Область техники, к которой относится изобретение
Настоящее изобретение относится к области компьютерных технологий, в частности, к способам обработки и анализа аудиозаписей. Более конкретно, изобретение можно использовать для повышения качества и разборчивости речевых записей, и/или использоваться как часть системы преобразования текста в речь в качестве нейронного вокодера.
Уровень техники
По мере развития области искусственного интеллекта генеративные модели становятся мощным инструментом для решения различных задач, включая обработку речи. В последнее время внимание привлекли диффузионные модели (см. [1, 2, 3]) благодаря своей способности эффективно моделировать сложные многомерные распределения. Диффузионные модели направлены на изучение неявной априорной информации базового распределения данных путем сопоставления градиента логарифмической плотности.
Один из развивающихся в настоящее время подходов к задаче обработки речи, в частности к восстановлению голоса, дифференциации речи, вокодированию и т.д., известен как безусловная генерация речи. Однако последний случай обычно представляет собой сложную задачу из-за большого разнообразия возможного лингвистического содержания.
В предшествующих работах в области диффузионных моделей обычно рассматривается условная генерация речи [10, 11] или их объем ограничен простыми наборами данных с предопределенными фразами (например, произносимыми цифрами) [12, 10]. В источнике [1] описаны основанные на вкладе диффузионные модели, относящиеся к классу нейронных генеративных моделей, которые можно неформально описать как постепенное преобразование аналитически известных и неизвестных (имеются только выборки) распределений данных друг в друге.
В источнике [7] описано применение одной диффузионной модели для решения нескольких задач восстановления аудиозаписи, а именно расширения полосы частот и деклиппинга. Однако способ [7] был экспериментально опробован на музыке, в частности для восстановления фортепианных аудиозаписей, в то время как настоящее изобретение предназначено главным образом для восстановления речевых записей. Кроме того, известное решение [7] не было протестировано на таких задачах, как нейронное вокодирование и разделение сигналов разных источников из смеси голосов. В известном решении [7] используется модель с архитектурой UNet, а не FFC-AE, которая, как известно, имеет преимущества перед UNet.
Раскрытие изобретения
Данный раздел, в котором раскрыты различные аспекты заявленного изобретения, предназначен для обеспечения краткого обзора заявленных объектов изобретения и их вариантов осуществления. Ниже приведены подробные характеристики технических средств и способов, которые реализуют комбинации признаков заявленного изобретения. Ни данное раскрытие изобретения, ни приведенное ниже подробное описание вместе с сопровождающими чертежами не следует рассматривать как определяющие объем заявленного изобретения. Объем правовой охраны заявленного изобретения определяется только нижеследующей формулой изобретения.
Техническая проблема, решаемая настоящим изобретением, состоит в обеспечении возможности применения заявляемого способа для различных задач обработки речи без какой-либо дополнительной подготовки.
Задача настоящего изобретения состоит в создании усовершенствованного способа и системы для восстановления голоса с использованием модели безусловной диффузии.
Технический результат, достигаемый с использованием заявленного изобретения, состоит в повышении качества и разборчивости речевых записей.
В первом аспекте упомянутая выше задача решается способом восстановления голоса в речевых записях, содержащим этапы, на которых: принимают аудиоданные речевой записи, содержащей голосовой аудиосигнал; применяют вероятностную модель диффузии, обученную на задаче подбора функции вклада для шумоподавления, для безусловной генерации речи, причем вероятностную модель диффузии применяют к аудиоданным речевой записи в виде формы волны, содержащей случайный гауссовский шум; осуществляют итеративную выборку формы волны с использованием функции условного вклада, которая является суммой функции безусловного вклада, оцененной вероятностной моделью диффузии, и логарифмического правдоподобия, для получения выборки с уменьшенным количеством шума для следующей итерации, пока не будет получена обесшумленная форма волны речевого сигнала; и выводят обработанный голосовой аудиосигнал, содержащий обесшумленную форму волны речевого сигнала.
Вероятностную модель диффузии выбирают из группы, включающей модель автоэнкодера быстрой свертки Фурье (FFC-AE), модель Diffwave и модель CQT-UNet. Способ может дополнительно включать выполнение расширения полосы частот в голосовом аудиосигнале, выполнение деклиппинга в голосовом аудиосигнале, выполнение нейронного вокодирования в голосовом аудиосигнале для преобразования спектральных представлений голосового
аудиосигнала в формы волны аудиосигнала, выполнение разделения сигналов разных источников в голосовом аудиосигнале. Вероятностная модель диффузии может быть адаптирована для инверсии деградации. Вероятностная модель диффузии может быть адаптирована для решения задач расширения полосы частот, деклиппинга, нейронного вокодирования и/или разделения сигналов разных источников путем модификации процедуры выборки голосового аудиосигнала, причем упомянутая модификация обусловливает выборку наблюдениями, которые представляют собой форму волны с уменьшенной полосой частот для задачи расширения полосы частот, клиппированной формой волны для задачи деклиппинга, мел-спектрограммой в случае задачи нейронного вокодирования и/или формой волны со смешанными голосами для задачи разделения сигналов разных источников.
Во втором аспекте упомянутая выше задача решается системой для восстановления голоса в речевых записях, содержащей: память; модуль приема речевой записи, выполненный с возможностью приема речевой записи, содержащей по меньшей мере голосовой аудиосигнал; модуль обработки по восстановлению голоса, причем модуль обработки по восстановлению голоса содержит: нейросетевой модуль, выполненный с возможностью применения вероятностной модели диффузии, обученной на задаче подбора функции вклада для шумоподавления для безусловной генерации речи, причем вероятностная модель диффузии применяется к аудиоданным речевой записи в виде формы волны, содержащей случайный гауссовский шум; при этом нейросетевой модуль выполнен с возможностью итеративной выборки формы волны с использованием функции условного вклада, которая является суммой функции безусловного вклада, оцененной вероятностной моделью диффузии, и логарифмического правдоподобия, для получения выборки с уменьшенным количеством шума для следующей итерации, пока не будет получена обесшумленная форма волны речевого сигнала; и модуль обработки по восстановлению голоса выполнен с возможностью вывода обработанного голосового аудиосигнала, содержащего обесшумленную форму волны речевого сигнала.
Вероятностная модель диффузии выбирается из группы, включающей модель автоэнкодера быстрой свертки Фурье (FFC-AE), модель Diffwave и модель UNet. Система может дополнительно содержать модуль расширения полосы частот, выполненный с возможностью выполнения расширения полосы частот в голосовом аудиосигнале, модуль деклиппинга, выполненный с возможностью выполнения деклиппинга в голосовом аудиосигнале, модуль нейронного вокодера, выполненный с возможностью преобразования спектральных представлений голосового аудиосигнала в формы волн аудиосигнала, модуль разделения сигналов разных источников, выполненный с возможностью выполнения разделения сигналов разных источников в голосовом аудиосигнале.
Система может дополнительно содержать модуль интерфейса ввода-вывода (I/O), выполненный с возможностью ввода речевой записи, содержащей по меньшей мере голосовой аудиосигнал, и/или вывода обработанного голосового аудиосигнала, причем модуль интерфейса ввода/вывода может содержать модуль аналого-цифрового преобразователя (АЦП), выполненный с возможностью выполнения аналого-цифрового преобразования входной речевой записи. Модуль интерфейса ввода/вывода может содержать модуль цифро-аналогового преобразователя (ПАП) для выполнения цифро-аналогового преобразования выходного обработанного голосового аудиосигнала.
В третьем аспекте упомянутая выше задача решается машиночитаемым носителем, на котором хранятся машиноисполняемые инструкции, которые, при выполнении одним или более процессорами, предписывают одному или более процессорам осуществлять способ согласно первому аспекту.
Краткое описание чертежей
Чертежи приведены в данном документе для облегчения понимания сущности настоящего изобретения. Данные чертежи схематичны и не выполнены в масштабе. Чертежи служат только для иллюстрации и предназначены для определения объема настоящего изобретения.
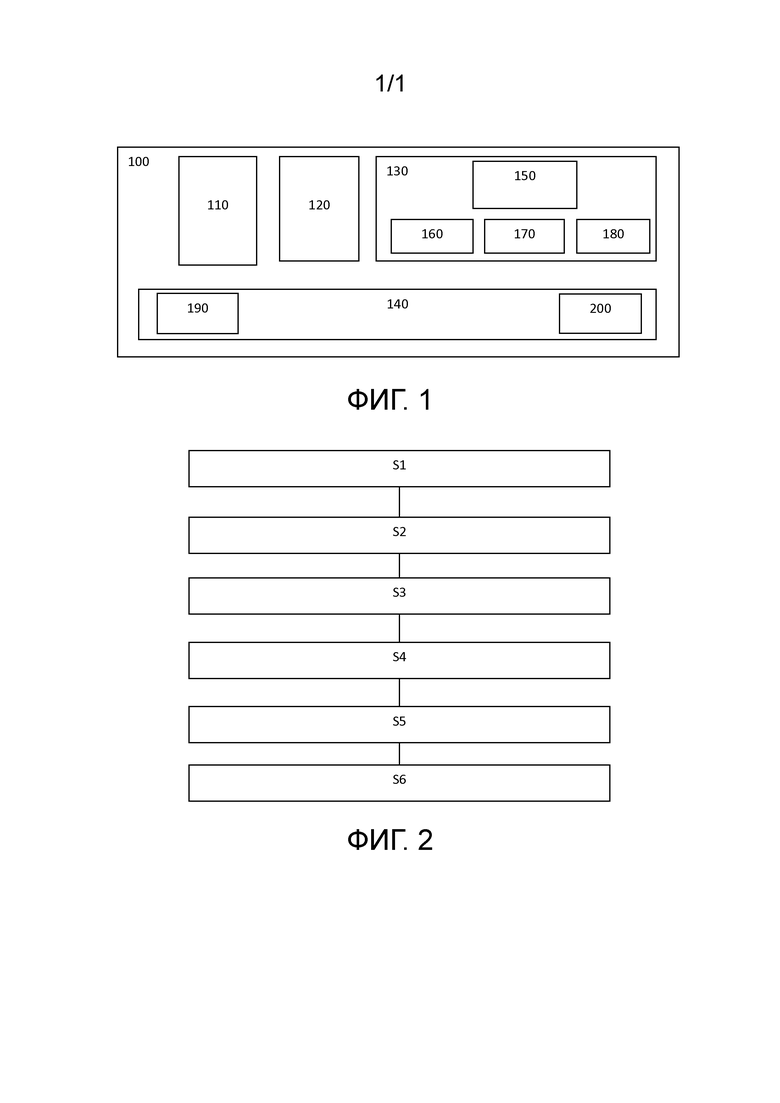
Фиг.1 иллюстрирует принципиальную схему системы для восстановления голоса в соответствии с одним или более вариантами осуществления настоящего изобретения;
Фиг. 2 иллюстрирует блок-схему способа восстановления голоса в соответствии с одним или более вариантами осуществления настоящего изобретения.
Осуществление изобретения
Далее будут подробно описаны иллюстративные варианты осуществления настоящего изобретения. Эти иллюстративные варианты проиллюстрированы на сопровождающих чертежах, на которых одинаковые или аналогичные ссылочные позиции обозначают одинаковые или аналогичные элементы или элементы, которые имеют одинаковые или аналогичные функции. Иллюстративные варианты осуществления, описанные с обращением к прилагаемым чертежам, являются примерными и используются лишь для объяснения настоящего изобретения и не должны рассматриваться как каким-либо образом ограничивающие его.
В основе заявленного способа лежит вероятностная модель диффузии, которая способна решать различные речевые обратные задачи. В общем, диффузионные модели предназначены для изучения неявной априорной информации базового распределения данных путем сопоставления градиента логарифмической плотности. Эта полученная ранее априорная информация может быть полезна для решения обратных задач, где целью является восстановление входного сигнала х из измерений у, которые обычно связаны через некоторый дифференцируемый оператор А, так что у=A(x) + n, где n - некоторый шум.
Этот метод можно использовать для повышения качества и разборчивости речевых записей путем расширения полосы частот, деклиппинга и разделения сигналов разных источников. Также его можно использовать как часть системы преобразования текста в речь в качестве нейронного вокодера. Настоящее изобретение предлагает новую вероятностную модель диффузии, способную решать различные речевые обратные задачи. Однажды обучив вероятностную модель диффузии генерировать форму волны речевого сигнала безусловным образом, ее можно адаптировать к различным задачам, включая инверсию деградации, нейронное вокодирование и разделение сигналов разных источников. Поэтому в контексте настоящего изобретения модель, используемая для достижения описанной выше цели изобретения, будет в общем именоваться в данном документе как модель безусловной диффузии (UnDiff).
В отличие от описанного выше уровня техники, настоящее изобретение сосредоточено на обучении модели безусловной диффузии, но не ограничивает при этом лингвистическое содержание обучающих наборов данных. Однако следует отметить, что концепция изобретения генерирует только синтаксически согласованные речевые записи (такие как речеподобные звуки), которых, по мнению авторов настоящего изобретения, достаточно для целей неконтролируемого восстановления голоса без учителя в соответствии с изобретением. В данном контексте неконтролируемое восстановление голоса без учителя означает восстановление, основанное на неконтролируемом алгоритме машинного обучения без учителя, который, как известно, не полагается на размеченные данные, в отличие от контролируемых алгоритмов обучения с учителем, которые требуют предварительного вмешательства человека для соответствующей разметки обучающих данных.
В контексте изобретения рассматриваются следующие три подхода к построению моделей безусловной диффузии, все из которых работают во временной области, но имеют различные предобусловливающие преобразования:
1. Диффузионная нейронная сеть, работающая непосредственно во временной области;
2. Нейронная сеть FFC-AE, работающая на спектрограммах кратковременного преобразования Фурье;
3. Нейронная сеть CQT-UNet, работающая на спектрограммах преобразования постоянной добротности.
Следует отметить, что эти подходы могут быть использованы в контексте настоящего изобретения в любой подходящей комбинации и/или по отдельности, и варианты осуществления настоящего изобретения в общем не ограничены применением какого-либо одного из этих подходов и/или их комбинаций, что может быть особенно выгодно в определенных случаях, как будет показано ниже.
В частности, в одном или более неограничивающих вариантах осуществления автоэнкодер быстрой свертки Фурье (FFC-AE) или вероятностная модель диффузии Diffwave обучается с целью сопоставления показателей шумоподавления для задачи генерации безусловной речи.
В общем случае, обучение модели выполняется по следующему принципу. Начиная со случайного гауссовского шума в виде формы волны, итеративное обесшумливание этой формы волны выполняется путем численного решения обратного стохастического уравнения (в качестве примера см. выражение (2) ниже) с функцией условного вклада (в качестве примера см. выражение (5) ниже), которое представляет собой сумму функции безусловного вклада и логарифмического правдоподобия (в качестве примера см. выражение (б) ниже). Таким образом, модель обусловливается на искаженном речевом сигнале логарифмическим правдоподобием, прибавляемым к функции безусловного вклада, которая оценивается моделью FFC-AE (или, например, Diffwave).
Во время итеративного шумоподавления (выборки) генерируется форма волны речевого сигнала, соответствующая заданному условию (искаженный сигнал или мел-спектрограмма). На каждой итерации процесса выборки вывод предыдущей итерации передается в модель для оценки функции вклада и получения выборки с уменьшенным количеством шума для следующей итерации. В заключение, модель выдает обесшумленную форму волны речевого сигнала.
Такую обученную модель можно использовать для решения различных речевых обратных задач, среди которых задачи расширения полосы частот, деклиппинга, нейронного вокодирования и разделения сигналов разных источников путем модификации процедуры выборки; эти модификации обусловливают выборку из модели наблюдениями, представляющими собой форму волны с уменьшенной полосой частот в случае задачи расширения полосы частот, клиппированную форму волны в случае задачи деклиппинга, мел-спектрограмму в случае нейронного вокодирования и форму волны со смешанными голосами в случае задачи разделения сигналов разных источников. Данный метод основан на вероятностной модели диффузии (также именуемой здесь UnDiff), специально разработанной для решения этих и других задач обратной обработки речи, включая инверсию деградации, нейронное вокодирование и разделения сигналов разных источников.
Основное преимущество предложенного способа заключается в его способности обучения безусловной генерации формы волны речевого сигнала и последующей адаптации к обратной задаче без какого-либо дополнительного обучения с учителем для решения конкретных задач.
Модель безусловной диффузии (UnDiff)
Согласно изобретению вероятностная модель диффузии (UnDiff), имеющая в одном или более неограничивающих примерах архитектуру FFC-AE и представляющая собой, в общем, класс моделей «с учителем» со скрытыми переменными, сначала обучается безусловной генерации формы воны речевого сигнала. В данном контексте «безусловный» означает не обусловленный какими-либо априорными разметками данных (описаниями).
Для обучения вероятностной модели диффузии можно использовать различные обучающие наборы данных. Лишь несколько неограничивающих примеров обучающих наборов данных, которые пригодны для обучения вероятностной модели диффузии (UnDiff) в соответствии с настоящим изобретением, включают в себя, например, общедоступный набор данных VCTK (см. [20]), содержащий себя 44200 речевых записей, принадлежащих 110 дикторам, чистое подмножество Librispeech (см. [20]), которое представляет собой большой корпус начитанной английской речи, содержащий около 1000 часов аудиоданных, включая записи 2456 носителей языка, читающих аудиокниги, находящиеся в общественном достоянии. Специалисту в данной области техники будет понятно, что вместо вышеупомянутых наборов данных в контексте настоящего изобретения могут использоваться многие другие виды обучающих наборов данных, и поэтому объем изобретения ни в коем случае не ограничен вышеупомянутыми деталями.
В данной вероятностной модели диффузии используется стабилизирующее дисперсию стохастическое дифференциальное уравнение (VP-SDE), которое эквивалентно вероятностным моделям диффузии для шумоподавления (DDPM) (см. например [2]).
Вообще говоря, основанные на вкладе диффузионные модели (подобные описанной в источнике [1]) представляют собой класс нейронных генеративных моделей, которые можно неформально описать как постепенное преобразование аналитически известных и неизвестных (где доступны только выборки) распределений данных pknown и pdata друг в друга. Более формально, в качестве одного примера можно рассмотреть прямое (1) и обратное (2) стохастические уравнения Ito (VP-SDE) для процесса зашумления данных в следующем виде:
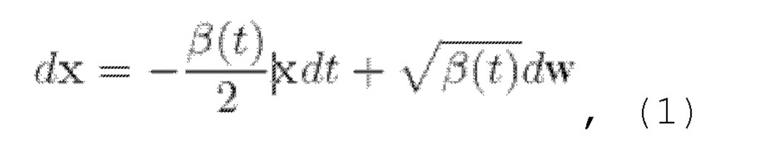
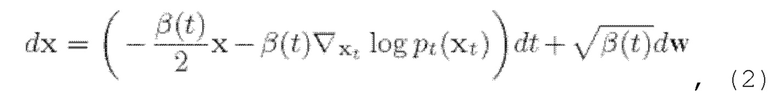
где t ∈ [0, Т] - временная переменная, β(t) - шумовой график процесса, выбранный так, что для 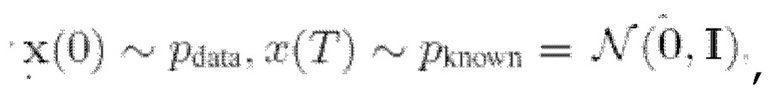 w - винеровский процесс.
w - винеровский процесс.
Хотя известны и другие формы стохастических дифференциальных уравнений, в одном или более неограничивающих вариантах осуществления настоящего изобретения конкретно используется VP-SDE для вероятностной модели диффузии, которая будет дополнительно использоваться в заявляемом способе восстановления голоса в речевых записях. VP-SDE - это форма стохастического дифференциального уравнения, используемая в изобретении для определения процесса диффузии.
При известной функции вклада 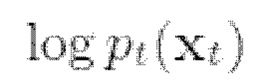 можно численно решить обратное SDE (2) и, таким образом, сгенерировать выборки из
можно численно решить обратное SDE (2) и, таким образом, сгенерировать выборки из  Функция вклада может быть аппроксимирована нейронной сетью
Функция вклада может быть аппроксимирована нейронной сетью 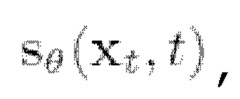 обученной на задаче подбора функции вклада для шумоподавления, что в конечном итоге приводит к функции потери L2:
обученной на задаче подбора функции вклада для шумоподавления, что в конечном итоге приводит к функции потери L2:
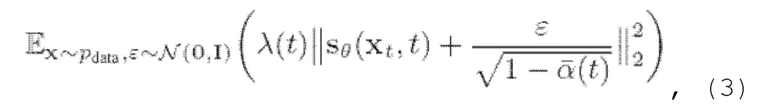
где 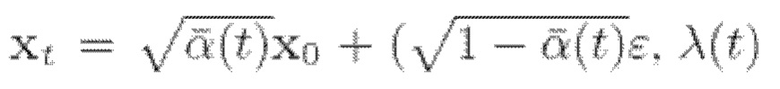 - весовая функция и
- весовая функция и 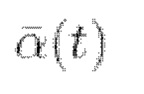 явная функция от
явная функция от 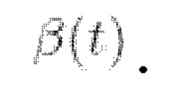 Масштабированная версия вклада оптимизируется,
Масштабированная версия вклада оптимизируется,  и устанавливается
и устанавливается 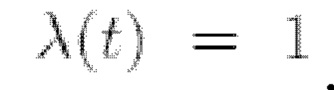 Используется линейный график для
Используется линейный график для 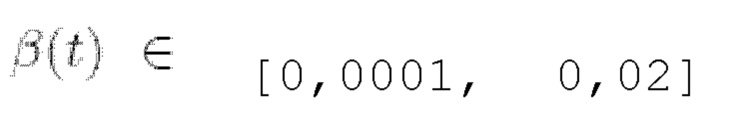 и устанавливается
и устанавливается 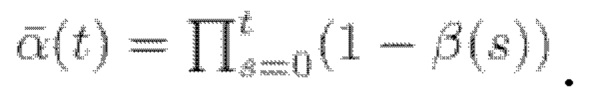 Приведенные выше математические выражения описывают один возможный пример функции SDE, пригодный для использования в контексте настоящего изобретения.
Приведенные выше математические выражения описывают один возможный пример функции SDE, пригодный для использования в контексте настоящего изобретения.
Известно, что в диффузионных моделях используется следующий принцип. Сначала они строят «генеративную цепь Маркова», которая преобразует известное распределение (например, упомянутое выше pknown) в «целевое» распределение (например, упомянутое выше Pdata) t используя процесс диффузии. Затем можно выполнить «обратное» преобразование, например, распределение обучающих данных в другое распределение, как было описано выше. Оба преобразования (например, данные в шум и шум в данные) можно выполнять с помощью одной и той же функциональной формы.
На практике в описанном выше процессе обучения модели используются распределения данных из обучающих наборов данных, упомянутых выше. Процесс обучения выполняется итеративно и на практике может включать в себя несколько сотен итераций на обучающем наборе данных (миллионы шагов градиентного спуска). Предложенный способ заметно отличается от известных аналогов тем, что этот алгоритм машинного обучения неконтролируемый без учителя и не основан на размеченных данных, в отличие от контролируемых алгоритмов обучения без учителя, которые требуют предварительного вмешательства человека на каждом этапе обучения для соответствующей разметки обучающих данных.
В способе согласно изобретению диффузионную модель обучают до тех пор, пока не будет достигнуто заданное условие завершения обучения. В качестве неограничивающего примера, диффузионная модель может обучаться до тех пор, пока не будет значительно повышено качество модели.
Задачи обратной обработки речи
В известных подходах для восстановления и генерации формы волны используются модели условной диффузии (см. например [4, 5, б]). В решении [7], как и в настоящем изобретении, также используется модель безусловной диффузии, но для конкретной задачи восстановления фортепианной музыки, и этот известный подход включает в себя решение проблем деклиппинга, расширения полосы частот и заполнения пробелов. В отличие от известного способа [7], настоящее изобретение направлено на решение более сложной проблемы восстановления речи и дополнительно рассматривает проблемы нейронного вокодирования и разделения сигналов разных источников речи, которые в контексте настоящего изобретения называются обратными задачами.
Было экспериментально доказано, что заявляемый способ эффективен при решении различных задач обработки речи, таких как расширение полосы частот, деклиппинг, нейронное вокодирование и разделения сигналов разных источников речи. Среди них расширение полосы частот (также известное как сверхразрешение звука) известно как задача реалистичного увеличения частоты дискретизации аудиосигнала. Деклиппинг аудиосигнала - это процесс реконструкции аудиосигнала с целью обратного клиппинга, то есть отсечения уровня сигнала, поднимающегося выше определенного максимального уровня. Нейронное вокодирование это процесс преобразования спектральных представлений аудиосигнала в формы волны аудиосигналов. Разделение сигналов разных источников речи обычно подразумевает извлечение одного или более интересующих исходных сигналов из аудиозаписи, которая включает в себя несколько источников звука. Следует отметить, что предлагаемый способ не ограничивается этими задачами, которые были упомянуты лишь в качестве иллюстрации. Способ согласно изобретению также можно применять как часть системы преобразования текста в речь в качестве нейронного вокодера.
Помимо прочего, в заявляемом способе используются методы постобучающего обусловливания диффузии (см. например [8, 1, 9]) для адаптации безусловной диффузии к каждой из вышеупомянутых задач.
Известно, что обратные задачи близки задаче извлечения объекта х при наличии его частичного наблюдения у и прямой модели p(y|x). Чтобы использовать обратное SDE (2) для выборки из условного распределения p(x|y), необходимо найти функцию вклада условного распределения 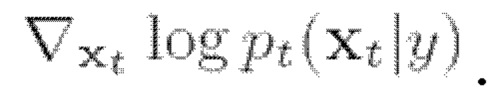 Одним из способов оценки указанной функции вклада условного распределения является применение управления подстановкой (согласования данных) (см., например, [1, 7, 9]). Идея, лежащая в основе этого метода, заключается в явном изменении вклада таким образом, чтобы некоторые части обесшумленной оценки
Одним из способов оценки указанной функции вклада условного распределения является применение управления подстановкой (согласования данных) (см., например, [1, 7, 9]). Идея, лежащая в основе этого метода, заключается в явном изменении вклада таким образом, чтобы некоторые части обесшумленной оценки 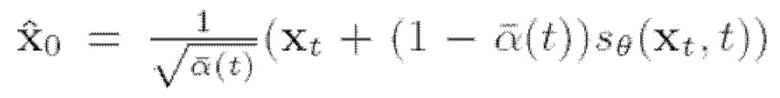 заменялись подстановкой наблюдений у. Возможные способы использования подстановки для различных речевых обратных задач будут более подробно рассмотрены ниже. Другим способом формализации поиска х является использование правила Байеса:
заменялись подстановкой наблюдений у. Возможные способы использования подстановки для различных речевых обратных задач будут более подробно рассмотрены ниже. Другим способом формализации поиска х является использование правила Байеса:
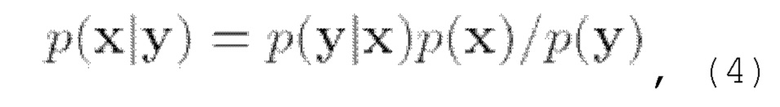
следовательно,
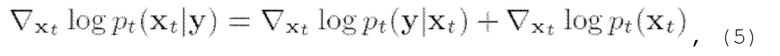
где 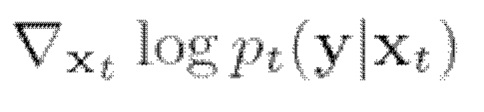 является вообще трудно решаемым.
является вообще трудно решаемым.
Однако из работы [8] известно, что можно сделать приближение 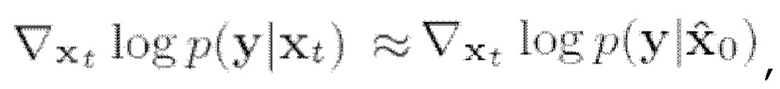 где
где 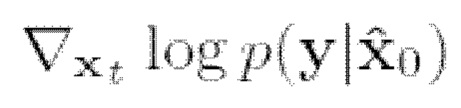 можно вычислить с использованием прямой модели. При наличии оператора наблюдения А и допущении гауссовой вероятности окончательное приближение принимает вид:
можно вычислить с использованием прямой модели. При наличии оператора наблюдения А и допущении гауссовой вероятности окончательное приближение принимает вид:
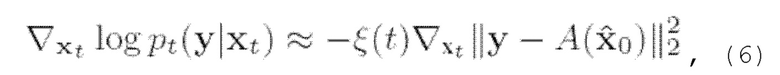
где 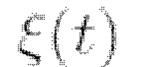 - заданный весовой коэффициент, который
- заданный весовой коэффициент, который
устанавливается обратно пропорциональным норме градиента. Как и в [7], в контексте настоящего изобретения этот способ можно назвать «управлением реконструкцией». В контексте настоящего изобретения по меньшей мере некоторые из вышеупомянутых математических уравнений можно применить для решения обратных задач, описанных выше. В общем, метод «управления реконструкцией» можно охарактеризовать следующим образом: как и в процессе выборки с безусловной моделью, обратное стохастическое уравнение (2) численно решается с использованием метода конечных разностей (выборки), но в процессе выборки функция вклада заменяется уравнением (5), где первый член вычисляется с использованием уравнения (б), а второй берется из безусловной модели.
После представленного выше обсуждения основ предлагаемого метода в вычислительных терминах, перейдем к подробному описанию модели безусловной диффузии в контексте настоящего изобретения. Безусловная генерация речи, в общем, является сложной задачей из-за большого разнообразия возможного лингвистического контента. При этом предшествующий уровень техники, связанный с моделями диффузии, имеет тенденцию рассматривать условную генерацию речи (см., например, [10, 11]) или ограничивать объем простыми наборами данных с предопределенными фразами (например, произносимыми цифрами) (см., например, [12, 10]). Что же касается настоящего изобретения, в нем, напротив, обучается модель безусловной диффузии и не ограничивается лингвистическое содержание наборов данных. Однако настоящее изобретение направлено на создание только синтаксически согласованных речевых записей (т.е. речеподобных звуков), которых, по мнению авторов изобретения, достаточно для целей восстановления голоса без учителя. Рассматриваются три подхода к построению моделей безусловной диффузии, все из которых работают во временной области, но имеют различные предобусловливающие преобразования:
1. Диффузионная нейронная сеть (например, как описанная в [10]), которая работает непосредственно во временной области;
2. Нейронная сеть FFC-AE (например, как описанная в [13]), которая работает на спектрограммах кратковременного преобразования Фурье;
3. Нейронная сеть CQT-UNet (например, как описанная в [7]), которая работает на спектрограммах преобразований постоянной Q.
Авторы настоящего изобретения отмечают, что в различных неограничивающих вариантах осуществления изобретения можно применить по меньшей мере один из этих трех подходов, и для использования в каждом случае выбирается самый оптимальный из них. Однако в других вариантах осуществления можно использовать комбинацию двух или трех подходов.
Расширение полосы частот
Предлагаемый способ может включать в себя этап расширения полосы частот (см., например, [14, 15], этот этап также называется сверхразрешением звука), который можно рассматривать как реалистичное увеличение частоты выборки сигнала. Оператор наблюдения - это фильтр нижних частот у =•A(x)=LPF(x). Таким образом, управление подстановкой в данном случае соответствует замене сгенерированной оценки низких частот наблюдаемыми низкими частотами у на каждом этапе. Более формально это соответствует изменению функции вклада во время выборки следующим образом:
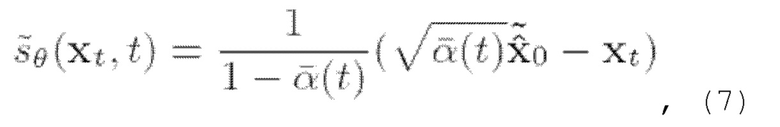
где  - подстановочная оценка хo, и
- подстановочная оценка хo, и 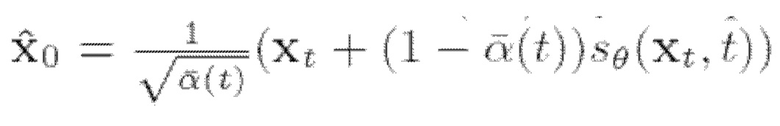 - оценка хo с использованием исходной функции вклада.
- оценка хo с использованием исходной функции вклада.
Деклиппинг
Затем выполняется деклиппинг на данных из предыдущего этапа способа. Аналогично тому, что делается в соответствующих операциях известного метода, описанного в [7], клиппинг рассматривается в контексте настоящего изобретения как обратная задача с функцией наблюдения, определяемой как 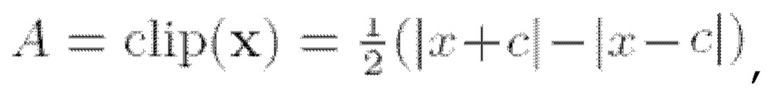 и применяется стратегия управления реконструкцией.
и применяется стратегия управления реконструкцией.
Нейронное вокодирование
Следующий этап способа можно охарактеризовать как "нейронное вокодирование". В большинстве современных систем синтеза речи эта задача разбивается на два этапа. На первом этапе на основе текстовых данных прогнозируются промежуточные представления с низким разрешением (например, лингвистические признаки, мел-спектрограммы) (см., например, [16, 17]). На втором этапе эти промежуточные представления преобразуются в необработанную форму волны (см., например, [18, 19]). Нейронные вокодеры относятся к методам, используемым на втором этапе процесса синтеза речи.
Нейронное вокодирование можно сформулировать как обратную задачу с оператором наблюдения, определяемым как вычисление мел-спектрограммы 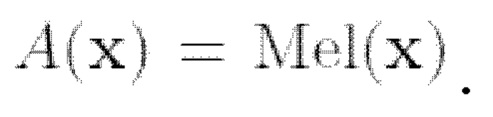 Вычисление синусоидальной мел-спектрограммы является дифференцируемой операцией, поэтому в данном случае можно легко применить управление реконструкцией.
Вычисление синусоидальной мел-спектрограммы является дифференцируемой операцией, поэтому в данном случае можно легко применить управление реконструкцией.
Следующий этап способа можно назвать разделением сигналов разных источников. В общем, целью одноканального выделения речи является извлечение отдельных речевых сигналов из смешанного аудиосигнала, в котором одновременно говорят несколько дикторов. К потенциальным областям применения разделения сигналов разных источников речи относятся телеконференции, распознавание речи и технология слуховых аппаратов. Пусть x1 и х2 будут двумя голосовыми записями. Рассмотрим модель наблюдения, которая смешивает эти две записи, т.е. 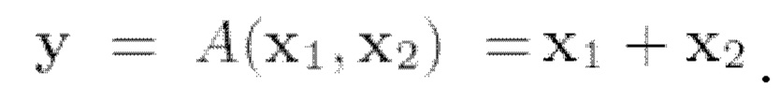 Следует отметить, что, поскольку х1 и х2 независимы, безусловную функцию плотности от их совместного распределения можно разложить на множители как
Следует отметить, что, поскольку х1 и х2 независимы, безусловную функцию плотности от их совместного распределения можно разложить на множители как 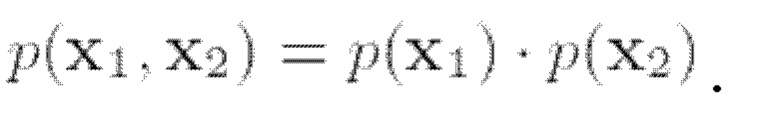
Таким образом, для функции безусловного вклада совместного распределения:
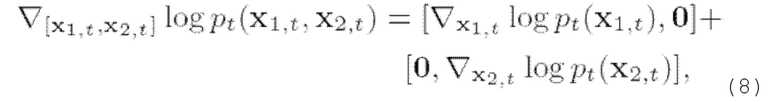
Согласно (5), для выборки из совместной условной плотности необходимо также оценить градиент логарифмического правдоподобия 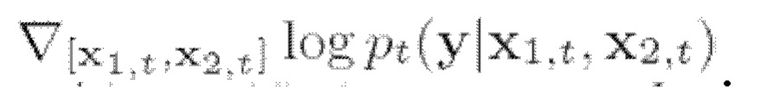 Можно применить управление реконструкцией (б), однако авторы настоящего изобретения нашли более естественный способ оценки градиента логарифмического правдоподобия для данного случая. В частности, поскольку у зависит только от суммы xi и х2, можно показать, что это же справедливо и для
Можно применить управление реконструкцией (б), однако авторы настоящего изобретения нашли более естественный способ оценки градиента логарифмического правдоподобия для данного случая. В частности, поскольку у зависит только от суммы xi и х2, можно показать, что это же справедливо и для 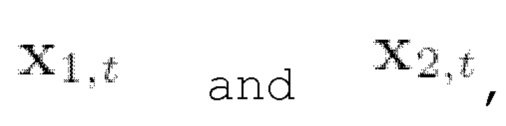 т.е.
т.е. 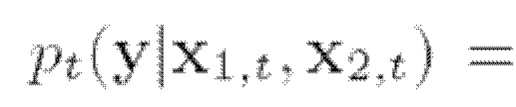
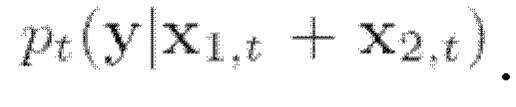 Действительно, эту вероятность можно вычислить аналитически, поскольку
Действительно, эту вероятность можно вычислить аналитически, поскольку 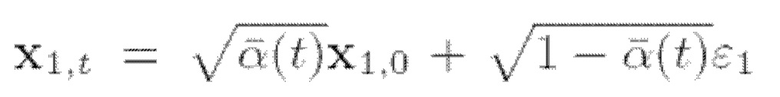 и
и 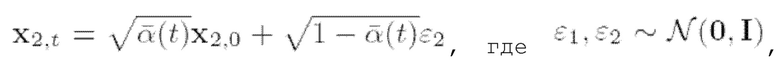 и таким образом:
и таким образом:
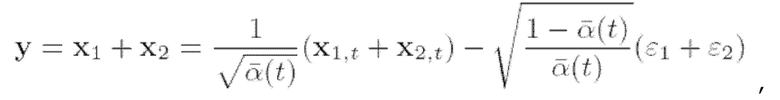
(9)
Значит
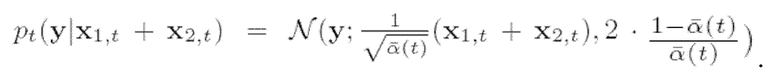
Следовательно, градиент логарифмического правдоподобия можно вычислить аналитически:
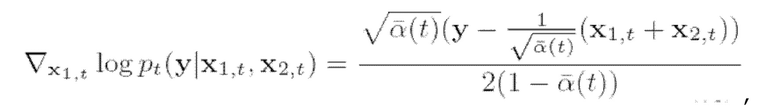
(10)
это же отношение справедливо и для 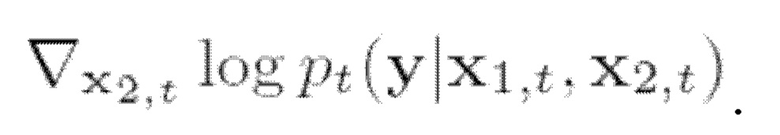
Можно рассмотреть два обобщения описанного выше случая разделения сигналов разных источников. Во-первых, можно ввести дополнительный параметр a ∈ [0,1], так что  . Это обобщение соответствует различной громкости смешанных голосов. Параметр а можно получить в процессе выборки путем максимального увеличения вероятности
. Это обобщение соответствует различной громкости смешанных голосов. Параметр а можно получить в процессе выборки путем максимального увеличения вероятности 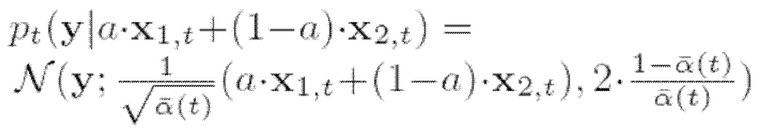 при каждой итерации:
при каждой итерации:
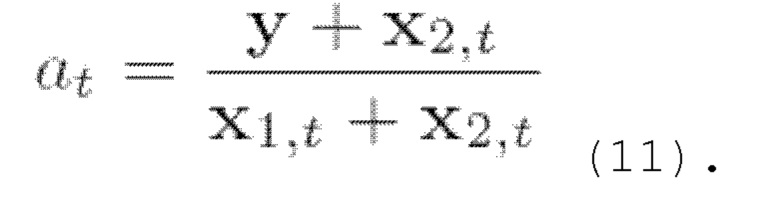
Второе возможное обобщение предложенной схемы состоит в рассмотрении более чем двух дикторов. Очевидно, что уравнения (8) и (10) можно было бы обобщить на случай, когда y=x1+x2+x3, приняв во внимание дополнительные члены, соответствующие третьему голосу.
Варианты осуществления системы
Во втором аспекте изобретение направлено на систему для восстановления голоса в речевых записях, которая, по существу, предназначена для реализации способа, описанного выше для первого аспекта настоящего изобретения.
Систему, в общем, можно охарактеризовать как содержащую по меньшей мере память и один или более процессоров, сконфигурированных для выполнения инструкций, хранящихся в памяти.
На фиг. 1 показана принципиальная схема системы 100 для восстановления голоса. Система обычно содержит память 110, модуль 120 приема речевой записи, модуль 130 обработки по восстановлению голоса и модуль 140 интерфейса ввода/вывода (I/O). Модуль обработки по восстановлению голоса может содержать нейросетевой модуль 150, модуль 160 расширения полосы частот, модуль 170 деклиппинга и модуль 180 нейронного вокодера. Модуль 140 интерфейса ввода-вывода (I/O) может содержать модуль 190 аналого-цифрового преобразователя (АЦП). Модуль 140 интерфейса ввода/вывода может содержать модуль 200 цифро-аналогового преобразователя (ЦАП). В одном или более вариантах осуществления в системе 100 можно дополнительно предусмотреть модуль 210 разделения сигналов разных источников как часть модуля 130 обработки по восстановлению голоса или иным образом.
«Ядро» системы 100 для восстановления голоса образует модуль 130 обработки по восстановлению голоса, который, в зависимости от конкретной неограничивающей реализации изобретения, можно реализовать в виде одного или более процессоров, например, процессоры общего назначения и/или процессоры цифровой обработки сигналов (DSP), микропроцессоры и/или интегральные схемы, ASIC, микрочипы, FPGA и т.д. Модуль 130 обработки по восстановлению голоса обычно выполняет основную часть обработки в отношении речевой записи, принятой через модуль 120 приема речевой записи, например, через одно или более средств ввода, таких как микрофон(ы) или беспроводное/проводное сетевое соединение(я), или память, например, память 110 системы 100, или любой внешний источник памяти, и, при необходимости, подвергается аналого-цифровому преобразованию (например, в случае, если запись принята в виде аналогового сигнала, например, от микрофона (микрофонов) посредством модуля 190 АЦП.
Затем нейросетевой модуль 150 выполняет обработку сигнала данных, который соответствует принятой речевой записи, применяя вероятностную модель диффузии с использованием автоэнкодера быстрой свертки Фурье (FFC-AE), обученную на задаче подбора функции вклада для шумоподавления, для безусловной генерации речи. Указанную модель можно обучить предварительно, как описано выше, чтобы она была наиболее пригодна для обработки по восстановлению голоса в данной неограничивающей реализации системы.
Затем модуль 160 расширения полосы частот в модуле 130 обработки по восстановлению голоса выполняет операцию расширения полосы частот на речевой записи, обработанной нейросетевым модулем. Процесс расширения полосы частот в данном случае происходит так, как было описано выше.
Затем модуль 170 деклиппинга обрабатывает цифровой сигнал, который представляет собой подлежащую обработке речевую запись, опять же, как было описано выше в связи с процессом деклиппинга.
Модуль 180 нейронного вокодера обрабатывает речевую запись для восстановления речи из мел-спектрограммы в виде формы волны речевого сигнала.
Модуль 210 разделения сигналов разных источников может выполнять разделение сигналов разных источников для выделения конкретной формы волны речевого сигнала из одного или более смешанных источников речи, как было описано выше.
После обработки в вышеупомянутых компонентах модуля 130 обработки по восстановлению голоса модуль 140 интерфейса ввода/вывода (I/O) может вывести полученную форму волны речевого сигнала с восстановленным сигналом источника голоса, при необходимости используя модуль 200 цифроаналогового преобразователя (ЦАП) и/или другие средства вывода, такие как один или более громкоговорителей, сетевые подключения и т.п., в зависимости от того, должна ли восстановленная форма волны речевого сигнала выводиться в виде воспроизведения звука через один или более громкоговорителей или передаваться в память для хранения, или в другой сетевой объект для воспроизведения и т.д.
Следует отметить, что модули системы 100 для восстановления голоса можно реализовать множеством различных способов в зависимости от заданного сценария реализации настоящего изобретения. В частности, эти модули, отвечающие за различные нейросетевые операторы, элементы и т.д., как описано выше, можно реализовать в одном или более процессорах, таких как процессоры общего назначения (CPU), процессоры обработки цифровых сигналов (DSP), микропроцессоры и т.д., работающие под управлением соответствующих программных элементов, интегральных схем, программируемых логических интегральных схем (FPGA) или любых других аналогичных средств, хорошо известных специалистам в данной области.
Следует также отметить, что вышеупомянутые обратные задачи, такие как расширение полосы частот, деклиппинг, нейронное вокодирование и/или разделение сигналов разных источников, могут выполняться вышеупомянутыми системными модулями в порядке, отличающегося от того, который был конкретно описан выше. Некоторые из этих операций могут выполняться одновременно или в любом выполнимом порядке, или могут быть исключены, продублированы, повторены один или более раз, если этого требует данная реализация изобретения. Объем изобретения ни в коем случае не ограничен каким-либо конкретным порядком выполнения вышеупомянутых операций соответствующими модулями предложенной системы или каким-либо конкретным способом реализации указанных модулей.
Следует понимать, что изобретение не ограничивается какими-либо деталями, касающимися наличия и/или специфического характера средств ввода/вывода или конкретных аппаратных средств обработки, используемых для реализации модулей системы 100 для восстановления голоса, как было указано выше.
Следует также четко понимать, что по меньшей мере некоторые из модулей системы 100 для восстановления голоса можно реализовать в программном обеспечении на одном или более языках программирования, или в исполняемом коде, как хорошо известно специалистам в данной области. Такое программное обеспечение можно реализовать в форме компьютерной программы или программ, компьютерного программного продукта, в частности, на материальном машиночитаемом носителе любого подходящего вида, элемента(ов) компьютерной программы, блоков или модулей. Оно может храниться локально или распространяться по одной или более проводным или беспроводным сетям с использованием одного или более удаленных серверов и т.д. Эти детали не ограничивают объем настоящего изобретения. В одном или более неограничивающих вариантах осуществления такое программное обеспечение может храниться в памяти 110. В ней может также храниться, временно или иным образом, по меньшей мере некоторая часть (части) или компонент (компоненты) подлежащей обработке речевой записи, при необходимости после преобразования в цифровую форму модулем 190 аналого-цифрового преобразователя (АЦП). На практике память 110 можно реализовать в различных формах, например, ROM, RAM, флэш-памяти, EPROM, EEPROM и т.п., и/или на съемном носителе информации, для постоянного или временного хранения соответствующих программных инструкций, а также сигнала(ов) и/или данных, задействованных в восстановлении голоса из речевой записи в соответствии с настоящим изобретением. Детали, касающиеся конкретного варианта(ов) запоминающего устройства 110, специфичны для различных вариантов осуществления настоящего изобретения и не ограничивают его объем.
На фиг. 2 представлена блок-схема, иллюстрирующая основные этапы способа восстановления голоса в соответствии с описанным выше первым аспектом настоящего изобретения.
На этапе S1 принимают аудиоданные речевой записи, содержащей голосовой аудиосигнал. Эти данные могут быть приняты с помощью любого подходящего средства ввода-вывода, например, микрофона или сетевого подключения и т.п.
На этапе S2 нейросетевой модуль 150 выполняет обработку сигнала данных, который соответствует принятой речевой записи, содержащей голосовой аудиосигнал, путем применения быстрой вероятностной модели диффузии, обученной на задаче подбора функции вклада для шумоподавления для безусловной генерации речи.
Этап S2 включает в себя S3, итеративную выборку формы волны с использованием функции условного вклада, и S4, формирование выборки с уменьшенным количеством шума для следующей итерации, пока не будет получена обесшумленная форма волны речевого сигнала.
На этапе S5 выводится обработанный голосовой аудиосигнал, содержащий обесшумленную форму волны речевого сигнала, и
На этапе S6 восстановленный голосовой аудиосигнал выводится через соответствующие средства ввода-вывода, и способ завершается.
Следует отметить, что описанные выше этапы способа не обязательно всегда выполняются в том определенном порядке, в котором они перечислены выше. В частности, один или более этапов способа могут выполняться одновременно/параллельно, в другом порядке и/или исключаться, дублироваться и т.д., если иное явно не указано в данном описании и/или не требуется сущностью предложенного способа.
В еще одном аспекте настоящего изобретения предложен машиночитаемый носитель, содержащий хранящиеся на нем машиноисполняемые инструкции, которые при их выполнении одним или более процессорами предписывают одному или более процессорам выполнять способ согласно первому аспекту. Следует отметить, что указанный машиночитаемый носитель может быть временным или постоянным в зависимости от его конкретной реализации. Машиночитаемый носитель может быть реализован на практике в форме одного или более ROM, RAM, флэш-памяти, EPROM, EEPROM и т.п., и/или съемного носителя для постоянного или временного хранения соответствующих машиноисполняемых команд, которые предписывают компьютеру или его одному или более процессорам выполнять соответствующие описанные выше функции модулей и/или соответствующие описанные выше этапы способа.
Примеры экспериментальных исследований
Следующие примеры подтверждают возможность реализации заявленного изобретения по назначению с достижением вышеуказанного технического результата.
Изобретение было протестировано экспериментально с использованием двух наборов данных для экспериментов. Первым набором данных был общедоступный набор данных VCTK (см., например, [20]), который включает в себя 44200 записей речи 110 дикторов. 6 дикторов и 8 записей фрагментов речи, соответствующих каждому диктору, были исключены из обучающего набора данных, чтобы исключить утечку данных на уровне текста и дикторов в обучающий набор данных. Для оценки использовались 4 8 фрагментов речи, соответствующих 6 дикторам, исключенным из обучающих данных. Важно отметить, что текст, соответствующий оценочным фрагментам, не был прочитан ни в одной записи, составляющей обучающие данные.
Вторым набором данных был набор данных LJ-Speech [21], который является стандартом в области синтеза речи. LJ-Speech -это набор данных от одного диктора, состоящий из 13100 аудиоклипов общей продолжительностью около 24 часов. Использовалось разбиение обучения и проверки из [18] размером 12950 обучающих клипов и 150 проверочных клипов. Частота дискретизации выборок звука составляла 22,05 кГц.
Для оценивания выборок, сгенерированных безусловной моделью, использовались абсолютная мера объективного качества речи на основе прямого прогнозировании показателя MOS согласно тонко настроенной модели wav2vec2.0 (см., например, [22]) (WV-MOS, см., например, [23]) и безусловной модели Frechet DeepSpeech Distance (FDSD), введенной в [24]. Известно, что WV-MOS измеряет качество каждой сгенерированной выборки в отдельности, a FDSD измеряет расстояние между распределениями сгенерированных и реальных выборок.
Для оценивания качества в речевых обратных задачах использовались традиционные метрики: расширенные STOI (см., например, [25]), масштабно-инвариантное отношение сигнал-искажение (SI-SNR) (см., например, [26]), логарифмическое спектральное расстояние (LSD) и WV-MOS. Также использовались 5-балльные MOS-тесты для субъективной оценки качества в соответствии с процедурой, описанной в [15].
Все модели обучались в течение 230 эпох с размером пакета 8 на аудиосегментах продолжительностью 2 секунды при частоте выборки 16 кГц путем экспоненциального усреднения весов моделей со скоростью 0,9999. Использовался оптимизатор Adam со скоростью обучения 0,0002 и бета-версии 0,9 и 0,999. Для диффузии шумоподавление выполнялось за более 200 шагов во время обучения и обусловливалось на β(t) в зависимости от модели.
В данном контексте шумоподавление означает процесс выборки с помощью диффузионной модели, т.е. процесс численного решения обратного стохастического уравнения, являющийся, как таковой, стандартным процессом для диффузионных моделей (см., например, алгоритм 2 в [2]).
Было проведено сравнение 3 подходов к генерации речи на основе безусловной диффузии и 3 дополнительных базовых вариантов. Все рассмотренные подходы работали во временной области, но использовали различные обратимые предобрабатывающие преобразования и соответствующие им обратные преобразования постобработки для предобусловливания нейронных сетей. Следует обратить внимание, что гиперпараметры всех моделей были скорректированы таким образом, чтобы они имели равные производительности, измеряемые памятью графического процессора, выделенной для обучения каждой модели при равном размере пакетов.
Первый подход состоял в обучении нейронной архитектуры непосредственно во временной области, т.е. без какого-либо предобусловливающего преобразования. Авторы изобретения обнаружили, что архитектура Diffwave обеспечивает наилучшую производительность среди протестированных архитектур во временной области (также тестировались UNIVERSE [4], UNet [27]). Производительность оригинальной архитектуры Diffwave была увеличена путем увеличения размера до 22 блоков с 512 каналами. Кроме того, были введены взвешивание сжатия-возбуждения на пропускных соединениях (см., например, [28]), условная генеративная модель на β(t) с помощью случайных признаков Фурье (см., например [29]).
Другой подход был основан на архитектуре FFC-AE в частотно-временной области (см., например, [13]), в которой для предобусловливания используется кратковременное преобразование Фурье (STFT). Эта архитектура основана на нейронном операторе быстрой свертки Фурье и оперирует комплекснозначными STFT-спектрограммами.
Было обнаружено, что FFC-AE обеспечивает превосходное качество по сравнению со сверточными архитектурами типа UNet.
В заключение, был протестирован подход к безусловной генерации звука, предложенный, например, в [7]. В этом подходе в качестве предобусловливающего преобразования использовалось преобразование постоянного Q (Constant-Q Transform (CQT)), а в качестве нейронной архитектуры использовалась сверточная нейронная архитектура UNet с расширенными остаточными блоками, как рекомендовано в [7]. Использовалась UNet глубиной 5 со следующими каналами=[64, 64, 128, 128, 256] с понижающей дискретизацией в 2 раза в каждом блоке.
Качество 8000 безусловно сгенерированных выборок сравнивалось в метриках WV-MOS и FDSD. Также были предоставлены метрики для 4 базовых вариантов: эталонной речи, гауссовского шума, выборок из безусловной Diffwave с оригинальной архитектурой [10] и модели преобразования текста в аудио AudioLDM [11], сгенерированной с подсказкой «Человек, говорящий по-английски». Экспериментальные данные, полученные в результате испытаний безусловной генерации речи, представлены в таблице 1.
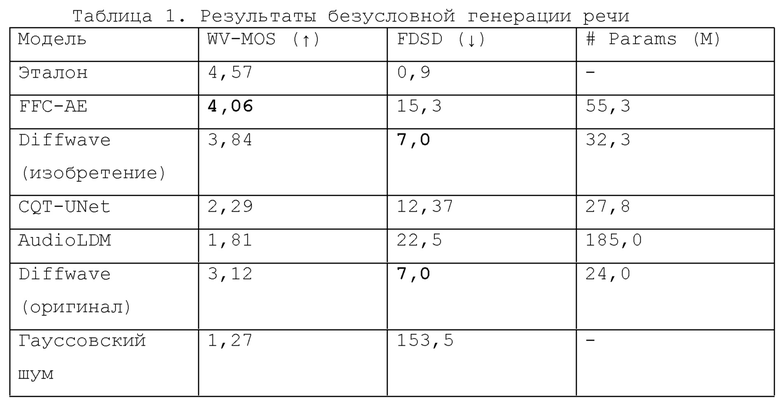
В общем случае, все протестированные модели
продемонстрировали способность генерировать речеподобные звуки, однако они не выдали никакой семантически согласованной речи. Такое поведение было вполне ожидаемым, поскольку лингвистическое содержание обучающего набора данных не было ограничено, и никаких руководств по пониманию языка не было предоставлено (в отличие, например, от AudioLM [30]).
Следует отметить, что авторы настоящего изобретения полагают, что понимание языка не является необходимым для восстановления речи в контексте настоящего изобретения, поскольку потенциально голос может быть извлечен на основе акустической (синтаксической) информации.
В результате экспериментов авторы изобретения обнаружили, что модель FFC-AE, используемая в настоящем изобретении, обеспечивает лучшее качество WVMOS, в то время как Diffwave обеспечивает самый низкий вклад FDSD. Для более полной оценки результатов реализации заявляемого способа были проведены последующие экспериментальные испытания как с моделями Diffwave, так и с моделями FFC-AE.
Далее, в таблицах 2, 3, 4, 5 представлены результаты экспериментов по расширению полосы частот, деклиппингу, нейронному вокодированию и разделению сигналов разных источников, где лучшие результаты выделены жирным шрифтом. Все метрики вычислялись на случайно вырезанных односекундных сегментах.
В экспериментах по расширению полосы частот в качестве целей использовались записи с частотой дискретизации 16 кГц, а для входных данных рассматривались две полосы частот: 2 кГц и 4 кГц. Исходный сигнал был искусственно ухудшен до желаемой полосы частот (2 кГц или 4 кГц) с помощью многофазной фильтрации. Результаты и сравнение с другими методами приведены в таблице 2. "UnDiff" обозначает модели, используемые в настоящем изобретении (оба варианта - Diffwave и FFC-AE), а все остальные модели представляют известный уровень техники (соответствующие источники из уровня техники, описывающие их, указаны в скобках).
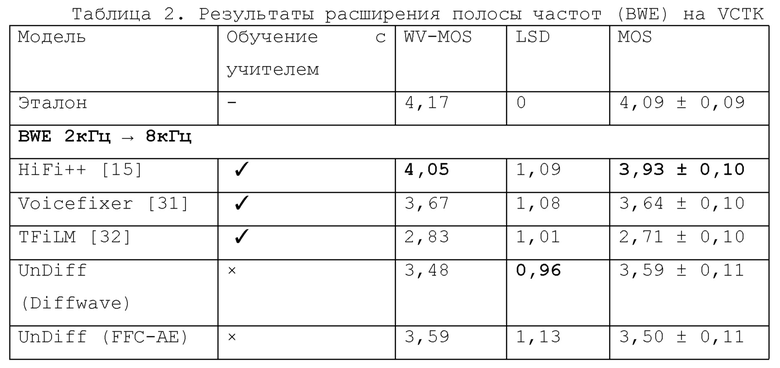
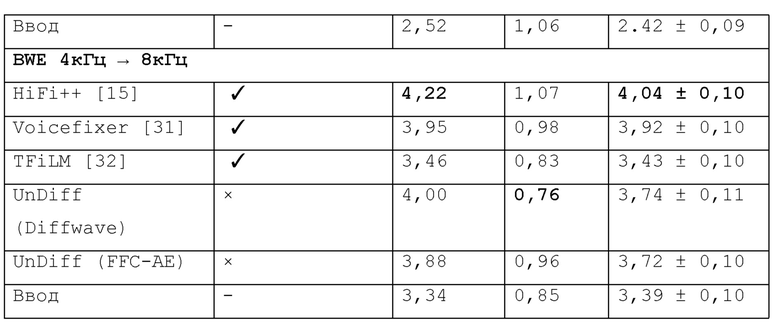
Затем предлагаемые модели FFC-AE и Diffwave тестировались экспериментально на задаче деклиппинга в сравнении с популярными методами деклиппинга аудио сигналов, известными как деклиппер анализа разреженного аудио (A-SPADE, см. [33]) и деклиппером синтеза разреженного аудиосигнала (S-SPADE, см. [33]). 34]), а также с общей платформой восстановления речи Voicefixer [31] на клиппированных аудиозаписях с SDR ввода равным 3 дБ (см. табл. 3).
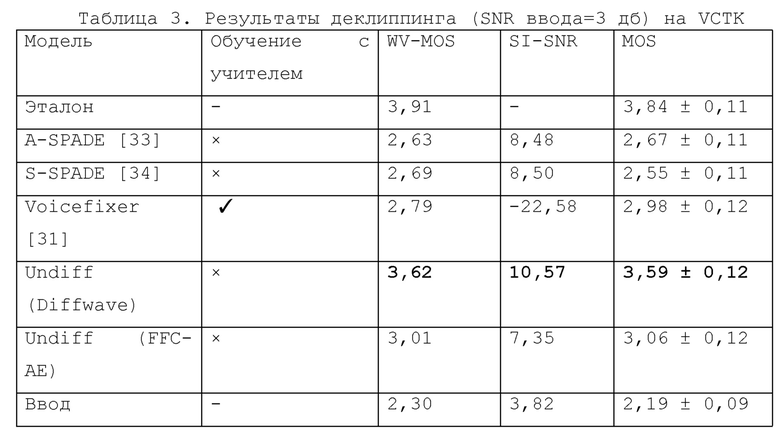
Чтобы продемонстрировать эффективность предлагаемой модели Unidiff на задаче нейронного вокодирования, модели EFFICIENCY и Driftwave были обучены безусловной генерации речевого набора данных LJ. Предлагаемую модель сравнивали с двумя контролируемыми базовыми вариантами из уровня техники, обученными с учителем и с неконтролируемым вокодером Гриффина-Лима (Griffin-Lim), не требующим обучения с учителем. Результаты экспериментальных испытаний приведены в таблице 4.
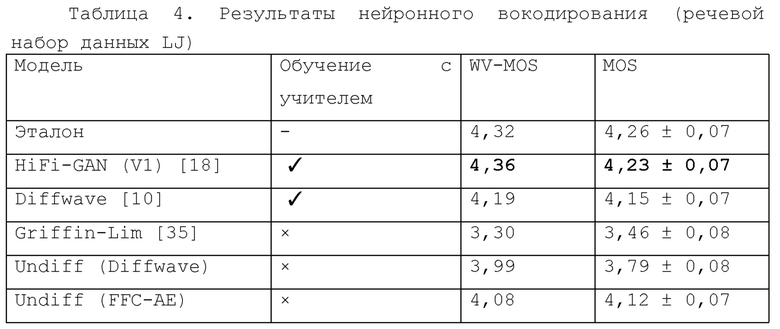
В заключение, чтобы оценить эффективность предложенной модели Undiff в задаче разделения сигналов разных источников, были случайным образом перемешаны записи, принадлежащие различным дикторам из данных проверки VCTK. Эти записи были нормализованы и сведены без весового коэффициента.
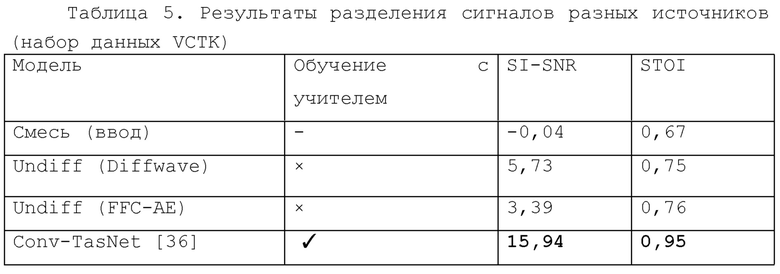
Результаты показали, что, несмотря на то, что предлагаемые в изобретении модели Undiff никогда не обучались явным образом решать какую-либо из рассматриваемых задач, они работают по меньшей мере сопоставимо с контролируемыми базовыми вариантами на задачах расширения полосы частот, деклиппинга и вокодирования, обученными с учителем. Также был продемонстрирован потенциал решения задачи разделения сигналов разных источников с помощью предлагаемых моделей. В одном или более вариантах осуществления изобретения может быть дополнительно рассмотрено использование различных весовых коэффициентов смешивания и возможности моделей согласно изобретению создавать глобально ясно произносимые голоса во время разделения сигналов разных источников. В целом, результаты экспериментальных испытаний продемонстрировали способность моделей безусловной диффузии (UnDiff) в соответствии с настоящим изобретением решать задачи восстановления голоса (речи) с помощью описанных выше вариантов способа и устройства.
В настоящем изобретении предложена вероятностная модель диффузии, способная решать различные речевые обратные задачи. Эффективность модели в задачах расширения полосы частот, деклиппинга, нейронного вокодирования и разделения сигналов разных источников была продемонстрирована и подтверждена представленными выше экспериментальными данными. Предлагаемая в изобретении вероятностная модель диффузии (также называемая в данном документе UnDiff) представляет собой новый инструмент для решения сложных обратных задач восстановления речи, демонстрирующий потенциал диффузионных моделей в качестве общей платформы для восстановления голоса. Однажды обучив эту модель безусловной генерации формы волны речевого сигнала, ее можно адаптировать к различным задачам, включая инверсию деградации, нейронное вокодирование и разделение сигналов разных источников, как упоминалось выше. Изобретение решает сложную проблему безусловной генерации формы волны путем сравнения различных нейронных архитектур и областей предобусловливания. Обученную безусловную диффузию можно адаптировать к различным задачам обработки речи с помощью различных методов постобучающего обусловливания моделей диффузии, как было показано выше.
Выше был описан способ восстановления голоса согласно изобретению. Специалистам в данной области будет понятно, что изобретение можно реализовать различными комбинациями аппаратных и программных средств, и никакие подобные конкретные комбинации не ограничивают объем настоящего изобретения. Описанные выше модули, которые составляют устройство согласно изобретению, можно реализовать в форме отдельных аппаратных средств, или же два или более модулей можно реализовать в форме одного аппаратного средства, или же систему согласно изобретению можно реализовать в виде одного или более компьютеров, процессоров (CPU), например, процессоров общего назначения или специализированных процессоров, например процессоров обработки цифровых сигналов (DSP), или одной или более ASIC, FPGA, логических элементов и т.д. В качестве альтернативы, один или более модулей можно реализовать как программное средство, например, программу или программы, элемент(ы) или модуль(и) компьютерной программы), которые управляют одним или более компьютерами, CPU и т.д. для реализации этапов способа и/или операций, подробно описанных выше. Это программное средство может быть реализовано на одном или более машиночитаемых носителей, которые хорошо известны специалистам в данной области, может храниться в одном или более блоках памяти, например, ROM, RAM, флеш-памяти, EEPROM и т.д., или поступать, например, от удаленных серверов через одно или более соединения проводной и/или беспроводной сети, интернет, соединение Ethernet, LAN или, при необходимости, другие локальные или глобальные компьютерные сети.
Промышленная применимость
Изобретение может найти применение в различных устройствах для передачи, приема и записи речи для улучшения пользовательского восприятия при прослушивании речевых записей, а также для преобразования текста в речь. Предложенный способ также может использоваться как часть системы преобразования текста в речь в качестве нейронного вокодера.
Специалистам в данной области будет понятно, что выше были описаны и показаны на чертежах только некоторые из возможных примеров способов и аппаратных средств, позволяющих реализовать варианты осуществления настоящего изобретения. Подробное описание вариантов осуществления изобретения, представленное выше, не предназначено для ограничения или определения объема правовой охраны настоящего изобретения.
Другие варианты осуществления, которые могут входить в объем настоящего изобретения, могут быть предложены специалистами в данной области техники по изучении вышеприведенного описания изобретения с обращением к сопровождающим чертежам, и все такие очевидные модификации, изменения и/или эквивалентные замены подлежат включению в объем настоящего изобретения. Все упомянутые и рассмотренные здесь источники из уровня техники настоящим включены в данное описание путем ссылки, когда это применимо.
Несмотря на то, что настоящее изобретение было описано и проиллюстрировано с обращением к различным вариантам осуществления, специалистам в данной области техники следует понимать, что могут быть выполнены различные изменения, касающиеся его формы и конкретных подробностей, не выходящие за рамки объема настоящего изобретения, который определяется только нижеприведенной формулой изобретения и ее эквивалентами.
Список цитированных источников
[1] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, "Score-based generative modeling through stochastic differential equations", in International Conference on Learning Representations.
[2] J. Ho, A. Jain, and P. Abbeel, "Denoising diffusion probabilistic models", Advances in Neural Information Processing Systems, vol. 33, pp.6840-6851, 2020.
[3] T. Karras, M. Aittala, T. Aila, and S. Laine, "Elucidating the design space of diffusion-based generative models", in Advances in Neural Information Processing Systems.
[4] J. Serr'a, S. Pascual, J. Pons, R. 0. Araz, and D. Scaini, "Universal speech enhancement with score-based diffusion", arXiv preprint arXiv:2206.03065, 2022.
[5] J. Richter, S. Welker, J.-M. Lemercier, B. Lay, and T. Gerkmann, "Speech enhancement and dereverberation with diffusion-based generative models", arXiv preprint arXiv:2208.05830, 2022.
[6] R. Scheibler, Y. Ji, S.-W. Chung, J. Byun, S. Choe, and M.-S. Choi, "Diffusion-based generative speech source separation", arXiv preprint arXiv:2210.17327, 2022.
[7] E. Moliner, J. Lehtinen, and V. V"alim"aki, "Solving audio inverse problems with a diffusion model", arXiv preprint arXiv:2210.15228, 2022.
[8] H. Chung, J. Kim, M. T. Mccann, M. L. Klasky, and J. C. Ye, "Diffusion posterior sampling for general noisy inverse problems", arXiv preprint arXiv:2209.14687, 2022.
[9] J. Choi, S. Kim, Y. Jeong, Y. Gwon, and S. Yoon, "Ilvr: Conditioning method for denoising diffusion probabilistic models", in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.14 367-14 376.
[10] Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, "Diffwave: A versatile diffusion model for audio synthesis", in International Conference on Learning Representations.
[11] H. Liu, Z. Chen, Y. Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, "Audioldm: Text-to-audio generation with latent diffusion models," arXiv preprint arXiv:2301.12503, 2023.
[12] K. Goel, A. Gu, C. Donahue, and C. R'e, "It's raw! audio generation with state-space models", in International Conference on Machine Learning. PMLR, 2022, pp.7616-7633.
[13] I. Shchekotov, P. K. Andreev, 0. Ivanov, A. Alanov, and D. Vetrov, "FFC-SE: Fast Fourier Convolution for Speech Enhancement", in Proc. Interspeech 2022, 2022, pp.1188-1192.
[14] V. Kuleshov, S. Z. Enam, and S. Ermon, "Audio super resolution using neural networks", arXiv preprint arXiv:1708.00853, 2017.
[15] P. Andreev, A. Alanov, 0. Ivanov, and D. Vetrov, "Hifi++: a unified framework for bandwidth extension and speech enhancement", arXiv preprint arXiv:2203.13086, 2022.
[16] N. Li, Y. Liu, Y. Wu, S. Liu, S. Zhao, and M. Liu, "Robutrans: A robust transformer-based text-to-speech model", in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, 2020, pp.8228-8235.
[17] J. Shen, Y. Jia, M. Chrzanowski, Y. Zhang, I. Elias, H. Zen, and Y. Wu, "Non-attentive tacotron: Robust and controllable neural tts synthesis including unsupervised duration modeling", arXiv preprint arXiv:2010.04301, 2020.
[18] J. Kong, J. Kim, and J. Bae, "Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis", Advances in Neural Information Processing Systems, vol. 33, pp.17 022-17 033, 2020.
[19] R. Prenger, R. Valle, and B. Catanzaro, "Waveglow: A flow-based generative network for speech synthesis", in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp.3617-3621.
[20] J. Yamagishi, C. Veaux, K. MacDonald et al., "Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92)", 2019.
[21] K. Ito and L. Johnson, "The lj speech dataset," https://keithito.com/LJ-Speech-Dataset/, 2017.
[22] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, "wav2vec 2.0: A framework for self-supervised learning of speech representations", in Advances in Neural Information Processing Systems, vol. 33, 2020, pp.12 449-12 460.
[23] "Wv-mos: Mos score prediction by fine-tuned wav2vec2.0 model", https://github.com/AndreevP/wvmos, accessed: 2022-01-20.
[24] M. Bi'nkowski, J. Donahue, S. Dieleman, A. Clark, E. Elsen, N. Casagrande, L. C. Cobo, and K. Simonyan, "High fidelity speech synthesis with adversarial networks", in International Conference on Learning Representations.
[25] J. Jensen and С.H. Taal, "An algorithm for predicting the intelligibility of speech masked by modulated noise maskers", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp.2009-2022, 2016.
[26] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, "Sdr-half-baked or well done?" in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp.626-630.
[27] A. Q. Nichol and P. Dhariwal, "Improved denoising diffusion probabilistic models", in International Conference on Machine Learning. PMLR, 2021, pp.8162-8171.
[28] J. Hu, L. Shen, and G. Sun, "Squeeze-and-excitation networks", 2018.
[29] S. Rouard and G. Hadjeres, "Crash: Raw audio score-based generative modeling for controllable high-resolution drum sound synthesis", in Music Information Retrieval Conf. (ISMIR), 2021, pp.579-585.
[30] Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, O. Teboul, D. Grangier, M. Tagliasacchi, and N. Zeghidour, "Audiolm: a language modeling approach to audio generation", arXiv preprint arXiv:2209.03143, 2022.
[31] H. Liu, Q. Kong, Q. Tian, Y. Zhao, D. Wang, C. Huang, and Y. Wang, "Voicefixer: Toward general speech restoration with neural vocoder", arXiv preprint arXiv:2109.13731, 2021.
[32] S. Birnbaum, V. Kuleshov, Z. Enam, P. W. W. Koh, and S. Ermon, "Temporal film: Capturing long-range sequence dependencies with feature-wise modulations". Advances in Neural Information Processing Systems, vol. 32, 2019.
[33] P. Zaviska and P. Rajmic, "Analysis social sparsity audio declipper", arXiv preprint arXiv:2205.10215, 2022.
[34] P. Zaviska, P. Rajmic, O. Mokry, and Z. Pruvsa, "A proper version of synthesis-based sparse audio declipper," in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp.591-595.
[35] D. Griffin and J. Lim, "Signal estimation from modified short-time fourier transform", IEEE Transactions on acoustics, speech, and signal processing, vol. 32, no. 2, pp.236-243, 1984.
[36] Y. Luo and N. Mesgarani, "Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation," IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 8, pp.1256-1266, 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО УЛУЧШЕНИЯ РЕЧЕВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ БЫСТРОЙ СВЕРТКИ ФУРЬЕ | 2022 |
|
RU2795573C1 |
| Способ улучшения речевого сигнала с низкой задержкой, вычислительное устройство и считываемый компьютером носитель, реализующий упомянутый способ | 2023 |
|
RU2802279C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823016C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823015C1 |
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| АУДИОКОДЕР И СПОСОБ ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА | 2016 |
|
RU2707144C2 |
| СПОСОБ И ДИСКРИМИНАТОР ДЛЯ КЛАССИФИКАЦИИ РАЗЛИЧНЫХ СЕГМЕНТОВ СИГНАЛА | 2009 |
|
RU2507609C2 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ГЕНЕРАЦИИ АУДИОСИГНАЛА С РАСШИРЕННОЙ ПОЛОСОЙ С ИСПОЛЬЗОВАНИЕМ ПРОЦЕССОРА НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2745298C1 |
| Способ определения признаков паркинсонизма по голосу с использованием искусственного интеллекта | 2023 |
|
RU2841464C2 |
| СИСТЕМА И СПОСОБ АВТОМАТИЗИРОВАННОЙ ОЦЕНКИ НАМЕРЕНИЙ И ЭМОЦИЙ ПОЛЬЗОВАТЕЛЕЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2020 |
|
RU2762702C2 |
Изобретение относится к области компьютерных технологий, в частности к способам обработки и анализа аудиозаписей, и может использоваться для повышения качества и разборчивости речевых записей. Способ восстановления голоса в речевых записях содержит этапы, на которых: принимают аудиоданные речевой записи, содержащей голосовой аудиосигнал; применяют вероятностную модель диффузии, обученную на задаче подбора функции вклада для шумоподавления, для безусловной генерации речи, причем вероятностную модель диффузии применяют к аудиоданным речевой записи в виде формы волны, содержащей случайный гауссовский шум; осуществляют итеративную выборку формы волны с использованием функции условного вклада, которая является суммой функции безусловного вклада, оцененной вероятностной моделью диффузии, и логарифмического правдоподобия, для получения выборки с уменьшенным количеством шума для следующей итерации, пока не будет получена обесшумленная форма волны речевого сигнала; и выводят обработанный голосовой аудиосигнал, содержащий обесшумленную форму волны речевого сигнала. Также предложены система и машиночитаемый носитель для реализации способа. Технический результат заключается в повышении качества и разборчивости речевых записей. 3 н. и 15 з.п. ф-лы, 2 ил., 5 табл.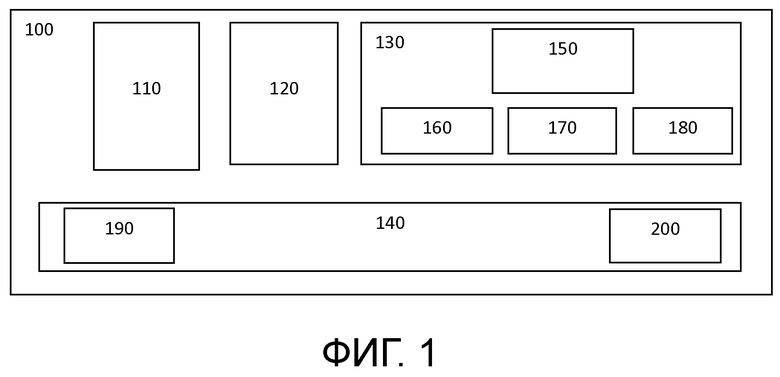
1. Способ восстановления голоса в речевых записях, содержащий этапы, на которых:
принимают аудиоданные речевой записи, содержащей голосовой аудиосигнал;
применяют вероятностную модель диффузии, обученную на задаче подбора функции вклада для шумоподавления, для безусловной генерации речи,
причем вероятностную модель диффузии применяют к аудиоданным речевой записи в виде формы волны, содержащей случайный гауссовский шум;
осуществляют итеративную выборку формы волны с использованием функции условного вклада, которая является суммой функции безусловного вклада, оцененной вероятностной моделью диффузии, и логарифмического правдоподобия, для получения выборки с уменьшенным количеством шума для следующей итерации, пока не будет получена обесшумленная форма волны речевого сигнала; и
выводят обработанный голосовой аудиосигнал, содержащий обесшумленную форму волны речевого сигнала.
2. Способ по п. 1, в котором вероятностную модель диффузии выбирают из группы, включающей модель автоэнкодера быстрой свертки Фурье (FFC-AE), модель Diffwave и модель CQT-UNet.
3. Способ по п. 1, в котором дополнительно выполняют расширение полосы частот в голосовом аудиосигнале.
4. Способ по п. 1, в котором дополнительно выполняют деклиппинг в голосовом аудиосигнале.
5. Способ по п. 1, в котором дополнительно выполняют нейронное вокодирование в голосовом аудиосигнале для преобразования спектральных представлений голосового аудиосигнала в формы волны аудиосигнала.
6. Способ по п. 1, в котором дополнительно выполняют разделение сигналов разных источников в голосовом аудиосигнале.
7. Способ по п. 1, в котором вероятностная модель диффузии адаптирована для инверсии деградации.
8. Способ по любому из пп. 3-6, в котором вероятностная модель диффузии адаптирована для решения задач расширения полосы частот, деклиппинга, нейронного вокодирования и/или разделения сигналов разных источников путем модификации процедуры выборки голосового аудиосигнала, причем упомянутая модификация обусловливает выборку наблюдениями, которые представляют собой форму волны с уменьшенной полосой частот для задачи расширения полосы частот, клиппированной формой волны для задачи деклиппинга, мел-спектрограммой в случае задачи нейронного вокодирования и/или формой волны со смешанными голосами для задачи разделения сигналов разных источников.
9. Система для восстановления голоса в речевых записях, содержащая:
память;
модуль приема речевой записи, выполненный с возможностью приема речевой записи, содержащей по меньшей мере голосовой аудиосигнал;
модуль обработки по восстановлению голоса,
причем модуль обработки по восстановлению голоса содержит:
нейросетевой модуль, выполненный с возможностью применения вероятностной модели диффузии, обученной на задаче подбора функции вклада для шумоподавления, для безусловной генерации речи,
причем вероятностная модель диффузии применяется к аудиоданным речевой записи в виде формы волны, содержащей случайный гауссовский шум;
при этом нейросетевой модуль выполнен с возможностью итеративной выборки формы волны с использованием функции условного вклада, которая является суммой функции безусловного вклада, оцененной вероятностной моделью диффузии, и логарифмического правдоподобия, для получения выборки с уменьшенным количеством шума для следующей итерации, пока не будет получена обесшумленная форма волны речевого сигнала; и
модуль обработки по восстановлению голоса выполнен с возможностью вывода обработанного голосового аудиосигнала, содержащего обесшумленную форму волны речевого сигнала.
10. Система по п. 9, в которой вероятностная модель диффузии выбирается из группы, включающей модель автоэнкодера быстрой свертки Фурье (FFC-AE), модель Diffwave и модель UNet.
11. Система по п. 9, дополнительно содержащая модуль расширения полосы частот, выполненный с возможностью выполнения расширения полосы частот в голосовом аудиосигнале.
12. Система по п. 9, дополнительно содержащая модуль деклиппинга, выполненный с возможностью выполнения деклиппинга в голосовом аудиосигнале.
13. Система по п. 9, дополнительно содержащая модуль нейронного вокодера, выполненный с возможностью преобразования спектральных представлений голосового аудиосигнала в формы волны аудиосигнала.
14. Система по п. 9, дополнительно содержащая модуль разделения сигналов разных источников, выполненный с возможностью выполнения разделения сигналов разных источников в голосовом аудиосигнале.
15. Система по п. 9, дополнительно содержащая модуль интерфейса ввода-вывода (I/O), выполненный с возможностью ввода речевой записи, содержащей по меньшей мере голосовой аудиосигнал, и/или вывода обработанного голосового аудиосигнала.
16. Система по п. 15, в которой модуль интерфейса ввода/вывода содержит модуль аналого-цифрового преобразователя (АЦП), выполненный с возможностью выполнения аналого-цифрового преобразования входной речевой записи.
17. Система по п. 15, в которой модуль интерфейса ввода/вывода содержит модуль цифроаналогового преобразователя (ЦАП) для выполнения цифроаналогового преобразования выходного обработанного голосового аудиосигнала.
18. Машиночитаемый носитель, на котором хранятся машиноисполняемые инструкции, которые, при выполнении одним или более процессорами, предписывают одному или более процессорам осуществлять способ по любому из пп. 1-8.
| Прибор для проверки веса монет | 1925 |
|
SU2107A1 |
| US 2006136203 A1, 22.06.2006 | |||
| US 2014257801 A1, 11.09.2014 | |||
| US 2011238416 A1, 29.09.2011. | |||

