Настоящее раскрытие изобретения относится к способу создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, и к способу определения концентрации аналита в образце физиологической жидкости. Дополнительно, настоящее раскрытие изобретения относится к системе создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, и к системе определения концентрации аналита в образце физиологической жидкости. Кроме того, упомянут компьютерный программный продукт.
УРОВЕНЬ ТЕХНИКИ
Машинное обучение (МО) - это отрасль информатики, которая используется для получения алгоритмов, управляемых данными. Вместо использования подробных формул МО алгоритмы используют реальные обучающие данные для создания моделей, которые являются более точными и сложными, чем традиционные, придуманные людьми, модели. Искусственные нейронные сети (ИНС) относятся к направлению машинного обучения и основываются на искусственных нейронах, расположенных на нескольких уровнях. Концепция нейронных сетей существует уже несколько десятилетий, но только в последнее время вычислительная мощность приблизилась к объемным вычислениям, которые необходимы для эффективной разработки алгоритмов нейронных сетей. Потенциал распределенных вычислений позволяет разработчикам распределять вычисления на несколько устройств вместо использования суперкомпьютеров. Известные реализации для распределенных вычислений включают Apache Hadoop, Apache Spark и MapReduce.
Модели нейронных сетей хорошо подходят для обнаружения закономерностей/нелинейных связей между входом и выходом, когда непосредственная взаимосвязь отсутствует или является плохой. Это важно, поскольку точность модели сильно зависит от того, насколько хорошо охарактеризована основная система и как определены связи между входными и выходными данными.
В документе US 2006/0008923 А1 представлены системы и способы медицинской диагностики или оценки риска для пациента. Эти системы и способы предназначены для использования в месте оказания медицинской помощи, например в отделениях неотложной помощи и операционных, или в любой ситуации, в которой требуется быстрый и точный результат. Системы и способы обрабатывают данные пациента, в частности данные диагностических тестов или анализов в месте оказания медицинской помощи, включая иммунохимический метод анализа, электрокардиограммы, рентгеновские снимки и другие подобные тесты, и обеспечивают указание на медицинское состояние или риск или его отсутствие. Данные системы содержат прибор для считывания или оценки тестовых данных и программное обеспечение для преобразования этих данных в диагностическую информацию или информацию об оценке риска. Информация о пациенте содержит данные физических и биохимических тестов, таких как иммуноанализ, и других процедур. Тест проводится на пациенте в месте оказания медицинской помощи и создает данные, которые могут быть оцифрованы, например, с помощью электронного считывателя отражательной способности или трансмиссии, который создает данные сигнала. Сигнал обрабатывается с использованием программного обеспечения, использующего алгоритмы сжатия данных и подбора кривой, или системы поддержки решений, такой как обученная нейронная сеть, или их комбинации, для преобразования сигнала в данные, которые используются для помощи в диагностике состояния здоровья или определение риска заболевания. Этот результат может быть дополнительно введен во вторую систему поддержки принятия решений, такую как нейронная сеть, для уточнения или улучшения оценки.
Документ WO 2018/0194525 А1 относится к способу биохимического анализа для количественного определения метаболитов в биологическом образце. Способ основан на создании и изучении внешнего вида тест-полоски (указателя) в различных условиях для оценки значения/метки для неизвестного изображения образца. Способ состоит из двух частей: обучающей и тестовой. В обучающей части количество метаболитов тест-полоски измеряется биохимическим анализатором. Набор изображений одной и той же тест-полоски снимается устройством, моделирующем различные условия освещения окружающей среды. Модель машинного обучения обучается с использованием изображений тест-полоски и соответствующих ей количеств метаболитов, а обучающаяся модель передается на интеллектуальное устройство. В тестовой части изображения тест-полоски для анализа снимаются с помощью интеллектуального устройства, и обрабатываются с использованием модели обучения, определенной в рамках обучения.
Документ US 2018/0211380 А1 относится к системе визуализации биологических образцов и анализа изображений биологических образцов. Система предназначена для автоматического анализа изображений биологических образцов для классификации клеток, представляющих интерес с использованием методов машинного обучения. В одном варианте реализации могут быть диагностированы заболевания, связанные с конкретными типами клеток.
Документ US 2016/0048739 А1 относится к диагностической системе для биологических образцов. Диагностическая система содержит диагностический инструмент и портативное электронное устройство. Диагностический инструмент имеет контрольную цветовую полоску и множество химических тестовых площадок для получения биологического образца. Портативное электронное устройство содержит цифровую камеру для снятия цифрового изображения диагностического инструмента в неконтролируемых условиях освещения, датчик для снятия освещенности поверхности диагностического инструмента, процессор, соединенный с цифровой камерой, и датчик для получения цифрового изображения и освещенности, и запоминающее устройство, подключенное к процессору. Запоминающее устройство хранит инструкции для выполнения процессором обработки цифрового изображения и освещенности, для нормализации цветов от множества химических тестовых площадок и определения результатов диагностических тестов в ответ на количественную оценку изменений цвета в химических тестовых площадках.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Целью данного раскрытия является обеспечение улучшенной технологии для определения концентрации аналита в образце физиологической жидкости.
Для решения проблемы обеспечивается способ создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости по независимому пункту 1 формулы изобретения. Дополнительно, обеспечивается способ определения концентрации аналита в образце физиологической жидкости по независимому пункту 2 формулы изобретения. Система для создания реализуемого программным обеспечением модуля, выполненная с возможностью определения концентрации аналита в образце физиологической жидкости, и система для определения концентрации аналита в образце физиологической жидкости обеспечиваются по независимым пунктам 11 и 12 соответственно. Кроме того, обеспечивается компьютерный программный продукт по п. 13. Дополнительные варианты реализации раскрыты в зависимых пунктах формулы изобретения.
Согласно одному аспекту, обеспечивается способ создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости. Способ включает, в одном или нескольких устройствах обработки данных, обеспечение первого набора данных измерения, первого набора данных измерения, представляющего первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок. Изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, а изображения записаны множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве. Способ дополнительно включает, одним или несколькими устройствами обработки данных, создание модели нейронной сети в процессе машинного обучения, применяющем искусственную нейронную сеть, содержащее обеспечение модели нейронной сети и обучение модели нейронной сети с помощью обучающих данных, выбранных из первого набора данных измерения. Создан реализуемый программным обеспечением модуль, содержащий первый анализирующий алгоритм, представляющий модель нейронной сети, причем реализуемый программным обеспечением модуль, выполненный с возможностью, при загрузке в устройство обработки данных, имеющего один или несколько процессоров, определения концентрации аналита во втором образце физиологической жидкости на основе анализа второго набора данных измерения, указывающих на вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение второго образца физиологической жидкости, содержащей аналит, на интересующий участок.
Согласно одному аспекту, способ определения концентрации аналита в образце физиологической жидкости, при этом способ включает, в одном или нескольких устройствах обработки данных: обеспечение данного набора данных измерения, указывающих на данную информацию о цвете, полученную путем обработки изображения из изображения интересующего участка данной тест-полоски или полоски, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение данного образца физиологической жидкости, содержащей аналит, на интересующий участок; обеспечение реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети, созданную в процессе машинного обучения применяющим искусственную нейронную сеть; определение концентрации аналита в данном образце физиологической жидкости, содержащее анализ данного набора данных измерения с помощью первого анализирующего алгоритма; и создание данных о концентрации, указывающих на концентрацию аналита в данном образце физиологической жидкости. Создание модели нейронной сети в процессе машинного обучения включает обеспечение первого набора данных измерения, при этом первый набор данных измерения указывает на первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок, изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок. Первый набор данных измерения представляет первую информацию о цвете, полученную из изображений, записанных множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множеству устройств обеспечивается другая конфигурация устройства, применяемая для записи изображения и обработки данных изображения в устройстве. Модель нейронной сети обучается с помощью обучающих данных, выбранных из первого набора данных измерения.
Согласно другому аспекту, обеспечивается система для создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, при этом система содержит одно или несколько устройств обработки данных, при этом одно или несколько устройств обработки данных выполнены с возможностью обеспечения первого набора данных измерения, при этом первый набор данных измерения представляет первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок. Изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок, и изображения записаны множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве. Одно или несколько устройств обработки данных выполнены с возможностью создания модели нейронной сети в процессе машинного обучения применяющим искусственную нейронную сеть, содержащее обеспечение модели нейронной сети и обучение модели нейронной сети с помощью обучающих данных, выбранных из первого набора данных измерения. Дополнительно, одно или несколько устройств обработки данных, выполненные с возможностью создания реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети, при этом реализуемый программным обеспечением модуль выполненный с возможностью, при загрузке в устройство обработки данных, имеющего один или несколько процессоров, определения концентрацию аналита во втором образце физиологической жидкости на основе анализа второго набора данных измерения, указывающих на вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение второго образца физиологической жидкости, содержащей аналит, на интересующий участок.
В соответствии с еще одним аспектом обеспечивается система для определения концентрации аналита в образце физиологической жидкости, при этом система содержит одно или несколько устройств обработки данных, при этом одно или несколько устройств обработки данных выполнены с возможностью: обеспечения данного набора данных измерения, указывающих на данную цветовую информацию, полученную путем обработки изображений из изображений интересующего участка данной тест-полоски, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение данного образца физиологической жидкости, содержащей аналит на интересующий участок; обеспечения реализуемого программным обеспечением модуля, содержащего первый анализирующего алгоритм, представляющий модель нейронной сети, созданную в процессе машинного обучения, применяющем искусственную нейронную сеть; определения концентрации аналита в данном образце физиологической жидкости, содержащий анализ данного набора данных измерения с помощью первого анализирующего алгоритма; и создания данных о концентрации, указывающих на концентрацию аналита в данном образце физиологической жидкости. Создание модели нейронной сети в процессе машинного обучения включает обеспечение первого набора данных измерения, при этом первый набор данных измерения указывает на первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок, изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок. Первый набор данных измерения представляет первую информацию о цвете, полученную из изображений, записанных множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве. Модель нейронной сети обучается с помощью обучающих данных, выбранных из первого набора данных измерения.
Дополнительно, компьютерный программный продукт содержащий программный код, выполненный с возможностью выполнения указанных выше способов при загрузке в компьютер, имеющий один или несколько процессоров.
Модель нейронной сети, созданная в процессе машинного обучения, позволяет улучшить определение концентрации аналита в (данном) образце физиологической жидкости. Создание модели нейронной сети основывается на первой информации о цвете, полученной из изображений, записанных множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве.
Модель нейронной сети, созданная ранее, применяется для анализа данного или второго набора данных измерения, указывающих на данную/вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка данной/второй тест-полоски, при этом изображения указывают на наличие изменения цвета интересующего участка в ответ на нанесение данного/ второго образца физиологической жидкости пациента, образца, содержащего аналит, на интересующий участок. В данном процессе концентрация аналита определяется для пациента, чей образец был обеспечен.
Способ может включать множество устройств, имеющих, по меньшей мере, одно из различных камерных устройств и различного программного обеспечения обработки изображений, применяемого для записи изображения и обработки данных изображения.
Записанные изображения могут включать изображения, записанные при различных условиях записи оптического изображения.
Способ может дополнительно включать следующее: обеспечение второго анализирующего алгоритма, при этом второй анализирующий алгоритм отличается от первого анализирующего алгоритма; и определение для концентрации аналита в данном образце физиологической жидкости первого оценочного значения путем анализа данного набора данных измерения с помощью второго анализирующего алгоритма. Второй алгоритм анализа может быть алгоритмом, не основанным на машинном обучении, таким как параметрическая многомерная линейная регрессия. Подобный не основанный на машинном обучении алгоритм, также может называться традиционным алгоритмом для определения концентрации аналита. Первое оценочное значение для концентрации аналита может обеспечивать входные данные для (дальнейшего) анализа с помощью модели нейронной сети. Как альтернатива, результат для концентрации, полученный из алгоритма, не основанного на машинном обучении, может быть применен в отказоустойчивом тесте для значений концентрации аналита, определенных с применением модели нейронной сети.
Определение может содержать определение целевого диапазона концентрации аналита в данном образце физиологической жидкости. Вместо определения фактических значений концентрации аналита или в дополнение к такому определению может быть определен целевой диапазон значений концентрации аналита.
Определение может содержать определение усредненной концентрации путем усреднения первого оценочного значения и значения концентрации, полученных путем анализа данного набора данных измерения с помощью первого анализирующего алгоритма. Результаты анализа модели нейронной сети и анализа, основанного на традиционном алгоритме, объединяются путем определения усредненных значений.
В другом варианте реализации определение может содержать определение концентрации глюкозы в крови во втором образце.
По меньшей мере один из первого, второго и данного набора данных измерения представляет собой первую, вторую и данную информацию о цвете, соответственно, полученную путем обработки изображения из изображений, записанных в течение временного периода измерения для интересующего участка одной или нескольких тест-полосок, при этом последовательные изображения, записываются с временным интервалом от примерно 0,1 до примерно 1,5 с.
Изображения, из которых получают первый набор данных измерения, могут содержать изображения интересующего участка до нанесения одного или нескольких первых образцов физиологической жидкости на интересующий участок. Подобным образом, в дополнение или в качестве альтернативы, изображения, из которых получен данный набор данных измерения, могут содержать изображения интересующего участка до нанесения данного образца физиологической жидкости на интересующий участок данной тест-полоски.
В одном из примеров может быть предусмотрено, что данные измерения разделены на набор обучающих данных, набор подтверждающих и набор тестовых данных. Например, около 60% данных измерения можно использовать для обучения (набор обучающих данных), около 20% для подтверждения (набор подтверждающих данных) и около 20% для тестирования (набор тестовых данных). Могут быть использованы методы перекрестного подтверждения, такие как перекрестное подтверждение с исключением по р или k-кратное перекрестное подтверждение. Набор обучающих данных может быть создан с использованием стратифицированной случайной выборки данных измерения. Стратификация может проводиться на основе по меньшей мере одного типа устройства, применяемого для сбора данных измерения, и типа эксперимента, применяемого при сборе данных измерения. Данные измерения разделены на отдельные подгруппы (слои), причем каждый слой может соответствовать разному типу устройства и/или разному типу эксперимента. Впоследствии данные могут быть отобраны отдельно для каждого слоя, а затем объединены для создания набора обучающих данных. Это может быть применено для обеспечения того, чтобы обучающие данные представляли, по существу, всю совокупность типов устройств и/или типов экспериментов. Аналогично могут быть созданы набор(ы) подтверждающих данных и набор(ы) тестовых данных.
Варианты реализации, раскрытые выше в отношении по меньшей мере одного из способов, могут применяться к одной или обеим системам с соответствующими изменениями.
Описание дополнительных вариантов реализации
Далее описаны варианты реализации в качестве примера со ссылкой на фигуры. На фигурах проиллюстрировано следующее:
Фиг. 1 графическое представление искусственной нейронной сети с прямой связью (ИНС);
Фиг. 2 графическое представление способа прогнозирования значений глюкозы в крови на основе изменения цвета дозированной тест-полоски;
Фиг. 3 графическое представление изображения тест-полоски;
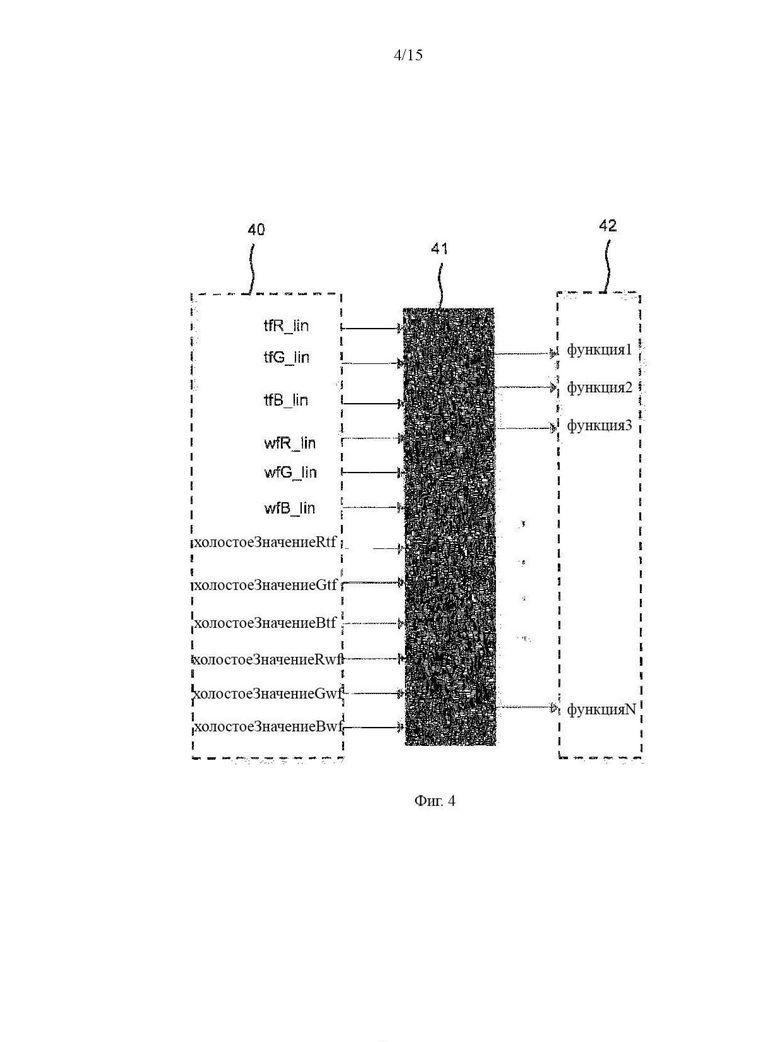
Фиг. 4 графическое представление процесса создания новых функций из таблицы функций путем применения изменения функций;
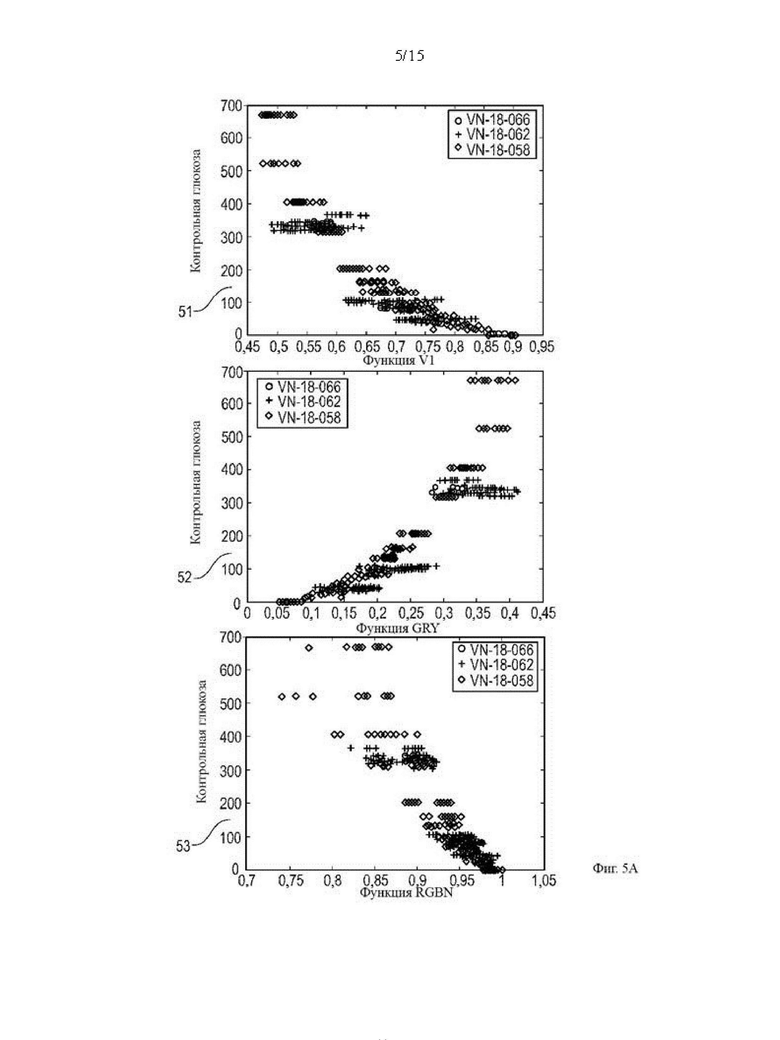
Фиг. 5А графическое представление корреляционного поведения примерных новых функций;
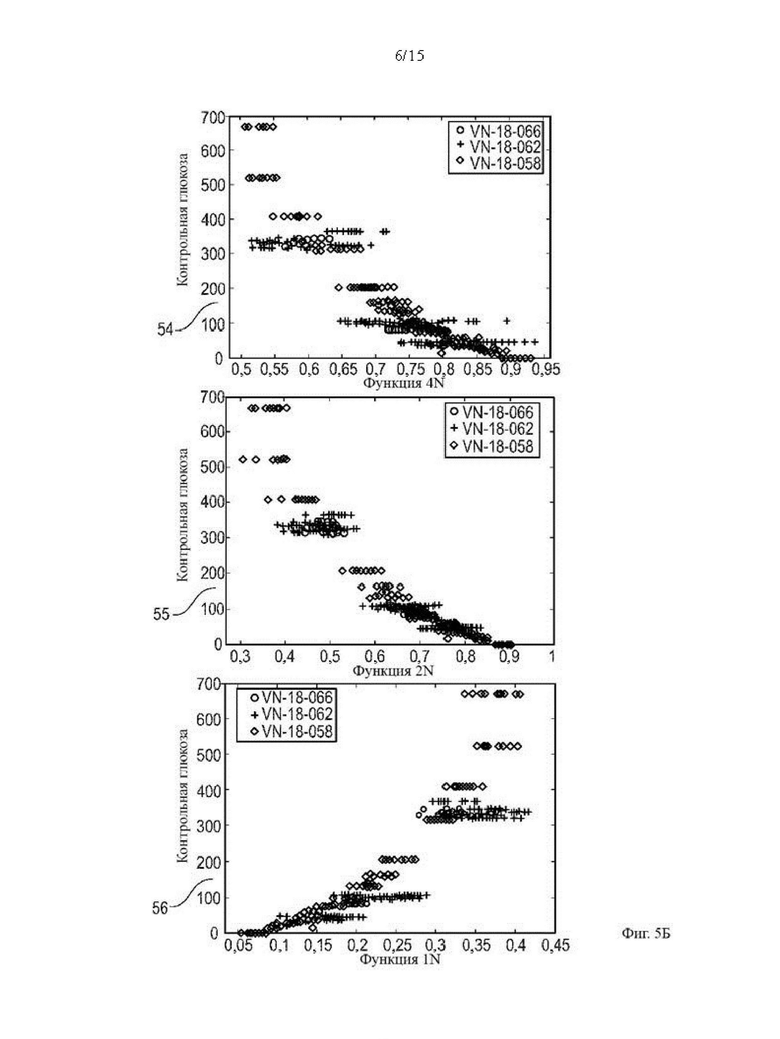
Фиг. 5Б дополнительное графическое представление корреляционного поведения примерных новых функций;
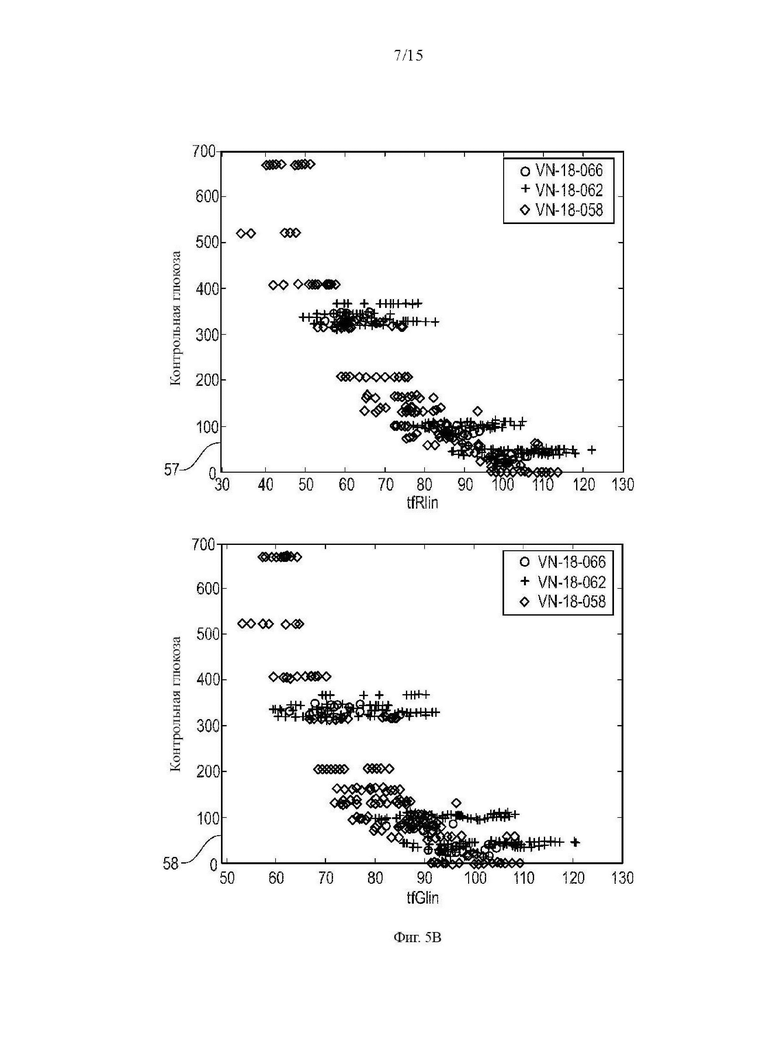
Фиг. 5В дополнительное графическое представление корреляционного поведения примерных новых функций;
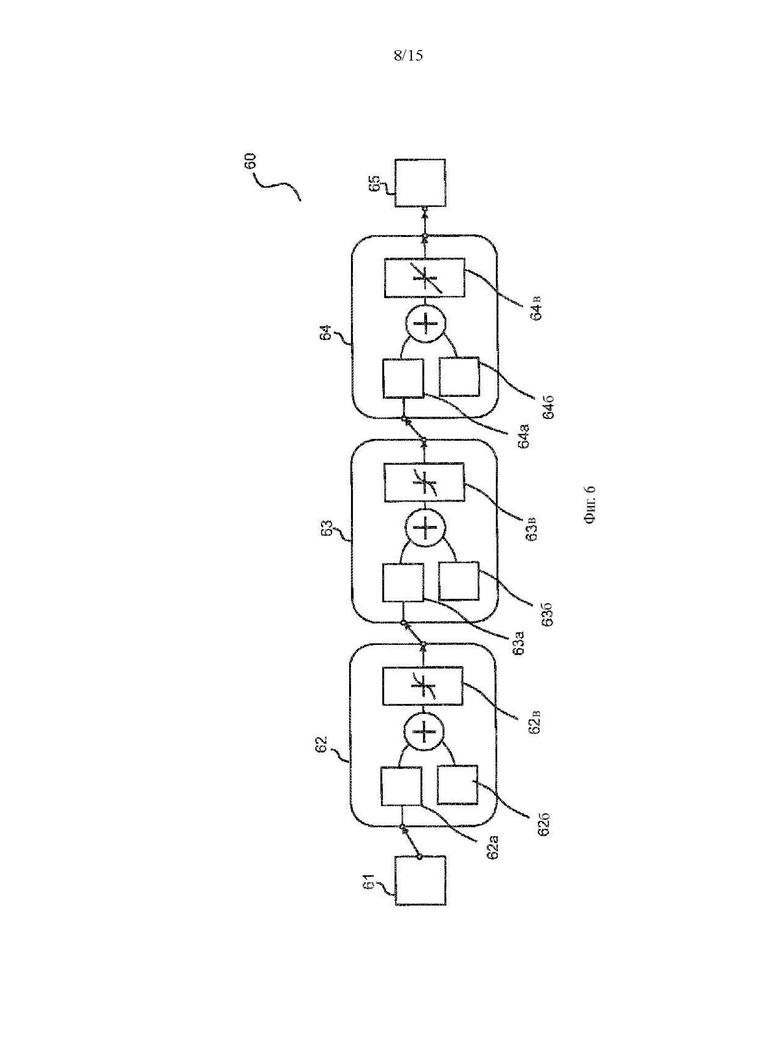
Фиг. 6 графическое представление архитектуры ИНС модели для обучения;
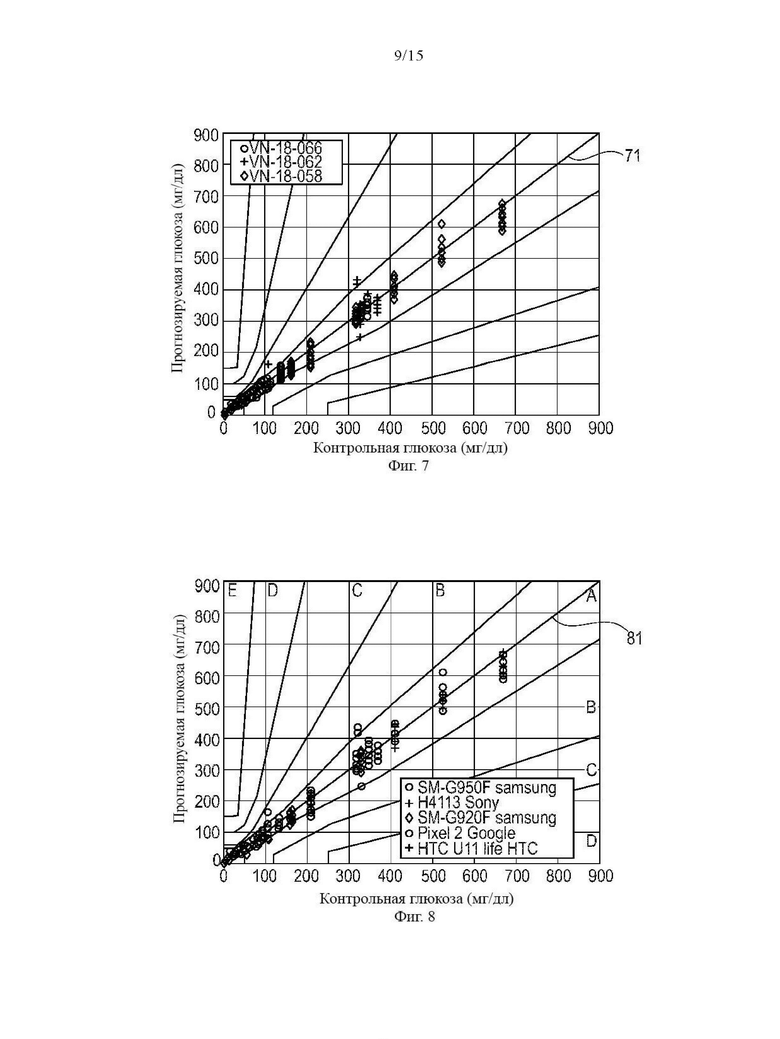
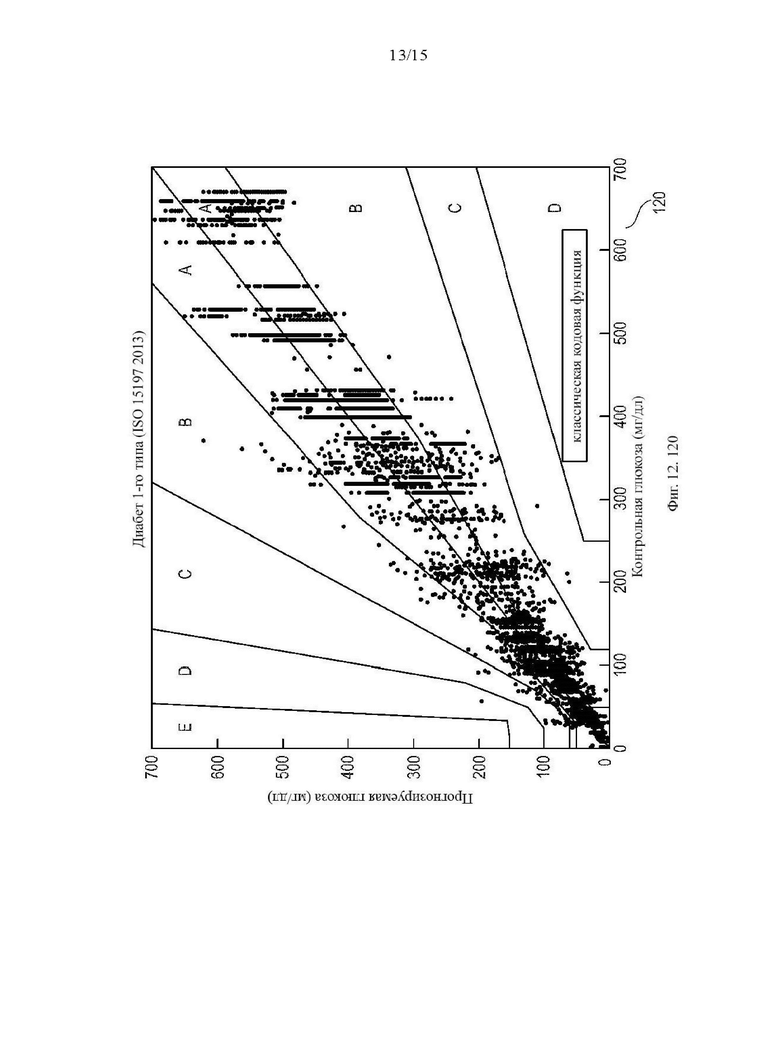
Фиг. 7 показывает сетку погрешностей Паркса, которая иллюстрирует эффективность прогнозируемых значений глюкозы в крови по сравнению с фактическими уровнями глюкозы в крови;
Фиг. 8 другая сетка погрешностей Паркса, иллюстрирующая эффективность прогнозируемых значений глюкозы в крови по сравнению с фактическими уровнями глюкозы в крови;
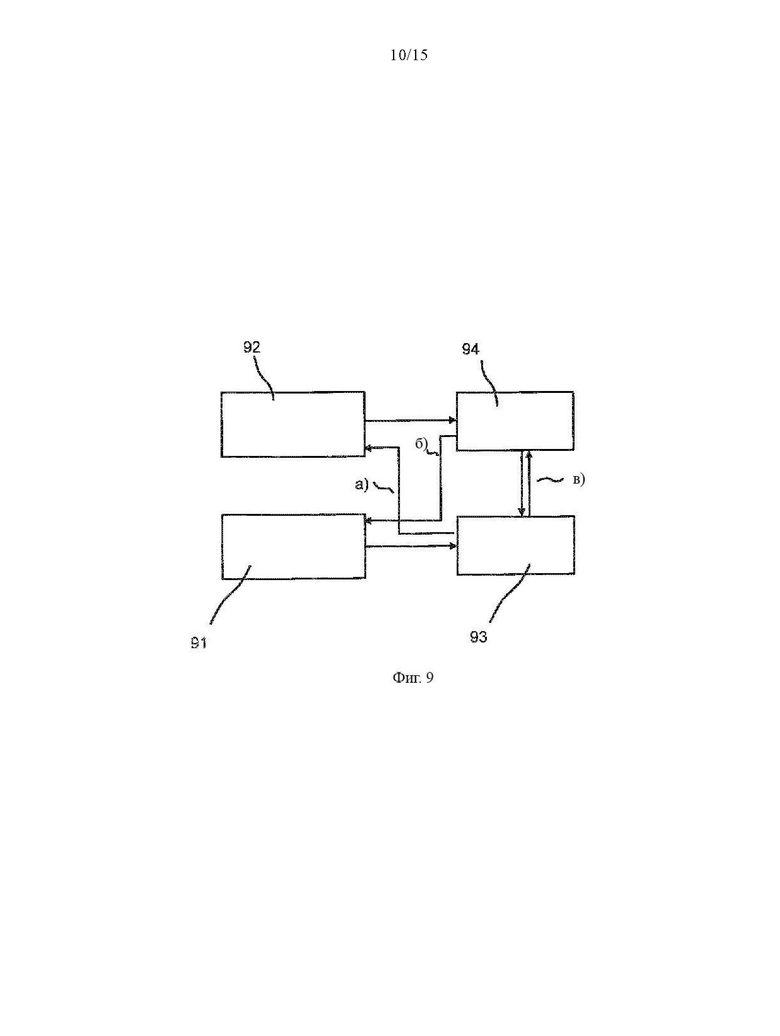
Фиг. 9 графическое представление различных типов комбинаций традиционных алгоритмов с ИНС моделями;
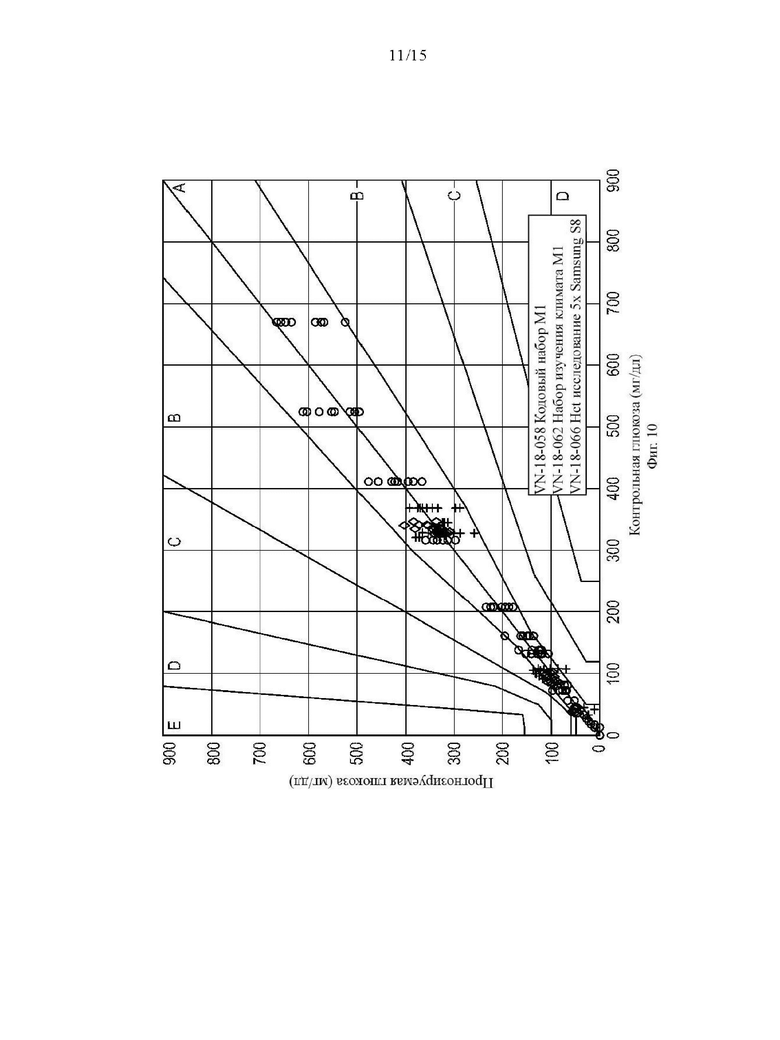
Фиг. 10 сетка погрешностей Паркса, изображающая прогнозы ИНС модели, которая использует прогнозы традиционного алгоритма в качестве одного из своих входных данных;
Фиг. 11 графическое представление другого варианта комбинированного традиционного алгоритма и ИНС алгоритма; и
Фиг. 12 три сетки погрешностей Паркса для сравнения производительности традиционного подхода и ИНС подхода.
Далее варианты реализации способа создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, раскрываются более подробно. После создания реализуемого программным обеспечением модуля, в дальнейшем способе его можно использовать на другом устройстве, таком как мобильные устройства, для анализа результатов экспериментов по определению концентрации аналита в образце физиологической жидкости, нанесенной на тест-полоску, для которой тестовый участок покажет изменение цвета в ответ на нанесение образца на тестовый участок полоски.
Способ создания реализуемого программным обеспечением модуля реализуется в одном или нескольких устройствах обработки данных. Обеспечение первого набора данных измерения, при этом первый набор данных измерения представляет собой первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок. Например, образцы крови можно наносить на тест-полоски, которые в ответ показывают изменение цвета интересующего участка (тестового участка). Такое изменение цвета может зависеть от концентрации глюкозы в крови в образцах, нанесенных на тестовый участок. Изображения, снятые для интересующего участка, указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащих аналит, на интересующий участок. Изображения записываются множеством устройств, таких как мобильные устройства, например мобильные телефоны или планшетный компьютер. Каждое устройство выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве. Например, устройство может быть предусмотрено с камерами разных типов, используемыми для снятия изображений. Кроме того, для устройств может быть обеспечена другая конфигурация программного обеспечения, в частности, различные программные приложения, применяемые в устройствах для обработки снятых изображений.
Модель нейронной сети создана в процессе машинного обучения, применяющем искусственную нейронную сеть, содержащее обеспечение модели нейронной сети и обучение модели нейронной сети с помощью обучающих данных, выбранных из первого набора данных измерения. Обеспечивается реализуемый программным обеспечением модуль, содержащий первый анализирующий алгоритм, представляющий модель нейронной сети.
Реализуемый программным обеспечением модуль выполнен с возможностью, при загрузке в устройство обработки данных, имеющее один или несколько процессоров, определения концентрации аналита во втором образце физиологической жидкости на основе анализа второго набора данных измерения, указывающих на вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение второго образца физиологической жидкости, содержащей аналит, на интересующий участок. Таким образом, после создания модели нейронной сети, она должна применяться для анализа результатов второго образца, который также может называться данным образцом и представляет собой образец физиологической жидкости, который должен быть определен с использованием модели нейронной сети после его создания, как более подробно объясняется ниже. Программное приложение, содержащее реализуемый программным обеспечением модуль, должно быть загружено в устройство анализа, такое как мобильный телефон или другое мобильное устройство. Анализ тест-полоски проводится путем запуска программного обеспечения для определения концентрации аналита.
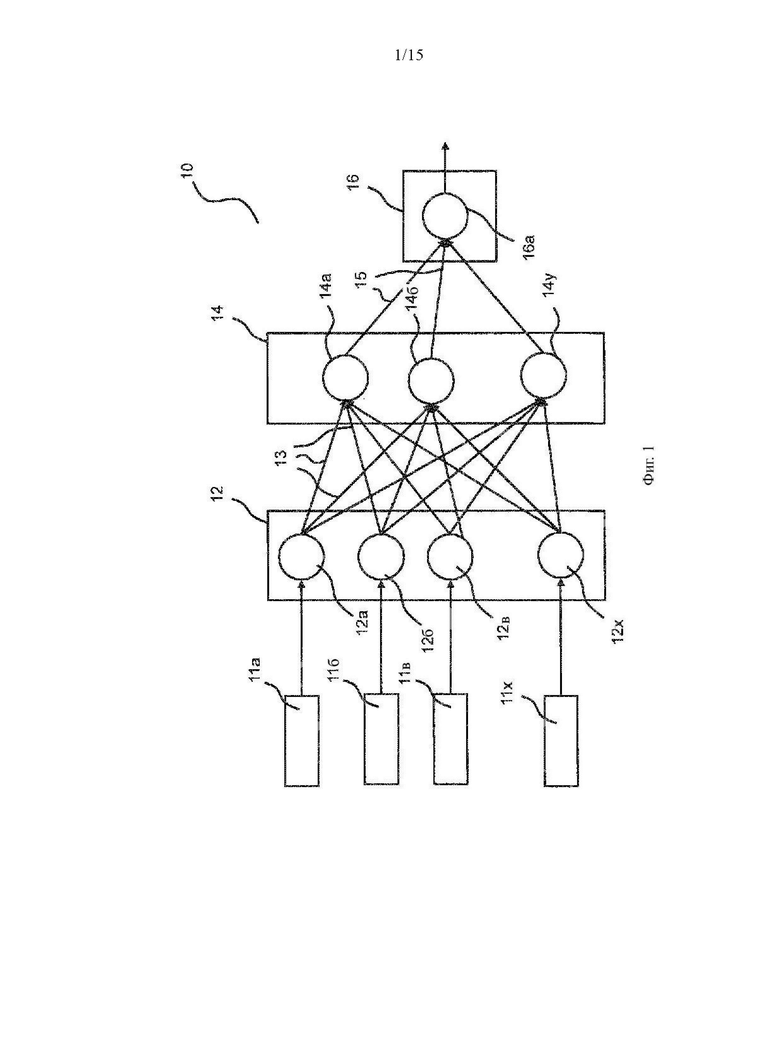
Фиг. 1 показывает схематическое графическое представление искусственной нейронной сети с прямой связью (ИНС) 10, известной как таковая. В типичной ИНС с прямой связью информация двигается в одном направлении. Входные объекты 11а, 11б, 11в, …, 11х подаются на узлы (или искусственные нейроны) 12а, 12б, 12в, …, 12х входного уровня 12. Количество узлов 12а, 12б, 12в, …, 12х в идеале должно быть равно количеству объектов в основном наборе данных. Входной уровень 12 просто принимает входные элементы 11а, 11б, 11в, …, 11х и передает входные элементы 11а, 11б, 11в, …, 11х через соединения 13 на скрытый уровень 14.
Скрытый уровень 14 содержит узлы 14а, 14б, …, 14у. Количество узлов скрытого уровня 14 зависит от количества узлов входного уровня 12 и выходного уровня 16. Количество узлов входного уровня 12 и скрытого уровня 14 может быть равным или неравным. В каждом узле 14а, 14б, …, 14у изменение применяется к его соответствующему входу. Затем измененные значения передаются через соединения 15 на выходной уровень 16. По мере обучения ИНС 10 узлы 12а, 12б, 12в, …, 12х, 14а, 14б, …, 14у, которые обеспечивают более высокую прогностическую ценность, имеют более значительный вес. При этом соответствующие соединения 13, 15 получают больший вес.
Выходной уровень 16 обеспечивает информацию, которая требуется для решения основной проблемы. Количество его узлов 16а зависит от решаемой проблемы. Если проблема заключается, например, в том, чтобы определить объект к одному из четырех классов, то выходной слой 16 будет состоять из четырех узлов (не показаны). Если проблема сводится к регрессии, то выходной слой 16 будет состоять из единственного узла 16а.
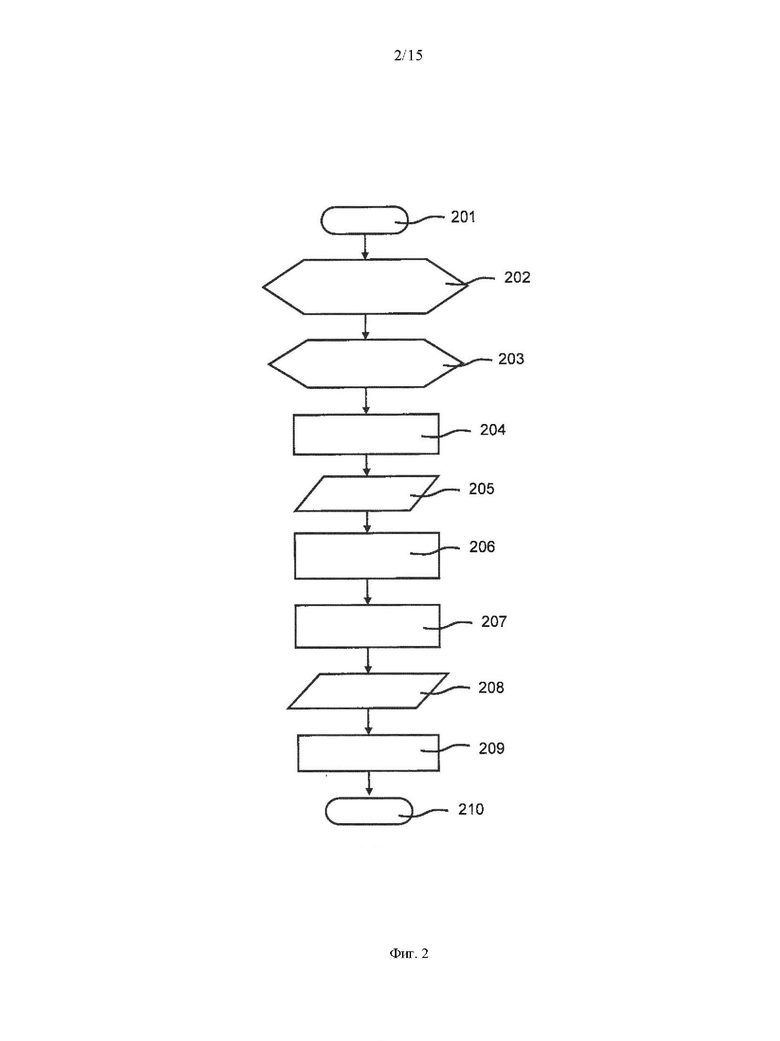
Далее раскрываются примеры применения ИНС для определения концентрации аналита в образце физиологической жидкости на основе измерений, основанных на изменении цвета в тестовом участке тест-полоски в ответ на нанесение образца физиологической жидкости. Например, может быть определен уровень глюкозы в крови. Фиг. 2 схематически иллюстрирует шаги для примера способа.
В ходе измерения серия изображений 201 тест-полосок снимается на шаге 202 сбора данных первого изображения с использованием различных устройств, каждое из которых выполняется с возможностью получения изображений и обработки данных изображения. Устройствами могут быть мобильные устройства, например сотовые или мобильные телефоны, или планшетные компьютеры.
Как известно, для получения изображений образец физиологической жидкости, например образец крови, наносится на тестовый участок тест-полоски. В ответ на нанесение образца тестовый участок покажет изменение цвета, которое должно быть обнаружено при получении изображения(ий). Изображения должны быть обработаны в процессе анализа для определения концентрации аналита в образце физиологической жидкости, например уровня глюкозы в крови.
Хотя изображения снимаются для определения образца физиологической жидкости, разные условия измерения могут присутствовать для снятия изображений путем сочетания, например, различных температур, значений относительной влажности, значений освещенности и/или гематокрита. Также могут быть использованы другие значения. В примере в отношении к различным климатическим условиям, могут применяться значения температуры от 5°С до 30°С с шагом, например, 5°С, и значения относительной влажности от 15% до 85% с шагом, например, 10%. Может быть предусмотрено, что каждое из значений относительной влажности комбинируется с каждым из значений температуры для формирования набора различных климатических условий. В качестве альтернативы, только определенные значения относительной влажности комбинируются с каждым из значений температуры, поскольку определенные комбинации относительной влажности/температуры менее актуальны.
Следующие условия измерения могут применяться в наборе данных для температуры и влажности в климатических исследованиях:

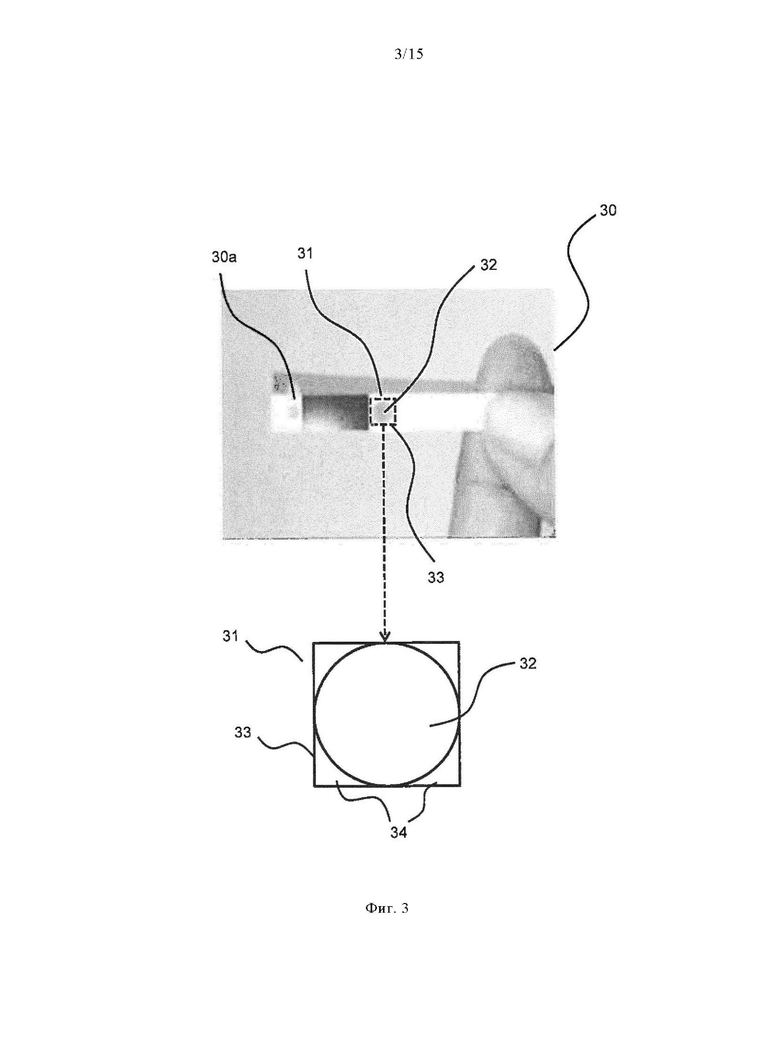
В течение периода измерения для каждой тест-полоски снимается серия изображений 201. Например, изображение 30 тест-полоски снимается каждые полсекунды в течение примерно 40 секунд (см. Фиг. 3 для графического представления изображения 30). Каждая серия изображений 201 на каждой тест-полоске начинается с изображения пустой тест-полоски (тест-полоски без нанесенной дозы крови или образца). Последующие изображения 30 снимаются после нанесения образца крови. Таким образом, изменение цвета тест-полоски полностью снимается в каждой серии изображений 201. Далее серия изображений 201 сохраняется в базе данных. Может быть предусмотрена дополнительная временная задержка между снятием первого и второго изображения, позволяющая пользователю нанести дозу крови на тест-полоску.
Изображения были засняты множеством различных сотовых или мобильных телефонов, каждый сотовый телефон предусмотрен с отдельной камерой и программной конфигурацией параметров обработки изображения RGGB, матрицей изменения цвета и кривой тонального отображения для снятия изображений и обработки данных изображения.
Изображения, полученные при измерениях, обеспечивают (измеренные) данные изображения, представляющие информацию о цвете в отношении изменения цвета тестового участка в ответ на нанесение образца(ов) физиологической жидкости, содержащей аналит, для которого необходимо определить концентрацию. Далее данные изображения используются для создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в данном образце. ИНС обеспечивается и обучается на основе набора обучающих данных, взятых из измеренных данных изображения.
На следующем шаге 203, как показано на Фиг. 2 и 3, данные изображения, полученные из серии изображений 201, которые могут быть сохранены в базе данных, обрабатываются, чтобы определить интересующий участок 31 для каждого изображения 30 из серии изображений 201. Интересующий участок 31 состоит из части изображения, показывающей нанесенный образец физиологической жидкости (например, образец крови) на тест-полоску 30а (целевое поле 32) и квадрата 33 вокруг целевого поля 32. Пространство за пределами целевого поля 32 и внутри квадрата 33, состоящего из четырех сегментов, называется белым полем 34. Интересующий участок (тестовый участок) 31 обнаруживается программным обеспечением для обработки изображений путем снятия значений цвета пикселей для целевого поля 32 и белого поля 34. Каждый цвет пикселя может быть, например, в кодировке формата RGB. Альтернативные цветовые пространства и цветовые модели, такие как CIE L*a*b*, CIE 1931 XYZ, CMYK, и HSV также могут быть использованы для кодировки цветов пикселей. Использование альтернативных цветовых пространств и изменения цветов в альтернативные цветовые пространства может улучшить качество сигнала, что приведет к более простым и/или более точным алгоритмам прогнозирования.
Может быть предусмотрено изменение необработанных пиксельных данных для повышения точности сигнала. Следующие типы цветовых изменений или их комбинаций могут быть использованы:
- Средние значения необработанных R, G и В каналов вычисляются из целевого поля 32, на которое наносится кровь;
- каналы R и G нормализуются по В из целевого поля 32 (нормализация выполняется путем деления каждого значения канала R и G на соответствующее значение В);
- вычисляется дельта между каналами R и В и дельта между каналами G и В из целевого поля 32;
- каналы R, G, В из целевого поля 32 нормализуются по каналам R, G, В из белого поля 34;
- вычисляется соотношение между целевыми нормализованными белыми каналами R, G, В целевого поля 32 и нормализованными белыми каналами R, G, В контрольного поля.
Данный список цветовых изменений не является исчерпывающим. Могут быть обеспечены дополнительные цветовые изменения для различных функций.
Для устройства, применяемого для фотосъемки, например для множества сотовых или мобильных телефонов, могут быть использованы разные способы калибровки. Различия в схемах настройки цвета для разных типов сотовых телефонов могут привести к различиям в прогнозируемых значениях глюкозы, если их не исправить. Можно использовать различные подходы для создания калибровочных кривых для конкретных типов мобильных телефонов, которые будут стандартизировать выходные данные по общей контрольной шкале. С одной стороны, автономная калибровка может выполняться с использованием контрольных цветовых карт, которые содержат участки с известными значениями цветов. Необязательно проводить подобную автономную калибровку перед каждым измерением. Может быть предусмотрено, что автономная калибровка выполняется один раз, перед выполнением пользователем любого измерения. В качестве альтернативы автономная калибровка выполняется через определенные промежутки времени. С другой стороны, можно использовать онлайн-калибровку с использованием контрольных цветов. Для этого изображения контрольных карточек снимаются вместе с тестовым полем в заранее заданное время после дозирования тест-полоски. Изображения тест-полоски снимаются до дозирования и после дозирования. Тест-полоска может дополнительно содержать предварительно напечатанные контрольные поля для онлайн-калибровки.
После определения локализации целевого поля 32, значения пикселей извлекаются и усредняются для каждого канала RGB из участка в целевом поле 32, например, круг с немного меньшим радиусом внутри целевого поля 32, давая средние значения для каждого из каналов R, G и В. Таким образом, можно избежать усреднения нежелательных пикселей на границе целевого поля 32.
Как следствие, средние значения для каждого цветового канала сохраняются в таблице данных вместе с дополнительными соответствующими данными, такими как контрольные значение глюкозы, идентификатор изображения, название исследования, коды ошибок, информация, связанная с исследованием, такая как температура, влажность, гематокрит или номера моделей устройств. Таблица данных может, например, быть сохранена как файл значений, разделенных запятыми (csv), или mat файл MATLAB для дальнейшей обработки.
Для конкретных целей моделирования важен не каждый столбец таблицы данных. Таким образом, меньшая таблица, таблица функций, создается из таблицы данных путем включения только тех столбцов, которые требуются для моделирования. Примерная таблица с четырьмя строками для таблицы функций изображена в Таблице 1.
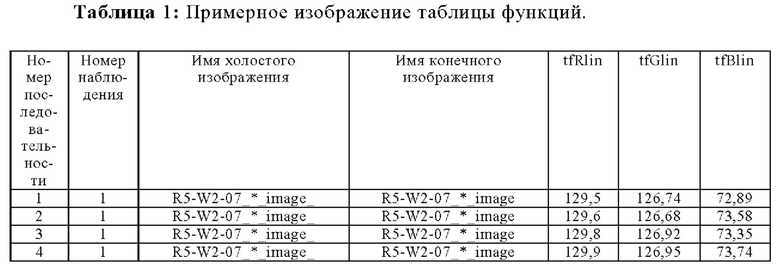
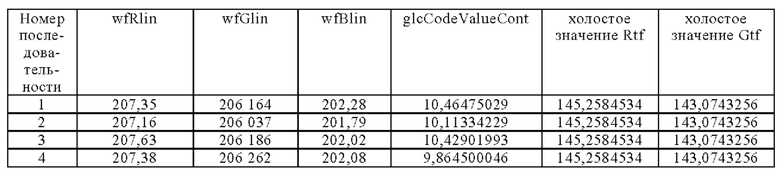

Таблица функций содержит линейные средние значения канала RGB как для целевого поля (tfRlin, tfGlin, tfBlin), так и для белого поля (wfRlin, wfGlin, wfBlin). Линеаризация достигается путем установки кривой тонального отображения смартфона на прямую 1:1 линию. Линеаризация необходима для обработки по умолчанию различных кривых тонального отображения в разных типах смартфонов. Без установки кривой тонального отображения связь между значениями будет искусственно нелинейной из-за того, что кривые тонального отображения являются по умолчанию нелинейными. Усреднение выполняется отдельно для каждого RGB канала путем взятия среднего арифметического значения каналов в соответствующем участке (целевое поле или белое поле).
Таблица функций дополнительно содержит линейные средние значения RGB канала для целевого поля (xoлocтoeЗнaчeниeRtf, холостоеЗначениеGtf, холостоеЗначениеBtf) и белого поля (xoлocтoeЗнaчeниeRwf, xoлocтoeЗнaчeниeRwf, xoлocтoeЗнaчeниeRwf) перед дозированием.
Данные могут быть оценены как недопустимые, если было определено, что данные были очень (частично) засвеченными, неоднородными, содержали слишком мало пикселей, соответствующее изображение было недостаточно резким или комбинация этого. Недопустимые данные могут быть удалены из таблицы функций. Таблица функций не содержит информацию обо всех изображениях одного и того же измерения. В общем, для каждой серии изображений 201 снимается примерно 80 изображений 30, но не все изображения 30 необходимы для моделирования. Достаточным или желательным для моделирования может быть использование данных из финального изображения и от 10 до 19 изображений, предшествующих финальному изображению. На финальных изображениях угловой коэффициент каналов R или G близок к нулю, то есть кинетика цвета стабилизируется в определенное время после дозирования, а цвета с этой точки не меняются или только минимально изменяются. Получение изображений со стационарной цветовой кинетикой может повысить сопоставимость изображений.
В дальнейшем ссылаясь на Фиг. 2, на шаге 204 данные таблицы функций используются для разработки функции. Одним из наиболее важных аспектов моделирования является выбор правильных функций для модели. Поскольку целью является прогнозирование значений глюкозы в крови, ожидается, что использование функций, которые имеют сильную корреляцию с контрольными значениями глюкозы в крови, приведет к созданию лучших моделей. Контрольные значения глюкозы в крови были определены с помощью известных систем измерения уровня глюкозы в крови. Линейные RGB каналы демонстрируют определенную степень корреляции с контрольными значениями глюкозы. Однако результаты все же можно улучшить, создав новые функции, которые имеют более сильную корреляцию с контрольными значениями глюкозы. Кроме того, создание таких новых функций может быть полезным в том смысле, что зависимости могут быть уменьшены в отношении различных типов сотовых телефонов и условий измерения, таких как климатические условия или условия освещения.
В связи с этим на Фиг. 4 показано графическое представление процесса создания новых функций 42 из функций 40 из таблицы функций путем применения изменения функции 41, такого как изменение цвета, к функциям 40. Функции 40 могут содержать линейные средние значения RGB канала для целевого поля (tfRlin, tfGlin, tfBlin) и/или белого поля (wfRlin, wfGlin, wfBlin), и/или значения RGB канала перед дозированием (xoлocтoeЗнaчeниeRtf, холостоеЗначениеGtf, холостоеЗначениеBtf), (xoлocтoeЗнaчeниeRwf, холостое значение Rwf, холостое значение Rwf).
На Фиг. 5а и 5б показаны изображения корреляционного поведения примерных новых функций 42, созданных изменением функции 41 из функций 40. Графики с 51 по 56 отображают корреляционное поведение одной из новых функций 42 (ось х) с контрольными значениями глюкозы в крови (ось у). Функция «GRY» на графике 52 относится к значениям цвета в градациях серого. В некоторых функциях суффикс «N» относится к нормализации. В частности, «RGBN» на графике 53 означает «нормализованный цвет RGB». Разные маркеры  соответствуют разным типам экспериментов. Изображенные новые функции 42 демонстрируют более сильную корреляцию с контрольными значениями глюкозы, чем просто необработанные значения RGB.
соответствуют разным типам экспериментов. Изображенные новые функции 42 демонстрируют более сильную корреляцию с контрольными значениями глюкозы, чем просто необработанные значения RGB.
С другой стороны, на Фиг. 5в показаны изображения корреляционного поведения необработанных значений RGB канала с контрольными значениями глюкозы в крови. График 57 показывает линейное среднее значение канала R для целевого поля tfRlin. График 58 показывает линейное среднее значение канала G для целевого поля tfGlin. Графики 57 и 58 показывают больший разброс значений и, следовательно, более слабую корреляцию с контрольными значениями глюкозы в крови, чем новые функции 42, изображенные на Фиг. 5а и 5б.
Снова ссылаясь к Фиг. 2, на последующем шаге 206 обучающие, подтверждающие, и тестовые наборы создаются из данных в таблице функций до того, как ИНС модель может быть обучена. Может быть предусмотрено, что данные разделены на обучающий, подтверждающий, и тестовый набор. 60% данных используются для обучения, 20% для подтверждения и 20% для тестирования. Также могут быть использованы методы перекрестного подтверждения, такие как перекрестное подтверждение с исключением по р или k-кратное перекрестное подтверждение Обучающий набор создается с использованием стратифицированной случайной выборки данных. Стратификация проводилась по типам смартфонов и типам экспериментов. То есть данные разделены на отдельные подгруппы (слои), причем каждый слой соответствует разному типу смартфона и типу эксперимента. Впоследствии данные отобраны отдельно для каждого слоя, а затем объединены для создания набора обучающих данных. Это применяется для обеспечения того, что обучающие данные представляют, по существу, всю совокупность типов смартфонов и экспериментов. Аналогично могут быть созданы наборы подтверждающих данных и наборы тестовых данных.
Подтверждающий набор используется для предотвращения перетренированности/переобучения, в то время как тестовый набор используется для независимой оценки модели во время обучения. К входному набору данных добавляется столбец для указания того, какие данные используются для обучения, тестирования и подтверждения. Добавленный столбец важен для определения правильных подгрупп при обучении ИНС.
На шаге 207 происходит обучение ИНС. ИНС обучается при различных условиях измерения, поэтому в обучающем наборе представлены разные условия измерения, которые могут быть включены в модель. Также может быть предусмотрено включение разных типов смартфонов в моделирование. Обучение ИНС может выполняться в числовых вычислительных средах, таких как MATLAB. Составленные языки программирования также можно использовать для повышения производительности. На Фиг. 6 показано графическое представление примерной архитектуры ИНС модели 60, которую необходимо обучить. Архитектура представленная на Фиг. 6 состоит из двух скрытых слоев 62 и 63. В качестве альтернативы можно использовать один скрытый слой из более чем двух скрытых слоев (не указано) в зависимости от сложности проблемы. Входные значения 61 передаются на скрытый слой 62. Выходные данные скрытого слоя 62 передается на скрытый слой 63. Выходные данные скрытого слоя 63, в свою очередь, передаются выходному слою 64, в результате чего получается выходное значение 65. Выходное значение 65 соответствует прогнозируемому значению глюкозы в крови. Для правильной модели глюкозы в крови весовые коэффициенты 62а, 62б, 63а, 63б, 64а и 64б оптимизируются во время обучения.
Для предотвращения перетренированности можно использовать такие способы регуляризации, как ранняя остановка. Например, может быть предусмотрено максимум 12 разрешенных итераций для обучения модели 60. Например, может быть установлено максимальное количество эпох на 1000. Обучаются множественные модели 60 с разными точками инициализации, а их показатели производительности сохраняются в табличном файле, таком как файл csv, для последующего выбора модели. После создания всех моделей 60 и оценки показателей производительности, в качестве окончательной обученной модели выбирается наиболее эффективная модель.
Возвращаясь к Фиг. 2, на шаге 208 обученная модель устанавливается с использованием формулы нейронной сети, которая состоит из линейной комбинации гиперболических тангенсов функций с оптимизированными коэффициентами, полученными из обученной ИНС. С помощью модели обученной нейронной сети определяются значения глюкозы в крови (шаг 209). Впоследствии определенные значения глюкозы в крови выводятся для дальнейшей обработки (шаг 210).
На Фиг. 7 и 8 показана сетка погрешностей Паркса, иллюстрирующая эффективность определенных значений глюкозы в крови по сравнению с фактическими значениями глюкозы в полном наборе данных. Сетки погрешностей Паркса (согласованные сетки ошибок) являются хорошо известными графическими инструментами для сравнения различных данных в количественной диагностике (Parkes et al., Diabetes Care 23: 1143-1148, 2000). Каждая ось у соответствует прогнозируемым значениям глюкозы в крови; каждая ось х соответствует фактическим значениям глюкозы в крови. Каждая сетка погрешностей разделена на разные зоны от А до D, соответствующие различным участкам погрешностей. Отклонения от биссектрисы 71, 81 в зоне А соответствуют небольшим погрешностям. Желательно, чтобы большинство значений находилось в пределах зоны А. Зона В соответствует умеренным ошибкам, зона С - недопустимо большим ошибкам для лечения пациентов, а зона D - чрезмерно большим ошибкам. На Фиг. 7 разные маркеры соответствуют разным типам экспериментов; на Фиг. 8 разные маркеры соответствуют разным типам смартфонов. Как видно из Фиг. 7 и 8, прогнозируемые значения глюкозы в крови достаточно хорошо соответствуют фактическим значениям глюкозы в крови как для разных типов сотовых телефонов, так и для разных типов экспериментов.
В Таблице 2 показано, как часто значения глюкозы в крови попадают в различные зоны сетки погрешностей Паркса от А до Е для традиционного или не-ИНС алгоритма (параметрическая многомерная линейная регрессия) по сравнению с подходом ИНС модели. Значения в зонах А и В считаются приемлемыми, значения в зонах С - Е от неприемлемых до критических. И традиционный алгоритм, и ИНС модель были обучены с помощью наборов кодовых данных M1 и М2. Впоследствии были охарактеризованы неизвестные типы сотовых телефонов (наборы кодовых данных М4, М5 и М6). Наборы кодовых данных от M1 до М5 походят из лабораторных данных, определенных при стандартных условиях (Т=24°С, Влажность = 45%) на стандартной измерительной станции и содержащих контрольное значение гексокиназы глюкозы. Влияние окружающей среды и обработки минимальное. Для каждого кодового набора данных использовалось пять различных типов сотовых телефонов. Таким образом, обучение проводилось с использованием 10 различных типов сотовых телефонов. Созданы таким образом алгоритмы впоследствии были предусмотрены неизвестными данными о 3×5=15 различных типов сотовых телефонов.
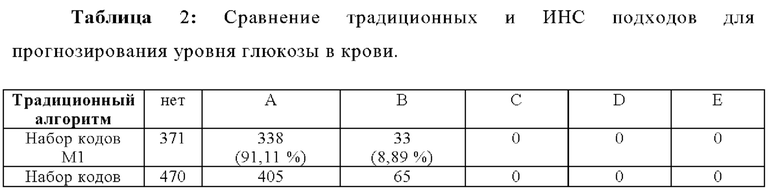
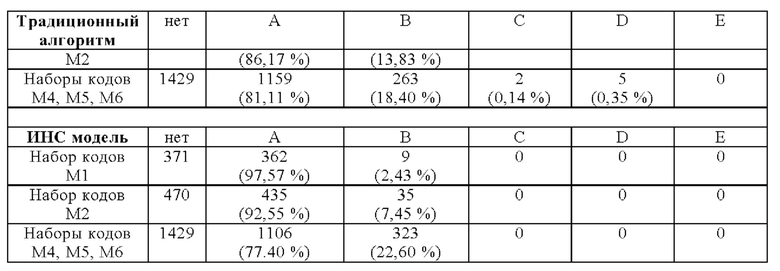
Как видно из Таблицы 2, ИНС модель лучше работает при оценке значений глюкозы в крови для неизвестных типов сотовых телефонов, чем традиционный алгоритм. Важно отметить, что значения из ИНС модели не находятся в неприемлемых зонах от С до Е, соответствующих грубым ошибкам при классификации уровней глюкозы в крови.
В дополнительных примерах для прогнозирования уровня глюкозы в крови может использоваться традиционный алгоритм 91, такой как, например, полиномиальные соответствия, в сочетании с ИНС моделями 92. На Фиг. 9 показано графическое представление различных типов комбинаций, которые могут быть использованы:
Прогнозы 93 из традиционного алгоритма 91 могут использоваться в качестве входных данных (функции) для ИНС модели 92;
а) прогнозы 94 из ИНС модели 92 могут использоваться в качестве входных данных для традиционного алгоритма 91; а также
б) Могут использоваться как традиционный алгоритм 91, так и ИНС модель 92, а различия в прогнозах 93, 94 обоих алгоритмов могут использоваться в качестве средства защиты от сбоев для исключения неверных прогнозов.
На Фиг. 10 показана сетка погрешностей Паркса, изображающая прогнозы ИНС модели, которая использует прогнозы традиционного алгоритма в качестве одного из входных данных.
На Фиг. 11 показано графическое представление другого варианта реализации алгоритма 110 комбинированной традиционной модели и ИНС модели. Из серии изображений 201, содержащей по меньшей мере два изображения, извлекаются определенные функции (шаг 111). Затем эти характеристики отслеживаются и определяются для сухого (пустого) значения и окончательного значения с использованием кинетического алгоритма (шаг 112).
Затем признаки обрабатываются в традиционном алгоритме (шаг 113) и в ИНС модели (шаг 114) параллельно, что приводит к прогнозированию значения глюкозы в крови (шаг 115). Флаги ошибок также могут быть обеспечены, если применимо.
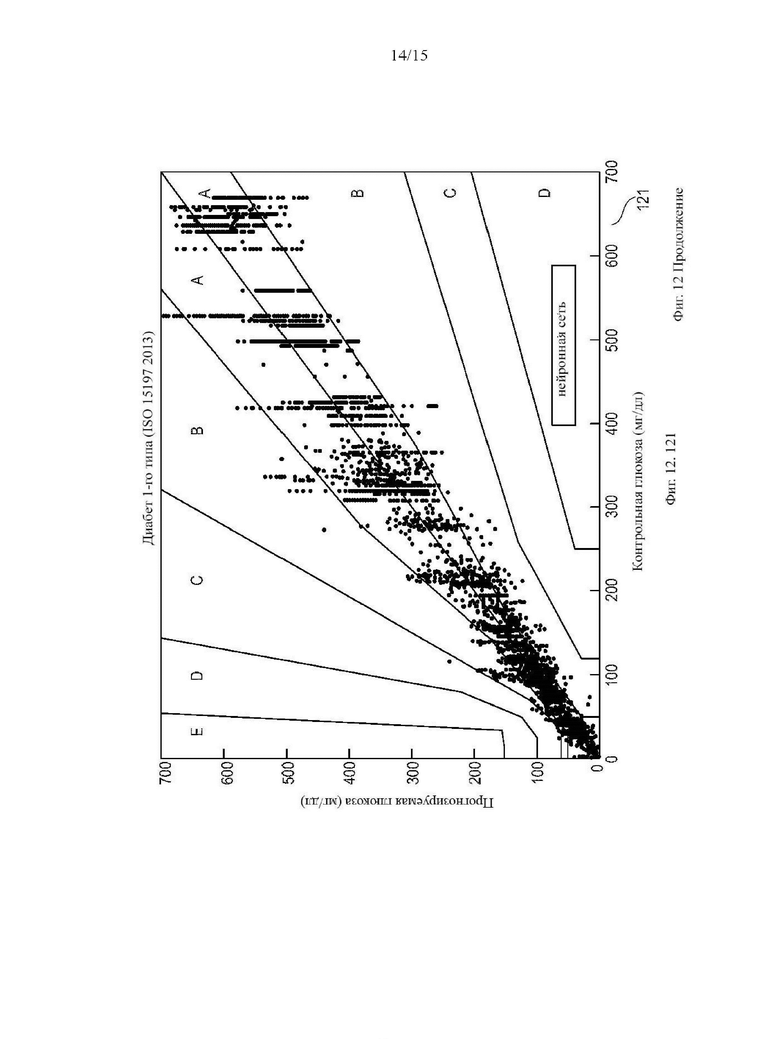
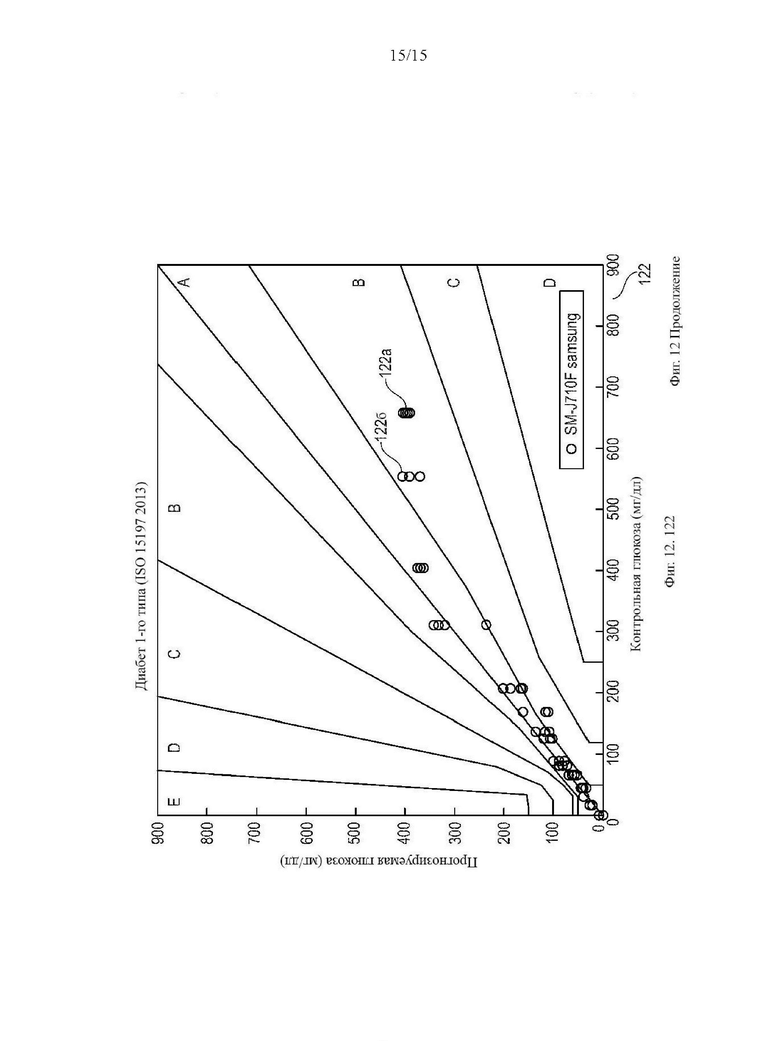
На Фиг. 12 показаны три сетки погрешностей Паркса 120, 121, 122 для сравнения производительности традиционного подхода и ИНС модели. Для сетки погрешностей 120 использовался только традиционный алгоритм; для сетки погрешностей 121 использовалась только ИНС модель. Как видно из сеток погрешностей 120 и 121, производительность измерения ИНС модели на основе функций лучше, чем у традиционного алгоритма. Сетка погрешностей 122 демонстрирует, почему не следует полагаться только на ИНС модели. Здесь, в качестве демонстрации, ИНС была обучена только на значениях глюкозы в крови ниже 450 мг/дл. Следовательно, образцы 122а, 122б, которые вне масштабов обучения серьезно ошибочно классифицируются. Для гарантии того, что любые неожиданные входные данные в ИНС приведут к неверным результатам измерения уровня глюкозы в крови, традиционно определенные значения глюкозы в крови могут использоваться в качестве средства защиты от ошибок для результатов измерения уровня глюкозы в крови ИНС.

Изобретения относятся к способу и системе для создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости. Способ создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, при этом способ содержит, в одном или нескольких устройствах обработки данных, обеспечение первого набора данных измерения. Первый набор данных измерения представляет собой первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок и записаны множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете. Множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве. Устройства снабжены камерами различных типов, используемыми для снятия изображений, или при этом устройства снабжены различными программными приложениями, применяемыми в устройствах для обработки снятых изображений; создание модели нейронной сети в процессе машинного обучения, применяющем искусственную нейронную сеть, содержащее обеспечение модели нейронной сети. Создание из первого набора данных измерения обучающих данных, подтверждающих данных и тестовых данных; и обучение модели нейронной сети с помощью обучающих данных, причем обучающие данные представляют всю совокупность устройств и типов экспериментов и создание реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети. Реализуемый программным обеспечением модуль выполнен с возможностью, при загрузке в устройство обработки данных, имеющее один или несколько процессоров, определения концентрации аналита во втором образце физиологической жидкости на основе анализа второго набора данных измерения, указывающих на вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение второго образца физиологической жидкости, содержащей аналит, на интересующий участок. Техническим результатом является обеспечение улучшенной технологии для определения концентрации аналита в образце физиологической жидкости. 5 н. и 8 з.п. ф-лы, 12 ил., 2 табл.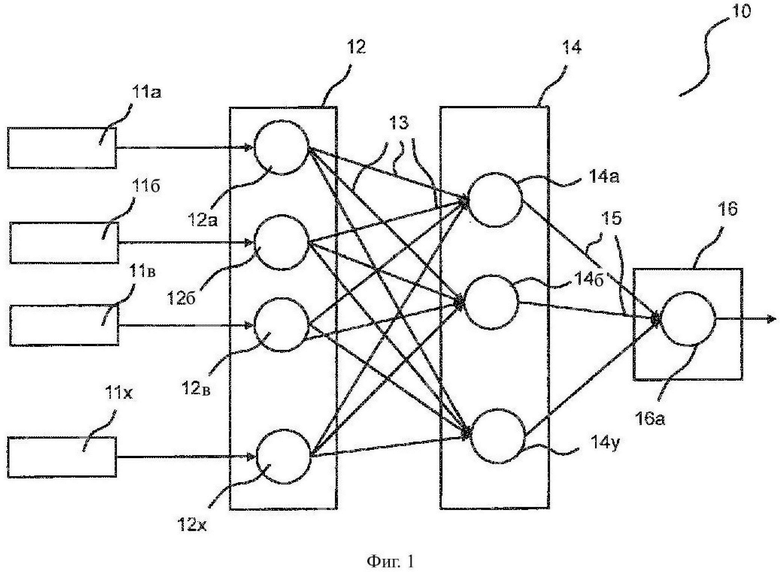
1. Способ создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, при этом способ содержит, в одном или нескольких устройствах обработки данных,
- обеспечение первого набора данных измерения, при этом первый набор данных измерения представляет собой первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка (31) одной или нескольких тест-полосок (30а), при этом изображения
- указывают на изменение цвета интересующего участка (31) в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок; и
- записаны множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве, при этом устройства снабжены камерами различных типов, используемыми для снятия изображений, или при этом устройства снабжены различными программными приложениями, применяемыми в устройствах для обработки снятых изображений;
- создание модели нейронной сети в процессе машинного обучения, применяющем искусственную нейронную сеть, содержащее
- обеспечение модели нейронной сети;
- создание из первого набора данных измерения обучающих данных, подтверждающих данных и тестовых данных; и
- обучение модели нейронной сети с помощью обучающих данных, причем обучающие данные представляют всю совокупность устройств и типов экспериментов; и
- создание реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети;
причем реализуемый программным обеспечением модуль выполнен с возможностью, при загрузке в устройство обработки данных, имеющее один или несколько процессоров, определения концентрации аналита во втором образце физиологической жидкости на основе анализа второго набора данных измерения, указывающих на вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение второго образца физиологической жидкости, содержащей аналит, на интересующий участок.
2. Способ определения концентрации аналита в образце физиологической жидкости, при этом способ содержит, в одном или нескольких устройствах обработки данных,
- обеспечение данного набора данных измерения, указывающих на данную информацию о цвете, полученную путем обработки изображений из изображений интересующего участка (31) данной тест-полоски (30а), при этом изображения указывают на изменение цвета интересующего участка (31) в ответ на нанесение данного образца физиологической жидкости, содержащей аналит, на интересующий участок (31);
- обеспечение реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети, созданную в процессе машинного обучения, применяющем искусственную нейронную сеть;
- определение концентрации аналита в данном образце физиологической жидкости, содержащее анализ данного набора данных измерения с помощью первого анализирующего алгоритма; и
- создание данных о концентрации, указывающих на концентрацию аналита в данном образце физиологической жидкости;
причем создание модели нейронной сети в процессе машинного обучения содержит
- обеспечение первого набора данных измерения, при этом первый набор данных измерения
- указывает на первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок; и
- представляет первую информацию о цвете, полученную из изображений, записанных множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве, при этом устройства снабжены камерами разных типов, применяемыми для снятия изображений, или при этом устройства снабжены различными программными приложениями, применяемыми в устройствах для обработки снятых изображений;
- создание из первого набора данных измерения обучающих данных, подтверждающих данных и тестовых данных; и
- обучение модели нейронной сети с помощью обучающих данных, причем обучающие данные представляют всю совокупность устройств и типов экспериментов.
3. Способ по п. 1 или 2, содержащий множество устройств, имеющих по меньшей мере одно из различных камерных устройств и различного программного обеспечения обработки изображений, применяемого для записи изображения и обработки данных изображения.
4. Способ по любому из предыдущих пунктов, в котором записанные изображения содержат изображения, записанные при различных условиях записи оптического изображения.
5. Способ по любому из пп. 2-4, дополнительно содержащий
- обеспечение второго анализирующего алгоритма, при этом второй анализирующий алгоритм отличается от первого анализирующего алгоритма; и
- определение, для концентрации аналита в данном образце физиологической жидкости, первого оценочного значения путем анализа данного набора данных измерения с помощью второго анализирующего алгоритма.
6. Способ по п. 5, в котором определение содержит определение целевого диапазона для концентрации аналита в данном образце физиологической жидкости.
7. Способ по п. 5 или 6, в котором определение содержит определение средней концентрации путем усреднения первого оценочного значения и значения концентрации, полученных путем анализа данного набора данных измерения с помощью первого анализирующего алгоритма.
8. Способ по любому из пп. 2-7, в котором определение содержит определение концентрации глюкозы в крови во втором образце.
9. Способ по любому из предыдущих пунктов, в котором по меньшей мере один из первого, второго и данного набора данных измерения представляет собой первую, вторую и данную информацию о цвете, соответственно, полученную путем обработки изображений из изображений, записанных в течение временного периода измерения для интересующего участка одной или нескольких тест-полосок, при этом последовательные изображения записываются с временным интервалом от примерно 0,1 до примерно 1,5 с.
10. Способ по любому из предыдущих пунктов, в котором изображения содержат изображения интересующего участка до нанесения одного или нескольких первых образцов физиологической жидкости на интересующий участок.
11. Система для создания реализуемого программным обеспечением модуля, выполненного с возможностью определения концентрации аналита в образце физиологической жидкости, при этом система содержит одно или несколько устройств обработки данных, при этом одно или несколько устройств обработки данных выполнены с возможностью
- обеспечения первого набора данных измерения, при этом первый набор данных измерения представляет первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка (31) одной или нескольких тест-полосок (30а), при этом изображения
- указывают на изменение цвета интересующего участка (31) в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок (31); и
- записаны множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве, при этом устройства снабжены камерами различных типов, применяемыми для снятия изображений, или при этом устройства снабжены различными программными приложениями, применяемыми в устройствах для обработки снятых изображений;
- создания модели нейронной сети в процессе машинного обучения, применяющем искусственную нейронную сеть, содержащего
- обеспечение модели нейронной сети;
- создание из первого набора данных измерения обучающих данных, подтверждающих данных и тестовых данных; и
- обучение модели нейронной сети с помощью обучающих данных, причем обучающие данные представляют всю совокупность устройств и типов экспериментов; и
- создания реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети;
причем реализуемый программным обеспечением модуль выполнен с возможностью, при загрузке в устройство обработки данных, имеющее один или несколько процессоров, определения концентрации аналита во втором образце физиологической жидкости на основе анализа второго набора данных измерения, указывающих на вторую информацию о цвете, полученную путем обработки изображений из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение второго образца физиологической жидкости, содержащей аналит, на интересующий участок.
12. Система для определения концентрации аналита в образце физиологической жидкости, при этом система содержит одно или несколько устройств обработки данных, при этом одно или несколько устройств обработки данных выполнены с возможностью
- обеспечения данного набора данных измерения, указывающих на данную информацию о цвете, полученную путем обработки изображений из изображений интересующего участка (31) данной тест-полоски, при этом изображения указывают на изменение цвета интересующего участка (31) в ответ на нанесение данного образца физиологической жидкости, содержащей аналит, на интересующий участок (31);
- обеспечения реализуемого программным обеспечением модуля, содержащего первый анализирующий алгоритм, представляющий модель нейронной сети, созданную в процессе машинного обучения, применяющем искусственную нейронную сеть;
- определения концентрации аналита в данном образце физиологической жидкости, содержащего анализ данного набора данных измерения с помощью первого анализирующего алгоритма; и
- создания данных о концентрации, указывающих на концентрацию аналита в данном образце физиологической жидкости;
причем создание модели нейронной сети в процессе машинного обучения содержит
- обеспечение первого набора данных измерения, при этом первый набор данных измерения
- указывает на первую информацию о цвете, полученную путем обработки данных изображения из изображений интересующего участка одной или нескольких тест-полосок, при этом изображения указывают на изменение цвета интересующего участка в ответ на нанесение одного или нескольких первых образцов физиологической жидкости, содержащей аналит, на интересующий участок; и
- представляет первую информацию о цвете, полученную из изображений, записанных множеством устройств, каждое из которых выполнено с возможностью записи изображения и обработки данных изображения для создания первой информации о цвете, при этом множество устройств предусмотрено с различной конфигурацией программного и/или аппаратного обеспечения устройства, применяющейся для записи изображения и обработки данных изображения в устройстве, при этом устройства снабжены камерами разных типов, применяемыми для снятия изображений, или при этом устройства снабжены различными программными приложениями, применяемыми в устройствах для обработки снятых изображений;
- создание из первого набора данных измерения обучающих данных, подтверждающих данных и тестовых данных; и
- обучение модели нейронной сети с помощью обучающих данных, причем обучающие данные представляют всю совокупность устройств и типов экспериментов.
13. Машиночитаемый носитель информации с сохраненным на нем программным кодом, причем программный код выполнен с возможностью, при загрузке в компьютер, имеющий один или несколько процессоров, выполнения способа по одному из пп. 1-10.
| WO 2018194525 A1, 25.10.2018 | |||
| US 20180211380 A1, 26.07.2018 | |||
| US 20160048739 A1, 18.02.2016 | |||
| US 20060008923 A1, 12.01.2006. |

