Область техники
Изобретение относится к области вычислительной техники, а именно, к системам проверки деятельности сотрудников и может быть использовано для проверки качества работы сотрудников, деятельность которых связана с использованием сети Интернет, в режиме реального времени.
Уровень техники
Уровень технологического развития средств коммуникации позволяет все большему количеству профессий, связанных с интеллектуальным трудом, переходить на удаленный режим работы. Однако, в этом случае перед руководителем встает вопрос, как контролировать работу удаленных сотрудников и понять, действительно ли сотрудник занят выполнением рабочих обязанностей, а не имитирует рабочую деятельность, создавая мнимую активность за компьютером.
Из уровня техники известны решения [1-3], которые помогают контролировать работу удаленных сотрудников и дифференцировать их активность за компьютером.
Например, из [1] известна система учета рабочего времени сотрудников. Система включает рабочие места сотрудников и руководителя, блок хранения информации об активности сотрудников, соединенный последовательно с блоком просмотра отчетов об активности сотрудников и рабочим местом руководителя, блоки анализа активности сотрудников. Блок анализа активности запускается автоматически при начале сеанса работы пользователя за компьютером и работает в течение всего сеанса. Это позволяет регистрировать время начала и конца сеансов. Регистрация и обработка данных событий выполняется в момент возникновения. В результате обработки блок слежения за устройствами ввода формирует записи о моментах, в которые пользователь вводил информацию в ЭВМ. Записи передаются в блок фильтрации и первичной обработки информации. Записи содержат время возникновения события, тип устройства (клавиатура, мышь, и т.д.), а также название программы, которой было адресовано событие. При этом блок фильтрации распознает мнимую активность за компьютером и не учитывает ее при подсчете активности пользователя за ЭВМ.
Несмотря на то, что в данной системе указывается название программы, к которой обращался сотрудник, система не позволяет автоматически в режиме реального времени дифференцировать активность сотрудника на «вредную» и «полезную».
В документе [2] раскрывается способ анализа рабочего поведения на основе массива данных о поведении пользователей. Для каждого ID учетной записи анализируется продолжительность работы в приложении с критическим и некритическим идентификаторами за указанный период времени. При этом рассчитывается совокупная активность для приложений с критическим идентификатором и приложений с некритическим идентификатором за указанный период времени. За указанный период времени для ID учетной записи суммируется время работы в приложении и количество операций. Затем, суммируются взвешенные значения, соответствующие времени работы и количеству операций, получая общее значение оценки для каждого основного приложения в порядке общего значения оценки от высокого к низкому, каждое основное приложение в тот же период времени сортируется.
Известный способ позволяет отличить действительную активность за компьютером от мнимой, за счет использования в оценке параметра, характеризующего количество операций в приложении за период времени, а также позволяет дифференцировать активность на «вредную» и «полезную» за счет присвоения приложениям критического и некритического идентификаторов для каждого ID учетной записи.
В указанном способе выполняется оценка для каждого приложения и выводится пользователю в виде общего ранжирного списка приложений, который включает как приложения с критическим идентификатором, так и приложения с некритическим идентификатором. При этом в способе не предусмотрено выполнение суммарной оценки активности отдельно для приложений с критическим идентификатором и приложений с некритическим идентификатором соответственно.
Наиболее близким аналогом к заявленному изобретению является способ обработки рабочей информации, раскрытый в документе [3]. В известном способе получают список идентификаторов приложений для типа работы. Определяют тип задания, который соответствует зарегистрированной учетной записи сотрудника и получают список идентификаторов приложений, соответствующий типу задания. В частности, терминал и/или сервер хранит множество списков идентификаторов рабочих приложений, каждый из которых соответствует различным типам работы, и каждый тип работы соответствует нескольким учетным записям сотрудников. Терминал сохраняет идентификатор приложения для каждого приложения и продолжительность операции, соответствующую идентификатору приложения. Терминал сохраняет значение веса, соответствующее каждому идентификатору рабочего приложения, и выполняет операцию взвешенной суммы в соответствии со значением веса, соответствующим каждому идентификатору рабочего приложения и запрошенной продолжительностью операции, тем самым получая эффективную продолжительность работы. Терминал инкапсулирует полученное эффективное рабочее время и зарегистрированную учетную запись сотрудника и посредством инкапсуляции генерирует рабочую сводку, соответствующую учетной записи сотрудника.
Известный способ позволяет дифференцировать активность сотрудника за компьютером на «вредную» и «полезную» в зависимости от типа работы, выполняемого сотрудником, указанного в его учетной записи, а также определить суммарную продолжительность использования приложений, необходимых для работы.
В документе [3] генерируемая рабочая сводка содержит суммарную продолжительность работы сотрудника в «полезных» для его типа работы приложениях, однако, данной информации может быть недостаточно, чтобы сделать вывод о том, что деятельность сотрудника является эффективной, и своевременно оповестить руководителя об обратном.
Технической проблемой, на решение которой направлено данное изобретение - создание способа, который позволяет объективно дифференцировать активность сотрудника за компьютером в период рабочего времени и своевременно оповещать о несоответствии этой активности определенному пороговому значению.
Раскрытие сущности изобретения
Техническим результатом является повышение точности определения времени использования компьютера в сети, в зависимости от посещаемых ресурсов.
Указанный технический результат при осуществлении изобретения достигается тем, что по сравнению с известным документом [3], являющимся наиболее близким аналогом к заявляемому изобретению, с общими признаками, включающие этапы, на которых:
формируют, по крайней мере, один профиль пользователя, включающий первый, второй и третий параметры, причем значение первого параметра зависит от значения третьего параметра;
объединяют профили пользователей, в зависимости от третьего параметра в семейство профилей;
определяют идентификатор первого типа;
идентифицируют ресурсы сети, размещенные, по крайней, мере на одном сервере сети;
определяют наличие общих признаков ресурсов и объединяют их в семейство ресурсов;
сопоставляют каждому ресурсу сети и/или полученному семейству ресурсов идентификатор первого типа;
собирают данные, по крайней мере, в первом и втором интервалах времени о запросах ресурсов сети, по крайней мере, от одного первого терминала, который подключен к той же сети, что и сервер
на основании полученных данных, по крайней мере, в первом и втором интервалах времени определяют первые параметры, связанные с ресурсами и/или семействами ресурсов, с первым типом идентификатора;
выявляют соответствия первых параметров, связанных с ресурсами и/или семействами ресурсов с первым типом идентификатора, с первым параметром профиля;
определяют количество выявленных соответствий за указанные интервалы времени;
производят передачу оповещения на второй терминал;
в предлагаемом способе
формируют по крайней мере один профиль пользователя, дополнительно включающий второй параметр, зависящий от значения третьего параметра;
дополнительно определяют идентификатор второго типа;
дополнительно сопоставляют каждому ресурсу сети и/или полученному семейству ресурсов идентификатор второго типа;
на основании полученных данных по крайней мере в первом и втором интервалах времени дополнительно определяют вторые параметры, связанные с ресурсами и/или семействами ресурсов, со вторым типом идентификатора;
дополнительно выявляют соответствия вторых параметров, связанных с ресурсами и/или семействами ресурсов со вторым типом идентификатора, со вторым параметром профиля;
дополнительно определяют пороговую величину, в зависимости от третьего параметра профиля пользователя;
при превышении количества накопленных соответствий первой и/или второй пороговой величины, производят передачу оповещения на второй терминал.
В частных случаях реализации заявленного изобретения:
- интервалы времени являются отрезками мониторинга, в которых фиксируется активность и данные передаются на сервер для последующей записи их в базу данных;
- отслеживаются данные активности пользователя за компьютером;
- в качестве данных активности может быть по меньшей мере одно из: посещенный URL сайта через браузер, название приложения, путь к исполняемому модулю, заголовок окна приложения;
- в качестве данных активности регистрируют нажатие клавиш на клавиатуре компьютера, движения и нажатия клавиш мыши.
Краткое описание чертежей
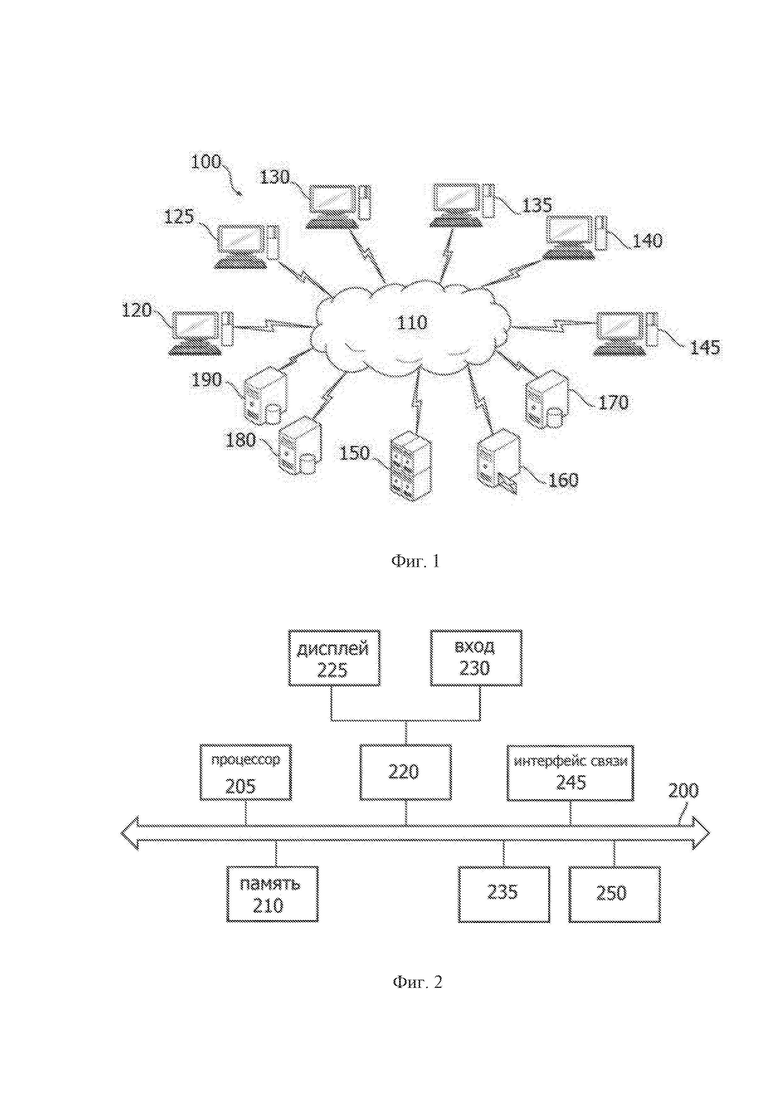
фиг. 1 - примерная схема системы, которая может быть использована для реализации способа автоматического оповещения о запрошенных ресурсах сети;
фиг. 2 - иллюстративные аппаратные компоненты одного из пользовательских вычислительных устройств и/или серверных вычислительных устройств.
Осуществление изобретения
Предлагается способ, содержащий этапы, на которых:
формируют, по крайней мере, один профиль пользователя, включающий первый, второй и третий параметры, причем значения первого и второго параметров зависят от значения третьего параметра;
объединяют профили пользователей, в зависимости от третьего параметра в семейство профилей;
определяют идентификатор первого типа или второго типа;
идентифицируют ресурсы сети, размещенные, по крайней, мере на одном сервере сети;
определяют наличие общих признаков ресурсов и объединяют их в семейство ресурсов;
сопоставляют каждому ресурсу сети и/или полученному семейству ресурсов идентификатор первого или второго типа;
собирают данные, по крайней мере, в первом и втором интервалах времени о запросах ресурсов сети, по крайней мере, от одного первого терминала, который подключен к той же сети, что и сервер
на основании полученных данных, по крайней мере, в первом и втором интервалах времени определяют первые параметры, связанные с ресурсами и/или семействами ресурсов, с первым типом идентификатора, и вторые параметры, связанные с ресурсами и/или семействами ресурсов, со вторым типом идентификатора;
выявляют соответствия первых параметров, связанных с ресурсами и/или семействами ресурсов с первым типом идентификатора, с первым параметром профиля и вторым параметром, связанных с ресурсами и/или семействами ресурсов со вторым типом идентификатора, со вторым параметром профиля;
определяют количество выявленных соответствий за указанные интервалы времени;
определяют пороговую величину, в зависимости от третьего параметра профиля пользователя;
при превышении количества накопленных соответствий первой и/или второй пороговой величины, производят передачу оповещения на второй терминал.
В предпочтительном варианте изобретения, первым параметром профиля пользователя является параметр, который включает список полезных ресурсов, таких как сайты и приложения, необходимые для работы каждого отдельного сотрудника. Вторым параметром профиля пользователя является параметр, включающий список неполезных ресурсов («вредных»), таких как сайты и приложения, используемые каждым отдельным сотрудником в нерабочих целях. Третьим параметром профиля пользователя является специальность сотрудника, его должность и/или опыт работы.
В другом варианте изобретения, первым параметром профиля пользователя является параметр, включающий список неполезных ресурсов, таких как сайты и приложения, используемые каждым отдельным сотрудником в нерабочих целях. Вторым параметром профиля пользователя является параметр, включающий список полезных ресурсов, таких как сайты и приложения, необходимые для работы каждого отдельного сотрудника.
В другом варианте изобретения, третий параметр профиля пользователя может определяться поставленной задачей для определенного количества сотрудников.
В предпочтительном варианте изобретения формирование профиля пользователя осуществляется на сервере и сохраняется в базе данных сервера. Причем массив значений первого параметра и второго параметра профиля пользователя заранее сформированы на сервере и сохранены в базе данных сервера для каждого элемента из массива значений третьего параметра профиля пользователя. Это необходимо для того, чтобы в автоматическом режиме исключить случаи, когда для работника, например, из HR-службы время на сайтах по поиску работы засчитывалось как «вредное», и наоборот - чтобы предусмотреть случаи, когда, допустим, для маркетологов время на медийных сайтах засчитывалось, как полезное. Таким образом, при формировании профиля сотрудника осуществляется автоматическое формирование списка полезных ресурсов, необходимых для работы конкретного сотрудника, а также формирования списка «вредных» для него ресурсов.
В предпочтительном варианте, после формирования профилей пользователей на сервере и сохранения их в базе данных, на сервере осуществляют объединение профилей пользователей в зависимости от третьего параметра профиля каждого пользователя в семейство профилей. Причем профили пользователей объединяются в семейство, в зависимости от рода деятельности сотрудников и/или поставленной задачи, тем самым, помогая собрать статистику по использованию ресурсов среди работников, деятельность которых аналогична.
Для провидения статистического анализа семейства профилей пользователей могут быть использованы различные модели. Например, модель на основании непараметрических методов оценки, где за основу выступает ранжирование всех показателей по убыванию и последующая калькуляция, или модель на основании параметрических методов оценки, где за основу выступают средние значения, стандартные отклонения и z-преобразования.
Параметрические методы более точные, так как используют средние арифметические значения и стандартные отклонения, но при этом значительно искажают данные, если распределение в выборке отличается от нормального и получено малое количество данных, например, относящихся к малой группе сотрудников, а также если в выборке имеются «выбросы». К примеру, в одном подразделении или выбранной группе - 10 человек, в среднем сотрудники ежедневно сидят на развлекательных сайтах от 0 до 3 часов, а один особо отличившийся тратит по 6 часов в день. В этом случае параметрические методы искажают оценку. И наоборот, при количестве пользователей в 500 человек покажут более адекватную оценку, чем непараметрические методы.
Согласно центральной предельной теореме, если в выборке присутствует 100 и более чисел (человек), то распределение этого массива стремится к нормальному.
В связи с тем, что не целесообразно каждый массив данных проверять на нормальность, предложенная система автоматически использует непараметрические методы, когда пользователь генерирует отчет по менее чем 100 сотрудникам, и, наоборот, использует параметрические методы, когда сотрудников в группе более 100, но при этом пользователю предоставлена возможность ручного выбора методов в любой момент.
Предложенный способ позволяет дать оценку, насколько «хорошим» или «плохим» является показатель пользователя/отдела в том или ином случае и сформировать оповещение в случае, если показатель является недопустимо «плохим».
Например, если параметрические методы, отталкивающиеся от среднего значения в группе, в которой 1 час 22 минуты в среднем тратятся на развлекательные ресурсы ежедневно, то при наличии «выброса» - одного сотрудника, который значительно отличается по количеству затраченного времени на просмотр сериалов на YouTube (6 часов в день), все оставшиеся сотрудники отдела будут принадлежать к группам «Нормальные» и «Значительно превышающие норму», однако трудно сказать, что просмотр «нормальными» работниками сериалов на YouTube 2-3 часа в день ежедневно не может быть признан нормой с точки зрения эффективности использования рабочего времени. Оценка не может быть признана корректной.
При использовании параметрических методов, считаются средние значения, стандартные отклонения от среднего, а оценка производится на основании того, как далеко находится показатель того или иного сотрудника от среднего значения по группе. За основу берется теоретическая модель нормального распределения:
значительно ниже нормы (2,28%)
ниже нормы (13,59%)
норма (68,26%)
выше нормы (13,59%)
значительно выше нормы (2,28%)
Иными словами, все, кто попадают в верхние 2,28% количества сотрудников, затративших рабочее время на непродуктивную активность, считаются как «Значительно выше среднего», к примеру, это один сотрудник, который проводил по 6 часов в день на YouTube. И наоборот, в нижних пределах - сотрудники, которые меньше всего проводили времени на развлекательных ресурсах, что в данном случае - «В пределах среднего/нормы». Если бы в данной группе отсутствовал «главный нарушитель», то среднее значение было бы значительно ниже, чем 1 час 22 мин, а значит 3 часа в день и 2 часа в день были расценены, как «Значительно выше среднего» и «Выше среднего». В данном случае присутствует «Выброс» и такие случаи на практике встречаются часто, что необходимо учитывать.
При использовании непараметрических методов для малой группы, например, в пределах 10 - 50 сотрудников, выбросы игнорируются, все сотрудники как бы «выстраиваются» в порядке убывания и далее происходит следующее распределение норм тоже на основе кривой нормального распределения:
значительно ниже нормы («нижние» 2,28%)
ниже нормы («нижние» 13,59%)
норма («средние» 68,26%)
выше нормы («верхние» 13,59%)
значительно выше нормы («верхние» 2,28%)
Иными словами, все, кто попадает в верхние 2,28% сотрудников - считаются как «Значительно выше среднего», в данном случае, это сотрудник, который проводил по 6 часов в день на YouTube. И наоборот, в нижних пределах - сотрудники, которые меньше всего проводили времени на развлекательных ресурсах, что «Значительно ниже среднего».
В малых группах при использовании непараметрических методов, градация оценок более равномерная, и дает больше информации относительно «Нормы», или отклонения от средних значений.
В больших группах, где более 100 сотрудников, параметрические методы, дают более корректную оценку. При использовании параметрических методов в группе свыше 100 человек, оценка получается более адекватной, особенно на нижних границах норм. При генерации отчетов при большом количестве сотрудников в выборку попадает множество «Пустых» или «Нулевых» учетных записей с частично собранными данными, либо 100-600 человек могли посещать развлекательные сайты крайне редко - до 5 минут в день. Из практики - большинство сотрудников в «дисциплинированной» компании практически не посещают развлекательные сайты.
Так как параметрические методы используют средние значения и отклонения на основании средних, то оценка средних происходит адекватная:
Те сотрудники, которые тратят более 34 минут в день на развлечения, считаются «Значительно выше нормы»;
От 18 до 34 минут в день - выше нормы;
Менее 18 минут в день - в пределах нормы;
Такие оценки, как «Ниже нормы» и «Значительно ниже нормы» - отсутствуют.
Оценка корректная.
В группах более 100 сотрудников (из опыта обработки данных в компании N с количеством 747 сотрудников), непараметрические методы дают некорректную оценку, поскольку в группе более 100 человек, оценка получается менее адекватной на нижних границах норм. В связи с большим количеством «Пустых» учетных профилей с частично собранными данными, либо большим количеством дисциплинированных сотрудников, которые посещают развлекательные сайты до 5 минут в день, непараметрические методы искажают оценку. Большинство сотрудников в дисциплинированной компании практически не посещают развлекательные сайты.
Непараметрические методы «принудительно» разбивают все данные в процентном соотношении без опоры на средние, поэтому в выборке обычно присутствует больше категорий, чем в случае с параметрическими методами, включая «Ниже среднего» и «Значительно ниже среднего», даже если по логике они должны отсутствовать.
В данном случае оценка не совсем адекватная:
Те сотрудники, которые тратят более 48 минут в день на развлечения - считаются «Значительно выше нормы»;
От 8 до 48 минут в день - выше нормы;
От 0,04 секунд в день до 8 минут в день - в пределах нормы (около 400 чел.);
Оценка «Ниже нормы» отсутствует;
От 0,04 секунд до 0 - «Значительно ниже нормы» (около 224 чел.).
В действительности нет разницы между теми сотрудниками, кто проводит на развлекательных сайтах 1 минуту, 7 секунд или 0,04 секунды в среднем ежедневно. Возможно, просто остальные проводят время на других некорпоративных ресурсах, которые отсутствуют в текущем словаре. На нижних границах оценка норм некорректная.
Таким образом, при оценке норм необходимо учесть количество сотрудников, по которым генерируется отчет и, опираясь на количество, подбирать соответствующий метод оценки. Ограничиваясь только одним методом, на выходе существует риск получить искаженные данные. А отказываясь от методов оценки полностью, упускаются широкие возможности по выявлению топа «Лидеров» и «Нарушителей», а также теряется возможность оценить, какие показатели являются «Хорошими», а какие «Плохими» и установить значение пороговой величины для разных групп сотрудников, при превышении которой, производится передача оповещения на второй терминал, например, руководителю подразделения/отдела.
В предпочтительном варианте реализации, на сервере определяется идентификатор первого типа или второго типа, которые служат в качестве метки для указания того, является ли используемый ресурс полезным или неполезным.
В другом варианте реализации, на сервере может дополнительно определяться третий идентификатор ресурсов, характеризующий нейтральность используемых во время работы ресурсов. Если ресурс для профиля не добавлен в полезные или вредные, то он считается нейтральным.
В предпочтительном варианте изобретения, на сервере заранее идентифицируют ресурсы сети, размещенные, по крайней мере, на одном сервере сети, определяют наличие общих признаков ресурсов и объединяют их в семейство ресурсов.
В дополнительном варианте реализации, семейство ресурсов, объединяется в зависимости от наличия общих признаков, необходимых для решения поставленной задачи и/или представленной на них тематики.
Одной из ключевых возможностей изобретения является разделение общего активного времени работы сотрудника на полезное, вредное, нейтральное, с возможностью более тонкого анализа по конкретному семейству ресурсов, принадлежащего к той или иной группе.
Например, важно не только увидеть количество времени нецелевого использования ПК сотрудником, но и посмотреть конкретные цифры активности в семействе ресурсов, представляющих потенциальный интерес или даже угрозу в данном конкретном случае. Примером может послужить «Поиск работы» как показатель потенциальной заинтересованности сотрудника покинуть текущее рабочее место.
В качестве исходной информации необходимо было собрать базу данных для дифференциации активности.
На текущий момент система располагает такими перехваченными клиентским «агентом» данными, передаваемыми на сервер:
- посещенный URL сайта через браузер;
- работа в конкретном приложении (название приложения, путь к исполняемому модулю, заголовок окна приложения);
- введенный текст (через кейлоггер) + скопированный из буфера обмена.
Таким образом, было принято решение, чтобы база содержала по каждому семейству ресурсов списки из следующих данных:
1. Домен сайта (без URI-части)
2. Название приложения (заданное разработчиками данного ПО)
3. Полный или частичный путь к исполняемому модулю приложения
4. Ключевые слова ввода, характерные для семейства ресурсов (точное указание)
5. Ключевые слова ввода, характерные для семейства ресурсов (указание с учетом морфологии языка).
Подготовленные семейства ресурсов в комплексе ПО хранятся в XML-формате.
Для каждого семейства ресурсов тег vocab содержит как имя, так и идентификатор типа ресурса rel_type (-1 = вредный, +1 = полезный, 0 = нейтральный).
Внутри каждого семейства ресурсов может содержаться один или более тегов с данными:
- url (для доменов сайтов)
- app (для приложений: название или путь)
- word (слово для кейлоггера, причем используется префикс «~» для слов, где необходимо учесть морфологию языка).
В результате были созданы следующие семейства ресурсов:

В предпочтительном варианте изобретения, каждому ресурсу сети и/или полученному семейству ресурсов сопоставляют идентификатор первого или второго типа. Таким образом, для каждого ресурса сети и/или семейства ресурсов в базе данных сохраняется признак, указывающий на его полезность или вредность. Однако, зачастую данный показатель может варьироваться от сотрудника к сотруднику, в зависимости от его вида деятельности. Как пример, семейство ресурсов «Социальные сети» скорее всего будет «вредным» для программиста, но в определенной степени «полезным» или «нейтральным» для маркетолога.
В предпочтительном варианте изобретения, после всех подготовительных операций, начинают сбор данных, по крайней мере, в первом и втором интервалах времени о запросах ресурсов сети, по крайней мере, от одного первого терминала, который подключен к той же сети, что сервер. В качестве активностей может быть посещенный URL сайта через браузер, название приложения, путь к исполняемому модулю, заголовок окна приложения. В дополнительном варианте, в качестве данных может быть регистрация различных действий пользователя, например, нажатие клавиш на клавиатуре компьютера, движение и нажатие клавиш мыши и т. д.
Данные об активности пользователя за пользовательским устройством могут быть собраны и оцифрованы программным модулем - агентом сбора пользовательских данных, находящемся на устройстве пользователя. Полученные данные о пользовательской активности сохраняются на запоминающем устройстве. При помощи компьютерной сети, в которой находятся все устройства, данные с запоминающего устройства передаются на сервер сбора и обработки данных.
В предпочтительном варианте, первый и второй интервалы являются отрезками мониторинга, которые могут быть равны, например, 5 минутам, а именно каждые 5 минут агент мониторинга фиксирует активность и передает данные на сервер для последующей записи их в БД. Расчет активности может быть только условным. Считаем, что каждый клик мыши или нажатие по клавиатуре порождает активность длительностью в 5 минут. Таким образом, из таких отрезков мониторинга складывается общая дневная активность сотрудника.
В дополнительном варианте реализации, в качестве интервалов времени может определяться одно из: время прихода/ухода, затраченное время на выполнение поставленной задачи, переработки/недоработки, время нахождения на полезных/неполезных ресурсах.
Далее, в предпочтительном варианте, на сервере выявляются соответствия первых параметров, связанных с ресурсами и/или семействами ресурсов, с первым типом идентификатора, с первым параметром профиля и вторым параметром, связанных с ресурсами и/или семействами ресурсов со вторым типом идентификатора, со вторым параметром профиля.
Всякий раз при передачи перехваченных данных с клиентского приложения на сервер, сервер должен принять решение, к какому конкретно семейству ресурсов относится эта активность.
На момент работы сервера он (сервер) уже считал с базы данных комплекса все существующие семейства ресурсов, поэтому задача сводится к поиску данных в семействах ресурсов. То семейство ресурсов, которое первое попадает под критерии сравнения, выбирается как найденное и в базу данных записывается информация активности именно в данном семействе ресурсов.
Это ключевая таблица 1 для сбора активности по дням с разбивкой по словарям, таким образом, всегда есть информация об активности того или иного сотрудника в каком-то из словарей за конкретный период.
Таблица 1
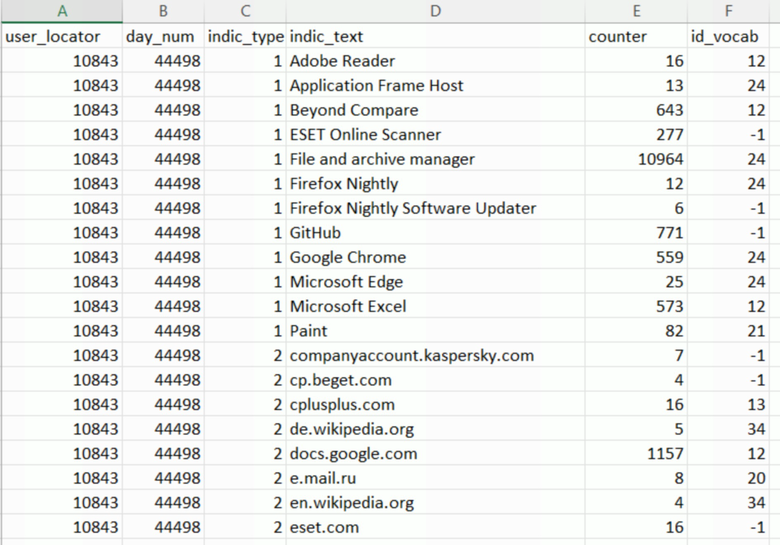
user_locator - поле для связи с информацией о логине, ФИО и прочих статических данных по сотруднику,
day_num - день, для которого накапливаются данные,
counter - счетчик в штуках или секундах для записи, в зависимости от ее типа (например, 150 секунд для action_id «Соц. сети» или 50 шт для отправленных писем),
indic_type - тип активности (посещение сайта, работа в программе или ввод текста)
id_vocab - id настраиваемого словаря, к которому отнесена данная активность.
Таким образом видно, какой ресурс был отнесен к какому именно словарю и сколько времени было в нем проведено за этот день данным сотрудником.
В дополнительном варианте реализации, на сервере сохраняют значение веса, соответствующее каждому ресурса сети и/или семейству ресурсов, и выполняют операцию взвешенной суммы в соответствии со значением веса, соответствующим каждому ресурса сети и/или семейству ресурсов, и запрошенной продолжительностью выполняемых операций, для получения параметра эффективности использования ресурса сети и/или семейства ресурсов. Причем, значение веса для ресурсов и/или семейств ресурсов с идентификатором второго типа, который указывает на неполезность (вред) ресурса, берется с отрицательным знаком.
В дополнительном варианте реализации, сервер выполнен с возможностью инкапсулировать полученный параметр эффективности использования ресурса сети и/или семейства ресурсов и зарегистрированную учетную запись сотрудника. А также посредством инкапсуляции генерировать рабочую сводку, соответствующую учетной записи сотрудника.
В дополнительном варианте реализации, сервер выполнен с возможностью предоставления доступа к рабочим сводкам каждого отдельного сотрудника и/или группы сотрудников.
В предпочтительном варианте изобретения на сервере накапливают определенные количества выявленных соответствий за указанные интервалы времени и при превышении количества накопленных соответствий первой и/или второй пороговой величины, производят передачу оповещения на второй терминал. В предпочтительном варианте, первой пороговой величиной может быть установленная величина для накопленных соответствий для первого параметра профиля, который содержит список полезных для работы ресурсов и/или семейств ресурсов, а второй пороговой величиной может быть установленная величина для накопленных соответствий для второго параметра профиля, содержащего список неполезных для работы ресурсов и/или семейств ресурсов. Причем, как было указано ранее, каждая пороговая величина может устанавливаться после проведения статистического анализа семейства профилей пользователей.
Таким образом, использование для дифференциации активности пользователя за компьютером второго параметра профиля пользователя, содержащего список неполезных для работы ресурсов и/или семейств ресурсов, и идентификатора второго типа, указывающего на неполезные ресурсы и/или семейства ресурсов, а также определение пороговой величины, в зависимости от третьего параметра профиля пользователя, обеспечивает технический результат, заключающийся в повышении точности определения времени использования компьютера в сети, в зависимости от посещаемых ресурсов.
На фиг. 1 представлена примерная схема системы, которая может быть использована для реализации предложенного способа.
Как показано на фиг. 1, компьютерная сеть 110 может включать в себя глобальную сеть (WAN), такую как Интернет, локальную сеть (LAN), сеть мобильной связи, телефонную сеть общего пользования (PSTN), персональную сеть (PAN), городскую сеть (MAN), виртуальную частную сеть (VPN) и/или другую сеть.
Компьютерная сеть 110 обычно может быть сконфигурирована для электронного соединения одного или нескольких вычислительных устройств и/или их компонентов.
Иллюстративные вычислительные устройства могут включать в себя, помимо прочего, одно или несколько вычислительных устройств, таких как пользовательское вычислительное устройство 120 исследователя, пользовательское вычислительное устройство 125 рецензента, административное пользовательское вычислительное устройство 130, пользовательское вычислительное устройство 135 аналитика, пользовательское вычислительное устройство 140 лица, принимающего организационные решения, и обычное пользовательское вычислительное устройство 145 и/или одно или несколько серверных вычислительных устройств, таких как сервер 150 приложений, сервер 160 передачи почты, внешний исходный сервер 170 базы данных, клиентский сервер 180 базы данных и главный сервер базы данных 190.
Обычно следует понимать другие вычислительные устройства, не указанные специально. Каждое из пользовательских вычислительных устройств, как правило, может использоваться в качестве интерфейса между пользователем и другими компонентами, подключенными к компьютерной сети 110 и/или различными другими компонентами, коммуникативно связанными с пользовательскими вычислительными устройствами (такими как компоненты, коммуникативно связанные через одну или несколько сетей, к пользовательским вычислительным устройствам) независимо от того, описаны ли они здесь или нет.
Таким образом, пользовательские вычислительные устройства могут использоваться для выполнения одной или нескольких функций, таких как получение одного или нескольких входных данных от пользователя или предоставление информации пользователю.
Кроме того, в случае, если одно или несколько серверных вычислительных устройств требуют надзора, обновления или исправления, одно или несколько пользовательских вычислительных устройств могут быть сконфигурированы для обеспечения желаемого надзора, обновления и/или исправления.
Одно или несколько пользовательских вычислительных устройств также могут использоваться для ввода дополнительных данных в часть хранения данных одного или нескольких серверных вычислительных устройств.
Каждое из пользовательских вычислительных устройств может быть специально сконфигурировано для конкретного пользователя или может быть обычным компьютером, который может быть конкретно сконфигурирован для любого из конкретных пользователей, описанных в данном документе.
Например, пользовательское вычислительное устройство 120 исследователя может предоставлять пользовательский интерфейс для пользователя-исследователя, пользовательское вычислительное устройство 125 рецензента может предоставлять пользовательский интерфейс для пользователя-рецензента, административное вычислительное устройство 130 может предоставлять пользовательский интерфейс для пользователя-администратора, пользовательское вычислительное устройство-аналитик 135 может предоставлять пользовательский интерфейс для пользователя-аналитика, пользовательское вычислительное устройство 140, принимающее решения, может предоставлять пользовательский интерфейс для пользователя, принимающего решения, и обычное пользовательское вычислительное устройство 145 может использоваться для предоставления любого пользовательского интерфейса, включая описанный здесь пользовательский интерфейс.
В некоторых вариантах осуществления обычное вычислительное устройство 145 может быть вычислительным устройством, которое отслеживается на предмет действий целевого сотрудника.
Каждое из различных серверных вычислительных устройств может получать электронные данные и/или тому подобное из одного или нескольких источников (например, одного или нескольких пользовательских вычислительных устройств, одного или нескольких внешних каналов/источников и/или одной или нескольких баз данных). Непосредственно работа одного или нескольких других устройств (например, одного или нескольких пользовательских вычислительных устройств), содержат данные, относящиеся к деятельности сотрудников, юридически защищенную информацию и данные социальных сетей.
Следует понимать, что хотя пользовательские вычислительные устройства изображены как персональные компьютеры, а серверные вычислительные устройства изображены как серверы, это не ограничивающие примеры.
Более конкретно в некоторых вариантах осуществления для любого из этих компонентов может использоваться любой тип вычислительного устройства (например, мобильное вычислительное устройство, персональный компьютер, сервер и т.д.).
Кроме того, хотя каждое из этих вычислительных устройств проиллюстрировано на фиг. 1, как единое оборудование, это также просто пример.
Более конкретно каждое из пользовательских вычислительных устройств и серверных вычислительных устройств может представлять множество компьютеров, серверов, баз данных, мобильных устройств, компонентов и/или тому подобного.
Кроме того, следует понимать, что хотя варианты осуществления, изображенные в данном документе, относятся к сети устройств, настоящее раскрытие не ограничивается исключительно такой сетью.
Например, в некоторых вариантах различные процессы, описанные в данном документе, могут выполняться одним вычислительным устройством, таким как вычислительное устройство, не подключенное к сети, или вычислительное устройство, подключенное к сети, которое не использует сеть для выполнения различных процессов, описанных в данном документе.
Иллюстративные аппаратные компоненты одного из пользовательских вычислительных устройств и/или серверных вычислительных устройств изображены на фиг. 2.
Шина 200 может соединять различные компоненты, например, в режиме разделения времени доступа к шине.
Устройство 205 обработки, такое как центральный процессор (ЦП), может быть центральным процессором вычислительного устройства, выполняющим вычисления и логические операции, необходимые для выполнения программы.
Память 210, такая как постоянное запоминающее устройство (ROM) и оперативное запоминающее устройство (RAM), может составлять иллюстративное запоминающее устройство (то есть энергонезависимый носитель данных, считываемый процессором).
Такая память 210 может включать в себя одну или несколько программных инструкций, которые при выполнении устройством 205 обработки заставляют устройство 205 обработки завершать различные процессы, такие как процессы, описанные в данном документе.
Программные инструкции могут быть сохранены на материальном машиночитаемом носителе, таком как компакт-диск, цифровой диск, флэш-память, карта памяти, USB-накопитель, оптический дисковый носитель, такой как диск Blu-Ray и/или на других энергонезависимых носителях данных, считываемых процессором.
В некоторых вариантах осуществления, программные инструкции, содержащиеся в памяти 210, могут быть воплощены в виде множества программных модулей, где каждый модуль предоставляет программные инструкции для выполнения одной или нескольких задач.
Запоминающее устройство 250 может быть носителем данных, отдельным от памяти 210, может содержать один или несколько репозиториев данных для хранения данных.
Запоминающее устройство 250 может быть любым физическим носителем данных, включая, помимо прочего, жесткий диск (HDD), память, съемное запоминающее устройство и / или подобное.
Хотя запоминающее устройство 250 изображено как локальное устройство, следует понимать, что запоминающее устройство 250 может быть удаленным запоминающим устройством, таким как удаленный сервер и т.п.
Показанный на фиг. 2 необязательный пользовательский интерфейс 220 может разрешать отображение информации с шины 200 на части дисплея 225 вычислительного устройства в аудио, визуальном, графическом или буквенно-цифровом формате.
Кроме того, пользовательский интерфейс 220 может также включать в себя один или несколько входов 230, которые позволяют передавать и получать данные от устройств ввода, таких как клавиатура, мышь, джойстик, сенсорный экран, пульт дистанционного управления, указывающее устройство, устройство ввода видео, устройство ввода звука, устройство тактильной обратной связи и / или подобное.
Такой пользовательский интерфейс 220 может использоваться, например, чтобы позволить пользователю взаимодействовать с вычислительным устройством или любым его компонентом.
Системный интерфейс 235 обычно может предоставлять вычислительному устройству возможность взаимодействовать с одним или несколькими компонентами компьютерной сети 110 (фиг. 1).
Связь с такими компонентами может происходить с использованием различных коммуникационных портов (не показаны).
Иллюстративный порт связи может быть присоединен к сети связи, такой как Интернет, интрасеть, локальная сеть, прямое соединение и/или тому подобное.
Интерфейс 245 связи обычно может предоставлять вычислительному устройству возможность взаимодействовать с одним или несколькими внешними компонентами, такими как, например, внешнее вычислительное устройство, удаленный сервер и / или тому подобное.
Связь с внешними устройствами может осуществляться через различные порты связи (не показаны).
Иллюстративный порт связи может быть присоединен к сети связи, такой как Интернет, интрасеть, локальная сеть, прямое соединение и/или тому подобное.
Источники информации
1. RU 13110 U1, опубл. 20.03.2000, G07C 1/00, 9 л.
2. CN 105243522 A, опубл. 13.01.2016, G06Q 10/06, 9 л.
3. WO 2018192432 A1, опубл. 25.10.2018, G06Q 10/06, 29 л.
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности определения времени использования компьютера в сети, в зависимости от посещаемых ресурсов. Способ, содержит этапы, на которых формируют, по крайней мере, один профиль пользователя, включающий первый, второй и третий параметры, причем значения первого и второго параметров зависят от значения третьего параметра. Объединяют профили пользователей, в зависимости от третьего параметра в семейство профилей. Определяют идентификатор первого типа или второго типа. Идентифицируют ресурсы сети, размещенные, по крайней мере, на одном сервере сети. Определяют наличие общих признаков ресурсов и объединяют их в семейство ресурсов. Сопоставляют каждому ресурсу сети и/или полученному семейству ресурсов идентификатор первого или второго типа. Собирают данные, по крайней мере, в первом и втором интервалах времени о запросах ресурсов сети, по крайней мере, от одного первого терминала, который подключен к той же сети, что и сервер. На основании полученных данных, по крайней мере, в первом и втором интервалах времени определяют первые параметры, связанные с ресурсами и/или семействами ресурсов, с первым типом идентификатора, и вторые параметры, связанные с ресурсами и/или семействами ресурсов, со вторым типом идентификатора. Выявляют соответствия первых параметров, связанных с ресурсами и/или семействами ресурсов с первым типом идентификатора, с первым параметром профиля и вторым параметром, связанных с ресурсами и/или семействами ресурсов со вторым типом идентификатора, со вторым параметром профиля. Определяют количество выявленных соответствий за указанные интервалы времени. Определяют пороговую величину, в зависимости от третьего параметра профиля пользователя. При превышении количества накопленных соответствий первой и/или второй пороговой величины, производят передачу оповещения на второй терминал.. 4 з.п. ф-лы, 2 ил., 1 табл.
1. Способ автоматического оповещения о запрошенных ресурсах сети, содержащий этапы, на которых:
формируют, по крайней мере, один профиль пользователя, включающий первый, второй и третий параметры, причем значения первого и второго параметров зависят от значения третьего параметра;
объединяют профили пользователей, в зависимости от третьего параметра в семейство профилей;
определяют идентификатор первого типа или второго типа;
идентифицируют ресурсы сети, размещенные, по крайней мере, на одном сервере сети;
определяют наличие общих признаков ресурсов и объединяют их в семейство ресурсов;
сопоставляют каждому ресурсу сети и/или полученному семейству ресурсов идентификатор первого или второго типа;
собирают данные, по крайней мере, в первом и втором интервалах времени о запросах ресурсов сети, по крайней мере, от одного первого терминала, который подключен к той же сети, что и сервер
на основании полученных данных, по крайней мере, в первом и втором интервалах времени определяют первые параметры, связанные с ресурсами и/или семействами ресурсов, с первым типом идентификатора, и вторые параметры, связанные с ресурсами и/или семействами ресурсов, со вторым типом идентификатора;
выявляют соответствия первых параметров, связанных с ресурсами и/или семействами ресурсов с первым типом идентификатора, с первым параметром профиля и вторым параметром, связанных с ресурсами и/или семействами ресурсов со вторым типом идентификатора, со вторым параметром профиля;
определяют количество выявленных соответствий за указанные интервалы времени;
определяют пороговую величину, в зависимости от третьего параметра профиля пользователя;
при превышении количества накопленных соответствий первой и/или второй пороговой величины, производят передачу оповещения на второй терминал.
2. Способ по п. 1, в котором интервалы времени являются отрезками мониторинга, в которых фиксируется активность и данные передаются на сервер для последующей записи их в базу данных.
3. Способ по п. 1, в котором отслеживаются данные активности пользователя за компьютером.
4. Способ по п. 3, в котором в качестве данных активности может быть по меньшей мере одно из: посещенный URL сайта через браузер, название приложения, путь к исполняемому модулю, заголовок окна приложения.
5. Способ по п. 3, в котором в качестве данных активности регистрируют нажатие клавиш на клавиатуре компьютера, движения и нажатия клавиш мыши.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| CN 105243522 A,13.01.2016 | |||
| CN 106127400 A, 16.11.2016 | |||
| CN 111222735 A, 02.06.2020 | |||
| Прибор для автоматического приведения в действие песочниц у ведущих подвижной состав повозок | 1927 |
|
SU13110A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| CN 1955995 A, 02.05.2007 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |

