Область техники, к которой относится изобретение
[0001] Настоящая технология относится в общем к классификации слова в качестве нецензурного слова, и в частности к системе и способу классификации слова в качестве нецензурного слова на веб-ресурсе.
Уровень техники
[2] Различные глобальные или локальные сети связи (Интернет, глобальная информационная сеть, локальные сети и тому подобное) предлагают пользователю огромное количество информации. Информация включает в себя множество контекстных тем, таких как, не ограничиваясь, новости и текущие события, карты, информация о компаниях, финансовая информация и ресурсы, информация о дорожном движении, игры и информация, связанная с развлечениями. Пользователи используют различные электронные устройства (настольные компьютеры, портативные компьютеры, ноутбуки, смартфоны, планшетные компьютеры и тому подобное), чтобы иметь доступ к любому количеству веб-страниц и разнообразному контенту (такому как изображения, аудио, видео, анимация и другой мультимедийный контент из таких сетей).
[3] Некоторые веб-страницы или веб-службы позволяют пользователям обмениваться или публиковать формируемый пользователями контент. Хотя подавляющее большинство пользователей обычно формируют контент, подходящий для всех, всегда имеется небольшое количество пользователей, которые менее вежливы и формируют неприемлемый контент, такой как контент, наполненный оскорбительными выражениями (ругательствами, неприемлемыми выражениями и тому подобным).
[4] В общем случае, существует несколько компьютерных подходов к идентификации оскорбительных выражений. Например, простой подход состоит в фильтрации контента, формируемого пользователями, с использованием базы данных нецензурных слов (так называемый подход на основе «черного списка»). Однако такой подход требует создания базы данных, что требует больших затрат времени и энергии. Кроме того, злонамеренный пользователь может обойти такой фильтр, намеренно неправильно написав нецензурное слово.
[5] Публикация заявки на патент США №2020/0142999 A1 под названием “Classification and Moderation of Text”, опубликованной 7 мая 2020 г. и принадлежащей Valve Corporation, раскрывает методы и системы для классификации и модерации текста с использованием подхода на основе машинного обучения, основанного на процессе встраивания слов. Например, могут использоваться векторы встраивания слов для определения кластеров связанного текста (например, похожих слов) из корпуса комментариев, поддерживаемого удаленной вычислительной системой. Затем удаленная вычислительная система может идентифицировать в пределах корпуса комментариев поднабор комментариев, которые включают в себя текст из определенного кластера, который был определен на основании введенных человеком меток, как включающий в себя конкретный тип слова или высказывания. Используя эту информацию, корпус комментариев может быть помечен одной из множества меток класса. Модели машинного обучения могут быть обучены классифицировать текст как одну из множества меток класса с использованием набора помеченных комментариев, из которого произведена выборка, в качестве обучающих данных. Во время выполнения текст можно модерировать на основании его метки класса.
[6] Публикация заявки на патент США №2017/147682 A1, озаглавленная “Automated Text-Evaluation of User Generated Text”, опубликованной 25 мая 2017 г. и принадлежащей King Abdulaziz City for Science and Technology, раскрывает способ для службы автоматической оценки текста, и в частности способ и устройство для автоматической оценки текста и возвращения оценки, которая отражает степень неприемлемой лексики. Способ реализуется в компьютерной инфраструктуре, имеющей машиноисполняемый код, материально реализованный на машиночитаемом носителе данных, имеющем программные инструкции. Программные инструкции выполнены с возможностью: приема входного текста, который содержит неструктурированное сообщение, на первом вычислительном устройстве; обработки введенного текста в соответствии с мерой подобия строковой структуры, которая сравнивает каждое слово введенного текста с заданным словарем для указания, есть ли сходство по значению, и формирования результата оценки для каждого слова введенного текста и отправки результата оценки на другое вычислительное устройство. Результат оценки для каждого введенного сообщения основана на мере подобия строковой структуры между каждым словом введенного текста и заданным словарем.
[7] В техническом документе под названием “A Web Forum Free of Disguised Profanity by Means of Sequence Alignment”, опубликованном в журнале Ingenieria y Universidad в декабре 2016 года, раскрываются методы и основные технические средства для фильтрации ненормативной лексики.
[8] В техническом документе под названием “An Abusive Text Detection System Based on Enhanced Abusive and Non-Abusive Word Lists”, опубликованном в Decision Support Systems в сентябре 2018 года, раскрыта система принятия решений, которая обнаруживает оскорбительный текст с использованием неконтролируемого изучения оскорбительных слов на основе скип-грамма word2vec и косинусного подобия.
[9] Патент США №9703872 B2, озаглавленный “Systems and Methods for Word Offensiveness Detection and Processing Using Weighted Dictionaries and Normalization”, опубликованный 11 июля 2017 г. и принадлежащий IPAR LLC, раскрывает компьютерные системы и способы идентификации выражений, которые можно рассматривать как нецензурные или иным образом оскорбительные для пользователя или владельца системы. Принимается множество оскорбительных слов, при этом каждому оскорбительному слову присваивается оценка серьезности, идентифицирующая оскорбительный характер этого слова. Принимается строка слов. Вычисляется расстояние между возможным словом и каждым оскорбительным словом во множестве оскорбительных слов, и вычисляется множество оценок оскорбительности для возможного слова, причем каждая оценка оскорбительности основана на вычисленном расстоянии между возможным словом и оскорбительным словом и оценке серьезности оскорбительного слова. Определяется, является ли возможное слово оскорбительным словом, причем возможное слово считается оскорбительным словом, если наивысшая оценка оскорбительности во множестве оценок оскорбительности превышает пороговое значение оскорбительности.
Раскрытие изобретения
[10] Задача настоящей технологии состоит в создании улучшенного способа и систем для классификации слова в качестве нецензурного слова. Более конкретно, настоящая технология направлена на идентификацию нецензурного слова, которое написано неправильно.
[11] При разработке настоящей технологии разработчики отметили, что можно создать алгоритм машинного обучения (MLA) для определения неправильно написанного слова, которое соответствует нецензурному слову, при условии, что он обучен на надлежащих обучающих данных.
[12] Не желая ограничиваться какой-либо конкретной теорией, варианты осуществления настоящей технологии были разработаны на основании предположения, что при искусственном создании неправильно написанных вариантов слов эти неправильно написанные варианты могут быть использованы для обучения вышеупомянутого MLA. По меньшей мере некоторые неограничивающие варианты осуществления настоящей технологии направлены на создание реалистичных неправильно написанных вариантов на основании эвристического правила, которые могут использоваться для обучения MLA.
[13] В соответствии с первым широким аспектом настоящей технологии предложен реализуемый компьютером способ классификации слова в качестве нецензурного слова, причем способ выполняется сервером, причем способ содержит, в фазе обучения: получение посредством сервера первого слова, причем первое слово соответствует определенному нецензурному слову; формирование посредством сервера первого набора неправильно написанных слов, причем первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова; формирование посредством сервера обучающих пар, причем обучающие пары содержат: набор положительных обучающих пар, содержащих первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова; обучение алгоритма машинного обучения (MLA), выполняемого сервером, причем обучение содержит: определение для каждой обучающей пары набора характеристик, представляющих свойство обучающих пар; формирование выводимой функции на основании упомянутого набора характеристик, при этом выводимая функция выполнена с возможностью присвоения, при использовании, оценки непристойности, причем оценка пристойности указывает на вероятность того, что слово является нецензурным.
[14] В некоторых неограничивающих вариантах осуществления способа способ дополнительно содержит: получение посредством сервера второго слова, причем второе слово не соответствует какому-либо нецензурному слову; формирование посредством сервера второго набора неправильно написанных слов, причем второй набор неправильно написанных слов содержит множество неправильно написанных вариантов второго слова; и обучающие пары дополнительно содержат набор отрицательных обучающих пар, содержащих второе слово, объединенное в пару с каждым неправильно написанным вариантом второго слова.
[15] В некоторых неограничивающих вариантах осуществления способа первый набор неправильно написанных слов и второй набор неправильно написанных слов формируются посредством выполнения алгоритма неправильного написания.
[16] В некоторых неограничивающих вариантах осуществления способа алгоритм неправильного написания выполнен с возможностью формирования множества неправильно написанных вариантов первого слова посредством по меньшей мере одного из: замены символа в первом слове типографским символом; перестановки одного или более символов в первом слове; удаления одного или более символов в первом слове; замены второго символа первого алфавита в первом слове третьим символом второго алфавита, причем первый алфавит и второй алфавит являются разными алфавитами.
[17] В некоторых неограничивающих вариантах осуществления способа алгоритм неправильного написания создается с использованием набора эвристических правил.
[18] В некоторых неограничивающих вариантах осуществления способа на сервере размещается веб-ресурс; причем способ дополнительно содержит, в фазе использования: получение посредством сервера от электронного устройства текста, содержащего множество слов, подлежащих публикации на веб-ресурсе; ввод посредством сервера текста в MLA, при этом MLA выполнен с возможностью присвоения оценки пристойности каждому из слов, включенных в упомянутое множество слов; и в ответ на то, что оценка непристойности по меньшей мере одного слова текста превышает заданное пороговое значение, применение ограничительного действия.
[19] В некоторых неограничивающих вариантах осуществления способа ограничительное действие представляет собой одно из: удаления упомянутого по меньшей мере одного слова перед публикацией текста на веб-ресурсе; предотвращения публикации текста на веб-ресурсе.
[20] В некоторых неограничивающих вариантах осуществления способа веб-ресурс связан с приложением социальной сети.
[21] В некоторых неограничивающих вариантах осуществления способа веб-ресурс представляет собой приложение для чата в реальном времени на игровой платформе.
[22] В некоторых неограничивающих вариантах осуществления способа MLA представляет собой нейронную сеть.
[23] При этом система содержит сервер, причем сервер содержит процессор, причем процессор выполнен с возможностью, в фазе обучения: получения первого слова, причем первое слово соответствует определенному нецензурному слову; формирования первого набора неправильно написанных слов, причем первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова; формирования обучающих пар, причем обучающие пары содержат: набор положительных обучающих пар, содержащих первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова; обучения алгоритма машинного обучения (MLA), исполняемого сервером, причем обучение содержит: определение для каждой обучающей пары набора характеристик, представляющих свойство обучающих пар; формирования выводимой функции на основании упомянутого набора характеристик, причем выводимая функция выполнена с возможностью присвоения, при использовании, оценки непристойности, причем оценка пристойности указывает на вероятность того, что слово является нецензурным. В некоторых неограничивающих вариантах осуществления системы процессор дополнительно выполнен с возможностью: получения второго слова, причем второе слово не соответствует какому-либо нецензурному слову; формирования второго набора неправильно написанных слов, причем второй набор неправильно написанных слов содержит множество неправильно написанных вариантов второго слова; и при этом обучающие пары дополнительно содержат набор отрицательных обучающих пар, содержащий второе слово, объединенное в пару с каждым неправильно написанным вариантом второго слова.
[24] В некоторых неограничивающих вариантах осуществления системы первый набор неправильно написанных слов и второй набор неправильно написанных слов формируются путем выполнения алгоритма неправильного написания.
[25] В некоторых неограничивающих вариантах осуществления системы алгоритм неправильного написания выполнен с возможностью формирования множества неправильно написанных вариантов первого слова посредством по меньшей мере одного из следующего: замены символа в первом слове типографским символом; перестановки одного или более символов в первом слове; удаления одного или более символов в первом слове; замены второго символа первого алфавита в первом слове третьим символом второго алфавита, причем первый алфавит и второй алфавит являются разными алфавитами.
[26] В некоторых неограничивающих вариантах осуществления системы алгоритм неправильного написания создается с использованием набора эвристических правил.
[27] В некоторых неограничивающих вариантах осуществления система дополнительно содержит веб-ресурс, размещенный на сервере; причем процессор дополнительно выполнен с возможностью в фазе использования: получения от электронного устройства текста, содержащего множество слов, подлежащего публикации на веб-ресурсе; ввода текста в MLA, при этом MLA выполнен с возможностью присвоения оценки пристойности каждому из слов, включенных в упомянутое множество слов; и в ответ на то, что оценка непристойности по меньшей мере одного слова текста превышает заданное пороговое значение, применения ограничительного действия.
[28] В некоторых неограничивающих вариантах осуществления системы ограничительное действие представляет собой одно из: удаления упомянутого по меньшей мере одного слова перед публикацией текста на веб-ресурсе; предотвращения публикации текста на веб-ресурсе.
[29] В некоторых неограничивающих вариантах осуществления системы веб-ресурс связан с приложением социальной сети.
[30] В некоторых неограничивающих вариантах осуществления системы веб-ресурс представляет собой приложение чата в реальном времени на игровой платформе.
[31] В некоторых неограничивающих вариантах осуществления системы MLA представляет собой нейронную сеть.
[32] В контексте настоящего описания «сервер» представляет собой компьютерную программу, которая выполняется на надлежащем аппаратном обеспечении и способна принимать запросы (например, от электронных устройств) по сети, и выполнять эти запросы или вызывать выполнение этих запросов. Аппаратное обеспечение может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным по отношению к настоящей технологии. В настоящем контексте использование выражения «по меньшей мере один сервер» не предназначено для указания на то, что каждая задача (например, принятые инструкции или запросы) или какая-либо конкретная задача будет принята, выполнена, или будет вызвано ее выполнение, посредством одного и того же сервера (то есть одного и того же программного и/или аппаратного обеспечения); оно предназначено для указания на то, что при приеме/отправке, выполнении или вызове выполнения любой задачи или запроса или последствий любой задачи или запроса может использоваться любое количество программных элементов или аппаратных устройств; и все это программное и аппаратное обеспечение может представлять собой один сервер или множество серверов, причем оба этих варианта включены в выражение «по меньшей мере один сервер».
[33] В контексте настоящего описания, если явным образом не указано иное, слова «первый», «второй», «третий» и т.д. используются в качестве прилагательных только для обеспечения различения между собой существительных, которые они модифицируют, а не для описания каких-либо конкретных отношений между такими существительными. Таким образом, например, следует понимать, что использование понятий «первый сервер» и «третий сервер» не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) упомянутых серверов, равно как и их использование (как таковое) не означает, что в любой определенной ситуации должен обязательно существовать какой-либо «второй сервер». Кроме того, как описано в других контекстах данного документа, упоминание «первого» элемента и «второго» элемента не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное обеспечение и/или аппаратное обеспечение, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[34] В контексте настоящего описания, если явным образом не указано иное, «база данных» представляет собой любую структурированную совокупность данных, независимо от ее конкретной структуры, программное обеспечение для администрирования баз данных, или компьютерное аппаратное обеспечение, на котором данные сохранены, реализованы или иным образом сделаны доступными для использования. База данных может находиться на том же аппаратном обеспечении, что и процесс, который сохраняет или использует информацию, сохраненную в базе данных, или она может находиться на отдельном аппаратном обеспечении, таком как выделенный сервер или множество серверов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[35] Для лучшего понимания настоящей технологии, а также других ее аспектов и дополнительных признаков, обратимся к нижеследующему описанию, которое следует использовать в сочетании с сопровождающими чертежами, на которых:
[36] Фиг. 1 - принципиальная схема системы, реализуемой в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[37] Фиг. 2 - принципиальная схема процесса в фазе использования приложения, выполняемого в системе по Фиг. 1.
[38] Фиг. 3 - схематичная иллюстрация первого слова и второго слова, используемых на этапе обучения MLA, выполняемого в системе по Фиг. 1.
[39] Фиг. 4 показан неограничивающий вариант осуществления для иллюстрации набора обучающих данных, формируемых в фазе обучения по Фиг. 3.
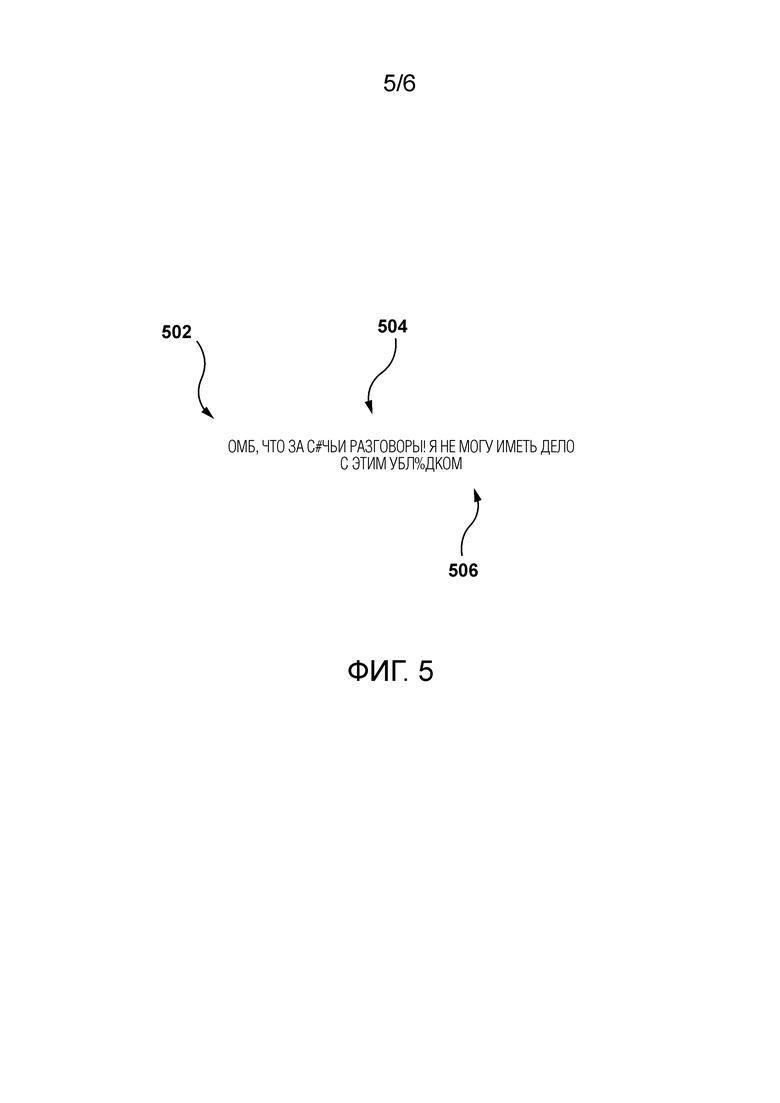
[40] Фиг. 5 - схематичная иллюстрация сообщения, полученного в фазе использования MLA, выполняемого в системе по Фиг. 1.
[41] Фиг. 6 блок-схема схемы последовательности операций способа классификации слова в качестве нецензурного слова, выполняемого в системе по Фиг. 1.
Осуществление изобретения
[42] Обращаясь к Фиг. 1, показана принципиальная схема системы 100, причем система 100 подходит для реализации неограничивающих вариантов осуществления настоящей технологии. Следует явным образом понимать, что система 100 изображена лишь в качестве иллюстративной реализации настоящей технологии. Таким образом, ее нижеследующее описание предназначено лишь для использования в качестве описания иллюстративных примеров настоящей технологии. Это описание не предназначено для определения объема или установления ограничений настоящей технологии. В некоторых случаях ниже также может быть представлено то, что считается полезными примерами модификаций системы 100. Это делается лишь для облегчения понимания и, опять же, не для определения объема или установления ограничений настоящей технологии. Эти модификации не представляют собой исчерпывающий перечень и, как будет понятно специалисту в данной области техники, вероятно возможны другие модификации. Кроме того, если это не сделано (то есть если примеры модификаций не приведены), это не следует понимать таким образом, что модификации не возможны и/или что описанное является единственным способом реализации этого элемента настоящей технологии. Специалисту в данной области будет понятно, что это, вероятно, не так. Кроме того, следует понимать, что в некоторых случаях система 100 может предусматривать простые реализации настоящей технологии, и что в таких случаях они представлены для облегчения понимания. Специалистам в данной области будет понятно, что различные реализации настоящей технологии могут иметь более высокую сложность.
[43] Приведенные в данном документе примеры и условные формулировки предназначены главным образом для помощи читателю в понимании принципов настоящей технологии, а не для ограничения ее объема такими конкретно приведенными примерами и условиями. Следует понимать, что специалисты в данной области смогут разработать различные механизмы, которые, хоть они и не описаны в данном документе явным образом, тем не менее реализуют принципы настоящей технологии и включены в пределы ее сущности и объема. Кроме того, нижеследующее описание может описывать реализации настоящей технологии в относительно упрощенном виде для облегчения понимания. Специалистам в данной области техники будет понятно, что различные реализации настоящей технологии могут иметь более высокую сложность.
[44] Кроме того, все содержащиеся в данном документе утверждения, в которых указаны принципы, аспекты и реализации настоящей технологии, а также их конкретные примеры, подразумевают охватит как их конструктивных, так и функциональных эквивалентов, вне зависимости от того, известны ли они в настоящее время или будут разработаны в будущем. Таким образом, например, специалистам в данной области будет понятно, что любые блок-схемы в данном документе представляют концептуальные виды иллюстративных схем, реализующих принципы настоящей технологии. Аналогичным образом, следует понимать, что любые блок-схемы, схемы последовательности операций, схемы изменения состояний, псевдо-коды и тому подобное представляют различные процессы, которые могут быть по существу представлены на машиночитаемых носителях и выполнены компьютером или процессором вне зависимости от того, показан ли такой компьютер или процессор явным образом.
[45] Функции различных элементов, показанных на чертежах, в том числе любого функционального блока, отмеченного как «процессор», могут быть обеспечены путем использования специализированного аппаратного обеспечения, а также аппаратного обеспечения, способного выполнять программное обеспечение, связанного с надлежащим программным обеспечением. При обеспечении процессором функции могут быть обеспечены одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут быть совместно используемыми. В некоторых вариантах осуществления настоящей технологии процессор может быть процессором общего назначения, таким как центральный процессор (CPU), или процессором, выделенным для конкретной цели, таким как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно истолковываться как относящееся исключительно к аппаратному обеспечению, способному выполнять программное обеспечение, и может в неявном виде включать в себя, не ограничиваясь, аппаратное обеспечение цифрового сигнального процессора (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянную память (ROM) для хранения программного обеспечения, оперативную память (RAM) и энергонезависимое запоминающее устройство. Также может быть включено другое аппаратное обеспечение, традиционное и/или специализированное.
[46] Учитывая эти основополагающие положения, теперь рассмотрим некоторые неограничивающие примеры для иллюстрации различных реализаций аспектов настоящей технологии.
[47] Система 100 содержит электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и при этом оно иногда может называться «клиентским устройством». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не означает, что это предполагает или подразумевает какой-либо режим работы, такой как необходимость входа в систему, необходимость регистрации или тому подобное.
[48] В контексте настоящего описания, если явным образом не указано иное, «электронное устройство» представляет собой любое компьютерное аппаратное обеспечение, которое способно выполнять программное обеспечение, подходящее для соответствующей рассматриваемой задачи. Таким образом, некоторые (не ограничивающие) примеры электронных устройств включают в себя персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.д.), смартфоны и планшетные компьютеры, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройство, выступающее в качестве электронного устройства в данном контексте, не исключает возможности функционирования в качестве сервера для других электронных устройств. Использование выражения «электронное устройство» не исключает использования множества клиентских устройств при приеме/отправке, выполнении или вызове выполнения какой-либо задачи или запроса, или последствий любой задачи или запроса, или этапов любого описанного в данном документе способа.
[49] Электронное устройство 102 содержит постоянное запоминающее устройство 104. Постоянное запоминающее устройство 104 может включать в себя один или более носителей данных и, как правило, обеспечивает место для хранения машиноисполняемых инструкций, выполняемых процессором 106. В качестве примера, постоянное запоминающее устройство 104 может быть реализовано в виде машиночитаемого носителя, включающего в себя постоянное запоминающее устройство (ПЗУ), жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
[50] Электронное устройство 102 включает в себя аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их сочетание) для выполнения приложения 108 браузера. В общем случае, назначение приложения 108 браузера состоит в том, чтобы позволить пользователю осуществлять навигацию по сети Интернет. То, каким способом реализовано приложение 108 браузера, известно в данной области техники и не описано в данном документе. Достаточно сказать, что приложение 108 браузера может быть реализовано в виде приложения браузера Yandex™. Следует явным образом понимать, что для реализации неограничивающих вариантов осуществления настоящей технологии может использоваться любое другое доступное на рынке или проприетарное приложение браузера.
[51] В общем случае, электронное устройство 102 содержит пользовательский интерфейс ввода (не показан) (такой как клавиатура) для приема пользовательских вводов, например, в интерфейс запросов (не показан). То, каким способом реализован пользовательский интерфейс ввода, не ограничено конкретно и будет зависеть от того, каким способом реализовано электронное устройство 102. Лишь в качестве примера, но не ограничения, в тех вариантах осуществления настоящей технологии, в которых электронное устройство 102 реализовано в виде устройства беспроводной связи (например, смартфона iPhone™), пользовательский интерфейс ввода может быть реализован в виде программной клавиатуры (также называемой экранной клавиатурой или программной клавиатурой). С другой стороны, если электронное устройство 102 реализовано в виде персонального компьютера, пользовательский интерфейс ввода может быть реализован в виде аппаратной клавиатуры.
[52] Электронное устройство 102 соединено с сетью 116 связи через линию 114 связи. В некоторых неограничивающих вариантах осуществления настоящей технологии сеть 116 связи может быть реализована в виде сети Интернет. В других вариантах осуществления настоящей технологии сеть 116 связи может быть реализована иным образом, например в виде любой глобальной сети связи, локальной сети связи, частной сети связи и тому подобного.
[53] То, каким способом реализована линия 114 связи, не ограничено конкретно и будет зависеть от того, каким образом реализовано электронное устройство 102. Лишь в качестве примера, но не ограничения, в тех вариантах осуществления настоящей технологии, в которых электронное устройство 102 реализовано в виде устройства беспроводной связи (например, смартфона), линия связи (не показана) может быть реализована в виде линии беспроводной связи (такой как, не ограничиваясь, линия связи 3G, линия связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и тому подобное). В тех примерах, в которых электронное устройство 102 реализовано в виде портативного компьютера, линия связи может быть либо беспроводной (например, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и тому подобное), либо проводной (такой как соединение на основе Ethernet).
[54] Следует явным образом понимать, что реализации для электронного устройства 102, линии 114 связи и сети 116 связи приведены лишь в иллюстративных целях. Таким образом, специалисты в данной области техники с легкостью предусмотрят другие конкретные подробности реализации электронного устройства 102, линии 114 связи и сети 116 связи. При этом приведенные выше примеры никоим образом не предназначены для ограничения объема настоящей технологии.
[55] Система 100 дополнительно включает в себя сервер 118, соединенный с сетью 116 связи. Сервер 118 может быть реализован в виде традиционного компьютерного сервера. В примере варианта осуществления настоящей технологии сервер 118 может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Разумеется, сервер 118 может быть реализован в любом другом подходящем аппаратном обеспечении и/или программном обеспечении и/или микропрограммном обеспечении или их сочетании. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 118 представляет собой один сервер. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 118 могут быть распределены и могут быть реализованы посредством множества серверов.
[56] Реализация сервера 118 хорошо известна. Однако, вкратце, сервер 118 содержит интерфейс связи (не показан), имеющий структуру и выполненный с возможностью осуществления связи с различными объектами (такими как электронное устройство 102 и другие устройства, потенциально соединенные с сетью 116 связи) через сеть 116 связи.
[57] Сервер 118 содержит память 120 сервера, имеющую один или более носителей данных, которые обычно обеспечивают место для хранения команд машиноисполняемых программ, выполняемых процессором 122 сервера. В качестве примера, память 120 сервера может быть реализована в виде материального машиночитаемого носителя данных, включающего в себя постоянную память (ROM) и/или оперативную память (RAM). Память 120 сервера также может включать в себя одно или более стационарных запоминающих устройств в виде, например, жестких дисков (HDD), твердотельных накопителей (SSD) и карт флэш-памяти.
[58] В некоторых неограничивающих вариантах осуществления сервер 118 может управляться тем же субъектом, который обеспечил вышеописанное приложение 108 браузера. Например, если приложение 108 браузера является приложением Яндекс.Навигатор™, сервером 118 может находиться под управлением ООО «Яндекс» на улице Льва Толстого, д. 16, Москва, 119021, Россия. В альтернативных вариантах осуществления сервер 118 может управляться субъектом, отличным от того, который обеспечил вышеупомянутое приложение 108 браузера.
[59] В некоторых неограничивающих вариантах осуществления настоящей технологии сервер 118 выполнен с возможностью хранения веб-ресурса, такого как приложение 124 социальной сети.
[60] Теперь будут более подробно описаны функции и работа различных компонентов приложения 124 социальной сети. Обращаясь к Фиг. 2, приведена схематичная иллюстрация приложения 124 социальной сети для обнаружения нецензурных слов. Приложение 124 социальной сети выполняет (или иным образом имеет доступ): процедуру 202 получения слова, процедуру 204 классификации и процедуру 206 вывода.
[61] В контексте настоящего описания термин «процедура» относится к поднабору машиноисполняемых программных инструкций приложения 124 социальной сети, которое выполняются процессором 122 сервера для выполнения функций, описанных ниже. Во избежание каких-либо сомнений следует явным образом понимать, что процедура 202 получения слова, процедура 204 классификации и процедура 206 вывода схематично проиллюстрированы здесь по отдельности и распределенно для простоты пояснения процессов, выполняемых приложением 124 социальной сети. Предполагается, что часть или вся процедура 202 получения слова, процедура 204 классификации и процедура 206 вывода могут быть реализованы в виде одной или более объединенных процедур.
[62] Для простоты понимания настоящей технологии функциональные возможности каждой из процедуры 202 получения слова, процедуры 204 классификации и процедуры 206 вывода, а также данные и/или информация, обрабатываемые или сохраняемые в них во время фазы перед фазой использования приложения 124 социальной сети описаны ниже. Далее следует описание фазы использования приложения 124 социальной сети.
Фаза перед использованием (фаза обучения)
[63] Как будет описано ниже более подробно, приложение 124 социальной сети содержит алгоритм 208 машинного обучения (MLA), который является частью процедуры 204 классификации. Способ обучения MLA 208 будет описан ниже.
[64] Для понимания основополагающих концепций настоящей технологии следует понимать, что обучение MLA 208 можно в общих чертах разделить на первую фазу и вторую фазу. На первом этапе формируются обучающие данные для обучения MLA 208. На втором этапе MLA 208 обучается с использованием обучающих данных.
Первая фаза (обучение)
[65] Первая фаза обучения будет пояснена с обращением к Фиг. 3, на которой проиллюстрированы первое слово 302 и второе слово 304. Первое слово 302 является нецензурным словом. В то же время, второе слово 304 не является нецензурным словом.
[66] В некоторых неограничивающих вариантах осуществления настоящей технологии первое слово 302 и второе слово 304 принимаются процедурой 202 получения слова от администратора (не показан) сервера 118. В некоторых неограничивающих вариантах осуществления настоящей технологии первое слово 302 и второе слово 304 могут быть приняты базой данных (не показана), сохраняющей черный список с набором нецензурных слов и белый список с набором слов, не являющихся нецензурными.
[67] В ответ на прием первого слова 302 и второго слова 304 процедура 202 получения слова выполнена с возможностью формирования первого набора 306 неправильно написанных слов и второго набора 308 неправильно написанных слов.
[68] Первый набор 306 неправильно написанных слов содержит множество неправильно написанных вариантов первого слова 302, а именно первое неправильно написанное слово 310, второе неправильно написанное слово 312 и третье неправильно написанное слово 314.
[69] Разумеется, что, хотя каждое из первого слова 302 и второго слова 304 представляет собой одно словом, это не ограничено таким образом. Предполагается, что процедура 202 получения слова принимает вместо отдельных слов словосочетания, для которых формируются неправильно написанные словосочетания.
[70] То, каким образом формируется первый набор 306 неправильно написанных слов , не ограничено. В некоторых неограничивающих вариантах осуществления настоящей технологии процедура 202 получения слова выполнена с возможностью выполнения алгоритма неправильного написания (не показан), который выполнен с возможностью формирования первого набора 306 неправильно написанных слов . Точнее, в ответ на получение первого слова 302 алгоритм орфографии выполнен с возможностью:
замены символа в первом слове 302 типографским символом;
перестановки одного или более символов в первом слове 302;
удаления одного или более символов в первом слове 302;
замены второго символа первого алфавита в первом слове 302 третьим символом второго алфавита, причем первый алфавит и второй алфавит являются разными алфавитами (например, замена латинского символа «k» кириллическим символом «к») ;
создания сокращения, если первое слово 302 является словосочетанием (например, «заткнись, черт возьми» на «ЗЧВ» и тому подобное).
[71] В некоторых неограничивающих вариантах осуществления настоящей технологии алгоритм неправильного написания создается на основе набора эвристических правил, вводимых администратором (ами) приложения 124 социальной сети.
[72] Например, в первом неправильно написанном слове 310 третий символ «i» заменен типографским символом «!». Во втором неправильно написанном слове 312 третий символ заменен вторым символом. В третьем неправильно написанном слове 314 второй символ заменен типографским символом «*».
[73] Процедура 202 получения слова (через алгоритм неправильного написания) также выполнена с возможностью формирования второго набора 308 неправильно написанных слов, который содержит множество неправильно написанных вариантов второго слова 304.
[74] Хотя на Фиг. 3 как первый набор 306 неправильно написанных слов , так и второй набор 308 неправильно написанных слов включают в себя определенное количество неправильно написанных слов, следует понимать, что это сделано лишь для простоты иллюстрации, и следует понимать, что могут быть включены, соответственно, больше или меньше неправильно написанных слов.
[75] Обращаясь к Фиг. 4, процедура 202 получения слова выполнена с возможностью формирования набора 402 положительных обучающих пар и набора 404 отрицательных обучающих пар.
[76] Набор 402 положительных обучающих пар содержит первое слово 302, объединенное в пару с каждым неправильно написанным словом с ошибкой, включенным в первый набор 306 неправильно написанных слов, а именно первое неправильно написанное слово 310, второе неправильно написанное слово 312 и третье неправильно написанное слово 314.
[77] Набор 404 отрицательных обучающих пар содержит второе слово 304, объединенное в пару с каждым неправильно написанным словом, включенным во второй набор 308 неправильно написанных слов.
[78] Набор 402 положительных обучающих пар и набор 404 отрицательных обучающих пар образуют обучающие данные для обучения MLA 208. Из нижеследующего описания будет очевидно, что каждое неправильно написанное слово (например, первое неправильно написанное слово 310, второе неправильно написанное слово 312 и третье неправильно написанное слово 314) можно рассматривать как обучающее слово.
[79] Процедура 202 получения слова дополнительно выполнена с возможностью присвоения первого значения метки набору 402 положительных обучающих пар. Первое значение метки указывает на то, что каждое из содержащихся в нем неправильно написанных слов, вероятно, является неправильно написанным нецензурным словом (то есть ненормативной лексикой, которая набирается, чтобы избежать обычных фильтров ненормативной лексики и/или с опечаткой). Точно так же можно сказать, что первое значение метки указывает на то, что первое слово 302 является правильно написанным нецензурным словом. Точно так же процедура 202 получения слова выполнена с возможностью присвоения второго значения метки набору 404 отрицательных обучающих пар. Второе значение метки указывает на то, что каждое из содержащихся в нем неправильно написанных слов, вероятно, является неправильно написанным словом, не являющимся нецензурным.
[80] Одним из преимуществ этого аспекта является то, что автоматическая маркировка посредством процедуры 202 получения слова исключает ручную маркировку набора обучающих пар (то есть обучающих данных), тем самым экономя время и/или сокращая затраты, поскольку процесс маркировки обычно является временнозатратным. В некоторых неограничивающих вариантах осуществления настоящей технологии первое значение метки и второе значение метки являются двоичными значениями.
Вторая фаза (обучение)
[81] Теперь будет описано обучение MLA 208. Процедура 202 получения слов выполнена с возможностью передачи обучающих данных (то есть набора 402 положительных обучающих пар и набора 404 отрицательных обучающих пар) в процедуру 204 классификации, которая вводит обучающие данные в MLA 208.
[82] В некоторых неограничивающих вариантах осуществления настоящей технологии MLA 208 реализован в виде нейронной сети. MLA 208 содержит обучающую логику для определения набора характеристик для каждой обучающей пары (то есть одного из первого слова 302 и второго слова 304 в паре с соответствующим неправильно написанным словом).
[83] После определения набора признаков для каждой обучающей пары MLA 208 выполнен с возможностью анализа набора характеристик между первым словом 302 и его неправильно написанными словами, и набора характеристик между вторым словом 304 и его неправильно написанными словами.
[84] Точнее, вспоминая, что каждая обучающая пара имеет слово, которое либо является неправильно написанным нецензурным слова, либо не является таковым, как указано присвоенной меткой, MLA 208 выполнен с возможностью узнавать, какой набор характеристик указывает на то, что определенное слово является нецензурным словом. Соответственно, MLA 208 выполнен с возможностью формирования выводимой функции, которая способна назначать оценку непристойности, которая указывает вероятность того, что слово является неправильно написанным нецензурным словом. То, как реализована оценка непристойности, не ограничено, и она может быть, например, значением в процентах.
[85] Хотя пояснение фазы обучения MLA 208 было приведено с использованием в качестве примера только первого слова 302 и второго слова 304, следует понимать, что MLA 208 обучается итеративно с использованием множества как нецензурных слов, так и слов, не являющихся нецензурными.
[86] Хотя обучение MLA 208 выполнялось с использованием как набора 404 положительных обучающих пар, так и набора 406 отрицательных обучающих пар, это не ограничено таким образом. Предусмотрено, что в некоторых неограничивающих вариантах осуществления настоящей технологии можно обучать MLA 208, используя только набор 404 положительных обучающих пар. Другими словами, предполагается, что нет необходимости во втором 304 (которое является нецензурным словом) или в формировании набора 406 отрицательных обучающих пар.
[87] Описав способ, которым MLA 208 подготавливается перед фазой использования, теперь обратим внимание на фазу использования.
Фаза использования
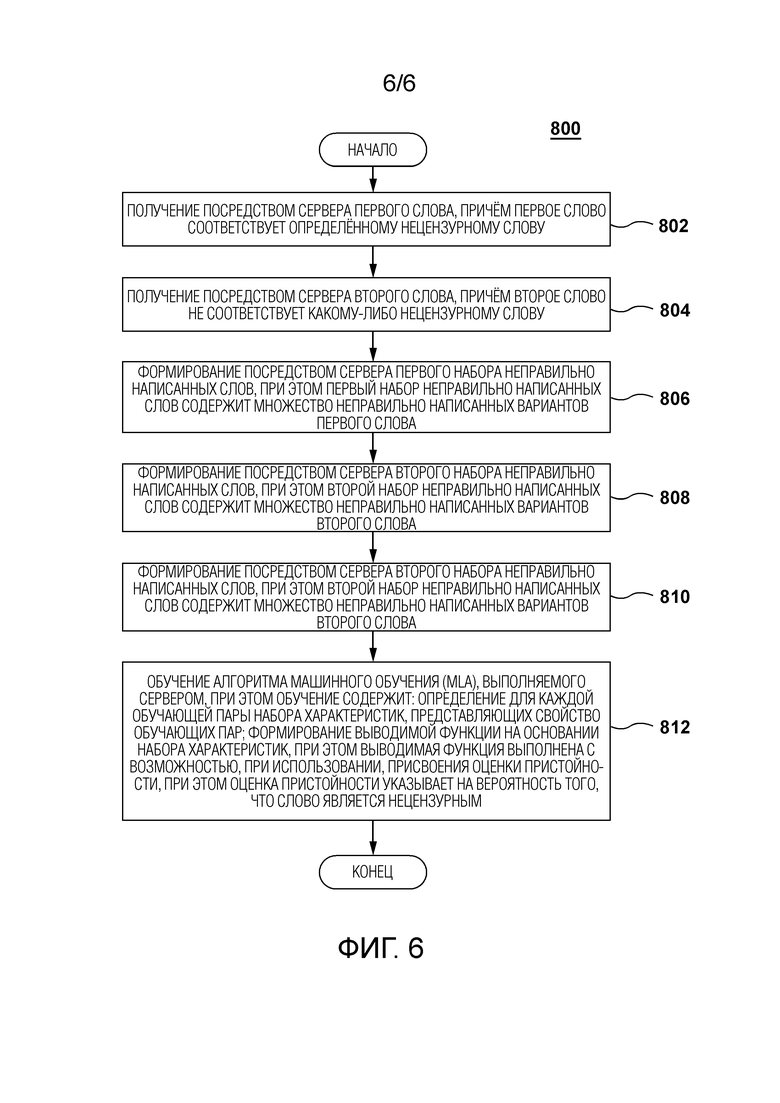
[88] Возвращаясь к Фиг. 2, функциональные возможности каждой из процедуры 202 получения слова, процедуры 204 классификации и процедуры 206 вывода, а также данных и/или информации, обрабатываемых или сохраняемых в них, во время фазы использования приложения 124 социальной сети описаны ниже.
Получение сообщения
[89] Процедура 202 получения слова выполнена с возможностью приема пакета 210 данных. Пакет 210 данных передается электронным устройством 102 и содержит текст, который должен быть опубликован в приложении 124 социальной сети. Например, текст может быть комментарием к сообщению, самим сообщением, личным сообщением (то есть “DM”) и тому подобным.
[90] Обращаясь к Фиг. 5, предположим, что пакет 210 данных содержит сообщение 502.
[91] Затем процедура 202 получения слова выполнена с возможностью синтаксического анализа сообщения 502 на отдельные слова и передачи отдельных слов в процедуру 204 классификации через пакет 212 данных.
Классификация
[92] В ответ на прием пакета 212 данных процедура 204 классификации выполнена с возможностью ввода отдельных слов сообщения 502 в MLA 208.
[93] MLA 208 выполнен с возможностью присвоения оценки непристойности каждому отдельному слову, включенному в сообщение 502.
[94] Например, предположим, что MLA 208 присвоила оценку непристойности 80% первому слову 504 сообщения (“b!tch”) и 90% второму слову 506 сообщения (“b@startd”).
[95] Затем процедура 204 классификации передает пакет 214 данных в процедуру 206 вывода. Пакет 214 данных содержит оценку непристойности для каждого из слов, включенных в сообщение 502.
[96] В ответ на прием пакета 214 данных процедура вывода выполнена с возможностью сравнения оценок непристойности с пороговым значением. Способ определения порогового значения не ограничен и может определяться администратором приложения 124 социальной сети. Если оценка непристойности выше порогового значения, это указывает на то, что связанное слово является нецензурным словом.
[97] Например, допустим, что пороговое значение соответствует 50%. Поскольку оценка непристойности первого слова 504 сообщения и второго слова 506 сообщения превышает пороговое значение, процедура 204 классификации выполнена с возможностью классификации первого слова 504 сообщения и второго слова 506 сообщения в качестве неправильно написанных нецензурных слов.
[98] Определив, что сообщение 502 содержит по меньшей мере одно нецензурное слово, процедура 206 вывода выполнена с возможностью применения ограничительного действия. В некоторых неограничивающих вариантах осуществления настоящей технологии ограничительное действие может заключаться в удалении неправильно написанных нецензурных слов (то есть первого слова 504 сообщения и второго слова 506 сообщения) до публикации сообщения 502 в приложении 124 социальной сети, или предотвращении публикации сообщения 502 в приложении 124 социальной сети.
[99] Хотя приведенное выше пояснение было приведено с обращением к приложению 124 для социальных сетей, следует понимать, что настоящая технология не ограничена приложениями для социальных сетей. Предусмотрено, что настоящая технология может быть реализована в любых веб-ресурсах, которые позволяют пользователю публиковать сообщения или общаться, таких как приложение для чата в реальном времени на игровой платформе, раздел комментариев новостных статей и тому подобное.
[100] Кроме того, следует понимать, что вследствие контекста и характера самого языка то, что может считаться нецензурным словом на определенном форуме, не обязательно может считаться таковым на другом форуме. Например, слово «какашки» (“poop”) может не считаться нецензурным на веб-ресурсе, имеющем отношение к медицине. Точно так же нет четкой линии, которая разделяет слова на нецензурные и не являющиеся нецензурными, поскольку некоторые слова могут быть «субъективно нецензурными». Например, некоторые люди могут посчитать так называемое «смягченное ругательство», такое как «чорт» (“darn”), нецензурным словом, в то время как другие - нет. Хотя в настоящей технологии упоминается понятие «нецензурное слово», следует понимать, что это сделано для простоты понимания и никоим образом не предназначено для ограничения. Администраторы приложения 124 социальной сети могут субъективно посчитать слово нецензурным, даже если оно выходит за рамки традиционного определения, и наоборот, и соответствующим образом обучить MLA 208.
[101] Учитывая архитектуру и примеры, приведенные выше, можно выполнить реализуемый компьютером способ классификации слова в качестве нецензурного слова. Обращаясь к Фиг. 6, изображена блок-схема способа 600 обучения MLA 208, причем способ 600 выполняется в соответствии с неограничивающими вариантами осуществления настоящей технологии. Способ 600 может выполняться сервером 118.
[102] Этап 602: получение посредством сервера первого слова, причем первое слово соответствует определенному нецензурному слову;
[103] Способ 600 будет поясняться ниже с обращением к ситуации, которая соответствует примеру, используемому с обращением к Фиг. 3.
[104] Способ 600 начинается на этапе 602, на котором процедура 202 получения слова получает первое слово 302, которое является нецензурным словом.
[105] Этап 604: формирование посредством сервера первого набора неправильно написанных слов, при этом первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова;
[106] На этапе 604 процедура 202 получения слова выполнена с возможностью выполнения алгоритма неправильного написания, который выполнен с возможностью формирования первого набора 306 неправильно написанных слов.
[107] Этап 606: формирование посредством сервера обучающих пар, причем обучающие пары содержат: набор положительных обучающих пар, содержащих первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова;
[108] На этапе 606 процедура 202 получения слова выполнена с возможностью формирования набора 402 положительных обучающих пар.
[109] Набор 402 положительных обучающих пар содержит первое слово 302, объединенное в пару с каждым неправильно написанным словом, включенным в первый набор 306 неправильно написанных слов, а именно первое неправильно написанное слово 310, второе неправильно написанное слово 312 и третье неправильно написанное слово 314.
[110] Набор 402 положительных обучающих пар формирует обучающие данные для обучения MLA 208.
[111] Этап 612: обучение алгоритма машинного обучения (MLA), выполняемого сервером, при этом обучение содержит: определение для каждой обучающей пары набора характеристик, представляющих свойство обучающих пар; формирование выводимой функции на основании набора характеристик, при этом выводимая функция выполнена с возможностью, при использовании, присвоения оценки пристойности, при этом оценка пристойности указывает на вероятность того, что слово является нецензурным
[112] На этапе 612 процедура 202 получения слова выполнена с возможностью передачи обучающих данных в процедуру 204 классификации, которая вводит обучающие данные в MLA 208.
[113] MLA 208 содержит обучающую логику для определения набора характеристик для каждой обучающей пары (то есть первое слово 302 4 в паре с неправильно написанным словом). В некоторых вариантах осуществления набор характеристик представляет свойства определенной обучающей пары.
[114] После определения набора характеристик для каждой обучающей пары MLA 208 выполнен с возможностью анализа набора характеристик между первым словом 302 и его неправильно написанными словами.
[115] Точнее, вспоминая, что каждая обучающая пара имеет слово, которое либо является неправильно написанным нецензурным словом, либо не является таковым, как указано присвоенной меткой, MLA 208 выполнен с возможностью узнавать, какой набор характеристик указывает на то, что определенное слово является нецензурным словом. Соответственно, MLA 208 выполнен с возможностью формирования выводимой функции, которая способна присваивать оценку непристойности, которая указывает вероятность того, что слово является неправильно написанным нецензурным словом. То, каким образом реализована оценка непристойности, не ограничено, и она может представлять собой, например, значение в процентах.
[116] Специалистам в данной области техники должно быть очевидно, что по меньшей мере некоторые варианты осуществления настоящей технологии направлены на расширение диапазона технических решений для решения конкретной технической проблемы, а именно классификации слова в качестве нецензурного слова, таким образом усовершенствуя потребление энергии и распределение памяти.
[117] Следует явным образом понимать, что не все технические эффекты, упомянутые в данном документе, должны достигаться в каждой реализации настоящей технологии. Например, реализации настоящей технологии могут быть осуществлены без обеспечения пользователю некоторых из этих технических эффектов, в то время как другие реализации могут быть осуществлены с обеспечением пользователю других технических эффектов или без обеспечения каких-либо технических эффектов.
[118] Специалистам в данной области техники могут стать очевидными модификации и усовершенствования вышеописанных реализаций настоящей технологии. Вышеприведенное описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому подразумевается, что объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
[119] Хотя вышеописанные реализации были описаны и показаны с обращением к конкретным этапам, выполняемым в конкретном порядке, следует понимать, что эти этапы могут быть объединены, подразделены или переупорядочены без выхода за рамки идей настоящей технологии. Соответственно, порядок и группировка упомянутых этапов не являются ограничениями настоящей технологии.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПЕРЕВОДУ | 2020 |
|
RU2770569C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБРАБОТКИ ТЕКСТОВОЙ ПОСЛЕДОВАТЕЛЬНОСТИ В ЗАДАЧЕ МАШИННОЙ ОБРАБОТКИ | 2020 |
|
RU2775820C2 |
| Способ и система для синтеза речи из текста | 2017 |
|
RU2692051C1 |
| Способ и система выбора целевого сообщения для включения в веб-ресурс | 2020 |
|
RU2827319C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПРЕДСТАВЛЕНИЯ ЭЛЕМЕНТА РЕКОМЕНДУЕМОГО СОДЕРЖИМОГО ПОЛЬЗОВАТЕЛЮ | 2017 |
|
RU2699574C2 |
| Способ и сервер для определения обучающего набора для обучения алгоритма машинного обучения (MLA) | 2020 |
|
RU2817726C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПРОГНОЗИРОВАНАНИЮ ОЦЕНКИ ВИДИМОСТИ | 2022 |
|
RU2814079C1 |




Изобретение относится к способам и системам обработки текста, а конкретнее к способам обнаружения нецензурных слов в тексте. Техническим результатом является повышение точности классификации слов. Технический результат достигается за счет того, что способ содержит в фазе обучения: получение первого слова, причем первое слово соответствует определенному нецензурному слову; формирование первого набора неправильно написанных слов, причем первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова; формирование обучающих пар, причем обучающие пары содержат: набор положительных обучающих пар, содержащих первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова; обучение алгоритма машинного обучения, причем обучение содержит: определение для каждой обучающей пары набора характеристик, представляющих свойство обучающих пар; формирование выводимой функции на основании набора характеристик, при этом выводимая функция выполнена с возможностью, при использовании, присвоения оценки непристойности, причем оценка пристойности указывает на вероятность того, что слово является нецензурным. 3 н. и 25 з.п. ф-лы, 6 ил.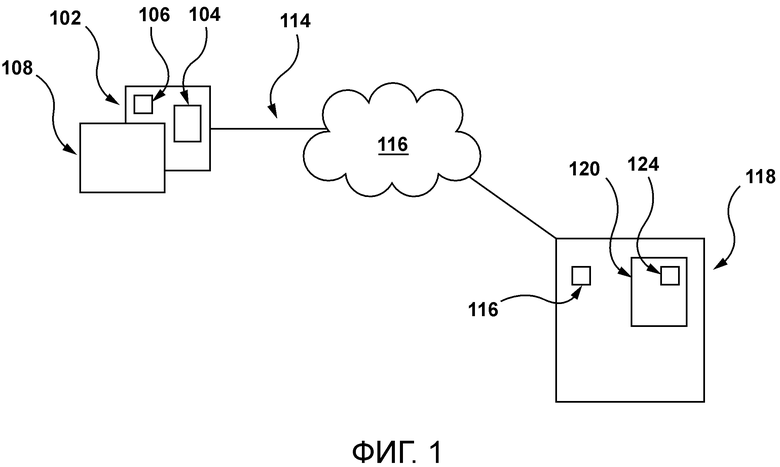
1. Реализуемый компьютером способ классификации слова в качестве нецензурного слова, причем способ выполняется сервером, причем способ содержит этапы, на которых в фазе обучения:
получают посредством сервера первое слово, причем первое слово соответствует определенному нецензурному слову;
формируют посредством сервера первый набор неправильно написанных слов, причем первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова;
формируют посредством сервера обучающие пары, причем обучающие пары содержат:
набор положительных обучающих пар, содержащий первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова;
обучают алгоритм машинного обучения (MLA), выполняемый сервером, при этом обучение содержит этапы, на которых:
определяют для каждой обучающей пары набор характеристик, представляющих свойство обучающих пар,
и формируют выводимую функцию на основании упомянутого набора характеристик, при этом выводимая функция выполнена с возможностью, при использовании, присвоения оценки непристойности, причем оценка пристойности указывает на вероятность того, что слово является нецензурным, а в фазе использования:
обеспечивают получение посредством сервера от электронного устройства текста, содержащего множество слов, подлежащих публикации на веб-ресурсе;
вводят посредством сервера текста в MLA, который на основании упомянутой выводимой функции определяет, превышает ли по меньшей мере одно из слов текста заданное пороговое значение, позволяющее классифицировать данное слово по степени пристойности;
и в ответ на то, что оценка непристойности по меньшей мере одного слова текста превышает заданное пороговое значение, применяют ограничительные действия к упомянутому веб-ресурсу.
2. Способ по п. 1, при этом способ дополнительно содержит этапы, на которых:
получают посредством сервера второе слово, причем второе слово не соответствует какому-либо нецензурному слову;
формируют посредством сервера второй набор неправильно написанных слов, причем второй набор неправильно написанных слов содержит множество неправильно написанных вариантов второго слова; и
обучающие пары дополнительно содержат набор отрицательных обучающих пар, содержащих второе слово, объединенное в пару каждым неправильно написанным вариантом второго слова.
3. Способ по п. 2, в котором первый набор неправильно написанных слов и второй набор неправильно написанных слов формируются путем выполнения алгоритма неправильного написания.
4. Способ по п. 3, в котором алгоритм неправильного написания выполнен с возможностью формирования множества неправильно написанных вариантов первого слова посредством по меньшей мере одного из:
замены символа в первом слове типографским символом;
перестановки одного или более символов в первом слове;
удаления одного или более символов в первом слове;
замены второго символа первого алфавита в первом слове третьим символом второго алфавита, причем первый алфавит и второй алфавит являются разными алфавитами.
5. Способ по п. 4, в котором алгоритм неправильного написания создан с использованием набора эвристических правил.
6. Способ по п. 1, в котором ограничительное действие представляет собой одно из:
удаления упомянутого по меньшей мере одного слова перед публикацией текста на веб-ресурсе;
предотвращение публикации текста на веб-ресурсе.
7. Способ по п. 1, в котором веб-ресурс связан с приложением социальной сети.
8. Способ по п. 1, в котором веб-ресурс представляет собой приложение для чата в реальном времени на игровой платформе.
9. Способ по п. 1, в котором MLA представляет собой нейронную сеть.
10. Система для классификации слова в качестве нецензурного слова, причем система содержит сервер, причем сервер содержит процессор, причем процессор выполнен с возможностью, в фазе обучения:
получения первого слова, причем первое слово соответствует определенному нецензурному слову;
формирования первого набора неправильно написанных слов, причем первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова;
формирования обучающих пар, причем обучающие пары содержат:
набор положительных обучающих пар, содержащий первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова;
обучения алгоритма машинного обучения (MLA), выполняемого сервером, причем обучение содержит:
определение для каждой обучающей пары набора характеристик, представляющих свойство обучающих пар;
формирования выводимой функции на основании набора характеристик, причем выводимая функция выполнена с возможностью, при использовании, присвоения оценки непристойности, причем оценка пристойности указывает на вероятность того, что слово является нецензурным,
а в фазе использования:
обеспечения получения от электронного устройства текста, содержащего множество слов, подлежащих публикации на веб-ресурсе;
введения текста в MLA, который на основании упомянутой выводимой функции определяет, превышает ли по меньшей мере одно из слов текста заданное пороговое значение, позволяющее классифицировать данное слово по степени пристойности;
и в ответ на то, что оценка непристойности по меньшей мере одного слова текста превышает заданное пороговое значение, применять ограничительные действия к упомянутому веб-ресурсу.
11. Система по п. 10, в которой процессор дополнительно выполнен с возможностью:
получения второго слова, причем второе слово не соответствует какому-либо нецензурному слову;
формирования второго набора неправильно написанных слов, причем второй набор неправильно написанных слов содержит множество неправильно написанных вариантов второго слова; и
при этом обучающие пары дополнительно содержат набор отрицательных обучающих пар, содержащих второе слово, объединенное в пару с каждым неправильно написанным вариантом второго слова.
12. Система по п. 11, в которой первый набор неправильно написанных слов и второй набор неправильно написанных слов формируются путем выполнения алгоритма неправильного написания.
13. Система по п. 12, в которой алгоритм неправильного написания выполнен с возможностью формирования множества неправильно написанных вариантов первого слова посредством по меньшей мере одного из:
замены символа в первом слове типографским символом;
перестановки одного или более символов в первом слове;
удаления одного или более символов в первом слове;
замены второго символа первого алфавита в первом слове третьим символом второго алфавита, причем первый алфавит и второй алфавит являются разными алфавитами.
14. Система по п. 13, в которой алгоритм неправильного написания обучается с использованием набора эвристических правил.
15. Система по п. 10, в которой ограничительное действие представляет собой одно из:
удаления упомянутого по меньшей мере одного слова перед публикацией текста на веб-ресурсе;
предотвращения публикации текста на веб-ресурсе.
16. Система по п. 10, в которой веб-ресурс связан с приложением социальной сети.
17. Система по п. 10, в которой веб-ресурс представляет собой приложение для чата в реальном времени на игровой платформе.
18. Система по п. 10, в которой MLA представляет собой нейронную сеть.
19. Реализуемый компьютером способ обучения алгоритма машинного обучения (MLA) для классификации слов в тексте в качестве нецензурных, причем способ выполняется сервером, причем способ содержит этапы, на которых, в фазе обучения:
получают посредством сервера первое слово, причем первое слово соответствует определенному нецензурному слову;
формируют посредством сервера первый набор неправильно написанных слов, причем первый набор неправильно написанных слов содержит множество неправильно написанных вариантов первого слова;
формируют посредством сервера обучающие пары, причем обучающие пары содержат:
набор положительных обучающих пар, содержащий первое слово, объединенное в пару с каждым неправильно написанным вариантом первого слова;
обучают алгоритм машинного обучения (MLA), выполняемый сервером, при этом обучение содержит этапы, на которых:
определяют для каждой обучающей пары набор характеристик, представляющих свойство обучающих пар;
формируют выводимую функцию на основании упомянутого набора характеристик, при этом выводимая функция выполнена с возможностью, при использовании, присвоения оценки непристойности, причем оценка пристойности указывает на вероятность того, что слово является нецензурным.
20. Способ по п. 19, при этом способ дополнительно содержит этапы, на которых:
получают посредством сервера второе слово, причем второе слово не соответствует какому-либо нецензурному слову;
формируют посредством сервера второй набор неправильно написанных слов, причем второй набор неправильно написанных слов содержит множество неправильно написанных вариантов второго слова; и
обучающие пары дополнительно содержат набор отрицательных обучающих пар, содержащих второе слово, объединенное в пару каждым неправильно написанным вариантом второго слова.
21. Способ по п. 20, в котором первый набор неправильно написанных слов и второй набор неправильно написанных слов формируются путем выполнения алгоритма неправильного написания.
22. Способ по п. 21, в котором алгоритм неправильного написания выполнен с возможностью формирования множества неправильно написанных вариантов первого слова посредством по меньшей мере одного из:
замены символа в первом слове типографским символом;
перестановки одного или более символов в первом слове;
удаления одного или более символов в первом слове;
замены второго символа первого алфавита в первом слове третьим символом второго алфавита, причем первый алфавит и второй алфавит являются разными алфавитами.
23. Способ по п. 22, в котором алгоритм неправильного написания создан с использованием набора эвристических правил.
24. Способ по п. 19, в котором на сервере размещен веб-ресурс; причем способ дополнительно содержит этапы, на которых в фазе использования:
получают посредством сервера от электронного устройства текст, содержащий множество слов, для публикации на веб-ресурсе;
вводят посредством сервера текст в MLA, при этом MLA выполнен с возможностью присвоения оценки пристойности каждому из слов, включенных в упомянутое множество слов; и
в ответ на то, что оценка непристойности по меньшей мере одного слова текста превышает заданное пороговое значение, применяют ограничительное действие.
25. Способ по п. 24, в котором ограничительное действие представляет собой одно из:
удаления упомянутого по меньшей мере одного слова перед публикацией текста на веб-ресурсе;
предотвращение публикации текста на веб-ресурсе.
26. Способ по п. 24, в котором веб-ресурс связан с приложением социальной сети.
27. Способ по п. 24, в котором веб-ресурс представляет собой приложение для чата в реальном времени на игровой платформе.
28. Способ по п. 19, в котором MLA представляет собой нейронную сеть.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 8296120 B2, 23.10.2012 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| RU 2015138140 A, 15.03.2017. | |||
