Вводные примечания
Ниже описаны различные варианты осуществления и аспекты согласно изобретению. Кроме того, дополнительные варианты осуществления определены прилагаемой формулой изобретения. Следует отметить, что любые варианты осуществления, определяемые формулой изобретения, могут быть дополнены любыми из подробностей (признаков и функциональностей), приведенных в данном описании.
Кроме того, варианты осуществления, приведенные в данном описании, могут использоваться по отдельности, а также могут дополняться любыми из признаков в данном документе или любым признаком, включенным в формулу изобретения.
Кроме того, следует отметить, что отдельные аспекты, описанные в данном документе, могут использоваться по отдельности или в сочетании. Таким образом, подробности могут быть добавлены в каждый из упомянутых отдельных аспектов без добавления подробностей в другой из упомянутых аспектов.
Также следует отметить, что в настоящем описании явно или неявно описаны признаки, применимые в генераторе аудиоданных и/или в способе и/или в компьютерном программном продукте. Таким образом, любой из признаков, описанных в данном документе, может использоваться в контексте устройства, способа и/или компьютерного программного продукта.
Кроме того, признаки и функциональности, раскрытые в данном документе по отношению к способу, также могут использоваться в устройстве (выполненном с возможностью реализации такой функциональности). Кроме того, любые признаки и функциональности, раскрытые в данном документе в отношении устройства, также могут использоваться в соответствующем способе. Другими словами, способы, раскрытые в данном документе, могут быть дополнены любыми из признаков и функциональностей, описанных в отношении устройств.
Кроме того, любые из признаков и функциональностей, описанных в данном документе, могут быть реализованы в аппаратных средствах или в программном обеспечении либо с использованием сочетания аппаратных средств и программного обеспечения, как описано в разделе «Альтернативные варианты реализации».
Альтернативные варианты реализации
При том, что некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют собой описание соответствующего способа, при этом признак соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего признака соответствующего устройства. Некоторые или все этапы способа могут выполняться аппаратным устройством, таким как, например, микропроцессор, программируемый компьютер либо электронная схема (или с их использованием). В некоторых вариантах осуществления один или более из самых важных этапов способа могут выполняться этим устройством.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя данных, например гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, E PROM, EEPROM или флэш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может сохраняться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно изобретению, таким образом, этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель данных (цифровой носитель данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель данных или носитель с записанными данными обычно является материальным и/или постоянным.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнен с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное или адаптированное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передачи (например, электронными или оптическими средствами) компьютерной программы для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления может использоваться программируемое логическое устройство (например, программируемая пользователем вентильная матрица) для того, выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем случае, способы предпочтительно осуществляются любым аппаратным устройством.
Устройства, описанные в данном документе, могут быть реализованы с использованием аппаратного устройства либо с использованием компьютера, либо с использованием сочетания аппаратного устройства и компьютера.
Устройства, описанные в данном документе, или любые компоненты устройств, описанных в данном документе, могут быть реализованы по меньшей мере частично в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием сочетания аппаратного устройства и компьютера.
Способы, описанные в данном документе или любая часть способов, описанных в данном документе, могут выполняться по меньшей мере частично аппаратными средствами и/или программным обеспечением.
Вышеописанные варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидны модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, но не конкретными подробностями, представленными в данном документе в качестве описания и пояснения вариантов осуществления.
Область техники, к которой относится изобретение
Изобретение относится к области техники формирования аудиоданных.
Варианты осуществления изобретения относятся к генератору аудиоданных, выполненному с возможностью формирования аудиосигнала из входного сигнала и целевых данных, причем целевые данные представляют аудиосигнал. Дополнительные варианты осуществления относятся к способам формирования аудиосигнала и к способам обучения генератора аудиоданных. Дополнительные варианты осуществления относятся к компьютерному программному продукту.
Уровень техники
В последние годы, нейронные вокодеры превосходят классические подходы к синтезу речи с точки зрения естественности и воспринимаемого качества синтезированных речевых сигналов. Наилучшие результаты могут достигаться посредством вычислительно емких нейронных вокодеров, таких как WaveNet и WaveGlow, тогда как легкие архитектуры на основе генеративно-состязательных сетей, например, MelGAN и Parallel WaveGAN, по-прежнему являются низкокачественными с точки зрения воспринимаемого качества.
Генеративные модели с использованием глубокого обучения для формирования форм аудиосигнала, такие как WaveNet, LPCNet и WaveGlow, обеспечивают существенные усовершенствования в естественно звучащем синтезе речи. Эти генеративные модели, называемые в вариантах применения для преобразования текста в речь (TTS) «нейронными вокодерами», превосходят способы как параметрического, так и конкатенативного синтеза. Они могут обусловливаться с использованием сжатых представлений целевой речи (например, мел-спектрограммы) для воспроизведения определенного говорящего и определенного речевого фрагмента.
Предыдущие работы продемонстрировали, что кодирование речи на очень низкой скорости передачи битов для чистой речи может достигаться с использованием таких генеративных моделей на стороне декодера. Это может осуществляться посредством обуславливания нейронных вокодеров с параметрами из классического речевого кодера с низкой скоростью передачи битов.
Нейронные вокодеры также используются для задач улучшения речи, таких как очистка от шума или дереверберация речи.
Основная проблема этих глубоких генеративных моделей обычно заключается в высоком числе требуемых параметров и результирующей сложности в ходе обучения и синтеза (логического вывода). Например, WaveNet, рассматриваемый в качестве уровня техники для качества синтезированной речи, формирует последовательно аудиовыборки одну за другой. Этот процесс является очень медленным и вычислительно емким и не может выполняться в реальном времени.
В последнее время, легкие состязательные вокодеры на основе генеративно-состязательных сетей (GAN), такие как MelGAN и Parallel WaveGAN, предложены для быстрого образования форм сигналов. Тем не менее, сообщенное воспринимаемое качество речи, сформированной с использованием этих моделей, значительно ниже стандарта нейронных вокодеров, таких как WaveNet и WaveGlow. Для ликвидации этого разрыва в качестве предложена GAN для преобразования текста в речь (GAN-TTS), но она все же сопряжена с высокими вычислительными затратами.
Существует огромное множество нейронных вокодеров, все из которых имеют недостатки. Авторегрессивные вокодеры, например, WaveNet и LPCNet, могут иметь очень высокое качество и быть подходящими для оптимизации для логического вывода на CPU, но они не являются подходящими для использования на GPU, поскольку их обработка не может параллелизоваться легко, и они не могут предлагать обработку не в реальном времени без ухудшения качества.
Нормализующие потоковые вокодеры, например, WaveGlow, также могут иметь очень высокое качество и быть подходящими для логического вывода на GPU, но они содержат очень сложную модель, для обучения и оптимизации которой требуется длительное время; она также является неподходящей для встроенных устройств.
Вокодеры GAN, например, MelGAN и Parallel WaveGAN, могут быть пригодными для логического вывода на GPU и легкими, но их качество ниже авторегрессивных моделей.
В общих словах, по-прежнему отсутствует решение с низкой сложностью, которое обеспечивало бы высококачественную речь. GAN представляет собой наиболее изученный подход для решения такой задачи. Настоящее изобретение представляет собой эффективное решение для этой проблемы.
Задача настоящего изобретения состоит в создании решения на основе легкого нейронного вокодера, который формирует речь с очень высоким качеством и является обучаемым при ограниченных вычислительных ресурсах, например для TTS (преобразования текста в речь).
Краткое описание чертежей
Ниже описаны варианты осуществления согласно настоящему изобретению с обращением к сопровождающим чертежам, на которых:
На Фиг. 1 показана архитектура генератора аудиоданных согласно вариантам осуществления настоящего изобретения,
На Фиг. 2 показана структура дискриминатора, который может использоваться для обучения генератора аудиоданных согласно настоящему изобретению,
На Фиг. 3 показана структуруа части генератора аудиоданных согласно вариантам осуществления настоящего изобретения,
На Фиг. 4 показана структура части генератора аудиоданных согласно вариантам осуществления настоящего изобретения, и
На Фиг. 5 показаны результаты экспертного теста MUSHRA на основе прослушивания различных моделей.
На Фиг. 6 показана архитектура генератора аудиоданных согласно вариантам осуществления настоящего изобретения.
На Фиг. 7 показаны операции, которые выполняются для сигналов согласно изобретению.
На Фиг. 8 показаны операции в варианте применения для преобразования текста в речь с использованием генератора аудиоданных.
На Фиг. 9а-9с показаны примеры генераторов.
На Фиг. 10 показано несколько возможностей для вводов и выводов блока, который может быть внутренним или внешним по отношению к генератору согласно изобретению.
На чертежах аналогичные ссылочные позиции обозначают аналогичные элементы и признаки.
Раскрытие изобретения
В соответствии с аспектом, предусмотрен генератор аудиоданных, выполненный с возможностью формирования аудиосигнала из входного сигнала и целевых данных, причем целевые данные представляют аудиосигнал, содержащий:
- первый блок обработки, выполненный с возможностью приема первых данных, извлекаемых из входного сигнала, и вывода первых выходных данных, при этом первые выходные данные содержат множество каналов, и
- второй блок обработки, выполненный с возможностью приема первых выходных данных или данных, извлекаемых из первых выходных данных, в качестве вторых данных,
- при этом первый блок обработки содержит для каждого канала первых выходных данных:
- обуславливающий набор обучаемых слоев, выполненных с возможностью обработки целевых данные для получения параметров обуславливающих признаков, причем целевые данные извлекаются из текста; и
- стилизующий элемент, выполненный с возможностью применения параметров обуславливающих признаков к первым данным или к нормализованным первым данным; и
- при этом второй блок обработки выполнен с возможностью комбинирования множества каналов вторых данных для получения аудиосигнала.
Генератор аудиоданных может быть таким, что целевые данные представляют собой спектрограмму. Генератор аудиоданных может быть таким, что целевые данные представляют собой мел-спектрограмму.
Генератор аудиоданных может быть таким, что целевые данные содержат по меньшей мере один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы или другого типа спектрограммы, полученной из текста.
Генератор аудиоданных может быть выполнен с возможностью получения целевых данных посредством преобразования ввода в форме текста или элементов текста по меньшей мере в один акустический признак.
Генератор аудиоданных может быть выполнен с возможностью получения целевых данных посредством преобразования по меньшей мере одного лингвистического признака по меньшей мере в один акустический признак.
Генератор аудиоданных может содержать по меньшей мере один лингвистический признак из фонемы, просодии слов, интонации, разрывов фраз и заполненных пауз, полученных из текста.
Генератор аудиоданных может быть выполнен с возможностью получения целевых данных посредством преобразования ввода в форме текста или элементов текста по меньшей мере в один лингвистический признак.
Генератор аудиоданных может быть таким, что целевые данные содержат по меньшей мере одно из символа и слова, полученного из текста.
Генератор аудиоданных может быть таким, что целевые данные извлекаются из текста с использованием статистической модели, выполняющей анализ текста и/или использующей акустическую модель.
Генератор аудиоданных может быть таким, что целевые данные извлекаются из текста с использованием обучаемой модели, выполняющей анализ текста и/или использующей акустическую модель.
Генератор аудиоданных может быть таким, что целевые данные извлекаются из текста с использованием алгоритма на основе правил, выполняющего анализ текста и/или акустическую модель.
Генератор аудиоданных может быть выполнен с возможностью получения целевых данных посредством подробного анализа ввода.
Генератор аудиоданных может быть выполнен с возможностью извлечения целевых данных по меньшей мере через один детерминированный слой.
Генератор аудиоданных может быть выполнен с возможностью извлечения целевых данных по меньшей мере через один обучаемый слой.
Генератор аудиоданных может быть таким, что обуславливающий набор обучаемых слоев состоит из одного или по меньшей мере двух сверточных слоев.
Генератор аудиоданных может быть таким, что первый сверточный слой выполнен с возможностью свертывания целевых данных или дискретизированных с повышением целевых данных для получения первых свернутых данных с использованием первой активирующей функции.
Генератор аудиоданных может быть таким, что обуславливающий набор обучаемых слоев и стилизующий элемент представляют собой часть слоя весовых коэффициентов в остаточном блоке нейронной сети, содержащей один или более остаточных блоков.
Способ может содержать по меньшей мере один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы или другого типа спектрограммы, полученной из текста.
Способ может получать целевые данные посредством преобразования ввода в форме текста или элементов текста по меньшей мере в один акустический признак.
Способ может получать целевые данные посредством преобразования по меньшей мере одного лингвистического признака по меньшей мере в один акустический признак.
Способ может содержать по меньшей мере один лингвистический признак из фонемы, просодии слов, интонации, разрывов фраз и заполненных пауз, полученных из текста.
Способ может получать целевые данные посредством преобразования ввода в форме текста или элементов текста по меньшей мере в один лингвистический признак.
Способ может содержать по меньшей мере одно из символа и слова, полученного из текста.
Способ может извлекать целевые данные посредством использования статистической модели, выполняющей анализ текста и/или использующей акустическую модель.
Способ может извлекать целевые данные посредством использования обучаемой модели, выполняющей анализ текста и/или использующей акустическую модель.
Способ может извлекать целевые данные посредством использования алгоритма на основе правил, выполняющего анализ текста и/или акустическую модель.
Способ может извлекать целевые данные по меньшей мере через один детерминированный слой.
Способ может извлекать целевые данные по меньшей мере через один обучаемый слой.
Способ формирования аудиосигнала дополнительно может содержать извлечение целевых данных из текста.
Способ может включать в себя то, что входная репрезентативная последовательность представляет собой текст.
Способ может включать в себя то, что входная репрезентативная последовательность представляет собой
спектрограмму. Способ может включать в себя то, что спектрограмма представляет собой мел-спектрограмму.
В числе прочего, предложен генератор аудиоданных (например, 10), выполненный с возможностью формирования аудиосигнала (например, 16) из входного сигнала (например, 14) и целевых данных (например, 12), причем целевые данные (например, 12), представляют аудиосигнал (например, 16), и которые могут быть извлечены из текста, содержащий по меньшей мере одно из следующего:
- первый блок обработки (например, 40, 50, 50a-50h), выполненный с возможностью приема первых данных (например, 15, 59а), извлекаемых из входного сигнала (например, 14), и вывода первых выходных данных (например, 69), при этом первые выходные данные (например, 69) содержат множество каналов (например, 47), и
- второй блок обработки (например, 45), выполненный с возможностью приема первых выходных данных (например, 69) или данных, извлекаемых из первых выходных данных (например, 69), в качестве вторых данных.
Первый блок обработки (например, 50) может содержать, для каждого канала первых выходных данных:
- обуславливающий набор обучаемых слоев (например, 71, 72, 73), выполненных с возможностью обработки целевых данных (например, 12) для получения параметров обуславливающих признаков (например, 74, 75); и
- стилизующий элемент (например, 77), выполненный с возможностью применения параметров обуславливающих признаков (например, 74, 75) к первым данным (например, 15, 59а) или к нормализованным первым данным (например, 59, 76').
Второй блок обработки (например, 45) может быть выполнен с возможностью комбинирования множества каналов (например, 47) вторых данных (например, 69) для получения аудиосигнала (например, 16).
Также предложен способ, например, формирования аудиосигнала (например, 16) посредством генератора аудиоданных (например, 10) из входного сигнала (например, 14) и целевых данных (например, 12), причем целевые данные (например, полученные из текста), представляют аудиосигнал (например, 16), содержащий:
- прием первым блоком обработки (например, 50, 50a-50h) первых данных (например, 16559, 59а, 59b), извлекаемых из входного сигнала (например, 14);
- для каждого канала первых выходных данных (например, 59b, 69):
- обработку целевых данных (например, 12), которые могут быть извлечены из текста, обуславливающим набором обучаемых слоев (например, 71, 72, 73) первого блока обработки (например, 50) для получения параметров обуславливающих признаков (например, 74, 75); и
- применение параметров обуславливающих признаков (например, 74, 75) стилизующим элементом (например, 77) первого блока обработки (например, 50) к первым данным (например, 15, 59) или к нормализованным первым данным (например, 76');
- вывод первым блоком обработки (например, 50) первых выходных данных (например, 69), содержащих множество каналов (например, 47);
- прием вторым блоком обработки (например, 45) первых выходных данных (например, 69) или данных, извлекаемых из первых выходных данных (например, 69), в качестве вторых данных; и
- комбинирование множества каналов (например, 47) вторых данных посредством второго блока обработки (например, 45) для получения аудиосигнала (например, 16).
Также предложен способ обучения нейронной сети для формирования аудиоданных, при этом нейронная сеть:
- выводит аудиовыборки с определенным временным шагом из входной последовательности (например, 12), представляющей аудиоданные (например, 16), которые должны формироваться,
- выполнена с возможностью формирования шумового вектора (например, 14) для создания выходных аудиовыборок (например, 16) с использованием входной репрезентативной последовательности (например, 12), и
- обучение конфигурировано с возможностью оптимизации функции потерь (например, 140).
Также предложен способ формирования аудиосигнала (например, 16), содержащего математическую модель, при этом математическая модель выполнена с возможностью вывода аудиовыборок с определенным временным шагом из входной последовательности (например, 12), представляющей аудиоданные (например, 16), которые должны формироваться. Математическая модель может формировать шумовой вектор (например, 14) для создания выходных аудиовыборок с использованием входной репрезентативной последовательности (например, 12).
Именно в этом контексте предложена StyleMelGAN (например, генератор 10 аудиоданных), легкий нейронный вокодер, обеспечивающий синтез высококачественной речи с низкой вычислительной сложностью. StyleMelGAN представляет собой полностью сверточную модель с прямой связью, которая использует временную адаптивную денормализацию (TADE) (например, 60а и 60b на фиг. 4 и 60 на фиг. 3), чтобы стилизовать (например, на 77) низкоразмерный шумовой вектор (например, вектор 128×1) через акустические признаки целевой формы речевого сигнала. Архитектура обеспечивает возможность высокопараллелизуемого формирования, в несколько раз быстрее, чем в реальном времени как на центральных процессорах (CPU), так и на графических процессорах (GPU). Для эффективного и быстрого обучения, можно использовать потери на спектральное восстановление с множеством масштабов вместе с состязательными потерями, вычисленными посредством множества дискриминаторов (например, 132a-132d), оценивающих речевой сигнал 16 во множестве полос частот и со случайным кодированием со взвешиванием (например, в окнах 105а, 105b, 105с, 105d кодирования со взвешиванием). Тесты MUSHRA и Р. 800 на основе прослушивания показывают, что StyleMelGAN (например, генератор 10 аудиоданных) превосходит известные существующие нейронные вокодеры в сценариях синтеза с копированием и в сценариях TTS.
В настоящей заявке предложен, в числе прочего, нейронный вокодер для формирования высококачественной речи 16, который может быть основан на генеративно-состязательной сети (GAN). Решение, называемое в данном документе "StyleMelGAN" (и, например, реализованное в генераторе 10 аудиоданных), представляет собой легкий нейронный вокодер, обеспечивающий синтез высококачественной речи 16 при низкой вычислительной сложности. StyleMelGAN представляет собой полностью сверточную модель с прямой связью, которая использует временную адаптивную денормализацию (TADE) для стилизации (например, в блоке 77) скрытого шумового представления (например, 69) с использованием, например, мел-спектрограммы (12) целевой формы речевого сигнала. Это обеспечивает возможность высокопараллелизуемого формирования, которое выполняется в несколько раз быстрее, чем в реальном времени как на CPU, так и на GPU. Для обучения, можно использовать потери на спектральное восстановление с множеством масштабов с последующими состязательными потерями. Это позволяет получать модель, которая может синтезировать высококачественные выводы менее чем через 2 дня после обучения на одном GPU.
Потенциальные варианты применения и преимущества изобретения заключаются в следующем:
Изобретение может применяться для преобразования текста в речь, и результирующее качество, т.е. сформированное качество речи для TTS и синтеза с копированием, находится близко к WaveNet и естественной речи. Оно также обеспечивает быстрое обучение, так что модель легко и быстро переобучается и персонализируется. Оно использует меньший объем памяти, поскольку оно представляет собой относительно небольшую нейронную сетевую модель. И в завершение, предложенное изобретение обеспечивает выгоду с точки зрения сложности, т.е. оно предусматривает очень хороший компромисс между качеством/сложностью.
Изобретение также может применяться для улучшения речи, причем оно может обеспечивать надежное решение с низкой сложностью для формирования чистой речи из зашумленной.
Изобретение также может применяться для кодирования речи, причем оно может значительно понижать скорость передачи битов посредством передачи только параметров, необходимых для обуславливания нейронного вокодера. Кроме того, в этой заявке решение на основе легкого нейронного вокодера является подходящим для встроенных систем и, в частности, подходящим для планируемого к выпуску (конечного) абонентского устройства (UE), оснащенного GPU или нейронным процессором (NPU).
Варианты осуществления настоящей заявки относятся к генератору аудиоданных, выполненному с возможностью формирования аудиосигнала из входного сигнала и целевых данных, причем целевые данные представляют аудиосигнал (например, из извлеченного текста), содержащему первый блок обработки, выполненный с возможностью приема первых данных, извлекаемых из входного сигнала, и вывода первых выходных данных, при этом первые выходные данные содержат множество каналов, и второй блок обработки, выполненный с возможностью приема первых выходных данных или данных, извлекаемых из первых выходных данных, в качестве вторых данных, при этом первый блок обработки содержит для каждого канала первых выходных данных обуславливающий набор обучаемых слоев, выполненных с возможностью обработки целевых данных для получения параметров обуславливающих признаков; и стилизующий элемент, выполненный с возможностью применения параметров обуславливающих признаков к первым данным или к нормализованным первым данным; и при этом второй блок обработки выполнен с возможностью комбинирования множества каналов вторых данных для получения аудиосигнала.
Согласно одному варианту осуществления, обуславливающий набор обучаемых слоев состоит из одного или двух сверточных слоев.
Согласно одному варианту осуществления, первый сверточный слой выполнен с возможностью свертывания целевых данных или дискретизированных с повышением целевых данных для получения первых свернутых данных с использованием первой активирующей функции.
Согласно одному варианту осуществления, обуславливающий набор обучаемых слоев и стилизующий элемент представляют собой часть слоя весовых коэффициентов в остаточном блоке нейронной сети, содержащей один или более остаточных блоков.
Согласно одному варианту осуществления, генератор аудиоданных дополнительно содержит нормализующий элемент, который выполнен с возможностью нормализации первых данных. Например, нормализующий элемент может нормализовать первые данные в нормальное распределение нулевого среднего и единичной дисперсии.
Согласно одному варианту осуществления, аудиосигнал представляет собой голосовой аудиосигнал.
Согласно одному варианту осуществления, целевые данные дискретизируются с повышением, предпочтительно посредством нелинейной интерполяции, на коэффициент 2 или кратный 2, или степень 2. В некоторых примерах вместо этого может использоваться коэффициент больше 2.
Согласно одному варианту осуществления первый блок обработки дополнительно содержит дополнительный набор обучаемых слоев, выполненных с возможностью обработки данных, извлекаемых из первых данных, с использованием второй активирующей функции, при этом вторая активирующая функция представляет собой стробированную активирующую функцию.
Согласно одному варианту осуществления, дополнительный набор обучаемых слоев состоит из одного или двух (или даже более) сверточных слоев.
Согласно одному варианту осуществления, вторая активирующая функция представляет собой стробированную гиперболическую тангенсную (TanH) функцию мягкого максимума.
Согласно одному варианту осуществления, первая активирующая функция представляет собой функцию на основе текучих единиц линейной ректификации (текучих ReLu).
Согласно одному варианту осуществления, операции свертки выполняются с максимальным коэффициентом растяжения в 2.
Согласно одному варианту осуществления, генератор аудиоданных содержит восемь первых блоков обработки и один второй блок обработки.
Согласно одному варианту осуществления, первые данные имеют более низкую степень размерности, чем аудиосигнал. Первые данные могут иметь первую размерность или по меньшей мере на одну размерность ниже, чем аудиосигнал. Первые данные могут иметь на одну размерность ниже, чем аудиосигнал, но число каналов, большее, чем аудиосигнал. Первые данные могут иметь общее число выборок по всем размерностям ниже, чем в аудиосигнале.
Согласно одному варианту осуществления, целевые данные представляют собой спектрограмму, предпочтительно мел-спектрограмму или поток битов.
Целевые данные могут быть извлечены из текста. Генератор аудиоданных может быть выполнен с возможностью извлечения целевых данных из текста. Целевые данные могут включать в себя, например, по меньшей мере одно из текстовых данных (символы, слова и т.п.), лингвистических признаков, акустических признаков и т.п.
В альтернативных примерах целевые данные могут представлять собой сжатое представление аудиоданных, или целевые данные представляют собой ухудшенный аудиосигнал.
Дополнительные варианты осуществления относятся к способу формирования аудиосигнала посредством генератора аудиоданных из входного сигнала и целевых данных, причем целевые данные представляют аудиосигнал (например, из извлеченного текста), содержащему прием, посредством первого блока обработки, первых данных, извлекаемых из входного сигнала; для каждого канала первых выходных данных, обработку, посредством обуславливающего набора обучаемых слоев первого блока обработки, целевых данных для получения параметров обуславливающих признаков; и применение стилизующим элементом первого блока обработки параметров обуславливающих признаков к первым данным или к нормализованным первым данным; вывод, посредством первого блока обработки, первых выходных данных, содержащих множество каналов; прием, посредством второго блока обработки, в качестве вторых данных, первых выходных данных или данных, извлекаемых из первых выходных данных; и комбинирование вторым блоком обработки множества каналов вторых данных для получения аудиосигнала. В некоторых примерах способ может содержать извлечение целевых данных из текста.
Нормализация может включать в себя, например, нормализацию первых данных в нормальное распределение нулевого среднего и единичной дисперсии.
В способе также может быть предусмотрен любой признак или сочетание признаков генератора аудиоданных.
Дополнительные варианты осуществления относятся к способу обучения генератора аудиоданных, как изложено выше, при этом обучение содержит повторение этапов любого из способов таким образом, как изложено выше, один или более раз.
Согласно одному варианту осуществления, способ обучения дополнительно содержит оценку сформированного аудиосигнала по меньшей мере посредством одного модуля оценки, который предпочтительно представляет собой нейронную сеть, и адаптацию весовых коэффициентов генератора аудиоданных согласно результатам оценки.
Согласно одному варианту осуществления, способ обучения дополнительно содержит адаптацию весовых коэффициентов модуля оценки согласно результатам оценки.
Согласно одному варианту осуществления, обучение содержит оптимизацию функции потерь.
Согласно одному варианту осуществления, оптимизация функции потерь содержит вычисление фиксированного показателя между сформированным аудиосигналом и опорным аудиосигналом.
Согласно одному варианту осуществления, вычисление фиксированного показателя содержит вычисление одного или более спектральных искажений между сформированным аудиосигналом и опорным сигналом.
Согласно одному варианту осуществления, вычисление одного или более спектральных искажений выполняется для абсолютной величины или логарифмической абсолютной величины спектрального представления сформированного аудиосигнала и опорного сигнала и/или для различных временных или частотных разрешений.
Согласно одному варианту осуществления, оптимизация функции потерь содержит извлечение одного или более состязательных показателей посредством случайной подачи и оценки представления сформированного аудиосигнала или представления опорного аудиосигнала посредством одного или более модулей оценки, при этом оценка содержит классификацию подаваемого аудиосигнала на заданное число классов, указывающее предварительно обученный уровень классификации естественности аудиосигнала.
Согласно одному варианту осуществления, оптимизация функции потерь содержит вычисление фиксированного показателя и извлечение состязательного показателя посредством одного или более модулей оценки.
Согласно одному варианту осуществления, генератор аудиоданных сначала обучается с использованием фиксированного показателя.
Согласно одному варианту осуществления, четыре модуля оценки извлекают четыре состязательных показателя.
Согласно одному варианту осуществления, модули оценки работают после разложения представления сформированного аудиосигнала или представления опорного аудиосигнала посредством гребенки фильтров.
Согласно одному варианту осуществления, каждый из модулей оценки принимает в качестве ввода одну или более частей представления сформированного аудиосигнала или представления опорного аудиосигнала.
Согласно одному варианту осуществления, части сигнала формируются посредством дискретизации случайного окна (окон) кодирования со взвешиванием из входного сигнала, с использованием случайной оконной функции (функций).
Согласно одному варианту осуществления, дискретизация случайного окна кодирования со взвешиванием повторяется многократно для каждого модуля оценки.
Согласно одному варианту осуществления, число раз, когда случайное окно (окна) кодирования со взвешиванием дискретизируется для каждого модуля оценки, является пропорциональным длине представления сформированного аудиосигнала или представления опорного аудиосигнала.
Дополнительные варианты осуществления относятся к компьютерному программному продукту, включающему в себя программу для обрабатывающего устройства, содержащую элементы программного кода для выполнения этапов способов, описанных в данном документе, когда программа выполняется на обрабатывающем устройстве.
Согласно одному варианту осуществления, компьютерный программный продукт содержит машиночитаемый носитель, на котором сохраняются элементы программного кода, при этом программа является непосредственно загружаемой во внутреннее запоминающее устройство обрабатывающего устройства.
Дополнительные варианты осуществления относятся к способу формирования аудиосигнала, содержащего математическую модель, при этом математическая модель выполнена с возможностью вывода аудиовыборок с определенным временным шагом из входной последовательности (например, извлеченной из текста), представляющей аудиоданные, которые должны формироваться, при этом математическая модель выполнена с возможностью формирования шумового вектора для создания выходных аудиовыборок с использованием входной репрезентативной последовательности.
Согласно одному варианту осуществления математическая модель обучается с использованием аудиоданных. Согласно одному варианту осуществления, математическая модель представляет собой нейронную сеть. Согласно одному варианту осуществления, сеть представляет собой сеть с прямой связью. Согласно одному варианту осуществления, сеть представляет собой сверточную сеть.
Согласно одному варианту осуществления, шумовой вектор может иметь более низкую степень размерности, чем аудиосигнал, который должен формироваться. Первые данные могут иметь первую размерность или по меньшей мере на одну размерность ниже, чем аудиосигнал. Первые данные могут иметь общее число выборок по всем размерностям ниже, чем аудиосигнал. Первые данные могут иметь на одну размерность ниже, чем аудиосигнал, но число каналов, большее, чем аудиосигнал.
Согласно одному варианту осуществления, технология временной адаптивной денормализации (TADE) используется для обуславливания математической модели с использованием входной репрезентативной последовательности и в силу этого для формирования шумового вектора.
Согласно одному варианту осуществления, модифицированная стробированная TanH мягкого максимума активирует каждый слой нейронной сети.
Согласно одному варианту осуществления, операции свертки выполняются с максимальным коэффициентом растяжения в 2.
Согласно одному варианту осуществления, шумовой вектор, а также входная репрезентативная последовательность дискретизируются с повышением для получения выходных аудиоданных с целевой частотой дискретизации.
Согласно одному варианту осуществления, повышающая дискретизация выполняется последовательно в различных слоях математической модели.
Согласно одному варианту осуществления, коэффициент повышающей дискретизации для каждого слоя равен 2 или кратному 2, например, степени 2. В некоторых примерах, значения коэффициента повышающей дискретизации могут, если обобщать, быть больше 2.
Сформированный аудиосигнал может в общем случае использоваться при применении преобразования текста в речь, при этом входная репрезентативная последовательность извлекается из текста.
Согласно одному варианту осуществления, сформированный аудиосигнал используется в аудиодекодере, при этом входная репрезентативная последовательность представляет собой сжатое представление исходных аудиоданных, которые следует передать или сохранить.
Согласно одному варианту осуществления, сформированный аудиосигнал используется для повышения качества звучания ухудшенного аудиосигнала, при этом входная репрезентативная последовательность извлекается из ухудшенного сигнала.
Дополнительные варианты осуществления относятся к способу обучения нейронной сети для формирования аудиоданных, при этом нейронная сеть выводит аудиовыборки с определенным временным шагом из входной последовательности, представляющей аудиоданные, которые должны формироваться, при этом нейронная сеть выполнена с возможностью формирования шумового вектора для создания выходных аудиовыборок с использованием входной репрезентативной последовательности, при этом нейронная сеть конфигурирована, как изложено выше, и при этом обучение конфигурировано с возможностью оптимизации функции потерь.
Согласно одному варианту осуществления, функция потерь содержит фиксированный показатель, вычисленный между сформированным аудиосигналом и опорным аудиосигналом.
Согласно одному варианту осуществления, фиксированный показатель представляет собой одно или более спектральных искажений, вычисленных между сформированным аудиосигналом и опорным сигналом.
Согласно одному варианту осуществления, одно или несколько спектральных искажений вычисляются для абсолютной величины или логарифмической абсолютной величины спектрального представления сформированного аудиосигнала и опорного сигнала.
Согласно одному варианту осуществления, одно или несколько спектральных искажений, формирующих фиксированный показатель, вычисляются для различных временных или частотных разрешений.
Согласно одному варианту осуществления, функция потерь содержит состязательный показатель, извлекаемый посредством дополнительных дискриминативных нейронных сетей, при этом дискриминативные нейронные сети принимают в качестве ввода представление сформированных или опорных аудиосигналов, и при этом дискриминативные нейронные сети выполнены с возможностью оценки того, насколько реалистичными являются сформированные аудиовыборки.
Согласно одному варианту осуществления, функция потерь содержит как фиксированный показатель, так и состязательный показатель, извлекаемые посредством дополнительных дискриминативных нейронных сетей.
Согласно одному варианту осуществления, нейронная сеть, формирующая аудиовыборки, сначала обучается с использованием только фиксированного показателя.
Согласно одному варианту осуществления, состязательный показатель извлекается посредством 4 дискриминативных нейронных сетей.
Согласно одному варианту осуществления, дискриминативные нейронные сети работают после разложения входного аудиосигнала посредством гребенки фильтров.
Согласно одному варианту осуществления, каждая дискриминативная нейронная сеть принимает в качестве ввода одну или несколько случайных кодированных со взвешиванием версий входного аудиосигнала.
Согласно одному варианту осуществления, дискретизация случайного окна кодирования со взвешиванием повторяется многократно для каждой дискриминативной нейронной сети.
Согласно одному варианту осуществления, число раз, когда случайное окно кодирования со взвешиванием дискретизируется для каждой дискриминативной нейронной сети, является пропорциональным длине входных аудиовыборок.
Осуществление изобретения
На Фиг. 8 показан пример генератора 10 аудиоданных. Генератор 10 аудиоданных может преобразовывать текст 112 в выходной аудиосигнал 16. Текст 112 может преобразовываться в целевые данные 12 (см. ниже), которые в некоторых примерах можно понимать как аудиопредставление (например, спектрограмма или, обобщенно, спектрограммы, MFCC, такие как логарифмическая спектрограмма или спектрограмма или MFCC, или мел-спектрограмма, или другие акустические признаки). Целевые данные 12 могут использоваться для обуславливания входного сигнала 14 (например, шума) таким образом, чтобы обрабатывать входной сигнал 14 таким образом, что он становится слышимой речью. Блок 1110 аудиосинтеза (блок анализа текста) может преобразовывать текст 112 в аудиопредставление (например, в спектрограмму или, обобщенно, в спектрограммы, MFCC, такие как логарифмическая спектрограмма или спектрограмма или MFCC, или мел-спектрограмма, или другие акустические признаки), например, при условиях, определяемых целевыми данными 12. Блок 1110 аудиосинтеза, например, может отвечать за обработку по меньшей мере одного из дикции, фазирования, интонации, длительности и т.д. речи. Блок 1110 аудиосинтеза (блок анализа текста) может выполнять по меньшей мере одну задачу, такую как нормализация текста, сегментация на слова, прогнозирование просодий и преобразование графенов в фонемы. Затем, сформированные целевые данные 12 могут вводиться в блок 1120 синтеза форм сигналов (например, вокодер), который может формировать форму 16 сигнала (выходной аудиосигнал), например, из входного сигнала 14 на основе условий, полученных из целевых данных 12, полученных из текста 112.
Тем не менее, следует отметить, что блок 1110 в некоторых примерах не представляет собой часть генератора 10, но блок 1110 может быть внешним для генератора 10. В некоторых примерах, блок 1110 может подразделяться на множество субблоков (и в некоторых конкретных случаях по меньшей мере один из субблоков может представлять собой часть генератора 10, и по меньшей мере один из субблоков может быть внешним для генератора 10).
В общих чертах, ввод, который может представлять собой текст (или другой ввод, извлекаемый из текста), который вводится в блок 1110 (или генератор 10 в некоторых примерах), может иметь форму по меньшей мере одного из:
- текста 112 (например, код ASCII),
- по меньшей мере одного лингвистического признака (например, по меньшей мере одного из фонемы, просодии слов, интонации, разрывов фраз и заполненных пауз, например, полученных из текста),
- по меньшей мере одного акустического признака (например, по меньшей мере одного из логарифмической спектрограммы, MFCC и мел-спектрограммы, например, полученной из текста).
Ввод может обрабатываться (например, блоком 1110) для получения целевых данных 12. Согласно другим примерам, блок 1110 может выполнять обработку таким образом, чтобы получить целевые данные 12 (извлекаемые из текста) в форме по меньшей мере одного из:
- по меньшей мере одного из символа текста или слова,
- по меньшей мере одного лингвистического признака (например, по меньшей мере одного из фонемы, просодии слов, интонации, разрывов фраз и заполненных пауз, например, полученных из текста),
- по меньшей мере одного акустического признака (например, по меньшей мере одного из логарифмической спектрограммы, MFCC и мел-спектрограммы, например, полученной из текста).
Целевые данные 12 (в форме ли символа, лингвистических признаков или акустического признака) используются посредством генератора 10 (например, посредством блока синтеза форм сигналов, вокодера, 1120) для обуславливания обработки для входного сигнала 14, таким образом формируя выходной аудиосигнал (акустическую волну).
На Фиг. 10 показана синоптическая таблица для нескольких возможностей для создания экземпляра блока 1110:
A) В случае А ввод, введенный в блок 1110, представляет собой простой текст 112, и вывод (целевые данные 12) из блока 1110 представляет собой по меньшей мере одно из символа текста или слова (которое также представляет собой текст). В случае А блок 1110 выполняет выбор текста 112 для элементов текста 112. Затем целевые данные 12 (в форме элементов текста 112) должны обуславливать обработку для входного сигнала 14 таким образом, чтобы получить выходной сигнал 16 (акустическую волну).
B) В случае В ввод, введенный в блок 1110, представляет собой простой текст 112, и вывод (целевые данные 12) из блока 1110 содержат по меньшей мере один лингвистический признак, например, например, лингвистический признак из фонемы, просодии слов, интонации, разрыва фразы и заполненных пауз, полученных из текста 112 и т.д. В случае В блок 1110 выполняет лингвистический анализ для элементов текста 112, таким образом получая по меньшей мере один лингвистический признак по меньшей мере из одного из фонемы, просодии слов, интонации, разрыва фразы и заполненных пауз и т.д. Затем целевые данные 12 (в форме по меньшей мере одного из фонемы, просодии слов, интонации, разрыва фразы и заполненных пауз и т.д.) должны обуславливать обработку для входного сигнала 14 таким образом, чтобы получить выходной сигнал 16 (акустическую волну).
C) В случае С ввод, введенный в блок 1110, представляет собой простой текст 112, и вывод (целевые данные 12) из блока 1110 содержат по меньшей мере один акустический признак, например, один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы, полученной из текста. В случае С блок 1110 выполняет акустический анализ для элементов текста 112, за счет этого получая по меньшей мере один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы, полученной из текста 112. Затем целевые данные 12 (например, в форме по меньшей мере одного из акустических признаков из логарифмической спектрограммы, MFCC, мел-спектрограммы, полученной из текста, и т.д.) должны обуславливать обработку для входного сигнала 14 таким образом, чтобы получить выходной сигнал 16 (акустическую волну).
D) В случае D ввод, введенный в блок 1110, представляет собой лингвистический признак (например по меньшей мере одно из фонемы, просодии слов, интонации, разрыва фразы и заполненной паузы), и вывод также представляет собой обработанный лингвистический признак (например по меньшей мере одно из фонемы, просодии слов, интонации, разрыва фразы и заполненной паузы). Затем целевые данные 12 (в форме по меньшей мере одного из фонемы, просодии слов, интонации, разрыва фразы и заполненных пауз и т.д.) должны обуславливать обработку для входного сигнала 14 таким образом, чтобы получить выходной сигнал 16 (акустическую волну).
E) В случае Е ввод, введенный в блок 1110, представляет собой лингвистический признак (например по меньшей мере одно из фонемы, просодии слов, интонации, разрыв фразы и заполненная пауза), и вывод (целевые данные 12) из блока 1110 содержит по меньшей мере один акустический признак, например, один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы, полученной из текста. В случае Е блок 1110 выполняет акустический анализ для элементов текста 112, чтобы получать по меньшей мере один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы. Затем целевые данные 12 (например, в форме по меньшей мере одного из акустических признаков из логарифмической спектрограммы, MFCC, мел-спектрограммы, полученной из текста, и т.д.) должны обуславливать обработку для входного сигнала 14 таким образом, чтобы получить выходной сигнал 16 (акустическую волну).
F) В случае F ввод, введенный в блок 1110, имеет форму акустического признака (например, форму по меньшей мере одного из акустических признаков из логарифмической спектрограммы, MFCC, мел-спектрограммы, полученной из текста, и т.д.), и вывод (целевые данные 12) имеет форму обработанного акустического признака (например, форму по меньшей мере одного из акустических признаков из логарифмической спектрограммы, MFCC, мел-спектрограммы, полученной из текста, и т.д.). Затем целевые данные 12 (например, в форме обработанных акустических признаков, таких как по меньшей мере один из акустических признаков из логарифмической спектрограммы, MFCC, мел-спектрограммы, полученной из текста, и т.д.) должны обуславливать обработку для входного сигнала 14 таким образом, чтобы получить выходной сигнал 16 (акустическую волну).
На Фиг. 9а показан пример, в котором блок 1110 включает в себя субблок 1112 (блок анализа текста), который обеспечивает промежуточные целевые данные 212, и, ниже него, субблок 1114 (аудиосинтез, например, с использованием акустической модели), который формирует целевые данные 12 в форме акустических признаков. Следовательно, на фиг. 9а, если оба субблока 1112 и 1114 представляют собой часть генератора 10, происходит случай С. Если субблок 1112 не представляет собой часть генератора 10, но субблок 1114 представляет собой часть генератора 10, происходит случай Е.
На Фиг. 9b показан пример, в котором блок 1110 выполняет только анализ текста и обеспечивает целевые данные 12 в форме лингвистических признаков. Следовательно, на фиг. 9b, если блок 1110 представляет собой часть генератора 10, происходит случай В.
На Фиг. 9с показан пример, в котором блок 1110 отсутствует, а целевые данные 112 имеют форму лингвистических признаков.
В общем случае, блок 1110 (если он присутствует) работает с возможностью все более и более подробного анализа текста (или другого ввода, полученного из текста), при обработке к целевым данным, которые анализируются более подробно, чем ввод, введенный в блок 1110. Блок 1110 также может использовать ограничения (например, функцию внимания, голос мужчины/женщины, акцент, эмоциональную характеризацию и т.д.), которые могут отсутствовать в исходном тексте. В общем случае эти ограничения могут быть установлены пользователем.
Следует отметить, что в вышеприведенных и нижеприведенных случаях блок 1110 (либо, если они присутствуют, любой из его субблоков, например любой из блоков 1112 и 1114) может использовать статистическую модель, например, выполняющую анализ текста и/или использующую акустическую модель. Помимо этого или в качестве альтернативы, блок 1110 (либо, если они присутствуют, любой из его субблоков, например любой из блоков 1112 и 1114) может использовать обучаемую модель, например, выполняющую анализ текста и/или использующую акустическую модель. Обучаемая модель может быть основана, например, на нейронных сетях, марковских цепях и т.д. Опять же кроме этого или в качестве дополнительной альтернативы, блок 1110 (либо, если они присутствуют, любой из его субблоков, например любой из блоков 1112 и 1114) может использовать алгоритм на основе правил, выполняющий анализ текста и/или основанный на акустической модели.
В некоторых примерах блок 1110 (либо, если они присутствуют, любой из его субблоков, например любой из блоков 1112 и 1114) может извлекать целевые данные детерминированным образом. Следовательно, имеется вероятность того, что некоторый субблок(и) является обучаемым, а другие субблоки являются детерминированными.
Блок 1110 также называется «блоком анализа текста» (например, при преобразовании текста по меньшей мере в один лингвистический признак) или «блоком аудиосинтеза» (например, при преобразовании текста или по меньшей мере одного лингвистического признака по меньшей мере в один акустический признак, такой как спектрограмма). В любом случае, установлено, что целевые данные 12 могут иметь форму текста, лингвистического признака или акустического признака согласно вариантам осуществления.
В частности, на фиг. 10 показано, что некоторые сочетания преобразований в общем не предусмотрены. Это обусловлено тем, что преобразования из подробно анализируемого признака в простой признак (например, из лингвистического признака в текст либо из акустического признака в текст или в лингвистический признак) не предполагаются.
На Фиг. 6 показан пример генератора 10 аудиоданных, который может формировать (например, синтезировать) аудиосигнал 16 (выходной сигнал), например, согласно StyleMelGAN. На фиг. 6 текст 112 может обрабатываться, например, посредством блока 1110 анализа текста для получения целевых данных 12. Затем в блоке 1120 синтеза форм сигналов могут использоваться целевые данные 12 для обработки входного сигнала 14 (например, шума) для получения слышимого аудиосигнала 16 (формы акустического сигнала). Полученные целевые данные 12 могут извлекаться из текста.
В частности, выходной аудиосигнал 16 может формироваться на основе входного сигнала 14 (также называемого «скрытым сигналом», который может представлять собой шум, например, белый шум) и целевых данных 12 (также называемых «входной последовательностью» и в некоторых примерах извлекаемых из текста), и которые могут быть получены, например, из текста 112 в блоке 1110. Целевые данные 12, например, могут содержать (например, представлять собой) спектрограмму (например, мел-спектрограмму), причем мел-спектрограмма обеспечивает преобразование, например, последовательности временных выборок в мел-шкалу. Помимо этого или в качестве альтернативы, целевые данные 12 могут содержать (например, представлять собой) поток битов. Например, целевые данные могут представлять собой или включать в себя текст (или в более общем случае могут быть извлечены из текста), который должен воспроизводиться в аудиоданных (например, преобразование текста в речь). В общем случае целевые данные 12 должны обрабатываться для получения речевого звука, распознаваемого слушателем-человеком как естественный звук. Входной сигнал 14 может представлять собой шум (который как таковой не переносит полезную информацию), например, белый шум, но, в генераторе 10, шумовой вектор, извлеченный из шума, стилизуется (например, в позиции 77) таким образом, что он имеет шумовой вектор с акустическими признаками, обусловленными посредством целевых данных 12. В конечном итоге выходной аудиосигнал 16 должен пониматься слушателем-человеком как речь. Шумовой вектор 14 может представлять собой, аналогично фиг. 1, вектор 128×1 (одну отдельную выборку, например, выборки временной области или выборки частотной области и 128 каналов). В других примерах может использоваться другая длина шумового вектора 14.
Первый блок 50 обработки показан на фиг. 6. Как показано (например, на фиг. 1), первый блок 50 обработки может подвергаться созданию экземпляра посредством каждого из множества блоков (на фиг. 1, посредством блоков 50а, 50b, 50с, 50d, 50е, 50f, 50g, 50h). Блоки 50a-50h могут пониматься как формирующие один отдельный блок 40. Показано, что в первом блоке 40, 50 обработки, обуславливающий набор обучаемых слоев (например, 71, 72, 73) может использоваться для обработки целевых данных 12 и/или входного сигнала 14. Соответственно, параметры 74, 75 обуславливающих признаков (также называемые «гамма, у» и «бета, [3», на фиг. 3) могут быть получены, например, посредством свертки во время обучения. Обучаемые слои 71-73 могут в силу этого представлять собой часть слоя весовых коэффициентов обучающей сети или, если обобщать, другой обучающей структуры. Первый блок 40, 50 обработки может включать в себя по меньшей мере один стилизующий элемент 77. По меньшей мере, один стилизующий элемент 77 может выводить первые выходные данные 69. По меньшей мере, один стилизующий элемент 77 может применять параметры 74, 75 обуславливающих признаков к входному сигналу 14 (скрытому) либо к первым данным 15, полученным из входного сигнала 14.
Первые выходные данные 69 в каждом блоке 50 находятся во множестве каналов. Генератор 10 аудиоданных может включать в себя второй блок 45 обработки (на фиг. 1 показан как включающий в себя блоки 42, 44, 46). Второй блок 45 обработки может быть выполнен с возможностью комбинирования множества каналов 47 первых выходных данных 69 (введенных в качестве вторых входных данных или вторых данных) таким образом, чтобы получить выходной аудиосигнал 16 в одном отдельном канале, но в последовательности выборок.
«Каналы» следует понимать не в контексте стереозвука, а в контексте нейронных сетей (например, сверточных нейронных сетей). Например, входной сигнал 14 (например, скрытый шум) может находиться в 128 каналах (в представлении во временной области), поскольку предусмотрена последовательность каналов. Например, когда сигнал имеет 176 выборок и 64 канала, он может пониматься в качестве матрицы из 176 столбцов и 64 строк, тогда как, когда сигнал имеет 352 выборки и 64 канала, он может пониматься в качестве матрицы из 352 столбцов и 64 строк (другие схематизации являются возможными). Следовательно, сформированный аудиосигнал 16 (который на фиг. 1 приводит к матрице-строке 1×22528, где 22528 может быть заменено любым другим числом) может пониматься как моносигнал. В случае если стереосигналы должны формироваться, то раскрытая технология должна просто повторяться для каждого стереоканала, с тем чтобы получать несколько аудиосигналов 16, которые впоследствии микшируются.
По меньшей мере исходный входной сигнал 14 и/или сформированная речь 16 могут представлять собой вектор. Наоборот, вывод каждого из блоков 30 и 50a-50h, 42, 44 имеет, в общем, различную степень размерности. Первые данные могут иметь первую размерность или по меньшей мере на одну размерность ниже размерности аудиосигнала. Первые данные могут иметь общее число выборок по всем размерностям ниже, чем аудиосигнал. Первые данные могут иметь на одну размерность ниже, чем аудиосигнал, но число каналов, большее, чем аудиосигнал. В каждом блоке 30 и 50a-50h, сигнал, меняющийся от шума 14 до речи 16, может подвергаться повышающей дискретизации. Например, в блоке 30 повышающей дискретизации перед первым блоком 50а из блоков 50а-50h, выполняется 88-кратная повышающая дискретизация. Пример повышающей дискретизации может включать в себя, например, следующую последовательность: 1) повторение одинакового значения, 2) вставка нулей, 3) еще одно повторение или вставка нулей + линейная фильтрация и т.д.
Сформированный аудиосигнал 16, в общем, может представлять собой одноканальный сигнал (например, 1×22528). В случае если требуются несколько аудиоканалов (например, для воспроизведения стереозвука), то заявленная процедура, в принципе, должна итеративно выполняться многократно.
Аналогичным образом, также целевые данные 12, в принципе, могут находиться в одном отдельном канале (например, если они представляют собой текст или в более общем случае если они извлечены из текста, как в случае А, или как на Фиг. 9с) или во множестве каналов (например, в спектрограммах, например в мел-спектрограммах, например извлеченных из текста, например как в случаях С, Е, F). В любом случае, они могут быть дискретизированы с повышением (например, на коэффициент два, степень 2, число, кратное 2 или значение больше 2) для адаптации к размерностям сигнала (59а, 15, 69), эволюционирующего вдоль последующих слоев (50a-50h, 42), например, таким образом, чтобы получить параметры 74, 75 обуславливающих признаков с размерностями, адаптированными к размерностям сигнала.
Когда для первого блока 50 обработки создаются экземпляры, например, по меньшей мере во множестве блоков 50a-50h, число каналов, например, может оставаться одинаковым для множества блоков 50a-50h. Первые данные могут иметь первую размерность или по меньшей мере на одну размерность ниже размерности аудиосигнала. Первые данные могут иметь общее число выборок по всем размерностям ниже, чем аудиосигнал. Первые данные могут иметь на одну размерность ниже, чем аудиосигнал, но число каналов, большее, чем аудиосигнал.
Сигнал в последующих блоках может иметь различные размерности относительно друг друга. Например, выборка может дискретизироваться с повышением все большее число раз для достижения, например, от 88 выборок до 22528 выборок в последнем блоке 50h. Аналогичным образом, также целевые данные 12 дискретизируются с повышением в каждом блоке 50 обработки. Соответственно, параметры 74, 75 обуславливающих признаков могут адаптироваться к числу выборок сигнала, который должен обрабатываться. Соответственно, семантическая информация, обеспечиваемая целевыми данными 12, не теряется в последующих слоях 50a-50h.
Следует понимать, что примеры могут выполняться согласно парадигмам генеративно-состязательных сетей (GAN). GAN включает в себя генератор 11 GAN (фиг. 1) и дискриминатор 100 GAN (фиг. 2), который также можно понимать как часть блока 1120 синтеза форм сигналов. Генератор 11 GAN стремится сформировать аудиосигнал 16, который является максимально близким к реальному сигналу. Дискриминатор 100 GAN должен распознавать, является ли сформированный аудиосигнал реальным (таким как реальный аудиосигнал 104 на фиг. 2) или поддельным (таким как сформированный аудиосигнал 16). Как генератор 11 GAN, так и дискриминатор 100 GAN могут быть получены в виде нейронных сетей. Генератор 11 GAN должен минимизировать потери (например, через способ градиентов или другие способы) и обновлять параметры 74, 75 обуславливающих признаков путем учета результатов в дискриминаторе 100 GAN. Дискриминатор 100 GAN должен уменьшать собственные дискриминационные потери (например, через способ градиентов или другие способы) и обновлять собственные внутренние параметры. Соответственно, генератор GAN 11 обучается для обеспечения всех лучших аудиосигналов 16, тогда как дискриминатор 100 GAN обучается для распознавания реальных сигналов 16 из поддельных аудиосигналов, сформированных генератором 11 GAN. В общих чертах, очевидно, что генератор 11 GAN может включать в себя функциональности генератора 10 по меньшей мере без функциональностей дискриминатора 100 GAN. Следовательно, в большей части вышеуказанного, очевидно, что генератор 11 GAN и генератор 10 аудиоданных могут иметь в той или иной степени одинаковые признаки, отличные от признаков дискриминатора 100. Генератор 10 аудиоданных может включать в себя дискриминатор 100 в качестве внутреннего компонента. Следовательно, генератор 11 GAN и -дискриминатор 100 GAN могут вместе составлять генератор 10 аудиоданных. В примерах, в которых дискриминатор 100 GAN отсутствует, генератор 10 аудиоданных может состоять только из -генератора 11 GAN.
Как поясняет формулировка «обуславливающий набор обучаемых слоев», генератор 10 аудиоданных может быть получен в соответствии с парадигмами условных GAN, например, на основании условной информации. Например, условная информация может состоять из целевых данных 12 (либо их дискретизированной с повышением версии), на которых обучается обуславливающий набор слоев 71-73 (слой весовых коэффициентов), и получаются параметры 74, 75 обуславливающих признаков. Следовательно, стилизующий элемент 77 обуславливается посредством обучаемых слоев 71-73.
Примеры могут быть основаны на сверточных нейронных сетях. Например, небольшая матрица (например, фильтр или ядро), которая может представлять собой матрицу 3×3 (или матрицу 4×4 и т.д.), сворачивается (свертывается) вдоль большей матрицы (например, канал х дискретизирует скрытый или входной сигнал и/или спектрограмму, и/или спектрограмму или дискретизированную с повышением спектрограмму либо, в общем случае, целевые данные 12), например, что подразумевает комбинирование (например, умножение и сумму произведений; произведение с точкой и т.д.) между элементами фильтра (ядра) и элементами большей матрицы (активационной картой или активационной сигнала). Во время обучения, получаются (обучаются) элементы фильтра (ядра), которые представляют собой элементы, которые минимизируют потери. Во время логического вывода, используются элементы фильтра (ядра), которые получены во время обучения. Примеры сверток приводятся в блоках 71-73, 61а, 61b, 62а, 62b (см. ниже). Если блок является условным (например, блок 60 по фиг. 3), то свертка не обязательно применяется к сигналу, эволюционирующему из входного сигнала 14, к аудиосигналу 16 через промежуточные сигналы 59а (15), 69 и т.д., но может применяться к целевому сигналу 14. В других случаях (например, в блоках 61а, 61b, 62а, 62b), свертка может быть не условной и, например, может непосредственно применяться к сигналу 59а (15), 69 и т.д., эволюционирующему из входного сигнала 14, к аудиосигналу 16. Как видно из фиг. 3 и 4, могут выполняться условные и безусловные свертки.
Можно иметь, в некоторых примерах, активирующие функции ниже свертки (ReLu, TanH, функцию мягкого максимума и т.д.), которые могут отличаться в соответствии с намеченным эффектом. ReLu может преобразовывать максимум между 0 и значением, полученным в свертке (на практике она сохраняет одинаковое значение, если оно является положительным, и выводит 0 в случае отрицательного значения). Текучая ReLu может выводить х, если х>0, и 0,1*х, если х≤0, причем х является значением, полученным посредством свертки (вместо 0,1, другое значение, например, заданное значение в 0,1±0,05, может использоваться в некоторых примерах). TanH (которая может быть реализована, например, в блоке 63а и/или 63b) может обеспечивать гиперболический тангенс значения, полученного в свертке, например:

причем х является значением, полученным в свертке (например, в блоке 61а и/или 61b). Функция мягкого максимума (например, применяемая, например, в блоке 64а и/или 64b) может применять экспоненциал к каждому элементу из элементов результата свертки (например, полученному в блоке 62а и/или 62b) и нормализовать его посредством деления на сумму экспоненциалов. Функция мягкого максимума (например, в 64а и/или 64b) может обеспечивать распределение вероятностей для записей, которые находятся в матрице, которая получается в результате свертки (например, как предусмотрено в 62а и/или 62b). После применения активирующей функции, этап объединения в пул может выполняться (не показан на чертежах) в некоторых примерах, но в других примерах он может исключаться.
На Фиг. 4 показано, что также можно иметь стробированную функцию TanH мягкого максимума, например, посредством умножения (например, в 65а и/или 65b) результата функции TanH (например, полученного в 63а и/или 63b) на результат функции мягкого максимума (например, полученный в 64а и/или 64b).
Несколько слоев сверток (например, обуславливающий набор обучаемых слоев) могут располагаться друг за другом и/или параллельно друг другу, с тем чтобы увеличивать эффективность. Если предусмотрено применение активирующей функции и/или объединения в пул, они также могут повторяться в различных слоях (либо, например, могут быть предусмотрены различные активирующие функции, которые могут применяться к различным слоям).
Входной сигнал 14 (например, шум) обрабатывается, на различных этапах, так что он становится сформированным аудиосигналом 16 (например, при условиях, заданных посредством обуславливающих наборов обучаемых слоев 71-73, и для параметров 74, 75, обученных посредством обуславливающих наборов обучаемых слоев 71-73). Следовательно, входной сигнал должен пониматься как эволюционирующий в направлении обработки (от 14 к 16 на фиг. 6) в сторону становления сформированным аудиосигналом 16 (например, речью). Условия фактически формируются на основе целевого сигнала 12 и на основе обучения (с тем чтобы достигать самого предпочтительного набора параметров 74, 75).
Также следует отметить, что может считаться, что множество каналов входного сигнала (либо любой из его эволюций) имеют набор обучаемых слоев и стилизующий элемент, ассоциированный с ними. Например, каждая строка матриц 74 и 75 ассоциирована с конкретным каналом входного сигнала (либо одной из его эволюций) и в силу этого получается из конкретного обучаемого слоя, ассоциированного с конкретным каналом. Аналогичным образом, можно считать, что стилизующий элемент 77 формируется посредством множества стилизующих элементов (каждый из которых предназначен для каждой строки входного сигнала х, с, 12, 76, 76', 59, 59а, 59b и т.д.).
На Фиг. 1 показан пример генератора 10 аудиоданных (который может осуществлять генератор 10 аудиоданных по фиг. 6), который также может содержать (например, представлять собой) генератор 11 GAN. Следует отметить, что на Фиг. 1 показаны только элементы блока 1120 синтеза форм сигналов, поскольку целевые данные 12 уже преобразованы из текста 112. Целевые данные 12, например, полученные из текста, указываются в виде мел-спектрограммы, входной сигнал 14 может представлять собой скрытый шум, и вывод сигнала 16 может представлять собой речь (тем не мене, другие примеры являются возможными, как пояснено выше). Как можно видеть, входной сигнал 14 имеет только одну выборку и 128 каналов (могут быть определены другие числа). Шумовой вектор 14 может получаться в векторе с 128 каналами (но другие числа являются возможными) и может иметь нормальное распределение нулевого среднего. Шумовой вектор может соответствовать формуле:
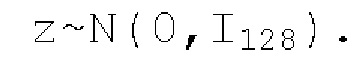
Шумовой вектор может представлять собой случайный шум размерности 128 со сформированным средним значением 0 и с автокорреляционной матрицей (квадратом 128×128), равной единичному элементу I (можно осуществлять другой выбор). Следовательно, в примерах, сформированный шум может полностью декоррелироваться между каналами и иметь дисперсию 1 (энергию). N(0,I128) может сформирован в каждых 22528 сформированных выборок (либо для других примеров могут быть выбраны другие числа); размерность может в силу этого быть равна 1 на временной оси и 128 на канальной оси.
Показано, что шумовой вектор 14 пошагово обрабатывается (например, в блоках 50a-50h, 42, 44, 46 и т.д.) таким образом, чтоб он эволюционирует, например, из шума 14, например, в речь 16 (эволюционирующий сигнал должен указываться, например, с помощью различных сигналов 15, 59а, х, с, 76', 79, 79а, 59b, 79b, 69 и т.д.).
В блоке 30, входной сигнал 14 (шум) может дискретизироваться с повышением таким образом, что он имеет 88 выборок (возможны различные числа) и 64 канала (возможны различные числа).
Как можно видеть, восемь блоков 50а, 50b, 50с, 50d, 50е, 50f, 50g, 50h обработки (все из которых осуществляют первый блок 50 обработки по фиг. 6) могут увеличивать число выборок посредством выполнения повышающей дискретизации (например, максимум 2-кратной повышающей дискретизации). Число каналов может всегда оставаться одинаковым (например, 64) вдоль блоков 50а, 50b, 50с, 50d, 50е, 50f, 50g, 50h. Выборки, например, могут составлять число выборок в секунду (или другую единицу времени): можно получать, в выводе блока 50h, звук при более чем 22 кГц.
Каждый из блоков 50a-50h (50) также может представлять собой остаточный блок TADE (остаточный блок в контексте TADE, временной адаптивной денормализации). В частности, каждый блок 50a-50h может обусловливаться целевыми данными 12 (например, текстовым признаком, лингвистическим признаком или акустическим признаком, таким как мел-спектрограмма).
Во втором блоке 45 обработки (фиг. 1 и 6), может получаться только один отдельный канал, и несколько выборок получаются в одной отдельной размерности. Как можно видеть, используется другой остаточный блок 42 TADE (помимо блоков 50a-50h) (который уменьшается в один отдельный канал). Затем сверточный слой 44 и активирующая функция (которая, например, может представлять собой TanH 46) могут выполняться. После этого, речь 16 получается (и, возможно, сохраняется, подготавливается посредством рендеринга, кодируется и т.д.).
По меньшей мере один из блоков 50a-50h (или каждый из них, в конкретных примерах), например, может представлять собой остаточный блок. Остаточный блок управляет прогнозированием только для остаточного компонента сигнала, эволюционирующего из входного сигнала 14 (например, шума) в выходной аудиосигнал 16. Остаточный сигнал представляет собой только часть (остаточный компонент) основного сигнала. Например, несколько остаточных сигналов могут суммироваться между собой, с тем чтобы получать конечный выходной аудиосигнал 16.
На Фиг. 4 показан пример одного из блоков 50a-50h (50). Как можно видеть, в каждый блок 50 вводятся первые данные 59а, которые представляют собой либо входной сигнал 14 (или его дискретизированную с повышением версию, например, версию, выводимую посредством блока 30 повышающей дискретизации), либо вывод из предшествующего блока. Например, в блок 50b может вводиться вывод блока 50а; в блок 50с может вводиться вывод блока 50b и т.д.
На фиг. 4, в силу этого можно видеть, что обрабатываются первые данные 59а, переданные в блок 50 (50a-50h), и его вывод представляет собой выходной сигнал 69 (который должен передаваться в качестве ввода в следующий блок). Как указано посредством линии 59а', основной компонент первых данных 59а, введенных в первый блок 50a-50h (50) обработки, фактически обходит большую часть обработки первого блока 50a-50h (50) обработки. Например, блоки 60а, 61а, 62а, 63а, 65а, 60b, 61b, 62b, 63b, 64b and 65b обходятся посредством обходной линии 59а'. Первые данные 59а затем должны суммироваться с остаточной частью 64b' в сумматоре 65с (который указывается на фиг. 4, но не показан). Эта обходная линия 59а' и суммирование в сумматоре 65с могут пониматься как создающие экземпляр такого факта, что каждый блок 50 (50a-50h) обрабатывает операции с остаточными сигналами, которые затем суммируются с основной частью сигнала. Следовательно, каждый из блоков 50a-50h может считаться остаточным блоком.
В частности, суммирование в сумматоре 65с не обязательно должно выполняться в остаточном блоке 50 (50a-50h). Одно суммирование множества остаточных сигналов 65b' (каждый из которых выводится посредством каждого из остаточных блоков 50а-50h) может выполняться (например, в блоке суммирования, например, во втором блоке 45 обработки). Соответственно, различные остаточные блоки 50a-50h могут работать параллельно друг другу.
В примере по фиг. 4, каждый блок 50 может повторять свои сверточные слои дважды (например, сначала в реплике 600, включающей в себя по меньшей мере один из блоков 60а, 61а, 62а, 63а, 64а, 65а и получающей сигнал 59b; затем в реплике 601, включающей в себя по меньшей мере один из блоков 60b, 61b, 62b, 63b, 64b, 65b и получающей сигнал 65b', который может суммироваться с основным компонентом 59а').
Для каждой реплики (600, 601), обуславливающий набор обучаемых слоев 71-7 3 и стилизующий элемент 77 применяются (например, дважды для каждого блока 50) к сигналу, эволюционирующему из входного сигнала 16 в выходной аудиосигнал 16. Первая временная адаптивная денормализация (TADE) выполняется в блоке 60а TADE для первых данных 59а в первой реплике 600. Блок 60а TADE выполняет модуляцию первых данных 59а (входного сигнала или, например, обработанного шума) при условиях, заданных посредством целевых данных 12. В первом блоке 60а TADE в блоке 70 повышающей дискретизации может выполняться повышающая дискретизация целевых данных 12 для получения дискретизированной с повышением версии 12' целевых данных 12. Повышающая дискретизация может получаться через нелинейную интерполяцию, например, с использованием коэффициента 2, степени 2, кратного двух либо другого значения, большего 2. Соответственно, в некоторых примерах спектрограмма 12' может иметь равные размерности (например, соответствует) с сигналом (76, 76', х, с, 59, 59а, 59b и т.д.), который должен обусловливаться посредством спектрограммы. Применение стилистической информации к обработанному шуму (76, 76', х, с, 59, 59а, 59b и т.д.) (первым данным) может выполняться в блоке 77 (в стилизующем элементе). В следующей реплике 601 к выводу 59b первой реплики 600 может применяться другой блок 60b TADE. Пример блока 60 TADE (60а, 60b) приведен на фиг. 3 (см. также ниже). После модуляции первых данных 59а, выполняются свертки 61а и 62а. Затем, активирующие функции TanH и мягкого максимума (например, составляющие стробированную функцию TanH мягкого максимума) также выполняются (63а, 64а). Выводы активирующих функций 63а и 64а умножаются в блоке 65а умножения (например, чтобы создавать экземпляр стробирования), с тем чтобы получать результат 59b. В случае использования двух различных реплик 600 и 601 (либо в случае использования более чем двух реплик), проходы блоков 60а, 61а, 62а, 63а, 64а, 65а, повторяются.
В примерах, первая и вторая свертки в 61b и 62b, соответственно, ниже блока 60а и 60b TADE, могут выполняться при равном числе элементов в ядре (например, 9, например, 3×3). Тем не менее, вторые свертки 61b и 62b могут иметь коэффициент растяжения в 2. В примерах максимальный коэффициент растяжения для сверток может быть равным 2 (двум).
На Фиг. 3 показан пример блока 60 TADE (60а, 60b). Как можно видеть, целевые данные 12 могут дискретизироваться с повышением, например, таким образом, чтобы соответствовать входному сигналу (либо сигналу, эволюционирующему из него, например, 59, 59а, 76', также называемому «скрытым сигналом» или «активационным сигналом»). Здесь могут выполняться свертки 71, 72, 73 (промежуточное значение целевых данных 12 указано позицией 71') для получения параметров у (гамма, 74) и β (бета, 75). Для свертки в любом из 71, 72, 73 также может быть необходима единица линейной ректификации (ReLu) или может выпрямляться текучая единица линейной ректификации (текучая ReLu). Параметры γ и β могут иметь одинаковую размерность активационного сигнала (причем сигнал обрабатывается таким образом, что он эволюционирует из входного сигнала 14 в сформированный аудиосигнал 16, который здесь представляется в качестве х, 59 или 76' в нормализованной форме). Следовательно, когда активационный сигнал (х, 59, 76') имеет две размерности, также γ и β (74 и 75) имеют две размерности, и каждый из них является наложимым на активационный сигнал (длина и ширина γ и β может быть равной длине и ширине активационного сигнала). В стилистическом элементе 77, параметры 74 и 75 обуславливающих признаков применяются к активационному сигналу (который представляет собой первые данные 59а или 59b, выводимые посредством умножителя 65а). Тем не менее, следует отметить, что активационный сигнал 76' может представлять собой нормализованную версию (10 в блоке 76 нормализации по экземплярам) первых данных 59, 59а, 59b (15). Также следует отметить, что формула, показанная в стилистическом элементе 77 (γx+β), может представлять собой поэлементное произведение, а не сверточное произведение или произведение с точкой (и фактически γх+β также указано как  , где
, где  указывает на поэлементное умножение).
указывает на поэлементное умножение).
После стилистического элемента 77, сигнал выводится. Свертки 72 и 73 не обязательно имеют активирующую функцию ниже них. Также следует отметить, что параметр γ (74) может пониматься как дисперсия, а β (75) как смещение. Кроме того, блок 42 по фиг. 1 может подвергаться созданию экземпляра в качестве блока 50 по фиг. 3. Затем, например, сверточный слой 44 должен уменьшить число каналов до 1, и после этого выполняется TanH 56 для получения речи 16.
На Фиг. 7 показан пример эволюции в одной из реплики 600 и 601 одного из блоков 50a-50h:
- целевые данные 14 (например, мел-спектрограмма); и
- скрытый шум с (12), также указываемый с помощью 59а или в качестве сигнала, эволюционирующего из входного сигнала 12 к сформированному аудиосигналу 16.
Следует отметить, что 61а, 61b, 62а, 62b могут представлять собой набор обучаемого слоя (или представлять собой его часть), выполненного с возможностью обработки данных, извлекаемых из первых данных (например, в свою очередь, из входного сигнала 14) с использованием активирующей функции (например, 63а, 64а, 63b, 64b), которая представляет собой стробированную активирующую функцию (вторую активирующую функцию). Этот набор обучаемых слоев может состоять из одного или двух или еще большего числа сверточных слоев. Вторая активирующая функция может представлять собой стробированную активирующую функцию (например, TanH и функцию мягкого максимума). Этот признак может объединяться с тем фактом, что первая активирующая функция (для получения первых свернутых данных 71') представляет собой ReLu или текучую ReLu.
Может выполняться следующая процедура (или по меньшей мере один из ее этапов):
1) Спектрограмма 12 подвергается по меньшей мере одному из следующих этапов:
- Из ввода, такого как текст 112 (например, код в формате американского стандартного кода для обмена информацией (ASCII) или другой тип кода), формируются целевые данные 12 (например, текстовый признак, лингвистический признак или акустический признак, такой как мел-спектрограмма) (могут использоваться различные типы целевых данных).
- Целевые данные (например, спектрограмма) 12 подвергаются по меньшей мере одному из следующих этапов:
° Повышающая дискретизация в блоке 70 повышающей дискретизации для получения дискретизированной с повышением спектрограммы 12';
° В сверточных слоях 71-73 (часть слоя весовых коэффициентов) выполняются свертки (например, ядро 12а сворачивается вдоль дискретизированной с повышением спектрограммы 12');
° Получаются (обучаются) γ (74) и β (75);
° Применяются γ (74) и β (75) (например, посредством свертки) к скрытому сигналу 59а (15), эволюционирующему из входного сигнала 14 и сформированного аудиосигнала 16.
TTS
Преобразование текста в речь (TTS) (например, выполняемое с использованием блока 1110) направлено на синтез понятной и естественно звучащей речи 16 с учетом текста 112. Оно может иметь широкий спектр вариантов применения в данной отрасли, в частности для связи между машиной и человеческом.
Генератор 10 аудиоданных согласно изобретению включает в себя различные компоненты, в числе которых на последней ступени вокодер 1120, и включает в себя главным образом блок(и) для преобразования текстовых признаков, лингвистических признаков или акустических признаков в форму 16 аудиосигнала.
В частности, в блоке 1110 может анализироваться текст 112 (ввод), и лингвистические признаки могут извлекаться из текста 112, например, посредством модуля (субблока) 1112 анализа текста, как показано на фиг. 9а. Анализ текста может включать в себя, например, множество задач, таких как нормализация текста, сегментация на слова, прогнозирование просодий и преобразование графенов в фонемы (см. также фиг. 8). Затем эти лингвистические признаки (которые могут играть роль промежуточных целевых данных 212) преобразуются, например, через акустическую модель (например, посредством субблока 1114), в акустические признаки, такие как MFCC, фундаментальная частота, мел-спектрограмма, например, либо их сочетания, которые могут составлять целевые данные 12 по фиг. 1 и 3-8.
Необходимо отметить, что этот конвейер может быть заменен сквозной обработкой, например, путем введения DNN. Например, можно обусловливать нейронный вокодер 1120 непосредственно лингвистическими признаками (например, в случаях В и D по фиг. 10), либо акустическая модель может непосредственно обрабатывать символы, минуя тестовую ступень анализа (при этом субблок 1114 на фиг. 9а не используется). Например, в блоке 1110 могут использоваться некоторые сквозные модели, такие как Tacotron 1 и 2, для упрощения модулей анализа текста и непосредственного приема последовательностей символов/фонем в качестве входной последовательности, например, с выводом в качестве акустических признаков (целевых данных 12), например, в форме мел-спектрограмм.
Текущее решение может использоваться в качестве системы TTS (т.е. включающей в себя оба блока 1110 и 1120), при этом целевые данные 12 могут включать в себя, в некоторых примерах, поток информации или речевое представление, извлекаемое из текста 112. Представление, например, может представлять собой символы или фонемы, извлекаемые из текста 112, которые означают обычные вводы блока 1110 анализа текста. В этом случае предварительно обусловленный (предварительно обуславливающий) обучаемый слой может использоваться для блока 1110, например, для извлечения акустических признаков или обуславливающих признаков, подходящих (целевых данных 12) для нейронного вокодера (например, блока 1120). Этот предварительно обуславливающий слой 1110 может использовать глубокие нейронные сети (DNN), такие как архитектура «кодер-внимание-декодер» для преобразования символов или фонем непосредственно в акустические признаки. В качестве альтернативы, представление 12 (целевые данные) может представлять собой или включать в себя лингвистические признаки, которые означают фонемы, ассоциированные с информацией, такой как просодия, интонация, паузы и т.д. В этом случае предварительно обусловленный обучаемый слой 1110 может представлять собой акустическую модель, преобразующую лингвистические признаки в акустические признаки на основе статистических моделей, таких как скрытая марковская модель (НММ), глубокая нейронная сеть (DNN) или рекуррентная нейронная сеть (RNN). Наконец, целевые данные 12 могут включать в себя непосредственно акустические признаки, извлекаемые из текста 112, который может использоваться в качестве обуславливающих признаков, например, после обучаемого или детерминированного предварительно обуславливающего слоя 1110. В крайнем случае (например, в случае если F по фиг. 10), акустические признаки в целевых данных 12 могут использоваться непосредственно в качестве обуславливающих признаков, и минуя все предварительно обуславливающие слои.
На основании вышеуказанного, в некоторых примерах блок 1110 аудиосинтеза (блок анализа текста) может быть детерминированным, но в других случаях он может быть получен по меньшей мере через один обучаемый слой.
В примерах, целевые данные 12 могут включать в себя акустические признаки, такие как логарифмическая спектрограмма или спектрограмма или MFCC, или мел-спектрограмма, полученная из текста 112.
В качестве альтернативы, целевые данные 12 могут включать в себя лингвистические признаки, такие как фонемы, просодия слов, интонация, разрывы фраз или заполненные паузы, полученные из текста.
Целевые данные могут извлекаться из текста с использованием по меньшей мере одного из статистических моделей, обучаемых моделей или алгоритма на основе правил, который может включать в себя анализ текста и/или акустическую модель.
В общих чертах, в силу этого блок 1110 аудиосинтеза, который выводит целевые данные 12 из ввода (например, текста), к примеру, текста 112 (так что целевые данные 12 извлекаются из текста 112), может представлять собой детерминированный блок или обучаемый блок.
В общих чертах, целевые данные 12 могут иметь множество каналов, тогда как текст 112 (из которого извлекаются целевые данные 12) может иметь один канал.
На Фиг. 9а показан пример генератора 10а (который может представлять собой пример генератора 10), в котором целевые данные 12 содержат по меньшей мере один из акустических признаков, таких как логарифмическая спектрограмма или спектрограмма или MFCC, или мел-спектрограмма, полученная из текста 112. В данном случае блок 1110 включает в себя блок 1112 анализа текста, который обеспечивает промежуточные целевые данные 212, которые могут включать в себя по меньшей мере одно из лингвистических признаков, таких как фонемы, просодия слов, интонация, разрывы фраз или заполненные паузы, полученные из текста 112. Затем блок 1114 аудиосинтеза (например, с использованием акустической модели) может формировать целевые данные 12 в качестве по меньшей мере одного из акустических признаков, таких как логарифмический спектр или спектрограмма или MFCC, или мел-спектрограмма, полученная из текста 112.
После этого может использоваться блок 1120 синтеза форм сигналов (который может представлять собой любой из блоков синтеза форм сигналов, поясненных выше) для формирования выходного аудиосигнала 16.
На Фиг. 9b показан пример генератора 10b (который может представлять собой пример генератора 10), в котором целевые данные 12 содержат по меньшей мере один из лингвистических признаков, таких как фонемы, просодия слов, интонация, разрывы фраз или заполненные паузы, полученные из текста 112. Для вывода аудиосигнала 16 может использоваться синтез форм сигналов (например, вокодер 1120). Блок 1120 синтеза форм сигналов может представлять собой любой из блоков, описанных на фиг. 1-8, поясненных выше. В этом случае, например, целевые данные могут непосредственно вводиться в условный набор обучаемых слоев 71-73 для получения γ и β (74 и 75).
На фиг. 9с показан пример генератора 10с (который может представлять собой пример любых генераторов 10 по фиг. 1-8), в котором текст 112 используется непосредственно в качестве целевых данных. По существу, целевые данные 12 содержат по меньшей мере одно из символов или слов, полученных из текста 112. Блок 1120 синтеза форм сигналов может представлять собой любой из примеров, поясненных выше.
В общих чертах, любой из вышеприведенных генераторов аудиоданных (в частности, любой из блоков 1110 анализа текста (например, по любому из фиг. 8 или 9а-9с) может извлекать целевые данные из текста с использованием по меньшей мере одного из статистических моделей, обучаемых моделей или алгоритма на основе правил, состоящего из анализа текста и/или акустической модели.
В некоторых примерах целевые данные 12 могут детерминированно получаться посредством блока 1120. В других примерах, целевые данные 12 могут получаться недетерминированно, и блок 1110 может представлять собой обучаемый слой или множество обучаемых слоев.
Дискриминатор GAJV
Дискриминатор 100 GAN по фиг. 2 может использоваться во время обучения для получения, например, параметров 74 и 75, которые должны применяться к входному сигналу 12 (либо к его обработанной и/или нормализованной версии). Обучение может выполняться до логического вывода, и параметры 74 и 75, например, могут сохраняться в постоянном запоминающем устройстве и использоваться впоследствии (тем не менее, в некоторых примерах также возможно то, что параметры 7 4 или 7 5 вычисляются в процессе работы).
Дискриминатор 100 GAN выполняет роль при обучении распознаванию сформированных аудиосигналов (например, аудиосигнала 16, синтезированного так, как пояснено выше) из реальных входных сигналов 104 (например, реальной речи). Следовательно, роль дискриминатора 100 GAN проявляется главным образом во время обучения (например, для обучающих параметров 72 и 73) и рассматривается как противоположная по отношению к роли генератора 11 GAN (который может рассматриваться в качестве генератора 10 аудиоданных без дискриминатора 100 GAN).
В общих чертах, в дискриминатор 100 GAN может вводиться как аудиосигнал 16, синтезированный и сформированный генератором 10 GAN, так и реальный аудиосигнал 104 (например, реальная речь), полученный, например, через микрофон, и он может обрабатывать сигналы для получения показателя (например, потерь), который должен минимизироваться. Реальный аудиосигнал 104 также может считаться опорным аудиосигналом. Во время обучения, например, операции, такие как операции, поясненные выше для синтеза речи 16, могут повторяться, например, многократно, с тем чтобы получать параметры 74 и 75.
В примерах, вместо анализа целого опорного аудиосигнала 104 и/или целого сформированного аудиосигнала 16, можно анализировать только его часть (например, фрагмент, срез, окно кодирования со взвешиванием и т.д.). Получаются части сигнала, сформированные в случайных окнах (105а-105d) кодирования со взвешиванием, дискретизированных из сформированного аудиосигнала 16 и из опорного аудиосигнала 104. Например, случайные функции кодирования со взвешиванием могут использоваться, так что априори не задается предварительно то, какое окно 105а, 105b, 105с, 105d кодирования со взвешиванием используется. Кроме того, число окон кодирования со взвешиванием не обязательно равно четырем, оно может варьироваться.
В окнах (105a-105d) кодирования со взвешиванием, может применяться гребенка 110 псевдоквадратурных зеркальных фильтров (PQMF). Следовательно, подполосы 120 частот получаются. Соответственно, разложение (110) представления сформированного аудиосигнала (16) или представления опорного аудиосигнала (104) получается.
Для выполнения оценок может быть использован блок 130 оценки. Может использоваться множество модулей 132а, 132b, 132с, 132d оценки (указываемых вместе позицией 132) (может использоваться и другое количество). В общем случае, в соответствующий модуль 132а, 132b, 132с, 132d оценки может вводиться каждое окно 105а, 105b, 105с, 105d кодирования со взвешиванием. Дискретизация случайного окна (105a-105d) кодирования со взвешиванием может повторяться многократно для каждого модуля (132a-132d) оценки. В примерах, число раз, когда случайное окно (105a-105d) кодирования со взвешиванием дискретизируется для каждого модуля (132a-132d) оценки, может быть пропорциональным длине представления сформированного аудиосигнала или представления опорного аудиосигнала (104). Соответственно, каждый из модулей (132a-132d) оценки может принимать в качестве ввода одну или более частей (105a-105d) представления сформированного аудиосигнала (16) или представления опорного аудиосигнала (104).
Каждый модуль 132a-132d оценки может представлять собой непосредственно нейронную сеть. Каждый модуль 132a-132d оценки, в частности, может придерживаться парадигм сверточных нейтральных сетей. Каждый модуль 132a-132d оценки может представлять собой остаточный модуль оценки. Каждый модуль 132а-132d оценки может иметь параметры (например, весовые коэффициенты), которые адаптируются во время обучения (например, способом, аналогичным одному из способов, поясненных выше).
Как показано на фиг. 2, каждый модуль 132a-132d оценки также выполняет понижающую дискретизацию (например, на 4 либо на другой коэффициент понижающей дискретизации). Число каналов увеличивается для каждого модуля 132a-132d оценки (например, на 4 или, в некоторых примерах, на число, которое является равным коэффициенту понижающей дискретизации).
Выше и/или ниже модулей оценки могут быть предусмотрены сверточные слои 131 и/или 134. Вышележащий сверточный слой 131 может иметь, например, ядро с размерностью 15 (например, 5×3 или 3×5). Нижележащий сверточный слой 134 может иметь, например, ядро с размерностью 3 (например, 3×3).
Во время обучения может быть оптимизирована функция 140 потерь (состязательные потери). Функция 140 потерь может включать в себя фиксированный показатель (например, полученный во время этапа предварительного обучения) между сформированным аудиосигналом (16) и опорным аудиосигналом (104). Фиксированный показатель может получаться посредством вычисления одного или нескольких спектральный искажений между сформированным аудиосигналом (16) и опорным аудиосигналом (104). Искажение может измеряться с учетом:
- абсолютной величины или логарифмической абсолютной величины спектрального представления сформированного аудиосигнала (16) и опорного аудиосигнала (104), и/или
- различных временных или частотных разрешений.
В примерах, состязательные потери могут получаться посредством случайной подачи и оценки представления сформированного аудиосигнала (16) или представления опорного аудиосигнала (104) посредством одного или более модулей (132) оценки. Оценка может содержать классификацию подаваемого аудиосигнала (16, 132) на заданное число классов, указывающее предварительно обученный уровень классификации естественности аудиосигнала (14, 16). Заданное число классов, например, может быть «реальным» или «поддельным».
Примеры потерь могут получаться следующим образом:

- где:
x является реальной речью 104,
z является скрытым шумом 14 (либо, если обобщать, входным сигналом или первым данным, или скрытым),
s является мел-спектрограммой х (либо, обобщенно, целевым сигналом 12).
D(…) является выводом модулей оценки с точки зрения распределения вероятности (при этом D(…)=0 означает «наверняка ложный», D(…)=1 означает «наверняка реальный»).
Потери  на спектральное восстановление по-прежнему используются для регуляризации, с тем чтобы предотвращать появление состязательных артефактов. Конечные потери, например, могут быть следующими:
на спектральное восстановление по-прежнему используются для регуляризации, с тем чтобы предотвращать появление состязательных артефактов. Конечные потери, например, могут быть следующими:

где каждое i является долей в каждом модуле 132a-132d оценки (например, в каждом модуле 132a-132d оценки, обеспечивающем различное D1), и  является предварительно обученными (фиксированными) потерями.
является предварительно обученными (фиксированными) потерями.
Во время обучения, предусмотрен поиск минимального значения  , которое может выражаться, например, следующим образом:
, которое может выражаться, например, следующим образом:

Другие виды минимизаций могут выполняться.
В общих чертах, минимальные состязательные потери 140 ассоциированы с наилучшими параметрами (например, 74, 75), которые должны применяться к стилистическому элементу 77.
Пояснение
Примеры настоящего изобретения подробно описаны с использованием прилагаемого описания. В частности, в нижеприведенном описании описано множество подробностей для обеспечения более полного пояснения примеров изобретения. Тем не менее, специалистам в данной области техники должно быть очевидно, что другие примеры могут быть реализованы без этих конкретных подробностей. Признаки различных описанных примеров могут быть объединены друг с другом, если только признаки соответствующего сочетания не являются взаимоисключающими, или такое сочетание не исключено в явном виде.
Следует отметить, что одинаковые или аналогичные элементы либо элементы, которые имеют одинаковую функциональность, могут содержать одинаковые или аналогичные номера ссылочных позиций или обозначаются одинаково, при этом повторное описание элементов, которые содержат одинаковые или аналогичные номера ссылочных позиций либо являются одинаковыми, как правило, не приводится. Описание элементов, которые имеют одинаковые или аналогичные номера ссылочных позиций либо указаны как одинаковые, является взаимозаменяемым.
Было обнаружено, что нейронные вокодеры превосходят классические подходы в синтезе естественной высококачественной речи во многих вариантах применения, таких как преобразование текста в речь, кодирование речи и улучшение речи. Разработана первая инновационная генеративная нейронная сеть, которая синтезирует высококачественную речь, WaveNet, и вскоре после этого множество других подходов. Эти модели предлагают качество уровня техники, но зачастую при очень высоких вычислительных затратах и очень медленном синтезе. Огромное количество моделей, формирующих речь с низкими вычислительными затратами, представлено в последние годы. Некоторые из них представляют собой оптимизированные версии существующих моделей, тогда как другие используют интеграцию с классическими способами. Кроме того, также введено множество абсолютно новых подходов, зачастую с базированием на GAN. Большинство вокодеров GAN предлагают очень быстрое формирование на GPU, но за счет ухудшения качества синтезированной речи.
Одна из основных задач данной работы состоит в том, чтобы предложить архитектуру GAN, которая называется "StyleMelGAN" (и может быть реализована, например, в генераторе 10 аудиоданных), которая может синтезировать очень высококачественную речь 16 при низких вычислительных затратах и при быстром обучении. Генеративная сеть StyleMelGAN может содержать 3,86М обучаемых параметров и синтезировать речь при 22,05 кГц примерно в 2,6 раз быстрее, чем в реальном времени, на CPU и более чем в 54 раза на GPU. Модель может состоять, например, из восьми блоков повышающей дискретизации, которые постепенно преобразуют низкоразмерный шумовой вектор (например, 30 на фиг. 1) в форму необработанного речевого сигнала (например, 16). Синтез может обусловливаться в отношении мел-спектрограммы целевой речи (либо, если обобщать, посредством целевых данных 12), которая может вставляться в каждый блок (50a-50h) генератора через слой (60, 60а, 60b) временной адаптивной денормализации (TADE). Этот подход для вставки обуславливающих признаков является очень эффективным и, насколько известно, новым в аудиообласти. Состязательные потери вычисляются (например, через структуру по фиг. 2 в дискриминаторе 100 GAN) посредством ансамбля из четырех дискриминаторов 132a-132d (но в некоторых примерах возможно другое число дискриминаторов), каждый из которых работает после дифференцируемой гребенки 110 псевдоквадратурных зеркальных фильтров (PQMF). Это позволяет анализировать различные полосы частот речевого сигнала (104 или 16) во время обучения. Чтобы сделать обучение более надежным и способствовать обобщению, дискриминаторы (например, четыре дискриминатора 132а-132d) не обусловливаются в отношении входных акустических признаков, используемых генератором 10, и речевой сигнал (104 или 16) дискретизируется с использованием случайных окон кодирования со взвешиванием (например, 105a-105d).
В общем случае, предложена StyleMelGAN, которая представляет собой GAN с низкой сложностью для синтеза высококачественной речи, обусловленную в отношении мел-спектрограммы (например, 12) через слои TADE (например, 60, 60а, 60b). Генератор 10 может быть высокопараллелизуемым. Генератор 10 может быть абсолютно сверточным. Вышеуказанный генератор 10 может обучаться состязательно с помощью ансамбля дискриминаторов случайных окон кодирования с множественной дискретизацией PQMF со взвешиванием (например, 132a-132d), которые могут регуляризоваться посредством потерь на спектральное восстановление с множеством масштабов. Качество сформированной речи 16 может оцениваться с использованием объективных (например, количественных показателей Фреше) и/или субъективных оценок. Проведено два теста на основе прослушивания - тест MUSHRA для сценария синтеза с копированием и тест Р.800 ACR для сценария TTS, при этом оба из них подтверждают, что StyleMelGAN достигает качества речи из уровня техники.
Существующие нейронные вокодеры обычно синтезируют речевые сигналы непосредственно во временной области, посредством моделирования амплитуды конечной формы сигнала. Большинство этих моделей представляют собой генеративные нейронные сети, т.е. они моделируют распределение вероятностей речевых выборок, наблюдаемых в естественных речевых сигналах. Они могут разделяться на авторегрессивные, которые явно факторизуют распределение на произведение условных распределений, и неавторегрессивные или параллельные, которые вместо этого моделируют объединенное распределение непосредственно.
Сообщается, что авторегрессивные модели, такие как WaveNet, SampleRNN и WaveRNN, синтезируют речевые сигналы высокого воспринимаемого качества. Большое семейство неавторегрессивных моделей представляет собой семейство нормализующих потоков, например, WaveGlow. Гибридный подход заключается в использовании обратных авторегрессивных потоков, которые используют факторизованное преобразование между шумовым скрытым представлением и распределением целевой речи. Вышеприведенные примеры главным образом относятся к авторегрессивным нейронным сетям.
Ранние варианты применения GAN для аудиоданных включают в себя WaveGAN для необусловленного формирования речи и Gan-Synth для формирования музыки. MelGAN изучает преобразование между мел-спектрограммой речевых сегментов и их соответствующими формами сигналов временной области. Она обеспечивает формирование быстрее, чем в реальном времени, и использует состязательное обучение дискриминаторов с множеством масштабов, регуляризованных посредством потерь на спектральное восстановление. GAN-TTS представляет собой первый вокодер GAN, который использует уникальное состязательное обучение для формирования речи, обусловленного в отношении акустических признаков. Его состязательные потери вычисляются посредством ансамбля из условных и безусловных дискриминаторов случайных окон кодирования со взвешиванием. Parallel WaveGAN использует генератор, аналогичный WaveNet по структуре, обученный с использованием необусловленного дискриминатора, регуляризованного посредством потерь на спектральное восстановление с множеством масштабов. Аналогичные идеи используются в Multiband-MelGAN, которая формирует каждую подполосу частот целевой речи отдельно, что позволяет уменьшать вычислительную мощность, и затем получает конечную форму сигнала с использованием синтезирующей PQMF. Ее дискриминаторы с множеством масштабов оценивают форму речевого сигнала полной полосы частот и регуляризуются с использованием потерь на спектральное восстановление с множеством масштабов. Исследования в данной области техники проводятся очень активно, и можно упомянуть самые последние вокодеры GAN, такие как VocGan и HooliGAN.
На Фиг. 1 показана архитектура генератора StyleMelGAN, реализованная в генераторе 10 аудиоданных. Модель генератора преобразует шумовой вектор z~N (0,I128) (указываемый позицией 30 на фиг. 1) в форму 16 речевого сигнала (например, при 22050 Гц) посредством прогрессивной повышающей дискретизации (например, в блоках 50a-50h) обусловленную в отношении мел-спектрограмм 12 (либо, если обобщать, целевых данных). Она использует временную адаптивную денормализацию (TADE) (см. блоки 60, 60а, 60b), которая может представлять собой обуславливание на основе признаков на основе линейной модуляции нормализованных активационных карт (76' на фиг. 3). Параметры модуляции у (гамма, 74 на фиг. 3) и В (бета, 75 на фиг. 3) адаптивно обучаются из обуславливающих признаков, и в одном примере имеют одинаковую размерность со скрытым сигналом. Это доставляет обуславливающие признаки во все слои модели генератора, в силу этого сохраняя структуру сигналов во всех каскадах повышающей дискретизации. В формуле z~N (0,I128), 128 является числом каналов для скрытого шума (различные числа могут выбираться в других примерах). Б силу этого может формироваться случайный шум размерности 128 со средним значением 0 и с автокорреляционной матрицей (квадрат 128 на 128), равной единичному элементу I. Следовательно, в примерах сформированный шум может считаться полностью декоррелированным между каналами и имеющим дисперсию 1 (энергию). N(0,I128) может быть реализован в каждых 22528 сформированных выборках (либо для других примеров могут быть выбраны другие числа); размерность может в силу этого быть равна 1 на временной оси и 128 на канальной оси (могут быть предусмотрены другие числа, отличные от 128).
Фиг. 3 показывает структуру части генератора 10 аудиоданных и иллюстрирует структуру блока 60 TADE (60а, 60b). Входная активация с (76') адаптивно модулируется через  , где
, где  указывает поэлементное умножение (а именно, γ и β имеют одинаковую размерность активационной карты; также следует отметить, что с является нормализованной версией х по фиг. 3, и в силу этого является нормализованной версией , которая также может указываться с помощью
указывает поэлементное умножение (а именно, γ и β имеют одинаковую размерность активационной карты; также следует отметить, что с является нормализованной версией х по фиг. 3, и в силу этого является нормализованной версией , которая также может указываться с помощью 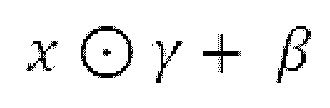 ). Перед модуляцией в блоке 77, используется слой 76 нормализации по экземплярам. Слой 76 (нормализующий элемент) может нормализовать первые данные в нормальное распределение нулевого среднего и единичной дисперсии. Могут использоваться стробированные активирующие функции TanH мягкого максимума (например, первая, экземпляр которой создается блоками 63а-64а-65а, и вторая, экземпляр которой создается блоками 63b-64b-65b в фиг. 4), которые, по некоторым данным, работают лучше функций на основе единиц линейной ректификации (ReLu). Стробирование на основе функции мягкого максимума (например, полученное посредством умножений 65а и 65b) обеспечивает возможность меньшего количества артефактов при образовании форм аудиосигналов.
). Перед модуляцией в блоке 77, используется слой 76 нормализации по экземплярам. Слой 76 (нормализующий элемент) может нормализовать первые данные в нормальное распределение нулевого среднего и единичной дисперсии. Могут использоваться стробированные активирующие функции TanH мягкого максимума (например, первая, экземпляр которой создается блоками 63а-64а-65а, и вторая, экземпляр которой создается блоками 63b-64b-65b в фиг. 4), которые, по некоторым данным, работают лучше функций на основе единиц линейной ректификации (ReLu). Стробирование на основе функции мягкого максимума (например, полученное посредством умножений 65а и 65b) обеспечивает возможность меньшего количества артефактов при образовании форм аудиосигналов.
На Фиг. 4 показана структура части генератора 10 аудиоданных и иллюстрирует остаточный блок 50 TADE (который может представлять собой любой из блоков 50a-50h), который представляет собой базовый компоновочный блок модели генератора. Полная архитектура показана на фиг. 1. Она включает в себя восемь каскадов 50a-50h повышающей дискретизации (в других примерах, другие числа являются возможными), состоящих, например, из остаточного блока TADE и слоя 601, дискретизирующего с повышением сигнал 79b на коэффициент два, плюс один конечный активационный модуль 46 (на фиг. 1). Конечная активация содержит один остаточный блок 42 TADE, после которого следует сверточный слой 44 изменения канала, например, с нелинейностью 46 TanH. Это проектирование позволяет использовать, например, глубину канала в 64 для операций свертки, в силу этого снижая сложность. Кроме того, эта процедура повышающей дискретизации позволяет поддерживать коэффициент растяжения ниже 2.
На Фиг. 2 показана архитектура дискриминаторов случайных окон кодирования со взвешиванием на основе гребенки фильтров (FB-RWD). StyleMelGAN может использовать множество (например, четыре) дискриминаторов 132а-132d для ее состязательного обучения, при этом в примерах архитектура дискриминаторов 132а-132d не имеет понижающей дискретизации с объединением в пул по среднему. Кроме того, каждый дискриминатор (132a-132d) может работать со случайным окном (105а-105d) кодирования со взвешиванием, отрезанным от формы (104 или 16) сигнала входной речи. Наконец, каждый дискриминатор (132a-132d) может анализировать подполосы 120 частот входного речевого сигнала (104 или 16), полученного посредством аналитической PQMF (например, 110). Более точно, можно использовать, в примерах, 1, 2, 4 и 8 подполос частот, вычисленных, соответственно, из избранных случайных сегментов, соответственно, по 512, 1024, 2048 и 4096 выборок, извлекаемых из формы сигнала одной секунды. Это обеспечивает состязательную оценку с переменным разрешением речевого сигнала (104 или 16) во временной и частотной областях.
Известно, что обучающие GAN являются сложными. При использовании случайной инициализации весовых коэффициентов (например, 74 и 75), состязательные потери (например, 140) могут приводить к серьезным аудиоартефактам и нестабильному обучению. Чтобы исключать эту проблему, генератор 10 может сначала предварительно обучаться только с использованием потерь на спектральное восстановление, состоящих из оценок ошибок спектральной сходимости и логарифмической абсолютной величины, вычисленной из различного STFT-анализа. Генератор, полученный этим способом, может формировать очень тональные сигналы, хотя и с существенным размыванием на высокий частотах. Тем не менее, это представляет собой хорошую начальную точку для состязательного обучения, которое затем может извлекать выгоду из лучшей гармонической структуры, чем если оно начинается непосредственно с полного случайного шумового сигнала. Состязательное обучение после этого приводит формирование к естественности за счет удаления тональных эффектов и заострения размытых полос частот. Кусочно-линейные потери 140 используются для оценки состязательного показателя, как можно видеть в нижеприведенном уравнении 1:

где x является реальной речью 104, z является скрытым шумом 14 (либо, если обобщать, входным сигналом), и s является мел-спектрограммой х (либо, если обобщать, целевым сигналом 12). Следует отметить, что потери  на спектральное восстановление (140) по-прежнему используются для регуляризации, с тем чтобы предотвращать появление состязательных артефактов. Конечные потери (140) задаются согласно уравнению 2, которое приводится ниже:
на спектральное восстановление (140) по-прежнему используются для регуляризации, с тем чтобы предотвращать появление состязательных артефактов. Конечные потери (140) задаются согласно уравнению 2, которое приводится ниже:

Нормализация весовых коэффициентов может применяться ко всем операциям свертки в G (либо, более точно, в генераторе 11 GAN) и в D (либо, более точно, в дискриминаторе 100). В экспериментах StyleMelGAN обучается с использованием одного GPU NVIDIA Tesla V100 в корпусе LJSpeech при 22050 Гц. Мел-спектрограммы на основе логарифмической абсолютной величины вычисляются для 80 мел-полос частот и нормализуются таким образом, что они имеют нулевое среднее и единичную дисперсию. Конечно, это представляет собой только один вариант; другие значения являются в равной степени возможными. Генератор предварительно обучается в течение 100000 этапов с использованием оптимизатора Адама с темпом обучения (1 гд) в 10-4, β1=0,5, β2=0,9. В начале состязательного обучения, темп обучения G (lrg) задается равным 5*10-5 и использует FB-RWD с оптимизатором Адама с темпом обучения дискриминатора (lrd) в 2*10-4 и с равным β. FB-RWD повторяют случайное кодирование со взвешиванием в течение 1 c/window_length, т.е. одной секунды в расчете на длину окна кодирования со взвешиванием, раз на каждом этапе обучения, чтобы поддерживать модель с достаточными обновлениями градиента. Размер пакета в 32 и сегменты с длиной в 1 с, т.е. в одну секунду, для каждой выборки в пакете используются. Обучение длится приблизительно полтора миллиона этапов, т.е. 1500000 этапов.
Далее перечислены модели, используемые в экспериментах:
- WaveNet для целевых экспериментов в синтезе с копированием и в преобразовании текста в речь,
- WGAN для целевых экспериментов в синтезе с копированием и в преобразовании текста в речь,
- MelGAN для целевых экспериментов в синтезе с копированием с объективной оценкой,
- WaveGlow для целевых экспериментов в синтезе с копированием,
- Trans former.v3 для целевых экспериментов в преобразовании текста в речь
Объективные и субъективные оценки StyleMelGAN относительно предварительно обученных вокодерных моделей на основе базовой линии, перечисленных выше, выполнены. Субъективное качество аудиовыводов TTS через тест Р.800 на основе прослушивания, выполняемый слушателями, оценивается в управляемом окружении. Тестовый набор содержит невидимые речевые фрагменты, записанные одним и тем же говорящим и случайно выбранные из онлайнового корпуса LibriVox. Таким образом, модель является надежной и не зависит главным образом от обучающих данных. Эти речевые фрагменты тестируют характеристики обобщения моделей, поскольку они записаны при немного отличающихся условиях и с присутствующей варьирующейся просодией. Исходные речевые фрагменты повторно синтезируются с использованием алгоритма Гриффина-Лима, и они используются вместо обычного привязочного условия. При этом предпочитается использование всей рейтинговой шкалы.
Традиционные объективные показатели, такие как PESQ и POLQA, не являются надежными для оценки форм речевого сигнала, сформированных нейронными вокодерами. Вместо этого используются условные глубокие речевые расстояния Фреше (cFDSD). Следующие количественные показатели cFDSD для различных нейронных вокодеров показывают, что StyleMelGAN значительно превосходит другие модели.
- Обучение cFDSD MelGAN 0,235 Тест cFDSD 0,227
- Обучение cFDSD WGAN 0,122 Тест cFDSD 0,101
- Обучение cFDSD WaveGlow 0,099 Тест cFDSD 0,078
- Обучение cFDSD WaveNet 0,176 Тест cFDSD 0,140
- Обучение cFDSD StyleMelGAN 0,044 Тест cFDSD 0,068
Можно видеть, что эта StyleMelGAN превосходит другие состязательные и несостязательные вокодеры.
Проведен тест MUSHRA на основе прослушивания с группой из 15 слушателей-экспертов. Этот тип теста выбран, поскольку он позволяет более точно оценивать качество сформированной речи. Привязка формируется с использованием реализации Py-Torch алгоритма Гриффина-Лима с 32 итерациями. Фиг. 5 показывает результат теста MUSHRA. Можно видеть, что StyleMelGAN значительно превосходит другие вокодеры приблизительно на 15 баллов MUSHRA. Результаты также показывают то, что WaveGlow, формирует выводы сравнимого качества с WaveNet, при нахождении на одном уровне с Parallel WaveGAN.
Субъективное качество аудиовыводов TTS может оцениваться через тест Р.800 ACR на основе прослушивания, выполняемый 31 слушателем в управляемом окружении. Для формирования мел-спектрограмм переложений тестового набора может использоваться модель Trans former.v3 ESPNET. Также может быть добавлена одинаковая привязка Гриффина-Лима, поскольку при этом предпочтительно использование всей рейтинговой шкалы.
Следующие средние экспертные оценки (MOS) Р800 для различных систем TTS показывают такие аналогичные выявленные сведения, что StyleMelGAN явно превосходит другие модели:
- GriffinLim Р800 MOS: 1,33+/- 0,04
- Transformer+Parallel WaveGAN P800 MOS: 3,19+/- 0,07
- Transformer+WaveNet P800 MOS: 3,82+/- 0,07
- Transformer+StyleMelGAN P800 MOS: 4,00+/- 0,07
- Recording P800 MOS: 4,29+/- 0,06
Далее показана скорость формирования в коэффициенте реального времени (RTF) с числом параметров различных параллельных вокодерных моделей. StyleMelGAN обеспечивает четкий компромисс между качеством формирования и скоростью логического вывода.
Здесь приведено число параметров и коэффициентов реального времени для формирования на CPU (например, Intel Core i7 6700 3,40 ГГц) и на GPU (например, Nvidia GeForce GTX1060) для различных изучаемых моделей.
- Параметры Parallel WaveGAN: 1,44М CPU: 0,8х GPU: 17х
- Параметры MelGAN: 4,2бМ CPU: 7х GPU: 110х
- Параметры StyleMelGAN: 3,86М CPU: 2,бх GPU: 54х
- Параметры WaveGlow: 80М GPU: 5х
В завершение, на фиг. 5 показаны результаты экспертного теста MUSHRA на основе прослушивания. Можно видеть, что StyleMelGAN превосходит модели из уровня техники.
Выводы
Данная работа представляет StyleMelGAN, легкий и эффективный состязательный вокодер для синтеза
высококачественной речи. Модель использует временную адаптивную нормализацию (TADE) для обеспечения достаточного и точного обуславливания для всех слоев формирования вместо простой подачи обуславливания в первый слой. Для состязательного обучения генератор конкурирует с дискриминаторами случайных окон кодирования со взвешиванием на основе гребенки фильтров, которые обеспечивает представления речевого сигнала с множеством масштабов во временной и частотной областях. StyleMelGAN работает как на CPU, так и на GPU на порядок абсолютной величины быстрее, чем в реальном времени. Экспериментальные объективные и субъективные результаты показывают, что StyleMelGAN значительно превосходит уже существующие состязательные вокодеры, а также авторегрессивные, потоковые и рассеянные вокодеры, обеспечивая новый стандарт в уровне техники для нейронного образования форм сигналов.
В качестве вывода, варианты осуществления, описанные в данном документе, могут быть при необходимости дополнены любым из важных моментов или аспектов, описанных в данном документе. Тем не менее, следует отметить, что важные моменты и аспекты, описанные в данном документе, могут использоваться по отдельности или в сочетании и могут быть введены в любой из вариантов осуществления, описанных в данном документе, как по отдельности, так и в сочетании.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом устройство или его часть соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего устройства либо части устройства, либо элемента или признака соответствующего устройства. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может осуществляться с использованием цифрового носителя данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, E PROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может сохраняться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно изобретению, таким образом, представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель данных (цифровой носитель данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель данных или носитель с записанными данными обычно является материальным и/или постоянным.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передачи (например, электронными или оптическими средствами) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления для выполнения части или всех из функциональностей способов, описанных в данном документе, может использоваться программируемое логическое устройство (например, программируемая пользователем вентильная матрица). В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем случае, способы предпочтительно осуществляются любым аппаратным устройством.
Устройство, описанное в данном документе, может быть реализовано с использованием аппаратного устройства или с использованием компьютера, либо с использованием сочетания аппаратного устройства и компьютера. Устройство, описанное в данном документе, или любые компоненты устройства, описанного в данном документе, могут быть реализованы по меньшей мере частично в аппаратных средствах и/или в программном обеспечении. Способы, описанные в данном документе, могут осуществляться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием сочетания аппаратного устройства и компьютера. Способы, описанные в данном документе, либо любые части способов, описанных в данном документе, могут выполняться по меньшей мере частично аппаратными средствами и/или программным обеспечением.
Вышеописанные варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидными модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, но не конкретными подробностями, представленными в данном документе в качестве описания и пояснения вариантов осуществления.
Библиография
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan и другие "WaveNet: A Generative Model for Raw Audio", arXiv:1609.03499, 2016 год.
R. Prenger, R. Valle и В. Catanzaro "Waveglow: A Flow-based Generative Network for Speech Synthesis", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019 год, стр. 3617-3621.
S. Mehri, K. Kumar, I. Gulrajani, R. Kumar и другие "SampleRNN: An Unconditional End-to-End Neural Audio Generation Model", arXiv:1612.07837, 2016 год.
N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury и другие "Efficient neural audio synthesis", arXiv:1802.08435, 2018 год.
A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan и другие "Parallel WaveNet: Fast High-Fidelity Speech Synthesis", in Proceedings of the 35th ICML, 2018 год, стр. 3918-3926.
J. Valin и J. Skoglund "LPCNET: Improving Neural Speech Synthesis through Linear Prediction", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019 год, стр. 5891-5895.
K. Kumar, R. Kumar, de T. Boissiere, L. Gestin и другие "MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis", in Advances in NeurlPS 32, стр. 14910-14921, 2019 год.
R. Yamamoto, E. Song и J. Kim "Parallel Wavegan: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020 год, стр. 6199-6203.
M. Binkowski, J. Donahue, S. Dieleman, A. Clark и другие "High Fidelity Speech Synthesis with Adversarial Networks", arXiv:1909.11646, 2019 год.
Т. Park, M.Y. Liu, Т.C. Wang и J.Y. Zhu "Semantic Image Synthesis With Spatially-Adaptive Normalization", in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 год.
P. Govalkar, J. Fischer, F. Zalkow и С. Dittmar "A Comparison of Recent Neural Vocoders for Speech Signal Reconstruction", in Proceedings of the ISCA Speech Synthesis Workshop, 2019 год, стр. 7-12.
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu и другие "Generative Adversarial Nets", in Advances in NeurlPS 27, стр. 2672-2680, 2014 год.
C. Donahue, J. McAuley и M. Puckette "Adversarial Audio Synthesis", arXiv:1802.04208, 2018 год.
J. Engel, K.K. Agrawal, S. Chen, I. Gulrajani и другие "GANSynth: Adversarial Neural Audio Synthesis", arXiv:1902.08710, 2019 год.
G. Yang, S. Yang, K. Liu, P. Fang и другие "Multiband MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech", arXiv:2005.05106, 2020 год.
J. Yang, J. Lee, Y. Kim, H. Cho и I. Kim "VocGAN: A High-Fidelity Real-time Vocoder with the Hierarchically-nested Adversarial Network", arXiv:2007.15256, 2020 год.
Jungil Kong, Jaehyeon Kim и Jaekyoung Bae "Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis", arXiv preprint arXiv:2010.05646, 2020 год.
D. Ulyanov, A. Vedaldi и V. Lempitsky "Instance normalization: The missing ingredient for fast stylization", arXiv:1607.08022, 2016 год.
A. Mustafa, A. Biswas, C. Bergler, J. Schottenhamml и A. Maier "Analysis by Adversarial Synthesis - A Novel Approach for Speech Vocoding", in Proc. Inter-speech, 2019 год, стр. 191-195.
Т. Q. Nguyen, "Near-perfect-reconstruction pseudo-QMF banks", IEEE Transactions on Signal Processing, издание 42, номер 1, стр. 65-76, 1994 год.
Т. Salimans и D. P. Kingma "Weight normalization: A simple reparameterization to accelerate training of deep neural networks", in Advances in NeurlPS, 2016 год, стр. 901-909.
K. Ito и L. Johnson "The LJ Speech Dataset", https://keithito.com/LJ-Speech-Dataset/, 2017 год.
D.P. Kingma и J. Ba "Adam: A method for stochastic optimization", arXiv:1412.6980, 2014 год.
Т. Hayashi, R. Yamamoto, K. Inoue, T. Yoshimura и другие "Espnet-tts: Unified, reproducible and integratable open source end-to-end text-to-speech toolkit", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2020 год, стр.7654-7658.
A. Gritsenko, T. Salimans, R. van den Berg, J. Snoek и N. Kalchbrenner "A Spectral Energy Distance for Parallel Speech Synthesis", arXiv:2008.01160, 2020 год.
"P.800: Methods for subjective determination of transmission quality", Standard, International Telecommunication Union, 1996 год.
| название | год | авторы | номер документа |
|---|---|---|---|
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823016C1 |
| СПОСОБЫ ОБУЧЕНИЯ МОДЕЛИ И КОНВЕРСИИ ГОЛОСА И УСТРОЙСТВО, ДРУГОЕ УСТРОЙСТВО И НОСИТЕЛЬ ДАННЫХ | 2022 |
|
RU2830834C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ГЕНЕРИРОВАНИЯ ВОЛНОВОЙ ФОРМЫ | 2021 |
|
RU2803488C2 |
| Неконтролируемое восстановление голоса с использованием модели безусловной диффузии без учителя | 2023 |
|
RU2823017C1 |
| СПОСОБ И УСТРОЙСТВО УЛУЧШЕНИЯ РЕЧЕВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ БЫСТРОЙ СВЕРТКИ ФУРЬЕ | 2022 |
|
RU2795573C1 |
| Способ синтеза речи с передачей достоверного интонирования клонируемого образца | 2020 |
|
RU2754920C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ГЕНЕРИРОВАНИЯ МОДИФИЦИРОВАННОГО АУДИО ДЛЯ ВИДЕО | 2022 |
|
RU2832236C2 |
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |
| Способы и электронные устройства для идентификации пользовательского высказывания по цифровому аудиосигналу | 2018 |
|
RU2761940C1 |
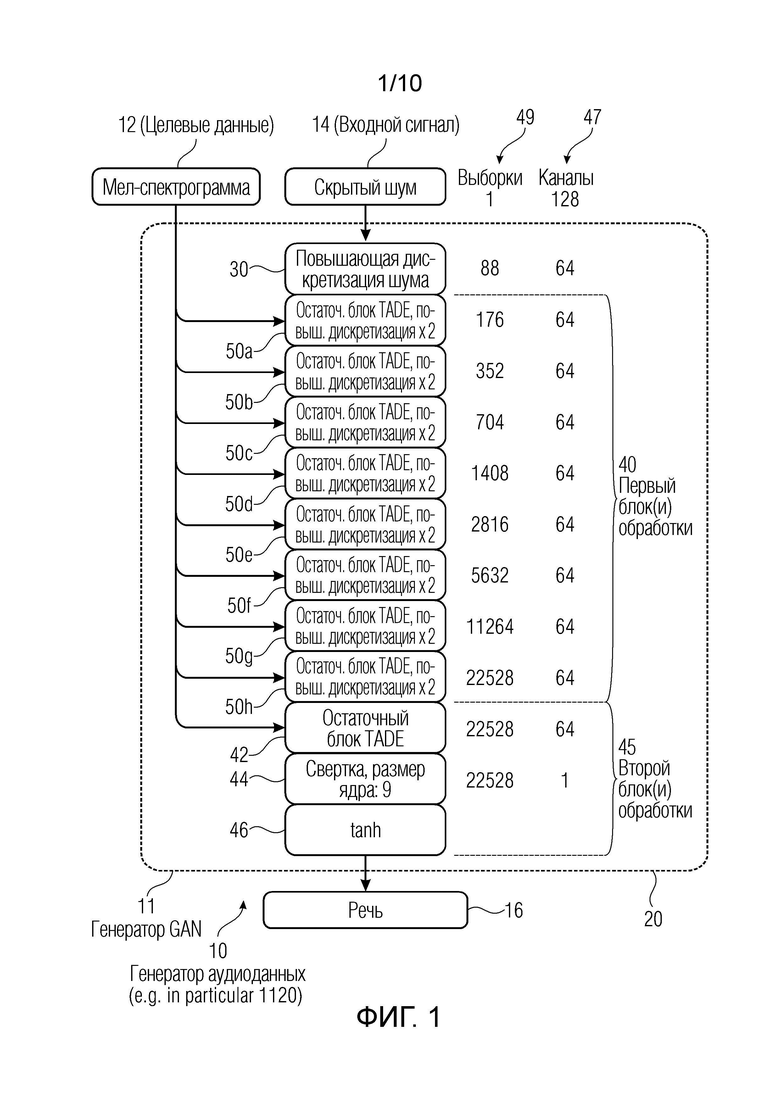
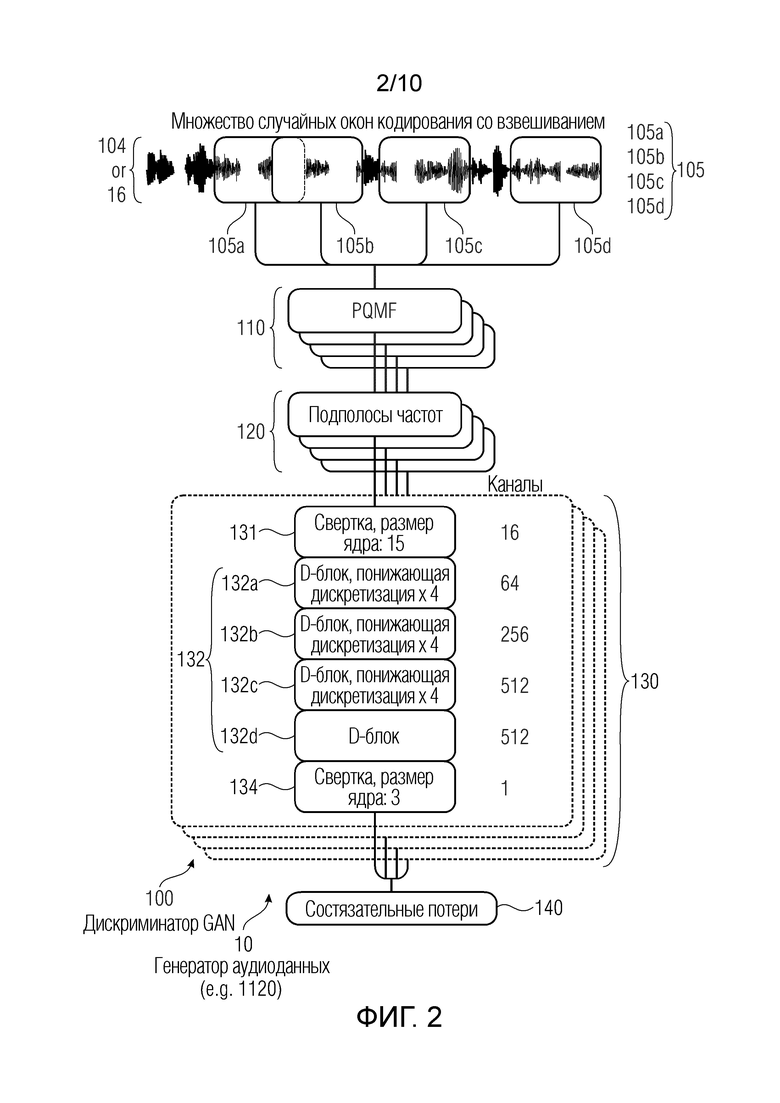



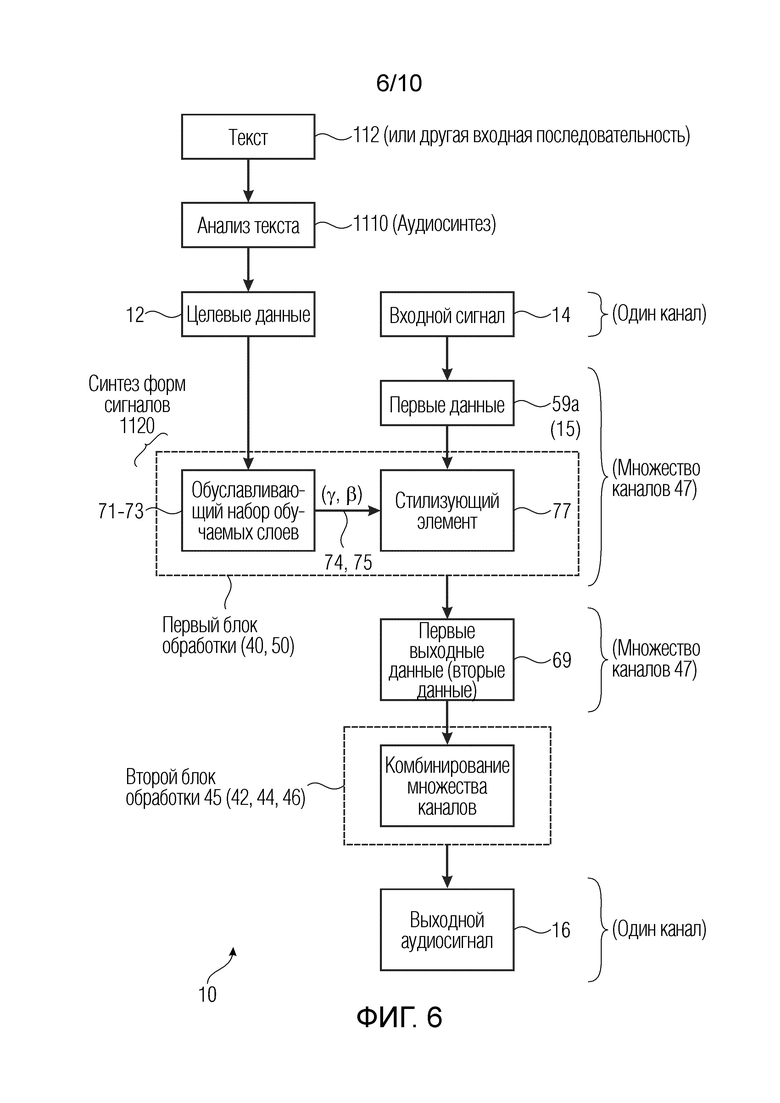
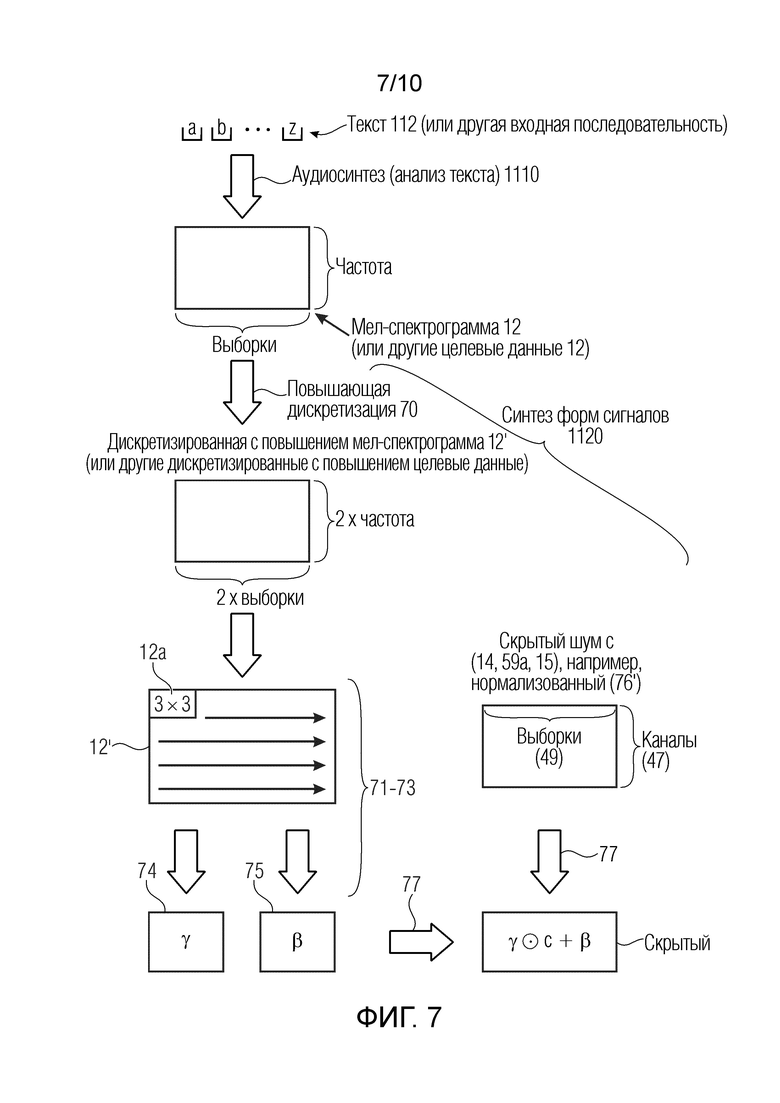
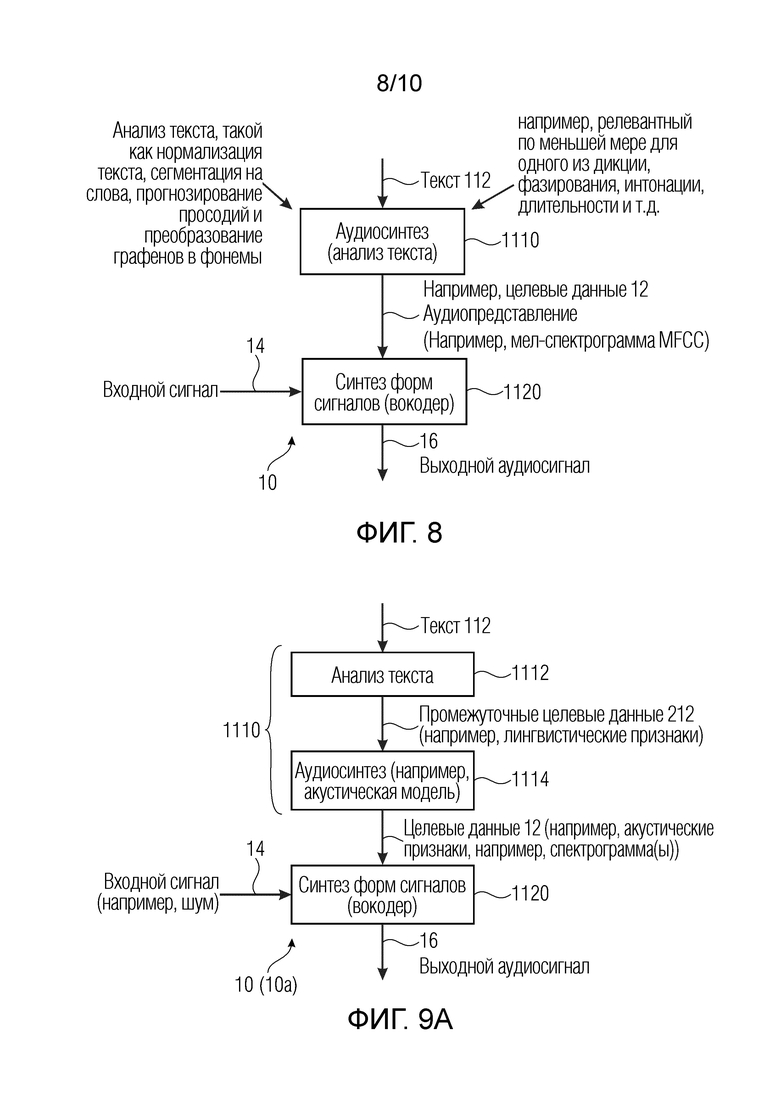


Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в повышении качества формирования аудиосигнала при ограниченных вычислительных ресурсах. Технический результат достигается за счет этапов, на которых: принимают посредством первого блока обработки первые данные, извлекаемые из входного сигнала; для каждого канала первых выходных данных: обрабатывают целевые данные посредством обуславливающего набора обучаемых слоев первого блока обработки для получения параметров обуславливающих признаков; и применяют параметры обуславливающих признаков к первым данным или к нормализованным первым данным посредством стилизующего элемента первого блока обработки; выводят первые выходные данные, содержащие множество каналов, посредством первого блока обработки; принимают первые выходные данные или данные, извлекаемые из первых выходных данных, посредством второго блока обработки в качестве вторых данных; и комбинируют множество каналов вторых данных посредством второго блока обработки, для получения аудиосигнала. 4 н. и 50 з.п. ф-лы, 12 ил.
1. Генератор (10) аудиоданных, выполненный с возможностью формирования аудиосигнала (16) из входного сигнала (14) и целевых данных (12), причем целевые данные (12) представляют аудиосигнал (16), содержащий:
- первый блок (40, 50, 50a-50h) обработки, выполненный с возможностью приема первых данных (15, 59а), извлекаемых из входного сигнала (14), и вывода первых выходных данных (69), при этом первые выходные данные (69) содержат множество каналов (47), и
- второй блок (45) обработки, выполненный с возможностью приема первых выходных данных (69) или данных, извлекаемых из первых выходных данных (69), в качестве вторых данных,
- при этом первый блок (50) обработки содержит для каждого канала первых выходных данных:
- обуславливающий набор обучаемых слоев (71, 72, 73), выполненных с возможностью обработки целевых данных (12) для получения параметров (74, 75) обуславливающих признаков, причем целевые данные (12) извлекаются из текста; и
- стилизующий элемент (77), выполненный с возможностью применения параметров (74, 75) обуславливающих признаков к первым данным (15, 59а) или к нормализованным первым данным (59, 76'); и
при этом второй блок (45) обработки выполнен с возможностью комбинирования множества каналов (47) вторых данных (69) для получения аудиосигнала (16).
2. Генератор аудиоданных по п. 1, в котором целевые данные (12) представляют собой спектрограмму.
3. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) представляют собой мел-спектрограмму.
4. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) содержат по меньшей мере один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы или другого типа спектрограммы, полученной из текста.
5. Генератор аудиоданных по любому из предшествующих пунктов, выполненный с возможностью получения целевых данных (12) посредством преобразования (1110) ввода в форме текста или элементов текста по меньшей мере в один акустический признак.
6. Генератор аудиоданных по любому из предшествующих пунктов, выполненный с возможностью получения целевых данных (12) посредством преобразования (1114) по меньшей мере одного лингвистического признака по меньшей мере в один акустический признак.
7. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) содержат по меньшей мере один лингвистический признак из фонемы, просодии слов, интонации, разрывов фраз и заполненных пауз, полученных из текста.
8. Генератор аудиоданных по п. 7, выполненный с возможностью получения целевых данных (12) посредством преобразования (1110) ввода в форме текста или элементов текста по меньшей мере в один лингвистический признак.
9. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) содержат по меньшей мере одно из символа и слова, полученного из текста.
10. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) извлекаются из текста (112) с использованием статистической модели, выполняющей анализ текста и/или использующей акустическую модель.
11. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) извлекаются из текста (112) с использованием обучаемой модели, выполняющей анализ текста и/или использующей акустическую модель.
12. Генератор аудиоданных по любому из предшествующих пунктов, в котором целевые данные (12) извлекаются из текста (112) с использованием алгоритма на основе правил, выполняющего анализ текста и/или акустическую модель.
13. Генератор аудиоданных по любому из предшествующих пунктов, выполненный с возможностью извлечения целевых данных по меньшей мере через один детерминированный слой.
14. Генератор аудиоданных по любому из предшествующих пунктов, выполненный с возможностью извлечения целевых данных по меньшей мере через один обучаемый слой.
15. Генератор аудиоданных по любому из предшествующих пунктов, в котором обуславливающий набор обучаемых слоев состоит из одного или по меньшей мере двух сверточных слоев (71-73).
16. Генератор аудиоданных по п. 15, в котором первый сверточный слой (71-73) выполнен с возможностью свертывания целевых данных (12) или дискретизированных с повышением целевых данных для получения первых свернутых данных (71') с использованием первой активирующей функции.
17. Генератор аудиоданных по любому из предшествующих пунктов, в котором обуславливающий набор обучаемых слоев (71-73) и стилизующий элемент (77) представляют собой часть слоя весовых коэффициентов в остаточном блоке (50, 50a-50h) нейронной сети, содержащей один или более остаточных блоков (50, 50a-50h).
18. Генератор аудиоданных по любому из пп. 1-17, при этом генератор (10) аудиоданных дополнительно содержит нормализующий элемент (76), который выполнен с возможностью нормализации первых данных (59а, 15).
19. Генератор аудиоданных по любому из пп. 1-18, в котором аудиосигнал (16) представляет собой голосовой аудиосигнал.
20. Генератор аудиоданных по любому из пп. 1-19, в котором целевые данные (12) дискретизируются с повышением на коэффициент по меньшей мере 2.
21. Генератор аудиоданных по п. 20, в котором целевые данные (12) дискретизируются (70) с повышением посредством нелинейной интерполяции.
22. Генератор аудиоданных по п. 16, в котором первая активирующая функция представляет собой функцию на основе текучих единиц линейной ректификации (текучих ReLu).
23. Генератор аудиоданных по любому из пп. 1-22, в котором операции (61а, 61b, 62а, 62b) свертки выполняются с максимальным коэффициентом растяжения, равным 2.
24. Генератор аудиоданных по любому из пп. 1-23, содержащий восемь первых блоков (50a-50h) обработки и один второй блок (45) обработки.
25. Генератор аудиоданных по любому из пп. 1-24, в котором первые данные (15, 59, 59а, 59b) имеют более низкую степень размерности, чем аудиосигнал.
26. Генератор аудиоданных по любому из пп. 17-21, в котором обуславливающий набор обучаемых слоев состоит из одного или по меньшей мере двух сверточных слоев (71-73), причем первый сверточный слой (71-73) выполнен с возможностью свертывания целевых данных (12) или дискретизированных с повышением целевых данных для получения первых свернутых данных (71') с использованием первой активирующей функции, причем первая активирующая функция представляет собой функцию на основе текучих единиц линейной ректификации (текучих ReLu).
27. Способ формирования аудиосигнала (16) посредством генератора (10) аудиоданных из входного сигнала (14) и целевых данных (12), причем целевые данные (12) представляют аудиосигнал (16) и извлекаются из текста, содержащий этапы, на которых:
- принимают посредством первого блока (50, 50a-50h) обработки первые данные (16559, 59а, 59b), извлекаемые из входного сигнала (14);
- для каждого канала первых выходных данных (59b, 69):
- обрабатывают целевые данные (12) посредством обуславливающего набора обучаемых слоев (71, 72, 73) первого блока (50) обработки для получения параметров (74, 75) обуславливающих признаков; и
- применяют параметры (74, 75) обуславливающих признаков к первым данным (15, 59) или к нормализованным первым данным (76') посредством стилизующего элемента (77) первого блока (50) обработки;
- выводят первые выходные данные (69), содержащие множество каналов (47), посредством первого блока (50) обработки,;
- принимают первые выходные данные (69) или данные, извлекаемые из первых выходных данных (69), посредством второго блока (45) обработки в качестве вторых данных; и
- комбинируют множество каналов (47) вторых данных посредством второго блока (45) обработки, для получения аудиосигнала (16).
28. Способ формирования аудиосигнала по п. 27, в котором целевые данные (12) содержат по меньшей мере один акустический признак из логарифмической спектрограммы или MFCC и мел-спектрограммы или другого типа спектрограммы, полученной из текста.
29. Способ формирования аудиосигнала по п. 27 или 28, включающий в себя этап, на котором получают целевые данные (12) посредством преобразования (1110) ввода в форме текста или элементов текста по меньшей мере в один акустический признак.
30. Способ формирования аудиосигнала по п. 27, 28 или 29, включающий в себя этап, на котором получают целевые данные (12) посредством преобразования (1114) по меньшей мере одного лингвистического признака по меньшей мере в один акустический признак.
31. Способ формирования аудиосигнала по любому из пп. 27-30, в котором целевые данные (12) содержат по меньшей мере один лингвистический признак из фонемы, просодии слов, интонации, разрывов фраз и заполненных пауз, полученных из текста.
32. Способ формирования аудиосигнала по п. 31, включающий в себя этап, на котором получают целевые данные (12) посредством преобразования (1110) ввода в форме текста или элементов текста по меньшей мере в один лингвистический признак.
33. Способ формирования аудиосигнала по любому из пп. 27-32, в котором целевые данные (12) содержат по меньшей мере одно из символа и слова, полученного из текста.
34. Способ формирования аудиосигнала по любому из пп. 27-33, дополнительно включающий в себя этап, на котором извлекают целевые данные (12) с использованием статистической модели, выполняющей анализ текста и/или использующей акустическую модель.
35. Способ формирования аудиосигнала по любому из пп. 27-34, дополнительно включающий в себя этап, на котором извлекают целевые данные (12) с использованием обучаемой модели, выполняющей анализ текста и/или использующей акустическую модель.
36. Способ для формирования аудиосигнала по любому из пп. 27-35, дополнительно включающий в себя этап, на котором извлекают целевые данные (12) с использованием алгоритма на основе правил, выполняющего анализ текста и/или акустическую модель.
37. Способ формирования аудиосигнала по любому из пп. 27-36, дополнительно включающий в себя этап, на котором извлекают целевые данные (12) по меньшей мере через один детерминированный слой.
38. Способ формирования аудиосигнала по любому из пп. 27-36, дополнительно включающий в себя этап, на котором извлекают целевые данные (12) по меньшей мере через один обучаемый слой.
39. Способ формирования аудиосигнала по любому из пп. 27-38, в котором обуславливающий набор обучаемых слоев (71-73) состоит из одного или двух сверточных слоев.
40. Способ формирования аудиосигнала по п. 39, в котором обработка посредством обуславливающего набора обучаемых слоев (71-73) содержит этап, на котором свертывают целевые данные (12) или дискретизированные с повышением целевые данные посредством первого сверточного слоя (71) для получения первых свернутых данных (71') с использованием первой активирующей функции.
41. Способ формирования аудиосигнала по любому из пп. 27-40, в котором обуславливающий набор обучаемых слоев (71-73) и стилизующий элемент (77) представляют собой часть слоя весовых коэффициентов в остаточном блоке (50, 50a-50h) нейронной сети, содержащей один или более остаточных блоков (50, 50a-50h).
42. Способ формирования аудиосигнала по любому из пп. 27-41, при этом способ дополнительно содержит этап, на котором нормализуют первые данные (15, 59) посредством нормализующего элемента (76).
43. Способ формирования аудиосигнала по любому из пп. 27-42, в котором аудиосигнал (16) представляет собой голосовой аудиосигнал.
44. Способ формирования аудиосигнала по любому из пп. 27-43, в котором целевые данные (12) дискретизируются (70) с повышением на коэффициент 2.
45. Способ формирования аудиосигнала по любому из пп. 27-44, в котором целевые данные (12) дискретизируются (70) с повышением посредством нелинейной интерполяции.
46. Способ формирования аудиосигнала по любому из пп. 27-45, в котором первая активирующая функция представляет собой функцию на основе текучих единиц линейной ректификации (текучих ReLu).
47. Способ формирования аудиосигнала по любому из пп. 27-46, в котором операции (61а, 62а, 61b, 62b) свертки выполняются с максимальным коэффициентом растяжения в 2.
48. Способ формирования аудиосигнала по любому из пп. 27-47, содержащий этап, на котором выполняют этапы первого блока (50, 50a-50h) обработки восемь раз и этапы второго блока (45) обработки один раз.
49. Способ формирования аудиосигнала по любому из пп. 27-48, в котором первые данные (15, 59) имеют более низкую степень размерности, чем аудиосигнал.
50. Способ формирования аудиосигнала по любому из пп. 27-49, дополнительно содержащий этап, на котором извлекают целевые данные из текста.
51. Способ формирования аудиосигнала по любому из пп. 27-50, в котором целевые данные (12) представляют собой спектрограмму.
52. Способ по п. 51, в котором спектрограмма представляет собой мел-спектрограмму.
53. Способ формирования аудиосигнала (16), содержащий математическую модель, при этом математическая модель выполнена с возможностью вывода аудиовыборок с определенным временным шагом из входной последовательности (12), представляющей аудиоданные (16), которые должны формироваться,
- при этом математическая модель выполнена с возможностью формирования шумового вектора (14) для создания выходных аудиовыборок с использованием входной репрезентативной последовательности (12),
- при этом входная репрезентативная последовательность извлекается из текста.
54. Постоянный носитель данных, на котором сохранены инструкции, которые при выполнении компьютером побуждают компьютер выполнять способ по любому из пп. 27-53.
| CN 110060690 A, 26.07.2019 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ГЕНЕРАЦИИ АУДИОСИГНАЛА | 2011 |
|
RU2595636C2 |

