Область техники
[1] Изобретение относится к компьютерной технике, в частности к компьютерам, снабженным микропроцессорами с параллельным исполнением нескольких команд, а более точно к компьютерам с микропроцессорами, выполненными в архитектуре VLIW (Very Long Instruction Word, далее - VLIW-процессоры).
Предпосылки к созданию изобретения
[2] Настоящее изложение раскрывает конфигурацию компьютера, создающую наилучшие условия для работы VLIW-процессора и позволяющую в максимальной степени реализовать его преимущества. Соответственно, предпосылки к созданию изобретения, показанные на примере VLIW-процессора, справедливы и для компьютера, оснащенного VLIW-процессором.
[3] VLIW-процессор реализует общеизвестный конвейерный процесс обработки команд (далее также - конвейерный процесс), в котором каждая команда последовательно проходит через несколько стадий обработки, таких как выборка, дешифрация, исполнение, обращение к запоминающему устройству и обратная запись результата. В дальнейшем изложении комплекс технических средств, входящих в состав процессора и непосредственно связанных с осуществлением конвейерного процесса, именуется «конвейер».
[4] Классический конвейер позволяет осуществлять одновременную обработку нескольких команд, причем каждая из команд в определенный момент времени находится на одной из стадий обработки, и на каждой стадии в определенный момент времени может обрабатываться только одна команда. Тем не менее, VLIW-процессор снабжен несколькими функциональными блоками, позволяющими, начиная со стадии исполнения, обрабатывать несколько команд одновременно уже на каждой стадии. Другими словами, конвейер типичного VLIW-процессора включает в себя один подготовительный конвейер, выполняющий стадии выборки и дешифрации, и несколько исполнительных конвейеров, выполняющих стадии исполнения, обращения к памяти и обратной записи.
[5] Однако один подготовительный конвейер не может вывести на стадию исполнения несколько команд одновременно, поскольку на каждой своей стадии он может обрабатывать только одну команду. В компьютере, оснащенном VLIW-процессором, данная проблема решается с помощью операции, выполняемой на этапе компиляции программы, а именно - операции объединения нескольких команд (далее - персонализированная команда) в одну команду (далее - широкая команда). Соответственно, на стадиях выборки и дешифрации широкая команда проходит обработку как одна команда, а на стадии исполнения разделяется на несколько персонализированных команд, каждая из которых поступает на исполнение в предписанный ей функциональный блок. Одно из названий этой широкой команды на английском языке по существу и зашифровано в аббревиатуре VLIW. Возможность использования лишь одного подготовительного конвейера для одновременной обработки нескольких персонализированных определяет преимущество VLIW-процессора над суперскалярными процессорами, которое выражается в минимизации числа компонентов процессора, снижении энергопотребления и тепловыделения. Описанная конфигурация VLIW-процессора известна специалисту в данной области, например, из патентной публикации US2012151192A1, 14.06.2012.
[6] Следует отметить, что наиболее ярко сильные стороны VLIW-процессора проявляются при ветвлении программы, когда из нескольких альтернативных ветвей персонализированных команд должна быть выбрана одна целевая ветвь. В этом случае посредством включения персонализированных команд из каждой альтернативной ветви в одну широкую команду и обработки последовательности таких широких команд, VLIW-процессор обеспечивает обработку всех альтернативных ветвей до того, как из них будет выбрана целевая ветвь. Благодаря данному свойству VLIW-процессора, при выполнении команды передачи управления VLIW-процессор, как правило, уже располагает прошедшей через стадии выборки и дешифрации целевой ветвью персонализированных команд независимо от того, какая из альтернативных ветвей персонализированных команд будет выбрана в качестве целевой ветви. Наличие целевой ветви, подготовленной к передаче исполнительному конвейеру, существенно увеличивает быстродействие VLIW-процессора при прохождении разветвляющегося участка программы.
[7] Тем временем программа может содержать несколько последовательных ветвлений, в которых каждая команда передачи управления (branch instruction) может порождать множество альтернативных ветвей, превышающее количество исполнительных конвейеров. В этой ситуации, широкие команды уже не могут вместить в себя все альтернативные ветви персонализированных команд по той причине, что число персонализированных команд в широкой команде ограничено числом исполнительных конвейеров. При передаче управления на целевую ветвь, персонализированные команды которой не включались в широкие команды, подготовительный конвейер должен быть загружен заново, и в связи с этим быстродействие VLIW-процессора естественным образом замедляется. Обусловленное перезагрузкой подготовительного конвейера увеличение времени, необходимого VLIW-процессору для выполнения программы с таким развитым ветвлением, вызывает избыточное потребление электроэнергии и повышенное тепловыделение, требующее принятия дополнительных мер по организации охлаждения.
[8] Ввиду данного обстоятельства особенно важное значение для VLIW-процессора приобретает точность подбора методики, используемой для определения вероятности передачи управления на каждую из альтернативных ветвей. Методически верное определение вероятности передачи управления необходимо в целях включения в последовательность широких команд только наиболее вероятных альтернативных ветвей, чтобы при выполнении команды передачи управления именно одна из них оказалась целевой ветвью. В оснащенных VLIW-процессорами известных компьютерах общепринятым считается подход, в котором вероятность передачи управления на конкретную альтернативную ветвь оценивается по статистике результатов команды передачи управления, порождающей эту альтернативную ветвь, а именно на основе соотношения числа передач управления, выполненных на эту альтернативную ветвь, и общего числа выполненных передач управления. Тем не менее, число промахов при загрузке альтернативных ветвей в подготовительный конвейер остается достаточно большим, что заметным образом отрицательно сказывается на быстродействии VLIW-процессора.
[9] Обратим внимание, что современные суперскалярные процессоры способны сохранять команды значительного числа альтернативных ветвей уже после их обработки подготовительными конвейерами. Соответственно, если целевая ветвь не была включена в поступающую во VLIW-процессор последовательность широких команд, то время, требуемое VLIW-процессору на передачу целевой ветви в исполнительные конвейеры, повышается в сравнении с такими суперскалярными процессорами по меньшей мере на период обработки целевой ветви подготовительным конвейером. Учитывая характерную для VLIW-процессора высокую цену ошибки, связанной с невключением целевой ветви в последовательность широких команд, представляется весьма желательным усовершенствовать методику определения вероятности передачи управления на альтернативные ветви с тем, чтобы состав наиболее вероятных альтернативных ветвей, включенных в последовательность широких команд, в подавляющем большинстве случаев включал бы целевую ветвь.
[10] Техническая проблема, на решение которой направлено изобретение, состоит в поиске способа, позволяющего увеличить производительность оснащенного VLIW-процессором компьютера при выполнении разветвленных программ и благодаря этому снизить потребление электроэнергии и уменьшить выделение тепла, а также поиске конфигурации компьютера для осуществления такого способа.
Сущность изобретения
[11] Для решения указанной технической проблемы предложены два объекта изобретения. В качестве первого объекта изобретения предложен способ конвейерной обработки команд, предназначенный для компьютера, процессор которого содержит подготовительный конвейер, а также S исполнительных конвейеров. Подготовительный конвейер при этом способен осуществлять подготовительную обработку последовательности широких команд, каждая из которых включает в себя S персонализированных команд, а i-й исполнительный конвейер способен выполнять последовательность i-х персонализированных команд, где i принимает значения от 1 до S. Согласно предложенному способу для ветвящегося потока команд, содержащего первую команду передачи управления, результатом которой является выбор одной исходной ветви из Q исходных ветвей, команду слияния всех исходных ветвей и вторую команду передачи управления, результатом которой является выбор одной последующей ветви из R последующих ветвей, где Q>S и R>S, собирают статистику результатов первой команды передачи управления и для каждого результата первой команды передачи управления собирают статистику результатов второй команды передачи управления. На основе собранных статистик определяют собственную вероятность для каждой исходной ветви и совместную вероятность для каждой пары из одной исходной и одной последующей ветви. Далее в последовательность широких команд включают те S исходных ветвей, которые имеют наибольшие по величине собственные вероятности, и те S последующих ветвей, которые имеет наибольшие по величине совместные вероятности с любыми исходными ветвями из S исходных ветвей, включенных в широкую команду.
[12] В качестве второго объекта изобретения предложен компьютер, содержащий процессор, способный обрабатывать ветвящийся поток команд, регистратор передачи управления и машиночитаемый носитель, который может быть прочитан процессором, и на котором записан компилятор. Процессор содержит подготовительный конвейер, а также S исполнительных конвейеров. Подготовительный конвейер способен осуществлять подготовительную обработку последовательности широких команд, каждая из которых включает в себя S персонализированных команд. В свою очередь, i-й исполнительный конвейер из S исполнительных конвейеров способен выполнять последовательность i-х персонализированных команд из S последовательностей персонализированных команд, где i может принимать значения от 1 до S. Ветвящийся поток команд содержит первую команду передачи управления, результатом которой является выбор одной исходной ветви из Q исходных ветвей, команду слияния всех исходных ветвей и вторую команду передачи управления, результатом которой является выбор одной последующей ветви из R последующих ветвей, где Q>S и R>S. Регистратор передачи управления способен собирать статистику результатов первой команды передачи управления и для каждого результата первой команды передачи управления способен собирать статистику результатов второй команды передачи управления. Компилятор способен на основе собранных статистик определять собственную вероятность для каждой исходной ветви и совместную вероятность для каждой пары из одной исходной и одной последующей ветви. В последовательность широких команд компилятор включает те S исходных ветвей, которые имеют наибольшие по величине собственные вероятности, и те S последующих ветвей, которые имеет наибольшие по величине совместные вероятности с любыми исходными ветвями из S исходных ветвей, включенных в широкую команду.
[13] Технический результат изобретения состоит в уменьшении времени, затрачиваемого компьютером, оснащенным VLIW-процессором, на выполнение разветвленной программы, что повышает быстродействие и производительность компьютера, снижает потребление энергии и выделение тепла, т.е. является решением поставленной перед изобретением технической проблемы. Следует отметить, что в контексте настоящего изложения понятие «выполнение программы» означает выполнение тех входящих в программу персонализированных команд, которые позволяют пройти путь от начальной персонализированной команды до конечной. Поскольку программа может содержать несколько таких путей, то понятие «выполнение программы» не подразумевает обязательное выполнение всех входящих в программу персонализированных команд.
[14] Причинно-следственная связь между признаками изобретения и техническим результатом заключается в следующем. Выбор альтернативных ветвей, а именно последующих ветвей для загрузки в подготовительный конвейер осуществляется на основе их совместной вероятности с каждой из загружаемых в подготовительный конвейер исходных ветвей. Благодаря этому вероятность того, что среди загруженных альтернативных ветвей окажется целевая ветвь, повышается, а значит снижается количество перезагрузок подготовительного конвейера, вызывающих длительные остановки.
[15] Поскольку повышенное быстродействие VLIW-процессора обеспечивает предложенному компьютеру, реализующему предложенный способ, возможность выполнения программы за меньшее время, то по сравнению с известными компьютерами для выполнения одной и той же программы предложенный компьютер, в частности его VLIW-процессор, расходует меньше электроэнергии и выделяет меньше тепла.
[16] В частном случае первого объекта изобретения в последовательность i-х персонализированных команд включают ту одну исходную ветвь из множества исходных ветвей, которая имеет i-ю по величине собственную вероятность, и ту одну последующую ветвь из оставшегося множества последующих ветвей, которая имеет i-ю по величине совместную вероятность с любой исходной ветвью от 1-й до i-й.
[17] В частном случае второго объекта изобретения в последовательность i-х персонализированных команд компилятор включает ту одну исходную ветвь из множества исходных ветвей, которая имеет i-ю по величине собственную вероятность, и ту одну последующую ветвь из оставшегося множества последующих ветвей, которая имеет i-ю по величине совместную вероятность с любой исходной ветвью от 1-й до i-й.
[18] Технический результат частных случаев первого и второго объектов изобретения выраженно проявляется при выполнении программ, в которых альтернативные ветви являются аналогичными друг другу и содержат равное количество команд. Достигается упрощение алгоритма компилятора, а также за счет включения в широкие команды однотипных персонализированных команд повышается производительность процессора.
Краткое описание чертежей
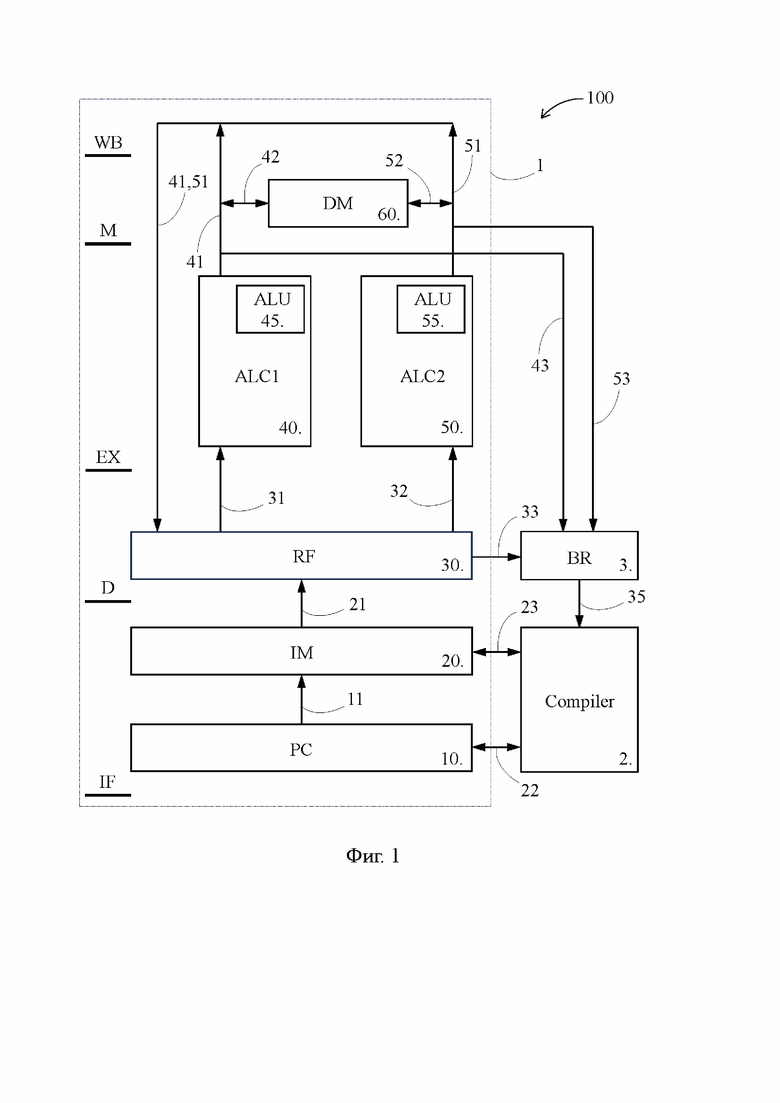
[19] Осуществление изобретения будет пояснено ссылками на фигуры:
Фиг. 1 - блок-схема компьютера, выполненного согласно второму объекту изобретения;
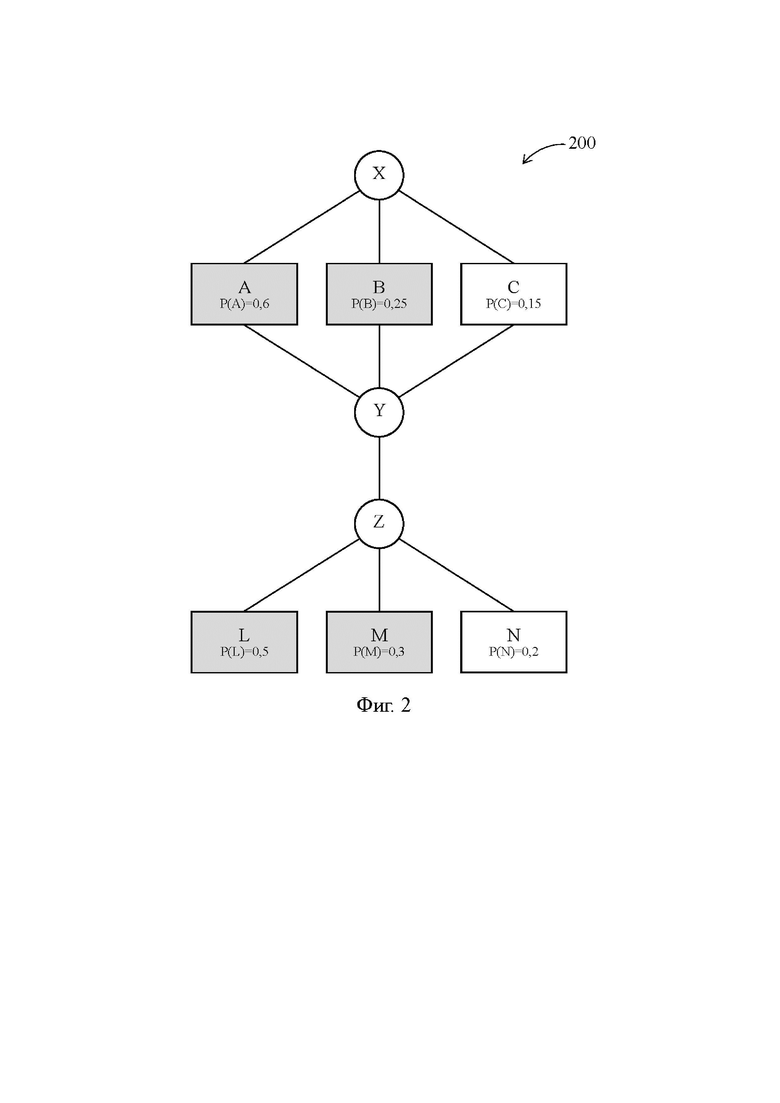
Фиг. 2 - схема выполняемой компьютером программы с иллюстрацией принципа формирования широких команд на основе известных решений (Сравнительный пример);
Фиг. 3 - схема выполняемой компьютером программы с иллюстрацией принципа формирования широких команд на основе изобретения (Пример 1);
Фиг. 4 - схема выполняемой компьютером программы с иллюстрацией принципа формирования широких команд на основе изобретения (Пример 2).
[20] Следует отметить, что форма и размеры отдельных элементов, отображенных на фигурах, являются условными и показаны так, чтобы наиболее наглядно проиллюстрировать взаимное расположение элементов предложенного компьютера, а также их причинно-следственную связь с техническим результатом. Кроме того, во избежание избыточного усложнения фигур некоторые элементы, как и взаимосвязи элементов, очевидные специалисту в данной области техники, могут быть не отображены. Фигуры также дополнены выполненными на английском языке буквенными и словесными обозначениями, которые являются общепринятыми в данной области техники, и которые способствуют более быстрому восприятию фигур специалистом в данной области техники.
Осуществление изобретения
[21] Осуществление изобретения будет показано на наилучших примерах его реализации, которые не являются ограничениями в отношении объема охраняемых прав.
[22] На Фиг. 1 представлена блок-схема компьютера 100, предложенного в качестве второго объекта изобретения и реализующего предложенный способ по первому объекту изобретения. Компьютер 100 содержит VLIW-процессор 1, машиночитаемый носитель 2, который может быть прочитан VLIW-процессором 1, и на котором записан компилятор (compiler), и регистратор 3 передачи управления (BR - branch recorder).
[23] VLIW-процессор 1 содержит счетчик 10 команд (PC1 - program counter), память 20 команд (IM1 - instruction memory), регистровый файл 30 (RF1 - register file), первый арифметико-логический функциональный блок 40 (ALC1 - arithmetic-logical channel), второй арифметико-логический функциональный блок 50 (ALC2), память 60 данных (DM - data memory). Первый и второй арифметико-логические функциональные блоки 40 и 50 далее также кратко именуются как «первый и второй функциональные блоки 40 и 50».
[24] Указанные элементы VLIW-процессора 1 представляют собой основные компоненты конвейера, задействованные в соответствующих стадиях конвейерного процесса, которые показаны в левой части Фиг. 1: выборка команды (IF - instruction fetch), дешифрация (D - decode), исполнение (EX - execute), обращение к памяти (M - memory) и обратная запись результата (WB - write back).
[25] Обратим внимание, что наличие во VLIW-процессоре 1 по одному элементу из перечисленных выше элементов 10, 20 и 30 эквивалентно наличию во VLIW-процессоре 1 одного подготовительного конвейера, способного в каждый момент времени обрабатывать на каждой из стадий IF и D только по одной команде, которая представляет собой широкую команду. Тем временем наличие во VLIW-процессоре 1 двух функциональных блоков 40 и 50 эквивалентно наличию во VLIW-процессоре 1 двух исполнительных конвейеров, способных в каждый момент времени обрабатывать на каждой из стадий E, M и WB сразу по две команды, которые представляют собой персонализированные команды, выделенные на стадии D из широкой команды.
[26] Хотя на Фиг. 1 показаны только два исполнительных конвейера, VLIW-процессор 1 может содержать, по существу, любое количество исполнительных конвейеров, при этом как правило, не все из этих исполнительных конвейеров содержат упомянутые выше арифметико-логические функциональные блоки. Некоторые исполнительные конвейеры VLIW-процессора 1 вместо арифметико-логических функциональных блоков могут содержать непоказанные на Фиг. 1 предикатно-логические функциональные блоки (PLC - predicate logical channel), назначение и функционирование которых известны специалисту в данной области. Например, VLIW-процессор 1 может содержать шесть арифметико-логических функциональных блоков и три предикатно-логических функциональных блока, а значит может выполнять широкую команду, включающую девять персонализированных команд.
[27] Однако упомянутые предикатно-логические функциональные блоки и выполняемые ими персонализированные команды, включенные компилятором в широкие команды, имеют лишь вспомогательные функции для выполнения программы и не находятся во взаимосвязи с содержанием программы. Исходя из этого, в контексте настоящего изложения в количество S исполнительных конвейеров включены только исполнительные конвейеры, содержащие арифметико-логические функциональные блоки, а в количество S персонализированных команд включены только персонализированные команды, предназначенные к выполнению арифметико-логическими функциональными блоками. Для VLIW-процессора 1 S=2, т.е. каждая широкая команда содержит первую и вторую персонализированные команды, которые поступают на выполнение соответственно в первый и второй арифметико-логические функциональные блоки 40 и 50.
[28] Следует также отметить, что часть конвейерного процесса, реализуемая подготовительным конвейером VLIW-процессора 1, может содержать гораздо больше стадий, чем указанные выше стадии IF и D. Аналогичное утверждение справедливо и для первого и второго исполнительных конвейеров VLIW-процессора 1, которые помимо стадий EX, M и WB могут осуществлять иные стадии конвейерного процесса. Принципы увеличения числа стадий конвейерного процесса, как правило, основанные на разделении указанных выше стадий на ряд более мелких стадий в целях уменьшения длительности такта, известны специалисту в данной области техники.
[29] Далее, в состав VLIW-процессора 1 входит блок управления (не показан), обеспечивающий выработку и передачу управляющих сигналов на перечисленные выше элементы. Кроме того, VLIW-процессор 1 содержит множество элементов, исполняющих тривиальные функции в конвейерном процессе и являющихся очевидными специалисту в данной области, таких как регистры, мультиплексоры, шины передачи данных и т.п. Некоторые из таких элементов отображены на Фиг. 1 и будут раскрыты по ходу изложения.
[30] Память 20 команд представляет собой раздел кэш-памяти, в котором сохранен массив широких команд, подлежащих выполнению в ближайшее время. По сигналу, поступающему от счетчика команд 10 по шине 11, из указанного массива широких команд производится выборка той широкой команды, которая должна быть выполнена следующей. Под выборкой широкой команды на стадии IF понимается выдача из памяти 20 команд N-битового сигнала, который указывает адреса as11, as12 регистров для исходных операндов первой персонализированной команды, адреса as21, as22 регистров для исходных операндов второй персонализированной команды, адреса ad1, ad2 регистров для результирующих операндов соответственно первой и второй персонализированных команд, а также коды opc1, opc2 операций, осуществляемых соответственно первой и второй персонализированными командами.
[31] Адреса as11, as12, as21, as22, ad1, ad2 регистров поступают из памяти 20 команд по шине 21 в регистровый файл 30, который представляет собой набор регистров, способных сохранять числовые данные целочисленного типа, с плавающей запятой и т.д. В свою очередь, коды opc1, opc2 операций поступают из памяти 20 команд в упомянутый выше блок управления. Регистровый файл 30 направляет исходные операнды src11 и src12, прочитанные в регистрах по адресам as11, as12, в первый функциональный блок 40 по шине 31, и по шине 32 направляет во второй функциональный блок 50 исходные операнды src21 и src22, прочитанные в регистрах по адресам as21, as22. Поступление соответствующих исходных операндов в первый и второй функциональные блоки 40 и 50, а также поступление кодов операций opc1 и opc2 в блок управления завершает стадию D, а вместе с ней и работу подготовительного конвейера по подготовительной обработке широкой команды и выделению из широкой команды первой и второй персонализированных команд.
[32] В состав первого функционального блока 40 включено арифметико-логическое устройство 45 (АЛУ, ALU - arithmetic-logical unit). Исходные операнды src11 и src12 поступают в АЛУ 45, в котором над ними выполняется операция, соответствующая коду opc1, после чего результат ALUres1 выполнения первой персонализированной команды по шине 41 направляется в память 60 данных или в регистровый файл 30, где записывается в регистр ad1 в качестве результирующего операнда первой персонализированной команды.
[33] Аналогично, исходные операнды src21 и src22 поступают в АЛУ 55, в котором над ними осуществляется операция, соответствующая коду opc2. Затем результат ALUres2 выполнения второй персонализированной команды по шине 51 направляется в память 60 данных или в регистровый файл 30 для записи в регистр ad2. На этом стадия EX конвейерного процесса, предусматривающая одновременное выполнение первой и второй персонализированных команд при помощи первого и второго исполнительных конвейеров, завершается.
[34] Далее, конвейерный процесс обработки некоторых персонализированных команд, таких как ld (load - загрузка (также - чтение) данных из памяти) или st (store - сохранение данных в память), включает обращение к памяти 60 данных, выполняемое с использованием шин 42 и 52, соединяющих память 60 данных соответственно с шинами 41 и 51. Память 60 данных представляет собой раздел кэш-памяти, сохраняющий массив данных, которые с большой вероятностью будут затребованы в ближайшее время. Передача данных по шинам 42 и 52 в память 60 данных или из нее представляет собой суть того действия, которое выполняется первым и вторым исполнительными конвейерами на стадии M.
[35] На стадии WB данные, прочитанные из памяти 60 данных или являющиеся результатом выполненной АЛУ математической операции, передаются по шинам 41 и 51 для записи в регистры ad1, ad2 регистрового файла 30. Вместе со стадией WB на этом завершается весь цикл конвейерного процесса обработки персонализированных команд.
[36] Следует отметить, что во VLIW-процессоре 1 под первым и вторым исполнительными конвейерами понимается совокупность элементов, являющихся необходимыми для осуществления стадий E, M, WB конвейерного процесса в отношении первой и второй персонализированных команд. В частности первый исполнительный конвейер включает в себя по меньшей мере первый функциональный блок 40, шины 41 и 42, а также входящие в блок управления устройства, управляющие первым функциональным блоком 40 и коммутирующими компонентами, которые реализуют функции обращения к памяти 60 данных и записи в регистровый файл 30. Аналогично второй исполнительный конвейер включает в себя по меньшей мере второй функциональный блок 50, шины 51 и 52, а также упомянутые управляющие устройства, входящие в блок управления, и коммутирующие компоненты.
[37] Обратим внимание, что термины «первый» и «второй», используемые в отношении первого и второго исполнительных конвейеров VLIW-процессора 1, не имеют какого-либо иного смысла помимо указания на их различие, т.е. любой из двух исполнительных конвейеров может быть принят в качестве первого или второго исполнительного конвейера. Аналогичное утверждение справедливо и для первой и второй персонализированных команд.
[38] Входящий в состав компьютера 100 машиночитаемый носитель 2 представляет собой машиночитаемый носитель информации, который может быть прочитан VLIW-процессором 1. В качестве машиночитаемого носителя 2 может выступать оперативная память, жесткий диск или любое другое запоминающее устройство компьютера, соединенное с VLIW-процессором 1, например шинами 22 и 23. Машиночитаемый носитель 2 содержит в себе запись компилятора, который представляет собой вспомогательную программу, предназначенную для перевода исходного программного кода, написанного на языке программирования, в машинный код, воспринимаемый VLIW-процессором 1. В дальнейшем изложении компилятор, записанный на машиночитаемом носителе 2, также именуется как «компилятор 2».
[39] Следует отметить, что помимо осуществления простой трансформации программного кода, компилятор 2 способен преобразовывать исходный алгоритм программы так, чтобы преобразованный алгоритм был в максимальной степени оптимизирован под описанную выше конфигурацию VLIW-процессора 1, которая согласно терминологии, используемой в профессиональной литературе, представляет собой микроархитектуру VLIW-процессора 1. Например, компилятор 2 способен распознавать в исходном алгоритме программы такие команды, которые по исходным операндам не зависят друг от друга, и включать эти команды в одну широкую команду в качестве персонализированных команд. Более того, компилятор 2 способен прослеживать в исходном алгоритме программы альтернативные ветви команд, и включать эти альтернативные ветви в последовательность широких команд в качестве последовательностей персонализированных команд.
[40] Далее, компилятор 2 способен дополнять преобразованный алгоритм программы новыми вспомогательными командами, такими как команда по расчету вероятности передачи управления, и использовать в качестве исходных операндов таких команд статистические данные, собранные регистратором 3 передачи управления. Другими словами, компилятор 2 способен определять вероятность выбора каждой из альтернативных ветвей, и в том случае, когда число альтернативных ветвей превышает число персонализированных команд в широкой команде, компилятор 2 способен включать в широкую команду персонализированные команды только тех альтернативных ветвей, передача управления на которые определена им как наиболее вероятная.
[41] Регистратор 3 передачи управления представляет собой известный специалисту в данной области техники регистратор событий, который при наступлении заданного события способен регистрировать это событие. Более точно, регистратор 3 передачи управления способен сохранять в памяти факт наступления этого события, а также регистрировать несколько событий, предшествующих этому событию. Естественным образом, регистрируемыми событиями для регистратора 3 передачи управления являются результаты выполнения команд передачи управления, а именно вызываемые команды, на которые передается управление. Поскольку вызываемые команды являются первыми командами своих альтернативных ветвей, то передача управления на вызываемую команду эквивалентна выбору содержащей ее альтернативной ветви.
[42] Во VLIW-процессоре 1 регистратор 3 передачи управления получает информацию о фактах выполнения команд передачи управления от первого и второго функциональных блоков 40 и 50 по шинам 43 и 53, и получает информацию о командах, на которые передается управление, от регистрового файла 30 по шине 33. Собранные статистические данные или информацию об их наличии регистратор 3 передачи управления передает компилятору 2 по шине 35.
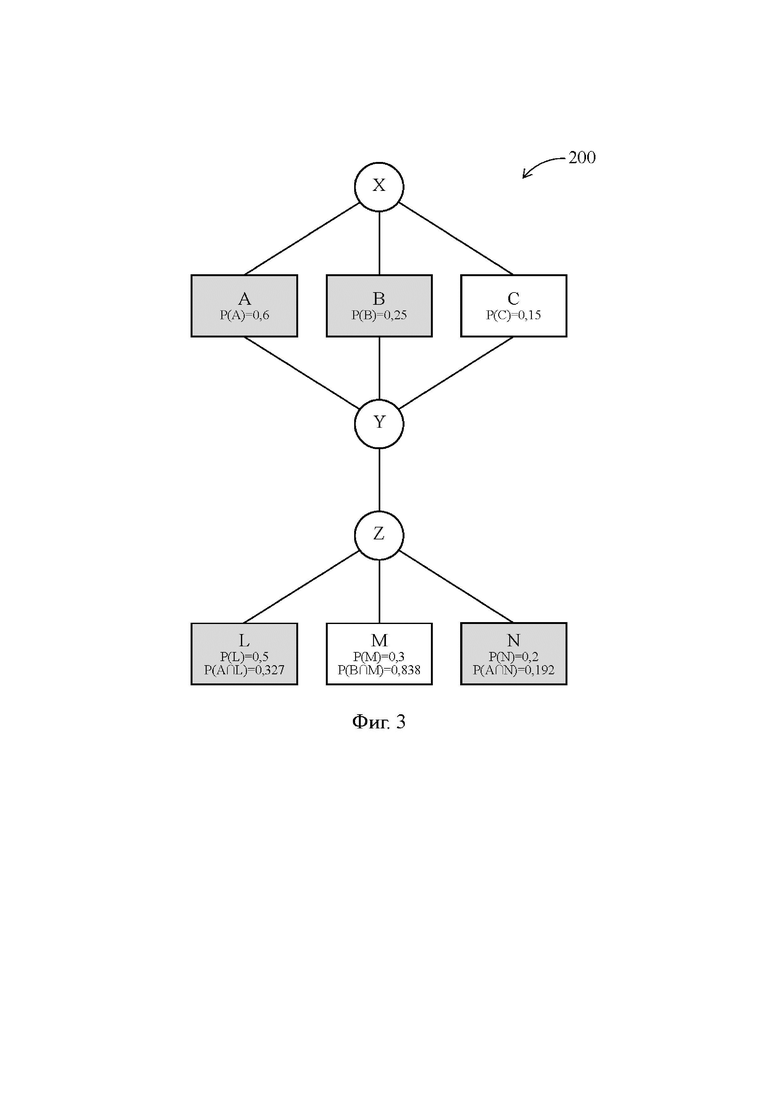
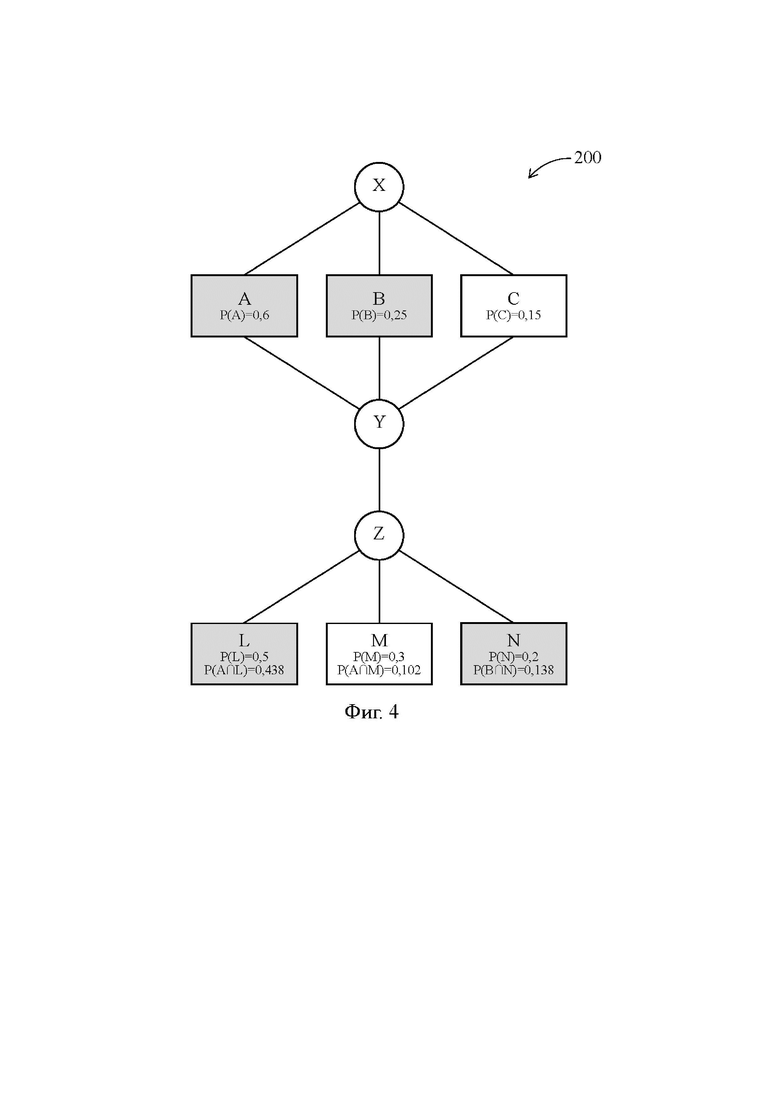
[43] Далее со ссылками на Фиг. 2 более подробно раскрыта техническая проблема, решаемая изобретением, а со ссылками на Фиг. 3 и 4 подробно описаны функционирование компьютера 100 и реализуемый им предложенный способ. На Фиг. 2-4 представлена схема исходного алгоритма одной и той же программы 200, при этом на Фиг. 2 проиллюстрирован результат компиляции широких команд, полученный согласно известному способу, реализуемому известным компьютером (Сравнительный пример), а на Фиг. 3 и 4 показан результат компиляции широких команд, полученный согласно предложенному способу (Примеры 1 и 2).
[44] Программа 200 представляет собой ветвящийся поток команд, который содержит первую команду X передачи управления, формирующую множество из Q исходных ветвей А, В и С, команду Y слияния всех исходных ветвей и вторую команду Z передачи управления, формирующую множество из R последующих ветвей L, M и N. Обратим внимание, что каждая из исходных ветвей А, В, С и каждая из последующих ветвей L, M и N может содержать множество последовательно выполняемых команд, при этом между командой Y слияния и второй командой Z передачи управления также может располагаться множество последовательно выполняемых команд. В зависимости от используемого языка программирования каждая из первой и второй команд X и Z передачи управления может представлять собой одну команду, формирующую три ветви, или представлять собой последовательность из двух команд, каждая из которых формирует две ветви.
[45] Что касается команды Y слияния, то в отличие от первой и второй команд X и Z передачи управления, согласно которым в зависимости от входящего условия производится выбор одной из трех операций для одного и того же набора исходных операндов, согласно команде Y слияния в зависимости от входящего условия производится выбор одного из трех наборов исходных операндов для одной и той же операции. В зависимости от используемого языка программирования команда Y слияния может быть объединена со второй командой Z передачи управления или может представлять собой отдельную команду.
[46] Программа 200 предназначена для выполнения VLIW-процессором 1, который по существу является одинаковым для компьютера 100 и известного компьютера. Обратим внимание, что в программе 200 Q=3, R=3, а во VLIW-процессоре 1 S=2, т.е. на каждом из двух ветвлений программы 200 VLIW-процессор 1 может обработать только две альтернативные ветви.
[47] Регистратор 3 передачи управления, как и известный регистратор передачи управления, входящий в состав известного компьютера, при предварительных циклах выполнения программы, т.е. при так называемом сэмплировании, или при начальных циклах выполнения программы, производимых в реальных условиях, собирает статистику результатов первой команды X передачи управления. Другими словами, на заданном промежутке времени регистратор 3 передачи управления определяет число выполненных передач управления на каждую из исходных ветвей А, В и С. На основе этих данных как известный компилятор, входящий в состав известного компьютера, так и компилятор 2 рассчитывают собственные вероятности Р(А), Р(В) и Р(С) передачи управления на исходные ветви А, В и С как отношение числа выполненных передач управления на соответствующую исходную ветвь к суммарному числу выполненных передач управления на все исходные ветви.
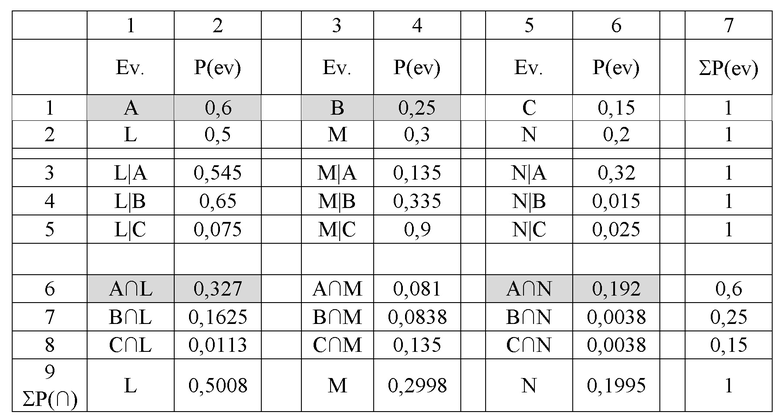
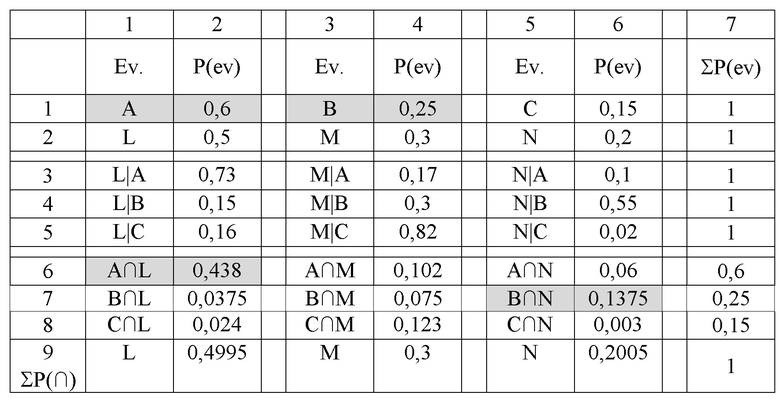
[48] Учитывая, что число персонализированных команд в широкой команде S=2, и число исходных ветвей Q=3, известный компилятор и компилятор 2 выбирают для включения в последовательность широких команд те исходные ветви, которые имеют наибольшие собственные вероятности, т.е. исходные ветви А и В. На Фиг. 2-4 и в представленных ниже Таблицах 1 и 2 выбранные исходные ветви, подлежащие включению в последовательность широких команд, отмечены затемнением. До этого момента компьютер 100 и предложенный способ не имеют отличий от известных решений.
[49] Тем временем выбор двух последующих ветвей, подлежащих включению в последовательность широких команд, из общего числа R=3 последующих ветвей известный компьютер осуществляет на основе собственных вероятностей Р(L), Р(M), Р(N) всех последующих ветвей L, M, N, которые он получает тем же самым образом, как и собственные вероятности Р(А), Р(В), Р(С) исходных ветвей А, В и С. Более точно известный компилятор выбирает из трех последующих ветвей L, M, N две ветви с наибольшими собственными вероятностями, которыми в данном случае являются последующие ветви L и M, как это показано на Фиг. 2.
[50] Обратим внимание, что например, полученная известным компьютером собственная вероятность Р(L) учитывает все собственные вероятности исходных ветвей, а также все корреляции между передачей управления на каждую из исходных ветвей А, В, С и передачей управления на последующую ветвь L. Другими словами, для последующей ветви L справедливо соотношение:
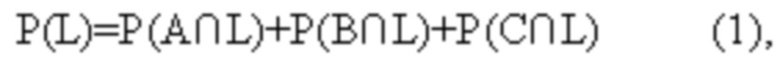
где например, P(A∩L) - совместная вероятность передачи управления на исходную ветвь A и передачи управления на последующую ветвь L, а P(B∩L) и P(C∩L) имеют аналогичную трактовку.
Однако известный компьютер не способен учесть влияние каждой из совместных вероятностей P(A∩L), P(B∩L), P(C∩L) на собственную вероятность P(L), что часто приводит к неэффективному выбору последующих ветвей для включения в последовательность широких команд.
[51] Согласно предложенному способу компьютер 100 не определяет собственные вероятности Р(L), Р(M), Р(N) для последующих ветвей L, M, N, а вместо этого определяет каждую из совместных вероятностей исходных ветвей А, В, С и последующих ветвей L, M, N отдельно. Например, для последующей ветви L компьютер 100 определяет P(A∩L), P(B∩L), P(C∩L) в отдельности, исходя при этом из того, что
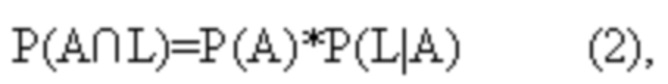
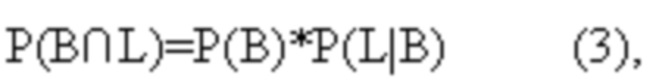
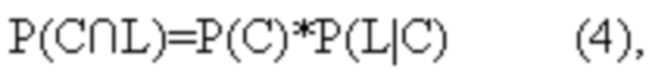
где например, P(L|A) - условная вероятность передачи управления на последующую ветвь L при выполненной передаче управления на исходную ветвь A, а P(L|B) и P(L|C) имеют аналогичную трактовку.
Следует отметить, что для предложенного способа принимается модель, в которой передача управления на исходную ветвь А и передача управления на последующую ветвь L при ранее выполненной передаче управления на исходную ветвь А являются независимыми событиями, т.е. при некотором изменении собственной вероятности P(A) условная вероятность P(L|A) остается неизменной.
[52] Для реализации предложенного способа регистратор 3 передачи управления способен собирать статистику результатов второй команды Z передачи управления для каждого результата первой команды X передачи управления. Более точно, регистратор 3 передачи управления отдельно определяет число передач управления на последующую ветвь L, выполненных при условии ранее выполненной передаче управления на исходную ветвь А, отдельно определяет число передач управления на последующую ветвь L, выполненных при условии ранее выполненной передаче управления на исходную ветвь B, и отдельно определяет число передач управления на последующую ветвь L, выполненных при условии ранее выполненной передаче управления на исходную ветвь C. На основе данной статистики передачи управления компилятор 2 рассчитывают каждую из условных вероятностей P(L|A), P(L|В), P(L|С) передачи управления на последующую ветвь L как отношение числа передач управления на последующую ветвь L, выполненных при условии ранее выполненной передаче управления на соответствующую исходную ветвь, к суммарному числу выполненных передач управления на последующую ветвь L.
[53] Аналогичную статистику регистратор 3 собирает для последующих ветвей M и N, и аналогичным образом компилятор 2 рассчитывает условные вероятности P(М|A), P(М|В), P(М|С) и P(N|A), P(N|В), P(N|С). Располагая определенными, как было описано выше, собственными вероятностями Р(А), Р(В), Р(С) исходных ветвей А, В и С, компилятор 2 в соответствии с приведенными выше соотношениями (2)-(4) рассчитывает совместные вероятности P(A∩L), P(B∩L), P(C∩L) для последующей ветви L, совместные вероятности P(A∩M), P(B∩M), P(C∩M) для последующей ветви M и совместные вероятности P(A∩N), P(B∩N), P(C∩N) для последующей ветви N.
[54] Далее компилятор 2 включает в первую последовательность персонализированных команд широкой команды, предназначенной к выполнению VLIW-процессором 1, первую исходную ветвь из множества исходных ветвей А, В, С, которая имеет первую (i=1) по величине собственную вероятность, и ту одну последующую ветвь из множества последующих ветвей L, M, N, которая имеет первую по величине совместную вероятность с этой первой исходной ветвью. Кроме того, компилятор 2 включает во вторую последовательность персонализированных команд широкой команды, предназначенной к выполнению VLIW-процессором 1, вторую исходную ветвь из множества исходных ветвей А, В, С, которая имеет вторую (i=2) по величине собственную вероятность, и ту одну последующую ветвь из оставшегося множества последующих ветвей L, M, N, которая имеет вторую по величине совместную вероятность с любой из этих первой и второй исходных ветвей.
[55] Как было показано выше со ссылками на Фиг. 2, при использовании известного способа (Сравнительный пример) выбор исходных и последующих ветвей для включения в первую и во вторую последовательности персонализированных команд широкой команды был произведен на основе собственных вероятностей исходных и последующих ветвей. Как следует из Фиг. 2, при использовании известного способа в первую последовательность персонализированных команд включены исходная ветвь A и последующая ветвь L, а во вторую последовательность персонализированных команд включены исходная ветвь B и последующая ветвь M.
[56] Таблицы 1 и 2 содержат два различных набора результатов сэмплирования, используемых соответственно для Примеров 1 и 2, в которых выбор исходных и последующих ветвей сделан согласно предложенному способу для той же самой программы 200, что являлась предметом анализа в Сравнительном примере. В Таблицах 1 и 2 столбцы 1, 3, 5 показывают события (events), а столбцы 2, 4, 6 - вероятности этих событий. Строки 1-5 показывают вероятности, полученные на основе непосредственного подсчета числа соответствующих событий. Строки 6-8 показывают вероятности, полученные на основе математической операции, произведенной согласно соотношениям (2)-(4) с соответствующими вероятностями из строк 1-5. Столбец 7 и строка 9 являются проверочными.
[57] Исходными данными программы 200 в Примерах 1 и 2 по-прежнему являются: S=2, Q=3, R=3, Р(А)=0,6, Р(В)=0,25, Р(С)=0,15, Р(L)=0,5, Р(M)=0,3, Р(N)=0,2. Тем не менее, Примеры 1 и 2 различаются значениями определенных регистратором 3 передачи управления и компилятором 2 условных вероятностей P(L|A), P(L|В), P(L|С), P(М|A), P(М|В), P(М|С), P(N|A), P(N|В), P(N|С), а значит и значениями рассчитанных на их основе совместными вероятностями P(A∩L), P(B∩L), P(C∩L), P(A∩M), P(B∩M), P(C∩M), P(A∩N), P(B∩N), P(C∩N).
[58] Пример 1
Как следует из Таблицы 1, первую по величине (i=1) совместную вероятность из оставшегося множества последующих ветвей, т.е. из множества L, M и N, имеет последующая ветвь L: P(A∩L)=0,327. Вторую по величине (i=2) совместную вероятность из оставшегося множества последующих ветвей, т.е. из множества M и N, имеет последующая ветвь N: P(A∩N)=0,192. Таким образом, включению в первую последовательность персонализированных команд по-прежнему подлежит последующая ветвь L, для которой i=1, а включению во вторую последовательность персонализированных команд подлежит последующая ветвь N, для которой i=2, вместо последующей ветви М, как это было в Сравнительном примере. Обратим внимание, что наибольшая совместная вероятность последующей ветви М с включенными в широкую команду исходными ветвями А и В составляет P(A∩М)=0,0838 против P(A∩N)=0,192, что свидетельствует в пользу более вероятной передачи управления от исходных ветвей А и В на последующую ветвь N. В Таблице 1 и на Фиг. 3, соответствующей Примеру 1, выбранные последующие ветви L и N отмечены затемнением.
[59] Таблица 1
[60] Пример 2
Как следует из Таблицы 2, первую по величине (i=1) совместную вероятность из оставшегося множества последующих ветвей, т.е. из множества L, M и N, имеет последующая ветвь L: P(A∩L)=0,438. Вторую по величине (i=2) совместную вероятность из оставшегося множества последующих ветвей, т.е. из множества M и N, имеет последующая ветвь N: P(В∩N)=0,1375. Таким образом, включению в первую последовательность персонализированных команд по-прежнему подлежит последующая ветвь L, для которой i=1, а включению во вторую последовательность персонализированных команд подлежит последующая ветвь N, для которой i=2, вместо последующей ветви М, как это было в Сравнительном примере. Обратим внимание, что и здесь наибольшая совместная вероятность последующей ветви М с включенными в широкую команду исходными ветвями А и В составляет P(A∩М)=0,102 против P(В∩N)=0,1375, что свидетельствует в пользу более вероятной передачи управления от исходных ветвей А и В на последующую ветвь N. В Таблице 2 и на Фиг. 4, соответствующей Примеру 2, выбранные последующие ветви L и N отмечены затемнением.
[61] Таблица 2
[62] Сопоставление Примеров 1 и 2 со Сравнительным примером доказывает, что при невключении маловероятной исходной ветви, в данном случае - исходной ветви С, в последовательность широких команд, выбор последующих ветвей для включения в последовательность широких команд, сделанный на основе собственных вероятностей последующих ветвей, уже не позволяет максимизировать вероятность того, что среди этих последующих ветвей окажется целевая ветвь. Компьютер 100 и реализуемый им предложенный способ минимизируют число ошибок в выборе целевой последующей ветви, и тем самым обеспечивают компьютеру повышенные быстродействие и производительность при выполнении разветвленной программы, благодаря чему снижается потребление электроэнергии и количество выделяемого тепла.
[63] Следует отметить, что предложенный способ обеспечивает достижение указанных технических результатов для компьютера, содержащего VLIW-процессор с любым количеством S функциональных блоков, и выполняющего программу, в которой первая команда передачи управления формирует любое количество Q исходных ветвей, и в которой вторая команда передачи управления которой формирует любое количество R последующих ветвей, при условии, что Q>S и R>S. Первая команда передачи управления при этом может представлять собой, например, первую по счету команду передачи управления в программе, либо команду передачи управления, в отношении которой компилятор 2 установил отсутствие корреляционных связей с предыдущей командой передачи управления, либо команду передачи управления, которая выбрана компилятором 2 произвольно.
[64] Обратим также внимание, что приведенные выше примеры реализации изобретения подразумевают включение в каждую широкую команду по одной персонализированной команде из каждой выбранной исходной ветви, а затем по одной персонализированной команде из каждой последующей ветви. Однако это не является обязательным, компилятор может формировать широкие команды произвольным образом. Принципиально важным остается выбор для включения в последовательность широких команд только тех исходных ветвей, которые имеют наибольшую собственную вероятность, и только тех последующих ветвей, которые имеют наибольшую совместную вероятность с любыми выбранными исходными ветвями, при этом как исходные, так и последующие ветви выбираются в количестве, равном количеству исполнительных конвейеров.
| название | год | авторы | номер документа |
|---|---|---|---|
| VLIW-ПРОЦЕССОР С ДОПОЛНИТЕЛЬНЫМ ПОДГОТОВИТЕЛЬНЫМ КОНВЕЙЕРОМ И ПРЕДСКАЗАТЕЛЕМ ПЕРЕХОДА | 2024 |
|
RU2816094C1 |
| VLIW-ПРОЦЕССОР С УЛУЧШЕННОЙ ПРОИЗВОДИТЕЛЬНОСТЬЮ ПРИ ЗАДЕРЖКЕ ОБНОВЛЕНИЯ ОПЕРАНДОВ | 2023 |
|
RU2816092C1 |
| ПРОЦЕССОР С ЗАГРУЗКОЙ КОМАНД В СОСТАВЕ КЭШЛАЙНА И ПРЕДСКАЗАНИЕМ ПЕРЕХОДА | 2024 |
|
RU2828600C1 |
| ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ МНОГОПРОЦЕССОРНАЯ АРХИТЕКТУРА | 2007 |
|
RU2427895C2 |
| КОМПЬЮТЕР | 1998 |
|
RU2216033C2 |
| ОПРЕДЕЛЕНИЕ ПРОФИЛЯ ПУТИ, ИСПОЛЬЗУЯ КОМБИНАЦИЮ АППАРАТНЫХ И ПРОГРАММНЫХ СРЕДСТВ | 2013 |
|
RU2614583C2 |
| СИСТЕМА И СПОСОБ РАСПРЕДЕЛЕННЫХ ВЫЧИСЛЕНИЙ | 2010 |
|
RU2554509C2 |
| МУЛЬТИПРОЦЕССОРНАЯ АРХИТЕКТУРА, ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ | 2008 |
|
RU2450339C2 |
| СПОСОБ ГЕНЕРАЦИИ СЛУЧАЙНОГО ЧИСЛА С ИСПОЛЬЗОВАНИЕМ КОМПЬЮТЕРА (ВАРИАНТЫ) | 2014 |
|
RU2577201C2 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ИДЕНТИФИКАЦИИ ИНСТРУКЦИЙ ДЛЯ УДАЛЕНИЯ В МНОГОПОТОЧНОМ ПРОЦЕССОРЕ С ИЗМЕНЕНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ | 2013 |
|
RU2644528C2 |
Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в снижении времени, затрачиваемого компьютером, оснащенным VLIW-процессором, на выполнение разветвленной программы, что повышает быстродействие и производительность компьютера. Технический результат достигается за счёт того, что подготовительный конвейер осуществляет подготовительную обработку последовательности широких команд, каждая из которых включает в себя S персонализированных команд, а i-й исполнительный конвейер способен выполнять последовательность i-х персонализированных команд, где i принимает значения от 1 до S, при этом в последовательность широких команд включают те S исходных ветвей, которые имеют наибольшие по величине собственные вероятности, и те S последующих ветвей, которые имеют наибольшие по величине совместные вероятности с любыми исходными ветвями из S исходных ветвей, включенных в широкую команду. 2 н. и 2 з.п. ф-лы, 4 ил., 2 табл.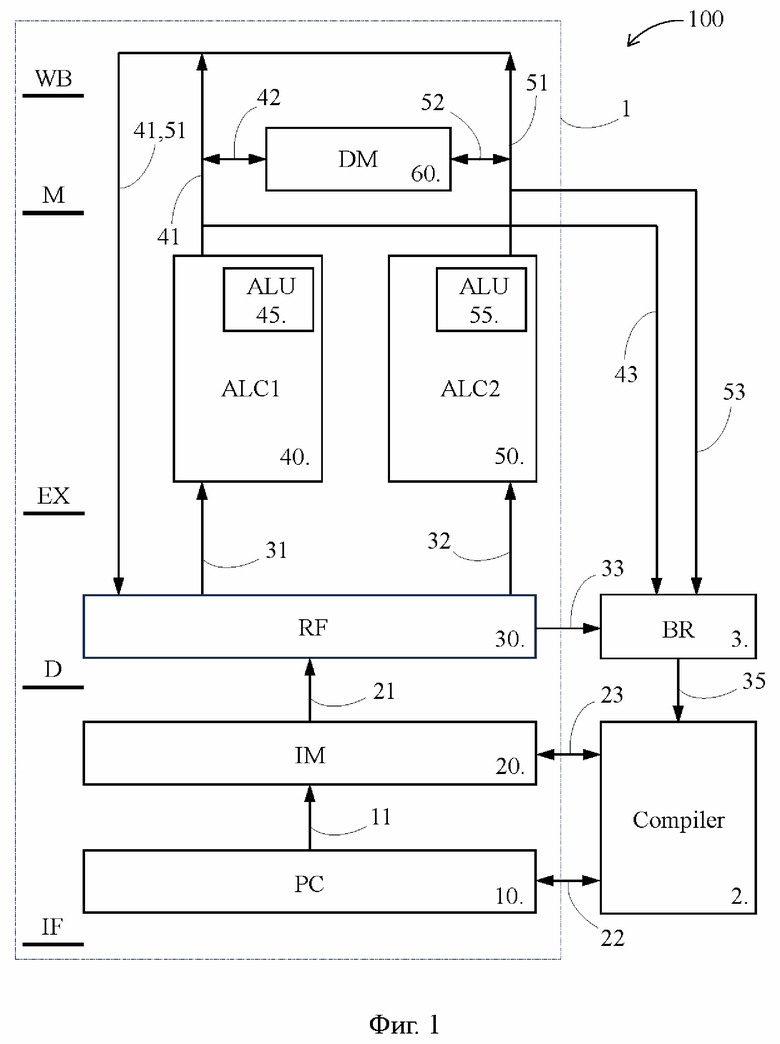
1. Способ конвейерной обработки команд, предназначенный для компьютера, процессор которого содержит подготовительный конвейер, а также S исполнительных конвейеров, причем
подготовительный конвейер способен осуществлять подготовительную обработку последовательности широких команд, каждая из которых включает в себя S персонализированных команд, а i-й исполнительный конвейер способен выполнять последовательность i-х персонализированных команд, где i принимает значения от 1 до S, при этом
согласно способу, для ветвящегося потока команд, содержащего первую команду передачи управления, результатом которой является выбор одной исходной ветви из Q исходных ветвей, команду слияния всех исходных ветвей и вторую команду передачи управления, результатом которой является выбор одной последующей ветви из R последующих ветвей, где Q>S и R>S, собирают статистику результатов первой команды передачи управления и для каждого результата первой команды передачи управления собирают статистику результатов второй команды передачи управления, после чего на основе собранных статистик определяют собственную вероятность для каждой исходной ветви и совместную вероятность для каждой пары из одной исходной и одной последующей ветви, причем
в последовательность широких команд включают те S исходных ветвей, которые имеют наибольшие по величине собственные вероятности, и те S последующих ветвей, которые имеют наибольшие по величине совместные вероятности с любыми исходными ветвями из S исходных ветвей, включенных в широкую команду.
2. Способ по п. 1, в котором в последовательность i-х персонализированных команд включают ту одну исходную ветвь из множества исходных ветвей, которая имеет i-ю по величине собственную вероятность, и ту одну последующую ветвь из оставшегося множества последующих ветвей, которая имеет i-ю по величине совместную вероятность с любой исходной ветвью от 1-й до i-й.
3. Компьютер, содержащий процессор, способный обрабатывать ветвящийся поток команд, регистратор передачи управления и машиночитаемый носитель, который может быть прочитан процессором и на котором записан компилятор, при этом
процессор содержит подготовительный конвейер, а также S исполнительных конвейеров, причем подготовительный конвейер способен осуществлять подготовительную обработку последовательности широких команд, каждая из которых включает в себя S персонализированных команд, а i-й исполнительный конвейер способен выполнять последовательность i-х персонализированных команд, где i может принимать значения от 1 до S, при этом
ветвящийся поток команд содержит первую команду передачи управления, результатом которой является выбор одной исходной ветви из Q исходных ветвей, команду слияния всех исходных ветвей и вторую команду передачи управления, результатом которой является выбор одной последующей ветви из R последующих ветвей, где Q>S и R>S, причем регистратор передачи управления способен собирать статистику результатов первой команды передачи управления и для каждого результата первой команды передачи управления способен собирать статистику результатов второй команды передачи управления, а компилятор способен на основе собранных статистик определять собственную вероятность для каждой исходной ветви и совместную вероятность для каждой пары из одной исходной и одной последующей ветви, причем
в последовательность широких команд компилятор включает те S исходных ветвей, которые имеют наибольшие по величине собственные вероятности, и те S последующих ветвей, которые имеют наибольшие по величине совместные вероятности с любыми исходными ветвями из S исходных ветвей, включенных в широкую команду.
4. Компьютер по п. 3, в котором в последовательность i-х персонализированных команд компилятор включает ту одну исходную ветвь из множества исходных ветвей, которая имеет i-ю по величине собственную вероятность, и ту одну последующую ветвь из оставшегося множества последующих ветвей, которая имеет i-ю по величине совместную вероятность с любой исходной ветвью от 1-й до i-й.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| JP 2013114608 A, 10.06.2013 | |||
| Sensen Hu, Jing Huang "Exploring Adaptive Cache for Reconfigurable VLIW Processor", опубл | |||
| Способ очистки нефти и нефтяных продуктов и уничтожения их флюоресценции | 1921 |
|
SU31A1 |

