Настоящее изобретение относится к обработке аудиосигнала и, в частности, к технологиям расширения полосы аудиосигналов, например, расширению полосы или интеллектуальному заполнению промежутков.
Наиболее используемым в настоящее время кодеком для мобильной речевой связи все еще является AMR-NB, который кодирует только частоты от 200 до 3400 Гц (обычно именуемые узкой полосой (NB)). Хотя человеческий речевой сигнал имеет значительно более широкую полосу - в особенности, большая часть энергии фрикативов часто приходится на частоты свыше 4 кГц. Речь с ограниченным частотным диапазоном будет не только звучать менее приятно, но также будет менее разборчивой [1, 2].
Традиционные аудиокодеки, например, EVS [3], способны кодировать значительно более широкий частотный диапазон сигнала, но использование этих кодеков потребуют изменения всей сети связи, включающей в себя принимающие устройства. Это очень большой вызов, известный в последние несколько лет. Слепое расширение полосы (BBWE - также известное под названием искусственное расширение полосы или слепое расширение полосы) способно расширять частотный диапазон сигнала без необходимости дополнительных битов. Оно применяется только к декодированному сигналу и не требует никакой адаптации сети или передающего устройства. Несмотря на привлекательное решение проблемы ограниченной полосы узкополосных кодеков многим системам не удается повысить качество речевых сигналов. В совместном оценивании последних расширений полосы, только четыре из 12 систем, управляемых для значительного повышения воспринимаемого качества для всех тестируемых языков [4].
Согласно модели "источник-фильтр" речеобразования большинство расширений полосы (слепых или неслепых) имеют два основных строительных блока - генерацию сигнала возбуждения и оценку формы речевого тракта. Это также подход, которому следует представленная система. Широко используется метод генерации сигнала возбуждения, а именно спектральное наложение, параллельный перенос или нелинейная обработка. Форма речевого тракта может генерироваться гауссовскими моделями смеси (GMM), скрытыми марковскими моделями (HMM), нейронными сетями или глубокими нейронными сетями (DNN). Эти модели прогнозируют форму речевого тракта из признаков, вычисленных на речевом сигнале.
В [5] и [6] сигнал возбуждения генерируется путем спектрального наложения, и фильтр речевого тракта реализуется как фильтр с одними полюсами во временной области посредством HMM. Сначала кодовая книга коэффициентов линейного предсказания (LPC), вычисленных на кадрах, содержащих речевой сигнал верхней полосы, создается путем векторного квантования. На стороне декодера, признаки вычисляются на декодированном речевом сигнале, и HMM используется для моделирования условной вероятности записи кодовой книги в зависимости от признаков. Окончательная огибающая является взвешенной суммой всех записей кодовой книги, где вероятности являются весовыми коэффициентами. В [6] фрикативные звуки дополнительно подчеркиваются нейронной сетью.
В [7] сигнал возбуждения также генерируется путем спектрального наложения, и речевой тракт моделируется нейронной сетью, которая выводит коэффициенты усиления, применяемые к наложенному сигналу в области банка фильтров для чистых тонов.
В [8] DNN используется для прогнозирования спектральной огибающей спектрально наложенного сигнала возбуждения (именуемого здесь изображаемой фазой). Система в [9] также использует спектрально наложенный сигнал возбуждения и формирует огибающую посредством DNN, содержащей слои LSTM. За счет использования нескольких кадров аудиосигнала в качестве ввода для DNN эти две системы имеют слишком большую алгоритмическую задержку для осуществления связи в реальном времени.
Последний подход непосредственно моделирует выпадающий сигнал во временной области [10] с алгоритмической задержкой от 0 до 32 мс с архитектурой, аналогичной WaveNet [11].
При осуществлении связи путем передачи речи, ее частотный диапазон обычно ограничивается, например, посредством ограничения полосы и понижающей дискретизации. Если это ограничение полосы приводит к удалению слишком широкой полосы из сигнала, воспринимаемое качество речи значительно снижается. Один путь решения этой проблемы предполагает изменение кодека путем передачи в более широкой полосе. Для этого часто предполагается изменение всей сетевой инфраструктуры, что очень затратно и может занять несколько лет.
Другой путь к расширению частоты предполагает искусственное расширение частотного диапазона путем расширения полосы. В случае расширения полосы вслепую, от кодера на декодер не передается никакой вспомогательной информации. В инфраструктуру передачи не вносится никаких изменений.
Задачей настоящего изобретения является обеспечение принципа улучшенной генерации аудиосигнала с расширенной полосой.
Эта задача решается посредством устройства для генерации аудиосигнала с расширенной полосой по п. 1, системы для обработки аудиосигнала по п. 26 или 27, способа генерации аудиосигнала с расширенной полосой по п. 29 или способа обработки аудиосигнала по п. 30 или 31 или компьютерной программы по п. 32.
Настоящее изобретение основано на том факте, что нейронную сеть выгодно использовать для генерации аудиосигнала с расширенной полосой. Однако процессор нейронной сети, реализующий нейронную сеть, не используется для генерации полного частотного диапазона расширения, т.е. отдельных спектральных линий в частотном диапазоне расширения. Напротив, процессор нейронной сети принимает, в качестве входного сигнала, частотный диапазон входного аудиосигнала и выводит параметрическое представление для частотного диапазона расширения. Это параметрическое представление используется для осуществления обработки первичного сигнала, сгенерированного отдельным генератором первичного сигнала. Генератор первичного сигнала может быть синтезатором сигнала любого рода для частотного диапазона расширения, например, заплатчиком, известным из расширения полосы, например, процедур дублирования спектральной полосы или из процедур интеллектуального заполнения промежутков. Затем сигнал с наложенной заплаткой может спектрально отбеливаться или, альтернативно, сигнал может спектрально отбеливаться до установления заплатки. Затем этот первичный сигнал, который является спектрально отбеленным сигналом с наложенной заплаткой, дополнительно обрабатывается процессором первичного сигнала с использованием параметрического представления, обеспеченного из нейронной сети для получения обработанного первичного сигнала, имеющего частотные составляющие в частотном диапазоне расширения. Частотный диапазон расширения является верхней полосой в сценарии применения прямого расширения полосы, где входной аудиосигнал является узкополосным или низкополосным сигналом. Альтернативно, частотный диапазон расширения относится к некоторым спектральным пробелам между максимальной частотой и некоторой минимальной частотой, которые заполняются процедурами интеллектуального заполнения промежутков.
Альтернативно, генератор первичного сигнала можно также реализовать для генерации сигнала частотный диапазон расширения с использованием обработки нелинейности или обработки шума или генерации шума любого рода.
Поскольку нейронная сеть используется только для обеспечения параметрического представления верхней полосы, а не полной верхней полосы или полного частотного диапазона расширения, нейронную сеть можно сделать менее сложной и, таким образом, экономичной по сравнению с другими процедурами, где нейронная сеть используется для генерации полной верхней полосы сигнал. С другой стороны, в нейронную сеть поступает низкополосный сигнал, и, таким образом, извлечение дополнительных признаков из низкополосного сигнала, также известное из процедур расширения полосы под управлением нейронной сети, не требуется. Кроме того, было установлено, что генерация первичного сигнала для частотного диапазона расширения может осуществляться напрямую и, таким образом, очень эффективно без обработки нейронной сети, и последующее масштабирование этого первичного сигнала или, в общем случае, последующая обработка первичного сигнала также может осуществляться без поддержки какой-либо конкретной нейронной сети. Альтернативно, поддержка нейронной сети требуется только для генерации параметрического представления сигнала частотного диапазона расширения и, таким образом, находится оптимальный компромисс между традиционной обработкой сигнала с одной стороны для генерации первичного сигнала для частотного диапазона расширения и формирования или обработки первичного сигнала и, дополнительно, нетрадиционной обработкой нейронной сети, которая, в итоге, генерирует параметрическое представление, которое используется процессором первичного сигнала.
Это распределение между традиционной обработкой и обработкой нейронной сети обеспечивает оптимальный компромисс в отношении качества аудиосигнала и сложность нейронной сети в отношении обучения нейронной сети, а также приложения нейронной сети, которое должно осуществляться на любых процессорах расширения полосы.
Предпочтительные варианты осуществления опираются на разные временные разрешения, т.е. очень низкое временное разрешение и, предпочтительно, очень высокое частотное разрешение для генерации отбеленного первичного сигнала. С другой стороны, процессор нейронной сети и процессор первичного сигнала действуют на основании высокого временного разрешения и, таким образом, предпочтительно, низкого частотного разрешения. Однако возможно также, что низкое временное разрешение сопровождается высоким частотным разрешением или высокое временное разрешение сопровождается низким частотным разрешением. Таким образом, опять же, можно найти оптимальный компромисс между тем фактом, что нейронная сеть имеет параметрическое разрешение, которое, например, в отношении частоты, грубее, чем полное амплитудное представление. Кроме того, процессор нейронной сети, действуя с более высоким временным разрешением, может оптимально использовать временную историю, т.е. может опираться с высокой эффективностью на временные изменения параметров для параметрического представления, которые особенно полезны для обработки аудиосигнала и, в частности, для расширения полосы или процедур расширения полосы.
Дополнительный предпочтительный аспект настоящего изобретения опирается на некоторую полезную процедуру отбеливания, которая делит первоначально генерируемый первичный сигнал на его спектральную огибающую, генерируемую путем низкочастотной или в общем случае FIR-фильтрации степенного спектра с помощью очень простого фильтра нижних частот, например, трех-, четырех- или пятиотводного фильтра нижних частот, где все отводы установлены только на 1. Эта процедура служит двум целям. Первая состоит в удалении формантной структуры из исходного первичного сигнала, и вторая состоит в снижении отношения энергии гармоник к энергии шума. Таким образом, такой отбеленный сигнал будет звучать гораздо естественнее, чем, например, остаточный сигнал LPC, и такой сигнал особенно пригоден для параметрической обработки с использованием параметрического представления, генерируемого процессором нейронной сети.
Дополнительный аспект настоящего изобретения опирается на преимущественный вариант осуществления, в котором процессор нейронной сети получает не амплитудный спектр, а мощностной входного аудиосигнала. Кроме того, в этом варианте осуществления, процессор нейронной сети выводит параметрическое представление и, например, параметры спектральной огибающей в области сжатия, например, области логарифма, области квадратного корня или области кубического корня. Затем обучение процессора нейронной сети в большей степени связано с человеческим восприятием, поскольку человеческое восприятие действует в области сжатия, а не в линейной области. С другой стороны, сгенерированные таким образом параметры преобразуются в линейную область процессором первичного сигнала, поэтому, в итоге, получается обработанное линейное спектральное представление сигнала частотного диапазона расширения, хотя нейронная сеть работает с мощностным спектром или даже спектром громкости (амплитуды возводятся в степень 3), и параметры параметрического представлению или по меньшей мере часть параметров параметрического представления выводятся в области сжатия, например, области логарифма или области кубического корня.
Дополнительный преимущественный аспект настоящего изобретения относится к реализации самой нейронной сети. В одном варианте осуществления входной слой нейронной сети принимает в двухмерном временно-частотном представлении амплитудный спектр или, предпочтительно, спектр мощности или громкости. Таким образом, входной слой нейронной сети является двухмерным слоем, имеющим полный частотный диапазон входного аудиосигнала и, дополнительно, имеющим также некоторое количество предыдущих кадров. Этот ввод предпочтительно реализуется в виде сверточного слоя, имеющего одно или более ядер свертки, которые, однако, являются очень малыми ядрами свертки, свертывающими, например, только не более пяти частотных бинов и не более 5 временных кадров, т.е. пять или менее частотных бинов из только пяти или менее временных кадров. За этим сверточным входным слоем следует предпочтительно дополнительный сверточный слой или дополнительный расширенный сверточный слой, который может или не может расширяться остаточными соединениями. Согласно варианту осуществления, выходной слой нейронной сети, выводящий параметры для параметрического представления, например, в значениях в некотором диапазоне значений, может быть сверточным слоем или полностью соединенным слоем, соединенным со сверточным слоем таким образом, что в нейронной сети не используются никакие рекуррентные слои. Такие нейронные сети описаны, например, в статье “An empiric evaluation of generic convolutional and recurrent networks for sequence modeling” авторов Shaojie Bai и др., 4 марта 2018 г., arXiv: 1803,01271v1 [cs. LG]. Такие сети, описанные в этой публикации, вовсе не опираются на рекуррентные слои, но опираются на только некоторые сверточные слои.
Однако в дополнительном варианте осуществления помимо одного или более сверточных слоев используются рекуррентные слои, например, LSTM-слои (или GRU-слои). Последний слой или выходной слой сети может быть или не быть полностью соединенным слоем с линейной выходной функцией. Эта линейная выходная функция позволяет сети выводить неограниченные непрерывные значения. Однако такой полностью соединенный слой не всегда требуется, поскольку редукция двухмерного (большого) входного слоя к одномерному выходному параметрическому слою для каждого временного индекса также может осуществляться путем подгонки двух или более высоких сверточных слоев или, конкретно, путем подгонки двух или более рекуррентных слоев, например, LSTM или GRU-слоев.
Дополнительные аспекты настоящего изобретения относятся к конкретному применению устройства расширения полосы, отвечающего изобретению, например, только для слепого расширения полосы для маскирования, т.е. в случае потери кадра. При этом аудиокодек может иметь неслепое расширение полосы или вообще не иметь расширения полосы, и принцип изобретения предсказывает часть сигнала, выпадающую вследствие потери кадра или предсказывает весь выпадающий сигнал.
Альтернативно, обработка, отвечающая изобретению, с использованием процессора нейронной сети используется не только как полностью слепое расширение полосы, но используется как часть неслепого расширения полосы или интеллектуального заполнения промежутков, где параметрическое представление, генерируемое процессором нейронной сети, используется как первое приближение, которое уточняется, например, в параметрической области посредством того или иного вида квантования данных под управлением очень малого количества битов, передаваемым в качестве дополнительной вспомогательной информации, например, одиночного бита для каждого выбранного параметра, например, параметров спектральной огибающей. Таким образом, получается управляемое расширение с чрезвычайно низкой битовой скоростью, которое, однако, опирается на обработку нейронной сети в кодере для генерации дополнительной вспомогательной информации с низкой битовой скоростью и которое, в то же время, действует на декодере для обеспечения параметрического представления из входного аудиосигнала, и затем это параметрическое представление уточняется дополнительной вспомогательной информацией с очень низкой битовой скоростью.
Дополнительные варианты осуществления предусматривают слепое расширение полосы (BBWE), которое расширяет полосу телефонной речи, которая часто ограничивается диапазоном от 0,2 до 3,4 кГц. Преимущество состоит в повышенном воспринимаемом качестве, а также в повышенной разборчивости. Вариант осуществления представляет слепое расширение аналогично традиционному расширению полосы, как при интеллектуальном заполнении промежутков, или расширение полосы или дублирование спектральной полосы с той разницей, что вся обработка осуществляется на декодере без необходимости в передаче дополнительных битов. Параметры наподобие параметров спектральной огибающей оцениваются регрессивной сверточной глубокой нейронной сетью (CNN) с долгой краткосрочной памятью (LSTM). Согласно варианту осуществления, процедура действует на кадрах 20 мс без дополнительной алгоритмической задержки и может применяться в традиционных речевых и аудиокодеках. Эти варианты осуществления используют работу сверточных и рекуррентных сетей для моделирования спектральной огибающей речевых сигналов.
Предпочтительные варианты осуществления настоящего изобретения рассмотрены ниже со ссылкой на прилагаемые чертежи, в которых:
фиг. 1 - блок-схема устройства для генерации аудиосигнала с расширенной полосой для входного аудиосигнала;
фиг. 2a - предпочтительная последовательность операций генератора первичного сигнала, показанного на фиг. 1;
фиг. 2b - предпочтительная реализация устройства, показанного на фиг. 1, где разные временные разрешения применяются в генераторе первичного сигнала с одной стороны и процессоре нейронной сети и процессоре первичного сигнала с другой стороны;
фиг. 2c - предпочтительная реализация осуществления операции спектрального отбеливания в генераторе первичного сигнала с использованием фильтра нижних частот по частоте;
фиг. 2d - диаграмма, иллюстрирующая спектральную ситуацию предпочтительной операции двукратного повышающего копирования;
фиг. 2e иллюстрирует спектральные векторы, используемые с целью генерации первичного сигнала и используемые с целью обработки первичного сигнала с использованием параметрического представления, выводимого процессором нейронной сети;
фиг. 3 - предпочтительная реализация генератора первичного сигнала;
фиг. 4 - предпочтительная реализация устройства для генерации аудиосигнала с расширенной полосой в соответствии с настоящим изобретением;
фиг. 5 - предпочтительный вариант осуществления процессора нейронной сети;
фиг. 6 - предпочтительный вариант осуществления процессора первичного сигнала;
фиг. 7 - предпочтительная схема нейронной сети;
фиг. 8a - сравнительная диаграмма производительности разных конфигураций DNN;
фиг. 8b - диаграмма, демонстрирующая ошибку на обучающем наборе и испытательном наборе в зависимости от объема данных;
фиг. 8c иллюстрирует результаты испытания прослушиванием ACR, отображаемые как значения MOS;
фиг. 9a иллюстрирует принцип сверточного слоя;
фиг. 9b иллюстрирует нейронную сеть с использованием нескольких сверточных слоев и слоя LSTM;
фиг. 10 иллюстрирует нейронную сеть, использующую только сверточные слои с коэффициентом расширения i;
фиг. 11 иллюстрирует применение двух слоев LSTM, нанесенных поверх сверточного слоя;
фиг. 12 иллюстрирует дополнительную предпочтительную нейронную сеть, использующую сверточные слои и по меньшей мере один слой LSTM и, наконец, полностью соединенный слой для понижения размерности является выходным слоем нейронной сети;
фиг. 13 иллюстрирует применение сверточного слоя с тремя ядрами фильтра;
фиг. 14 иллюстрирует систему для применения варианта осуществления, показанного на фиг. 1, с целью маскирования ошибок;
фиг. 15a иллюстрирует применение системы, показанной на фиг. 1 в управляемом расширении полосы с параметрической вспомогательной информацией очень низкой битовой скорости; и
фиг. 15b иллюстрирует предпочтительную реализацию процессора первичного сигнала в контексте системы, показанной на фиг. 15a.
Фиг. 1 иллюстрирует предпочтительный вариант осуществления устройства для генерации аудиосигнала с расширенной полосой из входного аудиосигнала 50, имеющего частотный диапазон входного аудиосигнала. Частотный диапазон входного аудиосигнала может быть низкополосный диапазон или полнополосный диапазон, но с меньшими или большими спектральными пробелами.
Устройство содержит генератор 10 первичного сигнала для генерации первичного сигнала 60, имеющего частотный диапазон расширения, причем частотный диапазон расширения не включен в частотный диапазон входного аудиосигнала. Устройство дополнительно содержит процессор 30 нейронной сети, выполненный с возможностью генерации параметрического представления 70 для частотного диапазона расширения с использованием частотного диапазона входного аудиосигнала и с использованием обученной нейронной сети. Устройство дополнительно содержит процессор 20 первичного сигнала для обработки первичного сигнала 60 с использованием параметрического представления 70 для частотного диапазона расширения для получения обработанного первичного сигнала 80, имеющего частотные составляющие в частотном диапазоне расширения. Кроме того, устройство содержит, в некоторой реализации, необязательный объединитель 40, который выводит аудиосигнал с расширенной полосой, например, сигнал с нижней полосой и верхней полосой или сигнал с полной полосой без спектральных пробелов или с меньшим количеством спектральных пробелов, чем раньше, т.е. по сравнению со входным аудиосигналом 50.
Обработанный первичный сигнал 80 уже может быть, в зависимости от обработки процессора первичного сигнала, сигналом с расширенной полосой, когда объединение обработанного первичного сигнала с частотным диапазоном входного аудиосигнала осуществляется, например, посредством спектрально-временного преобразования, например, рассмотренного со ссылкой на фиг. 4. Затем объединение уже осуществляется этим спектрально-временным преобразователем, и объединитель 40 на фиг. 1 составляет часть этого спектрально-временного преобразователя. Альтернативно, обработанный первичный сигнал может быть сигналом расширения во временной области, который объединяется со входным аудиосигналом временной области отдельным объединителем, который затем будет осуществлять суммирование на уровне выборок двух сигналов временной области. Другие процедуры для объединения сигнала расширения и исходного входного сигнала хорошо известны специалистам в данной области техники.
Кроме того, предпочтительно, чтобы генератор первичного сигнала использовал входной аудиосигнал для генерации первичного сигнала, как показано пунктирной линией 50, ведущей в генератор 10 первичного сигнала. Процедурами, которые выполняются с использованием входного аудиосигнала, являются операции постановки заплатки, например, операции повышающего копирования, операции постановки гармонической заплатки, смеси операций повышающего копирования и операций постановки гармонической заплатки, или другие операции постановки заплатки, которые, одновременно, осуществляют зеркалирование спектра.
Альтернативно, генератор первичного сигнала может действовать без необходимости ссылки на входной аудиосигнал. Затем первичный сигнал, генерируемый генератором 10 первичного сигнала, может быть шумоподобным сигналом, и генератор первичного сигнала будет содержать того или иного вида генератор шума или того или иного вида случайную функцию, генерирующую шум. Альтернативно, входной аудиосигнал 50 может использоваться и может обрабатываться посредством того или иного вида нелинейности во временной области, например, sgn(x) умноженной на x2, где sgn() является знаком x. Альтернативно, другой нелинейной обработкой будут процедуры обрезки или другие процедуры временной области. Дополнительной процедурой будет предпочтительная процедура частотной области, осуществляющая частотно-сдвинутую версию входного сигнала с ограниченной полосой, например, повышающее копирование, зеркалирование в спектральной области или что-то наподобие этого. Однако зеркалирование в спектральной области также может осуществляться операциями обработки во временной области, где нули вставляются между выборками, и, когда, например, между двумя выборками вставляется один нуль, получается зеркалирование спектра. Когда между двумя выборками вставляются два нуля, это будет операция повышающего копирования без зеркалирования в более высоком спектральном диапазоне и т.д. Таким образом, становится очевидным, что генератор первичного сигнала может действовать во временной области или в спектральной области для генерации первичного сигнала в частотном диапазоне расширения, который предпочтительно является отбеленным сигналом, как показано со ссылкой на фиг. 2a. Однако это отбеливание не обязательно должно осуществляться в спектральной области, но также может осуществляться во временной области, например, путем LPC-фильтрации, и тогда остаточный сигнал LPC будет отбеленным сигналом временной области. Однако как будет изложено далее, некоторая операция отбеливания в спектральной области предпочтительна в целях настоящего изобретения.
В предпочтительной реализации, процессор нейронной сети принимает, в качестве входного сигнала, аудиосигнал или, в частности, последовательность кадров спектральных значений аудиосигнала, где спектральные значения являются либо значениями амплитуды, но, более предпочтительно, являются значениями мощности, т.е. спектральными значениями или амплитудами, возведенными в некоторую степень, где степень равна, например, 2 (мощностная область) или 3 (громкостная область), но, в общем случае, для обработки спектральных значений до их подачи в нейронную сеть можно использовать степени от 1,5 до 4,5. Это, например, представлено на фиг. 5 блоком 32, иллюстрирующим преобразователь степенного спектра для преобразования последовательности кадров амплитуды нижней полосы спектра во временную последовательность спектральных кадров, и затем временная последовательность спектральных кадров, будь то линейные амплитуды или амплитуды мощности или амплитуды громкости, поступают в обученную нейронную сеть 31, которая выводит параметрические данные предпочтительно в области сжатия. Эти параметрические данные могут быть любыми параметрическими данными, описывающими выпадающий сигнал или сигнал расширения полосы, например, параметры тональности, параметры временной огибающей, параметры спектральной огибающей, например, энергии полос масштабного коэффициента, значения квантователя распределения, значения энергии или наклона. Другие параметры, известные, например, из обработки дублирования спектральной полосы, являются параметрами обратной фильтрации, параметрами добавления шума или параметрами выпадающих гармоник, которые также могут использоваться помимо параметров спектральной огибающей. Предпочтительные параметры спектральной огибающей или разновидность параметрического представления “базовой линии” являются параметрами спектральной огибающей и, предпочтительно, абсолютными энергиями или мощностями для нескольких полос. В контексте истинного расширения полосы, где входной аудиосигнал является только узкополосным сигналом, диапазон расширения может иметь, например, только четыре или пять полос или, максимум, десять полос расширения, и тогда параметрическое представление будет состоять только из одной энергии или мощности или амплитудно-связанного значения для каждой полосы, т.е. десять параметров для десять иллюстративных полос.
Согласно варианту осуществления, расширение полосы можно использовать как расширение любого рода речи и аудиокодека, например, расширенную речевую услугу (EVS) 3GPP или MPEG AAC. Входной сигнал обработки расширения полосы, представленной на фиг. 1, является декодированным аудиосигналом и, в порядке примера, ограниченными по полосе. Выводится оценка выпадающего сигнала. Оценка может представлять собой сигнал в виде формы волны или коэффициентов преобразования, например, FFT или модифицированного дискретного косинусного преобразования (MDCT) и т.п. Параметры, генерируемые процессором 30 нейронной сети, являются параметрами параметрического представления 70, которое в порядке примера было рассмотрено выше.
Когда сигнал описан некоторыми грубыми параметрами, искусственный сигнал генерируется и затем модифицируется параметрами, оцененными процессором 30 нейронной сети.
Фиг. 2a иллюстрирует предпочтительную процедуру, осуществляемую генератором 10 первичного сигнала. На этапе 11a, генератор первичного сигнала генерирует сигнал с первой тональностью, и на дополнительном этапе 11b, генератор первичного сигнала спектрально отбеливает сигнал с первой тональностью для получения сигнала со второй, более низкой тональностью. Другими словами, тональность второго сигнала ниже, чем тональность первого сигнала, и/или сигнал, полученный на этапе 11b, белее или более белый, чем сигнал, генерируемый на этапе 11a.
Кроме того, фиг. 2b иллюстрирует некоторую предпочтительную реализацию кооперации между генератором 10 первичного сигнала с одной стороны и процессором 30 нейронной сети и процессором 20 первичного сигнала с другой стороны. Как указано в блоке 12, генератор первичного сигнала генерирует первичный сигнал с первым (низким) временным разрешением, и как указано в блоке 32, процессор 30 нейронной сети генерирует параметрические данные со вторым (высоким) временным разрешением, и затем процессор 20 первичного сигнала масштабирует или обрабатывает первичный сигнал со вторым или высоким временным разрешением в соответствии с временным разрешением параметрического представления. Предпочтительно, временное разрешение в блоках 32 и 22 одинаково, но, альтернативно, эти блоки могут даже опираться на разные временные разрешения, при условии, что временное разрешение блока 32 выше, чем временное разрешение спектрального отбеливания, используемое на этапе 12, и при условии, что временное разрешение, используемое для масштабирования/обработки первичного сигнала выше, чем временное разрешение генерации первичного сигнала, проиллюстрированного на блоке 12 на фиг. 2b. Таким образом, в общем случае, существует два варианта осуществления, т.е. первичный сигнал генерируется с низким временным разрешением, и обработка нейронной сетью осуществляется с высоким временным разрешением, или первичный сигнал генерируется с высоким частотным разрешением, и обработка нейронной сетью осуществляется с низким временным разрешением.
Фиг. 2d иллюстрирует ситуацию спектров в реализации, где входной сигнал является узкополосным входным сигналом, например, от 200 Гц до 3,4 кГц, и операция расширения полосы является истинным расширением полосы. Здесь, входной аудиосигнал вводится во временно-частотный преобразователь 17, представленный на фиг. 3. Затем осуществляется постановка заплатки заплатчиком 18 и, после постановки заплатки, осуществляется этап 11b отбеливания, и, затем, результат преобразуется во временную область частотно-временным преобразователем. Выходным сигналом блока 19 на фиг. 3 может быть только первичный сигнал временной области или первичный сигнал временной области и входной аудиосигнал. Кроме того, следует отметить, что порядок операций отбеливателя 11b и заплатчика 18 может меняться на обратный, т.е. что отбеливатель может оперировать сигналом, выводимым временно-частотным преобразователем, т.е. низкополосным сигналом или входным аудиосигналом, и затем уже отбеленный сигнал ставится в виде заплатки либо один раз, либо, как показано на фиг. 2d, два раза, т.е. посредством первого повышающего копирования и второго повышающего копирования, благодаря чему, полный частотный диапазон расширения образован частотным диапазоном операции первого повышающего копирования и операция второго повышающего копирования. Естественно, заплатчику 18 на фиг. 3 не обязательно осуществлять операцию повышающего копирования, но также может осуществлять операцию спектрального зеркалирования или любую другую операцию для генерации сигнала в частотном диапазоне расширения, который отбеливается до или после генерации.
В предпочтительном варианте осуществления, операция спектрального отбеливания, проиллюстрированная в блоке 11b на фиг. 2b или проиллюстрированная в блоке 11b на фиг. 3, содержит процедуры, представленные на фиг. 2c. Линейный спектральный кадр, например, генерируемый временно-частотным преобразователем 17 на фиг. 3, который может быть процессором FFT, процессором MDCT или любым другим процессором для преобразования представления во временной области в спектральное представление, вводится в линейно-степенной преобразователь 13. Выходным сигналом линейно-степенного преобразователя 13 является мощностной спектр. Блок 13 может применять любую степенную операцию, например, операцию с показателем степени 2, или 3 или, в общем случае, от 1,5 до 4,5, хотя для получения мощностного спектра на выходе блока 13 предпочтительно значение 2. Затем мощностной кадр подвергалась низкочастотной фильтрации по частоте фильтром нижних частот для получения оценки мощностной спектральной огибающей.
Затем, в блоке 15, оценка мощностной спектральной огибающей преобразуется обратно в линейную область с использованием степенно-линейного преобразователя 15, после чего оценка линейной спектральной огибающей поступает на вычислитель 16 отбеливания, который также принимает линейный спектральный кадр для вывода отбеленного спектрального кадра, который соответствует первичному сигналу или спектральному кадру первичного сигнала в предпочтительной реализации. В частности, оценка линейной спектральной огибающей является некоторым линейным коэффициентом для каждого спектрального значения линейного спектрального кадра и, таким образом, каждое спектральное значение линейного спектрального кадра делится на соответствующий весовой коэффициент, включенный в оценку линейной спектральной огибающей, выводимую блоком 15.
Предпочтительно, фильтром 14 нижних частот является FIR-фильтр, имеющий, например, только 3, 4 или 5 отводов или, максимум, 8 отводов и, предпочтительно, по меньшей мере 3 отвода имеют одно и то же значение и, предпочтительно, равны 1 или даже всем 5 или, в общем случае, все отводы фильтра равны 1 для получения операции фильтрации нижних частот.
Фиг. 2e иллюстрирует обработку, осуществляемую в контексте операции системы на фиг. 4.
Базовая акустическая модель процесса речеобразования человека объединяет периодический, импульсный сигнал возбуждения (сигнал гортани), модулированный передаточным фильтром, определенным формой супраларингеального речевого тракта. Кроме того, существуют шумоподобные сигналы, порождаемые турбулентным воздушным потоком, обусловленным сужением речевого тракта или губами. На основании этой модели выпадающий частотный диапазон расширяется путем расширения сигнала возбуждения с плоским спектром с последующим его формированием с оценкой фильтра речевого тракта. Предложенная система изображена на фиг. 1. Из декодированного сигнала временной области блоки по 20 мс преобразуются посредством DFT в частотную область. Кадровое приращение (размер перескока) соседствующих кадров равно 10 мс. В частотной области сигнал дискретизируется с повышением до 16 кГц путем заполнения нулями, и выпадающее частотное содержание выше 3,4 кГц генерируется таким же образом, как в расширениях полосы наподобие интеллектуального заполнения промежутков (IGF) или SBR [12, 13]: нижние бины копируются с повышением для создания выпадающего сигнала. Поскольку кодеки наподобие AMR-NB кодируют только частоты от 200 до 3400 Гц, этого сигнала недостаточно для заполнения выпадающего диапазона 8000-3200=4800 Гц. Таким образом, эту операцию нужно производить дважды - первый раз для заполнения диапазона от 3400 до 6600 Гц и второй раз для заполнения диапазона от 6600 до 8000 Гц.
Этот искусственный генерируемый сигнал является слишком тональным по сравнению с исходным сигналом возбуждения. Менее сложный способ, используемый в IGF, используется для снижения тональности [14]. Идея здесь состоит в делении сигнала на его спектральную огибающую, генерируемую путем FIR-фильтрации степенного спектра. Это служит двум целям - первая состоит в удалении формантной структуры из скопированного сигнала (этого также можно добиться с использованием остатка LPC), вторая состоит в снижении отношения энергии гармоник к энергии шума. Таким образом этот сигнал будет звучать гораздо естественнее.
После обратного DFT вдвое большего размера, чем начальное DFT, сигнал временной области с частотой дискретизации 16 кГц генерируется путем суммирования с наложением блоков с перекрытием 50%. Этому сигналу временной области с плоским сигналом возбуждения свыше 3400 Гц будет придаваться форма, напоминающая формантную структуру исходного сигнала. Это делается в частотной области DFT с более высоким временным разрешением, действующим на блоках по 10 мс. Здесь сигнал в диапазоне от 3400 до 8000 Гц делится на 5 полос шириной примерно 1 барк [15], и каждый DFT-бин Xi в полосе b масштабируется с масштабным коэффициентом fb:
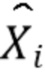 =
= 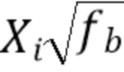 (1)
(1)
Масштабный коэффициент fb является отношением логарифмической оценки Lb энергии и суммарной или средней энергии бинов i в полосе b:
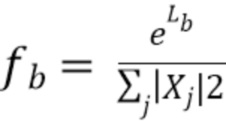 , (2)
, (2)
где j пробегает по всем бинам в полосе b. Lb вычисляется с помощью DNN, как объяснено в следующем разделе, и является оценкой истинной широкополосной энергии  :
:
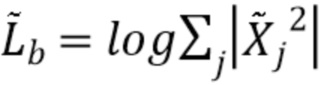 (3)
(3)
которая вычисляется на спектре исходного широкополосного сигнала 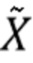 .
.
Наконец, масштабированный спектр преобразуется во временную область обратным DFT, и выходной сигнал генерируется путем суммирования с наложением предыдущих кадров с перекрытием 50%.
Таким образом, как показано на фиг. 4, узкополосный входной аудиосигнал 50 вводится в первый временно-частотный преобразователь, осуществляющий “короткое” преобразование в том смысле, что спектральный вектор имеет только частоты до половины частоты дискретизации, т.е. до 8 кГц. Длина временного окна равна 20 мс или, в общем случае, является определенное значение. Поскольку полезный спектр доходит только до 3,4 кГц, верхний участок спектрального вектора между 3,4 кГц и 4 кГц не используется, как показано позицией 70. Затем этот спектральный вектор 70 подвергается заполнению нулями для получения спектральный вектор 71. Затем нули в модуле заполнения нулями спектрального вектора 71 заполняются полезными значениями в процедуре повышающего копирования и, дополнительно, спектральные значения в модуле повышающего копирования спектрально отбеливаются блоком 11b на фиг. 4. Затем осуществляется обратное FFT со спектральным вектором 72. Алгоритм преобразования является длинным алгоритмом преобразования, поскольку количество значений, вводимых в алгоритм преобразования, вдвое больше количества спектральных значений, генерируемых временно-частотным преобразованием, осуществляемым блоком 17 на фиг. 4, что проиллюстрировано спектральным вектором 70.
Важно отметить, что сигнал на входе блока 50 имеет частоту дискретизации 8 кГц, например, и сигнал, выводимый блоком 19, имеет удвоенную частоту дискретизации, т.е. 16 кГц, но теперь спектральный диапазон доходит до 8 кГц.
Теперь процессор 20 первичного сигнала осуществляет дополнительное временно-частотное преобразование, но опять же с ядром короткого алгоритма. Предпочтительно, длина окна имеет 10 мс, благодаря чему, по отношению к спектральному вектору 72, теперь сгенерированный спектральный вектор 73, полученный блоком 22 на фиг. 4, имеет меньшее количество спектральных значений вследствие меньшей длины окна, и количество спектральных значений снова равно тому, которое было рассмотрено по отношению к спектральному вектору 70 вне диапазона от 3,4 до 4 кГц.
Таким образом, по отношению к спектральному вектору 73, количество спектральных значений нижней полосы вдвое меньше количества спектральных значений нижней полосы в блоке 72 и количество значений верхней полосы в блоке 73 также вдвое меньше количества значений верхней полосы в блоке 72, демонстрируя более низкое частотное разрешение, но более высокое временное разрешение.
Затем, как демонстрирует спектральный вектор 74, диапазон повышающего копирования масштабируется с использованием параметрического представления от процессора 30 нейронной сети и, в частности, от глубокой нейронной сети 31 в блоке 23 масштабирования и затем блок 74 преобразуется обратно во временную область, опять же, посредством короткого ядра, благодаря чему, в итоге, получается широкополосная речь.
Во всех операциях преобразования, будь то операции FFT или операции MDCT, осуществляется 50% перекрытие. Таким образом, два 10-миллисекундных временных кадра, соответствующие спектральным векторам 73 и 74, образуют тот же временной диапазон, что и единый спектральный вектор 70 на низкой частоте дискретизации или 71 и 72 на высокой частоте дискретизации.
Предпочтительно, чтобы продолжительность времени блока, обработанного алгоритмом 22 или 24 преобразования, вдвое меньше длины блока, обработанного процессором 17 или 19 на фиг. 4 или, альтернативно, соотношение может быть 1/3, 1/4, 1/5 и т.д. Таким образом, временные кадры не обязательно имеют длину 20 мс для процедуры в генераторе первичного сигнала и 10 мс для процедуры в процессоре 20 первичного сигнала. Вместо этого, если, например, процессор 10 первичного сигнала использует 10 мс, процессор 20 первичного сигнала будет использовать 5 мс или если генератор 10 первичного сигнала использует 40 мс, то процессор 20 первичного сигнала может использовать, например, 20 мс, 10 мс или 5 мс.
Кроме того, со ссылкой на фиг. 4, следует отметить, что нижняя полоса выходного сигнала преобразователя 22 вводится в нейронную сеть 31, и верхняя полоса ретранслируется на блок 23 масштабирования, и тем не менее, блок 24 обратного частотно-временного преобразования будет объединять нижнюю полосу, которая также вводится в блок 31, и верхнюю полосу на выходе блока 23 масштабирования, как показано на фиг. 2e. Естественно, нижняя полоса для процессора 31 DNN также может происходить из выходного сигнала блока 17 или может происходить непосредственно из входного сигнала 50. В целом, необходимо не только, чтобы конкретный входной аудиосигнал, поступающий на генератор первичного сигнала, вводился в процессор нейронной сети, а необходимо только, чтобы частотный диапазон входного аудиосигнала независимо от того, имеет ли он низкую частоту дискретизации или высокую частоту дискретизации, вводился в процессор нейронной сети, хотя предпочтительно, чтобы, в варианте осуществления на фиг. 4, частотный диапазон входного аудиосигнала с высокой частотой дискретизации вводился в процессор 31 нейронной сети как “нижняя полоса”, представленная на фиг. 4.
Фиг. 6 иллюстрирует предпочтительную реализацию процессора 20 первичного сигнала. Процессор первичного сигнала содержит оцениватель 25 мощности первичного сигнала, принимающий первичный сигнал от генератора 10 первичного сигнала. Затем оцениватель мощности первичного сигнала оценивает мощность первичного сигнала и ретранслирует эту оценку на вычислитель 27 масштабного коэффициента. Вычислитель 27 масштабного коэффициента дополнительно подключен к преобразователю 26 области для преобразования параметрических данных, например, оценки энергии в некоторой полосе широкополосного сигнала, обеспеченного процессором нейронной сети, из области log или ()1/3 в мощностную область. Затем вычислитель 27 масштабного коэффициента вычисляет, для каждой полосы, масштабный коэффициент fb, и это значение преобразуется в линейную область линейным преобразователем 28, после чего действительно - или комплекснозначные амплитуды первичного сигнала 60 масштабируются блоком масштабирования первичного сигнала, действующим в спектральной области, как показано на блоке 29, с использованием масштабного коэффициента. Таким образом, при наличии в полосе, например, пяти действительных или комплексных амплитуд, все эти пять амплитуд масштабируются одним и тем же линейным масштабным коэффициентом, генерируемым блоком 28, и это масштабирование осуществляется в блоке 29 для получения масштабированного первичного сигнала на выходе блока 29. Таким образом, в некотором варианте осуществления, вычислитель 27 масштабного коэффициента осуществляет вычисление Ур. (2), и блок 29 масштабирования первичного сигнала осуществляет операцию в Ур. (1) в некотором варианте осуществления. Операция преобразователя 26 области осуществляется экспоненциальной функцией в числителе вышеприведенного Ур. (2), и оценка мощности первичного сигнала, осуществляемая блоком 25, осуществляется в знаменателе вышеприведенного Ур. (2).
Следует отметить, что на фиг. 6 показана лишь схематическая диаграмма, и специалистам в данной области техники очевидно, что, как уже рассмотрено в отношении Ур. (2), функциональные возможности блоков 25, 26, 27 могут осуществляться в единой вычислительной операции, проиллюстрированной в Ур. (2). В то же время, функциональные возможности блоков 28 и 29 могут осуществляться в едином вычислении, как показано в отношении вышеприведенного Ур. (1).
Фиг. 7 иллюстрирует предпочтительную реализацию нейронной сети, используемой в процессоре 30 нейронной сети на фиг. 1 и, в частности, используемой в блоке 31 на фиг. 5. Предпочтительно, нейронная сеть содержит входной слой 32 и выходной слой 34 и, в некоторых вариантах осуществления, один или более промежуточных слоев 33. В частности, процессор 30 нейронной сети выполнен с возможностью приема, на входном слое 32, спектрограммы, выведенной из входного аудиосигнала, причем спектрограмма содержит временную последовательность спектральных кадров, где спектральный кадр имеет несколько спектральных значений, и нейронная сеть выводит, на выходном слое, индивидуальные параметры параметрического представления 70. В частности, спектральные значения, вводимые во входной слой 32, являются линейными спектральными значениями или, предпочтительно, степенными спектральными значениями, обработанными с использованием степенной функции с показателем от 1,5 до 4,5 и, предпочтительно, показателем 2 (мощностная область) или показателем 3 (громкостная область), или, наиболее предпочтительно, обработанными степенными спектральными значениями, обработанными с использованием степенной функции с показателем от 1,5 до 4,5 и, предпочтительно, показателем 2 (мощностная область) или показателем 3 (громкостная область), и затем обработанными с использованием функции сжатия, например, логарифмической функции или функции ()1/3 или, в общем случае, функции, имеющей показатель степени ниже, чем 1,0, для получения значений в области громкости или сжатия. Если линейные спектральные значения заданы в действительном/мнимом (real+j imag) представление, то предпочтительной обработкой для получения обработанного спектрального значения мощности будет log(real2+imag2) или (real2+imag2)1/3.
В некотором варианте осуществления, например, представленном на фиг. 9a или 9b, только входной слой или входной слой совместно с одним или более промежуточными слоями содержит сверточный слой, и сверточный слой содержит одно или более ядер сверточного фильтра, причем на фиг. 9a представлено два. В частности, на фиг. 9a, спектрограмма аудиосигнала проиллюстрирована в двухмерной форме, где время отложено слева направо, и частота отложена снизу вверх.
Ядро фильтра для кадра i проиллюстрировано как базовый квадрат, и ядро фильтра для кадра i+1 проиллюстрирован в правом квадрате, и ядро фильтра для частоты f+1 проиллюстрирован в верхней малом квадрате.
Проиллюстрированы также индивидуальные сверточные слои для базового слоя, то есть первый и второй слой 33a, 33b, и в этом варианте осуществления, после сверточных слоев следует по меньшей мере один рекуррентный слой, например, слой LSTM 34. Этот слой, в этой ситуации, уже представляет выходной слой 34.
Кроме того, фиг. 9b иллюстрирует ситуацию обучения, где целевая огибающая в этой реализации или, в общем случае, спектральное представление, обозначенное 80, и расхождение между целевой огибающей и оценками огибающей, произведенными выходным слоем 34, используется для повышения эффективности обучения за счет минимизации этой ошибки.
Фиг. 10 иллюстрирует дополнительную нейронную сеть. Нейронная сеть на фиг. 10 отличается от нейронной сети на фиг. 9b тем, что выходной слой 34 является сверточным слоем и, согласно варианту осуществления, представленному на фиг. 10, вторым сверточным слоем.
Кроме того, входной слой 32, как уже рассмотрено со ссылкой на фиг. 9b, является слоем, принимающим спектрограмму, и данные входного слоя обрабатываются одним или более ядер свертки, действующими для создания выходных результатов первого сверточного слоя 33. Второй сверточный слой 34, который одновременно является выходным слоем 34 на фиг. 10, осуществляет расширение с коэффициентом i. Это означает, что, например, данные с временным индексом i+1 во втором сверточном слое 34 вычисляются с использованием данных i+1 первого сверточного слоя 32 и данных с i-1 и i-3.
Соответственно, данные с временным индексом i для второго сверточного слоя 34 вычисляются из данных с временным индексом i для первого сверточного слоя, данных с временным индексом i-1 для первого сверточного слоя и данных с i-4 для первого сверточного слоя. Таким образом, некоторые результаты первого сверточного слоя дискретизируются с понижением при вычислении второго сверточного слоя, но обычно все данные из первого сверточного слоя, в конце концов, используются для вычисления некоторых данных во втором сверточном слое благодаря обработке перемежения, рассмотренной и представленной на фиг. 10.
Следует отметить, что фиг. 10 иллюстрирует только временной индекс, но частотный индекс или частотное измерение не представлено на фиг. 10. Частотное измерение уходит в плоскость фиг. 10 или выходит из плоскости фиг. 10. В отношении частотной обработки, также может осуществляться редукция измерения от слоя к слою благодаря чему, в итоге, т.е. для наивысшего сверточного слоя или выходного слоя, возникает только набор параметров, которые сравниваются с целевыми параметрами для минимизации ошибки как показано в верхней части фиг. 10 в слое 80, иллюстрирующем целевую огибающую длч обучения или, в общем случае, иллюстрирующем целевое спектральное представление для целей обучения.
Фиг. 11 иллюстрирует комбинацию наивысшего или “последнего” сверточного слоя 33a и последующего слоя LSTM с двумя разными ячейками LSTM. Таким образом, на фиг. 11 показан случай, когда в слое LSTM используются две ячейки LSTM, а именно LSTM1, LSTM2. Таким образом, становится очевидным, что размер слоя LSTM увеличен по сравнению со слоем, имеющим одну-единственную ячейку LSTM.
Согласно варианту осуществления, процессор рекуррентного слоя, действующий в рекуррентном слое, реализован в виде IIR-фильтра. Коэффициенты фильтрации IIR-фильтра определяются путем обучения нейронной сети, и прошлая ситуация входного аудиосигнала отражается состояниями памяти IIR-фильтра. Таким образом, благодаря тому, что рекуррентный процессор IIR обладает (бесконечной импульсной характеристикой), информация, уходящая далеко в прошлое, т.е. информация из спектрального кадра, имевшего место, например, за тридцать секунд или даже одну минуту до текущего кадра, тем не менее, оказывает влияние на текущую ситуацию.
Фиг. 12 иллюстрирует дополнительный вариант осуществления нейронной сети, состоящей из входного слоя 32, двух сверточных слоев 33a, 33b и вышележащего слоя LSTM 33d. Однако, в отличие от вышеописанных нейронных сетей, выходной слой является полностью соединенным слоем для осуществления снижения размерности, т.е. для снижения двухмерной высокой размерности от входного слоя 32 к низкой размерности, т.е. уменьшения количества параметров параметрического представления для каждого временного кадра. Кроме того, фиг. 13 иллюстрирует случай, когда двухмерный входной сигнал или выходной сигнал сверточного слоя обрабатывается, например, тремя ядрами сверточного фильтра. В этом случае, одно принимает, для каждого слоя, несколько матриц, которые, в итоге, суммируются друг с другом сумматором 90 и затем результат вводится в функцию, например, функцию RELU 92 для повторной генерации единой выходной матрицы, обозначенной 93, которая демонстрирует выходной сигнал слоя, сжатый в единую матрицу посредством операции суммирования на уровне выборок сумматора 90 и, для каждого результата операции суммирования, последующей функциональной процедуры, осуществляемой функциональным оператором 92. Естественно, функциональный оператор 92 может быть любым другим оператором, помимо RELU, известным в области обработки нейронной сети.
Целевая оценка энергии 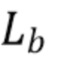 в уравнении 2 в разделе 2 масштабирует спектр синтезированного сигнала для аппроксимации энергии исходного сигнала. Это значение вычисляется с помощью DNN. Входным сигналом DNN являются сцепленные кадры нижней полосы мощностного спектра. В этом состоит отличие от традиционных способов, где вводятся признаки наподобие коэффициентов косинусного преобразования Фурье для частот чистых тонов. Напротив, первыми слоями DNN являются сверточные слои (CNN), сопровождаемые слоями LSTM и, в конце концов, полностью соединенным слоем с линейными функциями активации.
в уравнении 2 в разделе 2 масштабирует спектр синтезированного сигнала для аппроксимации энергии исходного сигнала. Это значение вычисляется с помощью DNN. Входным сигналом DNN являются сцепленные кадры нижней полосы мощностного спектра. В этом состоит отличие от традиционных способов, где вводятся признаки наподобие коэффициентов косинусного преобразования Фурье для частот чистых тонов. Напротив, первыми слоями DNN являются сверточные слои (CNN), сопровождаемые слоями LSTM и, в конце концов, полностью соединенным слоем с линейными функциями активации.
CNN являются разновидностью многослойных перцептронов, моделирующих организацию рецепторных полей в глазах. Слой CNN является слоем ядер фильтра, где коэффициенты ядра изучены в ходе обучения [16]. CNN используют локальные зависимости гораздо лучше и с меньшим количеством изучаемых коэффициентов, чем полностью соединенные слои. Размерность ядра фильтра в принципе является произвольной, но не должна превышать размерность входных данных. Здесь двухмерные ядра фильтра свертываются с входной спектрограммой во временном и частотном измерении.
Эти фильтры способны обнаруживать абстрактный шаблон в сигнале аналогично таким признакам, как спектральный центроид или коэффициенты косинусного преобразования Фурье для частот чистых тонов.
После сверточных слоев следуют рекуррентные слои. Рекуррентные слои пригодны для изучения более длинных временных зависимостей. Существуют разные типы рекуррентных слоев и здесь LSTM-слои продемонстрировали наилучшую производительность. LSTM-слои способны использовать кратковременную, а также долговременную структуру [17]. Аналогичной, но немного меньшей производительности можно добиться с помощью слоев управляемых рекуррентных блоков (GRU) [18].
Последний слой сети является полностью соединенным слоем с линейной выходной функцией. Линейная выходная функция позволяет сети выводить неограниченные непрерывные значения.
DNN обучается в режиме надзора за счет минимизации разности между энергиями истинного широкополосного спектра  и оценкой
и оценкой  для каждой итерации. Для этого использовалась разновидность алгоритма стохастического градиентного спуска (SGD) с редкими данными, именуемого Adagrad [19]. Как и в стандартном SGD, параметры сетей итерационно обновляются, пока не будет достигнут локальный минимум заранее заданной функции потерь, но скорость обучения не требуется настраивать вручную.
для каждой итерации. Для этого использовалась разновидность алгоритма стохастического градиентного спуска (SGD) с редкими данными, именуемого Adagrad [19]. Как и в стандартном SGD, параметры сетей итерационно обновляются, пока не будет достигнут локальный минимум заранее заданной функции потерь, но скорость обучения не требуется настраивать вручную.
Важным аспектом является определение функции потерь. Поскольку в конце концов систему будут оценивать слушатели-люди, предпочтительно рассматривать субъективно вопринимаемые потери. Кроме того, обучение следует осуществлять с помощью библиотек глубокого обучения наподобие Keras [20] и по этой причине нужно иметь возможность экономично вычислять функцию потерь и ее производную на CPU или GPU. В этой работе логарифм в уравнении 3 реализует грубую модель громкости. Ее преимущество состоит в том, что функция ошибки сводится к евклидову расстоянию. Также была предпринята попытка заменить логарифм в уравнении 3 на кубический корень, но неформальное прослушивание не выявило никаких преимуществ.
Другим важным аспектом является алгоритмическая задержка DNN, поскольку представленную систему следует использовать в приложениях реального времени. Поскольку DNN действует на сцепленных кадрах с кадровым приращением в один кадр, основным источником задержки является первый сверточный слой. Чтобы задержка оставалась максимально низкой, временной размер ядра был установлен равным трем, то есть ядро охватывает три кадра. Поскольку DNN действует на более коротких кадрах, чем повышающая дискретизация и генерация возбуждение в 2, сверточный слой не добавляет дополнительную алгоритмическую задержку. В частотном изменении ядра охватывают 250 Гц. Были протестированы ядра других размеров, но они не показали повышения производительности.
Один важный аспект обучения DNN состоит в универсальности обучающего набора. Чтобы построить модель, достаточно большую для моделирования в высокой степени нелинейные характеристики речевого тракта, обучающий набор должен быть большим и содержать самые разные данные - а именно, речь разных людей на разных языках, записанную на разных звукозаписывающих устройствах в разных помещениях. Обучающий набор длиной 400 минут был собран из нескольких публично доступных речевых массивов [21], а также собственных записей. Обучающий набор содержит речь на родных языках, включающих в себя следующие языки: местный американский английский, арабский, китайский (мандаринский), голландский, английский (британский), финский, французский, немецкий, греческий, венгерский, итальянский, японский, корейский, польский, португальский (бразильский), русский, испанский (кастильский), шведский. Оценочный набор не содержит ни говорящего из обучающего набора, ни настройки записи, используемой в обучающем наборе, и длится 8 минут.
Далее приведено дополнительное описание обработки нейронной сети.
В первый сверточный слой поступает матрица спектрограммы S[t, f], где t - временной индекс, и f - частотный индекс. S свертывается с ядром фильтра k, имеющим заранее заданный размер ядра, например, 3×2. Свертка S с одним ядром фильтра создает новую матрицу C. Один элемент C является векторным произведением:
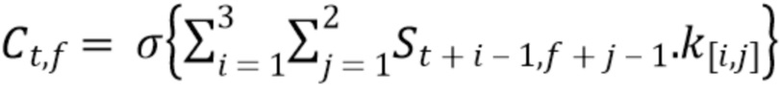 , (4)
, (4)
где сигма - некоторая нелинейная функция, например RELU. Поскольку заполнение не используется, размер матрицы C уменьшается в зависимости от размера ядра фильтра.
Второй и следующий сверточные слои действуют как первый сверточный слой с той только разницей, что операция свертки является расширенной сверткой. На вход расширенной свертки поступает дискретизированная с понижением версия предыдущего слоя. В математических терминах:
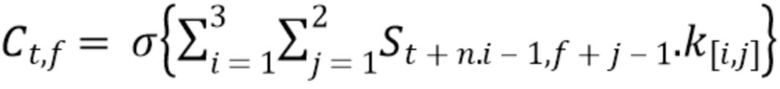 , (5)
, (5)
где n, m - положительные целые числа 2, 3 … и т.д. В случае, когда n, m равны 1, действующая свертка является простой операцией свертки.
На фиг. 10 показан пример операции расширенной свертки с одномерным сигналом. Важно обрабатывать два подряд аудиокадра i и i+1. Эта обработка обеспечивает низкую задержку, необходимую для оперирования аудиосигналом в реальном времени.
Свертку, описанную в предыдущих разделах, можно рассматривать как преобразование F от S:
 (6)
(6)
Добавление остаточных соединений изменяет Ур. (4) просто путем добавления обхода входного сигнала:
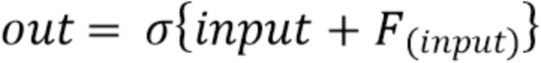 (7)
(7)
Преимущество обхода состоит в том, что сеть работает гораздо лучше после обучения, как описано в Kaiming He: Deep Residual Learning for Image Recognition, 2015.
Слой LSTM/GRU действует очень просто, принимая выходной вектор сверточного слоя для одиночного кадра, создавая при этом выходной вектор той же размерности:
 , (8)
, (8)
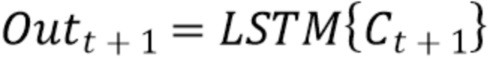 (9)
(9)
Далее будет описана обработка одиночного аудиокадра согласно варианту осуществления.
Одиночный аудиокадр обрабатывается путем:
- осуществления операции свертки первого слоя на основании спектрограммы текущего кадра и предыдущих кадров
- осуществления операции расширенной свертки последующих слоев на основании выходного сигнала предыдущих слоев
- выходным сигналом в расчете на кадр последнего сверточного слоя является одномерный вектор, поступающий в рекуррентный (LSTM, GRU) слой
- выходной сигнал слоя LSTM/GRU, являющийся оценкой огибающей выпадающего сигнала или, альтернативно, поступающий в один или более полностью соединенных слоев, которые, наконец, выводят огибающую выпадающего сигнала.
Таким образом, алгоритмическая задержка структуры в целом равна только одному аудиокадру.
Следует подчеркнуть, что другие структуры DNN, например, простые полностью соединенные слои, можно обучать для осуществления аналогичной, но не с такой низкой сложностью, как представленная система.
Существует две разновидности DNN, используемых для предсказания сигнала. Первая не описана в вышеупомянутой статье и является временной сверточной сетью (TNC), как описано в S. Bai et. al.: An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. Эта сеть является сверточной сетью с расширением и остаточными соединениями.
Второй разновидностью является DNN, содержащая один или более сверточных слоев, сопровождаемых одним или более рекуррентными слоями наподобие LTSM или GRU. Первый(е) слой(и) в необязательном порядке являе(ю)тся одним или более сверточным(и) слоем(ями). Функция активации выходного слоя (последнего слоя) способна представлять диапазон значений оцененного параметра (например, линейной функции для оценивания значений неограниченного диапазона или функции RELU для положительных значений). DNN обучается на обратном распространении или некоторой разновидности (ADAgrad, ADAM и т.д.), и ошибка является расстоянием для каждой итерации до исходного сигнала.
Затем производится оценивание другой системы. Для этого фиг. 8a сравнивает производительность разных конфигураций DNN. Система OPT (оптимальная система среди тестируемых систем) имеет 2 сверточных слоя (4 ядра), сопровождаемые 2 слоями LSTM (16 единиц каждый). Система A имеет один слой CNN (4 ядра) и один слой LSTM (16 единиц). Система B не имеет слоев CNN, но имеет 2 слоя LSTM (32 и 16 единиц). Система C имеет 2 слоя CNN (4 ядра каждый).
Фиг. 8b иллюстрирует расхождение между обучающим набором (пунктирная линия) и испытательным набором (сплошная линия) в зависимости от объема данных. При небольшом объеме обучающих данных (100 минут или менее), происходит сильное переобучение. Когда обучающий набор занимает более 400 минут, переобучение исчезает.
Фиг. 8c иллюстрирует результаты испытания прослушиванием ACR, отображаемые как значения MOS с интервалами доверительности 94%. Испытуемые кодеки указаны в направлении слева направо: 1) прямой широкополосный, 2) прямой узкополосный, 3-5) MNRU с шумом 10-30 дБ, 6) AMR-NB 7,4 кбит/с, 7) AMR-NB 7,4 кбит/с со слепым расширением полосы, 8) AMR-NB 7,4 кбит/с c oracle BWE, 9) AMR-NB 12,2 кбит/с; 10) AMR-NB 12,2 кбит/с c BBWE, 10) AMR-NB 12,2 кбит/с c oracle BWE.
Представленную систему оценивали с помощью объективных и субъективных тестов. Сначала структуру сети оптимизировали путем максимизации логарифмического спектрального искажения или LSD. LSD является общеизвестной мерой, используемой в большинстве публикаций, касающихся квантования коэффициентов линейного предсказания, и хорошо коррелирует с субъективным восприятием:
 (10)
(10)
где - спектр верхней полосы исходного сигнала, X - спектр верхней полосы прогнозируемого сигнала, и N - количество бинов в верхней полосе. M - количество кадров, используемых для оценивания.
Фиг. 8a сравнивает производительность разных конфигураций DNN. Наилучшим образом осуществляемая система (Opt) имеет два сверточных слоя с 4 ядрами фильтра на слой, сопровождаемые двумя слоями LSTM с 16 единицами в каждом слое. Система A имеет один слой CNN с 4 ядрами и один слой LSTM с 16 единицами. Система B вовсе не имеет слоев CNN, но два слоя LSTM (32 и 16 единиц). Система C имеет два слоя CNN (по 4 ядра фильтра на слой) и не имеет слоев LSTM. Здесь показано, что слои LSTM оказывают наибольшее влияние на производительность. Система без слоев LSTM работает гораздо хуже, чем система со слоем LSTM. Влияние сверточного слоя на производительность меньше - система без сверточного слоя работает лишь на 0,5 дБ хуже, чем наилучшая система.
На фиг. 8b показано влияние объема обучающих данных на производительность. Малые обучающие наборы могут приводить к построению моделей, которые очень хорошо работают на обучающем наборе, но на неизвестных данных. Здесь показано, что обучающего набора в 400 и более минут достаточно для создания модели почти без переобучения. Конечно, это трудно распространить на модели с гораздо более высокой емкостью.
Таблица 1 оценивает различие в производительности обучающего и испытательного набора, причем один кодируется с помощью AMR-NB, и другой не кодируется. В левом столбце показана производительность DNN, обученной на речи, кодированной посредством AMR-NB, в правом столбце показана производительность DNN, обученной на некодированной речи. В верхней строке испытательный набор кодировался с помощью AMR-NB, в нижней строке испытательный набор не кодировался. Очевидно DNN, обученная на речи, кодированной посредством AMR-NB, работает лучше, когда система применяется к некодированной речи, чем наоборот. Кроме того, AMR-NB снижает производительность почти на 0,5 дБ.
В вышеприведенной таблице показана производительность DNN, обучаемой речью, кодированной посредством AMR-NB (левый столбец) или некодированной речью (правый столбец), оцененная на испытательных наборах, кодированных посредством AMR-NB (верхняя строка) или не кодированных (нижняя строка). Производительность показана как логарифмическое спектральное искажение (LSD).
На фиг. 8c показаны результаты испытания прослушиванием ACR, отображаемые как значения MOS с интервалами доверительности 95%. Испытуемые кодеки указаны в направлении слева направо: 1) прямой широкополосный, 2) прямой узкополосный, 3-5) MNRU с шумом 10-30 дБ, 6) AMR-NB 7,4 кбит/с 7) AMR-NB 7,4 кбит/с со слепым расширением полосы 8) AMR-NB 7,4 кбит/с с oracle BWE 9) AMR-NB 12,2 кбит/с 10) AMR-NB 12,2 кбит/с с BBWE 10) AMR-NB 12,2 кбит/с с oracle BWE.
Наконец, представленную систему оценивали путем испытания прослушиванием тем же способом испытания, как в [4]. Испытание является испытанием оценкой по абсолютным категориям (ACR) [22], где стимул представляется слушателю без какой-либо ссылки. Слушатель ранжирует стимул по шкале от 1 до 5 (средняя экспертная оценка разборчивости речи, MOS). В испытании участвовали 29 неопытных слушателей, и материалом испытания были 30 записей женского и мужского голоса без фонового шума. Каждая запись содержит пару предложений и длительность 8 с. Каждое условие тестировалось 6 разными речевыми файлами от 3 женщин и 3 мужчин. До начала основного испытания, шесть речевых файлов, отличающиеся условиями обработки и дикторами, были представлены участникам, чтобы приучить их к диапазону уровней качества, с которыми им придется сталкиваться в ходе испытания.
Результаты испытания, представленные на фиг. 4, отображаются как средние значения MOS с интервалами доверительности 95%. Условие прямого WB достигало наивысших показателей 4,8 MOS, тогда как условие прямого NB достигало 2,8 MOS. Затем следуют эталонные блоки модулированного шума (MNRU) [23], которые представляют речь, ухудшенную модулированным шумом (дискретизированным с частотой 16 кГц). Они выступают в роли точки отсчета качества и производят тест, сравнимый с другими тестами. Наконец, результаты AMR-NB, AMR-NB с представленным слепым расширением полосы и AMR-NB с расширением полосы oracle показаны на двух разных битовых скоростях - 7,4 кбит/с и 12,2 кбит/с. Система oracle отличается от представленной системы путем масштабирования спектра для достижения энергии оригинала. Это делается путем замены оценки Lb DNN в уравнении 2 на , вычисленную на исходном WB спектре. Эта система является верхней границей качества, которой может достигать расширение полосы.
Результаты показывают, что представленное расширение полосы хорошо работает путем повышения качества AMR-NB на величину от 0,8 MOS (7 кбит/с) до 0,9 MOS (12,2 кбит/с). BBWE при 12,2 кбит/с также значительно лучше, чем условие прямого NB. Тем не менее, остается много возможностей для улучшения, как показывают результаты из oracle BWE.
Было представлено слепое расширение полосы, которое способно повышать качество AMR-NB на 0,8-0,9 MOS. Оно не добавляет дополнительную алгоритмическую задержку в AMR-NB. Сложность также является умеренной, что позволяет реализовать его на мобильных устройствах. Система может легко адаптироваться к разным базовым кодекам и переконфигурироваться на разные настройки полосы.
Достоинства некоторых вариантов осуществления предложенной системы таковы:
- отсутствие дополнительной алгоритмической задержки, если базовый кодер действует на кадрах 10 мс или более длинных
- структура DNN имеет низкую сложность
- комбинация сверточных и рекуррентных слоев или слоев TNC является хорошим предсказатель выпадающего сигнала. Таким образом, воспринимаемое качество системы повышается по сравнению со слепым расширением полосы, отвечающим уровню техники. Следует подчеркнуть, что другие структуры DNN, например, простые полностью соединенные слои, можно обучать для осуществления аналогичной, но не с такой низкой сложностью, как представленная система.
Хотя настоящее изобретение может применяться как полностью слепое расширение полосы для всех видов аудиоданных, например, речевые данные, музыкальные данные или общие аудиоданные, существуют другие варианты использования, которые особенно полезны.
Одним полезным применением является система для обработки аудиосигнала, показанная на фиг. 14. Система, показанная на фиг. 14, содержит базовый аудиодекодер 140 для декодирования базового аудиосигнала, организованного в кадры, причем базовый аудиодекодер выполнен с возможностью обнаружения ошибочной ситуации, указывающей потерю кадра или ошибочный кадр.
Кроме того, базовый аудиодекодер выполнен с возможностью осуществления операции маскирования ошибок для получения замещающего кадра для ошибочной ситуации. Кроме того, система на фиг. 14 содержит расширитель полосы, например, проиллюстрированный со ссылкой на фиг. 1 и обозначенный ссылочной позицией 100. Затем расширитель полосы генерирует замещающий кадр с расширением полосы из типичного кадра нижней полосы или кадр с некоторыми пробелами, обеспеченными в качестве замещающего кадра из базового аудиодекодера 140. Таким образом, система, представленная на фиг. 14, является расширением до аудиодекодера в ситуации, когда слепое расширение полосы осуществляется только для ситуации маскирования, т.е. при возникновении потери кадра или ошибочного кадра. При этом аудиокодек может иметь неслепое расширение полосы или вовсе не иметь расширения полосы или обработки расширения полосы, и представленная система проходит или предсказывает часть сигнала, выпадающую вследствие потери кадра, или весь выпадающий сигнал. Таким образом, базовый аудиодекодер, например, будет выполнен с возможностью осуществления кадра, только для базовой полосы, которая являются замещающим кадром, и затем слепой расширитель полосы расширяет замещающий кадр, генерируемый для ситуации потери кадра.
Дополнительный вариант осуществления настоящего изобретения проиллюстрирован на фиг. 15a и 15b. В этом варианте использования, расширитель 100 полосы используется не только для операции полностью слепое расширение полосы, но для составного элемента операции неслепого расширения полосы. В этой ситуации, грубое описание параметрического представления используется как первое приближение, и это первое приближение далее уточняется посредством того или иного вида дельта-квантования. Таким образом, система для обработки аудиосигнала, представленная на фиг. 15a, содержит входной интерфейс 150 для приема входного аудиосигнала и параметрической вспомогательной информации для частотного диапазона расширения. Кроме того, расширитель 100 полосы выполнен с возможностью приема, в частности, в отношении процессора 20 первичного сигнала на фиг. 1, для использования параметрической вспомогательной информации, выводимой входным интерфейсом 150 помимо параметрического представления, обеспеченного процессором 30 нейронной сети на фиг. 1, для генерации аудиосигнала с расширенной полосой.
На фиг. 15b представлена предпочтительная реализация, демонстрирующая процессор 20 первичного сигнала, принимающий, на своем параметрическом входе, параметрическое представление или параметры 70. Помимо того, что было рассмотрено прежде в отношении процессора 20 первичного сигнала, процессор первичного сигнала дополнительно содержит, в этой реализации, увеличитель/уменьшитель 160 параметров. Этот увеличитель/уменьшитель 160 параметров принимает, на своем входе, параметрическую вспомогательную информацию, например, вспомогательную информацию с очень низкой битовой скоростью, состоящую, например, только из одного бита на параметр. Затем увеличитель/уменьшитель 160 параметров применяет соответствующий бит к параметру параметрического представления 17 для генерации обновленного параметра, например, 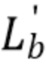 , и затем этот обновленный параметр, используемый с элементами обработки первичного сигнала, например, элементами 25-29, представленными на фиг. 6, вместо “исходного” параметра, принимаемого от процессора 30 нейронной сети. В зависимости от реализации, бит, принимаемый для каждого параметра, интерпретируется увеличителем/уменьшителем 160 параметров следующим образом. Когда бит имеет первое значение, параметр, принимаемый от процессора нейронной сети, увеличивается на некоторую величину, и когда бит имеет другое значение, увеличение не применяется. Альтернативно, блок 160 осуществляет операцию уменьшения параметра на заранее заданную величину, когда бит имеет первое значение и не осуществляет никакого изменения параметра, когда бит имеет второе значение. В альтернативном варианте осуществления, первое значение бита интерпретируется для осуществления увеличения на заранее заданную величину и для осуществления операции уменьшения на некоторую заранее заданную величину, когда бит находится в другом состоянии.
, и затем этот обновленный параметр, используемый с элементами обработки первичного сигнала, например, элементами 25-29, представленными на фиг. 6, вместо “исходного” параметра, принимаемого от процессора 30 нейронной сети. В зависимости от реализации, бит, принимаемый для каждого параметра, интерпретируется увеличителем/уменьшителем 160 параметров следующим образом. Когда бит имеет первое значение, параметр, принимаемый от процессора нейронной сети, увеличивается на некоторую величину, и когда бит имеет другое значение, увеличение не применяется. Альтернативно, блок 160 осуществляет операцию уменьшения параметра на заранее заданную величину, когда бит имеет первое значение и не осуществляет никакого изменения параметра, когда бит имеет второе значение. В альтернативном варианте осуществления, первое значение бита интерпретируется для осуществления увеличения на заранее заданную величину и для осуществления операции уменьшения на некоторую заранее заданную величину, когда бит находится в другом состоянии.
Другие процедуры могут осуществляться, например, с двумя или более битами вспомогательной информации для каждого параметра, что позволяет сигнализировать, например, дополнительные приращения или некоторые значения приращения. Однако в этом варианте осуществления, предпочтительно использовать единый бит для некоторой группы параметров в параметрическом представлении или всех параметров в параметрическом представлении или для использования, максимум, только двух таких битов на параметр для поддержания низкой битовой скорости.
Для вычисления бита, та же обученная нейронная сеть действует на стороне кодера и, на стороне кодера, параметрическое представление вычисляется из нейронной сети таким же образом, как на стороне декодера, после чего на кодере производится определение, приводит ли увеличение или уменьшение или отсутствие изменения параметрического представления к значению параметра, которое имеет, в итоге, более низкую ошибку декодированного сигнала по отношению к исходному сигналу.
Хотя это изобретение описано в отношении некоторых вариантов осуществления, возможны изменения, перестановки и эквиваленты, укладывающиеся в объем этого изобретения. Следует также заметить, что возможны многие альтернативные пути осуществления способов и составов настоящего изобретения. Таким образом предполагается, что нижеследующая формула изобретения может включать в себя все такие изменения, перестановки и эквиваленты, укладывающиеся в истинную сущность и объем настоящего изобретения.
Хотя некоторые аспекты были описаны применительно к устройству, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные применительно к этапу способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут выполняться аппаратным устройством (или с его помощью), например, микропроцессором, программируемым компьютером или электронной схемой. В некоторых вариантах осуществления, некоторые один или более из наиболее важных этапов способа могут выполняться таким устройством.
Кодированный сигнал изображения, отвечающий изобретению, может храниться на цифровом носителе данных или может передаваться по среде передачи, например, беспроводной среде передачи или проводной среде передачи, например, интернету.
В зависимости от некоторых требований реализации, варианты осуществления изобретения можно реализовать аппаратными средствами или программными средствами. Реализация может осуществляться с использованием цифрового носителя данных, например, флоппи-диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флеш-памяти, где хранятся электронно считываемые сигналы управления, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой для осуществления соответствующего способа. Таким образом, цифровой носитель данных может быть компьютерно-считываемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой, для осуществления одного из описанных здесь способов.
В общем случае, варианты осуществления настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, причем программный код способен осуществлять один из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из описанных здесь способов, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа, отвечающего изобретению, таким образом, предусматривает компьютерную программу, имеющую программный код для осуществления одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов, отвечающих изобретению, таким образом, является носителем данных (или цифровым носителем данных или компьютерно-считываемым носителем), на котором записан компьютерная программа для осуществления одного из описанных здесь способов. Носитель данных, цифровой носитель данных или носитель записи обычно являются материальным и/или нетранзиторным.
Дополнительный вариант осуществления способа, отвечающего изобретению, таким образом, предусматривает поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из описанных здесь способов. Поток данных или последовательность сигналов может, например, переноситься через соединение для передачи данных, например, через интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер, или программируемое логическое устройство, выполненное с возможностью или приспособленное для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления содержит компьютер, на котором установлена компьютерная программа для осуществления одного из описанных здесь способов.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему для переноса (например, электронного или оптического) компьютерной программы для осуществления одного из описанных здесь способов на приемник. Приемником может быть, например, компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система может содержать, например, файловый сервер для переноса компьютерной программы на приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, вентильная матрица, программируемая пользователем) может использоваться для осуществления некоторых или всех из функциональных возможностей описанных здесь способов. В некоторых вариантах осуществления, вентильная матрица, программируемая пользователем, может взаимодействовать с микропроцессором для осуществления одного из описанных здесь способов. В общем случае, способы предпочтительно осуществляются любым аппаратным устройством.
Описанное здесь устройство можно реализовать с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Описанные здесь способы могут осуществляться с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
ССЫЛКИ
[1] Patrick Bauer, Rosa-Linde Fischer, Martina Bellanova, Henning Puder, and Tim Fingscheidt, “On improving telephone speech intelligibility for hearing impaired persons,” in Proceedings of the 10. ITG Conference on Speech Communication, Braunschweig, Germany, September 26-28, 2012, 2012, pp. 1-4
[2] Patrick Bauer, Jennifer Jones, and Tim Fingscheidt, “Impact of hearing impairment on fricative intelligibility for artificially bandwidth-extended telephone speech in noise,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2013, Vancouver, BC, Canada, May 26-31, 2013, pp. 7039-7043.
[3] Stefan Bruhn, Harald Pobloth, Markus Schnell, Bernhard Grill, Jon Gibbs, Lei Miao, Kari Jaervinen, Lasse Laaksonen, Noboru Harada, N. Naka, Stephane Ragot, Stephane Proust, T. Sanda, Imre Varga, C. Greer, Milan Jelinek, M. Xie, and Paolo Usai, “Standardization of the new 3GPP EVS codec,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, 2015, pp. 5703-5707.
[4] Johannes Abel, Magdalena Kaniewska, Cyril Guillaume, Wouter Tirry, Hannu Pulakka, Ville Myllylae, Jari Sjoberg, Paavo Alku, Itai Katsir, David Malah, Israel Cohen, M. A. Tugtekin Turan, Engin Erzin, Thomas Schlien, Peter Vary, Amr H. Nour-Eldin, Peter Kabal, and Tim Fingscheidt, “A subjective listening test of six different artificial bandwidth extension approaches in English, Chinese, German, and Korean,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2016, Shanghai, China, March 20-25, 2016, 2016, pp. 5915-5919.
[5] Peter Jax and Peter Vary, “Wideband extension of telephone speech using a hidden markov model,” in 2000 IEEE Workshop on Speech Coding. Proceedings., 2000, pp. 133-135.
[6] Patrick Bauer, Johannes Abel, and Tim Fingscheidt, “Hmm-based artificial bandwidth extension supported by neural networks,” in 14th International Workshop on Acoustic Signal Enhancement, IWAENC 2014, Juan-les-Pins, France, September 8-11, 2014, 2014, pp. 1-5.
[7] Hannu Pulakka and Paavo Alku, “Bandwidth extension of telephone speech using a neural network and a filter bank implementation for highband mel spectrum,” IEEE Trans. Audio, Speech & Language Processing, vol. 19, no. 7, pp. 2170-2183, 2011.
[8] Kehuang Li and Chin-Hui Lee, “A deep neural network approach to speech bandwidth expansion,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, 2015, pp. 4395-4399.
[9] Yu Gu, Zhen-Hua Ling, and Li-Rong Dai, “Speech bandwidth extension using bottleneck features and deep recurrent neural networks,” in Interspeech 2016, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, September 8-12, 2016, 2016, pp. 297-301.
[10] Yu Gu and Zhen-Hua Ling, “Waveform modeling using stacked dilated convolutional neural networks for speech bandwidth extension,” in Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, August 20-24, 2017, 2017, pp. 1123-1127.
[11] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu, “Wavenet: A generative model for raw audio,” in The 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13-15 September 2016, 2016, p. 125.
[12] Sascha Disch, Andreas Niedermeier, Christian R. Helmrich, Christian Neukam, Konstantin Schmidt, Ralf Geiger, Jeremie Lecomte, Florin Ghido, Frederik Nagel, and Bernd Edler, “Intelligent gap filling in perceptual transform coding of audio,” in Audio Engineering Society Convention 141, Los Angeles, Sep 2016.
[13] Martin Dietz, Lars Liljeryd, Kristofer Kjorling, and Oliver Kunz, “Spectral band replication, a novel approach in audio coding,” in Audio Engineering Society Convention 112, Apr 2002.
[14] Konstantin Schmidt and Christian Neukam, “Low complexity tonality control in the intelligent gap filling tool,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2016, Shanghai, China, March 20-25, 2016, 2016, pp. 644-648.
[15] Hugo Fastl and Eberhard Zwicker, Psychoacoustics: Facts and Models, Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2006.
[16] Yann Lecun, Leon Bottou, Yoshua Bengio, and Patrick Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278- 2324, Nov 1998.
[17] Sepp Hochreiter and Juergen Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735-1780, 1997.
[18] Junyoung Chung, Caglar Guelcehre, KyungHyun Cho, and Yoshua Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” NIPS Deep Learning workshop, Montreal, Canada, 2014.
[19] John C. Duchi, Elad Hazan, and Yoram Singer, “Adaptive subgradient methods for online learning and stochastic optimization,” in COLT 2010 - The 23rd Conference on Learning Theory, Haifa, Israel, June 27-29, 2010, 2010, pp. 257-269.
[20] Francois Chollet et al., “Keras 1,2.2,” https://github. com/fchollet/keras, 2015.
[21] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, 2015, pp. 5206-5210.
[22] ITU-T, “ITU-T recommendation P.800. methods for objective and subjective assessment of quality,” 1996.
[23] ITU-T, “ITU-T recommendation P.810. modulated noise reference unit (MNRU),” 1996.
| название | год | авторы | номер документа |
|---|---|---|---|
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |
| МОДУЛЬ ОЦЕНКИ ПОДОБИЯ АУДИОСИГНАЛОВ, АУДИОКОДЕР, СПОСОБЫ И КОМПЬЮТЕРНАЯ ПРОГРАММА | 2019 |
|
RU2782981C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ ГЛУБОКОГО ФИЛЬТРА | 2020 |
|
RU2788939C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| УСТРОЙСТВО ДЛЯ РАСШИРЕНИЯ ПОЛОСЫ ЧАСТОТ | 2010 |
|
RU2552184C2 |
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| РЕШЕНИЕ ОТНОСИТЕЛЬНО НАЛИЧИЯ/ОТСУТСТВИЯ ВОКАЛИЗАЦИИ ДЛЯ ОБРАБОТКИ РЕЧИ | 2014 |
|
RU2636685C2 |
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ПАКЕТИРОВАНИЯ ЗАПРОСОВ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ ОБРАБОТКИ ОБРАБАТЫВАЮЩИМ БЛОКОМ | 2021 |
|
RU2810916C2 |
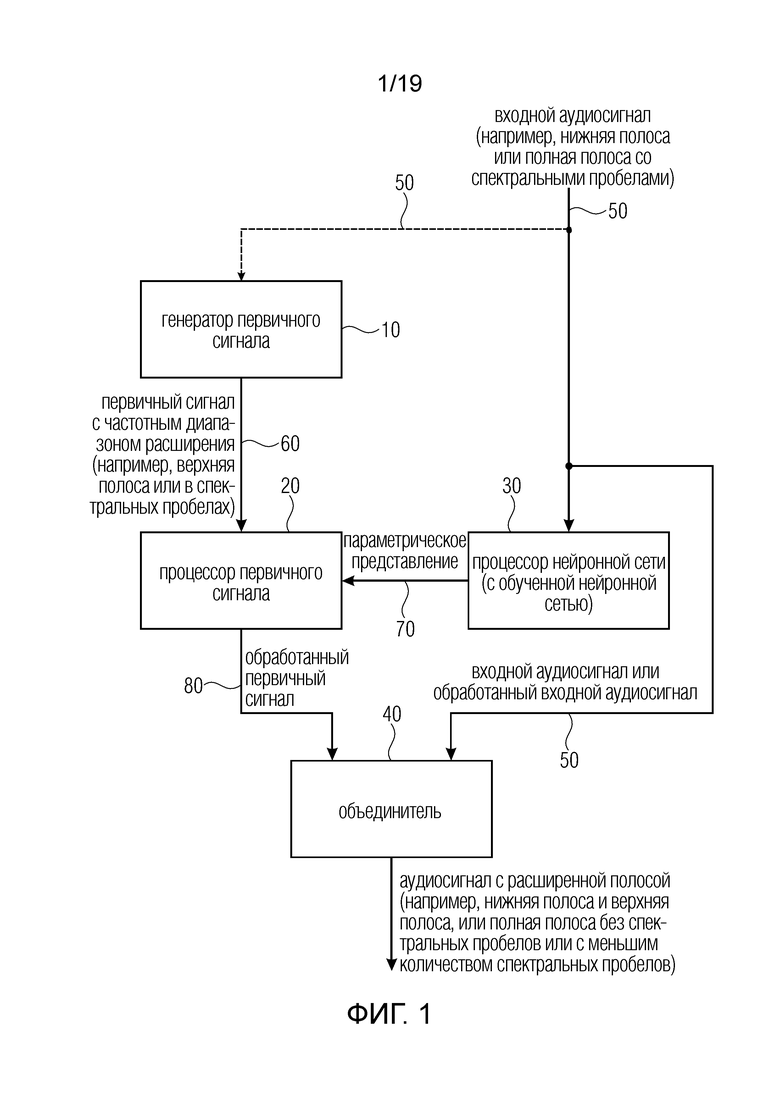
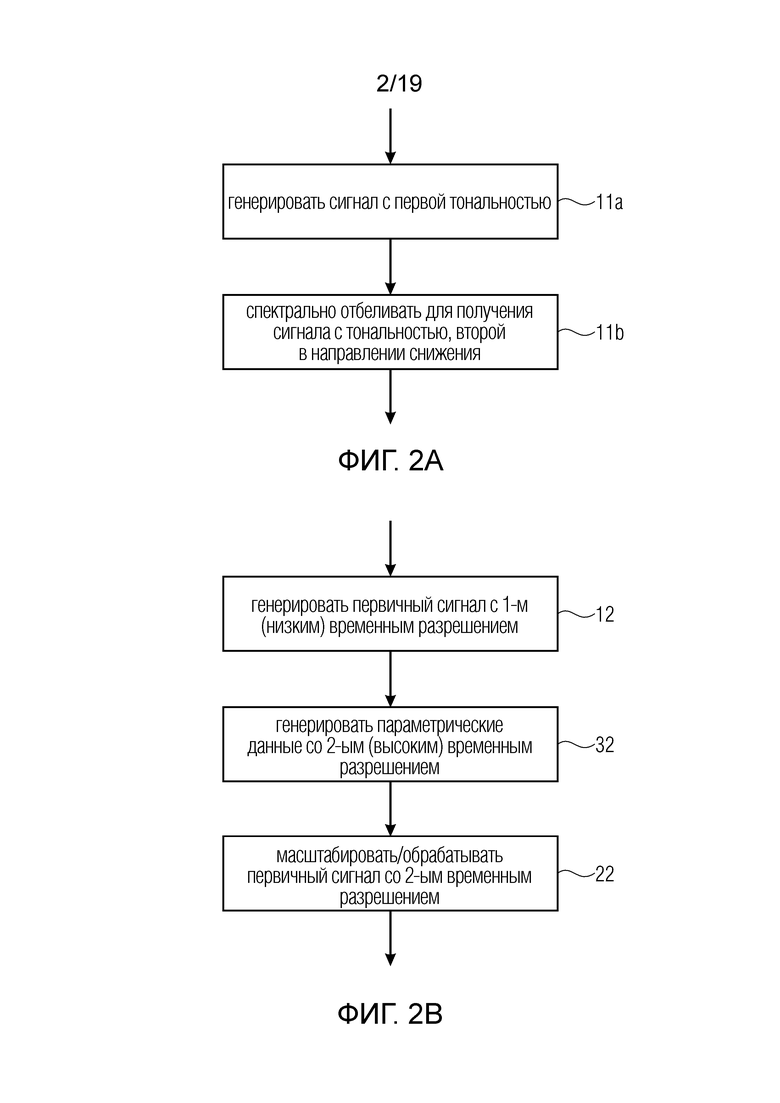
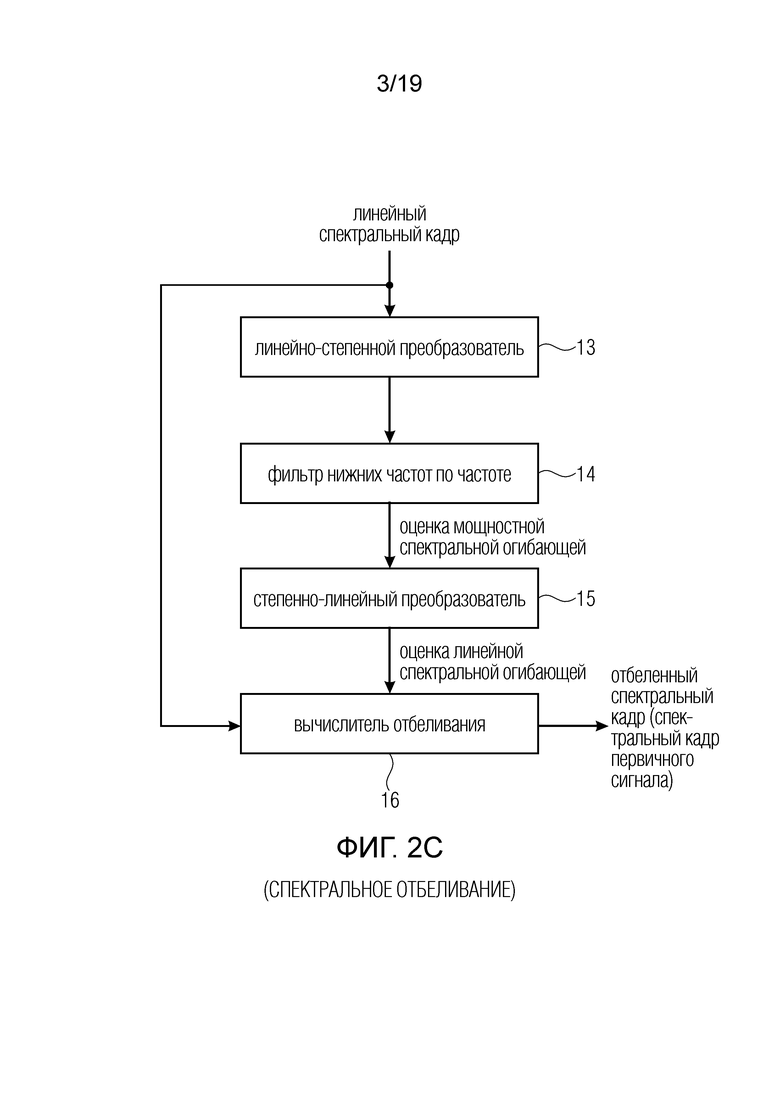

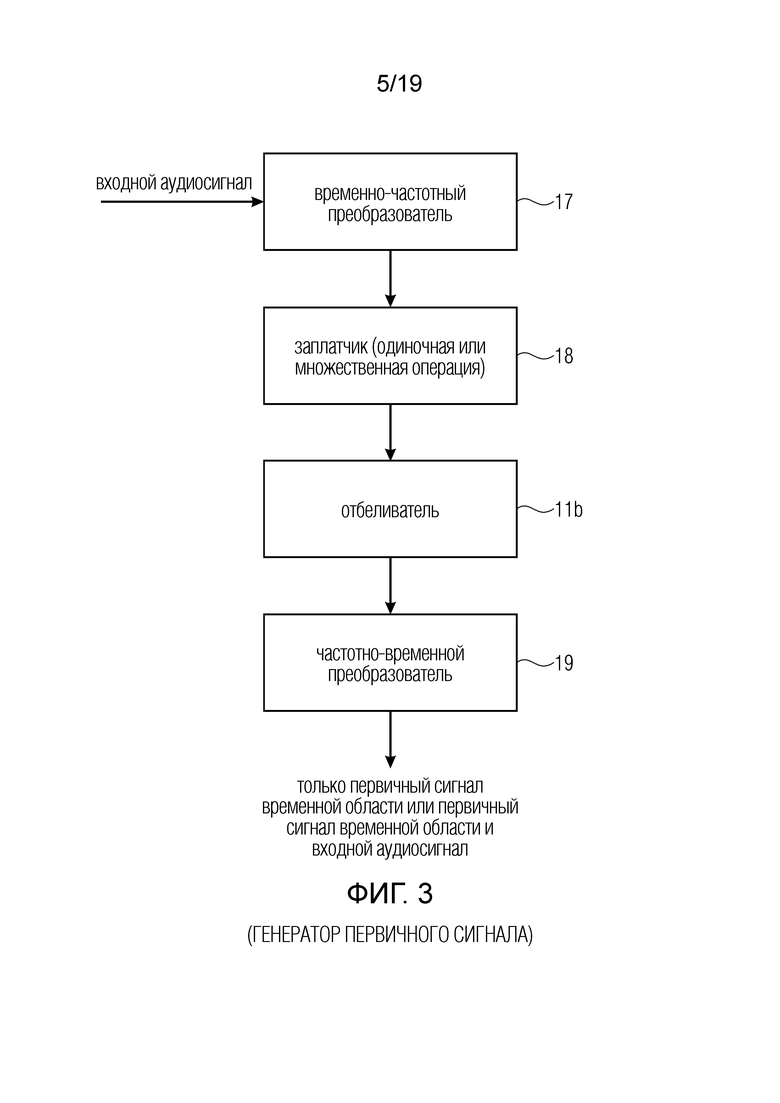
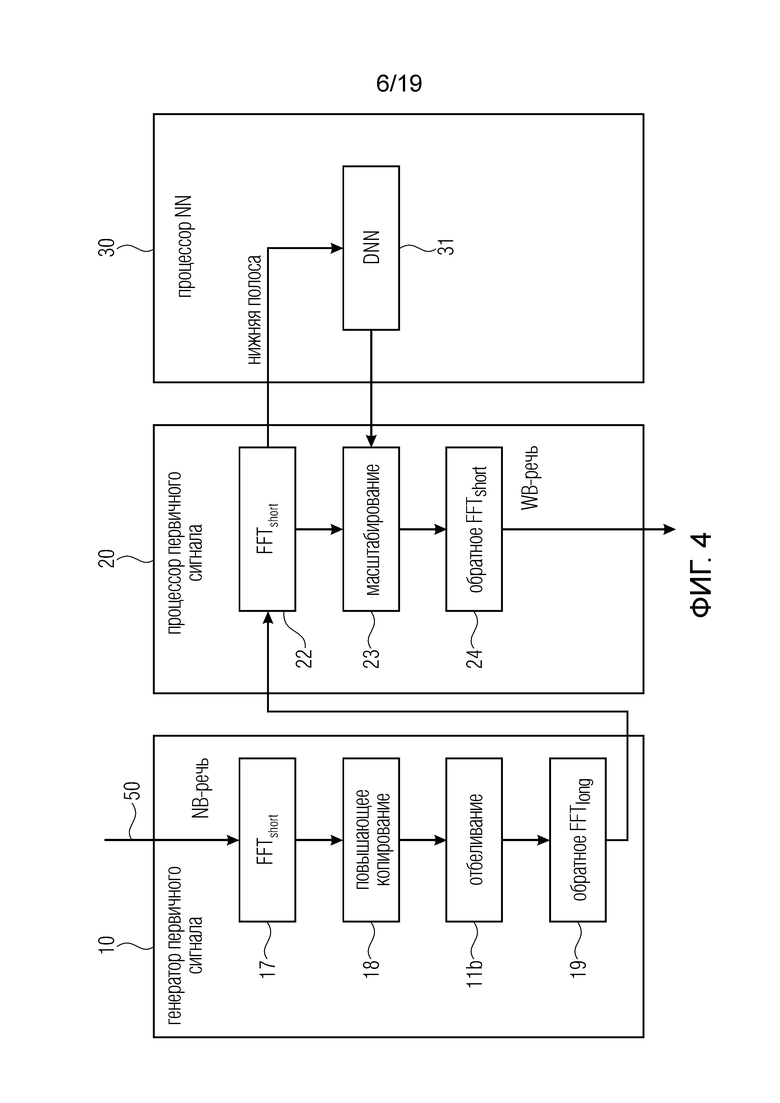
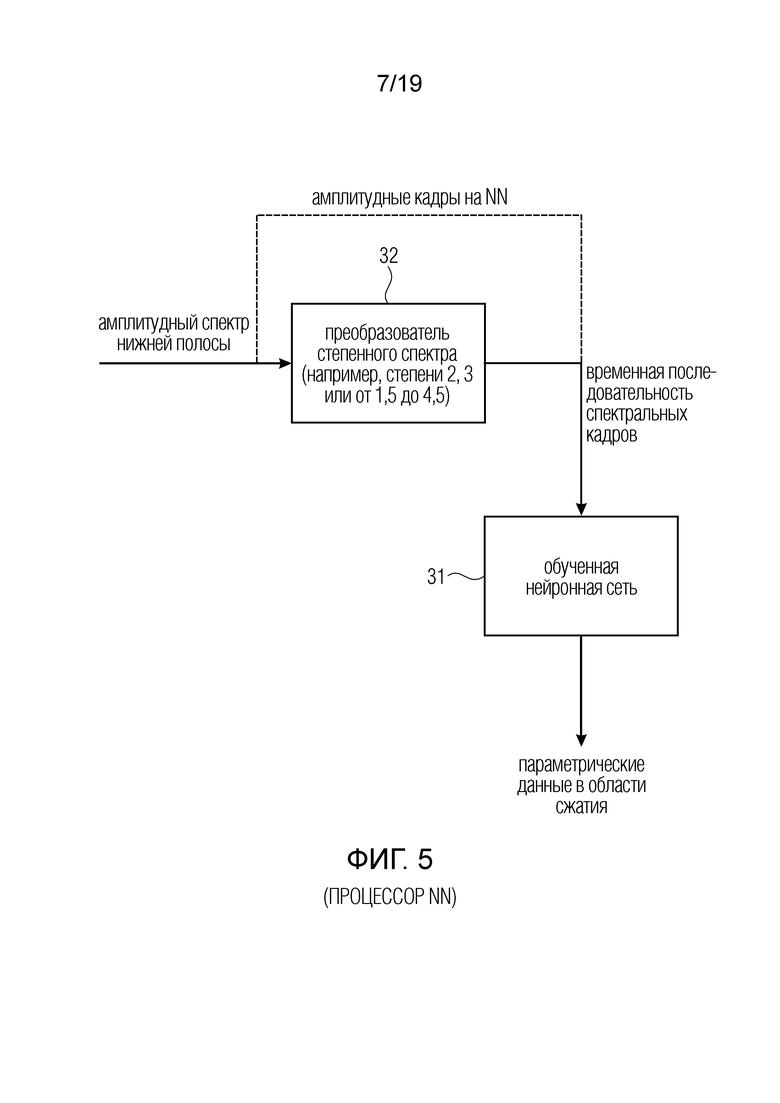
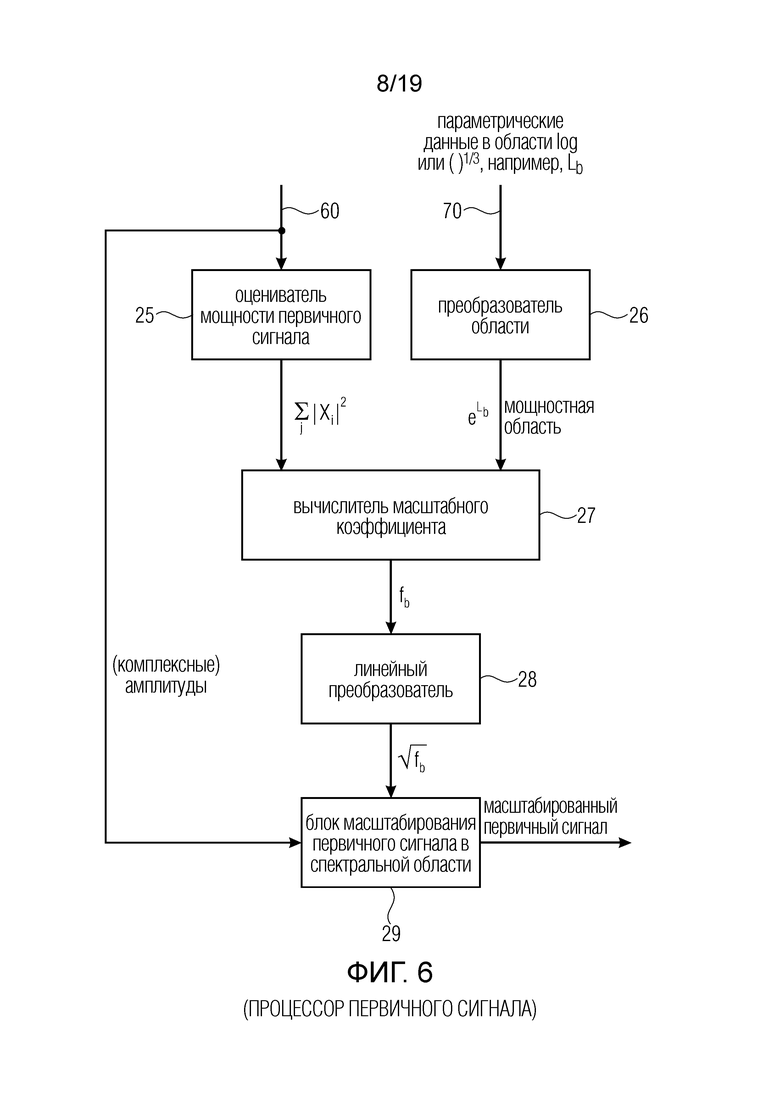
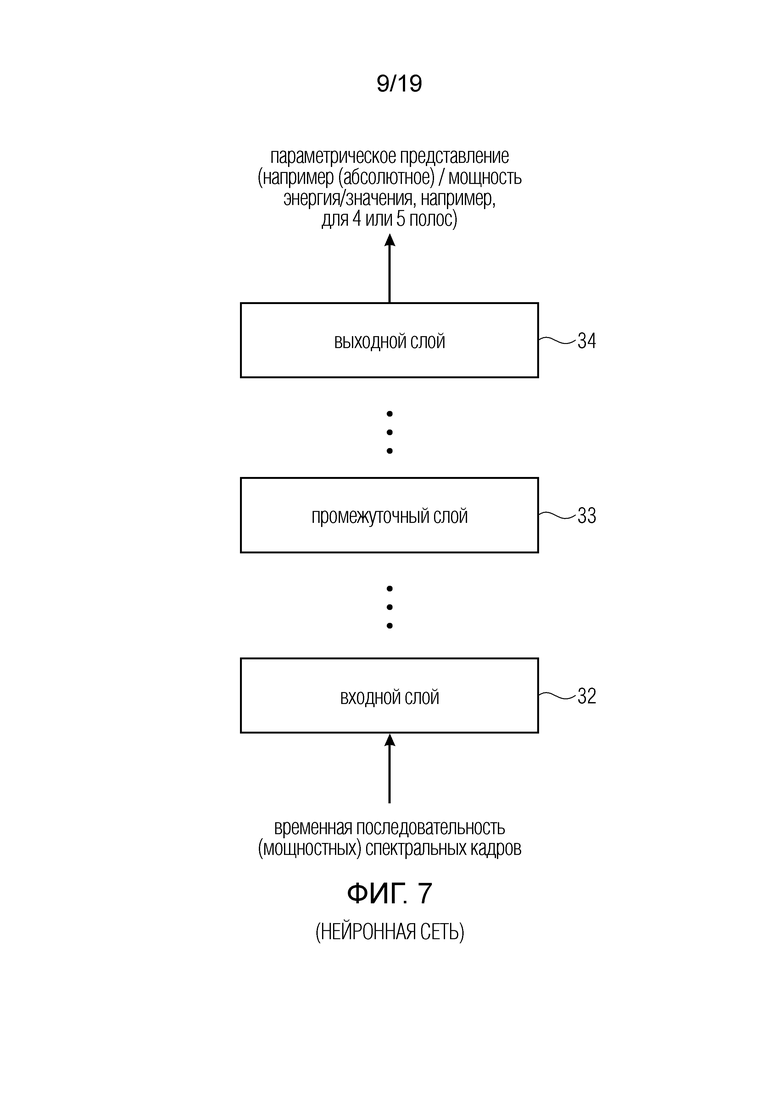
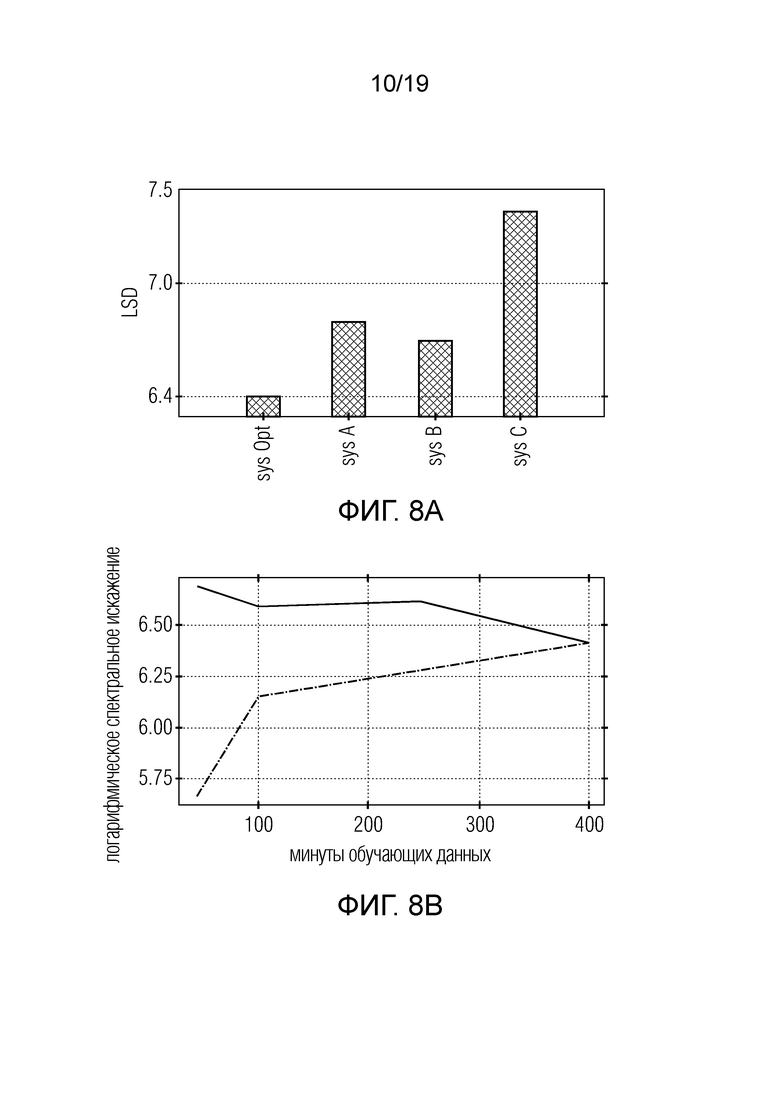
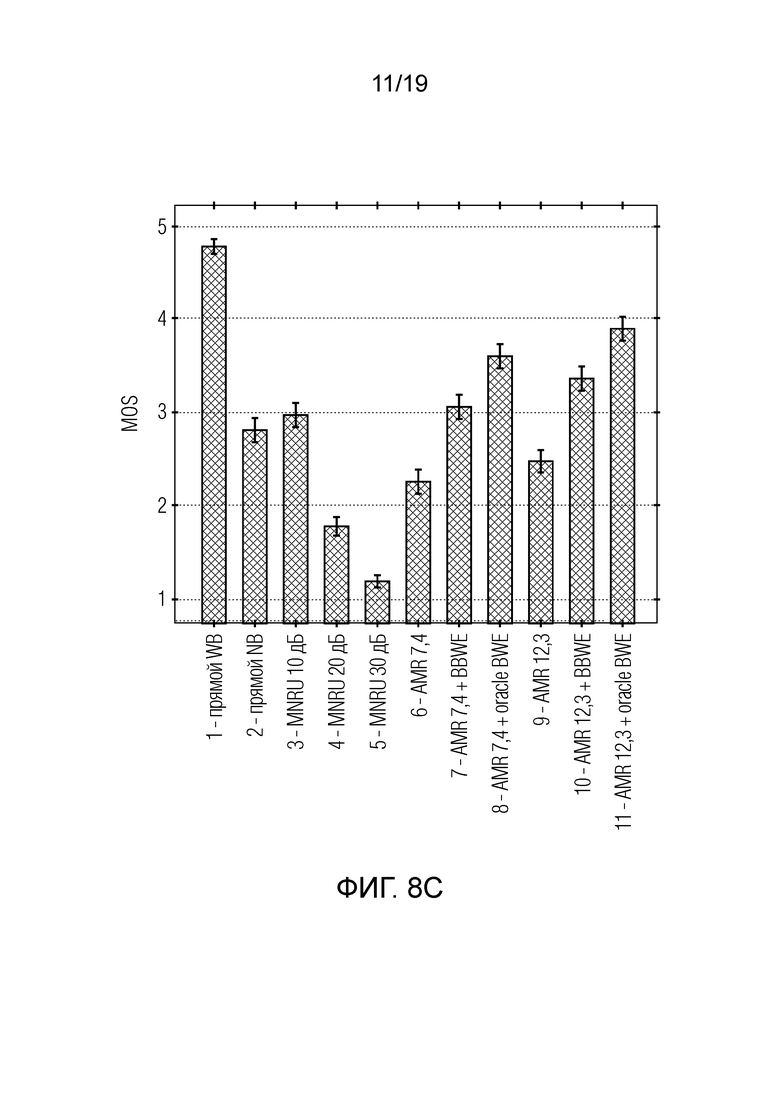
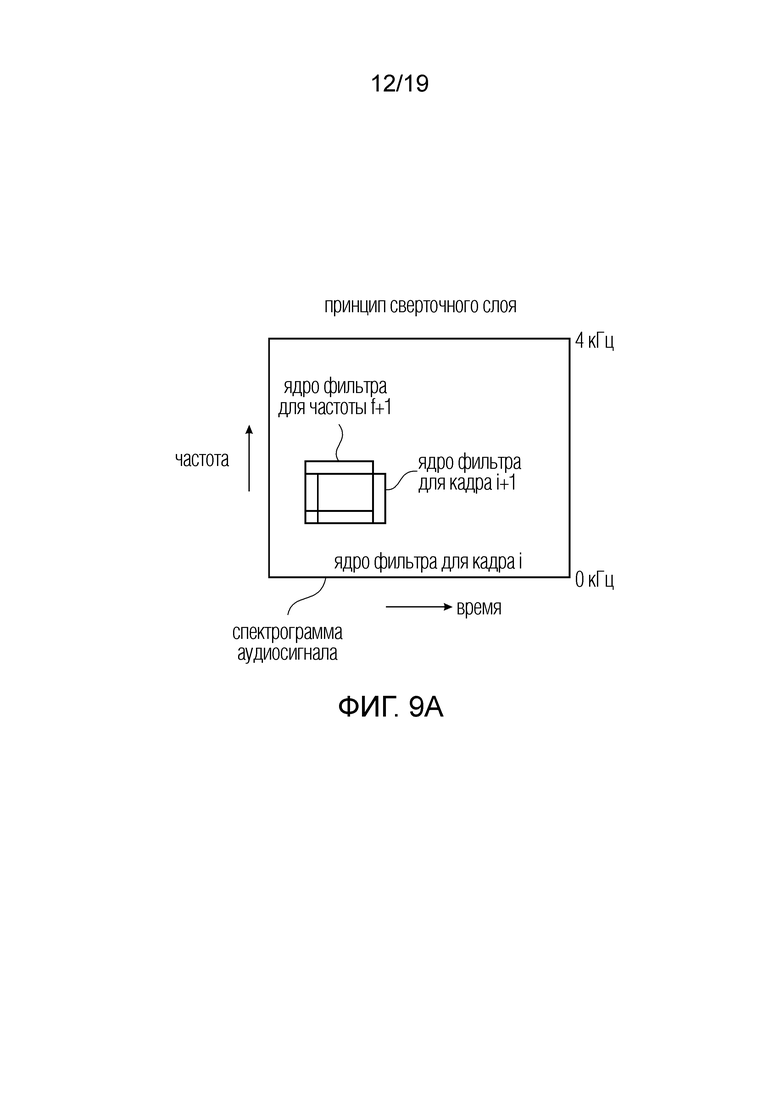
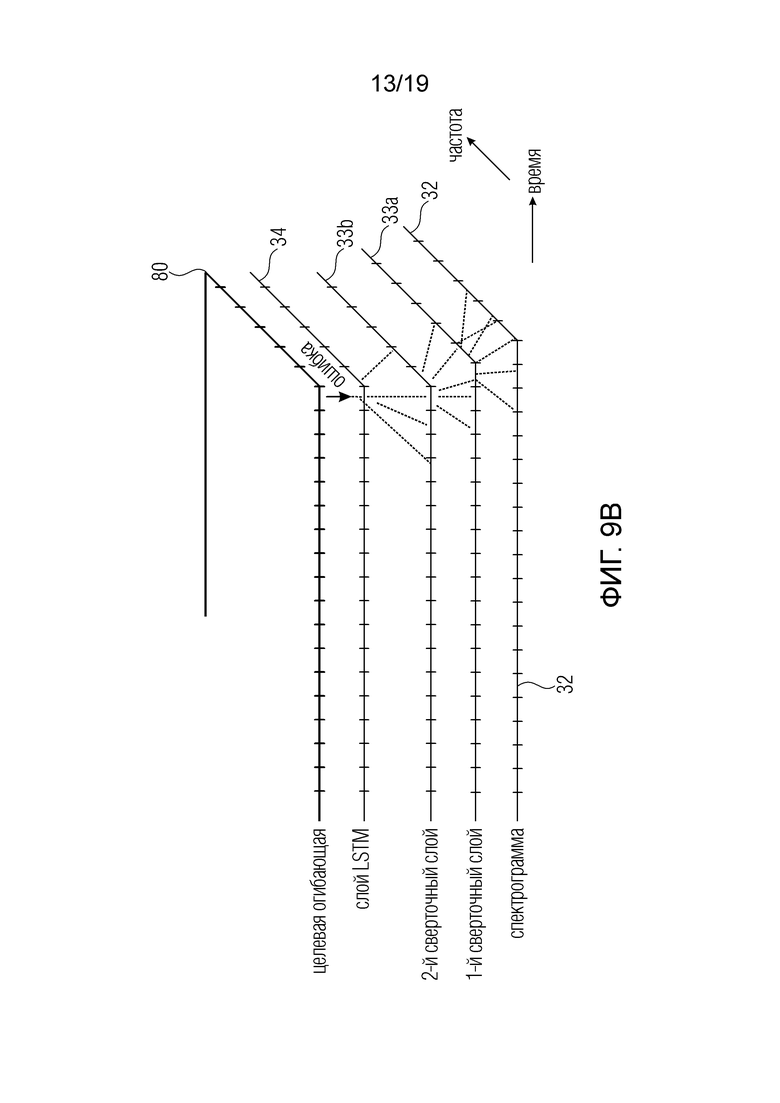

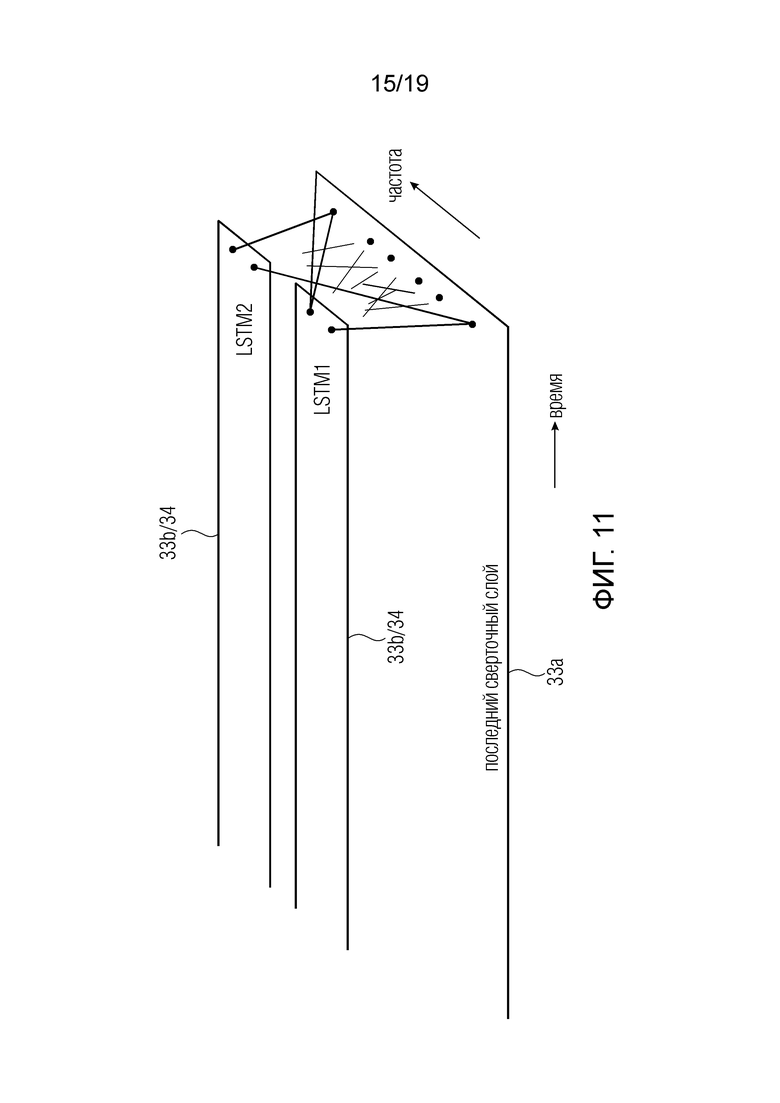


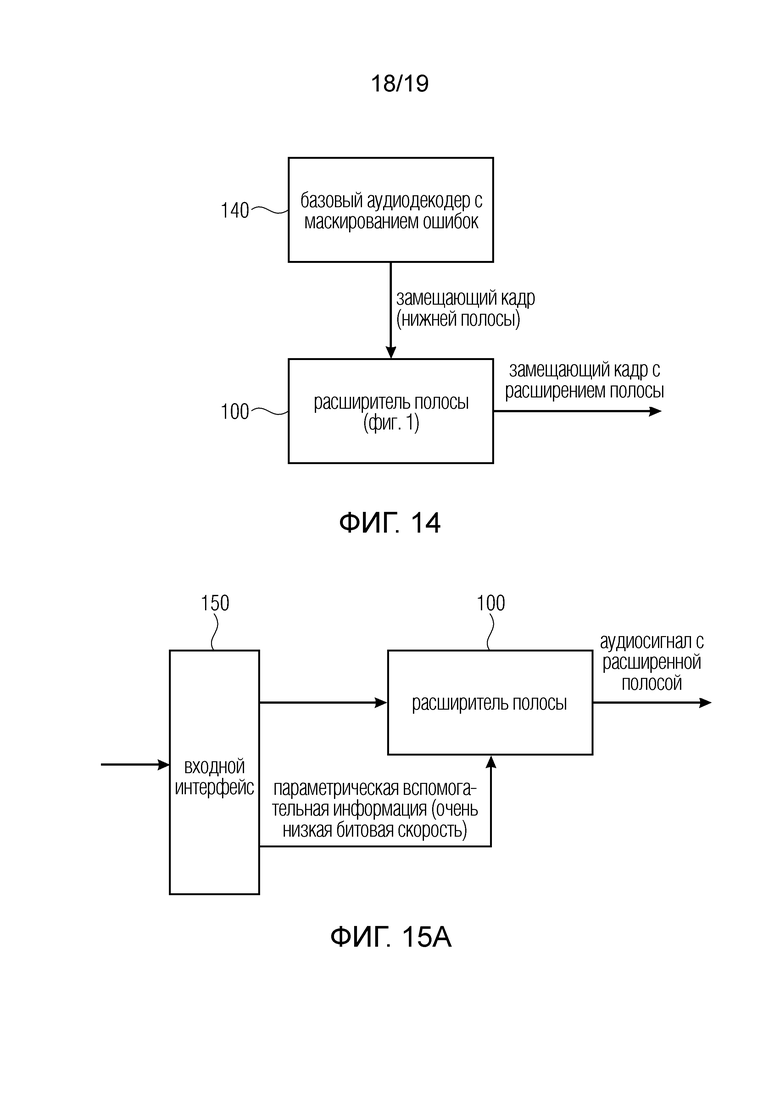

Изобретение относится к области вычислительной техники для обработки аудиосигналов. Технический результат заключается в обеспечение принципа улучшенной генерации аудиосигнала с расширенной полосой. Технический результат достигается за счет генерирования первичного сигнала, имеющего частотный диапазон расширения, причем частотный диапазон расширения не включен в частотный диапазон входного аудиосигнала; генерирования параметрического представления для частотного диапазона расширения с использованием частотного диапазона входного аудиосигнала и обученной нейронной сети; и обработки первичного сигнала с использованием параметрического представления для частотного диапазона расширения для получения обработанного первичного сигнала, имеющего частотные составляющие в частотном диапазоне расширения. 9 н. и 25 з.п. ф-лы, 23 ил.
1. Устройство для генерации аудиосигнала с расширенной полосой из входного аудиосигнала (50), имеющего частотный диапазон входного аудиосигнала, содержащее:
генератор (10) первичного сигнала, выполненный с возможностью генерации первичного сигнала (60), имеющего частотный диапазон расширения, причем частотный диапазон расширения не включен в частотный диапазон входного аудиосигнала;
процессор (30) нейронной сети, выполненный с возможностью генерации параметрического представления (70) для частотного диапазона расширения с использованием частотного диапазона входного аудиосигнала и обученной нейронной сети (31); и
процессор (20) первичного сигнала для обработки первичного сигнала (60) с использованием параметрического представления (70) для частотного диапазона расширения для получения обработанного первичного сигнала (80), имеющего частотные составляющие в частотном диапазоне расширения,
причем обработанный первичный сигнал (80) или обработанный первичный сигнал и частотный диапазон входного аудиосигнала представляют аудиосигнал с расширенной полосой.
2. Устройство по п. 1, в котором генератор (10) первичного сигнала выполнен с возможностью
генерации (11a) начального первичного сигнала, имеющего первую тональность; и
спектрального отбеливания (11b) начального первичного сигнала для получения первичного сигнала, причем первичный сигнал имеет вторую тональность, причем вторая тональность ниже, чем первая тональность.
3. Устройство по п. 1,
в котором генератор (10) первичного сигнала выполнен с возможностью осуществления спектрального отбеливания начального первичного сигнала с использованием первого временного разрешения (12) или генерации первичного сигнала (60) с использованием первого временного разрешения, или генератор (10) первичного сигнала выполнен с возможностью осуществления спектрального отбеливания начального первичного сигнала с использованием первого частотного разрешения (12) или генерации первичного сигнала (60) с использованием первого частотного разрешения, и
причем процессор (30) нейронной сети выполнен с возможностью генерации (32) параметрического представления со вторым временным разрешением, причем второе временное разрешение выше, чем первое временное разрешение, или причем процессор (30) нейронной сети выполнен с возможностью генерации (32) параметрического представления со вторым частотным разрешением, причем второе частотное разрешение ниже, чем первое частотное разрешение, и
причем процессор (20) первичного сигнала выполнен с возможностью использования (22) параметрического представления со вторым временным разрешением или частотным разрешением для обработки первичного сигнала для получения обработанного первичного сигнала (80).
4. Устройство по п. 1,
в котором генератор (10) первичного сигнала содержит заплатчик (18) для постановки заплатки в виде спектрального участка входного аудиосигнала на частотный диапазон расширения, причем постановка заплатки содержит операцию одной постановки заплатки или операцию постановки нескольких заплаток, причем, в операции постановки нескольких заплаток, конкретный спектральный участок входного аудиосигнала ставится в виде заплатки на два или более спектральных участков частотного диапазона расширения.
5. Устройство по п. 1,
в котором процессор (20) первичного сигнала содержит временно-частотный преобразователь (17) для преобразования входного сигнала в спектральное представление, причем спектральное представление содержит временную последовательность спектральных кадров, и спектральный кадр имеет спектральные значения,
причем процессор (30) нейронной сети выполнен с возможностью подачи спектральных кадров в обученную нейронную сеть (31) или обработки (32) спектральных кадров для получения обработанных спектральных кадров, в которых спектральные значения преобразуются в степенную область, приобретая показатель от 1,5 до 4,5 и, предпочтительно, показатель 2 или 3, и
нейронная сеть (31) выполнена с возможностью вывода параметрического представления в степенной области, и
процессор (20) первичного сигнала выполнен с возможностью преобразования (26) параметрического представления в линейную область и применения (27) параметрического представления в линейной области к временной последовательности спектральных кадров.
6. Устройство по п. 1,
причем процессор (30) нейронной сети выполнен с возможностью вывода параметрического представления (70) в логарифмическом представлении или сжатом представлении, с которых связан показатель степени ниже чем 0,9, и
причем процессор (20) первичного сигнала выполнен с возможностью преобразования (26) параметрического представления из логарифмического представления или сжатого представления в линейное представление.
7. Устройство по п. 1, в котором генератор (10) первичного сигнала содержит:
временно-частотный преобразователь (17) для преобразования входного аудиосигнала в последовательность спектральных кадров, причем спектральный кадр имеет последовательность значений;
заплатчик (18) для генерации сигнала с наложенной заплаткой для каждого спектрального кадра с использованием выходного сигнала временно-частотного преобразователя (17);
блок (11b) отбеливания для спектрального отбеливания сигнала с наложенной заплаткой для каждого спектрального кадра или для отбеливания соответствующего сигнала от временно-частотного преобразователя (17) до осуществления заплатчиком операции постановки заплатки; и
частотно-временной преобразователь (19) для преобразования последовательности кадров, содержащей снабженные заплатками и спектрально отбеленные кадры, во временную область для получения первичного сигнала (60), причем частотно-временной преобразователь выполнен с возможностью размещения частотного диапазона расширения.
8. Устройство по п. 1, в котором блок (11b) отбеливания в процессоре первичного сигнала содержит:
фильтр нижних частот для низкочастотной фильтрации (14) спектрального кадра или степенного представления (13) спектрального кадра для получения оценки огибающей для спектрального кадра; и
вычислитель для вычисления (16) отбеленного сигнала путем деления спектрального кадра на оценку огибающей, причем, при выводе огибающей из степенного представления, делитель вычисляет линейные весовые коэффициенты для спектральных значений (15) и делит спектральные значения на линейные весовые коэффициенты.
9. Устройство по п. 1,
в котором процессор (20) первичного сигнала содержит временно-частотный преобразователь (22) для преобразования входного аудиосигнала или сигнала, выведенного из входного аудиосигнала и первичного сигнала (60), в спектральное представление,
причем процессор (30) нейронной сети выполнен с возможностью приема спектрального представления частотного диапазона входного аудиосигнала,
процессор (20) первичного сигнала содержит спектральный процессор (23) для применения параметрического представления (70), обеспеченного процессором (30) нейронной сети в ответ на частотный диапазон спектрального представления входного аудиосигнала, к спектральному представлению первичного сигнала (60); и
процессор (20) первичного сигнала дополнительно содержит частотно-временной преобразователь (24) для преобразования обработанного спектрального представления первичного сигнала во временную область,
причем устройство выполнено с возможностью осуществления комбинации обработанного первичного сигнала и частотного диапазона входного аудиосигнала путем подачи обработанного спектрального представления и спектрального представления частотного диапазона входного аудиосигнала на частотно-временной преобразователь (24) или путем объединения временного представления частотного диапазона входного аудиосигнала и временного представления обработанного первичного сигнала (80) во временной области.
10. Устройство по п. 1,
в котором процессор (30) нейронной сети содержит нейронную сеть (31) с входным слоем (32) и выходным слоем (34), причем процессор нейронной сети выполнен с возможностью приема, на входном слое, спектрограммы, выведенной из входного аудиосигнала, причем спектрограмма содержит временную последовательность спектральных кадров, причем спектральный кадр имеет несколько спектральных значений, и вывода, на выходном слое (34), индивидуальных параметров параметрического представления (70),
причем спектральные значения являются линейными спектральными значениями или степенными спектральными значениями, обработанными с использованием степенной функции с показателем от 1,5 до 4,5 или обработанных значений мощности, причем обработка содержит сжатие с использованием логарифмической функции или степенной функции с показателем, меньшим 1.
11. Устройство по п. 10, в котором входной слой (32) или один или более промежуточных слоев (33) сформирован как сверточный слой, содержащий одно или более ядер свертки, причем ядро свертки выполнено с возможностью осуществления сверточной обработки нескольких спектральных значений из по меньшей мере двух разных кадров во временной последовательности спектральных кадров.
12. Устройство по п. 11,
в котором ядро свертки выполнено с возможностью осуществления двухмерной сверточной обработки, предусматривающей первое количество спектральных значений в расчете на кадр и второе количество кадров во временной последовательности кадров, причем первое количество и второе количество равны по меньшей мере двум и ниже чем десять.
13. Устройство по п. 11,
в котором входной слой (32) или первый промежуточный слой (33) содержит по меньшей мере одно ядро, обрабатывающее спектральные значения, соседствующие по частоте и соседствующие по времени,
и нейронная сеть (31) дополнительно содержит промежуточный сверточный слой (33b), действующий на основании коэффициента расширения, благодаря чему, в отношении временного индекса, только каждый второй или каждый третий результат предыдущего слоя в стопке слоев принимается сверточным слоем в качестве ввода.
14. Устройство по п. 10,
в котором нейронная сеть содержит, в качестве выходного слоя (34), или помимо выходного слоя (34), рекуррентный слой, причем рекуррентный слой принимает выходной вектор сверточного слоя для временного индекса и выводит выходной вектор с использованием функции рекуррентного слоя, имеющей память.
15. Устройство по п. 14, в котором рекуррентный слой содержит функцию долгой краткосрочной памяти (LSTM) или содержит функцию управляемых рекуррентных блоков (GRU) или является функцией IIR-фильтра.
16. Устройство по п. 10,
в котором входной слой (32) или один или более промежуточных слоев (33) содержит, для вычисления, для каждого входного сигнала, выходной сигнал с использованием сверточной функции сверточного слоя, причем сверточный слой содержит остаточное соединение, благодаря чему, по меньшей мере группа выходных сигналов является линейной комбинацией выхода сверточной функции и входа в сверточную функцию.
17. Устройство по п. 10,
в котором выходной слой содержит один или более полностью соединенных слоев, причем полностью соединенный слой или наивысший полностью соединенный слой обеспечивает, на выходе, параметры параметрического представления в текущий период времени первичного сигнала и при этом один полностью соединенный слой выполнен с возможностью приема, на своем входе, выходных значений входного слоя или промежуточного слоя в текущий период времени.
18. Устройство по п. 10,
в котором входной слой (32) или промежуточный слой (33) является сверточным слоем, имеющим вектор выходных данных для каждого целочисленного временного индекса,
причем нейронная сеть (31) дополнительно содержит дополнительный сверточный слой, имеющий одно или более ядер для обработки расширенной свертки,
причем одно или более ядер для дополнительного сверточного слоя принимает по меньшей мере два вектора данных из входного слоя или промежуточного слоя для временных индексов, которые отличаются друг от друга на более чем одно целочисленное значение, для вычисления выходного вектора для временного индекса,
и при этом, для вычисления выходного вектора для следующего временного индекса, одно или более ядер принимает по меньшей мере два вектора данных из входного слоя или промежуточного слоя для дополнительных временных индексов, которые перемежаются с временными индексами.
19. Устройство по п. 10, в котором нейронная сеть содержит:
первый сверточный слой в качестве входного слоя для приема текущего кадра, содержащего частотный диапазон входного аудиосигнала, соответствующего текущему временному индексу, причем первый сверточный слой выполнен с возможностью дополнительно использовать один или более предыдущих кадров;
по меньшей мере один второй сверточный слой для приема выходного сигнала первого сверточного слоя, причем по меньшей мере один второй сверточный слой выполнен с возможностью осуществления операции расширенной свертки для получения вектора для текущего временного индекса;
по меньшей мере один рекуррентный слой для обработки вектора для текущего временного индекса с использованием рекуррентной функции, предусматривающей функцию памяти, охватывающую по меньшей мере пять временных индексов, предшествующих текущему временному индексу;
причем рекуррентный слой образует выходной слой (34) или выходной слой (34) является полностью соединенным слоем, принимающим выходной сигнал рекуррентного слоя и выводящим параметры параметрического представления (70).
20. Устройство по п. 1,
в котором параметрическое представление (70) содержит значение спектральной огибающей для каждой полосы из множества полос частотного диапазона расширения, причем множество полос частотного диапазона расширения совместно образует частотный диапазон расширения, и
каждая полоса частот расширения содержит по меньшей мере два спектральных значения, и
при этом процессор первичного сигнала выполнен с возможностью масштабировать (27, 23) по меньшей мере два спектральных значения первичного сигнала в полосе частотного диапазона расширения с использованием значения спектральной огибающей для полосы частотного диапазона расширения.
21. Устройство по п. 20,
в котором значение спектральной огибающей указывает меру для абсолютной энергии полосы частот расширения, с которой связано значение спектральной огибающей,
причем процессор (20) первичного сигнала выполнен с возможностью вычисления (25) меры для энергии первичного сигнала в полосе частотного диапазона расширения,
причем процессор (20) первичного сигнала выполнен с возможностью масштабировать (27) значения амплитуды с использованием меры для абсолютной энергии таким образом, чтобы масштабированные спектральные значения в полосе частот расширения имели энергию, указанную мерой для абсолютной энергии.
22. Устройство по п. 21,
в котором процессор (20) первичного сигнала выполнен с возможностью вычисления (27) масштабного коэффициента из меры для энергии сигнала в полосе частот расширения и из меры для абсолютной энергии полосы частотного диапазона расширения, выведенной из параметрического представления (70).
23. Устройство по п. 20,
в котором процессор (20) первичного сигнала выполнен с возможностью вычисления масштабированных спектральных значений согласно следующему уравнению:
 ,
,
где fb - отношение логарифмической оценки Lb энергии и энергии бинов 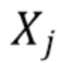 в полосе b, где j пробегает по всем бинам в полосе b, и при этом Lb - параметр, включенный в параметрическое представление (70).
в полосе b, где j пробегает по всем бинам в полосе b, и при этом Lb - параметр, включенный в параметрическое представление (70).
24. Устройство по п. 1,
в котором частотный диапазон аудиосигнала является узкополосным частотным диапазоном, и
частотный диапазон расширения содержит частоту, превышающую наибольшую частоту в узкополосном частотном диапазоне.
25. Устройство по п. 1,
в котором процессор (30) нейронной сети выполнен с возможностью обеспечения, в качестве параметров, по меньшей мере одного параметра из группы параметров, содержащих параметр тональности, параметр временной огибающей, параметр спектральной огибающей, набор энергий полос масштабного коэффициента, набор значений квантователя распределения или параметры энергии и наклона, и
процессор (20) первичного сигнала выполнен с возможностью применения параметров к первичному сигналу (60) для получения обработанного первичного сигнала (80).
26. Система для обработки аудиосигнала, содержащая:
базовый аудиодекодер (140) для декодирования базового аудиосигнала, организованного в кадры, причем базовый аудиодекодер (140) выполнен с возможностью обнаружения ошибочной ситуации, предусматривающей потерю кадра или ошибочный кадр, и
при этом базовый аудиодекодер (140) выполнен с возможностью осуществления операции маскирования ошибок для получения замещающего кадра для ошибочной ситуации, и
устройство (100) по п. 1, в котором устройство (100) выполнено с возможностью использования замещающего кадра в качестве входного аудиосигнала и генерации аудиосигнала с расширенной полосой для ошибочной ситуации.
27. Система для обработки аудиосигнала, содержащая:
входной интерфейс (150) для приема входного аудиосигнала и параметрической вспомогательной информации для частотного диапазона расширения;
устройство (100) для генерации аудиосигнала с расширенной полосой по п. 1,
в котором процессор (20) первичного сигнала выполнен с возможностью использования параметрической вспомогательной информации помимо параметрического представления (70), обеспеченного процессором (30) нейронной сети для генерации аудиосигнала с расширенной полосой.
28. Система по п. 27,
в которой параметрическая вспомогательная информация содержит один бит, связанный с параметром, обеспеченным процессором (30) нейронной сети, и
при этом процессор (20) первичного сигнала выполнен с возможностью изменения (160) параметров, обеспеченных процессором (30) нейронной сети в сторону увеличения в соответствии со значением бита для некоторого параметра.
29. Способ генерации аудиосигнала с расширенной полосой из входного аудиосигнала (50), имеющего частотный диапазон входного аудиосигнала, причем способ содержит этапы, на которых:
генерируют (10) первичный сигнал (60), имеющий частотный диапазон расширения, причем частотный диапазон расширения не включен в частотный диапазон входного аудиосигнала;
генерируют (30) параметрическое представление (70) для частотного диапазона расширения с использованием частотного диапазона входного аудиосигнала и обученной нейронной сети (31); и
обрабатывают (20) первичный сигнал (60) с использованием параметрического представления (70) для частотного диапазона расширения для получения обработанного первичного сигнала (80), имеющего частотные составляющие в частотном диапазоне расширения,
причем обработанный первичный сигнал (80) или обработанный первичный сигнал и частотный диапазон входного аудиосигнала представляют аудиосигнал с расширенной полосой.
30. Способ обработки аудиосигнала, содержащий этап, на котором:
декодируют (140) базовый аудиосигнал, организованный в кадры, причем базовый аудиодекодер (140) выполнен с возможностью обнаружения ошибочной ситуации, предусматривающей потерю кадра или ошибочный кадр, и
причем на этапе декодирования (140) осуществляют операцию маскирования ошибок для получения замещающего кадра для ошибочной ситуации, и
генерируют (100) аудиосигнал с расширенной полосой в соответствии со способом по п. 29, причем способ (100) использует замещающий кадр в качестве входного аудиосигнала и генерирует аудиосигнал с расширенной полосой для ошибочной ситуации.
31. Способ обработки аудиосигнала, содержащий этапы, на которых:
принимают (150) входной аудиосигнал и параметрическую вспомогательную информацию для частотного диапазона расширения;
генерируют (100) аудиосигнал с расширенной полосой в соответствии со способом по п. 29,
причем на этапе обработки (20) первичного сигнала используют параметрическую вспомогательную информацию помимо параметрического представления (70), обеспеченного нейронной сетью (31) для генерации аудиосигнала с расширенной полосой.
32. Компьютерно-считываемый носитель хранения данных, имеющий компьютерную программу, хранящуюся на нем, для осуществления, при выполнении на компьютере или процессоре, способа по п. 29.
33. Компьютерно-считываемый носитель хранения данных, имеющий компьютерную программу, хранящуюся на нем, для осуществления, при выполнении на компьютере или процессоре, способа по п. 30.
34. Компьютерно-считываемый носитель хранения данных, имеющий компьютерную программу, хранящуюся на нем, для осуществления, при выполнении на компьютере или процессоре, способа по п. 31.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ РАСШИРЕНИЯ ДИАПАЗОНА ЧАСТОТ ДЛЯ АКУСТИЧЕСКИХ СИГНАЛОВ | 2014 |
|
RU2688247C2 |
| УСТРОЙСТВО И СПОСОБ РАСШИРЕНИЯ ПОЛОСЫ ПРОПУСКАНИЯ АУДИО СИГНАЛА | 2009 |
|
RU2455710C2 |

