[001] Группа изобретений относится к области биотехнологии и генетической инженерии. В частности, изобретение относится к ферментам биолюминесцентной системы грибов.
Уровень техники
[002] Люциферазами называют ферменты, которые катализируют окисление низкомолекулярных соединений люциферинов, сопровождающееся испусканием света - биолюминесценцией. В результате окисления из люциферина образуется оксилюциферин, который высвобождается из комплекса с ферментом – люциферазой.
[003] Люциферазы широко используются в качестве репортерных генов в ряде биомедицинских приложений и в биотехнологии. Например, люциферазы используются для определения жизнеспособности клеток, активности промоторов и других компонентов живых систем, в исследованиях канцерогенеза на животных моделях, в способах выявления в среде микроорганизмов, токсических агентов, в качестве индикаторов для определения концентрации различных веществ, для визуализации прохождения сигнальных каскадов и т.д. [Scott et al., Annu Rev Anal Chem, 2011, 4: 297-319; Badr and Tannous, Trends Biotechnol. 2011, 29: 624-33; Andreu et al., FEMS Microbiol Rev. 2011, 35: 360-94]. Многие способы применения люцифераз описаны в обзорах [Kaskova et al., Chem Soc Rev., 2016, 45: 6048-6077; Scott et al., Annu Rev Anal Chem, 2011, 4: 297-319; Widder and Falls, IEEE Journal of Selected Topics in Quantum Electronics, 2014, 20: 232-241]. Все основные способы применения люцифераз включают детекцию света, испускаемого в зависимости от исследуемого явления или сигнала. В большинстве случаев детекция осуществляется с помощью люминометра или модифицированного оптического микроскопа.
[004] Известны тысячи способных к биолюминесценции видов, для которых описано около десятка различных по строению люциферинов и несколько десятков соответствующих им ферментов-люцифераз. Показано, что у различных организмов системы биолюминесценции возникали в эволюции независимо более сорока раз [Herring, Journal of Bioluminescence and Chemiluminescence, 1987, 1: 147-63; Haddock et al., Annual Review of Marine Science, 2010; 2: 443-93].
[005] Описана группа люцифераз насекомых, катализирующих окисление D-люциферина [de Wet et al., Proc. Natl. Acad. Sci. USA, 1985, 82: 7870-3; de Wet et al., Proc. Natl. Acad. Sci. USA, 1987, 7: 725-37]. Описана группа люцифераз, катализирующих окисление целентеразина [O. Shimomura, Bioluminescence: Chemical Principles and Methods, World Scientific Publishing Co. Pte. Ltd, Singapore, 2006, 470 p.]. Известны биолюминесцентные системы остракод рода Cypridina, которые характеризуются химически высокоактивным люциферином и высокостабильной люциферазой [Shimomura et al., Science, 1969, 164: 1299-300]. Также известны биолюминесцентные системы динофлагеллят и эвфаузиид. В настоящее время клонированы гены, кодирующие три люциферазы из этой группы [O. Shimomura, Bioluminescence: Chemical Principles and Methods, World Scientific Publishing Co. Pte. Ltd, Singapore, 2006]. Существенным недостатком данной системы является ее неполная изученность: полные люциферазные последовательности еще не установлены.
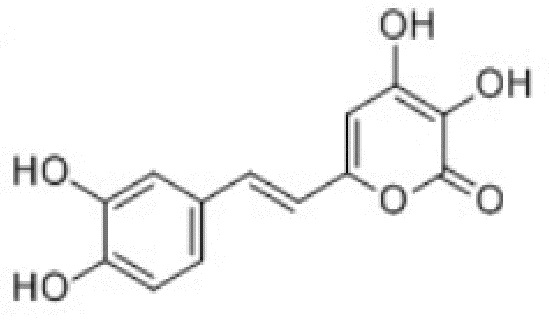
[006] Недавно были описаны группа люцифераз и люциферин биолюминесцентной системы грибов. Биолюминесценция грибов была известна на протяжении сотен лет, однако люциферин грибов был идентифицирован только в 2015 году: им оказался 3-гидроксигиспидин - способный проникать через мембраны клеток метаболит [Purtov et al., Angewandte Chemie, 2015, 54: 8124-28]. В этой же работе было подтверждено наличие в лизатах грибов фермента, осуществляющего гидроксилирование гиспидина с получением люциферина, однако фермент идентифицирован не был. В патентной заявке №2017102986 от 30.01.2017 были описаны гены люцифераз из нескольких грибов, использующие в качестве люциферина 3-гидроксигиспидин, имеющий структуру:
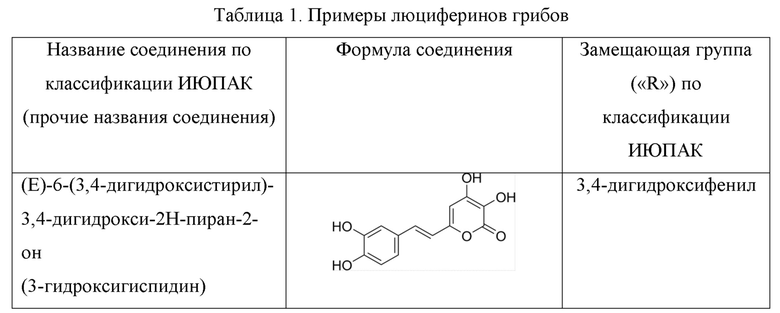
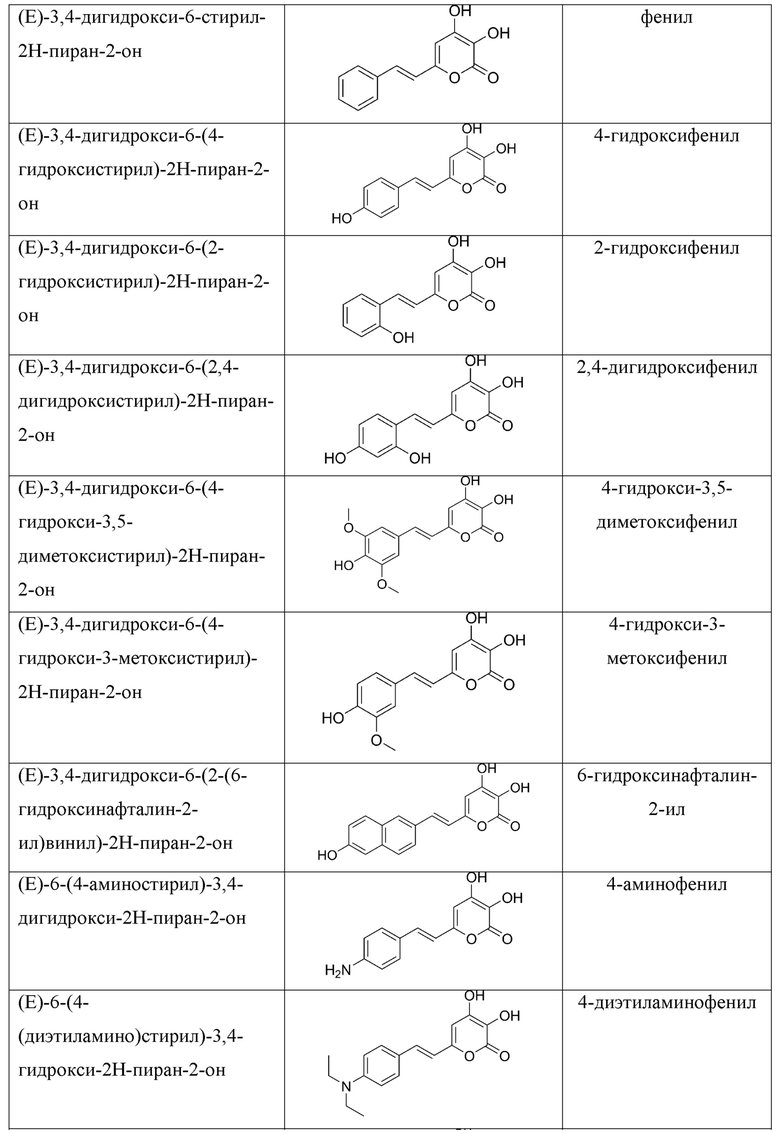
[007] Было показано, что люциферазы грибов могут катализировать сопровождающееся выделением света окисление и других химических соединений, структуры которых показаны в Таблице 1 [Kaskova et al., Sci. Adv. 2017;3: e1602847]. Все эти соединения, являющиеся люциферинами грибов, включая 3-гидроксигиспидин, относятся к группе 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-онов и имеют общую формулу:
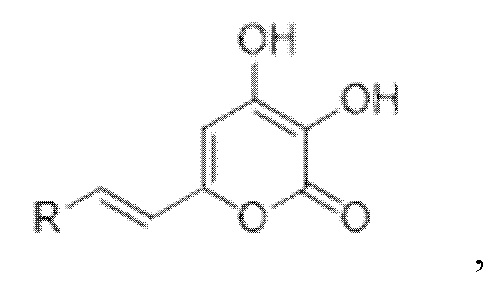
где R - арил или гетероарил.
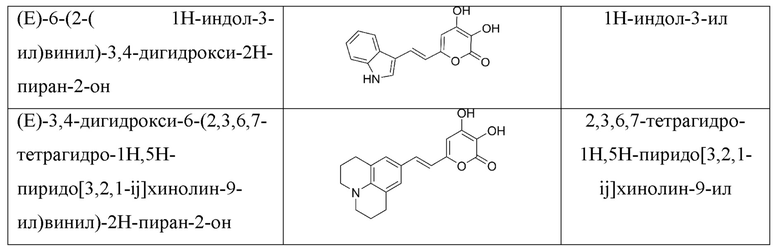
[008] Для подавляющего большинства люциферинов неизвестны ферменты, обеспечивающие их синтез в живом организме, а также восстановление оксилюциферина обратно в люциферин. Таким образом, большинство применений биолюминесценции предполагает добавление экзогенного люциферина в систему (например, культуру клеток или организм), содержащую люциферазу. Использование биолюминесцентных систем, таким образом, оказывается ограниченным из-за ряда причин: многие люциферины плохо проникают через клеточную мембрану, сами люциферины химически неустойчивы, и их химический синтез является сложным многостадийным и дорогостоящим процессом.
[009] Единственная биолюминесцентная система, для которой определены ферменты синтеза люциферина, описана у морских бактерий. Эта система значительно отличается от других биолюминесцентных систем. Бактериальный люциферин (миристиновый альдегид), окисляется в процессе реакции, но не является эмиттером биолюминесценции [O. Shimomura, Bioluminescence: Chemical Principles and Methods, World Scientific Publishing Co. Pte. Ltd, Singapore, 2006, 470 p.]. Помимо люциферина в качестве ключевых компонентов люминесцентной реакции выступают НАДН (никотинамидадениндинуклеотид) и ФМН-H2 (флавинмононуклеотид), окисленное производное которого и выступает в качестве истинного источника света. Биолюминесцентная система морских бактерий - единственная на сегодня может быть полностью закодирована в гетерологичной системе экспрессии и может рассматриваться как наиболее близкий аналог настоящего изобретения. Однако данная система применима преимущественно для прокариотических организмов. Для получения автономной биолюминесценции используется оперон luxCDABE, кодирующий люциферазы (гетеродимеры luxA и luxB) и белки биосинтеза субстрата биолюминесценции - люциферина luxCDE (Meighen 1991). В 2010 году удалось добиться автономной люминесценции с помощью этой системы в клетках человека - однако низкая интенсивность биолюминесценции, лишь в 12 раз превосходящая сигнал, исходящий от небиолюминесцентных клеток, не позволила использовать разработанную систему для решения большинства прикладных задач [Close et al. PloS One, 2010, 5 (8):e12441]. Работы по увеличению интенсивности испускаемого света не увенчались успехом из-за токсичности компонентов бактериальной системы для эукариотических клеток [Hollis et al. FEBS Letters, 2001, 506 (2):140-42].
[010] Идентификация ферментов, обеспечивающих синтез люциферина из устойчивых и/или широко распространенных в клетках соединений-предшественников и восстановление оксилюциферина обратно в люциферин, представляется актуальной задачей. Выявление таких ферментов позволяет обеспечить более простой и дешевый способ синтеза люциферина и открывает путь к созданию автономных биолюминесцентных систем. Особый интерес представляют нетоксичные для эукариотических клеток биолюминесцентные системы.
Сущность изобретения
[011] Заявители расшифровали стадии биосинтеза люциферина в биолюминесцентной системе грибов и идентифицировали ферменты, вовлеченные в циклическое обращение люциферина грибов и кодирующие их последовательности нуклеиновых кислот.
[012] Стадии оборота люциферина грибов показаны на схеме:
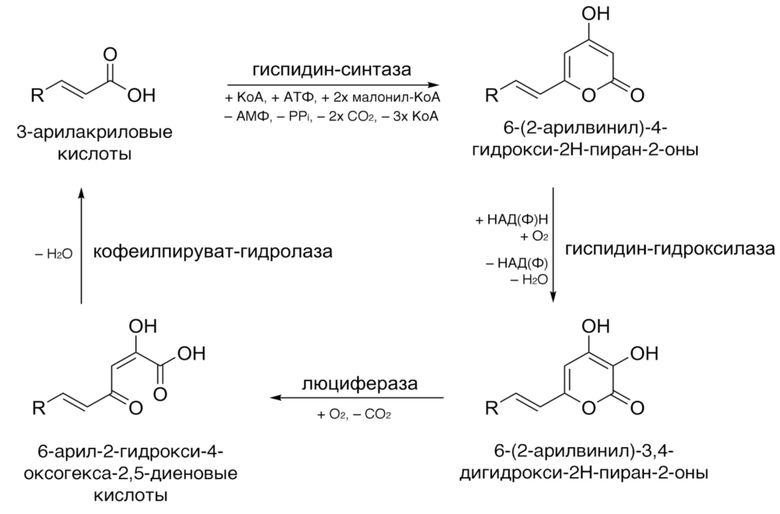
[013] Таким образом, настоящее изобретение прежде всего обеспечивает изолированные белки биосинтеза люциферина грибов, а также кодирующие их нуклеиновые кислоты.
[014] В преимущественных воплощениях настоящее изобретение обеспечивает гиспидин-гидроксилазы, характеризующиеся аминокислотной последовательностью, выбранной из группы в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, а также белки по существу сходные, гомологи, мутанты и производные указанных гиспидин-гидроксилаз.
[015] В некоторых воплощениях гиспидин-гидроксилазы настоящего изобретения характеризуются аминокислотной последовательностью, которая на протяжении по крайней мере 350 аминокислот имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NO: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28.
[016] В некоторых воплощениях аминокислотная последовательность гиспидин-гидроксилазы настоящего изобретения характеризуется наличием нескольких разделенных неконсервативными аминокислотными вставками консенсусных последовательностей, показанных в SEQ ID NOs: 29-33.
[017] Гиспидин-гидроксилазы настоящего изобретения катализируют реакцию превращения 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
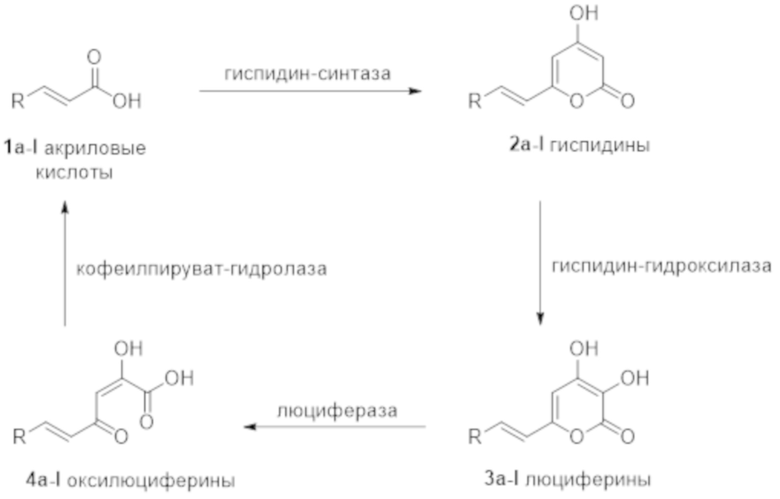 ,
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил.
[018] Также обеспечиваются гиспидин-синтазы, характеризующиеся аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55, а также белки по существу сходные, мутанты, гомологи и производные указанных гиспидин-синтаз.
[019] В некоторых воплощениях аминокислотная последовательность гиспидин-синтазы настоящего изобретения характеризуется наличием нескольких разделенных неконсервативными аминокислотными вставками консенсусных последовательностей, показанных в SEQ ID NOs: 56-63.
[020] В некоторых воплощениях гиспидин-синтазы настоящего изобретения характеризуются аминокислотной последовательностью, которая имеет не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55.
[021] Гиспидин-синтазы настоящего изобретения катализируют реакцию превращения 3-арилакриловой кислоты со структурной формулой
,
где R выбран из группы арил или гетероарил в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил.
[022] Также обеспечиваются кофеилпируват-гидролазы, характеризующиеся аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75, а также белки по существу сходные, мутанты, гомологи и производные указанных кофеилпируват-гидролаз.
[023] В некоторых воплощениях аминокислотная последовательность кофеилпируват-гидролазы настоящего изобретения характеризуется наличием нескольких разделенных неконсервативными аминокислотными вставками консенсусных последовательностей, показанных в SEQ ID NOs: 76-78.
[024] В некоторых воплощениях аминокислотная последовательность кофеилпируват-гидролазы настоящего изобретения имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75.
[025] Кофеилпируват-гидролазы настоящего изобретения катализируют реакцию превращения 6-арил-2-гидрокси-4-оксогекса-2,5-диеновые кислоты, имеющей структурную формулу
,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой
.
[026] В преимущественных воплощениях гиспидин-гидроксилазы настоящего изобретения катализируют реакцию превращения предлюциферина в люциферин грибов, например, гиспидина в 3-гидроксигиспидин.
[027] В преимущественных воплощениях гиспидин-синтазы настоящего изобретения катализируют превращение предшественника предлюциферина в предлюциферин, например, превращение кофейной кислоты в гиспидин.
[028] В преимущественных воплощениях кофеилпируват-гидролазы настоящего изобретения катализируют превращение оксилюциферина грибов в предшественник предлюциферина, например, превращение кофеилпирувата в кофейную кислоту.
[029] Также обеспечивается применение белка, аминокислотная последовательность которого на протяжении по крайней мере 350 аминокислот имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, и/или аминокислотная последовательность которого содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 29-33, в системах in vitro или in vivo как гиспидин-гидроксилазы, катализирующей реакцию превращения 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу ,
где R - арил или гетероарил.
[030] Также обеспечивается применение белка, аминокислотная последовательность которого имеет не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, и\или аминокислотная последовательность которого содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 56-63, в системах in vitro или in vivo как гиспидин-синтазы, катализирующей реакцию превращения 3-арилакриловой кислоты со структурной формулой
в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу ,
где R - арил или гетероарил.
[031] Также обеспечивается применение белка, аминокислотная последовательность которого имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75, и/или аминокислотная последовательность которого содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 76-78, в системах in vitro или in vivo как кофеилпируват-гидролазы, катализирующей реакцию превращения 6-арил-2-гидрокси-4-оксогекса-2,5-диеновые кислоты, имеющей структурную формулу ,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой .
[032] Также обеспечиваются нуклеиновые кислоты, кодирующие вышеозначенные гиспидин-гидроксилазы, гиспидин-синтазы и кофеилпируват-гидролазы.
[033] В некоторых воплощениях обеспечиваются нуклеиновые кислоты, кодирующие гиспидин-гидроксилазы, аминокислотная последовательность которых выбрана из группы:
(а) аминокислотная последовательность показана в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28;
(б) аминокислотная последовательность имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, на протяжении по крайней мере 350 аминокислот;
(в) аминокислотная последовательность содержит консенсусные последовательности, показанные в SEQ ID NOs: 29-33.
[034] В некоторых воплощениях обеспечиваются нуклеиновые кислоты, кодирующие гиспидин-синтазы, аминокислотная последовательность которых выбрана из группы:
(а) аминокислотная последовательность показана в SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55;
(б) аминокислотная последовательность имеет не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55;
(в) аминокислотная последовательность содержит консенсусные последовательности, показанные в SEQ ID NOs: 56-63.
[035] В некоторых воплощениях обеспечиваются нуклеиновые кислоты, кодирующие кофеилпируват-гидролазы, аминокислотная последовательность которых выбрана из группы:
(а) аминокислотная последовательность показана в SEQ ID NOs: 65, 67, 69, 71, 73, 75;
(б) аминокислотная последовательность имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75;
(в) аминокислотная последовательность содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 76-78.
[036] Также обеспечивается применение нуклеиновой кислоты, кодирующей белок, аминокислотная последовательность которого на протяжении по крайней мере 350 аминокислот имеет не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, или не менее 80% идентичности, или не менее 85% идентичности, или не менее 90% идентичности, или не менее 95% идентичности, (например, по крайней мере 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, или аминокислотная последовательность которого содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 29-33, для получения в системах in vitro или in vivo гиспидин-гидроксилазы, катализирующей реакцию превращения 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил.
[037] Также обеспечивается применение нуклеиновой кислоты, кодирующей белок, аминокислотная последовательность которого имеет не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, ли не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, или не менее 80% идентичности, или не менее 85% идентичности, или не менее 90% идентичности, или не менее 95% идентичности, (например, по крайней мере 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, или аминокислотная последовательность которого содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 56-63, для получения в системах in vitro или in vivo гиспидин-синтазы, катализирующей реакцию превращения 3-арилакриловой кислоты со структурной формулой
в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу ,
где R - арил или гетероарил.
[038] Также обеспечивается применение нуклеиновой кислоты, кодирующей белок, аминокислотная последовательность которого имеет не менее 60% идентичности или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, или не менее 80% идентичности, или не менее 85% идентичности, или не менее 90% идентичности, или не менее 95% идентичности, (например, по крайней мере 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75, или аминокислотная последовательность которого содержит разделенные неконсервативными аминокислотными вставками консенсусные последовательности, показанные в SEQ ID NOs: 76-78, для получения в системах in vitro или in vivo кофеилпируват-гидролазы, катализирующей реакцию превращения 6-арил-2-гидрокси-4-оксогекса-2,5-диеновые кислоты, имеющей структурную формулу ,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой .
[039] Также обеспечивается белок слияния, включающий оперативно сшитые непосредственно или через аминокислотные линкеры по крайней мере одну гиспидин-гидроксилазу по изобретению, и/или по крайней мере одну гиспидин-синтазу по изобретению, и/или по крайней мере одну кофеилпируват-гидролазу по изобретению, и сигнал внутриклеточной локализации и/или сигнальный пептид и/или люциферазу, способную окислять с выделением света люциферин грибов.
[040] Люцифераза, способная окислять с выделением света люциферин грибов, известна из уровня техники. В преимущественных воплощениях она имеет аминокислотную последовательность по существу сходную или идентичную с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Например, она может иметь аминокислотную последовательность, которая по крайней мере на 40% идентична, например, по крайней мере на 45% идентична, или по крайней мере на 50% идентична, или по крайней мере на 55% идентична, или по крайней мере на 60% идентична, или по крайней мере на 70% идентична, или по крайней мере на 75% идентична, или по крайней мере на 80% идентична, или по крайней мере на 85% идентична аминокислотной последовательности, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Во многих воплощениях аминокислотная последовательность указанной люциферазы имеет не менее 90% идентичности, или не менее 95% идентичности, (например, по крайней мере 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98.
[041] В некоторых воплощениях белок слияния имеет аминокислотную последовательность, показанную в SEQ ID NO: 101.
[042] Также обеспечивается нуклеиновая кислота, кодирующая вышеуказанный белок слияния.
[043] Также обеспечивается кассета экспрессии, включающая (а) регион инициации транскрипции функциональный в клетке-хозяине; (б) нуклеиновую кислоту, кодирующую фермент биосинтеза люциферина грибов, то есть гиспидин-синтазу, гиспидин-гидроксилазу или кофеилпируват-гидролазу или белок слияния по изобретению (в) регион терминации транскрипции, функциональный в клетке-хозяине.
[044] Также обеспечивается вектор для переноса нуклеиновой кислоты в клетку-хозяина, содержащий нуклеиновую кислоту, кодирующую фермент биосинтеза люциферина грибов по изобретению, то есть гиспидин-синтазу, гиспидин-гидроксилазу или кофеилпируват-гидролазу или белок слияния по изобретению.
[045] Также обеспечивается клетка-хозяин, содержащая как часть экстрахромосомного элемента или интегрированную в геном клетки как результат внедрения указанной кассеты в указанную клетку кассету экспрессии, в состав которой входит нуклеиновая кислота, кодирующая гиспидин-синтазу и/или гиспидин-гидроксилазу и/или кофеилпируват-гидролазу настоящего изобретения. Такая клетка продуцирует по крайней мере один из вышеперечисленных ферментов биосинтеза люциферина грибов за счет экспрессии введенной в нее нуклеиновой кислоты.
[046] Также обеспечивается антитело, полученное с помощью белка по изобретению.
[047] Также обеспечивается способ получения люциферина грибов, представляющего собой 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющего структурную формулу
,
где R - арил или гетероарил, в системе in vitro или in vivo, включающий объединение в физиологических условиях с по крайней мере одной молекулы гиспидин-гидроксилазы по изобретению с по крайней мере одной молекулой 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она со структурной формулой ,
с по крайней мере одной молекулой НАД(Ф)Н и с по крайней мере одной молекулы молекулярного кислорода.
[048] Также обеспечивается способ получения предлюциферина грибов, представляющего собой 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он со структурной формулой ,
где R - арил или гетероарил, в системе in vitro или in vivo, включающий объединение в физиологических условиях по крайней мере одной молекулы 3-арилакриловой кислоты со структурной формулой
с по крайней мере одной молекулой гиспидин-синтазы по изобретению, с по крайней мере одной молекулой кофермента А, с по крайней мере одной молекулы АТФ и с по крайней мере с двумя молекулами малонил-КоА.
[049] Также обеспечивается способ получения люциферина грибов, в системе in vitro или in vivo, включающий объединение в физиологических условиях с по крайней мере одной молекулы гиспидин-гидроксилазы по изобретению с по крайней мере одной молекулой 3-арилакриловой кислоты, с по крайней мере одной молекулой гиспидин-синтазы по изобретению, с по крайней мере одной молекулой кофермента А, с по крайней мере одной молекулы АТФ, с по крайней мере с двумя молекулами малонил-КоА, с по крайней мере одной молекулой НАД(Ф)Н и с по крайней мере одной молекулы молекулярного кислорода.
[050] Способы получения люциферина и предлюциферина грибов могут быть реализованы в клетке или организме, в этом случае способы включают введение в клетку нуклеиновых кислот, кодирующих соответствующие ферменты биосинтеза люциферина (гиспидин-синтазы и/или гиспидин-гидроксилазы), способные к экспрессии указанных ферментов в клетке или организме. В преимущественных воплощениях нуклеиновые кислоты вводят в клетку или организм в составе кассеты-экспрессии или вектора по изобретению.
[051] В некоторых воплощениях в клетку или организм дополнительно вводят нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу, способную осуществлять перенос 4-фосфопантетеинила от кофермента А на серин в ацилпереносящем домене поликетидсинтаз. В некоторых воплощениях 4'-фосфопантотеинил трансфераза имеет аминокислотную последовательность по существу сходную или идентичную с SEQ ID NO: 105.
[052] Также обеспечивается применение поликетидсинтазы (PKS) аминокислотная последовательность которой идентична последовательности, выбранной из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139 по крайней мере на 40%, или по крайней мере на 45%, или по крайней мере на 50%, или по крайней мере на 55%, или по крайней мере на 60%, по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99%, для получение гиспидина в системе in vitro или in vivo.
[053] В некоторых воплощениях способ получения гиспидина включает объединение в физиологических условиях по крайней мере одной молекулы PKS с по крайней мере двумя молекулами малонил-КоА и по крайней мере одной молекулой кофеил-КоА. В некоторых воплощениях способ включает объединение в физиологических условиях по крайней мере одной молекулы PKS с по крайней мере двумя молекулами малонил-КоА, по крайней мере одну молекулу кофейной кислоты, по крайней мере одну молекулу кофермента А, по крайней мере одну молекулу кумарат-КоА-лигазы и по крайней мере одну молекулу АТФ.
[054] Для нужд настоящего изобретения может быть использована любая кумарат-КоА-лигаза, катализирующая реакцию превращения кофейной кислоты в кофеил-КоА. Например, кумарат-КоА-лигаза имеет аминокислотную последовательность, которая идентична последовательности, показанной в SEQ ID NO:141 по крайней мере на 40%, или по крайней мере на 45%, или по крайней мере на 50%, или по крайней мере на 55%, или по крайней мере на 60%, по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99%.
[055] Реакция может быть использована в любых способах вместо реакции получения предлюциферина грибов из предшественников предлюциферина с помощью гиспидин-синтазы настоящего изобретения. Например, реакция может осуществляться в клетке или организме и включать введение в клетку или организм кассеты экспрессии, содержащей нуклеиновую кислоту, кодирующую PKS. При необходимости в клетку или организм также вводится нуклеиновая кислота, кодирующая кумарат-КоА-лигазу.
[056] В некоторых воплощениях в клетку или организм дополнительно вводят нуклеиновые кислоты, кодирующие ферменты биосинтеза 3-арилакриловой кислоты, например, нуклеиновые кислоты, кодирующие тирозин-аммоний-лиазу, аминокислотная последовательность которой по существу сходная или идентичная аминокислотной последовательности тирозин-аммоний-лиазы Rhodobacter capsulatus, показанной в SEQ ID NO: 107, и нуклеиновые кислоты, кодирующие компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы, аминокислотные последовательности которых по существу сходны с последовательностями компонентов HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E.coli, показанными в SEQ ID NOs: 109 и 111. В некоторых воплощениях используется нуклеиновая кислота, кодирующая фенилаланин-аммоний-лиазу, аминокислотная последовательность которой по существу сходна с аминокислотной последовательностью, показанной в SEQ ID NOs:117.
[057] Также обеспечиваются способы получения трансгенных биолюминесцентных клеток или организмов, в том числе клеток или организмов растений, или животных, или бактерий, или грибов.
[058] В преимущественных воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают введение в клетку или организм по крайней мере одной нуклеиновой кислоты по изобретению, а также нуклеиновой кислоты, кодирующей люциферазу, способную окислять люциферин грибов с выделением света. Нуклеиновые кислоты вводятся в клетку или организм в форме, которая обеспечивает их экспрессию и продукцию функциональных белковых продуктов. Например, нуклеиновые кислоты находятся в составе кассеты экспрессии. Нуклеиновые кислоты присутствуют в клетках как части экстрахромосомного элемента или интегрированную в геном клетки как результат внедрения в указанную клетку кассеты экспрессии.
[059] В преимущественных воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают введение в клетку или организм нуклеиновой кислоты, кодирующей гиспидин-гидроксилазу по изобретению и нуклеиновой кислоты, кодирующей люциферазу, способную окислять люциферин грибов с выделением света. Указанная клетка или организм приобретает способность к биолюминесценции в присутствии предлюциферина грибов, представляющего собой 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он со структурной формулой ,
где R - арил или гетероарил.
[060] В некоторых воплощениях вместо нуклеиновых кислот, кодирующих гиспидин-синтазу и люциферазу, в клетку вводят нуклеиновую кислоту, кодирующую белок слияния гиспидин-гидроксилазы и люциферазы.
[061] В некоторых воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают также введение в клетку или организм нуклеиновой кислоты, кодирующей гиспидин-синтазу по изобретению. Указанная клетка или организм приобретает способность к биолюминесценции в присутствии предшественника предлюциферина грибов, представляющего собой 3-арилакриловую кислоту со структурной формулой
,
где R - арил или гетероарил.
[062] В некоторых воплощениях в клетку вместо нуклеиновой кислоты, кодирующей гиспидин-синтазу, вводят нуклеиновую кислоту, кодирующую PKS.
[063] В некоторых воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают также введение в клетку или организм нуклеиновой кислоты, кодирующей кофеилпируват-гидролазу по изобретению, что приводит к увеличению интенсивности биолюминесценции.
[064] В некоторых воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают также введение в клетку или организм нуклеиновой кислоты, кодирующей 4'-фосфопантотеинил трансферазу.
[065] В некоторых воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают также введение в клетку или организм нуклеиновой кислоты, кодирующей кумарат-КоА-лигазу.
[066] В некоторых воплощениях способы получения трансгенных биолюминесцентных клеток или организмов включают также введение в клетку или организм нуклеиновых кислот, кодирующих ферменты биосинтеза 3-арилакриловой кислоты.
[067] Также обеспечиваются трансгенные биолюминесцентные клетки и организмы, полученные с помощью вышеописанных методов, и содержащие одну или несколько нуклеиновых кислот по изобретению как части экстрахромосомного элемента или интегрированную в геном клетки.
[068] В некоторых воплощениях трансгенные биолюминесцентные клетки и организмы по изобретению способны к автономной биолюминесценции без экзогенного добавления люциферина, предлюциферина и предшественника предлюциферина.
[069] Также обеспечиваются комбинации белков и нуклеиновых кислот по изобретению, изделия и наборы, содержащие белки и нуклеиновые кислоты по изобретению. Например, обеспечиваются комбинации нуклеиновых кислот для получения автономно светящихся клеток, клеточных линий или трансгенных организмов, комбинации для анализа активности промоторов, или комбинации для мечения клеток.
[070] В некоторых воплощениях обеспечиваются наборы для получения люциферина грибов и/или предлюциферина грибов, включающие вышеописанную гиспидин-гидроксилазу и/или гиспидин-синтазу и/или PKS или кодирующие их нуклеиновые кислоты.
[071] В некоторых воплощениях обеспечиваются наборы для получения биолюминесцентной клетки или биолюминесцентного трансгенного организма, включающие нуклеиновую кислоту, кодирующую гиспидин-гидроксилазу и нуклеиновую кислоту, кодирующую люциферазу, способную окислять люциферин грибов с выделением света. Набор может также содержать нуклеиновую кислоту, кодирующую кофеилпируват-гидролазу. Набор может также содержать нуклеиновую кислоту, кодирующую гиспидин-синтазу или PKS. Набор может также содержать нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу и/или нуклеиновую кислоту, кодирующую кумарат-КоА-лигазу и/или нуклеиновые кислоты, кодирующие ферменты биосинтеза 3-арилакриловой кислоты. Набор может также содержать дополнительные компоненты: буферные растворы, антитела, люциферин грибов, предлюциферин грибов, предшественник предлюциферина грибов и тд. Набор может также содержать инструкцию по применению набора. В некоторых воплощениях нуклеиновые кислоты находятся в составе кассеты экспрессии или вектора для внедрения в клетки или организмы.
[072] В преимущественных воплощениях клетки и трансгенные организмы по изобретению способны производить люциферин грибов из предшественников. В некоторых воплощениях клетки и трансгенные организмы по изобретению способны к биолюминесценции в присутствии предшественника люциферина грибов. В некоторых воплощениях клетки и трансгенные организмы по изобртению способны к автономной биолюминесценции.
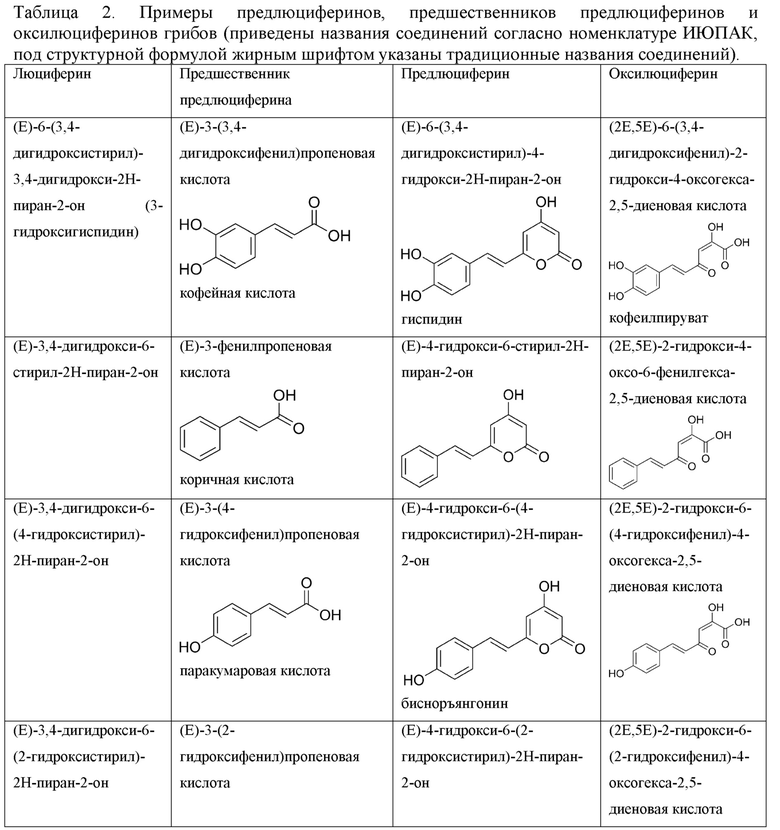
[073] В перечисленных выше способах и применениях в преимущественных воплощениях используется предлюциферин - 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, выбранный из группы:
(Е)-6-(3,4-дигидроксистирил)-4-гидрокси-2Н-пиран-2-он (гиспидин),
(Е)-4-гидрокси-6-стирил-2Н-пиран-2-он,
(Е)-4-гидрокси-6-(4-гидроксистирил)-2Н-пиран-2-он (бисноръянгонин),
(Е)-4-гидрокси-6-(2-гидроксистирил)-2Н-пиран-2-он,
(Е)-4-гидрокси-6-(2,4-дигидроксистирил)-2Н-пиран-2-он,
(Е)-4-гидрокси-6-(4-гидрокси-3,5-диметоксистирил)-2Н-пиран-2-он,
(Е)-4-гидрокси-6-(4-гидрокси-3-метоксистирил)-2Н-пиран-2-он,
(Е)-4-гидрокси-6-(2-(6-гидроксинафталин-2-ил)винил)-2Н-пиран-2-он,
(Е)-6-(4-аминостирил)-4-гидрокси-2Н-пиран-2-он,
(Е)-6-(4-(диэтиламино)стирил)-4-гидрокси-2Н-пиран-2-он,
(Е)-6-(2-(1Н-индол-3-ил)винил)-4-гидрокси-2Н-пиран-2-он,
(Е)-4-гидрокси-6-(2,3,6,7-тетрагидро-1Н,5Н-пиридо[3,2,1-ij]хинолин-9-ил)винил)-2Н-пиран-2-он.
[074] В преимущественных воплощениях для нужд настоящего изобретения применима 3-арилакриловая кислота, выбранная из группы: кофейная кислота, коричная кислота, паракумаровая кислота, кумаровая кислота, умбеллиновая кислота, синаповая кислота, феруловая кислота.
[075] В преимущественных воплощениях в качестве люциферина используется 3-гидроксигиспидин, в качестве предлюциферина - гиспидин, в качестве предшественника предлюциферина - кофейная кислота.
[076] Технический результат состоит в создании эффективного способа получения автономных биолюминесцентных систем, обладающих видимым свечением, в том числе на основе эукариотических несветящихся клеток и организмов.
[077] Также технический результат состоит в разработке нового эффективного способа синтеза гиспидина и его функциональных аналогов.
[078] Также технический результат состоит в разработке нового эффективного способа синтеза люциферина грибов и его функциональных аналогов.
[079] Также технический результат состоит в получении автономно светящихся клеток и организмов.
[080] Технический результат достигается за счет идентификации стадий превращения люциферина в биолюминесцентных грибах и выявлении аминокислотных и нуклеотидных последовательностей белков, вовлеченных в биосинтез люциферина. Функция всех белков была продемонстрирована впервые.
Краткое описание чертежей
[081] Фиг. 1 показывает множественное выравнивание аминокислотных последовательностей гиспидин-гидроксилаз. FAD/NAD(P)-связывающий домен отмечен подчеркиванием. Консенсусные последовательности показаны под выравниванием.
[082] Фиг. 2 показывает множественное выравнивание аминокислотных последовательностей гиспидин-синтаз. Консенсусные последовательности показаны под выравниванием.
[083] Фиг. 3 показывает множественное выравнивание аминокислотных последовательностей кофеилпируват-гидролаз. Консенсусные последовательности показаны под выравниванием.
[084] Фиг. 4 показывает интенсивности свечения клеток Pichia pastoris, экспрессирующих гиспидин-гидроксилазу и люциферазу (А) или только люциферазу (Б), или дрожжи дикого типа (И), при опрыскивании колоний 3-гидроксигиспидином (люциферин, левый график) и гиспидином (предлюциферин, правый график).
[085] Фиг. 5 показывает сравнение интенсивности свечения клеток HEK293NT, экспрессирующих гиспидин-гидроксилазу и люциферазу, и клеток HEK293NT, экспрессирующих только люциферазу, при добавлении гиспидина.
[086] Фиг. 6 показывает кривую люминесценции клеток HEK293T, экспрессирующих (1) гены гиспидин-гидроксилазы и люциферазы по отдельности при добавлении гиспидина; (2) ген химерного белка гиспидин-гидроксилазы и люциферазы при добавлении гиспидина; (3) ген химерного белка гиспидин-гидроксилазы и люциферазы при добавлении 3-гидроксигиспидина.
[087] Фиг. 7 иллюстрирует способность трансфицированных клеток Pichia pastoris к автономной биолюминесценции в отличие от клеток дикого типа: на чашке Петри слева клетки под дневным освещением, справа - клетки в темноте.
[088] Фиг. 8 показывает свечение культуры трансфицированных клеток Pichia pastoris в темноте.
[089] Рис. 9 показывает автономно биолюминесцентные трансгенные растения Nicotiana benthamiana. Фотография слева снята при внешнем освещении, фотография справа снята в темноте.
Осуществление изобретения
Определения
[090] Различные термины, относящиеся к объектам настоящего изобретения, используются выше и также в описании и в формуле изобретения. В описании данного изобретения термины «включает» и «включающий» интерпретируются как означающие «включает, помимо всего прочего». Указанные термины не предназначены для того, чтобы их истолковывали как «состоит только из».
[091] Термины «люминесценция» и «биолюминесценция» для нужд настоящего изобретения являются взаимозаменяемыми и обозначают явление выделения света в ходе химической реакции, катализируемой ферментом - люциферазой.
[092] Термины «способен к реакции», «осуществляет реакцию» и им подобные по отношению к активности белка означают, что указанной белок является ферментом, катализирующим означенную реакцию.
[093] Как здесь используется, термин «люцифераза» означает белок, который обладает способностью катализировать окисление молекулярным кислородом химического соединения (люциферина), где реакция окисления сопровождается выделением света (люминесценцией или биолюминесценцией) и происходит освобождение окисленного люциферина.
[094] Как здесь используется, термин «люциферин грибов» означает химическое соединение, выбранное из группы 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-онов, имеющих структурную формулу
[095] ,
где R арил или гетероарил.
[096] Люциферин грибов окисляется группой люцифераз, далее обозначаемых термином «люциферазы, способные окислять люциферин грибов с выделением света» или ему подобным. Указанные люциферазы найдены у биолюминесцентных грибов, например, они описаны в заявке RU №2017102986/10(005203) от 30.01.2017. Аминокислотные последовательности люцифераз применимых в рамках способов и комбинаций настоящего изобретения по существу сходны или идентичны аминокислотным последовательностям, выбранным из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Во многих вариантах осуществления настоящего изобретения применимые для нужд настоящего изобретения люциферазы характеризуются аминокислотными последовательностями, которые по крайней мере на 40% идентичны, например, по крайней мере на 45% идентичны, или по крайней мере на 50% идентичны, или по крайней мере на 55% идентичны, или по крайней мере на 60% идентичны, или по крайней мере на 70% идентичны, или по крайней мере на 75% идентичны, или по крайней мере на 80% идентичны, или по крайней мере на 85% идентичны аминокислотной последовательности, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Часто люциферазы характеризуются аминокислотными последовательностями, которые имеют с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88,90, 92, 94, 96, 98, не менее 90% идентичности (например, не менее 91%, не менее 92%, не менее 93%, не менее 94%, не менее 95%, не менее не менее 96%, не менее 97%, не менее 98%, не менее 99% идентичности или 100% идентичности).
[097] При окислении люциферина грибов образуется «оксилюциферин грибов», который представляет собой 6-арил-2-гидрокси-4-оксогекса-2,5-диеновую кислоту со структурной формулой
[098] .
[099] Термины «предлюциферин грибов» или просто «предлюциферин» используется здесь для обозначения соединений, относящихся к группе 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-онов, имеющих структурную формулу, где R - арил или гетероарил. В ходе химической реакции, катализируемой ферментом настоящего изобретения, предлюциферин превращается в люциферин грибов.
[0100] Термин «предшественник предлюциферина» используется здесь для обозначения соединений, относящихся к группе 3-арилакриловых кислот со структурной формулой
[0101] ,
где R - арил или гетероарил. Из 3-арилакриловых кислот в ходе химической реакции, катализируемой ферментом настоящего изобретения, образуются предлюциферины.
[0102] Примеры люциферинов гриба показаны в Таблице 1. Связанные с люциферинами грибов примеры предлюциферинов, оксилюциферинов и предшественников предлюциферинов показаны в Таблице 2.
[0103] Термин «арил» или «арильный заместитель» обозначает ароматический радикал в одинарной или конденсированной карбоциклической кольцевой системе, содержащий от пяти до четырнадцати кольцевых членов. В предпочтительном осуществлении кольцевая система содержит от шести до десяти членов кольца. Один или несколько атомов водорода могут также быть заменены на заместитель, выбранный из ацила, ациламино, ацилокси, алкенила, алкокси, алкила, алкинила, амино, арила, арилокси, азидо, карбамоила, карбоалкокси, карбокси, карбоксиамидо, карбоксиамино, циано, дизамещенного амино, формила, гуанидино, галогена, гетероарила, гетероциклила, гидрокси, иминоамино, монозамещенного амино, нитро, оксо, фосфонамино, сульфинила, сульфонамино, сульфонила, тио, тиоациламино, тиоуреидо или уреидо. Примеры арильных групп включают без ограничения фенил, нафтил, бифенил, терфенил. Кроме того, в значение термина «арил», так, как оно используется здесь, входят группы, в которых ароматический цикл соединен с одним или более неароматическими циклами.
[0104] Термин «гетероциклический ароматический заместитель», «гетероарильный заместитель» или «гетероарил» обозначает ароматический радикал, который содержит от одного до четырех гетероатомов или гетерогрупп, выбранных из O, N, S или SO, в одинарной или конденсированной гетероциклической кольцевой системе, содержащей от пяти до пятнадцати кольцевых членов. В предпочтительном осуществлении гетероарильная кольцевая система содержит от шести до десяти кольцевых членов. Один или несколько атомов водорода могут также быть заменены на заместитель, выбранный из ацила, ациламино, ацилокси, алкенила, алкокси, алкила, алкинила, амино, арила, арилокси, карбамоила, карбоалкокси, карбокси, карбоксиамидо, карбоксиамино, циано, дизамещенного амино, формила, гуанидино, галогена, гетероарила, гетероциклила, гидрокси, иминоамино, монозамещенного амино, нитро, оксо, фосфонамино, сульфинила, сульфонамино, сульфонила, тио, тиоациламино, тиоуреидо или уреидо. Примеры гетероарильных групп включают без ограничения пиридинильную, тиазолильную, тиадиазолильную, изохинолинильную, пиразолильную, оксазолильную, оксадиазоильную, триазолильную и пирролильную группы. Кроме того, в значение термина «гетероарил», так, как оно используется здесь, входят группы, в которых гетероароматический цикл соединен с одним или более неароматическими циклами.
[0105] В настоящем изобретении для обозначения химических соединений кроме традиционных названий (при наличии) используются названия в соответствии с международной номенклатурой ИЮПАК.
[0106] Термин «фермент биосинтеза люциферина» или «фермент, вовлеченный в циклический оборот превращений люциферина» или ему подобный используется для обозначения фермента, катализирующего реакции превращения предшественника предлюциферина в предлюциферин, и/или предлюциферина в люциферин грибов и/или оксилюциферина в предшественник предлюциферина в системах in vitro и/или in vivo. Если не указано иное, люциферазы не включены в понятие «ферменты биосинтеза люциферина грибов».
[0107] Термин «гиспидин-гидроксилаза» используется здесь для описания фермента, катализирующего реакцию превращения предлюциферина в люциферин грибов, например, синтез 3-гидроксигиспидина из гиспидина.
[0108] Термин «гиспидин-синтаза» используется здесь для описания фермента, способного катализировать синтез предлюциферина грибов из предшественника предлюциферина, например, синтез гиспидина из кофейной кислоты.
[0109] Термин «PKS» используется здесь для описания фермента, принадлежащего к группе поликетидсинтаз III типа, способного катализировать синтез гиспидина из кофеил-КоА.
[0110] Термин «кофеилпируват-гидролаза» используется здесь для описания фермента, способного катализировать расщепление оксилюциферина грибов на более простые соединения, например, с образованием предшественника предлюциферина. Примером такой реакции является превращение кофеилпирувата в кофейную кислоту.
[0111] Термин «функциональный аналог» используется в настоящем изобретении для описания химических соединений или белков, которые выполняют одну и ту же функцию и/или могут быть использованы для одного и того же назначения. Например, все люциферины грибов, перечисленные в Таблице 1, являются функциональными аналогами друг друга.
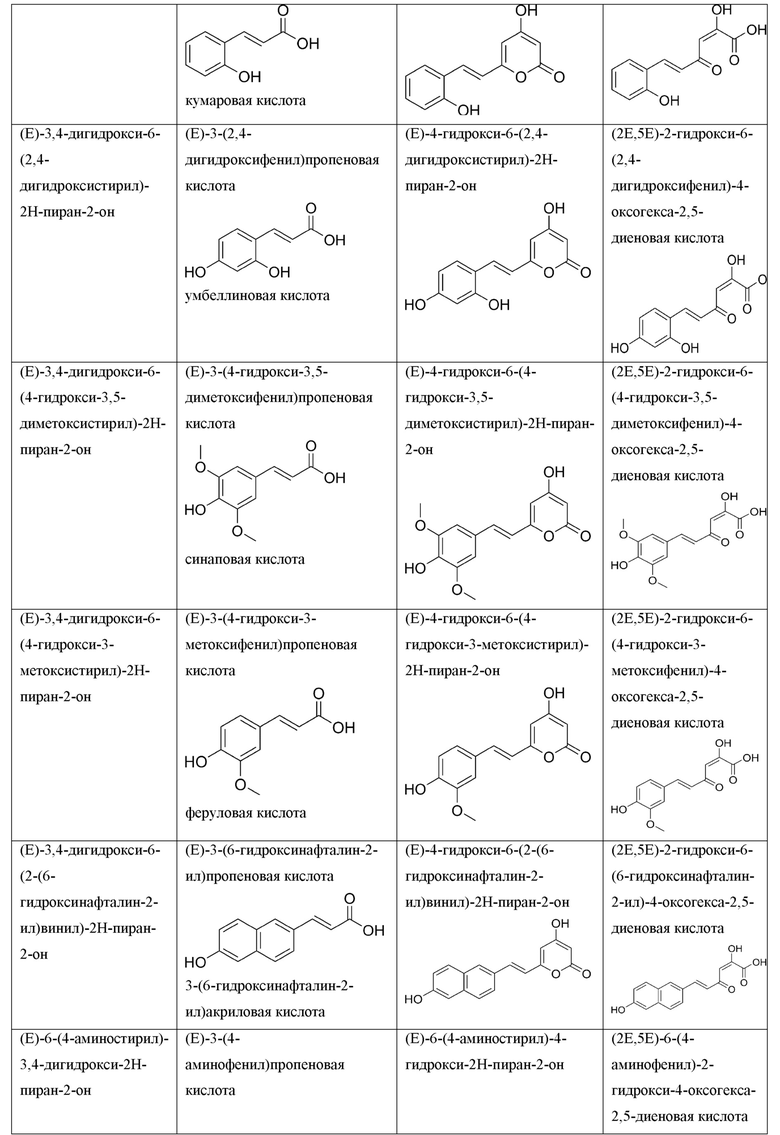
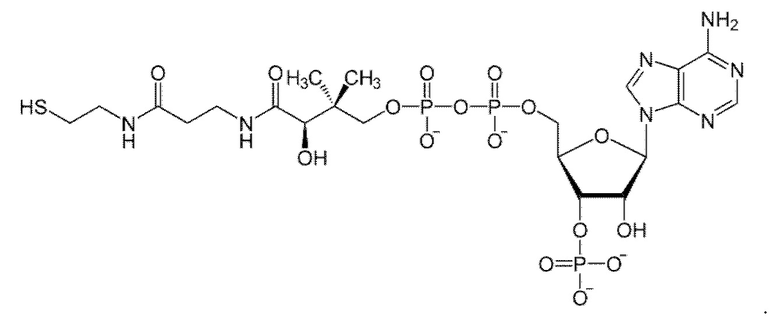
[0112] Термин «АТФ» относится к аденозинтрифосфату, который является основным переносчиком энергии в клетке и имеет структурную формулу:
 .
.
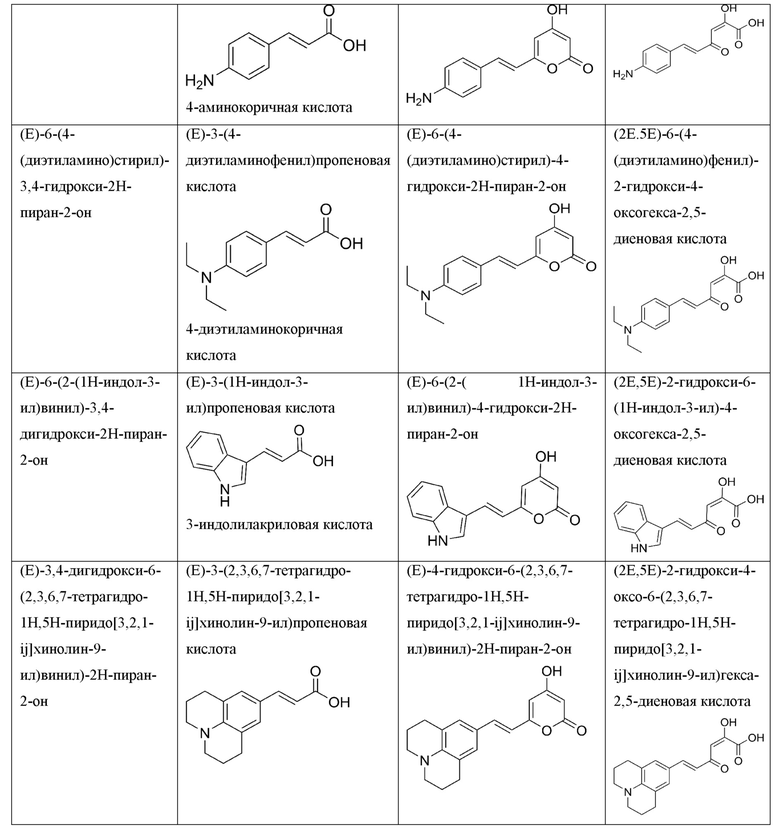
[0113] Термин «НАД(Ф)Н» используется здесь для обозначения молекулы восстановленного никотинамидадениндинуклеотидфосфата (НАДФН) или никотинамидадениндинуклеотида (НАДН). Термин «НАД(Ф)» используется для обозначения окисленной формы никотинамидадениндинуклеотидфосфата (НАДН) или никотинамидадениндинуклеотида (НАДН). Никотинамидадениндинуклеотид:
и никотинамидадениндинуклеотидфосфат:
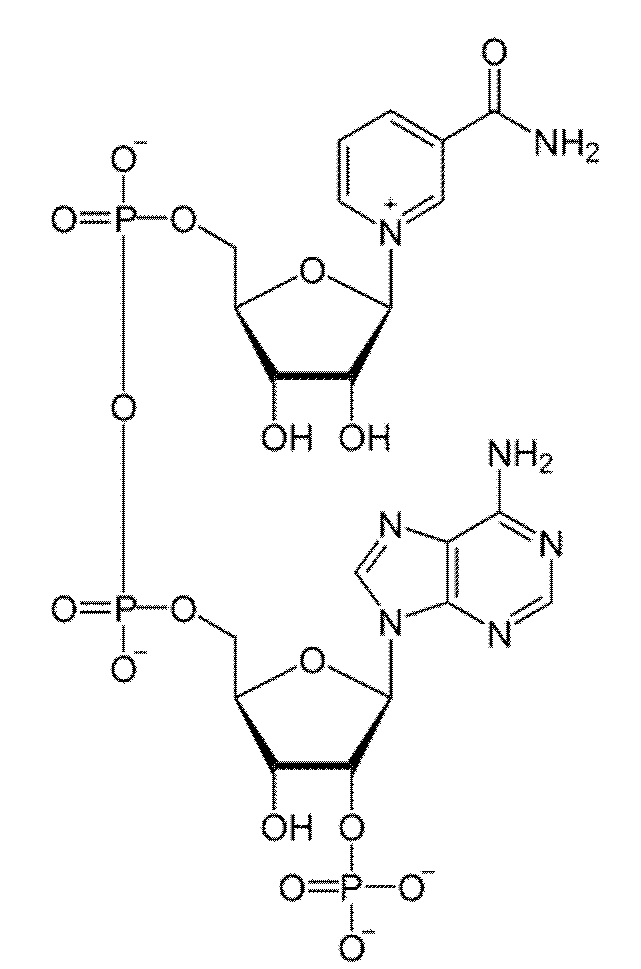
представляют собой динуклеотиды, построенные из амида никотиновой кислоты и аденина, соединенных между собой цепочкой, состоящей из двух остатков D-рибозы и двух остатков фосфорной кислоты. НАДФ отличается от НАД содержанием еще одного остатка фосфорной кислоты, присоединенного к гидроксилу одного из остатков D-рибозы. Оба соединения широко распространены в природе и участвуют во множестве окислительно-восстановительные реакций, выполняя функцию переносчиков электронов и водорода, которые принимает от окисляемых веществ. Восстановленные формы переносят полученные электроны и водород на другие вещества.
[0114] Термины «кофермент А» или «КоА» относится к хорошо известному из уровня техники коферменту, вовлеченному в процессы окисления и синтеза жирных кислот, биосинтеза жиров, окислительных превращений продуктов распада углеводов, со структурной формулой:
[0115] Термин «малонил-КоА» относится к производному кофермента А, образующемуся при синтезе жирных кислот и содержащему остаток малоновой кислоты:
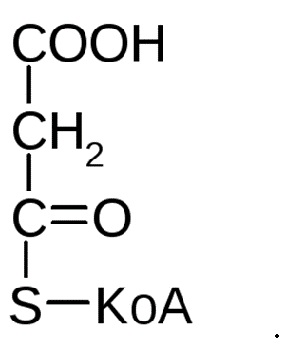 .
.
[0116] Термин «кумарил-КоА» относится к тиоэфиру кофермента А и кумаровой кислоты: 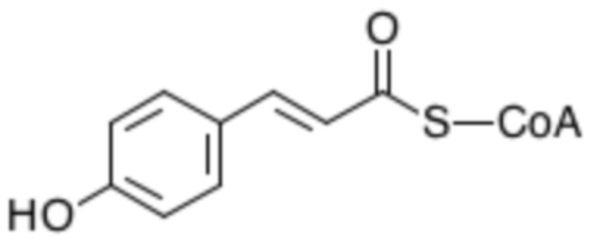
[0117] Термин «кофеил-КоА» относится к тиоэфиру кофермента А и кофейной кислоты: 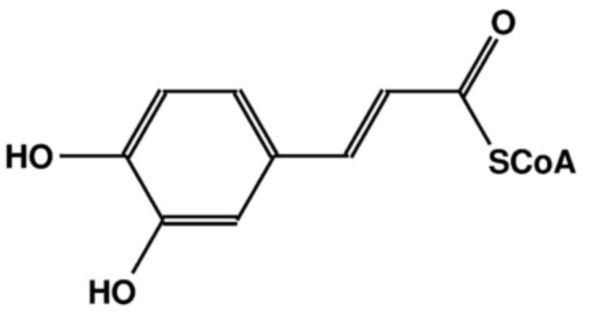
[0118] Используемый здесь термин «мутант» или «производное» относятся к белку, раскрытому в настоящем изобретении, в котором одна или более аминокислот добавлены и/или замещены и/или удалены (делетированы) и/или вставлены (инсертированы) в N-конец и/или С-конец, и/или в пределах нативных аминокислотных последовательностей белков настоящего изобретения. Как здесь используется, термин «мутант» относится к молекуле нуклеиновой кислоты, которая кодирует мутантный белок. Кроме того, термин «мутант» здесь относится к любому варианту, который короче или длиннее белка или нуклеиновой кислоты, раскрытых в настоящем изобретении.
[0119] Термин «гомология» используется для описания взаимосвязи последовательностей нуклеотидов или аминокислот с другими последовательностями нуклеотидов или аминокислот, которая определена степенью идентичности и/или сходства между указанными сравниваемыми последовательностями.
[0120] Как здесь используется, аминокислотная или нуклеотидная последовательности «по существу идентичны» или «по существу такие же» как референсная последовательность, если аминокислотная или нуклеотидная последовательности имеют по крайней мере 40% идентичности с указанной последовательностью внутри выбранного для сравнения региона. Таким образом, по существу сходные последовательности включают те, которые имеют, например, по крайней мере, 40% идентичности, или по крайней мере, 50% идентичности, или по крайней мере, 55% идентичности, или по крайней мере, 60% идентичности, или по крайней мере, 62% идентичности, или по крайней мере 65% идентичности, или по крайней мере 70% идентичности, или по крайней мере, 75% идентичности, например, по крайней мере, 80% идентичности, по крайней мере, 85% идентичности, по крайней мере, 90% идентичности (например, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности). Две последовательности, которые идентичны одна другой, так же по существу сходны. Для целей настоящего изобретения длина сравниваемых последовательностей составляет по крайней мере 100 или более аминокислот, предпочтительно, по крайней мере, 200 аминокислот, например, 300 аминокислот или более аминокислот. В частности, возможно сравнение аминокислотных последовательностей полноразмерных белков. Для нуклеиновых кислот длина сравниваемых последовательностей в основном составляет, по крайней мере, 300 или более нуклеотидов; предпочтительно, по крайней мере, 600 нуклеотидов, в том числе 900 или более нуклеотидов.
[0121] Одним из примеров алгоритма, пригодного для определения процента идентичности последовательности и подобности последовательностей, является алгоритм BLAST, описанный в работе Altschul и др., J. Mol. Biol. 215: 403-410 (1990). Программное обеспечение для выполнения анализов по BLAST можно получить через национальный центр информации по биотехнологии (http://www.ncbi.nlm.nih.gov/). Этот алгоритм включает в себя прежде всего нахождение пар с наиболее высокой степенью идентичности (ПВИ) путем идентификации коротких слов длиной W в тестируемой последовательности, которые либо полностью совпадают, либо удовлетворяют некоторому пороговому положительному значению Т при совмещении со словом такой же длины из последовательности, полученной в базе. Т - это пороговое значение близости слова (Altschul и др., 1990). Эти первоначальные нахождения близости слов (совпадений) служат затравкой для инициации поиска более длинных ПВИ, содержащих эти слова. Затем эти совпадения слов расширяются в обоих направлениях вдоль каждой последовательности настолько далеко, насколько может увеличиваться совокупное значение баллов за совпадения. Совокупные значения вычисляются при помощи (для нуклеотидных последовательностей) параметров М (премиальный балл, начисляемый за пару совпадающих остатков; он всегда>0) и N (штрафной балл за несовпадение остатков; он всегда<0). Для вычисления совокупного значения по последовательностям аминокислот применяется матрица начисления баллов. Расширение совпадений слов в каждом направлении останавливается тогда, когда совокупное значение баллов за совпадения падает от максимального достигнутого значения на величину X, когда совокупное значение счета падает до нуля или ниже нуля вследствие накопления одного или нескольких отрицательных результатов совпадения, или же при достижении конца любой из последовательностей. Параметры W, Т и X алгоритма BLAST определяют чувствительность и скорость совмещения. В программе BLASTN (для нуклеотидных последовательностей) по умолчанию длина слова (W) принимается равной 11, ожидаемое значение (Е) равным 10, падение (отсечка) равным 100, М=5, N=-4, и сравнение выполняется по обеим цепочкам. Для последовательностей аминокислот программа BLASTP по умолчанию принимает длину слова (W) равной 3, ожидаемое значение (Е) равным 10, а также использует матрицу начисления баллов BLOSUM62 (см. Henikoff и Henikoff, Proc. Natl. Acad. Sci. USA 89: 10915 (1989)).
[0122] Кроме вычисления процента идентичности последовательности алгоритм BLAST также выполняет статистический анализ подобности между двумя последовательностями (см., например, Karlin и Altschul, Proc. Nat'l. Acad. Sci. USA 90: 5873-5787 (1993)). Одной из величин определения подобности, предоставляемой алгоритмом BLAST, является наименьшая суммарная вероятность (P(N)), показывающая вероятность, с которой совпадение между двумя нуклеотидными или аминокислотными последовательностями может произойти случайно. Например, тестируемая последовательность нуклеиновых кислот считается подобной ссылочной последовательности, если наименьшая суммарная вероятность при сравнении тестовой последовательности нуклеиновых кислот со ссылочной последовательностью нуклеиновых кислот меньше 0,1, более предпочтительно меньше чем 0,01, а наиболее предпочтительно меньше чем 0,001.
[0123] Термин «консенсусная последовательность» относится к архетипичной аминокислотной последовательности, с которой сравнивают все варианты конкретных представляющих интерес белков или последовательностей. Консенсусные последовательности и методы их определения хорошо известны специалистам в данной области. Например, консенсусная последовательность определяется с помощью множественного сравнения известных гомологичных белков путем выявления аминокислот, наиболее часто встречающихся в данном положении во всей совокупности родственных последовательностей.
[0124] Термин «консервативная последовательность» используется для обозначения нуклеотидной последовательности в нуклеиновых кислотах или последовательности аминокислот в полипептидной цепи, которые совсем не изменяются или незначительно изменяются у разных организмов в ходе эволюции. Соответственно «неконсервативная последовательность» - это последовательность, которая значительно варьирует у сравниваемых организмов.
[0125] Термин «аминокислотная вставка» означает одну или несколько аминокислот внутри полипептидной цепи, которые находятся между обсуждаемыми фрагментами белка (белковыми доменами, линкерами, консенсусными последовательностями). Специалистам в данной области очевидно, что обсуждаемые фрагменты и аминокислотные вставки оперативно связаны и образуют единую полипептидную цепь.
[0126] Для определения доменной структуры белка может быть использован любое программное обеспечение, известное из уровня техники. Например, может быть использовано программное обеспечение SMART (Simple Modular Architecture Research Tool), доступное в сети Интернет по адресу http://smart.embl-heidelberg.de [Schultz et al., PNAS 1998; 95: 5857-5864; Letunic I, Doerks T, Bork P Nucleic Acids Res 2014; doi:10.1093/nar/gku949].
[0127] Термин «оперативно связанный» или ему подобный при описании белков слияния относиться к полипептидным последовательностям, которые находятся в физической и функциональной связи одна с другой. В наиболее предпочтительных воплощениях, функции полипептидных компонентов химерной молекулы не изменены по сравнению с функциональными свойствами выделенных полипептидных компонентов. Например, гиспидин-гидроксилаза настоящего изобретения может быть оперативно сшита с представляющим интерес партнером слияния, например, люциферазой. В этом случае белок слияния сохраняет свойства гиспидин-гидроксилазы, а представляющий интерес полипептид сохраняет его оригинальную биологическую активность - например, способность окислять люциферин с выделением света. В некоторых воплощениях настоящего изобретения, активности партнеров слияния могут быть снижены по сравнению с активностями изолированных белков. Такие белки слияния также находят применение в рамках настоящего изобретения.
[0128] Термин «оперативно связанный» или ему подобный при описании нуклеиновых кислот означает, что нуклеиновые кислоты ковалентно связаны таким образом, что в местах их соединения отсутствуют «сбои» рамки считывания и стоп-кодоны. Как очевидно для любого специалиста в данной области техники, нуклеотидные последовательности, кодирующие белок слияния, включающий «оперативно связанные» компоненты (белки, полипептиды, линкерные последовательности, аминокислотные вставки, белковые домены и т.д.), состоят из фрагментов, кодирующих указанные компоненты, где эти фрагменты ковалентно связаны таким образом, что в ходе транскрипции и трансляции нуклеотидной последовательности продуцируется полноразмерный белок слияния.
[0129] При описании связи нуклеиновой кислоты с регуляторными кодирующими последовательностями (промоторами, энхансерами, терминаторами транскрипции) термин «оперативно связаны» означает, что последовательности расположены и сшиты таким образом, регуляторная последовательность будет воздействовать на уровень экспрессии кодирующей или последовательности нуклеиновой кислоты.
[0130] В контексте настоящего изобретения «связывание» нуклеиновых кислот означает, что две или несколько нуклеиновых кислот соединяют вместе при помощи любых способов, известных в данной отрасли. Для примера, не являющегося ограничивающим, скажем, что нуклеиновые кислоты можно лигировать вместе при помощи, например, ДНК-лигазы или соединять отжигом при помощи ПЦР. Нуклеиновые кислоты также можно соединять путем химического синтеза нуклеиновой кислоты, используя последовательность из двух или нескольких отдельных нуклеиновых кислот.
[0131] Термины «регуляторные элементы» или «регуляторные последовательности» относятся к последовательностям, включенным в управление экспрессией кодирующей нуклеиновой кислоты. Регуляторные элементы включают в себя промотор, терминирующие сигналы и другие последовательности, влияющие на экспрессию нуклеиновой кислоты. В типичном случае они также охватывают последовательности, требуемые для надлежащей трансляции нуклеотидной последовательности.
[0132] Термин «промотор» используется для описания нетранслируемой и нетранскрибируемой последовательности ДНК, находящейся до кодирующей области и содержащей участок связывания РНК-полимеразы, а также инициирующей транскрипцию ДНК. Область промотора может также включать в себя другие элементы, работающие регуляторами экспрессии генов.
[0133] Как здесь используется, термин «функциональный» означает, что нуклеотидная или аминокислотная последовательность может функционировать для указанного испытания или задачи. Термин «функциональный», используемый для описания люцифераз, означает, что белок обладает способностью производить сопровождающуюся люминесценцией реакцию окисления люциферина. При описании гиспидин-гидроксилаз термин «функциональный» означает, что белок обладает способностью катализировать реакцию превращения по крайней мере одного из предлюциферинов, показанных в Таблице 2 в соответствующий люциферин. При описании гиспидин-синтаз термин «функциональный» означает, что белок обладает способностью катализировать реакцию превращения по крайней мере одного из предшественников предлюциферинов в предлюциферин, например, превращение кофейной кислоты в гиспидин. При описании кофеилпируват-гидролаз термин «функциональный» означает, что белок обладает способностью катализировать реакцию превращения по крайней мере одного из оксилюциферинов в предшественник предлюциферина (например, превращение кофеилпирувата в кофейную кислоту).
[0134] Как здесь используется, термин «ферментативные свойства» относятся к способности белка катализировать ту или иную химическую реакцию.
[0135] Как здесь используется, термин «биохимические свойства» относятся к белковому фолдингу (сворачиванию) и скорости созревания, времени полужизни, скорости катализа, pH и температурной стабильности, и другим подобным свойствам.
[0136] Как здесь используется, «спектральные свойства» относятся к спектрам, квантовому выходу и интенсивности люминесценции и другим подобным свойствам.
[0137] Ссылка на нуклеотидную последовательность, «кодирующую» полипептид, означает, что с нуклеотидной последовательности в ходе транскрипции мРНК и трансляции продуцируется этот полипептид. При этом может быть указана как кодирующая цепь, идентичная мРНК и обычно используемая в списке последовательностей, так и комплементарная цепь, которая используется как матрица при транскрипции. Как очевидно для любого специалиста в данной области техники, термин также включает любые вырожденные нуклеотидные последовательности, кодирующие одинаковую аминокислотную последовательность. Нуклеотидные последовательности, кодирующие полипептид, включают последовательности, содержащие интроны.
[0138] Термины «экспрессионная кассета» или «кассета экспрессии» используются здесь в значении последовательности нуклеиновых кислот, способной направлять экспрессию конкретной нуклеотидной последовательности в соответствующей клетке-хозяине. Как правило «кассета экспрессии» содержит гетерологичную нуклеиновую кислоту, кодирующую белок или его функциональный фрагмент, оперативно связанную с промотором и сигналами терминации. В типичном случае она также содержит последовательности, требуемые для надлежащей трансляции значимой нуклеотидной последовательности. Экспрессионная кассета может быть такой, которая встречается в природе (в том числе и в клетках хозяина), но была получена в рекомбинантной форме, полезной для экспрессии гетерологичной нуклеиновой кислоты. Часто «кассета экспрессии» является гетерологичной по отношению к хозяину, т.е. конкретная последовательность нуклеиновых кислот этой экспрессионной кассеты не встречается в природе в клетке-хозяине, и должна вводиться в клетку-хозяин или в предшественник клетки-хозяина путем трансформации. Экспрессия нуклеотидной последовательности может находиться под управлением конститутивного промотора или индуцируемого промотора, который инициирует транскрипцию только тогда, когда клетка-хозяин открыта для определенного внешнего стимула. В случае многоклеточного организма промотор может также обладать специфичностью к конкретной ткани, или органу, или к стадии развития.
[0139] «Гетерологичная» или «экзогенная» нуклеиновая кислота означает нуклеиновую кислоту, не имеющуюся в клетке-хозяине дикого типа.
[0140] Термин «эндогенный» относится к нативному белку или нуклеиновой кислоте в их природном положении в геноме организма.
[0141] Как здесь используется, термин «специфически гибридизуется» относится к ассоциации между двумя одноцепочечными молекулами нуклеиновых кислот или в достаточной степени комплементарными последовательностями, что разрешает такую гибридизацию в предопределенных условиях, обычно использующихся в данной области (иногда используется термин «по существу комплементарный»).
[0142] «Изолированная» молекула нуклеиновой кислоты или изолированный белок представляют собой молекулу нуклеиновой кислоты или белок, которые вследствие действий человека существуют отдельно от своей естественной среды, а поэтому не являются продуктом природы. Изолированная молекула нуклеиновой кислоты или изолированный белок могут существовать в очищенной форме или могут существовать в неестественной среде, например, (что не означает ограничений) такой, как рекомбинантная прокариотическая клетка, растительная клетка, животная клетка, клетка небиолюминесцентного гриба, трансгенный организм (гриб, растение, животное) и т.д.
[0143] «Трансформация» - это процесс для введения гетерологичной нуклеиновой кислоты в клетку-хозяин или в организм. В частности, «трансформация» означает устойчивую интеграцию молекулы ДНК в геном интересующего организма.
[0144] «Трансформированный / трансгенный / рекомбинантный» относится к организму-хозяину, такому как бактерия, или растение, или гриб, или животное, в который ввели гетерологичную молекулу нуклеиновой кислоты. Эта молекула нуклеиновой кислоты может быть устойчиво интегрирована в геном хозяина, или же эта молекула нуклеиновой кислоты также может присутствовать как внехромосомная молекула. Такая внехромосомная молекула может быть способна к саморепликации. Следует понимать, что к трансгенным или устойчиво-трансформированным клеткам, тканям или организмам относятся не только конечные продукты процесса трансформации, но также и их трансгенное потомство. Термины «не трансформированный», «не трансгенный» или «не рекомбинантный», или «дикого типа» относятся к природному организму-хозяину или клетке-хозяину, например, к бактерии или растению, который не содержит гетерологичной молекулы нуклеиновой кислоты.
[0145] Термин «автономно светящийся» или «автономно биолюминесцентный» относятся к трансгенным организмам и клеткам-хозяевам, которые обладают способностью к биолюминесценции без экзогенного добавления люциферинов, предлюциферинов или предшественников предлюциферинов.
[0146] Термин «4'-фосфопантотеинил трансфераза» используется здесь для обозначения фермента, осуществляющего перенос 4-фосфопантетеинила от кофермента А на серин в ацилпереносящем домене поликетидсинтазы. 4'-фосфопантотеинил трансферазы экпсрессируются в природе многими растениями и грибами и известны из уровня техники [Gao Menghao et al., Microbial Cell Factories 2013, 12:77]. Специалисту в данной области очевидно, что для нужд настоящего изобретения может быть использован любой функциональный вариант 4'-фосфопантотеинил трансферазы. Например, может быть использована 4'-фосфопантотеинил трансфераза NpgA из Aspergillus nidulans (SEQ ID NO 104, 105), описанная в [Gao Menghao et al., Microbial Cell Factories 2013, 12:77], или ее гомолог или мутант, то есть белок, аминокислотная последовательность которого по существу сходная или идентичная с последовательностью, показанной в SEQ ID NO: 105. Например, может быть использована 4'-фосфопантотеинил трансфераза, имеющая по крайней мере 40% идентичности с последовательностью SEQ ID NO: 105, в том числе, по крайней мере, 50% идентичности, или по крайней мере, 55% идентичности, или по крайней мере, 60% идентичности, или по крайней мере, 62% идентичности, или по крайней мере 65% идентичности, или по крайней мере 70% идентичности, или по крайней мере, 75% идентичности, например, или по крайней мере, 80% идентичности, или по крайней мере, 85% идентичности, или по крайней мере, 90% идентичности (например, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности).
[0147] Нуклеотиды обозначаются по их основаниям следующими стандартными сокращенными обозначениями: аденин (А), цитозин (С), тимин (Т) и гуанин (G). Аналогичным образом аминокислоты обозначаются следующими стандартными сокращенными обозначениями: аланин (Ala; А), аргинин (Arg; R), аспарагин (Asn; N), аспарагиновая кислота (Asp; D), цистеин (Cys; С), глутамин (Gln; Q), глутаминовая кислота (Glu; Е), глицин (Gly; G), гистидин (His; Н), изолейцин (Не; 1), лейцин (Leu; L), лизин (Lys; К), метионин (Met; М), фенилаланин (Phe; F), пролин (Pro; Р), серин (Ser; S), треонин (Thr; Т), триптофан (Trp; W), тирозин (Туг; Y) и валин (Val; V).
[0148] Настоящее изобретение направлено на новые ферменты биосинтеза люциферина грибов, кодирующие их нуклеиновые кислоты, применение белков в качестве ферментов, катализирующих стадии биосинтеза люциферина грибов. Также изобретение обеспечивает применение нуклеиновых кислот для получения указанных ферментов в клетке или организме. Также обеспечиваются способы получения химических соединений, являющихся люциферинами и предлюциферинами грибов, в системах in vitro и in vivo. Также обеспечиваются векторы, включающие нуклеиновую кислоту, описанную в настоящем изобретении. Кроме того, настоящее изобретение обеспечивает кассеты экспрессии, включающие нуклеиновую кислоту настоящего изобретения и регуляторные элементы, необходимые для экспрессии нуклеиновой кислоты в выбранной клетке-хозяине. Кроме того, обеспечиваются клетки, стабильные клеточные линии, трансгенные организмы (например, растения, животные, грибы, микроорганизмы), включающие нуклеиновые кислоты, векторы или экспрессионные кассеты настоящего изобретения. Также обеспечиваются комбинации нуклеиновых кислот для получения автономно светящихся клеток, клеточных линий или трансгенных организмов. В преимущественных воплощениях клетки и трансгенные организмы способны производить люциферин грибов из предшественников. В некоторых воплощениях клетки и трансгенные организмы способны производить предлюциферин грибов из предшественников. В некоторых воплощениях клетки и трансгенные организмы способны к биолюминесценции в присутствии предшественника люциферина грибов. В некоторых воплощениях клетки и трансгенные организмы способны к автономной биолюминесценции. Также обеспечиваются комбинации белков для получения люциферина и его предшественников из более простых химических соединений. Также обеспечивается набор, содержащий нуклеиновые кислоты или векторы или экспрессионные кассеты настоящего изобретения, предназначенный для получения светящихся клеток, клеточных линий или трансгенных организмов.
Белки
[0149] Как было указано выше, настоящее изобретение обеспечивает белки, вовлеченные в качестве ферментов в биосинтез (циклическую систему превращений) люциферина грибов.
[0150] Белки по изобретению могут быть получены из природных источников или получены с помощью рекомбинантных технологий. Например, белки дикого типа могут быть выделены из биолюминесцентных грибов, например, из грибов, относящихся к типу Basidiomycota, преимущественно к классу Basidiomycetes, в частности, к отряду Agaricales. Например, белки дикого типа могут быть выделены из грибов Neonothopanus nambi, Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos и т.д. Белки настоящего изобретения могут также быть получены экспрессией рекомбинантной нуклеиновой кислоты, кодирующей последовательность, белка в соответствующем хозяине или в бесклеточной системе экспрессии, как описано в разделе «Нуклеиновые кислоты». В некоторых воплощениях белки применяются внутри клеток-хозяев, в которые введены способные к экспрессии нуклеиновые кислоты, кодирующие указанные белки.
[0151] В преимущественных воплощениях заявленные белки укладываются быстро после экспрессии в клетке-хозяине. Под быстрым укладыванием понимается то, что белки достигают своей третичной структуры, которая обеспечивает их ферментативное свойство, через короткий период времени. В этих воплощениях, белки укладываются в течение периода времени, который в общем случае не превышает приблизительно 3 дня, обычно не превышает приблизительно 2 дня и чаще не превышает приблизительно 12-24 часа.
[0152] В некоторых воплощениях белки используются в изолированной форме. Для очистки белка могут применяться любые обычные методики, где подходящие методы очистки белка описаны в Guide to Protein Purification, (Deuthser ed., Academic Press, 1990). Например, лизат может быть приготовлен из исходного источника и очищен с использованием ВЭЖХ, вытеснительной хроматографии, гель-электрофореза, аффинной хроматографии и т.п.
[0153] Если белки согласно настоящему изобретению находятся в изолированной форме, то это означает, что данный белок по существу свободен от присутствия других белков или других природных биологических молекул, таких как олигосахариды, нуклеиновые кислоты и их фрагменты и т.п., где термин «по существу свободен» в данном случае означает, что менее чем 70%, обычно менее чем 60% и чаще менее чем 50% указанной композиции, содержащей выделенный белок, представляет собой другую природную биологическую молекулу. В некоторых вариантах указанные белки присутствуют по существу в очищенной форме, где термин «по существу очищенная форма» обозначает чистоту, равную по меньшей мере 95%, обычно равную по меньшей мере 97% и чаще равную по меньшей мере 99%.
[0154] Белки настоящего изобретения сохраняют активность при температурах ниже 50°С, чаще при температурах до 45°С, то есть они сохраняют активность при температурах 20-42°С и могут быть использованы в системах гетерологической экспрессии in vitro и in vivo.
[0155] Заявленные белки обладают рН стабильностью в диапазоне от 4 до 10, чаще в диапазоне от 6.5 до 9.5. Оптимум рН стабильности заявленных белков лежит в диапазоне между 6.8 и 8.5, например, между 7.3-8.3.
[0156] Заявленные белки активны в физиологических условиях. Термин «физиологические условия» в данном изобретении подразумевает среду, имеющую температуру в диапазоне от 20 до 42°С, pH в диапазоне от 6.8 до 8.5, солевой и осмолярностью 300-400 мосмоль/л. В частности, термин «физиологические условия» включает внутриклеточную среду, клеточный экстракт и жидкости, экстрагированные из живых организмов, такие как плазма крови. «Физиологические условия» могут быть созданы искусственно. Например, комбинируя известные химические соединения могут быть созданы реакционные смеси, обеспечивающие «физиологические условия». Способы создания таких сред хорошо известны из уровня техники. Неограничивающие примеры включают:
[0157] 1) Раствор Рингера, изотоничный плазме крови млекопитающих.
[0158] Раствор Рингера состоит из 6,5 г NaCl, 0,42 г KCl и 0,25 г CaCl2, растворенных в 1 литре бидистиллированной воды. При приготовлении раствора соли добавляются последовательно, каждую последующую соль прибавляют только после растворения предыдущей. Для предотвращения выпадения осадка углекислого кальция рекомендуется через раствор бикарбоната натрия пропускать углекислый газ. Раствор готовят на свежей дистиллированной воде.
[0159] 2) Раствор Версена
[0160] Раствор Версена представляет собой смесь ЭДТА и неорганических солей, растворенную в воде дистиллированной или в воде для инъекций, стерилизованную методом мембранной фильтрации с использованием фильтров с конечным размером пор 0,22 мкм. 1 л раствора Версена содержит NaCl 8.0 г, KCl 0.2 г, натрий фосфорнокислый двузамещенный 12-водный 1,45 г, калий фосфорнокислый однозамещенный 0,2 г, натриевая соль этилендиаминтетрауксусной кислоты 0,2 г, бидистиллированная вода - до 1 л. Раствор Версена должен иметь буферную емкость не менее 1,4 мл. Содержание иона хлора - от 4,4 до 5,4 г/л, ЭДТА - не менее 0,6 ммоль/л.
[0161] 3) фосфатно-солевой буфер (PBS, Na-фосфатный буфер)
[0162] Na-фосфатный буфер состоит из 137 мМ NaCl, 10 мМ Na2HPO4, 1,76 мМ KH2PO4. Буфер может также содержать KCl в концентрации до 2.7 мМ. Для приготовления 1 литра однократного натрий-фосфатного буфера используют: 8,00 г NaCl, 1,44 г Na2HPO4, 0,24 г KH2PO4, 0,20 г KCl (опционно). Растворяют в 800 мл дистиллированной воды. Требуемый pH доводят соляной кислотой или гидроксидом натрия. Далее доводят объем до 1 л дистиллированной водой.
[0163] Специфические белки, представляющие интерес, являются ферментами, вовлеченными в циклический биосинтез люциферина грибов, их мутантами, гомологами и производными. Каждый из этих специфических типов полипептидных структур, представляющих интерес, далее будет рассмотрен индивидуально более подробно.
[0164] Гиспидин-гидроксилазы
[0165] Гиспидин-гидрокислазами настоящего изобретения являются белки, которые обладают способностью катализировать синтез люциферина из предлюциферина. Иными словами, это ферменты, катализирующие реакцию превращения 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил.
[0166] Реакция осуществляется в физиологических условиях в системах in vitro и in vivo в присутствии по крайней мере одной молекулы НАД(Ф)Н и по крайней мере одной молекулы молекулярного кислорода (О2) на одну молекулу 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она:
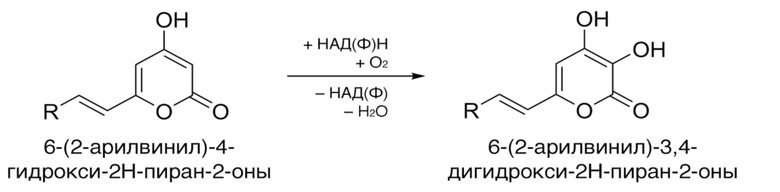
[0167] Гиспидин-гидроксилазы, представляющие интерес, включают белки из биолюминесцентных грибов Neonothopanus nambi, Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos, аминокислотные последовательности которых показаны в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, а также их функциональные мутанты, гомологи и производные.
[0168] В преимущественных воплощениях гиспидин-гидроксилазы настоящего изобретения характеризуются наличием ФАД/НАД-связывающего домена (FAD/NAD(P) binding domain, IPR002938 - код по публичной базе данных InterPro, доступной в сети Интернет по адресу http://www.ebi.ac.uk/interpro). Указанный домен участвует в связывании флавинадениндинуклеотида (FAD) и никотинамидадениндинуклеотиида (NAD) у множества ферментов, добавляющих гидроксильную группу к субстрату и найденных в метаболических путях множества организмов. Гиспидин-гидроксилазы настоящего изобретения содержат указанный домен длиной 350-385 аминокислот, чаще 360-380 аминокислот, например, 364-377 аминокислоты, фланкированный N- и C-концевые неконсервативными аминокислотными последовательностями, обладающими более низким процентом идентичности друг с другом. Положение ФАД/НАД-связывающего домена у заявленных гиспидин-гидроксилаз указано на множественном выравнивании аминокислотных последовательностей индивидуальных белков на фиг.1.
[0169] Также обеспечиваются гомологи или мутанты гиспидин-гидроксилаз, последовательность которых отличаются от описанных выше указанных специфических аминокислотных последовательностей, заявленных в изобретении, то есть SEQ ID NO: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28. Представляющие интерес гомологи или мутанты имеют по меньшей мере не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с белком, аминокислотная последовательность которого выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, на протяжении по крайней мере 350 аминокислот. В особенности это относится к последовательностям аминокислот, которые обеспечивают функциональные участки белка, то есть к последовательности входящего в состав гиспидин-гидроксилаз ФАД/НАД-связывающего домена.
[0170] В преимущественных воплощениях аминокислотная последовательность гиспидин-гидроксилазы настоящего изобретения характеризуется наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), характерных только для данной группы ферментов. Эти консенсусные последовательности показаны в SEQ ID NOs: 29-33. Консенсусные участки внутри аминокислотных последовательностей гиспидин-гидроксилаз оперативно связаны через аминокислотные вставки с меньшей консервативностью.
[0171] Гиспидин-синтазы
[0172] Гиспидин-синтазы настоящего изобретения представляют собой белки, которые обладают способностью катализировать синтез предлюциферина из его предшественников. Иными словами, это ферменты, катализирующие реакцию превращения 3-арилакриловой кислоты со структурной формулой
,
где R - арил или гетероарил в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил.
[0173] Примеры 3-арилакриловых кислот, служащих предшественниками предлюциферинов, показаны в Таблице 2.
[0174] Реакция осуществляется в физиологических условиях в системах in vitro и in vivo в присутствии по крайней мере одной молекулы кофермента А, по крайней мере одной молекулы АТФ и по крайней мере двух молекул малонил-КоА:
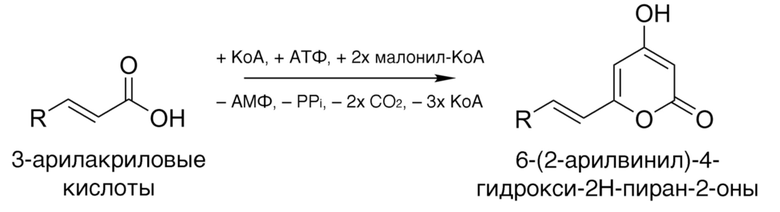
[0175] Гиспидин-синтазы, представляющие интерес, включают белки из биолюминесцентных грибов Neonothopanus nambi, Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos, аминокислотные последовательности которых показаны в SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, а также их функциональные мутанты, гомологи и производные.
[0176] В преимущественных воплощениях аминокислотная последовательность гиспидин-синтазы настоящего изобретения характеризуется наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), характерных только для данной группы ферментов. Эти консенсусные последовательности показаны в SEQ ID NOs: 56-63. Консенсусные участки внутри аминокислотных последовательностей гиспидин-синтаз оперативно связаны через аминокислотные вставки с меньшей консервативностью.
[0177] Во многих вариантах осуществления настоящего изобретения представляющие интерес аминокислотные последовательности гомологов и мутантов специфических гиспидин-синтаз характеризуются значительной идентичностью с последовательностями, показанными в SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, которая составляет, например, не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) на протяжении всей аминокислотной последовательности белка.
[0178] В преимущественных воплощениях гиспидин-синтазы настоящего изобретения являются полидоменными белками, относящимися к суперсемейству поликетидсинтаз. В преимущественных воплощениях гиспидин-синтазы настоящего изобретения подвергаются посттрансляционной модификации, а именно для их созревания требуется перенос 4-фосфопантетеинила от кофермента А на серин в ацилпереносящем домене поликетидсинтазы. Из уровня техники известны ферменты - 4'-фосфопантотеинил трансферазы, осуществляющие такую модификацию [Gao Menghao et al., Microbial Cell Factories 2013, 12:77]. 4'-фосфопантотеинил трансферазы экпсрессируются в природе многими растениями и грибами, в клетках которых созревание функциональной гиспидин-синтазы настоящего изобретения происходит без введения дополнительных ферментов или кодирующих их нуклеиновых кислот. В тоже время для созревания гиспидин-синтазы в клетках ряда низших грибов (например, дрожжей) и животных требуется введение в клетки-хозяева кодирующей последовательности 4'-фосфопантотеинил трансферазы. Специалисту в данной области очевидно, что для нужд настоящего изобретения может быть использован любой функциональный вариант 4'-фосфопантотеинил трансферазы, известный из уровня техники. Например, может быть использована 4'-фосфопантотеинил трансфераза NpgA из Aspergillus nidulans (SEQ ID NO 104, 105), описанная в [Gao Menghao et al., Microbial Cell Factories 2013, 12:77], любой ее гомолог или мутант с подтвержденной активностью.
[0179] Кофеилпируват-гидролазы
[0180] Кофеилпируват-гидролазы настоящего изобретения представляют собой белки, которые обладают способностью катализировать превращение оксилюциферина, представляющего собой 6-арил-2-гидрокси-4-оксогекса-2,5-диеновые кислоту, имеющую структурную формулу
[0181] ,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой
[0182] ,
где R - арил или гетероарил.
[0183] Примеры оксилюциферинов показаны в Таблице 2.
[0184] Реакция осуществляется в физиологических условиях в системах in vitro и in vivo:
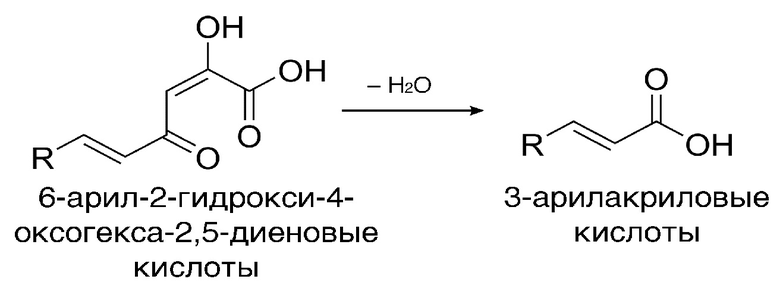
[0185] В преимущественных воплощениях кофеилпируват-гидролазы настоящего изобретения осуществляют превращение кофеилпирувата в кофейную кислоту. В преимущественных воплощениях они осуществляют превращение оксилюциферина, показанного в Таблице 2 в предшественник предлюциферина.
[0186] Кофеилпируват-гидролазы, представляющие интерес, включают белки из биолюминесцентных грибов Neonothopanus nambi, Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos, аминокислотные последовательности которых показаны в SEQ ID NOs: 65, 67, 69, 71, 73, 75, а также их функциональные мутанты, гомологи и производные.
[0187] В преимущественных воплощениях аминокислотная последовательность кофеилпируват-гидролаз настоящего изобретения (включая представляющие интерес гомологи и мутанты) характеризуется наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), характерных только для данной группы ферментов. Эти консенсусные последовательности показаны в SEQ ID NOs: 76-78. Консенсусные участки внутри аминокислотных последовательностей кофеилпируват-гидролаз оперативно связаны через аминокислотные вставки с меньшей консервативностью.
[0188] Во многих вариантах осуществления настоящего изобретения представляющие интерес аминокислотные последовательности кофеилпируват-гидролаз характеризуются значительной идентичностью с последовательностями, показанными в SEQ ID NOs: 65, 67, 69, 71, 73, 75, которая составляет, например, не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) на протяжении всей аминокислотной последовательности белка.
[0189] Гомологи вышеописанных специфических белков (то есть белков с аминокислотными последовательностями SEQ ID NO: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55, 65, 67, 69, 71, 73, 75) могут быть выделены из природных источников. Гомологи могут быть обнаружены во многих организмах (грибах, растениях, микроорганизмах, животных). В частности, гомологи могут быть обнаружены у различных видов биолюминесцентных грибов в частности из грибов, относящихся к типу Basidiomycota, преимущественно к классу Basidiomycetes, в частности, к отряду Agaricales. Также особый интерес в качестве источника гомологов белков настоящего изобретения представляют небиолюминесцентные грибы и растения, производящие гиспидин, такие как Pteris ensiformis [Yung-Husan Chen et al., «Identification of phenolic antioxidants from Sword Brake fern (Pteris ensiformis Burm.)», Food Chemistry, Volume 105, Issue 1, 2007, pp.48-56], Inonotus xeranticus [In-Kyoung Lee et al., «Hispidin Derivatives from the Mushroom Inonotus xeranticus and Their Antioxidant Activity», J. Nat. Prod., 2006, 69 (2), pp.299-301], Phellinus sp.[In-Kyoung Lee et al., «Highly oxygenated and unsaturated metabolites providing a diversity of hispidin class antioxidants in the medicinal mushrooms Inonotus and Phellinus». Bioorganic & Medicinal Chemistry. 15 (10): 3309-14.], Equisetum arvense [Markus Herderich et al., «Establishing styrylpyrone synthase activity in cell free extracts obtained from gametophytes of Equisetum arvense L. by high performance liquid chromatography-tandem mass spectrometry». Phytochem. Anal., 8: 194-197.].
[0190] Также обеспечиваются белки, которые являются производными или мутантами вышеописанных белков, встречающихся в природе. Мутанты и производные могут сохранять биологические свойства белков дикого типа (например, встречающихся в природе), или могут иметь биологические свойства, которые отличаются от белков дикого типа. Мутации включают замены одной или более аминокислот, делецию или инсерцию одной или более аминокислот, замены или усечения, или удлинения N-конца, замены или усечения, или удлинения C-конца и т.п. Мутанты и производные могут быть получены с использованием стандартных методов молекулярной биологии, как подробно описано в разделе «Нуклеиновые кислоты». Мутанты по существу идентичны белкам дикого типа, то есть имеют с ними по крайней мере 40% идентичности внутри выбранного для сравнения региона. Таким образом, по существу сходные последовательности включают те, которые имеют, например, по крайней мере, 40% идентичности, или по крайней мере, 50% идентичности, или по крайней мере, 55% идентичности, или по крайней мере, 60% идентичности, или по крайней мере, 62% идентичности, или по крайней мере 65% идентичности, или по крайней мере 70% идентичности, или по крайней мере, 75% идентичности, например, по крайней мере, 80% идентичности, или по крайней мере, 85% идентичности, или по крайней мере, 90% идентичности (например, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) внутри выбранного для сравнения региона. Во многих воплощениях гомологи, представляющие интерес, имеют намного более высокую идентичность последовательности, например, 70%, 75%, 80%, 85%, 90% (например, 92%, 93%, 94%) или выше, например, 95%, 96%, 97%, 98%, 99%, 99,5%, особенно для последовательности аминокислот, которые обеспечивают функциональные области белка.
[0191] Производные могут быть также получены с использованием стандартных методов и включают изменение при помощи РНК, химические модификации, модификации после трансляции и после транскрипции и т.п.Например, производные могут быть получены методами, такими как измененное фосфорилирование или гликозилирование, или ацетилирование, или липидирование, или различными типами расщепления при созревании и т.п.
[0192] Для поиска функциональных мутантов, гомологов и производных используются способы хорошо известные специалистам в данной области. Например, может быть использован функциональный скрининг экспрессионной библиотеки, содержащей варианты (например, мутантные формы белков, или гомологичные белки или производные белков). Экспрессионная библиотека получается путем клонирования нуклеиновых кислот, кодирующих тестируемые варианты белков в экспрессионный вектор и их введение в подходящие клетки-хозяина. Способы работы с нуклеиновыми кислотами описаны более подробно в разделе «Нуклеиновые кислоты». Для выявления функциональных ферментов настоящего изобретения к клеткам, экспрессирующим тестируемые нуклеиновые кислоты, добавляют подходящий субстрат.Появление ожидаемого продукта реакции, катализируемой функциональным ферментом, можно обнаружить с помощью методов высокоэффективной жидкостной хроматографии, используя синтетические варианты ожидаемых продуктов реакции в качестве стандартов. Например, для выявления функциональных гиспидин-гидроксилаз в качестве субстрата может быть использован гиспидин или иной предлюциферин, показанный в таблице 2. Ожидаемым продуктом реакции является люциферин грибов. Для выявления гиспидин-синтаз в качестве субстрата может быть использован предшественник предлюциферина (например, кофейная кислота), а продуктом реакции является соответствующий предлюциферин грибов. Следует учитывать, что для скрининга функциональных гиспидин-синтаз клетки-хозяева должны экспрессировать 4'-фосфопантотеинил трансферазу, обеспечивающую посттрансляционную модификацию белка.
[0193] Для поиска функциональных кофеилпируват-гидролаз в качестве субстрата реакции используется оксилюциферин (Таблица 2), а тестируемым продуктом реакции является предшественник предлюциферина - 3-арилакриловая кислота.
[0194] Во многих воплощениях настоящего изобретения для поиска функциональных ферментов настоящего изобретения может использоваться биолюминесцентная реакция. В этом случае для приготовления экспрессионной библиотеки используются клетки, продуцирующие люциферазу, способную окислять люциферин грибов с выделением света, и функциональные ферменты, обеспечивающие производство люциферина грибов из продукта ферментативной реакции, осуществляемой анализируемым белком.
[0195] Так для скрининга функциональных гиспидин-гидроксилаз используются клетки-хозяева, продуцирующие функциональную люциферазу, субтратом которой является люциферин грибов. При добавлении предлюциферина к клеткам, содержащим функциональный вариант гиспидин-гидроксилазы, происходит образование люциферина грибов и возникновение свечения за счет реакции окисления люциферина грибов люциферазой.
[0196] Для скрининга функциональных гиспидин-синтаз используются клетки-хозяева, дополнительно продуцирующие функциональную люциферазу, субстратом которой является люциферин грибов, и функциональную гиспидин-гидроксилазу. При добавлении предшественника люциферина к таким клеткам происходит образование люциферина грибов и возникновение свечения за счет реакции окисления люциферина грибов люциферазой.
[0197] Для скрининга функциональных кофеилпируват-гидролаз используются клетки-хозяева, продуцирующие функциональную люциферазу, субстратом которой является люциферин грибов, функциональную гиспидин-гидроксилазу и функциональную гиспидин-синтазу. При добавлении оксилюциферина к таким клеткам происходит образование люциферина грибов и возникновение свечения за счет реакции окисления люциферина грибов люциферазой.
[0198] Для скринига могут быть использованы любые люциферазы способные окислять с выделением света люциферин, выбранный из группы 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-онов с общей формулой ,
где R - арил или гетероарил. Неограничивающие примеры люциферинов приведены в таблице 1. Неограничивающие примеры подходящих люцифераз описаны в разделе «Применение, комбинации и способы использования» ниже.
[0199] Реакция окисления люциферинов люциферазой сопровождается выделением детектируемого света. Выделяемый в процессе реакции свет может быть выявлен обычными методами (например, при визуальном осмотре, осмотре с помощью приборов ночного видения, спектрофотометрией, спектрофлуориметрией, с использованием фотографической регистрации изображения, с использованием специализированного оборудования для детекции люминесценции и флуоресценции, такого, как, например, IVIS Spectrum In Vivo Imaging System (Perkin Elmer) и т.п.). Регистрируемый свет может испускаться в диапазоне интенсивностей от одного фотона до легко заметного глазу света, например, с интенсивностью 1 кд, и яркого света с интенсивностью, например, 100 кд, и более. Испускаемый при окислении 3-гидроксигиспидина свет находится в диапазоне от 400 до 700 нм, чаще в диапазоне от 450 до 650 нм, с максимумом эмиссии при 520-590 нм. Свет, испускаемый при окислении других 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-онов, может иметь сдвиг максимума эмиссии (Таблица 3).
[0200] Примеры осуществления функционального скрининга с использованием биолюминесценции описаны в экспериментальной части ниже.
[0201] Также изобретение охватывает белки слияния, включающие белок настоящего изобретения. Его гомолог, мутант, в том числе укороченную или удлиненную форму. Белок по изобретению может быть оперативно слит с сигналом внутриклеточной локализации (например, сигналом локализации в ядре, сигналом локализации в митохондриях, или пероксисомах, или лизосомах, или аппарате Гольджи, или в других клеточных органеллах), сигнальным пептидом, обеспечивающим выделение белка в межклеточное пространство, трансмембранным доменом или с любым белком или полипептидом (партнером слияния), представляющим интерес. Белки слияния могут включать оперативно сшитые, например, гиспидин-гидроксилазу, и/или гиспидин-синтазу, и/или кофеилпируват-гидролазу, заявленную в изобретении, с присоединенным на C- или N-конец партнером слияния. Неограничивающие примеры партнеров слияния могут включать белки настоящего изобретения, имеющие иную ферментативную функцию, антитела или их связывающие фрагменты, лиганды или рецепторы, люциферазы, способные использовать люциферины грибов в качестве субстратов в биолюминесцентной реакции. В некоторых воплощениях партнер слияния и белок по изобретению оперативно сшиты через линкерную последовательность (пептидный линкер), обеспечивающую независимый фолдинг и функционирование белка слияния. Способы изготовления белков слияния хорошо известны специалистам в данной области.
[0202] В некоторых воплощениях белки слияния включают оперативно сшитые через короткий пептидный линкер гиспидин-гидроксилазу по изобретению и люциферазу, способную осуществлять реакцию окисления люциферина гриба с выделением света. Подобный белок слияния может быть использован для получения биолюминесценции в системах in vitro и in vivo в присутствии предлюциферина (например, в присутствии гиспидина). Специалисту в области техники очевидно, что любая функциональная гиспидин-гидроксилаза, описанная выше, может быть использована с любой функциональной люциферазой для создания белка слияния. Специфические примеры белков слияния описаны ниже в Экспериментальной части. Примеры люцифераз, которые могут быть использованы при создании белков слияния, описаны в разделе «Применение, комбинации и способы использования» ниже.
Нуклеиновые кислоты
[0203] Настоящее изобретение обеспечивает нуклеиновые кислоты, кодирующие ферменты биосинтеза люциферина грибов, гомологи и мутанты этих белков, в том числе укороченные и удлиненные формы.
[0204] Нуклеиновая кислота, как здесь используется, представляет собой изолированную молекулу ДНК, такую как геномная молекула ДНК или молекула кДНК, или молекулу РНК, такую как молекула мРНК. В частности, указанные нуклеиновые кислоты представляют собой молекулы кДНК, имеющие открытую рамку считывания, которая кодирует фермент биосинтеза люциферина изобретения, и способна, при подходящих условиях, обеспечивать экспрессию фермента по изобретению.
[0205] Термин «кДНК» предназначен для описания нуклеиновых кислот, которые отражают расположение элементов последовательности, находящихся в нативной зрелой мРНК, где элементы последовательности представляют собой экзоны и 5-' и 3'-некодирующие области. Незрелая мРНК может иметь экзоны, разделенные промежуточными интронами, которые, если присутствуют, удаляются в ходе посттрансляционного РНК сплайсинга, с образованием зрелой мРНК, имеющей открытую рамку считывания.
[0206] Геномная последовательность, представляющая интерес, может включать нуклеиновую кислоту, присутствующую между инициирующим кодоном и терминирующим кодоном, как определено в перечисленных последовательностях, включая все интроны, которые обычно присутствуют в нативной хромосоме. Геномная последовательность, представляющая интерес, дополнительно может включать 5'- и 3'-нетранслируемые области, находящиеся в зрелой мРНК, так же как специфические транскрипционные и трансляционные регулирующие последовательности, такие как промоторы, энхансеры, и т.д., включающие фланкирующую геномную ДНК размером приблизительно 1 т.п.н., но возможно и больше, у 5'- или 3'-конца транскрибированной области.
[0207] Изобретение также охватывает нуклеиновые кислоты, которые являются гомологичными, по существу сходными, идентичными, производными или миметиками нуклеиновых кислот, кодирующих белки настоящего изобретения.
[0208] Заявленные нуклеиновые кислоты присутствуют в среде, отличной от их естественной среды; например, они выделены, присутствуют в обогащенных количествах, или присутствуют или экспрессированы in vitro или в клетке, или в организме, другом чем их естественно встречающаяся среда окружения.
[0209] Специфические нуклеиновые кислоты, представляющие интерес, включают нуклеиновые кислоты, которые кодируют гиспидин-гидроксилазу, или гиспидин-синтазу, или кофеилпируват-гидролазу, описанную в разделе «Белки» выше. Каждый из этих специфических типов нуклеиновых кислот, представляющих интерес, индивидуально раскрывается более детально.
[0210] Нуклеиновые кислоты, кодирующие гиспидин-гидроксилазы.
[0211] В преимущественных воплощениях нуклеиновые кислоты по изобретению кодируют белки, способные катализировать реакцию превращения 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она (предлюциферина), имеющего структурную формулу
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он (люциферин грибов), имеющий структурную формулу
,
[0212] где R - арил или гетероарил.
[0213] В преимущественных воплощениях, нуклеиновые кислоты кодируют гиспидин-гидроксилазы, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NO: 29-33.
[0214] Специфические примеры нуклеиновых кислот включают нуклеиновые кислоты, кодирующие гиспидин-гидроксилазы, аминокислотные последовательности которых показаны в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28. Примеры нуклеиновых кислот, кодирующих указанные белки, приведены в SEQ ID NOs: 1, 3,5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27. Также интерес представляют функциональные мутанты, гомологи и производные вышеуказанных специфических нуклеиновых кислот.
[0215] В преимущественных воплощениях нуклеиновые кислоты по изобретению кодируют белки, аминокислотные последовательности которых по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% идентичны последовательностям, показанным в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, на протяжении по крайней мере 350 аминокислот.
[0216] Нуклеиновые кислоты, кодирующие гиспидин-синтазы
[0217] В преимущественных воплощениях нуклеиновые кислоты по изобретению кодируют белки, способные катализировать реакцию превращения 3-арилакриловой кислоты со структурной формулой
[0218] ,
где R - арил илигетероарил в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу
[0219] ,
где R - арил или гетероарил.
[0220] В преимущественных воплощениях, нуклеиновые кислоты кодируют гиспидин-синтазы, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 56-63.
[0221] Специфические примеры нуклеиновых кислот включают нуклеиновые кислоты, кодирующие гиспидин-синтазы по изобретению, аминокислотные последовательности которых показаны в SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55. Примеры нуклеиновых кислот, кодирующих указанные белки, приведены в SEQ ID NOs: 34, 36,38,40,42, 44, 46, 48, 50, 52, 54.
[0222] Также интерес представляют функциональные мутанты, гомологи и производные вышеуказанных специфических нуклеиновых кислот.
[0223] В преимущественных воплощениях нуклеиновые кислоты по изобретению кодируют белки, аминокислотные последовательности которых по крайней мере на 45%, обычно по крайней мере на 50%, например, по крайней мере на 55%, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% идентичны последовательностям, показанным в SEQ ID NOs: 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55, на протяжении всей полипептидной цепи белка.
[0224] Нуклеиновые кислоты, кодирующие кофеилпируват-гидролазы
[0225] В преимущественных воплощениях нуклеиновые кислоты по изобретению кодируют белки, способные катализировать реакцию превращения оксилюциферина, имеющего структурную формулу
[0226] ,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой
[0227] ,
где R выбран из группы арил, гетероарил.
[0228] В преимущественных воплощениях, нуклеиновые кислоты кодируют кофеилпируват-гидролазы, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 76-78. Специфические примеры нуклеиновых кислот включают нуклеиновые кислоты, кодирующие кофеилпируват-гидролазы, аминокислотные последовательности которых показаны в SEQ ID NOs: 65, 67, 69, 71, 73, 75. Примеры нуклеиновых кислот, кодирующих указанные белки, приведены в SEQ ID NOs: 64, 66, 68, 70,72, 74.
[0229] Также интерес представляют нуклеиновые кислоты, кодирующие функциональные мутанты, гомологи и производные вышеуказанных белков.
[0230] В преимущественных воплощениях нуклеиновые кислоты по изобретению кодируют белки, аминокислотные последовательности которых по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% идентичны последовательностям, показанным в SEQ ID NOs: 65, 67, 69, 71, 73, 75, на протяжении всей полипептидной цепи.
[0231] Нуклеиновые кислоты, представляющие интерес (например, нуклеиновые кислоты, кодирующие гомологи белков, характеризующихся аминокислотными последовательностями показанными в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 35, 37, 39, 41, 43, 45,47,49, 51, 53,55, 65, 67, 69, 71, 73, 75), могут быть выделены из любых организмов (грибов, растений, микроорганизмов, животных), в частности из различных видов биолюминесцентных грибов, например, из грибов, относящихся к типу Basidiomycota, преимущественно к классу Basidiomycetes, в частности, к отряду Agaricales, например, из биолюминесцентных грибов Neonothopanus nambi, Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos и т.д. Также особый интерес в качестве источника нуклеиновых кислот, кодирующих гомологи белков настоящего изобретения, представляют небиолюминесцентные грибы и растения, производящие гиспидин, такие как Pteris ensiformis [Yung-Husan Chen et al., «Identification of phenolic antioxidants from Sword Brake fern (Pteris ensiformis Burm.)», Food Chemistry, Volume 105, Issue 1, 2007, pp.48-56], Inonotus xeranticus [In-Kyoung Lee et al., «Hispidin Derivatives from the Mushroom Inonotus xeranticus and Their Antioxidant Activity», J. Nat. Prod., 2006, 69 (2), pp.299-301], Phellinus sp.[In-Kyoung Lee et al., «Highly oxygenated and unsaturated metabolites providing a diversity of hispidin class antioxidants in the medicinal mushrooms Inonotus and Phellinus». Bioorganic & Medicinal Chemistry. 15 (10): 3309-14.], Equisetum arvense [Markus Herderich et al., «Establishing styrylpyrone synthase activity in cell free extracts obtained from gametophytes of Equisetum arvense L. by high performance liquid chromatography-tandem mass spectrometry». Phytochem. Anal., 8: 194-197.].
[0232] Гомологи идентифицируются любыми из множества способов. Фрагмент кДНК настоящего изобретения может использоваться как гибридизационный зонд против библиотеки кДНК от целевого организма, с использованием условий низкой жесткости. Зонд может быть большим фрагментом или одним или более коротким вырожденным праймером. Нуклеиновые кислоты, имеющие сходство последовательности, детектируются гибридизацией в условиях низкой жесткости, например, при 50°С и 6×SSC (0,9М хлористого натрия /0,09М цитрата натрия) с последующей промывкой при 55×С в 1×SSC (01,15М хлористого натрия/0,015 М цитрата натрия). Идентичность последовательности может быть определена гибридизацией в условиях высокой жесткости, например, при 50°С или выше и 0,1×SSC (15 мМ хлористого натрия/ 1,5 мМ цитрата натрия). Нуклеиновые кислоты, имеющие область, по существу идентичную представленным последовательностям, например, аллельным вариантам, генетически-измененным вариантам нуклеиновой кислоты, и т.д., связываются с представленными последовательностями в условиях высокой жесткости гибридизации. С использованием зондов, в частности меченых зондов последовательностей ДНК, можно выделить гомологичные или схожие гены.
[0233] Гомологи могут быть идентифицированы с помощью полимеразной цепной реакции из геномной или кДНК библиотеки. Олигонуклеотидные праймеры, представляющие фрагменты известных последовательностей специфических нуклеиновых кислот, можно использовать в качестве праймеров для ПЦР. В предпочтительном аспекте олигонуклеотидные праймеры имеют вырожденную структуру и соответствуют фрагментам нуклеиновой кислоты, кодирующим консервативные участки аминокислотной последовательности белка, например,. консенсусные последовательности, показанные в SEQ ID NOs: 29-33, 56-63, 76-78. Полноразмерные кодирующие последовательности могут быть затем выявлены с помощью методов 3'- и 5'-RACE, хорошо известных из уровня техники.
[0234] Гомологи могут быть также идентифицированы в результатах полногеномного секвенирования организмов с помощью сравнения аминокислотных последовательностей, предсказанных на основе полученной в ходе секвенирования с аминокислотными последовательностями SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 35, 37, 39, 41, 43, 45,47,49, 51, 53,55, 65, 67, 69, 71, 73, 75. Идентичность последовательностей определяется на основании референсной последовательности. Алгоритмы для анализа последовательности известны в данной области, такие как BLAST, описанный в Altschul et al., J. Mol. Biol., 215, pp.403-10 (1990). Для целей настоящего изобретения для определения уровня идентичности и сходства между нуклеотидными последовательностями и аминокислотными последовательностями может быть использовано сравнение нуклеотидных и аминокислотных последовательностей, производимое с помощью пакета программ Blast, предоставляемого National Center for Biotechnology Information (http://www.ncbi.nlm.nih.gov/blast) с использованием содержащего разрывы выравнивания со стандартными параметрами.
[0235] Также обеспечиваются нуклеиновые кислоты, которые гибридизуются с вышеописанными нуклеиновыми кислотами в жестких условиях, предпочтительно в условиях высокой жесткости (то есть, комплементарные предварительно описанным нуклеиновым кислотам). Примером гибридизации в жестких условиях является при 50°С или выше и 0,1×SSC (15 мМ хлористого натрия/ 1,5 мМ цитрата натрия). Другим примером гибридизации в условиях высокой жесткости является инкубация в течение ночи при 42°С в 50% растворе формамида, 5×SSC (150 мМ NaCl, 15 мМ тринатрий цитрат), 50 мМ фосфата натрия (рН 7,6), 5 × раствора Денхардта, 10% сульфата декстрана, и 20 мкг/мл денатурированной, разрезанной ДНК семенной жидкости лосося, с предварительной промывкой в 0,1×SSC при приблизительно 65°С. Другие условия высокой жесткости гибридизации известны в данной области и могут также использоваться для определения нуклеиновых кислот изобретения.
[0236] Также обеспечиваются нуклеиновые кислоты, кодирующие варианты, мутанты или производные белков изобретения. Мутанты или производные могут быть получены на матричной нуклеиновой кислоте, выбранной из вышеописанных нуклеиновых кислот, путем модификации, делеции или добавления одного или более нуклеотидов в матричной последовательности или их комбинации, для получения варианта матричной нуклеиновой кислоты. Модификации, добавления или делеции могут быть выполнены любым способом, известным в данной области (см., например, Gustin et al., Biotechniques (1993) 14: 22; Barany, Gene (1985) 37: 111-123; and Colicelli et al., Mol. Gen. Genet. (1985) 199:537-539, Sambrook et al., Molecular Cloning: A Laboratory Manual, (1989), CSH Press, pp.15.3-15.108), включая подверженный ошибкам ПЦР, перестановку, олигонуклеотид-направленный мутагенез, ПЦР со сборкой, парный ПЦР мутагенез, мутагенез in vivo, кассетный мутагенез, рекурсивный ensemble мутагенез, экспоненциальный множественный мутагенез, сайт-специфический мутагенез, неспецифический мутагенез, генное реассемблирование, генный сайт-насыщающий мутагенез (GSSM), искусственное реассемблирование с лигированием (SLR) или их комбинации. Модификации, добавления или делеции могут быть также выполнены способом, включающим рекомбинацию, рекурсивную рекомбинацию последовательности, фосфотиоат-модифицированный мутагенез ДНК, мутагенез на урацил-содержащей матрице, мутагенез с двойным пропуском, точечный восстановительный по рассогласованию мутагенез, мутагенез штамма, дефицитного по восстановлениям, химический мутагенез, радиоактивный мутагенез, делеционный мутагенез, рестрикционно-избирательный мутагенез, рестрикционный мутагенез с очисткой, синтез с искусственными генами, множественный мутагенез, создание химерных множественных нуклеиновых кислот и их комбинации. Нуклеиновые кислоты, кодирующие укороченные и удлиненные варианты указанных люцифераз, также входят в рамки настоящего изобретения. Как здесь используется, эти варианты белков содержат аминокислотные последовательности с измененными C-, N-, или обоими концами полипептидной цепи.
[0237] В преимущественных воплощениях обсуждаемые гомологи и мутанты являются функциональными ферментами, способными осуществлять реакции биосинтеза люциферина гриба, например, люциферина грибов. Гомологи и мутанты, представляющие интерес, могут иметь измененные свойства, такие как скорость созревания в клетке-хозяине, способность к агрегации или димеризации, период полураспада или иные биохимические свойства, в том числе константу связывания с субстратом, термостабильность, pH-стабильность, температурный оптимум активности, pH-оптимум активности, константу Михаэлиса-Ментен, субстратную специфичность, диапазон побочных продуктов. В некоторых воплощениях, гомологи и мутанты имеют такие же свойства как заявленные белки.
[0238] Нуклеиновые кислоты, кодирующие функциональные гомологи и мутанты настоящего изобретения, могут быть определены в ходе функциональных тестов, например, при функциональном скрининге экспрессионной библиотеки, описанном выше в разделе «Белки».
[0239] Кроме того, также обеспечиваются вырожденные варианты нуклеиновых кислот, которые кодируют белки настоящего изобретения. Вырожденные варианты нуклеиновых кислот включают замены кодонов нуклеиновой кислоты на другие кодоны, кодирующие те же самые аминокислоты. В частности, вырожденные варианты нуклеиновых кислот создаются, чтобы увеличить экспрессию в клетке-хозяине. В этом воплощении, кодоны нуклеиновой кислоты, которые не являются предпочтительными или являются менее предпочтительными в генах в клетке-хозяине, заменены кодонами, которые излишне представлены в кодирующих последовательностях в генах в клетке-хозяине, где указанные замененные кодоны кодируют ту же самую аминокислоту. В частности, интерес представляют гуманизированные версии нуклеиновых кислот настоящего изобретения. Как здесь используется, термин «гуманизированный» относится к заменам, сделанным в последовательности нуклеиновой кислоты для оптимизации кодонов для экспрессии белка в клетках млекопитающих (Yang et al., Nucleic Acids Research (1996) 24: 4592-4593). См. также Патент США №5795737, который описывает гуманизацию белков, раскрытие которого здесь включено ссылкой. Особый интерес представляют варианты нуклеиновых кислот.Оптимизированные для экспрессии в растительных клетках. Примеры таких нуклеиновых кислот, кодирующих белки настоящего изобретения показаны в SEQ ID NOs: 103, 113 и 114.
[0240] Заявленные нуклеиновые кислоты могут быть выделены и получены по существу в очищенной форме. По существу, очищенная форма означает, что нуклеиновые кислоты являются по меньшей мере приблизительно на 50% чистыми, обычно по меньшей мере приблизительно на 90% чистыми и являются обычно «рекомбинантными», то есть фланкированы одним или более нуклеотидов, с которыми она обычно не связывается в хромосоме, встречающейся в природе в ее естественном организме-хозяине.
[0241] Заявленные нуклеиновые кислоты могут быть синтезированы искусственно. Способы получения нуклеиновых кислот хорошо известны из области техники. Например, доступность информации о последовательности аминокислот или информации о нуклеотидной последовательности дает возможность изготовить выделенные молекулы нуклеиновых кислот настоящего изобретении с помощью олигонуклеотидного синтеза. В случае информации о последовательности аминокислот, может быть синтезировано несколько нуклеиновых кислот отличающихся друг от друга вследствие вырожденности генетического кода. Методы выбора вариантов кодонов для требуемого хозяина хорошо известны в данной области.
[0242] Синтетические олигонуклеотиды могут быть приготовлены с помощью фосфорамидитного метода, и полученные конструкты могут быть очищены с помощью методов хорошо известных в данной области, таких как высокоэффективная жидкостная хроматография (ВЭЖХ) или других методов как описано, например, в Sambrook et al., Molecular Cloning: A Laboratory Manual, 2nd Ed., (1989) Cold Spring Harbor Press, Cold Spring Harbor, NY, и по инструкции, описанной в, например, United States Dept. of HHS, National Institute of Health (NIH) Guidelines for Recombinant DNA Research. Длинные двухцепочечные молекулы ДНК настоящего изобретения могут быть синтезированы следующим образом: могут быть синтезированы несколько меньших фрагментов с необходимой комплементарностью, которые содержат подходящие концы, способные к когезии с соседним фрагментом. Соседние фрагменты могут быть сшиты с помощью ДНК-лигазы, методов, основанных на рекомбинации, или метода, основанного на ПЦР.
[0243] Также обеспечиваются нуклеиновые кислоты, кодирующие белки слияния, включающие белки настоящего изобретения. Примеры подобных белков приведены выше в разделе «Белки». Нуклеиновые кислоты, кодирующие белки слияния, могут быть синтезированы искусственно как описано выше.
[0244] Также обеспечиваются кассеты экспрессии или системы, использованные inter alia для получения заявленных белков (то есть гиспидин-гидроксилаз, гиспидин-синтаз и кофеилпируват-гидролаз) или белков слияния на их основе или для репликации заявленных молекул нуклеиновой кислоты. Кассета экспрессии может существовать как внехромосомный элемент или может быть включена в геном клетки в результате введения указанной кассеты экспрессии в клетку. При введении кассеты экспрессии в клетку происходит образование белкового продукта, кодируемого нуклеиновой кислотой изобретения; в этом случае говорят, что белок «продуцируется» или «экспрессируется» клеткой. Применима любая система экспрессии, включая, например, бактериальные системы, дрожжи, растения, насекомых, земноводных или клетки млекопитающих. В кассете экспрессии целевая нуклеиновая кислота оперативно соединяется с регуляторными последовательностями, которые могут включать промоторы, энхансеры, терминирующие последовательности, операторы, репрессоры и индукторы. Как правило, кассета экспрессии содержит по крайней мере (а) регион инициации транскрипции, функциональный в клетке-хозяине; (б) нуклеиновую кислоту по изобретению; и (в) регион терминации транскрипции, функциональный в клетке-хозяине. Способы получения кассет или систем экспрессии, способных экспрессировать желательный продукт, известны специалистам в данной области.
[0245] Также обеспечиваются вектор и другие конструкции нуклеиновой кислоты, содержащие заявленные нуклеиновые кислоты. Подходящие векторы включают вирусные и невирусные векторы, плазмиды, космиды, фаги и т.д., предпочтительно плазмиды, и используются для клонирования, амплификации, экспрессии, переноса и т.д., последовательности нуклеиновой кислоты настоящего изобретения в подходящего хозяина. Выбор подходящего вектора является понятным для квалифицированного специалиста в данной области. Полноразмерная нуклеиновая кислота или ее часть обычно вставляются в вектор посредством прикрепления ДНК-лигазой к расщепленному ферментами рестрикции сайту в векторе. Альтернативно, желательная нуклеотидная последовательность может быть вставлена гомологичной рекомбинацией in vivo, обычно, присоединением гомологичных участков к вектору на флангах желательной нуклеотидной последовательности. Гомологичные участки добавляются лигированием олигонуклеотидов или полимеразной цепной реакцией, с использованием праймеров, включающих, например, как гомологичные участки, так и часть желательной нуклеотидной последовательности. Вектор, как правило, имеет ориджин репликации, обеспечивающий его размножение в клетках-хозяевах в результате его введения в клетку как внехромосомного элемента. Вектор также может содержать регуляторные элементы, обеспечивающие экспрессию нуклеиновой кислоты в клетке-хозяине и получение рекомбинантного функционального белка. В экспрессионном векторе, указанная нуклеиновая кислота является функционально связанной с регуляторной последовательностью, которая может включить промоторы, энхансеры, терминаторы, операторы, репрессоры, сайленсеры, инсуляторы и индукторы. Для экспрессии функциональных белков или их укороченных форм кодирующие их нуклеиновые кислоты оперативно сшивают с нуклеиновыми кислотами, содержащими, по крайней мере, регуляторные последовательности и сайт начала транскрипции. Также эти нуклеиновые кислоты могут содержать последовательности, кодирующие гистидиновую метку (6 His tag), сигнальный пептид или функциональные белковые домены. Во многих воплощениях векторы обеспечивают интеграцию нуклеиновой кислоты, оперативно связанной с регуляторными элементами, в геном клетки-хозяина. Вектор может содержать кассету экспрессии для селектируемого маркера, такого как флуоресцентный белок (например, gfp), ген устойчивости к антибиотику (например, ген устойчивости к амфициллину, или канамицину, или неомицину или гигромицину и т.д.), гены, обусловливающие устойчивость к гербицидам, такие как гены, обусловливающие устойчивость к фосфинотрицину и гербицидам на основе сульфонамида, или иной селектируемый маркер, известный из уровня техники.
[0246] Вектор может содержать дополнительные кассеты экспрессии, включающие нуклеиновые кислоты, кодирующие 4'-фосфопантотеинил трансферазу, белки синтеза 3-арилакриловых кислот (например, описанные в разделе «Применение, комбинации и способы использования»), люциферазы и т.д.
[0247] Вышеописанные системы экспрессии могут использоваться в прокариотических или эукариотических хозяевах. Для получения белка могут использоваться клетки-хозяева, такие как Е. coli, В. subtilis, S. cerevisiae, клетки насекомого, или клетки высшего организма, не являющиеся эмбриональными клетками человека, такие как дрожжи, растения (например, Arabidopsis thaliana, Nicotiana benthamiana, Physcomitrella patens), позвоночные, например, COS 7 клетки, НЕК 293, СНО, ооциты Xenopus и т.д.
[0248] Клеточные линии, которые устойчиво продуцируют белки настоящего изобретения, могут быть выбраны способами, известными в данной области (например, ко-трансфекция с селектируемым маркером, таким как dhfr, gpt, генами устойчивости к антибиотику (ампициллину, или канамицину, или неомицину или гигромицину и т.д.), что делает возможным выявление и выделение трансфицированных клеток, которые содержат ген, включенный в геном или существующий в составе экстрахромосомного элемента.
[0249] Если используется любая вышеупомянутая клетка-хозяин или другие подходящие для репликации и/или экспрессии нуклеиновых кислот изобретения клетки-хозяева или организмы, то полученная реплицированная нуклеиновая кислота, экспрессированный белок или полипептид находятся в рамках притязания изобретения как продукт клетки-хозяина или организма. Продукт может быть выделен подходящим способом, известным в данной области.
[0250] Во многих воплощениях настоящего изобретения в клетку ко-трансфецируют несколькими кассетами экспрессии, содержащими нуклеиновые кислоты по изобретению, кодирующие различные ферменты биосинтеза люциферина грибов. В некоторых воплощениях в клетку дополнительно вводят кассету экспрессии, содержащую нуклеиновую кислоту, кодирующую люциферазу, способную окислять люциферин грибов с выделением света. В ряде случаев кассеты экспрессии объединяют в составе одного вектора, который используют для трансформации клеток. В некоторых воплощениях в клетку дополнительно вводят нуклеиновые кислоты, кодирующие 4'-фосфопантотеинил трансферазу и/или белки синтеза 3-арилакриловых кислот.
[0251] Также обеспечиваются короткие фрагменты ДНК заявленных нуклеиновых кислот, которые применяются как праймеры для ПЦР, амплификации rolling circle, гибридизационные скрининговые пробы и т.д. Длинные фрагменты ДНК применяются для получения кодируемых полипептидов, как ранее описано. Однако, для использования в геометрических реакциях амплификации, таких как ПЦР, используется пара коротких фрагментов ДНК, то есть праймеров. Точная последовательность праймера не является критической для изобретения, но для большинства применений праймеры будут гибридизоваться с заявленной последовательностью в условиях строгости, как известно в данной области. Предпочтительно выбрать пару праймеров, которые дадут продукт амплификации по меньшей мере приблизительно из 50 нуклеотидов, предпочтительно по меньшей мере приблизительно из 100 нуклеотидов и могут простираться на полную последовательность нуклеиновой кислоты. Алгоритмы отбора последовательностей праймеров обычно известны и доступны в коммерческих пакетах программ. Праймеры для амплификации гибридизуются с комплементарными цепочками ДНК и будут затравлять встречные реакции амплификации.
[0252] Молекулы нуклеиновых кислот настоящего изобретения также могут применяться для определения экспрессии гена в биологическом образце. Способ, в котором исследуются клетки на наличие специфических нуклеотидных последовательностей, таких как геномная ДНК или РНК, хорошо отработан в данной области. Кратко, выделяют ДНК или мРНК из образца клетки. мРНК может быть амплифицирована с помощью ОТ-ПЦР, с использованием обратной транскриптазы для формирования комплементарной цепочки ДНК, с последующей амплификацией с помощью полимеразной цепной реакцией с использованием праймеров, специфических для заявленных последовательностей ДНК. Альтернативно, образец мРНК отделяют с помощью гель-электрофореза, переносят на подходящий носитель, например, нитроцеллюлозу, нейлон и т.д., и затем тестируют фрагментом заявленной ДНК в качестве пробы. Могут также использоваться другие способы, такие как анализы сшивания олигонуклеотидов, гибридизация in situ и гибридизация ДНК-пробами, иммобилизованными на твердый чип.Обнаружение мРНК, гибридизующейся с заявленной последовательностью указывает на экспрессию гена в образце.
Трансгенные организмы
[0253] Также обеспечиваются трансгенные организмы, трансгенные клетки и трансгенные клеточные линии, экспрессирующие нуклеиновые кислоты согласно настоящему изобретению. Трансгенные клетки согласно настоящему изобретению включают одну или несколько нуклеиновых кислот, рассматриваемых в настоящем изобретении, которые присутствуют в качестве трансгена. Для целей настоящего изобретения может использоваться любая подходящая клетка-хозяин, включающая прокариотические (например, Escherichia coli, Streptomyces sp., Bacillus subtilis, Lactobacillus acidophilus и т.п.) или эукариотические клетки-хозяева, не являющиеся эмбриональными клетками человека. Трансгенные организмы согласно настоящему изобретению могут представлять прокариотические или эукариотические организмы, включающие бактерии, цианобактерии, грибы, растения и животные, в которые вводится одна или большее число клеток организма, содержащих гетерологичную нуклеиновую кислоту согласно настоящему изобретению, путем встраивания ее за счет манипуляции человеком, например, в рамках трансгенных методик, известных в данной области.
[0254] В одном варианте осуществления настоящего изобретения трансгенный организм может представлять собой прокариотический организм. Способы трансформации прокариотических хозяйских клеток хорошо известны в данной области (см., например, Sambrook et al. (Molecular Cloning: A Laboratory Manual, 2nd Ed., (1989) Cold Spring Harbor Laboratory Press и Ausubel et al., Current Protocols in Molecular Biology (1995) John Wiley & Sons, Inc).
[0255] В другом варианте осуществления настоящего изобретения указанный трансгенный организм может представлять собой гриб, например, дрожжи. Дрожжи широко используются в качестве носителя для гетерологичной генной экспрессии (см., например, Goodey et al., Yeast biotechnology, D R Berry et al., eds, (1987) Allen and Unwin, London, pp.401-429, и Kong et al., Molecular and Cell Biology of Yeasts, E. F. Walton and G. T. Yarronton, eds, Blackie, Glasgow (1989) pp.107-133). Доступно несколько типов дрожжевых векторов, включающих интегрирующиеся векторы, которые требуют рекомбинации с геномом-хозяином для своего поддержания, а также автономно реплицирующиеся плазмидные векторы.
[0256] Другим организмом-хозяином является организм животного. Трансгенные животные могут быть получены с использованием трансгенных методик, известных в данной области и описанных в стандартных руководствах (таких как: Pinkert, Transgenic Animal Technology: A Laboratory Handbook, 2nd edition (2003) San Diego: Academic Press; Gersenstein and Vinterstein, Manipulating the Mouse Embryo: A Laboratory Manual, 3rd ed, (2002) Nagy A. (Ed), Cold Spring Harbor Laboratory; Blau et al., Laboratory Animal Medicine, 2nd Ed., (2002) Fox J.G., Anderson L.C., Loew F.M., Quimby F.W. (Eds), American Medical Association, American Psychological Association; Gene Targeting: A Ptactical Approach by Alexandra L. Joyner (Ed.) Oxford University Press; 2nd edition (2000)). Например, трансгенные животные могут быть получены посредством гомологичной рекомбинации, в рамках которой меняется эндогенный локус.Альтернативно, конструкцию нуклеиновой кислоты интегрируют в случайном режиме в геном. Векторы для стабильной интеграции включают плазмиды, ретровирусы и другие вирусы животных, YAC и т.п.
[0257] Нуклеиновая кислота может быть введена в клетку, непосредственно или опосредованно, за счет введения в предшественник клетки, с помощью осторожной генетической манипуляции, такой как микроинъекция, или с помощью инфекции рекомбинантным вирусом или с использованием рекомбинантного вирусного вектора, трансфекции, трансформации, доставки с помощью генной пушки или трансконъюгации. Методики переноса молекул нуклеиновой кислоты (например, ДНК) в такие организмы хорошо известны и описаны в стандартных руководствах таких, как Sambrook et al. (Molecular Cloning: A Laboratory Manual, 3nd Ed., (2001) Cold Spring Harbor Press, Cold Spring Harbor, NY).
[0258] Термин «генетическая манипуляция» не включает классический кроссбридинг или оплодотворение in vitro, но, скорее, обозначает введение рекомбинантной молекулы нуклеиновой кислоты. Указанная молекула нуклеиновой кислоты может быть интегрирована в хромосому или может представлять собой внехромосомно реплицирующуюся ДНК.
[0259] Конструкции ДНК для гомологичной рекомбинации включают по меньшей мере часть нуклеиновой кислоты согласно настоящему изобретению, где нуклеиновая кислота по изобретению оперативно присоединена к участкам гомологии к целевому локусу. В конструкции ДНК для проведения случайной интеграции нет необходимости включать участки гомологии для облегчения рекомбинации. Могут быть также включены маркеры позитивной и негативной селекции. Способы получения клеток, содержащих целевые генные модификации, посредством гомологической рекомбинации, известны в данной области. Различные методики трансфекции клеток млекопитающих описаны, например, в работе Keown et al., Meth. Enzymol. (1990) 185:527-537).
[0260] В случае эмбриональных стволовых клеток (ES), может быть использована клеточная линия ES или эмбриональные клетки могут быть получены в свежем виде от организма-хозяина, такого как мышь, крыса, морская свинка и т.п.Такие клетки выращивают на соответствующем питательном слое для фибробластов или выращивают в присутствии фактора ингибирования лейкозных клеток (LIF). Трансформированные ES или эмбриональные клетки могут быть использованы для создания трансгенных животных с использованием соответствующей методики, известной в данной области.
[0261] Трансгенные животные могут представлять собой любых животных, отличных от человека, включая млекопитающее, отличное от человека (например, мышь, крыса), птицу или земноводное и т.п., и используются в функциональных исследованиях, при скрининге лекарственных препаратов и т.п.
[0262] Могут быть также получены трансгенные растения. Способы получения трансгенных растительных клеток и растений описаны в патентах №№US 5767367, US5750870, US5739409, US5689049, US5689045, US5674731, US5656466, US5633155, US5629470, US5595896, US5576198, US5538879 и US5484956, описание которых включено в настоящее изобретение в качестве ссылок. Способы получения трансгенных растений обобщены также в следующих обзорах: Plant Biochemistry and Molecular Biology (eds. Lea and Leegood, John Wiley & Sons (1993) pp.275-295 и в Plant Biotechnology and Transgenic Plants (eds. Oksman-Caldentey and Barz) (2002) 719 p.
[0263] Для получения трансгенного организма-хозяина могут использоваться, например, эмбриогенные эксплантаты, содержащие соматические клетки. После сбора клеток или тканей интересующую экзогенную ДНК вводят в растительные клетки, и для такого введения доступно множество различных методик. При наличии выделенных протопластов возникает возможность введения с использованием ДНК-опосредованных протоколов генного переноса, включающих инкубирование протопластов с депротеинезированной ДНК, такой как плазмида, включающей экзогенную кодирующую последовательность, представляющую интерес, в присутствии поливалентных катионов (например, ПЭГ или поли-L-орнитин); или по методу электропорации протопластов в присутствии оголенной ДНК, включающей интересующую экзогенную последовательность. Далее отбирают протопласты, которые успешно захватили экзогенную ДНК, растят их до образования каллуса и в итоге получают трансгенные растения посредством контакта с соответствующими количествами и взятыми в соответствующих соотношениях стимулирующих факторов, таких как ауксины и цитокинины.
[0264] Могут использоваться другие подходящие методы получения растений, такие как подход, основанный на использовании «генной пушки» или трансформация, опосредованная использованием Agrobacterium, известные специалистам в данной области.
Антитела
[0265] Термин «антитело» используется здесь для обозначения полипептида или группы полипептидов, включающих по крайней мере один активный центр антитела (антиген-связывающий сайт). Термин «антиген-связывающий сайт» обозначает пространственную структуру, параметры поверхности и распределение заряда у которой комплементарны параметрам эпитопа антигена: это обеспечивает связывание антитела с соответствующим антигеном. Понятие «антитело» охватывает, например, антитела позвоночных животных, химерные антитела, гибридные антитела, гуманизованные антитела, измененные антитела, моновалентные антитела, фрагменты Fab и монодоменные антитела.
[0266] Антитела, специфичные в отношении белков по настоящему изобретению, применимы в аффинной хроматографии, иммунологических тестах и в выявлении и идентификации белков по изобретению (гиспидин-гидроксилаз, гиспидин-синтаз и кофеилпируват-гидролаз). Антитела, представляющие интерес, связываются с антигенными полипептидами или белками, или белковыми фрагментами, которые описаны выше в разделе «Белки». Антитела по настоящему изобретению могут быть иммобилизованы на носитель и использованы в иммунологическом тесте или на аффинной хроматографической колонке с целью выявления и/или разделения полипептидов, белков или белковых фрагментов, или клеток, включающих такие полипептиды, белки или белковые фрагменты. Как альтернатива, такие полипептиды, белки или белковые фрагменты могут быть иммобилизованы так, чтобы выявлять антитела, способные связываться специфически с ними.
[0267] Антитела, специфичные в отношении белков по настоящему изобретению, как поликлональные, так и моноклональные, могут быть получены с применением стандартных методов. В целом, вначале белок используют для иммунизации подходящего млекопитающего, предпочтительно мыши, крысы, кролика или козы. Кролики и козы являются предпочтительными объектами для получения поликлональных сывороток благодаря получению значительного объема сыворотки крови, а также доступности помеченных антикроличьих и антикозьих антител. Иммунизацию обычно проводят путем перемешивания или эмульгирования конкретного белка в физиологическом растворе, предпочтительно с адъювантом, таким как полный адъювант Фрейнда, с последующим введением полученной смеси или эмульсии парентеральным путем (обычно путем подкожной или внутримышечной инъекции). Обычно достаточными дозами являются по 50-200 мкг за одну инъекцию.
[0268] В различных воплощениях изобретения для иммунизации используют рекомбинантные или природные белки в нативной или денатурированной форме. Для иммунизации могут быть использованы также белковые фрагменты или синтетические полипептиды, содержащие часть аминокислотной последовательности белка по изобретению.
[0269] Иммунизацию обычно бустируют через 2-6 недель путем одной или нескольких дополнительных инъекций белка в физиологическом растворе, предпочтительно с включением неполного адъюванта Фрейнда. Также антитела могут быть получены альтернативным путем с помощью иммунизации in vitro с применением известных в данной области техники методов, которые с точки зрения целей настоящего изобретения эквивалентны иммунизации in vivo. Поликлональные антисыворотки получают путем отбора крови у иммунизованных животных в стеклянную или пластиковую емкость с последующей инкубацией крови при 25 С в течение 1 часа и затем инкубацией при 4 С в течение 2-18 часов. Сыворотку выделяют центрифугированием (например, при 1000 g в течение 10 минут). У кроликов за один раз можно получить 20-50 мл крови.
[0270] Моноклональные антитела получают с использованием стандартного метода Келера-Мильштейна (Kohler & Milstein, 1975, Nature, 256, 495-496) или его модификаций. Обычно в соответствии с описанным выше иммунизуют мышь или крысу. Однако, в отличие от взятия крови у животных с целью получения сыворотки, в данном методе удаляют селезенку (и, что необязательно, некоторые крупные лимфатические узлы) и мацерируют ткань с целью разделения отдельных клеток. Если желательно, клетки селезенки могут быть подвергнуты скринингу (после удаления не специфически адгезировавшихся клеток) путем нанесения клеточной суспензии на планшет или в отдельную планшетную лунку, покрытые белком-антигеном. В-лимфоциты, экспрессирующие связанный с мембраной иммуноглобулин, специфичный в отношении тестируемого антигена, связываются на планшете таким образом, что с остатком суспензии не смываются с него. Затем проводят слияние полученных в результате В-лимфоцитов или же всех мацерированных спленоцитов с миеломными клетками, в результате чего образуются гибридомы: их затем культивируют в селективной среде (например, в среде HAT, содержащей гипоксантин, аминоптерин и тимидин). Полученные в результате гибридомы высевают в ограничивающем разведении и тестируют на выработку антител, которые специфическим образом связываются с использовавшимся для иммунизации антигеном (и которые не связываются с посторонними антигенами). Отобранные гибридомы, секретирующие моноклональные антитела (mAb), затем культивируют либо in vitro (например, в ферментерах в виде пучка полых волокон или стеклянных емкостях для тканевых культур), либо in vivo (в асцитной жидкости у мышей).
[0271] Антитела (как поликлональные, так и моноклональные) могут быть помечены с применением стандартных методов. Подходящими метками являются флуорофоры, хромофоры, радионуклиды (в частности, 32P и 125I), электронно-плотные реагенты, ферменты и лиганды, для которых известны специфичные партнеры по связыванию. Ферменты обычно выявляют по их каталитической активности. Например, пероксидазу хрена обычно выявляют по ее способности конвертировать 3,3',5,5'-тетраметилбензидин (ТМВ) в синий пигмент, количественно оцениваемый на спектрофотометре. Термин «специфичный партнер по связыванию» обозначает белок, способный связывать молекулу-лиганд, проявляя при этом высокий уровень специфичности, как, например, в случае с антигеном и специфичным в отношении него моноклональным антителом. Другими примерами специфичных партнеров по связыванию являются биотин и авидин (или стрептавидин), иммуноглобулин-G и белок-А, а также многочисленные пары рецепторов и их лигандов, известные в данной области техники. Другие варианты и возможности будут очевидны специалистам в данной области техники и в объеме настоящего изобретения рассматриваются как эквивалентные.
[0272] Антигены, иммуногены, полипептиды, белки или белковые фрагменты по настоящему изобретению вызывают образование специфических партнеров по связыванию - антител. Указанные антигены, иммуногены, полипептиды, белки или белковые фрагменты по настоящему изобретению включают иммуногенные композиции по настоящему изобретению. Такие иммуногенные композиции могут дополнительно содержать или включать адъюванты, носители или другие композиции, которые стимулируют или усиливают, или стабилизируют антигены, полипептиды, белки или белковые фрагменты по настоящему изобретению. Такие адъюванты и носители будут очевидны для специалистов в данной области техники.
Применение, комбинации и способы использования
[0273] Настоящее изобретение обеспечивает применение белков биосинтеза люциферина грибов в качестве ферментов, катализирующих реакции (1) синтеза люциферина (а именно 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-она), имеющего структурную формулу
,
где R - арил или гетероарил, из предлюциферина (а именно 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она), имеющего структурную формулу
;
или синтеза предлюциферина из 3-арилакриловой кислоты (предшественника предлюциферина) со структурной формулой
,
где R выбран из группы арил или гетероарил; или синтеза 3-арилакриловой кислоты из 6-арил-2-гидрокси-4-оксогекса-2,5-диеновую кислоты (оксилюциферина) со структурной формулой .
[0274] Белки биосинтеза люциферина грибов находят применение во многих способах реализации настоящего изобретения, неограничивающие примеры которых приведены в этой главе ниже.
[0275] Белки биосинтеза люциферина грибов, применение которых обеспечивается настоящим изобретением, могут быть получены из различных природных источников или получены с помощью рекомбинантных технологий. Например, белки дикого типа могут быть выделены из биолюминесцентных грибов, например, из грибов, относящихся к типу Basidiomycota, преимущественно к классу Basidiomycetes, в частности, к отряду Agaricales. Например, белки дикого типа могут быть выделены из биолюминесцентных грибов Neonothopanus nambi, Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos и т.д. Они могут также быть получены экспрессией рекомбинантной нуклеиновой кислоты, кодирующей последовательность, белка в соответствующем хозяине или в бесклеточной системе экспрессии.
[0276] В некоторых воплощениях белки применяются внутри клеток-хозяев, где они экспрессируются и осуществляют реакции циклического превращения люциферина грибов. В других воплощениях используются изолированные рекомбинантные или природные белки или экстракты, содержащие белки по применению.
[0277] Белки биосинтеза люциферина грибов активны в физиологических условиях.
[0278] В некоторых воплощениях обеспечивается применение белков - гиспидин-гидроксилаз в системах in vitro и in vivo для получения люциферина, который окисляется люциферазами биолюминесцентных грибов, их гомологами и мутантами с выделением света. Таким образом, настоящим изобретением обеспечивается применение гиспидин-гидроксилаз настоящего изобретения для катализа реакции превращения 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она (предлюциферина), имеющего структурную формулу
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он (люциферин грибов), имеющий структурную формулу
,
где R - арил или гетероарил.
[0279] Способ получения люциферина грибов из предлюциферина включает объединение по крайней мере одной молекулы гиспидин-гидроксилазы с по крайней мере одной молекулой 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, с по крайней мере одной молекулой НАД(Ф)Н и по крайней мере с одной молекулы молекулярного кислорода (О2). Реакция осуществляется в физиологических условиях в системах in vitro и in vivo при температуре от 20 до 42 градусов Цельсия, в том числе реакция может осуществляться в клетках, тканях и организмах-хозяевах, экспрессирующих гиспидин-гидроксилазу. В преимущественных воплощениях указанные клетки, ткани и организмы содержат достаточное количество НАД(Ф)Н и молекулярного кислорода для осуществления реакции. В реакции может быть использован экзогенно добавляемый 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, или эндогенный 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, производимый в клетках, тканях или организмах.
[0280] В преимущественных воплощениях гиспидин-гидроксилазы настоящего изобретения осуществляют синтез 3-гидроксигиспидина из гиспидина. В преимущественных воплощениях они осуществляют синтез по крайней мере одного функционального аналога 3-гидроксигиспидина из соответствующего предлюциферина, показанного в Таблице 2. В некоторых воплощениях гиспидин-гидроксилазы настоящего изобретения осуществляют синтез 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-она из любого соответствующего 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу ,
где R - арил или гетероарил.
[0281] Получаемый 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он находит применение для получения свечения в системах in vitro и in vivo, содержащих функциональную люциферазу, опознающую люциферин грибов в качестве субстрата.
[0282] Применимыми для нужд настоящего изобретения в качестве гиспидин-гидроксилаз являются белки, аминокислотные последовательности которых показаны в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, а также их мутанты, гомологи и производные. Например, могут быть использованы функциональные гиспидин-гидроксилазы 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% на протяжении по крайней мере 350 аминокислот. Например, они могут быть идентичны на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% на протяжении всей полипептидной цепи белка.
[0283] В преимущественных воплощениях, применимыми для нужд настоящего изобретения в качестве гиспидин-гидроксилазы являются белки, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 29-33. Консенсусные участки внутри аминокислотных последовательностей гиспидин-гидроксилаз оперативно связаны через аминокислотные вставки с меньшей консервативностью (Фиг. 1).
[0284] В некоторых воплощениях обеспечивается применение белков гиспидин-синтаз в системах in vitro и in vivo для получения предлюциферина грибов из его предшественника, то есть применение для катализа реакции превращения 3-арилакриловых кислот со структурной формулой
,
где R выбран из группы арил, гетероарил, в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил.
[0285] Способ получения предлюциферина включает объединение по крайней мере одной молекулы гиспидин-синтазы с по крайней мере одной молекулой 3-арилакриловой кислоты с по крайней мере одной молекулы кофермента А, с по крайней мере одной молекулы АТФ и по крайней мере с двумя молекулами малонил-КоА.
[0286] Реакция осуществляется в физиологических условиях при температуре от 20 до 42 градусов Цельсия, в том числе реакция может осуществляться в клетках, тканях и организмах - хозяевах, экспрессирующих функциональную гиспидин-синтазу. В преимущественных воплощениях указанные клетки, ткани и организмы содержат достаточное количество кофермента А, малонил-КоА и АТФ для осуществления реакции.
[0287] В реакции может быть использована экзогенно добавляемая 3-арилакриловая кислота или 3-арилакриловая кислота, производимая в клетках, тканях или организмах.
[0288] Например, гиспидин-синтазы настоящего изобретения могут быть использованы для получения гиспидина из кофейной кислоты. В преимущественных воплощениях они осуществляют синтез функционального аналога гиспидина (6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она) из соответствующей 3-арилакриловой кислоты, показанной в Таблице 2.
[0289] Получаемый 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он находит применение для получения люциферина грибов в присутствии гиспидин-гидроксилазы настоящего изобретения. Гиспидин и его функциональные аналоги также находят применение в медицине, так как проявляют антиоксидантные и противоопухолевые свойства; по некоторым данным гиспидин способен предотвращать ожирение [Be Tu et al., Drug Discov Ther. 2015 Jun; 9 (3): 197-204; Nguyen et al., Drug Discov Ther. 2014 Dec; 8 (6): 238-44; Yousfi et al., Phytother Res. 2009 Sep; 23 (9): 1237-42].
[0290] Применимыми для нужд настоящего изобретения в качестве гиспидин-синтаз являются белки, аминокислотные последовательности которых показаны в SEQ ID NOs: 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55, а также их мутанты, гомологи и производные. Например, могут быть использованы функциональные гиспидин-синтазы, имеющие аминокислотную последовательность, которая идентична последовательности, выбранной из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55, по крайней мере на 40%, чаще по крайней мере на 45%, обычно по крайней мере на 50%, например, по крайней мере на 55%, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99%.
[0291] В преимущественных воплощениях, применимыми для нужд настоящего изобретения в качестве гиспидин-синтаз являются белки, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 56-63. Консенсусные участки внутри аминокислотных последовательностей гиспидин-синтаз оперативно связаны через аминокислотные вставки с меньшей консервативностью (Фиг. 2).
[0292] В некоторых воплощениях обеспечивается применение белков кофеилпируват-гидролаз в системах in vitro и in vivo для получения 3-арилакриловых кислот со структурной формулой
[0293] ,
где R выбран из группы арил, гетероарил, из 6-арил-2-гидрокси-4-оксогекса-2,5-диеновой кислоты со структурной формулой
где R - арил или гетероарил. Реакция осуществляется в физиологических условиях в системах in vitro и in vivo. Кофеилпируват-гидролазы настоящего изобретения находят применение в системах автономной биолюминесценции, детально описанных ниже.
[0294] Применимыми для нужд настоящего изобретения в качестве кофеилпируват-гидролаз являются белки, аминокислотные последовательности которых показаны в SEQ ID NOs: 65, 67, 69, 71, 73, 75, а также их мутанты, гомологи и производные. Например, могут быть использованы функциональные кофеилпируват-гидролазы, имеющие аминокислотную последовательность, которая идентична последовательности, выбранной из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75, по крайней мере на 60%, по крайней мере на 65%, по крайней мере на 70%, по крайней мере на 80%, по крайней мере на 85%, по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99%.
[0295] В преимущественных воплощениях, применимыми для нужд настоящего изобретения в качестве кофеилпируват-гидролаз являются белки, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 76-78. Консенсусные участки внутри аминокислотных последовательностей кофеилпируват-гидролаз оперативно связаны через аминокислотные вставки с меньшей консервативностью (Фиг. 3).
[0296] Также обеспечиваются комбинации белков, применимые в способах настоящего изобретения. В преимущественных воплощениях комбинации включают функциональную гиспидин-гидроксилазу и функциональную гиспидин-синтазу. Комбинация находит применение для получения 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-она из 3-арилакриловой кислоты со структурной формулой
,
где R - арил или гетероарил. Например, комбинация может быть использована для получения гидроксигиспидина кофейной кислоты. Реакция осуществляется в физиологических условиях в присутствии по крайней мере одной молекулы гиспидин-гидроксилазы, по крайней мере одной молекулы гиспидин-синтазы, по крайней мере одной молекулы 3-арилакриловой кислоты, по крайней мере одной молекулы кофермента А, по крайней мере одной молекулы АТФ, по крайней мере двух молекул малонил-КоА, по крайней мере одной молекулы НАД(Ф)Н и по крайней мере одной молекулы молекулярного кислорода (О2).
[0297] В некоторых воплощениях комбинация включает также люциферазу, способную использовать 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он со структурной формулой
,
где R - арил или гетероарил, в качестве люциферина. Окисление указанного 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-она такой люциферазой сопровождается биолюминесценцией и образованием оксилюциферина (6-арил-2-гидрокси-4-оксогекса-2,5-диеновой кислоты).
[0298] В качестве люциферазы может быть использован любой белок, характеризующихся вышеуказанной активностью. Например, могут быть использованы известные люциферазы из биолюминесцентных грибов, в том числе описанные в заявке RU №2017102986/10(005203) от 30.01.2017, а также их гомологи, мутанты и химерные белки, обладающие люциферазной активностью.
[0299] Во многих вариантах осуществления настоящего изобретения применимые для нужд настоящего изобретения люциферазы характеризуются аминокислотными последовательностями, которые по крайней мере на 40% идентичны, например, по крайней мере на 45% идентичны, или по крайней мере на 50% идентичны, или по крайней мере на 55% идентичны, или по крайней мере на 60% идентичны, или по крайней мере на 70% идентичны, или по крайней мере на 75% идентичны, или по крайней мере на 80% идентичны, или по крайней мере на 85% идентичны аминокислотной последовательности, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Часто люциферазы характеризуются аминокислотными последовательностями, которые имеют с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88,90, 92, 94, 96, 98, не менее 90% идентичности (например, не менее 91%, не менее 92%, не менее 93%, не менее 94%, не менее 95%, не менее не менее 96%, не менее 97%, не менее 98%, не менее 99% идентичности или 100% идентичности).
[0300] Мутанты могут сохранять биологические свойства люциферазы дикого типа, из которого они были получены, или могут обладать биологическим свойствами, которые отличаются от свойств белков дикого типа. Термин «биологическое свойство» люцифераз согласно настоящему изобретению относится, без ограничения, к способности окислять различные люциферины; биохимическим свойствам, таким, как стабильность in vivo и/или in vitro (например, период полувыведения); скорость созревания; тенденция к агрегации или олигомеризации, а также другие подобные свойства. Мутации включают изменения одной или нескольких аминокислот, делеции или вставки одной или нескольких аминокислот; N-концевые усечения или расширения, С-концевые усечения или расширения и т.п.
[0301] В некоторых воплощениях настоящего изобретения люциферазы используются в изолированной форме, то есть это означает, что данный они по существу свободны от присутствия других белков или других природных биологических молекул, таких как олигосахариды, нуклеиновые кислоты и их фрагменты и т.п., где термин «по существу свободен» в данном случае означает, что менее чем 70%, обычно менее чем 60% и чаще менее чем 50% указанной композиции, содержащей выделенный белок, представляет собой другую природную биологическую молекулу. В некоторых вариантах указанные белки присутствуют по существу в очищенной форме, где термин «по существу очищенная форма» обозначает чистоту, равную по меньшей мере 95%, обычно равную по меньшей мере 97% и чаще равную по меньшей мере 99%.
[0302] В некоторых воплощениях люциферазы используются в составе экстрактов, полученных из биолюминесцентных грибов или из клеток-хозяев, содержащих кодирующие рекомбинантные люциферазы нуклеиновые кислоты.
[0303] В многих воплощениях люциферазы находятся гетерологических системах экспрессии (в клетках или организмах настоящего изобретения), которые содержат нуклеиновые кислоты, кодирующие рекомбинантные люциферазы.
[0304] Способы получения рекомбинантных белков, в частности люцифераз, как в выделенном виде, или в составе экстрактов, или в гетерологических системах экспрессии хорошо известны из уровня техники и описаны в разделе «Нуклеиновые кислоты». Способы очистки белков описаны в разделе «Белки».
[0305] В преимущественных воплощениях люциферазы сохраняют активность при температурах ниже 50°С, чаще при температурах до 45°С, то есть они сохраняют активность при температурах 20-42°С и могут быть использованы в системах гетерологической экспрессии in vitro и in vivo. Как правило, описываемые люциферазы обладают рН стабильностью в диапазоне от 4 до 10, чаще в диапазоне от 6.5 до 9.5. Оптимум рН стабильности заявленных белков лежит в диапазоне между 7.0 и 8.5, например, между 7.3-8.0. В преимущественных воплощениях, указанные люциферазы активны в физиологических условиях.
[0306] Комбинация гиспидин-гидроксилазы и люциферазы, окисляющей люциферин грибов с выделением света, находит применение в способах выявления гиспидина и его функциональных аналогов в биологических объектах: клетках, тканях, или организмах. Способ включает контакт исследуемого биологического объекта или полученного из него экстракта с комбинацией выделенных гиспидин-гидроксилазы и указанной люциферазы в подходящем реакционном буфере, создающим физиологические условия и содержащим необходимые компоненты для осуществления реакций. Специалист в области может составить множество реакционных буферов, удовлетворяющих данному условию. Неограничивающим примером реакционного буфера может служить 0.2 M натрий-фосфатный буфер (pH 7.0-8.0) с добавлением 0.5 M Na2SO4, 0.1% додецилмальтозида (DDM), 1 мМ НАДФН.
[0307] Наличие гиспидина или его функционального аналога определяется по появлению детектируемого света - биолюминесценции. Способы детекции детектируемого света описаны выше в разделе «Белки» при описании способов функционального скрининга.
[0308] Комбинация гиспидин-гидроксилазы, гиспидин-синтазы и люциферазы, окисляющей люциферин грибов с выделением света, находит применение в способах выявления 3-арилакриловой кислоты со структурной формулой
,
где R - арил или гетероарил, в биологических объектах. Способ включает контакт исследуемого биологического объекта или полученного из него экстракта с комбинацией выделенных гиспидин-гидроксилазы, гиспидин-синтазы и люциферазы, создающим физиологические условия и содержащим необходимые компоненты для осуществления реакций. Специалист в области может составить множество реакционных буферов, удовлетворяющих данному условию. Неограничивающим примером реакционного буфера может служить 0.2 M натрий-фосфатный буфер (pH 7.0-8.0) с добавлением 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM), 1 мМ НАДФН, 10 мМ АТФ, 1 мМ КоА, 1 мМ Малонил-КоА.
[0309] Наличие 3-арилакриловой кислоты определяется по появлению детектируемого света - биолюминесценции. Способы детекции детектируемого света описаны выше в разделе «Белки» при описании способов функционального скрининга.
[0310] В некоторых воплощениях вместо комбинации гиспидин-гидроксилазы и люциферазы, окисляющей люциферин грибов с выделением света, может быть использован белок слияния, описанный в разделе «Белки» выше. Белок слияния одновременно проявляет активность гиспидин-гидроксилазы и активность люциферазы и может быть использован в любых способах вместо комбинации двух указанных ферментов.
[0311] В некоторых воплощениях вместо вышеописанной гиспидин-синтазы используется поликетидсинтаза III типа, характеризующаяся аминокислотной последовательностью, по существу сходной с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139. Применимыми для нужд настоящего изобретения являются поликетидсинтазы III типа, имеющие аминокислотную последовательность, которая идентична последовательности, выбранной из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139 по крайней мере на 40%, чаще по крайней мере на 45%, обычно по крайней мере на 50%, например, или по крайней мере на 55%, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99%.
[0312] Представители указанных поликетидсинтаз (PKS) выявлены во многих растительных организмах, из уровня техники известна их способность и/или способность их мутантов катализировать синтез бисноръянгонина из кумарила-КоА [Lim et al., Molecules, 2016 Jun 22;21(6)]. Заявители продемонстрировали, что указанные ферменты также способны катализировать синтез гиспидин из кофеил-КоА в системах in vitro и in vivo:
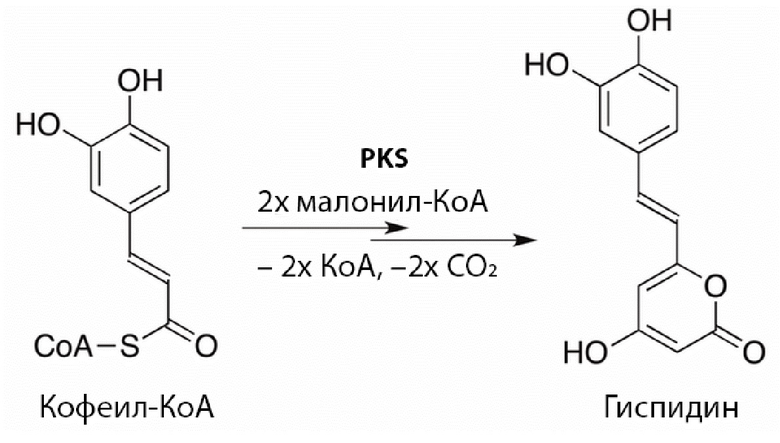
[0313] Таким образом применение указанных белков для синтеза гиспидина также находится в рамках настоящего изобретения.
[0314] В некоторых воплощениях настоящего изобретения PKS используются в изолированной форме, то есть это означает, что они по существу свободны от присутствия других белков или других природных биологических молекул, таких как олигосахариды, нуклеиновые кислоты и их фрагменты и т.п., где термин «по существу свободен» в данном случае означает, что менее чем 70%, обычно менее чем 60% и чаще менее чем 50% указанной композиции, содержащей выделенный белок, представляет собой другую природную биологическую молекулу. В некоторых вариантах указанные белки присутствуют по существу в очищенной форме, где термин «по существу очищенная форма» обозначает чистоту, равную по меньшей мере 95%, обычно равную по меньшей мере 97% и чаще равную по меньшей мере 99%.
[0315] В многих воплощениях PKS находятся в гетерологических системах экспрессии (в клетках или организмах настоящего изобретения), которые содержат нуклеиновые кислоты, кодирующие рекомбинантные ферменты.
[0316] Способы получения рекомбинантных белков как в выделенном виде, или в составе экстрактов, или в гетерологических системах экспрессии хорошо известны из уровня техники и описаны в разделе «Нуклеиновые кислоты». Способы очистки белков описаны в разделе «Белки».
[0317] В преимущественных воплощениях PKS сохраняют активность при температурах ниже 50°С, чаще при температурах до 45°С, то есть они сохраняют активность при температурах 20-42°С и могут быть использованы в системах гетерологической экспрессии in vitro и in vivo. Как правило описываемые PKS обладают рН стабильностью в диапазоне от 4 до 10, чаще в диапазоне от 6.0 до 9.0 Оптимум рН стабильности заявленных белков лежит в диапазоне между 6.5 и 8.5, например, между 7.0-7.5. В преимущественных воплощениях, указанные PKS активны в физиологических условиях.
[0318] Способ получения гиспидина включает объединение по крайней мере одной молекулы описанной выше поликетидсинтазы III типа с по крайней мере двумя молекулами малонил-КоА и по крайней мере одной молекулой кофеил-КоА.
[0319] В некоторых воплощениях способ включает получение кофеил-КоА из кофейной кислоты в ходе ферментативной реакции, катализируемой кумарат-КоА-лигазой. В этом случае способ включает объединение по крайней мере одной молекулы описанной выше поликетидсинтазы III типа с по крайней мере одной молекулой кофейной кислоты, с по крайней мере одной молекулой кофермента А, с по крайней мере одной молекулой кумарат-КоА-лигазы, с по крайней мере одной молекулой АТФ и по крайней мере двумя молекулами малонил-КоА.
[0320] Для нужд настоящего изобретения могут быть использованы любые известные из уровня техники ферменты кумарат-КоА-лигазы, осуществляющие реакцию присоединения кофермента А к кофейной кислоте с образованием кофеил-КоА:
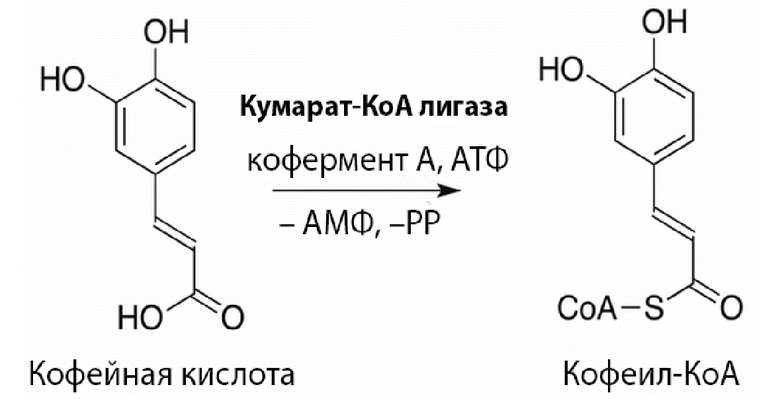
[0321] В частности, может быть использована кумарат-КоА-лигаза 1 из Arabidopsis thaliana, имеющая аминокислотную и нуклеотидную последовательности, показанные в SEQ ID NO: 141, а также ее функциональные мутанты и гомологи. Например, пригодной для нужд настоящего изобретения является функциональная кумарат-КоА-лигаза, аминокислотная последовательность которой имеет не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с аминокислотной последовательностью, показанной в SEQ ID NO: 141.
[0322] Все указанные реакции осуществляются в физиологических условиях при температуре от 20 до 50 градусов Цельсия, в том числе реакция может осуществляться в клетках, тканях и организмах - хозяевах, экспрессирующих функциональные ферменты.
[0323] В комбинации с гиспидин-гидроксилазой настоящего изобретения PKS и кумарат-КоА-лигаза могут быть использованы для получения 3-гидроксигиспидина из кофейной кислоты. Реакция осуществляется в физиологических условиях в присутствии по крайней мере одной молекулы гиспидин-гидроксилазы, по крайней мере одной молекулы PKS, по крайней мере одной молекулы кумарат-КоА-лигазы, по крайней мере одной молекулы кофейной кислоты или кофеил-КоА, по крайней мере одной молекулы кофермента А, с по крайней мере одной молекулой АТФ, с по крайней мере одной молекулой НАД(Ф)H, с по крайней мере одной молекулой кислорода и по крайней мере двумя молекулами малонил-КоА.
[0324] Также настоящее изобретение обеспечивает применение нуклеиновых кислот, кодирующих ферменты биосинтеза люциферина грибов, гомологи и мутанты этих белков, в том числе укороченные и удлиненные формы и белки слияния, для получения ферментов, вовлеченных в биосинтез люциферина грибов, в системах in vitro и\или in vivo.
[0325] В преимущественных воплощениях обеспечивается применение нуклеиновых кислот, кодирующих гиспидин-гидроксилазы по изобретению, а именно белки, характеризующиеся аминокислотными последовательностями, показанными в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, а также их функциональные гомологи, мутанты и производные. В преимущественных воплощениях нуклеиновые кислоты кодируют белки, аминокислотные последовательности которых по крайней мере на 40%, чаще по крайней мере на 45%, обычно по крайней мере на 50%, например, по крайней мере на 55%, по крайней мере на 60%, по крайней мере на 65%, по крайней мере на 70%, по крайней мере на 80%, по крайней мере на 85%, по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% идентичны последовательностям, показанным в SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, на протяжении по крайней мере 350 аминокислот.В преимущественных воплощениях нуклеиновые кислоты кодируют белки, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NO: 29-33.
[0326] Также обеспечивается применение нуклеиновых кислот, кодирующих гиспидин-синтазы, а именно белки, характеризующиеся аминокислотными последовательностями, показанными в SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, а также их функциональные гомологи, мутанты и производные. В преимущественных воплощениях нуклеиновые кислоты кодируют белки, аминокислотные последовательности которых по крайней мере на на 40%, чаще по крайней мере на 45%, обычно по крайней мере на 50%, например, по крайней мере на 55%, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% идентичны последовательностям, показанным в SEQ ID NOs: 35, 37, 39, 41, 43, 45,47,49, 51, 53, 55, на протяжении всей полипептидной цепи белка. В преимущественных воплощениях нуклеиновые кислоты кодируют белки, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 56-63.
[0327] Также обеспечивается применение нуклеиновых кислот, кодирующих кофеилпируват-гидролазы, а именно белки, характеризующиеся аминокислотными последовательностями, показанными в SEQ ID NOs: 65, 67, 69, 71, 73, 75, а также их функциональные гомологи, мутанты и производные. В преимущественных воплощениях нуклеиновые кислоты кодируют белки, аминокислотные последовательности которых по крайней мере 40%, чаще по крайней мере на 45%, обычно по крайней мере на 50%, например, по крайней мере на 55%, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99% идентичны последовательностям, показанным в SEQ ID NOs: 65, 67, 69, 71, 73, 75, на протяжении всей полипептидной цепи. В преимущественных воплощениях нуклеиновые кислоты кодируют белки, аминокислотные последовательности которых характеризуются наличием нескольких консервативных аминокислотных мотивов (консенсусных последовательностей), показанных в SEQ ID NOs: 76-78.
[0328] Вышеперечисленные группы нуклеиновых кислот находят применение для получения рекомбинантных белков гиспидин-гидроксилаз, гиспидин-синтаз и кофеилпируват-гидролаз, а также для экспрессии этих белков в гетерологических системах экспрессии.
[0329] В частности, нуклеиновые кислоты, кодирующие гиспидин-гидроксилазы находят применение для получения клеток-продуцентов 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-она, имеющего структурную формулу
[0330] из экзогенного или эндогенного 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
,
где R - арил или гетероарил.
[0331] Нуклеиновые кислоты, кодирующие кофеилпируват-гидролазы, находят применение для получения клеток и организмов, способных осуществлять реакцию превращения оксилюциферина в предшественник предлюциферинов.
[0332] Нуклеиновые кислоты, кодирующие гиспидин-синтазы, находят применение для получения клеток-продуцентов вышеуказанного 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она из соответствующей 3-арилакриловой кислоты. Например, клетки, экспрессирующие гиспидин-синтазу, находят применение для получения гиспидина из кофейной кислоты.
[0333] В некоторых воплощениях нуклеиновые кислоты, кодирующие гиспидин-синтазы, находят применение для получения гиспидина из тирозина. В указанных воплощениях в клетки дополнительно вводят нуклеиновые кислоты, кодирующие ферменты, обеспечивающие синтез кофейной кислоты из тирозина. Такие ферменты известны из уровня техники. Например, может быть использована комбинация нуклеиновых кислот, кодирующих тирозин-аммоний-лиазу Rhodobacter capsulatus, и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E.coli как описано в [Lin и Yan. Microb Cell Fact. 2012, 4;11:42]. Специалисту в данной области очевидно, что альтернативно могут быть использованы любые иные известные из уровня техники ферменты, осуществляющие реакции превращения тирозина в кофейную кислоту, например, ферменты, аминокислотные последовательности которых по существу сходны аминокислотным последовательностям тирозин-аммоний-лиазы Rhodobacter capsulatus и компонентам HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E. сoli, показанным в SEQ ID NOs: 107, 109 и 111. Например, указанные ферменты могут иметь аминокислотные последовательности, которые имеют не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, или не менее 80% идентичности, или или не менее 85% идентичности, или не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности) с последовательностями, показанными в SEQ ID NOs: 107, 109 и 111 соответственно.
[0334] В некоторых воплощениях нуклеиновые кислоты, кодирующие гиспидин-синтазы, находят применение для получения клеток-продуцентов функциональных аналогов гиспидина из ароматических соединений, в том числе ароматических аминокислот и их производных. В указанных воплощениях в клетки дополнительно вводят нуклеиновые кислоты, кодирующие ферменты, обеспечивающие синтез 3-арилакриловых кислот, из которых, в свою очередь, происходит биосинтез функциональных аналогов гиспидина. Такие ферменты известны из уровня техники. Например, для биосинтеза коричной кислоты может быть использована нуклеиновая кислота, кодирующая фенилаланин-аммоний-лиазу Streptomyces maritimus, как описано в [Bang, H.B., Lee, Y.H., Kim, S.C. et al. Microb Cell Fact (2016) 15: 16. https://doi.org/10.1186/s12934-016-0415-9]. Специалисту в данной области очевидно, что альтернативно могут быть использованы любые иные известные из уровня техники ферменты, осуществляющие реакции превращения ароматических аминокислот и других ароматических соединений в 3-арилакриловые кислоты. Например, для синтеза коричной кислоты может быть использована любая функциональная фенилаланин-аммоний-лиаза, например, фенилаланин-аммоний-лиаза, аминокислотная последовательность которой по существу сходна с последовательностью, показанной в SEQ ID NO: 117, например, последовательность которой идентична последовательности SEQ ID NO: 117 по крайней мере на 40%, в том числе, имеет с ней не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности).
[0335] В некоторых воплощениях для получения клеток-хозяев, экспрессирующих функциональную гиспидин-синтазу, требуется их ко-трансфекция нуклеиновой кислотой, кодирующей гиспидин-синтазу по изобретению, и нуклеиновой кислотой, кодирующей 4'-фосфопантотеинил трансферазу, способную осуществлять перенос 4-фосфопантетеинила от кофермента А на серин в ацилпереносящем домене поликетидсинтаз. В других воплощениях выбранные клетки-хозяева, например, клетки растений или клетки некоторых низших грибов (например, относящихся к роду Aspergillus) содержат эндогенную 4'-фосфопантотеинил трансферазу и ко-трансфекция не требуется.
[0336] Также обеспечивается применение комбинаций нуклеиновых кислот по изобретению. Так комбинация нуклеиновых кислот, кодирующих гиспидин-гидроксилазу и гиспидин-синтазу, находит применение для получения клеток-продуцентов 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-она из 3-арилакриловой кислоты, например, для получения 3-гидроксигиспидина из кофейной кислоты и/или из тирозина. В некоторых воплощениях комбинация нуклеиновых кислот включает нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу. В некоторых воплощениях комбинация нуклеиновых кислот включает нуклеиновые кислоты, кодирующие ферменты, обеспечивающие синтез 3-арилакриловой кислоты из метаболитов клетки, например, ферменты, обеспечивающие синтез кофейной кислоты из тирозина или синтез коричной кислоты из фенилаланина.
[0337] В некоторых воплощениях для получения клеток-продуцентов гиспидина из кофейной кислоты используется комбинация нуклеиновых кислот, кодирующих PKS и кумарат-КоА-лигазы. Пригодной для нужд настоящего изобретения являются нуклеиновая кислота, кодирующая функциональную PKS, аминокислотная последовательность которой по существу сходна или идентична последовательности, выбранной из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139; например, PKS, аминокислотная последовательность которой идентична последовательности, выбранной из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139, по крайней мере на 40%, чаще по крайней мере на 45%, обычно по крайней мере на 50%, например, по крайней мере на 55%, или по крайней мере на 60%, или по крайней мере на 65%, или по крайней мере на 70%, или по крайней мере на 80%, или по крайней мере на 85%, или по крайней мере на 90%, или по крайней мере на 91%, или по крайней мере на 92%, или по крайней мере на 93%, или по крайней мере на 94%, или по крайней мере на 95%, или по крайней мере на 96%, или по крайней мере на 97%, или по крайней мере на 98%, или по крайней мере на 99%. Также пригодной для нужд настоящего изобретения является нуклеиновая кислота, кодирующая функциональную кумарат-КоА-лигазу, катализирующую реакцию присоединения кофермента А к кофейной кислоте с образованием кофеил-КоА. Например, может быть использована нуклеиновая кислота, кодирующая функциональную кумарат-КоА-лигазу, аминокислотная последовательность которой идентична последовательности, показанной в SEQ ID NO: 141, или имеет с ней не менее 40% идентичности, например, не менее 45% идентичности, или не менее 50% идентичности, или не менее 55% идентичности, или не менее 60% идентичности, или не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, например, не менее 80% идентичности, не менее 85% идентичности, не менее 90% идентичности (например, по крайней мере 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности).
[0338] В некоторых воплощениях используется комбинация нуклеиновой кислоты, кодирующей гиспидин-гидроксилазу по изобретению, и нуклеиновой кислоты, кодирующей PKS. В преимущественных воплощениях комбинация также включает нуклеиновую кислоту, кодирующую кумарат-КоА-лигазу. Комбинация находит применение для получения клеток-продуцентов 3-гидроксигиспидина из кофейной кислоты и/или кофеил-КоА.
[0339] В некоторых воплощениях комбинация нуклеиновых кислот включает нуклеиновые кислоты, кодирующие ферменты, обеспечивающие синтез кофейной кислоты из тирозина.
[0340] Особый интерес представляют комбинации нуклеиновых кислот по изобретению, используемые вместе с нуклеиновой кислотой, кодирующей люциферазу, способную окислять люциферины гриба с выделением света. Молекулы нуклеиновой кислоты, кодирующие люциферазы для нужд настоящего изобретения, могут быть клонированы из биологических источников, например, из гриба, относящегося к типу Basidiomycota, преимущественно к классу Basidiomycetes, в частности, к отряду Agaricales или получены с помощью методов генной инженерии. Мутанты люцифераз, обладающие люциферазной активностью, могут быть получены с использованием стандартных методик молекулярной биологии, таких как подробно описанные выше в разделе «Нуклеиновые кислоты». Мутации включают изменения одной или нескольких аминокислот, делеции или вставки одной или нескольких аминокислот; N-концевые усечения или расширения, С-концевые усечения или расширения и т.п.В преимущественных воплощениях эти нуклеиновые кислоты кодируют люциферазы, аминокислотные последовательности которых по крайней мере на 40% идентичны, например, по крайней мере на 45% идентичны, или по крайней мере на 50% идентичны, или по крайней мере на 55% идентичны, или по крайней мере на 60% идентичны, или по крайней мере на 70% идентичны, или по крайней мере на 75% идентичны, или по крайней мере на 80% идентичны, или по крайней мере на 85% идентичны аминокислотной последовательности, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Например, они могут иметь аминокислотные последовательности, которые имеют не менее 90% идентичности (например, не менее 91%, не менее 92%, не менее 93%, не менее 94%, не менее 95%, не менее не менее 96%, не менее 97%, не менее 98%, не менее 99% идентичности или 100% идентичности) с аминокислотной последовательностью, выбранной из группы SEQ ID NOs: 80, 82, 84, 86, 88,90, 92, 94, 96, 98. Неограничивающие примеры нуклеиновых кислот, кодирующих люциферазы, показаны в SEQ ID NOs: 79, 81, 83, 85, 87, 89, 91, 93 и 95.
[0341] В некоторых воплощениях используется комбинация нуклеиновой кислоты, кодирующей гиспидин-гидроксилазу по изобретению, и нуклеиновой кислоты, кодирующей описанную выше люциферазу. Комбинация находит применение в широком спектре приложений при мечении организмов, тканей, клеток, клеточных органелл или белков с помощью биолюминесценции. Способы мечения организмов, тканей, клеток, клеточных органелл или белков с помощью люциферазы хорошо известны из уровня техники и подразумевают введение в клетку-хозяина нуклеиновой кислоты, кодирующей люциферазу, например, в составе кассеты экспрессии, обеспечивающей экспрессию люциферазы в указанной клетке, ткани или организме. При добавлении подходящего люциферина к клеткам, ткани или организму, экспрессирующим люциферазу, возникает детектируемый свет.При мечении клеточных органелл или белков, нуклеиновую кислоту, кодирующую люциферазу, оперативно связывают с нуклеиновой кислотой, кодирующей соответственно сигнал локализации в исследуемой клеточной органелле или исследуемый белок. При ко-экспрессии в клетках люциферазы и гиспидин-синтазы настоящего изобретения биологические объекты (клетки, ткани, организмы, клеточные органеллы или белки) приобретают способность светиться в присутствии не только люциферина грибов, но и предлюциферина (последний в большинстве случаев отличается большей стабильностью в присутствии кислорода воздуха).
[0342] Также комбинация нуклеиновых кислот находит применение при исследовании зависимости активности двух промоторов в гетерологических системах экспрессии. В этом случае в клетку-хозяина вводится оперативно связанная с промотором «А» нуклеиновая кислота, кодирующая люциферазу, и оперативно связанная с промотором «Б» нуклеиновая кислота, кодирующая гиспидин-гидроксилазу. Добавляя к аликвотам клеток (или клеточных экстрактов) люциферин, или предлюциферин, или смесь предлюциферина с люциферазой, по появлению свечения можно детектировать активность одного промотора «А» (свечение детектируется только в присутствии люциферина), одного промотора «Б» (свечение детектируется в присутствии смеси предлюциферина и люциферазы), или обоих промоторов (свечение детектируется во всех случаях).
[0343] В некоторых воплощениях комбинация также содержит нуклеиновую кислоту, кодирующую гиспидин-синтазу. В некоторых воплощениях комбинация содержит дополнительно нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу.
[0344] В некоторых воплощениях комбинация содержит нуклеиновую кислоту, кодирующую гиспидин-синтазу, нуклеиновую кислоту, кодирующую люциферазу, нуклеиновую кислоту, кодирующую PKS, и нуклеиновую кислоту, кодирующую кумарат-КоА-лигазу.
[0345] Комбинации находят применение в широком спектре приложений при мечении организмов, тканей, клеток, клеточных органелл или белков с помощью биолюминесценции. В данном воплощении для получения свечения к биологическим объектам, экспрессирующим гиспидин-гидроксилазу, люциферазу и гиспидин-синтазу или гиспидин-гидроксилазу, люциферазу, PKS и кумарат-КоА-лигазу добавляют подходящий предшественник предлюциферина, например, кофейную кислоту или кумаровую кислоту.
[0346] Комбинации также находят применение в способах исследования зависимости активности трех промоторов в гетерологических системах экспрессии. Способы предполагают введение к клетку-хозяина нуклеиновой кислоты, кодирующей люциферазу, под контролем промотора «А», нуклеиновой кислоты, кодирующей гиспидин-гидроксилазу под контролем промотора «Б» и нуклеиновой кислоты, кодирующей гиспидин-синтазу (или PKS), под контролем промотора «В». Если для созревания функциональной гиспидин-синтазы необходима ко-экспрессия 4'-фосфопантотеинил трансферазы, то ее также вводят в клетку под контролем любого пригодного конститутивного или индуцируемого промотора. Об одновременной активации всех трех промоторов будет свидетельствовать появление детектируемого света при добавлении к клеткам (или их экстрактам) подходящего предшественника предлюциферина.
[0347] Комбинации также находят применение при получении трансгенных светящихся организмов. В преимущественных воплощениях, трансгенные организмы получают из организмов, дикий тип которых не обладает способностью к биолюминесценции. Нуклеиновые кислоты, кодирующие целевые белки вводят в трансгенный организм в составе кассеты экспрессии или вектора, которые существуют в организме в виде внехромосомного элемента или интегрируются в геном организма, как описано выше в разделе «Трансгенные организмы», и обеспечиваю экспрессию целевых белков. Трансгенные организмы по изобретению отличаются тем, что экспрессируют кроме люциферазы, субстратом которой является люциферин гриба, по крайней мере гиспидин-гидроксилазу. В преимущественных воплощениях они также экспрессируют гиспидин-синтазу. В других преимущественных воплощениях они экспрессируют также PKS. В других преимущественных воплощениях они экспрессируют также PKS. В некоторых воплощениях, они экспрессируют также кумарат-КоА-лигазу. Известно, что эндогенная кумарат-КоА-лигаза присутствует во многих растительных организмах, поэтому ее дополнительное введение осуществляется в случаях, когда эндогенная кумарат-КоА-лигаза отсутствует.
[0348] В некоторых воплощениях они также экспрессируют кофеилпируват-гидролазу. В отличие от организмов, экспрессирующих только люциферазу, трансгенные организмы, полученные с использованием нуклеиновых кислот настоящего изобретения, приобретают способность светиться в присутствии предлюциферинов и/или предшественников предлюциферинов - 3-арилакриловой кислот (чаще всего - кофейной кислоты) - представляющих собой наиболее дешевый и стабильный субстрат для получения биолюминесценции, который может быть добавлен в воду для полива растений, или в среду культивирования микроорганизмов, или в корм или среду обитания животных (например, рыб). Биолюминесцентные трансгенные организмы (растения, или животные, или грибы) находят применение в качестве источников света, а также используются для декоративных целей. Биолюминесцентные трансгенные организмы, клетки и клеточные культуры также можно использовать в различных скринингах, в которых интенсивность биолюминесценции меняется в зависимости от внешнего воздействия. Например, их можно использовать при анализе влияния различных факторов на активность промоторов, регулирующих экспрессию экзогенных нуклеиновых кислот.
[0349] Особый интерес представляют автономно биолюминесцентные трансгенные организмы, которые также обеспечиваются настоящим изобретением.
[0350] В некоторых воплощениях в указанных организмах в качестве метаболита присутствует хотя бы одна 3-арилакриловая кислота со структурной формулой
,
где R - арил или гетероарил.
[0351] В качестве неограничивающих примеров подобных организмов можно привести высшие и низшие растения, включая цветковые растения и мхи. Для получения автономно светящихся трансгенных растений в них вводят способные к экспрессии соответствующих ферментов нуклеиновые кислоты, кодирующие гиспидин-синтазу, гиспидин-гидроксилазу и люциферазу, способную окислять люциферин гриба с выделением света. Так как растения содержат, как правило, эндогенную 4'-фосфопантотеинил трансферазу, то дополнительного введения нуклеиновой кислоты, кодирующий этот фермент, для получения автономно светящихся растений, как правило, не требуется.
[0352] В некоторых воплощениях для получения автономно биолюминесцентных трансгенных организмов используются организмы, которые в природе не производят 3-арилакриловых кислот.Примерами таких организмов являются животные и многие микроорганизмы, например, дрожжи и бактерии. Для получения автономной биолюминесценции в организмы в этом случае дополнительно вводят способные к экспрессии нуклеиновые кислоты, кодирующие ферменты, обеспечивающие биосинтез 3-арилакриловых кислот из метаболитов клетки, например, кофейной кислоты из тирозина. При необходимости в организмы также вводят нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу.
[0353] В некоторых воплощениях для получения автономно светящихся организмов в них вводят способные к экспрессии соответствующих ферментов нуклеиновые кислоты, кодирующие PKS, гиспидин-гидроксилазу и люциферазу, способную окислять люциферин гриба с выделением света. В преимущественных воплощениях указанные клетки, ткани и организмы содержат достаточное количество кофеил-КоА и малонил-коА для осуществления реакции синтеза гиспидина.
[0354] В случаях, когда трансгенный организм не производит достаточных количеств кофеил-КоА в ходе нормальных метаболических процессов, в указанные клетки или организмы также вводится нуклеиновая кислота, кодирующая кумарат-КоА-лигазу, а также, при необходимости, ферменты биосинтеза кофейной кислоты из тирозина.
[0355] В преимущественных воплощениях комбинация нуклеиновых кислот для получения автономно биолюминесцентных клеток или трансгенных организмов также включает нуклеиновую кислоту, кодирующую кофеилпируват-гидролазу. Как продемонстрировано в экспериментальной части ниже, экспрессия кофеилпируват-гидролазы приводит к увеличению интенсивности биолюминесценции автономно-светящихся биолюминесцентных клеток или трансгенных организмов. В преимущественных воплощениях интенсивность биолюминесценции увеличивается по крайней мере в 1.5 раза, чаще по крайней мере в 2 раза, обычно по крайней мере в пять раз, например, в 7-9 раз, например, в 8 или более раз.
[0356] Автономно биолюминесцентные трансгенные организмы (растения, или животные, или грибы), а также клетки и клеточные культуры отличаются от трансгенных организмов, клеток и клеточных культур, экспрессирующих только люциферазу и известных из уровня техники, тем, что для их свечения не требуется экзогенного добавления к ним люциферина или его предшественника.
[0357] В некоторых воплощениях вместо комбинации нуклеиновых кислот, кодирующих гиспидин-гидроксилазу и люциферазу, используется нуклеиновая кислота, кодирующая белок слияния этих двух ферментов. Специалисту в данной области очевидно, что указанный белок слияния и комбинация нуклеиновых кислот, кодирующих гиспидин-гидроксилазу и люциферазу, являются взаимозаменяемыми объектами во всех способах использования. Также очевидно, что на основе нуклеиновых кислот по изобретению могут быть изготовлены другие белки слияния, которые будут сохранять свойства партнеров слияния; такие белки слияния и кодирующие их нуклеиновые кислоты могут без ограничения использоваться вместо комбинаций отдельных белков и нуклеиновых кислот.
[0358] Во всех описанных выше применениях и способах нуклеиновые кислоты могут находиться в форме кассет экспрессии, которые можно применять для обеспечения экспрессии кодирующей последовательности в клетке-хозяине. Нуклеиновую кислоту можно интродуцировать в клетку-хозяина в составе вектора для осуществления экспрессии в пригодной клетке-хозяине или не включая ее в вектор, например, ее можно встраивать в липосому или вирусную частицу. В альтернативном варианте очищенную молекулу нуклеиновой кислоты можно встраивать непосредственно в клетку-хозяина с помощью пригодных средств, например, путем прямого эндоцитозного поглощения. Генетическую конструкцию можно интродуцировать непосредственно в клетки организма-хозяина (например, растения) путем трансфекции, инфекции, микроинъекции, клеточного слияния, слияния протопластов, путем бомбардировки микроснарядами или с помощью «генной пушки» (пушки для обстрела несущими генетические конструкции микрочастицами).
[0359] Так же обеспечивается применение поликлональных и моноклональных антител по изобретению. Они находят применение в способах окрашивания препаратов тканей, клеток или организмов для выявления локализации экспрессированных или природных гиспидин-гидроксилаз, гиспидин-синтаз и кофеилпируват-гидролаз по изобретению. Способы окрашивания с помощью специфческих антител хорошо известны из уровня техники и описаны, например, в [Быков В. Л. Цитология и общая гистология]. Прямой иммуногистохимический метод основан на реакции специфического связывания меченых антител непосредственно с выявляемым веществом, непрямой иммуногистохимический метод основан на том, что немеченые первичные антитела связываются с выявляемым веществом, а далее уже их выявляют при помощи вторичных меченых антител, при этом первичные антитела служат антигенами для вторичных антител. Также антитела находят применение для остановки ферментативной реакции. Контакт антитела со специфичным партнером по связыванию приводит к ингибированию ферментативной реакции. Также антитела находят применение в методах очистки рекомбинантных и природных белков по изобретению с помощью аффинной хроматографии. Способы аффинной хроматографии известны из уровня техники и описаны, например, в [Ninfa et al (2009). Fundamental Laboratory Approaches for Biochemistry and Biotechnology (2 ed.). Wiley. p.133.; Cuatrecasas (1970). JBC. Retrieved November 22, 2017].
Наборы и изделия
[0360] Следующим вариантом осуществления изобретения является изделие, которое включает описанные выше гиспидин-гидроксилазу, или гиспидин-синтазу, или кофеилпируват-гидролазу, или нуклеиновую кислоту, кодирующую вышеуказанный фермент, предпочтительно с элементами для обеспечения экспрессии целевого белка в клетке-хозяине, например, вектор или кассету экспрессии, содержащую нуклеиновую кислоту, кодирующую целевой белок. Альтернативно, нуклеиновые кислоты могут содержать фланкирующие последовательности для ее встраивания в целевой вектор. Нуклеиновые кислоты могут быть включены в лишенные промотора векторы, предназначенные для удобного клонирования целевых регуляторных элементов. Рекомбинантные белки могут находиться в лиофилизированном состоянии или в растворенном виде в буферном растворе. Нуклеиновые кислоты могут находится в лиофилизированном состоянии или в виде осадка в спиртовом растворе или в растворенном виде в воде или буферном растворе.
[0361] В некоторых воплощениях изделие включает клетки, экспрессирующие одну или несколько из вышеперечисленных нуклеиновых кислот.
[0362] В некоторых воплощениях изделие включает трансгенный организм, экспрессирующий одну или несколько из вышеперечисленных нуклеиновых кислот.
[0363] В некоторых воплощениях изделие включает антитела для окрашивания, и/или ингибирования и\или аффинной хроматографии вышеуказанных ферментов.
[0364] Изделие представляет собой контейнер с этикеткой и приложенной к нему инструкцией. Приемлемыми контейнерами являются, например, флаконы, ампулы, пробирки, шприцы, планшеты для клеток, чашки Петри и т.д. Контейнер может быть изготовлен из различных материалов, таких как стекло или полимерные материалы. Выбор подходящего контейнера очевиден специалисту в данной области.
[0365] Кроме того, изделие может включать другие продукты, необходимые с коммерческой точки зрения и с точки зрения потребителя, например, реакционный буфер, или компоненты для его изготовления, буфер для разведения и/или растворения и/или хранения белков или нуклеиновых кислот, или компоненты для его изготовления, деионизованую воду, вторичные антитела к специфическим антителам по изобретению, среду для культивирования клеток или компоненты для ее изготовления, питание для трансгенного организма.
[0366] Изделия также включают инструкции для осуществления предлагаемых методов. Инструкции могут присутствовать в разных формах, при этом к изделию может прилагаться одна или несколько таких форм, например, инструкция может быть представлена в виде файла на электронном носителе и\или быть представлена на печатном носителе.
[0367] Изобретение относится также к наборам, которые можно применять для различных целей. Набор может включать комбинацию белков по изобретению или комбинацию нуклеиновых кислот по изобретению, предпочтительно с элементами для обеспечения экспрессии целевых белков в клетке-хозяине, например, вектор или кассету экспрессии, содержащую нуклеиновую кислоту, кодирующую целевой белок. В некоторых воплощениях набор может также содержать нуклеиновую кислоту, кодирующую люциферазу, способную окислять люциферин гриба с выделением света. В некоторых воплощениях набор может содержать нуклеиновые кислоты, кодирующие ферменты, вовлеченные в биосинтез кофейной кислоты из тирозина. В некоторых воплощениях набор может также содержать нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу. В некоторых воплощениях набор может также содержать нуклеиновую кислоту, кодирующую PKS. В некоторых воплощениях набор может также содержать нуклеиновую кислоту, кодирующую кумарат-КоА-лигазу.
[0368] В некоторых воплощениях набор может также содержать антитела для очистки рекомбинантных белков или окрашивания экспрессированных белков в клетках-хозяевах. В некоторых воплощениях набор может также содержать праймеры, комплементарные участкам указанной нуклеиновой кислоты, для амплификации нуклеиновой кислоты или ее фрагмента. В некоторых воплощениях набор может также содержать один или несколько люциферинов грибов и/или предлюциферинов и/или предшественников предлюциферинов. Указанные соединения могут находиться в виде сухого порошка, в виде раствора в органическом растворителе, в виде раствора в воде. В некоторых воплощениях набор может включать клетки, содержащие одну или несколько из вышеперечисленных нуклеиновых кислот.В некоторых воплощениях набор может включать трансгенный организм по изобретение, например, штамм продуцент или трансгенное автономно биолюминесцентное растение. Все компоненты набора помещаются в подходящие контейнеры. Наборы как правило также включают инструкцию по использованию.
[0369] Для наилучшего понимания изобретения приводятся следующие примеры. Эти примеры приведены только в иллюстративных целях и не должны толковаться как ограничивающие сферу применения изобретения в любой форме.
[0370] Все публикации, патенты и патентные заявки, указанные в этой спецификации включены в данный документ путем отсылки. Хотя вышеупомянутое изобретение было довольно подробно описано путем иллюстрации и примера в целях исключения двусмысленного толкования, специалистам в данной области на основе идей, раскрытых в данном изобретении, будет вполне понятно, что могут быть внесены определенные изменения и модификации без отклонения от сущности и объема прилагаемых вариантов осуществления изобретения.
Экспериментальная часть (Примеры)
Пример 1. Выделение последовательностей гиспидин-гидроксилаз
[0371] Суммарная РНК из мицелия Neonothopanus nambi была выделена по методу, описанному в [Chomczynski and Sacchi, Anal. Biochem., 1987, 162, 156-159]. кДНК была амплифицирована с помощью SMART PCR cDNA Synthesis Kit (Clontech, США) согласно протоколу производителя. Полученная кДНК была использована для амплификации кодирующей последовательности люциферазы, нуклеотидная и аминокислотная последовательности которой показаны в SEQ ID NOs: 79, 80. Кодирующая последовательность была клонирована в вектор pGAPZ (Invitrogen, США) согласно протоколу производителя и трансформирована в компетентные клетки E.coli штамма XL1 Blue. Бактерии выращивали на чашках Петри в присутствии антибиотика зеоцина. Через 16 ч колонии были смыты с чашек, интенсивно перемешаны, и из них была выделена плазмидная ДНК с помощью набора для выделения плазмидной ДНК (Евроген, Россия). Выделенная плазмидная ДНК была линеаризована по сайту рестрикции AvrII и использована для трансформации клеток Pichia pastoris GS115. Электропорация была проведена по методу с использованием ацетата лития и дитиотреитола, описанному в [Wu and Letchworth, Biotechniques, 2004, 36:152-4]. Электропорированные клетки были рассеяны на чашки Петри со средой RDB medium, содержащей 1 M сорбитола, 2% (вес/объем) глюкозы, 1.34% (вес/объем) дрожжевую основу азотного агара (YNB), 0.005% (вес/объем) смеси аминокислот, 0.00004% (вес/объем) биотина и 2% (вес/объем) агара. Полученные колонии опрыскивали раствором 3-гидроксигиспидина, детектируя присутствие в клетках люциферазы по появлению света. Испускаемый колониями свет детектировали с помощью IVIS Spectrum CT (PerkinElmer, США). Колонии, в которых детектировалось свечение в ответ на добавление 3-гидроксигиспидина отбирали для дальнейшей работы.
[0372] Далее амплифицированную суммарную кДНК из Neonothopanus nambi клонировали в вектор pGAPZ и трансформировали в компетентные клетки E.coli штамма XL1 Blue. Бактерии выращивали на чашках Петри в присутствии антибиотика зеоцина. Через 16 ч колонии были смыты с чашек, интенсивно перемешаны, и из них была выделена плазмидная ДНК с помощью набора для выделения плазмидной ДНК (Евроген, Россия). Выделенная плазмидная ДНК была линеаризована по сайту рестрикции AvrII и использована для трансформации клеток дрожжей Pichia pastoris GS115, конститутивно экспрессирующих люциферазу Neonothopanus nambi. Трансформацию осуществляли методом электропорации как описано выше. Клетки были рассеяны на чашки Петри со средой RDB, содержащей 1 M сорбитола, 2% (вес/объем) глюкозы, 1.34% (вес/объем) дрожжевую основу азотного агара (YNB), 0.005% (вес/объем) смеси аминокислот, 0.00004% (вес/объем) биотина и 2% (вес/объем) агара. Разнообразие итоговой библиотеки кДНК Neonothopanus nambi в дрожжах составило порядка одного миллиона клонов. Полученные колонии опрыскивали раствором гиспидина, детектируя присутствие в клетках гиспидин-гидроксилазы по появлению света. Испускаемый колониями свет детектировали с помощью IVIS Spectrum CT (Perkin Elmer, США). В качестве отрицательного контроля использовали клетки, экспрессирующие только люциферазу, и клетки дрожжей дикого типа. При скрининге библиотеки колонии, в которых детектировалось свечение, отбирали и использовали для ПЦР в качестве матрицы со стандартными плазмидными праймерами. Продукты ПЦР секвенировали по методу Сенгера, чтобы определить последовательность экспрессируемого гена. Полученная последовательность нуклеиновой кислоты гиспидин-гидроксилазы показана в SEQ ID NO: 1. Кодируемая ею аминокислотная последовательность показана в SEQ ID NO: 2.
[0373] На Фиг. 4 показано свечение клеток Pichia pastoris, экспрессирующих гиспидин-гидроксилазу и люциферазу или только люциферазу, или дрожжи дикого типа, при опрыскивании колоний 3-гидроксигиспидином (люциферин) и гиспидином (предлюциферин). Данные показывают, что в присутствии гиспидин-гидроксилазы в клетках образуется люциферин.
[0374] На следующем этапе из грибов Armillaria fuscipes, Armillaria gallica, Armillaria ostoyae, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Mycena chlorophos, Neonothopanus nambi, Neonothopanus gardneri, Omphalotus olearius и Panellus stipticus была выделена геномная ДНК и проведено полногеномное секвенирование по технологии Illumina HiSeq (Illumina, США) согласно рекомендациям производителя. Результаты секвенирования были использованы для предсказания аминокислотных последовательностей гипотетических белков и использованы для поиска гомологов гиспидин-гидроксилазы из Neonothopanus nambi. Поиск гомологов осуществлялся с помощью программного обеспечения, предоставляемого National Center for Biotechnology Information. Был также проведен поиск аминокислотных последовательностей в данных геномного секвенирования грибов в базе данных NCBI Genbank. При поиске использовали стандартные параметры поиска blastp.В результате были идентифицированы последовательности гомологов гиспидин-гидроксилазы из Neonothopanus nambi - в Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos.
[0375] Нуклеотидные и аминокислотные последовательности гомологов гиспидин-синтазы Neonothopanus nambi показаны в SEQ ID NOs: 3-28.
[0376] Все выявленные ферменты по существу сходны друг с другом. Степень идентичности аминокислотных последовательностей показана в Таблице 4.
[0377] Из Panellus stipticus и Mycena citricolor было выделено несколько высокогомологичных аминокислотных последовательностей гиспидин-гидроксилазы, отличающихся единичными аминокислотными заменами. Их нуклеотидные и аминокислотные последовательности показаны в SEQ ID NOs 7-13 (Panellus stipticus) и SEQ ID NOs 15-18 (Mycena citricolor). Дальнейшее исследование свойств указанных белков не выявило влияния этих замен на ферментативные свойства.
[0378] Кодирующие последовательности выявленных гомологов (SEQ ID NOs: 3-28) были клонированы и трансформированы в клетки Pichia pastoris GS115, конститутивно экспрессирующие люциферазу Neonothopanus nambi по описанному выше протоколу. Полученные колонии опрыскивали раствором гиспидина, детектируя присутствие в клетках гиспидин-гидроксилазы по появлению света. Испускаемый колониями свет детектировали с помощью IVIS Spectrum CT (PerkinElmer, США). Все колонии, экспрессирующие тестируемые гены (SEQ ID NOs: 3,5,7,9,11,13,15,17,19, 21, 23, 25,27), производили в 1000-100000000 раз больше света при опрыскивании раствором гиспидина, чем контрольные клетки, что подтверждает способность ферментов, кодируемых протестированными генами, катализировать превращение гиспидина в 3-гидроксигиспидин (люциферин грибов).
[0379] Был проведен структурный анализ аминокислотных последовательностей выявленных ферментов. Анализ с помощью программного обеспечения SMART (Simple Modular Architecture Research Tool), доступное в сети Интернет по адресу http://smart.embl-heidelberg.de [Schultz et al., PNAS 1998; 95: 5857-5864; Letunic I, Doerks T, Bork P Nucleic Acids Res 2014; doi:10.1093/nar/gku949] выявил, что в состав всех выявленных белков входит FAD/NAD(P)-связывающий домен (FAD/NAD(P) binding domain, IPR002938 - код по публичной базе данных InterPro, доступной в сети Интернет по адресу http://www.ebi.ac.uk/interpro). Этот домен участвует в связывании ФАД и НАД у ряда ферментов, в частности, монооксигеназ - представителей крупного суперсемейства ферментов, добавляющих гидроксильную группу к субстрату и найденных в метаболических путях множества организмов. Выявленные гиспидин-гидроксилазы кроме FAD/NAD(P)-связывающего домена содержат оперативно связанные с ним N- и C-концевые аминокислотные последовательности (Фиг. 1). С помощью множественного выравнивания и сравнения аминокислотных последовательностей, выявленных гиспидин-гидроксилаз (Фиг. 1) было обнаружено, что они содержат в своем составе несколько консервативных аминокислотных мотивов (консенсусных последовательностей), характерных только для данной группы ферментов (SEQ ID NOs: 29-33). Консенсусные участки внутри аминокислотных последовательностей оперативно связаны через аминокислотные вставки.
Пример 2. Экспрессия гиспидин-гидроксилазы и люциферазы грибов в клетках млекопитающих и их совместное использование для мечения клеток
[0380] Кодирующие последовательности гиспидин-гидроксилазы и люциферазы из Neonothopanus nambi, полученные как описано в Примере 1, оптимизировали для экспрессии в клетках млекопитающих (гуманизировали). Оптимизированные нуклеиновые кислоты (SEQ ID NOs: 99 и 100) получали синтетическим путем. Кодирующую последовательность гиспидин-гидроксилазы клонировали в вектор pmKate2-keratin (Евроген, Россия), используя сайты рестрикции NheI и NotI вместо последовательности, кодирующий белок слияния mKate2-keratin. Последовательность люциферазы была амплифицирована с помощью ПЦР, обработана эндонуклеазами рестрикции NheI и EcoRV (New England Biolabs, Ipswich, MA) и лигирована в лентивирусный вектор pRRLSIN.cPPT.EF1. Плазмидную ДНК очищали с помощью наборов для очистки плазмидной ДНК (Евроген). Плазмидная ДНК, содержащая ген люциферазы, была использована для создания стабильно экспрессирующих линий HEK293NT. Векторные частицы были получены кальциево-фосфатной трансфекцией (Invitrogen, Carlsbad, CA) клеток HELK293T согласно протоколу, указанному на сайте производителя. За 24 часа до трансфекции 1 500 ООО клеток были посажены в 60-мм культуральную чашку. Для трансфекции использовали около 4 и 1.2 мкг упаковочных плазмид pR8.91 и pMD.G, а также 5 мкг трансферной плазмиды, содержащей последовательность люциферазы. Вирусные частицы были собраны спустя 24 часа после трансфекции, сконцентрированы в 10 раз и использованы для трансдукции клеток HEK293NT. Около 100% клеток HEK293NT стабильно экспрессировали люциферазу Neonothopanus nambi.
[0381] Полученные клетки подвергали повторной трансфекции вектором, содержащим кодирующую последовательность гиспидин-гидроксилазы, с помощью трансфекционного реагента FuGENE HD (Promega, США) по протоколу производителя. Спустя 24 часа после трансфекции в среду добавляли гиспидин в концентрации 800 мкг/мл, и детектировали свечение клеток с помощью IVIS Spectrum CT (PerkinElmer). Полученные клетки испускали свет с интенсивностью более чем на два порядка превышающей сигнал, исходящий от нетрансфицированных контрольных клеток (Рис. 5).
[0382] Клетки визуализировали в проходящем свете, в канале для детекции зеленой люминесценции. Экспрессия гиспидин-гидроксилазы Neonothopanus nambi в клетках человека приводила к появлению отчетливого светового сигнала в зеленой области спектра в присутствии гиспидина, позволяющего отличить трансфицированные клетки от нетрансфицированных.
Пример 3. Использование гиспидин-гидроксилазы с аналогами гиспидина в клеточном лизате
[0383] Клетки HEK293NT, экспрессирующие люциферазу и гиспидин-гидроксилазу Neonothopanus nambi, полученные как описано в Примере 2, смывали с чашек Петри спустя 24 часа после трансфекции с помощью раствора Версена с добавлением 0.025% трипсина, меняли среду на фосфатно-солевой буфер с pH 8.0 центрифугированием, ресуспендировали клетки, лизировали ультразвуком в приборе Bioruptor (Diagenode, Бельгия) в течение 7 минут при температуре 0°C в условиях, рекомендованных производителем, а в среду добавляли 1 мМ НАДФН (Sigma-Aldrich, США), а также гиспидин или один из его аналогов:
(E)-4-гидрокси-6-(4-гидроксистирил)-2H-пиран-2-он, (E)-6-(2-(1H-индол-3-ил)винил)-4-гидрокси-2H-пиран-2-он, (E)-6-(2-(1,2,3,5,6,7-гексагидропиридо[3,2,1-ij]хинолин-9-ил)винил)-4-гидрокси-2H-пиран-2-он, E)-6-(4-(диэтиламино)стирил)-4-гидрокси-2H-пиран-2-он, или (E)-4-гидрокси-6-(2-(6-гидроксинафталин-2-ил)винил)-2H-пиран-2-он в концентрации 660 мкг/мл. Спектры биолюминесценции детектировали с помощью спектрофлюориметра Varian Cary Eclipse. Испускание света в лизатах наблюдалось при добавлении всех указанных функциональных аналогов гиспидина. В зависимости от используемого люциферина наблюдалось ожидаемое смещение максимума люминесценции.
Пример 4. Получение рекомбинантных гиспидин-гидроксилаз
[0384] На 5'-конец нуклеиновых кислот, кодирующих гиспидин-3-гидроксилазы и люциферазу из Neonothopanus nambi, полученные как описано в примерах 1 и 2, была оперативно присоединена полигистидиновая последовательность (гис-таг). Полученные конструкции были клонированы в вектор pET-23 с помощью эндонуклеаз рестрикции BamHI и HindIII. Вектор использовали для трансформации клеток Escherichia coli штамма BL21-DE3. Клетки высевали на чашки Петри со средой LB, содержащей 1.5% агар, ампициллин 100 мкг/мл, и инкубировали в течение ночи при 37°С.Колонии Escherichia coli затем переносили в 4 мл жидкой среды LB с добавлением ампициллина, инкубировали в течение ночи при покачивании при 37oC. 1 мл ночной культуры переносили в 100 мл среду Overnight Express Autoinduction medium (Novagen), в которую был предварительно добавлен ампициллин. Культуру растили при 37oC в течение 2.5 часов до достижения оптической плотности 0.6 ОЕ при 600 нм, а затем растили на комнатной температуре в течение 16 часов. Затем клетки осаждали центрифугированием при 4500 об/мин в течение 20 минут в центрифуге Eppendorf 5810R, ресуспендировали в 35 мл буфера (50 мМ Тris HCl рН 8.0, 150 мМ NaCl). Клетки разрушали ультразвуком и снова центрифугировали. Для очистки рекомбинантных белков использовали металл-аффинную хроматографию на смоле TALON (Clontech, США). Наличие ожидаемого рекомбинантного продукта подтверждали с помощью электрофореза.
[0385] Аликвоты выделенных рекомбинантных гиспидин-гидроксилаз использовали для проверки функциональности и стабильности. Для определения функциональности 15 мкл раствора выделенного рекомбинантного белка вносили в пробирку, содержащую 100 мкл буфера (0.2 M Na-фосфат буфера, 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM) pH 8.0), 0.5 мкл очищенной рекомбинантной люциферазы Neonothopanus nambi, 1 мМ НАДФН и 0.2 мкМ гиспидина. Пробирку помещали в люминометр. Активность выделенных рекомбинантных белков приводила к испусканию света при соединении с гиспидином и его аналогами, описанными в примере 3, в присутствии люциферазы Neonothopanus nambi. Во всех случаях интенсивность испускаемого света при использовании гиспидина была наибольшей при использовании гиспидин-гидроксилазы Neonothopanus nambi, и наименьшей - у гиспидин-гидроксилазы Armillaria mellea.
Пример 5. Получение 3-гидроксигиспидина, (Е)-3,4-дигидрокси-6-стирил-2H-пиран-2-она и (Е)-3,4-дигидрокси-6-(4-гидроксистирил)-2H-пиран-2-она с использованием рекомбинантной гиспидин-гидроксилазы
[0386] Выделенную рекомбинантную гиспидин-гидроксилазу из Neonothopanus nambi, полученную как описано в Примере 4, добавляли к реакционным смесям, содержащим 1 мМ НАДФН и 0.2 мкМ гиспидина, (Е)-4-гидрокси-6-стирил-2H-пиран-2-она или (Е)-4-гидрокси-6-(4-гидроксистирил)-2H-пиран-2-она в 100 мкл буфера (0.2 M Na-фосфат буфера, 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM) pH 8.0). Через 30 минут реакционную смесь анализировали с помощью высокоэффективной жидкостной хроматографии, используя синтетические люциферины в качестве стандартов. Хроматография продемонстрировала возникновение пиков, соответствующих гидроксилированным по третьему положению производным: 3-гидроксигиспидину, (Е)-3,4-дигидрокси-6-стирил-2H-пиран-2-ону и (Е)-3,4-дигидрокси-6-(4-гидрокси-стирил)-2H-пиран-2-ону.
Пример 6. Детекция биолюминесценции с помощью белка слияния гиспидин-гидроксилазы и люциферазы
[0387] Гуманизированные последовательности ДНК, кодирующие гиспидин-гидроксилазу и люциферазу Neonothopanus nambi, полученные как описано в Примере 2, оперативно сшивали друг с другом посредством гибкого короткого пептидного линкера с аминокислотной последовательностью GGSGGSGGS (SEQ ID NOs:115). Последовательности нуклеотидов и аминокислот полученного химерного белка показаны в SEQ ID NO 101 и 102. Нуклеиновую кислоту, кодирующую химерный белок, клонировали в вектор pEGFP-N1 (Clontech, США) вместо гена EGFP под контроль цитомегаловирусного промотора. Полученную конструкцию трансфицировали в клетки HEK293T. Также в качестве контроля котрансфицировали аналогичные векторы, содержащие гены гиспидин-гидроксилазы и люциферазы по-отдельности. Трансфекцию проводили с помощью трансфекционного агента FuGENE HD (Promega, USA) по протоколу производителя. Через 24 часа после трансфекции 1 млн клеток ресуспендировали в 0,5 мл PBS и регистрировали люминесценцию без добавления гиспидина и с добавлением гиспидина (10 мкг на 1 млн клеток) с помощью люминометра. Добавление гиспидина приводило к появлению в клетках биолюминесценции в зеленой области спектра (Фиг. 6). К появлению биолюминесцентного сигнала также приводило и добавление 3-гидроксигиспидина. Экспрессия белков слияния гиспидин-гидроксилазы с люциферазой вместо одной люциферазы позволяет использовать более стабильные предшественники люциферина (гиспидин, бисноръянгонин и другие) для биолюминесцентного мечения клеток и не требует котрансфекции двух нуклеиновых кислот в клетки.
Пример 7. Приготовление поликлональных антител
[0388] Кодирующие последовательности гиспидин-гидроксилаз Neonothopanus nambi (SEQ ID NO: 1) и Armillaria mellea (SEQ ID NO: 19) были синтетически получены в виде линейной двуцепочечной ДНК и клонированы в экспрессионные векторы pQE-30 (Qiagen, Германия) таким образом, что рекомбинантные белки содержали на N-конце гистидиновую метку. После экспрессии в E.coli, рекомбинантные белки были очищены с помощью металл-аффинной смолы TALON (Clontech, США) в денатурирующих условиях. Препараты очищенного белка, эмульсифицированные в адъюванте Фрейнда, были использованы для четырех иммунизаций кроликов с месячными интервалами. Кровь кроликов отбирали на десятый или одиннадцатый дни после иммунизаций. Активность полученных поликлональных антисывороток проверяли с помощью методов ELISA и Вестерн-иммуноблоттинга на панели очищенных рекомбинантных гиспидин-гидроксилаз, полученных как описано в примере 4.
[0389] Антитела, полученные при иммунизации кролика белком из Neonothopanus nambi, демонстрировали активность против денатурированной и неденатурированной гиспидин-гидроксилазы Neonothopanus nambi и против денатурированной гиспидин-гидроксилазы Neonothopanus gardneri.
Антитела, полученные при иммунизации кролика белком из Armillaria mellea были активны против денатурированных и неденатурированных гиспидин-гидроксилаз из Armillaria mellea, Armillaria gallica, Armillaria ostoyae и Armillaria fuscipes.
Пример 8. Получение трансгенных растений, экспрессирующих гиспидин-гидроксилазу и люциферазу Neonothopanus nambi
[0390] Кодирующие последовательности гиспидин-гидроксилазы и люциферазы Neonothopanus nambi были оптимизированы для экспрессии в клетках мха Physcomitrella patens. Затем in silico была создана кассета экспрессии, содержащая промотор гена aktI риса, 5'-нетранслируемую область цитомегаловируса человека, кодирующую последовательность гиспидин-гидроксилазы, оптимизированную для экспрессии в клетках растений (SEQ ID NO 103), стоп-кодон, последовательность терминатора из гена osc агробактерии Agrobacterium tumefaciens, промотор убиквитина риса, оптимизированную для экспрессии в клетках мха кодирующую последовательность люциферазы Neonothopanus nambi (SEQ ID NO 112), терминатор из гена nos агробактерии Agrobacterium tumefaciens.
[0391] Полученная последовательность была синтезирована, таким образом, что все указанные фрагменты оказались оперативно сшиты между собой, и клонирована с помощью методики Gibson assembly [Gibson et al., Nat Methods, 2009, 6:343-5] в экспрессионный вектор pLand#1 (Institut Jean-Pierre Bourgin, Франция), между фрагментами ДНК, совпадающими с локусом геномной ДНК мха Physcomitrella patens между последовательностями высокоэкспрессируемых генов мха Pp3c16_6440V3.1 и Pp3c16_6460V3.1. Вектор pLand#1 также содержал последовательность гидовой РНК (sgRNA) для нуклеазы Cas9, комплементарную участку того же локуса ДНК.
[0392] Препарат плазмидной ДНК был котрансформирован вместе с экспрессионным вектором, содержащим последовательность нуклеазы Cas9 под промотором убиквитина Arabidopsis thaliana, в протопласты мха Physcomitrella patens согласно протоколу полиэтиленгликольной трансформации, описанному в [Cove et al., Cold Spring Harb Protoc., 2009, 2]. Протопласты затем инкубировали в среде BCD в течение двух дней в темноте при покачивании с интенсивностью 50 об/мин для регенерации клеточной стенки. Протопласты затем переносили на чашки Петри, содержащие агар и среду BCD и выращивали при 16-часовом освещении в течение недели. Трансформированные колонии мха скринировали с внешних геномных праймеров с помощью ПЦР для определения успешности интеграции генетической конструкции в геном, переносили на свежие чашки Петри и выращивали в тех же условиях освещения в течение 30 дней.
[0393] Полученные гаметофиты мха вымачивали в среде BCD, содержащей гиспидин в концентрации 900 мкг/мл, и анализировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Все проанализированные трансгенные растения демонстрировали биолюминесценцию с интенсивностью, как минимум на два порядка превышающую интенсивность сигнала контрольных растений, экспрессирующих только люциферазу, инкубированных в том же растворе с гиспидином.
Пример 9. Идентификация гиспидин-синтаз и кофеилпируват-гидролаз
[0394] Предшественники люциферина грибов, такие как гиспидин, относятся к большой группе химических соединений - производных поликетидов. Такие соединения могут быть теоретически получены из 3-арилакриловых кислот, в которых заместителем по третьему положению являются ароматические заместители, в том числе арил или гетероарил. Из уровня техники известно, что ферменты, вовлеченные в синтез поликетидов и их производных у различных организмов, представляют собой многодоменные комплексы, относящиеся к белковому суперсемейству поликетидсинтаз. В то же время из уровня техники не было известно ни одной поликетидсинтазы, способной осуществлять катализ реакции превращения 3-арилакриловой кислоты в замещенный 4-гидрокси-2H-пиран-2-он. Для поиска целевой поликетидсинтазы был использован скрининг библиотеки кДНК из Neonothopanus nambi.
[0395] Известно, что для получения функциональных поликетидсинтаз в дрожжевой системе гетерологической экспрессии необходимо дополнительно ввести в культуру ген, экспрессирующий 4'-фосфопантотеинил трансферазу - фермент, осуществляющий перенос 4-фосфопантетеинила от кофермента А на серин в ацилпереносящем домене поликетидсинтазы [Gao Menghao et al., Microbial Cell Factories 2013, 12:77]. Ген 4'-фосфопантотеинил трансферазы NpgA из Aspergillus nidulans (SEQ ID NOs 104, 105), известный из уровня техники, был получен синтетическим путем и клонирован в вектор pGAPZ. Плазмида была линеаризована по сайту рестрикции AvrII и использована для трансформации линии дрожжей Pichia pastoris GS115, конститутивно экспрессирующих люциферазу и гиспидин-гидроксилазу Neonothopanus nambi, полученнной как описано в Примере 1. Разнообразие итоговой библиотеки кДНК Neonothopanus nambi в дрожжах составило порядка одного миллиона клонов.
[0396] Библиотеку кДНК из Neonothopanus nambi, экспрессированную в указанной линии дрожжей Pichia pastoris, получали по протоколу, приведенному в Примере 1 и использовали для идентификации гиспидин-синтаз и кофеилпируват-гидролаз. Клетки были рассеяны на чашки Петри со средой RDB medium, содержащей 1 M сорбитола, 2% (вес/объем) глюкозы, 1.34% (вес/объем) дрожжевую основу азотного агара (YNB), 0.005% (вес/объем) смеси аминокислот, 0.00004% (вес/объем) биотина и 2% (вес/объем) агара.
[0397] Для идентификации гена гиспидин-синтазы полученные колонии опрыскивали раствором кофейной кислоты (потенциального предшественника гиспидина), детектируя присутствие в клетках гиспидин-синтазы по появлению света. Испускаемый колониями свет детектировали с помощью IVIS Spectrum CT (PerkinElmer, США). В качестве отрицательного контроля использовали клетки, экспрессирующие только люциферазу и гиспидин-гидроксилазу, и клетки дрожжей дикого типа. При скрининге библиотеки колонии, в которых детектировалось свечение, отбирали и использовали для ПЦР в качестве матрицы со стандартными плазмидными праймерами. Продукты ПЦР секвенировали по методу Сенгера, чтобы определить последовательность экспрессируемого гена. Полученная последовательность нуклеиновой кислоты гиспидин-синтазы показана в SEQ ID NO: 34. Кодируемая ею аминокислотная последовательность показана в SEQ ID NO: 35.
[0398] Полученную линию дрожжей Pichia pastoris, содержащую интегрированные в геном гены люциферазы, гиспидин-гидроксилазы и гиспидин-синтазы Neonothopanus nambi, а также ген 4'-фосфопантотеинил трансферазы NpgA из Aspergillus nidulans, использовали далее для идентификации фермента, катализирующего превращение оксилюциферина ((2Е,5Е)-6-(3,4-дигидроксифенил)-2-гидрокси-4-оксогекса-2,5-диеновой кислоты) в кофейную кислоту. Линию клеток снова трансформировали линеаризованной плазмидной библиотекой генов Neonothopanus nambi, полученной на первом этапе работы. Колонии опрыскивали раствором кофеилпирувата, детектируя присутствие в клетках целевого фермента по появлению света. Испускаемый колониями свет детектировали с помощью IVIS Spectrum CT (PerkinElmer, США). В качестве отрицательного контроля использовали клетки, экспрессирующие только люциферазу и гиспидин-гидроксилазу, и клетки дрожжей дикого типа. При скрининге библиотеки колонии, в которых детектировалось свечение, отбирали и использовали для ПЦР в качестве матрицы со стандартными плазмидными праймерами. Продукты ПЦР секвенировали по методу Сенгера, чтобы определить последовательность экспрессируемого гена. Полученная последовательность нуклеиновой кислоты выделенного фермента показана в SEQ ID NO: 64. Кодируемая ею аминокислотная последовательность показана в SEQ ID NO: 65. Выявленный фермент получил название кофеилпируват-гидролаза.
Пример 10. Идентификация гомологов гиспидин-синтазы Neonothopanus nambi и кофеилпируват-гидролазы Neonothopanus nambi
[0399] Для поиска гомологов гиспидин синтазы и кофеилпируват-гидролазы Neonothopanus nambi использовали данные полногеномного секвенирования из биолюминесцентных грибов, полученные как описано в Примере 1. Поиск гомологов осуществлялся с помощью программного обеспечения, предоставляемого National Center for Biotechnology Information. Был также проведен поиск аминокислотных последовательностей в данных геномного секвенирования грибов в базе данных NCBI Genbank. При поиске использовали стандартные параметры поиска blastp.
[0400] Были идентифицированы последовательности гомологов гиспидин-синтазы из Neonothopanus nambi - в Armillaria fuscipes, Armillaria mellea, Guyanagaster necrorhiza, Mycena citricolor, Neonothopanus gardneri, Omphalotus olearius, Panellus stipticus, Armillaria gallica, Armillaria ostoyae, Mycena chlorophos. Их нуклеотидные и аминокислотные последовательности показаны в SEQ ID NO 36-55. Все выявленные ферменты были по существу сходны друг с другом. Степень идентичности аминокислотных последовательностей показана в Таблице 5.
[0401] Из Panellus stipticus было выделено две высокогомологичные аминокислотные последовательности гиспидин-синтаз, отличающиеся единичной аминокислотной заменой. Их нуклеотидные и аминокислотные последовательности показаны в SEQ ID NO 36-39.
[0402] Выявленные ферменты были проверены на способность осуществлять реакцию превращения кофейной кислоты в гиспидин с помощью способа, описанного в примере 9.
[0403] Множественное выравнивание аминокислотных последовательностей выявленных белков позволило идентифицировать несколько высокогомологичных фрагментов аминокислотной последовательности, характерных для данной группы ферментов. Консенсусные последовательности для этих фрагментов показаны в SEQ ID NOs: 70-77. Указанные последовательности разделены протяженными аминокислотными последовательностями как показано на Фиг. 2.
[0404] Последовательности гомологов кофеилпируват-гидролазы Neonothopanus nambi были идентифицированы в Neonothopanus gardneri, Armillaria mellea, Armillaria fuscipes, Armillaria gallica, Armillaria ostoyae Нуклеотидные и аминокислотные последовательности выявленных гомологов показаны в SEQ ID NOs: 66-75. Выявленные ферменты были проверены на способность осуществлять реакцию превращения кофеилпирувата в кофейную кислоту с помощью способа, описанного в Примере 9.
[0405] Все выявленные ферменты по существу сходны друг с другом и имеют длину 280-320 аминокислот.Степень идентичности аминокислотных последовательностей показана в Таблице 6.
[0406] Анализ с помощью программного обеспечения SMART (Simple Modular Architecture Research Tool), доступное в сети Интернет по адресу http://smart.embl-heidelberg.de [Schultz et al., PNAS 1998; 95: 5857-5864; Letunic I, Doerks T, Bork P Nucleic Acids Res 2014; doi:10.1093/nar/gku949] выявил, что в состав выявленных ферментов входит расположенный ближе к С-концу фумарилацетазный домен (EC 3.7.1.2) длиной около 200 аминокислот, однако консервативная область начинается примерно с 8 аминокислоты согласно нумерации аминокислот кофеилпируват-гидролазы Neonothopanus nambi. Множественное выравнивание позволило выявить консенсусные последовательности (SEQ ID NOs 76-78), характерные для данной группы белков, разделенные аминокислотными вставками с более низкой идентичностью. Положение консенсусных последовательностей показано на (Фиг. 3).
Пример 11. Получение рекомбинантных гиспидин-синтазы и кофеилпируват-гидролазы и их использование для получения биолюминесценции
[0407] На 5'-концы нуклеиновых кислот, кодирующих гиспидин-синтазу и кофеилпируват-гидролазу Neonothopanus nambi, полученных как описано в примере 9, была оперативно присоединена последовательность, кодирующая полигистидин (гис-таг), и полученные конструкции были клонированы в вектор pET-23 с помощью эндонуклеаз рестрикции NotI и SacI. Векторы использовали для трансформации клеток Escherichia coli штамма BL21-DE3-codon+, которую осуществляли электропорацией. Трансформированные клетки высевали на чашки Петри со средой LB, содержащей 1.5% агар, ампициллин 100 мкг/мл, и инкубировали в течение ночи при 37°С.Колонии Escherichia coli затем переносили в 4 мл жидкой среды LB, содержащей 100 мкг/мл ампициллина, инкубировали в течение ночи при покачивании при 37°С.1 мл ночной культуры переносили в 200 мл среды Overnight Express Autoinduction medium (Novagen), в которую был предварительно добавлен ампициллин. Культуру инкубировали при 37°С в течение 3 часов до достижения оптической плотности 0.6 ОЕ при 600 нм, а затем инкубировали при комнатной температуре в течение 16 часов. Затем клетки осаждали центрифугированием при 4500 об/мин в течение 20 минут в центрифуге Eppendorf 5810R, ресуспендировали в 20 мл буфера (50 мМ Тris HCl рН 8.0, 150 мМ NaCl), лизировали ультразвуком в приборе Bioruptor (Diagenode, Бельгия) в течение 7 минут при температуре 0°C в условиях, рекомендованных производителем, и снова центрифугировали. Белок из лизата получали с помощью аффинной хроматографии на смоле Talon (Clontech, США). Наличие ожидаемого рекомбинантного продукта подтверждали с помощью электрофореза по наличию полос ожидаемой длины.
[0408] Аликвоты выделенных рекомбинантных белков использовали для проверки функциональности.
[0409] Для определения функциональности гиспидин-синтазы 30 мкл раствора выделенного рекомбинантного белка вносили в пробирку, содержащую 100 мкл буфера (0.2 M Na-фосфат буфера, 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM) pH 8.0, все компоненты - Sigma-Aldrich, США), 0.5 мкл очищенной рекомбинантной люциферазы Neonothopanus nambi, полученной как описано в Примере 4, 1 мМ НАДФН (Sigma-Aldrich, США), 15 мкл очищенной рекомбинантной гиспидин-гидроксилазы Neonothopanus nambi, полученной как описано в Примере 4, 10 мМ АТФ (ThermoFisher Scientific, США), 1 мМ КоА (Sigma-Aldrich, США), 1 мМ Малонил-КоА (Sigma-Aldrich, США). Пробирку помещали в люминометр GloMax 20/20 (Promega, США). Реакционные смеси демонстрировали биолюминесцентное свечение при добавлении в раствор 20 мкМ кофейной кислоты (Sigma-Aldrich, США). Испускаемый свет обладал максимумом эмиссии в области 520-535 нм.
[0410] Для определения функциональности кофеилпируват-гидролазы 10 мкл раствора выделенного рекомбинантного белка вносили в пробирку, содержащую 100 мкл буфера (0.2 M Na-фосфат буфера, 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM) pH 8.0), 0.5 мкл люциферазы Neonothopanus nambi, 1 мМ НАДФН (Sigma-Aldrich, США), 15 мкл гиспидин-гидроксилазы, 10 мМ АТФ (ThermoFisher Scientific, США), 1 мМ КоА (Sigma-Aldrich, США), 1 мМ Малонил-КоА (Sigma-Aldrich, США), 30 мкл очищенной рекомбинантной гиспидин-синтазы. Пробирку помещали в люминометр GloMax 20/20 (Promega, США). Биолюминесцентное свечение реакционной смеси детектировалось при добавлении в раствор 25 мкМ кофеилпирувата, свидетельствуя о способности тестируемого фермента разлагать кофеилпируват до кофейной кислоты. Испускаемый свет обладал максимумом эмиссии в области 520-535 нм.
[0411] Полученные ферменты использовали для получения свечения (биолюминесценции) в реакции с люциферазой и гиспидин-гидроксилазой Neonothopanus nambi, полученными как описано в Примере 4. По 5 мкл раствора каждого выделенного рекомбинантного белка вносили в пробирку, содержащую 100 мкл буфера (0.2 M Na-фосфат буфера, 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM) pH 8.0), 1 мМ НАДФН (Sigma-Aldrich, США), 10 мМ АТФ (ThermoFisher Scientific, США), 1 мМ КоА (Sigma-Aldrich, США), 1 мМ малонил-КоА (Sigma-Aldrich, США) и 0.2 мкМ одной из 3-арилакриловых кислот: паракумаровой кислоты (Sigma-Aldrich, США), коричной кислоты (Sigma-Aldrich, США) или феруловой кислоты (Abcam, США). В другом эксперименте в пробирку вместо замещенной 3-арилакриловой кислоты добавляли аналоги оксилюциферина грибов - (2Е,5Е)-2-гидрокси-6-(4-гидроксифенил)-4-оксогекса-2,5-диеновую, (2Е,5Е)-2-гидрокси-4-оксо-6-фенилгекса-2,5-диеновую, или (2Е,5Е)-2-гидрокси-6-(4-гидрокси-3-метоксифенил)-4-оксогекса-2,5-диеновую кислоты - также в концентрации 0.2 мкМ. Пробирки помещали в люминометр. Активность выделенных рекомбинантных белков приводила к испусканию света в каждой из описанных реакций.
Пример 13. Получение гиспидина из кофейной кислоты
[0412] Кассета экспрессии, содержащая нуклеиновую кислоту, кодирующую гиспидин-синтазу Neonothopanus nambi (SEQ ID NOs 34, 35), под контролем конститутивного промотора J23100, и кассета экспрессии, содержащая ген 4'-фосфопантотеинил трансферазы NpgA из Aspergillus nidulans (SEQ ID NOs 104, 105) под контролем промотора araBAD, фланкированные участками гомологии к сайту SS9 были получены синтетическим путем и клонированы в бактериальный экспрессионный вектор, содержащий кассету устойчивости к зеоцину. Полученную конструкцию использовали для трансформации и интеграции в геном E.coli BW25113 при помощи рекомбинации, опосредованной белками бактериофага лямбда как описано в Bassalo et al. [ACS Synth Biol. 2016 Jul 15;5(7):561-8], с использованием отбора на устойчивость к зеоцину. Интеграцию полноразмерной конструкции подтверждали с помощью ПЦР с праймеров, специфичных к участкам гомологии SS9, а затем убеждались в корректности интегрированной конструкции секвенированием ПЦР-продукта геномной ДНК по методу Сэнгера.
[0413] Полученный штамм E.coli использовали для получения гиспидина. На первой этапе, бактерии культивировали в пяти 50-мл пластиковых пробирках в среде LB в течение 10 часов при покачивании 200 оборотов в минуту при 37°C. 250 мл полученной культуры добавляли к 3.3 литрам ферментационной среды в ферментер Biostat B5 (Braun, Германия) так, что начальная оптическая плотность культуры при 600 нм составляла около 0.35. Ферментационная среда содержала 10 г/л пептона, 5 г/л кофейной кислоты, 5 г/л дрожжевого экстракта, 10 г/л NaCl, 25 г/л глюкозы, 15 г/л (NH4)2SO4, 2 г/л KH2PO4, 2 г/л MgSO4·7×H2O, 14.7× мг/л CaCl2, 0.1 мг/л тиамина, 1.8 мг/л, и 0.1% раствора следующего состава: ЭДТА 8 мг/л, CoCl2·6×H2O 2.5 мг/л, MnCl2·4H2O 15 мг/л, CuCl2·2H2O 1.5 мг/л, H3BO3 3 мг/л, Na2MoO4·2H2O 2.5 мг/л, Zn(CH3COO)2·2H2O 13 мг/л, цитрат железа(III) 100 мг/л, гидрохлорида тиамина 4.5 мг/л. Ферментацию осуществляли при 37×°C, с аэрацией 3×л/мин и перемешивании со скоростью 200 оборотов в минуту. Спустя 25 часов культивирования к культуре добавляли арабинозу до финальной концентрации 0.1×мМ. pH контролировали автоматически добавлением NH4OH, доводя pH до значения 7.0. Раствор, содержащий глюкозу 500 г/л, кофейную кислоту 5 г/ л, арабинозу 2 г/л, триптон 25 г/л, дрожжевой экстракт 50 г/л, MgSO4·7H2O 17.2 г/л, (NH4)SO4 7.5 г/л, аскорбиновую кислоту 18 г/л, добавляли в ферментер для поддержания уровня глюкозы каждый раз при повышении pH до 7.1. Спустя 56 часов культивирования концентрация гиспидина в среде составляла 1.23×г/л. Среда из ферментера, а также очищенный из нее с помощью высокоэффективной жидкостной хроматографии гиспидин, обладали активностью в биолюминесцентной реакции с гиспидин-гидроксилазой и люциферазой Neonothopanus nambi.
Пример 13. Получение 3-гидроксигиспидина из кофейной кислоты
[0414] Кассета экспрессии, содержащая нуклеиновую кислоту, кодирующую гиспидин-гидроксилазу Neonothopanus nambi (SEQ ID NOs 1, 2) под контролем промотора J23100, была получена синтетически и клонирована в бактериальный экспрессионный вектор, содержащий ген устойчивости к спектиномицину. Полученный вектор трансформировали в клетки E.coli, экспрессирующие гиспидин-синтазу Neonothopanus nambi, ген устойчивости к зеоцину и ген NpgA, полученные как описано в примере 12. Полученные бактерии использовали для получения 3-гидроксигиспидина путем ферментации, по протоколу, описанному в Примере 12, однако с добавлением спектиномицина в концентрации 50 мг/мл во все используемые для культивирования среды. Спустя 48 часов культивирования концентрация 3-гидроксигиспидина в среде составляла 2.3×г/л. Среда из ферментера, а также очищенный из нее с помощью высокоэффективной жидкостной хроматографии 3-гидроксигиспидин, обладали активностью в биолюминесцентной реакции с люциферазой Neonothopanus nambi.
Пример 14. Получение гиспидина из метаболитов клетки и тирозина
[0415] Для производства биосинтетического гиспидина из тирозина был получен штамм E.coli, эффективно производящий тирозин и кофейную кислоту. Штамм E.coli был получен как описано в [Lin и Yan. Microb Cell Fact. 2012 Apr 4;11:42]. За основу для создания штамма была взята линия E.coli BW25113 с интегрированным мутантным геном пермеазы lacY (lacY A177C) по сайту attB, обеспечивающим равномерное потребление арабинозы клетками бактерий. Кассеты экспрессии, содержащие кодирующие последовательности генов тирозин-аммоний-лиазы Rhodobacter capsulatus (SEQ ID NOs: 106, 107), и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E.coli (SEQ ID NOs: 108-111), каждый под контролем конститутивного промотора J23100, были получены синтетически и интегрированы в геном штамма E.coli, как описано в Примере 12. На следующем этапе в геном E.coli интегрировали плазмиду, полученную как описано в Примере 12 и содержащую кодирующую последовательность гиспидин-синтазы Neonothopanus nambi под контролем конститутивного промотора J23100, кассету устойчивости к зеоцину из вектора pGAP-Z, а также ген NpgA. Интеграцию в геном E.coli осуществляли при помощи рекомбинации, опосредованной белками бактериофага лямбда, по методике из [Bassalo et al., ACS Synth Biol. 2016; 5(7):561-568]. Интеграцию полноразмерной конструкции подтверждали с помощью ПЦР с праймеров, специфичных к участкам гомологии SS9 (5'-CGGAGCATTTTGCATG-3' и 5'-TGTAGGATCAAGCTCAG-3'), а затем убеждались в корректности интегрированной конструкции секвенированием ПЦР-продукта геномной ДНК по методу Сэнгера. Полученный штамм бактерий использовали для получения биосинтетического гиспидина в ферментере.
[0416] Культивирование бактерий производили в ферментере, как описано в Примере 12, с единственным отличием - в среды для культивирования бактерий не добавляли кофейную кислоту. Биосинтетический гиспидин выделяли из среды с помощью высокоэффективной жидкостной хроматографии. Созданный штамм был способен к производству 1.20 мг/л гиспидина за 50×часов ферментации. Чистота полученного препарат составила 97.3%. Добавление тирозина в среды для культивирования в концентрации 10 г/мл позволяло повысить выход гиспидина до 108.3 мг/мл.
Пример 15. Создание трансгенных автономно биолюминесцентных дрожжей Pichia pastoris
[0417] Для создания автономно биолюминесцентных дрожжей Pichia pastoris были синтезированы кассеты экспрессии, содержащие под контролем промотора GAP и терминатора tAOX1 кодирующие последовательности люциферазы Neonothopanus nambi (SEQ ID NOs: 79, 80), гиспидин-гидроксилазы Neonothopanus nambi (SEQ ID NOs: 1, 2), гиспидин-синтазы Neonothopanus nambi (SEQ ID NOs: 34, 35), кофеилпируват-гидролазы Neonothopanus nambi (SEQ ID NOs: 64, 65), белка NpgA Aspergillus nidulans (SEQ ID NOs: 104, 105), тирозин-аммоний-лиазы Rhodobacter capsulatus (SEQ ID NOs: 106, 107), и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E.coli (SEQ ID NOs: 108-111). Каждая кассета экспрессии была фланкирована последовательностями узнавания рестриктазы BsmBI. Также синтетически были получены участки гомологии к гену MET6 Pichia pastoris (Uniprot F2QTU9), фланкированные сайтами рестриктазы BsmBI. Синтетическую ДНК обрабатывали рестриктазами BsmBI и объединяли в одну плазмиду по протоколу клонирования Golden Gate, описанному в [Iverson et al., ACS Synth Biol. 2016 Jan 15;5(1):99-103]. 10 фмоль каждого из фрагментов ДНК смешивали в реакции, содержащей однократный буфер для ДНК-лигазы (Promega, США), 20 единиц активности ДНК-лигазы (Promega, США), 10 единиц активности эндонуклеазы рестрикции в общем объеме 10 мкл. Полученную реакционную смесь помещали в амплификатор и инкубировали при температурах 16°C и 37°C по следующему протоколу: 25 циклов инкубации при 37°C в течение 1.5 мин и при 16°C - 3 мин, затем единовременная инкубация при 50°C в течение 5 мин, а затем единовременная инкубация при 80°C в течение 10 мин. 5 мкл реакционной смеси трансформировали в химически компетентные клетки E.coli. Корректность сборки плазмидной ДНК подтверждали секвенированием по методу Сенгера, и препарат очищенной плазмидной ДНК использовали для трансформации клеток Pichia pastoris GS11 электропорацией. Электропорация была проведена по методу с использованием ацетата лития и дитиотреитола, описанному в [Wu and Letchworth, Biotechniques, 2004, 36:152-4]. Электропорированные клетки были рассеяны на чашки Петри со средой RDB, содержащей 1 M сорбитола, 2% (w/v) глюкозы, 1.34% (w/v) дрожжевую основу азотного агара (YNB), 0.005% (w/v) смеси аминокислот, 0.00004% (w/v) биотина и 2% (w/v) агара. Интеграцию кассеты генов в геном подтверждали с помощью ПЦР с праймеров, отжигающихся на участки гомологии. Полученный штамм дрожжей, содержащий корректную вставку в геноме, был способен автономно производить свет, в отличие от штамма дрожжей дикого типа (Фиг. 7, 8).
Пример 16. Создание трансгенных автономно биолюминесцентных цветковых растений
[0418] Для создания автономно биолюминесцентных цветковых растений на основе вектора pBI121 (Clontech, США) был создан бинарный вектор для агробактериальной трансформации, содержащий оптимизированные для экспрессии в растениях кодирующие последовательности люциферазы Neonothopanus nambi (SEQ ID NO: 112), гиспидин-гидроксилазы Neonothopanus nambi (SEQ ID NO: 103), гиспидин-синтазы Neonothopanus nambi (SEQ ID NO: 113), кофеилпируват-гидролазы Neonothopanus nambi (SEQ ID NO: 114) и ген устойчивости к канамицину, каждый ген - под контролем промотора 35S из вируса мозаики цветной капусты. Последовательности для сборки кассет экспрессии получали синтетическим путем, сборку вектора осуществляли по протоколу клонирования Golden Gate, описанному в [Iverson et al., ACS Synth Biol. 2016 Jan 15;5(1):99-103].
[0419] Arabidopsis thaliana трансформировали путем совместного культивирования ткани растения с бактериями Agrobacterium tumefaciens штамма AGL0 [Lazo et al., Biotechnology, 1991 Oct; 9(10):963-7], содержащими созданный бинарный вектор. Трансформацию осуществляли, применяя совместное культивирование сегментов корней Arabidopsis thaliana (экотип С24), как описано [Valvekens et al., 1988, Proc. Nat. Acad. Sci. USA 85, 5536-5540]. Корни растений арабидопсиса культивировали на агаризованной среде Гамборга B-5 c 20 г/л глюкозы, 0,5 г/л 2,4-дихлорфеноксиуксусной кислоты и 0,05 кинетина в течении 3 дней. Затем корни нарезали на кусочки длиной 0,5 см и переносили в 10 мл жидкой среды Гамборга B-5 c 20 г/л глюкозы, 0,5 г/л 2,4-дихлорфеноксиуксусной кислоты и 0,05 кинетина и добавляли 1,0 мл среды ночной культуры агробактерий. Кокультивацию эксплантов с агробактериями проводили в течении 2-3 минут.После этого экспланты помещали на стерильные фильтры в чашки Петри с агаризованной средой того же состава. Через 48 часов инкубации в термостате при температуре 25°C экспланты переносили на свежую среду с цефотаксимом 500 мг/л и канамицином 50 мг/л. Через три недели начинали регенерацию растений на селективной среде, содержащей канамицин 50 мг/л. Трансгенные растения укореняли и переносили в среду проращивания или на грунт.Биолюминесценцию визуализировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Более 90% трансгенных растений испускали свет, как минимум на два порядка превышающий сигнал от растений дикого типа.
[0420] Nicotiana benthamiana трансформировали путем совместного культивирования ткани растения с бактериями Agrobacterium tumefaciens штамма AGL0 [Lazo et al., Biotechnology, 1991 Oct; 9(10):963-7], содержащими созданный бинарный вектор. Трансформацию осуществляли, применяя совместное культивирование сегментов листьев Nicotiana benthamiana. Затем листья нарезали на кусочки длиной 0,5 см и переносили в 10 мл жидкой среды Гамборга B-5 c 20 г/л глюкозы, 0,5 г/л 2,4-дихлорфеноксиуксусной кислоты и 0,05 кинетина и добавляли 1,0 мл среды ночной культуры агробактерий. Кокультивацию эксплантов с агробактериями проводили в течении 2-3 минут.После этого экспланты помещали на стерильные фильтры в чашки Петри с агаризованной средой того же состава. Через 48 часов инкубации в термостате при температуре 25°C экспланты переносили на свежую среду с цефотаксимом 500 мг/л и канамицином 50 мг/л. Через три недели начинали регенерацию растений на селективной среде, содержащей канамицин 50 мг/л. Трансгенные растения укореняли и переносили в среду проращивания или на грунт.Биолюминесценцию визуализировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Более 90% трансгенных растений испускали свет, как минимум на два порядка превышающий сигнал от растений дикого типа. Фотографии автономно светящихся растений Nicotiana benthamiana приведены на Фиг. 9.
[0421] Для создания автономно биолюминесцентной полевицы побегоносной Agrostis stolonifera L. в вектор pBI121 (Clontech, США) клонировали кодирующие последовательности генов метаболического каскада люциферина гриба, оптимизированные для экспрессии в растениях и фланкированные сайтами эндонуклеазы рестрикции BsaI: люциферазы Neonothopanus nambi (SEQ ID NO: 126), гиспидин-гидроксилазы Neonothopanus nambi (SEQ ID NO: 117), гиспидин-синтазы Neonothopanus nambi (SEQ ID NO: 127), кофеилпируват-гидролазы Neonothopanus nambi (SEQ ID NO: 128) и ген устойчивости к гербициду глифосату (ген bar). Каждая последовательность находилась под контролем промотора CmYLCV [Stavolone et al., Plant Mol Biol. 2003 Nov;53(5):663-73]. Последовательности синтезировали по стандартной методике. Сборка вектора осуществлялась по протоколу клонирования Golden Gate. Трансформацию проводили методом агробактериальной трансформации эмбриогенного калусса. В жидкую среду добавляли ночную культуру бактерий Agrobacterium tumefaciens штамма AGL0 [Lazo et al., Biotechnology, 1991 Oct; 9(10):963-7], содержащую созданный бинарный вектор. После двух дней кокультивации на агаризованой среде Мурасиге-Скуга, растения переносили на свежую среду с добавлением цефотаксима 500 мг/л и фосфинотрицина 10 мг/л. Регенерация растений начиналась через три недели. Трансгенные растения пересаживали на среду с половинным содержанием солей Мурасиге-Скуга и фосфинотрицином 8 мг/л для укоренения. Укорененные растения высаживали в теплицу. Около 25% полученных растений с корректной и полной интеграцией в геном метаболического каскада, обладали биолюминесценцией, превышающей биолюминесценцию контрольных растений дикого типа.
[0422] Особый интерес представляют организмы, способные испускать свет в определенных тканях или в определенное время суток. Такие организмы более эффективно расходуют ресурсы, требуемые для излучения света. Для создания автономно биолюминесцентных роз, испускающих свет только в лепестках, были отобраны несколько разновидностей роз с белыми лепестками. На основе вектора pBI121 (Clontech, США) было создано два бинарных вектора для агробактериальной трансформации, содержащих метаболический каскад из оптимизированных для экспрессии в растениях кодирующих последовательностей люциферазы Neonothopanus nambi, гиспидин-гидроксилазы Neonothopanus nambi, гиспидин-синтазы Neonothopanus nambi, кофеилпируват-гидролазы Neonothopanus nambi и гена устойчивости к неомицину. Все гены, кроме гена люциферазы, были помещены под контроль промотора вируса мозаики цветной капусты 35S. В одном из векторов ген люциферазы был помещен под контроль промотора халконсинтазы розы, а в другом - под контроль промотора UEP1 хризантемы. Использовались синтетические нуклеиновые кислоты, необходимые для сборки вектора, фланкированные сайтами узнавания рестриктазы BsaI, сборка вектора осуществлялась по протоколу клонирования Golden Gate. Трансгенные растения розы Rosa hybrida L. cv. Tinike получали путем совместного культивирования эмбриогенного каллуса с бактериями Agrobacterium tumefaciens штамма AGL0 [Lazo et al., Biotechnology, 1991 Oct; 9(10):963-7], содержащим один из бинарных векторов, описанных выше. Культивирование проводили в жидкой среде, содержащей макро- и микро-соли Мурасиге-Скуга, с добавлением кинетина 1-2 мг/л, 2,4-дихлорфеноксиуксусной кислоты - 3 мг/л и 6-бензиламинопурина 1 мг/л в течении 40 минут.Каллус переносили на агаризованную среду того же состава. Через два дня экспланты переносили на свежую среду Мурасиге-Скуга с добавлением цефотаксима 500 мг/л и канамицина 50 мг/л. Формирование и регенерация побегов происходила через 5-8 недель. Побеги переносили на среду размножения или укоренения. Укорененные побеги высаживали в теплицу в торфяную смесь. Цветение наблюдали через 8 недель. Растения с развитыми цветками визуализировали в IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Для каждой из протестированных конструкций, все протестированные растения автономно испускали свет, как минимум на три порядка превышающий сигнал от растений дикого типа. Свет исходил только из тканей лепестков, подтверждая тканеспецифичное функционирование промоторов.
[0423] Для создания автономно биолюминесцентных растений, в которых биолюминесценция регулируется циркадными ритмами и активируется в темное время суток использовали ранее полученный бинарный вектор для агробактериальной трансформации, содержащий кодирующие последовательности люциферазы Neonothopanus nambi, гиспидин-гидроксилазы Neonothopanus nambi, гиспидин-синтазы Neonothopanus nambi, кофеилпируват-гидролазы Neonothopanus nambi и ген устойчивости к канамицину, каждый ген - под контролем промотора 35S из вируса мозаики цветной капусты. В нем заменяли промотор для экспрессии люциферазы Neonothopanus nambi на промотор гена CAT3 из Arabidopsis thaliana. Транскрипция с промотора гена CAT3 регулируется циркадными ритмами и активируется в вечернее время. Последовательность промотора CAT3 известна из уровня техники [Michael и McClung, Plant Physiol. 2002 Oct;130(2):627-38]. Arabidopsis thaliana трансформировали путем совместного культивирования ткани растения с бактериями Agrobacterium tumefaciens штамма AGL0 [Lazo et al., Biotechnology, 1991 Oct; 9(10):963-7], содержащими созданный бинарный вектор. Трансформацию осуществляли, применяя совместное культивирование сегментов корней Arabidopsis thaliana (экотип С24), как описано [Valvekens et al., 1988, Proc. Nat. Acad. Sci. USA 85, 5536-5540]. Корни растений арабидопсиса культивировали на агаризованной среде Гамборга B-5 c 20 г/л глюкозы, 0,5 г/л 2,4-дихлорфеноксиуксусной кислоты и 0,05 кинетина в течении 3 дней. Затем корни нарезали на кусочки длиной 0,5 см и переносили в 10 мл жидкой среды Гамборга B-5 c 20 г/л глюкозы, 0,5 г/л 2,4-дихлорфеноксиуксусной кислоты и 0,05 кинетина и добавляли 1,0 мл среды ночной культуры агробактерий. Кокультивацию эксплантов с агробактериями проводили в течении 2-3 минут.После этого экспланты помещали на стерильные фильтры в чашки Петри с агаризованной средой того же состава. Через 48 часов инкубации в термостате при температуре 25°C экспланты переносили на свежую среду с цефотаксимом 500 мг/л и канамицином 50 мг/л. Через три недели начинали регенерацию растений на селективной среде, содержащей канамицин 50 мг/л. Трансгенные растения укореняли и переносили в среду проращивания, растили в условиях естественной смены дня и ночи. Биолюминесценцию визуализировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer), помещая растения в прибор на сутки и регистрируя интенсивность биолюминесценции каждые полчаса. Растения испускали свет в течение суток, однако интенсивность биолюминесценции значительно модулировалась циркадными ритмами: интегральная интенсивность свечения в темное время суток превышала интегральную светимость в течение дня более, чем в 1000 раз для 85% процентов проанализированных растений.
Пример 17. Создание трансгенных автономно биолюминесцентных низших растений
[0424] Автономно биолюминесцентный мох Physcomitrella patens был создан с помощью котрансформации протопластов плазмидами способом, описанным в Примере 8. Были синтетически получены кассеты экспрессии, включающие оптимизированные для экспрессии в растениях кодирующие последовательности люциферазы Neonothopanus nambi (SEQ ID NO: 112), гиспидин-гидроксилазы Neonothopanus nambi (SEQ ID NO: 103), гиспидин-синтазы Neonothopanus nambi (SEQ ID NO: 113), кофеилпируват-гидролазы Neonothopanus nambi (SEQ ID NO: 114) и ген устойчивости к канамицину, каждая под контролем промотора актина 2 риса. Кассеты экспрессии оперативно сшивали в векторе pBI121 (Clontech, США) таким образом, чтобы конструкция, включающая полный метаболический каскад и ген устойчивости к канамицину, оказались фланкированы последовательностями, совпадающими с последовательностью целевого локуса в геноме мха. Сборка вектора осуществлялась по протоколу клонирования Golden Gate [Iverson et al., ACS Synth Biol. 2016 Jan 15;5(1):99-103]. Также в вектор клонировали ген гидовой РНК, комплементарный целевому участку в геноме мха. Плазмида с перечисленными генами была котрансформирована с плазмидой для конститутивной экспрессии нуклеазы Cas9, согласно протоколу полиэтиленгликольной трансформации, описанному в [Cove et al., Cold Spring Harb Protoc., 2009, 2]. Полученные трансформированные протопласты инкубировали без света в течение суток в среде BG-11, а затем переносили на чашки Петри со средой BG-11 и 8.5% агаром. Спустя месяц после выращивания на чашках при непрерывном облучении светом, проводили визуализацию в IVIS Spectrum In Vivo Imaging System (Perkin Elmer). 70% протестированных растений испускали свет, как минимум на порядок превышающий сигнал от растений дикого типа.
Пример 18. Получение трансгенных люминесцентных животных
[0425] Трансгенные рыбы Danio rerio, содержащие ген гиспидин-гидроксилазы Neonothopanus nambi, были созданы по методу, описанному в [Hisano et al., Sci Rep., 2015, 5:8841]. Методика включает экспрессию гидовой РНК и нуклеазы Cas9 для создания точечного разрыва в области, гомологичной последовательности гидовой РНК. Для создания трансгенных животных были заказаны синтетические фрагменты ДНК, содержащие последовательности гидовой РНК из плазмиды pX330, Addgene #42230 и мРНК нуклеазы Cas9 под контролем промотора полимеразы бактериофага T7. Полученные фрагменты использовали для транскрипции in vitro с помощью реагентов из набора MAXIscript T7 kit (Life Technologies, США), а синтезированную РНК очищали с помощью набора для выделения РНК (Евроген, Россия).
[0426] Кодирующую последовательность гиспидин-гидроксилазы Neonothopanus nambi, фланкированную 50-нуклеотидными последовательностями из гена krtt1c19e Danio rerio, описанные в [Hisano et al., Sci Rep., 2015, 5:8841] получали синтетическим путем и клонировали в основу плазмиды pEGFP/C1, содержащую ориджин репликации pUC и кассету устойчивости в канамицину. Полученный вектор, мРНК нуклеазы Cas9 и гидовая РНК были растворены в инъекционном буфере (40 мМ HEPES (pH 7.4), 240 мМ KCl с добавлением 0.5% фенолового красного) и инъецированы в 1-2-клеточные зародыши ранее полученной линии Danio rerio, стабильно экспрессирующей люциферазу Neonothopanus nambi, в объеме около 1-2 нл. Из 48 зародышей, около 12 зародышей пережили инъекцию и демонстрировали нормальное развитие на четвертый день после оплодотворения.
[0427] Для регистрации биолюминесцентного сигнала раствор гиспидина инъецировали внутривенно в личинки Danio rerio согласно методике, описанной в [Cosentino et al., J Vis Exp.2010; (42): 2079]. Биолюминесценцию регистрировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). После регистрации из личинок выделяли геномную ДНК для подтверждения интеграции гена гиспидин-гидроксилазы в геном. Все личинки с корректной интеграцией гена гиспидин-гидроксилазы Neonothopanus nambi в геном демонстрировали биолюминесценцию с интенсивностью, как минимум на два порядка превышающую интенсивность сигнала, исходящего от рыб дикого типа после инъекции раствора гиспидина.
Пример 19. Исследование влияния кофеилпируват-гидролазы на свечение автономно биолюминесцентных организмов
[0428] Для исследования влияния кофеилпируват-гидролазы на свечение автономно биолюминесцентных организмов использовали бинарный вектор для агробактериальной трансформации, содержащий кодирующие последовательности люциферазы Neonothopanus nambi, гиспидин-гидроксилазы Neonothopanus nambi, гиспидин-синтазы Neonothopanus nambi, кофеилпируват-гидролазы Neonothopanus nambi и ген устойчивости к канамицину, каждый ген - под контролем промотора 35S из вируса мозаики цветной капусты, полученный как описано в Примере 16 и контрольный вектор, отличающийся тем, что из него была удалена последовательность кофеилпируват-гидролазы. Векторы использовали для трансформации Arabidopsis thaliana в одинаковых условиях по протоколу, описанному в Примере 16. Биолюминесценцию визуализировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Сравнение интенсивностей биолюминесценции растений, экспрессирующих все четыре гена биолюминесцентной системы Neonothopanus nambi, с растениями, экспрессирующими только люциферазу, гиспидин-гидроксилазу и гиспидин-синтазу, выявило, что растения, дополнительно экспрессирующие кофеилпируват-гидролазу обладают в среднем в 8.3 раза более яркой биолюминесценцией. Приведенные данные свидетельствуют о том, что экспрессия кофеилпируват-гидролазы позволяет увеличить эффективность биолюминесцентного каскада, что приводит к увеличению интенсивности испускаемого растениями света.
Пример 20. Влияние внешнего добавления кофейной кислоты на биолюминесценцию трансгенных организмов
[0429] Автономно биолюминесцентные трансгенные растения Nicotiana benthamiana, полученные как описано в Примере 16, переносили на грунт и культивированы в течение восьми недель. Затем стебель растений срезали и помещали на два часа в воду, после чего измеряли интенсивность биолюминесценции с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Затем растения переносили в один из пяти водных растворов с концентрацией кофейной кислоты 0.4 г/л, 0.8 г/л, 1.6 г/л, 3.2 г/л или 6.4 г/л, а контрольные растения помещали в воду. Спустя еще два часа инкубации в растворе кофейной кислоты или воде снова измеряли биолюминесценцию. Во всех случаях интенсивность биолюминесценции растений, инкубированных в растворе кофейной кислоты, повышалась по сравнению с интенсивностью до помещения в раствор кофейной кислоты, причем наибольшие изменения наблюдались для растений, прошедших инкубацию в растворе c концентрацией 6.4 г/л. Контрольные растения, инкубированные в воде, не демонстрировали значимого изменения интенсивности биолюминесценции в течение четырех часов после начала инкубации.
Пример 21. Использование генов биолюминесцентной системы грибов для анализа активности промоторов и внутриклеточной логической интеграции внешних сигналов.
[0430] Кодирующие последовательности гиспидин-синтазы, гиспидин-гидроксилазы и люциферазы Neonothopanus nambi были использованы для мониторинга одновременной активации нескольких промоторов. Синтетические кассеты экспрессии, содержащие кодирующую последовательность гиспидин-синтазы Neonothopanus nambi (SEQ ID NOs: 34, 35) под контролем индуцируемого арабинозой промотора E.coli araBAD, кодирующую последовательность гиспидин-гидроксилазы (SEQ ID NOs 1, 2) под контролем индуцируемого IPTG промотора T7/lacO, и ген люциферазы (SEQ ID NOs: 79, 80) под контролем индуцируемого рамнозой промотора pRha, а также ген NpgA (SEQ ID NOs: 104, 105) под контролем конститутивного промотора J23100 (Registry of Standard Biological parts, Part:BBa_J23100). Полученные синтетические нуклеиновые кислоты клонировали в вектор MoClo_Level2 [Weber et al., PLoS One. 2011 Feb 18;6(2):e16765] вместо вставки, содержащий ген LacZ, с помощью эндонуклеазы рестрикции BpiI. Полученный вектор трансформировали в компетентные клетки штамма E.coli BL21 (NEB, США), содержащие геномную копию полимеразы бактериофага T7.
[0431] Для определения возможность регистрации одновременной активации нескольких промоторов, клетки, полученные на предыдущем этапе, подращивали в течение ночи в колбе в среде LB объемом 100 мл c добавлением ампициллина в концентрации 100 мг/л. На следующий день аликвоты культуры клеток помещали на 120 минут при температуре 24°С и покачивании 200 оборотов в минуту в одну из сред следующего состава:
1. Среда LB с добавлением 1% арабинозы,
2. Среда LB с добавлением 0.2% рамнозы,
3. Среда LB с добавлением 0.5% IPTG,
4. Среда LB с добавлением 1% арабинозы и 0.2% рамнозы,
5. Среда LB с добавлением 1% арабинозы и 0.5% IPTG,
6. Среда LB с добавлением 0.2% рамнозы и 0.5% IPTG,
7. Среда LB с добавлением 1% арабинозы, 0.2% рамнозы и 0.5% IPTG,
8. Среда LB (контроль).
[0432] После инкубации клетки осаждали центрифугированием, заменяли среду на фосфатно-солевой буфер с pH 7.4 (Sigma-Aldrich, США) с добавлением кофейной кислоты (Sigma-Aldrich, США) в концентрации 1 г/л, клетки ресуспендировали пипетированием. Биолюминесценцию клеток анализировали через полчаса с помощью люминометра GloMax 20/20 (Promega, США). Эксперимент повторяли в трех повторностях. Из восьми проанализированных проб интенсивность биолюминесценции значимо отличалась от биолюминесценции контрольных бактерий, инкубированных в среде LB (среда №8), только для бактерий, прошедших инкубацию в среде №7 (среда LB с добавлением 1% арабинозы, 0.2% рамнозы и 0.5% IPTG). Таким образом, свечение бактерий позволяло судить о помещении бактерий в среду, обеспечивающую одновременную активацию трех различных промоторов. В поставленном эксперименте бактериальные клетки интегрировали информацию о присутствии во внешней среде индуцирующих активность промоторов веществ и сигнализировали свечением только в случае, когда все три вещества присутствовали в среде одновременно, внутриклеточно выполняя логическую операцию «И».
[0433] Синтетические кассеты экспрессии, содержащие (1) кодирующую последовательность гиспидин-гидроксилазы (SEQ ID NOs: 1, 2) под контролем промотора Odf2 по [Pletz et al., Biochim Biophys Acta. 2013 Jun;1833(6):1338-46]; (2) кодирующую последовательность гиспидин-синтазы (SEQ ID NOs: 34, 35) под контролем промотора циклин-зависимой киназы CDK7; (3) люциферазы (SEQ ID NOs: 79, 80) под контролем промотора гена CCNH клонировали в вектор pmKate2-keratin (Евроген, Россия) вместо последовательностей цитомегаловирусного промотора и вставки mKate2-keratin. Так же кодирующую последовательность гена NpgA (SEQ ID NOs: 104, 105) клонировали в вектор pmKate2-keratin вместо последовательности вставки mKate2-keratin. Все полученные векторы ко-трансфицировали в клетки HEK293T с помощью трансфекционного реагента FuGENE HD (Promega, США) по протоколу производителя. Спустя 24 часа после трансфекции в среду добавляли кофейную кислоту в концентрации 5 мг/мл, и детектировали свечение клеток с помощью микроскопа Leica TCS SP8. Испускание света позволило определить одновременную активацию промоторов Odf2, CCNH и CDK7, причем интенсивность испускаемого света была связана со стадией клеточного цикла.
[0434] Полученные данные свидетельствуют о том, что гены биолюминесцентной системы грибов можно применять для мониторинга одновременной активности нескольких промоторов, для детекции наличия в среде различных веществ и их комбинаций, а также для логической интеграции внешних сигналов внутри клетки.
Пример 22. Выявление гиспидина в растительных экстрактах
[0435] Кодирующие последовательности гиспидин-гидроксилазы и люциферазы Neonothopanus nambi, полученные как описано в Примере 1, были клонированы в вектор pET23 под контроль промотора T7. Препараты очищенной плазмидной ДНК были использованы для транскрипции и трансляции белков in vitro с помощью набора PURExpress In Vitro Protein Synthesis Kit (NEB, США). Полученную реакционную смесь использовали для анализа наличия и концентрации гиспидина и его функциональных аналогов в лизатах около 19 различных растений (Chrysanthemum sp., Ananas comosus, Petunia atkinsiana, Picea abies, Urtica dioica, Solanum lycopersicum, Nicotiana benthamiana, Nicotiana tobacum, Arabidopsis thaliana, Rosa glauca, Rosa rubiginosa, Equisetum arvense, Equisetum telmateia, Polygala sabulosa, Rosa rugosa, Clematis tashiroi, Kalanchoe sp., Triticum aestivum, Dianthus caryophyllus), добавляя 2 мкл лизата растения к 100 мкл реакционной смеси и регистрируя интенсивность испускаемого света с помощью люминометра GloMax (Promega, США). Было определено, что максимальная концентрация гиспидина и его функциональных аналогов содержится в лизатах хвощей Equisetum arvense и Equisetum telmateia. Также гиспидин или его функциональные аналоги были обнаружены в лизатах Polygala sabulosa, Rosa rugosa и Clematis tashiroi.
Пример 23. Выявление PKS, способных катализировать синтез гиспидина, и их использование для получения гиспидина в системах in vitro и in vivo.
[0436] Предшественники люциферина грибов, такие как гиспидин, относятся к группе производных поликетидов. Из уровня техники известно, что ферменты, вовлеченные в синтез поликетидов в растениях относятся к белковому суперсемейству поликетидсинтаз, причем в отличие от поликетидсинтаз грибов, поликетидсинтазы растений являются сравнительно компактными белками, использующими в качестве субстрата КоА-эфиры кислот, в том числе 3-арилакриловых кислот.Из уровня техники не было известно ни одной поликетидсинтазы, способной осуществлять катализ реакции превращения КоА-эфира кофейной кислоты в гиспидин, однако гиспидин обнаруживается во многих растительных организмах.
[0437] С помощью биоинформатического анализа были отобраны потенциально способные катализировать синтез гиспидина 11 поликетидсинтаз из следующих источников:
Aquilaria sinensis (2 фермента),
Hydrangea macrophylla,
Arabidopsis thaliana,
Physcomitrella patens,
Polygonum cuspidatum,
Rheum palmatum,
Rheum tataricum,
Wachendorfia thyrsiflora,
Piper methysticum (два фермента).
[0438] Была проведена оптимизация выбранных нуклеотидных последовательностей для экспрессии в клетках дрожжей Pichia pastoris и растения Nicotiana benthamiana. Полученные нуклеиновые кислоты были получены синтетическим путем, клонированы в вектор pGAPZ и использованы для проверки способности экспрессированных белков синтезировать гиспидин.
[0439] Для этого в геном линии дрожжей Pichia pastoris GS115, конститутивно экспрессирующих люциферазу и гиспидин-гидроксилазу Neonothopanus nambi, полученной как описано в Примере 1, была дополнительно введена плазмида pGAPZ содержащая ген кумарат-КоА-лигазы 1 Arabidopsis thaliana (последовательности нуклеотидов и аминокислот для нее показаны в SEQ ID NOs: 140, 141), также полученный с помощью олигонуклеотидного синтеза. Плазмида была линеаризована по сайту рестрикции AvrII и использована для трансформации в клетки Pichia pastoris GS115.
[0440] Полученные клетки дрожжей, конститутивно экспрессирующие люциферазу и гиспидин-гидроксилазу Neonothopanus nambi и кумарат-КоА-лигазу 1 Arabidopsis thaliana, трансфецировали линеаризованными плазмидами, содержащими кодирующие последовательности PKS, и рассевали на чашки Петри со средой RDB, содержащей 1 M сорбитола, 2% (вес/объем) глюкозы, 1.34% (вес/объем) дрожжевую основу азотного агара (YNB), 0.005% (вес/объем) смеси аминокислот, 0.00004% (вес/объем) биотина и 2% (вес/объем) агара. Для идентификации ферментов, обладающих активностью гиспидин-синтаз, полученные колонии опрыскивали раствором кофейной кислоты, детектируя присутствие в клетках гиспидин-синтазы по появлению биолюминесценции. Испускаемый колониями свет детектировали с помощью IVIS Spectrum CT (PerkinElmer, США). В качестве отрицательного контроля использовали линию дрожжей, конститутивно экспрессирующих люциферазу, гиспидин-гидроксилазу и кумарат-КоА-лигазу 1, а также клетки дрожжей дикого типа. Среди проанализированных генов, активностью гиспидин-синтаз обладали 11 ферментов, последовательность которых показана в SEQ ID NOs: 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138. Кодируемые ими аминокислотные последовательности показаны в SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139 соответственно. Наибольшую активность проявляли ферменты из PKS1 и PKS2 из Aquilaria sinensis (SEQ ID NOs:119, 121), PKS из Arabidopsis thaliana (SEQ ID NO:123) и PKS из Hydrangea macrophylla (SEQ ID NO:125).
[0441] Нуклеиновая кислота, кодирующая PKS из Hydrangea macrophylla (SEQ ID NOs: 124, 125) была использована для получения рекомбинантного белка по методике, описанной в Примере 4. Наличие ожидаемого рекомбинантного продукта подтверждали с помощью электрофореза по наличию полос ожидаемой длины. Аликвоты выделенного рекомбинантного белка использовали для проверки функциональности: 30 мкл раствора выделенного рекомбинантного белка вносили в пробирку, содержащую 100 мкл буфера (0.2 M Na-фосфат буфера, 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM) pH 8.0, все компоненты - Sigma-Aldrich, США), 0.5 мкл очищенной рекомбинантной люциферазы Neonothopanus nambi, полученной как описано в Примере 4, 1 мМ НАДФН (Sigma-Aldrich, США), 15 мкл очищенной рекомбинантной гиспидин-гидроксилазы Neonothopanus nambi, полученной как описано в Примере 4, 10 мМ АТФ (ThermoFisher Scientific, США), 1 мМ КоА (Sigma-Aldrich, США), 1 мМ Малонил-КоА (Sigma-Aldrich, США). Пробирку помещали в люминометр GloMax 20/20 (Promega, США). Реакционные смеси демонстрировали биолюминесцентное свечение при добавлении в раствор 20 мкМ кофеил-КоА. Испускаемый свет обладал максимумом эмиссии в области 520-535 нм.
[0442] Нуклеиновая кислота, кодирующая PKS2 из Aquilaria sinensis (SEQ ID NO:120, 121) была использована для получения штамма продуцента гиспидина. Для этого синтезировали кассету экспрессии, содержащую нуклеиновую кислоту SEQ ID NO:120 под контролем конститутивного промотора J23100, и кассету экспрессии, содержащую нуклеиновую кислоту SEQ ID NO: 140, кодирующую 4-кумарат-КоА-лигазу 1 из Arabidopsis thaliana, под контролем промотора araBAD; обе кассеты экспрессии фланкировали участками гомологии к сайту SS9. Кассеты экспрессии клонировали в бактериальный экспрессионный вектор, содержащий кассету устойчивости к зеоцину и использовали для трансформации и интеграции в геном E.coli BW25113 при помощи рекомбинации, опосредованной белками бактериофага лямбда как описано в Bassalo et al. [ACS Synth Biol. 2016 Jul 15;5(7):561-8], с использованием отбора на устойчивость к зеоцину. Интеграцию полноразмерной конструкции подтверждали с помощью ПЦР с праймеров, специфичных к участкам гомологии SS9, а затем убеждались в корректности интегрированной конструкции секвенированием ПЦР-продукта геномной ДНК по методу Сэнгера.
[0443] Полученный штамм E.coli использовали для получения гиспидина. На первой этапе, бактерии культивировали в пяти 50-мл пластиковых пробирках в среде LB в течение 10 часов при покачивании 200 оборотов в минуту при 37°C. 250 мл полученной культуры добавляли к 3.3 литрам ферментационной среды в ферментер Biostat B5 (Braun, Германия) так, что начальная оптическая плотность культуры при 600 нм составляла около 0.35. Ферментационная среда содержала 10 г/л пептона, 5 г/л кофейной кислоты, 5 г/л дрожжевого экстракта, 10 г/л NaCl, 25 г/л глюкозы, 15 г/л (NH4)2SO4, 2 г/л KH2PO4, 2 г/л MgSO4·7×H2O, 14.7× мг/л CaCl2, 0.1 мг/л тиамина, 1.8 мг/л, и 0.1% раствора следующего состава: ЭДТА 8 мг/л, CoCl2·6×H2O 2.5 мг/л, MnCl2·4H2O 15 мг/л, CuCl2·2H2O 1.5 мг/л, H3BO3 3 мг/л, Na2MoO4·2H2O 2.5 мг/л, Zn(CH3COO)2·2H2O 13 мг/л, цитрат железа(III) 100 мг/л, гидрохлорида тиамина 4.5 мг/л. Ферментацию осуществляли при 37°C, с аэрацией 3×л/мин и перемешивании со скоростью 200 оборотов в минуту. Спустя 25 часов культивирования к культуре добавляли арабинозу до финальной концентрации 0.1×мМ. pH контролировали автоматически добавлением NH4OH, доводя pH до значения 7.0. Раствор, содержащий глюкозу 500 г/л, кофейную кислоту 5 г/ л, арабинозу 2 г/л, триптон 25 г/л, дрожжевой экстракт 50 г/л, MgSO4·7H2O 17.2 г/л, (NH4)SO4 7.5 г/л, аскорбиновую кислоту 18 г/л, добавляли в ферментер для поддержания уровня глюкозы каждый раз при повышении pH до 7.1. Спустя 56 часов культивирования концентрация гиспидина в среде составляла 3.48×г/л. Среда из ферментера, а также очищенный из нее с помощью высокоэффективной жидкостной хроматографии гиспидин, обладали активностью в биолюминесцентной реакции с гиспидин-гидроксилазой и люциферазой Neonothopanus nambi, полученными как описано в Примере 4.
[0444] Для создания автономно биолюминесцентных дрожжей Pichia pastoris были использованы кассеты экспрессии, содержащие под контролем промотора GAP и терминатора tAOX1 кодирующие последовательности люциферазы Neonothopanus nambi (SEQ ID NOs: 79, 80), гиспидин-гидроксилазы Neonothopanus nambi (SEQ ID NOs: 1, 2), гиспидин-синтазы Neonothopanus nambi (SEQ ID NOs: 34, 35), кофеилпируват-гидролазы Neonothopanus nambi (SEQ ID NOs: 64, 65), тирозин-аммоний-лиазы Rhodobacter capsulatus (SEQ ID NOs: 106, 107), и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E.coli (SEQ ID NOs: 108-111), описанные как описано в Примере 15, а так же были синтезированы аналогичные кассеты экспрессии, содержащие кодирующие последовательности 4-кумарат-КоА-лигазы 1 из Arabidopsis thaliana (SEQ ID NOs: 140, 141) и трех PKS: из Aquilaria sinensis (SEQ ID NOs:120, 121), PKS из Arabidopsis thaliana (SEQ ID NOs:122, 123) и PKS из Hydrangea macrophylla (SEQ ID NO:124, 125). Каждая кассета экспрессии была фланкирована последовательностями узнавания рестриктазы BsmBI. Также синтетически были получены участки гомологии к гену MET6 Pichia pastoris (Uniprot F2QTU9), фланкированные сайтами рестриктазы BsmBI. Синтетическую ДНК обрабатывали рестриктазами BsmBI и объединяли в одну плазмиду по протоколу клонирования Golden Gate, описанному в [Iverson et al., ACS Synth Biol. 2016 Jan 15;5(1):99-103]. Было изготовлено три плазмиды, отличающиеся включенной в их состав PKS. Полученные плазмиды использовали для получения трансгенных дрожжей Pichia pastoris по методике, описанной в Примере 15. Интеграцию кассеты генов в геном подтверждали с помощью ПЦР с праймеров, ожигающихся на участки гомологии. Все три полученных штамма дрожжей, содержащих корректную вставку в геноме, были способены автономно производить свет, в отличие от штамма дрожжей дикого типа.
[0445] Для создания автономно биолюминесцентных цветковых растений на основе вектора pBI121 (Clontech, США) был создан набор бинарных векторов для агробактериальной трансформации, содержащий оптимизированные для экспрессии в растениях кодирующие последовательности люциферазы Neonothopanus nambi (SEQ ID NO: 112), гиспидин-гидроксилазы Neonothopanus nambi (SEQ ID NO: 103), кофеилпируват-гидролазы Neonothopanus nambi (SEQ ID NO: 114), ген устойчивости к канамицину, и PKS (SEQ ID NOs: 122, 123), каждый ген - под контролем промотора 35S из вируса мозаики цветной капусты. Последовательности для сборки кассет экспрессии получали синтетическим путем, сборку вектора осуществляли по протоколу клонирования Golden Gate, описанному в [Iverson et al., ACS Synth Biol. 2016 Jan 15;5(1):99-103]. Nicotiana tabacum трансформировали путем совместного культивирования ткани растения с бактериями Agrobacterium tumefaciens штамма AGL0 [Lazo et al., Biotechnology, 1991 Oct; 9(10):963-7], содержащими созданный бинарный вектор. Трансформацию осуществляли, применяя совместное культивирование сегментов листьев Nicotiana tabacum. Затем листья нарезали на кусочки длиной 0,5 см и переносили в 10 мл жидкой среды Гамборга B-5 c 20 г/л глюкозы, 0,5 г/л 2,4-дихлорфеноксиуксусной кислоты и 0,05 кинетина и добавляли 1,0 мл среды ночной культуры агробактерий. Кокультивацию эксплантов с агробактериями проводили в течении 2-3 минут.После этого экспланты помещали на стерильные фильтры в чашки Петри с агаризованной средой того же состава. Через 48 часов инкубации в термостате при температуре 25°C экспланты переносили на свежую среду с цефотаксимом 500 мг/л и канамицином 50 мг/л. Через три недели начинали регенерацию растений на селективной среде, содержащей канамицин 50 мг/л. Трансгенные растения укореняли и переносили в среду проращивания или на грунт.Биолюминесценцию визуализировали с помощью IVIS Spectrum In Vivo Imaging System (Perkin Elmer). Трансгенных растений испускали свет, как минимум на три порядка превышающий сигнал от растений дикого типа.
Пример 24. Комбинации нуклеиновых кислот
[0446] Комбинация 1:
[0447] Состав: (а) Нуклеиновая кислота, кодирующая гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28; и (б) Нуклеиновая кислота, кодирующая люциферазу, аминокислотная последовательность которой выбрана из группы 80, 82, 84, 86, 88, 90, 92, 94, 96, 98.
[0448] Комбинация может быть использована для получения биолюминесценции в системах экспрессии in vitro или in vivo в присутствии вещества, выбранного из группы 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-онов, имеющих структурную формулу
,
в котором заместителем по шестому положению является 2-арилвинильный или 2-гетероарилвинильный заместитель (R-CH=CH-), в том числе 2-(3,4-дигидроксистирил), 2-(4-гидроксистирил), 2-(4-(диэтиламино)стирил), 2-(2-(1H-индол-3-ил)винил), 2-(2-(1,2,3,5,6,7-гексагидропиридо[3,2,1-ij]хинолин-9-ил)винил), 2-(6-гидроксинафталин-2-ил)винил.
[0449] Также указанная комбинация может быть использована для исследования зависимости двух промоторов в гетерологических системах экспрессии.
[0450] Также указанная комбинация может быть использована для выявления гиспидина и его аналогов в биологических образцах.
[0451] Также указанная комбинация может быть использована для мечения клеток с помощью биолюминесценции. Появляющейся в присутствии гиспидина и его функциональных аналогов.
[0452] Комбинация 2:
[0453] Состав: (а) Нуклеиновая кислота, кодирующая гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, и (б) Нуклеиновая кислота, кодирующая гиспидин-синтазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55.
[0454] Комбинация может быть использована для получения люциферина грибов в системах экспрессии in vitro или in vivo из вещества, выбранного из замещенной акриловой кислоты со структурной формулой
[0455] ,
где R - арил или гетероарил (например, из кофейной кислоты).
[0456] Комбинация 3:
[0457] Включает все компоненты, указанные в Комбинации 2, а также нуклеиновую кислоту, кодирующую люциферазу, аминокислотная последовательность которой выбрана из группы 80, 82, 84, 86, 88, 90, 92, 94, 96, 98.
[0458] Комбинация может быть использована для получения биолюминесценции в системах экспрессии in vitro или in vivo в присутствии вещества, выбранного из замещенной акриловой кислоты со структурной формулой
[0459] ,
где R - арил или гетероарил.
[0460] Комбинация может быть использована для получения биолюминесцентных клеток и трансгенных организмов. Также указанная комбинация может быть использована для исследования зависимости трех промоторов в гетерологических системах экспрессии.
[0461] Комбинация 4.
[0462] Включает все компоненты, указанные в Комбинации 3, также нуклеиновую кислоту, кодирующую кофеилпируват-гидролазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75.
[0463] Комбинация может быть использована для получения биолюминесцентных клеток и трансгенных организмов.
[0464] Комбинация 5.
[0465] Состав: (а) Нуклеиновая кислота, кодирующая гиспидин-синтазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55; и (б) Нуклеиновая кислота, кодирующая гена 4'-фосфопантотеинил трансферазу, аминокислотная последовательность которой показана в SEQ ID NO: 105
[0466] Комбинация может быть использована для получения гиспидина из кофейной кислоты в системах экспрессии in vitro и in vivo.
[0467] Комбинация 6
[0468] Состав: (а) Нуклеиновая кислота, кодирующая гиспидин-синтазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55; (б) Нуклеиновая кислота, кодирующая гена 4'-фосфопантотеинил трансферазу, аминокислотная последовательность которой показана в SEQ ID NO: 105; и (в) нуклеиновые кислоты, кодирующме ферменты биосинтеза 3-арилакриловой кислоты со структурной формулой
[0469] ,
где R - арил или гетероарил из метаболитов клетки (например, нуклеиновые кислоты, кодирующие тирозин-аммоний-лиазу и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы).
[0470] Комбинация может быть использована для получения гиспидина из тирозина в системах экспрессии in vitro и in vivo.
[0471] Комбинации 2-4 могут также включать кодирующую последовательность гена 4'-фосфопантотеинил трансферазы NpgA (SEQ ID NOs: 104, 105) или иного фермента, проявляющего ту же активность.
[0472] Комбинация 7
[0473] Состав: (а) Нуклеиновая кислота, кодирующая гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, и (б) Нуклеиновая кислота, кодирующая PKS, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139.
[0474] Комбинация может быть использована для получения 3-гидроксигиспидина в системах экспрессии in vitro или in vivo из кофеил-КоА.
[0475] Комбинация 8
[001] Включает все компоненты, указанные в Комбинации 7, а также нуклеиновую кислоту, кодирующую люциферазу, аминокислотная последовательность которой выбрана из группы 80, 82, 84, 86, 88, 90, 92, 94, 96, 98. Комбинация может быть использована для получения биолюминесценции в системах экспрессии in vitro или in vivo в присутствии кофеил-КоА.
[0476] Комбинация 9
[0477] Включает все компоненты, указанные в Комбинации 8, также нуклеиновую кислоту, кодирующую кофеилпируват-гидролазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 65, 67, 69, 71, 73, 75.
[0478] Комбинация может быть использована для получения биолюминесцентных клеток и трансгенных организмов.
[0479] Комбинация 10
[0480] Состав: (а) Нуклеиновая кислота, кодирующая PKS, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139; и (б) нуклеиновая кислота, кодирующая 4-кумарат-КоА-лигазу 1 из Arabidopsis thaliana, аминокислотная последовательность которой показана в SEQ ID NO: 141.
[0481] Комбинация может быть использована для получения гиспидина из кофейной кислоты в системах экспрессии in vitro и in vivo.
[0482] Комбинация 11
[0483] Включает все компоненты, указанные в Комбинации 10, также нуклеиновые кислоты, кодирующие ферменты биосинтеза кофейной кислоты (например, нуклеиновые кислоты, кодирующие тирозин-аммоний-лиазу и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы).
[0484] Комбинация может быть использована для получения гиспидина из тирозина в системах экспрессии in vitro и in vivo.
[0485] Пример 25. Комбинации рекомбинантных белков
[0486] Комбинация 1
[0487] Состав: (а) гиспидин-гидроксилаза, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28; и (б) гиспидин-синтаза, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55.
[0488] Комбинация может быть использована для получения люциферина грибов из вещества, выбранного из 3-арилакриловой кислоты со структурной формулой ,
где R - арил или гетероарил (например из кофейной кислоты).
[0489] Комбинация 2
[0490] Включает компоненты, указанные в комбинации 1, так же люциферазу, аминокислотная последовательность которой выбрана из группы 80, 82, 84, 86, 88, 90, 92, 94, 96, 98.
[0491] Комбинация может быть использована для детекции наличия в образце 3-арилакриловой кислоты со структурной формулой
[0492] ,
где R - арил или гетероарил (например, из кофейной кислоты).
[0493] Комбинация 3
[0494] Состав: (а) гиспидин-гидроксилаза, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28; и (б) PKS, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139; и (в) 4-кумарат-КоА-лигаза 1 из Arabidopsis thaliana, аминокислотная последовательность которой показана в SEQ ID NO: 141. Комбинация может быть использована для получения люциферина грибов из кофейной кислоты.
Пример 25. Наборы
[0495] В приведенных ниже примерах нуклеиновые кислоты могут быть включены в кассеты экспрессии или векторы и оперативно сшиты с регуляторными элементами для их экспрессии в клетке-хозяине. Альтернативно, нуклеиновые кислоты могут содержать фланкирующие последовательности для ее встраивания в целевой вектор. Нуклеиновые кислоты могут быть включены в лишенные промотора векторы, предназначенные для удобного клонирования целевых регуляторных элементов.
[0496] Набор реагентов #1 включает очищенный препарат гиспидин-синтазы настоящего изобретения и может быть использован для получения гиспидина из кофейной кислоты. Также набор может быть использован для получения другого 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
из соответствующей 3-арилакриловой кислоты со структурной формулой ,
где R - арил или гетероарил.
[0497] Набор реагентов может также включать реакционный буфер. Например, 0.2 M натрий-фосфатный буфер (pH 8.0) с добавлением 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM), 1 мМ НАДФН, 10 мМ АТФ, 1 мМ КоА, 1 мМ Малонил-КоА или компоненты для приготовления реакционного буфера.
[0498] Набор реагентов может также включать деионизованную воду.
[0499] Набор реагентов может также включать инструкцию по применению набора.
[0500] Набор реагентов #2 включает очищенный препарат гиспидин-синтазы настоящего изобретения и очищенный препарат гиспидин-гидроксилазы настоящего изобретения и может быть использован для получения люциферина грибов из вещества, выбранного из 3-арилакриловой кислоты со структурной формулой ,
где R - арил или гетероарил (например, из кофейной кислоты).
[0501] Набор реагентов может также включать реакционный буфер: 0.2 M натрий-фосфатный буфер (pH 8.0) с добавлением 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM), 1 мМ НАДФН, 10 мМ АТФ, 1 мМ КоА, 1 мМ Малонил-КоА или компоненты для приготовления реакционного буфера.
[0502] Набор реагентов может также включать деионизованную воду.
[0503] Набор реагентов может также включать инструкцию по применению набора.
[0504] Набор реагентов #3 включает очищенный препарат гиспидин-гидроксилазы настоящего изобретения и может быть использован для получения люциферина грибов из 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу ,
где R - арил или гетероарил. Например, набор может быть использован для получения 3-гидроксигиспидина из гиспидина.
[0505] Набор реагентов может также включать реакционный буфер. Например, 0.2 M натрий-фосфатный буфер (pH 8.0) с добавлением 0.5 M Na2SO4, 0.1% додецилмальтозида (DDM), 1 мМ НАДФН.
[0506] Набор реагентов может так же включать деионизованную воду.
[0507] Набор реагентов может также включать инструкцию по применению набора.
[0508] Наборы реагентов #4 и #5 отличатся от наборов #2 и #3 тем, что содержат очищенную люциферазу, субстратом которой является 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу ,
где R - арил или гетероарил.
[0509] Наборы могут быть использованы для выявления 3-арилакриловой кислоты со структурной формулой ,
где R - арил или гетероарил (например, из кофейной кислоты) и/или 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
,
где R - арил или гетероарил, (например, гиспидина) в биологических пробах, например, в растительных экстрактах, экстрактах грибов и в микроорганизмах.
[0510] Наборы реагентов могут также включать реакционный буфер (как описано в описании наборов 2 и 3) для осуществления реакции или компоненты для приготовления реакционного буфера.
[0511] Набор реагентов может так же включать деионизованную воду.
[0512] Набор реагентов может также включать инструкцию по применению набора.
[0513] Набор реагентов может также включать кофейную кислоту. Например, водный раствор кофейной кислоты или осадок для разведения в воде.
[0514] Набор реагентов может также включать гиспидин.
[0515] Способы применения наборов
[0516] Для определения присутствия кофейной кислоты в исследуемом образце в кювету следует добавить 5 мкл смеси ферментов к 95 мкл размороженного на льду реакционного буфера, аккуратно перемешать, добавить 5 мкл анализируемого образца, снова аккуратно перемешать и поместить в люминометр. Интегрировать биолюминесцентный сигнал в течение двух минут в температурных условиях, не превышающих 30°C. В таких же условиях провести контрольные измерения с добавлением вместо аликвоты анализируемого образца 5 мкл раствора кофейной кислоты или 5 мкл воды. О наличии кофейной кислоты в образце в детектируемых количествах можно говорить, если свет, излучаемый анализируемым образцом, превышает фоновый сигнал, зарегистрированный от образца с водой.
[0517] Чувствительность: набор позволяет определить наличие в среде кофейной кислоты в концентрации, превышающей 1 нМ.
[0518] Условия хранения: все компоненты набора следует хранить при температуре, не превышающей -20°С.
[0519] Для определения присутствия гиспидина в исследуемом образце в кювету следует добавить 5 мкл смеси ферментов к 95 мкл размороженного на льду реакционного буфера, аккуратно перемешать, добавить 5 мкл анализируемого образца, снова аккуратно перемешать и поместить в люминометр. Интегрировать биолюминесцентный сигнал в течение двух минут в температурных условиях, не превышающих 30°C. В таких же условиях провести контрольные измерения с добавлением вместо аликвоты анализируемого образца 5 мкл раствора гиспидина или 5 мкл воды. О наличии гиспидина в образце в детектируемых количествах можно говорить, если свет, излучаемый анализируемым образцом, превышает фоновый сигнал, зарегистрированный от образца с водой.
[0520] Чувствительность: набор позволяет определить наличие в среде гиспидина в концентрации, превышающей 100 пМ.
[0521] Условия хранения: все компоненты набора следует хранить при температуре, не превышающей -20°С.
[0522] Набор реагентов #6 включает нуклеиновую кислоту, кодирующую гиспидин-гидроксилазу настоящего изобретения. Например, гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28.
[0523] Набор реагентов может также содержать инструкцию по применению нуклеиновой кислоты.
[0524] Набор реагентов может также содержать деионизованную воду или буфер для растворения лиофилизированной нуклеиновой кислоты и/или разведения раствора нуклеиновой кислоты.
[0525] Набор реагентов может также содержать праймеры, комплементарные участкам указанной нуклеиновой кислоты, для амплификации нуклеиновой кислоты или ее фрагмента.
[0526] Набор реагентов может быть использован для получения рекомбинантной гиспидин-гидроксилазы настоящего изобретения или для экспрессии гиспидин-гидроксилазы в клетках и/или клеточных линиях и/или организмах. После экспрессии нуклеиновой кислоты в клетках, клеточных линиях и/или организмах эти клетки, клеточные линии и/или организмы приобретают способность катализировать реакцию превращения экзогенного или эндогенного 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-она, имеющего структурную формулу
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу ,
где R - арил или гетероарил. Например, они приобретают способность катализировать реакцию превращения гиспидина в 3-гидроксигиспидин.
[0527] Набор реагентов #7 включает нуклеиновую кислоту, кодирующую гиспидин-синтазу настоящего изобретения. Например, гиспидин-синтазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55.
[0528] Набор реагентов может также содержать инструкцию по применению нуклеиновой кислоты.
[0529] Набор реагентов может также содержать деионизованную воду или буфер для растворения лиофилизированной нуклеиновой кислоты и/или разведения раствора нуклеиновой кислоты.
[0530] Набор реагентов может также содержать праймеры, комплементарные участкам указанной нуклеиновой кислоты, для амплификации нуклеиновой кислоты или ее фрагмента.
[0531] Набор реагентов может также содержать нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу, например, 4'-фосфопантотеинил трансферазу, имеющую аминокислотную последовательность, показанную в SEQ ID NO 105.
[0532] Набор реагентов может быть использован для получения рекомбинантной гиспидин-синтазы настоящего изобретения или для экспрессии гиспидин-гидроксилазы в клетках и/или клеточных линиях и/или организмах.
[0533] После экспрессии нуклеиновой кислоты в клетках, клеточных линиях и/или организмах эти клетки, клеточные линии и/или организмы приобретают способность катализировать реакцию превращения 3-арилакриловой кислоты со структурной формулой
[0534] ,
где R - арил или гетероарил, в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющих структурную формулу
.
[0535] Например, они приобретают способность катализировать реакцию превращения кофейной кислоты в гиспидин и/или коричной кислоты в (Е)-4-гидрокси-6-стирил-2Н-пиран-2-он и/или паракумаровой кислоты в бисноръянгонин и/или (E)-3-(6-гидроксинафталин-2-ил)пропеновой кислоты в (Е)-4-гидрокси-6-(2-(6-гидроксинафталин-2-ил)винил)-2Н-пиран-2-он и/или (Е)-3-(1Н-индол-3-ил)пропеновой кислоты в (Е)-6-(2-(1Н-индол-3-ил)винил)-4-гидрокси-2Н-пиран-2-он.
[0536] Набор реагентов может также содержать нуклеиновые кислоты, кодирующие тирозин-аммоний-лиазу и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы. В этом составе набор может быть использован для получения гиспидина из тирозина в системах экспрессии in vitro и in vivo.
[0537] Набор реагентов #8 включает нуклеиновую кислоту, кодирующую гиспидин-синтазу настоящего изобретения и нуклеиновую кислоту, кодирующую гиспидин-гидроксилазу настоящего изобретения. Например, гиспидин-синтазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55 и гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28.
[0538] Набор реагентов может также содержать инструкцию по применению нуклеиновых кислот.
[0539] Набор реагентов может также содержать деионизованную воду или буфер для растворения лиофилизированной нуклеиновой кислоты и/или разведения раствора нуклеиновой кислоты.
[0540] Набор реагентов может также содержать праймеры, комплементарные участкам входящих в набор нуклеиновых кислот, для амплификации этих нуклеиновых кислот или их фрагментов.
[0541] Набор реагентов может также содержать нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу, например, 4'-фосфопантотеинил трансферазу, имеющую аминокислотную последовательность, показанную в SEQ ID NO 105.
[0542] Набор реагентов может также содержать нуклеиновые кислоты, кодирующие ферменты биосинтеза 3-арилакриловой кислоты из метаболитов клетки, например, кодирующие тирозин-аммоний-лиазу и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы.
[0543] Набор может быть использован для любого применения, описанного для наборов 6 и 7. Набор также может быть использован для экспрессии гиспидин-гидроксилазы и гиспидин-синтазы в клетках и/или клеточных линиях и/или организмах. После экспрессии нуклеиновой кислоты в клетках, клеточных линиях и/или организмах эти клетки, клеточные линии и/или организмы приобретают способность производить 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу ,
где R - арил или гетероарил, из соответствующей 3-арилакриловой кислоты со структурной формулой
.
[0544] Набор также может быть использован для экспрессии в клетках и/или клеточных линиях и/или организмах гиспидин-гидроксилазы, гиспидин- синтазы вместе с тирозин-аммоний-лиазой и компонентами HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы. После экспрессии нуклеиновой кислоты в клетках, клеточных линиях и/или организмах эти клетки, клеточные линии и/или организмы приобретают способность производить гиспидин из тирозина и метаболитов клетки.
[0545] Набор реагентов #9 включает нуклеиновую кислоту, кодирующую гиспидин-гидроксилазу настоящего изобретения. Например, гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28 и нуклеиновую кислоту, кодирующую люциферазу, способную окислять с выделением света по крайней мере один из люциферинов грибов. Например, может быть использована люцифераза, аминокислотная последовательность которой выбрана из в SEQ ID NOs: 80, 82, 84, 86, 88, 90, 92, 94, 96, 98.
[0546] Набор реагентов может также содержать инструкцию по применению нуклеиновых кислот.
[0547] Набор реагентов может также содержать деионизованную воду или буфер для растворения лиофилизированной нуклеиновой кислоты и/или разведения раствора нуклеиновой кислоты.
[0548] Набор реагентов может также содержать праймеры, комплементарные участкам входящих в набор нуклеиновых кислот, для амплификации этих нуклеиновых кислот или их фрагментов.
[0549] Набор может быть использован для мечения клеток и/или клеточных линий и/или организмов, где указанные клетки, клеточные линии и/или организмы эти клетки, клеточные линии и/или организмы приобретают в результате экспрессии указанных нуклеиновых кислот способность к биолюминесценции в присутствии экзогенного или эндогенного предлюциферина грибов. Например, они приобретают способность к биолюминесценции в присутствии гиспидина.
[0550] Набор может быть также использован для исследования ко-активации промоторов целевых генов.
[0551] Набор может также включать нуклеиновую кислоту, кодирующую гиспидин-синтазу настоящего изобретения, например, гиспидин-синтазу, аминокислотная последовательность которой выбрана из группы SEQ ID NO: 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55. В этом случае набор может быть использован для получения клеток, клеточных линий и трансгенных организмов, способных к биолюминесценции в присутствии экзогенной или эндогенной 3-арилакриловой кислоты со структурной формулой
[0552]
где R - арил или гетероарил. Например, в присутствии 3-арилакриловой кислоты, выбранной из группы: кофейная кислота, или коричная кислота, или пара-кумаровая кислота, или кумаровая кислота, или умбеллиновая кислота, или синаповая кислота, или феруловая кислота. В частности, набор может быть использован для получения автономно биолюминесцирующих трансгенных организмов, например, растений или грибов.
[0553] Набор может также включать нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу, например, 4'-фосфопантотеинил трансферазу, имеющую аминокислотную последовательность, показанную в SEQ ID NO 105 или ей подобную.
[0554] Набор может так же содержать нуклеиновые кислоты, кодирующие ферменты биосинтеза 3-арилакриловой кислоты из метаболитов клетки.
[0555] Набор может так же содержать нуклеиновую кислоту, кодирующую кофеилпируват-гидролазу настоящего изобретения, например, кофеилпируват-гидролазу, аминокислотная последовательность которой выбрана из группы SEQ ID NO: 65, 67, 69, 71, 73, 75.
[0556] Набор может быть также использован для любого применения, описанного для наборов #6-#8.
[0557] Набор может быть также использован для создания клеточных линий, позволяющих определить наличие кофейной кислоты в исследуемом образце.
[0558] Набор реагентов #10 включает клетки Agrobacterium tumefaciens штамма AGL0, несущие плазмиду, содержащую кодирующие последовательности гиспидин-синтазы, гиспидин-гидроксилазы, люциферазы, фосфопантотеинил-трансферазы NpgA и гена устойчивости к антибиотику (например, к канамицину) под контролем подходящего промотора, например, промотора 35S вируса мозаики цветной капусты.
[0559] Набор реагентов может так же включать праймеры для определения корректности интеграции кассеты экспрессии в клетки двудольных цветковых растений.
[0560] Набор реагентов может быть использован для получения автономно биолюминесцентных двудольных растений.
[0561] Набор реагентов может так же включать инструкцию по применению набора.
[0562] Способ применения: Произвести трансформацию двудольного растения клетками агробактерий из набора по протоколу, оптимально подходящему для данного вида растения. Селекцию растений проводить на среде с антибиотиком (например, канамицином). Корректность полноразмерной интеграции кассеты экспрессии произвести с помощью ПЦР с праймерами из набора.
[0563] Условия хранения: компетентные клетки агробактерий следует хранить при температуре, не превышающей -70°С, допускается хранение раствора кофейной кислоты при температурах, не превышающих -20°С.
[0564] Набор реагентов #11
[0565] Набор включает очищенный препарат PKS и очищенный препарат гиспидин-гидроксилазы настоящего изобретения и может быть использован для получения люциферина грибов из кофеил-КоА. Набор реагентов может так же включать реакционный буфер: 0.2 M натрий-фосфатный буфер (pH 8.0) с добавлением 0.5 M Na2SO4, 0.1% додецилмальтозид (DDM), 1 мМ НАДФН, 10 мМ АТФ, 1 мМ Малонил-КоА или компоненты для приготовления реакционного буфера. Набор реагентов может так же включать деионизованную воду. Набор реагентов может так же включать инструкцию по применению набора.
[0566] Набор реагентов #12
[0567] Набор включает нуклеиновую кислоту, кодирующую PKS и нуклеиновую кислоту, кодирующую гиспидин-гидроксилазу настоящего изобретения. Например, PKS, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 119, 121, 123, 125, 127, 129, 131, 133, 135, 137, 139 и гиспидин-гидроксилазу, аминокислотная последовательность которой выбрана из группы SEQ ID NOs: 2, 4, 6, 8 10, 12, 14, 16, 18, 20, 22, 24, 26, 28.
[0568] Набор реагентов может также содержать инструкцию по применению нуклеиновых кислот.Набор реагентов может также содержать деионизованную воду или буфер для растворения лиофилизированной нуклеиновой кислоты и/или разведения раствора нуклеиновой кислоты. Набор реагентов может также содержать праймеры, комплементарные участкам входящих в набор нуклеиновых кислот, для амплификации этих нуклеиновых кислот или их фрагментов.
[0569] Набор реагентов может также содержать нуклеиновую кислоту, кодирующую кумарат-КоА-лигазу, например, кумарат-КоА-лигазы, имеющую аминокислотную последовательность, показанную в SEQ ID NO 141.
[0570] Набор реагентов может также содержать нуклеиновые кислоты, кодирующие ферменты биосинтеза кофейной кислоты из метаболитов клетки, например, кодирующие тирозин-аммоний-лиазу и компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы. Набор реагентов может также содержать нуклеиновую кислоту, кодирующую кофеилпируват-гидролазу настоящего изобретения.
[0571] Набор реагентов может быть использован для экспрессии гиспидин-гидроксилазы и PKS в клетках и/или клеточных линиях и/или организмах. После экспрессии нуклеиновой кислоты в клетках, клеточных линиях и/или организмах эти клетки, клеточные линии и/или организмы приобретают способность производить 3-гидроксигиспидин из кофейной кислоты. Набор также может быть использован для экспрессии в клетках и/или клеточных линиях и/или организмах гиспидин-гидроксилазы, PKS вместе с кумарат-КоА-лигазой, кофеил-пируватгидролазой и/или комбинацией тирозин-аммоний-лиазы и компонентов HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы. После экспрессии нуклеиновых кислот в клетках, клеточных линиях и/или организмах эти клетки, клеточные линии и/или организмы приобретают способность производить 3-гидроксигиспидин из тирозина и метаболитов клетки.
[0572] Набор может также содержать нуклеиновую кислоту, кодирующую люциферазу, способную окислять 3-гидроксигиспидин с выделением света. В этом случае набор может быть использован для мечения клеток и/или клеточных линий и/или организмов, где указанные клетки, клеточные линии и/или организмы эти клетки, клеточные линии и/или организмы приобретают в результате экспрессии указанных нуклеиновых кислот способность к биолюминесценции в присутствии экзогенного или эндогенного гиспидина и/или кофеил-КоА и/или кофейной кислоты. Например, клетки, клеточные линии и/или организмы приобретают способность к автономной биолюминесценции.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Общество с ограниченной ответственностью «Планта»
<120> Кофеилпируват-гидролазы и их применение
<130> 424509
<160> 141
<170> PatentIn version 3.5
<210> 1
<211> 1266
<212> DNA
<213> Neonothopanus nambi
<400> 1
atggcatcgt ttgagaattc tctaagcgtt ttgattgtcg gggccggact tggtgggctt 60
gctgctgcca tcgcgctgcg tcgccaaggg catgtcgtga aaatatacga ctcctctagc 120
ttcaaagccg aacttggtgc gggactcgct gtgccgccta acaccttgcg cagtctacag 180
caacttggtt gcaataccga gaacctcaat ggtgtggata atctttgctt cactgcgatg 240
gggtatgacg ggagtgtagg gatgatgaac aacatgactg actatcgaga ggcatacggt 300
acttcttgga tcatggtcca ccgcgttgac ttgcataacg agctgatgcg cgtagcactt 360
gatccaggtg ggctcggacc tcctgcgaca ctccatctta atcatcgtgt cacattctgc 420
gatgtcgacg cttgcaccgt gacattcacc aacgggacca ctcaatcagc tgatctcatc 480
gttggtgcag acggtatacg ctctaccatt cggcggtttg tcttagaaga agacgtgact 540
gtgcctgcgt caggaatcgt cgggtttcga tggcttgtac aagctgacgc gctggaccca 600
tatcctgaac tcgactggat tgttaaaaag cctcctctag gcgcgcgact gatctccact 660
cctcagaatc cacagtctgg tgttggcttg gctgacaggc gcactatcat catctacgca 720
tgtcgtggcg gcaccatggt caatgtcctt gcagtgcatg atgacgaacg tgaccagaac 780
accgcagatt ggagtgtacc ggcttccaaa gacgatctat ttcgtgtttt ccacgattac 840
catccacgct ttcggcggct tttagagctt gcgcaggata ttaatctctg gcaaatgcgt 900
gttgtacctg ttttgaaaaa atgggttaac aagcgggttt gcttgttagg agatgctgcg 960
cacgcttctt taccgacgtt gggtcaaggt tttggtatgg gtctggaaga tgccgtagca 1020
cttggtacac tccttccaaa gggtaccact gcatctcaga tcgagactcg acttgcggtg 1080
tacgaacagc tacgtaagga tcgtgcggaa tttgttgcgg ctgaatcata tgaagagcaa 1140
tatgttcctg aaatgcgggg actttatctg aggtcaaagg aactgcgtga tagagtcatg 1200
ggttatgata tcaaagtgga gagcgagaag gttctcgaga cgctcctaag aagttctaat 1260
tctgcc 1266
<210> 2
<211> 422
<212> PRT
<213> Neonothopanus nambi
<400> 2
Met Ala Ser Phe Glu Asn Ser Leu Ser Val Leu Ile Val Gly Ala Gly
1 5 10 15
Leu Gly Gly Leu Ala Ala Ala Ile Ala Leu Arg Arg Gln Gly His Val
20 25 30
Val Lys Ile Tyr Asp Ser Ser Ser Phe Lys Ala Glu Leu Gly Ala Gly
35 40 45
Leu Ala Val Pro Pro Asn Thr Leu Arg Ser Leu Gln Gln Leu Gly Cys
50 55 60
Asn Thr Glu Asn Leu Asn Gly Val Asp Asn Leu Cys Phe Thr Ala Met
65 70 75 80
Gly Tyr Asp Gly Ser Val Gly Met Met Asn Asn Met Thr Asp Tyr Arg
85 90 95
Glu Ala Tyr Gly Thr Ser Trp Ile Met Val His Arg Val Asp Leu His
100 105 110
Asn Glu Leu Met Arg Val Ala Leu Asp Pro Gly Gly Leu Gly Pro Pro
115 120 125
Ala Thr Leu His Leu Asn His Arg Val Thr Phe Cys Asp Val Asp Ala
130 135 140
Cys Thr Val Thr Phe Thr Asn Gly Thr Thr Gln Ser Ala Asp Leu Ile
145 150 155 160
Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Arg Phe Val Leu Glu
165 170 175
Glu Asp Val Thr Val Pro Ala Ser Gly Ile Val Gly Phe Arg Trp Leu
180 185 190
Val Gln Ala Asp Ala Leu Asp Pro Tyr Pro Glu Leu Asp Trp Ile Val
195 200 205
Lys Lys Pro Pro Leu Gly Ala Arg Leu Ile Ser Thr Pro Gln Asn Pro
210 215 220
Gln Ser Gly Val Gly Leu Ala Asp Arg Arg Thr Ile Ile Ile Tyr Ala
225 230 235 240
Cys Arg Gly Gly Thr Met Val Asn Val Leu Ala Val His Asp Asp Glu
245 250 255
Arg Asp Gln Asn Thr Ala Asp Trp Ser Val Pro Ala Ser Lys Asp Asp
260 265 270
Leu Phe Arg Val Phe His Asp Tyr His Pro Arg Phe Arg Arg Leu Leu
275 280 285
Glu Leu Ala Gln Asp Ile Asn Leu Trp Gln Met Arg Val Val Pro Val
290 295 300
Leu Lys Lys Trp Val Asn Lys Arg Val Cys Leu Leu Gly Asp Ala Ala
305 310 315 320
His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly Leu Glu
325 330 335
Asp Ala Val Ala Leu Gly Thr Leu Leu Pro Lys Gly Thr Thr Ala Ser
340 345 350
Gln Ile Glu Thr Arg Leu Ala Val Tyr Glu Gln Leu Arg Lys Asp Arg
355 360 365
Ala Glu Phe Val Ala Ala Glu Ser Tyr Glu Glu Gln Tyr Val Pro Glu
370 375 380
Met Arg Gly Leu Tyr Leu Arg Ser Lys Glu Leu Arg Asp Arg Val Met
385 390 395 400
Gly Tyr Asp Ile Lys Val Glu Ser Glu Lys Val Leu Glu Thr Leu Leu
405 410 415
Arg Ser Ser Asn Ser Ala
420
<210> 3
<211> 1620
<212> DNA
<213> Omphalotus olearius
<400> 3
atgacgccct ccgagagtcc tttgaatatc tcgattgttg gtgctgggct cggggggctt 60
gctgcagcta ttgcgctgcg tcgtcaaggt catatcatca gaatcttcga ctcgtcaagt 120
tttaaaacgg aactgggtgc tggacttgct gttccaccca atacattacg cagtcttcag 180
gaacttggct gtgatattca gaacttcaat gccgtggaca atctttgttt caccgcgatg 240
ggctacgacg ggagtgtagg gatgatgaac aatatgactg actatcgtga ggcgtatggt 300
gttccctggg tcatggtcca ccgcgttgac ctacataatg aactgcgacg tgtggcactc 360
gatccagatg gccttggacc tcctgcagca ttgcacctca atcatcgtgt gacatcctgc 420
gatgtcgatt cctgcaccgt cacattcgct aacggaaccg ctcatacagc ggatctcatc 480
gttggcgcgg atggtatacg ctcttccatc cgacccttcg tgttgggaga agacgtaatc 540
gtacctgcaa caggaatcgc aggatttcga tggctcatac aagccgaccg gctagatgcg 600
tatcctgaac tcgactggat tgtcaagaac cctcctctcg gcgcgcgatt gatttctgct 660
ccggctcgga aggaacgttc tgtaatcagc gaagcccggc ctgatcgacg tacgattata 720
ttatatgcgt gtcgtggtgg tactattgtc aatgtccttg cggtgcacga cgacgaacgt 780
gatcaggaca ccgtagaatg gagcgtgcca gctaccaaag acgacctatt tcgcgttttc 840
aacgattatc acccaagatt tcggcgactt ctggacctgg cggaggatgt taatctctgg 900
cagatgcgtg ttgtgcctgt tttgagacga tgggttaata aacgggtttg cttgctggga 960
gatgcagcac atgcttcttt accgacattg ggtcaaggtt ttggtatggg tctcgaggat 1020
gcggtggcac ttggtacgct tcttccgagc gggactactg tgtcacagat tgaaatccga 1080
ctttgggtgt atgaaaaact gcgcaaggag cgtgctgaat ttgtttcggc tgaatcgtat 1140
gaagaacact gctctgtgga ttgctataaa tctcataaag cccagtcgac atccaataca 1200
gtgacagaag cagacgacat cttggaagaa ccaaagcctc tgaagccttt atcgtctctg 1260
aaatggccgt acgttcccga agaaccttcg tatcctgatc ccctccaaag aaacgacccc 1320
aaacccctac aactcagaca ctacgaagca atagctacat ctcctgcagt acgggaggtc 1380
ctatcgagtc atccgaatct ccctgcttta ttgacgtcta tcgacaaact gagaggtttt 1440
gatcgcgaac gagctttaga aaaggcgttg gaggttactg cgcctgcgct tgttgatgat 1500
tcaagggctg tagcgctgga ggacgatgta ctcgcaatga gagcattggt agaagcgatt 1560
gaaggtgctg ttaggggcaa taaagaagac gcattaggtc tggattggac tggtagtact 1620
<210> 4
<211> 540
<212> PRT
<213> Omphalotus olearius
<400> 4
Met Thr Pro Ser Glu Ser Pro Leu Asn Ile Ser Ile Val Gly Ala Gly
1 5 10 15
Leu Gly Gly Leu Ala Ala Ala Ile Ala Leu Arg Arg Gln Gly His Ile
20 25 30
Ile Arg Ile Phe Asp Ser Ser Ser Phe Lys Thr Glu Leu Gly Ala Gly
35 40 45
Leu Ala Val Pro Pro Asn Thr Leu Arg Ser Leu Gln Glu Leu Gly Cys
50 55 60
Asp Ile Gln Asn Phe Asn Ala Val Asp Asn Leu Cys Phe Thr Ala Met
65 70 75 80
Gly Tyr Asp Gly Ser Val Gly Met Met Asn Asn Met Thr Asp Tyr Arg
85 90 95
Glu Ala Tyr Gly Val Pro Trp Val Met Val His Arg Val Asp Leu His
100 105 110
Asn Glu Leu Arg Arg Val Ala Leu Asp Pro Asp Gly Leu Gly Pro Pro
115 120 125
Ala Ala Leu His Leu Asn His Arg Val Thr Ser Cys Asp Val Asp Ser
130 135 140
Cys Thr Val Thr Phe Ala Asn Gly Thr Ala His Thr Ala Asp Leu Ile
145 150 155 160
Val Gly Ala Asp Gly Ile Arg Ser Ser Ile Arg Pro Phe Val Leu Gly
165 170 175
Glu Asp Val Ile Val Pro Ala Thr Gly Ile Ala Gly Phe Arg Trp Leu
180 185 190
Ile Gln Ala Asp Arg Leu Asp Ala Tyr Pro Glu Leu Asp Trp Ile Val
195 200 205
Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Ser Ala Pro Ala Arg Lys
210 215 220
Glu Arg Ser Val Ile Ser Glu Ala Arg Pro Asp Arg Arg Thr Ile Ile
225 230 235 240
Leu Tyr Ala Cys Arg Gly Gly Thr Ile Val Asn Val Leu Ala Val His
245 250 255
Asp Asp Glu Arg Asp Gln Asp Thr Val Glu Trp Ser Val Pro Ala Thr
260 265 270
Lys Asp Asp Leu Phe Arg Val Phe Asn Asp Tyr His Pro Arg Phe Arg
275 280 285
Arg Leu Leu Asp Leu Ala Glu Asp Val Asn Leu Trp Gln Met Arg Val
290 295 300
Val Pro Val Leu Arg Arg Trp Val Asn Lys Arg Val Cys Leu Leu Gly
305 310 315 320
Asp Ala Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met
325 330 335
Gly Leu Glu Asp Ala Val Ala Leu Gly Thr Leu Leu Pro Ser Gly Thr
340 345 350
Thr Val Ser Gln Ile Glu Ile Arg Leu Trp Val Tyr Glu Lys Leu Arg
355 360 365
Lys Glu Arg Ala Glu Phe Val Ser Ala Glu Ser Tyr Glu Glu His Cys
370 375 380
Ser Val Asp Cys Tyr Lys Ser His Lys Ala Gln Ser Thr Ser Asn Thr
385 390 395 400
Val Thr Glu Ala Asp Asp Ile Leu Glu Glu Pro Lys Pro Leu Lys Pro
405 410 415
Leu Ser Ser Leu Lys Trp Pro Tyr Val Pro Glu Glu Pro Ser Tyr Pro
420 425 430
Asp Pro Leu Gln Arg Asn Asp Pro Lys Pro Leu Gln Leu Arg His Tyr
435 440 445
Glu Ala Ile Ala Thr Ser Pro Ala Val Arg Glu Val Leu Ser Ser His
450 455 460
Pro Asn Leu Pro Ala Leu Leu Thr Ser Ile Asp Lys Leu Arg Gly Phe
465 470 475 480
Asp Arg Glu Arg Ala Leu Glu Lys Ala Leu Glu Val Thr Ala Pro Ala
485 490 495
Leu Val Asp Asp Ser Arg Ala Val Ala Leu Glu Asp Asp Val Leu Ala
500 505 510
Met Arg Ala Leu Val Glu Ala Ile Glu Gly Ala Val Arg Gly Asn Lys
515 520 525
Glu Asp Ala Leu Gly Leu Asp Trp Thr Gly Ser Thr
530 535 540
<210> 5
<211> 1329
<212> DNA
<213> Guyanagaster necrorhiza
<400> 5
atgcaacaaa tcgacgaagt gtgcccattg aaagtgatcg ttgtaggtgc tggacttggg 60
ggcctttctg ctgccattgc ccttcgtagg caaggccatt gtgtccatat actggaatcg 120
tcaagtttca agagcgaact tggcgcaggt ctcgcagtac cgcccaatac tgtacgctca 180
cttcgaggcc taggctgtaa catcgacaat ctcaagcctg tggataatct ttgtttcact 240
gccatggcgc atgacggaag tcctggtatg atgaataaca tgacggacta tggccaggcg 300
tatggagatc cttgggtaat ggcgcatcgt gttgaccttc acaatgagct catgcgagtg 360
gcccttgaac ccgaaaaaac gggacctcct gcccagcttc gtctggacag ccaggtggca 420
tcttgcaatg tagatgcctg taccgtttct cttgtcgacg gaacaattta ttccgctgat 480
cttatcgttg gtgcagacgg aattaggtct accatacgct cctatgtttt ggacgcagaa 540
atagacatac ctcctaccgg tatcgctgga taccgttggc tcacacctgc agaagctttg 600
gagccatatc ccgaactcga ctggatcatc aagaacccac ccctaggagc acgtttaatc 660
acagctcctg tacgccgaaa cgacagcatt gagcagtcgg gtcctgctcc tatttctgag 720
aaggctgaca agcgtacgat catcatctac gcgtgccgga atggtactat gcttaacgtt 780
ctcggtgtac acgatgaccc tcgcaaccag aacgaagttg gatggaacgt gccagttacc 840
caagaaagtt tgctggattt ttttaaagac tatcatcccc gattcaagcg tctgcttgag 900
ctggctgaca atgttcatct gtggcaaatg cgcgtcgtcc cgcggcttga gacttggatc 960
aataaacgcg tgtgtttgtt gggcgattct gcgcatgcat cattaccaac actcggtcaa 1020
ggcttcggga tgggacttga ggatgccgta gcccttgcaa ccctccttcc gatgggaacc 1080
aaagtgtctg acatcgagaa ccgcctcgtc gcctacgaaa gcttgcgtaa ggggcgcgct 1140
gagtatgtgg ccatggaatc gttcgaacaa cagaatatcc cggaaaagcg aggcttgtat 1200
ctcaggtctt ctatgatgcg tgacgaaatc atgggttatg atgtcaaagc cgaggctgag 1260
aaggttttta aagaattaat gacctcgact gataaggtta cataccgtcc ccatgtggac 1320
tgtctatgg 1329
<210> 6
<211> 443
<212> PRT
<213> Guyanagaster necrorhiza
<400> 6
Met Gln Gln Ile Asp Glu Val Cys Pro Leu Lys Val Ile Val Val Gly
1 5 10 15
Ala Gly Leu Gly Gly Leu Ser Ala Ala Ile Ala Leu Arg Arg Gln Gly
20 25 30
His Cys Val His Ile Leu Glu Ser Ser Ser Phe Lys Ser Glu Leu Gly
35 40 45
Ala Gly Leu Ala Val Pro Pro Asn Thr Val Arg Ser Leu Arg Gly Leu
50 55 60
Gly Cys Asn Ile Asp Asn Leu Lys Pro Val Asp Asn Leu Cys Phe Thr
65 70 75 80
Ala Met Ala His Asp Gly Ser Pro Gly Met Met Asn Asn Met Thr Asp
85 90 95
Tyr Gly Gln Ala Tyr Gly Asp Pro Trp Val Met Ala His Arg Val Asp
100 105 110
Leu His Asn Glu Leu Met Arg Val Ala Leu Glu Pro Glu Lys Thr Gly
115 120 125
Pro Pro Ala Gln Leu Arg Leu Asp Ser Gln Val Ala Ser Cys Asn Val
130 135 140
Asp Ala Cys Thr Val Ser Leu Val Asp Gly Thr Ile Tyr Ser Ala Asp
145 150 155 160
Leu Ile Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Ser Tyr Val
165 170 175
Leu Asp Ala Glu Ile Asp Ile Pro Pro Thr Gly Ile Ala Gly Tyr Arg
180 185 190
Trp Leu Thr Pro Ala Glu Ala Leu Glu Pro Tyr Pro Glu Leu Asp Trp
195 200 205
Ile Ile Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Thr Ala Pro Val
210 215 220
Arg Arg Asn Asp Ser Ile Glu Gln Ser Gly Pro Ala Pro Ile Ser Glu
225 230 235 240
Lys Ala Asp Lys Arg Thr Ile Ile Ile Tyr Ala Cys Arg Asn Gly Thr
245 250 255
Met Leu Asn Val Leu Gly Val His Asp Asp Pro Arg Asn Gln Asn Glu
260 265 270
Val Gly Trp Asn Val Pro Val Thr Gln Glu Ser Leu Leu Asp Phe Phe
275 280 285
Lys Asp Tyr His Pro Arg Phe Lys Arg Leu Leu Glu Leu Ala Asp Asn
290 295 300
Val His Leu Trp Gln Met Arg Val Val Pro Arg Leu Glu Thr Trp Ile
305 310 315 320
Asn Lys Arg Val Cys Leu Leu Gly Asp Ser Ala His Ala Ser Leu Pro
325 330 335
Thr Leu Gly Gln Gly Phe Gly Met Gly Leu Glu Asp Ala Val Ala Leu
340 345 350
Ala Thr Leu Leu Pro Met Gly Thr Lys Val Ser Asp Ile Glu Asn Arg
355 360 365
Leu Val Ala Tyr Glu Ser Leu Arg Lys Gly Arg Ala Glu Tyr Val Ala
370 375 380
Met Glu Ser Phe Glu Gln Gln Asn Ile Pro Glu Lys Arg Gly Leu Tyr
385 390 395 400
Leu Arg Ser Ser Met Met Arg Asp Glu Ile Met Gly Tyr Asp Val Lys
405 410 415
Ala Glu Ala Glu Lys Val Phe Lys Glu Leu Met Thr Ser Thr Asp Lys
420 425 430
Val Thr Tyr Arg Pro His Val Asp Cys Leu Trp
435 440
<210> 7
<211> 1284
<212> DNA
<213> Panellus stipticus
<400> 7
atgtcacaag gcactgaaga ctcgccctca ctcttcgcaa tagttgtcgg tgctggtctg 60
gtcggctttg ccgctgccgt cgcgctgcgc cgtcaaggtc accgtgtcac gatctacgaa 120
tcttcaagct ttaagacaga acttggggcg ggcctcgcga tcccttcaaa cacattgcga 180
tgcttggttg gccttggatg tactgtcgcc aacatggatc ccgtcaataa tctttgtttt 240
acatcgatgg catacgatgg taccgcgggg atgaaaagcg acagctccga ctacgaggcg 300
cagtatggca ctccctggat catggcccac cgcgtcgatc tgcacaagga gcttcgtcgc 360
ctggcagtgg atcccgaggg caccggtccc cccgcagaac tgcaccttag ccaccgggtt 420
gtctcctgcg acgtcgaatc cggctccgtc acgctcctgg acggctccgt tcagtcagca 480
gacttgataa ttggggctga tggaattcgt tcaaccgttc gcaaatttgt cgtaggcgaa 540
gaaatagcaa tccccccatc tcgtacggcg ggcttccgct ggctcacaca agcaagcgct 600
cttgacccct accccgaact ggattggatc gtgaaaacgc cgccgttggg tgctcgggta 660
atctccgctc cgattcaacc tccagaagtc acccacatcg accaccgtac gatcgtcatc 720
tatgcctgtc gcggaggtcg tctcgtaaat gttctaggaa tacatgagga tctgcgcgac 780
caggattctg tcgactggaa cgtccccata acgcgagaag cgctgctcca ctttttcgga 840
gactaccacc cacggttcaa gcggctcttg gagctcgcgg aggacgtaca cgtctggcag 900
atgcgcgtgg tccccccact gccgacatgg gtgaacggcc gcgtatgcat catgggcgac 960
gcagcgcatg catcgcttcc cacactggga caagggtttg gcatgggcct cgaagacgcg 1020
gtcgcgctcg ggacgctgct ttctagttcg acgccgtcaa gcgacattcc aagccgtctc 1080
gtcgcgtacg agaagcttcg caaagcgcgc gctgagtatg tttccaaaga gtcgtacgaa 1140
cagcagcatg tccgagaaaa gagagggctg tatctccggt cccgagaaat gcgggatgtg 1200
atcatgggat acgacgtgaa gaaggaggca gaacggatct tgagcgagat cagcattgca 1260
caagaacagt gtgctgttca tgat 1284
<210> 8
<211> 428
<212> PRT
<213> Panellus stipticus
<400> 8
Met Ser Gln Gly Thr Glu Asp Ser Pro Ser Leu Phe Ala Ile Val Val
1 5 10 15
Gly Ala Gly Leu Val Gly Phe Ala Ala Ala Val Ala Leu Arg Arg Gln
20 25 30
Gly His Arg Val Thr Ile Tyr Glu Ser Ser Ser Phe Lys Thr Glu Leu
35 40 45
Gly Ala Gly Leu Ala Ile Pro Ser Asn Thr Leu Arg Cys Leu Val Gly
50 55 60
Leu Gly Cys Thr Val Ala Asn Met Asp Pro Val Asn Asn Leu Cys Phe
65 70 75 80
Thr Ser Met Ala Tyr Asp Gly Thr Ala Gly Met Lys Ser Asp Ser Ser
85 90 95
Asp Tyr Glu Ala Gln Tyr Gly Thr Pro Trp Ile Met Ala His Arg Val
100 105 110
Asp Leu His Lys Glu Leu Arg Arg Leu Ala Val Asp Pro Glu Gly Thr
115 120 125
Gly Pro Pro Ala Glu Leu His Leu Ser His Arg Val Val Ser Cys Asp
130 135 140
Val Glu Ser Gly Ser Val Thr Leu Leu Asp Gly Ser Val Gln Ser Ala
145 150 155 160
Asp Leu Ile Ile Gly Ala Asp Gly Ile Arg Ser Thr Val Arg Lys Phe
165 170 175
Val Val Gly Glu Glu Ile Ala Ile Pro Pro Ser Arg Thr Ala Gly Phe
180 185 190
Arg Trp Leu Thr Gln Ala Ser Ala Leu Asp Pro Tyr Pro Glu Leu Asp
195 200 205
Trp Ile Val Lys Thr Pro Pro Leu Gly Ala Arg Val Ile Ser Ala Pro
210 215 220
Ile Gln Pro Pro Glu Val Thr His Ile Asp His Arg Thr Ile Val Ile
225 230 235 240
Tyr Ala Cys Arg Gly Gly Arg Leu Val Asn Val Leu Gly Ile His Glu
245 250 255
Asp Leu Arg Asp Gln Asp Ser Val Asp Trp Asn Val Pro Ile Thr Arg
260 265 270
Glu Ala Leu Leu His Phe Phe Gly Asp Tyr His Pro Arg Phe Lys Arg
275 280 285
Leu Leu Glu Leu Ala Glu Asp Val His Val Trp Gln Met Arg Val Val
290 295 300
Pro Pro Leu Pro Thr Trp Val Asn Gly Arg Val Cys Ile Met Gly Asp
305 310 315 320
Ala Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly
325 330 335
Leu Glu Asp Ala Val Ala Leu Gly Thr Leu Leu Ser Ser Ser Thr Pro
340 345 350
Ser Ser Asp Ile Pro Ser Arg Leu Val Ala Tyr Glu Lys Leu Arg Lys
355 360 365
Ala Arg Ala Glu Tyr Val Ser Lys Glu Ser Tyr Glu Gln Gln His Val
370 375 380
Arg Glu Lys Arg Gly Leu Tyr Leu Arg Ser Arg Glu Met Arg Asp Val
385 390 395 400
Ile Met Gly Tyr Asp Val Lys Lys Glu Ala Glu Arg Ile Leu Ser Glu
405 410 415
Ile Ser Ile Ala Gln Glu Gln Cys Ala Val His Asp
420 425
<210> 9
<211> 1284
<212> DNA
<213> Panellus stipticus
<400> 9
atgtcacaag gcactgaaga ctcgccctca ctcttcgcaa tagttgtcgg tgctggtctg 60
gtcggctttg ccgctgccgt cgcgctgcgc cgtcaaggtc accgtgtcac gatctacgaa 120
tcttcaagct ttaagacaga acttggggcg ggcctcgcga tcccttcaaa cacattgcga 180
tgcttggttg gccttggatg tactgtcgcc aacatggatc ccgtcaataa tctttgtttt 240
acatcgatgg catacgatgg taccgcgggg atgaaaagcg acagctccga ctacgaggcg 300
cagtatggca ctccctggat catggcccac cgcgtcgatc tgcacaagga gcttcgtcgc 360
ctggcagtgg atcccgaggg caccggtccc cccgcagaac tgcaccttag ccaccgggtt 420
gtctcctgcg acgtcgaatc cggctccgtc acgctcctgg acggctccgt tcagtcagca 480
gacttgataa ttggggctga tggaattcgt tcaaccgttc gcaaatttgt cgtaggcgaa 540
gaaatagcaa tccccccatc tcgtacggcg ggcttccgct ggctcacaca agcaagcgct 600
cttgacccct accccgaact ggattggatc gtgaaaacgc cgccgttggg tgctcgggta 660
atctccgctc cgattcaacc tccagaagtc acccacatcg accaccgtac gatcgtcatc 720
tatgcctgtc gcggaggtcg tctcgtaaat gttctaggaa tacatgagga tctgcgcgac 780
caggattctg tcgactggaa cgtccccata acgcgagaag cgctgctcca ctttttcgga 840
gactaccacc cacggttcaa gcggctcttg gagctcgcgg aggacgtaca cgtctggcag 900
atgcgcgtgg tccccccact gccgacatgg gtgaacggcc gcgtatgcat catgggcgac 960
gcagcgcatg catcgcttcc cacactggga caagggtttg gcatgggcct cgaagacgcg 1020
gtcgcgctcg ggacgctgct tcctagttcg acgccgtcaa gcgacattcc aagccgtctc 1080
gtcgcgtacg agaagcttcg caaagcgcgc gctgagtatg tttccaaaga gtcgtacgaa 1140
cagcagcatg tccgagaaaa gagagggctg tatctccggt cccgagaaat gcgggatgtg 1200
atcatgggat acgacgtgaa gaaggaggca gaacggatct tgagcgagat cagcattgca 1260
caagaacagt gtgctgttca tgat 1284
<210> 10
<211> 428
<212> PRT
<213> Panellus stipticus
<400> 10
Met Ser Gln Gly Thr Glu Asp Ser Pro Ser Leu Phe Ala Ile Val Val
1 5 10 15
Gly Ala Gly Leu Val Gly Phe Ala Ala Ala Val Ala Leu Arg Arg Gln
20 25 30
Gly His Arg Val Thr Ile Tyr Glu Ser Ser Ser Phe Lys Thr Glu Leu
35 40 45
Gly Ala Gly Leu Ala Ile Pro Ser Asn Thr Leu Arg Cys Leu Val Gly
50 55 60
Leu Gly Cys Thr Val Ala Asn Met Asp Pro Val Asn Asn Leu Cys Phe
65 70 75 80
Thr Ser Met Ala Tyr Asp Gly Thr Ala Gly Met Lys Ser Asp Ser Ser
85 90 95
Asp Tyr Glu Ala Gln Tyr Gly Thr Pro Trp Ile Met Ala His Arg Val
100 105 110
Asp Leu His Lys Glu Leu Arg Arg Leu Ala Val Asp Pro Glu Gly Thr
115 120 125
Gly Pro Pro Ala Glu Leu His Leu Ser His Arg Val Val Ser Cys Asp
130 135 140
Val Glu Ser Gly Ser Val Thr Leu Leu Asp Gly Ser Val Gln Ser Ala
145 150 155 160
Asp Leu Ile Ile Gly Ala Asp Gly Ile Arg Ser Thr Val Arg Lys Phe
165 170 175
Val Val Gly Glu Glu Ile Ala Ile Pro Pro Ser Arg Thr Ala Gly Phe
180 185 190
Arg Trp Leu Thr Gln Ala Ser Ala Leu Asp Pro Tyr Pro Glu Leu Asp
195 200 205
Trp Ile Val Lys Thr Pro Pro Leu Gly Ala Arg Val Ile Ser Ala Pro
210 215 220
Ile Gln Pro Pro Glu Val Thr His Ile Asp His Arg Thr Ile Val Ile
225 230 235 240
Tyr Ala Cys Arg Gly Gly Arg Leu Val Asn Val Leu Gly Ile His Glu
245 250 255
Asp Leu Arg Asp Gln Asp Ser Val Asp Trp Asn Val Pro Ile Thr Arg
260 265 270
Glu Ala Leu Leu His Phe Phe Gly Asp Tyr His Pro Arg Phe Lys Arg
275 280 285
Leu Leu Glu Leu Ala Glu Asp Val His Val Trp Gln Met Arg Val Val
290 295 300
Pro Pro Leu Pro Thr Trp Val Asn Gly Arg Val Cys Ile Met Gly Asp
305 310 315 320
Ala Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly
325 330 335
Leu Glu Asp Ala Val Ala Leu Gly Thr Leu Leu Pro Ser Ser Thr Pro
340 345 350
Ser Ser Asp Ile Pro Ser Arg Leu Val Ala Tyr Glu Lys Leu Arg Lys
355 360 365
Ala Arg Ala Glu Tyr Val Ser Lys Glu Ser Tyr Glu Gln Gln His Val
370 375 380
Arg Glu Lys Arg Gly Leu Tyr Leu Arg Ser Arg Glu Met Arg Asp Val
385 390 395 400
Ile Met Gly Tyr Asp Val Lys Lys Glu Ala Glu Arg Ile Leu Ser Glu
405 410 415
Ile Ser Ile Ala Gln Glu Gln Cys Ala Val His Asp
420 425
<210> 11
<211> 1284
<212> DNA
<213> Panellus stipticus
<400> 11
atgtcacaag gcactgaaga ctcgccctca ctcttcgcaa tagttgtcgg tgctggtctg 60
gtcggctttg ccgctgccgt cgcgctgcgc cgtcaaggtc accgtgtcac tatctacgaa 120
tcttcaagct ttaagacaga acttggggcg ggcctcgcga tcccttcaaa cacattgcga 180
tgcttggttg gccttggatg tactgtcgcc aatctggatc ccgtcaataa tctttgtttt 240
acatcgatgg cttacgatgg taccgcgggg atgaaaagcg acagctccga ctacgaggcg 300
cagtatggca ctccctggat catggcccac cgcgtcgatc tgcacaagga gcttcgtcgc 360
ctggcagtgg atcccgaggg caccggtccc cccgcagaac tgcaccttag ccaccgggtt 420
gtctcctgcg acgtcgaatc cggctccgtc acgctcctgg acggctccat tcagtcagca 480
gacttgataa ttggggctga tggaattcgt tcaaccgttc gcaaatttgt cgtaggcgaa 540
gaaatagcaa tccccccatc tcgtacggcg ggcttccgtt ggctcacaca agcaagcgct 600
cttgacccct accccgaact ggattggatc gtgaaaacgc cgccgttggg tgctcgggta 660
atctccgctc cgattcaacc tccagaagtc acccacatcg accaccgtac gatcgtcatc 720
tatgcctgtc gcggaggtcg tctcgtaaat gttctaggaa tacatgagga tctgcgcgac 780
caggattctg tcgactggaa cgtccccata acgcgagaag cgctgctcca ctttttcgga 840
gactaccacc cacggttcaa gcggctcttg gagctcgcgg aggacgtaca cgtctggcag 900
atgcgcgtgg tccccccact gccgacatgg gtgaacggcc gcgtatgcat catgggcgac 960
gcagcgcatg catcgcttcc cacactggga caagggtttg gcatgggcct cgaagacgcg 1020
gtcgcgctcg ggacgctgct tcctagttcg acgccgtcag gcgacattcc aagccgtctc 1080
gtcgcgtacg agaagcttcg caaagcgcgc gctgagtatg tttccaaaga gtcgtacgaa 1140
cagcagcatg tccgagaaaa gagagggctg tatctccggt cccgagaaat gcgggatgtg 1200
atcatgggat acgacgtgaa gaaggaggca gaacggatct ttagcgagat cagcattgca 1260
caagaacagc gtgctgttca tgat 1284
<210> 12
<211> 428
<212> PRT
<213> Panellus stipticus
<400> 12
Met Ser Gln Gly Thr Glu Asp Ser Pro Ser Leu Phe Ala Ile Val Val
1 5 10 15
Gly Ala Gly Leu Val Gly Phe Ala Ala Ala Val Ala Leu Arg Arg Gln
20 25 30
Gly His Arg Val Thr Ile Tyr Glu Ser Ser Ser Phe Lys Thr Glu Leu
35 40 45
Gly Ala Gly Leu Ala Ile Pro Ser Asn Thr Leu Arg Cys Leu Val Gly
50 55 60
Leu Gly Cys Thr Val Ala Asn Leu Asp Pro Val Asn Asn Leu Cys Phe
65 70 75 80
Thr Ser Met Ala Tyr Asp Gly Thr Ala Gly Met Lys Ser Asp Ser Ser
85 90 95
Asp Tyr Glu Ala Gln Tyr Gly Thr Pro Trp Ile Met Ala His Arg Val
100 105 110
Asp Leu His Lys Glu Leu Arg Arg Leu Ala Val Asp Pro Glu Gly Thr
115 120 125
Gly Pro Pro Ala Glu Leu His Leu Ser His Arg Val Val Ser Cys Asp
130 135 140
Val Glu Ser Gly Ser Val Thr Leu Leu Asp Gly Ser Ile Gln Ser Ala
145 150 155 160
Asp Leu Ile Ile Gly Ala Asp Gly Ile Arg Ser Thr Val Arg Lys Phe
165 170 175
Val Val Gly Glu Glu Ile Ala Ile Pro Pro Ser Arg Thr Ala Gly Phe
180 185 190
Arg Trp Leu Thr Gln Ala Ser Ala Leu Asp Pro Tyr Pro Glu Leu Asp
195 200 205
Trp Ile Val Lys Thr Pro Pro Leu Gly Ala Arg Val Ile Ser Ala Pro
210 215 220
Ile Gln Pro Pro Glu Val Thr His Ile Asp His Arg Thr Ile Val Ile
225 230 235 240
Tyr Ala Cys Arg Gly Gly Arg Leu Val Asn Val Leu Gly Ile His Glu
245 250 255
Asp Leu Arg Asp Gln Asp Ser Val Asp Trp Asn Val Pro Ile Thr Arg
260 265 270
Glu Ala Leu Leu His Phe Phe Gly Asp Tyr His Pro Arg Phe Lys Arg
275 280 285
Leu Leu Glu Leu Ala Glu Asp Val His Val Trp Gln Met Arg Val Val
290 295 300
Pro Pro Leu Pro Thr Trp Val Asn Gly Arg Val Cys Ile Met Gly Asp
305 310 315 320
Ala Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly
325 330 335
Leu Glu Asp Ala Val Ala Leu Gly Thr Leu Leu Pro Ser Ser Thr Pro
340 345 350
Ser Gly Asp Ile Pro Ser Arg Leu Val Ala Tyr Glu Lys Leu Arg Lys
355 360 365
Ala Arg Ala Glu Tyr Val Ser Lys Glu Ser Tyr Glu Gln Gln His Val
370 375 380
Arg Glu Lys Arg Gly Leu Tyr Leu Arg Ser Arg Glu Met Arg Asp Val
385 390 395 400
Ile Met Gly Tyr Asp Val Lys Lys Glu Ala Glu Arg Ile Phe Ser Glu
405 410 415
Ile Ser Ile Ala Gln Glu Gln Arg Ala Val His Asp
420 425
<210> 13
<211> 1248
<212> DNA
<213> Neonothopanus gardneri
<400> 13
atggcactat ctgagagtcc tttgaacgtc ttgatagtag gagcggggct cggggggctt 60
gctgctgcca tagcactacg tcgtcaaggg catatcgtga aaatattcga ttcctccagt 120
ttcaaaaccg aacttggtgc aggacttgct gtcccgccta ataccctgcg tagtctgcag 180
gaactcgggt gcagtgtcga gaacctcaat gctgtggata atctttgctt cactgcgatg 240
gggtatgacg ggagtgtagg aatgatgaac aatatgaccg actatcgaga ggcgtacggt 300
catccttggg tcatggttca ccgtgtcgac ttgcataatg agctgaagcg cgtggcgctt 360
gatccagacg gcctcggacc tcctgcaact ttgcatctca accatcgtgt cacattctgc 420
gacatcgact cttgcactgt cacgttcgct aatgggactt ctaaatcggc agatcttatc 480
gtaggcgcag acggtatacg ctctaccatt cgcaagttca ttcttggaga agacgtcgtt 540
atacccgcgt caggaatagc agggtttcga tggcttgtgc aagctgacgc gctggatccg 600
tatcctgaac tcgactggat cgtgaagaac cctcctctag gagcccgact gatttccgct 660
cctaggaatc aacagtctac tgataggcgc actatcatca tctatgcgtg tcgtagcggc 720
accatggtca acgtactcgc agtacatgat gatgatcgtg accagaacgc cgtagattgg 780
agtgcaccag cttccaaaga tgatttattc cacatcttcc acgactacca cccacgattc 840
cagcggcttc tggagctggc gcaagatatc aatctctggc aaatgcgtgt tgttcctgtt 900
ctgaaacaat gggttaacaa acgtgtttgc ttgttaggag atgcggcaca cgcttcttta 960
cctacattag ggcagggatt tggtatgggt ctagaagatg ccgtagcact gggtacgctt 1020
cttccaaagg gggccacagt atctcagatc gagagccgac tcgcggtgta tgaaattctg 1080
cgcaaggagc gtgctgaatt tgtttcggct gagtcatatg aagagcagta cgttccagaa 1140
aaacgcgggc tttacttaag atcgaaggaa ttgcgcgaca gtgtcatggg ttacgatatt 1200
aaaatggaga gcgagaaggt tctcgtggca ttacttagcg gttcttca 1248
<210> 14
<211> 416
<212> PRT
<213> Neonothopanus gardneri
<400> 14
Met Ala Leu Ser Glu Ser Pro Leu Asn Val Leu Ile Val Gly Ala Gly
1 5 10 15
Leu Gly Gly Leu Ala Ala Ala Ile Ala Leu Arg Arg Gln Gly His Ile
20 25 30
Val Lys Ile Phe Asp Ser Ser Ser Phe Lys Thr Glu Leu Gly Ala Gly
35 40 45
Leu Ala Val Pro Pro Asn Thr Leu Arg Ser Leu Gln Glu Leu Gly Cys
50 55 60
Ser Val Glu Asn Leu Asn Ala Val Asp Asn Leu Cys Phe Thr Ala Met
65 70 75 80
Gly Tyr Asp Gly Ser Val Gly Met Met Asn Asn Met Thr Asp Tyr Arg
85 90 95
Glu Ala Tyr Gly His Pro Trp Val Met Val His Arg Val Asp Leu His
100 105 110
Asn Glu Leu Lys Arg Val Ala Leu Asp Pro Asp Gly Leu Gly Pro Pro
115 120 125
Ala Thr Leu His Leu Asn His Arg Val Thr Phe Cys Asp Ile Asp Ser
130 135 140
Cys Thr Val Thr Phe Ala Asn Gly Thr Ser Lys Ser Ala Asp Leu Ile
145 150 155 160
Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Lys Phe Ile Leu Gly
165 170 175
Glu Asp Val Val Ile Pro Ala Ser Gly Ile Ala Gly Phe Arg Trp Leu
180 185 190
Val Gln Ala Asp Ala Leu Asp Pro Tyr Pro Glu Leu Asp Trp Ile Val
195 200 205
Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Ser Ala Pro Arg Asn Gln
210 215 220
Gln Ser Thr Asp Arg Arg Thr Ile Ile Ile Tyr Ala Cys Arg Ser Gly
225 230 235 240
Thr Met Val Asn Val Leu Ala Val His Asp Asp Asp Arg Asp Gln Asn
245 250 255
Ala Val Asp Trp Ser Ala Pro Ala Ser Lys Asp Asp Leu Phe His Ile
260 265 270
Phe His Asp Tyr His Pro Arg Phe Gln Arg Leu Leu Glu Leu Ala Gln
275 280 285
Asp Ile Asn Leu Trp Gln Met Arg Val Val Pro Val Leu Lys Gln Trp
290 295 300
Val Asn Lys Arg Val Cys Leu Leu Gly Asp Ala Ala His Ala Ser Leu
305 310 315 320
Pro Thr Leu Gly Gln Gly Phe Gly Met Gly Leu Glu Asp Ala Val Ala
325 330 335
Leu Gly Thr Leu Leu Pro Lys Gly Ala Thr Val Ser Gln Ile Glu Ser
340 345 350
Arg Leu Ala Val Tyr Glu Ile Leu Arg Lys Glu Arg Ala Glu Phe Val
355 360 365
Ser Ala Glu Ser Tyr Glu Glu Gln Tyr Val Pro Glu Lys Arg Gly Leu
370 375 380
Tyr Leu Arg Ser Lys Glu Leu Arg Asp Ser Val Met Gly Tyr Asp Ile
385 390 395 400
Lys Met Glu Ser Glu Lys Val Leu Val Ala Leu Leu Ser Gly Ser Ser
405 410 415
<210> 15
<211> 1257
<212> DNA
<213> Mycena citricolor
<400> 15
atgaacaccc ccaataacgc tctcgatgtt attgttgtcg gtgctggcct ggttggtttc 60
gcggccgctg ctgctctacg ccgacaaggt catcgcgtga ctatctacga gacttccagc 120
ttcaagaacg agctaggagc tggccttgct attccaccca acactgtccg tggcctaatt 180
ggcttgggat gtgtgattga gaacttggac ccggtggaga atctatgcgt ttccgtcgct 240
tttgacggaa gtgctggtat gcgcagtgac cagaccaact acgaagcaag ctacggcctt 300
ccctggatca tggtgcatcg cgtcgatttg cacaatgagc ttcgtcgggt tgctctcagt 360
gccgagggga acattggtcc cccagccgag ctacgcctgg accaccgagt cagctcgtgt 420
gatgtcgaga aatgcactgt gacgctgagc aatggcgata cccaccacgc ggatctgatc 480
attggagcag acgggatcca ttctacaatc cgatccttcg tcgtgggcga ggaaatcgtc 540
attccgccct ccaagacagc cggtttccgc tggctcacag agagtactgc gttggagccc 600
tatccggaat tggactggat tgtgaagatc ccaccacttg gcgcccggct gatctctgcg 660
ccaatgaacc ctgcgccacc gcaggtcgac caccggacga tcatcatcta cgcctgtcgt 720
ggcagtacac tgataaatgt actcggagtc catgaggatc tccgcgatca agatacagtt 780
ccctggaatg cacccgtaac ccaatcggag ctgctccagt tctttggcga ttaccatccg 840
cgattcaaac gattgttgga gcttgcaaat gatgttcatg tgtggcagat gcgagtagtg 900
ccccgcttgg agacctgggt caatcgtcgg gtttgcatta tgggcgatgc tgcgcatgca 960
tcactcccca cgctgggtca aggtttcgga atggggctcg aggatgcagt cgctcttgga 1020
acactccttc cgcttgggac aactcccgaa gagatcccgg accgtctcac cctctggcag 1080
gatctcgtca aacctcgggc tgagtttgtc gcgactgaat cctacgaaca gcagcatatt 1140
cctgcgaaac ggggactcta tcttcgctcg caggagatgc gcgactgggt catgggatac 1200
gatgtccagg ctgaggcaca gaaggtcttg gcgggagctg tgaatagatc caaggga 1257
<210> 16
<211> 419
<212> PRT
<213> Mycena citricolor
<400> 16
Met Asn Thr Pro Asn Asn Ala Leu Asp Val Ile Val Val Gly Ala Gly
1 5 10 15
Leu Val Gly Phe Ala Ala Ala Ala Ala Leu Arg Arg Gln Gly His Arg
20 25 30
Val Thr Ile Tyr Glu Thr Ser Ser Phe Lys Asn Glu Leu Gly Ala Gly
35 40 45
Leu Ala Ile Pro Pro Asn Thr Val Arg Gly Leu Ile Gly Leu Gly Cys
50 55 60
Val Ile Glu Asn Leu Asp Pro Val Glu Asn Leu Cys Val Ser Val Ala
65 70 75 80
Phe Asp Gly Ser Ala Gly Met Arg Ser Asp Gln Thr Asn Tyr Glu Ala
85 90 95
Ser Tyr Gly Leu Pro Trp Ile Met Val His Arg Val Asp Leu His Asn
100 105 110
Glu Leu Arg Arg Val Ala Leu Ser Ala Glu Gly Asn Ile Gly Pro Pro
115 120 125
Ala Glu Leu Arg Leu Asp His Arg Val Ser Ser Cys Asp Val Glu Lys
130 135 140
Cys Thr Val Thr Leu Ser Asn Gly Asp Thr His His Ala Asp Leu Ile
145 150 155 160
Ile Gly Ala Asp Gly Ile His Ser Thr Ile Arg Ser Phe Val Val Gly
165 170 175
Glu Glu Ile Val Ile Pro Pro Ser Lys Thr Ala Gly Phe Arg Trp Leu
180 185 190
Thr Glu Ser Thr Ala Leu Glu Pro Tyr Pro Glu Leu Asp Trp Ile Val
195 200 205
Lys Ile Pro Pro Leu Gly Ala Arg Leu Ile Ser Ala Pro Met Asn Pro
210 215 220
Ala Pro Pro Gln Val Asp His Arg Thr Ile Ile Ile Tyr Ala Cys Arg
225 230 235 240
Gly Ser Thr Leu Ile Asn Val Leu Gly Val His Glu Asp Leu Arg Asp
245 250 255
Gln Asp Thr Val Pro Trp Asn Ala Pro Val Thr Gln Ser Glu Leu Leu
260 265 270
Gln Phe Phe Gly Asp Tyr His Pro Arg Phe Lys Arg Leu Leu Glu Leu
275 280 285
Ala Asn Asp Val His Val Trp Gln Met Arg Val Val Pro Arg Leu Glu
290 295 300
Thr Trp Val Asn Arg Arg Val Cys Ile Met Gly Asp Ala Ala His Ala
305 310 315 320
Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly Leu Glu Asp Ala
325 330 335
Val Ala Leu Gly Thr Leu Leu Pro Leu Gly Thr Thr Pro Glu Glu Ile
340 345 350
Pro Asp Arg Leu Thr Leu Trp Gln Asp Leu Val Lys Pro Arg Ala Glu
355 360 365
Phe Val Ala Thr Glu Ser Tyr Glu Gln Gln His Ile Pro Ala Lys Arg
370 375 380
Gly Leu Tyr Leu Arg Ser Gln Glu Met Arg Asp Trp Val Met Gly Tyr
385 390 395 400
Asp Val Gln Ala Glu Ala Gln Lys Val Leu Ala Gly Ala Val Asn Arg
405 410 415
Ser Lys Gly
<210> 17
<211> 1260
<212> DNA
<213> Mycena citricolor
<400> 17
atgaacaccc ccaataacgc tctcgatgtt attgttgtcg gtgctggcct ggttggtttc 60
gcggccgctg ctgctctacg ccgacaaggt catcgcgtga ctatctatga gacttccagc 120
ttcaagaacg agttaggagc tggcctggct attccaccca acactgtccg tggtctaatt 180
ggcttgggat gtgtgattga gaacttggac ccggtggaga atctatgctt cactgccgtc 240
gcgtttgacg gaagtgctgg tatgcgcagc gaccaaacca actacgaagc aagttacggc 300
cttccctgga tcatggtgca tcgtgtcgat ttgcacaacg agcttcgtcg ggttgctctc 360
agcgccgagg ggaacactgg tcccccagcg gagctacgcc tggaccaccg agtcagctcg 420
tgtgatgtcg agaaatgcac tgtgacgctg agcaatgggg atacccacca cgcagatctg 480
atcattggag cagacgggat ccattctaca atccgatcct tcgttgtggg cgaggaaatc 540
gtcattccgc cctccaagac agccggtttc cgctggctca cagagagtac tgcgttggag 600
ccctatccgg aattggactg gattgtgaag atcccaccac ttggcgcccg gctgatctct 660
gcgccaatga accctgcgcc accgcaggtc gaccaccgga cgatcatcat ctacgcctgt 720
cgtggcagta cactgataaa tgtactcgga gtccatgagg atctccgcga tcaagataca 780
gtcccctgga atgcacccgt aacccaatcg gagctgctcc agttctttgg cgattaccat 840
ccgcggttca aacgattgtt ggagcttgca aatgatgttc atgtgtggca gatgcgagta 900
gtgccccgct tggagacctg ggtcaatcgt cgggtttgca ttatgggcga tgctgcgcat 960
gcatcactcc ccacgctggg tcaaggtttc ggaatggggc tcgaggatgc agtcgctctt 1020
ggaacactcc ttccgcttgg gacaactccc gaagagatcc cggaccgtct caccctctgg 1080
caggatctcg tcaaacctcg ggctgagttt gtcgcgactg aatcctacga acagcagcat 1140
attcctgcga aacggggact ctatcttcgc tcgcaggaga tgcgcgactg ggtcatggga 1200
tacgatgtcc aggctgaggc acagaaggtc ttggcgggag ctgtgaatag atccaaggga 1260
<210> 18
<211> 420
<212> PRT
<213> Mycena citricolor
<400> 18
Met Asn Thr Pro Asn Asn Ala Leu Asp Val Ile Val Val Gly Ala Gly
1 5 10 15
Leu Val Gly Phe Ala Ala Ala Ala Ala Leu Arg Arg Gln Gly His Arg
20 25 30
Val Thr Ile Tyr Glu Thr Ser Ser Phe Lys Asn Glu Leu Gly Ala Gly
35 40 45
Leu Ala Ile Pro Pro Asn Thr Val Arg Gly Leu Ile Gly Leu Gly Cys
50 55 60
Val Ile Glu Asn Leu Asp Pro Val Glu Asn Leu Cys Phe Thr Ala Val
65 70 75 80
Ala Phe Asp Gly Ser Ala Gly Met Arg Ser Asp Gln Thr Asn Tyr Glu
85 90 95
Ala Ser Tyr Gly Leu Pro Trp Ile Met Val His Arg Val Asp Leu His
100 105 110
Asn Glu Leu Arg Arg Val Ala Leu Ser Ala Glu Gly Asn Thr Gly Pro
115 120 125
Pro Ala Glu Leu Arg Leu Asp His Arg Val Ser Ser Cys Asp Val Glu
130 135 140
Lys Cys Thr Val Thr Leu Ser Asn Gly Asp Thr His His Ala Asp Leu
145 150 155 160
Ile Ile Gly Ala Asp Gly Ile His Ser Thr Ile Arg Ser Phe Val Val
165 170 175
Gly Glu Glu Ile Val Ile Pro Pro Ser Lys Thr Ala Gly Phe Arg Trp
180 185 190
Leu Thr Glu Ser Thr Ala Leu Glu Pro Tyr Pro Glu Leu Asp Trp Ile
195 200 205
Val Lys Ile Pro Pro Leu Gly Ala Arg Leu Ile Ser Ala Pro Met Asn
210 215 220
Pro Ala Pro Pro Gln Val Asp His Arg Thr Ile Ile Ile Tyr Ala Cys
225 230 235 240
Arg Gly Ser Thr Leu Ile Asn Val Leu Gly Val His Glu Asp Leu Arg
245 250 255
Asp Gln Asp Thr Val Pro Trp Asn Ala Pro Val Thr Gln Ser Glu Leu
260 265 270
Leu Gln Phe Phe Gly Asp Tyr His Pro Arg Phe Lys Arg Leu Leu Glu
275 280 285
Leu Ala Asn Asp Val His Val Trp Gln Met Arg Val Val Pro Arg Leu
290 295 300
Glu Thr Trp Val Asn Arg Arg Val Cys Ile Met Gly Asp Ala Ala His
305 310 315 320
Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly Leu Glu Asp
325 330 335
Ala Val Ala Leu Gly Thr Leu Leu Pro Leu Gly Thr Thr Pro Glu Glu
340 345 350
Ile Pro Asp Arg Leu Thr Leu Trp Gln Asp Leu Val Lys Pro Arg Ala
355 360 365
Glu Phe Val Ala Thr Glu Ser Tyr Glu Gln Gln His Ile Pro Ala Lys
370 375 380
Arg Gly Leu Tyr Leu Arg Ser Gln Glu Met Arg Asp Trp Val Met Gly
385 390 395 400
Tyr Asp Val Gln Ala Glu Ala Gln Lys Val Leu Ala Gly Ala Val Asn
405 410 415
Arg Ser Lys Gly
420
<210> 19
<211> 1287
<212> DNA
<213> Armillaria mellea
<400> 19
atgcaacaaa tcgacgaagc gcgcccattg aaagtgatag tagtgggtgc tggactttgt 60
gggctttccg ccgccattgc acttcgtagg caagggcatc atgttcatat acttgaatct 120
tcaagtttta agagcgagct tggcgcaggt ctcgccgtcc cacccaatac tgtacgctct 180
cttcgaggcc taggttgtaa catcgacaat ctcaagcccg tggataattt gtgtttctct 240
gccatggcgc atgacggaag cccaggcatg atgaataaca tgacagacta tcacaaggcg 300
tacggtgatc cttgggtaat ggcacatcgt gtcgacctcc ataacgagct cttgcgagtg 360
gctttcgacc ccgaaggaac agggcctcct gctcaacttc gtttgggcgt ccaggtagtg 420
acttgcgata tggaagcttg tacaatttcc cttgtcgatg gaacagtctg ttccgccgat 480
cttatcgtag gagctgacgg tattaagtcg accatacgct cctgtgttct aggcaaagaa 540
atagacatac ctcctaccgg tatcgccgga taccgctggc tcataccggc agaagctttg 600
gagccctatc ccgagctcga ctggattatc aagaacccac ccctaggagc acgtttaatc 660
acggatcccg tacgccgaac tgaacaaacg gatgacggta agaaggctga caagcgcacg 720
atcataatct atgcgtgccg cagtggcacg atgatcaacg ttcttggtgt gcacgatgac 780
ctgcgcaacc agaatgaagt cggatggaac gtaccagtca cacgggaaaa cttgctggag 840
tttttcgggg actaccaccc acggtttaag cgtttactcc agctagccga tagtattcat 900
ttgtggcaaa tgcgtgttgt cccacggctt gacacatgga ttaatagatg cgtgtgtttg 960
ctgggcgatt ctgcacatgc gtcattacca actctcgggc aaggcttcgg aatgggtctt 1020
gaggatgccg tagctctcgc agccctcctt ccgatgggaa ccaatgcgtc tgacgttgag 1080
aaccgcctta tcgcctacga aagcttgcgt aaggagcgtg cagagtatgt agccacggaa 1140
tcattagaac agcaggatat tgcaggaaag cgaggcttgt atctcaggtc tcctatgatg 1200
cgcgataaaa taatgggtta tgatattaaa gcggaagctg agaaggtttt aatcgaatta 1260
aaaaattcga cagctcagca ggtcact 1287
<210> 20
<211> 429
<212> PRT
<213> Armillaria mellea
<400> 20
Met Gln Gln Ile Asp Glu Ala Arg Pro Leu Lys Val Ile Val Val Gly
1 5 10 15
Ala Gly Leu Cys Gly Leu Ser Ala Ala Ile Ala Leu Arg Arg Gln Gly
20 25 30
His His Val His Ile Leu Glu Ser Ser Ser Phe Lys Ser Glu Leu Gly
35 40 45
Ala Gly Leu Ala Val Pro Pro Asn Thr Val Arg Ser Leu Arg Gly Leu
50 55 60
Gly Cys Asn Ile Asp Asn Leu Lys Pro Val Asp Asn Leu Cys Phe Ser
65 70 75 80
Ala Met Ala His Asp Gly Ser Pro Gly Met Met Asn Asn Met Thr Asp
85 90 95
Tyr His Lys Ala Tyr Gly Asp Pro Trp Val Met Ala His Arg Val Asp
100 105 110
Leu His Asn Glu Leu Leu Arg Val Ala Phe Asp Pro Glu Gly Thr Gly
115 120 125
Pro Pro Ala Gln Leu Arg Leu Gly Val Gln Val Val Thr Cys Asp Met
130 135 140
Glu Ala Cys Thr Ile Ser Leu Val Asp Gly Thr Val Cys Ser Ala Asp
145 150 155 160
Leu Ile Val Gly Ala Asp Gly Ile Lys Ser Thr Ile Arg Ser Cys Val
165 170 175
Leu Gly Lys Glu Ile Asp Ile Pro Pro Thr Gly Ile Ala Gly Tyr Arg
180 185 190
Trp Leu Ile Pro Ala Glu Ala Leu Glu Pro Tyr Pro Glu Leu Asp Trp
195 200 205
Ile Ile Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Thr Asp Pro Val
210 215 220
Arg Arg Thr Glu Gln Thr Asp Asp Gly Lys Lys Ala Asp Lys Arg Thr
225 230 235 240
Ile Ile Ile Tyr Ala Cys Arg Ser Gly Thr Met Ile Asn Val Leu Gly
245 250 255
Val His Asp Asp Leu Arg Asn Gln Asn Glu Val Gly Trp Asn Val Pro
260 265 270
Val Thr Arg Glu Asn Leu Leu Glu Phe Phe Gly Asp Tyr His Pro Arg
275 280 285
Phe Lys Arg Leu Leu Gln Leu Ala Asp Ser Ile His Leu Trp Gln Met
290 295 300
Arg Val Val Pro Arg Leu Asp Thr Trp Ile Asn Arg Cys Val Cys Leu
305 310 315 320
Leu Gly Asp Ser Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe
325 330 335
Gly Met Gly Leu Glu Asp Ala Val Ala Leu Ala Ala Leu Leu Pro Met
340 345 350
Gly Thr Asn Ala Ser Asp Val Glu Asn Arg Leu Ile Ala Tyr Glu Ser
355 360 365
Leu Arg Lys Glu Arg Ala Glu Tyr Val Ala Thr Glu Ser Leu Glu Gln
370 375 380
Gln Asp Ile Ala Gly Lys Arg Gly Leu Tyr Leu Arg Ser Pro Met Met
385 390 395 400
Arg Asp Lys Ile Met Gly Tyr Asp Ile Lys Ala Glu Ala Glu Lys Val
405 410 415
Leu Ile Glu Leu Lys Asn Ser Thr Ala Gln Gln Val Thr
420 425
<210> 21
<211> 1278
<212> DNA
<213> Armillaria fuscipes
<400> 21
atgcaacaaa tcgacgaagc gcgtccattg aaggtgctag tcgtgggtgc tggactctgt 60
gggctttccg ccgccatcgc acttcgtaga caagggcatc acgtccatat acttgaatct 120
tcaagtttca agagcgaact tggggcaggt ctcgccgtgc cacctaatac tgtgcgctct 180
cttcgaggtc tcggctgtga catagacaat ctcaagcccg tggataatct ttgtttcact 240
gctatgtcgc atgacggaag cccaggcatg atgaataaca tgacggacta tcgcaaggcg 300
tatggtgatc cttgggtgat ggcacatcgt gtcgaccttc ataacgagct tatgcgagtg 360
gctctcgacc ctgatgggac aggtcctcct gcccaacttc gtttgggcgt ccaggttgtg 420
tcttgcgatg ttgaagcttg tactgtttcc cttgtcgatg gagaggtctg ttccgccgat 480
cttatcgttg gagctgatgg tatcaggtca accatacgct cctatgttct aggcaaagaa 540
atagatatac ctcctaccgg cattgccgga taccgctggc ttacaccatc agaggctttg 600
gagccttttc ccgaacttga ttggattatc aagaacccac ctctaggagc acgtctaatc 660
accgctccca tacgccggaa cgaacaaatg aatgacggtg agatggctga caagcgtacg 720
atcatcatct acgcgtgccg caacggcaca atgattaacg ttctcggtgt gcacgatgac 780
ccgcgcaacc agaatgaagt cggatggaac gtgccagtaa cccaagaaaa attgctcgaa 840
tttttcggag actaccaccc acggttcaaa agtttacttc agctatctga tagtattcat 900
ttgtggcaaa tgcgtgttgt tccacggctt gacacatgga tcaatcaacg tgtgtgtttg 960
ctgggcgatt ctgcacatgc gtcattacca acgctcgggc aaggcttcgg gatgggtctt 1020
gaggacgcca tagctcttgc aaccctcctt ccgatgggcg ccaaagtgtc ggacattgag 1080
aatcgcctta tcgcctacga aagcctgcgt aaggagcgtg cagagtttgt agccacggaa 1140
tcattagaac agcaagatat tcccgaaaag cgaggcttgt atctcagatc ccctatgatg 1200
cgcgataaaa taatgggtta cgatatcaaa gccgaagctg aaaaggtttt aatggagtta 1260
ttgagctcga aagctcaa 1278
<210> 22
<211> 426
<212> PRT
<213> Armillaria fuscipes
<400> 22
Met Gln Gln Ile Asp Glu Ala Arg Pro Leu Lys Val Leu Val Val Gly
1 5 10 15
Ala Gly Leu Cys Gly Leu Ser Ala Ala Ile Ala Leu Arg Arg Gln Gly
20 25 30
His His Val His Ile Leu Glu Ser Ser Ser Phe Lys Ser Glu Leu Gly
35 40 45
Ala Gly Leu Ala Val Pro Pro Asn Thr Val Arg Ser Leu Arg Gly Leu
50 55 60
Gly Cys Asp Ile Asp Asn Leu Lys Pro Val Asp Asn Leu Cys Phe Thr
65 70 75 80
Ala Met Ser His Asp Gly Ser Pro Gly Met Met Asn Asn Met Thr Asp
85 90 95
Tyr Arg Lys Ala Tyr Gly Asp Pro Trp Val Met Ala His Arg Val Asp
100 105 110
Leu His Asn Glu Leu Met Arg Val Ala Leu Asp Pro Asp Gly Thr Gly
115 120 125
Pro Pro Ala Gln Leu Arg Leu Gly Val Gln Val Val Ser Cys Asp Val
130 135 140
Glu Ala Cys Thr Val Ser Leu Val Asp Gly Glu Val Cys Ser Ala Asp
145 150 155 160
Leu Ile Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Ser Tyr Val
165 170 175
Leu Gly Lys Glu Ile Asp Ile Pro Pro Thr Gly Ile Ala Gly Tyr Arg
180 185 190
Trp Leu Thr Pro Ser Glu Ala Leu Glu Pro Phe Pro Glu Leu Asp Trp
195 200 205
Ile Ile Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Thr Ala Pro Ile
210 215 220
Arg Arg Asn Glu Gln Met Asn Asp Gly Glu Met Ala Asp Lys Arg Thr
225 230 235 240
Ile Ile Ile Tyr Ala Cys Arg Asn Gly Thr Met Ile Asn Val Leu Gly
245 250 255
Val His Asp Asp Pro Arg Asn Gln Asn Glu Val Gly Trp Asn Val Pro
260 265 270
Val Thr Gln Glu Lys Leu Leu Glu Phe Phe Gly Asp Tyr His Pro Arg
275 280 285
Phe Lys Ser Leu Leu Gln Leu Ser Asp Ser Ile His Leu Trp Gln Met
290 295 300
Arg Val Val Pro Arg Leu Asp Thr Trp Ile Asn Gln Arg Val Cys Leu
305 310 315 320
Leu Gly Asp Ser Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe
325 330 335
Gly Met Gly Leu Glu Asp Ala Ile Ala Leu Ala Thr Leu Leu Pro Met
340 345 350
Gly Ala Lys Val Ser Asp Ile Glu Asn Arg Leu Ile Ala Tyr Glu Ser
355 360 365
Leu Arg Lys Glu Arg Ala Glu Phe Val Ala Thr Glu Ser Leu Glu Gln
370 375 380
Gln Asp Ile Pro Glu Lys Arg Gly Leu Tyr Leu Arg Ser Pro Met Met
385 390 395 400
Arg Asp Lys Ile Met Gly Tyr Asp Ile Lys Ala Glu Ala Glu Lys Val
405 410 415
Leu Met Glu Leu Leu Ser Ser Lys Ala Gln
420 425
<210> 23
<211> 1266
<212> DNA
<213> Armillaria gallica
<400> 23
atgcaacaaa tcgacgaagc gcgcgcattg aaagtgatag tcgtgggtgc tggactttgc 60
gggctttccg ccgccattgt acttcgtagg caagggcatc acgtccatat acttgaatct 120
tcaagtttca agagcgaact tggtgcaggt cttgccgtgc cgcccaacac tgtacgctct 180
cttcgaggtc taggttgtaa catcgacaat ctcaagcccg tggataatct ttgtttcact 240
gccatggctc atgacggaag cccaggcatg atgaataaca tgacagacta tcagaaggcg 300
tacggcgatc cttgggtaat ggcgcatcgt gtcgacctcc ataacgagct catgcgagtg 360
gctctcgacc ctgaaggaac aggccctgct gcccagcttc gtttgggcgt ccaggtggtg 420
tcttgtgatg tggaagcttg taccatttct cttgtcgatg gatcaatctg taccgccgat 480
cttatcgtcg gagctgatgg tattaggtca accatacggt cctatgtttt gggcaaagaa 540
atagacatac ctcctaccgg tattgctgga taccgctggc tcacaccggc agaagctttg 600
gacccatatc ccgaactcga ctggattatc aagaacccac ccctgggagc acgtttaatc 660
acagctcccg ttcgccgaaa cgataaggcg gatgacggtg agaaagctga caagcgcacg 720
atcataatct acgcgtgccg cagtggcact atgatcaacg ttctcggtgt gcacgatgac 780
ccgcgcaacc agaatgaagt cggatggaac gtaccagtta cccaggaaaa tttgttggag 840
tttttcgaag actaccaccc acggtttaag cgtttacttc agctgaccga taacattcat 900
ttgtggcaaa tgcgtgttgt cccgcggctt gacacatgga ttaataaacg cgtgtgtttg 960
ctgggcgatt ctgcacatgc gtcattacca acactcgggc aaggcttcgg gatgggtctt 1020
gaggacgccg tagctctcgc aaccctcctt ccgatgggaa ccaaattgtc tgacattgaa 1080
aaccgtcttg tcgcctacga aagcttgcgt aaggagcgtg ctgagtatgt agccacggaa 1140
tcattagaac agcaggatat tccgggaaag cgaggcttgt atctcaggtc tcctgtgatg 1200
cgcgataaaa taatgggtta tgatatcaaa gccgaagctg agaaggtttt aatggaattg 1260
ataacc 1266
<210> 24
<211> 422
<212> PRT
<213> Armillaria gallica
<400> 24
Met Gln Gln Ile Asp Glu Ala Arg Ala Leu Lys Val Ile Val Val Gly
1 5 10 15
Ala Gly Leu Cys Gly Leu Ser Ala Ala Ile Val Leu Arg Arg Gln Gly
20 25 30
His His Val His Ile Leu Glu Ser Ser Ser Phe Lys Ser Glu Leu Gly
35 40 45
Ala Gly Leu Ala Val Pro Pro Asn Thr Val Arg Ser Leu Arg Gly Leu
50 55 60
Gly Cys Asn Ile Asp Asn Leu Lys Pro Val Asp Asn Leu Cys Phe Thr
65 70 75 80
Ala Met Ala His Asp Gly Ser Pro Gly Met Met Asn Asn Met Thr Asp
85 90 95
Tyr Gln Lys Ala Tyr Gly Asp Pro Trp Val Met Ala His Arg Val Asp
100 105 110
Leu His Asn Glu Leu Met Arg Val Ala Leu Asp Pro Glu Gly Thr Gly
115 120 125
Pro Ala Ala Gln Leu Arg Leu Gly Val Gln Val Val Ser Cys Asp Val
130 135 140
Glu Ala Cys Thr Ile Ser Leu Val Asp Gly Ser Ile Cys Thr Ala Asp
145 150 155 160
Leu Ile Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Ser Tyr Val
165 170 175
Leu Gly Lys Glu Ile Asp Ile Pro Pro Thr Gly Ile Ala Gly Tyr Arg
180 185 190
Trp Leu Thr Pro Ala Glu Ala Leu Asp Pro Tyr Pro Glu Leu Asp Trp
195 200 205
Ile Ile Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Thr Ala Pro Val
210 215 220
Arg Arg Asn Asp Lys Ala Asp Asp Gly Glu Lys Ala Asp Lys Arg Thr
225 230 235 240
Ile Ile Ile Tyr Ala Cys Arg Ser Gly Thr Met Ile Asn Val Leu Gly
245 250 255
Val His Asp Asp Pro Arg Asn Gln Asn Glu Val Gly Trp Asn Val Pro
260 265 270
Val Thr Gln Glu Asn Leu Leu Glu Phe Phe Glu Asp Tyr His Pro Arg
275 280 285
Phe Lys Arg Leu Leu Gln Leu Thr Asp Asn Ile His Leu Trp Gln Met
290 295 300
Arg Val Val Pro Arg Leu Asp Thr Trp Ile Asn Lys Arg Val Cys Leu
305 310 315 320
Leu Gly Asp Ser Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe
325 330 335
Gly Met Gly Leu Glu Asp Ala Val Ala Leu Ala Thr Leu Leu Pro Met
340 345 350
Gly Thr Lys Leu Ser Asp Ile Glu Asn Arg Leu Val Ala Tyr Glu Ser
355 360 365
Leu Arg Lys Glu Arg Ala Glu Tyr Val Ala Thr Glu Ser Leu Glu Gln
370 375 380
Gln Asp Ile Pro Gly Lys Arg Gly Leu Tyr Leu Arg Ser Pro Val Met
385 390 395 400
Arg Asp Lys Ile Met Gly Tyr Asp Ile Lys Ala Glu Ala Glu Lys Val
405 410 415
Leu Met Glu Leu Ile Thr
420
<210> 25
<211> 1278
<212> DNA
<213> Armillaria ostoyae
<400> 25
atgcaacaaa tcgacgaagc gcacccattg acagtgatag tcgtgggtgc tggactttgc 60
gggctttccg ccgccattgc acttcgtagg caagggcatc acgtccatat acttgaatct 120
tcaagtttca aaagcgaact tggcgcaggt ctcgccgtgc cgcccaacac tgtacgctct 180
cttcgaggtc taggttgtaa catcgacaat ctcaagcccg tggataatct ttgtttcact 240
gccatggcgc atgacggaag cccaggcatg atgaataaca tgacagacta tcacaaggcg 300
tacggcgagc cttgggtaat ggcgcatcgt gtcgacctcc ataacgagct catgcgagtg 360
gctctcgacc ctgaaggaac aggtcctcct gctcagcttc gtttgggtgt ccaggtggtg 420
tcttgcgatg tggaagcttg taccatttct cttgtcgatg gatcaatctg ttccgccgat 480
cttatcgtcg gagctgatgg tattaggtca accatacgct cctatgtttt gggcaaagaa 540
atagacatac ctcctaccgg tattgctgga taccgttggc tcacaccggc agaagctttg 600
gagccatatc ccgaactcga ctggattatc aagaacccac ccctgggagc acgtttaatc 660
acggctcccg tacgccgaaa cgataagacg gatgacggtg agaagactga caagcgcacg 720
atcataatct acgcgtgccg caatggcact atgatcaacg ttctcggtgt gcacgatgac 780
ccgcgcaacc agaatgaagt cggatggaac gtaccagtta cccaggaaaa tttgttggag 840
tttttcgaag actaccaccc acggtttaag cgtttacttc agttggccga tagtattcat 900
ttgtggcaaa tgcgtgttgt cccacggctt gacacatgga ttaataaacg cgtgtgtttg 960
ctgggcgatt ctgcacatgc gtcattacca acactcgggc aaggcttcgg gatgggtctt 1020
gaggacgccg tagctctcgc agccctcctt ccgatgggaa ccaaagtgtc tgacgttgag 1080
agtcgtctta tcgcctacga aagcttgcgt aaggagcgtg ctgagtatgt agccacggaa 1140
tcattagaac agcagaatat tccgggaaag cgaggcttgt atctcaggtc tcctatgatg 1200
cgcgataaaa taatgggtta tgatatcaaa gccgaagctg agaaggtttt aatggaatta 1260
ataacctcga cagctcag 1278
<210> 26
<211> 426
<212> PRT
<213> Armillaria ostoyae
<400> 26
Met Gln Gln Ile Asp Glu Ala His Pro Leu Thr Val Ile Val Val Gly
1 5 10 15
Ala Gly Leu Cys Gly Leu Ser Ala Ala Ile Ala Leu Arg Arg Gln Gly
20 25 30
His His Val His Ile Leu Glu Ser Ser Ser Phe Lys Ser Glu Leu Gly
35 40 45
Ala Gly Leu Ala Val Pro Pro Asn Thr Val Arg Ser Leu Arg Gly Leu
50 55 60
Gly Cys Asn Ile Asp Asn Leu Lys Pro Val Asp Asn Leu Cys Phe Thr
65 70 75 80
Ala Met Ala His Asp Gly Ser Pro Gly Met Met Asn Asn Met Thr Asp
85 90 95
Tyr His Lys Ala Tyr Gly Glu Pro Trp Val Met Ala His Arg Val Asp
100 105 110
Leu His Asn Glu Leu Met Arg Val Ala Leu Asp Pro Glu Gly Thr Gly
115 120 125
Pro Pro Ala Gln Leu Arg Leu Gly Val Gln Val Val Ser Cys Asp Val
130 135 140
Glu Ala Cys Thr Ile Ser Leu Val Asp Gly Ser Ile Cys Ser Ala Asp
145 150 155 160
Leu Ile Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Ser Tyr Val
165 170 175
Leu Gly Lys Glu Ile Asp Ile Pro Pro Thr Gly Ile Ala Gly Tyr Arg
180 185 190
Trp Leu Thr Pro Ala Glu Ala Leu Glu Pro Tyr Pro Glu Leu Asp Trp
195 200 205
Ile Ile Lys Asn Pro Pro Leu Gly Ala Arg Leu Ile Thr Ala Pro Val
210 215 220
Arg Arg Asn Asp Lys Thr Asp Asp Gly Glu Lys Thr Asp Lys Arg Thr
225 230 235 240
Ile Ile Ile Tyr Ala Cys Arg Asn Gly Thr Met Ile Asn Val Leu Gly
245 250 255
Val His Asp Asp Pro Arg Asn Gln Asn Glu Val Gly Trp Asn Val Pro
260 265 270
Val Thr Gln Glu Asn Leu Leu Glu Phe Phe Glu Asp Tyr His Pro Arg
275 280 285
Phe Lys Arg Leu Leu Gln Leu Ala Asp Ser Ile His Leu Trp Gln Met
290 295 300
Arg Val Val Pro Arg Leu Asp Thr Trp Ile Asn Lys Arg Val Cys Leu
305 310 315 320
Leu Gly Asp Ser Ala His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe
325 330 335
Gly Met Gly Leu Glu Asp Ala Val Ala Leu Ala Ala Leu Leu Pro Met
340 345 350
Gly Thr Lys Val Ser Asp Val Glu Ser Arg Leu Ile Ala Tyr Glu Ser
355 360 365
Leu Arg Lys Glu Arg Ala Glu Tyr Val Ala Thr Glu Ser Leu Glu Gln
370 375 380
Gln Asn Ile Pro Gly Lys Arg Gly Leu Tyr Leu Arg Ser Pro Met Met
385 390 395 400
Arg Asp Lys Ile Met Gly Tyr Asp Ile Lys Ala Glu Ala Glu Lys Val
405 410 415
Leu Met Glu Leu Ile Thr Ser Thr Ala Gln
420 425
<210> 27
<211> 1266
<212> DNA
<213> Mycena chlorophos
<400> 27
atgccctcca ccgccgaatc tccgcagccg ctcaagatcg tcatcgtcgg tgctgggctc 60
gttggtctcg ctgctgccat tgcgcttcgt cgcgagggtc atcatgtaga gatatacgaa 120
tcgtcgacgt tcaagaccga actcggcgcc ggtctcgcga taccgtgcaa taccctccgt 180
agcctcattg agctggggtg cattgtggct aacttgaacc cggtggagaa cctctgtttc 240
acgtctatgg cgcacgacgg aagcgagtca ggcatgcgaa gcgaccacac cgactacgag 300
gcgcgttatg ggaccccttg ggtcatggcg catcgcgtcg acatacacgc agagctgctc 360
cgaatggcca ccacctccga tattcccggc ccaccggcga cactgcatct cggccaacgc 420
gtccttgcct gcaatgtgtc cgactgctcc attgcactgg ccaccggcaa aacgatctca 480
gcggatctcg tcgttggtgc cgatgggatt cgctcgacca ttcgagctgc tgttcttggc 540
gaagatatcc acattccggc atcgggcact gccggcttcc gatggctcgt agattccgcc 600
gcgctggatc cctatcccga gctggactgg attgtgaaag cccgtccgct tggcgctcgc 660
gttatttctg ccccgatggg cctcgcactc gaagatcatc gtaccattgt gatctatgcg 720
tgtcgcggcg gtaacttgat caacgttctt gcggtccacg aagacaagcg cgaccaggag 780
gctgtccctt ggaatgtccc tttgacgcgc gaagccctct tggacttctt tagcgactac 840
cacccgcgtt tccgccgtct cttcgagctc gcgccggtcg acggaattca cgtctggcag 900
atgcgggtcg taccaccttt ggccaactgg atccgtgacc gcgtttgcat tctcggcgac 960
gcggcgcatg cgtctcttcc tactatgggc cagggctttg gccaaggtct cgaagacgcc 1020
gttgcgctag cgactttgct cccgctagga acgcgtagaa cggatatccc cgctcgtcta 1080
gtggcgtatg aggggatgcg caagcctcgg accgagtgga ttgcacgcga atcgtttgag 1140
cagcaggccg tcgcggaaaa gcgcggcatt tacttgcgct ctatcgaaat gcgcgatgcg 1200
gttatggggt ataatgttcg cgaggaggct aagcgcgtct tgtccgagct cactaaatct 1260
gattgt 1266
<210> 28
<211> 422
<212> PRT
<213> Mycena chlorophos
<400> 28
Met Pro Ser Thr Ala Glu Ser Pro Gln Pro Leu Lys Ile Val Ile Val
1 5 10 15
Gly Ala Gly Leu Val Gly Leu Ala Ala Ala Ile Ala Leu Arg Arg Glu
20 25 30
Gly His His Val Glu Ile Tyr Glu Ser Ser Thr Phe Lys Thr Glu Leu
35 40 45
Gly Ala Gly Leu Ala Ile Pro Cys Asn Thr Leu Arg Ser Leu Ile Glu
50 55 60
Leu Gly Cys Ile Val Ala Asn Leu Asn Pro Val Glu Asn Leu Cys Phe
65 70 75 80
Thr Ser Met Ala His Asp Gly Ser Glu Ser Gly Met Arg Ser Asp His
85 90 95
Thr Asp Tyr Glu Ala Arg Tyr Gly Thr Pro Trp Val Met Ala His Arg
100 105 110
Val Asp Ile His Ala Glu Leu Leu Arg Met Ala Thr Thr Ser Asp Ile
115 120 125
Pro Gly Pro Pro Ala Thr Leu His Leu Gly Gln Arg Val Leu Ala Cys
130 135 140
Asn Val Ser Asp Cys Ser Ile Ala Leu Ala Thr Gly Lys Thr Ile Ser
145 150 155 160
Ala Asp Leu Val Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Ala
165 170 175
Ala Val Leu Gly Glu Asp Ile His Ile Pro Ala Ser Gly Thr Ala Gly
180 185 190
Phe Arg Trp Leu Val Asp Ser Ala Ala Leu Asp Pro Tyr Pro Glu Leu
195 200 205
Asp Trp Ile Val Lys Ala Arg Pro Leu Gly Ala Arg Val Ile Ser Ala
210 215 220
Pro Met Gly Leu Ala Leu Glu Asp His Arg Thr Ile Val Ile Tyr Ala
225 230 235 240
Cys Arg Gly Gly Asn Leu Ile Asn Val Leu Ala Val His Glu Asp Lys
245 250 255
Arg Asp Gln Glu Ala Val Pro Trp Asn Val Pro Leu Thr Arg Glu Ala
260 265 270
Leu Leu Asp Phe Phe Ser Asp Tyr His Pro Arg Phe Arg Arg Leu Phe
275 280 285
Glu Leu Ala Pro Val Asp Gly Ile His Val Trp Gln Met Arg Val Val
290 295 300
Pro Pro Leu Ala Asn Trp Ile Arg Asp Arg Val Cys Ile Leu Gly Asp
305 310 315 320
Ala Ala His Ala Ser Leu Pro Thr Met Gly Gln Gly Phe Gly Gln Gly
325 330 335
Leu Glu Asp Ala Val Ala Leu Ala Thr Leu Leu Pro Leu Gly Thr Arg
340 345 350
Arg Thr Asp Ile Pro Ala Arg Leu Val Ala Tyr Glu Gly Met Arg Lys
355 360 365
Pro Arg Thr Glu Trp Ile Ala Arg Glu Ser Phe Glu Gln Gln Ala Val
370 375 380
Ala Glu Lys Arg Gly Ile Tyr Leu Arg Ser Ile Glu Met Arg Asp Ala
385 390 395 400
Val Met Gly Tyr Asn Val Arg Glu Glu Ala Lys Arg Val Leu Ser Glu
405 410 415
Leu Thr Lys Ser Asp Cys
420
<210> 29
<211> 72
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислот 1 для
гиспидин-гидроксилаз
<220>
<221> MISC_FEATURE
<222> (1)..(72)
<223> X - любая аминокислота
<400> 29
Val Gly Ala Gly Leu Xaa Gly Xaa Xaa Ala Ala Xaa Xaa Leu Arg Arg
1 5 10 15
Xaa Gly His Xaa Xaa Xaa Xaa Xaa Xaa Xaa Ser Xaa Phe Lys Xaa Glu
20 25 30
Xaa Gly Ala Gly Xaa Ala Xaa Pro Xaa Asn Thr Xaa Xaa Xaa Leu Xaa
35 40 45
Xaa Leu Gly Cys Xaa Xaa Xaa Asn Xaa Xaa Xaa Val Xaa Asn Leu Cys
50 55 60
Xaa Xaa Xaa Xaa Xaa Xaa Asp Gly
65 70
<210> 30
<211> 33
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислот 2 для
гиспидин-гидроксилаз
<220>
<221> MISC_FEATURE
<222> (1)..(33)
<223> X - любая аминокислота
<400> 30
Gly Met Xaa Xaa Xaa Xaa Xaa Xaa Tyr Xaa Xaa Xaa Tyr Gly Xaa Xaa
1 5 10 15
Trp Xaa Met Xaa His Arg Val Asp Xaa His Xaa Glu Leu Xaa Arg Xaa
20 25 30
Ala
<210> 31
<211> 96
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислот 3 для
гиспидин-гидроксилаз
<220>
<221> MISC_FEATURE
<222> (1)..(96)
<223> X - любая аминокислота
<400> 31
Gly Pro Xaa Ala Xaa Leu Xaa Leu Xaa Xaa Xaa Val Xaa Xaa Cys Xaa
1 5 10 15
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Gly Xaa Xaa Xaa Xaa Ala
20 25 30
Asp Leu Xaa Xaa Gly Ala Asp Gly Ile Xaa Ser Xaa Xaa Arg Xaa Xaa
35 40 45
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Pro Xaa Xaa Xaa Xaa Xaa Gly Xaa
50 55 60
Arg Trp Xaa Xaa Xaa Xaa Xaa Xaa Leu Xaa Xaa Xaa Pro Glu Leu Asp
65 70 75 80
Trp Xaa Xaa Lys Xaa Xaa Pro Leu Gly Ala Arg Xaa Xaa Xaa Xaa Pro
85 90 95
<210> 32
<211> 57
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислот 4 для
гиспидин-гидроксилаз
<220>
<221> MISC_FEATURE
<222> (1)..(57)
<223> X - любая аминокислота
<400> 32
Arg Thr Ile Xaa Xaa Tyr Ala Cys Arg Xaa Xaa Xaa Xaa Xaa Asn Val
1 5 10 15
Leu Xaa Xaa His Xaa Asp Xaa Arg Xaa Gln Xaa Xaa Xaa Xaa Trp Xaa
20 25 30
Xaa Pro Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Asp Tyr His
35 40 45
Pro Arg Phe Xaa Xaa Leu Xaa Xaa Leu
50 55
<210> 33
<211> 83
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислот 5 для
гиспидин-гидроксилаз
<220>
<221> MISC_FEATURE
<222> (1)..(82)
<223> X - любая аминоксилота
<400> 33
Trp Gln Xaa Arg Val Xaa Pro Xaa Leu Xaa Xaa Trp Xaa Xaa Xaa Xaa
1 5 10 15
Xaa Cys Xaa Xaa Gly Asp Xaa Ala His Ala Ser Leu Pro Thr Xaa Gly
20 25 30
Gln Gly Phe Gly Xaa Gly Leu Glu Asp Ala Xaa Ala Leu Xaa Xaa Leu
35 40 45
Leu Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Arg Leu Xaa Xaa
50 55 60
Xaa Xaa Xaa Xaa Xaa Lys Xaa Arg Xaa Glu Xaa Xaa Xaa Xaa Glu Ser
65 70 75 80
Xaa Glu Gln
<210> 34
<211> 4832
<212> DNA
<213> Neonothopanus nambi
<400> 34
aaaaccatcc ttatattctc gctttgatgc tggctgtatg gaaacttgga ggcaccttcg 60
ctcctattga tgtccattct cctgccgaat tggtagctgg catgctgaac atagtctctc 120
cttcttgctt ggttattccg agctcagatg taactaatca aactcttgcg tgcgatctta 180
atatccccgt cgttgcattt cacccacatc aatccactat tcctgagctg aacaagaagt 240
acctcaccga ttctcaaatt tctccggatc ttcctttttc agatccaaac cggcctgctc 300
tgtacctctt cacttcgtcc gccacttctc gaagtaatct caaatgcgtg cctctcactc 360
acacctttat cttacgcaac agcctctcga agcgtgcatg gtgcaagcgt atgcgtccag 420
agacagactt tgacggcata cgcgttcttg gatgggcccc gtggtctcac gtcctagcac 480
acatgcaaga catcggacca ctcaccttac ttaatgccgg atgctacgtt tttgcgacta 540
ctccatccac gtaccctacg gaattgaagg acgacaggga cctgatatct tgcgcggcaa 600
atgctatcat gtacaagggc gtcaagtcat ttgcttgtct tccctttgta ctcggagggc 660
tgaaggcatt atgcgagtct gagccatccg tgaaggcgca tctacaggtc gaggagagag 720
ctcaactcct gaagtctctg caacacatgg aaattcttga gtgtggaggt gccatgctcg 780
aagcaagtgt tgcgtcttgg gctattgaga actgcattcc catttcgatc ggtattggta 840
tgacggagac tggtggagcg ctctttgcag gccccgttca ggccatcaaa accgggtttt 900
cttcagagga taaattcatt gaagatgcta cttacttgct cgttaaggat gatcatgaga 960
gtcatgctga ggaggatatt aacgagggtg aactagttgt gaaaagtaaa atgctcccac 1020
gaggctacct tggctatagt gatccttcct tctcagtcga cgatgctggc tgggttacat 1080
ttagaacagg agacagatac agcgttacac ctgacggaaa gttttcctgg ctgggccgga 1140
acactgattt cattcagatg accagtggtg agacgctgga tccccgacca attgagagct 1200
cgctctgcga aagttctctt atttctagag catgcgttat cggagataaa tttctcaacg 1260
ggcctgctgc tgctgtttgt gcgatcattg agcttgagcc cacagcggtg gaaaaaggac 1320
aagctcactc gcgtgagata gcaagagttt tcgcacctat taatcgagac ctaccgcctc 1380
ctcttaggat tgcatggtcg cacgttttgg ttctccagcc ctcggagaag ataccgatga 1440
cgaagaaggg taccatcttc cgcaagaaaa ttgagcaggt gtttggctct gcgttgggtg 1500
gcagctctgg agataactct caagccactg cggatgctgg cgttgttcga cgagacgagt 1560
tatcgaacac tgtcaagcac ataattagcc gtgttttagg agtttccgat gacgaattac 1620
tttggacgct atcatttgcg gagttaggaa tgacgtcagc actagccact cgcatcgcca 1680
acgagttgaa cgaagtttta gttggagtta atctccctat caacgcttgc tatatacatg 1740
tcgaccttcc ttctctaagc aatgccgtct atgcgaaact tgcacacctc aagttaccag 1800
atcgtactcc cgaacccagg caagcccctg tcgaaaactc tggtgggaag gagatcgttg 1860
tcgttggcca ggcctttcgt cttcctggct caataaacga tgtcgcctct cttcgagacg 1920
cattcctggc gagacaagca tcatccatta tcactgaaat accatccgat cgctgggacc 1980
acgccagctt ctatcccaag gatatacgtt tcaacaaggc tggccttgtg gatatagcca 2040
attatgatca tagctttttc ggactgacgg caaccgaagc gctctatctg tcgccaacta 2100
tgcgtctagc attagaagtt tcgtttgaag cgctagagaa tgctaatatc ccggtgtcac 2160
aactcaaggg ttcgcaaaca gcggtttatg ttgctactac agatgacgga tttgagaccc 2220
ttttgaatgc cgaggccggc tatgatgctt atacaagatt ctatggcact ggtcgagcag 2280
caagtacagc gagcgggcgc ataagctgtc ttcttgatgt ccatggaccc tctattactg 2340
ttgatacggc atgcagtgga ggggctgttt gtattgacca agcaatcgac tatctacaat 2400
catcgagtgc agcagacacc gctatcatat gtgctagtaa cacgcactgc tggccaggct 2460
cgttcaggtt tctttccgca caagggatgg tatccccagg aggacgatgc gcgacattta 2520
caactgatgc tgatggctac gtgccctctg agggcgcggt cgccttcata ttgaaaaccc 2580
gagaagcagc tatgcgtgac aaggacacta tcctcgcgac aatcaaagcg acacagatat 2640
cgcacaatgg ccgatctcaa ggtcttgtgg caccgaatgt caactcgcaa gctgaccttc 2700
atcgctcgtt gcttcaaaaa gctggcctta gcccggctga tatccgtttc attgaagctc 2760
atgggacagg aacgtcactg ggagacctct cagaaattca agctataaat gatgcttata 2820
cctcctctca gccgcgcacg accggcccac tcatagtcag cgcttccaaa acggtcattg 2880
gtcataccga accagctggc cccttggtcg gtatgctgtc ggtcttgaac tctttcaaag 2940
aaggcgccgt ccctggtctc gcccatctta ccgcagacaa tttgaatccc tcgctggact 3000
gttcttctgt gccacttctc attccctatc aacctgttca cctggctgca cccaagcctc 3060
accgagctgc tgtaaggtca tacggctttt caggtaccct gggcggcatc gttctagagg 3120
ctcctgacga agaaagatta gaagaagagc tgccaaatga caagcccatg ttgttcgtcg 3180
tcagcgcaaa gacacataca gcactaatcg aatacctggg gcggtatctc gagttcctct 3240
tgcaggcgaa cccccaagat ttttgtgaca tttgttatac aagctgcgtt gggcgggagc 3300
actatagata tcgctatgct tgtgtagcaa atgatatgga ggacctcata ggccaactcc 3360
agaaacgttt gggcagcaag gtgccgccaa agccgtcata caaacgcggt gctttggcct 3420
ttgccttttc tggtcagggt acacaattcc gagggatggc gacagagctt gcaaaagcgt 3480
actccggctt ccgaaagatc gtgtcggatc tcgcaaagag agctagcgag ttgtcaggtc 3540
atgccattga ccgttttctt cttgcatatg acataggcgc tgaaaatgta gctcctgata 3600
gtgaggcaga ccagatttgc atctttgtgt atcagtgttc tgtccttcgc tggctgcaga 3660
ctatggggat tagacccagt gcagtgatag gccatagcct cggggagatc tcagcttctg 3720
tggcggcagg agcactttct cttgactccg ctttggatct tgtcatctca cgagctcgcc 3780
ttttgcgctc ttcggcaagt gctcctgcag gaatggcagc tatgtctgcc tcgcaagacg 3840
aggttgtgga gttgattggg aaactagacc tcgacaaggc taattcgctc agcgtttcgg 3900
tcataaatgg tccccaaaat actgtcgtgt ccggctcttc agcggctatt gaaagcatag 3960
tggctttagc gaaagggaga aagatcaaag cgtctgccct gaatatcaat caagcttttc 4020
atagtccata cgtcgacagt gccgtccctg gtctccgtgc ttggtcagaa aagcatatct 4080
cctcagctcg gccattgcaa attccgctgt attcaacgtt gttgggagca caaatctctg 4140
agggagagat gttgaatcca gatcactggg tcgaccatgc acggaagcct gtacagttcg 4200
cacaagcagc cacaaccatg aaagaatcct tcaccggagt catcatagat atcggccctc 4260
aagtagtggc ttggtcactt ctgctctcga acgggctcac gtccgtgact gcgctcgctg 4320
cgaaaagagg gagaagtcaa caggtggctt tcttaagcgc cttggcggat ttgtatcaag 4380
attacggtgt tgttcctgat tttgtcgggc tttatgctca gcaggaagat gcttcgaggt 4440
tgaagaagac ggatatcttg acgtatccgt tccagcgggg cgaagagact ctttctagtg 4500
gttctagcac tccgacattg gaaaacacgg atttggattc cggtaaggaa ttacttatgg 4560
gaccgactcg ggggttgtta cgcgcggacg acttgcgtga cagtatcgtt tcttctgtga 4620
aggatgttct ggaactcaag tcaaatgaag acctcgattt gtctgaaagt ctgaatgcgc 4680
ttggtatgga ctcgatcatg ttcgctcagt tacggaagcg tattggggaa ggactcggat 4740
tgaatgttcc gatggttttt ctgtcggacg cgttttctat tggtgagatg gttagtaatc 4800
ttgtggaaca ggcggaggcg tctgaggaca at 4832
<210> 35
<211> 1678
<212> PRT
<213> Neonothopanus nambi
<400> 35
Met Asn Ser Ser Lys Asn Pro Pro Ser Thr Leu Leu Asp Val Phe Leu
1 5 10 15
Asp Thr Ala Arg Asn Leu Asp Thr Ala Leu Arg Asn Val Leu Glu Cys
20 25 30
Gly Glu His Arg Trp Ser Tyr Arg Glu Leu Asp Thr Val Ser Ser Ala
35 40 45
Leu Ala Gln His Leu Arg Tyr Thr Val Gly Leu Ser Pro Thr Val Ala
50 55 60
Val Ile Ser Glu Asn His Pro Tyr Ile Leu Ala Leu Met Leu Ala Val
65 70 75 80
Trp Lys Leu Gly Gly Thr Phe Ala Pro Ile Asp Val His Ser Pro Ala
85 90 95
Glu Leu Val Ala Gly Met Leu Asn Ile Val Ser Pro Ser Cys Leu Val
100 105 110
Ile Pro Ser Ser Asp Val Thr Asn Gln Thr Leu Ala Cys Asp Leu Asn
115 120 125
Ile Pro Val Val Ala Phe His Pro His Gln Ser Thr Ile Pro Glu Leu
130 135 140
Asn Lys Lys Tyr Leu Thr Asp Ser Gln Ile Ser Pro Asp Leu Pro Phe
145 150 155 160
Ser Asp Pro Asn Arg Pro Ala Leu Tyr Leu Phe Thr Ser Ser Ala Thr
165 170 175
Ser Arg Ser Asn Leu Lys Cys Val Pro Leu Thr His Thr Phe Ile Leu
180 185 190
Arg Asn Ser Leu Ser Lys Arg Ala Trp Cys Lys Arg Met Arg Pro Glu
195 200 205
Thr Asp Phe Asp Gly Ile Arg Val Leu Gly Trp Ala Pro Trp Ser His
210 215 220
Val Leu Ala His Met Gln Asp Ile Gly Pro Leu Thr Leu Leu Asn Ala
225 230 235 240
Gly Cys Tyr Val Phe Ala Thr Thr Pro Ser Thr Tyr Pro Thr Glu Leu
245 250 255
Lys Asp Asp Arg Asp Leu Ile Ser Cys Ala Ala Asn Ala Ile Met Tyr
260 265 270
Lys Gly Val Lys Ser Phe Ala Cys Leu Pro Phe Val Leu Gly Gly Leu
275 280 285
Lys Ala Leu Cys Glu Ser Glu Pro Ser Val Lys Ala His Leu Gln Val
290 295 300
Glu Glu Arg Ala Gln Leu Leu Lys Ser Leu Gln His Met Glu Ile Leu
305 310 315 320
Glu Cys Gly Gly Ala Met Leu Glu Ala Ser Val Ala Ser Trp Ala Ile
325 330 335
Glu Asn Cys Ile Pro Ile Ser Ile Gly Ile Gly Met Thr Glu Thr Gly
340 345 350
Gly Ala Leu Phe Ala Gly Pro Val Gln Ala Ile Lys Thr Gly Phe Ser
355 360 365
Ser Glu Asp Lys Phe Ile Glu Asp Ala Thr Tyr Leu Leu Val Lys Asp
370 375 380
Asp His Glu Ser His Ala Glu Glu Asp Ile Asn Glu Gly Glu Leu Val
385 390 395 400
Val Lys Ser Lys Met Leu Pro Arg Gly Tyr Leu Gly Tyr Ser Asp Pro
405 410 415
Ser Phe Ser Val Asp Asp Ala Gly Trp Val Thr Phe Arg Thr Gly Asp
420 425 430
Arg Tyr Ser Val Thr Pro Asp Gly Lys Phe Ser Trp Leu Gly Arg Asn
435 440 445
Thr Asp Phe Ile Gln Met Thr Ser Gly Glu Thr Leu Asp Pro Arg Pro
450 455 460
Ile Glu Ser Ser Leu Cys Glu Ser Ser Leu Ile Ser Arg Ala Cys Val
465 470 475 480
Ile Gly Asp Lys Phe Leu Asn Gly Pro Ala Ala Ala Val Cys Ala Ile
485 490 495
Ile Glu Leu Glu Pro Thr Ala Val Glu Lys Gly Gln Ala His Ser Arg
500 505 510
Glu Ile Ala Arg Val Phe Ala Pro Ile Asn Arg Asp Leu Pro Pro Pro
515 520 525
Leu Arg Ile Ala Trp Ser His Val Leu Val Leu Gln Pro Ser Glu Lys
530 535 540
Ile Pro Met Thr Lys Lys Gly Thr Ile Phe Arg Lys Lys Ile Glu Gln
545 550 555 560
Val Phe Gly Ser Ala Leu Gly Gly Ser Ser Gly Asp Asn Ser Gln Ala
565 570 575
Thr Ala Asp Ala Gly Val Val Arg Arg Asp Glu Leu Ser Asn Thr Val
580 585 590
Lys His Ile Ile Ser Arg Val Leu Gly Val Ser Asp Asp Glu Leu Leu
595 600 605
Trp Thr Leu Ser Phe Ala Glu Leu Gly Met Thr Ser Ala Leu Ala Thr
610 615 620
Arg Ile Ala Asn Glu Leu Asn Glu Val Leu Val Gly Val Asn Leu Pro
625 630 635 640
Ile Asn Ala Cys Tyr Ile His Val Asp Leu Pro Ser Leu Ser Asn Ala
645 650 655
Val Tyr Ala Lys Leu Ala His Leu Lys Leu Pro Asp Arg Thr Pro Glu
660 665 670
Pro Arg Gln Ala Pro Val Glu Asn Ser Gly Gly Lys Glu Ile Val Val
675 680 685
Val Gly Gln Ala Phe Arg Leu Pro Gly Ser Ile Asn Asp Val Ala Ser
690 695 700
Leu Arg Asp Ala Phe Leu Ala Arg Gln Ala Ser Ser Ile Ile Thr Glu
705 710 715 720
Ile Pro Ser Asp Arg Trp Asp His Ala Ser Phe Tyr Pro Lys Asp Ile
725 730 735
Arg Phe Asn Lys Ala Gly Leu Val Asp Ile Ala Asn Tyr Asp His Ser
740 745 750
Phe Phe Gly Leu Thr Ala Thr Glu Ala Leu Tyr Leu Ser Pro Thr Met
755 760 765
Arg Leu Ala Leu Glu Val Ser Phe Glu Ala Leu Glu Asn Ala Asn Ile
770 775 780
Pro Val Ser Gln Leu Lys Gly Ser Gln Thr Ala Val Tyr Val Ala Thr
785 790 795 800
Thr Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Glu Ala Gly Tyr Asp
805 810 815
Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Ala Ser Thr Ala Ser
820 825 830
Gly Arg Ile Ser Cys Leu Leu Asp Val His Gly Pro Ser Ile Thr Val
835 840 845
Asp Thr Ala Cys Ser Gly Gly Ala Val Cys Ile Asp Gln Ala Ile Asp
850 855 860
Tyr Leu Gln Ser Ser Ser Ala Ala Asp Thr Ala Ile Ile Cys Ala Ser
865 870 875 880
Asn Thr His Cys Trp Pro Gly Ser Phe Arg Phe Leu Ser Ala Gln Gly
885 890 895
Met Val Ser Pro Gly Gly Arg Cys Ala Thr Phe Thr Thr Asp Ala Asp
900 905 910
Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys Thr Arg
915 920 925
Glu Ala Ala Met Arg Asp Lys Asp Thr Ile Leu Ala Thr Ile Lys Ala
930 935 940
Thr Gln Ile Ser His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn
945 950 955 960
Val Asn Ser Gln Ala Asp Leu His Arg Ser Leu Leu Gln Lys Ala Gly
965 970 975
Leu Ser Pro Ala Asp Ile Arg Phe Ile Glu Ala His Gly Thr Gly Thr
980 985 990
Ser Leu Gly Asp Leu Ser Glu Ile Gln Ala Ile Asn Asp Ala Tyr Thr
995 1000 1005
Ser Ser Gln Pro Arg Thr Thr Gly Pro Leu Ile Val Ser Ala Ser
1010 1015 1020
Lys Thr Val Ile Gly His Thr Glu Pro Ala Gly Pro Leu Val Gly
1025 1030 1035
Met Leu Ser Val Leu Asn Ser Phe Lys Glu Gly Ala Val Pro Gly
1040 1045 1050
Leu Ala His Leu Thr Ala Asp Asn Leu Asn Pro Ser Leu Asp Cys
1055 1060 1065
Ser Ser Val Pro Leu Leu Ile Pro Tyr Gln Pro Val His Leu Ala
1070 1075 1080
Ala Pro Lys Pro His Arg Ala Ala Val Arg Ser Tyr Gly Phe Ser
1085 1090 1095
Gly Thr Leu Gly Gly Ile Val Leu Glu Ala Pro Asp Glu Glu Arg
1100 1105 1110
Leu Glu Glu Glu Leu Pro Asn Asp Lys Pro Met Leu Phe Val Val
1115 1120 1125
Ser Ala Lys Thr His Thr Ala Leu Ile Glu Tyr Leu Gly Arg Tyr
1130 1135 1140
Leu Glu Phe Leu Leu Gln Ala Asn Pro Gln Asp Phe Cys Asp Ile
1145 1150 1155
Cys Tyr Thr Ser Cys Val Gly Arg Glu His Tyr Arg Tyr Arg Tyr
1160 1165 1170
Ala Cys Val Ala Asn Asp Met Glu Asp Leu Ile Gly Gln Leu Gln
1175 1180 1185
Lys Arg Leu Gly Ser Lys Val Pro Pro Lys Pro Ser Tyr Lys Arg
1190 1195 1200
Gly Ala Leu Ala Phe Ala Phe Ser Gly Gln Gly Thr Gln Phe Arg
1205 1210 1215
Gly Met Ala Thr Glu Leu Ala Lys Ala Tyr Ser Gly Phe Arg Lys
1220 1225 1230
Ile Val Ser Asp Leu Ala Lys Arg Ala Ser Glu Leu Ser Gly His
1235 1240 1245
Ala Ile Asp Arg Phe Leu Leu Ala Tyr Asp Ile Gly Ala Glu Asn
1250 1255 1260
Val Ala Pro Asp Ser Glu Ala Asp Gln Ile Cys Ile Phe Val Tyr
1265 1270 1275
Gln Cys Ser Val Leu Arg Trp Leu Gln Thr Met Gly Ile Arg Pro
1280 1285 1290
Ser Ala Val Ile Gly His Ser Leu Gly Glu Ile Ser Ala Ser Val
1295 1300 1305
Ala Ala Gly Ala Leu Ser Leu Asp Ser Ala Leu Asp Leu Val Ile
1310 1315 1320
Ser Arg Ala Arg Leu Leu Arg Ser Ser Ala Ser Ala Pro Ala Gly
1325 1330 1335
Met Ala Ala Met Ser Ala Ser Gln Asp Glu Val Val Glu Leu Ile
1340 1345 1350
Gly Lys Leu Asp Leu Asp Lys Ala Asn Ser Leu Ser Val Ser Val
1355 1360 1365
Ile Asn Gly Pro Gln Asn Thr Val Val Ser Gly Ser Ser Ala Ala
1370 1375 1380
Ile Glu Ser Ile Val Ala Leu Ala Lys Gly Arg Lys Ile Lys Ala
1385 1390 1395
Ser Ala Leu Asn Ile Asn Gln Ala Phe His Ser Pro Tyr Val Asp
1400 1405 1410
Ser Ala Val Pro Gly Leu Arg Ala Trp Ser Glu Lys His Ile Ser
1415 1420 1425
Ser Ala Arg Pro Leu Gln Ile Pro Leu Tyr Ser Thr Leu Leu Gly
1430 1435 1440
Ala Gln Ile Ser Glu Gly Glu Met Leu Asn Pro Asp His Trp Val
1445 1450 1455
Asp His Ala Arg Lys Pro Val Gln Phe Ala Gln Ala Ala Thr Thr
1460 1465 1470
Met Lys Glu Ser Phe Thr Gly Val Ile Ile Asp Ile Gly Pro Gln
1475 1480 1485
Val Val Ala Trp Ser Leu Leu Leu Ser Asn Gly Leu Thr Ser Val
1490 1495 1500
Thr Ala Leu Ala Ala Lys Arg Gly Arg Ser Gln Gln Val Ala Phe
1505 1510 1515
Leu Ser Ala Leu Ala Asp Leu Tyr Gln Asp Tyr Gly Val Val Pro
1520 1525 1530
Asp Phe Val Gly Leu Tyr Ala Gln Gln Glu Asp Ala Ser Arg Leu
1535 1540 1545
Lys Lys Thr Asp Ile Leu Thr Tyr Pro Phe Gln Arg Gly Glu Glu
1550 1555 1560
Thr Leu Ser Ser Gly Ser Ser Thr Pro Thr Leu Glu Asn Thr Asp
1565 1570 1575
Leu Asp Ser Gly Lys Glu Leu Leu Met Gly Pro Thr Arg Gly Leu
1580 1585 1590
Leu Arg Ala Asp Asp Leu Arg Asp Ser Ile Val Ser Ser Val Lys
1595 1600 1605
Asp Val Leu Glu Leu Lys Ser Asn Glu Asp Leu Asp Leu Ser Glu
1610 1615 1620
Ser Leu Asn Ala Leu Gly Met Asp Ser Ile Met Phe Ala Gln Leu
1625 1630 1635
Arg Lys Arg Ile Gly Glu Gly Leu Gly Leu Asn Val Pro Met Val
1640 1645 1650
Phe Leu Ser Asp Ala Phe Ser Ile Gly Glu Met Val Ser Asn Leu
1655 1660 1665
Val Glu Gln Ala Glu Ala Ser Glu Asp Asn
1670 1675
<210> 36
<211> 4512
<212> DNA
<213> Panellus stipticus
<400> 36
atgcctcctg ctccttcctc catccttgat gtgttcaccg agactgcata caatcctcgc 60
acctccaacc gtcctgtagt agaatgtggc gagcacctct ggacatactc acaacttgaa 120
gcagtttcca atgccatgtc gcaagacctg gagaactcga tcggtcttta cgcgaaggtc 180
gcttttgtcg gtgaaaacca tccatttgtt ttcgctctca tgcttgcggt ctggaaaatt 240
gctggcacat tcatccccat tgatgcgcac attcctcccg ccctcctaga tggcatggtc 300
gacattgtga agccgatgcg catctatgta tcatcggccg atacctctaa ttcctcctgg 360
gcctcagaac tcgcggtcga gtccaaactc gcgtggtggc gacgcatgca gccaagcatc 420
aacctagaca acacccgagt cctcggctgg gccccgtggt cgcatgtatt atcccacatg 480
caggacattg gcaccgctac cattctcacc gcaggctgtt acgtctttgc ctctatccct 540
tccacatatc agcttcagca ggcgccaaca gatcttacga cccaagtcat caacggtatc 600
ctcaataaaa acatctcggc gcttgctgcc cttccatttg ttttcggcgg tatcaaagca 660
gcgtgcgagt cgggcgatct ggatgtggag gcacttctgg gtgccctgcg ccgcatgacg 720
atgctcgaat gtggcggggc tgcgctcgac cctgcaattg caaattggac ggatataaat 780
ggtgtatcgc tcatggttgg gattggaatg acggaaacgg gtggtgcaat cttcgcgggg 840
agggcgaaag actcgctctc cgggtttctt gctgagggcc tgatctcaga tgccagaatt 900
gagcttgaca agggtaaatc tgatggctcg gatgagggag agcttgttgt cacaagcaag 960
ctacttccac atggctacat tggcttcgat gacgggtcat tttccgtgga tgcgcaaggg 1020
tgggtgacgt tcaagacaag ggattgctat cgtgtcaagg actcgaagtt tatttggcta 1080
ggccgggcca ctgattacat tcaggcgagc acatctctcc ttcctcagcg ctttaaacat 1140
gaactgcgct atcagatgac aagcggcgaa tcccttgacc cgcgtcccct cgaaaatttc 1200
ttacgctccg ccgagttcat ctccaatgtg tgcgtcatag gtgacaactt cctccggggt 1260
gcctccactt ctgtgtgggc cgttatcgag ctcacggaca gcgcgcaccg tctggatgcc 1320
gcttcagcga gaaagcaggt ggcgcgcgtg ctggcgccgc tcaatggtgg cctcccaccc 1380
gctctccgga tctcgatgtc ctcggtgttg atattgagcg gatcacagaa aattccgcgc 1440
acgaagaagg gcgaaatctt ccgtaagcag attgaggatc tgtttggtgc cgcgatgagc 1500
atgccgcctg aggctgagcc ggctctggag gatgaactaa caagtattgt tggaaatgtc 1560
ctcaacatat cggacagcga catgttgacc tcgatgactt ttgccgaact tggaatgacc 1620
tctgttctcg cagtaaaaat ctcagcaagg ctcaacgagc accttgctgg gcgggccgtc 1680
ctcccggcca acatctgtta catctacatc gatactccat cactgattgc cggcatccgg 1740
aacttccttt cgccggcatc ttctgatcaa gagccatcga actttgccac cacggcagac 1800
aagaaggacg aaatcgtcat cataggcaaa gccttccggc ttcccggcgg gatcaacgac 1860
gactctgctc tctgggctgc tcttatgggc aagaacgact ctgttattgc agacatcccg 1920
ccagaccgtt gggatcatgc tagcttctat cccgcccaca tctgcttgcg caaggccggg 1980
cttatagata tgtccagcta tgactatggg ttctttggcc tttcggcgac tgaggcgtac 2040
tatgtgtcgc ccaccatgcg cgcagcgctc gaggtggcgt tcgaagcgct ggaggatgcg 2100
aacatcccgg tgtcaagaat caaggggaca aatacgagtg tttttgttgc aacgaaagat 2160
gatggatttg agacattgct gaatgcggcg catggatttg atgatgctga cggatacgtc 2220
ccttcagaag gcgccgtcgc ttttatactg aagacacgga cggcggcgga gagggatggg 2280
gatcgaatta tggccatcat caaagccacg gaagtctcgc ataatggaag atctcaggga 2340
ctcgccgcgc cgaacgtcaa ggcgcaagcc gctcttcata gagcagtctt gcgcaaagct 2400
aagctcgacc ctctggacat ccatttcatt gaagcccacg gaactggaac accgctgggc 2460
gatctttgtg aaatacaagg cataaatgaa gcctttgtct ccgcacgtcc acgtgcggag 2520
gatccactca ttgtcagcgc ctcaaagtct tcccttgggc acaccgaacc ttcggctgga 2580
ttggttggga tgctatctgt gttgatggcc ttgaagcacg gcatcgtgcc tgggttgctc 2640
catctccgag cggacaatgc taaccaccaa ctggacctga cacaagttcc acttcgtata 2700
tcaccggaac ctgtagtcat cgccgcatcc aagccgcatc acgccatggt gctatcctat 2760
ggattttcag gtacattggc agacattgtt ttggagagtc cggaagaacc atcgtcccca 2820
aacccgggag ccgcgggccc aatgatattt gtcctcagcg cgaagacttc cgcggctctg 2880
tcggcatata tcaaggctta cattgcattt ctacagaatg cagacgcgca cgagttttac 2940
aacatctgct acaccgcctg cgttggaaga gaacattaca aacacagatt tgcttgcgtt 3000
gcaaatgacc ttgctgatct gattcgccaa ttacaagact gtgcgagtgc gctggctcca 3060
accaaaagta gtactggtgc cttggcgttc gcgttccctg gccaaggcgt gcaatttcca 3120
ggcatggccg ctgcacttgc taaaaggcat tccatatttc gcgactatgt catggaattc 3180
ggtgatagag cacaagatct ttgtggcttg cccatcgcaa agatgttgct ggacgtggat 3240
gcagcagagg aagaagatat ccacagtgac gtagaccaga tttgcgtctt tgtctatcag 3300
tattcgatgt gtcgatggct tagggagctc gggctcgagg caagtgcggt tatcgggcac 3360
agtttgggtg aaataacggc cgcacttatc ggggacgcat ttacatttga agtggctctc 3420
gatctcgttg tcactcgagg acggctactc cgcccttctc aagggaatcc aggcgggatg 3480
gctgcgctgg catgccccga ggagaatgtc ccggcgattt tggaccaatg tcgtgtggac 3540
agtaccatta gcgtctccgt tatcaatggt ccgaggagcc tttgtgtatc cggagcttcc 3600
aacgacatcg acgagtttgt caagatggca aaacggcaaa acatcaaagc gactcgactg 3660
agggtggacc aaggatttca tagccctcga gttgatagtg ccgcggttgg actgcgtgca 3720
tggtcaggtt ctttttccaa atcatttcag ccgttgcgca tcacattata ctctacttct 3780
ctgggtgctg caatctcgaa aggagagatt ttgaatcaga cgcattgggc cgatcacgtc 3840
cgccgtccgg tcatattctc aaaagcagca gcagccatcc tcgaggacaa gtccattggc 3900
gcgatcctgg atatcggacc acagacggtg gcatggtctc tccttctggc gaacggctgc 3960
aacgtcgcgt cagctgttgc cctgtccggc cgaagagtac aagatcagga aacagccttt 4020
ttatctgcac tggcgaatct gtatcaaaat cacggggtga cgccgaattt tcgcgtattt 4080
tatgctcacc aggcagtcca ggcgcgctat agaaccgtgg acatcccgaa gtatcccttc 4140
caacgccgac atcgatatcc atcctacatt ccatcgcgca atgccacggg tgccaacaga 4200
ctgaaagaac cattccgtag cgacctggat gaaccggctc aagacacgga gcacaccgcg 4260
gaactgagag tggacatgac tccggagaag ctccgggacg ccctgatgca ctgtgtgcgg 4320
gacacattgg aaggcgaaga ttttgatgaa tcggaatccc tcgtttcgcg tggaattgac 4380
tccattactt ttgcgggttt acggaagcgt gttcaagaac gacacggact taatctttcc 4440
atcattttct ggtctgatgg gttttctgtg aaagacatgg tcgacagcct catcgaacag 4500
cattttgtcc ac 4512
<210> 37
<211> 1504
<212> PRT
<213> Panellus stipticus
<400> 37
Met Pro Pro Ala Pro Ser Ser Ile Leu Asp Val Phe Thr Glu Thr Ala
1 5 10 15
Tyr Asn Pro Arg Thr Ser Asn Arg Pro Val Val Glu Cys Gly Glu His
20 25 30
Leu Trp Thr Tyr Ser Gln Leu Glu Ala Val Ser Asn Ala Met Ser Gln
35 40 45
Asp Leu Glu Asn Ser Ile Gly Leu Tyr Ala Lys Val Ala Phe Val Gly
50 55 60
Glu Asn His Pro Phe Val Phe Ala Leu Met Leu Ala Val Trp Lys Ile
65 70 75 80
Ala Gly Thr Phe Ile Pro Ile Asp Ala His Ile Pro Pro Ala Leu Leu
85 90 95
Asp Gly Met Val Asp Ile Val Lys Pro Met Arg Ile Tyr Val Ser Ser
100 105 110
Ala Asp Thr Ser Asn Ser Ser Trp Ala Ser Glu Leu Ala Val Glu Ser
115 120 125
Lys Leu Ala Trp Trp Arg Arg Met Gln Pro Ser Ile Asn Leu Asp Asn
130 135 140
Thr Arg Val Leu Gly Trp Ala Pro Trp Ser His Val Leu Ser His Met
145 150 155 160
Gln Asp Ile Gly Thr Ala Thr Ile Leu Thr Ala Gly Cys Tyr Val Phe
165 170 175
Ala Ser Ile Pro Ser Thr Tyr Gln Leu Gln Gln Ala Pro Thr Asp Leu
180 185 190
Thr Thr Gln Val Ile Asn Gly Ile Leu Asn Lys Asn Ile Ser Ala Leu
195 200 205
Ala Ala Leu Pro Phe Val Phe Gly Gly Ile Lys Ala Ala Cys Glu Ser
210 215 220
Gly Asp Leu Asp Val Glu Ala Leu Leu Gly Ala Leu Arg Arg Met Thr
225 230 235 240
Met Leu Glu Cys Gly Gly Ala Ala Leu Asp Pro Ala Ile Ala Asn Trp
245 250 255
Thr Asp Ile Asn Gly Val Ser Leu Met Val Gly Ile Gly Met Thr Glu
260 265 270
Thr Gly Gly Ala Ile Phe Ala Gly Arg Ala Lys Asp Ser Leu Ser Gly
275 280 285
Phe Leu Ala Glu Gly Leu Ile Ser Asp Ala Arg Ile Glu Leu Asp Lys
290 295 300
Gly Lys Ser Asp Gly Ser Asp Glu Gly Glu Leu Val Val Thr Ser Lys
305 310 315 320
Leu Leu Pro His Gly Tyr Ile Gly Phe Asp Asp Gly Ser Phe Ser Val
325 330 335
Asp Ala Gln Gly Trp Val Thr Phe Lys Thr Arg Asp Cys Tyr Arg Val
340 345 350
Lys Asp Ser Lys Phe Ile Trp Leu Gly Arg Ala Thr Asp Tyr Ile Gln
355 360 365
Ala Ser Thr Ser Leu Leu Pro Gln Arg Phe Lys His Glu Leu Arg Tyr
370 375 380
Gln Met Thr Ser Gly Glu Ser Leu Asp Pro Arg Pro Leu Glu Asn Phe
385 390 395 400
Leu Arg Ser Ala Glu Phe Ile Ser Asn Val Cys Val Ile Gly Asp Asn
405 410 415
Phe Leu Arg Gly Ala Ser Thr Ser Val Trp Ala Val Ile Glu Leu Thr
420 425 430
Asp Ser Ala His Arg Leu Asp Ala Ala Ser Ala Arg Lys Gln Val Ala
435 440 445
Arg Val Leu Ala Pro Leu Asn Gly Gly Leu Pro Pro Ala Leu Arg Ile
450 455 460
Ser Met Ser Ser Val Leu Ile Leu Ser Gly Ser Gln Lys Ile Pro Arg
465 470 475 480
Thr Lys Lys Gly Glu Ile Phe Arg Lys Gln Ile Glu Asp Leu Phe Gly
485 490 495
Ala Ala Met Ser Met Pro Pro Glu Ala Glu Pro Ala Leu Glu Asp Glu
500 505 510
Leu Thr Ser Ile Val Gly Asn Val Leu Asn Ile Ser Asp Ser Asp Met
515 520 525
Leu Thr Ser Met Thr Phe Ala Glu Leu Gly Met Thr Ser Val Leu Ala
530 535 540
Val Lys Ile Ser Ala Arg Leu Asn Glu His Leu Ala Gly Arg Ala Val
545 550 555 560
Leu Pro Ala Asn Ile Cys Tyr Ile Tyr Ile Asp Thr Pro Ser Leu Ile
565 570 575
Ala Gly Ile Arg Asn Phe Leu Ser Pro Ala Ser Ser Asp Gln Glu Pro
580 585 590
Ser Asn Phe Ala Thr Thr Ala Asp Lys Lys Asp Glu Ile Val Ile Ile
595 600 605
Gly Lys Ala Phe Arg Leu Pro Gly Gly Ile Asn Asp Asp Ser Ala Leu
610 615 620
Trp Ala Ala Leu Met Gly Lys Asn Asp Ser Val Ile Ala Asp Ile Pro
625 630 635 640
Pro Asp Arg Trp Asp His Ala Ser Phe Tyr Pro Ala His Ile Cys Leu
645 650 655
Arg Lys Ala Gly Leu Ile Asp Met Ser Ser Tyr Asp Tyr Gly Phe Phe
660 665 670
Gly Leu Ser Ala Thr Glu Ala Tyr Tyr Val Ser Pro Thr Met Arg Ala
675 680 685
Ala Leu Glu Val Ala Phe Glu Ala Leu Glu Asp Ala Asn Ile Pro Val
690 695 700
Ser Arg Ile Lys Gly Thr Asn Thr Ser Val Phe Val Ala Thr Lys Asp
705 710 715 720
Asp Gly Phe Glu Thr Leu Leu Asn Ala Ala His Gly Phe Asp Asp Ala
725 730 735
Asp Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys Thr
740 745 750
Arg Thr Ala Ala Glu Arg Asp Gly Asp Arg Ile Met Ala Ile Ile Lys
755 760 765
Ala Thr Glu Val Ser His Asn Gly Arg Ser Gln Gly Leu Ala Ala Pro
770 775 780
Asn Val Lys Ala Gln Ala Ala Leu His Arg Ala Val Leu Arg Lys Ala
785 790 795 800
Lys Leu Asp Pro Leu Asp Ile His Phe Ile Glu Ala His Gly Thr Gly
805 810 815
Thr Pro Leu Gly Asp Leu Cys Glu Ile Gln Gly Ile Asn Glu Ala Phe
820 825 830
Val Ser Ala Arg Pro Arg Ala Glu Asp Pro Leu Ile Val Ser Ala Ser
835 840 845
Lys Ser Ser Leu Gly His Thr Glu Pro Ser Ala Gly Leu Val Gly Met
850 855 860
Leu Ser Val Leu Met Ala Leu Lys His Gly Ile Val Pro Gly Leu Leu
865 870 875 880
His Leu Arg Ala Asp Asn Ala Asn His Gln Leu Asp Leu Thr Gln Val
885 890 895
Pro Leu Arg Ile Ser Pro Glu Pro Val Val Ile Ala Ala Ser Lys Pro
900 905 910
His His Ala Met Val Leu Ser Tyr Gly Phe Ser Gly Thr Leu Ala Asp
915 920 925
Ile Val Leu Glu Ser Pro Glu Glu Pro Ser Ser Pro Asn Pro Gly Ala
930 935 940
Ala Gly Pro Met Ile Phe Val Leu Ser Ala Lys Thr Ser Ala Ala Leu
945 950 955 960
Ser Ala Tyr Ile Lys Ala Tyr Ile Ala Phe Leu Gln Asn Ala Asp Ala
965 970 975
His Glu Phe Tyr Asn Ile Cys Tyr Thr Ala Cys Val Gly Arg Glu His
980 985 990
Tyr Lys His Arg Phe Ala Cys Val Ala Asn Asp Leu Ala Asp Leu Ile
995 1000 1005
Arg Gln Leu Gln Asp Cys Ala Ser Ala Leu Ala Pro Thr Lys Ser
1010 1015 1020
Ser Thr Gly Ala Leu Ala Phe Ala Phe Pro Gly Gln Gly Val Gln
1025 1030 1035
Phe Pro Gly Met Ala Ala Ala Leu Ala Lys Arg His Ser Ile Phe
1040 1045 1050
Arg Asp Tyr Val Met Glu Phe Gly Asp Arg Ala Gln Asp Leu Cys
1055 1060 1065
Gly Leu Pro Ile Ala Lys Met Leu Leu Asp Val Asp Ala Ala Glu
1070 1075 1080
Glu Glu Asp Ile His Ser Asp Val Asp Gln Ile Cys Val Phe Val
1085 1090 1095
Tyr Gln Tyr Ser Met Cys Arg Trp Leu Arg Glu Leu Gly Leu Glu
1100 1105 1110
Ala Ser Ala Val Ile Gly His Ser Leu Gly Glu Ile Thr Ala Ala
1115 1120 1125
Leu Ile Gly Asp Ala Phe Thr Phe Glu Val Ala Leu Asp Leu Val
1130 1135 1140
Val Thr Arg Gly Arg Leu Leu Arg Pro Ser Gln Gly Asn Pro Gly
1145 1150 1155
Gly Met Ala Ala Leu Ala Cys Pro Glu Glu Asn Val Pro Ala Ile
1160 1165 1170
Leu Asp Gln Cys Arg Val Asp Ser Thr Ile Ser Val Ser Val Ile
1175 1180 1185
Asn Gly Pro Arg Ser Leu Cys Val Ser Gly Ala Ser Asn Asp Ile
1190 1195 1200
Asp Glu Phe Val Lys Met Ala Lys Arg Gln Asn Ile Lys Ala Thr
1205 1210 1215
Arg Leu Arg Val Asp Gln Gly Phe His Ser Pro Arg Val Asp Ser
1220 1225 1230
Ala Ala Val Gly Leu Arg Ala Trp Ser Gly Ser Phe Ser Lys Ser
1235 1240 1245
Phe Gln Pro Leu Arg Ile Thr Leu Tyr Ser Thr Ser Leu Gly Ala
1250 1255 1260
Ala Ile Ser Lys Gly Glu Ile Leu Asn Gln Thr His Trp Ala Asp
1265 1270 1275
His Val Arg Arg Pro Val Ile Phe Ser Lys Ala Ala Ala Ala Ile
1280 1285 1290
Leu Glu Asp Lys Ser Ile Gly Ala Ile Leu Asp Ile Gly Pro Gln
1295 1300 1305
Thr Val Ala Trp Ser Leu Leu Leu Ala Asn Gly Cys Asn Val Ala
1310 1315 1320
Ser Ala Val Ala Leu Ser Gly Arg Arg Val Gln Asp Gln Glu Thr
1325 1330 1335
Ala Phe Leu Ser Ala Leu Ala Asn Leu Tyr Gln Asn His Gly Val
1340 1345 1350
Thr Pro Asn Phe Arg Val Phe Tyr Ala His Gln Ala Val Gln Ala
1355 1360 1365
Arg Tyr Arg Thr Val Asp Ile Pro Lys Tyr Pro Phe Gln Arg Arg
1370 1375 1380
His Arg Tyr Pro Ser Tyr Ile Pro Ser Arg Asn Ala Thr Gly Ala
1385 1390 1395
Asn Arg Leu Lys Glu Pro Phe Arg Ser Asp Leu Asp Glu Pro Ala
1400 1405 1410
Gln Asp Thr Glu His Thr Ala Glu Leu Arg Val Asp Met Thr Pro
1415 1420 1425
Glu Lys Leu Arg Asp Ala Leu Met His Cys Val Arg Asp Thr Leu
1430 1435 1440
Glu Gly Glu Asp Phe Asp Glu Ser Glu Ser Leu Val Ser Arg Gly
1445 1450 1455
Ile Asp Ser Ile Thr Phe Ala Gly Leu Arg Lys Arg Val Gln Glu
1460 1465 1470
Arg His Gly Leu Asn Leu Ser Ile Ile Phe Trp Ser Asp Gly Phe
1475 1480 1485
Ser Val Lys Asp Met Val Asp Ser Leu Ile Glu Gln His Phe Val
1490 1495 1500
His
<210> 38
<211> 4803
<212> DNA
<213> Panellus stipticus
<400> 38
atggcactgg tctctcccac ttgttcgtct cagatgcctc ctgctccttc ctccatcctt 60
gatgtgttca ccgagactgc atacaatcct cgcacctcca accgtcctgt agtagaatgt 120
ggcgagcacg tctggaccta ctcacaactt gaagcagttt ccaatgccat gtcgcaagac 180
ctggagaact cgatcggtct ttacgcgaag gtcgcttttg tcggtgaaaa ccatccattt 240
gttttcgctc tcatgcttgc agtctggaaa attgctggca cattcatccc cattgatgcg 300
cacattcctc ccgccctcct agatggcatg gtcgacattg tgaagccgat gtgcatctat 360
gtatcatcgg ccgatacctc taattcctcc tgggcctcag aactcgcggt cgaggttcgg 420
gtattccgtc cggaagaatc tacgattccg gctttgaacg aacactatgg aagatccagc 480
atcactcccg ctcagcatcg gccaatactc aacgtggtcc aggcagttcc cctgacacac 540
aaatttatcc tcagcaactg tcagtccaaa ctcgcgtggt ggcgacgcat gcagccaagc 600
atcaacctag acaacacccg agtcctcggc tgggccccgt ggtcgcatgt attatcccac 660
atgcaggaca ttggcaccgc taccattctc accgcaggct gttacgtctt tgcctctatc 720
ccttccacat atcagcttca gcaggcgcca acagatctta cgacccaagt catcaacggt 780
atcctcaata aaaacatctc ggcgcttgct gcccttccat ttgttttcgg cggtatcaaa 840
gcagcgtgcg agtcgggcga tctggatgtg gaggcacttc tgggtgccct gcgccgcatg 900
acgatgctcg aatgtggcgg ggctgcgctc gaccctgcaa ttgcaaattg gacggatata 960
aacggtgtat cgctcatggt tgggattgga atgacagaaa cgggcggtgc aatcttcgcg 1020
gggagggcga aagactcgct ctccgggttt cttgctgagg gtctgatctc agacgccaga 1080
attgagcttg acaagggtga atctgatggc tcggatggta cgacgttctc catcttctcg 1140
accactgccg gaattaaacc tgattgtcag agggagagct tgttgtcaca agcaagctac 1200
ttccacatgg ctacattggc ttcgatgacg ggtcattttc cgtggatgcg caagggtgac 1260
aacttcctcc ggggtgcctc cacttctgtg tgggccatta tcgagctcac ggacagcgcg 1320
caccgcctgg atgccgcttc agcgagaaag caggtggcgc gcgtactggc gccgctcaat 1380
ggtggcctcc cacccgctct ccggatctca atgtcctcgg tgttgatatt gagcggatca 1440
cagaaaattc cgcgcacgaa gaagggcgag atcttccgta agcagattga ggatctgttt 1500
ggtgccgcga tgagcatgcc gcctgaggct gagccggctc tggaggatga actaacaagt 1560
attgttggaa atgtcctcaa catatcggac agcgacatgt tgacctcgat gacttttgcc 1620
gaacttggaa tgacctctgt tctggcagta aaaatctcag caaggctcaa cgagcacctt 1680
gctgggcggg ccgtcctccc ggccaacatc tgttacatct acatcgatac tccatcactg 1740
attgccggca tccggaactt cctttcgccg acatcttctg atcaagagcc atcgaacttt 1800
gccaccacgg cagacaagaa ggacgagatc gtcatcatag gcaaagcctt tcggcttccc 1860
ggcgggatca acgacgactc tgctctctgg gctgctctta tgggcaagaa cgactctgtt 1920
attgcagaca tcccgccaga ccgttgggat catgctagct tctatcccgc ccacatctgc 1980
ttgcgcaagg ctgggcttat agatatgtcc agctatgact atgggttctt tggcctttcg 2040
gcgactgagg cgtactatgt gtcgcccacc atgcgcgcag cgctcgaggt ggcgttcgaa 2100
gcgctggagg atgcgaacat cccggtgtca agaattaagg ggacaaatac gagtgttttt 2160
gttgcaacga aagatgatgg atttgagaca ttgctgaatg cggcgcatgg atttgatgcg 2220
tatacccggt tctacgggac tgggcgggct ccaagtactg ccagtgggcg cataagctac 2280
cttcttgaca tccatgggcc ctcactcaca gtagatacgg cctgtagcgg aggaattgtc 2340
tgcattgatc aagatatacc agcgaattta tgtatcatag cgatcgcata cctccagtct 2400
ggcgccggtg aatcagccat cgaacgacaa tacaggtttc tcacggcgca gaacatggca 2460
tcgcccacta gccgctgttc caccttcact gcagatgctg acggatatgt cccttcagaa 2520
ggcgccgtcg cttttatact gaagacacgg actgcggcgg agagggatgg ggatcgaatt 2580
atggccatca tcaaagccac agaagtctcg cataatggaa gatctcaggg actcgccgcg 2640
ccgaacgtca aagcgcaagc cgctcttcat agagcagtct tgcgcaaagc taagctcgac 2700
cctctggaca tccatttcat tgaagcccac ggaactgttt taggaacacc gctgggtgat 2760
ctttgtgaaa tacaaggcat aaatgaagcc tttgtctccg cacgtccacg tgcggaggat 2820
ccactcattg tcagcgcctc caagtcttcc cttgggcaca ccgaaccttc ggctggattg 2880
gttgggatgc tatctgtgtt gatggccttg aagcacggca tcgtgcctgg gttgctccat 2940
ctccgagcgg acaatgctaa ccaccaactg gacctgacac gagtcccact gcgtatatca 3000
ccggaacctg tagtcatcgc cgcatccaag ccgcatcacg ccatggtgct gctcacagtc 3060
cgtacattgg cagacattgt tttggagagt ccggaagaac caccgtccca gaacccggga 3120
gccgcgggcc caatgatatt tgtcctcagc gcgaagactt ccgcggctct gtcggcatat 3180
atcaaggctt acattgcatt tctacagaat gcagacgcgc acgagtttta caacatctgc 3240
tacaccgcct gtgttggaag agaacattac aaacacagat ttgcttgcgt tgcaaatgac 3300
cttgctgatc tgattcgcca attacaagac tgtgcgagtg cgctggctcc aaccaaaagt 3360
agtactggtg ccttggcgtt cgcgttccct ggccaaggcg tgcaatttcc aggcatggcc 3420
gctgcacttg ctaaaaggca ttccatattt cgcgactatg tcatggaatt tggtcataga 3480
gcacaagatc tttgtggctt gcccatcgca aagatgttgc tggacgtgga tgcagcagag 3540
gaagaagata tccacagtga cgtagaccag atttgcgtct ttgtctatca gtattcgatg 3600
tgtcgatggc ttagggagct cgggctcgag gcaagtgcgg ttatcgggca cagtttgggc 3660
gaaataacag ccgcacttat cggggacgca tttacatttg aagtggctct cgatctcgtt 3720
gtcactcgag gacggctact ccgcccttct caagggaatc caggcgggat ggctgcgctg 3780
gcatgccccg aggagaatgt cccagcgatt ttggaccaat gtcgtgtgga cagtaccatt 3840
agcgtctccg ttatcaatgg tccgaggagc ctttgtgtat ccggagcttc caacgacatc 3900
gacgagtttg tcaagatggc aaaacggcaa aacatcaaag cgactcgact gagggtggac 3960
caaggatttc atagccctcg agttgatagt gccgcggttg gactgcgtga atggtcaggt 4020
tctttttcga aatcatttca gccgttgcgc atcacattat actctacgtc tctgggtgct 4080
gcaatctcga aaggagagat tttgactcag acacattggg ccgatcacgt ccgccgtccg 4140
gtcatattct caaaagcagc agcagccatc ctcgaggaca agtccattgg cgcgatcctg 4200
gatatcggac cacagacggt ggcatggtct ctccttctgg cgaacggctg caacgtcgcg 4260
tcagctgttg ccctgtccgg ccgaagagta caagatcagg aaacggcctt tttatctgca 4320
ctggcgaatc tgtatcaaaa tcacggggtg acgccgaatt ttcgcgtatt ttacgctcac 4380
caggcagtcc aggcgcgcta tagaaccgtg gacattccga agtatccctt ccaacgccga 4440
catcgatatc catcctacat tccatcgcgc aatgccacgg gtgccaacag actgaaagaa 4500
ccattccgta gcgacctgga tgaaccggct caagacacgg agcacaccgc ggaaatgaga 4560
gtggacatga ctccggagaa gctccgggac gccctgatgc actgtgtgcg ggacacactg 4620
gaaggcgaag attttgatga atcggaatcc ctcgtttcgc gtggaattga ctccattact 4680
tttgcgggtc tacggaagcg tgttcaagaa cgacacggac ttaatctttc catcattttc 4740
tggtctgatg ggttttctgt gaaagacatg gtcgacagcc tcatcgaaca gcattttgtc 4800
cac 4803
<210> 39
<211> 1601
<212> PRT
<213> Panellus stipticus
<400> 39
Met Ala Leu Val Ser Pro Thr Cys Ser Ser Gln Met Pro Pro Ala Pro
1 5 10 15
Ser Ser Ile Leu Asp Val Phe Thr Glu Thr Ala Tyr Asn Pro Arg Thr
20 25 30
Ser Asn Arg Pro Val Val Glu Cys Gly Glu His Val Trp Thr Tyr Ser
35 40 45
Gln Leu Glu Ala Val Ser Asn Ala Met Ser Gln Asp Leu Glu Asn Ser
50 55 60
Ile Gly Leu Tyr Ala Lys Val Ala Phe Val Gly Glu Asn His Pro Phe
65 70 75 80
Val Phe Ala Leu Met Leu Ala Val Trp Lys Ile Ala Gly Thr Phe Ile
85 90 95
Pro Ile Asp Ala His Ile Pro Pro Ala Leu Leu Asp Gly Met Val Asp
100 105 110
Ile Val Lys Pro Met Cys Ile Tyr Val Ser Ser Ala Asp Thr Ser Asn
115 120 125
Ser Ser Trp Ala Ser Glu Leu Ala Val Glu Val Arg Val Phe Arg Pro
130 135 140
Glu Glu Ser Thr Ile Pro Ala Leu Asn Glu His Tyr Gly Arg Ser Ser
145 150 155 160
Ile Thr Pro Ala Gln His Arg Pro Ile Leu Asn Val Val Gln Ala Val
165 170 175
Pro Leu Thr His Lys Phe Ile Leu Ser Asn Cys Gln Ser Lys Leu Ala
180 185 190
Trp Trp Arg Arg Met Gln Pro Ser Ile Asn Leu Asp Asn Thr Arg Val
195 200 205
Leu Gly Trp Ala Pro Trp Ser His Val Leu Ser His Met Gln Asp Ile
210 215 220
Gly Thr Ala Thr Ile Leu Thr Ala Gly Cys Tyr Val Phe Ala Ser Ile
225 230 235 240
Pro Ser Thr Tyr Gln Leu Gln Gln Ala Pro Thr Asp Leu Thr Thr Gln
245 250 255
Val Ile Asn Gly Ile Leu Asn Lys Asn Ile Ser Ala Leu Ala Ala Leu
260 265 270
Pro Phe Val Phe Gly Gly Ile Lys Ala Ala Cys Glu Ser Gly Asp Leu
275 280 285
Asp Val Glu Ala Leu Leu Gly Ala Leu Arg Arg Met Thr Met Leu Glu
290 295 300
Cys Gly Gly Ala Ala Leu Asp Pro Ala Ile Ala Asn Trp Thr Asp Ile
305 310 315 320
Asn Gly Val Ser Leu Met Val Gly Ile Gly Met Thr Glu Thr Gly Gly
325 330 335
Ala Ile Phe Ala Gly Arg Ala Lys Asp Ser Leu Ser Gly Phe Leu Ala
340 345 350
Glu Gly Leu Ile Ser Asp Ala Arg Ile Glu Leu Asp Lys Gly Glu Ser
355 360 365
Asp Gly Ser Asp Gly Thr Thr Phe Ser Ile Phe Ser Thr Thr Ala Gly
370 375 380
Ile Lys Pro Asp Cys Gln Arg Glu Ser Leu Leu Ser Gln Ala Ser Tyr
385 390 395 400
Phe His Met Ala Thr Leu Ala Ser Met Thr Gly His Phe Pro Trp Met
405 410 415
Arg Lys Gly Asp Asn Phe Leu Arg Gly Ala Ser Thr Ser Val Trp Ala
420 425 430
Ile Ile Glu Leu Thr Asp Ser Ala His Arg Leu Asp Ala Ala Ser Ala
435 440 445
Arg Lys Gln Val Ala Arg Val Leu Ala Pro Leu Asn Gly Gly Leu Pro
450 455 460
Pro Ala Leu Arg Ile Ser Met Ser Ser Val Leu Ile Leu Ser Gly Ser
465 470 475 480
Gln Lys Ile Pro Arg Thr Lys Lys Gly Glu Ile Phe Arg Lys Gln Ile
485 490 495
Glu Asp Leu Phe Gly Ala Ala Met Ser Met Pro Pro Glu Ala Glu Pro
500 505 510
Ala Leu Glu Asp Glu Leu Thr Ser Ile Val Gly Asn Val Leu Asn Ile
515 520 525
Ser Asp Ser Asp Met Leu Thr Ser Met Thr Phe Ala Glu Leu Gly Met
530 535 540
Thr Ser Val Leu Ala Val Lys Ile Ser Ala Arg Leu Asn Glu His Leu
545 550 555 560
Ala Gly Arg Ala Val Leu Pro Ala Asn Ile Cys Tyr Ile Tyr Ile Asp
565 570 575
Thr Pro Ser Leu Ile Ala Gly Ile Arg Asn Phe Leu Ser Pro Thr Ser
580 585 590
Ser Asp Gln Glu Pro Ser Asn Phe Ala Thr Thr Ala Asp Lys Lys Asp
595 600 605
Glu Ile Val Ile Ile Gly Lys Ala Phe Arg Leu Pro Gly Gly Ile Asn
610 615 620
Asp Asp Ser Ala Leu Trp Ala Ala Leu Met Gly Lys Asn Asp Ser Val
625 630 635 640
Ile Ala Asp Ile Pro Pro Asp Arg Trp Asp His Ala Ser Phe Tyr Pro
645 650 655
Ala His Ile Cys Leu Arg Lys Ala Gly Leu Ile Asp Met Ser Ser Tyr
660 665 670
Asp Tyr Gly Phe Phe Gly Leu Ser Ala Thr Glu Ala Tyr Tyr Val Ser
675 680 685
Pro Thr Met Arg Ala Ala Leu Glu Val Ala Phe Glu Ala Leu Glu Asp
690 695 700
Ala Asn Ile Pro Val Ser Arg Ile Lys Gly Thr Asn Thr Ser Val Phe
705 710 715 720
Val Ala Thr Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Ala His
725 730 735
Gly Phe Asp Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser
740 745 750
Thr Ala Ser Gly Arg Ile Ser Tyr Leu Leu Asp Ile His Gly Pro Ser
755 760 765
Leu Thr Val Asp Thr Ala Cys Ser Gly Gly Ile Val Cys Ile Asp Gln
770 775 780
Asp Ile Pro Ala Asn Leu Cys Ile Ile Ala Ile Ala Tyr Leu Gln Ser
785 790 795 800
Gly Ala Gly Glu Ser Ala Ile Glu Arg Gln Tyr Arg Phe Leu Thr Ala
805 810 815
Gln Asn Met Ala Ser Pro Thr Ser Arg Cys Ser Thr Phe Thr Ala Asp
820 825 830
Ala Asp Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys
835 840 845
Thr Arg Thr Ala Ala Glu Arg Asp Gly Asp Arg Ile Met Ala Ile Ile
850 855 860
Lys Ala Thr Glu Val Ser His Asn Gly Arg Ser Gln Gly Leu Ala Ala
865 870 875 880
Pro Asn Val Lys Ala Gln Ala Ala Leu His Arg Ala Val Leu Arg Lys
885 890 895
Ala Lys Leu Asp Pro Leu Asp Ile His Phe Ile Glu Ala His Gly Thr
900 905 910
Val Leu Gly Thr Pro Leu Gly Asp Leu Cys Glu Ile Gln Gly Ile Asn
915 920 925
Glu Ala Phe Val Ser Ala Arg Pro Arg Ala Glu Asp Pro Leu Ile Val
930 935 940
Ser Ala Ser Lys Ser Ser Leu Gly His Thr Glu Pro Ser Ala Gly Leu
945 950 955 960
Val Gly Met Leu Ser Val Leu Met Ala Leu Lys His Gly Ile Val Pro
965 970 975
Gly Leu Leu His Leu Arg Ala Asp Asn Ala Asn His Gln Leu Asp Leu
980 985 990
Thr Arg Val Pro Leu Arg Ile Ser Pro Glu Pro Val Val Ile Ala Ala
995 1000 1005
Ser Lys Pro His His Ala Met Val Leu Leu Thr Val Arg Thr Leu
1010 1015 1020
Ala Asp Ile Val Leu Glu Ser Pro Glu Glu Pro Pro Ser Gln Asn
1025 1030 1035
Pro Gly Ala Ala Gly Pro Met Ile Phe Val Leu Ser Ala Lys Thr
1040 1045 1050
Ser Ala Ala Leu Ser Ala Tyr Ile Lys Ala Tyr Ile Ala Phe Leu
1055 1060 1065
Gln Asn Ala Asp Ala His Glu Phe Tyr Asn Ile Cys Tyr Thr Ala
1070 1075 1080
Cys Val Gly Arg Glu His Tyr Lys His Arg Phe Ala Cys Val Ala
1085 1090 1095
Asn Asp Leu Ala Asp Leu Ile Arg Gln Leu Gln Asp Cys Ala Ser
1100 1105 1110
Ala Leu Ala Pro Thr Lys Ser Ser Thr Gly Ala Leu Ala Phe Ala
1115 1120 1125
Phe Pro Gly Gln Gly Val Gln Phe Pro Gly Met Ala Ala Ala Leu
1130 1135 1140
Ala Lys Arg His Ser Ile Phe Arg Asp Tyr Val Met Glu Phe Gly
1145 1150 1155
His Arg Ala Gln Asp Leu Cys Gly Leu Pro Ile Ala Lys Met Leu
1160 1165 1170
Leu Asp Val Asp Ala Ala Glu Glu Glu Asp Ile His Ser Asp Val
1175 1180 1185
Asp Gln Ile Cys Val Phe Val Tyr Gln Tyr Ser Met Cys Arg Trp
1190 1195 1200
Leu Arg Glu Leu Gly Leu Glu Ala Ser Ala Val Ile Gly His Ser
1205 1210 1215
Leu Gly Glu Ile Thr Ala Ala Leu Ile Gly Asp Ala Phe Thr Phe
1220 1225 1230
Glu Val Ala Leu Asp Leu Val Val Thr Arg Gly Arg Leu Leu Arg
1235 1240 1245
Pro Ser Gln Gly Asn Pro Gly Gly Met Ala Ala Leu Ala Cys Pro
1250 1255 1260
Glu Glu Asn Val Pro Ala Ile Leu Asp Gln Cys Arg Val Asp Ser
1265 1270 1275
Thr Ile Ser Val Ser Val Ile Asn Gly Pro Arg Ser Leu Cys Val
1280 1285 1290
Ser Gly Ala Ser Asn Asp Ile Asp Glu Phe Val Lys Met Ala Lys
1295 1300 1305
Arg Gln Asn Ile Lys Ala Thr Arg Leu Arg Val Asp Gln Gly Phe
1310 1315 1320
His Ser Pro Arg Val Asp Ser Ala Ala Val Gly Leu Arg Glu Trp
1325 1330 1335
Ser Gly Ser Phe Ser Lys Ser Phe Gln Pro Leu Arg Ile Thr Leu
1340 1345 1350
Tyr Ser Thr Ser Leu Gly Ala Ala Ile Ser Lys Gly Glu Ile Leu
1355 1360 1365
Thr Gln Thr His Trp Ala Asp His Val Arg Arg Pro Val Ile Phe
1370 1375 1380
Ser Lys Ala Ala Ala Ala Ile Leu Glu Asp Lys Ser Ile Gly Ala
1385 1390 1395
Ile Leu Asp Ile Gly Pro Gln Thr Val Ala Trp Ser Leu Leu Leu
1400 1405 1410
Ala Asn Gly Cys Asn Val Ala Ser Ala Val Ala Leu Ser Gly Arg
1415 1420 1425
Arg Val Gln Asp Gln Glu Thr Ala Phe Leu Ser Ala Leu Ala Asn
1430 1435 1440
Leu Tyr Gln Asn His Gly Val Thr Pro Asn Phe Arg Val Phe Tyr
1445 1450 1455
Ala His Gln Ala Val Gln Ala Arg Tyr Arg Thr Val Asp Ile Pro
1460 1465 1470
Lys Tyr Pro Phe Gln Arg Arg His Arg Tyr Pro Ser Tyr Ile Pro
1475 1480 1485
Ser Arg Asn Ala Thr Gly Ala Asn Arg Leu Lys Glu Pro Phe Arg
1490 1495 1500
Ser Asp Leu Asp Glu Pro Ala Gln Asp Thr Glu His Thr Ala Glu
1505 1510 1515
Met Arg Val Asp Met Thr Pro Glu Lys Leu Arg Asp Ala Leu Met
1520 1525 1530
His Cys Val Arg Asp Thr Leu Glu Gly Glu Asp Phe Asp Glu Ser
1535 1540 1545
Glu Ser Leu Val Ser Arg Gly Ile Asp Ser Ile Thr Phe Ala Gly
1550 1555 1560
Leu Arg Lys Arg Val Gln Glu Arg His Gly Leu Asn Leu Ser Ile
1565 1570 1575
Ile Phe Trp Ser Asp Gly Phe Ser Val Lys Asp Met Val Asp Ser
1580 1585 1590
Leu Ile Glu Gln His Phe Val His
1595 1600
<210> 40
<211> 5073
<212> DNA
<213> Neonothopanus gardneri
<400> 40
atgaattcca aagtgaatct tccctccact ttgcttgatg ttttcctcga gatcgctggc 60
gagccatcta ccgcttcgcg tgatgttttg gaatgtggcg agcacagatg gacttaccag 120
cagcttgacg ttgtttcatc tgctttagcc cagcatctca agtacactgt cggtctatct 180
cctacagtcg cagtgatcag cgaaaatcat ccttatgttt ttgccttgat cctggctgtg 240
tggaaagttg ggggcatttt cgcgcccctc gacgcacatg ctcctgctga gttggtagct 300
ggcatgttaa gcataatctc tccttcgtgc ttagtacttc agagcacaga tgtagctaat 360
caaactcttg cgtgtgatct cgatattcct gttgaggtat tccactcgcg tcaatccact 420
attcctgaac taaacaagaa atatctcacc gattctgggt taccggcggg ttttccgctc 480
tcagattcaa acaaaccggc tctgtatctc ttcacctcgt ctgccacttc tcggagcaat 540
cttaaatgcg tgcctctcac tcacgctttc atcctgagca atagcctctc gaaacgcgca 600
tggtgccaac gtatgcggcc agagacagac ttcgatggca tacgcgttct tggatgggct 660
ccatggtctc atgtcttggc gcacatgcag gacatcgggc ccgtcacttt actcaatgct 720
ggatgctacg tctttgctac tatcccttcc tcgtacccca cggatgtgca gagtgacagc 780
aatttgatat ctcatgtcgc aaatgctatc atacacaagg gtgtaaaatc gtttgcttgt 840
ctcccttttg tactcggagg gctgaaagca ttatgcgagt ccaagccatc cgtcaaagca 900
gatctacagg tcgaagagca agctcagctt ttgatctctc taaggcgcat ggaaattctt 960
gaatgcggag gtgcgatgct cgaagcgaat gttgcgtctt gggctatcga gaatcatatt 1020
ccggtctcta ttggtatcgg tatgacagaa actggtggcg cgcttttcgc tggacctgtt 1080
caggatatcc ggaccggttt ttctgcggac aataaattca tcaaggacgc tacctacttc 1140
ctagttgcaa atggagatga atctgggaac gatgtaactg aaggggagct agttgtgaaa 1200
agtaaaatgc tcccgcgagg ctatcttggc tacaatgatt cttccttttc cgttgacgat 1260
gacggattgg ttacgttcaa gacaggcgac agatacagtg ttacacgcga cggaagattc 1320
tcttggctag gcaggaatac tgatttcatt cagatgacta gtggagagac attagatccc 1380
cgacctgtcg agagttcgct ctgccaaagt cctctcatct ctcaagcatg cgttattgga 1440
gacaagtttc tcaacgggcc tgccactgct gtttgcgcga tcgttgagct tgagccgaca 1500
atggtagaaa cgggagaggc taactcgcgg gacatagtcc aagtctttgc acccatcaac 1560
cgagacctgc ctcctccttt aaggatagca tggtcgcaca ttttaattct caagcattcc 1620
gagaagatac cgatgacgaa gaagggaacg attttccgta agaagattga gcagatgttt 1680
ggcgctgcat tgggcattgc ttccatccct acaaacagtg tcaatggatc cgttggctcc 1740
ggagaagagc ctcaagctac tgcagatgag actgttctac aagatgaact atcaaatacc 1800
gtgaagaaaa taatcagccg tgttctagga gtaactgatg aggaattgct ttggacactg 1860
tcattcgcag agctgggaat gacctcaaca ctggctattc gtatcgtaaa cgagctgaac 1920
gaaactctcg ttgggggcga tctccctatc aatgcttgct acatttatgt cgacctttcc 1980
tctctgagca aggctgtgta tgcgaaactg gctcatctcg agctgtcaga tcatgttcct 2040
gagctcaaac aagctccctt caagtcttct ggcgggaaag agattgtcat tgtcggccaa 2100
gcgtttcgtc tacccggctc aatcaatgac gttgcctctc ttcgggatgc attcctagca 2160
agacagacat cgtccatcat cgctggaata ccttccgatc gctgggacca tgccagcttc 2220
tatcccaagg acatatgttt cgacaaggct ggtcttgtgg atatagctca ttatgatcat 2280
agcttcttcg gaatcacagc aacggaagcg ctccatctgt ctccaaccat gcgtcttgca 2340
ctggaagttt cgtttgaggc gcttgagaat gctaatatcc caacgtcgcg attgaaaggc 2400
tcgcagacgg cagtttatgt tgcaacaaca gatgacggat ttgagaccct gttgaatgct 2460
gaggctggct atgaagctta tacacggttt tatggtactg gtcgggcagc aagtacggcg 2520
agtgggcgca taagctatct tcttgatata catggaccct ccgtcactat tgacacggca 2580
tgcagtggtg gagttgtttg tatcgatcaa gcaatcaact atttacaatc gtcgagttca 2640
gcggacaccg ctatcgtgtt cctttctgct caagggatgg tctccccgag gggacgatgt 2700
gcgacattta cggctgatgc tgacggctat gtcccttctg agggtgcagt tgctttcgta 2760
ttgaaaactc gcgaagccgc tatacgcgac aaagacaaca ttctcgctac aatcaaagcg 2820
acacagattt cgcacaacgg ccgctcacaa ggacttgtag caccgaacgt aaactcgcaa 2880
gttgaccttc atcgttcgtt gctcgagaaa gctcgtctta gtcctgctga tgtccaattc 2940
attgaagctc atgggacagg aacgtcattg ggagatctct cagagattca agctataaac 3000
gctgcttaca cttcctctca gccacgtacg accggcccac tcatagtcag cgcttccaag 3060
actgtcgttg gccataccga accagctggt cctttggttg gtatgttgtc ggtcttgctg 3120
tctttccagg aaggcgcagt ccctggtctc gctcatctta ccacacgtaa cctcaatcct 3180
acgttggact attcttcagt gccgcttctc attccctctg aacctgttcg tctacaaaca 3240
ccaaagcctt atagagctgc cgtaatgtcc tacggctttt cgggtaccct ggccggcctc 3300
gttctagaga gccctgacga acgtagctca gaagaagagc cgcctgatga caagccgatg 3360
ctgttcgtcg ttagcgcaaa gacacacacg gcactaattg aatacctgca acggtatctc 3420
gagttcctct tacatgcgaa tccccgcgat ttctgtgata tctgctacac aagctgtgtc 3480
gggagggaac actatagata tcggtttgct tgtgttgcaa atgacatgga agacctcatt 3540
ggccaacttc aaagacgttt gtctagcaag ttaccatcga agccgctata caaacgcggt 3600
gctctggcct ttgcgttttc tggacagggg acacagtttc aaggaatggc gacagatctt 3660
gcgaagaggt actctggctt ccgaaaaatc gtttccggac tcgcaaagag tgctggcgag 3720
ctctcgggtt acgctattga ccgttatctt ctcgcgtatg acgttggtag cagtattgct 3780
actcctaata gtgaggtgga ccagatctgc attttcgtat accaatgctc tgtccttcgc 3840
tggttgggga gtattggaat taaaccaaac gtggtaatcg gccatagcct tggagagatt 3900
tcggcttctg tggcggcagg ggcactttct cttgacattg ctctggatct tgtcatctca 3960
cgagctgggt tgttgcgccc ctcgacagat gttcctgcgg gaatggctgc tgtggccgct 4020
tcacaacagg aggtcattga gttgattgat gcgctggacc ccgacaaggc aaattcgctc 4080
agtgtttcgg ttataaatgg acctcaaaat atcgttgtgt caggcgcttc agcagctatt 4140
gagagaatgg tcgcttctgc gaaggagaag aagatcaaag cttctgttct gaatattagc 4200
caagcttttc acagttcgta tgttgacagt gccattacgg gtcttcgagc ttggtcagaa 4260
aaacatattt cctcagcgat accactgcag attccgctgt attcgacatt gctgggagct 4320
cggatatcaa agggccaaaa actgaaccca gaccactggg tcgaccacgc acggaagccc 4380
gtacagttcg cacaagcagc tacggcgatg aaagaaacct tcaccggagt catcatggat 4440
atcggacccc aagcagtagc atggtcactt ctgcttgcaa acggactcac atccgtaacc 4500
gcgcttgctg cgaagagagg gaggagtcag caggtggctt tcttgagcgc cttggcggag 4560
ttgtatcagg attatggcat tgttcctgat tttgtggcgc tttatgctca ggaggaggaa 4620
atagacaagt tgaggaagac ggatattttg acatatccgt ttcagcgtgt taggaggtat 4680
ccgagtttta taccttcaag gcgtgtgaga ggtggagaaa ttccttcgag ccatcccagc 4740
gagtctgcga cgttggagaa cacgaatgag ggtacggctt tgcgtgctga gtcgagggtg 4800
ttgtgcaggg aggatctgca tgatagcatc gttacctctg tgaaggatgt tctagagctc 4860
aaaccaaatg aagatctaga tttgtctgaa agcctgaacg cgcttggtgt ggactctata 4920
atgtttgctc agttaaggaa acgtattggg gagggactcg ggttgagtat cccgacagtg 4980
ttcctttcgg atgccttttc tattaatgag atggttaata atcttatgga acaggcggag 5040
acgcctggtg aagagggcgt aatgcaggag aat 5073
<210> 41
<211> 1691
<212> PRT
<213> Neonothopanus gardneri
<400> 41
Met Asn Ser Lys Val Asn Leu Pro Ser Thr Leu Leu Asp Val Phe Leu
1 5 10 15
Glu Ile Ala Gly Glu Pro Ser Thr Ala Ser Arg Asp Val Leu Glu Cys
20 25 30
Gly Glu His Arg Trp Thr Tyr Gln Gln Leu Asp Val Val Ser Ser Ala
35 40 45
Leu Ala Gln His Leu Lys Tyr Thr Val Gly Leu Ser Pro Thr Val Ala
50 55 60
Val Ile Ser Glu Asn His Pro Tyr Val Phe Ala Leu Ile Leu Ala Val
65 70 75 80
Trp Lys Val Gly Gly Ile Phe Ala Pro Leu Asp Ala His Ala Pro Ala
85 90 95
Glu Leu Val Ala Gly Met Leu Ser Ile Ile Ser Pro Ser Cys Leu Val
100 105 110
Leu Gln Ser Thr Asp Val Ala Asn Gln Thr Leu Ala Cys Asp Leu Asp
115 120 125
Ile Pro Val Glu Val Phe His Ser Arg Gln Ser Thr Ile Pro Glu Leu
130 135 140
Asn Lys Lys Tyr Leu Thr Asp Ser Gly Leu Pro Ala Gly Phe Pro Leu
145 150 155 160
Ser Asp Ser Asn Lys Pro Ala Leu Tyr Leu Phe Thr Ser Ser Ala Thr
165 170 175
Ser Arg Ser Asn Leu Lys Cys Val Pro Leu Thr His Ala Phe Ile Leu
180 185 190
Ser Asn Ser Leu Ser Lys Arg Ala Trp Cys Gln Arg Met Arg Pro Glu
195 200 205
Thr Asp Phe Asp Gly Ile Arg Val Leu Gly Trp Ala Pro Trp Ser His
210 215 220
Val Leu Ala His Met Gln Asp Ile Gly Pro Val Thr Leu Leu Asn Ala
225 230 235 240
Gly Cys Tyr Val Phe Ala Thr Ile Pro Ser Ser Tyr Pro Thr Asp Val
245 250 255
Gln Ser Asp Ser Asn Leu Ile Ser His Val Ala Asn Ala Ile Ile His
260 265 270
Lys Gly Val Lys Ser Phe Ala Cys Leu Pro Phe Val Leu Gly Gly Leu
275 280 285
Lys Ala Leu Cys Glu Ser Lys Pro Ser Val Lys Ala Asp Leu Gln Val
290 295 300
Glu Glu Gln Ala Gln Leu Leu Ile Ser Leu Arg Arg Met Glu Ile Leu
305 310 315 320
Glu Cys Gly Gly Ala Met Leu Glu Ala Asn Val Ala Ser Trp Ala Ile
325 330 335
Glu Asn His Ile Pro Val Ser Ile Gly Ile Gly Met Thr Glu Thr Gly
340 345 350
Gly Ala Leu Phe Ala Gly Pro Val Gln Asp Ile Arg Thr Gly Phe Ser
355 360 365
Ala Asp Asn Lys Phe Ile Lys Asp Ala Thr Tyr Phe Leu Val Ala Asn
370 375 380
Gly Asp Glu Ser Gly Asn Asp Val Thr Glu Gly Glu Leu Val Val Lys
385 390 395 400
Ser Lys Met Leu Pro Arg Gly Tyr Leu Gly Tyr Asn Asp Ser Ser Phe
405 410 415
Ser Val Asp Asp Asp Gly Leu Val Thr Phe Lys Thr Gly Asp Arg Tyr
420 425 430
Ser Val Thr Arg Asp Gly Arg Phe Ser Trp Leu Gly Arg Asn Thr Asp
435 440 445
Phe Ile Gln Met Thr Ser Gly Glu Thr Leu Asp Pro Arg Pro Val Glu
450 455 460
Ser Ser Leu Cys Gln Ser Pro Leu Ile Ser Gln Ala Cys Val Ile Gly
465 470 475 480
Asp Lys Phe Leu Asn Gly Pro Ala Thr Ala Val Cys Ala Ile Val Glu
485 490 495
Leu Glu Pro Thr Met Val Glu Thr Gly Glu Ala Asn Ser Arg Asp Ile
500 505 510
Val Gln Val Phe Ala Pro Ile Asn Arg Asp Leu Pro Pro Pro Leu Arg
515 520 525
Ile Ala Trp Ser His Ile Leu Ile Leu Lys His Ser Glu Lys Ile Pro
530 535 540
Met Thr Lys Lys Gly Thr Ile Phe Arg Lys Lys Ile Glu Gln Met Phe
545 550 555 560
Gly Ala Ala Leu Gly Ile Ala Ser Ile Pro Thr Asn Ser Val Asn Gly
565 570 575
Ser Val Gly Ser Gly Glu Glu Pro Gln Ala Thr Ala Asp Glu Thr Val
580 585 590
Leu Gln Asp Glu Leu Ser Asn Thr Val Lys Lys Ile Ile Ser Arg Val
595 600 605
Leu Gly Val Thr Asp Glu Glu Leu Leu Trp Thr Leu Ser Phe Ala Glu
610 615 620
Leu Gly Met Thr Ser Thr Leu Ala Ile Arg Ile Val Asn Glu Leu Asn
625 630 635 640
Glu Thr Leu Val Gly Gly Asp Leu Pro Ile Asn Ala Cys Tyr Ile Tyr
645 650 655
Val Asp Leu Ser Ser Leu Ser Lys Ala Val Tyr Ala Lys Leu Ala His
660 665 670
Leu Glu Leu Ser Asp His Val Pro Glu Leu Lys Gln Ala Pro Phe Lys
675 680 685
Ser Ser Gly Gly Lys Glu Ile Val Ile Val Gly Gln Ala Phe Arg Leu
690 695 700
Pro Gly Ser Ile Asn Asp Val Ala Ser Leu Arg Asp Ala Phe Leu Ala
705 710 715 720
Arg Gln Thr Ser Ser Ile Ile Ala Gly Ile Pro Ser Asp Arg Trp Asp
725 730 735
His Ala Ser Phe Tyr Pro Lys Asp Ile Cys Phe Asp Lys Ala Gly Leu
740 745 750
Val Asp Ile Ala His Tyr Asp His Ser Phe Phe Gly Ile Thr Ala Thr
755 760 765
Glu Ala Leu His Leu Ser Pro Thr Met Arg Leu Ala Leu Glu Val Ser
770 775 780
Phe Glu Ala Leu Glu Asn Ala Asn Ile Pro Thr Ser Arg Leu Lys Gly
785 790 795 800
Ser Gln Thr Ala Val Tyr Val Ala Thr Thr Asp Asp Gly Phe Glu Thr
805 810 815
Leu Leu Asn Ala Glu Ala Gly Tyr Glu Ala Tyr Thr Arg Phe Tyr Gly
820 825 830
Thr Gly Arg Ala Ala Ser Thr Ala Ser Gly Arg Ile Ser Tyr Leu Leu
835 840 845
Asp Ile His Gly Pro Ser Val Thr Ile Asp Thr Ala Cys Ser Gly Gly
850 855 860
Val Val Cys Ile Asp Gln Ala Ile Asn Tyr Leu Gln Ser Ser Ser Ser
865 870 875 880
Ala Asp Thr Ala Ile Val Phe Leu Ser Ala Gln Gly Met Val Ser Pro
885 890 895
Arg Gly Arg Cys Ala Thr Phe Thr Ala Asp Ala Asp Gly Tyr Val Pro
900 905 910
Ser Glu Gly Ala Val Ala Phe Val Leu Lys Thr Arg Glu Ala Ala Ile
915 920 925
Arg Asp Lys Asp Asn Ile Leu Ala Thr Ile Lys Ala Thr Gln Ile Ser
930 935 940
His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn Val Asn Ser Gln
945 950 955 960
Val Asp Leu His Arg Ser Leu Leu Glu Lys Ala Arg Leu Ser Pro Ala
965 970 975
Asp Val Gln Phe Ile Glu Ala His Gly Thr Gly Thr Ser Leu Gly Asp
980 985 990
Leu Ser Glu Ile Gln Ala Ile Asn Ala Ala Tyr Thr Ser Ser Gln Pro
995 1000 1005
Arg Thr Thr Gly Pro Leu Ile Val Ser Ala Ser Lys Thr Val Val
1010 1015 1020
Gly His Thr Glu Pro Ala Gly Pro Leu Val Gly Met Leu Ser Val
1025 1030 1035
Leu Leu Ser Phe Gln Glu Gly Ala Val Pro Gly Leu Ala His Leu
1040 1045 1050
Thr Thr Arg Asn Leu Asn Pro Thr Leu Asp Tyr Ser Ser Val Pro
1055 1060 1065
Leu Leu Ile Pro Ser Glu Pro Val Arg Leu Gln Thr Pro Lys Pro
1070 1075 1080
Tyr Arg Ala Ala Val Met Ser Tyr Gly Phe Ser Gly Thr Leu Ala
1085 1090 1095
Gly Leu Val Leu Glu Ser Pro Asp Glu Arg Ser Ser Glu Glu Glu
1100 1105 1110
Pro Pro Asp Asp Lys Pro Met Leu Phe Val Val Ser Ala Lys Thr
1115 1120 1125
His Thr Ala Leu Ile Glu Tyr Leu Gln Arg Tyr Leu Glu Phe Leu
1130 1135 1140
Leu His Ala Asn Pro Arg Asp Phe Cys Asp Ile Cys Tyr Thr Ser
1145 1150 1155
Cys Val Gly Arg Glu His Tyr Arg Tyr Arg Phe Ala Cys Val Ala
1160 1165 1170
Asn Asp Met Glu Asp Leu Ile Gly Gln Leu Gln Arg Arg Leu Ser
1175 1180 1185
Ser Lys Leu Pro Ser Lys Pro Leu Tyr Lys Arg Gly Ala Leu Ala
1190 1195 1200
Phe Ala Phe Ser Gly Gln Gly Thr Gln Phe Gln Gly Met Ala Thr
1205 1210 1215
Asp Leu Ala Lys Arg Tyr Ser Gly Phe Arg Lys Ile Val Ser Gly
1220 1225 1230
Leu Ala Lys Ser Ala Gly Glu Leu Ser Gly Tyr Ala Ile Asp Arg
1235 1240 1245
Tyr Leu Leu Ala Tyr Asp Val Gly Ser Ser Ile Ala Thr Pro Asn
1250 1255 1260
Ser Glu Val Asp Gln Ile Cys Ile Phe Val Tyr Gln Cys Ser Val
1265 1270 1275
Leu Arg Trp Leu Gly Ser Ile Gly Ile Lys Pro Asn Val Val Ile
1280 1285 1290
Gly His Ser Leu Gly Glu Ile Ser Ala Ser Val Ala Ala Gly Ala
1295 1300 1305
Leu Ser Leu Asp Ile Ala Leu Asp Leu Val Ile Ser Arg Ala Gly
1310 1315 1320
Leu Leu Arg Pro Ser Thr Asp Val Pro Ala Gly Met Ala Ala Val
1325 1330 1335
Ala Ala Ser Gln Gln Glu Val Ile Glu Leu Ile Asp Ala Leu Asp
1340 1345 1350
Pro Asp Lys Ala Asn Ser Leu Ser Val Ser Val Ile Asn Gly Pro
1355 1360 1365
Gln Asn Ile Val Val Ser Gly Ala Ser Ala Ala Ile Glu Arg Met
1370 1375 1380
Val Ala Ser Ala Lys Glu Lys Lys Ile Lys Ala Ser Val Leu Asn
1385 1390 1395
Ile Ser Gln Ala Phe His Ser Ser Tyr Val Asp Ser Ala Ile Thr
1400 1405 1410
Gly Leu Arg Ala Trp Ser Glu Lys His Ile Ser Ser Ala Ile Pro
1415 1420 1425
Leu Gln Ile Pro Leu Tyr Ser Thr Leu Leu Gly Ala Arg Ile Ser
1430 1435 1440
Lys Gly Gln Lys Leu Asn Pro Asp His Trp Val Asp His Ala Arg
1445 1450 1455
Lys Pro Val Gln Phe Ala Gln Ala Ala Thr Ala Met Lys Glu Thr
1460 1465 1470
Phe Thr Gly Val Ile Met Asp Ile Gly Pro Gln Ala Val Ala Trp
1475 1480 1485
Ser Leu Leu Leu Ala Asn Gly Leu Thr Ser Val Thr Ala Leu Ala
1490 1495 1500
Ala Lys Arg Gly Arg Ser Gln Gln Val Ala Phe Leu Ser Ala Leu
1505 1510 1515
Ala Glu Leu Tyr Gln Asp Tyr Gly Ile Val Pro Asp Phe Val Ala
1520 1525 1530
Leu Tyr Ala Gln Glu Glu Glu Ile Asp Lys Leu Arg Lys Thr Asp
1535 1540 1545
Ile Leu Thr Tyr Pro Phe Gln Arg Val Arg Arg Tyr Pro Ser Phe
1550 1555 1560
Ile Pro Ser Arg Arg Val Arg Gly Gly Glu Ile Pro Ser Ser His
1565 1570 1575
Pro Ser Glu Ser Ala Thr Leu Glu Asn Thr Asn Glu Gly Thr Ala
1580 1585 1590
Leu Arg Ala Glu Ser Arg Val Leu Cys Arg Glu Asp Leu His Asp
1595 1600 1605
Ser Ile Val Thr Ser Val Lys Asp Val Leu Glu Leu Lys Pro Asn
1610 1615 1620
Glu Asp Leu Asp Leu Ser Glu Ser Leu Asn Ala Leu Gly Val Asp
1625 1630 1635
Ser Ile Met Phe Ala Gln Leu Arg Lys Arg Ile Gly Glu Gly Leu
1640 1645 1650
Gly Leu Ser Ile Pro Thr Val Phe Leu Ser Asp Ala Phe Ser Ile
1655 1660 1665
Asn Glu Met Val Asn Asn Leu Met Glu Gln Ala Glu Thr Pro Gly
1670 1675 1680
Glu Glu Gly Val Met Gln Glu Asn
1685 1690
<210> 42
<211> 5298
<212> DNA
<213> Guyanagaster necrorhiza
<400> 42
atggcggccg ataggcactt ttctcttctc gatgtctttc tcgacgttgc ccataatgct 60
gagacgtcac aacgcaatat tttggaatgc ggcctggaca cctggacata ctcagatttg 120
gacatcatct cgtcggccct ggcccaggat ctcagtacta ccttgggttg ctctcccagg 180
gttgcagtcg tcagcgagaa ccatccctat gtatttgctc tcatgctggc cgtatggaag 240
cttggaggaa tattcatccc catcgacgtc catgttcccg ccgagctttt aacgggcatg 300
ctacgcatcg ttgctccaga ctgcgtggtg attcctgaga ctgatctttc taatcagcgc 360
gtcatctctg cactttacct ccacgttatt cccttcaatg tcaatgcgtc gacaatgtct 420
acacttcgac agaaatatgt cctatctact cagaaaccct tgctgtctga gttccctctt 480
cctcatgttg atcgtgcatg cctctatctc tttacgtcct ccgcgtcttc caccgccaac 540
ttgaaatgcg tacctttgac tcatgcactt atcctcagca actgtcgttc caagcttgca 600
tggtggcggc gtgttcgtcc agaagaaaac atggatggga tgcgtgtttt ggggtgggcg 660
ccttggtcac atattctcgc gtacatgcag gatattggga cagcaacgct cctgaatgca 720
ggctgctatg tctttgcatc tgttccgtcc acatatccta cgcagcacgt agccaatggc 780
ctgcaagacc ccacttcaaa tataatcaag tcgcttctca accgccgtat cacggcgttc 840
gcatgtgtgc cgttcattct tagtgaactg aaagctatgt gcgacccagc ttccggtccg 900
gacgccaagg atcaaatgtg cttgggagct ggggagaaag tgcgtcttat aagcacactg 960
cagaatctca tcatgttcga gtgtggaggc gctgcgctcg aggcagatat cacggattgg 1020
accgtcgaaa atggtatatc agtcatggtc ggtattggaa tgacggagac cgccggcacg 1080
gttttggcag cgcgtgcaca agacgctcgt tcgaatggct attctgccga agaggctctc 1140
atcgctgatg gcatactatc attggtcgga cctgacgagg aggaaatggc ctttgacgga 1200
gaacttgtcg tgaaaagcaa gctcatccca catggataca tcaagtacca cgattcggca 1260
ttttcagtgg actcagatga ctgggtgacg ttcaaaactg gggacaaata tcagcgtaca 1320
ccagatggac atttcaagtg gcttggaaga aagaccgatt ttattcagat gacaagcagc 1380
gaaaccttag atcccagacc tatcgaaaaa gccctctgca tgaaccccat tatcgcaaat 1440
gcgtgtgtca ttggtgacag gtttctaagg gaacctgcga cgggtgtatg tgccattgtc 1500
gagatcaggt cagatgtgga tatggcttcc gccgaggttg acagggagat tgcgaatgtc 1560
ctcgctccaa tcaatcgtga tcttcctccg gctcttcgaa tagcatggtc tcgcgtactc 1620
ataatccgac ctcctcagaa aataccactc acaaagaaag gtgaggtgtt tcgcaagaag 1680
attgaagata tatttggcac cttcttgggt gtcggtgtta ctaccaaggt ggaagtggac 1740
catgaaagta aagaagatga tacggaacac atcgtgagac aggttgtgag caatcttctt 1800
ggagtccatg atcctgagct attgtctact ttatctttcg ctgagctcgg gatgacctca 1860
tttatggccg ttagcatcgt taacacttta aacaagcata ttggcggcct cgcacttcca 1920
cttaactcat gctacattca tattgatctt gattctcttg tagatgccat ttcacttgaa 1980
cgtggtcatc gaaagaaccc tacgcccttt tcttctaacc ctttcctcgc ctttgaatcc 2040
agccagcaaa aggatatgga gattgtgatt gttggtaaag cattccgttt gcccggctca 2100
ctcgacaata gcacctctct ctgggaagct ttgttgtcaa agagtgattc agtcatcggt 2160
gacatcccac ccgatcgctg ggatcatgca agtttttacc cccacgatat atgctttacg 2220
aaagcaggcc ttgtcgatgt ttcccattat gactatagat ttttcggtct cactgctaca 2280
gaggcgttgt acgtatctcc gacaatgcgc ctcgccttgg aagtgtcatt tgaggctctg 2340
gagaatgcaa atattccctt atccaagttg aaggggacac gaactgctgt ttatgttgcc 2400
actaaagacg atgggttcga gacactctta aatgctgaac aaggctacga tgcctacacg 2460
cgattctacg gcacgggacg tgctccgagt accgcaagtg gccgtataag ctatcttctt 2520
gatattcatg gaccttctgt taccgttgac acagcatgca gcggaggcat tgtatgtata 2580
gaccaagcca tcacttttct gcaatccgga ggggcagata ctgctattgt ttgttcgagc 2640
aatacgcact gttggccggg atcatttatg ttcctgacag cgcaaggcat ggtctctcca 2700
aatggaagat gtgccacatt cactacaaat gcagatggat atgtaccttc agaaggcgca 2760
gtggctttcg ttctcaagac acacagcgca gcaacacgcg acaaagacaa tatactggcc 2820
gtgataaagt caacagacgt gtctcataac ggccgttctc aagggctagt tgcaccaaac 2880
gtaaaggcac agacaaacct acaccagtcg ctgttacgaa aagctgggct gcatcctgat 2940
ctaattaact ttatcgaagc tcatggaaca ggtacatctt taggagacct ttcagaaatc 3000
cagggtatca ataatgccta cacctcatct cgacctcgtc cagccggtcc tctgatcatt 3060
agcgcgtcaa aaacggtttt gggacatagt gaaccaactg caggaatggc cggcatcctc 3120
acaaccttgc tcgcctttga gaaagagacg gttcctggtc tcaaccactt aacggaacat 3180
aatttaaacc cttcgcttga ttgctctgca gtgcctctcc tgattcctca cgagcctgtt 3240
catatcagtg gtgcaaagcc ccatcgagct gcggttctat catacggatt cgcggggaca 3300
ctggctggta ccatcttaga gagtccacct tgcgacctta caaggccctt gtcaaacgac 3360
atacaagaac atcctatgat tttcgtcgtc agtgggaaaa cggtgccctc tctggaagca 3420
tatctagagc ggtatttggt atttttacgg gtcgcaaaac caagcgaatt ccatgacatc 3480
tgctacacca cttgcatcgg gagggagctg tataaatacc ggttctcctg cgttgcccga 3540
aacatggccg acctcatttc tcaaattgaa catcgactga cgacttgttc cacttcgaaa 3600
gagaagcccc gtggctcgtt aggattcgtg ttctcgggtc aaggtaccca gttccccggc 3660
atggcagcag cacttgccga acgatattca gggttccgag cgctcgtctc caagtttggg 3720
cagatcgccc aagagcagtc gggctacccg atcgataggc tgctcctcga agttaccgat 3780
acattaccag aagcaaacag cgaggtcgac caaatttgca tttttgtcta ccaatattct 3840
gttctgcaat ggctgcaacg tctaggcatt caaccgaaaa cagtccttgg tcacagtcta 3900
ggagaaatta ccgcctcagt cgcagttggc gccttctctt ttaggtctgc attggacctt 3960
gtggtcaccc gcgctcgtct tcttcgtcct caaccaaaat tctctgcggg aatggctgca 4020
gtagcagcgt ccaaggaaga agttgaagga cttatagata tgctcaaact tgcggagtcg 4080
ctgagcgttg cggttcataa cagtccacgg agtatcgttg tatcaggcgc atcagctgcg 4140
gtcgatgcca tggttgtcgc tgctaaaaag cagggcttga aggcctcccg cttaaaggtt 4200
gaccaagcct ttcacagccc ttacgttgat tctgctgtat cggggttgct cgactggtcc 4260
aataagcatc gttcgacctt cctcccattg aacatccctt tatactcaac tttgactggc 4320
gcgcgtattc cgaaaggagg gaagttctgc tgggatcact gggttaatca tgctcgaaag 4380
cccgtccagt ttgcggcggc agctgcagca atggacgaag atcaatccat cggtgttctt 4440
gttgatgttg gaccccaacc tgttgcgtgg accctccttc aagcgaataa cctcctcaat 4500
acctcttcga ttgctctatc agcaaaaatt ggaaaggatc aggagatggc gttgctctct 4560
gctttgagct acctcgtcca agagcacaac ctttctctca gcttttatga gctttactct 4620
cagcgtcacg gtactctgaa gaagacagac gttcctacct acccgttccg tcgcgtccac 4680
cgctacccga ctttcatacc gtcacggaat agaagtcctg ctgacatgag ggtagctata 4740
ccacctaccg acctctctgt ccgaaagaat gtggatgcaa caccgcagtc tcgtcgtgct 4800
ggcctgatag cctgtcttaa agttatcctc gagttaacac caggagagga atttgacctt 4860
tctgagactc tcaatgctcg tggggtcgat tcagttatgt tcgcacagtt gcggaagcgt 4920
gttggggaag aattcgacct agatatacca atgatctatt tatcagacgt gttcacgatg 4980
gaacagatga ttgactacct cgtcgaacag tccagcccca catcaaagtt ggtagagatt 5040
tcggttaatc aatcattaga cggagaaggc ctccggacag ggcttgtatc atgccttagg 5100
gacgtactgg aaatctcctc cgacgaagaa cttgactttt ccgaaacttt gaacgctcgt 5160
ggtacggact caattatgtt cgctcagcta cgaaaacgtg tcggggaagg atttggtctt 5220
gaaattccga tgatatatct gtctgatgtg tttaccatgg aagacatgat caatttcctt 5280
gtctcggagc gctcgtgc 5298
<210> 43
<211> 1766
<212> PRT
<213> Guyanagaster necrorhiza
<400> 43
Met Ala Ala Asp Arg His Phe Ser Leu Leu Asp Val Phe Leu Asp Val
1 5 10 15
Ala His Asn Ala Glu Thr Ser Gln Arg Asn Ile Leu Glu Cys Gly Leu
20 25 30
Asp Thr Trp Thr Tyr Ser Asp Leu Asp Ile Ile Ser Ser Ala Leu Ala
35 40 45
Gln Asp Leu Ser Thr Thr Leu Gly Cys Ser Pro Arg Val Ala Val Val
50 55 60
Ser Glu Asn His Pro Tyr Val Phe Ala Leu Met Leu Ala Val Trp Lys
65 70 75 80
Leu Gly Gly Ile Phe Ile Pro Ile Asp Val His Val Pro Ala Glu Leu
85 90 95
Leu Thr Gly Met Leu Arg Ile Val Ala Pro Asp Cys Val Val Ile Pro
100 105 110
Glu Thr Asp Leu Ser Asn Gln Arg Val Ile Ser Ala Leu Tyr Leu His
115 120 125
Val Ile Pro Phe Asn Val Asn Ala Ser Thr Met Ser Thr Leu Arg Gln
130 135 140
Lys Tyr Val Leu Ser Thr Gln Lys Pro Leu Leu Ser Glu Phe Pro Leu
145 150 155 160
Pro His Val Asp Arg Ala Cys Leu Tyr Leu Phe Thr Ser Ser Ala Ser
165 170 175
Ser Thr Ala Asn Leu Lys Cys Val Pro Leu Thr His Ala Leu Ile Leu
180 185 190
Ser Asn Cys Arg Ser Lys Leu Ala Trp Trp Arg Arg Val Arg Pro Glu
195 200 205
Glu Asn Met Asp Gly Met Arg Val Leu Gly Trp Ala Pro Trp Ser His
210 215 220
Ile Leu Ala Tyr Met Gln Asp Ile Gly Thr Ala Thr Leu Leu Asn Ala
225 230 235 240
Gly Cys Tyr Val Phe Ala Ser Val Pro Ser Thr Tyr Pro Thr Gln His
245 250 255
Val Ala Asn Gly Leu Gln Asp Pro Thr Ser Asn Ile Ile Lys Ser Leu
260 265 270
Leu Asn Arg Arg Ile Thr Ala Phe Ala Cys Val Pro Phe Ile Leu Ser
275 280 285
Glu Leu Lys Ala Met Cys Asp Pro Ala Ser Gly Pro Asp Ala Lys Asp
290 295 300
Gln Met Cys Leu Gly Ala Gly Glu Lys Val Arg Leu Ile Ser Thr Leu
305 310 315 320
Gln Asn Leu Ile Met Phe Glu Cys Gly Gly Ala Ala Leu Glu Ala Asp
325 330 335
Ile Thr Asp Trp Thr Val Glu Asn Gly Ile Ser Val Met Val Gly Ile
340 345 350
Gly Met Thr Glu Thr Ala Gly Thr Val Leu Ala Ala Arg Ala Gln Asp
355 360 365
Ala Arg Ser Asn Gly Tyr Ser Ala Glu Glu Ala Leu Ile Ala Asp Gly
370 375 380
Ile Leu Ser Leu Val Gly Pro Asp Glu Glu Glu Met Ala Phe Asp Gly
385 390 395 400
Glu Leu Val Val Lys Ser Lys Leu Ile Pro His Gly Tyr Ile Lys Tyr
405 410 415
His Asp Ser Ala Phe Ser Val Asp Ser Asp Asp Trp Val Thr Phe Lys
420 425 430
Thr Gly Asp Lys Tyr Gln Arg Thr Pro Asp Gly His Phe Lys Trp Leu
435 440 445
Gly Arg Lys Thr Asp Phe Ile Gln Met Thr Ser Ser Glu Thr Leu Asp
450 455 460
Pro Arg Pro Ile Glu Lys Ala Leu Cys Met Asn Pro Ile Ile Ala Asn
465 470 475 480
Ala Cys Val Ile Gly Asp Arg Phe Leu Arg Glu Pro Ala Thr Gly Val
485 490 495
Cys Ala Ile Val Glu Ile Arg Ser Asp Val Asp Met Ala Ser Ala Glu
500 505 510
Val Asp Arg Glu Ile Ala Asn Val Leu Ala Pro Ile Asn Arg Asp Leu
515 520 525
Pro Pro Ala Leu Arg Ile Ala Trp Ser Arg Val Leu Ile Ile Arg Pro
530 535 540
Pro Gln Lys Ile Pro Leu Thr Lys Lys Gly Glu Val Phe Arg Lys Lys
545 550 555 560
Ile Glu Asp Ile Phe Gly Thr Phe Leu Gly Val Gly Val Thr Thr Lys
565 570 575
Val Glu Val Asp His Glu Ser Lys Glu Asp Asp Thr Glu His Ile Val
580 585 590
Arg Gln Val Val Ser Asn Leu Leu Gly Val His Asp Pro Glu Leu Leu
595 600 605
Ser Thr Leu Ser Phe Ala Glu Leu Gly Met Thr Ser Phe Met Ala Val
610 615 620
Ser Ile Val Asn Thr Leu Asn Lys His Ile Gly Gly Leu Ala Leu Pro
625 630 635 640
Leu Asn Ser Cys Tyr Ile His Ile Asp Leu Asp Ser Leu Val Asp Ala
645 650 655
Ile Ser Leu Glu Arg Gly His Arg Lys Asn Pro Thr Pro Phe Ser Ser
660 665 670
Asn Pro Phe Leu Ala Phe Glu Ser Ser Gln Gln Lys Asp Met Glu Ile
675 680 685
Val Ile Val Gly Lys Ala Phe Arg Leu Pro Gly Ser Leu Asp Asn Ser
690 695 700
Thr Ser Leu Trp Glu Ala Leu Leu Ser Lys Ser Asp Ser Val Ile Gly
705 710 715 720
Asp Ile Pro Pro Asp Arg Trp Asp His Ala Ser Phe Tyr Pro His Asp
725 730 735
Ile Cys Phe Thr Lys Ala Gly Leu Val Asp Val Ser His Tyr Asp Tyr
740 745 750
Arg Phe Phe Gly Leu Thr Ala Thr Glu Ala Leu Tyr Val Ser Pro Thr
755 760 765
Met Arg Leu Ala Leu Glu Val Ser Phe Glu Ala Leu Glu Asn Ala Asn
770 775 780
Ile Pro Leu Ser Lys Leu Lys Gly Thr Arg Thr Ala Val Tyr Val Ala
785 790 795 800
Thr Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Glu Gln Gly Tyr
805 810 815
Asp Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser Thr Ala
820 825 830
Ser Gly Arg Ile Ser Tyr Leu Leu Asp Ile His Gly Pro Ser Val Thr
835 840 845
Val Asp Thr Ala Cys Ser Gly Gly Ile Val Cys Ile Asp Gln Ala Ile
850 855 860
Thr Phe Leu Gln Ser Gly Gly Ala Asp Thr Ala Ile Val Cys Ser Ser
865 870 875 880
Asn Thr His Cys Trp Pro Gly Ser Phe Met Phe Leu Thr Ala Gln Gly
885 890 895
Met Val Ser Pro Asn Gly Arg Cys Ala Thr Phe Thr Thr Asn Ala Asp
900 905 910
Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Val Leu Lys Thr His
915 920 925
Ser Ala Ala Thr Arg Asp Lys Asp Asn Ile Leu Ala Val Ile Lys Ser
930 935 940
Thr Asp Val Ser His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn
945 950 955 960
Val Lys Ala Gln Thr Asn Leu His Gln Ser Leu Leu Arg Lys Ala Gly
965 970 975
Leu His Pro Asp Leu Ile Asn Phe Ile Glu Ala His Gly Thr Gly Thr
980 985 990
Ser Leu Gly Asp Leu Ser Glu Ile Gln Gly Ile Asn Asn Ala Tyr Thr
995 1000 1005
Ser Ser Arg Pro Arg Pro Ala Gly Pro Leu Ile Ile Ser Ala Ser
1010 1015 1020
Lys Thr Val Leu Gly His Ser Glu Pro Thr Ala Gly Met Ala Gly
1025 1030 1035
Ile Leu Thr Thr Leu Leu Ala Phe Glu Lys Glu Thr Val Pro Gly
1040 1045 1050
Leu Asn His Leu Thr Glu His Asn Leu Asn Pro Ser Leu Asp Cys
1055 1060 1065
Ser Ala Val Pro Leu Leu Ile Pro His Glu Pro Val His Ile Ser
1070 1075 1080
Gly Ala Lys Pro His Arg Ala Ala Val Leu Ser Tyr Gly Phe Ala
1085 1090 1095
Gly Thr Leu Ala Gly Thr Ile Leu Glu Ser Pro Pro Cys Asp Leu
1100 1105 1110
Thr Arg Pro Leu Ser Asn Asp Ile Gln Glu His Pro Met Ile Phe
1115 1120 1125
Val Val Ser Gly Lys Thr Val Pro Ser Leu Glu Ala Tyr Leu Glu
1130 1135 1140
Arg Tyr Leu Val Phe Leu Arg Val Ala Lys Pro Ser Glu Phe His
1145 1150 1155
Asp Ile Cys Tyr Thr Thr Cys Ile Gly Arg Glu Leu Tyr Lys Tyr
1160 1165 1170
Arg Phe Ser Cys Val Ala Arg Asn Met Ala Asp Leu Ile Ser Gln
1175 1180 1185
Ile Glu His Arg Leu Thr Thr Cys Ser Thr Ser Lys Glu Lys Pro
1190 1195 1200
Arg Gly Ser Leu Gly Phe Val Phe Ser Gly Gln Gly Thr Gln Phe
1205 1210 1215
Pro Gly Met Ala Ala Ala Leu Ala Glu Arg Tyr Ser Gly Phe Arg
1220 1225 1230
Ala Leu Val Ser Lys Phe Gly Gln Ile Ala Gln Glu Gln Ser Gly
1235 1240 1245
Tyr Pro Ile Asp Arg Leu Leu Leu Glu Val Thr Asp Thr Leu Pro
1250 1255 1260
Glu Ala Asn Ser Glu Val Asp Gln Ile Cys Ile Phe Val Tyr Gln
1265 1270 1275
Tyr Ser Val Leu Gln Trp Leu Gln Arg Leu Gly Ile Gln Pro Lys
1280 1285 1290
Thr Val Leu Gly His Ser Leu Gly Glu Ile Thr Ala Ser Val Ala
1295 1300 1305
Val Gly Ala Phe Ser Phe Arg Ser Ala Leu Asp Leu Val Val Thr
1310 1315 1320
Arg Ala Arg Leu Leu Arg Pro Gln Pro Lys Phe Ser Ala Gly Met
1325 1330 1335
Ala Ala Val Ala Ala Ser Lys Glu Glu Val Glu Gly Leu Ile Asp
1340 1345 1350
Met Leu Lys Leu Ala Glu Ser Leu Ser Val Ala Val His Asn Ser
1355 1360 1365
Pro Arg Ser Ile Val Val Ser Gly Ala Ser Ala Ala Val Asp Ala
1370 1375 1380
Met Val Val Ala Ala Lys Lys Gln Gly Leu Lys Ala Ser Arg Leu
1385 1390 1395
Lys Val Asp Gln Ala Phe His Ser Pro Tyr Val Asp Ser Ala Val
1400 1405 1410
Ser Gly Leu Leu Asp Trp Ser Asn Lys His Arg Ser Thr Phe Leu
1415 1420 1425
Pro Leu Asn Ile Pro Leu Tyr Ser Thr Leu Thr Gly Ala Arg Ile
1430 1435 1440
Pro Lys Gly Gly Lys Phe Cys Trp Asp His Trp Val Asn His Ala
1445 1450 1455
Arg Lys Pro Val Gln Phe Ala Ala Ala Ala Ala Ala Met Asp Glu
1460 1465 1470
Asp Gln Ser Ile Gly Val Leu Val Asp Val Gly Pro Gln Pro Val
1475 1480 1485
Ala Trp Thr Leu Leu Gln Ala Asn Asn Leu Leu Asn Thr Ser Ser
1490 1495 1500
Ile Ala Leu Ser Ala Lys Ile Gly Lys Asp Gln Glu Met Ala Leu
1505 1510 1515
Leu Ser Ala Leu Ser Tyr Leu Val Gln Glu His Asn Leu Ser Leu
1520 1525 1530
Ser Phe Tyr Glu Leu Tyr Ser Gln Arg His Gly Thr Leu Lys Lys
1535 1540 1545
Thr Asp Val Pro Thr Tyr Pro Phe Arg Arg Val His Arg Tyr Pro
1550 1555 1560
Thr Phe Ile Pro Ser Arg Asn Arg Ser Pro Ala Asp Met Arg Val
1565 1570 1575
Ala Ile Pro Pro Thr Asp Leu Ser Val Arg Lys Asn Val Asp Ala
1580 1585 1590
Thr Pro Gln Ser Arg Arg Ala Gly Leu Ile Ala Cys Leu Lys Val
1595 1600 1605
Ile Leu Glu Leu Thr Pro Gly Glu Glu Phe Asp Leu Ser Glu Thr
1610 1615 1620
Leu Asn Ala Arg Gly Val Asp Ser Val Met Phe Ala Gln Leu Arg
1625 1630 1635
Lys Arg Val Gly Glu Glu Phe Asp Leu Asp Ile Pro Met Ile Tyr
1640 1645 1650
Leu Ser Asp Val Phe Thr Met Glu Gln Met Ile Asp Tyr Leu Val
1655 1660 1665
Glu Gln Ser Ser Pro Thr Ser Lys Leu Val Glu Ile Ser Val Asn
1670 1675 1680
Gln Ser Leu Asp Gly Glu Gly Leu Arg Thr Gly Leu Val Ser Cys
1685 1690 1695
Leu Arg Asp Val Leu Glu Ile Ser Ser Asp Glu Glu Leu Asp Phe
1700 1705 1710
Ser Glu Thr Leu Asn Ala Arg Gly Thr Asp Ser Ile Met Phe Ala
1715 1720 1725
Gln Leu Arg Lys Arg Val Gly Glu Gly Phe Gly Leu Glu Ile Pro
1730 1735 1740
Met Ile Tyr Leu Ser Asp Val Phe Thr Met Glu Asp Met Ile Asn
1745 1750 1755
Phe Leu Val Ser Glu Arg Ser Cys
1760 1765
<210> 44
<211> 5034
<212> DNA
<213> Mycena citricolor
<400> 44
atgtccgcct cttcctccta ttctgaactg gagtctccga cgtcgctgct tgacgtattc 60
gtgcacgccg cgcgagaccc ccacaccgcg tcgcgtcgcg tgctggagtg cggctcggac 120
acatggacat acgcggcctt ggatgcggta tccgatggca tagcgaggga gctcgcgccc 180
ttcggtctgg cgcccaaggt cgctgtggtc agcgagaacc atccatttgt gttcgcgctg 240
ctgttcgcag tctggaagct cgggggaacg ttcatcccca tcgacgcgca tgtccccttt 300
gccatgctca cggggatggt gaacatcgtg aagccgacgt gtctctacct ccccgcctcc 360
gccacatcca acatatctct cgtgaaggcc ttcgacatac ggaccgtcgt atttgggcac 420
aaggagaatt ccatgcaagc tttgttcgac aagtactcat tgcacgcggc gccgttgcac 480
gcggcaccat tgcattacgc gcctcccagt gccgaccatg cctgtctgta tctcttcacg 540
tcgtcagcgt cctcgaccaa aaacctcaag gcggtcccgc tgacgcatac actcgtcctg 600
cgggggtgtc aatccaaact cgcttggtgg cgccgagtcc aacccggaaa gaatctcgac 660
gctatccgga tcctcggctg ggcaccctgg tctcacgttc tcgcctatat gcaggatatc 720
gggacagcga cactgctcaa cgcgggctgc tacgtctttg cgaccatccc ttcgtcctac 780
ccgcagctgc ctaccactac ccccgtcgat ctgacgactt cgctcatcga cgcgctcgtc 840
acgcggcgcg tcgcggcatt cgcctgtgtc cccttcgtcc tggcgaacct caaagccgcg 900
tgccagagca accaccccgc gcgctcccag ctgctcgagg cgctgcagaa gacgatcatg 960
ctcgagtgcg gtggggcggt gctggacgac gcgacggtgg actgggccga gcgcaacggc 1020
atccgcatct tcacgggaat cgggatgacc gagactggcg gggccgtttt cgtcggcctc 1080
gcgagcgaat ctagacgcgg gtttctaccg gaaggcctac tcggtgatgc atccttctcg 1140
atctcgagtg acacggacgc tcttgacgaa ggggaacttg tcgtgaaaag taaactcatc 1200
gcgcccggat atgtcggcta cgacgacgga gcgcactccg tggactgcga cggctgggtc 1260
acattcagga caggagatcg atatcgccag acccagccag acgggcgctt tacgtggcta 1320
ggaaggatca cagacttcat tcagatggtc agcggcgagt acctcgatcc gcggcccctc 1380
gaggagagtc tgcgtgcgtc cccgctgatc gccaacgcct gcatcgtggg cgacgcgttc 1440
ctcagcagcg cctcgacgag catcctcgcc atcatcgagc tcgcgacccc ggatctggcg 1500
cacacggcct ccatccgggc gcagctcgcg cgcgtcctcg cgcccctcaa ccgcgatctg 1560
cctccaccgc ttcggatcgc agcgtcttcg atcctggttc tggacgggat gcggaagatc 1620
ccgaagacga agaagggcga catcttccgc aaaaagctgg aagacacgtt cggtgcggag 1680
tttgagcaga tgctgcggac cgagaaagtc gggctgggtg acttggcgga tgtggatgcc 1740
ggtatcactc gtatcatcgg caacttgctc ggcatctccg acgacgagct tctgtcgacc 1800
atgtcgtttg ctgagctcgg gatgacctcg cttctcgccg tcaagatcgc gagcgaacta 1860
aacaagtttc tggacggccg ggctgtgctg cccacgaaca tctgttacat acactttgac 1920
gtgccctcgc tcacgagtag cgtccgagaa aggctatcct ccgcgccctc ctcgatcaca 1980
tccgccgcca gcgagcccgc ggcctcgtcc cccggcaccc cccgcgccga cgaaatcgtg 2040
atcgtgggca aggccttccg gctgccggac ggcgtgaacg acgacgccgc gctgtgggac 2100
gtcctgacgg gcgagtccgc gtcgatcatc aaggacatcc ccgccgaccg ctgggaccac 2160
gcgagcttct acccgaagga catccacttt ggcagagctg gtctggtgga tgtcgcgcgg 2220
ttcgactacg gctttttcgg catgacggcg agcgaggcgt attcgctgtc gccgacgatg 2280
cgcttggcgc tcgaagtcgc gtatgaggcg ttagaggacg cgaacattcc gttccgggcc 2340
gtcaagggct cgcgcatggg tgtgttcgtc gctgtgaaag acgatggatt cgagaccctg 2400
ttgcatgcgg ggcagggtta tgacgcttac acgcggttct atggaactgg aagggcgccg 2460
agcaccgcca gcggccgcat caactatctg ctcgatctcc acgggccgtc gatcaccgtc 2520
gacacggcct gcagcggcgg catcgtgtgc atcgaccagg ctgtcaccta tcttcaatcg 2580
ggcgctgcag agacggcgat cgtgtgttcg agcaacacac actgctggcc cggatccttc 2640
atgttcttga ccgcgcaagg catggcctcc cccaacggcc ggtgcgcatc cttcacatca 2700
gacgccgacg gatacgcgcc gtcggagggc gcggtgggct tcgtgctgaa gacgcggtct 2760
gccgctgtgc gcgacggcga tcggatactg gctacgatca gggccacgga gatcggacac 2820
aatggacggt ctcagggact cgctgcgccg aatgtcaggt cccaggcggc tgctcatcgg 2880
gcggtgctgc ggagagcgag gctggacccg tccgagattg acttcatcga agcgcatggg 2940
actggcacca cattgggcga tctgtgcgaa gtgcagggca tcaacgacag ctttgtctcg 3000
cccaagaaac gcgccaaccc tcttgtggtc agcgcgtcca agagcaccat cggccacacc 3060
gagccgtcgg cgggtctcgt cgggatcctg tccgcgctga tgtcgttcga gaagcgcatc 3120
gtgccgagat tggcatatct gactgagagc aatgtgaacc cggcgctcga cgcgagtgtc 3180
gttccgctgc actttcccac aaagcacatc gagctgcgcg ctgatgtgcc gtacaaggcc 3240
gtagtgatgt cgtacggatt cgcaggtacc ctagccgaca tcgtcctcga gagcgaggta 3300
ccccaaccca cgcccgcggt cgctcaggac acggccggcc aacagccaat gctcttcgtg 3360
ctcagcgcca aaaccccacg cgcactcgca gcctacatcg agctgtacct aggcttcctg 3420
cggcacgcgg acccgggcct cttcgcgcgc atctgctaca cggcgtgtgt cgcgcgcgag 3480
cactacaagc accgcgtcgc gtgcgttgcg acggacctcg tcgacctcat cgcgcagctc 3540
gagacgcgtc tggtgcagac ggcgtatgcg ggcggcggcg gggcccgggc cgcgcgcacc 3600
gggccgctgg tgtttgcgtt ttcggggcag ggcacgcagt tcccggcgat ggcggcgccg 3660
ctggcgcggc ggtacgcgcg cttcggggag atcgtggggg gctgtgcgcg catggcgcgc 3720
gagctgagcg ggttccccgt ggatggcatt ctcctcggag acgatgtgac gcccgtgaag 3780
gacaacagcg ctgcggcgga ggtgcacagc gaggtggacc agatctgcat atttgtgtac 3840
cagtatgcga tgtgtcggtg gttgggcgag ctgggtgtgg agcccaaggc tgccataggc 3900
cacagcttgg gagagatcac agcagcggtc atcgcaggag cactcccttt cgaagccgcc 3960
ctcgatctgg tcgtcacgcg cgcccggctg ctcaagccgt gcgccgagca accgagcggc 4020
atggcggcgc tcgcctgcac cccagacgtc gcatcgaagc tcacactcgg cgcgtcggtg 4080
tcggtgtcgg tctacaacgg cccgcagagc atctgcctgt ccggcgcgtc ggccgagctc 4140
gacgatgcgg tgcgggccgc gaaggcgcgg aacatcaagg cgacgcggct gcaggtcgac 4200
cagggcttcc actcgccgtg cgtcgacgcc gcggtgccgg ggctgcaggc gtggtgcgcg 4260
gcgcaccgtg cgtcagctgc gccgctgaag atgccgctgt actcgaccgt gcgcggggac 4320
gtcgttccga agggagcggc gctggatccg gagcactggg tggcgcacgc gcggaacccg 4380
gtgctgttcg cgcagacggc gcaggctctg aaagagtccc ttccgcatgg gatcactttg 4440
gacgtcggcc cgcaggcggt ggcgtggtcg ctgctgctgc tgaacgggct cagcgcgacg 4500
cgcacggtcg ctgccggggc gaagaagggc gcagaccagg agcgcgcgct gctgggggcg 4560
ctgggggcgc tgttcgagca gcacaaggtc acgccggact ttgggcggct gtacgcgccg 4620
ctcgagaaga cgcggatccc gacgtacccc tttgagcgcg cgcggtgcta cccgacgttc 4680
ataccctcgc gcttcgcgca cggggctgcg gctgctgcga agacagatgg cgaggtcctg 4740
tcggccgaag aagaaaatgt ggcacccgtg ggattgctga caaaggagga tctgcgtgcg 4800
gctctcgtcg cgtgtctccg agcgacgctc gagctgcgcc ccgacgaaga gctggacgaa 4860
gcagagccgc tgaccgtgca cggcgtggac tcgatcgggt ttgcgaagct gcgcaagcac 4920
gtcgaggacc gctgggggct ggacatcccc gtcgtgtact ggtccgacgc gttcaccgtc 4980
ggcgagatgc tcggcaactt ggtcggccag tatgacgtag tgtctactgc tgcg 5034
<210> 45
<211> 1678
<212> PRT
<213> Mycena citricolor
<400> 45
Met Ser Ala Ser Ser Ser Tyr Ser Glu Leu Glu Ser Pro Thr Ser Leu
1 5 10 15
Leu Asp Val Phe Val His Ala Ala Arg Asp Pro His Thr Ala Ser Arg
20 25 30
Arg Val Leu Glu Cys Gly Ser Asp Thr Trp Thr Tyr Ala Ala Leu Asp
35 40 45
Ala Val Ser Asp Gly Ile Ala Arg Glu Leu Ala Pro Phe Gly Leu Ala
50 55 60
Pro Lys Val Ala Val Val Ser Glu Asn His Pro Phe Val Phe Ala Leu
65 70 75 80
Leu Phe Ala Val Trp Lys Leu Gly Gly Thr Phe Ile Pro Ile Asp Ala
85 90 95
His Val Pro Phe Ala Met Leu Thr Gly Met Val Asn Ile Val Lys Pro
100 105 110
Thr Cys Leu Tyr Leu Pro Ala Ser Ala Thr Ser Asn Ile Ser Leu Val
115 120 125
Lys Ala Phe Asp Ile Arg Thr Val Val Phe Gly His Lys Glu Asn Ser
130 135 140
Met Gln Ala Leu Phe Asp Lys Tyr Ser Leu His Ala Ala Pro Leu His
145 150 155 160
Ala Ala Pro Leu His Tyr Ala Pro Pro Ser Ala Asp His Ala Cys Leu
165 170 175
Tyr Leu Phe Thr Ser Ser Ala Ser Ser Thr Lys Asn Leu Lys Ala Val
180 185 190
Pro Leu Thr His Thr Leu Val Leu Arg Gly Cys Gln Ser Lys Leu Ala
195 200 205
Trp Trp Arg Arg Val Gln Pro Gly Lys Asn Leu Asp Ala Ile Arg Ile
210 215 220
Leu Gly Trp Ala Pro Trp Ser His Val Leu Ala Tyr Met Gln Asp Ile
225 230 235 240
Gly Thr Ala Thr Leu Leu Asn Ala Gly Cys Tyr Val Phe Ala Thr Ile
245 250 255
Pro Ser Ser Tyr Pro Gln Leu Pro Thr Thr Thr Pro Val Asp Leu Thr
260 265 270
Thr Ser Leu Ile Asp Ala Leu Val Thr Arg Arg Val Ala Ala Phe Ala
275 280 285
Cys Val Pro Phe Val Leu Ala Asn Leu Lys Ala Ala Cys Gln Ser Asn
290 295 300
His Pro Ala Arg Ser Gln Leu Leu Glu Ala Leu Gln Lys Thr Ile Met
305 310 315 320
Leu Glu Cys Gly Gly Ala Val Leu Asp Asp Ala Thr Val Asp Trp Ala
325 330 335
Glu Arg Asn Gly Ile Arg Ile Phe Thr Gly Ile Gly Met Thr Glu Thr
340 345 350
Gly Gly Ala Val Phe Val Gly Leu Ala Ser Glu Ser Arg Arg Gly Phe
355 360 365
Leu Pro Glu Gly Leu Leu Gly Asp Ala Ser Phe Ser Ile Ser Ser Asp
370 375 380
Thr Asp Ala Leu Asp Glu Gly Glu Leu Val Val Lys Ser Lys Leu Ile
385 390 395 400
Ala Pro Gly Tyr Val Gly Tyr Asp Asp Gly Ala His Ser Val Asp Cys
405 410 415
Asp Gly Trp Val Thr Phe Arg Thr Gly Asp Arg Tyr Arg Gln Thr Gln
420 425 430
Pro Asp Gly Arg Phe Thr Trp Leu Gly Arg Ile Thr Asp Phe Ile Gln
435 440 445
Met Val Ser Gly Glu Tyr Leu Asp Pro Arg Pro Leu Glu Glu Ser Leu
450 455 460
Arg Ala Ser Pro Leu Ile Ala Asn Ala Cys Ile Val Gly Asp Ala Phe
465 470 475 480
Leu Ser Ser Ala Ser Thr Ser Ile Leu Ala Ile Ile Glu Leu Ala Thr
485 490 495
Pro Asp Leu Ala His Thr Ala Ser Ile Arg Ala Gln Leu Ala Arg Val
500 505 510
Leu Ala Pro Leu Asn Arg Asp Leu Pro Pro Pro Leu Arg Ile Ala Ala
515 520 525
Ser Ser Ile Leu Val Leu Asp Gly Met Arg Lys Ile Pro Lys Thr Lys
530 535 540
Lys Gly Asp Ile Phe Arg Lys Lys Leu Glu Asp Thr Phe Gly Ala Glu
545 550 555 560
Phe Glu Gln Met Leu Arg Thr Glu Lys Val Gly Leu Gly Asp Leu Ala
565 570 575
Asp Val Asp Ala Gly Ile Thr Arg Ile Ile Gly Asn Leu Leu Gly Ile
580 585 590
Ser Asp Asp Glu Leu Leu Ser Thr Met Ser Phe Ala Glu Leu Gly Met
595 600 605
Thr Ser Leu Leu Ala Val Lys Ile Ala Ser Glu Leu Asn Lys Phe Leu
610 615 620
Asp Gly Arg Ala Val Leu Pro Thr Asn Ile Cys Tyr Ile His Phe Asp
625 630 635 640
Val Pro Ser Leu Thr Ser Ser Val Arg Glu Arg Leu Ser Ser Ala Pro
645 650 655
Ser Ser Ile Thr Ser Ala Ala Ser Glu Pro Ala Ala Ser Ser Pro Gly
660 665 670
Thr Pro Arg Ala Asp Glu Ile Val Ile Val Gly Lys Ala Phe Arg Leu
675 680 685
Pro Asp Gly Val Asn Asp Asp Ala Ala Leu Trp Asp Val Leu Thr Gly
690 695 700
Glu Ser Ala Ser Ile Ile Lys Asp Ile Pro Ala Asp Arg Trp Asp His
705 710 715 720
Ala Ser Phe Tyr Pro Lys Asp Ile His Phe Gly Arg Ala Gly Leu Val
725 730 735
Asp Val Ala Arg Phe Asp Tyr Gly Phe Phe Gly Met Thr Ala Ser Glu
740 745 750
Ala Tyr Ser Leu Ser Pro Thr Met Arg Leu Ala Leu Glu Val Ala Tyr
755 760 765
Glu Ala Leu Glu Asp Ala Asn Ile Pro Phe Arg Ala Val Lys Gly Ser
770 775 780
Arg Met Gly Val Phe Val Ala Val Lys Asp Asp Gly Phe Glu Thr Leu
785 790 795 800
Leu His Ala Gly Gln Gly Tyr Asp Ala Tyr Thr Arg Phe Tyr Gly Thr
805 810 815
Gly Arg Ala Pro Ser Thr Ala Ser Gly Arg Ile Asn Tyr Leu Leu Asp
820 825 830
Leu His Gly Pro Ser Ile Thr Val Asp Thr Ala Cys Ser Gly Gly Ile
835 840 845
Val Cys Ile Asp Gln Ala Val Thr Tyr Leu Gln Ser Gly Ala Ala Glu
850 855 860
Thr Ala Ile Val Cys Ser Ser Asn Thr His Cys Trp Pro Gly Ser Phe
865 870 875 880
Met Phe Leu Thr Ala Gln Gly Met Ala Ser Pro Asn Gly Arg Cys Ala
885 890 895
Ser Phe Thr Ser Asp Ala Asp Gly Tyr Ala Pro Ser Glu Gly Ala Val
900 905 910
Gly Phe Val Leu Lys Thr Arg Ser Ala Ala Val Arg Asp Gly Asp Arg
915 920 925
Ile Leu Ala Thr Ile Arg Ala Thr Glu Ile Gly His Asn Gly Arg Ser
930 935 940
Gln Gly Leu Ala Ala Pro Asn Val Arg Ser Gln Ala Ala Ala His Arg
945 950 955 960
Ala Val Leu Arg Arg Ala Arg Leu Asp Pro Ser Glu Ile Asp Phe Ile
965 970 975
Glu Ala His Gly Thr Gly Thr Thr Leu Gly Asp Leu Cys Glu Val Gln
980 985 990
Gly Ile Asn Asp Ser Phe Val Ser Pro Lys Lys Arg Ala Asn Pro Leu
995 1000 1005
Val Val Ser Ala Ser Lys Ser Thr Ile Gly His Thr Glu Pro Ser
1010 1015 1020
Ala Gly Leu Val Gly Ile Leu Ser Ala Leu Met Ser Phe Glu Lys
1025 1030 1035
Arg Ile Val Pro Arg Leu Ala Tyr Leu Thr Glu Ser Asn Val Asn
1040 1045 1050
Pro Ala Leu Asp Ala Ser Val Val Pro Leu His Phe Pro Thr Lys
1055 1060 1065
His Ile Glu Leu Arg Ala Asp Val Pro Tyr Lys Ala Val Val Met
1070 1075 1080
Ser Tyr Gly Phe Ala Gly Thr Leu Ala Asp Ile Val Leu Glu Ser
1085 1090 1095
Glu Val Pro Gln Pro Thr Pro Ala Val Ala Gln Asp Thr Ala Gly
1100 1105 1110
Gln Gln Pro Met Leu Phe Val Leu Ser Ala Lys Thr Pro Arg Ala
1115 1120 1125
Leu Ala Ala Tyr Ile Glu Leu Tyr Leu Gly Phe Leu Arg His Ala
1130 1135 1140
Asp Pro Gly Leu Phe Ala Arg Ile Cys Tyr Thr Ala Cys Val Ala
1145 1150 1155
Arg Glu His Tyr Lys His Arg Val Ala Cys Val Ala Thr Asp Leu
1160 1165 1170
Val Asp Leu Ile Ala Gln Leu Glu Thr Arg Leu Val Gln Thr Ala
1175 1180 1185
Tyr Ala Gly Gly Gly Gly Ala Arg Ala Ala Arg Thr Gly Pro Leu
1190 1195 1200
Val Phe Ala Phe Ser Gly Gln Gly Thr Gln Phe Pro Ala Met Ala
1205 1210 1215
Ala Pro Leu Ala Arg Arg Tyr Ala Arg Phe Gly Glu Ile Val Gly
1220 1225 1230
Gly Cys Ala Arg Met Ala Arg Glu Leu Ser Gly Phe Pro Val Asp
1235 1240 1245
Gly Ile Leu Leu Gly Asp Asp Val Thr Pro Val Lys Asp Asn Ser
1250 1255 1260
Ala Ala Ala Glu Val His Ser Glu Val Asp Gln Ile Cys Ile Phe
1265 1270 1275
Val Tyr Gln Tyr Ala Met Cys Arg Trp Leu Gly Glu Leu Gly Val
1280 1285 1290
Glu Pro Lys Ala Ala Ile Gly His Ser Leu Gly Glu Ile Thr Ala
1295 1300 1305
Ala Val Ile Ala Gly Ala Leu Pro Phe Glu Ala Ala Leu Asp Leu
1310 1315 1320
Val Val Thr Arg Ala Arg Leu Leu Lys Pro Cys Ala Glu Gln Pro
1325 1330 1335
Ser Gly Met Ala Ala Leu Ala Cys Thr Pro Asp Val Ala Ser Lys
1340 1345 1350
Leu Thr Leu Gly Ala Ser Val Ser Val Ser Val Tyr Asn Gly Pro
1355 1360 1365
Gln Ser Ile Cys Leu Ser Gly Ala Ser Ala Glu Leu Asp Asp Ala
1370 1375 1380
Val Arg Ala Ala Lys Ala Arg Asn Ile Lys Ala Thr Arg Leu Gln
1385 1390 1395
Val Asp Gln Gly Phe His Ser Pro Cys Val Asp Ala Ala Val Pro
1400 1405 1410
Gly Leu Gln Ala Trp Cys Ala Ala His Arg Ala Ser Ala Ala Pro
1415 1420 1425
Leu Lys Met Pro Leu Tyr Ser Thr Val Arg Gly Asp Val Val Pro
1430 1435 1440
Lys Gly Ala Ala Leu Asp Pro Glu His Trp Val Ala His Ala Arg
1445 1450 1455
Asn Pro Val Leu Phe Ala Gln Thr Ala Gln Ala Leu Lys Glu Ser
1460 1465 1470
Leu Pro His Gly Ile Thr Leu Asp Val Gly Pro Gln Ala Val Ala
1475 1480 1485
Trp Ser Leu Leu Leu Leu Asn Gly Leu Ser Ala Thr Arg Thr Val
1490 1495 1500
Ala Ala Gly Ala Lys Lys Gly Ala Asp Gln Glu Arg Ala Leu Leu
1505 1510 1515
Gly Ala Leu Gly Ala Leu Phe Glu Gln His Lys Val Thr Pro Asp
1520 1525 1530
Phe Gly Arg Leu Tyr Ala Pro Leu Glu Lys Thr Arg Ile Pro Thr
1535 1540 1545
Tyr Pro Phe Glu Arg Ala Arg Cys Tyr Pro Thr Phe Ile Pro Ser
1550 1555 1560
Arg Phe Ala His Gly Ala Ala Ala Ala Ala Lys Thr Asp Gly Glu
1565 1570 1575
Val Leu Ser Ala Glu Glu Glu Asn Val Ala Pro Val Gly Leu Leu
1580 1585 1590
Thr Lys Glu Asp Leu Arg Ala Ala Leu Val Ala Cys Leu Arg Ala
1595 1600 1605
Thr Leu Glu Leu Arg Pro Asp Glu Glu Leu Asp Glu Ala Glu Pro
1610 1615 1620
Leu Thr Val His Gly Val Asp Ser Ile Gly Phe Ala Lys Leu Arg
1625 1630 1635
Lys His Val Glu Asp Arg Trp Gly Leu Asp Ile Pro Val Val Tyr
1640 1645 1650
Trp Ser Asp Ala Phe Thr Val Gly Glu Met Leu Gly Asn Leu Val
1655 1660 1665
Gly Gln Tyr Asp Val Val Ser Thr Ala Ala
1670 1675
<210> 46
<211> 4956
<212> DNA
<213> Mycena chlorophos
<400> 46
atgaatccgc cctcgtctat cctcgaagtc ttccagcgta ccgccctcga cccctcgggc 60
gccgaccggc gcgttctgga atgcgggccc gacttttgga cctacgcggg tctcgacgcg 120
gtttccacag gccttgcggc ggacttggct gctctcggag attctcccat cgtggctgtc 180
gtcgctgaga accatccctt cgtcttcgca ctcatgtttg ccgtctggaa attgcacggg 240
acgtttgttc ccatcgacgc gcatattccg tggaacctgc tcgacggcat gttggacatc 300
gtcaagccga cttgcatgtt tctcgtcgag tcggatacca acaatatctc gaacaccaag 360
gcccagggag tcgacttcgc tgtgcgcctc ttcggaggag aaggattcac catcccggcg 420
ctctcggcca aatatgcggg gaacgtctcg aatggcgccc ccgagtcact cccttctcca 480
gacgcgactg ctctgtatct gttcacgtcg tctgcctcgt cgcggcacaa tttgaaggcc 540
gttccgctca cgcatcgatt cattgccgct ggctgcgaag cgaaactcgc cttctggcac 600
cgtcttcatc ctcacaaccc caccgatgcg attcgcgtgc tgggatgggc tccgttgtcg 660
cacgtcctcg cgcatatgca ggatatcggc accgcggccc tcctcaacgc cggctgctat 720
gtcttttcga cgatcccctt gtcttacacc tcagcagaaa ctcagcccgc gcaagatatc 780
acctcggctc tcattcactc cgtgctccat tacgaggtca aagcatttgc gggcctgcct 840
tttgttattg cggcattcaa ggctgcttgt gaaggcggga acgaccgtct cctagcgcaa 900
ctacgctcca tgaccatgct cgagtgtggc ggggcgcagt tggacaagga catcgtggat 960
tgggcagtca agcaagcgat cccgctcgtg gttggggtcg ggatgacgga aacgggtggc 1020
gcgatactgg cgggccccgt cggggatgcg tcggatgggt ttcaccccca agggctgctg 1080
ctagatgcac agttctccct tatcggcaat gacgatgaat cggaaggcga gctggtcatc 1140
aagagtccca atcttccgcg cggatatctg aagtacgagg acggctcgtt cgacatcgac 1200
gcgcagggtg tcgtcacgtt caagactgga gacatctacc gcaaaagtgt cgagggtaaa 1260
ctcctttggg ttgggcgtag tacggatttc atccagatgg ctaccggcga gacgctcgat 1320
ccccgtcgtg ttgaacgggc gctacgcttc gcatcgggga tcaacgatgc ctgcatcatc 1380
gggaatgcgt tcctgaatgg ctcctctacc gcaatttacg ccatcatcga gctcgctccg 1440
cgcaccgtca acatcaataa tgattcaaat gtctcccatc tgcaggtggt tgcccgcgcc 1500
ctgtctccta tcaaccgcga ccttcctccc gcattacgca ttgtgttgtc ttctgtattg 1560
attctggctg aaggcatgaa gattccgagg acaaagaaag gcgaaatctt ccggaagaag 1620
attgatgaag ttttcggagc tgctctccgg gctttaggtc actcggcaac tccaacagag 1680
gttgttcttg agcaggaacc agcggcagcc agcaaaccca tttttgacaa gaacaagctg 1740
cagactgcta ttgcgcatag cttgggtctg gatattctgg agattgacct gctggacaag 1800
ctgacctttg ctgagcttgg catgacatct attcttgcaa ttcgggttgc agaagatctc 1860
aacaaattgc tgcagggaca agttaccctg ccagtcaata tctgctacct ctatccagat 1920
gcccagctgt tgtttgcagc agttcaggaa cagctgctca agcagcagca cccttcaacc 1980
ccaactgctc cctccgtgcc ggctttgctg tcagcaactt cctctgttcc aattctcttg 2040
caggaactag atgatgttgt cattgttggc aaatcattcc ggttgcctgg cggaatctac 2100
gatgatcgag cactctgggc agctctcacc aatcaagcta cccgaaaccc catctcatat 2160
atttcgggcc agcgctggga ccatacaagc ttttacccag ctgatattgc attcttgcag 2220
gcagggttgc ttgactccga ccactttacg gattttgatg cagctttctt cgggatgacc 2280
gagaaagagg catactatct gtccccgacc atgcggcttg ctcttgaagt agcctttgag 2340
gctctagaag atgcaaatat tcctgttggt caggtgaaag gcactagcat gggagtatat 2400
gcagctgtca aggatgatgg attcgaaacc cttttgaatg ctgctcatgg gtatgatgcc 2460
tacacacgat tctacggaac tggacgggca ccaagtacca ctagcgggcg gatcagtcaa 2520
ggagaatcag cgattgtctg ctccagcaat acacactgtt ggcctggctc cttcatgttc 2580
ttgactgccc aaggaatggt gtctcctcat ggacgttgtg cctccttcag tgctcaagca 2640
gatggatatg ttccttcaga gggtgctgtt gcatttatcc tgaagacccg caaagcagca 2700
gttcgggatg gaaaccaaat ttttgccaca attcgggctg cggtggtatc acacaatggt 2760
cgatcacaag gtcttgcagc accaaacatt caagcccaat ccgagttgca tcaacaagca 2820
ttgcagaagg caaatatcca acccactgat attcattttg tggaaactca tggaacaggg 2880
acttcgcttg gggatgtctg tgagattcat gggataaatg ctgcttttgc agcaggtcac 2940
cgtccctctg gacctctcat cattagtgca agcaaaggca ctattggaca tacagagcct 3000
tctgcaggtc ttgtgggcat catggcggca ctgctctcct tcaagcatgg ccttgttcct 3060
gggctgatcc atacatctca tgggcaactc aacccggcac ttgatcaatc caaagttccg 3120
cttatcttca gcccacaaac aatttccctg ggcggagaaa agccttacag atctgtggtc 3180
atgtcatatg gctttgcagg cacactagcg gatattgtgc ttgaaggccc tgctgaggag 3240
gctttttccg ggccaggcaa aaacagcagt gctcctccgc ctatgatctt tgccctcagt 3300
gccaaatctg catcagccct ccaagaatac aagcagaagt acatcacctt cctgcagaat 3360
gttggctctg gaggccaact gttcagcaag atctgtttga cttcttgcat tgcccgagag 3420
cactacaagc atagattctc ctgtgctgct cagaacacac tggatcttct tctgcagcta 3480
gagcactctg ttgctgccag ccacaaacct ccaacaactc gtaccggaac agtcaccttt 3540
gctttctctg gacagggagc ccaattcccc agcatggatg cagctctggc tcaaggctac 3600
tctgccttca aatccatctt gctggaactt ggaaacaagg ctgccaaact ctctggattc 3660
cccatcactg attgcctgtt ggcaacaaca gcatcagctg atgaagaagc cgtccatagt 3720
gaggtggacc aaatttgcat ttttgttcat caatatgcaa tggctctttt cctcgagatg 3780
ctaggaattg tccccggtgc tgccataggc cacagcttgg gagagatcac agcagcggtc 3840
gttgctggtg gactttcgtt tgaacttggc ctagagttgg tcatcctccg tgcacatctg 3900
ctccgtccag agcagaacaa gcccgctggc atggctgcct tggcatgctc agaagcggac 3960
ttcctcaagt ttccgtccac cgatgcaact atttctgttt tcaactctcc tcggagcatt 4020
gcagtctctg gagcagcaag ctccattgag acagttctta ctgctgccaa agagcagaat 4080
atcaaggcca cgaagctcag ggttgatcaa ggattccata gcagctatgt ggagcatgcg 4140
cttcccgggc tcaagcactg gtcagcaatg aattcaggct ccttccaggc actcaggatt 4200
ccactctatt caactgcact tggccatgtt gttcctgctg gagagaccct tcagccagat 4260
cactggatga accatacccg caatgctgtt cattttacgc aaactgcgca ggctctgaaa 4320
gagtcccttc cgcatgggat cactttggat cttggtcctc aggctgtagc tcaaactctc 4380
ctgctggcca atgaccatcc tgttggccgc accattggat tgtgtggcaa acgcacagga 4440
gatcaaagac atgcattcct gctcgctctt gctgagcttt accagcagca tggtcttgtg 4500
cccaactttc atgcacttta tggcgtagct gcccaggatc tcaaggacca tctcaccagc 4560
ctgccaacat atccattcca acgtgtccgc tgctatccca gctacattcc atcccgtcac 4620
tccaacactc ccgggaccac cgtggtgatt gatgcaaagc cgcgggatga agtgaaacct 4680
gtggcagagg tctcaaagtc ggacacggat tcttccacat cattttcttc gaccattctc 4740
ttccacattc gctccatcct tgagcttcgc ccccatgagg ttctggatac gtctgaatcc 4800
ctcttgacgt acggggtcga ctcgattggg tttgcagcac tgcagaaggc cctggagcag 4860
cagcatgggc taaacttgtc gattgtgttc tggagcgacg tgttttccat tgccgacatt 4920
gtgaagaatc ttgaggagca gaagagcttg aagatg 4956
<210> 47
<211> 1652
<212> PRT
<213> Mycena chlorophos
<400> 47
Met Asn Pro Pro Ser Ser Ile Leu Glu Val Phe Gln Arg Thr Ala Leu
1 5 10 15
Asp Pro Ser Gly Ala Asp Arg Arg Val Leu Glu Cys Gly Pro Asp Phe
20 25 30
Trp Thr Tyr Ala Gly Leu Asp Ala Val Ser Thr Gly Leu Ala Ala Asp
35 40 45
Leu Ala Ala Leu Gly Asp Ser Pro Ile Val Ala Val Val Ala Glu Asn
50 55 60
His Pro Phe Val Phe Ala Leu Met Phe Ala Val Trp Lys Leu His Gly
65 70 75 80
Thr Phe Val Pro Ile Asp Ala His Ile Pro Trp Asn Leu Leu Asp Gly
85 90 95
Met Leu Asp Ile Val Lys Pro Thr Cys Met Phe Leu Val Glu Ser Asp
100 105 110
Thr Asn Asn Ile Ser Asn Thr Lys Ala Gln Gly Val Asp Phe Ala Val
115 120 125
Arg Leu Phe Gly Gly Glu Gly Phe Thr Ile Pro Ala Leu Ser Ala Lys
130 135 140
Tyr Ala Gly Asn Val Ser Asn Gly Ala Pro Glu Ser Leu Pro Ser Pro
145 150 155 160
Asp Ala Thr Ala Leu Tyr Leu Phe Thr Ser Ser Ala Ser Ser Arg His
165 170 175
Asn Leu Lys Ala Val Pro Leu Thr His Arg Phe Ile Ala Ala Gly Cys
180 185 190
Glu Ala Lys Leu Ala Phe Trp His Arg Leu His Pro His Asn Pro Thr
195 200 205
Asp Ala Ile Arg Val Leu Gly Trp Ala Pro Leu Ser His Val Leu Ala
210 215 220
His Met Gln Asp Ile Gly Thr Ala Ala Leu Leu Asn Ala Gly Cys Tyr
225 230 235 240
Val Phe Ser Thr Ile Pro Leu Ser Tyr Thr Ser Ala Glu Thr Gln Pro
245 250 255
Ala Gln Asp Ile Thr Ser Ala Leu Ile His Ser Val Leu His Tyr Glu
260 265 270
Val Lys Ala Phe Ala Gly Leu Pro Phe Val Ile Ala Ala Phe Lys Ala
275 280 285
Ala Cys Glu Gly Gly Asn Asp Arg Leu Leu Ala Gln Leu Arg Ser Met
290 295 300
Thr Met Leu Glu Cys Gly Gly Ala Gln Leu Asp Lys Asp Ile Val Asp
305 310 315 320
Trp Ala Val Lys Gln Ala Ile Pro Leu Val Val Gly Val Gly Met Thr
325 330 335
Glu Thr Gly Gly Ala Ile Leu Ala Gly Pro Val Gly Asp Ala Ser Asp
340 345 350
Gly Phe His Pro Gln Gly Leu Leu Leu Asp Ala Gln Phe Ser Leu Ile
355 360 365
Gly Asn Asp Asp Glu Ser Glu Gly Glu Leu Val Ile Lys Ser Pro Asn
370 375 380
Leu Pro Arg Gly Tyr Leu Lys Tyr Glu Asp Gly Ser Phe Asp Ile Asp
385 390 395 400
Ala Gln Gly Val Val Thr Phe Lys Thr Gly Asp Ile Tyr Arg Lys Ser
405 410 415
Val Glu Gly Lys Leu Leu Trp Val Gly Arg Ser Thr Asp Phe Ile Gln
420 425 430
Met Ala Thr Gly Glu Thr Leu Asp Pro Arg Arg Val Glu Arg Ala Leu
435 440 445
Arg Phe Ala Ser Gly Ile Asn Asp Ala Cys Ile Ile Gly Asn Ala Phe
450 455 460
Leu Asn Gly Ser Ser Thr Ala Ile Tyr Ala Ile Ile Glu Leu Ala Pro
465 470 475 480
Arg Thr Val Asn Ile Asn Asn Asp Ser Asn Val Ser His Leu Gln Val
485 490 495
Val Ala Arg Ala Leu Ser Pro Ile Asn Arg Asp Leu Pro Pro Ala Leu
500 505 510
Arg Ile Val Leu Ser Ser Val Leu Ile Leu Ala Glu Gly Met Lys Ile
515 520 525
Pro Arg Thr Lys Lys Gly Glu Ile Phe Arg Lys Lys Ile Asp Glu Val
530 535 540
Phe Gly Ala Ala Leu Arg Ala Leu Gly His Ser Ala Thr Pro Thr Glu
545 550 555 560
Val Val Leu Glu Gln Glu Pro Ala Ala Ala Ser Lys Pro Ile Phe Asp
565 570 575
Lys Asn Lys Leu Gln Thr Ala Ile Ala His Ser Leu Gly Leu Asp Ile
580 585 590
Leu Glu Ile Asp Leu Leu Asp Lys Leu Thr Phe Ala Glu Leu Gly Met
595 600 605
Thr Ser Ile Leu Ala Ile Arg Val Ala Glu Asp Leu Asn Lys Leu Leu
610 615 620
Gln Gly Gln Val Thr Leu Pro Val Asn Ile Cys Tyr Leu Tyr Pro Asp
625 630 635 640
Ala Gln Leu Leu Phe Ala Ala Val Gln Glu Gln Leu Leu Lys Gln Gln
645 650 655
His Pro Ser Thr Pro Thr Ala Pro Ser Val Pro Ala Leu Leu Ser Ala
660 665 670
Thr Ser Ser Val Pro Ile Leu Leu Gln Glu Leu Asp Asp Val Val Ile
675 680 685
Val Gly Lys Ser Phe Arg Leu Pro Gly Gly Ile Tyr Asp Asp Arg Ala
690 695 700
Leu Trp Ala Ala Leu Thr Asn Gln Ala Thr Arg Asn Pro Ile Ser Tyr
705 710 715 720
Ile Ser Gly Gln Arg Trp Asp His Thr Ser Phe Tyr Pro Ala Asp Ile
725 730 735
Ala Phe Leu Gln Ala Gly Leu Leu Asp Ser Asp His Phe Thr Asp Phe
740 745 750
Asp Ala Ala Phe Phe Gly Met Thr Glu Lys Glu Ala Tyr Tyr Leu Ser
755 760 765
Pro Thr Met Arg Leu Ala Leu Glu Val Ala Phe Glu Ala Leu Glu Asp
770 775 780
Ala Asn Ile Pro Val Gly Gln Val Lys Gly Thr Ser Met Gly Val Tyr
785 790 795 800
Ala Ala Val Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Ala His
805 810 815
Gly Tyr Asp Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser
820 825 830
Thr Thr Ser Gly Arg Ile Ser Gln Gly Glu Ser Ala Ile Val Cys Ser
835 840 845
Ser Asn Thr His Cys Trp Pro Gly Ser Phe Met Phe Leu Thr Ala Gln
850 855 860
Gly Met Val Ser Pro His Gly Arg Cys Ala Ser Phe Ser Ala Gln Ala
865 870 875 880
Asp Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys Thr
885 890 895
Arg Lys Ala Ala Val Arg Asp Gly Asn Gln Ile Phe Ala Thr Ile Arg
900 905 910
Ala Ala Val Val Ser His Asn Gly Arg Ser Gln Gly Leu Ala Ala Pro
915 920 925
Asn Ile Gln Ala Gln Ser Glu Leu His Gln Gln Ala Leu Gln Lys Ala
930 935 940
Asn Ile Gln Pro Thr Asp Ile His Phe Val Glu Thr His Gly Thr Gly
945 950 955 960
Thr Ser Leu Gly Asp Val Cys Glu Ile His Gly Ile Asn Ala Ala Phe
965 970 975
Ala Ala Gly His Arg Pro Ser Gly Pro Leu Ile Ile Ser Ala Ser Lys
980 985 990
Gly Thr Ile Gly His Thr Glu Pro Ser Ala Gly Leu Val Gly Ile Met
995 1000 1005
Ala Ala Leu Leu Ser Phe Lys His Gly Leu Val Pro Gly Leu Ile
1010 1015 1020
His Thr Ser His Gly Gln Leu Asn Pro Ala Leu Asp Gln Ser Lys
1025 1030 1035
Val Pro Leu Ile Phe Ser Pro Gln Thr Ile Ser Leu Gly Gly Glu
1040 1045 1050
Lys Pro Tyr Arg Ser Val Val Met Ser Tyr Gly Phe Ala Gly Thr
1055 1060 1065
Leu Ala Asp Ile Val Leu Glu Gly Pro Ala Glu Glu Ala Phe Ser
1070 1075 1080
Gly Pro Gly Lys Asn Ser Ser Ala Pro Pro Pro Met Ile Phe Ala
1085 1090 1095
Leu Ser Ala Lys Ser Ala Ser Ala Leu Gln Glu Tyr Lys Gln Lys
1100 1105 1110
Tyr Ile Thr Phe Leu Gln Asn Val Gly Ser Gly Gly Gln Leu Phe
1115 1120 1125
Ser Lys Ile Cys Leu Thr Ser Cys Ile Ala Arg Glu His Tyr Lys
1130 1135 1140
His Arg Phe Ser Cys Ala Ala Gln Asn Thr Leu Asp Leu Leu Leu
1145 1150 1155
Gln Leu Glu His Ser Val Ala Ala Ser His Lys Pro Pro Thr Thr
1160 1165 1170
Arg Thr Gly Thr Val Thr Phe Ala Phe Ser Gly Gln Gly Ala Gln
1175 1180 1185
Phe Pro Ser Met Asp Ala Ala Leu Ala Gln Gly Tyr Ser Ala Phe
1190 1195 1200
Lys Ser Ile Leu Leu Glu Leu Gly Asn Lys Ala Ala Lys Leu Ser
1205 1210 1215
Gly Phe Pro Ile Thr Asp Cys Leu Leu Ala Thr Thr Ala Ser Ala
1220 1225 1230
Asp Glu Glu Ala Val His Ser Glu Val Asp Gln Ile Cys Ile Phe
1235 1240 1245
Val His Gln Tyr Ala Met Ala Leu Phe Leu Glu Met Leu Gly Ile
1250 1255 1260
Val Pro Gly Ala Ala Ile Gly His Ser Leu Gly Glu Ile Thr Ala
1265 1270 1275
Ala Val Val Ala Gly Gly Leu Ser Phe Glu Leu Gly Leu Glu Leu
1280 1285 1290
Val Ile Leu Arg Ala His Leu Leu Arg Pro Glu Gln Asn Lys Pro
1295 1300 1305
Ala Gly Met Ala Ala Leu Ala Cys Ser Glu Ala Asp Phe Leu Lys
1310 1315 1320
Phe Pro Ser Thr Asp Ala Thr Ile Ser Val Phe Asn Ser Pro Arg
1325 1330 1335
Ser Ile Ala Val Ser Gly Ala Ala Ser Ser Ile Glu Thr Val Leu
1340 1345 1350
Thr Ala Ala Lys Glu Gln Asn Ile Lys Ala Thr Lys Leu Arg Val
1355 1360 1365
Asp Gln Gly Phe His Ser Ser Tyr Val Glu His Ala Leu Pro Gly
1370 1375 1380
Leu Lys His Trp Ser Ala Met Asn Ser Gly Ser Phe Gln Ala Leu
1385 1390 1395
Arg Ile Pro Leu Tyr Ser Thr Ala Leu Gly His Val Val Pro Ala
1400 1405 1410
Gly Glu Thr Leu Gln Pro Asp His Trp Met Asn His Thr Arg Asn
1415 1420 1425
Ala Val His Phe Thr Gln Thr Ala Gln Ala Leu Lys Glu Ser Leu
1430 1435 1440
Pro His Gly Ile Thr Leu Asp Leu Gly Pro Gln Ala Val Ala Gln
1445 1450 1455
Thr Leu Leu Leu Ala Asn Asp His Pro Val Gly Arg Thr Ile Gly
1460 1465 1470
Leu Cys Gly Lys Arg Thr Gly Asp Gln Arg His Ala Phe Leu Leu
1475 1480 1485
Ala Leu Ala Glu Leu Tyr Gln Gln His Gly Leu Val Pro Asn Phe
1490 1495 1500
His Ala Leu Tyr Gly Val Ala Ala Gln Asp Leu Lys Asp His Leu
1505 1510 1515
Thr Ser Leu Pro Thr Tyr Pro Phe Gln Arg Val Arg Cys Tyr Pro
1520 1525 1530
Ser Tyr Ile Pro Ser Arg His Ser Asn Thr Pro Gly Thr Thr Val
1535 1540 1545
Val Ile Asp Ala Lys Pro Arg Asp Glu Val Lys Pro Val Ala Glu
1550 1555 1560
Val Ser Lys Ser Asp Thr Asp Ser Ser Thr Ser Phe Ser Ser Thr
1565 1570 1575
Ile Leu Phe His Ile Arg Ser Ile Leu Glu Leu Arg Pro His Glu
1580 1585 1590
Val Leu Asp Thr Ser Glu Ser Leu Leu Thr Tyr Gly Val Asp Ser
1595 1600 1605
Ile Gly Phe Ala Ala Leu Gln Lys Ala Leu Glu Gln Gln His Gly
1610 1615 1620
Leu Asn Leu Ser Ile Val Phe Trp Ser Asp Val Phe Ser Ile Ala
1625 1630 1635
Asp Ile Val Lys Asn Leu Glu Glu Gln Lys Ser Leu Lys Met
1640 1645 1650
<210> 48
<211> 5313
<212> DNA
<213> Armillaria gallica
<400> 48
atggaggccg acggtcacca ctctcttctc gatgtctttc tcagcgttgc acatgattct 60
gagaagtcca aacgtaatgt cttggaatgc ggccaggata cctggacata ctcagatttg 120
gacatcatct cgtcggcctt ggcacaggat ctcaaagcta ccttgggttg ttttcccaaa 180
gttgcagtcg tcagcgagaa ccatccctac gtgtttgctc tcatgctggc cgtttggaag 240
cttgaaggga tattcatccc catcgacgtc catattacag ctgaccttct aaagggcatg 300
ctacgcattg ttgcccccac ttgtctggcg atcccagaga ccgatatttc caaccagcgt 360
gttgcctctg cgattggtat acatgttctc cccttcaacg tgaatgcgtc gaccatgaat 420
gcacttcgac agaaatacga cccatttact cagaatgcct cgctatctgg atgcgcactt 480
ccttacgttg atcgcgcatg cctctatctc tttacatcct ccgcgtcctc tactgccaac 540
ttgaaatgtg tacctttgac ccatactctt atcctcagta actgccgttc caagctcgca 600
tggtggcggc gcgttcgtcc ggaaggcgaa atggatggga tacgtgttct agggtgggca 660
ccttggtcgc atatccttgc ctacatgcaa gatattggca cggcaacgtt cctgaatgcc 720
ggctgctatg tctttgcgtc cgttccatcc acatatcctt cacagctggc agcgaatggc 780
ctacaaggcc ccaccatgaa tatcatcgat tcacttcttg aacggcgagt cgccgcattt 840
gcttgcgtac cgttcatttt gagcgaacta aaagctatgt gcgagacggc tgccagtcca 900
gatgacaagc atctcatgtg cttgagagct gaggagaaag ttcgccttgt cagtgcgctg 960
cagcggctta tgatgctcga gtgcggaggc gctgcgctcg agtcggatgt cacacgttgg 1020
gccgtcgaaa atggcatatc ggtcatggtc ggcatcggga tgacggagac agtcggtacg 1080
ctgtttgcag agcgcgcgca agacgcctgt tccaatggct attctgcgca ggacgccctc 1140
attgctgatg gcatcatgtc actggtcggg tctgacaacg aggaagccac cttcgaaggg 1200
gaactagtcg tgaagagcaa gctcatccca cacggataca tcaactaccg tgattcgtcg 1260
ttttcggtgg actcggacgg ctgggtaacg ttcaaaacgg gagacaaata tcagcgcacg 1320
ccagatggac gattcaaatg gcttggaaga aagaccgatt ttattcagat gacaagcagc 1380
gaaacattgg atcccagacc cattgagcaa gccctctgtg cgaatccaag tatcgcaaat 1440
gcatgcgtca ttggtgacag gttcctgaga gagcctgcga ctagcgtatg cgccattgtc 1500
gagatcgggc ctgaagtgga catgccttcg tccaagatcg acagagaaat tgcgaatgcc 1560
ctcgctccaa tcaatcgcga ccttcctcct gctcttcgca tatcatggtc tcgcgtactc 1620
ataattcgac ctcctcagaa aataccagtt acgaggaaag gcgatgtgtt ccgtaagaag 1680
attgaagata tgtttgggcc tttccttggt gtcggcgttt ctaccgaggt cgaagccggc 1740
catgaaacta aagaagatga cacggaacac atcgtgagac aggttgtgag caatcttctt 1800
ggcgtccatg atcctgagct attgtctgct ttatctttcg ctgagctggg catgacctca 1860
tttatggctg ttagcatcgt caacgctctc aacaaacgca tcggcggcct cacccttccg 1920
tctaatgcat gctacatcca tattgatctt gattctcttg tggacgcgat ttcacttgaa 1980
tatggtcatg gaagtatccc tgcagagttg ccttctaacc ctttccccga catcgagtcc 2040
catcagcata atgataagga cattgtgata gtcggcaagg cattccgttt acccggctca 2100
ctcaacagta ctgcaactct ctgggaagct ttgttatcga ataacaattc ggtcatcagt 2160
gatatcccat ctgatcgctg ggatcatgca agcttttacc cccacaatat atgtttcacg 2220
aaagcaggcc tcgtcgatgt tgcacattac gactacagat tttttggcct catggcgaca 2280
gaggcgttgt acgtatctcc gacgatgcgc ctcgccttgg aagtgtcatt tgaagccctg 2340
gagaacgcaa atattccgct atccaagctg aaggggacac aaaccgctgt ctatgtcgcc 2400
actaaagacg atggcttcga gacactctta aatgccgagc aaggttacga tgcgtacacg 2460
cgattctacg gcacgggtcg cgctccgagt accgcaagcg gtcgcataag ctatcttctt 2520
gatattcatg ggccatctat taccgttgat acagcatgca gcggaggcat tgtatgtatg 2580
gatcaagcca tcactttctt gcaatccgga ggggccgata ccgcaattgt ctgttcgacc 2640
aatacgcact gttggccggg atcattcatg ttcctgacgg cacaaggcat ggtttctcca 2700
aatggaagat gcgctacatt cactaccgat gcagacggat atgtgccttc ggagggtgca 2760
gtggctttca ttctcaagac gcgcagcgct gcaatacgcg acaatgacaa tatactcgcc 2820
gtgatcaaat caacagatgt gtcccataac ggccgttctc aagggctagt tgcaccaaac 2880
gtaaaggcgc aggcaaacct acaccggtcg ttgctacgaa aagctgggct gtttcctgat 2940
caaattaact ttatcgaagc tcatggaaca ggtacatctc taggagacct ttcggaaatc 3000
cagggcatta ataacgccta catctcatca cgacctcgtc tggccggtcc ccttatcatt 3060
agtgcatcga aaacagtttt aggacacagt gaaccaacag cagggatggc cggcatcctc 3120
acagccttgc ttgcccttga gaaagagaca gttcctggtt taaatcactt aacggatcac 3180
aacctcaacc cttcgcttga ttgcagcgta gttcctctcc tgattcctca cgagtctatt 3240
cacattggtg gtgcaaagcc acatcgagct gcggttctgt catacggctt cgcgggtacg 3300
ctggccggtg ctatcttaga aggaccacct tctggtgtac catggccgtc gtcaaatgat 3360
atacaagaac accctatgat tttcgtcgtc agtgggaaaa ccgtgcctac actggaagcg 3420
tacctgggac ggtatttgac atttttgcgg gtcgcaaaaa cacacgactt ccaggacatc 3480
tgctacacca cttgcgtcgg gagggagcac tacaaatacc ggttctcctg cgttgcccga 3540
aacatggcag accttatttc tcaaattgaa catcgactga caactctttc cacttcgaaa 3600
cagaagcctc gcggctcgtt agggttcatg ttctcaggac aaggcacttg tttccctggt 3660
atggcttcag cacttgctga acaatattcg gggttccgaa tgctcgtctc taagtttggg 3720
caggctgccc aagagcggtc cggttatccg atcgataggc tgttgcttga agtttctgat 3780
acattaccag aaacaaacag cgaggtcgac caaatttgca tttttgtcta ccaatattct 3840
gttctgcaat ggttgcaatg tctaggcatt caaccgaaag cagtcctcgg tcacagcctg 3900
ggagaaatta ctgccgcagt cgcagctggc gccctttcgt tcgaatctgc gttggatctt 3960
gtggtcaccc gtgctcgtct tctccgtccc agaacaaaag actctgcagg aatggccgca 4020
gtagcagcgt ccaaggaaga agttgaagga gttatagaaa ccctccaact tgcaaactcg 4080
ctaagcgttg cggttcacaa cggtccgcgg agtgttgttg tgtcaggcgc atcagcagaa 4140
atcgatgccc tagttgtcgc agctaaagaa cggggcttga aagcctcccg cttaaaggtt 4200
gaccaaggct tccacagccc ttacgttgac tctgcggttc cgggtttact cgactggtca 4260
aacaagcatc gttcgacctt ctttccttta aacattcctc tatactcgac tttgaccggc 4320
gagcttattc cgaagggacg gaggttcgtc tcggatcact gggtaaacca tgctcgaaaa 4380
cctgttcagt ttgcggcggc agcggcagcg gtggatgaag atcgatccat tggtgtgctc 4440
gttgacgtcg gaccccaacc cgttgcgtgg accctccttc aagcaaacaa ccttctcaat 4500
acctctgcag ttgcgctatc cgcaaaggcc ggaaaggacc aggagatggc gctgctcact 4560
gctttgagct acctcttcca agagcacaac ctttctccca acttccacga gctttactct 4620
cagcgtcatg ggactctgca gaagacggac attcccacct acccattcca acgtgtccac 4680
cgctatccga ccttcatacc gtcacgaaat caaagtcctg ctattgcaac ggtagttata 4740
ccgccacctc gcttctctgt ccaaaaggct gcggatgtag catcacagtc gaaggaatca 4800
gactgtcgag ctggtttgat cagttgcctt agagccatcc tcgaattaac accggaagag 4860
gagtttgacc tttctgagac tctcaacgct cgtggtatgg attcgatcat gtttgcgcag 4920
ctacggaagc gggttgggga agaattcaac ctcgatatac ccatgatcta tctatcagac 4980
gtgttcacga tggaacagat ggtcgactac ctcgtcgaac agtccggatc cacacccgcg 5040
tcaaagcacg tagaaacttc agctaatcaa ccattagacg aagaagatct ccggacgggg 5100
ctcttgtcat gcctgaggaa cgtgctagaa attacccccg atgaagaact tgacctatct 5160
gaaactttga atgctcgtgg tgttgactcg atcatgttcg ctcagctgcg gaaacgcgtt 5220
ggggaaggtt ttggtgtgga aattccgatg atatatctgt ctgacgtgtt taccatggaa 5280
gacatgatca atttcctcgt ctccgagcgg tcg 5313
<210> 49
<211> 1771
<212> PRT
<213> Armillaria gallica
<400> 49
Met Glu Ala Asp Gly His His Ser Leu Leu Asp Val Phe Leu Ser Val
1 5 10 15
Ala His Asp Ser Glu Lys Ser Lys Arg Asn Val Leu Glu Cys Gly Gln
20 25 30
Asp Thr Trp Thr Tyr Ser Asp Leu Asp Ile Ile Ser Ser Ala Leu Ala
35 40 45
Gln Asp Leu Lys Ala Thr Leu Gly Cys Phe Pro Lys Val Ala Val Val
50 55 60
Ser Glu Asn His Pro Tyr Val Phe Ala Leu Met Leu Ala Val Trp Lys
65 70 75 80
Leu Glu Gly Ile Phe Ile Pro Ile Asp Val His Ile Thr Ala Asp Leu
85 90 95
Leu Lys Gly Met Leu Arg Ile Val Ala Pro Thr Cys Leu Ala Ile Pro
100 105 110
Glu Thr Asp Ile Ser Asn Gln Arg Val Ala Ser Ala Ile Gly Ile His
115 120 125
Val Leu Pro Phe Asn Val Asn Ala Ser Thr Met Asn Ala Leu Arg Gln
130 135 140
Lys Tyr Asp Pro Phe Thr Gln Asn Ala Ser Leu Ser Gly Cys Ala Leu
145 150 155 160
Pro Tyr Val Asp Arg Ala Cys Leu Tyr Leu Phe Thr Ser Ser Ala Ser
165 170 175
Ser Thr Ala Asn Leu Lys Cys Val Pro Leu Thr His Thr Leu Ile Leu
180 185 190
Ser Asn Cys Arg Ser Lys Leu Ala Trp Trp Arg Arg Val Arg Pro Glu
195 200 205
Gly Glu Met Asp Gly Ile Arg Val Leu Gly Trp Ala Pro Trp Ser His
210 215 220
Ile Leu Ala Tyr Met Gln Asp Ile Gly Thr Ala Thr Phe Leu Asn Ala
225 230 235 240
Gly Cys Tyr Val Phe Ala Ser Val Pro Ser Thr Tyr Pro Ser Gln Leu
245 250 255
Ala Ala Asn Gly Leu Gln Gly Pro Thr Met Asn Ile Ile Asp Ser Leu
260 265 270
Leu Glu Arg Arg Val Ala Ala Phe Ala Cys Val Pro Phe Ile Leu Ser
275 280 285
Glu Leu Lys Ala Met Cys Glu Thr Ala Ala Ser Pro Asp Asp Lys His
290 295 300
Leu Met Cys Leu Arg Ala Glu Glu Lys Val Arg Leu Val Ser Ala Leu
305 310 315 320
Gln Arg Leu Met Met Leu Glu Cys Gly Gly Ala Ala Leu Glu Ser Asp
325 330 335
Val Thr Arg Trp Ala Val Glu Asn Gly Ile Ser Val Met Val Gly Ile
340 345 350
Gly Met Thr Glu Thr Val Gly Thr Leu Phe Ala Glu Arg Ala Gln Asp
355 360 365
Ala Cys Ser Asn Gly Tyr Ser Ala Gln Asp Ala Leu Ile Ala Asp Gly
370 375 380
Ile Met Ser Leu Val Gly Ser Asp Asn Glu Glu Ala Thr Phe Glu Gly
385 390 395 400
Glu Leu Val Val Lys Ser Lys Leu Ile Pro His Gly Tyr Ile Asn Tyr
405 410 415
Arg Asp Ser Ser Phe Ser Val Asp Ser Asp Gly Trp Val Thr Phe Lys
420 425 430
Thr Gly Asp Lys Tyr Gln Arg Thr Pro Asp Gly Arg Phe Lys Trp Leu
435 440 445
Gly Arg Lys Thr Asp Phe Ile Gln Met Thr Ser Ser Glu Thr Leu Asp
450 455 460
Pro Arg Pro Ile Glu Gln Ala Leu Cys Ala Asn Pro Ser Ile Ala Asn
465 470 475 480
Ala Cys Val Ile Gly Asp Arg Phe Leu Arg Glu Pro Ala Thr Ser Val
485 490 495
Cys Ala Ile Val Glu Ile Gly Pro Glu Val Asp Met Pro Ser Ser Lys
500 505 510
Ile Asp Arg Glu Ile Ala Asn Ala Leu Ala Pro Ile Asn Arg Asp Leu
515 520 525
Pro Pro Ala Leu Arg Ile Ser Trp Ser Arg Val Leu Ile Ile Arg Pro
530 535 540
Pro Gln Lys Ile Pro Val Thr Arg Lys Gly Asp Val Phe Arg Lys Lys
545 550 555 560
Ile Glu Asp Met Phe Gly Pro Phe Leu Gly Val Gly Val Ser Thr Glu
565 570 575
Val Glu Ala Gly His Glu Thr Lys Glu Asp Asp Thr Glu His Ile Val
580 585 590
Arg Gln Val Val Ser Asn Leu Leu Gly Val His Asp Pro Glu Leu Leu
595 600 605
Ser Ala Leu Ser Phe Ala Glu Leu Gly Met Thr Ser Phe Met Ala Val
610 615 620
Ser Ile Val Asn Ala Leu Asn Lys Arg Ile Gly Gly Leu Thr Leu Pro
625 630 635 640
Ser Asn Ala Cys Tyr Ile His Ile Asp Leu Asp Ser Leu Val Asp Ala
645 650 655
Ile Ser Leu Glu Tyr Gly His Gly Ser Ile Pro Ala Glu Leu Pro Ser
660 665 670
Asn Pro Phe Pro Asp Ile Glu Ser His Gln His Asn Asp Lys Asp Ile
675 680 685
Val Ile Val Gly Lys Ala Phe Arg Leu Pro Gly Ser Leu Asn Ser Thr
690 695 700
Ala Thr Leu Trp Glu Ala Leu Leu Ser Asn Asn Asn Ser Val Ile Ser
705 710 715 720
Asp Ile Pro Ser Asp Arg Trp Asp His Ala Ser Phe Tyr Pro His Asn
725 730 735
Ile Cys Phe Thr Lys Ala Gly Leu Val Asp Val Ala His Tyr Asp Tyr
740 745 750
Arg Phe Phe Gly Leu Met Ala Thr Glu Ala Leu Tyr Val Ser Pro Thr
755 760 765
Met Arg Leu Ala Leu Glu Val Ser Phe Glu Ala Leu Glu Asn Ala Asn
770 775 780
Ile Pro Leu Ser Lys Leu Lys Gly Thr Gln Thr Ala Val Tyr Val Ala
785 790 795 800
Thr Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Glu Gln Gly Tyr
805 810 815
Asp Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser Thr Ala
820 825 830
Ser Gly Arg Ile Ser Tyr Leu Leu Asp Ile His Gly Pro Ser Ile Thr
835 840 845
Val Asp Thr Ala Cys Ser Gly Gly Ile Val Cys Met Asp Gln Ala Ile
850 855 860
Thr Phe Leu Gln Ser Gly Gly Ala Asp Thr Ala Ile Val Cys Ser Thr
865 870 875 880
Asn Thr His Cys Trp Pro Gly Ser Phe Met Phe Leu Thr Ala Gln Gly
885 890 895
Met Val Ser Pro Asn Gly Arg Cys Ala Thr Phe Thr Thr Asp Ala Asp
900 905 910
Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys Thr Arg
915 920 925
Ser Ala Ala Ile Arg Asp Asn Asp Asn Ile Leu Ala Val Ile Lys Ser
930 935 940
Thr Asp Val Ser His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn
945 950 955 960
Val Lys Ala Gln Ala Asn Leu His Arg Ser Leu Leu Arg Lys Ala Gly
965 970 975
Leu Phe Pro Asp Gln Ile Asn Phe Ile Glu Ala His Gly Thr Gly Thr
980 985 990
Ser Leu Gly Asp Leu Ser Glu Ile Gln Gly Ile Asn Asn Ala Tyr Ile
995 1000 1005
Ser Ser Arg Pro Arg Leu Ala Gly Pro Leu Ile Ile Ser Ala Ser
1010 1015 1020
Lys Thr Val Leu Gly His Ser Glu Pro Thr Ala Gly Met Ala Gly
1025 1030 1035
Ile Leu Thr Ala Leu Leu Ala Leu Glu Lys Glu Thr Val Pro Gly
1040 1045 1050
Leu Asn His Leu Thr Asp His Asn Leu Asn Pro Ser Leu Asp Cys
1055 1060 1065
Ser Val Val Pro Leu Leu Ile Pro His Glu Ser Ile His Ile Gly
1070 1075 1080
Gly Ala Lys Pro His Arg Ala Ala Val Leu Ser Tyr Gly Phe Ala
1085 1090 1095
Gly Thr Leu Ala Gly Ala Ile Leu Glu Gly Pro Pro Ser Gly Val
1100 1105 1110
Pro Trp Pro Ser Ser Asn Asp Ile Gln Glu His Pro Met Ile Phe
1115 1120 1125
Val Val Ser Gly Lys Thr Val Pro Thr Leu Glu Ala Tyr Leu Gly
1130 1135 1140
Arg Tyr Leu Thr Phe Leu Arg Val Ala Lys Thr His Asp Phe Gln
1145 1150 1155
Asp Ile Cys Tyr Thr Thr Cys Val Gly Arg Glu His Tyr Lys Tyr
1160 1165 1170
Arg Phe Ser Cys Val Ala Arg Asn Met Ala Asp Leu Ile Ser Gln
1175 1180 1185
Ile Glu His Arg Leu Thr Thr Leu Ser Thr Ser Lys Gln Lys Pro
1190 1195 1200
Arg Gly Ser Leu Gly Phe Met Phe Ser Gly Gln Gly Thr Cys Phe
1205 1210 1215
Pro Gly Met Ala Ser Ala Leu Ala Glu Gln Tyr Ser Gly Phe Arg
1220 1225 1230
Met Leu Val Ser Lys Phe Gly Gln Ala Ala Gln Glu Arg Ser Gly
1235 1240 1245
Tyr Pro Ile Asp Arg Leu Leu Leu Glu Val Ser Asp Thr Leu Pro
1250 1255 1260
Glu Thr Asn Ser Glu Val Asp Gln Ile Cys Ile Phe Val Tyr Gln
1265 1270 1275
Tyr Ser Val Leu Gln Trp Leu Gln Cys Leu Gly Ile Gln Pro Lys
1280 1285 1290
Ala Val Leu Gly His Ser Leu Gly Glu Ile Thr Ala Ala Val Ala
1295 1300 1305
Ala Gly Ala Leu Ser Phe Glu Ser Ala Leu Asp Leu Val Val Thr
1310 1315 1320
Arg Ala Arg Leu Leu Arg Pro Arg Thr Lys Asp Ser Ala Gly Met
1325 1330 1335
Ala Ala Val Ala Ala Ser Lys Glu Glu Val Glu Gly Val Ile Glu
1340 1345 1350
Thr Leu Gln Leu Ala Asn Ser Leu Ser Val Ala Val His Asn Gly
1355 1360 1365
Pro Arg Ser Val Val Val Ser Gly Ala Ser Ala Glu Ile Asp Ala
1370 1375 1380
Leu Val Val Ala Ala Lys Glu Arg Gly Leu Lys Ala Ser Arg Leu
1385 1390 1395
Lys Val Asp Gln Gly Phe His Ser Pro Tyr Val Asp Ser Ala Val
1400 1405 1410
Pro Gly Leu Leu Asp Trp Ser Asn Lys His Arg Ser Thr Phe Phe
1415 1420 1425
Pro Leu Asn Ile Pro Leu Tyr Ser Thr Leu Thr Gly Glu Leu Ile
1430 1435 1440
Pro Lys Gly Arg Arg Phe Val Ser Asp His Trp Val Asn His Ala
1445 1450 1455
Arg Lys Pro Val Gln Phe Ala Ala Ala Ala Ala Ala Val Asp Glu
1460 1465 1470
Asp Arg Ser Ile Gly Val Leu Val Asp Val Gly Pro Gln Pro Val
1475 1480 1485
Ala Trp Thr Leu Leu Gln Ala Asn Asn Leu Leu Asn Thr Ser Ala
1490 1495 1500
Val Ala Leu Ser Ala Lys Ala Gly Lys Asp Gln Glu Met Ala Leu
1505 1510 1515
Leu Thr Ala Leu Ser Tyr Leu Phe Gln Glu His Asn Leu Ser Pro
1520 1525 1530
Asn Phe His Glu Leu Tyr Ser Gln Arg His Gly Thr Leu Gln Lys
1535 1540 1545
Thr Asp Ile Pro Thr Tyr Pro Phe Gln Arg Val His Arg Tyr Pro
1550 1555 1560
Thr Phe Ile Pro Ser Arg Asn Gln Ser Pro Ala Ile Ala Thr Val
1565 1570 1575
Val Ile Pro Pro Pro Arg Phe Ser Val Gln Lys Ala Ala Asp Val
1580 1585 1590
Ala Ser Gln Ser Lys Glu Ser Asp Cys Arg Ala Gly Leu Ile Ser
1595 1600 1605
Cys Leu Arg Ala Ile Leu Glu Leu Thr Pro Glu Glu Glu Phe Asp
1610 1615 1620
Leu Ser Glu Thr Leu Asn Ala Arg Gly Met Asp Ser Ile Met Phe
1625 1630 1635
Ala Gln Leu Arg Lys Arg Val Gly Glu Glu Phe Asn Leu Asp Ile
1640 1645 1650
Pro Met Ile Tyr Leu Ser Asp Val Phe Thr Met Glu Gln Met Val
1655 1660 1665
Asp Tyr Leu Val Glu Gln Ser Gly Ser Thr Pro Ala Ser Lys His
1670 1675 1680
Val Glu Thr Ser Ala Asn Gln Pro Leu Asp Glu Glu Asp Leu Arg
1685 1690 1695
Thr Gly Leu Leu Ser Cys Leu Arg Asn Val Leu Glu Ile Thr Pro
1700 1705 1710
Asp Glu Glu Leu Asp Leu Ser Glu Thr Leu Asn Ala Arg Gly Val
1715 1720 1725
Asp Ser Ile Met Phe Ala Gln Leu Arg Lys Arg Val Gly Glu Gly
1730 1735 1740
Phe Gly Val Glu Ile Pro Met Ile Tyr Leu Ser Asp Val Phe Thr
1745 1750 1755
Met Glu Asp Met Ile Asn Phe Leu Val Ser Glu Arg Ser
1760 1765 1770
<210> 50
<211> 5310
<212> DNA
<213> Armillaria ostoyae
<400> 50
atggaggccg acggtcacta ctctcttctc gatgtctttc tcagcgttgc acatgattct 60
gagaagtcca aacgtaatgt cttggaatgc ggccaggata cttggacata ctcggatttg 120
gacattatct cgtcggccct ggcacaggat ctcaaagcta tcttgggttg ttttcccaaa 180
gttgcagtcg tcagcgagaa ccatccctac gtatttgctc tcatgctggc cgtatggaag 240
cttgaaggga tattcatccc tatcgacgtc cacgttacag ctgaccttct aaagggcatg 300
ctacgcattg ttgctcccac ttgtctggtg atcccagaga ccgatatttt taaccagcgt 360
gttgcctctg caattggtat acatgttctc cccttcaacg tgaatgcgtc gaccatgact 420
gcacttcgac agaaatacca cccatttact cagaaagcct cgctatctgg gtgcgcactg 480
ccttacgttg atcgcgcatg cctctatctc tttacatcct ccgcgtcctc tactgccaat 540
ttgaaatgcg tacctttgac ccatactctt atcctcagta actgccgttc caagctcgca 600
tggtggcggc gcgttcgtcc ggaaggcgaa atggatgaga tacgtgttct agggtgggca 660
ccttggtcgc atatccttgc ctacatgcaa gatattggca cggcaacgct cctgaacgcc 720
ggttgctatg tctttgcgtc cgttccatcc acatatccta cacaactggc agcgaatggc 780
ttacaaggcc ctatcatgaa tatcatcgat tcacttcttg aacgacgagt cgccgcattt 840
gcttgcgtac cgttcatttt gagcgaacta aaagctatgt gcgagacggc ttccagtcca 900
gacgacaagc atcaaatgtg cttgagagct gaggagaaag ttcgccttgt cagtgcgctg 960
cagcggctta taatgctcga gtgcggaggc gctgcgcttg agtcaggtgt cacacgttgg 1020
gccgtcgaga atggcatatc agtcatggtc ggcatcggga tgacggagac agtcggtacg 1080
ctgtttgcag agcgcgcgca agacgcccgt tccaacggct attctgcgca ggacgccctc 1140
atttctgatg ggatcatgtc actggtcggg tctgacaacg aggaagccac cctcgaaggg 1200
gaactagtcg tcaagagcaa gctcatccct catggataca tcaagtaccg tgattcgtcg 1260
ttttcggtgg actcggacgg ctgggtaact ttcaaaacgg gagacaaata tcagcgcacg 1320
ccagatggac gattcaaatg gcttggaaga aagaccgatt ttattcagat gacaagcagc 1380
gaaacactgg atcccagacc cattgaggaa gccctctgtg cgaatccaag tatcgcaaat 1440
gcatgcgtca ttggtgacag gttcctgagg gagcctgcga ctagcgtatg cgccattgtc 1500
gagatcgggc cggaagtgga catgccttcg tccaagatcg acagagaaat tgcgaatacc 1560
ctcactccaa tcaatcgcgg ccttcctcct gctcttcgca tatcatggtc tcgcgtactc 1620
ataattcgac ctcctcagaa aataccagtt acgaggaaag gtgatgtgtt ccgtaagaag 1680
attgaagata tgtttgggtc tttccttggt gtcggcgttt ctaccgaggt cgaagtcgac 1740
catgaaacta aagaagatga tacgaaacac gtcgtgagac aggttgtaag caatcttctt 1800
ggagtccatg atcttgagtt attgtctgct ttatccttcg ccgagctggg catgacatca 1860
tttatggctg ttagcatcgt caacactcta aacaaacgca tcgacggcct cacccttcca 1920
cctaatgcat gctacatcca tattgatctt gattctcttg tggacgcgat ttcacttgaa 1980
catggtcatg aaagtatccc tgcagagttg ccttctaacc ctttccccgt tatcgagtcc 2040
catcaacata acgataagga cattgtgata gtcggcaagg cattccgttt acccggctca 2100
ctcaacaata ctgcatctct ctgggaagct ttgttatcga agaacagttc agtcatcagt 2160
gacatcccat ccgatcgctg ggatcacgca agcttttacc cccacgatat atgcttcacg 2220
aaagcaggcc tcgtcgatgt tgcacattac gactacagat tttttggcct cacggcgaca 2280
gaggcgttgt acgtatctcc gacgatgcgc ctcgccttgg aagtgtcatt tgaggccctg 2340
gagaacgcaa atattccact atccaagctg aaggggacgc aaaccgccgt ctatgtcgcc 2400
actaaagacg atggcttcga gacactctta aatgccgagc aaggctacga tgcatacacg 2460
cgattctacg gtacgggtcg tgctccgagt accgcaagcg gccgtataag ctatcttctt 2520
gatattcatg ggccatctgt caccgttgat acagcatgca gcggaggcat tgtatgtatg 2580
gatcaagcca tcactttctt gcaatccgga ggggccgata ccgctattgt ctgttcgagc 2640
aatacgcact gttggccggg atcattcatg ttcctgacgg cgcaaggcat ggtttctcaa 2700
aatggaagat gcgctacatt tactaccgat gcagacggat atgtaccttc ggagggtgca 2760
gtggctttca ttctcaagac gcgcagcgct gcgatacgcg acaacgacaa tatactcgcc 2820
gtgatcagat caacagacgt gtcccataac ggccgttctc aagggctagt tgcaccaaac 2880
gtaaaggcgc agacaaacct acaccggtcg ttgctacgaa aagctgggct gtttcctgat 2940
caaattaact ttatcgaagc tcatgggaca ggtacgtctc taggagacct ttcggaaatc 3000
cagggcatta ataacgccta cacctcaaca cgacctcgtc tggccggtcc ccttatcatt 3060
agcgcatcga aaacagtttt aggacacagt gaaccaacag cagggatggc cggcatcctc 3120
acagccttgc ttgcccttga gaaagagaca gttcctggtc taaatcactt aacggagcac 3180
aaccttaacc cttcgcttga ttgcagcgta gttcctctcc tgattcctca cgagtctatt 3240
cacattggtg gtgcaaagcc acatcgagct gcggttctgt catacggctt cgcgggtacg 3300
ctggccggtg ccatcttaga gggaccacct tctgatgtac caaggccgtc gtcaaataat 3360
atacaagaac accctatgat tttcgtcgtc agtgggaaaa ccgtgcctgc actggaagcg 3420
tacctaggac ggtatttggc atttttgcgg gtcgcaaaaa cacacgactt ccatgacatc 3480
tgctacacta cttgcgtcgg gagggagcac tacaaatacc ggttctcctg cgttgcccga 3540
aacatggcag accttatttc tcaaattgaa catcgactga cagctctttc cacttcgaaa 3600
cagaagcctc gcggctcgct agggttcata ttctcaggac aaggcactta tttccctggt 3660
atggctgcag cacttgccga acaatattcg gggttccgag tgctcgtctc taagtttggg 3720
caggctgccc aagagcggtc gggttatccg atcgataggc tgttgcttga agtttctgat 3780
acattgccag aaacaaacag cgaggtcgat caaatttgca tttttgtcta ccaatattct 3840
gttctgcaat ggctgcagag tctaggcatt caaccgaaag cagtcctcgg tcacagtctg 3900
ggagaaatta ctgcagcagt cgcagctggt gccctttcgt tcgaatctgc gttggacctt 3960
gtggtcaccc gtgctcgtct tctccgtcct agagcaaaag attctgcagg aatggccgca 4020
gtagcagcat ccaaggaaga agtcaaaggg cttatagaaa ccctccaact tgcggactcg 4080
ctgagcgttg cggttcataa cggtccgcgg agtgttgttg tgtcaggcgc atcagccgaa 4140
atcgacgccc tggttgtcgc agctaaagaa cggggcttga aggcctcccg cttaaaggtt 4200
gaccaaggct tccacagccc ttacgttgat tctgcggttc caggtttact cgactggtca 4260
aataagcatc gttcgacctt ccttcctttg aacattcctt tatactcgac tttgactggc 4320
gagcttattc cgaagggacg gaggttcgtc tcggatcact gggtaaacca tgctcgaaaa 4380
cctgtccagt ttgcggcggc agcggcagcc gtggatgaag accgatccat tggtgtgctc 4440
gttgacgttg gaccccaacc cgtcgcgtgg accctccttc aagcaaacaa ccttctcaat 4500
acctctgcag ttgcactatt cgcaaaggct ggaaaggatc aggagatggc gctgcttact 4560
gctttgagct acctcgtcca agagcacaac ctttctccca acttccatga gctttactct 4620
cagcgtcatg gtgctctgaa gaagacagac gttcccacct acccattccg ccgtgtccac 4680
cgctatccga ccttcatacc gtcacgaaat caaagtcctg ctgctgcgac ggtagctatg 4740
ccgccacccc gcttctctgt ccaaaagaat gcggatgtag catcacagtc gaaggaatca 4800
gactgtcgag ctggtttgat cagttgcctt agagccatcc tcgaattaac accggaagag 4860
gagtttgacc tttctgagac tctcaacgct cgtggtatgg attcgatcat gtttgcgcag 4920
ctacggaagc gggttgggga agaattcgac cttgacatac ccatgatcta tttatcagat 4980
gtgttcacga tggaacagat ggttgattac ctcgtcaaac agtccggatc cagacccgca 5040
ttaaaacacg cagaaattcc agttaatcaa ccattagacg aagatctccg gacgaggctc 5100
gtttcatgcc tgaggaacgt gctagaaatc acccccgatg aagaacttga cctatctgaa 5160
actttgaacg ctcgtggtgt tgactcgatc atgttcgctc agctacgaaa acgcgttggg 5220
gaaggatttg gtgtggaaat tccgatgata tatctgtccg acgtgtttac catggaagac 5280
atgatcaatt tcctcgtctc tgagcgctcg 5310
<210> 51
<211> 1770
<212> PRT
<213> Armillaria ostoyae
<400> 51
Met Glu Ala Asp Gly His Tyr Ser Leu Leu Asp Val Phe Leu Ser Val
1 5 10 15
Ala His Asp Ser Glu Lys Ser Lys Arg Asn Val Leu Glu Cys Gly Gln
20 25 30
Asp Thr Trp Thr Tyr Ser Asp Leu Asp Ile Ile Ser Ser Ala Leu Ala
35 40 45
Gln Asp Leu Lys Ala Ile Leu Gly Cys Phe Pro Lys Val Ala Val Val
50 55 60
Ser Glu Asn His Pro Tyr Val Phe Ala Leu Met Leu Ala Val Trp Lys
65 70 75 80
Leu Glu Gly Ile Phe Ile Pro Ile Asp Val His Val Thr Ala Asp Leu
85 90 95
Leu Lys Gly Met Leu Arg Ile Val Ala Pro Thr Cys Leu Val Ile Pro
100 105 110
Glu Thr Asp Ile Phe Asn Gln Arg Val Ala Ser Ala Ile Gly Ile His
115 120 125
Val Leu Pro Phe Asn Val Asn Ala Ser Thr Met Thr Ala Leu Arg Gln
130 135 140
Lys Tyr His Pro Phe Thr Gln Lys Ala Ser Leu Ser Gly Cys Ala Leu
145 150 155 160
Pro Tyr Val Asp Arg Ala Cys Leu Tyr Leu Phe Thr Ser Ser Ala Ser
165 170 175
Ser Thr Ala Asn Leu Lys Cys Val Pro Leu Thr His Thr Leu Ile Leu
180 185 190
Ser Asn Cys Arg Ser Lys Leu Ala Trp Trp Arg Arg Val Arg Pro Glu
195 200 205
Gly Glu Met Asp Glu Ile Arg Val Leu Gly Trp Ala Pro Trp Ser His
210 215 220
Ile Leu Ala Tyr Met Gln Asp Ile Gly Thr Ala Thr Leu Leu Asn Ala
225 230 235 240
Gly Cys Tyr Val Phe Ala Ser Val Pro Ser Thr Tyr Pro Thr Gln Leu
245 250 255
Ala Ala Asn Gly Leu Gln Gly Pro Ile Met Asn Ile Ile Asp Ser Leu
260 265 270
Leu Glu Arg Arg Val Ala Ala Phe Ala Cys Val Pro Phe Ile Leu Ser
275 280 285
Glu Leu Lys Ala Met Cys Glu Thr Ala Ser Ser Pro Asp Asp Lys His
290 295 300
Gln Met Cys Leu Arg Ala Glu Glu Lys Val Arg Leu Val Ser Ala Leu
305 310 315 320
Gln Arg Leu Ile Met Leu Glu Cys Gly Gly Ala Ala Leu Glu Ser Gly
325 330 335
Val Thr Arg Trp Ala Val Glu Asn Gly Ile Ser Val Met Val Gly Ile
340 345 350
Gly Met Thr Glu Thr Val Gly Thr Leu Phe Ala Glu Arg Ala Gln Asp
355 360 365
Ala Arg Ser Asn Gly Tyr Ser Ala Gln Asp Ala Leu Ile Ser Asp Gly
370 375 380
Ile Met Ser Leu Val Gly Ser Asp Asn Glu Glu Ala Thr Leu Glu Gly
385 390 395 400
Glu Leu Val Val Lys Ser Lys Leu Ile Pro His Gly Tyr Ile Lys Tyr
405 410 415
Arg Asp Ser Ser Phe Ser Val Asp Ser Asp Gly Trp Val Thr Phe Lys
420 425 430
Thr Gly Asp Lys Tyr Gln Arg Thr Pro Asp Gly Arg Phe Lys Trp Leu
435 440 445
Gly Arg Lys Thr Asp Phe Ile Gln Met Thr Ser Ser Glu Thr Leu Asp
450 455 460
Pro Arg Pro Ile Glu Glu Ala Leu Cys Ala Asn Pro Ser Ile Ala Asn
465 470 475 480
Ala Cys Val Ile Gly Asp Arg Phe Leu Arg Glu Pro Ala Thr Ser Val
485 490 495
Cys Ala Ile Val Glu Ile Gly Pro Glu Val Asp Met Pro Ser Ser Lys
500 505 510
Ile Asp Arg Glu Ile Ala Asn Thr Leu Thr Pro Ile Asn Arg Gly Leu
515 520 525
Pro Pro Ala Leu Arg Ile Ser Trp Ser Arg Val Leu Ile Ile Arg Pro
530 535 540
Pro Gln Lys Ile Pro Val Thr Arg Lys Gly Asp Val Phe Arg Lys Lys
545 550 555 560
Ile Glu Asp Met Phe Gly Ser Phe Leu Gly Val Gly Val Ser Thr Glu
565 570 575
Val Glu Val Asp His Glu Thr Lys Glu Asp Asp Thr Lys His Val Val
580 585 590
Arg Gln Val Val Ser Asn Leu Leu Gly Val His Asp Leu Glu Leu Leu
595 600 605
Ser Ala Leu Ser Phe Ala Glu Leu Gly Met Thr Ser Phe Met Ala Val
610 615 620
Ser Ile Val Asn Thr Leu Asn Lys Arg Ile Asp Gly Leu Thr Leu Pro
625 630 635 640
Pro Asn Ala Cys Tyr Ile His Ile Asp Leu Asp Ser Leu Val Asp Ala
645 650 655
Ile Ser Leu Glu His Gly His Glu Ser Ile Pro Ala Glu Leu Pro Ser
660 665 670
Asn Pro Phe Pro Val Ile Glu Ser His Gln His Asn Asp Lys Asp Ile
675 680 685
Val Ile Val Gly Lys Ala Phe Arg Leu Pro Gly Ser Leu Asn Asn Thr
690 695 700
Ala Ser Leu Trp Glu Ala Leu Leu Ser Lys Asn Ser Ser Val Ile Ser
705 710 715 720
Asp Ile Pro Ser Asp Arg Trp Asp His Ala Ser Phe Tyr Pro His Asp
725 730 735
Ile Cys Phe Thr Lys Ala Gly Leu Val Asp Val Ala His Tyr Asp Tyr
740 745 750
Arg Phe Phe Gly Leu Thr Ala Thr Glu Ala Leu Tyr Val Ser Pro Thr
755 760 765
Met Arg Leu Ala Leu Glu Val Ser Phe Glu Ala Leu Glu Asn Ala Asn
770 775 780
Ile Pro Leu Ser Lys Leu Lys Gly Thr Gln Thr Ala Val Tyr Val Ala
785 790 795 800
Thr Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Glu Gln Gly Tyr
805 810 815
Asp Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser Thr Ala
820 825 830
Ser Gly Arg Ile Ser Tyr Leu Leu Asp Ile His Gly Pro Ser Val Thr
835 840 845
Val Asp Thr Ala Cys Ser Gly Gly Ile Val Cys Met Asp Gln Ala Ile
850 855 860
Thr Phe Leu Gln Ser Gly Gly Ala Asp Thr Ala Ile Val Cys Ser Ser
865 870 875 880
Asn Thr His Cys Trp Pro Gly Ser Phe Met Phe Leu Thr Ala Gln Gly
885 890 895
Met Val Ser Gln Asn Gly Arg Cys Ala Thr Phe Thr Thr Asp Ala Asp
900 905 910
Gly Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys Thr Arg
915 920 925
Ser Ala Ala Ile Arg Asp Asn Asp Asn Ile Leu Ala Val Ile Arg Ser
930 935 940
Thr Asp Val Ser His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn
945 950 955 960
Val Lys Ala Gln Thr Asn Leu His Arg Ser Leu Leu Arg Lys Ala Gly
965 970 975
Leu Phe Pro Asp Gln Ile Asn Phe Ile Glu Ala His Gly Thr Gly Thr
980 985 990
Ser Leu Gly Asp Leu Ser Glu Ile Gln Gly Ile Asn Asn Ala Tyr Thr
995 1000 1005
Ser Thr Arg Pro Arg Leu Ala Gly Pro Leu Ile Ile Ser Ala Ser
1010 1015 1020
Lys Thr Val Leu Gly His Ser Glu Pro Thr Ala Gly Met Ala Gly
1025 1030 1035
Ile Leu Thr Ala Leu Leu Ala Leu Glu Lys Glu Thr Val Pro Gly
1040 1045 1050
Leu Asn His Leu Thr Glu His Asn Leu Asn Pro Ser Leu Asp Cys
1055 1060 1065
Ser Val Val Pro Leu Leu Ile Pro His Glu Ser Ile His Ile Gly
1070 1075 1080
Gly Ala Lys Pro His Arg Ala Ala Val Leu Ser Tyr Gly Phe Ala
1085 1090 1095
Gly Thr Leu Ala Gly Ala Ile Leu Glu Gly Pro Pro Ser Asp Val
1100 1105 1110
Pro Arg Pro Ser Ser Asn Asn Ile Gln Glu His Pro Met Ile Phe
1115 1120 1125
Val Val Ser Gly Lys Thr Val Pro Ala Leu Glu Ala Tyr Leu Gly
1130 1135 1140
Arg Tyr Leu Ala Phe Leu Arg Val Ala Lys Thr His Asp Phe His
1145 1150 1155
Asp Ile Cys Tyr Thr Thr Cys Val Gly Arg Glu His Tyr Lys Tyr
1160 1165 1170
Arg Phe Ser Cys Val Ala Arg Asn Met Ala Asp Leu Ile Ser Gln
1175 1180 1185
Ile Glu His Arg Leu Thr Ala Leu Ser Thr Ser Lys Gln Lys Pro
1190 1195 1200
Arg Gly Ser Leu Gly Phe Ile Phe Ser Gly Gln Gly Thr Tyr Phe
1205 1210 1215
Pro Gly Met Ala Ala Ala Leu Ala Glu Gln Tyr Ser Gly Phe Arg
1220 1225 1230
Val Leu Val Ser Lys Phe Gly Gln Ala Ala Gln Glu Arg Ser Gly
1235 1240 1245
Tyr Pro Ile Asp Arg Leu Leu Leu Glu Val Ser Asp Thr Leu Pro
1250 1255 1260
Glu Thr Asn Ser Glu Val Asp Gln Ile Cys Ile Phe Val Tyr Gln
1265 1270 1275
Tyr Ser Val Leu Gln Trp Leu Gln Ser Leu Gly Ile Gln Pro Lys
1280 1285 1290
Ala Val Leu Gly His Ser Leu Gly Glu Ile Thr Ala Ala Val Ala
1295 1300 1305
Ala Gly Ala Leu Ser Phe Glu Ser Ala Leu Asp Leu Val Val Thr
1310 1315 1320
Arg Ala Arg Leu Leu Arg Pro Arg Ala Lys Asp Ser Ala Gly Met
1325 1330 1335
Ala Ala Val Ala Ala Ser Lys Glu Glu Val Lys Gly Leu Ile Glu
1340 1345 1350
Thr Leu Gln Leu Ala Asp Ser Leu Ser Val Ala Val His Asn Gly
1355 1360 1365
Pro Arg Ser Val Val Val Ser Gly Ala Ser Ala Glu Ile Asp Ala
1370 1375 1380
Leu Val Val Ala Ala Lys Glu Arg Gly Leu Lys Ala Ser Arg Leu
1385 1390 1395
Lys Val Asp Gln Gly Phe His Ser Pro Tyr Val Asp Ser Ala Val
1400 1405 1410
Pro Gly Leu Leu Asp Trp Ser Asn Lys His Arg Ser Thr Phe Leu
1415 1420 1425
Pro Leu Asn Ile Pro Leu Tyr Ser Thr Leu Thr Gly Glu Leu Ile
1430 1435 1440
Pro Lys Gly Arg Arg Phe Val Ser Asp His Trp Val Asn His Ala
1445 1450 1455
Arg Lys Pro Val Gln Phe Ala Ala Ala Ala Ala Ala Val Asp Glu
1460 1465 1470
Asp Arg Ser Ile Gly Val Leu Val Asp Val Gly Pro Gln Pro Val
1475 1480 1485
Ala Trp Thr Leu Leu Gln Ala Asn Asn Leu Leu Asn Thr Ser Ala
1490 1495 1500
Val Ala Leu Phe Ala Lys Ala Gly Lys Asp Gln Glu Met Ala Leu
1505 1510 1515
Leu Thr Ala Leu Ser Tyr Leu Val Gln Glu His Asn Leu Ser Pro
1520 1525 1530
Asn Phe His Glu Leu Tyr Ser Gln Arg His Gly Ala Leu Lys Lys
1535 1540 1545
Thr Asp Val Pro Thr Tyr Pro Phe Arg Arg Val His Arg Tyr Pro
1550 1555 1560
Thr Phe Ile Pro Ser Arg Asn Gln Ser Pro Ala Ala Ala Thr Val
1565 1570 1575
Ala Met Pro Pro Pro Arg Phe Ser Val Gln Lys Asn Ala Asp Val
1580 1585 1590
Ala Ser Gln Ser Lys Glu Ser Asp Cys Arg Ala Gly Leu Ile Ser
1595 1600 1605
Cys Leu Arg Ala Ile Leu Glu Leu Thr Pro Glu Glu Glu Phe Asp
1610 1615 1620
Leu Ser Glu Thr Leu Asn Ala Arg Gly Met Asp Ser Ile Met Phe
1625 1630 1635
Ala Gln Leu Arg Lys Arg Val Gly Glu Glu Phe Asp Leu Asp Ile
1640 1645 1650
Pro Met Ile Tyr Leu Ser Asp Val Phe Thr Met Glu Gln Met Val
1655 1660 1665
Asp Tyr Leu Val Lys Gln Ser Gly Ser Arg Pro Ala Leu Lys His
1670 1675 1680
Ala Glu Ile Pro Val Asn Gln Pro Leu Asp Glu Asp Leu Arg Thr
1685 1690 1695
Arg Leu Val Ser Cys Leu Arg Asn Val Leu Glu Ile Thr Pro Asp
1700 1705 1710
Glu Glu Leu Asp Leu Ser Glu Thr Leu Asn Ala Arg Gly Val Asp
1715 1720 1725
Ser Ile Met Phe Ala Gln Leu Arg Lys Arg Val Gly Glu Gly Phe
1730 1735 1740
Gly Val Glu Ile Pro Met Ile Tyr Leu Ser Asp Val Phe Thr Met
1745 1750 1755
Glu Asp Met Ile Asn Phe Leu Val Ser Glu Arg Ser
1760 1765 1770
<210> 52
<211> 5322
<212> DNA
<213> Armillaria fuscipes
<400> 52
atgaccatgg aggtcgacag ccactattct ctgctcgatg tctttctcag cattgcacat 60
gattctgaca agtccaaacg caatgtcttg gaatgcggcc tggaggcctg gacatactcg 120
gatttagaca tcatctcgtc ggctctggca caggatctca aagctacctt gggatgtttt 180
cccaaagttg cagtcgtcag cgagaaccat ccctacgtgt ttgctctcat gctggccgtc 240
tggaagctcg aagggatctt catccccata gacgtccacg ttacagctga ccttttaaag 300
ggcatgctac gcattgttgc tcctacttgt ctagtgatcc ctgagagcga tgtttccaac 360
cggcgtgttg cctctgcgat tggtatacgt gttctcccat ttgatgcgaa ttcgtcaacc 420
atgacggcac ttcgacaaaa gtacgaatca ttcactcaga aagcctcgcc atctgagtgc 480
acacttgccc acgccgatcg tacatgcctc tatcttttta catcctctgc atcctctacc 540
gccaacttga aatgtgtgcc tttgacccat actcttatcc tcaataactg ccgtaccaag 600
ctcgcatggt ggcagcgctt tcgtccagaa agcgaaatgg atgggatgcg tgttctaggg 660
tgggcacctt ggtcgcatat ccttgcctac atgcaagata tcggcacagc gacgctcctg 720
aacgccggtt gctatgtctt tgcgtccatt ccatccacat accctacaca actagcagca 780
aatggcttac aaggccccac tatgaatatc atcaacgcac ttcttgaacg acaaattgcc 840
gcatttgctt gcgtgccgtt cattttgagc gaactcaaag ctatgtgcga gatgacttcc 900
tgtacaggaa accaaatgtc cctaagagcc gaggagaaag ttcgcctggt cagggtgctg 960
caggggcttg taatgctcga gtgtggaggc gcggcacttg agtcagatgt tacgcgttgg 1020
gtcgttgaga atgacatacc agtcatggtt ggcattggga tgacggaaac agtcggtacg 1080
ctgttcgcag agcgcgccca agacgtccgt tccagcggat attccgccca agacgctctc 1140
attgctgatg gcattatgtc actggtcggt tctgacaacg aggaagccac tttcgaaggg 1200
gaactagtcg tgaagagcaa gctcatccca cagggataca tagggtaccg tgattcatcg 1260
ttctcggtgg actcagatgg ctgggtaacg ttcaaaactg gagataaata tcagcgcact 1320
ccagatggac gattaaaatg gcttgggaga aagaccgact ttatccagat gacaagcagc 1380
gaaacactgg atcccaggcc cattgagcaa actctttgtg cgaatccata cgtcgcaaaa 1440
gcatgcgtca ttggtgacag attcctgaga gatcccgcga ccagcgtatg tgccataatt 1500
gagatcaggc cggaagtgga catgccttcg tccaagatcg acagagaaat tgcgaatgcc 1560
cttgctccaa tcaatcgcga cctccctcct gctcttcgca tatcatggtc tcgcgtactc 1620
atgatcagac cccctcagaa aatcccagta acgaggaaag gcgatgtgtt ccgtaagaag 1680
attgaagata tgtttgggtc tttcctcggt gtcggtgttt ctactgaggt cggagtcgac 1740
catgaaactg aaaaagatga tacggaacac attgtgagac aggttgttac taatcttctt 1800
ggagtccatg atcccgagct attgtctgct ttatctttcg ctgagcttgg aatgacttca 1860
tttatggctg tcagcatcgt caactctcta aacaagtaca tcgatggcct cacccttcca 1920
cctaatgcat gttacatcca tattgatctt gattctcttg tggaggccat ttcacgtgaa 1980
cggggtcatg gaagtaacgc cacagagttg ccttctcaac ccgtccctgt tgagttacat 2040
caacctaacg ataaggacgt tgtgatagtt ggcaaggcat tccgtttacc tggctcactc 2100
gacagcactg catctctatg ggaagctttg ttatcaaaga acaattcagt cgtcagtgaa 2160
atcccatccg atcgctggga tcacgcaagc ttttaccccc acgacatttg cttcacgaaa 2220
gcaggcctcg tcgatgttgc ccattacgat tacagattct ttggcctcac ggctacagag 2280
gcattgtatg tatctccgac gatgcgtctc gccttggaag tgtcatttga agccctggag 2340
aatgcgaata ttccgttatc caatctgaag ggaacacaaa ccgctgtcta tgtcgccacc 2400
aaagacgatg gtttcgagac acttttaaat gccgagcagg gctatgatgc ctacacacga 2460
ttctatggca cgggccgcgc tccaagcacc gcaagtggcc gtataagcta tctacttgat 2520
attcatgggc catctgtcac cgttgataca gcatgcagcg gaggcattgt gtgtatggat 2580
caagccatca ctttcttgca gtccggaggg gcagatacag ctattgtctg ttcgagcaat 2640
acgcattgtt ggcctggatc atttatgttc ctgacggcgc aaggcatggt ttctccaaat 2700
ggaagatgcg ctacatttag taccgatgca gacggatatg tgccttcaga gggcgcagta 2760
gctttcgttc tcaagacgcg tagcgcagca atacgcgata atgacaatat cctcgccgta 2820
atcaaatcaa cagatgtgtc tcataacggc cgttctcaag ggctggttgc acctaacgtg 2880
aaggcgcaga caaacctgca tcaatcgttg ttacgaaaag ctgggctgtt tcctgatcaa 2940
atcaacttta tcgaagccca tggaacaggt acatctctag gagacctctc agaaatccag 3000
ggcatcaata acgcctacac ctcaacacga cctcgtctag acggtcccct tatcatcagc 3060
gcatcgaaaa cagtgatagg acacagcgaa ccaactgcag ggatggcggg catcctcaca 3120
gccttgcttg ctcttgagaa agaaacagtt cctggtctca atcacttaac ggagcacagc 3180
cttaaccctt cgcttgattg cagcatagtc ccgctcctga ttcctcacga gtctattcac 3240
attggtgggg taaagccaca tcgagctgcg gttctgtcat acggcttcgc gggtacactg 3300
gcgggtgcta tcttagaggg accgccttca gatgcaccaa ggccgtcgtc aaataatgtg 3360
caagatcacc ctatgatttt tgccctcagt gggaaaagcg cgtccgcact ggaagcatac 3420
ctaaggcggt atttggcatt cctgcggatt gcagatccac acgacttcca taacatctgc 3480
tacacttcct gtgtcgggag ggagcactac aaatatcggt tctcctgtgt tgcccgaaac 3540
atggcagacc ttatatctca aattgaacat cgactgacaa ctgtttccat tccgaaaccg 3600
aaacctcgtg gctcaatagg attcacgttc tcaggacaag gcacttattt ccctggcatg 3660
gccgcagcac tcactgaaca atattctgga ttccggacgc tcgtctctaa gcttgggcag 3720
gctgcgcaag agcggtcggg tcatccgatt gacaggctgt tacttgaagt ttccggtaca 3780
tcaccagaaa caaacagtga ggtcgagcaa atttgcacat ttatctacca atatgccgtt 3840
ctgcaatggt tgcagagcct aggcgttcaa ccgaaagcag tcctcggtca cagcctggga 3900
gaaattactg ccgcagtcgc agctggtgcc ctgtcgttcg aatccgcgtt ggaccttgtg 3960
gtgacccgtg ctcgtcttct ccgtcccgaa acaaaagatt ctgctgggat ggtcgcggta 4020
gcaacgtcca aggatgaagt tgaaggactt atagaaacac tccaagttgc ggacgcgcta 4080
agcgttgccg ttcacaacgg ttcacggagt gttgtggttt caggcacatc agcggaagtt 4140
gatgccctgg tcgtcgcagc taaagaacgg ggcttaaagg cttcccgctt aagagtcgac 4200
caaggtttcc acagcccttg cgttgattct gccgttcctg gtttactcga ctggtcaaat 4260
gagcatcgtt ccaccttcct tcctttgaat atgcctttat actcgacttt gaccggcgag 4320
gtcattccca agggacggaa attcgtctgg gatcactggg taaaccatgc tcgaaaacct 4380
gttcagtttg caccggcagc aaaagcggtg gacgaagacc gatccatcgg tgtgctcgtt 4440
gatgtaggac ctcaacctgt cgcttggacc cttttgcaag caaacaacct ttccaacacc 4500
tctacggttg cgctattcgc gaaagccgga aaggatcagg agatggcact gctcactgct 4560
ttgagctacc tcttccaaga gcacaacctt tctcccaagt ttcacgacct ttatactggg 4620
tataatggtg ctctgaagaa gacggacatt cccacgtacc cattccaacg tgtccatcgc 4680
tatcccacct tcataccatc acgaaatcag agtcctgctg tcgcgaaagc agtcgtgcag 4740
ccgccccgct tctctatcca aaggaatcga gaagccacat tacagtcgaa ggaaccagat 4800
caccgagctt gtttagtcac ttgccttaga gccatcctcg aattaacatc agaggaagaa 4860
cttgacctct ctgagaccct caacgctcgt ggcgtggact cgatcatgtt ttcacagcta 4920
cggaagcggg ttggagaaga attcaatctc gagataccca tgatctattt atcagacgta 4980
ttcacgatgg agcagatgat tgactacctc gtcgaacagt ccggatccaa tcccgcatca 5040
aagcaagtag gaactccggt taaccgacta tcaggcgaag aagatcttcg gacggggctc 5100
atctcatgcc tgagggacgt gctagaaatc actcctgatg atgaacttga tcacccaaaa 5160
gacctatctg aaactttaaa tgctcgtggt gttgattcga taatgttcgc tcagctacga 5220
aaacgcgtcg gggaaggatt tggtgtggaa attccgatga tatatctgtc tgatgtgttt 5280
accatggaag acatgattaa tttcctcgtt tctgagcgct ca 5322
<210> 53
<211> 1774
<212> PRT
<213> Armillaria fuscipes
<400> 53
Met Thr Met Glu Val Asp Ser His Tyr Ser Leu Leu Asp Val Phe Leu
1 5 10 15
Ser Ile Ala His Asp Ser Asp Lys Ser Lys Arg Asn Val Leu Glu Cys
20 25 30
Gly Leu Glu Ala Trp Thr Tyr Ser Asp Leu Asp Ile Ile Ser Ser Ala
35 40 45
Leu Ala Gln Asp Leu Lys Ala Thr Leu Gly Cys Phe Pro Lys Val Ala
50 55 60
Val Val Ser Glu Asn His Pro Tyr Val Phe Ala Leu Met Leu Ala Val
65 70 75 80
Trp Lys Leu Glu Gly Ile Phe Ile Pro Ile Asp Val His Val Thr Ala
85 90 95
Asp Leu Leu Lys Gly Met Leu Arg Ile Val Ala Pro Thr Cys Leu Val
100 105 110
Ile Pro Glu Ser Asp Val Ser Asn Arg Arg Val Ala Ser Ala Ile Gly
115 120 125
Ile Arg Val Leu Pro Phe Asp Ala Asn Ser Ser Thr Met Thr Ala Leu
130 135 140
Arg Gln Lys Tyr Glu Ser Phe Thr Gln Lys Ala Ser Pro Ser Glu Cys
145 150 155 160
Thr Leu Ala His Ala Asp Arg Thr Cys Leu Tyr Leu Phe Thr Ser Ser
165 170 175
Ala Ser Ser Thr Ala Asn Leu Lys Cys Val Pro Leu Thr His Thr Leu
180 185 190
Ile Leu Asn Asn Cys Arg Thr Lys Leu Ala Trp Trp Gln Arg Phe Arg
195 200 205
Pro Glu Ser Glu Met Asp Gly Met Arg Val Leu Gly Trp Ala Pro Trp
210 215 220
Ser His Ile Leu Ala Tyr Met Gln Asp Ile Gly Thr Ala Thr Leu Leu
225 230 235 240
Asn Ala Gly Cys Tyr Val Phe Ala Ser Ile Pro Ser Thr Tyr Pro Thr
245 250 255
Gln Leu Ala Ala Asn Gly Leu Gln Gly Pro Thr Met Asn Ile Ile Asn
260 265 270
Ala Leu Leu Glu Arg Gln Ile Ala Ala Phe Ala Cys Val Pro Phe Ile
275 280 285
Leu Ser Glu Leu Lys Ala Met Cys Glu Met Thr Ser Cys Thr Gly Asn
290 295 300
Gln Met Ser Leu Arg Ala Glu Glu Lys Val Arg Leu Val Arg Val Leu
305 310 315 320
Gln Gly Leu Val Met Leu Glu Cys Gly Gly Ala Ala Leu Glu Ser Asp
325 330 335
Val Thr Arg Trp Val Val Glu Asn Asp Ile Pro Val Met Val Gly Ile
340 345 350
Gly Met Thr Glu Thr Val Gly Thr Leu Phe Ala Glu Arg Ala Gln Asp
355 360 365
Val Arg Ser Ser Gly Tyr Ser Ala Gln Asp Ala Leu Ile Ala Asp Gly
370 375 380
Ile Met Ser Leu Val Gly Ser Asp Asn Glu Glu Ala Thr Phe Glu Gly
385 390 395 400
Glu Leu Val Val Lys Ser Lys Leu Ile Pro Gln Gly Tyr Ile Gly Tyr
405 410 415
Arg Asp Ser Ser Phe Ser Val Asp Ser Asp Gly Trp Val Thr Phe Lys
420 425 430
Thr Gly Asp Lys Tyr Gln Arg Thr Pro Asp Gly Arg Leu Lys Trp Leu
435 440 445
Gly Arg Lys Thr Asp Phe Ile Gln Met Thr Ser Ser Glu Thr Leu Asp
450 455 460
Pro Arg Pro Ile Glu Gln Thr Leu Cys Ala Asn Pro Tyr Val Ala Lys
465 470 475 480
Ala Cys Val Ile Gly Asp Arg Phe Leu Arg Asp Pro Ala Thr Ser Val
485 490 495
Cys Ala Ile Ile Glu Ile Arg Pro Glu Val Asp Met Pro Ser Ser Lys
500 505 510
Ile Asp Arg Glu Ile Ala Asn Ala Leu Ala Pro Ile Asn Arg Asp Leu
515 520 525
Pro Pro Ala Leu Arg Ile Ser Trp Ser Arg Val Leu Met Ile Arg Pro
530 535 540
Pro Gln Lys Ile Pro Val Thr Arg Lys Gly Asp Val Phe Arg Lys Lys
545 550 555 560
Ile Glu Asp Met Phe Gly Ser Phe Leu Gly Val Gly Val Ser Thr Glu
565 570 575
Val Gly Val Asp His Glu Thr Glu Lys Asp Asp Thr Glu His Ile Val
580 585 590
Arg Gln Val Val Thr Asn Leu Leu Gly Val His Asp Pro Glu Leu Leu
595 600 605
Ser Ala Leu Ser Phe Ala Glu Leu Gly Met Thr Ser Phe Met Ala Val
610 615 620
Ser Ile Val Asn Ser Leu Asn Lys Tyr Ile Asp Gly Leu Thr Leu Pro
625 630 635 640
Pro Asn Ala Cys Tyr Ile His Ile Asp Leu Asp Ser Leu Val Glu Ala
645 650 655
Ile Ser Arg Glu Arg Gly His Gly Ser Asn Ala Thr Glu Leu Pro Ser
660 665 670
Gln Pro Val Pro Val Glu Leu His Gln Pro Asn Asp Lys Asp Val Val
675 680 685
Ile Val Gly Lys Ala Phe Arg Leu Pro Gly Ser Leu Asp Ser Thr Ala
690 695 700
Ser Leu Trp Glu Ala Leu Leu Ser Lys Asn Asn Ser Val Val Ser Glu
705 710 715 720
Ile Pro Ser Asp Arg Trp Asp His Ala Ser Phe Tyr Pro His Asp Ile
725 730 735
Cys Phe Thr Lys Ala Gly Leu Val Asp Val Ala His Tyr Asp Tyr Arg
740 745 750
Phe Phe Gly Leu Thr Ala Thr Glu Ala Leu Tyr Val Ser Pro Thr Met
755 760 765
Arg Leu Ala Leu Glu Val Ser Phe Glu Ala Leu Glu Asn Ala Asn Ile
770 775 780
Pro Leu Ser Asn Leu Lys Gly Thr Gln Thr Ala Val Tyr Val Ala Thr
785 790 795 800
Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Glu Gln Gly Tyr Asp
805 810 815
Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser Thr Ala Ser
820 825 830
Gly Arg Ile Ser Tyr Leu Leu Asp Ile His Gly Pro Ser Val Thr Val
835 840 845
Asp Thr Ala Cys Ser Gly Gly Ile Val Cys Met Asp Gln Ala Ile Thr
850 855 860
Phe Leu Gln Ser Gly Gly Ala Asp Thr Ala Ile Val Cys Ser Ser Asn
865 870 875 880
Thr His Cys Trp Pro Gly Ser Phe Met Phe Leu Thr Ala Gln Gly Met
885 890 895
Val Ser Pro Asn Gly Arg Cys Ala Thr Phe Ser Thr Asp Ala Asp Gly
900 905 910
Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Val Leu Lys Thr Arg Ser
915 920 925
Ala Ala Ile Arg Asp Asn Asp Asn Ile Leu Ala Val Ile Lys Ser Thr
930 935 940
Asp Val Ser His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn Val
945 950 955 960
Lys Ala Gln Thr Asn Leu His Gln Ser Leu Leu Arg Lys Ala Gly Leu
965 970 975
Phe Pro Asp Gln Ile Asn Phe Ile Glu Ala His Gly Thr Gly Thr Ser
980 985 990
Leu Gly Asp Leu Ser Glu Ile Gln Gly Ile Asn Asn Ala Tyr Thr Ser
995 1000 1005
Thr Arg Pro Arg Leu Asp Gly Pro Leu Ile Ile Ser Ala Ser Lys
1010 1015 1020
Thr Val Ile Gly His Ser Glu Pro Thr Ala Gly Met Ala Gly Ile
1025 1030 1035
Leu Thr Ala Leu Leu Ala Leu Glu Lys Glu Thr Val Pro Gly Leu
1040 1045 1050
Asn His Leu Thr Glu His Ser Leu Asn Pro Ser Leu Asp Cys Ser
1055 1060 1065
Ile Val Pro Leu Leu Ile Pro His Glu Ser Ile His Ile Gly Gly
1070 1075 1080
Val Lys Pro His Arg Ala Ala Val Leu Ser Tyr Gly Phe Ala Gly
1085 1090 1095
Thr Leu Ala Gly Ala Ile Leu Glu Gly Pro Pro Ser Asp Ala Pro
1100 1105 1110
Arg Pro Ser Ser Asn Asn Val Gln Asp His Pro Met Ile Phe Ala
1115 1120 1125
Leu Ser Gly Lys Ser Ala Ser Ala Leu Glu Ala Tyr Leu Arg Arg
1130 1135 1140
Tyr Leu Ala Phe Leu Arg Ile Ala Asp Pro His Asp Phe His Asn
1145 1150 1155
Ile Cys Tyr Thr Ser Cys Val Gly Arg Glu His Tyr Lys Tyr Arg
1160 1165 1170
Phe Ser Cys Val Ala Arg Asn Met Ala Asp Leu Ile Ser Gln Ile
1175 1180 1185
Glu His Arg Leu Thr Thr Val Ser Ile Pro Lys Pro Lys Pro Arg
1190 1195 1200
Gly Ser Ile Gly Phe Thr Phe Ser Gly Gln Gly Thr Tyr Phe Pro
1205 1210 1215
Gly Met Ala Ala Ala Leu Thr Glu Gln Tyr Ser Gly Phe Arg Thr
1220 1225 1230
Leu Val Ser Lys Leu Gly Gln Ala Ala Gln Glu Arg Ser Gly His
1235 1240 1245
Pro Ile Asp Arg Leu Leu Leu Glu Val Ser Gly Thr Ser Pro Glu
1250 1255 1260
Thr Asn Ser Glu Val Glu Gln Ile Cys Thr Phe Ile Tyr Gln Tyr
1265 1270 1275
Ala Val Leu Gln Trp Leu Gln Ser Leu Gly Val Gln Pro Lys Ala
1280 1285 1290
Val Leu Gly His Ser Leu Gly Glu Ile Thr Ala Ala Val Ala Ala
1295 1300 1305
Gly Ala Leu Ser Phe Glu Ser Ala Leu Asp Leu Val Val Thr Arg
1310 1315 1320
Ala Arg Leu Leu Arg Pro Glu Thr Lys Asp Ser Ala Gly Met Val
1325 1330 1335
Ala Val Ala Thr Ser Lys Asp Glu Val Glu Gly Leu Ile Glu Thr
1340 1345 1350
Leu Gln Val Ala Asp Ala Leu Ser Val Ala Val His Asn Gly Ser
1355 1360 1365
Arg Ser Val Val Val Ser Gly Thr Ser Ala Glu Val Asp Ala Leu
1370 1375 1380
Val Val Ala Ala Lys Glu Arg Gly Leu Lys Ala Ser Arg Leu Arg
1385 1390 1395
Val Asp Gln Gly Phe His Ser Pro Cys Val Asp Ser Ala Val Pro
1400 1405 1410
Gly Leu Leu Asp Trp Ser Asn Glu His Arg Ser Thr Phe Leu Pro
1415 1420 1425
Leu Asn Met Pro Leu Tyr Ser Thr Leu Thr Gly Glu Val Ile Pro
1430 1435 1440
Lys Gly Arg Lys Phe Val Trp Asp His Trp Val Asn His Ala Arg
1445 1450 1455
Lys Pro Val Gln Phe Ala Pro Ala Ala Lys Ala Val Asp Glu Asp
1460 1465 1470
Arg Ser Ile Gly Val Leu Val Asp Val Gly Pro Gln Pro Val Ala
1475 1480 1485
Trp Thr Leu Leu Gln Ala Asn Asn Leu Ser Asn Thr Ser Thr Val
1490 1495 1500
Ala Leu Phe Ala Lys Ala Gly Lys Asp Gln Glu Met Ala Leu Leu
1505 1510 1515
Thr Ala Leu Ser Tyr Leu Phe Gln Glu His Asn Leu Ser Pro Lys
1520 1525 1530
Phe His Asp Leu Tyr Thr Gly Tyr Asn Gly Ala Leu Lys Lys Thr
1535 1540 1545
Asp Ile Pro Thr Tyr Pro Phe Gln Arg Val His Arg Tyr Pro Thr
1550 1555 1560
Phe Ile Pro Ser Arg Asn Gln Ser Pro Ala Val Ala Lys Ala Val
1565 1570 1575
Val Gln Pro Pro Arg Phe Ser Ile Gln Arg Asn Arg Glu Ala Thr
1580 1585 1590
Leu Gln Ser Lys Glu Pro Asp His Arg Ala Cys Leu Val Thr Cys
1595 1600 1605
Leu Arg Ala Ile Leu Glu Leu Thr Ser Glu Glu Glu Leu Asp Leu
1610 1615 1620
Ser Glu Thr Leu Asn Ala Arg Gly Val Asp Ser Ile Met Phe Ser
1625 1630 1635
Gln Leu Arg Lys Arg Val Gly Glu Glu Phe Asn Leu Glu Ile Pro
1640 1645 1650
Met Ile Tyr Leu Ser Asp Val Phe Thr Met Glu Gln Met Ile Asp
1655 1660 1665
Tyr Leu Val Glu Gln Ser Gly Ser Asn Pro Ala Ser Lys Gln Val
1670 1675 1680
Gly Thr Pro Val Asn Arg Leu Ser Gly Glu Glu Asp Leu Arg Thr
1685 1690 1695
Gly Leu Ile Ser Cys Leu Arg Asp Val Leu Glu Ile Thr Pro Asp
1700 1705 1710
Asp Glu Leu Asp His Pro Lys Asp Leu Ser Glu Thr Leu Asn Ala
1715 1720 1725
Arg Gly Val Asp Ser Ile Met Phe Ala Gln Leu Arg Lys Arg Val
1730 1735 1740
Gly Glu Gly Phe Gly Val Glu Ile Pro Met Ile Tyr Leu Ser Asp
1745 1750 1755
Val Phe Thr Met Glu Asp Met Ile Asn Phe Leu Val Ser Glu Arg
1760 1765 1770
Ser
<210> 54
<211> 5304
<212> DNA
<213> Armillaria mellea
<400> 54
atggaggcca acggtcacta ctctcttctc gatgtctttc tcagcattgc acacgattct 60
gacaagtcca aacgtaatgt cttggaatgc ggtcaggata cctggacata ctcagatttg 120
gacattatct cgtcggccct ggcacaggat ctccaagcta cgctgggttg ttttcccaaa 180
gttgcagtcg tcagcgagaa ccatccctac atttttgctc tcatgctggc cgtttggaag 240
ctcgaaggga tattcatccc tgtcgacgtc catgttacag ctgaccttct aaagggcatg 300
ttacatatcg tcgctcccac ttgtctggtg atccctgaga ccgatatttc caaccagcgt 360
attgcttccg cgattggtat acatgttctc cccttcagtg cgaatgcgtc gaccatgact 420
gcacttcgac agaaatacga cctatgcatt cagaaagcct cgctatctga gcgcgcactt 480
cctcacgttg atcgcgcttg cctctatctc tttacatcct ctgcgtcctc tactgccaac 540
ttgaaatgcg tacctttgac ccatagtctt atcctcagta actgccgttc caaactcgca 600
tggtggcggc gcgttcgtcc agaggaagaa atggatggga tacgtgttct agggtgggca 660
ccttggtccc atatccttgc ctacatgcaa gatattggca cagcgacgct cctgaacgcc 720
ggttgctacg tctttgcgtc aattccgtcc acatatccta cacaactggt ggtgaatggc 780
ttacaaggcc ccaccatgaa tatcatcgac tcacttctta aacggcgaat cgtcgcattt 840
gcttgtgtcc cgttcatttt gggcgaacta aaagctatgt gcgagacggc ttcgggtcca 900
gatgtcaagc atcatatggg cttgagagct gaggagaagg ttcgccttgt tagggcactg 960
cagcagctta tgatgctcga gtgcggaggc gctgcgctcg agtcagatgt cacgcgttgg 1020
gttgtcgaaa atggcatatc ggtcatggtt ggcatcggga tgacggagac agttggtacg 1080
ctgtttgcag agcgcgcgca agacgcccgt tccaacggct actctgcgca gaacgccctc 1140
attactgatg gcattatgtc actggtcggg cctgacaacg aggaagtcac ctttgaaggg 1200
gaactagtcg tgaagagcaa gctcatccca cacgaataca tcaattaccg tgattcgtcg 1260
ttctcggtgg actcggatgg ctgggtaacg tttaaaacgg gagataaata tcagcgcaca 1320
ccagatggac gattcaaatg gcttggaaga aagaccgact ttattcagat gacaagcagt 1380
gaaacactgg atcccagacc cattgagaaa accctctgtg cgaatccaag tattgtaaat 1440
gcatgcgtca ttggtgacag attcctgagg gagcctgcaa ctagcgtatg cgccattgtc 1500
gagatcaggc cggaagtgga catcccttcg tccaagatcg acagggaaat tgcgaatgcc 1560
cttgctccaa tcaatcgcga cctccctcct gctcttcgca tatcatggtc tcgcgtactc 1620
ataattcgac ctcctcagaa aataccagtt acaaggaaag gcgatgtgtt ccgtaagaag 1680
attgaagatg tatttgggtc tttccttggt gtcggttcta ccgagatcaa agtcgaccat 1740
gaatctaaag aagatgatac ggaacacatt gtgagacagg ttgtcagcaa tcttcttgga 1800
gtccatgatc ctgagctatt gtctgcttta tctttcgctg agctgggaat gacctcgttt 1860
atagctgtta gtattgtcaa cgctctaaac aagcgcatca gcggcctcac ccttccacct 1920
aatgcgtgct acctccatat tgatcttgat tctcttgtga acgccatttc acgtgaacat 1980
ggtcatggaa ctaaccccgc agagttgcct tctaaacttt tccccgtcac cgagtcctat 2040
caacgtaatg ataaggacgt tgtgataatc ggcaaagcat tccgtttacc aggctcactc 2100
gacaatactg catctctctg ggaagctttg ttatcgaaga acaattcagt cgtcagtgac 2160
atcccatccg atcgctggga tcacgcaagc ttttaccccc acgatatatg cttcacgaaa 2220
gcaggcctcg tcgatgttgc acattacgat tacagattct ttgggctcac agcgacagag 2280
gcattgtacg tatctccgac gatgcgcctc gccttggaag tgtcatttga agcccttgag 2340
aacgcgaata ttccgctatc caagctgaag gggacacaaa cccctgtcta tgtcgccact 2400
aaagacgatg gctttgagac actcttaaat gctgagcaag gctacgatgc ttacacgcga 2460
ttctatggta caggtcgcgc tccgagcacc gcaagtggtc gtataagcta tctactcgat 2520
attcatgggc catctgttac cgttgataca gcatgcagcg gaggcattgt atgtatggat 2580
caagccatca ctttcttgca atccggaagg gccgataccg ctattgtctg ttcgagcaat 2640
acgcactgtt ggccgggatc atttatgttc ctgacggcgc agggcatggt ttctccacat 2700
ggaagatgcg ctacatttac taccgatgca gacggttatg taccttcgga gggtgctgtg 2760
gctttcattc tcaagacgcg cagtgctgca atacgcgata atgacaatat actcgccgtg 2820
atcaaatcaa cagatgtgtc ccataacggc cgttctcaag ggctagttgc accaaacgta 2880
aaggcgcaga caagcctaca ccgatcgttg ctacgaaaag ctggactatt tcctgatcaa 2940
atcaatttta tcgaagccca tggaacaggt acatctctag gagacctctc ggaaatccag 3000
ggcatcaaca acgcctacac ctcaacacga cctcgtttgg acggtcccct tatcattagc 3060
gcgtcgaaaa cagtgttggg acacagcgaa ccaattgcgg ggatggccgg catcctcaca 3120
gccttgcttt ccctcgagaa agaaacagtt tttggtttaa atcacttaac agagcacaac 3180
cttaaccctt cgcttgattg cagcctagtt cctctcctga ttcctcacga gtctattcac 3240
attggtggtg aaaaaccaca tcgagctgcg gttctgtcat acggtttcgc gggtacgctg 3300
gccggtgcca tcttagaggg accaccttca gatgtaccaa ggccgtcgtc aagcgatatg 3360
caagaacacc ctatggtttt cgtcctcagt gggaaaagcg tgcctgcact ggaaacgtac 3420
ctaagacggt atttggcatt tttgcgcgcc gcaaaaacaa acgacttcca tagcatctgc 3480
tacaccactt gcgtcgggag ggagcattac aaataccggt tctcctgcgt tgcccaaaat 3540
atggcagacc ttgtgtctca aattgaacat cgactgacaa ctctttccaa ttcgaaacag 3600
aaacctcgtg gctcgccagg gtttatgttc tcaggacaag gcacttattt ccctggtatg 3660
gctgcagcgc ttgctgaaca atatttgggg tttcgagtgc tagtctctag gtttgggaag 3720
gctgctcaag agcggtcggg ttatccgatc gataggctgt tgcttgaagt ttctgataca 3780
tcatcagaaa caaacagcga ggctgaccaa atttgcattt ttgtctacca atattccgtt 3840
ctgcaatggc tgcagagtct aggcattcaa ccgaaagcag tcctcggtca cagcctggga 3900
gaaattaccg ccgcagtcgc agctggtgcc ctttcattcg aatctgcgtt ggaccttgta 3960
gtcacccgtg ctcgtcttct ccgtcctgaa acaaaagatt cagcaggaat ggccgcagta 4020
gcagcatcca aggaagaagt tgaagaactt atagaaaacc tccaacttgc gcatgcgtta 4080
agtgttgcgg ttcacaacgg tccacggagt gttgttgtgt caggcgcatc gaccgaaatt 4140
gatgccctgg tcgtcgcagc taaagaacgg ggcttgaagg cttcccgctt aagagttgac 4200
caaggcttcc atagccctta cgttgattct gccgttccgg gtttactcga ctggtcaagt 4260
gaacattgtt cgaccttcct tcctttaaat attcctttat actcgacttt gaccggcgaa 4320
gttattccaa agggacggag gttcgcctgg gatcactggg taaaccatgc tcgaaaacct 4380
gttcagtttg cggcggcggc agcagcggtg gacgaagacc gatccatcgg cgtgctcctt 4440
gatgttggac cccaacccgt tgcgtggacc atccttcaag caagcagcct tttcaacacc 4500
tctgcagttg cgctatttgc gaaggctgga aaggatcagg agatggcgct gcttactact 4560
ttgagctacc tcttccaaga gcacaatctt tgtcccaact ttcacgagct ttactctcag 4620
cgtcatggtg ctcttaagaa gacggacatt cccacctacc cattccaacg tgtccaccgc 4680
tatccaacct tcataccatc acgaaatcaa agtcctgctg tcgcgaaggt agtagtccca 4740
tcgcgctttc ctgtccaaag gaaaggggaa gcaatatcac aatcgaacga atcagattac 4800
cgagctggtt tgatcacttg cctcagaacc atcctcgaat taacatcaga agaagagttt 4860
gacctttctg agaccctcaa cgctcgtggt gtggattcga tcatgttttc acagctacgg 4920
aagcgggttg gggaagaatt cgatctcgat atacccatga tctatttatc agacgtgttc 4980
acgatggaac agatgatcga ctacctcgtc gaacagtccg gatccagacc cgcgccaaag 5040
cacgtagaaa ctccggttaa cgaaccttta ggcaaagatc tccggacggg gctcgtttca 5100
tgcctgagga atgtactaga aatcaccccc gatgaagaac tcgacctatc tgaaactttg 5160
aacgctcgtg gtgtcgactc gatcatgttc gctcagctac gaaaacgcgt cggggaagga 5220
tttggcgtgg aaattccgat gatatatctg tctgacgtgt ttactatgga agacatgatc 5280
aatttcctcg tctctgagca cgcg 5304
<210> 55
<211> 1768
<212> PRT
<213> Armillaria mellea
<400> 55
Met Glu Ala Asn Gly His Tyr Ser Leu Leu Asp Val Phe Leu Ser Ile
1 5 10 15
Ala His Asp Ser Asp Lys Ser Lys Arg Asn Val Leu Glu Cys Gly Gln
20 25 30
Asp Thr Trp Thr Tyr Ser Asp Leu Asp Ile Ile Ser Ser Ala Leu Ala
35 40 45
Gln Asp Leu Gln Ala Thr Leu Gly Cys Phe Pro Lys Val Ala Val Val
50 55 60
Ser Glu Asn His Pro Tyr Ile Phe Ala Leu Met Leu Ala Val Trp Lys
65 70 75 80
Leu Glu Gly Ile Phe Ile Pro Val Asp Val His Val Thr Ala Asp Leu
85 90 95
Leu Lys Gly Met Leu His Ile Val Ala Pro Thr Cys Leu Val Ile Pro
100 105 110
Glu Thr Asp Ile Ser Asn Gln Arg Ile Ala Ser Ala Ile Gly Ile His
115 120 125
Val Leu Pro Phe Ser Ala Asn Ala Ser Thr Met Thr Ala Leu Arg Gln
130 135 140
Lys Tyr Asp Leu Cys Ile Gln Lys Ala Ser Leu Ser Glu Arg Ala Leu
145 150 155 160
Pro His Val Asp Arg Ala Cys Leu Tyr Leu Phe Thr Ser Ser Ala Ser
165 170 175
Ser Thr Ala Asn Leu Lys Cys Val Pro Leu Thr His Ser Leu Ile Leu
180 185 190
Ser Asn Cys Arg Ser Lys Leu Ala Trp Trp Arg Arg Val Arg Pro Glu
195 200 205
Glu Glu Met Asp Gly Ile Arg Val Leu Gly Trp Ala Pro Trp Ser His
210 215 220
Ile Leu Ala Tyr Met Gln Asp Ile Gly Thr Ala Thr Leu Leu Asn Ala
225 230 235 240
Gly Cys Tyr Val Phe Ala Ser Ile Pro Ser Thr Tyr Pro Thr Gln Leu
245 250 255
Val Val Asn Gly Leu Gln Gly Pro Thr Met Asn Ile Ile Asp Ser Leu
260 265 270
Leu Lys Arg Arg Ile Val Ala Phe Ala Cys Val Pro Phe Ile Leu Gly
275 280 285
Glu Leu Lys Ala Met Cys Glu Thr Ala Ser Gly Pro Asp Val Lys His
290 295 300
His Met Gly Leu Arg Ala Glu Glu Lys Val Arg Leu Val Arg Ala Leu
305 310 315 320
Gln Gln Leu Met Met Leu Glu Cys Gly Gly Ala Ala Leu Glu Ser Asp
325 330 335
Val Thr Arg Trp Val Val Glu Asn Gly Ile Ser Val Met Val Gly Ile
340 345 350
Gly Met Thr Glu Thr Val Gly Thr Leu Phe Ala Glu Arg Ala Gln Asp
355 360 365
Ala Arg Ser Asn Gly Tyr Ser Ala Gln Asn Ala Leu Ile Thr Asp Gly
370 375 380
Ile Met Ser Leu Val Gly Pro Asp Asn Glu Glu Val Thr Phe Glu Gly
385 390 395 400
Glu Leu Val Val Lys Ser Lys Leu Ile Pro His Glu Tyr Ile Asn Tyr
405 410 415
Arg Asp Ser Ser Phe Ser Val Asp Ser Asp Gly Trp Val Thr Phe Lys
420 425 430
Thr Gly Asp Lys Tyr Gln Arg Thr Pro Asp Gly Arg Phe Lys Trp Leu
435 440 445
Gly Arg Lys Thr Asp Phe Ile Gln Met Thr Ser Ser Glu Thr Leu Asp
450 455 460
Pro Arg Pro Ile Glu Lys Thr Leu Cys Ala Asn Pro Ser Ile Val Asn
465 470 475 480
Ala Cys Val Ile Gly Asp Arg Phe Leu Arg Glu Pro Ala Thr Ser Val
485 490 495
Cys Ala Ile Val Glu Ile Arg Pro Glu Val Asp Ile Pro Ser Ser Lys
500 505 510
Ile Asp Arg Glu Ile Ala Asn Ala Leu Ala Pro Ile Asn Arg Asp Leu
515 520 525
Pro Pro Ala Leu Arg Ile Ser Trp Ser Arg Val Leu Ile Ile Arg Pro
530 535 540
Pro Gln Lys Ile Pro Val Thr Arg Lys Gly Asp Val Phe Arg Lys Lys
545 550 555 560
Ile Glu Asp Val Phe Gly Ser Phe Leu Gly Val Gly Ser Thr Glu Ile
565 570 575
Lys Val Asp His Glu Ser Lys Glu Asp Asp Thr Glu His Ile Val Arg
580 585 590
Gln Val Val Ser Asn Leu Leu Gly Val His Asp Pro Glu Leu Leu Ser
595 600 605
Ala Leu Ser Phe Ala Glu Leu Gly Met Thr Ser Phe Ile Ala Val Ser
610 615 620
Ile Val Asn Ala Leu Asn Lys Arg Ile Ser Gly Leu Thr Leu Pro Pro
625 630 635 640
Asn Ala Cys Tyr Leu His Ile Asp Leu Asp Ser Leu Val Asn Ala Ile
645 650 655
Ser Arg Glu His Gly His Gly Thr Asn Pro Ala Glu Leu Pro Ser Lys
660 665 670
Leu Phe Pro Val Thr Glu Ser Tyr Gln Arg Asn Asp Lys Asp Val Val
675 680 685
Ile Ile Gly Lys Ala Phe Arg Leu Pro Gly Ser Leu Asp Asn Thr Ala
690 695 700
Ser Leu Trp Glu Ala Leu Leu Ser Lys Asn Asn Ser Val Val Ser Asp
705 710 715 720
Ile Pro Ser Asp Arg Trp Asp His Ala Ser Phe Tyr Pro His Asp Ile
725 730 735
Cys Phe Thr Lys Ala Gly Leu Val Asp Val Ala His Tyr Asp Tyr Arg
740 745 750
Phe Phe Gly Leu Thr Ala Thr Glu Ala Leu Tyr Val Ser Pro Thr Met
755 760 765
Arg Leu Ala Leu Glu Val Ser Phe Glu Ala Leu Glu Asn Ala Asn Ile
770 775 780
Pro Leu Ser Lys Leu Lys Gly Thr Gln Thr Pro Val Tyr Val Ala Thr
785 790 795 800
Lys Asp Asp Gly Phe Glu Thr Leu Leu Asn Ala Glu Gln Gly Tyr Asp
805 810 815
Ala Tyr Thr Arg Phe Tyr Gly Thr Gly Arg Ala Pro Ser Thr Ala Ser
820 825 830
Gly Arg Ile Ser Tyr Leu Leu Asp Ile His Gly Pro Ser Val Thr Val
835 840 845
Asp Thr Ala Cys Ser Gly Gly Ile Val Cys Met Asp Gln Ala Ile Thr
850 855 860
Phe Leu Gln Ser Gly Arg Ala Asp Thr Ala Ile Val Cys Ser Ser Asn
865 870 875 880
Thr His Cys Trp Pro Gly Ser Phe Met Phe Leu Thr Ala Gln Gly Met
885 890 895
Val Ser Pro His Gly Arg Cys Ala Thr Phe Thr Thr Asp Ala Asp Gly
900 905 910
Tyr Val Pro Ser Glu Gly Ala Val Ala Phe Ile Leu Lys Thr Arg Ser
915 920 925
Ala Ala Ile Arg Asp Asn Asp Asn Ile Leu Ala Val Ile Lys Ser Thr
930 935 940
Asp Val Ser His Asn Gly Arg Ser Gln Gly Leu Val Ala Pro Asn Val
945 950 955 960
Lys Ala Gln Thr Ser Leu His Arg Ser Leu Leu Arg Lys Ala Gly Leu
965 970 975
Phe Pro Asp Gln Ile Asn Phe Ile Glu Ala His Gly Thr Gly Thr Ser
980 985 990
Leu Gly Asp Leu Ser Glu Ile Gln Gly Ile Asn Asn Ala Tyr Thr Ser
995 1000 1005
Thr Arg Pro Arg Leu Asp Gly Pro Leu Ile Ile Ser Ala Ser Lys
1010 1015 1020
Thr Val Leu Gly His Ser Glu Pro Ile Ala Gly Met Ala Gly Ile
1025 1030 1035
Leu Thr Ala Leu Leu Ser Leu Glu Lys Glu Thr Val Phe Gly Leu
1040 1045 1050
Asn His Leu Thr Glu His Asn Leu Asn Pro Ser Leu Asp Cys Ser
1055 1060 1065
Leu Val Pro Leu Leu Ile Pro His Glu Ser Ile His Ile Gly Gly
1070 1075 1080
Glu Lys Pro His Arg Ala Ala Val Leu Ser Tyr Gly Phe Ala Gly
1085 1090 1095
Thr Leu Ala Gly Ala Ile Leu Glu Gly Pro Pro Ser Asp Val Pro
1100 1105 1110
Arg Pro Ser Ser Ser Asp Met Gln Glu His Pro Met Val Phe Val
1115 1120 1125
Leu Ser Gly Lys Ser Val Pro Ala Leu Glu Thr Tyr Leu Arg Arg
1130 1135 1140
Tyr Leu Ala Phe Leu Arg Ala Ala Lys Thr Asn Asp Phe His Ser
1145 1150 1155
Ile Cys Tyr Thr Thr Cys Val Gly Arg Glu His Tyr Lys Tyr Arg
1160 1165 1170
Phe Ser Cys Val Ala Gln Asn Met Ala Asp Leu Val Ser Gln Ile
1175 1180 1185
Glu His Arg Leu Thr Thr Leu Ser Asn Ser Lys Gln Lys Pro Arg
1190 1195 1200
Gly Ser Pro Gly Phe Met Phe Ser Gly Gln Gly Thr Tyr Phe Pro
1205 1210 1215
Gly Met Ala Ala Ala Leu Ala Glu Gln Tyr Leu Gly Phe Arg Val
1220 1225 1230
Leu Val Ser Arg Phe Gly Lys Ala Ala Gln Glu Arg Ser Gly Tyr
1235 1240 1245
Pro Ile Asp Arg Leu Leu Leu Glu Val Ser Asp Thr Ser Ser Glu
1250 1255 1260
Thr Asn Ser Glu Ala Asp Gln Ile Cys Ile Phe Val Tyr Gln Tyr
1265 1270 1275
Ser Val Leu Gln Trp Leu Gln Ser Leu Gly Ile Gln Pro Lys Ala
1280 1285 1290
Val Leu Gly His Ser Leu Gly Glu Ile Thr Ala Ala Val Ala Ala
1295 1300 1305
Gly Ala Leu Ser Phe Glu Ser Ala Leu Asp Leu Val Val Thr Arg
1310 1315 1320
Ala Arg Leu Leu Arg Pro Glu Thr Lys Asp Ser Ala Gly Met Ala
1325 1330 1335
Ala Val Ala Ala Ser Lys Glu Glu Val Glu Glu Leu Ile Glu Asn
1340 1345 1350
Leu Gln Leu Ala His Ala Leu Ser Val Ala Val His Asn Gly Pro
1355 1360 1365
Arg Ser Val Val Val Ser Gly Ala Ser Thr Glu Ile Asp Ala Leu
1370 1375 1380
Val Val Ala Ala Lys Glu Arg Gly Leu Lys Ala Ser Arg Leu Arg
1385 1390 1395
Val Asp Gln Gly Phe His Ser Pro Tyr Val Asp Ser Ala Val Pro
1400 1405 1410
Gly Leu Leu Asp Trp Ser Ser Glu His Cys Ser Thr Phe Leu Pro
1415 1420 1425
Leu Asn Ile Pro Leu Tyr Ser Thr Leu Thr Gly Glu Val Ile Pro
1430 1435 1440
Lys Gly Arg Arg Phe Ala Trp Asp His Trp Val Asn His Ala Arg
1445 1450 1455
Lys Pro Val Gln Phe Ala Ala Ala Ala Ala Ala Val Asp Glu Asp
1460 1465 1470
Arg Ser Ile Gly Val Leu Leu Asp Val Gly Pro Gln Pro Val Ala
1475 1480 1485
Trp Thr Ile Leu Gln Ala Ser Ser Leu Phe Asn Thr Ser Ala Val
1490 1495 1500
Ala Leu Phe Ala Lys Ala Gly Lys Asp Gln Glu Met Ala Leu Leu
1505 1510 1515
Thr Thr Leu Ser Tyr Leu Phe Gln Glu His Asn Leu Cys Pro Asn
1520 1525 1530
Phe His Glu Leu Tyr Ser Gln Arg His Gly Ala Leu Lys Lys Thr
1535 1540 1545
Asp Ile Pro Thr Tyr Pro Phe Gln Arg Val His Arg Tyr Pro Thr
1550 1555 1560
Phe Ile Pro Ser Arg Asn Gln Ser Pro Ala Val Ala Lys Val Val
1565 1570 1575
Val Pro Ser Arg Phe Pro Val Gln Arg Lys Gly Glu Ala Ile Ser
1580 1585 1590
Gln Ser Asn Glu Ser Asp Tyr Arg Ala Gly Leu Ile Thr Cys Leu
1595 1600 1605
Arg Thr Ile Leu Glu Leu Thr Ser Glu Glu Glu Phe Asp Leu Ser
1610 1615 1620
Glu Thr Leu Asn Ala Arg Gly Val Asp Ser Ile Met Phe Ser Gln
1625 1630 1635
Leu Arg Lys Arg Val Gly Glu Glu Phe Asp Leu Asp Ile Pro Met
1640 1645 1650
Ile Tyr Leu Ser Asp Val Phe Thr Met Glu Gln Met Ile Asp Tyr
1655 1660 1665
Leu Val Glu Gln Ser Gly Ser Arg Pro Ala Pro Lys His Val Glu
1670 1675 1680
Thr Pro Val Asn Glu Pro Leu Gly Lys Asp Leu Arg Thr Gly Leu
1685 1690 1695
Val Ser Cys Leu Arg Asn Val Leu Glu Ile Thr Pro Asp Glu Glu
1700 1705 1710
Leu Asp Leu Ser Glu Thr Leu Asn Ala Arg Gly Val Asp Ser Ile
1715 1720 1725
Met Phe Ala Gln Leu Arg Lys Arg Val Gly Glu Gly Phe Gly Val
1730 1735 1740
Glu Ile Pro Met Ile Tyr Leu Ser Asp Val Phe Thr Met Glu Asp
1745 1750 1755
Met Ile Asn Phe Leu Val Ser Glu His Ala
1760 1765
<210> 56
<211> 40
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 1 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<223> X - любая аминокислота
<220>
<221> MISC_FEATURE
<222> (1)..(40)
<223> X - любая аминокислота
<400> 56
Val Ala Xaa Xaa Xaa Glu Asn His Pro Xaa Xaa Xaa Ala Leu Xaa Xaa
1 5 10 15
Ala Val Trp Lys Xaa Xaa Gly Xaa Phe Xaa Pro Xaa Asp Xaa His Xaa
20 25 30
Xaa Xaa Xaa Xaa Xaa Xaa Gly Met
35 40
<210> 57
<211> 36
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 2 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<222> (1)..(36)
<223> X - любая аминокислота
<400> 57
Leu Gly Trp Ala Pro Xaa Ser His Xaa Leu Xaa Xaa Met Gln Asp Ile
1 5 10 15
Gly Xaa Xaa Xaa Xaa Leu Xaa Ala Gly Cys Tyr Val Phe Xaa Xaa Xaa
20 25 30
Pro Xaa Xaa Tyr
35
<210> 58
<211> 33
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 3 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<222> (6)..(33)
<223> X - любая аминокислота
<400> 58
Glu Cys Gly Gly Ala Xaa Leu Xaa Xaa Xaa Xaa Xaa Xaa Trp Xaa Xaa
1 5 10 15
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Gly Xaa Gly Met Thr Glu Thr Xaa
20 25 30
Gly
<210> 59
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 4 гиспидин-синтаз
<400> 59
Phe Ala Glu Leu Gly Met Thr Ser
1 5
<210> 60
<211> 25
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 5 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<222> (2)..(24)
<223> X - любая аминокислота
<400> 60
Ile Xaa Xaa Xaa Arg Trp Asp His Xaa Ser Phe Tyr Pro Xaa Xaa Ile
1 5 10 15
Xaa Xaa Xaa Xaa Ala Gly Leu Xaa Asp
20 25
<210> 61
<211> 65
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 6 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<222> (2)..(64)
<223> X - любая аминокислота
<400> 61
Asp Xaa Xaa Phe Phe Gly Xaa Xaa Xaa Xaa Glu Ala Xaa Xaa Xaa Ser
1 5 10 15
Pro Thr Met Arg Xaa Ala Leu Glu Val Xaa Xaa Glu Ala Leu Glu Xaa
20 25 30
Ala Asn Ile Pro Xaa Xaa Xaa Xaa Lys Gly Xaa Xaa Xaa Xaa Val Xaa
35 40 45
Xaa Ala Xaa Xaa Asp Asp Gly Phe Glu Thr Leu Leu Xaa Ala Xaa Xaa
50 55 60
Gly
65
<210> 62
<211> 50
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 7 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<222> (5)..(47)
<223> X - любая аминокислота
<400> 62
Ala Asp Gly Tyr Xaa Pro Ser Glu Gly Ala Val Xaa Phe Xaa Leu Lys
1 5 10 15
Thr Xaa Xaa Ala Ala Xaa Arg Asp Xaa Xaa Xaa Ile Xaa Ala Xaa Ile
20 25 30
Xaa Xaa Xaa Xaa Xaa Xaa His Asn Gly Arg Ser Gln Gly Leu Xaa Ala
35 40 45
Pro Asn
50
<210> 63
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 8 гиспидин-синтаз
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> X - любая аминокислота
<400> 63
Gly His Ser Leu Gly Glu Ile Xaa Ala
1 5
<210> 64
<211> 867
<212> DNA
<213> Neonothopanus nambi
<400> 64
atggcgccaa tttcttcaac ttggtctcgt ctcattcgat ttgtggctat tgaaacgtcc 60
ctcgtgcata tcggtgaacc gatagacgcc accatggacg tcggtctggc gagacgagaa 120
ggcaagacga tccaagcata cgagattatt ggatcaggct cggctctaga cctctcagcc 180
caagtatcga agaatgtgct gactgtaagg gaactcctga tgccgctttc aagagaggaa 240
attaaaactg tacgatgctt ggggttgaac taccctgttc atgccaccga agcgaacgtt 300
gctgttccaa aattcccgaa tttgttctac aaaccagtga cctcgctcat tggccccgat 360
ggactcatta ccatcccttc cgttgtccaa cccccgaagg agcatcagtc cgattatgaa 420
gcggaacttg tcattgtcat cgggaaagca gcaaagaatg tatcggagga tgaggctttg 480
gattatgtat tgggatacac tgccgcgaac gatatttcgt ttaggaaaca ccagctagca 540
gtctcacaat ggtctttctc gaaaggattt ggtagccttc tactcactat ccgtatggca 600
caaacccact cgggtaacat taatcgcttc tccagagacc agattttcaa tgtcaagaag 660
acaatttcct tcctgtcaca aggcactaca ctggaaccag gttctatcat tttgactggt 720
acacctgacg gagtgggctt tgtgcgcaat ccaccacttt accttaaaga tggagatgaa 780
gtaatgacct ggattggaag tggaatcgga acattagcca atacagtgca agaagagaag 840
acttgcttcg ctagtggcgg acacgag 867
<210> 65
<211> 289
<212> PRT
<213> Neonothopanus nambi
<400> 65
Met Ala Pro Ile Ser Ser Thr Trp Ser Arg Leu Ile Arg Phe Val Ala
1 5 10 15
Ile Glu Thr Ser Leu Val His Ile Gly Glu Pro Ile Asp Ala Thr Met
20 25 30
Asp Val Gly Leu Ala Arg Arg Glu Gly Lys Thr Ile Gln Ala Tyr Glu
35 40 45
Ile Ile Gly Ser Gly Ser Ala Leu Asp Leu Ser Ala Gln Val Ser Lys
50 55 60
Asn Val Leu Thr Val Arg Glu Leu Leu Met Pro Leu Ser Arg Glu Glu
65 70 75 80
Ile Lys Thr Val Arg Cys Leu Gly Leu Asn Tyr Pro Val His Ala Thr
85 90 95
Glu Ala Asn Val Ala Val Pro Lys Phe Pro Asn Leu Phe Tyr Lys Pro
100 105 110
Val Thr Ser Leu Ile Gly Pro Asp Gly Leu Ile Thr Ile Pro Ser Val
115 120 125
Val Gln Pro Pro Lys Glu His Gln Ser Asp Tyr Glu Ala Glu Leu Val
130 135 140
Ile Val Ile Gly Lys Ala Ala Lys Asn Val Ser Glu Asp Glu Ala Leu
145 150 155 160
Asp Tyr Val Leu Gly Tyr Thr Ala Ala Asn Asp Ile Ser Phe Arg Lys
165 170 175
His Gln Leu Ala Val Ser Gln Trp Ser Phe Ser Lys Gly Phe Gly Ser
180 185 190
Leu Leu Leu Thr Ile Arg Met Ala Gln Thr His Ser Gly Asn Ile Asn
195 200 205
Arg Phe Ser Arg Asp Gln Ile Phe Asn Val Lys Lys Thr Ile Ser Phe
210 215 220
Leu Ser Gln Gly Thr Thr Leu Glu Pro Gly Ser Ile Ile Leu Thr Gly
225 230 235 240
Thr Pro Asp Gly Val Gly Phe Val Arg Asn Pro Pro Leu Tyr Leu Lys
245 250 255
Asp Gly Asp Glu Val Met Thr Trp Ile Gly Ser Gly Ile Gly Thr Leu
260 265 270
Ala Asn Thr Val Gln Glu Glu Lys Thr Cys Phe Ala Ser Gly Gly His
275 280 285
Glu
<210> 66
<211> 963
<212> DNA
<213> Neonothopanus gardneri
<400> 66
atggcgccga ttttgacagt gagttccagt tcaatggtgc tgaatagctc aaaacaggct 60
atattgaata tttctgaata tcaccagccc tggactcgtc tcattcgatt tgtagccgtt 120
gagacgtcac tcgtgcatat tggtgaaccc atcgaggtga ctttggacgt cgggcaggca 180
aaatgtgaag gcaagacgat caaagcgtac gagattattg gatcagggtc ggccttggac 240
ctctcagctc aggtatcgaa gaatgtgcta accgtaaagg aactcttgat gccgctttcg 300
agagaagagg tcaagactgt gcggtgcttg ggactgaact attttactca tgcttccacc 360
gggcgcccgc tgtcgactag attaccgact ttgttctata agccagtgac ttcactcatc 420
ggacctgagg cgttcattaa tattccttcc gctgttcaac caccgaagga gcatcagtcc 480
gattatgaag cggagttggt aattattatt gggagagcgg cgaaggatgt accggaagag 540
gaggctttga attatgtttt gggatacacc gccgccaacg acatttcatt taggaaatat 600
caatttgcag tttcccagtg gtgtttttcg aaaggtttcg ataatacaaa cccaatcggt 660
ccgtgcatcg tttccgcatc ttccattccg aacccgcaag acatccagat ccaatgcaaa 720
ctgaacggga atgtcgttca gaatggaaac accagtgatc aaatttttaa tatcaagaaa 780
acagtcgctt ttttgtcgca aggaacaaca cttgagtcag gatcaatcat cctgaccggt 840
acgcctggcg gagtgggatt tgtgcgcgat ccaccgcttt accttaaaga tggagatgaa 900
gtagtgactt ggattggaag tggggttgga agtttagtca acgtagtaaa agaagagaag 960
act 963
<210> 67
<211> 321
<212> PRT
<213> Neonothopanus gardneri
<400> 67
Met Ala Pro Ile Leu Thr Val Ser Ser Ser Ser Met Val Leu Asn Ser
1 5 10 15
Ser Lys Gln Ala Ile Leu Asn Ile Ser Glu Tyr His Gln Pro Trp Thr
20 25 30
Arg Leu Ile Arg Phe Val Ala Val Glu Thr Ser Leu Val His Ile Gly
35 40 45
Glu Pro Ile Glu Val Thr Leu Asp Val Gly Gln Ala Lys Cys Glu Gly
50 55 60
Lys Thr Ile Lys Ala Tyr Glu Ile Ile Gly Ser Gly Ser Ala Leu Asp
65 70 75 80
Leu Ser Ala Gln Val Ser Lys Asn Val Leu Thr Val Lys Glu Leu Leu
85 90 95
Met Pro Leu Ser Arg Glu Glu Val Lys Thr Val Arg Cys Leu Gly Leu
100 105 110
Asn Tyr Phe Thr His Ala Ser Thr Gly Arg Pro Leu Ser Thr Arg Leu
115 120 125
Pro Thr Leu Phe Tyr Lys Pro Val Thr Ser Leu Ile Gly Pro Glu Ala
130 135 140
Phe Ile Asn Ile Pro Ser Ala Val Gln Pro Pro Lys Glu His Gln Ser
145 150 155 160
Asp Tyr Glu Ala Glu Leu Val Ile Ile Ile Gly Arg Ala Ala Lys Asp
165 170 175
Val Pro Glu Glu Glu Ala Leu Asn Tyr Val Leu Gly Tyr Thr Ala Ala
180 185 190
Asn Asp Ile Ser Phe Arg Lys Tyr Gln Phe Ala Val Ser Gln Trp Cys
195 200 205
Phe Ser Lys Gly Phe Asp Asn Thr Asn Pro Ile Gly Pro Cys Ile Val
210 215 220
Ser Ala Ser Ser Ile Pro Asn Pro Gln Asp Ile Gln Ile Gln Cys Lys
225 230 235 240
Leu Asn Gly Asn Val Val Gln Asn Gly Asn Thr Ser Asp Gln Ile Phe
245 250 255
Asn Ile Lys Lys Thr Val Ala Phe Leu Ser Gln Gly Thr Thr Leu Glu
260 265 270
Ser Gly Ser Ile Ile Leu Thr Gly Thr Pro Gly Gly Val Gly Phe Val
275 280 285
Arg Asp Pro Pro Leu Tyr Leu Lys Asp Gly Asp Glu Val Val Thr Trp
290 295 300
Ile Gly Ser Gly Val Gly Ser Leu Val Asn Val Val Lys Glu Glu Lys
305 310 315 320
Thr
<210> 68
<211> 906
<212> DNA
<213> Armillaria gallica
<400> 68
atggcgccta ttatcactca atggtccaga cttatccgct ttgtcgccgt cgaaacctct 60
cgtgtacata ttggacagcc cgtagattct aacctggatg ttggtctagc ggcgtaccag 120
ggaatgctaa tcaaggctta cgaaatactt ggttctgctc tcgatccatc cgcccaaatg 180
actagcaaga tcctcactgt caaacaacta ttaaccccgc tgtctggcga agatgtcaag 240
gtcgttagat gcttgggtct caactaccca gcacatgcga atgaagggaa agtagaagca 300
cctaagtttc ctaacctttt ctataagcca gtgacgtcgc ttatcgggcc cctcgcacct 360
gtgatcattc ctgcagtcgc acaaccttct gcaatacatc aatccgatta tgaggctgaa 420
tttactgtcg tcataggcag ggcagctaag aatatcactg aagcggaagc tttagactat 480
gttctcggct acaccggcgg caatgacgtg tcttttcgtc agcatcaatt tgcggtctct 540
caatggtgtt tctccaaaag ttttgacaac acaaatccct ttgggccatg cttagttgcc 600
gcatcgtcta ttcccgaccc tcaaactgtg gccattaagt ttacactgaa tggtcaaact 660
gtccaagacg gaactactgc cgatcaactt ttcagcgtca aaaagaccat agcttatctt 720
tctcaaggca cgacgttaca gccgggctcc ataattatga ctggtactcc cagtggcgtt 780
ggattcgtcc gaaacccacc tctctacctc aaagatggag accatatgtt gacttggata 840
agcggtggaa tcggtacgct tgcaaacagc gtcgtggagg agaagactcc gactcctggt 900
ttagat 906
<210> 69
<211> 302
<212> PRT
<213> Armillaria gallica
<400> 69
Met Ala Pro Ile Ile Thr Gln Trp Ser Arg Leu Ile Arg Phe Val Ala
1 5 10 15
Val Glu Thr Ser Arg Val His Ile Gly Gln Pro Val Asp Ser Asn Leu
20 25 30
Asp Val Gly Leu Ala Ala Tyr Gln Gly Met Leu Ile Lys Ala Tyr Glu
35 40 45
Ile Leu Gly Ser Ala Leu Asp Pro Ser Ala Gln Met Thr Ser Lys Ile
50 55 60
Leu Thr Val Lys Gln Leu Leu Thr Pro Leu Ser Gly Glu Asp Val Lys
65 70 75 80
Val Val Arg Cys Leu Gly Leu Asn Tyr Pro Ala His Ala Asn Glu Gly
85 90 95
Lys Val Glu Ala Pro Lys Phe Pro Asn Leu Phe Tyr Lys Pro Val Thr
100 105 110
Ser Leu Ile Gly Pro Leu Ala Pro Val Ile Ile Pro Ala Val Ala Gln
115 120 125
Pro Ser Ala Ile His Gln Ser Asp Tyr Glu Ala Glu Phe Thr Val Val
130 135 140
Ile Gly Arg Ala Ala Lys Asn Ile Thr Glu Ala Glu Ala Leu Asp Tyr
145 150 155 160
Val Leu Gly Tyr Thr Gly Gly Asn Asp Val Ser Phe Arg Gln His Gln
165 170 175
Phe Ala Val Ser Gln Trp Cys Phe Ser Lys Ser Phe Asp Asn Thr Asn
180 185 190
Pro Phe Gly Pro Cys Leu Val Ala Ala Ser Ser Ile Pro Asp Pro Gln
195 200 205
Thr Val Ala Ile Lys Phe Thr Leu Asn Gly Gln Thr Val Gln Asp Gly
210 215 220
Thr Thr Ala Asp Gln Leu Phe Ser Val Lys Lys Thr Ile Ala Tyr Leu
225 230 235 240
Ser Gln Gly Thr Thr Leu Gln Pro Gly Ser Ile Ile Met Thr Gly Thr
245 250 255
Pro Ser Gly Val Gly Phe Val Arg Asn Pro Pro Leu Tyr Leu Lys Asp
260 265 270
Gly Asp His Met Leu Thr Trp Ile Ser Gly Gly Ile Gly Thr Leu Ala
275 280 285
Asn Ser Val Val Glu Glu Lys Thr Pro Thr Pro Gly Leu Asp
290 295 300
<210> 70
<211> 906
<212> DNA
<213> Armillaria ostoyae
<400> 70
atggcaccta ttattactca atggtccaga cttattcgct ttgttgccgt cgagacctct 60
cgtgtacata ttggacagcc catagattct accctggata ttggtctagc ggcgtaccag 120
ggaatgctaa tcaaggctta tgaaatactt ggttctgctc tcgatccatc cgcccaaatg 180
accagcaaga tcctcaccgt taaacagcta ttaactccgc tgtctggcga agatgtcaag 240
gtcgtccgat gcttgggtct taactatcca gctcatgcga atgaagggaa agtagaagcg 300
cctaagtttc ctaacctttt ctataagcca gtgacatcgc ttatcgggcc cctcgcacct 360
gtgatcattc ctgcagtcgc acagccttct gcaatacatc aatccgatta tgaggctgaa 420
tttactgtcg tcataggcag ggcagctaag aatgtcactg aagcggaagc tttagactat 480
gttctcgggt acaccggcgg caatgatgtg tcttttcgtc agcatcaatt tgcggtctct 540
caatggtgtt tctctaaaag ttttgacaat acaaatccct tcggtccatg cttagttgcc 600
gcatcgtcta ttcctgatcc tcaaactgtg gccattaagt ttacattgaa tggtgacacc 660
gtccaagacg gaactactgc tgatcaactt ttcagcgtca aaaagaccat cgcttatctt 720
tctcagggca cgacgttaca gccgggctcc ataattatga ctggcactcc cagtggtgtt 780
gggttcgtcc aaaacccacc tctctacctc aaagatgggg atcaaatgtt gacttggata 840
agcggtggaa tcggtacgct tgcaaacaac gtcgtagagg agaagactcc gactcctcgt 900
ttagac 906
<210> 71
<211> 302
<212> PRT
<213> Armillaria ostoyae
<400> 71
Met Ala Pro Ile Ile Thr Gln Trp Ser Arg Leu Ile Arg Phe Val Ala
1 5 10 15
Val Glu Thr Ser Arg Val His Ile Gly Gln Pro Ile Asp Ser Thr Leu
20 25 30
Asp Ile Gly Leu Ala Ala Tyr Gln Gly Met Leu Ile Lys Ala Tyr Glu
35 40 45
Ile Leu Gly Ser Ala Leu Asp Pro Ser Ala Gln Met Thr Ser Lys Ile
50 55 60
Leu Thr Val Lys Gln Leu Leu Thr Pro Leu Ser Gly Glu Asp Val Lys
65 70 75 80
Val Val Arg Cys Leu Gly Leu Asn Tyr Pro Ala His Ala Asn Glu Gly
85 90 95
Lys Val Glu Ala Pro Lys Phe Pro Asn Leu Phe Tyr Lys Pro Val Thr
100 105 110
Ser Leu Ile Gly Pro Leu Ala Pro Val Ile Ile Pro Ala Val Ala Gln
115 120 125
Pro Ser Ala Ile His Gln Ser Asp Tyr Glu Ala Glu Phe Thr Val Val
130 135 140
Ile Gly Arg Ala Ala Lys Asn Val Thr Glu Ala Glu Ala Leu Asp Tyr
145 150 155 160
Val Leu Gly Tyr Thr Gly Gly Asn Asp Val Ser Phe Arg Gln His Gln
165 170 175
Phe Ala Val Ser Gln Trp Cys Phe Ser Lys Ser Phe Asp Asn Thr Asn
180 185 190
Pro Phe Gly Pro Cys Leu Val Ala Ala Ser Ser Ile Pro Asp Pro Gln
195 200 205
Thr Val Ala Ile Lys Phe Thr Leu Asn Gly Asp Thr Val Gln Asp Gly
210 215 220
Thr Thr Ala Asp Gln Leu Phe Ser Val Lys Lys Thr Ile Ala Tyr Leu
225 230 235 240
Ser Gln Gly Thr Thr Leu Gln Pro Gly Ser Ile Ile Met Thr Gly Thr
245 250 255
Pro Ser Gly Val Gly Phe Val Gln Asn Pro Pro Leu Tyr Leu Lys Asp
260 265 270
Gly Asp Gln Met Leu Thr Trp Ile Ser Gly Gly Ile Gly Thr Leu Ala
275 280 285
Asn Asn Val Val Glu Glu Lys Thr Pro Thr Pro Arg Leu Asp
290 295 300
<210> 72
<211> 891
<212> DNA
<213> Armillaria mellea
<400> 72
atggcgccta ttatcactca gtggtccaga cttattcgct ttgttgccgt cgagacttct 60
cgtgtacatt ttggacagcc cgtagattct accctggatg ttggtctagc ggcgtaccag 120
ggtgtgttga tcaaggctta tgaaatactt ggttctgctc ttgatccatc cgcccaaatg 180
accagcaaga tcctcaccgt gaaacagcta ttaactccgc tgtctggcga ggatgtcaaa 240
gtcgtccgat gcttgggtct taactatcca gcacatgcga atgaagggaa agtagaagca 300
cccaagtttc ctaacctgtt ctataagcca gtgacatcgc ttatcgggcc cctcgcgcct 360
gtgatcattc ctgcagtcgc acagccttct gcaatacatc aatctgatta tgaggctgaa 420
tttactgttg tcctaggcag ggcagctaag aatgtcactg aagctgaagc cttggactat 480
gttctcggtt acaccggcgg caatgatgtg tcttttcggc agcatcaatt tgctgtctct 540
caatggtgtt tctccaaaag ttttgacaat acaaatccct tcggtccatg cttagttgcc 600
gcgtcgtcta ttcctgatcc tcaaactgtg gccattaagt ttacattgaa tggcaacacc 660
gtccaagatg gaactactgc tgatcaactt ttcagcgtca gaaagaccat cgcttatctt 720
tctcaaggca cgacgttaca gcctggctcc ataattatga ccggtactcc cagtggcgtt 780
gggttcgtcc gaaacccacc tctctacctc aaagatgggg atcaaatgtt gacttggatt 840
agcggtggaa tcggtacgct tgcaaacagc gtcatagagg agaagacccc a 891
<210> 73
<211> 297
<212> PRT
<213> Armillaria mellea
<400> 73
Met Ala Pro Ile Ile Thr Gln Trp Ser Arg Leu Ile Arg Phe Val Ala
1 5 10 15
Val Glu Thr Ser Arg Val His Phe Gly Gln Pro Val Asp Ser Thr Leu
20 25 30
Asp Val Gly Leu Ala Ala Tyr Gln Gly Val Leu Ile Lys Ala Tyr Glu
35 40 45
Ile Leu Gly Ser Ala Leu Asp Pro Ser Ala Gln Met Thr Ser Lys Ile
50 55 60
Leu Thr Val Lys Gln Leu Leu Thr Pro Leu Ser Gly Glu Asp Val Lys
65 70 75 80
Val Val Arg Cys Leu Gly Leu Asn Tyr Pro Ala His Ala Asn Glu Gly
85 90 95
Lys Val Glu Ala Pro Lys Phe Pro Asn Leu Phe Tyr Lys Pro Val Thr
100 105 110
Ser Leu Ile Gly Pro Leu Ala Pro Val Ile Ile Pro Ala Val Ala Gln
115 120 125
Pro Ser Ala Ile His Gln Ser Asp Tyr Glu Ala Glu Phe Thr Val Val
130 135 140
Leu Gly Arg Ala Ala Lys Asn Val Thr Glu Ala Glu Ala Leu Asp Tyr
145 150 155 160
Val Leu Gly Tyr Thr Gly Gly Asn Asp Val Ser Phe Arg Gln His Gln
165 170 175
Phe Ala Val Ser Gln Trp Cys Phe Ser Lys Ser Phe Asp Asn Thr Asn
180 185 190
Pro Phe Gly Pro Cys Leu Val Ala Ala Ser Ser Ile Pro Asp Pro Gln
195 200 205
Thr Val Ala Ile Lys Phe Thr Leu Asn Gly Asn Thr Val Gln Asp Gly
210 215 220
Thr Thr Ala Asp Gln Leu Phe Ser Val Arg Lys Thr Ile Ala Tyr Leu
225 230 235 240
Ser Gln Gly Thr Thr Leu Gln Pro Gly Ser Ile Ile Met Thr Gly Thr
245 250 255
Pro Ser Gly Val Gly Phe Val Arg Asn Pro Pro Leu Tyr Leu Lys Asp
260 265 270
Gly Asp Gln Met Leu Thr Trp Ile Ser Gly Gly Ile Gly Thr Leu Ala
275 280 285
Asn Ser Val Ile Glu Glu Lys Thr Pro
290 295
<210> 74
<211> 891
<212> DNA
<213> Armillaria fuscipes
<400> 74
atggcaccta ttatcactca atggtccaga cttattcgct ttgtctccat tgagacttct 60
ggtgttcata ttggacaacc cgtagatcct acccttgacg tcggtctagc ggcgtcccag 120
ggagtggcaa tcaaggttta tgaaataatt ggttctgcgc ttgatccatc cgcccaagtg 180
accagcaaaa tccttaccgt caaacagcta ttaactccgc tgtctggtga ggatgtcaag 240
gtcgtccggt gcttgggtct gaactatcca gcacatgcca atgaagggaa agtagaagca 300
cccaagtttc ctaacctttt ctataagcca gtgacatcgc ttattgggcc cctcgcgcct 360
gtgatcattc ctgcagtcgc acagccggcc gcaatacatc aatctgatta tgaggctgaa 420
tttactgttg tcattggcag ggcagccaag aatgtcacgg aagctgaagc cctggactat 480
gttcttggct acaccggcgg taatgatgtg tcttttcgga agcatcaatt tgcagtctct 540
caatggtgtt tctccaaaag ttttgacaat acaaatccct ttggaccatg cttagttgcc 600
gcttcgtcta tccctgatcc tcagaatgtg gccattaagt tcacgttgaa tggtaacacc 660
gttcaagatg gaactactgc tgaccaaatt ttcagcgtta gaaagactat cgcttatctt 720
tctcaaggca cgacgttaca gccaggctcc atcattatga ctggcactcc caatggcgtt 780
gggtttgtcc gagacccacc tctctacctc aaagacgggg atcaaatgct gacttggatt 840
agcggtggaa ttggtacgct tgcgaatggc gtcgtagaag agaagacccg g 891
<210> 75
<211> 297
<212> PRT
<213> Armillaria fuscipes
<400> 75
Met Ala Pro Ile Ile Thr Gln Trp Ser Arg Leu Ile Arg Phe Val Ser
1 5 10 15
Ile Glu Thr Ser Gly Val His Ile Gly Gln Pro Val Asp Pro Thr Leu
20 25 30
Asp Val Gly Leu Ala Ala Ser Gln Gly Val Ala Ile Lys Val Tyr Glu
35 40 45
Ile Ile Gly Ser Ala Leu Asp Pro Ser Ala Gln Val Thr Ser Lys Ile
50 55 60
Leu Thr Val Lys Gln Leu Leu Thr Pro Leu Ser Gly Glu Asp Val Lys
65 70 75 80
Val Val Arg Cys Leu Gly Leu Asn Tyr Pro Ala His Ala Asn Glu Gly
85 90 95
Lys Val Glu Ala Pro Lys Phe Pro Asn Leu Phe Tyr Lys Pro Val Thr
100 105 110
Ser Leu Ile Gly Pro Leu Ala Pro Val Ile Ile Pro Ala Val Ala Gln
115 120 125
Pro Ala Ala Ile His Gln Ser Asp Tyr Glu Ala Glu Phe Thr Val Val
130 135 140
Ile Gly Arg Ala Ala Lys Asn Val Thr Glu Ala Glu Ala Leu Asp Tyr
145 150 155 160
Val Leu Gly Tyr Thr Gly Gly Asn Asp Val Ser Phe Arg Lys His Gln
165 170 175
Phe Ala Val Ser Gln Trp Cys Phe Ser Lys Ser Phe Asp Asn Thr Asn
180 185 190
Pro Phe Gly Pro Cys Leu Val Ala Ala Ser Ser Ile Pro Asp Pro Gln
195 200 205
Asn Val Ala Ile Lys Phe Thr Leu Asn Gly Asn Thr Val Gln Asp Gly
210 215 220
Thr Thr Ala Asp Gln Ile Phe Ser Val Arg Lys Thr Ile Ala Tyr Leu
225 230 235 240
Ser Gln Gly Thr Thr Leu Gln Pro Gly Ser Ile Ile Met Thr Gly Thr
245 250 255
Pro Asn Gly Val Gly Phe Val Arg Asp Pro Pro Leu Tyr Leu Lys Asp
260 265 270
Gly Asp Gln Met Leu Thr Trp Ile Ser Gly Gly Ile Gly Thr Leu Ala
275 280 285
Asn Gly Val Val Glu Glu Lys Thr Arg
290 295
<210> 76
<211> 42
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 1
кофеилпируват-гидролаз
<220>
<221> MISC_FEATURE
<222> (2)..(39)
<223> X - любая аминокислота
<400> 76
Trp Xaa Arg Leu Ile Arg Phe Val Xaa Xaa Glu Thr Ser Xaa Val His
1 5 10 15
Xaa Gly Xaa Pro Xaa Xaa Xaa Xaa Xaa Asp Xaa Gly Xaa Ala Xaa Xaa
20 25 30
Xaa Gly Xaa Xaa Ile Xaa Xaa Tyr Glu Ile
35 40
<210> 77
<211> 137
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 2
кофеилпируват-гидролаз
<220>
<221> MISC_FEATURE
<222> (5)..(136)
<223> X - любая аминокислота
<400> 77
Ser Ala Leu Asp Xaa Ser Ala Gln Xaa Xaa Xaa Xaa Xaa Leu Thr Val
1 5 10 15
Xaa Xaa Leu Leu Xaa Pro Leu Ser Xaa Glu Xaa Xaa Lys Xaa Val Arg
20 25 30
Cys Leu Gly Leu Asn Tyr Xaa Xaa His Ala Xaa Xaa Xaa Xaa Xaa Xaa
35 40 45
Xaa Xaa Xaa Xaa Pro Xaa Leu Phe Tyr Lys Pro Val Thr Ser Leu Ile
50 55 60
Gly Pro Xaa Xaa Xaa Xaa Xaa Ile Pro Xaa Xaa Xaa Gln Pro Xaa Xaa
65 70 75 80
Xaa His Gln Ser Asp Tyr Glu Ala Glu Xaa Xaa Xaa Xaa Xaa Gly Xaa
85 90 95
Ala Ala Lys Xaa Xaa Xaa Glu Xaa Glu Ala Leu Xaa Tyr Val Leu Gly
100 105 110
Tyr Thr Xaa Xaa Asn Asp Xaa Ser Phe Arg Xaa Xaa Gln Xaa Ala Val
115 120 125
Ser Gln Trp Xaa Phe Ser Lys Xaa Phe
130 135
<210> 78
<211> 69
<212> PRT
<213> Искусственная последовательность
<220>
<223> Консенсуcная аминоксилотная последовательность 3
кофеилпируват-гидролаз
<220>
<221> MISC_FEATURE
<222> (3)..(65)
<223> X - любая аминокислота
<400> 78
Asp Gln Xaa Phe Xaa Xaa Xaa Lys Thr Xaa Xaa Xaa Leu Ser Gln Gly
1 5 10 15
Thr Thr Leu Xaa Xaa Gly Ser Ile Ile Xaa Thr Gly Thr Pro Xaa Gly
20 25 30
Val Gly Phe Val Xaa Xaa Pro Pro Leu Tyr Leu Lys Asp Gly Asp Xaa
35 40 45
Xaa Xaa Thr Trp Ile Xaa Xaa Gly Xaa Gly Xaa Leu Xaa Asn Xaa Val
50 55 60
Xaa Glu Glu Lys Thr
65
<210> 79
<211> 801
<212> DNA
<213> Neonothopanus nambi
<400> 79
atgcgcatta acattagcct ctcgtctctc ttcgaacgtc tctccaaact tagcagtcgc 60
agcatagcga ttacatgtgg agttgttctc gcctccgcaa tcgcctttcc catcatccgc 120
agagactacc agactttcct agaagtggga ccctcgtacg ctccgcagaa ctttagagga 180
tacatcatcg tctgtgtcct ctcgctattc cgccaagagc agaaagggct cgccatctat 240
gatcgtcttc ccgagaaacg caggtggttg gccgaccttc cctttcgtga aggaaccaga 300
cccagcatta ccagccatat cattcagcga cagcgcactc aactggtcga tcaggagttt 360
gccaccaggg agctcataga caaggtcatc cctcgcgtgc aagcacgaca caccgacaaa 420
acgttcctca gcacatcaaa gttcgagttt catgcgaagg ccatatttct cttgccttct 480
atcccaatca acgaccctct gaatatccct agccacgaca ctgtccgccg aacgaagcgc 540
gagattgcac atatgcatga ttatcatgat tgcacacttc atcttgctct cgctgcgcag 600
gatggaaagg aggtgctgaa gaaaggttgg ggacaacgac atcctttggc tggtcctgga 660
gttcctggtc caccaacgga atggactttt ctttatgcgc ctcgcaacga agaagaggct 720
cgagtagtgg agatgatcgt tgaggcttcc atagggtata tgacgaacga tcctgcagga 780
aagattgtag aaaacgccaa g 801
<210> 80
<211> 267
<212> PRT
<213> Neonothopanus nambi
<400> 80
Met Arg Ile Asn Ile Ser Leu Ser Ser Leu Phe Glu Arg Leu Ser Lys
1 5 10 15
Leu Ser Ser Arg Ser Ile Ala Ile Thr Cys Gly Val Val Leu Ala Ser
20 25 30
Ala Ile Ala Phe Pro Ile Ile Arg Arg Asp Tyr Gln Thr Phe Leu Glu
35 40 45
Val Gly Pro Ser Tyr Ala Pro Gln Asn Phe Arg Gly Tyr Ile Ile Val
50 55 60
Cys Val Leu Ser Leu Phe Arg Gln Glu Gln Lys Gly Leu Ala Ile Tyr
65 70 75 80
Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Ala Asp Leu Pro Phe Arg
85 90 95
Glu Gly Thr Arg Pro Ser Ile Thr Ser His Ile Ile Gln Arg Gln Arg
100 105 110
Thr Gln Leu Val Asp Gln Glu Phe Ala Thr Arg Glu Leu Ile Asp Lys
115 120 125
Val Ile Pro Arg Val Gln Ala Arg His Thr Asp Lys Thr Phe Leu Ser
130 135 140
Thr Ser Lys Phe Glu Phe His Ala Lys Ala Ile Phe Leu Leu Pro Ser
145 150 155 160
Ile Pro Ile Asn Asp Pro Leu Asn Ile Pro Ser His Asp Thr Val Arg
165 170 175
Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp Cys Thr
180 185 190
Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys Glu Val Leu Lys Lys
195 200 205
Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Val Pro Gly Pro
210 215 220
Pro Thr Glu Trp Thr Phe Leu Tyr Ala Pro Arg Asn Glu Glu Glu Ala
225 230 235 240
Arg Val Val Glu Met Ile Val Glu Ala Ser Ile Gly Tyr Met Thr Asn
245 250 255
Asp Pro Ala Gly Lys Ile Val Glu Asn Ala Lys
260 265
<210> 81
<211> 783
<212> DNA
<213> Omphalotus olearius
<400> 81
atgctcccag ctttcatcta caaaccaagg ctagtgatca cttgtgtatt cgttctggcc 60
tccgcactcg catttccctt catacgcaaa gattaccaga ctttcctgga ggtgggaccc 120
tcgtacgccc cgcagaacct ccaaggatac atcatcgtct gtgtactctc tctgttccgg 180
caagaacaga aagacgtagc gatttatgat cgccttcctg agaaaaggag gtggttagga 240
gacctcccgt ttcgcgaggg gccaagaccg agtatcacta gccatatcat ccagcgacag 300
cgcacccaat tggctgacgc cgagttcgct accaaagagc tgataggcaa aatcatccct 360
cgcgtccaag cccgacacac caacacaaca ttcctcagca catctaaatt cgaattccac 420
gcccaggcca tcttcctttt gccctctatc ccaatcaacg accctcaaaa cattccaagc 480
cacgataccg ttcgtcgcac gaaacgcgag atcgcgcata tgcatgatta tcacgactgt 540
acgttgcatc tcgcacttgc tgctcaagat gggaaggagg ttttagagaa aggatggggt 600
cagcgacatc ctcttgctgg acctggtgtt cctggcccgc cgacggagtg gacgtttctt 660
tatgcaccgc gcagcgaaga ggaggttcgg gttgtggaga tgattgttga ggcatcagtt 720
gtgtatatga cgaatgatcc tgcggataaa atcgtagaag ctactgtgca gggtactgaa 780
gaa 783
<210> 82
<211> 261
<212> PRT
<213> Omphalotus olearius
<400> 82
Met Leu Pro Ala Phe Ile Tyr Lys Pro Arg Leu Val Ile Thr Cys Val
1 5 10 15
Phe Val Leu Ala Ser Ala Leu Ala Phe Pro Phe Ile Arg Lys Asp Tyr
20 25 30
Gln Thr Phe Leu Glu Val Gly Pro Ser Tyr Ala Pro Gln Asn Leu Gln
35 40 45
Gly Tyr Ile Ile Val Cys Val Leu Ser Leu Phe Arg Gln Glu Gln Lys
50 55 60
Asp Val Ala Ile Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Gly
65 70 75 80
Asp Leu Pro Phe Arg Glu Gly Pro Arg Pro Ser Ile Thr Ser His Ile
85 90 95
Ile Gln Arg Gln Arg Thr Gln Leu Ala Asp Ala Glu Phe Ala Thr Lys
100 105 110
Glu Leu Ile Gly Lys Ile Ile Pro Arg Val Gln Ala Arg His Thr Asn
115 120 125
Thr Thr Phe Leu Ser Thr Ser Lys Phe Glu Phe His Ala Gln Ala Ile
130 135 140
Phe Leu Leu Pro Ser Ile Pro Ile Asn Asp Pro Gln Asn Ile Pro Ser
145 150 155 160
His Asp Thr Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp
165 170 175
Tyr His Asp Cys Thr Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys
180 185 190
Glu Val Leu Glu Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro
195 200 205
Gly Val Pro Gly Pro Pro Thr Glu Trp Thr Phe Leu Tyr Ala Pro Arg
210 215 220
Ser Glu Glu Glu Val Arg Val Val Glu Met Ile Val Glu Ala Ser Val
225 230 235 240
Val Tyr Met Thr Asn Asp Pro Ala Asp Lys Ile Val Glu Ala Thr Val
245 250 255
Gln Gly Thr Glu Glu
260
<210> 83
<211> 798
<212> DNA
<213> Armillaria gallica
<400> 83
atgtccttca tcgacagcat gaaacttgac ctcgtcggac acctctttgg catcaggaat 60
cgcggcttag ccgccgcttg ttgtgctcta gcagtcgcct ctactatcgc cttcccttac 120
attcgtaggg actaccagac atttttatct ggcggtccct cttacgctcc ccagaatatc 180
agaggatatt tcatcgtctg cgttctggcc ttgttccgtc aggagcaaaa gggccttgcg 240
atatatgatc gccttcccga gaagcgcagg tggctgcctg acttgcctcc tcgcaatggc 300
ccgcggccga tcacgaccag ccatataatc caaagacagc gcaaccaggc gccggacccc 360
aagttcgccc tcgaggaact caaggccacg gttattccac gggtgcaggc tcgccatact 420
gacctcaccc atctcagcct atccaaattc gagttccatg ctgaagcaat tttcctgctc 480
ccctctgtac ccatcgatga tccaaaaaat gttccaagtc acgacacggt gcgcaggacg 540
aaaagggaga tcgcgcatat gcacgactac catgacttca cgctgcatct tgcactggcc 600
gcccaagacg ggaaggaagt cgtgtcgaag ggatgggggc agcgacaccc cctagcaggc 660
cctggcgttc ctggtccacc tacggagtgg acatttattt atgcgccacg taacgaagag 720
gaactggcag tggtggaaat gattatcgag gcatcaatag gctatatgac caatgaccct 780
gctggagtag ttatcgca 798
<210> 84
<211> 266
<212> PRT
<213> Armillaria gallica
<400> 84
Met Ser Phe Ile Asp Ser Met Lys Leu Asp Leu Val Gly His Leu Phe
1 5 10 15
Gly Ile Arg Asn Arg Gly Leu Ala Ala Ala Cys Cys Ala Leu Ala Val
20 25 30
Ala Ser Thr Ile Ala Phe Pro Tyr Ile Arg Arg Asp Tyr Gln Thr Phe
35 40 45
Leu Ser Gly Gly Pro Ser Tyr Ala Pro Gln Asn Ile Arg Gly Tyr Phe
50 55 60
Ile Val Cys Val Leu Ala Leu Phe Arg Gln Glu Gln Lys Gly Leu Ala
65 70 75 80
Ile Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Pro Asp Leu Pro
85 90 95
Pro Arg Asn Gly Pro Arg Pro Ile Thr Thr Ser His Ile Ile Gln Arg
100 105 110
Gln Arg Asn Gln Ala Pro Asp Pro Lys Phe Ala Leu Glu Glu Leu Lys
115 120 125
Ala Thr Val Ile Pro Arg Val Gln Ala Arg His Thr Asp Leu Thr His
130 135 140
Leu Ser Leu Ser Lys Phe Glu Phe His Ala Glu Ala Ile Phe Leu Leu
145 150 155 160
Pro Ser Val Pro Ile Asp Asp Pro Lys Asn Val Pro Ser His Asp Thr
165 170 175
Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp
180 185 190
Phe Thr Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys Glu Val Val
195 200 205
Ser Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Val Pro
210 215 220
Gly Pro Pro Thr Glu Trp Thr Phe Ile Tyr Ala Pro Arg Asn Glu Glu
225 230 235 240
Glu Leu Ala Val Val Glu Met Ile Ile Glu Ala Ser Ile Gly Tyr Met
245 250 255
Thr Asn Asp Pro Ala Gly Val Val Ile Ala
260 265
<210> 85
<211> 798
<212> DNA
<213> Armillaria ostoyae
<400> 85
atgtccttca tcgacagcat gaaacttgac ttcgtcggac acctctttgg catcaggaat 60
cgcggcttag ccaccgcttg ttgtgctgtg gcagtcgctt ctgccatcgc cttcccttac 120
attcgtaggg actaccagac attcttatct ggcggtccct cttacgctcc ccagaacatc 180
aaaggatatc tcatcgtctg cgtcctggcc ttgttccgtc aggagcaaaa gggccttgcg 240
atatatgacc gccttcccga gaagcgcagg tggctacctg acttgcctcc tcgcaatggc 300
ccgcggccca tcacgaccag ccatataatc caaagacagc gcaaccaggc gccagactcc 360
aagttcgccc tcgaggaact caaggctacg gtcattccac gggtgcaggc tcgccacact 420
gacctcaccc atctcagcct atccaagttc gagttccatg ctgaagcaat cttcctgctc 480
ccctctgtac ccatcgatga tccaaaaaat gttccaagtc atgacacggt gcgcaggacg 540
aagagggaga tcgcgcatat gcacgactac catgacttta cgttgcatct tgcactggcc 600
gcccaagacg ggaaggaagt cgtggcgaag ggatgggggc agcgacaccc gctggcaggc 660
cctggcgttc ctggtccacc tacggagtgg acgtttattt atgcgccacg taacgaagag 720
gaactggcag tggtggaaat gattatcgag gcatcaatag gctatatgac caatgaccct 780
gctggaacag ttatcgta 798
<210> 86
<211> 266
<212> PRT
<213> Armillaria ostoyae
<400> 86
Met Ser Phe Ile Asp Ser Met Lys Leu Asp Phe Val Gly His Leu Phe
1 5 10 15
Gly Ile Arg Asn Arg Gly Leu Ala Thr Ala Cys Cys Ala Val Ala Val
20 25 30
Ala Ser Ala Ile Ala Phe Pro Tyr Ile Arg Arg Asp Tyr Gln Thr Phe
35 40 45
Leu Ser Gly Gly Pro Ser Tyr Ala Pro Gln Asn Ile Lys Gly Tyr Leu
50 55 60
Ile Val Cys Val Leu Ala Leu Phe Arg Gln Glu Gln Lys Gly Leu Ala
65 70 75 80
Ile Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Pro Asp Leu Pro
85 90 95
Pro Arg Asn Gly Pro Arg Pro Ile Thr Thr Ser His Ile Ile Gln Arg
100 105 110
Gln Arg Asn Gln Ala Pro Asp Ser Lys Phe Ala Leu Glu Glu Leu Lys
115 120 125
Ala Thr Val Ile Pro Arg Val Gln Ala Arg His Thr Asp Leu Thr His
130 135 140
Leu Ser Leu Ser Lys Phe Glu Phe His Ala Glu Ala Ile Phe Leu Leu
145 150 155 160
Pro Ser Val Pro Ile Asp Asp Pro Lys Asn Val Pro Ser His Asp Thr
165 170 175
Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp
180 185 190
Phe Thr Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys Glu Val Val
195 200 205
Ala Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Val Pro
210 215 220
Gly Pro Pro Thr Glu Trp Thr Phe Ile Tyr Ala Pro Arg Asn Glu Glu
225 230 235 240
Glu Leu Ala Val Val Glu Met Ile Ile Glu Ala Ser Ile Gly Tyr Met
245 250 255
Thr Asn Asp Pro Ala Gly Thr Val Ile Val
260 265
<210> 87
<211> 798
<212> DNA
<213> Armillaria mellea
<400> 87
atgtccttct tcgacagcgt gaaacttgac ctcgtcggac gcctctttgg catcaggaat 60
cgcggcttag ctgttacttg ttgtgctgtg gcagtcgcct ctatcatcgc gttcccttac 120
attcgtaggg actaccagac atttttatct gggggtccct cctacgctcc ccagaacatc 180
agaggatacc tcattgtctg cgtcctggcc ttgttccgtc aggagcaaaa aggccttgcg 240
atatacgacc gccttcccga gaagcgcagg tggctacctg acttgcctcc tcgcgatggc 300
ccacggccca tcacgaccag ccatataatc caaagacagc gcaaccaggc gccggacctc 360
aagttcgccc tcgaggaact caaggccacg gtcattccac gggtgcaggc tcgccacact 420
gacctcaccc atctcagcct atccaagttc gagttccatg ctgaagcaat cttcctgctc 480
ccctctgtac ccatcgatga tccaaagaat gtgccaagtc acgacacggt gcgcaggacg 540
aagagggaaa ttgcgcatat gcacgactac catgactaca cgctgcatct tgcgttggcc 600
gcccaagacg ggaaggaagt cgtatcaaag ggatgggggc agcgacaccc gctggcaggc 660
cctggcgttc ctggtccacc gacggagtgg acgtttattt atgcgccacg taacgaagag 720
gagctggcag tggtggaaat gattatcgag gcatcgatag gctatatgac caatgaccct 780
gcaggaaaaa ctatcgca 798
<210> 88
<211> 266
<212> PRT
<213> Armillaria mellea
<400> 88
Met Ser Phe Phe Asp Ser Val Lys Leu Asp Leu Val Gly Arg Leu Phe
1 5 10 15
Gly Ile Arg Asn Arg Gly Leu Ala Val Thr Cys Cys Ala Val Ala Val
20 25 30
Ala Ser Ile Ile Ala Phe Pro Tyr Ile Arg Arg Asp Tyr Gln Thr Phe
35 40 45
Leu Ser Gly Gly Pro Ser Tyr Ala Pro Gln Asn Ile Arg Gly Tyr Leu
50 55 60
Ile Val Cys Val Leu Ala Leu Phe Arg Gln Glu Gln Lys Gly Leu Ala
65 70 75 80
Ile Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Pro Asp Leu Pro
85 90 95
Pro Arg Asp Gly Pro Arg Pro Ile Thr Thr Ser His Ile Ile Gln Arg
100 105 110
Gln Arg Asn Gln Ala Pro Asp Leu Lys Phe Ala Leu Glu Glu Leu Lys
115 120 125
Ala Thr Val Ile Pro Arg Val Gln Ala Arg His Thr Asp Leu Thr His
130 135 140
Leu Ser Leu Ser Lys Phe Glu Phe His Ala Glu Ala Ile Phe Leu Leu
145 150 155 160
Pro Ser Val Pro Ile Asp Asp Pro Lys Asn Val Pro Ser His Asp Thr
165 170 175
Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp
180 185 190
Tyr Thr Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys Glu Val Val
195 200 205
Ser Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Val Pro
210 215 220
Gly Pro Pro Thr Glu Trp Thr Phe Ile Tyr Ala Pro Arg Asn Glu Glu
225 230 235 240
Glu Leu Ala Val Val Glu Met Ile Ile Glu Ala Ser Ile Gly Tyr Met
245 250 255
Thr Asn Asp Pro Ala Gly Lys Thr Ile Ala
260 265
<210> 89
<211> 798
<212> DNA
<213> Armillaria fuscipes
<400> 89
atgaccttct tggacagtat caaacttgac ctcgttgggc gcctctttgg catcaggaat 60
cacggcgtag ccgctgcctg ttgtgctgca gcagttgcct ctgccatcgt gttcccttat 120
attcgtaggg actaccagac atttctatct ggcggccctt cctacgctcc ccagaacatc 180
agaggataca tcattgtctg cgtcctagcc ttattccgcc aggagcaaaa aggccttgcg 240
atatatgacc gccttcccga gaagcgcagg tggttagctg acttgcctcc tcgcaatggc 300
ccacggccca tcacaaccag tcatataatt caaagacagc gcaaccaggc gccagacccc 360
aagttcgccc tcgaagaact caaggccaca gtcattccac gggtacaggc tcgccacact 420
gacctcaccc atctcagcct gtccaaattc gagtttcacg ctgaagcaat cttcctgctc 480
ccctctgtac ccatcgacga cccaaagaat atcccaagcc atgacacagt gcgcaggacg 540
aaaagggaga tcgcgcatat gcacgactat catgatttca cgctgcatct tgcactggct 600
gcccaagacg ggaaggaagt cgtatcaaag ggatgggggc agcggcaccc gctggcaggc 660
cctggtgtcc ctggtccacc aacggagtgg acgtttattt acgcgccacg gaacgaagag 720
gagctggcag tagtggaaat gataattgag gcatcaatag gctacatgac caatgaccct 780
gcaggatcag ttattcca 798
<210> 90
<211> 266
<212> PRT
<213> Armillaria fuscipes
<400> 90
Met Thr Phe Leu Asp Ser Ile Lys Leu Asp Leu Val Gly Arg Leu Phe
1 5 10 15
Gly Ile Arg Asn His Gly Val Ala Ala Ala Cys Cys Ala Ala Ala Val
20 25 30
Ala Ser Ala Ile Val Phe Pro Tyr Ile Arg Arg Asp Tyr Gln Thr Phe
35 40 45
Leu Ser Gly Gly Pro Ser Tyr Ala Pro Gln Asn Ile Arg Gly Tyr Ile
50 55 60
Ile Val Cys Val Leu Ala Leu Phe Arg Gln Glu Gln Lys Gly Leu Ala
65 70 75 80
Ile Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Ala Asp Leu Pro
85 90 95
Pro Arg Asn Gly Pro Arg Pro Ile Thr Thr Ser His Ile Ile Gln Arg
100 105 110
Gln Arg Asn Gln Ala Pro Asp Pro Lys Phe Ala Leu Glu Glu Leu Lys
115 120 125
Ala Thr Val Ile Pro Arg Val Gln Ala Arg His Thr Asp Leu Thr His
130 135 140
Leu Ser Leu Ser Lys Phe Glu Phe His Ala Glu Ala Ile Phe Leu Leu
145 150 155 160
Pro Ser Val Pro Ile Asp Asp Pro Lys Asn Ile Pro Ser His Asp Thr
165 170 175
Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp
180 185 190
Phe Thr Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys Glu Val Val
195 200 205
Ser Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Val Pro
210 215 220
Gly Pro Pro Thr Glu Trp Thr Phe Ile Tyr Ala Pro Arg Asn Glu Glu
225 230 235 240
Glu Leu Ala Val Val Glu Met Ile Ile Glu Ala Ser Ile Gly Tyr Met
245 250 255
Thr Asn Asp Pro Ala Gly Ser Val Ile Pro
260 265
<210> 91
<211> 738
<212> DNA
<213> Mycena citricolor
<400> 91
atggcttatc agctcacttg gattcagact ctcgtgctgg gtgcccttgt ggcaatggca 60
gtagcgttcc ccttcatcaa gaaagactac gagacgttcc tgaagggcgg cccctcctat 120
gcgccccaaa acgttcgcgg atacatcatc gtgctcgtgc tcgcgctctt ccgccaagag 180
cagctcgggc tggagatcta cgaccgcatg cccgagaaac gtcgctggct cgcgaatctc 240
cctcagcgcg agggcccccg ccccaagacc acaagtcaca tcatccagcg gcagctcagc 300
cagcacacgg accccgcatt cggcgccgcg tacctcaaag acaccgtcat tccgcgcgtc 360
caggcgcggc acgcagccaa cacgcacatc gcgcgctcga cgttcgagtt ccacgccgcc 420
gcgatcttcc tgaacgcgga cgtgccgctg cccgagggcc tgcccgcaag cgagacggtg 480
cggcggacca agggcgagat cgcgcacatg cacgactacc acgacttcac gctgcacctc 540
gcgctcgcgg cggcggatgg gaaggaggtg gtcggcaagg gctgggggca gcgccatccg 600
ctggcgggac ccggtgtgcc gggtccgccg aacgagtgga cctttgtgta tgcgccgagg 660
aatgaagagg agatgggcgt ggtcgagcag atcgtagagg cggcgattgg gtacatgtcg 720
aacgtgcctg cgctggaa 738
<210> 92
<211> 246
<212> PRT
<213> Mycena citricolor
<400> 92
Met Ala Tyr Gln Leu Thr Trp Ile Gln Thr Leu Val Leu Gly Ala Leu
1 5 10 15
Val Ala Met Ala Val Ala Phe Pro Phe Ile Lys Lys Asp Tyr Glu Thr
20 25 30
Phe Leu Lys Gly Gly Pro Ser Tyr Ala Pro Gln Asn Val Arg Gly Tyr
35 40 45
Ile Ile Val Leu Val Leu Ala Leu Phe Arg Gln Glu Gln Leu Gly Leu
50 55 60
Glu Ile Tyr Asp Arg Met Pro Glu Lys Arg Arg Trp Leu Ala Asn Leu
65 70 75 80
Pro Gln Arg Glu Gly Pro Arg Pro Lys Thr Thr Ser His Ile Ile Gln
85 90 95
Arg Gln Leu Ser Gln His Thr Asp Pro Ala Phe Gly Ala Ala Tyr Leu
100 105 110
Lys Asp Thr Val Ile Pro Arg Val Gln Ala Arg His Ala Ala Asn Thr
115 120 125
His Ile Ala Arg Ser Thr Phe Glu Phe His Ala Ala Ala Ile Phe Leu
130 135 140
Asn Ala Asp Val Pro Leu Pro Glu Gly Leu Pro Ala Ser Glu Thr Val
145 150 155 160
Arg Arg Thr Lys Gly Glu Ile Ala His Met His Asp Tyr His Asp Phe
165 170 175
Thr Leu His Leu Ala Leu Ala Ala Ala Asp Gly Lys Glu Val Val Gly
180 185 190
Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Val Pro Gly
195 200 205
Pro Pro Asn Glu Trp Thr Phe Val Tyr Ala Pro Arg Asn Glu Glu Glu
210 215 220
Met Gly Val Val Glu Gln Ile Val Glu Ala Ala Ile Gly Tyr Met Ser
225 230 235 240
Asn Val Pro Ala Leu Glu
245
<210> 93
<211> 747
<212> DNA
<213> Panellus stipticus
<400> 93
atgaacatca acctgaaagc tctgatcgga gtctgtgccg tgctcatcac cgctgcagtg 60
ttccccttcg ttcgtaaaga ctatcacacc tttcttgaag gtggaccatc ctacgcgccg 120
cagaatttgc aaggctatat catcgtgttg gtgctctcac tctttcgagg ggaggagacg 180
ggattggaaa tatacgaccg cttgcccgaa aaacgccgct ggctcgagga gctgcctgtt 240
cgcgaaggcc cgcgcccaaa gacaaccagc cacatcattc agagacaatt gaatcagcac 300
gttgacccgg acttcggaat gaactctttg aaaggctccg tcatccggcg ccttcaatcc 360
cgccaccagg acataactca actcgcactc tcgaaattcg aattccacgc cgaggccata 420
tttctgcgcc ccgatatcgc gatcaacgat cccaaacacg tcccgagcca cgacacggtg 480
cgccgcacaa agcgcgagat agctcacatg cacgactacc atgattacac gtgtcatttg 540
gcgctcgcag cgcaggatgg gaagcaagtg attgcaaaag ggtggggcca gagacatccg 600
ctcgcgggac cgggcatgcc ggggccgccg acggagtgga catttttgta tgcgccgagg 660
aatgaggcgg aggttcaagt gttggagacg attatcgaag cgtcaatcgg gtacatgtcg 720
aacgcaccag ccttgggtgg gagcgag 747
<210> 94
<211> 249
<212> PRT
<213> Panellus stipticus
<400> 94
Met Asn Ile Asn Leu Lys Ala Leu Ile Gly Val Cys Ala Val Leu Ile
1 5 10 15
Thr Ala Ala Val Phe Pro Phe Val Arg Lys Asp Tyr His Thr Phe Leu
20 25 30
Glu Gly Gly Pro Ser Tyr Ala Pro Gln Asn Leu Gln Gly Tyr Ile Ile
35 40 45
Val Leu Val Leu Ser Leu Phe Arg Gly Glu Glu Thr Gly Leu Glu Ile
50 55 60
Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Glu Glu Leu Pro Val
65 70 75 80
Arg Glu Gly Pro Arg Pro Lys Thr Thr Ser His Ile Ile Gln Arg Gln
85 90 95
Leu Asn Gln His Val Asp Pro Asp Phe Gly Met Asn Ser Leu Lys Gly
100 105 110
Ser Val Ile Arg Arg Leu Gln Ser Arg His Gln Asp Ile Thr Gln Leu
115 120 125
Ala Leu Ser Lys Phe Glu Phe His Ala Glu Ala Ile Phe Leu Arg Pro
130 135 140
Asp Ile Ala Ile Asn Asp Pro Lys His Val Pro Ser His Asp Thr Val
145 150 155 160
Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp Tyr
165 170 175
Thr Cys His Leu Ala Leu Ala Ala Gln Asp Gly Lys Gln Val Ile Ala
180 185 190
Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Met Pro Gly
195 200 205
Pro Pro Thr Glu Trp Thr Phe Leu Tyr Ala Pro Arg Asn Glu Ala Glu
210 215 220
Val Gln Val Leu Glu Thr Ile Ile Glu Ala Ser Ile Gly Tyr Met Ser
225 230 235 240
Asn Ala Pro Ala Leu Gly Gly Ser Glu
245
<210> 95
<211> 792
<212> DNA
<213> Neonothopanus gardneri
<400> 95
atgaatcttc cgtctttcgt ccaacgtctc tccacagcaa gcagtcgcag tatagcgatt 60
acttgcgtag ttgtccttgc ctctgcaatc gcctttccct tcatccgcag agactaccag 120
accttcctgg aagtgggacc ctcgtacgcc ccgcagaact ttagaggata catcatcgtc 180
tgtgtcctct cgttgttccg ccaagaacaa aaaggactcg aaatctacga tcggctccca 240
gagaaacgaa ggtggttgtc cgaccttccc tttcgtgacg ggcccagacc cagcatcaca 300
agccatatca ttcaacgaca gcgtacccaa ctagttgatc cggacttcgc tacccaggag 360
ctcataggca aagtcatccc tcgtgtgcaa gcacgacaca ccgacaaaac attcctcagc 420
acctccaaat tcgaatttca cgcaaaagcc atattcctcc tgccttccat cccaatcaac 480
gaccctctga acgttccaag ccacgacact gtccgacgaa cgaagcgcga gatcgcgcat 540
atgcatgatt atcatgattg cactcttcac atcgctctcg ctgctcagga cggaaaggag 600
gttttgaaga agggatgggg gcaacgacac ccactcgctg gacctggagt gcccggccca 660
ccgacggagt ggacgtttct ctatgcgcct cgaaacgaag aagaggttcg agttgtggag 720
atgattattg aggctgccat aggttacatg acgaatgatc cggcaggaaa agttgtagaa 780
gccactggaa ag 792
<210> 96
<211> 264
<212> PRT
<213> Neonothopanus gardneri
<400> 96
Met Asn Leu Pro Ser Phe Val Gln Arg Leu Ser Thr Ala Ser Ser Arg
1 5 10 15
Ser Ile Ala Ile Thr Cys Val Val Val Leu Ala Ser Ala Ile Ala Phe
20 25 30
Pro Phe Ile Arg Arg Asp Tyr Gln Thr Phe Leu Glu Val Gly Pro Ser
35 40 45
Tyr Ala Pro Gln Asn Phe Arg Gly Tyr Ile Ile Val Cys Val Leu Ser
50 55 60
Leu Phe Arg Gln Glu Gln Lys Gly Leu Glu Ile Tyr Asp Arg Leu Pro
65 70 75 80
Glu Lys Arg Arg Trp Leu Ser Asp Leu Pro Phe Arg Asp Gly Pro Arg
85 90 95
Pro Ser Ile Thr Ser His Ile Ile Gln Arg Gln Arg Thr Gln Leu Val
100 105 110
Asp Pro Asp Phe Ala Thr Gln Glu Leu Ile Gly Lys Val Ile Pro Arg
115 120 125
Val Gln Ala Arg His Thr Asp Lys Thr Phe Leu Ser Thr Ser Lys Phe
130 135 140
Glu Phe His Ala Lys Ala Ile Phe Leu Leu Pro Ser Ile Pro Ile Asn
145 150 155 160
Asp Pro Leu Asn Val Pro Ser His Asp Thr Val Arg Arg Thr Lys Arg
165 170 175
Glu Ile Ala His Met His Asp Tyr His Asp Cys Thr Leu His Ile Ala
180 185 190
Leu Ala Ala Gln Asp Gly Lys Glu Val Leu Lys Lys Gly Trp Gly Gln
195 200 205
Arg His Pro Leu Ala Gly Pro Gly Val Pro Gly Pro Pro Thr Glu Trp
210 215 220
Thr Phe Leu Tyr Ala Pro Arg Asn Glu Glu Glu Val Arg Val Val Glu
225 230 235 240
Met Ile Ile Glu Ala Ala Ile Gly Tyr Met Thr Asn Asp Pro Ala Gly
245 250 255
Lys Val Val Glu Ala Thr Gly Lys
260
<210> 97
<211> 753
<212> DNA
<213> Mycena chlorophos
<400> 97
atggtccaac tcacccgaac ctccggattc atcgccgctg cggccattgt tgctgccatc 60
gccttcccgt tcattcgtcg agactaccag acgttccttc gtggtgggcc gtcctatgcc 120
ccacagaaca tccgcggcta tatcatcgtc ctggttctgt ccctcttccg cggcgaggag 180
aagggtcttg caatctacga gccccttcct gagaagcgca catggctgcc ggagcttccg 240
cggcgcgcgg gagaccggcc caagacgacg agccacatca tccaacggca gctcgaccag 300
taccccgacc cggactttgt cctcaaagcc ctgaaagcga cggtcatccc gcgtgtccaa 360
gcccggcaca cagacaagac tcacctcgcg ctgtccaagt tcgagttcca tgctgaggcc 420
atcttcgtgc gcccggaaat cgccatcgac gacccgaagc atatccccag ccacgacacg 480
gtgcgacgga cgaagcgcga gattgcgcac atgcacgact atcacgactg cacgctgcat 540
ttggcgctag cggcgcagga cgcgaagcag gtgctgcaga agggctgggg ccagcgccat 600
ccgctggcag ggcctgggat gcccgggccg cccacggagt ggacgttctt gtatgccccg 660
aggaccgagg aggaagtgaa ggttgtggag accattgtcg aggcctctat cgcgtacatg 720
acgaacgcgg agaagccggt cgagctggtg cag 753
<210> 98
<211> 251
<212> PRT
<213> Mycena chlorophos
<400> 98
Met Val Gln Leu Thr Arg Thr Ser Gly Phe Ile Ala Ala Ala Ala Ile
1 5 10 15
Val Ala Ala Ile Ala Phe Pro Phe Ile Arg Arg Asp Tyr Gln Thr Phe
20 25 30
Leu Arg Gly Gly Pro Ser Tyr Ala Pro Gln Asn Ile Arg Gly Tyr Ile
35 40 45
Ile Val Leu Val Leu Ser Leu Phe Arg Gly Glu Glu Lys Gly Leu Ala
50 55 60
Ile Tyr Glu Pro Leu Pro Glu Lys Arg Thr Trp Leu Pro Glu Leu Pro
65 70 75 80
Arg Arg Ala Gly Asp Arg Pro Lys Thr Thr Ser His Ile Ile Gln Arg
85 90 95
Gln Leu Asp Gln Tyr Pro Asp Pro Asp Phe Val Leu Lys Ala Leu Lys
100 105 110
Ala Thr Val Ile Pro Arg Val Gln Ala Arg His Thr Asp Lys Thr His
115 120 125
Leu Ala Leu Ser Lys Phe Glu Phe His Ala Glu Ala Ile Phe Val Arg
130 135 140
Pro Glu Ile Ala Ile Asp Asp Pro Lys His Ile Pro Ser His Asp Thr
145 150 155 160
Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp Tyr His Asp
165 170 175
Cys Thr Leu His Leu Ala Leu Ala Ala Gln Asp Ala Lys Gln Val Leu
180 185 190
Gln Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro Gly Met Pro
195 200 205
Gly Pro Pro Thr Glu Trp Thr Phe Leu Tyr Ala Pro Arg Thr Glu Glu
210 215 220
Glu Val Lys Val Val Glu Thr Ile Val Glu Ala Ser Ile Ala Tyr Met
225 230 235 240
Thr Asn Ala Glu Lys Pro Val Glu Leu Val Gln
245 250
<210> 99
<211> 801
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в млекопитающих
(гуманизаированная) нуклеиновая кислота, кодирующая белок SEQ ID
No:80
<400> 99
atgcgcatta acatctccct ttcatctctt ttcgagcgat tgagcaaact gagttccagg 60
agtattgcaa tcacttgtgg ggttgtcctc gcgagcgcca tcgcattccc catcatccgg 120
agagattatc agacgtttct tgaggtgggc cctagctatg caccacagaa cttccgagga 180
tatatcatcg tgtgtgtact gtcactgttt aggcaagaac aaaagggatt ggctatctat 240
gataggttgc ctgagaaacg gcggtggctc gctgatctcc catttagaga ggggacacga 300
ccgagcatca cttcacacat catacaaaga cagcgaacgc agctcgttga ccaagagttc 360
gcaactaggg aactgattga taaggtgata cccagagtac aggcgcgaca caccgataaa 420
acttttcttt ccacctctaa attcgagttc catgccaaag ctattttctt gttgccttcc 480
ataccgatta atgatcctct gaatattcca tcccacgaca cagttcgacg gacgaaacgc 540
gaaattgcgc acatgcacga ctatcacgat tgcactttgc acctggcact ggctgctcaa 600
gacggaaaag aagttctgaa aaagggttgg gggcaaagac atccgctggc gggacccggt 660
gtacctgggc cgcctacgga atggacattt ttgtacgcac cgaggaacga agaggaggcc 720
agggtcgttg agatgattgt tgaggctagt attgggtaca tgacgaatga tccggctggt 780
aaaattgttg aaaatgcaaa g 801
<210> 100
<211> 1266
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в млекопитающих
(гуманизаированная) нуклеиновая кислота, кодирующая белок SEQ ID
No:2
<400> 100
atggcgtcat tcgagaacag tcttagcgtg ctgatcgtcg gcgctgggct cggcggtctt 60
gctgcggcaa tcgccctcag gcgacaagga cacgttgtta aaatctatga cagctcatca 120
tttaaggcag agttgggcgc aggcctcgcg gtccccccaa acactttgag atcactgcaa 180
caactgggtt gtaatactga gaaccttaac ggcgtggata acctctgctt cactgcaatg 240
ggttacgatg gcagtgtggg tatgatgaac aatatgaccg attataggga ggcgtacggc 300
actagctgga taatggtcca tcgggttgat ctccacaatg agcttatgcg cgtagcgttg 360
gatccgggcg gattgggacc cccagctacc ttgcacttga atcaccgcgt gactttttgt 420
gatgtcgacg catgcacagt aaccttcacc aatgggacga ctcagtcagc ggatctcatc 480
gtcggcgccg acggtatacg atccactatc cgcagattcg tcctggagga agatgtcaca 540
gttccggcat ccggaatcgt tggtttccgc tggctcgtcc aggctgatgc tttggatcct 600
taccctgaac ttgactggat tgttaaaaag ccccctctcg gcgctaggtt gataagtacg 660
cctcaaaacc cgcagtctgg ggtaggtctc gcggatcgca gaacgatcat tatatacgcg 720
tgtcgaggag gtactatggt aaacgtactt gccgtccatg acgatgagag ggatcagaat 780
acggcagatt ggtccgtgcc agctagcaag gatgatcttt tcagagtttt tcacgactat 840
catcctcgat ttcggcggct gttggagttg gcgcaagaca tcaatctgtg gcagatgcgg 900
gtggtccccg ttctgaagaa atgggtgaac aaaagagtct gtctcttggg ggatgcagcg 960
catgcgtccc tccctacctt ggggcagggt ttcggcatgg ggttggagga cgccgtagcc 1020
cttgggactt tgcttccaaa ggggacgaca gcatcccaaa tagaaacaag acttgccgta 1080
tatgagcagc tccgaaaaga tcgcgccgag ttcgtcgcgg ctgagtccta cgaagaacaa 1140
tatgtaccag aaatgagggg actttacctg cgatccaaag aattgcgcga ccgggtaatg 1200
ggctatgaca taaaggtgga gtccgaaaag gtcttggaga cactgttgcg gtcaagcaat 1260
tccgcc 1266
<210> 101
<211> 2112
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеиновая кислота. кодирующая белок слияния
гиспидин-гидроксилазы и люциферазы
<400> 101
atggcatcgt ttgagaattc tctaagcgtt ttgattgtcg gggccggact tggtgggctt 60
gctgctgcca tcgcgctgcg tcgccaaggg catgtcgtga aaatatacga ctcctctagc 120
ttcaaagccg aacttggtgc gggactcgct gtgccgccta acaccttgcg cagtctacag 180
caacttggtt gcaataccga gaacctcaat ggtgtggata atctttgctt cactgcgatg 240
gggtatgacg ggagtgtagg gatgatgaac aacatgactg actatcgaga ggcatacggt 300
acttcttgga tcatggtcca ccgcgttgac ttgcataacg agctgatgcg cgtagcactt 360
gatccaggtg ggctcggacc tcctgcgaca ctccatctta atcatcgtgt cacattctgc 420
gatgtcgacg cttgcaccgt gacattcacc aacgggacca ctcaatcagc tgatctcatc 480
gttggtgcag acggtatacg ctctaccatt cggcggtttg tcttagaaga agacgtgact 540
gtgcctgcgt caggaatcgt cgggtttcga tggcttgtac aagctgacgc gctggaccca 600
tatcctgaac tcgactggat tgttaaaaag cctcctctag gcgcgcgact gatctccact 660
cctcagaatc cacagtctgg tgttggcttg gctgacaggc gcactatcat catctacgca 720
tgtcgtggcg gcaccatggt caatgtcctt gcagtgcatg atgacgaacg tgaccagaac 780
accgcagatt ggagtgtacc ggcttccaaa gacgatctat ttcgtgtttt ccacgattac 840
catccacgct ttcggcggct tttagagctt gcgcaggata ttaatctctg gcaaatgcgt 900
gttgtacctg ttttgaaaaa atgggttaac aagcgggttt gcttgttagg agatgctgcg 960
cacgcttctt taccgacgtt gggtcaaggt tttggtatgg gcctggaaga tgccgtagca 1020
cttggtacac tccttccaaa gggtaccact gcatctcaga tcgagactcg acttgcggtg 1080
tacgaacagc tacgtaagga tcgtgcggaa tttgttgcgg ctgaatcata tgaagagcaa 1140
tatgttcctg aaatgcgggg actttatctg aggtcaaagg aactgcgtga tagagtcatg 1200
ggttatgata tcaaagtgga gagcgagaag gttctcgaga cgctcctaag aagttctaat 1260
tctgcctccg gaactggggg caacgcctct gacggtggtg ggtctggtgg tatgcgcatt 1320
aacattagcc tctcgtctct cttcgaacgt ctctccaaac ttagcagtcg cagcatagcg 1380
attacatgtg gagttgttct cgcctccgca atcgcctttc ccatcatccg cagagactac 1440
cagactttcc tagaagtggg accctcgtac gctccgcaga actttagagg atacatcatc 1500
gtctgtgtcc tctcgctatt ccgccaagag cagaaagggc tcgccatcta tgatcgtctt 1560
cccgagaaac gcaggtggtt ggccgacctt ccctttcgtg aaggaaccag acccagcatt 1620
accagccata tcattcagcg acagcgcact caactggtcg atcaggagtt tgccaccagg 1680
gagctcatag acaaggtcat ccctcgcgtg caagcacgac acaccgacaa aacgttcctc 1740
agcacatcaa agttcgagtt tcatgcgaag gccatatttc tcttgccttc tatcccaatc 1800
aacgaccctc tgaatatccc tagccacgac actgtccgcc gaacgaagcg cgagattgca 1860
catatgcatg attatcatga ttgcacactt catcttgctc tcgctgcgca ggatggaaag 1920
gaggtgctga agaaaggttg gggacaacga catcctttgg ctggtcctgg agttcctggt 1980
ccaccaacgg aatggacttt tctttatgcg cctcgcaacg aagaagaggc tcgagtagtg 2040
gagatgatcg ttgaggcttc catagggtat atgacgaacg atcctgcagg aaagattgta 2100
gaaaacgcca ag 2112
<210> 102
<211> 704
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность белка слияния
гиспидин-гидроксилазы и люциферазы
<400> 102
Met Ala Ser Phe Glu Asn Ser Leu Ser Val Leu Ile Val Gly Ala Gly
1 5 10 15
Leu Gly Gly Leu Ala Ala Ala Ile Ala Leu Arg Arg Gln Gly His Val
20 25 30
Val Lys Ile Tyr Asp Ser Ser Ser Phe Lys Ala Glu Leu Gly Ala Gly
35 40 45
Leu Ala Val Pro Pro Asn Thr Leu Arg Ser Leu Gln Gln Leu Gly Cys
50 55 60
Asn Thr Glu Asn Leu Asn Gly Val Asp Asn Leu Cys Phe Thr Ala Met
65 70 75 80
Gly Tyr Asp Gly Ser Val Gly Met Met Asn Asn Met Thr Asp Tyr Arg
85 90 95
Glu Ala Tyr Gly Thr Ser Trp Ile Met Val His Arg Val Asp Leu His
100 105 110
Asn Glu Leu Met Arg Val Ala Leu Asp Pro Gly Gly Leu Gly Pro Pro
115 120 125
Ala Thr Leu His Leu Asn His Arg Val Thr Phe Cys Asp Val Asp Ala
130 135 140
Cys Thr Val Thr Phe Thr Asn Gly Thr Thr Gln Ser Ala Asp Leu Ile
145 150 155 160
Val Gly Ala Asp Gly Ile Arg Ser Thr Ile Arg Arg Phe Val Leu Glu
165 170 175
Glu Asp Val Thr Val Pro Ala Ser Gly Ile Val Gly Phe Arg Trp Leu
180 185 190
Val Gln Ala Asp Ala Leu Asp Pro Tyr Pro Glu Leu Asp Trp Ile Val
195 200 205
Lys Lys Pro Pro Leu Gly Ala Arg Leu Ile Ser Thr Pro Gln Asn Pro
210 215 220
Gln Ser Gly Val Gly Leu Ala Asp Arg Arg Thr Ile Ile Ile Tyr Ala
225 230 235 240
Cys Arg Gly Gly Thr Met Val Asn Val Leu Ala Val His Asp Asp Glu
245 250 255
Arg Asp Gln Asn Thr Ala Asp Trp Ser Val Pro Ala Ser Lys Asp Asp
260 265 270
Leu Phe Arg Val Phe His Asp Tyr His Pro Arg Phe Arg Arg Leu Leu
275 280 285
Glu Leu Ala Gln Asp Ile Asn Leu Trp Gln Met Arg Val Val Pro Val
290 295 300
Leu Lys Lys Trp Val Asn Lys Arg Val Cys Leu Leu Gly Asp Ala Ala
305 310 315 320
His Ala Ser Leu Pro Thr Leu Gly Gln Gly Phe Gly Met Gly Leu Glu
325 330 335
Asp Ala Val Ala Leu Gly Thr Leu Leu Pro Lys Gly Thr Thr Ala Ser
340 345 350
Gln Ile Glu Thr Arg Leu Ala Val Tyr Glu Gln Leu Arg Lys Asp Arg
355 360 365
Ala Glu Phe Val Ala Ala Glu Ser Tyr Glu Glu Gln Tyr Val Pro Glu
370 375 380
Met Arg Gly Leu Tyr Leu Arg Ser Lys Glu Leu Arg Asp Arg Val Met
385 390 395 400
Gly Tyr Asp Ile Lys Val Glu Ser Glu Lys Val Leu Glu Thr Leu Leu
405 410 415
Arg Ser Ser Asn Ser Ala Ser Gly Thr Gly Gly Asn Ala Ser Asp Gly
420 425 430
Gly Gly Ser Gly Gly Met Arg Ile Asn Ile Ser Leu Ser Ser Leu Phe
435 440 445
Glu Arg Leu Ser Lys Leu Ser Ser Arg Ser Ile Ala Ile Thr Cys Gly
450 455 460
Val Val Leu Ala Ser Ala Ile Ala Phe Pro Ile Ile Arg Arg Asp Tyr
465 470 475 480
Gln Thr Phe Leu Glu Val Gly Pro Ser Tyr Ala Pro Gln Asn Phe Arg
485 490 495
Gly Tyr Ile Ile Val Cys Val Leu Ser Leu Phe Arg Gln Glu Gln Lys
500 505 510
Gly Leu Ala Ile Tyr Asp Arg Leu Pro Glu Lys Arg Arg Trp Leu Ala
515 520 525
Asp Leu Pro Phe Arg Glu Gly Thr Arg Pro Ser Ile Thr Ser His Ile
530 535 540
Ile Gln Arg Gln Arg Thr Gln Leu Val Asp Gln Glu Phe Ala Thr Arg
545 550 555 560
Glu Leu Ile Asp Lys Val Ile Pro Arg Val Gln Ala Arg His Thr Asp
565 570 575
Lys Thr Phe Leu Ser Thr Ser Lys Phe Glu Phe His Ala Lys Ala Ile
580 585 590
Phe Leu Leu Pro Ser Ile Pro Ile Asn Asp Pro Leu Asn Ile Pro Ser
595 600 605
His Asp Thr Val Arg Arg Thr Lys Arg Glu Ile Ala His Met His Asp
610 615 620
Tyr His Asp Cys Thr Leu His Leu Ala Leu Ala Ala Gln Asp Gly Lys
625 630 635 640
Glu Val Leu Lys Lys Gly Trp Gly Gln Arg His Pro Leu Ala Gly Pro
645 650 655
Gly Val Pro Gly Pro Pro Thr Glu Trp Thr Phe Leu Tyr Ala Pro Arg
660 665 670
Asn Glu Glu Glu Ala Arg Val Val Glu Met Ile Val Glu Ala Ser Ile
675 680 685
Gly Tyr Met Thr Asn Asp Pro Ala Gly Lys Ile Val Glu Asn Ala Lys
690 695 700
<210> 103
<211> 1266
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в растениях нуклеиновая кислота,
кодирующая белок SEQ ID No:2
<400> 103
atggcatctt ttgagaattc tctgagcgtt ttgattgtcg gggccggact tggtgggctt 60
gctgctgcca tcgccctgcg tcgacaaggg catgtcgtga aaatatacga ctcctctagc 120
ttcaaagccg aacttggtgc tggactcgct gtgccgccta acaccttgcg tagtctccag 180
caacttggtt gcaataccga gaacctcaat ggtgtggata atctttgctt cactgctatg 240
gggtatgacg ggagtgtagg gatgatgaac aacatgactg actatcgaga ggcatacggt 300
acttcttgga tcatggtcca cagagttgac ttgcataacg agctgatgag ggtagcactt 360
gatccaggtg ggctcggacc tcctgcaaca ctccatctta atcatcgtgt cacattctgc 420
gatgtcgacg cttgcaccgt gacattcacc aacgggacca ctcaatcagc tgatctcatc 480
gttggtgcag acggtataag atctaccatt cgaaggtttg tcctggaaga agacgtgact 540
gtgcctgcat caggaatcgt cgggtttcga tggcttgtac aagctgacgc tctggaccca 600
tatcctgaac tcgactggat tgttaaaaag cctcctcttg gcgcacgact gatctccact 660
cctcagaatc cacagtctgg tgttggcttg gctgacagga ggactatcat catctacgca 720
tgtcgtggcg gcaccatggt caatgtcctt gcagtgcatg atgacgaacg tgaccagaac 780
accgcagatt ggagtgtacc ggcttccaaa gacgatctct ttcgtgtttt ccacgattac 840
catccacgat ttaggaggct tctcgagctt gctcaggata ttaatctctg gcaaatgcgt 900
gttgtacctg ttttgaaaaa atgggttaac aagagggttt gcttgctcgg agatgctgca 960
cacgcttctc tgccgacgtt gggtcaaggt tttggtatgg gtctggaaga tgccgtagca 1020
cttggtacac tccttccaaa gggtaccact gcatctcaga tcgagactcg acttgctgtg 1080
tacgaacagt tgcgtaagga tcgtgccgaa tttgttgccg ctgaatcata tgaagagcaa 1140
tatgttcctg aaatgcgagg actttatctg aggtcaaagg aactgcgtga tagagtcatg 1200
ggttatgata tcaaagtgga gagcgagaag gttctcgaga cgctccttag aagttctaat 1260
tctgcc 1266
<210> 104
<211> 1032
<212> DNA
<213> Aspergillus nidulans
<400> 104
atggtgcagg acacgtcatc tgcttctact tcccccattt tgacacgttg gtacatcgac 60
acaagaccct taacagcatc cacggcagca cttcctcttc tggaaacgtt gcagcctgca 120
gatcagatta gtgtacagaa gtattatcat ttaaaggata aacatatgag tcttgcttct 180
aacttattga agtatctgtt tgttcatcgt aattgtcgta ttccctggag ttctatcgtg 240
atctcccgta cacctgatcc tcaccgtcgt ccatgctaca ttcctccctc aggctctcag 300
gaagattcct tcaaagacgg atacactggt atcaatgttg agttcaatgt atcacaccaa 360
gccagtatgg tcgccattgc tggaaccgca tttactccca attctggtgg cgattctaaa 420
ctgaagcctg aggtgggaat cgacatcaca tgtgtaaacg agcgtcaggg ccgtaacggt 480
gaggagcgtt cattggaatc tcttcgtcaa tatatcgaca tcttctctga agtattctcc 540
acggctgaga tggcaaacat ccgtcgtctt gatggcgtta gtagttcttc tttaagtgct 600
gatcgtcttg ttgactatgg ttaccgtctt ttttatacat actgggccct gaaggaagcc 660
tatatcaaga tgactggtga agcattgctt gcaccatggt tacgtgagct ggagttctcc 720
aatgttgttg cccctgccgc tgttgctgaa tccggtgact ctgccggcga cttcggtgag 780
ccatacacag gagtccgtac gactttatat aaaaatttag ttgaggatgt gcgtatcgag 840
gtagccgccc ttggtggcga ttatcttttt gcaaccgcag ctcgtggagg aggaattgga 900
gccagttcaa ggcccggagg cggccctgat ggtagtggta tccgttcaca ggacccttgg 960
cgtccattta agaaacttga tatcgagcgt gacattcagc catgtgcaac aggtgtatgc 1020
aactgcctta gt 1032
<210> 105
<211> 344
<212> PRT
<213> Aspergillus nidulans
<400> 105
Met Val Gln Asp Thr Ser Ser Ala Ser Thr Ser Pro Ile Leu Thr Arg
1 5 10 15
Trp Tyr Ile Asp Thr Arg Pro Leu Thr Ala Ser Thr Ala Ala Leu Pro
20 25 30
Leu Leu Glu Thr Leu Gln Pro Ala Asp Gln Ile Ser Val Gln Lys Tyr
35 40 45
Tyr His Leu Lys Asp Lys His Met Ser Leu Ala Ser Asn Leu Leu Lys
50 55 60
Tyr Leu Phe Val His Arg Asn Cys Arg Ile Pro Trp Ser Ser Ile Val
65 70 75 80
Ile Ser Arg Thr Pro Asp Pro His Arg Arg Pro Cys Tyr Ile Pro Pro
85 90 95
Ser Gly Ser Gln Glu Asp Ser Phe Lys Asp Gly Tyr Thr Gly Ile Asn
100 105 110
Val Glu Phe Asn Val Ser His Gln Ala Ser Met Val Ala Ile Ala Gly
115 120 125
Thr Ala Phe Thr Pro Asn Ser Gly Gly Asp Ser Lys Leu Lys Pro Glu
130 135 140
Val Gly Ile Asp Ile Thr Cys Val Asn Glu Arg Gln Gly Arg Asn Gly
145 150 155 160
Glu Glu Arg Ser Leu Glu Ser Leu Arg Gln Tyr Ile Asp Ile Phe Ser
165 170 175
Glu Val Phe Ser Thr Ala Glu Met Ala Asn Ile Arg Arg Leu Asp Gly
180 185 190
Val Ser Ser Ser Ser Leu Ser Ala Asp Arg Leu Val Asp Tyr Gly Tyr
195 200 205
Arg Leu Phe Tyr Thr Tyr Trp Ala Leu Lys Glu Ala Tyr Ile Lys Met
210 215 220
Thr Gly Glu Ala Leu Leu Ala Pro Trp Leu Arg Glu Leu Glu Phe Ser
225 230 235 240
Asn Val Val Ala Pro Ala Ala Val Ala Glu Ser Gly Asp Ser Ala Gly
245 250 255
Asp Phe Gly Glu Pro Tyr Thr Gly Val Arg Thr Thr Leu Tyr Lys Asn
260 265 270
Leu Val Glu Asp Val Arg Ile Glu Val Ala Ala Leu Gly Gly Asp Tyr
275 280 285
Leu Phe Ala Thr Ala Ala Arg Gly Gly Gly Ile Gly Ala Ser Ser Arg
290 295 300
Pro Gly Gly Gly Pro Asp Gly Ser Gly Ile Arg Ser Gln Asp Pro Trp
305 310 315 320
Arg Pro Phe Lys Lys Leu Asp Ile Glu Arg Asp Ile Gln Pro Cys Ala
325 330 335
Thr Gly Val Cys Asn Cys Leu Ser
340
<210> 106
<211> 1593
<212> DNA
<213> Rhodobacter capsulatus
<400> 106
atgactcttc aatcccaaac tgctaaggat tgcttggcac tggatggtgc actgactttg 60
gtgcagtgcg aggcaatcgc cacgcatcgt agtcgtattt ccgttacgcc agccttgcgt 120
gaacgttgtg ctcgtgccca cgcacgtttg gagcacgcaa tcgcagagca gcgtcatatt 180
tacggtatca ccactggatt tggacccctg gctaaccgtc ttattggagc cgatcagggc 240
gctgagctgc aacagaatct gatttaccat cttgcaacgg gcgttggacc caagctgtcc 300
tgggcagagg cccgtgcact tatgttggca cgtcttaatt ccattttgca gggcgctagt 360
ggtgcttctc ctgaaacgat cgaccgtatc gtcgcagtac ttaacgctgg ctttgctcct 420
gaagttcccg cacaaggtac tgttggcgca agtggcgact tgactcccct tgcccacatg 480
gtactggccc tgcaaggccg tggacgtatg atcgatccta gtggacgtgt gcaagaggct 540
ggagccgtca tggatcgtct ttgcggaggc cctcttacgt tggccgcacg tgacggcctt 600
gctctggtca acggtacaag tgctatgact gctatcgctg ctcttactgg agtcgaggcc 660
gctcgtgcta tcgatgctgc acttcgtcac tccgccgttt tgatggaagt cctgtctgga 720
catgcagaag cctggcaccc cgcctttgca gagttgagac cccacccagg ccagttgcgt 780
gctactgaac gtttggccca ggccctggat ggcgcaggcc gtgtatgccg tactctgacg 840
gctgcccgtc gtcttactgc agccgacctg cgtccagagg accaccccgc acaagacgct 900
tattctctgc gtgtcgttcc tcaactggtt ggtgccgtat gggatactct tgactggcac 960
gaccgtgtcg tgacctgtga gcttaattca gtaaccgata accccatttt tccagagggt 1020
tgcgccgttc ctgcacttca cggaggaaac ttcatgggag tccacgtcgc actggcttca 1080
gacgctttga atgcagccct ggttaccctt gccggtcttg tagagcgtca aattgcccgt 1140
cttaccgacg agaaacttaa taaaggtctg cctgctttcc ttcacggtgg acaggcaggc 1200
cttcagagtg gcttcatggg cgctcaggtt acagcaactg ccctgttggc tgagatgcgt 1260
gcaaatgcaa ctccagtctc agtacaatcc ttgtccacaa acggtgcaaa ccaagacgtc 1320
gtatctatgg gaactatcgc cgcacgtcgt gctcgtgcac aattgttgcc actgtcacag 1380
attcaggcta tcttggcttt ggcattggcc caggctatgg atcttcttga cgatcccgag 1440
ggtcaagccg gatggtcttt gacagcccgt gatttgcgtg accgtatccg tgccgtttct 1500
cccggactgc gtgccgaccg tccactggca ggccatatcg aagctgttgc tcagggactt 1560
cgtcacccat ctgctgcagc cgatccacca gcc 1593
<210> 107
<211> 531
<212> PRT
<213> Rhodobacter capsulatus
<400> 107
Met Thr Leu Gln Ser Gln Thr Ala Lys Asp Cys Leu Ala Leu Asp Gly
1 5 10 15
Ala Leu Thr Leu Val Gln Cys Glu Ala Ile Ala Thr His Arg Ser Arg
20 25 30
Ile Ser Val Thr Pro Ala Leu Arg Glu Arg Cys Ala Arg Ala His Ala
35 40 45
Arg Leu Glu His Ala Ile Ala Glu Gln Arg His Ile Tyr Gly Ile Thr
50 55 60
Thr Gly Phe Gly Pro Leu Ala Asn Arg Leu Ile Gly Ala Asp Gln Gly
65 70 75 80
Ala Glu Leu Gln Gln Asn Leu Ile Tyr His Leu Ala Thr Gly Val Gly
85 90 95
Pro Lys Leu Ser Trp Ala Glu Ala Arg Ala Leu Met Leu Ala Arg Leu
100 105 110
Asn Ser Ile Leu Gln Gly Ala Ser Gly Ala Ser Pro Glu Thr Ile Asp
115 120 125
Arg Ile Val Ala Val Leu Asn Ala Gly Phe Ala Pro Glu Val Pro Ala
130 135 140
Gln Gly Thr Val Gly Ala Ser Gly Asp Leu Thr Pro Leu Ala His Met
145 150 155 160
Val Leu Ala Leu Gln Gly Arg Gly Arg Met Ile Asp Pro Ser Gly Arg
165 170 175
Val Gln Glu Ala Gly Ala Val Met Asp Arg Leu Cys Gly Gly Pro Leu
180 185 190
Thr Leu Ala Ala Arg Asp Gly Leu Ala Leu Val Asn Gly Thr Ser Ala
195 200 205
Met Thr Ala Ile Ala Ala Leu Thr Gly Val Glu Ala Ala Arg Ala Ile
210 215 220
Asp Ala Ala Leu Arg His Ser Ala Val Leu Met Glu Val Leu Ser Gly
225 230 235 240
His Ala Glu Ala Trp His Pro Ala Phe Ala Glu Leu Arg Pro His Pro
245 250 255
Gly Gln Leu Arg Ala Thr Glu Arg Leu Ala Gln Ala Leu Asp Gly Ala
260 265 270
Gly Arg Val Cys Arg Thr Leu Thr Ala Ala Arg Arg Leu Thr Ala Ala
275 280 285
Asp Leu Arg Pro Glu Asp His Pro Ala Gln Asp Ala Tyr Ser Leu Arg
290 295 300
Val Val Pro Gln Leu Val Gly Ala Val Trp Asp Thr Leu Asp Trp His
305 310 315 320
Asp Arg Val Val Thr Cys Glu Leu Asn Ser Val Thr Asp Asn Pro Ile
325 330 335
Phe Pro Glu Gly Cys Ala Val Pro Ala Leu His Gly Gly Asn Phe Met
340 345 350
Gly Val His Val Ala Leu Ala Ser Asp Ala Leu Asn Ala Ala Leu Val
355 360 365
Thr Leu Ala Gly Leu Val Glu Arg Gln Ile Ala Arg Leu Thr Asp Glu
370 375 380
Lys Leu Asn Lys Gly Leu Pro Ala Phe Leu His Gly Gly Gln Ala Gly
385 390 395 400
Leu Gln Ser Gly Phe Met Gly Ala Gln Val Thr Ala Thr Ala Leu Leu
405 410 415
Ala Glu Met Arg Ala Asn Ala Thr Pro Val Ser Val Gln Ser Leu Ser
420 425 430
Thr Asn Gly Ala Asn Gln Asp Val Val Ser Met Gly Thr Ile Ala Ala
435 440 445
Arg Arg Ala Arg Ala Gln Leu Leu Pro Leu Ser Gln Ile Gln Ala Ile
450 455 460
Leu Ala Leu Ala Leu Ala Gln Ala Met Asp Leu Leu Asp Asp Pro Glu
465 470 475 480
Gly Gln Ala Gly Trp Ser Leu Thr Ala Arg Asp Leu Arg Asp Arg Ile
485 490 495
Arg Ala Val Ser Pro Gly Leu Arg Ala Asp Arg Pro Leu Ala Gly His
500 505 510
Ile Glu Ala Val Ala Gln Gly Leu Arg His Pro Ser Ala Ala Ala Asp
515 520 525
Pro Pro Ala
530
<210> 108
<211> 1560
<212> DNA
<213> Escherichia coli
<400> 108
atgaaacctg aagattttcg tgcttccacc cagcggccct ttactggaga agaatatctg 60
aagtctcttc aagacggccg tgagatctat atttacggcg agcgtgtaaa ggatgttaca 120
acgcaccctg cttttcgtaa tgctgctgcc tcagttgccc aactttatga cgccctgcat 180
aaacccgaaa tgcaggactc actttgttgg aatacggaca cggggtccgg tggttacaca 240
cacaagttct ttcgtgtcgc caaatctgcc gatgacttgc gtcaacaacg tgatgctatc 300
gctgaatggt cacgtctgag ttacggctgg atgggccgta cgcccgacta taaggccgcc 360
tttggttgcg cattgggtgc aaatcccggc ttttatggac agtttgaaca aaatgcacgt 420
aactggtata ctcgtatcca ggaaaccggc ttgtacttta atcatgctat tgttaaccca 480
cctatcgatc gtcatttgcc aaccgataag gtcaaggatg tatatattaa acttgaaaag 540
gagacggacg ctggtatcat tgtgtctggc gctaaagtgg tggctacgaa cagtgcattg 600
acgcattaca atatgattgg ttttggttcc gcccaagtga tgggcgagaa ccccgacttt 660
gccttgatgt ttgttgcccc tatggacgct gacggagtaa aacttatttc acgtgcctca 720
tatgaaatgg tagctggtgc cactggttct ccttatgatt atcctctttc atcccgtttt 780
gacgaaaacg acgccatcct ggtcatggac aatgttctta ttccctggga gaacgtgctg 840
atctaccgtg acttcgatcg ttgccgtcgt tggactatgg aaggaggttt cgctcgtatg 900
tatccactgc aggcctgtgt tcgtttggct gtgaagttgg actttatcac agcccttctt 960
aaaaagtcac ttgagtgtac tggaacgttg gagttccgtg gtgtacaggc agatctgggc 1020
gaagtagtag cctggcgtaa tactttctgg gcactgtctg actctatgtg ctccgaggca 1080
acaccatggg tgaacggcgc atacctgccc gatcacgccg ctcttcaaac atatcgtgtg 1140
cttgctccca tggcttatgc taaaatcaaa aatattatcg agcgtaatgt aacttctggt 1200
ctgatttacc tgccatccag tgctcgtgac cttaacaatc ctcaaatcga tcagtatctt 1260
gcaaaatatg tgcgtggctc aaacggaatg gaccatgtgc agcgtatcaa aatcctgaag 1320
ttgatgtggg atgccatcgg ttctgaattt ggcggacgtc atgaactgta tgagattaac 1380
tactctggat ctcaagacga aatcagactt cagtgtttgc gtcaggccca aaattctgga 1440
aatatggata aaatgatggc tatggtagac cgttgtctga gtgagtacga tcaagatggt 1500
tggacagttc ctcatcttca taataatgac gatattaata tgcttgataa gttgcttaaa 1560
<210> 109
<211> 520
<212> PRT
<213> Escherichia coli
<400> 109
Met Lys Pro Glu Asp Phe Arg Ala Ser Thr Gln Arg Pro Phe Thr Gly
1 5 10 15
Glu Glu Tyr Leu Lys Ser Leu Gln Asp Gly Arg Glu Ile Tyr Ile Tyr
20 25 30
Gly Glu Arg Val Lys Asp Val Thr Thr His Pro Ala Phe Arg Asn Ala
35 40 45
Ala Ala Ser Val Ala Gln Leu Tyr Asp Ala Leu His Lys Pro Glu Met
50 55 60
Gln Asp Ser Leu Cys Trp Asn Thr Asp Thr Gly Ser Gly Gly Tyr Thr
65 70 75 80
His Lys Phe Phe Arg Val Ala Lys Ser Ala Asp Asp Leu Arg Gln Gln
85 90 95
Arg Asp Ala Ile Ala Glu Trp Ser Arg Leu Ser Tyr Gly Trp Met Gly
100 105 110
Arg Thr Pro Asp Tyr Lys Ala Ala Phe Gly Cys Ala Leu Gly Ala Asn
115 120 125
Pro Gly Phe Tyr Gly Gln Phe Glu Gln Asn Ala Arg Asn Trp Tyr Thr
130 135 140
Arg Ile Gln Glu Thr Gly Leu Tyr Phe Asn His Ala Ile Val Asn Pro
145 150 155 160
Pro Ile Asp Arg His Leu Pro Thr Asp Lys Val Lys Asp Val Tyr Ile
165 170 175
Lys Leu Glu Lys Glu Thr Asp Ala Gly Ile Ile Val Ser Gly Ala Lys
180 185 190
Val Val Ala Thr Asn Ser Ala Leu Thr His Tyr Asn Met Ile Gly Phe
195 200 205
Gly Ser Ala Gln Val Met Gly Glu Asn Pro Asp Phe Ala Leu Met Phe
210 215 220
Val Ala Pro Met Asp Ala Asp Gly Val Lys Leu Ile Ser Arg Ala Ser
225 230 235 240
Tyr Glu Met Val Ala Gly Ala Thr Gly Ser Pro Tyr Asp Tyr Pro Leu
245 250 255
Ser Ser Arg Phe Asp Glu Asn Asp Ala Ile Leu Val Met Asp Asn Val
260 265 270
Leu Ile Pro Trp Glu Asn Val Leu Ile Tyr Arg Asp Phe Asp Arg Cys
275 280 285
Arg Arg Trp Thr Met Glu Gly Gly Phe Ala Arg Met Tyr Pro Leu Gln
290 295 300
Ala Cys Val Arg Leu Ala Val Lys Leu Asp Phe Ile Thr Ala Leu Leu
305 310 315 320
Lys Lys Ser Leu Glu Cys Thr Gly Thr Leu Glu Phe Arg Gly Val Gln
325 330 335
Ala Asp Leu Gly Glu Val Val Ala Trp Arg Asn Thr Phe Trp Ala Leu
340 345 350
Ser Asp Ser Met Cys Ser Glu Ala Thr Pro Trp Val Asn Gly Ala Tyr
355 360 365
Leu Pro Asp His Ala Ala Leu Gln Thr Tyr Arg Val Leu Ala Pro Met
370 375 380
Ala Tyr Ala Lys Ile Lys Asn Ile Ile Glu Arg Asn Val Thr Ser Gly
385 390 395 400
Leu Ile Tyr Leu Pro Ser Ser Ala Arg Asp Leu Asn Asn Pro Gln Ile
405 410 415
Asp Gln Tyr Leu Ala Lys Tyr Val Arg Gly Ser Asn Gly Met Asp His
420 425 430
Val Gln Arg Ile Lys Ile Leu Lys Leu Met Trp Asp Ala Ile Gly Ser
435 440 445
Glu Phe Gly Gly Arg His Glu Leu Tyr Glu Ile Asn Tyr Ser Gly Ser
450 455 460
Gln Asp Glu Ile Arg Leu Gln Cys Leu Arg Gln Ala Gln Asn Ser Gly
465 470 475 480
Asn Met Asp Lys Met Met Ala Met Val Asp Arg Cys Leu Ser Glu Tyr
485 490 495
Asp Gln Asp Gly Trp Thr Val Pro His Leu His Asn Asn Asp Asp Ile
500 505 510
Asn Met Leu Asp Lys Leu Leu Lys
515 520
<210> 110
<211> 510
<212> DNA
<213> Escherichia coli
<400> 110
atgcagcttg atgagcagcg tttgcgtttt cgtgacgcta tggcatcact tagtgccgct 60
gtgaacatca tcacgactga gggagacgcc ggtcagtgcg gaatcacagc aaccgcagta 120
tgtagtgtta cggacactcc cccatctctg atggtctgta tcaatgccaa tagtgctatg 180
aatccagtct ttcagggtaa tggtaaactt tgtgtcaacg tcctgaatca cgagcaagag 240
ttgatggctc gtcattttgc aggaatgact ggtatggcta tggaagagcg tttttccttg 300
tcttgttggc aaaaaggacc actggcccag cctgtattga aaggttcttt ggcttccctg 360
gagggtgaga tccgtgacgt tcaagccatt ggaactcatc tggtatattt ggtagaaatc 420
aagaatatta tcctgtcagc cgagggccat ggtctgatct actttaaacg tcgttttcac 480
cccgtgatgc tggagatgga ggcagccatt 510
<210> 111
<211> 170
<212> PRT
<213> Escherichia coli
<400> 111
Met Gln Leu Asp Glu Gln Arg Leu Arg Phe Arg Asp Ala Met Ala Ser
1 5 10 15
Leu Ser Ala Ala Val Asn Ile Ile Thr Thr Glu Gly Asp Ala Gly Gln
20 25 30
Cys Gly Ile Thr Ala Thr Ala Val Cys Ser Val Thr Asp Thr Pro Pro
35 40 45
Ser Leu Met Val Cys Ile Asn Ala Asn Ser Ala Met Asn Pro Val Phe
50 55 60
Gln Gly Asn Gly Lys Leu Cys Val Asn Val Leu Asn His Glu Gln Glu
65 70 75 80
Leu Met Ala Arg His Phe Ala Gly Met Thr Gly Met Ala Met Glu Glu
85 90 95
Arg Phe Ser Leu Ser Cys Trp Gln Lys Gly Pro Leu Ala Gln Pro Val
100 105 110
Leu Lys Gly Ser Leu Ala Ser Leu Glu Gly Glu Ile Arg Asp Val Gln
115 120 125
Ala Ile Gly Thr His Leu Val Tyr Leu Val Glu Ile Lys Asn Ile Ile
130 135 140
Leu Ser Ala Glu Gly His Gly Leu Ile Tyr Phe Lys Arg Arg Phe His
145 150 155 160
Pro Val Met Leu Glu Met Glu Ala Ala Ile
165 170
<210> 112
<211> 801
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в растениях нуклеиновая кислота,
кодирующая белок SEQ ID No:80
<400> 112
atgaggataa atatctcttt gtctagtctc tttgagagac tgagcaaatt gtcatcccga 60
tccatcgcaa ttacctgcgg cgtagtcttg gcaagtgcaa tagcattccc aattatccga 120
agagactatc aaacgttcct tgaagtcggt ccgagctatg ccccacagaa cttccgaggc 180
tatatcatcg tttgtgtctt gtcacttttt aggcaagagc agaaagggtt ggcaatctat 240
gacaggcttc cagaaaagag gcgttggctt gccgacttgc cgtttcgtga agggacgagg 300
ccatccataa cctcccacat tatacagcgt cagcgtactc agctggtaga tcaagagttt 360
gcaaccagag aacttatcga taaggtgatc ccacgtgtgc aagcaagaca cacagacaaa 420
acttttctca gtacgtcaaa atttgagttt catgcaaagg ccatcttcct tctcccctct 480
atccctatta atgatcctct taacattccc tcacacgata cggtaagaag aaccaagcgt 540
gagatcgctc acatgcatga ttaccatgat tgcactctgc acttggctct tgctgctcag 600
gatggtaagg aagttttgaa gaaggggtgg ggccagcgtc acccactggc cggaccagga 660
gtcccaggcc ctcctactga gtggaccttc ctttacgcac caaggaacga agaggaggcc 720
agagttgtcg agatgatagt cgaagctagt attggctaca tgactaacga tcctgctggt 780
aagattgtcg aaaatgccaa g 801
<210> 113
<211> 5034
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в растениях нуклеиновая кислота,
кодирующая белок SEQ ID No:35
<400> 113
atgaattcca gcaagaatcc tccttccact cttcttgatg tttttctgga tactgccagg 60
aaccttgata ccgctttgag gaatgtcttg gaatgcggcg aacacagatg gtcctacaga 120
gagcttgata ctgtttcatc tgctctcgcc cagcatctta ggtacactgt cggtcttagt 180
cctactgtcg ccgtcatcag tgaaaaccat ccttatattc tcgctttgat gctggctgta 240
tggaaacttg gaggcacctt cgctcctatt gatgtccatt ctcctgccga attggtagct 300
ggcatgctga acatagtctc tccttcttgc ttggttattc cgagctcaga tgtaactaat 360
caaactcttg cctgcgatct taatatcccc gtcgttgcat ttcacccaca tcaatccact 420
attcctgagc tgaacaagaa gtacctcacc gattctcaaa tttctccgga tcttcctttt 480
tcagatccaa acagacctgc tctgtacctc ttcacttcat ccgccacttc tcgaagtaat 540
ctcaaatgcg tgcctctcac tcacaccttt atcctccgaa acagcctctc taagcgtgca 600
tggtgcaagc gtatgcgtcc agagacagac tttgacggca tacgtgttct tggatgggcc 660
ccgtggtctc acgtcctcgc acacatgcaa gacatcggac cactcaccct gcttaatgcc 720
ggatgctacg tttttgcaac tactccatcc acgtacccta cggaattgaa ggacgacagg 780
gacctgatat cttgcgccgc aaatgctatc atgtacaagg gcgtcaagtc atttgcttgt 840
cttccctttg tactcggagg gctgaaggca ctctgcgagt ctgagccatc cgtgaaggcc 900
catcttcagg tcgaggagag agctcaactc ctgaagtctc tgcaacacat ggaaattctt 960
gagtgtggag gtgccatgct cgaagcaagt gttgcctctt gggctattga gaactgcatt 1020
cccatttcta tcggtattgg tatgacggag actggtggag ccctctttgc aggccccgtt 1080
caggccatca aaaccgggtt ttcttcagag gataaattca ttgaagatgc tacttacttg 1140
ctcgttaagg atgatcatga gagtcatgct gaggaggata ttaacgaggg tgaactcgtt 1200
gtgaaaagta aaatgctccc acgaggctac cttggctata gtgatccttc cttctcagtc 1260
gacgatgctg gctgggttac atttagaaca ggagacagat acagcgttac acctgacgga 1320
aagttttcct ggctgggccg aaacactgat ttcattcaga tgaccagtgg tgagacgctg 1380
gatccccgac caattgagag cagtctctgc gaaagttctc ttatttctag agcatgcgtt 1440
atcggagata aatttctcaa cgggcctgct gctgctgttt gtgctatcat tgagcttgag 1500
cccacagctg tggaaaaagg acaagctcac agccgtgaga tagcaagagt tttcgcacct 1560
attaatcgag acttgccgcc tcctcttagg attgcatgga gtcacgtttt ggttctccag 1620
cccagtgaga agataccgat gacgaagaag ggtaccatct tcaggaagaa aattgagcag 1680
gtgtttggct ctgccttggg tggcagctct ggagataact ctcaagccac tgctgatgct 1740
ggcgttgttc gacgagacga gctttcaaac actgtcaagc acataattag ccgtgttctc 1800
ggagtttccg atgacgaact cctttggacg ttgtcatttg ccgagctcgg aatgacgtca 1860
gcattggcca ctcgaatcgc caacgagttg aacgaagttt tggttggagt taatctccct 1920
atcaacgctt gctatataca tgtcgacctt ccttctctga gcaatgccgt ctatgccaaa 1980
cttgcacacc tcaagctgcc agatcgtact cccgaaccca ggcaagcccc tgtcgaaaac 2040
tctggtggga aggagatcgt tgtcgttggc caggcctttc gtcttcctgg ctcaataaac 2100
gatgtcgcct ctcttcgaga cgcattcctg gccagacaag catcatccat tatcactgaa 2160
ataccatccg ataggtggga ccacgccagc ttctatccca aggatatacg tttcaacaag 2220
gctggccttg tggatatagc caattatgat catagctttt tcggactgac ggcaaccgaa 2280
gcactctatc tgtccccaac tatgcgtttg gcactcgaag tttcctttga agccttggag 2340
aatgctaata tcccggtgtc acaactcaag ggttctcaaa cagctgttta tgttgctact 2400
acagatgacg gatttgagac ccttttgaat gccgaggccg gctatgatgc ttatacaaga 2460
ttctatggca ctggtcgagc agcaagtaca gccagcgggc gtataagctg tcttcttgat 2520
gtccatggac cctctattac tgttgatacg gcatgcagtg gaggggctgt ttgtattgac 2580
caagcaatcg actatctgca atcaagcagt gcagcagaca ccgctatcat atgtgctagt 2640
aacacgcact gctggccagg cagcttcagg tttctttccg cacaagggat ggtatcccca 2700
ggaggacgat gcgcaacatt tacaactgat gctgatggct acgtgccctc tgagggcgct 2760
gtcgccttca tattgaaaac ccgagaagca gctatgcgtg acaaggacac tatcctcgcc 2820
acaatcaaag ctacacagat atcacacaat ggccgatctc aaggtcttgt ggcaccgaat 2880
gtcaacagcc aagctgacct tcatagaagc ttgcttcaaa aagctggcct tagcccggct 2940
gatatccgtt tcattgaagc tcatgggaca ggaacgtcac tgggagacct ctcagaaatt 3000
caagctataa atgatgctta tacctcctct cagccgcgta cgaccggccc actcatagtc 3060
agcgcttcca aaacggtcat tggtcatacc gaaccagctg gccccttggt cggtatgctg 3120
agtgtcttga actctttcaa agaaggcgcc gtccctggtc tcgcccatct taccgcagac 3180
aatttgaatc ccagtctgga ctgttcttct gtgccacttc tcattcccta tcaacctgtt 3240
cacctggctg cacccaagcc tcaccgagct gctgtaaggt catacggctt ttcaggtacc 3300
ctgggcggca tcgttctcga ggctcctgac gaagaaagac tggaagaaga gctgccaaat 3360
gacaagccca tgttgttcgt cgtcagcgca aagacacata cagcacttat cgaatacctg 3420
gggcgttatc tcgagttcct cttgcaggca aacccccaag atttttgtga catttgttat 3480
acaagctgcg ttgggcgtga gcactataga tatcgatatg cttgtgtagc aaatgatatg 3540
gaggacctca taggccaact ccagaaacgt ttgggcagca aggtgccgcc aaagccgtca 3600
tacaaacgtg gtgctttggc ctttgccttt tctggtcagg gtacacaatt ccgagggatg 3660
gccacagagc ttgcaaaagc atactccggc ttccgaaaga tcgtgtccga tctcgcaaag 3720
agagctagcg agttgtcagg tcatgccatt gaccgttttc ttcttgcata tgacataggc 3780
gctgaaaatg tagctcctga tagtgaggca gaccagattt gcatctttgt gtatcagtgt 3840
tctgtccttc gttggctgca gactatgggg attagaccca gtgcagtgat aggccatagc 3900
ctcggggaga tctcagcttc tgtggcagca ggagcacttt ctcttgactc cgctttggat 3960
cttgtcatct cacgagctcg tcttttgagg tcttcagcaa gtgctcctgc aggaatggca 4020
gctatgtctg cctctcaaga cgaggttgtg gagttgattg ggaaactcga cctcgacaag 4080
gctaattctc tcagcgtttc agtcataaat ggtccccaaa atactgtcgt gtccggctct 4140
tcagctgcta ttgaaagcat agtggctctt gccaaaggga gaaagatcaa agcctctgcc 4200
ctgaatatca atcaagcttt tcatagtcca tacgtcgaca gtgccgtccc tggtctccgt 4260
gcttggtcag aaaagcatat ctcctcagct agaccattgc aaattccgct gtattcaacg 4320
ttgttgggag cacaaatctc tgagggagag atgttgaatc cagatcactg ggtcgaccat 4380
gcacgaaagc ctgtacagtt cgcacaagca gccacaacca tgaaagaatc cttcaccgga 4440
gtcatcatag atatcggccc tcaagtagtg gcttggtcac ttctgctcag taacgggctc 4500
acgtccgtga ctgctctcgc tgcaaaaaga gggagaagtc aacaggtggc tttcctcagc 4560
gccttggccg atttgtatca agattacggt gttgttcctg attttgtcgg gctttatgct 4620
cagcaggaag atgcttcaag gttgaagaag acggatatct tgacgtatcc gttccagcgt 4680
ggcgaagaga ctctttctag tggttctagc actccgacat tggaaaacac ggatttggat 4740
tccggtaagg aactccttat gggaccgact agagggttgc tccgtgctga cgacttgcgt 4800
gacagtatcg tttcttctgt gaaggatgtt ctggaactca agtcaaatga agacctcgat 4860
ttgtctgaaa gtctgaatgc acttggtatg gacagcatca tgttcgctca gctccgaaag 4920
cgtattgggg aaggactcgg attgaatgtt ccgatggttt ttctgagcga cgccttttct 4980
attggtgaga tggttagtaa tcttgtggaa caggcagagg cttctgagga caat 5034
<210> 114
<211> 867
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в растениях нуклеиновая кислота,
кодирующая белок SEQ ID No:65
<400> 114
atggctccaa tttcttcaac ttggtctcgt ctcattcgat ttgtggctat tgaaacgtcc 60
ctcgtgcata tcggtgaacc gatagacgcc accatggacg tcggtctggc cagacgagaa 120
ggcaagacga tccaagcata cgagattatt ggatcaggca gtgctcttga cctctcagcc 180
caagtaagta agaatgtgct gactgtaagg gaactcctga tgccgctttc aagagaggaa 240
attaaaactg tacgatgctt ggggttgaac taccctgttc atgccaccga agcaaacgtt 300
gctgttccaa aattcccgaa tttgttctac aaaccagtga cctccctcat tggccccgat 360
ggactcatta ccatcccttc cgttgtccaa cccccgaagg agcatcagtc cgattatgaa 420
gcagaacttg tcattgtcat cgggaaagca gcaaagaatg taagtgagga tgaggctttg 480
gattatgtat tgggatacac tgccgctaac gatatttcct ttaggaaaca ccagcttgca 540
gtctcacaat ggtctttctc taaaggattt ggtagccttt tgctcactat ccgtatggca 600
caaacccact ctggtaacat taatagattc tccagagacc agattttcaa tgtcaagaag 660
acaatttcct tcctgtcaca aggcactaca ctggaaccag gttctatcat tttgactggt 720
acacctgacg gagtgggctt tgtgcgaaat ccaccacttt accttaaaga tggagatgaa 780
gtaatgacct ggattggaag tggaatcgga acattggcca atacagtgca agaagagaag 840
acttgcttcg ctagtggcgg acacgag 867
<210> 115
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> Последовательность аминокислотного линкера
<400> 115
Gly Gly Ser Gly Gly Ser Gly Gly Ser
1 5
<210> 116
<211> 1569
<212> DNA
<213> Искусственная последовательность
<220>
<223> Оптимизированная для экспрессии в растениях нуклеиновая кислота,
кодирующая фенилаланин-аммоний-лиазу Streptomyces maritimus (SEQ
ID No: 117)
<400> 116
atgacattcg tgatagagct ggacatgaat gtcactcttg atcagttaga ggatgctgca 60
agacaaagaa cacccgtgga attgtctgca cctgtacgtt caagggtccg tgcttcacgt 120
gatgttttag ttaaattcgt acaagatgag cgtgtgattt acggtgtaaa tacttcaatg 180
ggcggattcg tggatcacct agtacctgtg agtcaggccc gtcaattgca agagaattta 240
atcaatgcag ttgccacaaa tgttggagca tatttagatg atacaacggc caggacgatt 300
atgttgagta ggattgtatc cctggcaagg ggcaattctg ccataactcc cgccaacctt 360
gacaaattag tggcagtgtt gaacgcagga atcgtcccat gcatccctga aaaaggttca 420
ttaggtactt caggtgactt aggccctctg gcagctatcg ccttagtatg cgctggccag 480
tggaaggcac gttacaatgg acaaataatg ccaggccgtc aggctctatc agaggccggt 540
gtcgaaccta tggaactttc atataaggac ggcctagcac ttataaacgg tacgtctgga 600
atggtaggcc ttggaactat ggttttacaa gccgctagga ggttagtgga caggtatttg 660
caagtaagtg ccttatctgt agaaggcttg gcaggcatga ctaaaccttt tgaccctcgt 720
gtacacggag ttaagcccca tagaggtcaa agacaagtag cttcccgtct atgggaagga 780
ttggccgatt ctcaccttgc cgtgaacgag cttgatactg aacaaaccct tgcaggtgaa 840
atgggcacgg tggcaaaggc tggaagttta gccatagagg atgcctactc cattcgttgc 900
acccctcaga tcctgggtcc agtcgtagac gtattggata ggatcggtgc aacattacaa 960
gacgagctga attcttcaaa cgataacccc attgtccttc ctgaggaagc agaagtattc 1020
cataatggac actttcatgg acagtatgtc gccatggcaa tggatcacct aaatatggct 1080
cttgctactg ttacgaatct tgccaataga agagtcgaca gatttctaga taaatcaaat 1140
tccaatggac taccagcctt tctttgccgt gaagacccag gccttaggct tggtttgatg 1200
ggcggccagt tcatgactgc atcaatcacc gctgaaaccc gtacactgac aatcccaatg 1260
tctgtacaat cacttacttc cacggcagat tttcaagaca tagtatcctt tggcttcgta 1320
gccgcaagga gagctagaga ggtgttgaca aacgctgctt atgtggtagc ctttgaacta 1380
ctgtgtgcct gtcaggctgt ggacatcaga ggagcagaca agctatcttc tttcacccgt 1440
cctctatatg aaagaaccag gaaaattgtt ccctttttcg acagagatga aacaattact 1500
gactacgttg agaagttagc tgctgattta atagcaggcg agcctgtaga tgccgctgtg 1560
gctgcacat 1569
<210> 117
<211> 523
<212> PRT
<213> Streptomyces maritimus
<400> 117
Met Thr Phe Val Ile Glu Leu Asp Met Asn Val Thr Leu Asp Gln Leu
1 5 10 15
Glu Asp Ala Ala Arg Gln Arg Thr Pro Val Glu Leu Ser Ala Pro Val
20 25 30
Arg Ser Arg Val Arg Ala Ser Arg Asp Val Leu Val Lys Phe Val Gln
35 40 45
Asp Glu Arg Val Ile Tyr Gly Val Asn Thr Ser Met Gly Gly Phe Val
50 55 60
Asp His Leu Val Pro Val Ser Gln Ala Arg Gln Leu Gln Glu Asn Leu
65 70 75 80
Ile Asn Ala Val Ala Thr Asn Val Gly Ala Tyr Leu Asp Asp Thr Thr
85 90 95
Ala Arg Thr Ile Met Leu Ser Arg Ile Val Ser Leu Ala Arg Gly Asn
100 105 110
Ser Ala Ile Thr Pro Ala Asn Leu Asp Lys Leu Val Ala Val Leu Asn
115 120 125
Ala Gly Ile Val Pro Cys Ile Pro Glu Lys Gly Ser Leu Gly Thr Ser
130 135 140
Gly Asp Leu Gly Pro Leu Ala Ala Ile Ala Leu Val Cys Ala Gly Gln
145 150 155 160
Trp Lys Ala Arg Tyr Asn Gly Gln Ile Met Pro Gly Arg Gln Ala Leu
165 170 175
Ser Glu Ala Gly Val Glu Pro Met Glu Leu Ser Tyr Lys Asp Gly Leu
180 185 190
Ala Leu Ile Asn Gly Thr Ser Gly Met Val Gly Leu Gly Thr Met Val
195 200 205
Leu Gln Ala Ala Arg Arg Leu Val Asp Arg Tyr Leu Gln Val Ser Ala
210 215 220
Leu Ser Val Glu Gly Leu Ala Gly Met Thr Lys Pro Phe Asp Pro Arg
225 230 235 240
Val His Gly Val Lys Pro His Arg Gly Gln Arg Gln Val Ala Ser Arg
245 250 255
Leu Trp Glu Gly Leu Ala Asp Ser His Leu Ala Val Asn Glu Leu Asp
260 265 270
Thr Glu Gln Thr Leu Ala Gly Glu Met Gly Thr Val Ala Lys Ala Gly
275 280 285
Ser Leu Ala Ile Glu Asp Ala Tyr Ser Ile Arg Cys Thr Pro Gln Ile
290 295 300
Leu Gly Pro Val Val Asp Val Leu Asp Arg Ile Gly Ala Thr Leu Gln
305 310 315 320
Asp Glu Leu Asn Ser Ser Asn Asp Asn Pro Ile Val Leu Pro Glu Glu
325 330 335
Ala Glu Val Phe His Asn Gly His Phe His Gly Gln Tyr Val Ala Met
340 345 350
Ala Met Asp His Leu Asn Met Ala Leu Ala Thr Val Thr Asn Leu Ala
355 360 365
Asn Arg Arg Val Asp Arg Phe Leu Asp Lys Ser Asn Ser Asn Gly Leu
370 375 380
Pro Ala Phe Leu Cys Arg Glu Asp Pro Gly Leu Arg Leu Gly Leu Met
385 390 395 400
Gly Gly Gln Phe Met Thr Ala Ser Ile Thr Ala Glu Thr Arg Thr Leu
405 410 415
Thr Ile Pro Met Ser Val Gln Ser Leu Thr Ser Thr Ala Asp Phe Gln
420 425 430
Asp Ile Val Ser Phe Gly Phe Val Ala Ala Arg Arg Ala Arg Glu Val
435 440 445
Leu Thr Asn Ala Ala Tyr Val Val Ala Phe Glu Leu Leu Cys Ala Cys
450 455 460
Gln Ala Val Asp Ile Arg Gly Ala Asp Lys Leu Ser Ser Phe Thr Arg
465 470 475 480
Pro Leu Tyr Glu Arg Thr Arg Lys Ile Val Pro Phe Phe Asp Arg Asp
485 490 495
Glu Thr Ile Thr Asp Tyr Val Glu Lys Leu Ala Ala Asp Leu Ile Ala
500 505 510
Gly Glu Pro Val Asp Ala Ala Val Ala Ala His
515 520
<210> 118
<211> 1173
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Aquilaria sinensis,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 118
atgggatctc aagatgttgc tggaggagct cttaagggag ttaatccagg aaaggctact 60
attcttgctc ttggaaaggc ttttccatat caacttgtta tgcaagaatt tcttgttgat 120
ggatatttta agaatacttc ttgtaaggat caagaactta agcaaaagct tgctagactt 180
tgtaagacta ctactgttaa gactagatat gttgttatgt ctgaagaaat tcttaataag 240
tatccagaac ttgctgttga aggaattcca actcttaagc aaagacttga tattggaaat 300
gaagctctta ctgaaatggc tattgaagct tctcaagctt gtattaagaa gtggggaaga 360
ccagcttctg aaattactca tcttgtttat gtttcttctt ctgaagctag acttccagga 420
ggagatcttt atcttgctca aggacttgga ctttctccaa gaactaagag agttgttctt 480
tattttatgg gatgttctgg aggagttgct ggacttagag ttgctaagga tattgctgaa 540
aataatccag gatctagagt tcttcttgct acttctgaaa ctactattgt tggatttaag 600
ccaccatctg ctcatagacc atatgatctt gttggagttg ctctttttgg agatggagct 660
ggagctatgg ttattggatc tgatccactt ccaggaactg aatctccact ttttgaactt 720
catactgcta ttcaaaattt tcttccaaat actgaaaaga ctattgatgg aagacttact 780
gaagaaggaa tttcttttaa gcttgctaga gaacttccac aaattgttga agatcatatt 840
gaaggatttt gtggacaact tactggagtt attggacttt ctcataagca atataataag 900
atgttttggg ctgttcatcc aggaggacca gctattctta atagagttga aaagagactt 960
gatcttcatc caaataagct tgatgcttct agaagagctc ttgaagatta tggaaatgct 1020
tcttctaatt ctattgttta tgttcttgat tatatgattg aagaaactct taagatgaag 1080
actgaatctc ttgaaccatc tgaatgggga cttattcttg cttttggacc aggagttact 1140
tttgaaggaa ttcttgctag aaatcttgct gtt 1173
<210> 119
<211> 391
<212> PRT
<213> Aquilaria sinensis
<400> 119
Met Gly Ser Gln Asp Val Ala Gly Gly Ala Leu Lys Gly Val Asn Pro
1 5 10 15
Gly Lys Ala Thr Ile Leu Ala Leu Gly Lys Ala Phe Pro Tyr Gln Leu
20 25 30
Val Met Gln Glu Phe Leu Val Asp Gly Tyr Phe Lys Asn Thr Ser Cys
35 40 45
Lys Asp Gln Glu Leu Lys Gln Lys Leu Ala Arg Leu Cys Lys Thr Thr
50 55 60
Thr Val Lys Thr Arg Tyr Val Val Met Ser Glu Glu Ile Leu Asn Lys
65 70 75 80
Tyr Pro Glu Leu Ala Val Glu Gly Ile Pro Thr Leu Lys Gln Arg Leu
85 90 95
Asp Ile Gly Asn Glu Ala Leu Thr Glu Met Ala Ile Glu Ala Ser Gln
100 105 110
Ala Cys Ile Lys Lys Trp Gly Arg Pro Ala Ser Glu Ile Thr His Leu
115 120 125
Val Tyr Val Ser Ser Ser Glu Ala Arg Leu Pro Gly Gly Asp Leu Tyr
130 135 140
Leu Ala Gln Gly Leu Gly Leu Ser Pro Arg Thr Lys Arg Val Val Leu
145 150 155 160
Tyr Phe Met Gly Cys Ser Gly Gly Val Ala Gly Leu Arg Val Ala Lys
165 170 175
Asp Ile Ala Glu Asn Asn Pro Gly Ser Arg Val Leu Leu Ala Thr Ser
180 185 190
Glu Thr Thr Ile Val Gly Phe Lys Pro Pro Ser Ala His Arg Pro Tyr
195 200 205
Asp Leu Val Gly Val Ala Leu Phe Gly Asp Gly Ala Gly Ala Met Val
210 215 220
Ile Gly Ser Asp Pro Leu Pro Gly Thr Glu Ser Pro Leu Phe Glu Leu
225 230 235 240
His Thr Ala Ile Gln Asn Phe Leu Pro Asn Thr Glu Lys Thr Ile Asp
245 250 255
Gly Arg Leu Thr Glu Glu Gly Ile Ser Phe Lys Leu Ala Arg Glu Leu
260 265 270
Pro Gln Ile Val Glu Asp His Ile Glu Gly Phe Cys Gly Gln Leu Thr
275 280 285
Gly Val Ile Gly Leu Ser His Lys Gln Tyr Asn Lys Met Phe Trp Ala
290 295 300
Val His Pro Gly Gly Pro Ala Ile Leu Asn Arg Val Glu Lys Arg Leu
305 310 315 320
Asp Leu His Pro Asn Lys Leu Asp Ala Ser Arg Arg Ala Leu Glu Asp
325 330 335
Tyr Gly Asn Ala Ser Ser Asn Ser Ile Val Tyr Val Leu Asp Tyr Met
340 345 350
Ile Glu Glu Thr Leu Lys Met Lys Thr Glu Ser Leu Glu Pro Ser Glu
355 360 365
Trp Gly Leu Ile Leu Ala Phe Gly Pro Gly Val Thr Phe Glu Gly Ile
370 375 380
Leu Ala Arg Asn Leu Ala Val
385 390
<210> 120
<211> 1164
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS2 из Aquilaria sinensis,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 120
atgtctcaag ctattgctga taatgcttat agacatcatc ttaagagagc tccaactcca 60
ggaaaggcta ctgttcttgc tcttggaaag gcttttccaa agcaagttat tccacaagaa 120
aatcttgttg aaggatatat tagagatact aagtgtgaag atgtttctat taaggaaaag 180
cttgaaagac tttgtaagac tactactgtt aagactagat atactgttat gtctaaggaa 240
attcttgata attatccaga acttgttact gaaggatctc caactattag acaaagactt 300
gaaattgcta atccagctgt tgttgaaatg gctaaggaag cttctcttgc ttgtattaag 360
caatggggaa gaccagctgg agatattact catattgttt atgtttcttc ttctgaaatt 420
agacttccag gaggagatct ttatcttgct aatgaacttg gacttaagaa tgatattaat 480
agaattatgc tttattttct tggatgttat ggaggagtta ctggacttag agttgctaag 540
gatattgctg aaaataatcc aggatctaga attcttctta ctacttctga aactactatt 600
cttggattta gaccaccaaa taagtctaga ccatatgatc ttgttggagc tgctcttttt 660
ggagatggag ctgctgctgt tattattgga gctaatccag aaattggaag agaatctcca 720
tttatggaac ttaattttgc tcttcaacaa tttcttccag gaactcatgg agttattgat 780
ggaagacttt ctgaagaagg aattaatttt aagcttggaa gagatcttcc acaaaagatt 840
gaagataata ttgaagattt ttgtagaaag cttatgatta aggctgatgg agatcttaag 900
gaatttaatg aacttttttg ggctgttcat ccaggaggac cagctattct taatagactt 960
gaatctattc ttgatcttaa gaatggaaag cttgaatgtt ctagaagagc tcttatggat 1020
tatggaaatg tttcttctaa tactattttt tatgttatgg aatatatgag agaagaactt 1080
aagagagaag gatctgaaga atggggactt gctcttgctt ttggaccagg aattactttt 1140
gaaggaattc ttcttagatc tctt 1164
<210> 121
<211> 388
<212> PRT
<213> Aquilaria sinensis
<400> 121
Met Ser Gln Ala Ile Ala Asp Asn Ala Tyr Arg His His Leu Lys Arg
1 5 10 15
Ala Pro Thr Pro Gly Lys Ala Thr Val Leu Ala Leu Gly Lys Ala Phe
20 25 30
Pro Lys Gln Val Ile Pro Gln Glu Asn Leu Val Glu Gly Tyr Ile Arg
35 40 45
Asp Thr Lys Cys Glu Asp Val Ser Ile Lys Glu Lys Leu Glu Arg Leu
50 55 60
Cys Lys Thr Thr Thr Val Lys Thr Arg Tyr Thr Val Met Ser Lys Glu
65 70 75 80
Ile Leu Asp Asn Tyr Pro Glu Leu Val Thr Glu Gly Ser Pro Thr Ile
85 90 95
Arg Gln Arg Leu Glu Ile Ala Asn Pro Ala Val Val Glu Met Ala Lys
100 105 110
Glu Ala Ser Leu Ala Cys Ile Lys Gln Trp Gly Arg Pro Ala Gly Asp
115 120 125
Ile Thr His Ile Val Tyr Val Ser Ser Ser Glu Ile Arg Leu Pro Gly
130 135 140
Gly Asp Leu Tyr Leu Ala Asn Glu Leu Gly Leu Lys Asn Asp Ile Asn
145 150 155 160
Arg Ile Met Leu Tyr Phe Leu Gly Cys Tyr Gly Gly Val Thr Gly Leu
165 170 175
Arg Val Ala Lys Asp Ile Ala Glu Asn Asn Pro Gly Ser Arg Ile Leu
180 185 190
Leu Thr Thr Ser Glu Thr Thr Ile Leu Gly Phe Arg Pro Pro Asn Lys
195 200 205
Ser Arg Pro Tyr Asp Leu Val Gly Ala Ala Leu Phe Gly Asp Gly Ala
210 215 220
Ala Ala Val Ile Ile Gly Ala Asn Pro Glu Ile Gly Arg Glu Ser Pro
225 230 235 240
Phe Met Glu Leu Asn Phe Ala Leu Gln Gln Phe Leu Pro Gly Thr His
245 250 255
Gly Val Ile Asp Gly Arg Leu Ser Glu Glu Gly Ile Asn Phe Lys Leu
260 265 270
Gly Arg Asp Leu Pro Gln Lys Ile Glu Asp Asn Ile Glu Asp Phe Cys
275 280 285
Arg Lys Leu Met Ile Lys Ala Asp Gly Asp Leu Lys Glu Phe Asn Glu
290 295 300
Leu Phe Trp Ala Val His Pro Gly Gly Pro Ala Ile Leu Asn Arg Leu
305 310 315 320
Glu Ser Ile Leu Asp Leu Lys Asn Gly Lys Leu Glu Cys Ser Arg Arg
325 330 335
Ala Leu Met Asp Tyr Gly Asn Val Ser Ser Asn Thr Ile Phe Tyr Val
340 345 350
Met Glu Tyr Met Arg Glu Glu Leu Lys Arg Glu Gly Ser Glu Glu Trp
355 360 365
Gly Leu Ala Leu Ala Phe Gly Pro Gly Ile Thr Phe Glu Gly Ile Leu
370 375 380
Leu Arg Ser Leu
385
<210> 122
<211> 1185
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Arabidopsis thaliana,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 122
atgtctaatt ctagaatgaa tggagttgaa aagctttctt ctaagtctac tagaagagtt 60
gctaatgctg gaaaggctac tcttcttgct cttggaaagg cttttccatc tcaagttgtt 120
ccacaagaaa atcttgttga aggatttctt agagatacta agtgtgatga tgcttttatt 180
aaggaaaagc ttgaacatct ttgtaagact actactgtta agactagata tactgttctt 240
actagagaaa ttcttgctaa gtatccagaa cttactactg aaggatctcc aactattaag 300
caaagacttg aaattgctaa tgaagctgtt gttgaaatgg ctcttgaagc ttctcttgga 360
tgtattaagg aatggggaag accagttgaa gatattactc atattgttta tgtttcttct 420
tctgaaatta gacttccagg aggagatctt tatctttctg ctaagcttgg acttagaaat 480
gatgttaata gagttatgct ttattttctt ggatgttatg gaggagttac tggacttaga 540
gttgctaagg atattgctga aaataatcca ggatctagag ttcttcttac tacttctgaa 600
actactattc ttggatttag accaccaaat aaggctagac catatgatct tgttggagct 660
gctctttttg gagatggagc tgctgctgtt attattggag ctgatccaag agaatgtgaa 720
gctccattta tggaacttca ttatgctgtt caacaatttc ttccaggaac tcaaaatgtt 780
attgaaggaa gacttactga agaaggaatt aattttaagc ttggaagaga tcttccacaa 840
aagattgaag aaaatattga agaattttgt aagaagctta tgggaaaggc tggagatgaa 900
tctatggaat ttaatgatat gttttgggct gttcatccag gaggaccagc tattcttaat 960
agacttgaaa ctaagcttaa gcttgaaaag gaaaagcttg aatcttctag aagagctctt 1020
gttgattatg gaaatgtttc ttctaatact attctttatg ttatggaata tatgagagat 1080
gaacttaaga agaagggaga tgctgctcaa gaatggggac ttggacttgc ttttggacca 1140
ggaattactt ttgaaggact tcttattaga tctcttactt cttct 1185
<210> 123
<211> 395
<212> PRT
<213> Arabidopsis thaliana
<400> 123
Met Ser Asn Ser Arg Met Asn Gly Val Glu Lys Leu Ser Ser Lys Ser
1 5 10 15
Thr Arg Arg Val Ala Asn Ala Gly Lys Ala Thr Leu Leu Ala Leu Gly
20 25 30
Lys Ala Phe Pro Ser Gln Val Val Pro Gln Glu Asn Leu Val Glu Gly
35 40 45
Phe Leu Arg Asp Thr Lys Cys Asp Asp Ala Phe Ile Lys Glu Lys Leu
50 55 60
Glu His Leu Cys Lys Thr Thr Thr Val Lys Thr Arg Tyr Thr Val Leu
65 70 75 80
Thr Arg Glu Ile Leu Ala Lys Tyr Pro Glu Leu Thr Thr Glu Gly Ser
85 90 95
Pro Thr Ile Lys Gln Arg Leu Glu Ile Ala Asn Glu Ala Val Val Glu
100 105 110
Met Ala Leu Glu Ala Ser Leu Gly Cys Ile Lys Glu Trp Gly Arg Pro
115 120 125
Val Glu Asp Ile Thr His Ile Val Tyr Val Ser Ser Ser Glu Ile Arg
130 135 140
Leu Pro Gly Gly Asp Leu Tyr Leu Ser Ala Lys Leu Gly Leu Arg Asn
145 150 155 160
Asp Val Asn Arg Val Met Leu Tyr Phe Leu Gly Cys Tyr Gly Gly Val
165 170 175
Thr Gly Leu Arg Val Ala Lys Asp Ile Ala Glu Asn Asn Pro Gly Ser
180 185 190
Arg Val Leu Leu Thr Thr Ser Glu Thr Thr Ile Leu Gly Phe Arg Pro
195 200 205
Pro Asn Lys Ala Arg Pro Tyr Asp Leu Val Gly Ala Ala Leu Phe Gly
210 215 220
Asp Gly Ala Ala Ala Val Ile Ile Gly Ala Asp Pro Arg Glu Cys Glu
225 230 235 240
Ala Pro Phe Met Glu Leu His Tyr Ala Val Gln Gln Phe Leu Pro Gly
245 250 255
Thr Gln Asn Val Ile Glu Gly Arg Leu Thr Glu Glu Gly Ile Asn Phe
260 265 270
Lys Leu Gly Arg Asp Leu Pro Gln Lys Ile Glu Glu Asn Ile Glu Glu
275 280 285
Phe Cys Lys Lys Leu Met Gly Lys Ala Gly Asp Glu Ser Met Glu Phe
290 295 300
Asn Asp Met Phe Trp Ala Val His Pro Gly Gly Pro Ala Ile Leu Asn
305 310 315 320
Arg Leu Glu Thr Lys Leu Lys Leu Glu Lys Glu Lys Leu Glu Ser Ser
325 330 335
Arg Arg Ala Leu Val Asp Tyr Gly Asn Val Ser Ser Asn Thr Ile Leu
340 345 350
Tyr Val Met Glu Tyr Met Arg Asp Glu Leu Lys Lys Lys Gly Asp Ala
355 360 365
Ala Gln Glu Trp Gly Leu Gly Leu Ala Phe Gly Pro Gly Ile Thr Phe
370 375 380
Glu Gly Leu Leu Ile Arg Ser Leu Thr Ser Ser
385 390 395
<210> 124
<211> 1197
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Hydrangea macrophylla,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 124
atggctacta agtctgttgc tgttgaagaa atgtgtaagg ctcaaaaggc tggaggacca 60
gctactattc ttgctattgg aactgctgtt ccatctaatt gttattatca atctgaatat 120
ccagattttt attttagagt tactaagtct gatcatctta ctgatcttaa gtctaagttt 180
aagagaatgt gtgaaagatc ttctattaag aagagatata tgcatcttac tgaagaaatt 240
cttgaagaaa atccaaatat gtgtactttt gctgctccat ctattgatgg aagacaagat 300
attgttgtta aggaaattcc aaagcttgct aaggaagctg cttctaaggc tattaaggaa 360
tggggacaac caaagtctaa tattactcat cttgtttttt gtactacttc tggagttgat 420
atgccaggat gtgattatca acttactaga cttcttggac ttagaccatc tattaagaga 480
cttatgatgt atcaacaagg atgtcatgct ggaggaactg gacttagact tgctaaggat 540
cttgctgaaa ataataaggg agctagagtt cttgttgttt gttctgaaat gactgttatt 600
aattttagag gaccatctga agctcatatg gattctcttg ttggacaatc tctttttgga 660
gatggagctt ctgctgttat tgttggatct gatccagatc tttctactga acatccactt 720
tatcaaatta tgtctgcttc tcaaattatt gttgctgatt ctgaaggagc tattgatgga 780
catcttagac aagaaggact tacttttcat cttagaaagg atgttccatc tcttgtttct 840
gataatattg aaaatactct tgttgaagct tttactccaa ttcttatgga ttctattgat 900
tctattattg attggaattc tattttttgg attgctcatc caggaggacc agctattctt 960
aatcaagttc aagctaaggt tggacttaag gaagaaaagc ttagagtttc tagacatatt 1020
ctttctgaat atggaaatat gtcttctgct tgtgtttttt ttattatgga tgaaatgaga 1080
aagagatcta tggaagaagg aaagggaact actggagaag gacttgaatg gggagttctt 1140
tttggatttg gaccaggatt tactgttgaa actattgttc ttcattctgt tccaatt 1197
<210> 125
<211> 399
<212> PRT
<213> Hydrangea macrophylla
<400> 125
Met Ala Thr Lys Ser Val Ala Val Glu Glu Met Cys Lys Ala Gln Lys
1 5 10 15
Ala Gly Gly Pro Ala Thr Ile Leu Ala Ile Gly Thr Ala Val Pro Ser
20 25 30
Asn Cys Tyr Tyr Gln Ser Glu Tyr Pro Asp Phe Tyr Phe Arg Val Thr
35 40 45
Lys Ser Asp His Leu Thr Asp Leu Lys Ser Lys Phe Lys Arg Met Cys
50 55 60
Glu Arg Ser Ser Ile Lys Lys Arg Tyr Met His Leu Thr Glu Glu Ile
65 70 75 80
Leu Glu Glu Asn Pro Asn Met Cys Thr Phe Ala Ala Pro Ser Ile Asp
85 90 95
Gly Arg Gln Asp Ile Val Val Lys Glu Ile Pro Lys Leu Ala Lys Glu
100 105 110
Ala Ala Ser Lys Ala Ile Lys Glu Trp Gly Gln Pro Lys Ser Asn Ile
115 120 125
Thr His Leu Val Phe Cys Thr Thr Ser Gly Val Asp Met Pro Gly Cys
130 135 140
Asp Tyr Gln Leu Thr Arg Leu Leu Gly Leu Arg Pro Ser Ile Lys Arg
145 150 155 160
Leu Met Met Tyr Gln Gln Gly Cys His Ala Gly Gly Thr Gly Leu Arg
165 170 175
Leu Ala Lys Asp Leu Ala Glu Asn Asn Lys Gly Ala Arg Val Leu Val
180 185 190
Val Cys Ser Glu Met Thr Val Ile Asn Phe Arg Gly Pro Ser Glu Ala
195 200 205
His Met Asp Ser Leu Val Gly Gln Ser Leu Phe Gly Asp Gly Ala Ser
210 215 220
Ala Val Ile Val Gly Ser Asp Pro Asp Leu Ser Thr Glu His Pro Leu
225 230 235 240
Tyr Gln Ile Met Ser Ala Ser Gln Ile Ile Val Ala Asp Ser Glu Gly
245 250 255
Ala Ile Asp Gly His Leu Arg Gln Glu Gly Leu Thr Phe His Leu Arg
260 265 270
Lys Asp Val Pro Ser Leu Val Ser Asp Asn Ile Glu Asn Thr Leu Val
275 280 285
Glu Ala Phe Thr Pro Ile Leu Met Asp Ser Ile Asp Ser Ile Ile Asp
290 295 300
Trp Asn Ser Ile Phe Trp Ile Ala His Pro Gly Gly Pro Ala Ile Leu
305 310 315 320
Asn Gln Val Gln Ala Lys Val Gly Leu Lys Glu Glu Lys Leu Arg Val
325 330 335
Ser Arg His Ile Leu Ser Glu Tyr Gly Asn Met Ser Ser Ala Cys Val
340 345 350
Phe Phe Ile Met Asp Glu Met Arg Lys Arg Ser Met Glu Glu Gly Lys
355 360 365
Gly Thr Thr Gly Glu Gly Leu Glu Trp Gly Val Leu Phe Gly Phe Gly
370 375 380
Pro Gly Phe Thr Val Glu Thr Ile Val Leu His Ser Val Pro Ile
385 390 395
<210> 126
<211> 1254
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Physcomitrella patens,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 126
atggcttcta gaagagttga agctgctttt gatggacaag ctgttgaact tggagctact 60
attccagctg ctaatggaaa tggaactcat caatctatta aggttccagg acatagacaa 120
gttactccag gaaagactac tattatggct attggaagag ctgttccagc taatactact 180
tttaatgatg gacttgctga tcattatatt caagaattta atcttcaaga tccagttctt 240
caagctaagc ttagaagact ttgtgaaact actactgtta agactagata tcttgttgtt 300
aataaggaaa ttcttgatga acatccagaa tttcttgttg atggagctgc tactgtttct 360
caaagacttg ctattactgg agaagctgtt actcaacttg gacatgaagc tgctactgct 420
gctattaagg aatggggaag accagcttct gaaattactc atcttgttta tgtttcttct 480
tctgaaatta gacttccagg aggagatctt tatcttgctc aacttcttgg acttagatct 540
gatgttaata gagttatgct ttatatgctt ggatgttatg gaggagcttc tggaattaga 600
gttgctaagg atcttgctga aaataatcca ggatctagag ttcttcttat tacttctgaa 660
tgtactctta ttggatataa gtctctttct ccagatagac catatgatct tgttggagct 720
gctctttttg gagatggagc tgctgctatg attatgggaa aggatccaat tccagttctt 780
gaaagagctt tttttgaact tgattgggct ggacaatctt ttattccagg aactaataag 840
actattgatg gaagactttc tgaagaagga atttctttta agcttggaag agaacttcca 900
aagcttattg aatctaatat tcaaggattt tgtgatccaa ttcttaagag agctggagga 960
cttaagtata atgatatttt ttgggctgtt catccaggag gaccagctat tcttaatgct 1020
gttcaaaagc aacttgatct tgctccagaa aagcttcaaa ctgctagaca agttcttaga 1080
gattatggaa atatttcttc ttctacttgt atttatgttc ttgattatat gagacatcaa 1140
tctcttaagc ttaaggaagc taatgataat gttaatactg aaccagaatg gggacttctt 1200
cttgcttttg gaccaggagt tactattgaa ggagctcttc ttagaaatct ttgt 1254
<210> 127
<211> 397
<212> PRT
<213> Physcomitrella patens
<400> 127
Met Ser Lys Thr Val Glu Asp Arg Ala Ala Gln Arg Ala Lys Gly Pro
1 5 10 15
Ala Thr Val Leu Ala Ile Gly Thr Ala Thr Pro Ala Asn Val Val Tyr
20 25 30
Gln Thr Asp Tyr Pro Asp Tyr Tyr Phe Arg Val Thr Lys Ser Glu His
35 40 45
Met Thr Lys Leu Lys Asn Lys Phe Gln Arg Met Cys Asp Arg Ser Thr
50 55 60
Ile Lys Lys Arg Tyr Met Val Leu Thr Glu Glu Leu Leu Glu Lys Asn
65 70 75 80
Leu Ser Leu Cys Thr Tyr Met Glu Pro Ser Leu Asp Ala Arg Gln Asp
85 90 95
Ile Leu Val Pro Glu Val Pro Lys Leu Gly Lys Glu Ala Ala Asp Glu
100 105 110
Ala Ile Ala Glu Trp Gly Arg Pro Lys Ser Glu Ile Thr His Leu Ile
115 120 125
Phe Cys Thr Thr Cys Gly Val Asp Met Pro Gly Ala Asp Tyr Gln Leu
130 135 140
Thr Lys Leu Leu Gly Leu Arg Ser Ser Val Arg Arg Thr Met Leu Tyr
145 150 155 160
Gln Gln Gly Cys Phe Gly Gly Gly Thr Val Leu Arg Leu Ala Lys Asp
165 170 175
Leu Ala Glu Asn Asn Ala Gly Ala Arg Val Leu Val Val Cys Ser Glu
180 185 190
Ile Thr Thr Ala Val Asn Phe Arg Gly Pro Ser Asp Thr His Leu Asp
195 200 205
Leu Leu Val Gly Leu Ala Leu Phe Gly Asp Gly Ala Ala Ala Val Ile
210 215 220
Val Gly Ala Asp Pro Asp Pro Thr Leu Glu Arg Pro Leu Phe Gln Ile
225 230 235 240
Val Ser Gly Ala Gln Thr Ile Leu Pro Asp Ser Glu Gly Ala Ile Asn
245 250 255
Gly His Leu Arg Glu Val Gly Leu Thr Ile Arg Leu Leu Lys Asp Val
260 265 270
Pro Gly Leu Val Ser Met Asn Ile Glu Lys Cys Leu Met Glu Ala Phe
275 280 285
Ala Pro Met Gly Ile His Asp Trp Asn Ser Ile Phe Trp Ile Ala His
290 295 300
Pro Gly Gly Pro Thr Ile Leu Asp Gln Val Glu Ala Lys Leu Gly Leu
305 310 315 320
Lys Glu Glu Lys Leu Lys Ser Thr Arg Ala Val Leu Arg Glu Tyr Gly
325 330 335
Asn Met Ser Ser Ala Cys Val Leu Phe Ile Leu Asp Glu Val Arg Lys
340 345 350
Arg Ser Met Glu Glu Gly Lys Thr Thr Thr Gly Glu Gly Phe Asp Trp
355 360 365
Gly Val Leu Phe Gly Phe Gly Pro Gly Phe Thr Val Glu Thr Val Val
370 375 380
Leu His Ser Met Pro Ile Pro Lys Ala Asp Glu Gly Arg
385 390 395
<210> 128
<211> 1179
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Polygonum cuspidatum,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 128
atggctccag ctgttgctga tattagaaag gctcaaagag ctgaaggacc agctactgtt 60
cttgctattg gaactgctac tccaccaaat tgtgtttatc aaaaggatta tccagattat 120
tattttagag ttactaattc tgatcatatg actgatctta aggaaaagtt tagaagaatg 180
tgtgaaaagt ctaatattga aaagagatat atgtatctta ctgaagaaat tcttaaggaa 240
aatccaaata tgtgttctta tatgcaaact tcttctcttg atactagaca agatatggtt 300
gtttctgaag ttccaagact tggaaaggaa gctgctcaaa aggctattaa ggaatgggga 360
caaccaaagt ctaagattac tcatgttatt atgtgtacta cttctggagt tgatatgcca 420
ggagctgatt atcaacttac taagcttctt ggacttcatc catctgttaa gagatttatg 480
atgtatcaac aaggatgttt tgctggagga actgttctta gacttgctaa ggatcttgct 540
gaaaataata gaggagctag agttcttgtt gtttgttctg aaattactgc tatttgtttt 600
agaggaccaa ctgatactca tccagattct atggttggac aagctctttt tggagatgga 660
tctggagctg ttattattgg agctgatcca gatctttcta ttgaaaagcc aatttttgaa 720
cttgtttgga ctgctcaaac tattcttcca gattctgaag gagctattga tggacatctt 780
agagaagttg gacttacttt tcatcttctt aaggatgttc caggacttat ttctaagaat 840
attgaaaaga atcttactga agctttttct ccacttaatg tttctgattg gaattctctt 900
ttttggattg ctcatccagg aggaccagct attcttgatc aagttgaaac taagcttgga 960
cttaaggaag aaaagcttaa ggctactaga caagttctta atgattatgg aaatatgtct 1020
tctgcttgtg ttctttttat tatggatgaa atgagaaaga agtctgttga aaatggacat 1080
gctactactg gagaaggact tgaatgggga gttctttttg gatttggacc aggacttact 1140
gttgaaactg ttgttcttca ttctgttcca gttgctaat 1179
<210> 129
<211> 393
<212> PRT
<213> Polygonum cuspidatum
<400> 129
Met Ala Pro Ala Val Ala Asp Ile Arg Lys Ala Gln Arg Ala Glu Gly
1 5 10 15
Pro Ala Thr Val Leu Ala Ile Gly Thr Ala Thr Pro Pro Asn Cys Val
20 25 30
Tyr Gln Lys Asp Tyr Pro Asp Tyr Tyr Phe Arg Val Thr Asn Ser Asp
35 40 45
His Met Thr Asp Leu Lys Glu Lys Phe Arg Arg Met Cys Glu Lys Ser
50 55 60
Asn Ile Glu Lys Arg Tyr Met Tyr Leu Thr Glu Glu Ile Leu Lys Glu
65 70 75 80
Asn Pro Asn Met Cys Ser Tyr Met Gln Thr Ser Ser Leu Asp Thr Arg
85 90 95
Gln Asp Met Val Val Ser Glu Val Pro Arg Leu Gly Lys Glu Ala Ala
100 105 110
Gln Lys Ala Ile Lys Glu Trp Gly Gln Pro Lys Ser Lys Ile Thr His
115 120 125
Val Ile Met Cys Thr Thr Ser Gly Val Asp Met Pro Gly Ala Asp Tyr
130 135 140
Gln Leu Thr Lys Leu Leu Gly Leu His Pro Ser Val Lys Arg Phe Met
145 150 155 160
Met Tyr Gln Gln Gly Cys Phe Ala Gly Gly Thr Val Leu Arg Leu Ala
165 170 175
Lys Asp Leu Ala Glu Asn Asn Arg Gly Ala Arg Val Leu Val Val Cys
180 185 190
Ser Glu Ile Thr Ala Ile Cys Phe Arg Gly Pro Thr Asp Thr His Pro
195 200 205
Asp Ser Met Val Gly Gln Ala Leu Phe Gly Asp Gly Ser Gly Ala Val
210 215 220
Ile Ile Gly Ala Asp Pro Asp Leu Ser Ile Glu Lys Pro Ile Phe Glu
225 230 235 240
Leu Val Trp Thr Ala Gln Thr Ile Leu Pro Asp Ser Glu Gly Ala Ile
245 250 255
Asp Gly His Leu Arg Glu Val Gly Leu Thr Phe His Leu Leu Lys Asp
260 265 270
Val Pro Gly Leu Ile Ser Lys Asn Ile Glu Lys Asn Leu Thr Glu Ala
275 280 285
Phe Ser Pro Leu Asn Val Ser Asp Trp Asn Ser Leu Phe Trp Ile Ala
290 295 300
His Pro Gly Gly Pro Ala Ile Leu Asp Gln Val Glu Thr Lys Leu Gly
305 310 315 320
Leu Lys Glu Glu Lys Leu Lys Ala Thr Arg Gln Val Leu Asn Asp Tyr
325 330 335
Gly Asn Met Ser Ser Ala Cys Val Leu Phe Ile Met Asp Glu Met Arg
340 345 350
Lys Lys Ser Val Glu Asn Gly His Ala Thr Thr Gly Glu Gly Leu Glu
355 360 365
Trp Gly Val Leu Phe Gly Phe Gly Pro Gly Leu Thr Val Glu Thr Val
370 375 380
Val Leu His Ser Val Pro Val Ala Asn
385 390
<210> 130
<211> 1152
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность мутанта L132S PKS из Rheum
palmatum, оптимизированная для экпрессии в Nicotiana benthamiana
<400> 130
atggctactg aagaaatgaa gaagcttgct actgttatgg ctattggaac tgctaatcca 60
ccaaattgtt attatcaagc tgattttcca gatttttatt ttagagttac taattctgat 120
catcttatta atcttaagca aaagtttaag agactttgtg aaaattctag aattgaaaag 180
agatatcttc atgttactga agaaattctt aaggaaaatc caaatattgc tgcttatgaa 240
gctacttctc ttaatgttag acataagatg caagttaagg gagttgctga acttggaaag 300
gaagctgctc ttaaggctat taaggaatgg ggacaaccaa agtctaagat tactcatctt 360
attgtttgtt gttctgctgg agttgatatg ccaggagctg attatcaact tactaagctt 420
cttgatcttg atccatctgt taagagattt atgttttatc atcttggatg ttatgctgga 480
ggaactgttc ttagacttgc taaggatatt gctgaaaata ataagggagc tagagttctt 540
attgtttgtt ctgaaatgac tactacttgt tttagaggac catctgaaac tcatcttgat 600
tctatgattg gacaagctat tcttggagat ggagctgctg ctgttattgt tggagctgat 660
ccagatctta ctgttgaaag accaattttt gaacttgttt ctactgctca aactattgtt 720
ccagaatctc atggagctat tgaaggacat cttcttgaat ctggactttc ttttcatctt 780
tataagactg ttccaactct tatttctaat aatattaaga cttgtctttc tgatgctttt 840
actccactta atatttctga ttggaattct cttttttgga ttgctcatcc aggaggacca 900
gctattcttg atcaagttac tgctaaggtt ggacttgaaa aggaaaagct taaggttact 960
agacaagttc ttaaggatta tggaaatatg tcttctgcta ctgttttttt tattatggat 1020
gaaatgagaa agaagtctct tgaaaatgga caagctacta ctggagaagg acttgaatgg 1080
ggagttcttt ttggatttgg accaggaatt actgttgaaa ctgttgttct tagatctgtt 1140
ccagttattt ct 1152
<210> 131
<211> 384
<212> PRT
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность мутанта L132S PKS из Rheum
palmatum, оптимизированная для экпрессии в Nicotiana benthamiana
<400> 131
Met Ala Thr Glu Glu Met Lys Lys Leu Ala Thr Val Met Ala Ile Gly
1 5 10 15
Thr Ala Asn Pro Pro Asn Cys Tyr Tyr Gln Ala Asp Phe Pro Asp Phe
20 25 30
Tyr Phe Arg Val Thr Asn Ser Asp His Leu Ile Asn Leu Lys Gln Lys
35 40 45
Phe Lys Arg Leu Cys Glu Asn Ser Arg Ile Glu Lys Arg Tyr Leu His
50 55 60
Val Thr Glu Glu Ile Leu Lys Glu Asn Pro Asn Ile Ala Ala Tyr Glu
65 70 75 80
Ala Thr Ser Leu Asn Val Arg His Lys Met Gln Val Lys Gly Val Ala
85 90 95
Glu Leu Gly Lys Glu Ala Ala Leu Lys Ala Ile Lys Glu Trp Gly Gln
100 105 110
Pro Lys Ser Lys Ile Thr His Leu Ile Val Cys Cys Ser Ala Gly Val
115 120 125
Asp Met Pro Gly Ala Asp Tyr Gln Leu Thr Lys Leu Leu Asp Leu Asp
130 135 140
Pro Ser Val Lys Arg Phe Met Phe Tyr His Leu Gly Cys Tyr Ala Gly
145 150 155 160
Gly Thr Val Leu Arg Leu Ala Lys Asp Ile Ala Glu Asn Asn Lys Gly
165 170 175
Ala Arg Val Leu Ile Val Cys Ser Glu Met Thr Thr Thr Cys Phe Arg
180 185 190
Gly Pro Ser Glu Thr His Leu Asp Ser Met Ile Gly Gln Ala Ile Leu
195 200 205
Gly Asp Gly Ala Ala Ala Val Ile Val Gly Ala Asp Pro Asp Leu Thr
210 215 220
Val Glu Arg Pro Ile Phe Glu Leu Val Ser Thr Ala Gln Thr Ile Val
225 230 235 240
Pro Glu Ser His Gly Ala Ile Glu Gly His Leu Leu Glu Ser Gly Leu
245 250 255
Ser Phe His Leu Tyr Lys Thr Val Pro Thr Leu Ile Ser Asn Asn Ile
260 265 270
Lys Thr Cys Leu Ser Asp Ala Phe Thr Pro Leu Asn Ile Ser Asp Trp
275 280 285
Asn Ser Leu Phe Trp Ile Ala His Pro Gly Gly Pro Ala Ile Leu Asp
290 295 300
Gln Val Thr Ala Lys Val Gly Leu Glu Lys Glu Lys Leu Lys Val Thr
305 310 315 320
Arg Gln Val Leu Lys Asp Tyr Gly Asn Met Ser Ser Ala Thr Val Phe
325 330 335
Phe Ile Met Asp Glu Met Arg Lys Lys Ser Leu Glu Asn Gly Gln Ala
340 345 350
Thr Thr Gly Glu Gly Leu Glu Trp Gly Val Leu Phe Gly Phe Gly Pro
355 360 365
Gly Ile Thr Val Glu Thr Val Val Leu Arg Ser Val Pro Val Ile Ser
370 375 380
<210> 132
<211> 1173
<212> PRT
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Rheum tataricum,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 132
Ala Thr Gly Gly Cys Thr Cys Cys Ala Gly Ala Ala Gly Ala Ala Thr
1 5 10 15
Cys Thr Ala Gly Ala Cys Ala Thr Gly Cys Thr Gly Ala Ala Ala Cys
20 25 30
Thr Gly Cys Thr Gly Thr Thr Ala Ala Thr Ala Gly Ala Gly Cys Thr
35 40 45
Gly Cys Thr Ala Cys Thr Gly Thr Thr Cys Thr Thr Gly Cys Thr Ala
50 55 60
Thr Thr Gly Gly Ala Ala Cys Thr Gly Cys Thr Ala Ala Thr Cys Cys
65 70 75 80
Ala Cys Cys Ala Ala Ala Thr Thr Gly Thr Thr Ala Thr Thr Ala Thr
85 90 95
Cys Ala Ala Gly Cys Thr Gly Ala Thr Thr Thr Thr Cys Cys Ala Gly
100 105 110
Ala Thr Thr Thr Thr Thr Ala Thr Thr Thr Thr Ala Gly Ala Gly Cys
115 120 125
Thr Ala Cys Thr Ala Ala Thr Thr Cys Thr Gly Ala Thr Cys Ala Thr
130 135 140
Cys Thr Thr Ala Cys Thr Cys Ala Thr Cys Thr Thr Ala Ala Gly Cys
145 150 155 160
Ala Ala Ala Ala Gly Thr Thr Thr Ala Ala Gly Ala Gly Ala Ala Thr
165 170 175
Thr Thr Gly Thr Gly Ala Ala Ala Ala Gly Thr Cys Thr Ala Thr Gly
180 185 190
Ala Thr Thr Gly Ala Ala Ala Ala Gly Ala Gly Ala Thr Ala Thr Cys
195 200 205
Thr Thr Cys Ala Thr Cys Thr Thr Ala Cys Thr Gly Ala Ala Gly Ala
210 215 220
Ala Ala Thr Thr Cys Thr Thr Ala Ala Gly Gly Ala Ala Ala Ala Thr
225 230 235 240
Cys Cys Ala Ala Ala Thr Ala Thr Thr Gly Cys Thr Thr Cys Thr Thr
245 250 255
Thr Thr Gly Ala Ala Gly Cys Thr Cys Cys Ala Thr Cys Thr Cys Thr
260 265 270
Thr Gly Ala Thr Gly Thr Thr Ala Gly Ala Cys Ala Thr Ala Ala Thr
275 280 285
Ala Thr Thr Cys Ala Ala Gly Thr Thr Ala Ala Gly Gly Ala Ala Gly
290 295 300
Thr Thr Gly Thr Thr Cys Thr Thr Cys Thr Thr Gly Gly Ala Ala Ala
305 310 315 320
Gly Gly Ala Ala Gly Cys Thr Gly Cys Thr Cys Thr Thr Ala Ala Gly
325 330 335
Gly Cys Thr Ala Thr Thr Ala Ala Thr Gly Ala Ala Thr Gly Gly Gly
340 345 350
Gly Ala Cys Ala Ala Cys Cys Ala Ala Ala Gly Thr Cys Thr Ala Ala
355 360 365
Gly Ala Thr Thr Ala Cys Thr Ala Gly Ala Cys Thr Thr Ala Thr Thr
370 375 380
Gly Thr Thr Thr Gly Thr Thr Gly Thr Ala Thr Thr Gly Cys Thr Gly
385 390 395 400
Gly Ala Gly Thr Thr Gly Ala Thr Ala Thr Gly Cys Cys Ala Gly Gly
405 410 415
Ala Gly Cys Thr Gly Ala Thr Thr Ala Thr Cys Ala Ala Cys Thr Thr
420 425 430
Ala Cys Thr Ala Ala Gly Cys Thr Thr Cys Thr Thr Gly Gly Ala Cys
435 440 445
Thr Thr Cys Ala Ala Cys Thr Thr Thr Cys Thr Gly Thr Thr Ala Ala
450 455 460
Gly Ala Gly Ala Thr Thr Thr Ala Thr Gly Thr Thr Thr Thr Ala Thr
465 470 475 480
Cys Ala Thr Cys Thr Thr Gly Gly Ala Thr Gly Thr Thr Ala Thr Gly
485 490 495
Cys Thr Gly Gly Ala Gly Gly Ala Ala Cys Thr Gly Thr Thr Cys Thr
500 505 510
Thr Ala Gly Ala Cys Thr Thr Gly Cys Thr Ala Ala Gly Gly Ala Thr
515 520 525
Ala Thr Thr Gly Cys Thr Gly Ala Ala Ala Ala Thr Ala Ala Thr Ala
530 535 540
Ala Gly Gly Ala Ala Gly Cys Thr Ala Gly Ala Gly Thr Thr Cys Thr
545 550 555 560
Thr Ala Thr Thr Gly Thr Thr Ala Gly Ala Thr Cys Thr Gly Ala Ala
565 570 575
Ala Thr Gly Ala Cys Thr Cys Cys Ala Ala Thr Thr Thr Gly Thr Thr
580 585 590
Thr Thr Ala Gly Ala Gly Gly Ala Cys Cys Ala Thr Cys Thr Gly Ala
595 600 605
Ala Ala Cys Thr Cys Ala Thr Ala Thr Thr Gly Ala Thr Thr Cys Thr
610 615 620
Ala Thr Gly Gly Thr Thr Gly Gly Ala Cys Ala Ala Gly Cys Thr Ala
625 630 635 640
Thr Thr Thr Thr Thr Gly Gly Ala Gly Ala Thr Gly Gly Ala Gly Cys
645 650 655
Thr Gly Cys Thr Gly Cys Thr Gly Thr Thr Ala Thr Thr Gly Thr Thr
660 665 670
Gly Gly Ala Gly Cys Thr Ala Ala Thr Cys Cys Ala Gly Ala Thr Cys
675 680 685
Thr Thr Thr Cys Thr Ala Thr Thr Gly Ala Ala Ala Gly Ala Cys Cys
690 695 700
Ala Ala Thr Thr Thr Thr Thr Gly Ala Ala Cys Thr Thr Ala Thr Thr
705 710 715 720
Thr Cys Thr Ala Cys Thr Thr Cys Thr Cys Ala Ala Ala Cys Thr Ala
725 730 735
Thr Thr Ala Thr Thr Cys Cys Ala Gly Ala Ala Thr Cys Thr Gly Ala
740 745 750
Thr Gly Gly Ala Gly Cys Thr Ala Thr Thr Gly Ala Ala Gly Gly Ala
755 760 765
Cys Ala Thr Cys Thr Thr Cys Thr Thr Gly Ala Ala Gly Thr Thr Gly
770 775 780
Gly Ala Cys Thr Thr Thr Cys Thr Thr Thr Thr Cys Ala Ala Cys Thr
785 790 795 800
Thr Thr Ala Thr Cys Ala Ala Ala Cys Thr Gly Thr Thr Cys Cys Ala
805 810 815
Thr Cys Thr Cys Thr Thr Ala Thr Thr Thr Cys Thr Ala Ala Thr Thr
820 825 830
Gly Thr Ala Thr Thr Gly Ala Ala Ala Cys Thr Thr Gly Thr Cys Thr
835 840 845
Thr Thr Cys Thr Ala Ala Gly Gly Cys Thr Thr Thr Thr Ala Cys Thr
850 855 860
Cys Cys Ala Cys Thr Thr Ala Ala Thr Ala Thr Thr Thr Cys Thr Gly
865 870 875 880
Ala Thr Thr Gly Gly Ala Ala Thr Thr Cys Thr Cys Thr Thr Thr Thr
885 890 895
Thr Thr Gly Gly Ala Thr Thr Gly Cys Thr Cys Ala Thr Cys Cys Ala
900 905 910
Gly Gly Ala Gly Gly Ala Ala Gly Ala Gly Cys Thr Ala Thr Thr Cys
915 920 925
Thr Thr Gly Ala Thr Gly Ala Thr Ala Thr Thr Gly Ala Ala Gly Cys
930 935 940
Thr Ala Cys Thr Gly Thr Thr Gly Gly Ala Cys Thr Thr Ala Ala Gly
945 950 955 960
Ala Ala Gly Gly Ala Ala Ala Ala Gly Cys Thr Thr Ala Ala Gly Gly
965 970 975
Cys Thr Ala Cys Thr Ala Gly Ala Cys Ala Ala Gly Thr Thr Cys Thr
980 985 990
Thr Ala Ala Thr Gly Ala Thr Thr Ala Thr Gly Gly Ala Ala Ala Thr
995 1000 1005
Ala Thr Gly Thr Cys Thr Thr Cys Thr Gly Cys Thr Thr Gly Thr
1010 1015 1020
Gly Thr Thr Thr Thr Thr Thr Thr Thr Ala Thr Thr Ala Thr Gly
1025 1030 1035
Gly Ala Thr Gly Ala Ala Ala Thr Gly Ala Gly Ala Ala Ala Gly
1040 1045 1050
Ala Ala Gly Thr Cys Thr Cys Thr Thr Gly Cys Thr Ala Ala Thr
1055 1060 1065
Gly Gly Ala Cys Ala Ala Gly Thr Thr Ala Cys Thr Ala Cys Thr
1070 1075 1080
Gly Gly Ala Gly Ala Ala Gly Gly Ala Cys Thr Thr Ala Ala Gly
1085 1090 1095
Thr Gly Gly Gly Gly Ala Gly Thr Thr Cys Thr Thr Thr Thr Thr
1100 1105 1110
Gly Gly Ala Thr Thr Thr Gly Gly Ala Cys Cys Ala Gly Gly Ala
1115 1120 1125
Gly Thr Thr Ala Cys Thr Gly Thr Thr Gly Ala Ala Ala Cys Thr
1130 1135 1140
Gly Thr Thr Gly Thr Thr Cys Thr Thr Thr Cys Thr Thr Cys Thr
1145 1150 1155
Gly Thr Thr Cys Cys Ala Cys Thr Thr Ala Thr Thr Ala Cys Thr
1160 1165 1170
<210> 133
<211> 391
<212> PRT
<213> Rheum tataricum
<400> 133
Met Ala Pro Glu Glu Ser Arg His Ala Glu Thr Ala Val Asn Arg Ala
1 5 10 15
Ala Thr Val Leu Ala Ile Gly Thr Ala Asn Pro Pro Asn Cys Tyr Tyr
20 25 30
Gln Ala Asp Phe Pro Asp Phe Tyr Phe Arg Ala Thr Asn Ser Asp His
35 40 45
Leu Thr His Leu Lys Gln Lys Phe Lys Arg Ile Cys Glu Lys Ser Met
50 55 60
Ile Glu Lys Arg Tyr Leu His Leu Thr Glu Glu Ile Leu Lys Glu Asn
65 70 75 80
Pro Asn Ile Ala Ser Phe Glu Ala Pro Ser Leu Asp Val Arg His Asn
85 90 95
Ile Gln Val Lys Glu Val Val Leu Leu Gly Lys Glu Ala Ala Leu Lys
100 105 110
Ala Ile Asn Glu Trp Gly Gln Pro Lys Ser Lys Ile Thr Arg Leu Ile
115 120 125
Val Cys Cys Ile Ala Gly Val Asp Met Pro Gly Ala Asp Tyr Gln Leu
130 135 140
Thr Lys Leu Leu Gly Leu Gln Leu Ser Val Lys Arg Phe Met Phe Tyr
145 150 155 160
His Leu Gly Cys Tyr Ala Gly Gly Thr Val Leu Arg Leu Ala Lys Asp
165 170 175
Ile Ala Glu Asn Asn Lys Glu Ala Arg Val Leu Ile Val Arg Ser Glu
180 185 190
Met Thr Pro Ile Cys Phe Arg Gly Pro Ser Glu Thr His Ile Asp Ser
195 200 205
Met Val Gly Gln Ala Ile Phe Gly Asp Gly Ala Ala Ala Val Ile Val
210 215 220
Gly Ala Asn Pro Asp Leu Ser Ile Glu Arg Pro Ile Phe Glu Leu Ile
225 230 235 240
Ser Thr Ser Gln Thr Ile Ile Pro Glu Ser Asp Gly Ala Ile Glu Gly
245 250 255
His Leu Leu Glu Val Gly Leu Ser Phe Gln Leu Tyr Gln Thr Val Pro
260 265 270
Ser Leu Ile Ser Asn Cys Ile Glu Thr Cys Leu Ser Lys Ala Phe Thr
275 280 285
Pro Leu Asn Ile Ser Asp Trp Asn Ser Leu Phe Trp Ile Ala His Pro
290 295 300
Gly Gly Arg Ala Ile Leu Asp Asp Ile Glu Ala Thr Val Gly Leu Lys
305 310 315 320
Lys Glu Lys Leu Lys Ala Thr Arg Gln Val Leu Asn Asp Tyr Gly Asn
325 330 335
Met Ser Ser Ala Cys Val Phe Phe Ile Met Asp Glu Met Arg Lys Lys
340 345 350
Ser Leu Ala Asn Gly Gln Val Thr Thr Gly Glu Gly Leu Lys Trp Gly
355 360 365
Val Leu Phe Gly Phe Gly Pro Gly Val Thr Val Glu Thr Val Val Leu
370 375 380
Ser Ser Val Pro Leu Ile Thr
385 390
<210> 134
<211> 1182
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS из Wachendorfia thyrsiflora,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 134
atggcttcta ctgaaggaat tcaagcttat agaaataata tggctgaagg accagctact 60
attatggcta ttggaactgc taatccacca aatgttgttg atgcttctac ttttccagat 120
tattattgga gagttactaa ttctgaacat ctttctccag aatatagagt taagcttaag 180
agaatttgtg aaagatcttc tattagaaag agacatcttg ttcttactga acaacttctt 240
aaggaaaatc caactcttac tacttatgtt gatgcttctt atgatgaaag acaatctatt 300
gttcttgatg ctgttccaaa gcttgcttgt gaagctgctg ctaaggctat taaggaatgg 360
ggaagaccaa agactgatat tactcatatg gttgtttgta ctggagctgg agttgatgtt 420
ccaggagttg attataagat gatgaatctt cttggacttc caccaactgt taatagagtt 480
atgctttata atgttggatg tcatgcttct ggaactgttc ttagaattgc taaggatctt 540
gctgaaaata ataagggagc tagagttctt gttgtttctt ctgaagtttc tgttatgttt 600
tttagaggac cagctgaagg agatgttgaa attcttcttg gacaagctct ttttggagat 660
ggatctgctg ctattattgt tggagctgat ccaattgaag gagttgaaaa gccaattttt 720
caaatttttt ctgcttctca aatgactctt ccagaaggag aacatcttgt tgctggacat 780
cttagagaac ttggacttac ttttcatctt aagccacaac ttccaaatac tgtttcttct 840
aatattcata agccacttaa gaaggctttt gaaccactta atattactga ttggaattct 900
attttttgga ttgttcatcc aggaggaaga gctattcttg atcaagttca agaaaagatt 960
ggacttgaag aaaataagct tgatgtttct agatatgttc ttgctgaaaa tggaaatatg 1020
atgtctgctt ctgttttttt tattatggat gaaatgagaa agagatctgc tgctcaagga 1080
tgttctacta ctggagaagg acatgaatgg ggagttcttt ttggatttgg accaggactt 1140
tctattgaaa ctgttgttct tcattctgtt ccactttcta tt 1182
<210> 135
<211> 394
<212> PRT
<213> Wachendorfia thyrsiflora
<400> 135
Met Ala Ser Thr Glu Gly Ile Gln Ala Tyr Arg Asn Asn Met Ala Glu
1 5 10 15
Gly Pro Ala Thr Ile Met Ala Ile Gly Thr Ala Asn Pro Pro Asn Val
20 25 30
Val Asp Ala Ser Thr Phe Pro Asp Tyr Tyr Trp Arg Val Thr Asn Ser
35 40 45
Glu His Leu Ser Pro Glu Tyr Arg Val Lys Leu Lys Arg Ile Cys Glu
50 55 60
Arg Ser Ser Ile Arg Lys Arg His Leu Val Leu Thr Glu Gln Leu Leu
65 70 75 80
Lys Glu Asn Pro Thr Leu Thr Thr Tyr Val Asp Ala Ser Tyr Asp Glu
85 90 95
Arg Gln Ser Ile Val Leu Asp Ala Val Pro Lys Leu Ala Cys Glu Ala
100 105 110
Ala Ala Lys Ala Ile Lys Glu Trp Gly Arg Pro Lys Thr Asp Ile Thr
115 120 125
His Met Val Val Cys Thr Gly Ala Gly Val Asp Val Pro Gly Val Asp
130 135 140
Tyr Lys Met Met Asn Leu Leu Gly Leu Pro Pro Thr Val Asn Arg Val
145 150 155 160
Met Leu Tyr Asn Val Gly Cys His Ala Ser Gly Thr Val Leu Arg Ile
165 170 175
Ala Lys Asp Leu Ala Glu Asn Asn Lys Gly Ala Arg Val Leu Val Val
180 185 190
Ser Ser Glu Val Ser Val Met Phe Phe Arg Gly Pro Ala Glu Gly Asp
195 200 205
Val Glu Ile Leu Leu Gly Gln Ala Leu Phe Gly Asp Gly Ser Ala Ala
210 215 220
Ile Ile Val Gly Ala Asp Pro Ile Glu Gly Val Glu Lys Pro Ile Phe
225 230 235 240
Gln Ile Phe Ser Ala Ser Gln Met Thr Leu Pro Glu Gly Glu His Leu
245 250 255
Val Ala Gly His Leu Arg Glu Leu Gly Leu Thr Phe His Leu Lys Pro
260 265 270
Gln Leu Pro Asn Thr Val Ser Ser Asn Ile His Lys Pro Leu Lys Lys
275 280 285
Ala Phe Glu Pro Leu Asn Ile Thr Asp Trp Asn Ser Ile Phe Trp Ile
290 295 300
Val His Pro Gly Gly Arg Ala Ile Leu Asp Gln Val Gln Glu Lys Ile
305 310 315 320
Gly Leu Glu Glu Asn Lys Leu Asp Val Ser Arg Tyr Val Leu Ala Glu
325 330 335
Asn Gly Asn Met Met Ser Ala Ser Val Phe Phe Ile Met Asp Glu Met
340 345 350
Arg Lys Arg Ser Ala Ala Gln Gly Cys Ser Thr Thr Gly Glu Gly His
355 360 365
Glu Trp Gly Val Leu Phe Gly Phe Gly Pro Gly Leu Ser Ile Glu Thr
370 375 380
Val Val Leu His Ser Val Pro Leu Ser Ile
385 390
<210> 136
<211> 1191
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS1 из Piper methysticum,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 136
atgtctaaga ctgttgaaga tagagctgct caaagagcta agggaccagc tactgttctt 60
gctattggaa ctgctactcc agctaatgtt gtttatcaaa ctgattatcc agattattat 120
tttagagtta ctaagtctga acatatgact aagcttaaga ataagtttca aagaatgtgt 180
gatagatcta ctattaagaa gagatatatg gttcttactg aagaacttct tgaaaagaat 240
ctttctcttt gtacttatat ggaaccatct cttgatgcta gacaagatat tcttgttcca 300
gaagttccaa agcttggaaa ggaagctgct gatgaagcta ttgctgaatg gggaagacca 360
aagtctgaaa ttactcatct tattttttgt actacttgtg gagttgatat gccaggagct 420
gattatcaac ttactaagct tcttggactt agatcttctg ttagaagaac tatgctttat 480
caacaaggat gttttggagg aggaactgtt cttagacttg ctaaggatct tgctgaaaat 540
aatgctggag ctagagttct tgttgtttgt tctgaaatta ctactgctgt taattttaga 600
ggaccatctg atactcatct tgatcttctt gttggacttg ctctttttgg agatggagct 660
gctgctgtta ttgttggagc tgatccagat ccaactcttg aaagaccact ttttcaaatt 720
gtttctggag ctcaaactat tcttccagat tctgaaggag ctattaatgg acatcttaga 780
gaagttggac ttactattag acttcttaag gatgttccag gacttgtttc tatgaatatt 840
gaaaagtgtc ttatggaagc ttttgctcca atgggaattc atgattggaa ttctattttt 900
tggattgctc atccaggagg accaactatt cttgatcaag ttgaagctaa gcttggactt 960
aaggaagaaa agcttaagtc tactagagct gttcttagag aatatggaaa tatgtcttct 1020
gcttgtgttc tttttattct tgatgaagtt agaaagagat ctatggaaga aggaaagact 1080
actactggag aaggatttga ttggggagtt ctttttggat ttggaccagg atttactgtt 1140
gaaactgttg ttcttcattc tatgccaatt ccaaaggctg atgaaggaag a 1191
<210> 137
<211> 397
<212> PRT
<213> Piper methysticum
<400> 137
Met Ser Lys Thr Val Glu Asp Arg Ala Ala Gln Arg Ala Lys Gly Pro
1 5 10 15
Ala Thr Val Leu Ala Ile Gly Thr Ala Thr Pro Ala Asn Val Val Tyr
20 25 30
Gln Thr Asp Tyr Pro Asp Tyr Tyr Phe Arg Val Thr Lys Ser Glu His
35 40 45
Met Thr Lys Leu Lys Asn Lys Phe Gln Arg Met Cys Asp Arg Ser Thr
50 55 60
Ile Lys Lys Arg Tyr Met Val Leu Thr Glu Glu Leu Leu Glu Lys Asn
65 70 75 80
Leu Ser Leu Cys Thr Tyr Met Glu Pro Ser Leu Asp Ala Arg Gln Asp
85 90 95
Ile Leu Val Pro Glu Val Pro Lys Leu Gly Lys Glu Ala Ala Asp Glu
100 105 110
Ala Ile Ala Glu Trp Gly Arg Pro Lys Ser Glu Ile Thr His Leu Ile
115 120 125
Phe Cys Thr Thr Cys Gly Val Asp Met Pro Gly Ala Asp Tyr Gln Leu
130 135 140
Thr Lys Leu Leu Gly Leu Arg Ser Ser Val Arg Arg Thr Met Leu Tyr
145 150 155 160
Gln Gln Gly Cys Phe Gly Gly Gly Thr Val Leu Arg Leu Ala Lys Asp
165 170 175
Leu Ala Glu Asn Asn Ala Gly Ala Arg Val Leu Val Val Cys Ser Glu
180 185 190
Ile Thr Thr Ala Val Asn Phe Arg Gly Pro Ser Asp Thr His Leu Asp
195 200 205
Leu Leu Val Gly Leu Ala Leu Phe Gly Asp Gly Ala Ala Ala Val Ile
210 215 220
Val Gly Ala Asp Pro Asp Pro Thr Leu Glu Arg Pro Leu Phe Gln Ile
225 230 235 240
Val Ser Gly Ala Gln Thr Ile Leu Pro Asp Ser Glu Gly Ala Ile Asn
245 250 255
Gly His Leu Arg Glu Val Gly Leu Thr Ile Arg Leu Leu Lys Asp Val
260 265 270
Pro Gly Leu Val Ser Met Asn Ile Glu Lys Cys Leu Met Glu Ala Phe
275 280 285
Ala Pro Met Gly Ile His Asp Trp Asn Ser Ile Phe Trp Ile Ala His
290 295 300
Pro Gly Gly Pro Thr Ile Leu Asp Gln Val Glu Ala Lys Leu Gly Leu
305 310 315 320
Lys Glu Glu Lys Leu Lys Ser Thr Arg Ala Val Leu Arg Glu Tyr Gly
325 330 335
Asn Met Ser Ser Ala Cys Val Leu Phe Ile Leu Asp Glu Val Arg Lys
340 345 350
Arg Ser Met Glu Glu Gly Lys Thr Thr Thr Gly Glu Gly Phe Asp Trp
355 360 365
Gly Val Leu Phe Gly Phe Gly Pro Gly Phe Thr Val Glu Thr Val Val
370 375 380
Leu His Ser Met Pro Ile Pro Lys Ala Asp Glu Gly Arg
385 390 395
<210> 138
<211> 1182
<212> DNA
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность PKS2 из Piper methysticum,
оптимизированная для экпрессии в Nicotiana benthamiana
<400> 138
atgtctaaga tggttgaaga acattgggct gctcaaagag ctagaggacc agctactgtt 60
cttgctattg gaactgctaa tccaccaaat gttctttatc aagctgatta tccagatttt 120
tattttagag ttactaagtc tgaacatatg actcaactta aggaaaagtt taagagaatt 180
tgtgataagt ctgctattag aaagagacat cttcatctta ctgaagaact tcttgaaaag 240
aatccaaata tttgtgctca tatggctcca tctcttgatg ctagacaaga tattgctgtt 300
gttgaagttc caaagcttgc taaggaagct gctactaagg ctattaagga atggggaaga 360
ccaaagtctg atattactca tcttattttt tgtactactt gtggagttga tatgccagga 420
gctgattatc aacttactac tcttcttgga cttagaccaa ctgttagaag aactatgctt 480
tatcaacaag gatgttttgc tggaggaact gttcttagac atgctaagga ttttgctgaa 540
aataatagag gagctagagt tcttgctgtt tgttctgaat ttactgttat gaatttttct 600
ggaccatctg aagctcatct tgattctatg gttggaatgg ctctttttgg agatggagct 660
tctgctgtta ttgttggagc tgatccagat tttgctattg aaagaccact ttttcaactt 720
gtttctacta ctcaaactat tgttccagat tctgatggag ctattaagtg tcatcttaag 780
gaagttggac ttactcttca tcttgttaag aatgttccag atcttatttc taataatatg 840
gataagattc ttgaagaagc ttttgctcca cttggaatta gagattggaa ttctattttt 900
tggactgctc atccaggagg agctgctatt cttgatcaac ttgaagctaa gcttggactt 960
aataaggaaa agcttaagac tactagaact gttcttagag aatatggaaa tatgtcttct 1020
gcttgtgttt gttttgttct tgatgaaatg agaagatctt ctcttgaaga aggaaagact 1080
acttctggag aaggacttga atggggaatt cttcttggat ttggaccagg acttactgtt 1140
gaaactgttg ttcttagatc tgttccaatt tctactgcta at 1182
<210> 139
<211> 394
<212> PRT
<213> Piper methysticum
<400> 139
Met Ser Lys Met Val Glu Glu His Trp Ala Ala Gln Arg Ala Arg Gly
1 5 10 15
Pro Ala Thr Val Leu Ala Ile Gly Thr Ala Asn Pro Pro Asn Val Leu
20 25 30
Tyr Gln Ala Asp Tyr Pro Asp Phe Tyr Phe Arg Val Thr Lys Ser Glu
35 40 45
His Met Thr Gln Leu Lys Glu Lys Phe Lys Arg Ile Cys Asp Lys Ser
50 55 60
Ala Ile Arg Lys Arg His Leu His Leu Thr Glu Glu Leu Leu Glu Lys
65 70 75 80
Asn Pro Asn Ile Cys Ala His Met Ala Pro Ser Leu Asp Ala Arg Gln
85 90 95
Asp Ile Ala Val Val Glu Val Pro Lys Leu Ala Lys Glu Ala Ala Thr
100 105 110
Lys Ala Ile Lys Glu Trp Gly Arg Pro Lys Ser Asp Ile Thr His Leu
115 120 125
Ile Phe Cys Thr Thr Cys Gly Val Asp Met Pro Gly Ala Asp Tyr Gln
130 135 140
Leu Thr Thr Leu Leu Gly Leu Arg Pro Thr Val Arg Arg Thr Met Leu
145 150 155 160
Tyr Gln Gln Gly Cys Phe Ala Gly Gly Thr Val Leu Arg His Ala Lys
165 170 175
Asp Phe Ala Glu Asn Asn Arg Gly Ala Arg Val Leu Ala Val Cys Ser
180 185 190
Glu Phe Thr Val Met Asn Phe Ser Gly Pro Ser Glu Ala His Leu Asp
195 200 205
Ser Met Val Gly Met Ala Leu Phe Gly Asp Gly Ala Ser Ala Val Ile
210 215 220
Val Gly Ala Asp Pro Asp Phe Ala Ile Glu Arg Pro Leu Phe Gln Leu
225 230 235 240
Val Ser Thr Thr Gln Thr Ile Val Pro Asp Ser Asp Gly Ala Ile Lys
245 250 255
Cys His Leu Lys Glu Val Gly Leu Thr Leu His Leu Val Lys Asn Val
260 265 270
Pro Asp Leu Ile Ser Asn Asn Met Asp Lys Ile Leu Glu Glu Ala Phe
275 280 285
Ala Pro Leu Gly Ile Arg Asp Trp Asn Ser Ile Phe Trp Thr Ala His
290 295 300
Pro Gly Gly Ala Ala Ile Leu Asp Gln Leu Glu Ala Lys Leu Gly Leu
305 310 315 320
Asn Lys Glu Lys Leu Lys Thr Thr Arg Thr Val Leu Arg Glu Tyr Gly
325 330 335
Asn Met Ser Ser Ala Cys Val Cys Phe Val Leu Asp Glu Met Arg Arg
340 345 350
Ser Ser Leu Glu Glu Gly Lys Thr Thr Ser Gly Glu Gly Leu Glu Trp
355 360 365
Gly Ile Leu Leu Gly Phe Gly Pro Gly Leu Thr Val Glu Thr Val Val
370 375 380
Leu Arg Ser Val Pro Ile Ser Thr Ala Asn
385 390
<210> 140
<211> 1734
<212> DNA
<213> Arabidopsis thaliana
<400> 140
atggaagaag attataagat ggctccacaa gaacaagctg tttctcaagt tatggaaaag 60
caatctaata ataataattc tgatgttatt tttagatcta agcttccaga tatttatatt 120
ccaaatcatc tttctcttca tgattatatt tttcaaaata tttctgaatt tgctactaag 180
ccatgtctta ttaatggacc aactggacat gtttatactt attctgatgt tcatgttatt 240
tctagacaaa ttgctgctaa ttttcataag cttggagtta atcaaaatga tgttgttatg 300
cttcttcttc caaattgtcc agaatttgtt ctttcttttc ttgctgcttc ttttagagga 360
gctactgcta ctgctgctaa tccatttttt actccagctg aaattgctaa gcaagctaag 420
gcttctaata ctaagcttat tattactgaa gctagatatg ttgataagat taagccactt 480
caaaatgatg atggagttgt tattgtttgt attgatgata atgaatctgt tccaattcca 540
gaaggatgtc ttagatttac tgaacttact caatctacta ctgaagcttc tgaagttatt 600
gattctgttg aaatttctcc agatgatgtt gttgctcttc catattcttc tggaactact 660
ggacttccaa agggagttat gcttactcat aagggacttg ttacttctgt tgctcaacaa 720
gttgatggag aaaatccaaa tctttatttt cattctgatg atgttattct ttgtgttctt 780
ccaatgtttc atatttatgc tcttaattct attatgcttt gtggacttag agttggagct 840
gctattctta ttatgccaaa gtttgaaatt aatcttcttc ttgaacttat tcaaagatgt 900
aaggttactg ttgctccaat ggttccacca attgttcttg ctattgctaa gtcttctgaa 960
actgaaaagt atgatctttc ttctattaga gttgttaagt ctggagctgc tccacttgga 1020
aaggaacttg aagatgctgt taatgctaag tttccaaatg ctaagcttgg acaaggatat 1080
ggaatgactg aagctggacc agttcttgct atgtctcttg gatttgctaa ggaaccattt 1140
ccagttaagt ctggagcttg tggaactgtt gttagaaatg ctgaaatgaa gattgttgat 1200
ccagatactg gagattctct ttctagaaat caaccaggag aaatttgtat tagaggacat 1260
caaattatga agggatatct taataatcca gctgctactg ctgaaactat tgataaggat 1320
ggatggcttc atactggaga tattggactt attgatgatg atgatgaact ttttattgtt 1380
gatagactta aggaacttat taagtataag ggatttcaag ttgctccagc tgaacttgaa 1440
gctcttctta ttggacatcc agatattact gatgttgctg ttgttgctat gaaggaagaa 1500
gctgctggag aagttccagt tgcttttgtt gttaagtcta aggattctga actttctgaa 1560
gatgatgtta agcaatttgt ttctaagcaa gttgtttttt ataagagaat taataaggtt 1620
ttttttactg aatctattcc aaaggctcca tctggaaaga ttcttagaaa ggatcttaga 1680
gctaagcttg ctaatggact ttctggatat ccatatgatg ttccagatta tgct 1734
<210> 141
<211> 578
<212> PRT
<213> Arabidopsis thaliana
<400> 141
Met Glu Glu Asp Tyr Lys Met Ala Pro Gln Glu Gln Ala Val Ser Gln
1 5 10 15
Val Met Glu Lys Gln Ser Asn Asn Asn Asn Ser Asp Val Ile Phe Arg
20 25 30
Ser Lys Leu Pro Asp Ile Tyr Ile Pro Asn His Leu Ser Leu His Asp
35 40 45
Tyr Ile Phe Gln Asn Ile Ser Glu Phe Ala Thr Lys Pro Cys Leu Ile
50 55 60
Asn Gly Pro Thr Gly His Val Tyr Thr Tyr Ser Asp Val His Val Ile
65 70 75 80
Ser Arg Gln Ile Ala Ala Asn Phe His Lys Leu Gly Val Asn Gln Asn
85 90 95
Asp Val Val Met Leu Leu Leu Pro Asn Cys Pro Glu Phe Val Leu Ser
100 105 110
Phe Leu Ala Ala Ser Phe Arg Gly Ala Thr Ala Thr Ala Ala Asn Pro
115 120 125
Phe Phe Thr Pro Ala Glu Ile Ala Lys Gln Ala Lys Ala Ser Asn Thr
130 135 140
Lys Leu Ile Ile Thr Glu Ala Arg Tyr Val Asp Lys Ile Lys Pro Leu
145 150 155 160
Gln Asn Asp Asp Gly Val Val Ile Val Cys Ile Asp Asp Asn Glu Ser
165 170 175
Val Pro Ile Pro Glu Gly Cys Leu Arg Phe Thr Glu Leu Thr Gln Ser
180 185 190
Thr Thr Glu Ala Ser Glu Val Ile Asp Ser Val Glu Ile Ser Pro Asp
195 200 205
Asp Val Val Ala Leu Pro Tyr Ser Ser Gly Thr Thr Gly Leu Pro Lys
210 215 220
Gly Val Met Leu Thr His Lys Gly Leu Val Thr Ser Val Ala Gln Gln
225 230 235 240
Val Asp Gly Glu Asn Pro Asn Leu Tyr Phe His Ser Asp Asp Val Ile
245 250 255
Leu Cys Val Leu Pro Met Phe His Ile Tyr Ala Leu Asn Ser Ile Met
260 265 270
Leu Cys Gly Leu Arg Val Gly Ala Ala Ile Leu Ile Met Pro Lys Phe
275 280 285
Glu Ile Asn Leu Leu Leu Glu Leu Ile Gln Arg Cys Lys Val Thr Val
290 295 300
Ala Pro Met Val Pro Pro Ile Val Leu Ala Ile Ala Lys Ser Ser Glu
305 310 315 320
Thr Glu Lys Tyr Asp Leu Ser Ser Ile Arg Val Val Lys Ser Gly Ala
325 330 335
Ala Pro Leu Gly Lys Glu Leu Glu Asp Ala Val Asn Ala Lys Phe Pro
340 345 350
Asn Ala Lys Leu Gly Gln Gly Tyr Gly Met Thr Glu Ala Gly Pro Val
355 360 365
Leu Ala Met Ser Leu Gly Phe Ala Lys Glu Pro Phe Pro Val Lys Ser
370 375 380
Gly Ala Cys Gly Thr Val Val Arg Asn Ala Glu Met Lys Ile Val Asp
385 390 395 400
Pro Asp Thr Gly Asp Ser Leu Ser Arg Asn Gln Pro Gly Glu Ile Cys
405 410 415
Ile Arg Gly His Gln Ile Met Lys Gly Tyr Leu Asn Asn Pro Ala Ala
420 425 430
Thr Ala Glu Thr Ile Asp Lys Asp Gly Trp Leu His Thr Gly Asp Ile
435 440 445
Gly Leu Ile Asp Asp Asp Asp Glu Leu Phe Ile Val Asp Arg Leu Lys
450 455 460
Glu Leu Ile Lys Tyr Lys Gly Phe Gln Val Ala Pro Ala Glu Leu Glu
465 470 475 480
Ala Leu Leu Ile Gly His Pro Asp Ile Thr Asp Val Ala Val Val Ala
485 490 495
Met Lys Glu Glu Ala Ala Gly Glu Val Pro Val Ala Phe Val Val Lys
500 505 510
Ser Lys Asp Ser Glu Leu Ser Glu Asp Asp Val Lys Gln Phe Val Ser
515 520 525
Lys Gln Val Val Phe Tyr Lys Arg Ile Asn Lys Val Phe Phe Thr Glu
530 535 540
Ser Ile Pro Lys Ala Pro Ser Gly Lys Ile Leu Arg Lys Asp Leu Arg
545 550 555 560
Ala Lys Leu Ala Asn Gly Leu Ser Gly Tyr Pro Tyr Asp Val Pro Asp
565 570 575
Tyr Ala
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| Ферменты биосинтеза люциферина и их применение | 2018 |
|
RU2730038C2 |
| Поликетидсинтазы III типа и их применение | 2020 |
|
RU2822532C2 |
| Гиспидин-синтазы и их применение | 2020 |
|
RU2809367C2 |
| Конструкции для направленного редактирования генов и способы с их применением | 2020 |
|
RU2832109C2 |
| ИММУНОЦИТОКИНЫ НА ОСНОВЕ IL-15 И IL-15Rα ДОМЕНА SUSHI | 2012 |
|
RU2763298C2 |
| МУЛЬТИМЕРИЗУЮЩИЕСЯ ПОЛИПЕПТИДЫ, ПРОИСХОДЯЩИЕ ОТ ДОМЕНА С УКЛАДКОЙ ТИПА РУЛЕТ ОСНОВАНИЯ ПЕНТОНА АДЕНОВИРУСА | 2019 |
|
RU2820522C2 |
| HPV-СПЕЦИФИЧЕСКИЕ СВЯЗЫВАЮЩИЕ МОЛЕКУЛЫ | 2018 |
|
RU2804664C2 |
| СОБАЧЬИ АНТИТЕЛА С МОДИФИЦИРОВАННЫМИ ПОСЛЕДОВАТЕЛЬНОСТЯМИ CH2-CH3 | 2014 |
|
RU2815059C2 |
| CD123-СПЕЦИФИЧЕСКИЕ ХИМЕРНЫЕ АНТИГЕННЫЕ РЕЦЕПТОРЫ ДЛЯ ИММУНОТЕРАПИИ РАКА | 2015 |
|
RU2727290C2 |
| СПОСОБЫ И ПРОДУКТЫ ДЛЯ ПОЛУЧЕНИЯ И ДОСТАВКИ НУКЛЕИНОВЫХ КИСЛОТ | 2015 |
|
RU2714404C2 |
























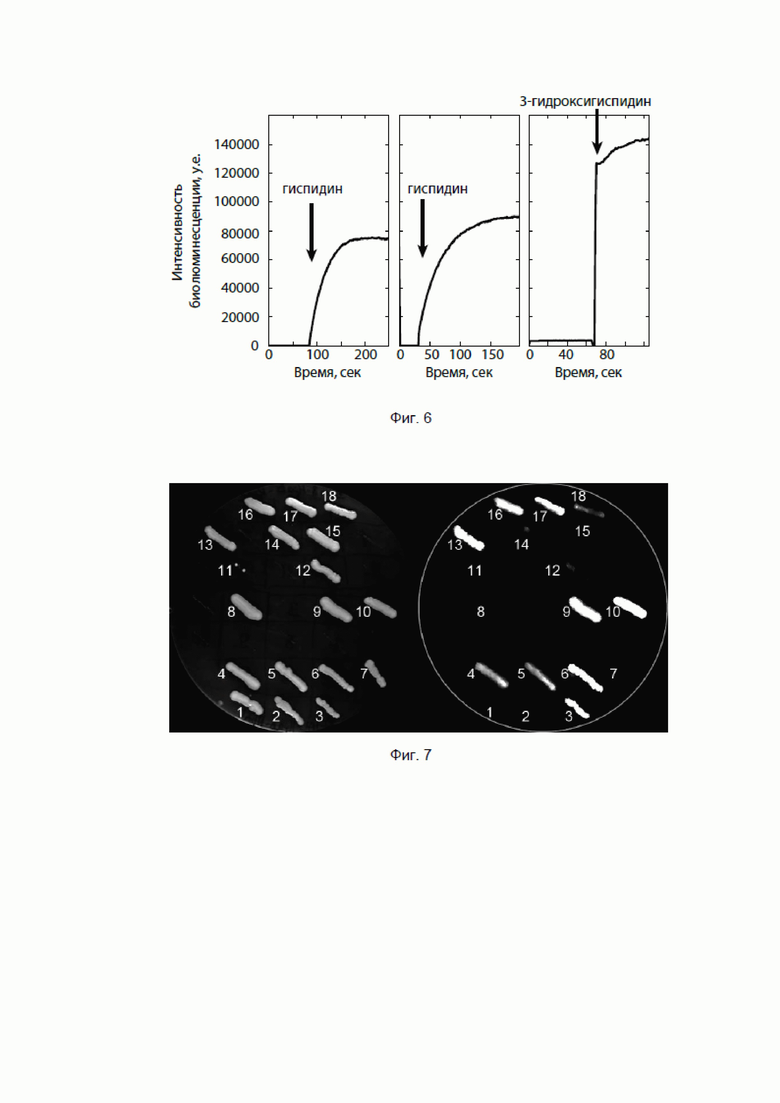
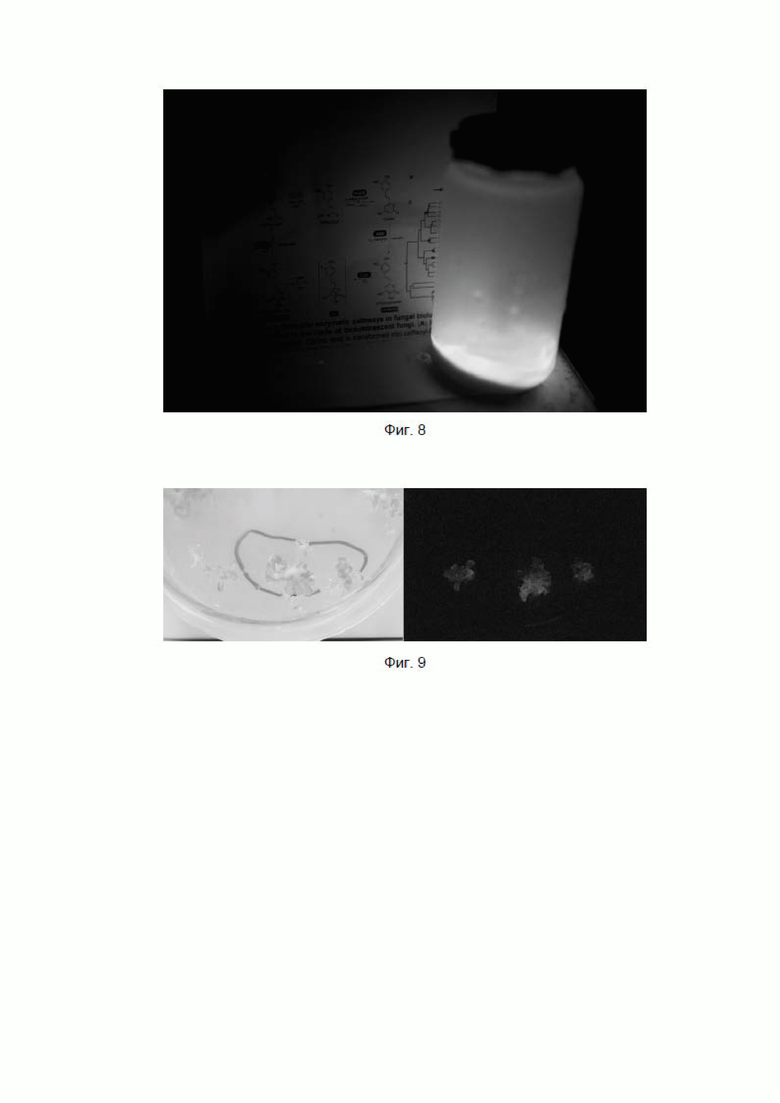
Настоящее изобретение относится к области биотехнологии, конкретно к белкам биосинтеза люциферина грибов. Изобретение раскрывает новые ферменты биосинтеза люциферина грибов и кодирующие их нуклеиновые кислоты, применение белков и нуклеиновых кислот в биосинтезе люциферина грибов. Раскрываются способы получения люциферина и предлюциферина грибов в системах in vitro и in vivo, а также применение таких веществ в качестве люминофоров в различных областях науки. 7 н. и 13 з.п. ф-лы, 25 пр., 6 табл., 9 ил.
1. Белок биосинтеза люциферина грибов, представляющий собой кофеилпируват-гидролазу, состоящий из:
а) аминокислотной последовательности, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75; или
б) аминокислотной последовательности, которая имеет не менее 60% идентичности с аминокислотной последовательностью, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75, где указанная кофеилпируват-гидролаза катализирует превращение 6-арил-2-гидрокси-4-оксогекса-2,5-диеновые кислоты, имеющей структурную формулу
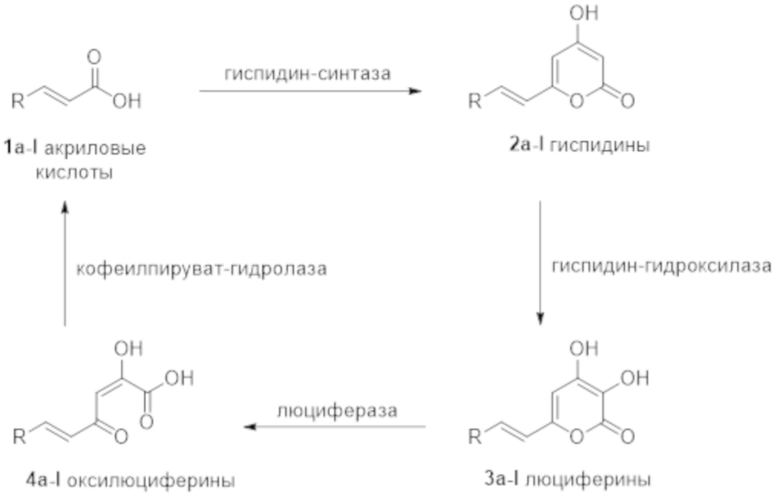 ,
,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой
.
2. Белок по п. 1, где аминокислотная последовательность кофеилпируват-гидролазы имеет не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, или не менее 80% идентичности, или не менее 85% идентичности, или не менее 90% идентичности, или не менее 95% идентичности с аминокислотной последовательностью, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75.
3. Белок по 2, где аминокислотная последовательность кофеилпируват-гидролазы имеет не менее 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98% или 99% идентичности с аминокислотной последовательностью, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75.
4. Белок по п. 1, где 3-арилакриловая кислота выбрана из группы: кофейная кислота, коричная кислота, паракумаровая кислота, кумаровая кислота, умбеллиновая кислота, синаповая кислота, феруловая кислота.
5. Применение белка биосинтеза люциферина грибов, состоящего из:
а) аминокислотной последовательности, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75; или
б) аминокислотной последовательности, которая имеет не менее 60% идентичности с аминокислотной последовательностью, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75,
в системах in vitro или in vivo как кофеилпируват-гидролазы, катализирующей реакцию превращения 6-арил-2-гидрокси-4-оксогекса-2,5-диеновые кислоты, имеющей структурную формулу
,
где R - арил или гетероарил, в 3-арилакриловую кислоту со структурной формулой
.
6. Применение по п. 5, где аминокислотная последовательность кофеилпируват-гидролазы имеет не менее 65% идентичности, или не менее 70% идентичности, или не менее 75% идентичности, или не менее 80% идентичности, или не менее 85% идентичности, или не менее 90% идентичности, или не менее 95% идентичности с аминокислотной последовательностью, выбранной из группы SEQ ID NO: 65, 67, 69, 71, 73, 75.
7. Применение по п. 5, где 3-арилакриловая кислота выбрана из группы: кофейная кислота, коричная кислота, паракумаровая кислота, кумаровая кислота, умбеллиновая кислота, синаповая кислота, феруловая кислота.
8. Нуклеиновая кислота, кодирующая белок биосинтеза люциферина грибов по п. 1.
9. Кассета экспрессии, содержащая (а) регион инициации транскрипции функциональный в клетке-хозяине; (б) нуклеиновую кислоту по п. 8; и (в) регион терминации транскрипции, функциональный в клетке-хозяине, причем клетка-хозяин не является эмбриональной клеткой человека.
10. Клетка-хозяин, содержащая по крайней мере одну кассету экспрессии по п. 9 как часть экстрахромосомного элемента или интегрированную в геном клетки как результат внедрения указанной кассеты в указанную клетку, где указанная клетка экспрессирует по крайней мере один из функциональных белков биосинтеза люциферина грибов, представляющего собой кофеилпируват-гидролазу, а также указанная клетка не является эмбриональной клеткой человека.
11. Применение нуклеиновой кислоты, кодирующей белок биосинтеза люциферина грибов, представляющего собой кофеилпируват-гидролазу, по п. 8 для получения в системах in vitro или in vivo кофеилпируват-гидролазы по п.1.
12. Применение по п. 11, где нуклеиновая кислота применяется для экспрессии белка биосинтеза люциферина грибов в составе кассеты экспрессии, которая также включает регион инициации транскрипции функциональный в клетке-хозяине и регион терминации транскрипции, функциональный в клетке-хозяине, причем клетка-хозяин не является эмбриональной клеткой человека.
13. Применение по п. 12, где кассета экспрессии применяется в клетке-хозяине, причем клетка-хозяин не является эмбриональной клеткой человека.
14. Трансгенный организм, способный к автономной биолюминесценции, где указанный организм содержит по крайней мере одну нуклеиновую кислоту по п. 8 как часть экстрахромосомного элемента или интегрированную в геном клетки как результат внедрения в указанную клетку кассеты экспрессии по п. 9, а также нуклеиновую кислоту, кодирующую:
(а) гиспидин-гидроксилазу, способную катализировать превращение 6-(2-арилвинил)-4- гидрокси-2H-пиран-2-она, имеющего структурную формулу
,
в 6-(2-арилвинил)-3,4-дигидрокси-2H-пиран-2-он, имеющий структурную формулу
,
где R - арил или гетероарил; и нуклеиновую кислоту, кодирующую:
(б) люциферазу, способную окислять люциферин грибов с выделением света,
причем трансгенный организм не является человеком или человеческим эмбрионом.
15. Трансгенный организм по п. 14, также содержащий нуклеиновую кислоту, кодирующую гиспидин-синтазу, способную катализировать превращение 3-арилакриловой кислоты со структурной формулой , где R – арил или гетероарил в 6-(2-арилвинил)-4-гидрокси-2H-пиран-2-он, имеющий структурную формулу , где R - арил или гетероарил.
16. Трансгенный организм по п. 15, также содержащий нуклеиновую кислоту, кодирующую поликетидсинтазу III типа, способную катализировать синтез гиспидин из кофеил-КоА.
17. Трансгенный организм по п. 15, также содержащий нуклеиновую кислоту, кодирующую 4'-фосфопантотеинил трансферазу и/или нуклеиновые кислоты, кодирующие ферменты биосинтеза 3-арилакриловой кислоты.
18. Трансгенный организм по п. 17, где ферменты биосинтеза 3-арилакриловой кислоты выбраны из группы:
(а) тирозин-аммоний-лиаза, аминокислотная последовательность которой представляет собой SEQ ID No: 107 или по крайней мере на 40% идентична последовательности, показанной в SEQ ID No: 107; компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы, аминокислотные последовательности которых представляет собой SEQ ID NO: 109 и 111 или по крайней мере на 40% идентичны последовательностями компонентов HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E. coli, показанными в SEQ ID NO: 109 и 111;
(б) фенилаланин-аммоний-лиаза, аминокислотная последовательность которой представляет собой SEQ ID NO:117 или по крайней мере на 40% идентична аминокислотной последовательности, показанной в SEQ ID NO:117.
19. Трансгенный организм по п. 16, также содержащий нуклеиновую кислоту, кодирующую кумарат-КоА-лигазу и/или нуклеиновые кислоты, кодирующие ферменты биосинтеза 3-арилакриловой кислоты.
20. Трансгенный организм по п. 19, где ферменты биосинтеза 3-арилакриловой кислоты выбраны из группы:
(а) тирозин-аммоний-лиаза, аминокислотная последовательность которой представляет собой SEQ ID NO: 107 или по крайней мере на 40% идентична последовательности, показанной в SEQ ID NO: 107; компоненты HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы, аминокислотные последовательности которых по крайней мере на 40% идентичны последовательностями компонентов HpaB и HpaC 4-гидроксифенилацетат 3-монооксигеназы-редуктазы E. coli, показанными в SEQ ID NO: 109 и 111;
(б) фенилаланин-аммоний-лиаза, аминокислотная последовательность которой представляет собой SEQ ID NO: 117 или по крайней мере на 40% идентична аминокислотной последовательности, показанной в SEQ ID NO: 117.
| RU 2017102986 A1, 30.01.2017 | |||
| WO 2012109470 A2, 16.08.2012 | |||
| KASKOVA Z | |||
| et al., 1001 lights: luciferins, luciferases, their mechanisms of action and applications in chemical analysis, biology and medicine, Chem Soc Rev., 2016, v.45, p | |||
| Способ ректификации спирта на аппарате периодического действия | 1926 |
|
SU6048A1 |
| KASKOVA Z | |||
| et al., Mechanism and color modulation of fungal bioluminescence, Sci | |||
| Adv., 2017, v.3, | |||

