ОБЛАСТЬ ТЕХНИКИ
[0001] Реализации изобретения в целом относятся к компьютерным системам, предназначенным для анализа документов, а более конкретно к системам и способам построения и оптимизации кодовых книг для обнаружения полей на документе.
УРОВЕНЬ ТЕХНИКИ
[0002] Задачи обработки изображений подразумевают использование кодовых книг визуальных слов, основанных на модели Bag-of-Words или аналогичных ей. Например, кодовая книга визуальных слов может использоваться для поиска или классификации изображений. Однако автоматическое извлечение информации с помощью кодовой книги может быть затруднено из-за сложной структуры и лейаута (layout, макет, "визуальный скелет") документов с различным расположением текста, полей, изображений, таблиц и т.д., и, возможно, с неоднозначным расположением границ этих элементов.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Варианты реализации настоящего изобретения описывают механизмы построения и оптимизации кодовых книг для обнаружения полей на изображении документа.
[0004] Способ построения и оптимизации кодовых книг для анализа документов включает: получение первого набора изображений документов; извлечение множества ключевых областей из каждого изображения документа первого набора изображений документов; вычисление локальных дескрипторов для каждой ключевой области из числа извлеченных ключевых областей; кластеризацию локальных дескрипторов таким образом, чтобы каждый центр кластера локальных дескрипторов соответствовал определенному визуальному слову; построение кодовой книги, содержащей набор визуальных слов; оптимизацию кодовой книги путем максимизации целевой функции взаимной информации (MI) между целевым полем второго набора изображений документов и, по меньшей мере, одним визуальным словом из набора визуальных слов.
[0005] Система построения и оптимизации кодовых книг для анализа документов включает запоминающее устройство и процессор, функционально связанный с запоминающим устройством, причем процессор сконфигурирован для: получения первого набора изображений документов; извлечения множества ключевых областей из каждого изображения документа первого набора изображений документов; вычисления локальных дескрипторов для каждой ключевой области из числа извлеченных ключевых областей; кластеризации локальных дескрипторов таким образом, чтобы каждый центр кластера локальных дескрипторов соответствовал определенному соответствующему визуальному слову; построения кодовой книги, содержащей набор визуальных слов; оптимизации кодовой книги путем максимизации целевой функции взаимной информации (MI) между целевым полем второго набора изображений документов и, по меньшей мере, одним визуальным словом из набора визуальных слов.
[0006] Способ анализа документа включает: получение устройством обработки данных кодовой книги, содержащей набор визуальных слов, при этом каждое визуальное слово соответствует центру кластера локальных дескрипторов; вычисление на основе набора изображений документов, размеченных пользователем, для каждого визуального слова кодовой книги соответствующего частотного распределения положения указанного размеченного поля относительно визуального слова; загрузку изображения документа для извлечения целевых полей; обнаружение визуальных слов на изображении документа; вычисление статистического предиката возможного положения целевого поля на изображении документа на основе частотных распределений; обнаружение полей на изображении документа на основе вычисленного статистического предиката с использованием обученной модели.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Изобретение станет более понятным благодаря приведенному ниже подробному описанию и прилагаемым чертежам различных вариантов реализации изобретения. Однако чертежи не должны использоваться для ограничения изобретения конкретными вариантами реализации, а предназначены только для пояснения и понимания.
[0008] На Фиг. 1 представлена блок-схема построения оптимизированной кодовой книги в соответствии с реализацией настоящего изобретения.
[0009] На Фиг. 2A-2D представлены ограничивающие прямоугольники итеративно увеличивающихся максимально стабильных экстремальных областей (MSER), извлеченных из изображения документа, где на Фиг. 2А показано исходное изображение документа, на Фиг. 2В изображены извлеченные области MSER, площадь которых меньше 0,005 площади изображения, на Фиг. 2С изображены извлеченные области MSER, площадь которых меньше 0,01 площади изображения, на Фиг. 2D изображены извлеченные области MSER, площадь которых меньше 0,05 площади изображения, в соответствии с реализацией настоящего изобретения.
[0010] На Фиг. 3 представлен процесс преобразования прямоугольной ограничивающей области MSER в квадратную область в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0011] На Фиг. 4 представлена блок-схема процесса оптимизации кодовой книги в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0012] На Фиг. 5 представлен набор изображений документов с низкими колебаниями лейаута в соответствии с некоторыми вариантами реализации настоящего изобретения.
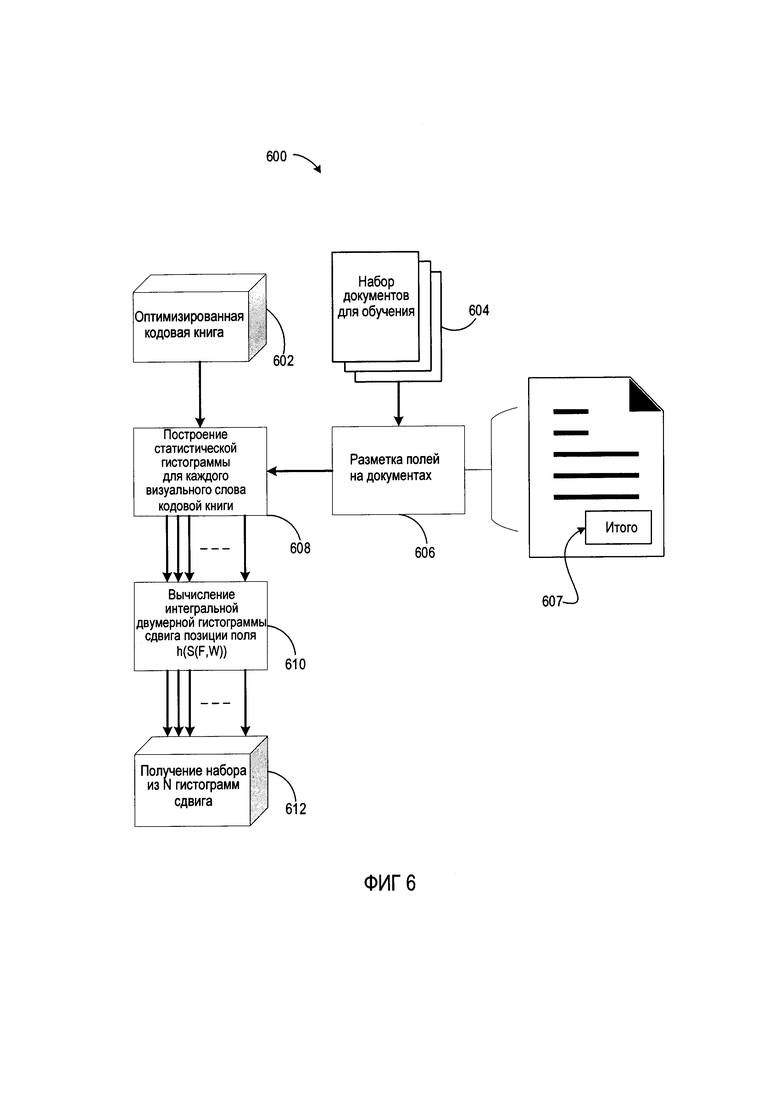
[0013] На Фиг. 6 представлена структурная схема процесса обучения для получения набора данных, необходимого для извлечения полей из новых изображений документов, в соответствии с некоторыми вариантами реализации настоящего изобретения.
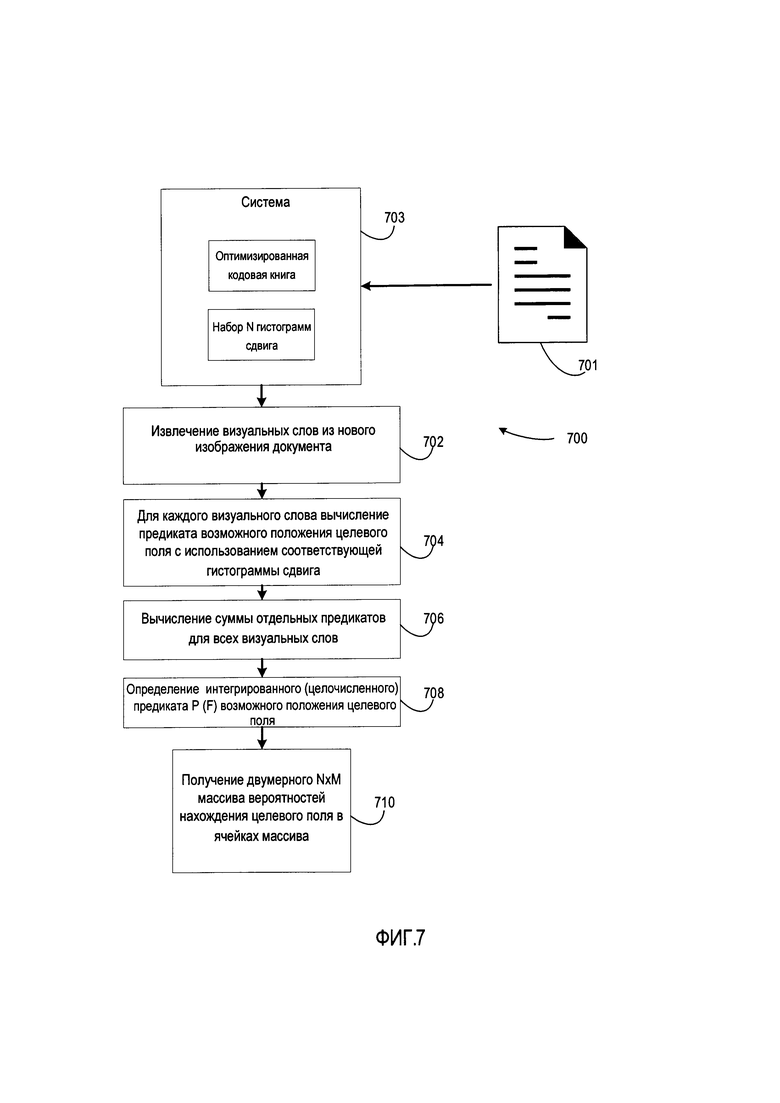
[0014] На Фиг. 7 представлена блок-схема процесса обнаружения целевого поля на новом изображении документа в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0015] На Фиг. 8 представлена структурная схема генерации статистических предикатов целевого поля на изображении документа в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0016] На Фиг. 9 представлена блок-схема компьютерной системы в соответствии с некоторыми вариантами реализации настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0017] В настоящем документе описаны способы и системы построения кодовых книг и их использования для обнаружения полей на изображениях документов. Извлечение информации из определенных типов документов может быть затруднено из-за слабой структурированности таких документов. Несмотря на то, что экземпляр определенного типа документа может содержать заранее определенный набор полей, которые необходимо извлечь (например, дата, валюта или общая сумма), положение и представление этих полей часто недостаточно четко определены. Однако документы, выпущенные или полученные из общего источника, могут иметь определенный лейаут/макет.
[0018] Некоторые подходы к извлечению информации часто требуют больших наборов данных размеченных изображений, получение которых может оказаться невозможным или нецелесообразным с практической точки зрения для многих задач извлечения информации в реальной жизни. Например, сверточные нейронные сети (CNN) могут использоваться для сегментации и классификации документов, а также для обнаружения текста в сценах естественного характера. Однако обучение CNN сетей обычно происходит на больших четко помеченных наборах данных, содержащих информацию о целевых объектах (например, метки уровня пикселей, ограничивающие рамки/прямоугольники и т.д.).
[0019] Способы и системы настоящего изобретения разработаны с целью устранения вышеупомянутых недостатков и проблем и создания нового подхода для извлечения информации из документов, основанного на построении и использовании оптимизированных кодовых книг. Способы и системы, описанные в настоящем документе, способны прогнозировать положение полей (например, важных полей, далее именуемых «целевыми полями») на документах с ранее неизвестными макетами, включая документы ранее неизвестных типов, с обучением на небольшом количестве предварительно размеченных документов.
Как более подробно объясняется ниже, новый подход направлен на извлечение целевых полей из изображений документов, таких как счета-фактуры, квитанции, удостоверения личности и другие документы. Однако различные реализации изобретения не требуют больших предварительно размеченных наборов данных для обучения и могут основываться только на заданном наборе изображений документов. Некоторые из способов, описанных здесь, могут основываться исключительно на модальности изображений документов, поскольку сложная пространственная структура деловых документов четко отражается в модальности их изображений. Следовательно, способы и системы, описанные в настоящем документе, могут использоваться как по отдельности, так и как вспомогательные методы для извлечения информации, основанные на результатах оптического распознавания символов (OCR), или же для облегчения процесса обучения нейронных сетей.
[0020] Различные реализации, описанные в настоящем документе, учитывают пространственную структуру документов, используя подход в области компьютерного зрения под названием модель Bag-of-Words (BoW). Несмотря на то, что модель BoW может использоваться для поиска естественных изображений и основана на различных детекторах/дескрипторах ключевых областей, изображения документов явно отличаются от естественных сцен, поскольку изображения документов имеют четкую структуру и высокую контрастность, что приводит к обнаружению множества стандартных ключевых областей. Кроме того, поскольку некоторые обнаруженные ключевые области могут не иметь какого-либо конкретного семантического или структурного значения для документов, в способах настоящего изобретения, специально разработанных для изображений документов, явно используются характеристики документов в их представлении признаков.
[0021] Соответственно, одним из основных аспектов настоящего изобретения является построение кодовой книги из набора изображений документов (которую следует понимать как словарь «визуальных слов», как описано более подробно ниже).
Ориентированная на документ кодовая книга визуальных слов может основываться на ключевых областях и нескольких типах составных локальных дескрипторов, содержащих как фотометрическую, так и геометрическую информацию об области. Соответственно, кодовую книгу можно понимать как базу данных, включающую набор визуальных слов. Визуальную кодовую книгу можно также использовать для вычисления статистических предикатов положения полей документа на основе пространственного расположения визуальных слов на изображении документа и корреляций между визуальными словами и полями документа.
[0022] Положение целевого поля (т.е. интересующего поля на документе) может быть спрогнозировано с помощью условных гистограмм, собранных в фиксированных позициях определенных визуальных слов. Интегральный предикат (т.е. накопленный предикат) вычисляется как линейная комбинация (например, сумма) отдельных предикатов всех обнаруженных визуальных слов.
[0023] Соответственно, реализации подходов, описанных в настоящем документе, в значительной степени зависят от модальности изображений документов, поскольку сложная пространственная структура, например, деловых документов, отражается в модальности их изображений. Модальность документов может определяться такими характеристиками изображений, как источник изображения (например, фотография, скан-копия, факсимильное сообщение, почта и т.д.), тип документа (например, счет-фактура, квитанция, удостоверение личности и т.д.) и структура документа (например, наличие логических блоков, изображений, рукописного текста, логотипов, полей, текста и т.д.).
[0024] Аспекты и сценарии реализации настоящего изобретения устраняют отмеченные выше и другие недостатки существующей технологии, предоставляя эффективные и полезные с точки зрения вычислений механизмы для разработки/построения кодовой книги визуальных слов и использования кодовой книги для обнаружения целевых полей в изображениях документов.
Обычно это достигается путем создания кодовой книги визуальных слов (далее именуемой «визуальной кодовой книгой») из банка или коллекции/набора документов и путем применения визуальной кодовой книги для вычисления статистических предикатов положения полей документа на основе пространственного отображения визуальных слов на изображении документа. Связанные компоненты, извлеченные (например, с помощью алгоритма MSER) из набора морфологически предварительно обработанных изображений документов, могут использоваться в качестве ключевых областей (далее именуемых «ключевыми областями») в описанных здесь реализациях. Затем, с целью построения кодовой книги, выполняется вычисление локальных дескрипторов для каждой полученной ключевой области с использованием различных методов. Локальные дескрипторы могут быть представлены в виде векторов фиксированного размера, которые описывают окрестности, окружающие характерную точку или ключевую область изображения. Кодовая книга включает в себя центры кластеров, полученные для локальных дескрипторов (под такими центрами кластеров понимаются «визуальные слова», включенные в кодовую книгу). После этого взаимная информация (MI) двух случайных величин, положения поля документа и положения конкретного визуального слова, могут использоваться в качестве меры релевантности или прогностической силы для этого визуального слова. Интегрированное качество визуальной кодовой книги может быть оценено как среднее значение MI по всем визуальным словам и может использоваться в качестве показателя эффективности/качества при оценке кодовой книги. Положения целевых полей документа можно спрогнозировать с помощью условных гистограмм, собранных в фиксированных позициях отдельных визуальных слов. Интегрированное предсказание положения поля рассчитывается как линейная комбинация предсказаний всех отдельных визуальных слов, обнаруженных на изображении документа.
[0025] Системы и способы настоящего изобретения направлены, в первую очередь, на построение кодовой книги и ее последующую оптимизацию, а также на идентификацию и извлечение полей с использованием оптимизированной кодовой книги.
[0026] В соответствии с реализацией настоящего изобретения способ создания или построения оптимизированной кодовой книги визуальных слов начинается с получения первого набора изображений документа. Каждое изображение документа в полученном наборе изображений документа затем может быть морфологически предварительно обработано. После этого ключевые области могут быть извлечены из изображения документа, а затем объединены и преобразованы в квадратную область. Затем для каждой полученной квадратной области выполняется вычисление набора локальных дескрипторов. Впоследствии локальные дескрипторы могут быть сгруппированы в набор классов, где центрами кластеров являются визуальные слова, из которых будет составлена кодовая книга. Таким образом, создается кодовая книга, включающая набор визуальных слов из первого набора изображений документов. Затем для каждого кластера рассчитывается выбранная статистическая агрегатная функция (например, стандартное отклонение) его локальных дескрипторов от изображений (т.е. визуальных слов) кодовой книги, а также выполняется нормализация расстояния между дескриптором и центром кластера на стандартное отклонение. Полученная кодовая книга затем может быть оценена и оптимизирована с применением второго набора изображений документов. Рассмотрим этапы способов оптимизации кодовой книги.
[0027] Сначала создается кодовая книга, как описано выше, или принимается уже существующая кодовая книга. Затем принимается второй набор изображений документов (т.е. дополнительный набор изображений документов, который отличается от первого набора изображений документов). После этого в каждом изображении документа второго набора выполняется разметка целевых полей автоматически, либо пользователем. Поля документа следует понимать как области изображения документа, в которых может быть размещен, найден или расположен определенный тип или категория информации (например, сумма, название, компания, адрес, таблица и т.д.). Затем извлекаются ключевые области и соответствующие им локальные дескрипторы из каждого размеченного изображения документа второго набора изображений документов.
Впоследствии визуальные слова могут быть обнаружены путем векторного квантования каждого локального дескриптора с использованием ближайшего визуального слова кодовой книги. После обнаружения визуальных слов во втором наборе изображений документов рассчитываются условные гистограммы положений целевых полей для каждого визуального слова. Затем рассчитывается взаимная информация (MI) между конкретным целевым полем и конкретным визуальным словом для всех полей и всех визуальных слов. Наконец, максимизация целевой функции MI приводит к оптимизации кодовой книги. Оптимизированная кодовая книга может использоваться для обнаружения и извлечения полей из новых изображений документов (этот способ описан ниже).
[0028] В первую очередь, для использования принимается оптимизированная кодовая книга. Затем пользователь может провести обучение модели (например, модели, реализованной с помощью нейронной сети), используя кодовую книгу, основанную на новом наборе изображений документов (например, третьем наборе изображений документов, отличающемся от первого и второго наборов изображений документов), далее именуемом набором «пользовательских документов». Для каждого визуального слова оптимизированной кодовой книги можно рассчитать условные гистограммы сдвига целевого поля. Они являются статистическими гистограммами распределения положения поля по отношению ко всем визуальным словам кодовой книги. После этого может быть получено новое (т.е. ранее невидимое) изображение документа для обнаружения или извлечения целевых полей, и, таким образом, могут быть обнаружены все визуальные слова на изображении документа. На основе всех визуальных слов рассчитывается статистический предикат возможного положения поля (т.е. может быть получена аккумулированная/интегрированная гистограмма распределения положений поля). Таким образом, могут быть обнаружены все необходимые области на новом изображении документа или в новом наборе изображений документов.
[0029] Описанные выше шаги и их реализация системой более подробно описаны ниже и представлены на Фиг. 1-9.
[0030] Начнем с подробного описания построения оптимизированной кодовой книги, на Фиг. 1 представлена блок-схема способа 100 построения оптимизированной кодовой книги в соответствии с реализацией настоящего изобретения. В некоторых реализациях способ 100 может выполняться одним потоком обработки, выполняемым устройством обработки данных. Кроме того, способ 100 может выполняться двумя или более потоками обработки, выполняемыми одним или более ядрами обработки, таким образом, чтобы каждый поток выполнял одну или несколько отдельных функций, программ, подпрограмм или действий способа. В иллюстративном примере потоки обработки, реализующие способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, реализующие способ 100, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то что на Фиг. 1 и в связанных с ней описаниях операции способа 100 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке.
[0031] Для получения кодовой книги на шаге 102 первоначально принимается первый набор изображений документов. Этот набор может состоять из любого количества изображений документов. Например, может быть достаточно набора, содержащего несколько тысяч изображений документов (например, 4000-8000 документов).
[0032] На этом этапе на шаге 104 каждое изображение документа из первого набора изображений документов подвергается процессу морфологической предварительной обработки для обнаружения ключевых областей, таких как слова, предложения, блоки текста и т.д. (именуемые далее «ключевые области» в этом изобретении). Морфологическая предварительная обработка может представлять собой применение набора нелинейных операций (например, эрозия, дилатация, открытие, закрытие и т.д.), связанных с формой или морфологией объектов на изображении.
С помощью морфологических методов можно исследовать изображение с небольшой формой или шаблоном, называемым структурным элементом, который может быть небольшим двоичным/бинарным изображением (например, матрицей пикселей, каждый из которых имеет значение 0 или 1). Структурный элемент может быть расположен в различных возможных местах изображения, а затем сопоставлен с соответствующими элементами, окружающими пиксели. Эрозия с небольшими квадратными структурными элементами может «сжать» изображение, удаляя слой пикселей как с внутренней, так и с внешней границ области. После эрозии пробелы и разрывы между различными областями могут увеличиться, и мелкие детали могут быть устранены. Дилатация, наоборот, может привести к противоположному эффекту, так как она добавляет слой пикселей как к внутренним, так и к внешним границам областей. После дилатации разрывы между различными областями могут уменьшиться, и небольшие вторжения в границы области могут быть заполнены.
[0033] Следовательно, целью морфологической предварительной обработки черно-белых изображений и изображений в оттенках серого является постепенное наращивание текстовой области (т.е. темной/черной области) и, наоборот, уменьшение белой/пустой области, не содержащей никакого текста. Поэтому, если под сигналом (1) мы понимаем черный текст, а под сигналом (0) белую/пустую область, то для уменьшений белой области можно применить дилатацию. Таким образом, имеет место дуализм морфологических операций, при котором наращивание черных областей напрямую коррелирует с сокращением белой области. Однако общая цель этого этапа состоит в наращивании текстовой области тем или иным способом.
[0034] После определения ядра дилатации каждый итерационный шаг будет приводить к появлению серии изображений, при этом каждое последующее изображение будет иметь больше склеившихся областей, чем предыдущее. Следовательно, это приведет к эрозии белого пространства на изображении.
Таким образом, если бы исходное изображение документа было бинаризовано, то в результате были бы получены отдельные символы (например, буквы, цифры). В соответствии с этим, морфологическая дилатация итеративно применяется по ряду заранее определенных пороговых значений там, где пороговые значения могут быть использованы в тех случаях, когда применяется морфологическая операция или результирующая площадь, охватываемая областью после применения морфологической операции. Другими словами, если изображение первоначально включает отдельные символы, такие как цифры или буквы, то буквы постепенно объединяются в слова, затем в предложения, а затем в отдельно расположенные текстовые блоки/абзацы, что приводит к набору связанных компонент (т.е. регионов, областей) разного масштаба/размера. Эти компоненты могут содержать различные объекты, такие как слова, строки, буквы, текстовые блоки и т.д. Пороговыми значениями могут быть значения измерений площадей связанных компонент или количество раз, когда выполняется дилатация.
[0035] На шаге 106 происходит извлечение ключевых областей из изображений документов. В одном примере ключевыми областями могут быть вышеупомянутые связанные компоненты, которые обнаруживаются/извлекаются детектором MSER из набора предварительно обработанных изображений документов. Соответственно, детектор MSER может быть применен для извлечения ключевых областей из изображения документа после морфологической предварительной обработки. Точнее говоря, все области MSER, обнаруженные на исходном изображении документа и на его копиях, полученных последовательным применением операции эрозии или дилатации, могут быть объединены для извлечения ключевых областей. Области MSER представляют собой связанные компоненты изображения документа, созданного с применением всех возможных пороговых значений изображения (т.е. с помощью итераций пороговых значений или с применением морфологических операций, описанных выше). Связанная компонента - это набор связанных пикселей, каждый из которых обладает таким определенным свойством, например как цвет.
[0036] Обнаруженные ключевые области могут соответствовать структурным элементам документа (т.е. символам, словам, строкам и т.д.). В сочетании с вышеупомянутой итеративной предварительной обработкой алгоритм MSER может обеспечить эффективную структуру многомасштабного анализа.
[0037] Примеры извлеченных прямоугольных областей MSER разных размеров показаны на Фиг. 2A-2D, которые иллюстрируют ограничивающие прямоугольники итеративно увеличивающихся/возрастающих максимально стабильных экстремальных областей (MSER). На Фиг. 2А представлено исходное изображение документа, на Фиг. 2В изображены извлеченные компоненты MSER, площадь которых меньше 0,005 площади изображения, на Фиг. 2С изображены извлеченные компоненты MSER, площадь которых меньше 0,01 площади изображения, на Фиг. 2D изображены извлеченные компоненты MSER, площадь которых меньше 0,05 площади изображения, в соответствии с реализацией настоящего изобретения. Можно заметить, что при каждом пороговом значении области MSER и при каждой итерации оставшееся белое пространство в изображении документа уменьшается/стирается. С каждой итерацией MSER области соответствуют все более и более крупным элементам (например, словам, строкам, блокам текста).
[0038] Возвращаясь к Фиг. 1, извлечение ключевых областей на шаге 106 может быть выполнено с использованием подходов, отличных от MSER, таких как адаптивная бинаризация. В случае использования алгоритма MSER связанные компоненты должны быть стабильны при изменении некоторых порогов бинаризации. Другими словами, когда мы бинаризуем изображение с определенным набором порогов, то в некотором диапазоне порогов могут возникать устойчивые связанные/связные компоненты (т.е. такие компоненты, которые незначительно изменяют свои размеры или площадь на последующем шаге порогового значения и, следовательно, устойчивы при применении морфологической операции), следовательно, такой набор связанных компонент является стабильным набором компонент.
И, наоборот, области соответствующих связанных компонент на более «размытых» объектах будут меняться более резко с применением каждого итеративного порогового шага.
[0039] Соответственно, если объект имеет хорошо очерченные контуры/границы, то в определенном диапазоне порогов связанные компоненты не меняются. Эти устойчивые компоненты будем называть MSERами. Таким образом, для каждой области MSER существует такое значение порога бинаризации, в котором относительное изменение площади области MSER при изменении порога бинаризации на величину Δ достигает локального минимума. В этом случае Δ является параметром алгоритма в соответствии с реализацией настоящего изобретения. Таким образом, далее выполняется объединение всех областей MSER, обнаруженных на оригинальном изображении документа (или его копии), полученных в результате последовательного/итеративного применения описанной выше морфологической операции (например, дилатации/эрозии).
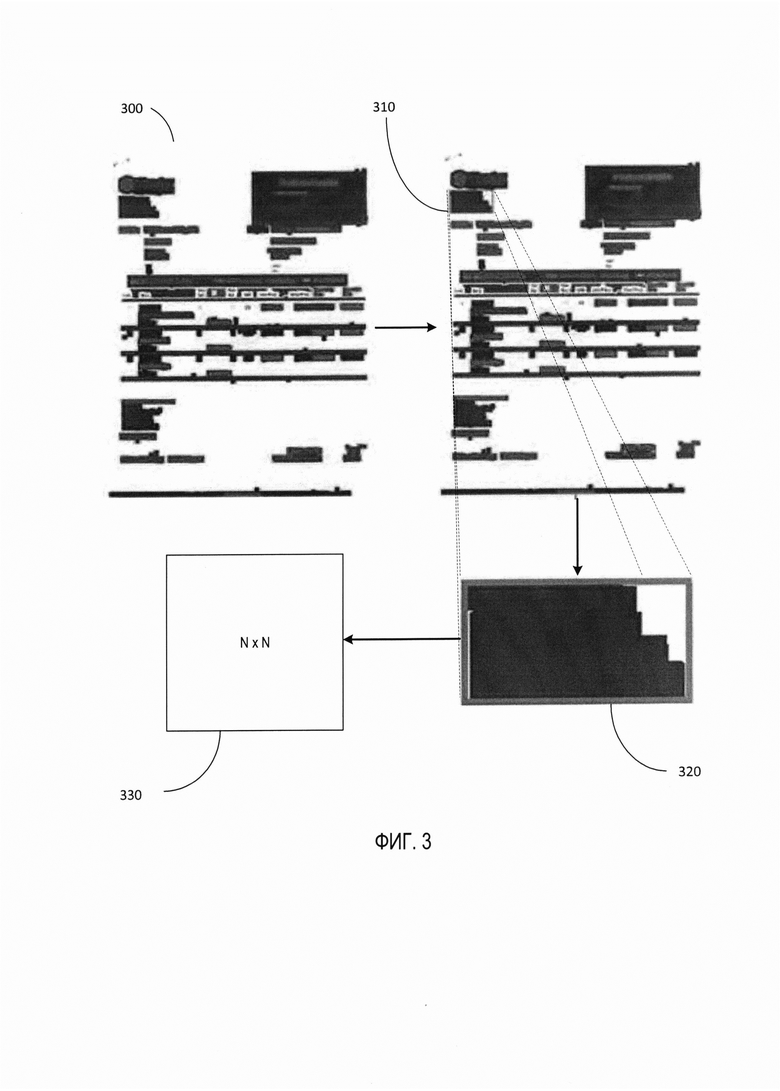
[0040] Получив MSERы, можно вычислить локальные дескрипторы (векторы) для каждого области. Однако, прежде чем вычислять локальные дескрипторы, возможно, потребуется преобразовать/нормализовать/нормировать ключевые области к заданному размеру. Для этого создаем ограничивающий прямоугольник/ограничивающую рамку (далее именуемый ограничивающей прямоугольной областью) для каждой извлеченной области MSER. Затем каждую прямоугольную область изображения документа преобразуем на шаге 108 в соответствующую квадратную область заданного фиксированного размера (например, 16×16, 32×32 пикселей или больше). На Фиг. 3 представлен процесс преобразования прямоугольной ограничивающей области MSER в квадратную область в соответствии с некоторыми вариантами реализации настоящего изобретения. Как схематично показано на Фиг. 3, MSER 310 идентифицирован на изображении документа 300. Ограничивающая прямоугольная область 320 генерируется для извлеченной области MSER 310.
Затем прямоугольная область 320 изображения документа преобразуется/нормируется в соответствующую квадратную область 330 заданного фиксированного размера.
[0041] При обработке изображений документов могут использоваться различные локальные дескрипторы, как фотометрические, так и геометрические. Примерами применимых фотометрических дескрипторов могут служить, но не ограничиваться ими, дескрипторы ускоренных устойчивых признаков (SURF), дескрипторы масштабно-инвариантной трансформации признаков (SIFT), дескрипторы бинарных устойчивых инвариантных масштабируемых ключевых точек (BRISK), а также дескрипторы, составленные с использованием коэффициентов дискретного преобразования Фурье (DFT) или коэффициентов дискретного Вейвлет-преобразования (DWT).
[0042] Каждый геометрический дескриптор может состоять из нескольких компонентов, в том числе размера области, соотношения ее сторон и т.д., а также включать геометрические соотношения между соседними областями аналогично методу локально вероятного хеширования расположения (LLAH). Необходимо отметить, что для получения дескрипторов каждой области MSER могут использоваться другие различные эвристические методы или методы машинного обучения, не выходящие за рамки настоящего изобретения.
[0043] В одной реализации DFT применяется к квадратной области, и вычисляются компоненты/коэффициенты DFT. В другой реализации могут использоваться следующие фотометрические дескрипторы извлечения MSERов: дескриптор SIFT, дескриптор SURF, два или более дескриптора, составленные с использованием коэффициентов DFT или DWT (где все дескрипторы рассчитываются для изображения в оттенках серого).
[0044] Кроме того, фотометрические и геометрические дескрипторы можно объединить. В итоге на шаге 110 получаем набор локальных дескрипторов, например, включающий, несколько компонентов DFT и два геометрических дескриптора, описывающих (а) соотношение сторон прямоугольника, вокруг которого строим дескрипторы и (b) масштаб или размер прямоугольника. Таким образом, для каждой ключевой области вычисляется свой оптимальный дескриптор.
[0045] После этого на следующем этапе на шаге 112 полученные локальные дескрипторы подразделяются или группируются в N классов/кластеров/признаков методом векторного квантования. Квантование выполняется с помощью кластеризации K-средних, хотя возможно применение и других методов (например, с использованием K-медоидов (K-medoids), биннинг/сортировка гистограмм (histogram binning) и т.д.). Как отмечалось ранее, центры каждого из полученных кластеров будут соответственно служить визуальными словами (W) для дальнейшего анализа изображения. Таким образом, на шаге 114 создается кодовая книга, содержащая набор визуальных слов (W).
[0046] На шаге 116 для каждого кластера вычисляется стандартное отклонение его локальных дескрипторов от изображений кодовой книги.
[0047] Далее на шаге 118 выполняется нормализация расстояния между дескриптором и центром кластера на стандартное отклонение, чтобы в дальнейшем можно было использовать евклидово расстояние при обнаружении визуальных слов.
[0048] Следует отметить, что на вышеупомянутых этапах первый набор изображений документов используется только один раз на этапе разработки/создания/использования визуальной кодовой книги. Полученная кодовая книга может быть использована для анализа большого количества разных типов документов, а не только тех, на примере которых она была построена. Следовательно, универсальная кодовая книга может быть построена с использованием большой базы данных различных типов документов.
[0049] На шаге 120 можно оценить эффективность или качество предсказательной силы кодовой книги по отношению к целевым полям, а затем кодовая книга может быть оптимизирована с использованием второго набора изображений документов. Главной целью оптимизации кодовой книги является обеспечение максимальной взаимной информации (MI) положения целевого поля (F) относительно визуального слова (W). Для этого необходимо рассчитать взаимную информацию двух случайных величин.
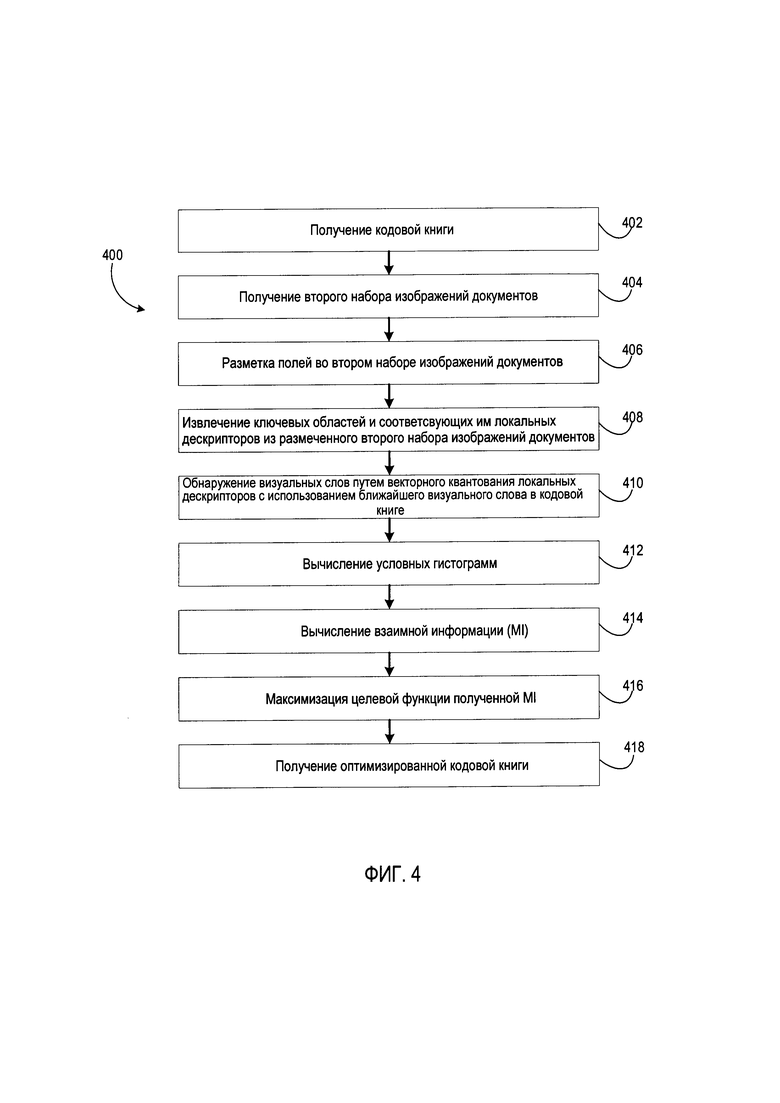
В этом случае существуют две независимые величины, F и W соответственно, обладающие независимыми распределениями, для которых возможно вычислить взаимную информацию MI между этими величинами. Упомянутую выше взаимную информацию MI можно получить по набору гистограмм распределения относительного положения поля по отношению к визуальному слову, найденному на данном изображении документа. Основные этапы оптимизации кодовой книги 400 представлены на блок-схеме на Фиг. 4 и более подробно описаны ниже.
[0050] В некоторых реализациях способ 400 может выполняться одним потоком обработки, выполняемым устройством обработки данных. Кроме того, способ 400 может выполняться двумя или более потоками обработки, выполняемыми одним или более ядрами обработки, таким образом, чтобы каждый поток выполнял одну или несколько отдельных функций, программ, подпрограмм или действий способа. В иллюстративном примере потоки обработки, реализующие способ 400, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, реализующие способ 400, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то что на Фиг. 4 и в связанных с ним описаниях операции способа 400 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке.
[0051] В соответствии с одной реализацией настоящего изобретения сначала создается кодовая книга или принимается уже существующая кодовая книга на шаге 402. Затем можно использовать другой набор изображений документов для оценки качества построенной кодовой книги. Соответственно, на шаге 404 принимается второй набор изображений документов. Этот дополнительный набор изображений документов может состоять, например, из 100, 500, 1000, 1200 или более изображений документов, которые отличаются от изображений документов, используемых для построения кодовой книги. Следует отметить, что для этой цели можно использовать любое количество изображений документов. В другой реализации может использоваться набор из 1000 изображений документов (например, изображений счетов-фактур), которые отличаются от изображений документов, используемых для построения кодовой книги.
[0052] После этого на шаге 406 такие важные поля (т.е. целевые поля) в наборе изображений документов, как «Дата», «Итого», «Компания», «Валюта» и т.д., могут быть автоматически размечены в зависимости от их важности, если они не были размечены при получении. Кроме того, изображения документов могут быть размечены пользователем в соответствии с реализацией изобретения. Например, в другой реализации важные поля, такие как «дата выставления счета» и «итого», могут быть заранее размечены.
[0053] Далее, на шаге 408 из каждого изображения документа второго набора изображений документов извлекаются все ключевые области и соответствующие им локальные дескрипторы. Эта операция осуществляется по аналогии с описанной ранее процедурой построения кодовой книги.
[0054] Каждый извлеченный локальный дескриптор затем подвергается векторному квантованию на шаге 410 с использованием ближайшего визуального слова в кодовой книге (т.е. ближайшего центра кластера, полученного при построении кодовой книги). Эту процедуру можно назвать «обнаружением визуальных слов». Таким образом, во втором наборе изображений документов выполняется обнаружение всех доступных визуальных слов W.
[0055] Далее, на шаге 412 осуществляется вычисление двумерной гистограммы h(Wi, Wj) координат (Wi, Wj) для каждого конкретного визуального слова W. Также осуществляется вычисление двумерной гистограммы h(Fi, Fj) координат (Fi, Fj) для конкретного помеченного поля F. Также могут быть вычислены следующие условные гистограммы: (а) условная гистограмма 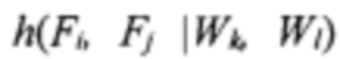 для положения поля F при фиксированном положении
для положения поля F при фиксированном положении 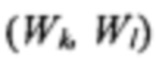 визуального слова W и (b) условная гистограмма
визуального слова W и (b) условная гистограмма 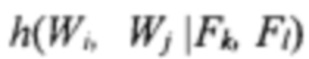 положения слова W при фиксированном положении
положения слова W при фиксированном положении 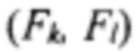 поля F.
поля F.
[0056] Значения бинов двумерных гистограмм вычисляются для ячеек из пространственной сетки M×N элементов. В одной реализации устанавливаем М и N равными определенному заданному значению, например, M=N=16, M=N=32, M=N=64, M=N=128, однако могут быть использованы другие значения для сетки M×N.
[0057] После получения всех вышеперечисленных гистограмм, на следующем этапе на шаге 414 выполняется вычисление взаимной информации MI (W, F) двух случайных величин, положения поля документа F и положения визуального слова W. MI двух случайных величин, положения поля документа F и положения слова W, является мерой взаимной зависимости между этими двумя переменными. MI рассчитывается по формуле: MI (W,F)=H(F)-H(F|W)=H(W)-H(W|F), где (a) H(F), H(W) - предельные энтропии случайных позиций F и W, вычисленные с использованием гистограмм h(Fi, Fj) и h(Wi, Wj); (b) H(F|W) - условная энтропия F при условии, что значение W известно, вычисленная с использованием условной гистограммы 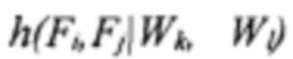 и последующего усреднения результата по всем возможным позициям
и последующего усреднения результата по всем возможным позициям 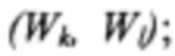 H(W|F) - условная энтропия W при условии, что значение F известно, вычисленная с использованием условной гистограммы
H(W|F) - условная энтропия W при условии, что значение F известно, вычисленная с использованием условной гистограммы 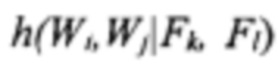 и последующего усреднения результата по всем возможным позициям
и последующего усреднения результата по всем возможным позициям 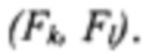
[0058] Так как MI является мерой взаимной зависимости между двумя переменными, то если мы усредняем MI по всем визуальным словам в кодовой книге, мы можем использовать MI в качестве интегрированной меры качества кодовой книги для конкретного поля документа F. Следовательно, MI может быть рассчитана для всех целевых полей документа F. Соответственно, на шаге 416 целевая функция полученной MI может быть максимизирована для оптимизации кодовой книги и построения оптимизированной кодовой книги на шаге 418.
[0059] В некоторых реализациях максимизация взаимной информации может быть выполнена в автоматическом режиме (например, градиентным спуском (gradient descent), дифференциальной эволюцией (differential evolution) или другим подходящим методом оптимизации).
Кроме того, максимизация взаимной информации может включать исчерпывающий поиск/перебор параметров или поиск по сетке (grid search). В данном случае вычисляется разность между безусловной гистограммой двух случайных величин и условной. То есть из общей двумерной энтропии нужно вычесть энтропии, полученные при фиксированных визуальных словах. Затем определяется уменьшение энтропии (т.е. насколько меньше случайные колебания полей F при фиксированных визуальных словах W).
[0060] Для различных случаев и наборов документов можно выбрать оптимальные значения необходимых параметров для достижения желаемой оптимизации. Например, можно выбрать количество визуальных слов, необходимых для включения в кодовую книгу, количество и вид используемых дескрипторов, количество используемых размеров/аспектов, тип предварительной обработки, веса дескрипторов и т.д., чтобы максимизировать целевую функцию MI на шаге 416.
[0061] Следует отметить, что вышеупомянутый процесс оптимизации кодовой книги с использованием ряда помеченных изображений документов второго набора изображений документов (например, счетов-фактур) выполняется только один раз на этапе разработки оптимизированной кодовой книги. Таким образом, на шаге 418 мы получаем оптимизированную кодовую книгу визуальных слов, построенную на основе первого набора изображений документов и оптимизированную на основе второго набора изображений документов, готовую к использованию для обнаружения и извлечения важных полей на изображении документа. Рассмотрим более подробно процесс использования/реализации оптимизированной кодовой книги (см. Фиг. 5 и Фиг. 6).
[0062] В некоторых реализациях использование оптимизированной кодовой книги подразумевает обучение (Фиг. 6) с использованием набора изображений документов, представленных на Фиг. 5. Соответственно, на Фиг. 5 представлен набор изображений документов с низкими колебаниями лейаута, а Фиг. 6 представляет собой структурную блок-схему способа обучения 600, предназначенного для получения набора данных с целью извлечения полей из новых изображений документов в соответствии с некоторыми реализациями. В некоторых реализациях способ 600 может выполняться одним потоком обработки, выполняемым устройством для обработки. Кроме того, способ 600 может выполняться двумя или более потоками обработки, выполняемыми одним или более ядрами обработки, таким образом, чтобы каждый поток выполнял одну или несколько отдельных функций, программ, подпрограмм или действий способа. В иллюстративном примере потоки обработки, реализующие способ 600, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, реализующие способ 600, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то, что на Фиг. 6 и в связанных с ним описаниях операции способа 600 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке.
[0063] В одной реализации настоящего изобретения получен еще один набор 604 изображений документов (т.е. третий набор изображений документов, набор пользовательских документов), включающий небольшое количество изображений документов (например, 3, 5, 10 или любое другое количество изображений документов) относительно первого и второго наборов изображений документов, описанных ранее. На шаге 606 ключевые или важные поля в изображениях документов размечаются либо пользователем, либо автоматически. Следует отметить, что на каждом изображении документа может быть размечено одно или несколько полей (каждое поле размечается аналогичным образом). Например, в квитанциях из набора изображений документов 500 на Фиг. 5 есть размеченное поле 502 «Итого».
[0064] Затем с использованием оптимизированной кодовой книги 602 можно построить гистограмму, отражающую частотное распределение положения этого поля (например, поля 607 «Итого») относительно всех визуальных слов кодовой книги. Гистограмма строится для каждого визуального слова из кодовой книги независимо от того, найдено оно или нет в конкретном рассматриваемом изображении анализируемого документа. Следовательно, если кодовая книга состоит из 500 визуальных слов, то на этом этапе на шаге 608 будет построено 500 гистограмм.
[0065] Если визуальное слово действительно существует на конкретном анализируемом изображении документа, то оно будет обладать следующими характеристиками: геометрическое положение, центр визуального слова и т.д. Также будет размеченное поле (например, поле «Итого»), которое характеризуется своим положением на изображении документа. Следовательно, между положением поля и положением визуального слова будет существовать пространственная разница.
[0066] Соответственно, на шаге 608 для каждого визуального слова из кодовой книги можно вычислить условную гистограмму 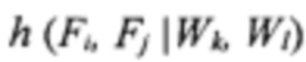 позиции для конкретного поля F при фиксированной позиции
позиции для конкретного поля F при фиксированной позиции 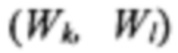 визуального слова W на размеченном наборе изображений документов (т.е. на третьем наборе изображений документов, полученном для обучения модели). Однако при вычислении этой гистограммы используется сдвиг S положения поля F относительно фиксированного положения слова W для пространственных координат. Данная процедура вычисления условной гистограммы повторяется для всех визуальных слов в кодовой книге. Таким образом, вычисляется множество таких гистограмм распределения со сдвигом/смещением. Также важно отметить, что сдвиги каждого изображения документа будут обладать своими собственными свойствами (т.е. отличными от других, уникальными свойствами), но, как правило, они будут коррелировать тем или иным способом. Иными словами, условные гистограммы могут приблизительно указывать, где находится целевое поле относительно каждого визуального слова.
визуального слова W на размеченном наборе изображений документов (т.е. на третьем наборе изображений документов, полученном для обучения модели). Однако при вычислении этой гистограммы используется сдвиг S положения поля F относительно фиксированного положения слова W для пространственных координат. Данная процедура вычисления условной гистограммы повторяется для всех визуальных слов в кодовой книге. Таким образом, вычисляется множество таких гистограмм распределения со сдвигом/смещением. Также важно отметить, что сдвиги каждого изображения документа будут обладать своими собственными свойствами (т.е. отличными от других, уникальными свойствами), но, как правило, они будут коррелировать тем или иным способом. Иными словами, условные гистограммы могут приблизительно указывать, где находится целевое поле относительно каждого визуального слова.
[0067] Затем на шаге 610 можно вычислить интегральную двумерную гистограмму h(S(F, W)) сдвига S позиции поля F, которая будет включать сдвиги относительно всех возможных позиций визуального слова W в размеченном наборе данных.
Это вычисление необходимо для того, чтобы получить набор N гистограмм сдвига на шаге 612. Набор N гистограмм сдвига h(S(F, Wj)) для всех визуальных слов Wj и сама кодовая книга представляют собой полный набор данных, достаточный для вычисления статистических предикатов положений полей счетов-фактур в соответствии с реализациями настоящего изобретения. С использованием данного полного набора данных можно вычислить статистический предикат P(Fj) для положения поля Fj на любом изображении документа, загруженном в систему в соответствии с реализацией. Применение предиката представлено на Фиг. 7, которая представляет собой блок-схему способа 700 для обнаружения целевого поля на новом изображении документа.
[0068] В некоторых реализациях способ 700 может выполняться одним потоком обработки, выполняемым устройством для обработки данных. Кроме того, способ 700 может выполняться двумя или более потоками обработки, выполняемыми одним или более ядрами обработки, таким образом, чтобы каждый поток выполнял одну или несколько отдельных функций, программ, подпрограмм или действий способа. В иллюстративном примере потоки обработки, реализующие способ 700, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, реализующие способ 700, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то что на Фиг. 7 и в связанных с ним описаниях операции способа 700 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке.
[0069] Для обнаружения или извлечения целевого поля из нового изображения документа сначала отправляется или загружается новое изображение 701 документа в систему 703, которая включает оптимизированную кодовую книгу и набор N гистограмм сдвига. На шаге 702 система сначала обнаруживает все визуальные слова W, имеющиеся в кодовой книге, на новом изображении документа.
Например, может быть найдено 20 слов, 200 слов или любое другое количество слов (в зависимости от количества слов, включенных в оптимизированную кодовую книгу системы 703). Затем на шаге 704 система может вычислить предикат Pik(F) возможной позиции поля F для каждого визуального слова Wk кодовой книги, используя соответствующую гистограмму сдвига h(S(F, Wk)), сохраненную в системе вместе с кодовой книгой. Интегральный/целочисленный предикат Pk(F) возможной позиции поля F на основе всех визуальных слов Wk вычисляется на шаге 708 как сумма отдельных предикатов Pik(F), полученных на шаге 706 для всех визуальных слов Wk на изображении документа. Точнее говоря, в некоторых реализациях все гистограммы накапливаются или накладываются друг на друга с учетом их определенных сдвигов. В итоге получается аккумулированная гистограмма распределения, полученная от всех визуальных слов.
[0070] Следует обратить внимание, что для каждого визуального слова Wk на изображении документа часть гистограмм сдвига h(S(F, Wk)) может не участвовать в вычислении предиката для этого визуального слова. Это связано с тем, что большие сдвиги могут привести к оценке положения поля F, которое находится за пределами области изображения документа.
[0071] Интегральный предикат Р(F) возможного положения поля F, основанный на появлении всех визуальных слов в изображении документа, может быть вычислен как линейная комбинация отдельных предикатов Pk(F) из различных визуальных слов Wk, обнаруженных в изображении документа. Следует обратить внимание, что в некоторых случаях отдельные предикаты, основанные на отдельных визуальных словах, не могут спрогнозировать положение поля с требуемым уровнем точности, в то время как интегральный предикат, рассчитанный для всех визуальных слов, обнаруженных на изображении документа, должен достаточно хорошо справиться с этой задачей.
[0072] По этой причине следует отметить, что прогнозирование положения полей на изображении документа может быть дополнительно оптимизировано (например, для повышения точности), если вычислить интегральный предикат для поля F, например, как линейную комбинацию предикатов из отдельных слов с их соответствующими весами, равными значениям MI(F, Wk) для отдельных слов Wk, возведенную в квадрат (т.е. во вторую степень). Такие статистические предикаты независимо от способа их вычисления (т.е. независимо от того, вычисляются ли они способом, описанным в предыдущем параграфе, способом, описанным в этом параграфе, или иным образом) могут быть представлены в виде M×N массива вероятностей появления целевого поля в ячейках массива на шаге 710. Такие предикаты более подробно представлены на Фиг. 8.
[0073] Фиг. 8 представляет собой блок-схему 800, показывающую генерацию статистических предикатов для целевого поля на изображении документа в соответствии с некоторыми сценариями реализаций настоящего изобретения. Совмещение/наложение индивидуального статистического предиката 804, основанного на конкретном визуальном слове, и интегрального статистического предиката 806 (т.е. аккумулированной гистограммы) на изображение 802 исходного документа представлено на Фиг. 8. Полученный статистический предикат Р(i, j|F) представляет собой двумерный массив вероятностей появления поля документа F в различных ячейках (i, j) пространственной сетки M×N, наложенной на изображение 802. Градиентная шкала 808 указывает затенение, используемое для различных значений предиката (при этом 0 находится в нижней части градиентной шкалы, а наибольшее значение находится вверху). При вычислении гистограмм с использованием набора данных с размеченными изображениями документов мы предполагаем, что конкретная ячейка содержит поле F (или слово W), если центр прямоугольника поля 807 или прямоугольника слова 805 расположен внутри ячейки. Примечательно, что могут быть заданы любые значения для М и N, подходящие для анализируемых изображений документов. Например, для чеков может быть подходящим массив 26×10, в то время как для счетов может быть более подходящим массив 16×16 и т.д. Соответственно, пространство/площадь изображения документа квантуется по координатам на заданное количество ячеек, и это разделение на ячейки и есть итоговая гистограмма.
[0074] Прогнозирование положения поля F может определяться положением элементов массива предикатов с топ-n значениями. Каждая ячейка гистограммы может содержать некоторое количество «голосов» (т.е. накопленную частоту) от визуальных слов. Таким образом, та ячейка, которая содержит максимальное количество голосов, представляет собой топ-1 предсказаний. Ячейки сетки, содержащие n максимальных значений предиката P(i; j|F), назовем «топ-n ячейками», и, например, для поиска поля на документе можно использовать любую точность от топ-1 до топ-5. Для примера, в соответствии с некоторыми реализациями могут быть использованы следующие метрики для измерения точности прогнозирования: топ-1 точность, представляющая собой процент правильных прогнозов на основе ячейки сетки с максимальным значением статистического предиката P(i; j|F); топ-3 точность, представляющая собой процент правильных прогнозов на основе ячеек сетки с топ-3 значениями статистического предиката P(i; j|F); и топ-5 точность, представляющая собой процент правильных прогнозов на основе ячеек сетки с топ-5 значениями статистического предиката P(i; j|F).
[0075] При этом количество гистограмм будет равно количеству целевых полей на документе. То есть, если есть N полей, то будет и N предикатов. Для примера предположим, что кодовая книга содержит 800 визуальных слов, в то время как 200 визуальных слов заполнили 200 из 800 гистограмм по всем визуальным словам. Берем все эти 800 гистограмм, аккумулируем их с учетом их относительного положения на документе и получаем одно предсказание для одного поля для всех 800 гистограмм. Это тензор гистограмм 800×N, где для каждого из N полей вычисляется 800 гистограмм, складывается их взаимное относительное положение и получается статистический предикат. Когда будут получены N таких статистических предикатов, можно спрогнозировать положение для всех N полей. Таким образом, можно спрогнозировать положение для каждого целевого поля (т.е. необходимого поля, важного поля) на изображении документа.
[0076] Повысить точность можно, если колебания лейаута/макета документа нового типа, к которому требуется применить кодовую книгу, сведены к минимуму. Другими словами, если кодовая книга применяется к набору изображений документов с ограниченными колебаниями лейаута, точность может значительно повыситься. Например, из-за помятости положение полей в квитанциях может сильно измениться. Однако, если изображения документов (например, изображения квитанций) более плоские/ровные, то результирующая точность прогнозирования положения поля будет очень высокой по сравнению с предыдущим примером.
[0077] Соответственно, для повышения скорости и точности в некоторых реализациях набор изображений документов может быть разделен на группы по визуальной схожести (например, по сходству лейаута) либо вручную, либо с помощью известных автоматических методов. Например, если перед загрузкой изображений документов в систему, пользователю удастся сгруппировать изображения документов (например, по типам документов, компаниям, от которых поступили документы и т.д.) таким образом, чтобы они были визуально похожи (т.е. имели одинаковый лейаут/макет), то процесс извлечения полей по каждой группе изображений документов будет в несколько раз точнее.
[0078] На Фиг. 9 представлена блок-схема компьютерной системы в соответствии с некоторыми вариантами реализации настоящего изобретения. На Фиг. 9 представлен пример компьютерной системы 900, которая может выполнять любой один или несколько описанных в настоящем документе способов. Компьютерная система может быть подключена (например, по сети) к другим компьютерным системам в локальной сети, интрасети, экстрасети или сети Интернет. Компьютерная система может работать в качестве сервера в сетевой среде клиент-сервер. Компьютерная система может быть персональным компьютером (PC), планшетным компьютером, ТВ-приставкой (STB), персональным цифровым помощником (PDA), мобильным телефоном, камерой, видеокамерой или любым устройством, способным выполнять набор инструкций (последовательных или иных), определяющих действия, которые должны выполняться этим устройством. Кроме того, несмотря на то что проиллюстрирована только одна компьютерная система, термин «компьютер» также следует понимать как любую совокупность компьютеров, которые индивидуально или совместно выполняют набор (или несколько наборов) инструкций для выполнения любого одного или нескольких способов, описанных в настоящем документе.
[0079] Примерная компьютерная система 900 состоит из устройства 902 обработки данных, оперативного запоминающего устройства 904 (например, постоянного запоминающего устройства (ROM), флеш-памяти, динамической памяти с произвольным доступом (DRAM), такой как синхронная динамическая память с произвольным доступом (SDRAM)), и устройства 918 хранения данных, которые взаимодействуют друг с другом через шину 930.
[0080] Устройство 902 обработки данных представляет собой одно или несколько устройств обработки общего назначения, таких как микропроцессор, центральный процессор и т.п. Точнее говоря, устройство 902 обработки данных может быть микропроцессором с полным наборов команд (CISC), микропроцессором для вычисления сокращенных наборов команд (RISC), микропроцессором с очень длинным командным словом (VLIW), процессором, реализующим другие наборы команд, или процессором, реализующим сочетание наборов команд. Устройство 902 обработки данных также может представлять собой одно или несколько устройств обработки специального назначения, таких как специализированная интегральная схема (ASIC), программируемая на месте матрица логических элементов (FPGA), цифровой сигнальный процессор (DSP), сетевой процессор и т.п. Устройство 902 обработки данных сконфигурировано для выполнения инструкций 926 с целью реализации таких способов, как построение кодовой книги 100 (Фиг. 1), морфологическая предварительная обработка и преобразование (Фиг. 2-3), оптимизация 400 (Фиг. 4), процесс обучения 600 (Фиг. 6) и/или обнаружение/извлечение полей 700 (Фиг. 7), а также для выполнения операций, описанных в настоящем документе.
[0081] Компьютерная система 900 может дополнительно включать сетевое интерфейсное устройство 922. Компьютерная система 900 также может включать в себя устройство 910 визуального отображения (например, жидкокристаллический дисплей (ЖК-дисплей) или электронно-лучевую трубку (ЭЛТ)), буквенно-цифровое устройство 912 ввода (например, клавиатуру) и устройство 914 управления курсором. В одном иллюстративном примере устройство 910 визуального отображения, устройство 912 буквенно-цифрового ввода и устройство 914 управления курсором объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0082] Устройство 918 хранения данных может включать машиночитаемый носитель 924 данных, на котором хранятся инструкции 926, воплощающие любую одну или несколько методик или функций, описанных в настоящем документе. Инструкции 926 также могут полностью или, по крайней мере, частично находиться в оперативной памяти 904 и/или на устройстве 902 обработки данных во время их выполнения компьютерной системой 900. Оперативная память 904 и устройство обработки 902 данных также представляют собой машиночитаемые носители данных. В некоторых реализациях инструкции 926 могут дополнительно передаваться или приниматься по сети 916 через сетевое интерфейсное устройство 922.
[0083] Несмотря на то, что в иллюстративных примерах машиночитаемый носитель 924 данных представлен в единственном числе, термин «машиночитаемый носитель» следует понимать как включающий в себя один или несколько носителей (например, централизованную или распределенную базу данных и (или) связанные с ней кэши и серверы), в которых хранится один или несколько наборов инструкций. Термин «машиночитаемый носитель» также следует понимать как включающий в себя какой-либо носитель, способный хранить, кодировать или переносить набор инструкций для выполнения машиной и вынуждающий машину выполнять любую одну или несколько методик настоящего изобретения. Следовательно, термин «машиночитаемый носитель» должен включать, помимо прочего, твердотельные запоминающие устройства, оптические и магнитные носители данных.
[0084] Несмотря на то, что операции описанных в настоящем документе способов показаны и описаны в определенном порядке, порядок операций каждого способа может быть изменен таким образом, чтобы определенные операции могли выполняться в обратном порядке или чтобы определенные операции могли выполняться по меньшей мере частично одновременно с другими операциями. В некоторых реализациях инструкции или подоперации отдельных операций могут быть прерывающимися и (или) чередующимися.
[0085] Следует понимать, что приведенное выше описание является иллюстративным, а не ограничительным. Специалистам в данной области техники станут очевидны многие другие варианты реализации после прочтения и понимания приведенного выше описания. Поэтому объем изобретения определяется со ссылкой на прилагаемую формулу изобретения, а также на полный объем эквивалентов, в отношении которых такая формула изобретения дает право предъявлять претензии.
[0086] В приведенном выше описании излагаются многочисленные детали. Однако специалисту в данной области техники будет очевидно, что аспекты настоящего изобретения могут быть реализованы на практике без этих конкретных деталей. В некоторых случаях, чтобы избежать затруднения понимания настоящего изобретения, хорошо известные структуры и устройства представлены в виде блок-схемы, а не подробно.
[0087] Некоторые части приведенных выше подробных описаний представлены в виде алгоритмов и символических представлений операций с битами данных в памяти компьютера. Эти алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных, для наиболее эффективной передачи сути своей работы другим специалистам в этой области техники. Алгоритм здесь и в целом понимается как самосогласованная последовательность шагов, ведущих к желаемому результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и которыми можно иным образом манипулировать. Со временем практика показала, что удобнее называть эти сигналы битами, значениями, элементами, символами, терминами, числами и т.п., главным образом из соображений общего использования.
[0088] Однако следует иметь в виду, что все эти и аналогичные термины должны быть связаны с соответствующими физическими величинами и являются просто удобными ярлыками, применяемыми к этим величинам. Следует отметить, что при отсутствии других конкретных указаний, как стало очевидно из последующего обсуждения, на протяжении всего описания такие термины в обсуждении, как «получение», «определение», «выбор», «хранение», «анализ» и т.п., относятся к действиям и процессам компьютерной системы или аналогичного электронного вычислительного устройства, которое манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти компьютерной системы, в другие данные, аналогичным образом представленные в виде физических величин в памяти или регистрах компьютерной системы или других таких устройствах хранения, передачи или отображения информации.
[0089] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Это устройство может быть специально сконструировано для требуемых целей или может содержать компьютер общего назначения, избирательно активируемый или реконфигурируемый компьютерной программой, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, на дисках любого типа, включая дискеты, оптические диски, компакт-диски и магнитно-оптические диски, постоянные запоминающие устройства (ROM), оперативную память (RAM), программируемые постоянные запоминающие устройства (EPROM), электронно-перепрограммируемые постоянные запоминающие устройства (EEPROM), магнитные или оптические карты или носители любого типа, пригодные для хранения электронных инструкций, каждый из которых подключен к компьютерной системной шине.
[0090] Представленные в настоящем документе алгоритмы и отображения, по своей сути, не связаны с конкретным компьютером или другим устройством. Различные системы общего назначения могут использоваться с программами в соответствии с приведенными в настоящем документе положениями, либо же будет удобнее создать более специализированное устройство для выполнения требуемых этапов способа. Требуемая структура для разнообразных таких систем будет выглядеть так, как указано в описании. Кроме того, аспекты настоящего изобретения не описаны со ссылкой на конкретный язык программирования. Следует иметь в виду, что для реализации положений настоящего изобретения могут использоваться различные языки программирования, как описано в настоящем документе.
[0091] Варианты реализации настоящего изобретения могут быть представлены в виде программного продукта или программного обеспечения, включающего машиночитаемый носитель с сохраненными на нем инструкциями, которые могут использоваться для программирования компьютерной системы (или других электронных устройств) с целью выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель включает любой механизм для хранения или передачи информации в форме, читаемой машиной (например, компьютером). К примеру, машиночитаемый (например, читаемый компьютером) носитель включает машиночитаемый (например, читаемый компьютером) носитель информации (например, постоянное запоминающее устройство (ROM), оперативную память (RAM), носитель информации на магнитных дисках, оптический носитель информации, устройства флэш-памяти).
[0092] Слова «пример» или «приведенный в качестве примера» в настоящем документе означают пример, случай или иллюстрацию.
Любой аспект или решение, описанные в настоящем документе как «пример» или «приведенный в качестве примера», необязательно должны рассматриваться как предпочтительный или преимущественный по сравнению с другими аспектами или решениями. Скорее, использование слов «пример» или «приведенный в качестве примера» предназначено для представления концепций с практической точки зрения. При использовании в настоящей заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». То есть, если не указано или из контекста не очевидно иное, «X включает в себя А или В» означает любую из естественных включающих перестановок. То есть, если X включает А, X включает В или X включает как А, так и В, то «X включает А или В» удовлетворяется в любом из вышеприведенных случаев. Кроме того, неопределенные артикли, используемые в настоящей заявке и прилагаемой формуле изобретения, как правило, следует толковать как означающие «один или несколько», если только не указано иное или не ясно из контекста, что такой артикль направлен для обозначения единственного числа. Кроме того, использование термина «реализация», «один вариант реализации», «пример реализации» или «один пример реализации» во всем тексте не означает один и тот же вариант или пример реализации, если только они не описаны как таковые. Кроме того, термины «первый», «второй», «третий», «четвертый» и т.д., используемые в настоящем документе, предназначены для обозначения различных элементов и необязательно имеют порядковое значение в соответствии с их числовым обозначением.
[0093] В то время как многие изменения и модификации изобретения без сомнения станут очевидными для специалиста, обладающего обычной квалификацией в данной области техники, после прочтения приведенного выше описания следует понимать, что любой конкретный вариант реализации, показанный и описанный в качестве иллюстрации, никоим образом не должен рассматриваться как ограничивающий.
Поэтому ссылки на детали различных вариантов реализации не предназначены для ограничения объема формулы изобретения, которая сама по себе содержит только признаки, рассматриваемые как раскрытие изобретения.




Группа изобретений относится к компьютерным системам, предназначенным для анализа документов, а более конкретно к технологиям построения и оптимизации кодовых книг для обнаружения полей на документе. Техническим результатом является повышение точности извлечения информации из изображений за счет использования оптимизированных кодовых книг. Предложен способ оптимизации кодовой книги. Согласно способу получают посредством устройства обработки данных первый набор изображений документов. Далее осуществляют извлечение множества ключевых областей из каждого изображения документа первого набора изображений документов. Осуществляют вычисление локальных дескрипторов для каждой ключевой области из числа извлеченных ключевых областей. А также производят кластеризацию локальных дескрипторов таким образом, чтобы каждый центр кластера локальных дескрипторов соответствовал соответствующему визуальному слову, и осуществляют построение кодовой книги, содержащей набор визуальных слов. 3 н. и 17 з.п. ф-лы, 12 ил.
1. Способ оптимизации кодовой книги, включающий:
получение устройством обработки данных первого набора изображений документов;
извлечение множества ключевых областей из каждого изображения документа первого набора изображений документов;
вычисление локальных дескрипторов для каждой ключевой области из числа извлеченных ключевых областей;
кластеризацию локальных дескрипторов таким образом, чтобы каждый центр кластера локальных дескрипторов соответствовал соответствующему визуальному слову;
построение кодовой книги, содержащей набор визуальных слов;
оптимизацию кодовой книги путем максимизации взаимной информации (MI) между целевым полем второго набора изображений документов и по меньшей мере одним визуальным словом из набора визуальных слов.
2. Способ по п. 1, в котором обнаружение каждой ключевой области из множества ключевых областей дополнительно включает морфологическую предварительную обработку каждого изображения документа из первого набора изображений документов.
3. Способ по п. 1, в котором извлечение множества ключевых областей включает идентификацию множества максимально стабильных экстремальных областей (MSER), причем способ дополнительно содержит:
объединение, по меньшей мере, подмножества максимально стабильных экстремальных областей (MSER) для построения соответствующей ограничивающей прямоугольной области; и
преобразование каждой ограничивающей прямоугольной области в квадратную область.
4. Способ по п. 1, дополнительно включающий:
вычисление для каждого кластера стандартного отклонения его локальных дескрипторов от визуальных слов кодовой книги; и
нормализацию расстояния между каждым локальным дескриптором и центром кластера на стандартное отклонение.
5. Способ по п. 1, дополнительно включающий:
разметку целевых полей в каждом изображении документа второго набора изображений документов;
извлечение ключевых областей и соответствующих им локальных дескрипторов из каждого изображения документа второго набора изображений документов;
обнаружение визуальных слов во втором наборе изображений документов путем векторного квантования каждого локального дескриптора с использованием ближайшего визуального слова в кодовой книге.
6. Способ по п. 1, дополнительно включающий:
вычисление условных гистограмм координат по меньшей мере для одного визуального слова и по меньшей мере для одного целевого поля второго набора изображений документов.
7. Способ по п. 6, в котором максимизация MI включает максимизацию целевой функции MI на основе условных гистограмм.
8. Система для оптимизации кодовой книги, содержащая:
запоминающее устройство,
процессор, соединенный с запоминающим устройством, причем процессор выполнен с возможностью:
получения первого набора изображений документов;
извлечения ключевых областей из каждого изображения документа первого набора изображений документов;
вычисления локальных дескрипторов для каждой ключевой области из числа извлеченных ключевых областей;
кластеризации локальных дескрипторов таким образом, чтобы каждый центр кластера локальных дескрипторов соответствовал соответствующему визуальному слову;
создания кодовой книги, содержащей набор визуальных слов;
оптимизации кодовой книги путем максимизации взаимной информации (MI) между целевым полем второго набора изображений документов и по меньшей мере одним визуальным словом из набора визуальных слов.
9. Система по п. 8, в которой обнаружение каждой ключевой области из множества ключевых областей дополнительно включает морфологическую предварительную обработку каждого изображения документа первого набора изображений документов.
10. Система по п. 8, в которой извлечение множества ключевых областей включает идентификацию множества максимально стабильных экстремальных областей (MSER) и в которой процессор дополнительно выполнен с возможностью:
объединения, по меньшей мере, подмножества максимально стабильных экстремальных областей (MSER) для построения соответствующей ограничивающей прямоугольной области; и
преобразования каждой ограничивающей прямоугольной области в квадратную область.
11. Система по п. 8, в которой процессор дополнительно выполнен с возможностью:
вычисления для каждого кластера стандартного отклонения его локальных дескрипторов от визуальных слов кодовой книги;
нормализации расстояния между каждым локальным дескриптором и центром кластера на стандартное отклонение.
12. Система по п. 8, в которой процессор дополнительно выполнен с возможностью:
разметки целевых полей в каждом изображении документа второго набора изображений документов;
извлечения ключевых областей и соответствующих им локальных дескрипторов из каждого изображения документа второго набора изображений документов;
обнаружения визуальных слов во втором наборе изображений документов путем векторного квантования каждого локального дескриптора с использованием ближайшего визуального слова в кодовой книге.
13. Система по п. 8, в которой процессор дополнительно выполнен с возможностью:
вычисления условных гистограмм координат по меньшей мере для одного визуального слова и по меньшей мере для одного целевого поля для оптимизации кодовой книги.
14. Система по п. 13, в которой максимизация MI включает максимизацию целевой функции MI на основе условных гистограмм.
15. Способ обработки изображения документа, включающий:
получение устройством обработки данных кодовой книги, содержащей набор визуальных слов, где каждое визуальное слово соответствует центру кластера локальных дескрипторов;
вычисление для каждого визуального слова кодовой книги соответствующего частотного распределения положения указанного размеченного поля относительно визуального слова на основе набора размеченных пользователем изображений документов;
загрузку изображения документа для извлечения целевых полей;
обнаружение визуальных слов в изображении документа;
вычисление статистического предиката возможного положения целевого поля в изображении документа на основе частотных распределений;
обнаружение полей в изображении документа на основе вычисленного статистического предиката с использованием обученной модели.
16. Способ по п. 15, в котором кодовая книга основана на первом наборе изображений документов и оптимизирована на втором наборе изображений документов и в котором набор изображений документов, размеченных пользователем, отличается от первого и второго наборов изображений документов.
17. Способ по п. 15, в котором вычисление соответствующего частотного распределения включает вычисление интегральной двумерной гистограммы сдвига положения указанного поля, причем интегральная двумерная гистограмма содержит множество сдвигов относительно возможных положений каждого визуального слова.
18. Способ по п. 15, в котором вычисление статистического предиката дополнительно включает получение аккумулированной гистограммы распределения на основе возможных положений целевого поля относительно двух или более визуальных слов из набора визуальных слов.
19. Способ по п. 15, в котором множество изображений документов из набора изображений пользовательских документов имеют аналогичный макет.
20. Способ по п. 15, дополнительно включающий разделение набора изображений пользовательских документов на группы по их сходству до выполнения по меньшей мере одного из: обучения модели или использования модели.
| US 20200019768 A1, 16.01.2020 | |||
| US 20170364594 A1, 21.12.2017 | |||
| CN 110728151 A, 24.01.2020 | |||
| CN 103559191 B, 14.09.2016 | |||
| US 9652688 B2, 16.05.2017 | |||
| СПОСОБ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ МОДЕЛИ ДОКУМЕНТА | 2011 |
|
RU2487403C1 |
| CN 1618066 A, 18.05.2005 | |||
| статья Sun, W., Kise, K.: Similar manga retrieval using visual vocabulary based on regions of interest, опубл | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |

