ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится главным образом к компьютерным системам и, в частности, к системам и способам идентификации систем письма, используемых в документах.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0002] Система письма - это метод визуального представления вербального общения, основанный на скрипте и наборе правил, регулирующих его использование. Системы письма можно разделить на широкие категории, такие как алфавиты, слоговые алфавиты или логографии, хотя некоторые системы письма могут иметь атрибуты более чем одной категории. В алфавитах каждый символ представляет соответствующие звуки речи. В абджадах гласные не указываются. В абджадах или алфавитно-слоговых алфавитах каждый символ представляет пару гласной и согласной. В слоговых азбуках каждый символ представляет слог или мору. В логографиях каждый символ представляет семантическую единицу, например морфему. Некоторые системы письма также включают в себя специальный набор символов, известный как пунктуация, который используется для облегчения интерпретации и выражения нюансов значения сообщения.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или несколькими аспектами настоящего изобретения, указанный в примере способ идентификации системы письма, используемой в документе, включает в себя: получение компьютерной системой изображения документа; разбиение изображения документа на множество фрагментов изображения; генерирование множества векторов вероятности посредством нейронной сети, обрабатывающей множество фрагментов изображения, причем каждый вектор вероятности из множества векторов вероятности создается путем обработки соответствующих фрагментов изображения и содержит множество числовых элементов, и причем каждый числовой элемент из множества числовых элементов отражает вероятность фрагмента изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в соответствующем векторе вероятности; вычисление агрегированного вектора вероятности путем агрегирования множества векторов вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в пределах агрегированного вектора вероятности; и с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает предварительно определенное пороговое значение, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с системой письма, которая идентифицируется посредством индекса максимального числового элемента в пределах агрегированного вектора вероятности.
[0004] В соответствии с одним или несколькими аспектами настоящего изобретения, указанная в примере система содержит запоминающее устройство и процессор, соединенный с запоминающим устройством. Процессор настроен для: получения изображения документа; разбиения изображения документа на множество фрагментов изображения; генерирования множества векторов вероятности посредством нейронной сети, обрабатывающей множество фрагментов изображения, причем каждый вектор вероятности из множества векторов вероятности создается путем обработки соответствующих фрагментов изображения и содержит множество числовых элементов, причем каждый числовой элемент из множества числовых элементов отражает вероятность фрагмента изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в соответствующем векторе вероятности; вычисления агрегированного вектора вероятности путем агрегирования множества векторов вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в пределах агрегированного вектора вероятности; и с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает предварительно определенное пороговое значение, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с системой письма, которая идентифицируется посредством индекса максимального числового элемента в пределах агрегированного вектора вероятности.
[0005] В соответствии с одним или несколькими аспектами настоящего изобретения, указанный в примере машиночитаемый энергонезависимый носитель данных содержит исполняемые команды, которые при исполнении компьютерной системой заставляют компьютерную систему выполнять следующие операции: получение изображения документа; разбиение изображения документа на множество фрагментов изображения; генерирование множества векторов вероятности посредством нейронной сети, обрабатывающей множество фрагментов изображения, причем каждый вектор вероятности из множества векторов вероятности создается путем обработки соответствующих фрагментов изображения и содержит множество числовых элементов, и причем каждый числовой элемент из множества числовых элементов отражает вероятность фрагмента изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в соответствующем векторе вероятности; вычисление агрегированного вектора вероятности путем агрегирования множества векторов вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в пределах агрегированного вектора вероятности; и с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает предварительно определенное пороговое значение, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с системой письма, которая идентифицируется посредством индекса максимального числового элемента в пределах агрегированного вектора вероятности.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение проиллюстрировано посредством примеров, а не посредством ограничения, и его можно более полно понять с помощью ссылок на следующее подробное описание при рассмотрении в связи с фигурами, на которых:
[0007] Фиг. 1 отражает блок-схему указанного в примере способа идентификации системы письма, используемой в документе, в соответствии с одним или несколькими аспектами настоящего изобретения;
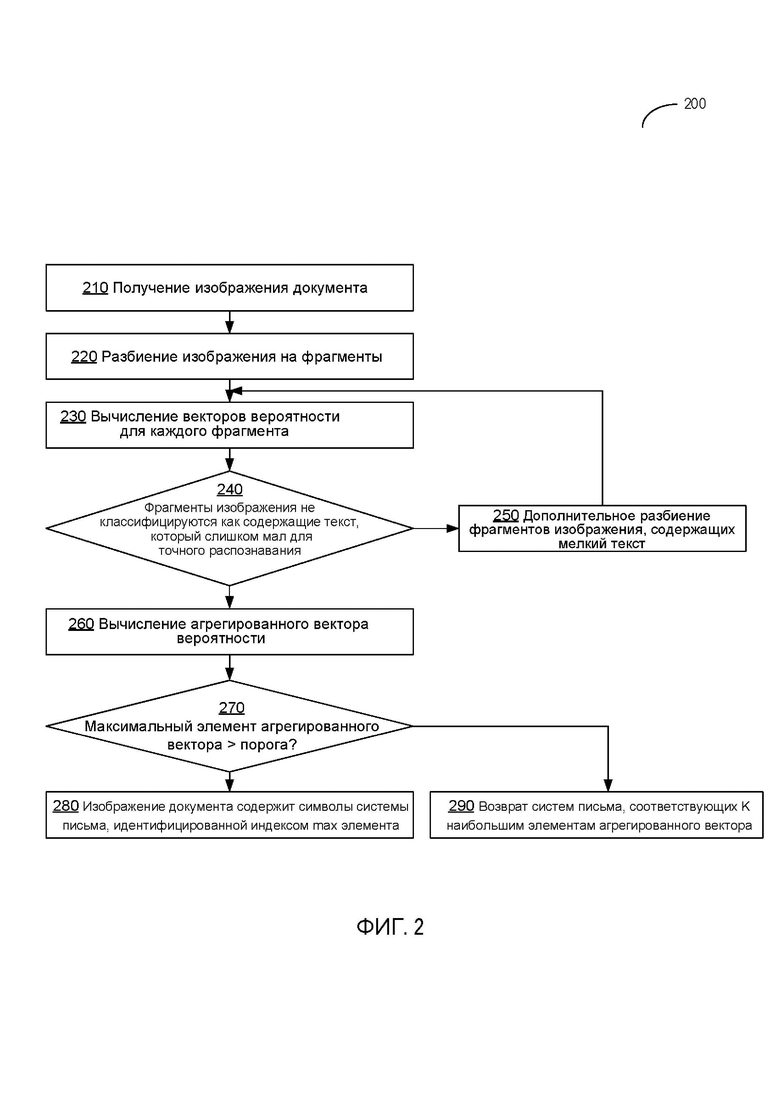
[0008] Фиг. 2 отражает блок-схему другого указанного в примере способа идентификации системы письма, используемой в документе, в соответствии с одним или несколькими аспектами настоящего изобретения;
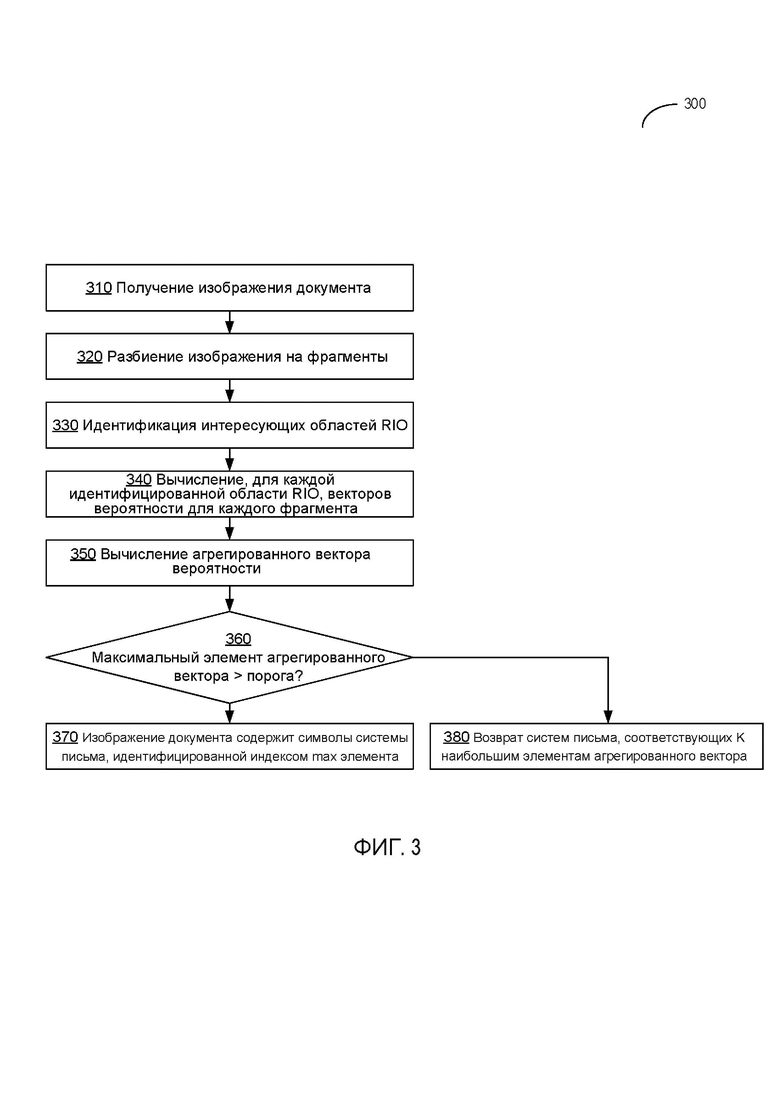
[0009] Фиг. 3 отражает блок-схему еще одного указанного в примере способа идентификации системы письма, используемой в документе, в соответствии с одним или несколькими аспектами настоящего изобретения;
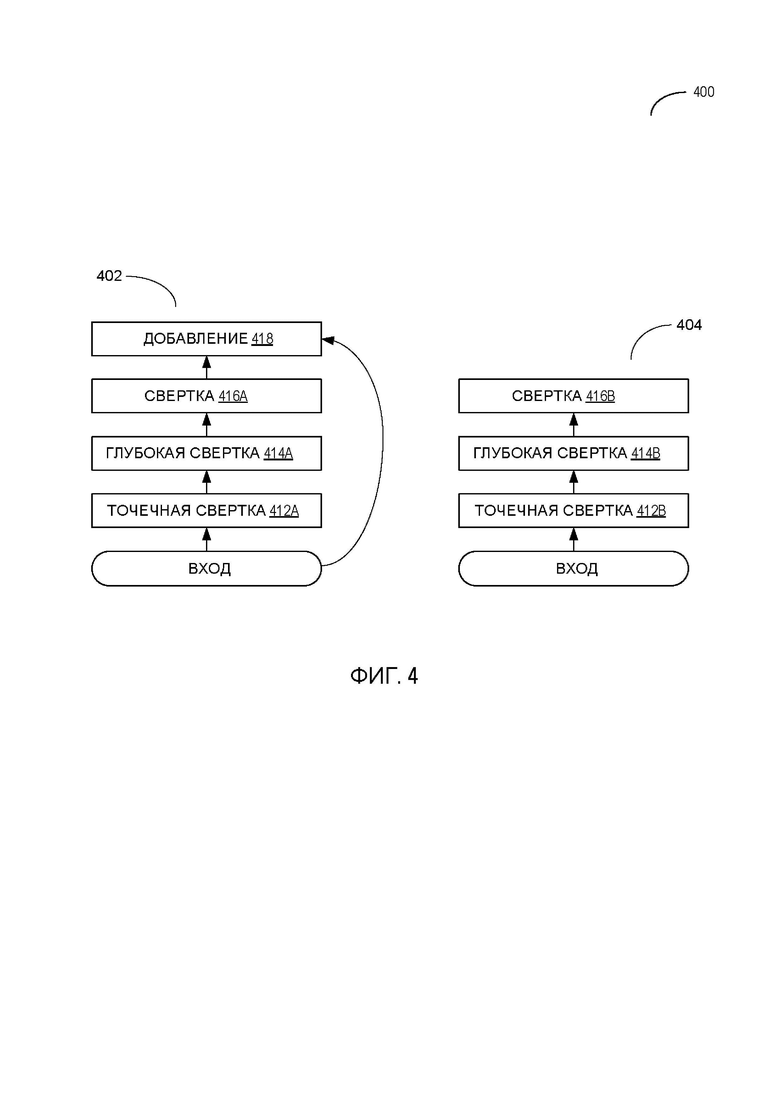
[00010] Фиг. 4 схематически отражает пример архитектуры нейронной сети, которая может использоваться системами и способами в рамках настоящего изобретения;
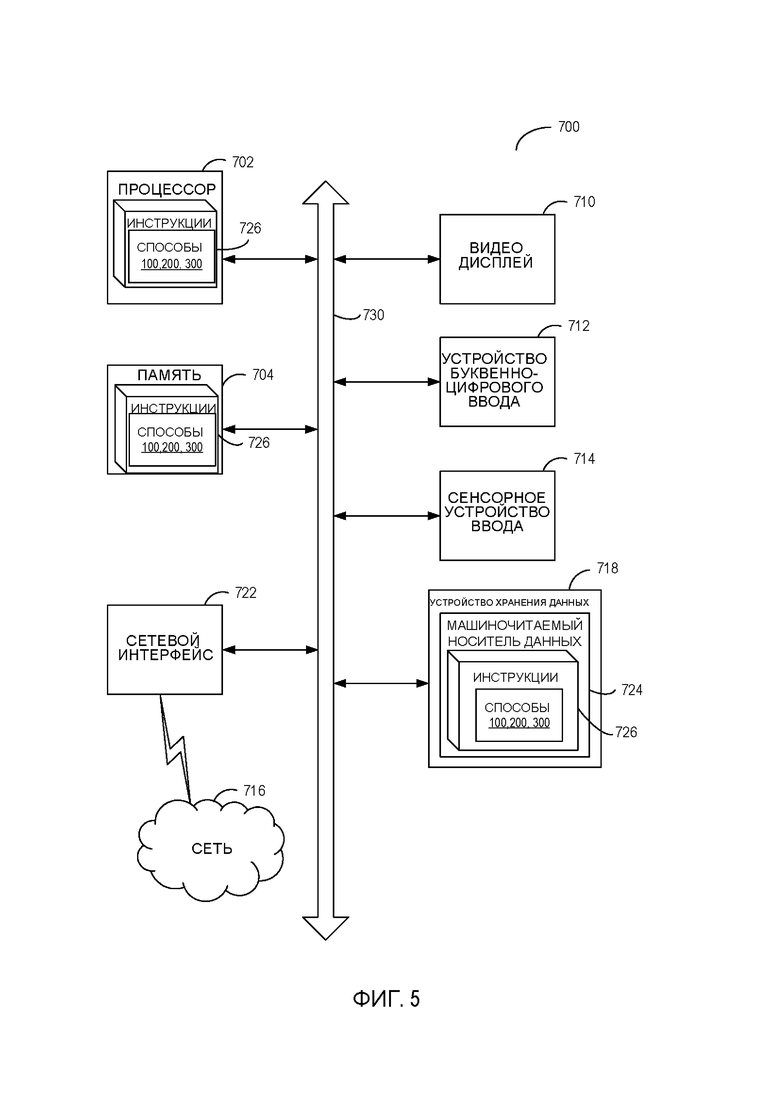
[00011] Фиг. 5 отражает схему компонентов указанной в примере компьютерной системы, которая может использоваться для реализации способов, указанных в настоящем документе.
ПОДРОБНОЕ ОПИСАНИЕ
[00012] В настоящем документе описаны методы и системы для идентификации систем письма, используемых в изображениях документов. Системы и способы в рамках настоящего изобретения обрабатывают изображения с указателями на различных носителях (например, печатные или рукописные бумажные документы, баннеры, плакаты, знаки, рекламные щиты и/или другие физические объекты, содержащие видимые графемы на одной или нескольких поверхностях). «Графема» здесь относится к элементарной единице алфавита. Графема может быть представлена, например, логограммой, означающей слово или морфему, слоговым символом, означающим слог, или буквенными символами, означающими фонему.
[00013] Системы и способы настоящего изобретения могут распознавать несколько систем письма, включая, например, латинский/кириллический алфавиты, корейский алфавит, китайскую/японскую логографии и/или арабский абджад. В некоторых вариантах осуществления идентификация системы письма, используемой в документе, является предварительным условием для выполнения оптического распознавания символов (OCR) изображения документа. В пояснительном примере описанные здесь системы и способы могут использоваться для определения значений одного или нескольких параметров мобильных приложений OCR, включая систему письма и/или ориентацию изображения.
[00014] Указанный в примере способ идентификации системы письма, используемый для входного изображения, предусматривает разбиение исходного изображения на заранее определенное количество прямоугольных фрагментов (например, на регулярную сетку 3 x 3, состоящую из девяти прямоугольных фрагментов, регулярную сетку 4 x 4, состоящую из 16 прямоугольных фрагментов, регулярную сетку 5 x 5, состоящую из 25 прямоугольных фрагментов и т. д.). После сжатия до предварительно определенного размера (например, 224 x 224 пикселя) прямоугольные фрагменты передаются в нейронную сеть, которая применяет набор функциональных преобразований ко множеству входных данных (например, пикселям изображения), а затем использует преобразованные данные для распознавания образов. Нейронная сеть создает числовой вектор, который включает в себя N+1 значений (где N - количество систем письма, распознаваемых нейронной сетью), так что i-ые элементы вектора отражают вероятность фрагмента изображения, на котором представлены символы i-ой системы письма, а последний элемент вектора отражает вероятность того, что на фрагменте изображения нет распознаваемых символов. Все векторы, созданные нейронной сетью для набора фрагментов входного изображения, после этого складываются вместе, а затем полученный вектор нормализуется. Если максимальное значение среди всех элементов полученного нормализованного вектора превышает заранее определенное пороговое значение, делается вывод о том, что изображение содержит символы системы письма, идентифицированной индексом максимального элемента вектора. В противном случае выдаются две системы письма, набравшие два наибольших значения.
[00015] Таким образом, система и способы настоящего изобретения повышают эффективность оптического распознавания символов, применяя нейронную сеть к фрагментам изображения, а не ко всему изображению, и уменьшая каждый фрагмент изображения до размера входного слоя сети, что приводит к значительному снижению требований к вычислительным ресурсам, используемым нейронной сетью, по сравнению с базовым сценарием передачи всего изображения в нейронную сеть.
[00016] Системы и способы, описанные в настоящем документе, могут быть реализованы с помощью аппаратных средств (например, универсальных и/или специальных устройств обработки и/или других устройств и соответствующих схем), программного обеспечения (например, команд, исполняемых устройством обработки) или их сочетания. Различные аспекты вышеуказанных способов и систем подробно описаны в настоящем документе ниже в качестве примеров, а не в качестве ограничения.
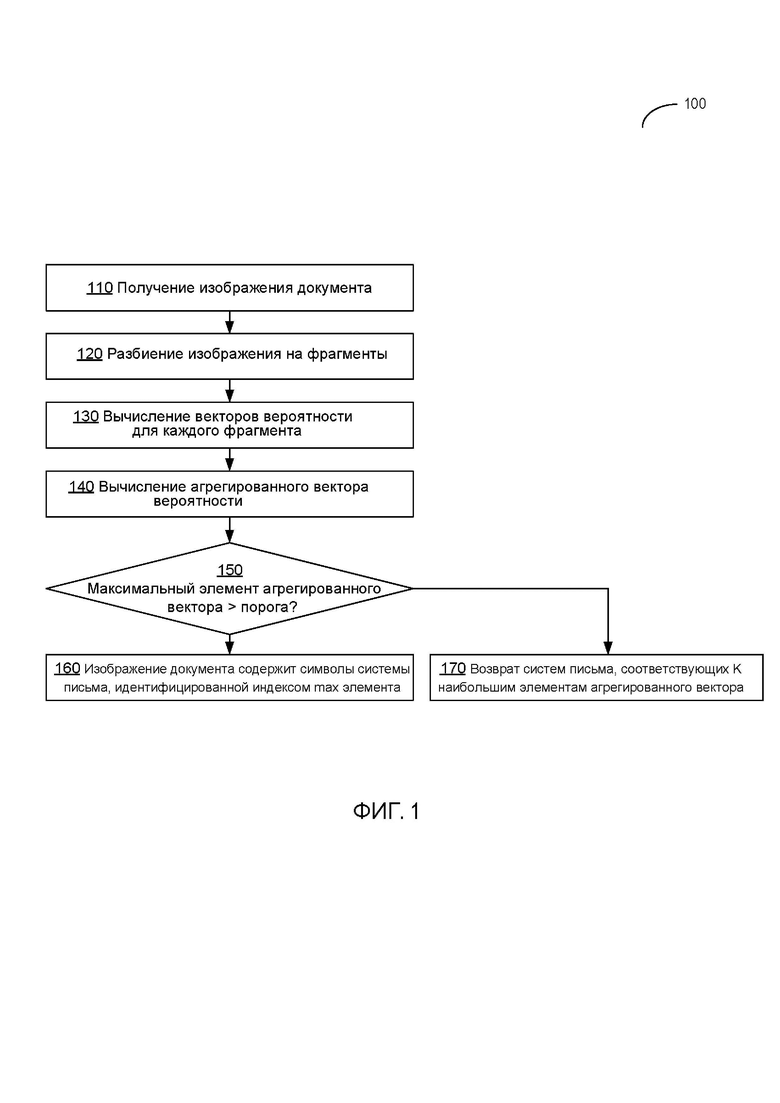
[00017] Фиг. 1 отражает блок-схему указанного в примере способа 100 идентификации системы письма, используемой в документе, в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 100 и/или каждая из его отдельных функций, программ, подпрограмм или операций могут выполняться одним или несколькими процессорами компьютерной системы (в частности, компьютерной системы 700, изображенной на Фиг. 5), реализующей способ. В некоторых вариантах осуществления способ 100 может выполняться с помощью одного потока обработки. В альтернативном варианте осуществления способ 100 может выполняться двумя или несколькими потоками обработки, каждый из которых выполняет одну или несколько отдельных функций, программ, подпрограмм или операций, относящихся к данному способу. В пояснительном примере потоки обработки, реализующие способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и/или других механизмов синхронизации потоков). В альтернативном варианте осуществления потоки обработки, реализующие способ 100, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то, что на Фиг. 1 и в связанных с ним описаниях операции способа 100 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и/или в произвольно выбранном порядке.
[00018] На этапе операции 110 компьютерная система, реализующая данный способ, получает входное изображение документа. В некоторых вариантах осуществления перед передачей для реализации способа 100 входное изображение документа может быть предварительно обработано, например, посредством обрезки исходного изображения, масштабирования исходного изображения и/или преобразования исходного изображения в полутоновое или черно-белое изображение.
[00019] На этапе операции 120 компьютерная система разбивает исходное изображение на заранее определенное количество прямоугольных фрагментов, применяя прямоугольную сетку. Необходимое количество фрагментов может быть вычислено предположительно для обеспечения желаемого баланса между вычислительной сложностью и точностью результата. В пояснительном примере исходное изображение может быть разбито на регулярную сетку 3 x 3, состоящую из девяти прямоугольных фрагментов. В других примерах могут использоваться различные другие сетки. Получившиеся прямоугольные фрагменты сжимаются до предварительно определенного размера (например, 224 x 224 пикселя), который может быть вычислен предположительно, обеспечивая желаемый баланс между вычислительной сложностью и точностью результата. В некоторых вариантах осуществления фрагменты могут быть дополнительно предварительно обработаны, например, путем нормализации яркости пикселя, чтобы привести ее к заранее определенному диапазону, например (-1, 1).
[00020] На этапе операции 130 компьютерная система последовательно передает предварительно обработанные фрагменты изображения в нейронную сеть, которая создает числовой вектор, включающий в себя N+1 значений (где N - количество систем письма, распознаваемых нейронной сетью), так что каждый элемент вектора отражает вероятность того, что фрагмент изображения отражает символы системы письма, идентифицированной индексом элемента вектора (т. е. i-ые элементы вектора отражают вероятность фрагмента изображения, на котором представлены символы i-ой системы письма). Последний элемент вектора отражает вероятность того, что на фрагменте изображения нет распознаваемых символов. Таким образом, для каждого фрагмента входного изображения нейронная сеть будет создавать соответствующий вектор вероятностей фрагмента изображения, содержащего символы соответствующей системы письма.
[00021] В некоторых вариантах осуществления нейронная сеть может быть представлена сверточной нейронной сетью, соответствующей определенной архитектуре, как более подробно описано путем ссылки на Фиг. 4.
[00022] В некоторых вариантах осуществления может быть введен классификатор второго уровня, который принимает карту пространственных характеристик, созданную нейронной сетью на этапе операции 130, и обучается идентифицировать систему письма на основе карты пространственных характеристик.
[00023] В некоторых вариантах осуществления нейронная сеть на этапе операции 130 и/или классификатор второго уровня могут быть обучены выполнять классификацию по нескольким признакам, которая выдаст две или более системы письма с соответствующими символами, присутствующими во входном изображении документа.
[00024] На этапе операции 140 компьютерная система агрегирует векторы, созданные нейронной сетью для набора фрагментов входного изображения, так что получившийся вектор имеет размерность N+1, а i-ый компонент получившегося вектора является суммой i-ых компонентов всех векторов, созданных нейронной сетью для набора фрагментов входного изображения:
[00025] 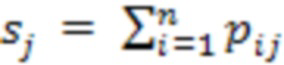
[00026] где 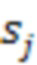 - j-ый компонент вектора суммы, а
- j-ый компонент вектора суммы, а
[00027] 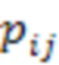 - j-ый компонент вектора вероятности, созданного нейронной сетью для i-го фрагмента изображения.
- j-ый компонент вектора вероятности, созданного нейронной сетью для i-го фрагмента изображения.
[00028] Получившийся вектор затем может быть нормализован, например, путем деления каждого элемента вектора на квадратный корень из нормы L2 вектора:
[00029] 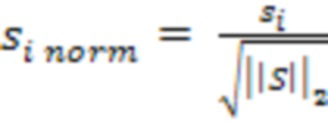
[00030] где  - i-ый компонент нормализованного получившегося вектора,
- i-ый компонент нормализованного получившегося вектора,
[00031] 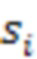 - i-ый элемент вектора, а
- i-ый элемент вектора, а
[00032] 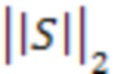 - норма L2 вектора.
- норма L2 вектора.
[00033] С учетом определения на этапе операции 150 того, что 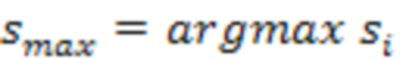 (т. е. максимальное значение среди всех элементов получившегося нормализованного вектора) превышает заранее определенное пороговое значение, компьютерная система на этапе операции 160 делает вывод о том, что изображение содержит символы системы письма, идентифицированной индексом максимального (max) элемента вектора. В противном случае, если максимальное значение ниже или равно заранее определенному пороговому значению, заранее определенное количество K (например, две) систем письма-кандидатов, набравших K наибольших значений, возвращается на этап операции 170, и способ завершается. Предварительно определенное пороговое значение может быть вычислено предположительно в качестве обеспечения желаемой точности распознавания.
(т. е. максимальное значение среди всех элементов получившегося нормализованного вектора) превышает заранее определенное пороговое значение, компьютерная система на этапе операции 160 делает вывод о том, что изображение содержит символы системы письма, идентифицированной индексом максимального (max) элемента вектора. В противном случае, если максимальное значение ниже или равно заранее определенному пороговому значению, заранее определенное количество K (например, две) систем письма-кандидатов, набравших K наибольших значений, возвращается на этап операции 170, и способ завершается. Предварительно определенное пороговое значение может быть вычислено предположительно в качестве обеспечения желаемой точности распознавания.
[00034] Как отмечалось выше в настоящем документе, количество фрагментов, на которые разбивается исходное изображение, может быть произвольным и может зависеть от типа и/или других известных параметров входного документа. В некоторых вариантах осуществления способ 100 может быть адаптирован для обработки входных документов, которые содержат текстовые фрагменты с шрифтами разных размеров (например, заголовки, обычный текст, нижние и верхние индексы и т. д.). Чтобы сеть давала надежный ответ в отношении данного фрагмента изображения, этот фрагмент должен содержать несколько строк текста (т. е. содержать достаточное количество графем), при уменьшении фрагмента до размера входного слоя сети (например, 224 x 224) текст должен оставаться достаточно большим, чтобы можно было идентифицировать систему письма. Это соображение можно использовать для определения диапазона размеров шрифта, который будет использоваться для обучения нейронной сети.
[00035] Обучение нейронной сети может включать в себя активацию нейронной сети в отношении каждого введенного значения в наборе обучающих данных. Значение функции потерь может быть вычислено на основе наблюдаемых выходных данных определенного уровня нейронной сети и желаемых выходных данных, указанных в наборе обучающих данных. Ошибка может быть передана обратно на предыдущие слои нейронной сети, в которых веса ребер и/или другие параметры сети могут быть скорректированы соответствующим образом. Этот процесс может повторяться до тех пор, пока значение функции потерь не стабилизируется вблизи определенного значения или не станет ниже заранее определенного порогового значения.
[00036] Для того, чтобы обученная сеть могла выдавать надежные результаты для произвольных размеров шрифтов, включая размеры шрифтов, выходящие за пределы диапазона размеров шрифта, на котором была обучена нейронная сеть, способ 100 может быть модифицирован для использования масштабированных фрагментов изображения. Чтобы обеспечить возможность обработки широкого диапазона размеров шрифта, нейронная сеть может быть обучена выдавать новую категорию изображений, соответствующую тексту, который слишком мал для точного распознавания системы письма.
[00037] Таким образом, после обработки исходного изображения, уменьшенного до размера, соответствующего размеру входного слоя сети, нейронная сеть может получать несколько фрагментов изображения, которые могут быть созданы, например, путем применения заранее заданной сетки (например, регулярной сетки 2 x 2, состоящей из четырех прямоугольных фрагментов) к исходному изображению. Сетка может рекурсивно применяться к фрагментам изображения, которые были охарактеризованы сетью как содержащие текст, который слишком мал для обеспечения точного распознавания, до тех пор, пока все фрагменты не будут содержать достаточно большие символы, которые позволили бы нейронной сети распознать систему письма, или до тех пор, пока не будет достигнут предварительно определенный минимальный размер фрагмента изображения.
[00038] Фиг. 2 отражает блок-схему указанного в примере способа 200 идентификации системы письма, используемой в документе, в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 200 и/или каждая из его отдельных функций, программ, подпрограмм или операций могут выполняться одним или несколькими процессорами компьютерной системы (в частности, компьютерной системы 700, изображенной на Фиг. 5), реализующей способ. В некоторых вариантах осуществления способ 200 может выполняться с помощью одного потока обработки. В альтернативном варианте осуществления способ 200 может выполняться двумя или несколькими потоками обработки, каждый из которых выполняет одну или несколько отдельных функций, программ, подпрограмм или операций, относящихся к данному способу. В пояснительном примере потоки обработки, реализующие способ 200, могут быть синхронизированы (например, с использованием семафоров, критических секций и/или других механизмов синхронизации потоков). В альтернативном варианте осуществления потоки обработки, реализующие способ 200, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то, что на Фиг. 2 и в связанных с ним описаниях, операции способа 200 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и/или в произвольно выбранном порядке.
[00039] На этапе операции 210 компьютерная система, реализующая данный способ, получает входное изображение документа. В некоторых вариантах осуществления перед передачей для реализации способа 200 входное изображение документа может быть предварительно обработано, например, посредством обрезки исходного изображения, масштабирования исходного изображения и/или преобразования исходного изображения в полутоновое или черно-белое изображение.
[00040] На этапе операции 220 компьютерная система разбивает исходное изображение на заранее определенное количество прямоугольных фрагментов, применяя прямоугольную сетку, как более подробно описано выше в настоящем документе. Получившиеся прямоугольные фрагменты сжимаются до предварительно определенного размера (например, 224 x 224 пикселя), который может быть вычислен предположительно, обеспечивая желаемый баланс между вычислительной сложностью и точностью результата. В некоторых вариантах осуществления фрагменты могут быть дополнительно предварительно обработаны, например, путем нормализации яркости пикселя, чтобы привести ее к заранее определенному диапазону, например (-1, 1).
[00041] На этапе операции 230 компьютерная система последовательно передает предварительно обработанные фрагменты изображения в нейронную сеть, которая создает для каждого фрагмента входного изображения соответствующий вектор вероятностей фрагмента изображения, содержащего символы соответствующей системы письма, как более подробно описано выше в настоящем документе. В некоторых вариантах осуществления нейронная сеть может быть представлена сверточной нейронной сетью, соответствующей определенной архитектуре, как более подробно описано путем ссылки на Фиг. 4.
[00042] С учетом определения на этапе операции 240 того, что нейронная сеть не классифицировала фрагменты изображения как содержащие текст, который слишком мал для обеспечения точного распознавания, или что достигнут заранее определенный минимальный размер фрагмента изображения, обработка продолжается в блоке 260; в противном случае способ переходит к операции 250.
[00043] На этапе операции 250 компьютерная система дополнительно разбивает на несколько субфрагментов фрагменты изображения, которые сеть охарактеризовала как содержащие текст, который слишком мал для обеспечения точного распознавания, и способ возвращается к блоку 230.
[00044] На этапе операции 260 компьютерная система агрегирует векторы, созданные нейронной сетью для набора фрагментов входного изображения, так что получившийся вектор имеет размерность N+1, а i-ый компонент получившегося вектора является суммой i-ых компонентов всех векторов, созданных нейронной сетью для набора фрагментов входного изображения. Получившейся вектор затем может быть нормализован, как более подробно описано выше в настоящем документе.
[00045] С учетом определения на этапе операции 270 того, что максимальное значение среди всех элементов нормализованного получившегося вектора превышает заранее определенное пороговое значение, компьютерная система на этапе операции 280 делает вывод о том, что изображение содержит символы системы письма, идентифицированной индексом максимального элемента вектора. В противном случае, если максимальное значение ниже или равно заранее определенному пороговому значению, заранее определенное количество K систем письма-кандидатов, набравших K наибольших значений, возвращается на этап операции 290, и способ завершается.
[00046] В некоторых вариантах осуществления в целях сокращения времени обработки только подмножество всех фрагментов изображения (например, «интересующие области» (ROI)) может подаваться в нейронную сеть для дальнейшей обработки. Чтобы повысить общую эффективность способа, выбранные фрагменты изображения не обязательно могут покрывать все изображение и/или могут быть выбраны в заранее определенном порядке, например, в шахматном порядке. В другом пояснительном примере нейронная сеть для идентификации системы письма может работать на полном наборе фрагментов изображения.
[00047] Набор обучающих данных, используемый для обучения нейронной сети идентификации интересующей области, может впоследствии состоять, по меньшей мере, из подмножества всех фрагментов изображения и их соответствующих значений точности вывода, демонстрируемых нейронной сетью идентификации системы письма. Затем фрагменты изображения могут быть отсортированы в порядке, обратном точности вывода, выполняемого нейронной сетью идентификации системы письма. Затем можно выбрать заранее определенное количество фрагментов изображения, соответствующее наибольшей точности логического вывода, выполняемого для этих фрагментов нейронной сетью идентификации системы письма, и использовать для обучения нейронной сети идентификации интересующей области.
[00048] В другом пояснительном примере может быть реализован планомерный подход эталонных данных, включающий в себя сохранение в структуре данных сегментации (например, тепловой карте) соответствующих вероятностей для каждого сегмента, которые были получены классификатором. Затем структура данных сегментации может использоваться для обучения нейронной сети идентификации системы письма путем выбора заранее определенного количества (например, N) лучших фрагментов (например, путем выбора M суперпикселей максимального размера из тепловой карты) для запуска классификатора. Для повышения эффективности тепловая карта может быть отсортирована путем подсчета, который демонстрирует вычислительную сложность O(N), где N - количество суперпикселей в тепловой карте. Затем классификатор может быть повторно обучен для обеспечения точного соответствия этим выбранным фрагментам, что может быть достигнуто путем взвешивания функции потерь для каждого фрагмента. После выбора заранее определенного количества фрагментов (интересующих областей) повторно обученный классификатор может быть запущен на них, чтобы получить заранее определенное количество вероятностей, которые могут быть агрегированы, как описано в настоящем документе выше.
[00049] В некоторых вариантах осуществления нейронная сеть идентификации интересующей области может быть обучена обрабатывать широкий диапазон размеров шрифта. Нейронная сеть идентификации системы письма может быть обучена идентифицировать систему письма для документов, использующих заранее определенный диапазон размера шрифта (например, размеры шрифта от X до 2X). Затем нейронная сеть идентификации системы письма может быть запущена на фрагментах изображений различных масштабов. Набор обучающих данных, используемый для обучения нейронной сети идентификации интересующей области, может впоследствии состоять из подмножества всех фрагментов изображения и их соответствующих значений точности вывода, демонстрируемых нейронной сетью идентификации системы письма.
[00050] Фиг. 3 отражает блок-схему указанного в примере способа 300 идентификации системы письма, используемой в документе, в соответствии с одним или несколькими аспектами настоящего изобретения. Способ 300 и/или каждая из его отдельных функций, программ, подпрограмм или операций могут выполняться одним или несколькими процессорами компьютерной системы (в частности, компьютерной системы 700, изображенной на Фиг. 5), реализующей способ. В некоторых вариантах осуществления способ 300 может выполняться с помощью одного потока обработки. В альтернативном варианте осуществления способ 300 может выполняться двумя или несколькими потоками обработки, каждый из которых выполняет одну или несколько отдельных функций, программ, подпрограмм или операций, относящихся к данному способу. В пояснительном примере потоки обработки, реализующие способ 300, могут быть синхронизированы (например, с использованием семафоров, критических секций и/или других механизмов синхронизации потоков). В альтернативном варианте осуществления потоки обработки, реализующие способ 300, могут выполняться асинхронно по отношению друг к другу. Поэтому, несмотря на то, что на Фиг. 3 и в связанных с ним описаниях операции способа 300 выполняются в определенном порядке, в различных вариантах осуществления данного способа как минимум некоторые из описанных операций могут выполняться параллельно и/или в произвольно выбранном порядке.
[00051] На этапе операции 310 компьютерная система, реализующая данный способ, получает входное изображение документа. В некоторых вариантах осуществления перед передачей для реализации способа 300 изображение входного документа может быть предварительно обработано, как более подробно описано выше в настоящем документе.
[00052] На этапе операции 320 компьютерная система разбивает исходное изображение на заранее определенное количество прямоугольных фрагментов, применяя прямоугольную сетку, как более подробно описано выше в настоящем документе.
[00053] На этапе операции 330 компьютерная система идентифицирует среди всех фрагментов изображения интересующие области (ROI). В некоторых вариантах осуществления идентификация интересующей области может выполняться специализированной нейронной сетью идентификации интересующей области, которая может идентифицировать подмножество, включающее заранее определенное количество фрагментов изображения, как более подробно описано выше в настоящем документе.
[00054] На этапе операции 340 компьютерная система последовательно передает предварительно обработанные фрагменты изображения в нейронную сеть, которая создает для каждого предварительно обработанного фрагмента входного изображения соответствующий вектор вероятностей фрагмента изображения, содержащего символы соответствующей системы письма, как более подробно описано выше в настоящем документе. В некоторых вариантах осуществления нейронная сеть может быть представлена сверточной нейронной сетью, соответствующей определенной архитектуре, как более подробно описано путем ссылки на Фиг. 4.
[00055] На этапе операции 350 компьютерная система агрегирует векторы, созданные нейронной сетью для набора фрагментов входного изображения, так что получившийся вектор имеет размерность N+1, а i-ый компонент получившегося вектора является суммой i-ых компонентов всех векторов, созданных нейронной сетью для набора фрагментов входного изображения. Получившейся вектор затем может быть нормализован, как более подробно описано выше в настоящем документе.
[00056] С учетом определения на этапе операции 360 того, что максимальное значение среди всех элементов нормализованного получившегося вектора превышает заранее определенное пороговое значение, компьютерная система на этапе операции 370 делает вывод о том, что изображение содержит символы системы письма, идентифицированной индексом максимального элемента вектора. В противном случае, если максимальное значение ниже или равно заранее определенному пороговому значению, заранее определенное количество K систем письма-кандидатов, набравших K наибольших значений, возвращается на этап операции 380, и способ завершается.
[00057] Кроме того, в некоторых вариантах осуществления нейронная сеть идентификации системы письма может использоваться для идентификации как системы письма, так и пространственной ориентации входного изображения. Соответственно, нейронная сеть может быть модифицирована для включения дополнительного вывода, который будет давать значение, описывающее пространственную ориентацию входного изображения. В пояснительном примере значение может отражать одну из четырех возможных ориентаций: нормальную, повернутую на 90 градусов по или против часовой стрелки, повернутую на 180 градусов, повернутую на 270 градусов по или против часовой стрелки и т. д. Подобно идентификации системы письма пространственная ориентация может быть определена в отношении набора фрагментов входного изображения, а затем агрегирована по всем фрагментам, чтобы определить пространственную ориентацию входного изображения. В некоторых вариантах осуществления пространственная ориентация изображения может быть идентифицирована классификатором второго уровня, который принимает карту пространственных характеристик, созданную нейронной сетью на этапе операции 130, и обучается идентифицировать пространственную ориентацию входного изображения.
[00058] Подобно наборам данных, которые используются для обучения нейронных сетей идентификации системы письма, набор данных для обучения сети распознаванию ориентации изображения может состоять из реальных и/или синтезированных изображений. Такой набор обучающих данных может включать в себя изображения, которые имеют разную пространственную ориентацию, так что ориентация изображения распределяется либо равномерно, либо на основе частоты появления изображений документа, имеющих различную ориентацию, в данном объеме документов.
[00059] Как отмечено выше в настоящем документе, нейронная сеть, реализованная в соответствии с аспектами настоящего изобретения, может включать несколько слоев разных типов. В пояснительном примере входное изображение может быть получено входным слоем и впоследствии обработано серией слоев, включая сверточные слои, слои объединения, слои блока линейной ректификации (ReLU) и/или полностью связанные слои, каждый из который может выполнять определенную операцию по распознаванию текста во входном изображении. Выходные данные слоя могут передаваться в качестве входных данных для одного или нескольких последующих слоев. Обработка исходного изображения сверточной нейронной сетью может итерационно применять каждый последующий слой до тех пор, пока каждый слой не выполнит свою соответствующую операцию.
[00060] В некоторых вариантах осуществления сверточная нейронная сеть может включать в себя чередующиеся сверточные слои и слои объединения. Каждый сверточный слой может выполнять операцию свертки, которая включает обработку каждого пикселя фрагмента входного изображения с помощью одного или нескольких фильтров (матриц свертки) и запись результата в соответствующую позицию выходного массива. Один или несколько фильтров свертки могут быть разработаны для обнаружения определенной характеристики изображения путем обработки входного изображения и получения соответствующей карты характеристик.
[00061] Выходные данные сверточного слоя могут передаваться в слой ReLU, который может применять нелинейное преобразование (например, функцию активации, которая заменяет отрицательные числа на ноль) для обработки выходных данных сверточного слоя. Выходные данные слоя ReLU могут передаваться на слой объединения, который может выполнять операцию субдискретизации для уменьшения разрешения и размера карты характеристик. Выходные данные слоя объединения могут передаваться на следующий сверточный слой.
[00062] В некоторых вариантах осуществления нейронные сети для идентификации системы письма, реализованные в соответствии с аспектами настоящего изобретения, могут быть совместимы с архитектурой MobileNet, которая представляет собой семейство нейронных сетей машинного зрения общего назначения, разработанных для мобильных устройств, чтобы выполнять классификацию изображений, обнаружение и/или другие подобные задачи. В пояснительном примере нейронная сеть для идентификации системы письма может следовать архитектуре MobileNetv2, как схематично показано на Фиг. 4. Как показано на Фиг. 4, пример нейронной сети 400 может включать в себя два вида блоков. Блок 402 - это остаточный блок с шагом единицы. Блок 404 - это блок с шагом два.
[00063] Каждый из блоков 402, 404 включает в себя три слоя: слой точечной свертки 412A-412B, который отвечает за создание новых характеристик посредством вычисления линейных комбинаций входных каналов; глубокий (глубинный) сверточный слой 414A-414B, который выполняет облегченную фильтрацию путем применения одного сверточного фильтра на входной канал; и второй сверточный слой 416A-416B без нелинейности. Когда начальная и конечная карты характеристик имеют одинаковые размеры (когда шаг свертки по глубине равен единице, а входные и выходные каналы равны), добавляется остаточное соединение 418, чтобы способствовать градиентному потоку во время обратного распространения.
[00064] В другом пояснительном примере нейронная сеть для идентификации системы письма может следовать архитектуре MobileNetv3, все блоки которой являются узкими местами (bottleneck) с механизмами сжатия и возбуждения. Нейронная сеть может иметь четыре общих слоя для выделения характеристик, за которыми следуют три ветви: ветвь идентификации системы письма, ветвь идентификации пространственной ориентации и ветвь кластеризации размера текста. Последняя может использоваться для постобработки и выбора соединений для выполнения дальнейшей классификации масштабированного текста. Каждая ветвь может включать заранее определенное количество блоков (например, три или четыре).
[00065] Несмотря на то, что Фиг. 4 и соответствующее описание поясняют конкретное количество и типы слоев примерной архитектуры сверточной нейронной сети, сверточные нейронные сети, используемые в различных альтернативных вариантах осуществления, могут включать в себя любое подходящее количество сверточных слоев, слоев ReLU, слоев объединения и/или любых других слоев. Порядок слоев, количество слоев, количество фильтров и/или любой другой параметр сверточных нейронных сетей можно регулировать (например, на основе эмпирических данных).
[00066] Нейронные сети, используемые системами и способами в рамках настоящего изобретения, могут быть обучены на основании обучающих наборов данных, включая реальные и/или синтезированные изображения текста. К синтезированным изображениям могут применяться различные способы увеличения изображения для достижения «фотореалистичного» качества изображения. Каждое изображение может включать в себя несколько строк текста на определенном языке, которые отображаются с использованием заданного размера шрифта. Язык, используемый в изображении, определяет систему письма, которая используется в качестве метки, связанной с фрагментом изображения при обучении нейронной сети.
[00067] Фиг. 5 отражает схему компонентов указанной в примере компьютерной системы, которая может использоваться для реализации способов, указанных в настоящем документе. Компьютерная система 700 может быть подключена к другой компьютерной системе в локальной сети, интрасети, экстрасети или сети Интернет. Компьютерная система 700 может работать в качестве сервера или клиентской компьютерной системы в сетевой среде «клиент-сервер», либо в качестве одноранговой компьютерной системы в одноранговой (или распределенной) сетевой среде. Компьютерная система 700 может представлять собой персональный компьютер (ПК), планшет, телевизионную приставку (STB), карманный персональный компьютер (КПК), мобильный телефон или любую компьютерную систему, способную выполнять набор команд (последовательных или иных), определяющих операции, которые должны быть выполнены такой компьютерной системой. Кроме того, несмотря на наглядное изображение только одной вычислительной системы термин «компьютерная система» должен также включать любую совокупность компьютерных систем, которые индивидуально или совместно выполняют набор (или несколько наборов) команд для реализации любого одного или нескольких способов, указанных в настоящем документе.
[00068] Приведенная в качестве примера компьютерная система 700 включает процессор 702, основное запоминающее устройство (память) 704 (например, постоянное запоминающее устройство (ПЗУ), динамическое запоминающее устройство с произвольной выборкой (ДЗУПВ)) и устройство хранения данных 718, которые взаимодействуют друг с другом по шине 730.
[00069] Процессор 702 может представлять собой одно или несколько устройств обработки общего назначения, таких как микропроцессор, центральный процессор и т. п. Точнее говоря, процессор 702 может быть микропроцессором для вычисления сложных наборов команд (CISC), микропроцессором для вычисления сокращенных наборов команд (RISC), микропроцессором с очень длинным командным словом (VLIW), процессором, реализующим другие наборы команд, или процессором, реализующим сочетание наборов команд. Процессор 702 также может представлять собой одно или несколько устройств обработки специального назначения, таких как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровой обработки сигнала (DSP), сетевой процессор и т. п. Процессор 702 сконфигурирован для выполнения команд 726 для реализации описанных в настоящем документе способов.
[00070] Компьютерная система 700 может дополнительно включать в себя устройство сетевого интерфейса 722, устройство визуального отображения (видео дисплей) 710, устройство буквенно-цифрового ввода 712 (например, клавиатуру) и сенсорное устройство ввода 714.
[00071] Устройство хранения данных 718 может включать в себя машиночитаемый носитель данных 724, на котором хранится один или несколько наборов команд/инструкций 726, реализующих любой один или несколько способов или функций, описанных в настоящем документе. Команды 726 также могут находиться, полностью или по меньшей мере частично, в основном запоминающем устройстве 704 и/или в процессоре 702 во время их выполнения компьютерной системой 700, основным запоминающим устройством 704 и процессором 702, также представляющими собой машиночитаемый носитель данных. Команды 726 могут дополнительно передаваться или приниматься по сети 716 через устройство сетевого интерфейса 722.
[00072] В пояснительном примере команды 726 могут включать в себя команды способов 100, 200 и/или 300 для идентификации системы письма, используемой в документе, реализованные в соответствии с одним или несколькими аспектами настоящего изобретения. Хотя машиночитаемый носитель 724 показан в примере на Фиг. 5 как один носитель, термин «машиночитаемый носитель данных» следует понимать как включающий в себя один или несколько носителей (например, централизованную или распределенную базу данных и/или соответствующие кэши и серверы), которые хранят один или несколько наборов команд. Термин «машиночитаемый носитель данных» также должен включать в себя любой носитель, который способен хранить, кодировать или нести набор команд для исполнения машиной и обеспечивает, чтобы машина выполняла любой один способ или несколько способов по настоящему изобретению. Термин «машиночитаемый носитель данных», соответственно, включает, помимо прочего, твердотельные запоминающие устройства, оптические и магнитные носители.
[00073] Описанные в настоящем документе способы, компоненты и характеристики могут быть реализованы дискретными аппаратными компонентами или могут быть интегрированы в функциональность других аппаратных компонентов, таких как микросхемы ASIC, FPGA, DSP или аналогичные устройства. Кроме того, способы, компоненты и характеристики могут быть реализованы программно-аппаратными модулями или функциональными схемами в аппаратных устройствах. Также способы, компоненты и характеристики могут быть реализованы в любой комбинации аппаратных устройств и программных компонентов или только в программном обеспечении.
[00074] В приведенном выше описании изложены многочисленные подробности. Однако специалисту в данной области, который сможет пользоваться преимуществами настоящего изобретения, будет очевидно, что аспекты настоящего изобретения могут быть реализованы без таких конкретных деталей. В некоторых случаях известные структуры и устройства показаны в виде блок-схемы без подробностей, чтобы не затруднять понимание предмета настоящего изобретения.
[00075] Некоторые части подробного описания представлены в виде алгоритмов и символьных представлений операций с битами данных в запоминающем устройстве компьютера. Такие алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных с целью наиболее эффективной передачи содержания своей работы другим специалистам в данной области. Как в рамках настоящего документа, так и в целом алгоритм понимается как самосогласованная последовательность операций, приводящая к желаемому результату. Эти операции - это этапы, требующие физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, такие величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать или использовать иным образом. Иногда, в основном по соображениям общепринятой практики, удобно называть такие сигналы битами, значениями, элементами, графемами, знаками, терминами, числами и т. п.
[00076] Однако следует помнить, что все такие и подобные термины должны быть связаны с соответствующими физическими величинами и являются лишь удобными обозначениями, применяемыми к таким величинам. Если специально не указано иное, как очевидно из последующего обсуждения, следует понимать, что во всем описании изобретения обсуждения, использующие такие термины, как «определение», «вычисление», «расчет», «подсчет», «получение», «идентификация», «модификация» и т. п., относятся к действиям и процессам вычислительной системы или аналогичного электронного вычислительного устройства, которое использует и преобразует данные, представленные в виде физических (например, электронных) величин в регистрах и памяти вычислительной системы, в иные данные, аналогично представленные в виде физических величин в памяти или регистрах вычислительной системы или иных подобных устройствах хранения, передачи или отображения информации.
[00077] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Данное устройство может быть специально сконструировано для требуемых целей, или оно может состоять из компьютера общего назначения, избирательно активируемого или реконфигурируемого компьютерной программой, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, таком как любой тип диска, включая дискеты, оптические диски, компакт-диски и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), ППЗУ, ЭСППЗУ, магнитные или оптические платы или любой тип носителя, подходящий для хранения электронных команд.
[00078] Следует понимать, что приведенное выше описание служит для наглядности и не носит ограничительный характер. Многие иные варианты осуществления будут очевидны специалистам в данной области после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться со ссылкой на прилагаемую формулу изобретения наряду с полным объемом эквивалентов, на которые распространяется такая формула.
Настоящее изобретение относится главным образом к компьютерным системам и, в частности, к системам и способам идентификации систем письма, используемых в документах. Технический результат заключается в повышении эффективности оптического распознавания символов, применяя нейронную сеть к фрагментам изображения, уменьшая каждый фрагмент изображения до размера входного слоя сети, для снижения требований к вычислительным ресурсам. Технический результат достигается за счёт следующего. Способ включает в себя: получение изображения документа; разбиение изображения на фрагменты; генерирование векторов вероятности посредством нейронной сети, содержащих множество числовых элементов, и каждый числовой элемент отражает вероятность фрагмента изображения, содержащего текст, связанный с соответствующей системой письма; вычисление агрегированного вектора вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма; и с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает определенное пороговое значение, делается вывод, что изображение документа содержит один или несколько символов, связанных с соответствующей системой письма. 3 н. и 17 з.п. ф-лы, 5 ил.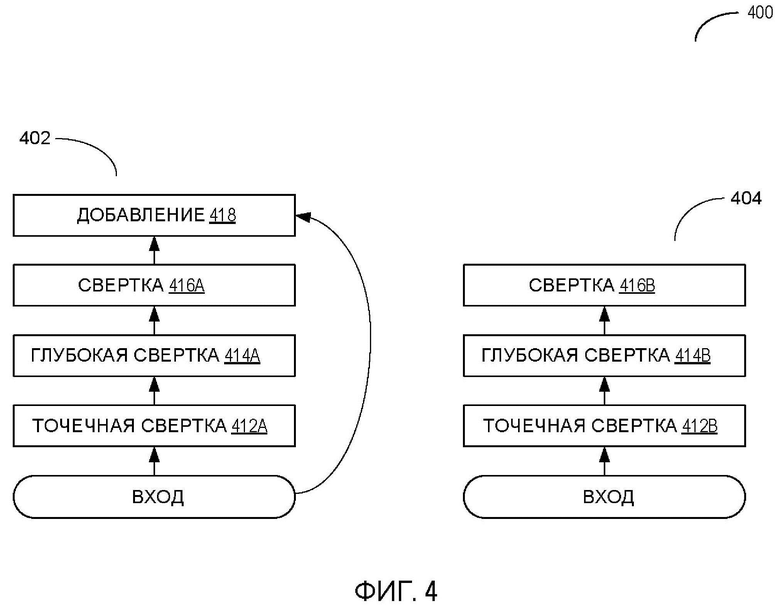
1. Способ идентификации системы письма, включающий:
получение изображения документа компьютерной системой;
разбиение изображения документа на множество фрагментов изображения;
генерирование множества векторов вероятности посредством нейронной сети, обрабатывающей множество фрагментов изображения, причем каждый вектор вероятности из множества векторов вероятности создается путем обработки соответствующих фрагментов изображения и содержит множество числовых элементов, при этом каждый числовой элемент из множества числовых элементов отражает вероятность фрагмента изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в соответствующем векторе вероятности;
вычисление агрегированного вектора вероятности путем агрегирования множества векторов вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в пределах агрегированного вектора вероятности; и
с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает предварительно определенное пороговое значение, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с системой письма, которая идентифицируется посредством индекса максимального числового элемента в пределах агрегированного вектора вероятности.
2. Способ по п. 1, дополнительно включающий:
с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности меньше или равен предварительно определенному пороговому значению, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с одной из следующих систем: первая система письма, которая идентифицируется посредством первого индекса максимального числового элемента в пределах агрегированного вектора вероятности, или вторая система письма, которая идентифицируется посредством второго индекса следующего наибольшего числового элемента в пределах агрегированного вектора вероятности.
3. Способ по п. 1, дополнительно включающий:
идентификацию среди множества фрагментов изображения множества интересующих областей (ROI).
4. Способ по п. 1, дополнительно включающий:
нормализацию агрегированного вектора вероятности.
5. Способ по п. 1, причем каждый фрагмент изображения из множества фрагментов изображения представляет собой прямоугольный фрагмент изображения предварительно определенного размера.
6. Способ по п. 1, дополнительно включающий:
рекурсивное разбиение на соответствующие субфрагменты изображения одного или нескольких фрагментов изображения, которые характеризуются нейронной сетью как содержащие текст, имеющий размер текста меньше минимального порогового размера.
7. Способ по п. 1, дополнительно включающий:
предварительную обработку изображения документа.
8. Способ по п. 1, при котором разбиение изображения документа на множество фрагментов изображения дополнительно включает в себя:
преобразование каждого фрагмента изображения из множества фрагментов изображения до предварительно определенного размера.
9. Способ по п. 1, дополнительно включающий:
определение пространственной ориентации изображения документа с помощью нейронной сети, обрабатывающей множество фрагментов изображения.
10. Способ по п. 1, дополнительно включающий:
идентификацию на основе заранее определенного порядка подмножества множества фрагментов изображения, которые должны быть переданы в нейронную сеть.
11. Система для идентификации системы письма, включающая:
запоминающее устройство;
процессор, соединенный с запоминающим устройством, причем процессор выполнен с возможностью выполнения таких действий, как:
получение изображения документа;
разбиение изображения документа на множество фрагментов изображения;
генерирование множества векторов вероятности посредством нейронной сети, обрабатывающей множество фрагментов изображения, причем каждый вектор вероятности из множества векторов вероятности создается путем обработки соответствующих фрагментов изображения и содержит множество числовых элементов, при этом каждый числовой элемент из множества числовых элементов отражает вероятность фрагмента изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в соответствующем векторе вероятности;
вычисление агрегированного вектора вероятности путем агрегирования множества векторов вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в пределах агрегированного вектора вероятности; и
с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает предварительно определенное пороговое значение, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с системой письма, которая идентифицируется посредством индекса максимального числового элемента в пределах агрегированного вектора вероятности.
12. Система по п. 11, в которой процессор дополнительно выполнен с возможностью:
с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности меньше или равен предварительно определенному пороговому значению, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с одной из следующих систем: первая система письма, которая идентифицируется посредством первого индекса максимального числового элемента в пределах агрегированного вектора вероятности, или вторая система письма, которая идентифицируется посредством второго индекса следующего наибольшего числового элемента в пределах агрегированного вектора вероятности.
13. Система по п. 11, в которой каждый фрагмент изображения из множества фрагментов изображения представляет собой прямоугольный фрагмент изображения предварительно определенного размера.
14. Система по п. 11, в которой процессор дополнительно выполнен с возможностью выполнять:
рекурсивное разбиение на соответствующие субфрагменты изображения одного или нескольких фрагментов изображения, которые характеризуются нейронной сетью как содержащие текст, имеющий размер текста меньше минимального порогового размера.
15. Система по п. 11, в которой разбиение изображения документа на множество фрагментов изображения дополнительно включает в себя:
преобразование каждого фрагмента изображения из множества фрагментов изображения до предварительно определенного размера.
16. Система по п. 11, в которой процессор дополнительно выполнен с возможностью выполнять:
определение пространственной ориентации изображения документа с помощью нейронной сети, обрабатывающей множество фрагментов изображения.
17. Машиночитаемый энергонезависимый носитель данных, включающий в себя исполняемые команды, которые при выполнении вычислительной системой обеспечивают выполнение вычислительной системой следующих операций:
получение изображения документа;
разбиение изображения документа на множество фрагментов изображения;
генерирование множества векторов вероятности посредством нейронной сети, обрабатывающей множество фрагментов изображения, причем каждый вектор вероятности из множества векторов вероятности создается путем обработки соответствующих фрагментов изображения и содержит множество числовых элементов, при этом каждый числовой элемент из множества числовых элементов отражает вероятность фрагмента изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в соответствующем векторе вероятности;
вычисление агрегированного вектора вероятности путем агрегирования множества векторов вероятности, причем каждый числовой элемент агрегированного вектора вероятности отражает вероятность изображения, содержащего текст, связанный с системой письма, которая идентифицируется посредством индекса числового элемента в пределах агрегированного вектора вероятности; и
с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности превышает предварительно определенное пороговое значение, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с системой письма, которая идентифицируется посредством индекса максимального числового элемента в пределах агрегированного вектора вероятности.
18. Носитель данных по п. 17, дополнительно включающий в себя исполняемые команды, которые при выполнении вычислительной системой обеспечивают выполнение следующих операций:
с учетом определения того, что максимальный числовой элемент агрегированного вектора вероятности меньше или равен предварительно определенному пороговому значению, делается вывод о том, что изображение документа содержит один или несколько символов, связанных с одной из следующих систем: первая система письма, которая идентифицируется посредством первого индекса максимального числового элемента в пределах агрегированного вектора вероятности, или вторая система письма, которая идентифицируется посредством второго индекса следующего наибольшего числового элемента в пределах агрегированного вектора вероятности.
19. Носитель данных по п. 17, в котором разбиение изображения документа на множество фрагментов изображения дополнительно включает в себя:
преобразование каждого фрагмента изображения из множества фрагментов изображения до предварительно определенного размера.
20. Носитель данных по п. 17, дополнительно включающий в себя исполняемые команды, которые при выполнении вычислительной системой обеспечивают выполнение следующих действий:
определение пространственной ориентации изображения документа с помощью нейронной сети, обрабатывающей множество фрагментов изображения.
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ ПРИМЕНЕНИЯ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ УВЕРЕННОСТИ, РЕАЛИЗУЕМОЕ НА БАЗЕ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2703270C1 |
| УСТРОЙСТВА И СПОСОБЫ, КОТОРЫЕ ИСПОЛЬЗУЮТ ИЕРАРХИЧЕСКИ УПОРЯДОЧЕННУЮ СТРУКТУРУ ДАННЫХ, СОДЕРЖАЩУЮ НЕПАРАМЕТРИЗОВАННЫЕ СИМВОЛЫ, ДЛЯ ПРЕОБРАЗОВАНИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ В ЭЛЕКТРОННЫЕ ДОКУМЕНТЫ | 2013 |
|
RU2643465C2 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| US 9934430 B2, 03.04.2018 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |

