Область техники, к которой относится изобретение
Варианты осуществления настоящего изобретения относятся к способу маскировки потерь пространственных аудиопараметров, к способу декодирования кодированной с помощью DirAC аудиосцены и к соответствующим компьютерным программам. Дополнительные варианты осуществления относятся к устройству маскировки потерь для маскировки потерь пространственных аудиопараметров и к декодеру, содержащему устройство маскировки потерь пакетов. Предпочтительные варианты осуществления описывают концепцию/способ компенсации ухудшений качества вследствие потерянных и поврежденных кадров или пакетов, возникающих во время передачи аудиосцены, для которой пространственное изображение параметрически кодировано посредством парадигмы на основе направленного кодирования аудиоданных (DirAC).
Уровень техники
Речевая связь и аудиосвязь могут испытывать различные проблемы качества вследствие потерь пакетов во время передачи. Фактически, плохие условия в сети, такие как битовые ошибки и дрожания, могут приводить к потерям некоторых пакетов. Эти потери приводят к серьезным артефактам, таким как щелчки, булькания или нежелательное молчание, которые значительно ухудшают воспринимаемое качество восстановленного речевого или аудиосигнала на стороне приемного устройства. Чтобы противостоять неблагоприятному влиянию потерь пакетов, алгоритме, на основе маскировки потерь пакетов (PLC) предлагаются в традиционных схемах кодирования речи и аудио. Такие алгоритмы нормально работают на стороне приемного устройства посредством формирования синтетического аудиосигнала для маскировки отсутствующих данных в принимаемом потоке битов.
DirAC представляет собой перцепционно обусловленную технологию пространственной аудиообработки, которая сжато и эффективно представляет звуковое поле посредством набора пространственных параметров и сигнала понижающего микширования. Сигнал понижающего микширования может представлять собой монофонические, стереофонические или многоканальные сигналы в аудиоформате, к примеру, в формате А или формате В, также известном как амбиофония первого порядка (FAO). Сигнал понижающего микширования дополняется посредством пространственных параметров DirAC, которые описывают аудиосцену с точки зрения направления поступления (DoA) и диффузности в расчете на частотно-временную единицу. В вариантах применения для хранения данных, потоковой передачи или связи, сигнал понижающего микширования кодируется посредством традиционного базового кодера (например, EVS или стерео/многоканального расширения EVS, или любого другого моно-/стерео-/многоканального кодека), для сохранения формы аудиосигнала каждого канала. Базовый кодер может компоноваться вокруг схемы кодирования на основе преобразования или схемы кодирования речи, работающей во временной области, такой как CELP. Базовый кодер затем может интегрировать уже существующие инструментальные средства обеспечения устойчивости к ошибкам, к примеру, алгоритмы на основе маскировки потерь пакетов (PLC).
С другой стороны, отсутствует существующее решение для защиты пространственных параметров DirAC. Следовательно, имеется потребность в усовершенствованном подходе.
Раскрытие изобретения
Задача настоящего изобретения состоит в создании концепции для маскировки потерь в контексте DirAC.
Данная задача решается объектами независимых пунктов формулы изобретения.
Варианты осуществления настоящего изобретения предусматривают способ маскировки потерь пространственных аудиопараметров, причем пространственные аудиопараметры содержат по меньшей мере информацию направления поступления. Способ содержит следующие этапы:
- прием первого набора пространственных аудиопараметров, содержащих первую информацию направления поступления и первую информацию диффузности;
- прием второго набора пространственных аудиопараметров, содержащих вторую информацию направления поступления и вторую информацию диффузности; и
- замену второй информации направления поступления второго набора заменяющей информацией направления поступления, извлекаемую из первой информации направления поступления, если по меньшей мере вторая информация направления поступления или часть второй информации направления поступления потеряна.
Варианты осуществления настоящего изобретения основаны на выводе о том, что в случае потерь или повреждения информации поступления, потерянная/поврежденная информация поступления может заменяться на информацию поступления, извлекаемую из другой доступной информации поступления. Например, если вторая информация поступления теряется, она может заменяться на первую информацию поступления. Другими словами, это означает, что вариант осуществления обеспечивает инструментальное средство маскировки потерь пакетов для пространственного параметрического аудио, для которого информация направления в случае потерь при передаче восстанавливается посредством использования ранее хорошо принятой информации направления и размывания. Таким образом, варианты осуществления позволяют противостоять потерям пакетов в передаче звука пространственных аудиоданных, кодированных с прямыми параметрами.
Дополнительные варианты осуществления предусматривают способ, в котором первые и вторые наборы пространственных аудиопараметров содержат первую и вторую информацию диффузности, соответственно. В таком случае, стратегия может заключаться в следующем: согласно вариантам осуществления, первая или вторая информация диффузности извлекается по меньшей мере из одного отношения энергий, связанного по меньшей мере с одной информацией направления поступления. Согласно вариантам осуществления, способ дополнительно' содержит замену второй информации диффузности второго набора заменяющей информацией диффузности, извлекаемой из первой информации диффузности. Это составляет часть так называемой стратегии запоминания при условии, что рассеяния сильно не изменяются между кадрами. По этой причине, простой, но эффективный подход заключается в сохранении параметров последнего хорошо принятого кадра для кадров, потерянных во время передачи. Другая часть этой целой стратегии заключается в замене второй информации поступления первой информацией поступления, тогда как она пояснена в контексте базового варианта осуществления. В общем можно с уверенностью считать, что пространственное изображение должно быть относительно стабильным во времени, что может истолковываться для параметров DirAC, т.е. для направления поступления, так, что они также сильно не изменяются между кадрами.
Согласно дополнительным вариантам осуществления, заменяющая информация направления поступления соответствует первой информации направления поступления. В таком случае может использоваться стратегия, называемая «размыванием направления». Здесь этап замены, согласно вариантам осуществления, может содержать этап размывания заменяющей информации направления поступления. В качестве альтернативы или дополнения, этапы замены могут содержать вставку, когда шум представляет собой первую информацию направления поступления, для получения заменяющей информации направления поступления. Размывание затем может помогать делать более естественным и более приятным подготовленное посредством рендеринга звуковое поле за счет введения случайного шума в предыдущее направление перед его использованием для того же кадра. Согласно вариантам осуществления, этап введения предпочтительно выполняется, если первая или вторая информация диффузности указывает высокую диффузность. В качестве альтернативы, он может выполняться, если первая или вторая информация диффузности выше заданного порогового значения для информации диффузности, указывающей высокую диффузность. Согласно дополнительным вариантам осуществления, информация диффузности содержит больше пространства для отношения между направленными и ненаправленными компонентами аудиосцены, описанной посредством первого и/или второго набора пространственных аудиопараметров. Согласно вариантам осуществления, случайный шум, который должен быть введен, зависит от первой и второй информации диффузности. В качестве альтернативы, случайный шум, который должен быть введен, масштабируется на коэффициент в зависимости от первой и/или второй информации диффузности. Следовательно, согласно вариантам осуществления, способ дополнит ель но может содержать этап анализа тональности аудиосцены, описанной посредством первого и/или второго набора пространственных аудиопараметров, для анализа тональности передаваемого понижающего микширования, относящегося к первому и/или второму пространственному аудиопараметру, для получения значения тональности, описывающего тональность. Случайный шум, который должен быть введен, затем зависит от значения тональности. Согласно вариантам осуществления, понижающее масштабирование выполняется на коэффициент, снижающийся вместе с инверсией значения тональности, либо если тональность увеличивается.
Согласно дополнительной стратегии, может использоваться способ, содержащим этап экстраполяции первой информации направления поступления для получения заменяющей информации направления поступления. Согласно этому подходу может быть предусмотрена возможность оценки направления звуковых событий в аудиосцене, с тем чтобы экстраполировать оцененный каталог. Это является, в частности, релевантным, если звуковое событие хорошо локализуется в пространстве и в качестве точечного источника (прямой модели, имеющей низкую диффузность). Согласно вариантам осуществления, экстраполяция основана на информации одного или более дополнительных направлений поступления, относящейся к одному или более наборам пространственных аудиопараметров. Согласно вариантам осуществления, экстраполяция выполняется, если первая и/или вторая информация диффузности указывает низкую диффузность, либо если первая и/или вторая информация диффузности ниже заданного порогового значения для информации диффузности.
Согласно вариантам осуществления, первый набор пространственных аудиопараметров относится к первому моменту времени и/или первому кадру, оба из второго набора пространственных аудиопараметров относятся ко второму моменту времени или второму кадру. В качестве альтернативы, второй момент времени следует после первого момента времени, либо второй кадр следует после первого кадра. Возвращаясь к варианту осуществления, в котором большинство наборов пространственных аудиопараметров используются для экстраполяции, очевидно, что предпочтительно используется большее число наборов пространственных аудиопараметров, относящихся ко множеству моментов времени/кадров, например, после друг друга.
Согласно дополнительному варианту осуществления, первый набор пространственных аудиопараметров содержит первый поднабор пространственных аудиопараметров для первой полосы частот и второй поднабор пространственных аудиопараметров для второй полосы частот. Второй набор пространственных аудиопараметров содержит другой первый поднабор пространственных аудиопараметров для первой полосы частот и другой второй поднабор пространственных аудиопараметров для второй полосы частот.
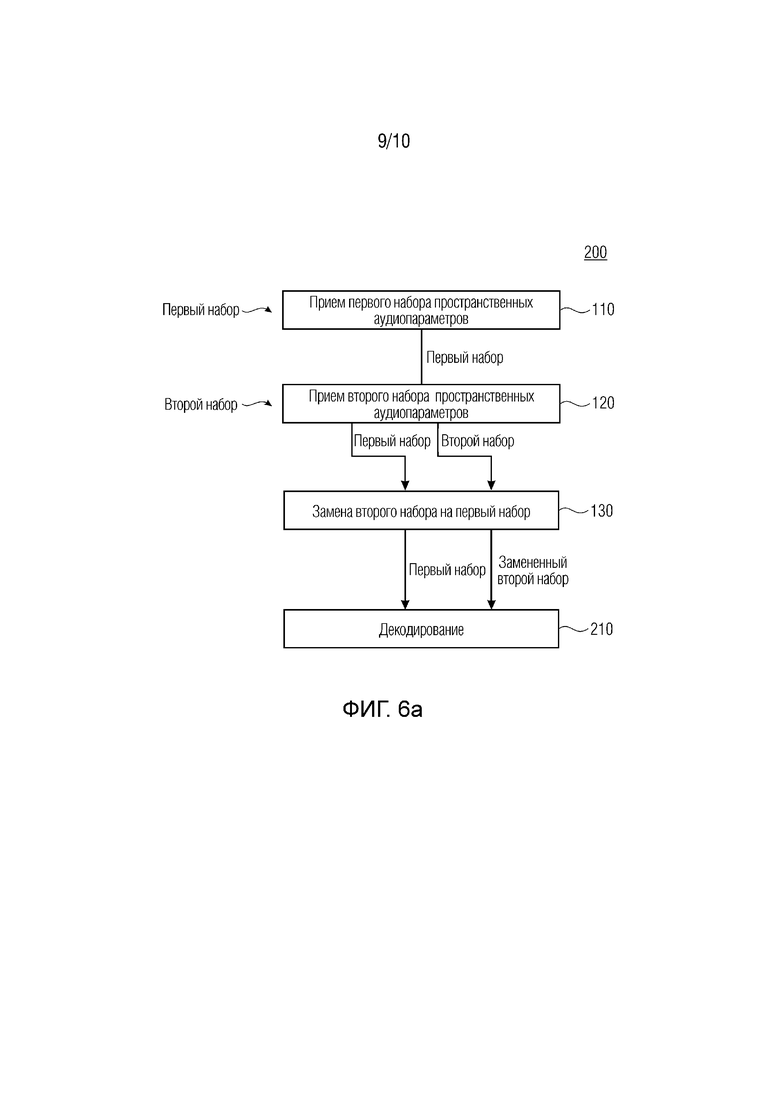
Другой вариант осуществления предусматривает способ декодирования кодированной с помощью DirAC аудиосцены, содержащий этапы декодирования кодированной с помощью DirAC аудиосцены, содержащей понижающее микширование, первый набор пространственных аудиопараметров и второй набор пространственных аудиопараметров. Этот способ дополнительно содержит этапы способа маскировки потерь, как пояснено выше.
Согласно вариантам осуществления, вышеописанные способы могут быть реализуемыми компьютером. Следовательно, вариант осуществления относится к машиночитаемому носителю хранения данных, на котором сохранена компьютерная программа, имеющая программный код для осуществления способа согласно одному из предыдущих пунктов формулы изобретения при ее выполнении на компьютере.
Другой вариант осуществления относится к устройству маскировки потерь для маскировки потерь пространственных аудиопараметров (они содержат по меньшей мере информацию направления поступления). Устройство содержит приемное устройство и процессор. Приемное устройство выполнено с возможностью приема первого набора пространственных аудиопараметров и второго набора пространственных аудиопараметров (как указано выше). Процессор выполнен с возможностью замены второй информации направления поступления второго набора заменяющей информацией направления поступления, извлекаемой из первой информации направления поступления в случае потерянной или поврежденной второй информации направления поступления. Другой вариант осуществления относится к декодеру для кодированной с помощью DirAC аудиосхемы, содержащему устройство маскировки потерь.
Краткое описание чертежей
Ниже варианты осуществления настоящего изобретения поясняются с обращением к сопровождающим чертежам, на которых:
На Фиг. 1a, 1b показаны принципиальные блок-схемы, иллюстрирующие анализ и синтез DirAC;
Фиг. 2 показывает подробную принципиальную блок-схему анализа и синтеза DirAC в трехмерном аудиокодере с более низкой скоростью передачи битов;
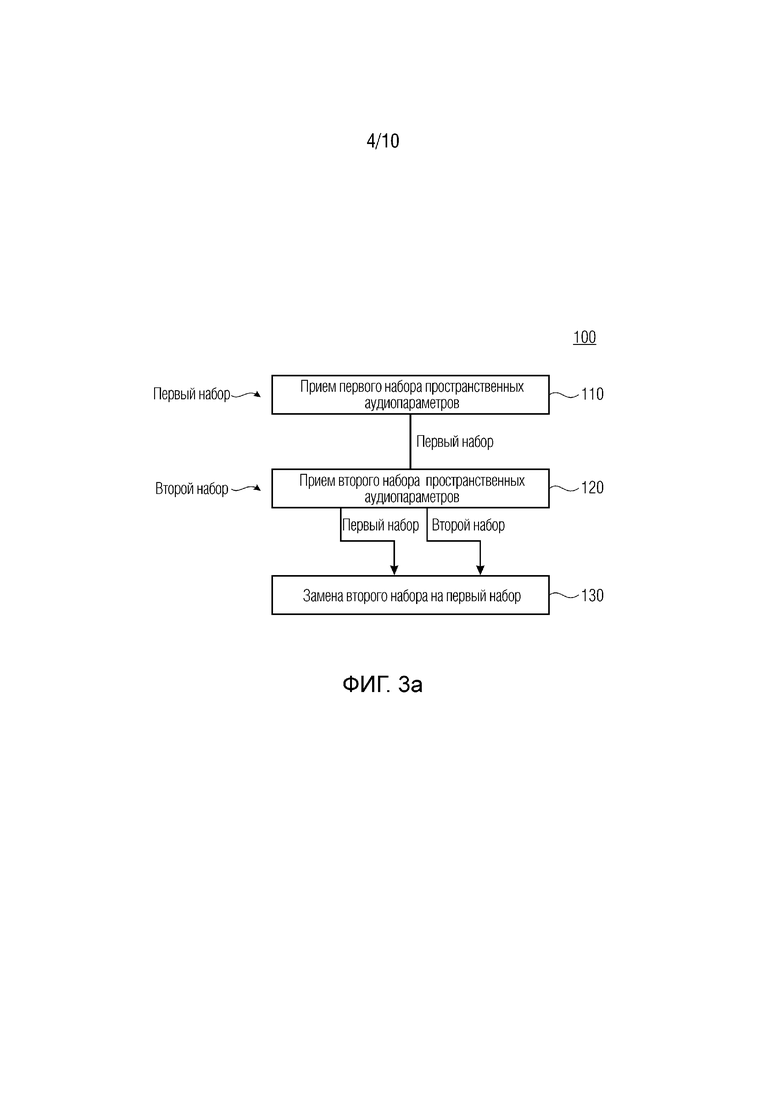
Фиг. 3а показывает блок-схему способа маскировки потерь согласно базовому варианту осуществления;
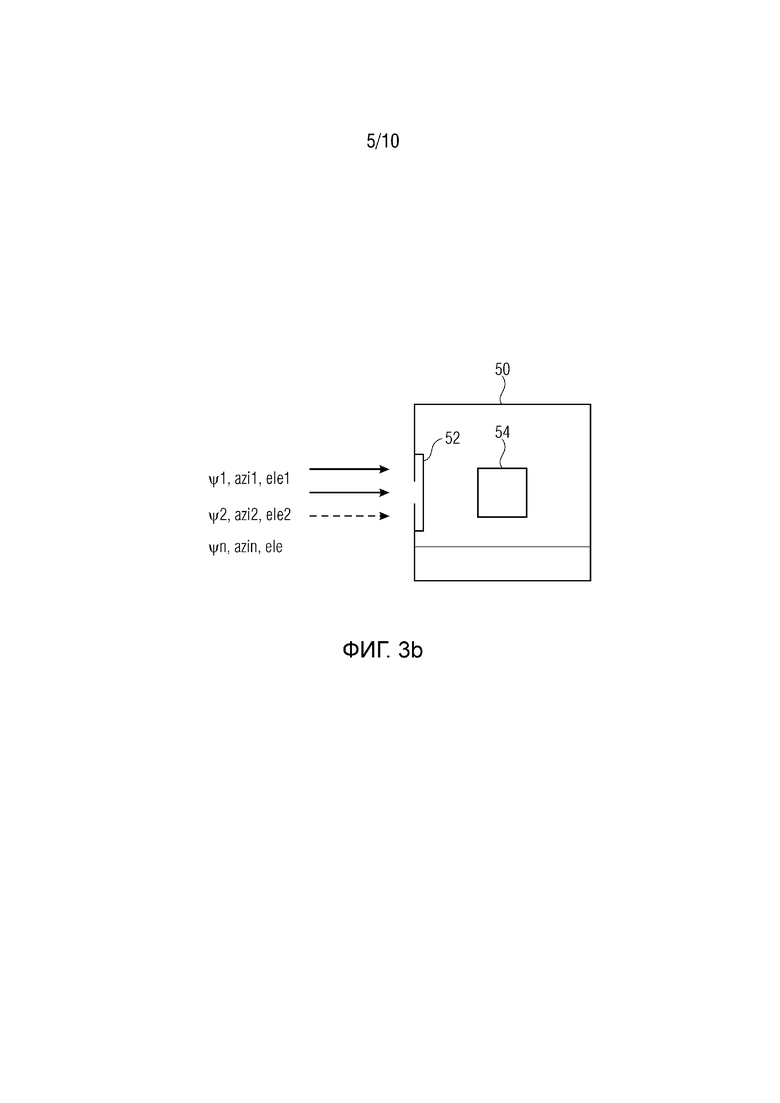
Фиг. 3b схематично показывает устройство маскировки потерь согласно базовому варианту осуществления;
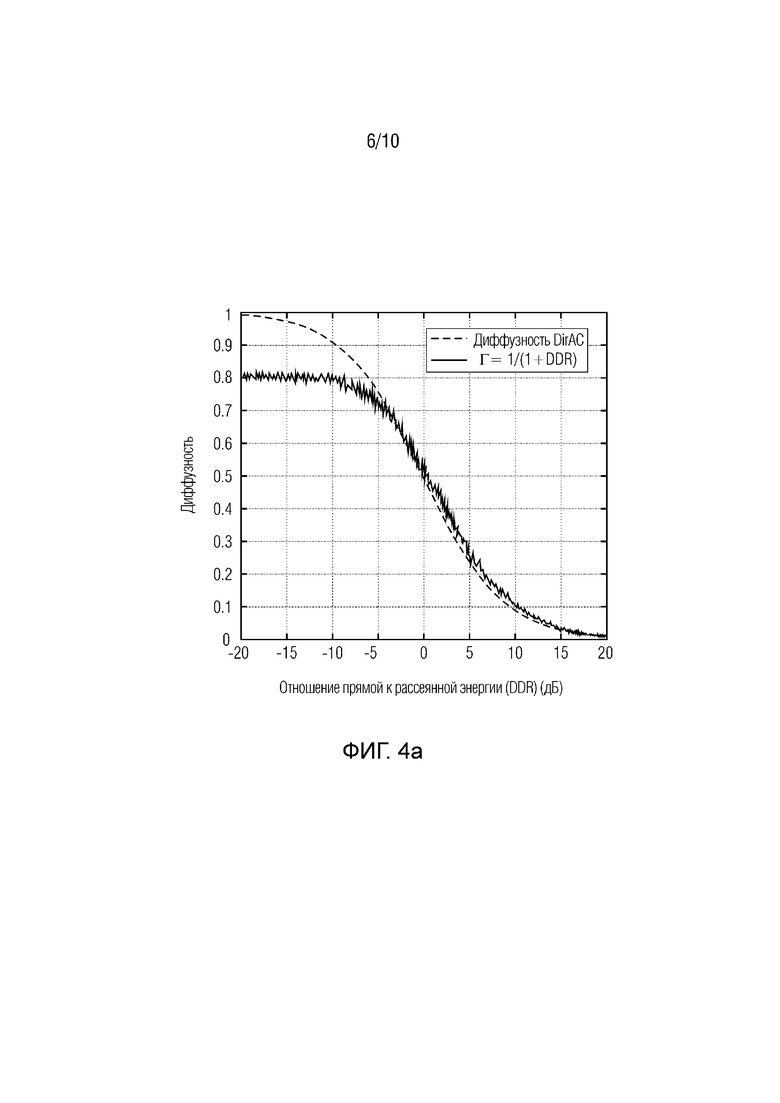
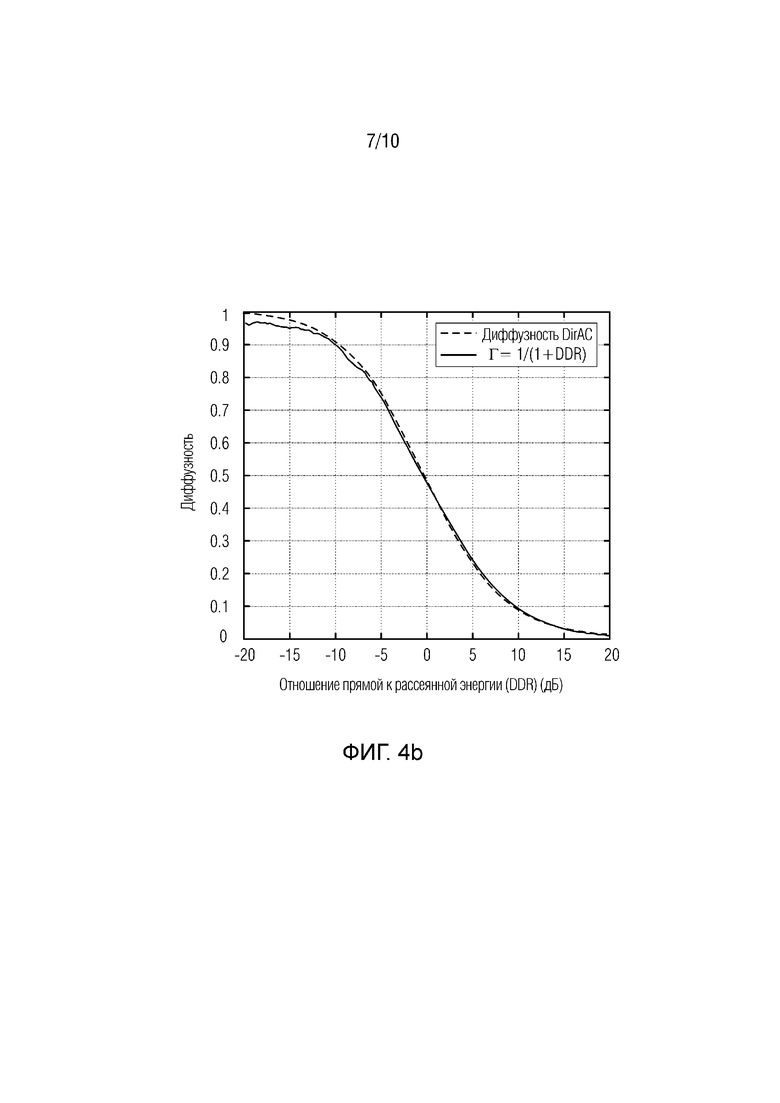
Фиг. 4а, 4b показывают принципиальные схемы функций измеренной диффузности DDR (на фиг.4а: размер окна W=16, на фиг.4b: размер окна W=512) для иллюстрации вариантов осуществления;
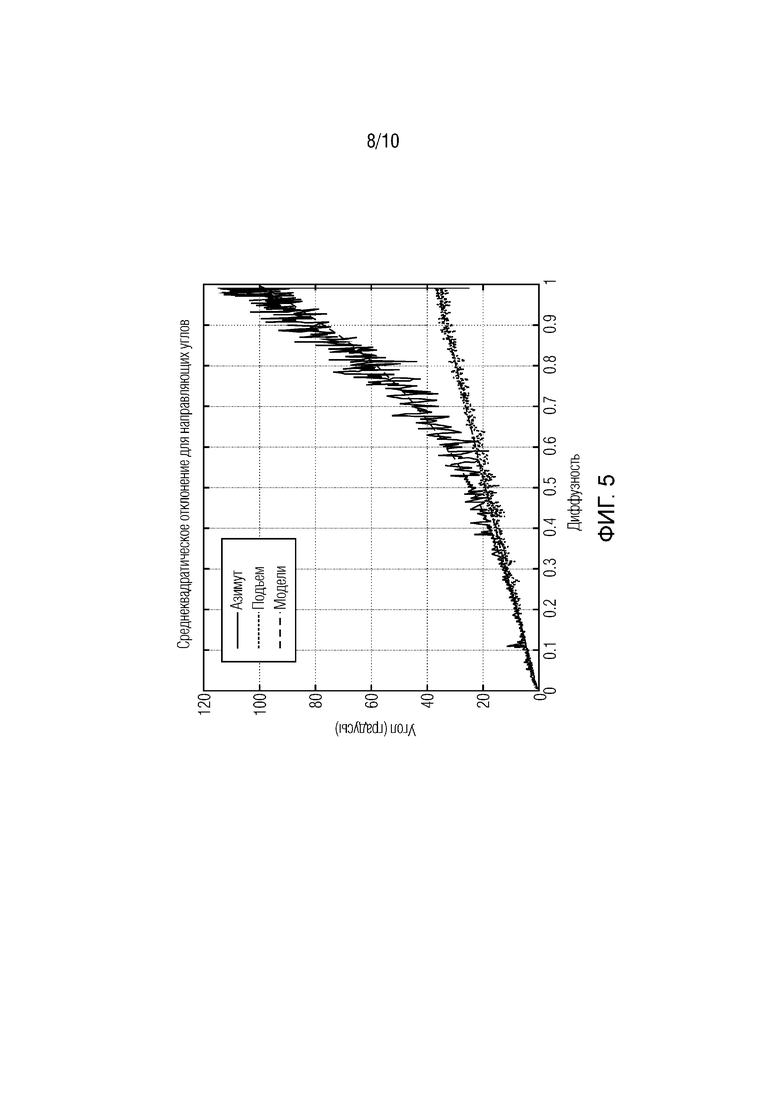
Фиг. 5 показывает принципиальную схему измеренного направления (азимута и подъема) в функции диффузности для иллюстрации вариантов осуществления;
Фиг. 6а показывает блок-схем/ способа декодирования кодированной с помощью DirAC аудиосцены согласно вариантам осуществления; и
Фиг. 6b показывает принципиальную блок-схему декодера для кодированной с помощью DirAC аудиосцены согласно варианту осуществления.
Ниже варианты осуществления настоящего изобретения поясняются с обращением к сопровождающим чертежам, на которых одинаковые ссылочные позиции предусмотрены для объектов/элементов, имеющих одинаковую или аналогичную функцию, так что их описание является взаимно применимым и взаимозаменяемым. Перед подробным пояснением вариантов осуществления настоящего изобретения, приводится введение в DirAC.
Осуществление изобретения
Введение в DirAC: DirAC представляет собой перцепционно обусловленное пространственное воспроизведение звука.
Предполагается, что в один момент времени и для одной критической полосы частот, пространственное разрешение слуховой системы ограничено' декодированием одной сигнальной метки для направления, а другой - для интерауральной когерентности.
На основе этих допущений, DirAC представляет пространственный звук в одной полосе частот посредством плавного перехода двух потоков: ненаправленного рассеянного потока и направленного нерассеянного потока. Обработка DirAC выполняется в две фазы:
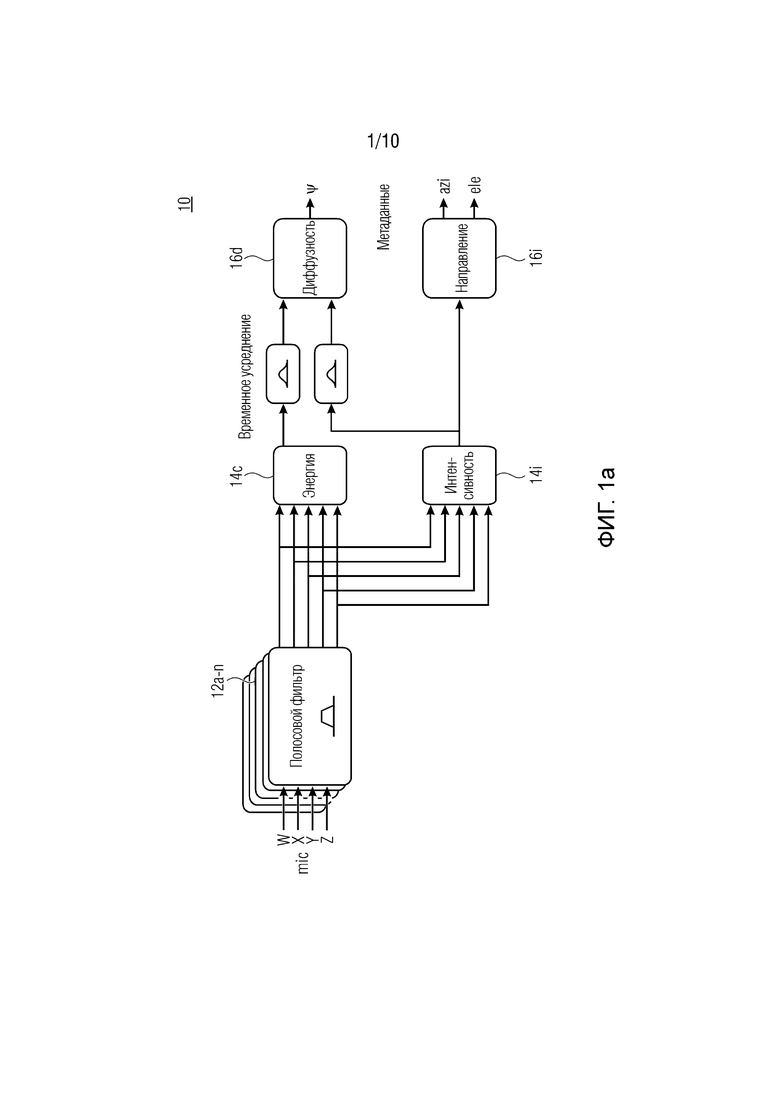
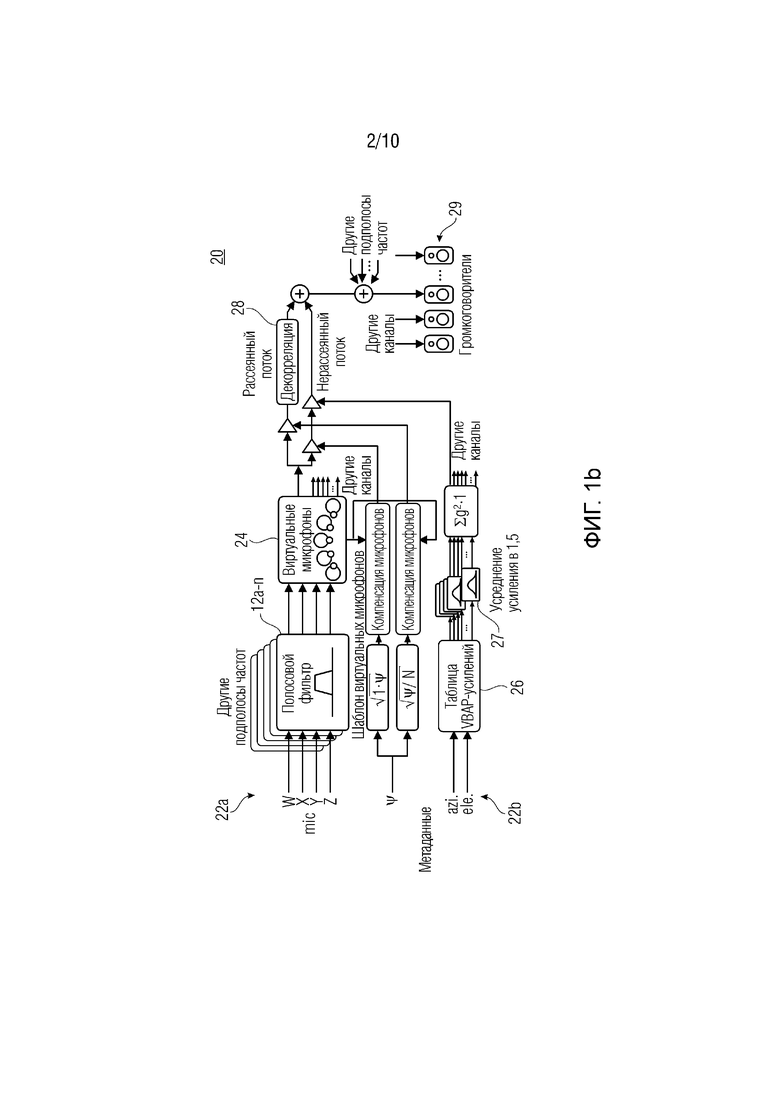
Первая фаза представляет собой анализ, как проиллюстрировано посредством фиг.1а, и вторая фаза представляет собой синтез, как проиллюстрировано посредством фиг, 1b.
Фиг. 1а показывает каскад 10 анализа, содержащий один или более полосовых фильтров 12а-n, принимающих сигналы W, X, Y и Z микрофонов, каскад анализа (14е) для энергии и (14i) для интенсивности, Посредством использования временного размещения, может определяться диффузность ψ (см. ссылочную позицию 16d). Диффузность ψ определяется на основе анализа энергии 14с и интенсивности 14i. На основе анализа интенсивности 14i, может определяться направление 16е. Результат определения направления представляет собой угол азимута и подъема. ψ, azi и ele выводятся в качестве метаданных. Эти метаданные используются посредством объекта 20 синтеза, показанного посредством фиг.1b.
Объект 20 синтеза, как показано посредством фиг.1b, содержит первый поток 22а и второй поток 22b. Первый поток содержит множество полосовых фильтров 12а-n и объект вычисления для виртуальных микрофонов 24. Второй поток 22b содержит средство для обработки метаданных, а именно, 26 для параметра диффузности и 27 для параметра направления. Кроме того, декоррелятор 28 используется в каскаде 20 синтеза, причем этот объект декорреляции 28 принимает данные двух потоков 22а, 22b. Вывод декоррелятора 28 может подаваться в громкоговорители 29.
В каскаде анализа DirAC совпадающий микрофон первого порядка в формате В рассматривается как ввод, и диффузность и направление поступления звука анализируются в частотной области.
В каскаде синтеза DirAC звук разделяется на два потока, нерассеянный поток и рассеянный поток. Нерассеянный поток воспроизводится в качестве точечных источников с использованием амплитудного панорамирования, которое может выполняться посредством использования векторного амплитудного панорамирования (VBAP) [2]. Рассеянный поток отвечает за ощущение огибания и формируется посредством передачи в громкоговорители взаимно декоррелированных сигналов.
Параметры DirAC, далее также называемые «пространственными метаданными» или «метаданными DirAC», состоят из кортежей диффузности и направления. Направление может представляться в сферической координате посредством двух углов, азимута и подъема, тогда как диффузность представляет собой скалярный множитель между 0 и 1.
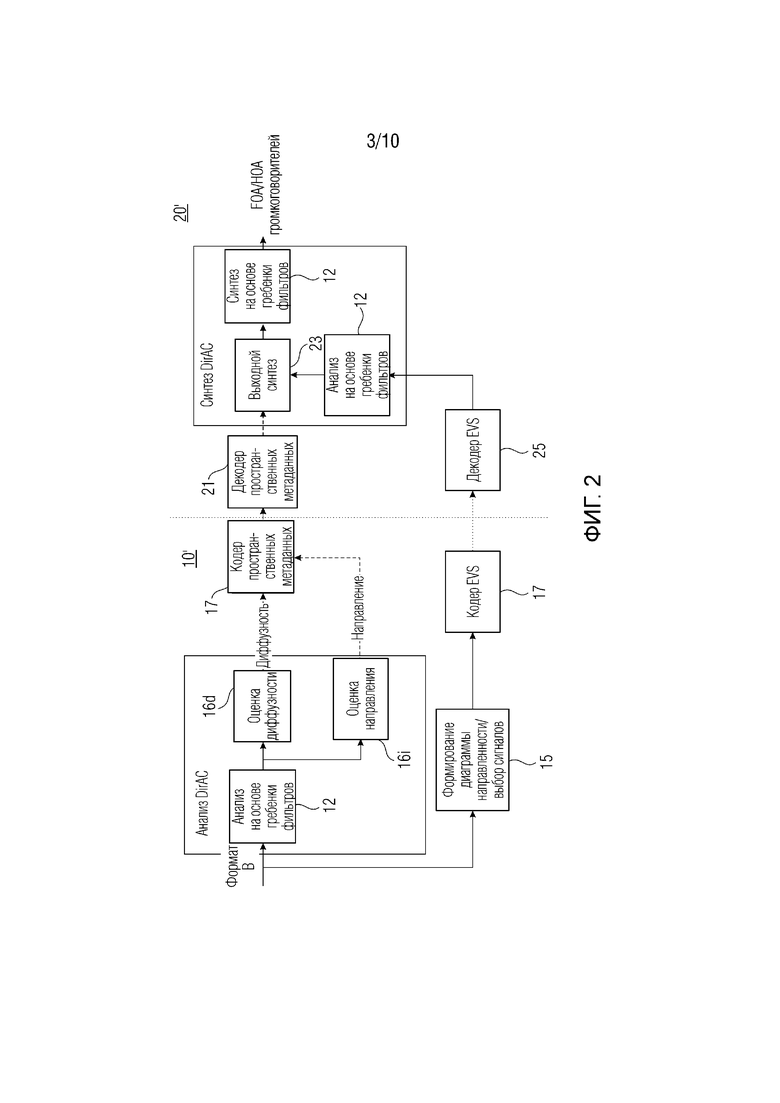
Ниже поясняется система пространственного кодирования аудиоданных DirAC относительно фиг.2, Фиг. 2 показывает двухкаскадный 10' DirAC и синтез 20' DirAC. Здесь анализ DirAC содержит анализ 12 на основе гребенки фильтров, модуль 16i оценки направления и модуль 16d оценки диффузности. Оба из 16i и 16d выводят данные диффузности/направления в качестве пространственных метаданных. Эти данные могут кодироваться с использованием кодера 17. Прямой анализ 20' содержит декодер 21 пространственных метаданных, выходной синтез 23, синтез 12 на основе гребенки фильтров, позволяющий выводить сигнал в FOA/HOA громкоговорителей.
Параллельно поясненным каскаду 10' прямого анализа и каскаду 20' прямого синтеза, которые обрабатывают пространственные метаданные, используется кодер/декодер EVS. На аналитической стороне, формирование диаграммы направленности/выбор сигналов выполняется на основе формата входных сигналов В (см. объект 15 формирования диаграммы направленности/выбора сигналов). Затем сигнал - кодируется с помощью EVS (см. ссылочную позицию 17). Затем сигнал кодируется с помощью EVS. На синтезирующей стороне (см. ссылочную позицию используется декодер EVS 25. Этот декодер EVS выводит сигнал в анализ 12 на основе гребенки фильтров, который выводит с сигнал в выходной синтез 23.
Поскольку здесь пояснена структура прямого анализа/прямого синтеза 10'/20', далее подробно поясняется функциональность.
Кодер 10' обычно анализирует пространственную аудиосцену в формате В. В качестве альтернативы, анализ DirAC может регулироваться для анализа различных аудиоформатов, таких как аудиообъекты или многоканальные сигналы, либо сочетания любых пространственных аудиоформатов. Анализ DirAC извлекает параметрическое представление из входной аудиосцены. Направление поступления (DoA) и диффузность, измеренные в расчете на частотно-временную единицу, формируют параметры. Анализ DirAC выполняется посредством кодера пространственных метаданных, который квантует и кодирует параметры DirAC для получения параметрического представления с низкой скоростью передачи битов.
Наряду с параметрами, сигнал понижающего микширования, извлекаемый из других источников или входных аудиосигналов, кодируется для передачи посредством традиционного базового аудиокодера. В предпочтительном варианте осуществления, аудиокодер EVS является предпочтительным для кодирования сигнала понижающего микширования, но изобретение не ограничено этим базовым кодером и может применяться к любому базовому аудиокодеру. Сигнал понижающего микширования состоит из различных каналов, называемых «транспортными каналами»: сигнал, например, может представлять собой четыре сигнала коэффициентов, составляющие сигнал в формате В, стереопару или монофоническое понижающее микширование, в зависимости от целевой скорости передачи битов. Кодированные пространственные параметры и кодированный поток аудиобитов мультиплексируются до передачи по каналу связи.
В декодере, транспортные каналы декодируются посредством базового декодера, в то время как метаданные DirAC сначала декодируются до передачи с декодированными транспортными каналами в синтез DirAC. Синтез DirAC использует декодированные метаданные для управления воспроизведением прямого звукового потока и его смешения с рассеянным звуковым потоком. Воспроизведенное звуковое поле может воспроизводиться при произвольной схеме размещения громкоговорителей или может формироваться в формате амбиофонии (HOA/FOA) с произвольным порядком.
Оценка параметров DirAC: В каждой полосе частот оценивается направление поступления звука вместе с диффузностыо звука. Из частотно-временного анализ а входных компонентов 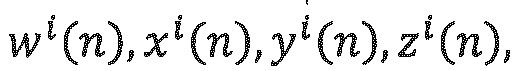 в формате В, векторы давления и скорости могут определяться следующим образом:
в формате В, векторы давления и скорости могут определяться следующим образом:
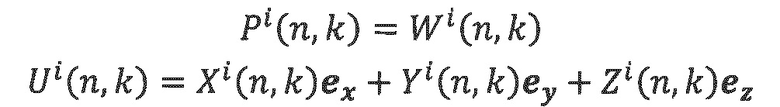
- где i является индексом ввода, и k, и n являются временным и частотным индексами частотно-временного мозаичного элемента, и ех, еу, ez представляют единичные декартовы векторы. Р(n, k) и U(n, k) используются для вычисления параметров DirAC, а именно DoA и диффузности, посредством вычисления вектора интенсивности:
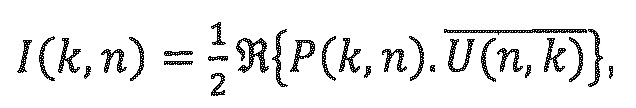
где  обозначает комплексное сопряжение. Диффузность комбинированного звукового поля задается следующим образом:
обозначает комплексное сопряжение. Диффузность комбинированного звукового поля задается следующим образом:
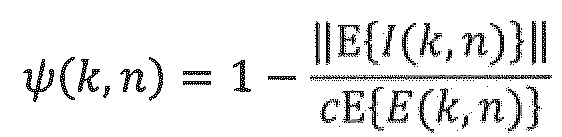
где 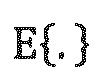 обозначает оператор временного усреднения, с является скоростью звука, и Е(k, n) является энергией звукового поля, заданной следующим образом:
обозначает оператор временного усреднения, с является скоростью звука, и Е(k, n) является энергией звукового поля, заданной следующим образом:
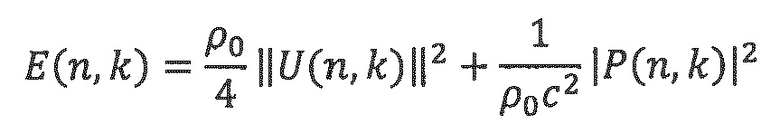
Рассеянность звукового поля задается как отношение между интенсивностью звука и плотностью энергии, имеющее значения между 0 и 1.
Направление поступления (DoA) выражается посредством единичного вектора direction (n, k), заданного следующим образом:
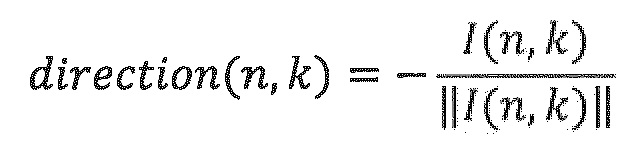
Направление поступления определяется посредством энергетического анализа ввода в формате В и может задаваться как противоположное направление вектора интенсивности. Направление задается в декартовых координатах, но может легко преобразовываться в сферические координаты, заданные посредством единичного радиуса, угла азимута и угла подъема.
В случае передачи, параметры должны передаваться в сторону приемного устройства через поток битов. Для надежной передачи по сети с ограниченной пропускной способностью, поток предпочтительным является битов с низкой скоростью передачи битов, который может достигаться посредством проектирования эффективной схемы кодирования для параметров DirAC. Он может использовать, например, такие технологии, как группировка полос частот, посредством усреднения параметров по различным полосам частот и/или единицам времени, прогнозирование, квантование и энтропийное кодирование. В декодере передаваемые параметры могут декодироваться для каждой частотно-временной единицы (k, n) в случае, если в сети не возникают ошибки. Тем не менее, если характеристики сети не являются достаточно хорошими, чтобы обеспечить надлежащую передачу пакетов, пакет может теряться во время передачи. Настоящее изобретение направлено на создание решения во втором случае.
Первоначально DirAC предназначено для обработки сигналов записи в формате В, также известных как амбиофонические сигналы первого порядка. Тем не менее, анализ может легко расширяться на любые массивы микрофонов, комбинирующие всенаправленные или направленные микрофоны. В этом случае, настоящее изобретение по-прежнему является релевантным, поскольку сущность параметров DirAC является неизменной.
Помимо этого, параметры DirAC, также известные как метаданные, могут вычисляться непосредственно во время обработки сигналов микрофонов перед передачей в пространственный аудиокодер. В систему пространственного кодирования на основе DirAC затем непосредственно подаются пространственные аудиопараметры, эквивалентные или аналогичные параметрам DirAC, в форме метаданных и формы аудиосигнала для микшированного с понижением сигнала, DoA и диффузность могут легко извлекаться в расчете на полосу частот параметров из входных метаданных. Такой входной формат иногда называется «форматом MAS А (пространственного аудио на основе метаданных)». МАЗА обеспечивает возможность системе игнорировать специфичность массивов микрофонов и их форм-факторов, необходимых для вычисления пространственных параметров. Они должны извлекаться из-за пределов системы пространственного кодирования аудио с использованием обработки, конкретной для устройства, которое включает микрофоны.
Варианты осуществления настоящего изобретения могут использовать систему пространственного кодирования, как проиллюстрировано посредством фиг.2, на котором проиллюстрированы пространственный аудиокодер и декодер на основе DirAC. Варианты осуществления поясняются относительно фиг.3а и 3b, при этом сначала поясняются расширения для модели DirAC.
Модель DirAC согласно вариантам осуществления может также расширяться посредством обеспечения возможности различных направленных компонентов с одинаковым частотно-временным мозаичным элементом. Она может расширяться двумя основными способами:
Первое расширение состоит из отправки двух или более DoA в расчете на мозаичный элемент T/F. Каждое DoA должно затем быть ассоциировано с энергией или отношением энергий. Например, 1-ое DoA может быть ассоциировано с отношением Г1 энергий между энергией направленного компонента и полной энергией аудиосцены:
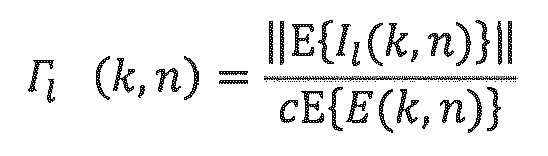
где I1 (k, n) является вектором интенсивности, ассоциированным с 1-ым направлением. Если L DoA передаются наряду с их L отношений энергий, диффузность затем может логически выводиться из L отношений энергий следующим образом:
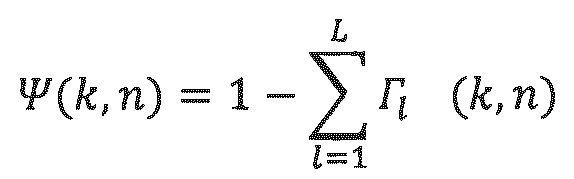
Пространственные параметры, передаваемые в потоке битов, могут представлять собой L направлений наряду с L отношений энергий, или эти последние параметры также могут преобразовываться в L-1 отношений энергий + параметр диффузности.
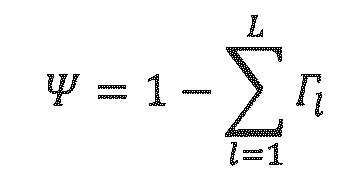
Второе расширение состоит из разбиения двумерного или трехмерного пространства на неперекрывающиеся секторы и передачи, для каждого сектора, набора параметров DirAC (DoA + посекторная диффузность). Далее поясняется DirAC высокого порядка, введенное в [5].
Оба расширения фактически могут комбинироваться, и настоящее изобретение является релевантным для обоих расширений.
Фиг. 3а и 3b иллюстрируют варианты осуществления настоящего изобретения, при этом фиг.3а показывает подход с фокусировкой на базовую концепцию/используемый способ 100, при этом используемое устройство 50 показано на фиг.3b.
Фиг. 3а иллюстрирует способ 100, содержащий базовые этапы 110, 120 и 130.
Первые этапы 110 и 12 0 являются сравнимыми друг с другом, а именно, означают прием наборов пространственных аудиопараметров. На первом этапе 110, первый набор принимается, при этом на втором этапе 12 0, второй набор принимается. Дополнительно, дополнительные этапы приема могут присутствовать (не показаны). Следует отметить, что первый набор может означать первый момент времени/первый кадр, второй набор может означать второй (последующий) момент времени/второй (по следующий) кадр и т.д. Как пояснено выше, первый набор, а также второй набор может содержать информацию диффузности (ψ) и/или информацию направления (азимут и подъем). Эта информация может кодироваться посредством использования кодера пространственных метаданных. Теперь выдвигается такое допущение, что второй набор информации теряется или повреждается во время передачи. В этом случае, второй набор заменяется посредством первого' набора. Это обеспечивает маскировку потерь пакетов для пространственных аудиопараметров, таких как параметры DirAC.
В случае потерь пакетов, стертые параметры DirAC потерянных кадров должны восстанавливаться для ограничения влияния на качество. Это может достигаться посредством синтетического формирования пропущенных параметров с учетом предыдущих принимаемых параметров. Нестабильное пространственное изображение может восприниматься как неприятное и как артефакт, хотя строго постоянное пространственное изображение может восприниматься как неестественное.
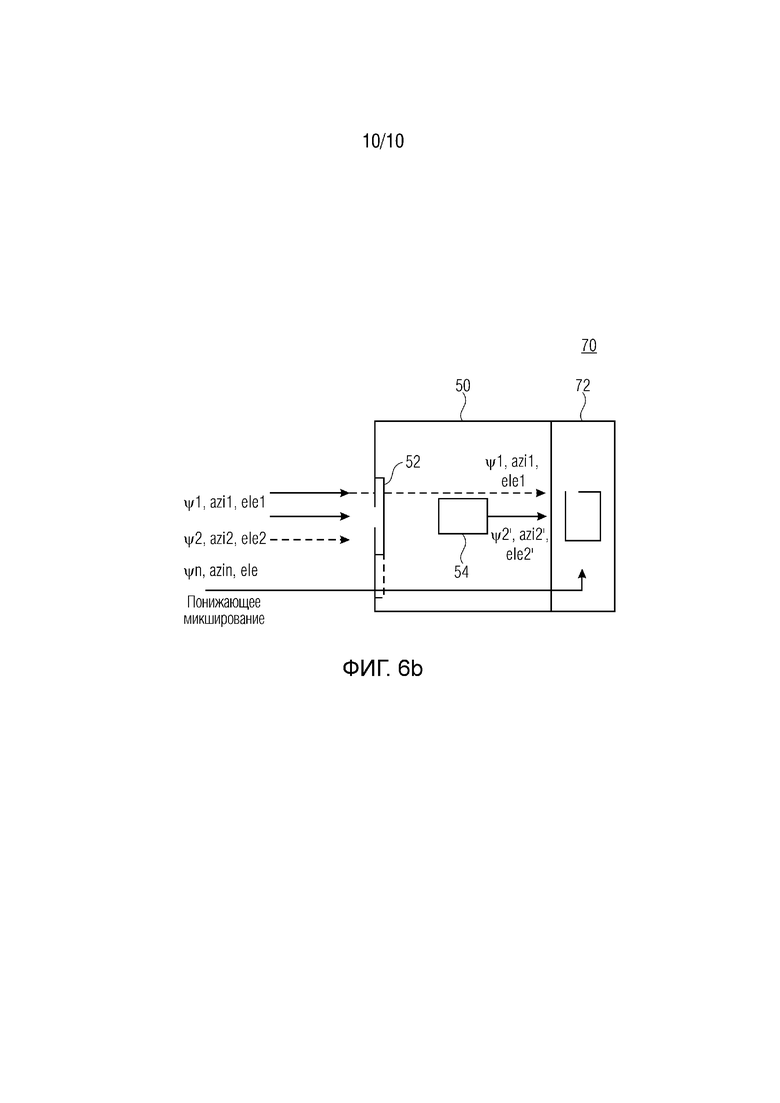
Подход 100, как пояснено на фиг.3а, может выполняться посредством объекта 50, как показано посредством фиг.3b. Устройство 50 маскировки потерь содержит интерфейс 52 и процессор 54. Через интерфейс могут приниматься наборы пространственных аудиопараметров, ψ1, azi1, ele1, ψ2, azi2, ele2, ψn, azin, ele. Процессор 54 анализирует принимаемые наборы и, в случае потерянного или поврежденного набора, он заменяет потерянный или поврежденный набор, например, на ранее принимаемый набор или сравнимый набор. Эти различные стратегии могут использоваться, что поясняется ниже.
Стратегия запоминания: В общем, можно с уверенностью считать, что пространственное изображение должно быть относительно стабильным во времени, что может истолковываться для параметров DirAC, т.е. для направления поступления и рассеяния, так, что они сильно не изменяются между кадрами. По этой причине, простой, но эффективный подход заключается в сохранении параметров последнего хорошо принятого кадра для кадров, потерянных во время передачи.
Экстраполяция направления: В качестве альтернативы, может быть предусмотрена возможность оценивать траекторию звуковых событий в аудиосцене и затем пытаться экстраполировать оцененную траекторию. Это является, в частности, релевантным, если звуковое событие хорошо локализуется в пространстве в качестве точечного источника, который отражается в модели DirAC посредством низкой диффузности. Оцененная траектория может вычисляться из наблюдений предыдущих направлений и подгонки кривой между этими точками, что может разворачивать интерполяцию или сглаживание. Также может использоваться регрессионный анализ. Экстраполяция затем выполняется посредством оценки подогнанной кривой за рамками диапазона наблюдаемых данных.
В DirAC направления зачастую выражаются, квантуются и кодируются в полярных координатах. Тем не менее, обычно более удобно обрабатывать направления и затем траекторию в декартовых координатах, чтобы исключить обработку операций по модулю 2pi.
Размывание направления: Когда звуковое событие является более рассеянным, направления являются менее значимыми и могут считаться реализацией стохастического процесса. Размывание затем может помогать делать более естественным и более приятным подготовленное посредством рендеринга звуковое поле посредством введения случайного шума в предыдущие направления перед его использованием для потерянных кадров. Вводимый шум и его дисперсия могут представлять собой функцию диффузности.
С использованием стандартного анализа DirAC аудиосцен, можно изучать влияние диффузности на точность и значимость направления модели. С использованием искусственного сигнала в формате В, для которого отношение прямой к рассеянной энергии (DDR) задается между компонентом плоской волны и компонентом рассеянного поля, можно анализировать результирующие параметры DirAC и их точность.
Теоретическая диффузность W представляет собой функцию отношения прямой к рассеянной энергии (DDR), Г, и выражается следующим образом:
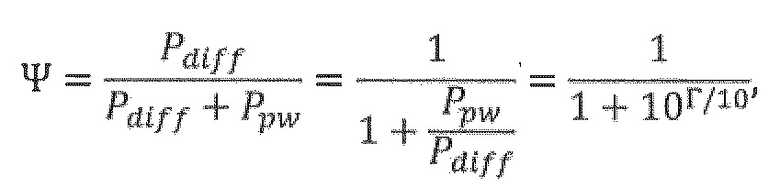
- где Ppw и Pdiff являются мощностями плоской волны и диффузности, соответственно, и Г является DDR, выражаемым на шкале в дБ.
Конечно, возможно то, что может использоваться одна либо комбинация трех поясненных стратегий. Используемая стратегия выбирается посредством процессора 54 в зависимости от принимаемых наборов пространственных аудиопараметров. Для этого, аудиопараметры, согласно вариантам осуществления, могут анализироваться для обеспечения применения различных стратегий согласно характеристикам аудиосцены, а более конкретно, согласно диффузности.
Это означает то, что, согласно вариантам осуществления, процессор 54 выполнен с возможностью обеспечения маскировки потерь пакетов для пространственного параметрического аудио посредством использования ранее хорошо принятой информации направления и размывания. Согласно дополнит ель ному варианту осуществления, размывание представляет собой функцию оцененной диффузности или отношения энергий между направленными и ненаправленными компонентами аудиосцены. Согласно вариантам осуществления, размывание представляет собой функцию тональности, измеренной передаваемого сигнала понижающего микширования. Следовательно, анализатор выполняет свой анализ на основе оцененной диффузности, отношения энергий и/или тональности.
На фиг.3а и 3b, измеренная диффузность задается в функции DDR посредством моделирования рассеянного поля с N=466 декоррелированных розовых шумов, равномерно позиционированных на сфере, и плоской волны посредством независимого розового шума, размещенного с азимутом в 0 градусов и с подъемом в 0 градусов. Подтверждено то, что диффузность, измеренная в анализе DirAC, является хорошей оценкой теоретической диффузности, если длина W окна наблюдения является достаточно большой. Это подразумевает, что диффузность имеет долговременные характеристики, что подтверждает, что параметр в случае потерь пакетов может хорошо прогнозироваться посредством простого поддержания ранее хорошо принятого значения.
С другой стороны, оценка параметров направления также может оцениваться в функции истинной диффузности, которая сообщается на фиг.4. Можно показывать, что оцененный подъем и азимут позиции плоской волны отклоняются от позиции на основе экспериментально полученных проверочных данных (азимута в 0 градусов и подъема в 0 градусов) со среднеквадратическим отклонением, увеличивающимся с диффузностью. Для диффузности 1, среднеквадратическое отклонение составляет примерно 90 градусов для угла азимута, заданного между 0 и 360 градусов, согласно абсолютно случайному углу для равномерного распределения. Другими словами, угол азимута в таком случае является незначащим. То же самое наблюдение может проводиться для подъема. В общем, точность оцененного' направления и его значимость снижается с диффузностью. В таком случае предполагается, что направление в DirAC должно колебаться во времени и отклоняться от своего ожидаемого значения с функцией дисперсии диффузности. Эта естественная дисперсия представляет собой часть модели DirAC, что важно для высококачественного воспроизведения аудиосцены. Фактически, рендеринг в постоянном направлении направленного компонента DirAC, даже если диффузность является высокой, должен в любом случае формировать точечный источник, который в реальности должен восприниматься как более широкий.
По причинам, раскрытым выше, предлагается применять размывание к направлению в дополнение к стратегии запоминания.
Амплитуда размывания задается в качестве функции диффузности и, например, может соответствовать моделям, приведенным на фиг.4. Две модели для подъема и измеренных углов подъема могут извлекаться, для которых среднеквадратическое отклонение выражается следующим образом:

Псевдокод маскировки параметра DirAC в таком случае может быть следующим:

- где bad frame indicator[к] является флагом, указывающим, принят ли хорошо кадр в индексе к. В случае хорошего кадра, параметры DirAC считываются, декодируются и деквантуются для каждой полосы частот параметров, соответствующей данному частотному диапазону. В случае плохого кадра, диффузность непосредственно запоминается из последнего хорошо принятого кадра в той же полосе частот параметров, в то время как азимут и подъем извлекаются из деквантования последних хорошо принятых индексов с введением случайного значения, масштабируемого на коэффициентную функцию индекса диффузности. Функция random() выводит случайное значение согласно данному распределению. Случайный процесс, например, может соответствовать стандартному нормальному распределению с нулевым средним и единичной дисперсией. В качестве альтернативы, он может соответствовать равномерному распределению между -1 и 1 либо соответствовать треугольной плотности распределения вероятностей с использованием, например, следующего псевдокода:


Масштабы размывания представляют собой функции индекса диффузности, унаследованного из последнего хорошо принятого' кадра в той же полосе частот параметров, и могут извлекаться из моделей, логически выведенных из фиг.4. Например, в случае если диффузность кодируется для 8 индексов, они могут соответствовать следующим таблицам:
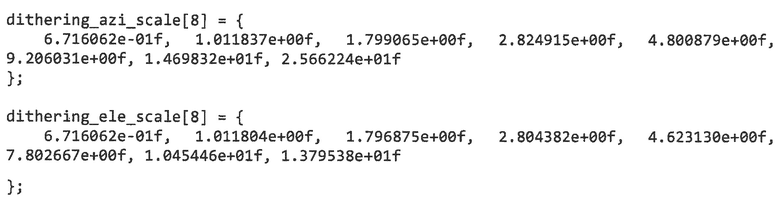
Дополнительно, интенсивность размывания также может регулироваться в зависимости от характера сигнала понижающего микширования. Фактически, очень тональный сигнал имеет тенденцию восприниматься как более локализованный источник в качестве нетональных сигналов. Следовательно, размывание затем может регулироваться в функции тональности передаваемого понижающего микширования, посредством снижения эффекта размывания для тональных элементов. Тональность может измеряться, например, во временной области посредством вычисления усиления долговременного прогнозирования или в частотной области посредством измерения спектральной сглаженности.
Относительно фиг.6а и 6b, в дальнейшем поясняются дополнительные варианты осуществления, связанные со способом для декодирования кодированной с помощью DirAC аудиосцены (см фиг.6а, способ 200) и декодером 17 для кодированной с помощью DirAC аудиосцены (см. фиг.6b).
Фиг. 6а иллюстрирует новый способ 200, содержащий этапы 110, 120 и 130 способа 100 и дополнительный этап декодирования 210. Этап декодирования предусматривает декодирование кодированной с помощью DirAC аудиосцены, содержащей понижающее микширование (не показано) посредством использования первого набора пространственных аудиопараметров и второго набора пространственных аудиопараметров, причем здесь используется замененный второй набор, выводимый посредством этапа 130. Эта концепция используется посредством устройства 17, показанного на фиг.6b. Фиг, 6b показывает декодер 70, содержащий процессор 15 для маскировки потерь пространственных аудиопараметров и декодер 72 DirAC, Декодер 72 DirAC или, подробнее процессор декодера 72 DirAC, принимает сигнал понижающего микширования и наборы пространственных аудиопараметров, например, непосредственно из интерфейса 52 и/или обработанные посредством процессора 52 в соответствии с вышеописанным подходом.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа.
Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства.
Кодированный аудиосигнал согласно изобретению может сохраняться на цифровом носителе хранения данных либо может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно изобретению в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), на котором записана компьютерная программа для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными обычно является физическим и/или постоянным.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, на котором установлена компьютерная программа для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передачи (например, электронной или оптической) компьютерной программы для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются лишь иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидны модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, а не конкретными подробностями, представленными в данном документе в качестве описания и пояснения вариантов осуществления.
Библиографический список
[1] V. Pulkki, M-V. Laitinen, J. Vilkamo, J. Ahonen, T. Lokki and T. Pihlajamaki, "Directional audio coding perception-based reproduction of spatial sound", International Workshop on the Principles and. pplication on Spatial Hearing, ноябрь 2009 г., Зао; Мияги, Япония.
[2] V. Pulkki, "Virtual source positioning using vector base amplitude panning", J. Audio Eng. Soc, 45(6):456-466, июнь 1997 г.
[3] J, Ahonen and V. Pulkki, "Diffuseness estimation using temporal variation of intensity vectors", in Workshop on Applications of Signal Processing to Audio and Acoustics WASPAA, Mononk Mountain House, Нью-Палц, 2009 г.
[4] T, Hirvonen, J. Ahonen and V. Pulkki, "Perceptual compression methods for metadata in Directional Audio Coding applied to audiovisual teleconference", AES 12 6th Convention, 7-10 мая 2009 г., Мюнхен, Германия.
[5] A. Politis, J. Vilkamo and V. Pulkki, "Sector-Based Parametric Sound Field Reproduction in the Spherical Harmonic Domain", in IEEE journal of Selected Topics in Signal Processing, том 9, номер 5, стр. 852-866, август 2015 г.
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в исключении артефактов в выводимом звуке при обработке аудиоданных посредством маскировки потерь технологией пространственной аудиообработки DirAC. Технический результат достигается за счет замены второй информации направления поступления второго набора заменяющей информацией направления поступления, извлекаемой из первой информации направления поступления, если по меньшей мере вторая информация направления поступления или часть второй информации направления поступления потеряна или повреждена; причём этап замены содержит этап, на котором размывают заменяющую информацию направления поступления путём введения случайного шума; и/или в котором этап замены содержит этап, на котором вводят случайный шум в первую информацию направления поступления для получения заменяющей информации направления поступления; при этом этап введения выполняется, если первая или вторая информация (ψ1, ψ2) диффузности указывает высокую диффузность; и/или если первая или вторая информация (ψ1, ψ2) диффузности выше заданного порогового значения для информации диффузности. 6 н. и 13 з.п. ф-лы, 10 ил.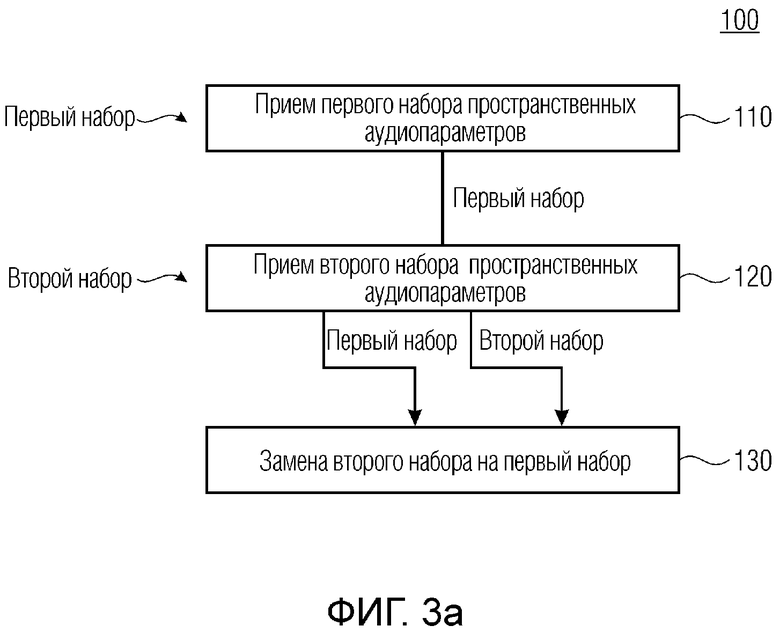
1. Способ (100) маскировки потерь пространственных аудиопараметров, причем пространственные аудиопараметры содержат по меньшей мере информацию направления поступления, при этом способ содержит следующие этапы, на которых:
- принимают (110) первый набор пространственных аудиопараметров, содержащих по меньшей мере первую информацию направления (azi1, ele1) поступления;
- принимают (120) второй набор пространственных аудиопараметров, содержащих по меньшей мере вторую информацию направления (azi2, ele2) поступления; и
- заменяют вторую информацию направления (azi2, ele2) поступления второго набора заменяющей информацией направления поступления, извлекаемой из первой информации направления (azi1, ele1) поступления, если по меньшей мере вторая информация направления (azi2, ele2) поступления или часть второй информации направления (azi2, ele2) поступления потеряна или повреждена;
причём этап замены содержит этап, на котором размывают заменяющую информацию направления поступления путём введения случайного шума; и/или
в котором этап замены содержит этап, на котором вводят случайный шум в первую информацию направления (azi1, ele1) поступления для получения заменяющей информации направления поступления;
при этом этап введения выполняется, если первая или вторая информация (ψ1, ψ2) диффузности указывает высокую диффузность; и/или если первая или вторая информация (ψ1, ψ2) диффузности выше заданного порогового значения для информации диффузности.
2. Способ (100) по п. 1, в котором первые наборы (1-е наборы) и вторые наборы (2-е наборы) пространственных аудиопараметров содержат первую и вторую информацию диффузности (ψ1, ψ2) соответственно.
3. Способ (100) по п. 2, в котором первая или вторая информация диффузности (ψ1, ψ2) извлекается по меньшей мере из одного отношения энергий, связанного по меньшей мере с одной информацией направления поступления.
4. Способ (100) по п. 2 или 3, при этом способ дополнительно содержит этап, на котором заменяют вторую информацию (ψ2) диффузности второго набора (2-го набора) заменяющей информацией диффузности, извлекаемой из первой информации (ψ1) диффузности.
5. Способ (100) по одному из предыдущих пунктов, в котором заменяющая информация направления поступления соответствует первой информации направления (azi1, ele1) поступления.
6. Способ (100) по п. 1, в котором информация диффузности содержит или основана на отношении между направленными и ненаправленными компонентами аудиосцены, описанной посредством первого набора (1-го набора) и/или второго набора (2-го набора) пространственных аудиопараметров.
7. Способ (100) по одному из пп. 1-6, в котором случайный шум, который должен быть введён, зависит от первой и/или второй информации (ψ1, ψ2) диффузности; и/или
- в котором случайный шум, который должен быть введён, масштабируется на коэффициент в зависимости от первой и/или второй информации (ψ1, ψ2) диффузности.
8. Способ (100) по одному из пп. 1-7, дополнительно содержащий этап, на котором анализируют тональность аудиосцены, описанной посредством первого набора (1-го набора) и/или второго набора (2-го набора) пространственных аудиопараметров, либо анализируют тональность передаваемого понижающего микширования, относящегося к первому набору (1-му набору) и/или второму набору (2-му набору) пространственных аудиопараметров, для получения значения тональности, описывающего тональность; и
- при этом случайный шум, который должен быть введён, зависит от значения тональности.
9. Способ (100) по п. 8, в котором случайный шум масштабируется с понижением на коэффициент, снижающийся вместе с инверсией значения тональности, либо если тональность увеличивается.
10. Способ (100) по одному из предыдущих пунктов, при этом способ (100) содержит этап, на котором экстраполируют первую информацию направления (azi1, ele1) поступления для получения заменяющей информации направления поступления.
11. Способ (100) по п. 10, в котором экстраполяция основана на одной или более дополнительной информации направления поступления, относящейся к одному или более наборам пространственных аудиопараметров.
12. Способ (100) по одному из пп. 10 или 11, в котором экстраполяция выполняется, если первая и/или вторая информация (ψ1, ψ2) диффузности указывает низкую диффузность; или если первая и/или вторая информация (ψ1, ψ2) диффузности ниже заданного порогового значения для информации диффузности.
13. Способ (100) по одному из предыдущих пунктов, в котором первый набор (1-й набор) пространственных аудиопараметров относится к первому моменту времени и/или первому кадру, и при этом второй набор (2-й набор) пространственных аудиопараметров относится ко второму моменту времени и/или второму кадру; или
- в котором первый набор (1-й набор) пространственных аудиопараметров относится к первому моменту времени, и при этом второй момент времени следует после первого момента времени, либо в котором второй кадр следует после первого кадра.
14. Способ (100) по одному из предыдущих пунктов, в котором первый набор (1-й набор) пространственных аудиопараметров содержит первый поднабор пространственных аудиопараметров для первой полосы частот и второй поднабор пространственных аудиопараметров для второй полосы частот; и/или
- в котором второй набор (2-й набор) пространственных аудиопараметров содержит другой первый поднабор пространственных аудиопараметров для первой полосы частот и другой второй поднабор пространственных аудиопараметров для второй полосы частот.
15. Способ (200) декодирования кодированной с помощью DirAC аудиосцены, содержащий следующие этапы, на которых:
- декодируют кодированную с помощью DirAC аудиосцену, содержащую понижающее микширование, первый набор пространственных аудиопараметров и второй набор пространственных аудиопараметров;
- осуществляют способ по одному из предыдущих этапов.
16. Машиночитаемый цифровой носитель хранения данных, на котором сохранена компьютерная программа, имеющая программный код для осуществления способа (100, 200) по одному из пп. 1-14 при её выполнении на компьютере.
17. Машиночитаемый цифровой носитель хранения данных, на котором сохранена компьютерная программа, имеющая программный код для осуществления способа (100, 200) по п. 15 при её выполнении на компьютере.
18. Устройство (50) маскировки потерь для маскировки потерь пространственных аудиопараметров, причем пространственные аудиопараметры содержат, по меньшей мере, информацию направления поступления, причем устройство содержит:
- приемное устройство (52) для приема (110) первого набора пространственных аудиопараметров, содержащих первую информацию направления (azi1, ele1) поступления, и для приема (120) второго набора пространственных аудиопараметров, содержащих вторую информацию направления (azi2, ele2) поступления;
- процессор (54) для замены второй информации направления (azi2, ele2) поступления второго набора заменяющей информацией направления поступления, извлекаемой из первой информации направления (azi1, ele1) поступления, если по меньшей мере вторая информация направления (azi2, ele2) поступления или часть второй информации направления (azi2, ele2) поступления потеряна или повреждена;
причём упомянутая замена содержит размытие заменяющей информации направления поступления; и/или
в котором упомянутая замена содержит введение случайного шума в первую информацию направления (azi1, ele1) поступления для получения заменяющей информации направления поступления;
при этом упомянутое введение выполняется, если первая или вторая информация (ψ1, ψ2) диффузности указывает высокую диффузность; и/или если первая или вторая информация (ψ1, ψ2) диффузности выше заданного порогового значения для информации диффузности.
19. Декодер (70) для кодированной с помощью DirAC аудиосцены, содержащий устройство маскировки потерь по п. 18.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| МАСШТАБИРУЕМЫЙ ИНФОРМАЦИОННЫЙ СИГНАЛ, УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ МАСШТАБИРУЕМОГО ИНФОРМАЦИОННОГО КОНТЕНТА, УСТРОЙСТВО И СПОСОБ ДЛЯ ИСПРАВЛЕНИЯ ОШИБОК МАСШТАБИРУЕМОГО ИНФОРМАЦИОННОГО СИГНАЛА | 2008 |
|
RU2461052C2 |

