ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение относится к области компьютерных технологий, в частности к способу и системе для обезличивания изображения документов, которые содержат персональные данные.
УРОВЕНЬ ТЕХНИКИ
[2] На сегодняшний день обработка персональных данных, содержащихся в различных видах документов, занимает все более важное место в ведении хозяйственной деятельности современного бизнеса. С постоянным ужесточением политики на обработку такого вида информации и контролем за соблюдением ее целостности, хранения, а также защитой от возможных утечек, современные технологии предлагают все более совершенные методы по работы с персональными данными в части их деперсонификации и анонимизации.
[3] Из патента США US 7,158,979 В2 "System and method of de-identifying data" (INGENiX Inc., 02.01.2007) известен метод, основанный на обработке текстовой информации. Для применения к изображениям документов необходимо сначала использовать технологии распознавания OCR (Optical Character Recognition). Так или иначе данные технологии используют средства распознавания именованных сущностей NER (Named Entity Recognition). Такой подход не может гарантировать полноты идентификации текста с персональными данными, содержащегося в изображении, что делает такой метод непригодным для работы в автоматическом режиме.
[4] Патентная заявка США US 20190279011 A1 "Data anonymization using neural networks" (Microsoft Technology Licensing LLC, 12.09.2019) раскрывает решение проблемы обучения классификатора на вычислительном узле сети, оператор которого не должен иметь доступа к данным для обучения. Технология основана на свойстве плохой интерпретируемости нейронной сети. Основной идеей изобретения в указанной заявке является идея выделения в предобученной сети энкодера, работающего в компьютерной сети владельца данных, и классификатора, работающего на вычислительных узлах, которые не имеют права читать исходные данные.
[5] Дообучение классификатора может быть выполнено передачей правильного отклика и закодированных энкодером данных. Преимуществом данной технологии является простота и хорошая масштабируемость на различные задачи машинного обучения. Данная технология дает возможность использовать несколько источников данных для обучения одной модели. Недостатком метода является необходимость привлекать для обучения людей, имеющих доступ к персональным данным.
[6] Другие известные подходы заключаются в разбиении изображения с персональными данными на информационные сегменты, которые по-отдельности не являются персональными данными. Данные подходы зависят от метода разбиения изображения и в общем случае не могут гарантировать правильной сегментации. Основной сложностью при работе с персональными данными является необходимость соблюдения требуемого уровня конфиденциальности.
[7] В различных странах и областях деятельности требования могут отличаться, но так или иначе эти требования не позволяют использовать краудсорсинговые площадки вроде Яндекс Толока или Amazon Mechanical Turk. Данные платформы целесообразно использовать для создания больших наборов данных, пригодных для построения классификатора документов с применением машинного обучения.
[8] Существует три подхода к решению проблемы создания больших дата сетов для классификации документов с персональными данными:
• выбор разметчиков, которые юридически имеют право работать с персональными данными;
• ручное удаление персональной информации из документа;
• автоматическое удаление персональных данных.
Первые два способа имеют относительно высокую цену и сложность их реализации. Реализации третьего способа страдает от проблем с полнотой анонимизации при осуществлении в автоматизированном режиме (некоторые данные могут быть пропущены алгоритмом).
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[9] Предложенное решение позволяет решить техническую проблему, связанную с полнотой обработки входных данных изображений, содержащих персональные данные, а также повысить качество анонимизации документов без возможности их восстановления при автоматической реализации обработки в режиме реального времени.
[10] Техническим результатом является повышение качества удаления персональных данных с изображения документов.
[11] Заявленное решение осуществляется за счет компьютерно-реализуемого способа удаления персональных данных с изображения документа, который выполняется с помощью процессора и содержит этапы, на которых:
получают первичное изображение документа;
выполняют предобработку упомянутого изображения, при которой осуществляют формирование изображения заданного размера и разрешения;
осуществляют уменьшение предобработанного изображения с помощью его четырехкратного преобразования с использованием перехода по пирамиде Гаусса; осуществляют применение по меньшей мере одной морфологической операции с окном в 3x3 пикселя к изображению документа;
осуществляют увеличение полученного изображения с помощью четырехкратного преобразования с использованием перехода по пирамиде Гаусса;
формируют итоговое изображение документа с удаленными персональными данными.
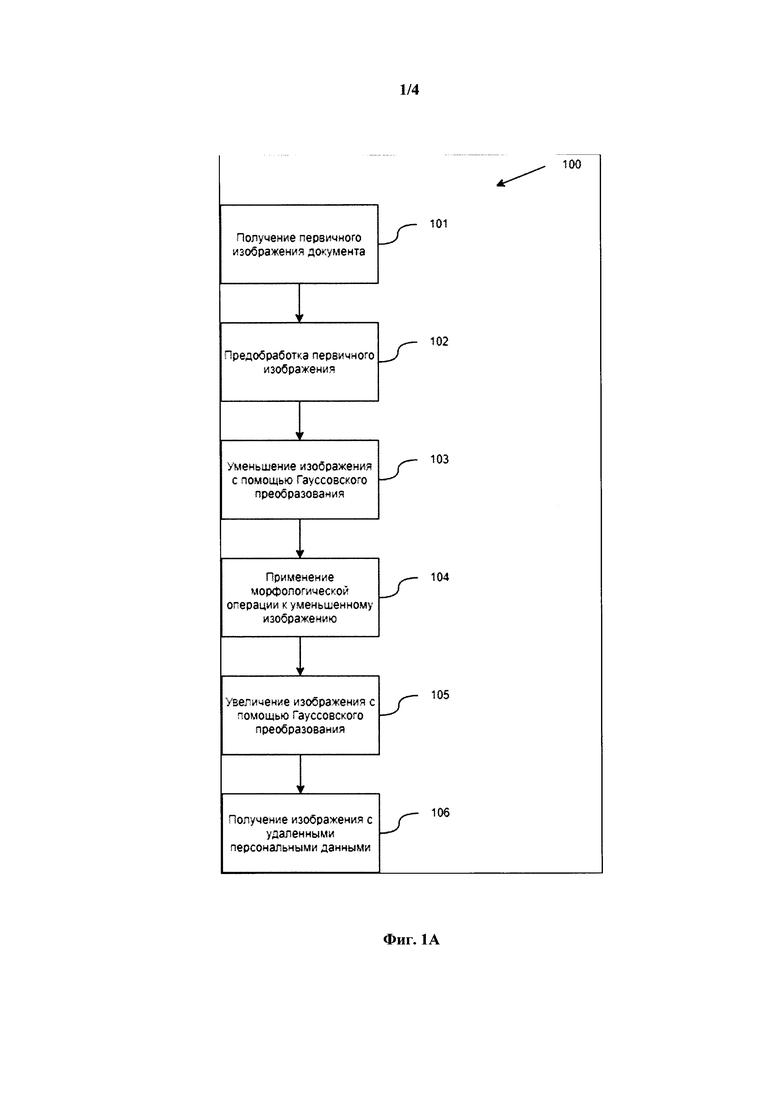
[12] В одном из частных вариантов осуществления способа на этапе предобработки осуществляется приведение соотношения сторон изображения для получения показателя 5:7.
[13] В другом частном варианте осуществления способа на этапе предобработки устанавливается разрешение изображения 840x600 пикселей.
[14] В другом частном варианте осуществления способа на этапе предобработки изображение преобразуется для получения показателя глубины цвета 24 бита.
[15] В другом частном варианте осуществления способа на этапе предобработки изображение дополнительно преобразуется в формат JPEG.
[16] В другом частном варианте осуществления способа тип морфологической операции выбирается из группы: открытие, закрытие, эрозия, дилатация, медианный фильтр, морфологический градиент, или их сочетания.
[17] В другом частном варианте осуществления способа документ содержит поля с персональными текстовыми данными.
[18] В другом частном варианте осуществления способа для итогового изображения сохраняется вектор признаков, на основании которого определяется тип документа.
[19] Заявленное решение также осуществляется с помощью системы удаления персональных данных с изображения документа, которая включает в себя по меньшей мере один процессор и по меньшей мере одно средство хранения данных, содержащее машиночитаемые инструкции, которые при их исполнении процессором реализуют вышеописанный способ.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[20] Фиг. 1А - Фиг. 1В иллюстрируют блок-схему выполнения заявленного способа.
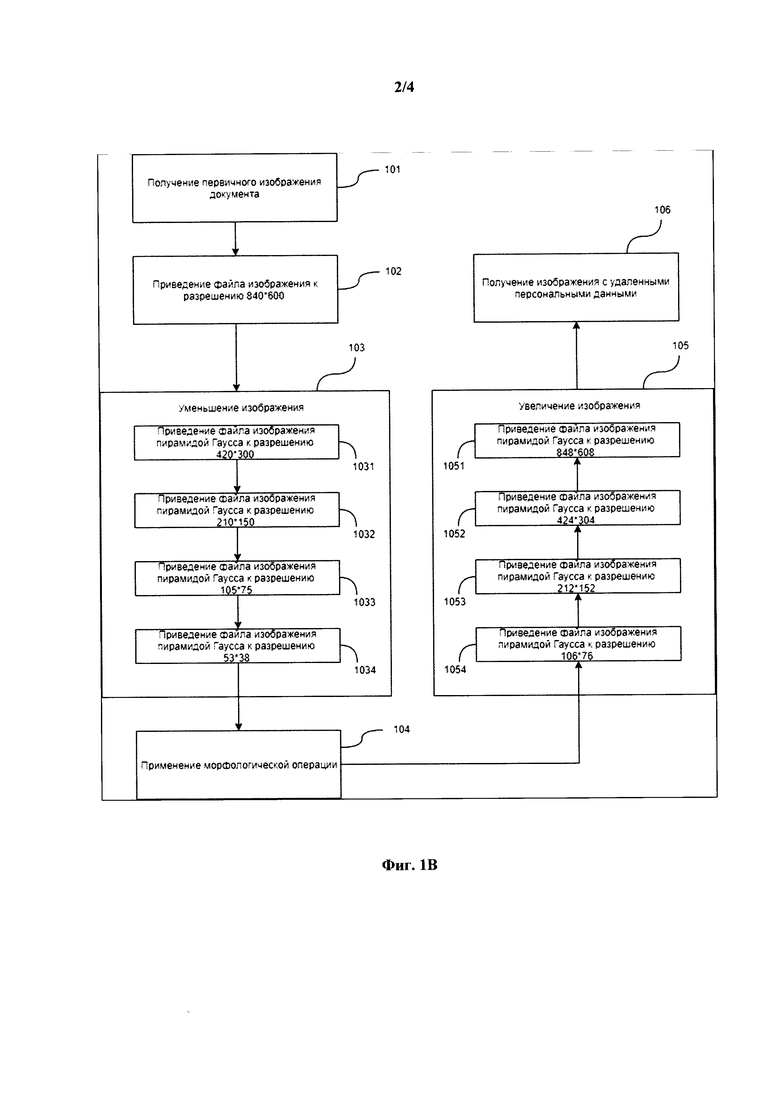
[21] Фиг. 2 иллюстрирует пример обработки документа.
[22] Фиг. 3 иллюстрирует пример вычислительного устройства для реализации заявленного решения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[23] На Фиг. 1А - Фиг. 1В представлен процесс выполнения заявленного способа (100) преобразования изображения документов, содержащих персональные данные. Преобразование документа реализуется в автоматизированном режиме при получении первичного изображения (101), подлежащего преобразованию. Изображение может получаться из различных источников в одном из поддерживаемых графических форматов, например, PDF, TIFF, JPG и т.п.
[24] Способ (100) преобразования документов может выполняться с помощью стандартизованного вычислительного устройства, например, компьютера. Информация для обработки изображений документов может передаваться на упомянутое устройство с помощью сети передачи данных, например, Интернет, Интранет, ЛВС и т.п.
[25] В качестве изображений документов, как правило, обрабатываются стандартизованные типы документов, например:
- ИНН;
- СНИЛС;
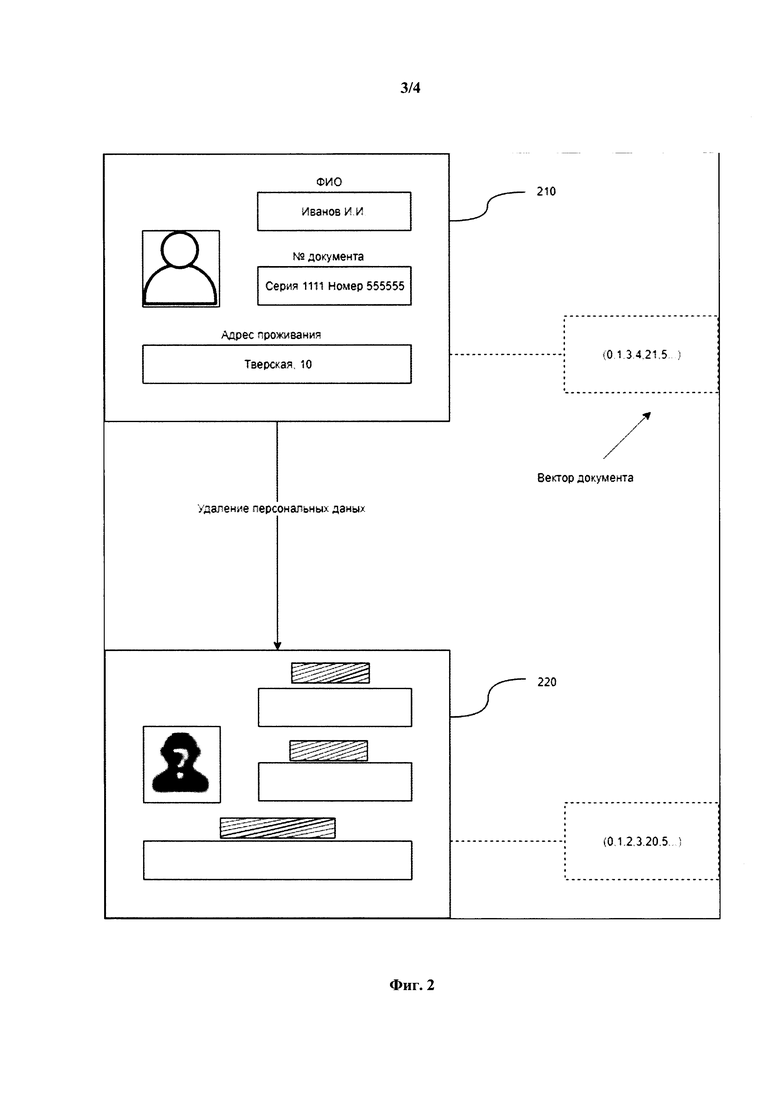
- Паспорт РФ, стран СНГ, загранпаспорт;
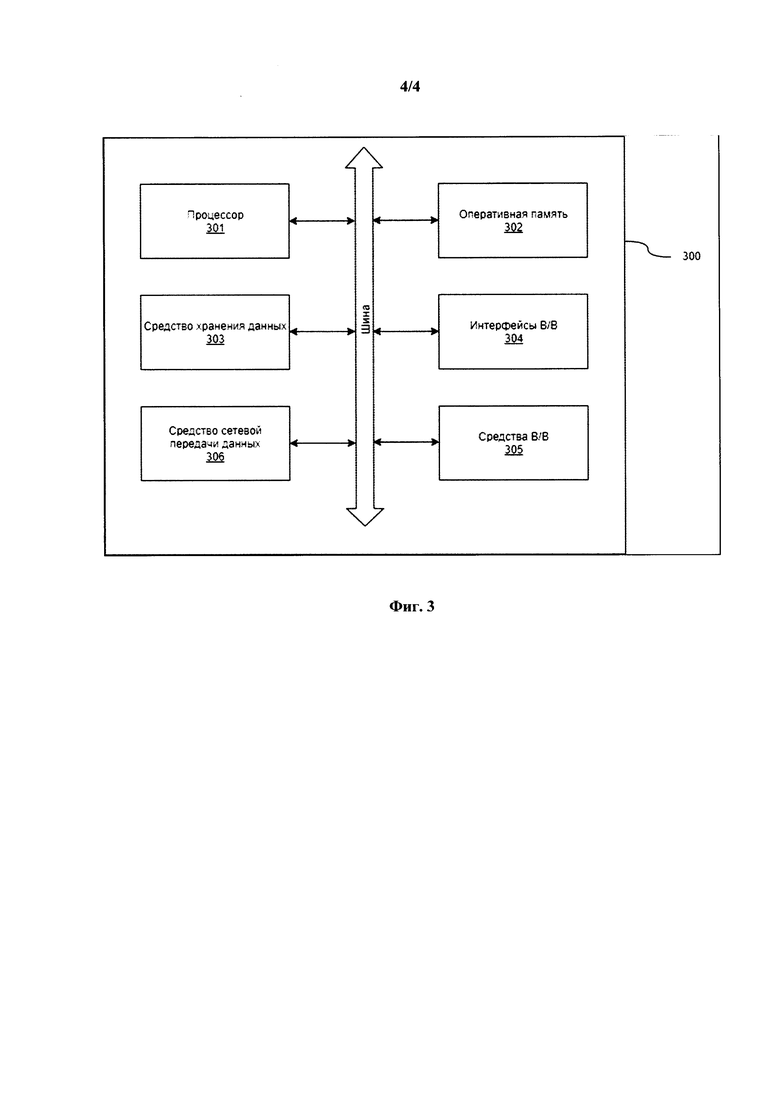
- Водительские удостоверение РФ/США/Европейского союза;
- национальные ID-карты Европейского союза и т.п.
[26] Приведенный перечень документов не является исчерпывающим и может быть дополнен новыми типами документов.
[27] Как правило каждый из приведенных выше типов документа содержит одно или несколько полей с текстовой информацией. Каждое такое поле представляет собой локальный блок логически связанного текста в документе. Так, например, полем текста в паспорте является Имя, Фамилия, дата рождения или номер паспорта. Поле присутствует в документе, если имеется возможность прочитать хотя-бы одну букву из текстового поля. В противном случае поле отсутствует.
[28] Задача анонимизации документа для целей его преобразования для удаления персональных данных может быть поставлена следующим образом. Пусть задано множество изображений документов I, например, фотографических изображений. Каждому такому изображению 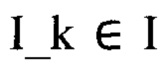 соответствует вектор признаков Р_k, которому однозначно соответствует один из типов, например, из приведенного выше перечня типов документов.
соответствует вектор признаков Р_k, которому однозначно соответствует один из типов, например, из приведенного выше перечня типов документов.
[29] Координаты вектора P_k неизвестны, но экспериментально было установлено, что они связаны с формой документа и расположением цветовых регионов на документе. А - множество всех полей с персональной информацией. В изображении I_k присутствуют поля текста с персональной информацией 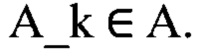 Стоит задача построить преобразование f:I ->I'. I' - множество изображений, без текстовых полей с персональной информацией.
Стоит задача построить преобразование f:I ->I'. I' - множество изображений, без текстовых полей с персональной информацией. 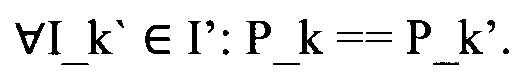
[30] Искомое преобразование f может быть построено следующим образом для обеспечения требуемого вида итогового изображения документа. Предпочтительно, чтобы первичное изображение документа было получено с помощью фотографической съемки на камеру, например, фотокамеру, при этом фотография должна содержать весь документ.
[31] Высота поля с текстом в документах составляет не более 1/26 от высоты всей фотографии (при расположении текста горизонтально относительно альбомной ориентации) и не более 1/19 от ширины изображения (при расположении текста вертикально относительно альбомной ориентации).
[32] При получении фотографических изображений с фотокамеры поля текста имеют форму, близкую к прямоугольной, при этом высотой считается высота самой высокой буквы в поле. Предпочтительно, чтобы соотношение сторон фотографии приблизительно было равно 14:5 и фотографическое изображение документа было цветным (глубина цвета 24 бита). Соблюдение данных требований позволяет полностью удалить печатный текст с фотографии, но оставить возможность классификации типа документа на достаточно высоком уровне.
[33] После получения изображения документа на этапе (101) выполняется его предобработка (102). На данном этапе выполняется приведение изображения к заданному размеру и разрешению. В частности, как показано на Фиг. 1В, для изображения устанавливается разрешение 840*600 пикселей (сжатие, при условии, что обрезанное изображение по размерам больше 840×600, иначе пропорциональное растяжение), а также приведение сторон изображения к показателю 5:7. Предпочтительно также выполняться преобразование формата изображения в JPEG с глубиной 24 бита и устанавливать альбомную ориентацию его расположения. Преобразование первичного изображения может осуществляться с помощью известных алгоритмов графической обработки, обеспечивающих требуемые операции.
[34] В случае, если входного изображение представляет собой файл формата PDF с несколькими страницами, то такой документ преобразуется в набор изображений формата JPEG, к каждому из которых применяется указанная выше обработка на этапе (102). Далее к предобработанному изображению на этапе (102) применяется преобразование для уменьшения документа (103), которое выполняется с помощью четырехкратного перехода по пирамиде Гаусса. Как показано на Фиг. 1В преобразование с помощью пирамиды Гаусса выполняется с последовательным уменьшением разрешения изображения от установленного на этапе (102).
[35] Пирамида изображений представляет собой последовательность N изображений, причем каждое последующее изображение получается из предыдущего путем фильтрации и прореживания в два раза по схеме:

[36] Фильтрация изображений необходима для подавления высокочастотных шумов. В качестве ядра h(u,v) используется функция Гаусса. По этой причине пирамида называется гауссовской. Согласно теореме Котельникова сжатие в гауссовской пирамиде происходит с минимальной потерей информации. Изображение fN(x,y) представляет собой уменьшенную копию исходного изображения f1(x,y). Размер пиксела изображения уровня N равен pN=2N-1. Для координат пикселов изображений двух произвольных уровней пирамиды с номерами n и m справедливы соотношения 2n-1xn=2m-1xm, 2n-1yn=2m-1ym.
[37] В результате выполнения этапов (1031) - (1034) изображение документа уменьшается до размера 53x38 пикселей. Высота строки текста в документах составляет не более 1/26 от высоты изображение (при расположении текста горизонтально относительно альбомной ориентации) и не более 1/19 от ширины изображения (при расположении текста вертикально относительно альбомной ориентации). Таким образом, после применения преобразования по пирамиде Гаусса, высота строки текста не будет превышать 2 пикселя, вследствие чего буквы текста будут почти не различимы.
[38] На этапе (104) выполняется применение одной или нескольких морфологических операций для гарантированного удаления возможной оставшейся информации в строках текста, а также для пресечения возможного восстановления части информации. Например, может применяться морфологическая операция открытие с окном в 3×3 пикселя, которая определяется формулой:
dst=open(source, element)=dilate(erode(source, element)), где dst - конечное изображение, source - начальное изображение, и element - окно применения операции (в данном случае 3×3). Операция дилатация (dilatate): dst(x,y)=max(x',y'): element(x',y')≠0 src(x+x',y+y')(поиск максимума в окне и заполнения окна этим максимумом), операция эрозия (erosion): dst(x,y)=min(x',y'): element(x',y')≠0 src(x+x',y+y')(поиск минимума в окне и заполнения окна этим минимумом). Также, в качестве морфологических операций могут применяться: закрытие, эрозия, медианный фильтр, морфологический градиент, или их сочетания.
[39] После применения морфологических операций над уменьшенным изображением на этапе (105) осуществляется последовательное применение пирамиды Гаусса для увеличения изображения (переход на 4 уровня выше по пирамиде Гаусса) для возвращения к первоначальному размеру (возможно с незначительными отклонениями в итоговом разрешении).
[40] Полученное изображение с удаленными персональными данными сохраняется (106), например, в базе данных, либо передается для дальнейшей его обработки. Важной особенностью представленного подхода является то, что информация удаляется без возможности ее восстановления. Для итогового изображения документа рассчитывается и сохраняется вектор признаков, по которому можно установить тип документа. Это процедура выполняется исходя из того, что для входного документа известен вектор признаков, характеризующих тип документа.
[41] На Фиг. 2 представлен пример обработки первичного изображения документа (210), содержащего персональные данные, для целей их удаления с итогового изображения документа (220). Итоговый документ преобразуется в вид, исключающий последующее восстановление первоначальной информации в нем, но по вектору признаков позволяет соотнести его с тем или иным типом документ установленного образца.
[42] На Фиг. 3 представлена архитектурное исполнение системы (300), пригодной для реализации заявленного способа, которая может выполняется на базе стандартизованной компоновки вычислительных устройств (персональный компьютер, сервер, серверный кластер, мейнфрейм и т.п.) и включает в себя такие компоненты, как: один или несколько процессоров (301), оперативную память (302), средство хранения данных (303), интерфейсы ввода/вывода (304), средства ввода/вывода (305) и средство сетевого взаимодействия (306).
[43] Процессор (301) предназначен для выполнения программной логики и требуемых вычислительных операций, необходимых для функционирования системы (300). Процессор (301) исполняет необходимые машиночитаемые команды и инструкции, содержащиеся в оперативной памяти (302). Процессор (301) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в архитектуре системы (300) также необходимо учитывать графический процессор, например, GPU NVIDIA или Graphcore, тип которых также является пригодным для полного или частичного выполнения способов реализации заявленного решения, а также может применяться для обучения и применения моделей машинного обучения.
[44] Оперативная память (302), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал. Средство хранения данных (303) может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средства (303) позволяют выполнять долгосрочное хранение различного вида информации.
[45] Интерфейсы (304) представляют собой стандартные средства для подключения и работы нескольких устройств, например, USB, RS232, RJ45, LPT, COM. HDMI, PS/2, Lightning, FireWire и т.п. Выбор интерфейсов (304) зависит от конкретного исполнения системы (300). В качестве средств ввода/вывода данных (305) может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
[46] Средства сетевого взаимодействия (306) выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств (305) обеспечивается организация обмена данными по проводному и/или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[47] Представленные описание заявленного решения раскрывает лишь предпочтительные примеры его реализации и не должно трактоваться как ограничивающее иные, частные примеры его осуществления, не выходящие за рамки объема правовой охраны, которые являются очевидными для специалиста соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ЭФФЕКТИВНОЙ ПОДГОТОВКИ СОДЕРЖАЩИХ ТЕКСТ ИЗОБРАЖЕНИЙ К ОПТИЧЕСКОМУ РАСПОЗНАВАНИЮ СИМВОЛОВ | 2016 |
|
RU2636097C1 |
| СПОСОБ И СИСТЕМА ПОИСКА ГРАФИЧЕСКИХ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2807639C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ И СИСТЕМА ПОДГОТОВКИ СОДЕРЖАЩИХ ТЕКСТ ИЗОБРАЖЕНИЙ К ОПТИЧЕСКОМУ РАСПОЗНАВАНИЮ СИМВОЛОВ | 2016 |
|
RU2628266C1 |
| СПОСОБ ВЫЯВЛЕНИЯ ОНКОЗАБОЛЕВАНИЙ В ОРГАНАХ МАЛОГО ТАЗА И СИСТЕМА ДЛЯ РЕАЛИЗАЦИИ СПОСОБА | 2023 |
|
RU2814790C1 |
| УЛУЧШЕНИЯ КАЧЕСТВА РАСПОЗНАВАНИЯ ЗА СЧЕТ ПОВЫШЕНИЯ РАЗРЕШЕНИЯ ИЗОБРАЖЕНИЙ | 2013 |
|
RU2538941C1 |
| АВТОМАТИЗИРОВАННЫЕ СПОСОБЫ И СИСТЕМЫ ВЫЯВЛЕНИЯ НА ИЗОБРАЖЕНИЯХ, СОДЕРЖАЩИХ ДОКУМЕНТЫ, ФРАГМЕНТОВ ИЗОБРАЖЕНИЙ ДЛЯ ОБЛЕГЧЕНИЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ВЫЯВЛЕННЫХ СОДЕРЖАЩИХ ДОКУМЕНТЫ ФРАГМЕНТОВ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2647670C1 |
Изобретение относится к способу и системе удаления текстовых персональных данных с изображения документа. Технический результат заключается в обеспечении деперсонализации данных на изображении. В способе получают первичное изображение документа, содержащего персональные данные, выполняют предобработку упомянутого изображения, при которой осуществляют формирование изображения заданного размера и разрешения, осуществляют уменьшение предобработанного изображения с помощью его четырехкратного преобразования с использованием перехода по пирамиде Гаусса, удаляют текстовые персональные данные путем применения по меньшей мере одной морфологической операции с окном в 3×3 пикселя к уменьшенному изображению документа, осуществляют увеличение полученного изображения с помощью четырехкратного преобразования с использованием перехода по пирамиде Гаусса, формируют итоговое изображение документа с удаленными текстовыми персональными данными. 2 н. и 7 з.п. ф-лы, 4 ил.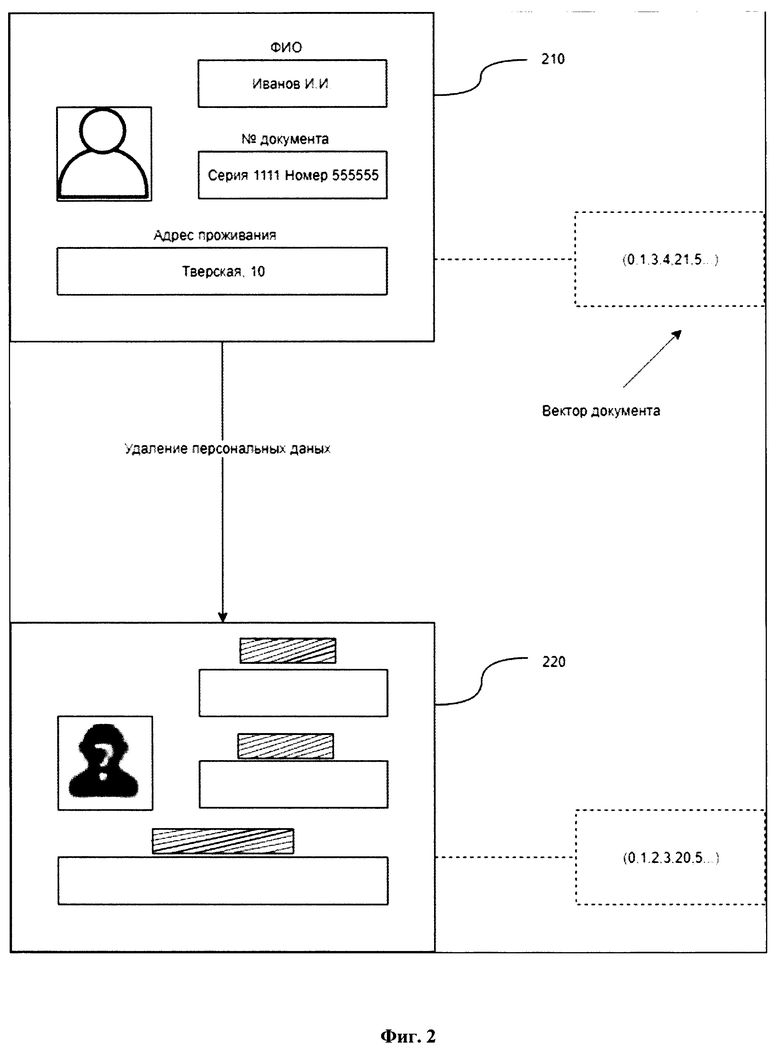
1. Компьютерно-реализуемый способ удаления текстовых персональных данных с изображения документа, выполняемый с помощью процессора и содержащий этапы, на которых:
- получают первичное изображение документа, содержащего персональные данные;
- выполняют предобработку упомянутого изображения, при которой осуществляют формирование изображения заданного размера и разрешения;
- осуществляют уменьшение предобработанного изображения с помощью его четырехкратного преобразования с использованием перехода по пирамиде Гаусса;
- удаляют текстовые персональные данные путем применения по меньшей мере одной морфологической операции с окном в 3×3 пикселя к уменьшенному изображению документа;
- осуществляют увеличение полученного изображения с помощью четырехкратного преобразования с использованием перехода по пирамиде Гаусса;
- формируют итоговое изображение документа с удаленными текстовыми персональными данными.
2. Способ по п. 1, характеризующийся тем, что на этапе предобработки осуществляется приведение соотношения сторон изображения для получения показателя 5:7.
3. Способ по п. 1, характеризующийся тем, что на этапе предобработки устанавливается разрешение изображения 840×600 пикселей.
4. Способ по п. 1, характеризующийся тем, что на этапе предобработки изображение преобразуется для получения показателя глубины цвета 24 бита.
5. Способ по п. 1, характеризующийся тем, что на этапе предобработки изображение дополнительно преобразуется в формат JPEG.
6. Способ по п. 1, характеризующийся тем, что тип морфологической операции выбирается из группы: открытие, закрытие, эрозия, дилатация, медианный фильтр, морфологический градиент или их сочетания.
7. Способ по п. 1, характеризующийся тем, что документ содержит поля с персональными текстовыми данными.
8. Способ по п. 1, характеризующийся тем, что для итогового изображения сохраняется вектор признаков, на основании которого определяется тип документа.
9. Система удаления текстовых персональных данных с изображения документа, причем система включает в себя по меньшей мере один процессор и по меньшей мере одно средство хранения данных, содержащее машиночитаемые инструкции, которые при их исполнении процессором реализуют способ по любому из пп. 1-8.
| ВИЗУАЛЬНАЯ ДЕПЕРСОНАЛИЗАЦИЯ МАССИВОВ МЕДИЦИНСКИХ ДАННЫХ ДЛЯ ЗАЩИТЫ ПРИ ОБЪЕМНОМ 3D-РЕНДЕРИНГЕ | 2015 |
|
RU2679969C2 |
| US 9799096 B1, 24.10.2017 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 7831571 B2, 09.11.2010 | |||
| EP 3100203 B1, 19.12.2018 | |||
| US 9147179 B2, 29.09.2015 | |||
| US 8069053 B2, 29.11.2011 | |||
| US 9426387 B2, 23.08.2016 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| US 7158979 B2, 02.01.2007 | |||
| US | |||

