Перекрестные ссылки на родственные заявки
Данная заявка притязает на приоритет предварительной заявки (США) № 62/680678, поданной 5 июня 2018 года; предварительной заявки (США) № 62/519952 и заявки на патент (Европа) № 17176248.7, обе из которых поданы 15 июня 2017 года; все из которых полностью содержатся по ссылке.
Область техники, к которой относится изобретение
Настоящее раскрытие сущности, например, относится к вариантам применения на основе машиноопосредованной реальности, к примеру, к вариантам применения на основе виртуальной реальности (VR), смешанной реальности (MR) и дополненной реальности (AR). Эти варианты применения могут включать в себя, но не только, бинаурализированные и небинаурализированные аудио- и видео-варианты применения для клиента/приемного устройства.
Уровень техники
Приложения и продукты в пространстве на основе машиноопосредованной реальности (например, VR-, AR- и MR-пространстве) быстро совершенствуются таким образом, что они включают в себя все более уточненные акустические модели источников звука и сцен. Без намеренного ограничения, следует обратиться к VR, AR и MR в оставшейся части этого документа. Чтобы оптимизировать восприятия на основе машиноопосредованной реальности, предпочтительно минимизировать задержку между перемещением пользователя (например, перемещением головы) и восприятием звука, адаптированного к этому перемещению (подготовленного посредством рендеринга звука). Эта задержка также известна как время задержки при передаче движения в звук или запаздывание при передаче движения в уши. Помимо этого, также желательно минимизировать число инструкций, требуемых для того, чтобы декодировать и подготавливать посредством рендеринга звук для общих приемных устройств, таких как смартфоны, в которых важно оптимизировать вычислительную сложность и потребление мощности. Когда целая аудиосцена передается, например, для не связанных со связью случаев, внимание акцентируется на времени задержки при рендеринге приемного устройства. Например, линейные приложения (например, фильмы) не реагируют динамически на действия пользователя. Тем не менее, для интерактивного контента, должны учитываться все накопленные времена задержки на полный обход (например, если пользователь инициирует событие, которое должно отправляться обратно на сервер для рендеринга). До того, как контент используется, динамически измененный контент должен кодироваться с достаточным временем упреждения таким образом, что пользователь не распознает время задержки между движением и его результирующим эффектом, и таким образом, что отсутствует неправильное совмещение между аудио- и видеоконтента. Время задержки при кодировании и декодировании не учитывается для времени задержки при передаче движения в звук в случае линейных приложений, поскольку перемещения (позиция и/или ориентация) пользователя не оказывают влияние непосредственно на контент. Наоборот, эти перемещения только затрагивают перспективу, из которой контент просматривается. Следовательно, для линейного контента, перемещение пользователя затрагивает только рендеринг, но не кодирование и/или декодирование выводимого звука. Связанные со связью случаи отличаются, поскольку система может начинать кодирование, передачу и декодирование мультимедиа только по мере того, как возникает контент (например, речь). То же касается случаев, в которых интерактивный контент (например, из игрового механизма) подготавливается посредством рендеринга и кодируется в реальном времени посредством удаленного сервера в облаке. Помимо этого, очень важно то, что полное время задержки видео- и аудиосистем должно быть идентичным, поскольку разности могут вызывать морскую болезнь. Следовательно, в зависимости от времени задержки видеосистемы, имеется потребность в том, чтобы достигать аналогичного уровня времени задержки в аудиосистеме.
Сущность изобретения
Настоящее изобретение разрешает техническую проблему общих AR-, VR- и MR-систем, имеющих слишком высокое время задержки, а также высокие требования по вычислительной сложности, чтобы доставлять захватывающее восприятие. Чтобы разрешать эту проблему, настоящий документ предлагает способ обработки мультимедийного контента, систему для обработки мультимедийного контента и соответствующее оборудование, имеющее признак соответствующих независимых пунктов формулы изобретения.
Аспект раскрытия сущности относится к способу обработки мультимедийного контента для воспроизведения посредством первого оборудования. Первое оборудование, например, может представлять собой одно из приемного устройства, приемного оборудования или оборудования воспроизведения. Упомянутое первое оборудование, например, может соответствовать, включать в себя или работать в сочетании с AR/VR/MR-оборудованием, таким как AR/VR/MR-гарнитура. В связи с этим, первое оборудование может включать в себя оборудование воспроизведения (например, динамики, наушники) для воспроизведения мультимедийного контента и процессор, который соединяется с оборудованием воспроизведения. Мультимедийный контент может представлять собой или включать в себя аудиоконтент и/или видео контент. Обработка может заключать в себе или соответствовать рендерингу. Воспроизведение может заключать в себе или соответствовать воспроизведению. Способ может включать в себя получение информации положения, указывающей позицию и/или ориентацию пользователя. Получение информации положения может выполняться в первом оборудовании. Пользователь может представлять собой пользователя первого оборудования. Информация положения, например, может быть связана с головой пользователя. Упомянутая информация положения может получаться посредством датчика, например, датчика положения, который может размещаться с совмещением с пользователем. Следовательно, информация положения может упоминаться как данные датчиков. Информация положения дополнительно может включать в себя одну или более первых производных положения и/или одну или более вторых производных положения. Пользователь может носить, например, AR/VR/MR-оборудование. Способ дополнительно может включать в себя передачу информации положения во второе оборудование, которое предоставляет (например, сохраняет, ретранслирует) мультимедийный контент. Второе оборудование, например, может представлять собой одно из отправляющего оборудования, серверного оборудования или оборудования доставки контента. Второе оборудование может представлять собой оборудование для предоставления мультимедийного контента в первое оборудование. Первое и второе оборудование могут быть пространственно разделенными друг от друга. Способ дополнительно может включать в себя рендеринг мультимедийного контента на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент. Рендеринг может выполняться во втором оборудовании. Подготовленный посредством рендеринга мультимедийный контент может упоминаться как предварительно подготовленный посредством рендеринга мультимедийный контент. Рендеринг может осуществляться, например, в два или более каналов в случае аудиоконтента. Способ дополнительно может включать в себя передачу подготовленного посредством рендеринга мультимедийного контента в первое оборудование для воспроизведения. Передача подготовленного посредством рендеринга мультимедийного контента может выполняться посредством второго оборудования. Способ еще дополнительно может включать в себя воспроизведение (например, воспроизведение) подготовленного посредством рендеринга мультимедийного контента (посредством первого оборудования).
Если должен передаваться только подготовленный посредством рендеринга мультимедийный контент, скорость передачи битов для передачи данных без потерь может быть аналогичной или сравнимой со скоростью передачи битов сжатой версии полного мультимедийного контента. Соответственно, сжатие может не требоваться в контексте предложенного способа. Передача несжатого (или без потерь) мультимедийного потока должна исключать или уменьшать время задержки для кодирования и декодирования. Например, время задержки, получающееся в результате кодирования/декодирования, может уменьшаться до нуля, что должно приводить к полному уменьшению времени задержки при передаче движения в уши и/или времени задержки при передаче движения в глаза. Кроме того, когда отсутствует сжатие предварительно подготовленного посредством рендеринга мультимедийного контента, первое оборудование (приемное устройство) может выводить аудио/видео без декодирования или рендеринга. Это должно приводить к уменьшению вычислительной сложности в приемном устройстве, поскольку декодирование не должно выполняться, и/или рендеринг уже завершен на стороне отправляющего устройства. Таким образом, предложенный способ обеспечивает возможность уменьшать время задержки при передаче движения в уши и/или время задержки при передаче движения в глаза и дополнительно обеспечивает возможность уменьшать вычислительную сложность на стороне приемного устройства.
В некоторых вариантах осуществления, мультимедийный контент может включать в себя аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент может включать в себя подготовленный посредством рендеринга аудиоконтент. Альтернативно или дополнительно, мультимедийный контент может включать в себя видеоконтент, и подготовленный посредством рендеринга мультимедийный контент может включать в себя подготовленный посредством рендеринга видеоконтент.
В некоторых вариантах осуществления, мультимедийный контент может включать в себя аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент может включать в себя подготовленный посредством рендеринга аудиоконтент. Затем способ дополнительно может включать в себя формирование слышимого (например, акустического) представления подготовленного посредством рендеринга аудиоконтента. Формирование слышимого представления может выполняться в первом оборудовании. Упомянутое формирование, например, может выполняться через два или более громкоговорителей первого оборудования в случае аудиоконтента.
В некоторых вариантах осуществления, аудиоконтент может представлять собой одно из ориентированного на амбиофонию первого порядка (FOA), ориентированного на амбиофонию высшего порядка (HOA), объектно-ориентированного или канальноориентированного аудиоконтента либо комбинацию двух или более из FOA-ориентированного, HOA-ориентированного, объектно-ориентированного или канальноориентированного аудиоконтента.
В некоторых вариантах осуществления, подготовленный посредством рендеринга аудиоконтент может представлять собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента.
В некоторых вариантах осуществления, рендеринг может заключать в себе получение прогнозированной информации положения на основе информации положения и дополнительно на основе информации предыдущего положения и/или одной или более первой и/или второй производных. Прогнозированная информация положения может представлять собой информацию положения для будущего времени. Информация предыдущего положения может представлять собой информацию положения, которая получена или принята в/из первого оборудования в предыдущее время. Прогнозирование может выполняться во втором оборудовании. Альтернативно, прогнозирование может выполняться в первом оборудовании. Во втором случае, первое оборудование может передавать прогнозированную информацию положения во второе оборудование. Рендеринг дополнительно может заключать в себе рендеринг мультимедийного контента на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент.
В силу рассмотрения прогнозированной информации положения, может учитываться задержка, которая может получаться в результате кодирования/декодирования подготовленного посредством рендеринга мультимедийного контента и/или передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование. Другими словами, упомянутая задержка может скрываться для надлежащей прогнозированной информации положения таким образом, что пользователь не выявляет эту задержку и может не воспринимать рассогласование между аудио, видео и перемещением.
В некоторых вариантах осуществления, способ дополнительно может включать в себя передачу прогнозированной информации положения в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом.
Это обеспечивает возможность первому оборудованию выполнять проверку того, является либо нет прогнозированная информация положения (т.е. информация положения, которая использована для рендеринга мультимедийного контента в этом случае) идентичной (или практически идентичной) с информацией фактического/текущего положения (т.е. информацией положения, в данный момент полученной в первом оборудовании), и надлежащим образом адаптировать подготовленный посредством рендеринга мультимедийный контент, если существует рассогласование между прогнозированной информацией положения и информацией фактического/текущего положения.
В некоторых вариантах осуществления, способ дополнительно может включать в себя сравнение прогнозированной информации положения с информацией фактического положения. Способ еще дополнительно может включать в себя обновление подготовленного посредством рендеринга мультимедийного контента на основе результата сравнения. Упомянутое сравнение и упомянутое обновление могут выполняться в первом оборудовании. Информация фактического положения, например, может представлять собой информацию положения во время (например, полученную во время), в которое подготовленный посредством рендеринга мультимедийный контент воспроизводится посредством первого оборудования. Обновление может выполняться, например, на основе разности между прогнозированной информацией положения и информацией фактического положения. Упомянутое обновление может заключать в себе экстраполяцию подготовленного посредством рендеринга мультимедийного контента, например, посредством вращения, изменений уровня и/или повышающего сведения вслепую.
В некоторых вариантах осуществления, прогнозированная информация положения может прогнозироваться для оценки времени, когда подготовленный посредством рендеринга мультимедийный контент предположительно должен обрабатываться посредством первого оборудования для воспроизведения. Обработка подготовленного посредством рендеринга мультимедийного контента посредством первого оборудования может заключать в себе воспроизведение (например, воспроизведение) подготовленного посредством рендеринга мультимедийного контента. Информация фактического положения (например, информация текущего положения) может представлять собой информацию положения, полученную в то время, когда подготовленный посредством рендеринга мультимедийный контент фактически обрабатывается посредством первого оборудования для воспроизведения. Информация фактического положения может получаться в то время, когда подготовленный посредством рендеринга мультимедийный контент фактически обрабатывается посредством первого оборудования.
В силу этого, рассогласования между прогнозированной информацией положения и информацией фактического положения могут учитываться, чтобы за счет этого лучше адаптировать подготовленный посредством рендеринга мультимедийный контент к положению пользователя (например, положению головы пользователя) и исключать расхождения между воспринимаемой и ожидаемой аудио/видеосценой для пользователя. Поскольку рассогласование между прогнозированной информацией положения и информацией фактического положения предположительно должно быть небольшим, такая адаптация может безопасно вверяться первому оборудованию, при управляемой вычислительной сложности.
В некоторых вариантах осуществления, подготовленный посредством рендеринга мультимедийный контент может передаваться в первое оборудование в несжатой форме.
Это позволяет уменьшать вычислительную сложность в первом оборудовании (приемном устройстве) и, кроме того, уменьшает задержку на полный обход между изменением положения и воспроизведением мультимедийного контента, который подготовлен посредством рендеринга в соответствии с измененным положением.
В некоторых вариантах осуществления, способ дополнительно может включать в себя кодирование (например, сжатие) подготовленного посредством рендеринга мультимедийного контента перед передачей в первое оборудование. Способ еще дополнительно может включать в себя декодирование (например, распаковку) кодированного подготовленного посредством рендеринга мультимедийного контента после приема в первом оборудовании. Кодирование/декодирование может заключать в себе или соответствовать сжатию/распаковке подготовленного посредством рендеринга мультимедийного контента. Кодирование/декодирование может представлять собой кодирование/декодирование с низкой задержкой.
В некоторых вариантах осуществления, оценка времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, может включать в себя оценку времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценку времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
В некоторых вариантах осуществления, прогнозированная информация положения может получаться дополнительно на основе оценки времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга мультимедийного контента, и/или оценки времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
В силу этого, задержки, получающиеся в результате кодирования/декодирования и/или передачи, могут скрываться в том смысле, что пользователь становится не знающим в отношении этих задержек.
В некоторых вариантах осуществления, способ дополнительно может включать в себя сравнение информации положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения. Информация текущего положения, например, может представлять собой информацию положения, которая получается во время воспроизведения подготовленного посредством рендеринга мультимедийного контента. Способ еще дополнительно может включать в себя обновление подготовленного посредством рендеринга мультимедийного контента на основе результата сравнения. Обновление может выполняться на основе разности между информацией положения, которая использована для рендеринга мультимедийного контента, и информацией текущего положения. Упомянутое обновление может заключать в себе экстраполяцию подготовленного посредством рендеринга мультимедийного контента, например, посредством вращения, изменений уровня и/или повышающего сведения вслепую.
В некоторых вариантах осуществления, способ дополнительно может включать в себя определение, во втором оборудовании, информации градиента, указывающей то, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения (например, изменения положения). Информация градиента может служить признаком (для аудиоконтента) изменений энергетических уровней подполосы частот (например, каждого канала) в ответ на перемещение в пространстве и/или вращение пользователя (например, головы пользователя). Способ дополнительно может включать в себя передачу информации градиента в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом. Способ дополнительно может включать в себя сравнение, в первом оборудовании, информации положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения. Информация положения, которая использована (посредством второго оборудования) для рендеринга мультимедийного контента, может передаваться в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом. В случае если эта информация положения не отправляется в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом, первое оборудование может обращаться к информации положения, которую оно отправляет во второе оборудование. Информация текущего положения, например, может представлять собой информацию положения, которая получается во время воспроизведения подготовленного посредством рендеринга мультимедийного контента. Способ еще дополнительно может включать в себя обновление подготовленного посредством рендеринга мультимедийного контента на основе информации градиента и результата сравнения. Обновление подготовленного посредством рендеринга мультимедийного контента может выполняться на основе разности между информацией положения, которая использована для рендеринга мультимедийного контента, и информацией текущего положения. Упомянутое обновление может заключать в себе экстраполяцию подготовленного посредством рендеринга мультимедийного контента, например, посредством вращения, изменений уровня и/или повышающего сведения вслепую.
В силу этого, небольшие неидеальности в прогнозировании информации положения могут корректироваться, и рассогласования между положением и воспроизведенным мультимедийным контентом могут не допускаться.
В некоторых вариантах осуществления, мультимедийный контент может включать в себя аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент может включать в себя подготовленный посредством рендеринга аудиоконтент. Затем способ дополнительно может включать в себя передачу информации окружения, указывающей акустические характеристики окружения, в котором расположено первое оборудование, во второе оборудование. В этом случае, рендеринг мультимедийного контента может быть дополнительно основан на информации окружения. Информация окружения может включать в себя характеристики помещения и/или функции бинауральной импульсной характеристики в помещении (BRIR).
Это позволяет, в частности, адаптировать воспроизведенный мультимедийный контент к конкретному окружению, в котором расположен пользователь, за счет этого улучшая восприятие на основе машиноопосредованной реальности пользователя.
В некоторых вариантах осуществления, мультимедийный контент может включать в себя аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент может включать в себя подготовленный посредством рендеринга аудиоконтент. Затем способ дополнительно может включать в себя передачу морфологической информации, указывающей морфологию пользователя либо части пользователя, во второе оборудование. В этом случае, рендеринг мультимедийного контента может быть дополнительно основан на морфологической информации. Морфология может включать в себя или соответствовать форме или размеру, например, форме или размеру головы пользователя. Морфологическая информация может включать в себя передаточные функции восприятия звука человеком (HRTF). Рендеринг может представлять собой бинауральный рендеринг.
Это позволяет, в частности, адаптировать воспроизведенный мультимедийный контент к конкретной морфологии пользователя или части пользователя, за счет этого улучшая восприятие на основе машиноопосредованной реальности пользователя.
Дополнительные аспекты раскрытия сущности относятся к первому оборудованию, второму оборудованию и системе из первого оборудования и второго оборудования в соответствии (например, для реализации) с вышеприведенным аспектом и его вариантами осуществления.
Таким образом, другой аспект раскрытия сущности относится к системе, содержащей первое оборудование для воспроизведения мультимедийного контента и второе оборудование, сохраняющее мультимедийный контент. Первое оборудование может быть адаптировано (выполнено) с возможностью получать информацию положения, указывающую позицию и/или ориентацию пользователя. Первое оборудование может быть дополнительно адаптировано (выполнено) с возможностью передавать информацию положения во второе оборудование. Второе оборудование может быть адаптировано (выполнено) с возможностью подготавливать посредством рендеринга мультимедийный контент на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент. Второе оборудование может быть дополнительно адаптировано (выполнено) с возможностью передавать подготовленный посредством рендеринга мультимедийный контент в первое оборудование для воспроизведения. Например, первое и второе оборудование может включать в себя соответствующие процессоры (или соответствующие наборы процессоров) и запоминающие устройства, соединенные с соответствующими процессорами (или соответствующими наборами процессоров). Процессоры могут быть адаптированы (выполнены) с возможностью выполнять операции, определенные выше.
Другой аспект раскрытия сущности относится ко второму оборудованию для предоставления мультимедийного контента для воспроизведения посредством первого оборудования. Второе оборудование может быть адаптировано (выполнено) с возможностью принимать информацию положения, указывающую позицию и/или ориентацию пользователя первого оборудования. Второе оборудование может быть дополнительно адаптировано (выполнено) с возможностью подготавливать посредством рендеринга мультимедийный контент на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент. Второе оборудование может быть еще дополнительно адаптировано (выполнено) с возможностью передавать подготовленный посредством рендеринга мультимедийный контент в первое оборудование для воспроизведения. Например, второе оборудование может включать в себя процессор (или набор процессоров) и запоминающее устройство, соединенное с процессором (или набором процессоров). Процессор (или набор процессоров) может быть адаптирован (выполнен) с возможностью выполнять операции, определенные выше.
Другой аспект раскрытия сущности относится к первому оборудованию для воспроизведения мультимедийного контента, предоставленного посредством второго оборудования. Первое оборудование может быть адаптировано (выполнено) с возможностью получать информацию положения, указывающую позицию и/или ориентацию пользователя первого оборудования. Первое оборудование может быть дополнительно адаптировано (выполнено) с возможностью передавать информацию положения во второе оборудование. Первое оборудование может быть дополнительно адаптировано (выполнено) с возможностью принимать подготовленный посредством рендеринга мультимедийный контент из второго оборудования. Подготовленный посредством рендеринга мультимедийный контент может быть получен посредством рендеринга мультимедийного контента на основе информации положения. Первое оборудование может быть еще дополнительно адаптировано (выполнено) с возможностью воспроизводить подготовленный посредством рендеринга мультимедийный контент. Например, первое оборудование может включать в себя процессор (или набор процессоров) и запоминающее устройство, соединенное с процессором (или набором процессоров). Процессор (или набор процессоров) может быть адаптирован (выполнен) с возможностью выполнять операции, определенные выше.
Следует отметить, что все утверждения, приведенные относительно способов аналогично, применяются к соответствующим системам и оборудованию, используемым в таких способах/системах, и наоборот.
Еще дополнительные аспекты настоящего раскрытия сущности относятся к системам, оборудованию, способам и машиночитаемым носителям хранения данных, выполненным с возможностью осуществлять способ для рендеринга аудиоконтента, содержащего прием, посредством отправляющего (S) оборудования, данных позиции и/или ориентации пользователя и отправку соответствующего предварительно подготовленного посредством рендеринга контента, типично извлекаемого из объектно-ориентированного или FOA/HOA-представления. Предварительно подготовленный посредством рендеринга сигнал, сформированный посредством отправляющего устройства, может представлять собой бинауральный, FOA, HOA или любой тип канальноориентированного рендеринга. Способ дополнительно может содержать передачу распакованного предварительно подготовленного посредством рендеринга контента. Способ дополнительно может содержать кодирование предварительно подготовленного посредством рендеринга контента и передачу кодированного предварительно подготовленного посредством рендеринга контента. Способ дополнительно может содержать прием предварительно подготовленного посредством рендеринга контента посредством приемного устройства. Способ дополнительно может содержать декодирование предварительно подготовленного посредством рендеринга предварительно кодированного бинаурализированного контента посредством приемного устройства. Данные позиции и/или ориентации пользователя могут содержать локальное положение, которое указывает позицию и ориентацию пользователя в мировом пространстве. Данные позиции пользователя могут передаваться в отправляющее устройство из приемного устройства. Способ дополнительно может содержать передачу данных позиции пользователя, используемых для предварительно подготовленного посредством рендеринга бинаурализированного контента, обратно в приемное устройство. Способ дополнительно может содержать экстраполяцию предварительно подготовленного посредством рендеринга контента на основе принимаемых данных позиции пользователя и данных локальной позиции, чтобы определять обновленный контент. Способ дополнительно может содержать передачу морфологических данных относительно пользователя (например, размера головы) для индивидуализированной бинауральной обработки. Способ дополнительно может содержать передачу данных относительно определения характеристик помещения и BRIR. Способ дополнительно может содержать, на основе определения того, что контент передается агностическим к слушателю способом (например, не включает в себя HRTF), выполнение бинаурального рендеринга и индивидуализации на стороне приемного устройства. Способ дополнительно может содержать предоставление данных P(t0) позиции и/или ориентации пользователя в момент t1 времени. Несжатый предварительно подготовленный посредством рендеринга контент может представлять собой бинаурализированный распакованный предварительно подготовленный посредством рендеринга контент.
Краткое описание чертежей
Ниже поясняются примерные варианты осуществления раскрытия сущности со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 иллюстрирует первый пример приемного устройства;
Фиг. 2 иллюстрирует второй пример приемного устройства;
Фиг. 3 иллюстрирует первый пример системы приемного устройства и сервера;
Фиг. 4 иллюстрирует второй пример системы отправляющего устройства и приемного устройства;
Фиг. 5 иллюстрирует третий пример системы отправляющего устройства и приемного устройства;
Фиг. 6 иллюстрирует четвертый пример системы отправляющего устройства и приемного устройства;
Фиг. 7 иллюстрирует первый пример способа обработки мультимедийного контента;
Фиг. 8 иллюстрирует второй пример способа обработки мультимедийного контента;
Фиг. 9 иллюстрирует третий пример способа обработки мультимедийного контента; и
Фиг. 10 иллюстрирует четвертый пример способа обработки мультимедийного контента.
Подробное описание изобретения
Специалисты в данной области техники должны принимать во внимание, что полное погружение в виртуальный мир "обманывает" мозг таким образом, что он верит в то, что опознается. Когда вид ограничен посредством поля зрения, звук добавляет размерность для того, что не является видимым (например, рев быка сзади, гремучая змея справа, даже шепот, перемещающийся из левого уха за головой в правое ухо). Следовательно, создатели контента могут использовать звук, чтобы направлять пристальный взгляд пользователя и в силу этого эффективно рассказывать историю. Аудиовосприятия на основе погружения теперь доставляются в кинотеатре и в домашнем кинотеатре через объектно-ориентированное и ориентированное на амбиофонию первого/высшего порядка (FOA/HOA) создание звука, пакетирование и воспроизведение контента. VR-звук требует точности звука для полного погружения в виртуальный мир. Создатели VR-контента требуют способности создавать объектно-ориентированный и/или HOA-ориентированный звук в трехмерном пространстве. Кроме того, такой контент должен кодироваться, доставляться, декодироваться и подготавливаться посредством рендеринга бинаурально (в наушниках или по громкоговорителям) с точностью и эффективностью, которая обеспечивает возможность пользователю пользоваться контентом.
Приемное устройство может выбирать представление в мультимедийном формате такого контента, как Интернет-видео- (OTT) контент, доставляемый через MPEG-DASH- или MPEG-MMT-формат, на основе различных параметров, например, полосы пропускания и скорости передачи битов мультимедиа. Приемное устройство также может принимать информацию относительно потребления мультимедиа. Выбор представления в мультимедийном формате может быть основан на таком потреблении мультимедиа. Например, предварительно подготовленные посредством рендеринга бинаурализированные данные могут выбираться на основе индикатора относительно вывода наушников или стереогромкоговорителей (например, с подавлением перекрестных помех).
Примерные варианты осуществления, описанные в данном документе, описывают способы, оборудование и процессы, которые выполнены с возможностью обрабатывать мультимедийный контент (например, подготавливать посредством рендеринга аудиоконтент). Хотя примерные варианты осуществления, в общем, относятся к обработке мультимедийного контента (например, содержащего аудиоконтент и/или видеоконтент), следует обратиться к аудиоконтенту в оставшейся части этого документа, без намеренного ограничения.
Фиг. 1 иллюстрирует пример системы 100 приемного устройства/клиента для бинаурального рендеринга. Система 100 может принимать аудиоввод 101. Аудиоввод 101 может включать в себя всю сцену, содержащуюся в кодированном потоке битов из отправляющего устройства. Система 100 приемного устройства может принимать или обнаруживать данные 110 датчиков (информацию положения), связанные с перемещениями пользователя и/или ориентацией головы пользователя. Данные 110 датчиков могут включать в себя информацию относительно ориентации и позиции, такую как, например, наклон относительно вертикальной оси, наклон в продольном направлении, крен и/или координаты (x, y, z). Система 100 приемного устройства дополнительно может включать в себя декодер 102, который может декодировать аудиоввод 101 в несжатые аудио- и/или метаданные 120. Система 100 приемного устройства дополнительно может включать в себя модуль 103 рендеринга, который может подготавливать посредством рендеринга несжатые аудио- и/или метаданные 120 в бинауральный вывод 150. Система 100 приемного устройства может выводить бинауральный вывод 150, например, в вывод наушников.
Система 100 приемного устройства/клиента, проиллюстрированная на фиг. 1, может страдать от проблем, связанных со временем задержки и/или вычислительной сложностью, которые описываются в начале этого документа.
Чтобы разрешать эти проблемы, настоящее раскрытие сущности предлагает, в системе для обработки мультимедийного контента (например, включающего в себя аудио- и/или видеоконтент), получать информацию положения для пользователя в приемном устройстве, передавать информацию положения в отправляющее устройство, подготавливать посредством рендеринга мультимедийный контент на основе информации положения и передавать подготовленный посредством рендеринга мультимедийный контент в приемное устройство. В силу этого, вычислительная сложность операций, которые должны выполняться на стороне приемного устройства, может значительно уменьшаться. Дополнительно, подготовленный посредством рендеринга мультимедийный контент может передаваться в несжатой форме, что позволяет уменьшать задержку между изменением положения (например, перемещением головы) и восприятием воспроизведенного мультимедийного контента (например, восприятием звука), адаптированного к этому изменению положения.
Фиг. 7 является блок-схемой последовательности операций, схематично иллюстрирующей пример способа 700 обработки мультимедийного контента в соответствии с вышеуказанными факторами. Мультимедийный контент может содержать аудиоконтент и/или видеоконтент. Аудиоконтент, например, может представлять собой FOA-ориентированный аудиоконтент, HOA-ориентированный аудиоконтент, объектно-ориентированный аудиоконтент, канальноориентированный аудиоконтент либо комбинации вышеозначенного. Обработка мультимедийного контента может заключать в себе рендеринг мультимедийного контента. Способ может осуществляться в системе, содержащей первое оборудование для воспроизведения мультимедийного контента и второе оборудование для предоставления мультимедийного контента. Воспроизведение мультимедийного контента может заключать в себе воспроизведение мультимедийного контента. Первое оборудование может упоминаться, например, как приемное устройство, приемное оборудование, клиент, клиентское оборудование или оборудование воспроизведения. Первое оборудование может содержать, соответствовать или работать в сочетании с оборудованием в стиле машиноопосредованной реальности (например, VR-, AR-, MR-), таким как VR/AR/MR-гарнитура (например, защитные очки), например, и может быть ассоциировано с пользователем. Пользователь может носить оборудование в стиле машиноопосредованной реальности. Первое оборудование может содержать или (функционально) соединяться с датчиком (например, датчиком положения) для обнаружения положения (например, позиции и/или ориентации) пользователя или части пользователя (например, головы пользователя). Датчик дополнительно может обнаруживать темп изменения положения (первую производную(ые), например, скорость, угловую скорость/скорости, угловую скорость относительно вертикальной оси/угловую скорость крена/скорость наклона в продольном направлении). Датчик еще дополнительно может обнаруживать темп изменения темпа изменения (вторую производную(ые), например, ускорение, угловое ускорение(я)). Вывод данных датчиков посредством датчика может упоминаться как информация положения. Следует понимать, что, в общем, информация положения служит признаком позиции и/или ориентации (положения) пользователя или части пользователя (например, головы пользователя). Дополнительно, информация положения может служить признаком одного или более темпов изменения (первых производных) положения. Еще дополнительно, информация положения может служить признаком одного или более темпов изменения темпов изменения (вторых производных), например, темпов изменения одного или более темпов изменения положения. Датчик может размещаться с совмещением с пользователем или релевантной частью пользователя (например, головой), например, в качестве части оборудования в стиле машиноопосредованной реальности (например, VR/AR/MR-гарнитура/защитные очки) или в качестве части мобильного (вычислительного) устройства, носимого пользователем (например, смартфона, игрового контроллера). В этом случае, датчик может упоминаться как встроенный датчик. Альтернативно, датчик может содержать или осуществляться посредством позиционного сервера (например, в OptiTrack-системе или OptiTrack-видной системе), который отслеживает положение пользователя (или части пользователя). В общем, датчик может составлять часть или осуществляться посредством системы отслеживания, которая отслеживает положение пользователя (или части пользователя). Такой позиционный сервер также может отслеживать положение более одного пользователя. Второе оборудование может упоминаться, например, как отправляющее устройство, отправляющее оборудование, сервер, серверное оборудование или оборудование доставки контента. Каждое из первого и второго оборудования может содержать процессор (или набор процессоров), который соединяется с соответствующим запоминающим устройством, и который адаптирован (выполнен) с возможностью выполнять соответствующие операции, определенные ниже. Например, упомянутые процессоры (или наборы процессоров) могут быть адаптированы (выполнены) с возможностью выполнять соответствующие этапы способа 700, описанного ниже. Альтернативно или дополнительно, упомянутые процессоры (или наборы процессоров) могут быть адаптированы (выполнены) с возможностью выполнять соответствующие этапы любого из способа 800, способа 900 и способа 1000, описанных дополнительно ниже.
На этапе S710, информация положения, указывающая позицию и/или ориентацию пользователя (или части пользователя, например, головы пользователя), получается (например, определяется). Эта операция может выполняться, например, посредством датчика (например, датчика положения). На этапе S720, информация положения передается во второе оборудование. На этапе S730, мультимедийный контент подготавливается посредством рендеринга на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент. Таким образом, мультимедийный контент подготавливается посредством рендеринга на основе позиции и/или ориентации пользователя или части пользователя. Подготовленный посредством рендеринга мультимедийный контент может упоминаться как предварительно подготовленный посредством рендеринга мультимедийный контент (например, предварительно подготовленный посредством рендеринга аудиоконтент и/или предварительно подготовленный посредством рендеринга видеоконтент). Если мультимедийный контент содержит аудиоконтент, аудиоконтент, например, может подготавливаться посредством рендеринга в бинауральный аудиоконтент, аудиоконтент B-формата, HOA-аудиоконтент, канальноориентированный аудиоконтент либо комбинации вышеозначенного. В общем, аудиоконтент может подготавливаться посредством рендеринга в два или более каналов и/или компонентов. Если мультимедийный контент содержит видеоконтент, видеоконтент, например, может мозаично размещаться, и интересующая область полной видеосцены может выводиться в качестве подготовленного посредством рендеринга видеоконтента. На этапе S740, подготовленный посредством рендеринга мультимедийный контент передается в первое оборудование для воспроизведения. Этапы S710 и S720 могут выполняться в/посредством первого оборудования, например, посредством датчика (например, датчика положения) и (первого) передающего модуля, соответственно. Этапы S730 и S740 могут выполняться в/посредством второго оборудования, например, в модуле рендеринга и (втором) передающем модуле.
Для аудиоконтента, способ 700 дополнительно может содержать этап формирования слышимого (например, акустического) представления подготовленного посредством рендеринга аудиоконтента, например, через два или более громкоговорителей, которые составляют часть или соединяются с первым оборудованием. Два или более громкоговорителей, например, могут составлять часть оборудования в стиле машиноопосредованной реальности. Для видеоконтента, способ 700 дополнительно может содержать этап формирования визуального представления подготовленного посредством рендеринга видеоконтента, например, через устройство отображения, которое составляет часть или соединяется с первым оборудованием. Устройство отображения, например, может составлять часть оборудования в стиле машиноопосредованной реальности. В общем, формирование таких представлений может выполняться в/посредством первого оборудования.
Пример системы 200 приемного устройства/клиента для бинаурального рендеринга в соответствии с вышеописанным способом схематично иллюстрируется на фиг. 2. Система может осуществлять первое оборудование в способе 700. Система 200 может принимать, в качестве примера подготовленного посредством рендеринга мультимедийного контента (подготовленного посредством рендеринга аудиоконтента), аудиоввод 201. Аудиоввод 201, например, может иметь форму бинаурализированного, распакованного аудио. Система 200 приемного устройства может выводить данные датчиков (в качестве примера, информацию положения), связанные с перемещением пользователя и/или ориентацией головы пользователя. Данные 220 датчиков положения головы, например, могут включать в себя информацию относительно наклона относительно вертикальной оси, наклона в продольном направлении, крена и/или координат (x, y, z). Система 200 приемного устройства может выводить данные датчиков в отправляющее устройство/сервер. Отправляющее устройство/сервер может осуществлять второе оборудование в способе 700. Система 200 приемного устройства дополнительно может формировать слышимое представление аудиоввода 201. Например, система приемного устройства может выводить несжатый аудиоввод 201 в вывод наушников.
Как подробнее описано далее, любая из систем, проиллюстрированных на фиг. 3, фиг. 4, фиг. 5 и фиг. 6 может реализовывать способ 700.
Чтобы дополнительно уменьшать задержку между изменением положения и соответствующей адаптацией представления мультимедийного контента, который представляется пользователю, второе оборудование может прогнозировать информацию положения, чтобы ожидать задержку, которая может получаться в результате передачи в первое оборудование и/или кодирования/декодирования (описано ниже). Например, рендеринг мультимедийного контента на этапе S730 в способе 700 может заключать в себе получение (например, определение, вычисление) прогнозированной информации положения и рендеринг мультимедийного контента на основе прогнозированной информации положения (а не на основе информации положения, принимаемой из первого оборудования).
Фиг. 8 является блок-схемой последовательности операций, схематично иллюстрирующей пример способа 800 обработки мультимедийного контента, которая применяет прогнозирование информации положения. Если не указано иное, утверждения, приведенные в связи со способом 700 выше, также применяются здесь.
Этап S810 и этап S820 соответствуют этапам S710 и S720, соответственно, в способе 700. На этапе S830a, прогнозированная информация положения получается (например, определяется, вычисляется) на основе информации положения, принимаемой на этапе S820, и информации предыдущего положения. Если информация положения содержит первую и/или вторую производные положения, прогнозирование может быть основано на упомянутой первой и/или второй производных, в дополнение или вместо информации предыдущего положения. Прогнозированная информация положения может представлять собой информацию положения для будущего времени, например, указывать позицию и/или ориентацию пользователя или части (например, головы) пользователя в будущее время. В определенных реализациях, прогнозированная информация положения может прогнозироваться для оценки времени, когда подготовленный посредством рендеринга мультимедийный контент предположительно должен обрабатываться посредством первого оборудования для воспроизведения. Оценка времени, когда первое оборудование предположительно должно обрабатывать подготовленное посредством рендеринга мультимедиа для воспроизведения, может включать в себя оценку времени (длительности), которое необходимо, или передачу подготовленного посредством рендеринга мультимедийного контента в первое оборудование. Альтернативно или дополнительно, если применяется кодирование/декодирование (например, сжатие/распаковка) (описано ниже), оценка упомянутого времени может включать в себя оценку времени (длительности), которое необходимо для кодирования/декодирования подготовленного посредством рендеринга мультимедийного контента. Таким образом, прогнозированная информация положения может получаться дополнительно на основе оценки времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента, и/или времени, которое необходимо для кодирования/декодирования подготовленного посредством рендеринга мультимедийного контента. Информация предыдущего положения может представлять собой информацию положения, которая принята из первого оборудования в предыдущее время. Один или более элементов информации предыдущего положения могут использоваться для того, чтобы получать прогнозированную информацию положения, например, через технологии экстраполяции или прогнозирования на основе модели. С этой целью, элементы (например, предварительно определенное число элементов) информации предыдущего положения могут сохраняться. На этапе S830b, мультимедийный контент подготавливается посредством рендеринга на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент. Эта операция может отличаться от этапа S730 в способе 700 тем, что прогнозированная информация положения вместо информации положения (принимаемая на этапе S720 или этап S820) используется, но в противном случае может выполняться идентично этапу S730. На этапе S840, подготовленный посредством рендеринга мультимедийный контент передается в первое оборудование для воспроизведения. Этапы S810 и S820 могут выполняться в/посредством первого оборудования. Этапы S830a, S830b и S840 могут выполняться в/посредством второго оборудования. Этап S830a, например, может выполняться посредством модуля прогнозирования положения.
Для аудиоконтента, способ 800 дополнительно может содержать этап формирования слышимого (например, акустического) представления подготовленного посредством рендеринга аудиоконтента, например, через два или более громкоговорителей, которые составляют часть или соединяются с первым оборудованием. Два или более громкоговорителей, например, могут составлять часть оборудования в стиле машиноопосредованной реальности. Для видеоконтента, способ 800 дополнительно может содержать этап формирования визуального представления подготовленного посредством рендеринга видеоконтента, например, через устройство отображения, которое составляет часть или соединяется с первым оборудованием. Устройство отображения, например, может составлять часть оборудования в стиле машиноопосредованной реальности. В общем, формирование таких представлений может выполняться в/посредством первого оборудования.
В модификации способа 800, прогнозированная информация положения может прогнозироваться в первом оборудовании. Таким образом, первое оборудование может выполнять обработку, как описано выше со ссылкой на этап S830a, и в дальнейшем отправлять прогнозированную информацию положения во второе оборудование. Следует понимать, что этап S820 может опускаться в этом случае. После приема прогнозированной информации положения из первого оборудования, второе оборудование может продолжать свою обработку с этапом S830b и следующими этапами, способом, описанным выше.
Как подробнее описано далее, любая из систем, проиллюстрированных на фиг. 3, фиг. 4, фиг. 5 и фиг. 6, может реализовывать способ 800 или модификацию способа 800.
Вышеуказанное прогнозирование информации положения для рендеринга мультимедийного контента обеспечивает возможность "скрывать" задержку, которая вызывается посредством передачи и/или кодирования/декодирования таким образом, что хорошее совмещение между перемещением пользователя и представлением подготовленного посредством рендеринга мультимедийного контента может достигаться. Соответственно, риск того, что пользователь затрагивается посредством морской болезни, может уменьшаться или вообще исключаться, и может улучшаться восприятие на основе машиноопосредованной реальности на базе погружения пользователя. В случае способа 800, улучшение совмещения между перемещением и представлением подготовленного посредством рендеринга мультимедийного контента достигается посредством процесса, выполняемого на стороне сервера/отправляющего устройства, т.е. посредством прогнозирования информации положения и с использованием прогнозированной информации положения вместо информации положения, принимаемой из стороны приемного устройства/воспроизведения для рендеринга мультимедийного контента. Тем не менее, при определенных условиях, может быть желательным достигать такого улучшения совмещения между перемещением и представлением подготовленного посредством рендеринга мультимедийного контента посредством мер, которые предпринимаются на стороне воспроизведения или приемном устройстве.
Фиг. 9 является блок-схемой последовательности операций, схематично иллюстрирующей пример способа 900 обработки мультимедийного контента в соответствии с вышеуказанными факторами, т.е. который улучшает совмещение между перемещением и представлением подготовленного посредством рендеринга мультимедийного контента посредством мер, которые предпринимаются на стороне приемного устройства/воспроизведения.
Этап S910, этап S920, этап S930 и этап S940 соответствуют этапам S710-S740, соответственно, в способе 700. На этапе S950, информация положения, которая использована для рендеринга мультимедийного контента (например, информация положения, которая принята из первого оборудования), передается в первое оборудование. Упомянутая информация положения может передаваться вместе с подготовленным посредством рендеринга мультимедийным контентом, например, в ассоциации с подготовленным посредством рендеринга мультимедийным контентом. На этапе S960, информация положения, которая использована для рендеринга мультимедийного контента, сравнивается с информацией текущего положения. Информация текущего положения может представлять собой информацию положения, которая получается во время воспроизведения (например, воспроизведения) подготовленного посредством рендеринга мультимедийного контента. Информация текущего положения может получаться способом, описанным выше со ссылкой на этап S710, хотя в другое (более позднее) время. На этапе S970, подготовленный посредством рендеринга мультимедийный контент обновляется на основе результата сравнения. Например, подготовленный посредством рендеринга мультимедийный контент может обновляться на основе разности между информацией положения, которая использована для рендеринга мультимедийного контента, и информацией текущего положения. Упомянутое обновление может заключать в себе экстраполяцию подготовленного посредством рендеринга мультимедийного контента. Ниже описываются неограничивающие примеры такого обновления со ссылкой на фиг. 3. Этапы S910, S920, S960 и S970 могут выполняться в/посредством первого оборудования. Этапы S930, S940 и S950 могут выполняться в/посредством второго оборудования.
В определенных реализациях, этап S950 может опускаться, т.е. информация положения, которая использована для рендеринга мультимедийного контента, может не передаваться в первое оборудование. В этом случае, можно упоминать, на этапе S960, информацию положения, которая отправлена во второе оборудование на этапе S920, в качестве информации положения, которая использована для рендеринга мультимедийного контента.
Дополнительно, в определенных реализациях, способ 900 может содержать определение информации градиента того, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения (например, в ответ на изменения положения пользователя или положения головы пользователя). Затем способ 900 еще дополнительно может содержать передачу информации градиента в первое оборудование. Например, информация градиента может передаваться в первое оборудование вместе (например, в ассоциации) с подготовленным посредством рендеринга мультимедийным контентом и необязательно информацией положения, которая использована для рендеринга мультимедийного контента. Эти дополнительные этапы могут выполняться во втором оборудовании. Для аудиоконтента, информация градиента может служить признаком изменений энергетических уровней подполосы частот (например, каждого канала или каждого компонента) в ответ на перемещение в пространстве и/или вращение пользователя либо части пользователя. Информация градиента затем может использоваться на этапе S970, чтобы обновлять/регулировать подготовленный посредством рендеринга мультимедийный контент. Например, энергетические уровни подполосы частот подготовленного посредством рендеринга аудиоконтента могут регулироваться на основе информации градиента и разности между информацией положения, которая использована для рендеринга мультимедийного контента, и информацией текущего положения. В общих чертах, подготовленный посредством рендеринга мультимедийный контент может обновляться/регулироваться на основе разности в положении и градиентах, которые указывают изменения подготовленного посредством рендеринга мультимедийного контента в ответ на изменения положения.
Для аудиоконтента, способ 900 дополнительно может содержать этап формирования слышимого (например, акустического) представления подготовленного посредством рендеринга аудиоконтента, например, через два или более громкоговорителей, которые составляют часть или соединяются с первым оборудованием. Два или более громкоговорителей, например, могут составлять часть оборудования в стиле машиноопосредованной реальности. Для видеоконтента, способ 900 дополнительно может содержать этап формирования визуального представления подготовленного посредством рендеринга видеоконтента, например, через устройство отображения, которое составляет часть или соединяется с первым оборудованием. Устройство отображения, например, может составлять часть оборудования в стиле машиноопосредованной реальности. В общем, формирование таких представлений может выполняться в/посредством первого оборудования.
Как подробнее описано далее, любая из систем, проиллюстрированных на фиг. 3, фиг. 4, фиг. 5 и фиг. 6 может реализовывать способ 900.
Чтобы дополнительно улучшать совмещение между перемещением пользователя и представлением подготовленного посредством рендеринга мультимедийного контента, прогнозирование информации положения на стороне сервера/отправляющего устройства и обновление подготовленного посредством рендеринга мультимедийного контента на стороне приемного устройства/воспроизведения могут комбинироваться.
Фиг. 10 является блок-схемой последовательности операций, схематично иллюстрирующей пример способа 1000 обработки мультимедийного контента в соответствии с вышеуказанными факторами, т.е. который улучшает совмещение между перемещением и представлением подготовленного посредством рендеринга мультимедийного контента посредством мер, которые предпринимаются на стороне сервера/отправляющего устройства, а также мер, которые предпринимаются на стороне приемного устройства/воспроизведения.
Этап S1010, этап S1020 и этап S1040 соответствуют этапам S710, S720 и S740, соответственно, в способе 700. Этап S1030a и этап S1030b соответствуют этапам S830 и S830b, соответственно, в способе 800. На этапе S1050, прогнозированная информация положения (т.е. информация положения, которая использована для рендеринга мультимедийного контента) передается в первое оборудование. Прогнозированная информация положения может передаваться вместе с подготовленным посредством рендеринга мультимедийным контентом, например, в ассоциации с подготовленным посредством рендеринга мультимедийным контентом. На этапе S1060, прогнозированная информация положения сравнивается с информацией фактического/текущего положения. Информация фактического положения может представлять собой информацию положения, которая получается во время воспроизведения (например, воспроизведения) подготовленного посредством рендеринга мультимедийного контента. Информация фактического положения может получаться способом, описанным выше со ссылкой на этап S710, хотя в другое (более позднее) время. На этапе S1070, подготовленный посредством рендеринга мультимедийный контент обновляется на основе результата сравнения. Например, подготовленный посредством рендеринга мультимедийный контент может обновляться на основе разности между прогнозированной информацией положения и информацией фактического положения. В общем, обновление может выполняться идентично этапу S970 в способе 900. Этапы S1010, S1020, S1060 и S1070 могут выполняться в/посредством первого оборудования. Этапы S1030a, S1030b, S1040 и S1050 могут выполняться в/посредством второго оборудования.
В определенных реализациях, способ 1000 может содержать определение информации градиента того, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения (например, в ответ на изменения положения пользователя или положения головы пользователя). Затем способ 1000 еще дополнительно может содержать передачу информации градиента в первое оборудование. Например, информация градиента может передаваться в первое оборудование вместе (например, в ассоциации) с подготовленным посредством рендеринга мультимедийным контентом и необязательно информацией положения, которая использована для рендеринга мультимедийного контента. Эти дополнительные этапы могут выполняться во втором оборудовании. Для аудиоконтента, информация градиента может служить признаком изменений энергетических уровней подполосы частот (например, каждого канала или каждого компонента) в ответ на перемещение в пространстве и/или вращение пользователя либо части пользователя. Информация градиента затем может использоваться на этапе S1070, чтобы обновлять/регулировать подготовленный посредством рендеринга мультимедийный контент. Например, энергетические уровни подполосы частот подготовленного посредством рендеринга аудиоконтента могут регулироваться на основе информации градиента и разности между информацией положения, которая использована для рендеринга мультимедийного контента, и информацией текущего положения. В общих чертах, подготовленный посредством рендеринга мультимедийный контент может обновляться/регулироваться на основе разности в положении и градиентах, которые указывают изменения подготовленного посредством рендеринга мультимедийного контента в ответ на изменения положения.
Для аудиоконтента, способ 1000 дополнительно может содержать этап формирования слышимого (например, акустического) представления подготовленного посредством рендеринга аудиоконтента, например, через два или более громкоговорителей, которые составляют часть или соединяются с первым оборудованием. Два или более громкоговорителей, например, могут составлять часть оборудования в стиле машиноопосредованной реальности. Для видеоконтента, способ 1000 дополнительно может содержать этап формирования визуального представления подготовленного посредством рендеринга видеоконтента, например, через устройство отображения, которое составляет часть или соединяется с первым оборудованием. Устройство отображения, например, может составлять часть оборудования в стиле машиноопосредованной реальности. В общем, формирование таких представлений может выполняться в/посредством первого оборудования.
В модификации способа 1000 прогнозированная, информация положения может прогнозироваться в первом оборудовании. Таким образом, первое оборудование может выполнять обработку, как описано выше со ссылкой на этап S1030a, и в дальнейшем отправлять прогнозированную информацию положения во второе оборудование. Следует понимать, что этап S1020 может опускаться в этом случае. После приема прогнозированной информации положения из первого оборудования, второе оборудование может подготавливать посредством рендеринга мультимедийный контент способом, описанным выше со ссылкой на этап S1030b, с использованием прогнозированной информации положения, и передавать подготовленный посредством рендеринга мультимедийный контент в первое оборудование, способом, описанным выше со ссылкой на этап S1040. Этап S1050 может опускаться в этом случае. После приема подготовленного посредством рендеринга мультимедийного контента, первое оборудование может выполнять этапы S1060 и S1070, способом, описанным выше. В частности, поскольку прогнозирование информации положения выполняется в первом оборудовании в этом случае, первое оборудование не должно принимать прогнозированную информацию положения из второго оборудования.
Как подробнее описано далее, любая из систем, проиллюстрированных на фиг. 3, фиг. 4, фиг. 5 и фиг. 6, может реализовывать способ 1000 или модификацию способа 1000.
В любом из вышеописанных способов, подготовленный посредством рендеринга мультимедийный контент может передаваться в первое оборудование в несжатой форме. Это обеспечивается посредством предварительного рендеринга во втором оборудовании таким образом, что передача полного мультимедийного контента (например, полного представления аудио/видеосцены) не требуется. Передача подготовленного посредством рендеринга мультимедийного контента в несжатой форме способствует уменьшению задержки на полный обход, поскольку время, которое традиционно расходуется для сжатия/распаковки, может сокращаться. С другой стороны, подготовленный посредством рендеринга мультимедийный контент может кодироваться (сжиматься) перед передачей в первое оборудование при необходимости посредством ограничений по полосе пропускания. В этом случае, как упомянуто выше, время, необходимое для кодирования/декодирования (например, сжатия/распаковки), может учитываться при получении прогнозированной информации положения.
Дополнительно, для аудиоконтента, любой из вышеописанных способов дополнительно может содержать передачу информации окружения, указывающей акустические характеристики окружения, в котором расположено первое оборудование, во второе оборудование. Информация окружения может включать в себя характеристики помещения и/или функции бинауральной импульсной характеристики в помещении (BRIR). Этот этап может выполняться в/посредством первого оборудования, например, во время настройки. Затем аудиоконтент может подготавливаться посредством рендеринга дополнительно на основе информации окружения. Альтернативно или дополнительно, любой из вышеописанных способов дополнительно может содержать передачу морфологической информации, указывающей морфологию пользователя либо части пользователя, во второе оборудование. Морфология может включать в себя или соответствовать форме или размеру, например, форме или размеру головы пользователя. Морфологическая информация может включать в себя передаточные функции восприятия звука человеком (HRTF). Рендеринг может представлять собой бинауральный рендеринг. Этот этап может выполняться в/посредством первого оборудования, например, во время настройки. Затем аудиоконтент может подготавливаться посредством рендеринга дополнительно на основе морфологической информации.
Фиг. 3 иллюстрирует более подробную информацию примерной системы, которая включает в себя сервер/отправляющее устройство 300 и клиент/приемное устройство 350. Как отмечено выше, эта система может реализовывать любой из способов 700, 800, 900 и 1000. Сервер/отправляющее устройство 300 (например, реализующее второе оборудование) может включать в себя модуль 320 рендеринга (например, модуль рендеринга аудио) и кодер 330. Клиент/приемное устройство 350 (например, реализующее первое оборудование) может отправлять текущее положение P(t0) (например, положение головы) в момент времени t0 на сервер/отправляющее устройство 300. Текущее положение P(t0) также может включать в себя непосредственно временную метку t0, которая указывает время, когда создано текущее положение P(t0). Положение P(t0) может определяться и отправляться посредством блока положения 350.
Сервер/отправляющее устройство 300 (например, реализующее второе оборудование) дополнительно может содержать модуль 310 прогнозирования позиции. Сервер/отправляющее устройство 300 может принимать позицию пользователя и текущее положение P(t0) (соответствующие главной ориентации) в момент t1 времени, где t1>t0. Непосредственно принимаемое текущее положение P(t0) и t0 могут использоваться посредством модуля 310 прогнозирования позиции для того, чтобы прогнозировать позицию P(t1). Модуль 310 прогнозирования позиции может учитывать ранее принимаемое положение P(tn) и tn для прогнозирования позиции P(t1), где n может быть составлять от 0 до -бесконечности (положение и значения временных меток от более ранних моментов времени). Позиция P(t1) может быть аналогичной положению P(t0). Позиция P(t1) может использоваться посредством модуля 320 рендеринга аудио для того, чтобы подготавливать посредством рендеринга аудиосцену в момент t1 времени и в силу этого определять подготовленные посредством рендеринга аудиоданные R(t1) 340. Подготовленные посредством рендеринга аудиоданные R(t1) 340 могут кодироваться с использованием аудиокодера 330, чтобы определять аудиоданные A(t1). Сервер/отправляющее устройство 300 может отправлять аудиоданные A(t1) и позицию P(t1) в клиент/приемное устройство 350. Позиция P(t1) может кодироваться как часть потока аудиобитов. Клиент/приемное устройство 350 может принимать аудиоданные A(t1) и позицию P(t1) (например, в форме метаданных) из сервера/отправляющего устройства 300 в момент t2 времени, где t2>t1. Клиент/приемное устройство 350 может принимать аудиоданные A(t1) и позицию P(t1) в аудиодекодере 351, который может определять несжатое аудио U(t1). Блок данных 352 датчиков положения головы может определять положение P(t2) в момент t2 времени. Аудиоэкстраполятор 353 может использовать принимаемую P(t1) для того, чтобы вычислять разность DeltaP положений посредством вычитания положения P(t1) из положения P(t2) в момент t2 времени. DeltaP может использоваться посредством аудиоэкстраполятора 353, чтобы адаптировать/экстраполировать несжатое аудио U(t1) перед выводом 390. Клиент/приемное устройство 350 может применять локальное вращение в качестве части экстраполяции в случае, если аудиоконтент представляет собой FOA, и движение ограничивается перемещением с наклоном относительно вертикальной оси, с наклоном в продольном направлении и/или по крену. Клиент/приемное устройство 350 дополнительно может применять повышающее сведение вслепую в качестве части экстраполяции в случае, аудиоконтент предварительно представляет собой подготовленный посредством рендеринга бинауральный контент или предварительно подготовленный посредством рендеринга канальноориентированный контент.
Вместо прогнозирования позиции P(t1), позиция P(t2') может прогнозироваться для момента t2' времени, в который клиент/приемное устройство 350 предположительно должно принимать или обрабатывать аудиоданные. Момент t2' времени может оцениваться начиная с момента t1 времени, с учетом времен (длительностей), которые необходимы для передачи и/или кодирования/декодирования аудиоданных. Вышеуказанные P(t1), R(t1), A(t1) и U(t1) должны затем заменяться посредством P(t2'), R(t2'), (t2') и U(t2'), соответственно. Любой из элементов, описанных выше, может реализовываться посредством процессора (или набор процессоров) соответствующего оборудования.
Следующий синтаксис из MPEG-H-стандарта трехмерного аудио (ISO/IEC 23008-3) и/или будущих версий MPEG-стандарта может использоваться для передачи P(t)-данных с 3 степенями свободы (3DoF):
Табл. 1
Семантика может задаваться согласно MPEG-H-стандарту трехмерного аудио (ISO/IEC 23008-3) и/или будущим версиям MPEG-стандарта.
Полный синтаксис для передачи 6DoF-данных и временной метки может выглядеть следующим образом:
Табл. 2
Семантика может задаваться согласно MPEG-H-стандарту трехмерного аудио (ISO/IEC 23008-3) и/или будущим версиям MPEG-стандарта.
Фиг. 4 иллюстрирует примерную систему, которая включает в себя отправляющее устройство 400 и приемное устройство 450. Система, описанная на фиг. 4, может включать в себя полностью или частично аспекты систем, описанных на фиг. 1-3. В частности, система может реализовывать любые из способов 700, 800, 900 и 1000, описанных выше. Отправляющее устройство/сервер 400 (например, реализующее второе оборудование) может принимать полную аудиосцену 401 (например, FOA/HOA или объектно-ориентированную сцену) и полную видеосцену 402 (например, видео на 360°) (в качестве примеров мультимедийного контента). Аудиосцена 401 может обрабатываться посредством аудиокодера 410, чтобы определять доставку 441 полных аудиосцен. Полная аудиосцена 441 может состоять из всей аудиосцены и/или сопровождающих метаданных (таких как позиции аудиообъектов, направления и т.д.). Полное видео 402 может обрабатываться посредством выбора 420 доставки контента. Полное видео 420 может разбиваться на различные части, к примеру, интересующие области, и "мозаично размещаться" соответствующим образом (видео на 360° может разбиваться на мозаичные фрагменты) посредством выбора 420 контента, чтобы определять мозаичные фрагменты 402a. Доставка и выбор 420 контента может использовать прогнозную позицию P(t1) (или прогнозную позицию P(t2')), как описано в качестве вывода из модуля 310 прогнозирования позиции на фиг. 3, либо он может использовать неизменные данные 454 датчиков положения головы. Например, мозаичные фрагменты 402a из полного видео 402 на 360° могут выбираться в выборе 420 доставки контента, на основе данных 454 датчиков, принимаемых из приемного устройства 450. Этот выбор может упоминаться как рендеринг видеоконтента. Видеокодер 430 кодирует мозаичные фрагменты 402a, чтобы выводить видео 442 интересующей области, которое может передаваться в клиент/приемное устройство 450 (например, реализующее первое оборудование). Приемное устройство 450 может включать в себя видеодекодер 452, который может принимать видео 442 интересующей области. Видеодекодер 452 может использовать интересующую область 442, чтобы декодировать видео и выводить его в видеовывод 492. Полная аудиосцена 441 может приниматься посредством аудиодекодера 451, который может декодировать контент и предоставлять декодированной аудиосцене в модуль 453 рендеринга аудио. Аудиодекодер 451 может предоставлять несжатые аудио- и метаданные 455 (которые могут соответствовать декодированной аудиосцене) в модуль 453 рендеринга аудио. Модуль 453 рендеринга аудио может подготавливать посредством рендеринга декодированное аудио на основе данных 454 датчиков и может выводить аудиовывод 491. Данные 454 датчиков могут приниматься из возможности датчика обнаруживать перемещение пользователя и/или ориентацию головы пользователя (например, гироскопического датчика). Они затем могут дополнительно предоставляться в модуль 453 рендеринга аудио, чтобы адаптировать полную аудиосцену 441 к текущей ориентации и/или позиции головы пользователя, и в выбор 420 доставки контента, чтобы адаптировать полную видеосцену 402 к текущей ориентации и/или позиции головы пользователя. В частности, в примерной системе по фиг. 4, видеоконтент подготавливается посредством рендеринга на стороне сервера/отправляющего устройства (т.е. видеоконтент, готовый к воспроизведению на стороне приемного устройства/воспроизведения, формируется на стороне сервера/отправляющего устройства), в то время как аудиоконтент подготавливается посредством рендеринга на стороне приемного устройства/воспроизведения. Любой из элементов, описанных выше, может реализовываться посредством процессора (или набор процессоров) соответствующего оборудования.
Фиг. 5 иллюстрирует примерную систему, которая включает в себя отправляющее устройство 500 и приемное устройство 550. Система может реализовывать любые из способов 700, 800, 900 и 1000, описанных выше. Отправляющее устройство/сервер 500 (например, реализующее второе оборудование) может принимать полную аудиосцену 501 (например, HOA-ориентированную или объектно-ориентированную сцену) и полную видеосцену 502 (например, видео на 360°) (в качестве примеров мультимедийного контента). Аудиосцена 501 может обрабатываться посредством модуля 510 рендеринга аудио, чтобы определять бинауральные аудиоданные 541. Модуль 510 рендеринга аудио может определять данные 545 датчиков с учетом бинауральных аудиоданных 541. Данные 545 датчиков могут включать в себя наклон относительно вертикальной оси, наклон в продольном направлении, крен, информацию x, y, z. Бинауральные аудиоданные 541 могут быть распакованными, сжатыми без потерь либо сжатыми с потерями с низкой задержкой. Например, бинауральные аудиоданные 551 могут представлять собой несжатое аудио 580, которое может приниматься посредством приемного устройства 550 (например, реализующего первое оборудование) и предоставляться в бинауральный аудиовывод 591. Полное видео 502 может обрабатываться посредством выбора 520 доставки контента. Полное видео 502 может разбиваться на различные части, к примеру, интересующие области, и "мозаично размещаться" соответствующим образом (видео на 360° может разбиваться на мозаичные фрагменты) в выборе 520 доставки контента, чтобы определять мозаичные фрагменты 502a. Мозаичные фрагменты 502a из полного видео на 360° 502 могут выбираться в выборе 520 доставки контента на основе данных 545 датчиков, принимаемых из приемного устройства 550. Этот выбор может упоминаться как рендеринг видеоконтента. Видеокодер 530 кодирует мозаичные фрагменты 502a, чтобы выводить видео 542 интересующей области, которое может передаваться в клиент/приемное устройство 550. Приемное устройство 550 может включать в себя видеодекодер 552, который может принимать видео 542 интересующей области. Видеодекодер 552 может использовать интересующую область 542, чтобы декодировать видео и выводить его в видеовывод 592. Данные 545 датчиков могут приниматься из возможности датчика обнаруживать перемещение пользователя и/или ориентацию головы пользователя (например, на гироскопического датчика). Они затем могут дополнительно предоставляться в выбор 520 доставки контента, чтобы адаптировать полную видеосцену 502 к текущей ориентации и/или позиции головы пользователя. Они затем могут дополнительно предоставляться в модуль 510 рендеринга аудиоконтента, чтобы адаптировать полную аудиосцену 501 к текущей ориентации и/или позиции головы пользователя. Любой из элементов, описанных выше, может реализовываться посредством процессора (или набор процессоров) соответствующего оборудования.
Фиг. 6 иллюстрирует примерную систему, которая включает в себя отправляющее устройство 600 и приемное устройство 650. Система может реализовывать любые из способов 700, 800, 900 и 1000, описанных выше. Отправляющее устройство/сервер 600 (например, реализующее второе оборудование) может принимать полную аудиосцену 601 (например, HOA-ориентированную или объектно-ориентированную сцену) и полную видеосцену 602 (например, видео на 360°) (в качестве примеров мультимедийного контента). Аудиосцена 601 может обрабатываться посредством модуля 610 рендеринга аудио, и вывод модуля 610 рендеринга аудио затем может обрабатываться посредством аудиокодера 660 с низкой задержкой. Модуль 610 рендеринга аудио может учитывать данные 645 датчиков. Аудиокодер 660 с низкой задержкой может выводить бинауральные аудиоданные 641, которые затем могут отправляться в приемное устройство 650 (например, реализующее первое оборудование). Бинауральные аудиоданные 641 могут приниматься в приемном устройстве 650 посредством аудиодекодера 670 с низкой задержкой, который преобразует бинауральные аудиоданные 641 в несжатое аудио 680. Несжатое аудио 680 затем может предоставляться в бинауральный аудиовывод 691. Полное видео 602 может обрабатываться посредством выбора 620 доставки контента. Полное видео 602 может разбиваться на различные части, к примеру, интересующие области, и "мозаично размещаться" соответствующим образом (видео на 360° может разбиваться на мозаичные фрагменты) в выборе 620 доставки контента, чтобы определять мозаичные фрагменты, которые могут выбираться в выборе 620 доставки контента на основе данных 645 датчиков, принимаемых из приемного устройства 650. Этот выбор может упоминаться как рендеринг видеоконтента. Видеокодер 630 кодирует мозаичные фрагменты и/или видео, чтобы выводить видео 642 интересующей области, которое может передаваться в клиент/приемное устройство 650. Приемное устройство 650 может включать в себя видеодекодер 652, который может принимать видео 642 интересующей области. Видеодекодер 652 может использовать интересующую область 642, чтобы декодировать видео и выводить его в видеовывод 692. Данные 645 датчиков могут приниматься из возможности датчика обнаруживать перемещение пользователя и/или ориентацию головы пользователя (например, на гироскопического датчика). Они затем могут дополнительно предоставляться в выбор 620 доставки контента, чтобы адаптировать полную видеосцену 602 к текущей ориентации и/или позиции головы пользователя. Они затем могут дополнительно предоставляться в модуль 610 рендеринга аудиоконтента, чтобы адаптировать полную аудиосцену 601 к текущей ориентации и/или позиции головы пользователя. Любой из элементов, описанных выше, может реализовываться посредством процессора (или набор процессоров) соответствующего оборудования.
Традиционно, аудио (в качестве неограничивающего примера мультимедийного контента), передаваемое из отправляющего устройства (S) в приемное устройство (R), подготавливается посредством рендеринга в приемном устройстве, как показано на фиг. 1 и фиг. 4. Чтобы максимизировать гибкость на стороне приемного устройства, можно отправлять сложное представление аудиосцены, такое как объекты или HOA, которые могут адаптивно подготавливаться посредством рендеринга на приемной стороне, например, так что они согласуются с локальной точкой обзора/положением слушателя. Тем не менее, кодирование таких представлений может требовать больших времен задержки, что должно предотвращать использование этих подходов для связи или интерактивных приложений.
Настоящее раскрытие сущности предоставляет способы, системы и оборудование для уменьшения упомянутого времени задержки и/или для снижения вычислительной сложности в приемном устройстве. Позиция и ориентация пользователя, передаваемые из приемного устройства в отправляющее устройство, обеспечивают возможность серверу/отправляющему устройству вычислять более компактную, предварительно подготовленную посредством рендеринга версию контента, которая тесно согласуется с текущим положением/точкой обзора приемного устройства. Тем не менее, время задержки при передаче из отправляющего устройства в приемное устройство должно вводить возможное рассогласование между локальным принимаемым положением и положением, для которого вычислен рендеринг на сервере. Настоящее раскрытие сущности предлагает то, что отправляющее устройство должно передавать в служебных сигналах позицию, для которой выполнен рендеринг, позволяя приемному устройству экстраполировать подготовленный посредством рендеринга сигнал в текущее локальное положение. Помимо этого, отправляющее устройство может отправлять предварительно подготовленное посредством рендеринга, несжатое или сжатое с потерями представление аудиосцены, чтобы исключать время задержки при кодировании и декодировании в системе. Отправляющее устройство выполняет алгоритм рендеринга, например, к бинауральному стерео-, FOA- или HOA-представлению. Алгоритм рендеринга может подготавливать посредством рендеринга аудиоданные, такие как аудиообъекты на два канала (например, предварительно подготовленный посредством рендеринга бинаурализированный контент), в выходные каналы. Каналы затем могут кодироваться, в частности, если сжатие требуется (например, в зависимости от полосы пропускания системы) для того, чтобы выводить кодированный поток битов аудиоданных. Сигнал может передаваться в клиент или приемное устройство, и он может выводиться через наушники или систему стереогромкоговорителей.
Когда бинаурализированное воспроизведение должно быть адаптировано к физике головы пользователя, приемное устройство может передавать передаточную функцию восприятия звука человеком (HRTF), которая соответствует свойствам головы пользователя. Приемное устройство дополнительно может передавать функцию бинауральной импульсной характеристики в помещении (BRIR), которая соответствует помещению, предназначенному для воспроизведения. Эта информация может передаваться во время настройки передачи.
Варианты осуществления настоящего раскрытия сущности могут предоставлять, по меньшей мере, следующие преимущества:
- Если передаются только бинаурализированные (стерео)данные, скорость передачи битов для передачи аудиоданных без потерь может быть аналогичной или сравнимой со скоростью передачи битов полной сжатой аудиосцены.
- Передача несжатого (или без потерь) аудиопотока должна исключать или уменьшать время задержки для кодирования и декодирования. Например, время задержки, получающееся в результате кодирования/декодирования, может уменьшаться до нуля, что должно приводить к полному уменьшению времени задержки при передаче движения в уши.
- Когда отсутствует сжатие аудиоданных, приемное устройство должно выводить только аудио без декодирования или рендеринга. Это должно приводить к уменьшению вычислительной сложности в приемном устройстве, поскольку декодирование не должно выполняться, и/или рендеринг уже завершен на стороне отправляющего устройства.
- Различные компромиссы могут находиться, например, между минимальным временем задержки и минимальной вычислительной сложностью приемного устройства при более высокой скорости передачи битов и минимальной скоростью передачи битов при большем времени задержки и более высокой вычислительной сложностью приемного устройства:
-- Передача несжатых данных для минимального времени задержки и вычислительной сложности, но достаточная полоса пропускания для того, чтобы передавать несжатые данные.
-- Передача сжатых без потерь данных для минимального времени задержки и немного более высокой вычислительной сложности, если полоса пропускания является недостаточной для того, чтобы передавать несжатые данные.
-- Передача сжатых данных с низкой задержкой, но с потерями, для и низкой задержки и более высокой вычислительной сложности, если полоса пропускания является ограниченной.
Вышеуказанное также применяется к двусторонней связи между R и S, когда R и S представляют собой приемные устройства и отправляющие устройства одновременно.
Таблица 3 показывает пример системного сравнения, иллюстрирующего такие компромиссы.
Табл. 3
В определенных контекстах, варианты осуществления настоящего раскрытия сущности могут заключать в себе скрытие времени задержки при передаче на основе экстраполяции контента. Когда полное время задержки (например, время задержки при передаче) является слишком высоким (типично выше 20 мс), желательно, если формат кодирования и/или система воспроизведения предоставляют средство для того, чтобы экстраполировать контент таким образом, что он согласуется с локальным положением (позицией и ориентацией) приемного устройства, при ожидании доставки следующего обновленного кадра контента. Полное время задержки может определяться на основе суммы всех времен задержки при полном обходе аудиоданных. Например, полное время задержки может быть основано на времени задержки на полный обход, времени задержки при кодировании, времени задержки при декодировании и времени задержки при рендеринге.
Скрытие этого времени задержки может достигаться посредством передачи локального положения из приемного устройства в отправляющее устройство/сервер для рендеринга (например, как описано выше со ссылкой на этапы S920 и S1020) и инструктирования отправляющему устройству/серверу отправлять обратно то, какое положение использовано для каждого подготовленного посредством рендеринга кадра контента (например, как описано выше со ссылкой на этапы S950 и S1050). Отправляющее устройство/отправляющее устройство может прогнозировать перемещение пользователя, чтобы компенсировать дополнительное время задержки, введенное между временем, когда контент подготавливается посредством рендеринга посредством отправляющего устройства и принимается в приемном устройстве, что включает в себя учет ранее принимаемых позиций.
Затем приемное устройство может экстраполировать предварительно подготовленное посредством рендеринга аудио, принимаемое из сервера, с учетом дельты между положением, используемым для того, чтобы подготавливать посредством рендеринга контент на стороне отправляющего устройства, и локальным положением (например, текущим или фактическим положением) приемного устройства R (например, как описано выше со ссылкой на этапы S970 и S1070).
Эта экстраполяция может реализовываться несколькими способами на основе гибкости подготовленного посредством рендеринга контента. В одном примере, когда контент представляет собой предварительно подготовленный посредством рендеринга амбиофонический B-формат, и движение представляет собой движение с тремя степенями свободы, экстраполяция может быть основана на клиентском локальном вращении контента в FOA- или B-формате до воспроизведения. В другом примере, для предварительно подготовленного посредством рендеринга бинаурального контента, экстраполяция может достигаться посредством повышающего сведения вслепую (см. приложение A), или посредством добавления метаданных в бинауральный поток (см. приложение B). В другом примере, для предварительно подготовленного посредством рендеринга канальноориентированного контента, повышающий микшер вслепую с низкой задержкой может применяться на приемном конце.
Если рендеринг и кодирование тесно интегрируются на стороне отправляющего устройства, можно увеличивать гибкость предварительно подготовленного посредством рендеринга контента посредством добавления кодирования метаданных, например, направления/расстояния различных подполос частот или энергетических градиентов на основе текущей позиции P, ∇E(P) рендеринга.
Если исходный контент, который должен подготавливаться посредством рендеринга, является объектно-ориентированным, можно вычислять несколько рендерингов вокруг требуемой позиции и кодировать градиент уровня. Этот градиент G уровня типично состоит из трехмерного вектора (по одному значению для каждой из трех осей x, y, z). Приемное устройство затем может просто регулировать энергию E(P) подполосы частот в принимаемом сигнале на основе разности между предварительно подготовленной посредством рендеринга позицией P и текущей позицией P' приемного устройства в качестве E(P')=E(P)*(P'-P)*∇E(P).
Эта дополнительная информация может использоваться посредством приемного устройства, чтобы дополнительно экстраполировать предварительно подготовленный посредством рендеринга поток (т.е. предварительно подготовленный посредством рендеринга мультимедийный контент), например, учет параллактических эффектов (с использованием информации расстояния) или регулирование уровня рендеринга (с использованием информации градиента уровня).
В одном примере, если приемное устройство ограничивается с точки зрения вычислительной мощности, повышающее сведение может выполняться во время кодирования на стороне отправляющего устройства. Например, B-формат или каналы могут преобразовываться в объекты. Это может увеличивать время задержки тракта кодирования, но результирующий контент может быть более гибким и может быть экстраполирован на конце приемного устройства.
Для вариантов использования в играх, в которых пользовательские действия (например, триггеры кнопки) могут затрагивать игру, полное время задержки системы по-прежнему должно составлять <20 мс, что позволяет предотвращать выполнение сложных операций повышающего сведения. Как результат, гибкий формат, такой как B-формат, может представлять собой наилучший возможный вариант для рендеринга/передачи с использованием кодека без потерь или с потерями с низкой задержкой, поскольку он также может подготавливаться посредством рендеринга и вращаться с низкой задержкой на приемном конце.
Различные аудиокодеки могут включать вышеописанные режимы передачи данных. Кодеки могут адаптироваться с возможностью следующего: (i) возможности передавать без потерь кодированные (кодированные с нулевым времени задержки) стереоаудиоданные или данные с потерями с низкой задержкой; (ii) средство передавать в служебных сигналах то, что контент уже предварительно подготовлен посредством рендеринга, в случае если "обычный" рендеринг (например, бинаурализация в устройстве) должен отключаться (например, поле синтаксиса потока битов; как Dolby AC-4, так и трехмерный аудиостандарт MPEG-H, часть 3, уже включают в себя такое битовое поле, к примеру, b_pre_virtualized в Dolby AC-4); и (iii) средство передавать HRTF и BRIR при необходимости.
Таким образом, в контексте настоящего раскрытия сущности, отправляющее устройство также может предоставлять приемному устройству индикатор (например, флаг, битовое поле, поле/элемент синтаксиса, параметр) того, что оно предоставляет предварительно подготовленный посредством рендеринга аудиоконтент. Если такой индикатор принимается посредством приемного устройства, приемное устройство может предварять любой рендеринг (на стороне приемного устройства) аудиоконтента. Например, для бинаурального предварительно подготовленного посредством рендеринга аудиоконтента, приемное устройство может непосредственно маршрутизировать предварительно подготовленный посредством рендеринга аудиоконтент, принимаемый из отправляющего устройства, на (динамики) наушник для воспроизведения без дальнейшего рендеринга. Такой индикатор может иметь форму параметра directHeadphone, который передается в служебных сигналах в приемное устройство в потоке битов. Параметр directHeadphone может задавать то, что соответствующая группа сигналов каналов (типа) идет на вывод наушников, непосредственно, если бинауральный вывод подготавливается посредством рендеринга. Сигналы могут маршрутизироваться в левый и правый канал наушника.
Возможный пример синтаксиса для этого параметра приводится в таблице 4.
Табл. 4
Семантика может задаваться согласно MPEG-H-стандарту трехмерного аудио (ISO/IEC 23008-3) и/или будущим версиям MPEG-стандарта.
Дополнительные примерные варианты осуществления раскрытия сущности обобщаются в нижеприведенных перечислимых примерных вариантах осуществления (EEE).
Первый EEE относится к способу обработки мультимедийного контента для воспроизведения посредством первого оборудования, при этом способ содержит: получение информации положения, указывающей позицию и/или ориентацию пользователя, передачу информации положения во второе оборудование, которое предоставляет мультимедийный контент, подготовку посредством рендеринга мультимедийного контента на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент, и передачу подготовленного посредством рендеринга мультимедийного контента в первое оборудование для воспроизведения.
Второй EEE относится к способу по первому EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент; и/или мультимедийный контент содержит видеоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга видеоконтент.
Третий EEE относится к способу по первому EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, и способ дополнительно содержит формирование слышимого представления подготовленного посредством рендеринга аудиоконтента.
Четвертый EEE относится к способу по второму EEE, в котором аудиоконтент представляет собой одно из ориентированного на амбиофонию первого порядка (FOA), ориентированного на амбиофонию высшего порядка (HOA), объектно-ориентированного или канальноориентированного аудиоконтента либо комбинацию двух или более из FOA-ориентированного, HOA-ориентированного, объектно-ориентированного или канальноориентированного аудиоконтента.
Пятый EEE относится к способу по второму или третьему EEE, в котором подготовленный посредством рендеринга аудиоконтент представляет собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента.
Шестой EEE относится к способу по любому из первого-пятого EEE, в котором рендеринг заключает в себе: получение прогнозированной информации положения на основе информации положения и информации предыдущего положения и рендеринг мультимедийного контента на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент.
Седьмой EEE относится к способу по шестому EEE, дополнительно содержащему: передачу прогнозированной информации положения в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом.
Восьмой EEE относится к способу по седьмому EEE, дополнительно содержащему: сравнение прогнозированной информации положения с информацией фактического положения и обновление подготовленного посредством рендеринга мультимедийного контента на основе результата сравнения.
Девятый EEE относится к способу по восьмому EEE, в котором прогнозированная информация положения прогнозируется для оценки времени, когда подготовленный посредством рендеринга мультимедийный контент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, и информация фактического положения представляет собой информацию положения, полученную в то время, когда подготовленный посредством рендеринга мультимедийный контент фактически обрабатывается посредством первого оборудования для воспроизведения.
Десятый EEE относится к способу по любому из первого-девятого EEE, в котором подготовленный посредством рендеринга мультимедийный контент передается в первое оборудование в несжатой форме.
Одиннадцатый EEE относится к способу по любому из первого-десятого EEE, дополнительно содержащему: кодирование подготовленного посредством рендеринга мультимедийного контента перед передачей в первое оборудование; и декодирование кодированного подготовленного посредством рендеринга мультимедийного контента после приема в первом оборудовании.
Двенадцатый EEE относится к способу по девятому EEE или по любому EEE, включающему в себя признаки девятого EEE, в котором оценка времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, включает в себя оценку времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценку времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
Тринадцатый EEE относится к способу по шестому EEE или по любому EEE, включающему в себя признаки шестого EEE, в котором прогнозированная информация положения получается дополнительно на основе оценки времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга мультимедийного контента, и/или оценки времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
Четырнадцатый относится к способу по любому из первого-тринадцатого EEE, дополнительно содержащему: сравнение информации положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения, и обновление подготовленного посредством рендеринга мультимедийного контента на основе результата сравнения.
15-й EEE относится к способу по любому из первого-четырнадцатого EEE, дополнительно содержащему: определение, во втором оборудовании, информации градиента, указывающей то, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения, передачу информации градиента в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом, сравнение, в первом оборудовании, информации положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения, и обновление подготовленного посредством рендеринга мультимедийного контента на основе информации градиента и результата сравнения.
16-й EEE относится к способу по любому из первого-пятнадцатого EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, способ дополнительно содержит передачу информации окружения, указывающей акустические характеристики окружения, в котором расположено первое оборудование, во второе оборудование, и рендеринг мультимедийного контента дополнительно основан на информации окружения.
17-й EEE относится к способу по любому из первого-шестнадцатого EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, способ дополнительно содержит передачу морфологической информации, указывающей морфологию пользователя либо части пользователя, во второе оборудование, и рендеринг мультимедийного контента дополнительно основан на морфологической информации.
18-й EEE относится к системе, содержащей первое оборудование для воспроизведения мультимедийного контента и второе оборудование, сохраняющее мультимедийный контент, при этом первое оборудование выполнено с возможностью: получать информацию положения, указывающую позицию и/или ориентацию пользователя, и передавать информацию положения во второе оборудование, и второе оборудование выполнено с возможностью: подготавливать посредством рендеринга мультимедийный контент на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент, и передавать подготовленный посредством рендеринга мультимедийный контент в первое оборудование для воспроизведения.
19-й EEE относится к системе по 18-му EEE, в которой мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, и/или мультимедийный контент содержит видеоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга видеоконтент.
20-й EEE относится к системе по 18-му EEE, в которой мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, и первое оборудование дополнительно выполнено с возможностью формировать слышимое представление подготовленного посредством рендеринга аудиоконтента.
21-й EEE относится к системе по 19-му EEE, в которой аудиоконтент представляет собой одно из ориентированного на амбиофонию первого порядка (FOA), ориентированного на амбиофонию высшего порядка (HOA), объектно-ориентированного или канальноориентированного аудиоконтента либо комбинацию двух или более из FOA-ориентированного, HOA-ориентированного, объектно-ориентированного или канальноориентированного аудиоконтента.
22-й EEE относится к системе по любому из 19-21-го EEE, в которой подготовленный посредством рендеринга аудиоконтент представляет собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента.
23-й EEE относится к системе по любому из 18-22-го EEE, в которой второе оборудование дополнительно выполнено с возможностью: получать прогнозированную информацию положения на основе информации положения и информации предыдущего положения и подготавливать посредством рендеринга мультимедийный контент на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент.
24-й EEE относится к системе по 23-му EEE, в которой второе оборудование дополнительно выполнено с возможностью: передавать прогнозированную информацию положения в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом.
25-й EEE относится к системе по 24-му EEE, в которой первое оборудование дополнительно выполнено с возможностью: сравнивать прогнозированную информацию положения с информацией фактического положения и обновлять подготовленный посредством рендеринга мультимедийный контент на основе результата сравнения.
26-й EEE относится к системе по 25-му EEE, в которой прогнозированная информация положения прогнозируется для оценки времени, когда подготовленный посредством рендеринга мультимедийный контент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, и информация фактического положения представляет собой информацию положения, полученную в то время, когда подготовленный посредством рендеринга мультимедийный контент фактически обрабатывается посредством первого оборудования для воспроизведения.
27-й EEE относится к системе по любому из 18-26-го EEE, в которой подготовленный посредством рендеринга мультимедийный контент передается в первое оборудование в несжатой форме.
28-й EEE относится к системе по любому из 18-27-го EEE, в которой второе оборудование дополнительно выполнено с возможностью кодировать подготовленный посредством рендеринга мультимедийный контент перед передачей в первое оборудование, и первое оборудование дополнительно выполнено с возможностью декодировать кодированный подготовленный посредством рендеринга мультимедийный контент после приема в первом оборудовании.
29-й EEE относится к системе по 26-му EEE или по любому EEE, включающему в себя признаки 26-го EEE, в которой оценка времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, включает в себя оценку времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценку времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
30-й EEE относится к системе по 23-му EEE или по любому EEE, включающему в себя признаки 23-го EEE, в которой прогнозированная информация положения получается дополнительно на основе оценки времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга мультимедийного контента, и/или оценки времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
31-й EEE относится к системе по любому из 18-30-го EEE, в которой первое оборудование дополнительно выполнено с возможностью: сравнивать информацию положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения, и обновлять подготовленный посредством рендеринга мультимедийный контент на основе результата сравнения.
32-й EEE относится к системе по любому из 18-31-го EEE, в которой второе оборудование дополнительно выполнено с возможностью: определять информацию градиента, указывающую то, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения, и передавать информацию градиента в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом, и первое оборудование дополнительно выполнено с возможностью: сравнивать информацию положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения, и обновлять подготовленный посредством рендеринга мультимедийный контент на основе информации градиента и результата сравнения.
33-й EEE относится к системе по любому из 18-32-го EEE, в которой мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, первое оборудование дополнительно выполнено с возможностью передавать информацию окружения, указывающую акустические характеристики окружения, в котором расположено первое оборудование, во второе оборудование, и рендеринг мультимедийного контента дополнительно основан на информации окружения.
34-й EEE относится к системе по любому из 18-33-го и EEE, в которой мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, первое оборудование дополнительно выполнено с возможностью передавать морфологическую информацию, указывающую морфологию пользователя либо части пользователя, во второе оборудование, и рендеринг мультимедийного контента дополнительно основан на морфологической информации.
35-й EEE относится ко второму оборудованию для предоставления мультимедийного контента для воспроизведения посредством первого оборудования, причем второе оборудование выполнено с возможностью: принимать информацию положения, указывающую позицию и/или ориентацию пользователя первого оборудования, подготавливать посредством рендеринга мультимедийный контент на основе информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент, и передавать подготовленный посредством рендеринга мультимедийный контент в первое оборудование для воспроизведения.
36-й EEE относится ко второму оборудованию по 35-му EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, и/или мультимедийный контент содержит видеоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга видеоконтент.
37-й EEE относится ко второму оборудованию по 36-го EEE, в котором аудиоконтент представляет собой одно из ориентированного на амбиофонию первого порядка (FOA), ориентированного на амбиофонию высшего порядка (HOA), объектно-ориентированного или канальноориентированного аудиоконтента либо комбинацию двух или более из FOA-ориентированного, HOA-ориентированного, объектно-ориентированного или канальноориентированного аудиоконтента.
38-й EEE относится ко второму оборудованию по 36-му EEE, в котором подготовленный посредством рендеринга аудиоконтент представляет собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента.
39-й EEE относится ко второму оборудованию по любому из 35-38-го EEE, дополнительно выполненному с возможностью: получать прогнозированную информацию положения на основе информации положения и информации предыдущего положения и подготавливать посредством рендеринга мультимедийный контент на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент.
40-й EEE относится ко второму оборудованию по 39-му EEE, дополнительно выполненному с возможностью: передавать прогнозированную информацию положения в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом.
41-й EEE относится ко второму оборудованию по 39-му или 40-му EEE, в котором прогнозированная информация положения прогнозируется для оценки времени, когда подготовленный посредством рендеринга мультимедийный контент предположительно должен обрабатываться посредством первого оборудования для воспроизведения.
42-й EEE относится ко второму оборудованию по любому из 35-41-го EEE, в котором подготовленный посредством рендеринга мультимедийный контент передается в первое оборудование в несжатой форме.
43-й EEE относится ко второму оборудованию по любому из 35-42-го EEE, дополнительно выполненному с возможностью кодировать подготовленный посредством рендеринга мультимедийный контент перед передачей в первое оборудование.
44-й EEE относится ко второму оборудованию по 41-му EEE или по любому EEE, включающему в себя признаки 41-го EEE, в котором оценка времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, включает в себя оценку времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценку времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
45-й EEE относится ко второму оборудованию по 39-му EEE или по любому EEE, включающему в себя признаки 39-го EEE, в котором прогнозированная информация положения получается дополнительно на основе оценки времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга мультимедийного контента, и/или оценки времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
46-й EEE относится ко второму оборудованию по любому из 35-45-го EEE, дополнительно выполненному с возможностью: определять информацию градиента, указывающую то, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения, и передавать информацию градиента в первое оборудование вместе с подготовленным посредством рендеринга мультимедийным контентом.
47-й EEE относится ко второму оборудованию по любому из 35-46-го EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, второе оборудование дополнительно выполнено с возможностью принимать информацию окружения, указывающую акустические характеристики окружения, в котором расположено первое оборудование, из первого оборудования, и рендеринг мультимедийного контента дополнительно основан на информации окружения.
48-й EEE относится ко второму оборудованию по любому из 35-47-го EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, второе оборудование дополнительно выполнено с возможностью принимать морфологическую информацию, указывающую морфологию пользователя либо части пользователя, из первого оборудования, и рендеринг мультимедийного контента дополнительно основан на морфологической информации.
49-й EEE относится к первому оборудованию для воспроизведения мультимедийного контента, предоставленного посредством второго оборудования, причем первое оборудование выполнено с возможностью: получать информацию положения, указывающую позицию и/или ориентацию пользователя первого оборудования, передавать информацию положения во второе оборудование, принимать подготовленный посредством рендеринга мультимедийный контент из второго оборудования, при этом подготовленный посредством рендеринга мультимедийный контент получен посредством рендеринга мультимедийного контента на основе информации положения, и воспроизводить подготовленный посредством рендеринга мультимедийный контент.
50-й EEE относится к первому оборудованию по 49-му EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, и/или мультимедийный контент содержит видеоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга видеоконтент.
51-й EEE относится к первому оборудованию по 49-му EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, и первое оборудование дополнительно выполнено с возможностью формировать слышимое представление подготовленного посредством рендеринга аудиоконтента.
52-й EEE относится к первому оборудованию по 50-му или 51-му EEE, в котором аудиоконтент представляет собой одно из ориентированного на амбиофонию первого порядка (FOA), ориентированного на амбиофонию высшего порядка (HOA), объектно-ориентированного или канальноориентированного аудиоконтента либо комбинацию двух или более из FOA-ориентированного, HOA-ориентированного, объектно-ориентированного или канальноориентированного аудиоконтента.
53-й EEE относится к первому оборудованию по любому из 50-52-го EEE, в котором подготовленный посредством рендеринга аудиоконтент представляет собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канальноориентированного аудиоконтента.
54-й EEE относится к первому оборудованию по любому из 49-53-го EEE, дополнительно выполненному с возможностью: принимать информацию положения, которая использована для рендеринга мультимедийного контента вместе с подготовленным посредством рендеринга мультимедийным контентом, из второго оборудования, сравнивать информацию положения, которая использована для рендеринга мультимедиа, с информацией фактического положения, и обновлять подготовленный посредством рендеринга мультимедийный контент на основе результата сравнения.
55-й EEE относится к первому оборудованию по 54-му EEE, в котором информация фактического положения представляет собой информацию положения, полученную в то время, когда подготовленный посредством рендеринга мультимедийный контент обрабатывается посредством первого оборудования для воспроизведения.
56-й EEE относится к первому оборудованию по любому из 49-55-го EEE, дополнительно выполненному с возможностью получать прогнозированную информацию положения на основе информации положения и информации предыдущего положения и передавать прогнозированную информацию положения во второе оборудование.
57-й EEE относится к первому оборудованию по 56-му EEE, в котором прогнозированная информация положения прогнозируется для оценки времени, когда подготовленный посредством рендеринга мультимедийный контент предположительно должен обрабатываться посредством первого оборудования для воспроизведения.
58-й EEE относится к первому оборудованию по любому из 49-57-го EEE, в котором подготовленный посредством рендеринга мультимедийный контент принимается из второго оборудования в несжатой форме.
59-й EEE относится к первому оборудованию по любому из 49-58-го EEE, в котором первое оборудование дополнительно выполнено с возможностью декодировать кодированный подготовленный посредством рендеринга мультимедийный контент.
60-й EEE относится к первому оборудованию по 57-му EEE или по любому EEE, включающему в себя признаки 57-го EEE, в котором оценка времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, включает в себя оценку времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценку времени, которое необходимо для передачи подготовленного посредством рендеринга мультимедийного контента в первое оборудование.
61-й EEE относится к первому оборудованию по любому из 49-60-го EEE, дополнительно выполненному с возможностью: сравнивать информацию положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения, и обновлять подготовленный посредством рендеринга мультимедийный контент на основе результата сравнения.
62-й EEE относится к первому оборудованию по любому из 49-61-го EEE, дополнительно выполненному с возможностью: принимать информацию градиента, указывающую то, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения вместе с подготовленным посредством рендеринга мультимедийным контентом, из второго оборудования, сравнивать информацию положения, которая использована для рендеринга мультимедийного контента, с информацией текущего положения, и обновлять подготовленный посредством рендеринга мультимедийный контент на основе информации градиента и результата сравнения.
63-й EEE относится к первому оборудованию по любому из 49-62-го EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, первое оборудование дополнительно выполнено с возможностью передавать информацию окружения, указывающую акустические характеристики окружения, в котором расположено первое оборудование, во второе оборудование, и рендеринг мультимедийного контента дополнительно основан на информации окружения.
64-й EEE относится к первому оборудованию по любому из 49-63-го EEE, в котором мультимедийный контент содержит аудиоконтент, и подготовленный посредством рендеринга мультимедийный контент содержит подготовленный посредством рендеринга аудиоконтент, первое оборудование дополнительно выполнено с возможностью передавать морфологическую информацию, указывающую морфологию пользователя либо части пользователя, во второе оборудование, и рендеринг мультимедийного контента дополнительно основан на морфологической информации.
65-й EEE относится к способу для рендеринга аудиоконтента. Способ содержит: прием, посредством отправляющего (S) оборудования, данных позиции и/или ориентации пользователя и отправку соответствующего предварительно подготовленного посредством рендеринга контента, типично извлекаемого из объектно-ориентированного или HOA-представления.
66-й EEE относится к способу по 65-му EEE, в котором предварительно подготовленный посредством рендеринга сигнал, сформированный посредством отправляющего устройства, может представлять собой бинауральный, FOA/B-формат, HOA- или любой тип канальноориентированного рендеринга.
67-й EEE относится к способу по 65-му или 66-му EEE, дополнительно содержащему передачу распакованного предварительно подготовленного посредством рендеринга контента.
68-й EEE относится к способу по 65-му или 66-му EEE, дополнительно содержащему кодирование предварительно подготовленного посредством рендеринга контента и передачу кодированного предварительно подготовленного посредством рендеринга контента.
69-й EEE относится к способу по любому из 65-68-го EEE, дополнительно содержащему прием предварительно подготовленного посредством рендеринга контента посредством приемного устройства.
70-й EEE относится к способу по любому из 65- 69-го EEE, дополнительно содержащему декодирование предварительно подготовленного посредством рендеринга предварительно кодированного бинаурализированного контента посредством приемного устройства.
71-й EEE относится к способу по любому из 65-70-го EEE, в котором данные позиции и/или ориентации пользователя содержат локальное положение, которое указывает позицию и ориентацию пользователя в мировом пространстве.
72-й EEE относится к способу по любому из 65-71-го EEE, в котором данные позиции пользователя передаются в отправляющее устройство из приемного устройства.
73-й EEE относится к способу по любому из 65-72-го EEE, дополнительно содержащему передачу данных позиции пользователя, используемых для предварительно подготовленного посредством рендеринга бинаурализированного контента, обратно в приемное устройство.
74-й EEE относится к способу по любому из 65-73-го EEE, дополнительно содержащему экстраполяцию предварительно подготовленного посредством рендеринга контента на основе принимаемых данных позиции пользователя и данных локальной позиции, чтобы определять обновленный контент.
75-й EEE относится к способу по любому из 65-74-го EEE, дополнительно содержащему передачу морфологических данных относительно пользователя (например, размера головы, форма головы) для индивидуализированной бинауральной обработки.
76-й EEE относится к способу по любому из 65-75-го EEE, дополнительно содержащему передачу данных относительно BRIR-функций и/или определения характеристик помещения.
77-й EEE относится к способу по любому из 65-76-го EEE, дополнительно содержащему, на основе определения того, что контент передается агностическим к слушателю способом (например, не включает в себя HRTF), то, что бинауральный рендеринг и индивидуализация выполняются на стороне приемного устройства.
78-й EEE относится к способу по любому из 65-77-го EEE, дополнительно содержащему предоставление данных P(t0) позиции и/или ориентации пользователя в момент t1 времени.
79-й EEE относится к способу по 67-му EEE, в котором несжатый предварительно подготовленный посредством рендеринга контент представляет собой бинаурализированный распакованный предварительно подготовленный посредством рендеринга контент.


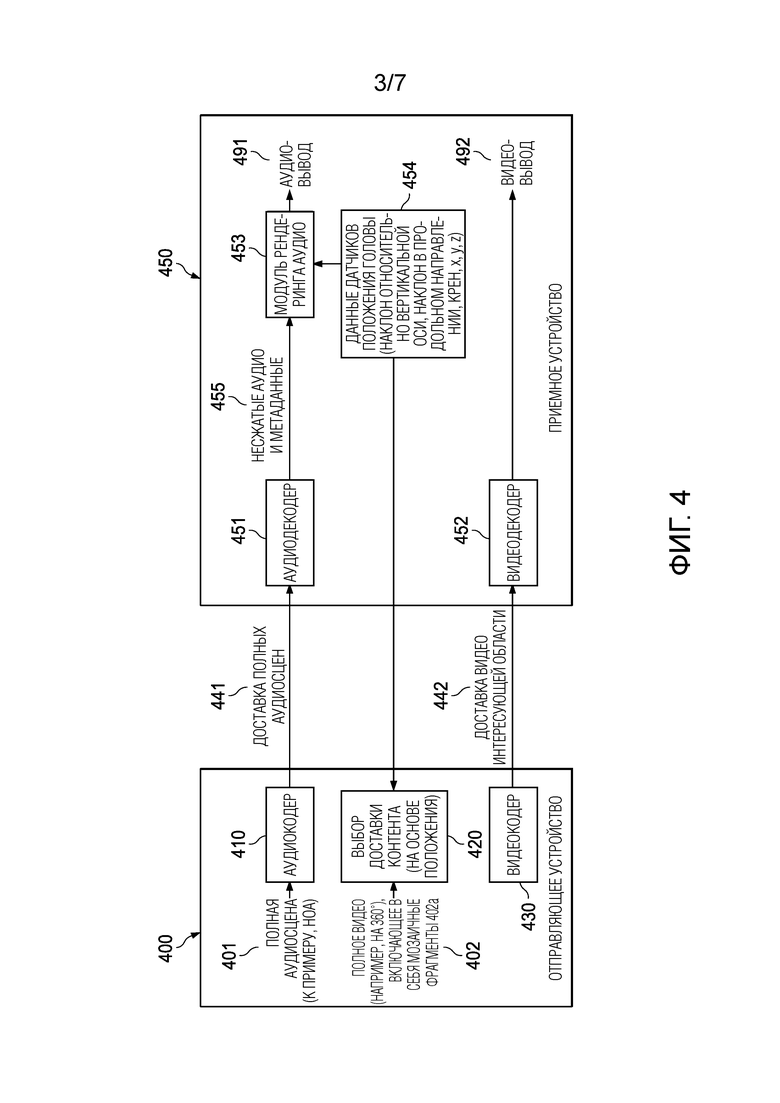

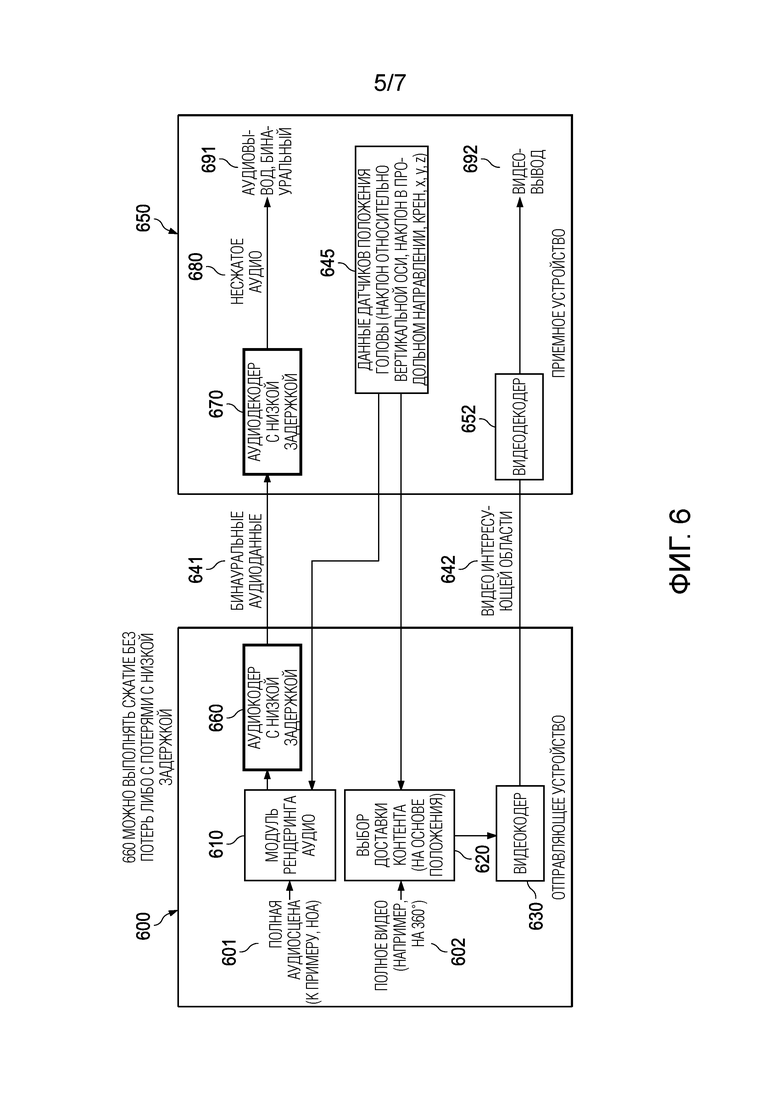

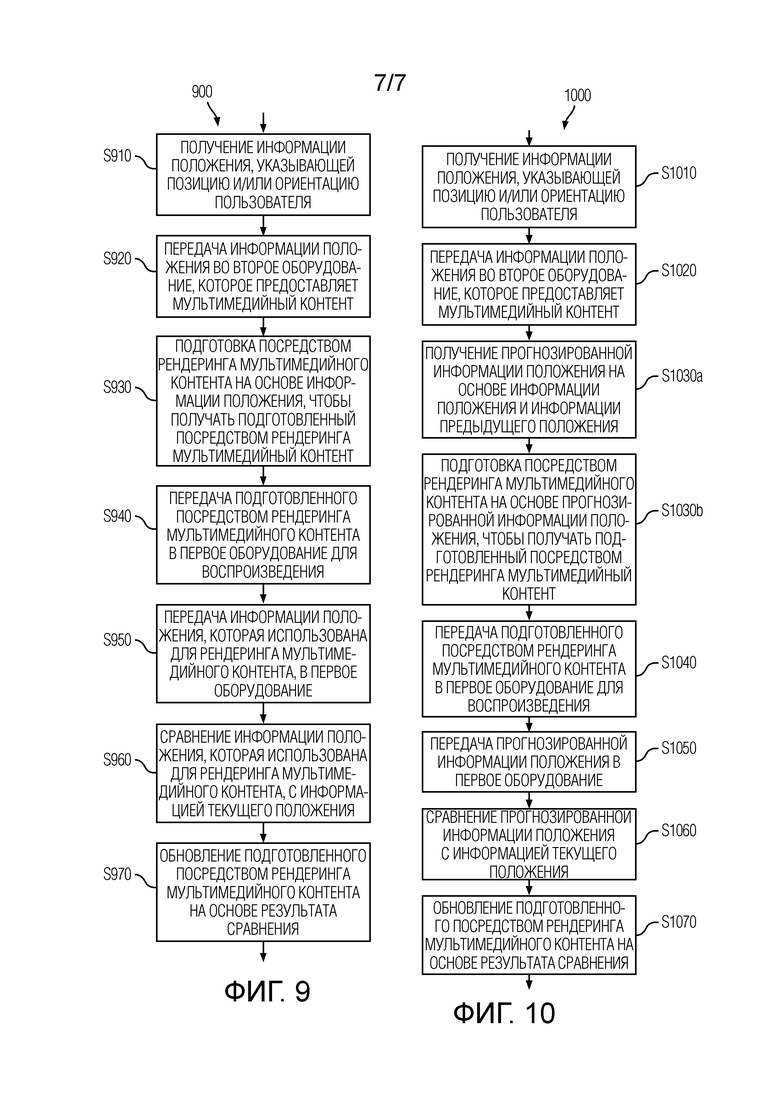
Изобретение относится к области информационных технологий, а именно к средствам обработки мультимедийного контента. Технический результат направлен на повышение точности обработки и снижения времени задержки. Способ обработки аудиоконтента, содержащий этапы, на которых: получают, используя один или более процессоров, первую информацию положения, указывающую первую позицию или ориентацию пользователя, получают, используя один или более процессоров, прогнозированную информацию положения на основе первой информации положения и информации предыдущего положения, подготавливают посредством рендеринга аудиоконтент и передают, используя один или более процессоров, подготовленный посредством рендеринга аудиоконтент и прогнозированную информацию положения в первое оборудование для воспроизведения, при этом прогнозированная информация положения и вторая информация положения используются для обновления подготовленного посредством рендеринга аудиоконтента перед воспроизведением обновленного подготовленного посредством рендеринга аудиоконтента в первом оборудовании. 5 н. и 16 з.п. ф-лы, 10 ил., 4 табл.
1. Способ обработки аудиоконтента, содержащий этапы, на которых:
получают, используя один или более процессоров, первую информацию положения, указывающую первую позицию или ориентацию пользователя;
получают, используя один или более процессоров, прогнозированную информацию положения на основе первой информации положения и информации предыдущего положения;
подготавливают посредством рендеринга, используя один или более процессоров, аудиоконтента на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга аудиоконтент; и
передают, используя один или более процессоров, подготовленный посредством рендеринга аудиоконтент и прогнозированную информацию положения в первое оборудование для воспроизведения, при этом прогнозированная информация положения и вторая информация положения используются для обновления подготовленного посредством рендеринга аудиоконтента перед воспроизведением обновленного подготовленного посредством рендеринга аудиоконтента в первом оборудовании.
2. Способ по п. 1, в котором аудиоконтент представляет собой одно из ориентированного на амбиофонию первого порядка (FOA), ориентированного на амбиофонию высшего порядка (HOA), объектно-ориентированного или канально-ориентированного аудиоконтента либо комбинацию двух или более из FOA-ориентированного, HOA-ориентированного, объектно-ориентированного или канально-ориентированного аудиоконтента.
3. Способ по п. 1, в котором подготовленный посредством рендеринга аудиоконтент представляет собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канально-ориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канально-ориентированного аудиоконтента.
4. Способ по п. 1, в котором использование прогнозированной информации положения и второй информации положения для обновления подготовленного посредством рендеринга аудиоконтента содержит этапы, на которых:
сравнивают прогнозированную информацию положения со второй информацией положения; и
обновляют подготовленный посредством рендеринга аудиоконтент на основе результата сравнения.
5. Способ по п. 4, в котором прогнозированная информация положения прогнозируется для оценки времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения; и
вторая информация положения представляет собой информацию положения, полученную в то время, когда подготовленный посредством рендеринга аудиоконтент фактически обрабатывается посредством первого оборудования для воспроизведения.
6. Способ по п. 1, в котором подготовленный посредством рендеринга аудиоконтент передается в первое оборудование в несжатой форме.
7. Способ по п. 1, содержащий также этап, на котором:
кодируют подготовленный посредством рендеринга аудиоконтент перед передачей в первое оборудование и декодируют кодированный подготовленный посредством рендеринга аудиоконтент после приема в первом оборудовании.
8. Способ по п. 5, в котором оценка времени, когда подготовленный посредством рендеринга аудиоконтент предположительно должен обрабатываться посредством первого оборудования для воспроизведения, включает в себя оценку времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценку времени, которое необходимо для передачи подготовленного посредством рендеринга аудиоконтента в первое оборудование.
9. Способ по п. 1, в котором прогнозированная информация положения получается дополнительно на основе оценки времени, которое необходимо для кодирования и декодирования подготовленного посредством рендеринга аудиоконтента, и/или оценки времени, которое необходимо для передачи подготовленного посредством рендеринга аудиоконтента в первое оборудование.
10. Способ по п. 1, содержащий также этапы, на которых:
сравнивают прогнозированную информацию положения, которая была использована для рендеринга аудиоконтента, со второй информацией положения; и
обновляют подготовленный посредством рендеринга аудиоконтент на основе результата сравнения.
11. Способ по п. 1, содержащий также этапы, на которых:
определяют, во втором оборудовании, информацию градиента, указывающую то, как подготовленный посредством рендеринга аудиоконтент изменяется в ответ на изменения информации положения;
передают информацию градиента в первое оборудование вместе с подготовленным посредством рендеринга аудиоконтентом;
сравнивают, в первом оборудовании, информацию положения, которая была использована для рендеринга аудиоконтента, с информацией текущего положения; и
обновляют подготовленный посредством рендеринга аудиоконтент на основе информации градиента и результата сравнения.
12. Способ по п. 1, содержащий также этап, на котором передают информацию окружения, указывающую акустические характеристики окружения, в котором расположено первое оборудование, во второе оборудование; и
- рендеринг аудиоконтента дополнительно основан на информации окружения.
13. Способ по п. 1, содержащий также этап, на котором передают морфологическую информацию, указывающую морфологию пользователя либо части пользователя, во второе оборудование; и
рендеринг аудиоконтента дополнительно основан на морфологической информации.
14. Система для обработки аудиоконтента, содержащая:
один или более процессоров;
запоминающее устройство, хранящее инструкции, которые при исполнении одним или более процессорами, побуждают один или более процессоры выполнять действия, содержащие:
получение первой информации положения, указывающей первую позицию или ориентацию пользователя;
получение прогнозированной информации положения на основе первой информации положения и информации предыдущего положения;
подготовку посредством рендеринга аудиоконтента на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга аудиоконтент; и
передачу подготовленного посредством рендеринга аудиоконтента и прогнозированной информации положения в первое оборудование для воспроизведения, при этом прогнозированная информация положения и вторая информация положения используются для обновления подготовленного посредством рендеринга аудиоконтента перед воспроизведением обновленного подготовленного посредством рендеринга аудиоконтента в первом оборудовании.
15. Система по п. 14, в которой подготовленный посредством рендеринга аудиоконтент представляет собой одно из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канально-ориентированного аудиоконтента либо комбинацию двух или более из бинаурального аудиоконтента, FOA-аудиоконтента, HOA-аудиоконтента или канально-ориентированного аудиоконтента.
16. Способ обработки мультимедийного контента для воспроизведения посредством первого оборудования, при этом способ содержит этапы, на которых:
получают, используя один или более процессоров, информацию положения, указывающую позицию или ориентацию пользователя;
получают, используя один или более процессоров, прогнозированную информацию положения на основе информации положения и информации предыдущего положения;
подготавливают посредством рендеринга, используя один или более процессоров, мультимедийный контент на основе прогнозированной информации положения, чтобы получать подготовленный посредством рендеринга мультимедийный контент;
получают, используя один или более процессоров, информацию градиента, указывающую то, как подготовленный посредством рендеринга мультимедийный контент изменяется в ответ на изменения информации положения; и
передают, используя один или более процессоров, подготовленный посредством рендеринга мультимедийный контент и информацию градиента в первое оборудование для использования в обновлении и воспроизведении обновленного подготовленного посредством рендеринга мультимедийного контента первым оборудованием.
17. Способ по п. 16, содержащий также этап, на котором передают, используя один или более процессоров, прогнозированное положение в первое оборудование для использования в обновлении и воспроизведении обновленного подготовленного посредством рендеринга мультимедийного контента первым оборудованием.
18. Способ обработки аудиоконтента, содержащий этапы, на которых:
получают, используя один или более процессоров, первую информацию положения, указывающую первую позицию или ориентацию пользователя;
передают, используя один или более процессоров, первую информацию положения на второе оборудование;
принимают, используя один или более процессоров, подготовленный посредством рендеринга аудиоконтент из второго оборудования, причем подготовленный посредством рендеринга аудиоконтент был подготовлен посредством рендеринга вторым оборудованием, используя прогнозированную информацию положения, причем прогнозированная информация положения основана на первой информации положения;
получают, используя один или более процессоров, вторую информацию положения, указывающую вторую позицию или ориентацию пользователя;
обновляют, используя один или более процессоров, подготовленный посредством рендеринга аудиоконтент на основе второй информации положения; и
воспроизводят, используя один или более процессоров, обновленный подготовленный посредством рендеринга аудиоконтент.
19. Способ по п. 18, содержащий также этапы, на которых:
принимают, используя один или более процессоров, прогнозированную информацию положения от второго оборудования; и
обновляют, используя один или более процессоров, подготовленный посредством рендеринга аудиоконтент на основе разности между прогнозированным положением и второй информацией положения.
20. Система для обработки мультимедийного контента для воспроизведения, содержащая первое оборудование для воспроизведения подготовленного посредством рендеринга аудиоконтента и второе оборудование для создания подготовленного посредством рендеринга аудиоконтента;
первое оборудование сконфигурировано с возможностью:
получать первую информацию положения, указывающую первую позицию или ориентацию пользователя;
передавать первую информацию положения на второе оборудование;
принимать подготовленный посредством рендеринга аудиоконтент из второго оборудования;
получать вторую информацию положения, указывающую вторую позицию или ориентацию пользователя;
обновлять подготовленный посредством рендеринга аудиоконтент, используя по меньшей мере вторую информацию положения; и
воспроизводить обновленный подготовленный посредством рендеринга аудиоконтент.
21. Система по п. 20, в которой первое оборудование также сконфигурировано с возможностью принимать прогнозированное положение из первого оборудования и обновлять подготовленный посредством рендеринга аудиоконтент на основе разности между прогнозированным положением и второй информацией положения.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ И ОТСЛЕЖИВАНИЯ ПАЛЬЦЕВ | 2012 |
|
RU2605370C2 |
| АВТОМАТИЧЕСКОЕ ГЕНЕРИРОВАНИЕ ВИЗУАЛЬНОГО ПРЕДСТАВЛЕНИЯ | 2010 |
|
RU2560340C2 |

