Настоящее изобретение относится к способу получения рекомбинантного полипептида, представляющего интерес, в микробной клетке-хозяине, включающему (a) введение полинуклеотида, кодирующего полипептид, представляющий интерес, в микробную клетку-хозяина, которая была модифицирована таким образом, что ферментативная активность, выбранная из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19), модулируется (например повышается) в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине, и (b) экспрессию указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине. Более того, настоящее изобретение относится к способу снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, экспрессируемый в микробной клетке-хозяине. В настоящем изобретении дополнительно предусмотрены микробная клетка-хозяин, содержащая (a) рекомбинантный полинуклеотид, кодирующий полипептид, представляющий интерес, и (b) рекомбинантный полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Экспрессия рекомбинантных белков в микробных хозяевах, таких как Escherichia coli (E. coli), стала стандартной методикой для изготовления рекомбинантных терапевтических белков, таких как инсулин. Сегодня множество биофармацевтических продуктов, полученных с помощью микробных клеток, таких как E. coli,, имеются в продаже.
Однако сверхэкспрессия рекомбинантных белков известна тем, что она вызывает стресс для микробного хозяина, часто приводя к неправильному сворачиванию белков или включению нежелательных аминокислот. Измененные белки могут демонстрировать нежелательные свойства, такие как модифицированная биологическая активность, повышенная чувствительность к протеолизу или иммуногенность. В частности, ошибочное включение аминокислот в рекомбинантные белки является проблемой, так как фармацевтические продукты, такие как рекомбинантный инсулин, должны быть гомогенными и чистыми. В результате, рекомбинантные белки, содержащие ошибочно включенные аминокислоты, должны быть удалены из продукта.
Аминокислоты с разветвленной цепью (BCAA) являются аминокислотами с нелинейной молекулярной структурой. BCAA содержат алифатические боковые цепи с разветвлением, т. е. центральный атом углерода связан с тремя или более атомами углерода. Лейцин, изолейцин и валин являются так называемыми протеиногенными или каноническими BCAA. Кроме канонических BCAA существуют также неканонические или непротеиногенные BCAA. Такими неканоническими BCAA (ncBCAA) являются норлейцин, норвалин, гомоизолейцин и β-метилнорлейцин.
Сообщалось, что неканонические аминокислоты с разветвленной цепью (ncBCAA),такие как норлейцин и норвалин, соответственно ошибочно включались вместо лейцина и метионина в рекомбинантные белки, экспрессируемые в E. coli (Apostol I. et al., 1997, Incorporation of norvaline at leucine positions in recombinant human hemoglobin expressed in Escherichia coli. Journal of Biological Chemistry 272.46: 28980-28988; Tsai et al., (1988), Control of misincorporation of de novo synthesized norleucine into recombinant interleukin-2 in E. coli. Biochemical and biophysical research communications 156(2):733-739). Синтез и накопление ncBCAA являются результатом низкой специфичности кодируемых оперонами leu и ilv ферментов, участвующих в пути биосинтеза BCAA для α-кетокислот. Несколько исследований продемонстрировали, что ферменты пути биосинтеза лейцина, кодируемые опероном leuABCD, являются необходимыми для получения неканонических аминокислот с разветвленной цепью, таких как норлейцин. В каноническом механизме ферменты пути биосинтеза лейцина превращают α-кетоизовалерат в α-кетоизокапроат; что означает, что они обусловливают добавление одного атома углерода к α-кетокислоте с пятью атомами углерода. Более того, для пути биосинтеза лейцина также показан довольно широкий спектр специфичности, и ферменты этого пути способны действовать на множество α-кетокислот. Например, ферменты пути биосинтеза лейцина способны также превращать α-кетовалерат в α-кетокапроат, который является предшественником норлейцина.
Ошибочное включение неканонических аминокислот с разветвленной цепью (ncBCAA) в образующиеся рекомбинантные белки происходит вследствие неразборчивости аминоацил-тРНК-синтетаз (aaRS). Точность синтеза белка зависит от способности aaRS присоединять соответствующую каноническую аминокислоту к соответствующей ей тРНК (например, обзор Reitz et al., 2018, Synthesis of non-canonical branched-chain amino acids in Escherichia coli and approaches to avoid their incorporation into recombinant proteins, Curr Opin Biotechnol. Oct;53:248-253). Такая точность может быть нарушена рядом неканонических аминокислот, в частности ncBCAA, которые по структуре подобны их каноническим эквивалентам (Martinis SA, Fox GE. Non-standard amino acid recognition by Escherichia coli leucyl-tRNA synthetase. Nucleic Acids Symp Ser. 1997;36:125-128). Например, лейцил-тРНК-синтаза (leuRS) должна отличить лейцин от его неканонического эквивалента норвалина, который отличается лишь одной метильной группой (Apostol, I., et al.,1997, Incorporation of norvaline at leucine positions in recombinant human hemoglobin expressed in Escherichia coli. Journal of Biological Chemistry, 272(46), 28980-28988.). То же самое верно для метионил-тРНК-синтетазы (metRS), которая должна различать метионин и норлейцин (Kiick, K. L., et al.., 2001, Identification of an expanded set of translationally active methionine analogues in Escherichia coli. FEBS Letters, 502(1-2), 25-30.), и изолейцил-тРНК-синтетазы (ileRS), которая должна различать изолейцин и β-метилнорлейцин (Muramatsu, R., et al., 2003,. Finding of an isoleucine derivative of a recombinant protein for pharmaceutical use. Journal of pharmaceutical and biomedical analysis, 31(5), 979-987.). Например, если E. coli выращивается в среде с минеральными солями, и метионин является лимитирующим фактором, норлейцин может подвергаться ацилированию на метионил-переносящую транспортную РНК и впоследствии становиться включенным в рекомбинантный белок в тех участках, где транслируются кодоны метионина.
Хотя различные системы экспрессии для получения рекомбинантных белков являются доступными, и сообщалось об адаптации условий культивирования для улучшения получения рекомбинантного белка, проблема потенциальной перегрузки метаболизма и неправильного включения нежелательных аминокислот в рекомбинантный белок, представляющий интерес, все еще не решена.
Условия, при которых происходит ошибочное включение неканонических аминокислот с разветвленной цепью в гетерологичные рекомбинантные белки, и то, как можно эффективно предотвратить такие события ошибочного включения, не полностью понятны. Способ получения рекомбинантных полипептидов без ошибочного включения неканонических аминокислот с разветвленной цепью был бы, следовательно, крайне желателен.
Техническая проблема, лежащая в основе настоящего изобретения, может рассматриваться как обеспечение средств и способов для удовлетворения вышеупомянутых потребностей. Техническая проблема решается с помощью вариантов осуществления, охарактеризованных в формуле изобретения и в данном документе.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к способу получения рекомбинантного полипептида, представляющего интерес, в микробной клетке-хозяине, включающему стадии
(a) введения полинуклеотида, кодирующего полипептид, представляющий интерес, в микробную клетку-хозяина, которая была модифицирована таким образом, что ферментативная активность, выбранная из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19), модулируется (например повышается) в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине, и
(b) экспрессии указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
Настоящее изобретение дополнительно относится к способу снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, экспрессируемый в микробной клетке-хозяине, при этом указанный способ включает
(a) модулирование (в частности, повышение) ферментативной активности, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19), в микробной клетке-хозяине,
(b) введение полинуклеотида, кодирующего полипептид, представляющий интерес, в указанную микробную клетку-хозяина, и
(c) экспрессию указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
Дополнительно в настоящем изобретении предусмотрена микробная клетка-хозяин, содержащая:
(a) рекомбинантный полинуклеотид, кодирующий полипептид, представляющий интерес, и
(b) рекомбинантный полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19).
Дополнительно в настоящем изобретении предусмотрен биореактор, содержащий микробную клетку-хозяина по настоящему изобретению. В некоторых вариантах осуществления биореактор имеет объем, составляющий по меньшей мере 10 л.
Более того, настоящее изобретение относится к применению полипептида, обладающего ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19), или полинуклеотида, кодирующего указанный полипептид, для снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, продуцируемый в микробной клетке-хозяине.
В конечном итоге, настоящее изобретение относится к применению микробной клетки-хозяина для получения рекомбинантного полипептида, представляющего интерес, где микробная клетка-хозяин была модифицирована таким образом, что ферментативная активность, выбранная из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19), модулируется в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине.
В одном варианте осуществления способа, применения или микробной клетки-хозяина по настоящему изобретению микробная клетка-хозяин не экспрессирует эндогенный полипептид, обладающий указанной ферментативной активностью. Соответственно, эндогенный, т. е. встречающийся в природе полинуклеотид, кодирующий полипептид, обладающий указанной ферментативной активностью, был удален, т. е. нокаутирован в микробной клетке-хозяине.
В одном варианте осуществления способа, применения или микробной клетки-хозяина по настоящему изобретению полипептид, представляющий интерес, является терапевтическим полипептидом, таким как проинсулин, инсулин или аналог инсулина.
В одном варианте осуществления способа, применения или микробной клетки-хозяина по настоящему изобретению полинуклеотид, кодирующий полипептид, представляющий интерес, и/или полинуклеотид кодирующий полипептид, обладающий указанной ферментативной активностью, функционально связан с индуцируемым промотором.
В одном варианте осуществления способа, применения или микробной клетки-хозяина по настоящему изобретению микробной клеткой-хозяином является клетка Escherichia coli.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Как указано выше, настоящее изобретение относится к способу получения рекомбинантного полипептида, представляющего интерес, в микробной клетке-хозяине. Способ включает (a) введение полинуклеотида, кодирующего полипептид, представляющий интерес, в микробную клетку-хозяина, которая была модифицирована таким образом, что ферментативная активность, как изложено в данном документе, является модулированной в указанной микробной клетке-хозяине по сравнению с ферментативной активностью немодифицированной микробной клетки-хозяина, и (b) экспрессию указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
В соответствии с настоящим изобретением рекомбинантный полипептид, представляющий интерес, будет продуцироваться в микробной клетке-хозяине. Термин "рекомбинантный полипептид", применяемый в данном документе, относится к генетически сконструированному полипептиду. Соответственно, полипептид, который будет продуцироваться, будет гетерологичным по отношению к микробной клетке-хозяину, что означает, что клетка-хозяин в естественных условиях не экспрессирует полипептид, представляющий интерес. Термин "гетерологичный", таким образом, означает, что полинуклеотид/полипептид не встречается в естественных условиях в микробной клетке-хозяине.
В предпочтительном варианте осуществления настоящего изобретения рекомбинантный полипептид, представляющий интерес, который будет продуцироваться, является терапевтическим полипептидом.
В частности предусмотрено, что рекомбинантный полипептид, представляющий интерес, является антителом или его антигенсвязывающим фрагментом, ферментом, рецептором, секретируемым белком, слитым белком или гормоном, в частности пептидным гормоном (таким как инсулин или его предшественник, такой как проинсулин).
В предпочтительном варианте осуществления, рекомбинантный полипептид, представляющий интерес, является антителом или его антиген-связывающим фрагментом. Антитело предпочтительно выбрано из полиспецифического антитела, человеческого антитела, гуманизированного антитела, химерного антитела и одноцепочечного антитела. Предпочтительно антигенсвязывающий фрагмент антитела выбран из группы, состоящей из Fab-фрагмента, Fab'-фрагмента, F(ab')2-фрагмента, scFv-фрагмента и Fv-фрагмента. Например, антигенсвязывающий фрагмент представляет собой F(ab')2-фрагмент.
В другом предпочтительном варианте осуществления рекомбинантный полипептид, представляющий интерес, представляет собой проинсулин или инсулин. Инсулин является пептидным гормоном, который естественных условиях секретируется островками Лангерганса и участвует в регуляции метаболизма углеводов и жиров, в частности превращения глюкозы в гликоген. Инсулин может представлять собой встречающийся в природе инсулин, в частности человеческий инсулин, или аналог встречающегося в природе инсулина, в частности аналог человеческого инсулина. Соответственно термин "инсулин" охватывает встречающиеся в природе формы инсулина и их аналоги. Аналог инсулина является измененной формой инсулина, отличной от любой встречающейся в природе, но все же доступной организму человека для выполнения той же функции, что и человеческий инсулин, в терминах гликемического контроля. Предпочтительно аналог инсулина выбран из инсулина лизпро, инсулина аспарта, инсулина глулизина, инсулина детемира и инсулина гларгина.
Другими рекомбинантными полипептидами, представляющими интерес, являются гирудин, соматотропин, интерлейкин, такой как интерлейкин-2, или гемоглобин.
Следует понимать, что рекомбинантный полипептид, представляющий интерес, будет содержать по меньшей мере один остаток изолейцина, по меньшей мере один остаток лейцина и/или по меньшей мере один остаток метионина.
В одном варианте осуществления рекомбинантным полипептидом, представляющим интерес, является лейцин-богатый полипептид. Например, по меньшей мере 5%, по меньшей мере 10% или по меньшей мере 15% всех аминокислот в полипептиде являются остатками лейцина. Например, рекомбинантный полипептид, представляющий интерес, может иметь длину, составляющую 96 аминокислот, и может содержать 14 остатков лейцина. В качестве альтернативы, рекомбинантный полипептид, представляющий интерес, может иметь длину, составляющую 44 аминокислоты, и может содержать 8 остатков лейцина. В качестве альтернативы, рекомбинантный полипептид, представляющий интерес, может иметь длину, составляющую 52 аминокислоты, и может содержать 6 остатков лейцина.
В другом варианте осуществления рекомбинантным полипептидом, представляющим интерес, является изолейцин-богатый полипептид. Например, по меньшей мере 5%, по меньшей мере 10% или по меньшей мере 15% всех аминокислот в полипептиде являются остатками изолейцина.
В другом варианте осуществления полипептид, представляющий интерес, является метионин-богатым полипептидом. Например, по меньшей мере 5%, по меньшей мере 10%, или по меньшей мере 15% всех аминокислот в полипептиде являются остатками метионина.
В частности аналогом инсулина является инсулин гларгин. Инсулин гларгин является аналогом базального инсулина длительного действия. Инсулин гларгин получают посредством технологии рекомбинантных ДНК с применением непатогенного лабораторного штамма Escherichia coli (K12) в качестве организма-продуцента. Это аналог человеческого инсулина, полученный посредством замены остатка аспарагина в положении A21 A-цепи на глицин и добавления двух остатков аргинина к C-концу (положения B31 и 32) B-цепи. Полученный в результате этого белок является растворимым при pH 4 и образует микропреципитаты при физиологическом pH 7,4. Небольшие количества инсулина гларгина медленно высвобождаются из микропреципитатов, что обеспечивает длительную продолжительность действия лекарственного средства (вплоть до 24 часов) без выраженной пиковой концентрации. Он представлен на рынке под наименованием Lantus®. Регистрационный номер CAS для инсулина гларгина представляет собой 160337-95-1.
Рекомбинантный полипептид, представляющий интерес, предпочтительно не является полипептидом, который экспрессируется в организме, находящемся в нетрансформированном состоянии. Предпочтительно он также не является полипептидом, который экспрессируется в качестве маркера для отбора (т. е. полипептид не должен обеспечивать устойчивость, такую как устойчивость клетки к антибиотику). Дополнительно, он предпочтительно не является полипептидом, который экспрессируется в качестве репортерного полипептида (такого как флуоресцентный полипептид или GUS-полипептид).
В одном варианте осуществления способа по настоящему изобретению рекомбинантный полипептид, представляющий интерес, и полипептид, обладающий ферментативной активностью, как указано в данном документе, экспрессируются совместно. Таким образом, рекомбинантный полипептид, представляющий интерес, не является полипептидом, обладающим ферментативной активностью, как указано в данном документе, в связи со способом по настоящему изобретению. Предпочтительно рекомбинантный полинуклеотид, кодирующий полипептид, представляющий интерес, и полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, как указано в данном документе, не присутствуют на одной и той же плазмиде. Соответственно, предусмотрено, что они экспрессируются с разных плазмид. Таким образом, полипептиды кодируются разными молекулами ДНК.
В соответствии с настоящим изобретением рекомбинантный полипептид, представляющий интерес, продуцируется посредством введения рекомбинантного полинуклеотида, кодирующего полипептид, представляющий интерес, в микробную клетку-хозяина, как определено в данном документе, и экспрессии указанного рекомбинантного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
Предпочтительно полинуклеотид, кодирующий полипептид, представляющий интерес, содержится в плазмиде для экспрессии, т. е. плазмиде, которая обеспечивает возможность экспрессии указанного полинуклеотида. То же самое относится к полинуклеотиду, кодирующему полипептид, обладающий ферментативной активностью, как определено в данном документе. Для обеспечения экспрессии полинуклеотида указанный полинуклеотид функционально связан с промотором. Применяемый в данном документе термин "функционально связанный" относится к такой функциональной связи между промотором и полинуклеотидом, который будет экспрессироваться, что промотор способен инициировать транскрипцию указанного полинуклеотида. Предпочтительные промоторы описаны в данном документе.
Плазмида для экспрессии может содержать дополнительные элементы. Предпочтительно плазмида дополнительно содержит ген маркера для отбора, что обеспечивает возможность отбора микробных клеток-хозяев. Например, он может представлять собой ген, который обеспечивает устойчивость к антибиотику, такому как ампициллин, хлорамфеникол, канамицин или тетрациклин.
Кроме того, предусмотрено, что плазмида содержит репликон, который обеспечивает репликацию плазмиды в микробной клетке-хозяине. В предпочтительном варианте осуществления только одна копия плазмиды, содержащая полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, как изложено в данном документе в связи со способом по настоящему изобретению, присутствует в микробной клетке-хозяине. Таким образом, число копий указанной плазмиды в микробной клетке-хозяине будет составлять единицу. Это может быть достигнуто наличием ori2 и его элементов repE, sopA, sopB и sopC, что обеспечивает 1 копию плазмиды на клетку. В противоположность этому, полинуклеотид, кодирующий полипептид, представляющий интерес, может присутствовать на плазмиде со средним или большим числом копий.
Способы введения полинуклеотида в микробную клетку-хозяина широко известны из уровня техники. Предпочтительно указанный полинуклеотид вводится в микробную клетку-хозяина посредством трансформации. Трансформация является процессом, при котором организм получает гетерогенный или рекомбинантный полинуклеотид. В одном варианте осуществления трансформация микробной клетки-хозяина включает применение двухвалентных катионов, таких как хлорид кальция, для повышения проницаемости мембраны клетки-хозяина, делая клетку-хозяина химически компетентной, с повышением таким образом вероятности поглощения рекомбинантного полинуклеотида. В другом варианте осуществления клетка-хозяин трансформируется полинуклеотидом посредством электропорации. Дополнительно, полинуклеотид может быть стабильно введен в клетку-хозяина, т. е. в хромосому клетки-хозяина.
Микробная клетка-хозяин предпочтительно является бактерией. Более предпочтительно, микробной клеткой-хозяином является клетка Escherichia coli (E. coli). E. coli представляет собой грамотрицательную гамма-протеобактерию. Потомки двух изолятов, K-12 и штамма В, обычно применяются в молекулярной биологии в качестве как инструмента, так и модельного организма. Предпочтительно клеткой E. coli является клетка E. coli штамма K12. Предпочтительно клеткой штамма E. coli является E. coli K12 BW25113 (см. Grenier, 2014, Genome Announc. Sep-Oct; 2(5): e01038-14).
Настоящее изобретение не ограничено E. coli, так как ошибочное включение ncBCAA также происходит в других бактериях, таких как B. subtilis или S. marcescens.
В соответствии с настоящим изобретением полинуклеотид, кодирующий полипептид, представляющий интерес, будет введен в микробную клетку-хозяина. Указанная микробная клетка-хозяин будет модифицирована таким образом, чтобы ферментативная активность, как указано в данном документе, подвергалась модулированию (например, повышалась) в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине. Таким образом, способ по настоящему изобретению может дополнительно включать (до стадии a), т. е. стадии введения) стадию обеспечения или получения микробной клетки-хозяина, обладающей подвергнутой модулированию ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19). В данном конкретном способе указанная ферментативная активность будет подвергаться модулированию по сравнению с немодифицированной микробной клеткой-хозяином. В качестве альтернативы, иллюстративный способ по настоящему изобретению может включать до стадии a) стадию модулирования ферментативной активности, как указано выше, в микробной клетке-хозяине.
В одном варианте осуществления настоящего изобретения термин "модулирование ферментативной активности" относится к повышению ферментативной активности (по сравнению с контролем или немодифицированной ферментативной активностью). В другом варианте осуществления термин относится к снижению ферментативной активности (по сравнению с контролем или немодифицированной ферментативной активностью).
Способы повышения ферментативной активности полипептида широко известны из уровня техники. Например, полипептид, обладающий ферментативной активностью, может быть подвергнут мутации для повышения его активности (например посредством дизайна ферментов или ферментативной инженерии).
В одном варианте осуществления настоящего изобретения ферментативная активность, как указано в данном документе, повышается в микробной клетке-хозяине, в которую вводится полинуклеотид, кодирующий полипептид, представляющий интерес. Предпочтительно ферментативная активность повышается на по меньшей мере 10% по сравнению с соответствующей ферментативной активностью в немодифицированной микробной клетке-хозяине. Более предпочтительно ферментативная активность повышается на по меньшей мере 20%, еще более предпочтительно на по меньшей мере 30% и еще более предпочтительно на по меньшей мере 50% по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине. В одном варианте осуществления ферментативная активность повышается на по меньшей мере 100% или в другом варианте осуществления на по меньшей мере 150%. Дополнительно предусмотрено, что ферментативная активность повышается с 20% до 300%, например с 50% до 200%. В одном варианте осуществления ферментативная активность повышается посредством сверхэкспрессии полинуклеотида, кодирующего полипептид, обладающий указанной ферментативной активностью.
В одном варианте осуществления настоящего изобретения ферментативная активность, как указано в данном документе, снижается в микробной клетке-хозяине, в которую вводится полинуклеотид, кодирующий полипептид, представляющий интерес. Предпочтительно ферментативная активность снижается на по меньшей мере 10% по сравнению с соответствующей ферментативной активностью в немодифицированной микробной клетке-хозяине. Более предпочтительно ферментативная активность снижается на по меньшей мере 20%, еще более предпочтительно на по меньшей мере 30% и еще более предпочтительно на по меньшей мере 50% по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине. В одном варианте осуществления ферментативная активность снижается на по меньшей мере 80% по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине. Однако предусматривается, что ферментативная активность не полностью нокаутирована. Например, клетка-хозяин может сохранить по меньшей мере 5%, по меньшей мере 10% или по меньшей мере 20% ферментативной активности немодифицированной микробной клетки-хозяина. Таким образом, ферментативная активность может быть повышена на 20-80%. В качестве альтернативы, ферментативная активность может быть снижена на 30-70%. В одном варианте осуществления ферментативная активность снижается с помощью антисмысловых РНК, которые подавляют экспрессию полинуклеотида, кодирующего полипептид, обладающий указанной ферментативной активностью. Таким образом, антисмысловые РНК должны быть комплементарны целевому гену.
В определенных вариантах осуществления немодифицированная микробная клетка-хозяин может представлять собой клетку дикого типа. В конкретном варианте осуществления немодифицированная микробная клетка-хозяин принадлежит к тому же штамму, который был модифицирован. Например, немодифицированная микробная клетка-хозяин может принадлежать к штамму K 12 E. coli, который может быть в дальнейшем модифицирован, как описано в данном документе.
Ферментативная активность, подлежащая модулированию, например повышению, в микробной клетке-хозяине, предпочтительно выбрана из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и активности L-треониндегидратазы (EC 4.3.1.19). Вышеуказанные ферментативные активности можно определять посредством анализов, широко известных из уровня техники. Число в скобках является так называемым шифром классификации ферментов (сокращенно "шифр EC"). Как известно из уровня техники, каждый шифр EC состоит из букв EC с последующими четырьмя цифрами, разделенными точками. Эти числа представляют собой более точную классификацию фермента. На основании шифра EC указывается реакция, катализируемая ферментом.
В одном варианте осуществления настоящего изобретения ферментативная активность, подлежащая модулированию, представляет собой активность кетол-кислотной редуктоизомеразы (NADP(+)). Соответственно активность кетол-кислотной редуктоизомеразы будет подвергаться модулированию, предпочтительно повышаться. Систематическим названием данного фермента является (R)-2,3-дигидрокси-3-метилбутаноат:NADP+ оксидоредуктаза (изомеризующая). Шифр EC для данного фермента представляет собой EC 1.1.1.86. Кетол-кислотная редуктоизомераза будет способна катализировать химическую реакцию (R)-2,3-дигидрокси-3-метилбутаноат+NADP+ в (S)-2-гидрокси-2-метил-3-оксобутаноат, NADPH и H+. Соответственно, она будет способна катализировать следующую химическую реакцию:
(R)-2,3-дигидрокси-3-метилбутаноат+NADP+ 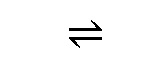 (S)-2-гидрокси-2-метил-3-оксобутаноат+NADPH+H+
(S)-2-гидрокси-2-метил-3-оксобутаноат+NADPH+H+
В другом варианте осуществления настоящего изобретения ферментативная активность, подлежащая модулированию, представляет собой активность синтазы ацетогидроксикислот. Соответственно, активность синтазы ацетогидроксикислот может быть подвергнута модулированию (например повышена или снижена). Данный фермент также известен как ацетолактатсинтаза. Шифр EC для данного фермента представляет собой EC 2.2.1.6. Синтаза ацетогидроксикислот будет способна катализировать превращение двух молекул пирувата в молекулу ацетолактата и диоксид углерода. В реакции используется тиаминпирофосфат для связывания двух молекул пирувата. Соответственно, она будет способна катализировать следующую химическую реакцию:
2 пируват 2 ацетолактат+CO2
В другом варианте осуществления настоящего изобретения ферментативная активность, подлежащая модулированию, представляет собой активность L-треониндегидратазы. Соответственно, активность треонинсинтазы будет подвергнута модулированию. Систематическое название данного фермента L-треонинаммиаклиаза (2-оксобутаноат-образующая). Шифр EC для данного фермента представляет собой EC 4.3.1.19.
В другом варианте осуществления настоящего изобретения ферментативная активность, подлежащая модулированию, представляет собой активность аспартаткиназы. Соответственно, активность аспартаткиназы будет подвергнута модулированию. Систематическое название данного фермента АТФ:L-аспартат-4-фосфотрансфераза. Шифр EC для данного фермента представляет собой EC 2.7.2.4. Аспартаткиназа будет способна катализировать образование бета-аспартилфосфата из аспарагиновой кислоты и АТФ. Треонин служит аллостерическим регулятором данного фермента для контроля пути биосинтеза треонина из аспарагиновой кислоты. Соответственно, она будет способна катализировать следующую химическую реакцию:
АТФ+L-аспартат АДФ+4-фосфо-L-аспартат
В другом варианте осуществления настоящего изобретения ферментативная активность, подлежащая модулированию, представляет собой активность гомосериндегидрогеназы. Соответственно, активность гомосериндегидрогеназы будет подвергнута модулированию. Систематическое название данного фермента L-гомосерин:NAD(P)+ оксидоредуктаза. Шифр EC для данного фермента представляет собой EC 1.1.1.3. Гомосериндегидрогеназа будет способна катализировать химическую реакцию превращения L-гомосерина и NAD+ (или NADP+) в L-аспартат 4-полуальдегид, NADP (или NADPН) и H+. Соответственно, она будет способна катализировать следующую химическую реакцию:
L-гомосерин+NAD(P)+ L-аспартат 4-полуальдегид+ NAD(P)H+H+
Фермент из Escherichia coli, который обладает активностью аспартаткиназы, также катализирует реакцию гомосериндегидрогеназы под EC 1.1.1.3. Соответственно, указанный фермент является бифункциональным ферментом, который обладает как активностью аспартаткиназы, так и активностью гомосериндегидрогеназы. Соответственно, предусмотрено, что обе ферментативные активности, т. е. активность аспартаткиназы и активность гомосериндегидрогеназы, модулируются в микробной клетке-хозяине по сравнению с активностью аспартаткиназы и активностью гомосериндегидрогеназы в немодифицированной микробной клетке-хозяине.
Ферментативная активность, как указано в данном документе, предпочтительно повышается посредством введения полинуклеотида, кодирующего полипептид, обладающий указанной ферментативной активностью, в микробную клетку-хозяина, и экспрессии указанного полинуклеотида. Например, полинуклеотид будет сверхэкспрессирован. Полипептид, кодируемый указанным полинуклеотидом, будет представлять собой фермент, обладающий ферментативной активностью, как указано в данном документе. Предпочтительные полипептиды, обеспечивающие указанные ферментативные активности, подробно раскрыты в данном описании. Следует понимать, что полипептиды, указанные в данном документе, могут также проявлять дополнительные биологические активности.
Следует понимать, что указанный полинуклеотид, кодирующий полипептид, обладающий указанной ферментативной активностью, не является полинуклеотидом, кодирующим полипептид, представляющий интерес. Соответственно, микробная клетка-хозяин, как указано в данном документе, содержит a) полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, как указано в данном документе, и b) полинуклеотид, кодирующий полипептид, представляющий интерес. Соответственно полинуклеотиды под a) и b) совместно экспрессируются в микробной клетке-хозяине. Дополнительно следует понимать, что оба полинуклеотида являются рекомбинантными полинуклеотидами, которые были введены в клетку-хозяина искусственно.
Предпочтительные последовательности полинуклеотида, кодирующего полипептид, обладающий ферментативной активностью, как указано в данном документе, представлены ниже.
В одном варианте осуществления настоящего изобретения полинуклеотид кодирует полипептид, обладающий активностью кетол-кислотной редуктоизомеразы (NADP(+)(EC 1.1.1.86). Предпочтительно, указанный полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 3, и/или
ii) кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 4.
В другом варианте осуществления настоящего изобретения полинуклеотид кодирует полипептид, обладающий активностью L-треониндегидратазы. Предпочтительно, указанный полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 11, и/или
ii) кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 12.
В одном варианте осуществления ферментативная активность, подлежащая модулированию, представляет собой активность синтазы ацетогидроксикислот (AHAS), в частности активность изоформы I AHAS или ее вариантов, изоформы II AHAS или ее вариантов или изоформы III AHAS или ее вариантов. Активность изоформы I AHAS или ее вариантов предпочтительно снижается для снижения ошибочного включения ncBCAA. Активность изоформ II и III AHAS или их вариантов предпочтительно повышается для снижения ошибочного включения ncBCAA.
Как известно из уровня техники, функциональная синтаза ацетогидроксикислот (например AHAS I, AHAS II или AHAS III) содержит две большие субъединицы и две малые субъединицы, которые образуют тетрамер (который обладает активностью синтазы ацетогидроксикислот). Две большие субъединицы, также как и две малые субъединицы, являются идентичными. Соответственно активность синтазы ацетогидроксикислот предпочтительно повышается в микробной клетке-хозяине посредством введения первого полинуклеотида, кодирующего большую субъединицу синтазы ацетогидроксикислот, и второго полинуклеотида, кодирующего малую субъединицу синтазы ацетогидроксикислот, в микробную клетку-хозяина, и экспрессии полинуклеотидов. В микробной клетке две большие субъединицы и две малые субъединицы предпочтительно образуют тетрамер. Следует понимать, что указанный тетрамер будет обладать активностью синтазы ацетогидроксикислот. Первый и второй полинуклеотиды предпочтительно присутствуют в одной и той же конструкции и предпочтительно экспрессируются бицистронно под контролем одного промотора.
AHAS I или ее варианты
В одном варианте осуществления настоящего изобретения указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 23, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 24,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 25, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 26.
SEQ ID NO: 24 представляет собой аминокислотную последовательность большой субъединицы изоформы I синтазы ацетогидроксикислот из E. coli, тогда как SEQ ID NO: 26 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы.
AHAS II или ее варианты
В другом варианте осуществления настоящего изобретения указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33 и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
SEQ ID NO: 6 представляет собой аминокислотную последовательность большой субъединицы изоформы II синтазы ацетогидроксикислот из E. coli, тогда как SEQ ID NO: 8 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы. В предпочтительном варианте осуществления применяется изоформа AHAS E. coli (или ее вариант).
SEQ ID NO: 28 представляет собой аминокислотную последовательность большой субъединицы изоформы III синтазы ацетогидроксикислот из Shigella boydii, тогда как SEQ ID NO: 30 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы.
SEQ ID NO: 32 представляет собой аминокислотную последовательность большой субъединицы изоформы III синтазы ацетогидроксикислот из Serratia marcescens, тогда как SEQ ID NO: 34 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы.
AHAS III или ее варианты
В другом варианте осуществления настоящего изобретения указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43 и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45 и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
SEQ ID NO: 14 представляет собой аминокислотную последовательность большой субъединицы изоформы III синтазы ацетогидроксикислот из E. coli, тогда как SEQ ID NO: 16 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы. В предпочтительном варианте осуществления применяется изоформа AHAS E. coli (или ее вариант).
SEQ ID NO: 36 представляет собой аминокислотную последовательность большой субъединицы изоформы III синтазы ацетогидроксикислот из Shigella boydii, тогда как SEQ ID NO: 38 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы.
SEQ ID NO: 40 представляет собой аминокислотную последовательность большой субъединицы изоформы III синтазы ацетогидроксикислот из Serratia marcescens, тогда как SEQ ID NO: 42 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы.
SEQ ID NO: 44 представляет собой аминокислотную последовательность большой субъединицы изоформы III синтазы ацетогидроксикислот из Bacillus subtilis, тогда как SEQ ID NO: 46 представляет собой аминокислотную последовательность малой субъединицы указанной изоформы.
Как указано выше, предусмотрено, что как активность аспартаткиназы, так и активность гомосериндегидрогеназы модулируются в микробной клетке-хозяине (по сравнению с немодифицированной микробной клеткой-хозяином). В предпочтительном варианте осуществления повышение этих двух активностей осуществляется посредством введения и экспрессии полинуклеотида, кодирующего полипептид, обладающий активностью аспартаткиназы и гомосериндегидрогеназы. Соответственно, указанный полипептид является бифункциональным полипептидом. Предпочтительно, указанный полинуклеотид, кодирующий полипептид, обладающий активностью аспартаткиназы и гомосериндегидрогеназы:
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 17, и/или
ii) кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 18.
Применяемый в данном документе термин "полинуклеотид" относится к линейной или кольцевой молекуле нуклеиновой кислоты. Он охватывает как молекулы ДНК, так и молекулы РНК. Полинуклеотид по настоящему изобретению будет предпочтительно предусмотрен либо в виде выделенного полинуклеотида (т. е. выделенного из его естественной среды), либо в генетически модифицированной форме. Термин охватывает как одноцепочечные, так и двухцепочечные полинуклеотиды. Более того, термин включает химически модифицированные полинуклеотиды, включая встречающиеся в природе модифицированные полинуклеотиды, такие как гликозилированные или метилированные полинуклеотиды или искусственно модифицированные полинуклеотиды, такие как биотинилированные полинуклеотиды. Полинуклеотид по настоящему изобретению характеризуется тем, что он будет кодировать полипептид, указанный выше. Полинуклеотид предпочтительно характеризуется конкретной нуклеотидной последовательностью, упомянутой выше. Более того, вследствие вырожденности генетического кода охватываются полинуклеотиды, которые кодируют конкретную аминокислотную последовательность, указанную выше.
Более того, термин "полинуклеотид", применяемый в соответствии с настоящим изобретением, дополнительно охватывает варианты вышеуказанных конкретных полинуклеотидов. Указанные варианты могут представлять собой ортологи, паралоги или иные гомологи полинуклеотида по настоящему изобретению. Варианты полинуклеотидов предпочтительно содержат последовательность нуклеиновой кислоты, характеризующуюся тем, что последовательность может быть получена из вышеуказанных конкретных последовательностей нуклеиновой кислоты посредством замены по меньшей мере одного нуклеотида, добавления и/или удаления одного нуклеотида, вследствие чего последовательность нуклеиновой кислоты варианта все еще будет кодировать полипептид, обладающий активностью, указанной выше.
В предпочтительном варианте осуществления настоящего изобретения полинуклеотид, указанный в данном документе выше, будет характеризоваться по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 3, 5, 7, 11, 13, 15, 17, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43 или 45. Дополнительно предусмотрено, что полинуклеотид кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 4, 6, 8, 12, 14, 16, 18, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44 или 46. Применяемый в данном документе термин "по меньшей мере 40%" обозначает 40% или более 40%. В частности термин обозначает по меньшей мере 50%, по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 98% или по меньшей мере 99% идентичность последовательностей (в порядке увеличения предпочтительности). Более того, термин охватывает точную последовательность, т. е., 100% идентичность последовательностей. Таким образом, полинуклеотид может характеризоваться последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 3, 5, 7, 11, 13, 15, 17, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43 или 45, или содержать ее, или может кодировать полипептид, содержащий аминокислотную последовательность, показанную под SEQ ID NO: 4, 6, 8, 12, 14, 16, 18, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44 или 46.
Идентичность последовательностей между аминокислотными последовательностями или последовательностями нуклеиновой кислоты, применяемая в данном документе, может быть оценена посредством определения числа идентичных нуклеотидов или аминокислот между двумя последовательностями нуклеиновой кислоты или аминокислотными последовательностями, где последовательности выровнены таким образом, что получено совпадение наиболее высокого порядка. Значения процента идентичности предпочтительно рассчитываются по участку всей аминокислотной последовательности или последовательности нуклеиновой кислоты. Ряд программ на основе различных алгоритмов доступен специалисту в данной области техники для сравнения различных последовательностей. В данном контексте алгоритмы Нидлмана и Вунша или Смита и Уотермана позволяют получить особенно надежные результаты. Это может быть рассчитано с применением опубликованных методик или способов, кодифицированных в компьютерных программах, таких как, например, BLASTP, BLASTN или FASTA (Altschul 1990, J Mol Biol 215, 403). Значения процента идентичности предпочтительно рассчитываются в окне сравнения. Окно сравнения предпочтительно совпадает по длине со всей последовательностью более короткой последовательности, подлежащей выравниванию, или с по меньшей мере половиной указанной последовательности. Чтобы провести выравнивание последовательностей можно использовать программу PileUp (Higgins 1989, CABIOS 5, 151) или программы Gap и BestFit (Needleman 1970, J Mol Biol 48: 443; Smith 1981, Adv Appl Math 2: 482), которые являются частью пакета программного обеспечения GCG (Genetics Computer Group 1991, 575 Science Drive, Мэдисон, Висконсин, США, 53711). Значения идентичности последовательностей, указанные выше в процентах (%), в другом аспекте настоящего изобретения определяются с применением программы GAP по участку всей последовательности со следующими настройками: штраф за открытие гэпа: 50, штраф за продление гэпа: 3, среднее совпадение: 10,000 и среднее несовпадение: 0,000, которые, если не указано иное, будут всегда применяться в качестве стандартных настроек для выравнивания последовательностей. Предпочтительно степень идентичности последовательностей рассчитывается по всей длине.
В одном варианте осуществления алгоритм Нидлмана и Вунша (см. выше) применяется для сравнения последовательностей. Алгоритм включен в пакеты программного обеспечения для выравнивания последовательностей GAP версии 10 и wNEEDLE. Например, wNEEDLE считывает две последовательности, подлежащие выравниванию, и находит оптимальное выравнивание по всей их длине. Если сравниваются аминокислотные последовательности, то по умолчанию используются штраф за открытие гэпа, составляющий 10, штраф за продление гэпа, составляющий 0,5, и матрица сравнения EBLOSUM62. Если последовательности ДНК сравниваются с применением wNEEDLE, то используются штраф за открытие гэпа, составляющий 10, штраф за продление гэпа, составляющий 0,5, и матрица сравнения EDNAFULL.
Варианты также охватывают полинуклеотиды, содержащие последовательность нуклеиновой кислоты, которая способна к гибридизации с вышеуказанными конкретными последовательностями нуклеиновой кислоты, предпочтительно в жестких условиях гибридизации. Эти жесткие условия известны специалисту в данной области техники и могут быть найдены в Current Protocols in Molecular Biology, John Wiley & Sons, N. Y. (1989), 6.3.1-6.3.6. Соответственно, предусмотрено, что полинуклеотид, указанный выше, будет способен к гибридизации с полинуклеотидом, характеризующимся последовательностью, показанной под SEQ ID NO: 3, 5, 7, 11, 13, 15, 17, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43 или 45, в частности полинуклеотид, указанный выше, будет комплементарен полинуклеотиду, характеризующемуся последовательностью, показанной под SEQ ID NO: 3, 5, 7, 11, 13, 15, 17, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43 или 45.
Термин "гибридизация" широко известен из уровня техники и относится к процессу, при котором практически гомологичные комплементарные нуклеотидные последовательности отжигаются друг с другом. Процесс гибридизации может происходить полностью в растворе, т. е. обе комплементарные нуклеиновые кислоты находятся в растворе. Гибридизация может также происходить с одной из комплементарных нуклеиновых кислот, иммобилизованной на матрице, такой как сефарозные гранулы. Чтобы позволить гибридизации произойти, молекулы нуклеиновой кислоты подвергаются термической или химической денатурации, чтобы расплавить двойную цепь на две отдельные цепи и/или удалить шпильки или другие вторичные структуры из одноцепочечных нуклеиновых кислот.
В соответствии с настоящим изобретением полинуклеотид будет способен к гибридизации в жестких условиях, в частности в очень жестких условиях гибридизации, с полинуклеотидом, характеризующимся последовательностью, показанной под SEQ ID NO: 3, 5, 7, 11, 13, 15, 17, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43 или 45. . Термин "жесткость" относится к условиям, в которых происходит гибридизация. На жесткость гибридизации влияют такие условия, как температура, концентрация солей, ионная сила и состав буфера для гибридизации. В предпочтительном варианте осуществления условия гибридизации высокой жесткости охватывают гибридизацию при 65°C в 1x SSC или при 42°C в 1x SSC и 50% формамиде с последующим промыванием при 65°C в 0,3x SSC. Дополнительно предусмотрено, что за гибридизацией следует промывание при 65°C в 0,1x SSC. 1×SSC представляет собой 0,15 М NaCl и 15 мМ цитрат натрия; раствор для гибридизации и растворы для промывания могут дополнительно содержать 5x реагента Денхардта, 0,5-1,0% SDS, 100 мкг/мл денатурированной фрагментированной ДНК спермы лосося и 0,5% пирофосфата натрия.
На стадии (b) способа по настоящему изобретению полипептид, представляющий интерес, экспрессируется в указанной микробной клетке-хозяине. Предпочтительно указанная стадия проводится в условиях, которые позволяют осуществлять экспрессию указанного полипептида. Подходящие условия культивирования могут быть определены специалистом в данной области техники без дальнейших разъяснений. Предпочтительно, стадия проводится в стандартных условиях. Таким образом, клетка-хозяин инкубируется в стандартных условиях, например в стандартных условиях, описанных в примере 9.
В одном варианте осуществления экспрессия осуществляется в биореакторе в условиях большого масштаба. Применяемый в данном документе термин "биореактор" относится к системе, в которой условия строго контролируются. В одном варианте осуществления указанный биореактор представляет собой биореактор с перемешиванием. Предпочтительно биореактор сделан из материала, не подвергающегося коррозии, такого как нержавеющая сталь. Биореактор может быть любого размера. В некоторых вариантах осуществления биореактор имеет объем, составляющий по меньшей мере 10, по меньшей мере 100, 500, по меньшей мере 1000, по меньшей мере 2500 или по меньшей мере 5000 литров или любой промежуточный объем.
В соответствии с настоящим изобретением полинуклеотид, кодирующий полипептид, представляющий интерес, функционально связан с промотором. То же самое относится к полинуклеотиду, кодирующему полипептид, обладающий ферментативной активностью, как указано в данном документе. Однако предпочтительно, что вышеуказанные полинуклеотиды связаны с разными промоторами.
Промотор будет обеспечивать экспрессию полинуклеотида. Предпочтительно, промотор является гетерологичным по отношению к последовательности, контролируемой им. Таким образом, промотор будет гетерологичным по отношению к полинуклеотиду, кодирующему полипептид, обладающий ферментативной активностью, и к полинуклеотиду, кодирующему полипептид, представляющий интерес, соответственно. Предпочтительно промотор является конститутивным или индуцируемым промотором. Конститутивные и индуцируемые промоторы, которые обеспечивают экспрессию в микробной клетке-хозяине, широко известны из уровня техники.
"Конститутивный промотор" относится к промотору, который транскрипционно активен во время большинства, но необязательно всех фаз роста и в большинстве условий среды.
"Индуцируемый промотор" относится к промотору, характеризующемуся повышением инициации транскрипции в ответ на стимул.
В соответствии с настоящим изобретением, в частности, предполагается, что промотор является индуцируемым промотором. Таким образом, полинуклеотид, кодирующий полипептид, представляющий интерес, и/или полинуклеотид, кодирующий полипептид, обладающий указанной ферментативной активностью, будет функционально связан с индуцируемым промотором. В данном случае ферментативная активность повышается лишь временно (т. е. после индукции промоторов).
В одном варианте осуществления индуцируемый промотор представляет собой индуцируемый арабинозой промотор araBAD. Этот промотор широко известен из уровня техники. Индуцируемый арабинозой промотор araBAD (PBAD) вместе с его регуляторным белком AraC были описаны в качестве системы экспрессии для продуцирования рекомбинантного белка на высоком уровне, а также для целей метаболической инженерии, так как экспрессия регулируется в широком диапазоне концентраций арабинозы (Guzman et al., 1995, Tight regulation, modulation, and high-level expression by vectors containing the arabinose PBAD promoter. Journal of bacteriology, 177(14), 4121-4130). Также было показано, что промоторная система AraC-PBAD регулируется посредством катаболитной репрессии (Schleif, R., 2000, Regulation of the L-arabinose operon of Escherichia coli. Trends in Genetics, 16(12), 559-565; Megerle et al, 2008, Timing and dynamics of single cell gene expression in the arabinose utilization system. Biophysical journal, 95(4), 2103-2115). Более того, сообщалось, что применимость системы экспрессии AraC-PBAD зависит от штамма E. coli. Клонирующие векторы обычно содержат природные последовательности промотора araBAD и гена araC из природной регуляторной системы araBAD.
Последовательность промотора araBAD показана под SEQ ID NO: 19. Соответственно, промотор araBAD предпочтительно содержит последовательность нуклеиновой кислоты, показанную под SEQ ID NO: 19, или последовательность, на по меньшей мере 70%, по меньшей мере 80% или по меньшей мере 90% идентичную по отношению к ней.
Последовательность нуклеиновой кислоты полинуклеотида araC показана под SEQ ID NO: 20. Данный ген кодирует полипептид AraC. Если применяется промотор araBAD, то полинуклеотид, экспрессирующий полипептид AraC, должен быть введен в микробную клетку-хозяина для активации промотора.
Дополнительными индуцируемыми промоторами являются промотор rhaBAD, варианты промотора lac (такие как промотор lacUV5, Ptac, Ptrc и T7lac), промотор XylSPm и промотор tet.
Полипептид, обладающий ферментативной активностью, как указано в данном документе, и/или полипептид, представляющий интерес, могут содержать дополнительные последовательности. Например, полипептид(полипептиды) может дополнительно содержать метку для очистки. Метка будет функционально связана с полипептидом.
Метка обеспечит очистку полипептида. Такие метки широко известны из уровня техники. Применяемый в данном документе термин "метка для очистки" предпочтительно относится к дополнительной аминокислотной последовательности (к пептиду полипептида), что обеспечивает очистку полипептида. В одном варианте осуществления меткой для очистки является пептид или полипептид, который не является естественным образом связанным с полипептидом, указанным в данном документе. Таким образом, метка для очистки будет гетерологичной по отношению к полипептиду.
Предпочтительно метка для очистки выбрана из группы, состоящей из полигистидиновой метки, полиаргининовой метки, глутатион- S-трансферазы (GST), мальтоза-связывающего белка (MBP), HA-метки вируса гриппа, тиоредоксина, метки стафилококкового белка А, эпитопа FLAG™ и эпитопа c-myc. В предпочтительном варианте осуществления меткой для очистки является полигистидиновая метка. Предпочтительно указанная полигистидиновая метка содержит по меньшей мере 6 последовательных остатков гистидина.
В предпочтительном варианте осуществления способов по настоящему изобретению способ дополнительно включает выделение полипептида, представляющего интерес, из клетки, и очистку указанного полипептида. Выделение полипептида может быть достигнуто посредством широко известных способов, таких как применение подходящей метки для очистки.
В одном варианте осуществления очистка включает обогащение полипептидов, которые не содержат неканонические аминокислоты с разветвленной цепью. Это может быть достигнуто посредством широко известных способов, которые описаны, например, в Min, C. K., et al., 2012, Insulin related compounds and identification. Journal of Chromatography B, 908, 105-112; Harris, R. P., et al., 2014, Amino acid misincorporation in recombinant biopharmaceutical products. Current opinion in biotechnology, 30, 45-50; Cvetesic, N., et al., 2016, Proteome-wide measurement of non-canonical bacterial mistranslation by quantitative mass spectrometry of protein modifications. Scientific reports, 6, 2863. Например, обогащение достигается посредством хроматографии.
Микробная клетка-хозяин была определена выше. Как указано выше, микробной клеткой-хозяином предпочтительно является клетка E. coli. Как известно специалисту в данной области техники, клетки E. coli естественным образом экспрессируют полипептиды, обладающие активностью кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активностью синтазы ацетогидроксикислот (EC 2.2.1.6), активностью аспартаткиназы (EC 2.7.2.4), активностью гомосериндегидрогеназы (EC 1.1.1.3) и активностью L-треониндегидратазы (EC 4.3.1.19).
• Ген ilvC кодирует полипептид, обладающий активностью кетол-кислотной редуктоизомеразы (NADP(+))
• оперон ilvIH кодирует полипептид, обладающий активностью синтазы ацетогидроксикислот (изофермент III синтазы ацетогидроксикислот),
• оперон ilvBN кодирует полипептид, обладающий активностью синтазы ацетогидроксикислот (изофермент I синтазы ацетогидроксикислот),
• оперон ilvGM кодирует полипептид, обладающий активностью синтазы ацетогидроксикислот (изофермент II синтазы ацетогидроксикислот),
• ген thrA кодирует бифункциональный полипептид, обладающий активностью аспартаткиназы и гомосериндегидрогеназы, и
• ген ilvA кодирует полипептид, обладающий активностью L-треониндегидратазы.
Соответственно, микробная клетка-хозяин, которая была модифицирована, может обладать эндогенными ферментативными активностями, т. е. активностями, которые естественным образом присутствуют в микробной клетке-хозяине. Однако в частности предусмотрено, что микробная клетка-хозяин не экспрессирует эндогенный полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, как указано в данном документе. Таким образом, эндогенная ферментативная активность может быть нокаутирована. Соответственно предусмотрено, что эндогенный полинуклеотид (и таким образом эндогенная ферментативная активность) был нокаутирован. Таким образом, ген ilvC, оперон ilvIH , оперон ilvBN , ген thrA , оперон ilvGM или ген ilvA могут быть нокаутированы. Это может быть достигнуто посредством способов, широко известных в данной области техники и описанных в разделе Примеры. Дополнительно такие нокауты уже известны и могут быть оценены, например, в Центре хранения генетического материала E. coli (CGSC) Йельского университета. Например, K12 BW25113 E. coli содержит вставку из двух оснований между парами оснований 1250 и 1253 генетической последовательности ilvG, что приводит к мутации со сдвигом рамки считывания. Как следствие, образуется стоп-кодон, что приводит к преждевременной терминации экспрессии гена ilvG (ilvG-). Функциональная AHASII затем не экспрессируется, и экспрессия дистальных генов оперона ilvEDA нарушается (Lawther et al., 1981, Molecular basis of valine resistance in Escherichia coli K-12, PNAS 78 (2) 922-925; Parekh, B.S. and Hatfield, G.W., 1997. Относящаяся к скорости роста регуляция оперона ilvGMEDA Escherichia coli K-12, является следствием полярной мутации со сдвигом рамки считывания в гене ilvG данного штамма. Journal of bacteriology, 179(6) 2086-2088.). В конкретных вариантах осуществления, раскрытых в данном документе, нокауты ΔthrA, ΔilvA и ΔilvC были получены из Центра хранения генетического материала E. coli (CGSC) Йельского университета (см. раздел Примеры).
В одном варианте осуществления эндогенный полинуклеотид, кодирующий полипептид, обладающий указанной ферментативной активностью, был подвергнут делеции. В качестве альтернативы, он мог быть подвергнут мутации с деактивацией таким образом эндогенной ферментативной активности. Эндогенный полинуклеотид является встречающимся в природе полинуклеотидом, который кодирует полипептид, обладающий ферментативной активностью, как указано в данном документе.
Например, активность L-треониндегидратазы может быть повышена в микробной клетке-хозяине посредством введения и экспрессии полинуклеотида (т. е. рекомбинантного полинуклеотида), кодирующего полипептид, обладающий активностью L-треониндегидратазы. В одном варианте осуществления указанная микробная клетка-хозяин экспрессирует эндогенный полинуклеотид, кодирующий полипептид, обладающий активностью L-треониндегидратазы (т. е. в дополнение к рекомбинантному полинуклеотиду). В другом более предпочтительном варианте осуществления эндогенный полинуклеотид, кодирующий полипептид, обладающий активностью L-треониндегидратазы (и таким образом ген ilvA ), был нокаутирован в указанной микробной клетке. Соответственно, указанная микробная клетка не экспрессирует эндогенный полипептид, обладающий активностью L-треониндегидратазы. Экспрессируется только рекомбинантный полипептид, обладающий указанной активностью.
Нокаут эндогенного гена (т. е. эндогенной ферментативной активности) вместе с применением индуцируемых промоторов, как описано выше, позволяет осуществлять улучшенную регуляцию ферментативной активности в микробной клетке-хозяине.
В предпочтительном варианте осуществления продуцируемый полипептид, представляющий интерес, демонстрирует сниженное ошибочное включение неканонических аминокислот с разветвленной цепью (ncBCAA) по сравнению с полипептидом, который был получен посредством экспрессии в немодифицированной микробной клетке-хозяине. Соответственно, ошибочное включение ncBCAA снижено.
Предпочтительно неканонические аминокислоты с разветвленной цепью выбраны из норвалина, норлейцина и бета-метилнорлейцина. Соответственно, полипептид, представляющий интерес, предпочтительно демонстрирует сниженное ошибочное включение норвалина, норлейцина и бета-метилнорлейцина по сравнению с полипептидом, который был получен посредством экспрессии в немодифицированной микробной клетке-хозяине.
В некоторых вариантах осуществления ошибочное включение неканонических аминокислот с разветвленной цепью снижено во фракции внутриклеточных растворимых белков. В некоторых вариантах осуществления ошибочное включение неканонических аминокислот с разветвленной цепью снижено во фракции телец включения.
Норвалин является аминокислотой с формулой CH3(CH2)2CH(NH2)CO2H. Соединение является изомером более часто встречающейся аминокислоты валина. Название по ИЮПАК - 2-аминопентановая кислота. Норвалин может быть ошибочно включен в рекомбинантные белки вместо остатков лейцина. Соответственно, термин "ошибочное включение норвалина" относится к включению остатка норвалина в полипептид, представляющий интерес, для которого остаток лейцина кодируется соответствующей нуклеиновой кислотой, кодирующей полипептид, представляющий интерес.
Норлейцин является аминокислотой с формулой CH3(CH2)3CH(NH2)CO2H. Норлейцин является изомером более часто встречающейся аминокислоты лейцина. Название по ИЮПАК - 2-аминогексановая кислота. Норлейцин может быть ошибочно включен в рекомбинантные белки вместо остатков метионина. Соответственно, термин "ошибочное включение норлейцина" относится к включению остатка норлейцина в полипептид, представляющий интерес, для которого остаток метионина кодируется соответствующей нуклеиновой кислотой, кодирующей полипептид, представляющий интерес.
Бета-метилнорлейцин является аминокислотой. Синонимами для данной аминокислоты являются бета-метилнорлейцин; (2S,3S)-2-амино-3-метилгексановая кислота и [2S,3S,(+)]-2-амино-3-метилгексановая кислота. Бета-метилнорлейцин может быть ошибочно включен в рекомбинантные белки вместо остатков изолейцина. Соответственно, термин "ошибочное включение бета-метилнорлейцина" относится к включению остатка бета-метилнорлейцина в полипептид, представляющий интерес, для которого остаток изолейцина кодируется соответствующей нуклеиновой кислотой, кодирующей полипептид, представляющий интерес.
Таким образом, ошибочное включение ncBCAA, как указано выше, может происходить, если полипептид, представляющий интерес, содержит по меньшей мере один остаток лейцина, по меньшей мере один остаток метионина и/или по меньшей мере один остаток изолейцина. Соответственно, предусмотрено, что полипептид, представляющий интерес, содержит по меньшей мере один остаток лейцина, по меньшей мере один остаток метионина и/или по меньшей мере один остаток изолейцина.
В одном варианте осуществления настоящего изобретения ошибочное включение норвалина снижено.
В одном варианте осуществления настоящего изобретения ошибочное включение норлейцина снижено.
В одном варианте осуществления настоящего изобретения ошибочное включение бета-метилнорлейцина снижено.
В одном варианте осуществления настоящего изобретения ошибочное включение норвалина и норлейцина снижено.
В одном варианте осуществления настоящего изобретения ошибочное включение норлейцина и бета-метилнорлейцина снижено.
В одном варианте осуществления настоящего изобретения ошибочное включение норвалина и бета-метилнорлейцина снижено.
В одном варианте осуществления настоящего изобретения ошибочное включение норвалина, норлейцина и бета-метилнорлейцина снижено.
В соответствии с настоящим изобретением снижение процента содержания ncBCAA, в частности содержания норвалина, норлейцина и/или бета-метилнорлейцина, предпочтительно составляет 5%, более предпочтительно по меньшей мере 10%, еще более предпочтительно по меньшей мере 15% и еще более предпочтительно по меньшей мере 20% (по сравнению с содержанием в полипептиде, который был получен посредством экспрессии в немодифицированной микробной клетке-хозяине, т. е. в контрольной клетке). Таким образом, ошибочное включение ncBCAA предпочтительно снижено на по меньшей мере 5%, по меньшей мере 10%, по меньшей мере 15% или по меньшей мере 20%. Снижение процента содержания ncBCAA или содержания норвалина, норлейцина и/или бета-метилнорлейцина предпочтительно рассчитывается как снижение процента содержания полипептидов, представляющих интерес, содержащих ncBCAA или норвалин, норлейцин и/или бета-метилнорлейцин.
Определения и пояснения, предусмотренные в данном документе, относятся mutatis mutandis к следующим вариантам осуществления настоящего изобретения.
Настоящее изобретение дополнительно относится к способу снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, экспрессируемый в микробной клетке-хозяине, при этом указанный способ включает
(a) модулирование ферментативной активности, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19), в микробной клетке-хозяине,
(b) введение полинуклеотида, кодирующего полипептид, представляющий интерес, в указанную микробную клетку-хозяина, и
(c) экспрессию указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
В качестве альтернативы, стадия (a) может включать получение микробной клетки-хозяина, обладающей подвергнутой модулированию активностью ферментативной активности, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19).
В одном варианте осуществления ферментативная активность, как указано выше, будет подвергнута модулированию (повышена или снижена) в микробной клетке-хозяине по сравнению с немодифицированной микробной клеткой-хозяином. Способы модулирования ферментативной активности описаны выше. Предпочтительно указанная ферментативная активность модулируется (например повышается) посредством введения и экспрессии полинуклеотида, кодирующего полипептид, обладающий указанной ферментативной активностью, в указанной микробной клетке-хозяине. Предпочтительные последовательности полинуклеотида/полипептида описаны выше.
Дополнительно в настоящем изобретении предусмотрена микробная клетка-хозяин, содержащая
(a) рекомбинантный полинуклеотид, кодирующий полипептид, представляющий интерес, и
(b) рекомбинантный полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19).
Более того, настоящее изобретение относится к применению полипептида, обладающего ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3), L-треониндегидратазы (EC 4.3.1.19), или полинуклеотида, кодирующего указанный полипептид, для снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, продуцируемый в микробной клетке-хозяине.
В конечном итоге, настоящее изобретение относится к применению микробной клетки-хозяина для получения рекомбинантного полипептида, представляющего интерес, где микробная клетка-хозяин была модифицирована таким образом, что ферментативная активность, выбранная из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19), модулируется в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине.
Ниже кратко описаны варианты осуществления настоящего изобретения. Определения и пояснения, предусмотренные выше, применяются mutatis mutandis к вариантам осуществления.
Перечень вариантов осуществления
1. Способ получения рекомбинантного полипептида, представляющего интерес, в микробной клетке-хозяине, включающий стадии
(a) введения полинуклеотида, кодирующего полипептид, представляющий интерес, в микробную клетку-хозяина, которая была модифицирована таким образом, что ферментативная активность, выбранная из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19), является модулированной в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине, и
(b) экспрессии указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
2. Способ согласно варианту осуществления 1, где полученный полипептид, представляющий интерес, демонстрирует сниженное ошибочное включение неканонических аминокислот с разветвленной цепью по сравнению с полипептидом, который был получен посредством экспрессии в немодифицированной микробной клетке-хозяине.
3. Способ согласно любому из вариантов осуществления 1-2, где количество продуцируемого полипептида повышают по сравнению с количеством указанного полипептида, продуцируемого в немодифицированной микробной клетке-хозяине.
4. Способ согласно любому из вариантов осуществления 1-3, где способ дополнительно включает выделение полипептида из клетки и очистку полипептида.
5. Способ согласно варианту осуществления 4, где очистка включает обогащение полипептидов, которые не содержат неканонические аминокислоты с разветвленной цепью.
6. Способ согласно любому из варианта осуществления 1 и варианта осуществления 5, где указанную ферментативную активность повышают посредством введения и экспрессии полинуклеотида, кодирующего полипептид, обладающий указанной ферментативной активностью, в указанной микробной клетке-хозяине.
7. Способ согласно варианту осуществления 6, где
(a) полинуклеотид кодирует полипептид, обладающий активностью кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), и где
i) полинуклеотид содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 3, и/или
ii) полинуклеотид кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 4,
или
(b) полинуклеотид кодирует полипептид, обладающий активностью L-треониндегидратазы (EC 4.3.1.19), и где
i) полинуклеотид содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 11, и/или
ii) полинуклеотид кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 12.
8. Способ согласно вариантам осуществления 6-7, где указанная микробная клетка-хозяин не экспрессирует эндогенный полипептид, обладающий указанной ферментативной активностью.
9. Способ согласно любому из вариантов осуществления 1-8, где полипептид, представляющий интерес, является терапевтическим пептидом или полипептидом.
10. Способ согласно любому из вариантов осуществления 1-9, где полинуклеотид, кодирующий полипептид, представляющий интерес, и/или полинуклеотид, кодирующий полипептид, обладающий указанной ферментативной активностью, функционально связан с индуцируемым промотором.
11. Способ согласно любому из вариантов осуществления 1-10, где указанная микробная клетка-хозяин представляет собой клетку Escherichia coli.
12. Способ снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, экспрессируемый в микробной клетке-хозяине, при этом указанный способ включает
(d) модулирование ферментативной активности, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19), в микробной клетке-хозяине,
(a) введение полинуклеотида, кодирующего полипептид, представляющий интерес, в указанную микробную клетку-хозяина, и
(b) экспрессию указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
13. Способ согласно варианту осуществления 12, где по меньшей мере одна неканоническая аминокислота с разветвленной цепью выбрана из норвалина, норлейцина и бета-метилнорлейцина.
14. Микробная клетка-хозяин, содержащая
(a) рекомбинантный полинуклеотид, кодирующий полипептид, представляющий интерес, и
(c) рекомбинантный полинуклеотид, кодирующий полипептид, обладающий ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19).
15. Применение полипептида, обладающего ферментативной активностью, выбранной из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19), или полинуклеотида, кодирующего указанный полипептид, для снижения ошибочного включения по меньшей мере одной неканонической аминокислоты с разветвленной цепью в рекомбинантный полипептид, представляющий интерес, продуцируемый в микробной клетке-хозяине.
16. Применение микробной клетки-хозяина для получения рекомбинантного полипептида, представляющего интерес, где микробная клетка-хозяин была модифицирована таким образом, что ферментативная активность, выбранная из группы, состоящей из активности кетол-кислотной редуктоизомеразы (NADP(+)) (EC 1.1.1.86), активности синтазы ацетогидроксикислот (EC 2.2.1.6), активности аспартаткиназы (EC 2.7.2.4), активности гомосериндегидрогеназы (EC 1.1.1.3) и L-треониндегидратазы (EC 4.3.1.19), модулируется в указанной микробной клетке-хозяине по сравнению с ферментативной активностью в немодифицированной микробной клетке-хозяине.
17. Способ в соответствии с любым из вариантов осуществления 1-13, микробной клетки согласно варианту осуществления 14 или применения согласно варианту осуществления 15 или варианту осуществления 16, где ферментативная активность является модулированной.
18. Способ в соответствии с любым из вариантов осуществления 1-13 и варианта осуществления 17, микробной клетки согласно варианту осуществления 14 или варианту осуществления 17, или применения согласно вариантам осуществления 15, 16 или варианту осуществления 17, где полипептидом, представляющим интерес, является проинсулин.
ФИГУРЫ
Фигура 1: Карта плазмиды pSW3_lacI+, экспрессирующей мини-проинсулин. Плазмида pSW3_lacI+ придает резистентность к ампициллину и экспрессирует рекомбинантный белок массой 11 кДа (мини-проинсулин) под контролем индуцируемого промотора IPTG. Плазмида также коэкспрессирует репрессор LacI, который находится под контролем варианта промотора lacI+. Создана с помощью Snapgene®.
Фигура 2: карта плазмиды 16ABZ5NP_1934177, содержащей фрагмент 1. Создана с помощью Snapgene®.
Фигура 3: карта плазмиды pCP20. Создана с помощью Snapgene®.
Фигура 4: карта плазмиды pETcoco1, включающей ori2 и ее элементы (repE, sopA, sopB, sopC). Создана с помощью Snapgene®.
Фигура 5: карта регулируемой арабинозой плазмиды pACG_araBAD. Она включает ori2 и ее элементы (repE, sopA, sopB, sopC) которые обеспечивают 1 копию плазмиды на клетку. Плазмида придает резистентность к хлорамфениколу. Экзогенные гены могут быть клонированы с помощью рестрикционного клонирования с использованием ферментов NheI и NotI. Клонированные гены находятся под контролем арабинозного промотора. AraC является необходимым для активации арабинозного промотора и также присутствует в плазмиде. Дополнительные уникальные сайты рестрикции (SmiI, XhoI, XmaJI, MssI) присутствуют для того, чтобы обеспечить обмен точки начала репликации, маркера резистентности к антибиотику и промоторного участка. Создана с помощью Snapgene®.
Фигура 6: карта регулируемой арабинозой плазмиды pACG_araBAD_ilvIH. Данная плазмида получена в результате рестрикционного клонирования гена ilvIH в исходную плазмиду pACG_araBAD с использованием ферментов NheI and NotI. Данная плазмида обеспечивает возможность регуляции экспрессии гена ilvIH путем добавлением арабинозы в среду. Создана с помощью Snapgene®.
Фигура 7: генетические модификации, осуществленные в данной работе с E. coli дикого типа. Геномная ДНК является нокаутной по определенному гену (gene A). Экспрессия данного гена затем может регулироваться L-арабинозой за счет присутствия плазмиды, обеспечивающей регулируемую экспрессию, содержащей такой ген (pACG_araBAD_geneA). Кроме того, плазмида pSW3_lacI+ экспрессирует мини-проинсулин, который позволяет проверить на предмет ошибочного встраивания ncBCAA.
Фигура 8: карта плазмиды pKD46. Создана с помощью Snapgene®.
Фигура 9: карта плазмиды pKD3. Создана с помощью Snapgene®.
Фигура 10: карта плазмиды pKD4. Создана с помощью Snapgene®.
Фигура 11: Молярная концентрация норвалина (A), норлейцина (B) и β-метилнорлейцина (C), приведенная к значениям оптической плотности OD600 нм, во фракции внутриклеточного растворимого белка, рассчитанная в течение некоторого периода времени, после добавления разных культур E. сoli в реактор объемом 15 л в стандартных условиях (STD) и в условиях, вызывающих накопление ncBCAA, т. е. пульсирующей подачи пирувата и ограничения кислорода (PYR-O2). Указанная в обозначениях "WT E. coli" относится к штамму E. coli дикого типа K-12 BW25113 pSW3_lacI+, при этом ilvGM-регулируемая E. coli" ссылается на штамм E. coli K-12 BW25113 pSW3_lacI+ pACG_araBAD_ilvGM, и "ilvIH-регулируемая E. coli" соответствует штамму E. coli K-12 BW25113 ΔilvIH pSW3_lacI+ pACG_araBAD_ilvIH. Стрелки указывают моменты времени, в которых кратковременное добавление 1 г/л пирувата сочетают с 5 мин ограничением O2.
Фигура 12: молярная концентрация норвалина (A), норлейцина (B) и β-метилнорлейцина (C), приведенная к значениям оптической плотности OD600 нм, во фракции телец включений, рассчитанная в течение некоторого периода времени, после добавления разных культур E. coli в реактор объемом 15л в стандартных условиях (STD) и в условиях, вызывающих накопление ncBCAA, т. е. пульсирующей подачи пирувата и ограничения кислорода (PYR-O2). Указанная в обозначениях "WT E. coli" относится к штамму E. coli дикого типа K-12 BW25113 pSW3_lacI+, при этом ilvGM-регулируемая E. coli" ссылается на штамм E. coli K-12 BW25113 pSW3_lacI+ pACG_araBAD_ilvGM, и "ilvIH-регулируемая E. coli" соответствует штамму E. coli K-12 BW25113 ΔilvIH pSW3_lacI+ pACG_araBAD_ilvIH. Стрелки указывают моменты времени, в которых кратковременное добавление 1 г/л пирувата сочетают с 5 мин ограничением O2.
Все ссылки, указанные выше, включены в данный документ посредством ссылки с учетом их полного раскрываемого содержания, а также их конкретного раскрываемого содержания, на которые ссылаются в описании выше.
Следующие примеры только иллюстрируют настоящее изобретение. Тем не менее, их не следует истолковывать как ограничивающие объем охранного документа.
ПРИМЕРЫ
Пример 1. Трансформация мутантов K12 BW25113 ΔthrA, ΔilvA, ΔilvC, ΔilvIH и ΔilvBN посредством плазмиды pSW3_lacI+
Нокауты ΔthrA, ΔilvA, ΔilvC
Штамм E. coli K12 BW25113, а также мутанты c с одним нокаутом E. coli K12 BW25113 ΔthrA, ΔilvA и ΔilvC получали из E. coli Genetic Stock Center (CGSC) Йельского университета. Данные штаммы принадлежат к так называемой коллекции KEIO (Baba, T., Ara, T., Hasegawa, M., Takai, Y., Okumura, Y., Baba, M., ... & Mori, H. (2006). Construction of Escherichia coli K-12 in-frame, single-gene knockout mutants: the Keio collection. Molecular systems biology, 2(1)). Данные штаммы содержат плазмиду pKD46 (фигура 8) и маркерный ген, придающий устойчивость к канамицину, вместо гена-мишени. CGSC идентификация для каждого полученного штамма указывается следующим образом:
Осуществляли удаление путем излечивания плазмиды pKD46 из мутантов с одним нокаутом E. coli K12 BW25113 и соответствующие электрокомпетентные клетки трансформировали с использованием pCP20 (фигура 3), представляющей собой чувствительную к температуре плазмиду, кодирующую флипазу. Осуществляли удаление путем излечивания плазмиды pCP20, а удаление маркерного-гена устойчивости к антибиотику из мутантов проверяли посредством секвенирования. Полученные соответствующие электрокомпетентные мутанты E. coli K12 BW25113 трансформировали с использованием pSW3_lacI+ (фигура 1), многокопийной плазмиды, кодирующей мини-проинсулин.
Нокауты ΔilvIH и ΔilvBN
Нокаутные штаммы E. coli K12 BW25113 ΔilvIH и ΔilvBN не приобретали, а создавали самостоятельно. Процедура получения нокаутных мутантов E. coli описана в "Datsenko, K. A., & Wanner, B. L. (2000). One-step inactivation of chromosomal genes in Escherichia coli K-12 using PCR products. Proceedings of the National Academy of Sciences, 97(12), 6640-6645", использованную в качестве ссылки. Электрокомпетентные клетки E. coli K12 BW25113 трансформировали с использованием pKD46, представляющую собой чувствительную к температуре рекомбинантную плазмиду-помощника. Мутанты, нокаутные по оперонам ilvIH и ilvBN, затем получали посредством трансформации электрокомпетентных клеток E. coli K12 BW25113, содержащих pKD46 с соответствующей делеционной кассеты, ранее полученной посредством ПЦР из pKD3 (фигура 9) или pKD4 (фигура 10). Проверку с использованием ПЦР проводили для того, чтобы удостовериться в правильном встраивании делеционной кассеты в геном. Осуществляли удаление путем излечивания плазмиды pKD46 из клеток и соответствующие электрокомпетентные мутанты E. coli K12 BW25113 трансформировали с использованием pCP20 (фигура 3), представляющей собой чувствительную к температуре плазмиду, кодирующую флипазу. Осуществляли удаление путем излечивания плазмиды pCP20, а удаление маркерного-гена устойчивости к антибиотику из мутантов проверяли посредством секвенирования. Полученные соответствующие электрокомпетентные мутанты E. coli K12 BW25113 трансформировали с использованием pSW3_lacI+ (фигура 1), многокопийной плазмиды, кодирующей мини-проинсулин.
Пример 2. Конструирование и получение регулируемого araC-PBAD вектора экспрессии (pACG_araBAD)
Плазмиду с регулируемой арабинозой экспрессией, обеспечивающую регуляцию исследуемых генов, которые ранее были подвергнуты нокауту, получали посредством соединения 3 разных сегментов ДНК: фрагмент 1 содержит промоторный участок araC-PBAD (Guzman et al., 1995, Tight regulation, modulation, and high-level expression by vectors containing the arabinose PBAD promoter. Journal of bacteriology, 177(14), 4121-4130), области UTR, терминатор T7, сайт клонирования, позволяющий клонирование генов с помощью редкощепящих рестриктаз NheI и NotI, и C-конец с последовательностью 6xhis-tag, обеспечивающей экспрессию слитых белков. Фрагмент 2 содержит кассету устойчивости к хлорамфениколу, тогда как фрагмент 3 включает точку начала репликации ori2 и гены sopA, sopB, sopC и repE.
Фрагмент 1 получали посредством химического синтеза и в дальнейшем клонировали в плазмиде 16ABZ5NP_1934177 (фигура 2). Затем фрагмент 1 амплифицировали с помощью ПЦР из плазмиды 16ABZ5NP_1934177. Фрагменты 2 и 3 непосредственно амплифицировали с помощью ПЦР из плазмид pCP20 (фигура 3) и pETcoco1 (фигура 4) соответственно. Три сегмента ДНК соединили вместе в соответствии со стратегией клонирования In-Fusion (Takara Bio USA; номер: 639649) с получением плазмиды pACG_araBAD (фигура 5).
Пример 3. Клонирование генов-мишеней в регулируемые векторы экспрессии
Исследуемые гены (ilvA, ilvC, ilvIH, ilvBN и thrA) амплифицировали с помощью ПЦР с геномной ДНК E. coli K12 BW25113 и затем их клонировали в ранее полученную плазмиду, обеспечивающую регулируемую экспрессию (фигура 5), с применением рестриктаз NheI и NotI. ilvGM амплифицировали из штамма E. coli, в котором ilvG не был мутирован. В качестве примера на фигуре 6 показана карта полученной регулируемой арабинозой плазмиды pACG_araBAD_ilvIH.
Пример 4. Трансформация регулируемых векторов экспрессии с клонированными генами в соответствующий мутант, содержащий pSW3_lacI+
Конечные соответствующие электрокомпетентные мутанты E. coli K12 BW25113, содержащие pSW3_lacI+, трансформировали плазмидой с регулируемой экспрессией, экспрессирующей соответствующий исследуемый ген.
После всех генетических модификаций полученные мутантные штаммы E. coli выглядят так, как это представлено на фигуре 7. В общей сложности получали 6 мутантных штаммов E. coli:
E. coli K12 BW25113 ΔilvC, экспрессирующий pSW3_lacI+ и pACG_araBAD_ilvC;
E. coli K12 BW25113 ΔilvIH, экспрессирующий pSW3_lacI+ и pACG_araBAD_ilvIH;
E. coli K12 BW25113 ΔilvBN,, экспрессирующий pSW3_lacI+ и pACG_araBAD_ilvBN;
E. coli K12 BW25113 ΔthrA, экспрессирующий pSW3_lacI+ и pACG_araBAD_thrA;
E. coli K12 BW25113 ΔilvA, экспрессирующий pSW3_lacI+ и pACG_araBAD_ilvA;
E. coli K12 BW25113, экспрессирующий pSW3_lacI+ и pACG_araBAD_ilvGM.
Пример 5. Оценка индуцирующего эффекта L-арабинозы на клеточный рост мутантных штаммов E. coli
Целью данного эксперимента являлось оценить влияние добавления разных концентраций L-арабинозы на экспрессию генов под контролем промотора araBAD и, как следствие, влияние на клеточный рост полученных мутантных штаммов E. coli.
Клетки E. coli выращивали в среде с определенным составом минеральных солей, содержащей (на л): 0,67 г Na2SO4, 0,82 г (NH4)2SO4, 0,17 г NH4Cl, 4,87 г K2HPO4, 1,2 г NaH2PO4×2H2O и 0,33 г (NH4)2-H-цитрата. Среду дополняли 0,67 мл/л раствором микроэлементов и 0,67 мл/л раствором MgSO4 (1,0 M). Раствор микроэлементов содержал (на л): 0,5 г CaCl2×2H2O, 0,18 г ZnSO4×7H2O, 0,1 г MnSO4 x H2O, 16,7 г FeCl3×6H2O, 0,16 г CuSO4×5H2O, 0,18 г CoCl2×6H2O. Дополнительно 0,1 M Na-фосфатный буфер использовали для дополнительного забуферивания среды.
С целью получения культуры 50 мкл замороженного стокового раствора, содержащего соответствующий штамм E. coli,, использовали для инокуляции 5 мл среды, дополненной определенными минеральными солями, содержащей 5 г/л глюкозы, 100 мкг/мл ампициллина, 25 мкг/мл хлорамфеникола (только для мутантных штаммов E. сoli) и заданную концентрацию L-арабинозы. Культуру инкубировали при 37°C и 220 об./мин в орбитальном шейкере в течение 15 ч. При завершении процесса оптическую плотность OD600 нм измеряли для каждой культуры. В следующей таблице приведены полученные результаты:
pACG_araBAD_ilvC
Пример 6. Условия культивирования для оценки эффекта индуцирования L-арабинозы в отношении продуцирования ncBCAA в мутантных штаммах E. сoli в масштабе минибиореактора
Среда для культивирования
Клетки E. coli выращивали в среде с определенным составом минеральных солей, содержащей (на л): 0,67 г Na2SO4, 0,82 г (NH4)2SO4, 0,17 г NH4Cl, 4,87 г K2HPO4, 1,2 г NaH2PO4×2H2O и 0,33 г (NH4)2-H-цитрата. Среду дополняли 0,67 мл/л раствором микроэлементов и 0,67 мл/л раствором MgSO4 (1,0 M). Раствор микроэлементов содержал (на л): 0,5 г CaCl2×2H2O, 0,18 г ZnSO4×7H2O, 0,1 г MnSO4 x H2O, 16,7 г FeCl3×6H2O, 0,16 г CuSO4×5H2O, 0,18 г CoCl2×6H2O. Дополнительно 0,1 M Na-фосфатный буфер использовали для дополнительного забуферивания среды.
Предварительное культивирование
30 мкл замороженного стокового раствора, содержащего соответствующий штамм E. coli,, использовали для инокуляции 30 мл среды, дополненной определенными минеральными солями, содержащей 5 г/л глюкозы, 100 мкг/мл ампициллина, 25 мкг/мл хлорамфеникола (только для мутантных штаммов E. сoli), с целью инициации предварительного культивирования. Для каждого мутантного штамма E. coli среда также содержала минимальную концентрацию L-арабинозы, необходимую для восстановления клеточного роста немодифицированного штамма, который ранее протестировали в примере 5. Предварительную культуру инкубировали при 37°C и 220 об./мин в орбитальном шейкере в течение ночи.
• Основное культивирование
Оптическую плотность OD600 нм измеряли в конце предварительного культивирования и указанный объем использовали для инокуляции 5 мл начального объема в мини-биореакторе Pall Micro24 (Microreactor Technologies Inc.) таким образом, что исходная оптическая плотность при 600 нм составляла 0,4. Среда в миниреакторе состояла из среды, дополненной определенными минеральными солями, содержащей 4 г/л глюкозы, 100 мкг/мл ампициллина, 25 мкг/мл хлорамфеникола (только для мутантных штаммов E. coli) и 1 мкл/мл пеногасителя Desmophen. Среду также дополняли разными концентрациями L-арабинозы. Культивирование проводили при 37°C и pH поддерживали на уровне 7 посредством автоматического контроля с использованием NH4OH и CO2. Скорость мешалки устанавливали на 800 об./мин и установленное значение DO доводили до 25%, причем последнее поддерживали автоматически путем увеличения подачи кислорода в миниреактор. Стационарная фаза продолжалось около 4 ч. После завершения стационарной фазы 1 мл 400 г/л раствора EnPump 200 и 50 мкл 3000 Ед/л раствора амилазы вручную добавляли в миниреактор, с этого момента начиналась стационарная фаза с подпиткой. EnPump 200 представляет собой полимер на основе глюкозы, в котором в присутствии амилазы происходит постоянный гидролиз полимера, высвобождая свободные молекулы глюкозы со временем, обеспечивая глюкозолимитированную ферментацию. Через 30 мин после начала стационарной фазы с подпиткой индуцировали экспрессию рекомбинантного белка путем кратковременного добавления вручную IPTG до конечной концентрации 0,5 мM. Стационарная фаза с подпиткой была активна в течение 3,5 ч.
Пример 7. Анализ аминокислот
Фракция внутриклеточного растворимого белка и фракция телец включений были выделены из клеточных экстрактов в соответствии с протоколами, предоставленными с набором "BugBuster Protein Extraction Reagent" (Merck, кат. № 70584-4). 250 мкл фракции выделенного внутриклеточного растворимого белка смешивали с 750 мкл 5 M HCl. Выделенные осадки с тельцами-включениями ресуспендировали с 200 л dH2O и 100 мкл полученной в результате суспензии телец-включений смешивали с 900 мкл 5 M HCl. Полученные растворы вносили в прозрачные стеклянные флаконы с завинчивающимися пробками и флаконы инкубировали в закрытом виде в течение 24 ч при 80°C для кислотного гидролиза. После этого флаконы оставляли открытыми в нагревательном блоке на 16-24 ч при 65°C с переворачиванием до испарения всей жидкости. Выделение аминокислот из высушенных гидролизованных образцов проводили в соответствии с протоколом, предоставленным с набором "EZ:faast™ for free (physiological) amino acid analysis by GC-FID" (Phenomenex, кат. № KG0-7165). После процесса выделения около 120 мкл полученного в результате верхнего слоя вносили в флаконы для газовой хроматографии, а затем 2 мкл вводили в газохроматографический анализатор. Газохроматографический анализатор запускали в соответствии со следующими условиями термостата: время уравновешивания 0,5 мин, 110°C на 1 мин, 30°C/мин нагревание до 320 °C, а затем 320°C в течение 1 мин. Азот использовали в качестве газа-носителя с постоянной скоростью потока 1,5 мл/мин. Введение проводили с коэффициентом разделения потока 1:15 при 250°C.
Пример 8. Оценка эффекта индуцирования L-арабинозы в отношении продуцирования ncBCAA в мутантных штаммах E. сoli в масштабе минибиореактора
В следующих таблицах обобщают результаты экспериментов для каждой протестированной белковой фракции, ncBCAA и мутантного штамма при разных концентрациях L-арабинозы. Указанные в таблицах данные, выделенные жирным шрифтом, соответствуют концентрации указанной ncBCAA в контрольном штамме E. coli BW25113 pSW3_lacI+. Указанные в таблицах данные в процентном формате соответствуют процентному изменению концентрации ncBCAA, полученной в мутантном штамме, при определенной концентрации L-арабинозы по отношению к концентрации ncBCAA, полученной в контрольном штамме E. coli BW25113 pSW3_lacI+.
Фракция телец-включений
A) Норвалин
В случае штаммов E. coli BW25113 ΔilvC pSW3_lacI+ pACG_araBAD_ilvC и E. coli BW25113 ΔilvIH pSW3_lacI+ pACG_araBAD_ilvIH концентрация норвалина снижалась при добавлении возрастающих концентраций L-арабинозы в среду. Противоположная реакция наблюдалась в случае штамма E. coli BW25113 ΔilvBN pSW3_lacI+ pACG_araBAD_ilvBN. В случае штаммов E. coli BW25113 ΔthrA pSW3_lacI+ pACG_araBAD_thrA и E. coli BW25113 pSW3_lacI+ pACG_araBAD_ilvGM концентрация норвалина в значительной степени уменьшалась, но влияние возрастающих концентраций L-арабинозы не продемонстрировало четкой тенденции к изменению концентрации норвалина. В случае штамма E. coli BW25113 ΔilvA pSW3_lacI+ pACG_araBAD_ilvA значительное снижение концентрации норвалина выявлено не было, и влияние возрастающих концентраций L-арабинозы не продемонстрировало четкой тенденции к изменению концентрации норвалина.
B) Норлейцин
В случае штаммов E. coli BW25113 ΔilvC pSW3_lacI+ pACG_araBAD_ilvC и E. coli BW25113 ΔilvIH pSW3_lacI+ pACG_araBAD_ilvIH концентрация норлейцина снижалась при добавлении возрастающих концентраций L-арабинозы в среду. Противоположная реакция наблюдалась в случае штамма E. coli BW25113 ΔilvBN pSW3_lacI+ pACG_araBAD_ilvBN. В случае штаммов E. coli BW25113 ΔthrA pSW3_lacI+ pACG_araBAD_thrA и E. coli BW25113 pSW3_lacI+ pACG_araBAD_ilvGM концентрация норлейцина в значительной степени уменьшалась, но влияние возрастающих концентраций L-арабинозы не продемонстрировало четкой тенденции к изменению концентрации норлейцина. В случае штамма E. coli BW25113 ΔilvA pSW3_lacI+ pACG_araBAD_ilvA значительное снижение концентрации норлейцина выявлено не было, но влияние возрастающих концентраций L-арабинозы не продемонстрировало четкой тенденции к изменению концентрации норлейцина.
Фракция внутриклеточного растворимого белка
A) Норвалин
В случае штаммов E. coli BW25113 ΔilvC pSW3_lacI+ pACG_araBAD_ilvC и E. coli BW25113 ΔilvIH pSW3_lacI+ pACG_araBAD_ilvIH концентрация норвалина снижалась при добавлении возрастающих концентраций L-арабинозы в среду. Противоположная реакция наблюдалась в случае штамма E. coli BW25113 ΔilvBN pSW3_lacI+ pACG_araBAD_ilvBN. В случае штаммов E. coli BW25113 ΔthrA pSW3_lacI+ pACG_araBAD_thrA, E. coli BW25113 ΔilvA pSW3_lacI+ pACG_araBAD_ilvA и E. coli BW25113 pSW3_lacI+ pACG_araBAD_ilvGM концентрация норвалина в значительной степени уменьшалась, но влияние возрастающих концентраций L-арабинозы не продемонстрировало четкой тенденции к изменению концентрации норвалина.
B) Норлейцин
В случае штаммов E. coli BW25113 ΔilvC pSW3_lacI+ pACG_araBAD_ilvC и E. coli BW25113 ΔilvIH pSW3_lacI+ pACG_araBAD_ilvIH концентрация норлейцина снижалась при добавлении возрастающих концентраций L-арабинозы в среду. Противоположная реакция наблюдалась в случае штамма E. coli BW25113 ΔilvBN pSW3_lacI+ pACG_araBAD_ilvBN. В случае штаммов E. coli BW25113 ΔthrA pSW3_lacI+ pACG_araBAD_thrA, E. coli BW25113 ΔilvA pSW3_lacI+ pACG_araBAD_ilvA and E. coli BW25113 pSW3_lacI+ pACG_araBAD_ilvGM концентрация норлейцина в значительной степени снижалась, но влияние концентрации L-арабинозы не продемонстрировало четкой тенденции к изменению концентрации норлейцина.
C) β-метилнорлейцин
В случае фактически всех протестированных штаммов и концентраций L-арабинозы выявили незначительное снижение концентрации β-метилнорлейцина во фракции внутриклеточного растворимого белка. Однако данное снижение не было в действительности значительным по сравнению с норвалином и норлейцином за исключением штамма E. coli BW25113 ΔilvBN pSW3_lacI+ pACG_araBAD_ilvBN, индуцированного 0,05% L-араб., в случае которого снижение достигло приблизительно 42%. Кроме того, влияние возрастающих концентраций L-арабинозы не демонстрирует четкой тенденции к изменению концентрации β-метилнорлейцина
ПРИМЕР 9. Скрининг в отношении потенциальных ilvGM- и ilvIH-регулируемых штаммов E. coli в масштабе 15 л реактора в условиях, инициирующих образование ncBCAA
В ходе ферментации в крупномасштабных реакторах образуются зоны градиентов субстратов, растворенного кислорода, pH и других параметров из-за неэффективного перемешивания, и клетки E. coli реагируют на такие изменения среды изменением своего метаболизма (Schweder (1999). Monitoring of genes that respond to process-related stress in large-scale bioprocesses. Biotechnology and bioengineering, 65(2), 151-159). Например, E. coli реагирует на избыток глюкозы и ограничение кислорода сдвигом метаболизма от клеточного дыхания к ферментации с образованием смеси органических кислот, что приводит к перегруженности метаболизма (Enfors et al. (2001). Physiological responses to mixing in large scale bioreactors. Journal of biotechnology, 85(2), 175-185). При таких условиях образуются не только продукты ферментации в виде смеси органических кислот, но и пируват (Soini, J. et al. (2008). Norvaline is accumulated after a down-shift of oxygen in Escherichia coli W3110. Microb. Cell Fact., 7: 1-14). Избыток внутриклеточного пирувата увеличивает поток метаболитов в пути биосинтеза ncBCAA через последовательное удлинение цепи кетокислоты от пирувата до α-кетокапроата через α-кетобутират и α-кетовалерат путем активации ферментов, кодируемых leu-опероном (Apostol, I. et al. (1997). Incorporation of norvaline at leucine positions in recombinant human hemoglobin expressed in Escherichia coli. Journal of Biological Chemistry, 272(46), 28980-28988). Данная гипотеза поддерживается наблюдениями, отмеченными в Soini et al. (2011, Accumulation of amino acids deriving from pyruvate in Escherichia coli W3110 during fed-batch cultivation in a two-compartment scale-down bioreactor. Advances in Bioscience and Biotechnology, 2(05), 336): комбинация ограничения кислорода c постоянной подачей глюкозой в двухкамерном реакторе STR-PFR уменьшенного масштаба значительно влияет на усиление биосинтеза норвалина вследствие накопления пирувата при культивировании рекомбинантной E. coli. Более того, Soini et al. (2008) изначально сообщили о накоплении аминокислот на основе пирувата, таких как ncBCAA, норлейцин и норвалин, а также аланина и валина при стандартном культивировании в STR с подпиткой E. coli в условиях избытка глюкозы и индуцированного ограничения кислорода при замедлении вращения мешалки.
Градиенты концентрации, образующиеся в крупномасштабных промышленных биореакторах из-за недостаточного перемешивания, также могут быть воспроизведены в небольших биореакторах в лаборатории. В данном исследовании воздействия увеличения масштаба воспроизводятся в реакторе объемом 15 л путем сочетания кратковременной подачи пирувата и ограничения подачи O2. Данная новая стратегия культивирования может более точно представлять физиологическое поведение бактериальных культур, происходящее в крупномасштабных биореакторах.
В соответствии со скринингом в минибиореакторе (пример 8) штаммы E. coli K-12 BW25113 pSW3_lacI+ pACG_araBAD_ilvGM (ilvGM-регулируемая E. coli) и E. coli K-12 BW25113 ΔlvIH pSW3_lacI+ pACG_araBAD_ilvIH (ilvIH-регулируемая E. coli), индуцированные 0,8% L-арабинозой, показали наилучшую продуктивность среди всех подвергнутых скринингу мутантов в 10 мл минибиореакторе, поскольку они показали наиболее значительное снижение ошибочного встраивания ncBCAA в рекомбинантный минипроинсулин по сравнению с контрольным немодифицированным штаммом E. coli. Цель данного эксперимента заключалась в том, чтоб проверить продуктивность вышеуказанного потенциального регулируемого штамма E. coli в 15 л реакторе в условиях культивирования, вызывающих образование ncBCAA, т. е. путем кратковременного добавления пирувата и ограничения кислорода, с целью подтверждения его преимущества как штамма, обеспечивающего качественный продукт. Для сравнения также культивировали контрольный немодифицированный штамм-хозяин E. сoli (E. coli K-12 BW25113 pSW3_lacI+).
Культивирование E. coli K-12 BW25113 pSW3_lacI+ (контрольного штамма) в стандартных условиях
100 мкл замороженного стокового раствора, содержащего E. coli K-12 BW25113 pSW3_lacI+, использовали для инокуляции 500 мл среды, дополненной минеральными солями, содержащей 5 г/л глюкозы и 100 мкг/мл ампициллина, с целью получения предварительной культуры. Состав минеральных солей был следующим: 2 г/л Na2SO4, 2,468 г/л (NH4)2SO4, 0,5 г/л NH4Cl, 14,6 г/л K2HPO4, 3,6 г/л NaH2PO4.2H2O и 1 г/л (NH4)2-H-цитрат. Среду с минеральными солями затем дополняли 2 мл/л раствором MgSO4 (1,0 M) и 2 мл/л раствором микроэлементов. Раствор микроэлементов содержал (на л): 0,5 г CaCl2×2H2O, 0,18 г ZnSO4×7H2O, 0,1 г MnSO4 x H2O, 16,7 г FeCl3×6H2O, 0,16 г CuSO4×5H2O, 0,18 г CoCl2×6H2O. Предварительную культуру инкубировали при 37°C и 220 об/мин в орбитальном шейкере в течение 12 ч с использованием методики начального холодного старта. Оптическую плотность OD600 нм измеряли в конце предварительного культивирования и указанный объем использовали для инокуляции 7 л начального объема в реакторе таким образом, чтобы исходная оптическая плотность OD600 нм составляла 0,4. Среда в реакторе состояла из среды, дополненной минеральными солями, содержащей 5 г/л глюкозы, 2 мл пеногасителя (Antifoam 2014, Sigma) и 100 мкг/мл ампициллина. Культивирование проводили при 37°C и pH поддерживали при 7 посредством автоматического контролем с использованием 25% NH4OH. Скорость воздушного потока была установлена на 7 об/об/мин и установленное значение DO доводили до 20%, причем последнее поддерживали с применением ступенчатого контроля, изменяющего скорость мешалки (начальная скорость мешалки была установлена на 800 об./мин) Стационарная фаза продолжалась фактически 4 ч, с промежуточной холодной фазой продолжительностью 13 ч при 15°C. В конце стационарной фазы начинался экспоненциальный рост в соответствии со следующим уравнением:
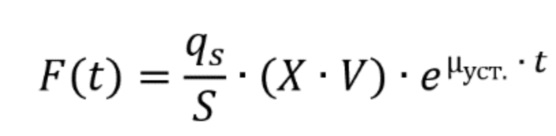
где F (t) представляет собой уровень подачи питательных веществ с течением времени (L ч-1), qs представляет собой заданное значение уровня потребления субстрата (0,514 г S gX-1 ч-1), S представляет собой концентрацию глюкозы в питательном растворе (442 г/л), X представляет собой концентрацию биомассы с течением времени (г/л), V представляет собой объем реактора с течением времени (л), µуст. представляет собой установленное значение скорости роста конкретной клетки (0,3 ч-1) и t представляет собой время продолжительности стационарной фазы с подпиткой. Подпиточный раствор состоял из среды с минеральными солями TUB, дополненной 4 мл/л раствора микроэлементов, 2 мл/л раствора MgSO4 (1,0 M), 100 мкг/мл ампициллина и 442 г/л глюкозы.
Экспоненциальную фазу с подпиткой проводили в течение 3 часов, а затем экспрессию рекомбинантного минипротоинсулина индуцировали автоматическим добавлением IPTG с достижением конечной концентрации 0,5 мM. Время индуцирования составляло 30 минут. В ходе фазы индуцирования питательные вещества не добавляли в реактор. После индуцированию начинали фазу с постоянной подпиткой, при этом постоянная скорость потока равнялась последней скорости потока, достигнутой в экспоненциальной фазе роста. Стационарная фаза с подпиткой была активна в течение 5-6 ч.
Культивирование E. coli K-12 BW25113 pSW3_lacI+ (контрольного штамма) в условиях, инициирующих образование ncBCAA
Культивирование проводили так, как это описано для стандартного культивирования в предыдущем разделе. Однако после экспоненциальной фазы с подпиткой осуществляли автоматическое кратковременное добавление 1 г/л пирувата в реактор. Раствор пирувата постоянно подавали в течение 5 минут. В ходе данного периода времени питательные вещества не добавляли, скорость воздушного потока временно устанавливали на 0 и ступенчатый контроль DO выключали. После первого добавления пирувата экспрессию рекомбинантного минипроинсулина индуцировали автоматическим добавлением IPTG с достижением конечной концентрации 0,5 мМ. Время индуцирования составляло 30 минут. В ходе фазы индуцирования питательные вещества не добавляли в реактор, а подачу воздушного потока и ступенчатый контроль DO включали. После индуцирования проводили последовательные добавления 1 г/л пирувата каждые 30 мин, как это описано выше, в количестве 4 кратковременных добавлений. Между добавлениями активировали фазу с постоянной подпиткой, при этом постоянная скорость потока равнялась последней скорости потока, достигнутой в экспоненциальной фазе роста, и скорость воздушного потока и ступенчатый контроль DO снова включали. Стационарная фаза с подпиткой была активна в течение 5-6 ч.
Культивирование ilvGM-регулируемой E. coli в условиях, инициирующих образование ncBCAA
Процесс культивирования проводили так, как это описано в предыдущем разделе, и вносили только небольшие изменения с целью адаптации процесса культивирования к штамму ilvGM-регулируемой E. coli. Как предварительная культура, так и среда в реакторе содержали дополнительно 25 мкг/мл хлорамфеникола. Среда в реакторе дополнительно содержала 0,8% L-арабинозы, необходимой для индуцирования экспрессии гена ilvGM, расположенного в плазмиде pACG_araBAD_ilvGM. В питательный раствор также дополнительно добавляли 25 мкг/мл хлорамфеникола и 0,8% L-арабинозы.
Культивирование ilvIH-регулируемой E. coli в условиях, вызывающих образование ncBCAA
Культивирование проводили так, как это описано в предыдущем разделе.
Пример 10. Анализ ncBCAA
Концентрации ncBCAA, присутствующие во фракции внутриклеточного растворимого белка и фракции телец-включений, для каждого протестированного штамма в ходе культивации в примере 9 показаны на фигуре 11 и фигуре 12 соответственно.
Культивирование контрольного штамма E. coli, к которому добавляли пирувата вместе с ограничением O2 ("WT E. coli, PYR-O2"), показало постепенное накопление норлейцина и β-метилнорлейцина во фракции внутриклеточного растворимого белка в течение времени после индуцирования, при этом такое накопление являлось более значительным для норлейцина. Кроме того, концентрация норвалина также постепенно повышалась в указанных выше условиях культивирования, но только через 3 ч после индуцирования. С того момента времени и далее, концентрация норвалина постепенно снижалась, пока не достигала исходных значений через 5 ч после индуцирования. Это может указывать на то, что через 2 ч после последнего кратковременного добавления пирувата в сочетании с ограничением O2 его эффект, ассоциируемый с накоплением норвалина, уже не является активным (фигура 11). Как и ожидалось, вышеуказанный штамм показал более высокий уровень норвалина и норлейцина по сравнению с контрольным штаммом E. сoli, культивируемым в стандартных условиях ("WT E. coli, STD"). Такое различие в концентрациях не выявили для β-метилнорлейцина.
Оба протестированных в культивировании потенциальных мутантных штамма "ilvGM-регулируемая E. coli, PYR-O2" и "ilvIH-регулируемая E. coli, PYR-O2" показали выраженное снижение концентраций норвалина и норлейцина во фракции внутриклеточного растворимого белка, при этом такое снижение было выражено сильнее для норлейцина в "ilvGM-регулируемой E. coli, PYR-O2". Однако концентрации β-метилнорлейцина не отличались в значительной степени от контрольной культуры. Следует подчеркнуть, что в большинстве образцов, норвалин не мог быть обнаружен с должным качеством, так как концентрации были ниже предела обнаружения оборудования GC-FID (фигура 11).
Культивирование контрольного штамма E. coli, к которому добавляли пируват вместе с ограничением O2 ("WT E. coli, PYR-O2"), показало постепенное накопление норвалина и норлейцина во фракции телец-включений с течением времени после индуцирования. Как и ожидалось, вышеуказанный штамм показал более высокий уровень норвалина и норлейцина по сравнению с контрольным штаммом E. сoli, культивируемым в стандартных условиях ("WT E. coli, STD"). И в данном случае аналогичный результат был получен по внутриклеточной растворимой фракции, причем оба протестированных в культивировании потенциальных мутанта "ilvGM-регулируемая E. coli, PYR-O2" и "ilvIH-регулируемая E. coli, PYR-O2" показали выраженное снижение концентраций норвалина и норлейцина во фракции телец включений, при этом такое снижение было еще более выраженным для норлейцина в случае "ilvGM-регулируемой E. coli, PYR-O2". Норвалин не смогли обнаружить ни в одном из случаев для обоих тестируемых мутантов. β-метилнорлейцин не смогли обнаружить ни в одном из тестируемых образцов (фигура 12).
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Sanofi-Aventis Deutschland GmbH
<120> Способ снижения ошибочного включения неканонических аминокислот
с разветвленной цепью
<130> DE2018-069
<150> EP 18 214 562.3
<151> 2018-12-20
<160> 46
<170> BiSSAP 1.3.6
<210> 1
<211> 1572
<212> ДНК
<213> Escherichia coli
<220>
<223> leuA, 2-изопропилмалатсинтаза
<400> 1
atgagccagc aagtcattat tttcgatacc acattgcgcg acggtgaaca ggcgttacag
60
gcaagcttga gtgtgaaaga aaaactgcaa attgcgctgg cccttgagcg tatgggtgtt
120
gacgtgatgg aagtcggttt ccccgtctct tcgccgggcg attttgaatc ggtgcaaacc
180
atcgcccgcc aggttaaaaa cagccgcgta tgtgcgttag ctcgctgcgt ggaaaaagat
240
atcgacgtgg cggccgaatc cctgaaagtc gccgaagcct tccgtattca tacctttatt
300
gccacttcgc caatgcacat cgccaccaag ctgcgcagca cgctggacga ggtgatcgaa
360
cgcgctatct atatggtgaa acgcgcccgt aattacaccg atgatgttga attttcttgc
420
gaagatgccg ggcgtacacc cattgccgat ctggcgcgag tggtcgaagc ggcgattaat
480
gccggtgcca ccaccatcaa cattccggac accgtgggct acaccatgcc gtttgagttc
540
gccggaatca tcagcggcct gtatgaacgc gtgcctaaca tcgacaaagc cattatctcc
600
gtacataccc acgacgattt gggcctggcg gtcggaaact cactggcggc ggtacatgcc
660
ggtgcacgcc aggtggaagg cgcaatgaac gggatcggcg agcgtgccgg aaactgttcc
720
ctggaagaag tcatcatggc gatcaaagtt cgtaaggata ttctcaacgt ccacaccgcc
780
attaatcacc aggagatatg gcgcaccagc cagttagtta gccagatttg taatatgccg
840
atcccggcaa acaaagccat tgttggcagc ggcgcattcg cacactcctc cggtatacac
900
caggatggcg tgctgaaaaa ccgcgaaaac tacgaaatca tgacaccaga atctattggt
960
ctgaaccaaa tccagctgaa tctgacctct cgttcggggc gtgcggcggt gaaacatcgc
1020
atggatgaga tggggtataa agaaagtgaa tataatttag acaatttgta cgatgctttc
1080
ctgaagctgg cggacaaaaa aggtcaggtg tttgattacg atctggaggc gctggccttc
1140
atcggtaagc agcaagaaga gccggagcat ttccgtctgg attacttcag cgtgcagtct
1200
ggctctaacg atatcgccac cgccgccgtc aaactggcct gtggcgaaga agtcaaagca
1260
gaagccgcca acggtaacgg tccggtcgat gccgtctatc aggcaattaa ccgcatcact
1320
gaatataacg tcgaactggt gaaatacagc ctgaccgcca aaggccacgg taaagatgcg
1380
ctgggtcagg tggatatcgt cgctaactac aacggtcgcc gcttccacgg cgtcggcctg
1440
gctaccgata ttgtcgagtc atctgccaaa gccatggtgc acgttctgaa caatatctgg
1500
cgtgccgcag aagtcgaaaa agagttgcaa cgcaaagctc aacacaacga aaacaacaag
1560
gaaaccgtgt ga
1572
<210> 2
<211> 523
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> leuA, 2-изопропилмалатсинтаза
<400> 2
Met Ser Gln Gln Val Ile Ile Phe Asp Thr Thr Leu Arg Asp Gly Glu
1 5 10 15
Gln Ala Leu Gln Ala Ser Leu Ser Val Lys Glu Lys Leu Gln Ile Ala
20 25 30
Leu Ala Leu Glu Arg Met Gly Val Asp Val Met Glu Val Gly Phe Pro
35 40 45
Val Ser Ser Pro Gly Asp Phe Glu Ser Val Gln Thr Ile Ala Arg Gln
50 55 60
Val Lys Asn Ser Arg Val Cys Ala Leu Ala Arg Cys Val Glu Lys Asp
65 70 75 80
Ile Asp Val Ala Ala Glu Ser Leu Lys Val Ala Glu Ala Phe Arg Ile
85 90 95
His Thr Phe Ile Ala Thr Ser Pro Met His Ile Ala Thr Lys Leu Arg
100 105 110
Ser Thr Leu Asp Glu Val Ile Glu Arg Ala Ile Tyr Met Val Lys Arg
115 120 125
Ala Arg Asn Tyr Thr Asp Asp Val Glu Phe Ser Cys Glu Asp Ala Gly
130 135 140
Arg Thr Pro Ile Ala Asp Leu Ala Arg Val Val Glu Ala Ala Ile Asn
145 150 155 160
Ala Gly Ala Thr Thr Ile Asn Ile Pro Asp Thr Val Gly Tyr Thr Met
165 170 175
Pro Phe Glu Phe Ala Gly Ile Ile Ser Gly Leu Tyr Glu Arg Val Pro
180 185 190
Asn Ile Asp Lys Ala Ile Ile Ser Val His Thr His Asp Asp Leu Gly
195 200 205
Leu Ala Val Gly Asn Ser Leu Ala Ala Val His Ala Gly Ala Arg Gln
210 215 220
Val Glu Gly Ala Met Asn Gly Ile Gly Glu Arg Ala Gly Asn Cys Ser
225 230 235 240
Leu Glu Glu Val Ile Met Ala Ile Lys Val Arg Lys Asp Ile Leu Asn
245 250 255
Val His Thr Ala Ile Asn His Gln Glu Ile Trp Arg Thr Ser Gln Leu
260 265 270
Val Ser Gln Ile Cys Asn Met Pro Ile Pro Ala Asn Lys Ala Ile Val
275 280 285
Gly Ser Gly Ala Phe Ala His Ser Ser Gly Ile His Gln Asp Gly Val
290 295 300
Leu Lys Asn Arg Glu Asn Tyr Glu Ile Met Thr Pro Glu Ser Ile Gly
305 310 315 320
Leu Asn Gln Ile Gln Leu Asn Leu Thr Ser Arg Ser Gly Arg Ala Ala
325 330 335
Val Lys His Arg Met Asp Glu Met Gly Tyr Lys Glu Ser Glu Tyr Asn
340 345 350
Leu Asp Asn Leu Tyr Asp Ala Phe Leu Lys Leu Ala Asp Lys Lys Gly
355 360 365
Gln Val Phe Asp Tyr Asp Leu Glu Ala Leu Ala Phe Ile Gly Lys Gln
370 375 380
Gln Glu Glu Pro Glu His Phe Arg Leu Asp Tyr Phe Ser Val Gln Ser
385 390 395 400
Gly Ser Asn Asp Ile Ala Thr Ala Ala Val Lys Leu Ala Cys Gly Glu
405 410 415
Glu Val Lys Ala Glu Ala Ala Asn Gly Asn Gly Pro Val Asp Ala Val
420 425 430
Tyr Gln Ala Ile Asn Arg Ile Thr Glu Tyr Asn Val Glu Leu Val Lys
435 440 445
Tyr Ser Leu Thr Ala Lys Gly His Gly Lys Asp Ala Leu Gly Gln Val
450 455 460
Asp Ile Val Ala Asn Tyr Asn Gly Arg Arg Phe His Gly Val Gly Leu
465 470 475 480
Ala Thr Asp Ile Val Glu Ser Ser Ala Lys Ala Met Val His Val Leu
485 490 495
Asn Asn Ile Trp Arg Ala Ala Glu Val Glu Lys Glu Leu Gln Arg Lys
500 505 510
Ala Gln His Asn Glu Asn Asn Lys Glu Thr Val
515 520
<210> 3
<211> 1476
<212> ДНК
<213> Escherichia coli
<220>
<223> ilvC, кетол-кислотная редуктоизомераза
<400> 3
atggctaact acttcaatac actgaatctg cgccagcagc tggcacagct gggcaaatgt
60
cgctttatgg gccgcgatga attcgccgat ggcgcgagct accttcaggg taaaaaagta
120
gtcatcgtcg gctgtggcgc acagggtctg aaccagggcc tgaacatgcg tgattctggt
180
ctcgatatct cctacgctct gcgtaaagaa gcgattgccg agaagcgcgc gtcctggcgt
240
aaagcgaccg aaaatggttt taaagtgggt acttacgaag aactgatccc acaggcggat
300
ctggtgatta acctgacgcc ggacaagcag cactctgatg tagtgcgcac cgtacagcca
360
ctgatgaaag acggcgcggc gctgggctac tcgcacggtt tcaacatcgt cgaagtgggc
420
gagcagatcc gtaaagatat caccgtagtg atggttgcgc cgaaatgccc aggcaccgaa
480
gtgcgtgaag agtacaaacg tgggttcggc gtaccgacgc tgattgccgt tcacccggaa
540
aacgatccga aaggcgaagg catggcgatt gccaaagcct gggcggctgc aaccggtggt
600
caccgtgcgg gtgtgctgga atcgtccttc gttgcggaag tgaaatctga cctgatgggc
660
gagcaaacca tcctgtgcgg tatgttgcag gctggctctc tgctgtgctt cgacaagctg
720
gtggaagaag gtaccgatcc agcatacgca gaaaaactga ttcagttcgg ttgggaaacc
780
atcaccgaag cactgaaaca gggcggcatc accctgatga tggaccgtct ctctaacccg
840
gcgaaactgc gtgcttatgc gctttctgaa cagctgaaag agatcatggc acccctgttc
900
cagaaacata tggacgacat catctccggc gaattctctt ccggtatgat ggcggactgg
960
gccaacgatg ataagaaact gctgacctgg cgtgaagaga ccggcaaaac cgcgtttgaa
1020
accgcgccgc agtatgaagg caaaatcggc gagcaggagt acttcgataa aggcgtactg
1080
atgattgcga tggtgaaagc gggcgttgaa ctggcgttcg aaaccatggt cgattccggc
1140
atcattgaag agtctgcata ttatgaatca ctgcacgagc tgccgctgat tgccaacacc
1200
atcgcccgta agcgtctgta cgaaatgaac gtggttatct ctgataccgc tgagtacggt
1260
aactatctgt tctcttacgc ttgtgtgccg ttgctgaaac cgtttatggc agagctgcaa
1320
ccgggcgacc tgggtaaagc tattccggaa ggcgcggtag ataacgggca actgcgtgat
1380
gtgaacgaag cgattcgcag ccatgcgatt gagcaggtag gtaagaaact gcgcggctat
1440
atgacagata tgaaacgtat tgctgttgcg ggttaa
1476
<210> 4
<211> 491
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> ilvC, кетол-кислотная редуктоизомераза
<400> 4
Met Ala Asn Tyr Phe Asn Thr Leu Asn Leu Arg Gln Gln Leu Ala Gln
1 5 10 15
Leu Gly Lys Cys Arg Phe Met Gly Arg Asp Glu Phe Ala Asp Gly Ala
20 25 30
Ser Tyr Leu Gln Gly Lys Lys Val Val Ile Val Gly Cys Gly Ala Gln
35 40 45
Gly Leu Asn Gln Gly Leu Asn Met Arg Asp Ser Gly Leu Asp Ile Ser
50 55 60
Tyr Ala Leu Arg Lys Glu Ala Ile Ala Glu Lys Arg Ala Ser Trp Arg
65 70 75 80
Lys Ala Thr Glu Asn Gly Phe Lys Val Gly Thr Tyr Glu Glu Leu Ile
85 90 95
Pro Gln Ala Asp Leu Val Ile Asn Leu Thr Pro Asp Lys Gln His Ser
100 105 110
Asp Val Val Arg Thr Val Gln Pro Leu Met Lys Asp Gly Ala Ala Leu
115 120 125
Gly Tyr Ser His Gly Phe Asn Ile Val Glu Val Gly Glu Gln Ile Arg
130 135 140
Lys Asp Ile Thr Val Val Met Val Ala Pro Lys Cys Pro Gly Thr Glu
145 150 155 160
Val Arg Glu Glu Tyr Lys Arg Gly Phe Gly Val Pro Thr Leu Ile Ala
165 170 175
Val His Pro Glu Asn Asp Pro Lys Gly Glu Gly Met Ala Ile Ala Lys
180 185 190
Ala Trp Ala Ala Ala Thr Gly Gly His Arg Ala Gly Val Leu Glu Ser
195 200 205
Ser Phe Val Ala Glu Val Lys Ser Asp Leu Met Gly Glu Gln Thr Ile
210 215 220
Leu Cys Gly Met Leu Gln Ala Gly Ser Leu Leu Cys Phe Asp Lys Leu
225 230 235 240
Val Glu Glu Gly Thr Asp Pro Ala Tyr Ala Glu Lys Leu Ile Gln Phe
245 250 255
Gly Trp Glu Thr Ile Thr Glu Ala Leu Lys Gln Gly Gly Ile Thr Leu
260 265 270
Met Met Asp Arg Leu Ser Asn Pro Ala Lys Leu Arg Ala Tyr Ala Leu
275 280 285
Ser Glu Gln Leu Lys Glu Ile Met Ala Pro Leu Phe Gln Lys His Met
290 295 300
Asp Asp Ile Ile Ser Gly Glu Phe Ser Ser Gly Met Met Ala Asp Trp
305 310 315 320
Ala Asn Asp Asp Lys Lys Leu Leu Thr Trp Arg Glu Glu Thr Gly Lys
325 330 335
Thr Ala Phe Glu Thr Ala Pro Gln Tyr Glu Gly Lys Ile Gly Glu Gln
340 345 350
Glu Tyr Phe Asp Lys Gly Val Leu Met Ile Ala Met Val Lys Ala Gly
355 360 365
Val Glu Leu Ala Phe Glu Thr Met Val Asp Ser Gly Ile Ile Glu Glu
370 375 380
Ser Ala Tyr Tyr Glu Ser Leu His Glu Leu Pro Leu Ile Ala Asn Thr
385 390 395 400
Ile Ala Arg Lys Arg Leu Tyr Glu Met Asn Val Val Ile Ser Asp Thr
405 410 415
Ala Glu Tyr Gly Asn Tyr Leu Phe Ser Tyr Ala Cys Val Pro Leu Leu
420 425 430
Lys Pro Phe Met Ala Glu Leu Gln Pro Gly Asp Leu Gly Lys Ala Ile
435 440 445
Pro Glu Gly Ala Val Asp Asn Gly Gln Leu Arg Asp Val Asn Glu Ala
450 455 460
Ile Arg Ser His Ala Ile Glu Gln Val Gly Lys Lys Leu Arg Gly Tyr
465 470 475 480
Met Thr Asp Met Lys Arg Ile Ala Val Ala Gly
485 490
<210> 5
<211> 1644
<212> ДНК
<213> Escherichia coli
<220>
<223> Природный ген ilvG, изоформа II AHAS
<400> 5
atgaatggcg cacagtgggt ggtacatgcg ttgcgggcac agggtgtgaa caccgttttc
60
ggttatccgg gtggcgcaat tatgccggtt tacgatgcat tgtatgacgg cggcgtggag
120
cacttgctat gccgacatga gcagggtgcg gcaatggcgg ctatcggtta tgctcgtgct
180
accggcaaaa ctggcgtatg tatcgccacg tctggtccgg gcgcaaccaa cctgataacc
240
gggcttgcgg acgcactgtt agattccatc cctgttgttg ccatcaccgg tcaagtgtcc
300
gcaccgttta tcggcactga cgcatttcag gaagtggatg tcctgggatt gtcgttagcc
360
tgtaccaagc acagctttct ggtgcagtcg ctggaagagt tgccgcgcat catggctgaa
420
gcattcgacg ttgcctgctc aggtcgtcct ggtccggttc tggtcgatat cccaaaagat
480
atccagttag ccagcggtga cctggaaccg tggttcacca ccgttgaaaa cgaagtgact
540
ttcccacatg ccgaagttga gcaagcgcgc cagatgctgg caaaagcgca aaaaccgatg
600
ctgtacgttg gcggtggcgt gggtatggcg caggcagttc cggctttgcg tgaatttctc
660
gctgccacaa aaatgcctgc cacctgtacg ctgaaagggc tgggcgcagt agaagcagat
720
tatccgtact atctgggcat gctggggatg cacggcacca aagcggcaaa cttcgcggtg
780
caggagtgtg acctgctgat cgccgtgggc gcacgttttg atgaccgggt gaccggcaaa
840
ctgaacacct tcgcgccaca cgccagtgtt atccatatgg atatcgaccc ggcagaaatg
900
aacaagctgc gtcaggcaca tgtggcatta caaggtgatt taaatgctct gttaccagca
960
ttacagcagc cgttaaatca atactggcag caacactgcg cgcagctgcg tgatgaacat
1020
tcctggcgtt acgaccatcc cggtgacgct atctacgcgc cgttgttgtt aaaacaactg
1080
tcggatcgta aacctgcgga ttgcgtcgtg accacagatg tggggcagca ccagatgtgg
1140
gctgcgcagc acatcgccca cactcgcccg gaaaatttca tcacctccag cggtttaggt
1200
accatgggtt ttggtttacc ggcggcggtt ggcgcacaag tcgcgcgacc gaacgatacc
1260
gttgtctgta tctccggtga cggctctttc atgatgaatg tgcaagagct gggcaccgta
1320
aaacgcaagc agttaccgtt gaaaatcgtc ttactcgata accaacggtt agggatggtt
1380
cgacaatggc agcaactgtt ttttcaggaa cgatacagcg aaaccaccct tactgataac
1440
cccgatttcc tcatgttagc cagcgccttc ggcatccatg gccaacacat cacccggaaa
1500
gaccaggttg aagcggcact cgacaccatg ctgaacagtg atgggccata cctgcttcat
1560
gtctcaatcg acgaacttga gaacgtctgg ccgctggtgc cgcctggcgc cagtaattca
1620
gaaatgttgg agaaattatc atga
1644
<210> 6
<211> 547
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> Природный белковый продукт ilvG, изоформа II AHAS
<400> 6
Met Asn Gly Ala Gln Trp Val Val His Ala Leu Arg Ala Gln Gly Val
1 5 10 15
Asn Thr Val Phe Gly Tyr Pro Gly Gly Ala Ile Met Pro Val Tyr Asp
20 25 30
Ala Leu Tyr Asp Gly Gly Val Glu His Leu Leu Cys Arg His Glu Gln
35 40 45
Gly Ala Ala Met Ala Ala Ile Gly Tyr Ala Arg Ala Thr Gly Lys Thr
50 55 60
Gly Val Cys Ile Ala Thr Ser Gly Pro Gly Ala Thr Asn Leu Ile Thr
65 70 75 80
Gly Leu Ala Asp Ala Leu Leu Asp Ser Ile Pro Val Val Ala Ile Thr
85 90 95
Gly Gln Val Ser Ala Pro Phe Ile Gly Thr Asp Ala Phe Gln Glu Val
100 105 110
Asp Val Leu Gly Leu Ser Leu Ala Cys Thr Lys His Ser Phe Leu Val
115 120 125
Gln Ser Leu Glu Glu Leu Pro Arg Ile Met Ala Glu Ala Phe Asp Val
130 135 140
Ala Cys Ser Gly Arg Pro Gly Pro Val Leu Val Asp Ile Pro Lys Asp
145 150 155 160
Ile Gln Leu Ala Ser Gly Asp Leu Glu Pro Trp Phe Thr Thr Val Glu
165 170 175
Asn Glu Val Thr Phe Pro His Ala Glu Val Glu Gln Ala Arg Gln Met
180 185 190
Leu Ala Lys Ala Gln Lys Pro Met Leu Tyr Val Gly Gly Gly Val Gly
195 200 205
Met Ala Gln Ala Val Pro Ala Leu Arg Glu Phe Leu Ala Ala Thr Lys
210 215 220
Met Pro Ala Thr Cys Thr Leu Lys Gly Leu Gly Ala Val Glu Ala Asp
225 230 235 240
Tyr Pro Tyr Tyr Leu Gly Met Leu Gly Met His Gly Thr Lys Ala Ala
245 250 255
Asn Phe Ala Val Gln Glu Cys Asp Leu Leu Ile Ala Val Gly Ala Arg
260 265 270
Phe Asp Asp Arg Val Thr Gly Lys Leu Asn Thr Phe Ala Pro His Ala
275 280 285
Ser Val Ile His Met Asp Ile Asp Pro Ala Glu Met Asn Lys Leu Arg
290 295 300
Gln Ala His Val Ala Leu Gln Gly Asp Leu Asn Ala Leu Leu Pro Ala
305 310 315 320
Leu Gln Gln Pro Leu Asn Gln Tyr Trp Gln Gln His Cys Ala Gln Leu
325 330 335
Arg Asp Glu His Ser Trp Arg Tyr Asp His Pro Gly Asp Ala Ile Tyr
340 345 350
Ala Pro Leu Leu Leu Lys Gln Leu Ser Asp Arg Lys Pro Ala Asp Cys
355 360 365
Val Val Thr Thr Asp Val Gly Gln His Gln Met Trp Ala Ala Gln His
370 375 380
Ile Ala His Thr Arg Pro Glu Asn Phe Ile Thr Ser Ser Gly Leu Gly
385 390 395 400
Thr Met Gly Phe Gly Leu Pro Ala Ala Val Gly Ala Gln Val Ala Arg
405 410 415
Pro Asn Asp Thr Val Val Cys Ile Ser Gly Asp Gly Ser Phe Met Met
420 425 430
Asn Val Gln Glu Leu Gly Thr Val Lys Arg Lys Gln Leu Pro Leu Lys
435 440 445
Ile Val Leu Leu Asp Asn Gln Arg Leu Gly Met Val Arg Gln Trp Gln
450 455 460
Gln Leu Phe Phe Gln Glu Arg Tyr Ser Glu Thr Thr Leu Thr Asp Asn
465 470 475 480
Pro Asp Phe Leu Met Leu Ala Ser Ala Phe Gly Ile His Gly Gln His
485 490 495
Ile Thr Arg Lys Asp Gln Val Glu Ala Ala Leu Asp Thr Met Leu Asn
500 505 510
Ser Asp Gly Pro Tyr Leu Leu His Val Ser Ile Asp Glu Leu Glu Asn
515 520 525
Val Trp Pro Leu Val Pro Pro Gly Ala Ser Asn Ser Glu Met Leu Glu
530 535 540
Lys Leu Ser
545
<210> 7
<211> 264
<212> ДНК
<213> Escherichia coli
<220>
<223> Природный ген ilvM
<400> 7
atgatgcaac atcaggtcaa tgtatcggct cgcttcaatc cagaaacctt agaacgtgtt
60
ttacgcgtgg tgcgtcatcg tggtttccac gtctgctcaa tgaatatggc cgccgccagc
120
gatgcacaaa atataaatat cgaattgacc gttgccagcc cacggtcggt cgacttactg
180
tttagtcagt taaataaact ggtggacgtc gcacacgttg ccatctgcca gagcacaacc
240
acatcacaac aaatccgcgc ctga
264
<210> 8
<211> 87
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> Природный белковый продукт ilvM
<400> 8
Met Met Gln His Gln Val Asn Val Ser Ala Arg Phe Asn Pro Glu Thr
1 5 10 15
Leu Glu Arg Val Leu Arg Val Val Arg His Arg Gly Phe His Val Cys
20 25 30
Ser Met Asn Met Ala Ala Ala Ser Asp Ala Gln Asn Ile Asn Ile Glu
35 40 45
Leu Thr Val Ala Ser Pro Arg Ser Val Asp Leu Leu Phe Ser Gln Leu
50 55 60
Asn Lys Leu Val Asp Val Ala His Val Ala Ile Cys Gln Ser Thr Thr
65 70 75 80
Thr Ser Gln Gln Ile Arg Ala
85
<210> 9
<211> 933
<212> ДНК
<213> Escherichia coli
<220>
<223> thrB, гомосеринкиназа
<400> 9
atggttaaag tttatgcccc ggcttccagt gccaatatga gcgtcgggtt tgatgtgctc
60
ggggcggcgg tgacacctgt tgatggtgca ttgctcggag atgtagtcac ggttgaggcg
120
gcagagacat tcagtctcaa caacctcgga cgctttgccg ataagctgcc gtcagaacca
180
cgggaaaata tcgtttatca gtgctgggag cgtttttgcc aggaactggg taagcaaatt
240
ccagtggcga tgaccctgga aaagaatatg ccgatcggtt cgggcttagg ctccagtgcc
300
tgttcggtgg tcgcggcgct gatggcgatg aatgaacact gcggcaagcc gcttaatgac
360
actcgtttgc tggctttgat gggcgagctg gaaggccgta tctccggcag cattcattac
420
gacaacgtgg caccgtgttt tctcggtggt atgcagttga tgatcgaaga aaacgacatc
480
atcagccagc aagtgccagg gtttgatgag tggctgtggg tgctggcgta tccggggatt
540
aaagtctcga cggcagaagc cagggctatt ttaccggcgc agtatcgccg ccaggattgc
600
attgcgcacg ggcgacatct ggcaggcttc attcacgcct gctattcccg tcagcctgag
660
cttgccgcga agctgatgaa agatgttatc gctgaaccct accgtgaacg gttactgcca
720
ggcttccggc aggcgcggca ggcggtcgcg gaaatcggcg cggtagcgag cggtatctcc
780
ggctccggcc cgaccttgtt cgctctgtgt gacaagccgg aaaccgccca gcgcgttgcc
840
gactggttgg gtaagaacta cctgcaaaat caggaaggtt ttgttcatat ttgccggctg
900
gatacggcgg gcgcacgagt actggaaaac taa
933
<210> 10
<211> 310
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> thrB, гомосеринкиназа
<400> 10
Met Val Lys Val Tyr Ala Pro Ala Ser Ser Ala Asn Met Ser Val Gly
1 5 10 15
Phe Asp Val Leu Gly Ala Ala Val Thr Pro Val Asp Gly Ala Leu Leu
20 25 30
Gly Asp Val Val Thr Val Glu Ala Ala Glu Thr Phe Ser Leu Asn Asn
35 40 45
Leu Gly Arg Phe Ala Asp Lys Leu Pro Ser Glu Pro Arg Glu Asn Ile
50 55 60
Val Tyr Gln Cys Trp Glu Arg Phe Cys Gln Glu Leu Gly Lys Gln Ile
65 70 75 80
Pro Val Ala Met Thr Leu Glu Lys Asn Met Pro Ile Gly Ser Gly Leu
85 90 95
Gly Ser Ser Ala Cys Ser Val Val Ala Ala Leu Met Ala Met Asn Glu
100 105 110
His Cys Gly Lys Pro Leu Asn Asp Thr Arg Leu Leu Ala Leu Met Gly
115 120 125
Glu Leu Glu Gly Arg Ile Ser Gly Ser Ile His Tyr Asp Asn Val Ala
130 135 140
Pro Cys Phe Leu Gly Gly Met Gln Leu Met Ile Glu Glu Asn Asp Ile
145 150 155 160
Ile Ser Gln Gln Val Pro Gly Phe Asp Glu Trp Leu Trp Val Leu Ala
165 170 175
Tyr Pro Gly Ile Lys Val Ser Thr Ala Glu Ala Arg Ala Ile Leu Pro
180 185 190
Ala Gln Tyr Arg Arg Gln Asp Cys Ile Ala His Gly Arg His Leu Ala
195 200 205
Gly Phe Ile His Ala Cys Tyr Ser Arg Gln Pro Glu Leu Ala Ala Lys
210 215 220
Leu Met Lys Asp Val Ile Ala Glu Pro Tyr Arg Glu Arg Leu Leu Pro
225 230 235 240
Gly Phe Arg Gln Ala Arg Gln Ala Val Ala Glu Ile Gly Ala Val Ala
245 250 255
Ser Gly Ile Ser Gly Ser Gly Pro Thr Leu Phe Ala Leu Cys Asp Lys
260 265 270
Pro Glu Thr Ala Gln Arg Val Ala Asp Trp Leu Gly Lys Asn Tyr Leu
275 280 285
Gln Asn Gln Glu Gly Phe Val His Ile Cys Arg Leu Asp Thr Ala Gly
290 295 300
Ala Arg Val Leu Glu Asn
305 310
<210> 11
<211> 1545
<212> ДНК
<213> Escherichia coli
<220>
<223> Природный ген ilvA, L-треониндегидратаза
<400> 11
atggctgact cgcaacccct gtccggtgct ccggaaggtg ccgaatattt aagagcagtg
60
ctgcgcgcgc cggtttacga ggcggcgcag gttacgccgc tacaaaaaat ggaaaaactg
120
tcgtcgcgtc ttgataacgt cattctggtg aagcgcgaag atcgccagcc agtgcacagc
180
tttaagctgc gcggcgcata cgccatgatg gcgggcctga cggaagaaca gaaagcgcac
240
ggcgtgatca ctgcttctgc gggtaaccac gcgcagggcg tcgcgttttc ttctgcgcgg
300
ttaggcgtga aggccctgat cgttatgcca accgccaccg ccgacatcaa agtcgacgcg
360
gtgcgcggct tcggcggcga agtgctgctc cacggcgcga actttgatga agcgaaagcc
420
aaagcgatcg aactgtcaca gcagcagggg ttcacctggg tgccgccgtt cgaccatccg
480
atggtgattg ccgggcaagg cacgctggcg ctggaactgc tccagcagga cgcccatctc
540
gaccgcgtat ttgtgccagt cggcggcggc ggtctggctg ctggcgtggc ggtgctgatc
600
aaacaactga tgccgcaaat caaagtgatc gccgtagaag cggaagactc cgcctgcctg
660
aaagcagcgc tggatgcggg tcatccggtt gatctgccgc gcgtagggct atttgctgaa
720
ggcgtagcgg taaaacgcat cggtgacgaa accttccgtt tatgccagga gtatctcgac
780
gacatcatca ccgtcgatag cgatgcgatc tgtgcggcga tgaaggattt attcgaagat
840
gtgcgcgcgg tggcggaacc ctctggcgcg ctggcgctgg cgggaatgaa aaaatatatc
900
gccctgcaca acattcgcgg cgaacggctg gcgcatattc tttccggtgc caacgtgaac
960
ttccacggcc tgcgctacgt ctcagaacgc tgcgaactgg gcgaacagcg tgaagcgttg
1020
ttggcggtga ccattccgga agaaaaaggc agcttcctca aattctgcca actgcttggc
1080
gggcgttcgg tcaccgagtt caactaccgt tttgccgatg ccaaaaacgc ctgcatcttt
1140
gtcggtgtgc gcctgagccg cggcctcgaa gagcgcaaag aaattttgca gatgctcaac
1200
gacggcggct acagcgtggt tgatctctcc gacgacgaaa tggcgaagct acacgtgcgc
1260
tatatggtcg gcggacgtcc atcgcatccg ttgcaggaac gcctctacag cttcgaattc
1320
ccggaatcac cgggcgcgct gctgcgcttc ctcaacacgc tgggtacgta ctggaacatt
1380
tctttgttcc actatcgcag ccatggcacc gactacgggc gcgtactggc ggcgttcgaa
1440
cttggcgacc atgaaccgga tttcgaaacc cggctgaatg agctgggcta cgattgccac
1500
gacgaaacca ataacccggc gttcaggttc tttttggcgg gttag
1545
<210> 12
<211> 514
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> Природный белковый продукт ilvA, L-треониндегидратаза
<400> 12
Met Ala Asp Ser Gln Pro Leu Ser Gly Ala Pro Glu Gly Ala Glu Tyr
1 5 10 15
Leu Arg Ala Val Leu Arg Ala Pro Val Tyr Glu Ala Ala Gln Val Thr
20 25 30
Pro Leu Gln Lys Met Glu Lys Leu Ser Ser Arg Leu Asp Asn Val Ile
35 40 45
Leu Val Lys Arg Glu Asp Arg Gln Pro Val His Ser Phe Lys Leu Arg
50 55 60
Gly Ala Tyr Ala Met Met Ala Gly Leu Thr Glu Glu Gln Lys Ala His
65 70 75 80
Gly Val Ile Thr Ala Ser Ala Gly Asn His Ala Gln Gly Val Ala Phe
85 90 95
Ser Ser Ala Arg Leu Gly Val Lys Ala Leu Ile Val Met Pro Thr Ala
100 105 110
Thr Ala Asp Ile Lys Val Asp Ala Val Arg Gly Phe Gly Gly Glu Val
115 120 125
Leu Leu His Gly Ala Asn Phe Asp Glu Ala Lys Ala Lys Ala Ile Glu
130 135 140
Leu Ser Gln Gln Gln Gly Phe Thr Trp Val Pro Pro Phe Asp His Pro
145 150 155 160
Met Val Ile Ala Gly Gln Gly Thr Leu Ala Leu Glu Leu Leu Gln Gln
165 170 175
Asp Ala His Leu Asp Arg Val Phe Val Pro Val Gly Gly Gly Gly Leu
180 185 190
Ala Ala Gly Val Ala Val Leu Ile Lys Gln Leu Met Pro Gln Ile Lys
195 200 205
Val Ile Ala Val Glu Ala Glu Asp Ser Ala Cys Leu Lys Ala Ala Leu
210 215 220
Asp Ala Gly His Pro Val Asp Leu Pro Arg Val Gly Leu Phe Ala Glu
225 230 235 240
Gly Val Ala Val Lys Arg Ile Gly Asp Glu Thr Phe Arg Leu Cys Gln
245 250 255
Glu Tyr Leu Asp Asp Ile Ile Thr Val Asp Ser Asp Ala Ile Cys Ala
260 265 270
Ala Met Lys Asp Leu Phe Glu Asp Val Arg Ala Val Ala Glu Pro Ser
275 280 285
Gly Ala Leu Ala Leu Ala Gly Met Lys Lys Tyr Ile Ala Leu His Asn
290 295 300
Ile Arg Gly Glu Arg Leu Ala His Ile Leu Ser Gly Ala Asn Val Asn
305 310 315 320
Phe His Gly Leu Arg Tyr Val Ser Glu Arg Cys Glu Leu Gly Glu Gln
325 330 335
Arg Glu Ala Leu Leu Ala Val Thr Ile Pro Glu Glu Lys Gly Ser Phe
340 345 350
Leu Lys Phe Cys Gln Leu Leu Gly Gly Arg Ser Val Thr Glu Phe Asn
355 360 365
Tyr Arg Phe Ala Asp Ala Lys Asn Ala Cys Ile Phe Val Gly Val Arg
370 375 380
Leu Ser Arg Gly Leu Glu Glu Arg Lys Glu Ile Leu Gln Met Leu Asn
385 390 395 400
Asp Gly Gly Tyr Ser Val Val Asp Leu Ser Asp Asp Glu Met Ala Lys
405 410 415
Leu His Val Arg Tyr Met Val Gly Gly Arg Pro Ser His Pro Leu Gln
420 425 430
Glu Arg Leu Tyr Ser Phe Glu Phe Pro Glu Ser Pro Gly Ala Leu Leu
435 440 445
Arg Phe Leu Asn Thr Leu Gly Thr Tyr Trp Asn Ile Ser Leu Phe His
450 455 460
Tyr Arg Ser His Gly Thr Asp Tyr Gly Arg Val Leu Ala Ala Phe Glu
465 470 475 480
Leu Gly Asp His Glu Pro Asp Phe Glu Thr Arg Leu Asn Glu Leu Gly
485 490 495
Tyr Asp Cys His Asp Glu Thr Asn Asn Pro Ala Phe Arg Phe Phe Leu
500 505 510
Ala Gly
<210> 13
<211> 1725
<212> ДНК
<213> Escherichia coli
<220>
<223> ilvI, изоформа III AHAS, большая субъединица
<400> 13
atggagatgt tgtctggagc cgagatggtc gtccgatcgc ttatcgatca gggcgttaaa
60
caagtattcg gttatcccgg aggcgcagtc cttgatattt atgatgcatt gcataccgtg
120
ggtggtattg atcatgtatt agttcgtcat gagcaggcgg cggtgcatat ggccgatggc
180
ctggcgcgcg cgaccgggga agtcggcgtc gtgctggtaa cgtcgggtcc aggggcgacc
240
aatgcgatta ctggcatcgc caccgcttat atggattcca ttccattagt tgtcctttcc
300
gggcaggtag cgacctcgtt gataggttac gatgcctttc aggagtgcga catggtgggg
360
atttcgcgac cggtggttaa acacagtttt ctggttaagc aaacggaaga cattccgcag
420
gtgctgaaaa aggctttctg gctggcggca agtggtcgcc caggaccagt agtcgttgat
480
ttaccgaaag atattcttaa tccggcgaac aaattaccct atgtctggcc ggagtcggtc
540
agtatgcgtt cttacaatcc cactactacc ggacataaag ggcaaattaa gcgtgctctg
600
caaacgctgg tagcggcaaa aaaaccggtt gtctacgtag gcggtggggc aatcacggcg
660
ggctgccatc agcagttgaa agaaacggtg gaggcgttga atctgcccgt tgtttgctca
720
ttgatggggc tgggggcgtt tccggcaacg catcgtcagg cactgggcat gctgggaatg
780
cacggtacct acgaagccaa tatgacgatg cataacgcgg atgtgatttt cgccgtcggg
840
gtacgatttg atgaccgaac gacgaacaat ctggcaaagt actgcccaaa tgccactgtt
900
ctgcatatcg atattgatcc tacttccatt tctaaaaccg tgactgcgga tatcccgatt
960
gtgggggatg ctcgccaggt cctcgaacaa atgcttgaac tcttgtcgca agaatccgcc
1020
catcaaccac tggatgagat ccgcgactgg tggcagcaaa ttgaacagtg gcgcgctcgt
1080
cagtgcctga aatatgacac tcacagtgaa aagattaaac cgcaggcggt gatcgagact
1140
ctttggcggt tgacgaaggg agacgcttac gtgacgtccg atgtcgggca gcaccagatg
1200
tttgctgcac tttattatcc attcgacaaa ccgcgtcgct ggatcaattc cggtggcctc
1260
ggcacgatgg gttttggttt acctgcggca ctgggcgtca aaatggcgtt gccagaagaa
1320
accgtggttt gcgtcactgg cgacggcagt attcagatga acatccagga actgtctacc
1380
gcgttgcaat acgagttgcc cgtactggtg gtgaatctca ataaccgcta tctggggatg
1440
gtgaagcagt ggcaggacat gatctattcc ggccgtcatt cacaatctta tatgcaatcg
1500
ctacccgatt tcgtccgtct ggcggaagcc tatgggcatg tcgggatcca gatttctcat
1560
ccgcatgagc tggaaagcaa acttagcgag gcgctggaac aggtgcgcaa taatcgcctg
1620
gtgtttgttg atgttaccgt cgatggcagc gagcacgtct acccgatgca gattcgcggg
1680
ggcggaatgg atgaaatgtg gttaagcaaa acggagagaa cctga
1725
<210> 14
<211> 574
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> ilvI, изоформа III AHAS, большая субъединица
<400> 14
Met Glu Met Leu Ser Gly Ala Glu Met Val Val Arg Ser Leu Ile Asp
1 5 10 15
Gln Gly Val Lys Gln Val Phe Gly Tyr Pro Gly Gly Ala Val Leu Asp
20 25 30
Ile Tyr Asp Ala Leu His Thr Val Gly Gly Ile Asp His Val Leu Val
35 40 45
Arg His Glu Gln Ala Ala Val His Met Ala Asp Gly Leu Ala Arg Ala
50 55 60
Thr Gly Glu Val Gly Val Val Leu Val Thr Ser Gly Pro Gly Ala Thr
65 70 75 80
Asn Ala Ile Thr Gly Ile Ala Thr Ala Tyr Met Asp Ser Ile Pro Leu
85 90 95
Val Val Leu Ser Gly Gln Val Ala Thr Ser Leu Ile Gly Tyr Asp Ala
100 105 110
Phe Gln Glu Cys Asp Met Val Gly Ile Ser Arg Pro Val Val Lys His
115 120 125
Ser Phe Leu Val Lys Gln Thr Glu Asp Ile Pro Gln Val Leu Lys Lys
130 135 140
Ala Phe Trp Leu Ala Ala Ser Gly Arg Pro Gly Pro Val Val Val Asp
145 150 155 160
Leu Pro Lys Asp Ile Leu Asn Pro Ala Asn Lys Leu Pro Tyr Val Trp
165 170 175
Pro Glu Ser Val Ser Met Arg Ser Tyr Asn Pro Thr Thr Thr Gly His
180 185 190
Lys Gly Gln Ile Lys Arg Ala Leu Gln Thr Leu Val Ala Ala Lys Lys
195 200 205
Pro Val Val Tyr Val Gly Gly Gly Ala Ile Thr Ala Gly Cys His Gln
210 215 220
Gln Leu Lys Glu Thr Val Glu Ala Leu Asn Leu Pro Val Val Cys Ser
225 230 235 240
Leu Met Gly Leu Gly Ala Phe Pro Ala Thr His Arg Gln Ala Leu Gly
245 250 255
Met Leu Gly Met His Gly Thr Tyr Glu Ala Asn Met Thr Met His Asn
260 265 270
Ala Asp Val Ile Phe Ala Val Gly Val Arg Phe Asp Asp Arg Thr Thr
275 280 285
Asn Asn Leu Ala Lys Tyr Cys Pro Asn Ala Thr Val Leu His Ile Asp
290 295 300
Ile Asp Pro Thr Ser Ile Ser Lys Thr Val Thr Ala Asp Ile Pro Ile
305 310 315 320
Val Gly Asp Ala Arg Gln Val Leu Glu Gln Met Leu Glu Leu Leu Ser
325 330 335
Gln Glu Ser Ala His Gln Pro Leu Asp Glu Ile Arg Asp Trp Trp Gln
340 345 350
Gln Ile Glu Gln Trp Arg Ala Arg Gln Cys Leu Lys Tyr Asp Thr His
355 360 365
Ser Glu Lys Ile Lys Pro Gln Ala Val Ile Glu Thr Leu Trp Arg Leu
370 375 380
Thr Lys Gly Asp Ala Tyr Val Thr Ser Asp Val Gly Gln His Gln Met
385 390 395 400
Phe Ala Ala Leu Tyr Tyr Pro Phe Asp Lys Pro Arg Arg Trp Ile Asn
405 410 415
Ser Gly Gly Leu Gly Thr Met Gly Phe Gly Leu Pro Ala Ala Leu Gly
420 425 430
Val Lys Met Ala Leu Pro Glu Glu Thr Val Val Cys Val Thr Gly Asp
435 440 445
Gly Ser Ile Gln Met Asn Ile Gln Glu Leu Ser Thr Ala Leu Gln Tyr
450 455 460
Glu Leu Pro Val Leu Val Val Asn Leu Asn Asn Arg Tyr Leu Gly Met
465 470 475 480
Val Lys Gln Trp Gln Asp Met Ile Tyr Ser Gly Arg His Ser Gln Ser
485 490 495
Tyr Met Gln Ser Leu Pro Asp Phe Val Arg Leu Ala Glu Ala Tyr Gly
500 505 510
His Val Gly Ile Gln Ile Ser His Pro His Glu Leu Glu Ser Lys Leu
515 520 525
Ser Glu Ala Leu Glu Gln Val Arg Asn Asn Arg Leu Val Phe Val Asp
530 535 540
Val Thr Val Asp Gly Ser Glu His Val Tyr Pro Met Gln Ile Arg Gly
545 550 555 560
Gly Gly Met Asp Glu Met Trp Leu Ser Lys Thr Glu Arg Thr
565 570
<210> 15
<211> 492
<212> ДНК
<213> Escherichia coli
<220>
<223> ilvH, изоформа III AHAS, малая субъединица
<400> 15
atgcgccgga tattatcagt cttactcgaa aatgaatcag gcgcgttatc ccgcgtgatt
60
ggcctttttt cccagcgtgg ctacaacatt gaaagcctga ccgttgcgcc aaccgacgat
120
ccgacattat cgcgtatgac catccagacc gtgggcgatg aaaaagtact tgagcagatc
180
gaaaagcaat tacacaaact ggtcgatgtc ttgcgcgtga gtgagttggg gcagggcgcg
240
catgttgagc gggaaatcat gctggtgaaa attcaggcca gcggttacgg gcgtgacgaa
300
gtgaaacgta atacggaaat attccgtggg caaattatcg atgtcacacc ctcgctttat
360
accgttcaat tagcaggcac cagcggtaag cttgatgcat ttttagcatc gattcgcgat
420
gtggcgaaaa ttgtggaggt tgctcgctct ggtgtggtcg gactttcgcg cggcgataaa
480
ataatgcgtt ga
492
<210> 16
<211> 163
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> ilvH, изоформа III AHAS, малая субъединица
<400> 16
Met Arg Arg Ile Leu Ser Val Leu Leu Glu Asn Glu Ser Gly Ala Leu
1 5 10 15
Ser Arg Val Ile Gly Leu Phe Ser Gln Arg Gly Tyr Asn Ile Glu Ser
20 25 30
Leu Thr Val Ala Pro Thr Asp Asp Pro Thr Leu Ser Arg Met Thr Ile
35 40 45
Gln Thr Val Gly Asp Glu Lys Val Leu Glu Gln Ile Glu Lys Gln Leu
50 55 60
His Lys Leu Val Asp Val Leu Arg Val Ser Glu Leu Gly Gln Gly Ala
65 70 75 80
His Val Glu Arg Glu Ile Met Leu Val Lys Ile Gln Ala Ser Gly Tyr
85 90 95
Gly Arg Asp Glu Val Lys Arg Asn Thr Glu Ile Phe Arg Gly Gln Ile
100 105 110
Ile Asp Val Thr Pro Ser Leu Tyr Thr Val Gln Leu Ala Gly Thr Ser
115 120 125
Gly Lys Leu Asp Ala Phe Leu Ala Ser Ile Arg Asp Val Ala Lys Ile
130 135 140
Val Glu Val Ala Arg Ser Gly Val Val Gly Leu Ser Arg Gly Asp Lys
145 150 155 160
Ile Met Arg
<210> 17
<211> 2463
<212> ДНК
<213> Escherichia coli
<220>
<223> thrA, аспартаткиназа и гомосериндегидрогеназа, бифункциональный
<400> 17
atgcgagtgt tgaagttcgg cggtacatca gtggcaaatg cagaacgttt tctgcgtgtt
60
gccgatattc tggaaagcaa tgccaggcag gggcaggtgg ccaccgtcct ctctgccccc
120
gccaaaatca ccaaccacct ggtggcgatg attgaaaaaa ccattagcgg ccaggatgct
180
ttacccaata tcagcgatgc cgaacgtatt tttgccgaac ttttgacggg actcgccgcc
240
gcccagccgg ggttcccgct ggcgcaattg aaaactttcg tcgatcagga atttgcccaa
300
ataaaacatg tcctgcatgg cattagtttg ttggggcagt gcccggatag catcaacgct
360
gcgctgattt gccgtggcga gaaaatgtcg atcgccatta tggccggcgt attagaagcg
420
cgcggtcaca acgttactgt tatcgatccg gtcgaaaaac tgctggcagt ggggcattac
480
ctcgaatcta ccgtcgatat tgctgagtcc acccgccgta ttgcggcaag ccgcattccg
540
gctgatcaca tggtgctgat ggcaggtttc accgccggta atgaaaaagg cgaactggtg
600
gtgcttggac gcaacggttc cgactactct gctgcggtgc tggctgcctg tttacgcgcc
660
gattgttgcg agatttggac ggacgttgac ggggtctata cctgcgaccc gcgtcaggtg
720
cccgatgcga ggttgttgaa gtcgatgtcc taccaggaag cgatggagct ttcctacttc
780
ggcgctaaag ttcttcaccc ccgcaccatt acccccatcg cccagttcca gatcccttgc
840
ctgattaaaa ataccggaaa tcctcaagca ccaggtacgc tcattggtgc cagccgtgat
900
gaagacgaat taccggtcaa gggcatttcc aatctgaata acatggcaat gttcagcgtt
960
tctggtccgg ggatgaaagg gatggtcggc atggcggcgc gcgtctttgc agcgatgtca
1020
cgcgcccgta tttccgtggt gctgattacg caatcatctt ccgaatacag catcagtttc
1080
tgcgttccac aaagcgactg tgtgcgagct gaacgggcaa tgcaggaaga gttctacctg
1140
gaactgaaag aaggcttact ggagccgctg gcagtgacgg aacggctggc cattatctcg
1200
gtggtaggtg atggtatgcg caccttgcgt gggatctcgg cgaaattctt tgccgcactg
1260
gcccgcgcca atatcaacat tgtcgccatt gctcagggat cttctgaacg ctcaatctct
1320
gtcgtggtaa ataacgatga tgcgaccact ggcgtgcgcg ttactcatca gatgctgttc
1380
aataccgatc aggttatcga agtgtttgtg attggcgtcg gtggcgttgg cggtgcgctg
1440
ctggagcaac tgaagcgtca gcaaagctgg ctgaagaata aacatatcga cttacgtgtc
1500
tgcggtgttg ccaactcgaa ggctctgctc accaatgtac atggccttaa tctggaaaac
1560
tggcaggaag aactggcgca agccaaagag ccgtttaatc tcgggcgctt aattcgcctc
1620
gtgaaagaat atcatctgct gaacccggtc attgttgact gcacttccag ccaggcagtg
1680
gcggatcaat atgccgactt cctgcgcgaa ggtttccacg ttgtcacgcc gaacaaaaag
1740
gccaacacct cgtcgatgga ttactaccat cagttgcgtt atgcggcgga aaaatcgcgg
1800
cgtaaattcc tctatgacac caacgttggg gctggattac cggttattga gaacctgcaa
1860
aatctgctca atgcaggtga tgaattgatg aagttctccg gcattctttc tggttcgctt
1920
tcttatatct tcggcaagtt agacgaaggc atgagtttct ccgaggcgac cacgctggcg
1980
cgggaaatgg gttataccga accggacccg cgagatgatc tttctggtat ggatgtggcg
2040
cgtaaactat tgattctcgc tcgtgaaacg ggacgtgaac tggagctggc ggatattgaa
2100
attgaacctg tgctgcccgc agagtttaac gccgagggtg atgttgccgc ttttatggcg
2160
aatctgtcac aactcgacga tctctttgcc gcgcgcgtgg cgaaggcccg tgatgaagga
2220
aaagttttgc gctatgttgg caatattgat gaagatggcg tctgccgcgt gaagattgcc
2280
gaagtggatg gtaatgatcc gctgttcaaa gtgaaaaatg gcgaaaacgc cctggccttc
2340
tatagccact attatcagcc gctgccgttg gtactgcgcg gatatggtgc gggcaatgac
2400
gttacagctg ccggtgtctt tgctgatctg ctacgtaccc tctcatggaa gttaggagtc
2460
tga
2463
<210> 18
<211> 820
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> thrA, аспартаткиназа и гомосериндегидрогеназа, бифункциональный
<400> 18
Met Arg Val Leu Lys Phe Gly Gly Thr Ser Val Ala Asn Ala Glu Arg
1 5 10 15
Phe Leu Arg Val Ala Asp Ile Leu Glu Ser Asn Ala Arg Gln Gly Gln
20 25 30
Val Ala Thr Val Leu Ser Ala Pro Ala Lys Ile Thr Asn His Leu Val
35 40 45
Ala Met Ile Glu Lys Thr Ile Ser Gly Gln Asp Ala Leu Pro Asn Ile
50 55 60
Ser Asp Ala Glu Arg Ile Phe Ala Glu Leu Leu Thr Gly Leu Ala Ala
65 70 75 80
Ala Gln Pro Gly Phe Pro Leu Ala Gln Leu Lys Thr Phe Val Asp Gln
85 90 95
Glu Phe Ala Gln Ile Lys His Val Leu His Gly Ile Ser Leu Leu Gly
100 105 110
Gln Cys Pro Asp Ser Ile Asn Ala Ala Leu Ile Cys Arg Gly Glu Lys
115 120 125
Met Ser Ile Ala Ile Met Ala Gly Val Leu Glu Ala Arg Gly His Asn
130 135 140
Val Thr Val Ile Asp Pro Val Glu Lys Leu Leu Ala Val Gly His Tyr
145 150 155 160
Leu Glu Ser Thr Val Asp Ile Ala Glu Ser Thr Arg Arg Ile Ala Ala
165 170 175
Ser Arg Ile Pro Ala Asp His Met Val Leu Met Ala Gly Phe Thr Ala
180 185 190
Gly Asn Glu Lys Gly Glu Leu Val Val Leu Gly Arg Asn Gly Ser Asp
195 200 205
Tyr Ser Ala Ala Val Leu Ala Ala Cys Leu Arg Ala Asp Cys Cys Glu
210 215 220
Ile Trp Thr Asp Val Asp Gly Val Tyr Thr Cys Asp Pro Arg Gln Val
225 230 235 240
Pro Asp Ala Arg Leu Leu Lys Ser Met Ser Tyr Gln Glu Ala Met Glu
245 250 255
Leu Ser Tyr Phe Gly Ala Lys Val Leu His Pro Arg Thr Ile Thr Pro
260 265 270
Ile Ala Gln Phe Gln Ile Pro Cys Leu Ile Lys Asn Thr Gly Asn Pro
275 280 285
Gln Ala Pro Gly Thr Leu Ile Gly Ala Ser Arg Asp Glu Asp Glu Leu
290 295 300
Pro Val Lys Gly Ile Ser Asn Leu Asn Asn Met Ala Met Phe Ser Val
305 310 315 320
Ser Gly Pro Gly Met Lys Gly Met Val Gly Met Ala Ala Arg Val Phe
325 330 335
Ala Ala Met Ser Arg Ala Arg Ile Ser Val Val Leu Ile Thr Gln Ser
340 345 350
Ser Ser Glu Tyr Ser Ile Ser Phe Cys Val Pro Gln Ser Asp Cys Val
355 360 365
Arg Ala Glu Arg Ala Met Gln Glu Glu Phe Tyr Leu Glu Leu Lys Glu
370 375 380
Gly Leu Leu Glu Pro Leu Ala Val Thr Glu Arg Leu Ala Ile Ile Ser
385 390 395 400
Val Val Gly Asp Gly Met Arg Thr Leu Arg Gly Ile Ser Ala Lys Phe
405 410 415
Phe Ala Ala Leu Ala Arg Ala Asn Ile Asn Ile Val Ala Ile Ala Gln
420 425 430
Gly Ser Ser Glu Arg Ser Ile Ser Val Val Val Asn Asn Asp Asp Ala
435 440 445
Thr Thr Gly Val Arg Val Thr His Gln Met Leu Phe Asn Thr Asp Gln
450 455 460
Val Ile Glu Val Phe Val Ile Gly Val Gly Gly Val Gly Gly Ala Leu
465 470 475 480
Leu Glu Gln Leu Lys Arg Gln Gln Ser Trp Leu Lys Asn Lys His Ile
485 490 495
Asp Leu Arg Val Cys Gly Val Ala Asn Ser Lys Ala Leu Leu Thr Asn
500 505 510
Val His Gly Leu Asn Leu Glu Asn Trp Gln Glu Glu Leu Ala Gln Ala
515 520 525
Lys Glu Pro Phe Asn Leu Gly Arg Leu Ile Arg Leu Val Lys Glu Tyr
530 535 540
His Leu Leu Asn Pro Val Ile Val Asp Cys Thr Ser Ser Gln Ala Val
545 550 555 560
Ala Asp Gln Tyr Ala Asp Phe Leu Arg Glu Gly Phe His Val Val Thr
565 570 575
Pro Asn Lys Lys Ala Asn Thr Ser Ser Met Asp Tyr Tyr His Gln Leu
580 585 590
Arg Tyr Ala Ala Glu Lys Ser Arg Arg Lys Phe Leu Tyr Asp Thr Asn
595 600 605
Val Gly Ala Gly Leu Pro Val Ile Glu Asn Leu Gln Asn Leu Leu Asn
610 615 620
Ala Gly Asp Glu Leu Met Lys Phe Ser Gly Ile Leu Ser Gly Ser Leu
625 630 635 640
Ser Tyr Ile Phe Gly Lys Leu Asp Glu Gly Met Ser Phe Ser Glu Ala
645 650 655
Thr Thr Leu Ala Arg Glu Met Gly Tyr Thr Glu Pro Asp Pro Arg Asp
660 665 670
Asp Leu Ser Gly Met Asp Val Ala Arg Lys Leu Leu Ile Leu Ala Arg
675 680 685
Glu Thr Gly Arg Glu Leu Glu Leu Ala Asp Ile Glu Ile Glu Pro Val
690 695 700
Leu Pro Ala Glu Phe Asn Ala Glu Gly Asp Val Ala Ala Phe Met Ala
705 710 715 720
Asn Leu Ser Gln Leu Asp Asp Leu Phe Ala Ala Arg Val Ala Lys Ala
725 730 735
Arg Asp Glu Gly Lys Val Leu Arg Tyr Val Gly Asn Ile Asp Glu Asp
740 745 750
Gly Val Cys Arg Val Lys Ile Ala Glu Val Asp Gly Asn Asp Pro Leu
755 760 765
Phe Lys Val Lys Asn Gly Glu Asn Ala Leu Ala Phe Tyr Ser His Tyr
770 775 780
Tyr Gln Pro Leu Pro Leu Val Leu Arg Gly Tyr Gly Ala Gly Asn Asp
785 790 795 800
Val Thr Ala Ala Gly Val Phe Ala Asp Leu Leu Arg Thr Leu Ser Trp
805 810 815
Lys Leu Gly Val
820
<210> 19
<211> 285
<212> ДНК
<213> Escherichia coli
<220>
<223> Промотор araBAD
<400> 19
aagaaaccaa ttgtccatat tgcatcagac attgccgtca ctgcgtcttt tactggctct
60
tctcgctaac caaaccggta accccgctta ttaaaagcat tctgtaacaa agcgggacca
120
aagccatgac aaaaacgcgt aacaaaagtg tctataatca cggcagaaaa gtccacattg
180
attatttgca cggcgtcaca ctttgctatg ccatagcatt tttatccata agattagcgg
240
atcctacctg acgcttttta tcgcaactct ctactgtttc tccat
285
<210> 20
<211> 879
<212> ДНК
<213> Escherichia coli
<220>
<223> Ген araC
<400> 20
atggctgaag cgcaaaatga tcccctgctg ccgggatact cgtttaatgc ccatctggtg
60
gcgggtttaa cgccgattga ggccaacggt tatctcgatt tttttatcga ccgaccgctg
120
ggaatgaaag gttatattct caatctcacc attcgcggtc agggggtggt gaaaaatcag
180
ggacgagaat ttgtttgccg accgggtgat attttgctgt tcccgccagg agagattcat
240
cactacggtc gtcatccgga ggctcgcgaa tggtatcacc agtgggttta ctttcgtccg
300
cgcgcctact ggcatgaatg gcttaactgg ccgtcaatat ttgccaatac ggggttcttt
360
cgcccggatg aagcgcacca gccgcatttc agcgacctgt ttgggcaaat cattaacgcc
420
gggcaagggg aagggcgcta ttcggagctg ctggcgataa atctgcttga gcaattgtta
480
ctgcggcgca tggaagcgat taacgagtcg ctccatccac cgatggataa tcgggtacgc
540
gaggcttgtc agtacatcag cgatcacctg gcagacagca attttgatat cgccagcgtc
600
gcacagcatg tttgcttgtc gccgtcgcgt ctgtcacatc ttttccgcca gcagttaggg
660
attagcgtct taagctggcg cgaggaccaa cgtatcagcc aggcgaagct gcttttgagc
720
accacccgga tgcctatcgc caccgtcggt cgcaatgttg gttttgacga tcaactctat
780
ttctcgcggg tatttaaaaa atgcaccggg gccagcccga gcgagttccg tgccggttgt
840
gaagaaaaag tgaatgatgt agccgtcaag ttgtcataa
879
<210> 21
<211> 81
<212> ДНК
<213> Escherichia coli
<220>
<223> Промотор Pm
<400> 21
agtccagcct tgcaagaagc ggatacagga gtgcaaaaaa tggctatctc tagaaaggcc
60
taccccttag gctttatgca a
81
<210> 22
<211> 1135
<212> ДНК
<213> Escherichia coli
<220>
<223> Промотор XylS и ген xylS
<400> 22
cttggcgtta tttttgcttg gaaaagtggt cactgattgc aaaaaggatg gcgcaacgtg
60
gcaatggggg taacccgtat acgcatcacg tcgagatgca ttttcatcga cttggcgcct
120
ttctacatca caccaagcag cccacattaa aataagagaa ccgtgaacta tggatttttg
180
cttattgaac gagaaaagtc agatcttcgt ccacgccgag ccctatgcag tctccgatta
240
tgttaaccag tatgtcggta cgcactctat tcgcctgccc aagggcgggc ccccggcagg
300
caggctgcac cacagaatct tcggatgcct cgacctgtgt cgaatcagct acggcggtag
360
cgtgagggta atctcgcctg gattagagac ctgttatcat ctgcaaataa tactcaaagg
420
ccattgcctg tggcgtggcc atggccagga gcactatttt gcgccgggcg aactattgct
480
gctcaatccg gatgaccaag ccgacctgac ctattcagaa gattgcgaga aatttatcgt
540
taaattgccc tcagtggtcc ttgatcgggc atgcagtgac aacaattggc acaagccgag
600
ggagggtatc cgtttcgccg cgcgacacaa tctccagcaa ctcgatggct ttatcaatct
660
actcgggtta gtttgtgacg aagcggaaca tacaaagtcg atgcctcggg tccaagagca
720
ctatgcgggg atcatcgctt ccaagctgct cgaaatgctg ggcagcaatg tcagccgtga
780
aattttcagc aaaggtaacc cgtctttcga gcgagtcgtt caattcattg aggagaatct
840
caaacggaat atcagccttg agcggttagc ggagctggcg atgatgagtc cacgctcgct
900
ctacaatttg ttcgagaagc atgccggcac cacgccgaag aactacatcc gcaaccgcaa
960
gctcgaaagc atccgcgcct gcttgaacga tcccagtgcc aatgtgcgta gtataactga
1020
gatagcccta gactacggct tcttacattt gggacgcttc gctgaaaact ataggagcgc
1080
gttcggcgag ttgccttccg acaccctgcg tcaatgcaaa aaggaagtgg cttga
1135
<210> 23
<211> 1689
<212> ДНК
<213> Escherichia coli
<220>
<223> ilvB, изоформа I AHAS, большая субъединица
<400> 23
atggcaagtt cgggcacaac atcgacgcgt aagcgcttta ccggcgcaga atttatcgtt
60
catttcctgg aacagcaggg cattaagatt gtgacaggca ttccgggcgg ttctatcctg
120
cctgtttacg atgccttaag ccaaagcacg caaatccgcc atattctggc ccgtcatgaa
180
cagggcgcgg gctttatcgc tcagggaatg gcgcgcaccg acggtaaacc ggcggtctgt
240
atggcctgta gcggaccggg tgcgactaac ctggtgaccg ccattgccga tgcgcggctg
300
gactccatcc cgctgatttg catcactggt caggttcccg cctcgatgat cggcaccgac
360
gccttccagg aagtggacac ctacggcatc tctatcccca tcaccaaaca caactatctg
420
gtcagacata tcgaagaact cccgcaggtc atgagcgatg ccttccgcat tgcgcaatca
480
ggccgcccag gcccggtgtg gatagacatt cctaaggatg tgcaaacggc agtttttgag
540
attgaaacac agcccgctat ggcagaaaaa gccgccgccc ccgcctttag cgaagaaagc
600
attcgtgacg cagcggcgat gattaacgct gccaaacgcc cggtgcttta tctgggcggc
660
ggtgtgatca atgcgcccgc acgggtgcgt gaactggcgg agaaagcgca actgcctacc
720
accatgactt taatggcgct gggcatgttg ccaaaagcgc atccgttgtc gctgggtatg
780
ctggggatgc acggcgtgcg cagcaccaac tatattttgc aggaggcgga tttgttgata
840
gtgctcggtg cgcgttttga tgaccgggcg attggcaaaa ccgagcagtt ctgtccgaat
900
gccaaaatca ttcatgtcga tatcgaccgt gcagagctgg gtaaaatcaa gcagccgcac
960
gtggcgattc aggcggatgt tgatgacgtg ctggcgcagt tgatcccgct ggtggaagcg
1020
caaccgcgtg cagagtggca ccagttggta gcggatttgc agcgtgagtt tccgtgtcca
1080
atcccgaaag cgtgcgatcc gttaagccat tacggcctga tcaacgccgt tgccgcctgt
1140
gtcgatgaca atgcaattat caccaccgac gttggtcagc atcagatgtg gaccgcgcaa
1200
gcttatccgc tcaatcgccc acgccagtgg ctgacctccg gtgggctggg cacgatgggt
1260
tttggcctgc ctgcggcgat tggcgctgcg ctggcgaacc cggatcgcaa agtgttgtgt
1320
ttctccggcg acggcagcct gatgatgaat attcaggaga tggcgaccgc cagtgaaaat
1380
cagctggatg tcaaaatcat tctgatgaac aacgaagcgc tggggctggt gcatcagcaa
1440
cagagtctgt tctacgagca aggcgttttt gccgccacct atccgggcaa aatcaacttt
1500
atgcagattg ccgccggatt cggcctcgaa acctgtgatt tgaataacga agccgatccg
1560
caggcttcat tgcaggaaat catcaatcgc cctggcccgg cgctgatcca tgtgcgcatt
1620
gatgccgaag aaaaagttta cccgatggtg ccgccaggtg cggcgaatac tgaaatggtg
1680
ggggaataa
1689
<210> 24
<211> 562
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> ilvB, изоформа I AHAS, большая субъединица
<400> 24
Met Ala Ser Ser Gly Thr Thr Ser Thr Arg Lys Arg Phe Thr Gly Ala
1 5 10 15
Glu Phe Ile Val His Phe Leu Glu Gln Gln Gly Ile Lys Ile Val Thr
20 25 30
Gly Ile Pro Gly Gly Ser Ile Leu Pro Val Tyr Asp Ala Leu Ser Gln
35 40 45
Ser Thr Gln Ile Arg His Ile Leu Ala Arg His Glu Gln Gly Ala Gly
50 55 60
Phe Ile Ala Gln Gly Met Ala Arg Thr Asp Gly Lys Pro Ala Val Cys
65 70 75 80
Met Ala Cys Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Ala Ile Ala
85 90 95
Asp Ala Arg Leu Asp Ser Ile Pro Leu Ile Cys Ile Thr Gly Gln Val
100 105 110
Pro Ala Ser Met Ile Gly Thr Asp Ala Phe Gln Glu Val Asp Thr Tyr
115 120 125
Gly Ile Ser Ile Pro Ile Thr Lys His Asn Tyr Leu Val Arg His Ile
130 135 140
Glu Glu Leu Pro Gln Val Met Ser Asp Ala Phe Arg Ile Ala Gln Ser
145 150 155 160
Gly Arg Pro Gly Pro Val Trp Ile Asp Ile Pro Lys Asp Val Gln Thr
165 170 175
Ala Val Phe Glu Ile Glu Thr Gln Pro Ala Met Ala Glu Lys Ala Ala
180 185 190
Ala Pro Ala Phe Ser Glu Glu Ser Ile Arg Asp Ala Ala Ala Met Ile
195 200 205
Asn Ala Ala Lys Arg Pro Val Leu Tyr Leu Gly Gly Gly Val Ile Asn
210 215 220
Ala Pro Ala Arg Val Arg Glu Leu Ala Glu Lys Ala Gln Leu Pro Thr
225 230 235 240
Thr Met Thr Leu Met Ala Leu Gly Met Leu Pro Lys Ala His Pro Leu
245 250 255
Ser Leu Gly Met Leu Gly Met His Gly Val Arg Ser Thr Asn Tyr Ile
260 265 270
Leu Gln Glu Ala Asp Leu Leu Ile Val Leu Gly Ala Arg Phe Asp Asp
275 280 285
Arg Ala Ile Gly Lys Thr Glu Gln Phe Cys Pro Asn Ala Lys Ile Ile
290 295 300
His Val Asp Ile Asp Arg Ala Glu Leu Gly Lys Ile Lys Gln Pro His
305 310 315 320
Val Ala Ile Gln Ala Asp Val Asp Asp Val Leu Ala Gln Leu Ile Pro
325 330 335
Leu Val Glu Ala Gln Pro Arg Ala Glu Trp His Gln Leu Val Ala Asp
340 345 350
Leu Gln Arg Glu Phe Pro Cys Pro Ile Pro Lys Ala Cys Asp Pro Leu
355 360 365
Ser His Tyr Gly Leu Ile Asn Ala Val Ala Ala Cys Val Asp Asp Asn
370 375 380
Ala Ile Ile Thr Thr Asp Val Gly Gln His Gln Met Trp Thr Ala Gln
385 390 395 400
Ala Tyr Pro Leu Asn Arg Pro Arg Gln Trp Leu Thr Ser Gly Gly Leu
405 410 415
Gly Thr Met Gly Phe Gly Leu Pro Ala Ala Ile Gly Ala Ala Leu Ala
420 425 430
Asn Pro Asp Arg Lys Val Leu Cys Phe Ser Gly Asp Gly Ser Leu Met
435 440 445
Met Asn Ile Gln Glu Met Ala Thr Ala Ser Glu Asn Gln Leu Asp Val
450 455 460
Lys Ile Ile Leu Met Asn Asn Glu Ala Leu Gly Leu Val His Gln Gln
465 470 475 480
Gln Ser Leu Phe Tyr Glu Gln Gly Val Phe Ala Ala Thr Tyr Pro Gly
485 490 495
Lys Ile Asn Phe Met Gln Ile Ala Ala Gly Phe Gly Leu Glu Thr Cys
500 505 510
Asp Leu Asn Asn Glu Ala Asp Pro Gln Ala Ser Leu Gln Glu Ile Ile
515 520 525
Asn Arg Pro Gly Pro Ala Leu Ile His Val Arg Ile Asp Ala Glu Glu
530 535 540
Lys Val Tyr Pro Met Val Pro Pro Gly Ala Ala Asn Thr Glu Met Val
545 550 555 560
Gly Glu
<210> 25
<211> 291
<212> ДНК
<213> Escherichia coli
<220>
<223> ilvN, изоформа I AHAS, малая субъединица
<400> 25
atgcaaaaca caactcatga caacgtaatt ctggagctca ccgttcgcaa ccatccgggc
60
gtaatgaccc acgtttgtgg cctttttgcc cgccgcgctt ttaacgttga aggcattctt
120
tgtctgccga ttcaggacag cgacaaaagc catatctggc tactggtcaa tgacgaccag
180
cgtctggagc agatgataag ccaaatcgat aagctggaag atgtcgtgaa agtgcagcgt
240
aatcagtccg atccgacgat gtttaacaag atcgcggtgt tttttcagta a
291
<210> 26
<211> 96
<212> БЕЛОК
<213> Escherichia coli
<220>
<223> ilvN, изоформа I AHAS, малая субъединица
<400> 26
Met Gln Asn Thr Thr His Asp Asn Val Ile Leu Glu Leu Thr Val Arg
1 5 10 15
Asn His Pro Gly Val Met Thr His Val Cys Gly Leu Phe Ala Arg Arg
20 25 30
Ala Phe Asn Val Glu Gly Ile Leu Cys Leu Pro Ile Gln Asp Ser Asp
35 40 45
Lys Ser His Ile Trp Leu Leu Val Asn Asp Asp Gln Arg Leu Glu Gln
50 55 60
Met Ile Ser Gln Ile Asp Lys Leu Glu Asp Val Val Lys Val Gln Arg
65 70 75 80
Asn Gln Ser Asp Pro Thr Met Phe Asn Lys Ile Ala Val Phe Phe Gln
85 90 95
<210> 27
<211> 1647
<212> ДНК
<213> Shigella boydii
<220>
<223> AHAS II, большая субъединица
<400> 27
atgaatggcg cacagtgggt ggtacatgcg ttgcgggcac agggtgtgaa caccgttttc
60
ggttatccgg gtggcgcaat tatgccggtt tacgatgcat tgtatgacgg cggcgtggag
120
cacttgctgt gccgacatga gcagggtgcg gcaatggcgg ctatcggtta tgcccgtgct
180
accggcaaaa ctggcgtatg tatcgccacg tctggtccgg gcgcaaccaa cctgataacc
240
gggcttgcgg acgcactgtt agattctatc cctgttgttg ccatcaccgg tcaagtgtcc
300
gcaccgttta tcggcactga tgcatttcag gaagtggatg tcctgggatt gtcgttagcc
360
tgtaccaagc acagctttct ggtgcagtcg ctggaagagt tgccgcgcat tatggctgaa
420
gcattcgacg ttgccagctc aggtcgtcct ggtccggttc tggtcgatat cccaaaagat
480
atccagctag ccagcggtga cctggaaccg tggttcacca ccgttgaaaa cgaagtgact
540
ttcccacatg ccgaagttga gcaagcgcgc cagatgctgg caaaagcgca aaaaccgatg
600
ctgtacgttg gtggtggcgt gggtatggcg caggcagttc ctgctttacg agaatttctc
660
gctaccacaa aaatgcctgc cacctgcacg ctgaaagggc tgggcgcagt tgaagcagat
720
tatccgtact atctgggcat gctgggaatg catggcacca aagcggcgaa cttcgcggtg
780
caggagtgcg acttgctgat cgccgtgggt gcacgttttg atgaccgggt gaccggcaaa
840
ctgaacacct tcgcaccaca cgccagcgtt atccatatgg atatcgaccc ggcagaaatg
900
aacaagctgc gtcaggcaca tgtggcatta caaggtgatt taaatgctct gttaccagaa
960
ttacagcagc cgttaaatat caatgactgg cagcaatact gcgcgcagct gcgtgatgaa
1020
catgcctggc gttacgacca tcccggcgac gctatctacg cgccgttgtt gttaaaacaa
1080
ctgtcggatc gtaaacctgc ggattgcgtc gtgaccacag atgtggggca gcaccagatg
1140
tgggctgcgc aacacatcgc ccacactcgc ccggaaaatt tcatcacctc cagcggctta
1200
ggcactatgg gttttggttt accagcggcg gttggcgcac aagtcgcgcg accgaacgat
1260
accgtcgtct gtatctccgg tgacggctct ttcatgatga atgtgcaaga gctgggcacc
1320
gtaaaacgca agcagttacc gttgaaaatc gtcttactcg ataaccaacg gttagggatg
1380
gttcgacaat ggcagcaact gttttttcag gaacgataca gcgaaaccac ccttactgat
1440
aaccccgatt tcctcatgtt agccagcgcc ttcggcatcc ctggccaaca catcacccgt
1500
aaagaccagg ttgaagcggc actcgacacc atgctgaaca gtgatgggcc atacctgctt
1560
catgtctcaa tcgacgaact tgagaacgtc tggccgctgg tgccgcctgg cgccagtaat
1620
tcagaaatgt tggagaaatt atcatga
1647
<210> 28
<211> 548
<212> БЕЛОК
<213> Shigella boydii
<220>
<223> AHAS II, большая субъединица
<400> 28
Met Asn Gly Ala Gln Trp Val Val His Ala Leu Arg Ala Gln Gly Val
1 5 10 15
Asn Thr Val Phe Gly Tyr Pro Gly Gly Ala Ile Met Pro Val Tyr Asp
20 25 30
Ala Leu Tyr Asp Gly Gly Val Glu His Leu Leu Cys Arg His Glu Gln
35 40 45
Gly Ala Ala Met Ala Ala Ile Gly Tyr Ala Arg Ala Thr Gly Lys Thr
50 55 60
Gly Val Cys Ile Ala Thr Ser Gly Pro Gly Ala Thr Asn Leu Ile Thr
65 70 75 80
Gly Leu Ala Asp Ala Leu Leu Asp Ser Ile Pro Val Val Ala Ile Thr
85 90 95
Gly Gln Val Ser Ala Pro Phe Ile Gly Thr Asp Ala Phe Gln Glu Val
100 105 110
Asp Val Leu Gly Leu Ser Leu Ala Cys Thr Lys His Ser Phe Leu Val
115 120 125
Gln Ser Leu Glu Glu Leu Pro Arg Ile Met Ala Glu Ala Phe Asp Val
130 135 140
Ala Ser Ser Gly Arg Pro Gly Pro Val Leu Val Asp Ile Pro Lys Asp
145 150 155 160
Ile Gln Leu Ala Ser Gly Asp Leu Glu Pro Trp Phe Thr Thr Val Glu
165 170 175
Asn Glu Val Thr Phe Pro His Ala Glu Val Glu Gln Ala Arg Gln Met
180 185 190
Leu Ala Lys Ala Gln Lys Pro Met Leu Tyr Val Gly Gly Gly Val Gly
195 200 205
Met Ala Gln Ala Val Pro Ala Leu Arg Glu Phe Leu Ala Thr Thr Lys
210 215 220
Met Pro Ala Thr Cys Thr Leu Lys Gly Leu Gly Ala Val Glu Ala Asp
225 230 235 240
Tyr Pro Tyr Tyr Leu Gly Met Leu Gly Met His Gly Thr Lys Ala Ala
245 250 255
Asn Phe Ala Val Gln Glu Cys Asp Leu Leu Ile Ala Val Gly Ala Arg
260 265 270
Phe Asp Asp Arg Val Thr Gly Lys Leu Asn Thr Phe Ala Pro His Ala
275 280 285
Ser Val Ile His Met Asp Ile Asp Pro Ala Glu Met Asn Lys Leu Arg
290 295 300
Gln Ala His Val Ala Leu Gln Gly Asp Leu Asn Ala Leu Leu Pro Glu
305 310 315 320
Leu Gln Gln Pro Leu Asn Ile Asn Asp Trp Gln Gln Tyr Cys Ala Gln
325 330 335
Leu Arg Asp Glu His Ala Trp Arg Tyr Asp His Pro Gly Asp Ala Ile
340 345 350
Tyr Ala Pro Leu Leu Leu Lys Gln Leu Ser Asp Arg Lys Pro Ala Asp
355 360 365
Cys Val Val Thr Thr Asp Val Gly Gln His Gln Met Trp Ala Ala Gln
370 375 380
His Ile Ala His Thr Arg Pro Glu Asn Phe Ile Thr Ser Ser Gly Leu
385 390 395 400
Gly Thr Met Gly Phe Gly Leu Pro Ala Ala Val Gly Ala Gln Val Ala
405 410 415
Arg Pro Asn Asp Thr Val Val Cys Ile Ser Gly Asp Gly Ser Phe Met
420 425 430
Met Asn Val Gln Glu Leu Gly Thr Val Lys Arg Lys Gln Leu Pro Leu
435 440 445
Lys Ile Val Leu Leu Asp Asn Gln Arg Leu Gly Met Val Arg Gln Trp
450 455 460
Gln Gln Leu Phe Phe Gln Glu Arg Tyr Ser Glu Thr Thr Leu Thr Asp
465 470 475 480
Asn Pro Asp Phe Leu Met Leu Ala Ser Ala Phe Gly Ile Pro Gly Gln
485 490 495
His Ile Thr Arg Lys Asp Gln Val Glu Ala Ala Leu Asp Thr Met Leu
500 505 510
Asn Ser Asp Gly Pro Tyr Leu Leu His Val Ser Ile Asp Glu Leu Glu
515 520 525
Asn Val Trp Pro Leu Val Pro Pro Gly Ala Ser Asn Ser Glu Met Leu
530 535 540
Glu Lys Leu Ser
545
<210> 29
<211> 264
<212> ДНК
<213> Shigella boydii
<220>
<223> AHAS II, малая субъединица
<400> 29
atgatgcaat atcaggtcaa tgtatcggct cgcttcaatc cggaaacctt agaacgtgtt
60
ttacgcgtgg tgcgtcatcg tggtttccac gtctgctcaa tgaatatggc cgccgccagc
120
gatgcacaaa atataaatat cgaattgacc gttgccagcc cacggtcggt cgacttactg
180
tttagtcagt taaataaact ggtggacgtc gcacacgttg ccatctgcca gagcacaacc
240
acatcacaac aaatccgcgc ctga
264
<210> 30
<211> 87
<212> БЕЛОК
<213> Shigella boydii
<220>
<223> AHAS II, малая субъединица
<400> 30
Met Met Gln Tyr Gln Val Asn Val Ser Ala Arg Phe Asn Pro Glu Thr
1 5 10 15
Leu Glu Arg Val Leu Arg Val Val Arg His Arg Gly Phe His Val Cys
20 25 30
Ser Met Asn Met Ala Ala Ala Ser Asp Ala Gln Asn Ile Asn Ile Glu
35 40 45
Leu Thr Val Ala Ser Pro Arg Ser Val Asp Leu Leu Phe Ser Gln Leu
50 55 60
Asn Lys Leu Val Asp Val Ala His Val Ala Ile Cys Gln Ser Thr Thr
65 70 75 80
Thr Ser Gln Gln Ile Arg Ala
85
<210> 31
<211> 1647
<212> ДНК
<213> Serratia marcescens
<220>
<223> AHAS II, большая субъединица
<400> 31
atgaatggcg ctcagtgggt agttcaagcg ttgcgtgcgc agggtgtgga taccgtattc
60
ggctatccgg gtggggcaat catgccggtg tacgatgcgc tgtacgacgg cggtgtggaa
120
cacctgctgt gtcgccatga acagggcgcc gcgatggccg ccatcggcta cgcccgcgcc
180
accggcaaag tcggcgtttg catcgccact tccggccctg gcgccaccaa cctgatcact
240
ggcctggctg atgcgctgct cgattccgtt cccgttgtcg ccatcaccgg tcaggtgggt
300
tccgcgctga tcggcaccga tgcctttcag gagatcgatg ttctcggcct gtctctggcc
360
tgcaccaagc acagcttcct ggtggaatcg ctggacgcct tgccgggcat catggcggaa
420
gcgttcgcca tcgccgcagg cggccgccct ggcccggtgc tgatcgatat cccgaaagac
480
attcagctgg cgcagggcga cttgcacccg catctgatgc cggtcgacga agcgccggcg
540
ttcccggcgg cagcgttggc agaagcggcc gagctgctgg cgcaggccca aaaaccgatg
600
ctgtacgtcg gcggcggcgt gggcatggcg caggcggtgc cggcgctgcg tgaatttatc
660
gccgtgaccc gcatgccgaa cgtcgccacc ctgaaggggc tgggtgcgcc ggatgcgcaa
720
gatccgctgt acctcggcat gttgggcatg cacggcacca aggctgccaa cctggcggtg
780
caggcgtgcg atttgctgat tgccgtcggc gcgcgtttcg atgaccgcgt aaccggcaaa
840
ctgaacgcct tcgcaccgca tgccaaagtg atccacatgg atatcgatcc ggcggagatg
900
agcaagctgc gccaggcgca tgtggccctg cagggcgatc tgaaagcgtt gctgccggcg
960
ttgcagcgcc cgctgaatat cgccgcctgg cagcagcagg tggcggtact gaaagctgag
1020
cacgcctgtc gctacgatca ccccggccag ccgatctacg cgccattgtt cttgcgccag
1080
ctgtccgccc gcaagccggc caacagcgtg gtgaccaccg acgtgggcca gcatcagatg
1140
tggagcgcgc agcacatgac gttcgaacgc ccggagaatt tcatcacctc cagcggcctc
1200
ggcaccatgg ggttcggcgt gccggcggcg gtgggggccc agatcgcgcg cccgcaagat
1260
acggtgatct gcgtctcggg cgatggctcc ttcatgatga acgtacagga gctgggcacc
1320
atcaagcgta aacagctgcc gctcaagatc gtgctgctgg acaaccaacg cctcggaatg
1380
gtgcgtcagt ggcagcagct gttcttcgac ggccgctaca gcgaaaccaa cctgtccgat
1440
aaccccgact tcctgatgct ggccgccgcc ttcggcattc ccggccagcg catcagccgc
1500
aaggatcagg tggaggacgc gctcgaggcg ctgttcaaca ccgaaggccc ttatctgctg
1560
caggtctcta tcgacgaact cgaaaacgtc tggccgctgg tgccgccggg cgccggcaac
1620
gaaaccatgt tggaggaaat atcatga
1647
<210> 32
<211> 548
<212> БЕЛОК
<213> Serratia marcescens
<220>
<223> AHAS II, большая субъединица
<400> 32
Met Asn Gly Ala Gln Trp Val Val Gln Ala Leu Arg Ala Gln Gly Val
1 5 10 15
Asp Thr Val Phe Gly Tyr Pro Gly Gly Ala Ile Met Pro Val Tyr Asp
20 25 30
Ala Leu Tyr Asp Gly Gly Val Glu His Leu Leu Cys Arg His Glu Gln
35 40 45
Gly Ala Ala Met Ala Ala Ile Gly Tyr Ala Arg Ala Thr Gly Lys Val
50 55 60
Gly Val Cys Ile Ala Thr Ser Gly Pro Gly Ala Thr Asn Leu Ile Thr
65 70 75 80
Gly Leu Ala Asp Ala Leu Leu Asp Ser Val Pro Val Val Ala Ile Thr
85 90 95
Gly Gln Val Gly Ser Ala Leu Ile Gly Thr Asp Ala Phe Gln Glu Ile
100 105 110
Asp Val Leu Gly Leu Ser Leu Ala Cys Thr Lys His Ser Phe Leu Val
115 120 125
Glu Ser Leu Asp Ala Leu Pro Gly Ile Met Ala Glu Ala Phe Ala Ile
130 135 140
Ala Ala Gly Gly Arg Pro Gly Pro Val Leu Ile Asp Ile Pro Lys Asp
145 150 155 160
Ile Gln Leu Ala Gln Gly Asp Leu His Pro His Leu Met Pro Val Asp
165 170 175
Glu Ala Pro Ala Phe Pro Ala Ala Ala Leu Ala Glu Ala Ala Glu Leu
180 185 190
Leu Ala Gln Ala Gln Lys Pro Met Leu Tyr Val Gly Gly Gly Val Gly
195 200 205
Met Ala Gln Ala Val Pro Ala Leu Arg Glu Phe Ile Ala Val Thr Arg
210 215 220
Met Pro Asn Val Ala Thr Leu Lys Gly Leu Gly Ala Pro Asp Ala Gln
225 230 235 240
Asp Pro Leu Tyr Leu Gly Met Leu Gly Met His Gly Thr Lys Ala Ala
245 250 255
Asn Leu Ala Val Gln Ala Cys Asp Leu Leu Ile Ala Val Gly Ala Arg
260 265 270
Phe Asp Asp Arg Val Thr Gly Lys Leu Asn Ala Phe Ala Pro His Ala
275 280 285
Lys Val Ile His Met Asp Ile Asp Pro Ala Glu Met Ser Lys Leu Arg
290 295 300
Gln Ala His Val Ala Leu Gln Gly Asp Leu Lys Ala Leu Leu Pro Ala
305 310 315 320
Leu Gln Arg Pro Leu Asn Ile Ala Ala Trp Gln Gln Gln Val Ala Val
325 330 335
Leu Lys Ala Glu His Ala Cys Arg Tyr Asp His Pro Gly Gln Pro Ile
340 345 350
Tyr Ala Pro Leu Phe Leu Arg Gln Leu Ser Ala Arg Lys Pro Ala Asn
355 360 365
Ser Val Val Thr Thr Asp Val Gly Gln His Gln Met Trp Ser Ala Gln
370 375 380
His Met Thr Phe Glu Arg Pro Glu Asn Phe Ile Thr Ser Ser Gly Leu
385 390 395 400
Gly Thr Met Gly Phe Gly Val Pro Ala Ala Val Gly Ala Gln Ile Ala
405 410 415
Arg Pro Gln Asp Thr Val Ile Cys Val Ser Gly Asp Gly Ser Phe Met
420 425 430
Met Asn Val Gln Glu Leu Gly Thr Ile Lys Arg Lys Gln Leu Pro Leu
435 440 445
Lys Ile Val Leu Leu Asp Asn Gln Arg Leu Gly Met Val Arg Gln Trp
450 455 460
Gln Gln Leu Phe Phe Asp Gly Arg Tyr Ser Glu Thr Asn Leu Ser Asp
465 470 475 480
Asn Pro Asp Phe Leu Met Leu Ala Ala Ala Phe Gly Ile Pro Gly Gln
485 490 495
Arg Ile Ser Arg Lys Asp Gln Val Glu Asp Ala Leu Glu Ala Leu Phe
500 505 510
Asn Thr Glu Gly Pro Tyr Leu Leu Gln Val Ser Ile Asp Glu Leu Glu
515 520 525
Asn Val Trp Pro Leu Val Pro Pro Gly Ala Gly Asn Glu Thr Met Leu
530 535 540
Glu Glu Ile Ser
545
<210> 33
<211> 258
<212> ДНК
<213> Serratia marcescens
<220>
<223> AHAS II, малая субъединица
<400> 33
atgatgcagc atcaactctc tatccaggcg cgttttcgcc ccgaaatgtt agagcgcgta
60
ttgcgggtcg tgcgtcatcg cggctttcag gtttgtgcta tgaatatggt ttctccggcc
120
aacgccgaca gcatcaatat cgaattgacc gttgccagcc cacgtccggt cgccctgttg
180
tcatctcagt taagcaaact gctggacgtc tcctgcgtcg agatccagca gccaacatca
240
caacaaatac gcgcctga
258
<210> 34
<211> 85
<212> БЕЛОК
<213> Serratia marcescens
<220>
<223> AHAS II, малая субъединица
<400> 34
Met Met Gln His Gln Leu Ser Ile Gln Ala Arg Phe Arg Pro Glu Met
1 5 10 15
Leu Glu Arg Val Leu Arg Val Val Arg His Arg Gly Phe Gln Val Cys
20 25 30
Ala Met Asn Met Val Ser Pro Ala Asn Ala Asp Ser Ile Asn Ile Glu
35 40 45
Leu Thr Val Ala Ser Pro Arg Pro Val Ala Leu Leu Ser Ser Gln Leu
50 55 60
Ser Lys Leu Leu Asp Val Ser Cys Val Glu Ile Gln Gln Pro Thr Ser
65 70 75 80
Gln Gln Ile Arg Ala
85
<210> 35
<211> 1725
<212> ДНК
<213> Shigella boydii
<220>
<223> AHAS III, большая субъединица
<400> 35
atggagatgt tgtctggagc cgagatggtc gtccgatcgc ttatcgatca gggcgttaaa
60
caagtattcg gttatcctgg aggcgcagtc cttgatattt acgatgcatt gcataccgtg
120
ggtggtatcg atcatgtttt agttcgtcat gagcaggcgg cagtgcatat ggccgatggt
180
ctggcgcgcg cgaccgggga agtcggcgtc gtgctggtaa cgtcgggtcc aggggcgacc
240
aatgcgatta ccggcatcgc caccgcttat atggattcca ttccattagt tgtcctttcc
300
gggcaggtag cgacctcgtt gataggttac gatgcctttc aggagtgcga catggtgggg
360
atttcgcgac cagtggttaa acacagtttt ctggttaagc aaacggaaga cattccgcag
420
gtgctgaaaa aggctttctg gctggcggca agtggtcgtc ctggaccagt agtcgttgat
480
ttaccgaaag atattcttaa tccggcgaac aaattaccct atgtctggcc ggagtcggtc
540
agtatgcgtt cttacaatcc cactactacc ggacataaag ggcaaattaa gcgtgctctg
600
caaacgctgg tagtggcaaa aaaaccggtt gtctacgtag gcggtggggc aatcatggcg
660
ggctgccatc agcagttgaa agaaacggtg gaggcgttga atctgcccgt tgtttcctca
720
ttgatggggc tgggggcgtt tccggcaacg catcgtcagg cactgggcat gctgggaatg
780
cacggtacct acgaagccaa tatgacgatg cataacgcgg atgtgatttt cgccgtcggg
840
gtacgatttg atgaccgaac gacgaacaat ctggcaaagt actgcccaaa tgccactgtt
900
ctgcatatcg atattgatcc tacttccatt tctaaaaccg tgactgcgga tatcccgatt
960
gtgggggatg ctcgccaggt cctcgaacaa atgcttgaac tcttgtcgca agaatccgcc
1020
catcaaccac tggatgagat ccgcgactgg tggcagcaaa ttgaacagtg gcgcgctcgt
1080
cagtgcctga aatatgacac tcacagtgaa aagattaaac cgcaggcggt gatcgagact
1140
ctttggcggt tgacgaaggg agacgcttac gtgacgtccg atgtcgggca gcaccagatg
1200
tttgctgcac tttattatcc attcgacaaa ccgcgtcgct ggatcaattc cggtggcctc
1260
ggcacgatgg gttttggttt acctgcggca ctgggcgtca aaatggcgtt gccagaagaa
1320
accgtggttt gcgtcactgg cgacggcagt attcagatga acattcagga actgtctacc
1380
gcgttgcaat acgagttgcc cgtactggtg gtgaatctca ataaccgcta tctggggatg
1440
gtgaaacagt ggcaggacat gatctattcc ggccgtcatt cacaatctta tatgcaatca
1500
ctacccgatt tcgtccgtct ggcggaagcc tatggtcacg tcgggatcca gatctctcat
1560
ccgcatgagc tggaaagcaa acttagcgag gcgctggaac aggtgcgcaa taatcgcctg
1620
gtgtttgttg atgttaccgt cgatggcagt gagcacgtct acccgatgca gattcgcggg
1680
ggcggaatgg atgaaatgtg gttaagcaaa acggagagaa cctga
1725
<210> 36
<211> 574
<212> БЕЛОК
<213> Shigella boydii
<220>
<223> AHAS III, большая субъединица
<400> 36
Met Glu Met Leu Ser Gly Ala Glu Met Val Val Arg Ser Leu Ile Asp
1 5 10 15
Gln Gly Val Lys Gln Val Phe Gly Tyr Pro Gly Gly Ala Val Leu Asp
20 25 30
Ile Tyr Asp Ala Leu His Thr Val Gly Gly Ile Asp His Val Leu Val
35 40 45
Arg His Glu Gln Ala Ala Val His Met Ala Asp Gly Leu Ala Arg Ala
50 55 60
Thr Gly Glu Val Gly Val Val Leu Val Thr Ser Gly Pro Gly Ala Thr
65 70 75 80
Asn Ala Ile Thr Gly Ile Ala Thr Ala Tyr Met Asp Ser Ile Pro Leu
85 90 95
Val Val Leu Ser Gly Gln Val Ala Thr Ser Leu Ile Gly Tyr Asp Ala
100 105 110
Phe Gln Glu Cys Asp Met Val Gly Ile Ser Arg Pro Val Val Lys His
115 120 125
Ser Phe Leu Val Lys Gln Thr Glu Asp Ile Pro Gln Val Leu Lys Lys
130 135 140
Ala Phe Trp Leu Ala Ala Ser Gly Arg Pro Gly Pro Val Val Val Asp
145 150 155 160
Leu Pro Lys Asp Ile Leu Asn Pro Ala Asn Lys Leu Pro Tyr Val Trp
165 170 175
Pro Glu Ser Val Ser Met Arg Ser Tyr Asn Pro Thr Thr Thr Gly His
180 185 190
Lys Gly Gln Ile Lys Arg Ala Leu Gln Thr Leu Val Val Ala Lys Lys
195 200 205
Pro Val Val Tyr Val Gly Gly Gly Ala Ile Met Ala Gly Cys His Gln
210 215 220
Gln Leu Lys Glu Thr Val Glu Ala Leu Asn Leu Pro Val Val Ser Ser
225 230 235 240
Leu Met Gly Leu Gly Ala Phe Pro Ala Thr His Arg Gln Ala Leu Gly
245 250 255
Met Leu Gly Met His Gly Thr Tyr Glu Ala Asn Met Thr Met His Asn
260 265 270
Ala Asp Val Ile Phe Ala Val Gly Val Arg Phe Asp Asp Arg Thr Thr
275 280 285
Asn Asn Leu Ala Lys Tyr Cys Pro Asn Ala Thr Val Leu His Ile Asp
290 295 300
Ile Asp Pro Thr Ser Ile Ser Lys Thr Val Thr Ala Asp Ile Pro Ile
305 310 315 320
Val Gly Asp Ala Arg Gln Val Leu Glu Gln Met Leu Glu Leu Leu Ser
325 330 335
Gln Glu Ser Ala His Gln Pro Leu Asp Glu Ile Arg Asp Trp Trp Gln
340 345 350
Gln Ile Glu Gln Trp Arg Ala Arg Gln Cys Leu Lys Tyr Asp Thr His
355 360 365
Ser Glu Lys Ile Lys Pro Gln Ala Val Ile Glu Thr Leu Trp Arg Leu
370 375 380
Thr Lys Gly Asp Ala Tyr Val Thr Ser Asp Val Gly Gln His Gln Met
385 390 395 400
Phe Ala Ala Leu Tyr Tyr Pro Phe Asp Lys Pro Arg Arg Trp Ile Asn
405 410 415
Ser Gly Gly Leu Gly Thr Met Gly Phe Gly Leu Pro Ala Ala Leu Gly
420 425 430
Val Lys Met Ala Leu Pro Glu Glu Thr Val Val Cys Val Thr Gly Asp
435 440 445
Gly Ser Ile Gln Met Asn Ile Gln Glu Leu Ser Thr Ala Leu Gln Tyr
450 455 460
Glu Leu Pro Val Leu Val Val Asn Leu Asn Asn Arg Tyr Leu Gly Met
465 470 475 480
Val Lys Gln Trp Gln Asp Met Ile Tyr Ser Gly Arg His Ser Gln Ser
485 490 495
Tyr Met Gln Ser Leu Pro Asp Phe Val Arg Leu Ala Glu Ala Tyr Gly
500 505 510
His Val Gly Ile Gln Ile Ser His Pro His Glu Leu Glu Ser Lys Leu
515 520 525
Ser Glu Ala Leu Glu Gln Val Arg Asn Asn Arg Leu Val Phe Val Asp
530 535 540
Val Thr Val Asp Gly Ser Glu His Val Tyr Pro Met Gln Ile Arg Gly
545 550 555 560
Gly Gly Met Asp Glu Met Trp Leu Ser Lys Thr Glu Arg Thr
565 570
<210> 37
<211> 492
<212> ДНК
<213> Shigella boydii
<220>
<223> AHAS III, малая субъединица
<400> 37
atgcgccgga tattatcagt cttactcgaa aatgaatcag gcgcgttatc ccgcgtgatt
60
ggcctttttt cccagcgagg ctacaacatt gaaagcctga ccgttgcgcc aaccgacgat
120
ccgacattat cgcgtatgac catccagacc gtgggcgatg aaaaagtact tgagcagatc
180
gaaaagcaat tacacaagct ggtcgatgtc ttgcgcgtga gtgagttggg gcagggcgcg
240
catgttgagc gggaaattat gctggtgaaa attcaggcca gcggttacgg gcgtgacgaa
300
gtgaaacgta atacggaaat attccgtggg caaattatcg atgtcacccc ctcgctttat
360
accgttcaat tagcaggcac cagcgataag cttgatgcat ttttagcatc gattcgcgag
420
gtggcgaaaa ttgtggaagt tgctcgctct ggtgtggtcg gactttcgcg cggcgataaa
480
ataatgcgtt ga
492
<210> 38
<211> 163
<212> БЕЛОК
<213> Shigella boydii
<220>
<223> AHAS III, малая субъединица
<400> 38
Met Arg Arg Ile Leu Ser Val Leu Leu Glu Asn Glu Ser Gly Ala Leu
1 5 10 15
Ser Arg Val Ile Gly Leu Phe Ser Gln Arg Gly Tyr Asn Ile Glu Ser
20 25 30
Leu Thr Val Ala Pro Thr Asp Asp Pro Thr Leu Ser Arg Met Thr Ile
35 40 45
Gln Thr Val Gly Asp Glu Lys Val Leu Glu Gln Ile Glu Lys Gln Leu
50 55 60
His Lys Leu Val Asp Val Leu Arg Val Ser Glu Leu Gly Gln Gly Ala
65 70 75 80
His Val Glu Arg Glu Ile Met Leu Val Lys Ile Gln Ala Ser Gly Tyr
85 90 95
Gly Arg Asp Glu Val Lys Arg Asn Thr Glu Ile Phe Arg Gly Gln Ile
100 105 110
Ile Asp Val Thr Pro Ser Leu Tyr Thr Val Gln Leu Ala Gly Thr Ser
115 120 125
Asp Lys Leu Asp Ala Phe Leu Ala Ser Ile Arg Glu Val Ala Lys Ile
130 135 140
Val Glu Val Ala Arg Ser Gly Val Val Gly Leu Ser Arg Gly Asp Lys
145 150 155 160
Ile Met Arg
<210> 39
<211> 1719
<212> ДНК
<213> Serratia marcescens
<220>
<223> AHAS III, большая субъединица
<400> 39
atggagatgt tgtcaggagc cgagatggtc gtccgatcgt tgatcgatca gggcgttaaa
60
catgtattcg gctaccccgg cggggcggtg ctcgatatct acgacgccct gcatacggtc
120
ggagggatcg atcatattct ggtgcgccac gagcaaggtg cggtgcacat ggccgacggt
180
tacgcgcgcg ccaccggcga agtgggcgtg gtgctggtga cgtccggccc cggcgccacc
240
aacgccatta ccggtatcgc taccgcttat atggactcga tcccgatggt cgtcctgtcg
300
gggcaggtgc ccagctcgct gatcggctac gacgcctttc aggagtgcga tatggtgggg
360
atttctcggc cggtggtgaa acacagcttc ctggtaaaac gcaccgaaga catcccggcg
420
gtgttgaaga aggcctttta cctggcctcc agcggccgcc ccggcccggt ggtgatcgat
480
ctgccgaaag acatcgtcgg cccggcggtg cggatgcctt atgcctaccc gcaggacgtg
540
agcatgcgtt cttataaccc gacggtgcag ggccatcgcg ggcaaatcaa acgcgcgttg
600
caaaccatcc tggcggccaa gaagccggtg atgtatgtcg gcggcggcgc gatcaacgcc
660
ggttgcgaag ccgaactgct ggcgttggcg gagcagctga acctgccggt gaccagcagc
720
ctgatgggac tgggcgcttt ccccggcacc catcgccaga gtgtcggcat gctcggtatg
780
cacggcactt atgaagccaa caaaaccatg caccatgccg acgtgatctt cgcggtcggc
840
gtgcgtttcg acgatcgcac gaccaacaat ctggccaaat actgcccgga tgccaccgtg
900
ctgcatatcg atatcgatcc gacctcgatc tccaaaacgg tggatgccga tattccgatc
960
gtcggcgatg ccaaacaggt gttggtgcag atgctggagc tgttggcgca ggatgacaag
1020
gcgcaggatc acgatgcgtt gcgcgattgg tggcagtcta ttgaacagtg gcgcgcccgc
1080
gactgtttgg ggtacgacaa aaacagcggc accatcaagc cgcaggcggt gatcgaaacc
1140
ctgcatcgcc tgaccaaagg cgatgcctat gtgacctccg acgtggggca gcaccagatg
1200
tttgccgcgc tctattaccc gttcgacaaa ccgcgccgtt ggatcaactc cggcggcctc
1260
ggcaccatgg gcttcggcct gccggcggca ttgggcgtca agctggcgct gccggaggaa
1320
accgtggtgt gcgtcaccgg cgacggcagc atccagatga acattcagga gctgtccacc
1380
gcgctgcaat ataacctgcc ggtggtggtg gtgaacctca acaaccgcta tctgggcatg
1440
gtcaagcagt ggcaggacat gatttattcc ggccgccact cgcagtctta catggattcg
1500
ctgccggact ttgtcaagct ggccgaggct tacggccatg tcggcatcgc catccgcacg
1560
ccggatgagc tggaaagcaa gctggcgcag gcgctggcgg aaaaagagcg gctggtgttc
1620
gtcgacgtga ccgtcgatga aaccgaacat gtttacccga tgcagatccg cggcggaagc
1680
atggacgaaa tgtggcttag caaaacggag aggacctga
1719
<210> 40
<211> 572
<212> БЕЛОК
<213> Serratia marcescens
<220>
<223> AHAS III, большая субъединица
<400> 40
Met Glu Met Leu Ser Gly Ala Glu Met Val Val Arg Ser Leu Ile Asp
1 5 10 15
Gln Gly Val Lys His Val Phe Gly Tyr Pro Gly Gly Ala Val Leu Asp
20 25 30
Ile Tyr Asp Ala Leu His Thr Val Gly Gly Ile Asp His Ile Leu Val
35 40 45
Arg His Glu Gln Gly Ala Val His Met Ala Asp Gly Tyr Ala Arg Ala
50 55 60
Thr Gly Glu Val Gly Val Val Leu Val Thr Ser Gly Pro Gly Ala Thr
65 70 75 80
Asn Ala Ile Thr Gly Ile Ala Thr Ala Tyr Met Asp Ser Ile Pro Met
85 90 95
Val Val Leu Ser Gly Gln Val Pro Ser Ser Leu Ile Gly Tyr Asp Ala
100 105 110
Phe Gln Glu Cys Asp Met Val Gly Ile Ser Arg Pro Val Val Lys His
115 120 125
Ser Phe Leu Val Lys Arg Thr Glu Asp Ile Pro Ala Val Leu Lys Lys
130 135 140
Ala Phe Tyr Leu Ala Ser Ser Gly Arg Pro Gly Pro Val Val Ile Asp
145 150 155 160
Leu Pro Lys Asp Ile Val Gly Pro Ala Val Arg Met Pro Tyr Ala Tyr
165 170 175
Pro Gln Asp Val Ser Met Arg Ser Tyr Asn Pro Thr Val Gln Gly His
180 185 190
Arg Gly Gln Ile Lys Arg Ala Leu Gln Thr Ile Leu Ala Ala Lys Lys
195 200 205
Pro Val Met Tyr Val Gly Gly Gly Ala Ile Asn Ala Gly Cys Glu Ala
210 215 220
Glu Leu Leu Ala Leu Ala Glu Gln Leu Asn Leu Pro Val Thr Ser Ser
225 230 235 240
Leu Met Gly Leu Gly Ala Phe Pro Gly Thr His Arg Gln Ser Val Gly
245 250 255
Met Leu Gly Met His Gly Thr Tyr Glu Ala Asn Lys Thr Met His His
260 265 270
Ala Asp Val Ile Phe Ala Val Gly Val Arg Phe Asp Asp Arg Thr Thr
275 280 285
Asn Asn Leu Ala Lys Tyr Cys Pro Asp Ala Thr Val Leu His Ile Asp
290 295 300
Ile Asp Pro Thr Ser Ile Ser Lys Thr Val Asp Ala Asp Ile Pro Ile
305 310 315 320
Val Gly Asp Ala Lys Gln Val Leu Val Gln Met Leu Glu Leu Leu Ala
325 330 335
Gln Asp Asp Lys Ala Gln Asp His Asp Ala Leu Arg Asp Trp Trp Gln
340 345 350
Ser Ile Glu Gln Trp Arg Ala Arg Asp Cys Leu Gly Tyr Asp Lys Asn
355 360 365
Ser Gly Thr Ile Lys Pro Gln Ala Val Ile Glu Thr Leu His Arg Leu
370 375 380
Thr Lys Gly Asp Ala Tyr Val Thr Ser Asp Val Gly Gln His Gln Met
385 390 395 400
Phe Ala Ala Leu Tyr Tyr Pro Phe Asp Lys Pro Arg Arg Trp Ile Asn
405 410 415
Ser Gly Gly Leu Gly Thr Met Gly Phe Gly Leu Pro Ala Ala Leu Gly
420 425 430
Val Lys Leu Ala Leu Pro Glu Glu Thr Val Val Cys Val Thr Gly Asp
435 440 445
Gly Ser Ile Gln Met Asn Ile Gln Glu Leu Ser Thr Ala Leu Gln Tyr
450 455 460
Asn Leu Pro Val Val Val Val Asn Leu Asn Asn Arg Tyr Leu Gly Met
465 470 475 480
Val Lys Gln Trp Gln Asp Met Ile Tyr Ser Gly Arg His Ser Gln Ser
485 490 495
Tyr Met Asp Ser Leu Pro Asp Phe Val Lys Leu Ala Glu Ala Tyr Gly
500 505 510
His Val Gly Ile Ala Ile Arg Thr Pro Asp Glu Leu Glu Ser Lys Leu
515 520 525
Ala Gln Ala Leu Ala Glu Lys Glu Arg Leu Val Phe Val Asp Val Thr
530 535 540
Val Asp Glu Thr Glu His Val Tyr Pro Met Gln Ile Arg Gly Gly Ser
545 550 555 560
Met Asp Glu Met Trp Leu Ser Lys Thr Glu Arg Thr
565 570
<210> 41
<211> 495
<212> ДНК
<213> Serratia marcescens
<220>
<223> AHAS III, малая субъединица
<400> 41
atcatgcgcc gtattttatc tgtcttgctg gaaaacgaat ccggcgccct ctcgcgcgtg
60
gtggggttgt tctcccagcg tggttataac attgagagcc tgacggtggc gccgaccgac
120
gatccgacgc tgtcgcgtat gactatccag accgtcggcg acgagaaagt gctggagcag
180
attgagaagc agttgcacaa gctggtggac gtgctgcgcg tcagcgagct ggtgcagggc
240
gctcacgtcg agcgcgagat catgctggtg aaactgcagg ccagcggcta cggccgtgaa
300
gaggtgaagc gctgcgccga cattttccgc ggccagatcg tcgatgtgac ggcgacgttg
360
tatacggtgc agttggccgg caccagcgat aaactggacg ccttcctgag tgcggtgcga
420
gacgtcgcgg agatcgtgga agtggcgcgt tccggcgtgg tcggcgtgtc gcgcggcgac
480
aaaatcatgc gctga
495
<210> 42
<211> 164
<212> БЕЛОК
<213> Serratia marcescens
<220>
<223> AHAS III, малая субъединица
<400> 42
Met Met Arg Arg Ile Leu Ser Val Leu Leu Glu Asn Glu Ser Gly Ala
1 5 10 15
Leu Ser Arg Val Val Gly Leu Phe Ser Gln Arg Gly Tyr Asn Ile Glu
20 25 30
Ser Leu Thr Val Ala Pro Thr Asp Asp Pro Thr Leu Ser Arg Met Thr
35 40 45
Ile Gln Thr Val Gly Asp Glu Lys Val Leu Glu Gln Ile Glu Lys Gln
50 55 60
Leu His Lys Leu Val Asp Val Leu Arg Val Ser Glu Leu Val Gln Gly
65 70 75 80
Ala His Val Glu Arg Glu Ile Met Leu Val Lys Leu Gln Ala Ser Gly
85 90 95
Tyr Gly Arg Glu Glu Val Lys Arg Cys Ala Asp Ile Phe Arg Gly Gln
100 105 110
Ile Val Asp Val Thr Ala Thr Leu Tyr Thr Val Gln Leu Ala Gly Thr
115 120 125
Ser Asp Lys Leu Asp Ala Phe Leu Ser Ala Val Arg Asp Val Ala Glu
130 135 140
Ile Val Glu Val Ala Arg Ser Gly Val Val Gly Val Ser Arg Gly Asp
145 150 155 160
Lys Ile Met Arg
<210> 43
<211> 1725
<212> ДНК
<213> Bacillus subtilis
<220>
<223> AHAS III, большая субъединица
<400> 43
atggggacta atgtacaggt ggattcagca tctgccgaat gtacacagac gatgagcgga
60
gcattaatgc tgattgaatc attaaaaaaa gagaaagtag aaatgatctt cggttatccg
120
ggcggggctg tgcttccgat ttacgataag ctatacaatt cagggttggt acatatcctt
180
ccccgtcacg aacaaggagc aattcatgca gcggagggat acgcaagggt ctccggaaaa
240
ccgggtgtcg tcattgccac gtcagggccg ggagcgacaa accttgttac aggccttgct
300
gatgccatga ttgattcatt gccgttagtc gtctttacag ggcaggtagc aacctctgta
360
atcgggagcg atgcatttca ggaagcagac attttaggga ttacgatgcc agtaacaaaa
420
cacagctacc aggttcgcca gccggaagat ctgccgcgca tcattaaaga agcgttccat
480
attgcaacaa ctggaagacc cggacctgta ttgattgata ttccgaaaga tgtagcaaca
540
attgaaggag aattcagcta cgatcatgag atgaatctcc cgggatacca gccgacaaca
600
gagccgaatt atttgcagat ccgcaagctt gtggaagccg tgagcagtgc gaaaaaaccg
660
gtgatcctgg cgggtgcggg cgtactgcac ggaaaagcgt cagaagaatt aaaaaattat
720
gctgaacagc agcaaatccc tgtggcacac acccttttgg ggctcggagg cttcccggct
780
gaccatccgc ttttcctagg gatggcggga atgcacggta cttatacagc caatatggcc
840
cttcatgaat gtgatctatt aatcagtatc ggcgcccgtt ttgatgaccg tgtcacagga
900
aacctgaaac actttgccag aaacgcaaag atagcccaca tcgatattga tccagctgaa
960
atcggaaaaa tcatgaaaac acagattcct gtagtcggag acagcaaaat tgtcctgcag
1020
gagctgatca aacaagacgg caaacaaagc gattcaagcg aatggaaaaa acagctcgca
1080
gaatggaaag aagagtatcc gctctggtat gtagataatg aagaagaagg ttttaaacct
1140
cagaaattga ttgaatatat tcatcaattt acaaaaggag aggccattgt cgcaacggat
1200
gtaggccagc atcaaatgtg gtcagcgcaa ttttatccgt tccaaaaagc agataaatgg
1260
gtcacgtcag gcggacttgg aacgatggga ttcggtcttc cggcggcgat cggcgcacag
1320
ctggccgaaa aagatgctac tgttgtcgcg gttgtcggag acggcggatt ccaaatgacg
1380
cttcaagaac tcgatgttat tcgcgaatta aatcttccgg tcaaggtagt gattttaaat
1440
aacgcttgtc tcggaatggt cagacagtgg caggaaattt tctatgaaga acgttattca
1500
gaatctaaat tcgcttctca gcctgacttc gtcaaattgt ccgaagcata cggcattaaa
1560
ggcatcagaa tttcatcaga agcggaagca aaggaaaagc tggaagaggc attaacatca
1620
agagaacctg ttgtcattga cgtgcgggtt gccagcgaag aaaaagtatt cccgatggtg
1680
gctccgggga aagggctgca tgaaatggtg ggggtgaaac cttga
1725
<210> 44
<211> 574
<212> БЕЛОК
<213> Bacillus subtilis
<220>
<223> AHAS III, большая субъединица
<400> 44
Met Gly Thr Asn Val Gln Val Asp Ser Ala Ser Ala Glu Cys Thr Gln
1 5 10 15
Thr Met Ser Gly Ala Leu Met Leu Ile Glu Ser Leu Lys Lys Glu Lys
20 25 30
Val Glu Met Ile Phe Gly Tyr Pro Gly Gly Ala Val Leu Pro Ile Tyr
35 40 45
Asp Lys Leu Tyr Asn Ser Gly Leu Val His Ile Leu Pro Arg His Glu
50 55 60
Gln Gly Ala Ile His Ala Ala Glu Gly Tyr Ala Arg Val Ser Gly Lys
65 70 75 80
Pro Gly Val Val Ile Ala Thr Ser Gly Pro Gly Ala Thr Asn Leu Val
85 90 95
Thr Gly Leu Ala Asp Ala Met Ile Asp Ser Leu Pro Leu Val Val Phe
100 105 110
Thr Gly Gln Val Ala Thr Ser Val Ile Gly Ser Asp Ala Phe Gln Glu
115 120 125
Ala Asp Ile Leu Gly Ile Thr Met Pro Val Thr Lys His Ser Tyr Gln
130 135 140
Val Arg Gln Pro Glu Asp Leu Pro Arg Ile Ile Lys Glu Ala Phe His
145 150 155 160
Ile Ala Thr Thr Gly Arg Pro Gly Pro Val Leu Ile Asp Ile Pro Lys
165 170 175
Asp Val Ala Thr Ile Glu Gly Glu Phe Ser Tyr Asp His Glu Met Asn
180 185 190
Leu Pro Gly Tyr Gln Pro Thr Thr Glu Pro Asn Tyr Leu Gln Ile Arg
195 200 205
Lys Leu Val Glu Ala Val Ser Ser Ala Lys Lys Pro Val Ile Leu Ala
210 215 220
Gly Ala Gly Val Leu His Gly Lys Ala Ser Glu Glu Leu Lys Asn Tyr
225 230 235 240
Ala Glu Gln Gln Gln Ile Pro Val Ala His Thr Leu Leu Gly Leu Gly
245 250 255
Gly Phe Pro Ala Asp His Pro Leu Phe Leu Gly Met Ala Gly Met His
260 265 270
Gly Thr Tyr Thr Ala Asn Met Ala Leu His Glu Cys Asp Leu Leu Ile
275 280 285
Ser Ile Gly Ala Arg Phe Asp Asp Arg Val Thr Gly Asn Leu Lys His
290 295 300
Phe Ala Arg Asn Ala Lys Ile Ala His Ile Asp Ile Asp Pro Ala Glu
305 310 315 320
Ile Gly Lys Ile Met Lys Thr Gln Ile Pro Val Val Gly Asp Ser Lys
325 330 335
Ile Val Leu Gln Glu Leu Ile Lys Gln Asp Gly Lys Gln Ser Asp Ser
340 345 350
Ser Glu Trp Lys Lys Gln Leu Ala Glu Trp Lys Glu Glu Tyr Pro Leu
355 360 365
Trp Tyr Val Asp Asn Glu Glu Glu Gly Phe Lys Pro Gln Lys Leu Ile
370 375 380
Glu Tyr Ile His Gln Phe Thr Lys Gly Glu Ala Ile Val Ala Thr Asp
385 390 395 400
Val Gly Gln His Gln Met Trp Ser Ala Gln Phe Tyr Pro Phe Gln Lys
405 410 415
Ala Asp Lys Trp Val Thr Ser Gly Gly Leu Gly Thr Met Gly Phe Gly
420 425 430
Leu Pro Ala Ala Ile Gly Ala Gln Leu Ala Glu Lys Asp Ala Thr Val
435 440 445
Val Ala Val Val Gly Asp Gly Gly Phe Gln Met Thr Leu Gln Glu Leu
450 455 460
Asp Val Ile Arg Glu Leu Asn Leu Pro Val Lys Val Val Ile Leu Asn
465 470 475 480
Asn Ala Cys Leu Gly Met Val Arg Gln Trp Gln Glu Ile Phe Tyr Glu
485 490 495
Glu Arg Tyr Ser Glu Ser Lys Phe Ala Ser Gln Pro Asp Phe Val Lys
500 505 510
Leu Ser Glu Ala Tyr Gly Ile Lys Gly Ile Arg Ile Ser Ser Glu Ala
515 520 525
Glu Ala Lys Glu Lys Leu Glu Glu Ala Leu Thr Ser Arg Glu Pro Val
530 535 540
Val Ile Asp Val Arg Val Ala Ser Glu Glu Lys Val Phe Pro Met Val
545 550 555 560
Ala Pro Gly Lys Gly Leu His Glu Met Val Gly Val Lys Pro
565 570
<210> 45
<211> 519
<212> ДНК
<213> Bacillus subtilis
<220>
<223> AHAS III, малая субъединица
<400> 45
ttgaaaagaa ttatcacatt gactgtggtg aaccgctccg gggtgttaaa ccggatcacc
60
ggtctattca caaaaaggca ttacaacatt gaaagcatta cagttggaca cacagaaaca
120
gccggcgttt ccagaatcac cttcgtcgtt catgttgaag gtgaaaatga tgttgaacag
180
ttaacgaaac agctcaacaa acagattgat gtgctgaaag tcacagacat cacaaatcaa
240
tcgattgtcc agagggagct ggccttaatc aaggttgtct ccgcaccttc aacaagaaca
300
gagattaatg gaatcataga accgtttaga gcctctgtcg ttgatgtcag cagagacagc
360
atcgttgttc aggtgacagg tgaatctaac aaaattgaag cgcttattga gttattaaaa
420
ccttatggca ttaaagaaat cgcgagaaca ggtacaacgg cttttgcgag gggaacccag
480
caaaaggcgt catccaataa aacaatatct attgtataa
519
<210> 46
<211> 172
<212> БЕЛОК
<213> Bacillus subtilis
<220>
<223> AHAS III, малая субъединица
<400> 46
Met Lys Arg Ile Ile Thr Leu Thr Val Val Asn Arg Ser Gly Val Leu
1 5 10 15
Asn Arg Ile Thr Gly Leu Phe Thr Lys Arg His Tyr Asn Ile Glu Ser
20 25 30
Ile Thr Val Gly His Thr Glu Thr Ala Gly Val Ser Arg Ile Thr Phe
35 40 45
Val Val His Val Glu Gly Glu Asn Asp Val Glu Gln Leu Thr Lys Gln
50 55 60
Leu Asn Lys Gln Ile Asp Val Leu Lys Val Thr Asp Ile Thr Asn Gln
65 70 75 80
Ser Ile Val Gln Arg Glu Leu Ala Leu Ile Lys Val Val Ser Ala Pro
85 90 95
Ser Thr Arg Thr Glu Ile Asn Gly Ile Ile Glu Pro Phe Arg Ala Ser
100 105 110
Val Val Asp Val Ser Arg Asp Ser Ile Val Val Gln Val Thr Gly Glu
115 120 125
Ser Asn Lys Ile Glu Ala Leu Ile Glu Leu Leu Lys Pro Tyr Gly Ile
130 135 140
Lys Glu Ile Ala Arg Thr Gly Thr Thr Ala Phe Ala Arg Gly Thr Gln
145 150 155 160
Gln Lys Ala Ser Ser Asn Lys Thr Ile Ser Ile Val
165 170
<---

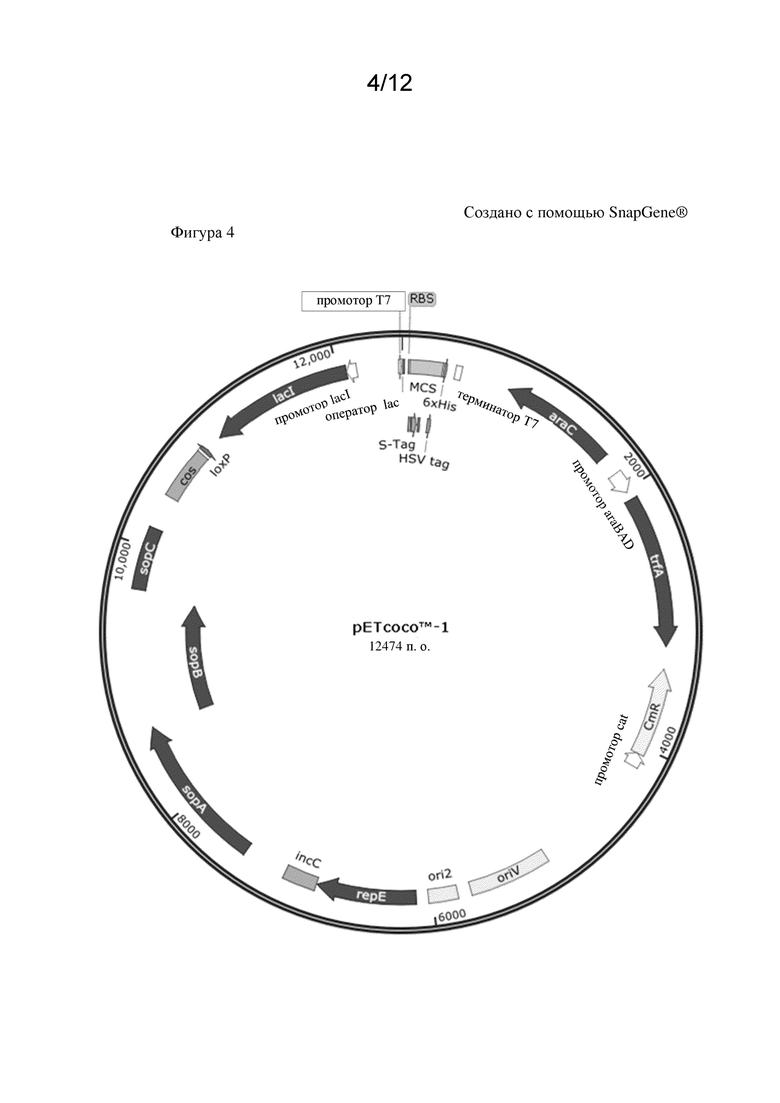
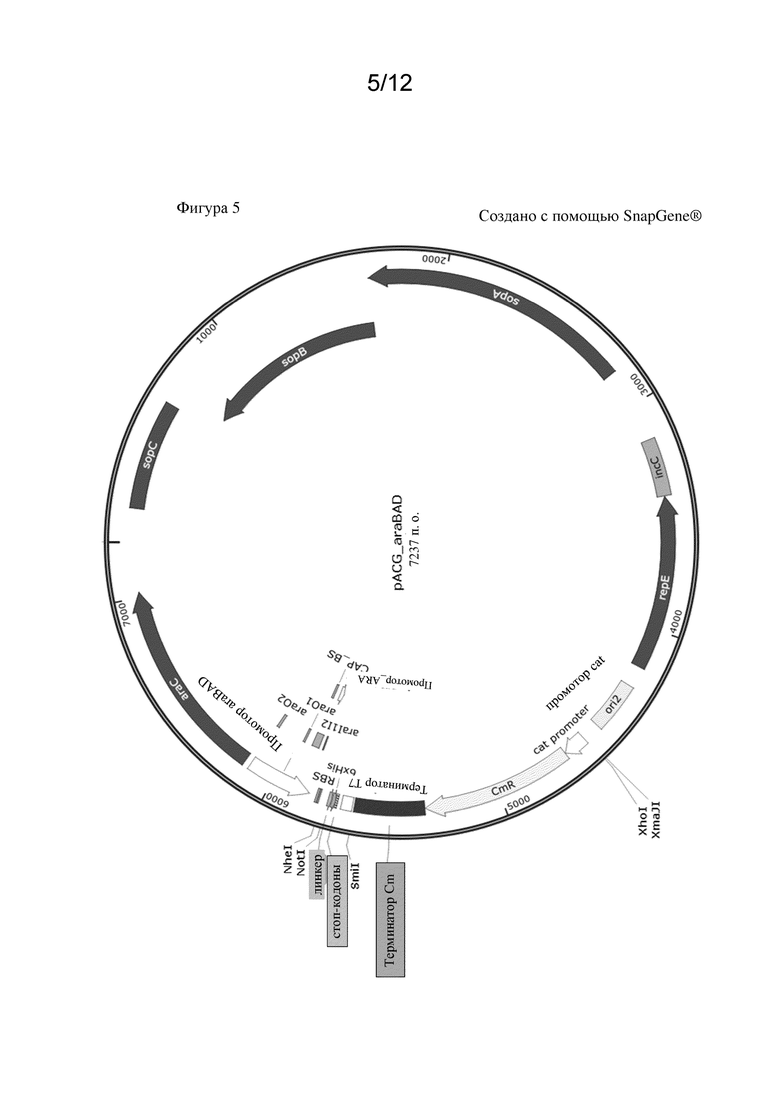
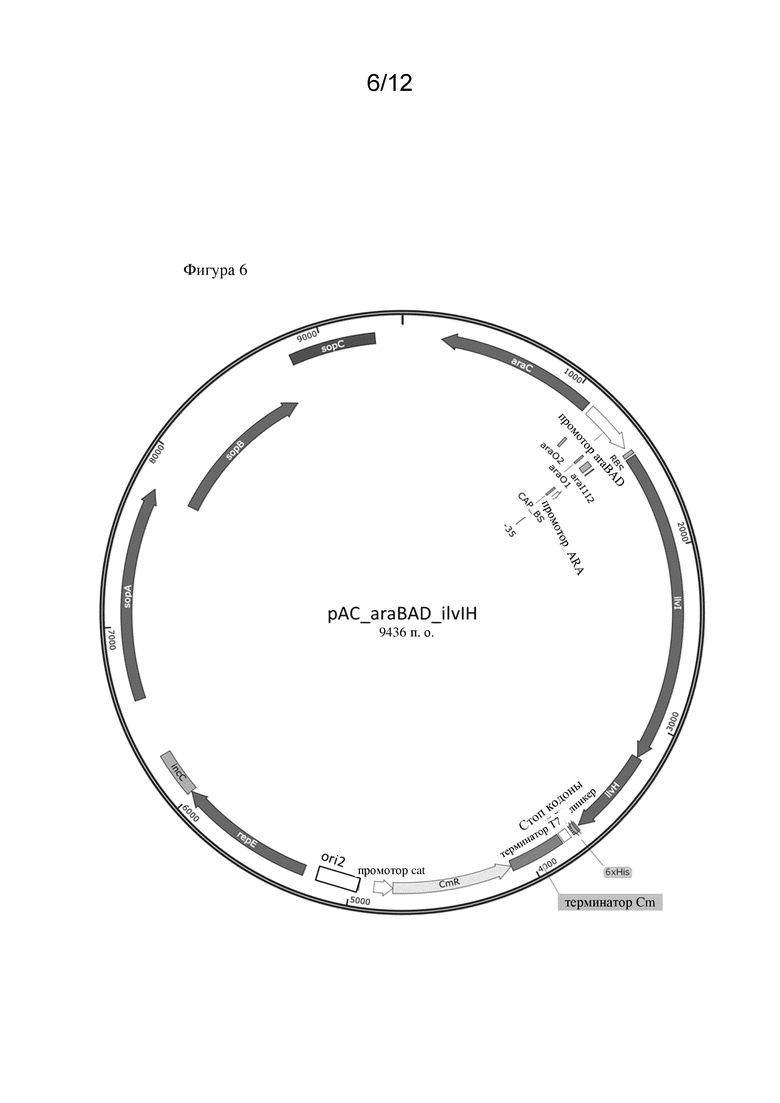
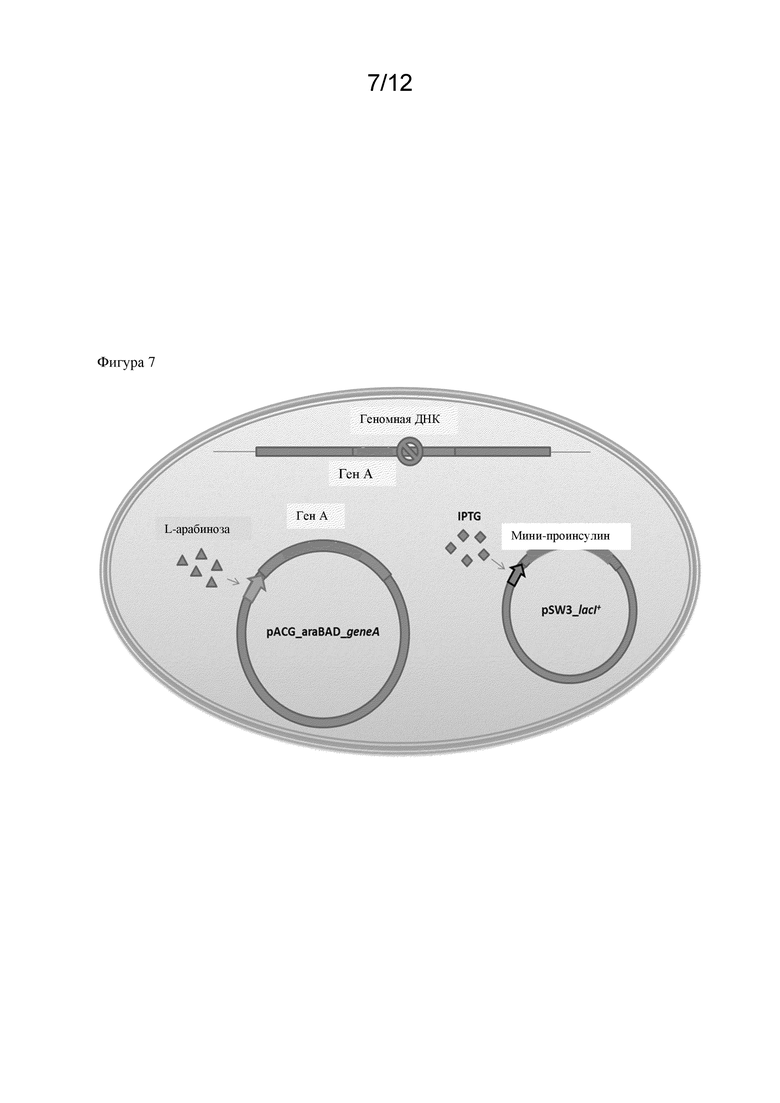
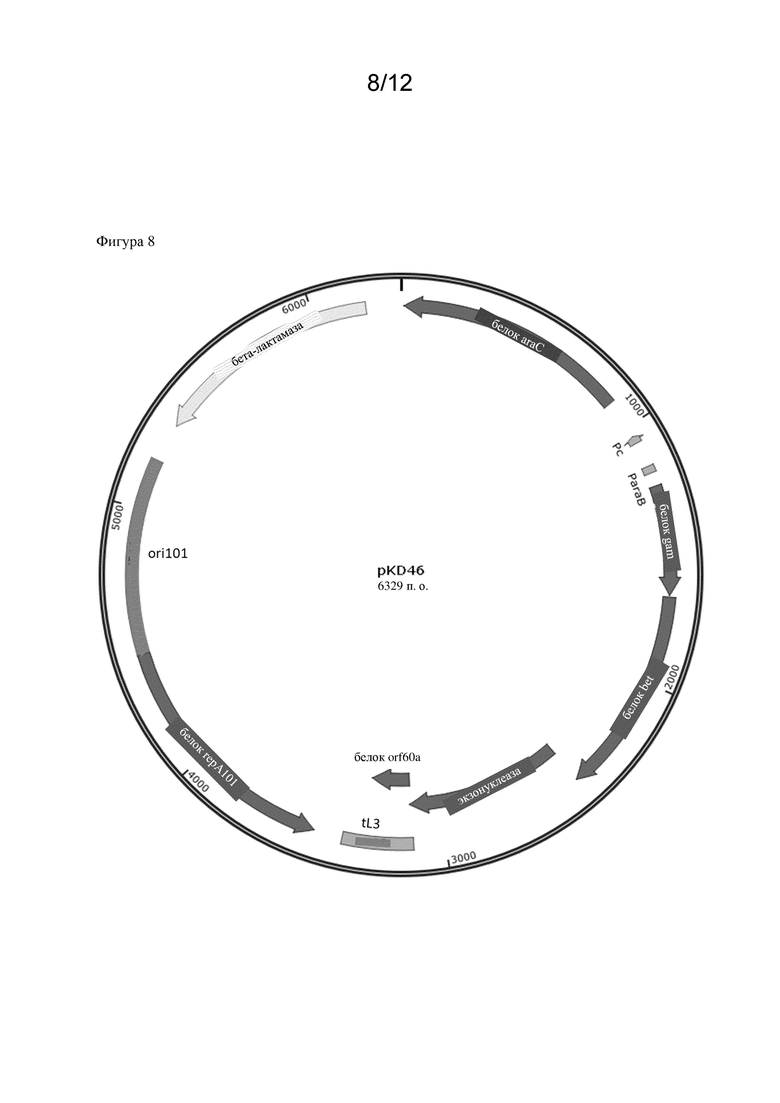
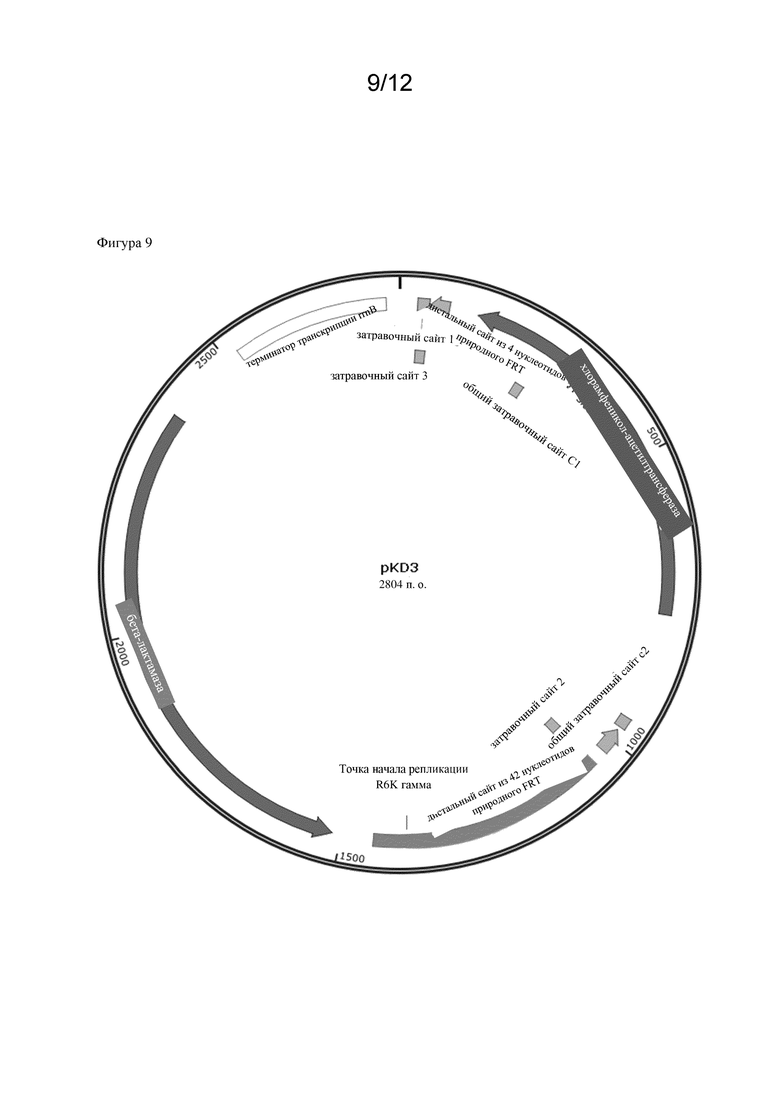

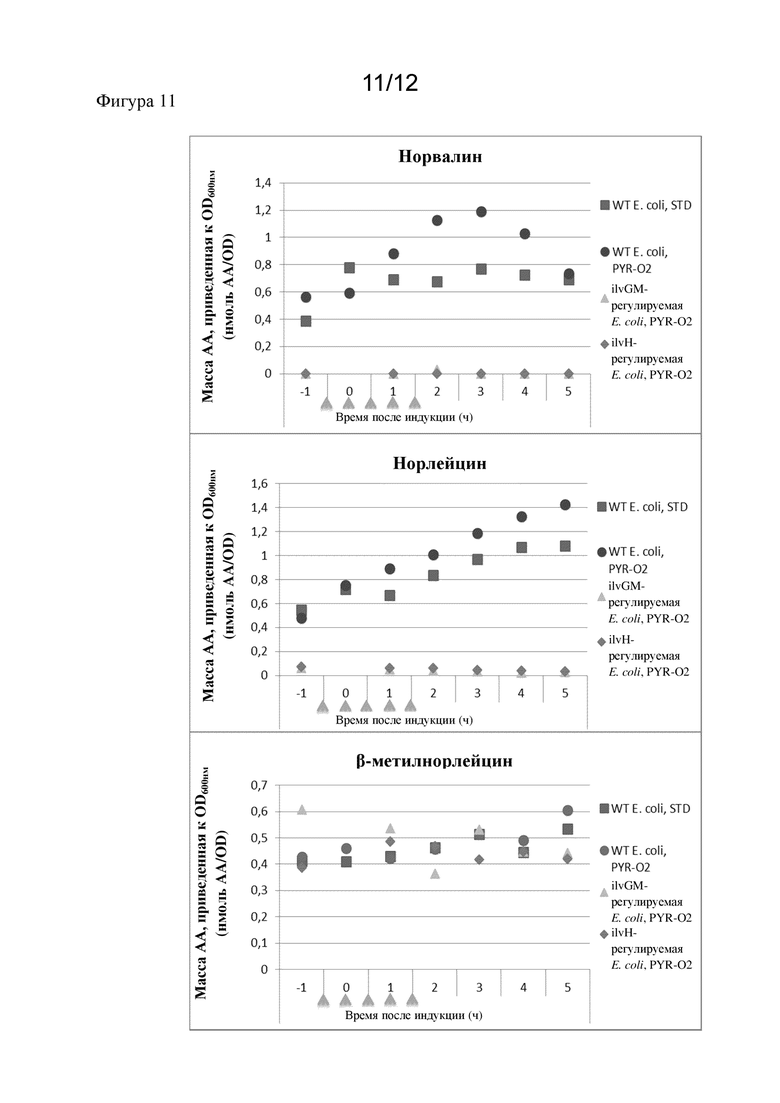
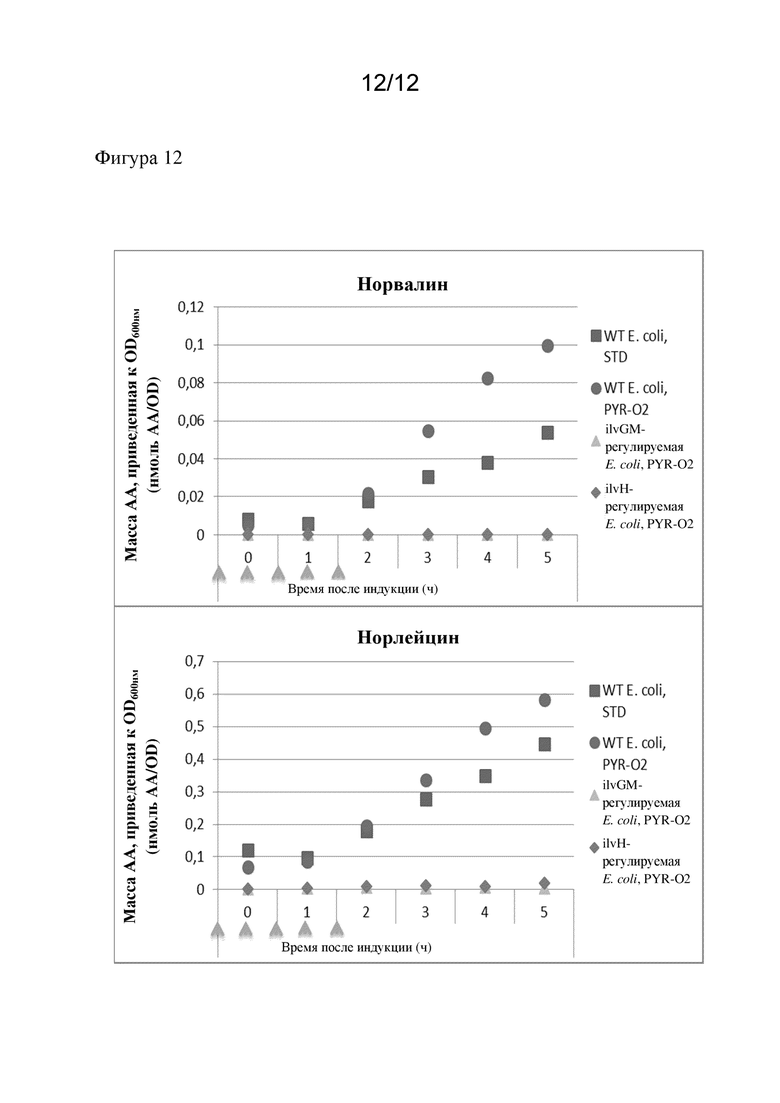
Изобретение относится к области биотехнологии, конкретно к рекомбинантному получению полипептидов, и может быть использовано для получения представляющих интерес полипептидов в микробных клетках-хозяевах. Изобретение направлено на повышение активности синтазы ацетогидроксикислот (AHAS) (EC 2.2.1.6) при продуцировании полипептида, представляющего интерес, в микробной клетке-хозяине, содержащей рекомбинантный полинуклеотид, кодирующий указанный полипептид, по сравнению с активностью AHAS в немодифицированной микробной клетке-хозяине. Изобретение обеспечивает снижение уровня ошибочного включения неканонических аминокислот с разветвленной цепью (ncBCAA), а именно норвалина и/или норлейцина, в рекомбинантный полипептид, представляющий интерес и продуцируемый в модифицированной микробной клетке-хозяине. 5 н. и 30 з.п. ф-лы, 12 ил., 10 пр., 12 табл.
1. Способ получения рекомбинантного полипептида, представляющего интерес, в микробной клетке-хозяине, включающий стадии
(a) введения полинуклеотида, кодирующего полипептид, представляющий интерес, в микробную клетку-хозяина, которая была модифицирована таким образом, что активность синтазы ацетогидроксикислот (AHAS) (EC 2.2.1.6) является повышенной в указанной микробной клетке-хозяине по сравнению с активностью AHAS в немодифицированной микробной клетке-хозяине, и
(b) экспрессии указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
2. Способ по п. 1, где полученный полипептид, представляющий интерес, демонстрирует сниженное ошибочное включение норвалина и/или норлейцина по сравнению с полипептидом, который был получен посредством экспрессии в немодифицированной микробной клетке-хозяине.
3. Способ по любому из п. 1 и 2, где способ дополнительно включает выделение полипептида из клетки и очистку полипептида.
4. Способ по п. 3, где очистка включает обогащение полипептидов, которые не содержат норвалина и/или норлейцина.
5. Способ по любому из п. 1 и 4, где указанную активность AHAS повышают посредством введения и экспрессии полинуклеотида, кодирующего полипептид, обладающий указанной активностью AHAS, в указанной микробной клетке-хозяине.
6. Способ по п. 5, где указанная микробная клетка-хозяин не экспрессирует эндогенный полипептид, обладающий указанной активностью AHAS.
7. Способ по п. 1, где полипептид, представляющий интерес, является терапевтическим пептидом или полипептидом.
8. Способ по п. 1, где полинуклеотид, кодирующий полипептид, представляющий интерес, и/или полинуклеотид, кодирующий полипептид, обладающий указанной активностью AHAS, функционально связан с индуцируемым промотором.
9. Способ по п. 1, где указанная микробная клетка-хозяин представляет собой клетку Escherichia coli.
10. Способ снижения ошибочного включения норвалина и/или норлейцина в рекомбинантный полипептид, представляющий интерес, экспрессируемый в микробной клетке-хозяине, при этом указанный способ включает
(a) повышение активности синтазы ацетогидроксикислот (AHAS) (EC 2.2.1.6) в микробной клетке-хозяине,
(b) введение полинуклеотида, кодирующего полипептид, представляющий интерес, в указанную микробную клетку-хозяина, и
(c) экспрессию указанного полипептида, представляющего интерес, в указанной микробной клетке-хозяине.
11. Способ по п. 10, где указанная микробная клетка-хозяин представляет собой клетку Escherichia coli.
12. Способ по п. 1 или 10, где полипептид, представляющий интерес, представляет собой проинсулин или аналог инсулина.
13. Способ по п. 1 или 10, где активность AHAS представляет собой активность изоформы II AHAS или изоформы III AHAS.
14. Способ по п. 13, где большая субъединица изоформы II AHAS кодируется первым полинуклеотидом, а малая субъединица изоформы II AHAS кодируется вторым полинуклеотидом, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
15. Способ по п. 14, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
16. Способ по п. 13, где большая субъединица изоформы III AHAS кодируется первым полинуклеотидом, а малая субъединица изоформы III AHAS кодируется вторым полинуклеотидом, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
17. Способ по п. 16, где указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
18. Применение полипептида, обладающего активностью синтазы ацетогидроксикислот (AHAS) (EC 2.2.1.6), или полинуклеотида, кодирующего указанный полипептид, для снижения ошибочного включения норвалина и/или норлейцина в рекомбинантный полипептид, представляющий интерес, продуцируемый в микробной клетке-хозяине, где указанные полипептид, обладающий активностью AHAS, или полинуклеотид, кодирующий указанный полипептид, присутствуют в указанной микробной клетке-хозяине.
19. Применение по п. 18, где активность AHAS в указанной микробной клетке-хозяине является повышенной по сравнению с активностью AHAS в указанной микробной клетке-хозяине в отсутствие указанных полипептида, обладающего активностью AHAS, или полинуклеотида, кодирующего указанный полипептид.
20. Применение микробной клетки-хозяина для получения рекомбинантного полипептида, представляющего интерес, где микробная клетка-хозяин была модифицирована таким образом, что активность синтазы ацетогидроксикислот (AHAS) (EC 2.2.1.6) повышается в указанной микробной клетке-хозяине по сравнению с активностью AHAS в немодифицированной микробной клетке-хозяине.
21. Применение по п. 18 или 20, где указанная микробная клетка-хозяин представляет собой клетку Escherichia coli.
22. Применение по п. 18 или 20, где полипептид, представляющий интерес, представляет собой проинсулин или аналог инсулина.
23. Применение по п. 18 или 20, где активность AHAS представляет собой активность изоформы II AHAS или изоформы III AHAS.
24. Применение по п. 23, где большая субъединица изоформы II AHAS кодируется первым полинуклеотидом, а малая субъединица изоформы II AHAS кодируется вторым полинуклеотидом, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
25. Применение по п. 24, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
26. Применение по п. 23, где большая субъединица изоформы III AHAS кодируется первым полинуклеотидом, а малая субъединица изоформы III AHAS кодируется вторым полинуклеотидом, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
27. Применение по п. 26, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
28. Микробная клетка-хозяин для получения рекомбинантного полипептида, представляющего интерес, содержащая
(a) рекомбинантный полинуклеотид, кодирующий полипептид, представляющий интерес, функционально связанный с промотором, и
(b) рекомбинантный полинуклеотид, кодирующий полипептид, обладающий активностью синтазы ацетогидроксикислот (AHAS) (EC 2.2.1.6), функционально связанный с промотором.
29. Микробная клетка-хозяин по п. 28, где промотор из (a) и/или промотор из (b) являются индуцируемыми.
30. Микробная клетка-хозяин по п. 28, где указанная микробная клетка-хозяин представляет собой клетку Escherichia coli.
31. Микробная клетка-хозяин по любому из п. 28-30, где активность AHAS представляет собой активность изоформы II AHAS или изоформы III AHAS.
32. Микробная клетка-хозяин по п. 31, где большая субъединица изоформы II AHAS кодируется первым полинуклеотидом, а малая субъединица изоформы II AHAS кодируется вторым полинуклеотидом, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
33. Микробная клетка-хозяин по п. 32, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 5, 27 или 31,
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 6, 28 или 32,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 7, 29 или 33, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 8, 30 или 34.
34. Микробная клетка-хозяин по п. 31, где большая субъединица изоформы III AHAS кодируется первым полинуклеотидом, а малая субъединица изоформы III AHAS кодируется вторым полинуклеотидом, где
указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 40% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 40% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
35. Микробная клетка-хозяин по п. 34, где указанный первый полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 13, 35, 39 или 43, и/или
ii) кодирует большую субъединицу синтазы ацетогидроксикислот, при этом указанная большая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 14, 36, 40 или 44,
и указанный второй полинуклеотид
i) содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 80% идентичностью последовательности с последовательностью нуклеиновой кислоты, показанной под SEQ ID NO: 15, 37, 41 или 45, и/или
ii) кодирует малую субъединицу синтазы ацетогидроксикислот, при этом указанная малая субъединица содержит аминокислотную последовательность, характеризующуюся по меньшей мере 80% идентичностью последовательности с аминокислотной последовательностью, показанной под SEQ ID NO: 16, 38, 42 или 46.
| WO 2005038017 A2, 28.04.2005 | |||
| REITZ C | |||
| et al., Synthesis of non-canonical branched-chain amino acids in Escherichia coli and approaches to avoid their incorporation into recombinant proteins, CURRENT OPINION IN BIOTECHNOLOGY, 2018, v | |||
| Веникодробильный станок | 1921 |
|
SU53A1 |
| Деревянная повозка с кузовом, устанавливаемым на упругих дрожинах | 1920 |
|
SU248A1 |
| SYCHEVA E.V | |||
| et al., Overproduction of noncanonical amino acids by Escherichia coli cells, | |||

