Настоящее изобретение относится к меченым полипептидам и к способам их получения и применения.
Бактерии рода Clostridia продуцируют в высокой степени сильнодействующие и специфические белковые токсины, которые могут отравлять нейроны и другие клетки, к которым они доставляются. Примеры таких клостридиальных нейротоксинов включают нейротоксины, продуцируемые C. tetani (TeNT) и C. botulinum (BoNT) серотипов A-G и X (см. WO 2018/009903 A2), а также нейротоксины, продуцируемые C. baratii и C. butyricum.
К клостридиальным нейротоксинам принадлежат некоторые из наиболее известных сильнодействующих токсинов. В качестве примера, ботулиновые нейротоксины имеют величины срединной летальной дозы (LD50) для мышей в диапазоне от 0,5 до 5 нг/кг в зависимости от серотипа. Как столбнячные, так и ботулиновые токсины действуют посредством ингибирования функции пораженных нейронов, в частности, высвобождения нейротрансмиттеров. В то время как ботулиновый токсин действует на нейромышечные соединения и ингибирует холинэргическую передачу в периферической нервной системе, столбнячный токсин действует в центральной нервной системе.
Клостридиальные нейротоксины экспрессируются в Clostridium в качестве одноцепочечных полипептидов. Каждый клостридиальный нейротоксин имеет каталитическую легкую цепь, отделенную от тяжелой цепи (охватывающую N-концевой домен транслокации и C-концевой рецептор-связывающий домен) находящейся на поверхности областью, называемой петлей активации. В ходе созревания белка протеолитическое расщепление петли активации разделяет легкую и тяжелую цепи клостридиального нейротоксина, которые удерживаются вместе дисульфидным мостиком, с образованием полностью активного двухцепочечного токсина.
Также в данной области известны перенацеленные клостридиальные нейротоксины, которые могут быть модифицированы включением экзогенного лиганда, известного ка нацеливающая часть (TM). TM выбирают для обеспечения специфичности связывания в отношении требуемой клетки-мишени, и в качестве части процесса перенацеливания нативная связывающая часть клостридиального нейротоксина (например, HC-домен или HCC-домен) может быть удалена. Технология перенацеливания описана, например, в: EP-B-0689459; WO 1994/021300; EP-B-0939818; US 6461617; US 7192596; WO 1998/007864; EP-B-0826051; US 5989545; US 6395513; US 6962703; WO 1996/033273; EP-B-0996468; US 7,052,702; WO 1999/017806; EP-B-1107794; US 6,632,440; WO 2000/010598; WO 2001/21213; WO 2006/059093; WO 2000/62814; WO 2000/04926; WO 1993/15766; WO 2000/61192; и WO 1999/58571; все из которых включены в качестве ссылок в полном объеме.
Следующий вариант включает полипептиды, полученные из одного или нескольких из нецитотоксической протеазы, доменов транслокации или связывания клостридиальных нейротоксинов или из полипептидов с эквивалентной/сходной функциональностью.
Связывание, транслокация и протеолитическое расщепление белков SNARE клостридиальными нейротоксинами (или другими полипептидами, описанными в настоящем описании) остаются малопонятными. Таким образом, остается потребность в способе анализа, который позволяет визуализацию каждой из этих стадий, в частности, в реальном времени и/или в живых клетках. Такой анализ может облегчить разработку и охарактеризацию терапевтических средств на основе клостридиальных нейротоксинов, особенно охарактеризацию новых терапевтических средств на основе BoNT, гибридных токсинов и перенацеленных клостридиальных нейротоксинов (и их вариантов).
Более того, количество антител (например, флуоресцентных антител), используемых в обычных способах для визуализации клостридиальных нейротоксинов и других таких полипептидов, является низким, с ограниченной специфичностью и/или чувствительностью. Более того, такие обычные способы, как правило, основаны на фиксации клеток, что может иметь неблагоприятный эффект на клеточную архитектуру, и они непригодны для прижизненной визуализации/визуализации в реальном времени, в частности, в комплексных биологических системах, например, у животных in vivo. Таким образом, сохраняется потребность в усовершенствованных/альтернативных способах.
Настоящее изобретение решает одну или несколько из вышеупомянутых проблем.
Авторы настоящего изобретения неожиданно обнаружили, что сортазу можно использовать для конъюгации поддающейся детекции метки с полипептидами по изобретению (включающими нецитотоксическую протеазу или ее протеолитически неактивный мутант; нацеливающую часть (TM), которая связывается с участком связывания на клетке-мишени; и домен транслокации) без снижения эффективности меченого полипептида. Иными словами, меченые полипептиды демонстрируют сходное (или улучшенное) связывание клеток, транслокацию и расщепление белка SNARE с эквивалентным немеченым полипептидом. Это было полностью неожиданным, учитывая, что полипептиды, меченные с использованием альтернативных технологий (например, несайтспецифическое мечение и SNAP-мечение), демонстрировали сниженную эффективность.
Более того, полипептиды по изобретению, содержащие акцепторный или донорный участок сортазы, могут быть без труда очищены и экспрессированы, вновь это было неожиданным, учитывая, что мечение посредством GFP было ассоциировано с трудностями экспрессии/очистки, что указывает на то, что включение акцепотрных или донорных участков для сортазы не оказывало отрицательного влияния на структуру или укладку полипептида.
Кроме того, способы, включающие использование сортазы, позволяли получение полипептида с двойным мечением, что также позволяло визуализацию событий транслокации, происходящих в клеточных эндосомах, одного из наименее понятных аспектов перемещения клостридиального нейротоксина (и перенацеленного клостридиального нейротоксина). Преимущественно, настоящее изобретение обеспечивает визуализацию транслокации с использованием живой визуализирующей микроскопии и внесет значительный вклад в понимание механизмов транслокации в нескольких клеточных моделях и тканях.
Меченые полипептиды по изобретению открывают новые направления для мониторинга прижизненно и/или в реальном времени механизма действия указанных полипептидов и устраняют необходимость в фиксирующих продуктах, что имеет неблагоприятный эффект на клеточную архитектуру. Таким образом, настоящее изобретение позволяет визуализацию токсинов в более комплексных биологических системах, таких как препараты тканей ex vivo (например, срезы головного мозга), гистопатологические образцы, и у животных in vivo, и оно не ограничивается простыми клеточными системами, такими как иммортализованные клеточные линии и нейроны, как в случае общепринятых способов. Таким образом, полипептиды по настоящему изобретению могут использоваться (например) для выявления распределения полипептида от области введения.
В одном аспекте изобретение относится к способу получения меченого полипептида, включающему:
a. получение полипептида, содержащего:
i. акцепторный или донорный участок для сортазы;
ii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации;
b. инкубацию полипептида с:
сортазой; и
меченым субстратом, содержащим донорный и акцепторный участок для сортазы и конъюгированную поддающуюся детекции метку;
где сортаза катализирует конъюгацию между аминокислотой акцепторного участка для сортазы и аминокислотой донорного участка для сортазы, с осуществлением тем самым мечения полипептида; и
c. получение меченого полипептида.
Когда способ по изобретению включает использование полипептида, содержащего акцепторный участок для сортазы, меченый субстрат, содержащий конъюгированную поддающуюся детекции метку (например, как указано в b.), содержит донорный участок для сортазы. Аналогично, когда способ по изобретению включает использование полипептида, содержащего донорный участок для сортазы, меченый субстрат, содержащий конъюгированную поддающуюся детекции метку (например, как указано в b.), содержит акцепторный участок для сортазы.
Таким образом, изобретение относится к применению акцепторного участка для сортазы и соответствующего донорного участка для сортазы, где сортаза способна катализировать конъюгацию аминокислоты акцепторного участка для сортазы и аминокислоты донорного участка для сортазы. Таким образом, соответствующие акцепторные и донорные участки для сортазы для применения в рамках изобретения выбирают таким образом, чтобы могла осуществляться конъюгация посредством сортазы.
Таким образом, в одном варианте осуществления способ по изобретению включает:
a. получение полипептида, содержащего:
i. акцепторный участок для сортазы;
ii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации;
b. инкубацию полипептида с:
сортазой; и
меченым субстратом, содержащим донорный участок для сортазы и конъюгированную поддающуюся детекции метку;
где сортаза катализирует конъюгацию между аминокислотой акцепторного участка для сортазы и аминокислотой донорного участка для сортазы, с осуществлением тем самым мечения полипептида; и
c. получение меченого полипептида.
В другом варианте осуществления способ по изобретению включает:
a. получение полипептида, содержащего:
i. донорный участок для сортазы;
ii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации;
b. инкубацию полипептида с:
сортазой; и
меченым субстратом, содержащим акцепторный участок для сортазы и конъюгированную поддающуюся детекции метку;
где сортаза катализирует конъюгацию между аминокислотой акцепторного участка для сортазы и аминокислотой донорного участка для сортазы, с осуществлением тем самым мечения полипептида; и
c. получение меченого полипептида.
Также настоящее изобретение относится к меченому полипептиду, который может быть получен способом по изобретению.
В одном варианте осуществления поддающаяся детекции метка конъюгирована в или вблизи акцепторного или донорного участка для сортазы в полипептиде, включающем нецитотоксическую протеазу или ее протеолитически неактивный мутант; нацеливающую часть (TM) и домен транслокации.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с акцепторным или донорным участком для сортазы, например, конъюгирована непосредственно с аминокислотой акцепторного или донорного участка для сортазы. Альтернативно поддающаяся детекции метка может быть конъюгирована с C-концевой стороны от акцепторного или донорного участка для сортазы, например, на расстоянии 1-50, например 1-25 или 1-10 аминокислот от C-конца акцепторного или донорного участка для сортазы.
В другом варианте осуществления поддающаяся детекции метка конъюгирована с N-концевой стороны от акцепторного или донорного участка для сортазы, например, на расстоянии 1-50, например, 1-25 или 1-10 аминокислот от N-конца акцепторного или донорного участка для сортазы.
Термин "который может быть получен", как его используют в рамках изобретения, также охватывает термин "полученный". В одном варианте осуществления термин " который может быть получен " означает "полученный".
В родственном аспекте изобретение относится к полипептиду для мечения с использованием сортазы, причем полипептид содержит:
i. акцепторный или донорный участок для сортазы;
ii. нецитотоксическую протеазу, которая способна расщеплять белок аппарата экзоцитарного слияния в клетке-мишени, или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации, который способен транслоцировать нецитотоксическую протеазу из эндосомы через эндосомальную мембрану и в цитозоль клетки-мишени;
где, когда полипептид содержит донорный участок для сортазы, донорный участок для сортазы находится на N-конце полипептида, и где, когда донорный участок для сортазы содержит Gn или An, n равен по меньшей мере 2; и
где N-концевой остаток донорного участка представляет собой N-концевой остаток полипептида; или
где полипептид содержит один или несколько аминокислотных остатков с N-концевой стороны от донорного участка для сортазы и расщепляемый участок, который при расщеплении экспонирует N-конец донорного участка для сортазы.
В одном варианте осуществления полипептид для мечения с использованием сортазы содержит:
i. донорный участок для сортазы;
ii. нецитотоксическую протеазу, которая способна расщеплять белок аппарата экзоцитарного слияния в клетке-мишени, или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации, который способен транслоцировать нецитотоксическую протеазу из эндосомы через эндосомальную мембрану и в цитозоль клетки-мишени;
где донорный участок для сортазы находится на N-конце полипептида, и где, когда донорный участок для сортазы содержит Gn или An, n равен по меньшей мере 2; и
где N-концевой остаток донорного участка представляет собой N-концевой остаток полипептида.
В одном варианте осуществления полипептид для мечения с использованием сортазы содержит:
i. донорный участок для сортазы;
ii. нецитотоксическую протеазу, которая способна расщеплять белок аппарата экзоцитарного слияния в клетке-мишени, или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации, который способен транслоцировать нецитотоксическую протеазу из эндосомы через эндосомальную мембрану и в цитозоль клетки-мишени;
где донорный участок для сортазы находится на N-конце полипептида, и где, когда донорный участок для сортазы содержит Gn или An, n равен по меньшей мере 2; и
где полипептид содержит один или несколько аминокислотных остатков с N-концевой стороны от донорного участка для сортазы и расщепляемый участок, который при расщеплении экспонирует N-конец донорного участка для сортазы.
В одном варианте осуществления полипептид для мечения с использованием сортазы содержит:
i. акцепторный участок для сортазы;
ii. нецитотоксическую протеазу, которая способна расщеплять белок аппарата экзоцитарного слияния в клетке-мишени, или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации, который способен транслоцировать нецитотоксическую протеазу из эндосомы через эндосомальную мембрану и в цитозоль клетки-мишени.
Полипептид подходящим образом используется в способе по изобретению.
Полипептид по изобретению может содержать акцепторный участок для сортазы. Альтернативно указанный полипептид может содержать донорный участок для сортазы.
В предпочтительном варианте осуществления указанный полипептид содержит акцепторный участок для сортазы и донорный участок для сортазы.
Полипептид по настоящему изобретению может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 2. В одном варианте осуществления полипептид по изобретению содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 2. Предпочтительно, полипептид по изобретению содержит (более предпочтительно состоит из) полипептид, представленный как SEQ ID NO: 2.
Полипептид по настоящему изобретению может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 4. В одном варианте осуществления полипептид по изобретению содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 4. Предпочтительно, полипептид по изобретению содержит (более предпочтительно состоит из) полипептид, представленный как SEQ ID NO: 4.
Полипептид по настоящему изобретению может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 40. В одном варианте осуществления полипептид по изобретению содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 40. Предпочтительно, полипептид по изобретению содержит (более предпочтительно состоит из) полипептид, представленный как SEQ ID NO: 40.
Полипептид может кодироваться нуклеиновой кислотой по изобретению.
Изобретение также относится к меченому полипептиду, причем полипептид содержит:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации.
Изобретение также относится к меченому полипептиду, причем полипептид содержит:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn (SEQ ID NO: 59), где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An (SEQ ID NO: 60), где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN (SEQ ID NO: 61), YPRTG (SEQ ID NO: 62), IPQTG (SEQ ID NO: 63), VPDTG (SEQ ID NO: 64), LPXTGS (SEQ ID NO: 65), где X представляет собой любую аминокислоту, NPKTG (SEQ ID NO: 46), XPETG (SEQ ID NO: 47), LGATG (SEQ ID NO: 48), IPNTG (SEQ ID NO: 49), IPETG (SEQ ID NO: 50), NSKTA (SEQ ID NO: 51), NPQTG (SEQ ID NO: 52), NAKTN (SEQ ID NO: 53), NPQSS (SEQ ID NO: 54), LPXTX (SEQ ID NO: 55), где X представляет собой любую аминокислоту, NPX1TX2 (SEQ ID NO: 56), где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G (SEQ ID NO: 57), где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G (SEQ ID NO: 58), где X1 представляет собой Ala, Cys или Ser, LPXS (SEQ ID NO: 66), LAXT (SEQ ID NO: 67), MPXT (SEQ ID NO: 68), MPXTG (SEQ ID NO: 69), LAXS (SEQ ID NO: 70), NPXT (SEQ ID NO: 71), NPXTG (SEQ ID NO: 72), NAXT (SEQ ID NO: 73), NAXTG (SEQ ID NO: 74), NAXS (SEQ ID NO: 75), NAXSG (SEQ ID NO: 76), LPXP (SEQ ID NO: 77), LPXPG (SEQ ID NO: 78), где X представляет собой любую аминокислоту, LRXTGn (SEQ ID NO: 111) или LPAXGn (SEQ ID NO: 106), где X представляет собой любую аминокислоту и n равен по меньшей мере 1;
iii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iv. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
v. домен транслокации.
Изобретение также относится к меченому полипептиду, причем полипептид содержит:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту;
iii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iv. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
v. домен транслокации.
В одном варианте осуществления меченый полипептид содержит:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1;
iii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iv. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
v. домен транслокации.
В одном варианте осуществления меченый полипептид содержит:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту;
iii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iv. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
v. домен транслокации.
В одном варианте осуществления меченый полипептид по изобретению демонстрирует сходное связывание клеток, транслокацию и расщепление белка SNARE с эквивалентным немеченым полипептидом. В другом варианте осуществления меченый полипептид демонстрирует улучшенное связывание клеток, транслокацию и/или расщепление белка SNARE по сравнению с эквивалентным немеченым полипептидом. В особенно предпочтительном варианте осуществления меченый полипептид демонстрирует улучшенное связывание клеток, транслокацию и расщепление белка SNARE по сравнению с эквивалентным немеченым полипептидом. Связывание клеток, транслокация и/или расщепление белка SNARE могут быть определены с использованием любого способа, известного в данной области и/или описанного в настоящем описании. В одном варианте осуществления связывание клеток, транслокация и/или расщепление белка SNARE могут быть определены с использованием анализа на клеточной основе или in vivo. Подходящие способы анализа могут включать числовой показатель отведения (DAS), анализ ганглиев задних корешков (DRG), анализ нейронов спинного мозга (SCN) и анализ диафрагмального нерва купола диафрагмы (PNHD), которые являются стандартными в данной области. Подходящий анализ может представлять собой анализ, описанный в Donald et al. (2018), Pharmacol Res Perspect, e00446, 1-14, который включен в настоящее описание в качестве ссылки. Предпочтительно, подходящим анализом является анализ расщепления SNAP25, как описано в Fonfria, E., S. Donald and V.A. Cadd (2016), "Botulinum neurotoxin A and an engineered derivate targeted secretion inhibitor (TSI) A enter cells via different vesicular compartments." J Recept Signal Transduct Res 36(1): 79-88, которая включена в настоящее описание в качестве ссылки.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с или вблизи последовательности, содержащей L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1. В одном варианте осуществления поддающаяся детекции метка конъюгирована с или вблизи последовательности, содержащей L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS.
В одном варианте осуществления аминокислотная последовательность, содержащая L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, может находиться с C-концевой стороны от TM полипептида. В одном варианте осуществления аминокислотная последовательность, содержащая L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS, может находиться с C-концевой стороны от TM полипептида. В другом варианте осуществления аминокислотная последовательность, содержащая L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, может находиться с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта в полипептиде. В другом варианте осуществления аминокислотная последовательность, содержащая L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS, может находиться с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта в полипептиде.
В одном варианте осуществления меченый полипептид содержит две или более поддающихся детекции меток, предпочтительно меченый полипептид содержит две поддающихся детекции метки. В предпочтительном варианте осуществления поддающиеся детекции метки различаются, например, представляют собой флуорофоры разного цвета.
Первая и вторая (или более) поддающиеся детекции метки могут быть конъюгированы с или вблизи аминокислотной последовательности, содержащей L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, где первая и вторая (или более) поддающиеся детекции метки конъюгированы с различными участками меченого полипептида. Первая и вторая (или более) поддающиеся детекции метки могут быть конъюгированы с или вблизи аминокислотной последовательности, содержащей L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS, где первая и вторая (или более) поддающиеся детекции метки конъюгированы с различными участками меченого полипептида. Например, первая поддающаяся детекции метка может быть конъюгирована с аминокислотной последовательностью, находящейся с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта, и вторая поддающаяся детекции метка может быть конъюгирована с аминокислотной последовательностью, находящейся с C-концевой стороны от TM (или наоборот). Предпочтительно аминокислотные последовательности, с которыми конъюгированы первая и вторая (или более) поддающиеся детекции метки, различаются.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1. Альтернативно поддающаяся детекции метка может быть конъюгирована с C-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, например, на расстоян 1-50, например, 1-25 или 1-10 аминокислот с C-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS. Альтернативно поддающаяся детекции метка может быть конъюгирована с C-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS, например, на расстоянии 1-50, например, 1-25 или 1-10 аминокислот с C-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS.
В другом варианте осуществления поддающаяся детекции метка конъюгирована с N-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, например, на расстоянии 1-50, например, 1-25 или 1-10 аминокислот с N-концевой стороны от L(A/P/S)X(T/S/A/C)Gn.
В другом варианте осуществления поддающаяся детекции метка конъюгирована с N-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, L(A/P/S)X(T/S/A/C)An, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS, например, на расстоянии 1-50, например, 1-25 или 1-10 аминокислот с N-концевой стороны от L(A/P/S)X(T/S/A/C)Gn.
В вариантах осуществления, где аминокислотная последовательность содержит L(A/P/S)X(T/S/A/C)An, X представляет собой любую аминокислоту и n может составлять по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9 или 10, например, аминокислотная последовательность может содержать LPXTAn (SEQ ID NO: 102). Предпочтительно n составляет 1-10, более предпочтительно 1-4. В таких вариантах осуществления конъюгированные поддающаяся детекции метка и аминокислотная последовательность, которая содержит L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, указывают на то, что полипептид успешно мечен сортазой (например, из Streptococcus pyogenes).
В особенно предпочтительном варианте осуществления аминокислотная последовательность содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1. Такая аминокислотная последовательность может содержать LPXSGn (SEQ ID NO: 103), LAXTGn (SEQ ID NO: 104), LPXTGn (SEQ ID NO: 105), LPXCGn (SEQ ID NO: 107), LAXSGn (SEQ ID NO: 108), LPXAGn (SEQ ID NO: 109), или LSXTGn (SEQ ID NO: 110). Предпочтительно аминокислотная последовательность может содержать LPXSGn, LAXTGn, LPXTGn или LAXSGn.
В одном варианте осуществления аминокислотная последовательность содержит LRXTGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1.
В одном варианте осуществления аминокислотная последовательность содержит LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1.
Конъюгированные поддающаяся детекции метка и аминокислотная последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, указывают на то, что полипептид успешно мечен сортазой. В одном варианте осуществления n может составлять по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9 или 10. Предпочтительно n составляет 1-10, более предпочтительно 1-4.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с или вблизи L(A/P/S)X(T/S/A/C)Gn.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с L(A/P/S)X(T/S/A/C)Gn, например, с ее аминокислотным остатком G. Альтернативно поддающаяся детекции метка может быть конъюгирована с C-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, например, на расстоянии 1-50, например, 1-25 или 1-10 аминокислот с C-концевой стороны от L(A/P/S)X(T/S/A/C)Gn.
В другом варианте осуществления поддающаяся детекции метка конъюгирована с N-концевой стороны от L(A/P/S)X(T/S/A/C)Gn, например, на расстоянии 1-50, например, 1-25 или 1-10 аминокислот с N-концевой стороны от L(A/P/S)X(T/S/A/C)Gn.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с или вблизи аминокислотной последовательности LPXSGn, где n равен по меньшей мере 1, например по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9 или 10. Предпочтительно n составляет 1-10, более предпочтительно 1-5. Поддающаяся детекции метка предпочтительно конъюгирована с C-концевой стороны от LPXSGn, например, с остатком лизина с C-концевой стороны от LPXSGn. X представляет собой любую аминокислоту, такую как E.
В одном варианте осуществления поддающаяся детекции метка конъюгирована с или вблизи аминокислотной последовательности LAXTGn, где n равен по меньшей мере 1, например, по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9 или 10. Предпочтительно, n составляет 1-10, более предпочтительно 1-4. Поддающаяся детекции метка предпочтительно конъюгирована с N-концевой стороны от LAXTGn, например, с остатком гистидина с N-концевой стороны от LAXTGn. X представляет собой любую аминокислоту, такую как E.
В одном варианте осуществления первая поддающаяся детекции метка конъюгирована с или вблизи аминокислотной последовательности LPXSGn (где n равен по меньшей мере 1, например по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9 или 10, предпочтительно где n составляет 1-10, более предпочтительно 1-5) и вторая поддающаяся детекции метка конъюгирована с или вблизи аминокислотной последовательности LAXTGn (где n равен по меньшей мере 1, например по меньшей мере 2, 3, 4, 5, 6, 7, 8, 9 или 10, предпочтительно где n составляет 1-10, более предпочтительно 1-4). Первая поддающаяся детекции метка предпочтительно конъюгирована с C-концевой стороны от LPXSGn, например, с остатком лизина с C-концевой стороны от LPXSGn и вторая поддающаяся детекции метка предпочтительно конъюгирована с N-концевой стороны от LAXTGn, например, с остатком гистидина с N-концевой стороны от LAXTGn. X представляет собой любую аминокислоту, такую как E. В одном варианте осуществления первая поддающаяся детекции метка находится с C-концевой стороны от TM полипептида, и вторая поддающаяся детекции метка находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта (предпочтительно нецитотоксической протеазы) в полипептиде.
Меченый полипептид по настоящему изобретению может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 26. В одном варианте осуществления меченый полипептид по изобретению содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 26. Предпочтительно, меченый полипептид по изобретению содержит (более предпочтительно состоит из) полипептид, представленный в качестве SEQ ID NO: 26.
Сортаза, описанная в настоящем описании, может представлять собой сортазу A, сортазу B, сортазу C или сортазу D. Обзор биологических свойств сортаз представлен в Mazmanian, S.K., G. Liu, H. Ton-That and O. Schneewind (1999). "Staphylococcus aureus sortase, an enzyme that anchors surface proteins to the cell wall." Science 285(5428): 760-763 и Paterson, G.K. and T.J. Mitchell (2004). "The biology of Gram-positive sortase enzymes." Trends Microbiol 12(2): 89-95, обе их которых включены в настоящее описание в качестве ссылок.
Также настоящее изобретения охватывает варианты сортаз. Варианты сортаз в подходящем случае обладают измененной специфичностью, так что они распознают альтернативные участки сортаз (например, акцепторные участки). Варианты сортаз описаны в Dorr, B.M., H.O. Ham, C. An, E.L. Chaikof and D.R. Liu (2014). "Reprogramming the specificity of sortase enzymes." Proc Natl Acad Sci U S A 111(37): 13343-13348, Chen, I., B.M. Dorr and D.R. Liu (2011). "A general strategy for the evolution of bond-forming enzymes using yeast display." Proc Natl Acad Sci U S A 108(28): 11399-11404, Dorr, B.M., H.O. Ham, C. An, E.L. Chaikof and D.R. Liu (2014). "Reprogramming the specificity of sortase enzymes." Proc Natl Acad Sci U S A 111(37): 13343-13348, и Chen, L., J. Cohen, X. Song, A. Zhao, Z. Ye, C. J. Feulner, P. Doonan, W. Somers, L.Lin and P. . Chen (2016). "Improved variants of SrtA for site-specific conjugation on antibodies and proteins with high efficiency." Sci Rep 6: 31899, каждая из которых включена в настоящее описание в качестве ссылки. Специализированные варианты сортаз можно получать с использованием методологии, описанной в указанных источниках литературы. Специалист в данной области выберет подходящие донорные и/или акцепторные участки для сортазы, распознаваемые вариантом сортазы, при использовании указанного варианта в рамках настоящего изобретения. Кроме того, специалисту в данной области будет понятно, что указанные донорные и/или акцепторные участки для сортазы могут отличаться от участков, приведенных в настоящем описании.
В одном варианте осуществления вариант сортазы может включать модифицированную сортазу A Staphylococcus aureus. Модифицированная сортаза A может включать одну или несколько мутаций относительно последовательности SEQ ID NO: 31, описанной в настоящем описании. Например, модифицированная сортаза A может содержать одну или несколько из следующих мутаций относительно последовательности SEQ ID NO: 31: P86L, P94S, P94R, N98S, A104T, E106G, A118T, F122S, F122Y, D124G, N127S, K134R, F154R, D160N, D165A, K173E, G174S, K177E, I182V, K190E, K196T или их комбинацию. В некоторых вариантах осуществления в рамках настоящего изобретения предусматривается модифицированная сортаза, которая включает 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 или все 19 из этих мутаций. Вышеупомянутые аминокислотные замены могут обеспечить модифицированную сортазу, которая эффективно использует акцепторные и/или донорные участки, с которыми не связывается соответствующая исходная сортаза дикого типа. Например, в некоторых вариантах осуществления модифицированная сортаза использует акцепторный участок для сортазы, имеющий последовательность LPXTG, и донорный участок, имеющий N-концевой полиглициновый мотив. В некоторых вариантах осуществления модифицированная сортаза использует акцепторный и/или донорный участок, который отличается от акцепторного и/или донорного участка (соответственно), используемого исходной сортазой, например, акцепторного участка для сортазы, включающего мотив LPXS, LAXT, LAXTG (SEQ ID NO: 116), MPXT, MPXTG, LAXS, LAXSG (SEQ ID NO: 120), NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG или LPXTA (SEQ ID NO: 114).
Предпочтительно сортаза представляет собой сортазу A или ее вариант. Сортаза A представляет собой транспептидазу, которая распознает (предпочтительно C-концевой) мотив L(A/P/S)X(T/S/A/C)(G/A) белков для расщепления между (T/S/A/C) и G/A, а затем переносит ацильный компонент на нуклеофил, содержащий (предпочтительно N-концевой) (олиго)глицин (где мотив представляет собой L(A/P/S)X(T/S/A/C)G) или (олиго)аланин (где мотив представляет собой L(A/P/S)X(T/S/A/C)A). В одном варианте осуществления сортаза A может представлять собой сортазу, получаемую из Streptococcus pyogenes (например, SEQ ID NO: 37), причем указанная сортаза распознает (среди прочих) акцепторный участок для сортазы, имеющий последовательность LPXTA, в таких случаях предпочтительно акцепторный участок для сортазы представляет собой An, где n равен по меньшей мере 1. Применение сортазы S. pyogenes описано в Antos et al (2009), J Am Chem Soc, 131, 10800-10801, которая включена в настоящее описание в качестве ссылки.
Предпочтительно, сортаза A может представлять собой сортазу, получаемую из Staphylococcus aureus, или ее вариант.
В одном варианте осуществления акцепторный участок для сортазы может содержать (или состоять из) L(A/P/S)X(T/S/A/C)(G/A), NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту. Например, акцепторный участок для сортазы может содержать (или состоять из) L(A/P/S)X(T/S/A/C)G, NPQTN, YPRTG, IPQTG, VPDTG или LPXTGS, где X представляет собой любую аминокислоту.
В одном варианте осуществления акцепторный участок для сортазы может содержать (или состоять из) NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTG (SEQ ID NO: 123) или LPAXG (SEQ ID NO: 118), где X представляет собой любую аминокислоту.
Акцепторный участок для сортазы X1PX2X3G может распознаваться сортазой A. В некоторых вариантах осуществления, где акцепторный участок для сортазы содержит (или состоит из) X1PX2X3G, X2 может представлять собой Asp, Glu, Ala, Gln, Lys или Met. в некоторых вариантах осуществления указанный акцепторный участок для сортазы содержит (или состоит из) LPX1TG, где X1 представляет собой любую аминокислоту. В других вариантах осуществления акцепторный участок для сортазы содержит (или состоит из): LPKTG, LPATG, LPNTG, LPETG, LPNAG, LPNTA, LGATG, IPNTG или IPETG.
Акцепторный участок для сортазы NPX1TX2 может распознаваться сортазой B. В некоторых вариантах осуществления акцепторный участок для сортазы содержит (или состоит из): NPQTN, NPKTG, NSKTA, NPQTG, NAKTN или NPQSS.
Акцепторный участок для сортазы LPXTX может распознаваться сортазой C.
В одном варианте осуществления акцепторный участок для сортазы не содержит (или не состоит из) NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTG или LPAXG, где X представляет собой любую аминокислоту.
В вариантах осуществления, где используется сортаза A, участок сортазы (например, акцепторный или донорный участок) представляет собой участок сортазы A.
В предпочтительном варианте осуществления акцепторный участок для сортазы, описанный в настоящем описании, может представлять собой участок сортазы A. Консенсусный акцепторный участок сортазы A может представлять собой L(A/P/S)X(T/S/A/C)(G/A), где X представляет собой любую аминокислоту, такую как E. Однако является предпочтительным, чтобы консенсусный акцепторный участок сортазы A представлял собой L(A/P/S)X(T/S/A/C)G.
В одном варианте осуществления акцепторный участок сортазы A содержит или выбран из LPXSG (SEQ ID NO: 115), LAXTG, LPXTG (SEQ ID NO: 117), LPAXG, LPXCG (SEQ ID NO: 119), LAXSG, LPXAG (SEQ ID NO: 121), LSXTG (SEQ ID NO: 122), LRXTG и LPXTA. Предпочтительно акцепторный участок сортазы A может быть выбран из LPXSG, LAXTG, LPXTG и LAXSG, более предпочтительно LPXSG или LAXTG. Например, акцепторный участок сортазы A может представлять собой LPESG (SEQ ID NO: 112) или LAETG (SEQ ID NO: 113), как проиллюстрировано в настоящем описании.
В некоторых вариантах осуществления после акцепторного участка для сортазы, описанного в настоящем описании, следует один или несколько C-концевых аминокислотных остатков, как например, 1-50, 1-10 или предпочтительно 1-5 (например, 2) аминокислотных остатков. В некоторых вариантах осуществления после акцепторного участка для сортазы следует один или несколько кислотных аминокислотных остатков. Кислотный аминокислотный остаток может представлять собой аспартат или глутамат.
Донорный участок для сортазы может содержать (или состоять из) Gn, где n равен по меньшей мере 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10. В одном варианте осуществления n равен по меньшей мере 2. Предпочтительно n равен 2-10, как например, 2-5. Более предпочтительно n равен 4. Такой донорный участок предпочтительно может представлять собой участок для сортазы A, предпочтительно для применения с акцепторным участком для сортазы A L(A/P/S)X(T/S/A/C)G.
В некоторых вариантах осуществления донорный участок для сортазы может представлять собой GnK, где n равен по меньшей мере 1 (например по меньшей мере 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10, в одном варианте осуществления n равен по меньшей мере 2, и предпочтительно n равен 2-10, как например, 2-5).
В одном варианте осуществления акцепторный участок для сортазы для применения в рамках изобретения содержит (или состоит из) L(A/P/S)X(T/S/A/C)G, где X представляет собой любую аминокислоту, и донорный участок для сортазы для применения в рамках изобретения содержит (или состоит из) Gn, где n равен по меньшей мере 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10.
Донорный участок для сортазы может содержать (или состоять из) An, где n равен по меньшей мере 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10. В одном варианте осуществления n равен по меньшей мере 2. Предпочтительно n равен 2-10, как например, 2-5. Более предпочтительно n равен 4. Такой донорный участок предпочтительно может представлять собой участок для сортазы A, предпочтительно для применения с акцепторным участком для сортазы A L(A/P/S)X(T/S/A/C)A.
В одном варианте осуществления акцепторный участок для сортазы для применения в рамках изобретения содержит (или состоит из) L(A/P/S)X(T/S/A/C)A, где X представляет собой любую аминокислоту, и донорный участок для сортазы для применения в рамках изобретения содержит (или состоит из) An, где n равен по меньшей мере 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10.
В контексте акцпторных или донорных участков для сортаз, X может представлять собой любую аминокислоту, например, выбранную из стандартных аминокислот: аспарагиновая кислота, глутаминовая кислота, аргинин, лизин, гистидин, аспарагин, глутамин, серин, треонин, тирозин, метионин, триптофан, цистеин, аланин, глицин, валин, лейцин, изолейцин, пролин и фенилаланин. В некоторых вариантах осуществления X может представлять собой любую аминокислоту за исключением пролина.
Когда используется акцепторный участок не сортазы A, такой как:
участок сортазы B Staphylococcus aureus: NPQTN;
участок сортазы B Streptococcus pneumoniae: YPRTG, IPQTG или VPDTG;
участок сортазы B Streptococcus pyogenes: LPXTGS;
участок сортазы C Streptococcus pneumoniae: YPRTG, IPQTG или VPDTG; и
участок сортазы D Streptococcus pneumoniae: YPRTG, IPQTG или VPDTG;
специалист в данной области выберет подходящий донорный участок для применения с указанным акцепторным участком не сортазы A, исходя из информации, имеющейся в данной области.
Сортаза B может представлять собой каталитически активный полипептид, обладающий по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 32 или 34. В одном варианте осуществления сортаза B может представлять собой каталитически активный полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 32 или 34. Предпочтительно сортаза B может представлять собой каталитически активный полипептид, содержащий (более предпочтительно состоящий из) SEQ ID NO: 32 или 34.
Сортаза C может представлять собой каталитически активный полипептид, обладающий по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 35. В одном варианте осуществления сортаза C может представлять собой каталитически активный полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 35. Предпочтительно сортаза C может представлять собой каталитически активный полипептид, содержащий (более предпочтительно состоящий из) SEQ ID NO: 35.
Сортаза D может представлять собой каталитически активный полипептид, обладающий по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 36. В одном варианте осуществления сортаза D может представлять собой каталитически активный полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 36. Предпочтительно сортаза D может представлять собой каталитически активный полипептид, содержащий (более предпочтительно состоящий из) SEQ ID NO: 36.
Акцепторный участок для сортазы предпочтительно находится на C-конце полипептида. Донорный участок для сортазы предпочтительно находится на N-конце полипептида.
Термин "находящийся на C-конце", как используют в этом контексте, может означать, что C-концевой остаток акцепторного участка находится на расстоянии вплоть до 50 аминокислотных остатков с N-концевой стороны от C-концевого остатка полипептида, например, что C-концевой остаток акцепторного участка находится на расстоянии 1-50, предпочтительно 10-40 аминокислотных остатков с N-концевой стороны от C-концевого остатка полипептида. В особенно предпочтительных вариантах осуществления C-концевой остаток акцепторного участка может представлять собой C-концевой остаток полипептида.
В вариантах осуществления, где существует один или несколько остатков с C-концевой стороны от акцепторного участка для сортазы полипептида, предпочтительно, чтобы указанные один или несколько остатков были удалены перед использованием полипептида в способе мечения, описанном в настоящем описании.
Термин "находящийся на N-конце", как используют в этом контексте, может означать, что C-концевой остаток донорного участка находится на расстоянии вплоть до 50 аминокислотных остатков с C-концевой стороны от N-концевого остатка полипептида, например, что N-концевой остаток донорного участка находится на расстоянии 1-50, предпочтительно 1-25 аминокислотных остатков с C-концевой стороны от N-концевого остатка полипептида. В особенно предпочтительных вариантах осуществления N-концевой остаток донорного участка может представлять собой N-концевой остаток полипептида.
В вариантах осуществления, где с N-концевой стороны от донорного участка для сортазы в полипептиде находится один или несколько остатков, предпочтительно, чтобы указанные один или несколько остатков были удалены перед применением полипептида в способе мечения, описанном в настоящем описании.
В одном варианте осуществления акцепторный или донорный участок для сортазы находится с C-концевой стороны от TM полипептида. В одном варианте осуществления акцепторный или донорный участок для сортазы находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта.
В одном варианте осуществления полипептид по изобретению содержит по меньшей мере два акцепторных участка для сортазы, по меньшей мере два донорных участка для сортазы, или по меньшей мере один акцепторный участок для сортазы и по меньшей мере один донорный участок для сортазы. Предпочтительно полипептид по изобретению содержит один акцепторный участок для сортазы и один донорный участок для сортазы. При мечении в способе по изобретению полипептиды, содержащие по меньшей мере два (предпочтительно два) участка, как описано в настоящем описании, содержат по меньшей мере две (предпочтительно две) поддающихся детекции метки. Для таких полипептидов по меньшей мере два участка предпочтительно различаются, например, один участок может представлять собой донорный участок, и один может представлять собой акцепторный участок, или альтернативно, когда по меньшей мере два участка являются одинаковыми (например, оба участка донорные или оба участка акцепторные), предпочтительно, чтобы участки имели различные аминокислотные последовательности. Это позволяет использовать различные сортазы для опосредования мечения, такие как сортазы, которые распознают различные акцепторные участки.
В одном варианте осуществления полипептид по изобретению содержит акцепторный участок для сортазы, находящийся с C-концевой стороны от TM полипептида и донорный участок для сортазы, находящийся с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта (предпочтительно нецитотоксической протеазы).
В одном варианте осуществления способ мечения полипептида включает двухстадийный процесс мечения. В одном варианте осуществления одна из стадий включает применение сортазы, которая распознает первый акцепторный участок для сортазы в полипептиде или меченом субстрате, и вторая стадия включает использование отличающейся сортазы, которая распознает отличающийся акцепторный участок полипептида или меченого субстрата. Специалисту в данной области будет понятно, что, если используют более двух различных участков для сортазы, способ может включать более двух стадий мечения и в нем может использоваться две различных сортазы, где каждая сортаза распознает один из различных акцепторных участков для сортазы.
Предпочтительно полипептид содержит акцепторный участок, содержащий (или состоящий из) LPXSG, и донорный участок, содержащий (или состоящий из) Gn, где n равен 2-5. В особенно предпочтительном варианте осуществления полипептид содержит акцепторный участок, содержащий (или состоящий из) LPESG, и донорный участок, содержащий (или состоящий из) G3.
В одном варианте осуществления способ по изобретению включает:
a. получение полипептида, содержащего акцепторный участок для сортазы и донорный участок для сортазы;
b. инкубацию полипептида с:
первой сортазой, которая распознает акцепторный участок для сортазы; и
первым меченым субстратом, содержащим донорный участок для сортазы и конъюгированную поддающуюся детекции метку;
где первая сортаза катализирует соединение аминокислоты акцепторного участка для сортазы и аминокислоты донорного участка для сортазы, с осуществлением тем самым мечения полипептида;
c. дальнейшую инкубацию полипептида с:
вторым меченым субстратом, содержащим другой акцепторный участок для сортазы и конъюгированную поддающуюся детекции метку, где акцепторный участок для сортазы отличается от акцепторного участка для сортазы в полипептиде; и
второй сортазой, которая распознает другой акцепторный участок для сортазы (и предпочтительно не распознает акцепторный участок для сортазы в полипептиде);
где вторая сортаза катализирует соединение между аминокислотой другого акцепторного участка для сортазы и аминокислотой донорного участка для сортазы, тем самым далее осуществляя мечение полипептида; и
d. получение меченого полипептида.
Специалисту в данной области будет понятно, что порядок стадий b. и c. вышеупомянутого способа может быть любым.
В другом варианте осуществления способ по изобретению включает:
a. получение полипептида, содержащего первый акцепторный участок для сортазы и второй акцепторный участок для сортазы, где первый и второй акцепторные участки для сортазы различаются;
b. инкубацию полипептида с:
первой сортазой, которая распознает первый акцепторный участок для сортазы (и предпочтительно не распознает второй акцепторный участок для сортазы); и
меченым субстратом, содержащим донорный участок для сортазы и конъюгированную поддающуюся детекции метку;
где первая сортаза катализирует соединение аминокислоты первого акцепторного участка для сортазы и аминокислоты донорного участка для сортазы, с осуществлением тем самым мечения полипептида;
c. дальнейшую инкубацию полипептида с:
второй сортазой, которая распознает второй акцепторный участок для сортазы (и предпочтительно не распознает первый акцепторный участок для сортазы); и
меченым субстратом, содержащим донорный участок для сортазы и конъюгированную поддающуюся детекции метку;
где вторая сортаза катализирует соединение аминокислоты второго акцепторного участка для сортазы с аминокислотой донорного участка для сортазы, тем самым далее осуществляя мечение полипептида; и
d. получение меченого полипептида.
Специалисту в данной области будет понятно, что порядок стадий b. и c. вышеупомянутого способа может быть любым.
На стадии c. меченый субстрат предпочтительно содержит отличающуюся поддающуюся детекции метку от меченого субстрата стадии b., например, флуорофоры различного цвета.
В другом варианте осуществления способ по изобретению включает:
a. получение полипептида, содержащего первый донорный участок для сортазы и второй донорный участок для сортазы;
b. инкубацию полипептида с:
первым меченым субстратом, содержащим первый акцепторный участок для сортазы и конъюгированную поддающуюся детекции метку; и
первой сортазой, которая распознает первый акцепторный участок для сортазы (и предпочтительно не распознает второй акцепторный участок для сортазы);
где первая сортаза катализирует соединение аминокислоты первого акцепторного участка для сортазы с аминокислотой первого или второго донорного участка для сортазы, с осуществлением тем самым мечения полипептида;
c. дальнейшую инкубацию полипептида с:
вторым меченым субстратом, содержащим второй акцепторный участок для сортазы и конъюгированную поддающуюся детекции метку, где второй акцепторный участок для сортазы отличается от первого акцепторного участка для сортазы; и
второй сортазой, которая распознает второй акцепторный участок для сортазы (и не распознает первый акцепторный участок для сортазы); и
где вторая сортаза катализирует соединение аминокислоты второго акцепторного участка для сортазы с аминокислотой первого или второго донорного участка для сортазы, тем самым далее осуществляя мечение полипептида; и
d. получение меченого полипептида.
Специалисту в данной области будет понятно, что порядок стадий b. и c. вышеупомянутого способа может быть любым.
На стадии c. меченый субстрат предпочтительно содержит отличающуюся поддающуюся детекции метку от меченого субстрата стадии b., например, флуорофоры различного цвета.
В предпочтительном варианте осуществления способ по изобретению включает:
a. получение полипептида, содержащего акцепторный участок для сортазы, содержащий LPXSG, где X представляет собой любую аминокислоту, и донорный участок для сортазы, содержащий Gn, где n равен 2-5;
b. инкубацию полипептида с:
первой сортазой, которая распознает акцепторный участок для сортазы, содержащий LPXSG (и предпочтительно не распознает акцепторный участок для сортазы, содержащий LAXTG); и
первым меченым субстратом, содержащим донорный участок для сортазы, содержащий Gn, где n равен 2-10 (предпочтительно 2-5) и конъюгированную поддающуюся детекции метку;
где первая сортаза катализирует соединение аминокислоты акцепторного участка для сортазы полипептида с аминокислотой донорного участка для сортазы первого меченого субстрата, с осуществлением тем самым мечения полипептида;
c. инкубацию полипептида с:
вторым меченым субстратом, содержащим акцепторный участок для сортазы, содержащий LAXTG, где X представляет собой любую аминокислоту, и конъюгированную поддающуюся детекции метку; и
второй сортазой, которая распознает акцепторный участок для сортазы, содержащий LAXTG (и предпочтительно не распознает акцепторный участок для сортазы, содержащий LPXSG);
где вторая сортаза катализирует соединение аминокислоты акцепторного участка для сортазы второго меченого субстрата с аминокислотой донорного участка для сортазы в полипептиде, тем самым далее осуществляя мечение полипептида; и
d. получение меченого полипептида.
Специалисту в данной области понятно, что порядок стадий b. и c. вышеупомянутого способа может быть любым.
Поддающиеся детекции метки, конъюгированные с первым и вторым мечеными субстратами, предпочтительно различаются, как например, флуорофоры разного цвета.
Специалисту в данной области будет понятно, что, когда намереваются добавить более двух поддающихся детекции меток к полипептиду, полипептид может содержать более двух участков (например, донорных или акцепторных участков) и что способ можно проводить неоднократно.
Термин "не распознает акцепторный участок для сортазы" (или его перестановки) может означать, что сортаза обладает более низкой активностью (например, расщепление или конъюгация) в отношении полипептида, содержащего данный акцепторный участок для сортазы, по сравнению с активностью в отношении полипептида сортазы, который распознает указанный участок. В одном варианте осуществления термин "не распознает акцепторный участок для сортазы" может означать, что сортаза по существу не имеет или не имеет активности (например, расщепление или конъюгация) в отношении полипептида, содержащего данный акцепторный участок для сортазы, по сравнению с активностью в отношении полипептида сортазы, который распознает указанный участок. В одном варианте осуществления термин "не распознает акцепторный участок для сортазы" (или его перестановки) может означать, что сортаза обладает более низкой активностью (например, расщепление или конъюгация) в отношении полипептида, содержащего данный акцепторный участок для сортазы, по сравнению с активностью указанной сортазы в отношении полипептида, содержащего акцепторный участок для сортазы, распознаваемый сортазой. В одном варианте осуществления термин "не распознает акцепторный участок для сортазы" может означать, что сортаза по существу не имеет или не имеет активности (например, расщепление или конъюгация) в отношении полипептида, содержащего данный акцепторный участок для сортазы, по сравнению с активностью указанной сортазы в отношении полипептида, содержащего акцепторный участок для сортазы, распознаваемый сортазой. Акцепторный участок для сортазы, распознаваемый сортазой, может представлять собой участок для сортазы, известный в данной области в качестве распознаваемого указанной сортазой.
Стадию инкубацию способа по изобретению можно проводить в любых условиях, которые позволяют успешное мечение полипептида с использованием сортазы. Такие условия могут быть определены специалистом в данной области с использованием стандартных способов/оптимизации.
Количества полипептида, сортазы и меченого субстрата для применения на стадии инкубации способа, как описано в настоящем описании, могут быть определены специалистом в данной области с использованием стандартных способов. В одном варианте осуществления способ включает применение избытка меченого субстрата для полипептида относительно сортазы, и необязательно избытка сортазы относительно полипептида. В одном варианте осуществления способ включает использование соотношения масс полипептида, сортазы и меченого субстрата 1:2:20. В другом варианте осуществления способ включает использование молярного соотношения полипептида, сортазы и меченого субстрата 1:2:20.
Условия реакции для стадии инкубации способа, как описано в настоящем описании, также могут быть определены специалистом в данной области с использованием стандартных способов. Например, реакцию можно проводить в течение по меньшей мере 2, 4, 6, 8, 10 или 12 часов. Предпочтительно реакцию можно проводить в течение по меньшей мере 10 часов. Реакцию можно проводить при 1-40°C, например, 1-37°C. В одном варианте осуществления реакцию можно проводить при 1-10°C, предпочтительно 3-5°C, например, приблизительно 4°C. Время реакции можно корректировать в зависимости от используемой температуры, например, более низкие температуры могут требовать более длительного времени инкубации.
После стадии инкубации способа по изобретению любой свободный меченый субстрат, и/или сортаза, и/или немеченый полипептид могут быть отделены от меченого полипептида. В одном варианте осуществления разделения достигают посредством метки на сортазе или меченом полипептиде, предпочтительно метки (например His-метки) на меченом полипептиде. Метка может присутствовать на меченом полипептиде, но не на немеченом полипептиде, например, где метка присутствует на меченом субстрате, конъюгированном с меченым полипептидом.
В одном варианте осуществления стадию разделения можно использовать, когда полипептид содержит два или более участков и способ включает две или более стадий инкубации/мечения. Стадию разделения можно использовать после каждой стадии инкубации/мечения.
В одном варианте осуществления способ по изобретению включает первую инкубацию и вторую инкубацию (например, как подробно описано в настоящем описании), где после первой инкубации используют первую метку для отделения меченого полипептида от немеченого полипептида. Предпочтительно первая метка отсутствует в меченом полипептиде, но присутствует в немеченом полипептиде, и немеченый полипептид может быть удален посредством иммунодеплеции. Первая метка может представлять собой Strep-метку. В одном варианте осуществления после второй инкубацию используют вторую метку для отделения двукратно меченого полипептида от любого однократно меченного (или немеченого) полипептида. Предпочтительно вторая метка присутствует в двукратно меченом полипептиде, но отсутствует в однократно меченном (или немеченом) полипептиде, и двукратно меченый полипептид может быть отделен посредством иммуноаффинной хроматографии. Вторая метка может представлять собой His-метку.
В вариантах осуществления, где полипептид для мечения с использованием сортазы содержит донорный участок для сортазы, N-конец указанного участка может быть защищен, например, посредством одного или нескольких аминокислотных остатков с N-концевой стороны от него. Преимущественно, это может препятствовать циркуляризации полипептида, дополнительно содержащего акцепторный участок для сортазы. Указанная одна или несколько аминокислот могут быть удалены посредством расщепляемого участка, такого как участок расщепления TEV, тем самым экспонируя N-конец указанного донорного участка для сортазы. Таким образом, способ по изобретению может включать стадию удаления защитной группы с N-конца донора для сортазы, например, посредством удаления одной или нескольких аминокислот с N-концевой стороны от него. Стадию удаления защитной группы можно проводить между первой и второй стадиями инкубации.
В одном варианте осуществления, когда полипептид по изобретению содержит участок расщепления (например, участок расщепления с N-концевой стороны от донорного участка для сортазы), указанный участок расщепления может представлять собой любой участок расщепления. В одном варианте осуществления участок расщепления может представлять собой участок, который является ненативным (т.е. экзогенным) для клостридиального нейротоксина. В некоторых вариантах осуществления участок расщепления представляет собой участок распознавания протеазой или его вариант при условии, что вариант расщепляется соответствующей протеазой. Участок расщепления может представлять собой участок, расщепляемый энтерокиназой, фактором Xa, вирусом гравировки табака (TEV), тромбином, PreScission, ADAM17, трипсин-подобной протеазой дыхательных путей человека (HAT), эластазой, фурином, гранзимом или каспазой 2, 3, 4, 7, 9 или 10. Участок расщепления может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с любой из SEQ ID NO: 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 или 100. В одном варианте осуществления участок расщепления может содержать полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с любой из SEQ ID NO: 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 или 100. В другом варианте осуществления участок расщепления содержит (предпочтительно состоит из) неклостридиального участка расщепления с полипептидной последовательностью, представленной в качестве любой из SEQ ID NO: 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 или 100. Предпочтительно, участок расщепления содержит (более предпочтительно состоит из) участок расщепления TEV, представленный в качестве SEQ ID NO: 87.
Сортаза для применения в рамках настоящего изобретения может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 14. В одном варианте осуществления сортаза для применения в рамках настоящего изобретения может содержать полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 14. Предпочтительно, сортаза для применения в рамках настоящего изобретения может содержать (более предпочтительно состоять из) полипептидную последовательность, представленную в качестве SEQ ID NO: 14.
Сортаза для применения в рамках изобретения может кодироваться последовательностью нуклеиновой кислоты, обладающей по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 13. В одном варианте осуществления сортаза для применения в рамках настоящего изобретения может кодироваться последовательностью нуклеиновой кислоты, обладающей по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 13. Предпочтительно сортаза для применения в рамках настоящего изобретения может кодироваться последовательностью нуклеиновой кислоты, содержащей (более предпочтительно состоящей из) последовательность нуклеиновой кислоты, представленную в качестве SEQ ID NO: 13.
Сортаза для применения в рамках настоящего изобретения может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 16. В одном варианте осуществления сортаза для применения в рамках настоящего изобретения может содержать полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 16. Предпочтительно, сортаза для применения в рамках настоящего изобретения может содержать (более предпочтительно состоять из) полипептидную последовательность, представленную в качестве SEQ ID NO: 16.
Сортаза для применения в рамках изобретения может кодироваться последовательностью нуклеиновой кислоты, обладающей по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 15. В одном варианте осуществления сортаза для применения в рамках настоящего изобретения может кодироваться последовательностью нуклеиновой кислоты, обладающей по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 15. Предпочтительно, сортаза для применения в рамках настоящего изобретения может кодироваться последовательностью нуклеиновой кислоты, содержащей (более предпочтительно состоящей из) последовательность нуклеиновой кислоты, представленную в качестве SEQ ID NO: 15.
Сортаза A может представлять собой каталитически активный полипептид, обладающий по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 31, 33 или 37. В одном варианте осуществления сортаза A может представлять собой каталитически активный полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 31, 33 или 37. Предпочтительно сортаза A может представлять собой каталитически активный полипептид, содержащий (более предпочтительно состоящий из) SEQ ID NO: 31, 33 или 37.
Настоящее изобретение может охватывать применение по меньшей мере двух сортаз (более предпочтительно двух), например, где указанные сортазы содержат полипептиды, обладающие по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 14 и 16, соответственно. В одном варианте осуществления настоящее изобретение может охватывать применение по меньшей мере двух сортаз, где указанные сортазы содержат полипептиды, обладающие по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 14 и 16, соответственно. Предпочтительно, настоящее изобретение может включать применение по меньшей мере двух сортаз, где указанные сортазы содержат (более предпочтительно состоят) полипептиды, имеющие SEQ ID NO: 14 и 16, соответственно.
Меченый субстрат для применения в способах, включающих применение сортазы, представляет собой субстрат сортазы, и содержит донорный или акцепторный участок для сортазы и конъюгирован с поддающейся детекции меткой. Когда предусматривается, что меченый субстрат предназначен для мечения полипептида, содержащего акцепторный участок для сортазы, меченый субстрат содержит донорный участок для сортазы и наоборот. Меченый субстрат может представлять собой пептид или полипептид, предпочтительно пептид.
Меченый субстрат может содержать любой из донорного или акцепторного участков для сортазы, описанных в настоящем описании. Меченый субстрат также может содержать одну или несколько меток, таких как метки для очистки (например, His-метка) для облегчения его очистки или отделения от меченого полипептида.
В одном варианте осуществления меченый субстрат содержит донорный участок для сортазы. Пример меченого субстрата, содержащего донорный участок для сортазы, приведен под SEQ ID NO: 29. Таким образом, в одном варианте осуществления предусматривается меченый субстрат, содержащий полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 29. Меченый субстрат может содержать полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 29. Предпочтительно меченый субстрат содержит (более предпочтительно состоит из) полипептидную последовательность, представленную в качестве SEQ ID NO: 29.
В одном варианте осуществления меченый субстрат содержит акцепторный участок для сортазы. Пример меченого субстрата, содержащего акцепторный участок для сортазы, представлен под SEQ ID NO: 30. Таким образом, в одном варианте осуществления предусматривается меченый субстрат, содержащий полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 30. Меченый субстрат может содержать полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 30. Предпочтительно меченый субстрат содержит (более предпочтительно состоит из) полипептидную последовательность, представленную в качестве SEQ ID NO: 30.
Акцепторный участок для сортазы предпочтительно находится на C-конце меченого субстрата. Донорный участок для сортазы предпочтительно находится на N-конце меченого субстрата.
Полипептид по изобретению предпочтительно предназначен для применения в качестве двухцепочечного полипептида, где две цепи соединены вместе посредством дисульфидной связи. В таких вариантах осуществления полипептид может содержать донорный участок для сортазы, находящийся на N-конце одной из двух полипептидных цепей. Например, двухцепочечный полипептид может содержать донорный участок для сортазы с N-концевой стороны от нецитотоксической протеазы (или ее протеолитически неактивного мутанта) и/или ее домена транслокации. В вариантах осуществления, где донорный участок для сортазы находится с N-концевой стороны от домена транслокации полипептида, донорный участок для сортазы может быть доступен для применения в способе по изобретению только после конвертирования полипептида в двухцепочечную форму (например, посредством протеолитической активации).
Термин "находящийся на C-конце", как используют в этом контексте, может означать, что C-концевой остаток акцепторного участка находится на расстоянии вплоть до 50 аминокислотных остатков с N-концевой стороны от C-концевого остатка меченого субстрата, например, что C-концевой остаток акцепторного участка находится на расстоянии 1-50, предпочтительно 10-40 аминокислотных остатков с N-концевой стороны от C-концевого остатка меченого субстрата. В особенно предпочтительных вариантах осуществления C-концевой остаток акцепторного участка может представлять собой C-концевой остаток меченого субстрата.
В вариантах осуществления, в которых существует один или несколько остатков с C-концевой стороны от акцепторного участка для сортазы меченого субстрата, предпочтительно, чтобы указанные один или несколько остатков были удалены перед использованием меченого субстрата в способе мечения, описанном в настоящем описании.
Термин "находящийся на N-конце", как используют в этом контексте, может означать, что C-концевой остаток донорного участка находится на расстоянии вплоть до 50 аминокислотных остатков с C-концевой стороны от N-концевого остатка меченого субстрата, например, что N-концевой остаток донорного участка находится на расстоянии 1-50, предпочтительно 1-25 аминокислотных остатков с C-концевой стороны от N-концевого остатка меченого субстрата. В особенно предпочтительных вариантах осуществления N-концевой остаток донорного участка может представлять собой N-концевой остаток меченого субстрата.
В вариантах осуществления, где существует один или несколько остатков с N-концевой стороны от донорного участка для сортазы в меченом субстрате, предпочтительно, чтобы указанные один или несколько остатков были удалены перед использованием меченого субстрата в способе мечения, описанном в настоящем описании.
Посредством данных для проверки и подтверждения принципа, авторы настоящего изобретения продемонстрировали, что в рамках настоящего изобретения может использоваться любой способ мечения, сходный с опосредуемым сортазой мечением, без негативного влияния на эффективность (например, связывание, транслокация и/или каталитическая активность) полипептида по изобретению. Таким образом, настоящее изобретение охватывает применение альтернативных ферментов, которые способны конъюгировать меченый полипептид с полипептидом по изобретению. Их можно использовать вместо или в дополнение к сортазе (предпочтительно дополнительно, например, когда проводят мечение в дополнительном участке). Ферменты, которые также применимы в рамках настоящего изобретения, могут включать альтернативные транспептидазы или лигазы. Таким образом, варианты осуществления, описанные в настоящем описании в отношении сортаз, могут быть применены к альтернативным транспептидазам или лигазам.
В одном варианте осуществления настоящее изобретение может охватывать применение лигазы, такой как бутелаза 1 (или ее вариант), которая представляет собой лигазу, получаемую из растений вида Clitoria ternatea и описана в Nguyen, G.K., Y. Cao, W. Wang, C.F. Liu and J.P. Tam (2015). "Site-Specific N-Terminal Labeling of Peptides and Proteins using Butelase 1 and Thiodepsipeptide." Angew Chem Int Ed Engl 54(52): 15694-15698 and Nguyen et al. (2016), Nature Protocols, 11, 10, 1977-1988, которые включены в настоящее описание в качестве ссылок. Когда изобретение включает применение транспептидазы или лигазы в альтернативной сортазе, меченый субстрат представляет собой субстрат указанной транспептидазы или лигазы, соответственно.
В вариантах осуществления, где используют бутелазу 1, полипептид содержит акцепторный или донорый участок для бутелазы 1, и используется меченый субстрат, содержащий донорный или акцепторный участок для бутелазы 1 и конъюгированную поддающуюся детекции метку. Аналогично способам, включающим применение сортазы, где полипептид содержит акцепторный участок для бутелазы, меченый субстрат, содержащий конъюгированную поддающуюся детекции метку, содержит донорный участок для бутелазы (и наоборот). В таких вариантах осуществления меченый субстрат представляет собой субстрат бутелазы (например, бутелазы 1).
Бутелаза осуществляет расщепление между Asn/Asp и His C-концевой консенсусной последовательности Asn/Asp-His-Val, и она может лигировать полипептид, содержащий N-концевую аминокислотную последовательность Xaa-(Ile/Leu/Val/Cys), где Xaa представляет собой любую аминокислоту кроме пролина, с образованием связи между Asn/Asp-Xaa-(Ile/Leu/Val/Cys). В одном варианте осуществления акцепторный участок для бутелазы содержит (или состоит из) Asn/Asp-His-Val. В одном варианте осуществления донорный участок для бутелазы содержит (или состоит из) Xaa-(Ile/Leu/Val/Cys), где Xaa представляет собой любую аминокислоту кроме пролина.
В контексте участков бутелазы Xaa может быть выбрана (например) из стандартных аминокислот: аспарагиновая кислота, глутаминовая кислота, аргинин, лизин, гистидин, аспарагин, глутамин, серин, треонин, тирозин, метионин, триптофан, цистеин, аланин, глицин, валин, лейцин, изолейцин и фенилаланин.
Таким образом, предусматривается способ получения меченого полипептида, причем способ включает:
a. получение полипептида, содержащего:
i. акцепторный или донорный участок для бутелазы;
ii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации;
b. инкубацию полипептида с:
бутелазой (например, бутелазой 1); и
меченым субстратом, содержащим донорный или акцепторный участок для бутелазы и конъюгированную поддающуюся детекции метку;
где бутелаза катализирует конъюгацию между аминокислотой акцепторного участка бутелазы и аминокислотой донорного участка бутелазы, с осуществлением тем самым мечения полипептида; и
c. получение меченого полипептида.
В другом аспекте изобретение относится к полипептиду для мечения бутелазой, содержащему:
акцепторный или донорный участок для бутелазы;
нецитотоксическую протеазу, которая способна расщеплять белок аппарата экзоцитарного слияния в клетке-мишени, или ее протеолитически неактивный мутант;
нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
домен транслокации, который способен транслоцировать нецитотоксическую протеазу из эндосомы через эндосомальную мембрану и в цитозоль клетки-мишени;
где, когда полипептид содержит донорный участок для бутелазы, донорный участок для бутелазы находится на N-конце полипептида; и
где N-концевой остаток донорного участка представляет собой N-концевой остаток полипептида; или
где полипептид содержит один или несколько аминокислотных остатков с N-концевой стороны от донорного участка для бутелазы и участок расщепления, который при расщеплении экспонирует N-конец донорного участка для бутелазы.
Изобретение также относится к меченому полипептиду, причем полипептид содержит:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. аминокислотную последовательность, которая содержит Asn/Asp-Xaa-(Ile/Leu/Val/Cys), где Xaa представляет собой любую аминокислоту кроме пролина;
iii. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
iv. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
v. домен транслокации.
Таким образом, меченый полипептид может содержать поддающуюся детекции метку, конъюгированную с или вблизи аминокислотной последовательности, которая содержит (или состоит из) Asn/Asp-Xaa-(Ile/Leu/Val/Cys), где Xaa представляет собой любую аминокислоту кроме пролина.
В одном варианте осуществления транспептидазу или лигазу, такую как бутелаза 1, используют в комбинации с сортазой для получения полипептида, имеющего две или более меток. Таким образом, в одном варианте осуществления полипептид по изобретению может содержать по меньшей мере один акцепторный или донорный участок для сортазы, как описано в настоящем описании, и по меньшей мере один акцепторный или донорный участок для бутелазы (например, бутелазы 1).
Бутелаза 1 может представлять собой каталитически активный полипептид, содержащий полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 27 или 28 (предпочтительно SEQ ID NO: 28). В одном варианте осуществления бутелаза 1 может содержать полипептидную последовательность, обладающую по меньшей мере 80%, 90% или 95% идентичностью последовательности с SEQ ID NO: 27 или 28 (предпочтительно SEQ ID NO: 28). Предпочтительно бутелаза 1 может содержать (более предпочтительно состоять из) полипептидную последовательность, представленную в качестве SEQ ID NO: 27 или 28 (предпочтительно SEQ ID NO: 28).
Другие лигазы могут включать PATG (SEQ ID NO: 41), PCY1 (SEQ ID NO: 42), POPB (SEQ ID NO: 43) или гомолог бутелазы OaAEP1b SEQ ID NO: 44 и 45) (Harris et al (2015), Nat Commun, 6, 10199). Когда указанные лигазы имеют сигнальный пептид или другую N-концевую лидерную последовательность, указанный сигнальный пептид или лидерную последовательность предпочтительно удаляют перед применением в рамках настоящего изобретения.
POPB, а также подходящие способы ее применения описаны в данной области. Например, они описаны в Luo H (2014), Chemistry and Biology 21: 1610-1617, которая включена в настоящее описание в качестве ссылки.
Таким образом, лигаза для применения в рамках настоящего изобретения может содержать полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с любой из SEQ ID NO: 41-44. В одном варианте осуществления лигаза может содержать полипептидную последовательность, обладающую по меньшей мере 80%, 90% или 95% идентичностью последовательности с любой из SEQ ID NO: 41-44. Предпочтительно лигаза может содержать (более предпочтительно состоять из) полипептидную последовательность, показанную в качестве любой из SEQ ID NO: 41-44.
Настоящее изобретение охватывает применение любой подходящей поддающейся детекции метки, известной специалисту в данной области. Поддающаяся детекции метка может представлять собой метку, детекцию которой можно проводить визуально вследствие оптических свойств метки. Детекцию такой метки можно проводить с использованием флуоресцентных способов, например, флуоресцентной микроскопии. Таким образом, в особенно предпочтительном варианте осуществления поддающаяся детекции метка представляет собой флуорофор. Предпочтительно поддающаяся детекции метка представляет собой (или содержит) флуоресцентный краситель, такой как флуоресцентные красители HiLyte (коммерчески доступные от AnaSpec), AlexaFluor (коммерчески доступный от Thermo Fisher), Atto (коммерчески доступный от Sigma-Aldrich), Quantum Dots, коммерчески доступный от Sigma-Aldrich), красители Janelia Fluor (available from Janelia, US), среди прочих. В предпочтительном варианте осуществления поддающаяся детекции метка не содержит полисахарид, и/или многоатомный спирт, и/или бактериальный или вирусный полимер (например, полисахарид или полипептид).
В одном аспекте изобретение также относится к способу анализа полипептида по настоящему изобретению, причем способ включает:
a. приведение клетки-мишени в контакт с меченым полипептидом по изобретению; и
b. детекцию поддающейся детекции метки.
Такие способы можно проводить in vitro или in vivo (например, у млекопитающего, такого как не являющееся человеком млекопитающее, например, мышь). Предпочтительно способы проводят in vitro. При проведении in vivo способ может включать извлечение образца ткани для анализа ex vivo.
Способы по изобретению предпочтительно проводят с использованием живых клеток/тканей, предпочтительно в реальном времени. Преимущественно указанные способы позволяют определение связывания, перемещения и транслокации полипептида по изобретению.
Способ может представлять собой эксперимент "пульс-чейз" или включать импульсную стадию (например, включающую применение меченого полипептида) и стадию отслеживания (например, не включающую применение меченого полипептида и необязательно включающую применение немеченого полипептида).
Детекция поддающейся детекции метки позволяет детекцию полипептида или его части. Например, когда полипептид содержит первую поддающуюся детекции метку, конъюгированную с нецитотоксической протеазой или ее протеолитически неактивным мутантом, и вторую поддающуюся детекции метку, конъюгированную с доменом транслокации или TM, способ может включать детекцию обеих указанных поддающихся детекции меток.
Способ по изобретению может включать детекцию наличия или отсутствия совместной локализации двух или более поддающихся детекции меток. Детекцию можно осуществлять с использованием любого способа, известного специалисту в данной области (например, FRET и сходные способы). В одном варианте осуществления способ по изобретению включает детекцию изменения совместной локализации двух или более поддающихся детекции меток, например, с течением времени. В вариантах осуществления, где полипептид содержит первую поддающуюся детекции метку, конъюгированную с нецитотоксической протеазой или ее протеолитически неактивным мутантом, и вторую поддающуюся детекции метку, конъюгированную с доменом транслокации или TM, детекция уменьшения совместной локализации первой и второй поддающихся детекции меток (например, с течением времени) может позволить определение транслокации нецитотоксической протеазы или ее протеолитически неактивного мутанта из эндосомы. Время, которое отнимает такое изменение совместной локализации, может использоваться для определения скорости транслокации. Детекция отсутствия изменения (например, по существу отсутствия изменения) совместной локализации может указывать на то, что транслокация не произошла.
Способ может включать детекцию присутствия первой поддающейся детекции метки в цитозоле клетки и/или второй поддающейся детекции метки в эндосоме клетки, которая может быть осуществлена посредством анализа транслокации. Аналогично, детекция первой и второй поддающихся детекции меток (совместная локализация) в эндосоме может указывать на то, что произошел успешный эндоцитоз полипептида.
В некоторых вариантах осуществления способ по изобретению может включать количественное определение поддающейся детекции метки, например в конкретном положении в клетке и/или на протяжении конкретного периода времени. Такое количественное определение можно проводить посредством детекции интенсивности поддающейся детекции метки в конкретном положении в клетке (например, с течением времени). Альтернативно или дополнительно, количественное определение можно проводить посредством определения количества или размера агломератов, содержащих указанную поддающуюся детекции метку, присутствующих к клетке.
В одном варианте осуществления способ по изобретению включает:
i) приведение в контакт клетки-мишени с меченым полипептидом по изобретению, который подлежит оценке в отношении способности высвобождения из эндосомы, где указанная клетка-мишень содержит клеточную мембрану, включающую участок связывания, присутствующий на наружной поверхности клеточной мембраны указанной клетки;
ii) инкубацию меченого полипептида с указанной клеткой-мишени, тем самым позволяя
a) меченому полипептиду связывать и образовывать связанный комплекс с участком связывания, присутствующим на клетке-мишени, тем самым позволяя указанному связанному комплексу входить в клетку-мишень посредством эндоцитоза;
b) образовываться одной или нескольким эндосомам в указанной клетке, где одна или несколько эндосом содержат меченый полипептид; и
c) входить указанному меченому полипептиду в цитозоль клетки-мишени посредством прохождения через эндосомальную мембрану одной или нескольких эндосом;
iii) удаление избытка меченого полипептида, который не связался с участками связывания, присутствующими на клетках-мишенях;
iv) детекцию через определенный период времени количества меченого полипептда, присутствующего в одной или нескольких эндосомах, или детекцию количества меченого полипептида, присутствующего в цитозоле указанной клетки-мишени;
v) сравнение количества меченого полипептида, выявленного на стадии iv), с контрольной величиной, где указанная контрольная величина представляет собой количество меченого полипептида, присутствующее водной или нескольких эндосомах, или количество меченого полипептида, присутствующего в цитозоле перед стадией iv);
vi) вычисление величины высвобождения из эндосом для меченого полипептида посредством определения относительного изменения количества меченого полипептида, которое присутствует в одной или нескольких эндосомах, или посредством определения относительного изменения количества меченого полипептида, присутствующего в цитозоле указанной клетки-мишени.
Клетка-мишень может представлять собой эукариотическую клетку, такую как клетка млекопитающего, например, клетка-мишень, описанная в настоящем описании.
Стадию инкубации ii) можно проводить в течение любого данного периода времени, например, в течение периода времени от 5 минут до 5 суток. Типичный период времени составляет 1-12 часов, например 2-10 часов, 4-8 часов, или 6-8 часов. В ходе этого периода клетка-мишень (т.е. наружная поверхность клеточной мембраны) может подвергаться воздействию меченого полипептида (как правило, избытка меченого полипептида) с результатом в виде достижения "стационарного состояния", при котором меченый полипептид входит в и покидает внутриклеточные эндосомы приблизительно с одной скоростью. Этот момент времени соответствует оптимальному моменту времени для проведения стадий iii) и/ или iv).
Стадия iii) может вовлекать сокращение или устранение источника меченого полипептида снаружи клетки-мишени, тем самым уменьшая количество меченого полипептида, входящего в клетку (или по существу препятствуя ему). Указанное уменьшение количества меченого полипептида, входящего в клетку-мишень, в свою очередь обеспечивает изменение количества меченого полипептида, входящего в эндосому, что в свою очередь приводит к изменению количества (или скорости) меченого полипептида, выходящего из эндосом и/или входящего в цитозоль клетки-мишени. Оно представляет собой количество (или скорость) меченого полипептида, покидающего структуры эндосом, которое в одном варианте осуществления может стать основой анализа - указанное количество (или скорость) меченого полипептида, покидающего структуры эндосом, можно измерять по изменению количества меченого полипептида, присутствующего в эндосомах и/ или по изменению количества меченого полипептида, присутствующего в цитозоле. При измерении количества меченого полипептида, присутствующего в эндосомах, как правило, наблюдают уменьшение количества присутствующего меченого полипептида. При измерении количества меченого полипептида, присутствующего в цитозоле, можно наблюдать увеличение или уменьшение количества меченого полипептида, присутствующего в цитозоле. В качестве примера, увеличение количества меченого полипептида в цитозоле может наблюдаться, когда стадию iii) начинают до установления стационарного эндосомального транспорта меченого полипептида. Альтернативно уменьшение количества меченого полипептида в цитозоле может наблюдаться, когда скорость клеточной секреции меченого полипептида из клетки-мишени превышает скорость эндосомального транспорта меченого полипептида из эндосом в цитозоль.
Клетки-мишени, используемые в анализе, могут быть иммобилизованы на поверхности. Иммобилизацию клеток можно проводить в качестве стадии до анализа (т.е. до иммобилизации), или ее можно проводить в качестве части протокола анализа. Таким образом, в одном варианте осуществления, клетки в анализе являются предварительно иммобилизованными. Иммобилизацию клеток-мишеней можно проводить любыми общепринятыми способами. В качестве примера, клетки высевают в планшеты для анализа с высокой плотностью, и перед проведением анализа им позволяют прикрепиться. Альтернативно клетки высевают на чашки для анализа и культивируют в течение нескольких суток перед применением для получения смыкающегося монослоя. Прикрепление клеток может быть усилено с использованием общепринятых покрытий, таких как чашки, покрытые поли-D-лизином.
В одном варианте осуществления иммобилизацию клеток-мишеней можно проводить до или в ходе стадии iii), тем самым обеспечивая простое средство для отделения указанных клеток от свободного от клеток (например, несвязанного или экзогенного) меченого полипептида. Альтернативно иммобилизацию можно проводить после стадии iii), например, для упрощения стадии детекции iv).
Стадия iii) может включать стадию фильтрования или стадию с аффинном лигандом, в ходе которой клетки отделяют от избыточного (например, несвязанного или экзогенного) меченого полипептида. Стадия iii) может включать стадию промывания, в которой избыточный (например, несвязанный или экзогенный) меченый полипептид вымывают из клеток-мишеней, например с использованием общепринятого буфера. Подразумевается, что избыточный меченый полипептид означает меченый полипептид, который присутствует в среде для анализа снаружи клеток-мишеней и который еще не связался с участком связывания, присутствующим на поверхности клеток-мишеней.
Детекцию меченого полипептида на стадии iv), как правило, проводят вскоре после стадии iii). В качестве примера, типичный период времени для стадии iv) составляет от 5 минут до 5 часов после стадии iii). В одном варианте осуществления стадию iv) проводят в течение 15-240 минут, или 30-180 минут, или 45-150 минут после стадии iii). Стадию детекции iv) можно повторять на протяжении нескольких временных интервалов, например, с интервалами 10 минут, или 15 минут, или 30 минут - это позволит вычисление скорости эндосомального высвобождения.
Стадию детекции iv) можно проводить любыми общепринятыми способами. Детекция меченого полипептида может быть основана на внутриклеточной локализации указанного меченого полипептида.
В стадии сравнения v) используется контрольная величина, которая соответствует количеству меченого полипептида, присутствующего в эндосомах и/ или цитозоле до стадии детекции iv). Контрольную величину, как правило, определяют посредством тех же средств/способа, посредством которых определяют количество меченого полипептида на стадии детекции iv). Контрольная величина, как правило, соответствует количеству меченого полипептида, присутствующего в эндосомах и/или цитозоле на входе или до стадии iii). В качестве примера, контрольная величина может соответствовать количеству меченого полипептида, присутствующего в эндосомах и/или цитозоле в ходе или в конце стадии ii) - в одном варианте осуществления контрольная величина соответствует количеству меченого полипептида, который присутствует в эндосомах и/или цитозоле после установления "стационарной" скорости транслокации, а именно, когда меченый полипептид входит в и покидает внутриклеточные эндосомы приблизительно с одинаковой скоростью.
В вышеуказанных вариантах осуществления термин "меченый полипептид" также может охватывать его часть, такую как нецитотоксический протеазный домен, домен транслокации или TM (например, домен транслокации и TM). Способы также могут включать детекцию двух или более меток, таких как метка на одной части полипептида и метка на второй части полипептида.
В одном варианте осуществления способ по изобретению также может включать анализ расщепления белка аппарата экзоцитарного слияния (например, белка SNARE).
Детекцию поддающейся детекции метки можно проводить с использованием любых подходящих способов, известных специалисту в данной области. В одном варианте осуществления для детекции поддающейся детекции метки используют микроскопию. Способы детекции поддающейся детекции метки могут включать любой подходящий световой, конфокальный (предпочтительно прижизненная конфокальная 3D-микроскопия) способ визуализации, способ визуализации сверхвысокого разрешения или способ визуализации единичных молекул (например, световая микроскопия, конфокальная микроскопия, микроскопия сверхвысокого разрешения или микроскопия единичных молекул). В способах по изобретению могут использоваться такие микроскопы, как STED, PALM, STORM и TIRF. Такие способы микроскопии являются хорошо отработанными и имеют высокое разрешение.
Подразумевают, что термин "протеолитически неактивный мутант" охватывает мутант нецитотоксической протеазы, который демонстрирует значительно сниженное расщепление белков аппарата экзоцитарного слияния в клетке-мишени по сравнению с ее немутантной формой. Предпочтительно, протеолитически неактивный мутант включает протеолитически неактивную L-цепь клостридиального нейротоксина. В одном варианте осуществления протеолитически неактивный мутант может содержать L-цепь SEQ ID NO: 38 или 40.
В одном варианте осуществления "протеолитически неактивный мутант" по существу не обладает активностью нецитотоксической протеазы, предпочтительно не обладает активностью нецитотоксической протеазы. Термин "по существу не обладает активностью нецитотоксической протеазы" означает, что протеолитически активный мутант имеет менее чем 5% от активности нецитотоксической протеазы его немутантной (т.е. протеолитически активной) формы, например, менее 2%, 1% или предпочтительно 0,1% от активности нецитотоксической протеазы его немутантной формы. Активность нецитотоксической протеазы может быть определена in vitro посредством инкубации мутанта нецитотоксической протеазы с белком SNARE и сравнения количества белка SNARE, расщепленного тестируемой нецитотоксической протеазой, с количеством белка SNARE, расщепленного его немутантной (т.е. протеолитически активной) формой в тех же условиях. Для количественного определения расщепленного белка SNARE можно использовать стандартные способы, такие как SDS-PAGE и вестерн-блоттинг. Подходящие способы анализа in vitro описаны в WO 2019/145577 A1, которая включена в настоящее описание в качестве ссылки. Альтернативно или дополнительно, можно использовать клеточный анализ, описанный в настоящем описании.
В одном варианте осуществления протеолитически неактивный мутант может иметь одну или несколько мутаций, которые инактивируют протеазу. Например, протеолитически неактивный мутант нецитотоксической протеазы может содержать L-цепь BoNT/A, содержащую мутацию остатка активного центра, такую как His223, Glu224, His227, Glu262 и/или Tyr366. Нумерация положений соответствует положениям аминокислот SEQ ID NO: 17 и может быть установлена посредством выравнивания полипептида с SEQ ID NO: 17.
Полипептид по изобретению предпочтительно обладает одной или несколькими видами активности, ассоциированными с клостридиальным нейротоксином (например, ботулиническим нейротоксином). Иными словами, полипептид по изобретению может представлять собой активный нейротоксин. Например, полипептид по изобретению может отщеплять белок от аппарата экзоцитарного слияния клетки-мишени, может быть способным связываться с участком связывания на клетке-мишени и/или может обладать активностью транслокации. Предпочтительно, полипептид по изобретению может расщеплять белок аппарата экзоцитарного слияния в клетке-мишени, может быть способным связывать участок связывания на клетке-мишени и может обладать активностью транслокации. Таким образом, предпочтительно полипептид не подвергается (и не подвергался) детоксикационной обработке. Например, полипептид может не быть (и мог не быть) химически инактивированным и/или инактивированным нагреванием. В одном варианте осуществления полипептид не приводят в контакт (и не приводили в контакт) с сшивающим агентом, более предпочтительно, полипептид не приводят в контакт (и не приводили в контакт) с формальдегидом.
Полипептид, описанный в настоящем описании, предпочтительно содержит нецитотоксическую протеазу, которая способна расщеплять белок аппарата экзоцитарного слияния в клетке-мишени.
Нацеливающая часть (TM) полипептида по изобретению предпочтительно способна связываться с участком связывания на клетке-мишени, который способен претерпевать эндоцитоз для включения в эндосому в клетке-мишени.
Домен транслокации предпочтительно способен к транслокации нецитотоксической протеазы из эндосомы через эндососмальную мембрану и в цитозоль клетки-мишени.
В предпочтительном варианте осуществления нецитотоксическая протеаза полипептида, описанного в настоящем описании, содержит L-цепь клостридиального нейротоксина. Более предпочтительно, L-цепь клостридиального нейротоксина представляет собой L-цепь ботулинического нейротоксина.
В предпочтительном варианте осуществления домен транслокации полипептида, описанного в настоящем описании, содержит домен транслокации клостридиального нейротоксина. Более предпочтительно, домен транслокации клостридиального нейротоксина представляет собой домен транслокации ботулинического нейротоксина.
В одном варианте осуществления полипептид, описанный в настоящем описании, лишен функционального HC-домена клостридиального нейротоксина.
В альтернативном варианте осуществления полипептид, описанный в настоящем описании, содержит TM связывающего домена (HC-домена) клостридиального нейротоксина. Более предпочтительно, TM связывающего домена (HC-домена) клостридиального нейротоксина представляет собой TM связывающего домена (HC-домена) ботулинического нейротоксина.
Таким образом, в предпочтительном варианте осуществления полипептид, описанный в настоящем описании, содержит L-цепь клостридиального нейротоксина, домен транслокации клостридиального нейротоксина и неклостридиальную TM.
В равной степени предпочтительном альтернативном варианте осуществления полипептид, описанный в настоящем описании, содержит L-цепь клостридиального нейротоксина и H-цепь клостридиального нейротоксина (имеющую домен транслокации клостридиального нейротоксина [HN] и HC-домен). В таких вариантах осуществления полипептид, описанный в настоящем описании, представляет собой клостридиальный нейротоксин.
Более предпочтительно, полипептид, описанный в настоящем описании, содержит L-цепь ботулинического нейротоксина, домен транслокации ботулинического нейротоксина и неклостридиальную TM.
В равной степени предпочтительном альтернативном варианте осуществления полипептид, описанный в настоящем описании, содержит L-цепь ботулинического нейротоксина и H-цепь ботулинического нейротоксина (имеющую домен транслокации ботулинического нейротоксина [HN] и HC-домен). В таких вариантах осуществления полипептид, описанный в настоящем описании, представляет собой ботулинический нейротоксин.
Предпочтительно полипептид представляет собой ботулинический нейротоксин (BoNT), дополнительно содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1). BoNT может представлять собой один или несколько, выбранных из BoNT/A, BoNT/B, BoNT/C, BoNT/D, BoNT/E, BoNT/F, BoNT/G или BoNT/X. Также предусматриваются их варианты, включающие протеолитически неактивный мутант нецитотоксической протеазы.
Предпочтительно полипептид представляет собой ботулинический нейротоксин (BoNT), дополнительно содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1). BoNT может представлять собой один или несколько, выбранных из BoNT/A, BoNT/B, BoNT/C, BoNT/D, BoNT/E, BoNT/F, BoNT/G или BoNT/X. Также предусматриваются их варианты, включающие протеолитически неактивный мутант нецитотоксической протеазы.
Альтернативно полипептид может представлять собой столбнячный нейротоксин (TeNT), дополнительно содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1). Также предусматриваются его варианты, содержащие протеолитически неактивный мутант нецитотоксической протеазы.
Альтернативно полипептид может представлять собой столбнячный нейротоксин (TeNT), дополнительно содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1). Также предусматриваются его варианты, содержащие протеолитически неактивный мутант нецитотоксической протеазы.
Репрезентативные полипептидные последовательности для BoNT/A, BoNT/B, BoNT/C, BoNT/D, BoNT/E, BoNT/F, BoNT/G, BoNT/X и TeNT описаны в настоящем описании в качестве SEQ ID NO: 17-25, соответственно. Указанные полипептидные последовательности могут быть модифицированы включением акцепторного или донорного участка для сортазы для применения в рамках настоящего изобретения.
Полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с любой из SEQ ID NO: 17-25. В одном варианте осуществления полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с любой из SEQ ID NO: 17-25. Предпочтительно полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно включает полипептид, содержащий (более предпочтительно состоящий из) любую из SEQ ID NO: 17-25.
Полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с любой из SEQ ID NO: 17-25. В одном варианте осуществления полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с любой из SEQ ID NO: 17-25. Предпочтительно полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно включает полипептид, содержащий (более предпочтительно состоящий из) любую из SEQ ID NO 17-25.
Альтернативно полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 38. В одном варианте осуществления полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 38. Предпочтительно полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, LPXTGS, где X представляет собой любую аминокислоту, NPKTG, XPETG, LGATG, IPNTG, IPETG, NSKTA, NPQTG, NAKTN, NPQSS, LPXTX, где X представляет собой любую аминокислоту, NPX1TX2, где X1 представляет собой Lys или Gln и X2 представляет собой Asn, Asp или Gly, X1PX2X3G, где X1 представляет собой Leu, Ile, Val или Met, X2 представляет собой любую аминокислоту и X3 представляет собой Ser, Thr или Ala, LPEX1G, где X1 представляет собой Ala, Cys или Ser, LPXS, LAXT, MPXT, MPXTG, LAXS, NPXT, NPXTG, NAXT, NAXTG, NAXS, NAXSG, LPXP, LPXPG, где X представляет собой любую аминокислоту, LRXTGn или LPAXGn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1 (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно включает полипептид содержащий (более предпочтительно состоящий из) SEQ ID NO: 38.
Альтернативно полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 38. В одном варианте осуществления полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно содержит полипептидную последовательность, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 38. Предпочтительно полипептид по изобретению может представлять собой полипептид, содержащий акцепторный и/или донорный участок для сортазы и/или поддающуюся детекции метку, конъюгированную с ним, и аминокислотную последовательность, которая содержит L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен по меньшей мере 1, NPQTN, YPRTG, IPQTG, VPDTG, или LPXTGS, где X представляет собой любую аминокислоту (более предпочтительно L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен по меньшей мере 1) и где полипептид дополнительно включает полипептид содержащий (более предпочтительно состоящий из) SEQ ID NO: 38.
Полипептиды, описанные в настоящем описании (или нуклеотидные последовательности, кодирующие их) могут содержать одну или несколько меток (например, меток для очистки), таких как His-метка или Strep-метка. Подразумевается, что настоящее изобретение также охватывает полипептидные последовательности (и нуклеотидные последовательности, кодирующие их), из которых метка удалена, например, перед их применением. Полипептид также может содержать один или несколько участков расщепления, таких как участок расщепления TEV, для упрощения удаления метки.
Настоящее изобретение является пригодным для применения для многих различных типов клостридиального нейротоксина. Таким образом, в контексте настоящего изобретения, термин "клостридиальный нейротоксин" охватывает токсины, продуцируемые C. botulinum (ботулинический нейротоксин серотипов A, B, C1, D, E, F, G, H и X), C. tetani (столбнячный нейротоксин), C. butyricum (ботулинический нейротоксин серотипа E), и C. baratii (ботулинический нейротоксин серотипа F), а также модифицированные клостридиальные нейротоксины или производные, происходящие из любого из вышеуказанных. Термин "клостридиальный нейротоксин" также охватывает ботулинический нейротоксин серотипа H. Предпочтительно клостридиальный нейротоксин не является BoNT/C1.
Ботулинический нейротоксин (BoNT) продуцируется C. botulinum в форме крупного белкового комплекса, состоящего из самого BoNT в комплексе с рядом вспомогательных белков. В настоящее время существует девять различных классов ботулинического нейротоксина, а именно: серотипы ботулинического нейротоксина A, B, C1, D, E, F, G, H и X, все из которых обладают сходными структурами и способами действия. Различные серотипы BoNT могут различаться на основе инактивации посредством специфической нейтрализующей антисыворотки, причем такая классификация по серотипам коррелирует с процентной идентичностью последовательностей на уровне аминокислот. Белки BoNT данного серотипа далее подразделяют на различные серотипы на основе процентной идентичности аминокислотных последовательностей.
BoNT всасываются в желудочно-кишечном тракте и после проникновения в общий кровоток связываются с пресинаптической мембраной холинэргических нервных окончаний и препятствует высвобождению их нейротрансмиттера ацетилхолина. BoNT/B, BoNT/D, BoNT/F и BoNT/G расщепляют синаптобревин/ассоциированный с везикулами белок (VAMP); BoNT/C1, BoNT/A и BoNT/E расщепляют ассоциированный с синаптосомами белок размером 25 кДа (SNAP-25); и BoNT/C1 расщепляет синтаксин. Было обнаружено, что BoNT/X расщепляет SNAP-25, VAMP1, VAMP2, VAMP3, VAMP4, VAMP5, Ykt6 и синтаксин 1.
Столбнячный токсин продуцируется в одном серотипе C. tetani. C. butyricum продуцируют BoNT/E, в то время как C. baratii продуцируют BoNT/F.
Также подразумевается, что термин "клостридиальный нейротоксин" охватывает модифицированные клостридиальные нейротоксины и их производные, включая, но не ограничиваясь ими, нейротоксины, описанные ниже. Модифицированный клостридиальный нейротоксин или производное может содержать одну или несколько аминокислот, которые модифицированы по сравнению с нативной (немодифицированной) формой клостридиального нейротоксина, или может содержать одну или несколько встроенных аминокислот, которые не присутствуют в нативной (немодифицированной) форме клостридиального нейротоксина. В качестве примера, модифицированный клостридиальный нейротоксин может иметь модифицированные аминокислотные последовательности в одном или нескольких доменах относительно нативной (немодифицированной) последовательности клостридиального нейротоксина. Такие модификации могут модифицировать функциональные аспекты токсина, например биологическую активность или стабильность. Таким образом, в одном варианте осуществления полипептид по изобретению представляет собой модифицированный клостридиальный нейротоксин или модифицированное производное клостридиального нейротоксина, или производное клостридиального нейротоксина.
Модифицированный клостридиальный нейротоксин может иметь одну или несколько модификаций в аминокислотной последовательности тяжелой цепи (такой как модифицированный домен HC), где указанная модифицированная тяжелая цепь связывается с нервными клетками, являющимися мишенями, с более высокой или более низкой аффинностью, чем нативный (немодифицированный) клостридиальный нейротоксин. Такие модификации в HC-домене могут включать модификацию остатков в ганглиозид-связывающем участке HC-домена или в связывающем белок (SV2 или синаптотагмин) участке, которая изменяет связывание с рецептором ганглиозида и/или рецептором белка нервной клетки, являющейся мишенью. Примеры таких модифицированных клостридиальных нейротоксинов описаны в WO 2006/027207 и WO 2006/114308, обе из которых включены в настоящее описание в качестве ссылок в полном объеме.
Модифицированный клостридиальный нейротоксин может иметь одну или несколько модификаций в аминокислотной последовательности легкой цепи, например, модификации в связывающем субстрат или каталитическом домене, которые могут изменять или модифицировать специфичность модифицированной L-цепи в отношении белка SNARE. Примеры таких модифицированных клостридиальных нейротоксинов описаны в WO 2010/120766 и US 2011/0318385, обе из которых включены в настоящее описание в качестве ссылок в полном объеме.
Модифицированный клостридиальный нейротоксин может содержать одну или несколько модификаций, которые повышают или снижают биологическую активность и/или биологическую стабильность модифицированного клостридиального нейротоксина. Например, модифицированный клостридиальный нейротоксин может содержать мотив на основе лейцина или тирозина, где указанный мотив повышает или снижает биологическую активность и/или биологическую стабильность модифицированного клостридиального нейротоксина. Подходящие мотивы на основе лейцина включают xDxxxLL (SEQ ID NO: 79), xExxxLL (SEQ ID NO: 80), xExxxIL (SEQ ID NO: 81) и xExxxLM (SEQ ID NO: 82) (где x представляет собой любую аминокислоту). Подходящие мотивы на основе тирозина включают Y-x-x-Hy (SEQ ID NO: 83) (где Hy представляет собой гидрофобную аминокислоту). Примеры модифицированных клостридиальных нейротоксинов, содержащих мотивы на основе лейцина и тирозина, описаны в WO 2002/08268, которая включена в настоящее описание в качестве ссылки в полном объеме.
Подразумевается, что термин "клостридиальный нейротоксин" охватывает гибридные и химерные клостридиальные нейротоксины. Гибридный клостридиальный нейротоксин содержит по меньшей мере часть легкой цепи из одного клостридиального нейротоксина или его подтипа, и по меньшей мере часть тяжелой цепи из другого клостридиального нейротоксина или подтипа клостридиального нейротоксина. В одном варианте осуществления гибридный клостридиальный нейротоксин может содержать всю легкую цепь из одного подтипа клостридиального нейротоксина и тяжелую цепь из другого подтипа клостридиального нейротоксина. В другом варианте осуществления химерный клостридиальный нейротоксин может содержать часть (например, связывающий домен) тяжелой цепи одного подтипа клостридиального нейротоксина, причем другая часть тяжелой цепи происходит из другого подтипа клостридиального нейротоксина. Аналогично или альтернативно, терапевтический элемент может содержать части легких цепей из различных клостридиальных нейротоксинов. Такие гибридные или химерные клостридиальные нейротоксины являются пригодными, например, в качестве средств для обеспечения терапевтической пользы таких клостридиальных нейротоксинов у пациентов, которые являются иммунологически резистентными к данному подтипу клостридиального нейротоксина, у пациентов, которые могут иметь более низкую чем средняя концентрация рецепторов к данному связывающему тяжелую цепь домену клостридиального нейротоксина, или у пациентов, которые могут иметь резистентный к протеазам вариант мембранного или везикулярного субстрата токсина (например, SNAP-25, VAMP и синтаксин). Гибридные и химерные клостридиальные нейротоксины описаны в US 8071110, которая включена в настоящее описание в качестве ссылки в полном объеме. Таким образом, в одном варианте осуществления сконструированный клостридиальный нейротоксин по изобретению представляет собой сконструированный гибридный клостридиальный нейротоксин или сконструированный химерный клостридиальный нейротоксин.
Также предусматривается, что термин "клостридиальный нейротоксин" охватывает вновь открытые представители белкового семейства ботулинических нейротоксинов, экспрессируемые неклостридиальными микроорганизмами, такие как кодируемый Enterococcus токсин, который имеет наиболее высокую идентичность последовательности с BoNT/X, кодируемый Weissella oryzae токсин, называемый BoNT/Wo (NCBI Ref Seq: WP_027699549.1), который расщепляет VAMP2 в W89-W90, кодируемый Enterococcus faecium токсин (GenBank: OTO22244.1), который расщепляет VAMP2 и SNAP25, и кодируемый Chryseobacterium pipero токсин (NCBI Ref.Seq: WP_034687872.1).
"Биологически активный" компонент полипептидов по настоящему изобретению обеспечивается нецитотоксической протеазой. Эта обособленная группа протеаз действует посредством протеолитического расщепления внутриклеточных транспортных белков, известных как белки SNARE (например, SNAP-25, VAMP или синтаксин) - см. Gerald K (2002) "Cell and Molecular Biology" (4th edition) John Wiley & Sons, Inc. Сокращенное название SNARE происходит из термина "рецептор, связывающий растворимый NSF (Soluble NSF Attachment Receptor)", где NSF означает N-этилмалеинимид-чувствительный фактор (N-ethylmaleimide-Sensitive Factor). Белки SNARE необходимы для образования внутриклеточных везикул и, таким образом, для секреции молекулы посредством везикулярного транспорта из клетки. Таким образом, после доставки в желаемую клетку-мишень нецитотоксическая протеаза способна ингибировать клеточную секрецию из клетки-мишени.
Нецитотоксические протеазы представляют собой обособленный класс молекул, которые не уничтожают клетки; вместо этого, они действуют, ингибируя клеточные процессы, отличные от синтеза белков. Нецитотоксические протеазы продуцируются в качестве части более крупной молекулы токсина различными растениями и различными микроорганизмами, такими как Clostridium sp. и Neisseria sp.
Клостридиальные нейротоксины представляют собой большую группу нецитотоксических молекул токсинов, и они содержат две полипептидных цепи, соединенных вместе дисульфидной связью. Две цепи называются тяжелой цепью (H-цепь), которая имеет молекулярную массу приблизительно 100 кДа, и легкой цепью (L-цепь), которая имеет молекулярную массу приблизительно 50 кДа. Она представляет собой L-цепь, которая обладает функцией протеазы и демонстрирует высокую субстратную специфичность в отношении белков, ассоциированных с везикулами и/или плазматической мембраной (SNARE), вовлеченных в экзоцитарный процесс (например, синаптобревин, синтаксин или SNAP-25). Эти субстраты являются важными компонентами неейросекреторного аппарата.
Neisseria sp., особенно важно вида N. gonorrhoeae, и Streptococcus sp., особенно важно вида S. pneumoniae, продуцируют функционально сходные нецитотоксические молекулы токсинов. Примером такой нецитотоксической протеазы является IgA-протеаза (см. WO99/58571, которая включена в настоящее описание в качестве ссылки в полном объеме). Таким образом, нецитотоксическая протеаза по настоящему изобретению предпочтительно представляет собой протеазу клостридиального нейротоксина или IgA-протеазу.
Обращаясь далее к компоненту в виде нацеливающей части (TM) по настоящему изобретению, именно этот компонент связывает полипептид по настоящему изобретению с клеткой-мишенью.
Таким образом, TM по настоящему изобретению связывается с рецептором на клетке-мишени. В качестве примера, TM по настоящему изобретению может связываться с рецептором на нейрональной клетке, таким как рецептор на чувствительном или двигательном нейроне. Альтернативно TM по настоящему изобретению может связываться с рецептором EGF. В одном варианте осуществления клетка-мишень представляет собой нейрональную клетку, такую как двигательный или чувствительный нейрон. В другом варианте осуществления клетка-мишень представляет собой клетку, экспрессирующую рецептор EGF. Однако специалист в данной области может выбрать пептид TM для нацеливания на выбранную клетку-мишень на основе присутствия участка связывания (например, рецептор клеточной поверхности) для указанного пептида на клетке-мишени.
В одном варианте осуществления полипептид по изобретению может содержать TM, содержащий один или несколько из следующих пептидов: пептид рилизинг-фактора гормона роста (GHRH), пептид соматостатина, пептид кортистатина, пептид грелина, пептид бомбезина, пептид уротензина, пептид меланин-концентрирующего гормона, пептид KISS-1, пептид гонадотропин-рилизинг гормона (GnRH) или пролактин-рилизинг пептид. Указанные TM и полипептиды, содержащие их, описаны в WO 2009/150469, которая включена в настоящее описание в качестве ссылки.
В одном варианте осуществления полипептид по изобретению может содержать TM, содержащую один или несколько из следующих пептидов: пептид лептина, пептид инсулиноподобного фактора роста (IGF), пептид трансформирующего фактора роста (TGF), пептид суперсемейства VIP-глюкагон-GRF-секретин, пептид PACAP, вазоактивный интестинальный пептид (VIP), пептид орексина, пептид интерлейкина, пептид фактора роста нервов (NGF), пептид сосудисто-эндотелиального фактора роста (VEGF), пептид гормона щитовидной железы, пептид эстрогена, пептид ErbB, пептид эпидермального фактора роста (EGF), химерный пептид EGF и TGF-α, пептид амфирегулина, пептид бетацеллюлина, пептид эпигена, пептид эпирегулина, пептид гепарин-связывающего EGF (HB-EGF), пептид бомбезина, пептид уротензина, пептид меланин-концентрирующего гормона (MCH), пептид Kisspeptin-10, пептид Kisspeptin-54, пептид кортикотропин-рилизинг гормона, пептид урокортина 1 или пептид урокортина 2. Указанные TM и полипептиды, содержащие их, описаны в WO2009/150470, которая включена в настоящее описание в качестве ссылки.
В другом варианте осуществления полипептид по изобретению может содержать TM, содержащую один или несколько из следующих: тиреостимулирующий гормон (TSH); антитела к рецептору TSH; антитела к специфическому для островков моносиалоганглиозиду, GM2-1; инсулин, инсулиноподобный фактор роста и антитела к рецепторам обоих из них; рилизинг-гормон TSH (протирелин) и антитела к его рецептору; рилизинг-гормон FSH/LH (гонадорелин) и антитела к его рецептору; кортикотрофин-рилизинг гормон (CRH) и антитела к его рецептору; и ACTH и антитела к его рецептору. Указанные TM и полипептиды, содержащие их, описаны в WO 01/21213, которая включена в настоящее описание в качестве ссылки.
Полипептиды по настоящему изобретению могут содержать 3 основных компонента: нецитотоксическая протеаза или ее протеолитически неактивный мутант; TM и домен транслокации. Основную технологию, ассоциированную с получением таких слитых белков, также называют технологией перенацеленных токсинов. В качестве примера, см.: WO94/21300; WO96/33273; WO98/07864; WO00/10598; WO01/21213; WO06/059093; WO00/62814; WO00/04926; WO93/15766; WO00/61192 и WO99/58571. Все из этих публикаций включены в настоящее описание в качестве ссылок.
Более подробно, компонент TM по настоящему изобретению может быть слит либо с протеазным компонентом, либо с компонентом транслокации по настоящему изобретению. Указанное слияние предпочтительно осуществляют посредством ковалентной связи, например, либо прямо ковалентной связи, либо через спейсерную/линкерную молекулу. Протеазный компонент и компонент транслокации предпочтительно связаны вместе через ковалентную связь, например, либо прямую ковалентную связь, либо через спейсерную/линкерную молекулу. Подходящие спейсерные/линкерные молекулы хорошо известны в данной области, и, как правило, содержат последовательность на основе аминокислот длиной 5-40, предпочтительно 10-30 аминокислотных остатков.
Применяемые полипептиды имеют двухцепочечную конформацию, где протеазный компонент и компонент транслокации связаны вместе, предпочтительно через дисульфидную связь.
Таким образом, полипептиды и меченые полипептиды по изобретению могут быть в одноцепочечной форме или двухцепочечной форме, предпочтительно в двухцепочечной форме.
Полипептиды по настоящему изобретению можно получать посредством общепринятых способов химической конъюгации, которые хорошо известны специалисту в данной области. В качестве примера могут быть упомянуты Hermanson, G.T. (1996), Bioconjugate techniques, Academic Press, and to Wong, S.S. (1991), Chemistry of protein conjugation and cross-linking, CRC Press, Nagy et al., PNAS 95 p1794-99 (1998). Дополнительные детальные методологии для связывания синтетических TM с полипептидом по настоящему изобретению приведены, например, в EP0257742. Вышеупомянутые публикации, касающиеся конъюгации, включены в настоящее описание в качестве ссылок.
Альтернативно полипептиды можно получать посредством рекомбинантного получения единого белка из слитых полипептидов (см., например, WO98/07864). Этот способ основан на бактериальном механизме in vivo, посредством которого получают нативный клостридиальный нейротоксин (т.е. голотоксин), и он приводит к слитому белку, имеющему следующую "упрощенную" структурную организацию:
NH2 - [протеазный компонент] - [компонент транслокации] - [TM] - COOH
Согласно WO98/07864, TM помещают с C-концевой стороны слитого белка. Затем слитый белок активируют посредством обработки протеазой, которая осуществляет расщепление в участке между протеазным компонентом и компонентом транслокации. Таким образом, получают двухцепочечный белок, содержащий протеазный компонент в качестве единой полипептидной цепи, ковалентно связанной (через дисульфидный мостик) с другой единой полипептидной цепью, содержащей компонент транслокации плюс TM.
Альтернативно, согласно WO06/059093, компонент TM слитого белка находится в середине линейной слитой белковой последовательности между участком расщепления протеазой и компонентом транслокации. Это приводит к тому, что TM связан с доменом транслокации (т.е. как и в случае нативного клостридиального голотоксина), хотя в этом случае порядок этих двух компонентов является обратным по отношению к нативному голотоксину. Последующее расщепление в участке расщепления протеазой экспонирует N-концевую часть TM и обеспечивает двухцепочечный полипептидный слитый белок.
Вышеупомянутая последовательность(и) расщепления протеазой может быть внесена (и/ или любая собственная последовательность расщепления удалена) на уровне ДНК общепринятыми способами, такими как сайт-направленный мутагенез. Скрининг для подтверждения присутствия последовательностей расщепления можно проводить вручную или с помощью компьютерного программного обеспечения (например, программа MapDraw от DNASTAR, Inc.). В то время как можно использовать любой участок расщепления протеазой (т.е. клостридиальный или неклостридиальный), предпочтительными являются следующие:
Энтерокиназа (DDDDK↓, SEQ ID NO: 84)
Фактор Xa (IEGR↓ / IDGR↓, SEQ ID NO: 85 и 86)
TEV (вирус гравировки табака) (ENLYFQ↓G, SEQ ID NO: 87)
Тромбин (LVPR↓GS, SEQ ID NO: 88)
PreScission (LEVLFQ↓GP, SEQ ID NO: 89).
Дополнительные участки расщепления протеазой включают последовательности распознавания, которые расщепляются нецитотоксической протеазой, например, клостридиальным нейротоксином. Они включают последовательности распознавания белков SNARE (например, SNAP-25, синтаксин, VAMP), которые расщепляются нецитотоксическими протеазами, такими как клостридиальные нейротоксины. Конкретные примеры приведены в US2007/0166332, которая включена в настоящее описание в качестве ссылки в полном объеме.
Также под термином "участок расщепления протеазой" подразумевается интеин, который представляет собой саморасщепляющуюся последовательность. Реакция самосплайсинга является контролируемой, например, посредством варьирования концентрации присутствующего восстановителя. Вышеупомянутые "активационные" участка расщепления также могут использоваться в качестве "деструктивного" участка расщепления (рассмотренного ниже), если его намереваются включить в полипептид по настоящему изобретению.
В предпочтительном варианте осуществления слитый белок по настоящему изобретению может содержать одну или несколько N-концевых и/ или C-концевых меток для очистки. В то время как можно использовать любую метку для очистки, предпочтительными являются следующие:
His-метка (например 6×гистидин), предпочтительно в качестве C-концевой и/ или N-концевой метки,
MBP-метка (мальтоза-связывающий белок), предпочтительно в качестве N-концевой метки,
GST-метка (глутатион-S-трансфераза), предпочтительно в качестве N-концевой метки,
His-MBP-метка, предпочтительно в качестве N-концевой метки,
GST-MBP-метка, предпочтительно в качестве N-концевой метки,
Тиоредоксиновая метка, предпочтительно в качестве N-концевой метки,
CBD-метка (хитин-связывающий домен), предпочтительно в качестве N-концевой метки.
В слитый белок может быть включена одна или несколько пептидных спейсерных/линкерных молекул. Например, пептидный спейсер может использоваться между меткой для очистки и остальной частью молекулы слитого белка.
В одном аспекте изобретение относится к способу производства полипептида для мечения с использованием сортазы, причем способ включает:
a. предоставление последовательности нуклеиновой кислоты, кодирующей полипептид, где полипептид содержит:
i. нецитотоксическую протеазу или ее протеолитически неактивный мутант;
ii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iii. домен транслокации; и
b. внесение акцепторного или донорного участка для сортазы в указанную нуклеиновую кислоту, тем самым получая модифицированную нуклеиновую кислоту, которая кодирует полипептид, содержащий акцепторный или донорный участок для сортазы.
Внесение акцепторного или донорного участка для сортазы можно осуществлять посредством любых модификаций/способов, известных специалисту в данной области, например, посредством замещения, вставки или делеции последовательностей, кодирующих аминокислотные остатки в конечном полипептиде. В качестве примера, модификации можно вносить посредством модификации последовательности нуклеиновой кислоты с использованием стандартных способов молекулярного клонирования, например, посредством сайт-направленного мутагенеза, где короткие цепи ДНК (олигонуклеотиды), кодирующие желаемую аминокислоту(ы) используют для замены исходной кодирующей последовательности с использованием фермента полимеразы, или посредством встраивания/делеции частей гена с использованием различных ферментов (например, лигазы и эндонуклеазы рестрикции). Альтернативно модифицированная последовательность гена может быть химически синтезирована.
Предпочтительно способ дополнительно включает экспрессию модифицированной нуклеиновой кислоты в клетке-хозяине. Более предпочтительно, способ дополнительно включает экспрессию модифицированной нуклеиновой кислоты в клетке-хозяине и получение экспрессированного полипептида. Полипептид может быть активирован с использованием способа, описанного в настоящем описании.
Также изобретение относится к полипептиду, получаемому способом по изобретению.
Термин "получение", используемый в контексте "получения меченого полипептида" или "получения экспрессированного полипептида", может означать выделение полипептида. Выделение можно осуществлять любыми способами очистки, такими как хроматографические или иммуноаффинные способы, известные специалисту в данной области.
Нуклеиновая кислота для применения в способах производства может представлять собой нуклеиновую кислоту, кодирующую полипептид, описанный в настоящем описании. Например, такая нуклеиновая кислота может кодировать полипептид, обладающий по меньшей мере 70% идентичностью последовательности с любой из SEQ ID NO: 6, 8, 17-25 или 38. В одном варианте осуществления нуклеиновая кислота может кодировать полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с любой из SEQ ID NO: 6, 8, 17-25 или 38. Предпочтительно нуклеиновая кислота может кодировать полипептид, содержащий (более предпочтительно состоящий из) любую из SEQ ID NO: 6, 8, 17-25 или 38.
Нуклеиновая кислота для применения в способах производства может представлять собой нуклеиновую кислоту, содержащую последовательность нуклеиновой кислоты, обладающую по меньшей мере 70% идентичностью последовательности с любой из SEQ ID NO: 5 или 7. В одном варианте осуществления a нуклеиновая кислота может представлять собой нуклеиновую кислоту, содержащую последовательность нуклеиновой кислоты, обладающую по меньшей мере 80% или 90% идентичностью последовательности с любой из SEQ ID NO: 5 или 7. Предпочтительно нуклеиновая кислота может содержать (более предпочтительно состоять из) SEQ ID NO: 5 или 7.
Таким образом, настоящее изобретение относится к последовательности нуклеиновой кислоты (например ДНК) последовательность (например, модифицированная нуклеиновая кислота), кодирующей полипептид по изобретению. Такая нуклеиновая кислота может быть включена в форме вектора, такого как плазмида, который необязательно может включать один или несколько из ориджина репликации, участка встраивания нуклеиновой кислоты, промотора, терминатора и участка связывания рибосомы.
Нуклеиновая кислота (например, модифицированная нуклеиновая кислота) по настоящему изобретению может содержать последовательность нуклеиновой кислоты, обладающую по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 1, 3 или 39. В одном варианте осуществления нуклеиновая кислота по настоящему изобретению может содержать последовательность нуклеиновой кислоты, обладающую по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 1,3 или 39. Предпочтительно, нуклеиновая кислота по настоящему изобретению содержит (более предпочтительно состоит из) последовательность нуклеиновой кислоты, представленную в качестве SEQ ID NO: 1, 3 или 39.
Нуклеиновая кислота (например, модифицированная нуклеиновая кислота) по настоящему изобретению может представлять собой нуклеиновую кислоту, которая кодирует полипептид, обладающий по меньшей мере 70% идентичностью последовательности с SEQ ID NO: 2,4 или 40. В одном варианте осуществления нуклеиновая кислота по настоящему изобретению может представлять собой нуклеиновую кислоту, которая кодирует полипептид, обладающий по меньшей мере 80% или 90% идентичностью последовательности с SEQ ID NO: 2, 4 или 40. Предпочтительно, нуклеиновая кислота по настоящему изобретению может представлять собой нуклеиновую кислоту, которая кодирует полипептид, содержащий (более предпочтительно состоящий из) SEQ ID NO: 2, 4 или 40.
Настоящее изобретение также охватывает клетку-хозяина, содержащую нуклеиновую кислоту или вектор по изобретению.
Настоящее изобретение также охватывает способ экспрессии описанной выше последовательности нуклеиновой кислоты в клетке-хозяине, в частности, в E. coli, или посредством бакуловирусной экспрессирующей системы.
Настоящее изобретение также относится к способу активации полипептида по настоящему изобретению, причем указанный способ включает приведение полипептида в контакт с протеазой (например, FXa), которая расщепляет полипептид в участке распознавания (участок расщепления, такой как участок FXa), находящемся между компонентом нецитотоксической протеазой и компонентом транслокации, тем самым конвертируя полипептид в двухцепочечный полипептид, где нецитотоксическая протеаза и компоненты транслокации соединены вместе дисульфидной связью. В предпочтительном варианте осуществления участок распознавания не является нативным для встречающегося в природе клостридиального нейротоксина и/ или для встречающейся в природе протеазы IgA.
Полипептиды по настоящему изобретению могут быть далее модифицированы для уменьшения или предупреждения нежелательных побочных эффектов, ассоциированных с распределением в области, не являющиеся мишенью. Согласно этому варианту осуществления, полипептид содержит деструктивный участок расщепления. Деструктивный участок расщепления отличается от "активационного" участка (т.е. образование двойной цепи) и расщепляется второй протеазой, но не нецитотоксической протеазой. Более того, при расщеплении таким образом в деструктивном участке расщепления посредством второй протеазы полипептид имеет сниженную эффективность (например, сниженную способность связываться с предполагаемой клеткой-мишенью, сниженную активность транслокации и/или сниженную активность нецитотоксической протеазы). Для полноты, любой из "деструктивных" участков расщепления по настоящему изобретению может отдельно использоваться в качестве "активационного" участка в полипептиде по настоящему изобретению.
Таким образом, согласно этому варианту осуществления, настоящее изобретение относится к полипептиду, который может быть контролируемым образом инактивирован и/или разрушен в положении вне целевой области.
В предпочтительном варианте осуществления деструктивный участок расщепления распознается и расщепляется второй протеазой (т.е. деструктивной протеазой), выбранной из циркулирующей протеазы (например, внеклеточная протеаза, такая как сывороточная протеаза или протеаза каскада свертывания крови), ассоциированной с тканью протеаза (например, матриксная металлопротеиназа (MMP), такая как MMP мышц) и внутриклеточной протеазы (предпочтительно протеаза, которая отсутствует в клетке-мишени).
Таким образом, если при применении полипептид по настоящему изобретению распределяется в другом направлении от предполагаемой клетки-мишени и/ или захватывается не являющейся мишенью клеткой, полипептид инактивируется посредством расщепления деструктивного участка расщепления (второй протеазой).
В одном варианте осуществления деструктивный участок расщепления распознается и расщепляется второй протеазой, которая присутствует в типе клеток вне целевой области. В этом варианте осуществления клетка вне целевой области и клетка-мишень предпочтительно представляют собой различные типы клеток. Альтернативно (или дополнительно), деструктивный участок расщепления распознается и расщепляется второй протеазой, которая присутствует вне целевой области (например, далеко от клетки-мишени). Таким образом, когда деструктивное расщепление происходит внеклеточно, клетка-мишень и клетка вне целевой области могут представлять собой один и тот же или различающиеся типы клеток. В этом отношении, клетка-мишень и клетка вне целевой области могут иметь рецепторы, с которыми связывается один и тот же полипептид по изобретению.
Деструктивный участок расщепления по настоящему изобретению обеспечивает инактивацию/разрушение полипептида, когда полипептид находится в или вблизи не являющейся целевой области. В связи с этим, расщепление в деструктивном участке расщепления минимизирует эффективность полипептида (по сравнению с идентичным полипептидом, лишенным того же деструктивного участка расщепления или обладающим тем же деструктивным участком, но в нерасщепленной форме). В качестве примера, сниженная эффективность включает: снижение связывания (с рецептором клеток млекопитающих) и/ или снижение транслокации (через эндосомальную мембрану клеточной линии млекопитающих в направлении цитозоля) и/ или снижение расщепление белка SNARE.
При выборе деструктивного участка(ов) расщепления в контексте настоящего изобретения предпочтительно, чтобы деструктивный участок(и) расщепления не являлся субстратом для каких-либо протеаз, которые могут отдельно использоваться для посттрансляционной модификации полипептида по настоящему изобретению в качестве части процесса его производства. В связи с этим, нецитотоксические протеазы по настоящему изобретению, как правило, используют событие активации протеазы (через отдельный "активационный" участок расщепления протеазой, который структурно отличается от деструктивного участка расщепления по настоящему изобретению). Целью активационного участка расщепления является расщепление пептидной связи между нецитотоксической протеазой и компонентом траслокации или связывания в полипептиде по настоящему изобретению, тем самым обеспечивая "активированный" двухцепочечный полипептид, где указанные два компонента связаны вместе посредством дисульфидной связи.
Таким образом, для облегчения обеспечения того, чтобы деструктивный участок(и) расщепления полипептидов по настоящему изобретению не оказывали неблагоприятного влияния на "активационный" участок расщепления и последующее образование дисульфидной связи, первый из них предпочтительно вносят в полипептид по настоящему изобретению в положении на расстоянии по меньшей мере 20, по меньшей мере 30, по меньшей мере 40, по меньшей мере 50, и более предпочтительно по меньшей мере 60, по меньшей мере 70, по меньшей мере 80 (последовательно расположенных) аминокислотных остатков от "активационного" участка расщепления.
Деструктивный участок(и) расщепления и активационный участок расщепления предпочтительно являются экзогенными (т.е. сконструированными/искусственными) относительно нативных компонентов полипептида. Иными словами, указанные участки расщепления предпочтительно не являются неотъемлемыми участками соответствующих нативных компонентов полипептида. В качестве примера, протеазный компонент или компонент транслокации на основе L-цепи или H-цепи BoNT/A (соответственно) можно модифицировать в соответствии с настоящим изобретением для включения участка расщепления. Однако указанное расщепление не будет происходить в соответствующей нативной L-цепи или H-цепи BoNT. Аналогично, когда компонент нацеливающей части в полипептиде модифицирован для включения участка расщепления протеазой, указанный участок расщепления не присутствует в соответствующей нативной последовательности соответствующей нацеливающей части.
В предпочтительном варианте осуществления настоящего изобретения деструктивный участок(и) расщепления и "активационный" участок расщепления не расщепляются одной и той же протеазой. В одном варианте осуществления два участка расщепления отличаются друг от друга тем, что по меньшей мере один, более предпочтительно по меньшей мере две, особенно предпочтительно по меньшей мере три и наиболее предпочтительно по меньшей мере четыре из допустимых аминокислот в соответствующих последовательностях распознавания отличаются.
В качестве примера, в случае полипептидной химеры, содержащей "активационный" участок фактора Xa между клостридиальными компонентами L-цепью и HN предпочтительно использовать деструктивный участок расщепления, который представляет собой участок, отличный от участка фактора Xa, который может быть встроен где-либо в компоненте(ах) L-цепи, и/ или HN, и/или TM. Согласно этому сценарию, полипептид может быть модифицирован внесением альтернативного "активационного" участка между компонентами L-цепью и HN (например, участок расщепления энтерокиназой), и в этом случае отдельный участок расщепления фактором Xa может быть включен куда-либо в полипептид в качестве деструктивного участка расщепления. Альтернативно существующий "активационный" участок фактора Xa между компонентами L-цепью и HN может быть сохранен и альтернативный участок расщепления, такой как участок расщепления тромбином, включен в качестве деструктивного участка расщепления.
При идентификации подходящих участков в первичной последовательности любых из компонентов по настоящему изобретению для включения участка(ов) расщепления является предпочтительным выбор первичной последовательности, которая в высокой степени соответствует предполагаемому участку расщепления, подлежащему встраиванию. Посредством этого в полипептид вносятся минимальные структурные изменения. В качестве примера, участки расщепления, как правило, содержат по меньшей мере 3 последовательно расположенных аминокислотных остатка. Таким образом, в предпочтительном варианте осуществления выбирают участок расщепления, который уже имеет (в правильном положении(ях)) по меньшей мере один, предпочтительно по меньшей мере два аминокислотных остатка, которые необходимы для внесения нового участка расщепления. В качестве примера, в одном варианте осуществления можно вносить участок расщепления каспазой 3 (DMQD). В этом отношении, идентифицируют предпочтительное положение для встраивания, которое уже включает первичную последовательность, выбранную, например, из Dxxx, xMxx, xxQx, xxxD, DMxx, DxQx, DxxD, xMQx, xMxD, xxQD, DMQx, xMQD, DxQD и DMxD.
Аналогично, предпочтительно вносить участки расщепления в экспонированные на поверхность области. В экспонированных на поверхности областях предпочтительными являются существующие области петель.
В предпочтительном варианте осуществления настоящего изобретения деструктивный участок(и) расщепления вносят в одно или несколько из следующих положений, которые основаны на первичной аминокислотной последовательности BoNT/A. В то время как положения встраивания идентифицируют (для удобства) на основе BoNT/A первичные аминокислотные последовательности альтернативных протеазных доменов и/или доменов транслокации могут быть без труда выровнены с указанными положениями BoNT/A.
Для протеазного компонента являются предпочтительными одно или несколько из следующих положений: 27-31, 56-63, 73-75, 78-81, 99-105, 120-124, 137-144, 161-165, 169-173, 187-194, 202-214, 237-241, 243-250, 300-304, 323-335, 375-382, 391-400 и 413-423. Приведенная выше нумерация предпочтительно начинается с N-конца протеазного компонента по настоящему изобретению.
В предпочтительном варианте осуществления деструктивный участок(и) расщепления находится в положении на расстоянии более 8 аминокислотных остатков, предпочтительно более 10 аминокислотных остатков, более предпочтительно более 25 аминокислотных остатков, особенно предпочтительно более 50 аминокислотных остатков от N-конца протеазного компонента. Аналогично, в предпочтительном варианте осуществления деструктивный участок(и) расщепления находится в положении на расстоянии более 20 аминокислотных остатков, предпочтительно более 30 аминокислотных остатков, более предпочтительно более 40 аминокислотных остатков, особенно предпочтительно более 50 аминокислотных остатков от C-конца протеазного компонента.
Что касается компонента транслокации, предпочтительными являются одно или несколько из следующих положений: 474-479, 483-495, 507-543, 557-567, 576-580, 618-631, 643-650, 669-677, 751-767, 823-834, 845-859. Согласно приведенной выше нумерации, за начальное положение предпочтительно признается положение 449 для N-концевого компонента домена транслокации по настоящему изобретению, и за конечное положение признается положение 871 для C-концевого компонента домена транслокации.
В предпочтительном варианте осуществления деструктивный участок(и) расщепления находится в положении на расстоянии более 10 аминокислотных остатков, предпочтительно более 25 аминокислотных остатков, более предпочтительно более 40 аминокислотных остатков, особенно предпочтительно более 50 аминокислотных остатков от N-конца компонента транслокации. Аналогично, в предпочтительном варианте осуществления деструктивный участок(и) расщепления находится в положении на расстоянии более 10 аминокислотных остатков, предпочтительно более 25 аминокислотных остатков, более предпочтительно более 40 аминокислотных остатков, особенно предпочтительно более 50 аминокислотных остатков от C-конца компонента транслокации.
В предпочтительном варианте осуществления деструктивный участок(и) расщепления находится на расстоянии более 10 аминокислотных остатков, предпочтительно более 25 аминокислотных остатков, более предпочтительно более 40 аминокислотных остатков, особенно предпочтительно более 50 аминокислотных остатков от N-конца компонента TM. Аналогично, в предпочтительном варианте осуществления деструктивный участок(и) расщепления находится в положении на расстоянии более 10 аминокислотных остатков, предпочтительно более 25 аминокислотных остатков, более предпочтительно более 40 аминокислотных остатков, особенно предпочтительно более 50 аминокислотных остатков от C-конца компонента TM.
Полипептид по настоящему изобретению может включать один или несколько (например, два, три, четыре, пять или более) деструктивных участков расщепления протеазой. Когда включено более одного деструктивного участка расщепления, участки расщепления могут быть одинаковыми или могут различаться. В этом отношении использование более одного деструктивного участка расщепления обеспечивает улучшенную инактивацию вне целевой области. Аналогично, использование двух или более различных деструктивных участков расщепления обеспечивает дополнительную универсальность конструкции.
Деструктивный участок(и) расщепления может быть встроен в любой из следующих компонентов полипептида: компонент нецитотоксической протеазы; компонент транслокации; нацеливающая часть или спейсерный пептид (при наличии). В этом отношении, деструктивный участок(и) расщепления выбирают для обеспечения минимального неблагоприятного эффекта на эффективность полипептида (например, посредством наличия минимального эффекта на нацеливающие/связывающие области и/или домен транслокации, и/ или на домен нецитотоксической протеазы), одновременно обеспечивая неустойчивость полипептида на отдалении от его целевой области/клетки-мишени.
Предпочтительные деструктивные участки расщепления (плюс соответствующие вторые протеазы) приведены в таблице ниже. Приведенные участки расщепления являются только иллюстративными и не предназначены для ограничения настоящего изобретения.
P4-P3-P2-P1-▼-P1’-P2’-P3’
Матриксные металлопротеиназы (MMP) являются предпочтительной группой деструктивных протеаз в контексте настоящего изобретения. В этой группе ADAM17 (EC 3.4.24.86, также известная как TACE), является предпочтительной и расщепляет множество заякоренных на мембране белков клеточной поверхности для "слущивания" внеклеточных доменов. Дополнительные предпочтительные MMP включают адамализины, серрализины и астацины.
Другой группой предпочтительных деструктивных протеаз является протеаза крови млекопитающих, такая как тромбин, фактор свертывания VIIa, фактор свертывания IXa, фактор свертывания Xa, фактор свертывания XIa, фактор свертывания XIIa, калликреин, белок C и MBP-ассоциированная сериновая протеаза.
В одном варианте осуществления настоящего изобретения указанный деструктивный участок расщепления содержит последовательность распознавания, имеющую по меньшей мере 3 или 4, предпочтительно 5 или 6, более предпочтительно 6 или 7, и особенно предпочтительно по меньшей мере 8 последовательно расположенных аминокислотных остатков. В связи с этим, чем более длинной (с точки зрения последовательно расположенных аминокислотных остатков) является последовательность распознавания, тем менее вероятным является неспецифическое расщепление деструктивного участка посредством непредусмотренной второй протеазы.
Предпочтительно, чтобы деструктивный участок расщепления по настоящему изобретению был внесен в протеазный компонент, и/или нацеливающую часть, и/или в компонент транслокации, и/или в спейсерный пептид. Из этих четырех компонентов протеазный компонент является предпочтительным. Таким образом, полипептид может быть быстро инактивирован посредством прямого разрушения компонента нецитотоксической протеазы, и/или компонента связывания и/или компонента транслокации.
Полипептиды по изобретению могут быть составлены в качестве части фармацевтической композиции, содержащей полипептид, вместе по меньшей мере с одним компонентом, выбранным из фармацевтически приемлемого носителя, эксципиента, адъюванта, пропеллента и/или соли.
Полипептиды по настоящему изобретению могут быть составлены для перорального, парентерального введения, непрерывной инфузии, имплантации, ингаляции или местного применения. Композиции, пригодные для инъекции, могут иметь форму растворов, суспензий или эмульсий, или сухих порошков, которые растворяют или суспендируют в подходящем носителе перед применением.
Средства локальной доставки могут включать аэрозоль или другой спрей (например, небулайзер). В этом отношении, аэрозольный состав полипептида позволяет доставку в легкие и/или другие носовые и/или бронхиальные, или дыхательные пути.
Предпочтительный путь введения выбран из: системного (например, в/в), лапараскопического и/или локализованной инъекции (например, транссфеноидальной инъекции непосредственно в опухоль).
В случае составов для инъекции, является необязательным включение фармацевтически активного вещества для облегчения удержания или уменьшения выхода полипептида из области введения. Одним из примеров такого фармацевтически активного вещества является сосудосуживающее средство, такое как адреналин. Такой состав обеспечивает преимущество повышения времени нахождения полипептида после введения и, таким образом, повышения и/или усиления его эффекта.
Диапазоны дозировок для введения полипептидов по настоящему изобретению представляют собой диапазоны, которые вызывают желаемый терапевтический эффект. Будет понятно, что требуемый диапазон дозировок зависит от точной природы полипептида или композиции, пути введения, природы состава, возраста пациента, природы, степени или тяжести состояния пациента, противопоказаний, при их наличии, и мнения лечащего врача. Эти дозировки могут варьироваться с использованием стандартных эмпирических способов оптимизации.
Подходящие суточные дозировки (на кг массы тела пациента) находятся в диапазоне 0,0001-1 мг/кг, предпочтительно 0,0001-0,5 мг/кг, более предпочтительно 0,002-0,5 мг/кг, и особенно предпочтительно 0,004-0,5 мг/кг. Единичная дозировка может варьироваться от менее 1 микрограмма до 30 мг, однако, как правило, она находится в диапазоне от 0,01 до 1 мг на дозу, которую можно вводить каждые сутки или предпочтительно менее часто, например, раз в неделю или раз в шесть месяцев.
Особенно предпочтительный режим дозирования основан на 2,5 нг полипептида в качестве 1X дозы. В этом отношении, предпочтительные дозировки находятся в диапазоне 1X-100X (т.е. 2,5-250 нг).
Жидкие дозированные формы, как правило, получают с использованием полипептида и свободного от пирогенов стерильного носителя. Полипептид, в зависимости от используемого носителя и концентрации, может быть либо растворен, либо суспендирован в носителе. При получении растворов полипептид можно растворять в носителе, раствор при необходимости можно преобразовывать в изотонический посредством добавления хлорида натрия и стерилизовать фильтрацией через стерильный фильтр с использованием асептических способов перед заполнением стерильных флаконов или ампул и герметизации. Альтернативно, если стабильность раствора является достаточной, раствор в его закрытых контейнерах можно стерилизовать автоклавированием. Преимущественно, добавки, такие как буферные вещества, солюбилизирующие вещества, стабилизрующие вещества, консерванты или бактерицидные средства, суспендирующие средства или эмульгаторы, и/или местные анестетики могут быть растворены в носителе.
Сухие порошки, которые растворяют или суспендируют в подходящем носителе перед применением можно получать путем заполнения предварительно стерилизованными ингредиентами стерильного контейнера с использованием асептического способа в стерильной зоне. Альтернативно ингредиенты могут быть растворены в подходящих контейнерах с использованием асептического способа в стерильной зоне. Затем продукт лиофилизируют и контейнеры запечатывают в асептических условиях.
Парентеральные суспензии, пригодные для внутримышечной, подкожной или внутрикожной инъекции, приготавливают по существу одним и тем же способом, за исключением того, что стерильные компоненты суспендируют в стерильном носителе вместо растворения, и стерилизация не может быть осуществлена посредством фильтрации. Компоненты можно выделять в стерильном состоянии или альтернативно они могут быть стерилизованы после выделения, например, посредством облучения гамма-излучением.
Преимущественно, в композицию(и) включают суспендирующее вещество, например, поливинилпирролидон, для облегчения однородного распределения компонентов.
Нацеливающая часть (TM) означает любую химическую структуру, которая функционально взаимодействует с участком связывания, вызывая физическую ассоциацию между полипептидом по изобретению и поверхностью клетки-мишени (как правило, клетка млекопитающих, особенно клетка человека). Термин "TM" охватывает любую молекулу (т.е. встречающаяся в природе молекула или ее химически/физически модифицированный вариант), которая способна связываться с участком связывания на клетке-мишени, которая предпочтительно способна к интернализации (например, формированию эндосом) - также называемой рецептор-опосредуемым эндоцитозом. TM может обладать функцией транслокации через эндосомальную мембрану, и в этом случае в средстве по настоящему изобретению не должны присутствовать TM и домен транслокации в качестве отдельных компонентов. На протяжении предшествующего описания описаны конкретные TM. Указание на указанные TM является только иллюстративным, и настоящее изобретение охватывает все их варианты и производные, которые обладают базовой способностью к связыванию (т.е. нацеливанию) с участком связывания на клетке-мишени, предпочтительно где участок связывания способен к интернализации.
TM по настоящему изобретению связывается (предпочтительно специфически связывается) с рассматриваемой клеткой-мишенью. Термин "специфически связывается" предпочтительно означает, что данный TM связывается с клеткой-мишенью с аффинностью связывания (Ka) 106 M-1 или более, предпочтительно 107 M-1 или более, или 108 M-1 или более, или 109 M-1 или более. TM по настоящему изобретению (когда они находятся в свободной форме, а именно, когда они отделены от какого-либо протеазного компонента и/или компонента транслокации), предпочтительно демонстрируют аффинность связывания (IC50) в отношении рассматриваемого рецептора-мишени в диапазоне 0,05-18 нМ.
TM по настоящему изобретению предпочтительно не является агглютинином зародышей пшеницы (WGA).
Указание на TM в настоящем описании охватывает его фрагменты и варианты, которые сохраняют способность к связыванию рассматриваемой клетки-мишени. В качестве примера, вариант может обладать по меньшей мере 80%, предпочтительно по меньшей мере 90%, более предпочтительно по меньшей мере 95% и наиболее предпочтительно по меньшей мере 97 или по меньшей мере 99% гомологией аминокислотной последовательности с эталонным TM - причем последний представляет собой любую последовательность TM, указанную в настоящей заявке. Таким образом, вариант может включать один или несколько аналогов аминокислот (например, неприродная аминокислота), или замещенную связь. Также в качестве примера термин "фрагмент", когда его используют в отношении TM, означает пептид, имеющий по меньшей мере пять, предпочтительно по меньшей мере десять, более предпочтительно по меньшей мере двадцать и наиболее предпочтительно по меньшей мере двадцать пять аминокислотных остатков эталонного TM. Термин фрагмент также относится к вышеупомянутым вариантам. Таким образом, в качестве примера, фрагмент по настоящему изобретению может содержать пептидную последовательность, имеющую по меньшей мере 7, 10, 14, 17, 20, 25, 28, 29 или 30 аминокислот, где пептидная последовательность обладает по меньшей мере 80% гомологией последовательности на протяжении соответствующих аминокислот пептидной последовательности (последовательно расположенных) эталонного пептида.
TM может содержать более длинную аминокислотную последовательность, например, по меньшей мере 30 или 35 аминокислотных остатков, или по меньшей мере 40 или 45 аминокислотных остатков при условии, что TM способен связываться с клеткой-мишенью.
Подтверждение того, что TM связывается с выбранной клеткой-мишенью, можно проводить стандартным способом. Например, можно использовать простой эксперимент по радиоактивному вытеснению, в котором ткань или клетки, соответствующие клеткам-мишеням, подвергают воздействию меченого (например, тритием) TM в присутствии избытка немеченого TM. В таком эксперименте можно оценивать относительное соотношение неспецифического и специфического связывания, тем самым позволяя подтверждение того, что TM связывается с клеткой-мишенью. Необязательно, анализ может включать один или несколько антагонистов связывания, и анализ, кроме того, может включать выявление снижения связывания TM. Примеры этого типа эксперимента могут быть найдены в Hulme, E.C. (1990), Receptor-binding studies, a brief outline, pp. 303-311, Receptor biochemistry, A Practical Approach, Ed. E.C. Hulme, Oxford University Press.
В некоторых вариантах осуществления полипептиды по настоящему изобретению лишены функционального HC-домена клостридиального нейротоксина. Таким образом, указанные полипептиды неспособны связывать синаптосомальные мембраны крысы (через клостридиальный компонент HC) в анализах связывания, как описано в Shone et al. (1985) Eur. J. Biochem. 151, 75-82. В предпочтительном варианте осуществления полипептиды предпочтительно лишены последних 50 C-концевых аминокислот клостридиального нейротоксина голотоксина. В другом варианте осуществления полипептиды предпочтительно лишены последних 100, предпочтительно последних 150, более предпочтительно последних 200, особенно предпочтительно последних 250, и наиболее предпочтительно последних 300 C-концевых аминокислотных остатков клостридиального нейротоксина голотоксина. Альтернативно активность связывания HC может быть устранена/уменьшена посредством мутагенеза - в качестве примера, обращаясь к BoNT/ A для удобства, модификация посредством мутации одного или двух аминокислотных остатков (W1266 на L и Y1267 на F) в связывающем кармане ганглиозида приводит к утрате HC-областью ее функции связывания рецептора. Аналогичные мутации можно вносить в клостридиальные пептидные компоненты не серотипа A, например, в конструкцию на основе ботулинического токсина B с мутациями (W1262 на L и Y1263 на F) или ботулинического токсина E (W1224 на L и Y1225 на F). Другие мутации активного центра достигают того же устранения активности связывания HC-рецептора, например, Y1267S в ботулиническом токсине типа A и соответствующего высококонсервативного остатка в других клостридиальных нейротоксинах. Детали этих и других мутаций описаны в Rummel et al (2004) (Molecular Microbiol. 51:631-634), которая включена в настоящее описание в качестве ссылки.
В другом варианте осуществления полипептиды по настоящему изобретению лишены функционального HC-домена клостридиального нейротоксина, а также лишены какого-либо функционально эквивалентного TM. Таким образом, указанные полипептиды лишены природной функции связывания клостридиального нейротоксина и неспособны связывать синаптосомальные мембраны крысы (через клостридиальный компонент HC или через любой функционально эквивалентный TM) в анализах связывания, как описано в Shone et al. (1985) Eur. J. Biochem. 151, 75-82.
HC-пептид нативного клостридиального нейротоксина содержит приблизительно 400-440 аминокислотных остатков и состоит из двух функционально обособленных домена размером приблизительно 25 кДа каждый, а именно, N-концевой области (часто обозначаемой как пептид или домен HCN) и C-концевой области (часто обозначаемой как пептид или домен HCC). Этот факт подтверждается следующими публикациями, каждая из которых включена в настоящее описание в качестве ссылки в полном объеме: Umland TC (1997) Nat. Struct. Biol. 4: 788-792; Herreros J (2000) Biochem. J. 347: 199-204; Halpern J (1993) J. Biol. Chem. 268: 15, pp. 11188-11192; Rummel A (2007) PNAS 104: 359-364; Lacey DB (1998) Nat. Struct. Biol. 5: 898-902; Knapp (1998) Am. Cryst. Assoc. Abstract Papers 25: 90; Swaminathan and Eswaramoorthy (2000) Nat. Struct. Biol. 7: 1751-1759; и Rummel A (2004) Mol. Microbiol. 51(3), 631-643. Более того, широко известно, что C-концевая область (HCC), которая составляет C-концевые 160-200 аминокислотных остатков, ответственна за связывание клостридиального нейротоксина с его природными клеточным рецепторами, а именно, с нервными окончаниями в нервно-мышечном соединении - этот факт также подтвержден вышеописанными публикациями. Таким образом, указание на протяжении настоящего описания на клостридиальную тяжелую цепь, лишенную функционального HC-пептида (или домена) тяжелой цепи, так чтобы тяжелая цепь была неспособна связываться с рецепторами клеточной поверхности, с которыми связывается нативный клостридиальный нейротоксин, означает, что клостридиальная тяжелая цепь лишена функционального HCC-пептида. Иными словами, область HCC-пептида либо частично, либо полностью удалена или иным образом модифицирована (например, посредством общепринятой химической или протеолитической обработки) для инактивации ее нативной связывающей способности в отношении нервных окончаний в нервно-мышечном соединении.
Таким образом, в одном варианте осуществления клостридиальный пептид HN по настоящему изобретению лишен части C-концевого пептидного участка (HCC) клостридиального нейротоксина и, таким образом, лишен функции связывания HC нативного клостридиального нейротоксина. В качестве примера, в одном варианте осуществления удлиненный на C-конце клостридиальный HN-пептид лишен 40 C-концевых аминокислотных остатков или 60 C-концевых аминокислотных остатков, или 80 C-концевых аминокислотных остатков, или 100 C-концевых аминокислотных остатков, или 120 C-концевых аминокислотных остатков, или 140 C-концевых аминокислотных остатков, или 150 C-концевых аминокислотных остатков, или 160 C-концевых аминокислотных остатков тяжелой цепи клостридиального нейротоксина. В другом варианте осуществления клостридиальный HN-пептид по настоящему изобретению лишен целой C-концевой пептидной части (HCC) клостридиального нейротоксина и, таким образом, лишен функции связывания HC нативного клостридиального нейротоксина. В качестве примера, в одном варианте осуществления клостридиальный HN-пептид лишен 165 C-концевых аминокислотных остатков, или 170 C-концевых 170 аминокислотных остатков, или 175 C-концевых аминокислотных остатков, или 180 C-концевых аминокислотных остатков, или 185 C-концевых аминокислотных остатков, или 190 C-концевых аминокислотных остатков, или 195 C-концевых аминокислотных остатков тяжелой цепи клостридиального нейротоксина. В качестве следующего примера, клостридиальный HN-пептид по настоящему изобретению лишен клостридиальной эталонной последовательности HCC, выбранной из группы, состоящей из следующих:
Ботулинический нейротоксин типа A - аминокислотные остатки (Y1111-L1296)
Ботулинический нейротоксин типа B - аминокислотные остатки (Y1098-E1291)
Ботулинический нейротоксин типа C - аминокислотные остатки (Y1112-E1291)
Ботулинический нейротоксин типа D - аминокислотные остатки (Y1099-E1276)
Ботулинический нейротоксин типа E - аминокислотные остатки (Y1086-K1252)
Ботулинический нейротоксин типа F - аминокислотные остатки (Y1106-E1274)
Ботулинический нейротоксин типа G - аминокислотные остатки (Y1106-E1297)
Столбнячный нейротоксин - аминокислотные остатки (Y1128-D1315).
Идентифицированные выше эталонные последовательности должны считаться определяющими, поскольку между подсеротипами может существовать небольшое варьирование.
Протеаза по настоящему изобретению охватывает все нецитотоксические протеазы, которые способны расщеплять один или несколько белков аппарата экзоцитарного слияния в эукариотических клетках.
Протеаза по настоящему изобретению предпочтительно представляет собой бактериальную протеазу (или ее фрагмент). Более предпочтительно, бактериальная протеаза выбрана из родов Clostridium или Neisseria/ Streptococcus (например, клостридиальная L-цепь, или IgA-протеаза нейсерий, предпочтительно из N. gonorrhoeae или S. pneumoniae).
Настоящее изобретение также охватывает варианты нецитотоксических протеаз (т.е. варианты встречающихся в природе молекул протеаз) при условии, что варианты протеаз все еще демонстрируют требуемую протеазную активность. В качестве примера, вариант может обладать по меньшей мере 70%, предпочтительно по меньшей мере 80%, более предпочтительно по меньшей мере 90% и наиболее предпочтительно по меньшей мере 95 или по меньшей мере 98% гомологией аминокислотных последовательностей с эталонной последовательностью протеазы. Таким образом, термин вариант включает нецитотоксические протеазы, обладающие повышенной (или сниженной) эндопептидазной активностью - конкретно в настоящем описании упоминается повышенное значение Kcat/Km мутантов BoNT/A Q161A, E54A и K165L, см. Ahmed, S.A. (2008) Protein J. DOI 10.1007/s10930-007-9118-8, которая включена в качестве ссылки. Термин "фрагмент", когда его используют в отношении протеазы, как правило, означает пептид, имеющий по меньшей мере 150, предпочтительно по меньшей мере 200, более предпочтительно по меньшей мере 250 и наиболее предпочтительно по меньшей мере 300 аминокислотных остатков эталонной протеазы. Как и в случае компонента, представляющего собой "фрагмент" TM (описанный выше), протеазные "фрагменты" по настоящему изобретению охватывают фрагменты вариантов протеаз на основе эталонной последовательности.
Протеаза по настоящему изобретению предпочтительно демонстрирует активность сериновой протеазы или металлопротеиназы (например, активность эндопептидазы). Протеаза предпочтительно является специфичной в отношении белка SNARE (например, SNAP-25, синаптобревин/VAMP или синтаксин).
В частности, могут быть упомянуты протеазные домены нейротоксинов, например, протеазные домены бактериальных нейротоксинов. Таким образом, настоящее изобретение охватывает применение доменов нейротоксинов, которые встречаются в природе, а также полученных рекомбинантными способами версий указанных встречающихся в природе нейротоксинов.
Иллюстративные нейротоксины продуцируются клостридиями, и термин "клостридиальный нейротоксин" охватывает нейротоксины, продуцируемые C. tetani (TeNT) и C. botulinum (BoNT) серотипов A-G, а также близкородственные BoNT-подобные нейротоксины, продуцируемые C. baratii и C. butyricum. На протяжении настоящего описания используются вышеупомянутые сокращенные обозначения. Например, номенклатура BoNT/A обозначает, что источником нейротоксина является BoNT (серотип A). Соответствующая номенклатура применима к другим серотипам BoNT.
BoNT являются наиболее сильнодействующими из известных токсинов со срединной величиной летальной дозы (LD50) для мышей в диапазоне от 0,5 до 5 нг/кг в зависимости от серотипа. BoNT адсорбируются в желудочно-кишечном тракте и после попадания в общий кровоток связываются с пресинаптической мембраной холинэргических нервных окончаний и препятствуют высвобождению их нейротрансмиттера ацетилхолина. BoNT/B, BoNT/D, BoNT/F и BoNT/G расщепляют синаптобревин/ассоциированный с везикулами мембранный белок (VAMP); BoNT/C, BoNT/A и BoNT/E расщепляют ассоциированный с синаптосомами белок 25 кДа (SNAP-25); и BoNT/C расщепляет синтаксин.
BoNT обладают общей структурой, являясь двухцепочечными белками массой ~150 кДа, состоящими из тяжелой цепи (H-цепь) массой ~100 кДа, ковалентно связанной одной дисульфидной связью с легкой цепью (L-цепь) массой ~50 кДа. H-цепь состоит из двух доменов, каждый массой ~50 кДа. C-концевой домен (HC) необходим для высокоаффинного нейронального связывания, в то время как N-концевой домен (HN) предположительно вовлечен в транслокацию через мембрану. L-цепь представляет собой цинк-зависимую металлопротеиназу, ответственную за расщепление белка SNARE, являющегося субстратом.
Термин фрагмент L-цепи означает компонент L-цепи нейротоксина, который демонстрирует активность металлопротеиназы и способен протеолитически расщеплять белок, ассоциированный с везикулами и/или плазматической мембраной, вовлеченный в клеточный экзоцитоз.
Примеры подходящих (эталонных) последовательностей протеаз включают:
Ботулинический нейротоксин типа A - аминокислотные остатки (1-448)
Ботулинический нейротоксин типа B - аминокислотные остатки (1-440)
Ботулинический нейротоксин типа C - аминокислотные остатки (1-441)
Ботулинический нейротоксин типа D - аминокислотные остатки (1-445)
Ботулинический нейротоксин типа E - аминокислотные остатки (1-422)
Ботулинический нейротоксин типа F - аминокислотные остатки (1-439)
Ботулинический нейротоксин типа G - аминокислотные остатки (1-441)
Столбнячный нейротоксин - аминокислотные остатки (1-457)
IgA-протеаза - аминокислотные остатки (1-959)*
* Pohlner, J. et al. (1987). Nature 325, pp. 458-462, которая включена в настоящее описание в качестве ссылки.
Для недавно идентифицированного BoNT/X было описано, что L-цепь соответствует его аминокислотам 1-439, причем граница L-цепи потенциально варьируется приблизительно на 25 аминокислот (например, 1-414 или 1-464).
Указанные выше эталонная последовательность должна рассматриваться в качестве ориентира, поскольку в зависимости от подсеротипов может встречаться небольшое варьирование. В качестве примера, в US 2007/0166332 (включенной в настоящее описание в качестве ссылки) цитированы несколько различающиеся клостридиальные последовательности:
Ботулинический нейротоксин типа A - аминокислотные остатки (M1-K448)
Ботулинический нейротоксин типа B - аминокислотные остатки (M1-K441)
Ботулинический нейротоксин типа C - аминокислотные остатки (M1-K449)
Ботулинический нейротоксин типа D - аминокислотные остатки (M1-R445)
Ботулинический нейротоксин типа E - аминокислотные остатки (M1-R422)
Ботулинический нейротоксин типа F - аминокислотные остатки (M1-K439)
Ботулинический нейротоксин типа G - аминокислотные остатки (M1-K446)
Столбнячный нейротоксин - аминокислотные остатки (M1-A457).
В аспектах настоящего изобретения могут использоваться различные фрагменты клостридиальных токсинов, содержащие легкую цепь, при условии, что эти фрагменты легкой цепи могут специфически нацеливаться на основные компоненты аппарата высвобождения нейротрансмиттеров и, таким образом, участвовать в осуществлении всего клеточного механизма, посредством которого клостридиальный токсин протеолитически расщепляет субстрат. Легкие цепи клостридиальных токсинов имеют длину приблизительно 420-460 аминокислот и содержат домен фермента. Исследование показало, что вся длина клостридиального токсина не является необходимой для ферментативной активности ферментного домена. В качестве неограничивающего примера, первые восемь аминокислот легкой цепи BoNT/A не являются необходимыми для ферментативной активности. В качестве другого неограничивающего примера, первые восемь аминокислот легкой цепи TeNT не являются необходимыми для ферментативной активности. Аналогично, карбоксильный конец легкой цепи не является необходимым для активности. В качестве неограничивающего примера, последние 32 аминокислоты легкой цепи BoNT/A (остатки 417-448) не являются необходимыми для ферментативной активности. В качестве другого неограничивающего примера, последняя 31 аминокислота легкой цепи TeNT (остатки 427-457) не является необходимой для ферментативной активности. Таким образом, аспекты этого варианта осуществления могут включать легкие цепи клостридиального токсина, содержащие ферментный домен, имеющий длину, например, по меньшей мере 350 аминокислот, по меньшей мере 375 аминокислот, по меньшей мере 400 аминокислот, по меньшей мере 425 аминокислот и по меньшей мере 450 аминокислот. Другие аспекты этого варианта осуществления могут включать легкие цепи клостридиального токсина, содержащие ферментный домен, имеющий длину, например, не более 350 аминокислот, не более 375 аминокислот, не более 400 аминокислот, не более 425 аминокислот и не более 450 аминокислот.
Компонент нецитотоксической протеазы по настоящему изобретению предпочтительно содержит L-цепь серотипа BoNT/A, BoNT/B, BoNT/C, BoNT/D, BoNT/E, BoNT/F, BoNT/G или BoNT/X (или ее фрагмент или вариант).
Полипептиды по настоящему изобретению, особенно их протеазный компонент, могут быть пегилированными, это может помочь повысить стабильность, например, длительность действия протеазного компонента. Пегилирование является особенно предпочтительным, когда протеаза включает протеазу B или C1 BoNT/A. Пегилирование предпочтительно включает присоединение ПЭГ к N-концу протеазного компонента. В качестве примера, N-конец протеазы может быть удлинен на один или несколько аминокислотных остатков (например цистеин), которые могут быть одинаковыми или могут различаться. Один или несколько из указанных аминокислотных остатков могут иметь их собственную присоединенную к ним (например, ковалентно связанную) молекулу ПЭГ. Пример этой технологии описан в WO2007/104567, которая включена в качестве ссылки в полном объеме.
Домен транслокации представляет собой молекулу, которая обеспечивает транслокацию протеазы в клетку-мишень, так чтобы в цитозоле клетки-мишени происходило функциональное проявление протеазной активности. Наличие у какой-либо молекулы (например, белка или пептида) требуемой функции транслокации по настоящему изобретению может быть подтверждено любым из ряда общепринятых способов анализа.
Например, Shone C. (1987) описал способ анализа in vitro с использованием липосом, нагруженных тестируемой молекулой. Присутствие требуемой функции транслокации подтверждают по высвобождению из липосом K+ и/или меченого NAD, мониторинг которого можно без труда проводить [см. Shone C. (1987) Eur. J. Biochem; vol. 167(1): pp. 175-180].
Следующий пример предоставлен Blaustein R. (1987), где описан простой анализ in vitro с использованием плоских фосфолипидных бислойных мембран. Мембраны нагружают тестируемой молекулой и требуемую функцию транслокации подтверждают повышением проводимости через указанные мембраны [см. Blaustein (1987) FEBS Letts; vol. 226, no. 1: pp. 115-120].
Дополнительная методология обеспечения оценки слияния мембран и, таким образом, идентификации доменов транслокации, пригодных для применения в рамках настоящего изобретения, представлена в Methods in Enzymology Vol 220 and 221, Membrane Fusion Techniques, Parts A and B, Academic Press 1993.
Настоящее изобретение также охватывает варианты доменов транслокации, предпочтительно при условии, что варианты доменов все еще демонстрируют требуемую активность транслокации. В качестве примера, вариант может обладать по меньшей мере 70%, предпочтительно по меньшей мере 80%, более предпочтительно по меньшей мере 90%, и наиболее предпочтительно по меньшей мере 95% или по меньшей мере 98% гомологией аминокислотной последовательности с эталонным доменом транслокации. Термин "фрагмент", когда его используют в отношении домена транслокации, означает пептид, имеющий по меньшей мере 20, предпочтительно по меньшей мере 40, более предпочтительно по меньшей мере 80, и наиболее предпочтительно по меньшей мере 100 аминокислотных остатков эталонного домена транслокации. В случае клостридиального домена транслокации, фрагмент предпочтительно имеет по меньшей мере 100, предпочтительно по меньшей мере 150, более предпочтительно по меньшей мере 200, и наиболее предпочтительно по меньшей мере 250 аминокислотных остатков эталонного домена транслокации (например, HN-домена). Что касается компонента в виде "фрагмента" TM (описанного выше), "фрагменты" транслокации по настоящему изобретению охватывают фрагменты вариантов доменов транслокации на основе эталонных последовательностей.
Домен транслокации предпочтительно способен образовывать проницаемые для ионов поры в липидных мембранах в условиях низкого значения pH. Предпочтительно было обнаружено, что могут использоваться только те части белковой молекулы, которые способны к образованию пор в эндосомальной мембране.
Домен транслокации может быть получен из микробного источника белка, в частности, из бактериального или вирусного источника белка. Таким образом, в одном варианте осуществления домен транслокации представляет собой транслоцирующийся домен фермента, такой как бактериальный токсин или вирусный белок.
Хорошо известно, что определенные домены молекул бактериальных токсинов способны образовывать такие поры. Также известно, что определенные домены транслокации экспрессируемых вирусами мембранных белков слияния способны образовывать такие поры. Такие домены могут использоваться в рамках настоящего изобретения.
Домен транслокации может быть клостридиального происхождения, такой как HN-домен (или его функциональный компонент). HN означает часть или фрагмент H-цепи клостридиального нейротоксина, приблизительно эквивалентную N-концевой половине H-цепи, или домен, соответствующий фрагменту интактной H-цепи. H-цепь может быть лишена натуральной функции связывания HC-компонента H-цепи. В некоторых вариантах осуществления функция HC может быть устранена посредством делеции аминокислотной последовательности HC (либо на уровне синтеза ДНК, либо на уровне после синтеза посредством обработки нуклеазой или протеазой). Альтернативно в некоторых вариантах осуществления функция HC может быть инактивирована посредством химической или биологической обработки. Таким образом, в некоторых вариантах осуществления H-цепь не способна связываться с участком связывания на клетке-мишени, с которой связывается нативный клостридиальный нейротоксин (т.е. голотоксин).
Примеры походящих (эталонных) доменов транслокации включают:
Ботулинический нейротоксин типа A - аминокислотные остатки (449-871)
Ботулинический нейротоксин типа B - аминокислотные остатки (441-858)
Ботулинический нейротоксин типа C - аминокислотные остатки (442-866)
Ботулинический нейротоксин типа D - аминокислотные остатки (446-862)
Ботулинический нейротоксин типа E - аминокислотные остатки (423-845)
Ботулинический нейротоксин типа F - аминокислотные остатки (440-864)
Ботулинический нейротоксин типа G - аминокислотные остатки (442-863)
Столбнячный нейротоксин - аминокислотные остатки (458-879).
Идентифицированная выше эталонная последовательность должна считаться ориентиром, поскольку в зависимости от подсеротипов может встречаться небольшое варьирование. В качестве примера, в US 2007/0166332 (включенной в настоящее описание в качестве ссылки) цитированы несколько различающиеся клостридиальные последовательности:
Ботулинический нейротоксин типа A - аминокислотные остатки (A449-K871)
Ботулинический нейротоксин типа B - аминокислотные остатки (A442-S858)
Ботулинический нейротоксин типа C - аминокислотные остатки (T450-N866)
Ботулинический нейротоксин типа D - аминокислотные остатки (D446-N862)
Ботулинический нейротоксин типа E - аминокислотные остатки (K423-K845)
Ботулинический нейротоксин типа F - аминокислотные остатки (A440-K864)
Ботулинический нейротоксин типа G - аминокислотные остатки (S447-S863)
Столбнячный нейротоксин - аминокислотные остатки (S458-V879).
В контексте настоящего изобретения в аспектах настоящего изобретения могут использоваться различные области HN клостридиального токсина, содержащего домен транслокации, предпочтительно при условии, что эти активные фрагменты могут способствовать высвобождению нецитотоксической протеазы (например, клостридиальной L-цепи) из внутриклеточных везикул в цитоплазму клетки-мишени и, таким образом, участвовать в осуществлении всего клеточного механизма, посредством которого клостридиальный токсин протеолитически расщепляет субстрат. Области HN из тяжелых цепей клостридиальных токсинов имеют длину приблизительно 410-430 аминокислот и содержат домен транслокации. Исследование показало, что вся длина HN-области тяжелой цепи клостридиального токсина не является необходимой для активности транслокации домена транслокации. Таким образом, аспекты этого варианта осуществления могут включать области HN клостридиального токсина, содержащие домен транслокации, имеющий длину, например, по меньшей мере 350 аминокислот, по меньшей мере 375 аминокислот, по меньшей мере 400 аминокислот и по меньшей мере 425 аминокислот. Другие аспекты этого варианта осуществления могут включать области HN клостридиального токсина, содержащие домен транслокации, имеющий длину, например, не более 350 аминокислот, не более 375 аминокислот, не более 400 аминокислот и не более 425 аминокислот.
Для дальнейших деталей, касающихся генетической основы продуцирования токсинов в Clostridium botulinum и C. tetani, см. Henderson et al (1997) в The Clostridia: Molecular Biology and Pathogenesis, Academic press.
Термин "HN" охватывает встречающиеся в природе части нейротоксина HN и модифицированные части HN, имеющие аминокислотные последовательности, которые не встречаются в природе, и/или синтетические аминокислотные остатки, предпочтительно при условии, что модифицированные части HN все еще демонстрируют вышеупомянутую функцию транслокации.
Альтернативно домен транслокации может иметь неклостридиальное происхождение. Примеры источников неклостридиальных (этолонных) доменов транслокации включают, но не ограничиваются ими, домен транслокации дифтерийного токсина [O’Keefe et al., Proc. Natl. Acad. Sci. USA (1992) 89, 6202-6206; Silverman et al., J. Biol. Chem. (1993) 269, 22524-22532; and London, E. (1992) Biochem. Biophys. Acta., 1112, pp.25-51], домен транслокации экзотоксина типа A Pseudomonas [Prior et al. Biochemistry (1992) 31, 3555-3559], домены транслокации токсина сибирской язвы [Blanke et al. Proc. Natl. Acad. Sci. USA (1996) 93, 8437-8442], различные фузогенные или гидрофобные пептиды с функцией транслокации [Plank et al. J. Biol. Chem. (1994) 269, 12918-12924; и Wagner et al (1992) PNAS, 89, pp.7934-7938], и амфифильные пептиды [Murata et al. (1992) Biochem., 31, pp.1986-1992]. Домен транслокации может соответствовать домену транслокации, присутствующему во встречающемся в природе белке, или может включать варьирование аминокислот, предпочтительно при условии, что варьирование не нарушает способности к транслокации у домена транслокации.
Конкретные примеры вирусных (эталонных) доменов транслокации, пригодных для применения в рамках настоящего изобретения, включают определенные домены транслокации экспрессируемые вирусами мембранных белков слияния. Например, Wagner et al. (1992) и Murata et al. (1992) описывают функцию к транслокации (т.е. слияние с мембраной и везикуляция) ряда фузогенных и амфифильных пептидов, происходящих из N-концевой области гемагглютинина вируса гриппа. Другие экспрессируемые вирусами мембранные белки слияния, известные тем, что они обладают желаемой активностью транслокации, представляют собой домен транслокации фузогенного пептида вируса леса Семлики (SFV), домен транслокации гликопротеина G вируса везикулярного стоматита (VSV), домен транслокации F-белка вируса SER и домен транслокации гликопротеина оболочки пенящих вирусов. Кодируемые вирусами белки Aspike являются особенно применимыми в контексте настоящего изобретения, например, белок E1 SFV и белок G VSV.
Использование (эталонных) доменов транслокации, приведенных в таблице (ниже), включает применение их вариантов последовательности. Вариант может содержать одну или несколько консервативных замен нуклеиновых кислот, и/ или делеций или вставок нуклеиновых кислот, предпочтительно при условии, что вариант обладает требуемой функцией транслокации. Вариант также может содержать одну или несколько аминокислотных замен и/или делеций или вставок аминокислот, предпочтительно при условии, что вариант обладает требуемой функцией транслокации.
London E., 1992, Biochem. Biophys. Acta., 1113, 25-51
Kihara & Pastan, 1994, Bioconj Chem. 5, 532-538
Его варианты
Wagner et al., 1992, PNAS, 89, 7934-7938
Murata et al., 1992, Biochemistry 31, 1986-1992
Примеры эталонных последовательностей домена HC клостридиального нейротоксина включают:
BoNT/A - N872-L1296
BoNT/B - E859-E1291
BoNT/C1 - N867-E1291
BoNT/D - S863-E1276
BoNT/E - R846-K1252
BoNT/F - K865-E1274
BoNT/G - N864-E1297
TeNT - I880-D1315.
Для недавно идентифицированного BoNT/X, HC-домен был описан в качестве соответствующего его аминокислотам 893-1306, причем границы домена потенциально варьируются в пределах приблизительно 25 аминокислот (например, 868-1306 или 918-1306).
Полипептиды по настоящему изобретению, кроме того, могут содержать способствующий транслокации домен. Указанный домен способствует доставке нецитотоксической протеазы в цитозоль клетки-мишени и описан, например, в WO 08/008803 и WO 08/008805, каждая из которых включена в настоящее описание в качестве ссылки.
В качестве примера, подходящие способствующие транслокации домены включают домен фузогенного пептида оболочечного вируса, например, подходящие домены фузогенных пептидов включают домен фузогенного пептида вируса гриппа (например, домен фузогенного пептида вируса гриппа A из 23 аминокислот), домен фузогенного пептида альфавируса (например, домен фузогенного пептида вируса леса Семлики из 26 аминокислот), домен фузогенного пептида везикуловируса (например, домен фузогенного пептида вируса везикулярного стоматита из 21 аминокислоты), домен фузогенного пептида респировируса (например, домен фузогенного пептида вируса Сендай из 25 аминокислот), домен фузогенного пептида морбиливируса (например, домен фузогенного пептида вируса собачьей чумы из 25 аминокислот), домен фузогенного пептида авулавируса (например, домен фузогенного пептида вируса болезни Ньюкасла из 25 аминокислот), домен фузогенного пептида хенипавируса (например, домен фузогенного пептида вируса Хендра из 25 аминокислот), домен фузогенного пептида метапневмовируса (например, домен фузогенного пептида метапневмовируса человека из 25 аминокислот) или домен фузогенного пептида спумавируса, такой как домен фузогенного пептида пенящего вируса обезьян; или их фрагменты или варианты.
В качестве следующего примера, способствующий транслокации домен может включать домен HCN клостридиального токсина или его фрагмент или вариант. Более подробно, способствующий транслокации домен HCN клостридиального токсина может иметь длину по меньшей мере 200 аминокислот, по меньшей мере 225 аминокислот, по меньшей мере 250 аминокислот, по меньшей мере 275 аминокислот. В связи с этим способствующий транслокации домен HCN клостридиального токсина предпочтительно имеет длину не более 200 аминокислот, не более 225 аминокислот, не более 250 аминокислот или не более 275 аминокислот. Конкретные (эталонные) примеры включают:
Ботулинический нейротоксин типа A - аминокислотные остатки (872-1110)
Ботулинический нейротоксин типа B - аминокислотные остатки (859-1097)
Ботулинический нейротоксин типа C - аминокислотные остатки (867-1111)
Ботулинический нейротоксин типа D - аминокислотные остатки (863-1098)
Ботулинический нейротоксин типа E - аминокислотные остатки (846-1085)
Ботулинический нейротоксин типа F - аминокислотные остатки (865-1105)
Ботулинический нейротоксин типа G - аминокислотные остатки (864-1105)
Столбнячный нейротоксин - аминокислотные остатки (880-1127).
Указанные выше положения последовательностей могут несколько варьироваться в зависимости от серотипа/ подтипа, и следующие примеры подходящих (эталонных) доменов HCN клостридиального токсина включают:
Ботулинический нейротоксин типа A - аминокислотные остатки (874-1110)
Ботулинический нейротоксин типа B - аминокислотные остатки (861-1097)
Ботулинический нейротоксин типа C - аминокислотные остатки (869-1111)
Ботулинический нейротоксин типа D - аминокислотные остатки (865-1098)
Ботулинический нейротоксин типа E - аминокислотные остатки (848-1085)
Ботулинический нейротоксин типа F - аминокислотные остатки (867-1105)
Ботулинический нейротоксин типа G - аминокислотные остатки (866-1105)
Столбнячный нейротоксин - аминокислотные остатки (882-1127).
Любые из описанных выше способствующих доменов можно комбинировать с любыми из ранее описанных пептидов доменов транслокации, которые пригодны для применения в рамках настоящего изобретения. Таким образом, в качестве примера, неклостридиальный способствующий домен можно комбинировать с пептидом неклостридиального домена транслокации или с пептидом транслокации клостридиального домена. Альтернативно способствующий транслокации домен HCN клостридиального токсина можно комбинировать с пептидом неклостридиального домена транслокации. Альтернативно, способствующий домен HCN клостридиального токсина можно комбинировать с пептидом клостридиального домена транслокации, примеры которого включают:
Ботулинический нейротоксин типа A - аминокислотные остатки (449-1110)
Ботулинический нейротоксин типа B - аминокислотные остатки (442-1097)
Ботулинический нейротоксин типа C - аминокислотные остатки (450-1111)
Ботулинический нейротоксин типа D - аминокислотные остатки (446-1098)
Ботулинический нейротоксин типа E - аминокислотные остатки (423-1085)
Ботулинический нейротоксин типа F - аминокислотные остатки (440-1105)
Ботулинический нейротоксин типа G - аминокислотные остатки (447-1105)
Столбнячный токсин - аминокислотные остатки (458-1127).
Предусматривается, что варианты осуществления, касающиеся различных способов, в равной степени применимы к другим способом, полипептидам, например, полипептидам, пригодным для мечения или меченым полипептидам, нуклеиновым кислотам, и наоборот.
ГОМОЛОГИЯ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
Для определения процентной идентичности можно использовать любой из различных способов выравнивания, включая, но не ограничиваясь ими, глобальные способы, локальные способы и гибридные способы, например, такие как способы сегментного подхода. Протоколы для определения процентной идентичности являются стандартными методиками, входящим в объем способностей специалиста в данной области. Глобальные способы выравнивают последовательности сначала до конца молекулы и определяют наилучшее выравнивание путем суммирования показателей индивидуальных пар остатков и путем применения штрафов за пропуски. Неограничивающие способы включают, например, CLUSTAL W, см., например, Julie D. Thompson et al., CLUSTAL W: Improving the Sensitivity of Progressive Multiple Sequence Alignment Through Sequence Weighting, Position-Specific Gap Penalties and Weight Matrix Choice, 22(22) Nucleic Acids Research 4673-4680 (1994); и итеративное уточнение, см., например, Osamu Gotoh, Significant Improvement in Accuracy of Multiple Protein Sequence Alignments by Iterative Refinement as Assessed by Reference to Structural Alignments, 264(4) J. MoI. Biol. 823-838 (1996). Локальные способы выравнивают последовательности посредством идентификации одного или нескольких консервативных мотивов, общих для всех из входных последовательностей. Неограничивающие способы включают, например, Match-box, см., например, Eric Depiereux and Ernest Feytmans, Match-Box: A Fundamentally New Algorithm for the Simultaneous Alignment of Several Protein Sequences, 8(5) CABIOS 501-509 (1992); Gibbs sampling, см., например, C. E. Lawrence et al., Detecting Subtle Sequence Signals: A Gibbs Sampling Strategy for Multiple Alignment, 262 (5131) Science 208-214 (1993); Align-M, см., например, Ivo Van Walle et al., Align-M - A New Algorithm for Multiple Alignment of Highly Divergent Sequences, 20(9) Bioinformatics:1428-1435 (2004).
Таким образом, процентную идентичность последовательностей определяют общепринятыми способами. См., например, Altschul et al., Bull. Math. Bio. 48: 603-16, 1986 и Henikoff and Henikoff, Proc. Natl. Acad. Sci. USA 89:10915-19, 1992. В кратком изложении, две аминокислотных последовательности выравнивают для оптимизации показателей выравнивания с использованием штрафа за внесение делеции 10, штрафа за продолжение делеции 1 и оценочной матрицы "blosum 62", Henikoff and Henikoff (там же), как показано ниже (аминокислоты указаны посредством стандартного однобуквенного кода).
"Процентная идентичность последовательностей" между двумя или более последовательностями нуклеиновых кислот или аминокислот является функцией количества идентичных положений между последовательностями. Таким образом, % идентичность можно вычислять как количество идентичных нуклеотидов/аминокислот на общее количество нуклеотидов/аминокислот, умноженное на 100. В вычислении % идентичности последовательностей также учитывается количество пропусков и длина каждого пропуска, который необходимо вносить для оптимизации выравнивания двух или более последовательностей. Сравнение последовательностей и определение процентной идентичности между двумя или более последовательностями можно проводить с использованием специальных математических алгоритмов, таких как BLAST, которые известны специалисту в данной области.
ПОКАЗАТЕЛИ ВЫРАВНИВАНИЯ ДЛЯ ОПРЕДЕЛЕНИЯ ИДЕНТИЧНОСТИ ПОСЛЕДОВАТЕЛЬНОСТЕЙ

Затем процентную идентичность вычисляют следующим образом:
Общее количество идентичных совпадений
__________________________________________ × 100
[длина наиболее длинной последовательности плюс количество пропусков, внесенное в более длинную последовательность, для выравнивания двух последовательностей]
По существу гомологичные полипептиды характеризуются наличием одной или нескольких аминокислотных замен, делеций или вставок. Эти изменения предпочтительно являются незначительными, т.е. представляют собой консервативные аминокислотные замены (см. ниже) и другие замены, которые не оказывают значительного влияния на сворачивание и активность полипептида; небольшие делеции, как правило, от одной до приблизительно 30 аминокислот; и небольшие N- или C-концевые удлинения, такие как N-концевой остаток метионина, небольшой линкерный пептид из вплоть до приблизительно 20-25 остатков, или аффинную метку.
КОНСЕРВАТИВНЫЕ АМИНОКИСЛОТНЫЕ ЗАМЕНЫ
Основные: аргинин, лизин, гистидин
Кислотные: глутаминовая кислота, аспарагиновая кислота
Полярные: глутамин, аспарагин
Гидрофобные: лейцин, изолейцин, валин
Ароматические: фенилаланин, триптофан, тирозин
Небольшие: глицин, аланин, серин, треонин, метионин.
В дополнение к 20 стандартным аминокислотам, нестандартными аминокислотами (такими как 4-гидроксипролин, 6-N-метиллизин, 2-аминоизомасляная кислота, изовалин и α-метилсерин) можно заменять аминокислотные остатки полипептидов по настоящему изобретению. Аминокислотные остатки полипептида можно заменять ограниченным количеством неконсервативных аминокислот, аминокислот, которые не кодируются генетическим кодом и неприродных аминокислот. Полипептиды по настоящему изобретению также могут содержать не встречающиеся в природе аминокислотные остатки.
Не встречающиеся в природе аминокислоты включают, но не ограничиваются ими, транс-3-метилпролин, 2,4-метанoпролин, цис-4-гидроксипролин, транс-4-гидроксипролин, N-метилглицин, аллотреонин, метилтреонин, гидроксиэтилцистеин, гидроксиэтилгомоцистеин, нитроглутамин, гомоглутамин, пипеколиновую кислоту, трет-лейцин, норвалин, 2-азафенилаланин, 3-азафенилаланин, 4-азафенилаланин и 4-фторфенилаланин. В данной области известно несколько способов включения не встречающихся в природе аминокислотных остатков в белки. Например, можно использовать систему in vitro, где нонсенс-мутации подавляются с использованием химически аминоацилированных супрессорных тРНК. Способы синтеза аминокислот и аминоацилирования тРНК известны в данной области. Транскрипцию и трансляцию плазмид, содержащих нонсенс-мутации, проводят в бесклеточной системе, содержащей экстракт E. coli S30 и коммерчески доступные ферменты и другие реагенты. Белки очищают посредством хроматографии. См., например, Robertson et al., J. Am. Chem. Soc. 113:2722, 1991; Ellman et al., Methods Enzymol. 202:301, 1991; Chung et al., Science 259:806-9, 1993; и Chung et al., Proc. Natl. Acad. Sci. USA 90:10145-9, 1993). Во втором способе трансляцию проводят в ооцитах Xenopus посредством микроинъекции мутантной мРНК и химически аминоацилированных супрессорных тРНК (Turcatti et al., J. Biol. Chem. 271:19991-8, 1996). В третьем способе клетки E. coli культивируют в отсутствии природной аминокислоты, подлежащей замене (например, фенилаланин) и в присутствии желаемой не встречающейся в природе аминокислоты(аминокислот) (например, 2-азафенилаланин, 3-азафенилаланин, 4-азафенилаланин или 4-фторфенилаланин). Не встречающуюся в природе аминокислоту включают в полипептид вместо ее природного аналога. См., Koide et al., Biochem. 33:7470-6, 1994. Встречающиеся в природе аминокислотные остатки можно конвертировать в не встречающиеся в природе формы посредством химической модификации in vitro. Химическую модификацию можно комбинировать с сайт-направленным мутагенезом для дальнейшего расширения диапазона замен (Wynn and Richards, Proteins Sci. 2:395-403, 1993).
Аминокислотные остатки полипептидов по настоящему изобретению могут быть замещены неконсервативными аминокислотами, аминокислотами, которые не кодируются генетическим кодом, не встречающимися в природе аминокислотами, и неприродными аминокислотами.
Незаменимые аминокислоты в полипептидах по настоящему изобретению можно идентифицировать с помощью методик, известных в данной области, таких как сайт-направленный мутагенез или аланин-сканирующий мутагенез (Cunningham and Wells, Science 244: 1081-5, 1989). Участки биологического взаимодействия также могут быть определены посредством физического анализа структуры, при определены такими способами, как ядерный магнитный резонанс, кристаллография, электрогография или фотоаффинное мечение, совместно с мутацией предполагаемых аминокислот участков контакта. См., например, de Vos et al., Science 255:306-12, 1992; Smith et al., J. Mol. Biol. 224:899-904, 1992; Wlodaver et al., FEBS Lett. 309:59-64, 1992. Тип незаменимых аминокислот также может быть установлен посредством анализа гомологов с родственными компонентами (например, компоненты транслокации или протеазные компоненты) полипептидов по настоящему изобретению.
Множество аминокислотных замен можно вносить и тестировать с использованием известных способов мутагенеза и скрининга, таких как способы, описанные Reidhaar-Olson and Sauer (Science 241:53-7, 1988) или Bowie and Sauer (Proc. Natl. Acad. Sci. USA 86:2152-6, 1989). В кратком изложении, эти авторы описывают способы одновременной рандомизации двух или более положений в полипептиде, селекции функционального полипептида, а затем секвенирования подвергнутых мутагенезу полипептидов для определения спектра допустимых замен в каждом положении. Другие способы, которые можно использовать, включают фаговый дисплей (например, Lowman et al., Biochem. 30:10832-7, 1991; Ladner et al., патент США № 5223409; Huse, публикация WIPO WO 92/06204) и мутагенез, целенаправленно воздействующий на область (Derbyshire et al., Gene 46:145, 1986; Ner et al., DNA 7:127, 1988).
Множество аминокислотных замен можно вносить и тестировать с использованием известных способов мутагенеза и скрининга, таких как способы, описанные Reidhaar-Olson and Sauer (Science 241:53-7, 1988) или Bowie and Sauer (Proc. Natl. Acad. Sci. USA 86:2152-6, 1989). В кратком изложении, эти авторы описывают способы одновременной рандомизации двух или более положений в полипептиде, выбора функционального полипептида, а затем секвенирования подвергнутых мутагенезу полипептидов для определения спектра допустимых замен в каждом положении. Другие способы, которые могут использоваться, включают фаговый дисплей (например, Lowman et al., Biochem. 30:10832-7, 1991; Ladner et al., патент США № 5223409; Huse, публикация WIPO WO 92/06204) и направленный на область мутагенез (Derbyshire et al., Gene 46:145, 1986; Ner et al., DNA 7:127, 1988).
Если не определено иначе, все технические и научные термины, используемые в настоящем описании, обладают тем же значением, которое обычно подразумевают специалистом в области, к которой относится настоящее изобретение. В Singleton, et al., DICTIONARY OF MICROBIOLOGY AND MOLECULAR BIOLOGY, 20 ED., John Wiley and Sons, New York (1994), и Hale & Marham, THE HARPER COLLINS DICTIONARY OF BIOLOGY, Harper Perennial, NY (1991) предоставлен специалисту в данной области общий словарь многих из терминов, используемых в настоящем описании.
Настоящее изобретение не ограничивается иллюстративными способами и материалами, описанными в настоящем описании, и любые способы и материалы, сходные или эквивалентные способам, описанным в настоящем описании, можно использовать для применения на практике или тестирования вариантов осуществления изобретения. Числовые диапазоны включают числа, определяющие диапазон. Если нет иных указаний, любые последовательности нуклеиновых кислот написаны слева направо в ориентации от 5' к 3'; аминокислотные последовательности написаны слева направо в ориентации от N к С, соответственно.
Заголовки, приведенные в настоящем описании, не являются ограничениями различных аспектов и вариантов осуществления настоящего изобретения.
Аминокислоты указывают в настоящем описании с использованием названия аминокислот, трехбуквенного сокращенного обозначения или однобуквенного сокращенного обозначения. Термин "белок", как используют в рамках изобретения, включает белки, полипептиды и пептиды. Как используют в рамках изобретения, термин "аминокислотная последовательность" является синонимом термина "полипептид" и/или термина "белок". В некоторых случаях термин "аминокислотная последовательность" является синонимом термина "пептид". В некоторых случаях термин "аминокислотная последовательность" является синонимом термина "фермент". Термины "белок" и "полипептид" используют в настоящем описании взаимозаменяемо. В настоящем описании и формуле изобретения можно использовать общепринятые однобуквенные и трехбуквенные коды аминокислотных остатков. 3-буквенный код аминокислот при определении в соответствии с Joint Commission on Biochemical Nomenclature (JCBN) IUPACIUB. Также понятно, что полипептид может кодироваться более чем одной нуклеотидной последовательностью вследствие вырожденности генетического кода.
На протяжении настоящего описания могут быть приведены другие определения. Перед более подробным описанием иллюстративных вариантов осуществления, следует понимать, что настоящее изобретение не ограничивается конкретными описанными вариантами осуществления, и они по существу могут варьироваться. Также понятно, что терминология, используемая в настоящем описании, приведена только для цели описания конкретных вариантов осуществления и не предназначена для ограничения, поскольку объем настоящего изобретения определяется прилагаемой формулой изобретения.
Когда предусматривается диапазон величин, понятно, что также конкретно предусматривается каждая входящая в этот диапазон величина до десятой доли единицы, если контекст не предусматривает иное, между верхним и нижним пределами этого диапазона. Изобретение охватывает каждый меньший диапазон между какой-либо указанной величиной или входящей в него величиной в указанном диапазоне и любой другой указанной или входящей в него величиной в этом указанном диапазоне. Верхний и нижний пределы этих меньших диапазонов могут быть независимо включены или исключены из диапазона, и изобретение охватывает каждый диапазон, где любой, ни один или оба из этих пределов включены в меньшие диапазоны при условии какого-либо конкретного исключенного предела в указанном диапазоне. Когда указанный диапазон включает один или оба из пределов, также изобретение включает любой или оба из этих включенных пределов.
Необходимо отметить, что, как используют в рамках изобретения и в прилагаемой формуле изобретения, форма единственного числа включает множественное число, если контекст явно не указывает на иное. Таким образом, например, указание на "полипептид" включает множество таких средств-кандидатов и указание на "полипептид" включает указание на один или несколько полипептидов и их эквивалентов, известных специалистам в данной области, и т.д.
Публикации, описанные в настоящем описании, предоставлены только для их раскрытия до даты подачи настоящей заявки. Ничто в настоящем описании не следует истолковывать как допущение того, что такие публикации составляют уровень техники для прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения описаны далее только в качестве примеров с помощью прилагаемых чертежей и примеров.
На фиг.1 представлена схема стратегии двойного мечения полипептидов с лигандами. Белок содержит участок распознавания SrtA на C-конце, за которым следует Strep-метка. На N-конце белок содержит участок из остатков глицина, защищенных участком расщепления TEV. Также получали пептид, содержащий участок из остатков глицина, связанных с предпочтительным для выбора флуорофором, и второй пептид, содержащий участок распознавания SrtA и 6 His-метку (HT). Два различных фермента SrtA позволяют сайт-специфическое мечение флуорофоров различного цвета на N- и C-концах.
На фиг.2 представлен анализ расщепления SNAP-25 для немеченых однократно меченых и двукратно меченых полипептидов. A. Расщепление SNAP-25 в кортикальных нейронах посредством 3, 10, 30, 100, 300 и 1000 нМ немеченого полипептида с EGF-лигандом, меченного TxRed EGF-полипептида, меченного SNAP594 полипептида с EGF-лигандом, однократно меченного посредством SrtA полипептида с EGF-лигандом и двукратно меченного посредством SrtA полипептида с EGF-лигандом. В качестве контроля использовали полипептид без лиганда (несвязанный с лигандом) для всех концентраций. Воздействие полипептидов проводили в течение 24 ч. B. Расщепление посредством SNAP-25 в кортикальных нейронов посредством 3, 10, 30, 100, 300 и 1000 нМ немеченого полипептида с ноцицептин-лигандом и двукратно меченого посредством SrtA ноцицептин-полипептида. В качестве контроля использовали полипептид без лиганда (несвязанный с лигандом) для всех концентраций. Воздействие полипептидов проводили в течение 24 ч.
На фиг.3 представлена прижизненная кофокальная визуализация двукратно меченого полипептида с EGF-лигандом. A. Фотография конфокальной прижизненной визуализации, регистрирующая клетки A549, обработанные полипептидом с EGF-лигандом, меченным посредством HF555 на N-конце и HF488 на C-конце. Изображения (справа) представляют собой фотографии заключенной в рамку области, представленной на крупном изображении (слева), полученные с различными интервалами, начиная с 0,5 минуты после добавления белка. Образование агломератов, характерных для этого полипептидов, может наблюдаться после 3 минуты. B. Фотография прижизненной конфокальной визуализации, регистрирующей клетки A549, обработанные полипептидом с EGF-лигандом, меченным HF555 на N-конце и HF488 на C-конце. Изображения (справа) представляют собой фотографии заключенной в рамку области, представленной на крупном изображении (слева), полученные с различными интервалами, начиная с 30 минуты после добавления белка. Исчезновение агломератов может наблюдаться после 45 минуты.
На фиг.4 представлена схема двукратно меченого полноразмерного протеолитически инактивированного мутанта BoNT/A1, обозначаемого как BoNT/A(0). Донорные и акцепторные участки сортазы и протокол являются такими же, как и на фиг.1.
На фиг.5 представлен анализ SDS-PAGE двукратно меченого протеолитически инактивированного BoNT/A (BoNT/A(0)), визуализированного с использованием флуоресцентного окрашивания (слева) и окрашивания Кумасси (справа). На дорожках 1 и 4 представлен маркер молекулярной массы белка, на дорожках 2 и 5 представлен невосстановленный двукратно меченный BoNT/A(0) и на дорожках 3 и 6 представлен восстановленный двукратно меченный (L-цепь снизу и H-цепь сверху) BoNT/A(0).
На фиг.6 представлены изображения времяпролетной микроскопии TIRF единичных молекул для однократно меченного BoNT/A(0), зарегистрированные с интервалами 5 секунд. Белой стрелкой показано движение единичной молекулы с течением времени в секундах.
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
Когда первоначальный аминокислотный остаток Met или соответствующий первоначальный кодон указан в любой из приведенных ниже SEQ ID NO, указанный остаток/кодон является необязательным. В случае каких-либо различий между последовательностями, описанными в описании и последовательности в списке последовательностей ST.25, последовательности в описании имеют преимущество.
SEQ ID NO: 1 - Нуклеотидная последовательность полипептида с EGF-лигандом (EGF TM) с участками двукратного мечения посредством SrtA.
SEQ ID NO: 2 - Полипептидная последовательность полипептида с EGF-лигандом (EGF TM) с участками двукратного мечения посредством SrtA.
SEQ ID NO: 3 - Нуклеотидная последовательность полипептида с ноцицептин-лигандом (ноцицептин TM) с участками двукратного мечения посредством SrtA
SEQ ID NO: 4 - Полипептидная последовательность полипептида с ноцицептин-лигандом (ноцицептин TM) с участками двукратного мечения посредством SrtA
SEQ ID NO: 5 - Нуклеотидная последовательность полипептида с EGF-лигандом (EGF TM)
SEQ ID NO: 6 - Полипептидная последовательность полипептида с EGF-лигандом (EGF TM)
SEQ ID NO: 7 - Нуклеотидная последовательность полипептида с ноцицептин-лигандом (ноцицептин TM)
SEQ ID NO: 8 - Полипептидная последовательность полипептида с ноцицептин-лигандом (ноцицептин TM)
SEQ ID NO: 9 - Нуклеотидная последовательность GFP-меченного полипептида с EGF-лигандом
SEQ ID NO: 10 - Полипептидная последовательность GFP-меченного полипептида с EGF-лигандом
SEQ ID NO: 11 - Нуклеотидная последовательность SNAP-меченного полипептида с EGF-лигандом
SEQ ID NO: 12 - Полипептидная последовательность SNAP-меченного полипептида с EGF-лигандом
SEQ ID NO: 13 - Нуклеотидная последовательность сортазы A (нацеливание на LPESG)
SEQ ID NO: 14 - Полипептидная последовательность сортазы A (нацеливание на LPESG)
SEQ ID NO: 15 - Нуклеотидная последовательность сортазы A (нацеливание на LAETG)
SEQ ID NO: 16 - Полипептидная последовательность сортазы A (нацеливание на LAETG)
SEQ ID NO: 17 - BoNT/A - UniProt P10845
SEQ ID NO: 18 - BoNT/B - UniProt P10844
SEQ ID NO: 19 - BoNT/C - UniProt P18640
SEQ ID NO: 20 - BoNT/D - UniProt P19321
SEQ ID NO: 21 - BoNT/E - UniProt Q00496
SEQ ID NO: 22 - BoNT/F - UniProt A7GBG3
SEQ ID NO: 23 - BoNT/G - UniProt Q60393
SEQ ID NO: 24 - Полипептидная последовательность BoNT/X
SEQ ID NO: 25 - TeNT - UniProt P04958
SEQ ID NO: 26 - Полипептидная последовательность меченого полипептида EGF TM
SEQ ID NO: 27 - Полипептидная последовательность бутелазы C. ternatea 1 (плюс сигнальный пептид)
SEQ ID NO: 28 - Полипептидная последовательность бутелазы 1 C. ternatea (минус сигнальный пептид)
SEQ ID NO: 29 - Пептид с конъюгированными поддающейся детекции меткой и донорным участком для сортазы
SEQ ID NO: 30 - Пептид с конъюгированной поддающейся детекции меткой и акцепторным участком для сортазы
SEQ ID NO: 31 - Полипептидная последовательность сортазы A Staphylococcus aureus
SEQ ID NO: 32 - Полипептидная последовательность сортазы B Staphylococcus aureus
SEQ ID NO: 33 - Полипептидная последовательность сортазы A Streptococcus pneumoniae
SEQ ID NO: 34 - Полипептидная последовательность сортазы B Streptococcus pneumoniae
SEQ ID NO: 35 - Полипептидная последовательность сортазы C Streptococcus pneumoniae
SEQ ID NO: 36 - Полипептидная последовательность сортазы D Streptococcus pneumoniae
SEQ ID NO: 37 - Полипептидная последовательность сортазы A Streptococcus pyogenes
SEQ ID NO: 38 - Полипептидная последовательность протеолитически неактивный мутант BoNT/A(0)
SEQ ID NO: 39 - Нуклеотидная последовательность полноразмерного протеолитически неактивного мутанта BoNT/A(0) с участками двукратного мечения посредством SrtA
SEQ ID NO: 40 - Полипептидная последовательность полноразмерного протеолитически неактивного мутанта BoNT/A(0) с участками двукратного мечения посредством SrtA
SEQ ID NO: 41 - Полипептидная последовательность PATG Prochloron didemni
SEQ ID NO: 42 - Полипептидная последовательность PCY1 Saponaria vaccaria
SEQ ID NO: 43 - Полипептидная последовательность POPB Galerina marginata
SEQ ID NO: 44 - Полипептидная последовательность гомолога бутелазы OaAEP1b Oldenlandia affinis (плюс сигнальный пептид)
SEQ ID NO: 45 - Полипептидная последовательность гомолога бутелазы OaAEP1b Oldenlandia affinis (минус сигнальный пептид)
SEQ ID NO: 1 - Нуклеотидная последовательность полипептида с EGF-лигандом с участками двукратного мечения посредством SrtA
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATgggatccatgGAGAACCTGTATTTTCAGGGCGGCGGTGGCAGCGGCGGCAGCGGCGGCAGCcctttcgttaacaaacagttcaactataaagacccagttaacggtgttgacattgcttacatcaaaatcccgaacgctggccagatgcagccggtaaaggcattcaaaatccacaacaaaatctgggttatcccggaacgtgatacctttactaacccggaagaaggtgacctgaacccgccaccggaagcgaaacaggtgccggtatcttactatgactccacctacctgtctaccgataacgaaaaggacaactacctgaaaggtgttactaaactgttcgagcgtatttactccaccgacctgggccgtatgctgctgactagcatcgttcgcggtatcccgttctggggcggttctaccatcgataccgaactgaaagtaatcgacactaactgcatcaacgttattcagccggacggttcctatcgttccgaagaactgaacctggtgatcatcggcccgtctgctgatatcatccagttcgagtgtaagagctttggtcacgaagttctgaacctcacccgtaacggctacggttccactcagtacatccgtttctctccggacttcaccttcggttttgaagaatccctggaagtagacacgaacccactgctgggcgctggtaaattcgcaactgatcctgcggttaccctggctcacgaactgattcatgcaggccaccgcctgtacggtatcgccatcaatccgaaccgtgtcttcaaagttaacaccaacgcgtattacgagatgtccggtctggaagttagcttcgaagaactgcgtacttttggcggtcacgacgctaaattcatcgactctctgcaagaaaacgagttccgtctgtactactataacaagttcaaagatatcgcatccaccctgaacaaagcgaaatccatcgtgggtaccactgcttctctccagtacatgaagaacgtttttaaagaaaaatacctgctcagcgaagacacctccggcaaattctctgtagacaagttgaaattcgataaactttacaaaatgctgactgaaatttacaccgaagacaacttcgttaagttctttaaagttctgaaccgcaaaacctatctgaacttcgacaaggcagtattcaaaatcaacatcgtgccgaaagttaactacactatctacgatggtttcaacctgcgtaacaccaacctggctgctaattttaacggccagaacacggaaatcaacaacatgaacttcacaaaactgaaaaacttcactggtctgttcgagttttacaagctgctgtgcgtcgacggcatcattacctccaaaactaaatctctgatagaaggtagaaacaaagcgctgaacctgcagtgtatcaaggttaacaactgggatttattcttcagcccgagtgaagacaacttcaccaacgacctgaacaaaggtgaagaaatcacctcagatactaacatcgaagcagccgaagaaaacatctcgctggacctgatccagcagtactacctgacctttaatttcgacaacgagccggaaaacatttctatcgaaaacctgagctctgatatcatcggccagctggaactgatgccgaacatcgaacgtttcccaaacggtaaaaagtacgagctggacaaatataccatgttccactacctgcgcgcgcaggaatttgaacacggcaaatcccgtatcgcactgactaactccgttaacgaagctctgctcaacccgtcccgtgtatacaccttcttctctagcgactacgtgaaaaaggtcaacaaagcgactgaagctgcaatgttcttgggttgggttgaacagcttgtttatgattttaccgacgagacgtccgaagtatctactaccgacaaaattgcggatatcactatcatcatcccgtacatcggtccggctctgaacattggcaacatgctgtacaaagacgacttcgttggcgcactgatcttctccggtgcggtgatcctgctggagttcatcccggaaatcgccatcccggtactgggcacctttgctctggtttcttacattgcaaacaaggttctgactgtacaaaccatcgacaacgcgctgagcaaacgtaacgaaaaatgggatgaagtttacaaatatatcgtgaccaactggctggctaaggttaatactcagatcgacctcatccgcaaaaaaatgaaagaagcactggaaaaccaggcggaagctaccaaggcaatcattaactaccagtacaaccagtacaccgaggaagaaaaaaacaacatcaacttcaacatcgacgatctgtcctctaaactgaacgaatccatcaacaaagctatgatcaacatcaacaagttcctgaaccagtgctctgtaagctatctgatgaactccatgatcccgtacggtgttaaacgtctggaggacttcgatgcgtctctgaaagacgccctgctgaaatacatttacgacaaccgtggcactctgatcggtcaggttgatcgtctgaaggacaaagtgaacaataccttatcgaccgacatcccttttcagctcagtaaatatgtcgataaccaacgccttttgtccactctagaaggcggTGGCGGTAGCGGTGGCGGTGGCAGCGGCGGTGGCGGTAGCGCACTAGacAACAGCGACCCTAAATGCCCACTgAGTCATGAAGGATACTGCCTTAATGATGGTGTTTGTATGTACATAGGAACATTGGACCGTTATGCTTGCAATTGTGTAGTGGGCTATGTCGGGGAAAGGTGTCAATATCGAGATCTCAAGCTGGCAGAGTTAAGAgggctagaagcaGGCGGCAGCGGCGGCGGCAGCGGCCTGCCCGAAAGCGGTGGCGGATCTGCTTGGTCTCACCCGCAGTTCGAAAAAGGTGGTGGTTCTGGTGGTGGTTCTGGTGGTTCTGCTTGGTCTCACCCGCAGTTCGAAAAAtaatgaAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 2 - Полипептидная последовательность полипептида с EGF-лигадом с участками двукратного мечения посредством SrtA
MENLYFQGGGGSGGSGGSPFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSLIEGRNKALNLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLEGGGGSGGGGSGGGGSALDNSDPKCPLSHEGYCLNDGVCMYIGTLDRYACNCVVGYVGERCQYRDLKLAELRGLEAGGSGGGSGLPESGGGSAWSHPQFEKGGGSGGGSGGSAWSHPQFEK
SEQ ID NO: 3 - Нуклеотидная последовательность полипептида с ноцицептин-лигандом с участками двукратного мечения посредством SrtA
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATatgGAGAACCTGTATTTTCAGGGCGGCGGTGGCAGCGGCGGCAGCGGCGGCAGCGGCAGCATGcctTTTGTGAACAAACAGTTCAACTATAAGGATCCGGTTAATGGTGTGGATATCGCCTATATCAAAATTCCGAATGCAGGTCAGATGCAGCCGGTTAAAGCCTTTAAAATCCATAACAAAATTTGGGTGATTCCGGAACGTGATACCTTTACCAATCCGGAAGAAGGTGATCTGAATCCGCCTCCGGAAGCAAAACAGGTTCCGGTTAGCTATTATGATAGCACCTATCTGAGCACCGATAACGAGAAAGATAACTATCTGAAAGGTGTGACCAAACTGTTTGAACGCATTTATAGTACCGATCTGGGTCGTATGCTGCTGACCAGCATTGTTCGTGGTATTCCGTTTTGGGGTGGTAGCACCATTGATACCGAACTGAAAGTTATTGACACCAACTGCATTAATGTGATTCAGCCGGATGGTAGCTATCGTAGCGAAGAACTGAATCTGGTTATTATTGGTCCGAGCGCAGATATCATTCAGTTTGAATGTAAATCCTTTGGCCACGAAGTTCTGAATCTGACCCGTAATGGTTATGGTAGTACCCAGTATATTCGTTTCAGTCCGGATTTTACCTTTGGCTTTGAAGAAAGCCTGGAAGTTGATACAAATCCGCTGTTAGGTGCAGGTAAATTTGCAACCGATCCGGCAGTTACCCTGGCACATGAACTGATTCATGCCGGTCATCGTCTGTATGGTATTGCAATTAATCCGAACCGTGTGTTCAAAGTGAATACCAACGCATATTATGAAATGAGCGGTCTGGAAGTGTCATTTGAAGAACTGCGTACCTTTGGTGGTCATGATGCCAAATTTATCGATAGCCTGCAAGAAAATGAATTTCGCCTGTACTACTATAACAAATTCAAGGATATTGCGAGCACCCTGAATAAAGCCAAAAGCATTGTTGGCACCACCGCAAGCCTGCAGTATATGAAAAATGTGTTTAAAGAAAAATATCTGCTGAGCGAAGATACCAGCGGTAAATTTAGCGTTGACAAACTGAAATTCGATAAACTGTACAAGATGCTGACCGAGATTTATACCGAAGATAACTTCGTGAAGTTTTTCAAAGTGCTGAACCGCAAAACCTACCTGAACTTTGATAAAGCCGTGTTCAAAATCAACATCGTGCCGAAAGTGAACTATACCATCTATGATGGTTTTAACCTGCGCAATACCAATCTGGCAGCAAACTTTAATGGTCAGAACACCGAAATCAACAACATGAACTTTACCAAACTGAAGAACTTCACCGGTCTGTTCGAATTTTACAAACTGCTGTGTGTGGATGGCATTATTACCAGCAAAACCAAATCCGATGATGACGATAAATTCGGTGGTTTTACCGGTGCACGTAAAAGCGCACGTAAACGTAAAAATCAGGCACTGGCAGGCGGTGGTGGTAGCGGTGGCGGTGGTTCAGGTGGTGGTGGCTCAGCACTGGTTCTGCAGTGTATTAAAGTTAATAACTGGGACCTGTTTTTTAGCCCGAGCGAGGATAATTTCACCAACGATCTGAACAAAGGCGAAGAAATTACCAGCGATACCAATATTGAAGCAGCCGAAGAAAACATTAGCCTGGATCTGATTCAGCAGTATTATCTGACCTTCAACTTCGATAATGAGCCGGAAAATATCAGCATTGAAAACCTGAGCAGCGATATTATTGGCCAGCTGGAACTGATGCCGAATATTGAACGTTTTCCGAACGGCAAAAAATACGAGCTGGATAAATACACCATGTTCCATTATCTGCGTGCCCAAGAATTTGAACATGGTAAAAGCCGTATTGCACTGACCAATAGCGTTAATGAAGCACTGCTGAACCCGAGCCGTGTTTATACCTTTTTTAGCAGCGATTACGTGAAAAAGGTTAACAAAGCAACCGAAGCAGCCATGTTTTTAGGTTGGGTTGAACAGCTGGTTTATGATTTCACCGATGAAACCAGCGAAGTTAGCACCACCGATAAAATTGCAGATATTACCATCATCATCCCGTATATCGGTCCGGCACTGAATATTGGCAATATGCTGTATAAAGACGATTTTGTGGGTGCCCTGATCTTTAGCGGTGCAGTTATTCTGCTGGAATTTATTCCGGAAATTGCCATTCCGGTTCTGGGCACCTTTGCACTGGTGAGCTATATTGCAAATAAAGTTCTGACCGTGCAGACCATCGATAATGCACTGAGCAAACGTAACGAAAAATGGGATGAAGTGTACAAGTATATCGTGACCAATTGGCTGGCAAAAGTTAACACCCAGATTGACCTGATTCGCAAGAAGATGAAAGAAGCACTGGAAAACCAGGCAGAAGCAACCAAAGCCATTATTAACTATCAGTACAACCAGTACACCGAAGAAGAGAAGAATAACATCAACTTCAACATCGATGATCTGAGCAGCAAGCTGAATGAAAGCATCAACAAAGCCATGATCAACATTAACAAATTTCTGAATCAGTGCAGCGTGAGCTATCTGATGAATAGCATGATTCCGTATGGTGTGAAACGTCTGGAAGATTTTGATGCAAGCCTGAAAGATGCCCTGCTGAAATATATCTATGATAATCGTGGCACCCTGATTGGTCAGGTTGATCGTCTGAAAGATAAAGTGAACAACACCCTGAGTACCGATATTCCTTTTCAGCTGAGCAAATATGTGGATAATCAGCGTCTGCTGAGTACCCTGGATGGCGGCAGCGGCGGCGGCAGCGGCCTGCCCGAAAGCGGTGGCGGATCTGCTTGGTCTCACCCGCAGTTCGAAAAAGGTGGTGGTTCTGGTGGTGGTTCTGGTGGTTCTGCTTGGTCTCACCCGCAGTTCGAAAAAtaatgaAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 4 - Полипептидная последовательность полипептида с ноцицептин-лигандом с участками двукратного мечения посредством SrtA
MENLYFQGGGGSGGSGGSGSMPFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSDDDDKFGGFTGARKSARKRKNQALAGGGGSGGGGSGGGGSALVLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLDGGSGGGSGLPESGGGSAWSHPQFEKGGG
SEQ ID NO: 5 - Нуклеотидная последовательность полипептида с EGF-лигандом
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATgggatccatggagttcgttaacaaacagttcaactataaagacccagttaacggtgttgacattgcttacatcaaaatcccgaacgctggccagatgcagccggtaaaggcattcaaaatccacaacaaaatctgggttatcccggaacgtgatacctttactaacccggaagaaggtgacctgaacccgccaccggaagcgaaacaggtgccggtatcttactatgactccacctacctgtctaccgataacgaaaaggacaactacctgaaaggtgttactaaactgttcgagcgtatttactccaccgacctgggccgtatgctgctgactagcatcgttcgcggtatcccgttctggggcggttctaccatcgataccgaactgaaagtaatcgacactaactgcatcaacgttattcagccggacggttcctatcgttccgaagaactgaacctggtgatcatcggcccgtctgctgatatcatccagttcgagtgtaagagctttggtcacgaagttctgaacctcacccgtaacggctacggttccactcagtacatccgtttctctccggacttcaccttcggttttgaagaatccctggaagtagacacgaacccactgctgggcgctggtaaattcgcaactgatcctgcggttaccctggctcacgaactgattcatgcaggccaccgcctgtacggtatcgccatcaatccgaaccgtgtcttcaaagttaacaccaacgcgtattacgagatgtccggtctggaagttagcttcgaagaactgcgtacttttggcggtcacgacgctaaattcatcgactctctgcaagaaaacgagttccgtctgtactactataacaagttcaaagatatcgcatccaccctgaacaaagcgaaatccatcgtgggtaccactgcttctctccagtacatgaagaacgtttttaaagaaaaatacctgctcagcgaagacacctccggcaaattctctgtagacaagttgaaattcgataaactttacaaaatgctgactgaaatttacaccgaagacaacttcgttaagttctttaaagttctgaaccgcaaaacctatctgaacttcgacaaggcagtattcaaaatcaacatcgtgccgaaagttaactacactatctacgatggtttcaacctgcgtaacaccaacctggctgctaattttaacggccagaacacggaaatcaacaacatgaacttcacaaaactgaaaaacttcactggtctgttcgagttttacaagctgctgtgcgtcgacggcatcattacctccaaaactaaatctctgatagaaggtagaaacaaagcgctgaacctgcagtgtatcaaggttaacaactgggatttattcttcagcccgagtgaagacaacttcaccaacgacctgaacaaaggtgaagaaatcacctcagatactaacatcgaagcagccgaagaaaacatctcgctggacctgatccagcagtactacctgacctttaatttcgacaacgagccggaaaacatttctatcgaaaacctgagctctgatatcatcggccagctggaactgatgccgaacatcgaacgtttcccaaacggtaaaaagtacgagctggacaaatataccatgttccactacctgcgcgcgcaggaatttgaacacggcaaatcccgtatcgcactgactaactccgttaacgaagctctgctcaacccgtcccgtgtatacaccttcttctctagcgactacgtgaaaaaggtcaacaaagcgactgaagctgcaatgttcttgggttgggttgaacagcttgtttatgattttaccgacgagacgtccgaagtatctactaccgacaaaattgcggatatcactatcatcatcccgtacatcggtccggctctgaacattggcaacatgctgtacaaagacgacttcgttggcgcactgatcttctccggtgcggtgatcctgctggagttcatcccggaaatcgccatcccggtactgggcacctttgctctggtttcttacattgcaaacaaggttctgactgtacaaaccatcgacaacgcgctgagcaaacgtaacgaaaaatgggatgaagtttacaaatatatcgtgaccaactggctggctaaggttaatactcagatcgacctcatccgcaaaaaaatgaaagaagcactggaaaaccaggcggaagctaccaaggcaatcattaactaccagtacaaccagtacaccgaggaagaaaaaaacaacatcaacttcaacatcgacgatctgtcctctaaactgaacgaatccatcaacaaagctatgatcaacatcaacaagttcctgaaccagtgctctgtaagctatctgatgaactccatgatcccgtacggtgttaaacgtctggaggacttcgatgcgtctctgaaagacgccctgctgaaatacatttacgacaaccgtggcactctgatcggtcaggttgatcgtctgaaggacaaagtgaacaataccttatcgaccgacatcccttttcagctcagtaaatatgtcgataaccaacgccttttgtccactctagaaggcggTGGCGGTAGCGGTGGCGGTGGCAGCGGCGGTGGCGGTAGCGCACTAGacAACAGCGACCCTAAATGCCCACTgAGTCATGAAGGATACTGCCTTAATGATGGTGTTTGTATGTACATAGGAACATTGGACCGTTATGCTTGCAATTGTGTAGTGGGCTATGTCGGGGAAAGGTGTCAATATCGAGATCTCAAGCTGGCAGAGTTAAGAgggctagaagcaCACCATCATCACcaccatcaccatcaccattaatgaAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 6 - Полипептидная последовательность полипептида с EGF-лигандом
MEFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSLIEGRNKALNLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLEGGGGSGGGGSGGGGSALDNSDPKCPLSHEGYCLNDGVCMYIGTLDRYACNCVVGYVGERCQYRDLKLAELRGLEAHHHHHHHHHH
SEQ ID NO: 7 - Нуклеотидная последовательность полипептида с ноцицептин-лигандом
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATGGGCAGCATGGAATTTGTGAACAAACAGTTCAACTATAAGGATCCGGTTAATGGTGTGGATATCGCCTATATCAAAATTCCGAATGCAGGTCAGATGCAGCCGGTTAAAGCCTTTAAAATCCATAACAAAATTTGGGTGATTCCGGAACGTGATACCTTTACCAATCCGGAAGAAGGTGATCTGAATCCGCCTCCGGAAGCAAAACAGGTTCCGGTTAGCTATTATGATAGCACCTATCTGAGCACCGATAACGAGAAAGATAACTATCTGAAAGGTGTGACCAAACTGTTTGAACGCATTTATAGTACCGATCTGGGTCGTATGCTGCTGACCAGCATTGTTCGTGGTATTCCGTTTTGGGGTGGTAGCACCATTGATACCGAACTGAAAGTTATTGACACCAACTGCATTAATGTGATTCAGCCGGATGGTAGCTATCGTAGCGAAGAACTGAATCTGGTTATTATTGGTCCGAGCGCAGATATCATTCAGTTTGAATGTAAATCCTTTGGCCACGAAGTTCTGAATCTGACCCGTAATGGTTATGGTAGTACCCAGTATATTCGTTTCAGTCCGGATTTTACCTTTGGCTTTGAAGAAAGCCTGGAAGTTGATACAAATCCGCTGTTAGGTGCAGGTAAATTTGCAACCGATCCGGCAGTTACCCTGGCACATGAACTGATTCATGCCGGTCATCGTCTGTATGGTATTGCAATTAATCCGAACCGTGTGTTCAAAGTGAATACCAACGCATATTATGAAATGAGCGGTCTGGAAGTGTCATTTGAAGAACTGCGTACCTTTGGTGGTCATGATGCCAAATTTATCGATAGCCTGCAAGAAAATGAATTTCGCCTGTACTACTATAACAAATTCAAGGATATTGCGAGCACCCTGAATAAAGCCAAAAGCATTGTTGGCACCACCGCAAGCCTGCAGTATATGAAAAATGTGTTTAAAGAAAAATATCTGCTGAGCGAAGATACCAGCGGTAAATTTAGCGTTGACAAACTGAAATTCGATAAACTGTACAAGATGCTGACCGAGATTTATACCGAAGATAACTTCGTGAAGTTTTTCAAAGTGCTGAACCGCAAAACCTACCTGAACTTTGATAAAGCCGTGTTCAAAATCAACATCGTGCCGAAAGTGAACTATACCATCTATGATGGTTTTAACCTGCGCAATACCAATCTGGCAGCAAACTTTAATGGTCAGAACACCGAAATCAACAACATGAACTTTACCAAACTGAAGAACTTCACCGGTCTGTTCGAATTTTACAAACTGCTGTGTGTGGATGGCATTATTACCAGCAAAACCAAATCCGATGATGACGATAAATTCGGTGGTTTTACCGGTGCACGTAAAAGCGCACGTAAACGTAAAAATCAGGCACTGGCAGGCGGTGGTGGTAGCGGTGGCGGTGGTTCAGGTGGTGGTGGCTCAGCACTGGTTCTGCAGTGTATTAAAGTTAATAACTGGGACCTGTTTTTTAGCCCGAGCGAGGATAATTTCACCAACGATCTGAACAAAGGCGAAGAAATTACCAGCGATACCAATATTGAAGCAGCCGAAGAAAACATTAGCCTGGATCTGATTCAGCAGTATTATCTGACCTTCAACTTCGATAATGAGCCGGAAAATATCAGCATTGAAAACCTGAGCAGCGATATTATTGGCCAGCTGGAACTGATGCCGAATATTGAACGTTTTCCGAACGGCAAAAAATACGAGCTGGATAAATACACCATGTTCCATTATCTGCGTGCCCAAGAATTTGAACATGGTAAAAGCCGTATTGCACTGACCAATAGCGTTAATGAAGCACTGCTGAACCCGAGCCGTGTTTATACCTTTTTTAGCAGCGATTACGTGAAAAAGGTTAACAAAGCAACCGAAGCAGCCATGTTTTTAGGTTGGGTTGAACAGCTGGTTTATGATTTCACCGATGAAACCAGCGAAGTTAGCACCACCGATAAAATTGCAGATATTACCATCATCATCCCGTATATCGGTCCGGCACTGAATATTGGCAATATGCTGTATAAAGACGATTTTGTGGGTGCCCTGATCTTTAGCGGTGCAGTTATTCTGCTGGAATTTATTCCGGAAATTGCCATTCCGGTTCTGGGCACCTTTGCACTGGTGAGCTATATTGCAAATAAAGTTCTGACCGTGCAGACCATCGATAATGCACTGAGCAAACGTAACGAAAAATGGGATGAAGTGTACAAGTATATCGTGACCAATTGGCTGGCAAAAGTTAACACCCAGATTGACCTGATTCGCAAGAAGATGAAAGAAGCACTGGAAAACCAGGCAGAAGCAACCAAAGCCATTATTAACTATCAGTACAACCAGTACACCGAAGAAGAGAAGAATAACATCAACTTCAACATCGATGATCTGAGCAGCAAGCTGAATGAAAGCATCAACAAAGCCATGATCAACATTAACAAATTTCTGAATCAGTGCAGCGTGAGCTATCTGATGAATAGCATGATTCCGTATGGTGTGAAACGTCTGGAAGATTTTGATGCAAGCCTGAAAGATGCCCTGCTGAAATATATCTATGATAATCGTGGCACCCTGATTGGTCAGGTTGATCGTCTGAAAGATAAAGTGAACAACACCCTGAGTACCGATATTCCTTTTCAGCTGAGCAAATATGTGGATAATCAGCGTCTGCTGAGTACCCTGGATCATCATCACCATCACCACTAAAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 8 - Полипептидная последовательность полипептида с ноцицептин-лигандом
MGSMEFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSDDDDKFGGFTGARKSARKRKNQALAGGGGSGGGGSGGGGSALVLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLDHHHHHH
SEQ ID NO: 9 - Нуклеотидная последовательность GFP-меченного полипептида с EGF-лигандом
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATgATGGTGAGCAAGGGCGAGGAGCTGTTCACCGGGGTGGTGCCCATCCTGGTCGAGCTGGACGGCGACGTAAACGGCCACAAGTTCAGCGTGTCCGGCGAGGGCGAGGGCGATGCCACCTACGGCAAGCTGACCCTGAAGTTCATCTGCACCACCGGCAAGCTGCCCGTGCCCTGGCCCACCCTCGTGACCACCCTGACCTACGGCGTGCAGTGCTTCAGCCGCTACCCCGACCACATGAAGCAGCACGACTTCTTCAAGTCCGCCATGCCCGAAGGCTACGTCCAGGAGCGCACCATCTTCTTCAAGGACGACGGCAACTACAAGACCCGCGCCGAGGTGAAGTTCGAGGGCGACACCCTGGTGAACCGCATCGAGCTGAAGGGCATCGACTTCAAGGAGGACGGCAACATCCTGGGGCACAAGCTGGAGTACAACTACAACAGCCACAACGTCTATATCATGGCCGACAAGCAGAAGAACGGCATCAAGGTGAACTTCAAGATCCGCCACAACATCGAGGACGGCAGCGTGCAGCTCGCCGACCACTACCAGCAGAACACCCCCATCGGCGACGGCCCCGTGCTGCTGCCCGACAACCACTACCTGAGCACCCAGTCCGCCCTGAGCAAAGACCCCAACGAGAAGCGCGATCACATGGTCCTGCTGGAGTTCGTGACCGCCGCCGGGATCACTCACGGCATGGACGAGCTGTACAAGGGCGGCAGCGGCGGCGGCAGCGGCGGCggatccatggagttcgttaacaaacagttcaactataaagacccagttaacggtgttgacattgcttacatcaaaatcccgaacgctggccagatgcagccggtaaaggcattcaaaatccacaacaaaatctgggttatcccggaacgtgatacctttactaacccggaagaaggtgacctgaacccgccaccggaagcgaaacaggtgccggtatcttactatgactccacctacctgtctaccgataacgaaaaggacaactacctgaaaggtgttactaaactgttcgagcgtatttactccaccgacctgggccgtatgctgctgactagcatcgttcgcggtatcccgttctggggcggttctaccatcgataccgaactgaaagtaatcgacactaactgcatcaacgttattcagccggacggttcctatcgttccgaagaactgaacctggtgatcatcggcccgtctgctgatatcatccagttcgagtgtaagagctttggtcacgaagttctgaacctcacccgtaacggctacggttccactcagtacatccgtttctctccggacttcaccttcggttttgaagaatccctggaagtagacacgaacccactgctgggcgctggtaaattcgcaactgatcctgcggttaccctggctcacgaactgattcatgcaggccaccgcctgtacggtatcgccatcaatccgaaccgtgtcttcaaagttaacaccaacgcgtattacgagatgtccggtctggaagttagcttcgaagaactgcgtacttttggcggtcacgacgctaaattcatcgactctctgcaagaaaacgagttccgtctgtactactataacaagttcaaagatatcgcatccaccctgaacaaagcgaaatccatcgtgggtaccactgcttctctccagtacatgaagaacgtttttaaagaaaaatacctgctcagcgaagacacctccggcaaattctctgtagacaagttgaaattcgataaactttacaaaatgctgactgaaatttacaccgaagacaacttcgttaagttctttaaagttctgaaccgcaaaacctatctgaacttcgacaaggcagtattcaaaatcaacatcgtgccgaaagttaactacactatctacgatggtttcaacctgcgtaacaccaacctggctgctaattttaacggccagaacacggaaatcaacaacatgaacttcacaaaactgaaaaacttcactggtctgttcgagttttacaagctgctgtgcgtcgacggcatcattacctccaaaactaaatctctgatagaaggtagaaacaaagcgctgaacctgcagtgtatcaaggttaacaactgggatttattcttcagcccgagtgaagacaacttcaccaacgacctgaacaaaggtgaagaaatcacctcagatactaacatcgaagcagccgaagaaaacatctcgctggacctgatccagcagtactacctgacctttaatttcgacaacgagccggaaaacatttctatcgaaaacctgagctctgatatcatcggccagctggaactgatgccgaacatcgaacgtttcccaaacggtaaaaagtacgagctggacaaatataccatgttccactacctgcgcgcgcaggaatttgaacacggcaaatcccgtatcgcactgactaactccgttaacgaagctctgctcaacccgtcccgtgtatacaccttcttctctagcgactacgtgaaaaaggtcaacaaagcgactgaagctgcaatgttcttgggttgggttgaacagcttgtttatgattttaccgacgagacgtccgaagtatctactaccgacaaaattgcggatatcactatcatcatcccgtacatcggtccggctctgaacattggcaacatgctgtacaaagacgacttcgttggcgcactgatcttctccggtgcggtgatcctgctggagttcatcccggaaatcgccatcccggtactgggcacctttgctctggtttcttacattgcaaacaaggttctgactgtacaaaccatcgacaacgcgctgagcaaacgtaacgaaaaatgggatgaagtttacaaatatatcgtgaccaactggctggctaaggttaatactcagatcgacctcatccgcaaaaaaatgaaagaagcactggaaaaccaggcggaagctaccaaggcaatcattaactaccagtacaaccagtacaccgaggaagaaaaaaacaacatcaacttcaacatcgacgatctgtcctctaaactgaacgaatccatcaacaaagctatgatcaacatcaacaagttcctgaaccagtgctctgtaagctatctgatgaactccatgatcccgtacggtgttaaacgtctggaggacttcgatgcgtctctgaaagacgccctgctgaaatacatttacgacaaccgtggcactctgatcggtcaggttgatcgtctgaaggacaaagtgaacaataccttatcgaccgacatcccttttcagctcagtaaatatgtcgataaccaacgccttttgtccactctagaaggcggTGGCGGTAGCGGTGGCGGTGGCAGCGGCGGTGGCGGTAGCGCACTAGacAACAGCGACCCTAAATGCCCACTaAGTCATGAAGGATACTGCCTTAATGATGGTGTTTGTATGTACATAGGAACATTGGACCGTTATGCTTGCAATTGTGTAGTGGGCTATGTCGGGGAAAGGTGTCAATATCGAGATCTCAAGCTGGCAGAGTTAAGAgggctagaagcaCACCATCATCACcaccatcaccatcaccattaatgaAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 10 - Полипептидная последовательность GFP-меченного полипептида с EGF-лигандом
MVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYKGGSGGGSGGGSMEFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSLIEGRNKALNLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLEGGGGSGGGGSGGGGSALDNSDPKCPLSHEGYCLNDGVCMYIGTLDRYACNCVVGYVGERCQYRDLKLAELRGLEAHHHHHHHHHH
SEQ ID NO: 11 - Нуклеотидная последовательность SNAP-меченного полипептида с EGF-лигандом
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATgATGGACAAAGACTGCGAAATGAAGCGCACCACCCTGGATAGCCCTCTGGGCAAGCTGGAACTGTCTGGGTGCGAACAGGGCCTGCACCGTATCATCTTCCTGGGCAAAGGAACATCTGCCGCCGACGCCGTGGAAGTGCCTGCCCCAGCCGCCGTGCTGGGCGGACCAGAGCCACTGATGCAGGCCACCGCCTGGCTCAACGCCTACTTTCACCAGCCTGAGGCCATCGAGGAGTTCCCTGTGCCAGCCCTGCACCACCCAGTGTTCCAGCAGGAGAGCTTTACCCGCCAGGTGCTGTGGAAACTGCTGAAAGTGGTGAAGTTCGGAGAGGTCATCAGCTACAGCCACCTGGCCGCCCTGGCCGGCAATCCCGCCGCCACCGCCGCCGTGAAAACCGCCCTGAGCGGAAATCCCGTGCCCATTCTGATCCCCTGCCACCGGGTGGTGCAGGGCGACCTGGACGTGGGGGGCTACGAGGGCGGGCTCGCCGTGAAAGAGTGGCTGCTGGCCCACGAGGGCCACAGACTGGGCAAGCCTGGGCTGGGTGGCGGCAGCGGCGGCGGCAGCGGCGGCggatccatggagttcgttaacaaacagttcaactataaagacccagttaacggtgttgacattgcttacatcaaaatcccgaacgctggccagatgcagccggtaaaggcattcaaaatccacaacaaaatctgggttatcccggaacgtgatacctttactaacccggaagaaggtgacctgaacccgccaccggaagcgaaacaggtgccggtatcttactatgactccacctacctgtctaccgataacgaaaaggacaactacctgaaaggtgttactaaactgttcgagcgtatttactccaccgacctgggccgtatgctgctgactagcatcgttcgcggtatcccgttctggggcggttctaccatcgataccgaactgaaagtaatcgacactaactgcatcaacgttattcagccggacggttcctatcgttccgaagaactgaacctggtgatcatcggcccgtctgctgatatcatccagttcgagtgtaagagctttggtcacgaagttctgaacctcacccgtaacggctacggttccactcagtacatccgtttctctccggacttcaccttcggttttgaagaatccctggaagtagacacgaacccactgctgggcgctggtaaattcgcaactgatcctgcggttaccctggctcacgaactgattcatgcaggccaccgcctgtacggtatcgccatcaatccgaaccgtgtcttcaaagttaacaccaacgcgtattacgagatgtccggtctggaagttagcttcgaagaactgcgtacttttggcggtcacgacgctaaattcatcgactctctgcaagaaaacgagttccgtctgtactactataacaagttcaaagatatcgcatccaccctgaacaaagcgaaatccatcgtgggtaccactgcttctctccagtacatgaagaacgtttttaaagaaaaatacctgctcagcgaagacacctccggcaaattctctgtagacaagttgaaattcgataaactttacaaaatgctgactgaaatttacaccgaagacaacttcgttaagttctttaaagttctgaaccgcaaaacctatctgaacttcgacaaggcagtattcaaaatcaacatcgtgccgaaagttaactacactatctacgatggtttcaacctgcgtaacaccaacctggctgctaattttaacggccagaacacggaaatcaacaacatgaacttcacaaaactgaaaaacttcactggtctgttcgagttttacaagctgctgtgcgtcgacggcatcattacctccaaaactaaatctctgatagaaggtagaaacaaagcgctgaacctgcagtgtatcaaggttaacaactgggatttattcttcagcccgagtgaagacaacttcaccaacgacctgaacaaaggtgaagaaatcacctcagatactaacatcgaagcagccgaagaaaacatctcgctggacctgatccagcagtactacctgacctttaatttcgacaacgagccggaaaacatttctatcgaaaacctgagctctgatatcatcggccagctggaactgatgccgaacatcgaacgtttcccaaacggtaaaaagtacgagctggacaaatataccatgttccactacctgcgcgcgcaggaatttgaacacggcaaatcccgtatcgcactgactaactccgttaacgaagctctgctcaacccgtcccgtgtatacaccttcttctctagcgactacgtgaaaaaggtcaacaaagcgactgaagctgcaatgttcttgggttgggttgaacagcttgtttatgattttaccgacgagacgtccgaagtatctactaccgacaaaattgcggatatcactatcatcatcccgtacatcggtccggctctgaacattggcaacatgctgtacaaagacgacttcgttggcgcactgatcttctccggtgcggtgatcctgctggagttcatcccggaaatcgccatcccggtactgggcacctttgctctggtttcttacattgcaaacaaggttctgactgtacaaaccatcgacaacgcgctgagcaaacgtaacgaaaaatgggatgaagtttacaaatatatcgtgaccaactggctggctaaggttaatactcagatcgacctcatccgcaaaaaaatgaaagaagcactggaaaaccaggcggaagctaccaaggcaatcattaactaccagtacaaccagtacaccgaggaagaaaaaaacaacatcaacttcaacatcgacgatctgtcctctaaactgaacgaatccatcaacaaagctatgatcaacatcaacaagttcctgaaccagtgctctgtaagctatctgatgaactccatgatcccgtacggtgttaaacgtctggaggacttcgatgcgtctctgaaagacgccctgctgaaatacatttacgacaaccgtggcactctgatcggtcaggttgatcgtctgaaggacaaagtgaacaataccttatcgaccgacatcccttttcagctcagtaaatatgtcgataaccaacgccttttgtccactctagaaggcggTGGCGGTAGCGGTGGCGGTGGCAGCGGCGGTGGCGGTAGCGCACTAGacAACAGCGACCCTAAATGCCCACTaAGTCATGAAGGATACTGCCTTAATGATGGTGTTTGTATGTACATAGGAACATTGGACCGTTATGCTTGCAATTGTGTAGTGGGCTATGTCGGGGAAAGGTGTCAATATCGAGATCTCAAGCTGGCAGAGTTAAGAgggctagaagcaCACCATCATCACcaccatcaccatcaccattaatgaAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 12 - Полипептидная последовательность SNAP-меченного полипептида с EGF-лигандом
MDKDCEMKRTTLDSPLGKLELSGCEQGLHRIIFLGKGTSAADAVEVPAPAAVLGGPEPLMQATAWLNAYFHQPEAIEEFPVPALHHPVFQQESFTRQVLWKLLKVVKFGEVISYSHLAALAGNPAATAAVKTALSGNPVPILIPCHRVVQGDLDVGGYEGGLAVKEWLLAHEGHRLGKPGLGGGSGGGSGGGSMEFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSLIEGRNKALNLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLEGGGGSGGGGSGGGGSALDNSDPKCPLSHEGYCLNDGVCMYIGTLDRYACNCVVGYVGERCQYRDLKLAELRGLEAHHHHHHHHHH
SEQ ID NO: 13 - Нуклеотидная последовательность сортазы A (нацеливание на LPESG)
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATCATATGCAGGCAAAACCGCAGATTCCGAAAGATAAAAGCAAAGTGGCAGGCTATATTGAAATTCCGGATGCCGATATTAAAGAACCGGTTTATCCGGGTCCTGCAACACGTGAACAGCTGGATCGTGGTGTTTGTTTTGTTGAAGAAAATGAGAGCCTGGATGATCAGAACATTAGCATTACCGGTCATACCGCAATTGATCGTCCGAATTATCAGTTTACCAATCTGCGTGCAGCCAAACCGGGTAGCATGGTTTATCTGAAAGTTGGTAATGAAACCCGCATCTACAAAATGACCAGCATTCGTAATGTTAAACCGACCGCAGTTGGTGTTCTGGATGAACAAAAAGGTAAAGATAAACAGCTGACCCTGGTTACCTGTGATGATTATAACTTTGAAACCGGTGTTTGGGAAACGCGCAAAATCTTTGTTGCAACCGAAGTTAAACATCACCATCACCACCATCATCATCACCATTAAAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 14 - Полипептидная последовательность сортазы A (нацеливание на LPESG)
MQAKPQIPKDKSKVAGYIEIPDADIKEPVYPGPATREQLDRGVCFVEENESLDDQNISITGHTAIDRPNYQFTNLRAAKPGSMVYLKVGNETRIYKMTSIRNVKPTAVGVLDEQKGKDKQLTLVTCDDYNFETGVWETRKIFVATEVKHHHHHHHHHH
SEQ ID NO: 15 - Нуклеотидная последовательность сортазы A (нацеливание на LAETG)
TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGTGTGGTGGTTACGCGCAGCGTGACCGCTACACTTGCCAGCGCCCTAGCGCCCGCTCCTTTCGCTTTCTTCCCTTCCTTTCTCGCCACGTTCGCCGGCTTTCCCCGTCAAGCTCTAAATCGGGGGCTCCCTTTAGGGTTCCGATTTAGTGCTTTACGGCACCTCGACCCCAAAAAACTTGATTAGGGTGATGGTTCACGTAGTGGGCCATCGCCCTGATAGACGGTTTTTCGCCCTTTGACGTTGGAGTCCACGTTCTTTAATAGTGGACTCTTGTTCCAAACTGGAACAACACTCAACCCTATCTCGGTCTATTCTTTTGATTTATAAGGGATTTTGCCGATTTCGGCCTATTGGTTAAAAAATGAGCTGATTTAACAAAAATTTAACGCGAATTTTAACAAAATATTAACGCTTACAATTTAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAATTAATTCTTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGTTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTCCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTAGAGCAAGACGTTTCCCGTTGAATATGGCTCATAACACCCCTTGTATTACTGTTTATGTAAGCAGACAGTTTTATTGTTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATCGGCGATAATGGCCTGCTTCTCGCCGAAACGTTTGGTGGCGGGACCAGTGACGAAGGCTTGAGCGAGGGCGTGCAAGATTCCGAATACCGCAAGCGACAGGCCGATCATCGTCGCGCTCCAGCGAAAGCGGTCCTCGCCGAAAATGACCCAGAGCGCTGCCGGCACCTGTCCTACGAGTTGCATGATAAAGAAGACAGTCATAAGTGCGGCGACGATAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATATCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCCGCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCAAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATGCAGGCAAAACCGCAGATTCCGAAAGATAAAAGCAAAGTGGCAGGCTATATTGAAATTCCGGATGCCGATATTAAAGAACCGGTTTATCCGGGTCCTGCAACACGTGAACAGCTGAATCGTGGTGTTTGTTTTCACGATGAAAATGAGAGCCTGGATGATCAGAATATTAGCATTGCAGGCCATACCTTTATTGATCGTCCGAATTATCAGTTCACCAATCTGAAAGCAGCAAAACCGGGTAGCATGGTTTATTTCAAAGTTGGTAATGAAACCCGCATCTACAAAATGACCAGCATTCGTAAAGTTCATCCGAATGCAGTTGGTGTTCTGGATGAACAAGAAGGCAAAGATAAACAGCTGACCCTGGTTACCTGTGATGATTATAACGAAGAAACCGGTGTTTGGGAAAGCCGTAAAATCTTTGTTGCAACCGAAGTGAAACATCATCACCACCATCACCATCATCATCACTAAAAGCTTGCGGCCGCACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGAT
SEQ ID NO: 16 - Полипептидная последовательность сортазы A (нацеливание на LAETG)
MQAKPQIPKDKSKVAGYIEIPDADIKEPVYPGPATREQLNRGVCFHDENESLDDQNISIAGHTFIDRPNYQFTNLKAAKPGSMVYFKVGNETRIYKMTSIRKVHPNAVGVLDEQEGKDKQLTLVTCDDYNEETGVWESRKIFVATEVKHHHHHHHHHH
SEQ ID NO: 17 - BoNT/A - UniProt P10845
MPFVNKQFNYKDPVNGVDIAYIKIPNVGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLN
PPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGG
STIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGY
GSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPN
RVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKA
KSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKV
LNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFT
GLFEFYKLLCVRGIITSKTKSLDKGYNKALNDLCIKVNNWDLFFSPSEDNFTNDLNKGEE
ITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNG
KKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEA
AMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSG
AVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAK
VNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKA
MININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDK
VNNTLSTDIPFQLSKYVDNQRLLSTFTEYIKNIINTSILNLRYESNHLIDLSRYASKINI
GSKVNFDPIDKNQIQLFNLESSKIEVILKNAIVYNSMYENFSTSFWIRIPKYFNSISLNN
EYTIINCMENNSGWKVSLNYGEIIWTLQDTQEIKQRVVFKYSQMINISDYINRWIFVTIT
NNRLNNSKIYINGRLIDQKPISNLGNIHASNNIMFKLDGCRDTHRYIWIKYFNLFDKELN
EKEIKDLYDNQSNSGILKDFWGDYLQYDKPYYMLNLYDPNKYVDVNNVGIRGYMYLKGPR
GSVMTTNIYLNSSLYRGTKFIIKKYASGNKDNIVRNNDRVYINVVVKNKEYRLATNASQA
GVEKILSALEIPDVGNLSQVVVMKSKNDQGITNKCKMNLQDNNGNDIGFIGFHQFNNIAK
LVASNWYNRQIERSSRTLGCSWEFIPVDDGWGERPL
SEQ ID NO: 18 - BoNT/B - UniProt P10844
MPVTINNFNYNDPIDNNNIIMMEPPFARGTGRYYKAFKITDRIWIIPERYTFGYKPEDFN
KSSGIFNRDVCEYYDPDYLNTNDKKNIFLQTMIKLFNRIKSKPLGEKLLEMIINGIPYLG
DRRVPLEEFNTNIASVTVNKLISNPGEVERKKGIFANLIIFGPGPVLNENETIDIGIQNH
FASREGFGGIMQMKFCPEYVSVFNNVQENKGASIFNRRGYFSDPALILMHELIHVLHGLY
GIKVDDLPIVPNEKKFFMQSTDAIQAEELYTFGGQDPSIITPSTDKSIYDKVLQNFRGIV
DRLNKVLVCISDPNININIYKNKFKDKYKFVEDSEGKYSIDVESFDKLYKSLMFGFTETN
IAENYKIKTRASYFSDSLPPVKIKNLLDNEIYTIEEGFNISDKDMEKEYRGQNKAINKQA
YEEISKEHLAVYKIQMCKSVKAPGICIDVDNEDLFFIADKNSFSDDLSKNERIEYNTQSN
YIENDFPINELILDTDLISKIELPSENTESLTDFNVDVPVYEKQPAIKKIFTDENTIFQY
LYSQTFPLDIRDISLTSSFDDALLFSNKVYSFFSMDYIKTANKVVEAGLFAGWVKQIVND
FVIEANKSNTMDKIADISLIVPYIGLALNVGNETAKGNFENAFEIAGASILLEFIPELLI
PVVGAFLLESYIDNKNKIIKTIDNALTKRNEKWSDMYGLIVAQWLSTVNTQFYTIKEGMY
KALNYQAQALEEIIKYRYNIYSEKEKSNINIDFNDINSKLNEGINQAIDNINNFINGCSV
SYLMKKMIPLAVEKLLDFDNTLKKNLLNYIDENKLYLIGSAEYEKSKVNKYLKTIMPFDL
SIYTNDTILIEMFNKYNSEILNNIILNLRYKDNNLIDLSGYGAKVEVYDGVELNDKNQFK
LTSSANSKIRVTQNQNIIFNSVFLDFSVSFWIRIPKYKNDGIQNYIHNEYTIINCMKNNS
GWKISIRGNRIIWTLIDINGKTKSVFFEYNIREDISEYINRWFFVTITNNLNNAKIYING
KLESNTDIKDIREVIANGEIIFKLDGDIDRTQFIWMKYFSIFNTELSQSNIEERYKIQSY
SEYLKDFWGNPLMYNKEYYMFNAGNKNSYIKLKKDSPVGEILTRSKYNQNSKYINYRDLY
IGEKFIIRRKSNSQSINDDIVRKEDYIYLDFFNLNQEWRVYTYKYFKKEEEKLFLAPISD
SDEFYNTIQIKEYDEQPTYSCQLLFKKDEESTDEIGLIGIHRFYESGIVFEEYKDYFCIS
KWYLKEVKRKPYNLKLGCNWQFIPKDEGWTE
SEQ ID NO: 19 - BoNT/C - UniProt P18640
MPITINNFNYSDPVDNKNILYLDTHLNTLANEPEKAFRITGNIWVIPDRFSRNSNPNLNK
PPRVTSPKSGYYDPNYLSTDSDKDPFLKEIIKLFKRINSREIGEELIYRLSTDIPFPGNN
NTPINTFDFDVDFNSVDVKTRQGNNWVKTGSINPSVIITGPRENIIDPETSTFKLTNNTF
AAQEGFGALSIISISPRFMLTYSNATNDVGEGRFSKSEFCMDPILILMHELNHAMHNLYG
IAIPNDQTISSVTSNIFYSQYNVKLEYAEIYAFGGPTIDLIPKSARKYFEEKALDYYRSI
AKRLNSITTANPSSFNKYIGEYKQKLIRKYRFVVESSGEVTVNRNKFVELYNELTQIFTE
FNYAKIYNVQNRKIYLSNVYTPVTANILDDNVYDIQNGFNIPKSNLNVLFMGQNLSRNPA
LRKVNPENMLYLFTKFCHKAIDGRSLYNKTLDCRELLVKNTDLPFIGDISDVKTDIFLRK
DINEETEVIYYPDNVSVDQVILSKNTSEHGQLDLLYPSIDSESEILPGENQVFYDNRTQN
VDYLNSYYYLESQKLSDNVEDFTFTRSIEEALDNSAKVYTYFPTLANKVNAGVQGGLFLM
WANDVVEDFTTNILRKDTLDKISDVSAIIPYIGPALNISNSVRRGNFTEAFAVTGVTILL
EAFPEFTIPALGAFVIYSKVQERNEIIKTIDNCLEQRIKRWKDSYEWMMGTWLSRIITQF
NNISYQMYDSLNYQAGAIKAKIDLEYKKYSGSDKENIKSQVENLKNSLDVKISEAMNNIN
KFIRECSVTYLFKNMLPKVIDELNEFDRNTKAKLINLIDSHNIILVGEVDKLKAKVNNSF
QNTIPFNIFSYTNNSLLKDIINEYFNNINDSKILSLQNRKNTLVDTSGYNAEVSEEGDVQ
LNPIFPFDFKLGSSGEDRGKVIVTQNENIVYNSMYESFSISFWIRINKWVSNLPGYTIID
SVKNNSGWSIGIISNFLVFTLKQNEDSEQSINFSYDISNNAPGYNKWFFVTVTNNMMGNM
KIYINGKLIDTIKVKELTGINFSKTITFEINKIPDTGLITSDSDNINMWIRDFYIFAKEL
DGKDINILFNSLQYTNVVKDYWGNDLRYNKEYYMVNIDYLNRYMYANSRQIVFNTRRNNN
DFNEGYKIIIKRIRGNTNDTRVRGGDILYFDMTINNKAYNLFMKNETMYADNHSTEDIYA
IGLREQTKDINDNIIFQIQPMNNTYYYASQIFKSNFNGENISGICSIGTYRFRLGGDWYR
HNYLVPTVKQGNYASLLESTSTHWGFVPVSE
SEQ ID NO: 20 - BoNT/D - UniProt P19321
MTWPVKDFNYSDPVNDNDILYLRIPQNKLITTPVKAFMITQNIWVIPERFSSDTNPSLSK
PPRPTSKYQSYYDPSYLSTDEQKDTFLKGIIKLFKRINERDIGKKLINYLVVGSPFMGDS
STPEDTFDFTRHTTNIAVEKFENGSWKVTNIITPSVLIFGPLPNILDYTASLTLQGQQSN
PSFEGFGTLSILKVAPEFLLTFSDVTSNQSSAVLGKSIFCMDPVIALMHELTHSLHQLYG
INIPSDKRIRPQVSEGFFSQDGPNVQFEELYTFGGLDVEIIPQIERSQLREKALGHYKDI
AKRLNNINKTIPSSWISNIDKYKKIFSEKYNFDKDNTGNFVVNIDKFNSLYSDLTNVMSE
VVYSSQYNVKNRTHYFSRHYLPVFANILDDNIYTIRDGFNLTNKGFNIENSGQNIERNPA
LQKLSSESVVDLFTKVCLRLTKNSRDDSTCIKVKNNRLPYVADKDSISQEIFENKIITDE
TNVQNYSDKFSLDESILDGQVPINPEIVDPLLPNVNMEPLNLPGEEIVFYDDITKYVDYL
NSYYYLESQKLSNNVENITLTTSVEEALGYSNKIYTFLPSLAEKVNKGVQAGLFLNWANE
VVEDFTTNIMKKDTLDKISDVSVIIPYIGPALNIGNSALRGNFNQAFATAGVAFLLEGFP
EFTIPALGVFTFYSSIQEREKIIKTIENCLEQRVKRWKDSYQWMVSNWLSRITTQFNHIN
YQMYDSLSYQADAIKAKIDLEYKKYSGSDKENIKSQVENLKNSLDVKISEAMNNINKFIR
ECSVTYLFKNMLPKVIDELNKFDLRTKTELINLIDSHNIILVGEVDRLKAKVNESFENTM
PFNIFSYTNNSLLKDIINEYFNSINDSKILSLQNKKNALVDTSGYNAEVRVGDNVQLNTI
YTNDFKLSSSGDKIIVNLNNNILYSAIYENSSVSFWIKISKDLTNSHNEYTIINSIEQNS
GWKLCIRNGNIEWILQDVNRKYKSLIFDYSESLSHTGYTNKWFFVTITNNIMGYMKLYIN
GELKQSQKIEDLDEVKLDKTIVFGIDENIDENQMLWIRDFNIFSKELSNEDINIVYEGQI
LRNVIKDYWGNPLKFDTEYYIINDNYIDRYIAPESNVLVLVQYPDRSKLYTGNPITIKSV
SDKNPYSRILNGDNIILHMLYNSRKYMIIRDTDTIYATQGGECSQNCVYALKLQSNLGNY
GIGIFSIKNIVSKNKYCSQIFSSFRENTMLLADIYKPWRFSFKNAYTPVAVTNYETKLLS
TSSFWKFISRDPGWVE
SEQ ID NO: 21 - BoNT/E - UniProt Q00496
MPKINSFNYNDPVNDRTILYIKPGGCQEFYKSFNIMKNIWIIPERNVIGTTPQDFHPPTS
LKNGDSSYYDPNYLQSDEEKDRFLKIVTKIFNRINNNLSGGILLEELSKANPYLGNDNTP
DNQFHIGDASAVEIKFSNGSQDILLPNVIIMGAEPDLFETNSSNISLRNNYMPSNHRFGS
IAIVTFSPEYSFRFNDNCMNEFIQDPALTLMHELIHSLHGLYGAKGITTKYTITQKQNPL
ITNIRGTNIEEFLTFGGTDLNIITSAQSNDIYTNLLADYKKIASKLSKVQVSNPLLNPYK
DVFEAKYGLDKDASGIYSVNINKFNDIFKKLYSFTEFDLRTKFQVKCRQTYIGQYKYFKL
SNLLNDSIYNISEGYNINNLKVNFRGQNANLNPRIITPITGRGLVKKIIRFCKNIVSVKG
IRKSICIEINNGELFFVASENSYNDDNINTPKEIDDTVTSNNNYENDLDQVILNFNSESA
PGLSDEKLNLTIQNDAYIPKYDSNGTSDIEQHDVNELNVFFYLDAQKVPEGENNVNLTSS
IDTALLEQPKIYTFFSSEFINNVNKPVQAALFVSWIQQVLVDFTTEANQKSTVDKIADIS
IVVPYIGLALNIGNEAQKGNFKDALELLGAGILLEFEPELLIPTILVFTIKSFLGSSDNK
NKVIKAINNALKERDEKWKEVYSFIVSNWMTKINTQFNKRKEQMYQALQNQVNAIKTIIE
SKYNSYTLEEKNELTNKYDIKQIENELNQKVSIAMNNIDRFLTESSISYLMKIINEVKIN
KLREYDENVKTYLLNYIIQHGSILGESQQELNSMVTDTLNNSIPFKLSSYTDDKILISYF
NKFFKRIKSSSVLNMRYKNDKYVDTSGYDSNININGDVYKYPTNKNQFGIYNDKLSEVNI
SQNDYIIYDNKYKNFSISFWVRIPNYDNKIVNVNNEYTIINCMRDNNSGWKVSLNHNEII
WTFEDNRGINQKLAFNYGNANGISDYINKWIFVTITNDRLGDSKLYINGNLIDQKSILNL
GNIHVSDNILFKIVNCSYTRYIGIRYFNIFDKELDETEIQTLYSNEPNTNILKDFWGNYL
LYDKEYYLLNVLKPNNFIDRRKDSTLSINNIRSTILLANRLYSGIKVKIQRVNNSSTNDN
LVRKNDQVYINFVASKTHLFPLYADTATTNKEKTIKISSSGNRFNQVVVMNSVGNCTMNF
KNNNGNNIGLLGFKADTVVASTWYYTHMRDHTNSNGCFWNFISEEHGWQEK
SEQ ID NO: 22 - BoNT/F - UniProt A7GBG3
MPVVINSFNYNDPVNDDTILYMQIPYEEKSKKYYKAFEIMRNVWIIPERNTIGTDPSDFD
PPASLENGSSAYYDPNYLTTDAEKDRYLKTTIKLFKRINSNPAGEVLLQEISYAKPYLGN
EHTPINEFHPVTRTTSVNIKSSTNVKSSIILNLLVLGAGPDIFENSSYPVRKLMDSGGVY
DPSNDGFGSINIVTFSPEYEYTFNDISGGYNSSTESFIADPAISLAHELIHALHGLYGAR
GVTYKETIKVKQAPLMIAEKPIRLEEFLTFGGQDLNIITSAMKEKIYNNLLANYEKIATR
LSRVNSAPPEYDINEYKDYFQWKYGLDKNADGSYTVNENKFNEIYKKLYSFTEIDLANKF
KVKCRNTYFIKYGFLKVPNLLDDDIYTVSEGFNIGNLAVNNRGQNIKLNPKIIDSIPDKG
LVEKIVKFCKSVIPRKGTKAPPRLCIRVNNRELFFVASESSYNENDINTPKEIDDTTNLN
NNYRNNLDEVILDYNSETIPQISNQTLNTLVQDDSYVPRYDSNGTSEIEEHNVVDLNVFF
YLHAQKVPEGETNISLTSSIDTALSEESQVYTFFSSEFINTINKPVHAALFISWINQVIR
DFTTEATQKSTFDKIADISLVVPYVGLALNIGNEVQKENFKEAFELLGAGILLEFVPELL
IPTILVFTIKSFIGSSENKNKIIKAINNSLMERETKWKEIYSWIVSNWLTRINTQFNKRK
EQMYQALQNQVDAIKTVIEYKYNNYTSDERNRLESEYNINNIREELNKKVSLAMENIERF
ITESSIFYLMKLINEAKVSKLREYDEGVKEYLLDYISEHRSILGNSVQELNDLVTSTLNN
SIPFELSSYTNDKILILYFNKLYKKIKDNSILDMRYENNKFIDISGYGSNISINGDVYIY
STNRNQFGIYSSKPSEVNIAQNNDIIYNGRYQNFSISFWVRIPKYFNKVNLNNEYTIIDC
IRNNNSGWKISLNYNKIIWTLQDTAGNNQKLVFNYTQMISISDYINKWIFVTITNNRLGN
SRIYINGNLIDEKSISNLGDIHVSDNILFKIVGCNDTRYVGIRYFKVFDTELGKTEIETL
YSDEPDPSILKDFWGNYLLYNKRYYLLNLLRTDKSITQNSNFLNINQQRGVYQKPNIFSN
TRLYTGVEVIIRKNGSTDISNTDNFVRKNDLAYINVVDRDVEYRLYADISIAKPEKIIKL
IRTSNSNNSLGQIIVMDSIGNNCTMNFQNNNGGNIGLLGFHSNNLVASSWYYNNIRKNTS
SNGCFWSFISKEHGWQEN
SEQ ID NO: 23 - BoNT/G - UniProt Q60393
MPVNIKXFNYNDPINNDDIIMMEPFNDPGPGTYYKAFRIIDRIWIVPERFTYGFQPDQFN
ASTGVFSKDVYEYYDPTYLKTDAEKDKFLKTMIKLFNRINSKPSGQRLLDMIVDAIPYLG
NASTPPDKFAANVANVSINKKIIQPGAEDQIKGLMTNLIIFGPGPVLSDNFTDSMIMNGH
SPISEGFGARMMIRFCPSCLNVFNNVQENKDTSIFSRRAYFADPALTLMHELIHVLHGLY
GIKISNLPITPNTKEFFMQHSDPVQAEELYTFGGHDPSVISPSTDMNIYNKALQNFQDIA
NRLNIVSSAQGSGIDISLYKQIYKNKYDFVEDPNGKYSVDKDKFDKLYKALMFGFTETNL
AGEYGIKTRYSYFSEYLPPIKTEKLLDNTIYTQNEGFNIASKNLKTEFNGQNKAVNKEAY
EEISLEHLVIYRIAMCKPVMYKNTGKSEQCIIVNNEDLFFIANKDSFSKDLAKAETIAYN
TQNNTIENNFSIDQLILDNDLSSGIDLPNENTEPFTNFDDIDIPVYIKQSALKKIFVDGD
SLFEYLHAQTFPSNIENLQLTNSLNDALRNNNKVYTFFSTNLVEKANTVVGASLFVNWVK
GVIDDFTSESTQKSTIDKVSDVSIIIPYIGPALNVGNETAKENFKNAFEIGGAAILMEFI
PELIVPIVGFFTLESYVGNKGHIIMTISNALKKRDQKWTDMYGLIVSQWLSTVNTQFYTI
KERMYNALNNQSQAIEKIIEDQYNRYSEEDKMNINIDFNDIDFKLNQSINLAINNIDDFI
NQCSISYLMNRMIPLAVKKLKDFDDNLKRDLLEYIDTNELYLLDEVNILKSKVNRHLKDS
IPFDLSLYTKDTILIQVFNNYISNISSNAILSLSYRGGRLIDSSGYGATMNVGSDVIFND
IGNGQFKLNNSENSNITAHQSKFVVYDSMFDNFSINFWVRTPKYNNNDIQTYLQNEYTII
SCIKNDSGWKVSIKGNRIIWTLIDVNAKSKSIFFEYSIKDNISDYINKWFSITITNDRLG
NANIYINGSLKKSEKILNLDRINSSNDIDFKLINCTDTTKFVWIKDFNIFGRELNATEVS
SLYWIQSSTNTLKDFWGNPLRYDTQYYLFNQGMQNIYIKYFSKASMGETAPRTNFNNAAI
NYQNLYLGLRFIIKKASNSRNINNDNIVREGDYIYLNIDNISDESYRVYVLVNSKEIQTQ
LFLAPINDDPTFYDVLQIKKYYEKTTYNCQILCEKDTKTFGLFGIGKFVKDYGYVWDTYD
NYFCISQWYLRRISENINKLRLGCNWQFIPVDEGWTE
SEQ ID NO: 24 - Полипептидная последовательность BoNT/X
MKLEINKFNYNDPIDGINVITMRPPRHSDKINKGKGPFKAFQVIKNIWIVPERYNFTNNT
NDLNIPSEPIMEADAIYNPNYLNTPSEKDEFLQGVIKVLERIKSKPEGEKLLELISSSIP
LPLVSNGALTLSDNETIAYQENNNIVSNLQANLVIYGPGPDIANNATYGLYSTPISNGEG
TLSEVSFSPFYLKPFDESYGNYRSLVNIVNKFVKREFAPDPASTLMHELVHVTHNLYGIS
NRNFYYNFDTGKIETSRQQNSLIFEELLTFGGIDSKAISSLIIKKIIETAKNNYTTLISE
RLNTVTVENDLLKYIKNKIPVQGRLGNFKLDTAEFEKKLNTILFVLNESNLAQRFSILVR
KHYLKERPIDPIYVNILDDNSYSTLEGFNISSQGSNDFQGQLLESSYFEKIESNALRAFI
KICPRNGLLYNAIYRNSKNYLNNIDLEDKKTTSKTNVSYPCSLLNGCIEVENKDLFLISN
KDSLNDINLSEEKIKPETTVFFKDKLPPQDITLSNYDFTEANSIPSISQQNILERNEELY
EPIRNSLFEIKTIYVDKLTTFHFLEAQNIDESIDSSKIRVELTDSVDEALSNPNKVYSPF
KNMSNTINSIETGITSTYIFYQWLRSIVKDFSDETGKIDVIDKSSDTLAIVPYIGPLLNI
GNDIRHGDFVGAIELAGITALLEYVPEFTIPILVGLEVIGGELAREQVEAIVNNALDKRD
QKWAEVYNITKAQWWGTIHLQINTRLAHTYKALSRQANAIKMNMEFQLANYKGNIDDKAK
IKNAISETEILLNKSVEQAMKNTEKFMIKLSNSYLTKEMIPKVQDNLKNFDLETKKTLDK
FIKEKEDILGTNLSSSLRRKVSIRLNKNIAFDINDIPFSEFDDLINQYKNEIEDYEVLNL
GAEDGKIKDLSGTTSDINIGSDIELADGRENKAIKIKGSENSTIKIAMNKYLRFSATDNF
SISFWIKHPKPTNLLNNGIEYTLVENFNQRGWKISIQDSKLIWYLRDHNNSIKIVTPDYI
AFNGWNLITITNNRSKGSIVYVNGSKIEEKDISSIWNTEVDDPIIFRLKNNRDTQAFTLL
DQFSIYRKELNQNEVVKLYNYYFNSNYIRDIWGNPLQYNKKYYLQTQDKPGKGLIREYWS
SFGYDYVILSDSKTITFPNNIRYGALYNGSKVLIKNSKKLDGLVRNKDFIQLEIDGYNMG
ISADRFNEDTNYIGTTYGTTHDLTTDFEIIQRQEKYRNYCQLKTPYNIFHKSGLMSTETS
KPTFHDYRDWVYSSAWYFQNYENLNLRKHTKTNWYFIPKDEGWDED
SEQ ID NO: 25 - TeNT - UniProt P04958
MPITINNFRYSDPVNNDTIIMMEPPYCKGLDIYYKAFKITDRIWIVPERYEFGTKPEDFN
PPSSLIEGASEYYDPNYLRTDSDKDRFLQTMVKLFNRIKNNVAGEALLDKIINAIPYLGN
SYSLLDKFDTNSNSVSFNLLEQDPSGATTKSAMLTNLIIFGPGPVLNKNEVRGIVLRVDN
KNYFPCRDGFGSIMQMAFCPEYVPTFDNVIENITSLTIGKSKYFQDPALLLMHELIHVLH
GLYGMQVSSHEIIPSKQEIYMQHTYPISAEELFTFGGQDANLISIDIKNDLYEKTLNDYK
AIANKLSQVTSCNDPNIDIDSYKQIYQQKYQFDKDSNGQYIVNEDKFQILYNSIMYGFTE
IELGKKFNIKTRLSYFSMNHDPVKIPNLLDDTIYNDTEGFNIESKDLKSEYKGQNMRVNT
NAFRNVDGSGLVSKLIGLCKKIIPPTNIRENLYNRTASLTDLGGELCIKIKNEDLTFIAE
KNSFSEEPFQDEIVSYNTKNKPLNFNYSLDKIIVDYNLQSKITLPNDRTTPVTKGIPYAP
EYKSNAASTIEIHNIDDNTIYQYLYAQKSPTTLQRITMTNSVDDALINSTKIYSYFPSVI
SKVNQGAQGILFLQWVRDIIDDFTNESSQKTTIDKISDVSTIVPYIGPALNIVKQGYEGN
FIGALETTGVVLLLEYIPEITLPVIAALSIAESSTQKEKIIKTIDNFLEKRYEKWIEVYK
LVKAKWLGTVNTQFQKRSYQMYRSLEYQVDAIKKIIDYEYKIYSGPDKEQIADEINNLKN
KLEEKANKAMININIFMRESSRSFLVNQMINEAKKQLLEFDTQSKNILMQYIKANSKFIG
ITELKKLESKINKVFSTPIPFSYSKNLDCWVDNEEDIDVILKKSTILNLDINNDIISDIS
GFNSSVITYPDAQLVPGINGKAIHLVNNESSEVIVHKAMDIEYNDMFNNFTVSFWLRVPK
VSASHLEQYGTNEYSIISSMKKHSLSIGSGWSVSLKGNNLIWTLKDSAGEVRQITFRDLP
DKFNAYLANKWVFITITNDRLSSANLYINGVLMGSAEITGLGAIREDNNITLKLDRCNNN
NQYVSIDKFRIFCKALNPKEIEKLYTSYLSITFLRDFWGNPLRYDTEYYLIPVASSSKDV
QLKNITDYMYLTNAPSYTNGKLNIYYRRLYNGLKFIIKRYTPNNEIDSFVKSGDFIKLYV
SYNNNEHIVGYPKDGNAFNNLDRILRVGYNAPGIPLYKKMEAVKLRDLKTYSVQLKLYDD
KNASLGLVGTHNGQIGNDPNRDILIASNWYFNHLKDKILGCDWYFVPTDEGWTND
SEQ ID NO: 26 - Полипептидная последовательность меченого полипептида EGF TM
*HHHHHHLAETGGSGGSGGSEFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHELIHAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVDGIITSKTKSLIEGRNKALNLQCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTLEGGGGSGGGGSGGGGSALDNSDPKCPLSHEGYCLNDGVCMYIGTLDRYACNCVVGYVGERCQYRDLKLAELRGLEAGGSGGGSGLPESGK†
* = HiLyte555; † = HiLyte488
SEQ ID NO: 27 - Полипептидная последовательность бутелазы 1 C. ternatea 1 (плюс сигнальный пептид)
MKNPLAILFLIATVVAVVSGIRDDFLRLPSQASKFFQADDNVEGTRWAVLVAGSKGYVNY
RHQADVCHAYQILKKGGLKDENIIVFMYDDIAYNESNPHPGVIINHPYGSDVYKGVPKDY
VGEDINPPNFYAVLLANKSALTGTGSGKVLDSGPNDHVFIYYTDHGGAGVLGMPSKPYIA
ASDLNDVLKKKHASGTYKSIVFYVESCESGSMFDGLLPEDHNIYVMGASDTGESSWVTYC
PLQHPSPPPEYDVCVGDLFSVAWLEDCDVHNLQTETFQQQYEVVKNKTIVALIEDGTHVV
QYGDVGLSKQTLFVYMGTDPANDNNTFTDKNSLGTPRKAVSQRDADLIHYWEKYRRAPEG
SSRKAEAKKQLREVMAHRMHIDNSVKHIGKLLFGIEKGHKMLNNVRPAGLPVVDDWDCFK
TLIRTFETHCGSLSEYGMKHMRSFANLCNAGIRKEQMAEASAQACVSIPDNPWSSLHAGF
SV
SEQ ID NO: 28 - Полипептидная последовательность бутелазы 1 C. ternatea (минус сигнальный пептид)
IRDDFLRLPSQASKFFQADDNVEGTRWAVLVAGSKGYVNYRHQADVCHAYQILKKGGLKD
ENIIVFMYDDIAYNESNPHPGVIINHPYGSDVYKGVPKDYVGEDINPPNFYAVLLANKSA
LTGTGSGKVLDSGPNDHVFIYYTDHGGAGVLGMPSKPYIAASDLNDVLKKKHASGTYKSI
VFYVESCESGSMFDGLLPEDHNIYVMGASDTGESSWVTYCPLQHPSPPPEYDVCVGDLFS
VAWLEDCDVHNLQTETFQQQYEVVKNKTIVALIEDGTHVVQYGDVGLSKQTLFVYMGTDP
ANDNNTFTDKNSLGTPRKAVSQRDADLIHYWEKYRRAPEGSSRKAEAKKQLREVMAHRMH
IDNSVKHIGKLLFGIEKGHKMLNNVRPAGLPVVDDWDCFKTLIRTFETHCGSLSEYGMKH
MRSFANLCNAGIRKEQMAEASAQACVSIPDNPWSSLHAGFSV
SEQ ID NO: 29 - Пептид с конъюгированной поддающейся детекции меткой и донорным участком для сортазы
GGGGK†
† = HiLyte488
SEQ ID NO: 30 - Пептид с конъюгированной поддающейся детекции меткой и акцепторным участком для сортазы
*HHHHHHLAETGGG
* = HiLyte555
SEQ ID NO: 31 - Полипептидная последовательность сортазы A Staphylococcus aureus
MKKWTNRLMTIAGVVLILVAAYLFAKPHIDNYLHDKDKDEKIEQYDKNVKEQASKDKKQQ
AKPQIPKDKSKVAGYIEIPDADIKEPVYPGPATPEQLNRGVSFAEENESLDDQNISIAGH
TFIDRPNYQFTNLKAAKKGSMVYFKVGNETRKYKMTSIRDVKPTDVGVLDEQKGKDKQLT
LITCDDYNEKTGVWEKRKIFVATEVK
SEQ ID NO: 32 - Полипептидная последовательность сортазы B Staphylococcus aureus
MRMKRFLTIVQILLVVIIIIFGYKIVQTYIEDKQERANYEKLQQKFQMLMSKHQEHVRPQ
FESLEKINKDIVGWIKLSGTSLNYPVLQGKTNHDYLNLDFEREHRRKGSIFMDFRNELKN
LNHNTILYGHHVGDNTMFDVLEDYLKQSFYEKHKIIEFDNKYGKYQLQVFSAYKTTTKDN
YIRTDFENDQDYQQFLDETKRKSVINSDVNVTVKDRIMTLSTCEDAYSETTKRIVVVAKI
IKVS
SEQ ID NO: 33 - Полипептидная последовательность сортазы A Streptococcus pneumoniae
MEKLYIHLKNLRKVAVVMLLVFTTFYLLLMFLNQSDNQEIAKNIEKFNDSVIVAKTDNTK
ADIKEIEKNIEKVRKIEGGNVERVNQLTSENEKVKENIDLNIEEEIIENSYKSLETTDNF
EKLGIIEIPKIDLNLSIFKGKPFVNTKNRQDTMLYGAVTNKKNQKMGRENYVLASHIISN
SNLLFTSINQLEKGDVITLKDSEYSYQYTVYNNFIVSKDETWILNDIKDYSILTLYTCYD
DSTKLPENRVVIRAVLTDIN
SEQ ID NO: 34 - Полипептидная последовательность сортазы B Streptococcus pneumoniae
MAKTKKQKRNNLLLGVVFFIGXAVMAYPLVSRLYYRVESNQQIADFDKEKATLDEADIDE
RMKLAQAFNDSLNNVVSGDPWSEEMKKKGRAEYARMLEIHERMGHVEIPAIDVDLPVYAG
TAEEVLQQGAGHLEGTSLPIGGNSTHAVITAHTGLPTAKMFTDLTKLKVGDKFYVHNIKE
VMAYQVDQVKVIEPTNFDDLLIVPGHDYVTLLTCTPYMINTHRLLVRGHRIPYVAEVEEE
FIAANKLSHLYRYLFYVAVGLIVILLWIIRRLRKKKRQSERALKALKEATKEVKVEDE
где X представляет собой Met или Ile.
SEQ ID NO: 35 - Полипептидная последовательность сортазы C Streptococcus pneumoniae
MDNSRRSRKKGTKKKKHPLILLLIFLVGFAVAIYPLVSRYYYRIESNEVIKEFDETVSQM
DKAELEERWRLAQAFNATLKPSEILDPFTEQEKKKGVSEYANMLKVHERIGYVEIPAIDQ
EIPMYVGTSEDILQKGAGLLEGASLPVGGKNTHTVITAHRGLPTAELFSQLDKMKKGDIF
YLHVLDQVLAYQVDQIVTVEPNDFEPVLIQHGEDYATLLTCTPYMINSHRLLVRGKRIPY
TAPIAERNRAVRERGQFWLWLLLGAMAVILLLLYRVYRNRRIVKGLEKQLEGRHVKD
SEQ ID NO: 36 - Полипептидная последовательность сортазы D Streptococcus pneumoniae
MSRTKLRALLGYLLMLVACLIPIYCFGQMVLQSLGQVKGHATFVKSMTTEMYQEQQNHSL
AYNQRLASQNRIVDPFLAEGYEVNYQVSDDPDAVYGYLSIPSLEIMEPVYLGADYHHLGM
GLAHVDGTPLPMDGTGIRSVIAGHRAEPSHVFFRHLDQLKVGDALYYDNGQEIVEYQMMD
TEIILPSEWEKLESVSSKNIMTLITCDPIPTFNKRLLVNFERVAVYQKSDPQTAAVARVA
FTKEGQSVSRVATSQWLYRGLVVLAFLGILFVLWKLARLLRGK
SEQ ID NO: 37 - Полипептидная последовательность сортазы A Streptococcus pyogenes
MVKKQKRRKIKSMSWARKLLIAVLLILGLALLFNKPIRNTLIARNSNKYQVTKVSKKQIK
KNKEAKSTFDFQAVEPVSTESVLQAQMAAQQLPVIGGIAIPELGINLPIFKGLGNTELIY
GAGTMKEEQVMGGENNYSLASHHIFGITGSSQMLFSPLERAQNGMSIYLTDKEKIYEYII
KDVFTVAPERVDVIDDTAGLKEVTLVTCTDIEATERIIVKGELKTEYDFDKAPADVLKAF
NHSYNQVST
SEQ ID NO: 38 - Полипептидная последовательность протеолитически неактивного мутанта BoNT/A(0)
MPFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHQLIYAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVRGIITSKTKSLDKGYNKALNDLCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTFTEYIKNIINTSILNLRYESNHLIDLSRYASKINIGSKVNFDPIDKNQIQLFNLESSKIEVILKNAIVYNSMYENFSTSFWIRIPKYFNSISLNNEYTIINCMENNSGWKVSLNYGEIIWTLQDTQEIKQRVVFKYSQMINISDYINRWIFVTITNNRLNNSKIYINGRLIDQKPISNLGNIHASNNIMFKLDGCRDTHRYIWIKYFNLFDKELNEKEIKDLYDNQSNSGILKDFWGDYLQYDKPYYMLNLYDPNKYVDVNNVGIRGYMYLKGPRGSVMTTNIYLNSSLYRGTKFIIKKYASGNKDNIVRNNDRVYINVVVKNKEYRLATNASQAGVEKILSALEIPDVGNLSQVVVMKSKNDQGITNKCKMNLQDNNGNDIGFIGFHQFNNIAKLVASNWYNRQIERSSRTLGCSWEFIPVDDGWGERPL
SEQ ID NO: 39 - Нуклеотидная последовательность полноразмерного протеолитически неактивного мутанта BoNT/A(0) с участками двукратного мечения посредством SrtA
ATGGAGAACCTGTATTTTCAGGGCGGCGGTGGCAGCGGCGGCAGCGGCGGCAGCCCGTTTGTGAACAAGCAGTTCAACTATAAAGATCCGGTTAATGGTGTGGATATCGCCTATATCAAAATTCCGAATGCAGGTCAGATGCAGCCGGTTAAAGCCTTTAAAATCCATAACAAAATTTGGGTGATTCCGGAACGTGATACCTTTACCAATCCGGAAGAAGGTGATCTGAATCCGCCTCCGGAAGCAAAACAGGTTCCGGTTAGCTATTATGATAGCACCTATCTGAGCACCGATAACGAGAAAGATAACTATCTGAAAGGTGTGACCAAACTGTTTGAACGCATTTATAGTACCGATCTGGGTCGTATGCTGCTGACCAGCATTGTTCGTGGTATTCCGTTTTGGGGTGGTAGCACCATTGATACCGAACTGAAAGTTATTGACACCAACTGCATTAATGTGATTCAGCCGGATGGTAGCTATCGTAGCGAAGAACTGAATCTGGTTATTATTGGTCCGAGCGCAGATATCATTCAGTTTGAATGTAAAAGCTTTGGCCACGAAGTTCTGAATCTGACCCGTAATGGTTATGGTAGTACCCAGTATATTCGTTTCAGTCCGGATTTTACCTTTGGCTTTGAAGAAAGCCTGGAAGTTGATACAAATCCGCTGTTAGGTGCAGGTAAATTTGCAACCGATCCGGCAGTTACCCTGGCACACCAGCTGATTTATGCCGGTCATCGTCTGTATGGTATTGCCATTAATCCGAATCGTGTGTTCAAAGTGAATACCAACGCCTATTATGAAATGAGCGGTCTGGAAGTGAGTTTTGAAGAACTGCGTACCTTTGGTGGTCATGATGCCAAATTTATCGATAGCCTGCAAGAAAATGAATTTCGCCTGTACTACTATAACAAATTCAAGGATATTGCGAGCACCCTGAATAAAGCCAAAAGCATTGTTGGCACCACCGCAAGCCTGCAGTATATGAAAAATGTGTTTAAAGAAAAATATCTGCTGAGCGAAGATACCAGCGGTAAATTTAGCGTTGACAAACTGAAATTCGATAAACTGTACAAGATGCTGACCGAGATTTATACCGAAGATAACTTCGTGAAGTTTTTCAAAGTGCTGAACCGCAAAACCTACCTGAACTTTGATAAAGCCGTGTTCAAAATCAACATCGTGCCGAAAGTGAACTATACCATCTATGATGGTTTTAACCTGCGCAATACCAATCTGGCAGCAAACTTTAATGGTCAGAACACCGAAATCAACAACATGAACTTTACCAAACTGAAGAACTTCACCGGTCTGTTCGAATTTTACAAACTGCTGTGTGTTCGTGGCATTATTACCAGCAAAACCAAAAGTCTGGATAAAGGCTACAATAAAGCCCTGAATGATCTGTGCATTAAGGTGAATAATTGGGACCTGTTTTTTAGCCCGAGCGAGGATAATTTCACCAACGATCTGAACAAAGGCGAAGAAATTACCAGCGATACCAATATTGAAGCAGCCGAAGAAAACATTAGCCTGGATCTGATTCAGCAGTATTATCTGACCTTCAACTTCGATAATGAGCCGGAAAATATCAGCATTGAAAACCTGAGCAGCGATATTATTGGCCAGCTGGAACTGATGCCGAATATTGAACGTTTTCCGAACGGCAAAAAATACGAGCTGGATAAATACACCATGTTCCATTATCTGCGTGCCCAAGAATTTGAACATGGTAAAAGCCGTATTGCACTGACCAATAGCGTTAATGAAGCACTGCTGAACCCGAGCCGTGTTTATACCTTTTTTAGCAGCGATTACGTGAAAAAGGTTAACAAAGCAACCGAAGCAGCCATGTTTTTAGGTTGGGTTGAACAGCTGGTTTATGATTTCACCGATGAAACCAGCGAAGTTAGCACCACCGATAAAATTGCAGATATTACCATCATCATCCCGTATATCGGTCCGGCACTGAATATTGGCAATATGCTGTATAAAGACGATTTTGTGGGTGCCCTGATTTTTAGCGGTGCAGTTATTCTGCTGGAATTTATTCCGGAAATTGCCATTCCGGTTCTGGGCACCTTTGCACTGGTGAGCTATATTGCAAATAAAGTTCTGACCGTGCAGACCATCGATAATGCACTGAGCAAACGTAACGAAAAATGGGATGAAGTGTACAAGTATATCGTGACCAATTGGCTGGCAAAAGTTAACACCCAGATTGACCTGATTCGCAAGAAGATGAAAGAAGCACTGGAAAATCAGGCAGAAGCAACCAAAGCCATTATCAACTATCAGTATAACCAGTACACCGAAGAAGAGAAAAATAACATCAACTTCAACATCGACGATCTGTCCAGCAAACTGAACGAAAGCATCAACAAAGCCATGATTAACATTAACAAATTTCTGAACCAGTGCAGCGTGAGCTATCTGATGAATAGCATGATTCCGTATGGTGTGAAACGTCTGGAAGATTTTGATGCAAGCCTGAAAGATGCCCTGCTGAAATATATCTATGATAATCGTGGCACCCTGATTGGTCAGGTTGATCGTCTGAAAGATAAAGTGAACAACACCCTGAGTACCGATATTCCTTTTCAGCTGAGCAAATATGTGGATAATCAGCGTCTGCTGTCAACCTTTACCGAATACATTAAGAACATCATCAACACCAGCATTCTGAACCTGCGTTATGAAAGCAATCATCTGATTGATCTGAGCCGTTATGCCAGCAAAATCAATATAGGCAGCAAGGTTAACTTCGACCCGATTGACAAAAATCAGATACAGCTGTTTAATCTGGAAAGCAGCAAAATTGAGGTGATCCTGAAAAACGCCATTGTGTATAATAGCATGTACGAGAATTTCTCGACCAGCTTTTGGATTCGTATCCCGAAATACTTTAATAGCATCAGCCTGAACAACGAGTACACCATTATTAACTGCATGGAAAACAATAGCGGCTGGAAAGTTAGCCTGAATTATGGCGAAATTATCTGGACCCTGCAGGATACCCAAGAAATCAAACAGCGTGTGGTTTTCAAATACAGCCAGATGATTAATATCAGCGACTATATCAACCGCTGGATTTTTGTGACCATTACCAATAATCGCCTGAATAACAGCAAGATCTATATTAACGGTCGTCTGATTGACCAGAAACCGATTAGTAATCTGGGTAATATTCATGCGAGCAACAACATCATGTTTAAACTGGATGGTTGTCGTGATACCCATCGTTATATTTGGATCAAGTACTTCAACCTGTTCGATAAAGAGTTGAACGAAAAAGAAATTAAAGACCTGTATGATAACCAGAGCAACAGCGGTATTCTGAAGGATTTTTGGGGAGATTATCTGCAGTATGACAAACCGTATTATATGCTGAATCTGTACGACCCGAATAAATACGTGGATGTGAATAATGTTGGCATCCGTGGTTATATGTACCTGAAAGGTCCGCGTGGTAGCGTTATGACCACAAACATTTATCTGAATAGCAGCCTGTATCGCGGAACCAAATTCATCATTAAAAAGTATGCCAGCGGCAACAAGGATAATATTGTGCGTAATAATGATCGCGTGTACATTAACGTTGTGGTGAAGAATAAAGAATATCGCCTGGCAACCAATGCAAGCCAGGCAGGCGTTGAAAAAATTCTGAGTGCCCTGGAAATTCCGGATGTTGGTAATCTGAGCCAGGTTGTTGTGATGAAAAGCAAAAATGATCAGGGCATCACCAACAAGTGCAAAATGAATCTGCAGGACAATAACGGCAACGATATTGGTTTTATTGGCTTCCACCAGTTCAACAATATTGCGAAACTGGTTGCAAGCAATTGGTATAATCGTCAGATTGAACGTAGCAGTCGTACCCTGGGTTGTAGCTGGGAATTTATCCCTGTGGATGATGGTTGGGGTGAACGTCCGCTGGGCGGCAGCGGCGGCGGCAGCGGCCTGCCCGAAAGCGGTGGCGGATCTGCTTGGTCTCACCCGCAGTTCGAAAAAGGTGGTGGTTCTGGTGGTGGTTCTGGTGGTTCTGCTTGGTCTCACCCGCAGTTCGAAAAATAATGA
SEQ ID NO: 40 - Полипептидная последовательность полноразмерного протеолитически неактивного мутанта BoNT/A(0) с участками двукратного мечения посредством SrtA
MENLYFQGGGGSGGSGGSPFVNKQFNYKDPVNGVDIAYIKIPNAGQMQPVKAFKIHNKIWVIPERDTFTNPEEGDLNPPPEAKQVPVSYYDSTYLSTDNEKDNYLKGVTKLFERIYSTDLGRMLLTSIVRGIPFWGGSTIDTELKVIDTNCINVIQPDGSYRSEELNLVIIGPSADIIQFECKSFGHEVLNLTRNGYGSTQYIRFSPDFTFGFEESLEVDTNPLLGAGKFATDPAVTLAHQLIYAGHRLYGIAINPNRVFKVNTNAYYEMSGLEVSFEELRTFGGHDAKFIDSLQENEFRLYYYNKFKDIASTLNKAKSIVGTTASLQYMKNVFKEKYLLSEDTSGKFSVDKLKFDKLYKMLTEIYTEDNFVKFFKVLNRKTYLNFDKAVFKINIVPKVNYTIYDGFNLRNTNLAANFNGQNTEINNMNFTKLKNFTGLFEFYKLLCVRGIITSKTKSLDKGYNKALNDLCIKVNNWDLFFSPSEDNFTNDLNKGEEITSDTNIEAAEENISLDLIQQYYLTFNFDNEPENISIENLSSDIIGQLELMPNIERFPNGKKYELDKYTMFHYLRAQEFEHGKSRIALTNSVNEALLNPSRVYTFFSSDYVKKVNKATEAAMFLGWVEQLVYDFTDETSEVSTTDKIADITIIIPYIGPALNIGNMLYKDDFVGALIFSGAVILLEFIPEIAIPVLGTFALVSYIANKVLTVQTIDNALSKRNEKWDEVYKYIVTNWLAKVNTQIDLIRKKMKEALENQAEATKAIINYQYNQYTEEEKNNINFNIDDLSSKLNESINKAMININKFLNQCSVSYLMNSMIPYGVKRLEDFDASLKDALLKYIYDNRGTLIGQVDRLKDKVNNTLSTDIPFQLSKYVDNQRLLSTFTEYIKNIINTSILNLRYESNHLIDLSRYASKINIGSKVNFDPIDKNQIQLFNLESSKIEVILKNAIVYNSMYENFSTSFWIRIPKYFNSISLNNEYTIINCMENNSGWKVSLNYGEIIWTLQDTQEIKQRVVFKYSQMINISDYINRWIFVTITNNRLNNSKIYINGRLIDQKPISNLGNIHASNNIMFKLDGCRDTHRYIWIKYFNLFDKELNEKEIKDLYDNQSNSGILKDFWGDYLQYDKPYYMLNLYDPNKYVDVNNVGIRGYMYLKGPRGSVMTTNIYLNSSLYRGTKFIIKKYASGNKDNIVRNNDRVYINVVVKNKEYRLATNASQAGVEKILSALEIPDVGNLSQVVVMKSKNDQGITNKCKMNLQDNNGNDIGFIGFHQFNNIAKLVASNWYNRQIERSSRTLGCSWEFIPVDDGWGERPLGGSGGGSGLPESGGGSAWSHPQFEKGGGSGGGSGGSAWSHPQFEK
SEQ ID NO: 41 - Полипептидная последовательность PATG Prochloron didemni
MFSIMITIDYPFTVSLNRDIQVTSTEDYYTLQVTESDPSAWLTFATTPAMDMAFDHLKAGTTTESLVQTLAELGGPAAREQFALTLQQLDERGWLSYAVLPLAEAIPMVESAELNLPGNPHWMETGVTLSRFAYQHPYEGTMVLESPLSKFRVKLLDWRASALLAQLAQPQTLGTIAPPPYLGPETAYQFLNLLWATGFLASDHEPVSLQLWDFHNLLFHSRSRLGRHDYPGTDLNVDNWSDFPVVKPPMSDRIVPLPRPNLEALMSNDATLTEAIETRKSVREYDDDNPITIEQLGELLYRAARVTKLLSPEERFGKLWQQNKPVFEEAGVDEGEFSHRPYPGGGAMYELEIYPVVRLCQGLSQGVYHYDPLNHQLEQIVESKDDIFAVSGSPLASKLGPHVLLVITARFGRLFRLYRSVAYALVLKHVGVLQQNLYLVATNMGLAPCAGGAGDSDAFAQVTGIDYVEESAVGEFILGSLASEVESDVVEGEDEIESAGVSASEVESSATKQKVALHPHDLDERIPGLADLHNQTLGDPQITIVIIDGDPDYTLSCFEGAEVSKVFPYWHEPAEPITPEDYAAFQSIRDQGLKGKEKEEALEAVIPDTKDRIVLNDHACHVTSTIVGQEHSPVFGIAPNCRVINMPQDAVIRGNYDDVMSPLNLARAIDLALELGANIIHCAFCRPTQTSEGEEILVQAIKKCQDNNVLIVSPTGNNSNESWCLPAVLPGTLAVGAAKVDGTPCHFSNWGGNNTKEGILAPGEEILGAQPCTEEPVRLTGTSMAAPVMTGISALLMSLQVQQGKPVDAEAVRTALLKTAIPCDPEVVEEPERCLRGFVNIPGAMKVLFGQPSVTVSFAGGQATRTEHPGYATVAPASIPEPMAERATPAVQAATATEMVIAPSTEPANPATVEASTAFSGNVYALGTIGYDFGDEARRDTFKERMADPYDARQMVDYLDRNPDEARSLIWTLNLEGDVIYALDPKGPFATNVYEIFLQMLAGQLEPETSADFIERLSVPARRTTRTVELFSGEVMPVVNVRDPRGMYGWNVNALVDAALATVEYEEADEDSLRQGLTAFLNRVYHDLHNLGQTSRDRALNFTVTNTFQAASTFAQAIASGRQLDTIEVNKSPYCRLNSDCWDVLLTFYDPEHGRRSRRVFRFTLDVVYVLPVTVGSIKSWSLPGKGTVSK
SEQ ID NO: 42 - Полипептидная последовательность PCY1 Saponaria vaccaria
MATSGFSKPLHYPPVRRDETVVDDYFGVKVADPYRWLEDPNSEETKEFVDNQEKLANSVLEECELIDKFKQKIIDFVNFPRCGVPFRRANKYFHFYNSGLQAQNVFQMQDDLDGKPEVLYDPNLREGGRSGLSLYSVSEDAKYFAFGIHSGLTEWVTIKILKTEDRSYLPDTLEWVKFSPAIWTHDNKGFFYCPYPPLKEGEDHMTRSAVNQEARYHFLGTDQSEDILLWRDLENPAHHLKCQITDDGKYFLLYILDGCDDANKVYCLDLTKLPNGLESFRGREDSAPFMKLIDSFDASYTAIANDGSVFTFQTNKDAPRKKLVRVDLNNPSVWTDLVPESKKDLLESAHAVNENQLILRYLSDVKHVLEIRDLESGALQHRLPIDIGSVDGITARRRDSVVFFKFTSILTPGIVYQCDLKNDPTQLKIFRESVVPDFDRSEFEVKQVFVPSKDGTKIPIFIAARKGISLDGSHPCEMHGYGGFGINMMPTFSASRIVFLKHLGGVFCLANIRGGGEYGEEWHKAGFRDKKQNVFDDFISAAEYLISSGYTKARRVAIEGGSNGGLLVAACINQRPDLFGCAEANCGVMDMLRFHKFTLGYLWTGDYGCSDKEEEFKWLIKYSPIHNVRRPWEQPGNEETQYPATMILTADHDDRVVPLHSFKLLATMQHVLCTSLEDSPQKNPIIARIQRKAAHYGRATMTQIAEVADRYGFMAKALEAPWID
SEQ ID NO: 43 - Полипептидная последовательность POPB Galerina marginata
MSSVTWAPGNYPSTRRSDHVDTYQSASKGEVPVPDPYQWLEESTDEVDKWTTAQADLAQSYLDQNADIQKLAEKFRASRNYAKFSAPTLLDDGHWYWFYNRGLQSQSVLYRSKEPALPDFSKGDDNVGDVFFDPNVLAADGSAGMVLCKFSPDGKFFAYAVSHLGGDYSTIYVRSTSSPLSQASVAQGVDGRLSDEVKWFKFSTIIWTKDSKGFLYQRYPARERHEGTRSDRNAMMCYHKVGTTQEEDIIVYQDNEHPEWIYGADTSEDGKYLYLYQFKDTSKKNLLWVAELDEDGVKSGIHWRKVVNEYAADYNIITNHGSLVYIKTNLNAPQYKVITIDLSKDEPEIRDFIPEEKDAKLAQVNCANEEYFVAIYKRNVKDEIYLYSKAGVQLTRLAPDFVGAASIANRQKQTHFFLTLSGFNTPGTIARYDFTAPETQRFSILRTTKVNELDPDDFESTQVWYESKDGTKIPMFIVRHKSTKFDGTAAAIQYGYGGFATSADPFFSPIILTFLQTYGAIFAVPSIRGGGEFGEEWHKGGRRETKVNTFDDFIAAAQFLVKNKYAAPGKVAINGASNGGLLVMGSIVRAPEGTFGAAVPEGGVADLLKFHKFTGGQAWISEYGNPSIPEEFDYIYPLSPVHNVRTDKVMPATLITVNIGDGRVVPMHSFKFIATLQHNVPQNPHPLLIKIDKSWLGHGMGKPTDKNVKDAADKWGFIARALGLELKTVE
SEQ ID NO: 44 - Полипептидная последовательность гомолога бутелазы OaAEP1b Oldenlandia affinis (плюс сигнальный пептид)
MVRYLAGAVLLLVVLSVAAAVSGARDGDYLHLPSEVSRFFRPQETNDDHGEDSVGTRWAVLIAGSKGYANYRHQAGVCHAYQILKRGGLKDENIVVFMYDDIAYNESNPRPGVIINSPHGSDVYAGVPKDYTGEEVNAKNFLAAILGNKS AITGGSGKVVDSGPNDHIFIYYTDHGAAGVIGMPSKPYLYADELNDALKKKHASGTYKSLVFYLEACESGSMFEGILPEDLNIYALTSTNTTESSWCYYCPAQENPPPPEYNVCLGDLFSVAWLEDSDVQNSWYETLNQQYHHVDKRISHASHATQYGNLKLGEEGLFVYMGSNPANDNYTSLDGNALTPSSIVVNQRDADLLHLWEKFRKAPEGSARKEVAQTQIFKAMSHRVHIDSSIKLIGKLLFGIEKCTEILNAVRPAGQPLVDDWACLRSLVGTFETHCGSLSEYGMRHTRTIA NICNAGISEEQMAEAASQACASIP
SEQ ID NO: 45 - Полипептидная последовательность гомолога бутелазы OaAEP1b Oldenlandia affinis (минус сигнальный пептид)
ARDGDYLHLPSEVSRFFRPQETNDDHGEDSVGTRWAVLIAGSKGYANYRHQAGVCHAYQILKRGGLKDENIVVFMYDDIAYNESNPRPGVIINSPHGSDVYAGVPKDYTGEEVNAKNFLAAILGNKSAITGGSGKVVDSGPNDHIFIYYTDHGAAGVIGMPSKPYLYADELNDALKKKHASGTYKSLVFYLEACESGSMFEGILPEDLNIYALTSTNTTESSWCYYCPAQENPPPPEYNVCLGDLFSVAWLEDSDVQNSWYETLNQQYHHVDKRISHASHATQYGNLKLGEEGLFVYMGSNPANDNYTSLDGNALTPSSIVVNQRDADLLHLWEKFRKAPEGSARKEVAQTQIFKAMSHRVHIDSSIKLIGKLLFGIEKCTEILNAVRPAGQPLVDDWACLRSLVGTFETHCGSLSEYGMRHTRTIANICNAGISEEQMAEAASQACASIP
ПРИМЕРЫ
ПРИМЕР 1
Конструирование однократно и двукратно меченного посредством техасского крастного, eGFP, SNAP и SrtA полипептида с EGF-лигандом
Было опробовано несколько стратегий мечения. Целью было получение меченой версии полипептида, которая не влияла на его структурные характеристики и на его способность к транспорту в клетки и расщеплению белков SNARE эффективно и аналогично немеченой версии.
Было опробовано 4 различных стратегии мечения полипептида с EGF-лигандом (Fonfria, E., S. Donald and V.A. Cadd (2016). "Botulinum neurotoxin A and an engineered derivate targeted secretion inhibitor (TSI) A enter cells via different vesicular compartments." J Recept Signal Transduct Res 36(1): 79-88). После клонирования при необходимости полипептид экспрессировали рекомбинантными способами и очищали с использованием стандартных методик, как опубликовано ранее (Masuyer, G., M. Beard, V.A. Cadd, J. A. Chaddock and K.R. Acharya (2011). "Structure and activity of a functional derivative of Clostridium botulinum neurotoxin B." J Struct Biol 174(1): 52-57, Somm, E., N. Bonnet, A. Martinez, P.M. Marks, V.A. Cadd, M. Elliott, A. Toulotte, S.L. Ferrari, R. Rizzoli, P.S. Huppi, E. Harper, S. Melmed, R. Jones and M.L. Aubert (2012). "A botulinum toxin-derived targeted secretion inhibitor downregulates the GH/IGF1 axis." J Clin Invest 122(9): 3295-3306). В кратком изложении, полипептид экспрессировали рекомбинантными способами в компетентных бактериях E. coli. Экспрессированный полипептид очищали с использованием аффинной колонки, а затем анионообменной хроматографии, ферментативной активации с получением двухцепочечного комплекса и, наконец, стадии полировки с использованием гидрофобного взаимодействия.
1. Немодифицированный пептид с EGF-лигандом, очищенный, как описано выше, метили с использованием набора Texas Red-X Protein Labelling Kit (Thermo Fisher Scientific) в соответствии с протоколом изготовителя. Успешное мечение белка подтверждали посредством конфокальной микроскопии и прижизненной визуализации. Нуклеотидные и полипептидные последовательности для полипептида, использованного для мечения, представлены в качестве SEQ ID NO: 5 и 6, соответственно.
2. Полипептид с EGF-лигандом метили на N-конце усиленным зеленым флуоресцентным белком (eGFP) посредством стандартных методик клонирования. Нуклеотидные и полипептидные последовательности представлены в качестве SEQ ID NO: 9 и 10, соответственно. Экспрессию и очистку белка проводили, как указано выше. После экспрессии была безуспешно предпринята попытка очистить меченный eGFP полипептид с EGF-лигандом.
3. Полипептид с EGF-лигандом метили на N-конце посредством субстрата SNAP-метка (New England Biolabs) с использованием стандартных методик клонирования. Нуклеотидные и полипептидные последовательности представлены в качестве SEQ ID NO: 11 и 12, соответственно. Экспрессия и очистка этого белка была успешной. Мечение SNAP-меченного полипептида с EGF-лигандом проводили с использованием флуоресцентного субстрата SNAP-Surface 594 (New England Biolabs) в соответствии с протоколом изготовителя. Успешное мечение белка подтверждали посредством конфокальной микроскопии и прижизненной визуализации.
4. Также предпринимались попытки получить полипептиды, содержащие неприродные аминокислоты, для сайт-специфического мечения. Однако эти попытки оказались неуспешными вследствие затрудненной экспрессии и/или очистки.
5. Полипептид с EGF-лигандом (т.е. полипептид, имеющий EGF TM) метили двумя различными участками распознавания сортазой A (SrtA), один на N-конце и один на C-конце. Использование SrtA позволяло конъюгацию двух флорофоров различного цвета на одном и том же белке. Полипептид конструировали, как проиллюстрировано на фиг.1. Было выбрано две мутантных версии SrtA (Dorr, B.M., H.O. Ham, C. An, E.L. Chaikof and D.R. Liu (2014). "Reprogrammming the specificity of sortase enzymes". Proc Natl Acad Sci U S A 111(37): 13343-13348) (SEQ ID NO: 14 и 16). Было показано, что они обладают 100% специфичностью в отношении их соответствующих участков распознавания. Полипептид с EGF-лигандом клонировали с участком распознавания LPESG для первой SrtA на C-конце, за которым следовал двойной участок распознавания StrepTag (IBA-lifesciences), что позволяет первоначальную аффинно-опосредуемую очистку белка. Нуклеотидные и полипептидные последовательности представлены в качестве SEQ ID NO: 1 и 2, соответственно. Отдельно получали пептид, содержащий участок остатков глицина, конъюгированных с выбранным флуорофором (Eurogentec). Последовательность этого пептида представляла собой: GGGGK(HF488) (SEQ ID NO: 29). В ходе SrtA-опосредуемой реакции глицин в участке LPESG отщеплялся посредством SrtA (SEQ ID NO: 14), и участок из остатков глицина, присутствующий на флуоресцентном пептиде, распознавался SrtA и использовался для опосредования конъюгации между полипептидом и пептидом. Это обеспечивало однократно флуоресцентно меченый полипептид с EGF-лигандом. Следует отметить, что меченый полипептид более не имел Strep-метки, и обратную аффинно-опосредуемую стадию очистки использовали для отбора меченой части полипептида. Для двукратно меченого полипептида с EGF-лигандом участок из 3 остатков глицина клонирования на N-конце полипептида после начального кодона и участка распознавания вирусом гравировки табака (TEV) для расщепления. Участок TEV вносили, чтобы помочь защитить участков из остатков глицина от циркуляризации в ходе первоначальной C-концевой реакции SrtA как подробно описано выше. Отдельно получали пептид, содержащий участок распознавания LAETG, конъюгированный с выбранным флуорофором (Eurogentec). Последовательность этого пептида представляла собой: HiLyte Fluor™ 555-HHHHHHLAETGGG (SEQ ID NO: 30). Кроме того, перед участком LAETG помещали 6 His-метку (6HT) для простоты очистки белка после реакции SrtA (SEQ ID NO: 16). Реакцию SrtA проводили аналогично C-концевому участку и конечный двукратно меченый белок с EGF-лигандом очищали с использованием стадии His-аффинной очистки. Успешное однократное и двойное мечение белка было подтверждено посредством SDS-PAGE гель-электрофореза, конфокальной микроскопии и прижизненной микроскопии.
Белки сортазы A (SrtA), имеющие C-концевую His-метку, экспрессировали в компетентных бактериях E. coli и очищали с использованием аффинной улавливающей колонки.
Конъюгацию посредством сортазы полипептида и флуоресцентных пептидов проводили в течение ночи при 4°C с использованием соотношения эквивалентов полипептида и SrtA и флуоресцентного пептида 1 к 2 к 20, соответственно.
В настоящем примере полипептид с EGF-лигандом конъюгировали с флуорофором HiLyte 555 на C-концевой части домен транслокации-лиганд и флуорофором HiLyte 488 на N-концевой части легкой цепи. Экспрессия полипептида, содержащего участки распознавания SrtA и два варианта SrtA, была успешной. Преимущественно, посредством получения полипептида, который может быть мечен двумя различными цветными флуорофорами, можно визуализировать механизмы транспорта как легкой цепи (содержащей нецитотоксическую протеазу), так и частей домен транслокации-лиганд в белке.
ПРИМЕР 2
Конструирование двукратно меченного посредством SrtA полипептида с ноцицептин-лигандом
Полипептид, имеющий ноцицептин-лиганд с TM (полипептид с ноцицептин-лигандом), получали для двукратного флуоресцентного мечения с использованием стратегии, использованной для полипептида с EGF-лигандом. Конструирование, очистка и флуоресцентные пептиды, использованные для двукратного мечения этого полипептида, были в точности такими же, как и для полипептида с EGF-лигандом. Успешное двукратное мечение полипептида подтверждали посредством SDS-PAGE гель-электрофореза, конфокальной микроскопии и прижизненной визуализации. Нуклеотидные и полипептидные последовательности для полипептида, содержащего участки сортазы, представлены в качестве SEQ ID NO: 3 и 4, соответственно.
Подтверждение меченых белков с использованием анализа отщепления SNAP25
Для определения того, что мечение полипептидов с лигандами не влияет на их способность связываться с их соответствующими рецепторами, транспортировкой в клетки и транслокацией, проводили анализ отщепления SNAP25 для определения относительной эффективности меченых полипептидов по сравнению с немечеными версиями. Сходный профиль эффективности может указывать на то, что меченый полипептид транспортируется аналогично немеченой версии. Анализ отщепления SNAP25 проводили, как описано ранее (Fonfria, E., S. Donald and V.A. Cadd (2016). "Botulinum neurotoxin A and an engineered derivate targeted secretion inhibitor (TSI) A enter cells via different vesicular compartments." J Recept Signal Transduct Res 36(1): 79-88). В кратком изложении, кортикальные нейроны обрабатывали 3-1000 нМ каждого из меченого и немеченого белка в течение 24 часов. После обработки клетки собирали в буфер для лизиса NuPAGE (Thermo Fischer Scientific), дополненный 0,1 M дитиотреитолом и 250 единиц/мл бензоназы (Sigma). Лизаты разделяли посредством SDS-PAGE и подвергали вестерн-блоттингу с использованием первичных антител против SNAP-25 (Sigma). Эти антитела позволяют распознавание как расщепленной, так и нерасщепленной части SNAP25. Относительную эффективность определяли по соотношению расщепленного SNAP25 и нерасщепленного SNAP25 (фиг.2). На фиг.2A представлена эффективность ответа на дозу полипептида с EGF-лигандом. По сравнению с немеченым полипептидом, меченные посредством техасского красного и SNAP594 версии продемонстрировали выраженное снижение эффективности с величинами, сходными с контрольным полипептидом без лиганда. Напротив, однократно и двукратно меченные посредством SrtA полипептиды продемонстрировали эффективность, сходную с немеченой версией, показав, что эта стратегия мечения не влияет на архитектуру белка и его механизмы клеточного транспорта. Аналогично двукратное мечение полипептида с ноцицептин-лигандом не влияло на его эффективность в кортикальных нейронах (фиг.2B) по сравнению с немеченым контрольным полипептидом.
В целом, изначально опробовали простые и ясные способы мечения, такие как несайтспецифическое мечение с использованием красителя техасского красного и SNAP-метки, первоначально опробованной сайт-специфической версии. Однако, хотя эти стратегии мечения были успешными, было показано, что они влияют на эффективность полипептидов по сравнению с немеченым аналогом, что указывает на то, что добавление нескольких флуоресцентных молекул в случае техасского красного или SNAP-метки влияло на свойства транспортировки меченого полипептида. Попытка получить eGFP-меченный полипептид с EGF-лигандом была неуспешной вследствие отсутствия экспрессии меченого белка. В противоположность этому, анализ отщепления SNAP25 подтвердил, что два флуорофора на полипептидах с EGF-лигандом и ноцицептин-лигандом не влияли на их эффективность, что указывает на то, что механизмы действия меченых полипептидов являются сходными с их немечеными аналогами. Это было неожиданным ввиду негативного влияния, которое оказывало мечение посредством SNAP и техасского красного, на эффективность.
ПРИМЕР 3
Визуализация двукратно меченого полипептида с EGF-лигандом в иммортализованных клеточных линиях
Способ опосредуемого SrtA двукратного мечения был выбран в качестве оптимальной стратегии для мечения полипептидов по изобретению. Для визуализации меченого полипептида в клетках млекопитающих проводили прижизненную конфокальную 3D-микроскопию. Клетки аденокарциномы легкого человека (A549) обрабатывали 50 нМ двукратно меченым полипептидом с EGF-лигандом и визуализировали непрерывно с течением времени с использованием конфокального микроскопа Zeiss 880, оборудованного AiryScan (Zeiss). Для этих экспериментов полипептид с EGF-лигандом метили на N-конце посредством флуорофора HiLyte 555 (AnaSpec) и на C-конце посредством флуорофора HiLyte 488 (AnaSpec). На фиг.3 представлены фотографии агломератов с двойным окрашиванием, образовавшихся из полипептида с EGF-лигандом в ходе интернализации в клетки A549. Из фиг.3A можно видеть, что агломераты появлялись через 3 минуты после добавления полипептида к клеткам, и их размер и количество возрастало с течением времени. На фиг.3B представлено исчезновение флуоресцентного агломерата с течением времени с полным исчезновением через 65 минут после добавления полипептида.
Прижизненная визуализация, проведенная с использованием двукратно меченного полипептида с EGF-лигандом, полностью подтвердила этот способ мечения и возможность осуществлять мониторинг прижизненной интернализации и транспорта меченых полипептидов.
После демонстрации того, что мечение сортазой является преимущественным и не влияет на эффективность, его далее можно использовать для других клостридиальных нейротоксинов, включая серотипы BoNT (и производные).
ПРИМЕР 4
Конструирование полипептида BoNT/A с опосредуемым SrtA двукратным мечением
Полноразмерный протеолитически неактивный мутант BoNT/A(0) (SEQ ID NO: 38) модифицировали, чтобы обеспечить двукратное флуоресцентное мечение с использованием сортазы (см. фиг.4). Двукратно меченная полипептидная последовательность представлена в качестве SEQ ID NO: 40, в то время как нуклеотидная последовательность, кодирующая указанный полипептид, представлена в качестве SEQ ID NO: 39. Конструирование, очистка и флуоресцентные пептиды, использованные для двукратного мечения SEQ ID NO: 40, были такими же, как и для полипептида с EGF-лигандом согласно примеру 1. Успешное двукратное мечение полипептида было подтверждено посредством SDS-PAGE (фиг.5). Более подробно, с использованием окрашивания Кумасси можно визуализировать обе полосы, соответствующие доменам L-цепи и H-цепи полипептида, в то время как воздействие на гель УФ-излучения продемонстрировало (посредством флуоресценции) успешное мечение как L-цепи, так и H-цепи.
ПРИМЕР 5
Визуализация однократно меченого полипептида BoNT/A(0) в первичных кортикальных нейронах
Для визуализации меченого полипептида BoNT/A(0) в первичных нейрональных клетках проводили прижизненную TIRF-микроскопию единичных молекул в обработанных им нейронах. Первичные кортикальные нейроны обрабатывали 1 нМ однократно меченнм полипептидом BoNT/A(0) и визуализировали непрерывно с течением времени с использованием специализированной TIRF-микроскопии единичных молекул. Для этих экспериментов полипептид BoNT/A(0) метили на N-конце посредством либо флуорофора HiLyte 555, либо флуорофора HiLyte 488 (AnaSpec). На фиг.6 представлены изображения с течением времени однократно окрашенной молекулы BoNT/A(0), транспортируемой в первичные кортикальные нейроны. Из фиг.6 можно видеть, что единичная молекула BoNT/A(0) (белая стрелка) двигается быстро в пределах выбранной нейрональной области. Прижизненная TIRF-визуализация единичных молекул однократно меченнго полипептида BoNT/A(0) отчетливо демонстрирует, что единичные молекулы BoNT/A(0), транспортирующиеся в нейроны, можно визуализировать с использованием специализированных способов микроскопии высокого разрешения.
После демонстрации того, что однократное мечение BoNT/A(0) может быть визуализировано на уровне единичной молекулы в первичных нейронах, этот способ может быть далее применен в отношении других серотипов и производных клостридиального нейротоксина, включая серотипы, обладающие активностью нецитотоксической протеазы.
Все публикации, упомянутые в приведенном выше описании, включены в настоящее описание в качестве ссылки. Различные модификации и изменения описанных способов и систем по настоящему изобретению станут очевидными специалистам в данной области без отклонения от объема и сущности настоящего изобретения. Хотя настоящее изобретение описано применительно к конкретным предпочтительным вариантам осуществления, следует понимать, что заявленное изобретение не должно чрезмерно ограничиваться такими конкретными вариантами осуществления. Действительно, подразумевается, что различные модификации описанных способов осуществления изобретения, которые являются очевидными в области биохимии и биотехнологии или родственных областях, входят в объем прилагаемой ниже формулы изобретения.
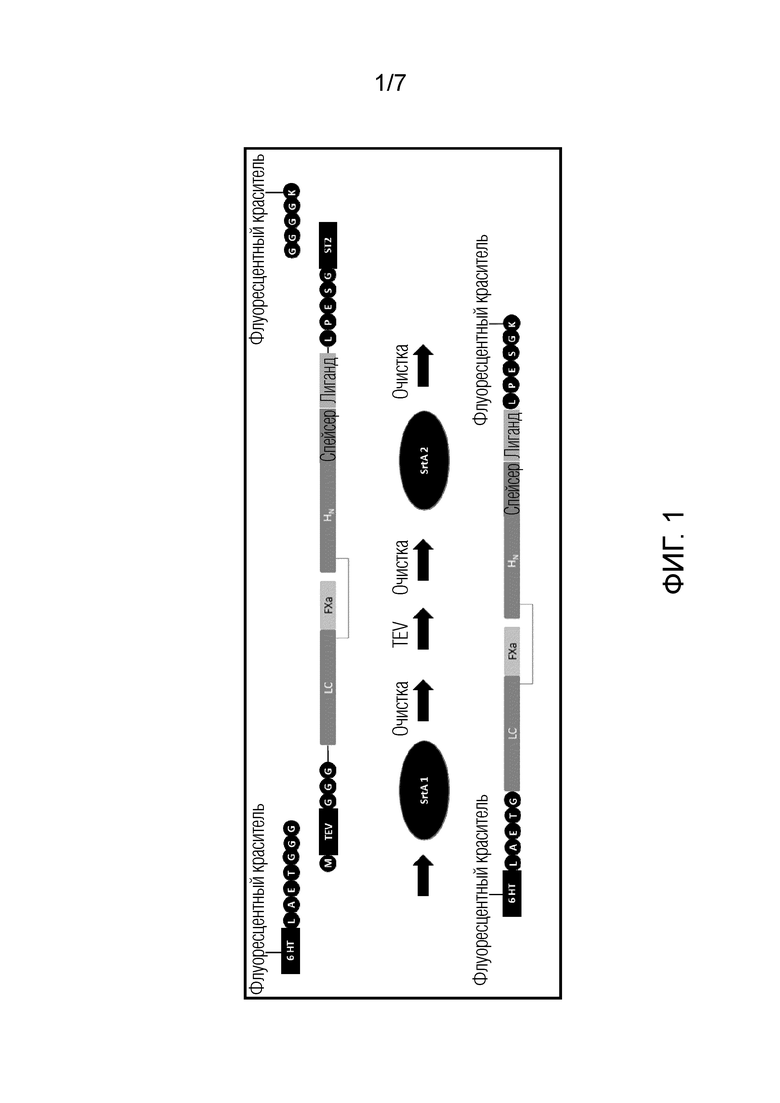
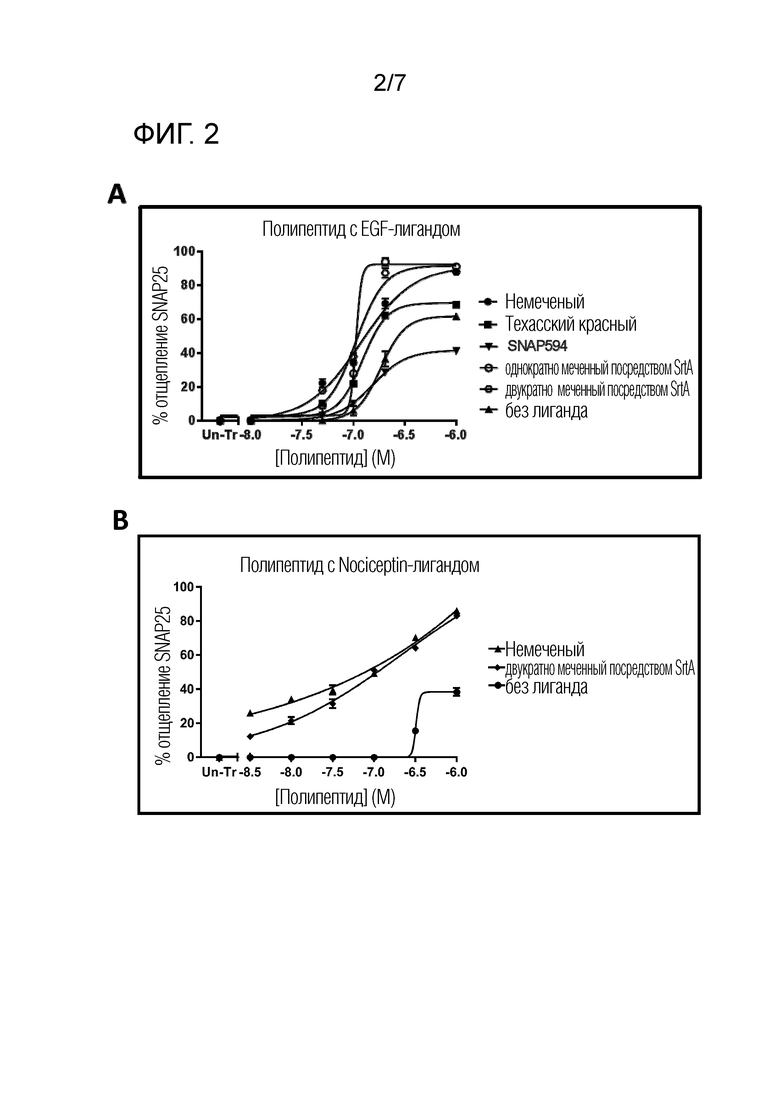
Группа изобретений относится к биотехнологии. Предложены способ получения меченого полипептида, меченый полипептид для его визуализации и способ определения по меньшей мере интернализации и/или внутриклеточного транспорта меченого полипептида. Получают полипептид, содержащий акцепторный участок для сортазы или донорный участок для сортазы, нецитотоксическую протеазу, содержащую L-цепь клостридиального нейротоксина, или ее протеолитически неактивный мутант, нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени, и домен транслокации. Инкубируют полипептид с сортазой и меченым субстратом, содержащим донорный участок для сортазы или акцепторный участок для сортазы, соответственно, и конъюгированную поддающуюся детекции метку. Получают меченый полипептид, не имеющий сниженную эффективность по сравнению с эквивалентным немеченым полипептидом и/или демонстрирующий сходное связывание клеток, транслокацию и расщепление белка SNARE с эквивалентным немеченым полипептидом. Изобретения обеспечивают визуализацию связывания клеток, транслокации и/или расщепления белка SNARE с использованием анализа на клеточной основе или in vivo. 3 н. и 12 з.п. ф-лы, 6 ил., 5 пр.
1. Способ получения меченого полипептида, включающий:
a. получение полипептида, содержащего:
i. акцепторный участок для сортазы или донорный участок для сортазы;
ii. нецитотоксическую протеазу, содержащую L-цепь клостридиального нейротоксина, или ее протеолитически неактивный мутант;
iii. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
iv. домен транслокации;
b. инкубацию полипептида с:
сортазой; и
меченым субстратом, содержащим донорный участок для сортазы или акцепторный участок для сортазы, соответственно, и конъюгированную поддающуюся детекции метку;
где сортаза катализирует:
конъюгацию между аминокислотой акцепторного участка для сортазы в полипептиде и аминокислотой донорного участка для сортазы в меченом субстрате; или
конъюгацию между аминокислотой акцепторного участка для сортазы в меченом субстрате и аминокислотой донорного участка для сортазы в полипептиде;
с осуществлением тем самым мечения полипептида; и
c. получение меченого полипептида, где меченый полипептид не имеет сниженную эффективность по сравнению с эквивалентным немеченым полипептидом и/или где меченый полипептид демонстрирует сходное связывание клеток, транслокацию и расщепление белка SNARE с эквивалентным немеченым полипептидом.
2. Способ по п.1, где:
a. акцепторный или донорный участок для сортазы находится с C-концевой стороны от TM или где акцепторный или донорный участок для сортазы находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта; и/или
b.
i. акцепторный участок для сортазы содержит: L(A/P/S)X(T/S/A/C)(G/A); NPQTN; YPRTG; IPQTG; VPDTG; или LPXTGS, где X представляет собой любую аминокислоту; и/или
ii. где донорный участок для сортазы содержит Gn или An, где n равен 1-10; или
c.
i. акцепторный участок для сортазы содержит: L(A/P/S)X(T/S/A/C)G, где X представляет собой любую аминокислоту; NPQTN; YPRTG; IPQTG; VPDTG; или LPXTGS, где X представляет собой любую аминокислоту; и/или
ii. где донорный участок для сортазы содержит Gn, где n равен 1-10; и/или
d. сортаза представляет собой сортазу A (SrtA).
3. Способ по п. 1, где:
a. акцепторный или донорный участок для сортазы находится с C-концевой стороны от TM или где акцепторный или донорный участок для сортазы находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта; и/или
b.
i. L(A/P/S)X(T/S/A/C)G, где X представляет собой любую аминокислоту; NPQTN; YPRTG; IPQTG; VPDTG; или LPXTGS, где X представляет собой любую аминокислоту; и/или
ii. где донорный участок для сортазы состоит из Gn или An, где n равен 1-10; или
c.
i. акцепторный участок для сортазы состоит из: L(A/P/S)X(T/S/A/C)G, где X представляет собой любую аминокислоту; NPQTN; YPRTG; IPQTG; VPDTG; или LPXTGS, где X представляет собой любую аминокислоту; и/или
ii. где донорный участок для сортазы состоит из Gn, где n равен 1-10; и/или
d. сортаза представляет собой сортазу A (SrtA).
4. Способ по п.1, где полипептид содержит по меньшей мере два акцепторных участка для сортазы; по меньшей мере два донорных участка для сортазы; или по меньшей мере один акцепторный участок для сортазы и по меньшей мере один донорный участок для сортазы.
5. Способ по п.4, где по меньшей мере два участка различаются, предпочтительно где по меньшей мере два участка имеют различные аминокислотные последовательности,
где:
первый акцепторный или донорный участок для сортазы находится с C-концевой стороны от TM и второй акцепторный или донорный участок для сортазы находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта; или
первый акцепторный или донорный участок для сортазы находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта и второй акцепторный или донорный участок для сортазы находится с C-концевой стороны от TM.
6. Меченый полипептид для его визуализации, содержащий:
i. поддающуюся детекции метку, конъюгированную с полипептидом;
ii. аминокислотную последовательность, которая содержит:
a. L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен 1-10;
b. L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен 1-10;
c. NPQTN;
d. YPRTG;
e. IPQTG;
f. VPDTG; или
g. LPXTGS, где X представляет собой любую аминокислоту;
iii. нецитотоксическую протеазу, содержащую L-цепь клостридиального нейротоксина, или ее протеолитически неактивный мутант;
iv. нацеливающую часть (TM), которая способна связываться с участком связывания на клетке-мишени; и
v. домен транслокации,
где меченый полипептид не имеет сниженную эффективность по сравнению с эквивалентным немеченым полипептидом и/или где меченый полипептид демонстрирует сходное связывание клеток, транслокацию и расщепление белка SNARE с эквивалентным немеченым полипептидом.
7. Меченый полипептид по п.6, где:
a. аминокислотная последовательность, которая содержит: L(A/P/S)X(T/S/A/C)Gn; L(A/P/S)X(T/S/A/C)An; NPQTN; YPRTG; IPQTG; VPDTG; или LPXTGS, находится с C-концевой стороны от TM; или
b. где аминокислотная последовательность, которая содержит: L(A/P/S)X(T/S/A/C)Gn; L(A/P/S)X(T/S/A/C)An; NPQTN; YPRTG; IPQTG; VPDTG; или LPXTGS, находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта.
8. Меченый полипептид по п.6, содержащий дополнительную поддающуюся детекции метку, конъюгированную с полипептидом, и дополнительную аминокислотную последовательность, которая содержит:
a. L(A/P/S)X(T/S/A/C)Gn, где X представляет собой любую аминокислоту и n равен 1-10;
b. L(A/P/S)X(T/S/A/C)An, где X представляет собой любую аминокислоту и n равен 1-10;
c. NPQTN;
d. YPRTG;
e. IPQTG;
f. VPDTG; или
g. LPXTGS, где X представляет собой любую аминокислоту.
9. Меченый полипептид по п.8, где
a. аминокислотная последовательность по п.6 отличается от дополнительной аминокислотной последовательности; и/или
b. аминокислотная последовательность по п.6 находится с C-концевой стороны от TM, и дополнительная аминокислотная последовательность находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта; или
аминокислотная последовательность по п.6 находится с N-концевой стороны от нецитотоксической протеазы или ее протеолитически неактивного мутанта и дополнительная аминокислотная последовательность находится с C-концевой стороны от TM.
10. Способ по любому из пп. 1-5 или меченый полипептид по любому из пп. 6-9, где домен транслокации включает домен транслокации клостридиального нейротоксина; и/или где TM представляет собой HC-пептид клостридиального нейротоксина.
11. Способ по любому из пп. 1-5 или меченый полипептид по любому из пп. 6-9, где полипептид представляет собой клостридиальный нейротоксин; и/илигде полипептид представляет собой ботулинический нейротоксин (BoNT); и/или где полипептид выбран из: BoNT/A, BoNT/B, BoNT/C, BoNT/D, BoNT/E, BoNT/F, BoNT/G, BoNT/X или TeNT.
12. Способ по любому из пп. 1-5 или меченый полипептид по любому из пп. 6-9, где полипептид не содержит функционального домена HС клостридиального нейротоксина.
13. Способ определения по меньшей мере интернализации и/или внутриклеточного транспорта меченого полипептида, включающий:
a. приведение клетки-мишени в контакт с меченым полипептидом по п.6; и
b. детекцию поддающейся детекции метки.
14. Способ по любому из пп. 1-5 или 13 или меченый полипептид по любому из пп. 6-9, где поддающаяся детекции метка представляет собой флуоресцентный краситель, предпочтительно где флуоресцентный краситель выбран из: HiLyte, AlexaFluor, Atto, Quantum Dots и Janelia Fluor.
15. Способ по любому из пп. 1-5 или 13 или меченый полипептид по любому из пп. 6-9, где меченый полипептид содержит две или более поддающихся детекции меток, предпочтительно где две или более поддающихся детекции меток представляют собой флуорофоры разного цвета.
| ANTOS J | |||
| M | |||
| et al | |||
| Site-Specific N- and C-Terminal Labeling of a Single Polypeptide Using Sortases of Different Specificity | |||
| J | |||
| AM | |||
| CHEM | |||
| SOC., 2009, v.131, p.10800-10801 | |||
| WO 2011091419 A2, 28.07.2011 | |||
| WO 2011133704 A2, 27.10.2011 | |||
| FISCHER A | |||
| et al | |||
| Botulinum Neurotoxin Devoid of Receptor Binding Domain Translocates Active Protease | |||
| PLoS |

