Область техники
Изобретение относится к области информационной безопасности, а более конкретно к системам и способам выявления вредоносных скриптов.
Уровень техники
Количество пользователей, количество компаний и разнообразие направлений их деятельности продолжает непрерывно расти. Одновременно увеличивается и количество создаваемых веб-сайтов и веб-страниц.
Создание веб-страницы как наиболее простого инструмента для доступа к информации в сети Интернет предусматривает использование ресурсов компьютерной системы. Использование ресурсов все чаще реализуют при помощи скриптовых языков программирования (PHP, JavaScript, Python, Ruby и прочие).
Скрипт – это программный код (сценарий), написанный на различных интерпретируемых языках программирования. Все скрипты выполняются с помощью внешней программы – интерпретатора. В отличие от исполняемых файлов, скрипты в большинстве своем существуют в виде текстовых файлов и могут быть прочитаны человеком. Вредоносные скрипты можно условно разделить на два вида. Первый вид включает скрипты, которые встраиваются в код веб-страниц, интерпретируются браузером и выполняют действия, заложенные злоумышленниками. Второй вид включает скрипты, которые предназначены для запуска на компьютере пользователя. Они исполняются компонентами операционной системы и имеют доступ к API (файловая система, процессы и т. д.).
Существует много способов выявления вредоносных скриптов. Одним из эффективных способов является детальный анализ текста файлов веб-страницы.
В публикации US7707634B2 представлена система, в которой используют сигнатуры для обнаружения вредоносных скриптов. Сигнатуры создают на основании известных образцов вредоносных скриптов. Прежде чем использовать сигнатуру, текст, содержащий скрипт, подвергают нормализации. В ходе нормализации осуществляют поиск начала скрипта, приводят имена функций и переменных скрипта в форму, пригодную для использования сигнатур.
Указанное решение частично осуществляет выявление вредоносных скриптов, но не позволяет эффективно решить задачу выявления обрезанных и частично поврежденных вредоносных скриптов, пересылаемых отличным от внедрения в веб-страницу способом.
Раскрытие изобретения
Изобретение предназначено для повышения эффективности выявления вредоносных скриптов. Технический результат настоящего изобретения заключается в обнаружении вредоносных скриптов или их частей, написанных на определенном языке программирования путем выявления файла, содержащего скрипт, распознавания языка скрипта при помощи правил распознавания языка, формирования набора хэш-кодов выявленного скрипта и сравнения набора хэш-кодов скрипта с известными наборами хэш-кодов вредоносных скриптов.
В одном из вариантов реализации предоставляется способ выявления вредоносного скрипта на основании набора хэш-кодов, содержащий этапы, на которых применяют компьютер, чтобы выполнить операции, которые включают в себя этапы, на которых: обнаруживают файл, содержащий скрипт, путем анализа каждого файла из множества файлов, которые проверяют на наличие вредоносного кода; формируют сводку скрипта на основании обнаруженного файла; подсчитывают статические и динамические параметры, содержащиеся в сформированной сводке скрипта; распознают язык программирования скрипта на основании подсчитанных параметров сформированной сводки скрипта с использованием правил распознавания языка; обрабатывают обнаруженный файл на основании данных о распознанном языке программирования и данных об обнаруженном файле; формируют набор хэш-кодов на основании обработанного файла с использованием правил формирования хэш-кодов; выявляют вредоносный скрипт путем сравнения сформированного набора хэш-кодов с известными вредоносными наборами хэш-кодов из базы данных хэш-кодов скриптов.
В другом варианте реализации способа в результате анализа каждого файла из множества файлов, которые проверяют на наличие вредоносного кода, при помощи эвристических алгоритмов, созданных для поиска структурированных типов файлов, в которых наличие скриптов маловероятно, исключают найденные файлы из указанного множества файлов.
Еще в одном варианте реализации способа формируют сводку скрипта путем выделения набора значимых байтов и набора исключенных байтов из обнаруженного файла.
Еще в другом варианте реализации способа набор значимых байтов выделяют из обнаруженного файла путем фильтрации обнаруженного файла при помощи алгоритмов фильтрации.
В другом варианте реализации способа набор исключенных байтов получают путем удаления из обнаруженного файла набора значимых байтов.
Еще в одном варианте реализации способа под правилом распознавания языка понимают набор результатов работы деревьев решений, при наличии которого считают, что выявлен скрипт, написанный на определенном языке программирования.
Еще в другом варианте реализации способа набор значимых байтов выделяют из обнаруженного файла путем фильтрации обнаруженного файла при помощи алгоритмов фильтрации.
В другом варианте реализации способа обрабатывают обнаруженный файл путем: удаления всех символов, кроме видимых символов, из таблицы ASCII; символов переноса строк, пробелов, символов из таблицы Unicode, строк, содержащих комментарии и отдельные отмеченные строки, характерные для распознанного языка программирования; приведения текста к нижнему регистру; указания начала и окончания строковых констант, характерных для распознанного языка программирования.
Еще в одном варианте реализации способа выполняют формирование набора хэш-кодов путем: разделения обработанного файла на конструкции, содержащие совокупность символов длиной от 4 до 10 символов; подсчета количества вхождений всех выявленных конструкций в обработанный файл; определения типа используемого хэш-кода с помощью правил формирования хэш-кодов; формирования набора хэш-кодов из хэш-кодов определенного типа.
В другом варианте реализации способа под правилом формирования хэш-кодов понимают набор условий, при выполнении которых используют определенный тип хэш-кода.
Еще в другом варианте реализации способа под статическими параметрами сформированной сводки скрипта понимают перечень признаков, посчитанный на основе набора значимых байт, количества вхождений комментариев, строк, содержащих символьные выражения, конструкций, содержащих выражения, известных языков программирования скриптов.
В другом варианте реализации способа под динамическими параметрами сформированной сводки скрипта понимают перечень признаков, подсчитанный на основе количества вхождений каждого вида конструкций, содержащих совокупность символов, характерных для каждого языка программирования, в набор значимых байтов.
В одном из вариантов реализации предоставляется cистема, содержащая по меньшей мере один компьютер, включающий взаимодействующие между собой средства: средство обнаружения, средство подсчета, средство формирования, средство выявления, базу данных правил, базу данных хэш-кодов скриптов и хранящий машиночитаемые инструкции, при выполнении которых система выполняет выявление вредоносного скрипта на основании набора хэш-кодов согласно способу по любому из пп. 1-11.
Краткое описание чертежей
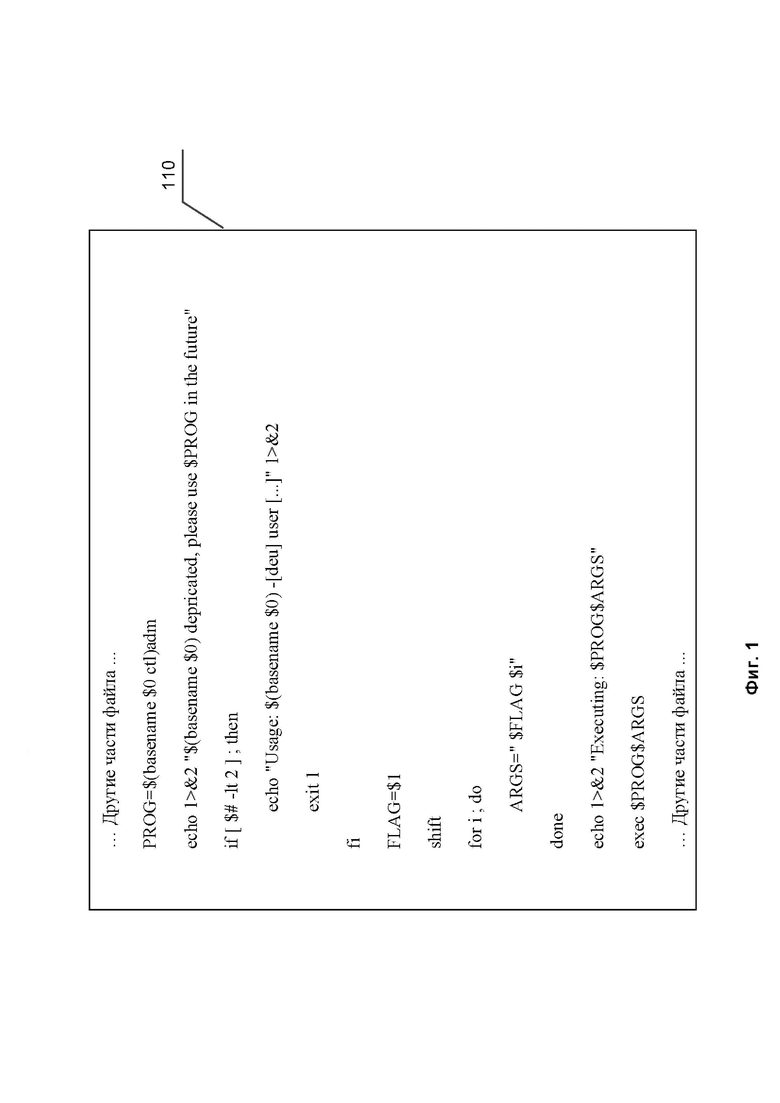
Фиг. 1 иллюстрирует пример файла, содержащего исходный код скрипта.
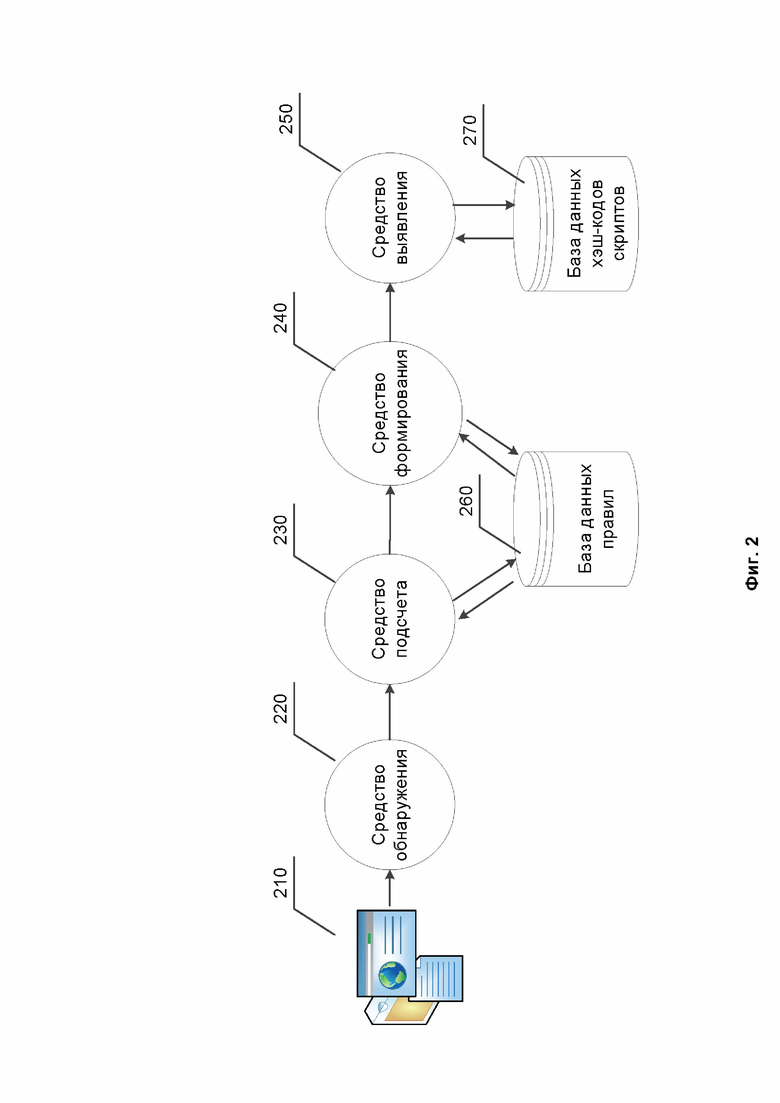
Фиг. 2 иллюстрирует структуру системы выявления вредоносного скрипта на основании набора хэш-кодов.
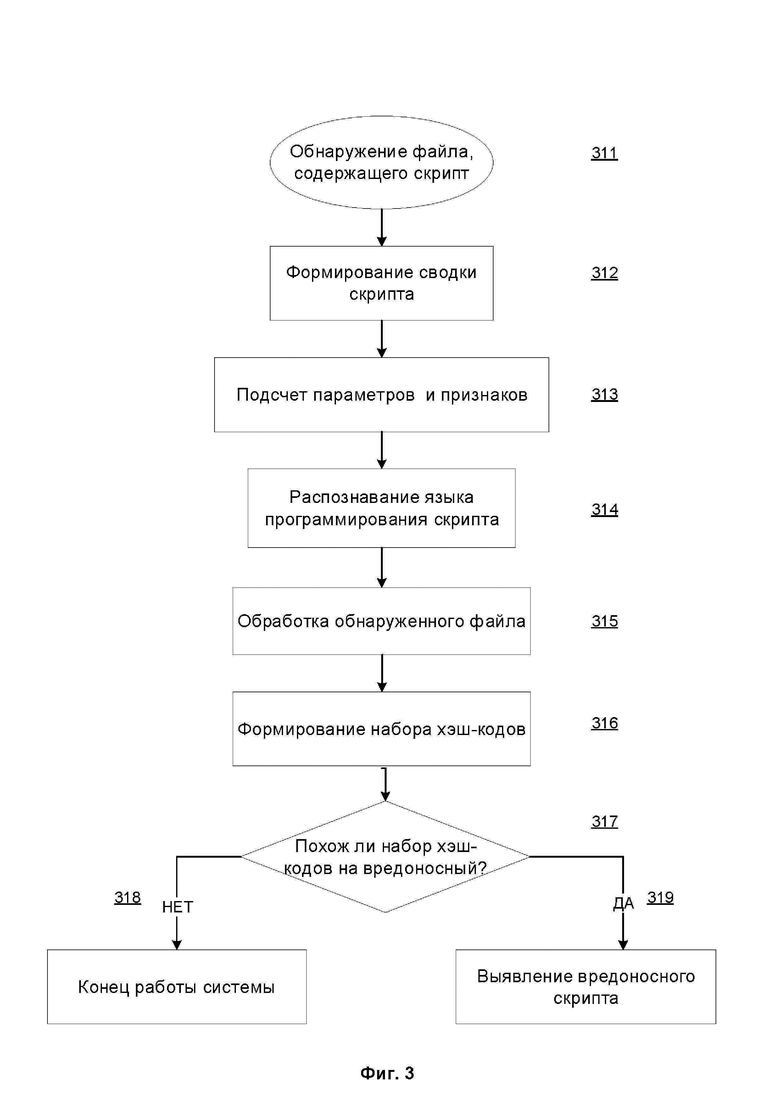
Фиг. 3 иллюстрирует алгоритм функционирования системы выявления вредоносного скрипта на основании набора хэш-кодов.
Фиг. 4 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено в приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
Введем ряд определений и понятий, которые будут использованы при описании вариантов осуществления изобретения.
Хэш-функцией называется алгоритм, конвертирующий строку произвольной длины (сообщение) в битовую строку фиксированной длины, называемой хэш-кодом, проверочной суммой или цифровым отпечатком. Во многих технологиях безопасности применяются односторонние функции шифрования, называемые также хэш-функциями. Основное назначение подобных функций – получение из сообщения произвольного размера его хэш-кода – значения фиксированного размера. Хэш-код может быть использован в качестве контрольной суммы исходного сообщения, обеспечивая таким образом (при использовании соответствующего протокола) контроль целостности информации (Брассар Ж. Современная криптология / Ж. Брассар – М.: ПОЛИМЕД, 1999. – 178 с.).
Сценарий, скрипт (англ. script, scenario) - программа (особый вид программного кода), обычно написанная на некотором интерпретируемом (не на компилируемом) языке и содержащая отдельные команды-инструкции. Например, сценарий включается в текст веб-страницы в виде исходного кода и интерпретируется системой, установленной на компьютере удаленного пользователя, запросившего эту страницу.
Java-сценарий (англ. Java script) - сценарий в виде текста на языке программирования Java или языке сценариев javascript, включаемый непосредственно в веб-страницу и загружаемый вместе с ней. Исполняется интерпретатором Jаvа, который встраивается практически в каждый современный браузер (Дорот В. Л., Новиков Ф. А., Толковый словарь современной компьютерной лексики. - 3-е из Д., перераб. и доп. - СПб.: БХВ-Петербург, 2004. - 608 с.: ил.).
Злоумышленники используют возможность скриптов обращаться к ресурсам компьютерной системы во вредоносных целях. Существующие в настоящее время способы передачи данных позволяют замаскировать скрипт в файле любого типа и вынудить пользователя тем или иным способом его активировать. Для выявления скрипта известного языка программирования скриптов или его части используют систему выявления вредоносного скрипта на основании набора хэш-кодов. Фиг 1. иллюстрирует пример файла, содержащего исходный код скрипта. Файл, содержит скрипт 1, написанный на языке программирования Bash 110. Скрипты командной строки Bash — это наборы команд для командной строки Linux, которые можно вводить с клавиатуры, собранные в файлы и объединенные общей целью. При этом результаты работы команд могут представлять либо самостоятельную ценность, либо служить входными данными для других команд и файлов.
Фиг 2. иллюстрирует структуру системы выявления вредоносного скрипта на основании набора хэш-кодов, которая включает в себя средство обнаружения 220, средство подсчета 230, средство формирования 240, средство выявления 250, базу данных правил 260, базу данных хэш-кодов скриптов 270.
Представленная на Фиг. 2 система является компьютерной системой, например, компьютером общего назначения, представленным на Фиг. 4 и обладающим аппаратным процессором и памятью. Упомянутая система содержит функциональные и/или аппаратные модули и средства 220-270, которые в свою очередь содержат инструкции для исполнения на аппаратном процессоре. Ниже описаны варианты реализации упомянутых модулей и средств 220-270 системы.
Средство обнаружения 220 предназначено для обнаружения файла, содержащего скрипт. Средство обнаружения 220 выполняет обнаружение файла, содержащего скрипт, путем анализа каждого файла из множества файлов, в которых необходимо проверить наличие вредоносного кода 210. Множество файлов 210 может содержать различные файлы, с которыми взаимодействовал пользователь в том или ином виде, в том числе файлы веб-сайтов и веб-страниц, файлы электронных сообщений и т.д. Анализ выполняют при помощи эвристических алгоритмов, которые созданы для поиска структурированных типов файлов, в которых наличие скриптов маловероятно (например, исполняемые файлы в формате PE/ELF/MACHO, архивы, отдельные типы файлов-документов и т.д.). Найденные упомянутые файлы исключают из множества файлов 210, наличие вредоносного кода в которых необходимо проверить. Оставшиеся после исключения файлы считают файлами, которые могут содержать вредоносный код.
Помимо этого, средство обнаружения 220 предназначено для формирования сводки скрипта на основании обнаруженного файла и передачи данных об обнаруженном файле и данных о сформированной сводке скрипта средству подсчета 230.
Средство обнаружения 220 формирует сводку скрипта путем выделения набора значимых байтов и набора исключенных байтов из обнаруженного файла. Далее на основе анализа выделенных наборов средство обнаружения 220 заполняет сводку скрипта.
Набор значимых байтов выделяют из обнаруженного файла путем фильтрации обнаруженного файла при помощи алгоритмов фильтрации.
Алгоритмы фильтрации включают в себя следующие действия:
• выделение части обнаруженного файла, которая предположительно содержит скрипт;
• удаление всех символов, кроме видимых символов, из таблицы ASCII;
• удаление символов переноса строк, пробела, символов из таблицы Unicode;
• приведение текста к нижнему регистру;
• удаление строк, содержащих комментарии популярных языков программирования скриптов;
• удаление строк, содержащих выражение «произвольный текст $ произвольный текст и знак препинания»;
• удаление строк, содержащих непрерывные выражения (без пробелов, переносов, знаков препинания) длинной выше предельного значения символов. Предельное значение длины является настраиваемым параметром.
Набор исключенных байтов получают путем удаления из обнаруженного файла набора значимых байтов.
Сводка скрипта (англ. script summary) - это структура данных, подсчитанная на основании параметров обнаруженного файла, которая характеризует содержащийся в файле скрипт. Сводка скрипта содержит следующие данные:
• набор значимых байтов;
• набор исключенных байтов;
• количество байтов в виде комментариев каждого шаблона из набора исключенных байтов;
• размер массива, который занимает набор значимых байтов;
• количество строк, содержащих по крайней мере один значимый байт;
• количество строк, содержащих выражение «[произвольный текст (набор произвольных одного или более символов)]» или его часть;
• количество строк, содержащих выражение «произвольный текст = произвольный текст» или его часть;
• количество строк, содержащих выражение «$ = произвольный текст» или его часть;
• количество конструкций, содержащих выражение «if произвольный текста - fi произвольный текст» или его часть;
• количество конструкций, содержащих выражение «произвольный текст do произвольный текст» или его часть;
• количество конструкций, содержащих выражение «произвольный текст case – esac произвольный текст» или его часть;
• количество конструкций, содержащих выражение «var произвольный текст» или его часть;
• количество конструкций, содержащих выражение «def произвольный текст» или его часть;
• количество конструкций, содержащих выражение «use произвольный текст» или его часть;
• количество конструкций, содержащих выражение «произвольное число: произвольное число» или его часть;
• количество строк, начинающихся с символа из латинского алфавита;
• количество строк, содержащих только один символ «:» среди всех символов в строке;
• количество строк, в которых последним символом является символ «\»;
• количество строк, в которых последним символом является символ «:»;
• количество строк, в которых последним символом является символ «;»;
• общее количество строк;
• количество значимых строк;
• количество зачитанных из файла байтов;
• наличие набора шебанг символов «#!/bin/bash».
Данные об обнаруженном файле включают сам файл и данные, полученные в результате его анализа.
Средство подсчета 230 предназначено для подсчета статических и динамических параметров сформированной сводки скрипта. Под статическими параметрами сформированной сводки скрипта понимают следующий перечень признаков:
• энтропия массива, который занимает набор значимых байтов;
• количество вхождений каждого из возможных значимых байтов в массив, который занимает набор значимых байтов, поделенное на общее количество значимых байтов и помноженное на 1024;
• количество исключенных комментариев каждого вида, поделенное на общее количество исключенных комментариев и помноженное на 1024;
• наличие набора шебанг символов: 512, если да, 0 иначе;
• количество строк, содержащих выражение «[произвольный текст]» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество строк, содержащих выражение «произвольный текст = произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество строк, содержащих выражение «$ = произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество конструкций, содержащих выражение «if произвольный текста - fi произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество конструкций, содержащих выражение «произвольный текст do произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество конструкций, содержащих выражение «произвольный текст case – esac произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество конструкций, содержащих выражение «var произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024
• количество конструкций, содержащих выражение «def произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество конструкций, содержащих выражение «use произвольный текст» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество конструкций, содержащих выражение «произвольное число: произвольное число» или его часть, поделенное на количество значимых строк и помноженное на 1024;
• количество строк, начинающихся с символа из латинского алфавита, поделенное на количество значимых строк и помноженное на 1024;
• количество строк, содержащих только один символ «:» среди всех символов в строке, поделенное на количество значимых строк и помноженное на 1024;
• количество строк, в которых последним символом является символ «\»;
• количество строк, в которых последним символом является символ «\», поделенное на количество значимых строк и помноженное на 1024;
• количество строк, в которых последним символом является символ «:», поделенное на количество значимых строк и помноженное на 1024;
• количество строк, в которых последним символом является символ «;», поделенное на количество значимых строк и помноженное на 1024;
• количество строк, начинающихся с символов латинского алфавита, поделенное на количество значимых строк и помноженное на 1024;
Под динамическими параметрами сформированной сводки скрипта понимают количество вхождений каждого вида конструкций, содержащих совокупность символов, характерных для каждого языка программирования, в набор значимых байтов, поделенное на общее количество вхождений всех конструкций и помноженное на 1024. Для языка Bash, например, вычисляют количество вхождений в набор значимых байтов конструкций, содержащих совокупность символов из следующего динамического списка совокупностей символов: my$; $$; "${; $!; $?; $x; $#; $*; $@; $-; $_; $(; $0; $1; $2; $3; ./; ==; !=; <=; >=; =~; --; +r; +w; +x; -a; -b; -c; -e; -f; -g; -h; -i; -j; -k; -l; -m; -n; -o; -p; -q; -r; -s; -t; -u; -v; -w; -x; -y; -z; >>; <<; /bin; /boot; /dev; /etc; /opt; /X11; /sgml; /xml; /home; /lib; /media; /mnt; /opt; /proc; /root; /run; /sbin; /srv; /sys; /tmp; /usr; /bin; /include; /lib; /local; /sbin; /share; /src; /var; /cache; /lib; /lock; /log; /mail; /run; /spool; /mail; /tmp; breaksw; endsw; *); if; fi; then; else; elif; case; esac; [[; ]]; true; false; do; done; while; for; until; break; continue; select; function; if["$; if[$; if("$; if($; if[-d; if[!-d; if[-f; if[!-f; iftest; ;then; case"$; echo$; echo"$; sed-; grep-; ne-; while[$; ]do; whileread; test; apt; zypp; dnf; dig; chown; sync; chsh; chattr; puts; rm-; rm*; rpm; fold; rmdir; less; more; readelf; mv; pg_dump; popd; last; @echooff; @echoon; echooff; echoon; scp; pwd; logout; find; lsof; uuencode; yum; cat; clear; xmllint; stat; ssh-copy-i; Prints; printf; host; chmod; split; xxd; top; cd; od; sed; bind; whoami; ionice; touch; screen; diff; set; dirname; ifconfig; uniq; uname; cpio; eval; brew; awk; which; shopt; pkg; pdfunite; bunzip2; watch; ifconfig; bzip2; join; exec; ...; seq; xhost; bash; unalias; env; comm; node; ping; file; zcat; cowsay; tac; unzip; which; netstat; pstree; readlink; getent; lspci; /bin/sh; apropos; ssh; cd$; bar; ant; ipcs; ldd; vagrant; tail; .sh; tar; hostname; setarch; mate; kill; cut; alias; nohup; trap; chgrp; grep; wget; lshw; rev; locate; shred; sshpass; make; ssh-keygen; nslookup; tee; mktemp; shift; objdump; gunzip; mount; cron; stdbuf; pushd; groups; qstat; xargs; tmux; sudo; mkdir; strace; timex; mvn; tree; eof; eod; exit$; /dev/null; expect; ../; pkill; 2>&1; install; gcc; python; perl; java; .so; "$@"; http; ->; class; module; import; def; std::; var; function; usestrict; export; default; jquery; const; from; namespace; public; private; protected; interface; usewarnind; uselib; foreach; my$; eval; =>; package; sub; usevars; useparent; $self; <-; body{; typedef; @shift; window; microsoft; font; .PHONY; CMAKE_; PROJECT_; CTEST_; CPACK_; gem::; gem"; gemspec; docker; ENTRYPOINT; post; host:; user-agent; Accept:; DNT:; Content-Ty; Content-Le; Disass; PUSHBUTTON; COMBOBOX; LTEXT; CONTROL; EDITTEXT; EDITTEXT; IDS_; DS_; WS_; IDD_; <tr><td. Совокупности символов, характерных для определенного языка, обновляют при помощи методов машинного обучения и математической статистики. В первую очередь рассмотрению подлежат ключевые слова, выражения, названия или части названий функций, классов, переменных из популярных библиотек определенного языка программирования.
Подсчет вхождений осуществляется путем вычисления значений скользящего хэш-кода (англ. rolling hash function) по набору значимых байтов. Оптимальным по сложности и скорости вычисления является последовательность байтов в 10 байт. Начиная с первого байта от последовательности байтов вычисляют упомянутый хэш-код. Затем смещают на один байт и уже со второго байта снова вычисляют от последовательности байтов упомянутый хэш-код. Далее повторяют упомянутое действие по всему набору значимых байтов. После этого подсчитывают количество вхождений хэш-кодов от упомянутых конструкций с точностью до попадания их в вероятностное множество Блума.
Помимо этого, средство подсчета 230 предназначено для распознавания языка программирования скрипта на основании подсчитанных параметров сформированной сводки скрипта с использованием правил распознавания языка из базы данных правил 260 и передачи данных об обнаруженном файле, данных о сформированной сводке скрипта и данных о распознанном языке программирования скрипта средству формирования 240.
Распознавание языка программирования скрипта осуществляют при помощи методов машинного обучения. Подсчитанные параметры используют в качестве признаков, которые подают на вход предварительно обученных моделей машинного обучения в виде деревьев принятия решений (англ. decision tree).
В упомянутой модели машинного обучения используют пять шаблонов деревьев принятия решений для подтверждения языка программирования. Для каждого языка программирования формируют набор признаков и используют при обучении деревьев принятия решений. В результате обучения формируют пять деревьев принятия решений для одного языка. Результатом работы каждого дерева является подтверждение или отсутствие подтверждения того, написан ли рассматриваемый скрипт на текущем языке программирования. По результатам работы всех пяти деревьев принятия решения для подтверждения текущего языка программирования можно сделать окончательный вывод. Помимо наборов деревьев для подтверждения языка программирования скрипта создают деревья для подтверждения альтернативных языков, например, языка файла конфигурации (ini-файл), языка программирования PostScript (pdf-файл). Упомянутые деревья принятия решений используют для снижения ложных срабатываний.
Правило распознавания языка – набор результатов работы всех деревьев принятия решения для подтверждения языка программирования для распознавания всех языков, при наличии которых считают, что выявленный скрипт написан на определенном языке программирования.
Примером правила распознавания языка является следующий набор результатов работы деревьев принятия решений: минимум 3 из 5 деревьев принятия решений для подтверждения одного языка программирования дали положительный результат; деревья принятия решения для подтверждения других языков дали не более 2 положительных результатов для каждого языка. При выполнении упомянутого набора условий считают, что выявленный скрипт написан на языке программирования, при распознавании которого дали положительный результат 3 из 5 деревьев принятия решений.
Другим примером правила распознавания языка является следующий набор результатов работы деревьев принятия решений: минимум 3 из 5 деревьев принятия решений для подтверждения одного языка решений дали положительный результат; деревья принятия решения для подтверждения других языков дали не более 2 положительных результатов для одного языка; минимум 4 из 5 деревьев принятия решений для распознавания одного альтернативного языка дали положительный результат. При выполнении упомянутого набора условий считают, что выявленный скрипт написан на альтернативном языке, при распознавании которого дали положительный результат 4 из 5 деревьев принятия решений.
Другим примером правила распознавания языка является следующий набор результатов работы деревьев принятия решений: минимум 3 из 5 деревьев принятия решений для подтверждения одного языка дали положительный результат; минимум 3 из 5 деревьев принятия решений для распознавания другого языка дали положительный результат. При выполнении упомянутого набора условий считают, что необходимо использовать дополнительное дерево принятия решения для уточнения результата деревьев принятия решений, которые дали положительный результат.
Средство формирования 240 предназначено для обработки обнаруженного файла на основании данных о распознанном языке программирования, преобразуя таким образом обнаруженный файл к определенному виду.
Средство формирования 240 осуществляет обработку обнаруженного файла путем:
• удаления всех символов, кроме видимых символов из таблицы ASCII; символов переноса строк, пробелов, символов из таблицы Unicode; строк, содержащих комментарии и отдельные отмеченные строки, характерные для распознанного языка программирования;
• приведения текста к нижнему регистру;
• указания начала и окончания строковых констант, характерных для распознанного языка программирования.
Помимо этого, средство формирования 240 предназначено для формирования набора хэш-кодов на основании обработанного файла с использованием правил формирования хэш-кодов из базы данных правил 260 и передачи сформированного набора хэш-кодов средству выявления 250.
Средство формирования 240 выполняет формирование набора хэш-кодов путем выполнения следующего перечня действий:
1) разделение обработанного файла на конструкции, содержащих совокупность символов длиной от 4 до 10 символов;
2) подсчета количества вхождений всех выявленных конструкций, содержащих совокупность символов длиной от 4 до 10 символов, в обработанный файл; например если обработанный файл представлен в виде символов "colacola", то в результате разделения на конструкции образуется следующий массив {cola: 2, colacola: 1, olacola: 1, lacola: 1, acola: 1, colac: 1, colaco: 1, colacol: 1};
3) с помощью правил формирования хэш-кодов определения типа используемого хэш-кода;
4) формирования набора хэш-кодов из хэш-кодов определенного типа.
Подсчет количества вхождений каждого вида конструкций из всех языков программирования, содержащих совокупность символов длиной от 4 до 10 символов, в обработанный файл выполняют путем вычисления скользящего хэш-кода, построенного из частей файла, в виде последовательности байтов размером в 10 байт, где количество символов в совокупности символов имеет длину от 4 до 10 символов. Вычисляют количество вхождений хэш-кодов от упомянутых конструкций с точностью до попадания их в вероятностное множество Блума (размер которого совпадает с размером вероятностного множества Блума, использованного на этапе распознавания языка).
Правило формирования хэш-кодов – это набор условий, при выполнении которых используют тот или иной тип хэш-кода. Подсчитанное количество вхождений является основным условием при создании правил формирования хэш-кодов. Примером правила формирования хэш-кодов является случай, когда количество вхождений ниже предельного значения. При выполнении этого набора условий при формировании набора хэш-кодов используют сокращенный тип хэш-кодов. Другим примером правила формирования хэш-кодов является случай, когда количество вхождений равно либо выше предельного значения. При выполнения этого набора условий при формировании набора хэш-кодов используют полноразмерный тип хэш-кодов. Предельное значение количества вхождений может быть определено статистически, эмпирически или задано экспертом, установлено в результате работы алгоритмов машинного обучения.
Сокращенный тип хэш-кодов – это 64-битное значение, полученное из комбинации двух половин 128-битной хэш-функции murmur3 (англ. MurmurHash3 hash function) от обработанного файла.
Полноразмерный тип хэш-кодов – тип хэш-кодов, которые считают от пары «хэш-код от совокупности символов - количество вхождений упомянутого хэш-кода на этапе обработки обнаруженного файла при подсчете скользящих хэш-кодов», с использование алгоритма подсчета хэш-функций murmur 3, xor и косинусного расстояния. При этом если есть несколько пар с разными хэш-кодами, но одинаковым количеством вхождений, то для вычисления полноразмерного хэш-кода может быть использована только одна из этих пар.
Средство выявления 250 предназначено для выявления вредоносного скрипта путем сравнения сформированного набора хэш-кодов с известными вредоносными наборами хэш-кодов из базы данных хэш-кодов скриптов 270. Сравнение преимущественно осуществляют с использованием алгоритмов локально-чувствительно хэширования (Local sensitive hash function) и выявления минимального косинусного расстояния. В случае, если сформированный набор хэш-кодов схож с известными вредоносными наборами хэш-кодов, скрипт признают содержащим вредоносный код.
База данных правил 260 предназначена для хранения правил распознавания языка и правил формирования хэш-кодов. База данных хэш-кодов скриптов 270 предназначена для хранения известных хэш-кодов, наборов хэш-кодов известных скриптов, в том числе и вредоносных. В качестве базы данных правил 260 и базы данных хэш-кодов скриптов 270 могут быть использованы различные виды баз данных, а именно: иерархические (IMS, TDMS, System 2000), сетевые (Cerebrum, Сronospro, DBVist), реляционные (DB2, Informix, Microsoft SQL Server), объектно-ориентированные (Jasmine, Versant, POET), объектно-реляционные (Oracle Database, PostgreSQL, FirstSQL/J), функциональные и т.д. Правила могут быть созданы при помощи алгоритмов машинного обучения и автоматизированной обработки больших массивов данных.
Ниже представлены подробности реализации в упрощенном виде.
Для скрипта 1 из файла 110, набор значимых байтов будет выглядеть следующим образом:
prog=$(basename$0ctl)admecho1>&2"$(basename$0)depricated,pleaseuse$proginthefuture"if[$#-lt2];thenecho"usage:$(basename$0)-[deu]user[...]"1>&2exit1fiflag=$1shiftfori;doargs="$flag$i"doneecho1>&2"executing:$prog$args"exec$prog$args
Для скрипта 1 сводка скрипта будет выглядеть следующим образом:
{
commentsCount = {0, 0, 0, 0, 0, 0, 0, 0, 0};
cleanBytes = " prog=$(basename$0ctl)admecho1>&2"$(basename$0)depricated,pleaseuse$proginthefuture"if[$#-lt2];thenecho"usage:$(basename$0)-[deu]user[...]"1>&2exit1fiflag=$1shiftfori;doargs="$flag$i"doneecho1>&2"executing:$prog$args"exec$prog$args";
cleanBytesCount = 230;
significantLinesCount = 13;
linesCount = 13;
iniSectionsCount = 0;
assignmentsCount = 3;
psAssignmentsCount = 0;
ifFiCount = 1;
bashCycleCount = 1;
caseEsacCount = 0;
varCount = 0;
defCount = 0;
useCount = 0;
timestampCount = 0;
bytesRawRead = 293;
linesStartedWithLetterCount = 13;
singleColonInLine = 2;
lastSlashCount = 0;
lastColonCount = 0;
lastSemicolonCount = 0;
hasShebang = false;
}
Полный набор признаков скрипта 1, передаваемого в модель машинного обучения для распознавания языка программирования Bash:
[4919, 0, 35, 4, 66, 0, 13, 0, 13, 13, 0, 0, 4, 8, 13, 0, 13, 22, 17, 0, 0, 0, 0, 0, 0, 0, 8, 8, 0, 13, 13, 0, 0, 13, 0, 13, 0, 0, 0, 66, 13, 31, 26, 115, 31, 48, 26, 40, 0, 0, 22, 17, 31, 44, 26, 0, 48, 48, 40, 31, 0, 0, 13, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 236, 0, 78, 78, 0, 0, 0, 0, 0, 1024, 157, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 8, 16, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 0, 0, 0, 0, 16, 0, 0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 8, 0, 8, 8, 8, 16, 24, 8, 0, 24, 8, 0, 0, 0, 0, 0, 0, 8, 0, 8, 0, 0, 0, 0, 8, 0, 8, 0, 0, 8, 0, 0, 0, 16, 0, 8, 0, 0, 0, 0, 0, 16, 0, 0, 0, 0, 0, 0, 8, 0, 8, 0, 8, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 0, 0, 0, 0, 8, 0, 0, 0, 8, 0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 8, 0, 16, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 8, 0, 0, 0, 16, 0, 0, 8, 0, 8, 0, 8, 0, 0, 0, 0, 8, 0, 0, 0, 8, 0, 8, 0, 0, 0, 0, 0, 0, 0, 8, 8, 16, 8, 0, 0, 0, 24, 8, 0, 16, 0, 0, 0, 8, 0, 0, 0, 0, 8, 0, 0, 0, 0, 8, 16, 8, 0, 0, 8, 0, 0, 0, 0, 0, 8, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 16, 0, 0, 0, 0, 0, 0, 16, 8, 0, 0, 0, 0, 0, 0, 0, 8, 0, 8, 8, 0, 16, 8, 0, 0, 8, 0, 0, 8, 8, 0, 8, 8, 8, 0, 0, 0, 0, 0, 8, 0, 0, 0, 8, 24, 0, 0, 0, 0, 0, 8, 8, 8, 16, 0, 8, 8, 0, 0, 0, 0, 16, 0, 0, 8, 0, 0, 8, 0, 0, 0, 8, 0, 0, 8, 0, 0, 8, 0, 0, 8, 0, 0, 24, 8, 8, 0, 0, 0, 8, 8, 0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0,]
Все пять деревьев принятия решения для подтверждения языка Bash дали положительный результат. Пример реализации одного из деревьев: def dt_code(features_original):
features = [0] + [feature * 2 for feature in features_original]
if features[76] <= 3: # CommentStyle.POWERSHELL_MULTILINE_COMMENT
if features[81] <= 178: # has_shebang
if features[79] <= 25: # assignment_share
if features[31] <= 0: # >
if features[81] <= 50: # has_shebang
if features[357] <= 39: # -reference
if features[14] <= 6: # -
if features[68] <= 94: # }
if features[400] <= 72: # break
if features[14] <= 1: # -
if features[382] <= 61: # $psculture
if features[49] <= 73: # j
if features[424] <= 272: # $($
if features[61] <= 250: # v
if features[387] <= 36: # [system.
if features[256] <= 128: # param
if features[420] <= 82: # .ps
if features[269] <= 49: # ]$
if features[12] <= 149: # +
if features[297] <= 298: # format-
if features[324] <= 163: # able-
if features[65] <= 106: # z
if features[367] <= 137: # ext.encodi
if features[5] <= 10: # $
if features[216] <= 59: # -type
if features[244] <= 151: # byte[]
if features[58] <= 201: # s
if features[367] <= 110: # ext.encodi
if features[233] <= 120: # select-
if features[212] <= 67: # @(
if features[362] <= 155: # -lt
if features[37] <= 71: # ^
if features[420] <= 38: # .ps
if features[315] <= 21: # -not
if features[16] <= 185: # /
if features[141] <= 74: # elseif
if features[245] <= 103: # ynamicpara
if features[178] <= 100: # -xor
if features[43] <= 205: # d
if features[162] <= 107: # -bnot
if features[319] <= 33: # -path
if features[92] <= 926: # last_colon_count
if features[221] <= 72: # iex
if features[95] <= 4: # -bxor$
if features[1] <= 5176: # entropy
if features[209] <= 42: # >>
if features[339] <= 60: # -as
if features[219] <= 31: # @{
if features[293] <= 158: # in
if features[18] <= 211: # 1
if features[376] <= 7: # register-
if features[251] <= 5: # -error
return [22482, 0]
else: # if features[251] > 5 # -error
if features[286] <= 71: # [intptr]
if features[145] <= 29: # -and$
if features[377] <= 30: # -in$
if features[320] <= 19: # -match
return [2700, 0] ……
Все остальные деревья дали отрицательный результат. Сработало правило, таким образом, данный обнаруженный файл распознан как скрипт на языке Bash. Далее формируют обработанный файл, а затем набор хэш-кодов:
prog=$(basename$0ctl)admecho1>&2"$(basename$0)depricated,pleaseuse$proginthefuture"if[$echo"usage:$(basename$0)-[deu]user[...]"1>&2exit1fiflag=$1shiftfori;doargs="$flag$i"doneecho1>&2"executing:$prog$args"exec$prog$args
Полноразмерный хэш-код построить невозможно, поскольку не сработало правило, и пар (хэш-вхождение) найдено всего две: (830, 4), (69, 3). Соответственно, будет выполнено вычисление сокращенного типа хэш-кодов. И поскольку обработанный файл имеет незначительный размер, хэш-код будет один и равен 0xd43903d3f56d64c1.
Фиг. 3 иллюстрирует алгоритм функционирования системы выявления вредоносного скрипта на основании набора хэш-кодов. На этапе 311 средство обнаружения 220 осуществляет обнаружение файла, содержащего скрипт. На этапе 312 средство обнаружения 220 осуществляет формирование сводки скрипта на основании обнаруженного файла и передает данные об обнаруженном файле и данные о сформированной сводке скрипта средству подсчета 230. На этапе 313 средство подсчета 230 осуществляет подсчет статических и динамических параметров сформированной сводки скрипта. На этапе 314 средство подсчета 230 осуществляет распознавание языка программирования скрипта на основании подсчитанных параметров сформированной сводки скрипта с использованием правил распознавания языка из базы данных правил 260 и передает данные об обнаруженном файле, данные о сформированной сводке скрипта и данные о распознанном языке программирования скрипта средству формирования 240. На этапе 315 средство формирования 240 осуществляет обработку обнаруженного файла на основании данных о распознанном языке программирования. На этапе 316 средство формирования 240 осуществляет формирование набора хэш-кодов на основании обработанного файла с использованием правил формирования хэш-кодов из базы данных правил 260, и передает сформированный набор хэш-кодов средству выявления 250. На этапе 317 средство выявления 250 проверяет, схож ли сформированный набор хэш-кодов с известными вредоносными наборами хэш-кодов из базы данных хэш-кодов скриптов 270. При наличии схожести с известными вредоносными наборами хэш-кодов на этапе 319 средство выявления 250 осуществляет выявление вредоносного скрипта. В противном случае на этапе 318 система завершает работу.
Фиг. 4 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жёсткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жёсткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жёсткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жёсткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединён к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединён к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащён другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удалёнными компьютерами 49. Удалённый компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 4. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключён к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключён к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведённые в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определённого формулой.
Изобретение относится к области информационной безопасности, в частности к системе и способу выявления вредоносных скриптов. Технический результат заключается в повышения эффективности выявления вредоносных скриптов. Технический результат достигается путем обнаружения вредоносных скриптов или их частей, написанных на определенном языке программирования, путем выявления файла, содержащего скрипт, распознавания языка скрипта при помощи правил распознавания языка, формирования набора хэш-кодов выявленного скрипта и сравнения набора хэш-кодов скрипта с известными наборами хэш-кодов вредоносных скриптов. 2 н. и 10 з.п. ф-лы, 4 ил.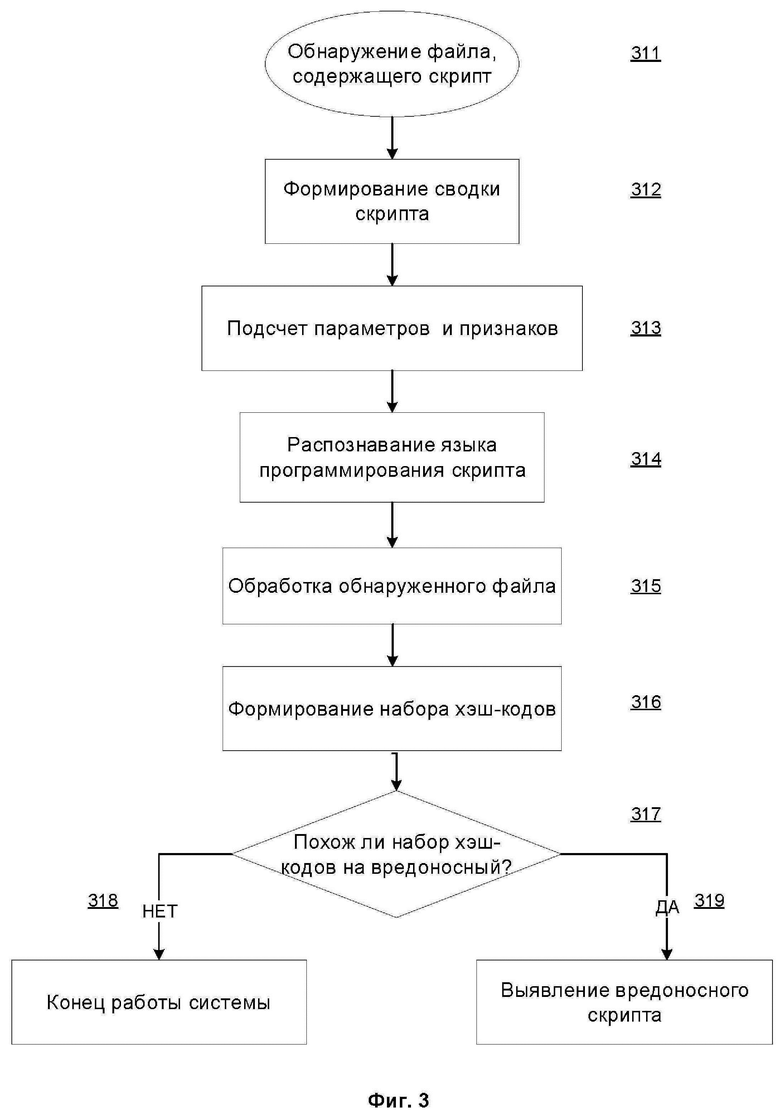
1. Способ выявления вредоносного скрипта на основании набора хэш-кодов, содержащий этапы, на которых применяют компьютер, чтобы выполнить операции, которые включают в себя этапы, на которых:
а) обнаруживают файл, содержащий скрипт, путем анализа каждого файла из множества файлов, которые проверяют на наличие вредоносного кода;
б) формируют сводку скрипта на основании обнаруженного файла;
в) подсчитывают статические и динамические параметры, содержащиеся в сформированной сводке скрипта;
г) распознают язык программирования скрипта на основании подсчитанных параметров сформированной сводки скрипта с использованием правил распознавания языка;
д) обрабатывают обнаруженный файл на основании данных о распознанном языке программирования и данных об обнаруженном файле;
е) формируют набор хэш-кодов на основании обработанного файла с использованием правил формирования хэш-кодов;
ж) выявляют вредоносный скрипт путем сравнения сформированного набора хэш-кодов с известными вредоносными наборами хэш-кодов из базы данных хэш-кодов скриптов.
2. Способ по п. 1, в котором в результате анализа каждого файла из множества файлов, которые проверяют на наличие вредоносного кода, при помощи эвристических алгоритмов, созданных для поиска структурированных типов файлов, в которых наличие скриптов маловероятно, исключают найденные файлы из указанного множества файлов.
3. Способ по п. 1, в котором формируют сводку скрипта путем выделения набора значимых байтов и набора исключенных байтов из обнаруженного файла.
4. Способ по п. 3, в котором набор значимых байтов выделяют из обнаруженного файла путем фильтрации обнаруженного файла при помощи алгоритмов фильтрации.
5. Способ п. 4, в котором набор исключенных байтов получают путем удаления из обнаруженного файла набора значимых байтов.
6. Способ по п. 1, в котором под правилом распознавания языка понимают набор результатов работы деревьев решений, при наличии которого считают, что выявлен скрипт, написанный на определенном языке программирования.
7. Способ по п. 1, в котором обрабатывают обнаруженный файл путем: удаления всех символов, кроме видимых символов, из таблицы ASCII; символов переноса строк, пробелов, символов из таблицы Unicode, строк, содержащих комментарии и отдельные отмеченные строки, характерные для распознанного языка программирования; приведения текста к нижнему регистру; указания начала и окончания строковых констант, характерных для распознанного языка программирования.
8. Способ по п. 1, в котором выполняют формирование набора хэш-кодов путем: разделения обработанного файла на конструкции, содержащие совокупность символов длиной от 4 до 10 символов; подсчета количества вхождений всех выявленных конструкций в обработанный файл; определения типа используемого хэш-кода с помощью правил формирования хэш-кодов; формирования набора хэш-кодов из хэш-кодов определенного типа.
9. Способ по. 1, в котором под правилом формирования хэш-кодов понимают набор условий, при выполнении которых используют определенный тип хэш-кода.
10. Способ по п. 1, в котором под статическими параметрами сформированной сводки скрипта понимают перечень признаков, посчитанный на основе набора значимых байт, количества вхождений комментариев, строк, содержащих символьные выражения, конструкций, содержащих выражения, известных языков программирования скриптов.
11. Способ по п. 1, в котором под динамическими параметрами сформированной сводки скрипта понимают перечень признаков, подсчитанный на основе количества вхождений каждого вида конструкций, содержащих совокупность символов, характерных для каждого языка программирования, в набор значимых байтов.
12. Система, содержащая по меньшей мере один компьютер, включающий взаимодействующие между собой средства: средство обнаружения, средство подсчета, средство формирования, средство выявления, базу данных правил, базу данных хэш-кодов скриптов и хранящий машиночитаемые инструкции, при выполнении которых система выполняет выявление вредоносного скрипта на основании набора хэш-кодов согласно способу по любому из пп. 1-11.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Система и способ обнаружения вредоносного скрипта | 2017 |
|
RU2659738C1 |
| Способ обнаружения вредоносных составных файлов | 2016 |
|
RU2634178C1 |
| СПОСОБ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ И ЭЛЕМЕНТОВ | 2015 |
|
RU2613535C1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| РЕАГЕНТНО-ЭЛЕКТРОЛИЗНЫЙ МЕТОД РЕГЕНЕРАЦИИ НИТРАТНО-АММОНИЙНОГО РАСТВОРА СНЯТИЯ КАДМИЕВЫХ ПОКРЫТИЙ | 2023 |
|
RU2823406C1 |
| US 7707634 B2, 27.04.2010. | |||

