ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области аналитической химии, а именно к способам обработки данных, полученных в ходе масс-спектрометрического анализа большого количества образцов для поиска диагностических маркеров.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известен источник информации RU 2 743 418 C1, опубликованный 18.02.2021г., раскрывающий способ анализа данных о содержании в образце интересующих классов липидов на основе масс-спектрометрического анализа с жидкостной хроматографией, включающий получение данных жидкостной хроматографии с масс-спектрометрией анализируемого образца, обработку спектров для получения таблиц с интенсивностями липидных признаков и их значениями масс-на-заряд и времени удерживания, определение модели решетки, поиск оптимальной решетки путем подбора оптимального набора параметров, формирование аннотации с использованием оптимальной решетки, где все признаки, попавшие в предсказанное время в пределах заранее заданной погрешности, считаются аннотированными, вывод результата аннотирования в виде таблицы, где липидным признакам сопоставлено название липида.
Из уровня техники известен источник информации RU 2 744 021 C1, опубликованный 02.03.2021г., раскрывающий способ диагностики стеатоза и неалкогольного стеатогепатита у женщин на основе венозной крови, причем анализ проводят хроматографическим методом. Полученные данные в ходе хроматорафического анализа обрабатывают с помощью MetAlign, AIoutput, в результате чего получают матрицу данных. Затем данные загружают в пакет программ BioClassificator.py, который позволяет проводить их обработку с помощью метода главных компонент (РСА), а также классификаторов- SVM (support vector machine), PLS-DA (Partial least squares Discriminant Analysis), Naive Bayes. В результате, строят ROC-кривую для каждого из методов, а также выводят среднюю точность и ее дисперсию. С помощью классификатора SVM (support vector machine) выбирают соединения, разделяющие группы здоровых и пациентов с неалкогольная жировая болезнь печени, которые являются диагностическими маркерами.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической задачей, на решение которой направлено заявленное решение, является разработка способа для обработки данных, полученных с использованием жидкостной хромато-масс-спектрометрии для создания панели маркеров для модели, выполняющей классификацию данных «патология/отсутствие патологии» при проведении клинических исследований, на основе логистической регрессии, охарактеризованного в независимом пункте формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в повышении точности определения диагностических маркеров при проведении клинических исследований. Дополнительно, технический результат заключатся в увеличении скорости обработки данных, полученных с использованием жидкостной хромато-масс-спектрометрии, и выявления заболевания у пациентов. Дополнительным техническим результатом является увеличение производительности вычислительной системы при решении поставленной задачи (т.е. позволяет производить обработку с получением результата (продукта) за меньшее количество времени), тем самым снижается нагрузка на центральный процессор вычислительного устройства, за счет уменьшения количества обрабатываемых запросов
Заявленный результат достигается за счет осуществления способа определения диагностических соединений-маркеров при проведении клинических исследований посредством обработки хромато-масс-спектрометрических данных выполняющийся на вычислительном устройстве, который содержит процессор и память, хранящую инструкции, исполняемые процессором и включающие следующие этапы:
получают биологические образцы полученные или выделенные от пациента;
осуществляют распределение биологических образцов от разных клинических групп равномерно между различными анализируемыми партиями;
осуществляют хромато-масс-спектрометрический анализ полученных партий;
результаты хромато-масс-спектрометрического анализа поступают на вычислительное устройство, где осуществляют предобработку полученных данных и идентификацию по меньшей мере одного соединения из полученных данных;
осуществляют автошкалирование площадей пиков в по меньшей мере одном соединении, полученном на предыдущем этапе;
полученные результаты автошкалирования поступают на вход обученной классификационной модели, на выходе получают набор соединений – потенциальных маркеров, при этом классификационная модель строится на основе ортогональных проекций на скрытых структурах;
осуществляют выбор соединений – потенциальных маркеров из набора, выбранного на предыдущем этапе, на основе информационного критерия Акаике;
осуществляют пошаговое удаление соединений из сформированного набора соединений – потенциальных маркеров у которых значение нулевого коэффициента больше заранее заданного значения.
В частном варианте реализации предлагаемого решения, биологический образец представляет собой липидомный, метаболомный или пептидомный экстракт крови, плазмы, сыворотки крови, соскоба эпителия, биопсийный материал.
В другом частном варианте реализации предлагаемого решения, хроматографический анализ производится на обратно-фазовой колонке.
В другом частном варианте реализации предлагаемого решения, хроматографический анализ производится на нормально-фазовой колонке.
В другом частном варианте реализации предлагаемого решения, хроматографический анализ производится на гидрофильной колонке.
В другом частном варианте реализации предлагаемого решения, масс-спектрометрический анализ производится с использованием зависимого сканирования.
В другом частном варианте реализации предлагаемого решения, масс-спектрометрический анализ производится с использованием независимого сканирования.
В другом частном варианте реализации предлагаемого решения, масс-спектрометрический анализ производится без использования сканирования.
В другом частном варианте реализации предлагаемого решения, граничная вероятность нулевого значения коэффициента больше или меньше 0,05.
В другом частном варианте реализации предлагаемого решения, граничная величина отличия вектора коэффициентов больше или меньше 0,0001.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
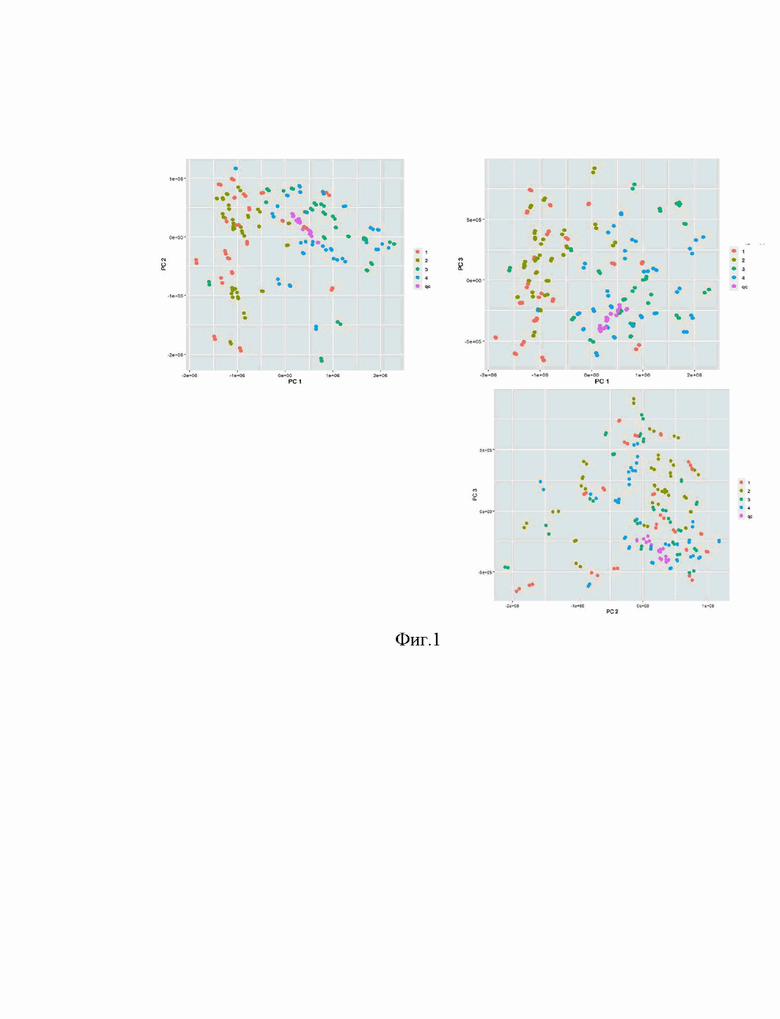
Фиг.1 иллюстрирует распределение биологических образцов, не подвергавшихся нормализации в пространстве трёх главных компонент. Группа 1 – нормальная ткань молочной железы от пациентов без метастазирования, группа 2 – ткань нормальной ткани молочной железы от пациентов с метастазированием, группа 3 – опухолевая ткань молочной железы от пациентов без метастазирования, группа 4 – опухолевая ткань молочной железы от пациентов с метастазированием, группа qc – группа образцов контроля качества.
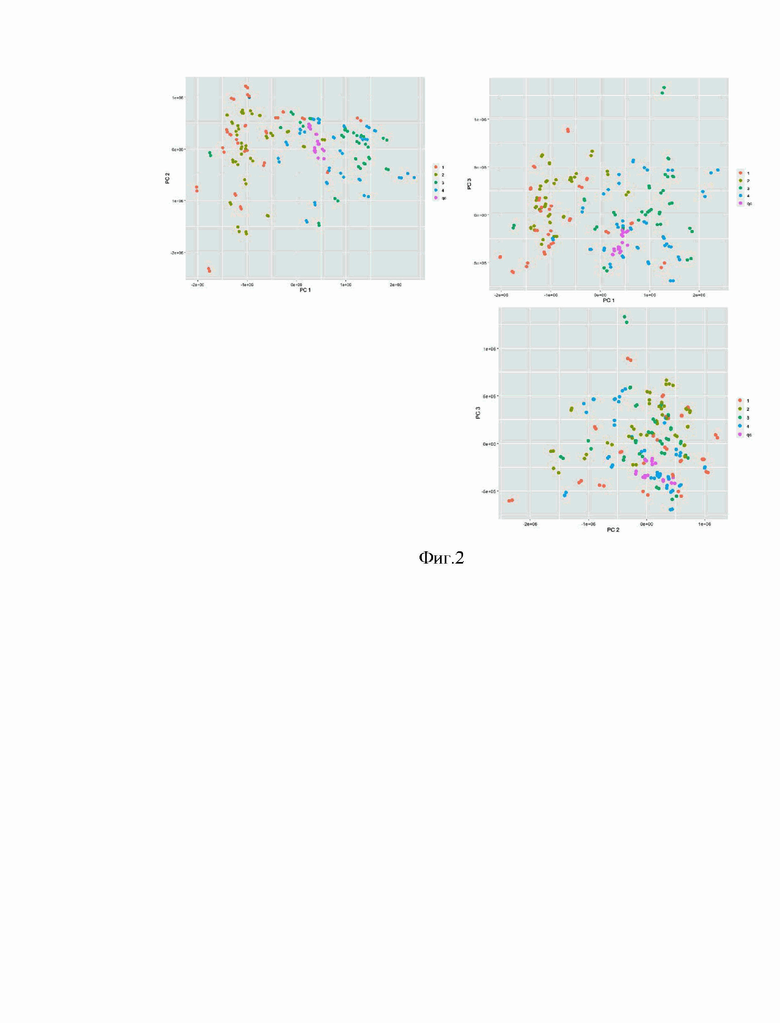
Фиг.2 иллюстрирует распределение биологических образцов после автошкалирования в пространстве трёх главных компонент. Группа 1 – нормальная ткань молочной железы от пациентов без метастазирования, группа 2 – ткань нормальной ткани молочной железы от пациентов с метастазированием, группа 3 – опухолевая ткань молочной железы от пациентов без метастазирования, группа 4 – опухолевая ткань молочной железы от пациентов с метастазированием, группа qc – группа образцов контроля качества.
Фиг.3 иллюстрирует липиды, выбранные как маркеры в опухолевой ткани посредством предлагаемого способа.
Фиг.4 иллюстрирует липиды, выбранные как маркеры в нормальной ткани посредством предлагаемого способа.
Фиг.5, иллюстрирует пример схемы работы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Нижеуказанные термины и определения применяются в данной заявке, если иное явно не указано. Ссылки на методики, используемые при описании данного изобретения, относятся к хорошо известным методам, включая изменения этих методов и замену их эквивалентными методами, известными специалистам в данной области техники.
В описании данного изобретения термины «включает» и «включающий» интерпретируются как означающие «включает, помимо всего прочего». Указанные термины не предназначены для того, чтобы их истолковывали как «состоит только из».
Термин «биологический образец» или «образец» включает кровь, плазму, сыворотку крови, соскоб эпителия, ткани, полученные в результате взятия биопсии от пациента или иные твёрдые, или жидкие биологические материалы.
Термин «пациент» относится к человеку.
Термин «партия» относится к группе образцов, чей анализ производится непрерывно.
Термин «клиническая группа» относится к группе образцов, объединённых общим диагнозом пациентов, у которых был взят биологический образец.
Если не определено отдельно, технические и научные термины в данной заявке имеют стандартные значения, общепринятые в научной и технической литературе.
Предлагаемый способ определения диагностических соединений-маркеров при проведении клинических исследований посредством обработки хромато-масс-спектрометрических данных включает следующие этапы:
• получают биологические образцы от пациента;
• создают партии для анализа, с таким распределением биологических образцов между ними, чтобы относительное количество биологических образцов, отдельно взятой клинической группы, было одинаковым в каждой партии. Например, если требуется анализ 20 образцов группы 1 (нормальная ткань молочной железы от пациентов без метастазирования) и 28 образцов группы 2 (ткань нормальной ткани молочной железы от пациентов с метастазированием), то предпочтительным является создание 2-х партий, содержащих по 10 образцов группы 1 (нормальная ткань молочной железы от пациентов без метастазирования) и 14 образцов группы 2 (ткань нормальной ткани молочной железы от пациентов с метастазированием), или 4-х партий, содержащих по 5 образцов группы 1 (нормальная ткань молочной железы от пациентов без метастазирования) и по 7 образцов группы 2 (ткань нормальной ткани молочной железы от пациентов с метастазированием);
• выполнение хромато-масс-спектрометрического анализа созданных партий с использованием жидкостной хроматографии и масс-анализаторов высокого разрешения и мягких методов ионизации (например, химическая ионизация, электроспрей). Хроматографический анализ может производиться на обратно-фазовой колонке или нормально-фазовой колонке, или на гидрофильной колонке. Масс-спектрометрический анализ может производиться с использованием зависимого сканирования или с использованием независимого сканирования. Результаты анализа записываются в файл и с помощью средств сетевого взаимодействия передаются на вычислительное устройство. Данные хромато-масс-спектрометрического анализа могут быть получены со стороны;
осуществляют конфигурацию вычислительного устройства, где под обработку данных, полученных в результате хромато-масс-спектрометрического анализа, выделяется ядро операционной системы, а также по меньшей мере два потока, при этом осуществляют:
• предобработку данных, полученных в результате хромато-масс-спектрометрического анализа и идентификацию соединений;
• автошкалирование площадей пиков в предобработанных данных;
• построение классификационной модели и выбор набора соединений в результате работы классификационной модели;
• выбор соединений из набора, созданного в предыдущем пункте, на основе информационного критерия Акаике;
• пошаговое удаление соединений из сформированного набора соединений, у которых вероятность нулевого значения коэффициента больше пороговой величины.
Предобработка данных может быть проведена с использованием бесплатно распространяемых пакетов программ MzMine или XCMS. Целью предобработки данных является получение таблицы, содержащей информацию об отношении массы к заряду зарегистрированных ионов, полученных в результате хромато-масс-спектрометрического анализа, их времён выхода и площадей пиков, к которому относится соответствующие ионы, для каждого образца.
Идентификация соединений может осуществляться на основе точных ионных масс, и/или времён выхода, а также информации о спектрах фрагментации, полученной в ходе масс-спектрометрического анализа, если осуществлялась тандемная масс-спектрометрия в формате зависимого или независимого сканирования. Для идентификации могут использоваться библиотеки HMDB, Lipid MAPS, SMDB, Metlin, а также созданные в лаборатории базы данных на основе вышеперечисленных.
Автошкалирование осуществляется для ликвидации различий между партиями.
Автошкалирование площадей пиков в предобработанных данных осуществлялось с использованием формулы 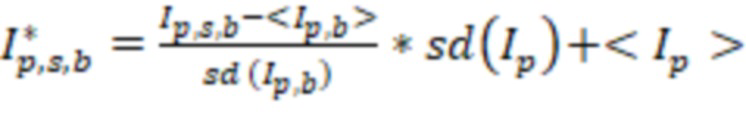 , где p – номер пика, s – номер образца, b – номер партии, <Ip,b> и sd(Ip,b) – среднее значение и стандартное отклонение площади пика p по партии b, <Ip> и sd(Ip) – среднее значение и стандартное отклонение площади пика p по всем образцам. Ip,s,b и I*p,s,b – значения площади пика p из образца s партии b до и после нормализации. В результате автошкалирования создается набор данных о принадлежности каждого образца к определённой клинической группе и значения площади пика каждого идентифицированного соединения.
, где p – номер пика, s – номер образца, b – номер партии, <Ip,b> и sd(Ip,b) – среднее значение и стандартное отклонение площади пика p по партии b, <Ip> и sd(Ip) – среднее значение и стандартное отклонение площади пика p по всем образцам. Ip,s,b и I*p,s,b – значения площади пика p из образца s партии b до и после нормализации. В результате автошкалирования создается набор данных о принадлежности каждого образца к определённой клинической группе и значения площади пика каждого идентифицированного соединения.
Набор данных, содержащий информацию о принадлежности каждого образца к определённой клинической группе и значения площади пика каждого идентифицированного соединения после автошкалирования, использовался для построения классификационной модели «патология/отсутствие патологии» на основе ортогональных проекций на скрытые структуры:
1. Информация об относительной интенсивности пиков в образцах представляется в виде матрицы независимых переменных n*m X, где n – число образцов, m – число соединений. Информация о клиническом состоянии образца представляется в виде столбца переменных отклика y высотой p, где 0 обозначается состояние «контроль», 1 – состояние «болезнь»;
2. Выполняется парето-масштабирование матрицы независимых переменных 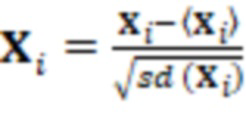 (1), где
(1), где 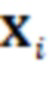 – i-ый столбец матрицы X,
– i-ый столбец матрицы X,  – среднее значение i-того столбца и
– среднее значение i-того столбца и  – стандартное отклонение переменных в i-ом столбце;
– стандартное отклонение переменных в i-ом столбце;
3. Выполняется парето-масштабирование столбца зависимых переменных  (2), где
(2), где 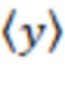 – среднее значение переменных отклика,
– среднее значение переменных отклика,  – стандартное отклонение переменных отклика;
– стандартное отклонение переменных отклика;
4. Рассчитываются веса для независимых переменных 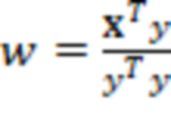 (3);
(3);
5. Выполняется нормализация рассчитанного вектора  (4);
(4);
6. Рассчитываются предсказательные счета  (5);
(5);
7. Рассчитывается предсказательная нагрузка независимых переменных 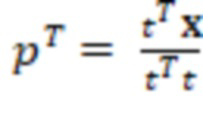 (6);
(6);
8. Вычисляется вектор ортогональных нагрузок  (7);
(7);
9. Выполняется нормализация рассчитанного вектора ортогональных нагрузок 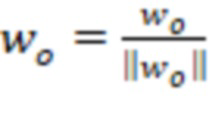 (8);
(8);
10. Рассчитываются ортогональные счета  (9);
(9);
11. Рассчитывается ортогональная нагрузка независимых переменных  (10);
(10);
12. Вычисляются данные, не содержащие ортогональной составляющей 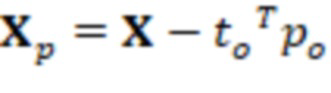 (11)
(11)
13. Вычисляются предсказательные счета от независимых переменных, не содержащих ортогональной составляющей  (12);
(12);
14. Вычисляется предсказательная нагрузка от независимых переменных, не содержащих ортогональной составляющей 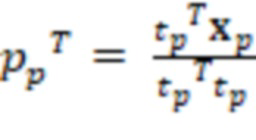 (13);
(13);
15. Вектор, содержащий предсказательную нагрузку от независимых переменных без ортогональной составляющей, нормируется  (14);
(14);
16. Рассчитывается вектор, содержащий значения проекций переменной  (15).
(15).
Полученные значения проекции переменной (ПП) использовались в качества критерия выбора соединений-потенциальных маркеров. Соединение -потенциальный маркер представляет собой соединение, чей уровень позволяет характеризовать клиническую принадлежность анализируемого биоматериала.
В частном варианте осуществления изобретения нижней границей ПП для отнесения к потенциальным маркерам являлась 1. Могут быть определены другие значения минимального значения ПП для отнесения соединений к потенциальным маркерам.
Из набора соединений, отобранных по значению ПП в предыдущем пункте, по одному выбирались соединения, приводящие к максимальному увеличению информационного критерия Акаике (ИКА) на каждой итерации отбора переменных по алгоритму, содержащему в себе этапы расчёта ИКА (Этап 1), выбора максимального ИКА (Этап 2) и сравнения старого и нового ИКА (Этап 3):
Произвольно выбирается переменная из набора переменных, сформированного на основе значений ПП. Далее следует этап расчёта ИКА (1) – 6))
Строится лог-функция правдоподобия  (16), где
(16), где  – переменная отклика, принимающая значения 0 или 1,
– переменная отклика, принимающая значения 0 или 1,  – объединённый вектор единицы и независимых переменных,
– объединённый вектор единицы и независимых переменных, 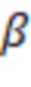 – объединённый вектор свободного члена и коэффициентов при переменных.
– объединённый вектор свободного члена и коэффициентов при переменных.
Выполняется дифференцирование функции по , получая уравнения:
 (17).
(17).
1) Рассчитывается вторая производная:
 (18).
(18).
2) На основе метода Ньютона-Рафсона рассчитывается вектор

где k – номер итерации, X – матрица единичного вектора и независимых переменных, W – диагональная матрица с элементами  , y- вектор переменной отклика и p – вектор вероятности
, y- вектор переменной отклика и p – вектор вероятности 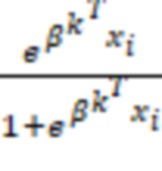 . Вычисление
. Вычисление  происходит, пока
происходит, пока  . В частном варианте осуществления изобретения относительная разница модулей векторов между итерациями от нуля
. В частном варианте осуществления изобретения относительная разница модулей векторов между итерациями от нуля  = 0,0001. Могут быть определены другие значения границы значимости отличия коэффициентов от нуля.
= 0,0001. Могут быть определены другие значения границы значимости отличия коэффициентов от нуля.
3) Подставить вычисленные значения в лог-функцию правдоподобия из п. 1).
4) Рассчитать информационный критерий по формуле 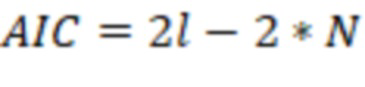 (19), где N – число независимых переменных, задействованных в регрессиях.
(19), где N – число независимых переменных, задействованных в регрессиях.
Повторить Этап 1 для всех m переменных.
Выбрать переменную, для которой рассчитанное значение AIC будет максимальным (Этап 2). Данное значение обозначено как AIC’.
Выполнить Этап 1 и Этап 2 для комбинации «выбранная ранее переменная + каждая из оставшихся переменных».
Сравнить AIC со значением AIC’ (Этап 3).
Если AIC из п. 5 больше AIC’, повторить Этапы 1-3, имея в качестве постоянных переменных переменные, отобранные ранее и обозначив как AIC’ значение из п. 5. Если AIC из п. 5 меньше AIC’, п. 7.
Переменные, при которых было получено AIC’ и рассчитанные для них коэффициенты используем дальше.
Далее осуществляют проверку на статистически значимое неравенство коэффициентов при переменных равных нулю с удалением переменных, не удовлетворявших этому условию:
1. С использованием выбранных ранее переменных строилась лог-функция правдоподобия (20), где – переменная отклика, принимающая значения 0 или 1, – объединённый вектор единицы и независимых переменных, – объединённый вектор свободного члена и коэффициентов при переменных.
2. Выполняется дифференцирование функции по , получая уравнения
(21)
3. Рассчитывается вторая производная
(22)
4. На основе метода Ньютона-Рафсона рассчитывается вектор
где k – номер итерации, X – матрица единичного вектора и независимых переменных, W – диагональная матрица с элементами , y- вектор переменной отклика и p – вектор вероятности . Вычисление происходит, пока . В частном варианте осуществления изобретения относительная разница модулей векторов между итерациями от нуля = 0,0001. Могут быть определены другие значения границы значимости отличия коэффициентов от нуля.
5. Подставив вычисленные значения в матрицу 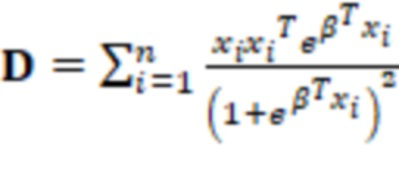 (23), вычисляют значения стандартной ошибки для коэффициента
(23), вычисляют значения стандартной ошибки для коэффициента 
 (24), где j – порядковый номер коэффициента в векторе .
(24), где j – порядковый номер коэффициента в векторе .
6. Вычисляют вероятность отличия от нуля коэффициента  (25), где
(25), где  – распределение квадрата независимой стандартной нормальной случайной величины θ.
– распределение квадрата независимой стандартной нормальной случайной величины θ.
7. Если существует  , где
, где 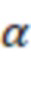 – некая критическая величина и i > 0, то переменная, соответствующая
– некая критическая величина и i > 0, то переменная, соответствующая 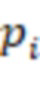 , исключается из задействованного набора переменных и действия 1-6 повторяются.
, исключается из задействованного набора переменных и действия 1-6 повторяются.
В частном варианте осуществления изобретения границей значимости отличия от нуля = 0,05. Могут быть определены другие значения границы значимости отличия коэффициентов от нуля.
Нижеследующие примеры осуществления способа приведены в целях раскрытия характеристик настоящего изобретения.
Пример 1. Нормализация данных, полученных в ходе хромато-масс-спектрометрического анализа биопсийного материала молочной железы.
У 40 пациентов с раком молочной железы без регионарного метастазирования и у 48 пациентов с раком молочной железы с регионарным метастазированием были взяты биологические образцы, а именно биопсийные материалы опухолевой ткани молочной железы и нормальной ткани молочной железы. Из тканей были выделены липиды методом Фолча [Folch J, Lees M, Sloane Stanley GH. A simple method for the isolation and purification of total lipides from animal tissues. J Biol Chem. 1957;226: 497–509].
Полученные биопсийные материалы ткани молочной железы были распределены на четыре группы:
Группа 1 – нормальная ткань молочной железы от пациентов без метастазирования;
Группа 2 – ткань нормальной ткани молочной железы от пациентов с метастазированием;
Группа 3 – опухолевая ткань молочной железы от пациентов без метастазирования;
Группа 4 – опухолевая ткань молочной железы от пациентов с метастазированием.
Липидные экстракты тканей были разбиты на три партии:
• 16 образцов из группы 1, 14 образцов из группы 2, 16 образцов из группы 3, 14 образцов из группы 4;
• 10 образцов из группы 1, 20 образцов из группы 2, 10 образцов из группы 3, 20 образцов из группы 4;
• 14 образцов из группы 1, 14 образцов из группы 2, 14 образцов из группы 3, 14 образцов из группы 4.
На основе 10 мкл. от каждого экстракта был создан образец контроля качества.
Разделение липидных экстрактов осуществлялось на хроматографе Dionex UltiMate 3000 (Thermo Scientific, Бремен, Германия) с использованием обратно-фазовой колонки Zorbax C18 (длина 150 мм, внутренний диаметр 2.1 мм, размер частиц 5 мкм, Agilent, США) и следующих элюентов в качестве подвижной фазы: элюент А - ацетонитрил/вода (60/40, о/о) с добавлением 0,1% муравьиной кислоты и 10 мМ формиата аммония; элюент В - ацетонитрил/изопропанол/вода, (90/8/2, о/о/о), с добавлением 0,1% муравьиной кислоты и 10 мМ формиата аммония. Скорость потока 35 мкл/мин, температура колонки 50 оС. Доля градиента В изменялась по заданному алгоритму: 0-0.5 мин – 30% В, до 20-ой минуты росла до 99% и сохраняла значение до 30-ой минуты и за полминуты возвращалось к значению 30%. Масс-спектрометрический анализ производился с использованием прибора Maxis Impact со следующими настройками: диапазон 100-1800 m/z, с напряжением на капилляре 4.1 кВ в режиме положительных ионов, давлением распыляющего газа 0.7 бар, скорости потока осушающего газа 6 л/мин и температурой 200 оС.
Выполнение тандемного масс-спектрометрического анализа осуществлялось с использованием зависимого сканирования, в котором после снятия спектра снимались спектры фрагментации при энергии столкновения в 35 эВ соединений, давших пять самых интенсивных пиков в спектре, с окном изоляции 5 Да и временем исключения 2 минуты.
Анализ образцов контроля качества производился через каждые 10 исследуемых образцов.
Данные, полученные в ходе анализа в виде .d файлов преобразовывались в формат MzXml посредством программного обеспечения msConvert (Proteowizard, 3.0.9987) и предобрабатывались с использованием алгоритма, предоставленного Koelmel, программного обеспечения MzMine [ Pluskal T, Castillo S, Villar-Briones A, Orešič M. MZmine 2: Modular framework for processing, visualizing, and analyzing mass spectrometry-based molecular profile data. BMC Bioinformatics. 2010;11. doi:10.1186/1471-2105-11-395]. Идентификация липидов осуществлялась программой Lipid Match за авторством Koelmel [ Koelmel JP, Kroeger NM, Ulmer CZ, Bowden JA, Patterson RE, Cochran JA, et al. LipidMatch: An automated workflow for rule-based lipid identification using untargeted high-resolution tandem mass spectrometry data. BMC Bioinformatics. 2017;18: 1–11. doi:10.1186/s12859-017-1744-3]. Номенклатура ионов использовалась согласно Lipid Maps терминологии в сокращённой форме записи [ Sud M, Fahy E, Cotter D, Brown A, Dennis EA, Glass CK, et al. LMSD: LIPID MAPS structure database. Nucleic Acids Res. 2007;35: 527–532. doi:10.1093/nar/gkl838].
Обработка данных осуществлялась посредством расчета для каждой партии: значения средней величины интенсивности пика каждого соединения 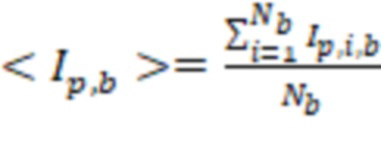 и стандартного отклонения интенсивности пика каждого соединения
и стандартного отклонения интенсивности пика каждого соединения , где
, где  – число образцов в партии b,
– число образцов в партии b,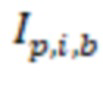 - интенсивность пика p в образце i партии b; для всего набора данных рассчитывались значения средней величины интенсивности пика каждого соединения
- интенсивность пика p в образце i партии b; для всего набора данных рассчитывались значения средней величины интенсивности пика каждого соединения  и стандартного отклонения интенсивности пика каждого соединения
и стандартного отклонения интенсивности пика каждого соединения  , где
, где  – общее число образцов
– общее число образцов - интенсивность пика p в образце i;
- интенсивность пика p в образце i;
На основе этих значений рассчитывались новые значения каждого пика в каждом образце по формуле , т.е. осуществляли автошкалирование полученных данных.
Изменение распределения координат образцов в первых трёх координатах главных компонент представлены на рисунках 1 и 2. После нормализации относительное отклонение значения полного ионного тока для образцов контроля качества снизилось с 7% до 4%.
Пример 2. Выбор маркеров регионарного метастазирования по биопсийному материалу опухолевой ткани молочной железы
На основе данных, полученных в примере 1, был определён вклад соединений в разделение образцов опухолевой ткани с и без метастазирования в пространстве главных компонент, ориентированных по дисперсии зависимой переменной и ортогонально ей на основе работы классификатора, который был обучен по формулам (1)-(15). Из 317 идентифицированных соединений, для 54 значение ПП составило больше 1. Эти соединения преимущественно относятся к классам триацилглицеридов (31), фосфотидилхолинов (14), сфингомиелинов (6) и диагцилглицеридов (3).
Пошаговый выбор переменный согласно информационному критерию Акаике по формулам (16) – (19) привел к выбору (соединения приведены в порядке добавления в модель) SM 18:2/16:0 (ИКА для модели с SM 18:2/16:0 -112,11), SM 18:1/16:0 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0} -90,26), SM 18:0/24:1 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1} -83,22), PC 16:0_18:2 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2 } -77,69), TG 12:0_14:1_18:2 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2} -73.70), TG 12:0_16:1_18:2 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2, TG 12:0_16:1_18:2} -65.19), TG 10:0_12:0_18:2 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2, TG 12:0_16:1_18:2, TG 10:0_12:0_18:2} -45.04), PC 16:0_18:1 (ИКА для модели с {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2, TG 12:0_16:1_18:2, TG 10:0_12:0_18:2, PC 16:0_18:1} -18,00).
Для модели, построенной на основе соединений {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2, TG 12:0_16:1_18:2, TG 10:0_12:0_18:2, PC 16:0_18:1}, вероятность равенства нулю коэффициентов при переменных, вычисленных по формулам (20)-(25) составила {0,98534, 0,98534, 0,98537, 0,98535, 0.98537, 0,98538, 0.98537, 0.98537} соответственно. Наибольшая вероятность равенства нулю коэффициента при переменной была у TG 12:0_16:1_18:2 (p = 0,98538). Исключая эту переменную из набора переменных, задействованных в модели, выполняем пересчёт вероятности равенства нулю коэффициентов для нового набора переменных {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2, TG 10:0_12:0_18:2, PC 16:0_18:1} и получаем {0,00001, 0,00005, 0,02287, 0,00790, 0,03214, 0,14315, 0,15197} соответственно. Наибольшая вероятность равенства нулю у коэффициента при переменной PC 16:0_18:1 (p = 0,15197). Исключая эту переменную из набора переменных, задействованных в модели, выполняем пересчёт вероятности равенства нулю коэффициентов для нового набора переменных {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2, TG 10:0_12:0_18:2} и получаем {0,000005, 0,000017, 0,032705, 0,009234, 0,041054, 0,1672568} соответственно. Наибольшая вероятность равенства нулю у коэффициента при переменной TG 10:0_12:0_18:2 (p = 0,1672568). Исключая эту переменную из набора переменных, задействованных в модели, выполняем пересчёт вероятности равенства нулю коэффициентов для нового набора переменных {SM 18:2/16:0, SM 18:1/16:0, SM 18:0/24:1, PC 16:0_18:2, TG 12:0_14:1_18:2}. Вероятность равенства нулю коэффициентов для этого набора переменных {0,00001, 0,00002, 0,03959, 0,00373, 0,02490}. Получаем модель со статистически значимо отличными от нуля коэффициентами при переменных (рисунок 3).
Тестирование модели методом внутренней кросс-валидации по отдельному объекту (метод, в котором выполняется M раз тестирование модели, построенной на основе М-1 образцов, на оставшемся образце, где M-количество образцов) дало значение площади под операционной кривой 0,81, чувствительность и специфичность 94% и 65% при пороге 0,39.
Пример 3. Выбор маркеров регионарного метастазирования по биопсийному материалу нормальной ткани молочной железы
На основе данных, полученных в примере 1, был определён вклад соединений в разделение образцов нормальной ткани с и без метастазирования в пространстве главных компонент, ориентированных по дисперсии зависимой переменной и ортогонально ей по формулам (1)-(15). Из 317 идентифицированных соединений для 60 значение ПП больше оказалось больше 1. Данные соединения относятся к классам лизо- и фосфотидилхолинов (20), триацилглицеридов (18), диагцилглицеридов (12), сфингомиелинов (6), фосфотидилэтаноламинов (4).
Пошаговый выбор переменный согласно информационному критерию Акаике по формулам (16) – (19) привел к выбору (соединения приведены в порядке добавления в модель) TG 10:0_18:1_18:3 (ИКА для модели с TG 10:0_18:1_18:3 -103,5), PC O-16:1/18:1 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1} -96,48), DG 18:0_18:1 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1} -92,43), SM d18:1/18:0 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0} -90,2), LPC 16:0 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0} -87,62), TG 12:0_18:1_8:0 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0} -85,65), TG 10:0_18:2_18:2 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, 10:0_18:2_18:2} -75,60), OxTG 18:1_18:2_18:3(OH) (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, 10:0_18:2_18:2, OxTG 18:1_18:2_18:3(OH)} -62,17), PC P-16:0/20:4 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, 10:0_18:2_18:2, OxTG 18:1_18:2_18:3(OH), PC P-16:0/20:4} -55,63), PC 12:0_14:1 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, 10:0_18:2_18:2, OxTG 18:1_18:2_18:3(OH), PC P-16:0/20:4, PC 12:0_14:1} -48,87), DG 18:2_18:2 (ИКА для модели с {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, TG 10:0_18:2_18:2, OxTG 18:1_18:2_18:3(OH), PC P-16:0/20:4, PC 12:0_14:1, DG 18:2_18:2} -24).
Для модели, построенной на основе соединений {TG 10:0_18:1_18:3, PC O-16:1/18:1, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, TG 10:0_18:2_18:2, OxTG 18:1_18:2_18:3(OH), PC P-16:0/20:4, PC 12:0_14:1, DG 18:2_18:2}, вероятность равенства нулю коэффициентов при переменных, вычисленных по формулам (20) - (25) составила {0,9956, 0,9973, 0,9964, 0,9970, 0,9968, 0,9972, 0,9959, 0,9970, 0,9967, 0.9967, 0.9966} соответственно. Наибольшая вероятность равенства нулю была у коэффициента при PC O-16:1/18:1 (p = 0,9973). Исключая эту переменную, строим модель на основе соединений {TG 10:0_18:1_18:3, DG 18:0_18:1, SM d18:1/18:0, LPC 16:0, TG 12:0_18:1_8:0, TG 10:0_18:2_18:2, OxTG 18:1_18:2_18:3(OH), PC P-16:0/20:4, PC 12:0_14:1, DG 18:2_18:2}, получим следующие вероятности равенства нулю коэффициентов при переменных: {0,003, 0,010, 0,039, 0,003, 0,007, 0,012, 0,004, 0,012, 0,021}. Получаем модель со статистически значимо отличными от нуля коэффициентами при переменных (рисунок 4). Тестирование модели в ходе внутренней кросс-валидации по отдельному объекту дало значение площади под операционной кривой 0,79, чувствительность и специфичность 88% и 58% при пороге 0,15.
На Фиг. 5 далее будет представлена общая схема вычислительного устройства (500), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (500) содержит такие компоненты, как: один или более процессоров (501), по меньшей мере одну память (502), средство хранения данных (503), интерфейсы ввода/вывода (504), средство В/В (505), средства сетевого взаимодействия (506).
Процессор (501) устройства сконфигурирован для выполнения вычислительных операций, необходимых для осуществления предлагаемого способа. Процессор (501) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (502). Процессор (501) содержит по меньшей мере два ядра и по меньшей мере один поток. Кроме того, для осуществления обработки данных по данному решению, выделают одно ядро и по меньшей мере два потока.
Память (502), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (503) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (503) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (504) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (504) зависит от конкретного исполнения устройства (500), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (505) в любом воплощении системы, реализующей описываемый способ, может использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (506) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (505) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (500) сопряжены посредством общей шины передачи данных (510).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ диагностики I-II стадий серозного рака яичников высокой степени злокачественности по липидному профилю сыворотки крови | 2022 |
|
RU2807396C1 |
| Способ неинвазивной диагностики эндометриоза по липидному профилю сухих капель менструальной крови | 2024 |
|
RU2829265C1 |
| Способ дифференциации неоплазий шейки матки по липидному составу ткани | 2019 |
|
RU2737220C1 |
| Способ дифференциации очагов эндометриоза различной локализации методом прямой масс-спектрометрии | 2019 |
|
RU2737224C1 |
| Способ оценки риска развития болезни Альцгеймера с использованием панели белков крови | 2021 |
|
RU2794040C1 |
| Способ дифференциации цервикальных интраэпителиальных неоплазий с помощью анализа протеомного состава цервиковагинальной жидкости | 2017 |
|
RU2674335C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ АЛКИЛЬНЫХ РАДИКАЛОВ СОЕДИНЕНИЙ ГОМОЛОГИЧЕСКОГО РЯДА О-АЛКИЛАЛКИЛФТОРФОСФОНАТОВ | 2016 |
|
RU2662047C2 |
| СПОСОБ ДИФФЕРЕНЦИАЛЬНОЙ ДИАГНОСТИКИ СТЕАТОЗА И НЕАЛКОГОЛЬНОГО СТЕАТОГЕПАТИТА У ЖЕНЩИН | 2020 |
|
RU2744021C1 |
| Способ прогнозирования риска развития отдаленных метастазов у больных операбельными формами рака молочной железы с метастазами в регионарные лимфоузлы | 2020 |
|
RU2733697C1 |
| НОВЫЕ БИОМАРКЕРЫ ДЛЯ ОЦЕНКИ БОЛЕЗНЕЙ ПОЧЕК | 2009 |
|
RU2559569C2 |



Изобретение относится к медицине, а именно к области аналитической химии и медицинской диагностики, и может быть использовано для определения потенциальных диагностических соединений-маркеров при проведении клинических исследований. Получают образцы биологического материала, полученные или выделенные от пациента. Осуществляют равномерное распределение образцов каждой клинической группы между различными анализируемыми партиями. Проводят хромато-масс-спектрометрический анализ полученных партий. Осуществляют предобработку полученных данных и идентификацию по меньшей мере одного соединения из полученных данных. Получают набор соединений – потенциальных маркеров при помощи обученной классификационной модели. На основе информационного критерия Акаике выбирают соединения – потенциальные маркеры из набора, выбранного на предыдущем этапе. Пошагово удаляют соединения из сформированного набора соединений – потенциальных маркеров, у которых значение вероятности отличия коэффициента от нуля меньше значения границы вероятности отличия коэффициента от нуля. Способ обеспечивает повышение точности определения диагностических маркеров при проведении клинических исследований за счет применения информационного критерия Акаике. 5 ил., 3 пр.
Способ определения потенциальных диагностических соединений-маркеров при проведении клинических исследований посредством обработки хромато-масс-спектрометрических данных, выполняющийся на вычислительном устройстве, которое содержит процессор и память, хранящую инструкции, исполняемые процессором и включающие следующие этапы:
получают образцы биологического материала, полученные или выделенные от пациента;
осуществляют равномерное распределение образцов каждой клинической группы между различными анализируемыми партиями;
осуществляют хромато-масс-спектрометрический анализ полученных партий;
результаты хромато-масс-спектрометрического анализа поступают на вычислительное устройство, где осуществляют предобработку полученных данных и идентификацию по меньшей мере одного соединения из полученных данных;
осуществляют выравнивание значений площадей пиков между партиями посредством автошкалирования по меньшей мере в одном соединении, полученном на предыдущем этапе;
полученные значения площадей пиков поступают на вход обученной классификационной модели, использующей ортогональные проекции на скрытые структуры, на выходе получают набор соединений – потенциальных маркеров;
осуществляют выбор соединений – потенциальных маркеров из набора, выбранного на предыдущем этапе, на основе информационного критерия Акаике;
осуществляют пошаговое удаление соединений из сформированного набора соединений – потенциальных маркеров, у которых значение вероятности отличия коэффициента от нуля меньше значения границы вероятности отличия коэффициента от нуля.
| СПОСОБ УЛУЧШЕНИЯ КАЧЕСТВА АННОТАЦИИ ЛИПИДНЫХ ПРИЗНАКОВ, ОТНОСЯЩИХСЯ К ОТДЕЛЬНЫМ ЛИПИДНЫМ КЛАССАМ, С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИИ О ВРЕМЕНИ ЗАДЕРЖКИ В МАСС-СПЕКТРОМЕТРЕ | 2020 |
|
RU2743418C1 |
| СПОСОБ ДИФФЕРЕНЦИАЛЬНОЙ ДИАГНОСТИКИ СТЕАТОЗА И НЕАЛКОГОЛЬНОГО СТЕАТОГЕПАТИТА У ЖЕНЩИН | 2020 |
|
RU2744021C1 |
| US 20020193950 A1, 19.12.2002 | |||
| US 20160282355 A1, 29.09.2016 | |||
| US 20170051358 A1, 23.02.2017. | |||
