Настоящее изобретение относится к обработке аудиосигнала и, в частности, к обработке аудиосигнала звуковых сцен, происходящей, например, в приложениях виртуальной реальности или дополненной реальности.
Геометрическая акустика применяется в аурализации, т.е. оперативном и автономном рендеринге аудиосигнала для слуховых сцен и окружений. Это включает в себя системы виртуальной реальности (VR) и дополненной реальности (AR) модуль рендеринга аудиосигнала с 6 DoF наподобие MPEG-I. Для рендеринга сложных аудиосцен с шестью степенями свободы (DoF), применяется область геометрической акустики, где распространение звуковых данных моделируется с использованием способов, известных из оптики, например, построение лучей. В частности, отражения на стенах моделируются на основании моделей выведенных из оптики, где угол падения луча, который отражается на стене, приводит к тому, что угол отражения оказывается равным углу падения.
Системы оперативной аурализации, наподобие модуля рендеринга аудиосигнала в системе виртуальной реальности (VR) или дополненной реальности (AR), обычно выполняют рендеринг ранних отражений на основании геометрических данных отражающего окружения. Затем способ геометрической акустики наподобие способа источника изображения совместно с построением лучей используется для отыскания пригодных путей распространения отраженного звука. Эти способы пригодны, если отражающие плоские поверхности велики по сравнению с длиной волны падающего звука. Расстояние от точки отражения на поверхности до границ отражающей поверхности также должно быть велико по сравнению с длиной волны падающего звука.
Рендеринг звука в виртуальной реальности (VR) и дополненной реальности (AR) выполняется для слушателя (пользователя). Входными сигналами этого процесса являются (обычно безэховые) аудиосигналы источников звука. Затем к этим входным сигналам применяются разнообразные методы обработки сигнала с целью имитации и включения соответствующих акустических эффектов, например, передачи звука через стены/окна/двери, дифракции и преграждения на сплошных или проницаемых структурах, распространения звука на большие расстояния, отражений в полуоткрытых и замкнутых окружениях, доплеровских сдвигов движущихся источников/слушателей и т.д. Рендеринг аудиосигнала приводит к выводу аудиосигналов, которые создают реалистическое, трехмерное акустическое восприятие представленной сцены VR/AR при доставке слушателю через наушники или громкоговорители.
Рендеринг осуществляется слушателецентрично, и система должна реагировать на движение и взаимодействие пользователя мгновенно, без значительных задержек. Поэтому обработка аудиосигналов должна осуществляться оперативно. Пользовательский ввод проявляется в изменениях обработки сигнала (например, разных фильтрах). Эти изменения подлежат включению в рендеринг без слышимых артефактов.
Большинство модулей рендеринга аудиосигнала использует заданную фиксированную структуру обработки сигнала (блок-схему, применяемую к множественным каналам, см. например [1]) с фиксированным бюджетом времени вычисления для каждого отдельного источника аудиосигнала (например, источника 16x объекта, 2x амбиофонии третьего порядка). Эти решения позволяют выполнять рендеринг динамичных сцен путем обновления фильтров, зависящих от положения и параметров реверберация, но они не позволяют динамически добавлять/удалять источники во время работы.
Кроме того, фиксированная архитектура обработка сигнала может быть недостаточно эффективной при рендеринге сложных сцен, поскольку требует однотипной обработки большого количества источников. Более новые принципы рендеринга облегчают принципы кластеризации и уровня детализации (LOD), где, в зависимости от восприятия, источники объединяются и выполняется их рендеринг с другой обработкой сигнала. Кластеризация источника (см. [2]) позволяет модулям рендеринга обрабатывать сложные сцены с сотнями объектов. В такой конфигурации, кластерный бюджет все еще фиксирован, что может приводить к слышимым артефактам обширной кластеризации в сложных сценах.
Задача настоящего изобретения состоит в создании улучшенного принципа рендеринга аудиосцены.
Эта задача решается устройством для рендеринга звуковой сцены по пункту 1 формулы или способом рендеринга звуковой сцены по пункту 21 формулы, или компьютерной программой по пункту 22 формулы.
Настоящее изобретение основано на понимании того, что в целях рендеринга сложной звуковой сцены с большим количеством источников в окружении, где могут частые происходить изменения звуковой сцены, полезна конвейероподобная архитектура рендеринга. Конвейероподобная архитектура рендеринга содержит первый каскад конвейера, содержащий первый слой управления и переконфигурируемый первый процессор аудиоданных. Кроме того, предусмотрен второй каскад конвейера, который располагается, относительно потока конвейера, после первого каскада конвейера. Этот второй каскад конвейера, опять же, содержит второй слой управления и переконфигурируемый второй процессор аудиоданных. Как первый, так и второй каскады конвейера выполнены с возможностью работы в соответствии с некоторой конфигурацией переконфигурируемого первого процессора аудиоданных в некоторый момент времени во время обработки. Для управления конвейерной архитектурой, предусмотрен центральный контроллер для управления первым слоем управления и вторым слоем управления. Управление осуществляется в ответ на звуковую сцену, т.е. в ответ на первоначальную звуковую сцену или изменение звуковой сцены.
Для достижения синхронизации операций устройства между всеми каскадами конвейера, и в случае необходимости переконфигурирования первого или второго переконфигурируемого процессора аудиоданных, центральный контроллер управляет слоями управления каскадов конвейера таким образом, что первый слой управления или вторым слоем управления подготавливает другую конфигурацию, например, вторую конфигурацию первого или второго переконфигурируемого процессора аудиоданных во время или после операции переконфигурируемого процессора аудиоданных в первой конфигурации. Поэтому новая конфигурация для переконфигурируемого первого или второго процессора аудиоданных подготавливается, пока переконфигурируемый процессор аудиоданных, принадлежащий этому каскаду конвейера, все еще оперирует в соответствии с другой конфигурацией или выполнен в другой конфигурации в случае задачи обработки с более ранней конфигурацией уже выполнена. Чтобы гарантировать, что оба каскады конвейера оперируют синхронно для получения так называемой «атомарной операции» или «атомарных обновлений», центральный контроллер управляет первым и вторым слоями управления с использованием управления переключением для переконфигурирования переконфигурируемого первого процессора аудиоданных или переконфигурируемого второго процессора аудиоданных в еще одну конфигурацию в некоторый момент времени. Даже когда переконфигурируется один-единственный каскад конвейера, варианты осуществления настоящего изобретения тем не менее гарантируют, что вследствие управления переключением в некоторый момент времени, правильные данные выборки аудиосигнала обрабатываются в рабочем потоке аудиосигнала благодаря обеспечению входных или выходных буферов аудиопотока, включенных в соответствующие списки рендеринга.
Предпочтительно, устройство для рендеринга звуковой сцены имеет больше каскадов конвейера, чем первый и второй каскады конвейера, но уже в системе с первым и вторым каскадами конвейера и без дополнительного каскада конвейера, синхронизированное переключение каскадов конвейера в ответ на управление переключением необходимо для получения улучшенной операции рендеринга высококачественного аудиосигнала, которая, в то же время, является очень гибкой.
В частности, в сложных сценах виртуальной реальности, где пользователь может двигаться в трех направлениях и где, дополнительно, пользователь может двигать головой в трех дополнительных направлениях, т.е. в ситуации с шестью степенями свободы (6 DoF), частые и внезапные изменения фильтров в конвейере рендеринга, например, для перехода от одной связанной с головой передаточной функции к другой, связанной с головой передаточной функции в случае движения головы слушателя или хождения слушателя требуется, чтобы происходило такое изменение связанных с головой передаточных функций.
Другие проблематичные ситуации с гибким рендерингом при высоком качестве состоят в том, что когда слушатель перемещается в сцене виртуальной или дополненной реальности, количество источников, подлежащих рендерингу все время изменяется. Это может, например, происходить ввиду того, что некоторые источники изображения становятся видимыми в некотором положении пользователя или ввиду того, что приходится принимать во внимание дополнительные дифракционные эффекты. Кроме того, другие процедуры состоят в том, что в некоторых ситуациях, кластеризация многих разных близкорасположенных источников возможна, хотя, когда пользователь приближается к этим источникам, кластеризация становится неосуществимой, поскольку пользователь настолько близок, что возникает необходимость в том, чтобы рендеринг каждого источника был выполнен в его отдельном положении. Таким образом, такие аудиосцены проблематичны в том, что изменять фильтры или изменять количество источников, подлежащих рендерингу, или, в общем случае, изменять параметры необходимо постоянно. С другой стороны, полезно распределять разные операции для рендеринга по разным каскадам конвейера, что позволяет осуществлять эффективный и высокоскоростной рендеринг, чтобы гарантировать, что достижимость рендеринга в реальном времени в сложных аудио-окружениях.
Дополнительный пример значительного изменения параметра состоит в том, что как только пользователь приближается к источнику или источнику изображения, частотнозависимое ослабление с расстоянием и задержка на распространение изменяются с расстоянием между пользователем и источником звука. Аналогичным образом, частотнозависимые характеристики отражающей поверхности могут изменяться в зависимости от конфигурации между пользователем и отражающим объектом. Кроме того, в зависимости от того, находится ли пользователь ближе к дифракционному объекту или дальше от дифракционного объекта или под другим углом, частотнозависимые дифракционные характеристики также будут изменяться. Таким образом, если все эти задачи распределяются по разным каскадам конвейера, продолжение изменений этих каскадов конвейера должно быть возможно и должно осуществляться синхронно. Все это достигается посредством центрального контроллера, который управляет слоями управления каскадов конвейера для подготовки к новой конфигурации во время или после операции соответствующего конфигурируемого процессора аудиоданных в более ранней конфигурации. В ответ на управление переключением для всех каскадов в конвейере, обусловленное обновлением управления через управление переключением, переконфигурирование происходит в некоторый момент времени, одинаковый или по меньшей мере очень близкий для разных каскадов конвейера в устройстве для рендеринга звуковой сцены.
Настоящее изобретение имеет преимущество в том, что позволяет оперативно осуществлять высококачественную аурализацию слуховых сцен с динамически изменяющимися элементами, например, движущимися источниками и слушателями. Таким образом, настоящее изобретение способствует достижению перцепционно убедительных звуковых ландшафтов, которые оказывают значительное влияние на ощущение погруженности в виртуальную сцену.
Варианты осуществления настоящего изобретения применяют отдельные и одновременные рабочие потоки, цепочки или процессы, которые очень хорошо подходят к ситуации рендеринга динамичных слуховых сцен.
1. Рабочий поток взаимодействия: манипулирование изменениями в виртуальной сцене (например, движением пользователя, взаимодействием с пользователем, анимациями сцены и т.д.), которые происходят в произвольные моменты времени.
2. Рабочий поток управления: снимок текущего состояние виртуальной сцены приводит к обновлениям обработки сигнала и ее параметров.
3. Рабочий поток обработки: выполнение оперативной обработки сигнала, т.е. на основании кадра входных выборок вычисление соответствующего кадра выходных выборок.
Выполнение рабочего потока управления изменяется во время прогона, в зависимости от того, какие необходимые вычисления инициируют изменение, аналогично циклу кадров в визуальном вычислении. Предпочтительные варианты осуществления изобретения имеют преимущество в том, что такие вариации выполнения рабочего потока управления вовсе не оказывают негативного влияния на рабочий поток обработки, который одновременно выполняется в фоновом режиме. Поскольку аудиосигнал реального времени обрабатывается поблочно, допустимое время вычисления рабочего потока обработки обычно ограничивается несколькими миллисекундами.
Рабочий поток обработки, который одновременно выполняется в фоновом режиме, обрабатывается первым и вторым переконфигурируемыми процессорами аудиоданных, и рабочий поток управления инициируется центральным контроллером и затем реализуется, на уровне каскада конвейера, слоями управления каскадов конвейера, параллельными фоновой операции рабочего потока обработки. Рабочий поток взаимодействия реализуется, на уровне устройств конвейерного рендеринга, посредством интерфейса центрального контроллера к внешним устройствам, например, модулю отслеживания головы или аналогичному устройству или управляется аудиосценой, имеющей движущийся источник или геометрию, которая представляет изменение звуковой сцены, а также изменение ориентации или местоположения пользователя, т.е. в общем случае положения пользователя.
Преимущество настоящего изобретения состоит в том, что множественные объекты в сцене могут изменяться когерентно, и выбираться синхронно вследствие управляемой из центра процедуры управления переключением. Кроме того, эта процедура допускает так называемые атомарные обновления множественных элементов, которые должны поддерживаться рабочим потоком управления и рабочим потоком обработки, чтобы не прерывать обработку аудиосигнала вследствие изменений на самом высоком уровне, т.е. в рабочем потоке взаимодействия или на промежуточном уровне, т.е. рабочем потоке управления.
Предпочтительные варианты осуществления настоящего изобретения относятся к устройству для рендеринга звуковой сцены, реализующему модульный конвейер рендеринга аудиосигнала, где необходимые этапы аурализации виртуальных слуховых сцен делятся на несколько каскадов, каждый из которых независимо отвечает за некоторые перцептивные эффекты. Отдельное разбиение на по меньшей мере два или, предпочтительно, еще больше отдельных каскадов конвейера зависит от применения и предпочтительно задается автором системы рендеринга, что проиллюстрировано ниже.
Настоящее изобретение предусматривает общую структуру для конвейера рендеринга, которая облегчает параллельную обработку и динамическое переконфигурирование параметров обработки сигнала в зависимости от текущего состояния виртуальной сцены. В этом процессе, варианты осуществления настоящего изобретения гарантируют
a) что каждый каскад может динамически изменять свою обработку DSP (например, количество каналов, обновленные коэффициенты фильтрации) без создания слышимых артефактов, и что любое обновление конвейера рендеринга, на основании последних изменений в сцене, обрабатывается синхронно и, при необходимости, атомарно
b) что изменения в сцене (например, перемещение слушателя) могут приниматься в произвольные моменты времени и не влиять на оперативную производительность системы и, в частности, обработку DSP, и
c) что отдельные каскады могут извлекать пользу из функциональности других каскадов в конвейере (например, унифицированной направленности рендеринга для первичных источников и источников изображения или непрозрачной кластеризации для снижения сложности).
Далее предпочтительные варианты осуществления настоящего изобретения рассмотрены с обращением к сопровождающим чертежам, на которых:
фиг. 1 иллюстрирует вход/выход каскада рендеринга;
фиг. 2 иллюстрирует переход состояния элементов рендеринга;
фиг. 3 иллюстрирует обзор конвейера рендеринга;
фиг. 4 иллюстрирует пример структуры конвейера аурализации виртуальной реальности;
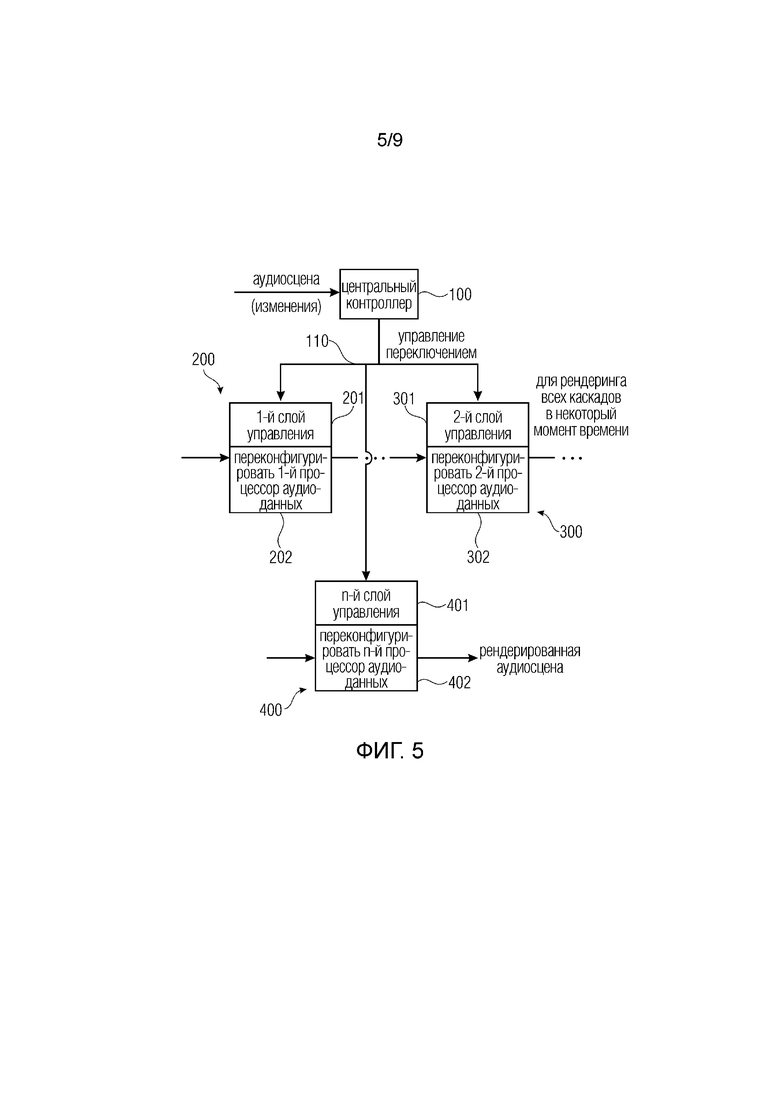
фиг. 5 иллюстрирует предпочтительную реализацию устройства для рендеринга звуковой сцены;
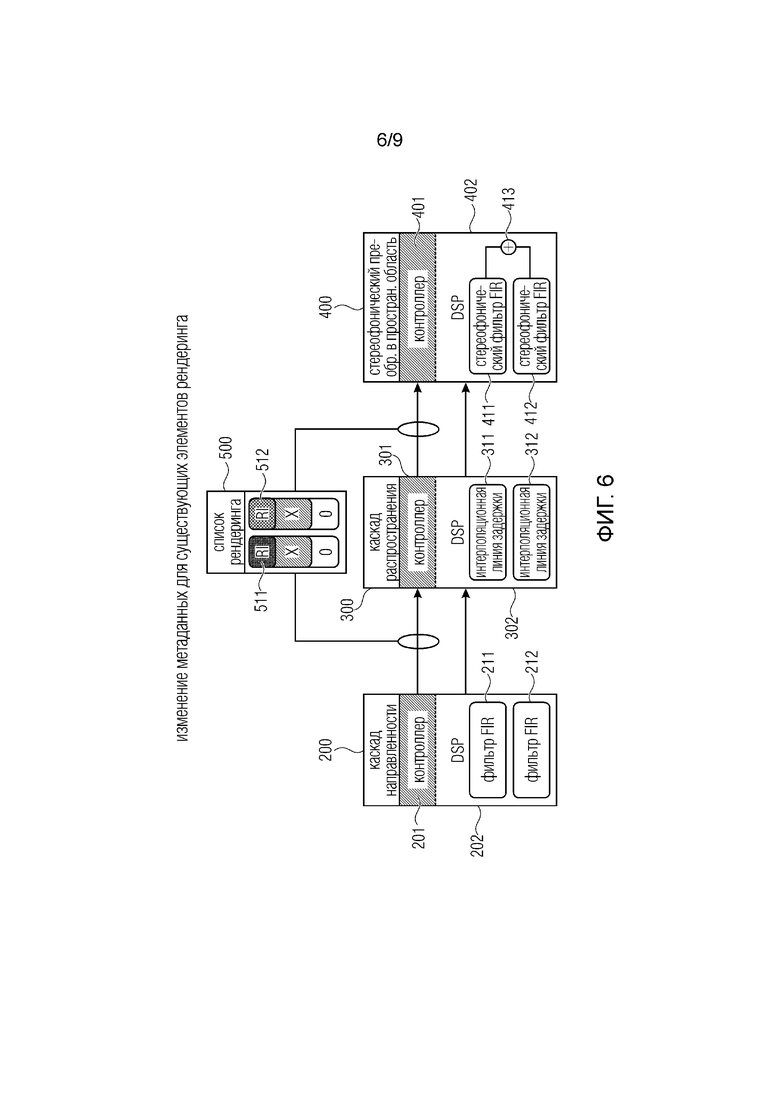
фиг. 6 иллюстрирует пример реализации для изменения метаданных для существующих элементов рендеринга;
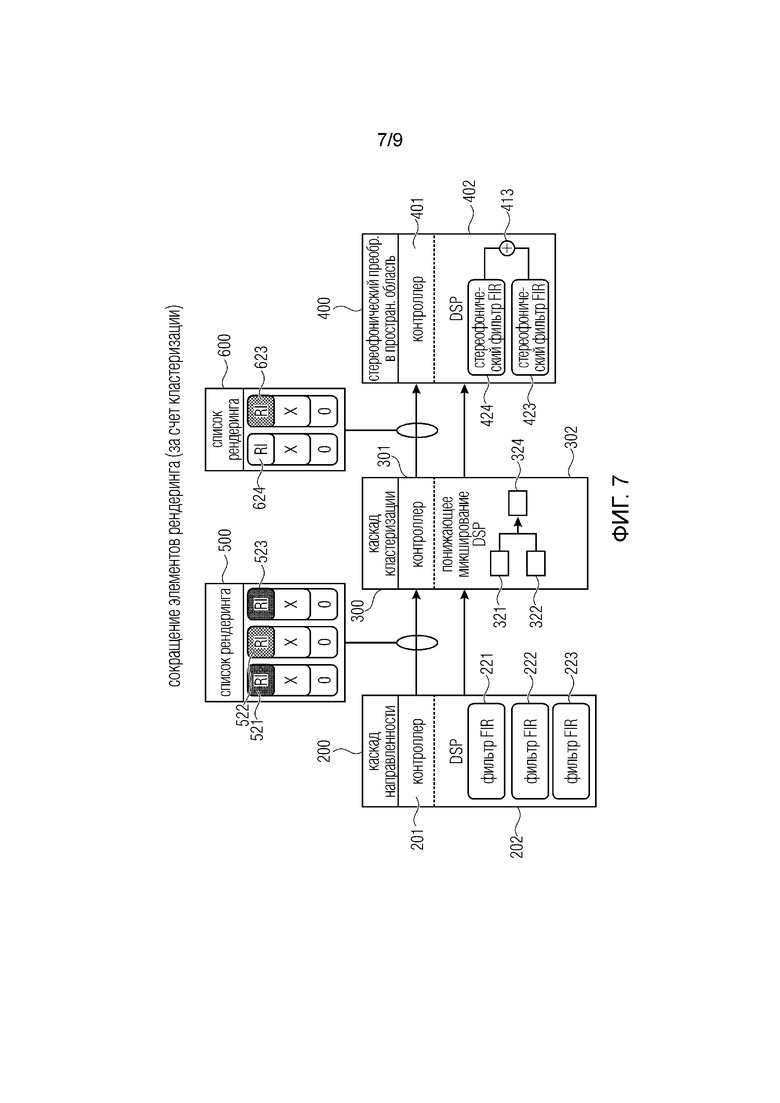
фиг. 7 иллюстрирует другой пример для сокращения элементов рендеринга, например, путем кластеризации;
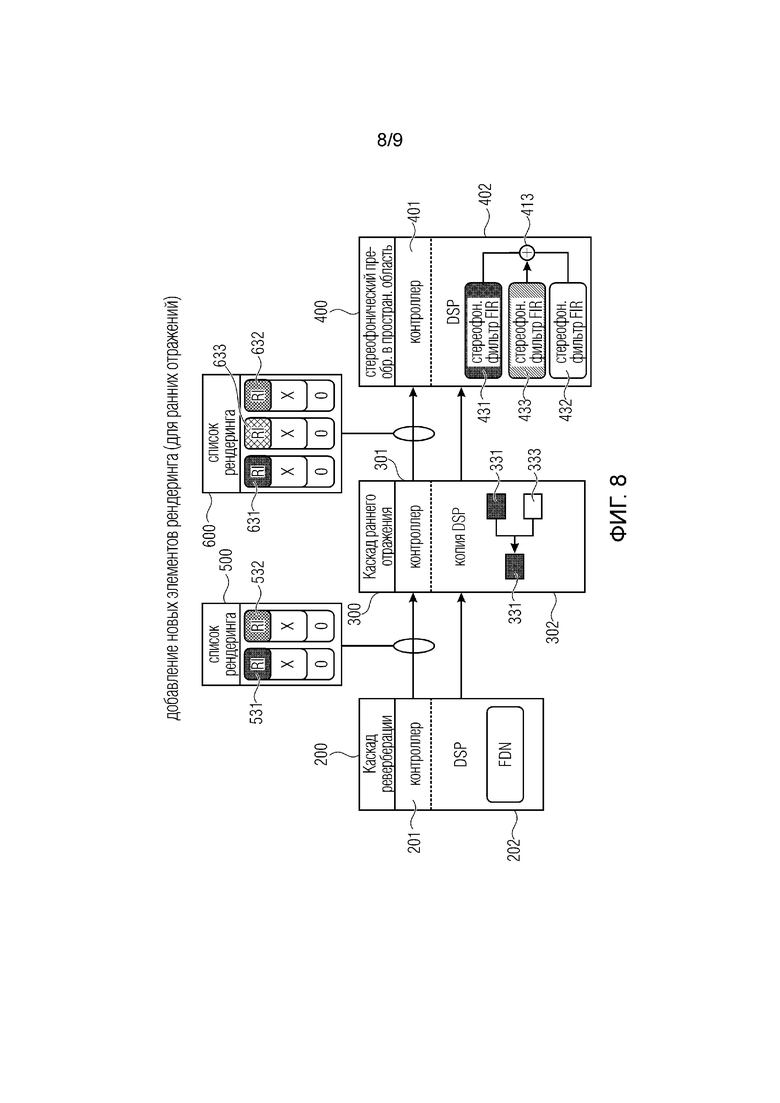
фиг. 8 иллюстрирует другой пример реализации для добавления новых элементов рендеринга например для ранних отражений; и
фиг. 9 иллюстрирует блок-схему операций для демонстрации потока управления из события высокого уровня, которое является аудиосценой (изменением) до плавного усиления или плавного ослабления низкого уровня старых или новых элементов или плавного изменения фильтров или параметров.
Фиг. 5 иллюстрирует устройство для рендеринга звуковой сцены или аудиосцены, принятой центральным контроллером 100. Устройство содержит первый каскад 200 конвейера с первым слоем 201 управления и переконфигурируемым первым процессором 202 аудиоданных. Кроме того, устройство содержит второй каскад 300 конвейера, расположенный, относительно потока конвейера, после первого каскада 200 конвейера. Второй каскад 300 конвейера может располагаться сразу после первого каскада 200 конвейера или может располагаться таким образом, что один или более каскадов конвейера находятся между каскадом 300 конвейера и каскадом 200 конвейера. Второй каскад 300 конвейера содержит второй слой 301 управления и переконфигурируемый второй процессор 302 аудиоданных. Кроме того, проиллюстрирован необязательный n-й каскад 400 конвейера, который содержит n-й слой 401 управления и переконфигурируемый n-й процессор 402 аудиоданных. В иллюстративном варианте осуществления на фиг. 5, результатом каскада 400 конвейера является уже рендерированная аудиосцена, т.е. результат полной обработки аудиосцены или изменений аудиосцены, поступивших на центральный контроллер 100. Центральный контроллер 100 выполнен с возможностью управления первым слоем 201 управления и вторым слоем 301 управления в ответ на звуковую сцену.
В ответ на звуковую сцену означает в ответ на ввод полной сцены в некоторый момент времени инициализации или начальный момент времени или в ответ на изменения звуковой сцены, которые, совместно с предыдущей сценой, существовавшей до изменений звуковой сцены опять же, представляют полную звуковую сцену, которая подлежит обработке центральным контроллером 100. В частности, центральный контроллер 100 управляет первым и вторым слоями управления и при наличии, любыми другими слоями управления, например, n-ым слоем 401 управления, благодаря чему подготавливается новая или вторая конфигурация первого, второго и/или n-го переконфигурируемого процессора аудиоданных, пока соответствующий переконфигурируемый процессор аудиоданных действует в фоновом режиме в соответствии с более ранней или первой конфигурацией. Для этого фонового режима не критично, все ли еще действует переконфигурируемый процессор аудиоданных, т.е., принимает входные выборки и вычисляет выходные выборки. Напротив, возможна ситуация, что некоторый каскад конвейера уже выполнил свои задачи. Таким образом, подготовка новой конфигурации происходит во время или после операции соответствующего переконфигурируемого процессора аудиоданных в более ранней конфигурации.
Чтобы гарантировать, что атомарные обновления отдельных каскадов 200, 300, 400 конвейера возможны, центральный контроллер выводит управление 110 переключением для переконфигурирования отдельного переконфигурируемого первого или второго процессора аудиоданных в некоторый момент времени. В зависимости от конкретного применения или изменения звуковой сцены, один-единственный каскад конвейера может переконфигурироваться в некоторый момент времени, или два каскада конвейера, например, каскады 200, 300 конвейера оба переконфигурируется в некоторый момент времени или все каскады конвейера полного устройства для рендеринга звуковой сцены или только подгруппа, имеющая более двух каскадов конвейера, но меньше, чем все каскады конвейера, также могут быть снабжены управлением переключением для переконфигурирования в некоторый момент времени. Для этого центральный контроллер 100 имеет линию управления к каждому слою управления соответствующего каскада конвейера помимо соединения рабочего потока обработки, последовательно, соединяющего каскады конвейера. Кроме того, соединение рабочего потока управления, которое рассмотрено ниже, может обеспечиваться также через первую структуру для центрального управления 110 переключением. Однако в предпочтительных вариантах осуществления рабочий поток управления также осуществляется через последовательное соединение между каскадами конвейера таким образом, что центральное соединение между каждым слоем управления отдельного каскада конвейера и центральным контроллером 100 зарезервировано только для управления 110 переключением для получения атомарных обновлений и, таким образом, правильного и высококачественного рендеринга аудиосигнала даже в сложных окружениях.
В следующей разделе описан общий конвейер рендеринга аудиосигнала, состоящий из независимых каскадов рендеринга, каждый с отдельными, синхронизированными рабочими потоками управления и обработки (фиг. 1). Наличие центрального контроллера гарантирует возможность одновременного атомарного обновления всех каскадов в конвейере.
Каждый каскад рендеринга имеет управляющую часть и обработочную часть с отдельными входами и выходами, соответствующими рабочему потоку управления и обработки соответственно. В конвейере, выходы одного каскада рендеринга являются входами следующего каскада рендеринга, тогда как общий интерфейс гарантирует возможность реорганизации и замены каскадов рендеринга, в зависимости от применения.
Этот общий интерфейс описан как плоский список элементов рендеринга, который поступает на каскад рендеринга в рабочем потоке управления. Элемент рендеринга объединяет инструкции обработки (т.е. метаданные, например, положение, ориентацию, частотную коррекцию и т.д.) с буфером аудиопотока (одно- или многоканальным). Отображение буферов в элементы рендеринга является произвольным, поэтому несколько элементов рендеринга могут относиться к одному и тому же буферу.
Каждый каскад рендеринга гарантирует, что следующие каскады могут считывать правильные выборки аудиосигнала из буферов аудиопотока, соответствующих соединенным элементам рендеринга на скорости рабочего потока обработки. С этой целью, каждый каскад рендеринга создает диаграмму обработки из информации в элементах рендеринга, которая описывает необходимые этапы DSP и его входной и выходной буферы. Дополнительные данные могут потребоваться для построения диаграммы обработки (например, геометрии в сцене или персонифицированных наборов HRIR) и обеспечиваются контроллером. Диаграммы обработки выравниваются для синхронизации и передаются в рабочий поток обработки одновременно для всех каскадов рендеринга, после прохождения обновления управления через весь конвейер. Обмен диаграмм обработки инициируется безотносительно к частоте оперативных аудиоблоков, тогда как отдельные каскады должны гарантировать, что обмен не приводит к сколько-нибудь слышимым артефактам. Если каскад рендеринга только действует на метаданных, рабочий поток DSP может быть нерабочим.
Контроллер поддерживает список элементов рендеринга, соответствующий фактическим источникам аудиосигнала в виртуальной сцене. В рабочем потоке управления, контроллер начинает новое обновление управления, передавая новый список элементов рендеринга на первый каскад рендеринга, атомарно накапливая все изменения метаданных, обусловленные взаимодействием с пользователем и другими изменениями в виртуальной сцене. Обновления управления инициируются с фиксированной частотой, которая может зависеть от имеющихся вычислительных ресурсов, но только после окончания предыдущего обновления. Каскад рендеринга создает новый список выходных элементов рендеринга из входного списка. В этом процессе, он может изменять существующие метаданные (например, добавлять характеристику частотной коррекции), а также добавлять новые и деактивировать или удалять существующие элементы рендеринга. Элементы рендеринга следуют заданному жизненному циклу (фиг. 2), который передается через индикатор состояния на каждом элементе рендеринга (например, «активировать», «деактивировать», «активный», «неактивный»). Это позволяет последующим каскадам рендеринга обновлять свои диаграммы DSP согласно вновь созданным или устаревшим элементам рендеринга. Безартефактовое плавное усиление и плавное ослабление элементов рендеринга при изменении состояния обрабатываются контроллером.
В оперативном применении, рабочий поток обработки инициируется обратным вызовом от аудио-оборудования. Когда запрашивается новый блок выборок, контроллер заполняет буферы элементов рендеринга, которые он поддерживает, входными выборками (например, с диска или из входящих аудиопотоков). Затем контроллер последовательно инициирует обработочную часть каскадов рендеринга, которые действуют на буферах аудиопотока согласно их текущим диаграммам обработки.
Конвейер рендеринга может содержать один или более преобразователей в пространственную область (фиг. 3), аналогичных каскаду рендеринга, но выходной сигнал их обработочной части является смешанным представлением всей виртуальной слуховой сцены, описанной окончательным списком элементов рендеринга, и может напрямую воспроизводиться согласно указанному способу воспроизведения (например, через стереофонические наушники или многоканальные акустические системы). Однако дополнительные каскады рендеринга могут следовать после преобразователя в пространственную область (например, для ограничения динамического диапазона выходного сигнала).
Преимущества предложенного решения
По сравнению с уровнем техники, конвейер рендеринга аудиосигнала, отвечающий изобретению, может гибко обрабатывать высокодинамичные сцены для адаптации обработки к разным аппаратным или пользовательским требованиям. В этом разделе перечислено несколько преимуществ над традиционными способами.
- новые аудио-элементы можно добавлять в виртуальную сцену и удалять из нее ненужные во время прогона.
Аналогичным образом, каскады рендеринга могут динамически регулировать уровень детализации их рендеринга на основании имеющихся вычислительных ресурсов и перцептивных требований.
- в зависимости от применения, каскады рендеринга можно переупорядочивать или новые каскады рендеринга можно вставлять в произвольных положениях в конвейере (например, каскад кластеризации или визуализации), не изменяя другие части программного обеспечения. Отдельные реализации каскада рендеринга можно изменять без необходимости изменять другие каскады рендеринга.
- множественные преобразователи в пространственную область могут совместно использовать общий конвейер обработки, позволяющий осуществлять рендеринг, например, на многопользовательских установках VR или с помощью наушников и, параллельно, громкоговорителей с минимальными вычислительными затратами.
- изменения в виртуальной сцене (например, обусловленные устройством высокочастотного отслеживания головы) накапливаются с динамически регулируемой частотой управления, снижая вычислительные затраты, например, для переключения фильтра. В то же время, обновления сцены, которые явно требуют атомарности (например, параллельное движение источников аудиосигнала) гарантированно выполняются одновременно по всем каскадам рендеринга.
- скорость управления и обработки можно регулировать по отдельности, на основании требований пользователя и оборудования (звуковоспроизведения).
Пример
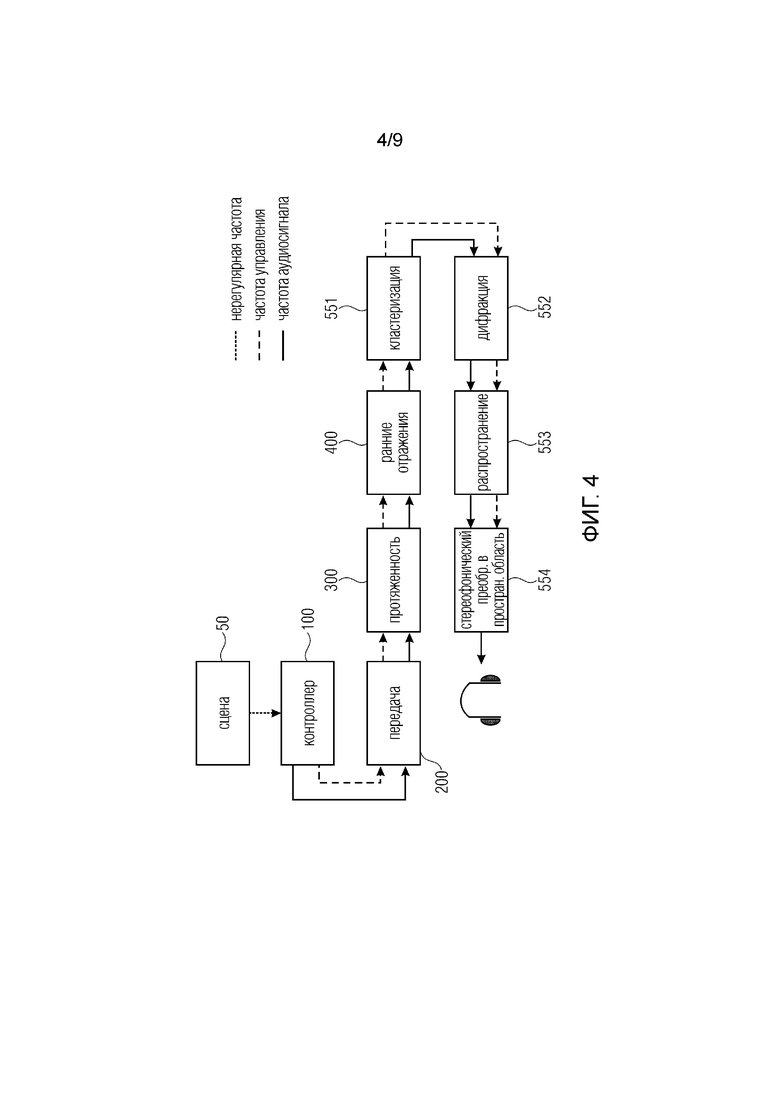
Практический пример конвейера рендеринга для создания виртуальных акустических окружений для приложений VR может содержать следующее каскады рендеринга в заданном порядке (см. также фиг. 4):
1. Передача: упрощение сложной сцены с множественными сопряженными подпространствами путем понижающего микширования сигналов и реверберирования отдаленных от слушателя частей с образованием единого элемента рендеринга (возможно с пространственной протяженностью).
Обработочная часть: понижающее микширование сигналов в объединенные буферы аудиопотока и обработка выборок аудиосигнала традиционными методами для создания поздней реверберации.
2. Протяженность: рендеринг перцептивного эффекта пространственно протяженных источников звука путем создания множественных, пространственно обособленных элементов рендеринга.
Обработочная часть: распределение входного аудиосигнала по нескольким буферам для новых элементов рендеринга (возможно, с дополнительной обработкой наподобие декорреляции).
3. Ранние отражения: включение перцепционно соответствующих геометрических отражений на поверхностях путем создания репрезентативных элементов рендеринга с соответствующей частотной коррекцией и метаданными положения.
Обработочная часть: распределение входного аудиосигнала по нескольким буферам для новых элементов рендеринга.
4. Кластеризация: объединение множественных элементов рендеринга с перцепционно неотличимыми положениями в единый элемент рендеринга для снижения вычислительной сложности последующих каскадов.
Обработочная часть: понижающее микширование сигналов в объединенные буферы аудиопотока.
5. Дифракция: добавление перцептивных эффектов заграждения и дифракции путей распространения за счет геометрии.
6. Распространение: рендеринг перцептивных эффектов на пути распространения (например, зависящих от направления характеристик излучения, поглощения в среде, задержки на распространение и т.д.)
Обработочная часть: фильтрация, линии дробной задержки и т.д.
7. Стереофонический преобразователь в пространственную область: рендеринг оставшихся элементов рендеринга в слушателецентричный стереофонический звуковой выход.
Обработочная часть: фильтрация HRIR, понижающее микширование и т.д.
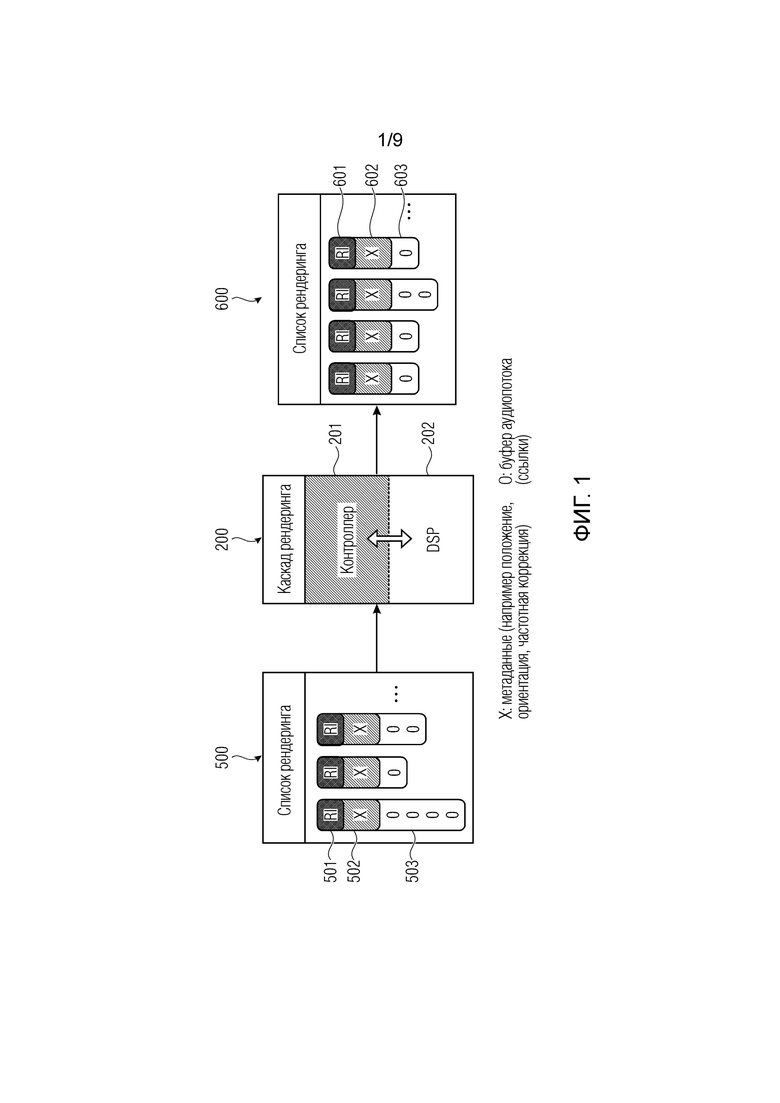
Далее на фиг. 1-4 описаны другими словами. Фиг. 1 иллюстрирует, например, первый каскад 200 конвейера также обозначается как «каскад рендеринга», который содержит слой 201 управления, указанный как «контроллер» на фиг. 1 и переконфигурируемый первый процессор 202 аудиоданных, указанный как “DSP” (цифровой сигнальный процессор). Однако каскад конвейера или каскад 200 рендеринга на фиг. 1 также может рассматриваться как второй каскад 300 конвейера на фиг. 1 или n-й каскад 400 конвейера на фиг. 5.
Каскад 200 конвейера принимает, в качестве входного сигнала через входной интерфейс, входной список 500 рендеринга и выводит, через выходной интерфейс, выходной список 600 рендеринга. В случае непосредственно последующего соединения второго каскада 300 конвейера на фиг. 5, входной список рендеринга для второго каскада 300 конвейера станет выходным списком 600 рендеринга первого каскада 200 конвейера, поскольку каскады конвейера последовательно соединены для потока конвейера.
Каждый список 500 рендеринга содержит выбор элементов рендеринга, проиллюстрированный столбцом во входном списке 500 рендеринга или выходном списке 600 рендеринга. Каждый элемент рендеринга содержит идентификатор 501 элемента рендеринга, метаданные 502 элемента рендеринга, указанные как “x” на фиг. 1, и один или более буферов аудиопотока в зависимости от того, сколько аудио-объектов или отдельных аудиопотоков принадлежит элементу рендеринга. Буферы аудиопотока обозначены “O” и предпочтительно реализованы посредством ссылок из памяти на фактические физические буферы в части текстовой памяти устройства для рендеринга звуковой сцены, которая, например, может управляться центральным контроллером или может управляться любым другим способом управления памятью. В качестве альтернативы, список рендеринга может содержать буферы аудиопотока, представляющие участки физической памяти, но предпочтительно реализовать буферы 503 аудиопотока как упомянутые ссылки на некоторую физическую память.
Аналогичным образом, выходной список 600 рендеринга, опять же, имеет один столбец для каждого элемента рендеринга, и соответствующий элемент рендеринга идентифицируется идентификацией 601 элемента рендеринга, соответствующими метаданными 602 и буферами 603 аудиопотока. Метаданные 502 или 602 для элементов рендеринга могут содержать положение источника, тип источника, частотный корректор, связанный с тем или иным источником или, в общем случае, частотно-избирательное поведение, связанное с тем или иным источником. Таким образом, каскад 200 конвейера принимает, в качестве входного сигнала, входной список 500 рендеринга и формирует в качестве выходного сигнала выходной список 600 рендеринга. В DSP 202, значения выборки аудиосигнала, идентифицированные соответствующими буферами аудиопотока, обрабатываются по мере необходимости соответствующей конфигурацией переконфигурируемого процессора 202 аудиоданных, например, как указано некоторой диаграммой обработки, сформированной слоем 201 управления для цифрового сигнального процессора 202. Поскольку входной список 500 рендеринга содержит, например, три элемента рендеринга, и выходной список 600 рендеринга содержит, например, четыре элемента рендеринга, т.е. больше элементов рендеринга, чем входной, каскад 202 конвейера может осуществлять, например, повышающее микширование. Другая реализация может, например, состоять в том, что первый элемент рендеринга с четырьмя аудиосигналами микшируется с понижением в элемент рендеринга с единым каналом. Второй элемент рендеринга может оставаться незатронутым обработкой, т.е. может, например, копироваться только от входа к выходу, и третий элемент рендеринга также может, например, оставаться незатронутым каскадом рендеринга. Только последний выходной элемент рендеринга в выходном списке 600 рендеринга не может формироваться DSP, например, путем объединения второго и третьего элементов рендеринга из входного списка 500 рендеринга в единый выходной аудиопоток для соответствующего буфера аудиопотока для четвертого элемента рендеринга выходного списка рендеринга.
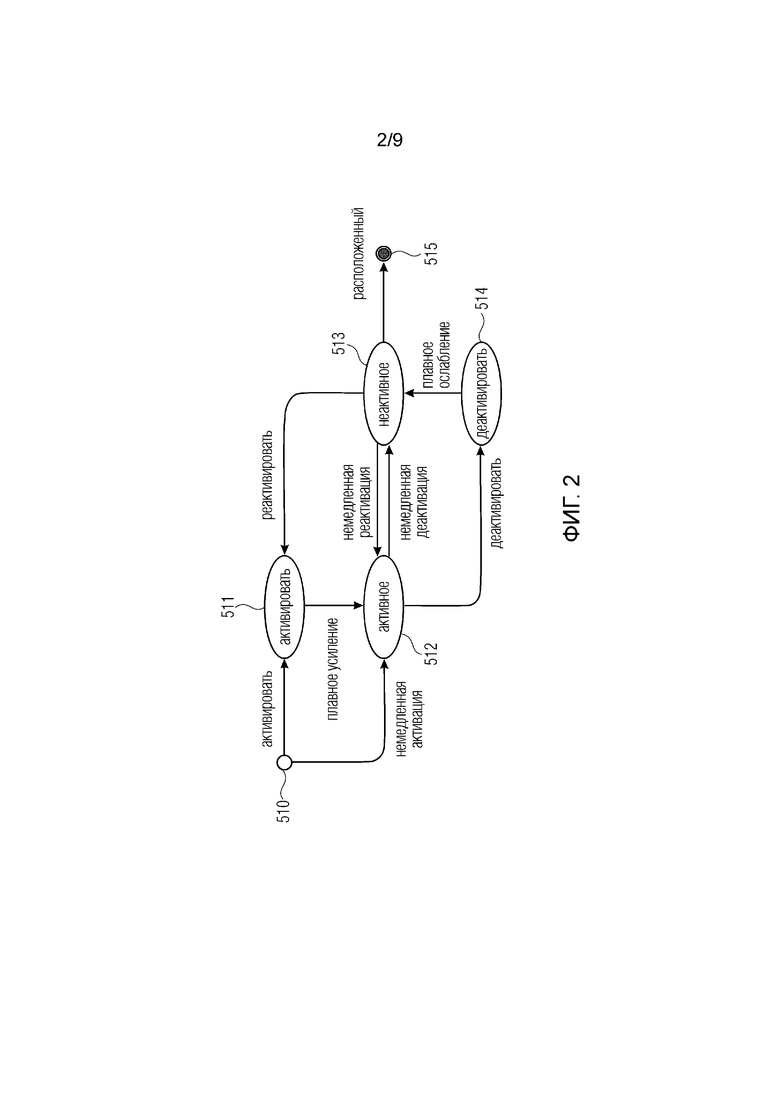
Фиг. 2 иллюстрирует диаграмму состояний для установления элемента рендеринга как «живой». Предпочтительно, чтобы соответствующее состояние диаграммы состояний также хранилось в метаданных 502 элемента рендеринга или в поле идентификации элемента рендеринга. В начальном узле 510 может осуществляться два разных способа активации. Один способ предусматривает нормальную активацию для перехода в состояние 511 активации. Другой способ предусматривает процедуру немедленной активации, чтобы сразу оказаться в активном состоянии 512. Различие между двумя процедурами состоит в том, что при переходе из состояния 511 активации в активное состояние 512 осуществляется процедура плавного усиления.
Если элемент рендеринга активен, он обрабатывается и и может либо немедленно деактивироваться, либо нормально деактивировали. В последнем случае, получается состояние 514 деактивации, и процедура плавного ослабления осуществляется для перехода из состояния 514 деактивации в неактивное состояние 513. В случае немедленной деактивации осуществляется прямой переход из состояния 512 в состояние 513. Из неактивного состояния возможно возвращение либо к немедленной реактивации, либо к инструкции реактивации, чтобы оказаться в состоянии 511 активации или, если не получена ни команда реактивации, ни команда немедленной реактивации, управление может переходить к расположенному выходному узлу 515.
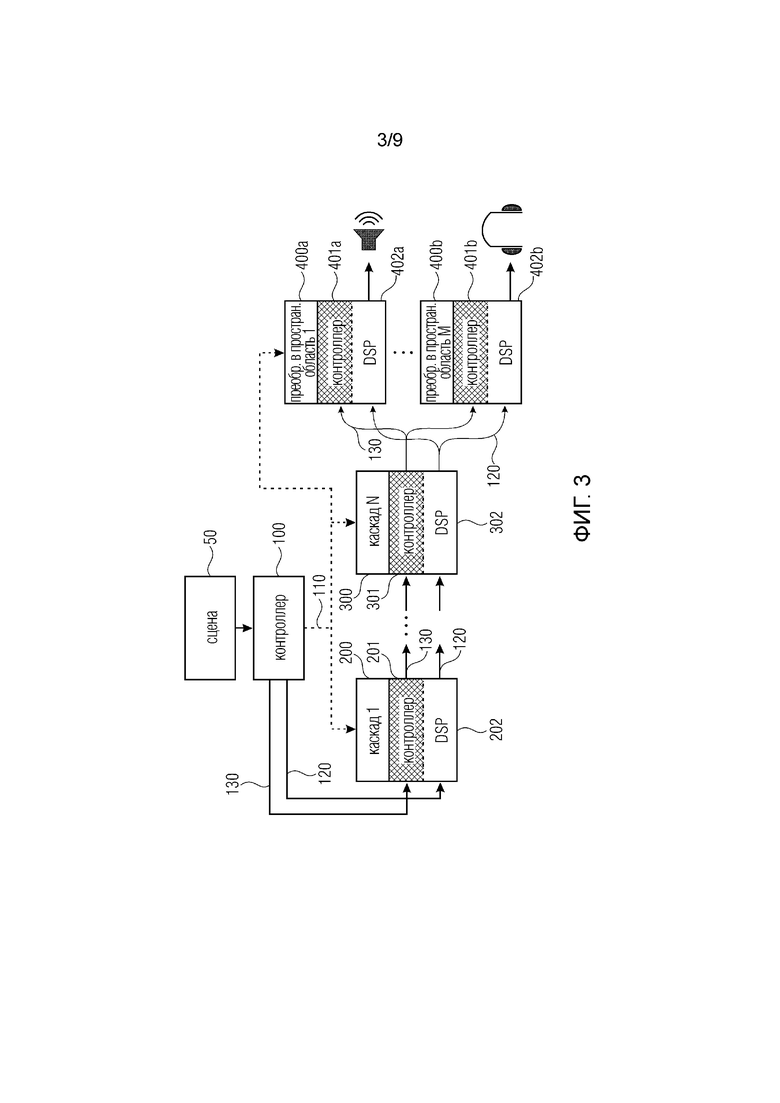
Фиг. 3 иллюстрирует обзор конвейера рендеринга, где аудиосцена проиллюстрирована в блоке 50, и где также проиллюстрированы отдельные потоки управления. Центральный поток управление переключением обозначен позицией 110. Рабочий поток 130 управления проиллюстрирован проходящим от контроллера 100 к первому каскаду 200 и оттуда, через соответствующую последовательную линию 120 рабочий поток управления. Таким образом, фиг. 3 иллюстрирует реализацию, где рабочий поток управления также поступает на начальный каскад конвейера и оттуда последовательно распространяется к последнему каскаду. Аналогичным образом, рабочий поток 120 обработки начинается от контроллера 120 через переконфигурируемые процессоры аудиоданных отдельных каскадов конвейера в оконечные каскады, где фиг. 3 иллюстрирует два оконечных каскада, каскад 400a вывода на громкоговоритель с преобразователем в пространственную область 1 или каскад 400b вывода на наушники с преобразователем в пространственную область M.
Фиг. 4 иллюстрирует конвейер рендеринга виртуальной реальности, имеющий представление 50 аудиосцены, контроллер 100 и, в качестве первого каскада конвейера, каскад 200 передачи конвейера. Второй каскад 300 конвейера реализуется как каскад протяженности рендеринга. Третий каскад 400 конвейера реализуется как каскад раннего отражения конвейера. Четвертый каскад конвейера реализуется как каскад 551 кластеризации конвейера. Пятый каскад конвейера реализуется как каскад 552 дифракции конвейера. Шестой каскад конвейера реализуется как каскад 553 распространения конвейера, и оконечный, седьмой, каскад 554 конвейера реализуется как стереофонический преобразователь в пространственную область для окончательного получения сигналов наушников для наушников, подлежащих ношению слушателем, ориентирующимся в аудиосцене виртуальной реальности или дополненной реальности.
Далее, на фиг. 6, 7 и 8 проиллюстрированы и рассмотрены для некоторые примеры конфигурирования и переконфигурирования каскадов конвейера.
Фиг. 6 иллюстрирует процедуру изменения метаданных для существующих элементов рендеринга.
Ситуация
Два объектных источника аудиосигнала представлены как два элемента рендеринга (RI). Каскад направленности отвечает за направленную фильтрацию сигнала источник звука. Каскад распространения отвечает за рендеринг задержки на распространение на основании расстояния до слушателя. Стереофонический преобразователь в пространственную область отвечает за стереофонию и понижающее микширование сцены до стереофонического сигнала.
На некотором этапе управления положением RI изменяется по сравнению с предыдущими этапами управления, что требует изменений в обработке DSP каждого отдельного каскада. Акустический сцена должна обновляться синхронно, чтобы, например, перцептивный эффект изменения расстояния синхронизировался с перцептивным эффектом изменения угла падения относительно слушателя.
Реализация
Список рендеринга распространяется через полный конвейер на каждом этапе управления. Во время выполнения этапа управления, параметры обработки DSP остаются постоянными для всех каскадов, пока последний каскад/преобразователь в пространственную область не обработает новый список рендеринга. После этого все каскады синхронно изменяют свои параметры DSP в начале следующего этапа DSP.
Каждый каскад отвечает за обновление параметров обработки DSP без заметных артефактов (например, плавный переход на выходе для обновлений фильтра FIR, линейную интерполяцию для линий задержки).
RI могут содержать поля для объединения метаданных. Таким образом, например, каскад направленности может не фильтровать сам сигнал, но может обновлять поле EQ в метаданных RI. Затем следующий каскад EQ применяет к сигналу объединенное поле EQ всех предыдущих каскадов.
Ключевые преимущества
- гарантированная атомарность изменений сцены (и по каскадам, и по RI)
- более крупные изменения конфигурации DSP не блокируют обработку аудиосигнала и синхронно выполняются по готовности всех каскадов /преобразователей в пространственную область
- при четко заданных сферах ответственности другие каскады конвейера не зависят от алгоритма, используемого для конкретной задачи (например, способа или даже доступности кластеризации)
- объединение метаданных позволяет многим каскадам (направленности, заграждения и т.д.) действовать только на этапе управления.
В частности, входной список рендеринга идентичен выходному списку 500 рендеринга в примере фиг. 6. В частности, список рендеринга имеет первый элемент 511 рендеринга и второй элемент 512 рендеринга, где каждый элемент рендеринга имеет единый буфер аудиопотока.
В первом каскаде 200 рендеринга или конвейера, который является каскадом направленности в этом примере, первый фильтр 211 FIR применяется к первому элементу рендеринга, и другой фильтр направленности или фильтр 212 FIR применяется ко второму элементу 512 рендеринга. Кроме того, во втором каскаде рендеринга или втором каскаде 33 конвейера, который в этом варианте осуществления является каскадом распространения, первая интерполяционная линия 311 задержки применяется к первому элементу 511 рендеринга, и вторая интерполяционная линия 312 задержки применяется ко второму элементу 512 рендеринга.
Кроме того, в третьем каскаде 400 конвейера, присоединенном после второго каскада 300 конвейера, для первого элемента 511 рендеринга используется первый стереофонический фильтр 411 FIR, и для второго элемента 512 рендеринга используется второй фильтр 412 FIR. В стереофоническом преобразователе в пространственную область, понижающее микширование двух выходных данных фильтра осуществляется на сумматоре 413 для получения стереофонического выходного сигнала. Таким образом, на основании двух объектных сигналов, указанных элементами 511, 512 рендеринга, на выходе сумматора 413 (не показан на фиг. 6) формируется стереофонический сигнал. Таким образом, как рассмотрено, все элементы 211, 212, 311, 312, 411, 412 изменяются в ответ на управление переключением в один и тот же некоторый момент времени под управлением слоя 201, 301, 401 управления. Фиг. 6 иллюстрирует ситуацию, где количество объектов, указанных в списке 500 рендеринга, остается неизменным, но метаданные для объектов изменяются вследствие изменения положения объекта. В качестве альтернативы, метаданные для объектов и, в частности, положение объекта остается неизменным, но, вследствие перемещения слушателя, соотношение между слушателем и соответствующим (фиксированным) объектом изменяется, приводя к изменениям фильтров 211, 212 FIR, и изменениям в линиях 311, 312 задержки, и изменениям фильтров 411, 412 FIR, которые, например, реализованы как фильтры передаточной функции, связанной с положением головы, которые изменяются с каждым изменением положения источника или объекта или положения слушателя, измеренной, например, модулем отслеживания головы.
Фиг. 7 иллюстрирует дополнительный пример, относящийся к сокращению элементов рендеринга (за счет кластеризации).
Ситуация
В сложной слуховой сцене, список рендеринга может содержать большое количество RI, перцепционно близких, т.е. различие в их положении неразличимо для слушателя. Для снижения вычислительной нагрузки для последующих каскадов, каскад кластеризации может заменять множественные отдельные RI единым репрезентативным RI.
На некотором этапе управления, конфигурация сцены может изменяться таким образом, что кластеризация больше не является перцепционно осуществимой. В этом случае, каскад кластеризации станет неактивным и будет пропускать список рендеринга без зменения.
Реализация
Когда некоторые входящие RI кластеризованы, первоначальные RI деактивируются в исходящем списке рендеринга. Сокращение является непрозрачным для последующих каскадах, и каскад кластеризации должен гарантировать, что, как только новый исходящий список рендеринга становится активным, пригодные выборки обеспечиваются в буферах, связанных с репрезентативным RI.
Когда кластер становится нереализуемым, новый исходящий список рендеринга каскада кластеризации содержит первоначальные, некластеризованные RI. Последующие каскады должны обрабатывать их по отдельности, начиная со следующего изменения параметров DSP (например, путем добавления нового фильтра FIR, линии задержки и т.д. к их диаграмме DSP).
Ключевые преимущества
- непрозрачное сокращение RI снижает вычислительную нагрузку для последующих каскадов без явного переконфигурирования
- вследствие атомарности изменения параметров DSP, каскады могут обрабатывать изменяющиеся количества входящих и исходящих RI без артефактов
На фиг. 7 показано, что входной список 500 рендеринга содержит 3 элемента 521, 522, 523 рендеринга, и выходной модуль 600 рендеринга содержит два элемента 623, 624 рендеринга.
Первый элемент 521 рендеринга поступает с выхода фильтра 221 FIR. Второй элемент 522 рендеринга формируется на выходе фильтра 222 FIR каскада направленности, и третий элемент 523 рендеринга получается на выходе фильтра 223 FIR первого каскада 200 конвейера, который является каскадом направленности. Следует отметить, что указание вывода элемента рендеринга из фильтра, это относится к выборкам аудиосигнала для буфера аудиопотока соответствующего элемента рендеринга.
В примере на фиг. 7, элемент 523 рендеринга остается независимым от состояния 300 кластеризации и становится выходным элементом 623 рендеринга. Однако элемент 521 рендеринга и элемент 522 рендеринга микшируются с понижением в микшированный с понижением элемент 324 рендеринга, который образуется в модуле 600 рендеринга в качестве выходного элемента 624 рендеринга. Понижающее микширование в каскаде 300 кластеризации указано местом 321 для первого элемента 521 рендеринга и местом 322 для второго элемента 522 рендеринга.
Опять же, третьим каскадом конвейера на фиг. 7 является стереофонический преобразователь 400 в пространственную область, и элемент 624 рендеринга обрабатывается первым стереофоническим фильтром 424 FIR, и элемент 623 рендеринга обрабатывается стереофоническим фильтром 423 FIR, и выходные сигналы обоих фильтров суммируются на сумматоре 413, давая стереофонический выходной сигнал.
Фиг. 8 иллюстрирует другой пример, демонстрирующий добавление новых элементов рендеринга (для ранних отражений).
Ситуация
В геометрической акустике комнаты может быть полезным моделирование отраженного звука как источников изображения (т.е. двух точечных источников с одним и тем же сигналом, положения которых симметричны относительно отражающей поверхности). Если конфигурация слушателя, источника и отражающей поверхности в сцене благоприятна для отражения, каскад ранних отражений добавляет в свой исходящий список рендеринга новый RI, который представляет источник изображения.
Слышимость источников изображения обычно быстро изменяется, когда слушатель движется. Каскад ранних отражений может активировать и деактивировать RI на каждом этапе управления, и последующие каскады должны соответственно регулировать свою обработку DSP.
Реализация
Каскады после каскада ранних отражений могут нормально обрабатывать отражение RI, поскольку каскад ранних отражений гарантирует, что соответствующий аудио-буфер содержит те же выборки, что и первоначальный RI. Таким образом, перцептивные эффекты наподобие задержки на распространение могут одинаково обрабатываться для первоначальных RI и отражений без явного переконфигурирования. Для повышения эффективности, когда статус активности RI изменяется часто, каскады могут сохранять необходимые артефакты DSP (например, экземпляры фильтра FIR) для повторного использования.
Каскады могут по-разному обрабатывать элементы рендеринга с некоторыми свойствами. Например, элемент рендеринга, созданный каскадом реверберации (изображенный элементом 532 на фиг. 8), может не обрабатываться каскадом ранних отражений и обрабатываться только преобразователем в пространственную область. Таким образом, элемент рендеринга может обеспечивать функциональность шины понижающее микширование. Аналогичным образом, каскад может обрабатывать элементы рендеринга, сформированные каскадом ранних отражений с помощью алгоритма DSP более низкого качество. поскольку они обычно менее акустически заметны.
Ключевые преимущества
- разные элементы рендеринга могут обрабатываться по-разному на основании их свойств
- каскад, который создает новые элементы рендеринга, может извлекать пользу из обработки последующих каскадов без явного переконфигурирования
Список 500 рендеринга содержит первый элемент 531 рендеринга и второй элемент 532 рендеринга. Каждый имеет единый буфер аудиопотока, который может переносить, например, моно- или стерео-сигнал.
Первый каскад 200 конвейера является каскадом реверберации, который имеет, например, сформированный элемент 531 рендеринга. Список 500 рендеринга дополнительно имеет элемент 532 рендеринга. В более раннем каскаде 300 отклонения, элемент 531 рендеринга и, в частности, его выборки аудиосигнала представлены входным сигналом 331 для операции копирования. Входной сигнал 331 операции копирования копируется в выходной буфер 331 аудиопотока, соответствующий буферу аудиопотока элемента 631 рендеринга выходного списка 600 рендеринга. Кроме того, другой скопированный аудио-объект 333 соответствует элементу 633 рендеринга. Кроме того, как указано, элемент 532 рендеринга входного списка 500 рендеринга просто копируется или подается на элемент 632 рендеринга выходного списка рендеринга.
Затем, в третьем каскаде конвейера, то есть, в вышеприведенном примере, стереофонический преобразователь в пространственную область, стереофонический фильтр 431 FIR применяется к первому элементу 631 рендеринга, стереофонический фильтр 433 FIR применяется ко второму элементу 633 рендеринга, и третий стереофонический фильтр 432 FIR применяется к третьему элементу 632 рендеринга. Затем соответственно суммируются вклады всех трех фильтров, т.е. поканально, сумматором 413, и сумматор 413 выводит левый сигнал с одной стороны и правый сигнал с другой стороны для наушников или, в общем случае, для стереофонического воспроизведения.
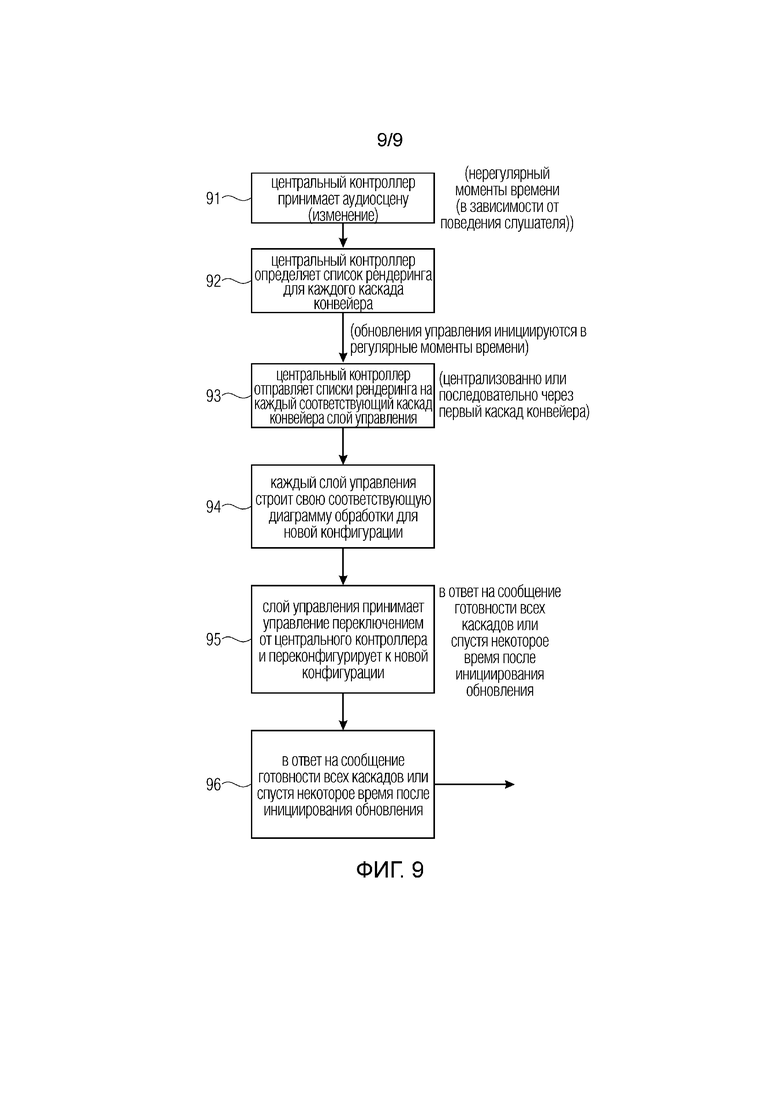
Фиг. 9 иллюстрирует обзор отдельных процедур управления от управления высокого уровня посредством интерфейса центрального контроллера аудиосцены до управления низкого уровня, осуществляемого слоем управления каскада конвейера.
В некоторые моменты, которые могут быть моментами времени, которые являются нерегулярными и зависят от поведения слушателя, которое, например, определяется модулем отслеживания головы, центральный контроллер принимает аудиосцену или изменение аудиосцены, как указано на этапе 91. На этапе 92 центральный контроллер определяет список рендеринга для каждого каскада конвейера под управлением центрального контроллера. В частности, обновления управления, которые затем отправляются от центрального контроллера на отдельные каскады конвейера, инициируются с регулярными интервалами, т.е. с некоторым/ой темпом обновления или частотой обновления.
Как показано на этапе 93, центральный контроллер отправляет отдельный список рендеринга на каждый слой управления конвейера соответствующего каскада. Это может осуществляться централизованно через инфраструктуру управления переключением, например, но предпочтительно осуществлять это последовательно через первый каскад конвейера и оттуда на следующий каскад конвейера и т.д., как указано линией 130 рабочего потока управления на фиг. 3. На дополнительном этапе 94, каждый слой управления строит свою соответствующую диаграмму обработки для новой конфигурации для соответствующего переконфигурируемого процессора аудиоданных, как показано на этапе 94. Старая конфигурация также указана как “первая конфигурация”, и новая конфигурация указана как “вторая конфигурация”.
На этапе 95 слой управления принимает управление переключением от центрального контроллера и переконфигурирует связанный с ним переконфигурируемый процессор аудиоданных к новой конфигурации. Этот прием управления переключением слоя управления на этапе 95 может происходить в ответ на прием сообщения готовности всех каскадов конвейера центральным контроллером или может осуществляться в ответ на отправку с центрального контроллера соответствующей инструкции управления переключением спустя некоторое время относительно инициирования обновления, что осуществляется на этапе 93. Затем, на этапе 96, слой управления соответствующего каскада конвейера заботится о плавном ослаблении элементов, которых не существуют в новой конфигурации, или заботится о плавном усилении новых элементов, которых не существуют в старой конфигурации. В случае некоторых объектов в старой конфигурации и новой конфигурации, и в случае изменений метаданных, например, относительно расстояния до источника или нового фильтра HRTF вследствие перемещения головы слушателя и т.д., плавный переход фильтров или плавный переход фильтрованных данных для плавного прихода с одного расстояния, например, до другого расстояния, также управляется слоем управления на этапе 96.
Фактическая обработка в новой конфигурации начинается через обратный вызов от аудио-оборудования. Таким образом, другими словами, рабочий поток обработки инициируется после переконфигурирования к новой конфигурации в предпочтительном варианте осуществления. Когда запрашивается новый блок выборок, центральный контроллер заполняет буферы аудиопотока элементов рендеринга, которые он поддерживает, входными выборками, например, с диска или из входящих аудиопотоков. Затем контроллер инициирует обработочную часть каскадов рендеринга, т.е. переконфигурируемые процессоры аудиоданных последовательно, и переконфигурируемые процессоры аудиоданных действуют на буферах аудиопотока согласно их текущей конфигурации, т.е. их текущим диаграммам обработки. Таким образом, центральный контроллер заполняет буферы аудиопотока первого каскада конвейера в устройстве для рендеринга звуковой сцены. Однако также возникает ситуация, где входные буферы других каскадов конвейера должны наполняться от центрального контроллера. Эта ситуация может, например, возникать, в отсутствие пространственно протяженных источников звука в более ранних ситуациях аудиосцены. Таким образом, в этой более ранней ситуации, каскад 300 на фиг. 4 отсутствует. Однако затем слушатель перемещается в некоторое место в виртуальной аудиосцене, где пространственно протяженный источник звука является видимым или подлежит рендеринга как пространственно протяженный источник звука, поскольку слушатель находится очень близко к этому источнику звука. Затем, в этот момент времени, для введения этого пространственно протяженного источника звука через блок 300, центральный контроллер 100 будет подавать, обычно через каскад 200 передачи, новый список рендеринга для каскада 300 протяженной рендеринга.
Список литературы
[1] Wenzel, E. M., Miller, J. D., and Abel, J. S. "Sound Lab: A real-time, software-based system for the study of spatial hearing." Audio Engineering Society Convention 108. Audio Engineering Society, 2000.
[2] Tsingos, N., Gallo, E., and Drettakis, G "Perceptual audio rendering of complex virtual environments." ACM Transactions on Graphics (TOG) 23.3 (2004): 249-258.
Изобретение относится к области вычислительной техники. Технический результат заключается в снижении артефактов звуковой сцены с динамически изменяющимися элементами в приложениях виртуальной реальности или дополненной реальности. Технический результат достигается за счёт того, что центральный контроллер управляет слоями управления каскадов конвейера таким образом, что первый слой управления или второй слой управления подготавливает другую конфигурацию, например вторую конфигурацию первого или второго процессора аудиоданных во время или после операции процессора аудиоданных в первой конфигурации. Новая конфигурация для первого или второго процессора аудиоданных подготавливается, пока процессор аудиоданных, принадлежащий этому каскаду конвейера, все еще оперирует в соответствии с другой конфигурацией или выполнен в другой конфигурации, в случае, если задача обработки с более ранней конфигурацией уже выполнена. Центральный контроллер управляет первым и вторым слоями управления с использованием управления переключением для переконфигурирования первого процессора аудиоданных или второго процессора аудиоданных в еще одну конфигурацию в некоторый момент времени. 2 н. и 19 з.п. ф-лы, 9 ил.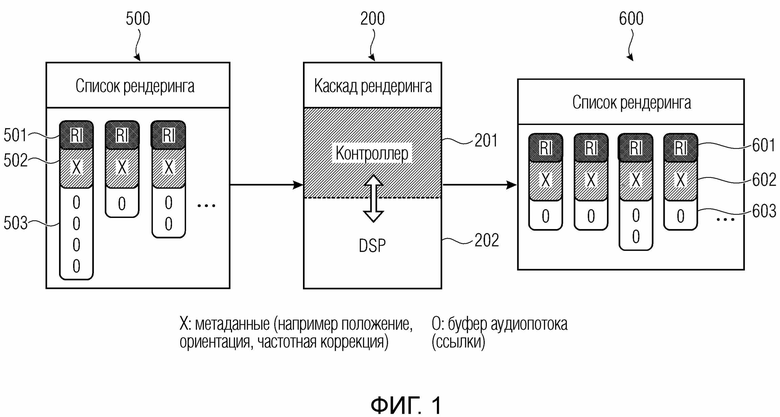
1. Устройство для рендеринга звуковой сцены (50), содержащее:
первый каскад (200) конвейера, содержащий первый слой (201) управления и переконфигурируемый первый процессор (202) аудиоданных, причем переконфигурируемый первый процессор (202) аудиоданных выполнен с возможностью работы в соответствии с первой конфигурацией переконфигурируемого первого процессора (202) аудиоданных;
второй каскад (300) конвейера, расположенный относительно потока конвейера после первого каскада (200) конвейера, причем второй каскад (300) конвейера содержит второй слой (301) управления и переконфигурируемый второй процессор (302) аудиоданных, причем переконфигурируемый второй процессор (302) аудиоданных выполнен с возможностью работы в соответствии с первой конфигурацией переконфигурируемого второго процессора (302) аудиоданных; и
центральный контроллер (100) для управления первым слоем (201) управления и вторым слоем (301) управления в ответ на звуковую сцену (50), таким образом, что первый слой (201) управления подготавливает вторую конфигурацию переконфигурируемого первого процессора (202) аудиоданных во время или после операции переконфигурируемого первого процессора (202) аудиоданных в первой конфигурации переконфигурируемого первого процессора (202) аудиоданных, или таким образом, что второй слой (301) управления подготавливает вторую конфигурацию переконфигурируемого второго процессора (302) аудиоданных во время или после операции переконфигурируемого второго процессора (302) аудиоданных в первой конфигурации переконфигурируемого второго процессора (302) аудиоданных, и
в котором центральный контроллер (100) выполнен с возможностью управления первым слоем (201) управления или вторым слоем (301) управления с использованием управления (110) переключением для переконфигурирования переконфигурируемого первого процессора (202) аудиоданных во вторую конфигурацию для переконфигурируемого первого процессора (202) аудиоданных или для переконфигурирования переконфигурируемого второго процессора (302) аудиоданных во вторую конфигурацию для переконфигурируемого второго процессора (302) аудиоданных в некоторый момент времени.
2. Устройство по п. 1, в котором центральный контроллер (100) выполнен с возможностью управления первым слоем (201) управления для подготовки второй конфигурации переконфигурируемого первого процессора (202) аудиоданных во время операции переконфигурируемого первого процессора (202) аудиоданных в первой конфигурации переконфигурируемого первого процессора (202) аудиоданных, и
управления вторым слоем (301) управления для подготовки второй конфигурации переконфигурируемого второго процессора (302) аудиоданных во время операции переконфигурируемого второго процессора (302) аудиоданных в первой конфигурации переконфигурируемого второго процессора (302) аудиоданных, и
управления первым слоем (201) управления и вторым слоем (301) управления с использованием управления (110) переключением для переконфигурирования переконфигурируемого первого процессора (202) аудиоданных во вторую конфигурацию для переконфигурируемого первого процессора (202) аудиоданных и для переконфигурирования переконфигурируемого второго процессора (302) аудиоданных во вторую конфигурацию для переконфигурируемого второго процессора (302) аудиоданных в некоторый момент времени.
3. Устройство по п. 1 или 2, в котором первый каскад (200) конвейера или второй каскад (300) конвейера содержит входной интерфейс, выполненный с возможностью приема входного списка (500) рендеринга, причем входной список рендеринга содержит входной список элементов (501) рендеринга, метаданные (502) для каждого элемента рендеринга и буфер (503) аудиопотока для каждого элемента рендеринга,
причём по меньшей мере первый каскад (200) конвейера содержит выходной интерфейс, выполненный с возможностью вывода выходного списка (600) рендеринга, где выходной список рендеринга содержит выходной список элементов (601) рендеринга, метаданные (602) для каждого элемента рендеринга и буфер (603) аудиопотока для каждого элемента рендеринга, и
причем, когда второй каскад (300) конвейера соединен с первым каскадом (200) конвейера, выходной список рендеринга первого каскада (200) конвейера является входным списком рендеринга для второго каскада (300) конвейера.
4. Устройство по п. 3, в котором первый каскад (200) конвейера выполнен с возможностью записи выборок аудиосигнала в соответствующий буфер (603) аудиопотока, указанный в выходном списке (600) элементов рендеринга, таким образом, что второй каскад (300) конвейера, следующий за первым каскадом (200) конвейера, способен извлекать выборки аудиопотока из соответствующего буфера (603) аудиопотока со скоростью рабочего потока обработки.
5. Устройство по любому из предыдущих пунктов, в котором центральный контроллер (100) выполнен с возможностью подачи входного или выходного списка (500, 600) рендеринга на первый или второй каскад (300) конвейера, причем первая или вторая конфигурация переконфигурируемого первого или второго процессора (202, 302) аудиоданных содержит диаграмму обработки, причем первый или второй слой (201, 301) управления выполнен с возможностью создания диаграммы обработки для второй конфигурации из входного или выходного списка (500, 600) рендеринга, принятого от центрального контроллера (100) или из предыдущего каскада конвейера,
причем диаграмма обработки содержит ступени процессора аудиоданных и ссылки на входной и выходной буферы соответствующего первого или второго переконфигурируемого процессора аудиоданных.
6. Устройство по п. 5, в котором центральный контроллер (100) выполнен с возможностью подачи дополнительных данных, необходимых для создания диаграммы обработки, на первый или второй каскад (200, 300) конвейера, причем дополнительные данные не включены во входной список (500) рендеринга или выходной список (600) рендеринга.
7. Устройство по любому из предыдущих пунктов, в котором центральный контроллер (100) выполнен с возможностью приема изменений звуковой сцены (50) через интерфейс звуковой сцены в момент изменения звуковой сцены,
причем центральный контроллер (100) выполнен с возможностью формирования первого списка рендеринга для первого каскада (200) конвейера и второго списка рендеринга для второго каскада (300) конвейера в ответ на изменение звуковой сцены и на основании текущей звуковой сцены, заданной изменением звуковой сцены, и при этом центральный контроллер (100) выполнен с возможностью отправки первого списка рендеринга в первый слой (201) управления и второго, центрального, списка рендеринга во второй слой (301) управления после момента времени изменения звуковой сцены.
8. Устройство по п. 7,
в котором первый слой (201) управления выполнен с возможностью вычисления второй конфигурации первого переконфигурируемого процессора (202) аудиоданных из первого списка рендеринга после момента времени изменения звуковой сцены и
второй слой (301) управления выполнен с возможностью вычисления второй конфигурации второго переконфигурируемого процессора (302) аудиоданных из второго списка рендеринга, и
при этом центральный контроллер (100) выполнен с возможностью инициирования управления (110) переключением одновременно для первого и второго каскадов (200, 300) конвейера.
9. Устройство по любому из предыдущих пунктов, в котором центральный контроллер (100) выполнен с возможностью использования управления (110) переключением безотносительно к операции вычисления выборок аудиосигнала, осуществляемой первым и вторым переконфигурируемыми процессорами (202, 302) аудиоданных.
10. Устройство по любому из предыдущих пунктов,
в котором центральный контроллер (100) выполнен с возможностью приема (91) изменений аудиосцены (50) в моменты времени изменения, имеющие нерегулярную частоту,
центральный контроллер (100) выполнен с возможностью подачи (93) инструкций управления в первый и второй слои (201, 301) управления с регулярной частотой управления, и
причем переконфигурируемые первый и второй процессоры (203, 302) аудиоданных оперируют на частоте аудиоблоков, вычисляя выходные выборки аудиосигнала из входных выборок аудиосигнала, принятых из входного буфера переконфигурируемого первого или второго процессора аудиоданных, причем выходные выборки сохраняются в выходном буфере переконфигурируемого первого или второго процессора аудиоданных, причем частота управления ниже частоты аудиоблоков.
11. Устройство по любому из предыдущих пунктов,
в котором центральный контроллер (100) выполнен с возможностью инициирования управления (110) переключением в некоторый период времени после управления первым и вторым слоями (201, 202) управления для подготовки второй конфигурации или в ответ на сигнал готовности, принятый от первого и второго каскадов (200, 300) конвейера, указывающий, что первый и второй каскады (200, 300) конвейера готовы к переходу к соответствующей второй конфигурации.
12. Устройство по любому из предыдущих пунктов,
в котором первый или второй каскад (200, 300) конвейера выполнен с возможностью создания списка (600) выходных элементов рендеринга из списка (500) входных элементов рендеринга,
причем создание содержит изменение метаданных для элементов рендеринга из входного списка и запись измененных метаданных в выходном списке или
содержит вычисление выходных аудиоданных для элементов рендеринга с использованием входных аудиоданных, извлеченных из буфера входного потока входного списка рендеринга, и запись выходных аудиоданных в буфер выходного потока выходного списка (600) рендеринга.
13. Устройство по любому из предыдущих пунктов,
в котором первый или второй слой (201, 301) управления выполнен с возможностью управления первым или вторым переконфигурируемым процессором аудиоданных для плавного усиления нового элемента рендеринга, подлежащего обработке после управления (110) переключением или для плавного ослабления старого элемента рендеринга, больше не существующего после управления (110) переключением, но существовавший до управления (110) переключением.
14. Устройство по любому из предыдущих пунктов,
в котором каждый элемент рендеринга из списка элементов рендеринга включает в себя, во входном списке или выходном списке первого или второго каскада рендеринга, индикатор состояния, указывающий по меньшей мере одно из следующих состояний: рендеринг активен, рендеринг подлежит активации, рендеринг неактивен, рендеринг подлежит деактивации.
15. Устройство по любому из предыдущих пунктов,
в котором центральный контроллер (100) выполнен с возможностью заполнения, в ответ на запрос от первого или второго каскада рендеринга, входных буферов элементов рендеринга, поддерживаемых центральным контроллером (100), новыми выборками и
центральный контроллер (100) выполнен с возможностью последовательного инициирования переконфигурируемых первого и второго процессоров (202, 302) аудиоданных таким образом, что конфигурируемые первый и второй процессоры (202, 302) аудиоданных действуют на соответствующих входных буферах элементов рендеринга в соответствии с первой или второй конфигурацией в зависимости от того, какая конфигурация на данный момент активна.
16. Устройство по любому из предыдущих пунктов,
в котором второй каскад (300) конвейера является каскадом преобразования в пространственную область, который обеспечивает, в качестве выходного сигнала, канальное представление для воспроизведения через наушники или акустическую систему.
17. Устройство по любому из предыдущих пунктов,
в котором первый и второй каскады (200, 300) конвейера содержат по меньшей мере одну из следующих групп каскадов:
каскад (200) передачи, каскад (300) протяженности, каскад (400) раннего отражения, каскад (551) кластеризации, каскад (552) дифракции, каскад (553) распространения, каскад (554) преобразования в пространственную область, каскад ограничителя и каскад визуализации.
18. Устройство по любому из предыдущих пунктов,
в котором первый каскад (200) конвейера является каскадом (200) направленности для одного или более элементов рендеринга, и в котором второй каскад (300) конвейера является каскадом (300) распространения для одного или более элементов рендеринга,
центральный контроллер (100) выполнен с возможностью приема изменений аудиосцены (50), указывающих, что один или более элементов рендеринга имеет одно или более новых положений,
центральный контроллер (100) выполнен с возможностью управления первым слоем (201) управления и вторым слоем (301) управления для адаптации настроек фильтра для первого и второго переконфигурируемых процессоров аудиоданных к одному или более новым положениям, и
первый слой (201) управления и второй слой (301) управления выполнены с возможностью перехода во вторую конфигурацию в некоторый момент времени, причем, при переходе во вторую конфигурацию, операция плавного перехода из первой конфигурации во вторую конфигурацию осуществляется в переконфигурируемом первом или втором процессоре (202, 302) аудиоданных.
19. Устройство по любому из пп. 1-17, в котором первый каскад (200) конвейера является каскадом (200) направленности и второй каскад (300) конвейера является каскадом кластеризации (300),
центральный контроллер (100) выполнен с возможностью приема изменений аудиосцены (50), указывающих, что кластеризация элементов рендеринга подлежит остановке, и
центральный контроллер (100) выполнен с возможностью управления первым слоем (201) управления для деактивации переконфигурируемого процессора аудиоданных каскада кластеризации и копирования входного списка элементов рендеринга в выходной список элементов рендеринга второго каскада (300) конвейера.
20. Устройство по любому из пп. 1-17,
в котором первый каскад (200) конвейера является каскадом реверберации и второй каскад (300) конвейера является каскадом ранних отражений,
центральный контроллер (100) выполнен с возможностью приема изменений аудиосцены (50), указывающих, что необходимо добавить дополнительный источник изображения, и
центральный контроллер (100) выполнен с возможностью управления слоем управления второго каскада (300) конвейера для умножения элемента рендеринга из входного списка рендеринга для получения умноженного элемент (333) рендеринга и для суммирования умноженного элемента (333) рендеринга с выходным списком рендеринга второго каскада (300) конвейера.
21. Способ рендеринга звуковой сцены (50) с использованием устройства, содержащего первый каскад (200) конвейера, содержащий первый слой (201) управления и переконфигурируемый первый процессор (202) аудиоданных, причем переконфигурируемый первый процессор (202) аудиоданных выполнен с возможностью работы в соответствии с первой конфигурацией переконфигурируемого первого процессора (202) аудиоданных; второй каскад (300) конвейера, расположенный, относительно потока конвейера, после первого каскада (200) конвейера, причем второй каскад (300) конвейера содержит второй слой (301) управления и переконфигурируемый второй процессор (302) аудиоданных, причем переконфигурируемый второй процессор (302) аудиоданных выполнен с возможностью работы в соответствии с первой конфигурацией переконфигурируемого второго процессора (302) аудиоданных, содержащий этапы, на которых:
управляют первым слоем (201) управления и вторым слоем (301) управления в ответ на звуковую сцену (50) таким образом, что первый слой (201) управления подготавливает вторую конфигурацию переконфигурируемого первого процессора (202) аудиоданных во время или после операции переконфигурируемого первого процессора (202) аудиоданных в первой конфигурации переконфигурируемого первого процессора (202) аудиоданных, или таким образом, что второй слой (301) управления подготавливает вторую конфигурацию переконфигурируемого второго процессора (302) аудиоданных во время или после операции переконфигурируемого второго процессора (302) аудиоданных в первой конфигурации переконфигурируемого второго процессора (302) аудиоданных, и
управляют первым слоем (201) управления или вторым слоем (301) управления с использованием управления (110) переключением для переконфигурирования переконфигурируемого первого процессора (202) аудиоданных во вторую конфигурацию для переконфигурируемого первого процессора (202) аудиоданных или для переконфигурирования переконфигурируемого второго процессора (302) аудиоданных во вторую конфигурацию для переконфигурируемого второго процессора (302) аудиоданных в некоторый момент времени.
| EP 3090573 A1, 09.11.2016 | |||
| РЕНДЕРИНГ ОТРАЖЕННОГО ЗВУКА ДЛЯ ОБЪЕКТНО-ОРИЕНТИРОВАННОЙ АУДИОИНФОРМАЦИИ | 2013 |
|
RU2602346C2 |
| US 8488796 B2, 16.07.2013 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ РЕНДЕРИНГА ЗВУКОВОГО СИГНАЛА И КОМПЬЮТЕРНО-ЧИТАЕМЫЙ НОСИТЕЛЬ ИНФОРМАЦИИ | 2018 |
|
RU2698775C1 |
| KR 20170125660 A, 15.11.2017. | |||
