ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Настоящая заявка испрашивает приоритет по предварительной заявке на патент США № 62/467467, поданной 6 марта 2017 года, полное содержание которой включено в данный документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Область настоящего изобретения относится к способам и процессам, которые можно применять для получения конкретного стевиолового гликозида посредством биосинтетического пути, сконструированного в выбранных микроорганизмах. Более конкретно, настоящее изобретение предусматривает получение ранее неизвестного ребаудиозида - ребаудиозида D4 ("Reb D4"), который можно синтезировать из ребаудиозида Е ("Reb Е") посредством ферментативного превращения.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Несколько стевиоловых гликозидов были обнаружены как соединения в листьях Stevia rebaudiana и широко использовались в качестве низкокалорийных подсластителей высокой интенсивности в пищевых продуктах, кормах и напитках. Встречающиеся в природе стевиоловые гликозиды имеют одинаковую основную структуру дитерпена (стевиоловый каркас), однако отличаются по количеству и структуре модификаций углеводных остатков (например, остатков глюкозы, рамнозы и ксилозы) в положениях C13 и C19 основного стевиолового каркаса. Интересно, что эти изменения в сахарной "орнаментации" базовой структуры стевиола резко и непредсказуемо влияют на свойства самих отдельных стевиоловых гликозидов. Эти признаки включают без ограничения вкусовой профиль, точку кристаллизации, растворимость и воспринимаемую сладость помимо прочих других различий. Стевиоловые гликозиды с известными структурами включают стевиозид, ребаудиозид A, ребаудиозид B, ребаудиозид C, ребаудиозид D, ребаудиозид E, ребаудиозид F, ребаудиозид M и дулкозид A. С точки зрения коммерческого применения ребаудиозид M обычно считается безопасным (т.е. имеет статус "GRAS") и изучается для широкого спектра применений на рынке продуктов питания и напитков.
В пересчете на сухую массу, стевиозид, ребаудиозид А, ребаудиозид С и дулкозид А составляют соответственно 9,l, 3,8, 0,6 и 0,30 процента от общего веса стевиоловых гликозидов, обнаруживаемых в листьях Stevia дикого типа, тогда как другие стевиоловые глюкозиды, такие как Reb Е, присутствуют в значительно меньших количествах, а Reb D4 вообще не присутствует. Экстракты растения Stevia rebaudiana коммерчески доступны, и в таких экстрактах стевиозиды и ребаудиозиды А чаще всего являются основными компонентами. Для сравнения, другие известные стевиоловые гликозиды обычно присутствуют в экстракте stevia в виде минорных или следовых компонентов. Например, количество ребаудиозида А в типичных коммерческих препаратах может варьировать от приблизительно 20% до более чем 90% от общего содержания стевиоловых гликозидов, тогда как количество ребаудиозида В обычно составляет приблизительно 1-2%, количество ребаудиозида С составляет приблизительно 7-15%, и количество ребаудиозида D может составлять приблизительно 2% от общего количества стевиоловых гликозидов. В таких экстрактах ребаудиозид М присутствует только в чрезвычайно ничтожных количествах. Интересно, что ребаудиозид Е также является одним из наименее распространенных стевиоловых гликозидов, присутствующих в сортах растений Stevia rebaudiana, составляя менее 0,5% от общего количества присутствующих гликозидов.
Как природные подсластители, и как упоминалось выше, различные стевиоловые гликозиды характеризуются различной степенью сладости, "вкусовыми ощущениями" и специфическими привкусами, связанными с каждым из них. По сравнению со столовым сахаром (т.е. "сахарозой") сладость стевиоловых гликозидов значительно выше. Например, стевиозид в 100-150 раз слаще сахарозы, однако имеет горький привкус, как отмечалось в многочисленных тестах на вкус, тогда как сладость у ребаудиозидов А и Е в 250-450 раз выше, чем у сахарозы, и профиль привкуса намного менее заметен, чем у стевиозида. Однако сами эти стевиоловые гликозиды все еще сохраняют заметный привкус. Соответственно, общеизвестно, что на вкусовые профили экстрактов stevia сильно влияет относительное содержание различных стевиоловых гликозидов в экстракте, что в свою очередь может зависеть от условий окружающей среды, в которых находятся основные растения, а также от применяемого способа экстракции. Такие различия в получении растений, погодных условиях и условиях экстракции могут приводить к непостоянным композициям стевиоловых гликозидов в экстрактах stevia, так что вкусовой профиль сильно варьируется между различными партиями продуктов экстракции. На вкусовой профиль экстрактов stevia также могут влиять загрязняющие вещества растительного происхождения или из окружающей среды (такие как пигменты, липиды, белки, фенольные смолы и сахариды), которые остаются в продукте после процесса экстракции. Эти загрязняющие вещества обычно имеют свои собственные неприятные запахи, что делает полученный экстракт нежелательным для применения в потребительских продуктах. Кроме того, стоимость выделения отдельных или конкретных комбинаций стевиоловых ребаудиозидов, которые являются немногочисленными в экстрактах stevia, является чрезмерно затратной и ресурсоемкой. Учитывая ограниченное качество и доступность некоторых конкретных стевиоловых гликозидов, коммерческое получение может быть в большей степени удовлетворено с помощью биоконверсии, при этом природные ферменты или конкретные микробы могут быть модифицированы для переноса необходимых ферментов и применения коммерчески значимых способов ферментации для значительного увеличения получения гликозидов, представляющих интерес. Например, ранее сообщалось о биоконверсии стевиозида в Reb E (см. Yu et al., заявка США № 15/016589, опубликованная как публикация заявки на патент США № US2016/0207954) посредством пути ферментации с участием модифицированных микробов. Как альтернатива, для разработки стевиоловых гликозидов, представляющих интерес, можно использовать другие инструменты, отличные от биосинтетических.
Соответственно, существует необходимость в разработке стевиоловых гликозидов с лучшими и более постоянными вкусовыми профилями в качестве коммерческих продуктов и обеспечении возможности применения в таких стевиоловых гликозидах соответствующего общего исходного субстрата, такого как более распространенные стевиоловые гликозиды в качестве исходных молекул, таким образом, чтобы такое получение требуемых гликозидов могло быть коммерчески настолько эффективным, насколько это возможно.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение охватывает способ получения Reb D4 из Reb E, такой как способ получения в клеточной системе.
В частности, настоящее изобретение предусматривает получение стевиолового гликозида ребаудиозида D4 "Reb D4", который идентифицирован как (13-[(2-O-β-D-глюкопиранозил-β-D-глюкопиранозил)окси]энт-каур-16-ен-19-оевая кислота-[(2-O-β-D-глюкопиранозил-3-O-β-D-глюкопиранозил-β-D-глюкопиранозил)сложный эфир]) с помощью специфической UDP-гликозилтрансферазы из Reb E.
Современные способы обеспечивают подход для синтеза конкретных стевиоловых гликозидов с применением конкретного синтетического пути.
В некоторых аспектах настоящее изобретение предусматривает мутантный фермент СР1, содержащий аминокислотную последовательность под SEQ ID NO: 7. В некоторых аспектах настоящее изобретение предусматривает рекомбинантный полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 7. В некоторых вариантах осуществления рекомбинантный полипептид обладает такой же или практически такой же активностью, что и мутантный фермент СР1, как описано в данном документе, например, мутантный фермент СР1, содержащий аминокислотную последовательность под SEQ ID NO: 7.
В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность под SEQ ID NO: 8. В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 8. В некоторых вариантах осуществления нуклеотидная последовательность кодирует мутантный фермент СР1, как описано в данном документе, например, мутантный фермент СР1, содержащий аминокислотную последовательность под SEQ ID NO: 7.
В некоторых аспектах настоящее изобретение предусматривает мутантный фермент СР1, содержащий аминокислотную последовательность под SEQ ID NO: 9. В некоторых аспектах настоящее изобретение предусматривает рекомбинантный полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 9. В некоторых вариантах осуществления рекомбинантный полипептид обладает такой же или практически такой же активностью, что и мутантный фермент СР1, как описано в данном документе, например, мутантный фермент СР1, содержащий аминокислотную последовательность под SEQ ID NO: 9.
В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность под SEQ ID NO: 10. В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 10. В некоторых вариантах осуществления нуклеотидная последовательность кодирует мутантный фермент СР1, как описано в данном документе, например, мутантный фермент СР1, содержащий аминокислотную последовательность под SEQ ID NO: 9.
В некоторых аспектах настоящее изобретение предусматривает мутантный фермент HV1, содержащий аминокислотную последовательность под SEQ ID NO: 11. В некоторых аспектах настоящее изобретение предусматривает рекомбинантный полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 11. В некоторых вариантах осуществления рекомбинантный полипептид характеризуется такой же или практически такой же активностью, что и мутантный фермент HV1, как описано в данном документе, например, мутантный фермент HV1, содержащий аминокислотную последовательность под SEQ ID NO: 11.
В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность под SEQ ID NO: 12. В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 12. В некоторых вариантах осуществления нуклеотидная последовательность кодирует мутантный фермент HV1, как описано в данном документе, например, мутантный фермент HV1, содержащий аминокислотную последовательность под SEQ ID NO: 11.
В некоторых аспектах настоящее изобретение предусматривает клетку-хозяина, содержащую вектор, обеспечивающий продуцирование фермента C1m2, содержащего аминокислотную последовательность под SEQ ID NO: 7. В некоторых аспектах настоящее изобретение предусматривает клетку-хозяина, содержащую вектор, обеспечивающий продуцирование фермента C1m3, содержащего аминокислотную последовательность под SEQ ID NO: 9. В некоторых аспектах настоящее изобретение предусматривает клетку-хозяина, содержащую вектор, обеспечивающий продуцирование мутантного фермента HV1, содержащего аминокислотную последовательность под SEQ ID NO: 11. В некоторых вариантах осуществления клетка-хозяин выбрана из группы, состоящей из бактерий, дрожжей, нитчатых грибов, водорослей, представляющих собой цианобактерии, и растительной клетки. В некоторых вариантах осуществления клетка-хозяин выбрана из группы, состоящей из Escherichia; Salmonella; Bacillus; Acinetobacter; Streptomyces; Corynebacterium; Methylosinus; Methylomonas; Rhodococcus; Pseudomonas; Rhodobacter; Synechocystis; Saccharomyces; Zygosaccharomyces; Kluyveromyces; Candida; Hansenula; Debaryomyces; Mucor; Pichia; Torulopsis; Aspergillus; Arthrobotlys; Brevibacteria; Microbacterium; Arthrobacter; Citrobacter; Escherichia; Klebsiella; Pantoea; Salmonella; Corynebacterium; Clostridium и Clostridium acetobutylicum. В некоторых вариантах осуществления клетка-хозяин представляет собой клетку, выделенную из растений, выбранных из группы, состоящей из сои; рапса; подсолнечника; хлопчатника; кукурузы; табака; люцерны; пшеницы; ячменя; овса; сорго; риса; брокколи; цветной капусты; капусты; сортов пастернака; сортов дыни; сортов моркови; сельдерея; петрушки; сортов томата; сортов картофеля; сортов клубники; сортов арахиса; сортов винограда; травяных культур; сортов сахарной свеклы; сахарного тростника; сортов фасоли; сортов гороха; ржи; льна; лиственных деревьев; хвойных деревьев; кормовых трав; Arabidopsis thaliana; риса (Oryza sativa); Hordeum yulgare; проса прутьевидного (Panicum vigratum); Brachypodium spp.; Brassica spp. и Crambe abyssinica.
В некоторых аспектах настоящее изобретение предусматривает способ получения композиции на основе стевиолового гликозида, при этом способ предусматривает инкубирование субстрата с рекомбинантным полипептидом, содержащим аминокислотную последовательность, характеризующуюся по меньшей мере 80% (например, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 7. В некоторых вариантах осуществления рекомбинантный полипептид представляет собой UDP-гликозилтрансферазу, характеризующуюся по меньшей мере 80% (например, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 7. В некоторых вариантах осуществления субстрат выбран из группы, состоящей из стевиозида или ребаудиозида Е и их комбинаций. В некоторых вариантах осуществления стевиол-гликозидное соединение, полученное с помощью данного способа, представляет собой ребаудиозид D4, так что композиция на основе стевиолового гликозида содержит ребаудиозид D4.
В некоторых аспектах настоящее изобретение предусматривает способ получения ребаудиозида D4, при этом способ предусматривает инкубирование субстрата с рекомбинантным полипептидом, содержащим аминокислотную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 7. В некоторых вариантах осуществления субстрат выбран из группы, состоящей из ребаудиозида Е, стевиозида и их комбинаций. В некоторых вариантах осуществления способ дополнительно предусматривает инкубирование рекомбинантной сахарозосинтазы с субстратом и рекомбинантным полипептидом.
В некоторых аспектах настоящее изобретение предусматривает способ синтеза ребаудиозида D4 из ребаудиозида E, при этом способ предусматривает (а) получение реакционной смеси, содержащей ребаудиозид E, субстрат, выбранный из группы, состоящей из сахарозы, уридиндифосфата (UDP), и уридиндифосфатглюкозы (UDP-глюкоза), и C1m2, и (b) инкубирование реакционной смеси в течение периода времени, достаточного для получения ребаудиозида D4, при этом обеспечивается ковалентное связывание глюкозы с ребаудиозидом E с получением ребаудиозида D4. В некоторых вариантах осуществления способ дополнительно предусматривает добавление в реакционную смесь сахарозосинтазы. В некоторых вариантах осуществления сахарозосинтаза выбрана из группы, состоящей из сахарозосинтазы 1 Arabidopsis, сахарозосинтазы 3 Arabidopsis и сахарозосинтазы Vigna radiate. В некоторых вариантах осуществления сахарозосинтаза представляет собой сахарозосинтазу 1 Arabidopsis thaliana. В некоторых вариантах осуществления получаемый Reb D4 характеризуется чистотой, составляющей более чем 70% (например, более чем 70%, более чем 75%, более чем 80%, более чем 85%, более чем 90%, более чем 91%, более чем 92% более чем 93%, более чем 94%, более чем 95%, более чем 96%, более чем 97%, более чем 98%, более чем 99% или 100%). В некоторых вариантах осуществления способ дополнительно предусматривает добавление в реакционную смесь фермента HV1.
В некоторых аспектах настоящее изобретение предусматривает способ синтеза ребаудиозида D4 из ребаудиозида E, при этом способ предусматривает (а) получение реакционной смеси, содержащей ребаудиозид E, субстрат, выбранный из группы, состоящей из сахарозы, уридиндифосфата (UDP), и уридиндифосфатглюкозы (UDP-глюкоза), и C1m3, и (b) инкубирование реакционной смеси в течение периода времени, достаточного для получения ребаудиозида D4, при этом обеспечивается ковалентное связывание глюкозы с ребаудиозидом E с получением ребаудиозида D4. В некоторых вариантах осуществления способ дополнительно предусматривает добавление в реакционную смесь сахарозосинтазы. В некоторых вариантах осуществления сахарозосинтаза выбрана из группы, состоящей из сахарозосинтазы 1 Arabidopsis, сахарозосинтазы 3 Arabidopsis и сахарозосинтазы Vigna radiate. В некоторых вариантах осуществления сахарозосинтаза представляет собой сахарозосинтазу 1 Arabidopsis thaliana. В некоторых вариантах осуществления получаемый Reb D4 характеризуется чистотой, составляющей более чем 70% (например, более чем 70%, более чем 75%, более чем 80%, более чем 85%, более чем 90%, более чем 91%, более чем 92% более чем 93%, более чем 94%, более чем 95%, более чем 96%, более чем 97%, более чем 98%, более чем 99% или 100%). В некоторых вариантах осуществления способ дополнительно предусматривает добавление в реакционную смесь фермента HV1.
В некоторых аспектах настоящее изобретение предусматривает подсластитель, содержащий композицию на основе стевиолового гликозида или стевиоловый гликозид, полученные с помощью способа, как описано выше, или иного способа, как описано в данном документе.
В некоторых аспектах настоящее изобретение предусматривает фермент GXT6, содержащий аминокислотную последовательность под SEQ ID NO: 5. В некоторых аспектах настоящее изобретение предусматривает рекомбинантный полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 90% (например, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%) идентичностью с SEQ ID NO: 5. В некоторых вариантах осуществления рекомбинантный полипептид обладает такой же или практически такой же активностью, что и фермент GXT6, как описано в данном документе, например, фермент GXT6, содержащий аминокислотную последовательность под SEQ ID NO: 5. В некоторых аспектах настоящее изобретение предусматривает клетку-хозяина, содержащую вектор, обеспечивающий продуцирование фермента GXT6, содержащего аминокислотную последовательность под SEQ ID NO: 5.
В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность под SEQ ID NO: 6.
В некоторых аспектах настоящее изобретение предусматривает фермент CP1, содержащий SEQ ID NO: 3. В некоторых аспектах настоящее изобретение предусматривает нуклеиновую кислоту, содержащую нуклеотидную последовательность под SEQ ID NO: 4.
В некоторых аспектах настоящее изобретение предусматривает способ получения Reb M с применением ферментов и субстратов, описанных на ФИГ. 9, или их подмножества (например, начиная со стевиозида, Reb E или Reb D4, и/или с применением HV1, C1m2, C1m3, UGT76G1, CP1 и/или CR1). В некоторых вариантах осуществления Reb M получают с применением реакционной смеси in vitro, содержащей ферменты и субстраты, описанные на ФИГ. 9, или их подмножества (например, начиная со стевиозида, Reb E или Reb D4, и/или с применением HV1, C1m2, C1m3, UGT76G1, CP1 и/или CR1). В некоторых вариантах осуществления Reb M получают in vivo в клетке, которая экспрессирует ферменты, описанные на ФИГ. 9, или их подмножество (например, HV1, C1m2, C1m3, UGT76G1, CP1 и/или CR1), где клетку инкубируют с субстратом, описанным на ФИГ. 14 (например, стевиозид, Reb Е или Reb D4). В некоторых вариантах осуществления клетка представляет собой дрожжевую клетку. В некоторых вариантах осуществления клетка представляет собой бактериальную клетку. В некоторых вариантах осуществления клетка представляет собой растительную клетку.
Что касается продукта/коммерческого применения, то в Соединенных Штатах на рынке имеется несколько десятков продуктов, содержащих стевиоловые гликозиды, и их можно использовать в составе чего угодно - от анальгетиков до репеллентов от вредителей, а также в продуктах питания и в качестве пищевой добавки. Продукты, содержащие стевиоловые гликозиды, могут представлять собой аэрозоли, жидкости, гели или гранулированные составы.
Что касается клеточной системы, то в некоторых вариантах осуществления она выбрана из группы, состоящей из бактерий, дрожжей и их комбинации, или любой клеточной системы, которая дала бы возможность осуществить генетическую трансформацию посредством выбранных генов, а затем биосинтетическое получение требуемых стевиоловых гликозидов из стевиола. В наиболее предпочтительной микробной системе для получения требуемых стевиол-гликозидных соединений используют E. coli.
Несмотря на то, что настоящее изобретение допускает различные модификации и альтернативные формы, его конкретные варианты осуществления показаны в виде примера в графических материалах и будут подробно описаны в данном документе. Однако следует понимать, что графические материалы и подробное описание, представленные в данном документе, не предназначены для ограничения настоящего изобретения описанным конкретным вариантом осуществления, а напротив - намерение состоит в том, чтобы охватить все модификации, эквиваленты и альтернативы, соответствующие духу и объему настоящего изобретения, как определено в прилагаемой формуле изобретения.
Другие признаки и преимущества данного изобретения станут очевидными из следующего подробного описания предпочтительных вариантов осуществления настоящего изобретения, взятых со ссылкой на прилагаемые графические материалы.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
ФИГ. 1. Отображает биосинтетический путь стевиолового гликозида для получения Reb D4 из Reb E.
ФИГ. 2. Отображает получение in vitro Reb D4 из Reb E, катализируемое ферментами C1m2 и C1m3. A: продемонстрирован стандарт ребаудиозида E ("Reb E"). B: продемонстрирован стандарт ребаудиозида D4 ("Reb D4"). Reb D4 ферментативно получают с помощью C1m2 (C) и C1m3 (D) в течение 16 ч.
ФИГ. 3. Продемонстрирован анализ LC-MS полученного соединения с помощью мутантного C1m2.
ФИГ. 4. Продемонстрирован анализ LC-MS полученного соединения с помощью мутантного C1m3.
ФИГ. 5. Продемонстрирован гидролиз Reb D4, Reb E и Reb D с помощью бета-глюкозидазы GXT6. Гидролиз Reb D4, Reb E и Reb D с помощью бета-глюкозидазы GXT6 в течение 16 ч. A: продемонстрированы стандарты ребаудиозида D ("Reb D"), ребаудиозида M ("Reb M") и ребаудиозида A ("Reb A"). B: продемонстрированы стандарты ребаудиозида E ("Reb E"), ребаудиозида KA ("KA"), стевиозида ("ST") и рубузозида ("Rub"). C: продемонстрированы стандарты ребаудиозида D4 ("Reb D4") и Reb WB2 ("WB2"). D: продемонстрированы стандарты ребаудиозида WB1 ("WB1") и Reb WB2 ("WB2"). E: продемонстрирован гидролиз Reb E. F: гидролиз D4. G: продемонстрирован гидролиз Reb D.
ФИГ. 6. Продемонстрирован гидролиз полученного соединения для подтверждения биоконверсии Reb E в Reb D4 с помощью мутантных C1m2 и C1m3. A: продемонстрированы стандарты ребаудиозида D ("Reb D"), ребаудиозида M ("Reb M") и ребаудиозида A ("Reb A"). B: продемонстрированы стандарты ребаудиозида E ("Reb E"), ребаудиозида KA ("KA"), стевиозида ("ST") и рубузозида ("Rub"). C: продемонстрированы стандарты ребаудиозида D4 ("Reb D4") и Reb WB2 ("WB2"). D: продемонстрированы стандарты ребаудиозида WB1 ("WB1") и Reb WB2 ("WB2"). Биоконверсия Reb E с помощью C1m2 (E) и C1m3 (F) в течение 16 ч. Гидролиз полученных соединений с помощью GXT6 в течение 16 ч. G: продемонстрирован гидролиз полученных соединений в реакции C1m2, H: продемонстрирован гидролиз полученных соединений в реакции C1m3.
ФИГ. 7. Продемонстрировано получение in vitro Reb D4 из стевиозида с помощью комбинации фермента Hv1 и C1m2 или C1m3. A: продемонстрированы стандарты ребаудиозида D ("Reb D"), ребаудиозида M ("Reb M") и ребаудиозида A ("Reb A"). B: продемонстрированы стандарты ребаудиозида E ("Reb E") и стевиозида ("ST"). С: продемонстрирован стандарт ребаудиозида D4 ("Reb D4"). Reb D4 получен с помощью комбинации HV1 и C1m2 (D) или C1m3 (E) в течение 16 ч.
ФИГ. 8. Продемонстрирован LC-MS анализ полученного Reb D4 с помощью комбинации HV1 с C1m2 (A) или C1m3 (B).
ФИГ. 9. Продемонстрирован путь биосинтеза Reb M из стевиозида.
ФИГ. 10. Продемонстрирована структура стевиолового гликозида WB1.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Объяснение терминов, используемых в данном документе
Стевиоловые гликозиды представляют собой класс химических соединений, отвечающих за сладкий вкус листьев южноамериканского растения Stevia rebaudiana (Asteraceae), и могут использоваться в качестве подсластителей в пищевых продуктах, кормах и напитках.
Определения
Клеточная система представляет собой любые клетки, которые обеспечивают экспрессию эктопических белков. Такая система включает бактерии, дрожжи, растительные клетки и животные клетки. Она включает как прокариотические, так и эукариотические клетки. Она также обеспечивает экспрессию белков in vitro на основе клеточных компонентов, таких как рибосомы.
Термин кодирующая последовательность представлен в своем обычном и общепринятом значении для специалиста в данной области техники и используется без ограничения для обозначения последовательности ДНК, которая кодирует конкретную аминокислотную последовательность.
Выращивание клеточной системы. Выращивание включает предоставление соответствующей среды, которая дала бы возможность клеткам размножаться и делиться. Оно также предусматривает предоставление ресурсов для того, чтобы клетки или клеточные компоненты могли транслироваться и производить рекомбинантные белки.
Экспрессия белка. Выработка белка может происходить после экспрессии гена. Она предусматривает стадии, после того, как ДНК была транскрибирована в матричную РНК (mRNA). Затем mRNA транслируется в полипептидные цепи, которые в конечном итоге сворачиваются в белки. ДНК присутствует в клетках в результате трансфекции - процесса намеренного введения нуклеиновых кислот в клетки. Термин часто используется для невирусных способов в эукариотических клетках. Данный термин может также относиться к другим способам и типам клеток, хотя предпочтительными являются другие термины: "трансформация" чаще используется для описания невирусного переноса ДНК в бактериях, эукариотических клетках неживотного происхождения, в том числе растительных клетках. Для животных клеток трансфекция является предпочтительным термином, поскольку трансформация также используется для обозначения прогрессирования до ракового состояния (канцерогенеза) в этих клетках. Термин трансдукция часто используется для описания вирус-опосредованного переноса ДНК. Трансформация, трансдукция и вирусная инфекция включены в определение трансфекции для данного применения.
Дрожжи. В соответствии с настоящим изобретением дрожжи представляют собой эукариотические одноклеточные микроорганизмы, классифицированные как представители царства грибов. Дрожжи представляют собой одноклеточные организмы, которые произошли от многоклеточных предков, однако некоторые виды, применимые в настоящем изобретении, представляют собой такие, которые обладают способностью развивать многоклеточные характеристики путем образования цепочек связанных зародышевых клеток, известных как псевдогифы или ложные гифы.
Названия ферментов UGT, используемые в настоящем описании, соответствуют системе номенклатуры, принятой Комитетом по номенклатуре UGT (Mackenzie et al., "The UDP glycosyltransferase gene super family: recommended nomenclature updated based on evolutionary divergence", Pharmacogenetics, 1997, vol. 7, pp. 255-269), который классифицирует гены UGT посредством комбинации номера семейства, буквы, обозначающей подсемейство, и номера для отдельного гена. Например, название "UGT76Gl" относится к ферменту UGT, кодируемому геном, принадлежащим к семейству UGT № 76 (растительного происхождения), подсемейству G и гену l.
Структурные термины
Используемые в данном документе формы существительных единственного числа включают ссылки на формы множественного числа, если контекст ясно не указывает на иное.
В той степени, в которой термин "включать", "иметь" или т.п. используется в описании или формуле изобретения, подразумевается, что такой термин предназначен для включения, аналогичным образом как термин "содержать", так как термин "содержать" интерпретируется при использовании как переходное слово в формуле.
Слово "примерный" используется в данном документе для обозначения "служащий примером, образцом или иллюстрацией". Любой вариант осуществления, описанный в данном документе как "примерный", не обязательно должен рассматриваться как предпочтительный или преимущественный по сравнению с другими вариантами осуществления.
Термин "комплементарный" приведен в его обычном и общепринятом значении для специалиста в данной области техники и используется без ограничения для описания взаимосвязи между нуклеотидными основаниями, которые способны гибридизироваться друг с другом. Например, в отношении ДНК аденозин комплементарен тимину, а цитозин комплементарен гуанину. Соответственно, применяемая технология также подразумевает выделенные фрагменты нуклеиновой кислоты, которые являются комплементарными полным последовательностям, как указано в прилагаемом перечне последовательностей, а также эти по существу сходные последовательности нуклеиновых кислот.
Термины "нуклеиновая кислота" и "нуклеотид" представлены в соответствии с их обычными и общепринятыми значениями для специалиста в данной области техники и используются без ограничения для обозначения дезоксирибонуклеотидов или рибонуклеотидов и их полимеров в одно- или двухнитевой форме. Если не указаны конкретные ограничения, то данный термин охватывает нуклеиновые кислоты, содержащие известные аналоги природных нуклеотидов, которые обладают свойствами связывания, сходными с эталонной нуклеиновой кислотой, и метаболизируются способом, сходным со встречающимися в природе нуклеотидами. Если не указано иное, то конкретная последовательность нуклеиновой кислоты также косвенно охватывает консервативно модифицированные или вырожденные варианты (например, замены вырожденного кодона) и комплементарные последовательности, а также явно указанную последовательность.
Термин "выделенный" приведен в его обычном и общепринятом значении для специалиста в данной области техники, и при использовании в контексте выделенной нуклеиновой кислоты или выделенного полипептида используется без ограничения для обозначения нуклеиновой кислоты или полипептида, которые, посредством производимых человеком манипуляций, существуют отдельно от его природной среды, а следовательно не являются продуктом природы. Выделенная нуклеиновая кислота или полипептид может существовать в очищенной форме или может существовать в ненативной среде, например такой как трансгенная клетка-хозяин.
Термины "инкубирование" и "инкубация", используемые в данном документе, означают способ смешивания двух или больше химических или биологических объектов (таких как химическое соединение и фермент) и предоставление им возможности взаимодействовать в условиях, благоприятных для получения композиции на основе стевиолового гликозида.
Термин "вырожденный вариант" относится к последовательности нуклеиновой кислоты, содержащей остаточную последовательность, которая отличается от контрольной последовательности нуклеиновой кислоты по одной или нескольким вырожденным заменам кодонов. Замена вырожденных кодонов может быть достигнута путем создания последовательностей, в которых третье положение одного или нескольких выбранных (или всех) кодонов замещено остатками смешанного основания и/или дезоксиинозина. Последовательность нуклеиновой кислоты и все ее вырожденные варианты будут экспрессировать одну и ту же аминокислоту или полипептид.
Термины "полипептид", "белок" и "пептид" представлены в соответствии с их обычными и общепринятыми значениями для специалиста в данной области техники; эти три термина иногда взаимозаменяемы и используются без ограничения для обозначения полимера аминокислот или аналогов аминокислот, независимо от их размера или функции. Хотя термин "белок" зачастую используется при ссылке на относительно большие полипептиды, а термин "пептид" зачастую используется при ссылке на небольшие полипептиды, - использование этих терминов в уровне техники перекрывается и варьирует. Используемый в данном документе термин "полипептид" относится к пептидам, полипептидам и белкам, если не указано иное. Термины "белок", "полипептид" и "пептид" используются в данном документе взаимозаменяемо в случае ссылки на полинуклеотидный продукт. Таким образом, полипептиды включают полинуклеотидные продукты, встречающиеся в природе полипептиды, гомологи, ортологи, паралоги, фрагменты и другие эквиваленты, варианты и аналоги вышеуказанных.
Термины "полипептидный фрагмент" и "фрагмент", в случае использования в отношении эталонного полипептида, представлены в их обычных и общепринятых значениях для специалиста в данной области техники и используются без ограничения для ссылки на полипептид, в котором аминокислотные остатки удалены по сравнению с самим эталонным полипептидом, но где оставшаяся аминокислотная последовательность обычно идентична соответствующим положениям в эталонном полипептиде. Такие делеции могут происходить на амино-конце и карбокси-конце эталонного полипептида или, как альтернатива, на обоих.
Термин "функциональный фрагмент" полипептида или белка относится к пептидному фрагменту, который является частью полноразмерного полипептида или белка и характеризуется практически такой же биологической активностью или выполняет по существу ту же функцию, что и полноразмерный полипептид или белок (например, проведение той же ферментативной реакции).
Термины "вариантный полипептид", "модифицированная аминокислотная последовательность" или "модифицированный полипептид", которые используются взаимозаменяемо, относятся к аминокислотной последовательности, которая отличается от эталонного полипептида одной или несколькими аминокислотами, например, одной или несколькими аминокислотными заменами, делециями и/или добавлениями. В одном аспекте вариант представляет собой "функциональный вариант", который сохраняет некоторые или все способности эталонного полипептида.
Термин "функциональный вариант" дополнительно включает консервативно замещенные варианты. Термин "консервативно замещенный вариант" относится к пептиду, имеющему аминокислотную последовательность, которая отличается от эталонного пептида одной или несколькими консервативными аминокислотными заменами и сохраняет некоторую или всю активность эталонного пептида. "Консервативная аминокислотная замена" представляет собой замену аминокислотного остатка функционально подобным остатком. Примеры консервативных замен включают замену одного неполярного (гидрофобного) остатка, такого как изолейцин, валин, лейцин или метионин, на другой; замену одного заряженного или полярного (гидрофильного) остатка на другой, как например, между аргинином и лизином, между глутамином и аспарагином, между треонином и серином; замену одного основного остатка, такого как лизин или аргинин, на другой; или замену одного кислотного остатка, такого как аспарагиновая кислота или глутаминовая кислота, на другой; или замена одного ароматического остатка, такого как фенилаланин, тирозин или триптофан, на другой. Ожидается, что такие замены будут проявлять незначительный эффект или вообще не будут проявлять эффекта в отношении кажущейся молекулярной массы или изоэлектрической точки белка или полипептида. Фраза "консервативно замещенный вариант" также подразумевает пептиды, в которых остаток заменен химически дериватизированным остатком, при условии, что полученный пептид сохраняет часть или всю активность эталонного пептида, как описано в данном документе.
Термин "вариант" в связи с полипептидами согласно заявленной технологии дополнительно включает функционально активный полипептид, характеризующийся аминокислотной последовательностью, на по меньшей мере 75%, по меньшей мере 76%, по меньшей мере 77%, по меньшей мере 78%, по меньшей мере 79%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% и даже на 100% идентичной аминокислотной последовательности эталонного полипептида.
Термин "гомологичный" во всех его грамматических формах и вариациях правописания относится к связи между полинуклеотидами или полипептидами, которые имеют "общее эволюционное происхождение", в том числе полинуклеотидами или полипептидами из суперсемейств и гомологичными полинуклеотидами или белками из разных видов (Reeck et al., Cell 50:667, 1987). Такие полинуклеотиды или полипептиды характеризуются гомологией последовательностей, что отражается в сходстве их последовательностей, будь то в отношении процентов идентичности или присутствия конкретных аминокислот или мотивов в консервативных положениях. Например, два гомологичных полипептида могут иметь аминокислотные последовательности, которые на по меньшей мере 75%, по меньшей мере 76%, по меньшей мере 77%, по меньшей мере 78%, по меньшей мере 79%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 900 по меньшей мере 91%, по меньшей мере 92% , по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% и даже на 100% идентичны.
Термин "подходящие регуляторные последовательности" представлен в своем обычном и общепринятом значении для специалиста в данной области техники, и он используется без ограничения для обозначения нуклеотидных последовательностей, расположенных выше (5'-некодирующие последовательности), в пределах или ниже (3'-некодирующие последовательности) кодирующей последовательности, и которые могут оказывать влияние на транскрипцию, процессинг или стабильность РНК или на трансляцию ассоциированной кодирующей последовательности. Регуляторные последовательности могут включать в себя промоторы, лидерные последовательности трансляции, интроны и последовательности распознавания полиаденилирования.
Термин "промотор" представлен в своем обычном и общепринятом значении для специалиста в данной области техники, и он используется без ограничения для обозначения последовательности ДНК, способной контролировать экспрессию кодирующей последовательности или функциональной РНК. Как правило, кодирующая последовательность расположена на 3'-конце относительно промоторной последовательности. Промоторы могут быть получены полностью из нативного гена или могут состоять из разных элементов, полученных из разных промоторов, обнаруживаемых в природе, или даже содержать сегменты синтетической ДНК. Специалисты в данной области техники поймут, что различные промоторы могут управлять экспрессией гена в различных тканях или типах клеток, на различных стадиях развития или в ответ на различные условия окружающей среды. Промоторы, которые обуславливают экспрессию генов в большинстве типов клеток в большинстве случаев, чаще всего обычно называют "конститутивными промоторами". Кроме того, известно, что поскольку в большинстве случаев точные границы регуляторных последовательностей не были полностью определены, то ДНК-фрагменты с разными значениями длины могут характеризоваться идентичной промоторной активностью.
Термин "функционально связанный" относится к ассоциации последовательностей нуклеиновой кислоты на одном фрагменте нуклеиновой кислоты таким образом, что функция одной регулируется другой. Например, промотор функционально связан с кодирующей последовательностью, в случае если он может влиять на экспрессию данной кодирующей последовательности (т. e. кодирующая последовательность находится под транскрипционным контролем промотора). Кодирующие последовательности могут быть функционально связаны с регуляторными последовательностями в смысловой или антисмысловой ориентации.
Используемый в данном документе термин "экспрессия" должен пониматься в его обычном и общепринятом значении для специалиста в данной области техники и использоваться без ограничения для обозначения транскрипции и стабильного накопления смысловой (mRNA) или антисмысловой РНК, происходящей из фрагмента нуклеиновой кислоты согласно заявленной технологии. "Сверхэкспрессия" относится к выработке генного продукта в трансгенных или рекомбинантных организмах, которая превышает уровни выработки в нормальных или нетрансформированных организмах.
Термин "трансформация" должен пониматься в его обычном и общепринятом значении для специалиста в данной области и использоваться без ограничения для обозначения переноса полинуклеотида в клетку-мишень. Перенесенный полинуклеотид может быть включен в геном или хромосомную ДНК клетки-мишени, что приводит к генетически стабильному наследованию, или он может реплицироваться независимо от хромосомы хозяина. Организмы-хозяева, содержащие трансформированные фрагменты нуклеиновой кислоты, называются "трансгенными" или "трансформированными".
Термины "трансформированный", "трансгенный" и "рекомбинантный", в случае использования в данном документе в связи с клетками-хозяевами, представлены в их соответствующих обычных и общепринятых значениях для специалиста в данной области техники и используются без ограничения в отношении клетки организма-хозяина, такой как растительная или микробная клетка, в которую была введена гетерологичная молекула нуклеиновой кислоты. Молекула нуклеиновой кислоты может быть стабильно интегрирована в геном клетки-хозяина, или молекула нуклеиновой кислоты может присутствовать в виде внехромосомной молекулы. Такая внехромосомная молекула может быть самореплицирующейся. Под трансформированными клетками, тканями или субъектами понимают не только конечный продукт процесса трансформации, но и его трансгенное потомство.
Термины "рекомбинантный", "гетерологичный" и "экзогенный", в случае использования в данном документе в связи с полинуклеотидами, представлены в их обычных и общепринятых значениях для специалиста в данной области техники и используются без ограничения для обозначения полинуклеотида (например, последовательности ДНК или гена), который происходит из источника, чужеродного по отношению к конкретной клетке-хозяину, или, если из того же источника, то модифицированного относительно своей первоначальной формы. Таким образом, гетерологичный ген в клетке-хозяине предусматривает ген, который является эндогенным для конкретной клетки-хозяина, однако был модифицирован, например, с помощью применения сайт-направленного мутагенеза или других рекомбинантных методов. Термины также включают не встречающиеся в природе множественные копии встречающейся в природе последовательности ДНК. Таким образом, термины относятся к сегменту ДНК, который является чужеродным или гетерологичным по отношению к клетке, или гомологичным по отношению к клетке, но в положении или форме внутри клетки-хозяина, в которой элемент обычно не обнаруживается.
Аналогично, термины "рекомбинантный", "гетерологичный" и "экзогенный", в случае использования в данном документе в связи с полипептидной или аминокислотной последовательностью, означают полипептидную или аминокислотную последовательность, которая происходит из источника, чужеродного по отношению к конкретной клетке-хозяину, или, если из того же источника, то модифицированного относительно своей первоначальной формы. Таким образом, рекомбинантные сегменты ДНК могут быть экспрессированы в клетке-хозяине с образованием рекомбинантного полипептида.
Термины "плазмида", "вектор" и "кассета" представлены в их соответствующих обычных и общепринятых значениях для специалиста в данной области техники и используются без ограничения для обозначения дополнительного хромосомного элемента, часто несущего гены, которые не являются частью центрального метаболизма клетки, и, как правило, в виде кольцевых двухнитевых молекул ДНК. Такие элементы могут представлять собой автономно реплицирующиеся последовательности, интегрируемые в геном последовательности, фаговые или нуклеотидные последовательности, линейные или кольцевые, одно- или двухнитевые ДНК или РНК, полученные из любого источника, в которых число нуклеотидных последовательностей было объединено или рекомбинировано в уникальную конструкцию, которая обладает способностью введения в клетку промоторного фрагмента и последовательности ДНК для выбранного генного продукта вместе с соответствующей 3'-нетранслируемой последовательностью. "Кассета для трансформации" относится к конкретному вектору, содержащему чужеродный ген и имеющему элементы, в дополнение к чужеродному гену, которые способствуют трансформации конкретной клетки-хозяина. "Кассета экспрессии" относится к конкретному вектору, содержащему чужеродный ген и содержащему элементы, в дополнение к чужеродному гену, которые обеспечивают усиленную экспрессию этого гена в чужеродном хозяине.
Настоящее изобретение частично относится к применению Reb E в получении Reb D4. С биологической точки зрения все стевиоловые гликозиды образуются в результате серии реакций гликозилирования стевиола, которые обычно катализируются ферментами UDP-гликозилтрансферазы (UGT) с использованием уридин-5'-дифосфоглюкозы (UDP-глюкозы) в качестве донора фрагмента сахара. У растений UGT представляют собой очень разнородную группу ферментов, которые могут переносить остаток глюкозы из UDP-глюкозы к стевиолу. В таких реакциях стевиозид часто является промежуточным звеном в биосинтезе различных ребаудиозидных соединений. Например, гликозилирование стевиозида в положении C-3' в С-13-О-глюкозе стевиозида дает в результате ребаудиозид А; тогда как гликозилирование в положении C-2' в 19-O-глюкозе стевиозида дает в результате ребаудиозид Е.
В соответствии с настоящим изобретением специфическое и направленное гликозилирование ребаудиозида E (по C-19-O-глюкозе) может приводить к получению ребаудиозида Reb D4 из Reb E, который затем может быть далее направлен на гликозилирование Reb D4 ферментами UGT с образованием ребаудиозида М. О стадиях синтеза для получения Reb D4 из Reb E ферментативным путем ранее не сообщалось. Первая фиксированная стадия пути биосинтеза стевиолового гликозида предусматривает превращение энтакауреновой кислоты в стевиол под действием фермента KAH. Было показано, что UGT76G1 проявляет множественные активности глюкозилирования по отношению к стевиоловому биозиду, образующему ребаудиозид В, и стевиозиду, приводящему к получению ребаудиозида А. Кроме того, оценивали аффинность взаимодействия KAH, UGT85C2, UGT74G1 и UGT76G1 для энт-кауреновой кислоты и стевиола. Модель, предсказанная для KAH, продемонстрировала самую высокую аффинность в отношении лиганда стевиола, за которым следуют стевиол-монозид и энт-кауреновая кислота. Результаты стыковки для трехмерной модели UGT76G1 позволяют предположить его наибольшую аффинность связывания с энт-кауреновой кислотой, но также предполагают, что эти ферменты обладают способностью взаимодействовать с более чем одним из лигандов в пути биосинтеза стевиолового гликозида. В соответствии с настоящим изобретением мутации в доменах в UGT76G1 могут вызывать специфическое изменение активности глюкозилирования, приводящее к выработке альтернативных ребаудиозидов.
В соответствии с настоящим изобретением, практический подход для улучшения вкусовых качеств экстрактов stevia состоит в том, чтобы увеличить выход тех ребаудиозидных соединений, которые в целом имеют более желательные вкусовые характеристики, и сделать это посредством более продуктивного пути синтеза. Считается, что из таких исследованных стевиоловых гликозидов Reb M обладает наиболее желательным вкусом и химическими характеристиками для применения в различных пищевых продуктах и напитках. Однако, как указывалось выше, растение содержит чрезвычайно небольшие количества этого соединения, присутствующего в его листьях, а следовательно необходимо разработать альтернативный путь биосинтеза для возможности крупномасштабного производства этого гликозида, а также обеспечить альтернативные подсластители для пищевой промышленности и производства напитков. Часть этого пути представлена в данном документе.
Соответственно, существует необходимость в разработке стевиоловых гликозидов с лучшими и более постоянными вкусовыми профилями в качестве коммерческих продуктов и обеспечении возможности применения в таких стевиоловых гликозидах соответствующего общего исходного субстрата, такого как более распространенные стевиоловые гликозиды в качестве исходных молекул, таким образом, чтобы такое получение требуемых гликозидов могло быть коммерчески настолько эффективным, насколько это возможно. В настоящем изобретении предусмотрен способ получения ребаудиозида D4 из стевиозида через ребаудиозид Е.
В дальнейшем, в способе экстракции из растений для извлечения стевиолового гликозида, как правило, применяют методы экстракции твердого вещества жидкостью с использованием растворителей, таких как гексан, хлороформ и этанол (Catchpole et al., 2003). Однако экстракция растворителем сама по себе является энергоемкой, приводит к проблемам утилизации токсичных отходов, требует обширной площади для выращивания самих растений и дает на выходе продукт, который требует дальнейшей очистки для извлечения незначительных компонентов. Таким образом, новые способы получения также необходимы для снижения затрат на получение стевиоловых гликозидов и уменьшения воздействия крупномасштабного выращивания и переработки на окружающую среду (Yao et al., 1994). Одним из таких потенциальных решений является применение технологии ферментационной биоконверсии, которая обеспечивает получение определенных видов микробов, что повышает селективность, количество и чистоту требуемых стевиоловых гликозидов, доступных для коммерческой деятельности.
В дополнение к вышесказанному, в то время как потребители одобряют и активно ищут природные и биологические источники для пищевых, кормовых, вкусовых или лекарственных компонентов, они также обращают внимание на источник, постоянный вкусовой профиль и экологически устойчивое производство. В данной ситуации с помощью микробной ферментации и способов получения согласно настоящему изобретению обеспечивают Reb D4 в количествах, применимых в различных отраслях промышленности и научных исследованиях, получая при этом более природным образом, чем неорганический синтез или существующие методы экстракции растений.
Соответственно, существует потребность в разработке нового способа получения Reb D4 с точки зрения экономики и удобства для дальнейшего обеспечения потребления человеком и животными. В частности, в настоящем изобретении предусмотрены способы применения Reb E для получения Reb D4 посредством сконструированных микроорганизмов.
Настоящее изобретение относится к получению представляющего интерес стевиолового гликозида Reb D4 из Reb E с применением ферментов UGT для обеспечения такого превращения. Заявляемая технология обеспечивает рекомбинантные полипептиды с активностями UDP-гликозилтрансферазы, такими как активность гликозилирования 1,3-19-O-глюкозы и гликозилирования 1,3-13-O-глюкозы, для синтеза стевиоловых гликозидов. Рекомбинантный полипептид согласно заявленной технологии применим для биосинтеза стевиол-гликозидных соединений. В настоящем описании UDP-гликозилтрансфераза (UGT) относится к ферменту, который переносит остаток сахара от молекулы активированного донора (обычно UDP-глюкоза) к молекуле акцептора. Активность гликозилирования 1,3-19-O-глюкозы относится к ферментативной активности, посредством которой осуществляется перенос фрагмента сахара к C-3'-19-O фрагмента глюкозы ребаудиозида E с получением ребаудиозида D4 (Reb D4) (фигура 1).
Биология синтеза
Применяемые в данном документе стандартные методики рекомбинантных ДНК и молекулярного клонирования хорошо известны из уровня техники и описаны, например, в Sambrook, J., Fritsch, E. F. and Maniatis, T. Molecular Cloning: A Laboratory Manual, 2nd ed.; Cold Spring Harbor Laboratory: Cold Spring Harbor, N.Y., 1989 (далее в данном документе "Maniatis"); и в Silhavy, T. J., Bennan, M. L. and Enquist, L. W. Experiments with Gene Fusions; Cold Spring Harbor Laboratory: Cold Spring Harbor, N.Y., 1984; и в Ausubel, F. M. et al., In Current Protocols in Molecular Biology, published by Greene Publishing and Wiley-Interscience, 1987; (полное содержание каждого из которых включено в данный документ посредством ссылки).
Гликозилирование часто считают убиквитарной реакцией, контролирующей биологическую активность и хранение растительных природных продуктов. Гликозилирование небольших молекул катализируется посредством суперсемейства трансфераз у большинства видов растений, которые были изучены до настоящего времени. Указанные гликозилтрансферазы (GT) были классифицированы на более чем 60 семейств. Из них ферменты GT семейства 1, также известные как UDP-гликозилтрансферазы (UGT), переносят UDP-активированные фрагменты сахара в специфические акцепторные молекулы. Они представляют собой молекулы, которые переносят такие фрагменты сахара в стевиоловых гликозидах для создания различных ребаудиозидов. Каждая из таких UGT имеет свой собственный профиль активности и предпочтительные структурные месторасположения, куда они переносят свои активированные фрагменты сахара.
Системы для получения
Экспрессия белков в прокариотах чаще всего осуществляется в бактериальной клетке-хозяине в присутствии векторов, содержащих конститутивные или индуцибельные промоторы, направляющие экспрессию слитых или не слитых белков. Слитые векторы добавляют некоторое количество аминокислот к белку, который они кодируют, обычно к аминоконцу рекомбинантного белка. Такие слитые векторы обычно служат трем целям: 1) увеличить экспрессию рекомбинантного белка; 2) повысить растворимость рекомбинантного белка и 3) помочь в очистке рекомбинантного белка, действуя в качестве лиганда в аффинной очистке. Часто в участок соединения слитого фрагмента и рекомбинантного белка вводят сайт протеолитического расщепления для обеспечения отделения рекомбинантного белка от слитого фрагмента после очистки слитого белка. Такие векторы находятся в пределах объема настоящего изобретения.
В одном варианте осуществления вектор экспрессии включает в себя указанные генетические элементы для экспрессии рекомбинантного полипептида в бактериальных клетках. Элементы для транскрипции и трансляции в бактериальной клетке могут включать в себя промотор, кодирующую область для белкового комплекса и терминатор транскрипции.
Специалист в данной области техники должен быть знаком с методами молекулярной биологии, доступными для получения векторов экспрессии. Полинуклеотид, используемый для включения в вектор экспрессии согласно заявленной технологии, описанной выше, может быть получен обычными методами, такими как полимеразная цепная реакция (ПЦР).
Разработаны несколько методов молекулярной биологии для функционального связывания ДНК с векторами посредством комплементарных липких концов. В одном варианте осуществления к молекуле нуклеиновой кислоты для вставки в векторную ДНК могут быть добавлены комплементарные гомополимерные участки. Вектор и молекула нуклеиновой кислоты затем соединяются посредством водородных связей между комплементарными гомополимерными хвостами с образованием молекул рекомбинантной ДНК.
В альтернативном варианте осуществления для функционального связывания полинуклеотида согласно заявленной технологии с вектором экспрессии используют синтетические линкеры, содержащие один или несколько сайтов рестрикции, В одном варианте осуществления полинуклеотид получают путем расщепления рестрикционной эндонуклеазой. В одном варианте осуществления молекулу нуклеиновой кислоты обрабатывают ДНК-полимеразой бактериофага T4 или ДНК-полимеразой I E. coli, ферментами, которые удаляют выступающие 3'-однонитевые концы с их 3'-5'-экзонуклеолитическими активностями, и заполняют углубленными 3'-концами с их полимеризующими активностями, с получением тем самым сегментов ДНК с тупыми концами. Затем сегменты с тупыми концами инкубируют с большим молярным избытком молекул линкера в присутствии фермента, который способен катализировать лигирование молекул ДНК с тупыми концами, такого как ДНК-лигаза бактериофага T4. Таким образом, продуктом реакции является полинуклеотид, несущий на своих концах полимерные линкерные последовательности. Такие полинуклеотиды затем расщепляются с помощью соответствующего рестрикционного фермента и лигируются с вектором экспрессии, который расщепляется с помощью фермента, образующего концы, совместимые с таковыми у полинуклеотида.
Как альтернатива, можно использовать вектор, содержащий сайты безлигазного клонирования (LIC). Необходимый полинуклеотид, амплифицированный с помощью ПЦР, может быть затем клонирован в вектор LIC без рестрикционного расщепления или лигирования (Aslanidis and de Jong, Nucl. Acid. Res. 18 6069-74, (1990), Haun, et al, Biotechniques 13, 515-18 (1992), который включен в данный документ посредством ссылки в полном объеме в такой степени, что он не противоречит настоящему документу).
В одном варианте осуществления для выделения и/или модификации полинуклеотида, представляющего интерес, для вставки в выбранную плазмиду целесообразно использовать ПЦР. Для использования при получении последовательности посредством ПЦР могут быть разработаны подходящие праймеры для выделения необходимой кодирующей области молекулы нуклеиновой кислоты, добавления рестрикционных эндонуклеаз или сайтов LIC, размещения кодирующей области в требуемой рамке считывания.
В одном варианте осуществления полинуклеотид для включения в вектор экспрессии согласно заявленной технологии получен путем применения ПЦР с использованием соответствующих олигонуклеотидных праймеров. Кодирующая область амплифицируется, тогда как сами праймеры включены в амплифицированный продукт последовательности. В одном варианте осуществления праймеры для амплификации содержат сайты узнавания рестрикционной эндонуклеазы, которые дают возможность клонировать амплифицированный продукт последовательности в соответствующий вектор.
Векторы экспрессии могут быть введены в растительные или микробные клетки-хозяева с помощью традиционных методов трансформации или трансфекции. Трансформация подходящих клеток с помощью вектора экспрессии согласно заявленной технологии осуществляется с помощью способов, известных из уровня техники, и обычно зависит как от типа вектора, так и от клетки. Подходящие методы включают совместное осаждение фосфата кальция или хлорида кальция, трансфекцию, опосредованную DEAE-декстраном, липофекцию, химиопорацию или электропорацию.
Успешно трансформированные клетки, т.е. те клетки, которые содержат вектор экспрессии, можно идентифицировать с помощью способов, хорошо известных из уровня техники. Например, клетки, трансфицированные посредством вектора экспрессии согласно заявленной технологии, можно культивировать для получения полипептидов, описанных в данном документе. Клетки можно исследовать на наличие ДНК вектора экспрессии с помощью методик, хорошо известных из уровня техники.
Клетки-хозяева могут содержать одну копию описанного ранее вектора экспрессии, или, как альтернатива, несколько копий вектора экспрессии.
В некоторых вариантах осуществления трансформированная клетка представляет собой животную клетку, клетку насекомого, растительную клетку, клетку водорослей, клетку гриба или дрожжевую клетку. В некоторых вариантах осуществления клетка представляет собой растительную клетку, выбранную из группы, состоящей из растительной клетки канолы, растительной клетки рапса, растительной клетки пальмы, растительной клетки подсолнечника, растительной клетки хлопчатника, растительной клетки кукурузы, растительной клетки арахиса, растительной клетки льна, растительной клетки кунжута, растительной клетки сои и растительной клетки петунии.
Системы экспрессии микробных клеток-хозяев и векторы экспрессии, содержащие регуляторные последовательности, которые направляют экспрессию высоких уровней чужеродных белков, хорошо известны специалистам в данной области техники. Любые из них можно использовать для конструирования векторов для экспрессии рекомбинантного полипептида согласно заявленной технологии в микробной клетке-хозяине. Такие векторы могут затем быть введены в соответствующие микроорганизмы посредством трансформации для обеспечения высокого уровня экспрессии рекомбинантного полипептида согласно заявленной технологии.
Векторы или кассеты, используемые для трансформации подходящих микробных клеток-хозяев, хорошо известны из уровня техники. Обычно вектор или кассета содержит последовательности, управляющие транскрипцией и трансляцией соответствующего полинуклеотида, селектируемый маркер и последовательности, обеспечивающие автономную репликацию или интеграцию в хромосому. Подходящие векторы содержат 5'-область полинуклеотида, которая несет элементы, управляющие инициацией транскрипции, и 3'-область ДНК фрагмента, которая управляет терминацией транскрипции. Предпочтительно, чтобы обе контрольных области были получены из генов, гомологичных трансформированной клетке-хозяину, хотя следует понимать, что такие контрольные области не должны быть получены из генов, нативных по отношению к конкретным видам, выбранным в качестве хозяина.
Управляющие инициацией области или промоторы, которые подходят для управления экспрессией рекомбинантного полипептида в требуемой микробной клетке-хозяине, многочисленны и знакомы специалистам в данной области техники. Фактически любой промотор, способный управлять этими генами, подходит для заявленной технологии, в том числе без ограничения CYCI, HIS3, GALI, GALIO, ADHI, PGK, PH05, GAPDH, ADCI, TRPI, URA3, LEU2, ENO, TPI (подходит для экспрессии в Saccharomyces); AOXI (подходит для экспрессии в Pichia); а также lac, trp, JPL, IPR, T7, tac и trc (подходят для экспрессии в Escherichia coli).
Области управления терминацией также можно получить из различных генов, нативных по отношению к предпочтительной клетке-хозяину. Сайт терминации необязательно может быть включен для микробных хозяев, описанных в данном документе.
В растительных клетках векторы экспрессии согласно заявленной технологии могут включать в себя кодирующую область, функционально связанную с промоторами, способными направлять экспрессию рекомбинантного полипептида согласно заявленной технологии в требуемых тканях на требуемой стадии развития. Для удобства, экспрессируемые полинуклеотиды могут содержать промоторные последовательности и лидерные последовательности трансляции, полученные из одного и того же полинуклеотида. Также должны присутствовать 3'-некодирующие последовательности, кодирующие сигналы терминации транскрипции. Векторы экспрессии также могут содержать один или несколько интронов для облегчения экспрессии полинуклеотидов.
Для растительных клеток-хозяев любая комбинация любого промотора и любого терминатора, способных индуцировать экспрессию кодирующей области, может использоваться в векторных последовательностях согласно заявленной технологии. Некоторые подходящие примеры промоторов и терминаторов включают гены нопалинсинтазы (nos), октопинсинтазы (ocs) и вируса мозаики цветной капусты (CaMV). Одним типом эффективного промотора растения, который можно использовать, является высокоэффективный промотор растения. Такие промоторы в функциональной связи с вектором экспрессии согласно заявленной технологии должны быть способны стимулировать экспрессию вектора. Высокоэффективные растительные промоторы, которые можно использовать в заявленной технологии, включают промотор малой субъединицы (ss) рибулозо-1,5-бифосфаткарбоксилазы, например, из сои (Berry-Lowe et al., J. Molecular and App. Gen., 1:483 498 (1982), полное содержание которого включено в данный документ в том объеме, в котором оно согласуется с ним), и промотор хлорофилл alb-связывающего белка. Известно, что эти два промотора индуцируются светом в растительных клетках (см., например, Genetic Engineering of Plants, an Agricultural Perspective, A. Cashmore, Plenum, N.Y. (1983), страницы 29 38; Coruzzi, G. et al., The Journal of Biological Chemistry, 258: 1399 (1983) и Dunsmuir, P. et al., Journal of Molecular and Applied Genetics, 2:285 (1983), полное содержание которого включено в данный документ в том объеме, в котором оно согласуется с ним).
Синтез предшественника Reb E
Как указывалось ранее, стевиоловые гликозиды являются химическими соединениями, ответственными за сладкий вкус листьев южноамериканского растения Stevia rebaudiana (Asteraceae) и растения Rubus chingii (Rosaceae). Эти соединения представляют собой гликозилированные дитерпены. В частности, их молекулы можно рассматривать как молекулу стевиола, где ее гидроксильный атом водорода заменен молекулой глюкозы с образованием сложного эфира, а гидроксильный водород - комбинациями глюкозы и рамнозы с образованием ацеталя.
Одним из способов получения соединений, представляющих интерес, в настоящем изобретении является использование обычных или недорогих предшественников, таких как стевиол или рубозозид, полученных химическим путем или полученных посредством биосинтеза в сконструированных микроорганизмах, таких как бактерии и/или дрожжи, и синтез целевых стевиоловых гликозидов, таких как Reb E, посредством известных или недорогих способов.
Аспекты настоящего изобретения относятся к способам, включающим рекомбинантно экспрессируемые ферменты в микробной системе, способной продуцировать стевиол. Обычно такие ферменты могут включать фермент копалилдифосфатсинтазу (CPS), кауренсинтазу (KS) и геранилгеранилдифосфатсинтазу (GGPPS). Выработка должна происходить в микробном штамме, который экспрессирует эндогенный путь синтеза изопреноидов, такой как путь, отличный от мевалонатного (MEP) или путь мевалоновой кислоты (MVA). В некоторых вариантах осуществления клетка представляет собой бактериальную клетку, в том числе E. coli,, или дрожжевую клетку, такую как клетка Saccharomyces, клетка Pichia или клетка Yarrowia. В некоторых вариантах осуществления клетка представляет собой клетку водорослей или растительную клетку.
После этого предшественник извлекают из ферментационной культуры для применения в химическом синтезе. Как правило, это стевиол, хотя он может представлять собой каурен или стевиоловый гликозид из клеточной культуры. В некоторых вариантах осуществления стевиол, каурен и/или стевиоловые гликозиды извлекают из газовой фазы, тогда как в других вариантах осуществления органический слой или полимерную смолу добавляют к клеточной культуре, и каурен, стевиол и/или стевиоловые гликозиды извлекают из органического слоя или полимерной смолы. В некоторых вариантах осуществления стевиоловый гликозид выбран из ребаудиозида A, ребаудиозида B, ребаудиозида C, ребаудиозида D, ребаудиозида E, ребаудиозида F или дулкозида A. В некоторых вариантах осуществления образующийся терпеноид представляет собой стевиобиозид или стевиозид. Следует также понимать, что в некоторых вариантах осуществления по меньшей мере одна ферментативная стадия, такая как одна или несколько стадий гликозилирования, осуществляется ex vivo.
Частью изобретения является получение стевиолового гликозида Reb E, который затем подвергается дальнейшему ферментативному превращению в Reb D4. В соответствии с настоящим изобретением биосинтез для превращения продуцируемого микроорганизмами стевиола в требуемый стевиоловый гликозид (в данном документе Reb D4) осуществляют, в случае если дитерпеноидный стевиол превращается из рубузозида и стевиозида, с применением многостадийной химической сборки фрагментов сахара, в основной стевиоловый каркас.
Биосинтез стевиоловых гликозидов
Как описано в данном документе, рекомбинантные полипептиды согласно настоящей технологии обладают активностями UDP-гликозилтрансферазы и подходят для разработки способов биосинтеза для получения стевиоловых гликозидов, которые либо не присутствуют в природе, либо обычно имеют низкое содержание в природных источниках, таких как ребаудиозид D4 и ребаудиозид М, соответственно. Рекомбинантные полипептиды согласно настоящей технологии обладают активностями UDP-гликозилтрансферазы, подходят для разработки способов биосинтеза для получения новых стевиоловых гликозидов, таких как ребаудиозид D4, и пригодны для синтетического получения ребаудиозида М.
Субстрат может представлять собой любое природное или синтетическое соединение, способное превращаться в соединение стевиолового гликозида в реакции, катализируемой одной или несколькими UDP-гликозилтрансферазами. Например, субстрат может представлять собой природный экстракт stevia, стевиол, стевиол-13-O-глюкозид, стевиол-19-O-глюкозид, стевиол-1,2-биозид, рубузозид, стевиозид, ребаудиозид A, ребаудиозид G или ребаудиозид E. Субстрат может представлять собой чистое соединение или смесь различных соединений. Предпочтительно, субстрат включает соединение, выбранное из группы, состоящей из рубузозида, стевиозида, стевиола, ребаудиозида А, ребаудиозида Е и их комбинаций.
Способы, описанные в данном документе, также предусматривают систему реакции связывания, в которой для рекомбинантных пептидов, описанных в данном документе, обеспечивают функционирование в комбинации с одним или несколькими дополнительными ферментами для повышения эффективности или модификации результата общего биосинтеза стевиол-гликозидных соединений. Например, дополнительный фермент может способствовать получению UDP-глюкозы, необходимой для реакции гликозилирования, путем преобразования UDP, полученного в результате реакции гликозилирования, обратно в UDP-глюкозу (с использованием, например, сахарозы в качестве донора остатка глюкозы), улучшая таким образом эффективность реакции гликозилирования. В некоторых вариантах осуществления фермент представляет собой сахарозосинтазу. В некоторых вариантах осуществления дополнительный фермент представляет собой сахарозосинтазу 1 Arabidopsis, сахарозосинтазу 3 Arabidopsis или сахарозосинтазу Vigna radiate. Такие ферменты раскрыты, например, в патенте США № 9522929, включенном в данный документ посредством ссылки.
В другом варианте осуществления способы согласно заявленной технологии дополнительно предусматривают инкубирование рекомбинантной UDP-гликозилтрансферазы с рекомбинантной сахарозосинтазой, субстратом и рекомбинантным полипептидом, описанными в данном документе. Рекомбинантная UDP-гликозилтрансфераза может катализировать реакцию гликозилирования, отличную от той, которая катализируется рекомбинантным полипептидом согласно заявленной технологии.
Подходящая UDP-гликозилтрансфераза включает любую UGT, известную из уровня техники или описанную в данном документе, как способную катализировать одну или несколько реакций в биосинтезе стевиол-гликозидных соединений, таких как UGT85C2, UGT74G1, UGT76G1 или их функциональные гомологи.
Как правило, в способе in vitro согласно заявленной технологии UDP-глюкоза включена в буфер в концентрации, составляющей от приблизительно 0,2 мМ до приблизительно 5 мМ, предпочтительно от приблизительно 0,5 мМ до приблизительно 2 мМ, более предпочтительно от приблизительно 0,7 мМ до приблизительно 1,5 мМ. В одном варианте осуществления, когда рекомбинантную сахарозосинтазу включают в реакцию, сахарозу также включают в буфер в концентрации, составляющей от приблизительно 100 мМ до приблизительно 500 мМ, предпочтительно от приблизительно 200 мМ до приблизительно 400 мМ, более предпочтительно от приблизительно 250 мМ до приблизительно 350 мM.
Как правило, в способе in vitro согласно заявленной технологии весовое отношение рекомбинантного полипептида к субстрату в пересчете на сухой вес составляет от приблизительно 1:100 до приблизительно 1:5, предпочтительно от приблизительно 1:50 до приблизительно 1:10, более предпочтительно от приблизительно 1:25 до приблизительно 1:15.
Как правило, температура реакции в способе in vitro составляет от приблизительно 20°С до приблизительно 40°С, в подходящем случае от 25°С до приблизительно 37°С, в более подходящем случае от 28°С до приблизительно 32°С.
Специалист в данной области техники поймет, что композиция на основе стевиолового гликозида, полученная с помощью описанных в данном документе способов, может быть дополнительно очищена и смешана с другими стевиоловыми гликозидами, ароматизаторами или подсластителями с получением требуемого вкуса или композиции подсластителя. Например, композицию, обогащенную ребаудиозидом M или Reb D4, полученными как описано в данном документе, можно смешивать с природным экстрактом stevia, содержащим ребаудиозид А как преобладающий стевиоловый гликозид, или с другими синтетическими или природными стевиол-гликозидными продуктами с получением требуемой композиции подсластителя. Как альтернатива, практически очищенный стевиоловый гликозид (например, ребаудиозид D4), полученный из композиции на основе стевиолового гликозида, описанной в данном документе, можно объединять с другими подсластителями, такими как сахароза, мальтодекстрин, аспартам, сукралоза, неотам, ацесульфам калия и сахарин. Количество стевиолового гликозида относительно других подсластителей можно регулировать для получения требуемого вкуса, как известно из уровня техники. Описанная в данном документе композиция на основе стевиолового гликозида (включающая ребаудиозид D, ребаудиозид E, ребаудиозид D4, ребаудиозид M или их комбинацию) может быть включена в пищевые продукты (такие как напитки, безалкогольные напитки, мороженое, молочные продукты, кондитерские изделия, крупы, жевательная резинка, хлебобулочные изделия и др.), биологически активные добавки, лечебное питание, а также фармацевтические продукты.
Специалист в данной области техники поймет, что композиция на основе стевиолового гликозида, полученная с помощью описанного в данном документе способа, может быть дополнительно очищена и смешана с другими стевиоловыми гликозидами, ароматизаторами или подсластителями с получением требуемого вкуса или композиции подсластителя. Например, композицию, обогащенную ребаудиозидом D4, полученным как описано в данном документе, можно смешивать с природным экстрактом stevia, содержащим ребаудиозид А как преобладающий стевиоловый гликозид, или с другими синтетическими или природными стевиол-гликозидными продуктами с получением требуемой композиции подсластителя. Как альтернатива, практически очищенный стевиоловый гликозид (например, ребаудиозид D4), полученный из композиции на основе стевиолового гликозида, описанной в данном документе, можно объединять с другими подсластителями, такими как сахароза, мальтодекстрин, аспартам, сукралоза, неотам, ацесульфам калия и сахарин. Количество стевиолового гликозида относительно других подсластителей можно регулировать для получения требуемого вкуса, как известно из уровня техники. Описанная в данном документе композиция на основе стевиолового гликозида (включающая ребаудиозид D, ребаудиозид E, ребаудиозид D4, ребаудиозид M или их комбинацию) может быть включена в пищевые продукты (такие как напитки, безалкогольные напитки, мороженое, молочные продукты, кондитерские изделия, крупы, жевательная резинка, хлебобулочные изделия и др.), биологически активные добавки, лечебное питание, а также фармацевтические продукты.
Анализ сходства последовательностей с использованием оценки идентичности
Используемый в данном документе термин "идентичность последовательности" относится к степени, в которой две оптимально выровненные полинуклеотидные или пептидные последовательности являются инвариантными во всем окне выравнивания компонентов, например нуклеотидов или аминокислот. "Доля идентичности" для выровненных сегментов тестовой последовательности и эталонной последовательности представляет собой количество идентичных компонентов, которые являются общими для двух выровненных последовательностей, деленное на общее число компонентов в сегменте эталонной последовательности, т.е. всей эталонной последовательности или определенной меньшей части эталонной последовательности.
Используемый в данном документе термин "процентная идентичность последовательности" или "процентная идентичность" относится к проценту идентичных нуклеотидов в линейной полинуклеотидной последовательности эталонной ("запрашиваемой") молекулы полинуклеотида (или ее комплементарной нити) по сравнению с тестовой ("субъект") полинуклеотидной молекулой (или ее комплементарной нитью), когда две последовательности оптимально выровнены (с соответствующими вставками нуклеотидов, делециями или гэпами, составляющими в общем итоге менее 20 процентов эталонной последовательности в окне сравнения). Оптимальное выравнивание последовательностей для выравнивания окна сравнения хорошо известно специалистам в данной области техники и может осуществляться с помощью таких инструментов, как алгоритм локальной гомологии Смита и Ватермана, алгоритм гомологичного выравнивания Нидлмана и Вунша, способ поиска подобия Персона и Липмана, и предпочтительно с помощью компьютеризированных реализаций этих алгоритмов, таких как GAP, BESTFIT, FASTA и TFASTA, доступных как часть GCG® Wisconsin Package® (Accelrys Inc., Берлингтон, Массачусетс). "Доля идентичности" для выровненных сегментов тестовой последовательности и эталонной последовательности представляет собой количество идентичных компонентов, которые являются общими для двух выровненных последовательностей, деленное на общее число компонентов в сегменте эталонной последовательности, т.е. всей эталонной последовательности или определенной меньшей части эталонной последовательности. Процент идентичности последовательностей представлен как доля идентичности, умноженная на 100. Сравнение одной или нескольких полинуклеотидных последовательностей можно осуществлять с полноразмерной полинуклеотидной последовательностью или ее частью или с более длинной полинуклеотидной последовательностью. Для целей настоящего изобретения "процент идентичности" также можно определить с использованием BLASTX версии 2.0 для транслированных нуклеотидных последовательностей и BLASTN версии 2.0 для полинуклеотидных последовательностей.
Процент идентичности последовательностей предпочтительно определяют с использованием программы "Best Fit" или "Gap" Sequence Analysis Software Package™ (версия 10; Genetics Computer Group, Inc., Мадисон, Висконсин). В "Gap" используется алгоритм Нидлмана и Вунша (Needleman and Wunsch, Journal of Molecular Biology 48:443-453, 1970), чтобы найти выравнивание двух последовательностей, который доводит до максимума число совпадений и сводит к минимуму число гэпов. В "BestFit" выполняют оптимальное выравнивание наилучшего сегмента сходства между двумя последовательностями и вставляют гэпы, чтобы максимизировать количество совпадений, с использованием алгоритма локальной гомологии Смита и Ватермана (Smith and Waterman, Advances in Applied Mathematics, 2:482-489, 1981, Smith et al., Nucleic Acids Research 11:2205-2220, 1983). Процент идентичности наиболее предпочтительно определяется с помощью программы "Best Fit".
Подходящие способы для определения идентичности последовательностей также раскрыты в программах Basic Local Alignment Search Tool (BLAST), которые общедоступны в Национальном центре биотехнологической информации (NCBI) в Национальной медицинской библиотеке, Национальный институт здравоохранения, Бетесда, Мэриленд. 20894; см. BLAST Manual, Altschul et al., NCBI, NLM, NIH; Altschul et al., J. Mol. Biol. 215:403-410 (1990); версия 2.0 или выше программ BLAST позволяет вводить гэпы (удаления и вставки) в выравнивания; для пептидной последовательности BLASTX может использоваться для определения идентичности последовательностей и для полинуклеотидной последовательности BLASTN может использоваться для определения идентичности последовательностей.
Используемый в данном документе термин "существенная процентная идентичность последовательности" относится к процентной идентичности последовательностей, составляющей по меньшей мере приблизительно 70% идентичность последовательностей, по меньшей мере приблизительно 80% идентичность последовательностей, по меньшей мере приблизительно 85% идентичность, по меньшей мере приблизительно 90% идентичность последовательностей или даже большую идентичность последовательностей, такую как приблизительно 98% или приблизительно 99% идентичность последовательностей. Таким образом, один вариант осуществления настоящего изобретения представляет собой полинуклеотидную молекулу, которая характеризуется по меньшей мере приблизительно 70% идентичностью последовательности, по меньшей мере приблизительно 80% идентичностью последовательности, по меньшей мере приблизительно 85% идентичностью, по меньшей мере приблизительно 90% идентичностью последовательности или даже большей идентичностью последовательности, такой как приблизительно 98% или приблизительно 99% идентичностью последовательности с полинуклеотидной последовательностью, описанной в данном документе. Полинуклеотидные молекулы, которые характеризуются активностью последовательностей C1m2 и C1m3 по настоящему изобретению, способны направлять выработку различных стевиоловых гликозидов и характеризуются значительной процентной идентичностью последовательностей с полинуклеотидными последовательностями, представленными в данном документе, и охвачены объемом настоящего изобретения.
Идентичность и сходство
Идентичность представляет собой долю аминокислот, которые являются одинаковыми между парой последовательностей после выравнивания последовательностей (что может быть выполнено с использованием только информации о последовательности, или структурной информации, или некоторой другой информации, но обычно она основана только на информации о последовательности), и сходство представляет собой оценку, назначаемую на основе выравнивания с использованием некоторой матрицы сходства. Индекс сходства может быть любым из следующих BLOSUM62, PAM250 или GONNET, или любой матрицей, используемой специалистом в данной области техники для выравнивания последовательностей белков.
Идентичность представляет собой степень соответствия между двумя подпоследовательностями (без гэпов между последовательностями). Идентичность 25% или выше подразумевает сходство функций, тогда как 18-25% подразумевает сходство структуры или функции. Следует иметь в виду, что две совершенно не связанные или случайные последовательности (которые составляют больше 100 остатков) могут характеризоваться идентичностью, составляющей более 20%. Сходство представляет собой степень подобия между двумя последовательностями при их сравнении. Это зависит от их идентичности.
Как очевидно из предшествующего описания, определенные аспекты настоящего изобретения не ограничены конкретными деталями примеров, проиллюстрированных в данном документе, и поэтому предполагается, что другие модификации и применения или их эквиваленты будут иметь место для специалистов в данной области техники. Соответственно, предполагается, что формула изобретения должна охватывать все такие модификации и применения, которые не выходят за пределы сущности и объема настоящего изобретения.
Кроме того, если не указано иное, то все технические и научные термины, используемые в данном документе, имеют то же значение, которое обычно понимают специалисты в области техники, к которой относится настоящее изобретение. Хотя любые способы и материалы, подобные, или эквивалентные, или описанные в данном документе, могут использоваться при практическом осуществлении или тестировании настоящего изобретения, причем предпочтительные способы и материалы описаны выше.
Хотя для целей понимания вышеизложенное изобретение было описано более подробно с помощью иллюстрации и примера, специалистам в данной области техники будет очевидно, что определенные изменения и модификации могут быть осуществлены на практике. Следовательно, описание и примеры не должны истолковываться как ограничивающие объем настоящего изобретения, который установлен приложенной формулой изобретения.
Если не определено иное, то все технические и научные термины, используемые в данном документе, имеют то же значение, которое обычно понятно специалисту обычной квалификации в области техники, к которой принадлежит настоящее изобретение. Хотя при практическом осуществлении или тестировании настоящего изобретения можно применять любые способы и материалы, сходные или эквивалентные описанным в данном документе, ниже будут описаны предпочтительные способы и материалы.
Настоящее изобретение станет более понятным при рассмотрении следующих неограничивающих примеров. Следует понимать, что эти примеры, несмотря на то, что указываются предпочтительные варианты осуществления заявленной технологии, приведены только для наглядности. Из вышеприведенного обсуждения и этих примеров специалист в данной области техники сможет установить существенные характеристики заявленной технологии и не отклоняясь от его идеи и объема сможет осуществить различные изменения и модификации заявленной технологии для адаптации его к различным видам применения и условиям.
ПРИМЕРЫ
1. Ферментативный синтез Reb D4
Существует несколько ферментативных способов получения Reb D4. Один из способов, начинающийся с Reb E, представлен в данном документе.
Экспрессионную конструкцию трансформировали в E. coli BL21 (DE3), которую впоследствии выращивали в среде LB, содержащей 50 мкг/мл канамицина, при 37°С до достижения OD600 0,8-1,0. Экспрессию белка индуцировали добавлением 1 мМ изопропил-β-D-1-тиогалактопиранозида (IPTG) и культуру дополнительно выращивали при 16°C в течение 22 часов. Клетки собирали с помощью центрифугирования (3000 х g; 10 мин.; 4°С). Клеточный осадок собирали и использовали сразу или хранили при -80°С.
Клеточный осадок ресуспендировали в буфере для лизиса (50 мМ калий-фосфатный буфер, рН 7,2, 25 мкг/мл лизоцима, 5 мкг/мл ДНКазы I, 20 мМ имидазола, 500 мМ NaCl, 10% глицерина и 0,4% TRITON Х-100). Клетки разрушали с помощью ультразвука при 4°С и клеточный дебрис осветляли с помощью центрифугирования (18000 x g; 30 мин.). Надосадочную жидкость загружали в уравновешенную аффинную колонку (уравновешивающий буфер: 50 мМ калий-фосфатный буфер, рН 7,2, 20 мМ имидазол, 500 мМ NaCl, 10% глицерин) Ni-NTA (Qiagen). После загрузки образца белка колонку промывали уравновешивающим буфером для удаления несвязанных загрязняющих белков. His-меченый рекомбинантный полипептид B-glu1 элюировали уравновешивающим буфером, содержащим 250 мМ имидазол.
HPLC-анализ осуществляли с использованием системы Dionex UPLC ultimate 3000 (Саннивейл, Калифорния), включающей в себя четвертичный насос, отсек колонки с регулируемой температурой, автоматический пробоотборник и датчик поглощения УФ-излучения. Колонку Synergi Hydro-RP с защитной колонкой использовали для характеризации стевиоловых гликозидов. Ацетонитрил в воде использовали для элюирования в HPLC-анализе. Длина волны выявления составляла 210 нм.
Мутантные ферменты
На основе структуры UGT76G1 разработали серию циклических перестановок (PLoS computational Biology, 2012; BIOINFORMATICS, 2015) и набор мутаций, и исследовали их функцию. Анализ циклической перестановки является мощным инструментом для разработки и модификации ферментов, представляющих интерес. После исследования нескольких версий циклических перестановок обнаружили значительную активность в одной версии UGT76G1. Такая циклическая мутация "циклическая перестановка 1" ("CP1") продемонстрировала значительную активность с точки зрения глюкозилирования стевиолового ядра. В соответствии с настоящим изобретением изучали активность фермента СР1 и оценивали его способность содействовать превращению Reb D4 в Reb М. В целом можно сказать, что CP1 является вариантом UGT76G1 с переключенными доменами и идентифицированными сайтами мутаций.
На основании анализа моделирования CP1 выбирали множественные сайты мутаций для фермента CP1 для исследования биоконверсии Reb E в Reb D4. После ряда таких мутаций выделили несколько мутантов, которые могли функционировать требуемым образом в отношении активности гликозилирования и орнаментации стевиолового ядра. Позиционные мутанты,удаленные из CP1 дикого типа, представлены в таблице 1. С участием имеющихся ферментов разработали генетически модифицированный микроорганизм, способный биоконвертировать Reb E в ребаудиозид D4 непосредственно. Например, были обнаружены два мутанта CP1 (C1m2 и C1m3), которые обладают высокой ферментативной активностью для биоконверсии Reb E в Reb D4. C1m2 (SEQ ID NO: 7) включает в себя два сайта мутации и C1m3 (SEQ ID NO: 9) содержит три сайта мутаций из последовательности CP1.
Таблица 1. Сайты мутации CP1
2. Идентификация мутантов UGT с активностью в отношении получения Reb D4 из Reb E
Для подтверждения превращения Reb E в ребаудиозид D4 in vitro анализировали мутантные ферменты C1m2 и C1m3 с применением Reb E в качестве стевиол-гликозидного субстрата. Рекомбинантный полипептид (10 мкг) тестировали в 200 мкл реакционной системы in vitro. Реакционная система содержала 50 мМ калий-фосфатный буфер, рН 7,2, 3 мМ MgCl2, 1 мг/мл субстрата Reb E и 1 мМ UDP-глюкозы. Реакцию осуществляли при 37°С и прекращали посредством добавления 200 мкл 1-бутанола. Образцы экстрагировали трижды с помощью 200 мкл 1бутанола. Объединенную фракцию высушивали и растворяли в 70 мкл 80% метанола для анализа высокоэффективной жидкостной хроматографии (HPLC).
HPLC-анализ осуществляли с использованием системы Dionex UPLC ultimate 3000 (Саннивейл, Калифорния), включающей в себя четвертичный насос, отсек колонки с регулируемой температурой, автоматический пробоотборник и датчик поглощения УФ-излучения. Колонку Synergi Hydro-RP с защитной колонкой использовали для характеризации стевиоловых гликозидов. Ацетонитрил в воде использовали для элюирования в HPLC-анализе. Длина волны выявления составляла 210 нм. Reb D и Reb D4 характеризуются различным временем удерживания в профиле HPLC. Однако Reb D4 и Reb E имеют близкое время удерживания (фиг. 2, A и B).
Как показано на Фиг. 2, фермент C1m2 и C1m3 может превращать Reb E в соединение с таким же временем удерживания, как и в стандартном Reb D4, что указывает на то, что эти два мутанта обладают ферментативной активностью в отношении получения Reb D4.
3. Идентификация получения Reb D4 с помощью LC-MS анализа
Как показано на фиг. 2, время удерживания Reb E и Reb D4 является очень сходным. Reb E и Reb D4 трудно различить в реакциях с помощью современных способов HPLC. Для подтверждения превращения Reb E в Reb D4 полученное соединение анализировали с помощью способа LC-MS.
Для идентификации соединения Reb D4 в связанных реакциях, образцы биоконверсии посредством C1m2 и C1m3 анализировали с помощью LC-MS с использованием колонки Synergy Hydro-RP. Подвижная фаза A содержала 0,1% муравьиной кислоты в воде, и подвижная фаза B представляла собой 0,1% муравьиной кислоты в ацетонитриле. Скорость потока составляла 0,5 мл/минута. Подвижная фаза B начиналась при 20% B и поддерживалась в течение 2 минут. Затем проводили линейный градиент до 45% В в течение 15 минут. Затем % B повышали до 90% в течение 0,5 минуты и поддерживали в течение следующих 8 минут. Исходные условия восстанавливали в течение 0,5 минуты и поддерживали в течение еще 4,5 минут до следующей инъекции для повторного уравновешивания колонки. Масс-спектрометрический анализ образцов выполняли на Bruker Impact II посредством оптимизированного способа в режиме положительных ионов. Воронку 1 RF поддерживали при 400 Vp-p, Воронку 2 RF при 400 Vp-p, время передачи составляло 120 мкс и предварительное сохранение импульсов составляло 15 мкс. Полную калибровку шкалы масса/заряд выполняли с кластерами формиата натрия в конце каждого цикла. Весь элюент отводили в отходы в течение первых 2 минут с использованием вторичного/дополнительного 6-портового клапана для поддержания чистоты источника.
Как показано на фиг. 3 и 4, полученное соединение имело такую же молекулярную массу, как Reb D4. Субстрат Reb E также может быть обнаружен в течение того же времени удерживания. Эти результаты свидетельствуют о том, что получение Reb D4 в этих реакциях катализировалось ферментом C1m2 или C1m3.
4. Идентификация получения Reb D4 с помощью ферментного анализа
В соответствии с настоящим изобретением проводили ферментативный анализ для подтверждения получения Reb D4. Анализ бета-глюкозидазы модифицировали для выявления получения Reb D4 в связанных реакциях. В данном анализе бета-глюкозидаза может гидролизовать стевиоловые гликозиды для удаления группы(групп) глюкозы. После скрининга было обнаружено, что бета-глюкозидаза (GXT6, SEQ: 5) обладала специфической ферментативной активностью в отношении гидролиза Reb D4, Reb E и Reb D. Таким образом, проводили ферментативный анализ для различения трех соединений, присутствующих в реакциях по настоящему изобретению.
Как показано на фиг. 5, GXT6 может гидролизовать Reb D4 до Reb WB1. Reb E можно гидролизовать до стевиозида и рубузозида с помощью GXT6; Reb D можно гидролизовать до Reb A с помощью GXT6. Все соединения имеют различное время удерживания в профиле HPLC и могут быть четко различимы.
Та же ферментативная реакция была проведена с использованием соединений Reb E, полученных в результате биоконверсии с помощью C1m2 и C1m3. Как показано на фиг. 6, Reb WB1 получали только в реакциях с участием C1m2 и C1m3. В реакциях с участием C1m2 и C1m3 получали меньшее количество Reb A и рубузозида или совсем не получали. Эти результаты предоставили доказательства для подтверждения биосинтеза Reb D4 в реакциях с участием C1m2 и C1m3. C1m2 и C1m3 обладали основной ферментативной активностью для превращения Reb E в Reb D4, обладали меньшей или не обладали какой-либо активностью в отношении превращения Reb E в Reb D.
В соответствии с настоящим изобретением Reb E гидролизовали с помощью ферментов C1m2 и C1m3 с получением Reb M. В каждом из проведенных измерений соединения получали наряду с тем, что предсказывал бы биосинтетический путь по настоящему изобретению.
5. Биоконверсия стевиозида в Reb D4 с помощью ферментативной реакции
Для подтверждения превращения стевиозида в ребаудиозид D4 in vitro ферменты HV1, C1m2 и C1m3 анализировали с использованием стевиозида в качестве стевиол-гликозидного субстрата. Реакционная система содержала 50 мМ калий-фосфатного буфера (рН 7,2), 3 мМ MgCl2, 1 мг/мл стевиозида, 1 мМ UDP-глюкозы, HV1 и C1m2 или C1m3. Реакцию осуществляли при 37°С и прекращали с помощью добавления 1-бутанола. Образцы экстрагировали трижды с помощью 1-бутанола. Объединенную фракцию высушивали и растворяли в 80% метаноле для анализа высокоэффективной жидкостной хроматографии (HPLC). Анализ HPLC проводили, как описано выше.
Как показано на фиг. 7, комбинация HV1 с C1m2 или C1m3 может превращать стевиозид в Reb D4. В реакциях стевиозид может быть превращен в Reb E с помощью фермента HV1, затем полученный Reb E может быть превращен в Reb D4 с помощью фермента C1m2 или C1m3. Для идентификации соединения Reb D4 в связанных реакциях образцы анализировали с помощью LC-MS с использованием колонки Synergy Hydro-RP. Как показано на фиг. 8, полученное соединение (время удерживания 9,1 мин.) характеризовалось такой же молекулярной массой, что и Reb D4. Субстрат Reb E также может быть обнаружен в течение того же времени удерживания. Эти результаты подтверждают получение Reb D4 в реакциях.
В соответствии с настоящим изобретением были разработаны два мутанта UGT, которые при введении в систему биоконверсии обеспечили получение Reb D4 из Reb E. Весь путь биосинтеза от стевиозида до Reb M через Reb D4 был подтвержден (фиг. 9). Стевиозид может быть превращен в Reb E с помощью фермента HV1, как описано ранее, затем Reb E может быть превращен в Reb D4 с помощью фермента C1m2 или C1m3, как описано в данном документе. Наконец, Reb D4 может быть превращен в Reb M с помощью одного из ферментов UGT76G1, CP1 и CR1.
Мутантов UGT идентифицировали для превращения Reb E в Reb D4. Исходя из анализа структурного моделирования, некоторые мутантные вариации фермента CP1 (который сам является циклической версией UGT76G1) подвергали скринингу в отношении их способности превращать Reb E в Reb D4. Было обнаружено, что два мутанта обладали такой способностью, их идентифицировали как C1m2 и C1m3.
Как описано выше, выполняли способ LC-MS для идентификации получения Reb D4. Как показано в профиле HPLC, время удерживания Reb E и Reb D4 являлось очень сходным. Reb E и Reb D4 трудно различить в реакциях с помощью существующих способов HPLC. Для подтверждения превращения Reb E в Reb D4 полученное соединение анализировали с помощью способа LC-MS. Соединение Reb D4 может быть обнаружено при биоконверсии Reb E с помощью обоих ферментов C1m2 и C1m3.
Как описано выше, проводили ферментативный анализ для подтверждения получения Reb D4. Для подтверждения получения Reb D4 в связанных реакциях проводили анализ бета-глюкозидазы с целью различить стевиоловые гликозиды Reb D4, Reb E и Reb D. В данном анализе бета-глюкозидаза может гидролизовать стевиоловые гликозиды для удаления группы(групп) глюкозы. GXT6 обладает специфической ферментативной активностью в отношении гидролиза Reb D4, Reb E и Reb D. Таким образом, проводили ферментативный анализ для различения трех соединений, присутствующих в реакциях по настоящему изобретению. После ферментативного анализа подтверждали наличие Reb D4 в связанных реакциях, с подтверждением тем самым ферментативной активности C1m2 и C1m3 в отношении синтеза Reb D4 из Reb E.
Последовательности, представляющие интерес
Последовательности
Последовательности UGT76G1
Аминокислотная последовательность последовательности UGT76G1: (SEQ ID NO: 1)
MENKTETTVRRRRRIILFPVPFQGHINPILQLANVLYSKGFSITIFHTNFNKPKTSNYPHFTFRFILDNDPQDERISNLPTHGPLAGMRIPIINEHGADELRRELELLMLASEEDEEVSCLITDALWYFAQSVADSLNLRRLVLMTSSLFNFHAHVSLPQFDELGYLDPDDKTRLEEQASGFPMLKVKDIKSAYSNWQILKEILGKMIKQTKASSGVIWNSFKELEESELETVIREIPAPSFLIPLPKHLTASSSSLLDHDRTVFQWLDQQPPSSVLYVSFGSTSEVDEKDFLEIARGLVDSKQSFLWVVRPGFVKGSTWVEPLPDGFLGERGRIVKWVPQQEVLAHGAIGAFWTHSGWNSTLESVCEGVPMIFSDFGLDQPLNARYMSDVLKVGVYLENGWERGEIANAIRRVMVDEEGEYIRQNARVLKQKADVSLMKGGSSYESLESLVSYISSL
Последовательность ДНК последовательности UGT76G1: (SEQ ID NO: 2)
ATGGAGAATAAGACAGAAACAACCGTAAGACGGAGGCGGAGGATTATCTTGTTCCCTGTACCATTTCAGGGCCATATTAATCCGATCCTCCAATTAGCAAACGTCCTCTACTCCAAGGGATTTTCAATAACAATCTTCCATACTAACTTTAACAAGCCTAAAACGAGTAATTATCCTCACTTTACATTCAGGTTCATTCTAGACAACGACCCTCAGGATGAGCGTATCTCAAATTTACCTACGCATGGCCCCTTGGCAGGTATGCGAATACCAATAATCAATGAGCATGGAGCCGATGAACTCCGTCGCGAGTTAGAGCTTCTCATGCTCGCAAGTGAGGAAGACGAGGAAGTTTCGTGCCTAATAACTGATGCGCTTTGGTACTTCGCCCAATCAGTCGCAGACTCACTGAATCTACGCCGTTTGGTCCTTATGACAAGTTCATTATTCAACTTTCACGCACATGTATCACTGCCGCAATTTGACGAGTTGGGTTACCTGGACCCGGATGACAAAACGCGATTGGAGGAACAAGCGTCGGGCTTCCCCATGCTGAAAGTCAAAGATATTAAGAGCGCTTATAGTAATTGGCAAATTCTGAAAGAAATTCTCGGAAAAATGATAAAGCAAACCAAAGCGTCCTCTGGAGTAATCTGGAACTCCTTCAAGGAGTTAGAGGAATCTGAACTTGAAACGGTCATCAGAGAAATCCCCGCTCCCTCGTTCTTAATTCCACTACCCAAGCACCTTACTGCAAGTAGCAGTTCCCTCCTAGATCATGACCGAACCGTGTTTCAGTGGCTGGATCAGCAACCCCCGTCGTCAGTTCTATATGTAAGCTTTGGGAGTACTTCGGAAGTGGATGAAAAGGACTTCTTAGAGATTGCGCGAGGGCTCGTGGATAGCAAACAGAGCTTCCTGTGGGTAGTGAGACCGGGATTCGTTAAGGGCTCGACGTGGGTCGAGCCGTTGCCAGATGGTTTTCTAGGGGAGAGAGGGAGAATCGTGAAATGGGTTCCACAGCAAGAGGTTTTGGCTCACGGAGCTATAGGGGCCTTTTGGACCCACTCTGGTTGGAATTCTACTCTTGAAAGTGTCTGTGAAGGCGTTCCAATGATATTTTCTGATTTTGGGCTTGACCAGCCTCTAAACGCTCGCTATATGTCTGATGTGTTGAAGGTTGGCGTGTACCTGGAGAATGGTTGGGAAAGGGGGGAAATTGCCAACGCCATACGCCGGGTAATGGTGGACGAGGAAGGTGAGTACATACGTCAGAACGCTCGGGTTTTAAAACAAAAAGCGGACGTCAGCCTTATGAAGGGAGGTAGCTCCTATGAATCCCTAGAATCCTTGGTAAGCTATATATCTTCGTTATAA
Последовательности CP1
Аминокислотная последовательность CP1: (SEQ ID NO:3)
MNWQILKEILGKMIKQTKASSGVIWNSFKELEESELETVIREIPAPSFLIPLPKHLTASSSSLLDHDRTVFQWLDQQPPSSVLYVSFGSTSEVDEKDFLEIARGLVDSKQSFLWVVRPGFVKGSTWVEPLPDGFLGERGRIVKWVPQQEVLAHGAIGAFWTHSGWNSTLESVCEGVPMIFSDFGLDQPLNARYMSDVLKVGVYLENGWERGEIANAIRRVMVDEEGEYIRQNARVLKQKADVSLMKGGSSYESLESLVSYISSLENKTETTVRRRRRIILFPVPFQGHINPILQLANVLYSKGFSITIFHTNFNKPKTSNYPHFTFRFILDNDPQDERISNLPTHGPLAGMRIPIINEHGADELRRELELLMLASEEDEEVSCLITDALWYFAQSVADSLNLRRLVLMTSSLFNFHAHVSLPQFDELGYLDPDDKTRLEEQASGFPMLKVKDIKSAYS
Последовательность ДНК последовательности CP1: (SEQ ID NO:4)
ATGAACTGGCAAATCCTGAAAGAAATCCTGGGTAAAATGATCAAACAAACCAAAGCGTCGTCGGGCGTTATCTGGAACTCCTTCAAAGAACTGGAAGAATCAGAACTGGAAACCGTTATTCGCGAAATCCCGGCTCCGTCGTTCCTGATTCCGCTGCCGAAACATCTGACCGCGAGCAGCAGCAGCCTGCTGGATCACGACCGTACGGTCTTTCAGTGGCTGGATCAGCAACCGCCGTCATCGGTGCTGTATGTTTCATTCGGTAGCACCTCTGAAGTCGATGAAAAAGACTTTCTGGAAATCGCTCGCGGCCTGGTGGATAGTAAACAGTCCTTCCTGTGGGTGGTTCGTCCGGGTTTTGTGAAAGGCAGCACGTGGGTTGAACCGCTGCCGGATGGCTTCCTGGGTGAACGCGGCCGTATTGTCAAATGGGTGCCGCAGCAAGAAGTGCTGGCACATGGTGCTATCGGCGCGTTTTGGACCCACTCTGGTTGGAACAGTACGCTGGAATCCGTTTGCGAAGGTGTCCCGATGATTTTCAGCGATTTTGGCCTGGACCAGCCGCTGAATGCCCGCTATATGTCTGATGTTCTGAAAGTCGGTGTGTACCTGGAAAACGGTTGGGAACGTGGCGAAATTGCGAATGCCATCCGTCGCGTTATGGTCGATGAAGAAGGCGAATACATTCGCCAGAACGCTCGTGTCCTGAAACAAAAAGCGGACGTGAGCCTGATGAAAGGCGGTAGCTCTTATGAATCACTGGAATCGCTGGTTAGCTACATCAGTTCCCTGGAAAATAAAACCGAAACCACGGTGCGTCGCCGTCGCCGTATTATCCTGTTCCCGGTTCCGTTTCAGGGTCATATTAACCCGATCCTGCAACTGGCGAATGTTCTGTATTCAAAAGGCTTTTCGATCACCATCTTCCATACGAACTTCAACAAACCGAAAACCAGTAACTACCCGCACTTTACGTTCCGCTTTATTCTGGATAACGACCCGCAGGATGAACGTATCTCCAATCTGCCGACCCACGGCCCGCTGGCCGGTATGCGCATTCCGATTATCAATGAACACGGTGCAGATGAACTGCGCCGTGAACTGGAACTGCTGATGCTGGCCAGTGAAGAAGATGAAGAAGTGTCCTGTCTGATCACCGACGCACTGTGGTATTTCGCCCAGAGCGTTGCAGATTCTCTGAACCTGCGCCGTCTGGTCCTGATGACGTCATCGCTGTTCAATTTTCATGCGCACGTTTCTCTGCCGCAATTTGATGAACTGGGCTACCTGGACCCGGATGACAAAACCCGTCTGGAAGAACAAGCCAGTGGTTTTCCGATGCTGAAAGTCAAAGACATTAAATCCGCCTATTCGTAA
GXT6: аминокислота. От Streptomyces sp. GXT6 (SEQ ID NO:5)
MTPPFGSELALPETFLMGAATSAHQVEGNNIGSDWWEIEHRPDTFVAQPSGDAADSYHRWPEDMDLLAGLGFNAYRFSIEWARIEPEPGRISRAALAHYRAMVRGALERGLTPLVTLHHFTCPRWFSARGGWLAPDAAETFTAYARTASEVVGEGVSHVATINEPNMLAHMYTLRRLAAEHGWSALAEGRRAGAAAFDPAAVAPDRDVTAALIEAHRRSAVVLRQAGLQVGWTVANQVYHAEPGAEEIATAYARPREDVFLEAAREDDWIGVQAYTRHRIGPDGPLPVPDGAPTTLTGWEVYPDALAEAVLHTVATVGAQVPVIVTENGIATGDDDQRIAYTRQALAGLARVMREGADVRGYFHWSALDNYEWGTYRPTFGLIGVDPDTFARTPKPSARWLGALARDRRLPAAKAPVGTGAPTAR
GXT6: оптимизация кодона ДНК для E. coli (SEQ ID NO:6)
ATGACCCCACCGTTTGGTAGCGAACTGGCGCTTCCGGAAACATTCCTTATGGGTGCGGCCACTTCAGCTCACCAGGTTGAAGGTAATAATATCGGTAGCGATTGGTGGGAAATTGAGCACCGCCCGGATACTTTTGTTGCTCAGCCGTCCGGAGATGCGGCAGATTCCTATCACCGCTGGCCGGAAGATATGGATTTGCTTGCCGGATTGGGCTTTAATGCTTATCGTTTTAGTATTGAGTGGGCTCGTATTGAACCGGAACCTGGTCGGATTTCAAGAGCGGCTCTGGCGCATTATCGTGCGATGGTCCGCGGAGCGCTGGAGCGTGGCCTGACACCATTAGTAACTTTGCATCACTTTACATGCCCACGGTGGTTTTCAGCTCGGGGCGGTTGGTTAGCTCCAGATGCAGCGGAAACTTTTACTGCTTATGCCAGAACTGCCAGCGAGGTAGTTGGTGAGGGCGTGTCTCATGTCGCGACGATCAACGAGCCTAACATGCTGGCACATATGTATACTTTGAGAAGACTTGCAGCGGAACACGGTTGGTCAGCCTTAGCGGAAGGAAGACGTGCTGGCGCCGCAGCTTTTGATCCGGCTGCTGTTGCCCCGGATCGCGATGTGACGGCTGCTCTGATTGAGGCGCACCGTCGCAGCGCCGTAGTGCTGCGCCAGGCCGGCCTGCAGGTTGGCTGGACAGTTGCCAATCAGGTTTATCACGCCGAACCGGGAGCAGAAGAAATTGCTACGGCCTATGCTCGGCCACGGGAGGATGTATTCTTGGAGGCAGCCCGCGAAGATGATTGGATCGGCGTGCAGGCATATACTCGTCACCGTATTGGACCGGATGGACCTCTGCCGGTACCTGATGGGGCACCTACAACACTTACTGGCTGGGAAGTTTATCCTGATGCCCTTGCAGAAGCCGTGCTGCATACAGTCGCCACCGTGGGTGCGCAGGTACCAGTTATTGTAACAGAGAATGGTATCGCCACCGGCGATGATGATCAGCGTATCGCATATACTAGACAGGCACTGGCAGGGTTGGCCCGTGTCATGCGCGAAGGTGCGGATGTGCGGGGATATTTTCATTGGTCCGCATTAGATAACTATGAATGGGGCACCTATCGTCCAACCTTCGGGTTAATCGGGGTTGATCCGGATACGTTTGCTCGGACGCCTAAACCTTCTGCACGCTGGCTGGGTGCTCTGGCACGCGATCGCAGACTGCCAGCCGCGAAAGCGCCTGTCGGCACTGGCGCCCCTACAGCTCGC
C1m2: аминокислотная последовательность для мутантного фермента (SEQ ID NO:7)
MNWQIAKEILGKMIKQTKASSGVIWNSFKELEESELETVIREIPAPSFLIPLPKHLTASSSSLLDHDRTVFQWLDQQPPSSVLYVSFGSTSEVDEKDFLEIARGLVDSKQSFLWVVRPGFVKGSTWVEPLPDGFLGERGRIVKWVPQQEVLAHGAIGAFWTHSGWNSTLESVCEGVPMIFSDFGGDQPLNARYMSDVLKVGVYLENGWERGEIANAIRRVMVDEEGEYIRQNARVLKQKADVSLMKGGSSYESLESLVSYISSLENKTETTVRRRRRIILFPVPFQGHINPILQLANVLYSKGFSITIFHTNFNKPKTSNYPHFTFRFILDNDPQDERISNLPTHGPLAGMRIPIINEHGADELRRELELLMLASEEDEEVSCLITDALWYFAQSVADSLNLRRLVLMTSSLFNFHAHVSLPQFDELGYLDPDDKTRLEEQASGFPMLKVKDIKSAYS
C1m2: последовательность ДНК для мутантного фермента (SEQ ID NO:8)
ATGAACTGGCAAATCGCGAAAGAAATCCTGGGTAAAATGATCAAACAAACCAAAGCGTCGTCGGGCGTTATCTGGAACTCCTTCAAAGAACTGGAAGAATCAGAACTGGAAACCGTTATTCGCGAAATCCCGGCTCCGTCGTTCCTGATTCCGCTGCCGAAACATCTGACCGCGAGCAGCAGCAGCCTGCTGGATCACGACCGTACGGTCTTTCAGTGGCTGGATCAGCAACCGCCGTCATCGGTGCTGTATGTTTCATTCGGTAGCACCTCTGAAGTCGATGAAAAAGACTTTCTGGAAATCGCTCGCGGCCTGGTGGATAGTAAACAGTCCTTCCTGTGGGTGGTTCGTCCGGGTTTTGTGAAAGGCAGCACGTGGGTTGAACCGCTGCCGGATGGCTTCCTGGGTGAACGCGGCCGTATTGTCAAATGGGTGCCGCAGCAAGAAGTGCTGGCACATGGTGCTATCGGCGCGTTTTGGACCCACTCTGGTTGGAACAGTACGCTGGAATCCGTTTGCGAAGGTGTCCCGATGATTTTCAGCGATTTTGGCGGCGACCAGCCGCTGAATGCCCGCTATATGTCTGATGTTCTGAAAGTCGGTGTGTACCTGGAAAACGGTTGGGAACGTGGCGAAATTGCGAATGCCATCCGTCGCGTTATGGTCGATGAAGAAGGCGAATACATTCGCCAGAACGCTCGTGTCCTGAAACAAAAAGCGGACGTGAGCCTGATGAAAGGCGGTAGCTCTTATGAATCACTGGAATCGCTGGTTAGCTACATCAGTTCCCTGGAAAATAAAACCGAAACCACGGTGCGTCGCCGTCGCCGTATTATCCTGTTCCCGGTTCCGTTTCAGGGTCATATTAACCCGATCCTGCAACTGGCGAATGTTCTGTATTCAAAAGGCTTTTCGATCACCATCTTCCATACGAACTTCAACAAACCGAAAACCAGTAACTACCCGCACTTTACGTTCCGCTTTATTCTGGATAACGACCCGCAGGATGAACGTATCTCCAATCTGCCGACCCACGGCCCGCTGGCCGGTATGCGCATTCCGATTATCAATGAACACGGTGCAGATGAACTGCGCCGTGAACTGGAACTGCTGATGCTGGCCAGTGAAGAAGATGAAGAAGTGTCCTGTCTGATCACCGACGCACTGTGGTATTTCGCCCAGAGCGTTGCAGATTCTCTGAACCTGCGCCGTCTGGTCCTGATGACGTCATCGCTGTTCAATTTTCATGCGCACGTTTCTCTGCCGCAATTTGATGAACTGGGCTACCTGGACCCGGATGACAAAACCCGTCTGGAAGAACAAGCCAGTGGTTTTCCGATGCTGAAAGTCAAAGACATTAAATCCGCCTATTCGTAA
C1m3: аминокислотная последовательность для мутантного фермента (SEQ ID NO:9)
MNWQIAKEILGKMIKQTKASSGVIWNSFKELEESELETVIREIPAPSFLIPLPKHLTASSSSLLDHDRTVFQWLDQQPPSSVLYVSFGSASEVDEKDFLEIARGLVDSKQSFLWVVRPGFVKGSTWVEPLPDGFLGERGRIVKWVPQQEVLAHGAIGAFWTHSGWNSTLESVCEGVPMIFSDFGGDQPLNARYMSDVLKVGVYLENGWERGEIANAIRRVMVDEEGEYIRQNARVLKQKADVSLMKGGSSYESLESLVSYISSLENKTETTVRRRRRIILFPVPFQGHINPILQLANVLYSKGFSITIFHTNFNKPKTSNYPHFTFRFILDNDPQDERISNLPTHGPLAGMRIPIINEHGADELRRELELLMLASEEDEEVSCLITDALWYFAQSVADSLNLRRLVLMTSSLFNFHAHVSLPQFDELGYLDPDDKTRLEEQASGFPMLKVKDIKSAYS
C1m3: последовательность ДНК для мутантного фермента (SEQ ID NO:10)
ATGAACTGGCAAATCGCGAAAGAAATCCTGGGTAAAATGATCAAACAAACCAAAGCGTCGTCGGGCGTTATCTGGAACTCCTTCAAAGAACTGGAAGAATCAGAACTGGAAACCGTTATTCGCGAAATCCCGGCTCCGTCGTTCCTGATTCCGCTGCCGAAACATCTGACCGCGAGCAGCAGCAGCCTGCTGGATCACGACCGTACGGTCTTTCAGTGGCTGGATCAGCAACCGCCGTCATCGGTGCTGTATGTTTCATTCGGTAGCGCCTCTGAAGTCGATGAAAAAGACTTTCTGGAAATCGCTCGCGGCCTGGTGGATAGTAAACAGTCCTTCCTGTGGGTGGTTCGTCCGGGTTTTGTGAAAGGCAGCACGTGGGTTGAACCGCTGCCGGATGGCTTCCTGGGTGAACGCGGCCGTATTGTCAAATGGGTGCCGCAGCAAGAAGTGCTGGCACATGGTGCTATCGGCGCGTTTTGGACCCACTCTGGTTGGAACAGTACGCTGGAATCCGTTTGCGAAGGTGTCCCGATGATTTTCAGCGATTTTGGCGGCGACCAGCCGCTGAATGCCCGCTATATGTCTGATGTTCTGAAAGTCGGTGTGTACCTGGAAAACGGTTGGGAACGTGGCGAAATTGCGAATGCCATCCGTCGCGTTATGGTCGATGAAGAAGGCGAATACATTCGCCAGAACGCTCGTGTCCTGAAACAAAAAGCGGACGTGAGCCTGATGAAAGGCGGTAGCTCTTATGAATCACTGGAATCGCTGGTTAGCTACATCAGTTCCCTGGAAAATAAAACCGAAACCACGGTGCGTCGCCGTCGCCGTATTATCCTGTTCCCGGTTCCGTTTCAGGGTCATATTAACCCGATCCTGCAACTGGCGAATGTTCTGTATTCAAAAGGCTTTTCGATCACCATCTTCCATACGAACTTCAACAAACCGAAAACCAGTAACTACCCGCACTTTACGTTCCGCTTTATTCTGGATAACGACCCGCAGGATGAACGTATCTCCAATCTGCCGACCCACGGCCCGCTGGCCGGTATGCGCATTCCGATTATCAATGAACACGGTGCAGATGAACTGCGCCGTGAACTGGAACTGCTGATGCTGGCCAGTGAAGAAGATGAAGAAGTGTCCTGTCTGATCACCGACGCACTGTGGTATTTCGCCCAGAGCGTTGCAGATTCTCTGAACCTGCGCCGTCTGGTCCTGATGACGTCATCGCTGTTCAATTTTCATGCGCACGTTTCTCTGCCGCAATTTGATGAACTGGGCTACCTGGACCCGGATGACAAAACCCGTCTGGAAGAACAAGCCAGTGGTTTTCCGATGCTGAAAGTCAAAGACATTAAATCCGCCTATTCGTAA
HV1: аминокислотная последовательность (SEQ ID NO:11)
MDGNSSSSPLHVVICPWLALGHLLPCLDIAERLASRGHRVSFVSTPRNIARLPPLRPAVAPLVDFVALPLPHVDGLPEGAESTNDVPYDKFELHRKAFDGLAAPFSEFLRAACAEGAGSRPDWLIVDTFHHWAAAAAVENKVPCVMLLLGAATVIAGFARGVSEHAAAAVGKERPAAEAPSFETERRKLMTTQNASGMTVAERYFLTLMRSDLVAIRSCAEWEPESVAALTTLAGKPVVPLGLLPPSPEGGRGVSKEDAAVRWLDAQPAKSVVYVALGSEVPLRAEQVHELALGLELSGARFLWALRKPTDAPDAAVLPPGFEERTRGRGLVVTGWVPQIGVLAHGAVAAFLTHCGWNSTIEGLLFGHPLIMLPISSDQGPNARLMEGRKVGMQVPRDESDGSFRREDVAATVRAVAVEEDGRRVFTANAKKMQEIVADGACHERCIDGFIQQLRSYKA
HV1: последовательность ДНК (SEQ ID NO:12)
ATGGATGGTAACTCCTCCTCCTCGCCGCTGCATGTGGTCATTTGTCCGTGGCTGGCTCTGGGTCACCTGCTGCCGTGTCTGGATATTGCTGAACGTCTGGCGTCACGCGGCCATCGTGTCAGTTTTGTGTCCACCCCGCGCAACATTGCCCGTCTGCCGCCGCTGCGTCCGGCTGTTGCACCGCTGGTTGATTTCGTCGCACTGCCGCTGCCGCATGTTGACGGTCTGCCGGAGGGTGCGGAATCGACCAATGATGTGCCGTATGACAAATTTGAACTGCACCGTAAGGCGTTCGATGGTCTGGCGGCCCCGTTTAGCGAATTTCTGCGTGCAGCTTGCGCAGAAGGTGCAGGTTCTCGCCCGGATTGGCTGATTGTGGACACCTTTCATCACTGGGCGGCGGCGGCGGCGGTGGAAAACAAAGTGCCGTGTGTTATGCTGCTGCTGGGTGCAGCAACGGTGATCGCTGGTTTCGCGCGTGGTGTTAGCGAACATGCGGCGGCGGCGGTGGGTAAAGAACGTCCGGCTGCGGAAGCCCCGAGTTTTGAAACCGAACGTCGCAAGCTGATGACCACGCAGAATGCCTCCGGCATGACCGTGGCAGAACGCTATTTCCTGACGCTGATGCGTAGCGATCTGGTTGCCATCCGCTCTTGCGCAGAATGGGAACCGGAAAGCGTGGCAGCACTGACCACGCTGGCAGGTAAACCGGTGGTTCCGCTGGGTCTGCTGCCGCCGAGTCCGGAAGGCGGTCGTGGCGTTTCCAAAGAAGATGCTGCGGTCCGTTGGCTGGACGCACAGCCGGCAAAGTCAGTCGTGTACGTCGCACTGGGTTCGGAAGTGCCGCTGCGTGCGGAACAAGTTCACGAACTGGCACTGGGCCTGGAACTGAGCGGTGCTCGCTTTCTGTGGGCGCTGCGTAAACCGACCGATGCACCGGACGCCGCAGTGCTGCCGCCGGGTTTCGAAGAACGTACCCGCGGCCGTGGTCTGGTTGTCACGGGTTGGGTGCCGCAGATTGGCGTTCTGGCTCATGGTGCGGTGGCTGCGTTTCTGACCCACTGTGGCTGGAACTCTACGATCGAAGGCCTGCTGTTCGGTCATCCGCTGATTATGCTGCCGATCAGCTCTGATCAGGGTCCGAATGCGCGCCTGATGGAAGGCCGTAAAGTCGGTATGCAAGTGCCGCGTGATGAATCAGACGGCTCGTTTCGTCGCGAAGATGTTGCCGCAACCGTCCGCGCCGTGGCAGTTGAAGAAGACGGTCGTCGCGTCTTCACGGCTAACGCGAAAAAGATGCAAGAAATTGTGGCCGATGGCGCATGCCACGAACGTTGTATTGACGGTTTTATCCAGCAACTGCGCAGTTACAAGGCGTAA
CR1: аминокислотная последовательность (SEQ ID NO:13)
MNWQIAKEILGKMIKQTKASSGVIWNSFKELEESELETVIREIPAPSFLIPLPKHLTASSSSLLDHDRTVFQWLDQQPPSSVLYVSFGSTSEVDEKDFLEIARGLVDSKQSFLWVVRPGFVKGSTWVEPLPDGFLGERGRIVKWVPQQEVLAHGAIGAFWTHSGWNSTLESVCEGVPMIFSDFGLDQPLNARYMSDVLKVGVYLENGWERGEIANAIRRVMVDEEGEYIRQNARVLKQKADVSLMKGGSSYESLESLVSYISSLENKTETTVRRRRRIILFPVPFQGHINPILQLANVLYSKGFSITIFHTNFNKPKTSNYPHFTFRFILDNDPQDERISNLPTHGPLAGMRIPIINEHGADELRRELELLMLASEEDEEVSCLITDALWYFAQSVADSLNLRRLVLMTSSLFNFHAHVSLPQFDELGYLDPDDKTRLEEQASGFPMLKVKDIKSAYS
CR1: последовательность ДНК (SEQ ID NO: 14)
ATGAACTGGCAAATCGCGAAAGAAATCCTGGGTAAAATGATCAAACAAACCAAAGCGTCGTCGGGCGTTATCTGGAACTCCTTCAAAGAACTGGAAGAATCAGAACTGGAAACCGTTATTCGCGAAATCCCGGCTCCGTCGTTCCTGATTCCGCTGCCGAAACATCTGACCGCGAGCAGCAGCAGCCTGCTGGATCACGACCGTACGGTCTTTCAGTGGCTGGATCAGCAACCGCCGTCATCGGTGCTGTATGTTTCATTCGGTAGCACCTCTGAAGTCGATGAAAAAGACTTTCTGGAAATCGCTCGCGGCCTGGTGGATAGTAAACAGTCCTTCCTGTGGGTGGTTCGTCCGGGTTTTGTGAAAGGCAGCACGTGGGTTGAACCGCTGCCGGATGGCTTCCTGGGTGAACGCGGCCGTATTGTCAAATGGGTGCCGCAGCAAGAAGTGCTGGCACATGGTGCTATCGGCGCGTTTTGGACCCACTCTGGTTGGAACAGTACGCTGGAATCCGTTTGCGAAGGTGTCCCGATGATTTTCAGCGACTTTGGCCTGGACCAGCCGCTGAATGCCCGCTATATGTCTGATGTTCTGAAAGTCGGTGTGTACCTGGAAAACGGTTGGGAACGTGGCGAAATTGCGAATGCCATCCGTCGCGTTATGGTCGATGAAGAAGGCGAATACATTCGCCAGAACGCTCGTGTCCTGAAACAAAAAGCGGACGTGAGCCTGATGAAAGGCGGTAGCTCTTATGAATCACTGGAATCGCTGGTTAGCTACATCAGTTCCCTGGAAAATAAAACCGAAACCACGGTGCGTCGCCGTCGCCGTATTATCCTGTTCCCGGTTCCGTTTCAGGGTCATATTAACCCGATCCTGCAACTGGCGAATGTTCTGTATTCAAAAGGCTTTTCGATCACCATCTTCCATACGAACTTCAACAAACCGAAAACCAGTAACTACCCGCACTTTACGTTCCGCTTTATTCTGGATAACGACCCGCAGGATGAACGTATCTCCAATCTGCCGACCCACGGCCCGCTGGCCGGTATGCGCATTCCGATTATCAATGAACACGGTGCAGATGAACTGCGCCGTGAACTGGAACTGCTGATGCTGGCCAGTGAAGAAGATGAAGAAGTGTCCTGTCTGATCACCGACGCACTGTGGTATTTCGCCCAGAGCGTTGCAGATTCTCTGAACCTGCGCCGTCTGGTCCTGATGACGTCATCGCTGTTCAATTTTCATGCGCACGTTTCTCTGCCGCAATTTGATGAACTGGGCTACCTGGACCCGGATGACAAAACCCGTCTGGAAGAACAAGCCAGTGGTTTTCCGATGCTGAAAGTCAAAGACATTAAATCCGCCTATTCGTAA
ЗАЯВЛЕНИЕ О ПРОМЫШЛЕННОЙ ПРИМЕНИМОСТИ/ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение применимо в областях промышленности, связанных с производством продуктов питания, кормов, напитков, а также в фармакологической промышленности. Настоящее изобретение в целом относится к способу биосинтетического получения стевиоловых гликозидов, например, посредством модифицированного микробного штамма.
Литературные источники, процитированные и включенные посредством ссылки
1. Brandle, J. E. et al., (1998). Stevia Rebaudiana: Its Agricultural, Biological, and Chemical Properties, Canadian J. Plant Science. 78 (4): 527-36.
2. Ceunen, S., and J.M. C. Geuns, Steviol Glycosides: Chemical Diversity, Metabolism, and Function, J. Nat. Prod., 2013, 76 (6), pp 1201-28 (2013).
3. Du J et al., (2011), Engineering microbial factories for synthesis of value-added products, J Ind Microbiol. Biotechnol. 38: 873-90.
4. GRAS Notices, USA Food and Drug Administration, United States Health & Human Services. (2016) (относится к стевиоловым гликозидам и полигликозидам).
5.  , and
, and  , (1997), Microbial production of natural flavors, ASM News 63:551-59.
, (1997), Microbial production of natural flavors, ASM News 63:551-59.
6. Prakash I., et al.; Isolation and Characterization of a Novel Rebaudioside M Isomer from a Bioconversion Reaction of Rebaudioside A and NMR Comparison Studies of Rebaudioside M Isolated from Stevia rebaudiana Bertoni and Stevia rebaudiana Morita, Biomolecules, 2014 Jun; 4(2): 374-89. (Опубликован онлайн 2014 г. 31 марта 2014 г.).
7. Prakash I., et al., Development of Next Generation Stevia Sweetener: Rebaudioside M, Foods, 2014, 3:162-175.
8. Richman A., et. al., Functional genomics uncovers three glucosyltransferases involved in the synthesis of the major sweet glucosides of Stevia rebaudiana, Plant J. 2005 Jan;41(1):56-67.
9. Shockey JM. Et a., (2003), Arabidopsis contains a large superfamily of acyl-activating enzymes: phylogenetic and biochemical analysis reveals a new class of acyl-coenzyme A synthetases. Plant Physiol. 132 1065-76.
10. Wang J., et al., Pathway mining-based integration of critical enzyme parts for de novo biosynthesis of steviolglycosides sweetener in Escherichia coli, Cell Research (2016) 26:258-61.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Conagen Inc.
<120> БИОСИНТЕТИЧЕСКОЕ ПОЛУЧЕНИЕ СТЕВИОЛОВОГО ГЛИКОЗИДА РЕБАУДИОЗИДА D4 ИЗ РЕБАУДИОЗИДА E
<130> C1497.70025WO00
<150> US 62/467,467
<151> 2017-03-06
<160> 14
<170> PatentIn версия 3.5
<210> 1
<211> 458
<212> БЕЛОК
<213> Stevia rebaudiana
<400> 1
Met Glu Asn Lys Thr Glu Thr Thr Val Arg Arg Arg Arg Arg Ile Ile
1 5 10 15
Leu Phe Pro Val Pro Phe Gln Gly His Ile Asn Pro Ile Leu Gln Leu
20 25 30
Ala Asn Val Leu Tyr Ser Lys Gly Phe Ser Ile Thr Ile Phe His Thr
35 40 45
Asn Phe Asn Lys Pro Lys Thr Ser Asn Tyr Pro His Phe Thr Phe Arg
50 55 60
Phe Ile Leu Asp Asn Asp Pro Gln Asp Glu Arg Ile Ser Asn Leu Pro
65 70 75 80
Thr His Gly Pro Leu Ala Gly Met Arg Ile Pro Ile Ile Asn Glu His
85 90 95
Gly Ala Asp Glu Leu Arg Arg Glu Leu Glu Leu Leu Met Leu Ala Ser
100 105 110
Glu Glu Asp Glu Glu Val Ser Cys Leu Ile Thr Asp Ala Leu Trp Tyr
115 120 125
Phe Ala Gln Ser Val Ala Asp Ser Leu Asn Leu Arg Arg Leu Val Leu
130 135 140
Met Thr Ser Ser Leu Phe Asn Phe His Ala His Val Ser Leu Pro Gln
145 150 155 160
Phe Asp Glu Leu Gly Tyr Leu Asp Pro Asp Asp Lys Thr Arg Leu Glu
165 170 175
Glu Gln Ala Ser Gly Phe Pro Met Leu Lys Val Lys Asp Ile Lys Ser
180 185 190
Ala Tyr Ser Asn Trp Gln Ile Leu Lys Glu Ile Leu Gly Lys Met Ile
195 200 205
Lys Gln Thr Lys Ala Ser Ser Gly Val Ile Trp Asn Ser Phe Lys Glu
210 215 220
Leu Glu Glu Ser Glu Leu Glu Thr Val Ile Arg Glu Ile Pro Ala Pro
225 230 235 240
Ser Phe Leu Ile Pro Leu Pro Lys His Leu Thr Ala Ser Ser Ser Ser
245 250 255
Leu Leu Asp His Asp Arg Thr Val Phe Gln Trp Leu Asp Gln Gln Pro
260 265 270
Pro Ser Ser Val Leu Tyr Val Ser Phe Gly Ser Thr Ser Glu Val Asp
275 280 285
Glu Lys Asp Phe Leu Glu Ile Ala Arg Gly Leu Val Asp Ser Lys Gln
290 295 300
Ser Phe Leu Trp Val Val Arg Pro Gly Phe Val Lys Gly Ser Thr Trp
305 310 315 320
Val Glu Pro Leu Pro Asp Gly Phe Leu Gly Glu Arg Gly Arg Ile Val
325 330 335
Lys Trp Val Pro Gln Gln Glu Val Leu Ala His Gly Ala Ile Gly Ala
340 345 350
Phe Trp Thr His Ser Gly Trp Asn Ser Thr Leu Glu Ser Val Cys Glu
355 360 365
Gly Val Pro Met Ile Phe Ser Asp Phe Gly Leu Asp Gln Pro Leu Asn
370 375 380
Ala Arg Tyr Met Ser Asp Val Leu Lys Val Gly Val Tyr Leu Glu Asn
385 390 395 400
Gly Trp Glu Arg Gly Glu Ile Ala Asn Ala Ile Arg Arg Val Met Val
405 410 415
Asp Glu Glu Gly Glu Tyr Ile Arg Gln Asn Ala Arg Val Leu Lys Gln
420 425 430
Lys Ala Asp Val Ser Leu Met Lys Gly Gly Ser Ser Tyr Glu Ser Leu
435 440 445
Glu Ser Leu Val Ser Tyr Ile Ser Ser Leu
450 455
<210> 2
<211> 1377
<212> ДНК
<213> Stevia rebaudiana
<400> 2
atggagaata agacagaaac aaccgtaaga cggaggcgga ggattatctt gttccctgta 60
ccatttcagg gccatattaa tccgatcctc caattagcaa acgtcctcta ctccaaggga 120
ttttcaataa caatcttcca tactaacttt aacaagccta aaacgagtaa ttatcctcac 180
tttacattca ggttcattct agacaacgac cctcaggatg agcgtatctc aaatttacct 240
acgcatggcc ccttggcagg tatgcgaata ccaataatca atgagcatgg agccgatgaa 300
ctccgtcgcg agttagagct tctcatgctc gcaagtgagg aagacgagga agtttcgtgc 360
ctaataactg atgcgctttg gtacttcgcc caatcagtcg cagactcact gaatctacgc 420
cgtttggtcc ttatgacaag ttcattattc aactttcacg cacatgtatc actgccgcaa 480
tttgacgagt tgggttacct ggacccggat gacaaaacgc gattggagga acaagcgtcg 540
ggcttcccca tgctgaaagt caaagatatt aagagcgctt atagtaattg gcaaattctg 600
aaagaaattc tcggaaaaat gataaagcaa accaaagcgt cctctggagt aatctggaac 660
tccttcaagg agttagagga atctgaactt gaaacggtca tcagagaaat ccccgctccc 720
tcgttcttaa ttccactacc caagcacctt actgcaagta gcagttccct cctagatcat 780
gaccgaaccg tgtttcagtg gctggatcag caacccccgt cgtcagttct atatgtaagc 840
tttgggagta cttcggaagt ggatgaaaag gacttcttag agattgcgcg agggctcgtg 900
gatagcaaac agagcttcct gtgggtagtg agaccgggat tcgttaaggg ctcgacgtgg 960
gtcgagccgt tgccagatgg ttttctaggg gagagaggga gaatcgtgaa atgggttcca 1020
cagcaagagg ttttggctca cggagctata ggggcctttt ggacccactc tggttggaat 1080
tctactcttg aaagtgtctg tgaaggcgtt ccaatgatat tttctgattt tgggcttgac 1140
cagcctctaa acgctcgcta tatgtctgat gtgttgaagg ttggcgtgta cctggagaat 1200
ggttgggaaa ggggggaaat tgccaacgcc atacgccggg taatggtgga cgaggaaggt 1260
gagtacatac gtcagaacgc tcgggtttta aaacaaaaag cggacgtcag ccttatgaag 1320
ggaggtagct cctatgaatc cctagaatcc ttggtaagct atatatcttc gttataa 1377
<210> 3
<211> 458
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> CP1
<400> 3
Met Asn Trp Gln Ile Leu Lys Glu Ile Leu Gly Lys Met Ile Lys Gln
1 5 10 15
Thr Lys Ala Ser Ser Gly Val Ile Trp Asn Ser Phe Lys Glu Leu Glu
20 25 30
Glu Ser Glu Leu Glu Thr Val Ile Arg Glu Ile Pro Ala Pro Ser Phe
35 40 45
Leu Ile Pro Leu Pro Lys His Leu Thr Ala Ser Ser Ser Ser Leu Leu
50 55 60
Asp His Asp Arg Thr Val Phe Gln Trp Leu Asp Gln Gln Pro Pro Ser
65 70 75 80
Ser Val Leu Tyr Val Ser Phe Gly Ser Thr Ser Glu Val Asp Glu Lys
85 90 95
Asp Phe Leu Glu Ile Ala Arg Gly Leu Val Asp Ser Lys Gln Ser Phe
100 105 110
Leu Trp Val Val Arg Pro Gly Phe Val Lys Gly Ser Thr Trp Val Glu
115 120 125
Pro Leu Pro Asp Gly Phe Leu Gly Glu Arg Gly Arg Ile Val Lys Trp
130 135 140
Val Pro Gln Gln Glu Val Leu Ala His Gly Ala Ile Gly Ala Phe Trp
145 150 155 160
Thr His Ser Gly Trp Asn Ser Thr Leu Glu Ser Val Cys Glu Gly Val
165 170 175
Pro Met Ile Phe Ser Asp Phe Gly Leu Asp Gln Pro Leu Asn Ala Arg
180 185 190
Tyr Met Ser Asp Val Leu Lys Val Gly Val Tyr Leu Glu Asn Gly Trp
195 200 205
Glu Arg Gly Glu Ile Ala Asn Ala Ile Arg Arg Val Met Val Asp Glu
210 215 220
Glu Gly Glu Tyr Ile Arg Gln Asn Ala Arg Val Leu Lys Gln Lys Ala
225 230 235 240
Asp Val Ser Leu Met Lys Gly Gly Ser Ser Tyr Glu Ser Leu Glu Ser
245 250 255
Leu Val Ser Tyr Ile Ser Ser Leu Glu Asn Lys Thr Glu Thr Thr Val
260 265 270
Arg Arg Arg Arg Arg Ile Ile Leu Phe Pro Val Pro Phe Gln Gly His
275 280 285
Ile Asn Pro Ile Leu Gln Leu Ala Asn Val Leu Tyr Ser Lys Gly Phe
290 295 300
Ser Ile Thr Ile Phe His Thr Asn Phe Asn Lys Pro Lys Thr Ser Asn
305 310 315 320
Tyr Pro His Phe Thr Phe Arg Phe Ile Leu Asp Asn Asp Pro Gln Asp
325 330 335
Glu Arg Ile Ser Asn Leu Pro Thr His Gly Pro Leu Ala Gly Met Arg
340 345 350
Ile Pro Ile Ile Asn Glu His Gly Ala Asp Glu Leu Arg Arg Glu Leu
355 360 365
Glu Leu Leu Met Leu Ala Ser Glu Glu Asp Glu Glu Val Ser Cys Leu
370 375 380
Ile Thr Asp Ala Leu Trp Tyr Phe Ala Gln Ser Val Ala Asp Ser Leu
385 390 395 400
Asn Leu Arg Arg Leu Val Leu Met Thr Ser Ser Leu Phe Asn Phe His
405 410 415
Ala His Val Ser Leu Pro Gln Phe Asp Glu Leu Gly Tyr Leu Asp Pro
420 425 430
Asp Asp Lys Thr Arg Leu Glu Glu Gln Ala Ser Gly Phe Pro Met Leu
435 440 445
Lys Val Lys Asp Ile Lys Ser Ala Tyr Ser
450 455
<210> 4
<211> 1377
<212> ДНК
<213> Искусственная последовательность
<220>
<223> CP1
<400> 4
atgaactggc aaatcctgaa agaaatcctg ggtaaaatga tcaaacaaac caaagcgtcg 60
tcgggcgtta tctggaactc cttcaaagaa ctggaagaat cagaactgga aaccgttatt 120
cgcgaaatcc cggctccgtc gttcctgatt ccgctgccga aacatctgac cgcgagcagc 180
agcagcctgc tggatcacga ccgtacggtc tttcagtggc tggatcagca accgccgtca 240
tcggtgctgt atgtttcatt cggtagcacc tctgaagtcg atgaaaaaga ctttctggaa 300
atcgctcgcg gcctggtgga tagtaaacag tccttcctgt gggtggttcg tccgggtttt 360
gtgaaaggca gcacgtgggt tgaaccgctg ccggatggct tcctgggtga acgcggccgt 420
attgtcaaat gggtgccgca gcaagaagtg ctggcacatg gtgctatcgg cgcgttttgg 480
acccactctg gttggaacag tacgctggaa tccgtttgcg aaggtgtccc gatgattttc 540
agcgattttg gcctggacca gccgctgaat gcccgctata tgtctgatgt tctgaaagtc 600
ggtgtgtacc tggaaaacgg ttgggaacgt ggcgaaattg cgaatgccat ccgtcgcgtt 660
atggtcgatg aagaaggcga atacattcgc cagaacgctc gtgtcctgaa acaaaaagcg 720
gacgtgagcc tgatgaaagg cggtagctct tatgaatcac tggaatcgct ggttagctac 780
atcagttccc tggaaaataa aaccgaaacc acggtgcgtc gccgtcgccg tattatcctg 840
ttcccggttc cgtttcaggg tcatattaac ccgatcctgc aactggcgaa tgttctgtat 900
tcaaaaggct tttcgatcac catcttccat acgaacttca acaaaccgaa aaccagtaac 960
tacccgcact ttacgttccg ctttattctg gataacgacc cgcaggatga acgtatctcc 1020
aatctgccga cccacggccc gctggccggt atgcgcattc cgattatcaa tgaacacggt 1080
gcagatgaac tgcgccgtga actggaactg ctgatgctgg ccagtgaaga agatgaagaa 1140
gtgtcctgtc tgatcaccga cgcactgtgg tatttcgccc agagcgttgc agattctctg 1200
aacctgcgcc gtctggtcct gatgacgtca tcgctgttca attttcatgc gcacgtttct 1260
ctgccgcaat ttgatgaact gggctacctg gacccggatg acaaaacccg tctggaagaa 1320
caagccagtg gttttccgat gctgaaagtc aaagacatta aatccgccta ttcgtaa 1377
<210> 5
<211> 425
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> GXT6
<400> 5
Met Thr Pro Pro Phe Gly Ser Glu Leu Ala Leu Pro Glu Thr Phe Leu
1 5 10 15
Met Gly Ala Ala Thr Ser Ala His Gln Val Glu Gly Asn Asn Ile Gly
20 25 30
Ser Asp Trp Trp Glu Ile Glu His Arg Pro Asp Thr Phe Val Ala Gln
35 40 45
Pro Ser Gly Asp Ala Ala Asp Ser Tyr His Arg Trp Pro Glu Asp Met
50 55 60
Asp Leu Leu Ala Gly Leu Gly Phe Asn Ala Tyr Arg Phe Ser Ile Glu
65 70 75 80
Trp Ala Arg Ile Glu Pro Glu Pro Gly Arg Ile Ser Arg Ala Ala Leu
85 90 95
Ala His Tyr Arg Ala Met Val Arg Gly Ala Leu Glu Arg Gly Leu Thr
100 105 110
Pro Leu Val Thr Leu His His Phe Thr Cys Pro Arg Trp Phe Ser Ala
115 120 125
Arg Gly Gly Trp Leu Ala Pro Asp Ala Ala Glu Thr Phe Thr Ala Tyr
130 135 140
Ala Arg Thr Ala Ser Glu Val Val Gly Glu Gly Val Ser His Val Ala
145 150 155 160
Thr Ile Asn Glu Pro Asn Met Leu Ala His Met Tyr Thr Leu Arg Arg
165 170 175
Leu Ala Ala Glu His Gly Trp Ser Ala Leu Ala Glu Gly Arg Arg Ala
180 185 190
Gly Ala Ala Ala Phe Asp Pro Ala Ala Val Ala Pro Asp Arg Asp Val
195 200 205
Thr Ala Ala Leu Ile Glu Ala His Arg Arg Ser Ala Val Val Leu Arg
210 215 220
Gln Ala Gly Leu Gln Val Gly Trp Thr Val Ala Asn Gln Val Tyr His
225 230 235 240
Ala Glu Pro Gly Ala Glu Glu Ile Ala Thr Ala Tyr Ala Arg Pro Arg
245 250 255
Glu Asp Val Phe Leu Glu Ala Ala Arg Glu Asp Asp Trp Ile Gly Val
260 265 270
Gln Ala Tyr Thr Arg His Arg Ile Gly Pro Asp Gly Pro Leu Pro Val
275 280 285
Pro Asp Gly Ala Pro Thr Thr Leu Thr Gly Trp Glu Val Tyr Pro Asp
290 295 300
Ala Leu Ala Glu Ala Val Leu His Thr Val Ala Thr Val Gly Ala Gln
305 310 315 320
Val Pro Val Ile Val Thr Glu Asn Gly Ile Ala Thr Gly Asp Asp Asp
325 330 335
Gln Arg Ile Ala Tyr Thr Arg Gln Ala Leu Ala Gly Leu Ala Arg Val
340 345 350
Met Arg Glu Gly Ala Asp Val Arg Gly Tyr Phe His Trp Ser Ala Leu
355 360 365
Asp Asn Tyr Glu Trp Gly Thr Tyr Arg Pro Thr Phe Gly Leu Ile Gly
370 375 380
Val Asp Pro Asp Thr Phe Ala Arg Thr Pro Lys Pro Ser Ala Arg Trp
385 390 395 400
Leu Gly Ala Leu Ala Arg Asp Arg Arg Leu Pro Ala Ala Lys Ala Pro
405 410 415
Val Gly Thr Gly Ala Pro Thr Ala Arg
420 425
<210> 6
<211> 1275
<212> ДНК
<213> Искусственная последовательность
<220>
<223> GXT6
<400> 6
atgaccccac cgtttggtag cgaactggcg cttccggaaa cattccttat gggtgcggcc 60
acttcagctc accaggttga aggtaataat atcggtagcg attggtggga aattgagcac 120
cgcccggata cttttgttgc tcagccgtcc ggagatgcgg cagattccta tcaccgctgg 180
ccggaagata tggatttgct tgccggattg ggctttaatg cttatcgttt tagtattgag 240
tgggctcgta ttgaaccgga acctggtcgg atttcaagag cggctctggc gcattatcgt 300
gcgatggtcc gcggagcgct ggagcgtggc ctgacaccat tagtaacttt gcatcacttt 360
acatgcccac ggtggttttc agctcggggc ggttggttag ctccagatgc agcggaaact 420
tttactgctt atgccagaac tgccagcgag gtagttggtg agggcgtgtc tcatgtcgcg 480
acgatcaacg agcctaacat gctggcacat atgtatactt tgagaagact tgcagcggaa 540
cacggttggt cagccttagc ggaaggaaga cgtgctggcg ccgcagcttt tgatccggct 600
gctgttgccc cggatcgcga tgtgacggct gctctgattg aggcgcaccg tcgcagcgcc 660
gtagtgctgc gccaggccgg cctgcaggtt ggctggacag ttgccaatca ggtttatcac 720
gccgaaccgg gagcagaaga aattgctacg gcctatgctc ggccacggga ggatgtattc 780
ttggaggcag cccgcgaaga tgattggatc ggcgtgcagg catatactcg tcaccgtatt 840
ggaccggatg gacctctgcc ggtacctgat ggggcaccta caacacttac tggctgggaa 900
gtttatcctg atgcccttgc agaagccgtg ctgcatacag tcgccaccgt gggtgcgcag 960
gtaccagtta ttgtaacaga gaatggtatc gccaccggcg atgatgatca gcgtatcgca 1020
tatactagac aggcactggc agggttggcc cgtgtcatgc gcgaaggtgc ggatgtgcgg 1080
ggatattttc attggtccgc attagataac tatgaatggg gcacctatcg tccaaccttc 1140
gggttaatcg gggttgatcc ggatacgttt gctcggacgc ctaaaccttc tgcacgctgg 1200
ctgggtgctc tggcacgcga tcgcagactg ccagccgcga aagcgcctgt cggcactggc 1260
gcccctacag ctcgc 1275
<210> 7
<211> 458
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> C1m2
<400> 7
Met Asn Trp Gln Ile Ala Lys Glu Ile Leu Gly Lys Met Ile Lys Gln
1 5 10 15
Thr Lys Ala Ser Ser Gly Val Ile Trp Asn Ser Phe Lys Glu Leu Glu
20 25 30
Glu Ser Glu Leu Glu Thr Val Ile Arg Glu Ile Pro Ala Pro Ser Phe
35 40 45
Leu Ile Pro Leu Pro Lys His Leu Thr Ala Ser Ser Ser Ser Leu Leu
50 55 60
Asp His Asp Arg Thr Val Phe Gln Trp Leu Asp Gln Gln Pro Pro Ser
65 70 75 80
Ser Val Leu Tyr Val Ser Phe Gly Ser Thr Ser Glu Val Asp Glu Lys
85 90 95
Asp Phe Leu Glu Ile Ala Arg Gly Leu Val Asp Ser Lys Gln Ser Phe
100 105 110
Leu Trp Val Val Arg Pro Gly Phe Val Lys Gly Ser Thr Trp Val Glu
115 120 125
Pro Leu Pro Asp Gly Phe Leu Gly Glu Arg Gly Arg Ile Val Lys Trp
130 135 140
Val Pro Gln Gln Glu Val Leu Ala His Gly Ala Ile Gly Ala Phe Trp
145 150 155 160
Thr His Ser Gly Trp Asn Ser Thr Leu Glu Ser Val Cys Glu Gly Val
165 170 175
Pro Met Ile Phe Ser Asp Phe Gly Gly Asp Gln Pro Leu Asn Ala Arg
180 185 190
Tyr Met Ser Asp Val Leu Lys Val Gly Val Tyr Leu Glu Asn Gly Trp
195 200 205
Glu Arg Gly Glu Ile Ala Asn Ala Ile Arg Arg Val Met Val Asp Glu
210 215 220
Glu Gly Glu Tyr Ile Arg Gln Asn Ala Arg Val Leu Lys Gln Lys Ala
225 230 235 240
Asp Val Ser Leu Met Lys Gly Gly Ser Ser Tyr Glu Ser Leu Glu Ser
245 250 255
Leu Val Ser Tyr Ile Ser Ser Leu Glu Asn Lys Thr Glu Thr Thr Val
260 265 270
Arg Arg Arg Arg Arg Ile Ile Leu Phe Pro Val Pro Phe Gln Gly His
275 280 285
Ile Asn Pro Ile Leu Gln Leu Ala Asn Val Leu Tyr Ser Lys Gly Phe
290 295 300
Ser Ile Thr Ile Phe His Thr Asn Phe Asn Lys Pro Lys Thr Ser Asn
305 310 315 320
Tyr Pro His Phe Thr Phe Arg Phe Ile Leu Asp Asn Asp Pro Gln Asp
325 330 335
Glu Arg Ile Ser Asn Leu Pro Thr His Gly Pro Leu Ala Gly Met Arg
340 345 350
Ile Pro Ile Ile Asn Glu His Gly Ala Asp Glu Leu Arg Arg Glu Leu
355 360 365
Glu Leu Leu Met Leu Ala Ser Glu Glu Asp Glu Glu Val Ser Cys Leu
370 375 380
Ile Thr Asp Ala Leu Trp Tyr Phe Ala Gln Ser Val Ala Asp Ser Leu
385 390 395 400
Asn Leu Arg Arg Leu Val Leu Met Thr Ser Ser Leu Phe Asn Phe His
405 410 415
Ala His Val Ser Leu Pro Gln Phe Asp Glu Leu Gly Tyr Leu Asp Pro
420 425 430
Asp Asp Lys Thr Arg Leu Glu Glu Gln Ala Ser Gly Phe Pro Met Leu
435 440 445
Lys Val Lys Asp Ile Lys Ser Ala Tyr Ser
450 455
<210> 8
<211> 1377
<212> ДНК
<213> Искусственная последовательность
<220>
<223> C1m2
<400> 8
atgaactggc aaatcgcgaa agaaatcctg ggtaaaatga tcaaacaaac caaagcgtcg 60
tcgggcgtta tctggaactc cttcaaagaa ctggaagaat cagaactgga aaccgttatt 120
cgcgaaatcc cggctccgtc gttcctgatt ccgctgccga aacatctgac cgcgagcagc 180
agcagcctgc tggatcacga ccgtacggtc tttcagtggc tggatcagca accgccgtca 240
tcggtgctgt atgtttcatt cggtagcacc tctgaagtcg atgaaaaaga ctttctggaa 300
atcgctcgcg gcctggtgga tagtaaacag tccttcctgt gggtggttcg tccgggtttt 360
gtgaaaggca gcacgtgggt tgaaccgctg ccggatggct tcctgggtga acgcggccgt 420
attgtcaaat gggtgccgca gcaagaagtg ctggcacatg gtgctatcgg cgcgttttgg 480
acccactctg gttggaacag tacgctggaa tccgtttgcg aaggtgtccc gatgattttc 540
agcgattttg gcggcgacca gccgctgaat gcccgctata tgtctgatgt tctgaaagtc 600
ggtgtgtacc tggaaaacgg ttgggaacgt ggcgaaattg cgaatgccat ccgtcgcgtt 660
atggtcgatg aagaaggcga atacattcgc cagaacgctc gtgtcctgaa acaaaaagcg 720
gacgtgagcc tgatgaaagg cggtagctct tatgaatcac tggaatcgct ggttagctac 780
atcagttccc tggaaaataa aaccgaaacc acggtgcgtc gccgtcgccg tattatcctg 840
ttcccggttc cgtttcaggg tcatattaac ccgatcctgc aactggcgaa tgttctgtat 900
tcaaaaggct tttcgatcac catcttccat acgaacttca acaaaccgaa aaccagtaac 960
tacccgcact ttacgttccg ctttattctg gataacgacc cgcaggatga acgtatctcc 1020
aatctgccga cccacggccc gctggccggt atgcgcattc cgattatcaa tgaacacggt 1080
gcagatgaac tgcgccgtga actggaactg ctgatgctgg ccagtgaaga agatgaagaa 1140
gtgtcctgtc tgatcaccga cgcactgtgg tatttcgccc agagcgttgc agattctctg 1200
aacctgcgcc gtctggtcct gatgacgtca tcgctgttca attttcatgc gcacgtttct 1260
ctgccgcaat ttgatgaact gggctacctg gacccggatg acaaaacccg tctggaagaa 1320
caagccagtg gttttccgat gctgaaagtc aaagacatta aatccgccta ttcgtaa 1377
<210> 9
<211> 458
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> C1m3
<400> 9
Met Asn Trp Gln Ile Ala Lys Glu Ile Leu Gly Lys Met Ile Lys Gln
1 5 10 15
Thr Lys Ala Ser Ser Gly Val Ile Trp Asn Ser Phe Lys Glu Leu Glu
20 25 30
Glu Ser Glu Leu Glu Thr Val Ile Arg Glu Ile Pro Ala Pro Ser Phe
35 40 45
Leu Ile Pro Leu Pro Lys His Leu Thr Ala Ser Ser Ser Ser Leu Leu
50 55 60
Asp His Asp Arg Thr Val Phe Gln Trp Leu Asp Gln Gln Pro Pro Ser
65 70 75 80
Ser Val Leu Tyr Val Ser Phe Gly Ser Ala Ser Glu Val Asp Glu Lys
85 90 95
Asp Phe Leu Glu Ile Ala Arg Gly Leu Val Asp Ser Lys Gln Ser Phe
100 105 110
Leu Trp Val Val Arg Pro Gly Phe Val Lys Gly Ser Thr Trp Val Glu
115 120 125
Pro Leu Pro Asp Gly Phe Leu Gly Glu Arg Gly Arg Ile Val Lys Trp
130 135 140
Val Pro Gln Gln Glu Val Leu Ala His Gly Ala Ile Gly Ala Phe Trp
145 150 155 160
Thr His Ser Gly Trp Asn Ser Thr Leu Glu Ser Val Cys Glu Gly Val
165 170 175
Pro Met Ile Phe Ser Asp Phe Gly Gly Asp Gln Pro Leu Asn Ala Arg
180 185 190
Tyr Met Ser Asp Val Leu Lys Val Gly Val Tyr Leu Glu Asn Gly Trp
195 200 205
Glu Arg Gly Glu Ile Ala Asn Ala Ile Arg Arg Val Met Val Asp Glu
210 215 220
Glu Gly Glu Tyr Ile Arg Gln Asn Ala Arg Val Leu Lys Gln Lys Ala
225 230 235 240
Asp Val Ser Leu Met Lys Gly Gly Ser Ser Tyr Glu Ser Leu Glu Ser
245 250 255
Leu Val Ser Tyr Ile Ser Ser Leu Glu Asn Lys Thr Glu Thr Thr Val
260 265 270
Arg Arg Arg Arg Arg Ile Ile Leu Phe Pro Val Pro Phe Gln Gly His
275 280 285
Ile Asn Pro Ile Leu Gln Leu Ala Asn Val Leu Tyr Ser Lys Gly Phe
290 295 300
Ser Ile Thr Ile Phe His Thr Asn Phe Asn Lys Pro Lys Thr Ser Asn
305 310 315 320
Tyr Pro His Phe Thr Phe Arg Phe Ile Leu Asp Asn Asp Pro Gln Asp
325 330 335
Glu Arg Ile Ser Asn Leu Pro Thr His Gly Pro Leu Ala Gly Met Arg
340 345 350
Ile Pro Ile Ile Asn Glu His Gly Ala Asp Glu Leu Arg Arg Glu Leu
355 360 365
Glu Leu Leu Met Leu Ala Ser Glu Glu Asp Glu Glu Val Ser Cys Leu
370 375 380
Ile Thr Asp Ala Leu Trp Tyr Phe Ala Gln Ser Val Ala Asp Ser Leu
385 390 395 400
Asn Leu Arg Arg Leu Val Leu Met Thr Ser Ser Leu Phe Asn Phe His
405 410 415
Ala His Val Ser Leu Pro Gln Phe Asp Glu Leu Gly Tyr Leu Asp Pro
420 425 430
Asp Asp Lys Thr Arg Leu Glu Glu Gln Ala Ser Gly Phe Pro Met Leu
435 440 445
Lys Val Lys Asp Ile Lys Ser Ala Tyr Ser
450 455
<210> 10
<211> 1377
<212> ДНК
<213> Искусственная последовательность
<220>
<223> C1m3
<400> 10
atgaactggc aaatcgcgaa agaaatcctg ggtaaaatga tcaaacaaac caaagcgtcg 60
tcgggcgtta tctggaactc cttcaaagaa ctggaagaat cagaactgga aaccgttatt 120
cgcgaaatcc cggctccgtc gttcctgatt ccgctgccga aacatctgac cgcgagcagc 180
agcagcctgc tggatcacga ccgtacggtc tttcagtggc tggatcagca accgccgtca 240
tcggtgctgt atgtttcatt cggtagcgcc tctgaagtcg atgaaaaaga ctttctggaa 300
atcgctcgcg gcctggtgga tagtaaacag tccttcctgt gggtggttcg tccgggtttt 360
gtgaaaggca gcacgtgggt tgaaccgctg ccggatggct tcctgggtga acgcggccgt 420
attgtcaaat gggtgccgca gcaagaagtg ctggcacatg gtgctatcgg cgcgttttgg 480
acccactctg gttggaacag tacgctggaa tccgtttgcg aaggtgtccc gatgattttc 540
agcgattttg gcggcgacca gccgctgaat gcccgctata tgtctgatgt tctgaaagtc 600
ggtgtgtacc tggaaaacgg ttgggaacgt ggcgaaattg cgaatgccat ccgtcgcgtt 660
atggtcgatg aagaaggcga atacattcgc cagaacgctc gtgtcctgaa acaaaaagcg 720
gacgtgagcc tgatgaaagg cggtagctct tatgaatcac tggaatcgct ggttagctac 780
atcagttccc tggaaaataa aaccgaaacc acggtgcgtc gccgtcgccg tattatcctg 840
ttcccggttc cgtttcaggg tcatattaac ccgatcctgc aactggcgaa tgttctgtat 900
tcaaaaggct tttcgatcac catcttccat acgaacttca acaaaccgaa aaccagtaac 960
tacccgcact ttacgttccg ctttattctg gataacgacc cgcaggatga acgtatctcc 1020
aatctgccga cccacggccc gctggccggt atgcgcattc cgattatcaa tgaacacggt 1080
gcagatgaac tgcgccgtga actggaactg ctgatgctgg ccagtgaaga agatgaagaa 1140
gtgtcctgtc tgatcaccga cgcactgtgg tatttcgccc agagcgttgc agattctctg 1200
aacctgcgcc gtctggtcct gatgacgtca tcgctgttca attttcatgc gcacgtttct 1260
ctgccgcaat ttgatgaact gggctacctg gacccggatg acaaaacccg tctggaagaa 1320
caagccagtg gttttccgat gctgaaagtc aaagacatta aatccgccta ttcgtaa 1377
<210> 11
<211> 459
<212> БЕЛОК
<213> Hordeum vulgare
<400> 11
Met Asp Gly Asn Ser Ser Ser Ser Pro Leu His Val Val Ile Cys Pro
1 5 10 15
Trp Leu Ala Leu Gly His Leu Leu Pro Cys Leu Asp Ile Ala Glu Arg
20 25 30
Leu Ala Ser Arg Gly His Arg Val Ser Phe Val Ser Thr Pro Arg Asn
35 40 45
Ile Ala Arg Leu Pro Pro Leu Arg Pro Ala Val Ala Pro Leu Val Asp
50 55 60
Phe Val Ala Leu Pro Leu Pro His Val Asp Gly Leu Pro Glu Gly Ala
65 70 75 80
Glu Ser Thr Asn Asp Val Pro Tyr Asp Lys Phe Glu Leu His Arg Lys
85 90 95
Ala Phe Asp Gly Leu Ala Ala Pro Phe Ser Glu Phe Leu Arg Ala Ala
100 105 110
Cys Ala Glu Gly Ala Gly Ser Arg Pro Asp Trp Leu Ile Val Asp Thr
115 120 125
Phe His His Trp Ala Ala Ala Ala Ala Val Glu Asn Lys Val Pro Cys
130 135 140
Val Met Leu Leu Leu Gly Ala Ala Thr Val Ile Ala Gly Phe Ala Arg
145 150 155 160
Gly Val Ser Glu His Ala Ala Ala Ala Val Gly Lys Glu Arg Pro Ala
165 170 175
Ala Glu Ala Pro Ser Phe Glu Thr Glu Arg Arg Lys Leu Met Thr Thr
180 185 190
Gln Asn Ala Ser Gly Met Thr Val Ala Glu Arg Tyr Phe Leu Thr Leu
195 200 205
Met Arg Ser Asp Leu Val Ala Ile Arg Ser Cys Ala Glu Trp Glu Pro
210 215 220
Glu Ser Val Ala Ala Leu Thr Thr Leu Ala Gly Lys Pro Val Val Pro
225 230 235 240
Leu Gly Leu Leu Pro Pro Ser Pro Glu Gly Gly Arg Gly Val Ser Lys
245 250 255
Glu Asp Ala Ala Val Arg Trp Leu Asp Ala Gln Pro Ala Lys Ser Val
260 265 270
Val Tyr Val Ala Leu Gly Ser Glu Val Pro Leu Arg Ala Glu Gln Val
275 280 285
His Glu Leu Ala Leu Gly Leu Glu Leu Ser Gly Ala Arg Phe Leu Trp
290 295 300
Ala Leu Arg Lys Pro Thr Asp Ala Pro Asp Ala Ala Val Leu Pro Pro
305 310 315 320
Gly Phe Glu Glu Arg Thr Arg Gly Arg Gly Leu Val Val Thr Gly Trp
325 330 335
Val Pro Gln Ile Gly Val Leu Ala His Gly Ala Val Ala Ala Phe Leu
340 345 350
Thr His Cys Gly Trp Asn Ser Thr Ile Glu Gly Leu Leu Phe Gly His
355 360 365
Pro Leu Ile Met Leu Pro Ile Ser Ser Asp Gln Gly Pro Asn Ala Arg
370 375 380
Leu Met Glu Gly Arg Lys Val Gly Met Gln Val Pro Arg Asp Glu Ser
385 390 395 400
Asp Gly Ser Phe Arg Arg Glu Asp Val Ala Ala Thr Val Arg Ala Val
405 410 415
Ala Val Glu Glu Asp Gly Arg Arg Val Phe Thr Ala Asn Ala Lys Lys
420 425 430
Met Gln Glu Ile Val Ala Asp Gly Ala Cys His Glu Arg Cys Ile Asp
435 440 445
Gly Phe Ile Gln Gln Leu Arg Ser Tyr Lys Ala
450 455
<210> 12
<211> 1380
<212> ДНК
<213> Hordeum vulgare
<400> 12
atggatggta actcctcctc ctcgccgctg catgtggtca tttgtccgtg gctggctctg 60
ggtcacctgc tgccgtgtct ggatattgct gaacgtctgg cgtcacgcgg ccatcgtgtc 120
agttttgtgt ccaccccgcg caacattgcc cgtctgccgc cgctgcgtcc ggctgttgca 180
ccgctggttg atttcgtcgc actgccgctg ccgcatgttg acggtctgcc ggagggtgcg 240
gaatcgacca atgatgtgcc gtatgacaaa tttgaactgc accgtaaggc gttcgatggt 300
ctggcggccc cgtttagcga atttctgcgt gcagcttgcg cagaaggtgc aggttctcgc 360
ccggattggc tgattgtgga cacctttcat cactgggcgg cggcggcggc ggtggaaaac 420
aaagtgccgt gtgttatgct gctgctgggt gcagcaacgg tgatcgctgg tttcgcgcgt 480
ggtgttagcg aacatgcggc ggcggcggtg ggtaaagaac gtccggctgc ggaagccccg 540
agttttgaaa ccgaacgtcg caagctgatg accacgcaga atgcctccgg catgaccgtg 600
gcagaacgct atttcctgac gctgatgcgt agcgatctgg ttgccatccg ctcttgcgca 660
gaatgggaac cggaaagcgt ggcagcactg accacgctgg caggtaaacc ggtggttccg 720
ctgggtctgc tgccgccgag tccggaaggc ggtcgtggcg tttccaaaga agatgctgcg 780
gtccgttggc tggacgcaca gccggcaaag tcagtcgtgt acgtcgcact gggttcggaa 840
gtgccgctgc gtgcggaaca agttcacgaa ctggcactgg gcctggaact gagcggtgct 900
cgctttctgt gggcgctgcg taaaccgacc gatgcaccgg acgccgcagt gctgccgccg 960
ggtttcgaag aacgtacccg cggccgtggt ctggttgtca cgggttgggt gccgcagatt 1020
ggcgttctgg ctcatggtgc ggtggctgcg tttctgaccc actgtggctg gaactctacg 1080
atcgaaggcc tgctgttcgg tcatccgctg attatgctgc cgatcagctc tgatcagggt 1140
ccgaatgcgc gcctgatgga aggccgtaaa gtcggtatgc aagtgccgcg tgatgaatca 1200
gacggctcgt ttcgtcgcga agatgttgcc gcaaccgtcc gcgccgtggc agttgaagaa 1260
gacggtcgtc gcgtcttcac ggctaacgcg aaaaagatgc aagaaattgt ggccgatggc 1320
gcatgccacg aacgttgtat tgacggtttt atccagcaac tgcgcagtta caaggcgtaa 1380
<210> 13
<211> 458
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> CR1
<400> 13
Met Asn Trp Gln Ile Ala Lys Glu Ile Leu Gly Lys Met Ile Lys Gln
1 5 10 15
Thr Lys Ala Ser Ser Gly Val Ile Trp Asn Ser Phe Lys Glu Leu Glu
20 25 30
Glu Ser Glu Leu Glu Thr Val Ile Arg Glu Ile Pro Ala Pro Ser Phe
35 40 45
Leu Ile Pro Leu Pro Lys His Leu Thr Ala Ser Ser Ser Ser Leu Leu
50 55 60
Asp His Asp Arg Thr Val Phe Gln Trp Leu Asp Gln Gln Pro Pro Ser
65 70 75 80
Ser Val Leu Tyr Val Ser Phe Gly Ser Thr Ser Glu Val Asp Glu Lys
85 90 95
Asp Phe Leu Glu Ile Ala Arg Gly Leu Val Asp Ser Lys Gln Ser Phe
100 105 110
Leu Trp Val Val Arg Pro Gly Phe Val Lys Gly Ser Thr Trp Val Glu
115 120 125
Pro Leu Pro Asp Gly Phe Leu Gly Glu Arg Gly Arg Ile Val Lys Trp
130 135 140
Val Pro Gln Gln Glu Val Leu Ala His Gly Ala Ile Gly Ala Phe Trp
145 150 155 160
Thr His Ser Gly Trp Asn Ser Thr Leu Glu Ser Val Cys Glu Gly Val
165 170 175
Pro Met Ile Phe Ser Asp Phe Gly Leu Asp Gln Pro Leu Asn Ala Arg
180 185 190
Tyr Met Ser Asp Val Leu Lys Val Gly Val Tyr Leu Glu Asn Gly Trp
195 200 205
Glu Arg Gly Glu Ile Ala Asn Ala Ile Arg Arg Val Met Val Asp Glu
210 215 220
Glu Gly Glu Tyr Ile Arg Gln Asn Ala Arg Val Leu Lys Gln Lys Ala
225 230 235 240
Asp Val Ser Leu Met Lys Gly Gly Ser Ser Tyr Glu Ser Leu Glu Ser
245 250 255
Leu Val Ser Tyr Ile Ser Ser Leu Glu Asn Lys Thr Glu Thr Thr Val
260 265 270
Arg Arg Arg Arg Arg Ile Ile Leu Phe Pro Val Pro Phe Gln Gly His
275 280 285
Ile Asn Pro Ile Leu Gln Leu Ala Asn Val Leu Tyr Ser Lys Gly Phe
290 295 300
Ser Ile Thr Ile Phe His Thr Asn Phe Asn Lys Pro Lys Thr Ser Asn
305 310 315 320
Tyr Pro His Phe Thr Phe Arg Phe Ile Leu Asp Asn Asp Pro Gln Asp
325 330 335
Glu Arg Ile Ser Asn Leu Pro Thr His Gly Pro Leu Ala Gly Met Arg
340 345 350
Ile Pro Ile Ile Asn Glu His Gly Ala Asp Glu Leu Arg Arg Glu Leu
355 360 365
Glu Leu Leu Met Leu Ala Ser Glu Glu Asp Glu Glu Val Ser Cys Leu
370 375 380
Ile Thr Asp Ala Leu Trp Tyr Phe Ala Gln Ser Val Ala Asp Ser Leu
385 390 395 400
Asn Leu Arg Arg Leu Val Leu Met Thr Ser Ser Leu Phe Asn Phe His
405 410 415
Ala His Val Ser Leu Pro Gln Phe Asp Glu Leu Gly Tyr Leu Asp Pro
420 425 430
Asp Asp Lys Thr Arg Leu Glu Glu Gln Ala Ser Gly Phe Pro Met Leu
435 440 445
Lys Val Lys Asp Ile Lys Ser Ala Tyr Ser
450 455
<210> 14
<211> 1377
<212> ДНК
<213> Искусственная последовательность
<220>
<223> CR1
<400> 14
atgaactggc aaatcgcgaa agaaatcctg ggtaaaatga tcaaacaaac caaagcgtcg 60
tcgggcgtta tctggaactc cttcaaagaa ctggaagaat cagaactgga aaccgttatt 120
cgcgaaatcc cggctccgtc gttcctgatt ccgctgccga aacatctgac cgcgagcagc 180
agcagcctgc tggatcacga ccgtacggtc tttcagtggc tggatcagca accgccgtca 240
tcggtgctgt atgtttcatt cggtagcacc tctgaagtcg atgaaaaaga ctttctggaa 300
atcgctcgcg gcctggtgga tagtaaacag tccttcctgt gggtggttcg tccgggtttt 360
gtgaaaggca gcacgtgggt tgaaccgctg ccggatggct tcctgggtga acgcggccgt 420
attgtcaaat gggtgccgca gcaagaagtg ctggcacatg gtgctatcgg cgcgttttgg 480
acccactctg gttggaacag tacgctggaa tccgtttgcg aaggtgtccc gatgattttc 540
agcgactttg gcctggacca gccgctgaat gcccgctata tgtctgatgt tctgaaagtc 600
ggtgtgtacc tggaaaacgg ttgggaacgt ggcgaaattg cgaatgccat ccgtcgcgtt 660
atggtcgatg aagaaggcga atacattcgc cagaacgctc gtgtcctgaa acaaaaagcg 720
gacgtgagcc tgatgaaagg cggtagctct tatgaatcac tggaatcgct ggttagctac 780
atcagttccc tggaaaataa aaccgaaacc acggtgcgtc gccgtcgccg tattatcctg 840
ttcccggttc cgtttcaggg tcatattaac ccgatcctgc aactggcgaa tgttctgtat 900
tcaaaaggct tttcgatcac catcttccat acgaacttca acaaaccgaa aaccagtaac 960
tacccgcact ttacgttccg ctttattctg gataacgacc cgcaggatga acgtatctcc 1020
aatctgccga cccacggccc gctggccggt atgcgcattc cgattatcaa tgaacacggt 1080
gcagatgaac tgcgccgtga actggaactg ctgatgctgg ccagtgaaga agatgaagaa 1140
gtgtcctgtc tgatcaccga cgcactgtgg tatttcgccc agagcgttgc agattctctg 1200
aacctgcgcc gtctggtcct gatgacgtca tcgctgttca attttcatgc gcacgtttct 1260
ctgccgcaat ttgatgaact gggctacctg gacccggatg acaaaacccg tctggaagaa 1320
caagccagtg gttttccgat gctgaaagtc aaagacatta aatccgccta ttcgtaa 1377
<---
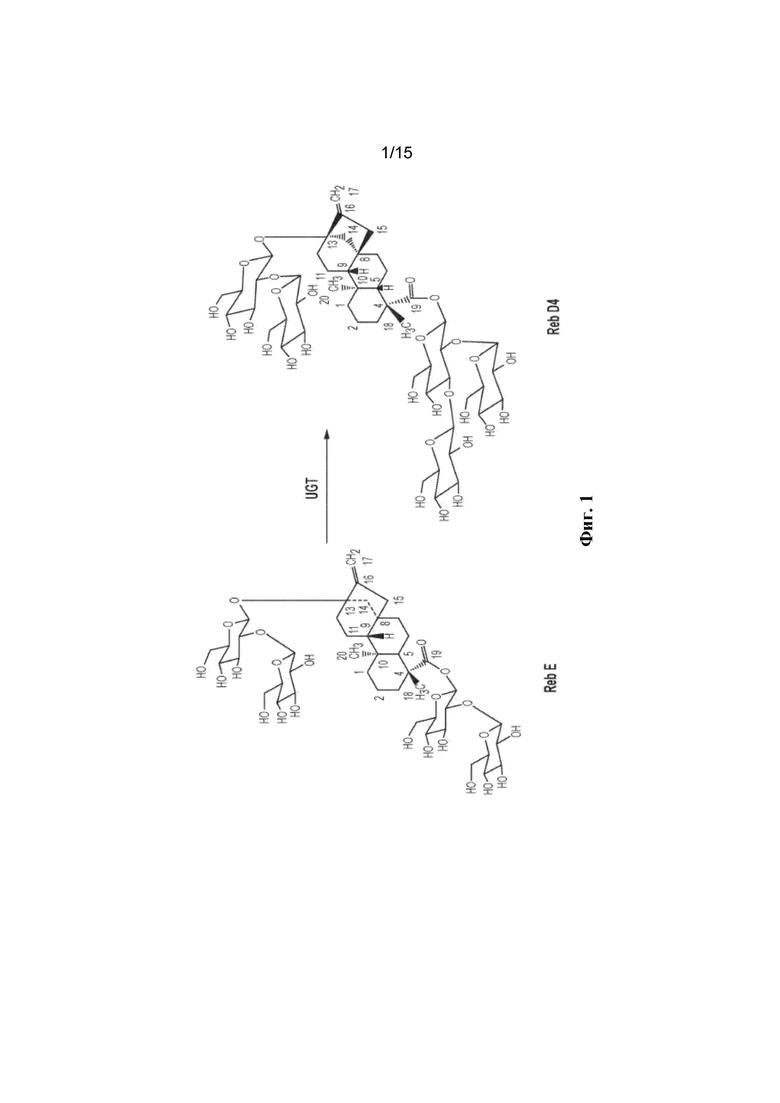
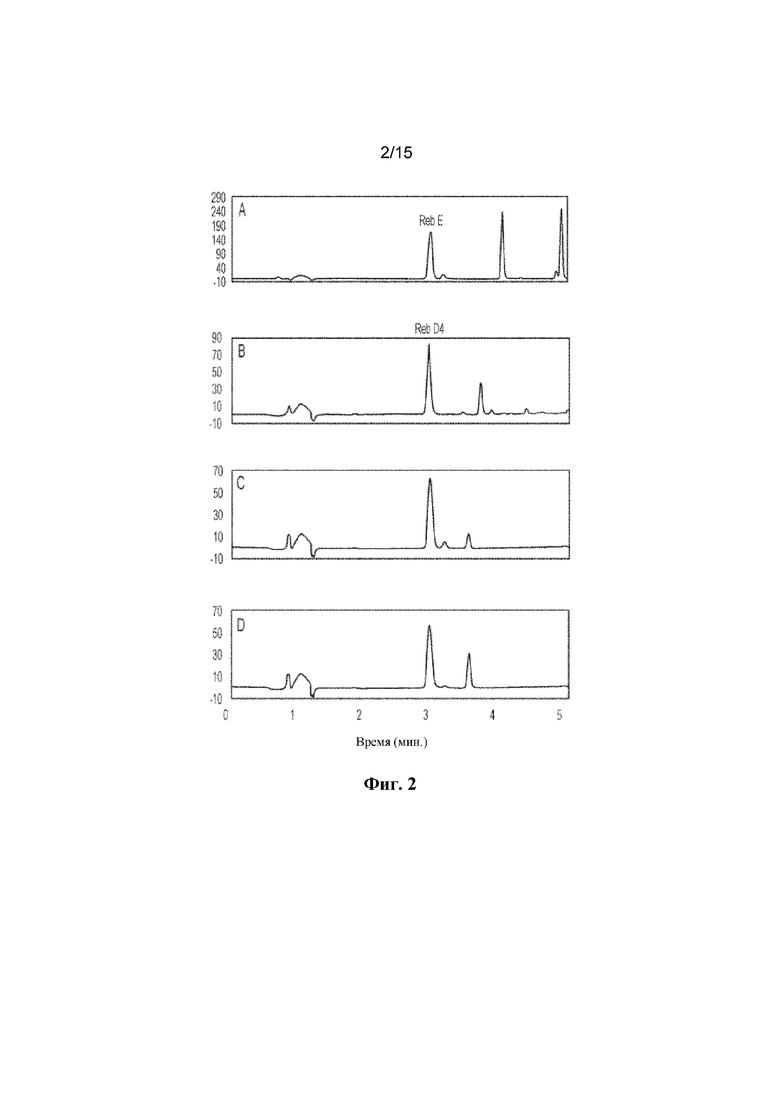
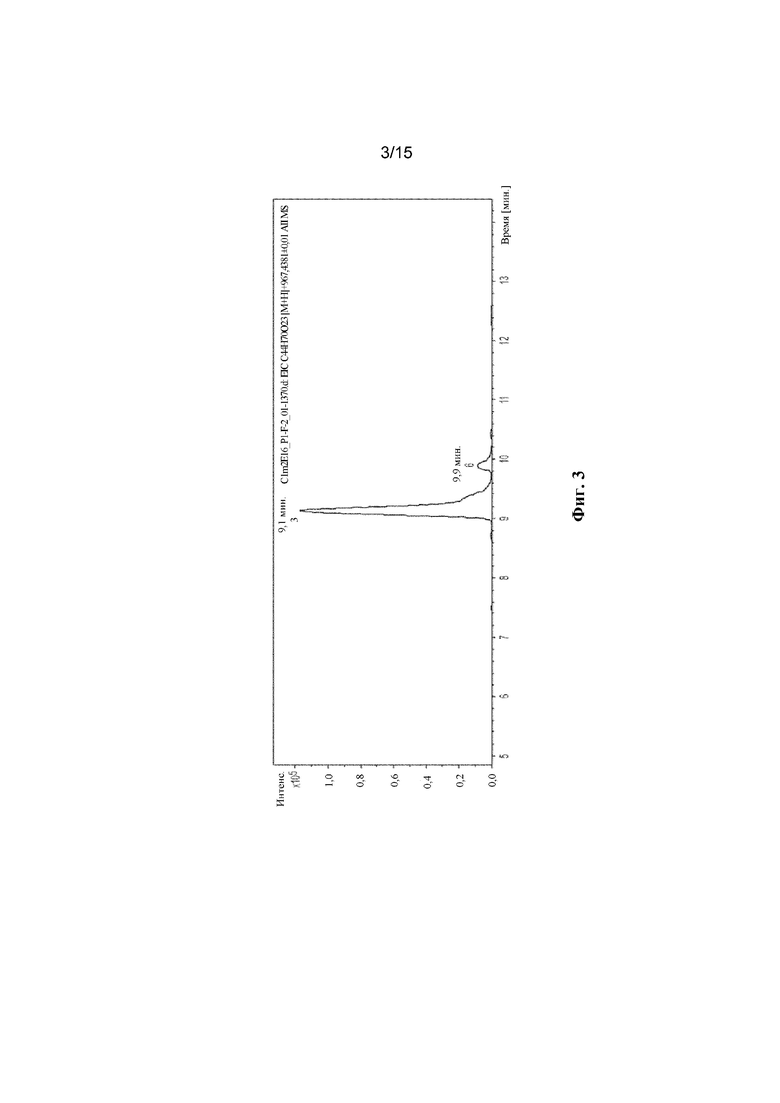

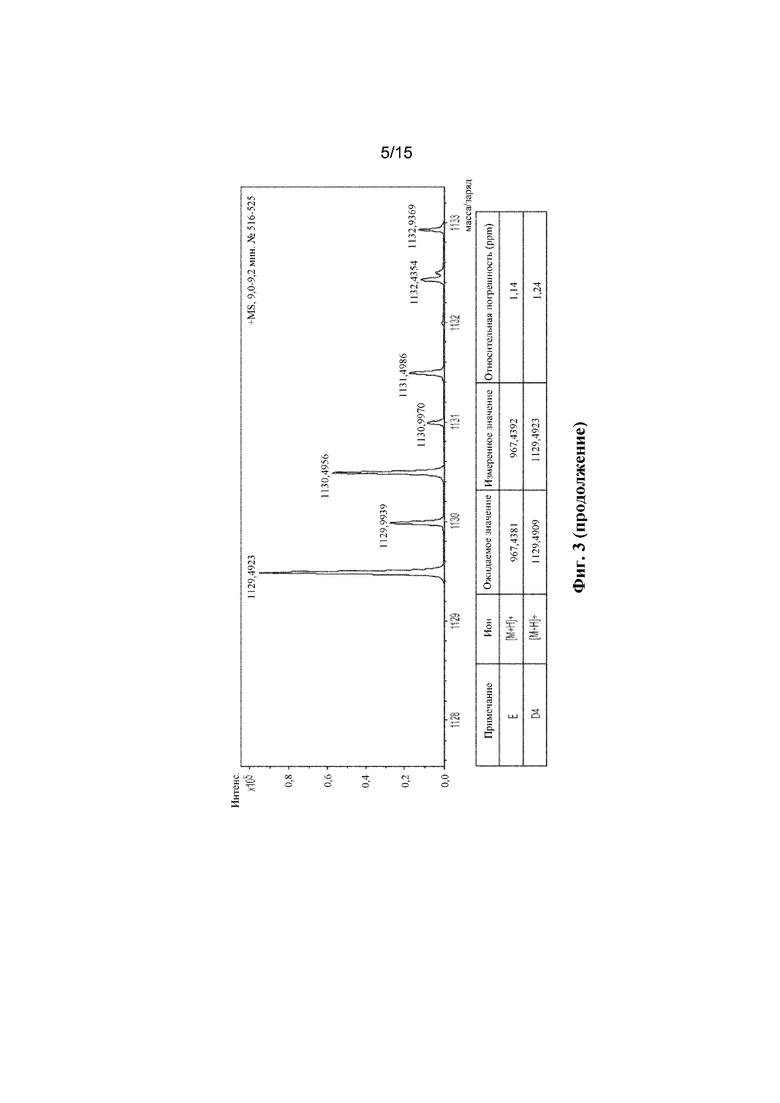
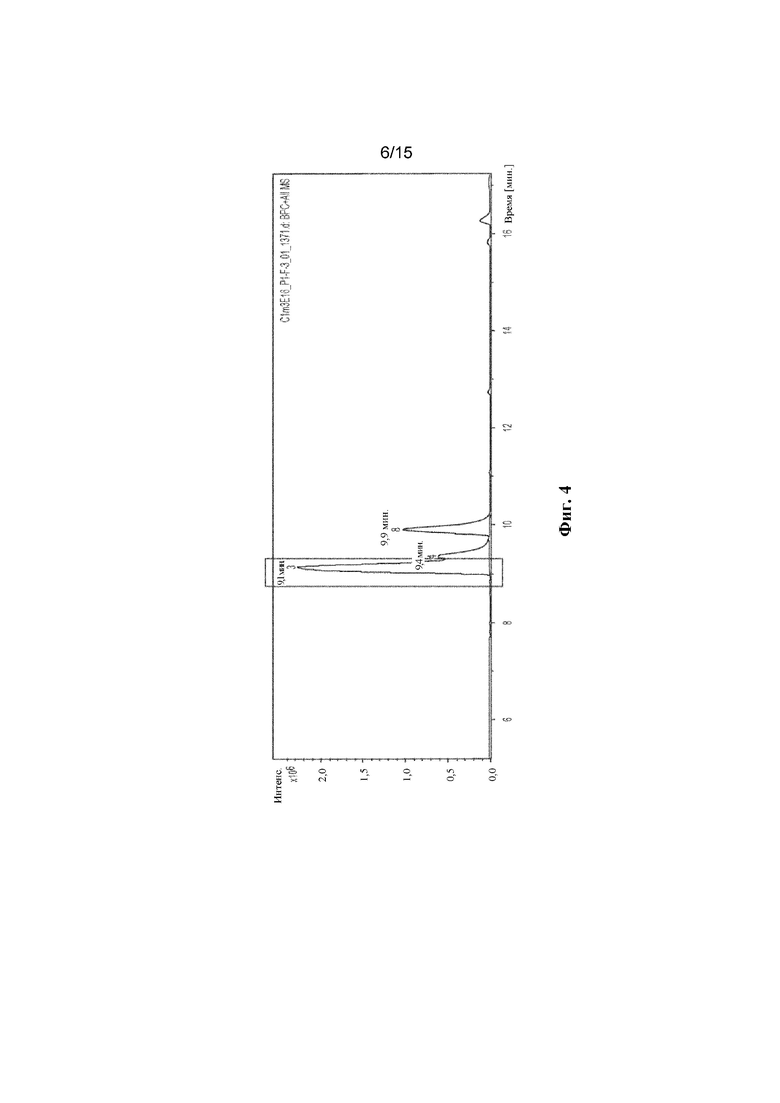


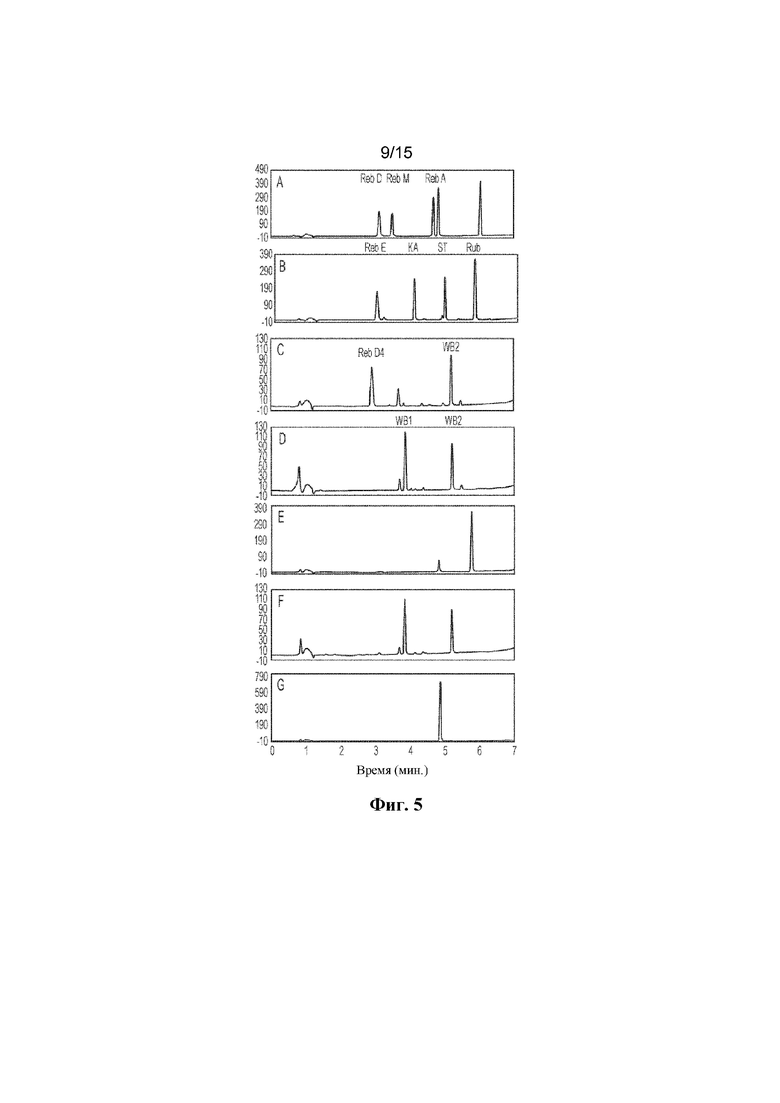
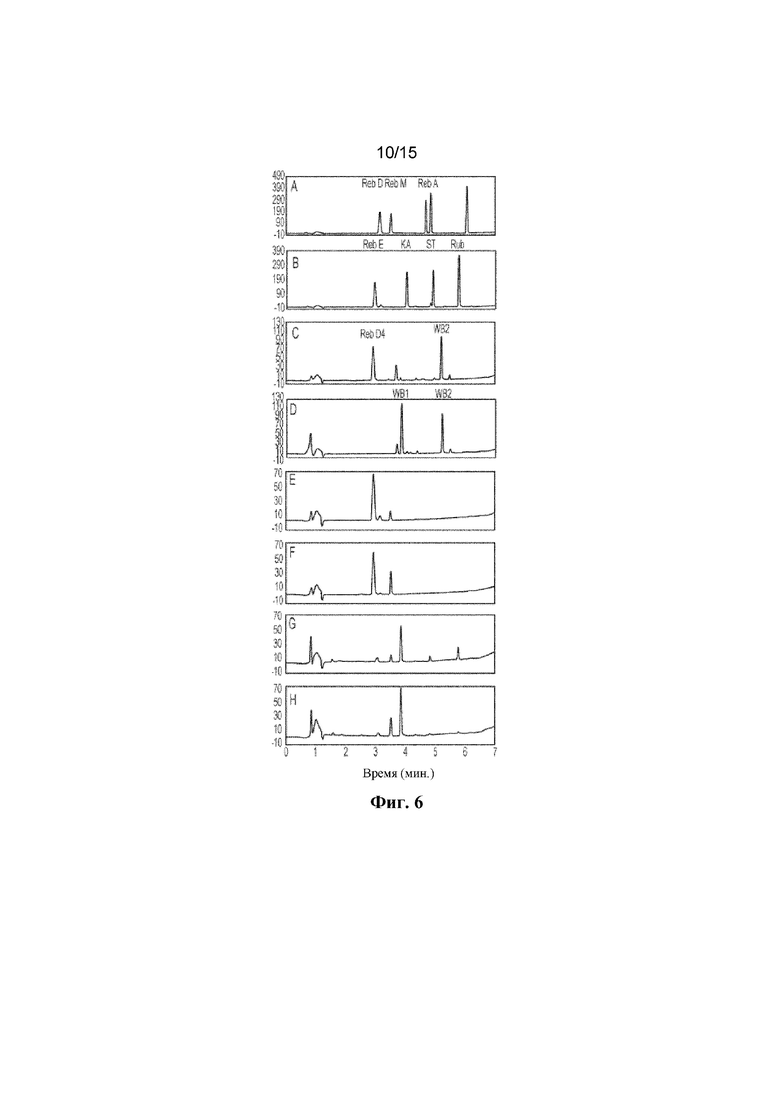
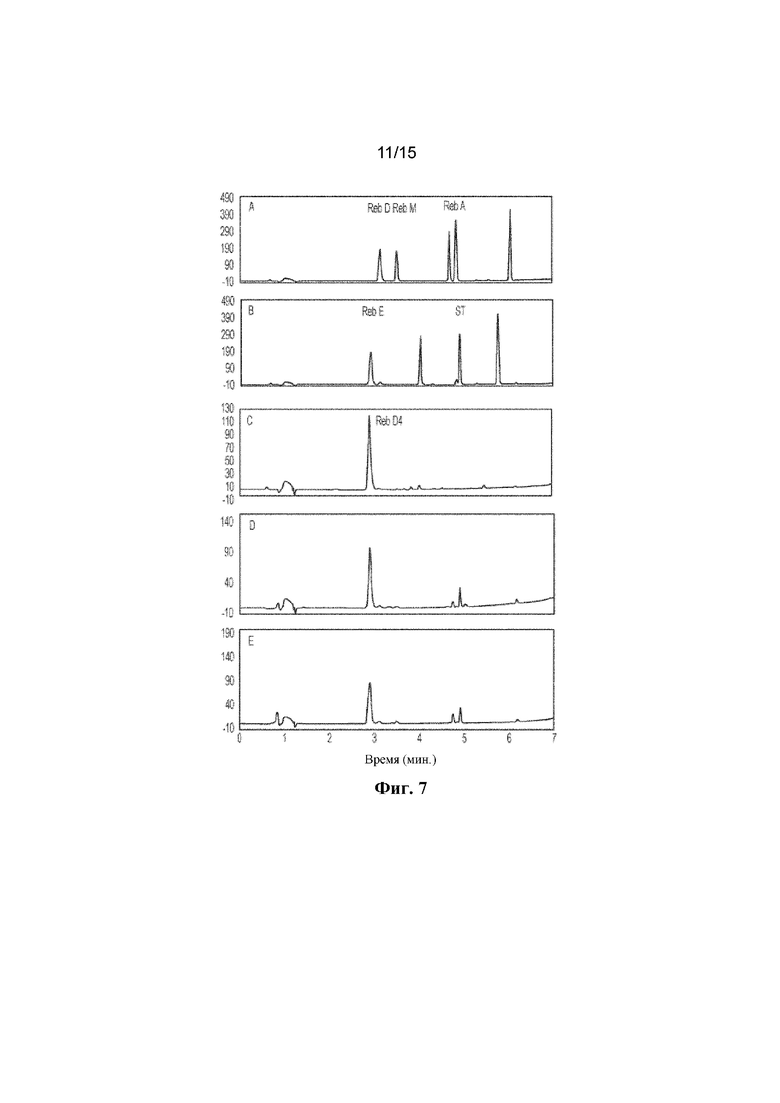
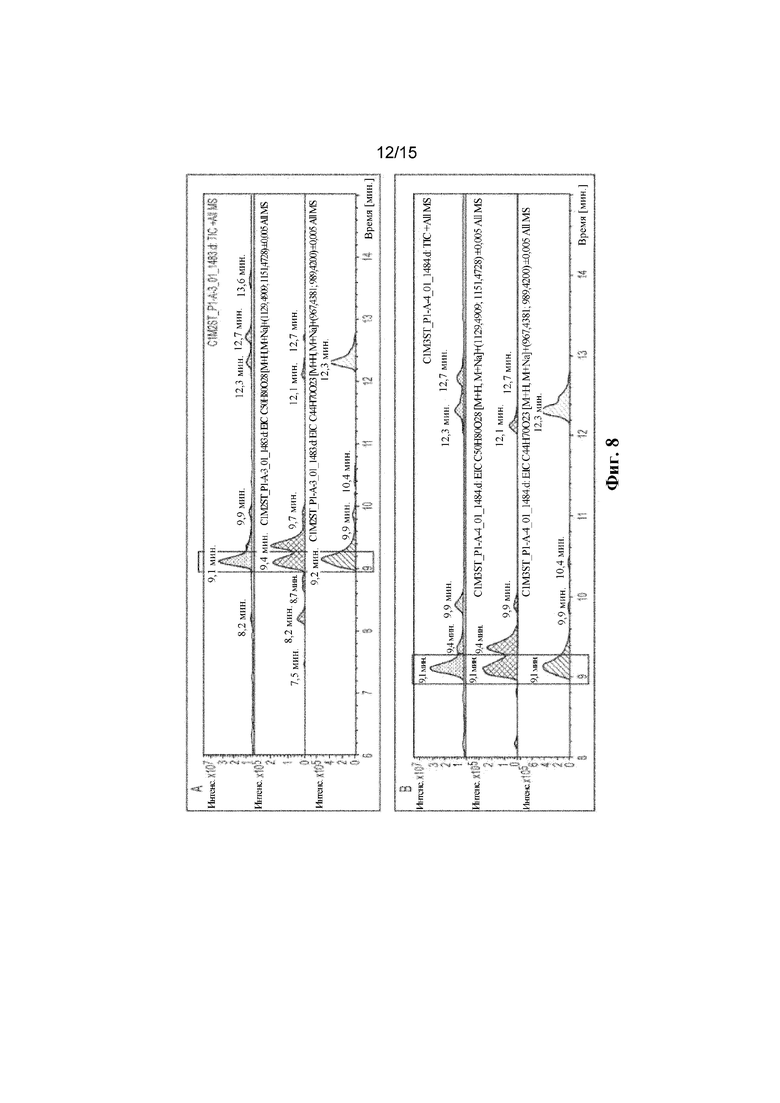
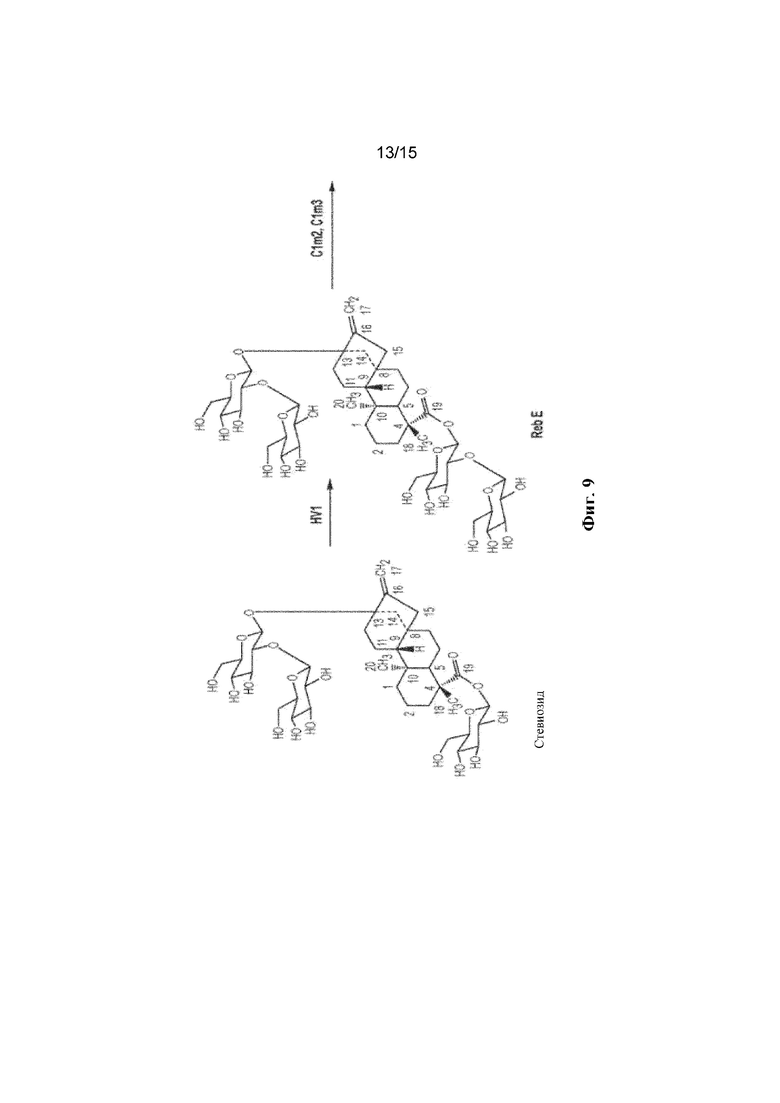
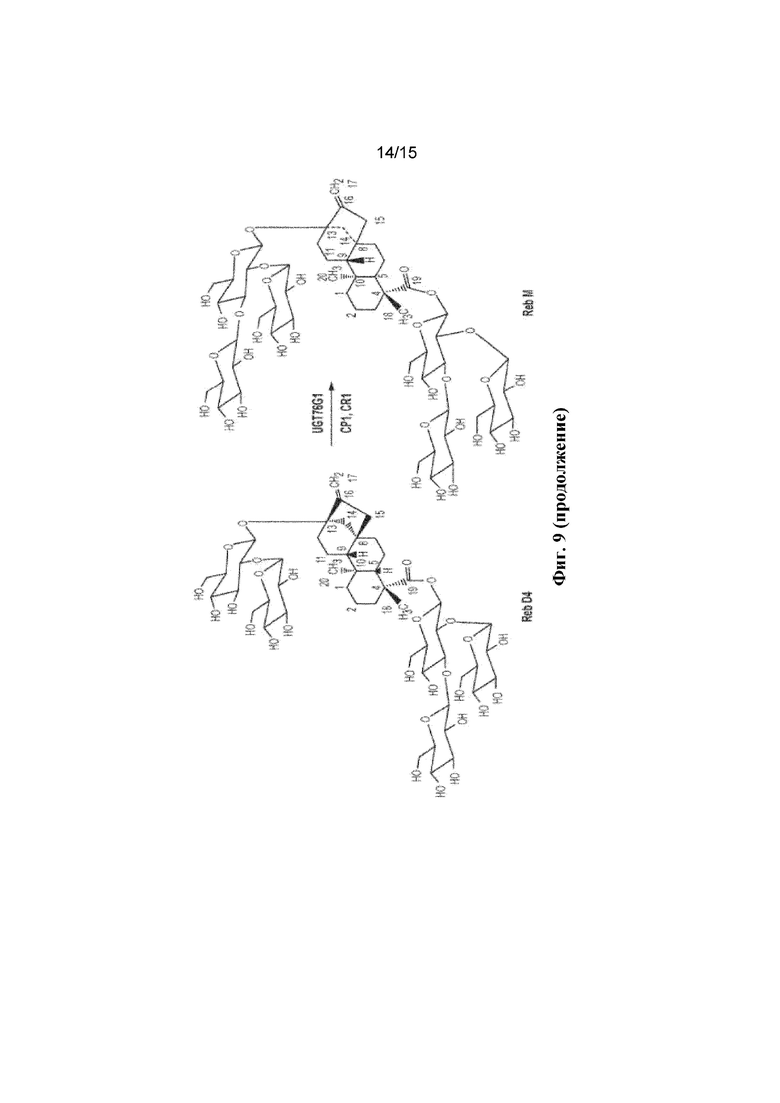
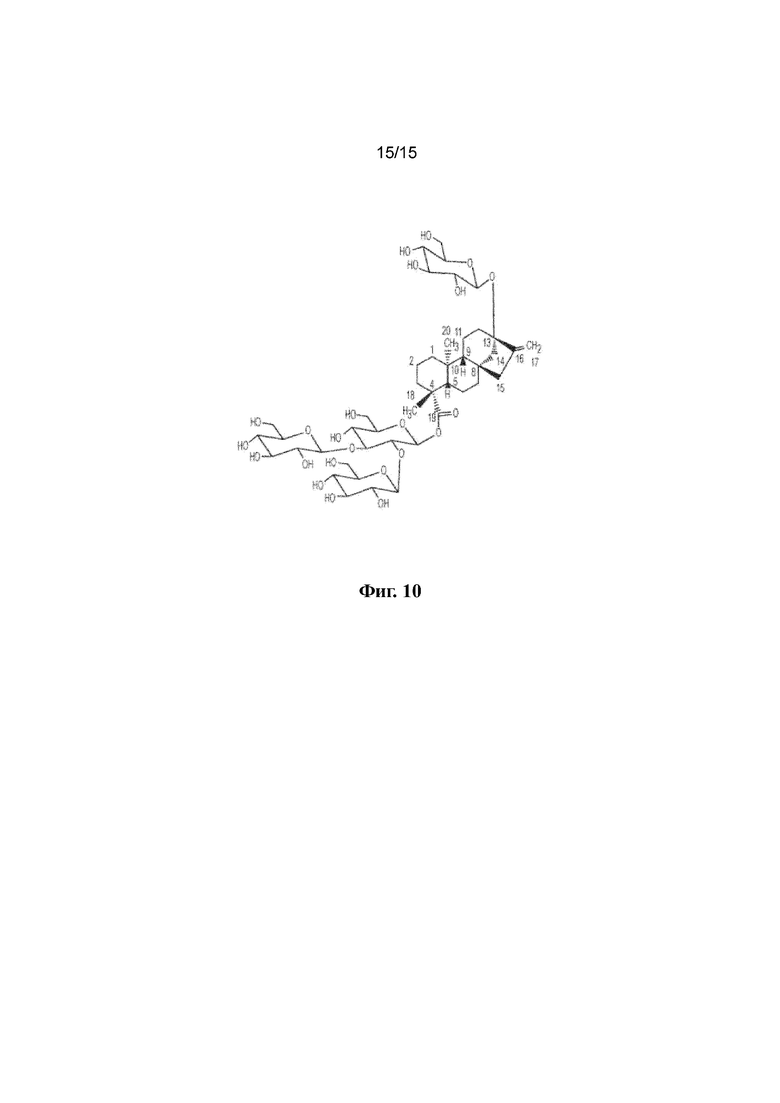
Изобретение относится к биотехнологии и пищевой промышленности. Способ получения ребаудиозида D4 осуществляют следующим образом. Инкубируют в реакционной смеси ребаудиозид E, рекомбинантный полипептид, который представляет собой UDP–гликозилтрансферазу (UGT), выбранную из Clm2, содержащую аминокислотную последовательность, характеризующуюся по меньшей мере 80%-ной идентичностью с SEQ ID NO: 7, и Clm3, содержащую аминокислотную последовательность, характеризующуюся по меньшей мере 80%-ной идентичностью с SEQ ID NO: 9, и субстрат, выбранный из группы, состоящей из сахарозы, уридиндифосфата (UDP) и уридиндифосфатглюкозы (UDP–глюкоза). Таким образом, ребаудиозид E превращается в ребаудиозид D4. Изобретение обеспечивает продуктивный способ синтеза для улучшения вкусовых качеств экстрактов stevia и увеличения выхода тех ребаудиозидных соединений, которые в целом имеют более желательные вкусовые характеристики, чистота ребаудиозида D4 составляет более 70%. 10 з.п. ф-лы, 10 ил., 1 табл., 5 пр.
1. Способ получения ребаудиозида D4, при этом способ предусматривает инкубирование в реакционной смеси:
ребаудиозида E;
рекомбинантного полипептида, который представляет собой UDP–гликозилтрансферазу (UGT), выбранную из Clm2, содержащую аминокислотную последовательность, характеризующуюся по меньшей мере 80%-ной идентичностью с SEQ ID NO: 7, и Clm3, содержащую аминокислотную последовательность, характеризующуюся по меньшей мере 80%-ной идентичностью с SEQ ID NO: 9; и
субстрат, выбранный из группы, состоящей из сахарозы, уридиндифосфата (UDP) и уридиндифосфатглюкозы (UDP–глюкоза),
таким образом ребаудиозид E превращается в ребаудиозид D4.
2. Способ по п.1, где ребаудиозид E формируется в реакционной смеси путем превращения стевиозида в ребаудиозид E.
3. Способ по п.1, дополнительно предусматривающий инкубирование рекомбинантной сахарозосинтазы в реакционной смеси.
4. Способ по п.1, где рекомбинантный полипептид содержит аминокислотную последовательность, имеющую по меньшей мере 90%-ную идентичность с SEQ ID NO: 7.
5. Способ по п.4, где рекомбинантный полипептид содержит аминокислотную последовательность SEQ ID NO: 7.
6. Способ по п.1, где рекомбинантный полипептид содержит аминокислотную последовательность, имеющую по меньшей мере 90%-ную идентичность последовательности SEQ ID NO: 9.
7. Способ по п.6, где рекомбинантный полипептид содержит аминокислотную последовательность SEQ ID NO: 9.
8. Способ по п.3, где сахарозосинтазу выбирают из группы, состоящей из сахарозосинтазы 1 Arabidopsis thaliana, сахарозосинтазы 3 Arabidopsis thaliana и сахарозосинтазы Vigna radiate.
9. Способ по п.8, где сахарозосинтаза представляет собой сахарозосинтаза 1 Arabidopsis thaliana.
10. Способ по п.1, где получаемый Reb D4 характеризуется чистотой более чем 70%.
11. Способ по п.1, дополнительно включающий инкубирование фермента HV1 с субстратом и рекомбинантным полипептидом.
| US 2016208303 A1, 21.07.2016 | |||
| US 2016298159 A1, 13.10.2016 | |||
| PRAKASH et al., Bioconversion of Rebaudioside I from Rebaudioside A, Molecules, vol | |||
| Способ изготовления электрических сопротивлений посредством осаждения слоя проводника на поверхности изолятора | 1921 |
|
SU19A1 |
| Тормозный рельсовый башмак | 1929 |
|
SU17345A1 |
| РЕБАУДИОЗИД D ВЫСОКОЙ СТЕПЕНИ ЧИСТОТЫ И ЕГО ПРИМЕНЕНИЕ | 2010 |
|
RU2596190C9 |

