ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Изобретение относится к пролонгированию времени полужизни белков, в частности, факторов свертывания человека, таких как фактор фон Виллебранда (VWF) и фактор VIII (FVIII).
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Гемофилия является группой наследственных генетических нарушений, влияющих на способность организма контролировать свертывание крови или коагуляцию. При наиболее распространенной форме, гемофилии A, наблюдают недостаточность фактора свертывания VIII (FVIII). Гемофилия A встречается с частотой приблизительно 1 на 5000-10000 рожденных мальчиков. Белок FVIII является необходимым кофактором для свертывания крови с многофункциональными свойствами. Недостаточность FVIII можно лечить с использованием полученных из плазмы концентратов FVIII или рекомбинантно полученного FVIII. Лечение концентратами FVIII приводит к нормализации жизни пациентов с гемофилией.
Пациентов с гемофилией A лечат с использованием FVIII по мере необходимости или в качестве профилактического терапевтического средства, вводимого несколько раз в неделю. В случае профилактического лечения 15-25 МЕ/кг массы тела FVIII вводят три раза в неделю, что необходимо в связи с постоянной потребностью в FVIII и его небольшого времени полужизни в кровотоке, составляющем у людей всего приблизительно 11 часов (Ewenstein et al., 2004).
В крови в нормальных условиях молекула FVIII всегда связана со своим кофактором фактором фон Виллебранда (VWF), защищающим молекулу FVIII от различных форм дегенерации. Нековалентный комплекс FVIII и VWF имеет высокую аффинность связывания 0,2-0,3 нМ (Vlot et al., 1996).
Исторически сложилось так, что гемофилию A лечили с использованием FVIII, полученного из плазмы крови человека. Однако, с 1990-х гг. на рынке появились различные рекомбинантно полученные белки FVIII. Однако, ни полученные из плазмы, ни полученные рекомбинантно белки FVIII не имеют оптимальных фармакокинетических свойств. Подобно многим другим терапевтическим белкам, они подвергаются метаболическому кругообороту под действием пептидаз, что значительно ограничивает их время полужизни in vivo.
Как описано Tiede et al. (2015), попытки пролонгирования времени полужизни FVIII включают слияние с Fc (элоктат, элокта, эфмороктоког альфа), добавление полиэтиленгликоля (туроктоког альфа пегол [N8-GP], BAY 94-9027, BAX 855) и одноцепочечную конструкцию (CSL627). С помощью всех этих технологий изменяют молекулу FVIII, и это приводит к пролонгированному приблизительно в 1,5 раз времени полужизни FVIII.
Дальнейшее увеличение времени полужизни FVIII ограничено временем полужизни VWF. Как показано Yee et al., домена D'D3 VWF человека достаточно для стабилизации FVIII в плазме. Однако, слитый белок D'D3-Fc способен увеличивать время полужизни FVIII только у мышей VWF-/-. У мышей с гемофилией A конструкция D'D3-Fc не приводит к пролонгированию времени полужизни FVIII по причине неэффективной конкуренции фрагментов белка с эндогенным VWF за связывание FVIII.
В WO 2014/011819 A2 описывают успешное пролонгирование времени полужизни конструкции FVIII, содержащей домен D'D3 VWF, домен Fc IgG и XTEN. Т.к. эта конструкция не связывается с эндогенным VWF, тот же эффект пролонгирования времени полужизни наблюдают у мышей с двойным нокаутом VWF/FVIII (DKO) и мышей с гемофилией A. Однако, хотя конструкция полностью функциональна in vitro, она проявляет значительно сниженную активность in vivo.
Другие подходы для повышения времени полужизни терапевтических белков включают генетическое слияние терапевтического белка с белком с природно большим временем полужизни, таким как трансферрин и альбумин, или с белковыми доменами, такими как C-концевой пептид (CTP) хорионического гонадотропина (CG).
CG принадлежит к семейству гликопротеиновых гормонов, включающему лютеинизирующий гормон (LH), фолликулостимулирующий гормон (FSH) и тиреотропный гормон (TSH). Эти гликогормоны являются гетеродимерами и состоят из общей α-субъединицы и уникальных β-субъединиц, придающих им разные активности. Время полужизни CG человека (hCG) значительно больше времени полужизни LH, FSH и TSH. Показано, что O-гликозилированный CTP hCG-β отвечает за пролонгирование его времени полужизни. Описывают, что CTP состоит из последовательности FQSSSS*KAPPPS*LPSPS*RLPGPS*DTPILPQ, содержащей четыре участка O-гликозилирования (обозначенных как S*) (Birken et al., 1977).
Как описано Strohl et al (2015), разработаны различные слитые белки терапевтического белка и CTP, и сейчас они проходят клинические исследования. Терапевтические белки включают FSH (Elonva®), FVIIa, FIX, IFN-β и оксинтомодулин.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение, помимо прочего, основано на обнаружении того, что добавление кластера O-гликозилированных аминокислот (присутствующего в полноразмерном VWF человек) к фрагменту VWF приводит к значительному повышению его времени полужизни. Время полужизни слитого белка пролонгируют по сравнению с фрагментом VWF без дополнительного O-гликанового кластера.
Таким образом, в первом аспекте изобретение относится к слитому белку, содержащему основной белок и по меньшей мере один пептид удлинения, где аминокислотная последовательность основного белка идентична или схожа с аминокислотной последовательностью белка млекопитающего, такого как VWF, или его фрагмента, и указанный пептид удлинения содержит кластер O-гликозилированных аминокислот.
Примечательно, что пептид удлинения, включающий кластер O-гликозилированных аминокислот, добавляемых к фрагменту VWF, получают из этого конкретного белка, а именно VWF. Таким образом, авторы настоящего изобретения определяли общий принцип повышения времени полужизни белков. Этим общим принципом является добавление внутреннего кластера O-гликозилированных аминокислот белка к указанному белку или его фрагменту.
Таким образом, в предпочтительном варианте осуществления слитого белка по первому аспекту аминокислотная последовательность одного или нескольких пептидов удлинения идентична или схожа с неповторяющейся частью аминокислотной последовательности указанного белка млекопитающего или фрагмента, в частности, указанного основного белка.
Другим выводом из результатов, полученных авторами настоящего изобретения, является то, что кластер O-гликозилированных аминокислот VWF, определенный в SEQ ID NO: 1, применим в качестве пептида для увеличения времени полужизни.
Т.к. свойство увеличения времени полужизни не ограничено VWF, в дополнительном предпочтительном варианте осуществления первого аспекта один или более пептидов удлинения имеют идентичность последовательности по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - по меньшей мере 100% по отношению к O-гликозилированному пептиду VWF, в частности, SEQ ID NO: 1.
Во втором аспекте изобретение относится к полинуклеотиду, кодирующему слитый белок по первому аспекту.
В третьем аспекте изобретение относится к вектору, содержащему полинуклеотид по второму аспекту.
В четвертом аспекте изобретение относится к клетке-хозяину, содержащей полинуклеотид по второму аспекту или вектор по третьему аспекту, где клетка-хозяин представляет собой клетку млекопитающего.
Авторы настоящего изобретения обнаружили, что повышается не только время полужизни VWF, но также и время полужизни его партнера по связыванию FVIII. Таким образом, в пятом аспекте изобретение относится к применению слитого белка по первому аспекту для повышения времени полужизни второго белка, где слитый белок способен связываться с указанным вторым белком.
Таким образом, в полученном комплексе или композиции слитого белка и второго белка второй белок также имеет повышенное время полужизни.
Таким образом, в шестом аспекте изобретение относится к композиции первого белка и второго белка, где указанный первый белок является слитым белком по первому аспекту и способен связываться с указанным вторым белком, и указанный второй белок является терапевтическим белком, содержащим аминокислотную последовательность, идентичную или схожую с аминокислотной последовательностью второго белка млекопитающего или его фрагмента.
В седьмом аспекте изобретение относится к комплексу первого белка и второго белка, где указанный первый белок является слитым белком по первому аспекту, и указанный второй белок имеет аминокислотную последовательность, идентичную или схожую с аминокислотной последовательностью второго белка млекопитающего или его фрагмента.
И наконец, в восьмом аспекте, изобретение также относится к фармацевтической композиции, содержащей слитый белок по первому аспекту, композицию по шестому аспекту или комплекс по седьмому аспекту, для применения в лечении или профилактике нарушения свертываемости, предпочтительно выбранного из лечения PUP или лечения ITI и другого родственного нарушения свертываемости.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 схематически представлены A) фрагмент VWF OCTA 11, и B) слитый белок по изобретению с фрагментом VWF в качестве основного белка: OCTA 12; C) слитый белок по изобретению с фрагментом VWF в качестве основного белка: OCTA14; D) слитый белок по изобретению с фрагментом VWF в качестве основного белка: OCTA15.
На фиг. 2 представлена временная зависимость активности FVIII после внутривенного введения FVIII, составленного совместно с разными белками VWF или полученным из плазмы полноразмерного VWF, в плазме мышей с двойным нокаутом (DKO) FVIII/VWF. Точки данных и планки погрешностей соответствуют среднему значению и стандартному отклонению (SD) для 5 значений. Из-за небольшого размера несколько из планок погрешностей неразличимы.
На фиг. 3 представлена временная зависимость концентрации антигена OCTA 12 после подкожного введения 100 ед./кг FVIII, составленного совместно с OCTA 12, в плазме карликовой свиньи.
На фиг. 4 представлена временная зависимость концентрации антигена FVIII после подкожной и внутривенной инъекции 100 ед./кг FVIII или подкожной инъекции 100 ед./кг FVIII, составленного совместно с белком VWF OCTA 12, в плазме карликовой свиньи.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Для обеспечения четкого и последовательного понимания описания и формулы изобретения и объема, данного этим терминам, представлены следующие определения.
Определения
В рамках изобретения "пептид" может состоять из любого количества аминокислот любого типа, предпочтительно, природных аминокислот, предпочтительно, соединенных пептидными связями. В частности, пептид содержит по меньшей мере 3 аминокислоты, предпочтительно - по меньшей мере 5, по меньшей мере 7, по меньшей мере 9, по меньшей мере 12 или по меньшей мере 15 аминокислот. Кроме того, нет верхнего предела длины пептида. Однако, предпочтительно, длина пептида по изобретению не превышает 500 аминокислот, более предпочтительно - не превышает 300 аминокислот; даже более предпочтительно - не превышает 250 аминокислот.
Таким образом, термин "пептид" включает термин "олигопептиды", как правило, относящийся к пептидам с длиной от 2 до 10 аминокислот, и термин "полипептиды", как правило, относящийся к пептидам с длиной более 10 аминокислот.
В рамках изобретения "белок" может содержать одну или несколько полипептидных цепей. Белки с несколькими полипептидными цепями часто экспрессируются в виде одной полипептидной цепи с одного гена и расщепляются посттрансляционно. Таким образом, термины "полипептид" и "белок" используют взаимозаменяемо. В рамках изобретения полипептиды и белки включают химически синтезированные белки, а также природно синтезированные белки, кодируемые генами. Полипептиды или белки можно получать из природного источника, такого как кровь человека, или в культуре клеток в виде рекомбинантных белков.
В рамках изобретения термин "терапевтический белок" относится к белкам или полипептидам с терапевтическим эффектом, т.е. белкам, используемым в качестве активного фармацевтического ингредиента.
По изобретению термины "предшественник белка", "про-белок" или "про-пептид" относятся к неактивному белку (или пептиду), который можно превращать в активную форму посредством посттрансляционной модификации, ферментативного расщепления части аминокислотной последовательности.
Родство между двумя аминокислотными последовательностями или двумя нуклеотидными последовательностями описывают с помощью параметра "идентичность последовательности". В целях по настоящему изобретению, степень идентичности последовательности между двумя аминокислотными последовательностями определяют с использованием алгоритма Needleman-Wunsch (Needleman and Wunsch, 1970, J. Mol. Biol. 48: 443-453), реализованного в программе Needle в пакете EMBOSS (EMBOSS: The European Molecular Biology Open Software Suite, Rice et al., 2000, Trends Genet. 16: 276-277), предпочтительно, версии 3.0.0 или более поздней версии. Необязательными используемыми параметрами являются штраф за открытие пропуска 10, штраф за увеличение пропуска 0,5 и подстановочная матрица EBLOSUM62 (EMBOSS-версия BLOSUM62). Выходные данные Needle, помеченные как "наибольшая идентичность" (полученные с использованием опции "no brief"), используют в качестве процента идентичности и вычисляют следующим образом:
(Идентичные остатки×100)/(длина выравнивания - общее количество пропусков при выравнивании).
В целях по настоящему изобретению, степень идентичности последовательности между двумя нуклеотидными последовательностями определяют с использованием алгоритма Needleman-Wunsch (Needleman and Wunsch, 1970, выше) реализованного в программе Needle в пакете EMBOSS (EMBOSS: The European Molecular Biology Open Software Suite, Rice et al., 2000, Trends Genet. 16: 276-277), предпочтительно, версии 3.0.0 или более поздней версии. Необязательными используемыми параметрами являются штраф за открытие пропуска 10, штраф за увеличение пропуска 0,5 и подстановочная матрица EDNAFULL (EMBOSS-версия NCBI NUC4.4). Выходные данные Needle, помеченные как "наибольшая идентичность" (полученные с использованием опции "no brief"), используют в качестве процента идентичности и вычисляют следующим образом:
(Идентичные дезоксирибонуклеотиды×100)/(длина выравнивания - общее количество пропусков при выравнивании)
В рамках изобретения термины "сходство" и "схожий" в отношении определения пептида или полинуклеотида относятся к определенной степени идентичности аминокислотной последовательности или нуклеотидной последовательности по отношению к референсу. Принято, чтобы схожая аминокислотная последовательность включала аминокислотную последовательность, по меньшей мере на 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или даже 99% идентичную рассматриваемой последовательности. Как правило, схожие последовательности будут включать одинаковые остатки в положениях, важные для функционирования пептида или полинуклеотида, такие как остатки в активном центре или гликозилированные аминокислоты, однако они могут включать любое количество консервативных аминокислотных замен. Принято, чтобы схожая нуклеотидная последовательность включала нуклеотидную последовательность, по меньшей мере на 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или даже 99% идентичную рассматриваемой последовательности.
В рамках изобретения термин "идентичный" относится к 100% идентичности аминокислотной или нуклеотидной последовательности по отношению к референсной последовательности.
Термин "рекомбинантный" при использовании по отношению к клетке, нуклеиновой кислоте, белку или вектору свидетельствует о том, что клетку, нуклеиновую кислоту, белок или вектор модифицировали посредством встраивания гетерологичной нуклеиновой кислоты или белка или изменения нативной нуклеиновой кислоты или белка, или что клетку получают из клетки, модифицированной таким образом. Таким образом, например, рекомбинантные клетки экспрессируют гены, не обнаруживаемые в нативной (нерекомбинантной) форме клетки, или экспрессируют нативные гены на иных уровнях или в иных условиях, чем в природе.
В рамках изобретения термин "время полужизни" представляет собой время, необходимое концентрации в плазме/крови, чтобы снизиться на 50% после достигнутого псевдоравновесия распределения (в соответствии с определением в Toutain et al., 2005). Термин "время полужизни" также обозначают как "время полужизни в кровотоке", "конечный период полувыведения" или "время полувыведения".
В рамках изобретения термины "трансформированный", "стабильно трансформированный" и "трансгенный", используемые в отношении клетки, означают, что клетка содержит ненативную (например, гетерологичную) последовательность нуклеиновой кислоты, интегрированную в ее геном или содержащуюся в виде эписомы, поддерживаемую во множестве поколений.
В рамках изобретения термин "фрагмент" относится к полипептиду, имеющему амино-концевую и/или карбокси-концевую делецию одной или нескольких аминокислот по сравнению с нативным белком или белком дикого типа, но в котором остальная аминокислотная последовательность идентична соответствующим положениям в аминокислотной последовательности, прослеживаемой из полноразмерной кДНК. Фрагменты, как правило, составляют по меньшей мере 50 аминокислот в длину.
В рамках изобретения термин "гликозилирование" относится к присоединению гликанов к молекулам, например, белкам. Гликозилирование может являться ферментативной реакцией. Присоединение может осуществляться с помощью ковалентных связей. Таким образом, в рамках изобретения гликозилированный полипептид является полипептидом, к которому присоединены один или множество гликанов. Фраза "высокогликозилированный" относится к молекуле, такой как фермент, гликозилированный по всем или почти всем из доступных участков гликозилирования, например O-сцепленным или N-сцепленным участкам гликозилирования.
В рамках изобретения термин "гликан" относится к полисахариду, или олигосахариду, или углеводной части гликопротеина или гликозилированного полипептида. Гликаны могут являться гомо- или гетерополимерами моносахаридных остатков. Они могут являться линейными или разветвленными молекулами. Гликаны, как правило, содержат по меньшей мере три сахара и могут являться линейными или разветвленными. Гликан может включать природные остатки сахаров (например, глюкозу, N-ацетилглюкозамин, N-ацетилнейраминовую кислоту, N-ацетилгалактозамин, галактозу, маннозу, фукозу, арабинозу, рибозу, ксилозу и т.д.) и/или модифицированные сахара (например, 2′-фторрибозу, 2′-дезоксирибозу, фосфоманнозу, 6′-сульфо-N-ацетилглюкозамин и т.д.).
В рамках изобретения термин "O-гликаны" относится к гликанам, как правило, обнаруживаемым ковалентно связанными с остатками серина и треонина гликопротеинов млекопитающих. O-гликаны могут являться α-сцепленными через остаток N-ацетилгалактозамина (GalNAc) с -OH серина или треонина O-гликозидной связью. Другие связи включают гликаны с α-сцепленной O-фукозой, β-сцепленной O-ксилозой, α-сцепленной O-маннозой, β-сцепленным O-GlcNAc (N-ацетилглюкозамином), α- или β-сцепленной O-галактозой и α- или β-сцепленной O-глюкозой.
В рамках изобретения термины "кластер O-гликозилирования", "O-гликановый кластер" и "кластер O-гликозилированных аминокислот" используют взаимозаменяемо, и они относятся к двум или более O-гликозилированным аминокислотам.
В рамках изобретения термин "сиалированный" относится к молекулам, в частности, гликанам, прореагировавшим с сиаловой кислотой или ее производными.
Переходный термин "содержащий", являющийся синонимом для терминов "включающий" или "отличающийся", является включительным или открытым и не исключает дополнительные, неперечисленные элементы или стадии способа. Переходная фраза "состоящий из" исключает любой элемент, стадию или ингредиент, не указанный в формуле изобретения, за исключением примесей, как правило, связанных с ними. Если фраза "состоит из" фигурирует в пункте формулы изобретения, а не сразу после преамбулы, она ограничивает только элемент, указанный в пункте; другие элементы не исключены из формулы изобретения в целом. Переходная фраза "состоящий, по существу, из" ограничивает объем формулы изобретения конкретными материалами или стадиями "и тем, что материально не влияет на основные и новые характеристики" описываемого в заявке изобретения. "Пункт "состоящий, по существу, из" охватывает среднюю позицию между замкнутыми пунктами, написанными в формате "состоящий из" и полностью открытыми пунктами, составленными в формате "содержащий"".
В контексте изобретения по практическим соображениям термин "гликозилированный белок", такой как слитый белок, используют в единственном числе. Как правило, на практике, белки встречаются в композиции белковых молекул одного типа. Однако в случае гликозилированных белков гликозилирование не будет идентичным в каждой молекуле композиции. Например, не все отдельные молекулы композиции могут являться гликозилированными на 100%. Кроме того, могут иметь место различия в гликанах, связанных со специфическим O-участком гликозилирования. Таким образом, в настоящей заявке ссылка на "слитый белок" также относится к композиции молекул слитых белков с идентичными аминокислотными последовательностями, но различиями в структуре O-гликана.
В рамках изобретения термины "аффинность связывания" или "аффинность" свидетельствуют о силе связывания между двумя молекулами, в частности, лигандом и белком-мишенью. На аффинности связывания влияют нековалентные межмолекулярные взаимодействия между двумя молекулами, такие как водородные связи, электростатические взаимодействия, гидрофобные взаимодействия и вандерваальсовы силы.
В рамках изобретения термин "иммунный ответ" относится к адаптивному или врожденному иммунному ответу. Термин "врожденный иммунный ответ" относится к неспецифическим защитным механизмам, активирующимся сразу или в течение нескольких часов после появления антигена в организме. Эти механизмы включают физические барьеры, такие как кожа, химические вещества в крови и клетки иммунной системы, атакующие чужеродные клетки в организме. Врожденный иммунный ответ активируется химическими свойствами антигена. Адаптивный иммунный ответ относится к антиген-специфическому иммунному ответу. В связи с этим, антиген сначала должен быть подвергнут обработке и распознаванию. После распознавания антигена адаптивная иммунная система создает большое количество иммунных клеток, конкретно предназначенных для воздействия на этот антиген.
Слитый белок
В первом аспекте изобретение относится к слитому белку, содержащему основной белок и по меньшей мере один пептид удлинения, где аминокислотная последовательность основного белка является идентичной или схожей с аминокислотной последовательностью белка млекопитающего или его фрагмента, и указанный пептид удлинения содержит кластер O-гликозилированных аминокислот.
Авторы настоящего изобретения идентифицировали модификацию белков, приводящую к повышению времени полужизни, а именно, добавление пептида удлинения, содержащего кластер O-гликозилированных аминокислот. Как показано в примерах, слияние кластера O-гликозилирования 1 VWF человека в качестве пептида удлинения с фрагментом VWF приводит к получению слитого белка (OCTA 12) с повышенным временем полужизни по сравнению с фрагментом VWF (OCTA 11) в отдельности.
Время полужизни (t1/2) можно вычислять посредством линейного регрессионного анализа линейно-логарифмической части отдельных кривых концентрация в плазме-время или посредством нелинейной регрессии с использованием однофазной модели экспоненциального уменьшения. Примерами программного обеспечения для вычисления являются GraphPad Prism версии 6.07 (La Jolla, CA 92037 USA) и WinNonlin версии 6,4 (Pharsight Corporation, Mountain View, CA, USA).
Вычисления основаны на следующих уравнениях:
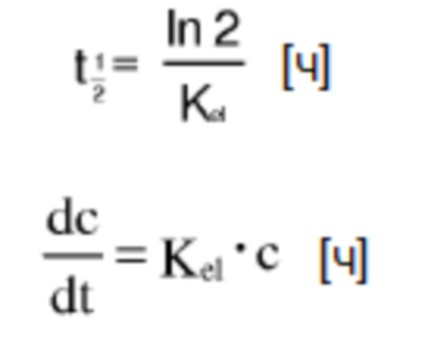
Kel=константа скорости элиминации
t½=время полувыведения
c=концентрация
t=время
Таким образом, в одном из вариантов осуществления слитый белок имеет повышенное время полужизни по сравнению с основным белком без пептида удлинения.
Т.к. можно было повысить время полужизни фрагмента VWF с использованием кластера гликозилированных аминокислот, полученного из VWF, авторы настоящего изобретения идентифицировали новый принцип пролонгирования времени полужизни. Т.е. повышение времени полужизни белка или фрагмента белка посредством добавления кластера O-гликозилированных аминокислот, также присутствующего в природном белке.
Таким образом, в одном из вариантов осуществления слитого белка аминокислотная последовательность одного или нескольких пептидов удлинения является идентичной или схожей с частью указанного белка млекопитающего. Эта часть белка млекопитающего, в частности, является неповторяющейся аминокислотной последовательностью.
В рамках изобретения неповторяющаяся аминокислотная последовательность является последовательностью, обнаруживаемой в природном белке млекопитающего по изобретению только в одной копии. Таким образом, неповторяющаяся аминокислотная последовательность явно исключает какие-либо повторяющиеся природные последовательности в белках. В частности, последовательность считают повторяющейся, если последовательность состоит из более чем 20 аминокислот, предпочтительно - более чем 15 аминокислот, более предпочтительно - более чем 10 аминокислот, и белок млекопитающего содержит несколько этих последовательностей.
Повторяющиеся последовательности можно получать из так называемых тандемных повторов с переменным количеством звеньев. Тандемный повтор с переменным количеством звеньев (VNTR) является участком в геноме, где короткая нуклеотидная последовательность организована в виде "тандемного повтора". "Тандемные повторы" встречаются в ДНК, когда паттерн из одного или нескольких нуклеотидов повторяется и повторы являются непосредственно смежными друг с другом. VNTR обнаруживают на многих хромосомах, и часто наблюдают вариации их длины от индивидуума к индивидууму. В случае, когда тандемные повторы локализуются в белок-кодирующих последовательностях ДНК, это приводит к повторам в аминокислотной последовательности. Примерами являются тандемные повторы, обнаруживаемые во всех членах семейства муциновых белков. Муцины являются семейством высокомолекулярных, сильно гликозилированных белков, продуцируемых эпителиальными тканями в большинстве организмов царства Животных. Неповторяющаяся аминокислотная последовательность по изобретению явно исключает такие тандемные повторы в аминокислотной последовательности, в частности, муциновые тандемные повторы.
Пептид удлинения не только можно получать из того же белка млекопитающего, что и основной белок, но, более конкретно, он может содержать часть, также присутствующую в основном белке. Таким образом, в одном из вариантов осуществления аминокислотная последовательность одного или нескольких пептидов удлинения является идентичной или схожей с частью неповторяющейся аминокислотной последовательности указанного основного белка.
Предпочтительно, один или более пептидов удлинения не получают из β-субъединицы хорионического гонадотропина (CG-β). Показано, что C-концевой пептид (CTP) β-субъединицы хорионического гонадотропина повышает время полужизни других белков, таких как FSH, FVIIa и FIX. Однако, в случае, когда был описан hCG с дополнительным CTP, т.е. несколькими копиями CTP, этот белок конкретно исключен из объекта настоящего изобретения. Таким образом, в частности, пептид удлинения не является идентичным или схожим с CTP CG-β.
По настоящему изобретению две или более O-гликозилированных аминокислот в непосредственной близости в аминокислотной последовательности считают кластером. Таким образом, в одном из вариантов осуществления слитого белка кластер O-гликозилированных аминокислот по меньшей мере одного пептида удлинения содержит по меньшей мере две O-гликозилированных аминокислоты. Кластер может содержать, например, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 или 15 O-гликозилированных аминокислот.
Теоретически, эффект повышения времени полужизни основан на отрицательном заряде O-гликанов. Таким образом, эффект пролонгирования времени полужизни должен повышаться с количеством O-гликозилированных аминокислот в кластере. Таким образом, кластер, предпочтительно, содержит по меньшей мере три O-гликозилированных аминокислоты. Как показано в примерах, значительного эффекта повышения времени полужизни достигали с использованием пептида удлинения с кластером из четырех O-гликозилированных аминокислот. Таким образом, в предпочтительном варианте осуществления кластер содержит по меньшей мере четыре O-гликозилированных аминокислоты.
В дополнение к O-гликозилированным аминокислотам кластера также могут присутствовать N-гликозилированные аминокислоты. Предпочтительно, в кластере O-гликозилирования нет N-гликозилированных аминокислотов.
В случае наличия нескольких пептидов удлинения, кластеры пептидов удлинения могут содержать разное количество O-гликозилированных аминокислот. Например, слитый белок может содержать один кластер с двумя и второй кластер с четырьмя O-гликозилированными аминокислотами. Кроме того, один кластер может содержать три участка O-гликозилирования, а другой - четыре участка O-гликозилирования.
O-гликозилированные аминокислоты пептида удлинения могут являться O-гликозилированными аминокислотами серином (Ser) и треонином (Thr) муцинового типа. Однако, в этой области также известны O-гликозилированный тирозин (Tyr), гидроксилизин (гидрокси-Lys) или гидроксипролин (гидрокси-Pro). Таким образом, одну или несколько O-гликозилированных аминокислот в слитом белке, в частности, в пептиде удлинения, можно выбирать из Ser, Thr, Tyr, гидрокси-Lys и гидрокси-Pro.
Пептид удлинения, слитый с фрагментом VWF в OCTA 12, что приводит к пролонгированию времени полужизни указанного фрагмента, содержит O-гликозилированные остатки треонина и остатки серина. Таким образом, в одном из вариантов осуществления первого аспекта кластер O-гликозилированных аминокислот содержит по меньшей мере один O-гликозилированный треонин. Предпочтительно, указанный кластер содержит и треонин, и серин в качестве O-гликозилированных аминокислот. Примечательно, что пептид удлинения OCTA 12 содержит два соседних остатка треонина, являющихся O-гликозилированными. Таким образом, в одном из вариантов осуществления пептид удлинения содержит по меньшей мере два соседних O-гликозилированных остатка треонина.
Как описано выше, полагают, что отрицательный заряд поверхности белка, генерируемый O-гликанами, приводит к пролонгированию времени полужизни. Не желая быть связанными какой-либо теорией, полагают, что для проявления эффекта необходимы два или более O-гликана в непосредственной близости. Эффект может быть слабым или отсутствовать, если пропуски между O-гликанами являются слишком большими, т.е. при менее чем одной O-гликозилированной аминокислоте на 15 аминокислот. Таким образом, в одном из вариантов осуществления слитого белка по меньшей мере один пептид удлинения содержит по меньшей мере одну O-гликозилированную аминокислоту на 15 аминокислот.
Более предпочтительно, по меньшей мере один пептид удлинения содержит по меньшей мере один O-участок гликозилирования на 10 аминокислот. Как показано в примерах, тестируемый пептид удлинения содержит кластеры с одним O-участком гликозилирования на 8 аминокислот. Таким образом, в предпочтительном варианте осуществления один или более кластеров содержат по меньшей мере один участок гликозилирования на 8 аминокислот.
Длину пептида удлинения определяют в соответствии с двумя разными аспектами. Пептид удлинения должен быть достаточно длинным, чтобы содержать участки распознавания, способствующие гликозилированию O-гликозилированных аминокислот. Таким образом, пептид удлинения должен составлять по меньшей мере 10 аминокислот в длину. С другой стороны, чем короче пептид удлинения, тем менее вероятно, что он будет мешать структурной целостности или активности и, таким образом, терапевтическому эффекту основного белка. Таким образом, пептид удлинения не должен превышать 100 аминокислот. В одном из вариантов осуществления один или более пептидов удлинения имеют длину в диапазоне от 15 до 60 аминокислот. Чтобы позволить четырем аминокислотам быть O-гликозилированными в пептиде удлинения, длина, предпочтительно, должна составлять в диапазоне от 22 до 40 аминокислот. Более предпочтительно, длина пептида удлинения приблизительно равна длине пептидов удлинения в OCTA 12, т.е. в диапазоне от 26 до 36 аминокислот. В одном из вариантов осуществления один или более пептидов удлинения имеют длину приблизительно 31 аминокислота.
Результаты, полученные авторами настоящего изобретения, не только приводят к выводу о принципе добавления одной или нескольких копий O-гликозилированного пептида, естественным образом присутствующего в белке, для повышения времени полужизни того же белка или его фрагмента. Кроме того, эти результаты свидетельствуют о том, что конкретный O-гликозилированный пептид VWF, по аналогии с CTP, может повышать время полужизни других белков, т.е. белков в целом.
Таким образом, в одном из вариантов осуществления один или более пептидов удлинения имеют идентичность последовательности по меньшей мере 90% по отношению к O-гликозилированному пептиду VWF человека. Этот полученный из VWF человека пептид удлинения можно подвергать слиянию с другими белками млекопитающих или их фрагментами, такими как FVIII. Идентичность последовательности одного или нескольких пептидов удлинения, предпочтительно, составляет по меньшей мере 95% по отношению к O-гликозилированному пептиду VWF человека. Более предпочтительно, идентичность последовательности составляет по меньшей мере 98%. Наиболее предпочтительно, последовательность пептида удлинения является идентичной O-гликозилированному пептиду VWF человека.
O-гликозилированный пептид VWF человека включает предпочтительно, по меньшей мере, частично, кластер 2O-гликозилирования VWF (аминокислоты 1238-1268 SEQ ID NO: 2): QEPGGLVVPPTDAPVSPTTLYVEDISEPPLH (SEQ ID NO: 1) или его вариант. Таким образом, в одном из вариантов осуществления пептид удлинения имеет идентичность последовательности по отношению к SEQ ID NO: 1 по меньшей мере 90%. Идентичность последовательности по отношению к SEQ ID NO: 1, предпочтительно, составляет по меньшей мере 95%. Более предпочтительно, идентичность последовательности пептида удлинения по отношению к SEQ ID NO: 1 составляет по меньшей мере 98%. Наиболее предпочтительно, один или более пептидов удлинения имеют идентичность последовательности 100% по отношению к SEQ ID NO: 1.
Основной белок основан на белке млекопитающего, т.е. содержит аминокислотную последовательность, схожую или идентичную белку млекопитающего или его фрагменту. Белок млекопитающего, в частности, является белком человека.
Белок млекопитающего, по отношению к которому аминокислотная последовательность основного белка является схожей или идентичной, может являться гликозилированным белком. В одном из вариантов осуществления слитого белка основной белок содержит гликозилированную часть белка млекопитающего. В другом варианте осуществления основной белок содержит по меньшей мере один кластер O-гликозилированных аминокислот. Этот кластер O-гликозилированных аминокислот может являться идентичным кластеру O-гликозилированных аминокислот в пептиде удлинения.
Белок млекопитающего, на котором основан основной белок, более предпочтительно, является белком крови. В одном из вариантов осуществления белок млекопитающего является белком крови человека.
Белок крови млекопитающего может являться фактором свертывания, транспортным белком, ингибитором протеазы, иммуноглобулином, клеточным белком плазмы, аполипопротеином, фактором комплемента, фактором роста, антиангиогенным белком, сильно гликозилированным белком, фактором крови или другим белком крови.
Фактор свертывания, в частности, фактор свертывания человека, предпочтительно, выбран из группы, состоящей из фибриногена (FI), протромбина (FII), тканевого фактора (FIII), FV, FVII, FVIII, FIX, FX, FXI, FXII, и FXIII, VWF и ADAMTS13.
Следует понимать, что факторы свертывания FI, FII, FV, FVII, FVIII, FIX, FX, FXI, FXII, и FXIII могут находиться в неактивной или активированной форме. Таким образом, в контексте по изобретению, ссылка на FI, FII, FV, FVII, FVIII, FIX, FX, FXI, FXII, и FXIII включает активированные формы FIa (фибрина), FIIa (тромбина), FVa, FIXa, FVIIa, FVIIIa, FXa, FXIa, FXIIa и FXIIIa, соответственно, если четко не указано иное или это не следует из контекста, активированную форму исключают логически. Таким образом, например, в этом контексте FI, FII, FV, FIX, FVII, FVIII, FX, FXI, FXII и FXIII можно читать как FI/FIa, FII/FIIa, FV/FVa, FVII/FVIIa, FVIII/FVIIIa, FIX/FXIa, FX/FXa, FXI/FXIa, FXII/FXIIa и FXIII/FXIIIa.
Транспортный белок, в частности, транспортный белок человека, можно выбирать из альбумина, трансферрина, церулоплазмина, гаптоглобина, гемоглобина и гемопексина.
В одном из вариантов осуществления белок млекопитающего является ингибитором протеазы, в частности, ингибитором протеазы человека. Примерами таких ингибиторов протеаз являются β-антитромбин, α-антитромбин, прелатентный антитромбин, окисленный антитромбин, 2-макроглобулин, ингибитор C1, ингибитор пути тканевого фактора (TFPI), кофактор гепарина II, ингибитор протеина C (PAI-3), протеин C, протеин S и протеин Z.
Примерами иммуноглобулинов являются поликлональные антитела (IgG), моноклональные антитела, IgG1, IgG2, IgG3, IgG4, IgA, IgA1, IgA2, IgM, IgE, IgD и белок Бенс-Джонса.
Клеточно-родственный белок плазмы может являться, например, фибронектином, тромбоглобулином или тромбоцитарным фактором 4. Примерами аполипопротеинов являются апо-A-I, апо-A-II и апо-E.
Факторами комплемента по изобретению являются, например, фактор B, фактор D, фактор H, фактор I, инактиватор C3b, пропердин, C4-связывающий белок и т.д.
Примеры факторов роста включают фактор роста тромбоцитов (PDGF), эпидермальный фактор роста (EGF), трансформирующий фактор роста альфа (TGF-α), трансформирующий фактор роста бета (TGF-α), фактор роста фибробластов (FGF) и фактор роста гепатоцитов (HGF).
Антиангиогенные белки включают латентный антитромбин, прелатентный антитромбин, окисленный антитромбин и плазминоген.
Примерами сильно гликозилированных белков являются альфа-1-кислый гликопротеин, антихимотрипсин, интер-α-ингибитор трипсина, α-2-HS-гликопротеин, C-реактивный белок.
Факторами крови могут являться, например, эритропоэтин, интерферон, опухолевые факторы, tPA или gCSF.
Другие белки крови человека включают богатый гистидином гликопротеин, маннозосвязывающий лектин, C4-связывающий белок, фибронектин, GC-глобулин, плазминоген/плазмин, α-1-микроглобулин, C-реактивный белок.
Белок млекопитающего, в частности, выбран из VWF человека, фибриногена, протромбина, FIII, FV, FVII, FVIII, FIX, FX, FXI, FXII, FXIII, ADAMTS13, антитромбина, альфа-1-антитрипсина, ингибитора C1, антихимотрипсина, PAI-1, PAI-3, 2-макроглобулина, TFPI, кофактора гепарина II, протеина Z, протеина C и протеина S.
Фактор VIII у людей кодируется геном F8, содержащим 187000 пар оснований в шести экзонах. Транскрибируемая мРНК имеет длину 9029 пар оснований и транслируется в белок из 2351 аминокислоты, из которого удалены 19 аминокислот. Молекула FVIII у людей гликозилирована по 31 аминокислоте, 25 из которых N-гликозилированы и 6 - O-гликозилированы (см. Kannicht et al., 2013).
После трансляции цепь аминокислот расщепляется специфическими протеазами в определенных положениях, что приводит к образованию тяжелой цепи из приблизительно 200 кДа и легкой цепи из приблизительно 80 кДа. Организация доменов, как правило, представляет собой A1-A2-B-A3-C1-C2. Легкая цепь состоит из доменов A3-C1-C2. Тяжелая цепь, в принципе, состоит из доменов A1-A2-B. Тяжелые цепи, обнаруживаемые в плазме, имеют гетерогенную композицию с молекулярными массами, варьирующимися от 90 до 200 кДа. Причиной этого является гетерогенность его гликозилирования, существование вариантов сплайсинга и существование протеолитических продуктов, таких как лишенная домена B тяжелая цепь A1-A2. Аминокислотную последовательность полноразмерного FVIII определяют по аминокислотам 20-2351 P00451 в UniProtKB, версии последовательности 1 от 21 июля 1986 года (в дальнейшем UniProtKB P00451.1).
В одном из вариантов осуществления белок млекопитающего, по отношению к которому основной белок является схожим или идентичным, является полноразмерным FVIII человека, определенным по аминокислотам 20-2351 UniProtKB P00451.1. В другом варианте осуществления основной белок является FVIII, в котором отсутствует, по меньшей мере, часть B-домена. В связи с этим, может отсутствовать весь B-домен. Отсутствующую часть B-домена, необязательно, заменяют линкером. Линкерная последовательность, в частности, содержит последовательность следующих аминокислот SFSQNSRHQAYRYRRG (SEQ ID NO: 12). Примером FVIII, в котором B-домен заменяют линкером, является симоктоког альфа, активный ингредиент Nuwiq® или Vihuma®. Симоктоког альфа имеет следующую последовательность:
ATRRYYLGAVELSWDYMQSDLGELPVDARFPPRVPKSFPFNTSVVYKKTLFVEFTDHLFNIAKPRPPWMGLLGPTIQAEVYDTVVITLKNMASHPVSLHAVGVSYWKASEGAEYDDQTSQREKEDDKVFPGGSHTYVWQVLKENGPMASDPLCLTYSYLSHVDLVKDLNSGLIGALLVCREGSLAKEKTQTLHKFILLFAVFDEGKSWHSETKNSLMQDRDAASARAWPKMHTVNGYVNRSLPGLIGCHRKSVYWHVIGMGTTPEVHSIFLEGHTFLVRNHRQASLEISPITFLTAQTLLMDLGQFLLFCHISSHQHDGMEAYVKVDSCPEEPQLRMKNNEEAEDYDDDLTDSEMDVVRFDDDNSPSFIQIRSVAKKHPKTWVHYIAAEEEDWDYAPLVLAPDDRSYKSQYLNNGPQRIGRKYKKVRFMAYTDETFKTREAIQHESGILGPLLYGEVGDTLLIIFKNQASRPYNIYPHGITDVRPLYSRRLPKGVKHLKDFPILPGEIFKYKWTVTVEDGPTKSDPRCLTRYYSSFVNMERDLASGLIGPLLICYKESVDQRGNQIMSDKRNVILFSVFDENRSWYLTENIQRFLPNPAGVQLEDPEFQASNIMHSINGYVFDSLQLSVCLHEVAYWYILSIGAQTDFLSVFFSGYTFKHKMVYEDTLTLFPFSGETVFMSMENPGLWILGCHNSDFRNRGMTALLKVSSCDKNTGDYYEDSYEDISAYLLSKNNAIEPRSFSQNSRHQAYRYRRGEITRTTLQSDQEEIDYDDTISVEMKKEDFDIYDEDENQSPRSFQKKTRHYFIAAVERLWDYGMSSSPHVLRNRAQSGSVPQFKKVVFQEFTDGSFTQPLYRGELNEHLGLLGPYIRAEVEDNIMVTFRNQASRPYSFYSSLISYEEDQRQGAEPRKNFVKPNETKTYFWKVQHHMAPTKDEFDCKAWAYFSDVDLEKDVHSGLIGPLLVCHTNTLNPAHGRQVTVQEFALFFTIFDETKSWYFTENMERNCRAPCNIQMEDPTFKENYRFHAINGYIMDTLPGLVMAQDQRIRWYLLSMGSNENIHSIHFSGHVFTVRKKEEYKMALYNLYPGVFETVEMLPSKAGIWRVECLIGEHLHAGMSTLFLVYSNKCQTPLGMASGHIRDFQITASGQYGQWAPKLARLHYSGSINAWSTKEPFSWIKVDLLAPMIIHGIKTQGARQKFSSLYISQFIIMYSLDGKKWQTYRGNSTGTLMVFFGNVDSSGIKHNIFNPPIIARYIRLHPTHYSIRSTLRMELMGCDLNSCSMPLGMESKAISDAQITASSYFTNMFATWSPSKARLHLQGRSNAWRPQVNNPKEWLQVDFQKTMKVTGVTTQGVKSLLTSMYVKEFLISSSQDGHQWTLFFQNGKVKVFQGNQDSFTPVVNSLDPPLLTRYLRIHPQSWVHQIALRMEVLGCEAQDLY (SEQ ID NO: 13)
VWF является мультимерным адгезивным гликопротеином, присутствующим в плазме млекопитающих, обладающим множеством физиологических функций. При первичном гемостазе, VWF действует в качестве медиатора между специфическими рецепторами на поверхности тромбоцитов и компонентами внеклеточного матрикса, такими как коллаген. Кроме того, VWF служит в качестве носителя и стабилизирующего белка для прокоагулянта фактора VIII. VWF синтезируется в эндотелиальных клетках и мегакариоцитах в качестве молекулы-предшественника из 2813 аминокислот.
Организация доменов VWF, как правило, представляет собой Til3-D3-TIL4-A1-A2-A3-D4-C1-C2-C3-CK.
Полипептид-предшественник, пре-про-VWF, состоит из сигнального пептида из 22 остатков, про-пептида из 741 остатка (домены D1-D2) и полипептида из 2050 остатков, обнаруживаемого в зрелом факторе фон Виллебранда в плазме (Fischer et al., 1994). Полноразмерный VWF определен в записи P04275 UniprotKB (версия записи 224 от 12 апреля 2017 года).
VWF человека по настоящему изобретению имеет аминокислотную последовательность любой из последовательностей указанной UniprotKB P04275, в частности, SEQ ID NO: 2 (изоформа 1). VWF содержит два кластера O-гликозилированных аминокислот. Первый кластер O-гликозилированных аминокислот обнаруживают между аминокислотами 1238-1268 SEQ ID NO: 2. Второй кластер включает аминокислоты 1468-1487 SEQ ID NO: 2.
После секреции в плазму VWF циркулирует в форме различных молекул разного размера. Эти молекулы VWF состоят из олиго- и мультимеров зрелой субъединицы из 2050 аминокислотных остатков. VWF, как правило, можно обнаружить в плазме в качестве мультимеров с диапазоном размеров приблизительно от 500 до 20000 кДа (Furlan et al., 1996).
В одном из вариантов осуществления основной белок имеет аминокислотную последовательность, идентичную или схожую с последовательностью зрелого VWF человека.
В другом варианте осуществления основной белок имеет аминокислотную последовательность, схожую или идентичную последовательности фрагмента VWF человека.
Например, в фрагменте VWF человека могут отсутствовать один или более доменов A1, A2, A3, D4, C1, C2, C3, CK относительно зрелого VWF человека (Til3-D3-TIL4-A1-A2-A3-D4-C1-C2-C3-CK). Фрагмент VWF, например, может иметь организацию доменов, выбранную из следующей группы, состоящей из Til3-D3-TIL4-A1, Til3-D3-TIL4-A1-A2, Til3-D3-TIL4-A1-A2-A3, Til3-D3-TIL4-A1-A2-A3-D4, Til3-D3-TIL4-A1-A2-A3-D4-C1, Til3-D3-TIL4-A1-A2-A3-D4-C1-C2 и Til3-D3-TIL4-A1-A2-A3-D4-C1-C2-C3-CK.
В связи с этим, фрагмент VWF человека, в частности, является фрагментом, начинающимся с аминокислоты 764 SEQ ID NO: 2. Аминокислоты 764-1035 SEQ ID NO: 2 содержат FVIII-связывающий домен VWF.
Основной белок, например, может содержать фрагмент VWF, как определено в WO 2015/185758 A2. Как представлено в WO 2015/185758 A2, комплекс FVIII и фрагментов VWF, как определено, проявляет сниженное связывание с фосфолипидными мембранами по сравнению с FVIII в отдельности, а также сниженное связывание с коллагеном III и гепарином по сравнению с комплексом FVIII и полноразмерного VWF.
Фрагмент VWF, предпочтительно, начинающийся с аминокислоты 764 SEQ ID NO: 2, предпочтительно, заканчивается аминокислотой в диапазоне 1905-2153 SEQ ID NO: 2. В одном из вариантов осуществления фрагмент VWF заканчивается аминокислотой VWF в диапазоне 2030-2153 SEQ ID NO: 2. В дополнительном варианте осуществления изобретения фрагмент VWF заканчивается аминокислотой в диапазоне 2100-2153 SEQ ID NO: 2.
В одном из вариантов осуществления основной белок имеет аминокислотную последовательность, схожую или идентичную аминокислотам 764-1268 SEQ ID NO: 2. В одном из вариантов осуществления аминокислотная последовательность основного белка имеет идентичность по меньшей мере 90% по отношению к аминокислотам 764-1268 SEQ ID NO: 2. Аминокислотная последовательность основного белка также может иметь идентичность по меньшей мере 95% по отношению к аминокислотам 764-1268 SEQ ID NO: 2. Кроме того, идентичность аминокислотной последовательности основного белка по отношению к аминокислотам 764-1268 SEQ ID NO: 2 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность основного белка может иметь идентичность 100% по отношению к аминокислотам 764-1268 SEQ ID NO: 2.
В одном из вариантов осуществления основной белок имеет аминокислотную последовательность, схожую или идентичную аминокислотам 764-1905 SEQ ID NO: 2. В одном из вариантов осуществления аминокислотная последовательность основного белка имеет идентичность по меньшей мере 90% по отношению к аминокислотам 764-1905 SEQ ID NO: 2. Аминокислотная последовательность основного белка также может иметь идентичность по меньшей мере 95% по отношению к аминокислотам 764-1905 SEQ ID NO: 2. Кроме того, идентичность аминокислотной последовательности основного белка по отношению к аминокислотам 764-1905 SEQ ID NO: 2 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность основного белка может иметь идентичность 100% по отношению к аминокислотам 764-1905 SEQ ID NO: 2.
Слитый белок может содержать любое количество пептидов удлинения, например, один, два, три, четыре, пять, шесть, семь, восемь, девять или десять пептидов удлинения. Слитый белок OCTA 12 содержит две копии пептида удлинения и проявляет значительное повышение времени полужизни по сравнению с фрагментом VWF OCTA 11. Таким образом, в одном из вариантов осуществления слитый белок содержит по меньшей мере два пептида удлинения.
Следует понимать, что эффект пролонгирования времени полужизни, по меньшей мере, частично основан на отрицательном заряде O-гликанов пептида удлинения. Таким образом, повышение количества копий пептида удлинения приводит к дополнительному усилению эффекта пролонгирования времени полужизни. Это подтверждено с помощью OCTA 14, содержащего четыре копии пептида удлинения. Таким образом, в одном из вариантов осуществления слитый белок содержит по меньшей мере четыре пептида удлинения.
С другой стороны, с повышением количества копий пептида удлинения повышается вероятность того, что пептиды удлинения будут мешать структурной целостности или активности и, таким образом, терапевтическому эффекту основного белка. Таким образом, в одном из вариантов осуществления количество пептидов удлинения составляет менее 11.
Слитый белок может содержать дополнительные пептидные компоненты помимо основного белка и пептидов удлинения. В частности, помимо пептида удлинения по изобретению слитый белок может содержать дополнительные пептиды для пролонгирования времени полужизни, такие как CTP, XTEN, трансферрин или его фрагменты, альбумин или его фрагменты.
Также возможно, что основной белок является фрагментом белка млекопитающего, и слитый белок содержит дополнительный фрагмент того же белка млекопитающего. В частности, два фрагмента разделяют одним или несколькими пептидами удлинения. Примером такого белка является OCTA 15, содержащий аминокислоты 764-1268 VWF, два пептида удлинения с последовательностью SEQ ID NO: 1 и "домен цистеиновый узел" VWF, состоящий из аминокислот 2721-2813 SEQ ID NO: 2.
В слитом белке один или более пептидов удлинения можно соединять с N-концом или C-концом основного белка. В частности, слитый белок может содержать один или более пептидов удлинения, соединенных с N-концом, и один или более пептидов удлинения, соединенных с C-концом основного белка.
Т.к. слитый белок может содержать дополнительные пептиды помимо основного белка и одного или нескольких пептидов удлинения. Таким образом, пептиды удлинения можно напрямую или косвенно соединять с основным белком. В связи с этим, термин "соединенный напрямую" означает, что аминокислотные последовательности основного белка и пептида удлинения являются смежными. Термин "косвенно соединенные" означает, что между основным белком и пептидом удлинения находится дополнительный пептид. В частности, линкерный пептид может находиться между основным белком и пептидом удлинения. Линкер может содержать участок расщепления, что делает пептид удлинения отщепляемым от основного белка.
Основной белок, один или более пептидов удлинения и, необязательно, дополнительные пептиды можно получать, соединяя гены, кДНК или последовательности, кодирующие их. Таким образом, основной белок, один или более пептидов удлинения и, необязательно, дополнительные пептиды соединены пептидными связями. По изобретению, пептиды слитого белка фактически можно соединять с помощью других линкеров, таких как химические линкеры или гликозидные связи. Предпочтительно, пептиды слитого белка соединены пептидными связями.
В одном из вариантов осуществления пептид удлинения напрямую соединяют с C-концом основного белка. В частности, слитый белок содержит по меньшей мере два последовательных пептида удлинения, соединенных с C-концом основного белка.
Слитый белок можно соединять с двумя или несколькими аффинными метками. Примерами аффинных меток являются полигистидин, протеин A, глутатион-S-трансфераза, вещество P, FLAG, стрептавидин и константная область тяжелой цепи иммуноглобулина. Хотя аффинная метка, как правило, является частью аминокислотной последовательности полной конструкции, ее не считают частью слитого белка. Одну или несколько аффинных меток, предпочтительно, соединяют с C-концом или N-концом слитого белка. В случае, когда слитый белок соединяют с одной или несколькими аффинными метками, он, предпочтительно, содержит участок расщепления между аффинной меткой и остальной частью белка, что делает аффинную метку отщепляемой, например, посредством расщепления протеазами.
В одном из вариантов осуществления один пептид удлинения образует N-конец слитого белка. Как описано выше, N-концевую аминокислоту указанного пептида удлинения, необязательно, соединяют с аффинной меткой. В одном из вариантов осуществления один пептид удлинения образует C-конец слитого белка. Как описано выше, C-концевую аминокислоту указанного пептида удлинения, необязательно, соединяют с аффинной меткой.
В одном из вариантов осуществления слитый белок содержит по меньшей мере 4, предпочтительно - по меньшей мере 8, более предпочтительно - по меньшей мере 12 дополнительных O-гликанов по сравнению с основным белком.
В одном из вариантов осуществления слитый белок содержит домен димеризации; в частности, основной белок содержит домен димеризации. В VWF димеры образуются посредством связывания CK-доменов. Таким образом, в случае, когда основной белок является фрагментом VWF, он, предпочтительно, содержит CK-домен.
Типичным слитым белком по изобретению является OCTA 12. OCTA 12 имеет следующую аминокислотную последовательность (SEQ ID NO: 3):
SLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLH
OCTA 12 является слитым белком фрагмента VWF, соответствующего аминокислотам 764-1268 SEQ ID NO: 2, и двух копий пептида удлинения (помеченного полужирным шрифтом), связанных с C-концом, состоящим из аминокислот 1238-1268 SEQ ID NO: 2.
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 3. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 3. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 3 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 3.
Следующая последовательность (SEQ ID NO: 4) представляет собой OCTA 12 с дополнительным сигнальным пептидом из 12 аминокислот (выделено полужирным шрифтом и подчеркнуто). При экспрессии этого пептида получают мономерную форму OCTA 12. Сигнальный пептид отщепляется.
MIPARFAGVLLALALILPGTLC SLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLH (SEQ ID NO: 4)
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 4. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 4. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 4 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 4.
Дополнительным типичным слитым белком по изобретению является про-OCTA 12, включающий OCTA 12 и пропептид (выделен полужирным шрифтом) с сигнальным пептидом (выделен полужирным шрифтом и подчеркнут). Про-OCTA 12 определен в SEQ ID NO: 5:
MIPARFAGVLLALALILPGTLCAEGTRGRSSTARCSLFGSDFVNTFDGSMYSFAGYCSYLLAGGCQKRSFSIIGDFQNGKRVSLSVYLGEFFDIHLFVNGTVTQGDQRVSMPYASKGLYLETEAGYYKLSGEAYGFVARIDGSGNFQVLLSDRYFNKTCGLCGNFNIFAEDDFMTQEGTLTSDPYDFANSWALSSGEQWCERASPPSSSCNISSGEMQKGLWEQCQLLKSTSVFARCHPLVDPEPFVALCEKTLCECAGGLECACPALLEYARTCAQEGMVLYGWTDHSACSPVCPAGMEYRQCVSPCARTCQSLHINEMCQERCVDGCSCPEGQLLDEGLCVESTECPCVHSGKRYPPGTSLSRDCNTCICRNSQWICSNEECPGECLVTGQSHFKSFDNRYFTFSGICQYLLARDCQDHSFSIVIETVQCADDRDAVCTRSVTVRLPGLHNSLVKLKHGAGVAMDGQDVQLPLLKGDLRIQHTVTASVRLSYGEDLQMDWDGRGRLLVKLSPVYAGKTCGLCGNYNGNQGDDFLTPSGLAEPRVEDFGNAWKLHGDCQDLQKQHSDPCALNPRMTRFSEEACAVLTSPTFEACHRAVSPLPYLRNCRYDVCSCSDGRECLCGALASYAAACAGRGVRVAWREPGRCELNCPKGQVYLQCGTPCNLTCRSLSYPDEECNEACLEGCFCPPGLYMDERGDCVPKAQCPCYYDGEIFQPEDIFSDHHTMCYCEDGFMHCTMSGVPGSLLPDAVLSSPLSHRSKRSLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLH (SEQ ID NO: 5)
Экспрессия про-OCTA 12 приводит к образованию димеров. После расщепления пропептида остаются пропептидные димеры.
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 5. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 5. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 5 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 5.
Дополнительным типичным слитым белком по изобретению является OCTA 14. OCTA 14 имеет следующую аминокислотную последовательность:
SLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLH (SEQ ID NO: 6)
OCTA 14 является слитым белком фрагмента VWF, соответствующего аминокислотам 764-1268 SEQ ID NO: 2, и четырех копий пептида удлинения (выделены полужирным шрифтом), связанных с C-концом, состоящим из аминокислот 1238-1268 SEQ ID NO: 2.
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 6. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 6. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 6.
Следующая последовательность (SEQ ID NO: 7) представляет собой OCTA 14 с дополнительным сигнальным пептидом из 12 аминокислот (выделен полужирным шрифтом и подчеркнут). При экспрессии этого пептида получают мономерную форму OCTA 14. Сигнальный пептид отщепляется.
MIPARFAGVLLALALILPGTLC SLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLH(SEQ ID NO: 7)
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 7. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 7. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 7 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 7.
Дополнительным типичным слитым белком по изобретению является про-OCTA 14, включающий OCTA 14 и пропептид (выделен полужирным шрифтом) с сигнальным пептидом (выделен полужирным шрифтом и подчеркнут). Про-OCTA 14 определен в SEQ ID NO: 8:
MIPARFAGVLLALALILPGTLCAEGTRGRSSTARCSLFGSDFVNTFDGSMYSFAGYCSYLLAGGCQKRSFSIIGDFQNGKRVSLSVYLGEFFDIHLFVNGTVTQGDQRVSMPYASKGLYLETEAGYYKLSGEAYGFVARIDGSGNFQVLLSDRYFNKTCGLCGNFNIFAEDDFMTQEGTLTSDPYDFANSWALSSGEQWCERASPPSSSCNISSGEMQKGLWEQCQLLKSTSVFARCHPLVDPEPFVALCEKTLCECAGGLECACPALLEYARTCAQEGMVLYGWTDHSACSPVCPAGMEYRQCVSPCARTCQSLHINEMCQERCVDGCSCPEGQLLDEGLCVESTECPCVHSGKRYPPGTSLSRDCNTCICRNSQWICSNEECPGECLVTGQSHFKSFDNRYFTFSGICQYLLARDCQDHSFSIVIETVQCADDRDAVCTRSVTVRLPGLHNSLVKLKHGAGVAMDGQDVQLPLLKGDLRIQHTVTASVRLSYGEDLQMDWDGRGRLLVKLSPVYAGKTCGLCGNYNGNQGDDFLTPSGLAEPRVEDFGNAWKLHGDCQDLQKQHSDPCALNPRMTRFSEEACAVLTSPTFEACHRAVSPLPYLRNCRYDVCSCSDGRECLCGALASYAAACAGRGVRVAWREPGRCELNCPKGQVYLQCGTPCNLTCRSLSYPDEECNEACLEGCFCPPGLYMDERGDCVPKAQCPCYYDGEIFQPEDIFSDHHTMCYCEDGFMHCTMSGVPGSLLPDAVLSSPLSHRSKRSLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLH (SEQ ID NO: 8)
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 8. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 8. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 8 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 8.
Дополнительным типичным слитым белком по изобретению является OCTA 15. OCTA 15 имеет следующую аминокислотную последовательность:
SLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVPTTLYVEDISEPPLHEEPECNDITARLQYVKVGSCKSEVEVDIHYCQGKCASKAMYSIDINDVQDQCSCCSPTRTEPMQVALHCTNGSVVYHEVLNAMECKCSPRKCSK (SEQ ID NO: 9)
OCTA 15 является слитым белком фрагмента VWF, соответствующего аминокислотам 764-1268 SEQ ID NO: 2, двух копий пептида удлинения (выделен полужирным шрифтом), связанных с C-концом, состоящим из аминокислот 1238-1268 SEQ ID NO: 2, и "домена цистеиновый узел" VWF, состоящего из аминокислот 2721-2813 SEQ ID NO: 2.
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 9. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 9. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 9 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 9.
Следующая последовательность (SEQ ID NO: 10) представляет собой OCTA 15 с дополнительным сигнальным пептидом из 12 аминокислот (выделен полужирным шрифтом и подчеркнут). При экспрессии этого пептида получают димерную форму OCTA 15. Сигнальный пептид отщепляется.
MIPARFAGVLLALALILPGTLC SLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVPTTLYVEDISEPPLHEEPECNDITARLQYVKVGSCKSEVEVDIHYCQGKCASKAMYSIDINDVQDQCSCCSPTRTEPMQVALHCTNGSVVYHEVLNAMECKCSPRKCSK (SEQ ID NO: 10)
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 10. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 10. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 10 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 10.
Дополнительным типичным слитым белком по изобретению является про-OCTA 15, включающий OCTA 15 и пропептид (выделен полужирным шрифтом) с сигнальным пептидом (выделен полужирным шрифтом и подчеркнут). Экспрессия этой последовательности будет приводить к образованию мультимеров. Про-OCTA 15 определен в SEQ ID NO: 11:
MIPARFAGVLLALALILPGTLCAEGTRGRSSTARCSLFGSDFVNTFDGSMYSFAGYCSYLLAGGCQKRSFSIIGDFQNGKRVSLSVYLGEFFDIHLFVNGTVTQGDQRVSMPYASKGLYLETEAGYYKLSGEAYGFVARIDGSGNFQVLLSDRYFNKTCGLCGNFNIFAEDDFMTQEGTLTSDPYDFANSWALSSGEQWCERASPPSSSCNISSGEMQKGLWEQCQLLKSTSVFARCHPLVDPEPFVALCEKTLCECAGGLECACPALLEYARTCAQEGMVLYGWTDHSACSPVCPAGMEYRQCVSPCARTCQSLHINEMCQERCVDGCSCPEGQLLDEGLCVESTECPCVHSGKRYPPGTSLSRDCNTCICRNSQWICSNEECPGECLVTGQSHFKSFDNRYFTFSGICQYLLARDCQDHSFSIVIETVQCADDRDAVCTRSVTVRLPGLHNSLVKLKHGAGVAMDGQDVQLPLLKGDLRIQHTVTASVRLSYGEDLQMDWDGRGRLLVKLSPVYAGKTCGLCGNYNGNQGDDFLTPSGLAEPRVEDFGNAWKLHGDCQDLQKQHSDPCALNPRMTRFSEEACAVLTSPTFEACHRAVSPLPYLRNCRYDVCSCSDGRECLCGALASYAAACAGRGVRVAWREPGRCELNCPKGQVYLQCGTPCNLTCRSLSYPDEECNEACLEGCFCPPGLYMDERGDCVPKAQCPCYYDGEIFQPEDIFSDHHTMCYCEDGFMHCTMSGVPGSLLPDAVLSSPLSHRSKRSLSCRPPMVKLVCPADNLRAEGLECTKTCQNYDLECMSMGCVSGCLCPPGMVRHENRCVALERCPCFHQGKEYAPGETVKIGCNTCVCQDRKWNCTDHVCDATCSTIGMAHYLTFDGLKYLFPGECQYVLVQDYCGSNPGTFRILVGNKGCSHPSVKCKKRVTILVEGGEIELFDGEVNVKRPMKDETHFEVVESGRYIILLLGKALSVVWDRHLSISVVLKQTYQEKVCGLCGNFDGIQNNDLTSSNLQVEEDPVDFGNSWKVSSQCADTRKVPLDSSPATCHNNIMKQTMVDSSCRILTSDVFQDCNKLVDPEPYLDVCIYDTCSCESIGDCACFCDTIAAYAHVCAQHGKVVTWRTATLCPQSCEERNLRENGYECEWRYNSCAPACQVTCQHPEPLACPVQCVEGCHAHCPPGKILDELLQTCVDPEDCPVCEVAGRRFASGKKVTLNPSDPEHCQICHCDVVNLTCEACQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVPTTLYVEDISEPPLHEEPECNDITARLQYVKVGSCKSEVEVDIHYCQGKCASKAMYSIDINDVQDQCSCCSPTRTEPMQVALHCTNGSVVYHEVLNAMECKCSPRKCSK (SEQ ID NO: 11)
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 11. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 11. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 11 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 11.
В одном из вариантов осуществления изобретения слитый белок является модифицированным белком FVIII на основе симоктокога альфа с двумя или более копиями пептида удлинения.
В этом варианте осуществления основной белок, предпочтительно, является идентичным или схожим с тяжелой цепью FVIII, в частности, с аминокислотами 20-759 UniprotKB P00451.1. Слитый белок с основным белком, идентичным или схожим с тяжелой цепью FVIII, в частности, с аминокислотами 20-759 UniprotKB P00451.1, предпочтительно, дополнительно содержит линкер, схожий или идентичный SEQ ID NO: 12, и дополнительную аминокислотную последовательность, схожую или идентичную легкой цепи, соответствующей аминокислотам 1668-2351 в записи UniprotKB P0045.1.
Пептиды удлинения можно подвергать слиянию с C-концом легкой цепи. Альтернативно, пептиды удлинения находится между тяжелой цепью и легкой цепью. В связи с этим, пептиды удлинения можно соединять с C-концом или N-концом линкера. Пептидами удлинения также можно заменять линкер. Кроме того, линкерная последовательность может прерываться одним или несколькими пептидами удлинения. Также возможно, чтобы пептиды удлинения находились между тяжелой и легкой цепью и на C-конце легкой цепи.
Предпочтительно, слитый белок, основанный на симоктокоге альфа, содержит, с N-конца к C-концу, тяжелую цепь FVIII, первую часть линкера, два или более, предпочтительно, три пептида удлинения (выделены полужирным шрифтом), вторую часть линкера (подчеркнута и выделена полужирным шрифтом) и легкую цепь. Примером такого белка является белок, определенный в SEQ ID NO: 14:
ATRRYYLGAVELSWDYMQSDLGELPVDARFPPRVPKSFPFNTSVVYKKTLFVEFTDHLFNIAKPRPPWMGLLGPTIQAEVYDTVVITLKNMASHPVSLHAVGVSYWKASEGAEYDDQTSQREKEDDKVFPGGSHTYVWQVLKENGPMASDPLCLTYSYLSHVDLVKDLNSGLIGALLVCREGSLAKEKTQTLHKFILLFAVFDEGKSWHSETKNSLMQDRDAASARAWPKMHTVNGYVNRSLPGLIGCHRKSVYWHVIGMGTTPEVHSIFLEGHTFLVRNHRQASLEISPITFLTAQTLLMDLGQFLLFCHISSHQHDGMEAYVKVDSCPEEPQLRMKNNEEAEDYDDDLTDSEMDVVRFDDDNSPSFIQIRSVAKKHPKTWVHYIAAEEEDWDYAPLVLAPDDRSYKSQYLNNGPQRIGRKYKKVRFMAYTDETFKTREAIQHESGILGPLLYGEVGDTLLIIFKNQASRPYNIYPHGITDVRPLYSRRLPKGVKHLKDFPILPGEIFKYKWTVTVEDGPTKSDPRCLTRYYSSFVNMERDLASGLIGPLLICYKESVDQRGNQIMSDKRNVILFSVFDENRSWYLTENIQRFLPNPAGVQLEDPEFQASNIMHSINGYVFDSLQLSVCLHEVAYWYILSIGAQTDFLSVFFSGYTFKHKMVYEDTLTLFPFSGETVFMSMENPGLWILGCHNSDFRNRGMTALLKVSSCDKNTGDYYEDSYEDISAYLLSKNNAIEPRSFSQNSRHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHQEPGGLVVPPTDAPVSPTTLYVEDISEPPLHRYRRGEITRTTLQSDQEEIDYDDTISVEMKKEDFDIYDEDENQSPRSFQKKTRHYFIAAVERLWDYGMSSSPHVLRNRAQSGSVPQFKKVVFQEFTDGSFTQPLYRGELNEHLGLLGPYIRAEVEDNIMVTFRNQASRPYSFYSSLISYEEDQRQGAEPRKNFVKPNETKTYFWKVQHHMAPTKDEFDCKAWAYFSDVDLEKDVHSGLIGPLLVCHTNTLNPAHGRQVTVQEFALFFTIFDETKSWYFTENMERNCRAPCNIQMEDPTFKENYRFHAINGYIMDTLPGLVMAQDQRIRWYLLSMGSNENIHSIHFSGHVFTVRKKEEYKMALYNLYPGVFETVEMLPSKAGIWRVECLIGEHLHAGMSTLFLVYSNKCQTPLGMASGHIRDFQITASGQYGQWAPKLARLHYSGSINAWSTKEPFSWIKVDLLAPMIIHGIKTQGARQKFSSLYISQFIIMYSLDGKKWQTYRGNSTGTLMVFFGNVDSSGIKHNIFNPPIIARYIRLHPTHYSIRSTLRMELMGCDLNSCSMPLGMESKAISDAQITASSYFTNMFATWSPSKARLHLQGRSNAWRPQVNNPKEWLQVDFQKTMKVTGVTTQGVKSLLTSMYVKEFLISSSQDGHQWTLFFQNGKVKVFQGNQDSFTPVVNSLDPPLLTRYLRIHPQSWVHQIALRMEVLGCEAQDLY (SEQ ID NO: 14)
В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 14. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 14. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 14 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 14.
Альтернативно, слитый белок, основанный на симоктокоге альфа, содержит два или более, предпочтительно, три пептида удлинения (выделены полужирным шрифтом), соединенных с C-концом симоктокога альфа. Примером такого белка является белок, определенный в SEQ ID NO: 21. В одном из вариантов осуществления аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90% по отношению к SEQ ID NO: 21. Аминокислотная последовательность слитого белка также может иметь идентичность по меньшей мере 95% по отношению к SEQ ID NO: 21. Кроме того, идентичность аминокислотной последовательности слитого белка по отношению к SEQ ID NO: 21 может составлять по меньшей мере 98%. В частности, аминокислотная последовательность слитого белка может иметь идентичность 100% по отношению к SEQ ID NO: 21.
Полинуклеотид
Во втором аспекте изобретение относится к выделенному полинуклеотиду, содержащему последовательность нуклеиновой кислоты, кодирующую слитый белок по первому аспекту изобретения.
Выделенный полинуклеотид может являться молекулой ДНК или молекулой РНК. Предпочтительно, выделенный полинуклеотид является молекулой ДНК, в частности, молекулой кДНК. Способы, используемые для выделения или клонирования полинуклеотида, кодирующего пептид, известны в этой области и включают выделение из геномной ДНК, получение из кДНК или их комбинацию. Клонирование полинуклеотидов из такой геномной ДНК можно осуществлять, например, с использованием хорошо известной полимеразной цепной реакции (ПЦР) или скрининга антител в экспрессионных библиотеках для определения клонированных фрагментов ДНК с общими структурными признаками (см., например, Innis et al, 1990) PCR: A Guide to Methods and Application, Academic Press, New York. Можно использовать другие способы амплификации нуклеиновой кислоты, такие как лигазная цепная реакция (LCR), активированная лигированием транскрипция (LAT) и амплификация на основе последовательности полинуклеотида (NASBA).
В частности, последовательность выделенного полинуклеотида может содержать первую часть, кодирующую основной белок, и по меньшей мере одну вторую часть последовательности. Первая часть, предпочтительно, является схожей или идентичной SEQ ID NO: 15. Первая часть, предпочтительно, имеет степень идентичности последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 15.
По меньшей мере одна вторая часть, предпочтительно, является схожей или идентичной SEQ ID NO: 16. Вторая часть, предпочтительно, имеет степень идентичности последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 16.
Выделенный полинуклеотид может являться молекулой ДНК, кодирующей слитый белок с аминокислотной последовательностью, схожей или идентичной последовательности, выбранной из группы, состоящей из SEQ ID NO: 4, SEQ ID NO: 5, SEQ ID NO: 7, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 11, SEQ ID NO: 14 и SEQ ID NO: 21.
В частности, выделенный полинуклеотид может являться молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 4. Альтернативно, выделенный полинуклеотид может являться молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%. Кроме того, выделенный полинуклеотид может являться молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 5. В одном из вариантов осуществления выделенный полинуклеотид является молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 7. В одном из вариантов осуществления выделенный полинуклеотид является молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 8. В одном из вариантов осуществления выделенный полинуклеотид является молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 10. В одном из вариантов осуществления выделенный полинуклеотид является молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 11. В одном из вариантов осуществления выделенный полинуклеотид является молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 14. В одном из вариантов осуществления выделенный полинуклеотид является молекулой ДНК, кодирующей слитый белок, имеющий аминокислотную последовательность с идентичностью по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к SEQ ID NO: 21.
Выделенный полинуклеотид может являться молекулой ДНК с последовательностью, схожей или идентичной последовательности, выбранной из группы, состоящей из SEQ ID NO: 17, SEQ ID NO: 18, SEQ ID NO: 19, SEQ ID NO: 20 и SEQ ID NO: 22.
В одном из вариантов осуществления одна цепь выделенного полинуклеотида имеет идентичность последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 17.
В дополнительном варианте осуществления изобретения выделенный полинуклеотид имеет идентичность последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 18. В другом варианте осуществления выделенный полинуклеотид имеет идентичность последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 19. В одном из вариантов осуществления выделенный полинуклеотид имеет идентичность последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 20. В одном из вариантов осуществления выделенный полинуклеотид имеет идентичность последовательности по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% по отношению к SEQ ID NO: 20.
Список полинуклеотидных последовательностей:
SEQ ID NO: 15: ДНК, кодирующая OCTA 11 (AA 1-1268 SEQ ID NO: 2)
SEQ ID NO: 16: ДНК, кодирующая пептид удлинения (SEQ ID NO: 1)
SEQ ID NO: 17: ДНК, кодирующая про-OCTA 12 (SEQ ID NO: 5)
SEQ ID NO: 18: ДНК, кодирующая про-OCTA 14 (SEQ ID NO: 8)
SEQ ID NO: 19: ДНК, кодирующая про-OCTA 15 (SEQ ID NO: 11)
SEQ ID NO: 20: ДНК, кодирующая симоктоког альфа с тремя пептидами удлинения в линкерной области (SEQ ID NO 14)
SEQ ID NO: 22: последовательность ДНК, кодирующая симоктоког альфа с тремя C-концевыми пептидами удлинения (SEQ ID NO: 21)
Экспрессирующий вектор
В третьем аспекте изобретение также относится к экспрессирующим векторам, содержащим полинуклеотид по второму аспекту изобретения.
Экспрессирующий вектор, предпочтительно, дополнительно содержит контрольные элементы, такие как промотор и транскрипционные и трансляционные стоп-сигналы. Полинуклеотид по второму аспекту и контрольные элементы можно соединять для получения рекомбинантного экспрессирующего вектора, который может включать один или более участков рестрикции, чтобы сделать возможной инсерцию или замену полинуклеотида, кодирующего полипептид, в таких участках. Полинуклеотид можно встраивать в подходящий экспрессирующий вектор для экспрессии. При получении экспрессирующего вектора кодирующую последовательность располагают в экспрессирующем векторе таким образом, что кодирующая последовательность функционально связана с подходящими контрольными последовательностями для экспрессии.
Рекомбинантный экспрессирующий вектор может являться любым вектором (например, плазмидой или вирусом), который можно подвергать способам рекомбинантной ДНК и который может вызывать экспрессию полинуклеотида по четвертому аспекту изобретения. Выбор экспрессирующего вектора, как правило, будет зависеть от совместимости экспрессирующего вектора с клеткой-хозяином, в которую будут встраивать экспрессирующий вектор. Экспрессирующие векторы могут быть линейными или представлять собой замкнутую кольцевую плазмиду.
Экспрессирующий вектор, предпочтительно, адаптируют для экспрессии в клетках млекопитающих. Экспрессирующий вектор может являться автономно реплицирующимся вектором, т.е. вектором, существующим в экстрахромосомном виде, репликация которого не зависит от хромосомной репликации, например, плазмидой, экстрахромосомным элементом, минихромосомой или искусственной хромосомой. В случае автономной репликации вектор может дополнительно содержать участок начала репликации, позволяющий вектору автономно реплицироваться в интересующей клетке-хозяине. Участок начала репликации может являться любым плазмидным репликатором, опосредующим автономную репликацию, функционирующим в клетке. Термин "участок начала репликации" или "плазмидный репликатор" означает полинуклеотид, позволяющий плазмиде или вектору реплицироваться in vivo.
Вектор, предпочтительно, является вектором, который при встраивании в клетку-хозяина интегрируется в геном и реплицируется с хромосомами, в которые он интегрируется. В случае интеграции в геном клетки-хозяина экспрессирующий вектор может быть основан на любом другом элементе экспрессирующего вектора для интеграции в геном посредством гомологичной или негомологичной рекомбинации. Альтернативно, вектор может содержать дополнительные полинуклеотиды для регуляции интеграции посредством гомологичной рекомбинации в геном клетки-хозяина в конкретный участок хромосомы.
Векторы по настоящему изобретению, предпочтительно, содержат один или более (например, несколько) селективных маркеров, делающих возможной простую селекцию трансформированных, трансфицированных, трансдуцированных или т.п. клеток. Селективный маркер является геном, продукт которого обеспечивает биоцидное действие или вирусную резистентность, резистентность к тяжелым металлам, прототрофность у ауксотрофов и т.п.
Способы, используемые для лигирования описываемых выше элементов для конструирования рекомбинантных экспрессирующих векторов по настоящему изобретению хорошо известны специалисту в этой области (см., например, Sambrook et al., 1989, выше).
В одном из вариантов осуществления остов вектора по третьему аспекту выбран из pCDNA3, pCDNA3,1, pCDNA4, pCDNA5, pCDNA6, pCEP4, pCEP-puro, pCET1019, pCMV, pEF1, pEF4, pEF5, pEF6, pExchange, pEXPR, pIRES и pSCAS.
Клетка-хозяин
В четвертом аспекте изобретение относится к клетке-хозяину, содержащему экспрессирующий вектор по третьему аспекту изобретения. Экспрессирующий вектор по третьему аспекту встраивают в клетку-хозяина таким образом, что экспрессирующий вектор поддерживают в виде хромосомного интегранта или самореплицирующегося экстрахромосомного вектора, как описано выше. Термин "клетка-хозяин" включает любое потомство родительской клетки, не идентичное родительской клетке по причине мутаций, возникающих при репликации. Выбор клетки-хозяина, в значительной степени, будет зависеть от гена, кодирующего полипептид, и его источника.
В одном из вариантов осуществления слитый белок получают посредством экспрессии в линии клеток-хозяев млекопитающего. Слитый белок, предпочтительно, получают в линии клеток-хозяев человека. В целом, любая линия клеток-хозяев человека подходит для экспрессии слитого белка. Предпочтительного гликозилирования слитого белка, в частности, достигают с использованием линий клеток почки человека. Предпочтительными линиями клеток почки человека являются линии клеток HEK, в частности, линии клеток HEK 293.
Примерами линий клеток HEK для получения гликозилированного полипептида являются HEK 293 F, Flp-In™-293 (Invitrogen, R75007), 293 (ATCC® CRL-1573), 293 EBNA, 293 H (ThermoScientific 11631017), 293S, 293T (ATCC® CRL-3216™), 293T/17 (ATCC® CRL11268™), 293T/17 SF (ATCC® ACS4500™), HEK 293 STF (ATCC® CRL 3249™), HEK-293.2sus (ATCC® CRL-1573™). Предпочтительной линией клеток для получения полипептида является линия клеток HEK 293 F.
Другие линии клеток, подходящие в качестве клеток-хозяев для экспрессии, включают линии клеток, полученные из клеток миелолейкоза человека. Конкретными примерами клеток-хозяев являются K562, NM-F9, NM-D4, NM-H9D8, NM-H9D8-E6, NM H9D8- E6Q12, GT-2X, GT-5s и клетки, полученные из любых из указанных клеток-хозяев. K562 является линией клеток миелолейкоза человека, находящейся в American Type Culture Collection (ATCC CCL-243). Остальные линии клеток получают из клеток K562 и выбирают по конкретным признакам гликозилирования.
Применение слитого белка
Как показано в примерах, пептиды удлинения SEQ ID NO: 1 в слитых белках OCTA 12 и OCTA 14 не только приводят к повышению времени полужизни слитого белка по сравнению с основным белком, т.е. фрагментом VWF. Слитые белки OCTA 12 и OCTA 14 при введении пациенту вместе с FVIII, партнером по связыванию VWF, также приводят к повышению времени полужизни FVIII.
Таким образом, в пятом аспекте изобретение относится к применению слитого белка по первому аспекту для повышения времени полужизни второго белка, где слитый белок способен связываться с указанным вторым белком.
Применение также можно описать как способ лечения пациента с использованием терапевтического белка, где способ включает введение терапевтического белка, например, белка FVIII вместе со слитым белком по первому аспекту.
Композиция и белковый комплекс
Таким образом, концепция изобретения, а именно пролонгирование времени полужизни, обеспечиваемое пептидами удлинения, не ограничено слитым белком, но, кроме того, можно повышать время полужизни второго белка, связывающегося со слитым белком.
Таким образом, в шестом аспекте изобретение относится к композиции первого белка и второго белка, где указанный первый белок является слитым белком по первому аспекту и способен связываться с указанным вторым белком, и указанный второй белок является терапевтическим белком, содержащим аминокислотную последовательность, идентичную или схожую с аминокислотной последовательностью второго белка млекопитающего или его фрагмента.
Первый белок может связываться со вторым белком ковалентно или нековалентно с образованием комплекса. Таким образом, настоящее изобретение также относится к комплексу первого белка и второго белка, где указанный первый белок является слитым белком по первому аспекту, и указанный второй белок имеет аминокислотную последовательность, идентичную или схожую с аминокислотной последовательностью второго белка млекопитающего или его фрагмента. Таким образом, комплексы образуются посредством нековалентного связывания первого белка со вторым белком.
В одном из вариантов осуществления первый белок связывается со вторым белком ковалентно. Линкер, облегчающий связывание первого и второго белка, можно выбирать из дисульфидного мостика, пептидной связи, химического линкера или гликозидной связи.
Альтернативно, первый белок связывается со вторым белком нековалентно. В случае нековалентного связывания первый белок, в частности, может содержать специфический связывающий домен, делающий возможным связывание указанного второго белка, т.е. связывающий домен второго белка. В зависимости от локализации одного или нескольких пептидов удлинения в последовательности первого белка они могут находиться в разных положениях первого белка. Предпочтительно, один или более пептидов удлинения локализуются в положении, экспонируемом на поверхности белка в свернутом состоянии. Один или более пептидов удлинения могут находиться в любом положении относительно участка связывания второго белка, например, связывающего домена.
В одном из вариантов осуществления композиции один или более пептидов удлинения находятся в положении первого белка в свернутом состоянии, не мешающем связыванию первого белка со вторым белком.
В одном из вариантов осуществления время полужизни второго белка, например, FVIII, связанного с первым белком, например, фрагментом VWF, повышается по сравнению со свободной формой указанного второго белка, например, белка FVIII.
Предпочтительно, время полужизни второго белка, например, белка FVIII, связанного с первым белком, например, OCTA 12, повышается по сравнению с указанным вторым белком, связанным с нативным белком млекопитающего, например, зрелым VWF.
Более предпочтительно, второй белок, например, белок FVIII, связанный с первым белком, например, OCTA 12, повышается по сравнению с указанным вторым белком, связанным с основным белком, без слитого пептида, например, OCTA 11.
Второй белок млекопитающего можно выбирать из списка, представленного выше для белка млекопитающего. Однако в композиции или комплексе второй белок млекопитающего не является тем же, что и первый белок млекопитающего.
В одном из вариантов осуществления второй белок млекопитающего является белком крови, в частности, белком крови человека. Предпочтительно, второй белок млекопитающего является фактором свертывания, в частности, фактором свертывания человека.
В одном из вариантов осуществления второй белок млекопитающего, по отношению к которому основной белок является схожим или идентичным, является полноразмерным FVIII человека, определяемым по аминокислотам 20-2351 UniProtKB P00451.1. В другом варианте осуществления основной белок является FVIII, в котором отсутствует, по меньшей мере, часть B-домена. В связи с этим может отсутствовать весь B-домен. Отсутствующую часть B-домена, необязательно, заменяют линкером. Линкерная последовательность, в частности, имеет следующую аминокислотную последовательность SFSQNSRHQAYRYRRG (SEQ ID NO: 12). Примером FVIII, в котором B-домен заменяют линкером, является симоктоког альфа (SEQ ID NO: 13), активный ингредиент Nuwiq® или Vihuma®.
В одном из вариантов осуществления белок FVIII является белком FVIII человека со сниженным иммунным ответом у пациентов.
Сниженный иммунный ответ на белок FVIII, предпочтительно, основан на связывании с SIGLEC SIG-5, SIG-7, SIG-8 и SIG-9. Не будучи связанными какой-либо теорией, полагают, что связывание с SIGLEC на антигенпрезентирующих клетках (подобных, например, дендритным клеткам) приводит к отрицательной регуляции экспрессии провоспалительных рецепторов и положительной регуляции экспрессии иммуносупрессорных рецепторов на поверхности клетки. Кроме того, связывание приводит к повышенной продукции противовоспалительных цитокинов, сниженной продукции провоспалительных цитокинов и, в результате, к ингибированию пролиферации T-клеток и продукции антител. Таким образом, связывание SIGLEC SIG-5, SIG-7, SIG-8 и SIG-9 приводит к сниженному иммунному ответу или повышенной иммунологической толерантности, когда гликозилированный полипептид вводят пациенту.
Связывание SIGLEC и, таким образом, сниженный иммунный ответ основаны на повышении количества или процентной доли O-гликанов с сиалированным кором 2 и/или удлиненным кором 1 в гликозилированном белке по сравнению с количеством O-гликанов с сиалированным кором 2 и/или удлиненным кором 1 природного FVIII человека.
Таким образом, в одном из вариантов осуществления белок FVIII имеет повышенное количество или процентную долю O-гликанов с сиалированным кором 2 и/или удлиненным кором 1 в гликозилированном белке по сравнению с количеством O-гликанов с сиалированным кором 2 и/или удлиненным кором 1 природного FVIII человека.
В случае, когда второй белок является белком FVIII, основной белок первого белка, предпочтительно, является фрагментом VWF, содержащим связывающий домен FVIII, что делает возможным связывание с белком FVIII.
В одном из вариантов осуществления композиции первый белок имеет аминокислотную последовательность с идентичностью по меньшей мере 95%, предпочтительно - по меньшей мере 98% более предпочтительно - 100% по отношению к SEQ ID NO: 3, и второй белок имеет аминокислотную последовательность с идентичностью по меньшей мере 95%, предпочтительно - по меньшей мере 98%, более предпочтительно - 100% по отношению к SEQ ID NO: 13.
В одном из вариантов осуществления композиции первый белок имеет аминокислотную последовательность с идентичностью по меньшей мере 95%, предпочтительно - по меньшей мере 98%. более предпочтительно - 100% по отношению к SEQ ID NO: 6, и второй белок имеет аминокислотную последовательность с идентичностью по меньшей мере 95%, предпочтительно - по меньшей мере 98% более предпочтительно - 100% по отношению к SEQ ID NO: 13.
В одном из вариантов осуществления композиции первый белок имеет аминокислотную последовательность с идентичностью по меньшей мере 95%, предпочтительно - по меньшей мере 98% более предпочтительно - 100% по отношению к SEQ ID NO: 9, и второй белок имеет аминокислотную последовательность с идентичностью по меньшей мере 95%, предпочтительно - по меньшей мере 98%, более предпочтительно - 100% по отношению к SEQ ID NO: 13.
Т.к. в крови пациента слитый белок, содержащий фрагмент VWF, в частности, OCTA 12, конкурирует с эндогенным VWF за связывание с белком FVIII, предпочтительно, чтобы композиция содержала слитый белок, содержащий фрагмент VWF, в частности, OCTA 12, в молярном избытке по сравнению с белком FVIII.
Предпочтительно, молярное соотношение первого белка и второго белка находится в диапазоне от 0,1 до 250, предпочтительно - в диапазоне от 0,5 до 50, более предпочтительно - в диапазоне от 1 до 25, наиболее предпочтительно - в диапазоне от 2 до 10.
Для образования стабильного нековалентно связанного комплекса и, таким образом, пролонгирования времени полужизни второго белка аффинность связывания первого белка со вторым белком, определяемая равновесной константой диссоциации (KD), должна составлять менее 10 мкМ. Предпочтительно, равновесная константа диссоциации фрагмента VWF в первом белке и белка FVIII находится в диапазоне от 0,05 до 3 нМ.
Первый и второй белок можно получать посредством раздельной рекомбинантной экспрессии, а затем соединять. Альтернативно, первый и второй белок рекомбинантно экспрессируют в одной клетке. В этом случае первый и второй белок могут кодироваться одним вектором или двумя разными векторами.
Конструкции VWF, используемые в примерах, т.е. OCTA 12, OCTA 14 и OCTA 15, экспрессировали в форме их про-белков, что приводит к образованию димеров или, в случае OCTA 15, к образованию мультимеров. Эти димеры остаются интактными даже после расщепления про-пептида, и, таким образом, каждая из копий конструкции VWF в димере может связываться с белком FVIII. Таким образом, в одном из вариантов осуществления комплекс содержит две копии первого и второго белка, где две копии первого белка образуют димер. Этот димер первого белка, предпочтительно, является нековалентно связанным димером.
Фармацевтическая композиция и медицинское применение
Как описано выше, слитый белок по первому аспекту, композиция по шестому аспекту и комплекс по седьмому аспекту изобретения обладают преимуществом повышенного времени полужизни в крови пациентов и, таким образом, повышенного терапевтического эффекта у пациентов. Таким образом, слитый белок по первому аспекту, композиция по шестому аспекту и комплекс по седьмому аспекту, в частности, применимы в качестве активных ингредиентов для лечения. Предпочтительно, они применимы для лечения или профилактики нарушения свертываемости. Слитый белок по первому аспекту, композицию по шестому аспекту, в частности, белковый комплекс, представленный в настоящем описании, можно вводить в отдельности или в форме фармацевтических композиций.
Таким образом, в восьмом аспекте изобретение относится к фармацевтической композиции слитого белка по первому аспекту, композиции по шестому аспекту и комплекса по седьмому аспекту.
По изобретению фармацевтическая композиция может содержать эффективное количество слитого белка по первому аспекту, композиции по шестому аспекту и комплекса по седьмому аспекту, составленных по меньшей мере с одним фармацевтически приемлемым носителем. Фармацевтические композиции по вариантам осуществления можно получать и вводить индивидууму любыми способами, хорошо известными в области фармацевтики. См., например, Goodman & Gilman's The Pharmacological Basis of Therapeutics, Hardman et al., eds., McGraw-Hill Professional (10th ed., 2001); Remington: The Science and Practice of Pharmacy, Gennaro, ed., Lippincott Williams & Wilkins (20th ed., 2003); and Pharmaceutical Dosage Forms and Drug Delivery Systems, Ansel et al. (eds), Lippincott Williams & Wilkins (7th ed., 1999). Кроме того, фармацевтические композиции по вариантам осуществления также можно составлять так, чтобы они включали другие медицински применимые лекарственные средства или биологические средства. Фармацевтическая композиция, как правило, содержит терапевтически эффективное количество слитого белка или белкового комплекса в комбинации с фармацевтически приемлемым носителем. Фармацевтически приемлемый носитель является любым носителем, известным в этой области. Примеры фармацевтически приемлемых носителей включают стерильную воду без пирогенов и стерильный физиологический раствор без пирогенов. Другие формы фармацевтически приемлемых носителей, которые можно использовать для вариантов осуществления изобретения, включают связывающие средства, разрыхлители, поверхностно-активные вещества, ускорители абсорбции, влагоудерживающие средства, абсорбирующие средства, смазочные средства, наполнители, увлажнители, консерванты, стабилизаторы, эмульгаторы, солюбилизаторы, соли, контролирующие осмотическое давление, разбавители, такие как буферы, и эксципиенты, как правило, используемые в зависимости от используемой формы состава. Необязательно, их выбирают и используют в соответствии с единицей дозирования полученного состава.
Таким образом, девятый аспект изобретения также относится к способу лечения или профилактики нарушения свертываемости у пациента, включающему введение указанному пациенту фармацевтической композиции по восьмому аспекту.
В рамках изобретения термин "нарушение свертываемости" относится к заболеванию или состоянию, нарушающему нормальный гемостаз. Нарушение свертываемости может являться, например, гемофилией A, гемофилией B, недостаточностью фактора VIII, недостаточностью фактора XI, болезнью фон Виллебранда, тромбастенией Гланцманна, синдромом Бернара-Сулье, идиопатической тромбоцитопенической пурпурой, внутримозговым кровоизлиянием, травмой, черепно-мозговой травмой и т.п.
В рамках изобретения термин "гемофилия" относится к группе нарушений свертываемости, ассоциированных с повышенным временем свертывания по сравнению с временем свертывания у здоровых индивидуумов без гемофилии. Гемофилия включает гемофилию A, являющуюся нарушением, приводящим к продукции дефектного фактора VIII, гемофилию B, являющуюся нарушением, приводящим к продукции дефектного фактора IX, и приобретенную гемофилию A, редкое нарушение свертываемости, вызываемое аутоантителами против фактора свертывания (F) VIII.
Нарушение свертываемости, предпочтительно, является гемофилией A или B. Лечение может представлять собой, например, лечение гемофилии PUPS (пациентов, ранее не подвергнутых лечению), или лечение с индукцией иммунологической толерантности (ITI), и/или другое лечение родственных гемофилических нарушений.
Для применения in vivo фармацевтические композиции можно вводить пациенту любым общепринятым способом введения, например, перорально, парентерально или посредством ингаляции. Парентеральное введение включает внутривенную инъекцию, подкожную инъекцию, интраперитонеальную инъекцию, внутримышечную инъекцию, введение жидких средств, суспензий, эмульсий и капельное введение. В случае парентерального введения фармацевтическая композиция должна являться инъецируемым средством, таким как жидкое средство или суспензия.
В других вариантах осуществления фармацевтическую композицию вводят пациенту перорально. В этих вариантах осуществления форма лекарственного средства включает твердые составы, такие как таблетки, таблетки с покрытием, порошки, гранулы, капсулы и пилюли, жидкие составы, такие как жидкие средства (например, глазные капли, назальные капли), суспензия, эмульсия и сироп, ингаляционные средства, такие как аэрозольные средства, атомайзеры и небулайзеры, и липосомные средства. В некоторых других вариантах осуществления гликозилированный полипептид, белковый комплекс или фармацевтическую композицию вводят посредством ингаляции в дыхательные пути пациента для воздействия на трахею и/или легкие индивидуума.
В одном из вариантов осуществления восьмого аспекта применение включает внутривенную или невнутривенную инъекцию. Невнутривенная инъекция, предпочтительно, является подкожной инъекцией.
Все публикации и патенты, процитированные в описании, включены в него в полном объеме в качестве ссылок. Если материал, включенный в качестве ссылки, противоречит или не соответствует описанию, описание обладает приоритетом относительно любого такого материала.
ПРИМЕРЫ
Пример 1 - Рекомбинантная экспрессия белков VWF
Следующие рекомбинантные белки VWF транзиторно экспрессировали в линии клеток HEK 293 F с C-концевой меткой Strep-Tag и очищали посредством аффинной хроматографии StrepTactin (IBA GmbH):
- OCTA 11
- OCTA 12
OCTA 12 является слитым белком по изобретению. OCTA 11 является сравнительным фрагментом VWF. Белки VWF схематически изображены на фиг. 1. Экспрессия про-белков приводит к образованию димеров. Пептидные димеры также остаются после расщепления пропептида.
Синтез и клонирование генов
В качестве первой стадии, гены, кодирующие про-белки белков VWF, синтезировали в GeneArt (Thermo Fisher Scientific):
- про-OCTA 11
- про-OCTA 12
Гены, кодирующие про-белки, клонировали в экспрессирующий вектор pDSG (IBA GmbH), содержащий метку Twin-Strep-tag. Отдельные культуры E.coli TOP10 (IBA GmbH) трансформировали с использованием векторных конструкций и отдельные клоны подвергали селекции после инкубации в течение ночи при 37°C на чашках с содержащим ампициллин LB-агаром.
Получение плазмидной ДНК осуществляли с использованием наборов QIAamp DNA Mini или Maxi kit (Qiagen) по инструкциям производителя. С помощью секвенирования подтверждали целостность векторов, в частности, правильную ориентацию и целостность генов, кодирующих про-OCTA 11, про-OCTA 12.
Экспрессия белка
Для эукариотической экспрессии белков VWF клетки MEXi-293 (IBA GmbH), выращенные в среде для трансфекции MEXi (IBA GmbH), трансфицировали с использованием 1,5 мг/л конструкций с использованием 4,5 мг/мл линейного полиэтиленимина 25 кДа. После инкубации в течение 2-4 при 37°C, 5% CO2 и 100-150 об./мин., культуру разводили 1:2 средой для трансфекции MEXi и продолжали культивирование до достижения жизнеспособности клеток 75%.
Затем супернатант отделяли от клеток посредством центрифугирования при 4°C и 300×g. Для минимизации ингибиторного эффекта биотина в среде для культивирования клеток и для коррекции pH к супернатанту добавляли 0,1 объема буфера (1 M Трис-HCl, 1,5 мМ NaCl, 10 мМ ЭДТА, pH 8,0) и 0,09% (об./об.) раствора BioLock (IBA GmbH) и инкубировали в течение 20 мин при 4°C.
Очистка белка
После центрифугирования супернатант наносили на колонку Strep-Tactin XT (IBA GmbH), промывали пять раз промывочным буфером (100 мМ Трис-HCl, 150 мМ NaCl, 1 мМ ЭДТА, pH 8,0) и связанные белки, содержащие метку Strep-tag, элюировали с помощью элюирующего буфера (100 мМ Трис-HCl, 150 мМ NaCl, 1 мМ ЭДТА, 10 мМ дестиобиотин, pH 8,0).
Пример 2 - Влияние полноразмерного VWF или белков VWF на время полужизни FVIII при совместном введении с FVIII мышам с двойным нокаутом (DKO) FVIII/VWF
2.1 Предпосылки
В этом эксперименте исследовали влияние белков VWF, полученных по примеру 1, и полноразмерного, полученного из плазмы VWF (pdVWF) на время полужизни FVIII.
Известно, что полноразмерный VWF и FVIII являются партнерами по связыванию, образующими нековалентный комплекс. Время полужизни FVIII в кровотоке определяется, в основном, временем полужизни VWF в кровотоке.
Т.к. в сыворотке эндогенный VWF конкурирует с вводимыми белками VWF (фрагментами) за связывание с FVIII, это конкурирование будет влиять на любой эффект вводимых белков VWF в отношении времени полужизни FVIII.
Таким образом, в этом эксперименте мышей C57Bl/6 с двойным нокаутом FVIII и VWF (FVIII/VWF-DKO) использовали в качестве модельных организмов для оценки влияния VWF на время полужизни FVIII.
2.2 Эксперимент
2.2.1 FVIII-содержащие продукты
Получали следующие FVIII-содержащие продукты:
1) FVIII в отдельности
2) FVIII и OCTA 11
3) FVIII и OCTA 12
4) FVIII и pdVWF
Белки VWF OCTA 11 и OCTA 12 получали, как описано в примере 1. pdVWF представлял собой концентрат VWF Wilate (Octapharma). FVIII являлся FVIII с делецией B-домена из линии клеток человека (Nuwiq, Octapharma). Продукт Nuwiq содержит следующую буферную композицию:
Молярное соотношение белка VWF и FVIII в FVIII-содержащих продуктах 2)-4) составляло 5:1. Белки VWF добавляли в продукт Nuwiq (FVIII).
2.2.2 Линия мышей FVIII/VWF-DKO
Использовали мышей C57Bl/6 с двойным нокаутом FVIII и VWF (FVIII/VWF-DKO).
2.2.3 Введение продуктов
Четыре FVIII-содержащих продукта вводили 20 мышам FVIII/VWF-DKO посредством инфузии в хвостовую вену в дозе 240 МЕ FVIII/кг (~6 МЕ/мышь).
2.2.4 Забор образцов и анализ
Образцы крови мышей получали через 5 минут и 1, 4, 8, 12, 24, 36 и 48 часов после введения FVIII-содержащих продуктов. Образцы крови получали из ретроорбитального сосудистого сплетения мышей. Для каждой временной точки получали образцы крови 5 мышей на FVIII-содержащий продукт и анализировали по отдельности. Образец от каждой мыши получали во временной точке 5 мин и максимально в двух дополнительных временных точках.
Активность FVIII в каждом из образцов крови анализировали с использованием хромогенного анализа (CHROMOGENIX).
2.3 Результаты
Вместе со значениями активности FVIII в образцах крови определяли динамику активности FVIII для каждого из FVIII-содержащих продуктов, как показано на фиг. 2.
Как и для каждой временной точки и FVIII-содержащего продукта, проводили измерения в образцах крови пяти животных, каждая точка данных на фиг. 2 представляет собой среднее для 5 значений.
Кроме того, активность FVIII в отдельных временных точках представляли в виде процента активности FVIII через 5 минут после введения, которую определяли как 100% активности для каждого из FVIII-содержащих продуктов.
Время полужизни FVIII в пяти продуктах вычисляли после аппроксимации кривой с использованием линейного регрессионного анализа линейно-логарифмической части отдельных кривых концентрация в плазме-время или посредством нелинейной регрессии с использованием однофазной модели экспоненциального уменьшения. Программным обеспечением, используемым для вычисления, являлось GraphPad Prism версии 6.07 (La Jolla, CA 92037 USA) и WinNonlin версии 6.4 (Pharsight Corporation, Mountain View, CA, USA).
Вычисления были основаны на следующих уравнениях:
Kel=константа скорости элиминации
t½=время полувыведения
c=концентрация
t=время
Результаты представлены в таблице 1.
Из этих чисел очевидно, что совместное введение FVIII с любым из белков VWF приводит к повышению времени полужизни. Совместное введение FVIII с pdVWF приводит к ~4,6-кратному повышению времени полужизни FVIII (0,31).
FVIII, вводимый совместно с белком VWF OCTA 11, демонстрирует сравнимое время полужизни 0,45 ч. (приблизительно 1,4-кратное повышение).
Примечательно, что совместное введение с белком VWF OCTA 12 приводит к времени полужизни FVIII 1,03 ч., что представляет собой повышение приблизительно в 3,2 раза по сравнению с flVWF. Повышение является 14,7-кратным по сравнению с FVIII.
Эти результаты свидетельствуют о том, что дополнительные O-гликановые повторы, присутствующие в OCTA 12, приводят к значительному эффекту пролонгирования времени полужизни в отношении фрагмента VWF и, в свою очередь, комплекса VWF/FVIII. Кроме того, эти результаты свидетельствуют о том, что добавление копий характерного O-гликанового кластера может повышать время полужизни белка.
Пример 3 - Фармакокинетический профиль FVIII и VWF OCTA 12 после IV и подкожного (SQ) введения у карликовых свиней
3.1 Предпосылки
Доставка SQ лекарственных средств привлекает все больше внимания в области факторов свертывания. Однако по причине очень низкого высвобождения этот путь пока не применим для введения FVIII. Карликовая свинья является наиболее известной моделью на животных для тестирования SQ введения лекарственных средств по причине близкого сходства со структурой эпидермиса человека. Целью этого эксперимента являлась оценка времени полужизни VWF OCTA 12 и FVIII при введении в отдельности или с пятикратным молярным избытком OCTA 12 у карликовой свиньи с помощью SQ пути. Кроме того, время полужизни FVIII при введении в отдельности общепринятым IV путем сравнивали с FVIII, вводимым SQ с VWF OCTA 12 или без него.
3.2 Эксперимент
Для этого исследования использовали девять самок карликовых свиней Aachener возрастом от 10 до 14 месяцев. Масса тела составляла от 13,7 до 19,5 кг. IV инъекцию делали в латеральную ушную вену, SQ инъекцию делали под кожу в паховой области. Доза составляла 100 ед. FVIII/кг BW, использовали 3 животных на группу с каждым продуктом:
- Группа 1: FVIII в отдельности, SQ
- Группа 2: FVIII с OCTA 12, SQ
- Группа 3: FVIII в отдельности, IV
Для получения 2×200 мкл плазмы с цитратом натрия на животное и время забора собирали достаточное количество крови из яремной вены всех животных в следующие моменты времени: 0 (до введения дозы), 0,5, 1, 2, 4, 8, 24, 32, 48, 72, 96 и 120 ч. после каждого введения.
Цельную кровь собирали в пробирки, содержащие цитрат натрия (0,15 M) в качестве антикоагулянта, и сразу охлаждали с использованием системы IsoTherm-Rack (Eppendorf). Плазму отделяли посредством центрифугирования в пределах 30 минут после забора крови. Сразу после центрифугирования образцы плазмы замораживали и хранили при ≤-20°C до транспортировки.
Каждый образец тестировали на антиген FVIII с использованием набора Asserachrom (Diagnostica Stago). OCTA 12 количественно анализировали с использованием анализа ELISA следующим образом: покрытый Strep-Tactin® XT микропланшет (IBA GmbH) блокировали блокирующим буфером (1% BSA in PBS) в течение 2 ч. при RT. Образцы плазмы разводили блокирующим буфером 1:15 и наносили на планшет. Через 2 ч. инкубации при 37°C фрагмент VWF определяли с использованием pAb против VWF (Dako P0226). После каждой инкубации планшет промывали 3 раза 0,1% Tween в PBS.
Фармакокинетическую оценку данных анализа осуществляли с использованием WinNonlin версии 6.4 (Pharsight Corporation, Mountain View, CA, USA).
3.3 Результаты
На фигуре 3 показана динамика концентрации VWF OCTA 12 в плазме карликовой свиньи после SQ введения смеси FVIII/VWF OCTA 12. Как представлено в таблице 2, OCTA 12 циркулирует с временем полужизни 219,31 ч. Время полужизни определяли, как описано в примере 2.
100 ед./кг BW FVIII с OCTA 12
SQ.
У свиней с болезнью фон Виллебранда (VWD) время полужизни полноразмерного рекомбинантного VWF человека (rhVWF) составляет приблизительно от 10 до 16 часов, и время полужизни полученного VWF свиньи в плазме составляет от 10 до 18 часов (Nichols et al.). Время полужизни фрагмента VWF, содержащего только связывающие домены FVIII, меньше времени полужизни flVWF, как показано Yee et al. на мышах с недостаточностью VWF. Таким образом, время полужизни OCTA 12 составляет приблизительно в 14-22 раза больше времени полужизни rhVWF у свиньи.
Кроме того, также наблюдали значительный эффект пролонгирования в отношении времени полужизни FVIII. Как показано на фигуре 4 и в таблице 3, FVIII при совместном введении с OCTA 12 имеет время полужизни 25,3 ч, что представляет собой 6,7-кратное повышение времени полужизни по сравнению с FVIII в отдельности, вводимого тем же путем (SQ), и 3,9-кратное улучшение по сравнению с FVIII, вводимым в отдельности общепринятым IV путем.
[ед./мл]
[ч.]
[ч.]
100 ед./кг BW
FVIII в отдельности
SQ
100 ед./кг BW
FVIII с OCTA 12
SQ
FVIII в отдельности
IV
Множество модификаций и других вариантов осуществления изобретения, представленного в настоящем описании, будут очевидны специалисту в области, к которой относится изобретение, который может извлечь пользу из идеи, представленной в изложенном выше описании и прилагаемых чертежах. Таким образом, следует понимать, что изобретение не должно быть ограничено конкретными описанными вариантами осуществления, и что в объем формулы изобретения должны быть включены модификации и другие варианты осуществления. Хотя в настоящем описании используют конкретные термины, их используют исключительно в общем и описательном смысле, а не для ограничения.
ССЫЛКИ
Birken S, Canfield RE. Isolation and amino acid sequence of COOH-terminal fragments from the beta subunit of human choriogonadotropin. J Biol Chem. 1977; vol. 252 pg. 5386-5392
Ewenstein BM, Collins P, Tarantino MD, Negrier C, Blanchette V, Shapiro AD, Baker D, Spotts G, Sensel M, Yi SE, Gomperts ED. Hemophilia therapy innovation development of an advanced category recombinant factor VIII by a plasma/albumin-free method Proceedings of a Special Symposium at the XIXth Congress of the International Society on Thrombosis and Haemostasis; 2004, vol. 41, pg. 1-16.
Fischer B, Mitterer A, Schlokat U, DenBouwmeester R, Dorner ʺStructural analysis of recombinant von Willebrand factor: identification of hetero- and homo-dimersʺ FFEBS Lett. 1994 Sep 12; 351(3):345-8. Erratum in: FEBS Lett 1994 Oct 24; 353(3):337.
Furlan M. ʺVon Willebrand factor: molecular size and functional activityʺ Ann Hematol. 1996 Jun; 72(6):341-8.
Kannicht C, Ramstrom M, Kohla G, et al. Characterisation of the post-translational modifications of a novel, human cell line-derived recombinant human factor VIII. Thromb Res. 2013; 131(1):78-88.
Needleman SB, Wunsch CD. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J Mol Biol. 1970; vol. 48(3); pg. 443-453.
Nichols TC, Bellinger DA, Merricks EP, et al. Porcine and Canine von Willebrand Factor and von Willebrand Disease: Hemostasis, Thrombosis, and Atherosclerosis Studies. Thrombosis. 2010;2010:461238.
Strohl WR. Fusion Proteins for Half-Life Extension of Biologics as a Strategy to Make Biobetters. BioDrugs. 2015 Aug; vol. 29(4), pg. 215-239.
Tiede A. Half-life extended factor VIII for the treatment of hemophilia A. J Thromb Haemost. 2015 Jun; vol. 13 Suppl 1; pg. S176-179
Vlot AJ, Koppelman SJ, Meijers JC, Dama C, van den Berg HM, Bouma BN, Sixma JJ, Willems GM. Kinetics of factor VIII-von Willebrand factor association. Blood. 1996 1; vol. 87(5); pg. 1809-1816
Yee A, Gildersleeve RD, Gu S, Kretz CA, McGee BM, Carr KM, Pipe SW, Ginsburg D. A von Willebrand factor fragment containing the D'D3 domains is sufficient to stabilize coagulation factor VIII in mice. Blood. 2014 Jul 17; vol. 124(3); pg. 445-452.
Innis et al, 1990 PCR: A Guide to Methods and Application, Academic Press, New York.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Octapharma AG
<120> ГЛИКОЗИЛИРОВАННЫЕ СЛИТЫЕ БЕЛКИ VWF С УЛУЧШЕННОЙ ФАРМАКОКИНЕТИКОЙ
<130> 4830P1098WORU
<140> 2018144112
<141> 2017-04-26
<150> EP 16170690.8
<151> 2016-05-20
<160> 22
<170> PatentIn version 3.5
<210> 1
<211> 31
<212> БЕЛОК
<213> Homo sapiens
<400> 1
Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser
1 5 10 15
Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His
20 25 30
<210> 2
<211> 2813
<212> БЕЛОК
<213> Homo sapiens
<400> 2
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ala Glu Gly Thr Arg Gly Arg Ser Ser Thr
20 25 30
Ala Arg Cys Ser Leu Phe Gly Ser Asp Phe Val Asn Thr Phe Asp Gly
35 40 45
Ser Met Tyr Ser Phe Ala Gly Tyr Cys Ser Tyr Leu Leu Ala Gly Gly
50 55 60
Cys Gln Lys Arg Ser Phe Ser Ile Ile Gly Asp Phe Gln Asn Gly Lys
65 70 75 80
Arg Val Ser Leu Ser Val Tyr Leu Gly Glu Phe Phe Asp Ile His Leu
85 90 95
Phe Val Asn Gly Thr Val Thr Gln Gly Asp Gln Arg Val Ser Met Pro
100 105 110
Tyr Ala Ser Lys Gly Leu Tyr Leu Glu Thr Glu Ala Gly Tyr Tyr Lys
115 120 125
Leu Ser Gly Glu Ala Tyr Gly Phe Val Ala Arg Ile Asp Gly Ser Gly
130 135 140
Asn Phe Gln Val Leu Leu Ser Asp Arg Tyr Phe Asn Lys Thr Cys Gly
145 150 155 160
Leu Cys Gly Asn Phe Asn Ile Phe Ala Glu Asp Asp Phe Met Thr Gln
165 170 175
Glu Gly Thr Leu Thr Ser Asp Pro Tyr Asp Phe Ala Asn Ser Trp Ala
180 185 190
Leu Ser Ser Gly Glu Gln Trp Cys Glu Arg Ala Ser Pro Pro Ser Ser
195 200 205
Ser Cys Asn Ile Ser Ser Gly Glu Met Gln Lys Gly Leu Trp Glu Gln
210 215 220
Cys Gln Leu Leu Lys Ser Thr Ser Val Phe Ala Arg Cys His Pro Leu
225 230 235 240
Val Asp Pro Glu Pro Phe Val Ala Leu Cys Glu Lys Thr Leu Cys Glu
245 250 255
Cys Ala Gly Gly Leu Glu Cys Ala Cys Pro Ala Leu Leu Glu Tyr Ala
260 265 270
Arg Thr Cys Ala Gln Glu Gly Met Val Leu Tyr Gly Trp Thr Asp His
275 280 285
Ser Ala Cys Ser Pro Val Cys Pro Ala Gly Met Glu Tyr Arg Gln Cys
290 295 300
Val Ser Pro Cys Ala Arg Thr Cys Gln Ser Leu His Ile Asn Glu Met
305 310 315 320
Cys Gln Glu Arg Cys Val Asp Gly Cys Ser Cys Pro Glu Gly Gln Leu
325 330 335
Leu Asp Glu Gly Leu Cys Val Glu Ser Thr Glu Cys Pro Cys Val His
340 345 350
Ser Gly Lys Arg Tyr Pro Pro Gly Thr Ser Leu Ser Arg Asp Cys Asn
355 360 365
Thr Cys Ile Cys Arg Asn Ser Gln Trp Ile Cys Ser Asn Glu Glu Cys
370 375 380
Pro Gly Glu Cys Leu Val Thr Gly Gln Ser His Phe Lys Ser Phe Asp
385 390 395 400
Asn Arg Tyr Phe Thr Phe Ser Gly Ile Cys Gln Tyr Leu Leu Ala Arg
405 410 415
Asp Cys Gln Asp His Ser Phe Ser Ile Val Ile Glu Thr Val Gln Cys
420 425 430
Ala Asp Asp Arg Asp Ala Val Cys Thr Arg Ser Val Thr Val Arg Leu
435 440 445
Pro Gly Leu His Asn Ser Leu Val Lys Leu Lys His Gly Ala Gly Val
450 455 460
Ala Met Asp Gly Gln Asp Val Gln Leu Pro Leu Leu Lys Gly Asp Leu
465 470 475 480
Arg Ile Gln His Thr Val Thr Ala Ser Val Arg Leu Ser Tyr Gly Glu
485 490 495
Asp Leu Gln Met Asp Trp Asp Gly Arg Gly Arg Leu Leu Val Lys Leu
500 505 510
Ser Pro Val Tyr Ala Gly Lys Thr Cys Gly Leu Cys Gly Asn Tyr Asn
515 520 525
Gly Asn Gln Gly Asp Asp Phe Leu Thr Pro Ser Gly Leu Ala Glu Pro
530 535 540
Arg Val Glu Asp Phe Gly Asn Ala Trp Lys Leu His Gly Asp Cys Gln
545 550 555 560
Asp Leu Gln Lys Gln His Ser Asp Pro Cys Ala Leu Asn Pro Arg Met
565 570 575
Thr Arg Phe Ser Glu Glu Ala Cys Ala Val Leu Thr Ser Pro Thr Phe
580 585 590
Glu Ala Cys His Arg Ala Val Ser Pro Leu Pro Tyr Leu Arg Asn Cys
595 600 605
Arg Tyr Asp Val Cys Ser Cys Ser Asp Gly Arg Glu Cys Leu Cys Gly
610 615 620
Ala Leu Ala Ser Tyr Ala Ala Ala Cys Ala Gly Arg Gly Val Arg Val
625 630 635 640
Ala Trp Arg Glu Pro Gly Arg Cys Glu Leu Asn Cys Pro Lys Gly Gln
645 650 655
Val Tyr Leu Gln Cys Gly Thr Pro Cys Asn Leu Thr Cys Arg Ser Leu
660 665 670
Ser Tyr Pro Asp Glu Glu Cys Asn Glu Ala Cys Leu Glu Gly Cys Phe
675 680 685
Cys Pro Pro Gly Leu Tyr Met Asp Glu Arg Gly Asp Cys Val Pro Lys
690 695 700
Ala Gln Cys Pro Cys Tyr Tyr Asp Gly Glu Ile Phe Gln Pro Glu Asp
705 710 715 720
Ile Phe Ser Asp His His Thr Met Cys Tyr Cys Glu Asp Gly Phe Met
725 730 735
His Cys Thr Met Ser Gly Val Pro Gly Ser Leu Leu Pro Asp Ala Val
740 745 750
Leu Ser Ser Pro Leu Ser His Arg Ser Lys Arg Ser Leu Ser Cys Arg
755 760 765
Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu
770 775 780
Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met
785 790 795 800
Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg
805 810 815
His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln
820 825 830
Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr
835 840 845
Cys Val Cys Arg Asp Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp
850 855 860
Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly
865 870 875 880
Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp
885 890 895
Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys
900 905 910
Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu
915 920 925
Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys
930 935 940
Arg Pro Met Lys Asp Glu Thr His Phe Glu Val Val Glu Ser Gly Arg
945 950 955 960
Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg
965 970 975
His Leu Ser Ile Ser Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val
980 985 990
Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr
995 1000 1005
Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val Asp Phe Gly Asn
1010 1015 1020
Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg Lys Val Pro
1025 1030 1035
Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met Lys Gln
1040 1045 1050
Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val Phe
1055 1060 1065
Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
1070 1075 1080
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala
1085 1090 1095
Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln
1100 1105 1110
His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln
1115 1120 1125
Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu
1130 1135 1140
Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln
1145 1150 1155
His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
1160 1165 1170
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln
1175 1180 1185
Thr Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly
1190 1195 1200
Arg Arg Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp
1205 1210 1215
Pro Glu His Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr
1220 1225 1230
Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr
1235 1240 1245
Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser
1250 1255 1260
Glu Pro Pro Leu His Asp Phe Tyr Cys Ser Arg Leu Leu Asp Leu
1265 1270 1275
Val Phe Leu Leu Asp Gly Ser Ser Arg Leu Ser Glu Ala Glu Phe
1280 1285 1290
Glu Val Leu Lys Ala Phe Val Val Asp Met Met Glu Arg Leu Arg
1295 1300 1305
Ile Ser Gln Lys Trp Val Arg Val Ala Val Val Glu Tyr His Asp
1310 1315 1320
Gly Ser His Ala Tyr Ile Gly Leu Lys Asp Arg Lys Arg Pro Ser
1325 1330 1335
Glu Leu Arg Arg Ile Ala Ser Gln Val Lys Tyr Ala Gly Ser Gln
1340 1345 1350
Val Ala Ser Thr Ser Glu Val Leu Lys Tyr Thr Leu Phe Gln Ile
1355 1360 1365
Phe Ser Lys Ile Asp Arg Pro Glu Ala Ser Arg Ile Thr Leu Leu
1370 1375 1380
Leu Met Ala Ser Gln Glu Pro Gln Arg Met Ser Arg Asn Phe Val
1385 1390 1395
Arg Tyr Val Gln Gly Leu Lys Lys Lys Lys Val Ile Val Ile Pro
1400 1405 1410
Val Gly Ile Gly Pro His Ala Asn Leu Lys Gln Ile Arg Leu Ile
1415 1420 1425
Glu Lys Gln Ala Pro Glu Asn Lys Ala Phe Val Leu Ser Ser Val
1430 1435 1440
Asp Glu Leu Glu Gln Gln Arg Asp Glu Ile Val Ser Tyr Leu Cys
1445 1450 1455
Asp Leu Ala Pro Glu Ala Pro Pro Pro Thr Leu Pro Pro Asp Met
1460 1465 1470
Ala Gln Val Thr Val Gly Pro Gly Leu Leu Gly Val Ser Thr Leu
1475 1480 1485
Gly Pro Lys Arg Asn Ser Met Val Leu Asp Val Ala Phe Val Leu
1490 1495 1500
Glu Gly Ser Asp Lys Ile Gly Glu Ala Asp Phe Asn Arg Ser Lys
1505 1510 1515
Glu Phe Met Glu Glu Val Ile Gln Arg Met Asp Val Gly Gln Asp
1520 1525 1530
Ser Ile His Val Thr Val Leu Gln Tyr Ser Tyr Met Val Thr Val
1535 1540 1545
Glu Tyr Pro Phe Ser Glu Ala Gln Ser Lys Gly Asp Ile Leu Gln
1550 1555 1560
Arg Val Arg Glu Ile Arg Tyr Gln Gly Gly Asn Arg Thr Asn Thr
1565 1570 1575
Gly Leu Ala Leu Arg Tyr Leu Ser Asp His Ser Phe Leu Val Ser
1580 1585 1590
Gln Gly Asp Arg Glu Gln Ala Pro Asn Leu Val Tyr Met Val Thr
1595 1600 1605
Gly Asn Pro Ala Ser Asp Glu Ile Lys Arg Leu Pro Gly Asp Ile
1610 1615 1620
Gln Val Val Pro Ile Gly Val Gly Pro Asn Ala Asn Val Gln Glu
1625 1630 1635
Leu Glu Arg Ile Gly Trp Pro Asn Ala Pro Ile Leu Ile Gln Asp
1640 1645 1650
Phe Glu Thr Leu Pro Arg Glu Ala Pro Asp Leu Val Leu Gln Arg
1655 1660 1665
Cys Cys Ser Gly Glu Gly Leu Gln Ile Pro Thr Leu Ser Pro Ala
1670 1675 1680
Pro Asp Cys Ser Gln Pro Leu Asp Val Ile Leu Leu Leu Asp Gly
1685 1690 1695
Ser Ser Ser Phe Pro Ala Ser Tyr Phe Asp Glu Met Lys Ser Phe
1700 1705 1710
Ala Lys Ala Phe Ile Ser Lys Ala Asn Ile Gly Pro Arg Leu Thr
1715 1720 1725
Gln Val Ser Val Leu Gln Tyr Gly Ser Ile Thr Thr Ile Asp Val
1730 1735 1740
Pro Trp Asn Val Val Pro Glu Lys Ala His Leu Leu Ser Leu Val
1745 1750 1755
Asp Val Met Gln Arg Glu Gly Gly Pro Ser Gln Ile Gly Asp Ala
1760 1765 1770
Leu Gly Phe Ala Val Arg Tyr Leu Thr Ser Glu Met His Gly Ala
1775 1780 1785
Arg Pro Gly Ala Ser Lys Ala Val Val Ile Leu Val Thr Asp Val
1790 1795 1800
Ser Val Asp Ser Val Asp Ala Ala Ala Asp Ala Ala Arg Ser Asn
1805 1810 1815
Arg Val Thr Val Phe Pro Ile Gly Ile Gly Asp Arg Tyr Asp Ala
1820 1825 1830
Ala Gln Leu Arg Ile Leu Ala Gly Pro Ala Gly Asp Ser Asn Val
1835 1840 1845
Val Lys Leu Gln Arg Ile Glu Asp Leu Pro Thr Met Val Thr Leu
1850 1855 1860
Gly Asn Ser Phe Leu His Lys Leu Cys Ser Gly Phe Val Arg Ile
1865 1870 1875
Cys Met Asp Glu Asp Gly Asn Glu Lys Arg Pro Gly Asp Val Trp
1880 1885 1890
Thr Leu Pro Asp Gln Cys His Thr Val Thr Cys Gln Pro Asp Gly
1895 1900 1905
Gln Thr Leu Leu Lys Ser His Arg Val Asn Cys Asp Arg Gly Leu
1910 1915 1920
Arg Pro Ser Cys Pro Asn Ser Gln Ser Pro Val Lys Val Glu Glu
1925 1930 1935
Thr Cys Gly Cys Arg Trp Thr Cys Pro Cys Val Cys Thr Gly Ser
1940 1945 1950
Ser Thr Arg His Ile Val Thr Phe Asp Gly Gln Asn Phe Lys Leu
1955 1960 1965
Thr Gly Ser Cys Ser Tyr Val Leu Phe Gln Asn Lys Glu Gln Asp
1970 1975 1980
Leu Glu Val Ile Leu His Asn Gly Ala Cys Ser Pro Gly Ala Arg
1985 1990 1995
Gln Gly Cys Met Lys Ser Ile Glu Val Lys His Ser Ala Leu Ser
2000 2005 2010
Val Glu Leu His Ser Asp Met Glu Val Thr Val Asn Gly Arg Leu
2015 2020 2025
Val Ser Val Pro Tyr Val Gly Gly Asn Met Glu Val Asn Val Tyr
2030 2035 2040
Gly Ala Ile Met His Glu Val Arg Phe Asn His Leu Gly His Ile
2045 2050 2055
Phe Thr Phe Thr Pro Gln Asn Asn Glu Phe Gln Leu Gln Leu Ser
2060 2065 2070
Pro Lys Thr Phe Ala Ser Lys Thr Tyr Gly Leu Cys Gly Ile Cys
2075 2080 2085
Asp Glu Asn Gly Ala Asn Asp Phe Met Leu Arg Asp Gly Thr Val
2090 2095 2100
Thr Thr Asp Trp Lys Thr Leu Val Gln Glu Trp Thr Val Gln Arg
2105 2110 2115
Pro Gly Gln Thr Cys Gln Pro Ile Leu Glu Glu Gln Cys Leu Val
2120 2125 2130
Pro Asp Ser Ser His Cys Gln Val Leu Leu Leu Pro Leu Phe Ala
2135 2140 2145
Glu Cys His Lys Val Leu Ala Pro Ala Thr Phe Tyr Ala Ile Cys
2150 2155 2160
Gln Gln Asp Ser Cys His Gln Glu Gln Val Cys Glu Val Ile Ala
2165 2170 2175
Ser Tyr Ala His Leu Cys Arg Thr Asn Gly Val Cys Val Asp Trp
2180 2185 2190
Arg Thr Pro Asp Phe Cys Ala Met Ser Cys Pro Pro Ser Leu Val
2195 2200 2205
Tyr Asn His Cys Glu His Gly Cys Pro Arg His Cys Asp Gly Asn
2210 2215 2220
Val Ser Ser Cys Gly Asp His Pro Ser Glu Gly Cys Phe Cys Pro
2225 2230 2235
Pro Asp Lys Val Met Leu Glu Gly Ser Cys Val Pro Glu Glu Ala
2240 2245 2250
Cys Thr Gln Cys Ile Gly Glu Asp Gly Val Gln His Gln Phe Leu
2255 2260 2265
Glu Ala Trp Val Pro Asp His Gln Pro Cys Gln Ile Cys Thr Cys
2270 2275 2280
Leu Ser Gly Arg Lys Val Asn Cys Thr Thr Gln Pro Cys Pro Thr
2285 2290 2295
Ala Lys Ala Pro Thr Cys Gly Leu Cys Glu Val Ala Arg Leu Arg
2300 2305 2310
Gln Asn Ala Asp Gln Cys Cys Pro Glu Tyr Glu Cys Val Cys Asp
2315 2320 2325
Pro Val Ser Cys Asp Leu Pro Pro Val Pro His Cys Glu Arg Gly
2330 2335 2340
Leu Gln Pro Thr Leu Thr Asn Pro Gly Glu Cys Arg Pro Asn Phe
2345 2350 2355
Thr Cys Ala Cys Arg Lys Glu Glu Cys Lys Arg Val Ser Pro Pro
2360 2365 2370
Ser Cys Pro Pro His Arg Leu Pro Thr Leu Arg Lys Thr Gln Cys
2375 2380 2385
Cys Asp Glu Tyr Glu Cys Ala Cys Asn Cys Val Asn Ser Thr Val
2390 2395 2400
Ser Cys Pro Leu Gly Tyr Leu Ala Ser Thr Ala Thr Asn Asp Cys
2405 2410 2415
Gly Cys Thr Thr Thr Thr Cys Leu Pro Asp Lys Val Cys Val His
2420 2425 2430
Arg Ser Thr Ile Tyr Pro Val Gly Gln Phe Trp Glu Glu Gly Cys
2435 2440 2445
Asp Val Cys Thr Cys Thr Asp Met Glu Asp Ala Val Met Gly Leu
2450 2455 2460
Arg Val Ala Gln Cys Ser Gln Lys Pro Cys Glu Asp Ser Cys Arg
2465 2470 2475
Ser Gly Phe Thr Tyr Val Leu His Glu Gly Glu Cys Cys Gly Arg
2480 2485 2490
Cys Leu Pro Ser Ala Cys Glu Val Val Thr Gly Ser Pro Arg Gly
2495 2500 2505
Asp Ser Gln Ser Ser Trp Lys Ser Val Gly Ser Gln Trp Ala Ser
2510 2515 2520
Pro Glu Asn Pro Cys Leu Ile Asn Glu Cys Val Arg Val Lys Glu
2525 2530 2535
Glu Val Phe Ile Gln Gln Arg Asn Val Ser Cys Pro Gln Leu Glu
2540 2545 2550
Val Pro Val Cys Pro Ser Gly Phe Gln Leu Ser Cys Lys Thr Ser
2555 2560 2565
Ala Cys Cys Pro Ser Cys Arg Cys Glu Arg Met Glu Ala Cys Met
2570 2575 2580
Leu Asn Gly Thr Val Ile Gly Pro Gly Lys Thr Val Met Ile Asp
2585 2590 2595
Val Cys Thr Thr Cys Arg Cys Met Val Gln Val Gly Val Ile Ser
2600 2605 2610
Gly Phe Lys Leu Glu Cys Arg Lys Thr Thr Cys Asn Pro Cys Pro
2615 2620 2625
Leu Gly Tyr Lys Glu Glu Asn Asn Thr Gly Glu Cys Cys Gly Arg
2630 2635 2640
Cys Leu Pro Thr Ala Cys Thr Ile Gln Leu Arg Gly Gly Gln Ile
2645 2650 2655
Met Thr Leu Lys Arg Asp Glu Thr Leu Gln Asp Gly Cys Asp Thr
2660 2665 2670
His Phe Cys Lys Val Asn Glu Arg Gly Glu Tyr Phe Trp Glu Lys
2675 2680 2685
Arg Val Thr Gly Cys Pro Pro Phe Asp Glu His Lys Cys Leu Ala
2690 2695 2700
Glu Gly Gly Lys Ile Met Lys Ile Pro Gly Thr Cys Cys Asp Thr
2705 2710 2715
Cys Glu Glu Pro Glu Cys Asn Asp Ile Thr Ala Arg Leu Gln Tyr
2720 2725 2730
Val Lys Val Gly Ser Cys Lys Ser Glu Val Glu Val Asp Ile His
2735 2740 2745
Tyr Cys Gln Gly Lys Cys Ala Ser Lys Ala Met Tyr Ser Ile Asp
2750 2755 2760
Ile Asn Asp Val Gln Asp Gln Cys Ser Cys Cys Ser Pro Thr Arg
2765 2770 2775
Thr Glu Pro Met Gln Val Ala Leu His Cys Thr Asn Gly Ser Val
2780 2785 2790
Val Tyr His Glu Val Leu Asn Ala Met Glu Cys Lys Cys Ser Pro
2795 2800 2805
Arg Lys Cys Ser Lys
2810
<210> 3
<211> 567
<212> БЕЛОК
<213> Homo sapiens
<400> 3
Ser Leu Ser Cys Arg Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp
1 5 10 15
Asn Leu Arg Ala Glu Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr
20 25 30
Asp Leu Glu Cys Met Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro
35 40 45
Pro Gly Met Val Arg His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys
50 55 60
Pro Cys Phe His Gln Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys
65 70 75 80
Ile Gly Cys Asn Thr Cys Val Cys Gln Asp Arg Lys Trp Asn Cys Thr
85 90 95
Asp His Val Cys Asp Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr
100 105 110
Leu Thr Phe Asp Gly Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr
115 120 125
Val Leu Val Gln Asp Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile
130 135 140
Leu Val Gly Asn Lys Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys
145 150 155 160
Arg Val Thr Ile Leu Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly
165 170 175
Glu Val Asn Val Lys Arg Pro Met Lys Asp Glu Thr His Phe Glu Val
180 185 190
Val Glu Ser Gly Arg Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser
195 200 205
Val Val Trp Asp Arg His Leu Ser Ile Ser Val Val Leu Lys Gln Thr
210 215 220
Tyr Gln Glu Lys Val Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln
225 230 235 240
Asn Asn Asp Leu Thr Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val
245 250 255
Asp Phe Gly Asn Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg
260 265 270
Lys Val Pro Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met
275 280 285
Lys Gln Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val
290 295 300
Phe Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
305 310 315 320
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala Cys
325 330 335
Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln His Gly
340 345 350
Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln Ser Cys Glu
355 360 365
Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu Trp Arg Tyr Asn
370 375 380
Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln His Pro Glu Pro Leu
385 390 395 400
Ala Cys Pro Val Gln Cys Val Glu Gly Cys His Ala His Cys Pro Pro
405 410 415
Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr Cys Val Asp Pro Glu Asp
420 425 430
Cys Pro Val Cys Glu Val Ala Gly Arg Arg Phe Ala Ser Gly Lys Lys
435 440 445
Val Thr Leu Asn Pro Ser Asp Pro Glu His Cys Gln Ile Cys His Cys
450 455 460
Asp Val Val Asn Leu Thr Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu
465 470 475 480
Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val
485 490 495
Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val
500 505 510
Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu
515 520 525
Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val
530 535 540
Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp
545 550 555 560
Ile Ser Glu Pro Pro Leu His
565
<210> 4
<211> 589
<212> БЕЛОК
<213> Homo sapiens
<400> 4
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ser Leu Ser Cys Arg Pro Pro Met Val Lys
20 25 30
Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu Gly Leu Glu Cys Thr
35 40 45
Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met Ser Met Gly Cys Val
50 55 60
Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg His Glu Asn Arg Cys
65 70 75 80
Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln Gly Lys Glu Tyr Ala
85 90 95
Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr Cys Val Cys Gln Asp
100 105 110
Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp Ala Thr Cys Ser Thr
115 120 125
Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly Leu Lys Tyr Leu Phe
130 135 140
Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp Tyr Cys Gly Ser Asn
145 150 155 160
Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys Gly Cys Ser His Pro
165 170 175
Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu Val Glu Gly Gly Glu
180 185 190
Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys Arg Pro Met Lys Asp
195 200 205
Glu Thr His Phe Glu Val Val Glu Ser Gly Arg Tyr Ile Ile Leu Leu
210 215 220
Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg His Leu Ser Ile Ser
225 230 235 240
Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val Cys Gly Leu Cys Gly
245 250 255
Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr Ser Ser Asn Leu Gln
260 265 270
Val Glu Glu Asp Pro Val Asp Phe Gly Asn Ser Trp Lys Val Ser Ser
275 280 285
Gln Cys Ala Asp Thr Arg Lys Val Pro Leu Asp Ser Ser Pro Ala Thr
290 295 300
Cys His Asn Asn Ile Met Lys Gln Thr Met Val Asp Ser Ser Cys Arg
305 310 315 320
Ile Leu Thr Ser Asp Val Phe Gln Asp Cys Asn Lys Leu Val Asp Pro
325 330 335
Glu Pro Tyr Leu Asp Val Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser
340 345 350
Ile Gly Asp Cys Ala Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His
355 360 365
Val Cys Ala Gln His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu
370 375 380
Cys Pro Gln Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu
385 390 395 400
Cys Glu Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys
405 410 415
Gln His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
420 425 430
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr
435 440 445
Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly Arg Arg
450 455 460
Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp Pro Glu His
465 470 475 480
Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr Cys Glu Ala Cys
485 490 495
Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser
500 505 510
Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln
515 520 525
Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro
530 535 540
Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu
545 550 555 560
Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr
565 570 575
Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His
580 585
<210> 5
<211> 1330
<212> БЕЛОК
<213> Homo sapiens
<400> 5
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ala Glu Gly Thr Arg Gly Arg Ser Ser Thr
20 25 30
Ala Arg Cys Ser Leu Phe Gly Ser Asp Phe Val Asn Thr Phe Asp Gly
35 40 45
Ser Met Tyr Ser Phe Ala Gly Tyr Cys Ser Tyr Leu Leu Ala Gly Gly
50 55 60
Cys Gln Lys Arg Ser Phe Ser Ile Ile Gly Asp Phe Gln Asn Gly Lys
65 70 75 80
Arg Val Ser Leu Ser Val Tyr Leu Gly Glu Phe Phe Asp Ile His Leu
85 90 95
Phe Val Asn Gly Thr Val Thr Gln Gly Asp Gln Arg Val Ser Met Pro
100 105 110
Tyr Ala Ser Lys Gly Leu Tyr Leu Glu Thr Glu Ala Gly Tyr Tyr Lys
115 120 125
Leu Ser Gly Glu Ala Tyr Gly Phe Val Ala Arg Ile Asp Gly Ser Gly
130 135 140
Asn Phe Gln Val Leu Leu Ser Asp Arg Tyr Phe Asn Lys Thr Cys Gly
145 150 155 160
Leu Cys Gly Asn Phe Asn Ile Phe Ala Glu Asp Asp Phe Met Thr Gln
165 170 175
Glu Gly Thr Leu Thr Ser Asp Pro Tyr Asp Phe Ala Asn Ser Trp Ala
180 185 190
Leu Ser Ser Gly Glu Gln Trp Cys Glu Arg Ala Ser Pro Pro Ser Ser
195 200 205
Ser Cys Asn Ile Ser Ser Gly Glu Met Gln Lys Gly Leu Trp Glu Gln
210 215 220
Cys Gln Leu Leu Lys Ser Thr Ser Val Phe Ala Arg Cys His Pro Leu
225 230 235 240
Val Asp Pro Glu Pro Phe Val Ala Leu Cys Glu Lys Thr Leu Cys Glu
245 250 255
Cys Ala Gly Gly Leu Glu Cys Ala Cys Pro Ala Leu Leu Glu Tyr Ala
260 265 270
Arg Thr Cys Ala Gln Glu Gly Met Val Leu Tyr Gly Trp Thr Asp His
275 280 285
Ser Ala Cys Ser Pro Val Cys Pro Ala Gly Met Glu Tyr Arg Gln Cys
290 295 300
Val Ser Pro Cys Ala Arg Thr Cys Gln Ser Leu His Ile Asn Glu Met
305 310 315 320
Cys Gln Glu Arg Cys Val Asp Gly Cys Ser Cys Pro Glu Gly Gln Leu
325 330 335
Leu Asp Glu Gly Leu Cys Val Glu Ser Thr Glu Cys Pro Cys Val His
340 345 350
Ser Gly Lys Arg Tyr Pro Pro Gly Thr Ser Leu Ser Arg Asp Cys Asn
355 360 365
Thr Cys Ile Cys Arg Asn Ser Gln Trp Ile Cys Ser Asn Glu Glu Cys
370 375 380
Pro Gly Glu Cys Leu Val Thr Gly Gln Ser His Phe Lys Ser Phe Asp
385 390 395 400
Asn Arg Tyr Phe Thr Phe Ser Gly Ile Cys Gln Tyr Leu Leu Ala Arg
405 410 415
Asp Cys Gln Asp His Ser Phe Ser Ile Val Ile Glu Thr Val Gln Cys
420 425 430
Ala Asp Asp Arg Asp Ala Val Cys Thr Arg Ser Val Thr Val Arg Leu
435 440 445
Pro Gly Leu His Asn Ser Leu Val Lys Leu Lys His Gly Ala Gly Val
450 455 460
Ala Met Asp Gly Gln Asp Val Gln Leu Pro Leu Leu Lys Gly Asp Leu
465 470 475 480
Arg Ile Gln His Thr Val Thr Ala Ser Val Arg Leu Ser Tyr Gly Glu
485 490 495
Asp Leu Gln Met Asp Trp Asp Gly Arg Gly Arg Leu Leu Val Lys Leu
500 505 510
Ser Pro Val Tyr Ala Gly Lys Thr Cys Gly Leu Cys Gly Asn Tyr Asn
515 520 525
Gly Asn Gln Gly Asp Asp Phe Leu Thr Pro Ser Gly Leu Ala Glu Pro
530 535 540
Arg Val Glu Asp Phe Gly Asn Ala Trp Lys Leu His Gly Asp Cys Gln
545 550 555 560
Asp Leu Gln Lys Gln His Ser Asp Pro Cys Ala Leu Asn Pro Arg Met
565 570 575
Thr Arg Phe Ser Glu Glu Ala Cys Ala Val Leu Thr Ser Pro Thr Phe
580 585 590
Glu Ala Cys His Arg Ala Val Ser Pro Leu Pro Tyr Leu Arg Asn Cys
595 600 605
Arg Tyr Asp Val Cys Ser Cys Ser Asp Gly Arg Glu Cys Leu Cys Gly
610 615 620
Ala Leu Ala Ser Tyr Ala Ala Ala Cys Ala Gly Arg Gly Val Arg Val
625 630 635 640
Ala Trp Arg Glu Pro Gly Arg Cys Glu Leu Asn Cys Pro Lys Gly Gln
645 650 655
Val Tyr Leu Gln Cys Gly Thr Pro Cys Asn Leu Thr Cys Arg Ser Leu
660 665 670
Ser Tyr Pro Asp Glu Glu Cys Asn Glu Ala Cys Leu Glu Gly Cys Phe
675 680 685
Cys Pro Pro Gly Leu Tyr Met Asp Glu Arg Gly Asp Cys Val Pro Lys
690 695 700
Ala Gln Cys Pro Cys Tyr Tyr Asp Gly Glu Ile Phe Gln Pro Glu Asp
705 710 715 720
Ile Phe Ser Asp His His Thr Met Cys Tyr Cys Glu Asp Gly Phe Met
725 730 735
His Cys Thr Met Ser Gly Val Pro Gly Ser Leu Leu Pro Asp Ala Val
740 745 750
Leu Ser Ser Pro Leu Ser His Arg Ser Lys Arg Ser Leu Ser Cys Arg
755 760 765
Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu
770 775 780
Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met
785 790 795 800
Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg
805 810 815
His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln
820 825 830
Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr
835 840 845
Cys Val Cys Gln Asp Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp
850 855 860
Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly
865 870 875 880
Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp
885 890 895
Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys
900 905 910
Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu
915 920 925
Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys
930 935 940
Arg Pro Met Lys Asp Glu Thr His Phe Glu Val Val Glu Ser Gly Arg
945 950 955 960
Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg
965 970 975
His Leu Ser Ile Ser Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val
980 985 990
Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr
995 1000 1005
Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val Asp Phe Gly Asn
1010 1015 1020
Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg Lys Val Pro
1025 1030 1035
Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met Lys Gln
1040 1045 1050
Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val Phe
1055 1060 1065
Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
1070 1075 1080
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala
1085 1090 1095
Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln
1100 1105 1110
His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln
1115 1120 1125
Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu
1130 1135 1140
Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln
1145 1150 1155
His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
1160 1165 1170
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln
1175 1180 1185
Thr Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly
1190 1195 1200
Arg Arg Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp
1205 1210 1215
Pro Glu His Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr
1220 1225 1230
Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr
1235 1240 1245
Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser
1250 1255 1260
Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro Pro
1265 1270 1275
Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile
1280 1285 1290
Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro
1295 1300 1305
Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp
1310 1315 1320
Ile Ser Glu Pro Pro Leu His
1325 1330
<210> 6
<211> 629
<212> БЕЛОК
<213> Homo sapiens
<400> 6
Ser Leu Ser Cys Arg Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp
1 5 10 15
Asn Leu Arg Ala Glu Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr
20 25 30
Asp Leu Glu Cys Met Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro
35 40 45
Pro Gly Met Val Arg His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys
50 55 60
Pro Cys Phe His Gln Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys
65 70 75 80
Ile Gly Cys Asn Thr Cys Val Cys Gln Asp Arg Lys Trp Asn Cys Thr
85 90 95
Asp His Val Cys Asp Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr
100 105 110
Leu Thr Phe Asp Gly Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr
115 120 125
Val Leu Val Gln Asp Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile
130 135 140
Leu Val Gly Asn Lys Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys
145 150 155 160
Arg Val Thr Ile Leu Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly
165 170 175
Glu Val Asn Val Lys Arg Pro Met Lys Asp Glu Thr His Phe Glu Val
180 185 190
Val Glu Ser Gly Arg Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser
195 200 205
Val Val Trp Asp Arg His Leu Ser Ile Ser Val Val Leu Lys Gln Thr
210 215 220
Tyr Gln Glu Lys Val Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln
225 230 235 240
Asn Asn Asp Leu Thr Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val
245 250 255
Asp Phe Gly Asn Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg
260 265 270
Lys Val Pro Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met
275 280 285
Lys Gln Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val
290 295 300
Phe Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
305 310 315 320
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala Cys
325 330 335
Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln His Gly
340 345 350
Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln Ser Cys Glu
355 360 365
Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu Trp Arg Tyr Asn
370 375 380
Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln His Pro Glu Pro Leu
385 390 395 400
Ala Cys Pro Val Gln Cys Val Glu Gly Cys His Ala His Cys Pro Pro
405 410 415
Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr Cys Val Asp Pro Glu Asp
420 425 430
Cys Pro Val Cys Glu Val Ala Gly Arg Arg Phe Ala Ser Gly Lys Lys
435 440 445
Val Thr Leu Asn Pro Ser Asp Pro Glu His Cys Gln Ile Cys His Cys
450 455 460
Asp Val Val Asn Leu Thr Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu
465 470 475 480
Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val
485 490 495
Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val
500 505 510
Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu
515 520 525
Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val
530 535 540
Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp
545 550 555 560
Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro
565 570 575
Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile
580 585 590
Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro Pro
595 600 605
Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser
610 615 620
Glu Pro Pro Leu His
625
<210> 7
<211> 651
<212> БЕЛОК
<213> Homo sapiens
<400> 7
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ser Leu Ser Cys Arg Pro Pro Met Val Lys
20 25 30
Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu Gly Leu Glu Cys Thr
35 40 45
Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met Ser Met Gly Cys Val
50 55 60
Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg His Glu Asn Arg Cys
65 70 75 80
Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln Gly Lys Glu Tyr Ala
85 90 95
Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr Cys Val Cys Gln Asp
100 105 110
Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp Ala Thr Cys Ser Thr
115 120 125
Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly Leu Lys Tyr Leu Phe
130 135 140
Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp Tyr Cys Gly Ser Asn
145 150 155 160
Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys Gly Cys Ser His Pro
165 170 175
Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu Val Glu Gly Gly Glu
180 185 190
Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys Arg Pro Met Lys Asp
195 200 205
Glu Thr His Phe Glu Val Val Glu Ser Gly Arg Tyr Ile Ile Leu Leu
210 215 220
Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg His Leu Ser Ile Ser
225 230 235 240
Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val Cys Gly Leu Cys Gly
245 250 255
Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr Ser Ser Asn Leu Gln
260 265 270
Val Glu Glu Asp Pro Val Asp Phe Gly Asn Ser Trp Lys Val Ser Ser
275 280 285
Gln Cys Ala Asp Thr Arg Lys Val Pro Leu Asp Ser Ser Pro Ala Thr
290 295 300
Cys His Asn Asn Ile Met Lys Gln Thr Met Val Asp Ser Ser Cys Arg
305 310 315 320
Ile Leu Thr Ser Asp Val Phe Gln Asp Cys Asn Lys Leu Val Asp Pro
325 330 335
Glu Pro Tyr Leu Asp Val Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser
340 345 350
Ile Gly Asp Cys Ala Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His
355 360 365
Val Cys Ala Gln His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu
370 375 380
Cys Pro Gln Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu
385 390 395 400
Cys Glu Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys
405 410 415
Gln His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
420 425 430
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr
435 440 445
Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly Arg Arg
450 455 460
Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp Pro Glu His
465 470 475 480
Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr Cys Glu Ala Cys
485 490 495
Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser
500 505 510
Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln
515 520 525
Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro
530 535 540
Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu
545 550 555 560
Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr
565 570 575
Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro
580 585 590
Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr
595 600 605
Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly
610 615 620
Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu
625 630 635 640
Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His
645 650
<210> 8
<211> 1392
<212> БЕЛОК
<213> Homo sapiens
<400> 8
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ala Glu Gly Thr Arg Gly Arg Ser Ser Thr
20 25 30
Ala Arg Cys Ser Leu Phe Gly Ser Asp Phe Val Asn Thr Phe Asp Gly
35 40 45
Ser Met Tyr Ser Phe Ala Gly Tyr Cys Ser Tyr Leu Leu Ala Gly Gly
50 55 60
Cys Gln Lys Arg Ser Phe Ser Ile Ile Gly Asp Phe Gln Asn Gly Lys
65 70 75 80
Arg Val Ser Leu Ser Val Tyr Leu Gly Glu Phe Phe Asp Ile His Leu
85 90 95
Phe Val Asn Gly Thr Val Thr Gln Gly Asp Gln Arg Val Ser Met Pro
100 105 110
Tyr Ala Ser Lys Gly Leu Tyr Leu Glu Thr Glu Ala Gly Tyr Tyr Lys
115 120 125
Leu Ser Gly Glu Ala Tyr Gly Phe Val Ala Arg Ile Asp Gly Ser Gly
130 135 140
Asn Phe Gln Val Leu Leu Ser Asp Arg Tyr Phe Asn Lys Thr Cys Gly
145 150 155 160
Leu Cys Gly Asn Phe Asn Ile Phe Ala Glu Asp Asp Phe Met Thr Gln
165 170 175
Glu Gly Thr Leu Thr Ser Asp Pro Tyr Asp Phe Ala Asn Ser Trp Ala
180 185 190
Leu Ser Ser Gly Glu Gln Trp Cys Glu Arg Ala Ser Pro Pro Ser Ser
195 200 205
Ser Cys Asn Ile Ser Ser Gly Glu Met Gln Lys Gly Leu Trp Glu Gln
210 215 220
Cys Gln Leu Leu Lys Ser Thr Ser Val Phe Ala Arg Cys His Pro Leu
225 230 235 240
Val Asp Pro Glu Pro Phe Val Ala Leu Cys Glu Lys Thr Leu Cys Glu
245 250 255
Cys Ala Gly Gly Leu Glu Cys Ala Cys Pro Ala Leu Leu Glu Tyr Ala
260 265 270
Arg Thr Cys Ala Gln Glu Gly Met Val Leu Tyr Gly Trp Thr Asp His
275 280 285
Ser Ala Cys Ser Pro Val Cys Pro Ala Gly Met Glu Tyr Arg Gln Cys
290 295 300
Val Ser Pro Cys Ala Arg Thr Cys Gln Ser Leu His Ile Asn Glu Met
305 310 315 320
Cys Gln Glu Arg Cys Val Asp Gly Cys Ser Cys Pro Glu Gly Gln Leu
325 330 335
Leu Asp Glu Gly Leu Cys Val Glu Ser Thr Glu Cys Pro Cys Val His
340 345 350
Ser Gly Lys Arg Tyr Pro Pro Gly Thr Ser Leu Ser Arg Asp Cys Asn
355 360 365
Thr Cys Ile Cys Arg Asn Ser Gln Trp Ile Cys Ser Asn Glu Glu Cys
370 375 380
Pro Gly Glu Cys Leu Val Thr Gly Gln Ser His Phe Lys Ser Phe Asp
385 390 395 400
Asn Arg Tyr Phe Thr Phe Ser Gly Ile Cys Gln Tyr Leu Leu Ala Arg
405 410 415
Asp Cys Gln Asp His Ser Phe Ser Ile Val Ile Glu Thr Val Gln Cys
420 425 430
Ala Asp Asp Arg Asp Ala Val Cys Thr Arg Ser Val Thr Val Arg Leu
435 440 445
Pro Gly Leu His Asn Ser Leu Val Lys Leu Lys His Gly Ala Gly Val
450 455 460
Ala Met Asp Gly Gln Asp Val Gln Leu Pro Leu Leu Lys Gly Asp Leu
465 470 475 480
Arg Ile Gln His Thr Val Thr Ala Ser Val Arg Leu Ser Tyr Gly Glu
485 490 495
Asp Leu Gln Met Asp Trp Asp Gly Arg Gly Arg Leu Leu Val Lys Leu
500 505 510
Ser Pro Val Tyr Ala Gly Lys Thr Cys Gly Leu Cys Gly Asn Tyr Asn
515 520 525
Gly Asn Gln Gly Asp Asp Phe Leu Thr Pro Ser Gly Leu Ala Glu Pro
530 535 540
Arg Val Glu Asp Phe Gly Asn Ala Trp Lys Leu His Gly Asp Cys Gln
545 550 555 560
Asp Leu Gln Lys Gln His Ser Asp Pro Cys Ala Leu Asn Pro Arg Met
565 570 575
Thr Arg Phe Ser Glu Glu Ala Cys Ala Val Leu Thr Ser Pro Thr Phe
580 585 590
Glu Ala Cys His Arg Ala Val Ser Pro Leu Pro Tyr Leu Arg Asn Cys
595 600 605
Arg Tyr Asp Val Cys Ser Cys Ser Asp Gly Arg Glu Cys Leu Cys Gly
610 615 620
Ala Leu Ala Ser Tyr Ala Ala Ala Cys Ala Gly Arg Gly Val Arg Val
625 630 635 640
Ala Trp Arg Glu Pro Gly Arg Cys Glu Leu Asn Cys Pro Lys Gly Gln
645 650 655
Val Tyr Leu Gln Cys Gly Thr Pro Cys Asn Leu Thr Cys Arg Ser Leu
660 665 670
Ser Tyr Pro Asp Glu Glu Cys Asn Glu Ala Cys Leu Glu Gly Cys Phe
675 680 685
Cys Pro Pro Gly Leu Tyr Met Asp Glu Arg Gly Asp Cys Val Pro Lys
690 695 700
Ala Gln Cys Pro Cys Tyr Tyr Asp Gly Glu Ile Phe Gln Pro Glu Asp
705 710 715 720
Ile Phe Ser Asp His His Thr Met Cys Tyr Cys Glu Asp Gly Phe Met
725 730 735
His Cys Thr Met Ser Gly Val Pro Gly Ser Leu Leu Pro Asp Ala Val
740 745 750
Leu Ser Ser Pro Leu Ser His Arg Ser Lys Arg Ser Leu Ser Cys Arg
755 760 765
Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu
770 775 780
Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met
785 790 795 800
Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg
805 810 815
His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln
820 825 830
Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr
835 840 845
Cys Val Cys Gln Asp Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp
850 855 860
Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly
865 870 875 880
Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp
885 890 895
Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys
900 905 910
Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu
915 920 925
Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys
930 935 940
Arg Pro Met Lys Asp Glu Thr His Phe Glu Val Val Glu Ser Gly Arg
945 950 955 960
Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg
965 970 975
His Leu Ser Ile Ser Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val
980 985 990
Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr
995 1000 1005
Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val Asp Phe Gly Asn
1010 1015 1020
Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg Lys Val Pro
1025 1030 1035
Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met Lys Gln
1040 1045 1050
Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val Phe
1055 1060 1065
Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
1070 1075 1080
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala
1085 1090 1095
Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln
1100 1105 1110
His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln
1115 1120 1125
Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu
1130 1135 1140
Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln
1145 1150 1155
His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
1160 1165 1170
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln
1175 1180 1185
Thr Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly
1190 1195 1200
Arg Arg Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp
1205 1210 1215
Pro Glu His Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr
1220 1225 1230
Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr
1235 1240 1245
Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser
1250 1255 1260
Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro Pro
1265 1270 1275
Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile
1280 1285 1290
Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro
1295 1300 1305
Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp
1310 1315 1320
Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val
1325 1330 1335
Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu
1340 1345 1350
Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val
1355 1360 1365
Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val
1370 1375 1380
Glu Asp Ile Ser Glu Pro Pro Leu His
1385 1390
<210> 9
<211> 660
<212> БЕЛОК
<213> Homo sapiens
<400> 9
Ser Leu Ser Cys Arg Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp
1 5 10 15
Asn Leu Arg Ala Glu Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr
20 25 30
Asp Leu Glu Cys Met Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro
35 40 45
Pro Gly Met Val Arg His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys
50 55 60
Pro Cys Phe His Gln Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys
65 70 75 80
Ile Gly Cys Asn Thr Cys Val Cys Gln Asp Arg Lys Trp Asn Cys Thr
85 90 95
Asp His Val Cys Asp Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr
100 105 110
Leu Thr Phe Asp Gly Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr
115 120 125
Val Leu Val Gln Asp Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile
130 135 140
Leu Val Gly Asn Lys Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys
145 150 155 160
Arg Val Thr Ile Leu Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly
165 170 175
Glu Val Asn Val Lys Arg Pro Met Lys Asp Glu Thr His Phe Glu Val
180 185 190
Val Glu Ser Gly Arg Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser
195 200 205
Val Val Trp Asp Arg His Leu Ser Ile Ser Val Val Leu Lys Gln Thr
210 215 220
Tyr Gln Glu Lys Val Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln
225 230 235 240
Asn Asn Asp Leu Thr Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val
245 250 255
Asp Phe Gly Asn Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg
260 265 270
Lys Val Pro Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met
275 280 285
Lys Gln Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val
290 295 300
Phe Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
305 310 315 320
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala Cys
325 330 335
Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln His Gly
340 345 350
Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln Ser Cys Glu
355 360 365
Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu Trp Arg Tyr Asn
370 375 380
Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln His Pro Glu Pro Leu
385 390 395 400
Ala Cys Pro Val Gln Cys Val Glu Gly Cys His Ala His Cys Pro Pro
405 410 415
Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr Cys Val Asp Pro Glu Asp
420 425 430
Cys Pro Val Cys Glu Val Ala Gly Arg Arg Phe Ala Ser Gly Lys Lys
435 440 445
Val Thr Leu Asn Pro Ser Asp Pro Glu His Cys Gln Ile Cys His Cys
450 455 460
Asp Val Val Asn Leu Thr Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu
465 470 475 480
Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val
485 490 495
Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val
500 505 510
Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu
515 520 525
Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val
530 535 540
Pro Pro Thr Asp Ala Pro Val Pro Thr Thr Leu Tyr Val Glu Asp Ile
545 550 555 560
Ser Glu Pro Pro Leu His Glu Glu Pro Glu Cys Asn Asp Ile Thr Ala
565 570 575
Arg Leu Gln Tyr Val Lys Val Gly Ser Cys Lys Ser Glu Val Glu Val
580 585 590
Asp Ile His Tyr Cys Gln Gly Lys Cys Ala Ser Lys Ala Met Tyr Ser
595 600 605
Ile Asp Ile Asn Asp Val Gln Asp Gln Cys Ser Cys Cys Ser Pro Thr
610 615 620
Arg Thr Glu Pro Met Gln Val Ala Leu His Cys Thr Asn Gly Ser Val
625 630 635 640
Val Tyr His Glu Val Leu Asn Ala Met Glu Cys Lys Cys Ser Pro Arg
645 650 655
Lys Cys Ser Lys
660
<210> 10
<211> 682
<212> БЕЛОК
<213> Homo sapiens
<400> 10
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ser Leu Ser Cys Arg Pro Pro Met Val Lys
20 25 30
Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu Gly Leu Glu Cys Thr
35 40 45
Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met Ser Met Gly Cys Val
50 55 60
Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg His Glu Asn Arg Cys
65 70 75 80
Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln Gly Lys Glu Tyr Ala
85 90 95
Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr Cys Val Cys Gln Asp
100 105 110
Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp Ala Thr Cys Ser Thr
115 120 125
Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly Leu Lys Tyr Leu Phe
130 135 140
Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp Tyr Cys Gly Ser Asn
145 150 155 160
Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys Gly Cys Ser His Pro
165 170 175
Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu Val Glu Gly Gly Glu
180 185 190
Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys Arg Pro Met Lys Asp
195 200 205
Glu Thr His Phe Glu Val Val Glu Ser Gly Arg Tyr Ile Ile Leu Leu
210 215 220
Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg His Leu Ser Ile Ser
225 230 235 240
Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val Cys Gly Leu Cys Gly
245 250 255
Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr Ser Ser Asn Leu Gln
260 265 270
Val Glu Glu Asp Pro Val Asp Phe Gly Asn Ser Trp Lys Val Ser Ser
275 280 285
Gln Cys Ala Asp Thr Arg Lys Val Pro Leu Asp Ser Ser Pro Ala Thr
290 295 300
Cys His Asn Asn Ile Met Lys Gln Thr Met Val Asp Ser Ser Cys Arg
305 310 315 320
Ile Leu Thr Ser Asp Val Phe Gln Asp Cys Asn Lys Leu Val Asp Pro
325 330 335
Glu Pro Tyr Leu Asp Val Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser
340 345 350
Ile Gly Asp Cys Ala Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His
355 360 365
Val Cys Ala Gln His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu
370 375 380
Cys Pro Gln Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu
385 390 395 400
Cys Glu Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys
405 410 415
Gln His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
420 425 430
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr
435 440 445
Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly Arg Arg
450 455 460
Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp Pro Glu His
465 470 475 480
Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr Cys Glu Ala Cys
485 490 495
Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser
500 505 510
Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln
515 520 525
Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro
530 535 540
Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu
545 550 555 560
Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Pro Thr Thr
565 570 575
Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Glu Glu Pro Glu
580 585 590
Cys Asn Asp Ile Thr Ala Arg Leu Gln Tyr Val Lys Val Gly Ser Cys
595 600 605
Lys Ser Glu Val Glu Val Asp Ile His Tyr Cys Gln Gly Lys Cys Ala
610 615 620
Ser Lys Ala Met Tyr Ser Ile Asp Ile Asn Asp Val Gln Asp Gln Cys
625 630 635 640
Ser Cys Cys Ser Pro Thr Arg Thr Glu Pro Met Gln Val Ala Leu His
645 650 655
Cys Thr Asn Gly Ser Val Val Tyr His Glu Val Leu Asn Ala Met Glu
660 665 670
Cys Lys Cys Ser Pro Arg Lys Cys Ser Lys
675 680
<210> 11
<211> 1423
<212> БЕЛОК
<213> Homo sapiens
<400> 11
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1 5 10 15
Leu Pro Gly Thr Leu Cys Ala Glu Gly Thr Arg Gly Arg Ser Ser Thr
20 25 30
Ala Arg Cys Ser Leu Phe Gly Ser Asp Phe Val Asn Thr Phe Asp Gly
35 40 45
Ser Met Tyr Ser Phe Ala Gly Tyr Cys Ser Tyr Leu Leu Ala Gly Gly
50 55 60
Cys Gln Lys Arg Ser Phe Ser Ile Ile Gly Asp Phe Gln Asn Gly Lys
65 70 75 80
Arg Val Ser Leu Ser Val Tyr Leu Gly Glu Phe Phe Asp Ile His Leu
85 90 95
Phe Val Asn Gly Thr Val Thr Gln Gly Asp Gln Arg Val Ser Met Pro
100 105 110
Tyr Ala Ser Lys Gly Leu Tyr Leu Glu Thr Glu Ala Gly Tyr Tyr Lys
115 120 125
Leu Ser Gly Glu Ala Tyr Gly Phe Val Ala Arg Ile Asp Gly Ser Gly
130 135 140
Asn Phe Gln Val Leu Leu Ser Asp Arg Tyr Phe Asn Lys Thr Cys Gly
145 150 155 160
Leu Cys Gly Asn Phe Asn Ile Phe Ala Glu Asp Asp Phe Met Thr Gln
165 170 175
Glu Gly Thr Leu Thr Ser Asp Pro Tyr Asp Phe Ala Asn Ser Trp Ala
180 185 190
Leu Ser Ser Gly Glu Gln Trp Cys Glu Arg Ala Ser Pro Pro Ser Ser
195 200 205
Ser Cys Asn Ile Ser Ser Gly Glu Met Gln Lys Gly Leu Trp Glu Gln
210 215 220
Cys Gln Leu Leu Lys Ser Thr Ser Val Phe Ala Arg Cys His Pro Leu
225 230 235 240
Val Asp Pro Glu Pro Phe Val Ala Leu Cys Glu Lys Thr Leu Cys Glu
245 250 255
Cys Ala Gly Gly Leu Glu Cys Ala Cys Pro Ala Leu Leu Glu Tyr Ala
260 265 270
Arg Thr Cys Ala Gln Glu Gly Met Val Leu Tyr Gly Trp Thr Asp His
275 280 285
Ser Ala Cys Ser Pro Val Cys Pro Ala Gly Met Glu Tyr Arg Gln Cys
290 295 300
Val Ser Pro Cys Ala Arg Thr Cys Gln Ser Leu His Ile Asn Glu Met
305 310 315 320
Cys Gln Glu Arg Cys Val Asp Gly Cys Ser Cys Pro Glu Gly Gln Leu
325 330 335
Leu Asp Glu Gly Leu Cys Val Glu Ser Thr Glu Cys Pro Cys Val His
340 345 350
Ser Gly Lys Arg Tyr Pro Pro Gly Thr Ser Leu Ser Arg Asp Cys Asn
355 360 365
Thr Cys Ile Cys Arg Asn Ser Gln Trp Ile Cys Ser Asn Glu Glu Cys
370 375 380
Pro Gly Glu Cys Leu Val Thr Gly Gln Ser His Phe Lys Ser Phe Asp
385 390 395 400
Asn Arg Tyr Phe Thr Phe Ser Gly Ile Cys Gln Tyr Leu Leu Ala Arg
405 410 415
Asp Cys Gln Asp His Ser Phe Ser Ile Val Ile Glu Thr Val Gln Cys
420 425 430
Ala Asp Asp Arg Asp Ala Val Cys Thr Arg Ser Val Thr Val Arg Leu
435 440 445
Pro Gly Leu His Asn Ser Leu Val Lys Leu Lys His Gly Ala Gly Val
450 455 460
Ala Met Asp Gly Gln Asp Val Gln Leu Pro Leu Leu Lys Gly Asp Leu
465 470 475 480
Arg Ile Gln His Thr Val Thr Ala Ser Val Arg Leu Ser Tyr Gly Glu
485 490 495
Asp Leu Gln Met Asp Trp Asp Gly Arg Gly Arg Leu Leu Val Lys Leu
500 505 510
Ser Pro Val Tyr Ala Gly Lys Thr Cys Gly Leu Cys Gly Asn Tyr Asn
515 520 525
Gly Asn Gln Gly Asp Asp Phe Leu Thr Pro Ser Gly Leu Ala Glu Pro
530 535 540
Arg Val Glu Asp Phe Gly Asn Ala Trp Lys Leu His Gly Asp Cys Gln
545 550 555 560
Asp Leu Gln Lys Gln His Ser Asp Pro Cys Ala Leu Asn Pro Arg Met
565 570 575
Thr Arg Phe Ser Glu Glu Ala Cys Ala Val Leu Thr Ser Pro Thr Phe
580 585 590
Glu Ala Cys His Arg Ala Val Ser Pro Leu Pro Tyr Leu Arg Asn Cys
595 600 605
Arg Tyr Asp Val Cys Ser Cys Ser Asp Gly Arg Glu Cys Leu Cys Gly
610 615 620
Ala Leu Ala Ser Tyr Ala Ala Ala Cys Ala Gly Arg Gly Val Arg Val
625 630 635 640
Ala Trp Arg Glu Pro Gly Arg Cys Glu Leu Asn Cys Pro Lys Gly Gln
645 650 655
Val Tyr Leu Gln Cys Gly Thr Pro Cys Asn Leu Thr Cys Arg Ser Leu
660 665 670
Ser Tyr Pro Asp Glu Glu Cys Asn Glu Ala Cys Leu Glu Gly Cys Phe
675 680 685
Cys Pro Pro Gly Leu Tyr Met Asp Glu Arg Gly Asp Cys Val Pro Lys
690 695 700
Ala Gln Cys Pro Cys Tyr Tyr Asp Gly Glu Ile Phe Gln Pro Glu Asp
705 710 715 720
Ile Phe Ser Asp His His Thr Met Cys Tyr Cys Glu Asp Gly Phe Met
725 730 735
His Cys Thr Met Ser Gly Val Pro Gly Ser Leu Leu Pro Asp Ala Val
740 745 750
Leu Ser Ser Pro Leu Ser His Arg Ser Lys Arg Ser Leu Ser Cys Arg
755 760 765
Pro Pro Met Val Lys Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu
770 775 780
Gly Leu Glu Cys Thr Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met
785 790 795 800
Ser Met Gly Cys Val Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg
805 810 815
His Glu Asn Arg Cys Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln
820 825 830
Gly Lys Glu Tyr Ala Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr
835 840 845
Cys Val Cys Gln Asp Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp
850 855 860
Ala Thr Cys Ser Thr Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly
865 870 875 880
Leu Lys Tyr Leu Phe Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp
885 890 895
Tyr Cys Gly Ser Asn Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys
900 905 910
Gly Cys Ser His Pro Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu
915 920 925
Val Glu Gly Gly Glu Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys
930 935 940
Arg Pro Met Lys Asp Glu Thr His Phe Glu Val Val Glu Ser Gly Arg
945 950 955 960
Tyr Ile Ile Leu Leu Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg
965 970 975
His Leu Ser Ile Ser Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val
980 985 990
Cys Gly Leu Cys Gly Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr
995 1000 1005
Ser Ser Asn Leu Gln Val Glu Glu Asp Pro Val Asp Phe Gly Asn
1010 1015 1020
Ser Trp Lys Val Ser Ser Gln Cys Ala Asp Thr Arg Lys Val Pro
1025 1030 1035
Leu Asp Ser Ser Pro Ala Thr Cys His Asn Asn Ile Met Lys Gln
1040 1045 1050
Thr Met Val Asp Ser Ser Cys Arg Ile Leu Thr Ser Asp Val Phe
1055 1060 1065
Gln Asp Cys Asn Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val
1070 1075 1080
Cys Ile Tyr Asp Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala
1085 1090 1095
Cys Phe Cys Asp Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln
1100 1105 1110
His Gly Lys Val Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln
1115 1120 1125
Ser Cys Glu Glu Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu
1130 1135 1140
Trp Arg Tyr Asn Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln
1145 1150 1155
His Pro Glu Pro Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys
1160 1165 1170
His Ala His Cys Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln
1175 1180 1185
Thr Cys Val Asp Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly
1190 1195 1200
Arg Arg Phe Ala Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp
1205 1210 1215
Pro Glu His Cys Gln Ile Cys His Cys Asp Val Val Asn Leu Thr
1220 1225 1230
Cys Glu Ala Cys Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr
1235 1240 1245
Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser
1250 1255 1260
Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro Pro
1265 1270 1275
Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile
1280 1285 1290
Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu Val Val Pro
1295 1300 1305
Pro Thr Asp Ala Pro Val Pro Thr Thr Leu Tyr Val Glu Asp Ile
1310 1315 1320
Ser Glu Pro Pro Leu His Glu Glu Pro Glu Cys Asn Asp Ile Thr
1325 1330 1335
Ala Arg Leu Gln Tyr Val Lys Val Gly Ser Cys Lys Ser Glu Val
1340 1345 1350
Glu Val Asp Ile His Tyr Cys Gln Gly Lys Cys Ala Ser Lys Ala
1355 1360 1365
Met Tyr Ser Ile Asp Ile Asn Asp Val Gln Asp Gln Cys Ser Cys
1370 1375 1380
Cys Ser Pro Thr Arg Thr Glu Pro Met Gln Val Ala Leu His Cys
1385 1390 1395
Thr Asn Gly Ser Val Val Tyr His Glu Val Leu Asn Ala Met Glu
1400 1405 1410
Cys Lys Cys Ser Pro Arg Lys Cys Ser Lys
1415 1420
<210> 12
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 12
Ser Phe Ser Gln Asn Ser Arg His Gln Ala Tyr Arg Tyr Arg Arg Gly
1 5 10 15
<210> 13
<211> 1440
<212> БЕЛОК
<213> Homo sapiens
<400> 13
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys Gly Val Lys
485 490 495
His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys
500 505 510
Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys
515 520 525
Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala
530 535 540
Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp
545 550 555 560
Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe
565 570 575
Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln
580 585 590
Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe
595 600 605
Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser
610 615 620
Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu
625 630 635 640
Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr
645 650 655
Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro
660 665 670
Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp
675 680 685
Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala
690 695 700
Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu
705 710 715 720
Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala
725 730 735
Ile Glu Pro Arg Ser Phe Ser Gln Asn Ser Arg His Gln Ala Tyr Arg
740 745 750
Tyr Arg Arg Gly Glu Ile Thr Arg Thr Thr Leu Gln Ser Asp Gln Glu
755 760 765
Glu Ile Asp Tyr Asp Asp Thr Ile Ser Val Glu Met Lys Lys Glu Asp
770 775 780
Phe Asp Ile Tyr Asp Glu Asp Glu Asn Gln Ser Pro Arg Ser Phe Gln
785 790 795 800
Lys Lys Thr Arg His Tyr Phe Ile Ala Ala Val Glu Arg Leu Trp Asp
805 810 815
Tyr Gly Met Ser Ser Ser Pro His Val Leu Arg Asn Arg Ala Gln Ser
820 825 830
Gly Ser Val Pro Gln Phe Lys Lys Val Val Phe Gln Glu Phe Thr Asp
835 840 845
Gly Ser Phe Thr Gln Pro Leu Tyr Arg Gly Glu Leu Asn Glu His Leu
850 855 860
Gly Leu Leu Gly Pro Tyr Ile Arg Ala Glu Val Glu Asp Asn Ile Met
865 870 875 880
Val Thr Phe Arg Asn Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser
885 890 895
Leu Ile Ser Tyr Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg Lys
900 905 910
Asn Phe Val Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys Val Gln
915 920 925
His His Met Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys Ala Trp Ala
930 935 940
Tyr Phe Ser Asp Val Asp Leu Glu Lys Asp Val His Ser Gly Leu Ile
945 950 955 960
Gly Pro Leu Leu Val Cys His Thr Asn Thr Leu Asn Pro Ala His Gly
965 970 975
Arg Gln Val Thr Val Gln Glu Phe Ala Leu Phe Phe Thr Ile Phe Asp
980 985 990
Glu Thr Lys Ser Trp Tyr Phe Thr Glu Asn Met Glu Arg Asn Cys Arg
995 1000 1005
Ala Pro Cys Asn Ile Gln Met Glu Asp Pro Thr Phe Lys Glu Asn
1010 1015 1020
Tyr Arg Phe His Ala Ile Asn Gly Tyr Ile Met Asp Thr Leu Pro
1025 1030 1035
Gly Leu Val Met Ala Gln Asp Gln Arg Ile Arg Trp Tyr Leu Leu
1040 1045 1050
Ser Met Gly Ser Asn Glu Asn Ile His Ser Ile His Phe Ser Gly
1055 1060 1065
His Val Phe Thr Val Arg Lys Lys Glu Glu Tyr Lys Met Ala Leu
1070 1075 1080
Tyr Asn Leu Tyr Pro Gly Val Phe Glu Thr Val Glu Met Leu Pro
1085 1090 1095
Ser Lys Ala Gly Ile Trp Arg Val Glu Cys Leu Ile Gly Glu His
1100 1105 1110
Leu His Ala Gly Met Ser Thr Leu Phe Leu Val Tyr Ser Asn Lys
1115 1120 1125
Cys Gln Thr Pro Leu Gly Met Ala Ser Gly His Ile Arg Asp Phe
1130 1135 1140
Gln Ile Thr Ala Ser Gly Gln Tyr Gly Gln Trp Ala Pro Lys Leu
1145 1150 1155
Ala Arg Leu His Tyr Ser Gly Ser Ile Asn Ala Trp Ser Thr Lys
1160 1165 1170
Glu Pro Phe Ser Trp Ile Lys Val Asp Leu Leu Ala Pro Met Ile
1175 1180 1185
Ile His Gly Ile Lys Thr Gln Gly Ala Arg Gln Lys Phe Ser Ser
1190 1195 1200
Leu Tyr Ile Ser Gln Phe Ile Ile Met Tyr Ser Leu Asp Gly Lys
1205 1210 1215
Lys Trp Gln Thr Tyr Arg Gly Asn Ser Thr Gly Thr Leu Met Val
1220 1225 1230
Phe Phe Gly Asn Val Asp Ser Ser Gly Ile Lys His Asn Ile Phe
1235 1240 1245
Asn Pro Pro Ile Ile Ala Arg Tyr Ile Arg Leu His Pro Thr His
1250 1255 1260
Tyr Ser Ile Arg Ser Thr Leu Arg Met Glu Leu Met Gly Cys Asp
1265 1270 1275
Leu Asn Ser Cys Ser Met Pro Leu Gly Met Glu Ser Lys Ala Ile
1280 1285 1290
Ser Asp Ala Gln Ile Thr Ala Ser Ser Tyr Phe Thr Asn Met Phe
1295 1300 1305
Ala Thr Trp Ser Pro Ser Lys Ala Arg Leu His Leu Gln Gly Arg
1310 1315 1320
Ser Asn Ala Trp Arg Pro Gln Val Asn Asn Pro Lys Glu Trp Leu
1325 1330 1335
Gln Val Asp Phe Gln Lys Thr Met Lys Val Thr Gly Val Thr Thr
1340 1345 1350
Gln Gly Val Lys Ser Leu Leu Thr Ser Met Tyr Val Lys Glu Phe
1355 1360 1365
Leu Ile Ser Ser Ser Gln Asp Gly His Gln Trp Thr Leu Phe Phe
1370 1375 1380
Gln Asn Gly Lys Val Lys Val Phe Gln Gly Asn Gln Asp Ser Phe
1385 1390 1395
Thr Pro Val Val Asn Ser Leu Asp Pro Pro Leu Leu Thr Arg Tyr
1400 1405 1410
Leu Arg Ile His Pro Gln Ser Trp Val His Gln Ile Ala Leu Arg
1415 1420 1425
Met Glu Val Leu Gly Cys Glu Ala Gln Asp Leu Tyr
1430 1435 1440
<210> 14
<211> 1530
<212> БЕЛОК
<213> Homo sapiens
<400> 14
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys Gly Val Lys
485 490 495
His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys
500 505 510
Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys
515 520 525
Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala
530 535 540
Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp
545 550 555 560
Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe
565 570 575
Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln
580 585 590
Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe
595 600 605
Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser
610 615 620
Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu
625 630 635 640
Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr
645 650 655
Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro
660 665 670
Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp
675 680 685
Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala
690 695 700
Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu
705 710 715 720
Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala
725 730 735
Ile Glu Pro Arg Ser Phe Ser Gln Asn Ser Arg His Gln Glu Pro Gly
740 745 750
Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu
755 760 765
Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly
770 775 780
Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr
785 790 795 800
Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu Pro Gly Gly Leu
805 810 815
Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr Thr Leu Tyr Val
820 825 830
Glu Asp Ile Ser Glu Pro Pro Leu His Arg Tyr Arg Arg Gly Glu Ile
835 840 845
Thr Arg Thr Thr Leu Gln Ser Asp Gln Glu Glu Ile Asp Tyr Asp Asp
850 855 860
Thr Ile Ser Val Glu Met Lys Lys Glu Asp Phe Asp Ile Tyr Asp Glu
865 870 875 880
Asp Glu Asn Gln Ser Pro Arg Ser Phe Gln Lys Lys Thr Arg His Tyr
885 890 895
Phe Ile Ala Ala Val Glu Arg Leu Trp Asp Tyr Gly Met Ser Ser Ser
900 905 910
Pro His Val Leu Arg Asn Arg Ala Gln Ser Gly Ser Val Pro Gln Phe
915 920 925
Lys Lys Val Val Phe Gln Glu Phe Thr Asp Gly Ser Phe Thr Gln Pro
930 935 940
Leu Tyr Arg Gly Glu Leu Asn Glu His Leu Gly Leu Leu Gly Pro Tyr
945 950 955 960
Ile Arg Ala Glu Val Glu Asp Asn Ile Met Val Thr Phe Arg Asn Gln
965 970 975
Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser Leu Ile Ser Tyr Glu Glu
980 985 990
Asp Gln Arg Gln Gly Ala Glu Pro Arg Lys Asn Phe Val Lys Pro Asn
995 1000 1005
Glu Thr Lys Thr Tyr Phe Trp Lys Val Gln His His Met Ala Pro
1010 1015 1020
Thr Lys Asp Glu Phe Asp Cys Lys Ala Trp Ala Tyr Phe Ser Asp
1025 1030 1035
Val Asp Leu Glu Lys Asp Val His Ser Gly Leu Ile Gly Pro Leu
1040 1045 1050
Leu Val Cys His Thr Asn Thr Leu Asn Pro Ala His Gly Arg Gln
1055 1060 1065
Val Thr Val Gln Glu Phe Ala Leu Phe Phe Thr Ile Phe Asp Glu
1070 1075 1080
Thr Lys Ser Trp Tyr Phe Thr Glu Asn Met Glu Arg Asn Cys Arg
1085 1090 1095
Ala Pro Cys Asn Ile Gln Met Glu Asp Pro Thr Phe Lys Glu Asn
1100 1105 1110
Tyr Arg Phe His Ala Ile Asn Gly Tyr Ile Met Asp Thr Leu Pro
1115 1120 1125
Gly Leu Val Met Ala Gln Asp Gln Arg Ile Arg Trp Tyr Leu Leu
1130 1135 1140
Ser Met Gly Ser Asn Glu Asn Ile His Ser Ile His Phe Ser Gly
1145 1150 1155
His Val Phe Thr Val Arg Lys Lys Glu Glu Tyr Lys Met Ala Leu
1160 1165 1170
Tyr Asn Leu Tyr Pro Gly Val Phe Glu Thr Val Glu Met Leu Pro
1175 1180 1185
Ser Lys Ala Gly Ile Trp Arg Val Glu Cys Leu Ile Gly Glu His
1190 1195 1200
Leu His Ala Gly Met Ser Thr Leu Phe Leu Val Tyr Ser Asn Lys
1205 1210 1215
Cys Gln Thr Pro Leu Gly Met Ala Ser Gly His Ile Arg Asp Phe
1220 1225 1230
Gln Ile Thr Ala Ser Gly Gln Tyr Gly Gln Trp Ala Pro Lys Leu
1235 1240 1245
Ala Arg Leu His Tyr Ser Gly Ser Ile Asn Ala Trp Ser Thr Lys
1250 1255 1260
Glu Pro Phe Ser Trp Ile Lys Val Asp Leu Leu Ala Pro Met Ile
1265 1270 1275
Ile His Gly Ile Lys Thr Gln Gly Ala Arg Gln Lys Phe Ser Ser
1280 1285 1290
Leu Tyr Ile Ser Gln Phe Ile Ile Met Tyr Ser Leu Asp Gly Lys
1295 1300 1305
Lys Trp Gln Thr Tyr Arg Gly Asn Ser Thr Gly Thr Leu Met Val
1310 1315 1320
Phe Phe Gly Asn Val Asp Ser Ser Gly Ile Lys His Asn Ile Phe
1325 1330 1335
Asn Pro Pro Ile Ile Ala Arg Tyr Ile Arg Leu His Pro Thr His
1340 1345 1350
Tyr Ser Ile Arg Ser Thr Leu Arg Met Glu Leu Met Gly Cys Asp
1355 1360 1365
Leu Asn Ser Cys Ser Met Pro Leu Gly Met Glu Ser Lys Ala Ile
1370 1375 1380
Ser Asp Ala Gln Ile Thr Ala Ser Ser Tyr Phe Thr Asn Met Phe
1385 1390 1395
Ala Thr Trp Ser Pro Ser Lys Ala Arg Leu His Leu Gln Gly Arg
1400 1405 1410
Ser Asn Ala Trp Arg Pro Gln Val Asn Asn Pro Lys Glu Trp Leu
1415 1420 1425
Gln Val Asp Phe Gln Lys Thr Met Lys Val Thr Gly Val Thr Thr
1430 1435 1440
Gln Gly Val Lys Ser Leu Leu Thr Ser Met Tyr Val Lys Glu Phe
1445 1450 1455
Leu Ile Ser Ser Ser Gln Asp Gly His Gln Trp Thr Leu Phe Phe
1460 1465 1470
Gln Asn Gly Lys Val Lys Val Phe Gln Gly Asn Gln Asp Ser Phe
1475 1480 1485
Thr Pro Val Val Asn Ser Leu Asp Pro Pro Leu Leu Thr Arg Tyr
1490 1495 1500
Leu Arg Ile His Pro Gln Ser Trp Val His Gln Ile Ala Leu Arg
1505 1510 1515
Met Glu Val Leu Gly Cys Glu Ala Gln Asp Leu Tyr
1520 1525 1530
<210> 15
<211> 3807
<212> ДНК
<213> Homo sapiens
<400> 15
atgatccccg ccagatttgc cggcgtgctg ctggccctgg ctctgatcct gcctggaaca 60
ctgtgtgccg agggcaccag aggcagatcc agcaccgcca gatgcagcct gttcggcagc 120
gacttcgtga acaccttcga cggcagcatg tacagcttcg ccggctactg ctcctacctg 180
ctggctggcg gctgccagaa gcggagcttt agcatcatcg gcgacttcca gaacggcaag 240
cgggtgtccc tgagcgtgta cctgggcgag ttcttcgaca tccacctgtt cgtgaacggc 300
accgtgaccc agggcgatca gagggtgtcc atgccctacg ccagcaaggg cctgtacctg 360
gaaacagagg ccggctatta caagctgagc ggcgaggcct acggcttcgt ggccagaatc 420
gatggcagcg gcaacttcca ggtgctgctg agcgaccggt acttcaacaa gacctgcggc 480
ctgtgcggca atttcaacat cttcgccgag gacgacttca tgacccagga aggcaccctg 540
accagcgacc cctacgactt cgccaatagc tgggccctgt ctagcggcga gcagtggtgc 600
gaaagagcca gccctcctag cagcagctgc aacatcagca gcggcgagat gcagaaaggc 660
ctgtgggagc agtgccagct gctgaagtcc accagcgtgt tcgccaggtg ccaccctctg 720
gtggaccctg agccttttgt ggccctgtgc gagaaaacac tgtgcgagtg tgccggcgga 780
ctggaatgtg cctgtcctgc cctgctggaa tacgccagaa cctgcgctca ggaagggatg 840
gtgctgtacg gctggaccga ccactctgcc tgtagccctg tgtgtcctgc cggcatggaa 900
tatcggcagt gcgtgtcccc ctgcgccagg acctgtcaga gcctgcacat caacgagatg 960
tgccaggaac gctgcgtgga cggctgtagc tgtcctgagg gacagctgct ggatgagggc 1020
ctgtgtgtgg aaagcaccga gtgcccttgt gtgcacagcg gcaagagata cccccctggc 1080
accagcctga gccgggactg caatacctgc atctgccgga acagccagtg gatctgctcc 1140
aacgaggaat gccctggcga gtgcctcgtg acaggccaga gccacttcaa gagcttcgac 1200
aacagatact tcaccttcag cggcatctgc cagtatctgc tggccagaga ctgccaggac 1260
cacagcttca gcatcgtgat cgagacagtg cagtgcgccg acgacagaga tgccgtgtgc 1320
accagatccg tgaccgtgcg gctgcctggc ctgcacaaca gcctcgtgaa gctgaaacac 1380
ggcgctgggg tggccatgga cggacaggac gtgcagctgc ctctgctgaa gggcgacctg 1440
agaatccagc acaccgtgac agcctctgtg cggctgagct acggcgagga cctccagatg 1500
gactgggatg gcaggggcag actgctcgtg aaactgagcc cagtgtatgc cggcaagact 1560
tgtggactgt gtggcaacta caacggcaac cagggcgacg atttcctgac cccttctggc 1620
ctggccgagc cccgggtgga agattttggc aacgcctgga agctgcacgg cgactgtcag 1680
gatctccaga agcagcacag cgacccttgc gccctgaacc cccggatgac cagattcagc 1740
gaagaggcct gtgccgtgct gaccagccct acctttgagg cctgccacag agccgtgtct 1800
ccactgcctt acctgcggaa ttgcagatac gacgtgtgct cctgctccga cggccgcgaa 1860
tgtctgtgtg gcgccctggc ctcttatgcc gccgcttgtg ctggaagagg cgtgcgggtg 1920
gcatggcggg aaccaggcag atgcgagctg aactgcccta agggccaggt gtacctccag 1980
tgcggcaccc cctgcaacct gacctgtaga agcctgagct accccgacga agagtgcaac 2040
gaggcctgtc tggaaggctg cttttgccct cccggcctgt atatggacga gcggggcgat 2100
tgtgtgccca aggcccagtg cccctgctac tacgacggcg agattttcca gcccgaggac 2160
atcttcagcg accaccacac catgtgctac tgcgaggatg gcttcatgca ctgcaccatg 2220
agcggcgtgc caggctccct gctgcctgat gctgtgctgt ctagccccct gagccacaga 2280
agcaagagaa gcctgtcttg cagacccccc atggtcaagc tcgtgtgccc tgccgacaac 2340
ctgagagccg agggcctgga atgcaccaag acatgccaga actacgacct ggaatgcatg 2400
agcatgggct gcgtgtccgg ctgtctgtgc cctcctggca tggtgcgcca cgagaataga 2460
tgcgtggccc tggaacggtg cccgtgcttt catcagggca aagagtacgc cccaggcgaa 2520
accgtgaaga tcggctgcaa cacatgcgtg tgtcaggacc ggaagtggaa ctgcaccgac 2580
cacgtgtgcg acgccacctg tagcacaatc ggcatggccc actacctgac cttcgatggc 2640
ctgaagtacc tgttccccgg cgagtgtcag tacgtgctgg tgcaggatta ctgcggcagc 2700
aaccccggca ccttcagaat cctcgtgggc aacaagggct gtagccaccc ctccgtgaag 2760
tgcaagaaac gcgtgaccat cctggtggaa ggcggagaga tcgagctgtt cgacggcgaa 2820
gtgaacgtga agcggcccat gaaggacgag acacacttcg aggtggtgga aagcggccgg 2880
tacatcatcc tgctgctggg caaagccctg tccgtcgtgt gggacagaca cctgagcatc 2940
agcgtggtgc tgaagcagac ctaccaggaa aaagtgtgcg ggctgtgtgg gaactttgac 3000
ggcatccaga acaacgatct gaccagcagc aatctccagg tggaagagga ccccgtggac 3060
ttcggcaatt cctggaaggt gtccagccag tgtgccgaca ccagaaaggt gcccctggat 3120
agcagccccg ccacatgcca caacaacatc atgaagcaga caatggtgga cagcagctgc 3180
cgcatcctga cctccgatgt gtttcaggac tgcaacaaac tggtggaccc cgaaccctac 3240
ctggacgtgt gcatctacga cacatgcagc tgcgagagca tcggcgattg cgcctgcttc 3300
tgcgacacca ttgccgccta cgcccatgtg tgcgcccagc acggaaaggt cgtgacttgg 3360
agaaccgcca ccctgtgccc acagagctgc gaggaacgga acctgcggga aaacggctac 3420
gagtgcgagt ggcggtacaa cagctgtgcc ccagcctgcc aagtgacctg ccagcaccct 3480
gaacctctgg cttgccccgt gcagtgcgtg gaaggatgtc acgcccattg cccacccggc 3540
aagatcctgg atgagctgct ccagacctgt gtggacccag aggactgccc agtgtgcgaa 3600
gtggccggaa gaagattcgc ctccggcaag aaagtgaccc tgaatccctc cgaccccgag 3660
cactgtcaga tttgtcactg cgacgtcgtg aatctgacat gcgaagcctg ccaggaacct 3720
ggcggactgg tggtgcctcc tacagatgcc cctgtgtccc ccaccaccct gtacgtggaa 3780
gatatcagcg agccccccct gcactaa 3807
<210> 16
<211> 93
<212> ДНК
<213> Homo sapiens
<400> 16
caggaacctg gcggactggt ggtgcctcct acagatgccc ctgtgtcccc caccaccctg 60
tacgtggaag atatcagcga gccccccctg cac 93
<210> 17
<211> 3993
<212> ДНК
<213> Homo sapiens
<400> 17
atgatccccg ccagatttgc cggcgtgctg ctggccctgg ctctgatcct gcctggaaca 60
ctgtgtgccg agggcaccag aggcagatcc agcaccgcca gatgcagcct gttcggcagc 120
gacttcgtga acaccttcga cggcagcatg tacagcttcg ccggctactg ctcctacctg 180
ctggctggcg gctgccagaa gcggagcttt agcatcatcg gcgacttcca gaacggcaag 240
cgggtgtccc tgagcgtgta cctgggcgag ttcttcgaca tccacctgtt cgtgaacggc 300
accgtgaccc agggcgatca gagggtgtcc atgccctacg ccagcaaggg cctgtacctg 360
gaaacagagg ccggctatta caagctgagc ggcgaggcct acggcttcgt ggccagaatc 420
gatggcagcg gcaacttcca ggtgctgctg agcgaccggt acttcaacaa gacctgcggc 480
ctgtgcggca atttcaacat cttcgccgag gacgacttca tgacccagga aggcaccctg 540
accagcgacc cctacgactt cgccaatagc tgggccctgt ctagcggcga gcagtggtgc 600
gaaagagcca gccctcctag cagcagctgc aacatcagca gcggcgagat gcagaaaggc 660
ctgtgggagc agtgccagct gctgaagtcc accagcgtgt tcgccaggtg ccaccctctg 720
gtggaccctg agccttttgt ggccctgtgc gagaaaacac tgtgcgagtg tgccggcgga 780
ctggaatgtg cctgtcctgc cctgctggaa tacgccagaa cctgcgctca ggaagggatg 840
gtgctgtacg gctggaccga ccactctgcc tgtagccctg tgtgtcctgc cggcatggaa 900
tatcggcagt gcgtgtcccc ctgcgccagg acctgtcaga gcctgcacat caacgagatg 960
tgccaggaac gctgcgtgga cggctgtagc tgtcctgagg gacagctgct ggatgagggc 1020
ctgtgtgtgg aaagcaccga gtgcccttgt gtgcacagcg gcaagagata cccccctggc 1080
accagcctga gccgggactg caatacctgc atctgccgga acagccagtg gatctgctcc 1140
aacgaggaat gccctggcga gtgcctcgtg acaggccaga gccacttcaa gagcttcgac 1200
aacagatact tcaccttcag cggcatctgc cagtatctgc tggccagaga ctgccaggac 1260
cacagcttca gcatcgtgat cgagacagtg cagtgcgccg acgacagaga tgccgtgtgc 1320
accagatccg tgaccgtgcg gctgcctggc ctgcacaaca gcctcgtgaa gctgaaacac 1380
ggcgctgggg tggccatgga cggacaggac gtgcagctgc ctctgctgaa gggcgacctg 1440
agaatccagc acaccgtgac agcctctgtg cggctgagct acggcgagga cctccagatg 1500
gactgggatg gcaggggcag actgctcgtg aaactgagcc cagtgtatgc cggcaagact 1560
tgtggactgt gtggcaacta caacggcaac cagggcgacg atttcctgac cccttctggc 1620
ctggccgagc cccgggtgga agattttggc aacgcctgga agctgcacgg cgactgtcag 1680
gatctccaga agcagcacag cgacccttgc gccctgaacc cccggatgac cagattcagc 1740
gaagaggcct gtgccgtgct gaccagccct acctttgagg cctgccacag agccgtgtct 1800
ccactgcctt acctgcggaa ttgcagatac gacgtgtgct cctgctccga cggccgcgaa 1860
tgtctgtgtg gcgccctggc ctcttatgcc gccgcttgtg ctggaagagg cgtgcgggtg 1920
gcatggcggg aaccaggcag atgcgagctg aactgcccta agggccaggt gtacctccag 1980
tgcggcaccc cctgcaacct gacctgtaga agcctgagct accccgacga agagtgcaac 2040
gaggcctgtc tggaaggctg cttttgccct cccggcctgt atatggacga gcggggcgat 2100
tgtgtgccca aggcccagtg cccctgctac tacgacggcg agattttcca gcccgaggac 2160
atcttcagcg accaccacac catgtgctac tgcgaggatg gcttcatgca ctgcaccatg 2220
agcggcgtgc caggctccct gctgcctgat gctgtgctgt ctagccccct gagccacaga 2280
agcaagagaa gcctgtcttg cagacccccc atggtcaagc tcgtgtgccc tgccgacaac 2340
ctgagagccg agggcctgga atgcaccaag acatgccaga actacgacct ggaatgcatg 2400
agcatgggct gcgtgtccgg ctgtctgtgc cctcctggca tggtgcgcca cgagaataga 2460
tgcgtggccc tggaacggtg cccgtgcttt catcagggca aagagtacgc cccaggcgaa 2520
accgtgaaga tcggctgcaa cacatgcgtg tgtcaggacc ggaagtggaa ctgcaccgac 2580
cacgtgtgcg acgccacctg tagcacaatc ggcatggccc actacctgac cttcgatggc 2640
ctgaagtacc tgttccccgg cgagtgtcag tacgtgctgg tgcaggatta ctgcggcagc 2700
aaccccggca ccttcagaat cctcgtgggc aacaagggct gtagccaccc ctccgtgaag 2760
tgcaagaaac gcgtgaccat cctggtggaa ggcggagaga tcgagctgtt cgacggcgaa 2820
gtgaacgtga agcggcccat gaaggacgag acacacttcg aggtggtgga aagcggccgg 2880
tacatcatcc tgctgctggg caaagccctg tccgtcgtgt gggacagaca cctgagcatc 2940
agcgtggtgc tgaagcagac ctaccaggaa aaagtgtgcg ggctgtgtgg gaactttgac 3000
ggcatccaga acaacgatct gaccagcagc aatctccagg tggaagagga ccccgtggac 3060
ttcggcaatt cctggaaggt gtccagccag tgtgccgaca ccagaaaggt gcccctggat 3120
agcagccccg ccacatgcca caacaacatc atgaagcaga caatggtgga cagcagctgc 3180
cgcatcctga cctccgatgt gtttcaggac tgcaacaaac tggtggaccc cgaaccctac 3240
ctggacgtgt gcatctacga cacatgcagc tgcgagagca tcggcgattg cgcctgcttc 3300
tgcgacacca ttgccgccta cgcccatgtg tgcgcccagc acggaaaggt cgtgacttgg 3360
agaaccgcca ccctgtgccc acagagctgc gaggaacgga acctgcggga aaacggctac 3420
gagtgcgagt ggcggtacaa cagctgtgcc ccagcctgcc aagtgacctg ccagcaccct 3480
gaacctctgg cttgccccgt gcagtgcgtg gaaggatgtc acgcccattg cccacccggc 3540
aagatcctgg atgagctgct ccagacctgt gtggacccag aggactgccc agtgtgcgaa 3600
gtggccggaa gaagattcgc ctccggcaag aaagtgaccc tgaatccctc cgaccccgag 3660
cactgtcaga tttgtcactg cgacgtcgtg aatctgacat gcgaagcctg ccaggaacct 3720
ggcggactgg tggtgcctcc tacagatgcc cctgtgtccc ccaccaccct gtacgtggaa 3780
gatatcagcg agccccccct gcaccaggaa cctggcggac tggtggtgcc tcctacagac 3840
gctcctgtgt ctcctacaac actgtatgtg gaagatattt ccgagcctcc tctgcatcag 3900
gaaccagggg gcctggtggt gccaccaact gatgcaccag tgtctccaac tactctgtac 3960
gtggaagata tttctgaacc ccccctgcat taa 3993
<210> 18
<211> 4179
<212> ДНК
<213> Homo sapiens
<400> 18
atgatccccg ccagatttgc cggcgtgctg ctggccctgg ctctgatcct gcctggaaca 60
ctgtgtgccg agggcaccag aggcagatcc agcaccgcca gatgcagcct gttcggcagc 120
gacttcgtga acaccttcga cggcagcatg tacagcttcg ccggctactg ctcctacctg 180
ctggctggcg gctgccagaa gcggagcttt agcatcatcg gcgacttcca gaacggcaag 240
cgggtgtccc tgagcgtgta cctgggcgag ttcttcgaca tccacctgtt cgtgaacggc 300
accgtgaccc agggcgatca gagggtgtcc atgccctacg ccagcaaggg cctgtacctg 360
gaaacagagg ccggctatta caagctgagc ggcgaggcct acggcttcgt ggccagaatc 420
gatggcagcg gcaacttcca ggtgctgctg agcgaccggt acttcaacaa gacctgcggc 480
ctgtgcggca atttcaacat cttcgccgag gacgacttca tgacccagga aggcaccctg 540
accagcgacc cctacgactt cgccaatagc tgggccctgt ctagcggcga gcagtggtgc 600
gaaagagcca gccctcctag cagcagctgc aacatcagca gcggcgagat gcagaaaggc 660
ctgtgggagc agtgccagct gctgaagtcc accagcgtgt tcgccaggtg ccaccctctg 720
gtggaccctg agccttttgt ggccctgtgc gagaaaacac tgtgcgagtg tgccggcgga 780
ctggaatgtg cctgtcctgc cctgctggaa tacgccagaa cctgcgctca ggaagggatg 840
gtgctgtacg gctggaccga ccactctgcc tgtagccctg tgtgtcctgc cggcatggaa 900
tatcggcagt gcgtgtcccc ctgcgccagg acctgtcaga gcctgcacat caacgagatg 960
tgccaggaac gctgcgtgga cggctgtagc tgtcctgagg gacagctgct ggatgagggc 1020
ctgtgtgtgg aaagcaccga gtgcccttgt gtgcacagcg gcaagagata cccccctggc 1080
accagcctga gccgggactg caatacctgc atctgccgga acagccagtg gatctgctcc 1140
aacgaggaat gccctggcga gtgcctcgtg acaggccaga gccacttcaa gagcttcgac 1200
aacagatact tcaccttcag cggcatctgc cagtatctgc tggccagaga ctgccaggac 1260
cacagcttca gcatcgtgat cgagacagtg cagtgcgccg acgacagaga tgccgtgtgc 1320
accagatccg tgaccgtgcg gctgcctggc ctgcacaaca gcctcgtgaa gctgaaacac 1380
ggcgctgggg tggccatgga cggacaggac gtgcagctgc ctctgctgaa gggcgacctg 1440
agaatccagc acaccgtgac agcctctgtg cggctgagct acggcgagga cctccagatg 1500
gactgggatg gcaggggcag actgctcgtg aaactgagcc cagtgtatgc cggcaagact 1560
tgtggactgt gtggcaacta caacggcaac cagggcgacg atttcctgac cccttctggc 1620
ctggccgagc cccgggtgga agattttggc aacgcctgga agctgcacgg cgactgtcag 1680
gatctccaga agcagcacag cgacccttgc gccctgaacc cccggatgac cagattcagc 1740
gaagaggcct gtgccgtgct gaccagccct acctttgagg cctgccacag agccgtgtct 1800
ccactgcctt acctgcggaa ttgcagatac gacgtgtgct cctgctccga cggccgcgaa 1860
tgtctgtgtg gcgccctggc ctcttatgcc gccgcttgtg ctggaagagg cgtgcgggtg 1920
gcatggcggg aaccaggcag atgcgagctg aactgcccta agggccaggt gtacctccag 1980
tgcggcaccc cctgcaacct gacctgtaga agcctgagct accccgacga agagtgcaac 2040
gaggcctgtc tggaaggctg cttttgccct cccggcctgt atatggacga gcggggcgat 2100
tgtgtgccca aggcccagtg cccctgctac tacgacggcg agattttcca gcccgaggac 2160
atcttcagcg accaccacac catgtgctac tgcgaggatg gcttcatgca ctgcaccatg 2220
agcggcgtgc caggctccct gctgcctgat gctgtgctgt ctagccccct gagccacaga 2280
agcaagagaa gcctgtcttg cagacccccc atggtcaagc tcgtgtgccc tgccgacaac 2340
ctgagagccg agggcctgga atgcaccaag acatgccaga actacgacct ggaatgcatg 2400
agcatgggct gcgtgtccgg ctgtctgtgc cctcctggca tggtgcgcca cgagaataga 2460
tgcgtggccc tggaacggtg cccgtgcttt catcagggca aagagtacgc cccaggcgaa 2520
accgtgaaga tcggctgcaa cacatgcgtg tgtcaggacc ggaagtggaa ctgcaccgac 2580
cacgtgtgcg acgccacctg tagcacaatc ggcatggccc actacctgac cttcgatggc 2640
ctgaagtacc tgttccccgg cgagtgtcag tacgtgctgg tgcaggatta ctgcggcagc 2700
aaccccggca ccttcagaat cctcgtgggc aacaagggct gtagccaccc ctccgtgaag 2760
tgcaagaaac gcgtgaccat cctggtggaa ggcggagaga tcgagctgtt cgacggcgaa 2820
gtgaacgtga agcggcccat gaaggacgag acacacttcg aggtggtgga aagcggccgg 2880
tacatcatcc tgctgctggg caaagccctg tccgtcgtgt gggacagaca cctgagcatc 2940
agcgtggtgc tgaagcagac ctaccaggaa aaagtgtgcg ggctgtgtgg gaactttgac 3000
ggcatccaga acaacgatct gaccagcagc aatctccagg tggaagagga ccccgtggac 3060
ttcggcaatt cctggaaggt gtccagccag tgtgccgaca ccagaaaggt gcccctggat 3120
agcagccccg ccacatgcca caacaacatc atgaagcaga caatggtgga cagcagctgc 3180
cgcatcctga cctccgatgt gtttcaggac tgcaacaaac tggtggaccc cgaaccctac 3240
ctggacgtgt gcatctacga cacatgcagc tgcgagagca tcggcgattg cgcctgcttc 3300
tgcgacacca ttgccgccta cgcccatgtg tgcgcccagc acggaaaggt cgtgacttgg 3360
agaaccgcca ccctgtgccc acagagctgc gaggaacgga acctgcggga aaacggctac 3420
gagtgcgagt ggcggtacaa cagctgtgcc ccagcctgcc aagtgacctg ccagcaccct 3480
gaacctctgg cttgccccgt gcagtgcgtg gaaggatgtc acgcccattg cccacccggc 3540
aagatcctgg atgagctgct ccagacctgt gtggacccag aggactgccc agtgtgcgaa 3600
gtggccggaa gaagattcgc ctccggcaag aaagtgaccc tgaatccctc cgaccccgag 3660
cactgtcaga tttgtcactg cgacgtcgtg aatctgacat gcgaagcctg ccaggaacct 3720
ggcggactgg tggtgcctcc tacagatgcc cctgtgtccc ccaccaccct gtacgtggaa 3780
gatatcagcg agccccccct gcaccaagaa cctggtggac tggtggtgcc tcctacagat 3840
gctcctgtgt ctcccaccac actgtacgtg gaagatatca gcgagcctcc tctgcaccaa 3900
gagccaggcg gacttgtggt cccaccaact gatgcccctg tcagccctac aactctgtac 3960
gtcgaggaca tctccgagcc accactgcat caagaacctg gcggccttgt cgttcctcca 4020
acagacgcac ctgttagccc aactacactg tatgttgagg acataagcga accgcctctc 4080
catcaagaac ccggtggtct tgttgtccca cctacagacg ccccagtctc tcctaccact 4140
ctctatgtcg aagatatttc cgaacctcca ctgcactaa 4179
<210> 19
<211> 4275
<212> ДНК
<213> Homo sapiens
<400> 19
atgatccccg ccagatttgc cggcgtgctg ctggccctgg ctctgatcct gcctggaaca 60
ctgtgtgccg agggcaccag aggcagatcc agcaccgcca gatgcagcct gttcggcagc 120
gacttcgtga acaccttcga cggcagcatg tacagcttcg ccggctactg ctcctacctg 180
ctggctggcg gctgccagaa gcggagcttt agcatcatcg gcgacttcca gaacggcaag 240
cgggtgtccc tgagcgtgta cctgggcgag ttcttcgaca tccacctgtt cgtgaacggc 300
accgtgaccc agggcgatca gagggtgtcc atgccctacg ccagcaaggg cctgtacctg 360
gaaacagagg ccggctatta caagctgagc ggcgaggcct acggcttcgt ggccagaatc 420
gatggcagcg gcaacttcca ggtgctgctg agcgaccggt acttcaacaa gacctgcggc 480
ctgtgcggca atttcaacat cttcgccgag gacgacttca tgacccagga aggcaccctg 540
accagcgacc cctacgactt cgccaatagc tgggccctgt ctagcggcga gcagtggtgc 600
gaaagagcca gccctcctag cagcagctgc aacatcagca gcggcgagat gcagaaaggc 660
ctgtgggagc agtgccagct gctgaagtcc accagcgtgt tcgccaggtg ccaccctctg 720
gtggaccctg agccttttgt ggccctgtgc gagaaaacac tgtgcgagtg tgccggcgga 780
ctggaatgtg cctgtcctgc cctgctggaa tacgccagaa cctgcgctca ggaagggatg 840
gtgctgtacg gctggaccga ccactctgcc tgtagccctg tgtgtcctgc cggcatggaa 900
tatcggcagt gcgtgtcccc ctgcgccagg acctgtcaga gcctgcacat caacgagatg 960
tgccaggaac gctgcgtgga cggctgtagc tgtcctgagg gacagctgct ggatgagggc 1020
ctgtgtgtgg aaagcaccga gtgcccttgt gtgcacagcg gcaagagata cccccctggc 1080
accagcctga gccgggactg caatacctgc atctgccgga acagccagtg gatctgctcc 1140
aacgaggaat gccctggcga gtgcctcgtg acaggccaga gccacttcaa gagcttcgac 1200
aacagatact tcaccttcag cggcatctgc cagtatctgc tggccagaga ctgccaggac 1260
cacagcttca gcatcgtgat cgagacagtg cagtgcgccg acgacagaga tgccgtgtgc 1320
accagatccg tgaccgtgcg gctgcctggc ctgcacaaca gcctcgtgaa gctgaaacac 1380
ggcgctgggg tggccatgga cggacaggac gtgcagctgc ctctgctgaa gggcgacctg 1440
agaatccagc acaccgtgac agcctctgtg cggctgagct acggcgagga cctccagatg 1500
gactgggatg gcaggggcag actgctcgtg aaactgagcc cagtgtatgc cggcaagact 1560
tgtggactgt gtggcaacta caacggcaac cagggcgacg atttcctgac cccttctggc 1620
ctggccgagc cccgggtgga agattttggc aacgcctgga agctgcacgg cgactgtcag 1680
gatctccaga agcagcacag cgacccttgc gccctgaacc cccggatgac cagattcagc 1740
gaagaggcct gtgccgtgct gaccagccct acctttgagg cctgccacag agccgtgtct 1800
ccactgcctt acctgcggaa ttgcagatac gacgtgtgct cctgctccga cggccgcgaa 1860
tgtctgtgtg gcgccctggc ctcttatgcc gccgcttgtg ctggaagagg cgtgcgggtg 1920
gcatggcggg aaccaggcag atgcgagctg aactgcccta agggccaggt gtacctccag 1980
tgcggcaccc cctgcaacct gacctgtaga agcctgagct accccgacga agagtgcaac 2040
gaggcctgtc tggaaggctg cttttgccct cccggcctgt atatggacga gcggggcgat 2100
tgtgtgccca aggcccagtg cccctgctac tacgacggcg agattttcca gcccgaggac 2160
atcttcagcg accaccacac catgtgctac tgcgaggatg gcttcatgca ctgcaccatg 2220
agcggcgtgc caggctccct gctgcctgat gctgtgctgt ctagccccct gagccacaga 2280
agcaagagaa gcctgtcttg cagacccccc atggtcaagc tcgtgtgccc tgccgacaac 2340
ctgagagccg agggcctgga atgcaccaag acatgccaga actacgacct ggaatgcatg 2400
agcatgggct gcgtgtccgg ctgtctgtgc cctcctggca tggtgcgcca cgagaataga 2460
tgcgtggccc tggaacggtg cccgtgcttt catcagggca aagagtacgc cccaggcgaa 2520
accgtgaaga tcggctgcaa cacatgcgtg tgtcaggacc ggaagtggaa ctgcaccgac 2580
cacgtgtgcg acgccacctg tagcacaatc ggcatggccc actacctgac cttcgatggc 2640
ctgaagtacc tgttccccgg cgagtgtcag tacgtgctgg tgcaggatta ctgcggcagc 2700
aaccccggca ccttcagaat cctcgtgggc aacaagggct gtagccaccc ctccgtgaag 2760
tgcaagaaac gcgtgaccat cctggtggaa ggcggagaga tcgagctgtt cgacggcgaa 2820
gtgaacgtga agcggcccat gaaggacgag acacacttcg aggtggtgga aagcggccgg 2880
tacatcatcc tgctgctggg caaagccctg tccgtcgtgt gggacagaca cctgagcatc 2940
agcgtggtgc tgaagcagac ctaccaggaa aaagtgtgcg ggctgtgtgg gaactttgac 3000
ggcatccaga acaacgatct gaccagcagc aatctccagg tggaagagga ccccgtggac 3060
ttcggcaatt cctggaaggt gtccagccag tgtgccgaca ccagaaaggt gcccctggat 3120
agcagccccg ccacatgcca caacaacatc atgaagcaga caatggtgga cagcagctgc 3180
cgcatcctga cctccgatgt gtttcaggac tgcaacaaac tggtggaccc cgaaccctac 3240
ctggacgtgt gcatctacga cacatgcagc tgcgagagca tcggcgattg cgcctgcttc 3300
tgcgacacca ttgccgccta cgcccatgtg tgcgcccagc acggaaaggt cgtgacttgg 3360
agaaccgcca ccctgtgccc acagagctgc gaggaacgga acctgcggga aaacggctac 3420
gagtgcgagt ggcggtacaa cagctgtgcc ccagcctgcc aagtgacctg ccagcaccct 3480
gaacctctgg cttgccccgt gcagtgcgtg gaaggatgtc acgcccattg cccacccggc 3540
aagatcctgg atgagctgct ccagacctgt gtggacccag aggactgccc agtgtgcgaa 3600
gtggccggaa gaagattcgc ctccggcaag aaagtgaccc tgaatccctc cgaccccgag 3660
cactgtcaga tttgtcactg cgacgtcgtg aatctgacat gcgaagcctg ccaggaacct 3720
ggcggactgg tggtgcctcc tacagatgcc cctgtgtccc ccaccaccct gtacgtggaa 3780
gatatcagcg agccccccct gcaccaagaa cctggtggac tggtggtgcc tcctacagat 3840
gctcctgtgt ctcccaccac actgtacgtg gaagatatca gcgagcctcc tctgcaccaa 3900
gagccaggcg gacttgtggt cccaccaact gatgcccctg tcagccctac aactctgtac 3960
gtcgaggaca tctccgagcc accactgcac gaggaacccg agtgcaacga tatcaccgcc 4020
agactgcagt acgtgaaagt gggcagctgc aagagcgagg tggaagtgga catccactac 4080
tgccagggca agtgtgccag caaggccatg tacagcatcg acatcaacga cgtgcaggac 4140
cagtgcagct gctgcagccc aacaagaacc gagcctatgc aggtcgccct gcactgtaca 4200
aatggcagcg tggtgtacca cgaggtgctg aacgccatgg aatgcaagtg cagccccaga 4260
aagtgcagca agtaa 4275
<210> 20
<211> 4659
<212> ДНК
<213> Homo sapiens
<400> 20
atgcaaatag agctctccac ctgcttcttt ctgtgccttt tgcgattctg ctttagtgcc 60
accagaagat actacctggg tgcagtggaa ctgtcatggg actatatgca aagtgatctc 120
ggtgagctgc ctgtggacgc aagatttcct cctagagtgc caaaatcttt tccattcaac 180
acctcagtcg tgtacaaaaa gactctgttt gtagaattca cggatcacct tttcaacatc 240
gctaagccaa ggccaccctg gatgggtctg ctaggtccta ccatccaggc tgaggtttat 300
gatacagtgg tcattacact taagaacatg gcttcccatc ctgtcagtct tcatgctgtt 360
ggtgtatcct actggaaagc ttctgaggga gctgaatatg atgatcagac cagtcaaagg 420
gagaaagaag atgataaagt cttccctggt ggaagccata catatgtctg gcaggtcctg 480
aaagagaatg gtccaatggc ctctgaccca ctgtgcctta cctactcata tctttctcat 540
gtggacctgg taaaagactt gaattcaggc ctcattggag ccctactagt atgtagagaa 600
gggagtctgg ccaaggaaaa gacacagacc ttgcacaaat ttatactact ttttgctgta 660
tttgatgaag ggaaaagttg gcactcagaa acaaagaact ccttgatgca ggatagggat 720
gctgcatctg ctcgggcctg gcctaaaatg cacacagtca atggttatgt aaacaggtct 780
ctgccaggtc tgattggatg ccacaggaaa tcagtctatt ggcatgtgat tggaatgggc 840
accactcctg aagtgcactc aatattcctc gaaggtcaca catttcttgt gaggaaccat 900
cgccaggcgt ccttggaaat ctcgccaata actttcctta ctgctcaaac actcttgatg 960
gaccttggac agtttctact gttttgtcat atctcttccc accaacatga tggcatggaa 1020
gcttatgtca aagtagacag ctgtccagag gaaccccaac tacgaatgaa aaataatgaa 1080
gaagcggaag actatgatga tgatcttact gattctgaaa tggatgtggt caggtttgat 1140
gatgacaact ctccttcctt tatccaaatt cgctcagttg ccaagaagca tcctaaaact 1200
tgggtacatt acattgctgc tgaagaggag gactgggact atgctccctt agtcctcgcc 1260
cccgatgaca gaagttataa aagtcaatat ttgaacaatg gccctcagcg gattggtagg 1320
aagtacaaaa aagtccgatt tatggcatac acagatgaaa cctttaagac tcgtgaagct 1380
attcagcatg aatcaggaat cttgggacct ttactttatg gggaagttgg agacacactg 1440
ttgattatat ttaagaatca agcaagcaga ccatataaca tctaccctca cggaatcact 1500
gatgtccgtc ctttgtattc aaggagatta ccaaaaggtg taaaacattt gaaggatttt 1560
ccaattctgc caggagaaat attcaaatat aaatggacag tgactgtaga agatgggcca 1620
actaaatcag atcctcggtg cctgacccgc tattactcta gtttcgttaa tatggagaga 1680
gatctagctt caggactcat tggccctctc ctcatctgct acaaagaatc tgtagatcaa 1740
agaggaaacc agataatgtc agacaagagg aatgtcatcc tgttttctgt atttgatgag 1800
aaccgaagct ggtacctcac agagaatata caacgctttc tccccaatcc agctggagtg 1860
cagcttgagg atccagagtt ccaagcctcc aacatcatgc acagcatcaa tggctatgtt 1920
tttgatagtt tgcagttgtc agtttgtttg catgaggtgg catactggta cattctaagc 1980
attggagcac agactgactt cctttctgtc ttcttctctg gatatacctt caaacacaaa 2040
atggtctatg aagacacact caccctattc ccattctcag gagaaactgt cttcatgtcg 2100
atggaaaacc caggtctatg gattctgggg tgccacaact cagactttcg gaacagaggc 2160
atgaccgcct tactgaaggt ttctagttgt gacaagaaca ctggtgatta ttacgaggac 2220
agttatgaag atatttcagc atacttgctg agtaaaaaca atgccattga accaagaagc 2280
ttctcccaga attcaagaca tcaggaacct ggcggactgg tggtgcctcc tacagatgcc 2340
cctgtgtccc ccaccaccct gtacgtggaa gatatcagcg agccccccct gcaccaggaa 2400
cctggcggac tggtggtgcc tcctacagac gctcctgtgt ctcctacaac actgtatgtg 2460
gaagatattt ccgagcctcc tctgcatcag gaaccagggg gcctggtggt gccaccaact 2520
gatgcaccag tgtctccaac tactctgtac gtggaagata tttctgaacc ccccctgcat 2580
caagcttatc gataccgtcg aggggaaata actcgtacta ctcttcagtc agatcaagag 2640
gaaattgact atgatgatac catatcagtt gaaatgaaga aggaagattt tgacatttat 2700
gatgaggatg aaaatcagag cccccgcagc tttcaaaaga aaacacgaca ctattttatt 2760
gctgcagtgg agaggctctg ggattatggg atgagtagct ccccacatgt tctaagaaac 2820
agggctcaga gtggcagtgt ccctcagttc aagaaagttg ttttccagga atttactgat 2880
ggctccttta ctcagccctt ataccgtgga gaactaaatg aacatttggg actcctgggg 2940
ccatatataa gagcagaagt tgaagataat atcatggtaa ctttcagaaa tcaggcctct 3000
cgtccctatt ccttctattc tagccttatt tcttatgagg aagatcagag gcaaggagca 3060
gaacctagaa aaaactttgt caagcctaat gaaaccaaaa cttacttttg gaaagtgcaa 3120
catcatatgg cacccactaa agatgagttt gactgcaaag cctgggctta tttctctgat 3180
gttgacctgg aaaaagatgt gcactcaggc ctgattggac cccttctggt ctgccacact 3240
aacacactga accctgctca tgggagacaa gtgacagtac aggaatttgc tctgtttttc 3300
accatctttg atgagaccaa aagctggtac ttcactgaaa atatggaaag aaactgcagg 3360
gctccctgca atatccagat ggaagatccc acttttaaag agaattatcg cttccatgca 3420
atcaatggct acataatgga tacactacct ggcttagtaa tggctcagga tcaaaggatt 3480
cgatggtatc tgctcagcat gggcagcaat gaaaacatcc attctattca tttcagtgga 3540
catgtgttca ctgtacgaaa aaaagaggag tataaaatgg cactgtacaa tctctatcca 3600
ggtgtttttg agacagtgga aatgttacca tccaaagctg gaatttggcg ggtggaatgc 3660
cttattggcg agcatctaca tgctgggatg agcacacttt ttctggtgta cagcaataag 3720
tgtcagactc ccctgggaat ggcttctgga cacattagag attttcagat tacagcttca 3780
ggacaatatg gacagtgggc cccaaagctg gccagacttc attattccgg atcaatcaat 3840
gcctggagca ccaaggagcc cttttcttgg atcaaggtgg atctgttggc accaatgatt 3900
attcacggca tcaagaccca gggtgcccgt cagaagttct ccagcctcta catctctcag 3960
tttatcatca tgtatagtct tgatgggaag aagtggcaga cttatcgagg aaattccact 4020
ggaaccttaa tggtcttctt tggcaatgtg gattcatctg ggataaaaca caatattttt 4080
aaccctccaa ttattgctcg atacatccgt ttgcacccaa ctcattatag cattcgcagc 4140
actcttcgca tggagttgat gggctgtgat ttaaatagtt gcagcatgcc attgggaatg 4200
gagagtaaag caatatcaga tgcacagatt actgcttcat cctactttac caatatgttt 4260
gccacctggt ctccttcaaa agctcgactt cacctccaag ggaggagtaa tgcctggaga 4320
cctcaggtga ataatccaaa agagtggctg caagtggact tccagaagac aatgaaagtc 4380
acaggagtaa ctactcaggg agtaaaatct ctgcttacca gcatgtatgt gaaggagttc 4440
ctcatctcca gcagtcaaga tggccatcag tggaccctct tttttcagaa tggcaaagta 4500
aaggtttttc agggaaatca agactccttc acacctgtgg tgaactctct agacccaccg 4560
ttactgactc gctaccttcg aattcacccc cagagttggg tgcaccagat tgccctgagg 4620
atggaggttc tgggctgcga ggcacaggac ctctactga 4659
<210> 21
<211> 1533
<212> БЕЛОК
<213> Homo sapiens
<400> 21
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys Gly Val Lys
485 490 495
His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys
500 505 510
Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys
515 520 525
Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala
530 535 540
Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp
545 550 555 560
Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe
565 570 575
Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln
580 585 590
Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe
595 600 605
Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser
610 615 620
Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu
625 630 635 640
Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr
645 650 655
Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro
660 665 670
Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp
675 680 685
Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala
690 695 700
Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu
705 710 715 720
Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala
725 730 735
Ile Glu Pro Arg Ser Phe Ser Gln Asn Ser Arg His Gln Ala Tyr Arg
740 745 750
Tyr Arg Arg Gly Glu Ile Thr Arg Thr Thr Leu Gln Ser Asp Gln Glu
755 760 765
Glu Ile Asp Tyr Asp Asp Thr Ile Ser Val Glu Met Lys Lys Glu Asp
770 775 780
Phe Asp Ile Tyr Asp Glu Asp Glu Asn Gln Ser Pro Arg Ser Phe Gln
785 790 795 800
Lys Lys Thr Arg His Tyr Phe Ile Ala Ala Val Glu Arg Leu Trp Asp
805 810 815
Tyr Gly Met Ser Ser Ser Pro His Val Leu Arg Asn Arg Ala Gln Ser
820 825 830
Gly Ser Val Pro Gln Phe Lys Lys Val Val Phe Gln Glu Phe Thr Asp
835 840 845
Gly Ser Phe Thr Gln Pro Leu Tyr Arg Gly Glu Leu Asn Glu His Leu
850 855 860
Gly Leu Leu Gly Pro Tyr Ile Arg Ala Glu Val Glu Asp Asn Ile Met
865 870 875 880
Val Thr Phe Arg Asn Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser
885 890 895
Leu Ile Ser Tyr Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg Lys
900 905 910
Asn Phe Val Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys Val Gln
915 920 925
His His Met Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys Ala Trp Ala
930 935 940
Tyr Phe Ser Asp Val Asp Leu Glu Lys Asp Val His Ser Gly Leu Ile
945 950 955 960
Gly Pro Leu Leu Val Cys His Thr Asn Thr Leu Asn Pro Ala His Gly
965 970 975
Arg Gln Val Thr Val Gln Glu Phe Ala Leu Phe Phe Thr Ile Phe Asp
980 985 990
Glu Thr Lys Ser Trp Tyr Phe Thr Glu Asn Met Glu Arg Asn Cys Arg
995 1000 1005
Ala Pro Cys Asn Ile Gln Met Glu Asp Pro Thr Phe Lys Glu Asn
1010 1015 1020
Tyr Arg Phe His Ala Ile Asn Gly Tyr Ile Met Asp Thr Leu Pro
1025 1030 1035
Gly Leu Val Met Ala Gln Asp Gln Arg Ile Arg Trp Tyr Leu Leu
1040 1045 1050
Ser Met Gly Ser Asn Glu Asn Ile His Ser Ile His Phe Ser Gly
1055 1060 1065
His Val Phe Thr Val Arg Lys Lys Glu Glu Tyr Lys Met Ala Leu
1070 1075 1080
Tyr Asn Leu Tyr Pro Gly Val Phe Glu Thr Val Glu Met Leu Pro
1085 1090 1095
Ser Lys Ala Gly Ile Trp Arg Val Glu Cys Leu Ile Gly Glu His
1100 1105 1110
Leu His Ala Gly Met Ser Thr Leu Phe Leu Val Tyr Ser Asn Lys
1115 1120 1125
Cys Gln Thr Pro Leu Gly Met Ala Ser Gly His Ile Arg Asp Phe
1130 1135 1140
Gln Ile Thr Ala Ser Gly Gln Tyr Gly Gln Trp Ala Pro Lys Leu
1145 1150 1155
Ala Arg Leu His Tyr Ser Gly Ser Ile Asn Ala Trp Ser Thr Lys
1160 1165 1170
Glu Pro Phe Ser Trp Ile Lys Val Asp Leu Leu Ala Pro Met Ile
1175 1180 1185
Ile His Gly Ile Lys Thr Gln Gly Ala Arg Gln Lys Phe Ser Ser
1190 1195 1200
Leu Tyr Ile Ser Gln Phe Ile Ile Met Tyr Ser Leu Asp Gly Lys
1205 1210 1215
Lys Trp Gln Thr Tyr Arg Gly Asn Ser Thr Gly Thr Leu Met Val
1220 1225 1230
Phe Phe Gly Asn Val Asp Ser Ser Gly Ile Lys His Asn Ile Phe
1235 1240 1245
Asn Pro Pro Ile Ile Ala Arg Tyr Ile Arg Leu His Pro Thr His
1250 1255 1260
Tyr Ser Ile Arg Ser Thr Leu Arg Met Glu Leu Met Gly Cys Asp
1265 1270 1275
Leu Asn Ser Cys Ser Met Pro Leu Gly Met Glu Ser Lys Ala Ile
1280 1285 1290
Ser Asp Ala Gln Ile Thr Ala Ser Ser Tyr Phe Thr Asn Met Phe
1295 1300 1305
Ala Thr Trp Ser Pro Ser Lys Ala Arg Leu His Leu Gln Gly Arg
1310 1315 1320
Ser Asn Ala Trp Arg Pro Gln Val Asn Asn Pro Lys Glu Trp Leu
1325 1330 1335
Gln Val Asp Phe Gln Lys Thr Met Lys Val Thr Gly Val Thr Thr
1340 1345 1350
Gln Gly Val Lys Ser Leu Leu Thr Ser Met Tyr Val Lys Glu Phe
1355 1360 1365
Leu Ile Ser Ser Ser Gln Asp Gly His Gln Trp Thr Leu Phe Phe
1370 1375 1380
Gln Asn Gly Lys Val Lys Val Phe Gln Gly Asn Gln Asp Ser Phe
1385 1390 1395
Thr Pro Val Val Asn Ser Leu Asp Pro Pro Leu Leu Thr Arg Tyr
1400 1405 1410
Leu Arg Ile His Pro Gln Ser Trp Val His Gln Ile Ala Leu Arg
1415 1420 1425
Met Glu Val Leu Gly Cys Glu Ala Gln Asp Leu Tyr Gln Glu Pro
1430 1435 1440
Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro Thr
1445 1450 1455
Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln Glu
1460 1465 1470
Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser Pro
1475 1480 1485
Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His Gln
1490 1495 1500
Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val Ser
1505 1510 1515
Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu His
1520 1525 1530
<210> 22
<211> 4659
<212> ДНК
<213> Homo sapiens
<400> 22
atgcaaatag agctctccac ctgcttcttt ctgtgccttt tgcgattctg ctttagtgcc 60
accagaagat actacctggg tgcagtggaa ctgtcatggg actatatgca aagtgatctc 120
ggtgagctgc ctgtggacgc aagatttcct cctagagtgc caaaatcttt tccattcaac 180
acctcagtcg tgtacaaaaa gactctgttt gtagaattca cggatcacct tttcaacatc 240
gctaagccaa ggccaccctg gatgggtctg ctaggtccta ccatccaggc tgaggtttat 300
gatacagtgg tcattacact taagaacatg gcttcccatc ctgtcagtct tcatgctgtt 360
ggtgtatcct actggaaagc ttctgaggga gctgaatatg atgatcagac cagtcaaagg 420
gagaaagaag atgataaagt cttccctggt ggaagccata catatgtctg gcaggtcctg 480
aaagagaatg gtccaatggc ctctgaccca ctgtgcctta cctactcata tctttctcat 540
gtggacctgg taaaagactt gaattcaggc ctcattggag ccctactagt atgtagagaa 600
gggagtctgg ccaaggaaaa gacacagacc ttgcacaaat ttatactact ttttgctgta 660
tttgatgaag ggaaaagttg gcactcagaa acaaagaact ccttgatgca ggatagggat 720
gctgcatctg ctcgggcctg gcctaaaatg cacacagtca atggttatgt aaacaggtct 780
ctgccaggtc tgattggatg ccacaggaaa tcagtctatt ggcatgtgat tggaatgggc 840
accactcctg aagtgcactc aatattcctc gaaggtcaca catttcttgt gaggaaccat 900
cgccaggcgt ccttggaaat ctcgccaata actttcctta ctgctcaaac actcttgatg 960
gaccttggac agtttctact gttttgtcat atctcttccc accaacatga tggcatggaa 1020
gcttatgtca aagtagacag ctgtccagag gaaccccaac tacgaatgaa aaataatgaa 1080
gaagcggaag actatgatga tgatcttact gattctgaaa tggatgtggt caggtttgat 1140
gatgacaact ctccttcctt tatccaaatt cgctcagttg ccaagaagca tcctaaaact 1200
tgggtacatt acattgctgc tgaagaggag gactgggact atgctccctt agtcctcgcc 1260
cccgatgaca gaagttataa aagtcaatat ttgaacaatg gccctcagcg gattggtagg 1320
aagtacaaaa aagtccgatt tatggcatac acagatgaaa cctttaagac tcgtgaagct 1380
attcagcatg aatcaggaat cttgggacct ttactttatg gggaagttgg agacacactg 1440
ttgattatat ttaagaatca agcaagcaga ccatataaca tctaccctca cggaatcact 1500
gatgtccgtc ctttgtattc aaggagatta ccaaaaggtg taaaacattt gaaggatttt 1560
ccaattctgc caggagaaat attcaaatat aaatggacag tgactgtaga agatgggcca 1620
actaaatcag atcctcggtg cctgacccgc tattactcta gtttcgttaa tatggagaga 1680
gatctagctt caggactcat tggccctctc ctcatctgct acaaagaatc tgtagatcaa 1740
agaggaaacc agataatgtc agacaagagg aatgtcatcc tgttttctgt atttgatgag 1800
aaccgaagct ggtacctcac agagaatata caacgctttc tccccaatcc agctggagtg 1860
cagcttgagg atccagagtt ccaagcctcc aacatcatgc acagcatcaa tggctatgtt 1920
tttgatagtt tgcagttgtc agtttgtttg catgaggtgg catactggta cattctaagc 1980
attggagcac agactgactt cctttctgtc ttcttctctg gatatacctt caaacacaaa 2040
atggtctatg aagacacact caccctattc ccattctcag gagaaactgt cttcatgtcg 2100
atggaaaacc caggtctatg gattctgggg tgccacaact cagactttcg gaacagaggc 2160
atgaccgcct tactgaaggt ttctagttgt gacaagaaca ctggtgatta ttacgaggac 2220
agttatgaag atatttcagc atacttgctg agtaaaaaca atgccattga accaagaagc 2280
ttctcccaga attcaagaca tcaagcttat cgataccgtc gaggggaaat aactcgtact 2340
actcttcagt cagatcaaga ggaaattgac tatgatgata ccatatcagt tgaaatgaag 2400
aaggaagatt ttgacattta tgatgaggat gaaaatcaga gcccccgcag ctttcaaaag 2460
aaaacacgac actattttat tgctgcagtg gagaggctct gggattatgg gatgagtagc 2520
tccccacatg ttctaagaaa cagggctcag agtggcagtg tccctcagtt caagaaagtt 2580
gttttccagg aatttactga tggctccttt actcagccct tataccgtgg agaactaaat 2640
gaacatttgg gactcctggg gccatatata agagcagaag ttgaagataa tatcatggta 2700
actttcagaa atcaggcctc tcgtccctat tccttctatt ctagccttat ttcttatgag 2760
gaagatcaga ggcaaggagc agaacctaga aaaaactttg tcaagcctaa tgaaaccaaa 2820
acttactttt ggaaagtgca acatcatatg gcacccacta aagatgagtt tgactgcaaa 2880
gcctgggctt atttctctga tgttgacctg gaaaaagatg tgcactcagg cctgattgga 2940
ccccttctgg tctgccacac taacacactg aaccctgctc atgggagaca agtgacagta 3000
caggaatttg ctctgttttt caccatcttt gatgagacca aaagctggta cttcactgaa 3060
aatatggaaa gaaactgcag ggctccctgc aatatccaga tggaagatcc cacttttaaa 3120
gagaattatc gcttccatgc aatcaatggc tacataatgg atacactacc tggcttagta 3180
atggctcagg atcaaaggat tcgatggtat ctgctcagca tgggcagcaa tgaaaacatc 3240
cattctattc atttcagtgg acatgtgttc actgtacgaa aaaaagagga gtataaaatg 3300
gcactgtaca atctctatcc aggtgttttt gagacagtgg aaatgttacc atccaaagct 3360
ggaatttggc gggtggaatg ccttattggc gagcatctac atgctgggat gagcacactt 3420
tttctggtgt acagcaataa gtgtcagact cccctgggaa tggcttctgg acacattaga 3480
gattttcaga ttacagcttc aggacaatat ggacagtggg ccccaaagct ggccagactt 3540
cattattccg gatcaatcaa tgcctggagc accaaggagc ccttttcttg gatcaaggtg 3600
gatctgttgg caccaatgat tattcacggc atcaagaccc agggtgcccg tcagaagttc 3660
tccagcctct acatctctca gtttatcatc atgtatagtc ttgatgggaa gaagtggcag 3720
acttatcgag gaaattccac tggaacctta atggtcttct ttggcaatgt ggattcatct 3780
gggataaaac acaatatttt taaccctcca attattgctc gatacatccg tttgcaccca 3840
actcattata gcattcgcag cactcttcgc atggagttga tgggctgtga tttaaatagt 3900
tgcagcatgc cattgggaat ggagagtaaa gcaatatcag atgcacagat tactgcttca 3960
tcctacttta ccaatatgtt tgccacctgg tctccttcaa aagctcgact tcacctccaa 4020
gggaggagta atgcctggag acctcaggtg aataatccaa aagagtggct gcaagtggac 4080
ttccagaaga caatgaaagt cacaggagta actactcagg gagtaaaatc tctgcttacc 4140
agcatgtatg tgaaggagtt cctcatctcc agcagtcaag atggccatca gtggaccctc 4200
ttttttcaga atggcaaagt aaaggttttt cagggaaatc aagactcctt cacacctgtg 4260
gtgaactctc tagacccacc gttactgact cgctaccttc gaattcaccc ccagagttgg 4320
gtgcaccaga ttgccctgag gatggaggtt ctgggctgcg aggcacagga cctctaccag 4380
gaacctggcg gactggtggt gcctcctaca gatgcccctg tgtcccccac caccctgtac 4440
gtggaagata tcagcgagcc ccccctgcac caggaacctg gcggactggt ggtgcctcct 4500
acagacgctc ctgtgtctcc tacaacactg tatgtggaag atatttccga gcctcctctg 4560
catcaggaac cagggggcct ggtggtgcca ccaactgatg caccagtgtc tccaactact 4620
ctgtacgtgg aagatatttc tgaacccccc ctgcattga 4659
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ ЛЕЧЕНИЯ ГЕМОФИЛИИ A | 2019 |
|
RU2812863C2 |
| ПОЛИПЕПТИДЫ, МОДУЛИРУЮЩИЕ SIGLEC-ЗАВИСИМЫЕ ИММУННЫЕ ОТВЕТЫ | 2017 |
|
RU2776807C2 |
| ПРЕПАРАТ, СОДЕРЖАЩИЙ ФАКТОР VIII И ПЕПТИДЫ ФАКТОРА ФОН ВИЛЛЕБРАНДА | 2015 |
|
RU2714154C2 |
| Выделенная нуклеиновая кислота, которая кодирует слитый белок на основе FVIII-BDD и гетерологичного сигнального пептида, и ее применение | 2022 |
|
RU2818229C2 |
| ВЫСОКОГЛИКОЗИЛИРОВАННЫЙ СЛИТЫЙ БЕЛОК НА ОСНОВЕ ФАКТОРА СВЕРТЫВАНИЯ КРОВИ ЧЕЛОВЕКА VIII, СПОСОБ ЕГО ПОЛУЧЕНИЯ И ЕГО ПРИМЕНЕНИЕ | 2016 |
|
RU2722374C1 |
| УЛУЧШЕННЫЙ БЕЛОК СЛИЯНИЯ FVIII И ЕГО ПРИМЕНЕНИЕ | 2019 |
|
RU2789085C2 |
| МОЛЕКУЛЫ НУКЛЕИНОВОЙ КИСЛОТЫ И ПУТИ ИХ ПРИМЕНЕНИЯ | 2018 |
|
RU2819144C2 |
| МОЛЕКУЛЫ НУКЛЕИНОВОЙ КИСЛОТЫ И ПУТИ ИХ ПРИМЕНЕНИЯ ДЛЯ НЕВИРУСНОЙ ГЕННОЙ ТЕРАПИИ | 2019 |
|
RU2834625C2 |
| СЛИТЫЙ БЕЛОК GDF15 ДЛИТЕЛЬНОГО ДЕЙСТВИЯ И СОДЕРЖАЩАЯ ЕГО ФАРМАЦЕВТИЧЕСКАЯ КОМПОЗИЦИЯ | 2020 |
|
RU2836280C1 |
| КОНСТРУКЦИИ СЛИТОГО БЕЛКА ДЛЯ ЗАБОЛЕВАНИЯ, СВЯЗАННОГО С КОМПЛЕМЕНТОМ | 2019 |
|
RU2824402C2 |
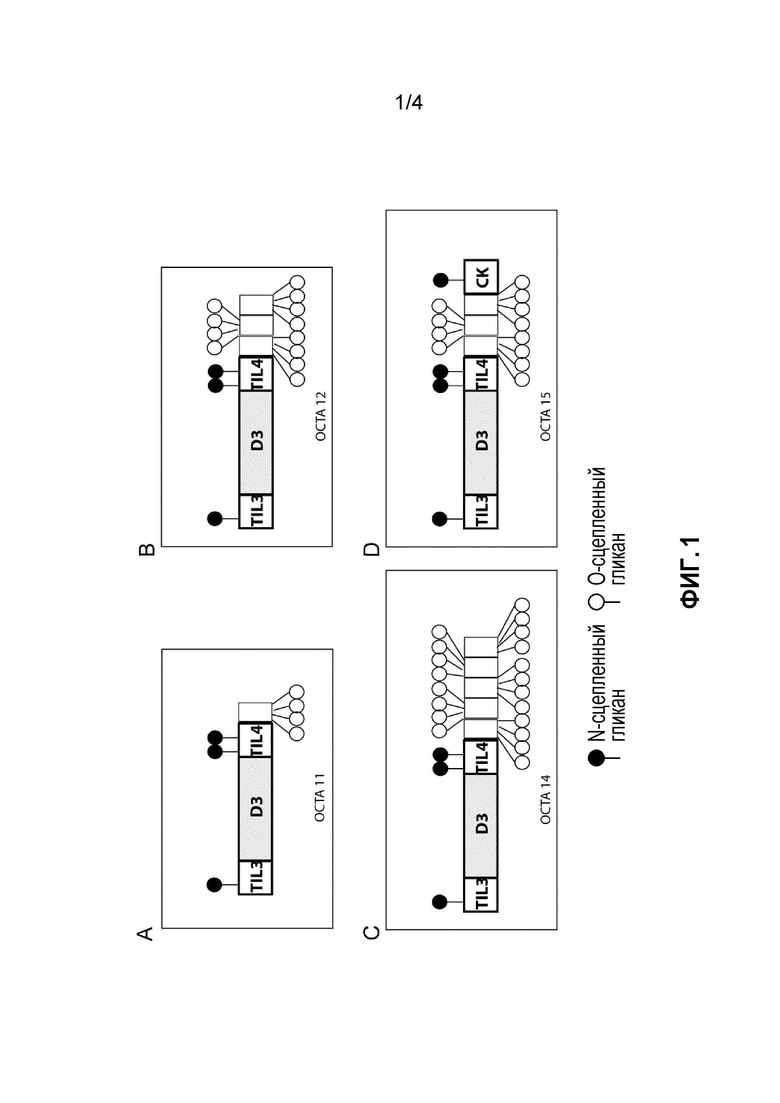
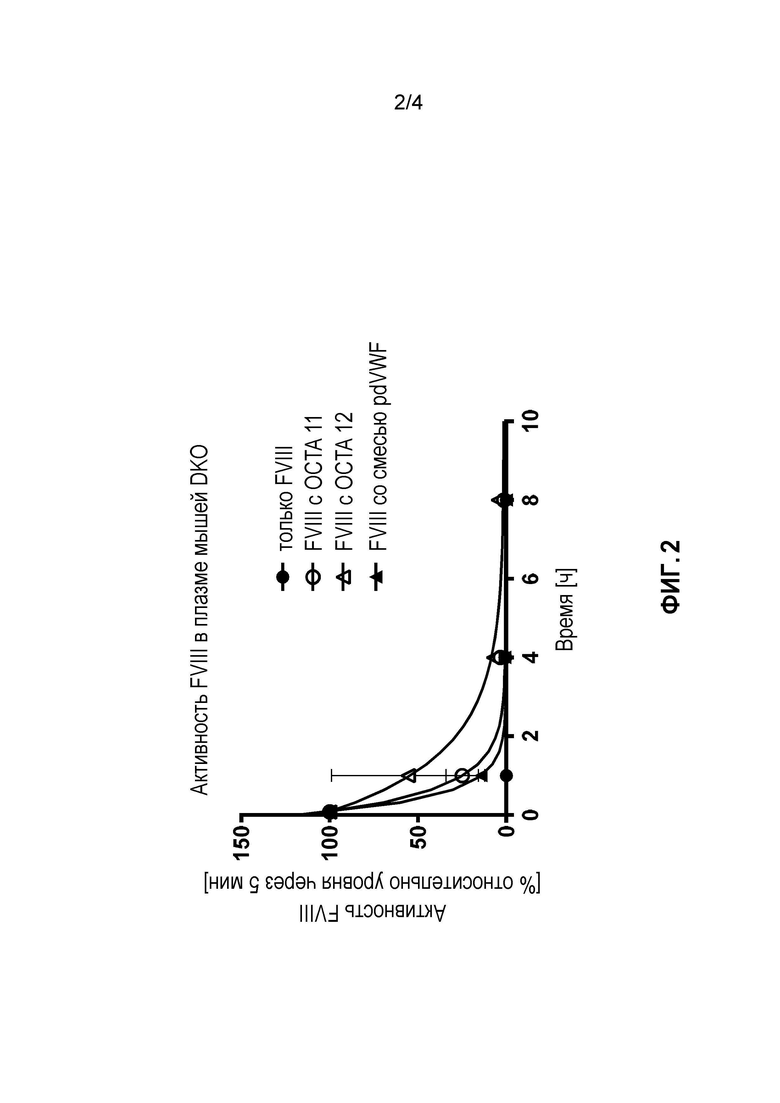
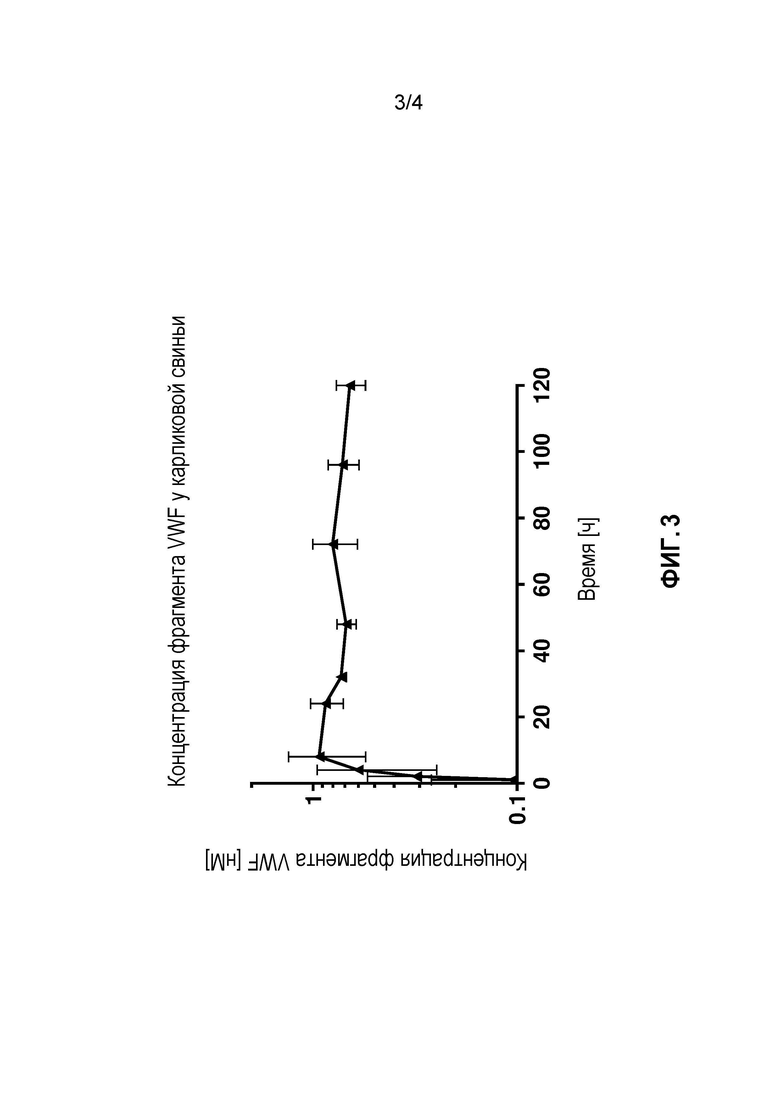
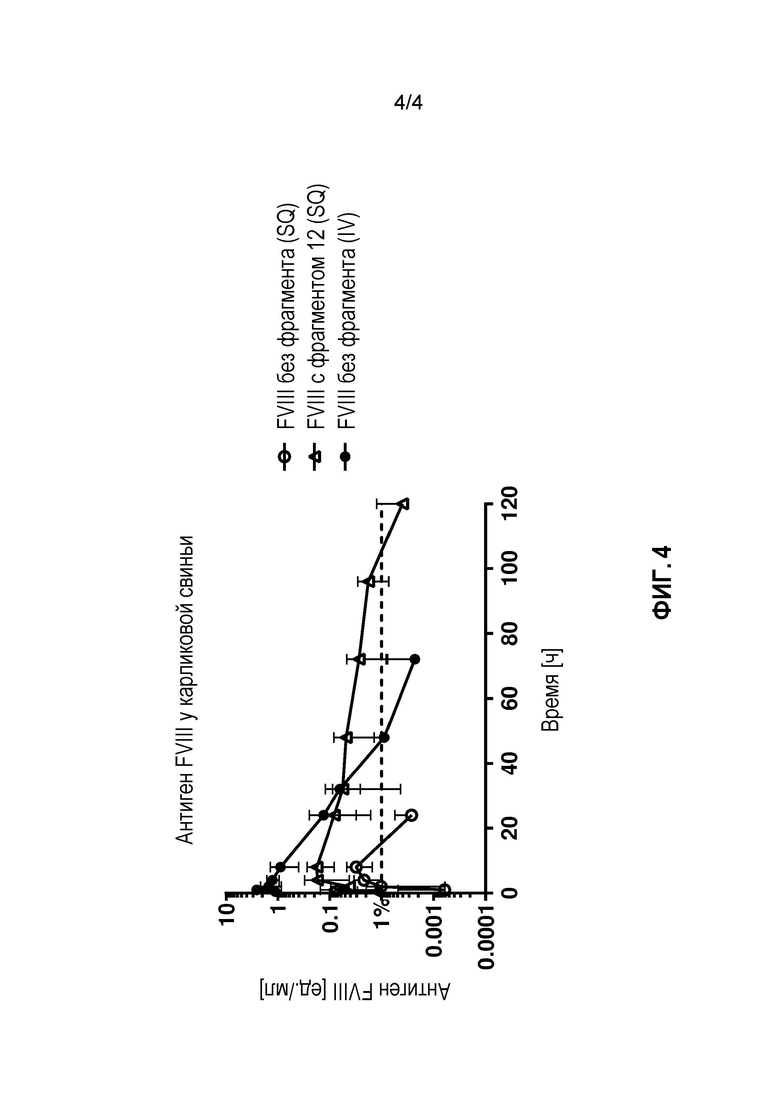
Изобретение относится к биотехнологии. Представлен слитый белок, содержащий основной белок и один или более пептиды удлинения, где аминокислотная последовательность основного белка идентична или схожа с аминокислотной последовательностью белка крови человека или его фрагмента. Причем указанный(е) пептид(ы) удлинения содержит(ат) кластер O-гликозилированных аминокислот с по меньшей мере двумя О-гликозилированными аминокислотами и имеет(ют) идентичность последовательности по меньшей мере 90% к SEQ ID NO: 1. Также представлены: композиция первого белка и второго белка для лечения или профилактики нарушения свертываемости крови, комплекс, образованный слитым белком, полинуклеотид, кодирующий слитый белок, вектор, клетка-хозяин, содержащей полинуклеотид, применение слитого белка для повышения времени полужизни второго белка и применение фармацевтической композиции или комплекса для лечения или профилактики нарушения свертываемости крови. Изобретение позволяет получить слитый белок, который имеет повышенное время полужизни по сравнению с основным белком и его можно использовать для повышения времени полужизни партнера по связыванию. 8 н. и 23 з.п. ф-лы, 3 табл., 4 ил., 3 пр.
1. Слитый белок, содержащий основной белок и один или более пептидов удлинения, где аминокислотная последовательность основного белка идентична или схожа с аминокислотной последовательностью белка крови человека или его фрагмента и указанный(е) пептид(ы) удлинения содержит(ат) кластер O-гликозилированных аминокислот с по меньшей мере двумя О-гликозилированными аминокислотами и имеет(ют) идентичность последовательности по меньшей мере 90% к SEQ ID NO: 1 и где слитый белок имеет повышенное время полужизни по сравнению с основным белком без пептида(ов) удлинения.
2. Слитый белок по п.1, где кластеры O-гликозилированных аминокислот пептидов удлинения содержат по меньшей мере три, по меньшей мере четыре O-гликозилированных аминокислоты.
3. Слитый белок по любому из пп. 1 или 2, где один или более пептидов удлинения имеют идентичность последовательности по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - по меньшей мере 100% по отношению к O-гликозилированному пептиду фактора фон Виллебранда (VWF), в частности SEQ ID NO: 1.
4. Слитый белок по любому из предшествующих пунктов, содержащий по меньшей мере две копии, предпочтительно - по меньшей мере четыре копии пептида удлинения.
5. Слитый белок по любому из предшествующих пунктов, где пептид удлинения напрямую или косвенно слит с C-концом основного белка.
6. Слитый белок по любому из предшествующих пунктов, где пептид удлинения образует C-конец слитого белка, где C-концевая аминокислота указанного пептида удлинения, необязательно, соединена с аффинной меткой слитого пептида.
7. Слитый белок по любому из пп. 3-6, где основной белок содержит по меньшей мере один кластер O-гликозилированных аминокислот.
8. Слитый белок по любому из предшествующих пунктов, где слитый белок содержит домен димеризации, в частности основной белок содержит домен димеризации.
9. Слитый белок по любому из предшествующих пунктов, где белок млекопитающего является фактором свертывания или ингибитором протеазы, более предпочтительно выбран из группы, состоящей из VWF, протромбина, фибриногена, FIII, FV, FVII, FVIII, FIX, FX, FXI, FXII, FXIII, ADAMTS13, антитромбина, альфа-1-антитрипсина, ингибитора C1, антихимотрипсина, PAI-1, PAI-3, 2-макроглобулина, TFPI, кофактора гепарина II, протеина Z, протеина C и протеина S.
10. Слитый белок по любому из предшествующих пунктов, где основной белок имеет идентичность последовательности по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к аминокислотам 764-1268 SEQ ID NO: 2.
11. Слитый белок по любому из предшествующих пунктов, где слитый белок содержит по меньшей мере 4, предпочтительно - по меньшей мере 8, более предпочтительно - по меньшей мере 12 дополнительных O-гликанов по сравнению с основным белком.
12. Слитый белок по любому из предшествующих пунктов, где аминокислотная последовательность слитого белка имеет идентичность по меньшей мере 90%, предпочтительно - по меньшей мере 95%, более предпочтительно - по меньшей мере 98%, наиболее предпочтительно - 100% по отношению к последовательности, выбранной из SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 7, SEQ ID NO: 8, SEQ ID NO: 9, SEQ ID NO: 10, SEQ ID NO: 11, SEQ ID NO: 14 или SEQ ID NO: 21.
13. Слитый белок по любому из предшествующих пунктов, где слитый белок получают посредством экспрессии в линии клеток млекопитающего, предпочтительно - линии клеток человека, более предпочтительно - линии клеток почки человека, наиболее предпочтительно - линии эмбриональных клеток почки человек, в частности линии клеток HEK293, такой как HEK293F, где указанные клетки не являются клетками, полученными путем разрушения эмбриона человека.
14. Композиция первого белка и второго белка для лечения или профилактики нарушения свертываемости, где указанный первый белок является слитым белком по любому из пп. 1-13 и способен связываться с указанным вторым белком и указанный второй белок является терапевтическим белком, содержащим аминокислотную последовательность, идентичную или схожую с аминокислотной последовательностью второго белка крови человека или его фрагмента, где второй белок крови человека выбирают из VWF, протромбина, фибриногена, FIII, FV, FVII, FVIII, FIX, FX, FXI, FXII, FXIII, ADAMTS13, антитромбина, альфа-1-антитрипсина, ингибитора C1, антихимотрипсина, PAI-1, PAI-3, 2-макроглобулина, TFPI, кофактора гепарина II, протеина Z, протеина C и протеина S.
15. Композиция по п. 14, где время полужизни второго белка, связанного с первым белком, повышается по сравнению со свободной формой указанного второго белка, предпочтительно, где время полужизни второго белка, связанного с первым белком, повышается по сравнению с указанным вторым белком, связанным с нативным белком млекопитающего, или основным белком без слитого пептида.
16. Композиция по п. 14 или 15, где молярное соотношение первого белка и второго белка находится в диапазоне от 0,1 до 250, предпочтительно - в диапазоне от 0,5 до 50, более предпочтительно - в диапазоне от 1 до 25, наиболее предпочтительно - в диапазоне от 2 до 10.
17. Композиция по любому из пп. 14-16, где аффинность связывания первого белка со вторым белком находится в диапазоне от 0,05 до 3 нМ.
18. Композиция по любому из пп. 14-17, где второй белок млекопитающего является белком крови, более предпочтительно указанный второй белок млекопитающего является белком плазмы, наиболее предпочтительно указанный второй белок является фактором свертывания.
19. Композиция по любому из пп. 14-18, где второй белок является белком FVIII, выбранным из полноразмерного FVIII, белка FVIII, в котором по меньшей мере часть B-домена отсутствует, и белка FVIII, в котором по меньшей мере часть B-домена заменяют пептидом удлинения, где пептид удлинения определяют по любому из пп. 1-3.
20. Композиция по любому из пп. 14-19, где один или более пептидов удлинения находятся в положении в свернутом состоянии первого белка, не мешающем связыванию первого белка со вторым белком.
21. Комплекс первого белка и второго белка для лечения или профилактики нарушения свертываемости, где указанный первый белок является слитым белком по любому из пп. 1-13 и указанный второй белок представляет собой терапевтический белок, содержащий аминокислотную последовательность, идентичную или схожую с аминокислотной последовательностью второго белка крови человека или его фрагмента, где второй белок крови человека выбирают из VWF, протромбина, фибриногена, FIII, FV, FVII, FVIII, FIX, FX, FXI, FXII, FXIII, ADAMTS13, антитромбина, альфа-1-антитрипсина, ингибитора C1, антихимотрипсина, PAI-1, PAI-3, 2-макроглобулина, TFPI, кофактора гепарина II, протеина Z, протеина C и протеина S.
22. Комплекс по п. 21, где первый белок нековалентно связан со вторым белком.
23. Комплекс по п. 21 или 22, содержащий две копии первого и второго белка, где две копии первого белка образуют димер, предпочтительно нековалентно связанный димер.
24. Комплекс по п. 21, где первый белок ковалентно связан со вторым белком, где линкер выбран из пептидной связи, химического линкера или гликозидной связи.
25. Полинуклеотид, кодирующий слитый белок по любому из пп. 1-13.
26. Полинуклеотид по п. 25, кодирующий слитый белок по п. 12.
27. Экспрессирующий вектор, содержащий полинуклеотид по п. 25 или 26, где остов вектора, предпочтительно, выбран из pCDNA3, pCDNA3.1, pCDNA4, pCDNA5, pCDNA6, pCEP4, pCEP-puro, pCET1019, pCMV, pEF1, pEF4, pEF5, pEF6, pExchange, pEXPR, pIRES и pSCAS.
28. Клетка-хозяин для получения слитого белка по любому из пп. 1-13, содержащая полинуклеотид по п. 25 или 26 или вектор по п. 27, где клетка-хозяин является клеткой линии клеток млекопитающего, предпочтительно - линии клеток человека, более предпочтительно - линии клеток почки человека, наиболее предпочтительно - линии эмбриональных клеток почки человека, в частности линии клеток HEK293, такой как HEK293F, где указанная клетка не является клеткой, полученной путем разрушения эмбриона человека.
29. Применение слитого белка по любому из пп. 1-13 для повышения времени полужизни второго белка, где слитый белок способен связываться с указанным вторым белком.
30. Применение фармацевтической композиции, содержащей слитый белок по любому из пп. 1-13, композиции по любому из пп. 14-20 или комплекса по любому из пп. 21-24 для лечения или профилактики нарушения свертываемости, предпочтительно, выбранного из лечения пациентов, ранее не подвергнутых лечению (PUP), и лечения с индукцией иммунологической толерантности (ITI) и/или родственных нарушений свертываемости.
31. Применение по п. 30, где применение включает внутривенную или невнутривенную инъекцию, предпочтительно подкожную инъекцию.
| WO 9315200 A1, 05.08.1993 | |||
| WO 9315199 A1, 05.08.1993 | |||
| DORON CALO et al.: "Enhancing the longevity and in vivo potency of therapeutic proteins: The power of OTP", Precision Medicine, 30.09.2015 | |||
| НОВЫЙ КЛАСС ТЕРАПЕВТИЧЕСКИХ БЕЛКОВЫХ МОЛЕКУЛ | 2005 |
|
RU2468080C2 |

