Область техники
Изобретение относится к безопасности компьютерных сетей, включая несанкционированный доступ к интернет-ресурсам, а именно к способам формирования изображений и видам заданий пользователю при прохождении пользователем полностью автоматизированного теста Тьюринга (САРТСНА) и может быть использовано пользователями интернета.
Уровень техники
Все крупные и средние интернет-сервисы и Веб-порталы, почтовые серверы, поисковики, а также банковские системы являются очень привлекательными площадками для действий злоумышленников. В большинстве случаев в настоящее время действия хакеров не направлены на то, чтобы получить права администратора на управление веб-ресурсом (защита от таких прямых взломов достаточно надежна и сводится к простой аккуратности в администрировании портала). Наиболее массовый способ организации интернет-мошенничеств - это имитация с помощью специальной программы (интернет-робота) действий пользователя. К примеру: интернет-робот может создать тысячи новых аккаунтов (т.е. зарегистрировать якобы новых пользователей ресурса, например, бесплатного почтового сервиса), а затем осуществить массовую рассылку рекламы, поддельных счетов на оплату услуг, оставлять спам-комментарии на форумах, добавлять друзей в социальной сети «ВКонтакте», публиковать сообщения, провоцирующие раскрытие конфиденциальной информации или личных данных. Если бы не было защиты от программ (интернет-роботов), имитирующих действия человека, то все без исключения социальные интернет-ресурсы, в том числе и сайты системы Госуслуг, превратились бы в информационные помойки и их попросту невозможно было бы использовать.
Тест на то, что доступ на сайт осуществляет человек, имеет общепринятое название - капча.  (от абревиатуры САРТСНА-англ.
(от абревиатуры САРТСНА-англ.
Completely Automated Public Turing test to tell Computers and Humans Apart - полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей)- компьютерный тест, используемый для того, чтобы определить, кем является пользователь системы: человеком или компьютером. Термин появился в 2000 году. Основная идея капчи: предложить пользователю такую задачу, которая с легкостью решается человеком, но крайне сложна и трудоемка для компьютера (в идеале неразрешима). Поскольку в данном случае тест осуществляется не человеком, а машиной, такой тест часто называют обратным тестом Тьюринга. По состоянию на 2013 год, каждый день пользователями по всей планете вводится примерно 320 миллионов «капчей» (см. статью на Википедии https://en.wikipedia.org/wiki/CAPTCHA). Некоторые требования к интернет ресурсам, которые используют тест капча, предъявляет «ГОСТ Р 52872-2012. Национальный стандарт Российской Федерации. Интернет-ресурсы. Требования доступности для инвалидов по зрению».
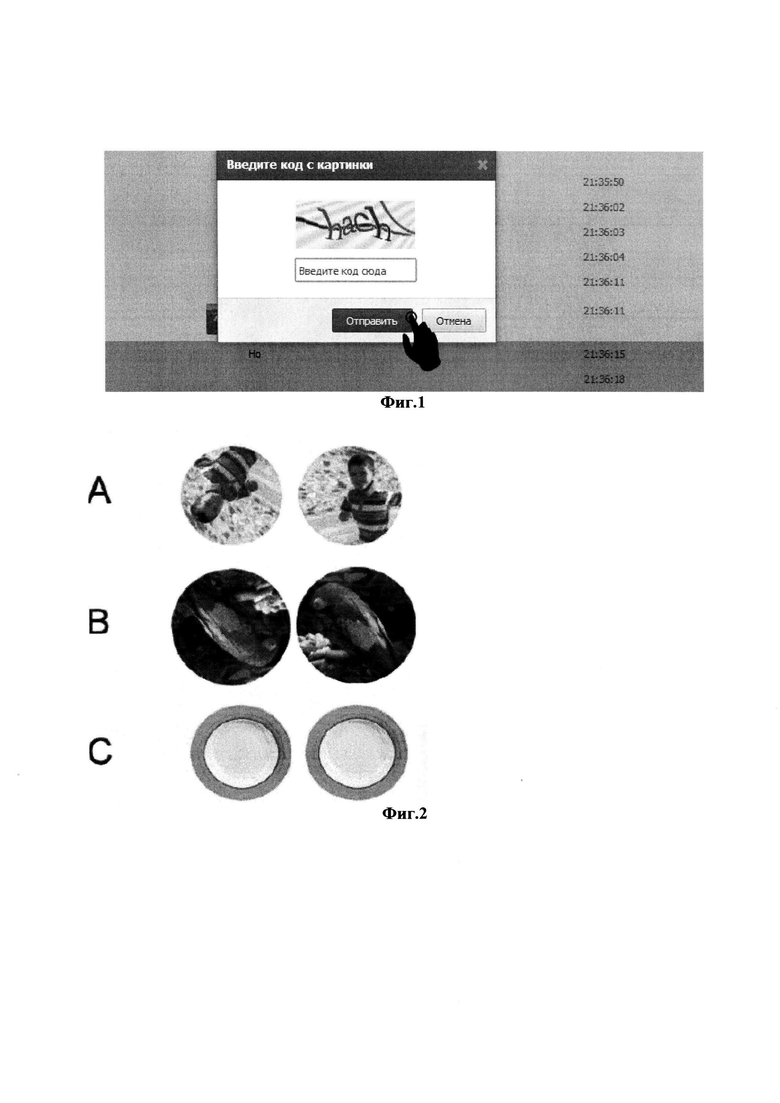
Основной мерой противодействия интернет-роботам является дополнительная проверка пользователя, которая осуществляется в виде предложения пользователю выполнить небольшое тестовое задание. Предполагается, что если доступ к ресурсу пытается выполнить человек, то тест легко и успешно им будет пройден, а для интернет-робота, даже специально запрограммированного, вероятность выполнить проверочное задание будет мала. Например, на самом популярном сайте российского сектора интернета (социальной сети «ВКонтакте») такая проверка организована в виде следующего теста: человеку демонстрируется сильно искаженный набор четырех символов, над которыми высвечивается просьба -прочитать «кодовое слово», а затем ввести кодовый набор символов с помощью клавиатуры в специальном окне (см. фиг. 1).
Для затруднения распознавания интернет-роботом кодовые символы на картинке специально перечеркиваются, наклоняются, растягиваются, имеют разрывное начертание и пр. Наложение все более сложных «шумов» и частую модификацию искажений приходится делать по причине появления все более изощренных программ распознавания символов. Так, в описании изобретения к патенту RU №2608262 «ИСКАЖЕНИЕ СИМВОЛОВ ДЛЯ СИМВОЛЬНО-ГРАФИЧЕСКОГО ОБРАТНОГО ТЕСТА ТЬЮРИНГА» предлагается получать новые виды графически искаженных символов путем морфинга (получения промежуточных начертаний), основанного на двух или более известных стандартных шрифтах.
В открытых источниках доступен программный код интернет-робота, который выполняет распознавание символов для любых современных символьных капча с вероятностью 85% (см. http://www.opermet.m/opermews/art.shtml?num=47477). Владельцы сайтов вынуждены модифицировать, усложнять тест, вносить еще больше искажений и шумов в начертание символов. Однако и сильно усложненные текстовые капчи с легкостью распознаются современными методами распознавания на основе нейросетей (см. https://habrahabr.ru/post/343222/).
Из анализа успешных методов «взлома» текстовой капчи можно сделать выводы об основных недостатках теста на основе символьного кодового слова:
а) имеется ограниченный набор символов, который может быть продемонстрирован человеку, так для русского языка это 33 буквы и 10 цифр, ограниченность такого набора образов для автоматического распознавания существенно облегчают задачу прохождения теста интернет-роботом, сделанным, например, на основе нейросети;
б) слишком искаженные символы уже с трудом распознаются даже человеком, и порог допустимых шумов и искажений для этой технологии уже достигнут.
Помимо капчи на основе искаженных символов в интернете распространены и иные способы проверки пользователя. Так, довольно часто капча появляется только в случае необычного поведения пользователя (т.е. при подозрении, что проводится атака интернет-роботом). Например, если пользователем выполняется ряд подозрительно быстрых однотипных действий, защита поисковика Google сначала предлагает пройти простой тест (капчу) (пример по адресу: https://patrickhlauke.github.io/recaptcha/); если действия пользователя еще более угрожающие, то появляется более сложное (для робота) задание - требуется указать картинки с заданным содержанием среди нескольких. Например, предлагается указать с помощью мыши те (три-четыре) картинки из 16, на которых присутствует, например, дорожный знак. Компания Google, по-видимому, использует этот способ проверки пользователя (на «человечность») из-за того, что защиту по «кодовому слову» приходилось часто модифицировать, изощряясь в искажениях и шумах. Google демонстрирует выбранные 16 изображений из большой базы, где все картинки просмотрены и вручную классифицированы.
Проблема этого метода состоит в том, что злоумышленники вполне могут при автоматическом многократном обращении на сайт компании Google собрать достаточно большую часть изображений, которые хранятся в базе данных Google, затем эти изображения самим расклассифицировать, а далее «обучить» нейросеть распознавать их. Чтобы этого не допустить, необходимо создать много тестовых изображений, а также не меньше сотни категорий тестовых изображений. Но создание большой базы классифицированных изображений является очень трудоемкой и дорогой задачей даже для Google. Кроме того, т.к. база изображений капчи от Google - это изображения из сети интернет, то злоумышленникам для тренировки современных обучающихся систем распознавания изображений также не сложно собрать обучающую выборку в сети интернет. И, кроме того, оказывается, что для использования в качестве взламывающих программных средств вполне подходят бесплатные библиотеки тренировки нейросетей от самой компании Google, то есть фактически алгоритмы распознавания от Google (https://arxiv.org/pdf/1312.6082v4.pdf) неплохо взламывают капчи Google.
Известны способы преодоления вышеуказанных недостатков для самых распространенных в настоящее время видов капчи (напомним, в рамках одного вида капчи демонстрируются искаженные символы, во втором виде требуется указать изображения (из нескольких) с заданным содержанием).
Одним из самых перспективных способов преодоления, указанных выше недостатков является создание капчи, где пользователю задается вопрос не по узнаванию объекта, представленного на изображении (например, «какая цифра», или «укажите картинки с собакой»), а пользователь должен дать некую обобщенную характеристику изображению. Например, вопрос капчи может быть - сколько объектов на изображении (такой вопрос - предлагается в патенте - RU 2663475 С1), или «укажите те изображения, которые кажутся неестественными» (такой вопрос содержит капча настоящей заявки).
Известен способ формирования изображений Капчи по заявке US 8090219 В2 «Systems and methods for socially-based correction of tilted images», который основывается на способности человека узнавать наклонные изображения. Представление о том, есть ли у объекта на изображении наклон от естественного его расположения, у человека всегда возникает, т.к. человек должен знать, когда предмет устойчиво может стоять или лежать на горизонтальной поверхности. Обучить компьютер представлению об устойчивом вертикальном состоянии всех объектов, которые известны пользователю человеку, представляется невозможным при современном уровне техники. Количество объектов, о которых человек имеет представление об их «правильной» ориентации, гораздо больше того, которое нынешние алгоритмы могут классифицировать. Но классифицировать объект еще недостаточно, после того, как объект распознан для каждого ракурса в кадре компьютерная программа должна вычислить - объект этот представлен под наклоном?
Недостаток источника US 8090219 B2 «Systems and methods for socially-based correction of tilted images», состоит в том, что очень небольшая доля изображений, которые есть в сети интернет, может быть использована в такой капче. А значит, все изображения капчи, которые потом увидит пользователь, должны быть предварительно просмотрены реальными людьми, на них оператор по подготовке изображений должен выделить область объекта, который потом поворачивается. Для создания надежной капчи (когда злоумышленники не смогут получить массовыми запросами существенную долю всех изображений) потребуется предварительно людям просмотреть и обработать несколько сотен тысяч изображений. А значит, развертывание такой капчи в виде интернет-сервиса будет очень затратным. Кроме того, у большинства объектов и без их распознавания можно указать вертикальную ось. Область, которую объект занимает на изображении (например, стоящий человек) сама по себе имеет ориентацию - она как бы вытянута (от головы до ног), и направление такой «вытянутости» в огромной доле случаев совпадает с естественной вертикалью объекта. Это свойство многих объектов быть вытянутыми по вертикали легко можно использовать для создания интернет-бота по автоматическому доступу к серверу. Таким образом, способ US 8090219 В2 «Systems and methods for socially-based correction of tilted images» не следует считать надежным способом, по которому отличают человека от интернет-робота.
Раскрытие изобретения Технической проблемой, на решение которой направлено заявляемое изобретение, является значительное повышение вероятности распознавания человека от интернет-робота с помощью теста-капчи при предоставлении разрешения на доступ к интернет-ресурсам.
Техническим результатом заявляемого изобретения является обеспечение безопасного доступа к интернет-ресурсам.
Для достижения технического результата предложен способ идентификации пользователя компьютера «человек или интернет-робот», включающий этапы:
(а) формируют базу исходных изображений для демонстрации пользователям,
(б) выбирают случайным образом из базы изображений, которую заранее формируют, одно или более изображений,
(в) на экран пользователя выводят вопрос капчи пользователю в текстовом виде - в вопросах к изображению используют одно или несколько слов из списка: «неестественное», «естественное», «коллаж»,
(г) выполняют сравнения параметров ответных действий пользователя, которые сохраняют на этапе (в) с параметрами описания изображения, которые формируют на этапе (б),
(д) в случае не совпадения параметров, полученных в результате восприятия пользователем и параметров хранящихся на сервере пользователь получает отказ в доступе к ресурсу или наоборот, при положительном результате сравнения пользователю предоставляется доступ к информации, при этом, в качестве источника изображения капчи выбирают видеоряд естественной сцены и формируют два изображения: первое - изображение заднего плана, второе - изображение переднего плана, так что изображение переднего плана располагают в произвольном месте кадра или искажают его пропорции, или вносят искажения в его целостность, или наклоняют его, или производят перечисленные изменения изображения переднего плана в их сочетании, затем второе - изображение переднего плана накладывают поверх первого - изображение заднего плана и формируют автоматически единое изображение - «неестественный коллаж», по крайней мере, одно изображение «неестественного коллажа» демонстрируют пользователю капчи.
В заявляемом изобретении предложен способ автоматического и массового синтезирования изображений, которые с точки зрения человека определенно не могут являться снимками естественной обстановки. При этом создать компьютерную программу, с помощью которой можно было бы надежно отличать предложенные «неестественные» изображения (коллажи) от естественных фотографий при текущем уровне техники не представляется возможным. Для этого в естественный снимок «вставляют» объект, и при этом объект деформируют псевдослучайным процессом, при этом случайно задают не менее чем три параметра такой деформации. Таким образом, добиваются того, что возможных вариантов изображений деформированных объектов существенно больше чем количества их предполагаемых демонстраций. В процессе каждой вышеуказанной деформации нарушают множество приемлемых для человека характеристик - по нормальному положению объекта, его пропорциях, целостности и пр. При синтезе «неестественных» изображений используют большую базу исходных изображений, как самого объекта, так и естественных снимков. Такую базу исходных изображений формируют на основе видеорядов скаченных из сети интернет и постоянно ее пополняют. Для осуществления безопасного доступа к интернет ресурсу удаленному пользователю предлагается - рассмотреть несколько изображений и ответить на вопрос к каждому из них - «является ли картинка естественным изображением?». При этом набор изображений для каждого сеанса проверки пользователя уникален. Ни синтезированный и продемонстрированный «естественный коллаж» (изображение «естественного коллажа» с точки зрения человека ничем не отличающиеся от естественной фотографии), ни синтезированные и однажды продемонстрированный «неестественные коллажи» не демонстрируют второй раз - в другом сеансе проверки пользователя.
Совокупность приведенных выше существенных признаков формирования изображений и их демонстрации приводит к тому, что разнообразных изображений, которые предлагают рассматривать удаленным пользователям так много, что невозможно запрограммировать обобщающие правила по различению «естественных» и «неестественных» изображений, невозможно, также, сформировать достаточную обучающую выборку для обучения одного из известных методов машинного обучения, например, нейросетей. При этом предполагают, что человек разглядывая каждое изображение, которое видит впервые, легко ответит на вопрос - было ли оно искусственно синтезировано или является естественным снимком.
Краткое описание чертежей
На фиг. 1 показана «классическая» текстовая капча, в которой требуется ввести кодовое слово, изображенное на картинке.
На фиг. 2 показано то, как выглядит изображение капчи у ближайшего прототипа по данной заявке (US 8090219 В2), заданием к пользователю по капче по заявке US 8090219 В2 является - указать с помощью манипулятора те изображения на экране, которые наклонены.
На фиг. 3 показан «неестественный» коллаж, это такое изображение, которое явно синтезировано компьютерным редактированием, и не может быть получено путем фото-фиксирования некоторой реальной сцены, объект переднего плана расположен неестественно, не имеет опоры и нарушена его целостность.
На фиг. 4 показано как на основе двух кадров двух естественных сцен (на одном присутствует только фон, а на другом объект на том же фоне) путем компьютерной обработки, с применением процедуры «вычитания», получают область кадра («маску»), которая «покрывает» только объект переднего плана, а далее применяют маску к естественному изображению с объектом и получают изображение (правое нижнее), в котором все пиксели изображения, которые не относятся к объекту переднего плана, помечают как прозрачные.
На фиг. 5 показано, как на основе двух изображений - изображения фона и изображения с выделенным объектом, получают два других изображения, первое - естественный коллаж, второе - «неестественный» коллаж.
На фиг. 6 показано, какие изображения будет видеть пользователь при ответе на задания капчи по настоящей заявке, при этом пользователю будет предложено с помощью мыши или пальца (для мобильных устройств) указать те изображения, которые являются «неестественными».
Осуществление и примеры реализации
«Неестественный коллаж», это изображение, в которое искусственно «вставляют» объект, и изображение этого объекта не сочетается с основной частью изображения. Например, для изображения «неестественного» объекта, который искусственно вставляют в естественный снимок:
а) нарушают правильные пропорции;
б) исключают необходимые части объекта;
в) объект изображают «подвешенным» без опоры;
г) существенно и неестественно деформируют изображение объекта
д) применяют различные сочетания из перечисленных выше пунктов а)-г) (см. Фиг. 3).
Для этого в предлагаемом способе пользователю на экране выводят несколько отдельных изображений при предоставлении разрешения на доступ к интернет-ресурсам.
При каждом запросе пользователя начинает автоматически исполняться последовательность нижеследующих рабочих этапов отклика:
- выбирают случайным образом из базы изображений, которую заранее формируют, одно или более изображений;
- каждое выбранное изображение поворачивают на угол, величину которого выбирают случайно;
- выбранное изображение размещают на экране пользователя рядом с исходным не наклоненным (естественным) изображением;
- на экран пользователя выводят вопрос капчи (или задание) к пользователю в текстовом виде, например, «укажите те изображения, которые наклонены»;
- далее предполагают, что пользователь разглядывает изображение, читает текст задания и выполняет его, при этом пользователь с помощью манипулятора «мышь» или пальцем на экране отмечает те изображения, которые наклонены от своего естественного положения;
- при выполнении пользователем последовательности ответных действий браузер пользователя формирует набор параметров, характеризующих восприятие пользователем изображения, далее браузер пользователя отправляет на сервер значения этих параметров;
- сервер получает параметрическое описание ответных действий пользователя и выполняет сравнение двух наборов параметров: а) параметров, характеризующих восприятие пользователем изображения на экране компьютера и б);
- в случае не совпадения параметров, полученных в результате восприятия пользователем и параметров хранящихся на сервере пользователь получает отказ в доступе к ресурсу или наоборот, при положительном результате сравнения пользователю предоставляется доступ к информации.
Технический результат по предлагаемому способу достигается следующим образом.
В настоящем способе пользователю предлагается отличать изображение, которое содержит «неестественный коллаж» (Фиг. 3) от изображения, которое получают, например, фотосьемкой естественной обстановки. При этом существенным фактором, затрудняющим распознавание изображения программным роботом, является множество случайных параметров, изменяющих начальное «естественное» изображение, в отличие от прототипа, в котором изображение меняется по одному параметру - поворачивается на некоторый случайный угол.
И «естественный коллажи», и «неестественный коллажи» составляют из двух заранее подготовленных изображений путем «наложения» одного поверх другого: первого - «фонового изображения» и второго - изображения переднего плана с непрозрачной областью. И «естественный коллажи», и «неестественные коллаж» составляют автоматически по программе.
Область на втором изображении деформируют случайным образом, например, растягивают в случайном направлении, либо поворачивают на случайный угол. Кроме того, во втором изображении часть непрозрачной делают прозрачной, тем самым создавая эффект «откусывания». Таким образом, достигают эффекта «неестественности» изображения при его восприятии человеком.
При синтезе и «естественного коллажа», и «неестественного коллажа» в качестве исходных данных используют видеоряд. Видеоряд получают и сохраняют заранее путем записи данных с камер наружного видеонаблюдения или записи учебных программ, которые в достаточном количестве находятся в свободном доступе в сети Интернет.
На первом этапе при синтезе и «естественного коллажа», и «неестественного коллажа» часть исходного видеоряда обрабатывают так, что формируют «фоновое» изображение или изображение заднего плана (на Фиг. 4 - левый верхний кадр). При этом используют способ из патента RU 2395787C2 «СПОСОБ ОБНАРУЖЕНИЯ ОБЪЕКТОВ». Из известного патента используют следующие действия: 1) проводят инициализацию фонового кадра, например, нулевыми значениями; 2) берут первый кадр видеопоследовательности и далее для каждого нового кадра выполняют для каждого пикселя фонового кадра по некоторому правилу рассчитывают «постоянную обновления фона», на основе этой постоянной, текущего кадра и предыдущего «фонового кадра» рассчитывают новый «фоновый кадр».
На втором этапе создания «неестественного» коллажа (см. правый нижний кадр на Фиг. 4) с использованием фонового кадра и некоторого кадра выполняют «обнаружение объекта» (правый верхний кадр Фиг. 4) по способу, описанному в RU 2395787 C2. Из известного патента используют следующие действия: вычисляют абсолютную разность между текущим кадром и фоном и проводят бинаризацию с пороговым кадром, при этом значения пикселей порогового кадра вычисляют по формуле, в которой используют значение пикселей текущего кадра, значение пикселей фонового кадра. В результате получают кадр с выделенным объектом (см. правый нижний кадр на Фиг. 4).
На третьем этапе автоматического синтеза «неестественного» коллажа берут а) фоновый кадр видеоряда, который был получен на первом этапе (см. правый верхний кадр Фиг. 5) и берут б) кадр с выделенным объектом и прозрачным фоном (см. правый верхний кадр Фиг. 5). Далее, на кадре с выделенным объектом и прозрачным фоном производят искажения в области изображения объекта - эту область частично делают прозрачной - обрезают объект, поворачивают, сдвигают и пр. Потом искаженный объект накладывают на фоновый кадр - и тем самым получают «неестественный» коллаж, (см. правый нижний кадр Фиг. 5). Алгоритм такого наложения изображений общеизвестен и используются в распространенных пакетах компьютерной графики, например, в Adobe Photoshop.
В целях получения более точных ответов пользователей-людей на вопрос капчи по одному из способов в настоящей заявке на экран пользователя выводится «естественный коллаж» (см. левый нижний кадр Фиг. 5) рядом с «неестественным коллажем» (см. правый нижний кадр Фиг. 5). Предполагают, что пользователь будет сравнивать два кадра с одинаковым фоном, эти кадры располагают рядом, и отвечать пользователь должен будет на вопрос - «какая картинка «неестественный» коллаж?» или «какое изображение неестественное?» (см. Фиг. 6).
По основному из способов настоящей заявки изображение, которое предполагают, что на экране человек его всегда будет воспринимать как естественное, также создается как автоматически синтезированный «естественный коллаж». Такой коллаж делают на основе «фонового кадра» и кадра с выделенным объектом и прозрачным фоном, но при этом область объекта никак не искажают и не деформируют. Иначе - объект выделяют из текущего кадра и «кладут» обратно, но на рассчитанный «фоновый кадр» - тем самым получают «естественный коллаж». То, что это автоматически синтезированный коллаж пользователь человек заметить не должен, т.к. выделенный объект накладывают на фоновый кадр без искажений, без сдвига, без обрезания и без поворота и пр. Эту процедуру проводят, т.к. существуют программы обнаружения коллажей (фотомонтажа). Если «естественные» изображения не делать также по технологии синтеза коллажа (незаметными с точки зрения человека), то программные инструменты для обнаружения коллажей могут быть использованы для автоматического прохождения (взлома) капчи. Такие программы отличат коллаж от не коллажа, а если коллажами (т.е. «накладывать» объект на фон) делать только «неестественные» кадры, а в качестве естественных брать просто кадры видеоряда без наложения, то программы по обнаружению коллажей будут отличать «естественные» изображения от «неестественных» по невидимым человеческому глазу техническим признакам, а не по существу.
И «естественный коллаж» и «неестественный коллаж» автоматически составляют из двух заранее подготовленных изображений путем «наложения» одного поверх другого. В качестве одного изображение используют «фоновое изображение» (изображение заднего плана), в качестве второго используют изображение, на котором непрозрачна только область, которая относится к изображению переднего плана (объекту на переднем плане).
Пред тем как формируют «неестественный коллаж», область переднего объекта на втором изображении деформируют случайным образом (со случайными параметрами растягивают по «случайному» направлению, осуществляют «случайный» поворот области объекта на изображении, а также случайно «обрезают» часть объекта или делают в нем «дыры»). При этом, часть непрозрачной области второго объекта делают прозрачной, тем самым создают эффект «откусывания» от объекта случайной части. Этими средствами достигают эффекта «неестественности» изображения при его восприятии человеком.


Настоящее изобретение относится к безопасности компьютерных сетей, включая несанкционированный доступ к интернет-ресурсам, а именно к способам формирования изображений и видам заданий пользователю при прохождении пользователем полностью автоматизированного теста Тьюринга (САРТСНА). Технический результат заключается в обеспечении безопасного доступа к интернет-ресурсам. Такой результат достигается тем, что в качестве источника изображения капчи выбирают видеоряд естественной сцены и формируют два изображения: первое - изображение заднего плана, второе - изображение переднего плана, так что изображение переднего плана располагают в произвольном месте кадра или искажают его пропорции, или вносят искажения в его целостность, или наклоняют его, или производят перечисленные изменения изображения переднего плана в их сочетании, затем второе - изображение переднего плана накладывают поверх первого - изображение заднего плана и формируют автоматически единое изображение - «неестественный коллаж», по крайней мере, одно изображение «неестественного коллажа» демонстрируют пользователю капчи. 6 ил.
Способ идентификации пользователя компьютера «человек или интернет-робот», включающий этапы:
(а) формируют базу исходных изображений для демонстрации пользователям,
(б) выбирают случайным образом из базы изображений, которую заранее формируют, одно или более изображений,
(в) на экран пользователя выводят вопрос капчи пользователю в текстовом виде - в вопросах к изображению используют одно или несколько слов из списка: «неестественное», «естественное», «коллаж»,
(г) выполняют сравнения параметров ответных действий пользователя, которые сохраняют на этапе (в) с параметрами описания изображения, которые формируют на этапе (б),
(д) в случае не совпадения параметров, полученных в результате восприятия пользователем и параметров хранящихся на сервере пользователь получает отказ в доступе к ресурсу или наоборот, при положительном результате сравнения пользователю предоставляется доступ к информации, отличающийся тем, что в качестве источника изображения капчи выбирают видеоряд естественной сцены и формируют два изображения: первое - изображение заднего плана, второе - изображение переднего плана, так что изображение переднего плана располагают в произвольном месте кадра или искажают его пропорции, или вносят искажения в его целостность, или наклоняют его, или производят перечисленные изменения изображения переднего плана в их сочетании, затем второе - изображение переднего плана накладывают поверх первого - изображение заднего плана и формируют автоматически единое изображение - «неестественный коллаж», по крайней мере, одно изображение «неестественного коллажа» демонстрируют пользователю капчи.
| US 20110113378 A1, 12.05.2011 | |||
| JP 2012003467 A, 05.01.2012 | |||
| US 20100210358 A1, 19.08.2010 | |||
| JP 2012173953 A, 10.09.2012 | |||
| US 20080066014 A1, 13.03.2008 | |||
| US 20060033754 A1, 16.02.2006 | |||
| WO 2016135963 A1, 01.09.2016 | |||
| СПОСОБ ПОЛУЧЕНИЯ КОНСЕРВОВ "САЛАТ ИЗ КАЛЬМАРОВ, КВАШЕНОЙ КАПУСТЫ И ЛУКА" | 2007 |
|
RU2330529C1 |
| US 8090219 B2, 03.01.2012 | |||
| СПОСОБ ОБНАРУЖЕНИЯ ОБЪЕКТОВ | 2008 |
|
RU2395787C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ КОМПЬЮТЕРА "ЧЕЛОВЕК ИЛИ ИНТЕРНЕТ-РОБОТ" | 2017 |
|
RU2663475C1 |
| ИСКАЖЕНИЕ СИМВОЛОВ ДЛЯ СИМВОЛЬНО-ГРАФИЧЕСКОГО ОБРАТНОГО ТЕСТА ТЬЮРИНГА | 2013 |
|
RU2608262C2 |

