Изобретение относится к области распознавания речи, т.е. к способам перевода акустического сигнала, содержащего речь, в текст, состоящий из слов, входящих в лексический и произносительный словари системы распознавания речи.
Заявленное изобретение позволяет распознавать слитную непрерывную речь вне зависимости от индивидуальных особенностей говорящего на основе определения групп фонем по характеризующим их признакам и методе последовательного декодирования последовательностей символов, обозначающих группы фонем, на основе двухуровнего морфофонемного префиксного графа (ДМПГ) в цепочку слов, составляющих высказывание (текст).
Известен способ дикторонезависимого распознавания звуков речи (патент на изобретение РФ 2234746 от 30.10.2002), включающий в себя предварительную сегментацию речевого сигнала для определения временной длительности звуковых сегментов, определение периодичности каждого сегмента акустических составляющих речевого сигнала для соотнесения звукового сегмента по способу его образования к голосовому, шумному или шумно-голосовому виду звуков речи, определение амплитуды и частоты каждой из первых трех формант в спектре звукового сегмента в качестве информативных признаков звуков речи, интеграцию упомянутых информативных признаков для каждого звукового сегмента, фонемное распознавание каждого звукового сегмента путем сопоставления интегральных значений его информативных признаков с имеющимся банком данных отдельно для каждого вида звуков речи, принятие решения относительно распознаваемого звука речи и представление его в виде буквенного или транскрипционного обозначения. Основную сегментацию речевого сигнала выполняют по трем основным режимам в зависимости от ранее найденного вида звукового сегмента, при упомянутом фонемном распознавании сопоставляют интегральные значения информативных признаков каждого звукового сегмента как для каждого упомянутого вида звуков речи, так и для каждого типа в зависимости от числа формант в звуковом сегменте, затем устанавливают временные границы звуков речи в зависимости от изменения фонемной принадлежности звукового сегмента, после чего и принимают упомянутое решение относительно распознаваемого звука речи. К числу недостатков данного решения следует отнести низкую различительную способность и скорость распознавания речи по формантам, поступательный характер распознавания, обуславливающие последовательное распознавание каждой форманты, а также необходимость обращаться в процессе распознавания к словарям и эталонным образцам.
Известен способ распознавания слов в слитной речи (патент на изобретение РФ 2297676 от 30.03.2005), состоящий в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании, для чего применяют сеть лексического декодирования, которая задает закономерности следования эталонных акустических состояний в языке. При этом проводится поиск рабочей гипотезы, являющийся оптимальным в смысле максимума степени ее совпадения с исходным речевым сигналом, что обеспечивается использованием алгоритма перемещаемого маркера, а восстанавливают рабочую гипотезу из маркера, который в этот момент времени находится в конечной вершине сети лексического декодирования. Несмотря на то, что в данном способе различительная способность выше, чем в предыдущем способе, однако, аналогично с предыдущим известным способом распознавания речи к числу недостатков данного метода следует также отнести длительность процесса распознавания, обусловленного необходимостью обращения к эталонным образцам, а также поочередным распознаванием каждой форманты в слове.
Известны также способ и система распознавания речи, построенные с использованием методов фонемного анализа (патент США №5315689, 1995), в котором применяется двухуровневая обработка речевого сигнала. Блок первого уровня осуществляет распознавание слова (команды) как звукового (слухового) образа в целом. Альтернативный блок второго уровня производит фонемное распознавание звукового сигнала. Недостатком этого способа является снижение степени вероятности правильного распознавания слов (фраз) при увеличении объема речевого фрагмента и распознавании слитной речи.
Известен также способ распознавания речи (заявка на изобретение США US 2010332231 А1 от 01.06.2010), заключающийся в том, что из слитной речи на первом этапе определяют последовательность фонем, подлежащих распознаванию, которые затем сравнивают с хранящимся в памяти устройства списком слов, соответствующих отобранным фонемам, при этом далее осуществляют вероятностную оценку, по установленным ранее критериям на основании которой выбирают из ранее сформированного слова наиболее вероятные, а незнакомое слово вносят в словарь и определяют критерии для последующей вероятностной оценки. К числу недостатков данного способа можно отнести его чрезмерную сложность и высокие требования к ресурсам памяти устройства, осуществляющего распознавание речи в соответствии с данным способом, кроме того, решение не позволяет осуществлять распознавание слитной речи, так как распознавание идет слишком медленно и с достаточной степенью точности возможно лишь определение отдельных речевых команд, а не слитной речи.
Наиболее близким по технической сущности к заявляемому способу и выбранным в качестве прототипа является способ распознавания речи (патент RU 2 466 468 от 10.11.2012), включающий последовательно исполняемые этапы приема речевого сигнала на входе блока приема; обработки речевого сигнала блоком обработки информации, включающей его обработку аналого-цифровым преобразователем с предустановленной частотой дискретизации и разделением на сегменты, спектрального анализа сегментов речевого сигнала и нормализации спектра на высоких частотах; выделения в нормализованном спектре пауз, шумов и звуковых сигналов с последующим его распознаванием и преобразованием в текст с использованием предустановленного словаря, при этом на этапе распознавания на основе исходного речевого сигнала и нормализованного спектра в каждом сегменте определяют наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых характеризуют группы фонем, параметры которых предустановлены в блоке памяти, и осуществляют сравнение определенных комбинаторных наборов акустических признаков сегмента с предустановленными параметрами групп фонем, с одновременным формированием последовательности символов, обозначающих группы фонем, соответствующие комбинаторным наборам акустических признаков каждого сегмента, преобразование которой в связный текст осуществляют последовательным декодированием комбинаторного сочетания символов групп фонем последовательности на основе словаря, размеченного по символам групп фонем.
Способу-прототипу присущи следующие недостатки:
1) анализируются только префиксы словоформ (сочетаний групп фонем), тогда как для русского языка с относительно высоким уровнем флективности этого недостаточно, поскольку вариативность окончаний очень велика для большинства слов. В среднем наличие нескольких десятков различных окончаний у одного и того же слова приводит к существенному увеличению размера словаря (требуемого объема элементов памяти);
2) существенная вычислительная сложность метода последовательного декодирования последовательностей символов, обозначающих группы фонем, использующем произносительный словарь, состоящий из списка слов и соответствующих им транскрипций, размеченных в символах групп фонем;
3) необходимость использования больших текстовых корпусов для обучения предустановленного словаря.
Для компактного представления словаря транскрипций флективных языков признано эффективным разложение словоформы на сублексические единицы, так как это позволяет сократить размер словаря системы распознавания и, соответственно, повысить скорость декодирования речевого сигнала [Kurimo М., Creutz М., Varjokallio М., Arisoy Е., Saraclar М. Unsupervised segmentation of words into morphemes - Morpho challenge 2005 application to automatic speech recognition // Proc. Interspeech 2006. Pittsburgh, USA, 2006. - pp. 1021-1024]. Разложение на основе статистических моделей позволяет сильнее сократить размер словаря, но увеличивает риск возникновения грамматически некорректных последовательностей сублексических единиц, которые, тем не менее, с акустической точки зрения являются наиболее правдоподобными [Kneissler J., Klakow D. Speech recognition for huge vocabularies by using optimized subword units // Proc. Eurospeech 2001. Aalborg, Denmark, 2001. - pp. 69-72].
Классической моделью словаря (слов или морфов) является структура, представляющая собой список всех словоформ и их транскрипций (фиг. 1, а). Транскрипция каждого слова представляет собой цепочку составляющих ее фонем. Модель фонемы обычно строится на основе скрытых моделей Маркова (СММ) и лево-правой модели Бэкиса. Более точное распознавание фонем достигается путем учета фонетического контекста и построения моделей Трифонов, а также применения смесей гауссовских плотностей распределения вероятностей векторов наблюдений в состояниях фонем.
С помощью СММ обеспечивается объединение моделей фонем, слов, фраз в единую структуру графа, обеспечивающего поиск лучшей гипотезы распознавания. При проектировании системы распознавания речи в зависимости от размера словаря и типа модели языка, которая используется при построении моделей фраз, меняется в основном структура (lattice) графа. Поэтому методы параметрического представления речи, методы оценки вероятности состояний, фонем, фраз остаются практически неизменными, а производится наполнение и оптимизация графа словаря декодера.
С увеличением размера словаря появляются слова с одинаковыми начальными участками, соответственно их транскрипции будут иметь одинаковые начальные фонемы. Объединяя начальные участки транскрипций, словарь преобразуется в лексикофонетическое дерево (фиг. 1, б), за счет чего достигается значительное сокращение объема памяти [Ortmanns, S., Eiden, А., Ney, Н. Improved Lexical Tree Search for Large Vocabulary Recognition. IEEE Int. Conf. on Acoustics, Speech and Signal Processing, Seattle, WA, 1998. - pp. 817-820]. Прохождение по дереву позволяет синтезировать все возможные слова из словаря. Существующие методы распознавания на основе префиксного лексико-фонетического дерева успешно применяются для английского и других языков [Prazak A., Psutka J., Hoidekr J., Kanis J., Muller L., Psutka, J. Adaptive language model in automatic online subtitling // Proc. 2nd IASTED International Conference on Computational Intelligence CI 2006. San Francisco, California, USA, 2006. - pp. 479-483].
Для компактного представления словаря транскрипций предлагается использовать декомпозирование словоформы на основу и концовку при помощи морфоанализатора [Леонтьева Ан.Б. Модуль морфофонетической обработки слов для построения словаря распознавателя русской слитной речи. Научно-теоретический журнал «Искусственный интеллект», №3. - Донецк, Украина, 2007. - С. 319-327], построенного на базе правил словообразования и словоизменения, что позволяет хранить словарь в виде префиксного дерева основ и автоматически генерировать произвольную словоформу [Ронжин А.Л., Леонтьева Ан.Б., Кагиров И.А.? Леонтьева Ал.Б. Двухуровневый морфофонемный префиксный граф для декодирования русской слитной речи // Труды СПИИРАН. Вып. 4, т. 1. - СПб.: Наука, 2007. - С. 388-404; Ронжин А.Л. Топологические особенности морфофонемного способа представления словаря для распознавания русской речи // Вестник компьютерных и информационных технологий, №9, 2008. - С. 12-19].
Полученное лексическое префиксное дерево имеет двухуровневую структуру, где первый уровень представляет собой граф основ, а второй - список концовок (элементы, следующие за основой, могут состоять из словообразовательных и словоизменительных суффиксов, окончания и постфикса). Данный ДМПГ наиболее компактно описывает все используемые словоформы и их транскрипции (фиг. 1, в). Генерация ДМПГ производится по списку транскрибированных словоформ, и поэтому полученный граф способен генерировать только грамматически правильные слова. Для использования данного графа в способе распознавания слитной речи вводится обратная связь, обеспечивающая генерацию последовательности словоформ с неограниченной длиной. Строго говоря, число слов в последовательности будет зависеть от длины записанного речевого сигнала и при поступлении последней фонемы, гипотеза распознанной фразы (путь по графу) заканчивается последним начатым словом.
Задачей изобретения является разработка способа распознавания речи на основе двухуровневого морфофонемного, префиксного графа, позволяющего сократить объем элементов памяти, необходимый для хранения предустановленного словаря, и снизить вычислительную сложность процесса распознавания.
В заявленном способе эта задача решается тем, что в способе распознавания речи на основе двухуровневого морфофонемного префиксного графа, включающем последовательно исполняемые этапы приема речевого сигнала на входе блока приема; обработки речевого сигнала блоком обработки информации, включающей его обработку аналого-цифровым преобразователем с предустановленной частотой дискретизации и разделением на сегменты, спектрального анализа сегментов речевого сигнала и нормализации спектра на высоких частотах; выделения в нормализованном спектре пауз, шумов и звуковых сигналов с последующим его распознаванием и преобразованием в текст с использованием предустановленного словаря, при этом на этапе распознавания на основе исходного речевого сигнала и нормализованного спектра в каждом сегменте определяют наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых характеризуют группы фонем, параметры которых предустановлены в блоке памяти, дополнительно после этого определяют вероятности всех состояний фонем по отношению к текущему сегменту. Затем обрабатывают гипотезы распознавания с использованием предустановленного словаря на базе двухуровневого мор-фофонетического префиксного графа и осуществляют сравнение параметров гипотез распознавания с целью их упорядочивания. Осуществляют синтаксическое согласование гипотез, содержащих две и более основ, после чего формируют результат распознавания на основе комплексной оценки гипотезы фразы. Затем преобразуют результаты распознавания всех сегментов речевого сигнала в связный текст и выводят его с помощью устройств вывода.
Новая совокупность существенных признаков позволяет достичь указанного технического результата за счет:
- выделения двух этапов обработки и соответственно двух уровней представления: лексического дерева основ (неизменяемой части слова) и списка уникальных грамматических концовок (изменяемой части в зависимости от грамматических показателей: род, число, падеж, склонение, вид и др.), позволяющих сократить размер предустановленного словаря и, соответственно, повысить скорость декодирования речевого сигнала;
- использования грамматических правил русского языка при декомпозиции словоформы на основу и концовку, а также сохранения связей между основой и соответствующими концовками, обеспечивающих формирование только корректных словоформ при прохождении по двухуровневому графу в процессе обработки гипотезы распознавания.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного способа распознавания речи на основе двухуровневого морфофонемного префиксного графа, отсутствуют. Следовательно, заявленное изобретение соответствует условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения преобразований на достижение указанного технического результата. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Заявленное изобретение поясняется следующими чертежами:
- фиг. 1, отображающей способы представления словаря для распознавания слитной речи;
- фиг. 2, на которой представлена блок-схема последовательности действий, реализующих предлагаемый способ;
- фиг. 3, на которой представлен алгоритм генерации ДМПГ по списку транскрибированных словоформ;
- фиг. 4, отображающей сущность синтаксического согласования;
- фиг. 5, на которой приведены результаты сравнения моделей предустановленного словаря: а - по числу узлов фонем; б - по числу концевых узлов; в - по суммарному числу узлов и дуг; г - по плотности графа.
Реализация заявленного способа заключается в следующем (фиг. 2).
Речевой сигнал в виде звукового потока данных принимают (блок 201) и осуществляют его преобразование в цифровой вид (блок 202). Полученный цифровой речевой сигнал сегментируют при обработке короткими окнами одинаковой длины и со смещением в два раза меньше длины (блок 203), что позволяет выявлять как плавные переходы от одного звука в потоке речи к другому, так и кратковременные характерные явления внутри звуков речи, например, взрывы смычных согласных. Окна обработки выбирают по длине таким образом, чтобы получить наиболее оптимальные и сглаженные признаки групп фонем по времени их звучания в потоке речи. Эмпирически установлено, что длина окон в 25 мс дает оптимальный результат.
Акустические признаки речевого сигнала, характерные для групп фонем, используемых в качестве базовых элементов для распознавания, определяют в рамках каждого окна (сегмента речевого сигнала) параллельно и одномоментно программно-аппаратным образом, При этом часть акустических признаков определяют напрямую из осциллограммы речевого сигнала, полученной от аналого-цифрового преобразователя* а часть - из спектра речевого сигнала, получаемого при спектральном анализе сегментов речевого сигнала и нормализации при помощи быстрого преобразования Фурье (блок 204). Полученный спектр нормализуется на высоких частотах в соответствии с нелинейным восприятием разных частот человеческой слуховой системой, что позволяет компенсировать более низкую интенсивность высоких частот по сравнению с низкими частотами в речевом сигнале.
Как указано выше, для определения акустических признаков речевого сигнала в каждом окне используют как исходный речевой сигнал, так и нормализованный спектр. На основе комбинаций значений акустических признаков определяется группа фонем, к которой относится речевой сигнал в рамках текущего окна обработки (блок 205). Так, например, при классификации групп фонем может быть использован следующий набор акустических признаков: наличие/отсутствие основного тона, наличие/отсутствие широкополосных шумов, наличие/отсутствие перепада интенсивности речевого сигнала, наличие/отсутствие высокочастотных шумов, наличие/отсутствие сонорности, акустический признак присутствия/отсутствия гласного, акустический признак ряда гласного.
Одной из важнейших акустических характеристик является наличие основного тона в речевом сигнале. Отсутствие основного тона в сигнале свидетельствует о том, что в данный момент времени либо произносится глухой согласный, либо присутствует перерыв в речи (пауза). Присутствие основного тона определяют по высокой интенсивности частотных составляющих в низкочастотной области в диапазоне возможных значений частоты основного тона. Интенсивность частотных составляющих в текущем окне определяют относительного их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала длиной около 5 секунд. Если в речевом сигнале в рамках предыдущего окна обработки было определено отсутствие основного тона и широкополосных шумов, а в речевом сигнале в текущем окне был определен один из других признаков, то данное окно дополнительно проверяется на наличие в нем широкополосных шумов, что является признаком, характеризующим группу смычные глухие шумные согласные или смычные звонкие шумные согласные.
Кратковременные перепады интенсивности речевого сигнала, свидетельствующие о присутствии в сигнале коротких смычек, характерных для дрожащих сонантов, определяют по соотношению интенсивности речевого сигнала в трех последовательно идущих окнах обработки. Интенсивность речевого сигнала в среднем окне существенно ниже интенсивности речевого сигнала в правом и левом окнах, в то время как интенсивность речевого сигнала в правом и левом окнах практически одинакова.
Наличие широкополосных шумов в речевом сигнале, связанных с произношением щелевых согласных или присутствием взрыва, происходящего во время размыкания смычки при произнесении смычных согласных, определяют по наличию интенсивных частотных составляющих в диапазоне выше возможных значений частоты основного тона и ее первой гармоники. Интенсивность частотных составляющих в текущем окне определяют относительного их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала длиной около 5 секунд.
Наличие высокочастотных шумов в речевом сигнале, связанных с произношением щелевых сибилянтов, определяют в диапазоне выше возможных значений частоты основного тона и ее первой гармоники, по отношению интенсивности частотных составляющих в области средних частот и интенсивности частотных составляющих в области высоких частот. Интенсивность высокочастотных шумов существенно превосходит интенсивность средних частот в случае произнесения щелевых сибилянтов.
Сонорность речевого сигнала, характерную для произнесения сонантов и гласных, в противоположность шумным согласным, определяют по высокой интенсивности частотных составляющих в диапазоне средних частот выше низкочастотной области в диапазоне возможных значений частоты основного тона, но вмещающих в себя диапазон возможных значений частот формант сонантов. Интенсивность частотных составляющих в текущем окне считается относительно их максимальной интенсивности в речевом сигнале на протяжении сравнительно длинного отрезка речевого сигнала длиной около 5 секунд.
Еще одним акустическим признаком, используемым при распознавании речи и для характеристики групп фонем, является отсутствие или наличие гармонических составляющих в спектре в частотной области выше диапазона возможных значений частот формант сонантов. Отсутствие гармонических составляющих в области средних и верхних частот характерно для сонантов, а присутствие для гласных. Наличие или отсутствие гармонических составляющих определяется по отношению интенсивности частотных составляющих ниже и выше частотного порога.
Другой важной акустической характеристикой звуков речи является качество возможно произнесенного гласного, а именно ряд его произнесения, т.е. положения основной массы языка в полости рта в горизонтальном положении. Ряд произнесения гласного определяют по соотношению интенсивности гармонических составляющих в спектре речевого сигнала в области низких частот, области средних частот и области верхних частот. Отсутствие гармонических составляющих в спектре речевого сигнала в области средних частот и области верхних частот свидетельствует о произнесении гласного заднего ряда. Присутствие гармонических составляющих в спектре речевого сигнала в области средних частот свидетельствует о произнесении гласного среднего ряда. Одновременное присутствие гармонических составляющих в спектре речевого сигнала в области низких частот и области верхних частот и их отсутствие в области средних частот свидетельствует о произнесении гласного заднего ряда. Наличие или отсутствие гармонических составляющих определяют по отношению интенсивности частотных составляющих в области низких частот, области средних частот и области верхних частот.
В способе согласно изобретению используют следующие группы фонем: смычные глухие шумные согласные, смычные звонкие шумные согласные, глухие шумные щелевые согласные, звонкие шумные щелевые согласные, глухие сибилянты, звонкие сибилянты, носовые и щелевые сонанты, дрожащие сонанты, гласные переднего ряда, гласные смешанного ряда и гласные заднего ряда.
Смычные глухие шумные согласные определяются следующими акустическими признаками: отсутствием основного тона и широкополосных шумов, и характеризуются смычкой, то есть фактическим отсутствием речевого сигнала, и последующими кратковременными широкополосными шумами. Смычные глухие шумные согласные отличаются от пауз между словами длиной смычки, которая значительно короче паузы между словами, и наличием последующего взрыва, характеризующегося кратковременными широкополосными шумами.
Смычные звонкие шумные согласные однозначно определяются следующими акустическими признаками: наличием основного тона и отсутствием широкополосных шумов на месте смычки, а также последующими кратковременными широкополосными шумами на месте взрыва.
Глухие шумные щелевые согласные определяются следующими акустическими признаками: отсутствием основного тона, наличием широкополосных шумов, отсутствием высокочастотных шумов, отсутствием сонорности.
Звонкие шумные щелевые согласные определяются следующими акустическими признаками: наличием основного тона, наличием широкополосных шумов, отсутствием высокочастотных шумов, отсутствием сонорности.
Глухие сибилянты определяются следующими акустическими признаками: отсутствием основного тона, наличием широкополосных шумов, наличием высокочастотных шумов, отсутствием сонорности.
Звонкие сибилянты определяются следующими акустическими признаками: наличием основного тона, наличием широкополосных шумов, наличием высокочастотных шумов, отсутствием сонорности.
Носовые и щелевые сонанты определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой отсутствия гласного.
Дрожащие сонанты определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, наличием перепада интенсивности речевого сигнала.
Гласные заднего ряда определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой присутствия гласного, акустической характеристикой заднего ряда гласного.
Гласные смешанного ряда определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой присутствия гласного, акустической характеристикой смешанного ряда гласного.
Гласные переднего ряда определяются следующими акустическими признаками: наличием основного тона, наличием сонорности, акустической характеристикой присутствия гласного, акустической характеристикой переднего ряда гласного.
Аффрикаты рассматриваются как последовательное произнесение соответствующих смычного и щелевого согласного.
Следующим этапом в ходе обработки речевого сигнала (фиг. 2) является вычисление вероятностей всех состояний фонем по отношению к текущему сегменту (блок 206). При описании фонем используются скрытые марковские модели с тремя состояниями (модель Бэкиса).
Проблема, возникающая при использовании дискретных марковских моделей, заключается в том, что в большинстве практических задач наблюдения являются непрерывными сигналами (или векторами) и их квантование с помощью кодовых книг может иногда приводить к серьезным искажениям исходного сигнала. Поэтому часто для распознавания речи используют СММ с непрерывными плотностями наблюдений. В таких моделях плотность наблюдений описывается следующим образом:
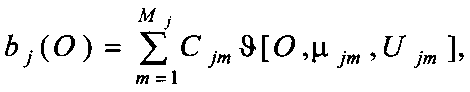
где О - моделируемый вектор наблюдений, Mj - число компонент в состоянии j, Cmj - весовой коэффициент m-й компоненты в состоянии j и ϑ - произвольная логарифмически-вогнутая или эллиптически-симметричная плотность вероятности (например, гауссовская) с вектором средних значений µjm и ковариационной матрицей Ujm для m-й компоненты в состоянии j. Как правило, в качестве плотности вероятности используется гауссовская плотность. Плотности такого вида часто используются на практике, поскольку позволяют с любой точностью аппроксимировать произвольную непрерывную функцию плотности вероятности, содержащую конечное число компонент.
Выбор числа компонент зависит, прежде всего, от объема обучающих данных и вычислительной мощности устройства, где будет производиться распознавание речи. При недостаточном объеме данных может оказаться, что число обучающих векторов будет меньше, чем число компонент и в этом случае на этапе обучения произойдет сбой. Также следует учитывать, что с увеличением числа компонент, возрастает и вычислительная сложность алгоритма распознавания речи.
В блоке 206 осуществляется обработка гипотезы распознавания с использованием предустановленного словаря на базе ДМПГ [Ронжин А.Л. Методы и программные средства многоканальной дистанционной обработки речи и их применение в интерактивных многомодальных приложениях: дис.… д-ра техн. наук: 05.13.11. - СПб. - 2010. - 299 с].
Описание гипотезы включает: указатель на текущий узел в графе, число обработанных сегментов речи, цепочку пройденных фонем по графу, массив пройденных основ и окончаний по графу, указатель на структуру текущей модели фонемы, длительность нахождения гипотезы в текущем состоянии, а также акустическую вероятность, вероятность модели языка, морфологическую оценку согласованности концовок в гипотезе, наконец, комплексную оценку гипотезы и многие другие параметры, необходимые для обработки гипотезы. В зависимости от типа текущего узла гипотеза распознавания следует на обработку фонем или же концевых узлов (основы или концовки).
В первом случае производится обработка фонемного узла или из текущей гипотезы формируется j дочерних гипотез по числу дуг, исходящих из начального узла. Затем каждая из дочерних гипотез независимо анализируется в блоке обработки фонемного узла. После анализа всех дочерних гипотез, производится их оценка и отсеивание маловероятных гипотез.
Во втором случае, когда текущая гипотеза содержит концевой узел, то соответственно индекс основы или концовки сохраняется в структуре гипотезы. Далее в случае анализа основы выполняется оценка вероятности накопленной цепочки основ по модели языка. После чего во всех случаях гипотеза размножается по числу дуг, исходящих из текущего узла, а затем производятся рекурсивные действия над каждой дочерней гипотезы в блоке обработки гипотезы распознавания по графу ДМПГ. Движение по графу продолжается до тех пор, пока текущая гипотеза и все ее дочерние не будут обработаны. При поступлении гипотезы в блок обработки фонемного узла в первую очередь определяется название фонемы и число состояний, достижимых из текущего узла. После чего гипотеза размножается, а каждая дочерняя последовательно обрабатывается в цикле, где проверяется длительность нахождения в текущем состоянии, оценивается вероятность перехода в следующее состояние и вероятность текущего состояния по отношению к входному вектору признаков. При переходе в следующее состояние акустическая вероятность гипотезы увеличивается на сумму логарифмов вероятности перехода в следующее состояние и вероятности текущего состояния.
В случае перехода в конечное состояние фонемы, производится запись названия фонемы в структуру гипотезы, и на этом оценка гипотезы в модели фонемы завершается, а сама гипотеза размножается по числу дуг, исходящих из текущего узла фонемы, а затем производятся рекурсивные действия над каждой дочерней гипотезы в блоке обработки гипотезы распознавания по графу ДМПГ.
Формирование предустановленного словаря на базе ДМПГ, т.е. преобразование списка словоформ и их транскрипций в граф ДМПГ, производится следующим образом (фиг. 3). В ходе обработки каждая транскрипция раскладывается по существующему графу, в случае отсутствия соответствующего фонетического пути для продолжения данной транскрипции строится свой дополнительный путь, состоящий из узлов оставшихся фонем в основе транскрипции. После разложения основы, производится поиск концовки среди существующих в графе. Если такая концовка уже существует, то ее узел связывается дугой с узлом анализируемой основы, если же нет, то строится новый узел концовки и последовательность узлов фонем для ее транскрипции. Информация о грамматических показателях словоформы не хранится в графе ДМПГ, так как при декодировании используется специальный модуль морфосинтаксического анализа, где обеспечивается, в том числе, построение парадигмы слова по индексу основы [Леонтьева Ан.Б. Модуль морфофонетической обработки слов для построения словаря распознавателя русской слитной речи. Научно-теоретический журнал «Искусственный интеллект», №3. - Донецк, Украина, 2007. - С. 319-327].
В блоке 302 производится загрузка списка всех уникальных транскрипций, полученного в результате обработки словаря предметной области.
В блоке 304 осуществляется подготовка переменных и структур графа ДМПГ, в частности инициализируется начальный узел, обнуляется счетчик исходящих из него дуг. Счетчик транскрипций устанавливается в ноль i=0.
Для текущей транскрипции в блоке 306 производится заполнение полей структуры, содержащей ее основные данные: фонетическую транскрипцию Ti с разметкой на основу и концовку, а также порядковый номер основы Ni для данной словоформы. Пофонемное сравнение транскрипции Ti начинается с начального узла графа, для этого в блоке 308 текущим узлом устанавливается начальный узел графа, а счетчик фонем анализируемой транскрипции устанавливается в ноль j=0.
В блоке 310 производится сравнение текущей фонемы Tij анализируемой транскрипции со всеми дочерними узлами фонем от текущего узла. Если в блоке 312 определяют, что символ Tij уже существует в дочерних узлах, то алгоритм 300 переходит в блок 314, где значением текущего узла устанавливается дочерний узел с найденным символом Tij. Если в блоке 312 определяют, что дочернего узла с символом Tij не существует у текущего узла, то алгоритм 300 переходит в блок 316, где производится создание нового дочернего узла для фонемы Tij, а затем в блоке 318 текущим узлом устанавливается новый созданный дочерний узел с фонемой Tij. Далее работа алгоритма 300 продолжается в блоке 320.
В блоке 320 счетчик фонем анализируемой транскрипции увеличивается на единицу для перехода к следующей фонеме. В блоке 322 проверяется, достигнут ли конец основы в транскрипции. Если в блоке 322 определяют, что текущим символом транскрипции является прямой слеш Tij=′/′, то алгоритм 300 переходит в блок 324. Если в блоке 322 определяют, что текущий символ является фонемой, то алгоритм 300 снова продолжается в блоке 306 до тех пор, пока не будет проанализирована транскрипция всей основы словоформы.
Алгоритм 300 приходит в блок 324, когда транскрипция основы разложена по первому уровню графа ДМПГ и требуется сохранить в графе информацию о самой словоформе. Для этого в блоке 324 проводится анализ всех существующих в графе узлов основ, и, прежде всего, анализируются дочерние узлы текущего узла фонемы. Если в блоке 326 определяют, что узла основы с индексом Ni не существует, то алгоритм 300 продолжается в блоке 328, где для основы с индексом Ni создается новый дочерний узел, а затем в блоке 330 он устанавливается текущим узлом. Если же в блоке 326 определяют, что узел основы с индексом Ni уже существует в графе, то алгоритм 300 продолжается в блоке 332, где найденный узел становится текущим.
Следует отметить, что для одного слова может существовать несколько основ и транскрипций с различными индексами. Сведение различных фонетических путей к одному узлу основы может быть только в случае существования нескольких вариантов произношения одной и той же основы вследствие внутрисловной ассимиляции, редукции и других коартикуляционных эффектов в процессе речеобразования [Леонтьева Ал.Б., Кипяткова И.С. Моделирование нефонемных речевых элементов и создание альтернативных транскрипций для распознавания спонтанной речи. Труды первого междисциплинарного семинара «Анализ разговорной русской речи» (АР3-2007). - СПб.: ГУАП, 2007. - С. 77-85].
В блоке 334 производится переход к анализу концовки, для этого счетчик фонем транскрипции увеличивается на единицу, и текущей фонемой в транскрипции становится первая фонема в концовке, соответственно оставшаяся часть транскрипции является транскрипцией концовки. В блоке 336 проводится ее сравнение со всеми существующими узлами концовок. Если в блоке 338 определяют, что узел с идентичной транскрипцией концовки уже существует, то алгоритм 300 переходит к анализу следующей словоформы в блоке 354. Если в блоке 338 определяют, что такой транскрипции концовки не существует, то алгоритм 300 продолжается в блоке 340.
Обработка новой концовки и ее сохранение в структуре графа производится в блоках 340-352. В блоке 340 создается новый дочерний узел, содержащий транскрипцию концовки и порядковый номер концовки. В блоке 346 созданный узел устанавливается текущим. Затем в блоках 348-350 создается последовательность связанных узлов фонем для транскрипции концовки. Построение фонетического пути концовки осуществляется независимо от других концовок, так в структуре графа хранятся только уникальные транскрипции концовок. По завершению разбора транскрипции в блоке 352 из узла последней фонемы транскрипции концовки устанавливается обратная связь в начальный узел. Далее алгоритм 300 переходит к анализу следующей словоформы в блоке 354. Если в блоке 354 определяют, что словоформ больше нет, то алгоритм 300 переходит в блок 356, где полученный граф ДМПГ для анализируемого списка словоформ и их транскрипций сохраняется в виде бинарного файла для последующего использования согласно предложенного способа распознавания речи.
После того как все текущие их дочерние гипотезы были обработаны с учетом текущего сегмента речи, производится их взвешенная оценка по акустической вероятности и вероятности модели языка (блок 208). Для сокращения числа гипотез осуществляется сравнение параметров гипотез. В результате среди гипотез, прошедших одинаковый путь по графу, содержащих одинаковую последовательность фонем и находящихся в одном и том же состоянии, выбирается одна с наибольшей вероятностью.
После обработки и упорядочивания всех гипотез по вероятности осуществляется окончательное сокращение набора, учитывая максимальное допустимое число гипотез, переходящих на следующий шаг по графу ДМПГ. В зависимости от вычислительной мощности системы распознавания число лучших гипотез переходящих на следующий шаг выбирается таким образом, чтобы суммарное время обработки не превышало длительность обрабатываемого сигнала в 5-10 раз.
Далее в блоке 209 осуществляется синтаксическое согласование гипотез, которые содержат две и более основ. Основной принцип синтаксического согласования концовок схематично представлен на фиг. 4.
Гипотезы содержат индексы распознанных основ S, концовок Е, их акустические вероятности РА, а также оценку по модели языка основ PSLM. Этот поток данных далее поступает на вход синтаксического анализатора, где проверяется синтаксическая и грамматическая согласованность гипотезы фразы. Концовки, вызывающие сомнение, исправляются посредством синтаксического анализа и морфологического синтезатора, который генерирует все подходящие концовки для основ во фразе [Ронжин А.Л., Леонтьева Ан.Б., Кагиров И.А., Леонтьева Ал.Б. Двухуровневый морфофонемный префиксный граф для декодирования русской слитной речи // Труды СПИИРАН. Вып. 4, т. 1. - СПб.: Наука, 2007. - С. 388-404]. Если концовка была распознана неверно, то после ее замены на синтаксически правильный вариант акустическая вероятность концовки PA(E1) будет перемножена с некоторым понижающим коэффициентом kG. Если возможно несколько вариантов правильных гипотез фраз с разными концовками, то гипотеза фразы размножается.
При выставлении окончательной комплексной оценки гипотезы фразы (блок 210) учитывается: акустическая вероятность последовательности основ и концовок; вероятность комбинации основ с учетом модели языка; соответствие гипотезы правилам синтаксиса; число грамматически верных окончаний в последовательности словоформ. Последние два показателя нормализуются таким образом, чтобы их значения варьировались в диапазоне от нуля до единицы. Линейная комбинация всех четырех показателей используется для выбора гипотезы фразы с максимальной вероятностью, которая и является результатом распознавания.
В блоке 211 осуществляется преобразование результатов распознавания всех сегментов речевого сигнала в связный текст и вывод его с помощью устройств вывода.
Способ распознавания речи на основе двухуровневого морфофонемного префиксного графа может быть реализован с помощью известных устройств. Так, блок приема представляет собой буферное устройство, которое может быть реализовано с использованием матрицы ОЗУ. Схемы ОЗУ известны и описаны, например, в книге В.Н. Вениаминова, О.Н. Лебедева, А.И. Мирошниченко «Микросхемы и их применение» (М: Радио и связь, 1989, с. 146). В частности, ОЗУ может быть реализовано на микросхемах К565 серии.
Аналого-цифровой преобразователь является известным устройством и описан, например, в книге Рахтор Т.С. Цифровые измерения. АЦП / ЦАП. - М.: Техносфера, 2006. - С. 239-243. В частности схема может быть реализована на микросхемах AD1482.
Блоки 203-211 представляют собой устройства сходящихся вычислений. Схемы устройств сходящихся вычислений известны и описаны, например, в книге Э. Айфичера, Б. Джервиса «Цифровая обработка сигналов: практический подход» (М.: Издательский дом «Вильяме», 2004. - С. 850). В частности, такая схема может быть реализована на комплексных умножителях PDSP16112A (Mitel) и комплексных накопителях PDSP16318A (Mitel).
Предустановленный словарь на базе ДМПГ может быть реализован на основе постоянных запоминающих устройств (ПЗУ). Схемы ПЗУ известны и описаны, например, в книге В.Н. Вениаминова, О.Н. Лебедева, А.И. Мирошниченко. Микросхемы и их применение. М.: Радио и связь, 1989. - С. 156. В частности, ПЗУ может быть реализовано на микросхемах К555 серии.
Устройство вывода реализует функции устройства предварительного просмотра и содержит дисплей или тому подобное устройство. Описание устройств вывода представлено в книге Авдеев В. А. Периферийные устройства: интерфейсы, схемотехника, программирование. - М.: ДМК Пресс, 848 с: ил. - С. 451-526.
Заявленный способ распознавания речи на основе двухуровневого морфофонемного префиксного графа позволяет сократить объем элементов памяти, необходимый для хранения предустановленного словаря, и снизить вычислительную сложность процесса распознавания речи.
Для доказательства достижения заявленного технического результата приведен следующий сравнительный анализ ДМПГ с двумя общепринятыми моделями представления словаря: линейная модель списка всех словоформ и лексическое дерево (фиг.1). Показателем вычислительной сложности во многих практических случаях являются оценки требуемого количества вычислений по графу, в роли которых часто используются: число узлов и дуг, а также плотность графа [Ney Н., Ortmarms S., Lindam I. Extensions to the Word Graph Method for Large Vocabulary Continuous Speech Recognition" Proc. of ICASSP′97, Vol. 3, 1997. - pp. 1787-1790]. Плотность графа словаря в рассматриваемом случае вычисляется как отношение суммарного числа узлов и дуг к числу словоформ в словаре.
Указанные характеристики графов, построенных по трем разным подходам, представлены в таблице 1.
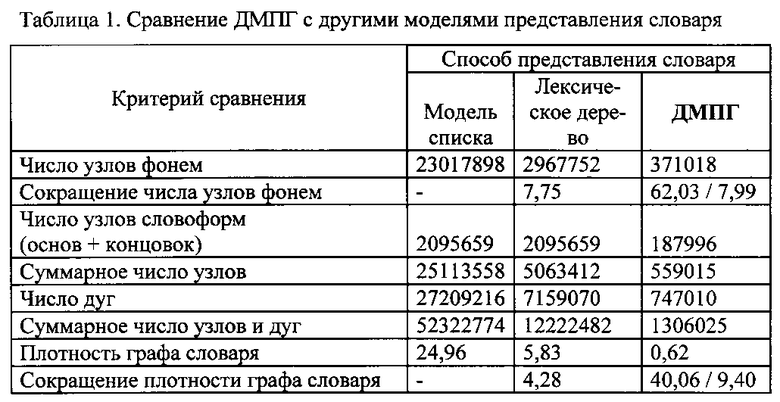
ДМПГ описывая точно такой же словарь, как и основные модели, используя при этом в 7,99 раз меньше число узлов фонем, а также имеет в 9,4 раз меньше плотность графа по сравнению с лексическим деревом, что однозначно указывает на уменьшение объем элементов памяти, необходимый для хранения предустановленного словаря.
Также было проанализировано, как изменяются параметры моделей в зависимости от размера словаря (фиг. 5). Сокращенные словари создавались путем случайного отбора заданного числа уникальных словоформ из базового словаря. По суммарному числу узлов словарь на базе ДМПГ имеет явное преимущество, начиная с размера около 10000 словоформ. По остальным показателям, в том числе по плотности графа (таблица 2) ДМПГ лидирует уже после 100 словоформ.
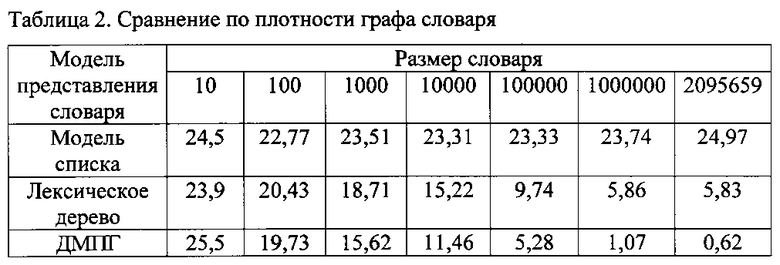
Для ДМПГ лексическое дерево строится для основ, а не полных словоформ и поэтому в среднем длина транскрипций основ будет меньше. Поскольку в ДМПГ хранятся только уникальные концовки, то при формировании транскрипций словоформ по графу алгоритм будет использовать одни и те же концовки несколько раз. Во избежание многократного подсчета узлов одной и той же концовки, при анализе запоминаются все использованные концовки и учитываются узлы фонем только концовки, которая встретилась впервые. В результате декомпозиции словоформы на основу и концовку, а также учета транскрипций только новых концовок число срезов в словаре на базе ДМПГ на пять меньше по сравнению с линейной моделью и лексическим деревом.
Таким образом, для предустановленного словаря на базе ДМПГ, включающего 2095659 уникальные транскрипции словоформ, предложенный способ распознавания речи показал заметное преимущество. Используя лексическое дерево для представления транскрипций основ и объединяя одинаковые концовки, срез с максимальным числом узлов фонем достигается почти в 2 раза быстрее, а значение максимума в ДМПГ в 6 раз меньше, чем в лексическом дереве. Полученные при этом результаты распознавании отдельно произнесенных фраз по точности оказались не хуже, чем в способе прототипе, а скорость обработки оказалась выше, особенно при получении списка лучших гипотез, а не единственного варианта.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| Способ и устройство классификации сегментов зашумленной речи с использованием полиспектрального анализа | 2014 |
|
RU2606566C2 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2297676C2 |
| СПОСОБ РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ | 2008 |
|
RU2403628C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА РЕЧЕВОГО СИГНАЛА В ТРАНСКРИПЦИОННОЕ ПРЕДСТАВЛЕНИЕ С МЕТАДАННЫМИ | 2014 |
|
RU2589851C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |




Изобретение относится к области распознавания речи. Техническим результатом является сокращение объема элементов памяти, необходимого для хранения предустановленного словаря, и снижение сложности вычислительного процесса распознавания. Способ распознавания речи содержит этапы: прием речевого сигнала, обработку речевого сигнала, выделение в нормализованном спектре пауз, шумов и звуковых сигналов, распознавание и преобразование речевого сигнала, определение в нем наличия/отсутствия акустических признаков речевого сигнала, определение вероятности всех состояний фонем, обработку гипотезы распознавания, сравнение параметров гипотез распознавания, синтаксическое согласование гипотез, формирование результата распознавания, преобразование результатов распознавания всех сегментов речевого сигнала, вывод речевого сигнала в виде связного текста. 5 ил., 2 табл.
Способ распознавания речи на основе двухуровневого морфофонемного префиксного графа, включающий последовательно исполняемые этапы приема речевого сигнала на входе блока приема; обработки речевого сигнала блоком обработки информации, включающей его обработку аналого-цифровым преобразователем с предустановленной частотой дискретизации и разделением на сегменты, спектрального анализа сегментов речевого сигнала и нормализации спектра на высоких частотах; выделения в нормализованном спектре пауз, шумов и звуковых сигналов с последующим его распознаванием и преобразованием в текст с использованием предустановленного словаря, при этом на этапе распознавания на основе исходного речевого сигнала и нормализованного спектра в каждом сегменте определяют наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых характеризуют группы фонем, параметры которых предустановлены в блоке памяти, отличающийся тем, что после того, как определяют наличие/отсутствие акустических признаков речевого сигнала, комбинаторные наборы которых характеризуют группы фонем, определяют вероятности всех состояний фонем по отношению к текущему сегменту, обрабатывают гипотезы распознавания с использованием предустановленного словаря на базе двухуровневого морфофонетического префиксного графа, осуществляют сравнение параметров гипотез распознавания с целью их упорядочивания, осуществляют синтаксическое согласование гипотез, содержащих две и более основ, формируют результат распознавания на основе комплексной оценки гипотезы фразы, а затем преобразуют результаты распознавания всех сегментов речевого сигнала в связный текст и выводят его с помощью устройств вывода.
| Кипятильник для воды | 1921 |
|
SU5A1 |
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Приспособление для останова мюля Dobson аnd Barlow при отработке съема | 1919 |
|
SU108A1 |
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |

