Область техники, к которой относится изобретение
Предлагаемое изобретение относится к области обработки и анализа многомерных данных, машинного обучения.
Уровень техники
Обнаружение аномалий в многомерных данных - это поиск редких, непредвиденных образцов данных, событий или наблюдений, которые вызывают подозрения ввиду существенного отличия от нормальных данных. Стоит отметить, что аномалии в некоторых источниках могут упоминаться как выбросы. Обычно аномальные данные характеризуют некоторый вид проблемы, интерпретирующийся различным образом в зависимости от источника данных и прикладной области (ошибки при получении и сборе данных, отклонение поведения системы от нормального и ожидаемого, поломки, аварии, преднамеренные взломы и т.д.).
Решение задачи поиска аномалий состоит из двух основных этапов:
1) определение области, представляющей собой нормальное поведение исследуемого объекта, на основе имеющихся нормальных данных об объекте;
2) поиск данных, которые находятся за пределами этой области.
Таким образом, аномалия определяется не по собственным характеристикам, а в результате сравнения с тем, что есть норма.
Несмотря на известность ряда статистических способов обнаружения аномалий, в настоящее время для решения задач поиска аномалий чаще применяются нейронные сети и другие методы машинного обучения. Такое решение обусловлено известными ограничениями статистических методов, выражающимися в их применимости только для ограниченного ряда практических задач.
При этом задача обнаружения аномалий в многомерных данных актуальна для множества прикладных областей:
• в промышленности для обнаружения неполадок и угроз безопасности,
• в сфере информационной безопасности для обнаружения сетевых и пользовательских аномалий как признаков кибератак,
• в медицине для ранней диагностики заболеваний,
• в банковской сфере для обнаружения подозрительных транзакций и т.д., а ее решение позволит своевременно обнаруживать нештатные ситуации, которые могут повлечь за собой серьезный ущерб.
Задача обнаружения аномалий в многомерных данных сводится к поиску аномальных образцов данных, представленных в виде числовой последовательности, среди множества других образцов. В большинстве случаев для интеллектуального решения такой задачи используют нейронную сеть типа автокодировщик. Известны способы обнаружения аномалий для конкретных прикладных областей, использующие автокодировщик.
Известен способ обнаружения аномалий (заявка США №2020349470, приоритет от 11.02.2017 г.), согласно которому для обнаружения аномалий используется автокодировщик, который включает входной слой, скрытые слои меньшего размера и выходной слой, при этом входной и выходной слои имеют одинаковый размер. На первом шаге способа в сконфигурированный автокодировщик вводятся данные для обучения; затем следует обучение для настройки параметров автокодировщика таким образом, чтобы обучающая выборка, поданная на входной слой, воспроизводилась в выходном слое с минимальной ошибкой. На втором шаге способа на вход обученного автокодировщика подается тестовая выборка, для обнаружения аномалий в которой осуществляется вычисление степени аномальности тестовых данных на основе выходных данных автокодировщика и тестовой выборки. При этом степень аномальности может рассчитываться на основе средневзвешенной ошибки реконструкции между тестовыми и восстановленными автокодировщиком данными.
Описанный способ имеет следующие недостатки:
• отсутствует удаление дубликатов строк из обучающей выборки с целью ускорения процесса обучения автокодировщика;
• отсутствует удаление выбросов из обучающей выборки, что делает возможным ошибочное распознавание аномалий как нормы.
Известен также способ обнаружения аномальных транзакций электронных платежей (заявка США № 2020210849, приоритет от 31.12.2018 г.), согласно которому на первом шаге осуществляется доступ к данным, содержащим множество транзакций за прошлые периоды. На следующем шаге из множества транзакций определяется множество законных транзакций и осуществляется обучение автокодировщика. Обученный автокодировщик способен измерять сходство новой транзакции с множеством законных транзакций. После ввода во входной слой обученного автокодировщика новой транзакции происходит реконструкция транзакции на выходном слое. На последнем шаге определяют, является ли новая транзакция аномальной, на основе ошибки реконструкции между новой транзакцией и реконструированной транзакцией. При этом определение обучающей выборки законных транзакций из множества исторических транзакций осуществляется на основе правил или с привлечением эксперта.
Этот способ принимается в качестве прототипа. Однако известный способ имеет следующие недостатки:
• отсутствует удаление дубликатов строк из обучающей выборки с целью ускорения процесса обучения автокодировщика;
• удаление выбросов из обучающей выборки осуществляется на основе эвристических правил или с помощью человека, что далеко не всегда возможно ввиду специфики прикладных областей, а также значительного размера и сложности обучающей выборки;
• используемый способ удаления выбросов из обучающей выборки делает возможным удаление из обучающей выборки нормальных транзакций и пропуск аномальных, что может повысить количество ошибок первого (false positive) и второго рода (false negative).
Раскрытие изобретения
Техническим результатом является:
1) сокращение времени подготовки автокодировщика к обнаружению аномалий;
2) уменьшение количества ошибок первого (false positive) и второго рода (false negative) при обнаружении аномалий.
Для этого предлагается способ обнаружения аномалий в многомерных данных в вычислительной системе, включающей:
• по крайней мере один персональный компьютер, имеющий установленную операционную систему и прикладные программы и выполненный с возможностью:
- хранить и обрабатывать одномерные и двухмерные числовые массивы данных;
- обеспечивать формирование, функционирование и обучение нейронной сети типа автокодировщик; заключающийся в том, что:
• запускают персональный компьютер в режиме контролируемой нормальной работы;
• формируют обучающую выборку, представляющую собой двухмерный числовой массив;
• выбирают минимальное и достаточное для обучения автокодировщика количество строк обучающей выборки Nmin;
• если количество строк сформированной обучающей выборки N превышает Nmin, то сжимают обучающую выборку, выполняя следующие действия:
- вычисляют коэффициент сжатия Kcmp=N/Nmin;
- создают пустой двухмерный числовой массив Tcmp;
- находят количество повторов Ri каждой уникальной строки в обучающей выборке, где i – номер уникальной строки;
- для каждой уникальной строки i вычисляют Rmini=Ri/Kcmp и округляют получившийся Rmini до ближайшего целого числа, при этом, если в результате округления Rmini оказывается равным 0, то устанавливают Rmini=1;
- каждую уникальную строку i добавляют Rmini раз в конец массива Tcmp;
- в качестве обучающей выборки используют массив Tcmp;
• формируют первый автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя;
• обучают первый автокодировщик с использованием обучающей выборки;
• выбирают точность округления значений IRE;
• вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления;
• на основании полученных значений IRE формируют два одномерных числовых массива: массив IREu, содержащий только уникальные значения IRE в порядке возрастания, массив IREc, содержащий количества повторов уникальных значений IRE для обучающей выборки;
• если массив IREu содержит менее трех элементов, и первый элемент массива равен 0, то устанавливают первый элемент массива равным 0.01;
• устанавливают порог мгновенной ошибки реконструкции IREm равным IREu0, где 0 - номер первого элемента массива;
• если массив IREu содержит более одного элемента, то выполняют следующие действия:
- выбирают значение критерия выброса Kout;
- если массив IREu содержит два элемента, и при этом IREu1 - IREu0≤Kout, то устанавливают IREm равным IREu1;
- если массив IREu содержит более двух элементов, то выполняют следующие действия:
1) находят наибольшее значение CNTm массива IREc;
2) вычисляют одномерный массив метрик М по формуле:
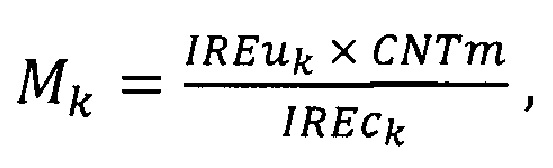
где k - номер элемента массива IREu;
3) получают массив Msrt путем сортировки элементов массива М по возрастанию;
4) устанавливают порог мгновенной ошибки реконструкции IREm равным значению последнего элемента массива IREu, при этом переменной Kan присваивают значение 0;
5) выполняют проверку элементов массива IREu, начиная с третьего от начала и до последнего, где k - номер текущего элемента массива, нумерацию начинают с 0, причем, если для k-го элемента массива одновременно выполняются два условия:
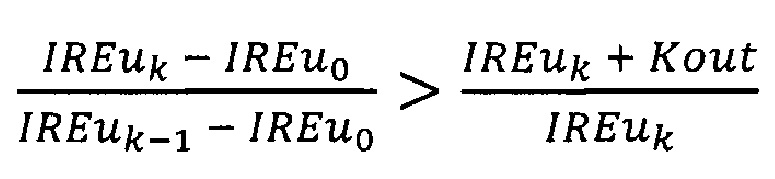
и
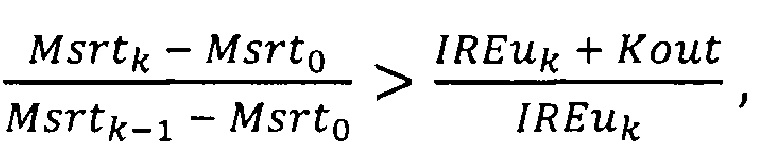
то проверку массива IREu прекращают, при этом текущее значение k присваивают переменной Kan;
если Kan>0, то выполняют проверку элементов массива IREu в обратном порядке, начиная с последнего элемента и до элемента с номером Kan, где n - номер текущего элемента массива, причем, если для n-го элемента массива выполняется условие Mn≥MsrtKan,
то устанавливают IREm равным IREun-1, иначе проверку массива IREu прекращают;
• удаляют из обучающей выборки выбросы - строки, для которых IREj>IREm,
где j - номер строки обучающей выборки;
• удаляют из обучающей выборки дубликаты строк;
• удаляют первый автокодировщик;
• формируют второй автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя;
• обучают второй автокодировщик с использованием полученной обучающей выборки;
• вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления;
• устанавливают порог мгновенной ошибки реконструкции IREm равным наибольшему значению IRE для обучающей выборки;
• формируют тестовую выборку, представляющую собой двухмерный числовой массив;
• выполняют реконструкцию тестовой выборки обученным вторым автокодировщиком;
• вычисляют IRE для каждой строки тестовой выборки и округляют с выбранной точностью округления;
• если IRE строки тестовой выборки превышает IREm, то данная строка считается аномальной и помечается;
• формируют отчет об обнаруженных в тестовой выборке аномальных строках.
Дополнительно в способе вместо первого и второго автокодировщика используют первый и второй разреженный автокодировщик.
Кроме того, в способе вместо первого и второго автокодировщика используют первый и второй сжимающий автокодировщик.
В предложенном способе многомерные данные представляют в виде обучающей выборки. Причем многомерные данные - это данные, которые могут быть представлены в табличном виде и содержат информацию о трех или более признаках, характеризующих каждый исследуемый на аномальность объект (событие, процесс, материальный объект и др.). Например, общеизвестен многомерный набор данных «Ирисы Фишера» (сведения по адресу http://archive.ics.uci.edu/ml/datasets/Iris), содержащий измерения четырех признаков (длина, ширина лепестка и длина, ширина чашелистика) для каждого из 150 экземпляров ириса.
Обучающая выборка - это двухмерный числовой массив (матрица), содержащий многомерные данные и предназначенный для обучения нейронной сети (в способе - автокодировщика). Причем, каждая строка массива содержит совокупность значений признаков, характеризующих один объект. Строки обучающей выборки, в общем случае одномерные числовые массивы, называют по-разному: примеры, образцы, строки, векторы. Представление объекта в виде ограниченной совокупности значений его признаков приводит к потере части информации об объекте. В связи с этим похожие объекты представляются одинаково в ограниченном пространстве признаков, а обучающая выборка оказывается избыточной (содержит дубликаты строк). Известно, что избыточность обучающей выборки уменьшает скорость обучения нейронной сети и негативно влияет на качество обучения ввиду настройки нейронной сети на распознавание только часто встречающихся в обучающей выборке объектов. Также возможно наличие в обучающей выборке выбросов, которые характеризуются существенным отличием от нормы и минимальным количеством повторов.
Сначала выбирают минимальное и достаточное для обучения автокодировщика количество строк обучающей выборки Nmin. Причем, выбор Nmin выполняется экспериментально один раз для рассматриваемых многомерных данных и заключается в подборе такого значения Nmin, которое бы обеспечивало, как наискорейшее обучение автокодировщика, так и выявление всех известных выбросов в обучающей выборке, количество которых должно быть не менее 1% от размера обучающей выборки. Для проверки правильности выбора Nmin эксперимент проводят не менее 3 раз с разными обучающими выборками. Далее в ходе сжатия обучающую выборку размером N сокращают до размера, максимально приближенного к Nmin, при этом пропорции количества повторов уникальных строк в обучающей выборке сохраняются. В качестве метода округления используют математическое округление до ближайшего целого числа.
После сжатия обучающей выборки формируют и обучают первый автокодировщик с использованием сжатой обучающей выборки. Автокодировщик - это нейронная сеть специальной архитектуры, которая обучается кодировать поступающие на вход примеры так, чтобы восстанавливать их из внутреннего представления низкой размерности на выходном слое с минимальной ошибкой. Условно автокодировщик состоит из двух частей: энкодера, который кодирует поступающие на вход примеры в свое внутреннее представление низкой размерности, и декодера, который восстанавливает примеры на выходе в исходной размерности. Простейшая архитектура автокодировщика - нейронная сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая: входной слой, промежуточный слой и выходной слой, причем размеры входного и выходного слоев совпадают, а промежуточный слой должен иметь меньшую размерность. Если размерность (количество признаков) примера высока, что характерно для многомерных данных, то архитектура автокодировщика усложняется - увеличивается количество промежуточных слоев. Особенность архитектуры автокодировщика заключается в том, что размерность входного и выходного слоев (количество нейронов в них) должна совпадать с размерностью примера, а размерность промежуточных слоев постепенно уменьшается до минимального среднего слоя «узкое горло», а затем снова увеличивается до выходного слоя. Восстановление примера на выходе автокодировщика называют реконструкцией, а ошибку, с которой автокодировщик восстановил пример - мгновенной ошибкой реконструкции (Immediate Reconstruction Error, IRE). Мгновенная ошибка реконструкции подаваемого на вход автокодировщика одномерного числового массива X (x1, х2, …, xm) длины m рассчитывается по формуле:

где Y (y1, y2, …, ym) - одномерный числовой массив, восстановленный на выходном слое автокодировщика.
После обучения автокодировщика примеры обучающей выборки и близкие к ним восстанавливаются автокодировщиком с минимальной мгновенной ошибкой реконструкции (ошибкой реконструкции), а сильно отличающиеся примеры восстанавливаются с большой ошибкой реконструкции, что и позволяет обнаруживать аномальные примеры - по высокой ошибке реконструкции.
В предложенном способе после второго обучения происходит выбор порога ошибки реконструкции, который далее используется следующим образом: если ошибка реконструкции тестового примера превышает порог, то пример является аномальным, в противном случае - нормальным.
Если подать обучающую выборку на вход обученного автокодировщика, выполнить реконструкцию строк обучающей выборки, а затем вычислить и построить график ошибки реконструкции, то в случае наличия выбросов в обучающей выборке на графике будут видны пики. Предложенный способ позволяет обнаруживать пики, соответствующие сильно отличающимся от нормы и редко встречающимся в обучающей выборке строкам - выбросам, и удалять из обучающей выборки такие строки.
Для удаления выбросов из обучающей выборки в способе используются две эмпирические величины: точность округления значений IRE и критерий выброса Kout, которые выбираются экспериментально один раз для рассматриваемых многомерных данных. Эксперимент заключается в том, что в обучающую выборку добавляют некоторое количество (не менее 1% от размера обучающей выборки) строк, являющихся выбросами по отношению к обучающей выборке. После обучения автокодировщика на получившейся обучающей выборке и вычисления значений ошибки реконструкции подбирают такие эмпирические величины, при которых в качестве выбросов обнаруживаются только все добавленные строки. Для проверки правильности выбора эмпирических величин эксперимент проводят не менее 5 раз с разными обучающими выборками. В качестве метода округления используют математическое округление до ближайшего числа в естественной форме с фиксированной точкой и заданной точностью округления.
Удаление выбросов из обучающей выборки позволяет избежать обучения автокодировщика на аномальных примерах, которое приводит к росту ошибок второго рода - когда аномалия распознается как нормальный пример (false negative). Во многих прикладных областях ошибки второго рода способа обнаружения аномалий могут нанести существенный ущерб.
Также стоит отметить, что в случае отсутствия выбросов в обучающей выборке из нее ничего не удаляется. Такое свойство предложенного способа является преимуществом по сравнению, например, с таким часто используемым методом машинного обучения, как метод опорных векторов (Support Vector Machines, SVM), обязательным условием использования которого является задание параметра, содержащего ненулевую долю аномалий в обучающей выборке, которые требуется отбросить. В общем случае, при отсутствии выбросов в обучающей выборке SVM все равно выделит в качестве аномалий редко встречающиеся и наиболее отдаленные от основного класса нормальные примеры. Исключение нормальных примеров из обучающей выборки и дальнейшее обучение автокодировщика на такой обучающей выборке приведет к росту ошибок первого рода - когда нормальные примеры распознаются как аномалии (false positive).
После удаления выбросов из обучающей выборки удаляют дубликаты строк. Это полезно для обучения, так как избыточность обучающей выборки увеличивает время обучения, а наличие в обучающей выборке наборов одинаковых строк негативно влияет на качество обучения ввиду настройки автокодировщика на распознавание только объектов, которых в обучающей выборке представлено больше. В результате формируется обучающая выборка, не содержащая выбросов и дубликатов строк и обеспечивающая наискорейшее обучение автокодировщика. На этом первый этап обучения завершается, а первый автокодировщик больше не используется и удаляется, поскольку он был необходим только для уточнения состава обучающей выборки.
Второй автокодировщик обучают с использованием полученной выше оптимизированной обучающей выборки, и целью этого этапа является получение обученного автокодировщика, который далее будет использоваться для обнаружения аномалий в тестовых данных.
После обучения второго автокодировщика для каждой строки обучающей выборки вычисляют мгновенную ошибку реконструкции по формуле (1). Наибольшее значение полученных ошибок принимается в качестве порога ошибки реконструкции (порога), который необходим далее для обнаружения аномалий.
Тестовая выборка - это набор многомерных данных, количество признаков объектов в котором равно количеству признаков объектов в обучающей выборке. Другими словами, количество столбцов обучающей и тестовой выборок должно совпадать. С тестовой выборкой не выполняют никаких оптимизирующих операций. Тестовая выборка в обучении не участвует.
После реконструкции тестовой выборки обученным вторым автокодировщиком для каждой строки тестовой выборки вычисляют ошибку реконструкции по формуле (1). Если полученная для очередной строки ошибка реконструкции больше порога, то строка считается аномальной по отношению к обучающей выборке и заносится в отчет об аномалиях. В противном случае строка считается похожей на примеры обучающей выборки и нормальной.
Помимо автокодировщика, использующегося в способе, существуют и другие виды автокодировщиков того же назначения: разреженный автокодировщик (sparse autoencoder) и сжимающий автокодировщик (contractive autoencoder). Они отличаются друг от друга архитектурой и особенностями функционирования, при этом каждый из них предназначен для работы с данными, обладающими определенными свойствами.
Например, автокодировщик, использующийся в способе, применяется, когда в данных немного зависимостей и ключевых свойств. А разреженный автокодировщик, наоборот, эффективен для исследования данных с большим количеством внутренних зависимостей и неявных, скрытых свойств, а также данных, включающих разные классы. В отличие от автокодировщика, использующегося в способе, скрытый слой разреженного автокодировщика содержит больше нейронов, чем во входном и выходном слое. При этом для определенных классов входных данных активируются лишь определенные нейроны скрытого слоя.
Особенность сжимающих автокодировщиков заключается в сжатии похожих входных данных в одну точку в скрытом пространстве. Благодаря данному свойству такие автокодировщики устойчивы к изменениям в данных и могут быть использованы, например, в случае риска зашумления или повреждения входных данных.
В зависимости от специфики исходных данных в предлагаемом способе может быть использован любой из описанных типов автокодировщиков.
Заявленный технический результат достигается благодаря следующему.
1. Чем меньше строк в обучающей выборке, тем быстрее происходит обучение автокодировщика. Используемые в способе сжатие обучающей выборки и удаление дубликатов из обучающей выборки позволяют уменьшить количество строк в обучающей выборке и таким образом уменьшить время обучения первого и второго автокодировщиков по сравнению с обучением на полных выборках.
2. Предложенный способ позволяет обнаружить и удалить из обучающей выборки строки, которые значениями признаков сильно отличаются от основной массы строк обучающей выборки, а также повторяются редко и, таким образом, являются выбросами по отношению к обучающей выборке. Если в обучающей выборке подобных выбросов нет, то ничего удалено не будет. Описанные операции происходят без участия человека и использования ограниченных сигнатурных и эмпирических правил. В результате, не происходит обучения второго автокодировщика на выбросах, что снижает количество ошибок второго рода (false negative), и не происходит удаления из обучающей выборки нормальных строк, что снижает количество ошибок первого рода (false positive).
Осуществление изобретения
Предлагаемый способ может быть реализован в следующей программно-аппаратной среде.
В качестве вычислительной системы выбирается персональный компьютер со следующими аппаратными характеристиками:
• процессор Intel Core i7-4770 3.40GHz;
• оперативная память 16GB;
• жесткий диск SSD 240GB,
и установленным программным обеспечением:
• операционная система Microsoft Windows 10;
• Python 3.7.2;
• модули Python: numpy 1.16.4, Keras 2.3.1, tensorflow 1.14.0.
Далее рассмотрим вариант реализации способа, заключающийся в обнаружении аномальных запусков таких системных утилит, как: powershell.exe, rundll32.exe, cscript.exe и других на персональном компьютере под управлением операционной системы Microsoft Windows. Подобные аномальные по отношению к нормальному поведению хоста запуски могут быть признаками бесфайловых атак, атак нулевого дня и не всегда могут быть обнаружены традиционными сигнатурными методами.
Метод оцифровки данных предметной области и выбор признаков объектов всегда специфичны для предметной области, требуют экспертных знаний и не являются частью предлагаемого способа. Тем не менее далее рассмотрим, как происходит оцифровка данных и формирование изначальной обучающей и тестовой выборок в данном варианте реализации.
Информация о запусках системных утилит может быть извлечена из записей журналов безопасности Windows. В данном варианте реализации в качестве данных для оцифровки используется только выполненная командная строка, содержащаяся в секции <CommandLine> записи. Сбор данных для формирования обучающей выборки выполняется в течение 30 дней, при этом данные сохраняются в файл на жестком диске компьютера.
Пример командной строки запуска утилиты cscript.exe из записи события:

Для того, чтобы преобразовать строку такого типа в числовое представление без потери информации о параметрах, предлагается для каждой командной строки формировать числовой вектор фиксированной длины, элементы которого будут заполняться в соответствии с найденными в строке составляющими - параметрами. Для этого строка разбивается на подстроки или токены, принадлежность которых к определенному классу определяется с помощью регулярных выражений. Каждая ячейка вектора, а в некоторых случаях две подряд идущие ячейки вектора, соответствуют некоторому классу параметров, которые могут присутствовать в строке запуска утилиты. В случае совпадения токена из векторизуемой строки запуска с одним из классов, описываемых регулярными выражениями, заполняются соответствующие этому классу одна или несколько ячеек вектора. В общем случае, в каждую ячейку вектора заносится количество совпадений с регулярным выражением класса. Для описания некоторых классов параметров используются две ячейки, где первая соответствует количеству совпадений, а вторая - количеству символов в токене. В случае, если токен - путь, то в ячейку, соответствующую классу этого пути, заносится степень неизвестности пути относительно заранее построенного по обучающей выборке дерева известных путей (дерева).
Степень неизвестности пути определяется на основе расстояния проверяемого пути от путей дерева. Для всех путей из обучающей выборки степень неизвестности минимальна и равна 1. Для путей, отличающихся от путей дерева, степень неизвестности будет больше 1. Для путей, значительно отличающихся от путей дерева, степень неизвестности будет максимальна и равна 1,9. В табл.1 приведены классы параметров, которые чаще всего встречаются в строках запуска утилит, примеры токенов каждого класса, а также смысловое значение каждой ячейки вектора.
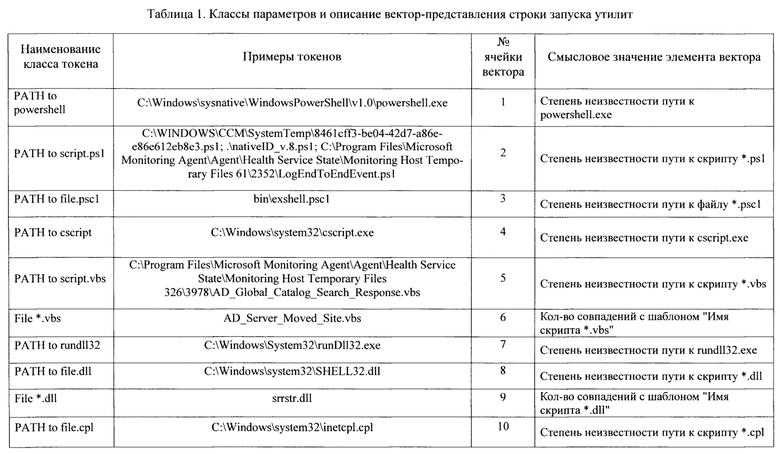
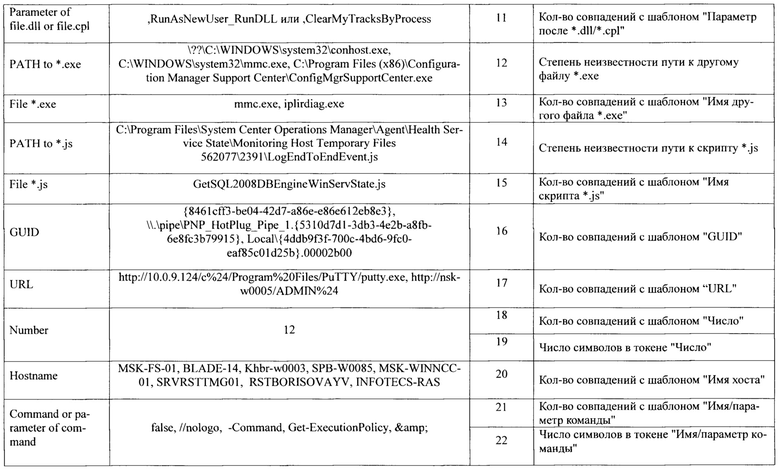
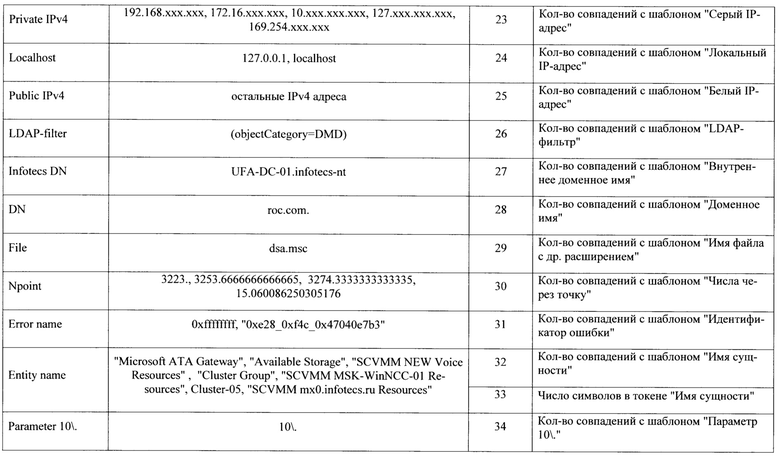

В соответствии с табл. 1 командная строка запуска утилиты может быть описана числовым вектором длиной 41 элемент. Перечислим этапы процесса оцифровки командной строки в вектор.
1. Выделение содержимого секции <CommandLine> записи события запуска утилиты. В результате получаем командную строку.
2. Разбиение командной строки на токены.
3. Классификация полученных токенов с использованием регулярных выражений.
4. Расчет значений элементов вектора для токенов командной строки.
Совокупность векторов является начальной обучающей выборкой способа, в которой каждому вектору соответствует одна строка обучающей выборки.
Формирование тестовой выборки выполняется аналогично за тем исключением, что данные для очередной тестовой выборки в описываемом варианте реализации способа собирают в течение 15 мин, после чего происходит их оцифровка, анализ при помощи автокодировщика и сбор следующей тестовой выборки.
Далее рассмотрим обработку данных, собранных на сервере под управлением Microsoft Windows в течение 30 дней. После оцифровки получают изначальную обучающую выборку размером N=40288 строк, из которых уникальных - 45 строк. Все остальное - дубликаты уникальных строк. Такое малое количество уникальных строк характерно для узкоспециализированных серверов.
Сначала выбирают размер сжатой обучающей выборки Nmin=7000 строк. Данный выбор базируется на отдельном эксперименте, в котором в обучающую выборку (не обязательно ту, о которой идет речь выше) добавляют некоторое количество аномальных строк (не менее 1% от размера обучающей выборки), и подбирают такое значение Nmin, при котором все аномальные строки корректно обнаруживаются обученным на сжатой обучающей выборке автокодировщиком (имеют высокую ошибку IRE по сравнению с IRE нормальных строк), и при этом время обучения минимально. Для подтверждения правильности выбора Nmin описанный эксперимент может быть проведен 3-5 раз для различных обучающих выборок. Найденный размер Nmin далее используется при сжатии всех обучающих выборок рассматриваемой предметной области и модели данных, для которых выполняется условие N>Nmin.
Коэффициент сжатия для изначальной обучающей выборки будет равен
Kcmp=40288/7000=5.755
После выполнения сжатия с использованием рассчитанного коэффициента получают сжатую обучающую выборку размером 7006 строк. Наличие дополнительных шести строк является результатом установки одного повтора для тех строк, для которых количество повторов в сжатой обучающей выборке оказалось равным 0. Благодаря этому не происходит потерь редких уникальных строк.
Первый и второй автокодировщики способа имеют одинаковую архитектуру: 9 слоев, количество нейронов в слоях - 41, 28, 20, 15, 10, 15, 20, 28, 41. Параметры обучения обоих автокодировщиков также выбирают одинаковыми: среднеквадратичная ошибка, до которой происходит обучение, MSE_stop=0.005; максимальное количество эпох обучения - 60000.
После обучения первого автокодировщика и вычисления ошибки реконструкции IRE для каждой строки сжатой обучающей выборки получают одномерный массив ошибок реконструкции размером 7006 элементов и приступают к обнаружению и удалению выбросов из обучающей выборки.
Выбирают точность округления значений ошибки реконструкции и критерий выброса Kout. Данный выбор базируется на отдельном эксперименте, в котором в обучающую выборку без выбросов (не обязательно ту, о которой идет речь выше) добавляют некоторое количество аномальных строк - выбросов (не менее 1% от размера обучающей выборки), причем эти строки должны значениями элементов существенно отличаться от нормальных строк и повторяться в обучающей выборке один раз. Далее подбирают такие точность округления и критерий Kout, при которых после обучения автокодировщика на обучающей выборке с выбросами в качестве выбросов обнаруживаются только добавленные аномальные строки. Для подтверждения правильности выбора параметров описанный эксперимент может быть проведен 5-10 раз для различных обучающих выборок. Найденные точность округления и критерий выброса Kout далее используют для всех обучающих выборок рассматриваемой предметной области и модели данных. В данном варианте реализации способа округление значений IRE выполняют до сотых при записи чисел в естественной форме с фиксированной точкой. Критерий выброса составил 4.5.
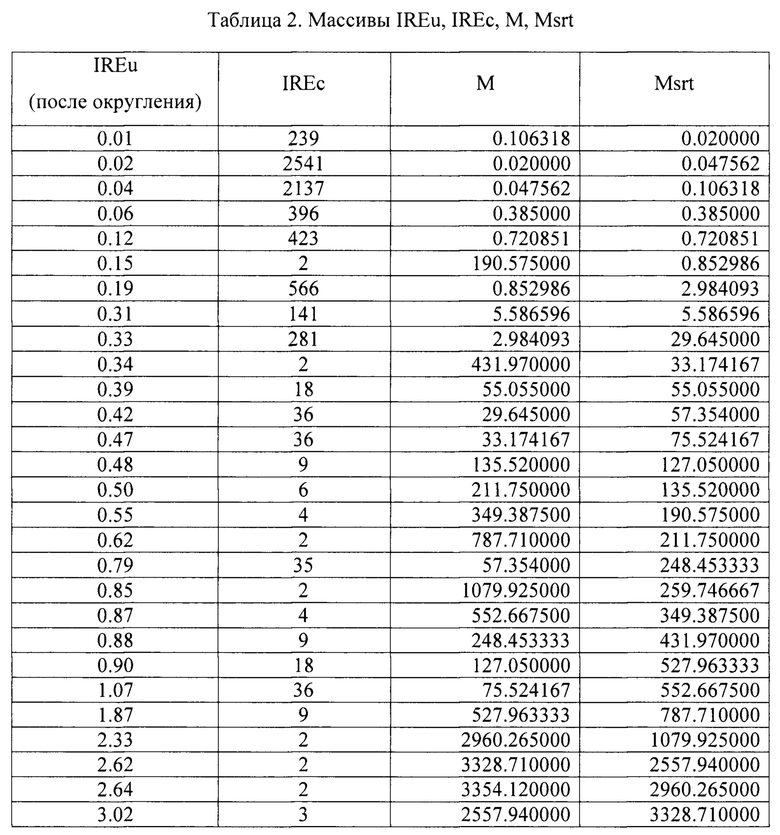
Вычисленные для обнаружения выбросов массивы IREu (уникальные значения IRE, отсортированные в порядке возрастания), IREc (количества повторов уникальных значений IRE), М (значения метрики), Msrt (значения массива М, отсортированные в порядке возрастания) представлены в табл. 2. Для вычисления значений массива М используют формулу:
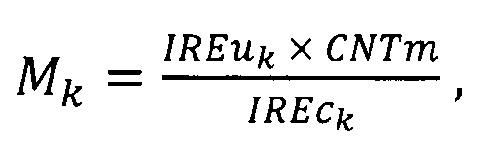
где k - номер элемента массива IREu;
CNTm - наибольшее значение массива IREc, равное в данном случае 2541.

Далее выполняют проверку элементов массива IREu, начиная с третьего от начала и до последнего, причем для каждого проверяют два условия:

и

где k - номер элемента массива IREu.
Первым по порядку элементом массива IREu, для которого выполняются условия (2) и (3) одновременно является значение IRE 8.18. Таким образом, возможными выбросами в массиве IREu являются значения: 8.18 и 8.80.
MsrtKan для значения IRE 8.18 равно 11180.4. Значения метрик М обоих возможных выбросов превышают либо равны значению MsrtKan.
Таким образом, в результате проведенных вычислений находят, что выбросами в массиве IREu являются значения 8.18 и 8.80, которым соответствуют количества повторов 1 и 2 соответственно. В качестве порога ошибки реконструкции IREm выбирают значение IRE 4.22, после чего удаляют из сжатой обучающей выборки соответствующие выбросы - строки, IRE которых превышает IREm. В результате из сжатой обучающей выборки удаляются 3 строки, остаются 7003 строки, из которых 43 уникальных.
Из получившейся обучающей выборки удаляют дубликаты строк, в результате чего получают итоговую обучающую выборку, включающую 43 уникальные строки. Данную обучающую выборку используют далее для обучения второго автокодировщика, который имеет архитектуру и параметры обучения полностью аналогичные первому автокодировщику, как было описано выше. Первый автокодировщик, предназначенный только для очистки обучающей выборки от выбросов, на данном этапе уже не нужен и удаляется из оперативной памяти компьютера.
После обучения второго автокодировщика для каждой строки итоговой обучающей выборки рассчитывают ошибку реконструкции IRE и округляют ее до сотых. В качестве порога ошибки реконструкции IREm принимают наибольшее полученное значение IRE. Для рассматриваемой в варианте реализации обучающей выборки оно составило 1.01. На этом этап подготовки второго автокодировщика к обнаружению аномалий считают завершенным, при необходимости обученный второй автокодировщик и значение IREm для него сохраняют на жесткий диск компьютера. Далее переходят к этапу обнаружения аномалий в тестовых выборках.
Как было описано выше, сбор данных для очередной тестовой выборки в рассматриваемом варианте реализации выполняют 15 мин, после чего происходит их оцифровка. Сжатие, удаление выбросов, удаление дубликатов строк для тестовой выборки не выполняют.
После реконструкции тестовой выборки обученным вторым автокодировщиком, для каждой строки рассчитывают ошибку реконструкции IRE и округляют ее до сотых. Аномальными считают те строки тестовой выборки, для которых выполняется условие IRE>IREm. Отчет об аномалиях формируют для каждой тестовой выборки отдельно и при необходимости сохраняют на жесткий диск компьютера. Отчет включает: аномальную командную строку, полную запись события, IRE, IREm. Если в тестовой выборке аномалий не обнаружено, то отчет не формируют.
После завершения обработки текущей тестовой выборки, начинают сбор данных для следующей тестовой выборки. Таким образом обнаружение аномалий и формирование отчетов о них происходит в непрерывном автоматическом режиме без участия пользователя.
В другом варианте осуществления изобретения вместо первого и второго автокодировщика используют первый и второй разреженный автокодировщик.
В еще одном варианте осуществления вместо первого и второго автокодировщика используют первый и второй сжимающий автокодировщик.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения. Специалисту в данной области понятно, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обнаружения аномального трафика в сети | 2023 |
|
RU2811840C1 |
| Способ обнаружения и противодействия атакам типа отказ в обслуживании | 2024 |
|
RU2841028C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ДАННЫХ, ПОДВЕРЖЕННЫХ ДЕАНОНИМИЗАЦИИ, В ОБЕЗЛИЧЕННОМ НАБОРЕ ДАННЫХ | 2024 |
|
RU2837785C1 |
| ИНТЕЛЛЕКТУАЛЬНОЕ АУДИОАНАЛИТИЧЕСКОЕ УСТРОЙСТВО И СПОСОБ ДЛЯ КОСМИЧЕСКОГО АППАРАТА | 2019 |
|
RU2793797C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ МОШЕННИЧЕСКИХ ТРАНЗАКЦИЙ ПОЛЬЗОВАТЕЛЯ | 2024 |
|
RU2839053C1 |
| СПОСОБ ОБНАРУЖЕНИЯ АНОМАЛИИ ГИПЕРСПЕКТРАЛЬНОГО ИЗОБРАЖЕНИЯ НА ОСНОВЕ МОДЕЛИ "ОБУЧАЮЩИЙ-ОБУЧАЕМЫЙ", КОМПЬЮТЕРНЫЙ НОСИТЕЛЬ ДАННЫХ И УСТРОЙСТВО | 2023 |
|
RU2817001C1 |
| Оценка толщины стенки сердца по результатам ЭКГ | 2020 |
|
RU2767883C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ОБФУСЦИРОВАННЫХ ВРЕДОНОСНЫХ КОМАНД В СИСТЕМНОЙ КОНСОЛИ ОПЕРАЦИОННОЙ СИСТЕМЫ | 2024 |
|
RU2838483C1 |
| Способ и система для предупреждения о предстоящих аномалиях в процессе бурения | 2021 |
|
RU2772851C1 |
| СПОСОБ ОБНАРУЖЕНИЯ АНОМАЛИЙ ФОРМЫ ЭЛЕКТРИЧЕСКОГО СИГНАЛА | 2021 |
|
RU2786156C1 |
Изобретение относится к способу обнаружения аномалий в многомерных данных в вычислительной системе. Технический результат заключается в сокращении времени подготовки автокодировщика к обнаружению аномалий и в уменьшении количества ошибок первого (false positive) и второго рода (false negative) при обнаружении аномалий. В способе запускают персональный компьютер в режиме контролируемой нормальной работы; формируют обучающую выборку, представляющую собой двухмерный числовой массив; выбирают минимальное и достаточное для обучения автокодировщика количество строк обучающей выборки Nmin; если количество строк сформированной обучающей выборки N превышает Nmin, то сжимают обучающую выборку, выполняя следующие действия: вычисляют коэффициент сжатия Kcmp=N/Nmin; создают пустой двухмерный числовой массив Tcmp; находят количество повторов Ri каждой уникальной строки в обучающей выборке, где i - номер уникальной строки; для каждой уникальной строки i вычисляют Rmini=Ri/Kcmp и округляют получившийся Rmini до ближайшего целого числа, при этом, если в результате округления Rmini оказывается равным 0, то устанавливают Rmini=1; каждую уникальную строку i добавляют Rmini раз в конец массива Tcmp; в качестве обучающей выборки используют массив Tcmp; далее формируют первый автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя; обучают первый автокодировщик с использованием обучающей выборки; выбирают точность округления значений IRE; вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления; на основании полученных значений IRE формируют два одномерных числовых массива: массив IREu, содержащий только уникальные значения IRE в порядке возрастания, массив IREc, содержащий количества повторов уникальных значений IRE для обучающей выборки; если массив IREu содержит менее трех элементов, и первый элемент массива равен 0, то устанавливают первый элемент массива равным 0.01; устанавливают порог мгновенной ошибки реконструкции IREm равным IREu0, где 0 - номер первого элемента массива; если массив IREu содержит более одного элемента, то выполняют следующие действия: выбирают значение критерия выброса Kout; если массив IREu содержит два элемента, и при этом IREu1-IREu0≤Kout, то устанавливают IREm равным IREu1; если массив IREu содержит более двух элементов, то выполняют следующие действия: находят наибольшее значение CNTm массива IREc; вычисляют одномерный массив метрик М по формуле: 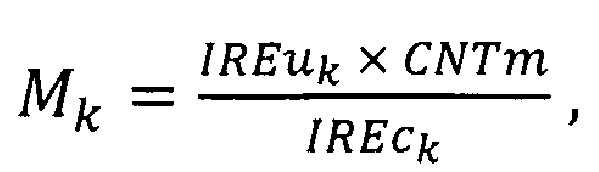 где k - номер элемента массива IREu; получают массив Msrt путем сортировки элементов массива М по возрастанию; устанавливают порог мгновенной ошибки реконструкции IREm равным значению последнего элемента массива IREu, при этом переменной Kаn присваивают значение 0; выполняют проверку элементов массива IREu, начиная с третьего от начала и до последнего, где k - номер текущего элемента массива, нумерацию начинают с 0, причем, если для k-го элемента массива одновременно выполняются два условия:
где k - номер элемента массива IREu; получают массив Msrt путем сортировки элементов массива М по возрастанию; устанавливают порог мгновенной ошибки реконструкции IREm равным значению последнего элемента массива IREu, при этом переменной Kаn присваивают значение 0; выполняют проверку элементов массива IREu, начиная с третьего от начала и до последнего, где k - номер текущего элемента массива, нумерацию начинают с 0, причем, если для k-го элемента массива одновременно выполняются два условия: 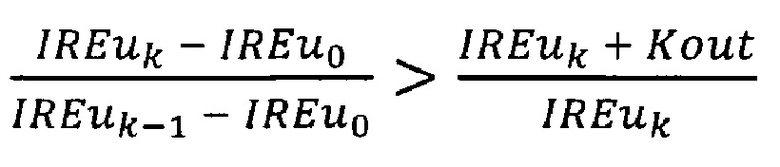 и
и 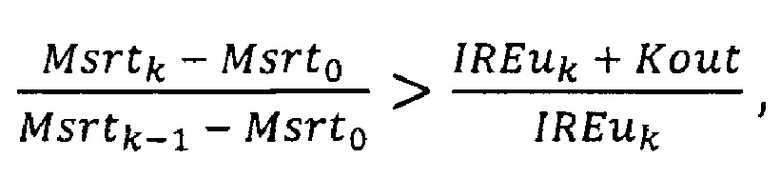 то проверку массива IREu прекращают, при этом текущее значение k присваивают переменной Kan; если Kan>0, то выполняют проверку элементов массива IREu в обратном порядке, начиная с последнего элемента и до элемента с номером Kan, где n - номер текущего элемента массива, причем, если для n-го элемента массива выполняется условие Mn≥MsrtKan, то устанавливают IREm равным IREun-1, иначе проверку массива IREu прекращают; удаляют из обучающей выборки выбросы - строки, для которых IREj>IREm, где j - номер строки обучающей выборки; удаляют из обучающей выборки дубликаты строк; удаляют первый автокодировщик; формируют второй автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя; обучают второй автокодировщик с использованием полученной обучающей выборки; вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления; устанавливают порог мгновенной ошибки реконструкции IREm равным наибольшему значению IRE для обучающей выборки; формируют тестовую выборку, представляющую собой двухмерный числовой массив; выполняют реконструкцию тестовой выборки обученным вторым автокодировщиком; вычисляют IRE для каждой строки тестовой выборки и округляют с выбранной точностью округления; если IRE строки тестовой выборки превышает IREm, то данная строка считается аномальной и помечается; формируют отчет об обнаруженных в тестовой выборке аномальных строках. 2 з.п. ф-лы, 2 табл.
то проверку массива IREu прекращают, при этом текущее значение k присваивают переменной Kan; если Kan>0, то выполняют проверку элементов массива IREu в обратном порядке, начиная с последнего элемента и до элемента с номером Kan, где n - номер текущего элемента массива, причем, если для n-го элемента массива выполняется условие Mn≥MsrtKan, то устанавливают IREm равным IREun-1, иначе проверку массива IREu прекращают; удаляют из обучающей выборки выбросы - строки, для которых IREj>IREm, где j - номер строки обучающей выборки; удаляют из обучающей выборки дубликаты строк; удаляют первый автокодировщик; формируют второй автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя; обучают второй автокодировщик с использованием полученной обучающей выборки; вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления; устанавливают порог мгновенной ошибки реконструкции IREm равным наибольшему значению IRE для обучающей выборки; формируют тестовую выборку, представляющую собой двухмерный числовой массив; выполняют реконструкцию тестовой выборки обученным вторым автокодировщиком; вычисляют IRE для каждой строки тестовой выборки и округляют с выбранной точностью округления; если IRE строки тестовой выборки превышает IREm, то данная строка считается аномальной и помечается; формируют отчет об обнаруженных в тестовой выборке аномальных строках. 2 з.п. ф-лы, 2 табл.
1. Способ обнаружения аномалий в многомерных данных в вычислительной системе, включающей:
по крайней мере один персональный компьютер, имеющий установленную операционную систему и прикладные программы и выполненный с возможностью:
хранить и обрабатывать одномерные и двухмерные числовые массивы данных;
обеспечивать формирование, функционирование и обучение нейронной сети типа автокодировщик;
заключающийся в том, что:
запускают персональный компьютер в режиме контролируемой нормальной работы;
формируют обучающую выборку, представляющую собой двухмерный числовой массив;
выбирают минимальное и достаточное для обучения автокодировщика количество строк обучающей выборки Nmin;
если количество строк сформированной обучающей выборки N превышает Nmin, то сжимают обучающую выборку, выполняя следующие действия:
вычисляют коэффициент сжатия Kcmp=N/Nmin;
создают пустой двухмерный числовой массив Tcmp;
находят количество повторов Ri каждой уникальной строки в обучающей выборке, где i - номер уникальной строки;
для каждой уникальной строки i вычисляют Rmini=Ri/Kcmp и округляют получившийся Rmini до ближайшего целого числа, при этом, если в результате округления Rmini оказывается равным 0, то устанавливают Rmini=1;
каждую уникальную строку i добавляют Rmini раз в конец массива Tcmp;
в качестве обучающей выборки используют массив Tcmp;
формируют первый автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя; обучают первый автокодировщик с использованием обучающей выборки;
выбирают точность округления значений IRE;
вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления;
на основании полученных значений IRE формируют два одномерных числовых массива: массив IREu, содержащий только уникальные значения IRE в порядке возрастания, массив IREc, содержащий количества повторов уникальных значений IRE для обучающей выборки;
если массив IREu содержит менее трех элементов, и первый элемент массива равен 0, то устанавливают первый элемент массива равным 0.01;
устанавливают порог мгновенной ошибки реконструкции IREm равным IREu0, где 0 - номер первого элемента массива;
если массив IREu содержит более одного элемента, то выполняют следующие действия:
выбирают значение критерия выброса Kout;
если массив IREu содержит два элемента, и при этом IREu1 - IREu0≤Kout,
то устанавливают IREm равным IREu1;
если массив IREu содержит более двух элементов, то выполняют следующие действия:
находят наибольшее значение CNTm массива IREc;
вычисляют одномерный массив метрик М по формуле:
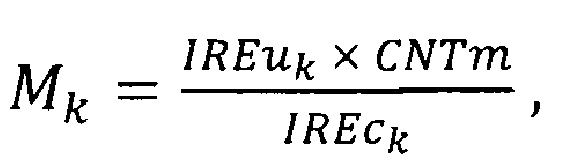
где k - номер элемента массива IREu;
получают массив Msrt путем сортировки элементов массива М по возрастанию;
устанавливают порог мгновенной ошибки реконструкции IREm равным значению последнего элемента массива IREu, при этом переменной Kan присваивают значение 0;
выполняют проверку элементов массива IREu, начиная с третьего от начала и до последнего, где k - номер текущего элемента массива, нумерацию начинают с 0, причем, если для k-го элемента массива одновременно выполняются два условия:
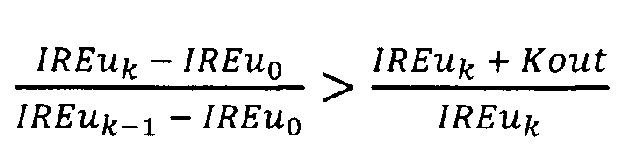
и
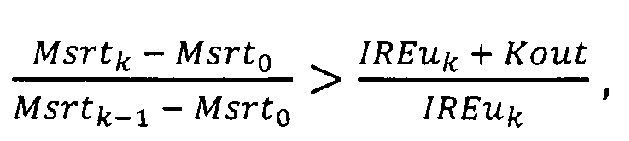
то проверку массива IREu прекращают, при этом текущее значение k присваивают переменной Kan;
если Kan>0, то выполняют проверку элементов массива IREu в обратном порядке, начиная с последнего элемента и до элемента с номером Kan, где n - номер текущего элемента массива, причем, если для n-го элемента массива выполняется условие Mn≥MsrtKan, то устанавливают IREm равным IREun-1, иначе проверку массива IREu прекращают;
удаляют из обучающей выборки выбросы - строки, для которых IREj>IREm,
где j - номер строки обучающей выборки;
удаляют из обучающей выборки дубликаты строк;
удаляют первый автокодировщик;
формируют второй автокодировщик, содержащий входной слой, по крайней мере один скрытый слой и выходной слой, причем размеры входного и выходного слоев совпадают, размер скрытого слоя меньше размера входного слоя; обучают второй автокодировщик с использованием полученной обучающей выборки;
вычисляют мгновенную ошибку реконструкции IREj для каждой строки j обучающей выборки и округляют IREj с выбранной точностью округления;
устанавливают порог мгновенной ошибки реконструкции IREm равным наибольшему значению IRE для обучающей выборки;
формируют тестовую выборку, представляющую собой двухмерный числовой массив;
выполняют реконструкцию тестовой выборки обученным вторым автокодировщиком;
вычисляют IRE для каждой строки тестовой выборки и округляют с выбранной точностью округления;
если IRE строки тестовой выборки превышает IREm, то данная строка считается аномальной и помечается;
формируют отчет об обнаруженных в тестовой выборке аномальных строках.
2. Способ по п. 1, в котором вместо первого и второго автокодировщика используют первый и второй разреженный автокодировщик.
3. Способ по п. 1, в котором вместо первого и второго автокодировщика используют первый и второй сжимающий автокодировщик.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| ОБНАРУЖЕНИЕ АНОМАЛИЙ ПЕРСПЕКТИВНЫХ ПРЕДСТАВЛЕНИЙ ДАННЫХ | 2005 |
|
RU2378694C2 |
| ВЫПОЛНЯЕМЫЙ В ОКНЕ СТАТИСТИЧЕСКИЙ АНАЛИЗ ДЛЯ ОБНАРУЖЕНИЯ АНОМАЛИЙ В НАБОРАХ ГЕОФИЗИЧЕСКИХ ДАННЫХ | 2011 |
|
RU2554895C2 |
| Способ определения источников аномалии в кибер-физической системе | 2020 |
|
RU2749252C1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| EP 3719711 A2, 07.10.2020 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |

