Область техники, к которой относится изобретение
Настоящее изобретение относится к области прогностических тестов определения внешности человека в судебно-медицинской экспертизе и используется для определения вероятности цвета глаз индивидуума, происходящего из популяций России.
Уровень техники
Признаками внешности, наиболее соответствующими целям разработки прогностических тестов внешности человека по ДНК, в судебно-медицинской экспертизе единодушно выбраны цвет глаз, волос и кожи. Они являются одними из наиболее заметных и легко фиксируемых фенотипических характеристик, удобны для использования в криминалистической практике и имеют относительно небольшое количество маркеров, определяющих большую часть вариативности. При этом важно, что окраска кожи, волос и радужины глаз определяется одним пигментом - меланином (его вариантами). От количества и расположения меланина в коже, радужине и волосах и зависит все разнообразие в окраске этих органов. Однако для криминалистики оценка предполагаемой внешности человека по его ДНК цвет кожи имеет второстепенное значение, поскольку зависит от интенсивности загара человека. Например, при сильном загаре свидетели происшествия могут оценивать цвет кожи как темный, хотя по ДНК он будет оцениваться как светлый. Искусственная окраска волос также встречается нередко. Поэтому первостепенное практическое значение имеет разработка систем для предсказания цвета глаз.
Под цветом глаз подразумевают окраску радужины. Она зависит как от количества, так и от глубины залегания пигмента. Радужина состоит из пяти слоев: 1) эндотелия, обращенного к передней камере глаза; 2) ретикулярного слоя; 3) сосудистого слоя; 4) заднего пограничного слоя; 5) пигментного слоя. Пигмент может располагаться как в пигментном и заднем пограничном слое, так и в соединительнотканной строме сосудистого слоя. Пигментный и задний пограничный слои всегда содержат то или иное количество пигмента (за исключением случаев альбинизма). В ретикулярном и сосудистом слоях пигмент может отсутствовать и тогда пигмент глубоких слоев просвечивает через передние слои радужины, что обусловливает синюю или голубую окраску. Наличие пигмента в передних слоях обусловливает желтую или бурую окраску радужины. При неравномерном расположении в них пигмента получаются различные смешанные оттенки [Рогинский, 1978; Хрисанфова Е.Н., 2005]. Поскольку изменчивость цвета глаз представляет собой сложный ряд количественных изменений нескольких параметров, то в антропологии существует и целый ряд классификации цвета радужной оболочки глаз: признак обычно анализируется путем размещения цвета глаз в отдельные категории или классы, определяемые визуальной оценкой одиночных наблюдателей или по фотографиям радужной оболочки глаза. Такие классификации используются в большинстве публикаций о цвете глаз. В криминалистической практике столь сложные классификации обычно не используются, и принято деление глаз на светлые и темные (иногда выделяются также промежуточные оттенки).
Исследования генетического контроля пигментации радужной оболочки глаз человека ведутся с 2000-х годов, и особенно после того, как стала доступной технология GWAS (Genome-wide association studies - генотипирование сотен тысяч маркеров, покрывающих весь геном, для образцов с известными фенотипами, и поиск генетических маркеров, высокодостоверно ассоциированных с конкретными фенотипами). Нарастание числа работ по этой теме с каждым годом наглядно показано на фигуре 1.
Достаточно быстро [Kayser et al., 2008] был обнаружен ген HERC2, вносящий наиболее важный вклад в генетическую детерминацию цвета глаз. В то же время было показано, что один этот ген не определяет цвет глаз человека, поскольку суммарное влияние ряда других генов также является весьма значимым. Поэтому последующие исследования были нацелены на выявление возможно более широкого списка этих генов (и конкретных полиморфизмов внутри генов), с последующим сужением списка с целью оставить лишь полиморфизмы, вносящие существенный вклад. Целью, таким образом, было выявить наборы полиморфизмов, достаточно обширные для достоверного прогноза цвета глаз по генотипу, но при этом не слишком обширны для целей удобства генотипирования этих маркеров. Такие исследования выполнены в мире для нескольких групп населения (популяций) и наше исследование является одним из них. Ниже следует обзор основных проведенных работ.
Большинство генов, которые связаны с вариативностью цвета глаз напрямую связаны с метаболическими путями синтеза меланина. Основные гены этого метаболического пути, ассоциированные с пигментацией, приведены в Таблице 1а.
Таблица 1а – гены, связанные с вариацией пигментации у человека.
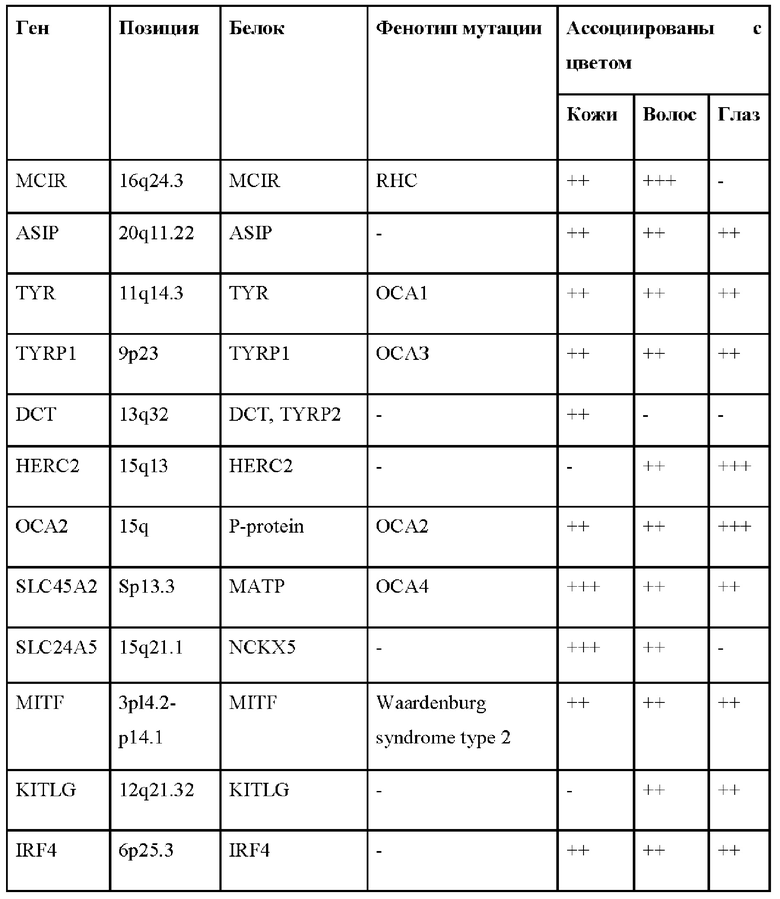

Знаками "+" или "-" отмечено соответственно наличие или отсутствие ассоциации каждого гена с конкретным признаком. В первом столбце указаны названия генов, во втором позиции в геноме, соответствующие полиморфизмам, в третьем - название кодируемого геном белка, в четвертом - фенотип, наблюдаемый в случае мутаций (RHC - рыжие волосы, ОСА1-ОСА4 - глазо-кожный альбинизм 1-4 типов, три последних столбца признаки, с которыми ассоциирован ген, в таком порядке: цвет кожи, волос, глаз (таблица 1а приведена по [Maronas et al., 2015]).
В работе [Spichenok et al., 2011] было протестировано 7 маркеров, расположенных около или в пределах генов, о которых известна их ассоциация с пигментацией. По результатам оценок корреляции на выборке, состоящей из 554 образцов представителей разных популяций (68,7% - европейцы, 17,1% - смешанное происхождение, 6% - афроамериканцы, 4,5% - индийцы, 4% - японцы и китайцы) были выбраны 6 маркеров, которые определяли цвет глаз с довольно высокой точностью. При этом, при сравнении полученных данных с базой данных НарМар были обнаружены проблемы предикции цвета глаз для индивидов европеоидного антропологического облика. Предположительно, данные ошибки предикции возникли в связи с тем, что в НарМар были изучены только индивиды, живущие в Европейском регионе, в то время как в исследовании участвовали потомки европейских переселенцев, давно живущих в США. Различия в качестве предикции для афроамериканцев и выходцев из Нигерии были еще значительнее по аналогичным причинам.
В работе [Hart et al., 2013] были изучены 5 SNP-маркеров, 4 из которых были представлены в прошлой работе и новый ДНК маркер rs12896399 (мутация в гене SLC24A4), для которого была показана статистически достоверная связь с цветом глаз. Помимо 803 тестовых образцов, систему опробовали еще на 212 независимых образцах. Анализ показал, что ошибка предикции цвета глаз (карие, зеленые, синие) составила около 5%.
В работе [Caliebe et al., 2016] была разработана модель прогноза пигментации для северных немцев. Изученная выборка составила 400 человек (197 мужчин, 203 женщины), все индивидуумы были из северной Германии, где они родились и имели предков. В ходе исследования было показано, что пять SNP - rs12913832, rs916977 (HERC2), rs7495174, rs4778241 и rs4778138 (OCA2) значимо ассоциируются с голубым цветом глаз. Однако при множественном тесте выявился лишь единственный SNP маркер, который проявляет значительную ассоциацию с голубым цветом глаз - rs12913832 в гене HERC2 с умеренной прогнозируемой мощностью.
В работе [Pospiech et al., 2014], была проверена ассоциация с пигментацией 38 полиморфизмов из 13 генов, насколько их взаимодействие связано с пигментацией. Исследовали 718 поляков, для проверки модели взяли 307 независимых образцов поляков и 72 образцов японцев. Для зеленого цвета глаз взаимодействие между HERC2 rs12913832 и ОСА2 rs1800407 или TYRP1 rs1408799 увеличили точность прогноза.
Наконец, наибольшее признание получила система IrisPlex (опубликована в [Walsh et al., 2011]). Она позволяет, прогнозировать цвет радужной оболочки глаза с точностью более 90% - с градацией вида карий/голубой. Кроме мультиплексного набора для генотипирования 6 информативных маркеров, система включает также и прогнозную модель, которая позволяет при предикции вычислять достоверность полученного результата. Панель включает следующие маркеры: rs12913832 (HERC2), rs1800407 (ОСА2), rs12896399 (SLC4A4), rs16891982 (SLC4A2 (MATP)), rs1393350 (TYR) и rs12203592 (IRF4). Система тестировалась на данных более 6168 образцов ДНК представителей населения Голландии, относящихся к европеоидному антропологическому типу, при этом согласно работе [Liu et al., 2009] на данной выборке система позволила предсказать карий цвет глаз с вероятностью 93%, голубой -91%, смешанные цвета радужной оболочки с вероятностью 72%. При тестировании данной модели на иных выборках (включающих не только население Нидерландов), к примеру, в работе [Kastelic et al., 2013], где тестировалась выборка, состоящая из словенцев (70 мужчин и 35 женщин), данная система показала пониженную вероятность предикции цвета глаз, 71% для карих глаз.
В 2013 году эта система была расширена, чтобы включить также предсказание цвета волос (к названию системы была добавлена буква Н от английского Hair) [Walsh et al., 2013]. Эта система включает 24 маркера (SNPs и инделы) - добавленные маркеры важны главным образом для предсказания цвета волос, но некоторые из них также дополнительно увеличивают точность прогноза цвета глаз. Была показана применимость этой системы для криминалистической практики [Walsh et al., 2014]
С 2016 г. доступен онлайн-ресурс https://hirisplex.erasmusmc.nl, который определяет вероятность цвета глаз и волос из полных и неполных профилей генотипов с использованием параметров, созданных из баз данных большого генотипа и фенотипа. Этот комбинированный инструмент прогнозирования представляет собой онлайн-систему, свободно доступную для пользователей.
В 2018 году системы была вновь расширена еще на 17 маркеров, чтобы включить также возможность прогноза цвета кожи [Chaitanya et al., 2018].
В целом, система IrisPlex во всех трех ее модификациях является широко используемым ресурсом, причем не только судебными экспертами, но и исследователями в других областях науки (например, она используется в исследованиях древних популяций для определения вероятного цвета глаз по древней ДНК).
В то же время данная панель работает для индивидов европейского происхождения, поскольку была разработана на европейских популяциях (главным образом, на голландцах). Ее верификация была проведена на трех популяциях Зарубежной Европы: ирландцев, греков и поляков. Проверка же ее на популяциях других регионов мира практически не проводилась. При этом существенно, что для большинства популяций за пределами Европы характерны только коричневые глаза и темные волосы, поэтому для них задача предсказания пигментации не актуальна. Но существуют и популяции Северной Евразии (например, некоторые группы на Алтае, на Кавказе) у которых нередко встречается фенотип со светлыми глазами и светлыми волосами. Генетически эти популяции не состоят в близком родстве с населением Зарубежной Европы, на которых была верифицирована система HIrisPlex. Поэтому вполне возможно, что они имеют аллели пигментации, которые не входят в систему HIrisPlex-S, но обеспечивают у них фенотип светлых глаз и волос. Если это так, то эти неизвестные еще аллели имеют важное значение для криминалистических исследований в России. Кроме того, разработка отечественной системы предсказания глаз, независимой от HIrisPlex, имеет значение в рамках политики импортозамещения, принятой в России.
Таким образом, существует потребность в разработке нового, более точного способа прогнозирования цвета глаз индивида по его ДНК, разработанной на основе изучения генофонда народонаселения России, оптимизированного для применения на российских популяциях.
Сущность изобретения
Настоящее изобретение основано на панели генетических маркеров, позволяющих определить цвет глаз индивидуума, происходящего из популяций России, по его ДНК и способа определения вероятности цвета глаз. Более конкретно, изобретение относится к способу определения вероятности цвета глаз индивидуума, происходящего из популяций России, на основе генотипа по однонуклеотидным полиморфизмам в образце ДНК, полученном от индивидуума, где полиморфизмы определены в таблице 2, и определение вероятности темного цвета глаз проводят по формуле:
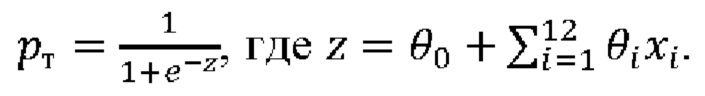
θ0 и θi определены в таблице 2,
xi - генотип данного образца ДНК по данному полиморфизму в формате 0, 1 или 2,
а вероятность светлого цвета глаз определяется по формуле: рс=1-рт,
где при полученном значении вероятности светлого цвета глаз (рс) выше 0,5 делается вывод о наличии у индивидуума светлых глаз, при полученном значении вероятности темного цвета (рт) глаз выше 0,5 делается вывод о наличии у индивидуума темных глаз.
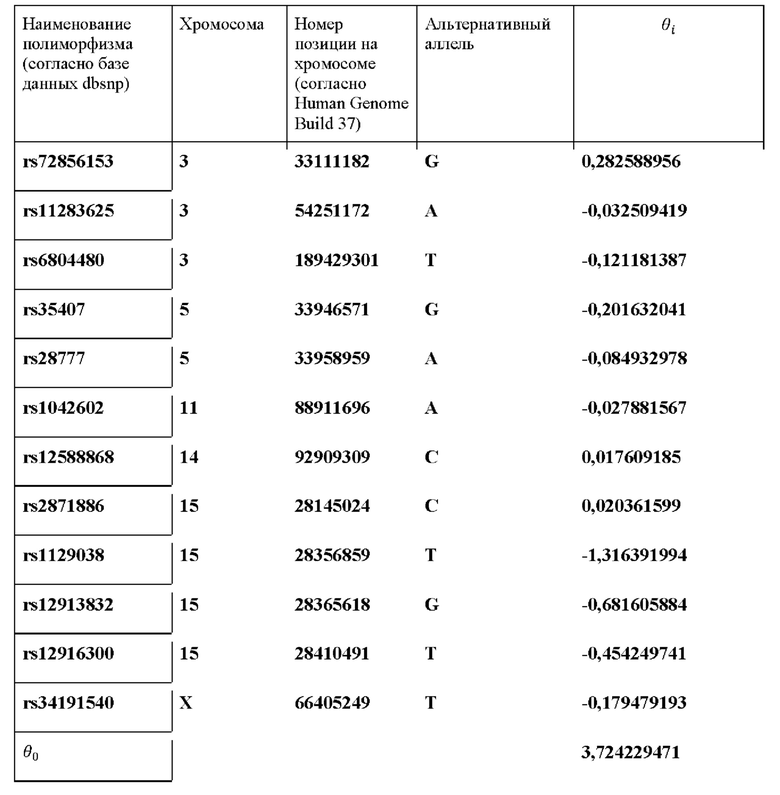
Таблица 2. Наименования и локализация в геноме однонуклеотидных
полиморфизмов для определения вероятности цвета глаз.

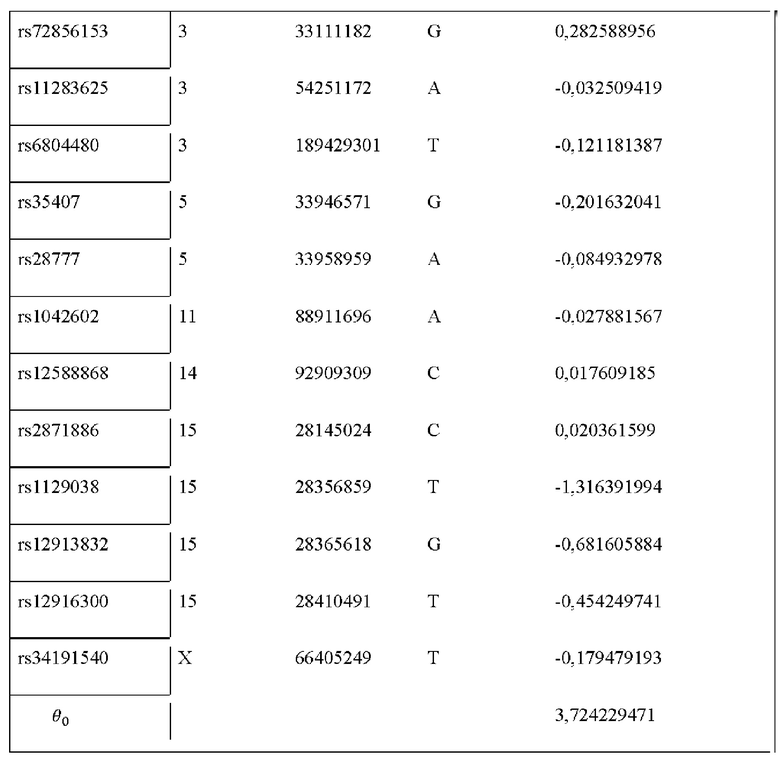
Также изобретение относится к панели для определения вероятности цвета глаз индивидуума, происходящего из популяций России, включающей в себя следующие однонуклеотидные полиморфизмы:
rs72856153, rs11283625, rs6804480, rs35407, rs28777, rs1042602, rs12588868, rs2871886, rs1129038, rs12913832, rs12916300, rs34191540,
где указанные однонуклеотидные полиморфизмы определяют в образце ДНК, полученном от индивидуума.
Задачей изобретения является разработка нового способа определения цвета глаз индивида по его ДНК на основе данных о российских популяциях.
Достигаемым техническим результатом является возможность определения вероятности цвета глаз индивида за счет оценки комплекса генетических данных по геномным сайтам, тесно ассоциированным с признаками пигментации глаз, верифицированным для населения генетически различающихся регионов России.
Техническая проблема, решаемая настоящим изобретением, заключается в расширении арсенала технических средств, которые используют для определения вероятности цвета глаз индивидуума.
Таким образом, изобретение состоит в обнаружении генетических полиморфизмов (маркеров), тесно ассоциированных с пигментацией радужной оболочки глаз человека, формировании панели (набора) таким маркеров, совместное использование которых позволяет определить цвет глаз с высокой вероятностью, и разработка метода определения цвета глаз по генотипам, определенным по данной панели маркеров, причем данная панель и метод разработаны на основе изучения российских популяций и оптимизированы.
Для разработки изобретения были проведены следующие работы:
Этап 1: Выбор популяций для исследования (из числа народов России и сопредельных стран)
Этап 2: Формирование коллекций образцов ДНК
Этап 3: Фенотипирование образцов
Этап 4: Выбор кандидатных генов и таргетное секвенирование
Этап 5: Идентификация потенциально высокоинформативных маркеров
Этап 6: Генотипирование подтверждающей выборки по панели потенциально высокоинформативных маркеров
Этап 7: Построение финальной версии предиктора
Ниже описаны каждый из этих этапов, после этого следуют примеры применения предиктора и описание его валидации.
Этап 1: Выбор популяций для исследования
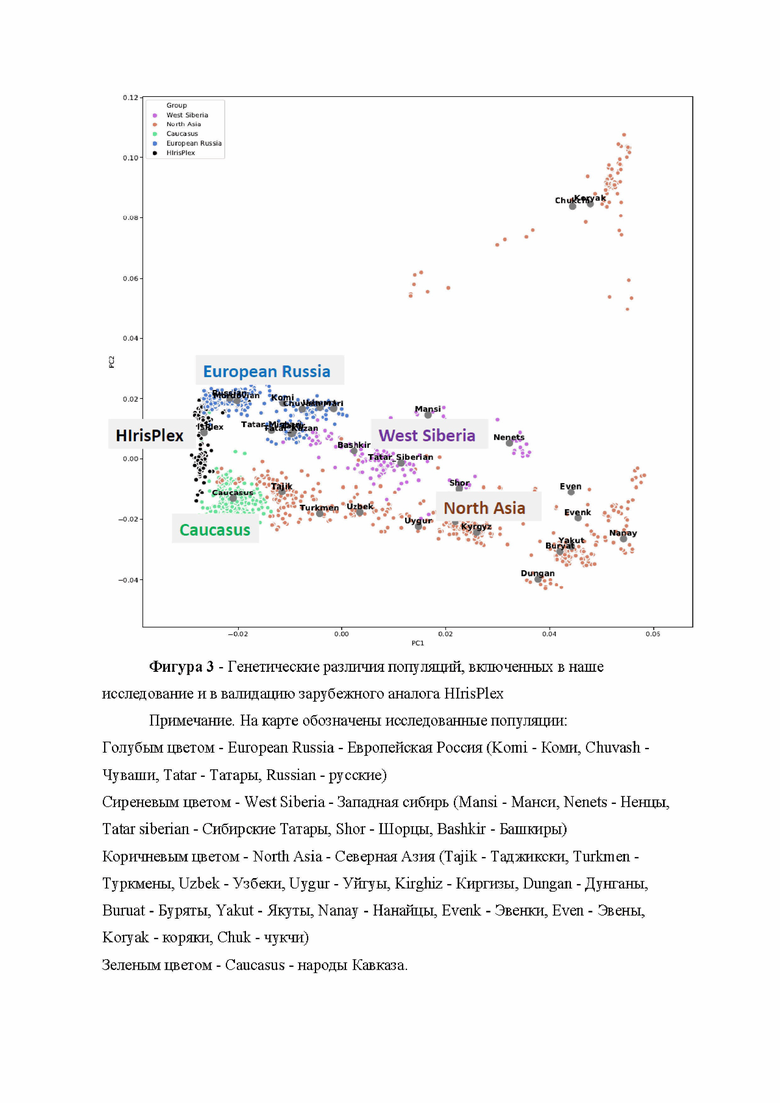
Поскольку основной зарубежный аналог был валидирован только на популяциях Зарубежной Европы, для построения независимого предиктора, ориентированного на использование применительно к населению России и сопредельных стран, было необходимо изучить представителей различных, генетически различных групп населения. Анализ опубликованных широкогеномных исследований народонаселения России СНГ [Triska et al., 2019; Jeong et al., 2019] указал на наличие четырех основных генетически контрастных метапопуляций: Европейская Россия, Кавказ, Сибирь (и центральная Азия), а также группы населения, промежуточные между типично европейскими и типично азиатскими, сосредоточенные в основной в Западной и Южной Сибири. Поэтому в наше исследование были включены популяции четырех регионов: Европейская Россия, Западная Сибирь, Кавказ и Северная Азия. Каждый из регионов представлен не одной, а несколькими популяциями. Карта расположения изученных популяций и их перечень приведены на фигуре 2.
Чтобы оценить степень генетической гетерогенности изученных популяций, был проведен анализ главных компонент изменчивости по широкогеномным данным, доступным для этих популяций (первичные данные были взяты из базы данных gg-base.org). Результирующий график представлен в фигуре 3. Из графика следует, что изученные популяции четырех регионов значительно генетически различаются, поэтому могут обладать различающимися спектрами аллелей, определяющих пигментацию радужной оболочки глаз. Поэтому идентификацию таких аллелей генетических маркеров целесообразно провести не только на общей выборке, но и на четырех подвыборках, по одной из каждого региона (см. описание Этапа 6).
График (фигура 3) также указывает, что популяции, включенные в валидацию зарубежного набора (голландцы, поляки, ирландцы, греки - Dutch, Polish, Irish, and Greek) занимают узкую зону на графике (генетически схожи друг с другом), тогда как большинство популяций России сопредельных стран характеризуются значительно отличающимися генофондами. Таким образом, произведенный на Этапе 1 выбор изучаемых популяций соответствует цели исследования - анализ основных групп народонаселения России сопредельных стран, в том числе значительно генетически отличных от популяций, на которых разработан и валидирован имеющийся зарубежный аналог.
Этап 2: Формирование коллекций образцов ДНК и антропологических фотографий
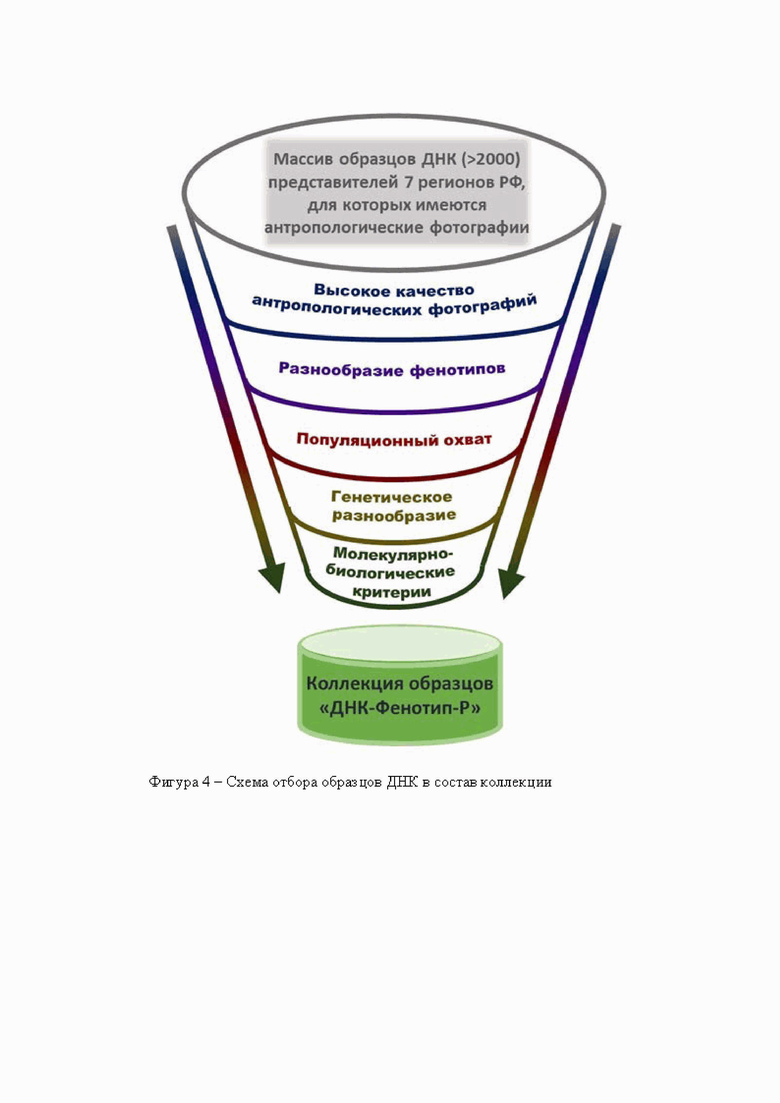
Для исследования ассоциаций генетических маркеров с фенотипом (цветом глаз) необходима коллекция образцов ДНК от индивидов, для каждого из которых имеется также качественная антропологическая фотография, позволяющая провести определение цвета глаз (фенотипирование). Поэтому задача второго этапа состояла в формировании коллекции образцов ДНК и коллекции антропологических фотографий для тех же индивидуумов. Глубина проработки параметров коллекции «ДНК-Фенотип-Р» обоснована ценностью генотипирования- дорогостоящего генетического анализа методом массового параллельного секвенирования для всех образцов данной коллекции. Поэтому подходы к формированию коллекции «ДНК-Фенотип-Р» должны были охватить весь возможный спектр характеристик, влияющих на репрезентативность коллекции «ДНК-Фенотип-Р», ее генетического и фенотипического разнообразия.
А) Формирование базы антропологических фотографий.
Первичный сбор антропологического материала происходил во время экспедиционных обследований коренного народонаселения различных регионов России (популяции указаны в фигуре 2). При этом соблюдались следующие критерии включения в выборку:
1) правило «трех поколений»: из каждой популяции выбираются образцы индивидов, соответствующих международному правилу «трех поколений» - в выборку включаются только те люди, у которых и оба его родителя, и все четверо его бабушек и дедов (т.е. до третьего поколения) родились в данной популяции и все четверо относили себя к данной этнической (или субэтнической) группе;
2) генеалогическая анкета: для подтверждения соблюдения правила «трех поколений» каждый образец ДНК сопровождается генеалогической анкетой (родословной), в которой указываются только места рождения и этническая принадлежность обследуемого индивида и его предков, но ни для кого из них не указываются никакие имена и адреса; поэтому генеалогическая анкета не содержит конфиденциальную информацию (фактически анонимна) и потому может быть доступна всем исследователям;
3) неродственность индивидов: из каждой популяции выбираются образцы индивидов, не состоящие в родстве как минимум до третьего колена;
4) информированное согласие: каждый образец ДНК сопровождается обязательным письменным информированным согласием, соответствующим стандартным требованиям информированности и конфиденциальности, на предоставление биологического образца для популяционно-генетических исследований, на хранение ДНК и индивидуальной информации, одобренное Этической комиссией, под контролем которой проводилось экспедиционное обследование индивидов.
Каждый участник обследования заполнял генеалогическую анкету и письменное информированное согласие на участие в данном исследовании, одобренное Этическим комитетом. Участнику присваивался стандартный индивидуальный код, содержащий условную буквенную аббревиатуру и цифровой номер. Далее производилось фотографирование анкеты участника, на которой виден индивидуальный код, делалась серия антропологических фотографий самого участника и завершалось я фотографированием кода, наклеенного на информированном согласии (ФИО участника является конфиденциальной информацией и не фотографируется). Такой алгоритм фотографирования исключает в дальнейшем ошибки сортировки файлов, поскольку в цепочке сохраненных файлов для многих участников позволяет однозначно идентифицировать, какая фотография относится к участнику с каким кодом.
Непосредственно после фотографирования квалифицированным медицинским персоналом производился забор крови (в стерильные вакууумные пробирки с антикоагулянтов ЭДТА, оптимизированные для последующего выделения ДНК из крови). По завершению экспедиционного выезда фотоматериал переносился с фотоаппарата в отдельное хранилище на сервере для дальнейшей обработки. Существенно, что фотоматериал не содержал никакой персональной информации. Из собранных образцов крови производилось выделение ДНК методом фенол-хлороформной экстракции, измерение качества и количества ДНК (спектрофотометрически и флюорометрически).
Работа с фотографиями произведена только с копией исходного материала, а папка с исходными фотографиями в неизменном виде хранится в хранилище (на сервере) с ограничением доступа.
Б) Формирование коллекции образцов ДНК.
Эта работа проведена согласно логике, представленной на схеме (фигура 4), и включала в себя следующие этапы:
- фильтр №1; отбор образцов ДНК индивидов, для которых имеются в наличии высококачественные антропологические фотографии, которые позволяют фенотипировать цвет глаз;
- фильтр №2; отбор образцов ДНК, прошедших фильтр №1, по критерию максимального фенотипического разнообразия цвета глаз (наличие различных оттенков, в том числе представленность редких вариантов у максимально возможного числа образцов, необходимых для включения всей возможной палитры фенотипов цвета глаз;
- фильтр №3; отбор образцов ДНК из числа прошедших фильтры №1 и №2, но теперь с учетом популяционного охвата (включение представителей не только высоких уровней популяционной иерархии - региональных генофондов, но также этнических, субэтнических групп), а также контроль максимально возможной равномерной представленности популяций на каждом уровне иерархии;
- фильтр №4; отбор образцов ДНК, из числа прошедших фильтры №1, №2, №3, по критерию максимального генетического разнообразия (на основе данных о маркерах Y-хромосомы);
- фильтр №5; отбор образцов ДНК, из числа прошедших фильтры №1, №2, №3, №4, по молекулярно-биологическим критериям (качество, количество и концентрация ДНК).
На последнем фильтре необходимо остановиться подробнее для описания процедуры отбора высококачественных образцов ДНК.
Качественные и количественные характеристики образцов ДНК играют первоочередное значение для корректного и высококачественного отбора подходящих для таргетного секвенирования проб и позволяют в дальнейшем в дальнейшем избежать как технических проблем при проведении массового параллельного секвенирования, так и понижают вероятность появления ошибок при проведении биоинформационного анализа результатов исследований.
Для качественной и количественной оценки образцов ДНК наиболее эффективной является многоуровневая система, учитывающая результаты спектрофотометрических и флуориметрических измерений, а также оценку степени деградации ДНК, проводимую с помощью электрофореза в агарозном геле.
Измерения с помощью спектрофотометра позволяют оценить чистоту ДНК выделенных образцов. При измерении анализируют интенсивность поглощения образцов в целом спектре частот; наиболее используемыми являются показатели интенсивности поглощения на частотах 230 нм, 260 нм и 280 нм. Наиболее информативным являются соотношения 260/280 и 260/230, позволяющие оценить примеси белка, а также органических растворителей. Не рекомендуется в дальнейшую работу брать образцы ДНК с соотношением поглощаемых волн 260/280<1.8 или 260/230>2.3. Спектрофотометр оценивает общую концентрацию НК, не разделяя ДНК и РНК. Одним из наиболее часто используемых спектрофотометров являются спектрофотометры серии Nanodrop, например, Nanodrop 2000С. Необходимо также иметь ввиду, что метод выделения ДНК может оказывать влияние на количественные характеристики; так при фенол-хлороформном выделении необходимо тщательно следить за содержанием фенола в пробе, поскольку примеси фенола могут значительно завысить измеренные значения концентрации ДНК. Кроме этого, наличие органических примесей может приводить к ингибированию полимеразно-цепной реакции.
Для оценки качества и степени деградированности выделенной ДНК используют агарозный (т.н. «горизонтальный») электрофорез образцов выделенной ДНК. Данный метод является оптимальным, совмещая простоту, экономичность и информативность. Высококачественные образцы имеют наименьшую степень деградации ДНК. Такие образцы содержат ДНК-фрагменты размером преимущественно свыше 20-40 тысяч пар нуклеотидных оснований. Необходимость наличия высокомолекулярной фракции ДНК обуславливается следующими причинами: (1) сильная фрагментация ДНК приводит к невозможности «посадки» праймеров с ДНК-фрагментами, что усложняет отбор нужных областей генома; (2) при приготовлении библиотек для таргетного секвенирования фрагментация приводит к затруднению гибридизации олигонуклеотидных зондов, за счет чего может существенно ограничиться необходимая полнота исследования. Высококачественные образцы имеют четко выраженные яркие полосы в области высоких концентраций, что свидетельствует о предпочтительном содержании качественной ДНК. В случае сильно фрагментированной ДНК результаты фореза выглядят как так называемый «шмер», который визуализирует наличие фрагментов разных концентраций. На качество проведения ДНК могут оказать влияние концентрация агарозного геля и напряжение проведения электрофореза. Для контроля длин фрагментов используют молекулярные лэддеры, - маркеры длин ДНК-стандарте в (фрагментов ДНК определенного размера).
Наиболее точное и быстрое измерение концентрации исследуемой двухцепочечной ДНК может быть обеспечено флуориметрическими методами измерения с использованием флуоресцентных зондов (измерения с помощью ПЦР в реальном времени еще более точны, однако они существенно дороже и более продолжительны по времени). При проведении флуориметрического измерения концентрации есть несколько особенностей. Для проведения максимально быстрых измерений и получения наиболее точных результатов измерений рекомендуется хранить краситель и буфер при комнатной температуре, но при долговременном хранении возможно использование холодильника и морозильника. Вне зависимости от условий хранения, перед началом измерений необходимо выдержать все реагенты и образцы при комнатной температуре до достижения ими комнатной температуры, а все используемые реактивы и образцы ДНК перед использованием необходимо аккуратно перемешать. Необходимо иметь ввиду, что использование холодных реагентов может привести к завышению измеренных концентраций по сравнению с действительными концентрациями.
Поскольку концентрация ДНК неизвестна, а для точного измерения концентрации рабочего раствора необходимо чтобы его концентрация находилась в диапазоне концентраций между двумя рабочими растворами, то оптимально для оценки примерной концентрации образца использовать спектрофотометр. При измерении с помощью флуориметра возможно использование как правило от 1 до 20 мкл образца. В случае низких начальных значений концентраций ДНК образца, при рекомендуется первоначально использовать 5 мкл образца, в остальных случаях допустимо использование 1-2 мкл. При возникновении затруднений следует индивидуально подбирать вносимый объем образца.
Нагревание влияет на измеренные значения концентрации ДНК, поэтому при необходимости проведения двух и более измерений одного образца необходимо извлечь пробирку из прибора для охлаждения пробирки и выдержать ее в штативе при комнатной температуре в течение как минимум 30 секунд и повторить измерение. Также, для предотвращения нагревания пробирки теплом рук необходимо минимизировать время нахождения пробирки в руках или осуществлять перенос пробирок с помощью пинцета.
Предварительную нормализацию (приведения образцов к единой концентрации) отобранных образцов используют для создания растворов примерно равной концентрации. Нормализацию проводят только по результатам флуориметрического измерения концентрации (на это надо обращать особое внимание, так как использование спектрофотометрических методов приводит к неправильным результатам).
Вышеприведенная трехэтапная оценка качества и концентрации образцов ДНК после выделения ДНК позволила получить ДНК пробы максимально хорошего качества, подходящие как для формирования коллекций ДНК образцов, так и позволяет пустить в дальнейшую работу только те образцы, которые отвечают установленным требованиям к образцам для успешного проведения дальнейших исследований (например, генотипирования и секвенирования).
В целом, результатом представленного выше пятиэтапного алгоритма фильтрации стала коллекция включающая 500 образцов ДНК, сопровождающихся антропологическими фотографиями и представляющая 7 региональных генофондов, с оптимальными параметрами качества, количества и концентрации сформированных аликвот ДНК.
Этап 3: Фенотипирование
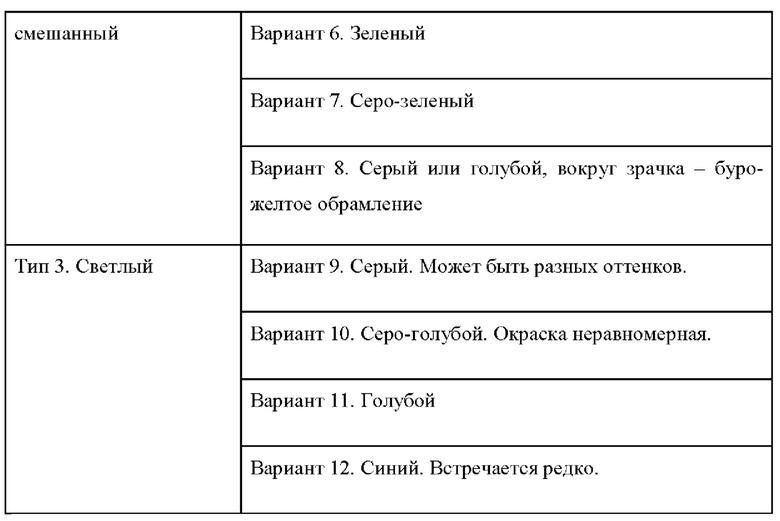
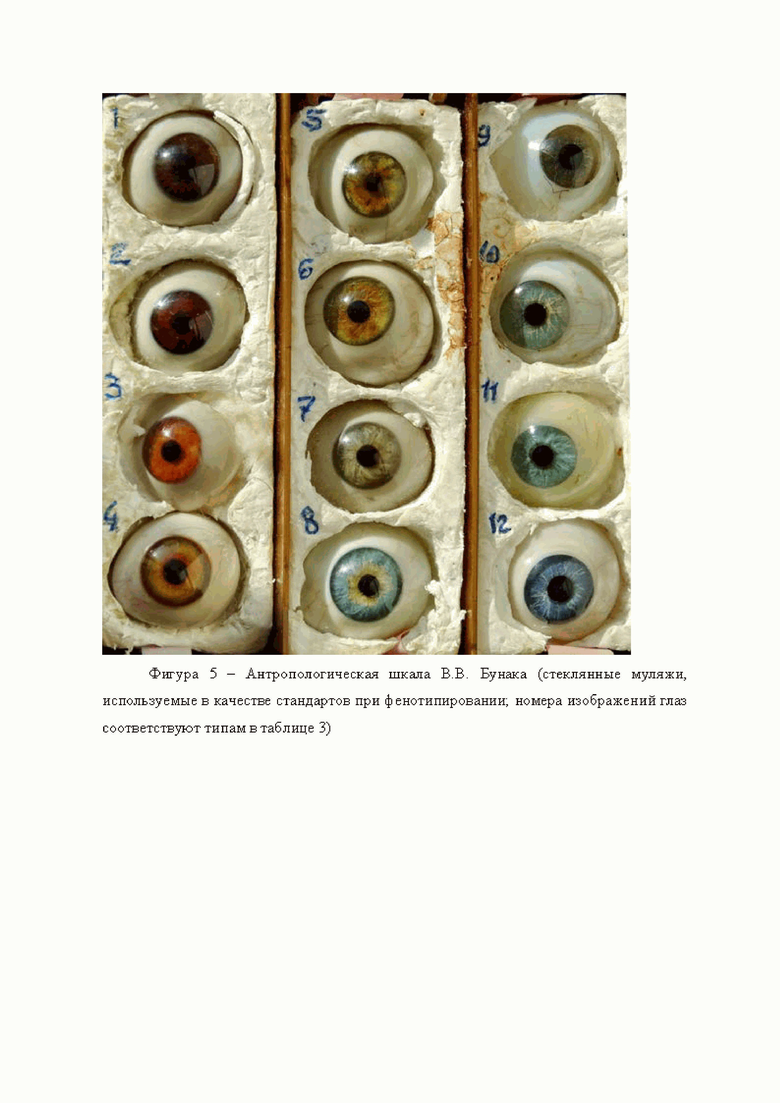
Поскольку изменчивость цвета глаз представляет собой сложный ряд количественных изменений нескольких параметров, то в антропологии существует целый ряд классификации цвета радужной оболочки глаз: признак обычно анализируется путем размещения цвета глаз в отдельные категории или классы по фотографиям радужной оболочки глаза. Классификация цвета глаз по шкале В.В. Бунака приведена в соответствии с таблицей 3 и фигурой 5, где номера изображений глаз соответствуют типам в таблице 3.

Фенотипирование цвета глаз проводится в два этапа.
На первом этапе определяется пригодность фотографий по пятибальной шкале для детального фенотипирования. Важным на данном этапе является наличие серии успешно выполненных антропологических фотографий, сделанных с разных ракурсов. Образцы с высокими баллами (5, для популяций где необходимо увеличить выборку - 5 и 4) поступают в анализ второго этапа.
На втором этапе, с помощью специальной шкалы проводится детальное фенотипирование цвета глаз и выставляется балл (например, балл 2, которому соответствует цвету глаз - темно-карие), который соответствует тому или иному типу. Самым трудным считается определение смешанного (переходного) типа, поскольку блики на фотографиях могут искажать цвет, а значит и результаты могут быть не точными.
Ниже приведены конкретные примеры каждого из цветов глаз, встреченные в процессе фенотипирования.
Тип 1 - «Темный»
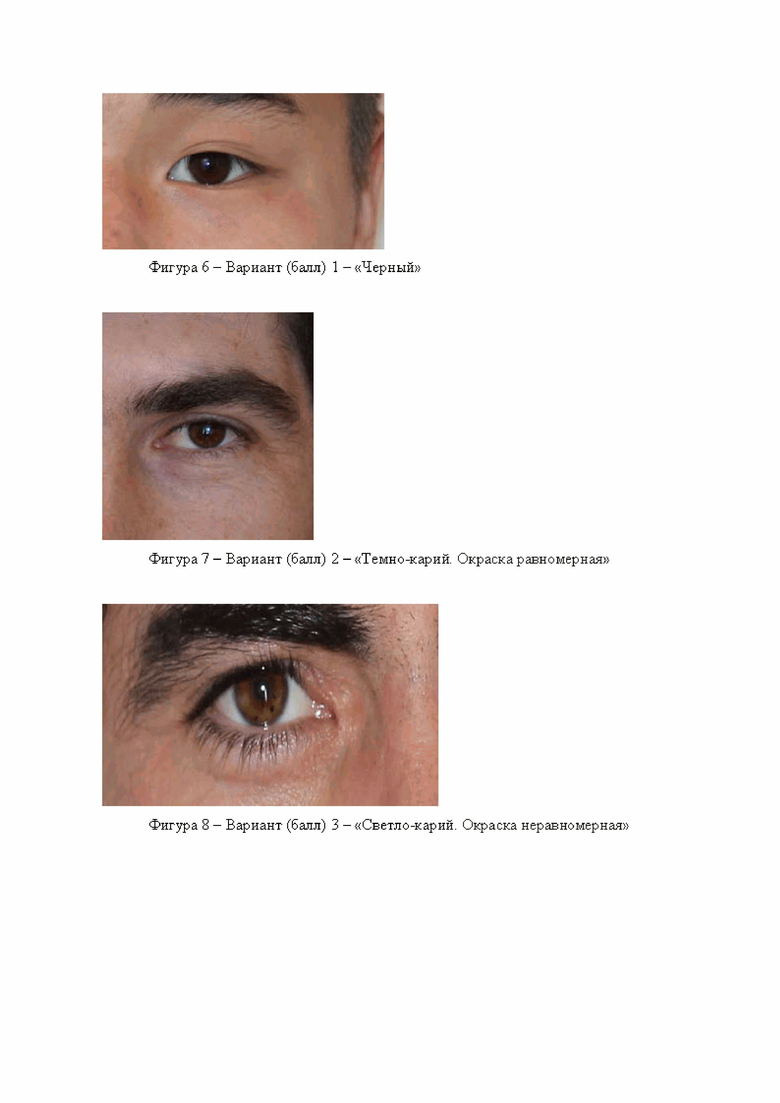
Самые распространенные варианты по шкале Бунака - варианты 2 и 3 - темно-карие и светло-карие соответственно. Вариант 1 «Черный» встречается реже, а самый редкий вариант 4 «Желтый». Примеры данных вариантов приведены на фигурах 6, 7, 8, 9.
Тип 2 - «Переходный, смешанный»
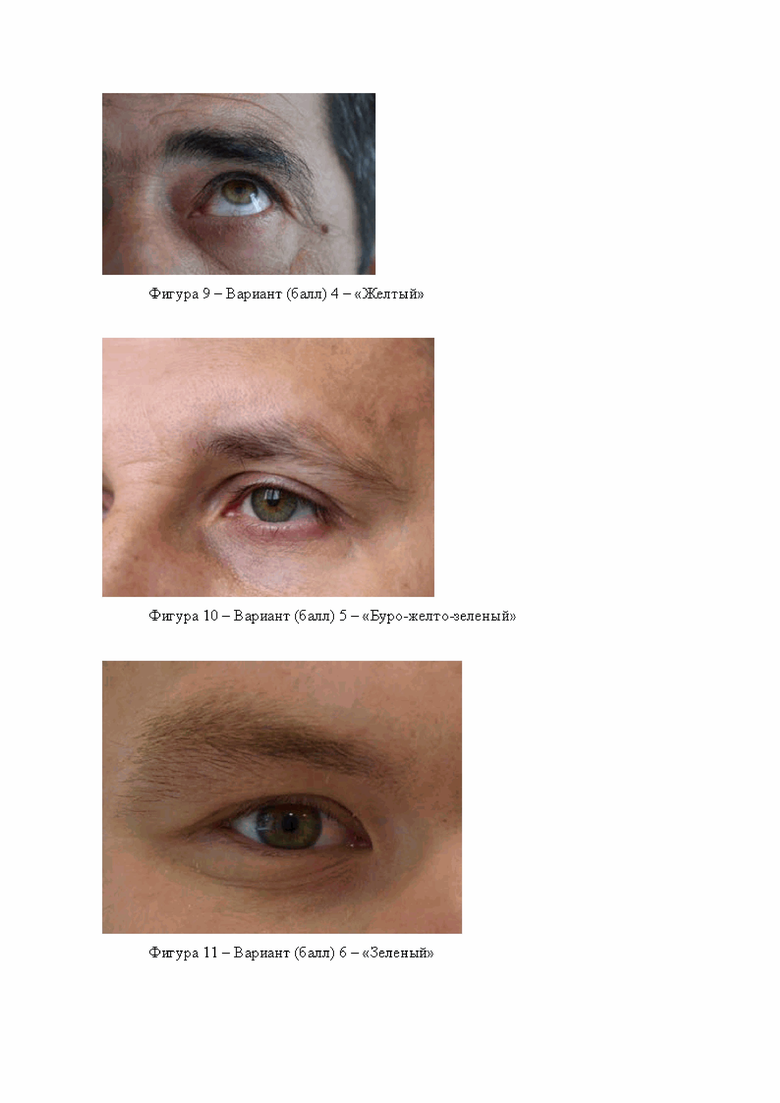
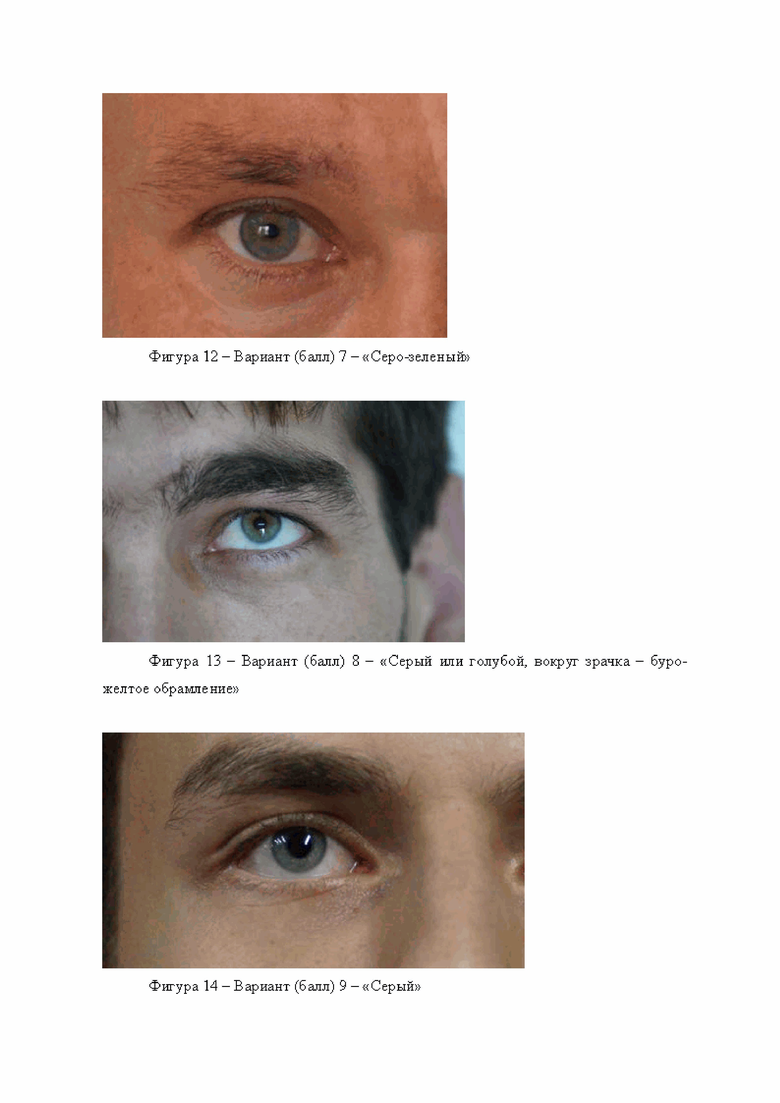
Включает себя вариант 5 - буро-желто-зеленый, вариант 6 - зеленый, вариант 7 серо-зеленый, вариант 8 серый или голубой, вокруг зрачка буро-желтое обрамление. Примеры данных вариантов приведены на фигурах 10, 11, 12, 13.
Тип 3 - «Светлый»
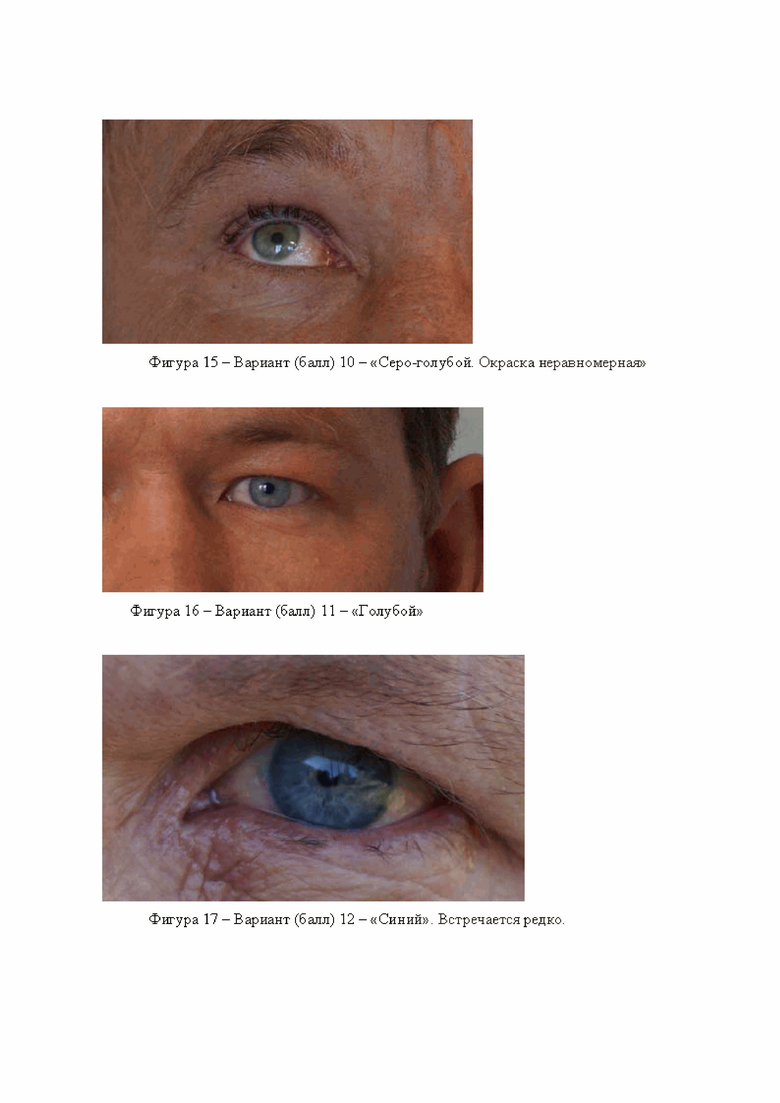
Включает себя вариант 9 серый, вариант 10 серо-голубой, окраска неравномерная, вариант 11 голубой, вариант 12 синий, последний вариант встречается редко. Примеры данных вариантов приведены на фигурах 14, 15, 16, 17.
Как указывалось, для практических целей применения в криминалистике оптимальным является использование только двух основных градаций - светлые и темные глаза. Поэтому в дальнейшем производилась группировка различных оттенков глаз в три группы - светлые, темные и промежуточные (смешанные).
Такое фенотипирование было проведено независимо тремя экспертами. Двое из них являлись дипломированными специалистами - физическими антропологами Института антропологии МГУ, имеющими большой опыт в фенотипировании цвета глаз. Третий эксперт являлся генетиком, специально обученным антропологическому фотографированию и фенотипирования, данный эксперт определял цвет глаз только по трехбалльной шкале (светлые, темные, промежуточные).
Независимое фенотипирование тремя экспертами и доступность фотографий для перепроверки обеспечивает надежность и воспроизводимость результатов фенотипирования.
Этап 4: Выбор кандидатных генов и таргетное секвенирование
Для поиска генетических маркеров, ассоциированных с признаком цвета глаз, было применен подход кандидатных генов. Список генов был достаточно большим для включения всех вариантов, которые по результатам всех накопленных в мировой науке данных могут быть в той или иной степени связаны с генетическим контролем пигментации глаз. Список генов и межгенных областей, которые потенциально могут содержать полиморфизмы, ассоциированные с цветом глаз, был сформирован на основе тщательного анализа мировой научной литературы, и включил гены, выявленные в следующих двенадцати исследованиях, преимущественно GWAS, в т.ч. каталог на сайте https://www.ebi.ac.uk/gwas/ [Kayser et al., 2008; Eiberg et al., 2008; Mengel-From et al., 2010; Jacobs et al., 2015; Kenny et al., 2012; Sochtig et al., 2015; Soejima et al., 2007; Sulem et al., 2007, 2008; Branicki et al., 2008; Duffy et al., 2007; Dimisianos et al., 2009]
Существенно, что в число кандидатных регионов были включены не только экзоны, но и интроны важнейших генов, таких как HERC2 и CACNA2D3.
Для анализа выбранных геномных регионов было использовано не генотипирование, а секвенирование. Это позволяет анализировать не только полиморфизмы, которые ранее были описаны в научной литературе, но и обнаружить новые полиморфные сайты и аллели, характерные для российских популяций. Для этого была разработана панель таргетного секвенирования, включившая 53 геномных региона.
Секвенирование сформированной таргетной панели включило несколько технических шагов.
На первом шаге была проведена подготовка и предварительная амплификация фрагментных библиотек геномной ДНК человека. Эту подготовку фрагментных библиотек геномной ДНК человека проводили с использованием набора КАРА Hyper Prep Kit и набора индексированных адаптеров SeqCap Adapter Kit А. Сочетания индексов для библиотек в одном запуске прибора и реакции гибридизации выбирали согласно рекомендациям производителя Illumina (TruSeq Library Prep Pooling Guide). После проведения реакции амплификации количество ДНК геномных библиотек в растворе определяли с помощью флуориметра Qubit 2.0 (bivitrogen) с использованием набора Quant-iT dsDNA HS Assay Kit согласно рекомендациям производителя. Качество готовых экзомных библиотек оценивали с помощью микрофлюидного анализатора BioAnalyzer 2100 (Agilent) с использованием набора Agilent DNA High Sensitivity Kit согласно инструкциям производителя. В результате было получено 284 фрагментные библиотеки. Далее готовили объединенные пулы библиотек для последующего экзомного обогащения. Библиотеки смешивали в равных пропорциях в соответствии с полученными ранее концентрациями так, чтобы получить суммарно 1,25 мкг ДНК в каждом из пулированных образцов.
На втором шаге проводили экзомное обогащение фрагментных библиотек геномной ДНК человека с использованием набора SeqCap HE-Oligo Kit (Roche Sequencing, США)
На третьем шаге проводили секвенирование обогащенных экзомных библиотек методом массового параллельного секвенирования. Секвенирование готовых пулов библиотек осуществляли с использованием генетического анализатора HiSeq 2500 и станции cBot 2 (Illumina) с использованием набора расходных материалов HiSeq SBS Kit v4 (Illumina) согласно рекомендациям производителя. В результате были получены сырые данные секвенирования для 174 обогащенных экзомных (таргетных) библиотек методом массового параллельного секвенирования. При первичной оценке качества секвенирования использовали данные, предоставляемые самим секвенатором HiSeq 2500 в процессе запуска. Основными показателями являлись суммарный выход прочитанных нуклеотидов, доля верифицированных ошибок секвенирования и доля достоверно прочитанных нуклеотидов.
На четвертом шаге проводили первичный биоинформационный анализ результатов секвенирования всех 300 образцов, включая удаление адаптеров и дупликатов, картирование на геном и коллинг.Этот анализ включал следующие элементы:
- Демультиплексирование *.bcl файлов и формирование из них *.fastq.
- Проведение контроля качества входных данных (утилита fastqc).
- Удаление адаптерных и прочих артефактных последовательностей.
- Удаление дубликатов.
- Выравнивание на референс (hg19) программным пакетом BWA.
- Проведение контроля качества выравнивания (утилита NGSRich).
- Формирование списка состояний (*.gvcf) программным пакетом Samtools.
- Выделение отличий от референса в отдельный файл формата *.vcf.
Так как использованная панель является кастомной, то для получения максимально полного набора генетических данных с ее использованием потребовалось провести дополнительный подбор фильтров в каждом из программных пакетов.
Результатов явилось выявление более ста тысяч полиморфных сайтов (117,012 SNPs) в исследуемом наборе из 53 генов и межгенных участков у 300 образцов, для каждого из которых имелись также определенные фенотипы цвета глаз. Последующие этапы (за исключением анализа тестовой выборки, включившей другие 200 обрзцов) проводились именно с этим массивов данных.
Этап 5: Идентификация потенциально высокоинформативных маркеров
Данные фенотипированных образцов содержали образцы из 48 популяций России и сопредельных стран и включали в себя данные секвенирования генов, ассоциированных с пигментацией, и соответствующих межгенных регионов, а не только ранее известные аллели. Для определения вероятного цвета глаз были исключены популяции, которые были единообразны по цвету глаз, что позволило достичь лучшего баланса между различными фенотипическими классами. Были извлечены данные о 117012 маркерах в 53 генах и межгенных регионах.
Отбор признаков для поиска новых аллелей, информативных для определения вероятности цвета глаз, был проведен на 4 наборах данных:
1. Полный набор образцов Северной Евразии
2. Европейская часть России
3. Кавказ
4. Западная Сибирь
Каждый набор данных был разделен в соотношении 60:40 на обучающую и тестовую выборки с использованием К-кратного кросс-валидатора, который сохраняет процентное соотношение образцов в каждом классе. Для полного набора данных было соблюдено, чтобы образцы из разных регионов, включенные в полный датасет были поделены в той же пропорции (60:40), чтобы избежать искажения результатов в связи с неравномерным распределением образцов по регионам. Методы отбора признаков были проведены на обучающей выборке, а показатели качества прогноза для отобранных маркеров были рассчитаны с использованием тестовой выборки. Минимальный набор маркеров с наибольшей предсказательной силой был определен в тестовом наборе данных, и на основе этих финальных отобранных маркеров был построен классификатор. Для оценки качества модели были подсчитаны такие метрики качества, как R2 (коэффициент детерминации), ROC-AUC, precision (точность), recall (полнота), accuracy (доля правильных ответов) с помощью библиотеки Scikit-learn для языка программирования Python 3.
Отбор признаков был проведен для полного датасета и для каждого региона отдельно на обучающей выборке с использованием трех алгоритмов:
1. f-регрессия - линейная модель для тестирования индивидуального эффекта каждого из множества регрессоров
Алгоритм был осуществлен в 2 этапа:
1) была вычислена корреляция между каждым регрессором и целью
2) затем она преобразуется в параметр F, а затем в значение p-value
Были выбраны только признаки, для которых значение р<0,01, а затем маркеры были отсортированы в порядке убывания значения F. Признаки, имеющие наивысшие значения F, рассматривались как потенциально наиболее информативные.
2. mutual_info_regression (взаимная инфо-регрессия) - оценивает взаимную информацию (MI) для непрерывной переменной. Взаимная информация между двумя случайными величинами - это неотрицательный параметр, который измеряет зависимость между переменными. Он равен нулю, только когда две случайные величины независимы, более высокие значения означают более высокую зависимость.
3. метод отбора признаков Lasso с разными значениями параметра альфа (0.7, 0.5, 0.2, 0.1, 0.05, 0.01, 0.005, 0.001, 0.0005). Модели, в которых применяется регуляризация по норме L1, имеют много нулевых коэффициентов при признаках. Лассо - метод отбора признаков, основанный на обучении регрессии с L1-регуляризацией и выборе признаков, имеющих ненулевые коэффициенты в такой модели. Параметр альфа контролирует разреженность: чем выше параметр альфа, тем меньше признаков выбирается. Были протестированы значения альфа: 0,7, 0,5, 0,2, 0,1, 0,05, 0,01, 0,005, 0,001, 0,0005. Лучшие характеристики были найдены с использованием самых больших значений альфа: 0,7, 0,5 и 0,2. Для каждого значения альфа было вычислено значение параметра R2 для обучающей выборки на соответствующем подмножестве маркеров, имеющих ненулевые коэффициенты. Среди этих подмножеств были выбраны наиболее значимые в соответствии с полученными значениями R2 для каждого набора данных в отдельности.
Из всей совокупности анализируемых маркеров по каждому критерию были отобраны лучшие маркеры, т.е. наиболее значительно ассоциированные с цветом глаз.
Для объединенной выборки по всем регионам этот отбор был проведен отдельно по каждому критерию с использованием следующих пороговых значений:
1)10 лучших маркеров с наивысшими значениями F для f_regression
2) 10 лучших маркеров с наивысшими значениями MI для mutial_info_regression
3) маркеры с ненулевыми коэффициентами для модели Lasso с значениями альфа 0,5 и 0,2 и маркеры с коэффициентами по модулю больше или равными 0,1 для модели Lasso с альфа равным 0,005
Для выборок по отдельным регионам был проведен аналогичный отбор лучших признаков со следующими пороговыми значениями:
1) 6 лучших маркеров с наивысшими значениями F для f_regression
2) 6 лучших SNP с наивысшими значениями MI для mutial_info_regression
3) маркеры с ненулевыми коэффициентами для модели Lasso с значениями альфа 0,7 и 0,5.
На последнем этапе отбора маркеров были сопоставлены списки маркеров, выявленные при анализе каждого из четырех массивов данных (объединенного и трех региональных) и каждому маркеру был присвоен балл его значимости. Балл «3» был присвоен только маркерам, выявленным на объединенном массиве данных, которые или имели одно из 5 наивысших значений F, или имели коэффициенты по модулю не меньшие 0,1 в моделях Lasso при альфа 0,2 или имели ненулевые коэффициенты в моделях Lasso при альфа 0,5. Балл 2 был присвоен маркерам из объединенного массива данных, которые обладали одним из 10 наивысших значений F или MI или ненулевыми коэффициентами в моделях Lasso при альфа 0.2. Балл 1 был присвоен маркерам, имевшим коэффициенты не меньшие 0,1 в моделях Lasso при альфа 0.005. Всем остальным маркерам был присвоен балл 0.
Аналогичный анализ был проведен для региональных массивов данных, но им присваивались баллы не выше 2. Сравнение списков наилучших маркеров, выявленных в объединенном и региональных массивах данных выявило его стабильность - одни и те же 7 маркеров имели наивысшие баллы во всех видах анализа. В результате наилучшими были признаны эти 7 маркеров, а также все маркеры, имевшие ненулевые баллы, были включены в финальный список маркеров, высоко информативных для прогноза цвета глаз в популяциях России и сопредельных стран.
Этап 6: Генотипирование подтверждающей выборки по панели потенциально высокоинформативных маркеров
Панель потенциально высокоинформативных маркеров для прогноза цвета глаз включила маркеры, отобранные на предыдущем этапе как эффективные для прогноза цвета глаз для популяций России. Эта панель была дополнена 24 маркерами, эффективными для популяций зарубежной Европы (панель HIrisPlex). Суммарно панель включила 93 однонуклеотидных полиморфизмов (маркеров). Полученная объединенная панель была генотипирована на тестовой выборке.
Тестовая выборка необходима для определения истинной точности разработанной системы, поскольку показатели, на обучающей выборки могут являться завышенными из-за явления переобучения. Поэтому тестовая выборка включила 200 образцов ДНК индивидов, для которых, так же как и для обучающей выборки, было проведено фенотипирование цвета глаз, но ни один из этих образцов, не участвовал в исследованиях на предыдущих этапах.
Генотипирование всей панели из 93 высокоинформативных маркеров проведено с помощью кастомного (специально разработанного производителем по нашему заказу) биочипа Illumina. Каждый образец тестовой выборки был подготовлен в соответствии с техническими требованиями к ДНК для генотипирования биочипов Illumina (объем не менее 10 мкл с концентрацией ДНК не менее 30 нг/мкл.). Генотипирование образцов ДНК осуществляли с использованием Infinium iSelect-24 BeadChip Kit (Illumina, США) в соответствии с предварительно отработанным протоколом.
Генотипирование 79 маркеров прошло успешно (получены достоверные результаты для более чем 99% образцов), для 14 маркеров были получены менее качественные результаты генотипирования (такое соотношение является сравнительно удачным для кастомных биочипов), поэтому эти 14 маркеров были исключены из финального массива данных и дальнейшего анализа. Финальный массив данных, таким образом, включил 90 маркеров, генотипированных на 500 образцах, фенотипированных по цвету глаз. 300 из этих образцов вошли в обучающую и 200 образцов - в тестовую выборку.
Этап 7: Построение финальной версии предиктора
Построение финальной версии системы определения вероятности цвета глаз включала отбор наиболее информативных маркеров, оптимизацию математического алгоритма предикции (главным образом подбор веса для каждого маркера) и определение параметров чувствительности и специфичности разработанной системы.
Для определения чувствительности и специфичности использовалась тестовая выбора (200 образцов), из остальных образцов 70% вошло в собственно обучающую выборку, а 30% были выделены в валидирующую выборку, используемую для оптимизации параметров.
Для отбора ДНК-маркеров в итоговый реестр применялся метод на основе логистической регрессии с применением одновременно двух регуляризаций: L1 и L2. Необходимость применения регуляризации обусловлена проблемой переобучения, с которой сталкиваются модели на основе логистической регрессии при небольших размерах обучающих выборок. При переобучении в предсказывающей модели подбираются большие по значению коэффициенты для каждого маркера и предсказывающая модель начинает очень хорошо работать на обучающей выборке, однако начинает гораздо сильнее ошибаться на данных, на которых она не обучалась. Для этого в модели добавляют дополнительные члены, которые препятствуют сильному увеличению коэффициентов маркеров. Члены регуляризации можно добавлять в метрике L1 или метрике L2. При регуляризации по метрике L1 коэффициенты маркеров, не имеющих большого значение для предсказания, принимают значение 0, таким образом позволяя отбирать наиболее высокоинформативные маркеры. Метод, основанный на применении L1 регуляризации для отбора признаков также известен как метод «лассо». При регуляризации по метрике L2 коэффициенты для всех маркеров уменьшаются по модулю, но чем ближе они к 0, тем медленнее идет уменьшение, таким образом данная регуляризация не приводит их значения к нулю.
В данной модели существует три варьирующихся гиперпараметра: веса предсказываемых классов, коэффициент, обратный силе регуляризации и доля регуляризации L1. Изменение веса предсказываемых классов помогает сделать выборку более равномерной, придав больший вес при обучении модели классу, имеющему меньшее число образцов (в нашем случае - светлые глаза). Коэффициент, обратный силе регуляризации, регулирует силу, с которой дополнительные члены регуляризации уменьшают коэффициенты маркеров. При слишком большом его значении коэффициенты маркеров принимают большие значения и возникает переобучение. При слишком малом значении коэффициенты маркеров принимают слишком малые значение, либо вообще приравниваются к 0, в результате чего ухудшается предсказательная сила модели. Доля регуляризации L1 контролирует соотношение L1 и L2 регуляризаций, позволяя поддерживать баланс исключения маркеров и уменьшения коэффициентов маркеров, не приводящего к исключению маркера.
Модели обучались на обучающей выборке с перебором различных вариантов перечисленных трех гиперпараметров. Модель, обученная с каждым набором гиперпараметров, проходила тестирование на валидирующей выборке. Для этого модель предсказывала вероятности пигментации для всех образцов валидирующей выборки и рассчитывались оценки качества предсказания данной модели, а именно ROC AUC, чувствительность, специфичность и точность. Модель, показавшая наивысшие результаты по данным оценкам качества, признавалась лучшей. Таким образом были отобраны лучшие модели по каждому из трех признаков пигментации.
Наиболее высокоинформативными маркерами по конкретному признаку считались маркеры, коэффициенты которых оказались не равными нулю в лучшей предсказывающей этот признак модели. По каждому признаку был составлен список наиболее высокоинформативных маркеров.
Полученный список из 12 маркеров представлен в таблице 2, которая также содержит финальные веса признаков.
Примеры использования.
Пример применения 1: прогноз цвета глаз для представителей народов Кавказа.
Были изучены два индивидуума, обозначенные 1А и 1Б (см. табл. 4). Оба происходили из популяции адыгейцев. Генотипирование по панели генетических маркеров, указанных в таблице 2, дало следующие результаты (0 означает гомозиготный генотип по референсному аллелю, 1 - гетерозиготный генотип, 2 - гомозиготный генотип по альтернативному аллелю.
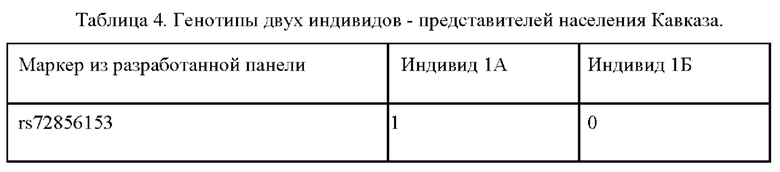
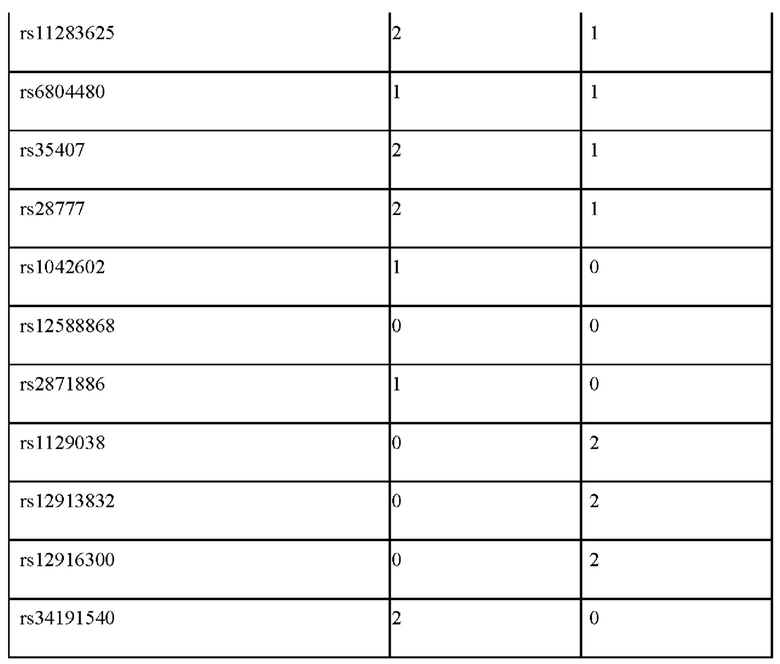
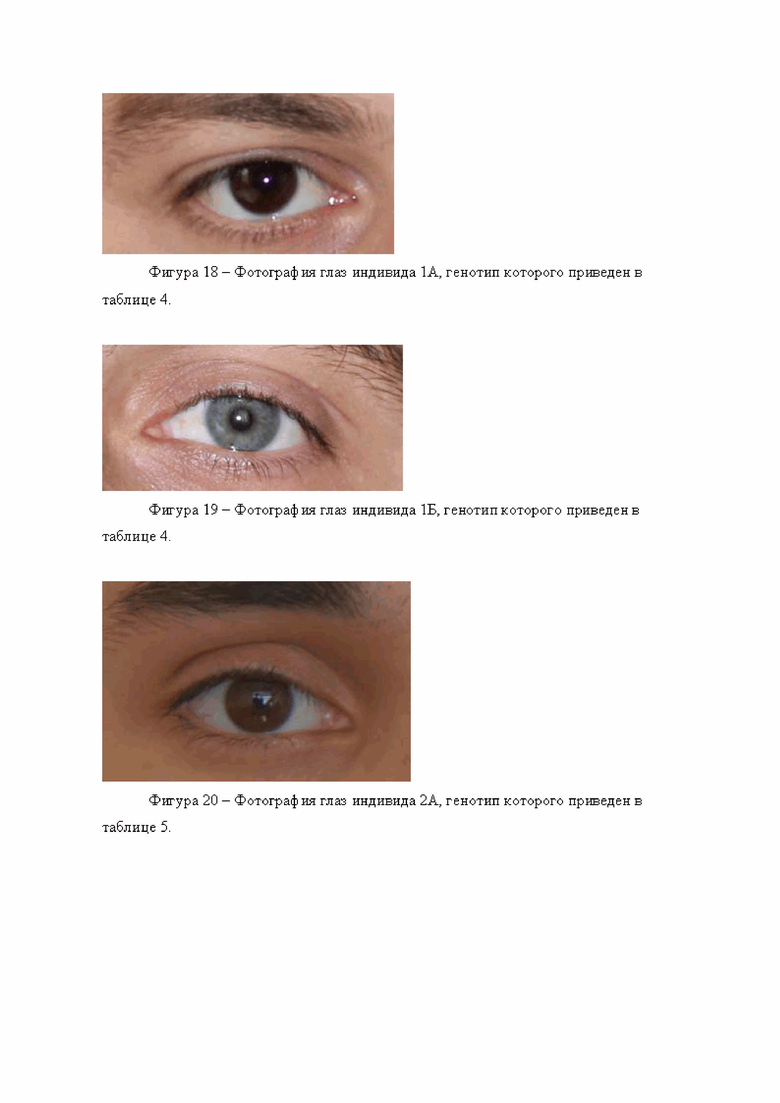
Обработка полученных генотипов индивидуума 1А согласно предложенному по изобретению способу, дает следующие значения вероятности:
р светлых глаз = 0,0531
р темных глаз = 0,9469
Согласно расчету, проведенному по предложенному способу, сделан прогноз о наличии у данного индивидуума темных глаз.
При верификации метода результат сопоставляли с фотографией глаз исследуемого индивидуума (фигура 18). Можно убедиться, что прогноз справедлив, его глаза действительно темные.
Для генотипа индивидуума 1Б получены следующие значения:
р светлых глаз = 0,834867
р темных глаз = 0,165133
Следует сделать прогноз о наличии у него светлых глаз. Прогноз соответствует действительности (фигура 19).
Таким образом, первый пример иллюстрирует, что разработанная система позволяет правильно прогнозировать цвет глаз для представителей народонаселения Западного Кавказа.
Пример применения 2: прогноз цвета глаз для представителей русского населения Центральной России.
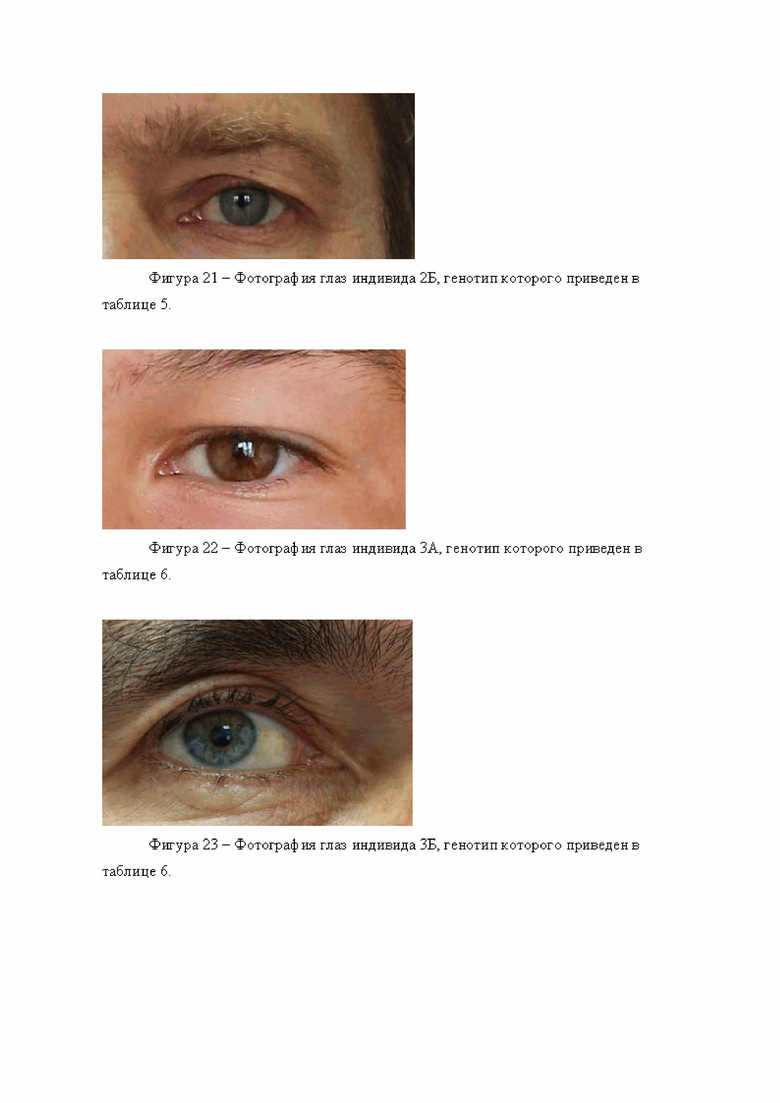
Были изучены два индивидуума, происходящих из русских популяций Нижегородской области, обозначенные 2А и 2Б (см. табл. 5). Генотипирование по панели генетических маркеров, указанных в таблице 2, дало следующие результаты (0 означает гомозиготный генотип по референсному аллелю, 1 - гетерозиготный генотип, 2 - гомозиготный генотип по альтернативному аллелю.
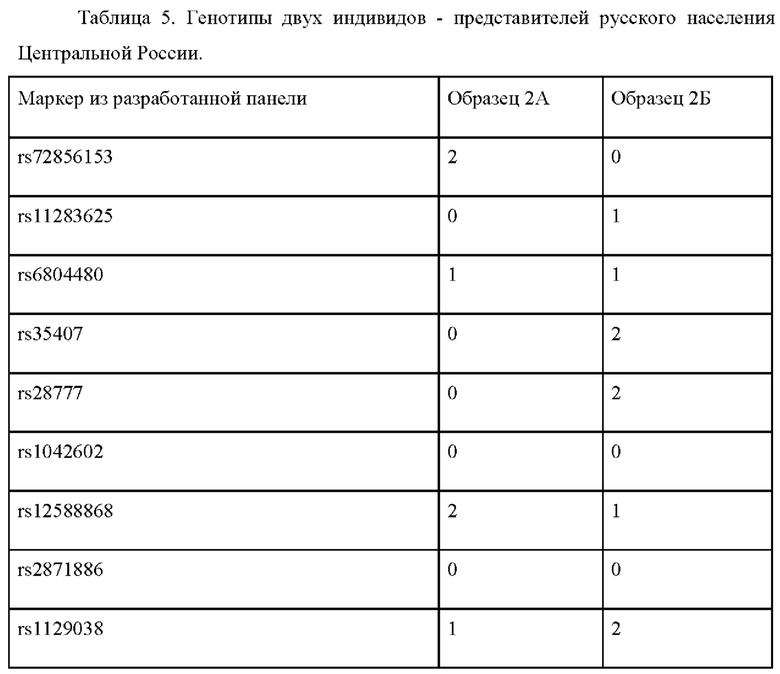
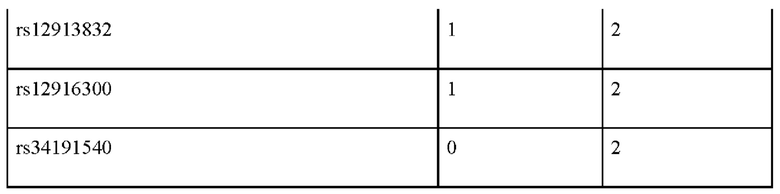
Обработка полученных генотипов индивидуума 2А согласно предложенному по изобретению способу, дает следующие значения вероятности:
р светлых глаз = 0,147896317
р темных глаз = 0,852103683
Согласно расчету, проведенному по предложенному способу, сделан прогноз о наличии у данного индивидуума темных глаз.
При верификации метода результат сопоставляли с фотографией глаз исследуемого индивидуума, (фигура 20). Можно убедиться, что прогноз справедлив, его глаза действительно темные.
Для генотипа индивидуума 2Б получены следующие значения:
р светлых глаз = 0,904515526
р темных глаз = 0,095484474
Следует сделать прогноз о наличии у него светлых глаз. Прогноз соответствует действительности (фигура 21).
Таким образом, первый пример иллюстрирует, что разработанная система позволяет правильно прогнозировать цвет глаз для представителей русского населения Центральной России.
Пример применения 3: прогноз цвета глаз для представителей народов Волго-Уральского региона.
Были изучены два индивида, происходящие из популяции чувашей, обозначенные 3А и 3Б (см. табл. 6). Генотипирование по панели генетических маркеров, указанных в таблице 2, дало следующие результаты (0 означает гомозиготный генотип по референсному аллелю, 1 - гетерозиготный генотип, 2 - гомозиготный генотип по альтернативному аллелю.
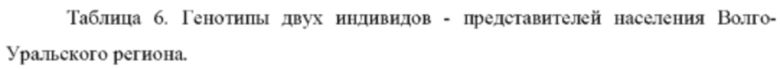
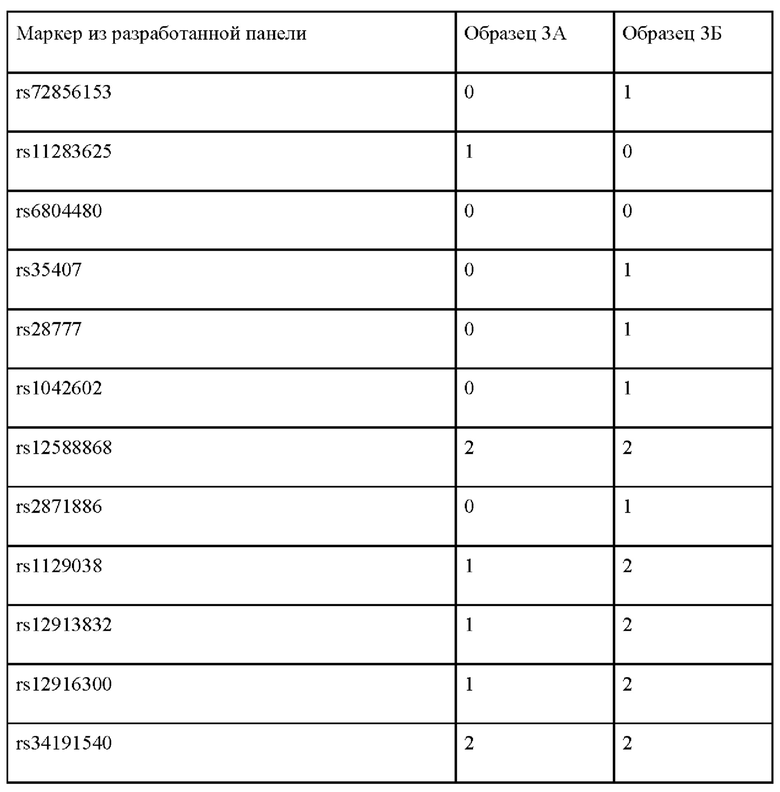
Обработка полученных генотипов индивидуума 3А согласно предложенному по изобретению способу, дает следующие значения вероятности:
р светлых глаз = 0,285828241
р темных глаз = 0,714171759
Согласно расчету, проведенному по предложенному способу, сделан прогноз о наличии у данного индивидуума темных глаз.
При верификации метода результат сопоставляли с фотографией глаз исследуемого индивидуума, (фигура 22). Можно убедиться, что прогноз справедлив, его глаза действительно темные.
Для генотипа индивидуума 3Б получены следующие значения:
р светлых глаз = 0,819875145
р темных глаз = 0,180124855
Следует сделать прогноз о наличии у него светлых глаз. Прогноз соответствует действительности (фигура 23).
Таким образом, первый пример иллюстрирует, что разработанная система позволяет правильно прогнозировать цвет глаз для представителей народонаселения Волго-Уральского региона.
Пример применения 4: прогноз цвета глаз для представителей населения Средней Азии.
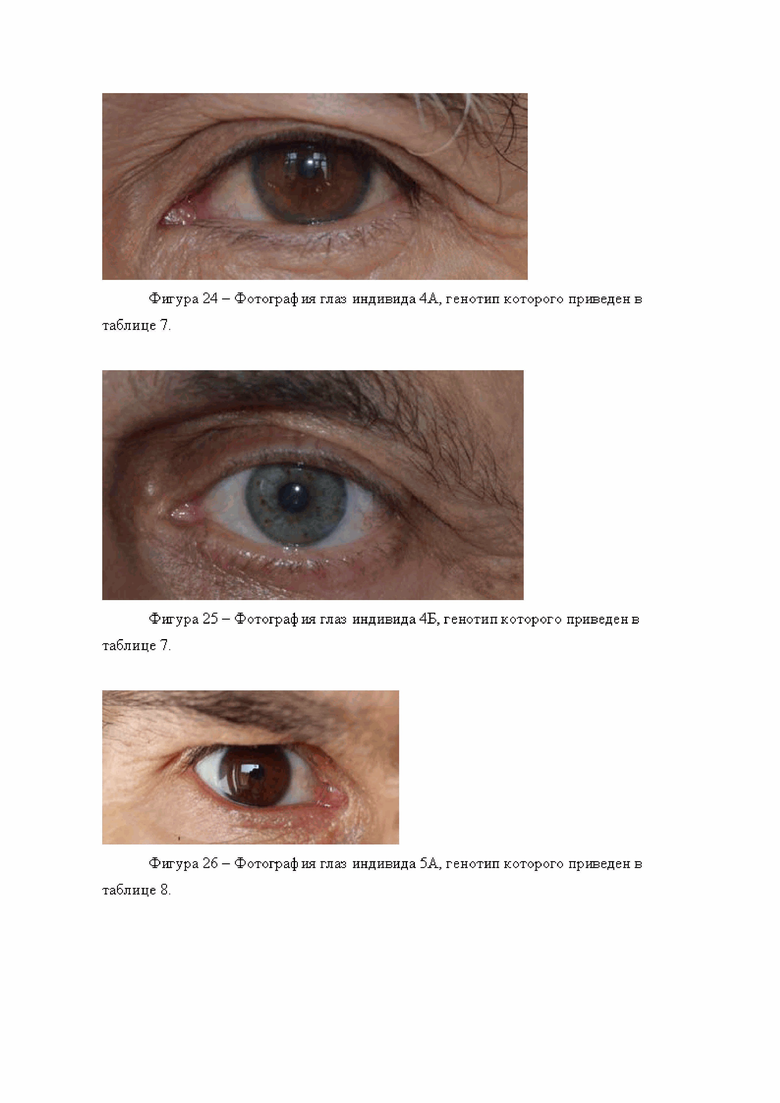
Были изучены два индивидуума, происходящие из популяций Казахстана, обозначенные 4А и 4Б (см. табл. 7). Генотипирование по панели генетических маркеров, указанных в таблице 2, дало следующие результаты (0 означает гомозиготный генотип по референсному аллелю, 1 - гетерозиготный генотип, 2 - гомозиготный генотип по альтернативному аллелю.
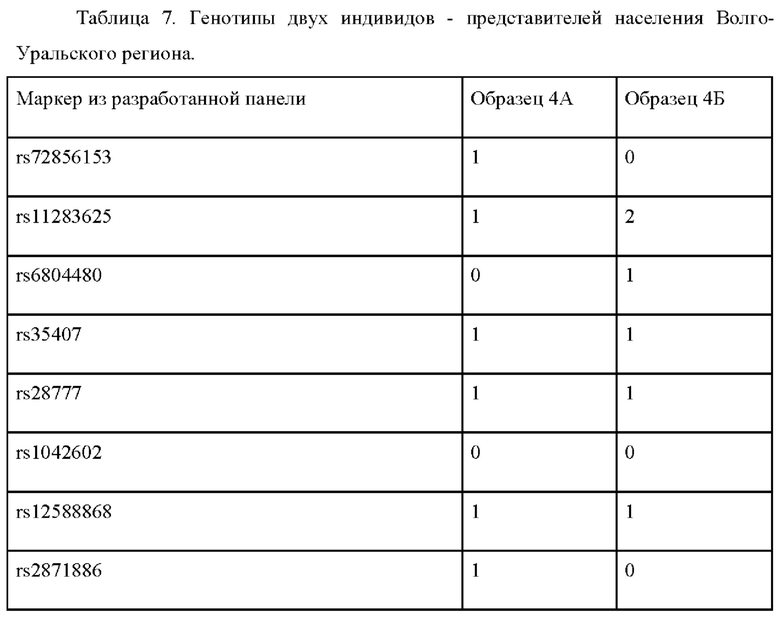

Обработка полученных генотипов индивидуума 4А согласно предложенному по изобретению способу, дает следующие значения вероятности:
р светлых глаз = 0,023528921
р темных глаз = 0,976471079
Согласно расчету, проведенному по предложенному способу, сделан прогноз о наличии у данного индивидуума темных глаз.
При верификации метода результат сопоставляли с фотографией глаз исследуемого индивидуума, (фигура 24). Можно убедиться, что прогноз справедлив, его глаза действительно темные.
Для генотипа индивидуума 4Б получены следующие значения:
р светлых глаз = 0,880205772
р темных глаз = 0,119794228
Следует сделать прогноз о наличии у него светлых глаз. Прогноз соответствует действительности (фигура 25).
Таким образом, первый пример иллюстрирует, что разработанная система позволяет правильно прогнозировать цвет глаз для представителей народонаселения Средней Азии.
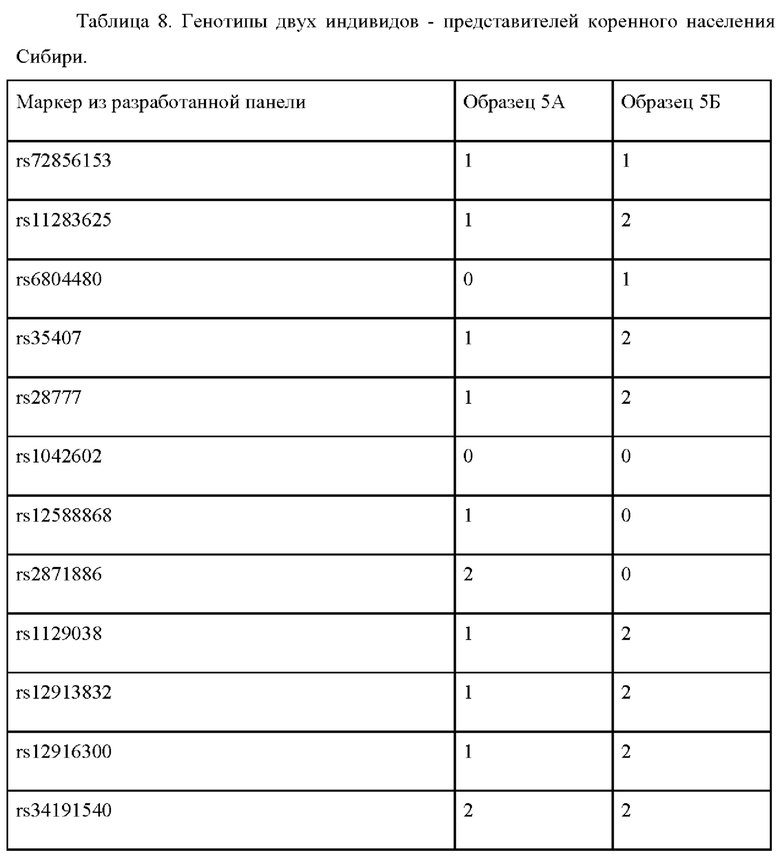
Пример применения 5: прогноз цвета глаз для представителей народов Сибири.
Были изучены два индивидуума, происходящие из популяции манси, обозначенные 5А и 5Б (см. табл. 8). Были изучены два индивидуума, обозначенные 5А и 5Б. Генотипирование по панели генетических маркеров, указанных в таблице 2, дало следующие результаты (0 означает гомозиготный генотип по референсному аллелю, 1 - гетерозиготный генотип, 2 - гомозиготный генотип по альтернативному аллелю.
Обработка полученных генотипов индивидуума 5А согласно предложенному по изобретению способу, дает следующие значения вероятности:
р светлых глаз = 0,281937668
р темных глаз = 0,718062332
Согласно расчету, проведенному по предложенному способу, сделан прогноз о наличии у данного индивидуума темных глаз.
При верификации метода результат сопоставляли с фотографией глаз исследуемого индивидуума, (фигура 26). Можно убедиться, что прогноз справедлив, его глаза действительно темные.
Для генотипа индивидуума 5Б получены следующие значения:
р светлых глаз = 0,882463184
р темных глаз = 0,117536816
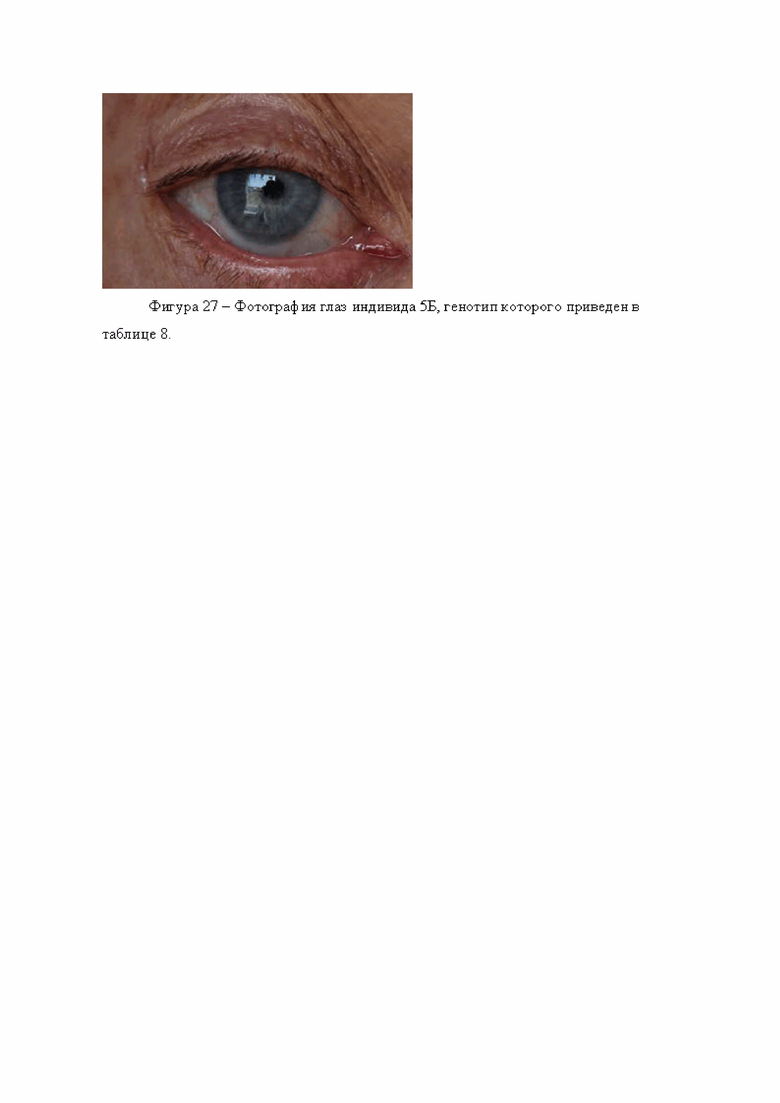
Следует сделать прогноз о наличии у него светлых глаз. Прогноз соответствует действительности (фигура 27).
Таким образом, первый пример иллюстрирует, что разработанная система позволяет правильно прогнозировать цвет глаз для представителей народонаселения Сибири.
Итак, рассмотрены десять примеров применения разработанной системы к реальным индивидуумам, происходящим из разных регионов России и сопредельных стран: Центральной России, Уральского региона, Сибири, Средней Азии, Кавказа (по два примера на каждый регион). Во всех случаях продемонстрировано наличие в населении регионов носителей как светлых, так и темных глаз, и способность системы правильно прогнозировать цвет глаз по результату анализа генотипа, с использованием разработанной панели генетических маркеров.
Валидация набора.
Выше приведены примеры успешного использования набора.
Статистическая оценка точности предикции проведена для 200 индивидуумов. Результирующие показатели чувствительности и специфичности приведены в Таблице 9.
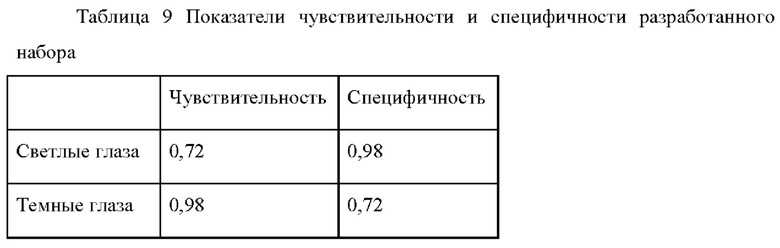
Таким образом, разработанный российский набор характеризуется высокими показателями чувствительности и специфичности как в отношении признака светлых глаз, так и темных глаз.
Список литературы
1. Антропология. Учебное пособие. Издание 3-е. / Рогинский Я.Я.Л., М.Г. Москва: Высшая школа, 1978. - 528 с. 10.
2. Антропология: учебник. / Хрисанфова Е.Н.П., И.В. - Москва: Изд-во Моск. унта: Наука, 2005. - 232-400 с.
3. Branicki W, Brudnik U, Kupiec T, Wolanska-Nowak P, Szczerbinska A, Wojas-Pelc A: Association of polymorphic sites in the OCA2 gene with eye colour using the tree scanning method. Ann Hum Genet 2008, 72(Pt 2): 184-192.
4. Caliebe A., Harder M., Schuett R., Krawczak M., Nebel A., von Wurmb-Schwark N. The more the merrier? How a few SNPs predict pigmentation phenotypes in the Northern German population // Eur J Hum Genet. - 2016. - T. 24, №5. - C. 739-47.
5. Chaitanya L, Breslin K, Zuñiga S, Wirken L, Pośpiech E, Kukla-Bartoszek M, Sijen T, de Knijff P, Liu F, Branicki W, Kayser M, Walsh S: The HIrisPlex-S system for eye, hair and skin colour prediction from DNA: Introduction and forensic developmental validation. Forensic Sci Int Genet 2018, 35:123-135.
6. Dimisianos G, Stefanaki I, Nicolaou V, Sypsa V, Antoniou C, Poulou M, Papadopoulos O, Gogas H, Kanavakis E, Nicolaidou E, Katsambas AD, Stratigos AJ: A study of a single variant allele (rs1426654) of the pigmentation-related gene SLC24A5 in Greek subjects. Exp Dermatol 2009, 18(2): 175-177.
7. Duffy DL, Montgomery GW, Chen W, Zhao ZZ, Le L, James MR, Hayward NK, Martin NG, Sturm RA: A three-single-nucleotide polymorphism haplotype in intron 1 of OCA2 explains most human eye-color variation. Am J Hum Genet 2007, 80(2):241-252.
8. Eiberg H, Troelsen J, Nielsen M, Mikkelsen A, Mengel-From J, Kjaer KW, Hansen L: Blue eye color in humans may be caused by a perfectly associated founder mutation in a regulatory element located within the HERC2 gene inhibiting OCA2 expression. Hum Genet 2008, 123(2): 177-187.
9. Hart K. L., Kimura S. L., Mushailov V., Budimlija Z. M., Prinz M., Wurmbach E. Improved eye- and skin-color prediction based on 8 SNPs // Croat Med J. - 2013. - T. 54, №3. - C. 248-56.
10. Jacobs LC, Hamer MA, Gunn DA, Deelen J, Lall JS, van Heemst D, Uh HW, Hofman A, Uitterlinden AG, Griffiths СЕМ, Beekman M, Slagboom PE, Kayser M, Liu F, Nijsten T: A genome-wide association study identifies the skin color genes IRF4, MC1R, AS IP, and BNC2 influencing facial pigmented spots. J Invest Dermatol 2015, 135(7):1735-1742.
11. Jeong, C, Balanovsky, O., Lukianova, E. et al. The genetic history of admixture across inner Eurasia. Nat Ecol Evol 3, 966 976 (2019).
12. Kastelic V., Pospiech E., Draus-Barini J., Branicki W., Drobnic K. Prediction of eye color in the Slovenian population using the IrisPlex SNPs // Croat Med J. - 2013. - T. 54, №4. - C. 381-6.
13. Kayser M, Liu F, Janssens AC, Rivadeneira F, Lao O, van Duijn K, Vermeulen M, Arp P, Jhamai MM, van Ijcken WF, den Dunnen JT, Heath S, Zelenika D, Despriet DD, Klaver CC, Vingerling JR, de Jong PT, Hofman A, Aulchenko YS, Uitterlinden AG, Oostra BA, van Duijn CM: Three genome-wide association studies and a linkage analysis identify HERC2 as a human iris color gene. Am J Hum Genet 2008, 82(2):411-423.
14. Kayser M, Liu F, Janssens AC, Rivadeneira F, Lao O, van Duijn K, Vermeulen M, Arp P, Jhamai MM, van Ijcken WF, den Dunnen JT, Heath S, Zelenika D, Despriet DD, Klaver CC, Vingerling JR, de Jong PT, Hofman A, Aulchenko YS, Uitterlinden AG, Oostra BA, van Duijn CM: Three genome-wide association studies and a linkage analysis identify HERC2 as a human iris color gene. Am J Hum Genet 2008, 82(2):411-423.
15. Kenny ETN, Sikora M, Yee MC, Moreno-Estrada A, Eng C, Huntsman S, Burchard EG, Stoneking M, Bustamante CD, Myles S: Melanesian blond hair is caused by an amino acid change in TYRP1. Science 2012, 336(6081):554.
16. Liu F., van Duijn K., Vingerling J. R., Hofman A., Uitterlinden A. G., Janssens A. C, Kayser M. Eye color and the prediction of complex phenotypes from genotypes // Curr Biol. - 2009. - T. 19, №5. - C. R192-3.
17. Maronas O., Sochtig J., Ruiz Y., Phillips C, Carracedo A., Lareu M. V. The genetics of skin, hair, and eye color variation and its relevance to forensic pigmentation predictive tests // Forensic Sci Rev. 2015. T. 27, №1. - C. 13-40.
18. Mengel-From J, Borsting C, Sanchez JJ, Eiberg H, Morling N: Human eye colour and HERC2, OCA2 and MATP. Forensic Sci hit Genet 2010, 4(5):323-328.
19. Pospiech E., Wojas-Pelc A., Walsh S., Liu F., Maeda H., Ishikawa Т., Skowron M., Kayser M., Branicki W. The common occurrence of epistasis in the determination of human pigmentation and its impact on DNA-based pigmentation phenotype prediction // Forensic Sci Int Genet. - 2014. - T. 11. - C. 64-72.
20. Sochtig J, Phillips C, Maronas O, Gomez-Tato A, Cruz R, Alvarez-Dios J, de Cal MA, Ruiz Y, Reich K, Fondevila M, Carracedo A, Lareu MV: Exploration of SNP variants affecting hair colour prediction in Europeans. Int J Legal Med 2015, 129(5):963-975.
21. Soejima M, Koda Y: Population differences of two coding SNPs in pigmentation-related genes SLC24A5 and SLC45A2. Int J Legal Med 2007, 121(1):36-39.
22. Spichenok O., Budimlija Z. M., Mitchell A. A., Jenny A., Kovacevic L., Marjanovic D., Caragine Т., Prinz M., Wurmbach E. Prediction of eye and skin color in diverse populations using seven SNPs // Forensic Sci hit Genet. 2011. T. 5, №5. C. 472-8.
23. Sulem P, Gudbjartsson DF, Stacey SN, Helgason A, Rafnar T, Jakobsdottir M, Steinberg S, Gudjonsson SA, Palsson A, Thorleifsson G, Palsson S, Sigurgeirsson B, Thorisdottir K, Ragnarsson R, Benediktsdottir KR, Aben KK, Vermeulen SH, Goldstein AM, Tucker MA, Kiemeney LA, Olafsson JH, Gulcher J, Kong A, Thorsteinsdottir U, Stefansson K: Two newly identified genetic determinants of pigmentation in Europeans. Nat Genet 2008, 40(7):835-837.
24. Sulem P, Gudbjartsson DF, Stacey SN, Helgason A, Rafnar T, Magnusson KP, Manolescu A, Karason A, Palsson A, Thorleifsson G, Jakobsdottir M, Steinberg S, Palsson S, Jonasson F, Sigurgeirsson B, Thorisdottir K, Ragnarsson R, Benediktsdottir KR, Aben KK, Kiemeney LA, Olafsson JH, Gulcher J, Kong A, Thorsteinsdottir U, Stefansson K: Genetic determinants of hair, eye and skin pigmentation in Europeans. Nat Genet 2007, 39(12): 1443-1452.
25. Triska, P., Chekanov, N., Stepanov, V. et al. Between Lake Baikal and the Baltic Sea: genomic history of the gateway to Europe. BMC Genet 18, 110 (2017).
26. Walsh S, Chaitanya L, Clarisse L, Wirken L, Draus-Barini J, Kovatsi L, Maeda H, Ishikawa T, Sijen T, de Knijff P, Branicki W, Liu F, Kayser M: Developmental validation of the HMsPlex system: DNA-based eye and hair colour prediction for forensic and anthropological usage. Forensic Sci Int Genet 2014, 9:150-161.
27. Walsh S, Liu F, Wollstein A, Kovatsi L, Ralf A, Kosiniak-Kamysz A, Branicki W, Kayser M: The HIrisPlex system for simultaneous prediction of hair and eye colour from DNA. Forensic Sci Int Genet 2013, 7(1):98-115.
28. Walsh S., Liu F., Ballantyne K. N., van Oven M., Lao O., Kayser M. IrisPlex: a sensitive DNA tool for accurate prediction of blue and brown eye colour in the absence of ancestry information // Forensic Sci Int Genet. - 2011. - T. 5, №3. - C. 170-80.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ получения молекулярных маркеров для определения вероятной внешности человека методом мультиплексной амплификации для работы с образцами деградированной ДНК | 2021 |
|
RU2786246C2 |
| Способ прогнозирования риска развития первичной открытоугольной глаукомы с использованием данных о полиморфизме гена CDKN2B-AS1 | 2021 |
|
RU2771137C1 |
| Способ прогнозирования риска развития первичной открытоугольной глаукомы без синдрома эксфолиации | 2022 |
|
RU2790757C1 |
| Способ прогнозирования веса новорожденного с учетом полиморфного локуса гексокиназы 2, дифференциально экспрессирующегося в плаценте | 2021 |
|
RU2786313C1 |
| Способ прогнозирования риска развития задержки роста плода | 2021 |
|
RU2775435C1 |
| Способ прогнозирования риска развития преэклампсии на основе молекулярно-генетического анализа | 2021 |
|
RU2775433C1 |
| Способ прогнозирования риска развития эссенциальной гипертензии на основе комбинаций генов матриксных металлопротеиназ | 2016 |
|
RU2624480C1 |
| Способ прогнозирования риска развития остеоартроза коленного сустава у мужчин | 2023 |
|
RU2816024C1 |
| Способ прогнозирования риска развития язвенной болезни желудка и двенадцатиперстной кишки на основе молекулярно-генетического тестирования | 2023 |
|
RU2816514C1 |
| Способ прогнозирования риска развития инсульта у мужчин на основе генетического тестирования | 2017 |
|
RU2664430C1 |

Изобретение относится к области биотехнологии и используется для определения вероятности цвета глаз индивидуума, происходящего из популяций России. Заявленный способ может применяться для прогностических тестов определения внешности человека в судебно-медицинской экспертизе. 2 н.п. ф-лы, 27 ил., 9 табл., 5 пр.
1. Способ определения вероятности цвета глаз индивидуума, происходящего из популяций России, на основе генотипа по однонуклеотидным полиморфизмам в образце ДНК, полученном от индивидуума, где полиморфизмы определены в таблице ниже, и определение вероятности темного цвета глаз проводят по формуле
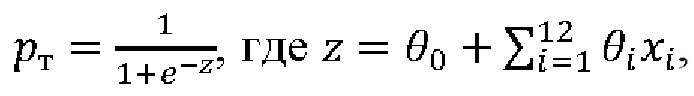
θo и θi определены в таблице ниже
xi - генотип данного образца по данному полиморфизму в формате 0, 1 или 2, а вероятность светлого цвета глаз определяют по формуле рс = 1 - рт, где при полученном значении вероятности светлого цвета глаз (рс) выше 0,5 делают вывод о наличии у индивидуума светлых глаз, при полученном значении вероятности темного цвета (рт) глаз выше 0,5 делают вывод о наличии у индивидуума темных глаз.
2. Панель для определения вероятности цвета глаз индивидуума, происходящего из популяций России, включающая в себя следующие однонуклеотидные полиморфизмы:
rs72856153, rs11283625, rs6804480, rs35407, rs28777, rs1042602, rs12588868, rs2871886, rs1129038, rs12913832, rs12916300, rs34191540,
где указанные однонуклеотидные полиморфизмы определяют в образце ДНК, полученном от индивидуума.
| Кильчевский А | |||
| и др | |||
| Генетика - судебной экспертизе Беларуси, Наука и инновации, 2020, номер 10 (212), стр | |||
| Машина для добывания торфа и т.п. | 1922 |
|
SU22A1 |
| Дорофеева А | |||
| А | |||
| и др | |||
| Современные методы изучения цвета и структуры радужки в различных науках и перспективы их развития в антропологии, Вестник Московского университета, Серия 23, Антропология, 2012 номер 3, стр | |||
| Устройство для выпрямления опрокинувшихся на бок и затонувших у берега судов | 1922 |
|
SU85A1 |
| Dembinski G | |||

