Область техники, к которой относится изобретение
Заявленное изобретение относится к информационным технологиям, в частности, к методам и средствам обеспечения информационного обмена между компьютерными системами с использованием механизма компрессии передаваемых данных кодированием запросов простой синтаксической заменой на основе таблицы кодировки и может быть использовано для поддержания в идентичном состоянии баз данных (БД), размещенных в независимых компьютерах.
Уровень техники
а) Описание аналогов
Известен способ поточного кодирования дискретной информации по патенту РФ №2005120259 (класс Н04Н 9/00 заявл. 29.06.2005). В известном способе осуществляют поточное побитовое кодирование передаваемых данных с целью защиты информации от несанкционированного доступа.
Недостатком данного способа является:
данный способ подходит для решения задач защиты передаваемой информации от несанкционированного доступа, но не осуществляет компрессию передаваемых данных в режиме реального времени и не осуществляет репликацию данных между базами данных.
Известен способ поточного кодирования дискретной информации по патенту РФ №2205516 (класс H04L 9/00 заявл. 20.02.2002). В известном способе осуществляют поточное побитовое кодирование передаваемых данных с целью защиты информации от несанкционированного доступа.
Недостатком данного способа является:
данный способ подходит для решения задач защиты передаваемой информации от несанкционированного доступа, но не осуществляет компрессию передаваемых данных в режиме реального времени и не осуществляет репликацию данных между базами данных.
Известен способ компрессии-декомпрессии данных и устройство для его осуществления по патенту РФ №2011124978, (класс Н03М 7/30 заявл. 17.06.2011). В известном способе осуществляют блочное преобразование данных с целью уменьшения объема таких данных.
Недостатком данного способа является:
данный способ подходит для решения задач компрессии данных, но не осуществляет преобразование в поточном режиме и не осуществляет репликацию данных между базами данных.
б) Описание ближайшего аналога (прототипа)
Наиболее близкой по своей технической сущности к заявленному способу является система репликации информации в базах данных по патенту РФ №2703961 «Система репликации информации в базах данных», (класс G06F 16/27, заявл. 25.07.2018, опубл. 22.10.2019 бюл. №30). Технический результат системы-прототипа заключается в том, что, при репликации два компьютера соединяют по локальной сети и производят обмен данными между базами данных компьютеров, причем, в каждый из двух компьютеров с установленными в них ORACLE-серверами предварительно загружают базу данных с неизменяемой базой знаний и изменяемой базой данных о клиентах и исследованиях, выполненной с возможностью независимых изменений и дополнений на каждом из двух компьютеров, причем, сначала один из компьютеров переводят в компьютер-источник путем формирования на его ORACLE-сервере обращения к ORACLE-серверу другого компьютера, который переводят в компьютер-приемник, сравнивают данные в их изменяемых базах данных по набору полей, определяющему записи в изменяемых базах данных, выделяют данные, имеющиеся в изменяемой базе данных компьютера-источника и отсутствующие в изменяемой базе данных компьютера-приемника, и вставляют в изменяемую базу данных компьютера-приемника, а затем другой компьютер переводят в компьютер-источник путем формирования на его ORACLE-сервере обращения к ORACLE-серверу первого компьютера, который переводят в компьютер-приемник, и производят указанные выше операции между этими компьютером-источником и компьютером-приемником.
По сравнению с аналогами, способ-прототип может быть использован в более широкой области применения
Недостатками прототипа являются:
1. Низкая скорость репликации информации при работе с базами данных, содержащими большие объемы данных различных типов при использовании высоко нагруженных каналов связи;
2. Невозможность использования нестабильных каналов связи с низкой пропускной способностью;
3. Отсутствие механизма, обеспечивающего компрессию передаваемых данных в режиме реального времени.
В настоящем изобретении предложен способ, позволяющий устранить выявленные недостатки.
Раскрытие изобретения (его сущность)
а) технический результат, на достижение которого направлено изобретение
Целью заявленного технического решения является разработка системы, позволяющей значительно сократить объем передаваемых данных без утраты информативности, используемой при репликации информации в распределенных базах данных, в частности, применительно к двум компьютерам, в каждый из которых загружена одинаковая по структуре база данных с неизменной базой знаний и независимо изменяемой и дополняемой информацией в базе клиентов и исследований и используемой для периодической синхронизации базы данных в обоих компьютерах.
б) совокупность существенных признаков
Способ репликации информации в базах данных с использованием механизма кодирования запросов простой синтаксической заменой на основе таблицы кодировки, заключается в том, что в систему, выполненную в виде блока обеспечения локальной сети между первым и вторым компьютерами, содержащими синхронизируемые базы данных, блока синхронизации режимов работы компьютеров, при этом первый и второй входы-выходы блока обеспечения локальной сети между первым и вторым компьютерами соединены с первыми входами-выходами первого и второго компьютеров соответственно, а первый и второй входы-выходы блока синхронизации режимов работы компьютеров соединены со вторыми входами-выходами первого и второго компьютеров соответственно, блока сравнения данных в изменяемых базах данных первый вход-выход которого соединен с третьим входом-выходом блока синхронизации режимов работы компьютеров, блока выделения несовпадающих фрагментов в изменяемых базах данных, первый вход-выход которого соединен со вторым входом-выходом блока сравнения данных в изменяемых базах данных, а также блока внесения изменений в изменяемые базы данных, первый вход-выход которого соединен со вторым входом-выходом блока выделения несовпадающих фрагментов в изменяемых базах данных, вводится блок кодирования-декодирования данных, первый и второй входы-выходы которого соединены с третьими входами-выходами первого и второго компьютера соответственно, а третий и четвертый входы-выходы соединены с четвертыми входами-выходами первого и второго компьютера соответственно.
Дополнительно, способ репликации информации в базах данных с кодированием простой синтаксической заменой на основе таблицы прямой замены, который основан на выполнении следующих действий: предварительно на основе базы данных создается файл, содержащий словарь замены (таблицу кодировки): принимают информацию, включающую в себя словарь table_names <x1, …, x2, …, xn>, содержащий названия таблиц базы данных, где n - количество таблиц, формируют формируют запрос на подключение к базе данных, в случае если подключение не выполнено, выводится сообщение об ошибке подключения и подтверждают отправку повторного запроса на подключение к базе данных, в случае если отправка подтверждена, выполняют повторное обращение к базе данных, если отправке не подтверждена, происходит завершение работы, если подключение выполнено успешно, формируют маркер номера обрабатываемой таблицы i, изначально равный 1, формирует список data для хранения записей таблицы, формируют запрос на извлечение всех данных из таблицы table_namesi, ответ на запрос записывают в словарь data, и в случае если ответ на запрос представляет собой некорректные данные, выводится сообщение о соответствующей ошибке и подтверждают отправку повторного запроса на подключение к базе данных, а в случае если отправка подтверждена, выполняют повторное обращение к базе данных, если отправка не подтверждена, формируется отчет о проделанной работе и происходит завершение работы, если данные корректны, формируется флаг достижения последней записи data_quantity, записывают в него значение длины словаря data, формируют флаг достижения последнего поля таблицы field_quantity, записывают в него значение длины словаря data0, формируют маркеры j, k, номера обрабатываемого элемента словаря data, формируют маркер t, представляющий собой значение, которое будет поставлено способом синтаксической замены в соответствие данным базы данных, формируют словарь уникальных данных field_unique формата «ключ» : «значение», устанавливают значение маркера k равное 0, устанавливают значение маркера j равное 0, устанавливают значение маркера t равное 0, производится проверка: если в словаре field_unique отсутствует запись с ключом datajk, в словарь field_unique добавляют запись с ключом datajk и значением t, значение t увеличивают на 1, значение j увеличивают на 1, если в словаре field_unique запись с ключом datajk имеется, происходит переход к шагу инкрементирования j, происходит проверка: если последняя запись таблицы не обработана, а именно значение маркера j не равно значению флага data_quantity, происходит возвращение к шагу проверки вхождения datajk в словарь field_unique, если последняя запись таблицы обработана, словарь field_unique записывают в файл таблицы кодировки, очищают словарь field_unique и увеличивают значение маркера k на 1, происходит проверка: если последнее поле таблицы не обработано, а именно значение маркера k не равно значению флага fields_quantity, происходит возвращение к шагу установления значения маркера j, если последнее поле обработано, значение маркера номера обрабатываемой таблицы i увеличивается на 1, происходит проверка: если база данных не обработана полностью, а именно значение флага i больше значения количества таблиц n, происходит переход к шагу создания словаря data, если конец таблицы достигнут, формируется отчет о проделанной работе и происходит завершение работы, процесс передачи запроса к базе данных производится следующим образом: устанавливают соединение с базой данных для приема/передачи данных, если соединение не установлено, выводится сообщение об ошибке соединения и подтверждают установку повторного соединения, в случае если установка повторного соединения подтверждена, выполняют повторное соединение с базой данных, если установка повторного соединения не подтверждена, формируется отчет о проделанной работе и происходит завершение работы, если подключение выполнено успешно, открывают для чтения и записи файл таблицы кодировки, принимают информацию, содержащую пользовательский запрос к базе данных, записывают принятые данные в словарь open_data_list_src, формируют строку кодированных данных encoded_data_src, формируют маркер обхода словаря i и флаг внесения изменений в таблицу кодировки f с начальными значениями, равными 0, формируют флаг достижения конца словаря len_src, записывают в него значение длины словаря open_data_list_src, происходит проверка: если в таблице кодировки имеется значение open_data_list_srci, в encoded_data_src записывают кодированное значение, соответствующее open_data_list_srci, если в таблице кодировки значение open_data_list_srcj отсутствует, в таблицу кодировки заносится значение open_data_list_srci, значение флага f устанавливают равным 1 и переходят к шагу записи кодированного значения в encoded_data_src, значение маркера i увеличивается на 1, происходит проверка: если конец словаря open_data_list_src не достигнут, а именно значение маркера i не равно значению флага len_src, переходят к шагу проверки наличия open_data_list_srcj в таблице кодировки, если конец словаря open_data_list_src достигнут, производят проверку: если флаг внесения изменений в таблицу f равен 0, значение encoded_data_src передается по каналу связи, если флаг f не равен 0, производят синхронизацию таблиц кодировки и переходят к передаче значения encoded_data_src, осуществляют прием переданных данных, записывают принятые данные в словарь encoded_data_list_dst, открывают для чтения таблицу кодировки, формируют строку декодированных данных decoded_data_dst, формируют маркер обхода словаря j с начальным значением 0, формируют флаг достижения конца словаря len_dst, записывают в него значение длины словаря encoded_data_list_dst, записывают в decoded_data_dst декодированное значение, соответствующее encoded_data_list_srcj, увеличивают значение маркера j на 1, производят проверку: если конец словаря encoded_data_list_src не достигнут, а именно значение маркера j не равно значение флага len_dst, переходят к шагу занесения в decoded_data_dst декодированных данных, если конец словаря encoded_data_list_src достигнут, значение decoded_data_dst передается обработчику событий, формируется отчет о проделанной работе и происходит завершение работы.
Сопоставительный анализ заявляемого решения с прототипом показывает, что предлагаемый способ отличается от известного:
наличием дополнительного блока, позволяющего производить поточное кодирование-декодирование реплицируемых данных;
заданием конфигурационного файла, содержащего в себе значения, необходимые для формирования запроса на внесение изменений и получения данных из удаленной базы данных;
создание на основе баз данных словаря замены кодируемых данных;
формированием отчетов о проделанной работе и достигнутых результатах.
в) причинно-следственная связь между признаками и техническим результатом
Благодаря новой совокупности существенных признаков в заявленном способе расширяется функционал работы системы, обеспечивающей репликацию информации в распределенных базах данных и поддержание в идентичном состоянии баз данных, размещенных в независимых компьютерах посредством снижения объема передаваемых данных без утраты информативности с использованием технологии кодирования реплицируемых данных при выполнении синхронизации баз данных двух независимых компьютеров, в каждый из которых загружена одинаковая по структуре база данных с неизменной базой знаний и независимо изменяемой в этих компьютерах и дополняемой информацией в базе клиентов и исследований.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обусловливающих тот же технический результат, который достигнут в заявляемом способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Краткое описание чертежей
Заявленный способ поясняется чертежами, на которых показаны:
Фиг. 1 - структурная схема репликации данных;
Фиг. 2 - таблица «Исследование»;
Фиг. 3 - таблица «Пациенты»;
Фиг. 4 - таблица для выполнения синхронизации;
Фиг. 5 - таблица с настройками автоматического запуска синхронизации;
Фиг. 6 - Блок-схема процесса формирования таблицы кодировки;
Фиг. 7 - Блок-схема процесса кодирования/декодирования реплицируемых данных.
Осуществление изобретения
Реализация заявленного способа объясняется следующим образом.
В систему, выполненную в виде блока обеспечения локальной сети между первым и вторым компьютерами, содержащими синхронизируемые базы данных, блока синхронизации режимов работы компьютеров, при этом первый и второй входы-выходы блока обеспечения локальной сети между первым и вторым компьютерами соединены с первыми входами-выходами первого и второго компьютеров соответственно, а первый и второй входы-выходы блока синхронизации режимов работы компьютеров соединены со вторыми входами-выходами первого и второго компьютеров соответственно, блока сравнения данных в изменяемых базах данных первый вход-выход которого соединен с третьим входом-выходом блока синхронизации режимов работы компьютеров, блока выделения несовпадающих фрагментов в изменяемых базах данных, первый вход-выход которого соединен со вторым входом-выходом блока сравнения данных в изменяемых базах данных, а также блока внесения изменений в изменяемые базы данных, первый вход-выход которого соединен со вторым входом-выходом блока выделения несовпадающих фрагментов в изменяемых базах данных согласно изобретению, введены блоки кодирования-декодирования данных, первый и второй входы-выходы которых соединены с третьими и четвертыми входами-выходами первого и второго компьютера соответственно, а третьи и четвертые входы-выходы соединены со вторыми и третьими входами-выходами блоков сравнения данных в изменяемых базах данных и внесения изменений в изменяемые базы данных соответственно.
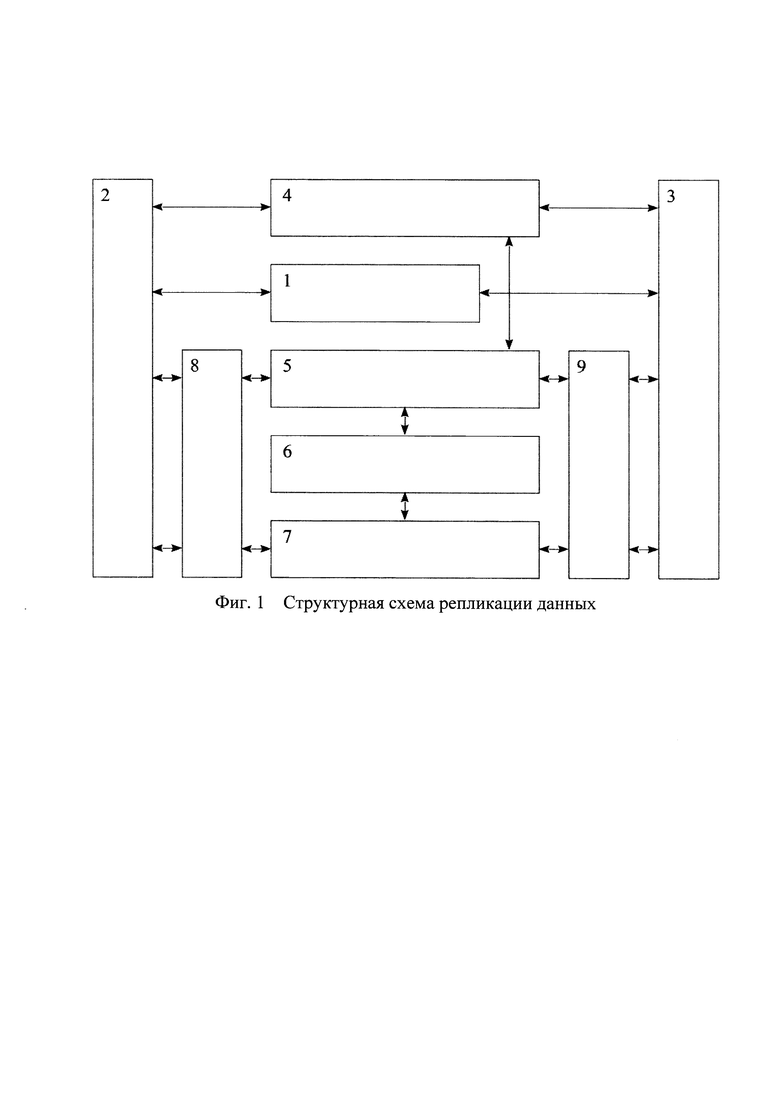
На фигуре 1 представлена функциональная схема системы репликации информации в базах данных совместно с первым и со вторым компьютерами.
Система репликации информации в базах данных содержит блок 1 обеспечения локальной сети между первым 2 и вторым 3 компьютерами, содержащими синхронизируемые базы данных, первый и второй входы-выходы которого соединены с первыми входами-выходами первого 2 и второго 3 компьютеров, соответственно. Кроме того, система репликации информации в базах данных содержит блок 4 синхронизации режимов работы компьютеров, первый и второй входы-выходы которого соединены со вторыми входами-выходами первого 2 и второго 3 компьютеров, соответственно, блок 5 сравнения данных в изменяемых базах данных, первый вход-выход которого соединен с третьим входом-выходом блока 4 синхронизации режимов работы компьютеров, блок 6 выделения несовпадающих фрагментов в изменяемых базах данных, первый вход-выход которого соединен с четвертым входом-выходом блока 5 сравнения данных в изменяемых базах данных, блок 7 внесения изменений в изменяемые базы данных, первый вход-выход которого соединен со вторым входом-выходом блока 6 выделения несовпадающих фрагментов в изменяемых базах, а также блоки 8 и 9 кодирования-декодирования данных, первый и второй входы-выходы которых соединены с третьими и четвертыми входами-выходами первого 2 и второго 3 компьютера соответственно, а третьи и четвертые входы-выходы блоков 8 и 9 кодирования-декодирования данных соединены со вторыми и третьими входами-выходами блоков 5 сравнения данных в изменяемых базах данных и 7 внесения изменений в изменяемые базы данных соответственно.
Система содержит элементы и блоки, охарактеризованные на функциональном уровне, и описываемая форма реализации предполагает использование программируемого (настраиваемого) многофункционального средства, поэтому при описании его работы представляются сведения, подтверждающие возможность выполнения таким средством конкретной предписываемой ему в составе данной системы функции.
Типичной практической задачей, которая возникает для компьютерных систем, содержащих, например, основную (главную) стационарную часть (например, настольный компьютер) и мобильную (периферийную) часть (например, ноутбук), информация в которых может изменяться без привязки к интернету, и работа на ноутбуке производится в выездном режиме. В этом случае возникает необходимость регулярно производить полную репликацию/синхронизацию баз данных, загруженных в компьютерах.
Рассмотрим работу способа репликации информации в базах данных с использованием кодирования запросов технологией простой синтаксической замены с использованием таблицы кодировки на примере медицинской базы данных. В научно-медицинском центре в качестве средства хранения данных используется два независимых компьютера, один из которых применяется, например, как мобильный вариант, в котором используется модификация локальной установки СУБД ORACLE. Задача состоит в объединении данных с двух компьютеров и разработке механизма, позволяющего проводить регулярную синхронизацию данных между двумя ORACLE-серверами. База данных состоит из двух частей - практически неизменяемой базы знаний и регулярно изменяемой базой данных о клиентах и исследованиях, выполненной с возможностью независимых изменений и дополнений на каждом из двух компьютеров. Задача предполагает синхронизацию только изменяемой части базы данных, так как изменения в базу знаний вносятся централизовано, и база знаний считается одинаковой в разных репликах СУБД. Центральной таблицей базы данных является таблица «Исследование» (ANALYSIS), представленная на фигуре 2, все остальные таблицы связаны с ней по идентификационному номеру исследования (ID исследования) отношением один-ко-многим. Исключение составляет таблица «Пациенты» (CLIENTS), изображенная на фигуре 3, которая связана с таблицей «Исследование» по идентификационному номеру пациента связью один-к-одному.
В базе данных не обеспечивается как уникальность пациента и для каждого нового исследования делается новая запись в таблице «Пациенты», так и уникальность данных об исследовании. Такая особенность базы данных затрудняет сравнение двух ее модификаций на двух независимых компьютерах. В качестве уникальных данных об исследовании в рамках локальной СУБД предлагается использовать совокупность полей ID пациента + ID типа биосубстрата + ID минералограммы + ID профиля исследования + Дата забора биосубстрата + Признак наличия диабета + Признак наличия ожирения + Признак наличия ССЗ + Признак ограничения по алкоголю. Для таблицы «Пациенты» поле ID пациента является автоматически наращиваемым счетчиком и не может быть использовано в уникальной комбинации полей для сравнения данных между двумя серверами. Вместо него необходимо использовать уникальную совокупность полей таблицы «Пациенты» для однозначной идентификации данных о пациентах Номер карты + Фамилия + Имя + День рождения + Пол. Таким образом, совокупность полей ID пациента + ID типа биосубстрата + ID минералограммы + ID профиля исследования + Дата забора биосубстрата + Признак наличия диабета + Признак наличия ожирения + Признак наличия ССЗ + Признак ограничения по алкоголю + Номер карты + Фамилия + Имя + День рождения + Пол однозначно определяют каждое исследование и могут быть взяты в качестве идентификационной комбинации полей. Поле «Системный статус исследования» содержит значения, характеризующие завершенность обработки результатов исследования и может быть использовано в качестве критерия для обновления записей, совпадающих по идентификационной совокупности полей. Множество исследований в каждой из сравниваемых баз данных задается комбинацией полей, однозначно определяющих каждое исследование. Задача сводится к объединению этих множеств, при этом в области пересечения множеств необходимо оставить исследования, обработка которых максимально завершена (степень «завершенности» исследования определяется значением в поле Системный статус исследования). Предполагается что исследования, совпадающие по комбинации полей для идентификации и с одинаковым значением в поле Системный статус исследования, идентичны и их сравнение не производится. Обозначим множество исследовании в сравниваемых базах данных А и В. Для объединения множеств необходимо выполнить следующие действия:
- найти разность множеств А\В;
- добавить полученную разность к множеству В;
- в области пересечения множеств найти записи, имеющие разное значение поля Системный статус исследования;
- обновить в множестве В те записи, для которых в области пересечения имеются записи с «большим завершением» по значению в поле Системный статус исследования и совпадающие по остальным полям идентификации исследования;
- повторить описанные действия, поменяв местами базы данных А и В.
Поскольку таблица «Исследование» (ANALYSIS) связана с большим количеством других таблиц, детализирующих проведенные анализы, по идентификационному номеру исследования (ID исследования), и этот номер является внутренним для каждой Базы данных, то есть одинаковым значением поля ID исследования могут быть обозначены разные исследования на разных базах данных, при переносе информации с одной базы данных на другую необходимо обеспечить вычисление соответствующего значения ID исследования, и использовать его в связанных таблицах. Объект базы данных DATABASE LINK с именем MASTER - это подключение локального сервера к удаленной базе данных. Настройка триггеров таблицы «Пациенты» и «Исследования». Для этого требуется изменить автоматическое увеличение первичного ключа таблицы таким образом, чтобы вычисление нового ключа происходило, только в случае когда ключ не заполнен. Вычисление новых значений первичного ключа при выполнении задачи объединения данных будет происходить не посредством триггера, а внутри программы объединения, так чтобы значение первичного ключа можно было использовать при добавлении данных из связанных таблиц. Запросы на сравнение таблиц NEWDATA и UPDDATA.NEWDATA -запрос, вычисляющий разность множеств исследований на локальном сервере и сервере, присоединенном через DBLink MASTER. Результат представлен в виде пар (ID_ANALYSIS, IDCLIENTS), определяющих исследования, которых нет в таблице ANALYSIS@MASTER. UPDDATA - запрос, находящий те исследования на локальном сервере, у которых значение поля Системный статус исследования (STATUS) больше, чем значение поля Системный статус исследования (STATUS) на сервере, присоединенном через DBLink MASTER. Результат представлен в виде пар (ID_ANALYSIS, IDCLIENTS). Таблица SYNCHRONIZE, изображенная на фигуре 4, необходима для подготовки данных для синхронизации. Агрегирует в себе данные из запросов NEWDATA и UPDDATA. В нее помещаются новые идентификаторы записей, которые будут вставлены в соответствующие таблицы сервера MASTER. А также помечаются записи для вставки при ручном отборе записей. Таблица SYNCHRONIZEPARAMETERS, изображенная на фигуре 5, является таблицей с настройками автоматического запуска синхронизации.
Все запросы на извлечение данных и внесение изменений в удаленную базу данных кодируются простой синтаксической заменой, механизм кодирования реализуется следующим образом: запрос или ответ на запрос разбивается на части, пригодные для кодирования и на основе этих частей производится поиск в таблице в таблице синтаксической замены (кодировки). Найденные кодированные аналоги составляют готовый к передаче по каналу связи запрос или ответ на запрос.
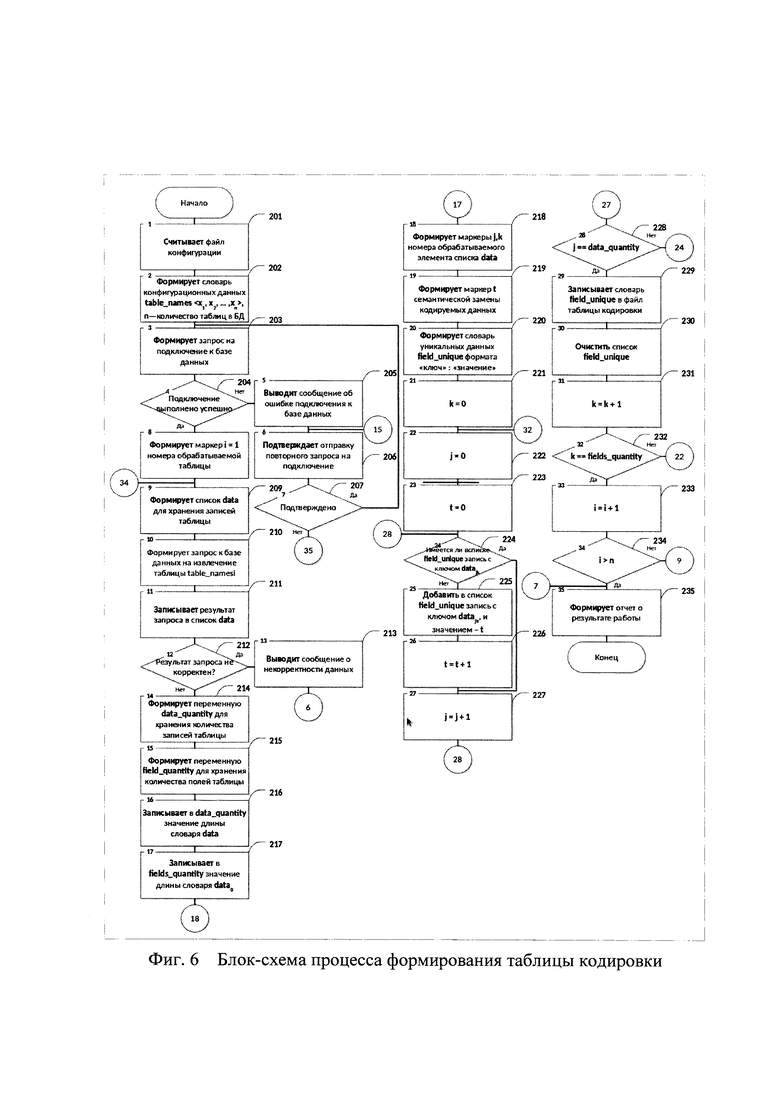
Таблица синтаксической замены создается на основе локальной базы. Данная таблица предназначена для хранения уникальных данных по каждому полю всех таблиц базы данных в совокупности с кодированным значением, которое будет поставлено в соответствие этим данным. Формирование подобной таблицы представлено в виде блок-схемы 200, изображенной на фигуре 6. Блок 202 формирования конфигурационных данных на основе считанных блоком 201 данных создает словарь конфигурационных данных, содержащий список имен таблиц базы данных, на основе которой производится формирование таблицы синтаксической замены, а также количество таблиц в данной базе данных. Эти конфигурационные данные нужны для реализации запросов на выгрузку информации из базы данных. Блок 203 формирует запрос на подключение к базе данных и на основе блока 204 проверки успешности подключения к базе данных, в случае, если подключение по какой-либо причине не выполнено, блоками 205 и 206 производится вывод сообщения об ошибке подключения к базе данных и выполняется запрос реакции пользователя: выполнить повторное подключение к базе данных, либо завершить работу. Обработка данного ответа пользователя выполняется блоком 207.
Далее блоками 208 и 209 формируются маркер итерации i номера обрабатываемой таблицы равный 1 и словарь data для хранения записей таблицы базы данных. Формируется запрос 210 к базе данных на извлечение всех данных i-й таблицы базы данных и ответ на данный запрос записывается 211 в data и на основе блока проверки корректности ответа на запрос 212 в случае, если ответ на запрос представляет собой некорректные данные, блоками 213 и 206 производится вывод сообщения о некорректности данных и выполняется запрос реакции пользователя: выполнить повторное подключение к базе данных, либо завершить работу. Обработки данного ответа пользователя выполняется блоком 207.
Далее формируются следующие технические значения:
data_quantity - для хранения количества записей таблицы 214;
field_quantity - для хранения количества полей таблицы 215;
j, k - маркеры номера обрабатываемого элемента списка data 218;
t - маркер синтаксической замены кодируемых данных 219;
field_unique - словарь уникальных данных формата «ключ» : «значение» 220.
Значения k, j, t устанавливаются равными 0 блоками 221, 222, 223 соответственно.
Нахождение уникальных значений по полям таблицы происходит следующим образом: блок проверки уникальности значений 224 в случае, если в словаре уникальных данных field_unique значение datajk отсутствует, следовательно, это значение по k-му полю ранее не встречалось и является уникальным, в field_unique добавляется 225 запись с ключом datajk и значением - t, значение маркера t увеличивается 226 на 1, и обработчик таблицы переходит 227 к следующей записи, увеличивая маркер j на 1. В случае, если значение datajk в словаре отсутствует, и, следовательно, данное значение по k-му полю уникальным не является, обработка сразу переходит 227 к следующей записи. После достижения 228 последней записи k-го поля таблицы, то есть установления равенства j и data_quantity, словарь уникальных значений по данному полю записывается 229 в таблицу кодировки, а затем очищается 230. Далее обработчик таблицы переходит 231 к следующему полю таблицы, увеличивая маркер k на 1. После достижения 232 последней записи последнего поля, то есть установления равенства k и fields_quantity, обработка переходит 233 к следующей таблице базы данных, значение маркера i увеличивается на 1. После окончания обработки последней таблицы, формируется 235 отчет о результатах работы.
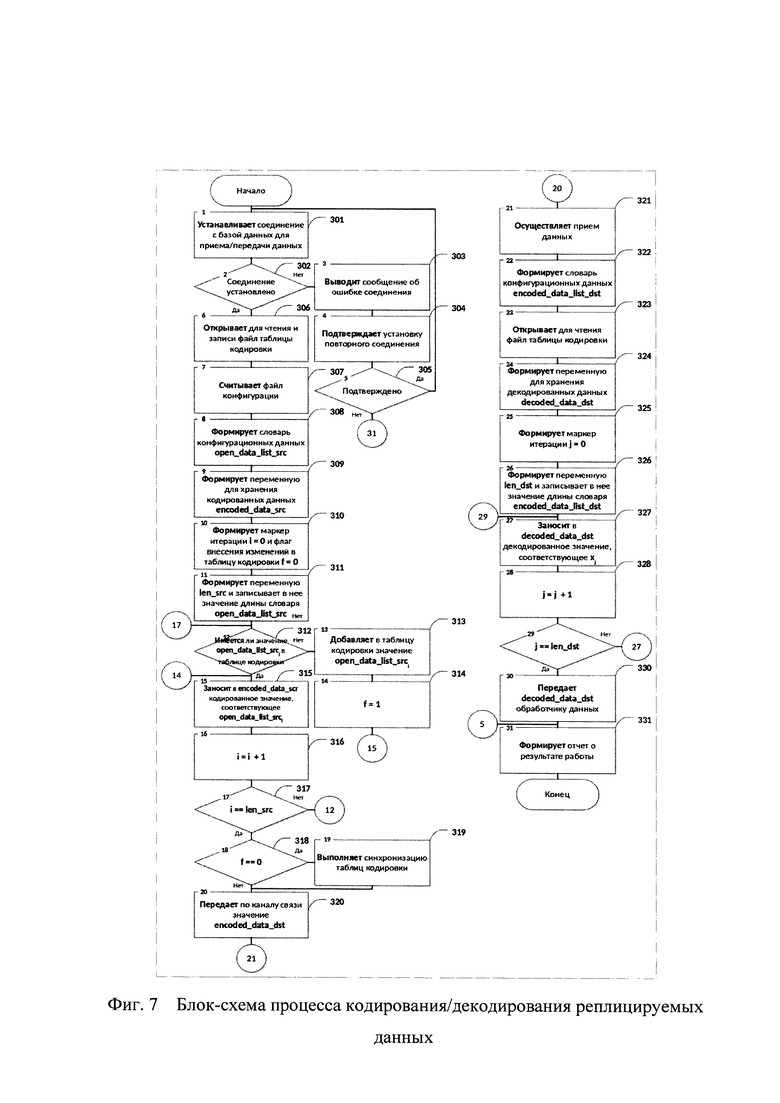
Кодирование и раскодирование запросов и ответов на запросы представлено на блок схеме 300, изображенной на фигуре 7. Блок 301 устанавливает соединение с удаленной базой данных для приема и передачи данных и на основе блока 302 проверки успешности установления соединения с базой данных, в случае, если подключение по какой-либо причине не выполнено, блоками 303 и 304 производится вывод сообщения об ошибке подключения к базе данных и выполняется запрос реакции пользователя: выполнить повторное соединения с базой данных, либо завершить работу. Обработка данного ответа пользователя выполняется блоком 305. Далее для чтения и записи открывается 306 вышеописанная предварительно сгенерированная таблица кодировки. Считывается 307 файл конфигурации и на его основе формируется 308 словарь конфигурационных данных, содержащий запрос или ответ на запрос, разбитые на блоки, пригодные для кодирования.
Далее формируются следующие технические значения:
encoded_data_src - для хранения кодированных данных 309;
i - маркер итерации обхода словаря конфигурационных данных 310;
f - флаг внесения изменений в таблицу кодировки;
len_src - для хранения значения длины словаря конфигурационных данных 311.
Выполняется проверка необходимости внесения изменений 312 в таблицу кодировки: в случае если в таблице кодировки i-e значения словаря конфигурационных данных отсутствует, данное значение записывается 313 в таблицу и флаг внесения изменений f устанавливается 314 равным 1. В encoded_data_src записывается 315 кодированное значение из таблицы кодировки, соответствующее i-му значению словаря конфигурационных данных и обработка переходит 316 к следующему элементу словаря, значение i увеличивается на 1. После обработки 317 последнего элемента словаря в том случае, если в таблицу синтаксической замены вносились 318 новые данные, иными словами значение флага f равняется 1, происходит 319 синхронизация словарей кодировки локального и удаленного компьютеров.
Далее происходит передача 320 закодированного запроса или ответа на запрос по каналу связи, данные принимаются 321 удаленным компьютером, разбиваются на блоки, пригодные для раскодирования и на их основе формируется 322 словарь конфигурационных данных, затем для чтения открывается 323 файл таблицы кодировки и формируются следующие технические значения:
decoded_data_dst - для хранения декодированных данных 324;
j - маркер итерации обхода словаря конфигурационных данных 325;
len_dst - для хранения значения длины словаря конфигурационных данных 326.
В decoded_data_dst записывается 327 раскодированное значение из таблицы кодировки, соответствующее j-му значению словаря конфигурационных данных и обработка переходит 328 к следующему элементу словаря, значение j увеличивается на 1. После обработки 329 последнего элемента словаря decoded_data_dst передается 330 обработчику данных, формируется отчет о результате работы.
При реализации рассмотренного способа репликации данных предложенная система используется следующим образом. Блок 1, первый и второй входы-выходы которого соединены с первыми входами-выходами первого 2 и второго 3 компьютеров, соответственно, обеспечивает локальную сеть между первым 2 и вторым 3 компьютером, содержащими синхронизируемые базы данных. Блок 4 синхронизации режимов работы компьютеров, первый и второй входы-выходы которого соединены со вторыми входами-выходами первого 2 и второго 3 компьютеров, соответственно, обеспечивает перевод первого 2 и второго 3 компьютеров поочередно в режим компьютера-приемника и компьютера-источника. Блок 5 сравнения данных в изменяемых базах данных, первый вход-выход которого соединен с третьим входом-выходом блока 4 синхронизации режимов работы компьютеров, производит сравнения в изменяемых базах данных первого 2 и второго 3 компьютеров, а блок 6 выделения несовпадающих фрагментов в изменяемых базах данных, первый вход-выход которого соединен с четвертым входом-выходом блока 5 сравнения данных в изменяемых базах данных, выделяет фрагменты для замены (обновления) изменяемых баз данных, которые с помощью блока 7 внесения изменений в изменяемые базы данных вносятся в виде изменений в изменяемые базы данных. Блоки 8 и 9 кодирования-декодирования данных, первый и второй входы-выходы которых соединены с третьими и четвертыми входами-выходами первого 2 и второго 3 компьютера соответственно, а третьи и четвертые входы-выходы блоков 8 и 9 кодирования-декодирования данных соединены со вторыми и третьими входами-выходами блоков 5 сравнения данных в изменяемых базах данных и 7 внесения изменений в изменяемые базы данных соответственно осуществляют прямое преобразование данных к сжатому (закодированному) виду при их передаче и обратное преобразование данных к развернутому (раскодированному) виду при их приеме во время осуществления информационного обмена по каналам связи от первого компьютера ко второму и от второго компьютера к первому.
После проведения процедуры репликации для обоих компьютеров изменяемые части их базах данных становятся полностью одинаковыми.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРОВЕДЕНИЯ МИГРАЦИИ И РЕПЛИКАЦИИ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2020 |
|
RU2745679C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОГО ПОИСКА И КОРРЕКЦИИ ОШИБОК В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2021 |
|
RU2785207C1 |
| УСТРОЙСТВО КОММУНИКАЦИОННОГО ИНТЕРФЕЙСА | 2010 |
|
RU2460124C2 |
| УСТРОЙСТВО КОММУНИКАЦИОННОГО ИНТЕРФЕЙСА ДЛЯ СЕТИ SpaceWire | 2012 |
|
RU2483351C1 |
| СПОСОБ ЗАЩИТЫ ДЕСКРИПТОРОВ РЕЛЯЦИОННОЙ БАЗЫ ДАННЫХ | 2021 |
|
RU2774098C1 |
| СПОСОБ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2019 |
|
RU2709288C1 |
| Способ и система для визуального создания программ для вычислительных устройств | 2017 |
|
RU2668738C1 |
| МЕХАНИЗМ ДИНАМИЧЕСКОГО СИНТАКСИЧЕСКОГО АНАЛИЗА/КОМПОНОВКИ НА ОСНОВЕ СХЕМ ДЛЯ СИНТАКСИЧЕСКОГО АНАЛИЗА МУЛЬТИФОРМАТНЫХ СООБЩЕНИЙ | 2006 |
|
RU2429533C2 |
| СПОСОБ РАЗРАБОТКИ, ХРАНЕНИЯ И ИСПОЛЬЗОВАНИЯ КОМПИЛИРОВАННЫХ В БИНАРНОЕ ПРЕДСТАВЛЕНИЕ ПРОГРАММ В ТАБЛИЦАХ БАЗ ДАННЫХ | 2017 |
|
RU2666287C1 |
| ИНИЦИАЛИЗАТОР ПРЕДСКАЗАТЕЛЯ ПАЛИТРЫ ПРИ КОДИРОВАНИИ ИЛИ ДЕКОДИРОВАНИИ САМОСТОЯТЕЛЬНЫХ КОДИРУЕМЫХ СТРУКТУР | 2016 |
|
RU2686559C2 |




Изобретение относится к информационным технологиям. Техническим результатом является сокращение объема передаваемых данных без утраты информативности, используемой при репликации информации в распределенных базах данных, в частности, применительно к двум компьютерам, в каждый из которых загружена одинаковая по структуре база данных с неизменной базой знаний и независимо изменяемой и дополняемой информацией в базе клиентов и исследований и используемой для периодической синхронизации базы данных в обоих компьютерах. Способ заключается в том, что в систему, выполненную в виде блока обеспечения локальной сети между первым и вторым компьютерами, содержащими синхронизируемые базы данных, блока синхронизации режимов работы компьютеров, блока сравнения данных в изменяемых базах данных, блока выделения несовпадающих фрагментов в изменяемых базах данных, а также блока внесения изменений в изменяемые базы данных, интегрируются два блока кодирования-декодирования данных, позволяющие производить кодирование входящих и исходящих запросов, используемых в процессе репликации информации в базах данных. 7 ил.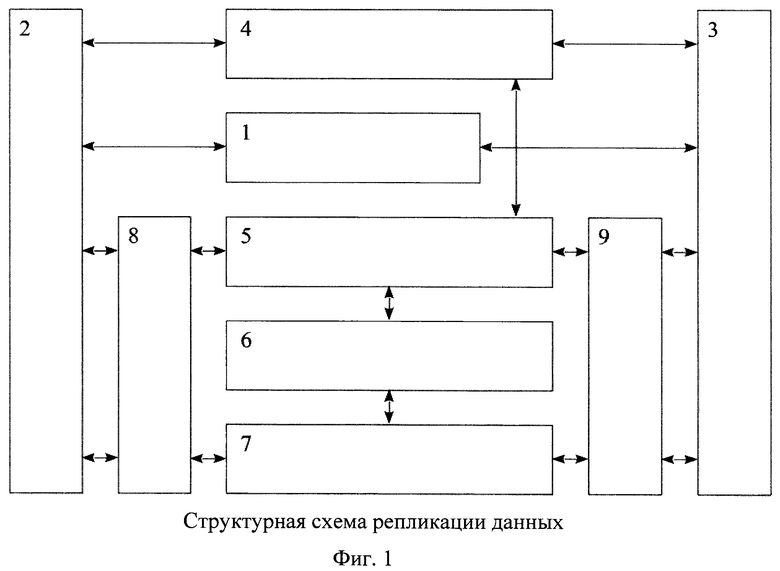
Способ репликации информации в базах данных с использованием механизма кодирования запросов простой синтаксической заменой на основе таблицы кодировки, осуществляемый системой, выполненной в виде блока обеспечения локальной сети между первым и вторым компьютерами, содержащими синхронизируемые базы данных, блока синхронизации режимов работы компьютеров, при этом первый и второй входы-выходы блока обеспечения локальной сети между первым и вторым компьютерами соединены с первыми входами-выходами первого и второго компьютеров соответственно, а первый и второй входы-выходы блока синхронизации режимов работы компьютеров соединены со вторыми входами-выходами первого и второго компьютеров соответственно, блока сравнения данных в изменяемых базах данных, первый вход-выход которого соединен с третьим входом-выходом блока синхронизации режимов работы компьютеров, блока выделения несовпадающих фрагментов в изменяемых базах данных, первый вход-выход которого соединен с входом-выходом блока сравнения данных в изменяемых базах данных, а также блока внесения изменений в изменяемые базы данных, первый вход-выход которого соединен со вторым входом-выходом блока выделения несовпадающих фрагментов в изменяемых базах данных, отличающийся тем, что введены два блока кодирования-декодирования данных в систему, первый и второй входы-выходы которых соединены с третьими и четвертыми входами-выходами первого и второго компьютера соответственно, а третьи и четвертые входы-выходы соединены со вторыми и третьими входами-выходами блоков сравнения данных в изменяемых базах данных и внесения изменений в изменяемые базы данных соответственно, а первый вход-выход блока выделения несовпадающих фрагментов изменяемых базах данных соединен с четвертым входом-выходом блока сравнения данных в изменяемых базах данных, причем блоки кодирования-декодирования данных реализованы следующим образом: предварительно на основе базы данных создается файл, содержащий таблицу кодировки: принимают информацию, включающую в себя словарь table_names <х1, …, х2, …, xn>, содержащий названия таблиц базы данных, где n - количество таблиц, формируют запрос на подключение к базе данных, в случае если подключение не выполнено, выводится сообщение об ошибке подключения и подтверждают отправку повторного запроса на подключение к базе данных, в случае если отправка подтверждена, выполняют повторное обращение к базе данных, если отправке не подтверждена, происходит завершение работы, если подключение выполнено успешно, формируют маркер номера обрабатываемой таблицы i, изначально равный 1, формирует список data для хранения записей таблицы, формируют запрос на извлечение всех данных из таблицы table_namesi, ответ на запрос записывают в словарь data, и в случае если ответ на запрос представляет собой некорректные данные, выводится сообщение о соответствующей ошибке и подтверждают отправку повторного запроса на подключение к базе данных, а в случае если отправка подтверждена, выполняют повторное обращение к базе данных, если отправка не подтверждена, формируется отчет о проделанной работе и происходит завершение работы, если данные корректны, формируется флаг достижения последней записи data_quantity, записывают в него значение длины словаря data, формируют флаг достижения последнего поля таблицы field_quantity, записывают в него значение длины словаря data0, формируют маркеры j, k, номера обрабатываемого элемента словаря data, формируют маркер t, представляющий собой значение, которое будет поставлено способом синтаксической замены в соответствие данным базы данных, формируют словарь уникальных данных field_unique формата «ключ»: «значение», устанавливают значение маркера k, равное 0, устанавливают значение маркера j, равное 0, устанавливают значение маркера t, равное 0, производится проверка: если в словаре field_unique отсутствует запись с ключом datajk, в словарь field_unique добавляют запись с ключом datajk и значением t, значение t увеличивают на 1, значение j увеличивают на 1, если в словаре field_unique запись с ключом datajk имеется, происходит переход к шагу инкрементирования j, происходит проверка: если последняя запись таблицы не обработана, а именно значение маркера j не равно значению флага data_quantity, происходит возвращение к шагу проверки вхождения datajk в словарь field_unique, если последняя запись таблицы обработана, словарь field_unique записывают в файл таблицы кодировки, очищают словарь field_unique и увеличивают значение маркера k на 1, происходит проверка: если последнее поле таблицы не обработано, а именно значение маркера k не равно значению флага fields_quantity, происходит возвращение к шагу установления значения маркера j, если последнее поле обработано, значение маркера номера обрабатываемой таблицы i увеличивается на 1, происходит проверка: если база данных не обработана полностью, а именно значение флага i больше значения количества таблиц n, происходит переход к шагу создания словаря data, если конец таблицы достигнут, формируется отчет о проделанной работе и происходит завершение работы, процесс передачи запроса к базе данных производится следующим образом: устанавливают соединение с базой данных для приема/передачи данных, если соединение не установлено, выводится сообщение об ошибке соединения и подтверждают установку повторного соединения, в случае если установка повторного соединения подтверждена, выполняют повторное соединение с базой данных, если установка повторного соединения не подтверждена, формируется отчет о проделанной работе и происходит завершение работы, если подключение выполнено успешно, открывают для чтения и записи файл таблицы кодировки, принимают информацию, содержащую пользовательский запрос к базе данных, записывают принятые данные в словарь open_data_list_src, формируют строку кодированных данных encoded_data_src, формируют маркер обхода словаря i и флаг внесения изменений в таблицу кодировки f с начальными значениями, равными 0, формируют флаг достижения конца словаря len_src, записывают в него значение длины словаря open_data_list_src, происходит проверка: если в таблице кодировки имеется значение open_data_list_srci, в encoded_data_src записывают кодированное значение, соответствующее open_data_list_srcj, если в таблице кодировки значение open_data_list_srci отсутствует, в таблицу кодировки заносится значение open_data_list_srci, значение флага f устанавливают равным 1 и переходят к шагу записи кодированного значения в encoded_data_src, значение маркера i увеличивается на 1, происходит проверка: если конец словаря open_data_list_src не достигнут, а именно значение маркера i не равно значению флага len_src, переходят к шагу проверки наличия open_data_list_srci в таблице кодировки, если конец словаря open_data_list_src достигнут, производят проверку: если флаг внесения изменений в таблицу f равен 0, значение encoded_data_src передается по каналу связи, если флаг f не равен 0, производят синхронизацию таблиц кодировки и переходят к передаче значения encoded_data_src, осуществляют прием переданных данных, записывают принятые данные в словарь encoded_data_list_dst, открывают для чтения таблицу кодировки, формируют строку декодированных данных decoded_data_dst, формируют маркер обхода словаря j с начальным значением 0, формируют флаг достижения конца словаря len_dst, записывают в него значение длины словаря encoded_data_list_dst, записывают в decoded_data_dst декодированное значение, соответствующее encoded_data_list_srcj, увеличивают значение маркера j на 1, производят проверку: если конец словаря encoded_data_list_src не достигнут, а именно значение маркера j не равно значение флага len_dst, переходят к шагу занесения в decoded_data_dst декодированных данных, если конец словаря encoded_data_list_src достигнут, значение decoded_data_dst передается обработчику событий, формируется отчет о проделанной работе и происходит завершение работы.
| Система репликации информации в базах данных | 2018 |
|
RU2703961C1 |
| СПОСОБ ПОЛУЧЕНИЯ ПОЛИУРЕТАНОВ | 0 |
|
SU188004A1 |
| СПОСОБ РЕПЛИКАЦИИ БАЗ ДАННЫХ И УСТРОЙСТВО ОБНОВЛЕНИЯ ТАБЛИЦЫ | 2009 |
|
RU2531572C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2740865C1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 8204856 B2, 19.06.2012. | |||

