Область техники
[1] Изобретение относится к микропроцессорной технике, в частности к микропроцессорам с конвейерной обработкой команд.
Предпосылки к созданию изобретения
[2] Традиционный процессор осуществляет обработку команд программы посредством конвейерного процесса, в котором каждая команда последовательно проходит через несколько стадий обработки, таких как выборка, дешифрация, исполнение, обращение к запоминающему устройству и обратная запись результата. В дальнейшем изложении комплекс технических средств, входящих в состав процессора и непосредственно связанных с осуществлением конвейерного процесса, именуется «конвейер». Классический конвейер позволяет осуществлять одновременную обработку нескольких команд, что существенно повышает производительность процессора, при этом каждая команда в определенный момент времени может находиться только на одной из стадий обработки, и на каждой стадии в определенный момент времени может обрабатываться только одна команда.
[3] Обработка команды на стадии выборки, именуемая также «загрузкой в конвейер», как правило, производится путем чтения команды из кэш-памяти процессора непосредственно в буфер команд. Однако даже притом, что кэш-память процессора обеспечивает самую быструю выдачу сохраняемой информации по сравнению с другими запоминающими устройствами, на чтение каждой команды из кэш-памяти требуется несколько тактов. С учетом чрезвычайно большого множества команд, составляющих типичную программу, потеря нескольких тактов на каждую команду существенно снижает производительность процессора.
[4] В патентной публикации RU2816094C1, 26.03.2024 раскрыт процессор (далее – известный процессор), в котором вместо упомянутой одностадийной выборки команды предусмотрена двухстадийная выборка команды (далее - выборка команды с использованием кэшлайна), в которой на первой стадии из кэш-памяти в буфер кэшлайнов читается кэшлайн, содержащий несколько команд (далее – выборка команды в составе кэшлайна), а на второй стадии из буфера кэшлайнов в буфер команд читается команда, подлежащая обработке (далее – выборка команды из кэшлайна). Поскольку в известном процессоре чтение всех команд кэшлайна из кэш-памяти производится за одно обращение к ней, а передача каждой команды из буфера кэшлайнов в буфер команд может быть осуществлена за один такт, то при последовательной обработке команд кэшлайна известный процессор обеспечивает существенную экономию времени и энергии по сравнению с описанным выше традиционным процессором.
[5] Однако последовательная обработка команд кэшлайна может прерваться, когда кэшлайн содержит команду перехода (далее – вызывающая команда), результатом выполнения которой в зависимости от входного условия может стать как осуществление, так и неосуществление перехода. При осуществлении перехода вслед за вызывающей командой должна быть выполнена команда, сохраняемая в кэш-памяти по адресу, который не является следующим по счету адресом, или в оперативной памяти (далее – вызываемая команда), а при неосуществлении перехода вслед за вызывающей командой должна быть выполнена команда, имеющая в кэш-памяти следующий по счету адрес (далее – последующая команда). В качестве последующей команды может выступать команда этого же кэшлайна, непосредственно следующая за вызывающей командой, или первая команда следующего кэшлайна, если вызывающая команда является последней командой текущего кэшлайна.
[6] Тем временем решение о том, какая из вызываемой и последующей команд будет загружена в конвейер сразу за вызывающей командой должно быть принято до выполнения вызывающей команды, а точнее, когда вызывающая команда находится на самой первой стадии конвейера. Ошибка в выборе между вызываемой и последующей командами приводит к тому, что обработка всей альтернативной ветви команд, определяемой выбранной командой, оказывается невостребованной, и конвейер должен приступить к обработке другой альтернативной ветви с самой первой стадии. Очевидно, что данный исход приводит к значительному снижению производительности процессора.
[7] Известный процессор снабжен предсказателем перехода, который на основе статистики выполненных переходов способен с высокой точностью предсказывать результат выполнения вызывающей команды. Благодаря этому вслед за вызывающей командой в конвейер загружается наиболее вероятная альтернативная ветвь программы, что в большинстве случаев позволяет избежать перезагрузки конвейера и вызванной этим потери времени. Связь между предсказателем перехода и конвейером реализуется через сохранение в кэш-памяти адреса вызываемой команды. Другими словами, загрузке в конвейер подлежит вызываемая команда и определяемая ею альтернативная ветвь, если в кэш-памяти сохранен адрес вызываемой команды, и загрузке в конвейер подлежит последующая команда и ее альтернативная ветвь, если в кэш-памяти отсутствует адрес вызываемой команды.
[8] Возвращаясь к осуществляемой в известном процессоре выборке команд с использованием кэшлайна, следует отметить, что для своевременной загрузки в конвейер вероятной альтернативной ветви каждая команда кэшлайна перед тем, как она будет передана в буфер команд, должна быть проверена на предмет того, является ли она вызывающей командой с предсказанным переходом. Другими словами, после чтения кэшлайна из кэш-памяти в буфер кэшлайнов каждая команда кэшлайна проверяется на наличие в кэш-памяти соответствующего ей адреса вызываемой команды, что подразумевает осуществляемое для каждой команды кэшлайна обращение в кэш-память. Поскольку, как было отмечено выше, каждое обращение в кэш-память требует временных и энергетических затрат, то преимущества известного процессора, состоящие в повышении производительности и снижении энергопотребления за счет уменьшения числа обращений в кэш-память при выборке команд с использованием кэшлайна, в определенной степени нивелируются.
[9] Техническая проблема, на решение которой направлено изобретение, состоит в поиске решения, способного повысить производительность процессора, сочетающего выборку команд с использованием кэшлайна и предсказание перехода.
Сущность изобретения
[10] Для решения указанной технической проблемы в качестве изобретения предложен процессор (далее также – предложенный процессор), содержащий кэш-память команд, кэш-память масок, кэш-память целевых адресов и конвейер, который включает в себя буфер кэшлайнов, буфер масок и буфер команд. Кэш-память команд способна сохранять команды в составе кэшлайна, который является минимальным фрагментом, читаемым из памяти команд, и способна передавать кэшлайн в буфер кэшлайнов, Кэш-память масок способна для каждого кэшлайна сохранять маску кэшлайна и способна передавать маску кэшлайна в буфер масок, когда кэш-память команд передает соответствующий кэшлайн в буфер кэшлайнов. Маска кэшлайна при этом содержит последовательность битовых значений, где каждое битовое значение соответствует своей команде кэшлайна, причем вызывающие команды, для которых в памяти целевых адресов сохранен адрес вызываемой команды, получают заданное битовое значение, отличающее их от других команд. Буфер кэшлайнов на основе сохраненной в буфере масок маски кэшлайна способен последовательно передавать в буфер команд команды кэшлайна, начиная с исходной команды и до первой команды с заданным битовым значением. После передачи команды с заданным битовым значением буфер кэшлайнов способен принимать из кэш-памяти команд вызываемый кэшлайн, содержащий вызываемую команду, которая становится исходной командой для вызываемого кэшлайна.
[11] Технический результат изобретения состоит в уменьшении времени, требуемого на поиск вызывающей команды, для которой в кэш-памяти целевых адресов сохранен адрес вызываемой команды (далее - вызывающей команды с предсказанным переходом), в кэшлайне, переданном из кэш-памяти команд в буфер кэшлайнов. Благодаря этому передача команд кэшлайна из буфера кэшлайнов в буфер команд, т.е. выборка команд из кэшлайна, производится быстрее, и производительность предложенного процессора возрастает. Одновременно с этим обеспечивается снижение энергопотребления предложенного процессора, что становится возможным за счет уменьшения числа обращений в кэш-память.
[12] Причинно-следственная связь между признаками изобретения и техническим результатом заключается в следующем. Как было показано выше, в известном процессоре поиск вызывающей команды с предсказанным переходом в кэшлайне, переданном в буфер кэшлайнов, осуществляется после того, как этот кэшлайн был передан в буфер кэшлайнов. Повторимся, указанный поиск состоит в последовательной проверке каждой команды кэшлайна на предмет наличия в кэш-памяти целевых адресов соответствующего ей адреса вызываемой команды, что для каждой команды кэшлайна сопровождается задержкой ее передачи в буфер команд. В отличие от известного процессора, в предложенном процессоре указанный поиск осуществляется заранее и отражается в маске кэшлайна, передаваемой в буфер масок одновременно с передачей кэшлайна в буфер кэшлайнов. Соответственно, по заданному битовому значению в маске кэшлайнов поиск вызывающей команды с предсказанным переходом в кэшлайне, переданном в буфер кэшлайнов, осуществляется за один такт, и выборка команд из кэшлайна производится без задержек.
[13] В частном случае изобретения предложенный процессор содержит предсказатель перехода, который способен на основе статистики переходов идентифицировать вызывающую и вызываемую команды, и способен передавать адрес вызываемой команды в память целевых адресов. Данное исполнение изобретения позволяет использовать для выявления вызывающей команды с предсказанным переходом статистику переходов, которая представляет собой фактически наблюдаемые данные. Благодаря использованию фактических данных увеличивается точность предсказания перехода, что снижает число перезагрузок конвейера, а значит, повышает производительность процессора.
Краткое описание чертежей
[14] Осуществление изобретения будет пояснено ссылками на фигуры:
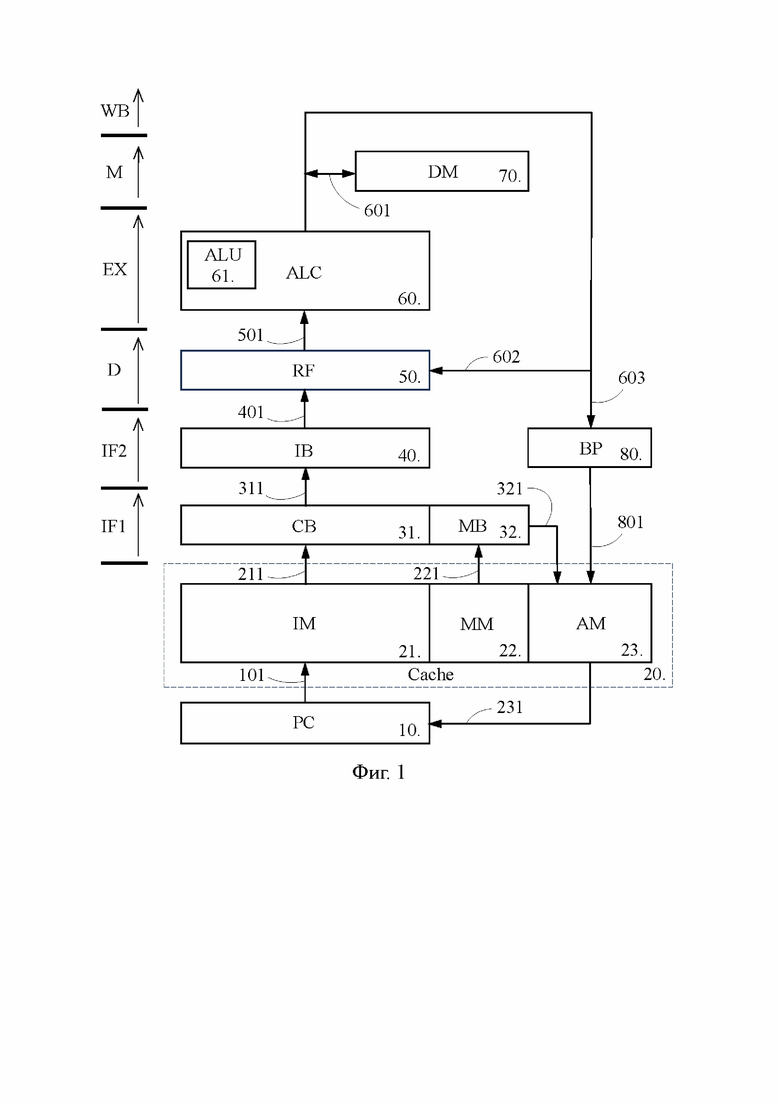
фиг. 1 – блок-схема предложенного процессора, выполненного согласно наиболее предпочтительному варианту осуществления изобретения;
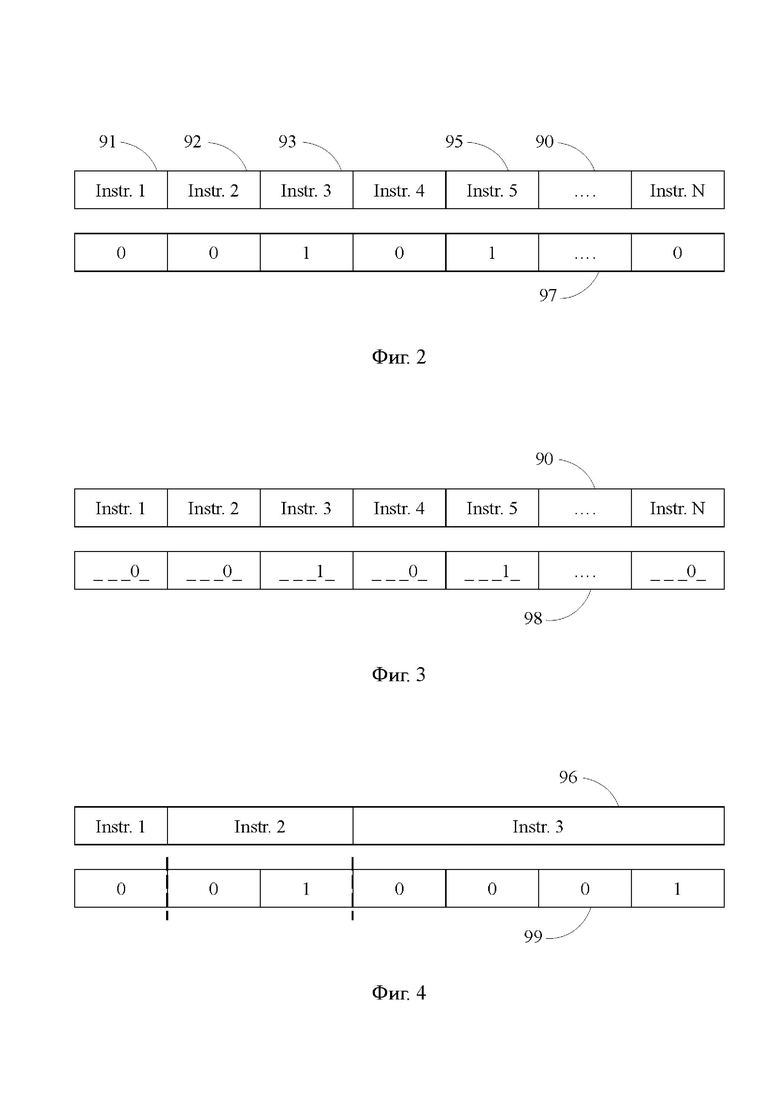
фиг. 2 – схема буфера кэшлайнов и буфера масок в предпочтительном варианте осуществления изобретения;
фиг. 3 – схема буфера кэшлайнов и буфера масок в другом варианте осуществления изобретения;
фиг. 4 - схема буфера кэшлайнов и буфера масок в процессоре архитектуры VLIW.
[15] Следует отметить, что форма и размеры отдельных элементов, отображенных на фигурах, являются условными и показаны так, чтобы наиболее наглядно проиллюстрировать взаимное расположение элементов предложенного процессора, а также их причинно-следственную связь с техническим результатом. Кроме того, во избежание избыточного усложнения фигур некоторые взаимосвязи элементов, очевидные специалисту в данной области техники, могут быть не отображены. Фигуры также дополнены выполненными на английском языке буквенными и словесными обозначениями, которые способствуют более быстрому восприятию фигур специалистом в данной области техники.
Осуществление изобретения
[16] Осуществление изобретения будет показано на наилучших примерах его реализации, которые не являются ограничениями в отношении объема охраняемых прав.
[17] На фиг. 1 схематично показан процессор 1, выполненный согласно предпочтительному варианту осуществления изобретения. Процессор 1 может представлять собой самостоятельный процессор или входить в состав более сложного процессора в качестве ядра.
[18] Процессор 1 содержит счетчик 10 команд (PC – program counter), кэш-память 20 управления (Cache), буфер 31 кэшлайнов (CB – cacheline buffer), буфер 32 масок (MB – mask buffer), буфер 40 команд (IB - instruction buffer), регистровый файл 50 (RF - register file), арифметико-логический функциональный блок 60 (ALC - arithmetic-logical channel), кэш-память 70 данных (DM – data memory), предсказатель 80 перехода (BP – branch predictor). В состав арифметико-логического функционального блока 60 включено арифметико-логическое устройство 61 (АЛУ, ALU - arithmetic-logical unit).
[19] Далее в состав процессора 1 входит блок управления (не показан), обеспечивающий выработку и передачу управляющих сигналов на перечисленные выше элементы, а также множество элементов, исполняющих тривиальные функции в конвейерном процессе и являющихся очевидными специалисту в данной области, таких как регистры, мультиплексоры, шины передачи данных и т.п. Некоторые из таких элементов отображены на фиг. 1 и будут раскрыты по ходу изложения.
[20] Буфер 31 кэшлайнов, буфер 32 масок, буфер 40 команд, регистровый файл 50, арифметико-логический функциональный блок 60, кэш-память 70 данных представляют собой основные компоненты конвейера, задействованные в соответствующих стадиях конвейерного процесса, которые показаны в левой части фиг. 1: выборка команды в составе кэшлайна (IF1 – instruction fetch), выборка команды из кэшлайна (IF2), дешифрация (D – decode), исполнение (EX – execute), обращение к памяти (M – memory) и обратная запись результата (WB – write back). Вместе с тем конвейерный процесс, реализуемый процессором 1, может содержать гораздо больше стадий, чем указанные стадии IF1, IF2, D, EX, M, WB. Принципы увеличения числа стадий конвейерного процесса, как правило, основанные на разделении указанных выше стадий на ряд более мелких стадий в целях уменьшения длительности такта, известны специалисту в данной области техники.
[21] Хотя на фиг. 1 показан лишь один арифметико-логический функциональный блок 60, процессор 1 может иметь по существу любое количество арифметико-логических функциональных блоков 60, а также включать в себя предикатно-логические функциональные блоки (PLC - predicate logical channel), назначение и функционирование которых известны специалисту в данной области. Соответственно, процессор 1 может быть скалярным или суперскалярным процессором, осуществлять выполнение команд в порядке загрузки в конвейер (in-order execution) или в ином порядке (out-of-order execution). При том, что процессор 1 может быть выполнен по существу в любой архитектуре, предпочтительным является выполнение процессора 1 в архитектуре VLIW (Very Long Instruction Word).
[22] Каждая из кэш-памяти 20 управления и кэш-памяти 70 данных представляет собой кэш-память первого уровня, характеризующуюся наиболее быстрым доступом и известную как L1. Кэш-память 20 управления включает в себя: кэш-память 21 команд (IM - instruction memory), кэш-память 22 масок (MM – mask memory) и кэш-память 23 целевых адресов (AM – address memory), каждая из которых может быть выполнена либо в виде отдельного устройства, либо в виде раздела единого устройства, как показано на фиг. 1. Кэш-память 70 данных выполнена в виде отдельного устройства, однако, возможно исполнение, когда кэш-память 70 данных и кэш-память 20 управления объединены в одно устройство, в котором память 70 данных представлена в виде раздела.
[23] Кэш-память 21 команд способна сохранять команды в составе кэшлайна 90 (фиг. 2), который представляет собой минимальный извлекаемый из кэш-памяти 21 команд фрагмент информации, и который обычно физически записан на одной строке кэш-памяти. Кэшлайн 90 включает в себя несколько команд, которые могут быть прочитаны из кэш-памяти 21 команд за одно обращение к ней, что позволяет уменьшить число обращений к кэш-памяти 21 команд и таким образом повысить производительность процессора 1, а также снизить его энергопотребление. В отношении самих команд следует отметить, что в зависимости от архитектуры процессора это могут быть одиночные команды или так называемые широкие команды, включающие в себя несколько персонализированных команд и используемые в архитектуре VLIW.
[24] Кэш-память 22 масок способна для каждого кэшлайна 90 сохранять маску 97 кэшлайна (фиг. 2), которая в наиболее простом случае представляет собой последовательность битовых значений по числу команд кэшлайна 90, причем каждое битовое значение определенным образом характеризует соответствующую команду. В маске 97 кэшлайна битовое значение «1», именуемое «заданным битовым значением», присвоено командам, являющимися вызывающими командами с предсказанным переходом, а битовое значение «0» присвоено командам, после выполнения которых подлежит выполнению последующая команда. Следует отметить, что указанные битовые значения могут быть назначены и противоположным образом, когда заданным битовым значением является «0».
[25] В другом случае (фиг. 3) маска 98 кэшлайна образована группами битовых значений по числу команд кэшлайна 90 и содержит несколько последовательностей битовых значений. Каждая последовательность при этом включает в себя по одному битовому значению из каждой группы, имеющему один и тот же порядковый номер в группе и отражающему одну и ту же характеристику соответствующей команды. Например, битовое значение с порядковым номером 4 каждой группы (фиг. 3) отражает ту же характеристику, что битовое значение на фиг. 2, а именно: является ли данная команда вызывающей командой с предсказанным переходом.
[26] В некоторых архитектурах, например в архитектуре VLIW, команды не имеют фиксированного битового размера, и число таких команд (в архитектуре VLIW – широких команд) в кэшлайнах может быть различным. В этом случае маска кэшлайна формируется так, чтобы число ее битовых значений было равно максимально возможному числу команд в кэшлайне. Тем временем формирование анализируемой последовательности битовых значений может быть произведено по разным принципам. В одном варианте изобретения для архитектуры VLIW в качестве анализируемой последовательности битовых значений принимаются первые битовые значения маски кэшлайна по числу команд кэшлайна, т.е. если маска кэшлайна содержит 10 битовых значений, а число команд в кэшлайне равно 3, то в качестве последовательности битовых значений рассматриваются первые 3 значения из 10, каждое из которых соответствует своей команде.
[27] В другом варианте изобретения для архитектуры VLIW, представленном на фиг. 4, маска 99 кэшлайна условно разбивается на группы битовых значений, которые на фиг. 4 разделены вертикальными пунктирными линиями. Каждая группа битовых значений соответствует своей команде и включает в себя такое число битовых значений из общего числа битовых значений маски кэшлайна, которое пропорционально битовому пространству, занимаемому командой в битовом пространстве кэшлайна. При сопоставлении кэшлайна 96 и соответствующей ему маски 99 кэшлайна в качестве анализируемой последовательности битовых значений принимаются последние битовые значения каждой группы. В указанных целях возможно также использование первых значений каждой группы.
[28] Кэш-память 23 целевых адресов сохраняет адреса вызываемых команд, переход на которые предсказан предсказателем 80 перехода для следующего выполнения соответствующих вызывающих команд. Если для какой-либо вызывающей команды в кэш-памяти 23 целевых адресов появляется адрес вызываемой команды, то битовое значение маски кэшлайна, соответствующее данной вызывающей команде, становится «1», и наоборот, если связанный с какой-либо вызывающей командой адрес вызываемой команды исчезает из кэш-памяти 23 целевых адресов, то битовое значение маски кэшлайна, соответствующее данной вызывающей команде, становится «0».
[29] Предсказатель 80 перехода способен для каждой вызывающей команды собирать статистику выполненных и невыполненных переходов, и способен трактовать собранную статистику в соответствии с заложенным в него алгоритмом предсказания перехода. Специалисту в данной области техники известно множество алгоритмов предсказания перехода, и как таковые они не являются предметом настоящего изложения. Предсказатель 80 перехода может функционировать согласно любому из этих алгоритмов, например использовать алгоритм двухбитного насыщающегося счетчика.
[30] Принцип формирования маски кэшлайна состоит в следующем. При запуске программы предсказатель 80 перехода не располагает какой-либо статистикой, и все команды любого кэшлайна считаются последующими, а все битовые значения масок кэшлайна равны «0». Когда результат выполнения какой-либо команды предписывает выполнение перехода на другую команду, не являющуюся последующей, то предсказатель 80 перехода идентифицирует первую из этих команд как вызывающую команду, а вторую – как вызываемую команду. Далее в ходе выполнения программы предсказатель 80 перехода фиксирует все выполненные и невыполненные переходы от вызывающей команды на вызываемую команду. После того, как накопленная статистика в соответствии с алгоритмом предсказания перехода позволит сделать предсказание перехода для следующего выполнения вызывающей команды, предсказатель 80 перехода передает адрес вызываемой команды в кэш-память 23 целевых адресов, а битовое значение маски, соответствующее вызывающей команде, устанавливается на «1».
[31] Вместе с тем, битовое значение «1» для данной вызывающей команды не является фиксированным, оно подтверждается изменяющейся статистикой выполненных и невыполненных переходов на вызываемую команду. Например, если предсказатель 80 перехода один или несколько раз зафиксировал невыполнение перехода, что в соответствии с алгоритмом предсказания позволяет предсказать невыполнение перехода для следующего выполнения вызывающей команды, то адрес вызываемой команды исчезает из кэш-памяти 23 целевых адресов, а битовое значение маски, соответствующее вызывающей команде, становится равным «0». Применительно к маске 97 кэшлайна (фиг. 2), если битовое значение, соответствующее команде 93 устанавливается на «0», то первой командой кэшлайна 90 с заданным битовым значением становится команда 95.
[32] Процессор 1 работает следующим образом.
По сигналу, поступающему в кэш-память 21 команд по шине 101 от счетчика 10 команд и содержащему указание на адрес требуемой команды, кэш-память 21 команд находит требуемый кэшлайн, содержащий требуемую команду в составе других команд. Предположим, что требуемой командой является команда 91, а требуемым кэшлайном – кэшлайн 90 (фиг. 2). На стадии IF1 конвейерного процесса производится выборка команды в составе кэшлайна, для чего кэшлайн 90 передается из кэш-памяти 21 команд в буфер 31 кэшлайнов по шине 211, и одновременно с этим из кэш-памяти 22 масок в буфер 32 масок по шине 221 передается соответствующая кэшлайну 90 маска 97 кэшлайна.
[33] На стадии IF2 производится выборка команды 91 из кэшлайна 90, в результате которой команда 91, представленная в виде N-битовой последовательности, передается из буфера 31 кэшлайнов по шине 311 в буфер 40 команд. На стадии D происходит расшифровка команды 91, в ходе которой из указанной N-битовой последовательности выделяется по меньшей мере первая группа битов, указывающая на код операции, вторая и третья группы битов, указывающие на адреса исходных операндов в регистровом файле 50, и четвертая группа битов, указывающая на адрес для записи результирующего операнда в регистровом файле 50. Первая группа битов при этом передается из буфера 40 команд в блок управления, а вторая, третья и четвертая группы передаются из буфера 40 команд в регистровый файл 50 по шине 401. В свою очередь, буфер 40 команд освобождается от команды 91 и принимает из буфера 31 кэшлайнов последующую команду 92, которая переходит на стадию IF2.
[34] Таким образом, команда 91 является исходной командой в кэшлайне 90 для обработки на стадии IF2, и начиная с команды 91 на стадию IF2 последовательно переходят все другие последующие команды кэшлайна 90, т.е. подлежащие выполнению друг за другом. Следует отметить, что для всех выполняемых друг за другом команд кэшлайна 90, начиная с исходной команды 91, стадия IF1 происходит одновременно. Обратим при этом внимание, что исходная команда не обязательно должна быть первой по счету командой кэшлайна и может быть расположена позади одной или нескольких других команд. Например, в качестве исходной команды кэшлайна может выступать вызываемая команда, на которую совершен переход, и в этом случае команды кэшлайна, расположенные до исходной команды, на стадию IF2 не поступают.
[35] Как было показано выше, в известном процессоре перед тем как команда 91 будет передана из буфера кэшлайнов в буфер команд, должна быть произведена проверка, не содержит ли кэш-память адрес вызываемой команды, для которой команда 91 является вызывающей командой. Если такой адрес в кэш-памяти сохранен, то после того, как команда 91 будет передана в буфер команд на стадию IF2, в буфер кэшлайнов из кэш-памяти будет загружен кэшлайн, содержащий вызываемую команду. Аналогичная проверка должна быть произведена и для последующей команды 92 и т.д., а поскольку данная проверка связана с обращением в кэш-память, то она существенно замедляет обработку каждой команды и в целом снижает производительность известного процессора.
[36] В противоположность этому в процессоре 1 одновременно с передачей кэшлайна 90 из кэш-памяти 21 команд в буфер 31 кэшлайнов, производится передача маски 97 кэшлайна из кэш-памяти 22 масок в буфер 32 масок. Каждая команда кэшлайна 90 имеет содержащееся в маске 97 кэшлайна битовое значение, которое указывает, сохранен ли в кэш-памяти 23 целевых адресов адрес вызываемой команды, для которой данная команда кэшлайна 90 является вызывающей командой. Если битовое значение для данной команды является заданным битовым значением, которое в настоящем изложении принято как «1», это означает, что данная команда является вызывающей командой, для которой в кэш-памяти 23 целевых адресов сохранен адрес вызываемой команды, или другими словами данная команда является вызывающей командой с предсказанным переходом.
[37] Соответственно, проверка каждой команды на предмет того, является ли она вызывающей командой с предсказанным переходом, проводимая в известном процессоре после загрузки кэшлайна в буфер кэшлайнов, в процессоре 1 является излишней. Более точно, в процессоре 1 эта проверка для кэшлайна 90 произведена заранее, а ее результаты отражены в маске 97 кэшлайна. Данное обстоятельство обеспечивает уменьшение времени, требуемого на поиск вызывающей команды с предсказанным переходом, и благодаря этому увеличивает производительность процессора 1. Одновременно с этим уменьшается общее число обращений в кэш-память 20 управления, что позволяет снизить энергопотребление процессора 1.
[38] Далее, командам 91 и 92 кэшлайна 90 в маске 97 кэшлайна соответствует битовое значение «0», а команде 93 в маске 97 кэшлайна соответствует заданное битовое значение «1», при этом команда 91 является исходной командой, а команда 93 является первой командой кэшлайна 90 с заданным битовым значением. В этом случае команды 91, 92, 93 передаются из буфера 31 кэшлайнов в буфер 40 команд последовательно одна за другой, например по одной команде в каждом такте. Поскольку после команды 93 в буфер 40 команд должна быть предана вызываемая команда, для которой команда 93 является вызывающей командой, то буфер 32 масок по шине 321 передает в кэш-память 23 целевых адресов сигнал на передачу адреса этой вызываемый команды в кэш-память 21 команд. Получив адрес данной вызываемый команды, кэш-память 21 команд находит вызываемый кэшлайн, содержащий эту вызываемую команду и по шине 211 передает его в буфер 31 кэшлайнов. Кэш-память 23 целевых адресов, в свою очередь, по шине 231 передает на счетчик 10 команд сигнал о том, что счет команд далее надо вести с данной вызываемой команды.
[39] Таким образом, после того, как команда 93 передана в буфер 40 команд, из кэш-памяти 21 команд в буфер 31 кэшлайнов передается вызываемый кэшлайн, который содержит в качестве исходной команды вызываемую команду для вызывающей команды 93, найденную по адресу, сохраненному в кэш-памяти 23 целевых адресов для вызывающей команды 93. Одновременно с этим из кэш-памяти 22 масок в буфер 32 масок по шине 221 передается маска кэшлайна, соответствующая этому вызываемому кэшлайну. Обратим внимание, что в этом вызываемом кэшлайне исходная команда может находиться, например, на второй позиции, считая от первой команды данного кэшлайна.
[40] Вместе с тем, если бы всем командам кэшлайна 90 в маске 97 кэшлайна соответствовало битовое значение «0», то, начиная с команды 91, все команды кэшлайна 90 были бы последовательно переданы из буфера 31 кэшлайнов в буфер 40 команд. После этого из кэш-памяти 21 команд в буфер 31 кэшлайнов был бы передан последующий кэшлайн, в котором первая по счету команда имеет адрес, непосредственно следующий за адресом последней команды кэшлайна 90, а из кэш-памяти 22 масок в буфер 32 масок была бы передана маска кэшлайна, соответствующая этому последующему кэшлайну.
[41] Возвращаясь к конвейерной обработке команды 91, на стадии EX в арифметико-логический функциональный блок 60 по шине 501 поступают исходные операнды, прочитанные в регистровом файле 50. Одновременно с этим из блока управления в арифметико-логический функциональный блок 60 поступает сигнал, предписывающий выполнение операции, соответствующей упомянутому коду операции. После выполнения указанной операции над исходными операндами стадия EX завершается, а результат выполнения команды 91 из арифметико-логического функционального блока 60 по шине 601 направляется в кэш-память 70 данных (стадия M), а затем или вместо этого по шине 602 направляется в регистровый файл 50 (стадия WB), где записывается в качестве результирующего операнда команды 91.
[42] Одновременно с направлением результата выполнения команды 91 по шине 602, результат выполнения команды 91 из арифметико-логического функционального блока 60 по шине 603 направляется в предсказатель 80 перехода, который игнорирует его до тех пор, пока с команды 91 не будет совершен переход на вызываемую команду, и команда 91 не будет распознана как вызывающая команда. Заметим, что в качестве вызывающей команды предсказатель 80 перехода распознал команду 93, в отношении которой предсказателем 80 перехода была собрана статистика выполненных и невыполненных переходов. Обработка данной статистики, проведенная предсказателем 80 перехода согласно используемому им алгоритму предсказания перехода, позволила предсказателю 80 перехода сделать предсказание перехода на вызываемую команду для следующего выполнения команды 93. В результате адрес этой вызываемой команды, ранее переданный предсказателем 80 перехода в кэш-память 23 целевых адресов по шине 801, продолжает сохраняться в кэш-памяти 23 целевых адресов, а битовое значение маски 97 кэшлайна, соответствующее команде 93, продолжает оставаться заданным битовым значением «1».
[43] Невыполнение предсказанного перехода с команды 93 не означает автоматического удаления адреса вызываемой команды из кэш-памяти 23 целевых адресов и изменения битового значения в маске 97 кэшлайна для команды 93, поскольку на основании обработки собранной статистики переходов, проведенной согласно алгоритму предсказания перехода, предсказатель 80 перехода может сохранять предсказание перехода для следующего выполнения команды 93. В свою очередь, при наличии собранной статистики переходов, например для команды 92, выполнение непредсказанного перехода с команды 92 не означает автоматического сохранения адреса вызываемой команды в кэш-памяти 23 целевых адресов и изменения битового значения в маске 97 кэшлайна для команды 92, поскольку на основании обработки собранной статистики переходов, проведенной согласно алгоритму предсказания перехода, предсказатель 80 перехода может сохранять предсказание невыполнения следующего перехода для следующего выполнения команды 92.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОЦЕССОР С УСОВЕРШЕНСТВОВАННЫМ ХРАНИЛИЩЕМ ВЫЗЫВАЕМЫХ АДРЕСОВ | 2024 |
|
RU2832273C1 |
| ПРОЦЕССОР С УСОВЕРШЕНСТВОВАННЫМ ПРЕДСКАЗАТЕЛЕМ ПЕРЕХОДА | 2024 |
|
RU2832441C1 |
| VLIW-ПРОЦЕССОР С ДОПОЛНИТЕЛЬНЫМ ПОДГОТОВИТЕЛЬНЫМ КОНВЕЙЕРОМ И ПРЕДСКАЗАТЕЛЕМ ПЕРЕХОДА | 2024 |
|
RU2816094C1 |
| ЭНЕРГОЭФФЕКТИВНЫЙ МЕХАНИЗМ УПРЕЖДАЮЩЕЙ ВЫБОРКИ ИНСТРУКЦИЙ | 2006 |
|
RU2375745C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДСКАЗАНИЯ ВЕТВЛЕНИЙ | 2012 |
|
RU2602335C2 |
| МИКРОПРОЦЕССОР ГИБРИДНЫЙ | 2007 |
|
RU2359315C2 |
| ОЧИСТКА СЕГМЕНТИРОВАННОГО КОНВЕЙЕРА ДЛЯ НЕВЕРНО ПРЕДСКАЗАННЫХ ПЕРЕХОДОВ | 2008 |
|
RU2427889C2 |
| ПРЕДСТАВЛЕНИЕ ПЕРЕХОДОВ ЦИКЛА В РЕГИСТРЕ ПРЕДЫСТОРИИ ПЕРЕХОДОВ С ПОМОЩЬЮ МНОЖЕСТВА БИТ | 2007 |
|
RU2447486C2 |
| ОБРАБОТКА ОШИБОК ПРЕДВАРИТЕЛЬНОГО ДЕКОДИРОВАНИЯ ЧЕРЕЗ КОРРЕКЦИЮ ВЕТВЛЕНИЙ | 2005 |
|
RU2367004C2 |
| Способ кодирования атрибутов для кодирования облака точек | 2021 |
|
RU2773384C1 |
Изобретение относится к процессорам с конвейерной обработкой команд. Технический результат заключается в повышении производительности процессора и снижении его энергопотребления. Технический результат достигается за счет того, что процессор содержит кэш-память команд, кэш-память масок, кэш-память целевых адресов и конвейер, который включает в себя буфер кэшлайнов, буфер масок и буфер команд; при этом память команд способна сохранять команды в составе кэшлайна и передавать кэшлайн в буфер кэшлайнов; память масок способна для каждого кэшлайна сохранять маску кэшлайна и передавать ее в буфер масок, когда память команд передает соответствующий кэшлайн в буфер кэшлайнов; маска кэшлайна при этом содержит последовательность битовых значений, где каждое битовое значение соответствует своей команде кэшлайна; буфер кэшлайнов на основе сохраненной в буфере масок маски кэшлайна способен последовательно передавать в буфер команд команды кэшлайна, начиная с исходной команды и до первой команды с заданным битовым значением; после передачи команды с заданным битовым значением буфер кэшлайнов способен принимать из памяти команд вызываемый кэшлайн, содержащий вызываемую команду, которая становится исходной командой для вызываемого кэшлайна. 1 з.п. ф-лы, 4 ил.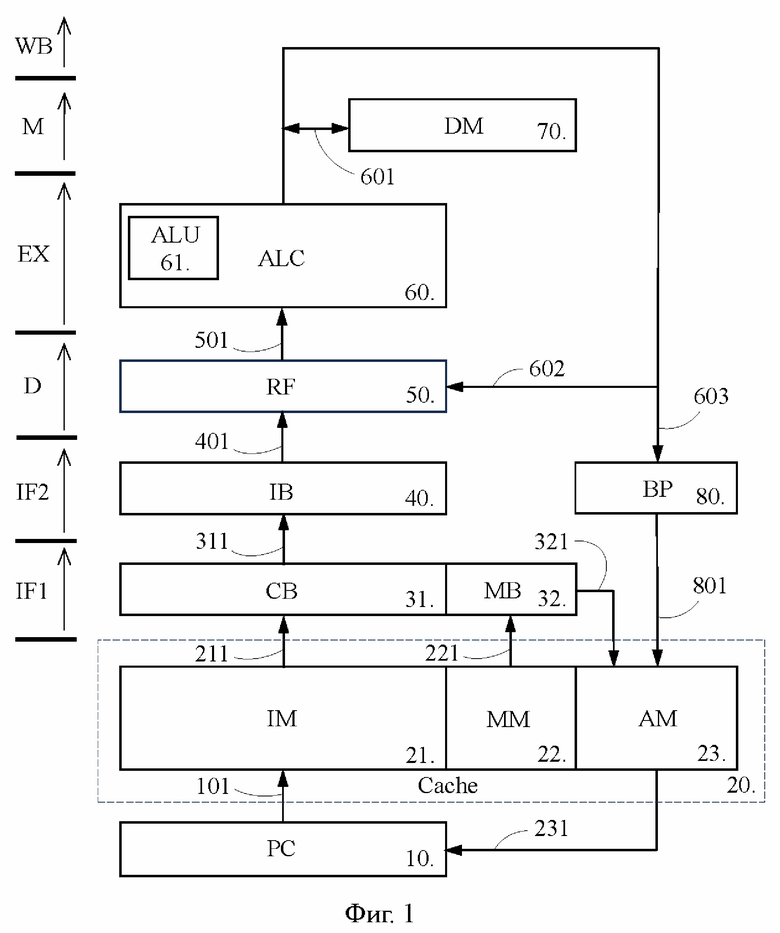
1. Процессор, содержащий кэш-память команд, кэш-память масок, кэш-память целевых адресов и конвейер, который включает в себя буфер кэшлайнов, буфер масок и буфер команд, причем
кэш-память команд способна сохранять команды в составе кэшлайна, который является минимальным фрагментом, читаемым из кэш-памяти команд, и способна передавать кэшлайн в буфер кэшлайнов, а
кэш-память масок способна для каждого кэшлайна сохранять маску кэшлайна и способна передавать маску кэшлайна в буфер масок, когда кэш-память команд передает соответствующий кэшлайн в буфер кэшлайнов, при этом
маска кэшлайна содержит последовательность битовых значений, где каждое битовое значение соответствует своей команде кэшлайна, причем вызывающие команды, для которых в кэш-памяти целевых адресов сохранен адрес вызываемой команды, получают заданное битовое значение, отличающее их от других команд, а
буфер кэшлайнов на основе сохраненной в буфере масок маски кэшлайна способен последовательно передавать в буфер команд команды кэшлайна, начиная с исходной команды и до первой команды с заданным битовым значением, после передачи которой буфер кэшлайнов способен принимать из кэш-памяти команд вызываемый кэшлайн, содержащий вызываемую команду, которая становится исходной командой для вызываемого кэшлайна.
2. Процессор по п. 1, который содержит предсказатель перехода, способный на основе статистики переходов идентифицировать вызывающую и вызываемую команды и способный передавать адрес вызываемой команды в кэш-память целевых адресов.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СКАЛЯРНО-ВЕКТОРНЫЙ ПРОЦЕССОР | 2021 |
|
RU2781355C1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| ПОСТОЯННЫЕ ЗАПИСИ ДЛЯ ЭНЕРГОНЕЗАВИСИМОЙ ПАМЯТИ | 2018 |
|
RU2780441C2 |

