ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к мутанту О-сукцинилгомосеринтрансферазы, полинуклеотиду, кодирующему этот мутант, микроорганизму, включающему мутант, и способу получения О-сукцинилгомосерина с использованием микроорганизма.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
О-сукцинилгомосерин действует в качестве предшественника метионина, одной из незаменимых аминокислот человеческого организма. Метионин использовали в качестве синтетического сырья для лекарственных растворов и медицинских препаратов, а также кормов и пищевых добавок.
Метионин получают путем химического или биологического синтеза. Между тем сообщалось о двухстадийном способе получения L-метионина посредством реакции ферментативного превращения из предшественника L-метионина, полученного путем ферментации (международная публикация № WO/2008/013432).
В двухстадийном способе в качестве предшественников метионина используют О-сукцинилгомосерин или О-ацетилгомосерин, и для экономически выгодного массового производства метионина очень важно получать О-сукцинилгомосерин с высоким выходом.
Ген metA представляет собой ген, кодирующий О-сукцинилгомосеринтрансферазу (MetA) в качестве фермента, вовлеченного в синтез О-сукцинилгомосерина посредством связывания сукцинильной группы сукцинил-СоА с гомосерином. Ген metA представляет собой один из наиболее важных генов в разработке продуцирующих О-сукцинилгомосерин штаммов.
Штаммы, в которых накапливается О-сукцинилгомосерин, могут быть получены путем делеции гена metB, который кодирует цистатионин-гамма-синтазу в пути биосинтеза метионина. Однако продуцирующие О-сукцинилгомосерин штаммы имеют потребность в L-метионине. По этой причине активность О-сукцинилгомосеринтрансферазы ослабляется вследствие ингибирования конечным продуктом метионином, добавленным в культуральную среду, и в конечном счете О-сукцинилгомосерии не может быть получен в высокой концентрации.
Таким образом, многие из выданных ранее патентов сосредотачивали внимание на том, как высвободить ингибирование конечным продуктом metA из системы регуляции конечным продуктом. Однако О-сукцинилгомосеринтрансфераза, кодированная геном metA, имеет низкую стабильность даже в виде белка дикого типа, и стабильность ее можно дополнительно ухудшить посредством внесения вариации для высвобождения конечного продукта. Существует потребность в исключении ингибирования конечным продуктом гена metA и увеличении ферментативной стабильности для разработки штаммов, имеющих высокую способность к продуцированию О-сукцинилгомосерина.
Большая часть микроорганизмов в природе использует О-сукцинилгомосерин или О-ацетилгомосерин в качестве промежуточного соединения для биосинтеза метионина. В общем, MetA продуцирует О-сукцинилгомосерин и О-ацетилгомосеринтрансфераза (MetX) продуцирует О-ацетилгомосерин. Кроме того, в отличие от MetA, MetX не подвергается ингибированию конечным продуктом и имеет высокую ферментативную стабильность.
ОПИСАНИЕ ВОПЛОЩЕНИЙ ТЕХНИЧЕСКАЯ ЗАДАЧА
В результате интенсивных усилий для повышения продуцирования О-сукцинилгомосерина авторы настоящего изобретения обнаружили белок, имеющий активность О-сукцинилгомосеринтрансферазы, тем самым создав настоящее изобретение.
РЕШЕНИЕ ЗАДАЧИ
Задача настоящего изобретения заключается в том, чтобы предложить полипептид, имеющий активность О-сукцинилгомосеринтрансферазы и включающий замену аргинином аминокислоты в положении 313 и замену аминокислоты в положении 176 в аминокислотной последовательности SEQ ID NO: 1 аминокислотой, отличной от глутамина.
Другая задача настоящего изобретения заключается в том, чтобы предложить полинуклеотид, кодирующий полипептид.
Другая задача настоящего изобретения заключается в том, чтобы предложить микроорганизм рода Corynebacterium, продуцирующий О-сукцинилгомосерин и включающий полипептид, имеющий активность О-сукцинилгомосеринтрансферазы. Другая задача настоящего изобретения заключается в том, чтобы предложить способ получения О-сукцинилгомосерина, включающий культивирование микроорганизма в культуральной среде и выделение или извлечение О-сукцинилгомосерина из микроорганизма, культивированного на стадии культивирования, или из культуральной среды.
Другая задача настоящего изобретения заключается в том, чтобы предложить способ получения L-метионина, включающий культивирование микроорганизма в культуральной среде и взаимодействие O-сукцинилгомосерина с сульфидом.
ПОЛЕЗНЫЕ ЭФФЕКТЫ ИЗОБРЕТЕНИЯ
Так как мутированный белок О-сукцинилгомосеринтрансферазы согласно настоящему изобретению имеет повышенную активность превращения О-сукцинилгомосерина по сравнению с белками дикого типа, его можно использовать очень эффективно в массовом производстве О-сукцинилгомосерина в качестве альтернативы общепринятым путям химического синтеза.
НАИЛУЧШЕЕ ВОПЛОЩЕНИЕ ИЗОБРЕТЕНИЯ
Ниже настоящее изобретение будет описано более подробно.
Между тем каждое описание и воплощение, раскрытые в настоящем изобретении, могут быть применены здесь для описания различных описаний и воплощений. Другими словами, все комбинации различных компонентов, раскрытых в настоящем изобретении, включаются в объем настоящего изобретения. Кроме того, объем настоящего изобретения не следует ограничивать подробным описанием, предложенным ниже.
Специалист в данной области техники определит или сможет установить, с использованием не более чем стандартного экспериментирования, многие эквиваленты к конкретным воплощениям настоящего изобретения. Такие эквиваленты предназначены для охвата объемом следующей формулы изобретения.
В аспекте настоящего изобретения для успешного выполнения указанных выше задач предложен новый полипептид, имеющий активность О-сукцинилгомосеринтрансферазы. Новый вариантный полипептид может представлять собой полипептид, имеющий активность О-сукцинилгомосеринтрансферазы, у которого аминокислота в положении 313 замещена аргинином, и аминокислота в положении 176 замещена аминокислотой, отличной от глутамина, в аминокислотной последовательности, полученной из Corynebacterium glutamicum, конкретно, аминокислотной последовательности SEQ ID NO: 1. Кроме того, полипептид может иметь активность О-сукцинилгомосеринтрансферазы и включать замену аргинином для аминокислоты в положении 313 и замену аминокислотой, отличной от глутамина, для аминокислоты в положении 176 в аминокислотной последовательности SEQ ID NO: 1. Более конкретно, полипептид может представлять собой полипептид, имеющий активность О-сукцинилгомосеринтрансферазы, в котором аминокислота в положении 176 замещена аспарагином, триптофаном, гистидином или глицином в аминокислотной последовательности SEQ ID NO: 1, без ограничения этим.
Описанный выше вариантный полипептид имеет увеличенную активность О-сукцинилгомосеринтрансферазы по сравнению с таковой у полипептида SEQ ID NO: 1, имеющего активность О-сукцинилгомосеринтрансферазы.
В контексте настоящего изобретения, термин «активность О-сукцинилгомосеринтрансферазы» относится к активности, которая превращает гомосерин в О-сукцинилгомосерин. «О-сукцинилгомосеринтрансфераза» представляет собой родовое название ферментов, способных к превращению сукцинил-СоА и L-гомосерина в качестве субстратов, в СоА и О-сукцинилгомосерин.
Схема реакции
Сукцинил-СоА + L-гомосерин ↔ СоА + О-сукцинилгомосерин
В настоящем изобретении О-сукцинилгомосеринтрансфераза относится к белку MetX, представляющему собой О-ацетилгомосеринтрансферазу, модифицированному посредством модификации части его аминокислотной последовательности с помощью других аминокислот, таким образом приобретая активность О-сукцинилгомосеринтрансферазы. Белок MetX может представлять собой MetX, полученный из рода Corynebacterium, более конкретно MetX, имеющий аминокислотную последовательность SEQ ID NO: 1, полученную из Corynebacterium glutamicum, но без ограничения этим. Белок MetX может быть получен из известной базы данных GenBank Национального центра биотехнологической информации (NCBI).
В настоящем изобретении О-сукцинилгомосеринтрансфераза может быть получена посредством различных способов, хорошо известных в данной области техники. Примеры способов включают методику синтеза генов, включающую оптимизацию кодона так, чтобы получать фермент с высоким выходом в микроорганизме рода Corynebacterium, который широко использовали в экспрессии ферментов, и способ скрининга полезных источников фермента с использованием способа биоинформатики на основе огромных количеств генетической информации о микроорганизмах, но без ограничения этим.
В настоящем изобретении термин «мутант О-сукцинилгомосеринтрансферазы» можно взаимозаменяемо использовать с терминами «мутированная О-сукцинилгомосеринтрансфераза» или «вариантная О-сукцинилгомосеринтрансфераза». Между тем, этот мутант может представлять собой не встречающийся в природе мутант.
Конкретно, мутированная О-сукцинилгомосеринтрансфераза по настоящему изобретению может включать аминокислотную последовательность, в которой 313 аминокислотный остаток с N-конца MetX, полученного из Corynebacterium sp., имеющего аминокислотную последовательность SEQ ID NO: 1, замещен аргинином и ее 176^ аминокислота замещена аминокислотой, отличной от глутамина. Конкретно, 176ой аминокислотный остаток глутамина может быть замещен аспарагином, триптофаном, гистидином или глицином, без ограничения этим. Мутированная О-сукцинилгомосеринтрансфераза по настоящему изобретению может включать полипептид, имеющий вариацию в положении 313 и/или положении 176 с N-конца аминокислотной последовательности, изложенной в SEQ ID NO: 1, где вариация в положении 313 включает аминокислотную замену аргинином и/или вариация в положении 176 включает аминокислотную замену аспарагином, триптофаном, гистидином или глицином, и полипептид имеет гомологию или идентичность по меньшей мере 85% с SEQ ID NO: 1, без ограничения этим.
Кроме того, полипептид, имеющий активность О-сукцинилгомосеринтрансферазы по настоящему изобретению, может состоять из по меньшей мере одной аминокислотной последовательности, выбранной из группы, состоящей из аминокислотных последовательностей SEQ ID NO: 63, 75, 95 и 97. Конкретно, эти аминокислотные последовательности могут представлять собой аминокислотные последовательности полипептидов, имеющих активность мутированной О-сукцинилгомосеринтрансферазы, у которой 313я аминокислота с N-конца аминокислотной последовательности SEQ ID NO: 1 замещена аргинином и ее 116 ш аминокислота замещена аспарагином, триптофаном, гистидином или глицином, но настоящее изобретение не ограничивается этим. Любые полипептиды, имеющие гомологию или идентичность по меньшей мере 50%, 60%, 70%, 75%, 80%, 85%, 90%, 95%, 97% или 99% с последовательностями, описанными выше, можно использовать без ограничения до тех пор, пока полипептиды имеют вариации и увеличенную активность превращения О-сукцинилгомосерина, чем у дикого типа.
Также MetX по настоящему изобретению может представлять собой белок MetX, имеющий аминокислотную последовательность SEQ ID NO: 1 или аминокислотную последовательность, имеющую гомологию или идентичность с ней по меньшей мере 80%, но без ограничения этим. Конкретно, белок MetX по настоящему изобретению может включать белки, имеющие аминокислотную последовательность SEQ ID NO: 1 и аминокислотную последовательность, имеющую гомологию или идентичность 80% или более, 85% или более, конкретно 90% или более, более конкретно 95% или более, еще более конкретно 99% или более с SEQ ID NO: 1.
В контексте настоящего изобретения, термин «вариант» полипептида относится к полипептиду, имеющему аминокислотную последовательность, отличающуюся от изложенной последовательности консервативными заменами и/или модификациями, такими, что функции и свойства полипептида сохраняются. Вариантные полипептиды отличаются от идентифицированной последовательности вследствие замены, делеции или добавления нескольких аминокислот. Такие варианты обычно могут быть идентифицированы посредством модификации одной из приведенных выше полипептидных последовательностей и оценки свойств модифицированного полипептида. То есть, способность варианта может быть увеличена, оставлена без изменения или уменьшена по сравнению с нативным белком. Такие варианты обычно могут быть идентифицированы посредством модификации одной из приведенных выше полипептидных последовательностей и оценки свойств модифицированного полипептида. Кроме того, некоторые варианты могут включать такие, у которых одна или более частей, таких как N-концевая лидерная последовательность или трансмембранный домен, были исключены. Другие варианты могут включать такие, у которых часть была исключена из N- и/или С-конца зрелого белка. Термин «вариант» можно использовать взаимозаменяемо с терминами, такими как мутант, модификация, мутированный белок, вариантный полипептид, модифицированный белок, модифицированный полипептид, мутеин, дивергент и тому подобными, без ограничения, при условии, что термины используют для обозначения вариации. Конкретно, вариант включает варианты, имеющие эффективно увеличенную активность О-сукцинилгомосеринтрансферазы по сравнению с диким типом вследствие вариации аминокислот О-сукцинилгомосеринтрансферазы, полученной из Corynebacterium glutamicum.
В контексте настоящего изобретения, термин «консервативная замена» относится к одной аминокислоте, замененной другой аминокислотой, имеющей подобное структурное и/или химическое свойство. Например, вариант может иметь по меньшей мере одну консервативную замену, сохраняя при этом по меньшей мере одну биологическую активность. Такая аминокислотная замена обычно может происходить на основе подобия полярности, заряда, растворимости, гидрофобности, гидрофильности и/или амфипатической природы остатка. Например, положительно заряженные (основные) аминокислоты включают аргинин, лизин и гистидин; отрицательно заряженные (кислые) аминокислоты включают глутаминовую кислоту и аспарагиновую кислоту; ароматические аминокислоты включают фенилаланин, триптофан и тирозин; и гидрофобные аминокислоты включают аланин, валин, изолейцин, лейцин, метионин, фенилаланин, тирозин и триптофан. В общем, консервативная замена оказывает незначительное влияние или не оказывает влияния на активность полученного полипептида.
Варианты также могут включать другие модификации, включающие делецию или добавление аминокислот, которые имеют минимальное влияние на свойства и вторичную структуру полипептида. Например, полипептид может быть конъюгирован с сигнальной (или лидерной) последовательностью на N-конце белка, которая котрансляционно или посттрансляционно направляет перенос белка. Полипептид также может быть конъюгирован с другой последовательностью или линкером для идентификации, очистки или синтеза полипептида. Другими словами, хотя он раскрыт как «белок или полипептид, имеющий аминокислотную последовательность, изложенную в данной SEQ ID NO:», специалисту в данной области техники будет очевидно, что любой белок, имеющий аминокислотную последовательность, включающую делецию, модификацию, замену, консервативную замену или добавление одной или нескольких аминокислот, также можно использовать в настоящем изобретении при условии, что белок имеет активность гомологичную или идентичную с таковой у полипептида, имеющего такую же SEQ ID NO:. Например, специалисту в данной области техники очевидно, что любой белок, имеющий добавление последовательности, не изменяющей функции белка, встречающуюся в природе мутацию или ее молчащую мутацию, или консервативную замену в прямом или обратном направлении, не исключается при условии, что белок имеет активность, гомологичную или идентичную таковой у вариантного полипептида, и любой белок, имеющий такое добавление последовательности или мутацию, также может быть в пределах объема настоящего изобретения.
Также очевидно, что также можно использовать полинуклеотид, который транслируется в белок, содержащий по меньшей мере одну аминокислотную последовательность, выбранную из группы, состоящей из аминокислотных последовательностей SEQ ID NO: 63, 75, 95 и 97, или белков, имеющих гомологию или идентичность с ним вследствие вырожденности кодона. Или любой зонд, полученный из известных последовательностей гена, например, последовательности, которая в жестких условиях гибридизуется с последовательностью, полностью или частично комплементарной полинуклеотидной последовательности, и кодирует белок, имеющий активность О-сукцинилгомосеринтрансферазы, также можно использовать, без ограничения. Термин «жесткие условия» относится к условиям, которые обеспечивают специфическую гибридизацию между полинуклеотидами. Такие условия подробно раскрыты в известных документах (например, J. Sambrook et al., выше, 9.50-9.51, 11.7-11.8). Например, жесткие условия могут включать выполнение гибридизации между генами, имеющими высокую гомологию или идентичность, гомологию или идентичность 80% или более, 85% или более, конкретно 90% или более, более конкретно 95% или более, еще более конкретно 97% или более, и наиболее конкретно 99% или более, без выполнения гибридизации между генами, имеющими гомологию или идентичность более низкую, чем указанные выше гомологии или идентичности, или выполнение отмывки один раз, конкретно два или три раза, при общепринятых условиях отмывки для Саузерн-гибридизации 60°С, 1×SSC (хлорид натрия/цитрат натрия) и 0,1% SDS (додецилсульфат натрия), конкретно при концентрации солей и температуре 60°С, 0,1×SSC и 0,1% SDS и более конкретно при 68°С, 0,1×SSC и 0,1% SDS.
Гибридизация требует, чтобы две нуклеиновые кислоты имели комплементарные последовательности, хотя возможно ошибочное спаривание между основаниями в зависимости от степени жесткости гибридизации. Термин «комплементарный» используют для описания взаимоотношения между нуклеотидными основаниями, способными к гибридизации друг с другом. Например, что касается ДНК, аденозин комплементарен тимину и цитозин комплементарен гуанину. Таким образом, настоящее изобретение может включать не только по существу подобную последовательность нуклеиновой кислоты, но также фрагмент нуклеиновой кислоты, выделенный, но комплементарный целой последовательности.
Конкретно, полинуклеотид, имеющий гомологию или идентичность, может быть обнаружен с использованием описанных выше условий гибридизации, включая процесс гибридизации при значении Тm (температура плавления) 55°С. Также, значение Тm может представлять собой, но без ограничения, 60°С, 63°С или 65°С, и его может подходящим образом регулировать специалист в данной области техники согласно цели.
Подходящая степень жесткости для гибридизации полинуклеотидов может зависеть от длин полинуклеотидов и степени комплементарности, и параметры этого хорошо известны в данной области техники (Sambrook et al., выше, 9.50-9.51, 11.7-11.8).
Гомология или идентичность относится к степени релевантности между двумя аминокислотными последовательностями или нуклеотидными последовательностями и может быть выражена в процентном отношении.
Термины гомология и идентичность часто могут быть использованы взаимозаменяемо.
Гомология или идентичность последовательностей консервативных полинуклеотидов или полипептидов может быть определена посредством стандартного алгоритма выравнивания и вместе с ним можно использовать по умолчанию штрафы за гэп, установленные используемой программой. По существу, гомологичные или идентичные последовательности могут гибридизоваться друг с другом на длине по меньшей мере примерно 50%, 60%, 70%, 80% или 90% полной последовательности или полной длине в умеренных или очень жестких условиях. В гибридизованных полинуклеотидах также можно принимать во внимание полинуклеотиды, включающие вырожденный кодон вместо кодона.
Имеют или нет любые два полинуклеотида или полипептидные последовательности гомологию, подобие или идентичность, можно определять с использованием компьютерных алгоритмов, известных в данной области техники, например, программы «FASTA», использующей параметры по умолчанию, введенные Pearson et al. (1988) [Proc. Natl. Acad. Sci. USA 85]: 2444. Альтернативно, можно использовать алгоритм Нидлмана-Вунша (1970, J. Mol. Biol. 48: 443-453), который задействован в программе Нидлмана в пакете программ Европейского пакета открытого программного обеспечения по молекулярной биологии (EMBOSS) (Rice et al., 2000, Trends Genet. 16: 276-277) (версия 5.0.0 или более поздняя) для определения этого (включая пакет программ GCG (Devereux, J., et al., Nucleic Acids Research 12: 387 (1984)), BLASTP, BLASTN, FASTA (Atschul, [S.] [F.,] [ET AL, J MOLEC BIOL 215]: 403 (1990); Guide to Huge Computers, Martin J. Bishop, [ED.,] Academic Press, San Diego, 1994, и [CARILLO ЕТА/.](1988) SIAM J Applied Math 48: 1073). Например, гомологию, подобие или идентичность можно определять с использованием BLAST из базы данных Национального центра биотехнологической информации или ClustalW.
Гомология, подобие или идентичность между полинуклеотидами или полипептидами может быть определена путем сравнения информации о последовательностях с использованием компьютерной программы GAP, такой как программа, введенная Needleman et al., (1970), J Mol Biol. 48: 443, что раскрыто в Smith and Waterman, Adv. Appl. Math (1981) 2:482. Кратко, программа GAP определяет гомологию, подобие или идентичность в виде количества выровненных символов (то есть нуклеотидов или аминокислот), которые являются подобными, разделенного на суммарное количество символов в более короткой из двух последовательностей. Параметры по умолчанию для программы GAP могут включать: (1) унарную матрицу сравнения (содержащую значение 1 для идентичностей и 0 для отсутствия идентичностей) и взвешенную матрицу сравнения Gribskov, et al., (1986) Nucl. Acids Res. 14: 6745, как описано у Schwartz and Dayhoff, eds., Atlas Of Protein Sequence And Structure, National Biomedical Research Foundation, pp.353-358 (1979) (или подстановочную матрицу EDNAFULL (EMBOSS версия NCBI NUC4.4)); (2) штраф 3,0 за каждый гэп и дополнительный штраф 0,10 за каждый символ в каждом гэпе (или штраф за открытие гэпа 10 и штраф за продление гэпа 0,5); и (3) отсутствие штрафа для концевых гэпов. Таким образом, в контексте настоящего изобретения, термин «гомология» или «идентичность» относится к релевантности между последовательностями.
Другой аспект настоящего изобретения заключается в том, чтобы предложить полинуклеотид, кодирующий полипептид, имеющий активность О-сукцинилгомосеринтрансферазы.
В контексте настоящего изобретения, термин «полинуклеотид» относится к полимеру из нуклеотидов, где нуклеотидные мономеры соединены аналогично длинной цепи посредством ковалентных связей, где обычно указывают нить ДНК или РНК, имеющую определенную минимальную длину, более конкретно, к полинуклеотидному фрагменту, кодирующему вариантный полипептид.
В настоящем изобретении ген, кодирующий аминокислотную последовательность О-сукцинилгомосеринтрансферазы, представляет собой ген вариантной О-сукцинилгомосеринтрансферазы, конкретно, полученной из Corynebacterium glutamicum. Исходя из вырожденности генетического кода, нуклеотидную последовательность, кодирующую аналогичную аминокислотную последовательность, и ее мутанты также включают в настоящее изобретение, и их примеры могут быть изложены в SEQ ID NO: 64, 76, 96 или 98, без ограничения этим.
Кроме того, в случае вариантного полинуклеотида, нуклеотидную последовательность, кодирующую аналогичную аминокислотную последовательность, и ее мутанты также включают в настоящее изобретение исходя из вырожденности генетического кода.
Другой аспект настоящего изобретения заключается в том, чтобы предложить клетку-хозяина, включающую полинуклеотид, кодирующий вариантный полипептид, и микроорганизм, трансформированный вектором, включающим полинуклеотид, кодирующий вариантный полипептид. Конкретно, введение может быть выполнено посредством трансформации, но без ограничения этим.
Конкретно, так как микроорганизм, включающий вариантный полипептид О-сукцинилгомосеринтрансферазы, имеет увеличенную способность продуцирования О-сукцинилгомосерина без ингибирования роста клетки-хозяина по сравнению с микроорганизмом, включающим полипептид О-сукцинилгомосеринтрансферазы дикого типа, О-сукцинилгомосерин может быть получен из этих микроорганизмов с высоким выходом.
В контексте настоящего изобретения, термин «вектор» относится к ДНК-конструкции, содержащей нуклеотидную последовательность кодирующего целевой белок полинуклеотида, функционально связанную с подходящей регуляторной последовательностью, чтобы иметь возможность экспрессировать целевой белок в подходящей клетке-хозяине. Регуляторная последовательность может включать промотор, способный к инициации транскрипции, любую операторную последовательность для регуляции транскрипции, последовательность, кодирующую подходящий мРНК-сайт связывания рибосомы, и последовательность регуляции терминации транскрипции и трансляции. После трансформации в подходящую клетку-хозяина вектор может реплицироваться или действовать независимо от генома хозяина, или может сам интегрироваться в геном.
Вектор, используемый в настоящем изобретении, не ограничивается конкретно при условии, что он может реплицироваться в хозяине и может представлять собой любой вектор, известный в данной области техники. Примеры обычно используемых векторов могут включать естественные или рекомбинантные плазмиды, космиды, вирусы и бактериофаги. Например, pWE15, М13, MBL3, MBL4, IXII, ASHII, АРII, t10, t11, Charon4A и Charon21A можно использовать в качестве фагового вектора или космидного вектора, и векторы на основе pBR, pUC, pBluescriptll, pGEM, pTZ, pCL и pET можно использовать в качестве плазмидного вектора. Конкретно, можно использовать векторы pDZ, pACYC177, pACYC184, pCL, pECCG117, pUC19, pBR322, pMW118 и pCC1BAC, без ограничения этим.
Векторы, применяемые в настоящем изобретении, не ограничиваются конкретно, и можно использовать любые известные векторы экспрессии. Кроме того, полинуклеотид, кодирующий целевой белок, может быть вставлен в хромосому с использованием вектора для хромосомной вставки в клетки. Вставка полинуклеотида в хромосому может быть выполнена посредством любого способа, известного в данной области техники, например, гомологичной рекомбинации, без ограничения этим. Полинуклеотид может дополнительно включать селективный маркер для подтверждения хромосомной вставки. Селективный маркер используют для селекции клеток, которые трансформированы вектором, то есть для подтверждения вставки целевой молекулы нуклеиновой кислоты, и селективный маркер может включать маркеры, обеспечивающие селектируемые фенотипы, такие как устойчивость к лекарственным препаратам, потребность в питательных веществах, устойчивость к цитотоксическим агентам или экспрессия поверхностного белка. Только клетки, экспрессирующие селективный маркер, способны выживать или демонстрировать различные фенотипы в условиях окружающей среды, обработанной селективным агентом, и таким образом трансформированные клетки могут быть отобраны.
В контексте настоящего изобретения, термин «трансформация» обозначает перенос вектора, включающего полинуклеотид, кодирующий целевой белок, в клетку-хозяина таким образом, чтобы белок, кодированный полинуклеотидом, экспрессировался в клетке-хозяине. До тех пор, пока трансформированный полинуклеотид может экспрессироваться в клетке-хозяине, он может быть вставлен в хромосому и обнаружен в хромосоме клетки-хозяина, или может продолжать находиться вне хромосомы. Кроме того, полинуклеотид включает ДНК и РНК, кодирующие целевой белок. Полинуклеотид может быть введен в любой форме до тех пор, пока он способен к введению в клетку-хозяина и экспрессии в ней. Например, полинуклеотид может быть введен в клетку-хозяина в форме кассеты экспрессии, которая представляет собой генетическую конструкцию, включающую все элементы, необходимые для ее автономной экспрессии. Обычно кассета экспрессии включает промотор, функционально связанный с полинуклеотидом, сигнал терминации транскрипции, сайт связывания рибосомы, и сигнал терминации трансляции. Кассета экспрессии может быть в форме самореплицирующегося вектора экспрессии. Также, полинуклеотид как таковой может быть введен в клетку-хозяина и функционально связан с последовательностью, необходимой для экспрессии в клетке-хозяине, без ограничения этим. Способы трансформации включают любые способы введения нуклеиновой кислоты в клетки, и могут быть выполнены посредством подходящих стандартных методик, известных в данной области техники. Например, способы трансформации могут включать электропорацию, осаждение фосфатом кальция (Са(Н2РO4)2, СаНРO4, или Са3(РO4)2), осаждение хлоридом кальция (СаСl2), микроинъекцию, способ с использованием полиэтиленгликоля (ПЭГ), способ с DEAE-декстраном (диэтиламиноэтилдекстраном), способ с катионными липосомами и способ с дигидратом ацетата лития и DMSO (диметилсульфоксид), без ограничения этим.
Кроме того, в контексте настоящего изобретения, термин «функционально связанный» обозначает функциональную связь между последовательностью промотора, который инициирует и опосредует транскрипцию полинуклеотида, кодирующего целевой белок по настоящему изобретению, и полинуклеотидной последовательностью. Функциональная связь может быть получена с использованием технологии генетической рекомбинации, известной в данной области техники, и сайт-специфическое расщепление ДНК и лигирование может быть получено с использованием фермента рестрикции, лигазы, и тому подобных, известных в данной области техники, без ограничения этим.
В контексте настоящего изобретения, «микроорганизм, продуцирующий О-сукцинилгомосерин» относится к микроорганизму, по природе имеющему способность к продуцированию О-сукцинилгомосерина, или микроорганизму, полученному путем предоставления родительскому штамму, не способному продуцировать О-сукцинилгомосерин, способности продуцировать О-сукцинилгомосерин.
Микроорганизм, продуцирующий О-сукцинилгомосерин, может представлять собой клетку или микроорганизм, включающий полинуклеотид, кодирующий вариантный полипептид, или клетку или микроорганизм, трансформированный вектором, включающим полинуклеотид, кодирующий вариантный полипептид, для получения способности экспрессировать вариантный полипептид. Для цели настоящего изобретения клетка-хозяин или микроорганизм может представлять собой любые микроорганизмы, способные продуцировать О-сукцинилгомосерин в результате включения вариантного полипептида MetX. Примеры микроорганизма могут включать микроорганизмы, принадлежащие к роду Escherichia, роду Serratia, роду Erwinia, роду Enter obacieria, роду Salmonella, роду Streptomyces, роду Pseudomonas, роду Brevibacterium или роду Corynebacterium, конкретно, микроорганизмам рода Corynebacterium и, более конкретно, Corynebacterium glutamicum, без ограничения этим.
В контексте настоящего изобретения, термин «микроорганизм рода Corynebacterium, продуцирующий О-сукцинилгомосерин», относится к микроорганизму, принадлежащему к роду Corynebacterium, по природе имеющему способность продуцировать О-сукцинилгомосерин или имеющему таковую в результате мутации. В данной области техники хорошо известно, что культуры микроорганизма рода Corynebacterium содержат О-сукцинилгомосерин. Однако способность продуцировать О-сукцинилгомосерин является очень низкой, и ген или механизм, влияющий на механизм его продуцирования, еще не был обнаружен. Таким образом, микроорганизм рода Corynebacterium, имеющий способность продуцировать О-сукцинилгомосерин по настоящему изобретению, относится к микроорганизму рода Corynebacterium дикого типа, микроорганизму рода Corynebacterium, в который вставлен чужой ген, связанный с механизмом продуцирования О-сукцинилгомосерина, или микроорганизму рода Corynebacterium, модифицированному для получения увеличенной способности продуцировать О-сукцинилгомосерин посредством увеличения свойственной гену активности или ее инактивации.
В настоящем изобретении термин «микроорганизм рода Corynebacterium» относится конкретно к Corynebacterium glutamicum, Corynebacterium ammoniagenes, Brevibacterium lactofermentum, Brevibacterium flavum, Corynebacterium thermoaminogenes, Corynebacterium efficiens или тому подобным, без ограничения этим. Более конкретно, микроорганизм рода Corynebacterium по настоящему изобретению может представлять собой Corynebacterium glutamicum, клеточный рост и выживаемость которого менее подвержена влиянию, даже при воздействии высокой концентрации O-сукцинилгомосерина.
В микроорганизме по меньшей мере один белок, выбранный из группы, состоящей из цистатионинсинтазы, O-ацетилгомосерин-(тиол)-лиазы и гомосеринкиназы, может быть инактивирован. То есть один, два или три белка, выбранные из нее, могут быть инактивированы.
В контексте настоящего изобретения, термин «инактивация» активности белка означает, что активность белка ослаблена по сравнению со свойственной ему активностью, или белок не имеет активности.
Инактивация активности белка может быть достигнута посредством различных способов, хорошо известных в данной области техники. Примеры способов могут включать: способ делеции части или полностью гена, кодирующего белок на хромосоме, включая устранение активности белка; способ замены гена, кодирующего белок на хромосоме, мутированным геном для снижения ферментативной активности; способ внесения вариации в последовательность регуляции экспрессии гена, кодирующего белок на хромосоме; способ замены последовательности регуляции экспрессии гена, кодирующего белок, последовательностью, имеющей слабую активность или не обладающей активностью (например, способ замены промотора гена промотором, более слабым, чем эндогенный промотор); способ делеции части или полностью гена, кодирующего белок на хромосоме; способ внесения антисмыслового олигонуклеотида (например, антисмысловой РНК), который ингибирует трансляцию с мРНК в белок посредством комплементарного связывания с транскриптом гена на хромосоме; способ создания невозможности прикрепления рибосомы посредством формирования вторичной структуры посредством искусственного добавления комплементарной последовательности к последовательности Шайна-Дельгарно (SD) на переднем конце последовательности SD гена, кодирующего белок; и способ инженерии обратной транскрипции (RTE), в котором добавляется промотор для обратной транскрипции в 3'-конце открытой рамки считывания (ОРС) соответствующей последовательности, и их комбинацию, но без конкретного ограничения этим.
Конкретно, способ делеции части или полностью гена, кодирующего белок, может быть выполнен путем замены полинуклеотида, кодирующего эндогенный целевой белок в хромосоме полинуклеотидом или маркерным геном, имеющим частично делетированную последовательность нуклеиновой кислоты, с использованием вектора для хромосомной вставки в микроорганизмы. Например, можно использовать способ делеции гена посредством гомологичной рекомбинации, без ограничения этим. Также, в контексте настоящего изобретения, термин «часть» может конкретно подразумевать от 1 нуклеотида до 300 нуклеотидов, более конкретно от 1 нуклеотида до 100 нуклеотидов и еще более конкретно от 1 нуклеотида до 50 нуклеотидов, хотя она может варьировать в зависимости от видов полинуклеотида, и специалист в данной области техники может определять это подходящим образом. Однако «часть» не ограничивается конкретно этим.
Дополнительно, способ модификации последовательности регуляции экспрессии может быть выполнен посредством индукции вариации последовательности нуклеиновой кислоты в последовательности регуляции экспрессии посредством делеции, вставки, консервативной замены, неконсервативной замены, или любой их комбинации, с тем чтобы дополнительно ослаблять активность последовательности регуляции экспрессии; или посредством замены последовательности последовательностью нуклеиновой кислоты, имеющей более слабую активность. Последовательность регуляции экспрессии может включать промотор, операторную последовательность, последовательность, кодирующую сайт связывания рибосомы, и последовательность регуляции транскрипции и трансляции, но без ограничения этим.
Кроме того, способ модификации последовательности гена на хромосоме может быть выполнен путем индукции вариации в последовательности гена посредством делеции, вставки, консервативной замены, неконсервативной замены или любой их комбинации, чтобы дополнительно ослабить активность белка; или путем замены последовательности последовательностью гена, модифицированной для получения более слабой активности, или последовательностью гена, модифицированной для получения полного отсутствия активности, но без ограничения этим. Конкретно, в микроорганизме по меньшей мере один ген, выбранный из группы, состоящей из гена metB, кодирующего цистатионин-гамма-синтазу, ген metY, кодирующего О-ацетилгомосерин-(тиол)-лиазу, используемую в пути деградации О-сукцинилгомосерина, и гена thrB, кодирующего гомосеринкиназу, может быть дополнительно делетирован или ослаблен.
В контексте настоящего изобретения, термин «делеция» относится к типу удаления в хромосоме нуклеотидной последовательности, представляющей собой целевой ген, от инициирующего кодона до стоп-кодона, или части или полностью нуклеотидной последовательности его регуляторного участка.
В контексте настоящего изобретения, термин «ослабление» относится к удалению или снижению внутриклеточной активности по меньшей мере одного фермента, кодированного соответствующей ДНК в штамме микроорганизма. Например, экспрессия белка может быть ослаблена посредством модификации промоторного участка и нуклеотидной последовательности 5'-нетранслированной области (UTR), или активность белка может быть ослаблена посредством внесения мутации в участок ОРС соответствующего гена. Конкретно, в микроорганизме по меньшей мере один ген, выбранный из группы, состоящей из гена metB, кодирующего цистатионин-гамма-синтазу, гена metY, кодирующего O-ацетилгомосерин-(тиол)-лиазу в пути деградации О-сукцинилгомосерина, и гена thrB, кодирующего гомосеринкиназу, может быть дополнительно делетирован или ослаблен.
Кроме того, микроорганизм рода Corynebacterium может представлять собой микроорганизм рода Corynebacterium, продуцирующий О-сукцинилгомосерин с увеличенной активностью аспартокиназы по сравнению с немутированными микроорганизмами.
В контексте настоящего изобретения, термин «усиление» активности белка означает, что активность белка введена или увеличена по сравнению с его свойственной активностью. «Введение» активности означает, что микроорганизм получает активность конкретного полипептида, которой микроорганизм не обладал по природе или искусственным образом.
В контексте настоящего изобретения, термин «повышение» активности белка по сравнению со свойственной активностью означает, что активность белка, включенного в микроорганизм, повышена по сравнению со свойственной активностью белка или активностью до модификации. Термин «свойственная активность» относится к активности конкретного белка, которой первоначально обладает родительский штамм или немодифицированный микроорганизм до трансформации, когда микроорганизм трансформируется посредством генетической вариации, вызванной естественным или искусственным фактором. «Свойственную активность» также можно использовать взаимозаменяемо с «активностью до модификации».
Конкретно, повышение активности по настоящему изобретению может быть достигнуто посредством одного из следующих способов:
1) способ увеличения числа копий полинуклеотида, кодирующего белок,
2) способ модификации последовательности регуляции экспрессии для повышения экспрессии полинуклеотида,
3) способ модификации полинуклеотидной последовательности на хромосоме для усиления активности белка,
4) способ внесения чужеродного полинуклеотида, имеющего активность белка, или кодон-оптимизированного вариантного полинуклеотида, или
5) способ увеличения активности посредством любой комбинации способов, но способы не ограничиваются этими.
Повышение числа копий полинуклеотида, описанное в (1) выше, не ограничивается конкретно, но может быть выполнено в форме, функционально связанной с вектором, или в интегрированной форме в хромосоме клетки-хозяина.
Конкретно, этот способ может быть выполнен посредством введения вектора, который может реплицироваться и действовать независимо от хозяина, функционально связанного с полинуклеотидом, кодирующим белок по настоящему изобретению, в клетке-хозяине; или путем введения вектора, который может вставлять полинуклеотид в хромосому клетки-хозяина, функционально связанного с полинуклеотидом в клетке-хозяине, таким образом увеличивая число копий полинуклеотида в хромосоме клетки-хозяина.
Далее, модификация последовательности регуляции экспрессии для повышения экспрессии полинуклеотида, описанная в (2) выше, может быть выполнена путем индукции вариации в последовательности нуклеиновой кислоты посредством делеции, вставки, консервативной замены, неконсервативной замены или любой их комбинации для дополнительного усиления активности последовательности регуляции экспрессии, или путем замены последовательностью нуклеиновой кислоты, имеющей более сильную активность, без ограничения этим. Последовательность регуляции экспрессии может включать промотор, операторную последовательность, последовательность, кодирующую сайт связывания рибосомы, и последовательность для регуляции терминации транскрипции и трансляции, без ограничения этим.
Сильный гетер о логичный промотор вместо первоначального промотора может быть связан слева от единицы экспрессии полинуклеотида, и примеры сильного промотора могут включать промотор CJ7 (патент Кореи №0620092 и международная публикация WO 2006/065095), промотор lysCP1 (международная публикация WO 2009/096689), промотор EF-Tu, промотор groEL, или промотор асеА или асеВ, без ограничения этим. Кроме того, модификация полинуклеотидной последовательности на хромосоме, описанная в (3) выше, может быть выполнена посредством индукции вариации в последовательности регуляции экспрессии посредством делеции, вставки, консервативной замены, неконсервативной замены, или любой их комбинации для дополнительного усиления активности полинуклеотидной последовательности, или путем замены полинуклеотидной последовательностью, модифицированной для получения более сильной активности, без ограничения этим.
Кроме того, введение чужеродной полинуклеотидной последовательности, описанное в (4) выше, может быть выполнено внесением чужеродного полинуклеотида, кодирующего белок, имеющий активность, идентичную/подобную таковой у белка, или его кодон-оптимизированного вариантного полинуклеотида в клетку-хозяина. Чужеродный полинуклеотид может представлять собой любые полинуклеотиды, имеющие активность, идентичную/подобную таковой у белка, без ограничения. Кроме того, их оптимизированный кодон может быть введен в клетку-хозяина для выполнения оптимизированной транскрипции и трансляции введенного чужеродного полинуклеотида в клетке-хозяине. Введение может быть выполнено посредством любого известного способа трансформации, выбранного специалистом в данной области техники соответствующим образом. Когда введенный полинуклеотид экспрессируется в клетке-хозяине, белок продуцируется, и его активность может быть увеличена.
В конечном счете, способ усиления активности посредством любой комбинации способов с (1) по (4), описанный в (5) выше может быть выполнен путем комбинирования по меньшей мере одного из способов увеличения числа копий полинуклеотида, кодирующего белок, модификации последовательности регуляции экспрессии для повышения его экспрессии, модификации полинуклеотидной последовательности на хромосоме и модификации чужеродного полинуклеотида, имеющего активность белка, или его кодон-оптимизированного вариантного полинуклеотида.
В настоящем изобретении последовательности генов или полинуклеотидов, описанных выше, могут быть получены из базы данных Национального центра биотехнологической информации (NCBI) и тому подобного.
Другой аспект настоящего изобретения заключается в том, чтобы предложить способ получения О-сукцинилгомосерина, где способ включает культивирование описанного выше микроорганизма и извлечение О-сукцинилгомосерина из культивированного микроорганизма или из культуральной среды.
Другой аспект настоящего изобретения заключается в том, чтобы предложить способ получения L-метионина, где способ включает культивирование описанного выше микроорганизма и взаимодействие культивированного микроорганизма или О-сукцинилгомосерина с сульфидом.
Конкретно, реакция с сульфидом относится к процессу образования L-метионина из О-сукцинилгомосерина с использованием любого известного способа. Например, L-метионин может быть получен посредством взаимодействия О-сукцинилгомосерина с метилмеркаптаном в качестве сульфида или путем ступенчатой реакции после получения цистатионина посредством реакции с цистеином в качестве сульфида. Кроме того, может быть добавлен катализатор или фермент, или реакция может быть выполнена в микроорганизме, включающем фермент, для повышения скоростей реакции и выходов.
«О-сукцинилгомосерин» может представлять собой ферментационную жидкость или очищенную форму, содержащую О-сукцинилгомосерин, продуцированный микроорганизмом по настоящему изобретению. Кроме того, «сульфид» может представлять собой, например, метилмеркаптан, и метилмеркаптан может обозначать любые производные метилмеркаптана, способные предоставлять атомы серы, такие как диметилсульфид (DMS), раскрытый в международной публикации WO 2010/098629, а также метилмеркаптид натрия (CH3S-Na) в жидкой фазе и метилмеркаптан (CH3SH) в газообразном или жидком состоянии.
Способ получения L-метионина может быть легко определен специалистом в данной области техники на основе оптимизированных условий культивирования и условий ферментативной активности, хорошо известных в данной области техники. Подробные описания способа культивирования и культуральной среды даны выше.
Кроме того, способ получения L-метионина может дополнительно включать отделение или извлечение О-сукцинилгомосерина из микроорганизма, культивированного в процессе культивирования, или из среды.
Будет очевидно, что «О-сукцинилгомосерин» по настоящему изобретению может включать формы соли О-сукцинилгомосерина, а также сам О-сукцинилгомосерин.
В способе стадия культивирования микроорганизма может быть выполнена, но без ограничения, путем периодического культивирования, непрерывного культивирования и периодического культивирования с подпиткой, известных в данной области техники. С этой целью условия культивирования не ограничивают конкретно, но оптимальный рН (например, рН от 5 до 9, предпочтительно рН от 6 до 8 и наиболее предпочтительно рН 6,8) можно регулировать с использованием основного соединения (например, гидроксида натрия, гидроксида калия или аммиака) или кислого соединения (например, фосфорной кислоты или серной кислоты). Также, аэробные условия можно поддерживать добавлением кислорода или кислородсодержащей газовой смеси в клеточную культуру. Температуру культивирования можно поддерживать от 20°С до 45°С и предпочтительно от 25°С до 40°С, и культивирование можно выполнять в течение примерно от 10 часов до 160 часов, без ограничения этим. О-сукцинилгомосерин, полученный во время культивирования, может быть выделен в среду или может оставаться в клетках.
Примеры источника углерода для содержания в культуральной среде могут включать сахариды и углеводы (например, глюкозу, сахарозу, лактозу, фруктозу, мальтозу, мелассу, крахмал и целлюлозу), масла и жиры (например, соевое масло, подсолнечное масло, арахисовое масло и кокосовое масло), жирные кислоты (например, пальмитиновую кислоту, стеариновую кислоту и линолевую кислоту), спирты (например, глицерин и этиловый спирт) и органические кислоты (например, уксусную кислоту). Эти источники углерода можно использовать по отдельности или в комбинации, но без ограничения этим. Примеры источника азота могут включать азотсодержащие органические соединения (например, пептон, дрожжевой экстракт, мясной экстракт, солодовый экстракт, жидкий кукурузный экстракт, соевая мука и мочевина) или неорганические соединения (например, сульфат аммония, хлорид аммония, фосфат аммония, карбонат аммония и нитрат аммония). Эти источники азота можно использовать по отдельности или в комбинации, но без ограничения этим. В качестве источника фосфора можно использовать дигидрофосфат калия, гидрофосфат калия и соответствующие им натрийсодержащие соли, по отдельности или в комбинации, без ограничения этим. Кроме того, среда может включать необходимые ускоряющие рост вещества, такие как соль металла (например, сульфат магния или сульфат железа), аминокислоты и витамины.
О-сукцинилгомосерин или L-метионин, полученный на стадии культивирования, в настоящем изобретении может быть выделен из культуральной среды с использованием любого известного способа сбора желаемых аминокислот, соответствующим образом выбранного согласно способу культивирования. Например, можно использовать центрифугирование, фильтрацию, анионообменную хроматографию, кристаллизацию, ВЭЖХ (высокоэффективную жидкостную хроматографию) и так далее, и целевой О-сукцинилгомосерин или L-метионин может быть выделен из сред или из микроорганизма с использованием любого подходящего способа, хорошо известного в данной области техники.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Ниже настоящее изобретение будет описано более подробно со ссылкой на следующие примеры. Однако эти Примеры приведены только для иллюстративных целей, и не предназначены ограничивать объем настоящего изобретения.
Пример 1: Получение плазмиды metX, имеющей активность О-ацетилгомосеринтрансферазы Для того чтобы амплифицировать ген, кодирующий О-ацетилгомосеринтрансферазу (MetX), сайт фермента рестрикции BamHI вставляли в оба конца каждого из праймеров (SEQ ID NO: 5 и 6) для амплификации от промоторного участка (расположенного примерно 300 п.н. (пар нуклеотидов) слева от инициирующего кодона) до терминаторного участка (расположенного примерно 100 п.н.справа от стоп-кодона) на основе описанной последовательности, полученной из дикого типа (WT).
ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут, циклы денатурации при 95°С в течение 30 секунд, отжига при 55°С в течение 30 секунд и полимеризации при 72°С в течение 90 секунд повторяли 30 раз, и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате получали фрагмент ДНК из 1546 п.н.в качестве кодирующего участка гена metX. Вектор pECCG117 (патент Кореи №10-0057684) и фрагмент ДНК metX обрабатывали ферментом рестрикции BamHI, лигировали с использованием ДНК-лигазы и клонировали с получением плазмиды, которая была названа pECCG117-metX WT.
Пример 2: Получение вариантной плазмиды metX, имеющей активность О-сукцинилгомосеринтрансферазы
Были выбраны новые сайты мутации metX и аминокислоты в положениях 176 и 313 аминокислотной последовательности SEQ ID NO: 1 были заменены другой аминокислотой, соответственно.
Более конкретно, выполняли мутацию Q176N и L313R. Конструировали пару праймеров для мутации в положении 176 (SEQ ID NO: 7 и 8) и пару праймеров для мутации в положении 313 (SEQ ID NO: 9 и 10) с получением вектора мутации для замены 176й аминокислоты О-ацетилгомосеринтрансферазы другой аминокислотой и замены ее 313ой аминокислоты аргинином с использованием плазмиды pECCG117-metX WT, полученной в Примере 1, в качестве матрицы.

Мутированный ген metX получали с использованием праймеров и набора для сайт-направленного мутагенеза (Stratagene, USA). Мутированная плазмида L313R на основе существующей плазмиды дикого типа (WT) была названа WT_L313R и мутированная плазмида Q176N и L313R была названа WT_Q176N_L313R.
Пример 3: Тест на сравнение субстратной специфичности и активности варианта metX имеющего О-сукцинилгомосерин трансферазную активность
Для сравнения активностей мутированного metX, который продуцирует избыточные количества О-сукцинилгомосерина, были получены штаммы, в которых накапливается гомосерин, а использование продуцированного О-сукцинилгомосерина было делетировано. Получали штаммы, в которых ген metB, кодирующий цистатионин-гамма-синтазу в пути деградации О-сукцинилгомосерина, был делетирован и ген metY, кодирующий O-ацетилгомосерин-(тиол)-лиазу в пути деградации О-сукцинилгомосерина, был делетирован. Сначала для делеции гена metB на основе информации о нуклеотидной последовательности гена metB, полученного из WT, конструировали пару праймеров (SEQ ID NO: 11 и 12) для амплификации 5' слева участка гена metB и пару праймеров (SEQ ID NO: 13 и 14) для амплификации 3' справа участка гена metB. Сайт фермента рестрикции XbaI (подчеркнуто) был вставлен в концы каждого из праймеров SEQ ID NO: 11 и 14.

ПЦР выполняли с использованием WT-хромосомы в качестве матрицы и с использованием праймеров SEQ ID NO: 11 и 12 и SEQ ID NO: 13 и 14. ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут, циклы денатурации при 95°С в течение 30 секунд, отжиг при 55°С в течение 30 секунд, и полимеризации при 72°С в течение 90 секунд повторяли 30 раз и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате был получен фрагмент ДНК из 450 п.н.5' слева участка гена metB и фрагмент ДНК из 467 п.н. 3' справа участка гена metB.
ПЦР выполняли с использованием двух амплифицированных фрагментов ДНК в качестве матриц и праймеров SEQ ID NO: 11 и 14. ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут, циклы денатурации при 95°С в течение 30 секунд, отжига при 55°С в течение 30 секунд и полимеризации при 72°С в течение 3 минут повторяли 30 раз и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате был амплифицирован фрагмент ДНК из 917 п.н., включающий только концы гена metB слева и справа с делетированным центральным его участком.
Вектор pDZ и фрагмент ДНК из 917 п.н. обрабатывали ферментом рестрикции XbaI, лигировали с использованием ДНК-лигазы и клонировали с получением плазмиды, которая была названа pDZ-ΔmetB.
Вектор pDZ-ΔmetB вводили в WT штаммы посредством электроимпульсного способа, и трасформированные штаммы получали из селективной среды, включающей 25 мг/л канамицина. Отобранные штаммы подвергали процессу вторичной рекомбинации, кроссинговера, для получения штамма WTΔmetB, в котором ген metB был делетирован посредством фрагмента ДНК, вставленного в хромосому.
Для делеции гена metY в другом пути деградации О-сукцинилгомосерина, конструировали пару праймеров (SEQ ID NO: 15 и 16) для амплификации 5' слева участка гена metY и пару праймеров (SEQ ID NO: 17 и 18) для амплификации 3' справа участка гена metY, на основе информации о нуклеотидной последовательности гена metY, полученного из WT. Сайт фермента рестрикции XbaI (подчеркнуто) был вставлен в концы каждого из праймеров SEQ ID NO: 15 и 18.

ПЦР выполняли с использованием WT-хромосомы в качестве матрицы и с использованием праймеров SEQ ID NO: 15 и 16 и SEQ ID NO: 17 и 18. ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут, циклы денатурации при 95°С в течение 30 секунд, отжига при 55°С в течение 30 секунд и полимеризации при 72°С в течение 90 секунд повторяли 30 раз и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате были получены фрагмент ДНК из 512 п.н. 5' слева участка гена metY и фрагмент ДНК из 520 п.н. 3' справа участка гена metY.
ПЦР выполняли с использованием двух амплифицированных фрагментов ДНК в качестве матриц и праймеров SEQ ID NO: 15 и 18. ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут, циклы денатурации при 95°С в течение 30 секунд, отжига при 55°С в течение 30 секунд и полимеризации при 72°С в течение 3 минут повторяли 30 раз, и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате был амплифицирован фрагмент ДНК из 1032 п.н., включающий только концы слева и справа гена metY с делетированным центральным его участком.
Вектор pDZ и фрагмент ДНК из 1032 п.н. обрабатывали ферментом рестрикции XbaI, лигировали с использованием ДНК-лигазы и клонировали для получения плазмиды, которая была названа pDZ-ΔmetY.
Вектор pDZ-ΔmetY вводили в полученный штамм WTΔmetB посредством электроимпульсного способа, и трансформированные штаммы получали из селективной среды, включающей 25 мг/л канамицина. Отобранные штаммы подвергали процессу вторичной рекомбинации, кроссинговера, с получением штамма WTΔmetBΔmetY, в котором ген metY был делетирован посредством фрагмента ДНК, вставленного в хромосому.
Для того чтобы получить вектор для введения мутации в ген lysC (SEQ ID NO: 20), кодирующий полученную из WT аспартокиназу (SEQ ID NO: 19), для максимального увеличения продуцирования О-сукцинилгомосерина, конструировали пару праймеров (SEQ ID NO: 21 и 22) для амплификации 5' слева участка сайта мутации и пару праймеров (SEQ ID NO: 23 и 24) для амплификации 3' справа участка сайта мутации. Сайт фермента рестрикции XbaI (подчеркнуто) был вставлен в концы каждого из праймеров SEQ ID NO: 21 и 24, и праймеры SEQ ID NO: 22 и 23 располагали с возможностью помещения нуклеотидной замены (подчеркнуто) в сайты, сконструированные для кроссинговера друг с другом.
ПЦР выполняли с использованием WT-хромосомы в качестве матрицы и с использованием праймеров SEQ ID NO: 21 и 22 и SEQ ID NO: 23 и 24. ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут, циклы денатурации при 95°С в течение 30 секунд, отжига при 55°С в течение 30 секунд и полимеризации при 72°С в течение 30 секунд повторяли 30 раз и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате получали фрагмент ДНК из 509 п.н. 5' слева участка мутации гена lysC и фрагмент ДНК из 520 п.н. 3' справа участка мутации гена lysC.
ПЦР выполняли с использованием двух амплифицированных фрагментов ДНК в качестве матриц и праймеров SEQ ID NO: 21 и 24. ПЦР выполняли в следующих условиях. После денатурации при 95°С в течение 5 минут циклы денатурации при 95°С в течение 30 секунд, отжига при 55°С в течение 30 секунд и полимеризации при 72°С в течение 60 секунд повторяли 30 раз и затем выполняли полимеризацию при 72°С в течение 7 минут. В результате был амплифицирован фрагмент ДНК из 1011 п.н., включающий мутированный ген lysC (SEQ ID NO: 26), кодирующий мутант аспартокиназы (SEQ ID NO: 25), в котором треонин в положении 311 был заменен изолейцином.
Вектор pDZ (патент Кореи №0924065), не способный реплицироваться в Corynebacterium glutamicum и фрагмент ДНК из 1011 п.н. обрабатывали ферментом рестрикции XbaI, лигировали с использованием ДНК-лигазы и клонировали с получением плазмиды, которая была названа pDZ-lysC(T311I).
Вектор pDZ-lysC(T311I) вводили в WTΔmetBΔmetY посредством электроимпульсного способа (Appl. Microbiol. Biothcenol. (1999) 52:541-545) и трансформированные штаммы получали из селективной среды, включающей 25 мг/л канамицина. Отобранные штаммы подвергали процессу вторичной рекомбинации, кроссинговера, с получением штамма WTΔmetBΔmetY, lysC(T311I), в котором мутация нуклеотида была введена в ген lysC посредством фрагмента ДНК, вставленного в хромосому, и штамм была назван Corynebacterium glutamicum WTΔmetBΔmetY, lysC(T311I).
Векторы pECCG117-metX WT, pECCG117-metX WT_L313R и pECCG117-metX WT_Q176N_L313R, полученные в Примерах 1 и 2, вводили в полученный WTΔmetBΔmetY посредством электроимпульсного способа и размазывали по селективной среде, включающей 25 мг/л канамицина, для получения трансформированных штаммов.
Для сравнения способностей к продуцированию О-ацетилгомосерина (О-АН) и способностей к продуцированию О-сукцинилгомосерина (O-SH) у полученных штаммов, штаммы культивировали нижеследующим способом и анализировали концентрации О-ацетилгомосерина и О-сукцинилгомосерина в культуральной среде.
Одну платиновую петлю каждого штамма инокулировали в 250 мл колбу с угловыми перегородками, содержащую 25 мл нижеследующей среды и культивировали при встряхивании при 37°С при 200 об/мин в течение 20 часов. Концентрации О-ацетилгомосерина и О-сукцинилгомосерина анализировали посредством высокоэффективной жидкостной хроматографии (ВЭЖХ) и анализированные концентрации показаны Таблице 6.
Состав культуральной среды (рН 7,0)
100 г глюкозы, 40 г (NH4)2SO4, 2,5 г соевого белка, 5 г твердой фазы кукурузного экстракта, 3 г мочевины, 1 г KН2РО4, 0,5 г MgSO4⋅7H2O, 100 мкг биотина, 1000 мкг тиамина НСl, 2000 мкг пантотената кальция, 3000 мкг никотинамида, 30 г СаСО3 и 0,3 г L-метионина (на основе 1 л дистиллированной воды).
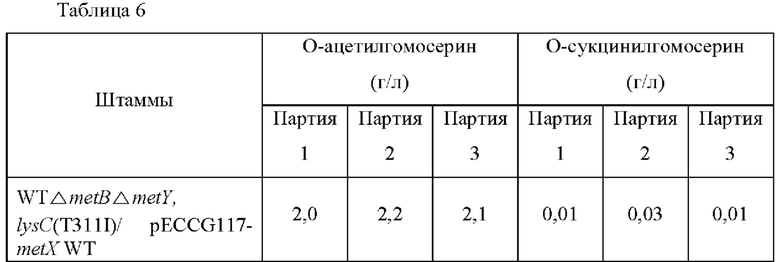
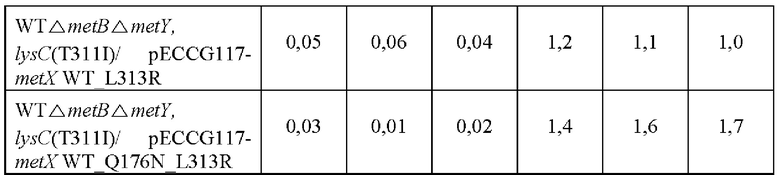
Как показано в Таблице 6 выше, было подтверждено, что, в то время как О-ацетилгомосерин продуцировался штаммом, в который была введена контрольная плазмида metX WT, О-сукцинилгомосерин продуцировался обоими штаммами, в которые были введены мутированные плазмиды metX. Конкретно, было подтверждено, что продуцирование О-сукцинилгомосерина было значительно увеличено в случае metX WT_Q176N_L313R. То есть, штаммы, в которые была введена мутация, изменяли субстратную специфичность трансферазы, продуцируя таким образом О-сукцинилгомосерин.
Пример 4: Получение мутации MetX посредством насыщающего мутагенеза и оценка способности продуцировать О-ацетилгомосерин
Для того чтобы получить мутант MetX, который имеет высокую способность продуцировать О-сукцинилгомосерин, мутированный посредством замены аминокислоты в положении 176 другой аминокислотой, использовали насыщающий мутагенез. Используя плазмиду, полученную в Примере 1, в качестве матрицы, получали 18 типов мутантов, в которых аминокислота в положении 313 была заменена аргинином, а аминокислота в положении 176 была заменена другой аминокислотой. Варианты, замененные аминокислоты и номера последовательностей праймеров, используемых в соответствующих вариантах, показаны в Таблице 7 ниже.
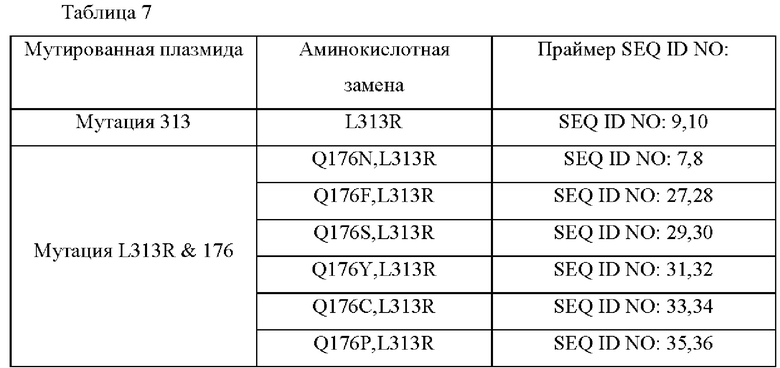
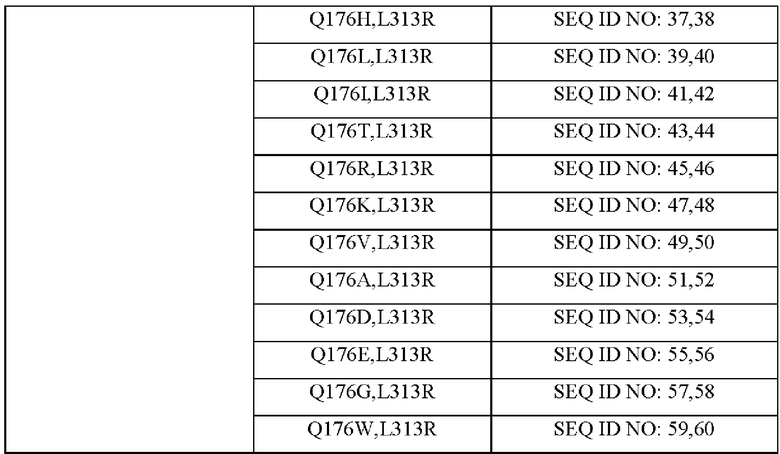
Конкретно, вариант гена metX был получен с использованием праймеров, показанных в Таблице 2, и набора для сайт-направленного мутагенеза (Stratagene, USA). Полученную мутированную плазмиду вводили в штаммы WTΔmetBΔmetY, lysC(T311I) и затем выполняли оценку в колбах таким же образом, как в Примере 4. Результаты показаны в Таблице 8 ниже.
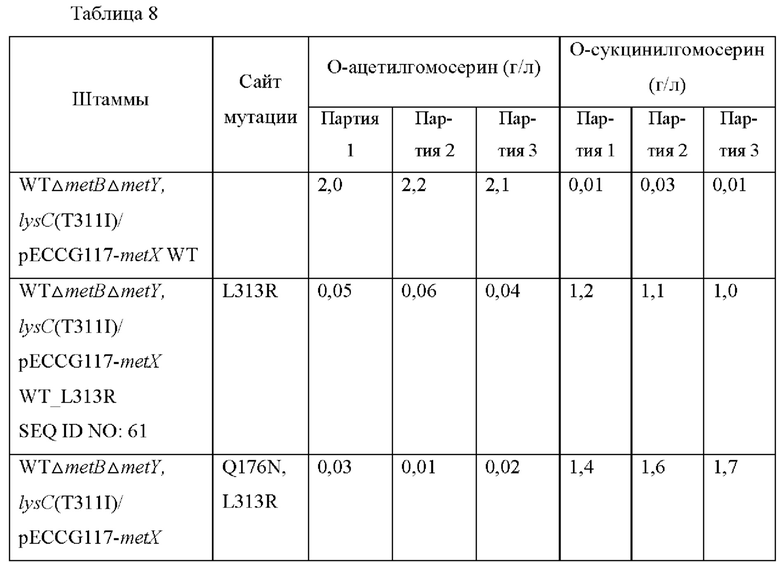
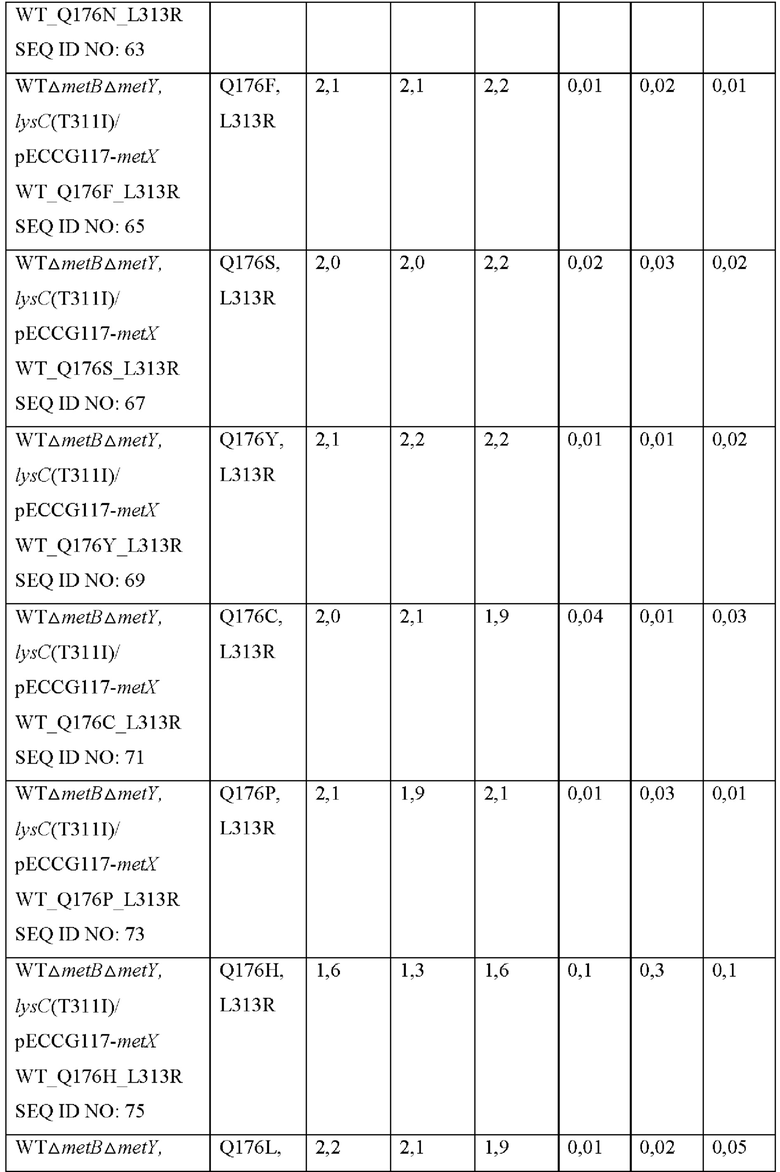
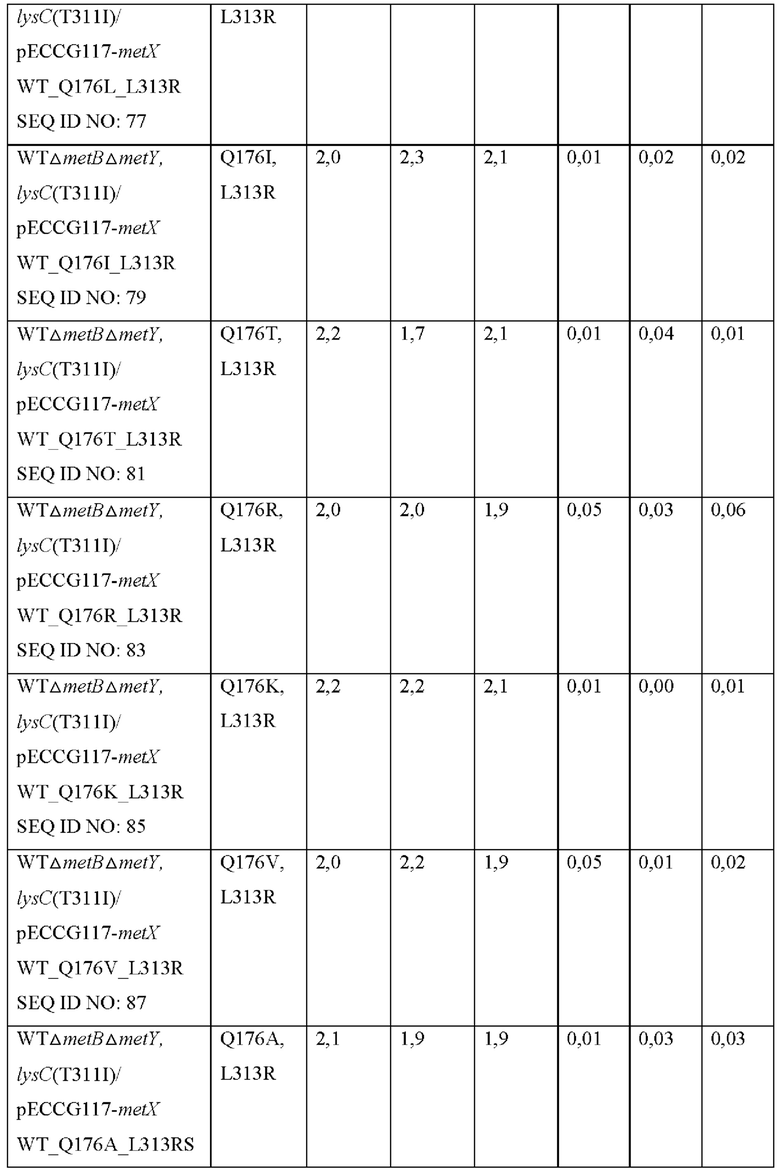
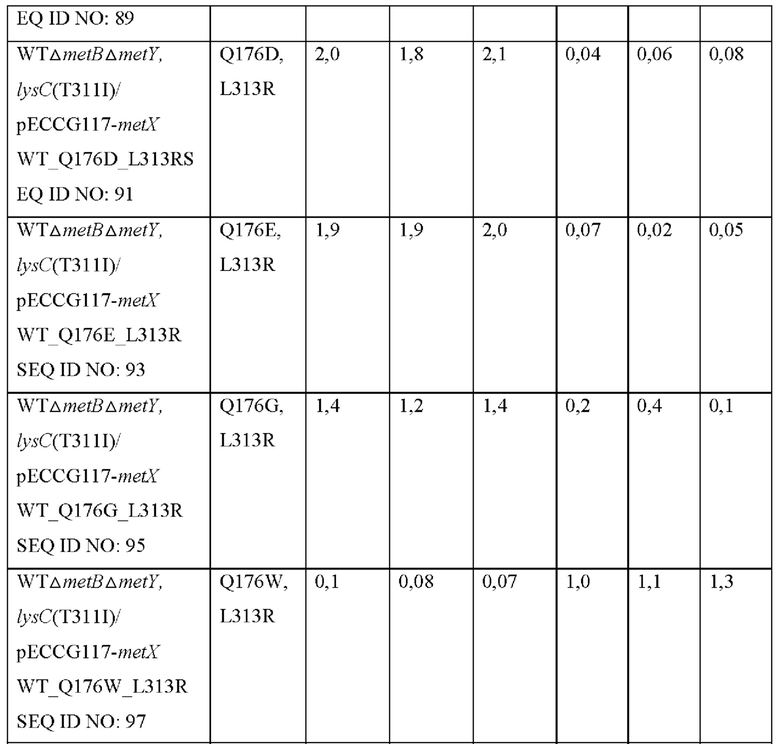
Как показано в Таблице 8, было подтверждено, что, хотя большая часть мутантов была неспособна продуцировать О-сукцинилгомосерин, мутированные metX (L313R, Q176N), (L313R, Q176W), (L313R, Q176H) или (L313R, Q176G) продуцировали О-сукцинилгомосерин с высоким уровнем по сравнению с диким типом, соответственно. То есть, было подтверждено, что, когда аминокислота в положении 313 аминокислотной последовательности SEQ ID NO: 1 замещена аргинином и аминокислота в положении 176 этой последовательности замещена аспарагином, триптофаном, гистидином или глицином, субстратная специфичность к сукцинил-СоА предоставляется трансферазе, благодаря этому продуцирующей О-сукцинилгомосерин.
Описанные выше результаты показывают, что мутант по настоящему изобретению может повышать продуцирование О-сукцинилгомосерина.
Кроме того, полученные штаммы WTΔmetBΔmetY, lysC(T311T)/pECCG117-metX WT_Q176N_L313R и штаммы WTΔmetBΔmetY, lysC(T311I)/pECCG117-metX WT_Q176W_L313R обозначили как CA05-5136 и CA05-5137, соответственно, и депонировали Корейском центре культур микроорганизмов (КССМ) в соответствии с Будапештским договором 11 мая 2017 с номерами доступа №№ КССМ12024Р и КССМ12025Р.
Приведенное выше описание настоящего изобретения предлагается для цели иллюстрации, и специалисту в данной области техники будет понятно, что могут быть выполнены различные изменения и модификации без изменения технической идеи и существенных признаков настоящего изобретения. Таким образом очевидно, что описанные выше воплощения являются иллюстративными во всех аспектах и не ограничивают настоящее изобретение. Различные воплощения, раскрытые здесь, не предназначены быть ограничивающими, где подлинные объем и сущность выражаются следующей ниже формулой изобретения. Настоящее изобретение подлежит ограничению только посредством терминов прилагаемой формулы изобретения, наряду с полным объемом эквивалентов, на которые такая формула изобретения дает право.
Номер депонирования
Орган депонирования: Корейский центр культур микроорганизмов (КССМ)
Номер доступа: КССМ12024Р
Дата депонирования: 11 мая 2017
Орган депонирования: Корейский центр культур микроорганизмов (КССМ)
Номер доступа: КССМ12025Р
Дата депонирования: 11 мая 2017.
--->
Перечень последовательностей
<110> CJ CheilJedang Corporation
<120> NOVEL O-SUCCINYL HOMOSERINE TRANSFERASE MUTANT AND METHOD FOR PRODUCING O-SUCCINYL HOMOSERINE USING SAME
<130> OPA18186
<150> KR 10-2017-0083439
<151> 2017-06-30
<160> 98
<170> KoPatentIn 3.0
<210> 1
<211> 377
<212> PRT
<213> Corynebacterium glutamicum
<220>
<221> PEPTIDE
<222> (1)..(377)
<223> metX
<400> 1
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Gln
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Leu Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 2
<211> 1134
<212> DNA
<213> Corynebacterium glutamicum
<220>
<221> gene
<222> (1)..(1134)
<223> metX
<400> 2
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggcaaat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattttgt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 3
<211> 379
<212> PRT
<213> Pseudomonas aeruginosa
<400> 3
Met Pro Thr Val Phe Pro Asp Asp Ser Val Gly Leu Val Ser Pro Gln
1 5 10 15
Thr Leu His Phe Asn Glu Pro Leu Glu Leu Thr Ser Gly Lys Ser Leu
20 25 30
Ala Glu Tyr Asp Leu Val Ile Glu Thr Tyr Gly Glu Leu Asn Ala Thr
35 40 45
Gln Ser Asn Ala Val Leu Ile Cys His Ala Leu Ser Gly His His His
50 55 60
Ala Ala Gly Tyr His Ser Val Asp Glu Arg Lys Pro Gly Trp Trp Asp
65 70 75 80
Ser Cys Ile Gly Pro Gly Lys Pro Ile Asp Thr Arg Lys Phe Phe Val
85 90 95
Val Ala Leu Asn Asn Leu Gly Gly Cys Asn Gly Ser Ser Gly Pro Ala
100 105 110
Ser Ile Asn Pro Ala Thr Gly Lys Val Tyr Gly Ala Asp Phe Pro Met
115 120 125
Val Thr Val Glu Asp Trp Val His Ser Gln Ala Arg Leu Ala Asp Arg
130 135 140
Leu Gly Ile Arg Gln Trp Ala Ala Val Val Gly Gly Ser Leu Gly Gly
145 150 155 160
Met Gln Ala Leu Gln Trp Thr Ile Ser Tyr Pro Glu Arg Val Arg His
165 170 175
Cys Leu Cys Ile Ala Ser Ala Pro Lys Leu Ser Ala Gln Asn Ile Ala
180 185 190
Phe Asn Glu Val Ala Arg Gln Ala Ile Leu Ser Asp Pro Glu Phe Leu
195 200 205
Gly Gly Tyr Phe Gln Glu Gln Gly Val Ile Pro Lys Arg Gly Leu Lys
210 215 220
Leu Ala Arg Met Val Gly His Ile Thr Tyr Leu Ser Asp Asp Ala Met
225 230 235 240
Gly Ala Lys Phe Gly Arg Val Leu Lys Thr Glu Lys Leu Asn Tyr Asp
245 250 255
Leu His Ser Val Glu Phe Gln Val Glu Ser Tyr Leu Arg Tyr Gln Gly
260 265 270
Glu Glu Phe Ser Thr Arg Phe Asp Ala Asn Thr Tyr Leu Leu Met Thr
275 280 285
Lys Ala Leu Asp Tyr Phe Asp Pro Ala Ala Ala His Gly Asp Asp Leu
290 295 300
Val Arg Thr Leu Glu Gly Val Glu Ala Asp Phe Cys Leu Met Ser Phe
305 310 315 320
Thr Thr Asp Trp Arg Phe Ser Pro Ala Arg Ser Arg Glu Ile Val Asp
325 330 335
Ala Leu Ile Ala Ala Lys Lys Asn Val Ser Tyr Leu Glu Ile Asp Ala
340 345 350
Pro Gln Gly His Asp Ala Phe Leu Met Pro Ile Pro Arg Tyr Leu Gln
355 360 365
Ala Phe Ser Gly Tyr Met Asn Arg Ile Ser Val
370 375
<210> 4
<211> 1140
<212> DNA
<213> Pseudomonas aeruginosa
<400> 4
atgcccacag tcttccccga cgactccgtc ggtctggtct ccccccagac gctgcacttc 60
aacgaaccgc tcgagctgac cagcggcaag tccctggccg agtacgacct ggtgatcgaa 120
acctacggcg agctgaatgc cacgcagagc aacgcggtgc tgatctgcca cgccctctcc 180
ggccaccacc acgccgccgg ctaccacagc gtcgacgagc gcaagccggg ctggtgggac 240
agctgcatcg gtccgggcaa gccgatcgac acccgcaagt tcttcgtcgt cgccctcaac 300
aacctcggcg gttgcaacgg atccagcggc cccgccagca tcaatccggc gaccggcaag 360
gtctacggcg cggacttccc gatggttacg gtggaagact gggtgcatag ccaggcgcgc 420
ctggcagacc gcctcggcat ccgccagtgg gccgcggtgg tcggcggcag cctcggcggc 480
atgcaggcgc tgcaatggac catcagctat cccgagcgcg tccgtcactg cctgtgcatc 540
gccagcgcgc cgaagctgtc ggcgcagaac atcgccttca acgaagtcgc ccggcaggcg 600
attctttccg accctgagtt cctcggcggc tacttccagg agcagggcgt gattcccaag 660
cgcggcctca agctggcgcg gatggtcggc catatcacct acctgtccga cgacgccatg 720
ggcgccaagt tcggccgtgt actgaagacc gagaagctca actacgacct gcacagcgtc 780
gagttccagg tcgagagtta cctgcgctac cagggcgagg agttctccac ccgcttcgac 840
gccaatacct acctgctgat gaccaaggcg ctggactact tcgaccccgc cgccgcccac 900
ggcgacgacc tggtgcgcac cctggagggc gtcgaggcgg acttctgcct gatgtccttc 960
accaccgact ggcgtttctc gccggcccgc tcgcgggaaa tcgtcgacgc cctgatcgcg 1020
gcgaaaaaga acgtcagcta cctggagatc gacgccccgc aaggccacga cgccttcctc 1080
atgccgatcc cccggtacct gcaagccttc agcggttaca tgaaccgcat cagcgtgtga 1140
1140
<210> 5
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 1
<400> 5
ggatcccctc gttgttcacc cagcaacc 28
<210> 6
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 2
<400> 6
ggatcccaaa gtcacaacta cttatgttag 30
<210> 7
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 3
<400> 7
acgcgccagc gcctggaaca tcggcattca atccg 35
<210> 8
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 4
<400> 8
cggattgaat gccgatgttc caggcgctgg cgcgt 35
<210> 9
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 5
<400> 9
gtagataccg atattcggta cccctaccac cag 33
<210> 10
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 6
<400> 10
ctggtggtag gggtaccgaa tatcggtatc tac 33
<210> 11
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 7
<400> 11
tctagatgcg ctgattatct cacc 24
<210> 12
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 8
<400> 12
actggtgggt catggttgca tatgagatca actcctgtaa 40
<210> 13
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 9
<400> 13
ttacaggagt tgatctcata tgcaaccatg acccaccagt 40
<210> 14
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 10
<400> 14
tctagacctt gaagttcttg actg 24
<210> 15
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 11
<400> 15
tctagaagta gcgttgctgt acac 24
<210> 16
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 12
<400> 16
atcaatggtc tcgatgccca tatggcattt ggaggtcctt aag 43
<210> 17
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 13
<400> 17
cttaaggacc tccaaatgcc atatgggcat cgagaccatt gat 43
<210> 18
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 14
<400> 18
tctagatgga accgttgcaa ccac 24
<210> 19
<211> 421
<212> PRT
<213> Corynebacterium glutamicum
<220>
<221> PEPTIDE
<222> (1)..(421)
<223> lysC
<400> 19
Met Ala Leu Val Val Gln Lys Tyr Gly Gly Ser Ser Leu Glu Ser Ala
1 5 10 15
Glu Arg Ile Arg Asn Val Ala Glu Arg Ile Val Ala Thr Lys Lys Ala
20 25 30
Gly Asn Asp Val Val Val Val Cys Ser Ala Met Gly Asp Thr Thr Asp
35 40 45
Glu Leu Leu Glu Leu Ala Ala Ala Val Asn Pro Val Pro Pro Ala Arg
50 55 60
Glu Met Asp Met Leu Leu Thr Ala Gly Glu Arg Ile Ser Asn Ala Leu
65 70 75 80
Val Ala Met Ala Ile Glu Ser Leu Gly Ala Glu Ala Gln Ser Phe Thr
85 90 95
Gly Ser Gln Ala Gly Val Leu Thr Thr Glu Arg His Gly Asn Ala Arg
100 105 110
Ile Val Asp Val Thr Pro Gly Arg Val Arg Glu Ala Leu Asp Glu Gly
115 120 125
Lys Ile Cys Ile Val Ala Gly Phe Gln Gly Val Asn Lys Glu Thr Arg
130 135 140
Asp Val Thr Thr Leu Gly Arg Gly Gly Ser Asp Thr Thr Ala Val Ala
145 150 155 160
Leu Ala Ala Ala Leu Asn Ala Asp Val Cys Glu Ile Tyr Ser Asp Val
165 170 175
Asp Gly Val Tyr Thr Ala Asp Pro Arg Ile Val Pro Asn Ala Gln Lys
180 185 190
Leu Glu Lys Leu Ser Phe Glu Glu Met Leu Glu Leu Ala Ala Val Gly
195 200 205
Ser Lys Ile Leu Val Leu Arg Ser Val Glu Tyr Ala Arg Ala Phe Asn
210 215 220
Val Pro Leu Arg Val Arg Ser Ser Tyr Ser Asn Asp Pro Gly Thr Leu
225 230 235 240
Ile Ala Gly Ser Met Glu Asp Ile Pro Val Glu Glu Ala Val Leu Thr
245 250 255
Gly Val Ala Thr Asp Lys Ser Glu Ala Lys Val Thr Val Leu Gly Ile
260 265 270
Ser Asp Lys Pro Gly Glu Ala Ala Lys Val Phe Arg Ala Leu Ala Asp
275 280 285
Ala Glu Ile Asn Ile Asp Met Val Leu Gln Asn Val Ser Ser Val Glu
290 295 300
Asp Gly Thr Thr Asp Ile Thr Phe Thr Cys Pro Arg Ser Asp Gly Arg
305 310 315 320
Arg Ala Met Glu Ile Leu Lys Lys Leu Gln Val Gln Gly Asn Trp Thr
325 330 335
Asn Val Leu Tyr Asp Asp Gln Val Gly Lys Val Ser Leu Val Gly Ala
340 345 350
Gly Met Lys Ser His Pro Gly Val Thr Ala Glu Phe Met Glu Ala Leu
355 360 365
Arg Asp Val Asn Val Asn Ile Glu Leu Ile Ser Thr Ser Glu Ile Arg
370 375 380
Ile Ser Val Leu Ile Arg Glu Asp Asp Leu Asp Ala Ala Ala Arg Ala
385 390 395 400
Leu His Glu Gln Phe Gln Leu Gly Gly Glu Asp Glu Ala Val Val Tyr
405 410 415
Ala Gly Thr Gly Arg
420
<210> 20
<211> 1266
<212> DNA
<213> Corynebacterium glutamicum
<220>
<221> gene
<222> (1)..(1266)
<223> lysC
<400> 20
atggccctgg tcgtacagaa atatggcggt tcctcgcttg agagtgcgga acgcattaga 60
aacgtcgctg aacggatcgt tgccaccaag aaggctggaa atgatgtcgt ggttgtctgc 120
tccgcaatgg gagacaccac ggatgaactt ctagaacttg cagcggcagt gaatcccgtt 180
ccgccagctc gtgaaatgga tatgctcctg actgctggtg agcgtatttc taacgctctc 240
gtcgccatgg ctattgagtc ccttggcgca gaagcccaat ctttcacggg ctctcaggct 300
ggtgtgctca ccaccgagcg ccacggaaac gcacgcattg ttgatgtcac tccaggtcgt 360
gtgcgtgaag cactcgatga gggcaagatc tgcattgttg ctggtttcca gggtgttaat 420
aaagaaaccc gcgatgtcac cacgttgggt cgtggtggtt ctgacaccac tgcagttgcg 480
ttggcagctg ctttgaacgc tgatgtgtgt gagatttact cggacgttga cggtgtgtat 540
accgctgacc cgcgcatcgt tcctaatgca cagaagctgg aaaagctcag cttcgaagaa 600
atgctggaac ttgctgctgt tggctccaag attttggtgc tgcgcagtgt tgaatacgct 660
cgtgcattca atgtgccact tcgcgtacgc tcgtcttata gtaatgatcc cggcactttg 720
attgccggct ctatggagga tattcctgtg gaagaagcag tccttaccgg tgtcgcaacc 780
gacaagtccg aagccaaagt aaccgttctg ggtatttccg ataagccagg cgaggctgcg 840
aaggttttcc gtgcgttggc tgatgcagaa atcaacattg acatggttct gcagaacgtc 900
tcttctgtag aagacggcac caccgacatc accttcacct gccctcgttc cgacggccgc 960
cgcgcgatgg agatcttgaa gaagcttcag gttcagggca actggaccaa tgtgctttac 1020
gacgaccagg tcggcaaagt ctccctcgtg ggtgctggca tgaagtctca cccaggtgtt 1080
accgcagagt tcatggaagc tctgcgcgat gtcaacgtga acatcgaatt gatttccacc 1140
tctgagattc gtatttccgt gctgatccgt gaagatgatc tggatgctgc tgcacgtgca 1200
ttgcatgagc agttccagct gggcggcgaa gacgaagccg tcgtttatgc aggcaccgga 1260
cgctaa 1266
<210> 21
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 15
<400> 21
tcctctagag ctgcgcagtg ttgaatacg 29
<210> 22
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 16
<400> 22
caccgacatc atcttcacct gcc 23
<210> 23
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 17
<400> 23
ggcaggtgaa gatgatgtcg gtg 23
<210> 24
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 18
<400> 24
gactctagag ttcacctcag agacgatta 29
<210> 25
<211> 421
<212> PRT
<213> Corynebacterium glutamicum
<220>
<221> PEPTIDE
<222> (1)..(421)
<223> вариант lysC (T311I)
<400> 25
Met Ala Leu Val Val Gln Lys Tyr Gly Gly Ser Ser Leu Glu Ser Ala
1 5 10 15
Glu Arg Ile Arg Asn Val Ala Glu Arg Ile Val Ala Thr Lys Lys Ala
20 25 30
Gly Asn Asp Val Val Val Val Cys Ser Ala Met Gly Asp Thr Thr Asp
35 40 45
Glu Leu Leu Glu Leu Ala Ala Ala Val Asn Pro Val Pro Pro Ala Arg
50 55 60
Glu Met Asp Met Leu Leu Thr Ala Gly Glu Arg Ile Ser Asn Ala Leu
65 70 75 80
Val Ala Met Ala Ile Glu Ser Leu Gly Ala Glu Ala Gln Ser Phe Thr
85 90 95
Gly Ser Gln Ala Gly Val Leu Thr Thr Glu Arg His Gly Asn Ala Arg
100 105 110
Ile Val Asp Val Thr Pro Gly Arg Val Arg Glu Ala Leu Asp Glu Gly
115 120 125
Lys Ile Cys Ile Val Ala Gly Phe Gln Gly Val Asn Lys Glu Thr Arg
130 135 140
Asp Val Thr Thr Leu Gly Arg Gly Gly Ser Asp Thr Thr Ala Val Ala
145 150 155 160
Leu Ala Ala Ala Leu Asn Ala Asp Val Cys Glu Ile Tyr Ser Asp Val
165 170 175
Asp Gly Val Tyr Thr Ala Asp Pro Arg Ile Val Pro Asn Ala Gln Lys
180 185 190
Leu Glu Lys Leu Ser Phe Glu Glu Met Leu Glu Leu Ala Ala Val Gly
195 200 205
Ser Lys Ile Leu Val Leu Arg Ser Val Glu Tyr Ala Arg Ala Phe Asn
210 215 220
Val Pro Leu Arg Val Arg Ser Ser Tyr Ser Asn Asp Pro Gly Thr Leu
225 230 235 240
Ile Ala Gly Ser Met Glu Asp Ile Pro Val Glu Glu Ala Val Leu Thr
245 250 255
Gly Val Ala Thr Asp Lys Ser Glu Ala Lys Val Thr Val Leu Gly Ile
260 265 270
Ser Asp Lys Pro Gly Glu Ala Ala Lys Val Phe Arg Ala Leu Ala Asp
275 280 285
Ala Glu Ile Asn Ile Asp Met Val Leu Gln Asn Val Ser Ser Val Glu
290 295 300
Asp Gly Thr Thr Asp Ile Ile Phe Thr Cys Pro Arg Ser Asp Gly Arg
305 310 315 320
Arg Ala Met Glu Ile Leu Lys Lys Leu Gln Val Gln Gly Asn Trp Thr
325 330 335
Asn Val Leu Tyr Asp Asp Gln Val Gly Lys Val Ser Leu Val Gly Ala
340 345 350
Gly Met Lys Ser His Pro Gly Val Thr Ala Glu Phe Met Glu Ala Leu
355 360 365
Arg Asp Val Asn Val Asn Ile Glu Leu Ile Ser Thr Ser Glu Ile Arg
370 375 380
Ile Ser Val Leu Ile Arg Glu Asp Asp Leu Asp Ala Ala Ala Arg Ala
385 390 395 400
Leu His Glu Gln Phe Gln Leu Gly Gly Glu Asp Glu Ala Val Val Tyr
405 410 415
Ala Gly Thr Gly Arg
420
<210> 26
<211> 1266
<212> DNA
<213> Corynebacterium glutamicum
<220>
<221> gene
<222> (1)..(1266)
<223> вариант lysC (T311I)
<400> 26
atggccctgg tcgtacagaa atatggcggt tcctcgcttg agagtgcgga acgcattaga 60
aacgtcgctg aacggatcgt tgccaccaag aaggctggaa atgatgtcgt ggttgtctgc 120
tccgcaatgg gagacaccac ggatgaactt ctagaacttg cagcggcagt gaatcccgtt 180
ccgccagctc gtgaaatgga tatgctcctg actgctggtg agcgtatttc taacgctctc 240
gtcgccatgg ctattgagtc ccttggcgca gaagcccaat ctttcacggg ctctcaggct 300
ggtgtgctca ccaccgagcg ccacggaaac gcacgcattg ttgatgtcac tccaggtcgt 360
gtgcgtgaag cactcgatga gggcaagatc tgcattgttg ctggtttcca gggtgttaat 420
aaagaaaccc gcgatgtcac cacgttgggt cgtggtggtt ctgacaccac tgcagttgcg 480
ttggcagctg ctttgaacgc tgatgtgtgt gagatttact cggacgttga cggtgtgtat 540
accgctgacc cgcgcatcgt tcctaatgca cagaagctgg aaaagctcag cttcgaagaa 600
atgctggaac ttgctgctgt tggctccaag attttggtgc tgcgcagtgt tgaatacgct 660
cgtgcattca atgtgccact tcgcgtacgc tcgtcttata gtaatgatcc cggcactttg 720
attgccggct ctatggagga tattcctgtg gaagaagcag tccttaccgg tgtcgcaacc 780
gacaagtccg aagccaaagt aaccgttctg ggtatttccg ataagccagg cgaggctgcg 840
aaggttttcc gtgcgttggc tgatgcagaa atcaacattg acatggttct gcagaacgtc 900
tcttctgtag aagacggcac caccgacatc atcttcacct gccctcgttc cgacggccgc 960
cgcgcgatgg agatcttgaa gaagcttcag gttcagggca actggaccaa tgtgctttac 1020
gacgaccagg tcggcaaagt ctccctcgtg ggtgctggca tgaagtctca cccaggtgtt 1080
accgcagagt tcatggaagc tctgcgcgat gtcaacgtga acatcgaatt gatttccacc 1140
tctgagattc gtatttccgt gctgatccgt gaagatgatc tggatgctgc tgcacgtgca 1200
ttgcatgagc agttccagct gggcggcgaa gacgaagccg tcgtttatgc aggcaccgga 1260
cgctaa 1266
<210> 27
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176F,L313R
<400> 27
acgcgccagc gcctggttta tcggcattca atccg 35
<210> 28
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176F,L313R
<400> 28
cggattgaat gccgataaac caggcgctgg cgcgt 35
<210> 29
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176S,L313R
<400> 29
acgcgccagc gcctggtcta tcggcattca atccg 35
<210> 30
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176S,L313R
<400> 30
cggattgaat gccgatagac caggcgctgg cgcgt 35
<210> 31
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176Y,L313R
<400> 31
acgcgccagc gcctggtata tcggcattca atccg 35
<210> 32
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176Y,L313R
<400> 32
cggattgaat gccgatatac caggcgctgg cgcgt 35
<210> 33
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176C,L313R
<400> 33
acgcgccagc gcctggtgca tcggcattca atccg 35
<210> 34
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176C,L313R
<400> 34
cggattgaat gccgatgcac caggcgctgg cgcgt 35
<210> 35
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176P,L313R
<400> 35
acgcgccagc gcctggccaa tcggcattca atccg 35
<210> 36
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176P,L313R
<400> 36
cggattgaat gccgattggc caggcgctgg cgcgt 35
<210> 37
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176H,L313R
<400> 37
acgcgccagc gcctggcaca tcggcattca atccg 35
<210> 38
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176H,L313R
<400> 38
cggattgaat gccgatgtgc caggcgctgg cgcgt 35
<210> 39
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176L,L313R
<400> 39
acgcgccagc gcctggctca tcggcattca atccg 35
<210> 40
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176L,L313R
<400> 40
cggattgaat gccgatgagc caggcgctgg cgcgt 35
<210> 41
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176I,L313R
<400> 41
acgcgccagc gcctggatta tcggcattca atccg 35
<210> 42
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176I,L313R
<400> 42
cggattgaat gccgataatc caggcgctgg cgcgt 35
<210> 43
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176T,L313R
<400> 43
acgcgccagc gcctggacta tcggcattca atccg 35
<210> 44
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176T,L313R
<400> 44
cggattgaat gccgatagtc caggcgctgg cgcgt 35
<210> 45
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176R,L313R
<400> 45
acgcgccagc gcctggcgca tcggcattca atccg 35
<210> 46
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176R,L313R
<400> 46
cggattgaat gccgatgcgc caggcgctgg cgcgt 35
<210> 47
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176K,L313R
<400> 47
acgcgccagc gcctggaaaa tcggcattca atccg 35
<210> 48
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176K,L313R
<400> 48
cggattgaat gccgattttc caggcgctgg cgcgt 35
<210> 49
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176V,L313R
<400> 49
acgcgccagc gcctgggtta tcggcattca atccg 35
<210> 50
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176V,L313R
<400> 50
cggattgaat gccgataacc caggcgctgg cgcgt 35
<210> 51
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176A,L313R
<400> 51
acgcgccagc gcctgggcaa tcggcattca atccg 35
<210> 52
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176A,L313R
<400> 52
cggattgaat gccgattgcc caggcgctgg cgcgt 35
<210> 53
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176D,L313R
<400> 53
acgcgccagc gcctgggaca tcggcattca atccg 35
<210> 54
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176D,L313R
<400> 54
cggattgaat gccgatgtcc caggcgctgg cgcgt 35
<210> 55
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176E,L313R
<400> 55
acgcgccagc gcctgggaga tcggcattca atccg 35
<210> 56
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176E,L313R
<400> 56
cggattgaat gccgatctcc caggcgctgg cgcgt 35
<210> 57
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176G,L313R
<400> 57
acgcgccagc gcctggggca tcggcattca atccg 35
<210> 58
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176G,L313R
<400> 58
cggattgaat gccgatgccc caggcgctgg cgcgt 35
<210> 59
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Прямой праймер для Q176W,L313R
<400> 59
acgcgccagc gcctggtgga tcggcattca atccg 35
<210> 60
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> Обратный праймер для Q176W,L313R
<400> 60
cggattgaat gccgatccac caggcgctgg cgcgt 35
<210> 61
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> metX L313R
<400> 61
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Gln
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 62
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> metX L313R
<400> 62
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggcaaat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 63
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> metX Q176N_L313R
<400> 63
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Asn
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 64
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> metX Q176N_L313R
<400> 64
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggaacat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 65
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176F,L313R
<400> 65
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Phe
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 66
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176F,L313R
<400> 66
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggtttat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 67
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176S,L313R
<400> 67
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Ser
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 68
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176S,L313R
<400> 68
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggtctat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 69
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176Y,L313R
<400> 69
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Tyr
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 70
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176Y,L313R
<400> 70
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggtatat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 71
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176C,L313R
<400> 71
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Cys
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 72
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176C,L313R
<400> 72
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggtgtat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 73
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176P,L313R
<400> 73
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Pro
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 74
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176P,L313R
<400> 74
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggccaat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 75
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176H,L313R
<400> 75
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp His
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 76
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176H,L313R
<400> 76
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggcacat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 77
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176L,L313R
<400> 77
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Leu
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 78
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176L,L313R
<400> 78
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggctcat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 79
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176I,L313R
<400> 79
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Ile
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 80
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176I,L313R
<400> 80
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggattat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 81
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176T,L313R
<400> 81
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Thr
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 82
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176T,L313R
<400> 82
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggactat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 83
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176R,L313R
<400> 83
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Arg
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 84
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176R,L313R
<400> 84
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggcgcat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 85
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176K,L313R
<400> 85
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Lys
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 86
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176K,L313R
<400> 86
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggaaaat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 87
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176V,L313R
<400> 87
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Val
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 88
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176V,L313R
<400> 88
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctgggttat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 89
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176A,L313R
<400> 89
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Ala
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 90
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176A,L313R
<400> 90
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctgggcaat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 91
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176D,L313R
<400> 91
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Asp
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 92
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176D,L313R
<400> 92
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctgggacat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 93
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176E,L313R
<400> 93
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Glu
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 94
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176E,L313R
<400> 94
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctgggagat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 95
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176G,L313R
<400> 95
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Gly
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 96
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176G,L313R
<400> 96
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggggcat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<210> 97
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Q176W,L313R
<400> 97
Met Pro Thr Leu Ala Pro Ser Gly Gln Leu Glu Ile Gln Ala Ile Gly
1 5 10 15
Asp Val Ser Thr Glu Ala Gly Ala Ile Ile Thr Asn Ala Glu Ile Ala
20 25 30
Tyr His Arg Trp Gly Glu Tyr Arg Val Asp Lys Glu Gly Arg Ser Asn
35 40 45
Val Val Leu Ile Glu His Ala Leu Thr Gly Asp Ser Asn Ala Ala Asp
50 55 60
Trp Trp Ala Asp Leu Leu Gly Pro Gly Lys Ala Ile Asn Thr Asp Ile
65 70 75 80
Tyr Cys Val Ile Cys Thr Asn Val Ile Gly Gly Cys Asn Gly Ser Thr
85 90 95
Gly Pro Gly Ser Met His Pro Asp Gly Asn Phe Trp Gly Asn Arg Phe
100 105 110
Pro Ala Thr Ser Ile Arg Asp Gln Val Asn Ala Glu Lys Gln Phe Leu
115 120 125
Asp Ala Leu Gly Ile Thr Thr Val Ala Ala Val Leu Gly Gly Ser Met
130 135 140
Gly Gly Ala Arg Thr Leu Glu Trp Ala Ala Met Tyr Pro Glu Thr Val
145 150 155 160
Gly Ala Ala Ala Val Leu Ala Val Ser Ala Arg Ala Ser Ala Trp Trp
165 170 175
Ile Gly Ile Gln Ser Ala Gln Ile Lys Ala Ile Glu Asn Asp His His
180 185 190
Trp His Glu Gly Asn Tyr Tyr Glu Ser Gly Cys Asn Pro Ala Thr Gly
195 200 205
Leu Gly Ala Ala Arg Arg Ile Ala His Leu Thr Tyr Arg Gly Glu Leu
210 215 220
Glu Ile Asp Glu Arg Phe Gly Thr Lys Ala Gln Lys Asn Glu Asn Pro
225 230 235 240
Leu Gly Pro Tyr Arg Lys Pro Asp Gln Arg Phe Ala Val Glu Ser Tyr
245 250 255
Leu Asp Tyr Gln Ala Asp Lys Leu Val Gln Arg Phe Asp Ala Gly Ser
260 265 270
Tyr Val Leu Leu Thr Asp Ala Leu Asn Arg His Asp Ile Gly Arg Asp
275 280 285
Arg Gly Gly Leu Asn Lys Ala Leu Glu Ser Ile Lys Val Pro Val Leu
290 295 300
Val Ala Gly Val Asp Thr Asp Ile Arg Tyr Pro Tyr His Gln Gln Glu
305 310 315 320
His Leu Ser Arg Asn Leu Gly Asn Leu Leu Ala Met Ala Lys Ile Val
325 330 335
Ser Pro Val Gly His Asp Ala Phe Leu Thr Glu Ser Arg Gln Met Asp
340 345 350
Arg Ile Val Arg Asn Phe Phe Ser Leu Ile Ser Pro Asp Glu Asp Asn
355 360 365
Pro Ser Thr Tyr Ile Glu Phe Tyr Ile
370 375
<210> 98
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Q176W,L313R
<400> 98
atgcccaccc tcgcgccttc aggtcaactt gaaatccaag cgatcggtga tgtctccacc 60
gaagccggag caatcattac aaacgctgaa atcgcctatc accgctgggg tgaataccgc 120
gtagataaag aaggacgcag caatgtcgtt ctcatcgaac acgccctcac tggagattcc 180
aacgcagccg attggtgggc tgacttgctc ggtcccggca aagccatcaa cactgatatt 240
tactgcgtga tctgtaccaa cgtcatcggt ggttgcaacg gttccaccgg acctggctcc 300
atgcatccag atggaaattt ctggggtaat cgcttccccg ccacgtccat tcgtgatcag 360
gtaaacgccg aaaaacaatt cctcgacgca ctcggcatca ccacggtcgc cgcagtactt 420
ggtggttcca tgggtggtgc ccgcacccta gagtgggccg caatgtaccc agaaactgtt 480
ggcgcagctg ctgttcttgc agtttctgca cgcgccagcg cctggtggat cggcattcaa 540
tccgcccaaa ttaaggcgat tgaaaacgac caccactggc acgaaggcaa ctactacgaa 600
tccggctgca acccagccac cggactcggc gccgcccgac gcatcgccca cctcacctac 660
cgtggcgaac tagaaatcga cgaacgcttc ggcaccaaag cccaaaagaa cgaaaaccca 720
ctcggtccct accgcaagcc cgaccagcgc ttcgccgtgg aatcctactt ggactaccaa 780
gcagacaagc tagtacagcg tttcgacgcc ggctcctacg tcttgctcac cgacgccctc 840
aaccgccacg acattggtcg cgaccgcgga ggcctcaaca aggcactcga atccatcaaa 900
gttccagtcc ttgtcgcagg cgtagatacc gatattcggt acccctacca ccagcaagaa 960
cacctctcca gaaacctggg aaatctactg gcaatggcaa aaatcgtatc ccctgtcggc 1020
cacgatgctt tcctcaccga aagccgccaa atggatcgca tcgtgaggaa cttcttcagc 1080
ctcatctccc cagacgaaga caacccttcg acctacatcg agttctacat ctaa 1134
<---
Изобретение относится к биотехнологии, в частности к мутанту О-сукцинилгомосеринтрансферазы, полинуклеотиду для кодирования этого мутанта, микроорганизму, содержащему мутант, и способу получения О-сукцинилгомосерина и L-метионина с использованием микроорганизма. Представлен полипептид, имеющий активность О-сукцинилгомосеринтрансферазы, который содержит замену аминокислоты в положении 313 в аминокислотной последовательности SEQ ID NO: 1 аргинином и замену аминокислоты в положении 176 в аминокислотной последовательности SEQ ID NO: 1 аминокислотой, отличной от глутамина. Изобретение позволяет получать L-метионин с высокой степенью эффективности. 5 н. и 9 з.п. ф-лы, 8 табл., 4 пр.
1. Полипептид, имеющий активность О-сукцинилгомосеринтрансферазы, который содержит замену аминокислоты в положении 313 в аминокислотной последовательности SEQ ID NO: 1 аргинином и замену аминокислоты в положении 176 в аминокислотной последовательности SEQ ID NO: 1 аминокислотой, отличной от глутамина.
2. Полипептид по п. 1, где аминокислота в положении 176 замещена аспарагином, триптофаном, гистидином или глицином.
3. Полипептид по п. 1, который содержит по меньшей мере одну аминокислотную последовательность, выбранную из группы, состоящей из аминокислотных последовательностей SEQ ID NO: 63, 75, 95 и 97.
4. Полинуклеотид, кодирующий полипептид, имеющий активность О-сукцинилгомосеринтрансферазы, по п. 1.
5. Полинуклеотид по п. 4, где полинуклеотид содержит по меньшей мере одну последовательность нуклеиновой кислоты, выбранную из группы, состоящей из последовательностей нуклеиновых кислот SEQ ID NO: 64, 76, 96 и 98.
6. Микроорганизм рода Corynebacterium, продуцирующий О-сукцинилгомосерин, содержащий полипептид, имеющий активность О-сукцинилгомосеринтрансферазы по п. 1, или полинуклеотид по п. 4 или 5, или где в указанном микроорганизме полипептид, имеющий активность О-сукцинилгомосеринтрансферазы по п. 1, или полинуклеотид по п. 4 или 5 сверхэкспрессирован.
7. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium имеет дополнительно увеличенную активность аспартокиназы по сравнению с немутированными микроорганизмами.
8. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium представляет собой Corynebacterium glutamicum.
9. Микроорганизм по п. 6, где активность по меньшей мере одного фермента, выбранного из группы, состоящей из цистатионинсинтазы, О-ацетилгомосерин(тиол)-лиазы и гомосеринкиназы, инактивирована в микроорганизме рода Corynebacterium.
10. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium имеет дополнительно увеличенную активность аспартокиназы по сравнению с немутированными микроорганизмами, и активность по меньшей мере одного фермента, выбранного из группы, состоящей из цистатионинсинтазы, О-ацетилгомосерин-(тиол)-лиазы и гомосеринкиназы инактивирована.
11. Способ получения О-сукцинилгомосерина, включающий:
культивирование микроорганизма рода Corynebacterium, продуцирующего О-сукцинилгомосерин, по любому из пп. 6-10 в культуральной среде; и
отделение или извлечение О-сукцинилгомосерина из микроорганизма, культивированного на стадии культивирования, или из культуральной среды.
12. Способ получения L-метионина, включающий:
а) культивирование микроорганизма рода Corynebacterium, продуцирующего О-сукцинилгомосерин по любому из пп. 6-10 в культуральной среде; и
б) взаимодействие О-сукцинилгомосерина с сульфидом.
13. Способ по п. 12, дополнительно включающий отделение или извлечение О-сукцинилгомосерина из культивированного микроорганизма или из культуральной среды на стадии (а).
14. Способ по п. 12, дополнительно включающий отделение или извлечение L-метионина, полученного в результате реакции между О-сукцинилгомосерином и сульфидом на стадии (б).
| WO 2015060649 A1, 30.04.2015 | |||
| US 20150211034 A1, 30.07.2015 | |||
| РЕКОМБИНАНТНЫЕ МИКРООРГАНИЗМЫ, ПРОДУЦИРУЮЩИЕ МЕТИОНИН | 2006 |
|
RU2447146C2 |

