)полимеразы, KRKGDEVDGVDEVAKKKSKK (SEQ ID NO:326); или последовательность RKCLQAGMNLEARKTKK (SEQ ID NO:327), происходящую от глюкокортикоида рецептора стероидного гормона (человеческого), однако, настоящее изобретение не ограничивается ими.
Дополнительный домен, пептид, полипептид или белок могут представлять собой нефункциональный домен, пептид, полипептид или белок, специфическая функция которых не осуществляется. В данном случае, нефункциональный домен, пептид, полипептид или белок могут представлять собой домен, пептид, полипептид или белок, которые не влияют на функцию фермента.
Гибридный белок может представлять собой форму, при которой нефункциональный домен, пептид, полипептид или белок присоединен к одному или более амино-концу фермента или поблизости от него; к карбоксильному концу фермента или поблизости от него; к центральной части фермента; либо они присоединены в любых комбинациях.
Белок-редактор может представлять собой природный фермент или гибридный белок.
Белок-редактор может присутствовать в форме частично модифицированного природного фермента или гибридного белка.
Белок-редактор может представлять собой искусственно продуцированный фермент или гибридный белок, не существующий в природе.
Белок-редактор может присутствовать в форме частично модифицированного искусственного фермента или гибридного белка, не существующего в природе.
В данном описании, модификация может представлять собой замену, удаление, добавление аминокислот, содержащихся в белке-редакторе или их комбинацию.
Альтернативно, модификация может представлять собой замену, удаление, добавление некоторых нуклеотидов в нуклеотидную последовательность, кодирующую белок-редактор или их комбинацию.
Кроме того, композиция для регуляции экспрессии может также включать, но необязательно, донор, имеющий нужную специфическую нуклеотидную последовательность, которая должна быть встроена, или последовательность нуклеиновой кислоты, кодирующую эту последовательность.
В данном случае, встроенная последовательность нуклеиновой кислоты может представлять собой неполную нуклеотидную последовательность в области регуляции транскрипции дуплицированного гена.
В данном случае, встроенная последовательность нуклеиновой кислоты может представлять собой последовательность нуклеиновой кислоты, используемую для введения мутации в область регуляции транскрипции дуплицированного гена. В данном случае, мутацией может быть мутация, которая негативно влияет на транскрипцию дуплицированного гена.
Термин «донор» означает нуклеотидную последовательность, которая способствует репарации поврежденного гена или поврежденной нуклеиновой кислоты на основе гомологичной рекомбинации (HR).
Донором может быть двухцепочечная или одноцепочечная нуклеиновая кислота.
Донор может присутствовать в линейной или в кольцевой форме.
Донор может включать нуклеотидную последовательность, гомологичную нуклеиновой кислоте в области регуляции транскрипции гена-мишени.
Так, например, донор может включать нуклеотидную последовательность, гомологичную каждой нуклеотидной последовательности в положении, в котором была встроена специфическая нуклеотидная последовательность, например, выше (слева) и ниже (справа) от поврежденной нуклеиновой кислоты. В частности, встроенная специфическиая нуклеотидная последовательность может быть локализована между нуклеотидной последовательностью, гомологичной нуклеотидной последовательности, расположенной ниже поврежденной нуклеиновой кислоты, и нуклеотидной последовательностью, гомологичной нуклеотидной последовательности, расположенной выше поврежденной нуклеиновой кислоты. В данном случае, нуклеотидная последовательность может быть гомологичной по меньшей мере на 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% или 95% или более или полностью гомологичной.
Донор может включать специфическую последовательность нуклеиновой кислоты.
В данном случае, специфическая последовательность нуклеиновой кислоты может представлять собой неполную нуклеотидную последовательность гена-мишени или нуклеотидную последовательность, аналогичную этой последовательности. Неполная нуклеотидная последовательность гена-мишени может включать, например, обычную последовательность нуклеиновой кислоты, в которой мутация для редактирования гена-мишени, имеющего мутацию, была отредактирована. Альтернативно, аналогичная неполная нуклеотидная последовательность гена-мишени может включать индуцированную мутацией последовательность нуклеиновой кислоты, в которой часть неполной обычной последовательности нуклеиновой кислоты гена-мишени для мутации нормального гена-мишени была модифицирована.
В данном случае, специфическая последовательность нуклеиновой кислоты может представлять собой экзогенную последовательность нуклеиновой кислоты. Так, например, экзогенная последовательность нуклеиновой кислоты может представлять собой экзогенный ген, который предпочтительно экспрессируется в клетках, имеющих ген-мишень.
В данном случае, специфическая последовательность нуклеиновой кислоты может представлять собой последовательность нуклеиновой кислоты, которая предпочтительно экспрессируется в клетках, имеющих ген-мишень. Так, например, специфическая последовательность нуклеиновой кислоты может представлять собой специфический ген, экспрессируемый в клетках, имеющих ген-мишень, и в этом случае, специфический ген может иметь увеличенное число копий в клетках из-за присутствия композиции для регуляции экспрессии, имеющей донор, и тем самым, может экспрессироваться на высоком уровне.
Донор может включать, но необязательно, дополнительную нуклеотидную последовательность. В данном случае, дополнительная нуклеотидная последовательность может способствовать повышению стабильности донора, эффективности встраивания в мишень или эффективности гомологичной рекомбинации.
Так, например, дополнительная нуклеотидная последовательность может представлять собой последовательность нуклеиновой кислоты, богатую основаниями А и Т, то есть, A-T-богатый домен. Так, например, дополнительная нуклеотидная последовательность может представлять собой область присоединения каркаса/матрицы (SMAR).
Руководящая нуклеиновая кислота, белок-редактор или комплекс «руководящая нуклеиновая кислота - белок-редактор», раскрытые в настоящем описании, могут быть доставлены или введены индивидууму различными способами.
Используемый здесь термин «индивидуум» означает организм, в который вводят руководящую нуклеиновую кислоту, белок-редактор или комплекс «руководящая нуклеиновая кислота - белок-редактор»; организм, в котором функционируют руководящая нуклеиновая кислота, белок-редактор или комплекс «руководящая нуклеиновая кислота - белок-редактор», или образец или пробу, взятые из этого организма.
Индивидуумом может быть организм, включающий ген-мишень или хромосому-мишень, состоящие из комплекса «руководящая нуклеиновая кислота - белок-редактор».
Организмом может быть животное, ткань животного или клетка животного.
Организмом может быть человек, ткань человека или клетка человека.
Тканями могут быть ткани глазного яблока, кожи, печени, почек, сердца, легких, головного мозга или мышцы, или кровь.
Клетками могут быть фибробласты, шванновские клетки, нервные клетки, олигодендроциты, миобласты, глиальные клетки, макрофаги, иммунные клетки, гепатоциты, пигментные эпителиальные клетки сетчатки, раковые клетки или стволовые клетки.
Образец или проба могут быть взяты из организма, включающего ген-мишень или хромосому-мишень, и могут представлять собой слюну, кровь, ткань сетчатки, ткань головного мозга, шванновские клетки, олигодендроциты, миобласты, фибробласты, нейроны, глиальные клетки, макрофаги, гепатоциты, иммунные клетки, раковые клетки или стволовые клетки.
Предпочтительным индивидуумом может быть организм, имеющий дуплицированный ген. В данном случае, индивидуумом может быть организм, в котором дуплицированный ген находится в состоянии дупликации.
Руководящая нуклеиновая кислота, белок-редактор или комплекс «руководящая нуклеиновая кислота - белок-редактор» могут быть доставлены или введены индивидууму в форме ДНК, РНК или в смешанной форме.
В данном случае, руководящая нуклеиновая кислота и/или белок-редактор могут быть доставлены или введены индивидууму в форме ДНК, РНК или в смешанной форме известным методом.
Или, форма ДНК, РНК или их смесь, которые кодируют руководящую нуклеиновую кислоту и/или белок-редактор, могут быть доставлены или введены индивидууму посредством вектора, не-векторного соединения или их комбинации.
Вектором может быть вирусный или невирусный вектор (например, плазмида).
Не-векторным соединением может быть «оголенная» ДНК, ДНК-комплекс или мРНК.
В одном репрезентативном варианте осуществления изобретения, последовательность нуклеиновой кислоты, кодирующая руководящую нуклеиновую кислоту и/или белок-редактор, может быть доставлена или введена индивидууму посредством вектора.
Вектор может включать последовательность нуклеиновой кислоты, кодирующую руководящую нуклеиновую кислоту и/или белок-редактор.
В одном примере, вектор может одновременно включать последовательности нуклеиновой кислоты, кодирующие руководящую нуклеиновую кислоту и белок-редактор, соответственно.
В другом примере, вектор может включать последовательность нуклеиновой кислоты, кодирующую руководящую нуклеиновую кислоту.
Так, например, домены, включенные в руководящую нуклеиновую кислоту, могут содержаться в одном векторе, либо они могут быть разделены, а затем помещены в различные векторы.
В другом примере, вектор может включать последовательность нуклеиновой кислоты, кодирующую белок-редактор.
Так, например, в случае белка-редактора, последовательность нуклеиновой кислоты, кодирующая белок-редактор, может содержаться в одном векторе, либо она может быть разделена, а затем помещена в несколько векторов.
Вектор может включать один или более регуляторных/контрольных компонентов.
В данном описании, регуляторные/контрольные компоненты могут включать промотор, энхансер, интрон, сигнал полиаденилирования, консенсусную последовательность Козака, внутренний сайт связывания с рибосомой (IRES), акцептор сплайсинга и/или последовательность 2A.
Промотором может быть промотор, распознаваемый РНК-полимеразой II.
Промотором может быть промотор, распознаваемый РНК-полимеразой III.
Промотором может быть индуцибельный промотор.
Промотором может быть промотор, специфичный для индивидуума.
Промотором может быть вирусный или невирусный промотор.
В качестве промотора может быть использован подходящий промотор в зависимости от регуляторной области (то есть, последовательности нуклеиновой кислоты, кодирующей руководящую нуклеиновую кислоту или белок-редактор).
Так, например, промотором, подходящим для руководящей нуклеиновой кислоты, может быть промотор H1, EF-1a, тРНК или U6. Так, например, промотором, подходящим для белка-редактора, может быть промотор CMV, EF-1a, EFS, MSCV, PGK или CAG.
Вектором может быть вирусный вектор или рекомбинантный вирусный вектор.
Вирусом может быть ДНК-вирус или РНК-вирус.
В данном описании, ДНК-вирусом может быть вирус на основе двухцепочечной ДНК (дцДНК) или одноцепочечной ДНК (оцДНК).
В данном описании, РНК-вирусом может быть вирус на основе одноцепочечной РНК (оцРНК).
Вирусом может быть ретровирус, лентивирус, аденовирус, аденоассоциированный вирус (AAV), вирус осповакцины, поксвирус или вирус простого герпеса, однако, настоящее изобретение не ограничивается ими.
В общих чертах, вирус может инфицировать хозяина (например, клетки), и, тем самым, вводить нуклеиновую кислоту, кодирующую генетическую информацию вируса, хозяину или встраивать нуклеиновую кислоту, кодирующую генетическую информацию, в геном хозяина. Руководящая нуклеиновая кислота и/или белок-редактор могут быть введены индивидууму с использованием вируса, обладающего таким свойством. Руководящая нуклеиновая кислота и/или белок-редактор, вводимые с использованием вируса, могут временно экспрессироваться у индивидуума (например, в клетках). Альтернативно, руководящая нуклеиновая кислота и/или белок-редактор, вводимые с использованием вируса, могут экспрессироваться у индивидуума (например, в клетках) в течение длительного периода времени (например, в течение 1, 2 или 3 недель, 1, 2, 3, 6 или 9 месяцев, 1 года или 2 лет или постоянно).
Упаковывающая емкость вируса может варьироваться по меньшей мере от 2 т.п.о. до 50 т.п.о. в зависимости от типа вируса. В зависимости от такой упаковывающей емкости может быть сконструирован вирусный вектор, включающий руководящую нуклеиновую кислоту или белок-редактор, или вирусный вектор, включающий руководящую нуклеиновую кислоту и белок-редактор. Альтернативно, может быть сконструирован вирусный вектор, включающий руководящую нуклеиновую кислоту, белок-редактор и дополнительные компоненты.
В одном примере, последовательность нуклеиновой кислоты, кодирующая руководящую нуклеиновую кислоту и/или белок-редактор, может быть доставлена или введена посредством рекомбинантного лентивируса.
В другом примере, последовательность нуклеиновой кислоты, кодирующая руководящую нуклеиновую кислоту и/или белок-редактор, может быть доставлена или введена посредством рекомбинантного аденовируса.
В другом примере, последовательность нуклеиновой кислоты, кодирующая руководящую нуклеиновую кислоту и/или белок-редактор, может быть доставлена или введена посредством рекомбинантного AAV.
В другом примере, последовательность нуклеиновой кислоты, кодирующая руководящую нуклеиновую кислоту и/или белок-редактор, может быть доставлена или введена посредством гибридного вируса, например, одного или более гибридных вирусов, перечисленных в настоящей заявке.
В другом репрезентативном варианте, последовательность нуклеиновой кислоты, кодирующая руководящую нуклеиновую кислоту и/или белок-редактор, может быть доставлена или введена индивидууму с использованием не-векторного соединения.
Не-векторное соединение может включать последовательность нуклеиновой кислоты, кодирующую руководящую нуклеиновую кислоту и/или белок-редактор.
Не-векторным соединением может быть «оголенная» ДНК, ДНК-комплекс, мРНК или их смесь.
Не-векторное соединение может быть доставлено или введено индивидууму путем электропорации, бомбардировки частицами, ультразвуковой обработки, магнитографии, спрессовывания или сжатия транзиентных клеток (например, как описано в литературе [Lee, et al, (2012) Nano Lett., 12, 6322-6327]), трансфекции, опосредованной липидом, с использованием дендримера, наночастиц, фосфата кальция, двуокиси кремния, силиката (Ormosil) или их комбинации.
В одном примере, доставка посредством электропорации может быть осуществлена путем смешивания клеток и последовательности нуклеиновой кислоты, кодирующей руководящую нуклеиновую кислоту и/или белок-редактор, в кассете, в камере или в кювете, и подачи в клетки электрического импульса с предварительно заданной длительностью и амплитудой.
В другом примере, не-векторное соединение может быть доставлено с использованием нановчастиц. Наночастицами могут быть неорганические наночастицы (например, магнитные наночастицы, двуокись кремния и т.п.) или органические наночастицы (например, липид, покрытый полиэтиленгликолем (ПЭГ) и т.п). Внешняя поверхность наночастиц может быть конъюгирована с положительно заряженным полимером, который присоединяют путем связывания (например, с полиэтиленимином, полилизином, полисерином и т.п.).
В некоторых вариантах осуществления изобретения, не-векторное соединение может быть доставлено с использованием липидной оболочки.
В некоторых вариантах осуществления изобретения, не-векторное соединение может быть доставлено с использованием экзосомы. Экзосома представляет собой эндогенную нановезикулу для переноса белка и РНК, которая может доставлять РНК в головной мозг и в другой орган-мишень.
В некоторых вариантах осуществления изобретения, не-векторное соединение может быть доставлено с использованием липосомы. Липосома представляет собой сферическую везикулярную структуру, состоящую из одного или множества ламелярных липидных бислоев, окружающих внутренние водные компартменты, и внешнего липофильного фосфолипидного бислоя, который является относительно непрозначным. Хотя липосома может быть получена из липидов нескольких различных типов, однако, фосфолипиды обычно используют, главным образом, для продуцирования липосомы в качестве носителя лекарственного средства.
Кроме того, композиция для доставки не-векторного соединения может включать и другие добавки.
Белок-редактор может быть доставлен или введен индивидууму в форме пептида, полипептида или белка.
Белок-редактор может быть доставлен или введен индивидууму в форме пептида, полипептида или белка известным методом.
Пептид, полипептид или белок могут быть доставлены или введены индивидууму путем электропорации, микроинжекции, спрессовывания или сжатия транзиентных клеток [Lee, et al, (2012) Nano Lett., 12, 6322-6327]), опосредованной липидом трансфекции, с использованием частиц, липосом, доставки, опосредуемой пептидами, или их комбинаций.
Пептид, полипептид или белок могут быть доставлены с использованием последовательности нуклеиновой кислоты, кодирующей руководящую нуклеиновую кислоту.
В одном примере, перенос посредством электропорации может быть осуществлен путем смешивания клеток, в которые вводят белок-редактор, с руководящей нуклеиновой кислотой или без нее, в кассете, в камере или в кювете, и подачи в клетки электрического импульса с предварительно заданной длительностью и амплитудой.
Руководящая нуклеиновая кислота и белок-редактор могут быть доставлены или введены индивидууму в форме смеси нуклеиновой кислоты и белка.
Руководящая нуклеиновая кислота и белок-редактор могут быть доставлены или введены индивидууму в форме комплекса «руководящая нуклеиновая кислота - белок-редактор».
Так, например, руководящей нуклеиновой кислотой может быть ДНК, РНК или их смесь. Белком-редактором может быть пептид, полипептид или белок.
В одном примере, руководящая нуклеиновая кислота и белок-редактор могут быть доставлены или введены индивидууму в форме комплекса «руководящая нуклеиновая кислота - белок-редактор», содержащего руководящую нуклеиновую кислоту типа РНК и белок-редактор белкового типа, то есть, рибонуклеопротеин (RNP).
Комплекс «руководящая нуклеиновая кислота - белок-редактор», раскрытый в настоящем описании, может модифицировать нуклеиновую кислоту-, ген- или хромосому-мишень.
Так, например, комплекс «руководящая нуклеиновая кислота - белок-редактор» индуцирует модификацию в последовательности нуклеиновой кислоты-мишени, в гене- или хромосоме-мишени. В результате, белок, экспрессируемый нуклеиновой кислотой-, геном- или хромосомой-мишенью, может быть модифицирован по своей структуре и/или функции, либо экспрессия белка может быть устранена или ингибирована.
Комплекс «руководящая нуклеиновая кислота - белок-редактор» может действовать на уровне ДНК, РНК, гена или хромосомы.
В одном примере, комплекс «руководящая нуклеиновая кислота - белок-редактор» может изменять или модифицировать область регуляции транскрипции гена-мишени, что будет приводить к регуляции (например, к подавлению, ингибировании, снижению, повышению или стимуляции) экспрессии белка, кодируемого геном-мишенью, или экспрессии белка, активность которого будет регулироваться (например, подавляться, ингибироваться, снижаться, повышаться или стимулироваться) или модифицироваться.
Комплекс «руководящая нуклеиновая кислота - белок-редактор» может действовать на стадии транскрипции и трансляции гена.
В одном примере, комплекс «руководящая нуклеиновая кислота - белок-редактор» может стимулировать или ингибировать транскрипцию гена-мишени и тем самым, регулировать (например, подавлять, ингибировать, снижать, повышать или стимулировать) экспрессию белка, кодируемого геном-мишенью.
В другом примере, комплекс «руководящая нуклеиновая кислота - белок-редактор» может стимулировать или ингибировать трансляцию гена-мишени и тем самым, регулировать (например, подавлять, ингибировать, снижать, повышать или стимулировать) экспрессию белка, кодируемого геном-мишенью.
В одном репрезентативном варианте осуществления изобретения, раскрытом в настоящем описании, композиция для регуляции экспрессии может включать рРНК и фермент CRISPR.
Композиция для регуляции экспрессии может включать:
(а) рРНК, которая может нацеливаться на последовательность-мишень, локализованную в области регуляции транскрипции дуплицированного гена, или последовательность нуклеиновой кислоты, кодирующую эту последовательность; и
(b) один или более ферментов CRISPR или последовательностей нуклеиновой кислоты, кодирующих эти ферменты.
Описание дуплицированного гена приводится выше.
Описание области регуляции транскрипции приводится выше.
Описание последовательности-мишени приводится выше.
Композиция для регуляции экспрессии может включать комплекс «рРНК - фермент CRISPR».
Термин «комплекс рРНК - фермент CRISPR» означает комплекс, образующийся в результате взаимодействия рРНК и фермента CRISPR.
Описание рРНК приводится выше.
Термин «фермент CRISPR» означает главный белковый компонент системы CRISPR-Cas, который образует комплекс с рРНК и тем самым систему CRISPR-Cas.
Фермент CRISPR может представлять собой нуклеиновую кислоту, имеющую последовательность, кодирующую фермент CRISPR или полипептид (или белок).
Фермент CRISPR может представлять собой Фермент CRISPR типа II.
Кристаллическая структура фермента CRISPR типа II была определена в исследованиях молекул фермента CRISPR типа II природных микроорганизмов двух или более типов (Jinek et al., Science, 343(6176):1247997, 2014), и в исследованиях Cas9 (SpCas9) Streptococcus pyogenes, образующего комплекс с рРНК (Nishimasu et al., Cell, 156:935-949, 2014; и Anders et al., Nature, 2014, doi: 10.1038/nature13579).
Фермент CRISPR типа II включает две области, то есть, область распознавания (REC) и нуклеазную область (NUC), и каждая из них включает несколько доменов.
Область REC включает богатый аргинином домен мостиковой спирали (BH), домен REC1 и домен REC2.
В данном описании, домен BH представляет собой длинную α-спиральную и богатую аргинином область, а домены REC1 и REC2 играют важную роль в распознавании двойной цепи в рРНК, например, в одноцепочечной рРНК, двухцепочечной рРНК или tracr-РНК.
Область NUC включает домен RuvC, домен HNH и домен взаимодействия с PAM (PI). В данном описании, домен RuvC включает RuvC-подобные домены, либо домен HNH включает HNH-подобные домены.
В данном описании, домен RuvC имеет структурное сходство с членами семейства микроорганизмов, существующих в природе и имеющих фермент CRISPR типа II, и расщепляет одну цепь, например, некомплементарную цепь нуклеиновой кислоты в области регуляции транскрипции гена-мишени, то есть, цепь, не образующую комплементарную связь с рРНК. В литературе, домен RuvC иногда называется доменом RuvCI, RuvCII или RuvCIII, но обычно он обозначается RuvCI, RuvCII или RuvCIII.
Домен HNH имеет структурное сходство с эндонуклеазой HNH и расщепляет одну цепь, например, комплементарную цепь молекулы нуклеиновой кислоты-мишени, то есть, цепь, образующую комплементарную связь с рРНК. Домен HNH локализован между мотивами RuvC II и III.
Домен PI распознает специфическую нуклеотидную последовательность в области регуляции транскрипции гена-мишени, то есть, мотив, смежный с протоспейсером (PAM), или взаимодействует с PAM. В данном случае, PAM может варьироваться в зависимости от происхождения фермента CRISPR типа II. Так, например, если ферментом CRISPR является SpCas9, то PAM может представлять собой 5’-NGG-3’; если ферментом CRISPR является Cas9 Streptococcus thermophilus (StCas9), то PAM может представлять собой 5’-NNAGAAW-3’(W=A или T); если ферментом CRISPR является Cas9 (NmCas9) Neisseria meningitides (NmCas9), то PAM может представлять собой 5’-NNNNGATT-3’, а если ферментом CRISPR является Cas9 Campylobacter jejuni (CjCas9), то PAM может представлять собой 5’-NNNVRYAC-3’ (V=G или C или A, R=A или G, Y=C или T, где N может представлять собой A, T, G или C; или A, U, G или C). Однако, следует отметить, что РАМ определяют в зависимости от происхождения вышеописанного фермента, и по мере продолжения исследований мутанта фермента, происходящего от соответствующих источников, РАМ может быть изменен.
Фермент CRISPR типа II может представлять собой Cas9.
Cas9 может происходить от различных микроорганизмов, таких как Streptococcus pyogenes, Streptococcus thermophilus, Streptococcus sp., Staphylococcus aureus, Nocardiopsis dassonvillei, Streptomyces pristinaespiralis, Streptomyces viridochromogenes, Streptomyces viridochromogenes, Streptosporangium roseum, Streptosporangium roseum, AlicyclobacHlus acidocaldarius, Bacillus pseudomycoides, Bacillus selenitireducens, Exiguobacterium sibiricum, Lactobacillus delbrueckii, Lactobacillus salivarius, Microscilla marina, Burkholderiales bacterium, Polaromonas naphthalenivorans, Polaromonas sp., Crocosphaera watsonii, Cyanothece sp., Microcystis aeruginosa, Synechococcus sp., Acetohalobium arabaticum, Ammonifex degensii, Caldicelulosiruptor bescii, Candidatus Desulforudis, Clostridium botulinum, Clostridium difficile, Finegoldia magna, Natranaerobius thermophilus, Pelotomaculum thermopropionicum, Acidithiobacillus caldus, Acidithiobacillus ferrooxidans, Allochromatium vinosum, Marinobacter sp., Nitrosococcus halophilus, Nitrosococcus watsoni, Pseudoalteromonas haloplanktis, Ktedonobacter racemifer, Methanohalobium evestigatum, Anabaena variabilis, Nodularia spumigena, Nostoc sp., Arthrospira maxima, Arthrospira platensis, Arthrospira sp., Lyngbya sp., Microcoleus chthonoplastes, Oscillatoria sp., Petrotoga mobilis, Thermosipho africanus и Acaryochloris marina.
Cas9 представляет собой фермент, который связывается с рРНК и расщепляет или модифицирует последовательность-мишень в положении области регуляции транскрипции гена-мишени и может состоять из домена HNH, способного расщеплять цепь нуклеиновой кислоты с образованием комплементарной связи с рРНК; домена RuvC, способного расщеплять цепь нуклеиновой кислоты с образованием некомплементарной связи с рРНК; домена REC, взаимодействующего с мишенью и доменом PI, распознающим PAM. Описание специфических структурных свойств Cas9 можно найти у Hiroshi Nishimasu et al. (2014) Cell 156:935-949.
Cas9 может быть выделен из микроорганизма, существующего в природе, либо он может быть получен искусственно рекомбинантным методом или методом синтеза.
Кроме того, фермент CRISPR может представлять собой фермент CRISPR типа V.
Фермент CRISPR типа V включает аналогичные домены RuvC, соответствующие доменам RuvC фермента CRISPR типа II; и вместо домена HNH фермента CRISPR типа II, может состоять из домена Nuc, доменов REC и WED, распознающих мишень; и домена PI, распознающего PAM. Описание специфических структурных свойств фермента CRISPR типа V можно найти у Takashi Yamano et al. (2016) Cell 165:949-962.
Фермент CRISPR типа V может взаимодействовать с рРНК с образованием комплекса «рРНК - фермент CRISPR», то есть, комплекса CRISPR, и позволяет нацеливать руководящую последовательность на последовательность-мишень, включающую последовательность РАМ в комбинации с рРНК. В данном случае, способность фермента CRISPR типа V взаимодействовать с нуклеиновой кислотой в области регуляции транскрипции гена-мишени зависит от последовательности РАМ.
Последовательность РАМ может представлять собой последовательность, присутствующую в области регуляции транскрипции гена-мишени и распознаваемую доменом PI фермента CRISPR типа V. Последовательности РАМ могут быть различными в зависимости от происхождения фермента CRISPR типа V. То есть, каждый вид имеет специфически распознаваемую последовательность РАМ. Так, например, последовательность РАМ, распознаваемая Cpf1, может представлять собой 5’-TTN-3’ (N представляет собой A, T, C или G). Однако, следует отметить, что РАМ определяют в зависимости от происхождения вышеописанного фермента, и по мере продолжения исследований мутанта фермента, происходящего от соответствующих источников, РАМ может быть изменен.
Фермент CRISPR типа V может представлять собой Cpf1.
Cpf1 может происходить от Streptococcus, Campylobacter, Nitratifractor, Staphylococcus, Parvibaculum, Roseburia, Neisseria, Gluconacetobacter, Azospirillum, Sphaerochaeta, Lactobacillus, Eubacterium, Corynebacter, Carnobacterium, Rhodobacter, Listeria, Paludibacter, Clostridium, Lachnospiraceae, Clostridiaridium, Leptotrichia, Francisella, Legionella, Alicyclobacillus, Methanomethyophilus, Porphyromonas, Prevotella, Bacteroidetes, Helcococcus, Letospira, Desulfovibrio, Desulfonatronum, Opitutaceae, Tuberibacillus, Bacillus, Brevibacillus, Methylobacterium или Acidaminococcus.
Cpf1 может состоять из RuvC-подобного домена, соответствующего домену RuvC Cas9; домена Nuc, вместо домена HNH Cas9, доменов REC и WED, распознающих мишень; и домена PI, распознающего PAM. Описание специфических структурных свойств Cpf1 можно найти у Takashi Yamano et al. (2016) Cell 165:949-962.
Cpf1 может быть выделен из микроорганизма, существующего в природе, либо он может быть получен искусственно рекомбинантным методом или методом синтеза.
Фермент CRISPR может представлять собой нуклеазу или рестриктирующий фермент, функция которого заключается в расщеплении двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени.
Фермент CRISPR может представлять собой полностью активный фермент CRISPR.
Термин «полностью активный» относится к состоянию, при котором фермент обладает такой же функцией, как и фермент дикого типа, и фермент CRISPR в таком состоянии называется полностью активным ферментом CRISPR. В данном случае, «функциия фермента CRISPR дикого типа» означает состояние, при котором фермент обладает способностью расщеплять двухцепочечную ДНК, то есть, обладает первой функцией, заключающейся в расщеплении первой цепи двухцепочечной ДНК, и второй функцией, заключающейся в расщеплении второй цепи двухцепочечной ДНК.
Полностью активный фермент CRISPR может представлять собой фермент CRISPR дикого типа, расщепляющий двухцепочечную ДНК.
Полностью активный фермент CRISPR может представлять собой вариант фермента CRISPR, полученный посредством модификации или обработки фермента CRISPR дикого типа, который расщепляет двухцепочечную ДНК.
Вариант фермента CRISPR может представлять собой фермент, где одна или более аминокислот аминокислотной последовательности фермента CRISPR дикого типа заменены другими аминокислотами, либо где одна или более аминокислот были удалены.
Вариант фермента CRISPR может представлять собой фермент, где одна или более аминокислот были добавлены к аминокислотной последовательности фермента CRISPR дикого типа. В данном случае, добавленные аминокислоты могут присутствовать у N-конца, С-конца или в аминокислотной последовательности фермента дикого типа.
Вариант фермента CRISPR может представлять собой полностью активный фермент, обладающий улучшенной функцией по сравнению с функцией фермента CRISPR дикого типа.
Так, например, специфически модифицированная или измененная форма фермента CRISPR дикого типа, то есть, вариант фермента CRISPR может расщеплять двухцепочечную ДНК, но не связывается с расщепленной двухцепочечной ДНК, или находится на определенном расстоянии от нее. В этом случае, модифицированная или измененная форма может представлять собой полностью активный фермент CRISPR, обладающий улучшенной функциональной активностью по сравнению с активностью фермента CRISPR дикого типа.
Вариант фермента может представлять собой полностью активный фермент CRISPR, обладающий пониженной функцией по сравнению с функцией фермента CRISPR дикого типа.
Так, например, специфически модифицированная или измененная форма фермента CRISPR дикого типа, то есть, вариант фермента CRISPR может расщеплять двухцепочечную ДНК, но расположен очень близко к расщепленной двухцепочечной ДНК или образует специфическую связь с этой ДНК. В этом случае, специфическая связь может представлять собой, например, связь между аминокислотой специфической области фермента CRISPR и последовательностью ДНК в положении расщепления. В этом случае, модифицированная или измененная форма может представлять собой полностью активный фермент CRISPR, обладающий пониженной функциональной активностью по сравнению с активностью фермента CRISPR дикого типа.
Фермент CRISPR может представлять собой не полностью или частично активный фермент CRISPR.
Термин «не полностью или частично активный» относится к состоянию, при котором фермент обладает функциями, выбранными из функций фермента CRISPR дикого типа, то есть, первой функцией, заключающейся в расщеплении первой цепи двухцепочечной ДНК, и второй функцией, заключающейся в расщеплении второй цепи двухцепочечной ДНК. Фермент CRISPR в этом состоянии называется не полностью или частично активным ферментом CRISPR. Кроме того, не полностью или частично активный фермент CRISPR может называться никазой.
Термин «никаза» означает фермент CRISPR, измененный или модифицированный так, чтобы он расщеплял только одну цепь двухцепочечной нуклеиновой кислоты в области регуляции транскрипции гена-мишени, и такая никаза обладает нуклеазной активностью, способствующей расщеплению одной цепи, например, цепи, которая не является комплементарной или комплементарна рРНК нуклеиновой кислоты в области регуляции транскрипции гена-мишени. Поэтому, для расщепления двойной цепи необходима нуклеазная активность двух никаз.
Никаза может обладать нуклеазной активностью, сообщаемой доменом RuvC. То есть, никаза может не обладать нуклеазной активностью домена HNH, и для этой цели, домен HNH может быть изменен или модифицирован.
В одном примере, если ферментом CRISPR является фермент CRISPR типа II, то никаза может представлять собой фермент CRISPR типа II, включающий модифицированный домен HNH.
Так, например, если ферментом CRISPR типа II является фермент SpCas9 дикого типа, то никаза может представлять собой вариант SpCas9, в котором нуклеазная активность домена HNH была инактивирована путем мутации, то есть, замены 840-й аминокислоты в аминокислотной последовательности SpCas9 дикого типа, а именно, замены гистидина на аланин. Поскольку никаза, продуцируемая таким образом, то есть, вариант SpCas9, обладает нуклеазной активностью домена RuvC, то она способна расщеплять цепь, которая представляет собой некомплементарную цепь нуклеиновой кислоты в области регуляции транскрипции гена-мишени, то есть, цепь, не образующую комплементарную связь с рРНК.
В другом примере, если ферментом CRISPR типа II является фермент CjCas9 дикого типа, то никаза может представлять собой вариант CjCas9, в котором нуклеазная активность домена HNH была инактивирована путем мутации, то есть, замены 559-й аминокислоты в аминокислотной последовательности CjCas9 дикого типа, а именно, замены гистидина на аланин. Поскольку никаза, продуцируемая таким образом, то есть, вариант CjCas9, обладает нуклеазной активностью домена RuvC, то она способна расщеплять цепь, которая представляет собой некомплементарную цепь нуклеиновой кислоты в области регуляции транскрипции гена-мишени, то есть, цепь, не образующую комплементарную связь с рРНК.
Кроме того, никаза может обладать нуклеазной активностью, сообщаемой доменом HNH фермента CRISPR. То есть, никаза может не обладать нуклеазной активностью домена RuvC, и для этой цели, домен RuvC может быть изменен или модифицирован.
В одном примере, если ферментом CRISPR является фермент CRISPR типа II, то никаза может представлять собой фермент CRISPR типа II, включающий модифицированный домен RuvC.
Так, например, если ферментом CRISPR типа II является SpCas9 дикого типа, то никаза может представлять собой вариант SpCas9, в котором нуклеазная активность домена RuvC была инактивирована путем мутации, то есть, замены 10-й аминокислоты в аминокислотной последовательности SpCas9 дикого типа, а именно, замены аспарагиновой кислоты на аланин. Поскольку никаза, продуцируемая таким образом, то есть, вариант SpCas9, обладает нуклеазной активностью домена HNH, то она способна расщеплять цепь, которая представляет собой комплементарную цепь нуклеиновой кислоты в области регуляции транскрипции гена-мишени, то есть, цепь, образующую комплементарную связь с рРНК.
В другом примере, если ферментом CRISPR типа II является фермент CjCas9 дикого типа, то никаза может представлять собой вариант CjCas9, в котором нуклеазная активность домена RuvC была инактивирована путем мутации, то есть, замены 8-й аминокислоты в аминокислотной последовательности CjCas9 дикого типа, а именно, замены аспарагиновой кислоты на аланин. Поскольку никаза, продуцируемая таким образом, то есть, вариант CjCas9, обладает нуклеазной активностью домена HNH, то она способна расщеплять цепь, которая представляет собой комплементарную цепь нуклеиновой кислоты в области регуляции транскрипции гена-мишени, то есть, цепь, образующую комплементарную связь с рРНК.
Фермент CRISPR может представлять собой неактивный фермент CRISPR.
Используемый здесь термин «неактивный фермент» относится к состоянию, при котором функции фермента CRISPR дикого типа, то есть, первая функция, заключающаяся в расщеплении первой цепи двухцепочечной ДНК, и вторая функция, заключающаяся в расщеплении второй цепи двухцепочечной ДНК, были потеряны. Фермент CRISPR в этом состоянии называется неактивным ферментом CRISPR.
Неактивный фермент CRISPR может не обладать нуклеазной активностью, что обусловлено изменениями в домене, обладающем нуклеазной активностью фермента CRISPR дикого типа.
Неактивный фермент CRISPR может не обладать нуклеазной активностью, что обусловлено изменениями в домене RuvC и в домене HNH. То есть, неактивный фермент CRISPR может не обладать нуклеазной активностью, сообщаемой доменом RuvC и доменом HNH фермента CRISPR, а поэтому, домен RuvC и домен HNH могут быть изменены или модифицированы.
В одном примере, если ферментом CRISPR является фермент CRISPR типа II, то неактивный фермент CRISPR может представлять собой фермент CRISPR типа II, имеющий модифицированный домен RuvC и домен HNH.
Так, например, если ферментом CRISPR типа II является SpCas9 дикого типа, то неактивный фермент CRISPR может представлять собой вариант SpCas9, в котором нуклеазная активность домена RuvC и домена HNH была инактивирована путем мутации, то есть, замены аспарагиновой кислоты 10 и гистидана 840 в аминокислотной последовательности SpCas9 дикого типа на аланин. В данном случае, поскольку в продуцируемом неактивном ферменте CRISPR, то есть, в варианте SpCas9, нуклеазная активность домена RuvC и домена HNH была инактивирована, то двухцепочечная нуклеиновая кислота в области регуляции транскрипции гена-мишени может быть полностью расщеплена.
В другом примере, если ферментом CRISPR типа II является CjCas9 дикого типа, то неактивный фермент CRISPR может представлять собой вариант CjCas9, в котором нуклеазная активность домена RuvC и домена HNH была инактивирована путем мутации, то есть, замены аспарагиновой кислоты 8 и гистидана 559 в аминокислотной последовательности CjCas9 дикого типа на аланин. В данном случае, поскольку в продуцируемом неактивном ферменте CRISPR, то есть, в варианте CjCas9, нуклеазная активность домена RuvC и домена HNH была инактивирована, то двухцепочечная нуклеиновая кислота в области регуляции транскрипции гена-мишени не может быть полностью расщеплена.
Фермент CRISPR может обладать, помимо вышеописанной нуклеазной активности, геликазной активностью, то есть, способностью к гибридизации спиральной структуры двухцепочечной нуклеиновой кислоты.
Кроме того, фермент CRISPR может быть модифицирован для полной, неполной или частичной активации или инактивации геликазной активности.
Фермент CRISPR может представлять собой вариант фермента CRISPR, полученный путем искусственной обработки или модификации фермента CRISPR дикого типа.
Вариант фермента CRISPR может представлять собой искусственно обработанный или модифицированный вариант фермента CRISPR для изменения функций фермента CRISPR дикого типа, то есть, первой функции, заключающейся в расщеплении первой цепи двухцепочечной ДНК, и/или второй функции, заключающейся в расщеплении второй цепи двухцепочечной ДНК.
Так, например, вариант фермента CRISPR может представлять собой форму, в которой первая функция фермента CRISPR дикого типа была потеряна.
Альтернативно, вариант фермента CRISPR может представлять собой форму, в которой вторая функция фермента CRISPR дикого типа была потеряна.
Так, например, вариант фермента CRISPR может представлять собой форму, в которой обе функции фермента CRISPR дикого типа. то есть, первая и вторая функции были потеряны.
Вариант фермента CRISPR может образовывать комплекс рРНК-фермент CRISPR посредством взаимодействий с рРНК.
Вариант фермента CRISPR может представлять собой искусственно обработанный или модифицированный вариант фермента CRISPR для изменения функции взаимодействия с рРНК фермента CRISPR дикого типа.
Так, например, вариант фермента CRISPR может иметь форму, обладающую пониженной способностью взаимодействовать с рРНК по сравнению с ферментом CRISPR дикого типа.
Альтернативно, вариант фермента CRISPR может иметь форму, обладающую повышенной способностью взаимодействовать с рРНК по сравнению с ферментом CRISPR дикого типа.
Так, например, вариант фермента CRISPR может иметь форму, обладающую первой функцией фермента CRISPR дикого типа и пониженной способностью взаимодействовать с рРНК.
Альтернативно, вариант фермента CRISPR может иметь форму, обладающую первой функцией фермента CRISPR дикого типа и повышенной способностью взаимодействовать с рРНК.
Так, например, вариант фермента CRISPR может иметь форму, обладающую второй функцией фермента CRISPR дикого типа и пониженной способностью взаимодействовать с рРНК.
Альтернативно, вариант фермента CRISPR может иметь форму, обладающую второй функцией фермента CRISPR дикого типа и повышенной способностью взаимодействовать с рРНК.
Так, например, вариант фермента CRISPR может иметь форму, не обладающую первой и второй функциями фермента CRISPR дикого типа и пониженной способностью взаимодействовать с рРНК.
Альтернативно, вариант фермента CRISPR может иметь форму, не обладающую первой и второй функциями фермента CRISPR дикого типа и повышенной способностью взаимодействовать с рРНК.
В данном случае, в зависимости от силы взаимодействия между рРНК и вариантом фермента CRISPR могут быть получены различные комплексы рРНК - фермент CRISPR, и в зависимости от варианта фермента CRISPR, функции нацеливания на последовательность-мишень или ее расщепления могут отличаться.
Так, например, комплекс рРНК - фермент CRISPR, образованный вариантом фермента CRISPR, обладающим пониженной способностью взаимодействовать с рРНК, может расщеплять двойную цепь или одиночную цепь последовательности-мишени только, если он расположен очень близко к последовательности-мишени или локализован перед последовательностью-мишенью, которая полностью комплементарно связывается с рРНК.
Вариант фермента CRISPR может представлять собой форму, в которой по меньшей мере одна аминокислота аминокислотной последовательности фермента CRISPR дикого типа была модифицирована.
Так, например, вариант фермента CRISPR может представлять собой форму, в которой по меньшей мере одна аминокислота аминокислотной последовательности фермента CRISPR дикого типа была заменена.
В другом примере, вариант фермента CRISPR может представлять собой форму, в которой по меньшей мере одна аминокислота аминокислотной последовательности фермента CRISPR дикого типа была делетирована.
В другом примере, вариант фермента CRISPR может представлять собой форму, в которой по меньшей мере одна аминокислота аминокислотной последовательности фермента CRISPR дикого типа была добавлена.
В одном примере, вариант фермента CRISPR может представлять собой форму, в которой по меньшей мере одна аминокислота аминокислотной последовательности фермента CRISPR дикого типа была заменена, делетирована и/или добавлена.
Кроме того, вариант фермента CRISPR, помимо исходных функций фермента CRISPR дикого типа, может также включать, но необязательно, функциональный домен, то есть, домен, выполняющий первую функцию расщепления первой ципи двухцепочечной ДНК и вторую функцию расщепления второй ципи этой ДНК. В данном случае, вариант фермента CRISPR, может обладать, помимо исходных функций фермента CRISPR дикого типа, дополнительной функцией.
Функциональный домен может представлять собой домен, обладающий метилазной активностью, демитилазной активностью, активностью в стимудяции активации транскрипции, активностью в ингибировании транскрипции, активностью в высвобождении фактора транскрипции, активностью в модификации гистона, активностью в расщеплении РНК или связывании с нуклеиновой кислотой; или метку или репортерный ген для выделения и очистки белка (включая пептид), однако, настоящее изобретение не ограничивается ими.
Метка включает гистидиновую (His) метку, V5-метку, FLAG-метку, метку гемагглютинина вируса гриппа (HA), Myc-метку, VSV-G-метку и тиоредоксиновую метку (Trx), а ген-репортер включает ген глутатион-S-трансферазы (GST), пероксидазы хрена (ПХ), хлорамфеникол-ацетилтрансферазы (CAT), β-галактозидазы, β-глюкуронидазы, люциферазы, аутофлуоресцентных белков, включая белок, флуоресцирующий в зеленом диапазоне спектра (GFP), HcRed, DsRed, белок, флуоресцирующий в голубом диапазоне спектра (CFP), белок, флуоресцирующий в желтом диапазоне спектра (YFP) и белок, флуоресцирующий в синем диапазоне спектра (BFP), однако, настоящее изобретение не ограничивается ими.
Функциональный домен может представлять собой дезаминазу.
Так, например, не полностью или частично активный фермент CRISPR может дополнительно включать цитидин-дезаминазу в качестве функционального домена. В одном репрезентативном варианте осуществления изобретения, гибридный белок может быть получен путем добавления цитидин-дезаминазы, например, комплекса 1, редактирующего аполипопротеин B (APOBEC1), к никазе SpCas9. Образованный комплекс [никаза SpCas9]-[APOBEC1], описанный выше, может быть использован для редактирования нуклеотидов с заменой C на T или U, или G на A.
В другом примере, не полностью или частично активный фермент CRISPR может дополнительно включать аденин-дезаминазу в качестве функционального домена. В одном репрезентативном варианте осуществления изобретения, гибридный белок может быть получен путем добавления аденин-дезаминаз, например, вариантов TadA, вариантов ADAR2 или вариантов ADAT2, к никазе SpCas9. Образованный комплекс [никаза SpCas9]-[вариант TadA], [никаза SpCas9]-[вариант ADAR2] или [никаза SpCas9]-[вариант ADAT2] описанный выше, может быть использован для редактирования нуклеотидов с заменой A на G или T на С, поскольку гибридный белок имеет замену нуклеотида А на инозин, и такая инозиновая модификация распознается полимеразой как нуклеотид G, что тем самым, позволяет осуществлять эффективное редактирование с заменой нуклеотида А на G.
Функциональный домен может представлять собой последовательность или сигнал локализации в ядре (NLS) или последовательность или сигнал выхода из ядра (NES).
В одном примере, фермент CRISPR может включать один или более NLS. В данном описании, один или более NLS могут быть включены у N-конца фермента CRISPR или поблизости от него, у C-конца этого фермента или поблизости от него или их комбинацию. NLS может представлять собой последовательность NLS, происходящую, но не ограничивающуюся ими, от следующих NLS: NLS крупного Т-антигена вируса SV40 с аминокислотной последовательностью PKKKRKV (SEQ ID NO:312); NLS, происходящего от нуклеоплазмина (например, двухкомпонентного NLS нуклеоплазмина с последовательностью KRPAATKKAGQAKKKK (SEQ ID NO:313)); NLS c-myc с аминокислотной последовательностью PAAKRVKLD (SEQ ID NO:314) или RQRRNELKRSP (SEQ ID NO:315); NLS hRNPA1 M9 с последовательностью NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY (SEQ ID NO:316); последовательности домена IBB, происходящей от импортина-α, RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV (SEQ ID NO:317); последовательности T-белка миомы VSRKRPRP (SEQ ID NO:318) и PPKKARED (SEQ ID NO:319); последовательности человеческого p53, PQPKKKPL (SEQ ID NO:320); последовательности мышиного c-abl IV, SALIKKKKKMAP (SEQ ID NO:321); последовательности вируса гриппа NS1, DRLRR (SEQ ID NO:322) и PKQKKRK (SEQ ID NO:323); последовательности антигена вируса гепатита дельта, RKLKKKIKKL (SEQ ID NO:324); последовательности мышиного белка Mx1, REKKKFLKRR (SEQ ID NO:325); последовательности человеческой поли(АДФ-рибозо)полимеразы, KRKGDEVDGVDEVAKKKSKK (SEQ ID NO:326); или последовательности RKCLQAGMNLEARKTKK (SEQ ID NO:327), происходящей от глюкокортикоида рецептора стероидного гормона (человеческого).
Кроме того, мутантный фермент CRISPR может включать фермент CRISPR расщепленного типа, полученный путем разделения фермента CRISPR на две или более частей. Термин «расщепленный» относится к функциональному или структурному разделению белка или рандомизированному разделению белка на две или более частей.
Фермент CRISPR расщепленного типа может представлять собой полностью, не полностью или частично активный фермент или неактивный фермент.
Так, например, если фермент CRISPR представляет собой SpCas9, то SpCas9 может быть разделен на две части между тирозиновым остатком 656 и треониновым остатком 657 с образованием расщепленного SpCas9.
Фермент CRISPR расщепленного типа может селективно включать дополнительный домен, пептид, полипептид или белок для восстановления.
Дополнительный домен, пептид, полипептид или белок для восстановления могут быть подвергнуты сборке для получения фермента CRISPR расщепленного типа, структура которого является такой же, как структура фермента CRISPR дикого типа, или аналогичной структуре этого фермента.
Дополнительный домен, пептид, полипептид или белок для восстановления могут представлять собой домены димеризации FRB и FKBP; интеин; домены ERT и VPR; или домены, которые образуют гетеродимер в специфических условиях.
Так, например, если фермент CRISPR представляет собой SpCas9, то SpCas9 может быть разделен на две части между сериновым остатком 713 и глициновым остатком 714 с образованием расщепленного SpCas9. Домен FRB может быть присоединен к одной из двух частей, а домен FKBP может быть присоединен к другой части. При продуцировании расщепленного SpCas9, домен FRB и домен FKBP могут образовывать димер в среде, в которой присутствует рапамицин, в результате чего образуется восстановленный фермент CRISPR.
Фермент CRISPR или вариант фермента CRISPR, раскрытые в настоящей заявке, могут представлять собой полипептид, белок или нуклеиновую кислоту, имеющую последовательность, кодирующую такой полипептид или белок, и могут быть оптимизированы по кодонам для введения индивидууму фермента CRISPR или варианта фермента CRISPR.
Термин «оптимизация по кодонам» означает способ модификации последовательности нуклеиновой кислоты путем сохранения нативной аминокислотной последовательности с заменой по меньшей мере одного кодона нативной последовательности на кодон, который встречается более часто или более часто используется в клетках-хозяевах в целях повышения уровня экспрессии в клетках-хозяевах. У различных видов наблюдается специфическое смещение кодона специфической аминокислоты, и такое смещение кодонов (различие кодонов у различных организмов) часто коррелирует с эффективностью трансляции мРНК, которая, вероятно зависит от свойств транслированного кодона и доступности специфической молекулы тРНК. Доминирование тРНК, отобранных в клетках, обычно указывает на кодоны, которые наиболее часто используются в пептидном синтезе. Поэтому, ген может быть специально отобран по оптимальной экспрессии генов в данном организме исходя из оптимизации по кодонам.
рРНК, фермент CRISPR или комплекс рРНК - фермент CRISPR, раскрытые в настоящем описании, могут быть доставлены или введены индивидууму различными методами доставки и в различных формах.
Описание индивидуумов приводится выше.
В одном репрезентативном варианте осуществления изобретения, последовательность нуклеиновой кислоты, кодирующая рРНК и/или фермент CRISPR, могут быть доставлены или введены индивидууму с помощью вектора.
Вектор может включать последовательность нуклеиновой кислоты, кодирующую рРНК и/или фермент CRISPR.
В одном примере, вектор может одновременно включать последовательности нуклеиновой кислоты, кодирующие рРНК и фермент CRISPR.
В другом примере, вектор может включать последовательность нуклеиновой кислоты, кодирующую рРНК.
Так, например, домены, включенные в рРНК, могут содержаться в одном векторе, либо они могут быть разделены, а затем помещены в различные векторы.
В другом примере, вектор может включать последовательность нуклеиновой кислоты, кодирующую фермент CRISPR.
Так, например, в случае фермента CRISPR, последовательность нуклеиновой кислоты, кодирующая фермент CRISPR, может содержаться в одном векторе, либо она может быть разделена, а затем помещена в несколько векторов.
Вектор может включать один или более регуляторных/контрольных компонентов.
В данном описании, регуляторные/контрольные компоненты могут включать промотор, энхансер, интрон, сигнал полиаденилирования, консенсусную последовательность Козака, внутренний сайт связывания с рибосомой (IRES), акцептор сплайсинга и/или последовательность 2A.
Промотором может быть промотор, распознаваемый РНК-полимеразой II.
Промотором может быть промотор, распознаваемый РНК-полимеразой III.
Промотором может быть индуцибельный промотор.
Промотором может быть промотор, специфичный для индивидуума.
Промотором может быть вирусный или невирусный промотор.
В качестве промотора может быть использован подходящий промотор в зависимости от регуляторной области (то есть, последовательности нуклеиновой кислоты, кодирующей рРНК и/или фермент CRISPR).
Так, например, промотором, подходящим для рРНК, может быть промотор H1, EF-1a, тРНК или U6. Так, например, промотором, подходящим для фермента CRISPR, может быть промотор CMV, EF-1a, EFS, MSCV, PGK или CAG.
Вектором может быть вирусный вектор или рекомбинантный вирусный вектор.
Вирусом может быть ДНК-вирус или РНК-вирус.
В данном описании, ДНК-вирусом может быть вирус на основе двухцепочечной ДНК (дцДНК) или одноцепочечной ДНК (оцДНК).
В данном описании, РНК-вирусом может быть вирус на основе одноцепочечной РНК (оцРНК). Вирусом может быть ретровирус, лентивирус, аденовирус, аденоассоциированный вирус (AAV), вирус осповакцины, поксвирус или вирус простого герпеса, однако, настоящее изобретение не ограничивается ими.
В одном примере, последовательность нуклеиновой кислоты, кодирующая рРНК и/или фермент CRISPR, может быть доставлена или введена посредством рекомбинантного лентивируса.
В другом примере, последовательность нуклеиновой кислоты, кодирующая рРНК и/или фермент CRISPR, может быть доставлена или введена посредством рекомбинантного аденовируса. В другом примере, последовательность нуклеиновой кислоты, кодирующая рРНК и/или фермент CRISPR, может быть доставлена или введена посредством рекомбинантного AAV. В другом примере, последовательность нуклеиновой кислоты, кодирующая рРНК и/или фермент CRISPR, может быть доставлена или введена посредством одного или более гибридов, например, описанных здесь гибридных вирусов.
В одном репрезентативном варианте осуществления изобретения, комплекс «рРНК - фермент CRISPR» может быть доставлен или введен индивидууму.
Так, например, рРНК может быть представлена в форме ДНК, РНК или их смеси. Фермент CRISPR может быть представлен в форме пептида, полипептида или белка.
В одном примере, рРНК и фермент CRISPR могут быть доставлены или введены индивидууму в форме комплекса «рРНК - фермент CRISPR», содержащего рРНК типа РНК и CRISPR белкового типа, то есть, рибонуклеопротеин (RNP).
Комплекс «рРНК - фермент CRISPR» может быть доставлен или введен индивидууму путем электропорации, микроинжекции, спрессовывания или сжатия транзиентных клеток (например, как описано в литературе [Lee, et al, (2012) Nano Lett., 12, 6322-6327]), опосредованной липидом трансфекции; с использованием наночастиц, липосомы, доставки, опосредуемой пептидами, или их комбинаций.
Комплекс рРНК - фермент CRISPR, раскрытый в настоящем описании, может быть использован для искусственной обработки или модификации гена-мишени, то есть, области регуляции транскрипции дуплицированного гена.
Область регуляции транскрипции гена-мишени может быть изменена или модифицирована с использованием вышеописанного комплекса «рРНК-фермент-CRISPR», то есть, комплекса CRISPR. В данном описании, изменение или модификация области регуляции транскрипции гена-мишени могут включать все стадии: i) расщепления или повреждения области регуляции транскрипции гена-мишени и ii) репарации поврежденной области регуляции транскрипции.
i) Расщепление или повреждение области регуляции транскрипции гена-мишени может представлять собой расщепление или повреждение области регуляции транскрипции гена-мишени с использованием комплекса CRISPR, а, в частности, расщепление или повреждение последовательности-мишени в области регуляции транскрипции.
Последовательность-мишень может стать мишенью для комплекса «рРНК - фермент CRISPR», и эта последовательность-мишень может включать, а может и не включать, последовательность РАМ, распознаваемую ферментом CRISPR. Такая последовательность-мишень может служить важной стандартной последовательностью для конструирования рРНК.
Последовательность-мишень может специфически распознаваться рРНК комплекса «рРНК - фермент CRISPR», а поэтому, комплекс «рРНК - фермент CRISPR» может быть локализован возле распознаваемой последовательности-мишени.
Термин «расщепление» в сайте-мишени означает разрыв ковалентной связи остова полинуклеотида. Такое расщепление включает, но не ограничивается ими, ферментативный или химический гидролиз фосфодиэфирной связи. Так или иначе, расщепление может быть осуществлено различными методами. Может быть осуществлено расщепление одной цепи и двойной цепи, где расщепление двойной цепи может быть результатом расщепления двух отдельных одиночных цепей. Расщепление двойных цепей может приводить к образованию тупого конца или ступенчатого конца (или «липкого» конца).
В одном примере, расщепление или повреждение области регуляции транскрипции гена-мишени с использованием комплекса CRISPR может представлять собой полное расщепление или повреждение двойной цепи последовательности-мишени.
В одном репрезентативном варианте осуществления изобретения, если ферментом CRISPR является SpCas9 дикого типа, то двойная цепь последовательности-мишени, образующей комплементарную связь с рРНК, может быть полностью расщеплена под действием комплекса CRISPR.
В другом репрезентативном варианте осуществления изобретения, если ферментами CRISPR являются никаза SpCas9 (D10A) и никаза SpCas9 (H840A), то две одиночных цепи последовательности-мишени, образующей комплементарную связь с рРНК, могут соответственно расщепляться под действием каждого комплекса CRISPR. То есть, одна комплементарная цепь последовательности-мишени, образующей комплементарную связь с рРНК, может расщепляться под действием никазы SpCas9 (D10A), а одна некомплементарная цепь последовательности-мишени, образующая комплементарную связь с рРНК, может расщепляться под действием никазы SpCas9 (H840A), и такие расщепления могут происходить последовательно или одновременно.
В другом примере, расщепление или повреждение области регуляции транскрипции гена-мишени с использованием комплекса CRISPR может представлять собой расщепление или повреждение только одной цепи двухцепочечной последовательности-мишени. В данном описании, одна цепь может представлять собой последовательность-мишень, связывающуюся с руководящей нуклеиновой кислотой, и комплементарно связывающуюся с рРНК, то есть, одну комплементарную цепь, или последовательность, не связывающуюся с руководящей нуклеиновой кислотой, и комплементарно не связывающуюся с рРНК, то есть, одну цепь, которая не является комплементарной рРНК.
В одном репрезентативном варианте осуществления изобретения, если ферментом CRISPR является никаза SpCas9 (D10A), то комплекс CRISPR может расщеплять последовательность-мишень, связывающуюся с руководящей нуклеиновой кислотой и комплементарно связывающуюся с рРНК, то есть, одну комплементарную цепь, под действием никазы SpCas9 (D10A), и не может расщеплять последовательность, не связывающуюся с руководящей нуклеиновой кислотой и комплементарно не связывающуюся с рРНК, то есть, одну цепь, которая не является комплементарной рРНК.
В другом репрезентативном варианте осуществления изобретения, если ферментом CRISPR является никаза SpCas9 (H840A), то комплекс CRISPR может расщеплять последовательность-мишень, не связывающуюся с руководящей нуклеиновой кислотой и комплементарно не связывающуюся с рРНК, то есть, одну цепь, которая не является комплементарной рРНК, под действием никазы SpCas9 (H840A), и не может расщеплять последовательность-мишень, связывающуюся с руководящей нуклеиновой кислотой и комплементарно связывающуюся с рРНК, то есть, одну комплементарную цепь.
В другом примере, расщепление или повреждение области регуляции транскрипции гена-мишени с использованием комплекса CRISPR может представлять собой частичное удаление фрагмента нуклеиновой кислоты.
В одном репрезентативном варианте осуществления изобретения, если комплексы CRISPR состоят из SpCas9 дикого типа и двух рРНК, имеющих различные последовательности-мишени, то двойная цепь последовательности-мишени, образующей комплементарную связь с первой рРНК, может быть расщеплена, и двойная цепь последовательности-мишени, образующей комплементарную связь со второй рРНК, может быть расщеплена, что будет приводить к удалению фрагментов нуклеиновой кислоты под действием первой и второй рРНК и SpCas9.
Так, например, если два комплекса CRISPR состоят из двух рРНК, комплементарно связывающихся с различными последовательностями-мишенями, такими как одна рРНК, комплементарно связывающаяся с последовательностью-мишенью, расположенной выше энхансера, и другая рРНК, комплементарно связывающаяся с последовательностью-мишенью, расположенной ниже энхансера, и SpCas9 дикого типа, то двойная цепь последовательности-мишени, расположенной выше энхансера и комплементарно связывающейся с первой рРНК, может быть расщеплена, и двойная цепь последовательности-мишени, расположенной ниже энхансера и комплементарно связывающейся со второй рРНК, может быть расщеплена, что будет приводить к удалению фрагмента нуклеиновой кислоты, то есть, энхансерной области под действием первой рРНК, второй рРНК и SpCas9.
ii) Репарация поврежденной области регуляции транскрипции может представлять собой репарацию или восстановление, осуществляемое посредством присоединения негомологичных концов (NHEJ) и гомологичной репарации (HDR).
Присоединение негомологичных концов (NHEJ) представляет собой процесс восстановления или репарации двухцепочечных разрывов в ДНК посредством соединения обоих концов расщепленной двойной или одной цепи вместе, и обычно, если два совместимых конца, образованных посредством разрыва двойной цепи (например, расщепления), часто контактируют друг с другом с полным их соединением, то разорванная двойная цепь восстанавливается. NHEJ представляет собой процесс восстановления, который может происходить во всем клеточном цикле, а обычно, если в клетках присутствует негомологичный геном в качестве матрицы, например, в фазе G1.
В процессе репарации поврежденного гена или поврежденной нуклеиновой кислоты посредством NHEJ, некоторые инсерции и/или делеции (INDEL) в последовательности нуклеиновой кислоты присутствуют в NHEJ-репарированной области, и такие инсерции и/или делеции приводят к сдвигу рамки считывания, и тем самым, к образованию мРНК транскриптомы со сдвигом рамки считывания. В результате этого, природные функции теряются из-за разрушения цепи, опосредуемого нонсенс-мутациями или невозможности синтеза нормальных белков. Кроме того, при сохранении рамки считывания, мутации, в которых инсерции или делеции присутствуют в последовательности в значительном количестве, могут вызывать нарушение функциональных свойств белков. Такая мутация зависит от локуса, поскольку мутации в функционально значимом домене, вероятно, менее толерантны, чем мутации в функционально незначимой области белка.
Хотя невозможно предсказать INDEL-мутации, продуцируемые в природе посредством NHEJ, однако, специфическая INDEL-последовательность является предпочтительной в данной области разрыва и может происходить от небольшой области с микрогомологией. Обычно, делеции имеют длину в пределах от 1 п.о. до 50 п.о., а инсерции имеют тенденцию укорачиваться и часто включают небольшую повторяющуюся последовательность, непосредственно окружающую область разрыва.
Кроме того, NHEJ представляет собой процесс, приводящий к мутации, и если он не является необходимым для продуцирования специфической конечной последовательности, то он может быть использован для делеции мотива небольшой последовательности.
Специфический нокаут гена-мишени, в котором экспрессия регулируется областью регуляции транскрипции, которая является мишенью для комплекса CRISPR, может быть осуществлен с использованием такого NHEJ. Двойная цепь или две одиночных цепи области регуляции транскрипции гена-мишени могут расщепляться под действием фермена CRISPR, такого как Cas9 или Cpf1, а двойная цепь с разрывом или две отдельные цепи могут иметь инсерции-делеции (INDEL) в результате NHEJ, что будет приводить к индуцированию специфического нокаута гена-мишени, экспрессия которого регулируется областью регуляции транскрипции.
В одном примере, двойная цепь области регуляции транскрипции гена-мишени может быть расщеплена с использованием комплекса CRISPR и могут быть введены различные «INDEL» (инсерции и делеции) в репарированную область посредством репарации с помощью NHEJ.
Термин «INDEL» означает изменение, введенное путем инсерции неполного нуклеотида в нуклеотидную последовательность/делеции нуклеотида из нуклеотидной последовательности ДНК. Инсерции/делеции могут быть введены в последовательность-мишень в процессе репарации с помощью HDR или NHEJ, если комплекс «рРНК -фермент CRISPR», описанный выше, расщепляет последовательность-мишень в области регуляции транскрипции гена-мишени.
Прямая гомологичная репарация (HDR) представляет собой метод безошибочной коррекции, в котором гомологичная последовательность используется в качестве матрицы для репарации или восстановления поврежденной области регуляции транскрипции, а обычно, для репарации или восстановления ДНК с разрывом, то есть, для восстановления природной клеточной информации, ДНК с разрывом подвергают репарации на основе информации о комплементарной нуклеотидной последовательности, которая не была модифицирована, или на основе информации о сестринской хроматиде. Наиболее распространенным типом HDR является гомологичная рекомбинация (HR). HDR представляет собой процесс репарации, обычно происходящий в фазе S или G2/M активно делящихся клеток.
Для репарации или восстановления поврежденной ДНК посредством HDR, но не с использованием комплементарной нуклеотидной последовательности или сестринского хроматина в клетках, в эти клетки вводят матричную ДНК, искусственно синтезированную на основе информации о комплементарной нуклеотидной последовательности или гомологичной нуклеотидной последовательности, то есть, матричной нуклеиновой кислоты, включающей комплементарную нуклеотидную последовательность или гомологичную нуклеотидную последовательность, что будет приводить к репарации ДНК с разрывом. В данном описании, при последующем введении последовательности нуклеиновой кислоты или фрагмента нуклеиновой кислоты в матричную нуклеиновую кислоту для репарации ДНК с разрывом, такая последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, дополнительно введенные в ДНК с разрывом, могут подвергаться нокину. Такая дополнительно добавленная последовательность нуклеиновой кислоты или фрагмента нуклеиновой кислоты могут представлять собой, но не ограничиваются ими, последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты для коррекции области регуляции транскрипции гена-мишени, модифицированных путем мутации, вводимой в нормальный ген или в нормальную нуклеиновую кислоту, экспрессируемые в клетках.
В одном примере, двойная или одиночная цепь области регуляции транскрипции гена-мишени могут быть расщеплены под действием комплекса CRISPR, а затем в клетки может быть введена матричная нуклеиновая кислота, включающая нуклеотидную последовательность, комплементарную нуклеотидной последовательности, смежной с сайтом расщепления, и такая расщепленная нуклеотидная последовательность области регуляции транскрипции гена-мишени может быть подвергнута репарации или восстановлению посредством HDR.
В данном описании, матричная нуклеиновая кислота, включающая комплементарную нуклеотидную последовательность, может иметь комплементарную нуклеотидную последовательность ДНК с разрывом, то есть, расщепленную двойную или одиночную цепь, а также последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, встроенные в ДНК с разрывом. Дополнительная последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты могут быть встроены в ДНК с разрывом, то есть, в сайт расщепления области регуляции транскрипции гена-мишени с использованием матричной нуклеиновой кислоты, включающей комплементарную нуклеотидную последовательность и последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, встроенные в эту последовательность. В данном случае встроенная последовательность нуклеиновой кислоты или фрагмента нуклеиновой кислоты, и дополнительная последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты могут представлять собой последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, предназначенные для коррекции области регуляции транскрипции гена-мишени, модифицированной посредством мутации нормального гена или гена или нуклеиновой кислоты, экспрессирующихся в клетках. Комплементарная нуклеотидная последовательность может представлять собой нуклеотидную последовательность, имеющую комплементарные связи с ДНК с разрывом, то есть, правые и левые нуклеотидные последовательности в расщепленной двойной или в одиночной цепи области регуляции транскрипции гена-мишени. Альтернативно, комплементарная нуклеотидная последовательность может представлять собой нуклеотидную последовательность, имеющую комплементарные связи с ДНК с разрывом, то есть, у 3’- и 5’-концов расщепленной двойной или одиночной цепи области регуляции транскрипции гена-мишени. Комплементарная нуклеотидная последовательность может представлять собой последовательность из 15-3000 нуклеотидов, где длина или размер комплементарной нуклеотидной последовательности могут быть соответствующим образом скорректированы в зависимости от размера матричной нуклеиновой кислоты или области регуляции транскрипции гена-мишени. В данном описании, в качестве матричной нуклеиновой кислоты может быть использована двухцепочечная или одноцепочечная нуклеиновая кислота, либо такая нуклеиновая кислота может быть линейной или кольцевой, однако, настоящее изобретение не ограничивается ими.
В другом примере, двухцепочечную или одноцепочечную область регуляции транскрипции гена-мишени расщепляют с использованием комплекса CRISPR, а затем в клетки вводят матричную нуклеиновую кислоту, включающую гомологичную нуклеотидную последовательность, содержащую нуклеотидную последовательность, смежную с сайтом расщепления, и такая расщепленная нуклеотидная последовательность области регуляции транскрипции гена-мишени может быть подвергнута репарации или восстановлению посредством HDR.
В данном описании, матричная нуклеиновая кислота, включающая гомологичную нуклеотидную последовательность, может иметь гомологичную нуклеотидную последовательность ДНК с разрывом, то есть, расщепленную двухцепочечную или одноцепочечную последовательность, а также последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, встроенные в ДНК с разрывом. Дополнительная последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты могут быть встроены в ДНК с разрывом, то есть, в сайт расщепления области регуляции транскрипции гена-мишени с использованием матричной нуклеиновой кислоты, включающей гомологичную нуклеотидную последовательность и встроенную последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты. В данном случае встраивают последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, и дополнительная последовательностью нуклеиновой кислоты или фрагмент нуклеиновой кислоты могут представлять собой последовательность нуклеиновой кислоты или фрагмент нуклеиновой кислоты, предназначенные для коррекции области регуляции транскрипции гена-мишени или нуклеиновой кислоты, модифицированных посредством мутации нормального гена или гена или нуклеиновой кислоты, экспрессирующихся в клетках. Гомологичная нуклеотидная последовательность может представлять собой нуклеотидную последовательность, гомологичную ДНК с разрывом, то есть, правую и левую нуклеотидную последовательность расщепленной двойной цепи области регуляции транскрипции. Альтернативно, комплементарная нуклеотидная последовательность может представлять собой нуклеотидную последовательность, гомологичную ДНК с разрывом, то есть, у 3’- и 5’-концов расщепленной двойной или одиночной цепи области регуляции транскрипции. Гомологичная нуклеотидная последоватльность может представлять собой последовательность из 15-3000 оснований, где длина или размер гомологичной нуклеотидной последоватльности могут быть подходящим образом скорректированы в зависимости от размера матричной нуклеиновой кислоты или области регуляции транскрипции гена-мишени. В данном описании, в качестве матричной нуклеиновой кислоты может быть использована двухцепочечная или одноцепочечная нуклеиновая кислота, и такая нуклеиновая кислота может быть линейной или кольцевой, однако, настоящее изобретение не ограничивается ими.
Помимо NHEJ и HDR, могут быть использованы и другие методы репарации или восстановления поврежденной области регуляции транскрипции. Так, например, метод репарации или восстановления поврежденной области регуляции транскрипции может представлять собой отжиг одной цепи, репарацию разрыва одной цепи, репарацию ошибочных спариваний, репарацию нуклеотидных расщеплений или метод с применением репарации нуклеотидных расщеплений.
Отжиг одноцепочечной нуклеиновой кислоты (SSA) представляет собой метод репарации разрывов двойной цепи между двумя повторяющимися последовательностями, присутствующими в нуклеиновой кислоте-мишени, и обычно, в этом методе используется повторяющаяся последовательность из более, чем 30 нуклеотидов. Повторяющуюся последовательность расщепляют (с образованием «липких» концов) с получением одной цепи, соответствующей двухцепочечной нуклеиновой кислоте-мишени у каждого разорванного конца, и после расщепления, одноцепочечный выступающий конец, содержащий повторяющуюся последовательность, достраивают белком RPA в целях предотвращения несоответствующего отжига повторяющихся последовательностей друг с другом. RAD52 связывается с каждой повторяющейся последовательностью на выступающем конце, в результате чего происходит сборка последовательности, способной гибридизоваться с комплементарной повторяющейся последовательностью. После отжига, одноцепочечный выступающий фрагмент отщепляют, и посредством синтеза новой ДНК заполняют определенный гэп для восстановления двухцепочечной ДНК. В результате этой репарации, последовательность ДНК между двумя повторами делетируется, а длина делеции может зависеть от различных факторов, включая участки локализации двух используемых здесь повторов и путь или степень расщепления.
В SSA, аналогично HDR, используется комплементарная последовательность, которая представляет собой комплементарную повторяющуюся последовательность, но в отличие от HDR, для модификации или коррекции последовательности нуклеиновой кислоты-мишени не требуется матричной нуклеиновой кислоты.
Одноцепочечные разрывы в геноме подвергают репарации по отдельному механизму, а именно, по механизму репарации одноцепочечного разрыва (SSBR), исходя из вышеописанных механизмов репарации. В случае одноцепочечных ДНК-разрывов, PARP1 и/или PARP2 распознают разрывы и инициируют механизмы репарации. Связывание PARP1 и его активность по отношению к ДНК-разрывам являются временными, а SSBR стимулируется посредством индуцирования стабильности белкового комплекса SSBR в поврежденных областях. Наиболее важным белком в комплексе SSBR является XRCC1, который взаимодействует с белком, стимулирующим процессинг ДНК у 3’- и 5’-концов для стабилизации ДНК. Процессинг по концам обычно приводит к репарации поврежденного 3’-конца с образованием гидроксилированной группы и/или поврежденного 5’-конца с образованием фосфатной группы, и после процессинга этих концов происходит достраивание гэпа ДНК. Существует два метода достраивания гэпа ДНК, то есть, репарация коротких пэтчей и репарация длинных пэтчей, причем, репарация коротких пэтчей включает инсерцию одного нуклеотида. После достраивания гэпа ДНК, ДНК-лигаза стимулирует соединение концов.
Репарация ошибочных спариваний (MMR) осуществляется на ошибочно спаренных нуклеотидах ДНК. Каждый из комплексов MSH2/6 или MSH2/3 обладает АТФазной активностью, и таким образом, играет важную роль в распознавании ошибочного спаривания и в инициации репарации, где MSH2/6 распознает, главным образом, ошибочные спаривания нуклеотидов и идентифицирует одно или два ошибочных спариваний нуклеотидов, а MSH2/3 распознает, главным образом, большее число ошибочных спариваний.
Репарация вырезания оснований (BER) представляет собой механизм репарации, который является активным на протяжении всего клеточного цикла и применяется для удаления из генома небольшой поврежденной области оснований, не дестабилизирующих спираль. В поврежденной ДНК, поврежденные нуклеотиды удаляют путем расщепления N-гликозидной связи, соединяющей нуклеотид с остовом «фосфат-дезоксирибоза», с последующим расщеплением фосфодиэфирного остова и генерированием разрывов в одноцепочечной ДНК. Разорванные одноцепочечные концы, продуцированные таким образом, удаляют, а затем гэп, генерируемый посредством удаления одной цепи, достраивают новым комплементарным нуклеотидом, и конец только что достроенного комплементарного нуклеотида лигируют с остовом под действием ДНК-лигазы, что способствует репарации поврежденной ДНК.
Репарация вырезания нуклеотидов (NER) представляет собой механизм вырезания, играющий важную роль в удалении из ДНК крупного повреждения, разрушающего спираль, и при распознавании такого повреждения, короткий сегмент одноцепочечной ДНК, содержащий поврежденную область, удаляют с образованием одноцепочечного гэпа в 22-30 нуклеотидов. Образовавшийся гэп достраивают новым комплементарным нуклеотидом, и конец только что достроенного комплементарного нуклеотида лигируют с остовом под действием ДНК-лигазы, что способствует репарации поврежденной ДНК.
Эффекты искусственной модификации области регуляции транскрипции гена-мишени под действием комплекса рРНК - фермент CRISPR могут давать, главным образом, эффекты нокаута, нокдауна, нокина и повышения уровня экспрессии.
Термин «нокаут» означает инактивацию гена-мишени или нуклеиновой кислоты-мишени, а «инактивация» гена-мишени или нуклеиновой кислоты-мишени означает состояние, при котором не происходит транскрипции и/или трансляции гена-мишени или нуклеиновой кислоты-мишени. Транскрипция и трансляция гена, вызывающего заболевание, или гена, имеющего аномальную функцию, могут быть ингибированы посредством нокаута, что позволяет предотвратить экспрессию белка.
Так, например, при редактировании области регуляции транскрипции гена-мишени с использованием комплекса «рРНК- фермент CRISPR», то есть, комплекса CRISPR, область регуляции транскрипции гена-мишени может быть расщеплена с использованием комплекса CRISPR. Область регуляции транскрипции, поврежденная с использованием комплекса CRISPR, может быть подвергнута репарации посредством NHEJ. В поврежденной области регуляции транскрипции, INDEL образуются посредством NHEJ, и поврежденная область регуляции транскрипции инактивируется, что приводит к индуцированию нокаута, специфичного к гену-мишени или к хромосоме-мишени.
В другом примере, при редактировании области регуляции транскрипции гена-мишени с использованием комплекса «рРНК- фермент CRISPR», то есть, комплекса CRISPR и донора, область регуляции транскрипции гена-мишени может быть расщеплена с использованием комплекса CRISPR. Область регуляции транскрипции, поврежденная с использованием комплекса CRISPR, может быть подвергнута репарации посредством HDR с использованием донора. В данном описании, донор включает гомологичную нуклеотидную последовательность и нуклеотидную последовательность, необходимую для встраивания. В данном случае, число встраиваемых нуклеотидных последовательностей может варьироваться в зависимости от локализации или цели встраивания. При репарации поврежденной области регуляции транскрипции с использованием донора, нуклеотидную последовательность встраивают в поврежденную область нуклеотидной последовательности, а поэтому область регуляции транскрипции может инактивироваться, что приводит к индуцированию нокаута, специфичного к гену-мишени или к хромосоме-мишени.
Термин «нокдаун» означает снижение уровня транскрипции и/или трансляции гена-мишени или нуклеиновой кислоты-мишени или экспрессии белка-мишени. Начало развития заболевания может быть предотвращено, либо заболевание может быть подвергнуто лечению посредством регуляции сверхэкспрессии гена или белка посредством нокдауна.
Так, например, при редактировании области регуляции транскрипции гена-мишени с использованием комплекса рРНК-фермент CRISPR, то есть, комплекса CRISPR, область регуляции транскрипции гена-мишени может быть расщеплена с использованием комплекса CRISPR. Область регуляции транскрипции, поврежденная с использованием комплекса CRISPR, может быть подвергнута репарации посредством NHEJ. В поврежденной области регуляции транскрипции, INDEL образуются посредством NHEJ, и поврежденная область регуляции транскрипции инактивируется, что приводит к индуцированию нокдауна, специфичного к гену-мишени или к хромосоме-мишени.
В другом примере, при редактировании области регуляции транскрипции гена-мишени с использованием комплекса «рРНК- фермент CRISPR», то есть, комплекса CRISPR и донора, область регуляции транскрипции гена-мишени может быть расщеплена с использованием комплекса CRISPR. Область регуляции транскрипции, поврежденная с использованием комплекса CRISPR, может быть подвергнута репарации посредством HDR с использованием донора. В данном описании, донор включает гомологичную нуклеотидную последовательность и нуклеотидную последовательность, необходимую для встраивания. В данном случае, число встраиваемых нуклеотидных последовательностей может варьироваться в зависимости от локализации или цели встраивания. При репарации поврежденной области регуляции транскрипции с использованием донора, нуклеотидную последовательность встраивают в поврежденную область нуклеотидной последовательности, а поэтому область регуляции транскрипции может инактивироваться, что приводит к индуцированию нокдауна, специфичного к гену-мишени или к хромосоме-мишени.
Так, например, при редактировании области регуляции транскрипции гена-мишени с использованием комплекса «рРНК- неактивный фермент CRISPR-домен активности, ингибирующей транскрипцию», то есть, комплекса неактивного CRISPR, включающего домен, обладающий активностью ингибирования транскрипции, комплекс неактивного CRISPR может специфически связываться с областью регуляции транскрипции гена-мишени, и активность области регуляции транскрипции ингибируется посредством домена, обладающего активностью ингибирования транскрипции и включенного в комплекс неактивного CRISPR, что будет приводить к индуцированию нокдауна, при котором будет ингибироваться экспрессия гена-мишени или хромосомы-мишени.
Термин «нокин» означает инсерцию специфической нуклеиновой кислоты или специфического гена в ген-мишень или нуклеиновую кислоту-мишень, и в данном описании, термин «специфическая нуклеиновая кислота» или «специфический ген» означает встроенные или экспрессированные представляющие интерес ген или нуклеиновую кислоту. Мутантный ген, вызывающий заболевание, может быть использован для лечения заболеваний посредством точной коррекции нормального гена или инсерции нормального гена для индуцирования экспрессии нормального гена посредством нокина.
Кроме того, для нокина может также потребоваться донор.
Так, например, при редактировании гена-мишени или нуклеиновой кислоты-мишени с использованием комплекса «рРНК-фермент CRISPR», то есть, комплекса CRISPR и донора, ген-мишень или нуклеиновая кислота-мишень могут быть расщеплены с использованием комплекса CRISPR. Ген-мишень или нуклеиновая кислота-мишень, поврежденные с использованием комплекса CRISPR, могут быть репарированы посредством HDR с использованием донора. В данном случае, донор может включать специфическую нуклеиновую кислоту или специфический ген и может быть использован для встраивания специфической нуклеиновой кислоты или специфического гена в поврежденный ген или в поврежденную хромосому. В данном случае, встроенные специфические нуклеиновая кислота или ген могут индуцировать экспрессию белка.
«Повышение уровня экспрессии» означает повышение уровня транскрипции и/или трансляции гена-мишени или нуклеиновой кислоты-мишени или экспрессии белка-мишени по сравнению с уровнем до искусственной модификации. Заболевание может быть предотвращено или вылечено путем регуляции экспрессии гена или белка с низким уровнем экспрессии или неэкспрессируемого гена или белка.
Так, например, при редактировании области регуляции транскрипции гена-мишени с использованием комплекса рРНК-фермент CRISPR, то есть, комплекса CRISPR, область регуляции транскрипции гена-мишени может быть расщеплена с использованием комплекса CRISPR. Область регуляции транскрипции, поврежденная с использованием комплекса CRISPR, может быть подвергнута репарации посредством NHEJ. В поврежденной области регуляции транскрипции, INDEL образуются посредством NHEJ, что приводит к повышению активности области регуляции транскрипции и к индуцированию экспрессии нормального гена-мишени или нормальной хромосомы-мишени.
В одном репрезентативном варианте осуществления изобретения, раскрытом в настоящем описании, комплекс «рРНК - фермент CRISPR» может быть добавлен в область регуляции транскрипции дуплицированного гена для искусственной обработки или модификации.
Комплекс «рРНК - фермент CRISPR» может специфически распознавать последовательность-мишень в области регуляции транскрипции дуплицированного гена.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Описание области регуляции транскрипции приводится выше.
Последовательность-мишень может специфически распознаваться рРНК комплекса рРНК - фермент CRISPR, а поэтому комплекс рРНК - фермент CRISPR может быть локализован рядом с распознаваемой последовательностью-мишенью.
Последовательность-мишень может представлять собой сайт или область, в которых искусственная модификация присутствует в области регуляции транскрипции дуплицированного гена.
Описание последовательности-мишени приводится выше.
В одном репрезентативном варианте осуществления изобретения, последовательность-мишень может представлять собой одну или более нуклеотидных последовательностей, перечисленных в Таблицах 1, 2, 3 и 4.
Комплекс рРНК - фермент CRISPR может состоять из рРНК и фермента CRISPR.
рРНК может включать руководящий домен, способный к частичному или полному комплементарному связыванию с последовательностью-мишенью, связывающейся с руководящей нуклеиновой кислотой, в области регуляции транскрипции дуплицированного гена.
Руководящий домен может быть по меньшей мере на 70%, 75%, 80%, 85%, 90%, 95% или более или на 100% комплементарен последовательности, связывающейся с руководящей нуклеиновой кислотой.
Руководящий домен может включать нуклеотидную последовательность, комплементарную последовательности-мишени, связывающейся с руководящей нуклеиновой кислотой, в области регуляции транскрипции дуплицированного гена. В данном случае, комплементарная нуклеотидная последовательность может включать 0-5, 0-4, 0-3 или 0-2 ошибочных спариваний.
рРНК может включать один или более доменов, выбранных из группы, состоящей из первого комплементарного домена, линкерного домена, второго комплементарного домена, проксимального домена и хвостового домена.
Фермент CRISPR может представлять собой один или более белков, выбранных из группы, состоящей из белка Cas9, происходящего от Streptococcus pyogenes, белка Cas9, происходящего от Campylobacter jejuni, белка Cas9, происходящего от Streptococcus thermophilus, белка Cas9, происходящего от Staphylococcus aureus, белка Cas9, происходящего от Neisseria meningitidis, и белка Cpf1. В одном примере, белок-редактор может представлять собой белок Cas9, происходящий от Campylobacter jejuni, или белок Cas9, происходящий от Staphylococcus aureus.
Комплекс «рРНК - фермент CRISPR» может вводить различные искусственные изменения или модификации в область регуляции транскрипции дуплицированного гена.
Искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., локализованной в последовательности-мишени или у 5’-конца и/или 3’-конца в последовательности-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
Так, например, искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать делецию одного или более нуклеотидов в непрерывной области нуклеотидной последовательности из 1-50 п.о., локализованной в последовательности-мишени или у 5’-конца и/или 3’-конца в последовательности-мишени. В одном примере, делетированными нуклеотидами могут быть 1, 2, 3, 4 или 5 смежных или несмежных пар оснований. В другом примере, делетированными нуклеотидами может быть нуклеотидный фрагмент, состоящий из 2 п.о. или более смежных нуклеотидов. В данном случае, нуклеотидный фрагмент может представлять собой 2-5, 6-10, 11-15, 16-20, 21-25, 26-30, 31-35, 36-40, 41-45 или 46-50 пар оснований. В другом примере, делетированными нуклеотидами могут быть два или более нуклеотидных фрагментов. В данном случае, два или более нуклеотидных фрагментов могут представлять собой нуклеотидные фрагменты, каждый из которых имеет несмежную нуклеотидную последовательность, то есть, один или более гэпов в нуклеотидной последовательности и может иметь два или более сайтов делеции из-за делеции двух или более нуклеотидных фрагментов.
Альтернативно, например, искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать инсерцию одного или более нуклеотидов в непрерывную область нуклеотидной последовательности из 1-50 п.о., локализованной в последовательности-мишени или у 5’-конца и/или 3’-конца в последовательности-мишени. В одном примере, встроенными нуклеотидами могут быть 1, 2, 3, 4 или 5 смежных пар оснований. В другом примере, встроенными нуклеотидами может быть нуклеотидный фрагмент, состоящий из 5 или более смежных пар оснований. В данном случае, нуклеотидный фрагмент может представлять собой 5-10, 11-50, 50-100, 100-200, 200-300, 300-400, 400-500, 500-750 или 750-1000 пар оснований. В другом примере, встроенные нуклеотиды могут представлять собой неполную или полноразмерную нуклеотидную последовательность специфического гена. В данном случае, специфический ген может представлять собой чужеродный ген, который не присутствует у индивидуума, например, в человеческих клетках с дуплицированным геном. Альтернативно, специфический ген может представлять собой ген, имеющийся у индивидуума, например, в человеческих клетках с дуплицированным геном, например, ген, присутствующий в геноме человеческой клетки.
Альтернативно, например, искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать делецию и инсерцию одного или более нуклеотидов из непрерывной области или в непрерывную область нуклеотидной последовательности из 1-50 п.о., локализованной в последовательности-мишени или у 5’-конца и/или 3’-конца в последовательности-мишени. В одном примере, делетированными нуклеотидами могут быть 1, 2, 3, 4 или 5 смежных или несмежных пар оснований. В данном случае, встроенными нуклеотидами могут быть 1, 2, 3, 4 или 5 пар оснований; нуклеотидный фрагмент, или неполная или полноразмерная нуклеотидная последовательность специфического гена, и такие делеции и инсерции могут быть введены последовательно или одновременно. В данном случае, встроенный нуклеотидный фрагмент может представлять собой 5-10, 11-50, 50-100, 100-200, 200-300, 300-400, 400-500, 500-750 или 750-1000 пар оснований. В данном случае, специфический ген может представлять собой чужеродный ген, который не присутствует у индивидуума, например, в человеческих клетках с дуплицированным геном. Альтернативно, специфический ген может представлять собой ген, имеющийся у индивидуума, например, в человеческих клетках с дуплицированным геном, например, ген, присутствующий в геноме человеческой клетки. В другом примере, делетированным нуклеотидом может быть нуклеотидный фрагмент, состоящий из 2 пар оснований или более. В данном случае, делетированным нуклеотидным фрагментом могут быть 2-5, 6-10, 11-15, 16-20, 21-25, 26-30, 31-35, 36-40, 41-45 или 46-50 пар оснований. В данном случае, встроенный нуклеотид может представлять собой 1, 2, 3, 4 или 5 пар оснований; нуклеотидный фрагмент, или неполная или полноразмерная нуклеотидная последовательность специфического гена, и такие делеции и инсерции могут быть введены последовательно или одновременно. В другом примере, делетированными нуклеотидами могут быть два или более нуклеотидных фрагментов. В данном случае, встроенными нуклеотидами могут быть 1, 2, 3, 4 или 5 пар оснований; нуклеотидный фрагмент, или неполная или полноразмерная нуклеотидная последовательность специфического гена, и такие делеции и инсерции могут быть введены последовательно или одновременно. Кроме того, инсерция может присутствовать в части делетированных двух или более сайтов или во всех этих сайтах.
Комплекс «рРНК - фермент CRISPR» может вводить различные искусственные изменения или модификации в область регуляции транскрипции дуплицированного гена, в зависимости от типов рРНК и фермента CRISPR.
В одном примере, если ферментом CRISPR является белок SpCas9, то искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., 1-40 п.о., 1-30 п.о., или предпочтительно, 1-25 п.о., локализованной у 5’-конца и/или 3’-конца последовательности РАМ 5'-NGG-3' (N представляет собой A, T, G или C), присутствующей в области-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
В другом примере, если ферментом CRISPR является белок CjCas9, то искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., 1-40 п.о., 1-30 п.о., или предпочтительно, 1-25 п.о., локализованной у 5’-конца и/или 3’-конца последовательности РАМ 5’-NNNNRYAC-3’ (каждый N независимо представляет собой A, T, C или G, R представляет собой A или G, а Y представляет собой C или T), присутствующей в области-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
В одном примере, если ферментом CRISPR является белок StCas9, то искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., 1-40 п.о., 1-30 п.о., или предпочтительно, 1-25 п.о., локализованной у 5’-конца и/или 3’-конца последовательности РАМ 5'-NNAGAAW-3' (каждый N независимо представляет собой A, T, C или G, а W представляет собой А или T), присутствующей в области-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
В одном примере, если ферментом CRISPR является белок NmCas9, то искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., 1-40 п.о., 1-30 п.о., или предпочтительно, 1-25 п.о., локализованной у 5’-конца и/или 3’-конца последовательности РАМ 5’-NNNNGATT-3’ (каждый N независимо представляет собой A, T, C или G), присутствующей в области-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
В другом примере, если ферментом CRISPR является белок SaCas9, то искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., 1-40 п.о., 1-30 п.о., или предпочтительно, 1-25 п.о., локализованной у 5’-конца и/или 3’-конца последовательности РАМ 5’-NNGRR(T)-3’ (каждый N независимо представляет собой A, T, C или G, R представляет собой A или G, а (Т) представляет собой любую последовательность, которая может быть включена, но необязательно), присутствующей в области-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
В другом примере, если ферментом CRISPR является белок Cpf1, то искусственно измененная или модифицированная область регуляции транскрипции дуплицированного гена может включать одну или более из нижеследующих модификаций в непрерывной области нуклеотидной последовательности из 1-50 п.о., 1-40 п.о., 1-30 п.о., или предпочтительно, 1-25 п.о., локализованной у 5’-конца и/или 3’-конца последовательности РАМ 5'-TTN-3' (N представляет собой A, T, C или G), присутствующей в области-мишени:
i) делецию одного или более нуклеотидов;
ii) замену одного или более нуклеотидов нуклеотидами, отличающимися от гена дикого типа;
iii) инсерцию одного или более нуклеотидов или
iv) комбинацию двух или более модификаций, выбранных их i)- iii).
Эффект искусственной модификации области регуляции транскрипции дуплицированного гена под действием комплекса «рРНК - фермент CRISPR» может представлять собой нокаут.
Экспрессия белка, кодируемого дуплицированным геном, под действием комплекса «рРНК - фермент CRISPR», может быть ингибирована.
Эффект искусственной модификации области регуляции транскрипции дуплицированного гена под действием комплекса «рРНК - фермент CRISPR» может представлять собой нокдаун.
Экспрессия белка, кодируемого дуплицированным геном, под действием комплекса «рРНК - фермент CRISPR», может быть снижена.
Эффект искусственной модификации области регуляции транскрипции дуплицированного гена под действием комплекса «рРНК - фермент CRISPR» может представлять собой нокин.
В данном случае, эффект нокина может быть индуцирован под действием комплекса «рРНК - фермент CRISPR» и донора, дополнительно включающего экзогенную нуклеотидную последовательность или экзогенный ген.
Эффект искусственной модификации области регуляции транскрипции дуплицированного гена под действием комплекса «рРНК - фермент CRISPR» и донора может быть индуцирован посредством экспрессии пептида или белка, кодируемого экзогенной нуклеотидной последовательностью или экзогенным геном.
В данном случае, эффект нокина может быть индуцирован под действием комплекса «рРНК - фермент CRISPR» и донора, включающего нуклеотидную последовательность, которая должна быть встроена.
Один из аспектов, раскрытых в настоящем описании, относится к способу регуляции экспрессии.
Один из репрезентативных вариантов осуществления изобретения, раскрытых в настоящем описании, относится к способу регуляции экспрессии дуплицированного гена, который может быть осуществлен in vivo, ex vivo или in vitro.
В некоторых вариантах осуществления изобретения, способ может включать взятие образца клеток или колонии клеток у человека или у животного, не являющегося человеком, и модификацию клетки или клеток. Культивирование может быть осуществлено на любой стадии ex vivo. Клетка или клетки могут быть даже повторно введены животному, не являющемуся человеком, или в растение.
Такой способ может представлять собой способ искусственного конструирования эукариотических клеток, включающий введение композиции для регуляции экспрессии в эукариотическую клетку, имеющую дуплицированный ген.
Описание композиции для регуляции экспрессии приводится выше.
В одном варианте осуществления изобретения, композиция для регуляции экспрессии может включать:
(а) руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, локализованную в области регуляции транскрипции дуплицированного гена, или последовательность нуклеиновой кислоты, кодирующую эту нуклеиновую кислоту; и
(b) белок-редактор, включающий один или более белков, выбранных из группы, состоящей из белка Cas9, происходящего от Streptococcus pyogenes, белка Cas9, происходящего от Campylobacter jejuni, белка Cas9, происходящего от Streptococcus thermophilus, белка Cas9, происходящего от Staphylococcus aureus, белка Cas9, происходящего от Neisseria meningitidis, и белка Cpf1, или последовательность нуклеиновой кислоты, кодирующую этот белок.
В данном случае, дуплицированный ген может представлять собой один или более генов выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Описание области регуляции транскрипции приводится выше.
Руководящая нуклеиновая кислота и белок-редактор могут присутствовать в одном или более векторах в форме отдельной последовательности нуклеиновой кислоты или в виде комплекса, образованного посредством связывания руководящей нуклеиновой кислоты и белка-редактора.
Композиции для регуляции экспрессии может также включать, но необязательно, донор, содержащий последовательность нуклеиновой кислоты, необходимую для встраивания, или последовательность нуклеиновой кислоты, кодирующую эту последовательность.
Руководящая нуклеиновая кислота, белок-редактор и/или донор могут присутствовать в одном или более векторах в форме отдельной последовательности нуклеиновой кислоты.
Стадия введения может быть осуществлена in vivo или ex vivo.
Так, например, стадия введения может быть осуществлена с применением одного или более методов, выбранных из метода электропорации, метода с использованием липосом, плазмид, вирусных векторов, наночастиц и гибридного белка «белок-домен транслокации» (PTD).
Так, например, вирусный вектор может представлять собой один или более векторов, выбранных из группы, состоящей из ретровируса, лентивируса, аденовируса, аденоассоциированного вируса (AAV), вируса осповакцины, поксвируса и вируса простого герпеса.
Один из аспектов, раскрытых в настоящем описании, относится к способу лечения заболевания, вызываемого дупликацией гена, с использованием композиции для регуляции экспрессии, вводимой для лечения заболевания, вызываемого дупликацией гена.
Один из репрезентативных вариантов, раскрытых в настоящем описании, относится к применению для лечения заболевания, вызываемого дупликацией гена, способом, включающим введение индивидууму, подвергаемому лечению, композиции для регуляции экспрессии в целях искусственной модификации области регуляции транскрипции дуплицированного гена.
В данном случае, индивидуумами, подвергаемыми лечению, могут быть млекопитающие, включая человека, приматы, такие как обезьяны, и грызуны, такие как мыши и крысы.
Описание заболевания, вызываемого дупликацией гена, приводится выше.
В одном репрезентативном варианте осуществления изобретения, заболевание, вызываемое дупликацией гена, может представлять собой заболевание, вызываемое дупликацией гена PMP22.
В одном примере, заболевание, вызванное дупликацией гена PMP22, может представлять собой болезнь Шарко-Мари-Туфа типа 1А (CMT1A), болезнь Дежерина-Сотта (синдром Дежерина-Сотта, DSS), врожденную гипомиелинизирующую невропатию (CHN) или синдром Русси-Леви (RLS).
- Болезнь Шарко-Мари-Туфа (CMT). Болезнь CMT представляет собой наследственное заболевание, вызываемое дупликацией гена, которая происходит в хромосомах человека, и гены, участвующие в развитии периферических нервов рук и ног, дуплицируются посредством мутаций, вызывая тем самым деформацию в форме, напоминающей перевернутую бутылку шампанского. Болезнь СМТ является относительно распространенным нервным генетическим заболеванием, которое встречается у 36 из 100000 человек в Соединенных Штатах, а число пациентов во всем мире составляет 2,8 миллиона человек и, по оценкам специалистов, приблизительно 17000 пациентов проживает в Корее. Болезнь CMT, в основном, классифицируется по 5 типам, таким как CMT1, CMT2, CMT3, CMT4 и CMTX, с точки зрения наследованности, где CMT1, CMT2 и CMT3 являются доминантными и наследуются с вероятностью 50% у детей, а CMT4 является рецессивным и наследуется с вероятностью 25%. CMT1 и CMT2, в большинстве случаев, наследуются, в основном, членами семьи (80% и от 20 до 40%, соответственно), а CMT3 и CMT4 встречаются крайне редко. CMTX наследуется по материнской линии в X-хромосомах, но частота его встречаемости составляет от 10 до 20%. CMT1 представляет собой заболевание, вызываемое нарушением нормальных процессов экспрессии генов из-за дупликации генов, участвующих в образовании белков миелиновой оболочки, окружающей нервный аксон. CMT1 подразделяется на 3 типа. CMT1A является аутосомно-доминантным генетическим заболеванием, вызываемым дупликацией гена PMP22, локализованного на хромосоме №17 17p11.2-p12, что приводит к структурным и функциональным нарушениям миелиновой оболочки, вызываемым сверхэкспрессией PMP22, который является важным компонентом миелиновой оболочки.
CMT2 ассоциируется с патологией аксонов и представляет собой невропатию со значительно сниженным потенциалом действия двигательных сенсорных нервов, в то время как скорость нервной проводимости близка к нормальному состоянию, а CMT3 встречается в раннем детстве как крайне редкое аутосомно-рецессивное генетическое заболевание и относится к типу заболеваний, при которых клинические симптомы и снижение скорости нервной проводимости являются очень тяжелыми. CMT4 также относится к типу заболевания, которое проявляется в раннем возрасте тяжелыми клиническими симптомами и наследуется по аутосомно-рецессивному типу, а CMTX ассоциируется с Х-хромосомами, и его симптомы у мужчин являются более выраженными, чем у женщин.
- Болезнь Дежерина-Сотта (синдром Дежерина-Сотта, DSS).
DSS представляет собой демиелинизирующую невропатию двигательных сенсорных нейронов, возникающую в раннем возрасте и представляющую собой заболевание, которое обычно наследуется по аутосомно-доминантному типу, а также и по аутосомно-рецессивному типу, проявляется тяжелой демиелинизирующей невропатией, аномалиями двигательных нервов с детства и характеризуется очень медленной нервной проводимостью и увеличением уровней специфических белков в спинномозговой жидкости. Болезнь Дежерина-Сотта очень быстро прогрессирует и характеризуется нарушением походки уже в раннем возрасте и представляет собой наследуемое заболевание, но оно также возникает и спорадически. Подобно CMT1A, дупликация PMP22 обнаруживается у некоторых пациентов с DSS, и, кроме того, было подтверждено, что оно ассоциируется с присутствием миссенс-мутации соответствующего гена.
- Врожденная гипомиелинизирующая невропатия (CHN). CHN представляет собой заболевание нервной системы, симптомы которого появляются сразу после рождения, и основными симптомами являются недостаточность дыхательных путей, мышечная слабость, диссонанс мышечных движений, снижение мышечного тонуса, арефлексия, нарушение моторики (кинезионевроз; атаксия), паралич или дизестезия, которые поражают мужчин и женщин в одинаковой степени. CHN является генетическим заболеванием, которое характеризуется расстройством двигательных и сенсорных нервов и уменьшением степени образования миелиновой оболочки, при повторяющейся демиелинизации и ремиелинизации миелиновой оболочки.
- Синдром Русси-Леви (RLS)
RLS представляет собой редкий тип наследственной невропатии двигательной сенсорной системы, который впервые был описан Русси и Леви и др. в 1926 году и представляет собой случай, характеризующийся тремором конечностей, нарушением походки и т.п., которые являются более тяжелыми, чем при других наследственных невропатиях двигательной сенсорной системы, однако, те же симптомы были позже обнаружены при наследственных невропатиях двигательной сенсорной системы различных подтипов, и в настоящее время, RLS рассматривается как один из симптомов, который проявляется при наследственной невропатии двигательной сенсорной системы. Что касается RLS, то мутация гена MPZ в виде гена миелинового белка 0 была обнаружена в генетическом тесте у пациентов, у которых впервые был наблюдалось наличие RLS, а у других пациентов наблюдалось заболевание, ассоциированное с дупликацией гена PMP22 как гена миелинового белка 22 периферических нервов.
В одном репрезентативном варианте осуществления изобретения, заболевание, вызываемое дупликацией генов, может представлять собой заболевание, вызываемое дупликацией гена PLP1.
В одном примере, заболевание, вызываемое дупликацией гена PLP1, может представлять собой болезнь Пелициуса-Мерцбахера (PMD).
- Болезнь Пелициуса-Мерцбахера (PMD)
Болезнь Пелициуса-Мерцбахера (PMD) представляет собой очень редкую суданофильную лейкодистрофию, проявляющуюся различными неврологическими симптомами вследствие дисмиелинизации белого вещества центральной нервной системы. Ее распространенность оценивается приблизительно как 1/400000. В 1885 году, Пелициус впервые сообщил об одной семье, имеющей наследственную церебральную диплегию, которая наследуется по механизмму, зависимому от хромосомы X, и характеризуется нистагмом, атаксией, ригидностью и приобретенной микроцефалией, наблюдающимися в начале развития заболевания. Клинические признаки PMD проявляются в раннем детстве и в подростковом периоде, и характерными клиническими симптомами PMD являются маятниковый нистагм, одышка, расстройство психомоторного развития или дегенерация, атаксия, нерегулярные движения, непроизвольные движения, дисфункция полости рта и умственная отсталость.
PMD представляет собой нейродегенеративное заболевание или лейкодистрофию, вызываемую дисмиелинизацией белого вещества центральной нервной системы из-за уменьшения количества олигодендроцитов и нарушения синтеза протеолипидного белка (PLP). Протеолипидный белок (PLP) является белком, наиболее распространенным в миелиновой оболочке центральной нервной системы, и он аномально экспрессируется или продуцируется вследствие мутации гена PLP1 (Xq22), расположенного на длинном плече хромосомы X, что приводит к дисмиелинизации в центральной нервной системе. PMD обладает аффинностью к судановому красному при патологии ткани головного мозга, которая вызывается некоторыми азосоединениями, реагирующими с липидами, и приводит к разрушению миелиновой оболочки, а также наблюдается в средней доле, в мозжечке и в стволе головного мозга. Однако, поскольку продукты распада не были обнаружены, то причиной PMD считается дисмиелинизация или гипомиелинизация, а не демиелинизация. Обычно, врожденная форма PMD характеризуется полной дисмиелинизацией, а классическая форма PMD характеризуется частичной дисмиелинизацией. Если наблюдается частичная дисмиелинизация, то белое вещество, присутствующее в нормальном мозговом веществе, имеет тигроидный внешний вид. Аксоны и нейроны при поражениях с дисмиелинизацией обычно хорошо сохраняются, число редких олигодендроцитов снижается, и в белом веществе обнаруживается увеличение астроцитов и фиброзный глиоз, а также наблюдается атрофия в области микрополигирии и в зернистом слое мозжечка. У 80% или более пациентов мужского пола была обнаружена мутация гена PLP1 (Xq22), локализованного на длинном плече хромосомы X. У 10-30% из этих пациентов наблюдается точковая мутация в гене, и в этом случае, как известно, проявляются более серьезные клинические симптомы. Феномен дупликации всего гена PLP1 часто встречается у 60-70% или более пациентов с PMD. Недавно было установлено, что поскольку ген PLP1 находится на хромосоме X, то обычно, PMD наследуется по механизму, зависимому от хромосомы X, является наследственной и, в основном, встречается у мужчин. Однако, патогенез PMD не может быть объяснен только наличием гена PLP1, и иногда врожденная форма PMD является аутосомно-рецессивной, причем, форма PMD у взрослых является аутосомно-доминантной, либо PMD возникает спорадически и отсутствует в семейном анамнезе. Сообщалось, что выраженные симптомы PMD встречаются даже у женщин, но редко.
В одном репрезентативном варианте осуществления изобретения, заболевание, вызываемое дупликацией генов, может представлять собой заболевание, которое вызывается дупликацией гена MECP2.
В одном примере, заболевание, вызываемое дупликацией гена MECP2, может представлять собой синдром дупликации MECP2.
- Синдром дупликации MECP2
Заболевание головного мозга, называемое синдромом дупликации MECP2, вызывается дупликацией генетического материала, которая происходит в определенной области хромосомы X, имеющей ген MECP2. Это заболевание сопровождается различными симптомами и включает такие симптомы, как низкий мышечный тонус, задержки в развитии, респираторные инфекции, нарушения речи, судороги, аутизм и серьезные нарушения умственного развития.
Это заболевание является генетическим расстройством, но оно возникает у людей при отсутствия этого заболевания в семейном анамнезе. Синдром дупликации MECP2, в основном, встречается у мужчин, а синдром Ретта, вызываемый дефицитом гена MECP2, в основном, встречается у женщин.
В одном репрезентативном варианте осуществления изобретения, заболевание, вызываемое дупликацией генов, может представлять собой заболевание, которое вызывается дупликацией гена RAI1.
В одном примере, заболевание, вызываемое дупликацией гена RAI1, может представлять собой синдром Потоцкого-Лупски (PTLS).
- Синдром Потоцкого-Лупски (PTLS)
PTLS представляет собой синдром смежных генов с микродупликацией области 11.2 (17p11.2) на коротком плече хромосомы 17, и первый случай заболевания PTLS был зарегистрирован в 1996 году. Известно, что PTLS возникает вследствие дупликации 1,3-3,7 Mb в области 17p11.2, имеющей ген-1 (RAI1), индуцированный ретиноевой кислотой. PTLS считается редким заболеванием, и предполагается, что он встречается у одного из 20000 новорожденных. PTLS характеризуется различными врожденными аномалиями и умственной отсталостью, и в 80% случаев, PTLS представляет собой расстройство аутического спектра. Кроме того, другими уникальными признаками PTLS являются апноэ во сне, структурные сердечно-сосудистые нарушения, аномальное социальное поведение, неспособность к обучению, синдром дефицита внимания, навязчивые состояния и низкий рост.
В одном репрезентативном варианте осуществления изобретения, заболевание, ассоциированное с дупликацией генов, может представлять собой заболевание, вызываемое дупликацией гена ELN.
В одном примере, заболевание, вызываемое дупликацией гена ELN, может представлять собой синдром Уильямса-Бейрена (WBS).
- Синдром Уильямса-Бейрена (WBS)
WBS представляет собой синдром проксимального гена, ассоциированный с аномалией хромосомы 7, имеющей характерные клинические признаки, и этот WBS встречается у одного из 20000 новорожденных. Причиной микроделеции проксимальной части длинного плеча хромосомы 7 (7q11.23) в этой области является локализация различных генов, включая ген эластина, ассоциированный с продуцированием белка эластина, выстилающего эластиновую ткань, такую как стенки кровеносных сосудов, и ген LIMK1, ассоциированный с когнитивной способностью. Из-за делеции таких генов наблюдаются различные и характерные признаки и клинические симптомы. Микроделеция 7q11.23 обычно наблюдается у большинства пациентов, но в семейном анамнезе, такая микроделеция встречается редко. Дети с WBS имеют характерные признаки, такие как слегка приподнятый, тонкий кончик носа, длинный подносовой желобок, широкий рот, полные губы, впалые щеки (гипоплазия скуловой кости), выпученные глаза, нарушение формирования ногтей и вальгусная деформация большого пальца стопы.
В одном репрезентативном варианте осуществления изобретения, заболевание, ассоциированное с дупликацией генов, может представлять собой заболевание, вызванное дупликацией гена JAGGED1.
В одном примере, заболевание, вызываемое дупликацией гена JAGGED1, может представлять собой синдром Аладжилля (AS).
- Синдром Аладжилля (AS)
AS представляет собой синдром, при котором количество желчных протоков в печени значительно уменьшается, что вызывает холестаз и сопровождается нарушениями в сердечно-сосудистой системе, скелетной системе, глазных яблоках, в области лица, в поджелудочной железе и в развитии нервов. Согласно зарубежным отчетам, заболеваемость AS составляет 1/100000, и из-за особенностей такого заболевания, если оно проявляется у пациентов с незначительными симптомами, предполагается, что это заболевание встречается чаще. AS возникает из-за аномалии гена JAGGED1, расположенного на коротком плече хромосомы 20. В настоящее время известно, что причинная мутация или дупликация может быть обнаружена в 50-70% случаев с помощью генетического тестирования.
Клинические симптомы AS обычно проявляются в течение трех месяцев после рождения. AS обычно возникает в неонатальном периоде из-за сопутствующей желтухи и холестаза, и обнаруживается в подростковом периоде при хроническом заболевании печени, и даже встречается в пожилом возрасте. Поскольку AS имеет различные клинические симптомы и может наследоваться не полностью, его диагностика может быть затруднена. У большинства пациентов наблюдаются симптомы желтухи и холестаза, вследствие чего возникает зуд и прогрессирующая печеночная недостаточность в младенчестве. Желтуха наблюдается у большинства пациентов и длится до пожилого возраста у более, чем половины пациентов. В результате холестаза происходит зуд, и у некоторых детей наблюдается ксантома в подкожной клетчатке. Хотя функция синтеза в печени относительно хорошо сохраняется, приблизительно у 20% пациентов развивается цирроз печени и печеночная недостаточность.
В одном репрезентативном варианте осуществления изобретения, заболевание, связанное с дупликацией генов, может представлять собой заболевание, вызываемое дупликацией гена SNCA.
В одном примере, заболевание, вызываемое дупликацией генов SNCA, может представлять собой болезнь Паркинсона.
- Болезнь Паркинсона
Болезнь Паркинсона представляет собой заболевание, которое обычно проявляется тремором, скованностью мышц и нарушениями движений, такими как медлительность. Если болезнь Паркинсона не лечится надлежащим образом, то двигательные расстройства постепенно прогрессируют, что приводит к затруднению ходьбы и к нарушению повседневной активности. Болезнь Паркинсона представляет собой заболевание, которое встречается, в основном, у пожилых людей, и с возрастом, риск возникновения этого заболевания может постепенно увеличиваться. Хотя в Корее нет точных статистических данных, однако, по оценкам специалистов, болезнь Паркинсона встречается у 1-2 из 1000 человек. Из различных исследований известно, что в большинстве случаев, болезнь Паркинсона, которая наблюдается в пожилом возрасте, менее подвержена влиянию генетических факторов. Однако известно, что некоторые случаи болезни Паркинсона, возникающие в более молодом возрасте до 40 лет, связаны с генетическими факторами.
Болезнь Паркинсона представляет собой заболевание, вызываемое пониженной концентрацией допамина, поскольку допаминовые нейроны, присутствующие в черной субстанции, постепенно погибают. Другим патологическим свойством болезни Паркинсона является образование белкового агрегата, называемого тельцами Леви, которые наблюдаются при аутопсии головного мозга. Тельца Леви имеют белок, называемый α-синуклеином, который является основным компонентом, и тельца Леви и α-синуклеин также ассоциируются с другими заболеваниями, такими как деменция, развивающаяся при болезни телец Леви, и синуклеинопатия. Агрегация α-синуклеина начинается в блуждающем нерве и в переднем обонятельном ядре, но не в среднем мозге, а затем распространяется на кору головного мозга на последней стадии через средний мозг. Предположение, что α-синуклеин широко распространяется в различные области головного мозга при прогрессировании болезни Паркинсона, подтверждается недавними сообщениями о том, что α-синуклеин высвобождается из одной клетки, а затем передается в другую клетку.
О наследственности болезни Паркинсона было впервые высказано в отчете, в котором указывалось, что мутанты (A53T и A30P) α-синуклеина, которые являются основным компонентом телец Леви, вызывают болезнь Паркинсона. Впоследствии сообщалось, что дупликация и трипликация гена α-синуклеина (SNCA) являются другими причинами болезни Паркинсона. Это означает, что сверхэкспрессия нормального белка, помимо мутации белка α-синуклеина, приводит к накоплению α-синуклеина в клетках и к образованию агрегата, способствующих развитию болезни Паркинсона.
В одном репрезентативном варианте осуществления изобретения, заболевание, ассоциированное с дупликацией генов, может представлять собой заболевание, вызываемое дупликацией гена APP.
В одном примере, заболевание, вызываемое дупликацией гена APP, может представлять собой болезнь Альцгеймера.
- Болезнь Альцгеймера
Болезнь Альцгеймера представляет собой заболевание, ассоциированное с патологией головного мозга, приводящей к прогрессирующему нарушению памяти. Кроме того, болезнь Альцгеймера приводит к деменции, то есть, к серьезной потере интеллектуальных функций (мышления, памяти и способности к рассуждению), которые создают много проблем в повседневной жизни. В большинстве случаев, болезнь Альцгеймера встречается в возрасте старше 65 лет, но редко встречается до 65 лет. В Соединенных Штатах приблизительно 3% людей в возрасте от 65 до 74 лет, приблизительно 19% людей в возрасте от 75 до 84 лет, и приблизительно 50% людей в возрасте 85 лет и более страдают болезнью Альцгеймера. В Корее, согласно недавнему исследованию, проводимому в сельских районах, сообщалось, что приблизительно 21% людей в возрасте 60 лет или старше страдают деменцией, и приблизительно 63% из них страдают деменцией Альцгеймера. В 2006 году, во всем мире от болезни Альцгеймера страдают 266000 человек. При этом предполагается, что к 2050 году, болезнь Альцгеймера затронет одного из 85 человек.
Признаки заболевания у различных людей варьируются, но некоторые из них являются общими для всех людей с этим заболеванием. Ранние симптомы обычно ошибочно принимают за простые симптомы, вызванные старением, или симптомы, вызванные стрессом. На ранних стадиях развития этой болезни, люди, страдающие таким заболеванием, испытывают общую потерю кратковременной памяти, при которой имена, даты и места исчезают из памяти. Если болезнь прогрессирует, то проявляются симптомы спутанности сознания, импульсивного поведения, биполярного расстройства, нарушения речи и потери долгосрочной памяти. Следовательно, физические функции теряются, что приводит к летальному исходу. Из-за различных симптомов у каждого человека трудно предсказать, как это заболевание повлияет на человека. При подозрении на болезнь Альцгеймера обычно проводится диагностика, при которой проверяется мышление или способность к действию, и, если необходимо, проводится анализ головного мозга. Однако для точного диагноза необходимо исследовать черепные нервы. Даже при наличии болезни Альцгеймера обычно требуется много времени для ее полного диагностирования, а поэтому болезнь может прогрессировать в течение нескольких лет без постановки диагноза. При возникновении такого заболевания, средняя продолжительность жизни составляет 7 лет, и менее 3% людей с этим заболеванием живут 14 лет после постановки диагноза.
Болезнь Альцгеймера классифицируется как нейродегенеративное заболевание. Причина такого заболевания точно не выяснена, но, по оценкам специалистов, при болезни Альцгеймера, амилоидные бляшки модифицируют нормальный белок с образованием массы бляшек, что приводит к потере соответствующей функции. Болезнь Альцгеймера имеет гистопатологические признаки, включая общую атрофию головного мозга, расширение желудочка, наличие нейрофибриллярных клубков и нейритных бляшек.
В одном репрезентативном варианте осуществления изобретения, заболевание, вызываемое дупликацией генов, может представлять собой заболевание, вызываемое дупликацией гена SOX3, гена TBX1, гена NSD1, гена MMP23 или гена LMB1.
В одном примере, заболевание, ассоциированное с дупликацией гена, может представлять собой Х-сцепленный гипопитуитаризм, ассоциированный с Х-хромосомой (XLHP), велокардиосиндром лицевой области (VCFS), синдром задержки роста, преждевременное закрытие черепных швов или аутосомно-доминантную лейкодистрофию (ADLD).
В одном репрезентативном варианте осуществления изобретения, заболевание, ассоциированное с дупликацией гена, может представлять собой рак, вызванный дупликацией онкогена.
В данном случае, онкогеном может быть ген MYC, ген ERBB2 (HER2), ген CCND1 (циклина D1), ген FGFR1, ген FGFR2, ген HRAS, ген KRAS, ген MYB, ген MDM2, ген CCNE (циклина E), ген MET, ген CDK4, ген ERBB1, ген MYCN или ген AKT2.
В одном примере, раком может быть рак молочной железы, рак шейки матки, рак прямой и ободочной кишки, рак пищевода, рак желудка, глиобластома, рак головы и шеи, гепатоцеллюлярный рак, нейробластома, рак яичников, саркома или мелкоклеточный рак легких.
Один репрезентативныый вариант осуществления изобретения, раскрытый в настоящем описании, относится к фармацевтической композиции, включающей композицию для регуляции экспрессии, которая может быть использована для искусственного конструирования области регуляции транскрипции дуплицированного гена.
Описание композиции для регуляции экспрессии приводится выше.
В одном репрезентативном варианте осуществления изобретения, композиция для регуляции экспрессии может включать:
(а) руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, локализованную в области регуляции транскрипции дуплицированного гена, или последовательность нуклеиновой кислоты, кодирующую эту нуклеиновую кислоту; и
(b) белок-редактор, включающий один или более белков, выбранных из группы, состоящей из белка Cas9, происходящего от Streptococcus pyogenes, белка Cas9, происходящего от Campylobacter jejuni, белка Cas9, происходящего от Streptococcus thermophilus, белка Cas9, происходящего от Staphylococcus aureus, белка Cas9, происходящего от Neisseria meningitidis, и белка Cpf1, или последовательность нуклеиновой кислоты, кодирующую этот белок.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Описание области регуляции транскрипции приводится выше.
Каждая руководящая нуклеиновая кислота и белок-редактор могут присутствовать в одном или более векторах в форме последовательности нуклеиновой кислоты или в виде комплекса, образованного посредством связывания руководящей нуклеиновой кислоты и белка-редактора.
Композиция для регуляции экспрессии может также включать, но необязательно, донор, содержащий последовательность нуклеиновой кислоты, необходимую для встраивания, или последовательность нуклеиновой кислоты, кодирующую эту последовательность.
Каждая руководящая нуклеиновая кислота, белок-редактор и/или донор могут присутствовать в одном или более векторах в форме последовательности нуклеиновой кислоты.
Фармацевтическая композиция может также включать дополнительный элемент.
Дополнительный элемент может включать носитель, подходящий для его доставки в организм индивидуума.
Один репрезентативный вариант, раскрытый в настоящем описании, относится к способу лечения заболевания, вызываемого дупликацией гена, где указанный способ включает введение композиции для конструирования гена в организм пациента с заболеванием, вызываемым дупликацией гена, в целях лечения такого заболевания.
Способом лечения может быть способ лечения для регуляции экспрессии дуплицированного гена посредством модификации области регуляции транскрипции дуплицированного гена, присутствующего в живом организме. Такой способ может быть осуществлен путем непосредственного введения композиции для регуляции экспрессии в целях модификации области регуляции транскрипции дуплицированного гена, присутствующего в живом организме.
Описание композиции для регуляции экспрессии приводится выше.
В одном репрезентативном варианте осуществления изобретения, композиция для регуляции экспрессии может включать:
(а) руководящую нуклеиновую кислоту, способную нацеливаться на последовательность-мишень, локализованную в области регуляции транскрипции дуплицированного гена, или последовательность нуклеиновой кислоты, кодирующую эту нуклеиновую кислоту; и
(b) белок-редактор, включающий один или более белков, выбранных из группы, состоящей из белка Cas9, происходящего от Streptococcus pyogenes, белка Cas9, происходящего от Campylobacter jejuni, белка Cas9, происходящего от Streptococcus thermophilus, белка Cas9, происходящего от Staphylococcus aureus, белка Cas9, происходящего от Neisseria meningitidis, и белка Cpf1, или последовательность нуклеиновой кислоты, кодирующую этот белок.
В данном случае, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена PMP22, гена PLP1, гена MECP2, гена SOX3, гена RAI1, гена TBX1, гена ELN, гена JAGGED1, гена NSD1, гена MMP23, гена LMB1, гена SNCA и гена APP.
Альтернативно, дуплицированный ген может представлять собой один или более генов, выбранных из группы, состоящей из гена MYC, гена ERBB2 (HER2), гена CCND1 (циклина D1), гена FGFR1, гена FGFR2, гена HRAS, гена KRAS, гена MYB, гена MDM2, гена CCNE (циклина E), гена MET, гена CDK4, гена ERBB1, гена MYCN и гена AKT2.
Описание области регуляции транскрипции приводится выше.
Каждая руководящая нуклеиновая кислота и белок-редактор могут присутствовать в одном или более векторах в форме последовательности нуклеиновой кислоты или в виде комплекса, образованного посредством связывания руководящей нуклеиновой кислоты и белка-редактора.
Композиция для регуляции экспрессии может также включать, но необязательно, донор, содержащий последовательность нуклеиновой кислоты, необходимую для встраивания, или последовательность нуклеиновой кислоты, кодирующую эту последовательность.
Каждая руководящая нуклеиновая кислота, белок-редактор и/или донор могут присутствовать в одном или более векторах в форме последовательности нуклеиновой кислоты.
В данном случае, вектор может представлять собой плазмиду или вирусный вектор.
В данном случае, вирусный вектор может представлять собой один или более векторов, выбранных из группы, состоящей из ретровируса, лентивируса, аденовируса, аденоассоциированного вируса (AAV), вируса осповакцины, поксвируса и вируса герпеса.
Описание заболевания, ассоциированного с дупликацией генов, приводится выше.
Заболевание, вызываемое дупликацией гена, может представлять собой болезнь Шарко-Мари-Туфа 1A (CMT1A), болезнь Дежерина-Сотта (DSD), врожденную гипомиелинизирующую невропатию (CHN), синдром Русси-Леви (RLS), болезнь Пелициуса-Мерцбахера (PMD), синдром дупликации MECP2, X-сцепленный гипопитуитаризм (XLHP), синдром Потоцкого-Лупски (PTLS), синдром лицевого велокардита (VCFS), синдром Уильямса-Бейрена (WBS), синдром Аладжилля (AS), синдром замедления роста, преждевременное закрытие черепных швов, аутосомно-доминантную лейкодистрофию (ADLD), болезнь Паркинсона или болезнь Альцгеймера.
Кроме того, заболеванием, ассоциированным с дупликацией гена может быть рак молочной железы, рак шейки матки, рак прямой и ободочной кишки, рак пищевода, рак желудка, глиобластома, рак головы и шеи, гепатоцеллюлярный рак, нейробластома, рак яичника, саркома или мелкоклеточный рак легких.
Композиция для регуляции экспрессии может быть введена индивидууму для лечения заболевания, вызываемого дупликацией гена.
Индивидуумами, подвергаемыми лечению, могут быть млекопитающие, включая человека, приматы, такие как обезьяны, и грызуны, такие как мыши и крысы.
Композиция для регуляции экспрессии может быть введена индивидууму, подвергаемому лечению.
Введение может быть осуществлено путем инъекции, переливания крови, имплантации или трансплантации.
Введение может быть осуществлено способом введения, выбранным из интраневрального введения, субретинального введения, подкожного введения, интрадермального введения, внутриглазного введения, введения в стекловидное тело, введения вовнутрь опухоли, интранодального введения, интрамедуллярного введения, внутримышечного введения, внутривенного введения, введения в лимфатическую систему и внутрибрюшинного введения.
Доза композиции для регуляции экспрессии (фармацевтически эффективное количество для достижения предварительно определенного желаемого эффекта) составляет приблизительно от 104 до 109 клеток/кг (массы тела индивидуума, которому осуществляют введение), например, приблизительно от 105 до 106 клеток/кг (массы тела), и эта доза может быть выбрана из всех целых величин в числовом диапазоне, однако, настоящее изобретение не ограничивается ими. Композиция может быть надлежащим образом назначена врачом с учетом возраста, состояния здоровья и массы тела индивидуума, которому осуществляют введение, типа сопутствующего лечения и, если это возможно, частоты введения и желаемого эффекта.
При искусственной модификации области регуляции транскрипции дуплицированного гена с применением способов и композиций согласно некоторым репрезентативным вариантам, раскрытым в настоящем описании, можно регулировать экспрессию мРНК и/или белка, кодируемого дуплицированным геном, и, следовательно, может быть достигнут эффект обычной регуляции экспрессии дуплицированного гена.
[Примеры]
Далее настоящее изобретение будет более подробно описано со ссылкой на примеры.
Эти примеры приводятся лишь для более подробного описания настоящего изобретения, и специалистам в данной области очевидно, что объем настоящего изобретения не ограничивается этими примерами.
Экспериментальный метод
1. Конструирование рРНК
Области-мишени CRISPR/Cas9 человеческого гена PMP22, человеческого гена PLP1 и мышиного гена PLP1 подвергали скринингу с использованием пакета программ CRISPR RGEN (www.rgenome.net). Области-мишени гена PMP22 и гена PLP1 могут варьироваться в зависимости от типа фермента CRISPR. Последовательности-мишени промоторной области (TATA-бокса) и энхансерной области (например, области связывания EGR2, SOX10 или TEAD1); или дистальной энхансерной области B или C человеческого гена PMP22 для SpCas9, систематизированы выше в Таблице 1, а последовательности-мишени промоторной области (TATA-бокса) и энхансерной области (например, области, связывающейся с EGR2 или SOX10) человеческого гена PMP22 для CjCas9 систематизированы в Таблице 2. Кроме того, последовательности-мишени промоторной области (области TATA-бокса) и энхансерной области (например, энхансера wmN1) человеческого гена PLP1 для SpCas9 систематизированы выше в Таблице 3, а последовательности-мишени промоторной области (области TATA-бокса) и энхансерной области (например, энхансера wmN1) человеческого гена PLP1 для CjCas9 систематизированы выше в Таблице 4. Последовательности-мишени промоторной области (области TATA-бокса) и энхансерной области (например, энхансера wmN1) мышиного гена PLP1 для SpCas9 систематизированы выше в Таблице 5, а последовательности-мишени промоторной области (области TATA-бокса) и энхансерной области (например, энхансера wmN1) мышиного гена PLP1 для CjCas9 систематизированы выше в Таблице 6.
Все рРНК были получены в форме химерной одноцепочечной РНК (оцрРНК). Каркасные последовательности Cj- и Sp-специфических оцрРНК, за исключением последовательностей-мишеней, представляют собой

2. Конструирование и синтез рРНК
оцрРНК упаковывали в вектор AAV или синтезировали с помощью РНК. Для встраивания оцрРНК в вирусный вектор синтезировали ДНК-олигонуклеотид, соответствующий 20-22 последовательностям оснований оцрРНК, а затем его гибридизовали и лигирован в вектор pRGEN-CAS9 (разработанный в лаборатории) с использованием сайта BsmBI. Cas9 и оцрРНК, включающие вариабельную последовательность-мишень у 5’-конца, экспрессировались посредством промоторов CMV и U6, соответственно.
Кроме того, для системной доставки с помощью RNP, оцрРНК транскрибировали посредством РНК-полимеразы Т7, а затем получали матрицу путем отжига двух частично комплементарных олигонуклеотидов, полученных с помощью Phusion Taq-опосредованной полимеризации. Транскрибированная оцрРНК была очищена и количественно оценена с помощью спектрометрии.
3. Очистка белка Cas9
Оптимизированные по кодонам последовательности ДНК Cas9, включающие эпитопы NLS и HA, субклонировали в вектор pET28 и экспрессировали в BL21 (DE3) с использованием IPTG в оптимальных условиях культивирования. Экспрессированный белок Cas9 очищали с использованием Ni-NTA-агарозных сфер и диализовали с помощью подходящего буфера. Активность Cas9 подтверждали с помощью теста на расщепление in vitro с использованием хорошо известной эффективной оцрРНК.
4. Клеточная культура
Клеточную линию, подобную человеческим шванновским клеткам (ATCC), и первичные шванновские клетки человека (ScienCell) культивировали в соответствии с руководством производителя. Человеческие клетки, подобные шванновским клеткам, культивировали в модифицированной по способу Дульбекко среде Игла (DMEM) (WelGene), содержащей высокую концентрацию глюкозы с добавлением 1× пенициллина/стрептомицина (WelGene) и 10% фетальной телячьей сыворотки (WelGene).
Первичные шванновские клетки человека выдерживали в растворе для культивирования шванновских клеток (ScienCell), предоставленных поставщиком. Для дифференцировки, клетки культивировали в DMEM (WelGene), содержащей низкую концентрацию глюкозы с добавлением 1% фетальной телячьей сыворотки (WelGene), 100 нг/мл Nrg1 (Peprotech) для передачи сигналов образования миелиновой оболочки (миелинизации) и 100 мкМ dbcAMP (Sigma-Aldrich) в течение 7 дней.
5. Трансдукция (трансфекция)
Для трансдукции (трансфекции), комплекс RNP, содержащий 4 мкг белка Cas9 (ToolGen) и 1 мкг оцрРНК, инкубировали при комнатной температуре в течение 15 минут. После этого комплекс RNP подвергали электропорации с использованием 10 мкл раствора в наконечнике для электропорации и электропоратора Neon (ThermoFisher) и доставляли в 2 × 105 клеток. Для целевого глубокого секвенирования, геномную ДНК (гДНК) собирали из трансдуцированных клеток через 72 часа после трансдукции.
6. ПЦР в реальном времени in vitro (кол.ОТ-ПЦР)
мРНК экстрагировали из первичных человеческих шванновских клеток в соответствии с протоколом производителя с использованием мини-набора RNeasy (Qiagen). Затем 100 нг мРНК подвергали обратной транскрипции с помощью набора для обратной транскрипции с использованием кДНК с высокой емкостью (ThermoFisher). кол.ОТ-ПЦР проводили с использованием 100 нг смеси master mix для экспрессии гена Taqman в соответствии с протоколом производителя с использованием QuantStudio 3 (ThermoFisher). Уровни экспрессии PMP22 вычисляли с использованием величин Ct, а GAPDH использовали в качестве эндогенного контроля. Зонды Taqman (ThermoFisher), используемые в настоящем исследовании, систематизированы ниже в Таблице 7.
Таблица 7
7. Целевое глубокое секвенирование
Сайт-мишень амплифицировали с помощью ПЦР из гДНК, экстрагированной из трансдуцированных клеток, с использованием полимеразы taq Phusion (New England BioLabs). После этого проводили глубокое секвенирование парных концов с использованием Mi-Seq (Illumina) в качестве продукта ПЦР-амплификации. Результаты глубокого секвенирования были проанализированы с использованием пакета онлайн-программ для анализа Cas (www.rgenome.net). Было подтверждено наличие мутации в 3 п.о. выше последовательности PAM в результате инсерций-делеций, индуцированных Cas9. Праймеры, используемые в настоящем исследовании, систематизированы ниже в Таблице 8.
Таблица 8

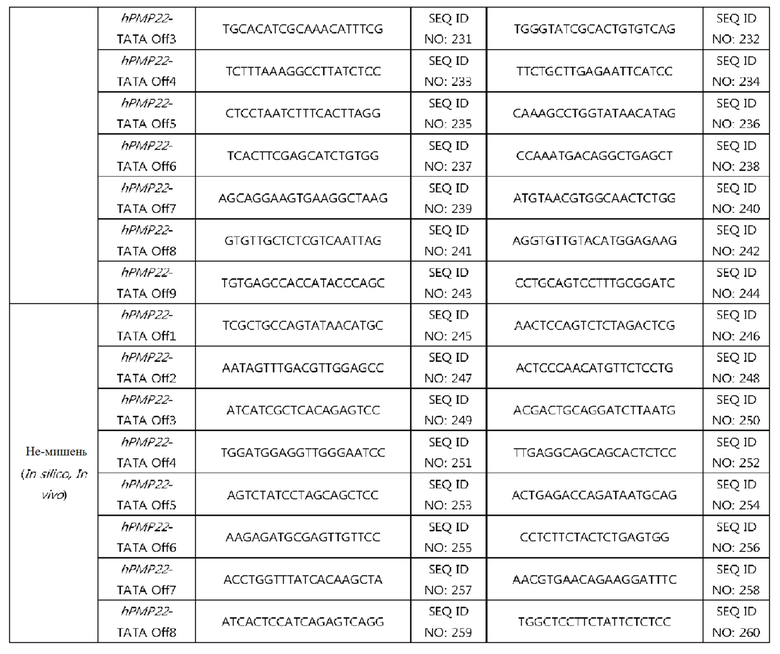
8. Конструирование in silico сайта, не являющегося мишенью
Потенциальный сайт, не являющийся мишенью, был сконструирован in silico с использованием пакета онлайн-программ (www.rgenome.net). Максимальное ошибочное спаривание в 3 п.о. рассматривалось как сайт, не являющийся мишенью.
9. Дигеномное секвенирование
Геномную ДНК клеток HeLa очищали в соответствии с протоколом поставщика с использованием набора DNeasy Blood & Tissue (Qiagen). Белок Cas9 (100 нМ) и оцрРНК (300 нМ), которые были предварительно инкубированы, смешивали с геномной ДНК (10 мкг) в 1 мл реакционного раствора (100 мМ NaCl, 50 мМ Трис-HCl, 10 мМ MgCl2, 100 мкг/мл BSA, рН 7,9) при 37°C в течение 8 часов. Расщепленную геномную ДНК обрабатывали РНКазой А (50 мкг/мл) и снова очищали с использованием набора для тканей DNeasy (Qiagen). 1 мкг расщепленной геномной ДНК разделяли на фрагменты с использованием системы Covaris, и к фрагментам ДНК был присоединен адаптер для создания библиотеки. После этого, библиотеку подвергали секвенированию всего генома (WGS) с использованием секвенатора HiSeq × Ten (Illumina) на глубине секвенирования от 30 до 40 × (Macrogen). Показатели расщепления in vitro вычисляли с помощью системы оценки расщепления ДНК в положениях каждой последовательности оснований, расщепленной в геноме.
10. Мыши и интраневральная инъекция
Линии мышей C22 (B6; CBACa-Tg(PMP22)C22Clh/H), используемые в настоящем исследовании, были закуплены у MRC Harwell (Оксфордшир, Великобритания). Мышей C22 (4 самца и 7 самок) обрабатывали PMP22-TATA RNP. Интраневральную инъекцию осуществляли так же, как и в предыдущем исследовании (Daisuke Ino., J Vis Exp., (2016) 115). 6-дневных мышей анестезировали, и извлекали седалищные нервы посредством хирургической операции. Для минимизации повреждения нервов, у основания надреза седалищного нерва сразу делали интраневральную инъекцию с помощью микропипетки из вытянутого стекла, подсоединенной к микроинжектору. Комплекс RNP, состоящий из 11 мкг белка Cas9 и 2,75 мкг оцрРНК на мышь, вводили мышам вместе с липофектамином 3000 (Invitrogen, Carlsbad, CA, USA). Обработку, использование и наблюдение всех животных, используемых в настоящем исследовании, осуществляли в соответствии с руководствами, подготовленными Комитетом по наблюдению и использованию животных Samsung (SMC-20170206001) вместе со специалистами Ассоциации по оценке и аккредитации Международной лаборатории по уходу за животными.
11. Эксперимент с использованием вращающегося стержня (тест с использованием вращающегося стержня)
Координация движений была оценена с помощью устройства в виде вращающегося стержня (B.S. Technolab INC., Korea). Этот эксперимент осуществляли для оценки равновесия и координации движений мышей. До эксперимента, мыши проходили 3-дневный тренинг. В этом эксперименте, проводимом с помощью вращающегося стержня, использовали вращающийся горизонтальный стержень (21 об/мин). Затем измеряли время удерживания мыши на вращающемся стержне, и мышь оставляли на этом стержне до 300 секунд.
12. Электрофизиологический тест
Для оценки электрофизиологического состояния, тест на нервную проводимость (NCS) осуществляли так же, как описано в предыдущем исследовании (Jinho Lee., J Biomed Sci., (2015) 22, 43). Вкратце, мышей анестезировали газообразным диоксидом углерода, и анестезию поддерживали с использованием носового конуса для подачи 1,5% изофлурана во время эксперимента. Шерсть от конца до задней лапы была полностью удалена. NCS проводили с использованием устройства Nicolet VikingQuest (Natus Medical). Для теста на двигательную проводимость седалищного нерва, каждый ответ для дистальной части и проксимальной части определяли путем помещения игольного электрода для регистрации активности на икроножную мышцу вместе с электродом сравнения, прикрепленным к сухожилию, и размещения стимулирующего отрицательного электрода в положение, находящееся по отношению к записывающему электроду на расстоянии 6 мм к центру тела внутри бедра и центральной линии бедра за орбитальной частью. Затем измеряли дистальную латентность (DL), скорость нервной проводимости двигательного нерва (MNCV) и амплитуду потенциала мышечного действия с использованием соединения (CMAP). CMAP измеряли при максимальной сверхстимуляции.
13. Гистологический анализ нервов и получение изображений
Седалищные нервы мышей подвергали биопсии и проводили оценку патологического изменения пораженного образца путем анализа под микроскопом. Образцы соответственно фиксировали с использованием 25 мМ какодилатного буфера, содержащего 2% глутаральдегид. Полутонкие срезы окрашивали толуидиновым синим. После инкубирования в 1% OsO4 в течение 1 часа, образцы дегидратировали в сериях этанола, а затем пропускали через пропиленоксид и погружали в эпоксидную смолу (Epon 812, Oken, Nagano, Japan). Клетки разрезали до определенной толщины (1 мкм) с использованием ультрамикротома Leica (Leica Microsystems) и окрашивали толуидиновым синим в течение 30-45 секунд. g-Отношение (диаметр аксона/диаметр волокна) вычисляли путем измерения внутреннего диаметра и внешнего диаметра миелина с использованием программы Zeiss Zen 2 (Carl Zeiss, Oberkochen, Germany).
14. Статистический анализ
Статистическую значимость данных, связанных с уровнями экспрессии мРНК, оценивали с помощью одностороннего ANOVA путем множественных сравнений апостериорных значений Тьюки. Представленные данные других типов вычисляли с использованием U-критерия Манна-Уитни (http://www.socscistatistics.com/tests/mannwhitney/Default2.aspx). Данные и графики, полученные в настоящем исследовании, были проанализированы с использованием GraphPad Prism. Уровень значимости был установлен на 0,05.
15. Скрининг на нацеливание оцрРНК на ген Plp1
Мышиные фибробласты NIH-3T3 (ATCC, CRL-1658), миобласты, то есть линию C2C12, (ATCC, CRL-1772) и олигодендроциты N20.1 (Cedarlane Laboratories, CLU108-P) культивировали в соответствии с руководством производителей. Клетки культивировали в модифицированной по способу Дульбекко среде Игла (DMEM) с высокой концентрацией глюкозы с добавлением 1 × пенициллина/стрептомицина (WelGene) и 10% фетальной бычьей сыворотки (WelGene) при 37°C и 5% CO2. Для трансфекции композиции CRISPR/Cas9 был получен комплекс RNP (SpCas9), состоящий из 4 мкг белка Cas9 и 1 мкг оцрРНК или плазмиды CjCas9 (фиг. 18). После этого, комплекс RNP или плазмиду CjCas9 доставляли к 2 × 105 клеток путем электропорации с использованием 10 мкл раствора в наконечнике для электропорации и электропоратора Neon (ThermoFisher). Для целевого глубокого секвенирования, через 72 часа после трансфекции, геномную ДНК (гДНК) собирали из трансфицированных клеток.
16. Анализ на ингибирование гена Plp1.
мРНК экстрагировали из клеточной линии N20.1 с использованием мини-набора RNeasy (Qiagen) в соответствии с протоколом производителя. Затем, 1 мкг мРНК подвергали обратной транскрипции с помощью набора для обратной транскрипции с использованием кДНК с высокой емкостью (ThermoFisher). Количественную полимеразную цепную реакцию обратной транскрипции в реальном времени (кол.ОТ-ПЦР) проводили с использованием 100 нг смеси master mix для экспрессии гена Taqman в соответствии с протоколом производителя с использованием QuantStudio 3 (ThermoFisher). Уровень экспрессии Plp1 вычисляли с использованием величины CT, а GAPDH использовали в качестве эндогенного контроля. Зонды Taqman (ThermoFisher), используемые в настоящем исследовании, систематизированы ниже в Таблице 9.
Таблица 9
17. Скрининг на нацеливание оцрРНК на ген PLP1
Клеточную линию лимфобластов человека Jurkat (ATCC, TIB-152) и эпителиальную клеточную линию человеческих клеток 293T (ATCC, CRL-3216) культивировали в соответствии с руководством производителя. Клетки культивировали в модифицированной по способу Дульбекко среде Игла (DMEM) с высокой концентрацией глюкозы с добавлением 1 × пенициллина/стрептомицина (WelGene) и 10% фетальной бычьей сыворотки (WelGene) при 37°C и 5% CO2. Для трансфекции композиции CRISPR/Cas9 был получен комплекс RNP (SpCas9), состоящий из 4 мкг белка Cas9 и 1 мкг оцрРНК или плазмиды CjCas9 (фиг. 18). После этого, комплекс RNP или плазмиду CjCas9 доставляли к 2 × 105 клеток путем электропорации с использованием 10 мкл раствора в наконечнике для электропорации и электропоратора Neon (ThermoFisher). Для целевого глубокого секвенирования, через 72 часа после трансфекции, геномную ДНК (гДНК) собирали из трансфицированных клеток.
Пример 1. Скрининг на оцрРНК для гена PMP22
Для скрининга терапевтически эффективных последовательностей оцрРНК, которые могут снижать экспрессию человеческого PMP22 до нормального уровня, человеческие клеточные линии трансдуцировали различными оцрРНК и Cas9, сконструированными для нацеливания на сайт связывания с промотором (TATA-боксом) и интронным энхансером гена PMP. Вкратце, человеческие Т-клетки Jurkat использовали для скрининга SpCas9, а клетки HEK293T использовали для CjCas9. гДНК собирали из клеток и подвергали целевому глубокому секвенированию. Различные паттерны мутаций, индуцированных последовательностями оцрРНК, были идентифицированы с помощью NHEJ-опосредованных инсерций-делеций. Несколько SpCas9-оцрРНК в занчительной степени индуцировали инсерции-делеции в двух регуляторных сайтах (фиг. 1). Было подтверждено, что 30-40% инсерций-делеций было индуцировано в специфической CjCas9-оцрРНК (фиг. 2).
Пример 2. Модификация генов в клетках, подобных шванновским клеткам
Хотя эффективные мутации, то есть, инсерции-делеции, вызываемые оцрРНК, были идентифицированы в человеческих клетках однако, неясно, будет ли этот эффект наблюдаться в шванновских клетках. Таким образом, для оценки эффектов ингибирования экспрессии PMP22 и модификации генов в шванновских клетках, эффект SpCas9-оцрРНК был подтвержден с использованием клеток sNF2.0, которые являются клетками, подобными шванновским клеткам. Эффективная SpCas9-оцрРНК, идентифицированная в клетках Jurkat, была повторно протестирована в клетках sNF02.0. После трансдукции, с помощью глубокого секвенирующего анализа было подтверждено, что та же самая высокая частота была инсерций-делеций достигалась с использованием той же самой оцрРНК. Трансдукция одной оцрРНК, нацеленной на сайт связывания с промотором (TATA-бокса) и сайт связывания с энхансером, индуцировала инсерции-делеции на уровне 31% и 59%, соответственно (фиг.3). Интересно отметить, что небольшая делеция в 40-50 п.о., содержащая основной фактор регуляции (например, сайт связывания с EGR или SOX10) гена миелина или играющий важную роль TATA-бокс, были обнаружены в очень большом количестве клеток, обработанных двойной оцрРНК (фиг. 5)
Пример 3. Регуляции экспрессии PMP22 с помощью модификации генов
Для оценки изменения уровня экспрессии PMP22 с использованием эффективной оцрРНК, клетки, подобными шванновским клеткам, дифференцировали и проводили кол.ОТ-ПЦР. В результате, большинство оцрРНК, нацеленных на PMP22, эффективно ингибировали экспрессию PMP22 (фиг. 6). При использовании одной оцрРНК, экспрессия PMP22 снижалась приблизительно на 30% по сравнению с контролем, обработанным только Cas9, а при использовании двойной оцрРНК, экспрессия PMP22 снижалась приблизительно на 50% по сравнению с контролем, обработанным только Cas9.
Пример 4. Модификация генов в шванновских клетках
После подтверждения эффектов ингибирования экспрессии и модификации генов PMP22 в клетках, подобными шванновским клеткам, был проведен анализ для того, чтобы подтвердить, дают ли эти результаты аналогичный эффект в человеческих первичных шванновских клетках. Частоту инсерций-делеций в сайте-мишени наблюдали с использованием SpCas9-оцрРНК в каждом сайте-мишени человеческого гена PMP22 в человеческих первичных шванновских клетках. В результате было подтверждено, что частота инсерций-делеций была высокой в сайте-мишени в большинстве оцрРНК, нацеленных на TATA-бокс, в энхансере и в кодирующих последовательностях гена PMP22 (фиг. 7A). Кроме того, даже при использовании двойных оцрРНК, каждая из которых была нацелена на TATA-бокс и энхансер, наблюдалась высокая частота инсерций-делеций. Было подтверждено, что инсерции-делеции присутствовали в сайте-мишени также при использовании оцрРНК, нацеленных на последовательности, кодирующие дистальные энхансерные сайты B и C (фиг. 7C), и в этом случае, в качестве контроля использовали оцрРНК, нацеленную на APOC3.
Кроме того, чтобы подтвердить, вызывает ли SpCas9-оцрРНК в каждом сайте-мишени снижение экспрессии гена PMP22, был проведен кол.ОТ-ПЦР-анализ. Поскольку PMP22 транскрибируется на конечной стадии дифференцировки шванновских клеток, первичные человеческие шванновские клетки обрабатывали хорошо известным фактором сигнала дифференцировки, включая нейрегулин-1 (Nrg1) и дибутиральный циклический AMP (dbcAMP), в течение 7 дней. В результате было подтверждено, что экспрессия PMP22 увеличивалась в 9 раз в клетках, обработанных Nrg1 и dbcAMP, по сравнению с клетками, которые не обрабатывались ни Nrg1, ни dbcAMP. Напротив, когда клетки обрабатывали SpCas9-оцрРНК в каждом сайте-мишени, было подтверждено, что экспрессия PMP22 повышалась в 4-6 раз. Было установлено, что это происходит из-за ингибирования экспрессии PMP22 вследствие модификации каждого сайта-мишени PMP22 под действием SpCas9-оцрРНК в каждом сайте-мишени (фиг. 7B).
Пример 5. Эффекты снижения эффективной и специфической экспрессии PMP22 с использованием CRISPR/Cas9, нацеленного на сайт ТАТА-бокса человеческого гена PMP22
Этот эксперимент проводили на первичных человеческих шванновских клетках путем отбора оцрРНК_TATA_Sp#1 (далее обозначаемой оцрРНК PMP22-TATA), и этот эксперимент продемонстрировал высокую эффективность инсерций-делеций среди оцрРНК, нацеленных на сайт TATA-бокса, который ранее подвергался скринингу, и эти оцрРНК могут быть нацелены на TATA-бокс. Инсерции-делеции были индуцированы путем трансдукции первичных человеческих шванновских клеток комплексом RNP, включающим оцрРНК и белок Cas9 (фиг. 8В), и с помощью целевого глубокого секвенирующего анализа было подтверждено, что 89,54 ± 1,39% от общего количества инсерций-делеций наблюдалось в сайте TATA-бокса человеческого PMP22 (фиг. 8C).
Кроме того, для того, чтобы подтвердить, может ли мутация, образованная в TATA-боксе PMP22, вызывать снижение уровня экспрессии гена PMP22, был проведен кол.ОТ-ПЦР-анализ. Поскольку PMP22 транскрибируется на конечной стадии дифференцировки шванновских клеток, то первичные человеческие шванновские клетки обрабатывали хорошо известным фактором сигнала дифференцировки, включая нейрегулин-1 (Nrg1) и дибутиральный циклический AMP (dbcAMP), в течение 7 дней. В результате было подтверждено, что экспрессия PMP22 увеличивалась в 9 раз в клетках, обработанных Nrg1 и dbcAMP, по сравнению с клетками, которые не обрабатывались ни Nrg1, ни dbcAMP. Напротив, когда клетки обрабатывали вместе с PMP22-TATA RNP, то было подтверждено, что экспрессия PMP22 повышалась в 6 раз. Было установлено, что это происходит из-за ингибирования экспрессии PMP22 вследствие модификации ТАТА PMP22 под действием CRISPR/Cas9 (фиг. 8D). В контроле, обработанном как фактором сигнала дифференцировки, так и AAVS1, нццеленным на RNP, какого-либо отличия в экспрессии гена PMP22 не обнаруживалось.
Для подтверждения специфичности PMP22-TATA RNP был проведен анализ in silico на отсутствие мишени. В результате целевого глубокого секвенирования, какой-либо мутации, а именно, инсерции-делеции, превышающей отношения ошибок секвенирования (в среднем 0,1%) не наблюдалось, на что указывал анализ in silico в сайте, не являющемся мишенью (фиг. 9). Поскольку анализ in silico на отсутствие мишени может давать определенное смещение, то был также проведен анализ методом дигеномного секвенирования (полный секвенирующий анализ на отсутствие мишени, который не давал смещений). В результате было подтверждено девять сайтов, которые не являются мишенями и которые были расщеплены под действием PMP22-TATA RNP in vitro (фиг. 10A, фиг. 10B). Однако, в результате повторного анализа методом целевого глубокого секвенирования, какой-либо аномальной инсерции-делеции в сайте, не являющемся мишенью, не наблюдалось (фиг. 10C).
Эти результаты показали, что эффективная и специфическая модификация TATA-бокса PMP22 под действием PMP22-TATA RNP может регулировать уровень транскрипции PMP22 в человеческих первичных шванновских клетках.
Пример 6. Эффекты ослабления фенотипа заболевания посредством ингибирования экспрессии CRISPR/Cas9-опосредуемого PMP22 у мышей CMT1A
Для того, чтобы протестировать регуляцию транскрипции PMP22 с помощью PMP22-TATA RNP in vivo, PMP22-TATA RNP, заключенный в липосомы, непосредственно вводили в седалищный нерв мыши C22 (фиг. 11). В этом случае, в качестве контроля использовали комплекс RNP, нацеленный на Rosa26 (mRosa26). mRosa26 RNP или PMP22-TATA RNP инъецировали внутривенно и доставляли в левый седалищный нерв (ипсилатерально) 6-дневной мыши (p6), а правый седалищный нерв использовали в качестве внутреннего контроля (контралатерально). Через четыре недели после инъекции, эффективность интраневральной доставки комплекса RNP подтверждали посредством целевого глубокого секвенирования путем сбора геномной ДНК из седалищного нерва. В результате, все седалищные нервы, соответственно обработанные RNP mRosa26 и RNP PMP22-TATA, показали эффективность инсерций-делеций приблизительно 11% (фиг. 12A). Кроме того, мутация ТАТА-бокса 98,48 ± 0,15% была подтверждена во всех секвенирующих ридах инсерций-делеций, что соответствует результатам in vitro (фиг. 12B).
Кроме того, для подтверждения ингибирования экспрессии PMP22 вследствие мутации TATA-бокса in vivo, был проведен кол.ОТ-ПЦР-анализ мРНК, экстрагированной из всего седалищного нерва, на RNP-обработанном седалищном нерве. Аналогично результатам in vitro было подтверждено, что экспрессия гена PMP22 снижалась на 38% по сравнению с контролем (фиг. 12C).
Для подтверждения нецелевой мутации в седалищном нерве, вызываемой PMP22-TATA RNP, был проведен анализ in silico на отсутствие мишени. В результате было подтверждено наличие восьми нецелевых мишеней, включающих ошибочные спаривания в 3 п.о., или более, в мышином геноме (фиг. 13A), и в результате проведения целевого глубокого секвенирования, какой-либо мутации, а именно, инсерции-делеции, превышающей отношения ошибок секвенирования не наблюдалось в нервах, обработанных (ипсилатерально) PMP22-TATA RNP (фиг. 13B).
Для того, чтобы проверить, может ли снижение уровня транскрипции PMP22, вызываемое РНК PMP22-TATA, предотвратить демиелинизацию, был получен седалищный нерв мыши C22, обработанной PMP22-TATA RNP или mRosa26 RNP, и его полутонкие поперечные срезы окрашивали толуидиновым синим (окрашивание на миелин). Кроме того, для измерения g-отношения определяли диаметр аксона и диаметр волокна (аксона, включающего миелин). В результате было подтверждено, что более толстый миелиновый слой наблюдался в экспериментальной группе, обработанной PMP22-TATA RNP (фиг. 14A, фиг. 14B). Кроме того, при обработке экспериментальной группы RNP PMP22-TATA, по сравнению с контролем, обработанным RNP mRosa26, было обнаружено, что число аксонов, имеющих большой диаметр, увеличилось (фиг. 14A, фиг. 14B). Результат измерения количества крупных миелинизированных волокон, имеющих диаметр 6 мкм или более, в экспериментальной группе (16,5%), обработанной RNP PMP22-TATA, продемонстрировал больший терапевтический эффект, чем у контроля (2,6%, р <0,01).
Принимая во внимание значительное усовершенствование гистологического анализа на миелинизацию, были изучены электрофизиологические профили двух групп. В результате было подтверждено, что дистальная латентность (DL) была снижена, а скорость проводимости двигательных нервов (NCV) была увеличена в седалищном нерве у экспериментальной группы, обработанной RNP PMP22-TATA, по сравнению с контролем, обработанным RNP mRosa26 (фиг. 15A, фиг. 15B), и эти результаты соответствовали увеличению толщины миелина и диаметра аксона в нерве, обработанном PMP22-TATA RNP. Кроме того, было подтверждено, что амплитуда потенциала действия мышц (CMAP), индуцируемого соединением, значительно повышалась в нерве, обработанном PMP22-TATA RNP (фиг. 15C), что соответствует предыдущему результату.
Принимая во внимание улучшение гистологических и электрофизиологических эффектов PMP22-TATA RNP, была проанализирована двигательная активность мышей в эксперименте с использованием вращающегося стержня. В результате было подтверждено, что мыши (в возрасте от 11 до 16 недель), обработанные RNP PMP22-TATA, оставались на стержне дольше, чем мыши (в возрасте от 11 до 16 недель), обработанные RNP mRosa26 (фиг.16А). Кроме того, было подтверждено, что у мышей, обработанных RNP MP22-TATA, мышцы увеличивались по сравнению с мышами, обработанными RNP mRosa26 (фиг. 16B).
Эти результаты указывали на терапевтический эффект PMP22-TATA RNP в отношении ослабления или устранения демиелинизации посредством сверхэкспрессии PMP22, такого как CMT1A.
В соответствии с этим, вышеупомянутые результаты показали эффект ингибирования экспрессии PMP22 с использованием CRISPR/Cas9, нацеленного на промоторный сайт PMP22. Кроме того, результаты показали, что прямая невирусная доставка PMP22-TATA RNP в седалищный нерв мыши C22 может улучшать клинические и невропатологические фенотипы, ассоциированные с демиелинизацией, вызываемой сверхэкспрессией PMP22. Следовательно, очевидно, что CRISPR/Cas9-опосредуемая модификация области регуляции транскрипции PMP22 может представлять собой хорошую стратегию для лечения CMT1A и других заболеваний, ассоциированных с демиелинизирующей невропатией.
Пример 7. Эффект регуляции экспрессии гена PLP
При дупликация гена PLP1, ген PLP1 сверхэкспрессируется, что становится основной причиной развития заболевания PMD. Следовательно, для регуляции транскрипции PLP1 в целях лечения заболевания PMD, область регуляции транскрипции гена PLP была искусственно модифицирована с использованием CRISPR/Cas9 для подтверждения такого эффекта.
С этой целью проводили скрининг SpCas9 и CjCas9 на TATA-бокс промоторной последовательности и энхансер (wMN1) мышиного Plp1, а затем отбирали оцрРНК с самой высокой активностью, после чего подтверждали ингибирование Plp1 с помощью кол.ОТ-ПЦР (фиг. 17). В данном случае, энхансер Plp1 может представлять собой область ASE (Hamdan et al., 2015; Meng et al., 2005; Wight, 2017) или wMN1 (Hamdan et al., 2018; Tuason et al., 2008).
На основании результатов скрининга оцрРНК были отобраны оцрРНК для SpCas9 и CjCas9 с высокими отношениями инсерций-делеций (фиг. 19-22 и Таблица 10), если области TATA-бокса и энхансерные области wMN1 Plp1 были выбраны в качестве мишеней с использованием олигодендроцитов, то есть клеточной линии N20.1, экспрессирующей ген Plp1, а затем было проведено исследование на ингибирование гена Plp1 с помощью кол.ОТ-ПЦР.
Таблица 10
Список скринируемых оцрРНК (список оцрРНК, нацеленных на mPlp1-TATA, mPlp1-wmN1 SpCas9 и CjCas9)
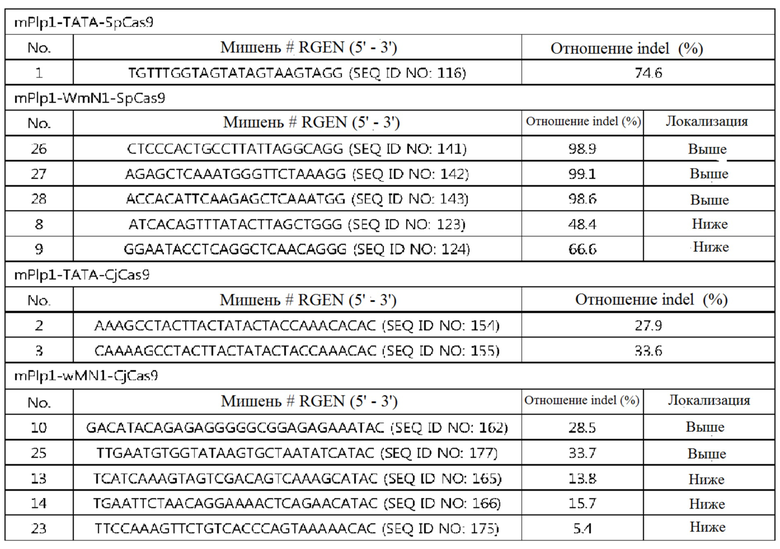
В результате было подтверждено, что нацеливание на TATA-бокс или энхансерную область wmN1 Plp1 с использованием SpCas9 и CjCas9 приводит к значительному ингибированию Plp1 (фиг. 23). Кроме того, проводили скрининг SpCas9 и CjCas9 для энхансерной области wmN1 человеческого гена PLP1 в целях подтверждения отношения инсерций-делеций (%) (фиг. 24 и 25).
Следовательно, считается, что CRISPR/Cas9-опосредуемая искусственная модификация области регуляции транскрипции PLP1 может быть хорошей стратегией для лечения PMD.
Промышленное применение
Терапевтический агент для лечения заболевания, вызываемого дупликацией гена, может быть получен с использованием композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена. Так, например, композиция для регуляции экспрессии, включающая руководящую нуклеиновую кислоту, способную нацеливаться на область регуляции транскрипции дуплицированного гена, может быть использована в качестве терапевтического агента для лечения заболевания, вызываемого дупликацией гена, посредством регуляции экспрессии дуплицированного гена в результате искусственной обработки и/или модификации области регуляции транскрипции дуплицированного гена.
[Список последовательностей в свободном формате]
Последовательности-мишени для области регуляции транскрипции дуплицированного гена и праймерные последовательности, используемые в Примерах.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> TOOLGEN INCORPORATED
<120> ИСКУССТВЕННАЯ МОДИФИКАЦИЯ ГЕНОМА ДЛЯ РЕГУЛЯЦИИ ЭКСПРЕССИИ ГЕНА
<130> OPP17-074-PCT-RU
<150> US 62/564478
<151> 2017-09-28
<150> US 62/565868
<151> 2017-09-29
<160> 381
<170> KoPatentIn 3.0
<210> 1
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 1
ggaccagccc ctgaataaac 20
<210> 2
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 2
ggcgtctttc cagtttattc 20
<210> 3
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 3
gcgtctttcc agtttattca 20
<210> 4
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 4
cgtctttcca gtttattcag 20
<210> 5
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 5
ttcaggggct ggtccaatgc 20
<210> 6
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 6
tcaggggctg gtccaatgct 20
<210> 7
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 7
accatgacat atcccagcat 20
<210> 8
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 8
tttccagttt attcaggggc 20
<210> 9
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 9
cagttacagg gagcaccacc 20
<210> 10
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 10
ctggtctggc ttcagttaca 20
<210> 11
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 11
cctggtctgg cttcagttac 20
<210> 12
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 12
aactggaaag acgcctggtc 20
<210> 13
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 13
gaataaactg gaaagacgcc 20
<210> 14
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 14
tccaatgctg ggatatgtca 20
<210> 15
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 15
aatgctggga tatgtcatgg 20
<210> 16
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 16
atagaggctg agaacctctc 20
<210> 17
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 17
ttgggcatgt ttgagctggt 20
<210> 18
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 18
tttgggcatg tttgagctgg 20
<210> 19
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 19
gagctggtgg gcgaagcata 20
<210> 20
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 20
agctggtggg cgaagcatat 20
<210> 21
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 21
tgggcgaagc atatgggcaa 20
<210> 22
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 22
ggcctccatc ctaaacaatg 20
<210> 23
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 23
gggttgggag gtttgggcgt 20
<210> 24
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 24
aggtttgggc gtgggagtcc 20
<210> 25
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 25
ttcagagact cagctattt 19
<210> 26
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 26
ggccacattg tttaggatg 19
<210> 27
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 27
ggctttgggc atgtttgag 19
<210> 28
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 28
aacatgccca aagcccagc 19
<210> 29
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 29
acatgcccaa agcccagcg 19
<210> 30
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 30
cgatgatact cagcaacagg 20
<210> 31
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 31
atggacacgc aactgatctc 20
<210> 32
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 32
gccctctgaa tctccagtca at 22
<210> 33
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 33
aatctccagt caattccaac ac 22
<210> 34
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 34
aattaggcaa ttcttgtaaa gc 22
<210> 35
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 35
ttaggcaatt cttgtaaagc at 22
<210> 36
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 36
aaagcatagg cacacatcac cc 22
<210> 37
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 37
gcctggtctg gcttcagtta ca 22
<210> 38
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 38
gtgtccaact ttgtttgctt tc 22
<210> 39
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 39
gtattctgga aagcaaacaa ag 22
<210> 40
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 40
cagtcttggc atcacaggct tc 22
<210> 41
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 41
ggacctcttg gctattacac ag 22
<210> 42
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 42
ggagccagtg ggacctcttg gc 22
<210> 43
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 43
taaatcacag aggcaaagag tt 22
<210> 44
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 44
ttgcatagtg ctagactgtt tt 22
<210> 45
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 45
gggtcatgtg ttttgaaaac ag 22
<210> 46
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 46
cccaaacctc ccaacccaca ac 22
<210> 47
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 47
actcagctat ttctggaatg ac 22
<210> 48
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 48
tcatcgcctt tgtgagctcc at 22
<210> 49
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 49
cagacacagg ctttgctcta gc 22
<210> 50
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 50
caaagcctgt gtctggccac ta 22
<210> 51
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 51
agcagtttgt gcccactagt gg 22
<210> 52
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 52
atgtcaaggt attccagcta ac 22
<210> 53
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 53
gaataactgt atcaaagtta gc 22
<210> 54
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 54
ttcctaatta agaggctttg tg 22
<210> 55
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 55
gagctagttt gtcagggtct ag 22
<210> 56
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 56
gactttggga gctaatatct 20
<210> 57
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 57
ccctttcatc ttcccattcg 20
<210> 58
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 58
cctttcatct tcccattcgt 20
<210> 59
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 59
cccacgaatg ggaagatgaa 20
<210> 60
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 60
catcttccca ttcgtgggca 20
<210> 61
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 61
tctccacctt gcccacgaat 20
<210> 62
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 62
gtctccacct tgcccacgaa 20
<210> 63
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 63
cccaatgctt gcacataaat 20
<210> 64
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 64
ccaatttatg tgcaagcatt 20
<210> 65
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 65
tccaatttat gtgcaagcat 20
<210> 66
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 66
tgtgcgcgtc tgaagaggag 20
<210> 67
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 67
gtgcgcgtct gaagaggagt 20
<210> 68
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 68
tgcgcgtctg aagaggagtg 20
<210> 69
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 69
tagtccagat gctgttgccg 20
<210> 70
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 70
attaccacgg caacagcatc 20
<210> 71
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 71
gacacgattt agtattacca 20
<210> 72
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 72
ctaaatcgtg tccaaagagg 20
<210> 73
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 73
aggaatctca gcctcctctt 20
<210> 74
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 74
gtggacaagg ttaactaaaa 20
<210> 75
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 75
atagtcaaat catgtggaca 20
<210> 76
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 76
tgctggatag tcaaatcatg 20
<210> 77
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 77
acatgatttg actatccagc 20
<210> 78
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 78
atttgactat ccagcaggct 20
<210> 79
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 79
gtcccgaagt ctctggggcc 20
<210> 80
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 80
aaaacagtcc cgaagtctct 20
<210> 81
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 81
gaaaacagtc ccgaagtctc 20
<210> 82
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 82
tatataccac attcaagtgc 20
<210> 83
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 83
tggatataac gaagttgtgt 20
<210> 84
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 84
atggatataa cgaagttgtg 20
<210> 85
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 85
atatgtttgt tcaccccaac 20
<210> 86
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 86
gaaaacttga aatcctgttg 20
<210> 87
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 87
tagacattag gagaaacaga 20
<210> 88
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 88
ctagcagtga catagacatt 20
<210> 89
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 89
agccacctga ctttgatgaa 20
<210> 90
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 90
tgagaaatgt tattactata 20
<210> 91
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 91
agactgcgag atgagagagt 20
<210> 92
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 92
ctcgcagtct gtacttagac 20
<210> 93
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 93
aatgtctctt gagagagcca 20
<210> 94
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 94
atgggaagat gaaagggaag ta 22
<210> 95
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 95
actttgattg ttaaaactta tc 22
<210> 96
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 96
agtcctacct cagcttccca at 22
<210> 97
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 97
caatgcttgc acataaattg ga 22
<210> 98
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 98
acacagagag agacagaatg aa 22
<210> 99
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 99
tcctcttcag acgcgcacac ac 22
<210> 100
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 100
actcctcttc agacgcgcac ac 22
<210> 101
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 101
ccactcctct tcagacgcgc ac 22
<210> 102
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 102
ccccactcct cttcagacgc gc 22
<210> 103
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 103
ctccccactc ctcttcagac gc 22
<210> 104
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 104
tactccccac tcctcttcag ac 22
<210> 105
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 105
tatactcccc actcctcttc ag 22
<210> 106
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 106
acagcatctg gactatcttg tt 22
<210> 107
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 107
atagtccaga tgctgttgcc gt 22
<210> 108
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 108
aaaaggaatc tcagcctcct ct 22
<210> 109
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 109
tgtcactgct agtgtgctta at 22
<210> 110
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 110
atgtgaattc agtacaagaa tt 22
<210> 111
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 111
ttatgtgaat tcagtacaag aa 22
<210> 112
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 112
ctttcatttc tgtttatgtg aa 22
<210> 113
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 113
ttcacataaa cagaaatgaa ag 22
<210> 114
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 114
atgccaactc tctcatctcg ca 22
<210> 115
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 115
gagacattct cacatttcca gt 22
<210> 116
<211> 20
<212> ДНК
<213> Mus musculus
<400> 116
tgtttggtag tatagtaagt 20
<210> 117
<211> 20
<212> ДНК
<213> Mus musculus
<400> 117
ggtctagaaa agatcaagcc 20
<210> 118
<211> 20
<212> ДНК
<213> Mus musculus
<400> 118
gccaggactg tgacctgata 20
<210> 119
<211> 20
<212> ДНК
<213> Mus musculus
<400> 119
tcaccttcac actttaacca 20
<210> 120
<211> 20
<212> ДНК
<213> Mus musculus
<400> 120
caaggttgag acaatgttcc 20
<210> 121
<211> 20
<212> ДНК
<213> Mus musculus
<400> 121
ccaattcatg tgcaaacatt 20
<210> 122
<211> 20
<212> ДНК
<213> Mus musculus
<400> 122
catcacagtt tatacttagc 20
<210> 123
<211> 20
<212> ДНК
<213> Mus musculus
<400> 123
atcacagttt atacttagct 20
<210> 124
<211> 20
<212> ДНК
<213> Mus musculus
<400> 124
ggaatacctc aggctcaaca 20
<210> 125
<211> 20
<212> ДНК
<213> Mus musculus
<400> 125
tctctgtttc ggaatacctc 20
<210> 126
<211> 20
<212> ДНК
<213> Mus musculus
<400> 126
ctgtcgacta ctttgatgaa 20
<210> 127
<211> 20
<212> ДНК
<213> Mus musculus
<400> 127
tgaaccaaga tgattatttg 20
<210> 128
<211> 20
<212> ДНК
<213> Mus musculus
<400> 128
atcttggttc atagaaattt 20
<210> 129
<211> 20
<212> ДНК
<213> Mus musculus
<400> 129
agccttgcat ggcagagctt 20
<210> 130
<211> 20
<212> ДНК
<213> Mus musculus
<400> 130
acactttaac caaggaaaga 20
<210> 131
<211> 20
<212> ДНК
<213> Mus musculus
<400> 131
taccagatcc cctctttcct 20
<210> 132
<211> 20
<212> ДНК
<213> Mus musculus
<400> 132
catttggagg ccaaaataca 20
<210> 133
<211> 20
<212> ДНК
<213> Mus musculus
<400> 133
ccaaatgttt gcacatgaat 20
<210> 134
<211> 20
<212> ДНК
<213> Mus musculus
<400> 134
agtccagatg ctgtccctga 20
<210> 135
<211> 20
<212> ДНК
<213> Mus musculus
<400> 135
cgcaagccat tcaaacacaa 20
<210> 136
<211> 20
<212> ДНК
<213> Mus musculus
<400> 136
tcaaaaccct gttgagcctg 20
<210> 137
<211> 20
<212> ДНК
<213> Mus musculus
<400> 137
cggaatacct caggctcaac 20
<210> 138
<211> 20
<212> ДНК
<213> Mus musculus
<400> 138
gtcaaaatgt gaattctaac 20
<210> 139
<211> 20
<212> ДНК
<213> Mus musculus
<400> 139
ttatctattc tattagagct 20
<210> 140
<211> 20
<212> ДНК
<213> Mus musculus
<400> 140
atcaagtaat gaaatggaca 20
<210> 141
<211> 20
<212> ДНК
<213> Mus musculus
<400> 141
ctcccactgc cttattaggc 20
<210> 142
<211> 20
<212> ДНК
<213> Mus musculus
<400> 142
agagctcaaa tgggttctaa 20
<210> 143
<211> 20
<212> ДНК
<213> Mus musculus
<400> 143
accacattca agagctcaaa 20
<210> 144
<211> 20
<212> ДНК
<213> Mus musculus
<400> 144
ttacagattg gttacacttg 20
<210> 145
<211> 20
<212> ДНК
<213> Mus musculus
<400> 145
atcactgctg ctactactta 20
<210> 146
<211> 20
<212> ДНК
<213> Mus musculus
<400> 146
atacctgcct aataaggcag 20
<210> 147
<211> 20
<212> ДНК
<213> Mus musculus
<400> 147
gatcaggaga gtcagtggga 20
<210> 148
<211> 20
<212> ДНК
<213> Mus musculus
<400> 148
ctattgtgag tctcagatta 20
<210> 149
<211> 20
<212> ДНК
<213> Mus musculus
<400> 149
tattacagat tggttacact 20
<210> 150
<211> 20
<212> ДНК
<213> Mus musculus
<400> 150
attacagatt ggttacactt 20
<210> 151
<211> 20
<212> ДНК
<213> Mus musculus
<400> 151
tacagattgg ttacacttgg 20
<210> 152
<211> 20
<212> ДНК
<213> Mus musculus
<400> 152
acagattggt tacacttggg 20
<210> 153
<211> 22
<212> ДНК
<213> Mus musculus
<400> 153
ctacttacta tactaccaaa ca 22
<210> 154
<211> 22
<212> ДНК
<213> Mus musculus
<400> 154
aaagcctact tactatacta cc 22
<210> 155
<211> 22
<212> ДНК
<213> Mus musculus
<400> 155
caaaagccta cttactatac ta 22
<210> 156
<211> 22
<212> ДНК
<213> Mus musculus
<400> 156
gggtctgaat caaaagccta ct 22
<210> 157
<211> 22
<212> ДНК
<213> Mus musculus
<400> 157
agagtgggat tctacaagtc ac 22
<210> 158
<211> 22
<212> ДНК
<213> Mus musculus
<400> 158
ggaaagaggg gatctggtag ca 22
<210> 159
<211> 22
<212> ДНК
<213> Mus musculus
<400> 159
gggatctggt agcataaagt ac 22
<210> 160
<211> 22
<212> ДНК
<213> Mus musculus
<400> 160
atctgtcact agcgacaagt gt 22
<210> 161
<211> 22
<212> ДНК
<213> Mus musculus
<400> 161
tcatgtgcaa acatttggag gc 22
<210> 162
<211> 22
<212> ДНК
<213> Mus musculus
<400> 162
gacatacaga gagggggcgg ag 22
<210> 163
<211> 22
<212> ДНК
<213> Mus musculus
<400> 163
atactgacgc catcacatca ca 22
<210> 164
<211> 22
<212> ДНК
<213> Mus musculus
<400> 164
taaaactata agctctctgt tt 22
<210> 165
<211> 22
<212> ДНК
<213> Mus musculus
<400> 165
tcatcaaagt agtcgacagt ca 22
<210> 166
<211> 22
<212> ДНК
<213> Mus musculus
<400> 166
tgaattctaa caggaaaact ca 22
<210> 167
<211> 22
<212> ДНК
<213> Mus musculus
<400> 167
actgctgcta ctacttatgg tg 22
<210> 168
<211> 22
<212> ДНК
<213> Mus musculus
<400> 168
agtcaccata agtagtagca gc 22
<210> 169
<211> 22
<212> ДНК
<213> Mus musculus
<400> 169
cataagtagt agcagcagtg at 22
<210> 170
<211> 22
<212> ДНК
<213> Mus musculus
<400> 170
ttgaatggct tgcgaacaaa ga 22
<210> 171
<211> 22
<212> ДНК
<213> Mus musculus
<400> 171
ttaatctttg ttcgcaagcc at 22
<210> 172
<211> 22
<212> ДНК
<213> Mus musculus
<400> 172
ttgctgcatc tctaacgtga ac 22
<210> 173
<211> 22
<212> ДНК
<213> Mus musculus
<400> 173
ttcacgttag agatgcagca aa 22
<210> 174
<211> 22
<212> ДНК
<213> Mus musculus
<400> 174
tggaagcaac tctaaatcac ca 22
<210> 175
<211> 22
<212> ДНК
<213> Mus musculus
<400> 175
ttccaaagtt ctgtcaccca gt 22
<210> 176
<211> 22
<212> ДНК
<213> Mus musculus
<400> 176
ttcaagagct caaatgggtt ct 22
<210> 177
<211> 22
<212> ДНК
<213> Mus musculus
<400> 177
ttgaatgtgg tataagtgct aa 22
<210> 178
<211> 22
<212> ДНК
<213> Mus musculus
<400> 178
gtataagtgc taatatcata ca 22
<210> 179
<211> 22
<212> ДНК
<213> Mus musculus
<400> 179
gtgtttcctg tatgatatta gc 22
<210> 180
<211> 22
<212> ДНК
<213> Mus musculus
<400> 180
gactttgtgt ttcctgtatg at 22
<210> 181
<211> 22
<212> ДНК
<213> Mus musculus
<400> 181
aaaacaatta tcaggcagtg ac 22
<210> 182
<211> 22
<212> ДНК
<213> Mus musculus
<400> 182
ccaagatact agagtagctg tg 22
<210> 183
<211> 22
<212> ДНК
<213> Mus musculus
<400> 183
ggcctatagc cattcaaatg gc 22
<210> 184
<211> 22
<212> ДНК
<213> Mus musculus
<400> 184
gtcccatctc cctaagtctc ga 22
<210> 185
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 185
cacagggcag tcagagaccc 20
<210> 186
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 186
gcaaacaaag ttggacactg 20
<210> 187
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 187
agactcccgc ccatcttcta gaaa 24
<210> 188
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 188
aagtcgctct gagttgttat cagt 24
<210> 189
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 189
cagtgaaacg caccagacg 19
<210> 190
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 190
aatctgccta acaggaggtg 20
<210> 191
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 191
gagggaatgg ggaccaaagg catt 24
<210> 192
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 192
tcatgtgggg tgatgttcag gaag 24
<210> 193
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 193
agagcagctg acctgaggtc caa 23
<210> 194
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 194
cccaagggta gagtgcaagt aaac 24
<210> 195
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 195
gcatcctagc tcatttggtc tgct 24
<210> 196
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 196
gagaggattc ctcatgaatg ggat 24
<210> 197
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 197
accaaacact acacttggtt actg 24
<210> 198
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 198
ctcccactag caattttaaa gtct 24
<210> 199
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 199
gaatgttcag cacaggtttc cttg 24
<210> 200
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 200
ggtcaaaagg agctccatat ttga 24
<210> 201
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 201
caggacaccc atggccaaat ccag 24
<210> 202
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 202
cagagcctcc tgcagggatg tcaa 24
<210> 203
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 203
gcctgccaag gtgactctca tcta 24
<210> 204
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 204
tgcccaggct gatcttgaac tcct 24
<210> 205
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 205
cccagagtta agaggttctt tcct 24
<210> 206
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 206
gaagctactc cagtgcaact agct 24
<210> 207
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 207
acgcagtctg ttctgtgcag tgt 23
<210> 208
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 208
aggccttccc aaggaagacc ctga 24
<210> 209
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 209
gctgatcact ggccaaatcc agct 24
<210> 210
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 210
gggaaacaat gggatcaagc tgca 24
<210> 211
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 211
gcccctttgt aagttgagga gcat 24
<210> 212
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 212
ccctctacct ctctcaatgg gctt 24
<210> 213
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 213
cagacaagca aatgctgaga gatt 24
<210> 214
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 214
cctgtcatta tgatgttcgc tagt 24
<210> 215
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 215
ccagagttgg cctcctacag agat 24
<210> 216
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 216
gtggatgccc cactactgtt catt 24
<210> 217
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 217
tacccaattt gccagtctgt gtct 24
<210> 218
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 218
accaccaggc ctgccctaca aga 23
<210> 219
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 219
tgtgaatttg atcctggcat tatg 24
<210> 220
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 220
tacagacaag cagatgctga gaga 24
<210> 221
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 221
cagtcaacag agctctaacc tcct 24
<210> 222
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 222
agcacctggt tgcacatcaa ctt 23
<210> 223
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 223
catgtggtcc ctgaacgtga atga 24
<210> 224
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 224
gtctgtcgct tgccctcttc tct 23
<210> 225
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 225
atgcagggcc tctagaccat ttca 24
<210> 226
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 226
ctcagccctt tgtgcactca cct 23
<210> 227
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 227
tgcacatcgc aaacatttcg 20
<210> 228
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 228
tgggtatcgc actgtgtcag 20
<210> 229
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 229
aggttcacat ggcttgtggt 20
<210> 230
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 230
atatctgaaa tgcccgcagg 20
<210> 231
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 231
tgcacatcgc aaacatttcg 20
<210> 232
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 232
tgggtatcgc actgtgtcag 20
<210> 233
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 233
tctttaaagg ccttatctcc 20
<210> 234
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 234
ttctgcttga gaattcatcc 20
<210> 235
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 235
ctcctaatct ttcacttagg 20
<210> 236
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 236
caaagcctgg tataacatag 20
<210> 237
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 237
tcacttcgag catctgtgg 19
<210> 238
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 238
ccaaatgaca ggctgagct 19
<210> 239
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 239
agcaggaagt gaaggctaag 20
<210> 240
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 240
atgtaacgtg gcaactctgg 20
<210> 241
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 241
gtgttgctct cgtcaattag 20
<210> 242
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 242
aggtgttgta catggagaag 20
<210> 243
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 243
tgtgagccac catacccagc 20
<210> 244
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 244
cctgcagtcc tttgcggatc 20
<210> 245
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 245
tcgctgccag tataacatgc 20
<210> 246
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 246
aactccagtc tctagactcg 20
<210> 247
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 247
aatagtttga cgttggagcc 20
<210> 248
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 248
actcccaaca tgttctcctg 20
<210> 249
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 249
atcatcgctc acagagtcc 19
<210> 250
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 250
acgactgcag gatcttaatg 20
<210> 251
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 251
tggatggagg ttgggaatcc 20
<210> 252
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 252
ttgaggcagc agcactctcc 20
<210> 253
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 253
agtctatcct agcagctcc 19
<210> 254
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 254
actgagacca gataatgcag 20
<210> 255
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 255
aagagatgcg agttgttcc 19
<210> 256
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 256
cctcttctac tctgagtgg 19
<210> 257
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 257
acctggttta tcacaagcta 20
<210> 258
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 258
aacgtgaaca gaaggatttc 20
<210> 259
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 259
atcactccat cagagtcagg 20
<210> 260
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 260
tggctccttc tattctctcc 20
<210> 261
<211> 4
<212> ДНК
<213> Homo sapiens
<400> 261
tata 4
<210> 262
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 262
tatawaw 7
<210> 263
<211> 8
<212> ДНК
<213> Homo sapiens
<400> 263
tatawawr 8
<210> 264
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 264
cataaaa 7
<210> 265
<211> 5
<212> ДНК
<213> Homo sapiens
<400> 265
tataa 5
<210> 266
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 266
tataaaa 7
<210> 267
<211> 8
<212> ДНК
<213> Homo sapiens
<400> 267
cataaata 8
<210> 268
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 268
tatataa 7
<210> 269
<211> 15
<212> ДНК
<213> Homo sapiens
<400> 269
tatatatata tataa 15
<210> 270
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 270
tatattata 9
<210> 271
<211> 6
<212> ДНК
<213> Homo sapiens
<400> 271
tataaa 6
<210> 272
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 272
tataaaata 9
<210> 273
<211> 6
<212> ДНК
<213> Homo sapiens
<400> 273
tatata 6
<210> 274
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 274
gattaaaaa 9
<210> 275
<211> 8
<212> ДНК
<213> Homo sapiens
<400> 275
tataaaaa 8
<210> 276
<211> 6
<212> ДНК
<213> Homo sapiens
<400> 276
ttataa 6
<210> 277
<211> 8
<212> ДНК
<213> Homo sapiens
<400> 277
ttttaaaa 8
<210> 278
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 278
tctttaaaa 9
<210> 279
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 279
gacatttaa 9
<210> 280
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 280
tgatatcaa 9
<210> 281
<211> 8
<212> ДНК
<213> Homo sapiens
<400> 281
tataaata 8
<210> 282
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 282
tataaga 7
<210> 283
<211> 6
<212> ДНК
<213> Homo sapiens
<400> 283
aataaa 6
<210> 284
<211> 6
<212> ДНК
<213> Homo sapiens
<400> 284
tttata 6
<210> 285
<211> 8
<212> ДНК
<213> Homo sapiens
<400> 285
cataaaaa 8
<210> 286
<211> 6
<212> ДНК
<213> Homo sapiens
<400> 286
tataca 6
<210> 287
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 287
tttaaga 7
<210> 288
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 288
gataaag 7
<210> 289
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 289
tataaca 7
<210> 290
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 290
tcttatctt 9
<210> 291
<211> 9
<212> ДНК
<213> Homo sapiens
<400> 291
ttgtacttt 9
<210> 292
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 292
catataa 7
<210> 293
<211> 7
<212> ДНК
<213> Homo sapiens
<400> 293
tataaat 7
<210> 294
<211> 15
<212> ДНК
<213> Homo sapiens
<400> 294
tatatataaa aaaaa 15
<210> 295
<211> 18
<212> ДНК
<213> Homo sapiens
<400> 295
cataaataaa aaaaatta 18
<210> 296
<211> 12
<212> РНК
<213> Streptococcus pyogenes
<400> 296
guuuuagagc ua 12
<210> 297
<211> 25
<212> РНК
<213> Campylobacter jejuni
<400> 297
guuuuagucc cuuuuuaaau uucuu 25
<210> 298
<211> 9
<212> РНК
<213> Неизвестна
<220>
<223> Parcubacteria bacterium
<400> 298
uuuguagau 9
<210> 299
<211> 14
<212> РНК
<213> Streptococcus pyogenes
<400> 299
uagcaaguua aaau 14
<210> 300
<211> 25
<212> РНК
<213> Campylobacter jejuni
<400> 300
aagaaauuua aaaagggacu aaaau 25
<210> 301
<211> 11
<212> РНК
<213> Неизвестна
<220>
<223> Parcubacteria bacterium
<400> 301
aaauuucuac u 11
<210> 302
<211> 12
<212> РНК
<213> Streptococcus pyogenes
<400> 302
aaggcuaguc cg 12
<210> 303
<211> 11
<212> РНК
<213> Campylobacter jejuni
<400> 303
aaagaguuug c 11
<210> 304
<211> 34
<212> РНК
<213> Streptococcus pyogenes
<400> 304
uuaucaacuu gaaaaagugg caccgagucg gugc 34
<210> 305
<211> 38
<212> РНК
<213> Campylobacter jejuni
<400> 305
gggacucugc gggguuacaa uccccuaaaa ccgcuuuu 38
<210> 306
<211> 22
<212> РНК
<213> Streptococcus thermophilus
<400> 306
guuuuagagc uguguuguuu cg 22
<210> 307
<211> 24
<212> РНК
<213> Streptococcus thermophilus
<400> 307
cgaaacaaca cagcgaguua aaau 24
<210> 308
<211> 13
<212> РНК
<213> Streptococcus thermophilus
<400> 308
aaggcuuagu ccg 13
<210> 309
<211> 38
<212> РНК
<213> Streptococcus thermophilus
<400> 309
uacucaacuu gaaaaggugg caccgauucg guguuuuu 38
<210> 310
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность-мишень
<400> 310
atcattggca gactagttcg 20
<210> 311
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность-мишень
<400> 311
cgaactagtc tgccaatgat 20
<210> 312
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 312
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 313
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 313
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 314
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 314
Pro Ala Ala Lys Arg Val Lys Leu Asp
1 5
<210> 315
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 315
Arg Gln Arg Arg Asn Glu Leu Lys Arg Ser Pro
1 5 10
<210> 316
<211> 38
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 316
Asn Gln Ser Ser Asn Phe Gly Pro Met Lys Gly Gly Asn Phe Gly Gly
1 5 10 15
Arg Ser Ser Gly Pro Tyr Gly Gly Gly Gly Gln Tyr Phe Ala Lys Pro
20 25 30
Arg Asn Gln Gly Gly Tyr
35
<210> 317
<211> 42
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 317
Arg Met Arg Ile Glx Phe Lys Asn Lys Gly Lys Asp Thr Ala Glu Leu
1 5 10 15
Arg Arg Arg Arg Val Glu Val Ser Val Glu Leu Arg Lys Ala Lys Lys
20 25 30
Asp Glu Gln Ile Leu Lys Arg Arg Asn Val
35 40
<210> 318
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 318
Val Ser Arg Lys Arg Pro Arg Pro
1 5
<210> 319
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 319
Pro Pro Lys Lys Ala Arg Glu Asp
1 5
<210> 320
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 320
Pro Gln Pro Lys Lys Lys Pro Leu
1 5
<210> 321
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 321
Ser Ala Leu Ile Lys Lys Lys Lys Lys Met Ala Pro
1 5 10
<210> 322
<211> 5
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 322
Asp Arg Leu Arg Arg
1 5
<210> 323
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 323
Pro Lys Gln Lys Lys Arg Lys
1 5
<210> 324
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 324
Arg Lys Leu Lys Lys Lys Ile Lys Lys Leu
1 5 10
<210> 325
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 325
Arg Glu Lys Lys Lys Phe Leu Lys Arg Arg
1 5 10
<210> 326
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 326
Lys Arg Lys Gly Asp Glu Val Asp Gly Val Asp Glu Val Ala Lys Lys
1 5 10 15
Lys Ser Lys Lys
20
<210> 327
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность локализации в ядре
<400> 327
Arg Lys Cys Leu Gln Ala Gly Met Asn Leu Glu Ala Arg Lys Thr Lys
1 5 10 15
Lys
<210> 328
<211> 77
<212> РНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность химерной одноцепочечной РНК
<400> 328
guuuuagucc cugaaaaggg acuaaaauaa agaguuugcg ggacucugcg ggguuacaau 60
ccccuaaaac cgcuuuu 77
<210> 329
<211> 76
<212> РНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность химерной одноцепочечной РНК
<400> 329
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugc 76
<210> 330
<211> 89
<212> ДНК
<213> Homo sapiens
<400> 330
ggcctccatc ctaaacaatg tggcctttgc ccatatgctt cgcccaccag ctcaaacatg 60
cccaaagccc aaagcccagc gtgggtctt 89
<210> 331
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность, модифицированная путем нацеливания на
последовательности-мишени с использованием Enh-Sp5 и Enh-Sp16
<400> 331
ggcctccatc ctaaacaatg tggcctttgc gtgggtctt 39
<210> 332
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 332
cctttgccca tatgcttcgc cca 23
<210> 333
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 333
acatgcccaa agcccagcgt ggg 23
<210> 334
<211> 89
<212> ДНК
<213> Homo sapiens
<400> 334
ggtgctccct gtaactgaag ccagaccagg cgtctttcca gtttattcag gggctggtcc 60
aatgctggga tatgtcatgg tggcctgag 89
<210> 335
<211> 41
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность, модифицированная путем нацеливания
на последовательности-мишени с использованием TATA-Sp12 и TATA-Sp14
<400> 335
ggtgctccct gtaactgaag ccagactcat ggtggcctga g 41
<210> 336
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 336
ccagaccagg cgtctttcca gtt 23
<210> 337
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 337
tccaatgctg ggatatgtca tgg 23
<210> 338
<211> 120
<212> ДНК
<213> Homo sapiens
<400> 338
cctggtggtg ctccctgtaa ctgaagccag accaggcgtc tttccagttt attcaggggc 60
tggtccaatg ctgggatatg tcatggtggc ctgagaggtt ctcagcctct attatttaaa 120
120
<210> 339
<211> 120
<212> ДНК
<213> Homo sapiens
<400> 339
tttaaataat agaggctgag aacctctcag gccaccatga catatcccag cattggacca 60
gcccctgaat aaactggaaa gacgcctggt ctggcttcag ttacagggag caccaccagg 120
120
<210> 340
<211> 90
<212> ДНК
<213> Homo sapiens
<400> 340
actgaagcca gaccaggcgt ctttccagtt tattcagggg ctggtccaat gctgggatat 60
gtcatggtgg cctgagaggt tctcagcctc 90
<210> 341
<211> 89
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PMP22-TATA PNP-модифицированная последовательность
<400> 341
actgaagcca gaccaggcgt ctttccagtt attcaggggc tggtccaatg ctgggatatg 60
tcatggcggc ctgagaggtt ctcagcctc 89
<210> 342
<211> 88
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PMP22-TATA PNP-модифицированная последовательность
<400> 342
actgaagcca gaccaggcgt ctttccagtt ttcaggggct ggtccaatgc tgggatatgt 60
catggtggcc tgagaggttc tcagcctc 88
<210> 343
<211> 91
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PMP22-TATA PNP-модифицированная последовательность
<400> 343
actgaagcca gaccaggcgt ctttccagtt ttattcaggg gctggtccaa tgctgggata 60
tgtcatggcg gcctgagagg ttctcagcct c 91
<210> 344
<211> 87
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PMP22-TATA PNP-модифицированная последовательность
<400> 344
actgaagcca gaccaggcgt ctttccagtt tcaggggctg gtccaatgct gggatatgtc 60
atggcggcct gagaggttct cagcctc 87
<210> 345
<211> 86
<212> ДНК
<213> Искусственная последовательность
<220>
<223> PMP22-TATA RNP-модифицированная последовательность
<400> 345
actgaagcca gaccaggcgt ctttccagtt caggggctgg tccaatgctg ggatatgtca 60
tggcggcctg agaggttctc agcctc 86
<210> 346
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 346
ggaccagccc ctgaataaac tgg 23
<210> 347
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 347
ggaccagcca cagaataaac aag 23
<210> 348
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 348
tgaccagtcc atgaataaac cag 23
<210> 349
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 349
ggaccagaca ctgaatatac cag 23
<210> 350
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 350
ggaccagcca cagaataaat tgg 23
<210> 351
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 351
ggatcagccc cagaataaat tag 23
<210> 352
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 352
ggagcatccc cagaataaac cag 23
<210> 353
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 353
ggatcagcgt ctgaataaac aag 23
<210> 354
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 354
agaccagccc cagaacaaac aag 23
<210> 355
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 355
gtacgagccc ctgaataaat agg 23
<210> 356
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 356
ggaccaaaca ctgaataaac cag 23
<210> 357
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 357
gcaccagcca ctgaattaac aag 23
<210> 358
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 358
gtaccagcca ctgaaaaaac agg 23
<210> 359
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 359
gaaccagccc ctgattagac cag 23
<210> 360
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 360
gtaccagcca ctgaaaaaac agg 23
<210> 361
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 361
gtaccagccc ctgcaaaaac agg 23
<210> 362
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 362
gcaccaggcc ttgaataaac aag 23
<210> 363
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 363
ggcccagcca ctgagtaaac tag 23
<210> 364
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 364
ggaattgccc ctgaataaac aag 23
<210> 365
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 365
gggaacagcc ctgaataaac ctg 23
<210> 366
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 366
aggaccagct ctgaataacc agg 23
<210> 367
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 367
ggaacagccc tgaataaacc tgg 23
<210> 368
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 368
gagttcagcc cctgaataac agg 23
<210> 369
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 369
gggaccagcc ccagaataaa ggg 23
<210> 370
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 370
aagccaaccc ctgaataaac agg 23
<210> 371
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 371
cacacagccc ctcaataaac tgg 23
<210> 372
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 372
gaggcagccc ctgtataaac tgg 23
<210> 373
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 373
gaccagcccc ctgaataaca tgg 23
<210> 374
<211> 23
<212> ДНК
<213> Mus musculus
<400> 374
gtaccagccc ctgacaaaac agg 23
<210> 375
<211> 23
<212> ДНК
<213> Mus musculus
<400> 375
ggagcagccc cggaatgaac agg 23
<210> 376
<211> 23
<212> ДНК
<213> Mus musculus
<400> 376
ggaccagccc ctgtataccc tgg 23
<210> 377
<211> 23
<212> ДНК
<213> Mus musculus
<400> 377
ggaccagccc ctgtataccc tgg 23
<210> 378
<211> 23
<212> ДНК
<213> Mus musculus
<400> 378
ggaccagccc ctgtataccc tgg 23
<210> 379
<211> 23
<212> ДНК
<213> Mus musculus
<400> 379
ggccctgccc ctaaataaac agg 23
<210> 380
<211> 23
<212> ДНК
<213> Mus musculus
<400> 380
ggatcagccc cagaataacc tgg 23
<210> 381
<211> 23
<212> ДНК
<213> Mus musculus
<400> 381
ggactagccc ctgagtacac tgg 23
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ИСКУССТВЕННО СОЗДАННАЯ СИСТЕМА УПРАВЛЕНИЯ ФУНКЦИЕЙ ШК | 2017 |
|
RU2768043C2 |
| МОДИФИЦИРОВАННЫЙ ИММУНОРЕГУЛЯТОРНЫЙ ЭЛЕМЕНТ И ИЗМЕНЕНИЕ ИММУНИТЕТА ПОСРЕДСТВОМ ЭТОГО ЭЛЕМЕНТА | 2017 |
|
RU2767206C2 |
| ДНК-СОДЕРЖАЩИЕ ПОЛИНУКЛЕОТИДЫ И РУКОВОДЯЩИЕ ПОСЛЕДОВАТЕЛЬНОСТИ ДЛЯ СИСТЕМ CRISPR ТИПА V И СПОСОБЫ ИХ ПОЛУЧЕНИЯ И ПРИМЕНЕНИЯ | 2021 |
|
RU2832314C1 |
| РЕДАКТИРОВАНИЕ ГЕНОВ С ИСПОЛЬЗОВАНИЕМ МОДИФИЦИРОВАННОЙ ДНК С ЗАМКНУТЫМИ КОНЦАМИ (зкДНК) | 2018 |
|
RU2811724C2 |
| ВАРИАНТЫ HSD17B13 И ИХ ПРИМЕНЕНИЯ | 2018 |
|
RU2760851C2 |
| НАЦЕЛИВАНИЕ НА КЛЕТКИ, ОПОСРЕДУЕМОЕ ХИМЕРНЫМ АНТИГЕННЫМ РЕЦЕПТОРОМ | 2018 |
|
RU2783316C2 |
| ИСКУССТВЕННЫЕ МОЛЕКУЛЫ НУКЛЕИНОВОЙ КИСЛОТЫ | 2014 |
|
RU2717986C2 |
| МОДУЛЯТОРЫ И МОДУЛЯЦИЯ РНК РЕЦЕПТОРА КОНЕЧНЫХ ПРОДУКТОВ ГЛУБОКОГО ГЛИКИРОВАНИЯ | 2020 |
|
RU2820247C2 |
| МОДУЛЯТОРЫ ТАУ И СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ ИХ ДОСТАВКИ | 2017 |
|
RU2789459C2 |
| МОДУЛЯТОРЫ ЭКСПРЕССИИ ГЕНА ОТКРЫТОЙ РАМКИ СЧИТЫВАНИЯ 72 ХРОМОСОМЫ 9 И ИХ ПРИМЕНЕНИЯ | 2020 |
|
RU2828216C2 |
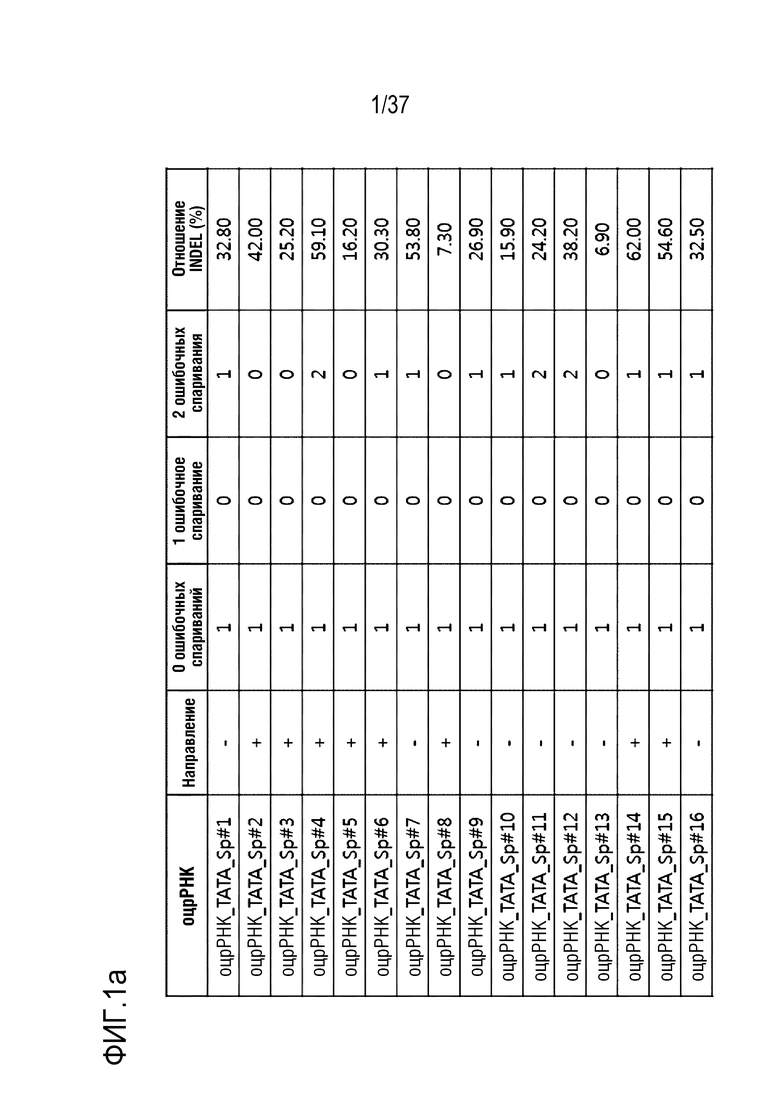
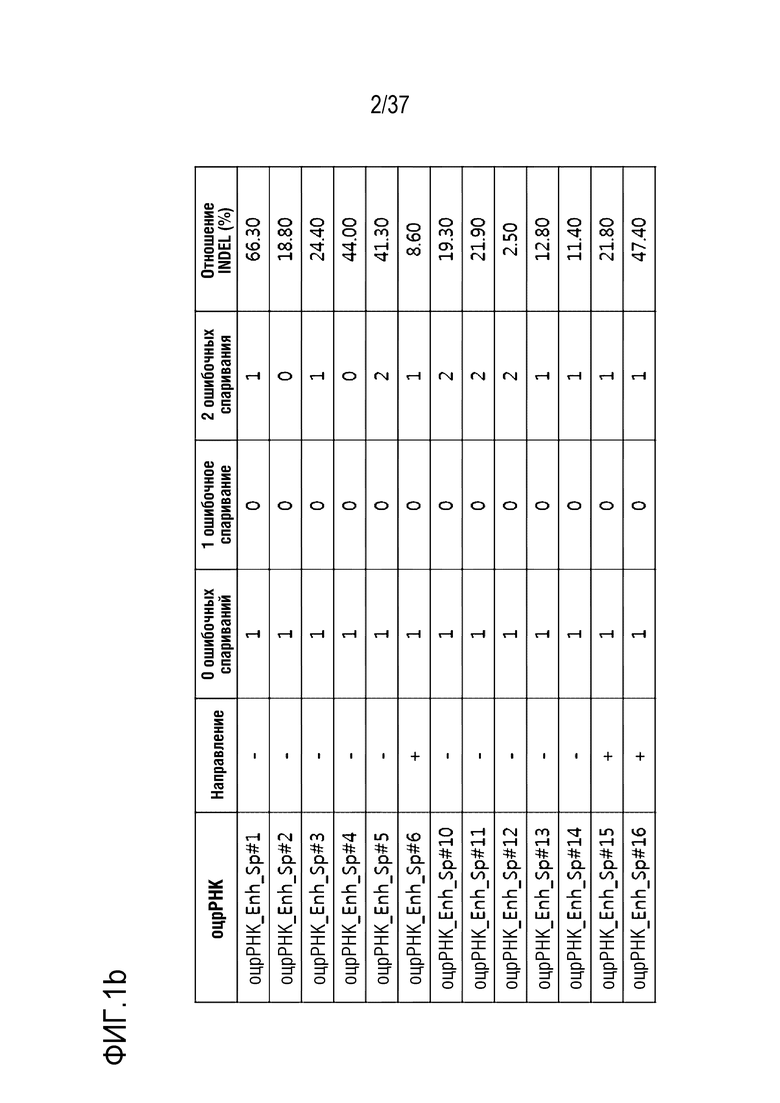
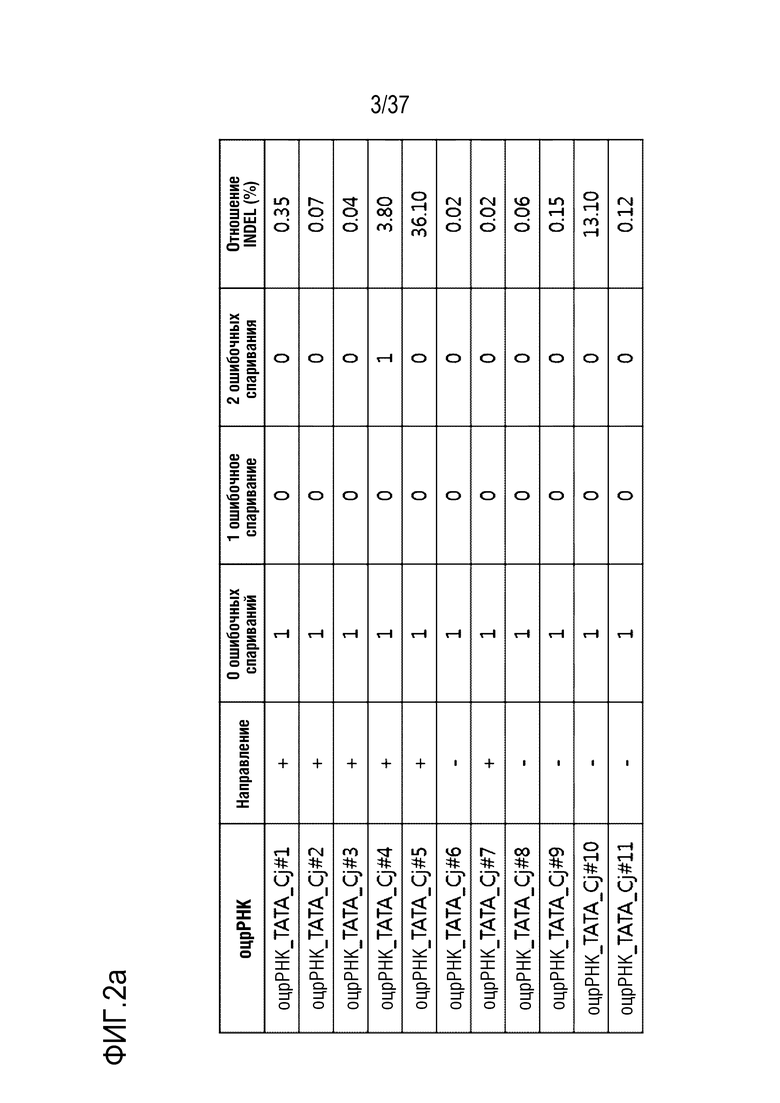
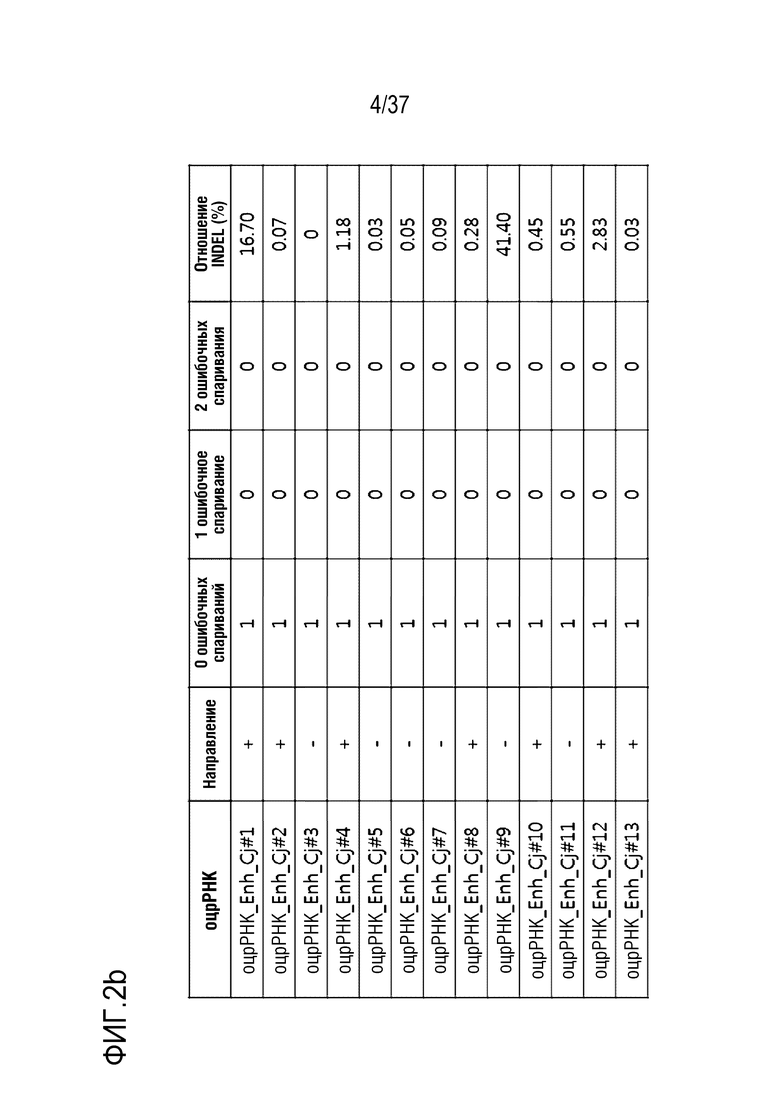
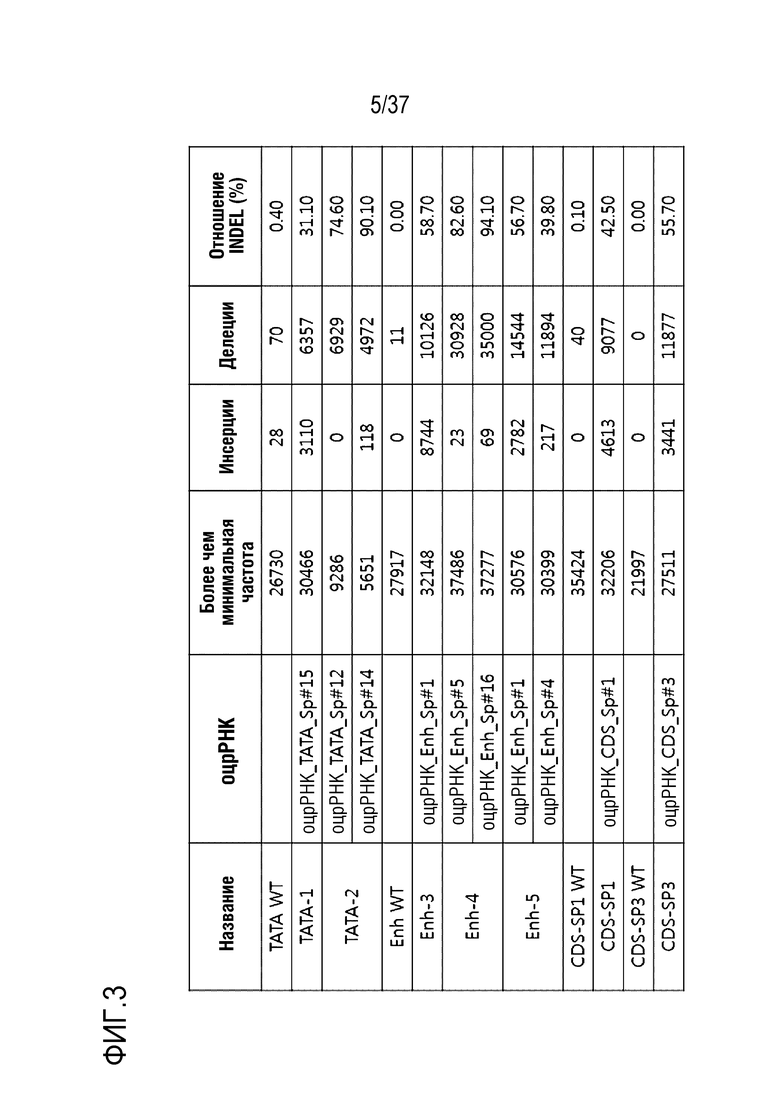
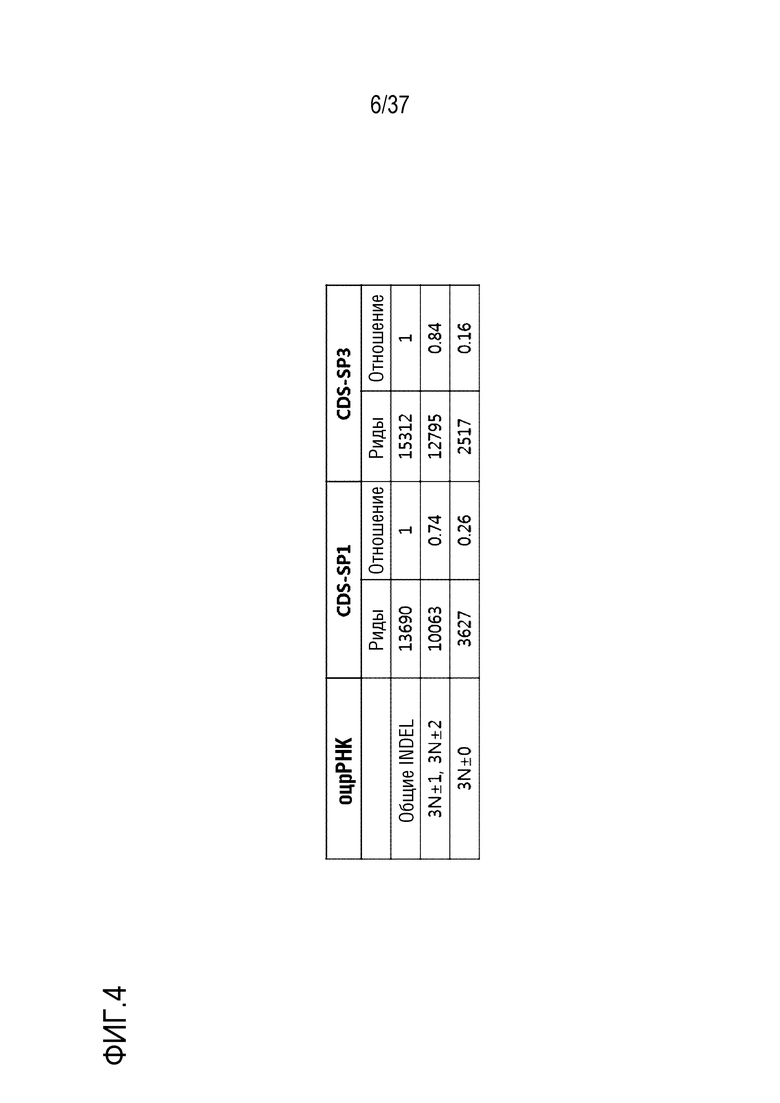

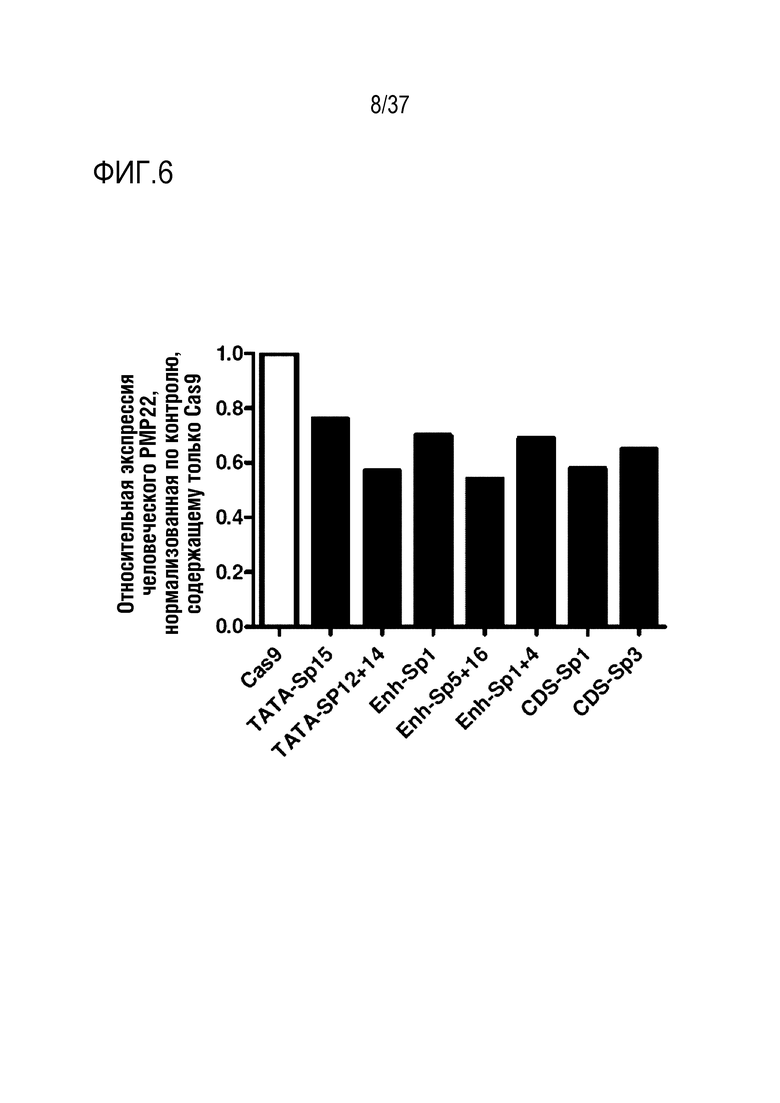

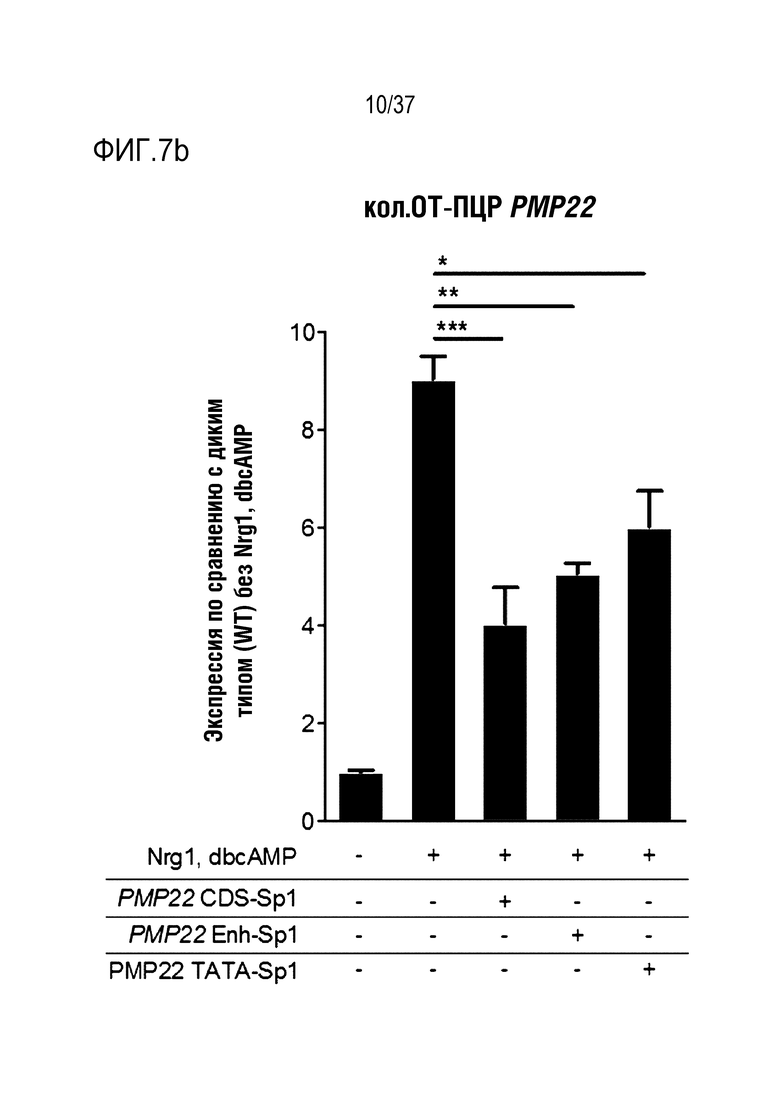
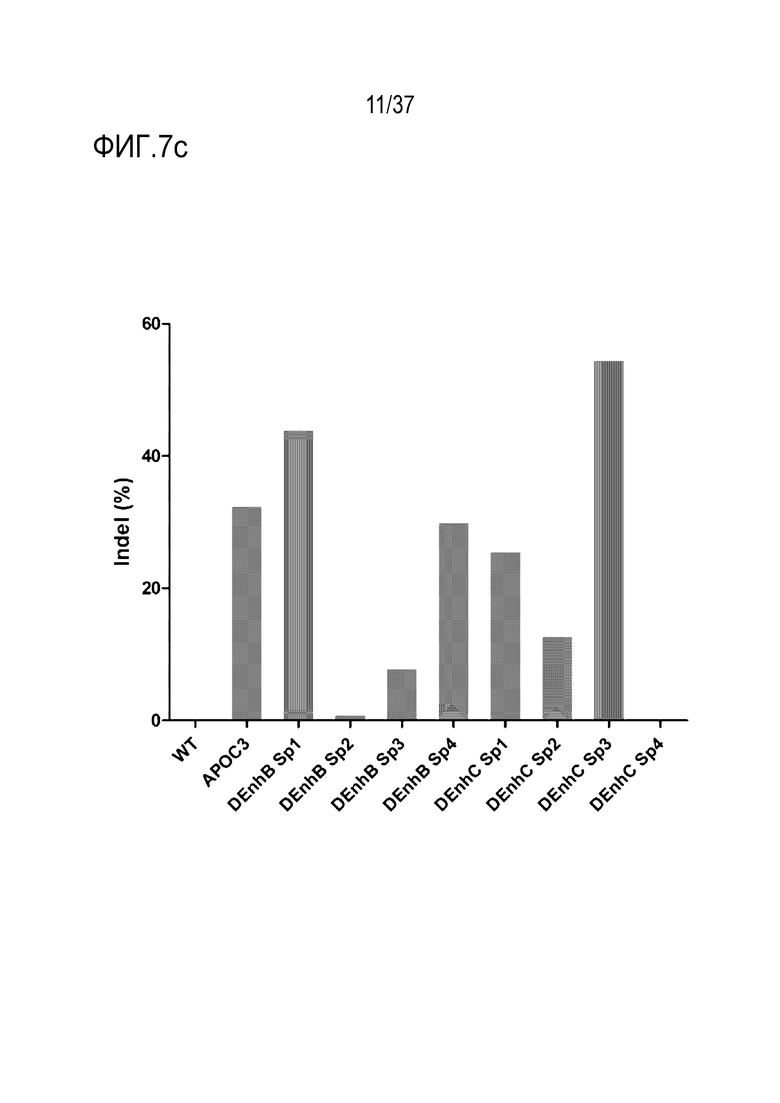
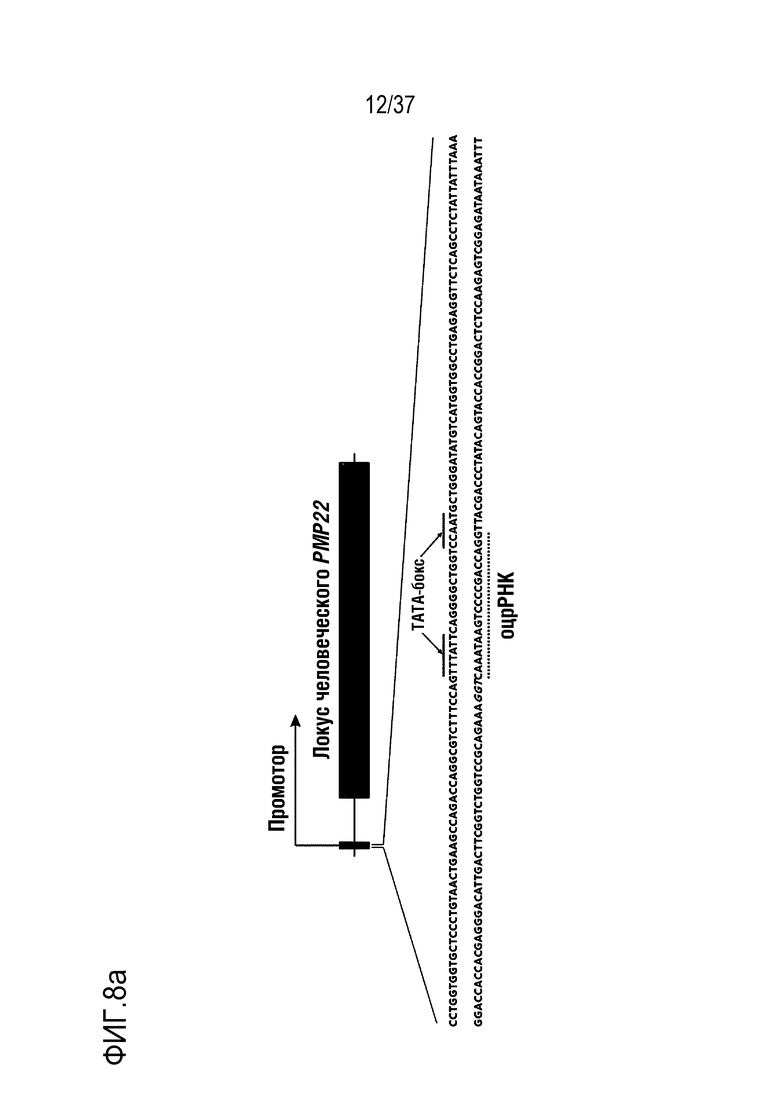
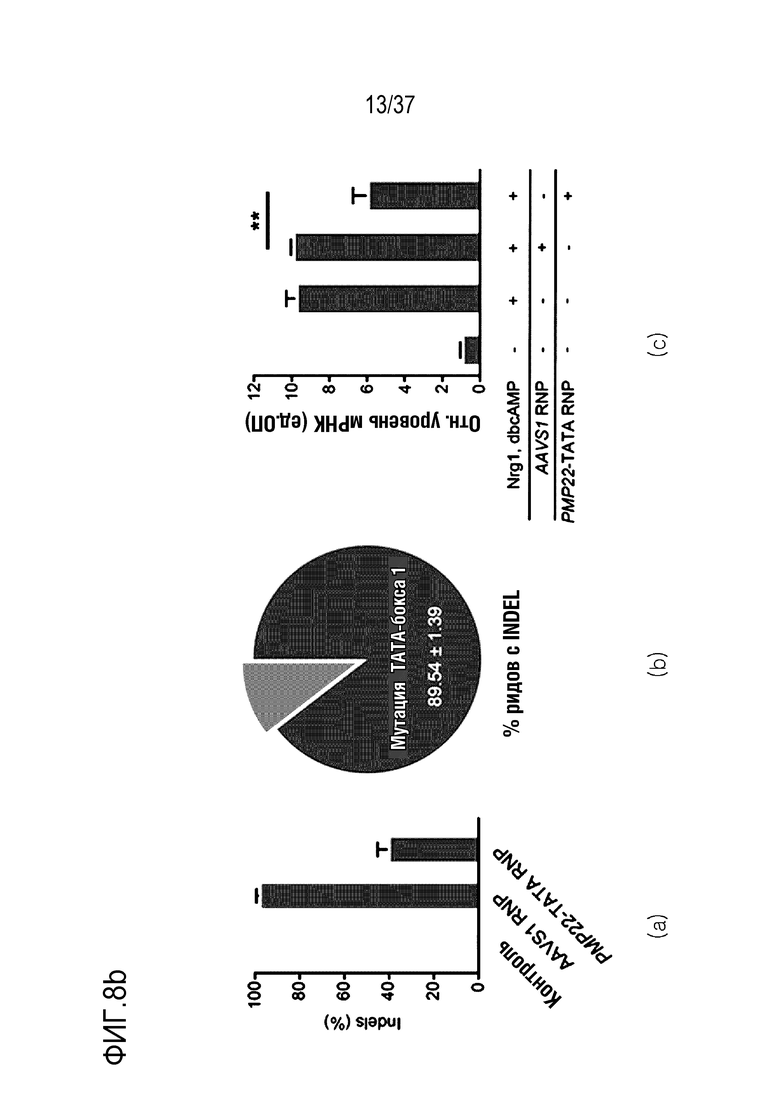
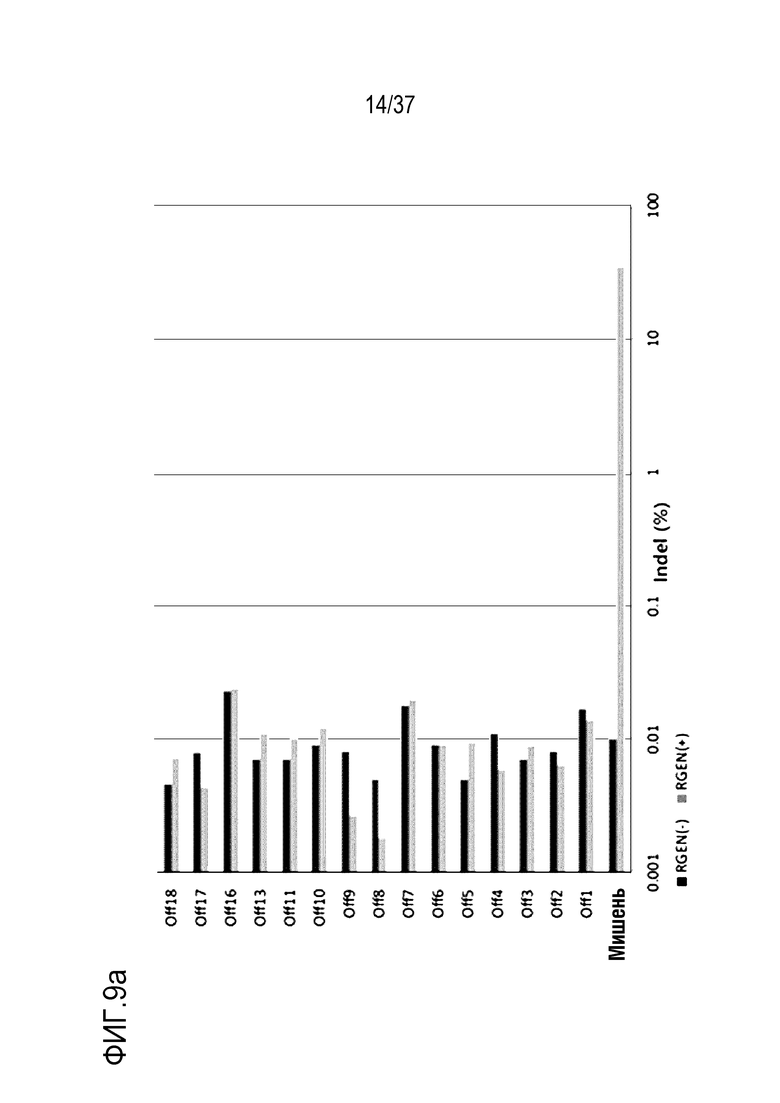
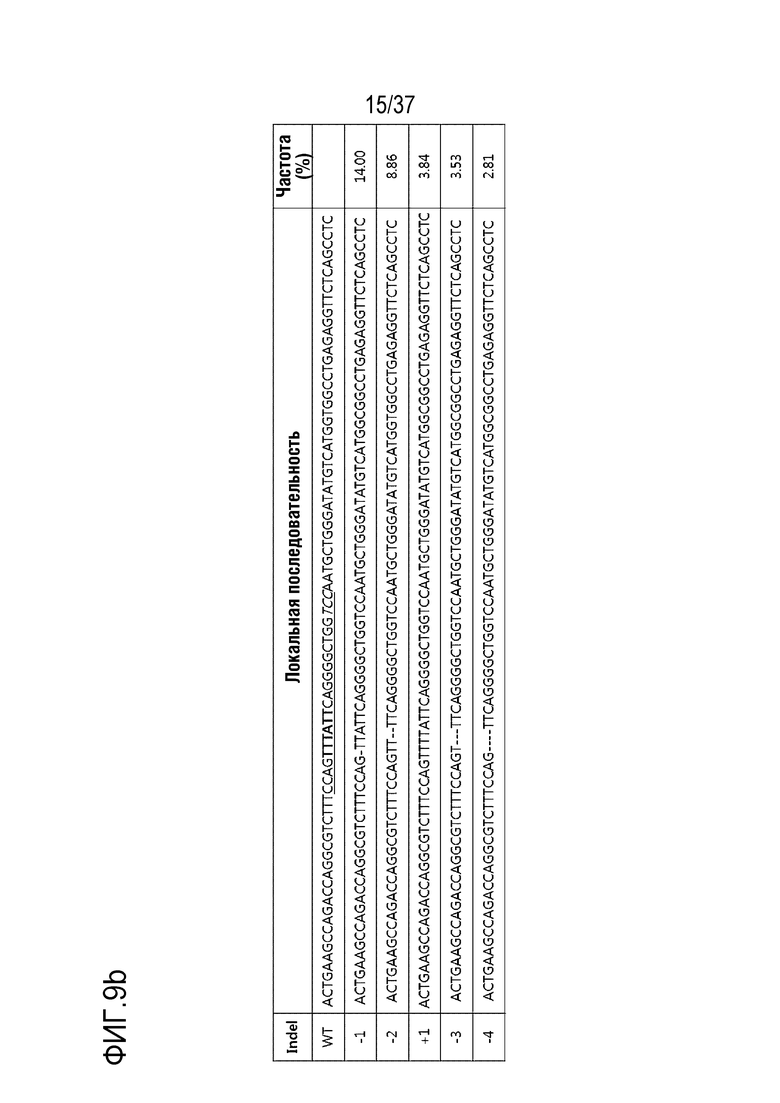
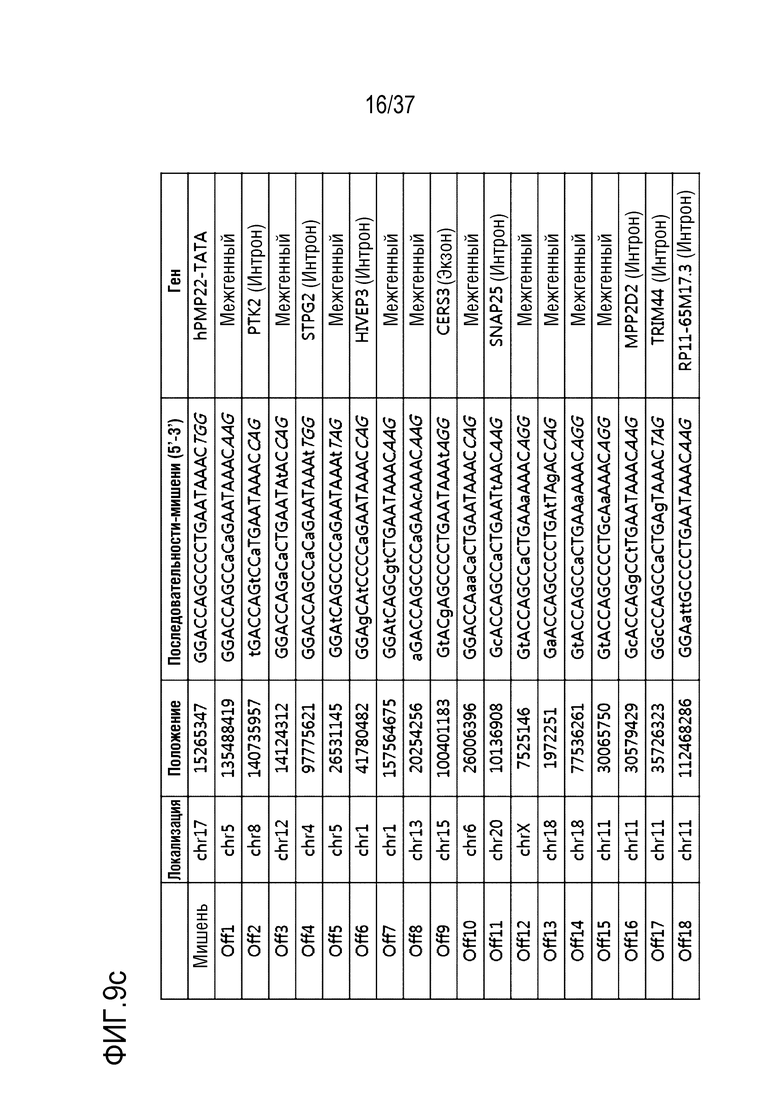
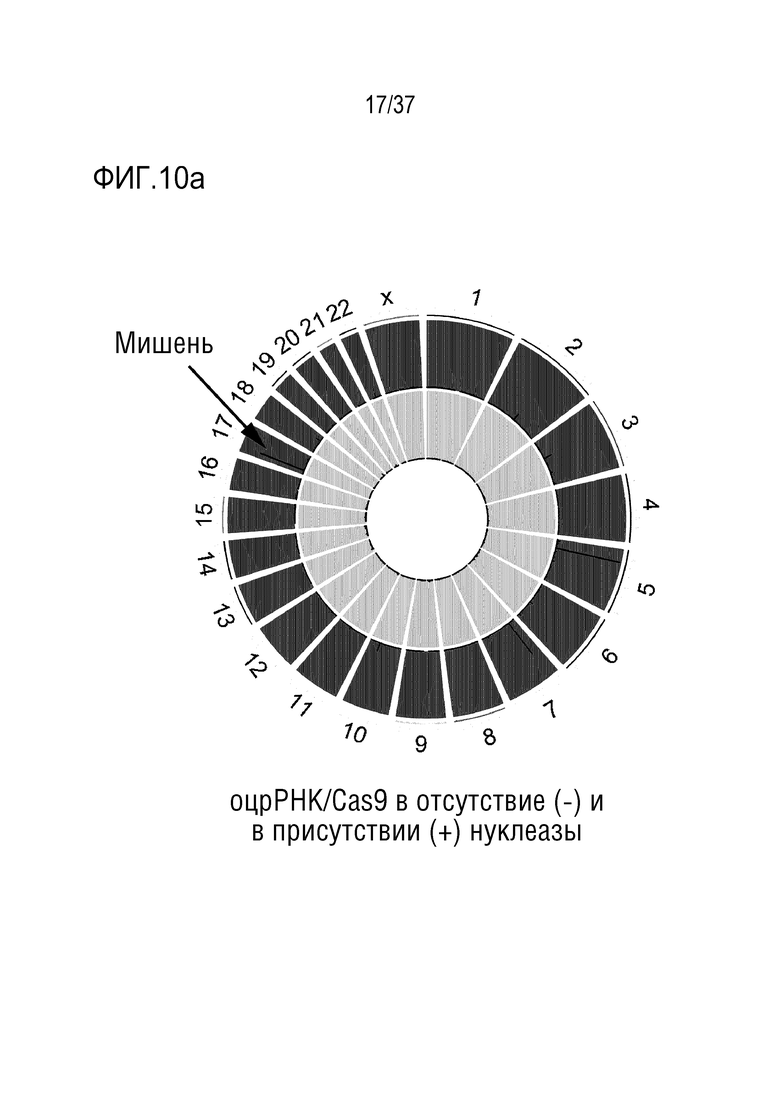

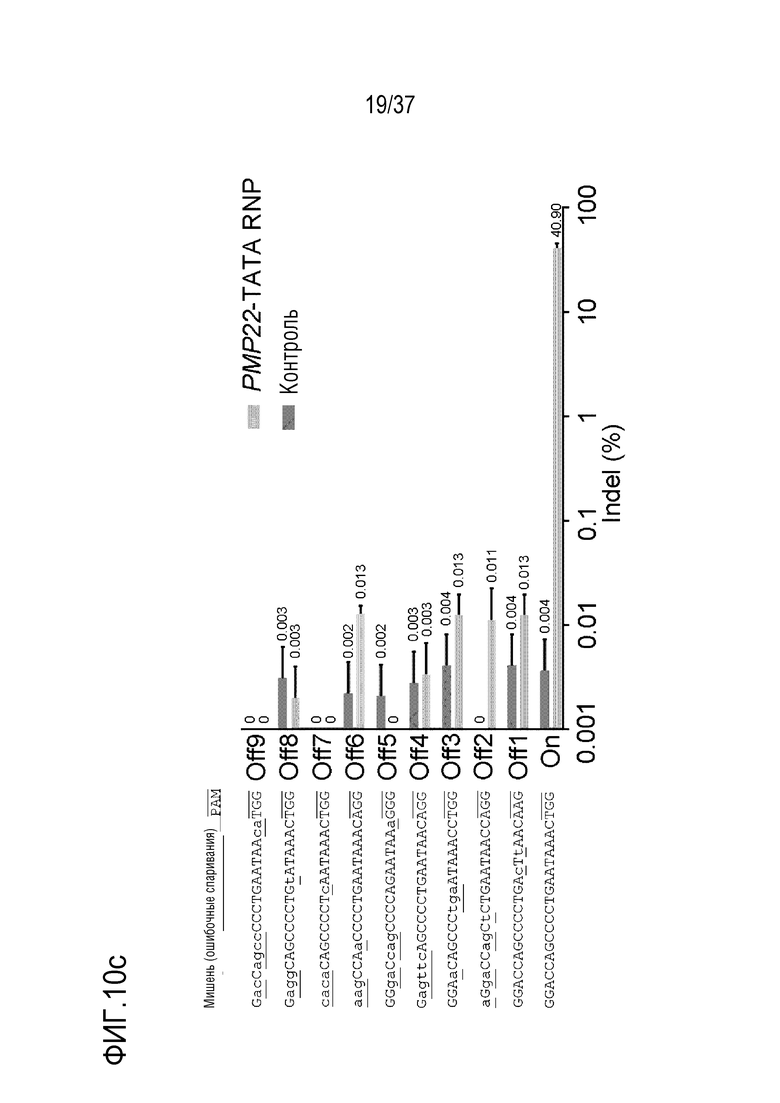
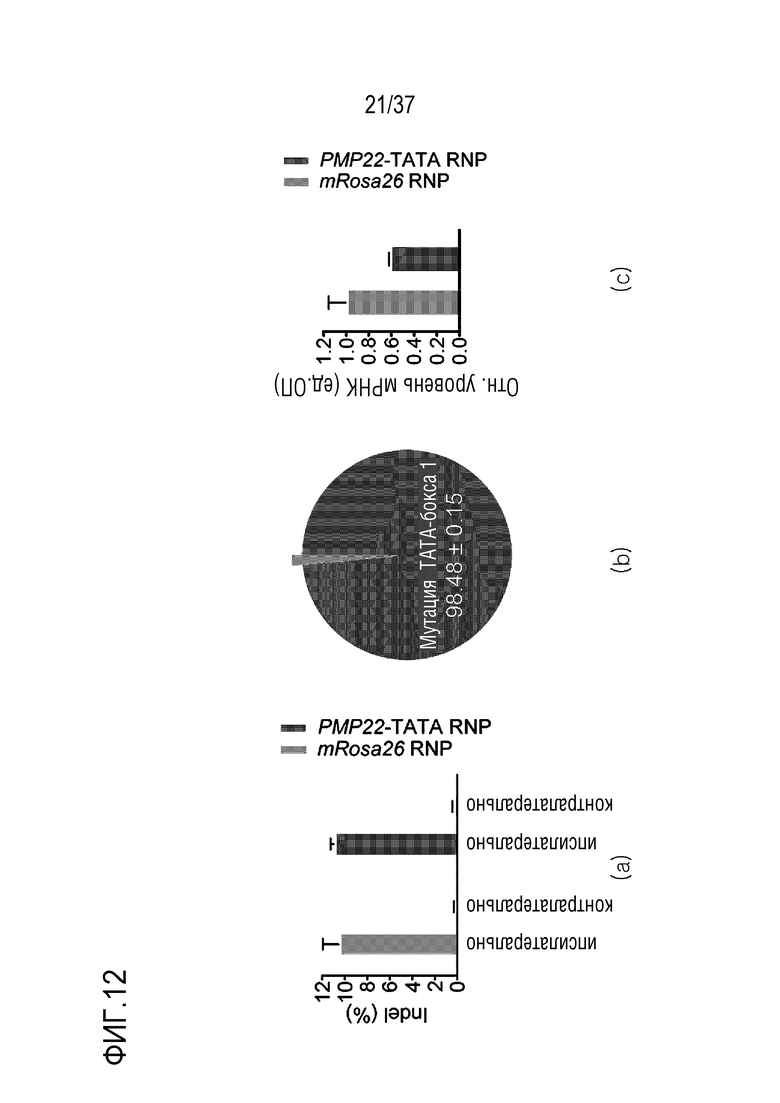

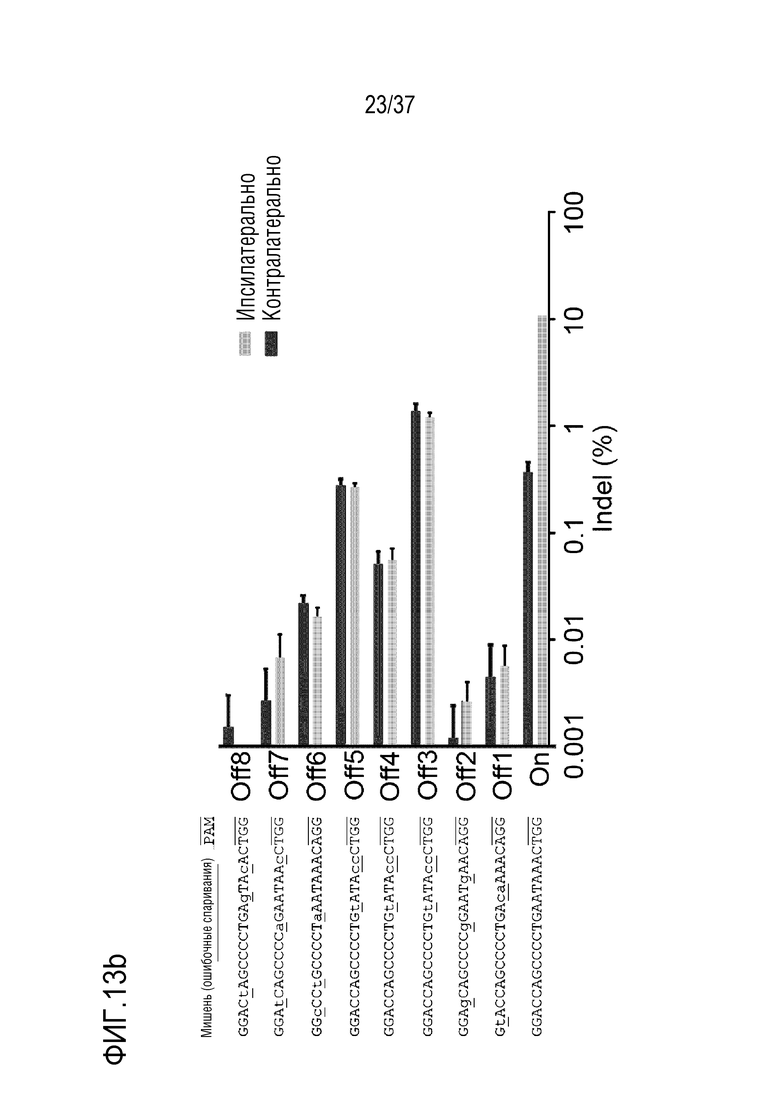

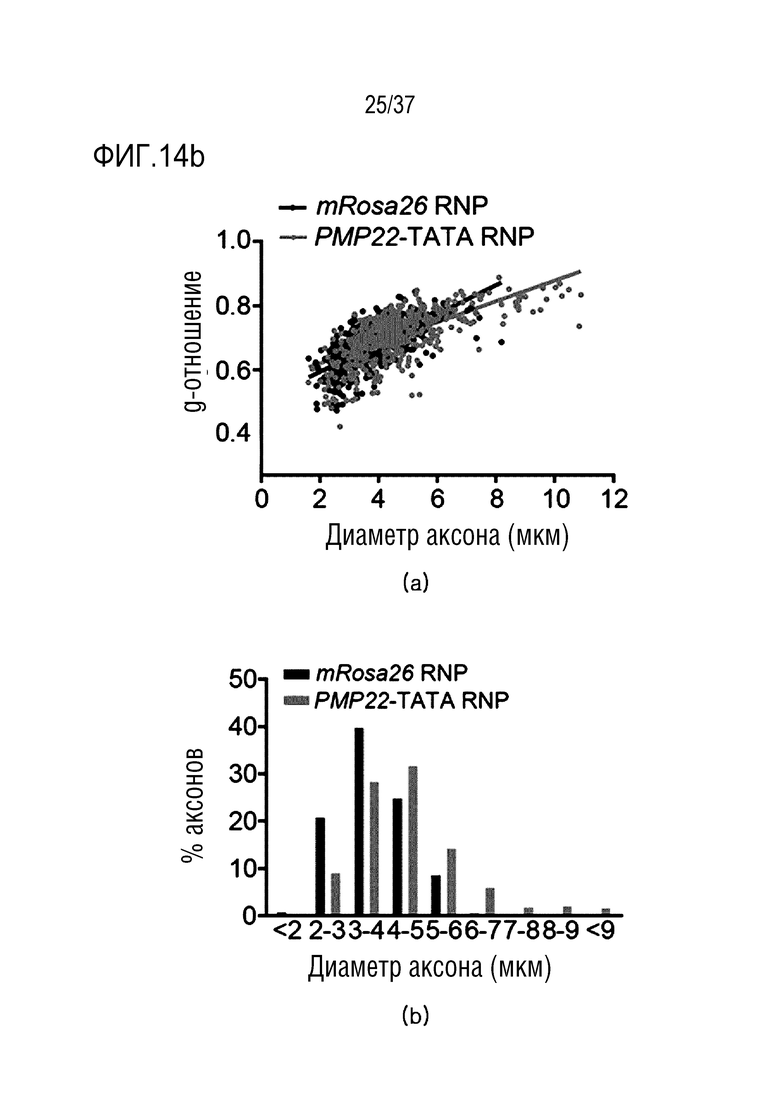

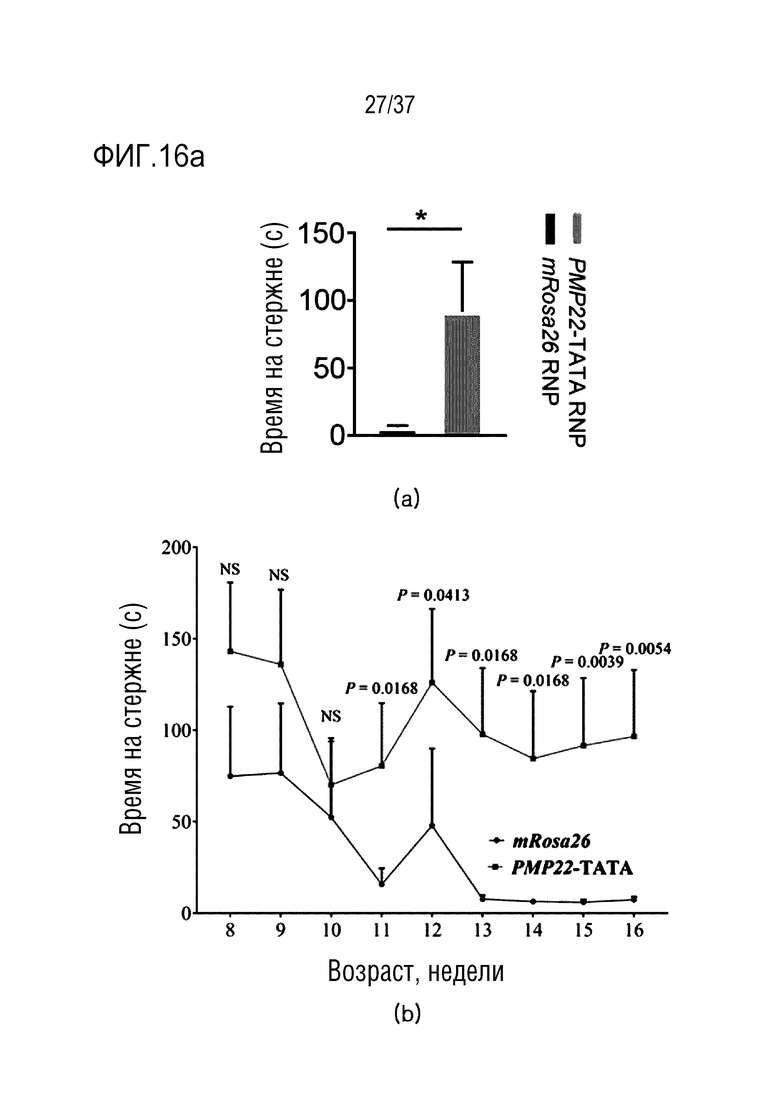

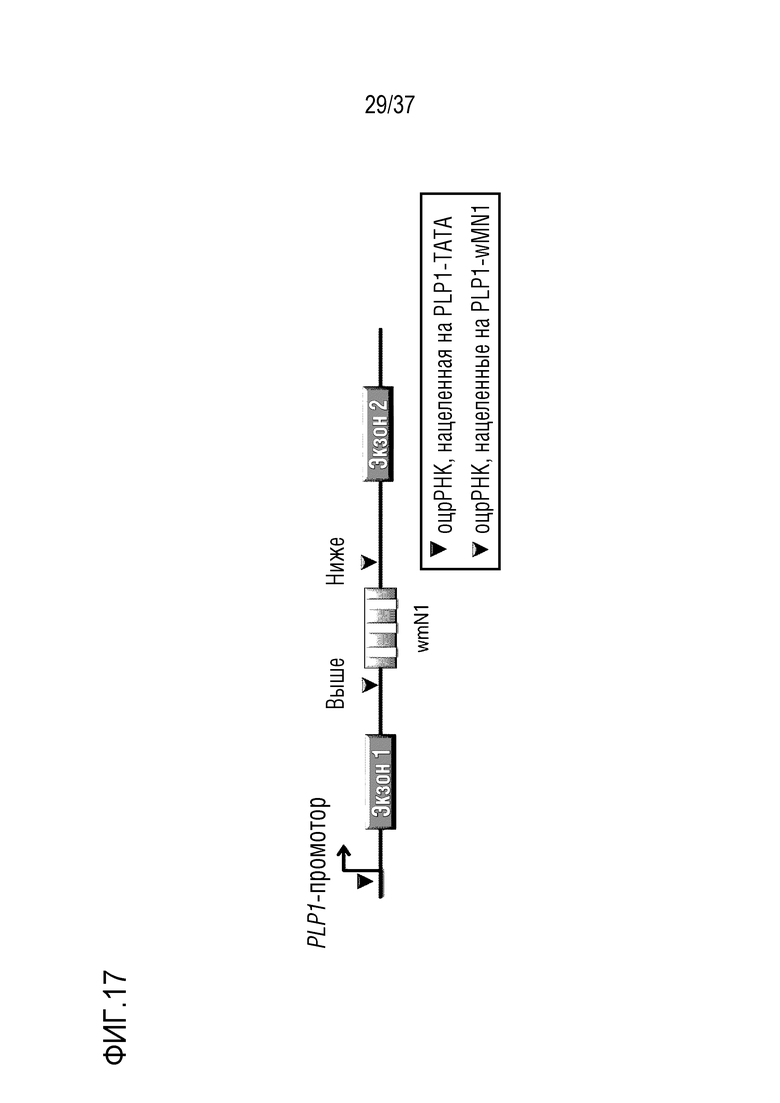
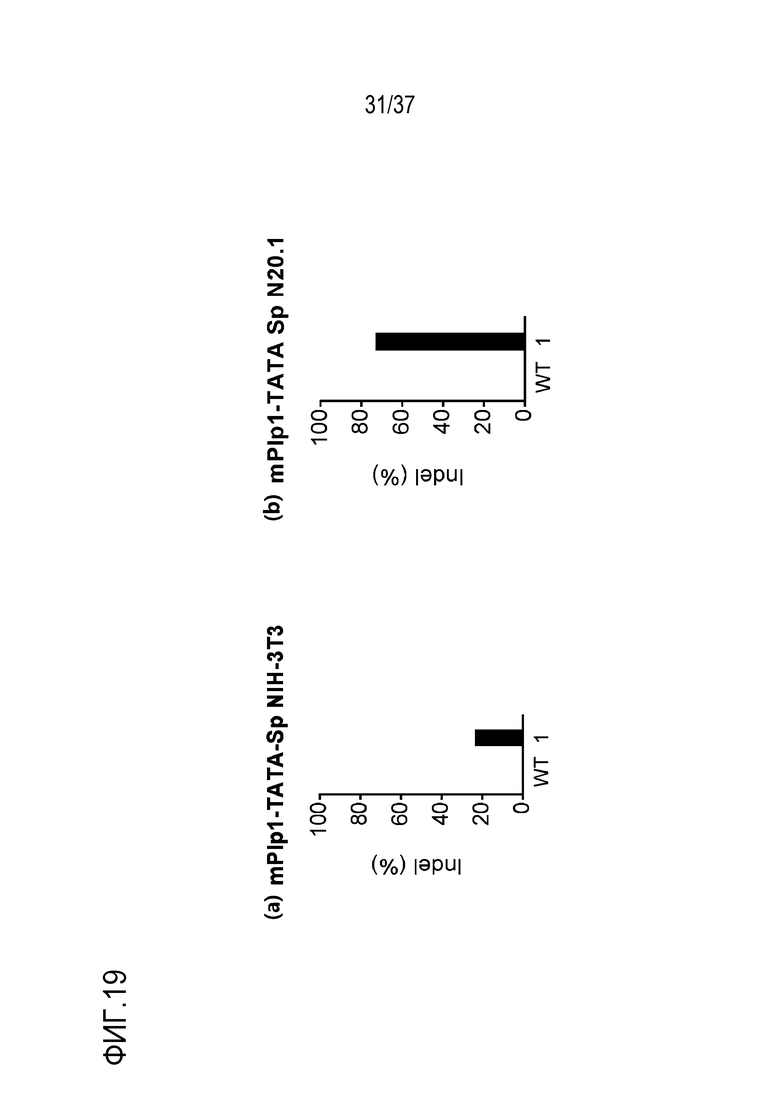

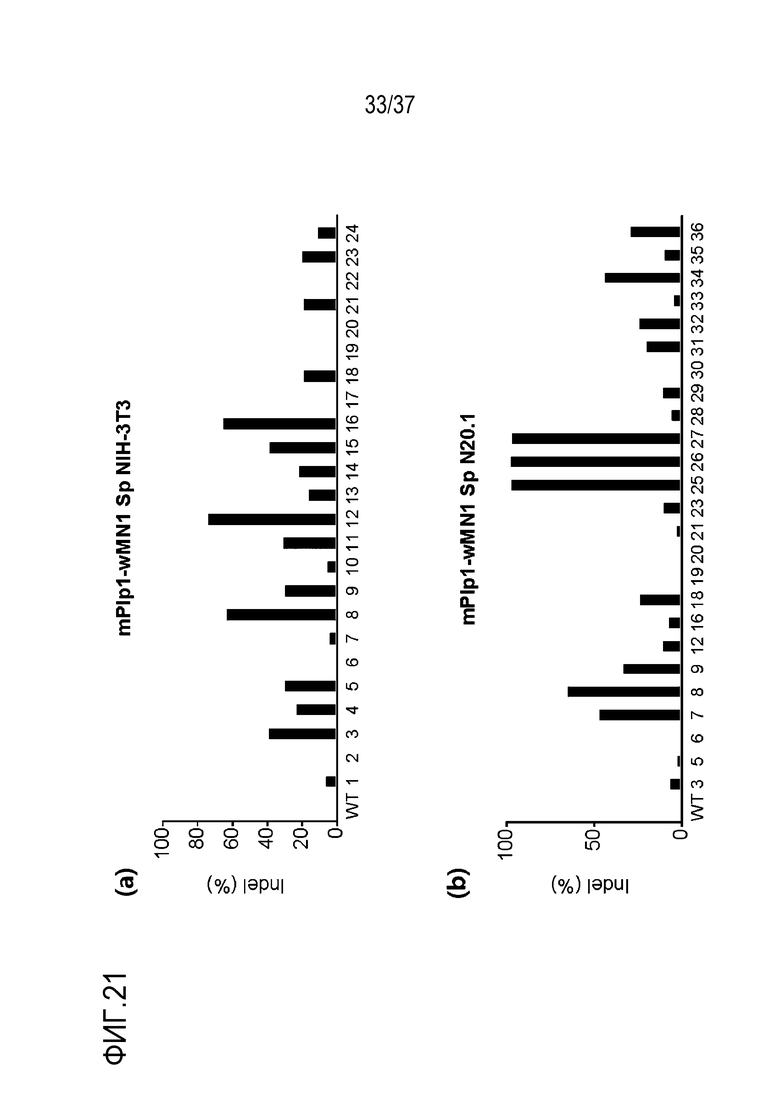

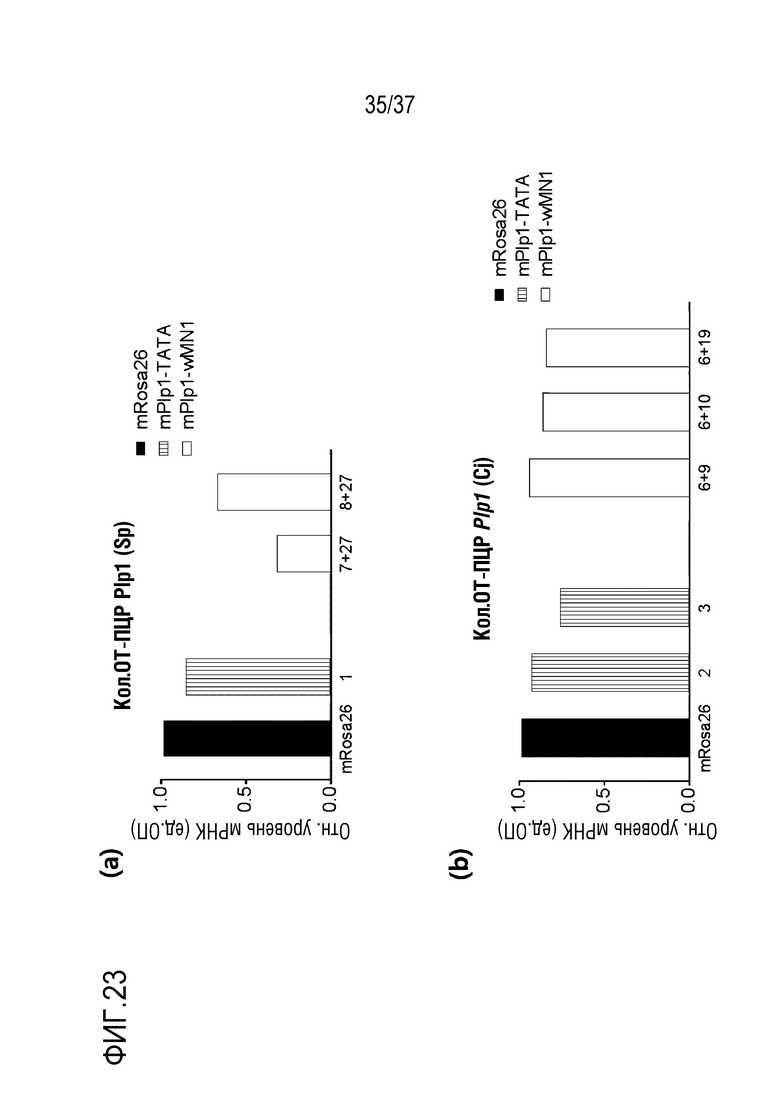
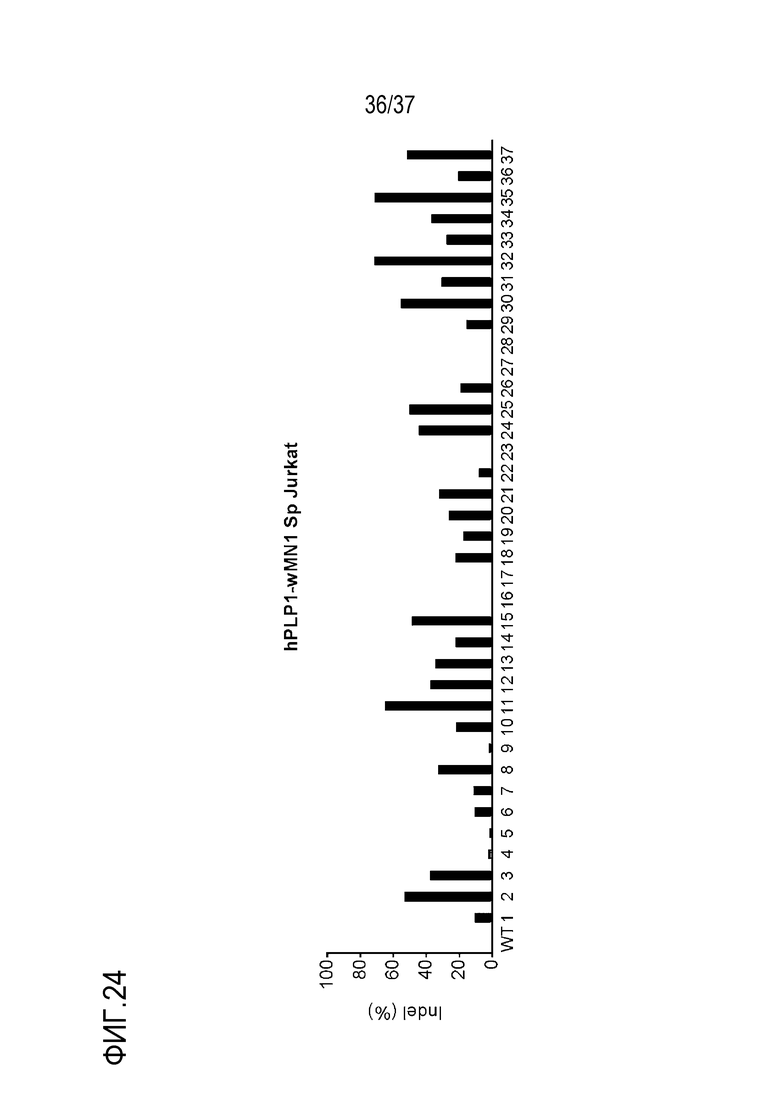
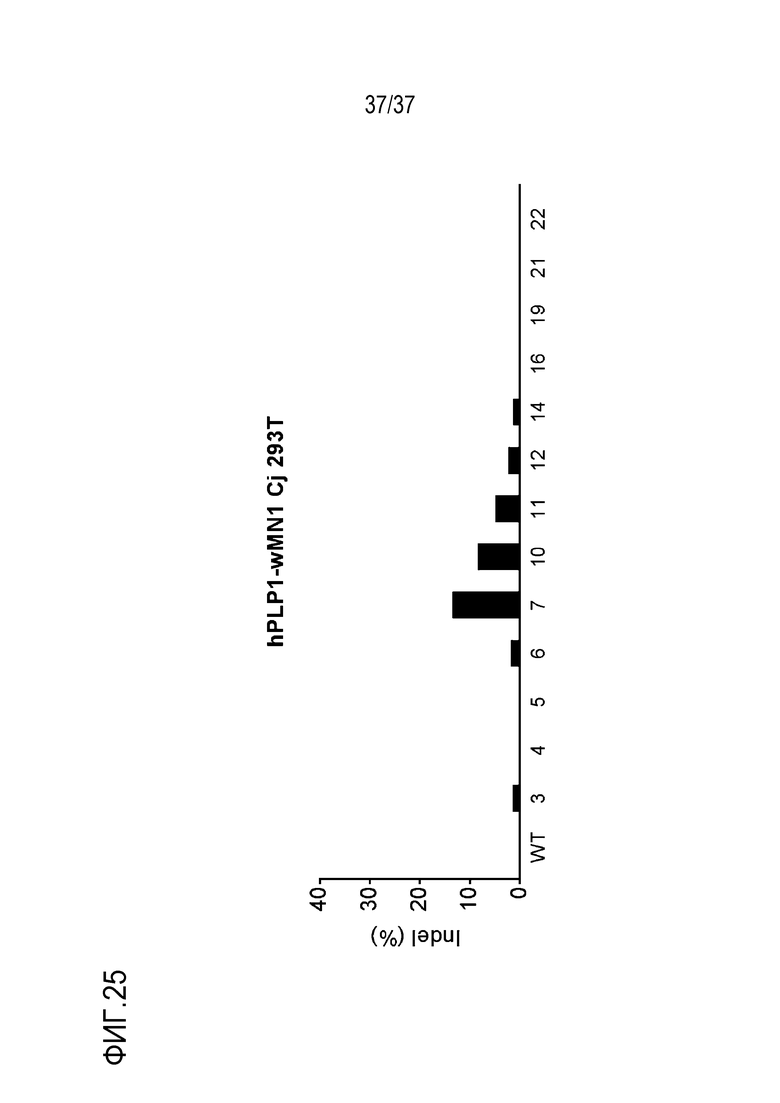
Изобретение относится к биотехнологии. Описаны композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена и способ их применения. Композиции для регуляции экспрессии включают руководящую нуклеиновую кислоту, способную нацеливаться на область регуляции транскрипции дуплицированного гена. Также описан способ регуляции экспрессии дуплицированного гена путем искусственного изменения и/или модификации области регуляции транскрипции дуплицированного гена. Кроме того, настоящее изобретение относится к способу лечения или ослабления заболевания, вызываемого дупликацией гена, с использованием композиции для регуляции экспрессии в целях регуляции экспрессии дуплицированного гена. Изобретение расширяет арсенал средств для регуляции экспрессии генов. 7 н. и 7 з.п. ф-лы, 25 ил., 10 табл., 7 пр.
1. Композиция, которая нацелена на непрерывную последовательность-мишень из 10-25 нуклеотидов в области TATA-бокса или энхансерной области дуплицированного гена, для применения при лечении заболевания, вызванного сверхэкспрессией дуплицированного гена, содержащая:
руководящую РНК, включающую руководящий домен и каркас, или нуклеиновую кислоту, кодирующую руководящую РНК; и
белок Cas9, происходящий из Streptococcus pyogenes или Campylobacter jejuni, или нуклеиновую кислоту, кодирующую белок Cas9,
где руководящий домен и каркас последовательно связаны в направлении от 5’ до 3’,
где руководящий домен способен нацеливаться на непрерывную последовательность-мишень из 10-25 нуклеотидов в области TATA-бокса или энхансерной области дуплицированного гена,
где, когда белок Cas9 происходит из Campylobacter jejuni, последовательность каркаса представляет собой

где, когда белок Cas9 происходит из Streptococcus pyogenes, последовательность каркаса представляет собой

где дуплицированный ген представляет собой ген PLP1.
2. Композиция, которая нацелена на непрерывную последовательность-мишень из 10-25 нуклеотидов в области TATA-бокса или энхансерной области дуплицированного гена, для применения при лечении заболевания, вызванного сверхэкспрессией дуплицированного гена, содержащая:
двухцепочечную руководящую РНК, включающую сr-РНК и tracr-РНК,
где сr-РНК содержит руководящий домен и первый комплементарный домен,
где руководящий домен и первый комплементарный домен последовательно связаны от 5’ до 3’-конца,
где tracr-РНК содержит второй комплементарный домен, проксимальный домен и хвостовой домен,
где второй комплементарный домен, проксимальный домен и хвостовой домен последовательно связаны от 5’ до 3’-конца; и
белок Cas9, происходящий из Streptococcus pyogenes или Campylobacter jejuni, или нуклеиновую кислоту, кодирующую белок Cas9,
где руководящий домен и каркас последовательно связаны в направлении от 5’ до 3’,
где руководящий домен способен нацеливаться на непрерывную последовательность-мишень из 10-25 нуклеотидов в области TATA-бокса или энхансерной области дуплицированного гена,
где, когда белок Cas9 происходит из Campylobacter jejuni, первый комплементарный домен представлен 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’ (SEQ ID NO: 297), второй комплементарный домен представлен 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’ (SEQ ID NO: 300), проксимальный домен представлен 5’-AAAGAGUUUGC-3’ (SEQ ID NO: 303) и хвостовой домен представлен 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’ (SEQ ID NO: 305),
где, когда белок Cas9 происходит из Streptococcus pyogenes, первый комплементарный домен представлен 5’-GUUUUAGAGCUA-3’ (SEQ ID NO: 296), второй комплементарный домен представлен 5’-UAGCAAGUUAAAAU-3’ (SEQ ID NO: 299), проксимальный домен представлен 5’-AAGGCUAGUCCG-3’ (SEQ ID NO: 302) и хвостовой домен представлен 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’ (SEQ ID NO: 304),
где дуплицированный ген представляет собой ген PLP1.
3. Композиция по п. 1 или 2, где область TATA-бокса включает одну или более последовательность, выбранную из группы, состоящей из последовательности 5’-TATA-3’, последовательности 5’-TATAWAW-3’ (W=A или T), последовательности 5’-TATAWAWR-3’ (W=A или T, R=A или G), последовательности 5’-CATAAAA-3’, последовательности 5’-CATAAAA-3’, последовательности 5’-TATAA-3’, последовательности 5’-TATAAAA-3’, последовательности 5’-CATAAATA-3’, последовательности 5’-TATATAA-3’, последовательности 5’-TATATATATATATAA-3’, последовательности 5’-TATATTATA-3’, последовательности 5’-TATAAA-3’, последовательности 5’-TATAAAATA-3’, последовательности 5’-TATATA-3’, последовательности 5’-GATTAAAAA-3’, последовательности 5’-TATAAAAA-3’, последовательности 5’-TTATAA-3’, последовательности 5’-TTTTAAAA-3’, последовательности 5’-TCTTTAAAA-3’, последовательности 5’-GACATTTAA-3’, последовательности 5’-TGATATCAA-3’, последовательности 5’-TATAAATA-3’, последовательности 5’-TATAAGA-3’, последовательности 5’-AATAAA-3’, последовательности 5’-TTTATA-3’, последовательности 5’-CATAAAAA-3’, последовательности 5’-TATACA-3’, последовательности 5’-TTTAAGA-3’, последовательности 5’-GATAAAG-3’, последовательности 5’-TATAACA-3’, последовательности 5’-TCTTATCTT-3’, последовательности 5’-TTGTACTTT-3’, последовательности 5’-CATATAA-3’, последовательности 5’-TATAAAT-3’, последовательности 5’-TATATATAAAAAAAA-3’ и последовательности 5’-CATAAATAAAAAAAATTA-3’.
4. Композиция по п. 1 или 2, где дуплицированный ген представляет собой ген PLP1.
5. Композиция по п. 4, где белок Cas9 происходит из Streptococcus pyogenes, где последовательность-мишень выбирают из SEQ ID NO: 56-93.
6. Композиция по п. 4, где белок Cas9 происходит из Campylobacter jejuni, где последовательность-мишень выбирают из SEQ ID NO: 94-115.
7. Композиция по п. 1 или 2, где композиция содержит руководящую РНК и белок Cas9 в форме рибонуклеопротеина.
8. Композиция по п. 1 или 2, где композиция содержит нуклеиновую кислоту, кодирующую руководящую РНК, и нуклеиновую кислоту, кодирующую белок Cas9.
9. Композиция по п. 8, где композиция представлена в форме одного или более векторов.
10. Руководящая РНК, которая нацелена на область TATA-бокса или энхансерную область дуплицированного гена, для применения при лечении заболевания, вызванного сверхэкспрессией дуплицированного гена, содержащая:
руководящий домен, представленный последовательностью, выбранной из SEQ ID NO: 56-93; и
каркас, представленный последовательностью
где руководящий домен и каркас последовательно связаны от 5’ до 3’-конца,
где дуплицированный ген представляет собой ген PLP1 человека.
11. Двухцепочечная руководящая РНК, которая нацелена на область TATA-бокса или энхансерную область дуплицированного гена, для применения при лечении заболевания, вызванного сверхэкспрессией дуплицированного гена, содержащая:
сr-РНК, содержащую руководящий домен, представленный последовательностью, выбранной из SEQ ID NO: 56-93, и первый комплементарный домен, представленный 5’-GUUUUAGAGCUA-3’ (SEQ ID NO: 296),
где руководящий домен и первый комплементарный домен последовательно связаны от 5’ до 3’-конца; и
tracr-РНК, содержащую второй комплементарный домен, представленный 5’-UAGCAAGUUAAAAU-3’ (SEQ ID NO: 299), и проксимальный домен, представленный 5’-AAGGCUAGUCCG-3’ (SEQ ID NO: 302), и хвостовой домен, представленный 5’-UUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC-3’ (SEQ ID NO: 304),
где второй комплементарный домен, проксимальный домен и хвостовой домен последовательно связаны от 5’ до 3’-конца,
где дуплицированный ген представляет собой ген PLP1 человека.
12. Руководящая РНК, которая нацелена на энхансерную область дуплицированного гена, для применения при лечении заболевания, вызванного сверхэкспрессией дуплицированного гена, содержащая:
руководящий домен, представленный последовательностью, выбранной из SEQ ID NO: 94-115; и
каркас, представленный последовательностью

где руководящий домен и каркас последовательно связаны от 5’ до 3’-конца руководящей РНК,
где дуплицированный ген представляет собой ген PLP1 человека.
13. Двухцепочечная руководящая РНК, которая нацелена на энхансерную область дуплицированного гена, для применения при лечении заболевания, вызванного сверхэкспрессией дуплицированного гена, содержащая:
сr-РНК, содержащую руководящий домен, представленный последовательностью, выбранной из SEQ ID NO: 94-115, и первый комплементарный домен, представленный 5’-GUUUUAGUCCCUUUUUAAAUUUCUU-3’ (SEQ ID NO: 297),
где руководящий домен и первый комплементарный домен последовательно связаны от 5’ до 3’-конца; и
tracr-РНК, содержащую второй комплементарный домен, представленный 5’-AAGAAAUUUAAAAAGGGACUAAAAU-3’ (SEQ ID NO: 300), и проксимальный домен, представленный 5’-AAAGAGUUUGC-3’ (SEQ ID NO: 303), и хвостовой домен, представленный 5’-GGGACUCUGCGGGGUUACAAUCCCCUAAAACCGCUUUU-3’ (SEQ ID NO: 305),
где второй комплементарный домен, проксимальный домен и хвостовой домен последовательно связаны от 5’ до 3’-конца,
где дуплицированный ген представляет собой ген PLP1 человека.
14. Нуклеиновая кислота, кодирующая руководящую РНК по любому из пп. 10-13.
| WOJTAL D et al | |||
| Разборный с внутренней печью кипятильник | 1922 |
|
SU9A1 |
| Дорожная спиртовая кухня | 1918 |
|
SU98A1 |
| Пожарный двухцилиндровый насос | 0 |
|
SU90A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для ограничения силы тормозного тока при электродинамическом торможении моторных повозок электрических железных дорог | 1928 |
|
SU20140A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| RU | |||

