Настоящее изобретение относится к разработке и получению новых полипептидных каркасов для оптимальной презентации олигопептидов, полипептидных последовательностей, белковых доменов, белков и/или белковых комплексов, состоящих из двух, нескольких или многих субъединиц. Такие олигопептиды, полипептидные последовательности, белковые домены и/или белки, представленные полипептидными каркасами по настоящему изобретению, могут включать антигенные частицы, которые стимулируют иммунную систему, чтобы вызвать иммунный ответ, например, для вакцинации или для получения антител или других связывающих молекул в культуре клеток, либо in vivo, либо in vitro в пробирке. В предпочтительном варианте осуществления полипептиды по настоящему изобретению собираются в вирусоподобные частицы (ВПЧ), оптимизированные для представления антигенов, применимых в контексте вакцинации против инфекционных агентов или опухолей.
Предпосылкой для успешной разработки белкового каркаса для презентации олигопептидов, полипептидных последовательностей, белковых доменов, белков и/или белковых комплексов является компактный, стабильный домен мультимеризации, который может включать модальности, представляющие собой открытые и гибкие петлевые структуры, которые могут вмещать такие олигопептиды, полипептидные последовательности, белковые домены, белки и/или белковые комплексы. Предпочтительно, такие отображаемые частицы могут представлять собой иммуногенные антигены, которые представлены иммунной системе. Белки основания пентона (протомеры) из ряда серотипов аденовируса (Ag) собираются в пентамеры, которые затем образуют додекаэдры, напоминающие вирусоподобные частицы. В отличие от живого вируса, они не несут генетического материала, поэтому такие ВПЧ полезны с точки зрения безопасности.
Аденовирус представляет собой один из наиболее часто применяемых векторов генной терапии у людей. Оболочка аденовируса преимущественно состоит из двух различных типов белков, белка гексона и белка основания пентона, причем последний образует пентамерные сборки, к которым прикрепляются фибриллы, характерные для данного вируса. Было показано, что белки основания пентона некоторых серотипов аденовирусов способны к спонтанной самосборке в мультимерную суперструктуру при рекомбинантной экспрессии в отсутствие других аденовирусных компонентов. Такая супер структура представляет собой додекамер, образованный в общей сложности 60 белками основания аденовируса, расположенными в двенадцати идентичных копиях пентамерной "коронообразной" сборки (фиг. 1). Сам белок основания аденовируса имеет двухдоменную архитектуру, в которой один домен представляет собой бета-цилиндр, соединенный со вторым доменом, стабилизированным альфа-спиралями (фиг. 1В). Первый опосредует мультимеризацию в додекаэдр, что подтверждено мутационными исследованиями, в то время как последний представляет собой протяженные петли к растворителю на поверхности додекаэдра. Такие петли чрезвычайно вариабельны по длине и содержанию последовательностей у разных серотипов аденовирусов, в то время как остаток белка основания является высококонсервативным для всех видов. Додекаэдр аденовируса представляет собой очень универсальный каркас для отображения, например, для иммуногенных пептидов, которые можно вставлять в петли, заменяя встречающиеся в природе последовательности. Таким образом, буквально сотни гетер о логичных пептидов могут эффективно отображаться на одном додекаэдре, если все сайты инсерции заняты. Додекаэдр может быть получен рекомбинантным способом в очень больших количествах, он исключительно стабилен и может храниться при температуре окружающей среды в течение неопределенного времени. С применением таких очень выгодных характеристик, были разработаны синтетические частицы на основе додекаэдра, демонстрирующие иммуногенные пептиды в своих открытых петлях, для потенциального применения, включая онкоиммунологию и возникающие инфекционные заболевания.
В WO 2017167988 А1 раскрыты синтетические додекаэдры аденовируса, способствующие встраиванию эпитопа в открытые петли, а также раскрыто получение белка основания аденовируса.
Задача, лежащая в основе настоящего изобретения, заключается в обеспечении новой системы для презентации антигенов или другого груза через белковые каркасы, которые могут собираться в структуры ВПЧ.
Вышеупомянутая техническая задача обеспечена вариантами осуществления настоящего изобретения, как определено в формуле настоящего изобретения, а также дополнительно описана в настоящем документе и проиллюстрирована сопроводительными графическими материалами.
Настоящее изобретение основано, по меньшей мере частично, на обнаружении того факта, что структура белков основания пентона аденовируса представляет собой настоящую двухдоменную структуру, которая могла возникнуть в процессе эволюции в результате слияния генов (фиг. 1В). Указанные два домена, как оказалось, можно легко разделить на две отдельных компактных частицы: бета-цилиндр, содержащий информацию о мультимеризации, и домен альфа-спираль, напоминающая "корону".
Следовательно, в соответствии с настоящим изобретением обеспечен полипептид "минимальной" мультимеризации, который может быть связан с антигеном или другими частицами, несущими груз, что обеспечивает максимальную универсальность и гибкость. Сконструированный таким образом полипептид по настоящему изобретению является производным аминокислотных последовательностей белков основания пентона аденовируса (также называемых в настоящем документе "протомерами основания пентона"), которые образуют домен бета-цилиндр основания пентона аденовирусов. Домен бета-цилиндр белков основания пентона аденовируса образует так называемый домен с укладкой типа рулет (jelly roll fold), содержащий восемь бета-листов с 1 по 8 (см. фиг. 2), Zubieta et al. (2005) Mol. Cell 17, 121-135. Авторами настоящего изобретения было неожиданно обнаружено, что для эффективной мультимеризации и, таким образом, отображения связанного груза, например, олигопептидов или полипептидов, таких как антигены или другие связанные частицы, например, лекарственные средства, метки, нуклеиновые кислоты, две петли (образующие домен «корона»), вставленные в последовательности между аминокислотными участками, образующими домен с укладкой типа рулет, могут быть полностью или в других вариантах осуществления частично заменены желаемыми неаденовирусными последовательностями такими как олигопептидные линкеры (с которыми, в свою очередь, могут быть связаны антигены или другой груз) или любой желаемой аминокислотной последовательностью, такой как полипептиды, белки, белковые домены, белковые комплексы и т.д.
Следовательно, в предпочтительных вариантах осуществления настоящего изобретения нуклеиновая кислота, лекарственное средство, метка и/или партнер по связыванию биологически связывающейся пары присоединен/присоединены к L1 и/или L2. "Биологически связывающаяся" пара в соответствии с настоящим изобретением представляет собой пары биологических частиц или соединений, соответственно, которые обычно встречаются в природе или которые по меньшей мере происходят от пар связывания, встречающихся в природе. Примеры включают, но не ограничиваются ими, антигены, антитела, фрагменты антител, диатела, миметики антител, рецепторы и их лиганды, биотин, стрептавидин и т.п.
Такие частицы могут быть связаны с L1 и/или L2 с помощью средств, известных в данной области техники. При необходимости линкеры любого типа могут быть связаны с подходящей группой в положении в L1 и/или L2, и этот линкер затем присоединяется к желаемой частице. Типичные группы, присутствующие в L1 и/или L2, которые могут быть вовлечены в химическое связывание, включают группы NH2 и SH аминокислотных остатков, присутствующих в L1 и/или L2. Однако связывание груза с L1 и/или L2 не ограничено химическими связями, но также включает любые другие взаимодействия, такие как ионные взаимодействия, водородные связи и Ван-дер-Ваальсовы взаимодействия.
Домен с укладкой типа рулет в соответствии с настоящим изобретением образован тремя аминокислотными участками (которые также могут называться, например, "сегментами" или "областями"): N-концевым участком, промежуточным участком и С-концевым участком. В нативном протомере основания пентона аденовируса сегменты петли обнаружены между N-концевым аминокислотным участком и промежуточным участком (большая петля) и между промежуточным аминокислотным участком и С-концевым аминокислотным участком (малая петля). Как указано выше, типичные неаденовирусные последовательности полипептида по настоящему изобретению, которые могут быть обозначены в данном документе как "линкеры", заменяют сегменты петли нативного протомера основания пентона аденовируса. В других вариантах осуществления настоящего изобретения одна из больших петель и малая петля нативного основания пентона могут присутствовать в полипептиде по настоящему изобретению и формировать L1 или L2.
Таким образом, полипептид по настоящему изобретению обычно имеет структуру, представленную следующей общей формулой (I)
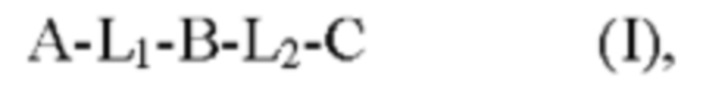
где
А представляет собой N-концевой аминокислотный участок белка основания пентона аденовируса,
В представляет собой аминокислотный участок белка основания пентона аденовируса,
С представляет собой С-концевой аминокислотный участок основания пентона аденовируса,
где В представляет собой аминокислотный участок, расположенный между А и С в последовательности указанного основания пентона аденовируса,
где А, В и С образуют домен с укладкой типа рулет указанного белка основания пентона аденовируса.
L1 и L2 представляют собой линкеры, как указано выше. Таким образом, L1 и L2 могут быть выбраны практически из любой аминокислотной последовательности (при условии, что она не препятствует мультимеризации полипептида). Таким образом, L1 и L2 могут быть одинаковыми или различными и независимо друг от друга выбраны из группы, состоящей из олигопептида, полипептида, белка и белкового комплекса. Последовательности L1 и L2, как правило, не являются аденовирусными, т.е. имеют аминокислотную последовательность из по меньшей мере 5, 6, 7, 8, 9 10 или более аминокислот, причем такая последовательность не существует или не встречается в известных последовательностях протомеров основания пентона любого серотипа аденовируса, более предпочтительно любого аденовирусного белка.
В альтернативном варианте осуществления настоящего изобретения линкеры L1 и L2 могут быть выбраны из последовательностей петель (т.е. областей, содержащих первую и вторую петли RGD и/или вариабельную петлю, как раскрыто в WO 2017/167988 А1) основания пентона аденовируса. Однако в данном варианте осуществления последовательности сегментов петли происходят от аденовируса, имеющего серотип отличный от серотипа аденовируса, от которого происходят указанные аминокислотные участки А, В и С.Соответственно, в данном варианте осуществления настоящего изобретения обеспечены химеры протомеров основания пентона, где бета-цилиндр, домен с укладкой типа рулет происходит от одного подтипа аденовируса, тогда как L1 и L2 представляют собой полипептиды, содержащие сегменты петли RGD и/или вариабельные сегменты петли VL (образующие домен «корона»), происходящие от подтипа аденовируса, отличного от подтипа аденовируса, от которого происходит домен с укладкой типа рулет.
В предпочтительном варианте осуществления настоящего изобретения, как показано на фиг. 2, аминокислотный участок А содержит бета-листы 1, 2 и 3 домена с укладкой типа рулет протомера основания пентона аденовируса, аминокислотный участок В содержит бета-листы 4 и 5 домена с укладкой типа рулет указанного протомера основания пентона аденовируса и аминокислотный участок С содержит бета-листы 6, 7 и 8 домена с укладкой типа рулет указанного протомера основания пентона аденовируса. Следует понимать, что каждый сегмент А, В и С может быть независимо получен из одного или различных аденовирусов.
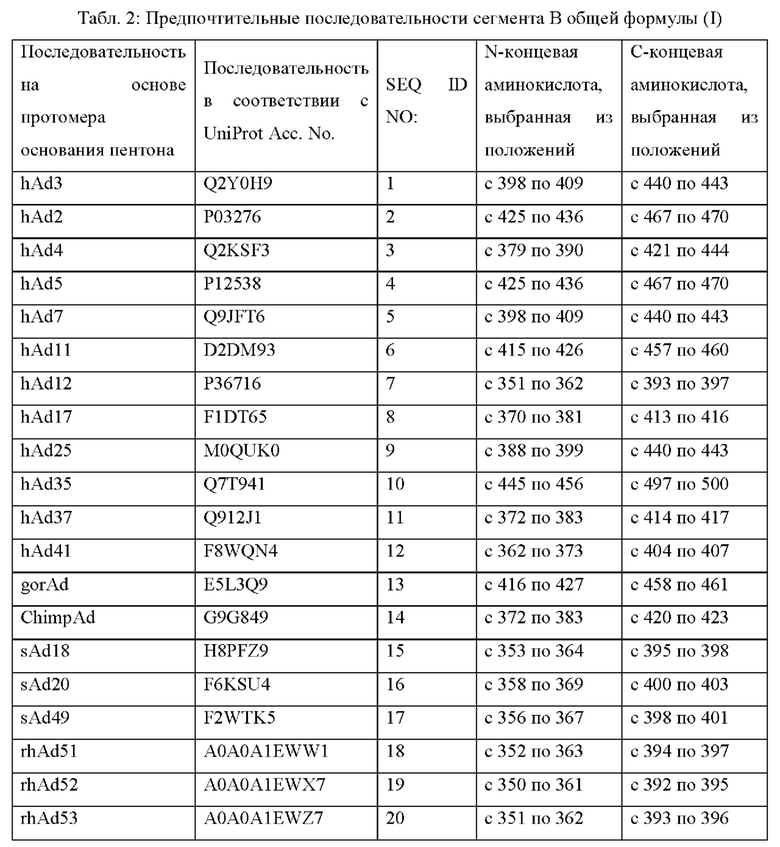
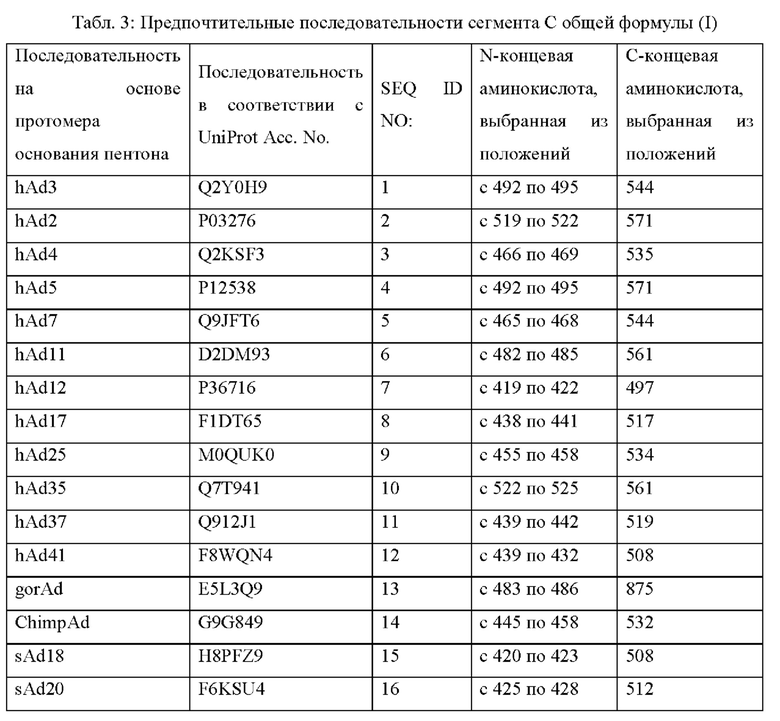
Предпочтительно аминокислотные участки А, В и С имеют аминокислотную последовательность, каждая из которых независимо происходит от последовательностей основания пентона, выбранных из группы, состоящей из оснований пентона аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd1S), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53).
Предпочтительные аминокислотные последовательности вышеупомянутых аденовирусных оснований пентона находятся в общедоступных базах данных, таких как UniProt и UniProtE, и особенно предпочтительные последовательности, описанные в данном документе для вышеупомянутых подтипов аденовирусов, представлены в UniProt Асе. № Q2Y0H9 (аденовируса человека 3 серотипа, SEQ ID NO: 1), UniProt Асе. № Р03276 (аденовируса человека 2 серотипа, SEQ ID NO: 2), UniProt Асе. № Q2KSF3 (аденовируса человека 4 серотипа, SEQ ID NO: 3), UniProt Асе. № Р12538 (аденовируса человека 5 серотипа, SEQ ID NO: 4), UniProt Асе. № Q9JFT6 (аденовируса человека 7 серотипа, SEQ ID NO: 5), UniProt Асе. № D2DM93 (аденовируса человека 11 серотипа, SEQ ID NO: 6), UniProt Асе. № Р36716 (аденовируса человека 12 серотипа, SEQ ID NO: 7), UniProt Асе. № F1DT65 (аденовируса человека 17 серотипа, SEQ ID NO: 8), UniProt Асе. № M0QUK0 (аденовируса человека 25 серотипа, SEQ ID NO: 9), UniProt Асе. № Q7T941 (аденовируса человека 35 серотипа, SEQ ID NO: 10), UniProt Асе. № Q912J1 (аденовируса человека 37 серотипа, SEQ ID NO: 11), UniProt Асе. № F8WQN4 (аденовируса человека 41 серотипа, SEQ ID NO: 12), UniProt Асе. № E5L3Q9 (аденовируса гориллы, SEQ ID NO: 13), UniProt Асе. № G9G849 (аденовируса шимпанзе, SEQ ID NO: 14), UniProt Асе. № H8PFZ9 (аденовируса обезьяны 18 серотипа, SEQ ID NO: 15), UniProt Асе. № F6KSU4 (аденовируса обезьяны 18 серотипа, SEQ ID NO: 16), UniProt Асе. № F2WTK5 (аденовируса обезьяны 49 серотипа, SEQ ID NO: 17), UniProt Асе. № A0A0A1EWW1 (аденовируса макака-резуса 51 серотипа, SEQ ID NO: 18), UniProt Асе. № A0A0A1EWX7 (аденовируса макака-резуса 52 серотипа, SEQ ID NO: 19) и UniProt Асе. № A0A0A1EWZ7 (аденовируса макака-резуса 53 серотипа, SEQ ID NO: 20).
Аминокислотные последовательности вышеуказанных оснований пентона представляют собой (в скобках указан соответствующий номер UniProt Асе):
Основание пентона hAd3 аденовируса человека 3 серотипа (Q2Y0H9), SEQ ID NO: 1:


hAd2 (P03276), SEQ ID NO: 2:

hAd4 (Q2KSF3), SEQ ID NO: 3:

hAd5 (P12538), SEQ ID NO: 4:

hAd7 (Q9JFT6), SEQ ID NO: 5:

hAd11 (D2DM93), SEQ ID NO: 6:


hAd12 (P36716), SEQ ID NO: 7:

hAd17 (F1DT65), SEQ ID NO: 8:

hAd25 (MOQUKO), SEQ ID NO: 9:


hAd35 (Q7T941), SEQ ID NO: 10:

hAd37 (Q912J1), SEQ ID NO: 11

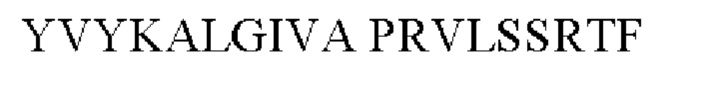
hAd41 (F8WQN4), SEQ ID NO: 12:

Основание пентона аденовируса гориллы gorAd (E5L3Q9), SEQ ID NO: 13:

Основание пентона аденовируса шимпанзе chimpAd (G9G849), SEQ ID NO: 14:


Основание пентона аденовируса обезьяны 18 серотипа, sAd18 (H8PFZ9); SEQ ID NO: 15:

sAd20 (F6KSU4), SEQ ID NO: 16:

sAd49 (F2WTK5), SEQ ID NO: 17:

Основание пентона аденовируса макака-резуса 51 серотипа, rhAd51 (A0A0A1EWW1), SEQ ID NO: 18:

rhAd52 (A0A0A1EWX7), SEQ ID NO: 19:


rhAd53 (A0A0A1EWZ7), SEQ ID NO: NO 20:

Полипептид по настоящему изобретению не ограничивается теми известными специфическими последовательностями для аминокислотных участков А, В и С, образующих мультимеризационный домен с укладкой типа рулет упомянутых выше суб-и серотипов аденовируса, соответственно. Аминокислотные сегменты А, В и С могут также иметь аминокислотные последовательности, сходные с последовательностями известных протомеров оснований пентона аденовируса, при условии, что последовательности А, В и С таковы, что полученный полипептид принимает укладку типа рулет и собирается в пентамерные комплексы (также обозначаемые как "белки пентона"), двенадцать из которых, в свою очередь, самоорганизуются с образованием додекамерного суперкомплекса (ВПЧ по настоящему изобретению) в соответствующих условиях, как дополнительно описано ниже. Обычно такие похожие последовательности сегментов А, В и С имеют идентичность аминокислотной последовательности не менее 85%, более предпочтительно не менее 90%, еще более предпочтительно 95%, особенно предпочтительно не менее 98%, наиболее предпочтительно не менее 99%, с соответствующей аминокислотной последовательностью известного пентона основания аденовируса, предпочтительно с последовательностями SEQ ID NO: с 1 по 20, более предпочтительно, аминокислотные участки А, В и С, как представлено в таблицах 1-3 ниже.
В данном контексте аминокислотные последовательности указаны от N до С-конца с применением однобуквенного кода ИЮПАК, если не указано иное.
Согласно предпочтительному варианту осуществления настоящего изобретения аминокислотный участок А имеет следующую консенсусную последовательность (SEQ ID NO: 21):
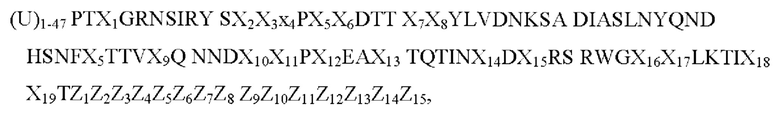
где: аминокислотный участок А заканчивается на С-конце перед Z1 у остатка Т или у аминокислоты с Z1 по Z15,
U представляет собой любую аминокислоту или отсутствует,
X1 представляет собой Е или G,
Х2 представляет собой Е или S,
Х3 представляет собой L или V,
Х4 представляет собой А или S,
Х5 представляет собой L или Q,
Х6 представляет собой Y или Е,
Х7 представляет собой R или К,
Х8 представляет собой V или L,
Х9 представляет собой V или I,
Х10 представляет собой F или Y,
Х11 представляет собой Т или S,
Х12 представляет собой А, или Т, или I, или G,
Х13 представляет собой S или G,
Х14 представляет собой F или L,
Х15 представляет собой Е или D,
Х16 представляет собой А или G,
Х17 представляет собой D или Q,
X18 представляет собой L или М,
Х19 представляет собой Н или R,
Z1, если присутствует, представляет собой N,
Z2, если присутствует, представляет собой М,
Z3, если присутствует, представляет собой Р,
Z4, если присутствует, представляет собой N,
Z5, если присутствует, представляет собой V или I,
Z6, если присутствует, представляет собой N,
Z7, если присутствует, представляет собой Е или D,
Z8, если присутствует, представляет собой Y или F,
Z9, если присутствует, представляет собой М,
Z10, если присутствует, представляет собой F, или S, или Y,
Z11, если присутствует, является Т или S,
Z12, если присутствует, является S или N,
Z13, если присутствует, представляет собой K,
Z14, если присутствует, представляет собой F,
Z16 если присутствует, представляет собой K.
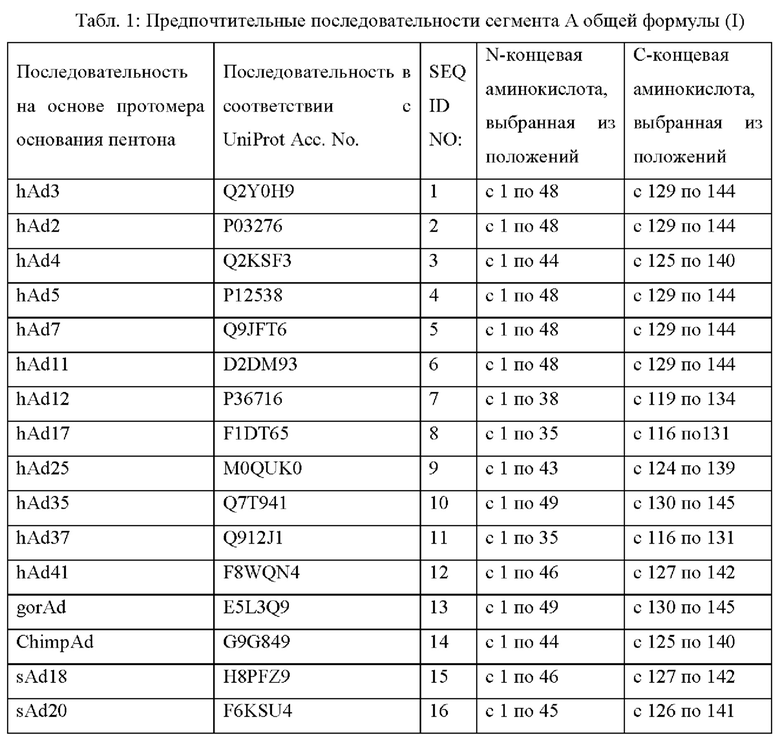
Более предпочтительные аминокислотные последовательности сегмента А полипептида по настоящему изобретению представлены в следующей таблице 1:

Согласно еще одному предпочтительному варианту осуществления настоящего изобретения аминокислотный участок В вышеуказанной общей формулы (I) имеет следующую последовательность (SEQ ID NO: 22):
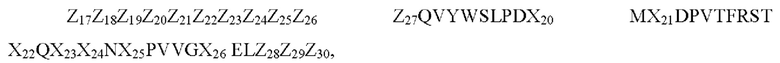
где: аминокислотный участок В начинается на N-конце у аминокислоты с Z17 по Z27 или у аминокислоты Q после Z27,
аминокислотный участок В заканчивается на С-конце перед Z28 у аминокислоты L или у аминокислоты с Z28 по Z30,
Z17, если присутствует, представляет собой L или S,
Z18, если присутствует, представляет собой Т или Р или С,
Z19, если присутствует, представляет собой Т или Р,
Z20, если присутствует, представляет собой Р или S или А или R,
Z21, если присутствует, представляет собой N или D,
Z22, если присутствует, представляет собой G или V,
Z23, если присутствует, представляет собой Н или Т,
Z24, если присутствует, представляет собой С,
Z25, если присутствует, представляет собой G,
Z26, если присутствует, представляет собой А, или V, или S,
Z27, если присутствует, представляет собой Е или Q,
Х20 представляет собой L или М,
Х21 представляет собой Q или K,
Х22 представляет собой Q или R, или S,
Х23 представляет собой V или I,
Х24 представляет собой S или N,
Х25 представляет собой Y или F,
Х26 представляет собой А или V,
Z28, если присутствует, представляет собой М или L,
Z29, если присутствует, представляет собой Р,
Z30, если присутствует, представляет собой V или F.
Более предпочтительные аминокислотные последовательности сегмента В полипептида по настоящему изобретению представлены в следующей таблице 2:
Согласно дополнительному предпочтительному варианту осуществления настоящего изобретения сегмент С вышеуказанной общей формулы (I) имеет следующую последовательность (SEQ ID NO: 23):
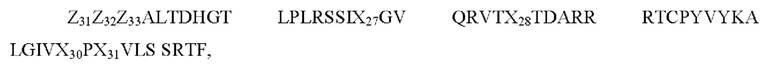
где: аминокислотный участок С начинается на N-конце у аминокислоты с Z31 по Z33 или у аминокислоты А после Z33,
Z31, если присутствует, представляет собой N,
Z32, если присутствует, представляет собой V,
Z33, если присутствует, представляет собой Р,
Х27 представляет собой R или S или G,
Х28 представляет собой V или I,
Х29 представляет собой Y или Н,
Х30 представляет собой А или S,
Х31 представляет собой R или K.
Более предпочтительные аминокислотные последовательности сегмента С полипептида по настоящему изобретению представлены в следующей таблице 3:

Особенно предпочтительные полипептиды по настоящему изобретению основаны на домене с укладкой типа рулет протомера основания пентона hAd3. В частности, предпочтительны полипептиды, где аминокислотный участок А имеет аминокислотную последовательность, начинающуюся с положения, выбранного из аминокислот с 1 по 48, наиболее предпочтительно положения аминокислоты 1, до положения аминокислоты, выбранного из положений с 129 по 144, наиболее предпочтительно положения аминокислоты 132, где аминокислотный участок В имеет аминокислотную последовательность, начинающуюся с положения, выбранного из положений с 398 по 409, наиболее предпочтительно положения аминокислоты 407, до положения, выбранного из положений с 440 по 443, наиболее предпочтительно положения аминокислоты 442, и где аминокислотный участок С имеет аминокислотную последовательность, начинающуюся с положения, выбранного из положения с 492 по 495, наиболее предпочтительно положения аминокислоты 493, до положения аминокислоты 544, где положения аминокислот относятся к последовательности, представленной в UniProt Асе. № QY0H9 (SEQ ID NO: 1).
Связывающие сегменты L1 и L2 полипептида по настоящему изобретению могут быть выбраны из о л иго пептидных линкеров, таких как олигопептиды, содержащие от 4 до 10 аминокислот, предпочтительно содержащие аминокислоты G и S. Предпочтительный пример представляет собой GGGS (SEQ ID 24). Другой пример представляет собой линкер, состоящий из G и S и имеющий несколько повторов GGS, например, 2, 3, 4, 5 или более повторов GGS. Особенно предпочтительный линкер этого типа id GGSGGS (SEQ ID NO: 25).
В других предпочтительных вариантах осуществления L1 представляет собой полипептидную последовательность, содержащую петлю RGD основания пентона аденовируса, имеющего серотип отличный от серотипа аденовируса(ов), от которого происходят указанные аминокислотные участки А, В и С и/или D представляет собой полипептидную последовательность, содержащую вариабельную петлю основания пентона аденовируса, имеющего серотип отличный от серотипа аденовируса, от которого происходят указанные аминокислотные участки А, В и С.
В дополнительных вариантах осуществления настоящего изобретения L1 представляет собой петлю RDG, a L2 представляет собой предпочтительно неаденовирусный олигопептид, предпочтительно из от 4 до 20 аминокислот, более предпочтительно из от 4 до 10 аминокислот, особенно предпочтительно олигопептидный линкер, состоящий из G и S, как определено выше. В аналогичных вариантах осуществления L2 представляет собой или содержит вариабельную петлю, a L1 представляет собой олигопептидный линкер, как определено выше. Согласно настоящему изобретению также предполагается, что L2 представляет собой или содержит петлю RGD, a L1 представляет собой олигопептидный линкер, и также предполагается, что L1 представляет собой вариабельную петлю, a L2 представляет собой олигопептидный линкер.
В других предпочтительных вариантах осуществления, как упоминалось выше, последовательности L1 и L2, соответственно, могут быть выбраны из последовательностей домена «корона» белков основания пентона аденовируса, отличного от аденовируса, от которого происходит домен мультимеризации. Обычно комбинация химеры домена «корона» и домена мультимеризации не ограничена. Предпочтительные химеры выбирают из комбинаций доменов «корона» и доменов мультимеризации, как указано выше. Домены «корона», необязательно и предпочтительно, включая неаденовирусные последовательности, встроенные в петлю RGD и/или вариабельную петлю соответствующего домена «корона», более предпочтительно раскрыты в WO 2017/167988 А1.
Таким образом, понятно, что домены «корона» оснований пентона аденовируса обычно состоят из двух аминокислотных участков: так называемого большого фрагмента и малого фрагмента. Большой фрагмент домена «корона» расположен обычно на N-конце в аминокислотной последовательности соответствующего белка основания пентона аденовируса, тогда как малый фрагмент домена «корона» расположен обычно на С-конце. Согласно настоящему изобретению предпочтительно, чтобы большой фрагмент (содержащий петлю RGD, как упомянуто выше) соответствовал L1 общей формулы (I), и дополнительно предпочтительно, чтобы малый фрагмент (содержащий вариабельную петлю) соответствовал L2 общей формулы (I). Согласно некоторым вариантам осуществления настоящего изобретения большой и малый фрагменты происходят от одного и того же основания пентона аденовируса. Согласно другим вариантам осуществления настоящего изобретения большой фрагмент и малый фрагмент происходят от различных оснований пентона аденовируса или что только один из больших и малых фрагментов происходит от белка оснований пентона аденовируса, отличного от аденовируса, от которого происходит домен мультимеризации, т.е. от которого происходят аминокислотные участки А, В и С.
Предпочтительные домены «корона» для применения в химерных конструкциях по настоящему изобретению включают домены «корона», выбранные из группы, состоящей из оснований пентона аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd1S), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd 49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53).
Предпочтительные аминокислотные последовательности указанных выше оснований пентона аденовируса, применяемых для домена «корона», представлены в общедоступных базах данных, таких как UniProt и UniProtE, и особенно предпочтительные последовательности, описанные в данном документе для вышеупомянутых подтипов аденовирусов, представлены в UniProt Асе. № Q2Y0H9 (аденовируса человека 3 серотипа, SEQ ID NO: 1), UniProt Асе. № Р03276 (аденовируса человека 2 серотипа, SEQ ID NO: 2), UniProt Асе. № Q2KSF3 (аденовируса человека 4 серотипа, SEQ ID NO: 3), UniProt Асе. № PI2538 (аденовируса человека 5 серотипа, SEQ ID NO: 4), UniProt Асе. № Q9JFT6 (аденовируса человека 7 серотипа, SEQ ID NO: 5), UniProt Асе. № D2DM93 (аденовируса человека 11 серотипа, SEQ ID NO: 6), UniProt Асе. № Р36716 (аденовируса человека 12 серотипа, SEQ ID NO: 7), UniProt Асе. № F1DT65 (аденовируса человека 17 серотипа, SEQ ID NO: 8), UniProt Асе. № M0QUK0 (аденовируса человека 25 серотипа, SEQ ID NO: 9), UniProt Асе. № Q7T941 (аденовируса человека 35 серотипа, SEQ ID NO: 10), UniProt Асе. № Q912J1 (аденовируса человека 37 серотипа, SEQ ID NO: 11), UniProt Асе. № F8WQN4 (аденовируса человека 41 серотипа, SEQ ID NO: 12), UniProt Асе. № E5L3Q9 (аденовируса гориллы, SEQ ID NO: 13), UniProt Асе. № G9G849 (аденовируса шимпанзе, SEQ ID NO: 14), UniProt Асе. № H8PFZ9 (аденовируса обезьяны 18 серотипа, SEQ ID NO: 15), UniProt Асе. № F6KSU4 (аденовируса обезьяны 20 серотипа, SEQ ID NO: 16), UniProt Асе. № F2WTK5 (аденовируса обезьяны 49 серотипа, SEQ ID NO: 17), UniProt Асе. № A0A0A1EWW1 (аденовируса макака-резуса 51 серотипа, SEQ ID NO: 18), UniProt Асе. № A0A0A1EWX7 (аденовируса макака-резуса 52 серотипа, SEQ ID NO: 19) и UniProt Асе. № A0A0A1EWZ7 (аденовируса макака-резуса 53 серотипа, SEQ ID NO: 20).
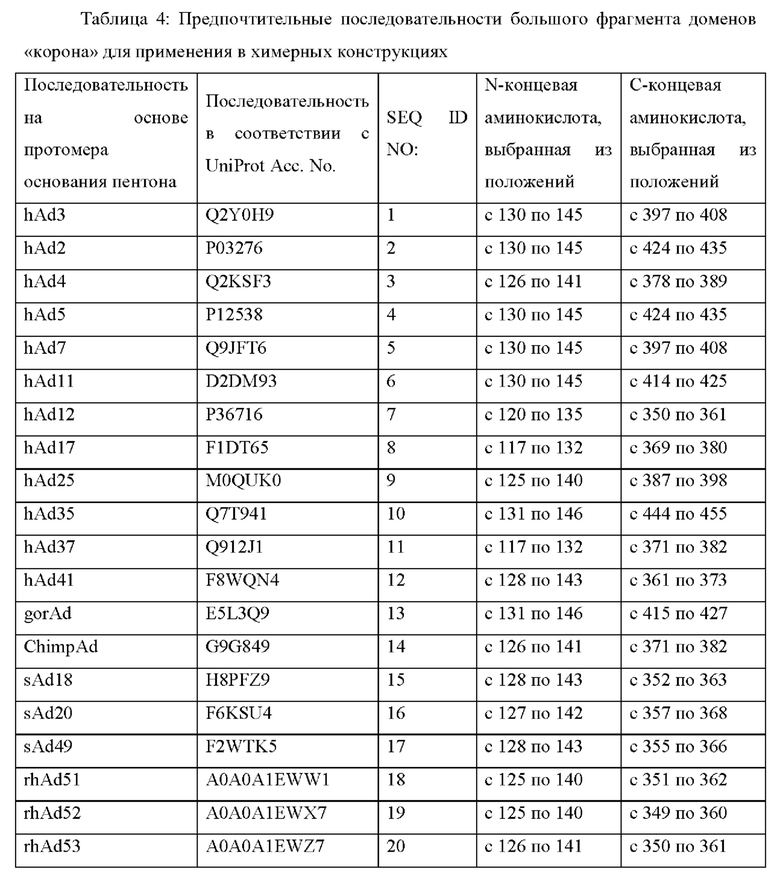
Наиболее предпочтительные последовательности больших фрагментов доменов «корона» для применения в химерных конструкциях по настоящему изобретению приведены в следующей таблице 4:
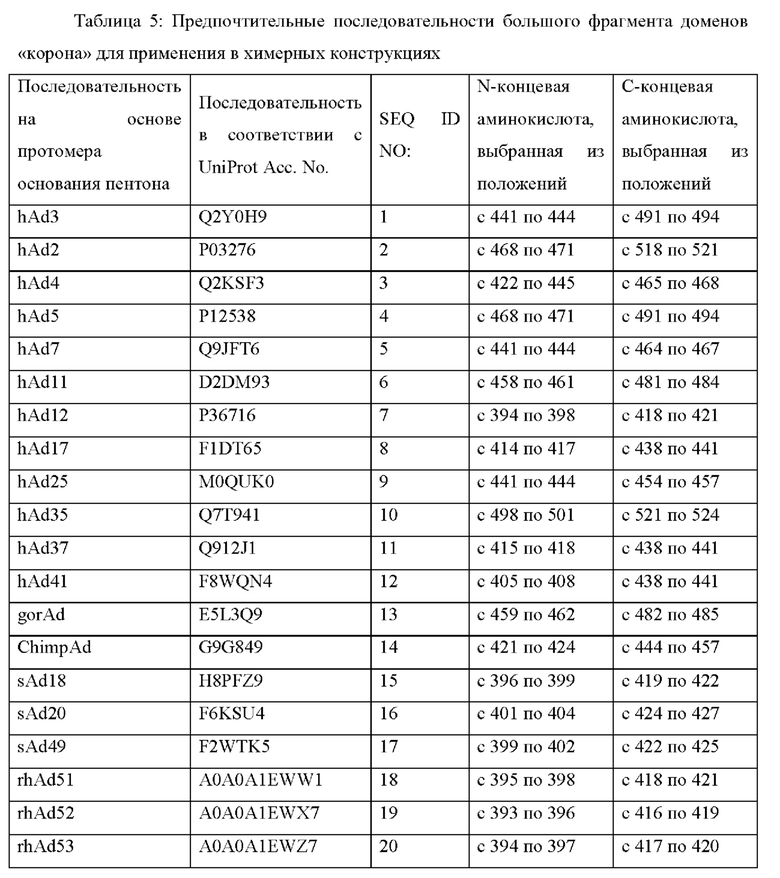
Наиболее предпочтительные последовательности больших фрагментов доменов «корона» для применения в химерных конструкциях по настоящему изобретению приведены в следующей таблице 5:
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 2 серотипа (hAd2) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 3 серотипа (hAd3) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 4 серотипа (hAd4) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 5 серотипа (hAd5) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 7 серотипа (hAd7) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека серотипа 2 (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 11 серотипа (hAd11) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 12 серотипа (hAd12) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 17 серотипа (hAd17) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 25 серотипа (hAd25) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 35 серотипа (hAd35) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 37 серотипа (hAd37) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса человека 41 серотипа (hAd41) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса гориллы (gorAd) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса шимпанзе (ChimpAd) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса обезьяны 18 серотипа (sAd1S) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса обезьяны 20 серотипа (sAd20) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd1S), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса обезьяны 49 серотипа (sAd49) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса макака-резуса 51 серотипа (rhAd51) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса макака-резуса 52 серотипа (rhAd52) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Предпочтительный вариант осуществления настоящего изобретения представляет собой химеру, где домен мультимеризации аденовируса макака-резуса 53 серотипа (rhAd53) объединен с доменом «корона» основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 3 серотипа (hAd3), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd41), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51) и аденовируса макака-резуса 52 серотипа (rhAd52). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Особенно предпочтительный домен «корона» для получения химер по настоящему изобретению представляет собой домен «корона» белка основания пентона аденовируса человека 3 серотипа (hAd3). Предпочтительные последовательности в отношении положений аминокислот SEQ ID NO: 1 представлены в таблице 4 (большой фрагмент) и таблице 5 (малый фрагмент).
В еще более предпочтительных химерах по настоящему изобретению домен «корона» белка основания пентона аденовируса человека 3 серотипа (hAd3) объединен с доменом мультимеризации белка основания пентона аденовируса, выбранного из аденовируса человека 2 серотипа (hAd2), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса шимпанзе (ChimpAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Особенно предпочтительный домен «корона» для получения химер по настоящему изобретению представляет собой домен «корона» основания пентона аденовируса шимпанзе (ChimpAd). Предпочтительные последовательности в отношении аминокислотных положений SEQ ID NO: 14 представлены в таблице 4 (большой фрагмент) и таблице 5 (малый фрагмент).
В еще более предпочтительных химерах по настоящему изобретению домен «корона» белка основания пентона аденовируса шимпанзе (ChimpAd) объединен с доменом мультимеризации белка основания пентона аденовируса, выбранного из аденовируса человека 3 серотипа (hAd3), аденовируса человека 2 серотипа (hAd2), аденовируса человека 4 серотипа (hAd4), аденовируса человека 5 серотипа (hAd5), аденовируса человека 7 серотипа (hAd7), аденовируса человека 11 серотипа (hAd11), аденовируса человека 12 серотипа (hAd12), аденовируса человека 17 серотипа (hAd17), аденовируса человека 25 серотипа (hAd25), аденовируса человека 35 серотипа (hAd35), аденовируса человека 37 серотипа (hAd37), аденовируса человека 41 серотипа (hAd41), аденовируса гориллы (gorAd), аденовируса обезьяны 18 серотипа (sAd18), аденовируса обезьяны 20 серотипа (sAd20), аденовируса обезьяны 49 серотипа (sAd49), аденовируса макака-резуса 51 серотипа (rhAd51), аденовируса макака-резуса 52 серотипа (rhAd52) и аденовируса макака-резуса 53 серотипа (rhAd53). Конкретные последовательности домена мультимеризации и домена «корона», выбранные для данной комбинации относятся к конкретным примерам в соответствии с таблицами с 1 по 5.
Как уже указано выше, один из основных вариантов осуществления настоящего изобретения представляет собой включение антигена, более конкретно антигена инфекционного агента, такого как вирус, бактерия или другой патоген, или опухолевый или раковый антиген, в один или оба из L1 и L2. Предпочтительные сайты включения антигенов в петли RGD и/или вариабельные петли аденовирусных доменов «корона» раскрыты в WO 2017/167988 А1. В контексте данного документа термин "антиген" относится к структуре, распознаваемой молекулами иммунного ответа, например, антителами, рецепторами Т-клеток (TCR) и т.д.
Антигены инфекционных агентов включают, но не ограничиваются ими, например, вирусные инфекционные агенты, такие как ВИЧ, вирусы гепатита, такие как вирус гепатита А, вирус гепатита В или вирус гепатита С, вирус герпеса, вирус ветряной оспы, вирус краснухи, вирус желтой лихорадки, вирус лихорадки Денге, флавивирусы (например, вирус Зика), вирусы гриппа, марбургская вирусная болезнь, вирусы Эбола и арбовирусы, такие как вирус чикунгунья. Антигены бактериальных инфекционных агентов включают, но не ограничиваются ими, антигены, например, Legionella, Helicobacter, Vibrio, инфекционные штаммы Е. coli, Staphylococci, Salmonella и Streptococci. Антигены инфекционных патогенов простейших включают, но не ограничиваются ими, антигены Plasmodium, Trypanosoma, Leishmania и Toxoplasma. Дополнительные примеры антигенов патогенных агентов включают антигены грибковых патогенов, такие как антигены Cryptococcus neoformans, Histoplasma capsulatum, Coccidioides immitis, Blastomyces dermatitidis и Candida albicans.
Конкретные примеры опухолевых антигенов, которые можно применять в соответствии с настоящим изобретением, включают, но не ограничиваются ими, 707-АР, AFP, ART-4, BAGE, бета-катенин/m, Bcr-abl, CAMEL, САР-1, CASP-8, CDC27/m, CDK4/m, CEA, CT, Cyp-B, DAM, ELF2M, ETV6-AML1, G250, GAGE, GnT-V, Gp100, HAGE, HER-2/neu, HLA-A*0201-R170I, HPV-E7, HSP70-2M, HAST-2, hTERT (или hTRT), iCE, KIAA0205, LAGE, LDLR/FUT, MAGE, MART- 1/Melan-A, MC1R, миозин/м, MUC1, MUM-1, -2, -3, NA88-A, NY-ESO-1, pl90 minor bcr-abl, Pml/RAR.alpha., PRAME, PSA, PSM, RAGE, RU1 или RU2, SAGE, SART-1 или SART- 3, TEL/AML1, TPI/m, TRP-1, TRP-2, TRP-2/TNT2h WT1.
Особенно в контексте антигенов, включенных в полипептиды по настоящему изобретению, как L1 и/или L2, но также в отношении любого белок-белкового взаимодействия, такого как связывание рецептора с лигандом, можно включить процесс отбора и/или эволюции для обеспечения последовательностей, оптимизированных для связывания мишени, таких как оптимизированные антигены, для проявления улучшенного иммунного ответа. Предпочтительный способ представляет собой рибосомный дисплей, как подробно описано в публикации Schaffitzel et al. (2001) in: Protein-Protein Interactions, A Molecular Cloning Manual: In vitro selection and evolution of protein-ligand interaction by ribosome display (Golemis E., ed.), pages 535-567, Cold Spring Harbor Laboratory Press, New York. Преимуществом способа рибосомного дисплея является его полное выполнение in vitro на всех стадиях отбора. Другие возможные способы отбора также известны в данной области техники и включают фаговый дисплей (Smith (1985) Science 228, 1315-1317; Winter et al. (1994) Annu. Rev. Immunol. 12, 433-455), дрожжевую двухгибридную систему (Fields and Song (19899 Nature 340, 245-246, Chien et al. (1983) Proc. Natl. Acad. Sci. USA 88, 9578-9582) и способы отображения на клеточной поверхности (Georgiu et al. (1993) Trends Biotechnol. 11, 6-10, Boder and Wittrup (1997) Nat. Biotechnol. 15, 553-557).
Способ рибосомного дисплея в основном можно применять двумя путями для оптимизации антигенов или других аминокислотных последовательностей, участвующих в нацеливании на конкретную молекулу, с применением полипептидов по настоящему изобретению. Либо последовательность антигена (или другого связывающего агента) может быть выбрана первой из исходной библиотеки последовательностей полипептидов, которая может достигать 1014 индивидуальных последовательностей, чаще от 109 до 1010 последовательностей, необязательно с применением эволюционных процедур, как подробно описано в публикации Schaffitzel et al. (2001), выше. После выбора оптимизированных последовательностей антигена нуклеотидную последовательность, кодирующую ее, клонируют в соответствующий вектор по настоящему изобретению, так что экспрессируется полипептид, в котором оптимизированный антиген включен или представляет собой L1 и/или L2 согласно приведенной выше формуле (I).
Согласно альтернативному варианту осуществления данного аспекта настоящего изобретения, библиотека потенциальных последовательностей, кодирующих антиген, непосредственно клонируется в нуклеиновую кислоту по настоящему изобретению, так что каждая последовательность кодирует полипептид, который представляет собой часть или представляет собой, соответственно, один или оба из L1 и L2, как определено в формуле (I), выше. Полипептиды по настоящему изобретению, содержащие исходную библиотеку последовательностей антигенов (или, в других вариантах осуществления, другие связывающие последовательности), экспрессируются затем in vitro, и выбор оптимизированных последовательностей антигена (или другого связывающего агента) осуществляют в соответствии со способом рибосомного дисплея, как подробно описано в публикации Schaffitzel et al. (2001), выше.
Дополнительный вариант осуществления полипептидов по настоящему изобретению относится к полипептидам, где L1 и/или L2 представляют собой или связаны с, соответственно, последовательностями антител или частями антител, такими как фрагменты антител. В контексте настоящего изобретения термин "антитело" означает иммуноглобулин, специфически связывающийся с антигеном.
Термин "фрагмент антитела" относится к части антитела, которая сохраняет способность полного антитела специфически связываться с антигеном. Примеры фрагментов антител включают, но не ограничиваются ими, фрагменты Fab, фрагменты Fab', фрагменты F(ab')2, антитела, состоящие только из тяжелых цепей, однодоменные антитела (sdAb), фрагменты scFv, вариабельные фрагменты (Fv), домены VH, домены VL, нанотела, IgNAR (новые антигенные рецепторы иммуноглобулина), ди-scFv, биспецифические Т-клеточные агенты (BITE), молекулы, переориентирующие антитело двойной аффинности (DART), тройные тела, диатела, одноцепочечные диатела и т.п.
"Диатело" представляет собой слитый белок или бивалентное антитело, которое может связывать различные антигены. Диатело состоит из двух одиночных белковых цепей (обычно двух scFv-фрагментов), каждая из которых содержит вариабельные фрагменты антитела. Таким образом, диатела содержат два антигенсвязывающих сайта и, таким образом, могут нацеливаться на один и тот же (моноспецифическое диатело) или различные антигены (биспецифическое диатело).
Термин "однодоменное антитело", в контексте настоящего изобретения, относится к фрагментам антитела, состоящим из одного мономерного вариабельного домена антитела. Просто они включают только вариабельные области мономерной тяжелой цепи антител, состоящих только из тяжелых цепей, продуцируемых хрящевыми рыбами или верблюдовыми. В следствие различного происхождения их также называют фрагментами VHH или VNAR (вариабельный нового антигенный рецептор). Альтернативно, однодоменные антитела можно получить мономеризацией вариабельных доменов обычных мышиных или человеческих антител с помощью генной инженерии. Они обладают молекулярной массой приблизительно от 12 до 15 кДа и, таким образом, представляют собой самые маленькие фрагменты антител, способные распознавать антиген. Дополнительные примеры включают нанотела или наноантитела.
Антигенсвязывающие частицы, применимые в контексте настоящего изобретения, также включают "миметики антител", в контексте настоящего описания относящиеся к соединениям, которые специфически связывают антигены, аналогичные антителам, но которые структурно не связаны с антителами. Обычно миметики антител представляют собой искусственные пептиды или белки с молярной массой от приблизительно 3 до 20 кДа, которые содержат один, два или более доступных доменов, специфически связывающихся с антигеном. Примеры включают, помимо прочего, LACI-D1 (липопротеин-ассоциированный ингибитор свертывания крови), аффилины, например, человеческий-γ В кристаллический или человеческий убиквитин, цистатин, Sac7D из Sulfolobus acidocaldarius, липокалин и антикалины, полученные из липокалинов, DARPins (сконструированные повторяющиеся домены анкирина), CH3-домен Fyn, Kunits-домен ингибиторов протеазы, монотела, например домен 10-го типа фибронектина III типа, аднектины: кноттины (минипротеины цистеиновых узлов), атримеры, эвитела, например связывающие агенты на основе CTLA4, аффитела, например, трехспиральный пучок из Z-домена протеина А из Staphylococcus aureus, транс-тела, например человеческий трансферрин, тетранектины, например мономерный или тримерный домен лектина С-типа человека, микротела, например ингибитор трипсина-П, аффилины, белки броненосцев, несущие повторы. Нуклеиновые кислоты и малые молекулы иногда также считаются миметиками антител (аптамеры), но не искусственными антителами, фрагментами антител и слитыми белками, состоящими из них. Общими преимуществами перед антителами являются лучшая растворимость, проникновение в ткани, устойчивость к нагреванию и воздействию ферментов, а также сравнительно низкие затраты при получении.
Как и нативные белки оснований пентона, полипептиды по настоящему изобретению собираются в пентамерные комплексы, 12 из которых, в свою очередь, собираются в вирусоподобные частицы (ВПЧ) в буферном растворе при значении рН предпочтительно от приблизительно 5,0 до приблизительно 8,0. Предпочтительные примеры представляют собой буферные условия при физиологических условиях или близких к ним, таких как фосфатно-солевой буфер (ФСБ), рН 7,4 или трис-буфер солевой (TBS) или TBS-T рН от 7,2 до 7,6. В таких условиях полипептиды по настоящему изобретнию образуют ВПЧ при температуре приблизительно от 20 до 42°С. Настоящее изобретение также относится к таким пентамерным комплексам и ВПЧ.
Еще один объект настоящего изобретения относится к нуклеиновой кислоте, кодирующей полипептид, как определено в данном документе.
Согласно настоящему изобретению термины "нуклеиновая кислота" и "полинуклеотид" применяются взаимозаменяемо и относятся к ДНК, РНК или видам, содержащим один или более аналогов нуклеотидов. Предпочтительные нуклеиновые кислоты или полинуклеотиды по настоящему изобретению представляют собой ДНК, более предпочтительно двухцепочечную (дц) ДНК. Нуклеотидные последовательности по настоящему изобретению представлены в направлении от 5' до 3', и применяется однобуквенный код ИЮПАК для оснований, если не указано иное.
Другой вариант осуществления относится к нуклеиновой кислоте, полученной для вставки универсальных сегментов L1 и L2, как определено в общей формуле (1). То есть этот вариант нуклеиновой кислоты кодирует сегменты А, В и С, но имеет сайты инсерции между сегментами, кодирующими А и В, и между сегментами, кодирующими В и С.
Таким образом, данный вариант осуществления может быть представлен следующей общей формулой (II):
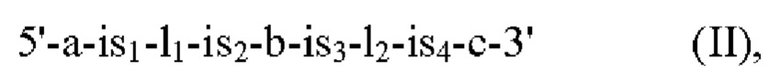
где
а представляет собой нуклеотидную последовательность, кодирующую А общей формулы (I),
b представляет собой нуклеотидную последовательность, кодирующую В общей формулы (I),
с представляет собой нуклеотидную последовательность, кодирующую С общей формулы (I), и
l1, l2 каждый представляет собой нуклеотидную последовательность,
с is1 по is4 каждый независимо представляет собой нуклеотидную последовательность, содержащую по меньшей мере один сайт инсерции.
Сайт инсерции в контексте указанного варианта осуществления настоящего изобретения предпочтительно представляет собой последовательность узнавания рестрикционного фермента или хоминг-эндонуклеазы. Более предпочтительно, каждый с is1 по is4 представляет собой различные сайты инсерции, более конкретно, каждый с is1 по is4 представляет собой последовательность распознавания различных рестрикционных ферментов. Предпочтительный вариант осуществления нуклеиновой кислоты, полученной для встраивания нуклеотидных последовательностей, кодирующих L1 и L2, имеет нуклеотидную последовательность, где is1 содержит сайт EcoRI, is2 содержит сайт RsrII, is3 содержит сайт SacI и 1&4 содержит сайтХЬа!
Сайты рестрикционных ферментов обычно хорошо известны специалисту в данной области техники. Предпочтительные примеры представляют собой такие, как определено выше, но сайты рестрикции могут быть выбраны из большого разнообразия, и рекомендации можно найти у различных производителей рестрикционных ферментов, таких как New England Biolabs, Inc., Ipswich, MA, USA.
Примеры таких сайтов хоминг-эндонуклеазы (НЕ) включают, но не ограничиваются ими, последовательности распознавания PI-SceI, I-CeuI, I-PpoI, I-HmuI, I-CreI, I-DmoI, PI-PfuI и I-MsoI, PI-PspI, I-Scel, другие члены группы LAGLIDAG и их варианты, SegH и Hef или другие хоминг-эндонуклеазы GIY-YIG, I-ApeII, I-Anil, цитохром b мРНК матураза bl3, PI-THI и PI-TfuII, PI-ThyI и другие, см. Stoddard B.L. (2005) Q. Rev. Biophys. 38, 49-95. Соответствующие ферменты представлены в продаже, например, от New England Biolabs Inc., Ipswich, MA, USA.
В предпочтительных вариантах осуществления настоящего изобретения указанная выше нуклеиновая кислота дополнительно содержит по меньшей мере один сайт интеграции нуклеиновой кислоты в вектор или клетку-хозяин. Сайт интеграции может допускать временное или геномное включение.
Что касается интеграции в вектор, в частности в плазмиду или вирус, сайт интеграции предпочтительно является совместимым для интеграции нуклеиновой кислоты в аденовирус, аденоассоциированный вирус (AAV), автономный парвовирус, вирус простого герпеса (HSV), ретровирус, радиновирус, вирус Эпштейн-Барра, лентивирус, вирус леса Семлики или бакуловирус.
Особенно предпочтительные сайты интеграции, которые могут быть включены в нуклеиновую кислоту по настоящему изобретению, могут быть выбраны из транспозонного элемента Tn7, сайтов связывания, специфичных для λ-интегразы, и сайт-специфичных рекомбиназ (SSR), в частности сайта LoxP или сайта рекомбинации, специфичного для рекомбиназы FLP (FRT). Другими предпочтительными механизмами интеграции нуклеиновой кислоты по настоящему изобретению являются специфические гомологичные рекомбинационные последовательности, такие как Ief2-603/Orf1629.
В других предпочтительных вариантах осуществления настоящего изобретения описанная в настоящем документе нуклеиновая кислота дополнительно содержит один или более маркеров устойчивости для отбора против токсичных веществ. Предпочтительные примеры маркеров устойчивости, применимых в контексте настоящего изобретения, включают, но не ограничиваются ими, антибиотики, такие как ампициллин, хлорамфеникол, гентамицин, спектиномицин и маркеры устойчивости к канамицину.
Нуклеиновая кислота по настоящему изобретению может также содержать один или более сайтов связывания рибосомы (RBS).
Еще один объект настоящего изобретения относится к вектору, содержащему нуклеиновую кислоту, как определено выше.
Предпочтительные векторы по настоящему изобретению представляют собой плазмиды, векторы экспрессии, векторы для переноса, более предпочтительно векторы для переноса генов эукариот, векторы для переноса генов, опосредованные временными или вирусными векторами. Другие векторы по настоящему изобретению представляют собой вирусы, такие как векторы аденовируса, векторы аденоассоциированного вируса (AAV), векторы автономных парвовирусов, векторы вируса простого герпеса (HSV), ретровирусные векторы, векторы радиновируса, векторы вируса Эпштейн-Барра, векторы лентивирусов, векторы вируса леса Семлики и бакуловирусные векторы.
Бакуловирусные векторы, подходящие для интеграции нуклеиновой кислоты по настоящему изобретению (например, присутствующие на подходящей плазмиде, такой как вектор для переноса), также представляют собой объект настоящего изобретения и предпочтительно содержат сайт-специфичные сайты интеграции, такие как сайт присоединения Tn7 (который может быть встроенным в ген lacZ для синего/белого скрининга продуктивной интеграции) и/или сайт LoxP. Дополнительные предпочтительные бакуловирусы по настоящему изобретению содержат (альтернативно или в дополнение к вышеописанным сайтам интеграции) ген экспрессии вещества, токсичного для хозяина, фланкированный последовательностями для гомологичной рекомбинации. Примером гена, экспрессирующего токсичное вещество, является ген дифтерийного токсина А. Предпочтительной парой последовательностей для гомологичной рекомбинации является, например, Isf2-603/Orf1629. Бакуловирус может также содержать дополнительный маркерный ген(ы), как описано выше, включая также флуоресцентные маркеры, такие как GFP, YFP и так далее. Конкретные примеры соответствующих бакуловирусов раскрыты, например, в WO 2010/100278 А1.
Другие полезные векторы для применения по настоящему изобретению раскрыты в WO 2005/085456 А1.
Векторы, применимые в прокариотических клетках-хозяевах, содержат предпочтительно, помимо приведенных выше примеров маркерных генов (один или более из них), точку начала репликации (ori). Примеры представляют собой BR322, ColE1 и условные точки начала репликации, такие как OriV и R6Ky, причем последний является предпочтительным условным источником репликации, который делает распространение вектора по настоящему изобретению зависимым от гена pir в прокариотическом хозяине. OriV делает распространение вектора по настоящему изобретению зависимым от гена trfA в прокариотическом хозяине.
Кроме того, настоящее изобретение относится к клетке-хозяину, содержащей нуклеиновую кислоту по настоящему изобретению и/или вектор по настоящему изобретению.
Клетки-хозяева могут быть прокариотическими или эукариотическими. Эукариотические клетки-хозяева могут быть, например, клетками млекопитающих, предпочтительно клетками человека. Примеры клеток-хозяев человека включают, но не ограничиваются ими, HeLa, Huh7, HEK293, HepG2, КАТО-III, IMR32, МТ-2, β-клетки поджелудочной железы, кератиноциты, фибробласты костного мозга, СНР212, первичные нервные клетки, W12, SK-N-MC, Saos-2, WI38, первичные гепатоциты, FLC4, 143ТК, DLD-1, эмбриональные фибробласты легких, первичные фибробласты крайней плоти, клетки MRC5 и MG63. Другие предпочтительные клетки-хозяева по настоящему изобретению представляют собой клетки свиней, предпочтительно клетки СРК, FS-13, РК-15, клетки крупного рогатого скота, предпочтительно клетки MDB, ВТ, клетки крупного рогатого скота, такие как клетки FLL-YFT. Другие эукариотические клетки, применимые в контексте настоящего изобретения, представляют собой клетки С.elegans. Дополнительно эукариотические клетки включают дрожжевые клетки, такие как S. cerevisiae, S. pombe, С.albicans и P. pastoris. Кроме того, настоящее изобретение относится к клеткам насекомых в качестве клеток-хозяев, которые включают клетки S. frugiperda, более предпочтительно клетки Sf9, Sf21, Express Sf+, High Five H5 и клетки D. melanogaster, в частности клетки S2 Schneider. К другим клеткам-хозяевам относятся клетки Dictyostelium discoideum и клетки паразитов, таких как Leishmania spec.
Прокариотические хозяева согласно настоящему изобретению включают бактерии, в частности Е. coli, например, коммерчески доступные штаммы, такие как ТОР10, DH5α, НВ101. BL21 (DE3) и др.
Специалист в данной области техники легко сможет выбрать подходящие пары векторной конструкции/клетки-хозяина для соответствующего размножения и/или переноса элементов нуклеиновой кислоты по настоящему изобретению в подходящего хозяина. Конкретные способы введения соответствующих векторных элементов и векторов в соответствующие клетки-хозяев а известны в данной области техники, и способы можно найти в последнем издании публикации Ausubel et al. (ed.) Current Protocols ш Molecular Biology, John Wiley & Sons, New York, USA.
В предпочтительных вариантах осуществления настоящего изобретения вектор, как определено выше, дополнительно включает сайт для сайт-специфичных рекомбиназ (SSR), предпочтительно один или более сайтов LoxP для Сге-1ох-специфической рекомбинации. В других предпочтительных вариантах осуществления вектор по настоящему изобретению содержит элемент транспозона, предпочтительно сайт прикрепления Тп7.
Кроме того, предпочтительно, чтобы сайт связывания, как определено выше, находился внутри маркерного гена. Такое расположение делает возможным отбор последовательностей, успешно интегрированных в сайт связывания, путем транспозиции. Согласно предпочтительным вариантам осуществления такой маркерный ген выбран из генов люциферазы, β-GAL, CAT, генов, кодирующих флуоресцентные белки, предпочтительно GFP, BFP, YFP, CFP и их варианты, а также гена lacZa.
Кроме того, настоящее изобретение относится к клетке-хозяину, содержащей нуклеиновую кислоту по настоящему изобретению и/или вектор по настоящему изобретению.
Клетки-хозяева могут быть прокариотическими или эукариотическими. Эукариотические клетки-хозяева могут представлять собой, например, клетки млекопитающих, предпочтительно клетки человека. Примеры человеческих клеток-хозяев включают, но не ограничиваются ими, HeLa, Huh7, HEK293, HepG2, КАТО-III, IMR32, МТ-2, β-клетки поджелудочной железы, кератиноциты, фибробласты костного мозга, СНР212, первичные нервные клетки, W12, SK-N-MC, Saos-2, WI38, первичные гепатоциты, FLC4, 143TK, DLD-1, эмбриональные фибробласты легких, первичные фибробласты крайней плоти, клетки MRC5 и MG63. Дополнительные предпочтительные клетки-хозяева по настоящему изобретению представляют собой клетки свиней, предпочтительно клетки СРК, FS-13, РК-15, клетки крупного рогатого скота, предпочтительно клетки MDB, ВТ, клетки крупного рогатого скота, такие как клетки FLL-YFT. Другие эукариотические клетки, применимые в контексте настоящего изобретения, представляют собой клетки С.elegans. Дополнительные эукариотические клетки включают дрожжевые клетки, такие как S. cerevisiae, S. pombe, С.albicans и P. pastoris. Кроме того, настоящее изобретение относится к клеткам насекомых в качестве клеток-хозяев, которые включают клетки S. frugiperda, более предпочтительно клетки Sf9, Sf21, Express Sf+, High Five H5 и клетки D. melanogaster, особенно клетки S2 Schneider. Дополнительные клетки-хозяева включают клетки Dictyostelium discoideum и клетки паразитов, таких как Leishmania spec.
Прокариотические хозяева согласно настоящему изобретению включают бактерии, в частности Е. coli, например, коммерчески доступные штаммы, такие как TOP10, DH5a, НВ101, BL21 (DE3) и т.д.
Специалист в данной области техники легко сможет выбрать подходящие пары конструкции вектор/клетка-хозяин для соответствующего размножения и/или переноса элементов нуклеиновых кислот по настоящему изобретению в подходящего хозяина. Конкретные способы введения соответствующих векторных элементов и векторов в соответствующие клетки-хозяева в равной степени известны в данной области техники, и способы описаны в последнем издании публикации Ausubel et al. (ed.) Current Protocols In Molecular Biology, John Wiley & Sons, New York, USA.
Настоящее изобретение также относится к полипептиду, нуклеиновой кислоте, кодирующей такой полипептид, вектору, содержащему нуклеиновую кислоту, кодирующую полипептид, клетке-хозяину, содержащей такой вектор, а также ВПЧ, как определено выше, для применения в качестве лекарственного средства, в частности, для применения в лечении и/или предотвращении инфекционного заболевания, иммунного заболевания, опухоли или рака.
Следовательно, настоящее изобретение также относится к фармацевтическим композициям, содержащим полипептид, как определено в настоящем документе, нуклеиновую кислоту, кодирующую такой полипептид, вектор, содержащий нуклеиновую кислоту, кодирующую полипептид, клетку-хозяин, содержащую такой вектор, или ВПЧ, как описано выше, вместе с по меньшей мере одним фармацевтически приемлемым носителем, эксципиентом и/или разбавителем.
Как правило, получение фармацевтических композиций в контексте настоящего изобретения, их дозировки и пути введения известны квалифицированному специалисту, и руководство можно найти в последнем издании Remington's Pharmaceutical Sciences (Mack publishing Co., Eastern, PA, USA).
Фармацевтические композиции по настоящему изобретению содержат терапевтически эффективное количество активного ингредиента, как указано выше. Терапевтически эффективное количество зависит от активного ингредиента и, в частности, от пути введения. Фармацевтическую композицию по настоящему изобретению предпочтительно применяют путем парентерального введения, в частности путем инфузии, такой как внутривенная, внутриартериальная или внутрикостная инфузия, или путем инъекции, такой как внутривенная, внутриартериальная, внутрибрюшинная, внутримышечная, внутрикожная, подкожная или интратекальная инъекция. В случае противоопухолевой терапии фармацевтическая композиция, такая как фармацевтическая композиция, содержащая ВПЧ по настоящему изобретению, также может быть введена путем внутриопухолевой инъекции.
Растворы для инъекций или инфузий по настоящему изобретению обычно содержат ВПЧ по настоящему изобретению в воде или водном буферном растворе, предпочтительно в изотоническом буфере при физиологическом значении рН. Жидкие фармацевтические композиции по настоящему изобретению могут содержать дополнительные ингредиенты, такие как фармацевтически приемлемые стабилизаторы, суспендирующие добавки, эмульгаторы и тому подобное. Другими ингредиентами фармацевтической композиции по настоящему изобретению являются вспомогательные вещества, в частности, в контексте применения конструкций по настоящему изобретению для целей вакцинации.
Следующий объект настоящего изобретения относится к способам лечения с применением полезных свойств полипептидов, нуклеиновых кислот, клеток-хозяев, векторов и/или ВПЧ по настоящему изобретению. В предпочтительном варианте осуществления настоящего изобретение обеспечен способ профилактики и/или лечения инфекционного заболевания, включающий стадию введения субъекту, предпочтительно человеку, терапевтически эффективного количества фармацевтической композиции, как определено выше, где фармацевтическая композиция содержит ВПЧ по настоящему изобретению, содержащие антигены (в частности, содержащиеся в L1 и/или L2 полипептида по настоящему изобретению, как определено выше) инфекционного агента, вызывающего инфекционное заболевание. Другой вариант осуществления представляет собой способ предотвращения и/или лечения опухоли или ракового заболевания на стадии введения терапевтически эффективного количества фармацевтической композиции, как определено выше, субъекту, предпочтительно человеку, где фармацевтическая композиция содержит ВПЧ по настоящему изобретению, содержащие один или более опухолевых антигенов (в частности, содержащихся в L1 и/или L2 полипептида по настоящему изобретению, как определено выше).
Настоящее изобретение дополнительно относится к способу получения полипептида, как описано в данном документе, включающему стадию культивирования рекомбинантной клетки-хозяина в подходящей среде, где клетка-хозяин содержит вектор, который содержит нуклеиновую кислоту, кодирующую полипептид, в условиях, обеспечивающих экспрессию указанного полипептида.
Предпочтительно, способ получения полипептида по настоящему изобретению дополнительно включает стадию выделения экспрессированного полипептида из клеток-хозяев и/или среды. Более предпочтительно, способ также включает стадию очистки выделенного полипептида с помощью средств очистки, известных в данной области техники, таких как центрифугирование, гель-проникающая хроматография, аффинная хроматография и т.д.
Настоящее изобретение также относится к способу получения ВПЧ, как определено в данном документе, включающему стадию инкубации раствора полипептида в условиях, обеспечивающих сборку полипептида в ВПЧ, как описано ранее. Правильное образование ВПЧ можно проверить, исследуя раствор образца с помощью электронного микроскопа.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Фиг. 1: (А) Додекаэдры, образованные белками основания определенных серотипов аденовируса, представляют собой универсальный каркас.(В) Они содержат 60 копий белка основания аденовируса, которые можно разделить на домен «корона» (оранжевый) и домен мультимеризации (синий). В домене мультимеризации концы, образованные в результате расщепления, могут быть повторно соединены короткими олигопептидными линкерами, с образованием непрерывных полипептидных цепей. N-конец и С-конец белка основания содержатся в домене мультимеризации.
Фиг. 2: схема домена с укладкой типа рулет предпочтительного варианта осуществления полипептида по настоящему изобретению на основе протомера основания пентона hAd3.
Фиг. 3: белок основания аденовируса схематически показан крайним слева. Домен «корона» (см. фиг. 1) окрашен в желтый цвет, домен мультимеризации окрашен в синий цвет. N- и С-концы белка основания содержатся в домене мультимеризации, который опосредует образование пентона и додекаэдра. Удаление домена «корона» приводит к автономному домену мультимеризации, который вместо прежнего домена «корона» теперь содержит олигопептиды, полипептиды, белки или белковые комплексы, как показано схематически в направлении от середины направо. Домены мультимеризации теперь дают начало вирусоподобным частицам, представляющим указанные частицы на своей поверхности. Естественно, домены «корона» и сконструированные домены «корона», происходящие от ряда серотипов аденовирусов, также могут быть приспособлены к каркасу доменов мультимеризации, включая сконструированные домены «корона», содержащие гетерологичные пептидные и полипептидные последовательности.
Фиг. 4: додекаэдрическая платформа (ADDomer), полученная из аденовируса, показана схематично. Исходная частица показана слева. Белок основания образован доменом мультимеризации (синий) и доменом «корона» (желтый). 60 белков основания образуют вирусоподобные частицы (ВПЧ). Справа показаны ADDomers, отображающие (вместо домена «корона») множественные копии олигопептидов, полипептидов и белковых доменов, белков или белковых комплексов. Цветовая кодировка как на фиг. 3.
Фиг. 5: Схематическое изображение вектора рАСЕВас VAJB-CHIK.
Настоящее изобретение дополнительно проиллюстрировано следующим неограничивающим примером:
Пример
Нуклеиновая кислота с последовательностью, обозначенной DNAsegVAJB-CHIK (SEQ ID NO: 26, фланкирована сайтом BamHI на 5' конце и сайтом HindIII на 3' конце, ggatcc в начале последовательности и aagctt в конце последовательности) была получена коммерческим поставщиком:

Конструкцию клонировали в плазмиду для переноса рАСЕВас (Geneva Biotech, Женева, Швейцария) с применением сайтов расщепления BamHI и HindIII, в результате чего была получена конструкция рАСЕВас VAJB-CHIK (SEQ ID NO: 27):


Для проверки правильности вставки применяли секвенирование ДНК. Открытая рамка считывания кодирует белок VAJB-CHIK (SEQ ID NO: 28), который содержит главный нейтрализующий эпитоп вируса чикунгунья STKDNFNVYKATRPYLAH (SEQ ID NO: 29) в петле L1.
VAJB-CHIK (SEQ ID NO: 28):

Затем pACEBac_VAJB-CHIK применяли для трансформации клеток DHlOEMBacY (Geneva Biotech, Женева, Швейцария), несущих бакул о вирусный геном EMBacY в качестве искусственной хромосомы (описан в Fitzgerald DJ et al. Nat Methods. 2006 Dec, 3(12): 1021-32 PMID: 17117155). Композитный бакуловирус с кассетой экспрессии для VAJB1, интегрированной посредством транспозиции Тп7 в клетки DHlOEMBacY, затем идентифицировали с помощью синего/белого скрининга, и рекомбинантный бакуловирус получали, как описано (там же). Культуры клеток насекомых Spodoptera frugiperda линии 21 (Sf21) инфицировали бакуловирус ом, полученным таким образом, как описано в Fitzgerald et al. (2006) Nat Methods, см. выше.
Крупномасштабную (от 100 до 500 мл) экспрессию проводили в клетках Trichoplusia ni Hi5 во встряхиваемых колбах и экспрессию рекомбинантного белка с последующим измерением флуоресценции желтого флуоресцентного белка (YFP), как описано (Fitzgerald DJ et Nat Methods. 2006 Dec;3(12): 1021-32 PMID: 17117155). Когда флуоресценция YFP достигла плато (обычно через 72 часа после остановки пролиферации в культуре клеток, см. Fitzgerald et al, Nat Methods 2006), культуры клеток насекомых собирали и клетки осаждали центрифугированием (4000 g, 10 мин). Клетки замораживали в жидком азоте и хранили при минус 80 градусах Цельсия.
Для получения белка клетки лизировали замораживанием-оттаиванием в фосфатно-солевом буфере (ФСБ), содержащем цельную смесь ингибиторов протеазы (Roche Ltd). Белок очищали путем нанесения градиента сахарозы от 15 до 40% мас./об. сахарозы и ультрацентрифугирования в течение ночи при 100000 g. Собирали градиент и определяли содержание белка с помощью денатурирующего электрофореза в полиакриламидном геле (SDS-PAGE) с последующим окрашиванием кумасси бриллиантовым голубым. Фракции, содержащие VAJB1, объединяли и подвергали диализу против ФСБ (или 10 мМ HEPES, рН 7,4, 50 мМ NaCl). Вторую стадию очистки проводили на колонке HiQ объемом 5 мл (BioRAD) с применением линейного градиента от 50 до 500 мМ NaCl. Образование пентамера и додекамера подтверждали с помощью электронной микроскопии с отрицательным окрашиванием (уранилацетат).
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> ИМОФОРОН ЛИМИТЕД
<120> МУЛЬТИМЕРИЗАЦИЯ ПОЛИПЕПТИДОВ, ПОЛУЧЕННЫХ ИЗ ДОМЕНА ТИПА
«JELLY ROLL» ПЕНТОНА АДЕНОВИРУСА
<130> I 2444 WO
<150> EP18186731.8
<151> 2018-07-31
<160> 29
<170> PatentIn версии 3.5
<210> 1
<211> 544
<212> ПРТ
<213> Аденовирус человека C серотипа 3
<400> 1
Met Arg Arg Arg Ala Val Leu Gly Gly Ala Val Val Tyr Pro Glu Gly
1 5 10 15
Pro Pro Pro Ser Tyr Glu Ser Val Met Gln Gln Gln Ala Ala Met Ile
20 25 30
Gln Pro Pro Leu Glu Ala Pro Phe Val Pro Pro Arg Tyr Leu Ala Pro
35 40 45
Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ser Pro Leu Tyr
50 55 60
Asp Thr Thr Lys Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val
85 90 95
Gln Asn Asn Asp Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile Asn
100 105 110
Phe Asp Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met His
115 120 125
Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Ser Asn Lys Phe Lys
130 135 140
Ala Arg Val Met Val Ser Arg Lys Ala Pro Glu Gly Val Thr Val Asn
145 150 155 160
Asp Thr Tyr Asp His Lys Glu Asp Ile Leu Lys Tyr Glu Trp Phe Glu
165 170 175
Phe Ile Leu Pro Glu Gly Asn Phe Ser Ala Thr Met Thr Ile Asp Leu
180 185 190
Met Asn Asn Ala Ile Ile Asp Asn Tyr Leu Glu Ile Gly Arg Gln Asn
195 200 205
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe
210 215 220
Arg Leu Gly Trp Asp Pro Glu Thr Lys Leu Ile Met Pro Gly Val Tyr
225 230 235 240
Thr Tyr Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly
245 250 255
Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
260 265 270
Arg His Pro Phe Gln Glu Gly Phe Lys Ile Met Tyr Glu Asp Leu Glu
275 280 285
Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Thr Ala Tyr Glu Glu Ser
290 295 300
Lys Lys Asp Thr Thr Thr Glu Thr Thr Thr Leu Ala Val Ala Glu Glu
305 310 315 320
Thr Ser Glu Asp Asp Asp Ile Thr Arg Gly Asp Thr Tyr Ile Thr Glu
325 330 335
Lys Gln Lys Arg Glu Ala Ala Ala Ala Glu Val Lys Lys Glu Leu Lys
340 345 350
Ile Gln Pro Leu Glu Lys Asp Ser Lys Ser Arg Ser Tyr Asn Val Leu
355 360 365
Glu Asp Lys Ile Asn Thr Ala Tyr Arg Ser Trp Tyr Leu Ser Tyr Asn
370 375 380
Tyr Gly Asn Pro Glu Lys Gly Ile Arg Ser Trp Thr Leu Leu Thr Thr
385 390 395 400
Ser Asp Val Thr Cys Gly Ala Glu Gln Val Tyr Trp Ser Leu Pro Asp
405 410 415
Met Met Gln Asp Pro Val Thr Phe Arg Ser Thr Arg Gln Val Asn Asn
420 425 430
Tyr Pro Val Val Gly Ala Glu Leu Met Pro Val Phe Ser Lys Ser Phe
435 440 445
Tyr Asn Glu Gln Ala Val Tyr Ser Gln Gln Leu Arg Gln Ala Thr Ser
450 455 460
Leu Thr His Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Ile Arg
465 470 475 480
Pro Pro Ala Pro Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu
485 490 495
Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile Arg Gly Val Gln
500 505 510
Arg Val Thr Val Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr
515 520 525
Lys Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
530 535 540
<210> 2
<211> 571
<212> ПРТ
<213> Аденовирус человека C серотипа 2
<400> 2
Met Gln Arg Ala Ala Met Tyr Glu Glu Gly Pro Pro Pro Ser Tyr Glu
1 5 10 15
Ser Val Val Ser Ala Ala Pro Val Ala Ala Ala Leu Gly Ser Pro Phe
20 25 30
Asp Ala Pro Leu Asp Pro Pro Phe Val Pro Pro Arg Tyr Leu Arg Pro
35 40 45
Thr Gly Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Phe
50 55 60
Asp Thr Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Thr Asp Val Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Ile
85 90 95
Gln Asn Asn Asp Tyr Ser Pro Gly Glu Ala Ser Thr Gln Thr Ile Asn
100 105 110
Leu Asp Asp Arg Ser His Trp Gly Gly Asp Leu Lys Thr Ile Leu His
115 120 125
Thr Asn Met Pro Asn Val Asn Glu Phe Met Phe Thr Asn Lys Phe Lys
130 135 140
Ala Arg Val Met Val Ser Arg Ser Leu Thr Lys Asp Lys Gln Val Glu
145 150 155 160
Leu Lys Tyr Glu Trp Val Glu Phe Thr Leu Pro Glu Gly Asn Tyr Ser
165 170 175
Glu Thr Met Thr Ile Asp Leu Met Asn Asn Ala Ile Val Glu His Tyr
180 185 190
Leu Lys Val Gly Arg Gln Asn Gly Val Leu Glu Ser Asp Ile Gly Val
195 200 205
Lys Phe Asp Thr Arg Asn Phe Arg Leu Gly Phe Asp Pro Val Thr Gly
210 215 220
Leu Val Met Pro Gly Val Tyr Thr Asn Glu Ala Phe His Pro Asp Ile
225 230 235 240
Ile Leu Leu Pro Gly Cys Gly Val Asp Phe Thr His Ser Arg Leu Ser
245 250 255
Asn Leu Leu Gly Ile Arg Lys Arg Gln Pro Phe Gln Glu Gly Phe Arg
260 265 270
Ile Thr Tyr Asp Asp Leu Glu Gly Gly Asn Ile Pro Ala Leu Leu Asp
275 280 285
Val Asp Ala Tyr Gln Ala Ser Leu Lys Asp Asp Thr Glu Gln Gly Gly
290 295 300
Asp Gly Ala Gly Gly Gly Asn Asn Ser Gly Ser Gly Ala Glu Glu Asn
305 310 315 320
Ser Asn Ala Ala Ala Ala Ala Met Gln Pro Val Glu Asp Met Asn Asp
325 330 335
His Ala Ile Arg Gly Asp Thr Phe Ala Thr Arg Ala Glu Glu Lys Arg
340 345 350
Ala Glu Ala Glu Ala Ala Ala Glu Ala Ala Ala Pro Ala Ala Gln Pro
355 360 365
Glu Val Glu Lys Pro Gln Lys Lys Pro Val Ile Lys Pro Leu Thr Glu
370 375 380
Asp Ser Lys Lys Arg Ser Tyr Asn Leu Ile Ser Asn Asp Ser Thr Phe
385 390 395 400
Thr Gln Tyr Arg Ser Trp Tyr Leu Ala Tyr Asn Tyr Gly Asp Pro Gln
405 410 415
Thr Gly Ile Arg Ser Trp Thr Leu Leu Cys Thr Pro Asp Val Thr Cys
420 425 430
Gly Ser Glu Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro
435 440 445
Val Thr Phe Arg Ser Thr Ser Gln Ile Ser Asn Phe Pro Val Val Gly
450 455 460
Ala Glu Leu Leu Pro Val His Ser Lys Ser Phe Tyr Asn Asp Gln Ala
465 470 475 480
Val Tyr Ser Gln Leu Ile Arg Gln Phe Thr Ser Leu Thr His Val Phe
485 490 495
Asn Arg Phe Pro Glu Asn Gln Ile Leu Ala Arg Pro Pro Ala Pro Thr
500 505 510
Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr
515 520 525
Leu Pro Leu Arg Asn Ser Ile Gly Gly Val Gln Arg Val Thr Ile Thr
530 535 540
Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile
545 550 555 560
Val Ser Pro Arg Val Leu Ser Ser Arg Thr Phe
565 570
<210> 3
<211> 535
<212> ПРТ
<213> Аденовирус человека E серотипа 4
<400> 3
Met Met Arg Arg Ala Tyr Pro Glu Gly Pro Pro Pro Ser Tyr Glu Ser
1 5 10 15
Val Met Gln Gln Ala Met Ala Ala Ala Ala Ala Ile Gln Pro Pro Leu
20 25 30
Glu Ala Pro Tyr Val Pro Pro Arg Tyr Leu Ala Pro Thr Glu Gly Arg
35 40 45
Asn Ser Ile Arg Tyr Ser Glu Leu Thr Pro Leu Tyr Asp Thr Thr Arg
50 55 60
Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu Asn Tyr
65 70 75 80
Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn Asn Asp
85 90 95
Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile Asn Phe Asp Glu Arg
100 105 110
Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met His Thr Asn Met Pro
115 120 125
Asn Val Asn Gln Phe Met Tyr Ser Asn Lys Phe Lys Ala Arg Val Met
130 135 140
Val Ser Arg Lys Thr Pro Asn Gly Val Thr Val Gly Asp Asn Tyr Asp
145 150 155 160
Gly Ser Gln Asp Glu Leu Lys Tyr Glu Trp Val Glu Phe Glu Leu Pro
165 170 175
Glu Gly Asn Phe Ser Val Thr Met Thr Ile Asp Leu Met Asn Asn Ala
180 185 190
Ile Ile Asp Asn Tyr Leu Ala Val Gly Arg Gln Asn Gly Val Leu Glu
195 200 205
Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe Arg Leu Gly Trp
210 215 220
Asp Pro Val Thr Glu Leu Val Met Pro Gly Val Tyr Thr Asn Glu Ala
225 230 235 240
Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly Val Asp Phe Thr
245 250 255
Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys Arg Gln Pro Phe
260 265 270
Gln Glu Gly Phe Gln Ile Met Tyr Glu Asp Leu Asp Gly Gly Asn Ile
275 280 285
Pro Ala Leu Leu Asp Val Glu Ala Tyr Glu Lys Ser Lys Glu Glu Ser
290 295 300
Val Ala Ala Ala Thr Thr Ala Val Ala Thr Ala Ser Thr Glu Val Arg
305 310 315 320
Asp Asp Asn Phe Ala Ser Ala Ala Ala Val Ala Ala Val Lys Ala Asp
325 330 335
Glu Thr Lys Ser Lys Ile Val Ile Gln Pro Val Glu Lys Asp Ser Lys
340 345 350
Glu Arg Ser Tyr Asn Val Leu Ser Asp Lys Lys Asn Thr Ala Tyr Arg
355 360 365
Ser Trp Tyr Leu Ala Tyr Asn Tyr Gly Asp Arg Asp Lys Gly Val Arg
370 375 380
Ser Trp Thr Leu Leu Thr Thr Ser Asp Val Thr Cys Gly Val Glu Gln
385 390 395 400
Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro Val Thr Phe Arg
405 410 415
Ser Thr His Gln Val Ser Asn Tyr Pro Val Val Gly Ala Glu Leu Leu
420 425 430
Pro Val Tyr Ser Lys Ser Phe Phe Asn Glu Gln Ala Val Tyr Ser Gln
435 440 445
Gln Leu Arg Ala Phe Thr Ser Leu Thr His Val Phe Asn Arg Phe Pro
450 455 460
Glu Asn Gln Ile Leu Val Arg Pro Pro Ala Pro Thr Ile Thr Thr Val
465 470 475 480
Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu Arg
485 490 495
Ser Ser Ile Arg Gly Val Gln Arg Val Thr Val Thr Asp Ala Arg Arg
500 505 510
Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile Val Ala Pro Arg
515 520 525
Val Leu Ser Ser Arg Thr Phe
530 535
<210> 4
<211> 571
<212> ПРТ
<213> Аденовирус человека C серотипа 5
<400> 4
Met Arg Arg Ala Ala Met Tyr Glu Glu Gly Pro Pro Pro Ser Tyr Glu
1 5 10 15
Ser Val Val Ser Ala Ala Pro Val Ala Ala Ala Leu Gly Ser Pro Phe
20 25 30
Asp Ala Pro Leu Asp Pro Pro Phe Val Pro Pro Arg Tyr Leu Arg Pro
35 40 45
Thr Gly Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Phe
50 55 60
Asp Thr Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Thr Asp Val Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Ile
85 90 95
Gln Asn Asn Asp Tyr Ser Pro Gly Glu Ala Ser Thr Gln Thr Ile Asn
100 105 110
Leu Asp Asp Arg Ser His Trp Gly Gly Asp Leu Lys Thr Ile Leu His
115 120 125
Thr Asn Met Pro Asn Val Asn Glu Phe Met Phe Thr Asn Lys Phe Lys
130 135 140
Ala Arg Val Met Val Ser Arg Leu Pro Thr Lys Asp Asn Gln Val Glu
145 150 155 160
Leu Lys Tyr Glu Trp Val Glu Phe Thr Leu Pro Glu Gly Asn Tyr Ser
165 170 175
Glu Thr Met Thr Ile Asp Leu Met Asn Asn Ala Ile Val Glu His Tyr
180 185 190
Leu Lys Val Gly Arg Gln Asn Gly Val Leu Glu Ser Asp Ile Gly Val
195 200 205
Lys Phe Asp Thr Arg Asn Phe Arg Leu Gly Phe Asp Pro Val Thr Gly
210 215 220
Leu Val Met Pro Gly Val Tyr Thr Asn Glu Ala Phe His Pro Asp Ile
225 230 235 240
Ile Leu Leu Pro Gly Cys Gly Val Asp Phe Thr His Ser Arg Leu Ser
245 250 255
Asn Leu Leu Gly Ile Arg Lys Arg Gln Pro Phe Gln Glu Gly Phe Arg
260 265 270
Ile Thr Tyr Asp Asp Leu Glu Gly Gly Asn Ile Pro Ala Leu Leu Asp
275 280 285
Val Asp Ala Tyr Gln Ala Ser Leu Lys Asp Asp Thr Glu Gln Gly Gly
290 295 300
Gly Gly Ala Gly Gly Ser Asn Ser Ser Gly Ser Gly Ala Glu Glu Asn
305 310 315 320
Ser Asn Ala Ala Ala Ala Ala Met Gln Pro Val Glu Asp Met Asn Asp
325 330 335
His Ala Ile Arg Gly Asp Thr Phe Ala Thr Arg Ala Glu Glu Lys Arg
340 345 350
Ala Glu Ala Glu Ala Ala Ala Glu Ala Ala Ala Pro Ala Ala Gln Pro
355 360 365
Glu Val Glu Lys Pro Gln Lys Lys Pro Val Ile Lys Pro Leu Thr Glu
370 375 380
Asp Ser Lys Lys Arg Ser Tyr Asn Leu Ile Ser Asn Asp Ser Thr Phe
385 390 395 400
Thr Gln Tyr Arg Ser Trp Tyr Leu Ala Tyr Asn Tyr Gly Asp Pro Gln
405 410 415
Thr Gly Ile Arg Ser Trp Thr Leu Leu Cys Thr Pro Asp Val Thr Cys
420 425 430
Gly Ser Glu Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro
435 440 445
Val Thr Phe Arg Ser Thr Arg Gln Ile Ser Asn Phe Pro Val Val Gly
450 455 460
Ala Glu Leu Leu Pro Val His Ser Lys Ser Phe Tyr Asn Asp Gln Ala
465 470 475 480
Val Tyr Ser Gln Leu Ile Arg Gln Phe Thr Ser Leu Thr His Val Phe
485 490 495
Asn Arg Phe Pro Glu Asn Gln Ile Leu Ala Arg Pro Pro Ala Pro Thr
500 505 510
Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr
515 520 525
Leu Pro Leu Arg Asn Ser Ile Gly Gly Val Gln Arg Val Thr Ile Thr
530 535 540
Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile
545 550 555 560
Val Ser Pro Arg Val Leu Ser Ser Arg Thr Phe
565 570
<210> 5
<211> 544
<212> ПРТ
<213> Аденовирус человека B серотипа 7
<400> 5
Met Arg Arg Arg Ala Val Leu Gly Gly Ala Met Val Tyr Pro Glu Gly
1 5 10 15
Pro Pro Pro Ser Tyr Glu Ser Val Met Gln Gln Gln Ala Ala Met Ile
20 25 30
Gln Pro Pro Leu Glu Ala Pro Phe Val Pro Pro Arg Tyr Leu Ala Pro
35 40 45
Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ser Pro Leu Tyr
50 55 60
Asp Thr Thr Lys Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val
85 90 95
Gln Asn Asn Asp Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile Asn
100 105 110
Phe Asp Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met His
115 120 125
Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Ser Asn Lys Phe Lys
130 135 140
Ala Arg Val Met Val Ser Arg Lys Ala Pro Glu Gly Val Ile Val Asn
145 150 155 160
Asp Thr Tyr Asp His Lys Glu Asp Ile Leu Lys Tyr Glu Trp Phe Glu
165 170 175
Phe Thr Leu Pro Glu Gly Asn Phe Ser Ala Thr Met Thr Ile Asp Leu
180 185 190
Met Asn Asn Ala Ile Ile Asp Asn Tyr Leu Glu Ile Gly Arg Gln Asn
195 200 205
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe
210 215 220
Arg Leu Gly Trp Asp Pro Glu Thr Lys Leu Ile Met Pro Gly Val Tyr
225 230 235 240
Thr Tyr Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly
245 250 255
Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
260 265 270
Arg His Pro Phe Gln Glu Gly Phe Lys Ile Met Tyr Glu Asp Leu Glu
275 280 285
Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Thr Ala Tyr Glu Glu Ser
290 295 300
Lys Lys Asp Thr Thr Thr Glu Thr Thr Thr Leu Ala Val Ala Glu Glu
305 310 315 320
Thr Ser Glu Asp Asp Asn Ile Thr Arg Gly Asp Thr Tyr Ile Thr Glu
325 330 335
Lys Gln Lys Arg Glu Ala Ala Ala Ala Glu Val Lys Lys Glu Leu Lys
340 345 350
Ile Gln Pro Leu Glu Lys Asp Ser Lys Ser Arg Ser Tyr Asn Val Leu
355 360 365
Glu Asp Lys Ile Asn Thr Ala Tyr Arg Ser Trp Tyr Leu Ser Tyr Asn
370 375 380
Tyr Gly Asn Pro Glu Lys Gly Ile Arg Ser Trp Thr Leu Leu Thr Thr
385 390 395 400
Ser Asp Val Thr Cys Gly Ala Glu Gln Val Tyr Trp Ser Leu Pro Asp
405 410 415
Met Met Gln Asp Pro Val Thr Phe Arg Ser Thr Arg Gln Val Asn Asn
420 425 430
Tyr Pro Val Val Gly Ala Glu Leu Met Pro Val Phe Ser Lys Ser Phe
435 440 445
Tyr Asn Glu Gln Ala Val Tyr Ser Gln Gln Leu Arg Gln Ala Thr Ser
450 455 460
Leu Thr His Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Ile Arg
465 470 475 480
Pro Pro Ala Pro Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu
485 490 495
Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile Arg Gly Val Gln
500 505 510
Arg Val Thr Val Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr
515 520 525
Lys Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
530 535 540
<210> 6
<211> 557
<212> ПРТ
<213> Аденовирус человека B серотипа 11
<400> 6
Met Arg Arg Val Val Leu Gly Gly Ala Val Val Tyr Pro Glu Gly Pro
1 5 10 15
Pro Pro Ser Tyr Glu Ser Val Met Gln Gln Gln Ala Thr Ala Val Met
20 25 30
Gln Ser Pro Leu Glu Ala Pro Phe Val Pro Pro Arg Tyr Leu Ala Pro
35 40 45
Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Gln Tyr
50 55 60
Asp Thr Thr Arg Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val
85 90 95
Gln Asn Asn Asp Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile Asn
100 105 110
Phe Asp Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met His
115 120 125
Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Ser Asn Asn Phe Lys
130 135 140
Ala Arg Val Met Val Ser Arg Lys Pro Pro Glu Gly Ala Ala Val Gly
145 150 155 160
Asp Thr Tyr Asp His Lys Gln Asp Ile Leu Glu Tyr Glu Trp Phe Glu
165 170 175
Phe Thr Leu Pro Glu Gly Asn Phe Ser Val Thr Met Thr Ile Asp Leu
180 185 190
Met Asn Asn Ala Ile Ile Asp Asn Tyr Leu Lys Val Gly Arg Gln Asn
195 200 205
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe
210 215 220
Lys Leu Gly Trp Asp Pro Glu Thr Lys Leu Ile Met Pro Gly Val Tyr
225 230 235 240
Thr Tyr Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly
245 250 255
Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
260 265 270
Lys Gln Pro Phe Gln Glu Gly Phe Lys Ile Leu Tyr Glu Asp Leu Glu
275 280 285
Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Asp Ala Tyr Glu Asn Ser
290 295 300
Lys Lys Glu Gln Lys Ala Lys Ile Glu Ala Ala Ala Glu Ala Lys Ala
305 310 315 320
Asn Ile Val Ala Ser Asp Ser Thr Arg Val Ala Asn Ala Gly Glu Val
325 330 335
Arg Gly Asp Asn Phe Ala Pro Thr Pro Val Pro Thr Ala Glu Ser Leu
340 345 350
Leu Ala Asp Val Ser Gly Gly Thr Asp Val Lys Leu Thr Ile Gln Pro
355 360 365
Val Glu Lys Asp Ser Lys Asn Arg Ser Tyr Asn Val Leu Glu Asp Lys
370 375 380
Ile Asn Thr Ala Tyr Arg Ser Trp Tyr Leu Ser Tyr Asn Tyr Gly Asp
385 390 395 400
Pro Glu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr Thr Ser Asp Val
405 410 415
Thr Cys Gly Ala Glu Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln
420 425 430
Asp Pro Val Thr Phe Arg Ser Thr Arg Gln Val Ser Asn Tyr Pro Val
435 440 445
Val Gly Ala Glu Leu Met Pro Val Phe Ser Lys Ser Phe Tyr Asn Glu
450 455 460
Gln Ala Val Tyr Ser Gln Gln Leu Arg Gln Ser Thr Ser Leu Thr His
465 470 475 480
Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Ile Arg Pro Pro Ala
485 490 495
Pro Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr Asp His
500 505 510
Gly Thr Leu Pro Leu Arg Ser Ser Ile Arg Gly Val Gln Arg Val Thr
515 520 525
Val Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu
530 535 540
Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
545 550 555
<210> 7
<211> 497
<212> ПРТ
<213> Аденовирус человека A серотипа 12
<400> 7
Met Arg Arg Ala Val Glu Leu Gln Thr Val Ala Phe Pro Glu Thr Pro
1 5 10 15
Pro Pro Ser Tyr Glu Thr Val Met Ala Ala Ala Pro Pro Tyr Val Pro
20 25 30
Pro Arg Tyr Leu Gly Pro Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser
35 40 45
Glu Leu Ser Pro Leu Tyr Asp Thr Thr Arg Val Tyr Leu Val Asp Asn
50 55 60
Lys Ser Ser Asp Ile Ala Ser Leu Asn Tyr Gln Asn Asp His Ser Asn
65 70 75 80
Phe Leu Thr Thr Val Val Gln Asn Asn Asp Tyr Ser Pro Ile Glu Ala
85 90 95
Gly Thr Gln Thr Ile Asn Phe Asp Glu Arg Ser Arg Trp Gly Gly Asp
100 105 110
Leu Lys Thr Ile Leu His Thr Asn Met Pro Asn Val Asn Asp Phe Met
115 120 125
Phe Thr Thr Lys Phe Lys Ala Arg Val Met Val Ala Arg Lys Thr Asn
130 135 140
Asn Glu Gly Gln Thr Ile Leu Glu Tyr Glu Trp Ala Glu Phe Val Leu
145 150 155 160
Pro Glu Gly Asn Tyr Ser Glu Thr Met Thr Ile Asp Leu Met Asn Asn
165 170 175
Ala Ile Ile Glu His Tyr Leu Arg Val Gly Arg Gln His Gly Val Leu
180 185 190
Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe Arg Leu Gly
195 200 205
Trp Asp Pro Glu Thr Gln Leu Val Thr Pro Gly Val Tyr Thr Asn Glu
210 215 220
Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly Val Asp Phe
225 230 235 240
Thr Glu Ser Arg Leu Ser Asn Ile Leu Gly Ile Arg Lys Arg Gln Pro
245 250 255
Phe Gln Glu Gly Phe Val Ile Met Tyr Glu His Leu Glu Gly Gly Asn
260 265 270
Ile Pro Ala Leu Leu Asp Val Lys Lys Tyr Glu Asn Ser Leu Gln Asp
275 280 285
Gln Asn Thr Val Arg Gly Asp Asn Phe Ile Ala Leu Asn Lys Ala Ala
290 295 300
Arg Ile Glu Pro Val Glu Thr Asp Pro Lys Gly Arg Ser Tyr Asn Leu
305 310 315 320
Leu Pro Asp Lys Lys Asn Thr Lys Tyr Arg Ser Trp Tyr Leu Ala Tyr
325 330 335
Asn Tyr Gly Asp Pro Glu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr
340 345 350
Thr Pro Asp Val Thr Gly Gly Ser Glu Gln Val Tyr Trp Ser Leu Pro
355 360 365
Asp Met Met Gln Asp Pro Val Thr Phe Arg Ser Ser Arg Gln Val Ser
370 375 380
Asn Tyr Pro Val Val Ala Ala Glu Leu Leu Pro Val His Ala Lys Ser
385 390 395 400
Phe Tyr Asn Glu Gln Ala Val Tyr Ser Gln Leu Ile Arg Gln Ser Thr
405 410 415
Ala Leu Thr Arg Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Val
420 425 430
Arg Pro Pro Ala Ala Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala
435 440 445
Leu Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile Ser Gly Val
450 455 460
Gln Arg Val Thr Ile Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val
465 470 475 480
Tyr Lys Ala Leu Gly Ile Val Ser Pro Arg Val Leu Ser Ser Arg Thr
485 490 495
Phe
<210> 8
<211> 517
<212> ПРТ
<213> Аденовирус человека D серотипа 17
<400> 8
Met Arg Arg Ala Val Val Ser Ser Ser Pro Pro Pro Ser Tyr Glu Ser
1 5 10 15
Val Met Ala Gln Ala Thr Leu Glu Val Pro Phe Val Pro Pro Arg Tyr
20 25 30
Met Ala Pro Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala
35 40 45
Pro Leu Tyr Asp Thr Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Ala
50 55 60
Asp Ile Ala Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr
65 70 75 80
Thr Val Val Gln Asn Asn Asp Phe Thr Pro Ala Glu Ala Ser Thr Gln
85 90 95
Thr Ile Asn Phe Asp Glu Arg Ser Arg Trp Gly Gly Asp Leu Lys Thr
100 105 110
Ile Leu His Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Thr Ser
115 120 125
Lys Phe Lys Ala Arg Val Met Val Ala Arg Lys His Pro Gln Gly Val
130 135 140
Glu Ala Thr Asp Leu Ser Lys Asp Ile Leu Glu Tyr Glu Trp Phe Glu
145 150 155 160
Phe Thr Leu Pro Glu Gly Asn Phe Ser Glu Thr Met Thr Ile Asp Leu
165 170 175
Met Asn Asn Ala Ile Leu Glu Asn Tyr Leu Gln Val Gly Arg Gln Asn
180 185 190
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Ser Arg Asn Phe
195 200 205
Lys Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val Tyr
210 215 220
Thr Tyr Glu Ala Phe His Pro Asp Val Val Leu Leu Pro Gly Cys Gly
225 230 235 240
Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
245 250 255
Lys Gln Pro Phe Gln Glu Gly Phe Arg Ile Met Tyr Glu Asp Leu Glu
260 265 270
Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Pro Lys Tyr Leu Glu Ser
275 280 285
Lys Lys Lys Leu Glu Glu Ala Leu Glu Asn Ala Ala Lys Ala Asn Gly
290 295 300
Pro Ala Arg Gly Asp Ser Ser Val Ser Arg Glu Val Glu Lys Ala Ala
305 310 315 320
Glu Lys Glu Leu Val Ile Glu Pro Ile Lys Gln Asp Asp Ser Lys Arg
325 330 335
Ser Tyr Asn Leu Ile Glu Gly Thr Met Asp Thr Leu Tyr Arg Ser Trp
340 345 350
Tyr Leu Ser Tyr Thr Tyr Gly Asp Pro Glu Lys Gly Val Gln Ser Trp
355 360 365
Thr Leu Leu Thr Thr Pro Asp Val Thr Cys Gly Ala Glu Gln Val Tyr
370 375 380
Trp Ser Leu Pro Asp Leu Met Gln Asp Pro Val Thr Phe Arg Ser Thr
385 390 395 400
Gln Gln Val Ser Asn Tyr Pro Val Val Gly Ala Glu Leu Met Pro Phe
405 410 415
Arg Ala Lys Ser Phe Tyr Asn Asp Leu Ala Val Tyr Ser Gln Leu Ile
420 425 430
Arg Ser Tyr Thr Ser Leu Thr His Val Phe Asn Arg Phe Pro Asp Asn
435 440 445
Gln Ile Leu Cys Arg Pro Pro Ala Pro Thr Ile Thr Thr Val Ser Glu
450 455 460
Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser
465 470 475 480
Ile Arg Gly Val Gln Arg Val Thr Val Thr Asp Ala Arg Arg Arg Thr
485 490 495
Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile Val Ala Pro Arg Val Leu
500 505 510
Ser Ser Arg Thr Phe
515
<210> 9
<211> 520
<212> ПРТ
<213> Аденовирус человека 25
<400> 9
Met Arg Arg Ala Val Val Ser Ser Ser Pro Pro Pro Ser Tyr Glu Ser
1 5 10 15
Val Met Ala Gln Ala Thr Leu Glu Val Pro Phe Val Pro Pro Arg Tyr
20 25 30
Met Ala Pro Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala
35 40 45
Pro Gln Tyr Asp Thr Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Ala
50 55 60
Asp Ile Ala Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr
65 70 75 80
Thr Val Val Gln Asn Asn Asp Phe Thr Pro Ala Glu Ala Ser Thr Gln
85 90 95
Thr Ile Asn Phe Asp Glu Arg Ser Arg Trp Gly Gly Asp Leu Lys Thr
100 105 110
Ile Leu His Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Thr Ser
115 120 125
Lys Phe Lys Ala Arg Val Met Val Ala Arg Lys His Pro Glu Asn Val
130 135 140
Asp Lys Thr Asp Leu Ser Gln Asp Lys Leu Glu Tyr Glu Trp Phe Glu
145 150 155 160
Phe Thr Leu Pro Glu Gly Asn Phe Ser Glu Thr Met Thr Ile Asp Leu
165 170 175
Met Asn Asn Ala Ile Leu Glu Asn Tyr Leu Gln Val Gly Arg Gln Asn
180 185 190
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Ser Arg Asn Phe
195 200 205
Lys Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val Tyr
210 215 220
Thr Tyr Glu Ala Phe His Pro Asp Val Val Leu Leu Pro Gly Cys Gly
225 230 235 240
Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
245 250 255
Lys Gln Pro Phe Gln Glu Gly Phe Arg Ile Met Tyr Glu Asp Leu Glu
260 265 270
Gly Gly Asn Ile Pro Ala Leu Leu Asp Thr Lys Lys Tyr Leu Asp Ser
275 280 285
Lys Lys Glu Leu Glu Asp Ala Ala Lys Glu Ala Ala Lys Gln Gln Gly
290 295 300
Asp Gly Ala Val Thr Arg Gly Asp Thr His Leu Thr Val Ala Gln Glu
305 310 315 320
Lys Ala Ala Glu Lys Glu Leu Val Ile Val Pro Ile Glu Lys Asp Glu
325 330 335
Ser Asn Arg Ser Tyr Asn Leu Ile Lys Asp Thr His Asp Thr Met Tyr
340 345 350
Arg Ser Trp Tyr Leu Ser Tyr Thr Tyr Gly Asp Pro Glu Lys Gly Val
355 360 365
Gln Ser Trp Thr Leu Leu Thr Thr Pro Asp Val Thr Cys Gly Ala Glu
370 375 380
Gln Val Tyr Trp Ser Leu Pro Asp Leu Met Gln Asp Pro Val Thr Phe
385 390 395 400
Arg Ser Thr Gln Gln Val Ser Asn Tyr Pro Val Val Gly Ala Glu Leu
405 410 415
Met Pro Phe Arg Ala Lys Ser Phe Tyr Asn Asp Leu Ala Val Tyr Ser
420 425 430
Gln Leu Ile Arg Ser Tyr Thr Ser Leu Thr His Val Phe Asn Arg Phe
435 440 445
Pro Asp Asn Gln Ile Leu Cys Arg Pro Pro Ala Pro Thr Ile Thr Thr
450 455 460
Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu
465 470 475 480
Arg Ser Ser Ile Arg Gly Val Gln Arg Val Thr Val Thr Asp Ala Arg
485 490 495
Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile Val Ala Pro
500 505 510
Arg Val Leu Ser Ser Arg Thr Phe
515 520
<210> 10
<211> 561
<212> ПРТ
<213> Аденовирус человека B серотипа 35
<400> 10
Met Arg Arg Val Val Leu Gly Gly Ala Val Val Tyr Pro Glu Gly Pro
1 5 10 15
Pro Pro Ser Tyr Glu Ser Val Met Gln Gln Gln Gln Ala Thr Ala Val
20 25 30
Met Gln Ser Pro Leu Glu Ala Pro Phe Val Pro Pro Arg Tyr Leu Ala
35 40 45
Pro Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Gln
50 55 60
Tyr Asp Thr Thr Arg Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile
65 70 75 80
Ala Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val
85 90 95
Val Gln Asn Asn Asp Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile
100 105 110
Asn Phe Asp Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met
115 120 125
His Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Ser Asn Lys Phe
130 135 140
Lys Ala Arg Val Met Val Ser Arg Lys Pro Pro Asp Gly Ala Ala Val
145 150 155 160
Gly Asp Thr Tyr Asp His Lys Gln Asp Ile Leu Glu Tyr Glu Trp Phe
165 170 175
Glu Phe Thr Leu Pro Glu Gly Asn Phe Ser Val Thr Met Thr Ile Asp
180 185 190
Leu Met Asn Asn Ala Ile Ile Asp Asn Tyr Leu Lys Val Gly Arg Gln
195 200 205
Asn Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn
210 215 220
Phe Lys Leu Gly Trp Asp Pro Glu Thr Lys Leu Ile Met Pro Gly Val
225 230 235 240
Tyr Thr Tyr Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys
245 250 255
Gly Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg
260 265 270
Lys Lys Gln Pro Phe Gln Glu Gly Phe Lys Ile Leu Tyr Glu Asp Leu
275 280 285
Glu Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Asp Ala Tyr Glu Asn
290 295 300
Ser Lys Lys Glu Gln Lys Ala Lys Ile Glu Ala Ala Thr Ala Ala Ala
305 310 315 320
Glu Ala Lys Ala Asn Ile Val Ala Ser Asp Ser Thr Arg Val Ala Asn
325 330 335
Ala Gly Glu Val Arg Gly Asp Asn Phe Ala Pro Thr Pro Val Pro Thr
340 345 350
Ala Glu Ser Leu Leu Ala Asp Val Ser Glu Gly Thr Asp Val Lys Leu
355 360 365
Thr Ile Gln Pro Val Glu Lys Asp Ser Lys Asn Arg Ser Tyr Asn Val
370 375 380
Leu Glu Asp Lys Ile Asn Thr Ala Tyr Arg Ser Trp Tyr Leu Ser Tyr
385 390 395 400
Asn Tyr Gly Asp Pro Glu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr
405 410 415
Thr Ser Asp Val Thr Cys Gly Ala Glu Gln Val Tyr Trp Ser Leu Pro
420 425 430
Asp Met Met Lys Asp Pro Val Thr Phe Arg Ser Thr Arg Gln Val Ser
435 440 445
Asn Tyr Pro Val Val Gly Ala Glu Leu Met Pro Val Phe Ser Lys Ser
450 455 460
Phe Tyr Asn Glu Gln Ala Val Tyr Ser Gln Gln Leu Arg Gln Ser Thr
465 470 475 480
Ser Leu Thr His Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Ile
485 490 495
Arg Pro Pro Ala Pro Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala
500 505 510
Leu Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile Arg Gly Val
515 520 525
Gln Arg Val Thr Val Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val
530 535 540
Tyr Lys Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr
545 550 555 560
Phe
<210> 11
<211> 519
<212> ПРТ
<213> Аденовирус человека D37
<400> 11
Met Arg Arg Ala Val Val Ser Ser Ser Pro Pro Pro Ser Tyr Glu Ser
1 5 10 15
Val Met Ala Gln Ala Thr Leu Glu Val Pro Phe Val Pro Pro Arg Tyr
20 25 30
Met Ala Pro Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala
35 40 45
Pro Leu Tyr Asp Thr Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Ala
50 55 60
Asp Ile Ala Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr
65 70 75 80
Thr Val Val Gln Asn Asn Asp Phe Thr Pro Ala Glu Ala Ser Thr Gln
85 90 95
Thr Ile Asn Phe Asp Glu Arg Ser Arg Trp Gly Gly Asp Leu Lys Thr
100 105 110
Ile Leu His Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Thr Ser
115 120 125
Lys Phe Lys Ala Arg Val Met Val Ala Arg Lys Lys Ala Glu Gly Ala
130 135 140
Asp Ala Asn Asp Arg Ser Lys Asp Ile Leu Glu Tyr Gln Trp Phe Glu
145 150 155 160
Phe Thr Leu Pro Glu Gly Asn Phe Ser Glu Thr Met Thr Ile Asp Leu
165 170 175
Met Asn Asn Ala Ile Leu Glu Asn Tyr Leu Gln Val Gly Arg Gln Asn
180 185 190
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Ser Arg Asn Phe
195 200 205
Lys Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val Tyr
210 215 220
Thr Tyr Glu Ala Phe His Pro Asp Val Val Leu Leu Pro Gly Cys Gly
225 230 235 240
Val Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
245 250 255
Lys Gln Pro Phe Gln Glu Gly Phe Arg Ile Met Tyr Glu Asp Leu Val
260 265 270
Gly Gly Asn Ile Pro Ala Leu Leu Asn Val Lys Glu Tyr Leu Lys Asp
275 280 285
Lys Glu Glu Ala Gly Lys Ala Asp Ala Asn Thr Ile Lys Ala Gln Asn
290 295 300
Asp Ala Val Pro Arg Gly Asp Asn Tyr Ala Ser Ala Ala Glu Ala Lys
305 310 315 320
Ala Ala Gly Lys Glu Ile Glu Leu Lys Ala Ile Leu Lys Asp Asp Ser
325 330 335
Asp Arg Ser Tyr Asn Val Ile Glu Gly Thr Thr Asp Thr Leu Tyr Arg
340 345 350
Ser Trp Tyr Leu Ser Tyr Thr Tyr Gly Asp Pro Glu Lys Gly Val Gln
355 360 365
Ser Trp Thr Leu Leu Thr Thr Pro Asp Val Thr Cys Gly Ala Glu Gln
370 375 380
Val Tyr Trp Ser Leu Pro Asp Leu Met Gln Asp Pro Val Thr Phe Arg
385 390 395 400
Ser Thr Gln Gln Val Ser Asn Tyr Pro Val Val Gly Ala Glu Leu Met
405 410 415
Pro Phe Arg Ala Lys Ser Phe Tyr Asn Asp Leu Ala Val Tyr Ser Gln
420 425 430
Leu Ile Arg Ser Tyr Thr Ser Leu Thr His Val Phe Asn Arg Phe Pro
435 440 445
Asp Asn Gln Ile Leu Cys Arg Pro Pro Ala Pro Thr Ile Thr Thr Val
450 455 460
Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu Arg
465 470 475 480
Ser Ser Ile Arg Gly Val Gln Arg Val Thr Val Thr Asp Ala Arg Arg
485 490 495
Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile Val Ala Pro Arg
500 505 510
Val Leu Ser Ser Arg Thr Phe
515
<210> 12
<211> 508
<212> ПРТ
<213> Аденовирус человека F серотипа 41
<400> 12
Met Arg Arg Ala Val Gly Val Pro Pro Val Met Ala Tyr Ala Glu Gly
1 5 10 15
Pro Pro Pro Ser Tyr Glu Ser Val Met Gly Ser Ala Asp Ser Pro Ala
20 25 30
Thr Leu Glu Ala Leu Tyr Val Pro Pro Arg Tyr Leu Gly Pro Thr Glu
35 40 45
Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr
50 55 60
Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu
65 70 75 80
Asn Tyr Gln Asn Asp His Ser Asn Phe Gln Thr Thr Val Val Gln Asn
85 90 95
Asn Asp Phe Thr Pro Ala Glu Ala Gly Thr Gln Thr Ile Asn Phe Asp
100 105 110
Glu Arg Ser Arg Trp Gly Ala Asp Leu Lys Thr Ile Leu Arg Thr Asn
115 120 125
Met Pro Asn Ile Asn Glu Phe Met Ser Thr Asn Lys Phe Lys Ala Arg
130 135 140
Leu Met Val Glu Lys Lys Asn Lys Glu Thr Gly Leu Pro Arg Tyr Glu
145 150 155 160
Trp Phe Glu Phe Thr Leu Pro Glu Gly Asn Tyr Ser Glu Thr Met Thr
165 170 175
Ile Asp Leu Met Asn Asn Ala Ile Val Asp Asn Tyr Leu Glu Val Gly
180 185 190
Arg Gln Asn Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr
195 200 205
Arg Asn Phe Arg Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro
210 215 220
Gly Val Tyr Thr Asn Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro
225 230 235 240
Gly Cys Gly Val Asp Phe Thr Gln Ser Arg Leu Ser Asn Leu Leu Gly
245 250 255
Ile Arg Lys Arg Leu Pro Phe Gln Glu Gly Phe Gln Ile Met Tyr Glu
260 265 270
Asp Leu Glu Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Thr Lys Tyr
275 280 285
Glu Ala Ser Ile Gln Lys Ala Lys Glu Glu Gly Lys Glu Ile Gly Asp
290 295 300
Asp Thr Phe Ala Thr Arg Pro Gln Asp Leu Val Ile Glu Pro Val Ala
305 310 315 320
Lys Asp Ser Lys Asn Arg Ser Tyr Asn Leu Leu Pro Asn Asp Gln Asn
325 330 335
Asn Thr Ala Tyr Arg Ser Trp Phe Leu Ala Tyr Asn Tyr Gly Asp Pro
340 345 350
Asn Lys Gly Val Gln Ser Trp Thr Leu Leu Thr Thr Ala Asp Val Thr
355 360 365
Cys Gly Ser Gln Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp
370 375 380
Pro Val Thr Phe Arg Pro Ser Thr Gln Val Ser Asn Tyr Pro Val Val
385 390 395 400
Gly Val Glu Leu Leu Pro Val His Ala Lys Ser Phe Tyr Asn Glu Gln
405 410 415
Ala Val Tyr Ser Gln Leu Ile Arg Gln Ser Thr Ala Leu Thr His Val
420 425 430
Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Val Arg Pro Pro Ala Pro
435 440 445
Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly
450 455 460
Thr Leu Pro Leu Arg Ser Ser Ile Ser Gly Val Gln Arg Val Thr Ile
465 470 475 480
Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val His Lys Ala Leu Gly
485 490 495
Ile Val Ala Pro Lys Val Leu Ser Ser Arg Thr Phe
500 505
<210> 13
<211> 575
<212> ПРТ
<213> Аденовирус гориллы B7
<400> 13
Met Met Arg Arg Ala Val Leu Gly Gly Ala Val Val Tyr Pro Glu Gly
1 5 10 15
Pro Pro Pro Ser Tyr Glu Ser Val Met Gln Gln Gln Ala Ala Ala Val
20 25 30
Met Gln Pro Ser Leu Glu Ala Pro Phe Val Pro Pro Arg Tyr Leu Ala
35 40 45
Pro Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Gln
50 55 60
Tyr Asp Thr Thr Arg Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile
65 70 75 80
Ala Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val
85 90 95
Val Gln Asn Asn Asp Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile
100 105 110
Asn Phe Asp Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met
115 120 125
His Thr Asn Met Pro Asn Val Asn Glu Tyr Met Phe Ser Asn Lys Phe
130 135 140
Lys Ala Arg Val Met Val Ser Arg Glu Ala Ser Lys Ile Asp Ser Glu
145 150 155 160
Lys Asn Asp Arg Ser Lys Asp Thr Leu Lys Tyr Glu Trp Phe Glu Phe
165 170 175
Thr Leu Pro Glu Gly Asn Phe Ser Ala Thr Met Thr Ile Asp Leu Met
180 185 190
Asn Asn Ala Ile Ile Asp Asn Tyr Leu Ala Val Gly Arg Gln Asn Gly
195 200 205
Val Leu Gln Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe Arg
210 215 220
Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val Tyr Thr
225 230 235 240
Tyr Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Asp Cys Gly Val
245 250 255
Asp Phe Thr Glu Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys Arg
260 265 270
His Pro Phe Gln Glu Gly Phe Lys Ile Met Tyr Glu Asp Leu Glu Gly
275 280 285
Gly Asn Ile Pro Ala Leu Leu Asp Val Ala Glu Tyr Glu Lys Ser Lys
290 295 300
Lys Glu Ile Ala Ser Ser Thr Thr Thr Thr Ala Val Thr Thr Val Ala
305 310 315 320
Arg Asn Val Ala Asp Thr Ser Val Glu Ala Val Ala Val Ala Val Val
325 330 335
Asp Thr Ile Lys Ala Glu Asn Asp Ser Ala Val Arg Gly Asp Asn Phe
340 345 350
Gln Ser Lys Asn Asp Met Lys Ala Ser Glu Glu Val Thr Val Val Pro
355 360 365
Val Ser Pro Pro Thr Val Thr Glu Thr Glu Thr Lys Glu Pro Thr Ile
370 375 380
Lys Pro Leu Glu Lys Asp Thr Lys Asp Arg Ser Tyr Asn Val Ile Ser
385 390 395 400
Gly Thr Asn Asp Thr Ala Tyr Arg Ser Trp Tyr Leu Ala Tyr Asn Tyr
405 410 415
Gly Asp Pro Glu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr Thr Ser
420 425 430
Asp Val Thr Cys Gly Ala Glu Gln Val Tyr Trp Ser Leu Pro Asp Met
435 440 445
Met Gln Asp Pro Val Thr Phe Arg Ser Thr Arg Gln Val Ser Asn Tyr
450 455 460
Pro Val Val Gly Ala Glu Leu Met Pro Val Phe Ser Lys Ser Phe Tyr
465 470 475 480
Asn Glu Gln Ala Val Tyr Ser Gln Gln Leu Arg Gln Thr Thr Ser Leu
485 490 495
Thr His Ile Phe Asp Arg Phe Pro Glu Asn Gln Ile Leu Ile Arg Pro
500 505 510
Pro Ala Pro Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr
515 520 525
Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile Arg Gly Val Gln Arg
530 535 540
Val Thr Val Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys
545 550 555 560
Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
565 570 575
<210> 14
<211> 532
<212> ПРТ
<213> Аденовирус шимпанзе Y25
<400> 14
Met Met Arg Arg Ala Tyr Pro Glu Gly Pro Pro Pro Ser Tyr Glu Ser
1 5 10 15
Val Met Gln Gln Ala Met Ala Ala Ala Ala Ala Met Gln Pro Pro Leu
20 25 30
Glu Ala Pro Tyr Val Pro Pro Arg Tyr Leu Ala Pro Thr Glu Gly Arg
35 40 45
Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr Thr Arg
50 55 60
Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu Asn Tyr
65 70 75 80
Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn Asn Asp
85 90 95
Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile Asn Phe Asp Glu Arg
100 105 110
Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met His Thr Asn Met Pro
115 120 125
Asn Val Asn Glu Phe Met Tyr Ser Asn Lys Phe Lys Ala Arg Val Met
130 135 140
Val Ser Arg Lys Thr Pro Asn Gly Val Thr Val Thr Asp Gly Ser Gln
145 150 155 160
Asp Ile Leu Glu Tyr Glu Trp Val Glu Phe Glu Leu Pro Glu Gly Asn
165 170 175
Phe Ser Val Thr Met Thr Ile Asp Leu Met Asn Asn Ala Ile Ile Asp
180 185 190
Asn Tyr Leu Ala Val Gly Arg Gln Asn Gly Val Leu Glu Ser Asp Ile
195 200 205
Gly Val Lys Phe Asp Thr Arg Asn Phe Arg Leu Gly Trp Asp Pro Val
210 215 220
Thr Glu Leu Val Met Pro Gly Val Tyr Thr Asn Glu Ala Phe His Pro
225 230 235 240
Asp Ile Val Leu Leu Pro Gly Cys Gly Val Asp Phe Thr Glu Ser Arg
245 250 255
Leu Ser Asn Leu Leu Gly Ile Arg Lys Arg Gln Pro Phe Gln Glu Gly
260 265 270
Phe Gln Ile Met Tyr Glu Asp Leu Glu Gly Gly Asn Ile Pro Ala Leu
275 280 285
Leu Asp Val Asp Ala Tyr Glu Lys Ser Lys Glu Glu Ser Ala Ala Ala
290 295 300
Ala Thr Ala Ala Val Ala Thr Ala Ser Thr Glu Val Arg Gly Asp Asn
305 310 315 320
Phe Ala Ser Pro Ala Ala Val Ala Ala Ala Glu Ala Ala Glu Thr Glu
325 330 335
Ser Lys Ile Val Ile Gln Pro Val Glu Lys Asp Ser Lys Asp Arg Ser
340 345 350
Tyr Asn Val Leu Pro Asp Lys Ile Asn Thr Ala Tyr Arg Ser Trp Tyr
355 360 365
Leu Ala Tyr Asn Tyr Gly Asp Pro Glu Lys Gly Val Arg Ser Trp Thr
370 375 380
Leu Leu Thr Thr Ser Asp Val Thr Cys Gly Val Glu Gln Val Tyr Trp
385 390 395 400
Ser Leu Pro Asp Met Met Gln Asp Pro Val Thr Phe Arg Ser Thr Arg
405 410 415
Gln Val Ser Asn Tyr Pro Val Val Gly Ala Glu Leu Leu Pro Val Tyr
420 425 430
Ser Lys Ser Phe Phe Asn Glu Gln Ala Val Tyr Ser Gln Gln Leu Arg
435 440 445
Ala Phe Thr Ser Leu Thr His Val Phe Asn Arg Phe Pro Glu Asn Gln
450 455 460
Ile Leu Val Arg Pro Pro Ala Pro Thr Ile Thr Thr Val Ser Glu Asn
465 470 475 480
Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile
485 490 495
Arg Gly Val Gln Arg Val Thr Val Thr Asp Ala Arg Arg Arg Thr Cys
500 505 510
Pro Tyr Val Tyr Lys Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser
515 520 525
Ser Arg Thr Phe
530
<210> 15
<211> 508
<212> ПРТ
<213> Аденовирус обезьяны 18
<400> 15
Met Arg Arg Ala Val Gly Val Pro Pro Val Met Ala Tyr Ala Glu Gly
1 5 10 15
Pro Pro Pro Ser Tyr Glu Thr Val Met Gly Ala Ala Asp Ser Pro Ala
20 25 30
Thr Leu Glu Ala Leu Tyr Val Pro Pro Arg Tyr Leu Gly Pro Thr Glu
35 40 45
Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr
50 55 60
Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu
65 70 75 80
Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn
85 90 95
Asn Asp Phe Thr Pro Val Glu Ala Gly Thr Gln Thr Ile Asn Phe Asp
100 105 110
Glu Arg Ser Arg Trp Gly Gly Asp Leu Lys Thr Ile Leu Arg Thr Asn
115 120 125
Met Pro Asn Ile Asn Glu Phe Met Ser Thr Asn Lys Phe Arg Ala Arg
130 135 140
Leu Met Val Glu Lys Val Asn Lys Glu Thr Asn Ala Pro Arg Tyr Glu
145 150 155 160
Trp Phe Glu Phe Thr Leu Pro Glu Gly Asn Tyr Ser Glu Thr Met Thr
165 170 175
Ile Asp Leu Met Asn Asn Ala Ile Val Asp Asn Tyr Leu Glu Val Gly
180 185 190
Arg Gln Asn Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr
195 200 205
Arg Asn Phe Arg Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro
210 215 220
Gly Val Tyr Thr Asn Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro
225 230 235 240
Gly Cys Gly Val Asp Phe Thr Gln Ser Arg Leu Ser Asn Leu Leu Gly
245 250 255
Ile Arg Lys Arg Met Pro Phe Gln Ala Gly Phe Gln Ile Met Tyr Glu
260 265 270
Asp Leu Glu Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Ala Lys Tyr
275 280 285
Glu Ala Ser Ile Gln Lys Ala Arg Glu Gln Gly Gln Glu Ile Arg Gly
290 295 300
Asp Asn Phe Thr Val Ile Pro Arg Asp Val Glu Ile Val Pro Val Glu
305 310 315 320
Lys Asp Ser Lys Asp Arg Ser Tyr Asn Leu Leu Pro Gly Asp Gln Thr
325 330 335
Asn Thr Ala Tyr Arg Ser Trp Phe Leu Ala Tyr Asn Tyr Gly Asp Pro
340 345 350
Glu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr Thr Thr Asp Val Thr
355 360 365
Cys Gly Ser Gln Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp
370 375 380
Pro Val Thr Phe Arg Pro Ser Ser Gln Val Ser Asn Tyr Pro Val Val
385 390 395 400
Gly Val Glu Leu Leu Pro Val His Ala Lys Ser Phe Tyr Asn Glu Gln
405 410 415
Ala Val Tyr Ser Gln Leu Ile Arg Gln Ser Thr Ala Leu Thr His Val
420 425 430
Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Val Arg Pro Pro Ala Pro
435 440 445
Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly
450 455 460
Thr Leu Pro Leu Arg Ser Ser Ile Ser Gly Val Gln Arg Val Thr Ile
465 470 475 480
Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val His Lys Ala Leu Gly
485 490 495
Ile Val Ala Pro Lys Val Leu Ser Ser Arg Thr Phe
500 505
<210> 16
<211> 512
<212> ПРТ
<213> Аденовирус обезьяны 20
<400> 16
Met Arg Arg Ala Val Ala Ile Pro Ser Ala Ala Val Ala Leu Gly Pro
1 5 10 15
Pro Pro Ser Tyr Glu Ser Val Met Ala Ser Ala Asn Leu Gln Ala Pro
20 25 30
Leu Glu Asn Pro Tyr Val Pro Pro Arg Tyr Leu Glu Pro Thr Gly Gly
35 40 45
Arg Asn Ser Ile Arg Tyr Ser Glu Leu Thr Pro Leu Tyr Asp Thr Thr
50 55 60
Arg Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Thr Leu Asn
65 70 75 80
Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Ser Val Val Gln Asn Ser
85 90 95
Asp Tyr Thr Pro Ala Glu Ala Ser Thr Gln Thr Ile Asn Leu Asp Asp
100 105 110
Arg Ser Arg Trp Gly Gly Asp Leu Lys Thr Ile Leu His Thr Asn Met
115 120 125
Pro Asn Val Asn Glu Phe Met Phe Thr Asn Ser Phe Arg Ala Lys Leu
130 135 140
Met Val Ala His Glu Thr Asn Lys Asp Pro Val Tyr Lys Trp Val Glu
145 150 155 160
Leu Thr Leu Pro Glu Gly Asn Phe Ser Glu Thr Met Thr Ile Asp Leu
165 170 175
Met Asn Asn Ala Ile Val Asp His Tyr Leu Ala Val Gly Arg Gln Asn
180 185 190
Gly Val Lys Glu Ser Glu Ile Gly Val Lys Phe Asp Thr Arg Asn Phe
195 200 205
Arg Leu Gly Trp Asp Pro Gln Thr Glu Leu Val Met Pro Gly Val Tyr
210 215 220
Thr Asn Glu Ala Phe His Pro Asp Val Val Leu Leu Pro Gly Cys Gly
225 230 235 240
Val Asp Phe Thr Tyr Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
245 250 255
Arg Met Pro Phe Gln Glu Gly Phe Gln Ile Met Tyr Glu Asp Leu Val
260 265 270
Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Pro Ala Tyr Glu Ala Ser
275 280 285
Ile Thr Thr Val Ala Ala Lys Glu Val Arg Gly Asp Asn Phe Glu Ala
290 295 300
Ala Ala Ala Ala Ala Ala Thr Gly Ala Gln Pro Gln Ala Ala Pro Val
305 310 315 320
Val Arg Pro Val Thr Gln Asp Ser Lys Gly Arg Ser Tyr Asn Ile Ile
325 330 335
Thr Gly Thr Asn Asn Thr Ala Tyr Arg Ser Trp Tyr Leu Ala Tyr Asn
340 345 350
Tyr Gly Asp Pro Glu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr Thr
355 360 365
Pro Asp Val Thr Cys Gly Ser Glu Gln Val Tyr Trp Ser Met Pro Asp
370 375 380
Met Tyr Val Asp Pro Val Thr Phe Arg Ser Ser Gln Gln Val Ser Ser
385 390 395 400
Tyr Pro Val Val Gly Ala Glu Leu Leu Pro Ile His Ser Lys Ser Phe
405 410 415
Tyr Asn Glu Gln Ala Val Tyr Ser Gln Leu Ile Arg Gln Gln Thr Ala
420 425 430
Leu Thr His Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Val Arg
435 440 445
Pro Pro Ala Pro Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu
450 455 460
Thr Asp His Gly Thr Leu Pro Leu Gln Asn Ser Ile Arg Gly Val Gln
465 470 475 480
Arg Val Thr Ile Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr
485 490 495
Lys Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
500 505 510
<210> 17
<211> 511
<212> ПРТ
<213> Аденовирус обезьяны 49
<400> 17
Met Arg Arg Ala Val Pro Ala Ala Ala Ile Pro Ala Thr Val Ala Tyr
1 5 10 15
Ala Asp Pro Pro Pro Ser Tyr Glu Ser Val Met Ala Gly Val Pro Ala
20 25 30
Thr Leu Glu Ala Pro Tyr Val Pro Pro Arg Tyr Leu Gly Pro Thr Glu
35 40 45
Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr
50 55 60
Thr Arg Val Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu
65 70 75 80
Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn
85 90 95
Asn Asp Phe Thr Pro Val Glu Ala Gly Thr Gln Thr Ile Asn Phe Asp
100 105 110
Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Leu His Thr Asn
115 120 125
Met Pro Asn Val Asn Glu Phe Met Phe Thr Asn Ser Phe Arg Ala Lys
130 135 140
Val Met Val Ser Arg Lys Gln Asn Glu Glu Gly Gln Thr Glu Leu Glu
145 150 155 160
Tyr Glu Trp Val Glu Phe Val Leu Pro Glu Gly Asn Tyr Ser Glu Thr
165 170 175
Met Thr Leu Asp Leu Met Asn Asn Ala Ile Val Asp His Tyr Leu Leu
180 185 190
Val Gly Arg Gln Asn Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe
195 200 205
Asp Thr Arg Asn Phe Arg Leu Gly Trp Asp Pro Val Thr Lys Leu Val
210 215 220
Met Pro Gly Val Tyr Thr Asn Glu Ala Phe His Pro Asp Val Val Leu
225 230 235 240
Leu Pro Gly Cys Gly Val Asp Phe Thr Gln Ser Arg Leu Ser Asn Leu
245 250 255
Leu Gly Ile Arg Lys Arg Gln Pro Phe Gln Glu Gly Phe Arg Ile Met
260 265 270
Tyr Glu Asp Leu Glu Gly Gly Asn Ile Pro Ala Leu Leu Asn Val Lys
275 280 285
Ala Tyr Glu Asp Ser Ile Ala Ala Ala Met Arg Lys His Asn Leu Pro
290 295 300
Leu Arg Gly Asp Val Phe Ala Val Gln Pro Gln Glu Ile Val Ile Gln
305 310 315 320
Pro Val Glu Lys Asp Gly Lys Glu Arg Ser Tyr Asn Leu Leu Pro Asp
325 330 335
Asp Lys Asn Asn Thr Ala Tyr Arg Ser Trp Tyr Leu Ala Tyr Asn Tyr
340 345 350
Gly Asp Pro Leu Lys Gly Val Arg Ser Trp Thr Leu Leu Thr Thr Pro
355 360 365
Asp Val Thr Cys Gly Ser Glu Gln Val Tyr Trp Ser Leu Pro Asp Leu
370 375 380
Met Gln Asp Pro Val Thr Phe Arg Pro Ser Ser Gln Val Ser Asn Tyr
385 390 395 400
Pro Val Val Gly Ala Glu Leu Leu Pro Leu Gln Ala Lys Ser Phe Tyr
405 410 415
Asn Glu Gln Ala Val Tyr Ser Gln Leu Ile Arg Gln Ser Thr Ala Leu
420 425 430
Thr His Val Phe Asn Arg Phe Pro Glu Asn Gln Ile Leu Val Arg Pro
435 440 445
Pro Ala Ala Thr Ile Thr Thr Val Ser Glu Asn Val Pro Ala Leu Thr
450 455 460
Asp His Gly Thr Leu Pro Leu Arg Ser Ser Ile Ser Gly Val Gln Arg
465 470 475 480
Val Thr Ile Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys
485 490 495
Ala Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
500 505 510
<210> 18
<211> 505
<212> ПРТ
<213> Аденовирус макака-резуса 51
<400> 18
Met Arg Arg Ala Val Arg Val Thr Pro Ala Ala Tyr Glu Gly Pro Pro
1 5 10 15
Pro Ser Tyr Glu Ser Val Met Gly Ser Ala Asn Val Pro Ala Thr Leu
20 25 30
Glu Ala Pro Tyr Val Pro Pro Arg Tyr Leu Gly Pro Thr Glu Gly Arg
35 40 45
Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr Thr Lys
50 55 60
Val Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu Asn Tyr
65 70 75 80
Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn Asn Asp
85 90 95
Phe Thr Pro Thr Glu Ala Gly Thr Gln Thr Ile Asn Phe Asp Glu Arg
100 105 110
Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Leu His Thr Asn Met Pro
115 120 125
Asn Ile Asn Glu Phe Met Ser Thr Asn Lys Phe Arg Ala Lys Leu Met
130 135 140
Val Glu Lys Ser Asn Ala Glu Thr Arg Gln Pro Arg Tyr Glu Trp Phe
145 150 155 160
Glu Phe Thr Ile Pro Glu Gly Asn Tyr Ser Glu Thr Met Thr Ile Asp
165 170 175
Leu Met Asn Asn Ala Ile Val Asp Asn Tyr Leu Gln Val Gly Arg Gln
180 185 190
Asn Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn
195 200 205
Phe Arg Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val
210 215 220
Tyr Thr Asn Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys
225 230 235 240
Gly Val Asp Phe Thr Gln Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg
245 250 255
Lys Arg Arg Pro Phe Gln Glu Gly Phe Gln Ile Met Tyr Glu Asp Leu
260 265 270
Glu Gly Gly Asn Ile Pro Ala Leu Leu Asp Val Ser Lys Tyr Glu Ala
275 280 285
Ser Ile Gln Arg Ala Lys Ala Glu Gly Arg Glu Ile Arg Gly Asp Thr
290 295 300
Phe Ala Val Ala Pro Gln Asp Leu Glu Ile Val Pro Leu Thr Lys Asp
305 310 315 320
Ser Lys Asp Arg Ser Tyr Asn Ile Ile Asn Asn Thr Thr Asp Thr Leu
325 330 335
Tyr Arg Ser Trp Phe Leu Ala Tyr Asn Tyr Gly Asp Pro Glu Lys Gly
340 345 350
Val Arg Ser Trp Thr Ile Leu Thr Thr Thr Asp Val Thr Cys Gly Ser
355 360 365
Gln Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro Val Thr
370 375 380
Phe Arg Pro Ser Thr Gln Val Ser Asn Phe Pro Val Val Gly Thr Glu
385 390 395 400
Leu Leu Pro Val His Ala Lys Ser Phe Tyr Asn Glu Gln Ala Val Tyr
405 410 415
Ser Gln Leu Ile Arg Gln Ser Thr Ala Leu Thr His Val Phe Asn Arg
420 425 430
Phe Pro Glu Asn Gln Ile Leu Val Arg Pro Pro Ala Pro Thr Ile Thr
435 440 445
Thr Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro
450 455 460
Leu Arg Ser Ser Ile Ser Gly Val Gln Arg Val Thr Ile Thr Asp Ala
465 470 475 480
Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Val Val Ala
485 490 495
Pro Lys Val Leu Ser Ser Arg Thr Phe
500 505
<210> 19
<211> 503
<212> ПРТ
<213> Аденовирус макака-резуса 52
<400> 19
Met Arg Arg Ala Val Arg Val Thr Pro Ala Ala Tyr Glu Gly Pro Pro
1 5 10 15
Pro Ser Tyr Glu Ser Val Met Gly Ser Ala Asn Val Pro Ala Thr Leu
20 25 30
Glu Ala Pro Tyr Val Pro Pro Arg Tyr Leu Gly Pro Thr Glu Gly Arg
35 40 45
Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr Thr Lys
50 55 60
Val Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu Asn Tyr
65 70 75 80
Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn Asn Asp
85 90 95
Phe Thr Pro Thr Glu Ala Gly Thr Gln Thr Ile Asn Phe Asp Glu Arg
100 105 110
Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Leu His Thr Asn Met Pro
115 120 125
Asn Ile Asn Glu Phe Met Ser Thr Asn Lys Phe Arg Ala Arg Leu Met
130 135 140
Val Lys Lys Val Glu Asn Gln Pro Pro Glu Tyr Glu Trp Phe Glu Phe
145 150 155 160
Thr Ile Pro Glu Gly Asn Tyr Ser Glu Thr Met Thr Ile Asp Leu Met
165 170 175
Asn Asn Ala Ile Val Asp Asn Tyr Leu Gln Val Gly Arg Gln Asn Gly
180 185 190
Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe Arg
195 200 205
Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val Tyr Thr
210 215 220
Asn Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly Val
225 230 235 240
Asp Phe Thr Gln Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys Arg
245 250 255
Arg Pro Phe Gln Glu Gly Phe Gln Ile Met Tyr Glu Asp Leu Glu Gly
260 265 270
Gly Asn Ile Pro Ala Leu Leu Asp Val Thr Lys Tyr Glu Gln Ser Val
275 280 285
Gln Arg Ala Lys Ala Glu Gly Arg Glu Ile Arg Gly Asp Thr Phe Ala
290 295 300
Val Ser Pro Gln Asp Leu Val Ile Glu Pro Leu Glu His Asp Ser Lys
305 310 315 320
Asn Arg Ser Tyr Asn Leu Leu Pro Asn Lys Thr Asp Thr Ala Tyr Arg
325 330 335
Ser Trp Phe Leu Ala Tyr Asn Tyr Gly Asp Pro Glu Lys Gly Val Arg
340 345 350
Ser Trp Thr Ile Leu Thr Thr Thr Asp Val Thr Cys Gly Ser Gln Gln
355 360 365
Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro Val Thr Phe Arg
370 375 380
Pro Ser Thr Gln Val Ser Asn Phe Pro Val Val Gly Thr Glu Leu Leu
385 390 395 400
Pro Val His Ala Lys Ser Phe Tyr Asn Glu Gln Ala Val Tyr Ser Gln
405 410 415
Leu Ile Arg Gln Ser Thr Ala Leu Thr His Val Phe Asn Arg Phe Pro
420 425 430
Glu Asn Gln Ile Leu Val Arg Pro Pro Ala Pro Thr Ile Thr Thr Val
435 440 445
Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu Arg
450 455 460
Ser Ser Ile Ser Gly Val Gln Arg Val Thr Ile Thr Asp Ala Arg Arg
465 470 475 480
Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Val Val Ala Pro Lys
485 490 495
Val Leu Ser Ser Arg Thr Phe
500
<210> 20
<211> 504
<212> ПРТ
<213> Аденовирус макака-резуса 53
<400> 20
Met Arg Arg Ala Val Arg Val Thr Pro Ala Val Tyr Ala Glu Gly Pro
1 5 10 15
Pro Pro Ser Tyr Glu Ser Val Met Gly Ser Ala Asn Val Pro Ala Thr
20 25 30
Leu Glu Ala Pro Tyr Val Pro Pro Arg Tyr Leu Gly Pro Thr Glu Gly
35 40 45
Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ala Pro Leu Tyr Asp Thr Thr
50 55 60
Lys Val Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala Ser Leu Asn
65 70 75 80
Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val Gln Asn Asn
85 90 95
Asp Phe Thr Pro Thr Glu Ala Gly Thr Gln Thr Ile Asn Phe Asp Glu
100 105 110
Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Leu His Thr Asn Met
115 120 125
Pro Asn Ile Asn Glu Phe Met Ser Thr Asn Lys Phe Arg Ala Arg Leu
130 135 140
Met Val Glu Lys Thr Ser Gly Gln Pro Pro Lys Tyr Glu Trp Phe Glu
145 150 155 160
Phe Thr Ile Pro Glu Gly Asn Tyr Ser Glu Thr Met Thr Ile Asp Leu
165 170 175
Met Asn Asn Ala Ile Val Asp Asn Tyr Leu Gln Val Gly Arg Gln Asn
180 185 190
Gly Val Leu Glu Ser Asp Ile Gly Val Lys Phe Asp Thr Arg Asn Phe
195 200 205
Arg Leu Gly Trp Asp Pro Val Thr Lys Leu Val Met Pro Gly Val Tyr
210 215 220
Thr Asn Glu Ala Phe His Pro Asp Ile Val Leu Leu Pro Gly Cys Gly
225 230 235 240
Val Asp Phe Thr Gln Ser Arg Leu Ser Asn Leu Leu Gly Ile Arg Lys
245 250 255
Arg Arg Pro Phe Gln Glu Gly Phe Gln Ile Met Tyr Glu Asp Leu Glu
260 265 270
Gly Gly Asn Ile Pro Gly Leu Leu Asp Val Pro Ala Tyr Glu Gln Ser
275 280 285
Leu Gln Gln Ala Gln Glu Glu Gly Arg Val Thr Arg Gly Asp Thr Phe
290 295 300
Ala Thr Ala Pro Asn Glu Val Val Ile Lys Pro Leu Leu Lys Asp Ser
305 310 315 320
Lys Asp Arg Ser Tyr Asn Ile Ile Thr Asp Thr Thr Asp Thr Leu Tyr
325 330 335
Arg Ser Trp Phe Leu Ala Tyr Asn Tyr Gly Asp Pro Glu Asn Gly Val
340 345 350
Arg Ser Trp Thr Ile Leu Thr Thr Thr Asp Val Thr Cys Gly Ser Gln
355 360 365
Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro Val Thr Phe
370 375 380
Arg Pro Ser Thr Gln Val Ser Asn Phe Pro Val Val Gly Thr Glu Leu
385 390 395 400
Leu Pro Val His Ala Lys Ser Phe Tyr Asn Glu Gln Ala Val Tyr Ser
405 410 415
Gln Leu Ile Arg Gln Ser Thr Ala Leu Thr His Val Phe Asn Arg Phe
420 425 430
Pro Glu Asn Gln Ile Leu Val Arg Pro Pro Ala Pro Thr Ile Thr Thr
435 440 445
Val Ser Glu Asn Val Pro Ala Leu Thr Asp His Gly Thr Leu Pro Leu
450 455 460
Arg Ser Ser Ile Ser Gly Val Gln Arg Val Thr Ile Thr Asp Ala Arg
465 470 475 480
Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala Leu Gly Val Val Ala Pro
485 490 495
Lys Val Leu Ser Ser Arg Thr Phe
500
<210> 21
<211> 144
<212> ПРТ
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислотного участка A
<220>
<221> MISC_FEATURE
<222> (1)..(47)
<223> В этом положении нет аминокислоты или какой-либо аминокислоты
<220>
<221> MISC_FEATURE
<222> (50)..(50)
<223> E или G
<220>
<221> MISC_FEATURE
<222> (59)..(59)
<223> E или S
<220>
<221> MISC_FEATURE
<222> (60)..(60)
<223> L или V
<220>
<221> MISC_FEATURE
<222> (61)..(61)
<223> A или S
<220>
<221> MISC_FEATURE
<222> (63)..(63)
<223> L или Q
<220>
<221> MISC_FEATURE
<222> (64)..(64)
<223> Y или E
<220>
<221> MISC_FEATURE
<222> (68)..(68)
<223> R или K
<220>
<221> MISC_FEATURE
<222> (69)..(69)
<223> V или L
<220>
<221> MISC_FEATURE
<222> (92)..(92)
<223> L или Q
<220>
<221> MISC_FEATURE
<222> (96)..(96)
<223> V или I
<220>и
<221> MISC_FEATURE
<222> (101)..(101)
<223> F или Y
<220>
<221> MISC_FEATURE
<222> (102)..(102)
<223> T или S
<220>
<221> MISC_FEATURE
<222> (104)..(104)
<223> A, или T, или I, или G
<220>
<221> MISC_FEATURE
<222> (107)..(107)
<223> S или G
<220>
<221> MISC_FEATURE
<222> (113)..(113)
<223> F или L
<220>
<221> MISC_FEATURE
<222> (115)..(115)
<223> E или D
<220>
<221> MISC_FEATURE
<222> (121)..(121)
<223> A или G
<220>
<221> MISC_FEATURE
<222> (122)..(122)
<223> D или Q
<220>
<221> MISC_FEATURE
<222> (127)..(127)
<223> L или M
<220>
<221> MISC_FEATURE
<222> (128)..(128)
<223> H или R
<220>
<221> MISC_FEATURE
<222> (130)..(130)
<223> нет аминокислоты или, если присутствует, N
<220>
<221> MISC_FEATURE
<222> (131)..(131)
<223> нет аминокислоты или, если присутствует, M
<220>
<221> MISC_FEATURE
<222> (132)..(132)
<223> нет аминокислоты или, если присутствует, P
<220>
<221> MISC_FEATURE
<222> (133)..(133)
<223> нет аминокислоты или, если присутствует, N
<220>
<221> MISC_FEATURE
<222> (134)..(134)
<223> нет аминокислоты или, если присутствует, V, или I
<220>
<221> MISC_FEATURE
<222> (135)..(135)
<223> нет аминокислоты или, если присутствует, N
<220>
<221> MISC_FEATURE
<222> (136)..(136)
<223> нет аминокислоты или, если присутствует, E, или D
<220>
<221> MISC_FEATURE
<222> (137)..(137)
<223> нет аминокислоты или, если присутствует, Y, или F
<220>
<221> MISC_FEATURE
<222> (138)..(138)
<223> нет аминокислоты или, если присутствует, M
<220>
<221> MISC_FEATURE
<222> (139)..(139)
<223> нет аминокислоты или, если присутствует, F, или S, или Y
<220>
<221> MISC_FEATURE
<222> (140)..(140)
<223> нет аминокислоты или, если присутствует, T, или S
<220>
<221> MISC_FEATURE
<222> (141)..(141)
<223> нет аминокислоты или, если присутствует, S, или N
<220>
<221> MISC_FEATURE
<222> (142)..(142)
<223> нет аминокислоты или, если присутствует, K
<220>
<221> MISC_FEATURE
<222> (143)..(143)
<223> нет аминокислоты или, если присутствует, F
<220>
<221> MISC_FEATURE
<222> (144)..(144)
<223> нет аминокислоты или, если присутствует, K
<400> 21
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5 10 15
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
20 25 30
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Pro
35 40 45
Thr Xaa Gly Arg Asn Ser Ile Arg Tyr Ser Xaa Xaa Xaa Pro Xaa Xaa
50 55 60
Asp Thr Thr Xaa Xaa Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Xaa Thr Thr Val Xaa
85 90 95
Gln Asn Asn Asp Xaa Xaa Pro Xaa Glu Ala Xaa Thr Gln Thr Ile Asn
100 105 110
Xaa Asp Xaa Arg Ser Arg Trp Gly Xaa Xaa Leu Lys Thr Ile Xaa Xaa
115 120 125
Thr Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa
130 135 140
<210> 22
<211> 46
<212> ПРТ
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислотного участка B
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> нет аминокислоты или, если присутствует, L, или S
<220>
<221> MISC_FEATURE
<222> (2)..(2)
<223> нет аминокислоты или, если присутствует, T, или P, или C
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> нет аминокислоты или, если присутствует, T, или P
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> нет аминокислоты или, если присутствует, P, или S, или A, или R
<220>
<221> MISC_FEATURE
<222> (5)..(5)
<223> нет аминокислоты или, если присутствует, N, или D
<220>
<221> MISC_FEATURE
<222> (6)..(6)
<223> нет аминокислоты или, если присутствует, G, или V
<220>
<221> MISC_FEATURE
<222> (7)..(7)
<223> нет аминокислоты или, если присутствует, H, или T
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> нет аминокислоты или, если присутствует, C
<220>
<221> MISC_FEATURE
<222> (9)..(9)
<223> нет аминокислоты или, если присутствует, G
<220>
<221> MISC_FEATURE
<222> (10)..(10)
<223> нет аминокислоты или, если присутствует, A, или V, или S
<220>
<221> MISC_FEATURE
<222> (11)..(11)
<223> нет аминокислоты или, если присутствует, E, или Q
<220>
<221> MISC_FEATURE
<222> (20)..(20)
<223> L или M
<220>
<221> MISC_FEATURE
<222> (22)..(22)
<223> Q или K
<220>
<221> MISC_FEATURE
<222> (31)..(31)
<223> Q, или R, или S
<220>
<221> MISC_FEATURE
<222> (33)..(33)
<223> V или I
<220>
<221> MISC_FEATURE
<222> (34)..(34)
<223> S или N
<220>
<221> MISC_FEATURE
<222> (36)..(36)
<223> Y или F
<220>
<221> MISC_FEATURE
<222> (41)..(41)
<223> A или V
<220>
<221> MISC_FEATURE
<222> (44)..(44)
<223> нет аминокислоты или, если присутствует, M, или L
<220>
<221> MISC_FEATURE
<222> (45)..(45)
<223> нет аминокислоты или, если присутствует, P
<220>
<221> MISC_FEATURE
<222> (46)..(46)
<223> нет аминокислоты или, если присутствует, V, или F
<400> 22
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Xaa Gln Val Tyr Trp Ser
1 5 10 15
Leu Pro Asp Xaa Met Xaa Asp Pro Val Thr Phe Arg Ser Thr Xaa Gln
20 25 30
Xaa Xaa Asn Xaa Pro Val Val Gly Xaa Glu Leu Xaa Xaa Xaa
35 40 45
<210> 23
<211> 53
<212> ПРТ
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность аминокислотного участка C
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> нет аминокислоты или, если присутствует, N
<220>
<221> MISC_FEATURE
<222> (2)..(2)
<223> нет аминокислоты или, если присутствует, V
<220>
<221> MISC_FEATURE
<222> (3)..(3)
<223> нет аминокислоты или, если присутствует, P
<220>
<221> MISC_FEATURE
<222> (18)..(18)
<223> R, или S, или G
<220>
<221> MISC_FEATURE
<222> (25)..(25)
<223> V или I
<220>
<221> MISC_FEATURE
<222> (44)..(44)
<223> A или S
<220>
<221> MISC_FEATURE
<222> (46)..(46)
<223> R или K
<400> 23
Xaa Xaa Xaa Ala Leu Thr Asp His Gly Thr Leu Pro Leu Arg Ser Ser
1 5 10 15
Ile Xaa Gly Val Gln Arg Val Thr Xaa Thr Asp Ala Arg Arg Arg Thr
20 25 30
Cys Pro Tyr Val Tyr Lys Ala Leu Gly Ile Val Xaa Pro Xaa Val Leu
35 40 45
Ser Ser Arg Thr Phe
50
<210> 24
<211> 4
<212> ПРТ
<213> Искусственная последовательность
<220>
<223> Связывающий сегмент
<400> 24
Gly Gly Gly Ser
1
<210> 25
<211> 6
<212> ПРТ
<213> Искусственная последовательность
<220>
<223> Связывающий сегмент
<400> 25
Gly Gly Ser Gly Gly Ser
1 5
<210> 26
<211> 778
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Конструкция DNAsegVAJB-CHIK
<400> 26
ggatccatga ggagacgagc cgtgctaggc ggagcggtgg tgtatccgga gggtcctcct 60
ccttcttacg agagcgtgat gcagcaacag gcggcgatga tacagccccc actggaggct 120
cccttcgtac ccccacggta cctggcgcct acggaaggga gaaacagcat tcgttactcg 180
gagctgtcgc ccctgtacga taccaccaag ttgtatctgg tggacaacaa gtcggcggac 240
atcgcctccc tgaactatca gaacgaccac agcaacttcc tgaccacggt ggtgcagaac 300
aatgacttta cccccacgga ggctagcacc cagaccatca actttgacga gcggtcgcga 360
tggggcggtc agctgaagac catcatgcac accaacatgc ccggaggtga aaacctgtat 420
tttcagagca ccaaagataa ctttaacgtg tataaagcga cccgcccgta tctggcgcat 480
ggaggtgcag agcaggtcta ctggtcgctc cctgacatga tgcaagaccc agtcaccttc 540
cgctccacaa gacaagtcaa caactaccca gtggtgggtg cagagcttat gcccggtgga 600
agcggaggta gcgttcctgc tctcacagat cacgggaccc tgccgttacg cagcagtatc 660
cggggagtcc agcgcgtgac cgttactgac gccagacgcc gcacctgtcc ctacgtttac 720
aaggccctgg gcatagtcgc gccgcgcgtt ctttcaagcc gcactttctg ataagctt 778
<210> 27
<211> 3699
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Конструкция pACEBac_VAJB-CHIK
<400> 27
accggttgac ttgggtcaac tgtcagacca agtttactca tatatacttt agattgattt 60
aaaacttcat ttttaattta aaaggatcta ggtgaagatc ctttttgata atctcatgac 120
caaaatccct taacgtgagt tttcgttcca ctgagcgtca gaccccgtag aaaagatcaa 180
aggatcttct tgagatcctt tttttctgcg cgtaatctgc tgcttgcaaa caaaaaaacc 240
accgctacca gcggtggttt gtttgccgga tcaagagcta ccaactcttt ttccgaaggt 300
aactggcttc agcagagcgc agataccaaa tactgttctt ctagtgtagc cgtagttagg 360
ccaccacttc aagaactctg tagcaccgcc tacatacctc gctctgctaa tcctgttacc 420
agtggctgct gccagtggcg ataagtcgtg tcttaccggg ttggactcaa gacgatagtt 480
accggataag gcgcagcggt cgggctgaac ggggggttcg tgcacacagc ccagcttgga 540
gcgaacgacc tacaccgaac tgagatacct acagcgtgag ctatgagaaa gcgccacgct 600
tcccgaaggg agaaaggcgg acaggtatcc ggtaagcggc agggtcggaa caggagagcg 660
cacgagggag cttccagggg gaaacgcctg gtatctttat agtcctgtcg ggtttcgcca 720
cctctgactt gagcgtcgat ttttgtgatg ctcgtcaggg gggcggagcc tatggaaaaa 780
cgccagcaac gcggcctttt tacggttcct ggccttttgc tggccttttg ctcacatgtt 840
ctttcctgcg ttatcccctg attgacttgg gtcgctcttc ctgtggatgc gcagatgccc 900
tgcgtaagcg ggtgtgggcg gacaataaag tcttaaactg aacaaaatag atctaaacta 960
tgacaataaa gtcttaaact agacagaata gttgtaaact gaaatcagtc cagttatgct 1020
gtgaaaaagc atactggact tttgttatgg ctaaagcaaa ctcttcattt tctgaagtgc 1080
aaattgcccg tcgtattaaa gaggggcgtg gccaagggca tgtaaagact atattcgcgg 1140
cgttgtgaca atttaccgaa caactccgcg gccgggaagc cgatctcggc ttgaacgaat 1200
tgttaggtgg cggtacttgg gtcgatatca aagtgcatca cttcttcccg tatgcccaac 1260
tttgtataga gagccactgc gggatcgtca ccgtaatctg cttgcacgta gatcacataa 1320
gcaccaagcg cgttggcctc atgcttgagg agattgatga gcgcggtggc aatgccctgc 1380
ctccggtgct cgccggagac tgcgagatca tagatataga tctcactacg cggctgctca 1440
aacttgggca gaacgtaagc cgcgagagcg ccaacaaccg cttcttggtc gaaggcagca 1500
agcgcgatga atgtcttact acggagcaag ttcccgaggt aatcggagtc cggctgatgt 1560
tgggagtagg tggctacgtc tccgaactca cgaccgaaaa gatcaagagc agcccgcatg 1620
gatttgactt ggtcagggcc gagcctacat gtgcgaatga tgcccatact tgagccacct 1680
aactttgttt tagggcgact gccctgctgc gtaacatcgt tgctgctgcg taacatcgtt 1740
gctgctccat aacatcaaac atcgacccac ggcgtaacgc gcttgctgct tggatgcccg 1800
aggcatagac tgtacaaaaa aacagtcata acaagccatg aaaaccgcca ctgcgccgtt 1860
accaccgctg cgttcggtca aggttctgga ccagttgcgt gagcgcatac gctacttgca 1920
ttacagttta cgaaccgaac aggcttatgt caactgggtt cgtgccttca tccgtttcca 1980
cggtgtgcgt cacccggcaa ccttgggcag cagcgaagtc gccataactt cgtatagcat 2040
acattatacg aagttatctg taactataac ggtcctaagg tagcgagttt aaacactagt 2100
atcgattcgc gacctactcc ggaatattaa tagatcatgg agataattaa aatgataacc 2160
atctcgcaaa taaataagta ttttactgtt ttcgtaacag ttttgtaata aaaaaaccta 2220
taaatattcc ggattattca taccgtccca ccatcgggcg cggatccatg aggagacgag 2280
ccgtgctagg cggagcggtg gtgtatccgg agggtcctcc tccttcttac gagagcgtga 2340
tgcagcaaca ggcggcgatg atacagcccc cactggaggc tcccttcgta cccccacggt 2400
acctggcgcc tacggaaggg agaaacagca ttcgttactc ggagctgtcg cccctgtacg 2460
ataccaccaa gttgtatctg gtggacaaca agtcggcgga catcgcctcc ctgaactatc 2520
agaacgacca cagcaacttc ctgaccacgg tggtgcagaa caatgacttt acccccacgg 2580
aggctagcac ccagaccatc aactttgacg agcggtcgcg atggggcggt cagctgaaga 2640
ccatcatgca caccaacatg cccggaggtg aaaacctgta ttttcagagc accaaagata 2700
actttaacgt gtataaagcg acccgcccgt atctggcgca tggaggtgca gagcaggtct 2760
actggtcgct ccctgacatg atgcaagacc cagtcacctt ccgctccaca agacaagtca 2820
acaactaccc agtggtgggt gcagagctta tgcccggtgg aagcggaggt agcgttcctg 2880
ctctcacaga tcacgggacc ctgccgttac gcagcagtat ccggggagtc cagcgcgtga 2940
ccgttactga cgccagacgc cgcacctgtc cctacgttta caaggccctg ggcatagtcg 3000
cgccgcgcgt tctttcaagc cgcactttct gataagcttc catcaacttt gacgagcggt 3060
cgcgatgggg cggtcagctg aagaccatca tgcacaccaa catgcccaac gtgaacgagt 3120
acatgttcag caacaagttc aaggcgaggg agcttgtcga gaagtactag aggatcataa 3180
tcagccatac cacatttgta gaggttttac ttgctttaaa aaacctccca cacctccccc 3240
tgaacctgaa acataaaatg aatgcaattg ttgttgttaa cttgtttatt gcagcttata 3300
atggttacaa ataaagcaat agcatcacaa atttcacaaa taaagcattt ttttcactgc 3360
attctagttg tggtttgtcc aaactcatca atgtatctta tcatgtctgg atctgatcac 3420
tgcttgagcc tagaagatcc ggctgctaac aaagcccgaa aggaagctga gttggctgct 3480
gccaccgctg agcaataact atcataaccc ctagggtata cccatctaat tggaaccaga 3540
taagtgaaat ctagttccaa actattttgt catttttaat tttcgtatta gcttacgacg 3600
ctacacccag ttcccatcta ttttgtcact cttccctaaa taatccttaa aaactccatt 3660
tccacccctc ccagttccca actattttgt ccgcccaca 3699
<210> 28
<211> 254
<212> ПРТ
<213> Искусственная последовательность
<220>
<223> Белок VAJB-CHIK
<400> 28
Met Arg Arg Arg Ala Val Leu Gly Gly Ala Val Val Tyr Pro Glu Gly
1 5 10 15
Pro Pro Pro Ser Tyr Glu Ser Val Met Gln Gln Gln Ala Ala Met Ile
20 25 30
Gln Pro Pro Leu Glu Ala Pro Phe Val Pro Pro Arg Tyr Leu Ala Pro
35 40 45
Thr Glu Gly Arg Asn Ser Ile Arg Tyr Ser Glu Leu Ser Pro Leu Tyr
50 55 60
Asp Thr Thr Lys Leu Tyr Leu Val Asp Asn Lys Ser Ala Asp Ile Ala
65 70 75 80
Ser Leu Asn Tyr Gln Asn Asp His Ser Asn Phe Leu Thr Thr Val Val
85 90 95
Gln Asn Asn Asp Phe Thr Pro Thr Glu Ala Ser Thr Gln Thr Ile Asn
100 105 110
Phe Asp Glu Arg Ser Arg Trp Gly Gly Gln Leu Lys Thr Ile Met His
115 120 125
Thr Asn Met Pro Gly Gly Glu Asn Leu Tyr Phe Gln Ser Thr Lys Asp
130 135 140
Asn Phe Asn Val Tyr Lys Ala Thr Arg Pro Tyr Leu Ala His Gly Gly
145 150 155 160
Ala Glu Gln Val Tyr Trp Ser Leu Pro Asp Met Met Gln Asp Pro Val
165 170 175
Thr Phe Arg Ser Thr Arg Gln Val Asn Asn Tyr Pro Val Val Gly Ala
180 185 190
Glu Leu Met Pro Gly Gly Ser Gly Gly Ser Val Pro Ala Leu Thr Asp
195 200 205
His Gly Thr Leu Pro Leu Arg Ser Ser Ile Arg Gly Val Gln Arg Val
210 215 220
Thr Val Thr Asp Ala Arg Arg Arg Thr Cys Pro Tyr Val Tyr Lys Ala
225 230 235 240
Leu Gly Ile Val Ala Pro Arg Val Leu Ser Ser Arg Thr Phe
245 250
<210> 29
<211> 18
<212> ПРТ
<213> Вирус чикунгуньи
<400> 29
Ser Thr Lys Asp Asn Phe Asn Val Tyr Lys Ala Thr Arg Pro Tyr Leu
1 5 10 15
Ala His
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| АДЕНОВИРУСЫ И СПОСОБЫ ПРИМЕНЕНИЯ АДЕНОВИРУСОВ | 2019 |
|
RU2782528C1 |
| МУТАНТЫ FIMH E. COLI И ИХ ПРИМЕНЕНИЕ | 2021 |
|
RU2831010C1 |
| ИММУНОЦИТОКИНЫ НА ОСНОВЕ IL-15 И IL-15Rα ДОМЕНА SUSHI | 2012 |
|
RU2763298C2 |
| КОНСТРУКЦИИ, ИМЕЮЩИЕ SIRP-АЛЬФА ДОМЕН ИЛИ ЕГО ВАРИАНТ | 2016 |
|
RU2740672C2 |
| Конструкции для направленного редактирования генов и способы с их применением | 2020 |
|
RU2832109C2 |
| СТАБИЛЬНЫЕ И РАСТВОРИМЫЕ АНТИТЕЛА, ИНГИБИРУЮЩИЕ VEGF | 2019 |
|
RU2747735C2 |
| Выделенный модифицированный белок VP1 капсида аденоассоциированного вируса 5 серотипа (AAV5), капсид и вектор на его основе | 2019 |
|
RU2751592C2 |
| АНТИГЕННЫЕ ПОЛИПЕПТИДЫ НА ОСНОВЕ ПОСЛЕДОВАТЕЛЬНОСТИ OspA | 2019 |
|
RU2816208C2 |
| МУТАЦИИ В ГЕНАХ OAS1 | 2006 |
|
RU2465328C2 |
| СПОСОБЫ И ПРОДУКТЫ ДЛЯ ПОЛУЧЕНИЯ И ДОСТАВКИ НУКЛЕИНОВЫХ КИСЛОТ | 2015 |
|
RU2714404C2 |
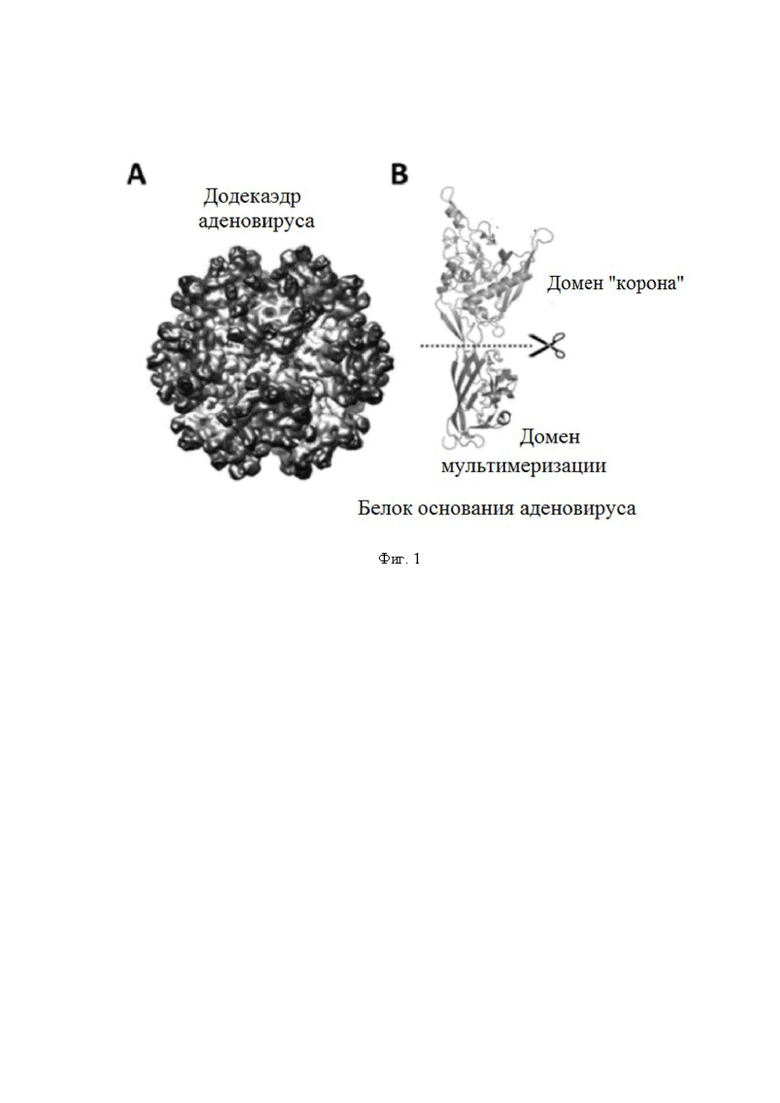
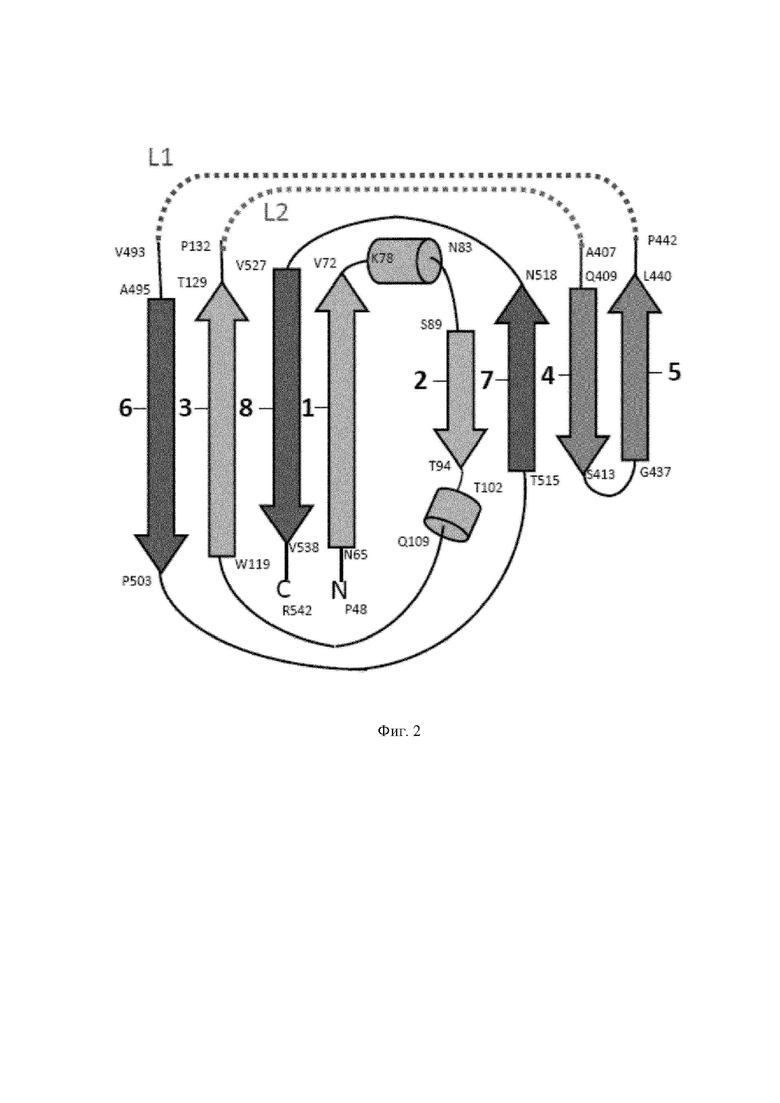
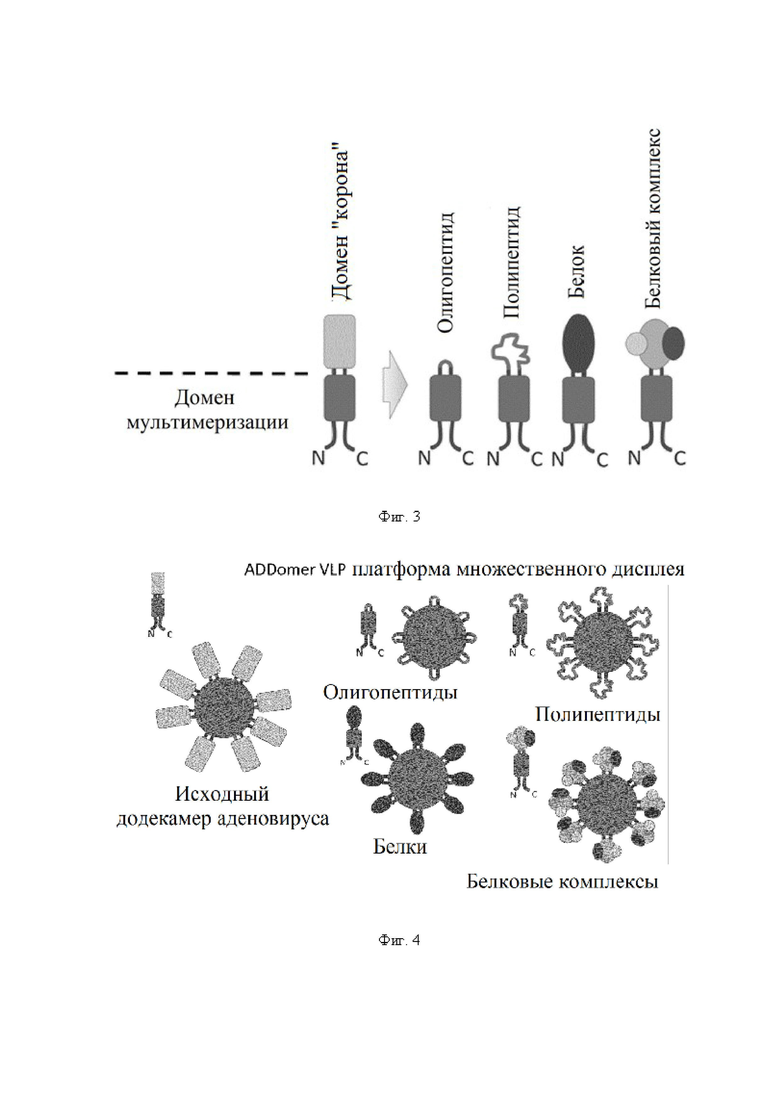
Изобретение относится к биотехнологии. Описан полипептид для презентации олигопептида, полипептида, белка и/или белкового комплекса, имеющий структуру A-L1-B-L2-C (формула (I)), где A представляет собой N-концевой аминокислотный участок белка основания пентона аденовируса, B представляет собой аминокислотный участок белка основания пентона аденовируса, C представляет собой C-концевой аминокислотный участок основания пентона аденовируса, где B представляет собой аминокислотный участок, расположенный между A и C в последовательности указанного основания пентона аденовируса, где A, B и C образуют домен с укладкой типа рулет (jelly roll fold) указанного белка основания пентона аденовируса, L1 и L2 независимо друг от друга выбраны из группы, состоящей из олигопептида, полипептида, белка и белкового комплекса, где указанный олигопептид, полипептид, белок и белковый комплекс, соответственно, являются либо по существу неаденовирусными, либо, если являются аденовирусными, A-L1-B-L2-C образует химеру основания пентона, где A, B и C образуют домен с укладкой типа рулетоснования пентона аденовируса одного подтипа аденовируса, и L1 и L2 образуют домен «корона» основания пентона аденовируса подтипа аденовируса, отличного от подтипа аденовируса домена с укладкой типа рулет. Описана нуклеиновая кислота, кодирующая указанный полипептид. Раскрыта нуклеиновая кислота для получения нуклеиновой кислоты путем вставки нуклеотидных последовательностей, кодирующих L1 и L2, содержащая последовательность, имеющую следующую общую 5'-a-is1-l1-is2-b-is3-l2-is4-c-3', где а представляет собой нуклеотидную последовательность, кодирующую А формулы (I), b представляет собой нуклеотидную последовательность, кодирующую B общей формулы (I), c представляет собой нуклеотидную последовательность, кодирующую C общей формулы (I), и l1, l2 каждый представляет собой нуклеотидную последовательность, с is1 по is4 каждый независимо представляет собой нуклеотидную последовательность, содержащую по меньшей мере один сайт инсерции. Раскрыт вектор для получения указанного полипептида. Описана рекомбинантная клетка-хозяин для получения указанного полипептида. Описан пентамерный комплекс полипептида для презентации олигопептида, полипептида, белка и/или белкового комплекса, где A-L1-B-L2-C образует химеру основания пентона и где A, B и C образуют домен с укладкой типа рулетоснования пентона аденовируса одного подтипа аденовируса, и L1 и L2 образуют домен «корона» основания пентона аденовируса подтипа аденовируса, отличного от подтипа аденовируса домена с укладкой типа рулет. Раскрыта вирусоподобная частица (ВПЧ) для презентации олигопептида, полипептида, белка и/или белкового комплекса, содержащая 12 пентамерных комплексов. Раскрыта фармацевтическая композиция для презентации олигопептида, полипептида, белка и/или белкового комплекса, содержащая полипептид, нуклеиновую кислоту, вектор, клетку-хозяина или ВПЧ вместе с по меньшей мере одним фармацевтически приемлемым носителем, эксципиентом и/или разбавителем. Раскрыт способ получения полипептида. Полипептидные каркасы по изобретению предназначены для оптимальной презентации пептидов, полипептидных последовательностей, белковых доменов, белков и белковых комплексов, состоящих из двух, нескольких или многих субъединиц. Такие олигопептиды, полипептидные последовательности, белковые домены и белки, представленные полипептидными каркасами по настоящему изобретению, могут включать антигенные частицы, которые стимулируют иммунную систему, чтобы вызвать иммунный ответ, например, для целей вакцинации, или для получения антител или других связывающих молекул в культуре клеток, или в пробирке. 12 н. и 24 з.п. ф-лы, 5 ил., 5 табл., 1 пр.
1. Полипептид для презентации олигопептида, полипептида, белка и/или белкового комплекса, имеющий структуру формулы (I)
где
A представляет собой N-концевой аминокислотный участок белка основания пентона аденовируса,
B представляет собой аминокислотный участок белка основания пентона аденовируса,
C представляет собой C-концевой аминокислотный участок основания пентона аденовируса,
где B представляет собой аминокислотный участок, расположенный между A и C в последовательности указанного основания пентона аденовируса,
где A, B и C образуют домен с укладкой типа рулет (jelly roll fold) указанного белка основания пентона аденовируса,
L1 и L2 независимо друг от друга выбраны из группы, состоящей из олигопептида, полипептида, белка и белкового комплекса,
где указанный олигопептид, полипептид, белок и белковый комплекс, соответственно, являются либо по существу неаденовирусными, либо, если являются аденовирусными, A-L1-B-L2-C образует химеру основания пентона, где A, B и C образуют домен с укладкой типа рулет основания пентона аденовируса одного подтипа аденовируса, и L1 и L2 образуют домен «корона» основания пентона аденовируса подтипа аденовируса, отличного от подтипа аденовируса домена с укладкой типа рулет.
2. Полипептид по п. 1, где аминокислотный участок А содержит бета-листы 1, 2 и 3 домена с укладкой типа рулет указанного аденовируса.
3. Полипептид по п. 1 или 2, где аминокислотный участок В содержит бета-листы 4 и 5 домена с укладкой типа рулет указанного аденовируса.
4. Полипептид по любому из пп. 1-3, где аминокислотный участок С содержит бета-листы 6, 7 и 8 домена с укладкой типа рулет аденовируса.
5. Полипептид по любому из пп. 1-4, где аминокислотные участки A, B и C имеют аминокислотную последовательность, причем каждая независимо выбрана из группы, состоящей из оснований пентона аденовируса человека 2 серотипа, аденовируса человека 3 серотипа, аденовируса человека 4 серотипа, аденовируса человека 5 серотипа, аденовируса человека 7 серотипа, аденовируса человека 11 серотипа, аденовируса человека 12 серотипа, аденовируса человека 17 серотипа, аденовируса человека 25 серотипа, аденовируса человека 35 серотипа, аденовируса человека 37 серотипа, аденовируса человека 41 серотипа, аденовируса гориллы, аденовируса шимпанзе, аденовируса обезьяны 18 серотипа, аденовируса обезьяны 20 серотипа, аденовируса обезьяны 49 серотипа, аденовируса макака-резуса 51 серотипа, аденовируса макака-резуса 52 серотипа и аденовируса макака-резуса 53 серотипа.
6. Полипептид по п. 5, где аминокислотный участок A имеет следующую консенсусную последовательность (SEQ ID NO: 21):
(U)1-47 PTX1GRNSIRY SX2X3x4PX5X6DTT X7X3YLVDNKSA DIASLNYQND
HSNFX5TTVX9Q NNDX10X11PX12EAX13 TQTINX14DX15RS RWGX16X17LKTIX18
X19TZ1Z2Z3Z4Z5Z6Z7Z8 Z9Z10Z11Z12Z13Z14Z15,
где: аминокислотный участок A заканчивается на C-конце перед Z1 у остатка T или у аминокислоты с Z1 по Z15,
U представляет собой любую аминокислоту или отсутствует,
X1 представляет собой E или G,
X2 представляет собой E или S,
X3 представляет собой L или V,
X4 представляет собой A или S,
X5 представляет собой L или Q,
X6 представляет собой Y или E,
X7 представляет собой R или K,
X8 представляет собой V или L,
X9 представляет собой V или I,
X10 представляет собой F или Y,
X11 представляет собой T или S,
X12 представляет собой A, или T, или I, или G,
X13 представляет собой S или G,
X14 представляет собой F или L,
X15 представляет собой E или D,
X16 представляет собой A или G,
X17 представляет собой D или Q,
X18 представляет собой L или M,
X19 представляет собой H или R,
Z1, если присутствует, представляет собой N,
Z2, если присутствует, представляет собой M,
Z3, если присутствует, представляет собой P,
Z4, если присутствует, представляет собой N,
Z5, если присутствует, представляет собой V или I,
Z6, если присутствует, представляет собой N,
Z7, если присутствует, представляет собой E или D,
Z8, если присутствует, представляет собой Y или F,
Z9, если присутствует, представляет собой M,
Z10, если присутствует, представляет собой F, или S, или Y,
Z11, если присутствует, представляет собой T или S,
Z12, если присутствует, представляет собой S или N,
Z13, если присутствует, представляет собой K,
Z14, если присутствует, представляет собой F,
Z16, если присутствует, представляет собой K.
7. Полипептид по п. 6, где аминокислотный участок A выбран из группы, состоящей из следующих последовательностей:
от аминокислоты, выбранной из положений с 1 по 48, до аминокислоты, выбранной из положений с 129 по 144, UniProtAcc. № Q2Y0H9,
от аминокислоты, выбранной из положений с 1 по 48, до аминокислоты, выбранной из положений с 129 по 144, UniProtAcc. № P03276,
от аминокислоты, выбранной из положений с 1 по 44, до аминокислоты, выбранной из положений с 125 по 140, UniProtAcc. № Q2KSF3,
от аминокислоты, выбранной из положений с 1 по 48, до аминокислоты, выбранной из положений с 129 по 144, UniProtAcc. № P12538,
от аминокислоты, выбранной из положений с 1 по 48, до аминокислоты, выбранной из положений с 129 по 144, UniProtAcc. № Q9JFT6,
от аминокислоты, выбранной из положений с 1 по 48, до аминокислоты, выбранной из положений с 129 по 144, UniProtAcc. № D2DM93,
от аминокислоты, выбранной из положений с 1 по 38, до аминокислоты, выбранной из положений с 119 по 134, UniProtAcc. № P36716,
от аминокислоты, выбранной из положений с 1 по 35, до аминокислоты, выбранной из положений с 116 по 131, UniProtAcc. № F1DT65,
от аминокислоты, выбранной из положений с 1 по 43, до аминокислоты, выбранной из положений с 124 по 139, UniProtAcc. № M0QUK0,
от аминокислоты, выбранной из положений с 1 по 49, до аминокислоты, выбранной из положений с 130 по 145, UniProtAcc. № Q7T941,
от аминокислоты, выбранной из положений с 1 по 35, до аминокислоты, выбранной из положений с 116 по 131, UniProtAcc. № Q912J1,
от аминокислоты, выбранной из положений с 1 по 46, до аминокислоты, выбранной из положений с 127 по 142, UniProtAcc. № F8WQN4,
от аминокислоты, выбранной из положений с 1 по 49, до аминокислоты, выбранной из положений с 130 по 145, UniProtAcc. № E5L3Q9,
от аминокислоты, выбранной из положений с 1 по 44, до аминокислоты, выбранной из положений с 125 по 140, UniProtAcc. № G9G849,
от аминокислоты, выбранной из положений с 1 по 46, до аминокислоты, выбранной из положений с 127 по 142, UniProtAcc. № H8PFZ9,
от аминокислоты, выбранной из положений с 1 по 45, до аминокислоты, выбранной из положений с 126 по 141, UniProtAcc. № F6KSU4,
от аминокислоты, выбранной из положений с 1 по 46, до аминокислоты, выбранной из положений с 127 по 142, UniProtAcc. № F2WTK5,
от аминокислоты, выбранной из положений с 1 по 43, до аминокислоты, выбранной из положений с 124 по 139, UniProtAcc. № A0A0A1EWW1,
от аминокислоты, выбранной из положений с 1 по 43, до аминокислоты, выбранной из положений с 124 по 139, UniProtAcc. № A0A0A1EWX7, и
от аминокислоты, выбранной из положений с 1 по 44, до аминокислоты, выбранной из положений с 125 по 140, UniProtAcc. № A0A0A1EWZ7.
8. Полипептид по любому из пп. 5-7, где аминокислотный участок B вышеуказанной общей формулы (I) имеет следующую последовательность (SEQ ID NO: 22):
Z17Z18Z19Z20Z21Z22Z23Z24Z25Z26 Z27QVYWSLPDX20 MX21DPVTFRST X22QX23X24NX25PVVGX26 ELZ28Z29Z30,
где: аминокислотный участок B начинается на N-конце у аминокислоты с Z17 по Z27 или у аминокислоты Q после Z27,
аминокислотный участок B заканчивается на С-конце перед Z28 у аминокислоты L или у аминокислоты с Z28 по Z30,
Z17, если присутствует, представляет собой L или S,
Z18, если присутствует, представляет собой T, или P, или C,
Z19, если присутствует, представляет собой T или P,
Z20, если присутствует, представляет собой P, или S, или A, или R,
Z21, если присутствует, представляет собой N или D,
Z22, если присутствует, представляет собой G или V,
Z23, если присутствует, представляет собой H или T,
Z24, если присутствует, представляет собой C,
Z25, если присутствует, представляет собой G,
Z26, если присутствует, представляет собой A, или V, или S,
Z27, если присутствует, представляет собой E или Q,
X20 представляет собой L или M,
X21 представляет собой Q или K,
X22 представляет собой Q, или R, или S,
X23 представляет собой V или I,
X24 представляет собой S или N,
X25 представляет собой Y или F,
X26 представляет собой A или V,
Z28, если присутствует, представляет собой M или L,
Z29, если присутствует, представляет собой P,
Z30, если присутствует, представляет собой V или F.
9. Полипептид по п. 8, где аминокислотный участок В выбран из группы, состоящей из следующих последовательностей:
от аминокислоты, выбранной из положений с 398 по 409, до аминокислоты, выбранной из положений с 440 по 443, UniProtAcc. № Q2Y0H9,
от аминокислоты, выбранной из положений с 425 по 436, до аминокислоты, выбранной из положений с 467 по 470, UniProtAcc. № P03276,
от аминокислоты, выбранной из положений с 379 по 390, до аминокислоты, выбранной из положений с 421 по 444, UniProtAcc. № Q2KSF3,
от аминокислоты, выбранной из положений с 425 по 436, до аминокислоты, выбранной из положений с 467 по 470, UniProtAcc. № P12538,
от аминокислоты, выбранной из положений с 398 по 409, до аминокислоты, выбранной из положений с 440 по 443, UniProtAcc. № Q9JFT6,
от аминокислоты, выбранной из положений с 415 по 426, до аминокислоты, выбранной из положений с 457 по 460, UniProtAcc. № D2DM93,
от аминокислоты, выбранной из положений с 351 по 362, до аминокислоты, выбранной из положений с 393 по 397, UniProtAcc. № P36716,
от аминокислоты, выбранной из положений с 370 по 381, до аминокислоты, выбранной из положений с 413 по 416, UniProtAcc. № F1DT65,
от аминокислоты, выбранной из положений с 388 по 399, до аминокислоты, выбранной из положений с 440 по 443, UniProtAcc. № M0QUK0,
от аминокислоты, выбранной из положений с 445 по 456, до аминокислоты, выбранной из положений с 497 по 500, UniProtAcc. № Q7T941,
от аминокислоты, выбранной из положений с 372 по 383, до аминокислоты, выбранной из положений с 414 по 417, UniProtAcc. № Q912J1,
от аминокислоты, выбранной из положений с 362 по 373, до аминокислоты, выбранной из положений с 404 по 407, UniProtAcc. № F8WQN4,
от аминокислоты, выбранной из положений с 416 по 427, до аминокислоты, выбранной из положений с 458 по 461, UniProtAcc. № E5L3Q9,
от аминокислоты, выбранной из положений с 372 по 383, до аминокислоты, выбранной из положений с 420 по 423, UniProtAcc. № G9G849,
от аминокислоты, выбранной из положений с 353 по 364, до аминокислоты, выбранной из положений с 395 по 398, UniProtAcc. № H8PFZ9,
от аминокислоты, выбранной из положений с 358 по 369, до аминокислоты, выбранной из положений с 400 по 403, UniProtAcc. № F6KSU4,
от аминокислоты, выбранной из положений с 356 по 367, до аминокислоты, выбранной из положений с 398 по 401, UniProtAcc. № F2WTK5,
от аминокислоты, выбранной из положений с 352 по 363, до аминокислоты, выбранной из положений с 394 по 397, UniProtAcc. № A0A0A1EWW1,
от аминокислоты, выбранной из положений с 350 по 361, до аминокислоты, выбранной из положений с 392 по 395, UniProtAcc. № A0A0A1EWX7, и
от аминокислоты, выбранной из положений с 351 по 362, до аминокислоты, выбранной из положений с 393 по 396, UniProtAcc. № A0A0A1EWZ7.
10. Полипептид по любому из пп. 5-9, где аминокислотный участок C вышеуказанной общей формулы (I) имеет следующую последовательность (SEQ ID NO: 23):
Z31Z32Z33ALTDHGT LPLRSSIX27GV QRVTX28TDARR RTCPYVYKA LGIVX30PX31VLS SRTF,
где: аминокислотный участок C начинается на N-конце у аминокислоты с Z31 по Z33 или у аминокислоты A после Z33,
Z31, если присутствует, представляет собой N,
Z32, если присутствует, представляет собой V,
Z33, если присутствует, представляет собой P,
X27 представляет собой R, или S, или G,
X28 представляет собой V или I,
X29 представляет собой Y или H,
X30 представляет собой A или S,
X31 представляет собой R или K.
11. Полипептид по п. 10, где аминокислотный участок C выбран из группы, состоящей из следующих последовательностей:
от аминокислоты, выбранной из положений с 492 по 495, до С-концевой аминокислоты UniProtAcc. № Q2Y0H9,
от аминокислоты, выбранной из положений с 519 по 522, до С-концевой аминокислоты UniProtAcc. № P03276,
от аминокислоты, выбранной из положений с 466 по 469, до С-концевой аминокислоты UniProtAcc. № Q2KSF3,
от аминокислоты, выбранной из положений с 492 по 495, до С-концевой аминокислоты UniProtAcc. № P12538,
от аминокислоты, выбранной из положений с 465 по 468, до С-концевой аминокислоты UniProtAcc. № Q9JFT6,
от аминокислоты, выбранной из положений с 482 по 485, до С-концевой аминокислоты UniProtAcc. № D2DM93,
от аминокислоты, выбранной из положений с 419 по 422, до С-концевой аминокислоты UniProtAcc. № P36716,
от аминокислоты, выбранной из положений с 438 по 441, до С-концевой аминокислоты UniProtAcc. № F1DT65,
от аминокислоты, выбранной из положений с 455 по 458, до С-концевой аминокислоты UniProtAcc. № M0QUK0,
от аминокислоты, выбранной из положений с 522 по 525, до С-концевой аминокислоты UniProtAcc. № Q7T941,
от аминокислоты, выбранной из положений с 439 по 442, до С-концевой аминокислоты UniProtAcc. № Q912J1,
от аминокислоты, выбранной из положений с 429 по 432, до С-концевой аминокислоты UniProtAcc. № F8WQN4,
от аминокислоты, выбранной из положений с 483 по 486, до С-концевой аминокислоты UniProtAcc. № E5L3Q9,
от аминокислоты, выбранной из положений с 445 по 448, до С-концевой аминокислоты UniProtAcc. № G9G849,
от аминокислоты, выбранной из положений с 420 по 423, до С-концевой аминокислоты UniProtAcc. № H8PFZ9,
от аминокислоты, выбранной из положений с 425 по 428, до С-концевой аминокислоты UniProtAcc. № F6KSU4,
от аминокислоты, выбранной из положений с 423 по 426, до С-концевой аминокислоты UniProtAcc. № F2WTK5,
от аминокислоты, выбранной из положений с 419 по 422, до С-концевой аминокислоты UniProtAcc. № A0A0A1EWW1,
от аминокислоты, выбранной из положений с 417 по 420, до С-концевой аминокислоты UniProtAcc. № A0A0A1EWX7, и
от аминокислоты, выбранной из положений с 418 по 421, до С-концевой аминокислоты UniProtAcc. № A0A0A1EWZ7.
12. Полипептид по любому из пп. 1-11, где аминокислотный участок A имеет последовательность положений с 1 по 132 UniProtAcc. № Q2Y0H9, аминокислотный участок B имеет последовательность положений с 407 по 442 UniProtAcc. № Q2Y0H9, и аминокислотный участок C имеет последовательность положений с 493 по 544 UniProtAcc. № Q2Y0H9.
13. Полипептид по любому из пп. 1-12, где L1 и/или L2 представляет собой олигопептид, имеющий последовательность из от 4 до 40 аминокислот, выбранных из аминокислот G и S.
14. Полипептид по п. 13, где L1 и/или L2 независимо выбраны из группы, состоящей из GGGS (SEQ ID NO: 24) и GGSGGS (SEQ ID NO: 25).
15. Полипептид по любому из пп. 1-12, где L1 представляет собой аденовирусную последовательность, содержащую петлю RGD основания пентона аденовируса, имеющего серотип отличный от серотипа аденовируса(ов), от которого происходят указанные аминокислотные участки A, B и C, и/или L2 представляет собой аденовирусную последовательность, содержащую вариабельную петлю основания пентона аденовируса, имеющего серотип отличный от серотипа аденовируса, от которого происходят указанные аминокислотные участки A, B и C.
16. Полипептид по п. 15, где L1 представляет собой большой фрагмент домена «корона» основания пентона аденовируса, имеющего серотип отличный от серотипа аденовируса(ов), от которого происходят указанные аминокислотные участки A, B и C, и L2 представляет собой малый фрагмент домена «корона» основания пентона аденовируса, имеющего серотип отличный от серотипа аденовируса(ов), от которого происходят указанные аминокислотные участки A, B и C.
17. Полипептид по п. 16, где большой и малый фрагменты происходят из белка основания пентона одного и того же аденовируса.
18. Полипептид по п. 16, где большой и малый фрагменты происходят из белка основания пентона различных аденовирусов.
19. Полипептид по любому из пп. 15-18, где одна или более неаденовирусных последовательностей вставлены в петлю RGD и/или вариабельную петлю.
20. Полипептид по любому из пп. 1-19, где L1 и/или L2 содержат антиген.
21. Полипептид по п. 20, где антиген выбран из группы, состоящей из антигена инфекционного агента и опухолевого антигена.
22. Полипептид по любому из пп. 1-21, где к L1 и/или L2 присоединен/присоединены нуклеиновая кислота, лекарственное средство, метка и/или партнер по связыванию биологически связывающейся пары.
23. Нуклеиновая кислота, кодирующая полипептид по любому из пп. 1-22.
24. Нуклеиновая кислота для получения нуклеиновой кислоты по п. 23 путем вставки нуклеотидных последовательностей, кодирующих L1 и L2 общей формулы (I), содержащая последовательность, имеющую следующую общую формулу (II)
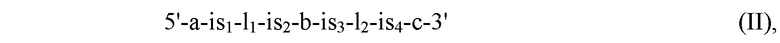
где
а представляет собой нуклеотидную последовательность, кодирующую А общей формулы (I),
b представляет собой нуклеотидную последовательность, кодирующую B общей формулы (I),
c представляет собой нуклеотидную последовательность, кодирующую C общей формулы (I), и
l1, l2 каждый представляет собой нуклеотидную последовательность,
с is1 по is4 каждый независимо представляет собой нуклеотидную последовательность, содержащую по меньшей мере один сайт инсерции.
25. Нуклеиновая кислота по п. 24, где значения с is1 по is4 выбраны из группы, состоящей из последовательностей распознавания рестрикционных ферментов и последовательностей распознавания хоминг-эндонуклеаз.
26. Нуклеиновая кислота по п. 25, где is1 содержит сайт EcoRI, is2 содержит сайт RsrII, is3 содержит сайт SacI, и is4 содержит сайт XbaI.
27. Вектор для получения полипептида по любому из пп. 1-22, содержащий нуклеиновую кислоту по п. 23.
28. Вектор по п. 27, содержащий нуклеиновую кислоту по п. 23 в кассете экспрессии.
29. Рекомбинантная клетка-хозяин для получения полипептида по любому из пп. 1-22, содержащая нуклеиновую кислоту по п. 23 или вектор по п. 27 или 28.
30. Пентамерный комплекс полипептида по любому из пп. 1-12 и 15-22 для презентации олигопептида, полипептида, белка и/или белкового комплекса, где A-L1-B-L2-C образует химеру основания пентона, и где A, B и C образуют домен с укладкой типа рулет основания пентона аденовируса одного подтипа аденовируса, и L1 и L2 образуют домен «корона» основания пентона аденовируса подтипа аденовируса, отличного от подтипа аденовируса домена с укладкой типа рулет.
31. Вирусоподобная частица (ВПЧ) для презентации олигопептида, полипептида, белка и/или белкового комплекса, содержащая 12 пентамерных комплексов по п. 30.
32. Полипептид по любому из пп. 1-22, нуклеиновая кислота по п. 23, вектор по п. 27 или 28, клетка-хозяин по п. 29 или ВПЧ по п. 31 для применения в качестве лекарственного средства.
33. Фармацевтическая композиция для презентации олигопептида, полипептида, белка и/или белкового комплекса, содержащая полипептид по любому из пп. 1-22, нуклеиновую кислоту по п. 23, вектор по п. 27 или 28, клетку-хозяин по п. 29 или ВПЧ по п. 31 вместе с по меньшей мере одним фармацевтически приемлемым носителем, эксципиентом и/или разбавителем.
34. Способ получения полипептида по любому из пп. 1-22, включающий стадию культивирования рекомбинантной клетки-хозяина по п. 29, где клетка-хозяин содержит вектор по п. 28 в условиях, обеспечивающих экспрессию указанного полипептида.
35. Способ получения ВПЧ по п. 31, включающий стадию инкубации раствора полипептида по любому из пп. 1-22 в условиях, обеспечивающих сборку полипептида в ВПЧ.
36. Полипептид по любому из пп. 1-22, нуклеиновая кислота по п. 23, вектор по п. 27 или 28, клетка-хозяин по п. 29 или ВПЧ по п. 31 для применения в лечении и/или предотвращении инфекционного заболевания, иммунного заболевания, опухоли или рака.
| WO 2017167988 A1, 05.10.2017 | |||
| CHLOE ZUBIETA et al | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Печь для сжигания твердых и жидких нечистот | 1920 |
|
SU17A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Ребристый каток | 1922 |
|
SU121A1 |
| SZURGOT INGA et al | |||
| Self-adjuvanting influenza candidate vaccine presenting epitopes for cell-mediated immunity on a proteinaceous multivalent nanoplatform, VACCINE,Vol | |||
| Способ очистки нефти и нефтяных продуктов и уничтожения их флюоресценции | 1921 |
|
SU31A1 |

