Область техники
[1] Изобретение относится к микропроцессорной технике, в частности к микропроцессорам с параллельным исполнением нескольких команд, а более точно к микропроцессорам, выполненным в архитектуре Very Long Instruction Word (далее – VLIW-процессоры).
Предпосылки к созданию изобретения
[2] VLIW-процессор реализует общеизвестный конвейерный процесс обработки команд (далее также – конвейерный процесс), в котором каждая команда последовательно проходит через несколько стадий обработки, таких как выборка, дешифрация, исполнение, обращение к запоминающему устройству и обратная запись результата. В дальнейшем изложении комплекс технических средств, входящих в состав процессора и непосредственно связанных с осуществлением конвейерного процесса, именуется «конвейер». Упомянутое запоминающее устройство представляет собой кэш-память процессора, которая в дальнейшем изложении кратко именуется как «память», если не указано иное.
[3] Классический конвейер позволяет осуществлять одновременную обработку нескольких команд, причем каждая из команд в определенный момент времени находится на одной из стадий обработки, и на каждой стадии в определенный момент времени может обрабатываться только одна команда. Тем не менее VLIW-процессор снабжен несколькими функциональными блоками, позволяющими, начиная со стадии исполнения, обрабатывать несколько команд одновременно уже на каждой стадии. Другими словами, конвейер VLIW-процессора включает в себя один подготовительный конвейер, выполняющий стадии выборки и дешифрации, и несколько исполнительных конвейеров, выполняющих стадии исполнения, обращения к памяти и обратной записи.
[4] Однако один подготовительный конвейер не может вывести на стадию исполнения несколько команд одновременно, поскольку на каждой своей стадии он может обрабатывать только одну команду. Во VLIW-процессоре данная проблема решается с помощью операции, выполняемой на этапе компиляции, а именно операции объединения нескольких команд (далее – персонализированная команда) в одну команду (далее – широкая команда). Соответственно, на стадиях выборки и дешифрации широкая команда проходит обработку как одна команда, а на стадии исполнения разделяется на несколько персонализированных команд, каждая из которых поступает на исполнение в предписанный ей функциональный блок. Одно из названий этой широкой команды на английском языке по существу и зашифровано в аббревиатуре VLIW.
[5] Наиболее ярко преимущество VLIW-процессора проявляется при ветвлении программы, когда из нескольких альтернативных ветвей команд должна быть выбрана одна действительная ветвь, на которую и должен быть осуществлен переход. В этом случае посредством включения по одной персонализированной команде из каждой альтернативной ветви в одну широкую команду и обработки последовательности таких широких команд, VLIW-процессор обеспечивает обработку всех альтернативных ветвей до того, как из них будет выбрана действительная ветвь. При выполнении команды передачи управления VLIW-процессор уже располагает обработанной действительной ветвью команд, независимо от того, какая из альтернативных ветвей команд выбрана в качестве действительной ветви, что существенно увеличивает быстродействие VLIW-процессора.
[6] Описанная конфигурация и преимущества VLIW-процессора известны специалисту в данной области и раскрыта, например, в патентной публикации US2012151192A1, 14.06.2012. Характерной особенностью VLIW-процессора является одновременное выполнение всех персонализированных команд, составляющих широкую команду, и если какая-то персонализированная команда не может быть выполнена, например, из-за задержки чтения операндов из памяти, то приостанавливается выполнение всей широкой команды.
[7] Данное обстоятельство зачастую приводит к тому, что выполнение безусловно необходимых команд попадает в зависимость от выполнения спекулятивных команд для маловероятной альтернативной ветви, что в известном VLIW-процессоре существенно увеличивает среднее время обработки команд. Указанный недостаток известного VLIW-процессора более подробно проиллюстрирован ниже со ссылками на фигуры, а здесь отметим, что увеличенное время работы процессора также вызывает избыточное потребление электроэнергии и повышенное тепловыделение, требующее принятие дополнительных мер по организации охлаждения.
[8] Техническая проблема, на решение которой направлено изобретение, состоит в поиске решения, способного повысить производительность VLIW-процессора, снизить потребление электроэнергии, а также уменьшить выделение тепла.
Сущность изобретения
[9] Для решения указанной технической проблемы в качестве изобретения предложен процессор (далее также – VLIW-процессор), содержащий подготовительный конвейер, регистровый файл, первый и второй исполнительные конвейеры, блок контроля готовности операндов, регистр готовности операндов и блок управления. Подготовительный конвейер способен выделять из широкой команды первую и вторую персонализированные команды. Первый и второй исполнительные конвейеры способны синхронно друг с другом выполнять соответственно первую и вторую персонализированные команды с использованием соответственно первой и второй групп операндов. Блок контроля готовности операндов способен контролировать обновление первой группы операндов в регистровом файле. Регистр готовности операндов способен сохранять компрометирующий флаг, когда первая группа операндов не была обновлена до выполнения первой персонализированной команды. Блок управления при наличии компрометирующего флага способен распознавать результат выполнения первой персонализированной команды как недостоверный результат.
[10] Технический результат изобретения состоит в уменьшении времени, затрачиваемого VLIW-процессором на выполнение программы, что повышает производительность VLIW-процессора, снижает потребление энергии и выделение тепла, т.е. является решением поставленной перед изобретением технической проблемы. Следует отметить, что в контексте настоящего изложения понятие «выполнение программы» означает выполнение тех входящих в программу персонализированных команд, которые позволяют пройти путь от начальной персонализированной команды до конечной. Поскольку программа может содержать несколько таких путей, то понятие «выполнение программы» не подразумевает обязательное выполнение всех входящих в программу персонализированных команд.
[11] Причинно-следственная связь между признаками изобретения и техническим результатом заключается в том, что выполнение первой персонализированной команды, а вместе с ней и всей широкой команды не приостанавливается, а продолжается, даже если первая группа операндов не обновлена, при этом результат выполнения первой персонализированной команды признается недостоверным. Ввиду того, что результат первой персонализированной команды может в дальнейшем не понадобиться, незамедлительное выполнение широкой команды экономит время на ожидание обновления первой группы операндов, которое может составлять до 100 тактов или больше.
[12] Если же выполнение первой персонализированной команды станет необходимым, она будет выполнена посредством исполнения компенсирующего кода, предусматривающего возможность повторной загрузки первой персонализированной команды в подготовительный конвейер. Обновление первой группы операндов в этом случае будет произведено значительно быстрее, поскольку повторное обращение в память для загрузки операндов удовлетворяется за меньшее время, что в конечном итоге обеспечивает преимущество во времени для повторного выполнения первой персонализированной команды относительно первой попытки.
[13] В первом частном случае изобретения блок управления способен запускать повторное выполнение первой персонализированной команды посредством обращения к компенсирующему коду. Как было показано выше, если необходимость выполнения первой персонализированной команды подтверждена, то данное исполнение позволяет получить достоверный результат выполнения первой персонализированной команды.
[14] Во втором частном случае изобретения блок управления способен не запускать повторное выполнение первой персонализированной команды, когда блок управления определил, что первая персонализированная команда является спекулятивной командой для неисполненного перехода. Данное исполнение позволяет сэкономить время, которое не было затрачено на ожидание обновления первой группы операндов, а также сэкономить вычислительный ресурс, который не будет затрачен на запуск повторного выполнения первой персонализированной команды.
[15] В третьем частном случае изобретения блок управления использует компрометирующий флаг для передачи управления или логической операции. Данное исполнение позволяет не выполнять команды, использующие результат выполнения первой персонализированной команды и потому также воспроизводящие недостоверные результаты, а перейти на другую альтернативную ветвь (далее кратко – ветвь), где проблема с достоверностью результатов отсутствует.
[16] В четвертом частном случае изобретения регистр готовности операндов способен сохранять компрометирующий флаг для всей цепочки команд, следующих за первой персонализированной командой и являющихся зависимыми от нее, а блок управления способен признавать недостоверным результат выполнения всех команд из указанной цепочки. Данное исполнение позволяет выполнять без задержки не только текущую, но и последующие широкие команды, содержащие персонализированные команды, зависимые от первой персонализированной команды. Повторное выполнение указанной цепочки команд происходит быстрее по сравнению с временем возможного ожидания обновления первой группы операндов.
[17] В пятом частном случае изобретения первый исполнительный конвейер содержит результирующий регистр, сохраняющий результат выполнения первой персонализированной команды, причем регистр готовности операндов включен в результирующий регистр в качестве разряда. В развитии данного частного случая дополнительным разрядом, предназначенным для сохранения компрометирующего флага, снабжены предназначенные для входящих операндов регистры первого исполнительного конвейера, а также предназначенные для операндов регистры регистрового файла и памяти. Данное исполнение позволяет освободить описанный ниже исполнительный конвейер для логических операций от функции сохранения компрометирующего флага и предписать ему выполнение других команд, что в конечном итоге способствует увеличению производительности процессора.
[18] В шестом частном случае изобретения содержит исполнительный конвейер для логических операций, а регистр готовности операндов входит в состав регистров исполнительного конвейера для логических операций. Данное исполнение позволяет использовать для сохранения компрометирующего флага имеющиеся технические средства, что упрощает конструкцию предложенного процессора.
[19] В седьмом частном случае изобретения блок контроля готовности операндов способен контролировать обновление второй группы операндов в регистровом файле. Регистр готовности операндов при этом является первым регистром готовности операндов, а компрометирующий флаг является первым компрометирующим флагом. Процессор содержит также второй регистр готовности операндов, который способен сохранять второй компрометирующий флаг, когда вторая группа операндов не была обновлена до выполнения второй персонализированной команды. Блок управления при наличии второго компрометирующего флага способен распознавать результат выполнения второй персонализированной команды как недостоверный результат.
[20] Данное исполнение позволяет выполнить с недостоверным результатом две персонализированные команды или даже всю широкую команду с тем, чтобы не задерживать выполнение следующей широкой команды. Если необходимость выполнения какой-либо персонализированной команды будет впоследствии подтверждена, то данная персонализированная команда может быть выполнена по компенсирующему коду с сокращением времени, требуемого на обновление операндов.
Краткое описание чертежей
[21] Осуществление изобретения будет пояснено ссылками на фигуры:
Фиг. 1 – блок-схема известного VLIW-процессора;
Фиг. 2 – фрагмент программного кода, отображающий последовательность персонализированных команд для одного исполнительного конвейера и используемый для иллюстрации технической проблемы;
Фиг. 3 – схема конвейерного процесса обработки команд, отображенных во фрагменте программного кода с Фиг. 2, для известного VLIW-процессора при отсутствии задержки обновления операндов;
Фиг. 4 – схема конвейерного процесса обработки команд, отображенных во фрагменте программного кода с Фиг. 2, для известного VLIW-процессора при возникновении задержки обновления операндов;
Фиг. 5 – фрагмент программного кода, отображающий последовательность широких команд для двух исполнительных конвейеров и используемый для иллюстрации технической проблемы;
Фиг. 6 – блок-схема VLIW-процессора, выполненного согласно первому предпочтительному варианту осуществления изобретения;
Фиг. 7 – блок-схема VLIW-процессора, выполненного согласно второму предпочтительному варианту осуществления изобретения;
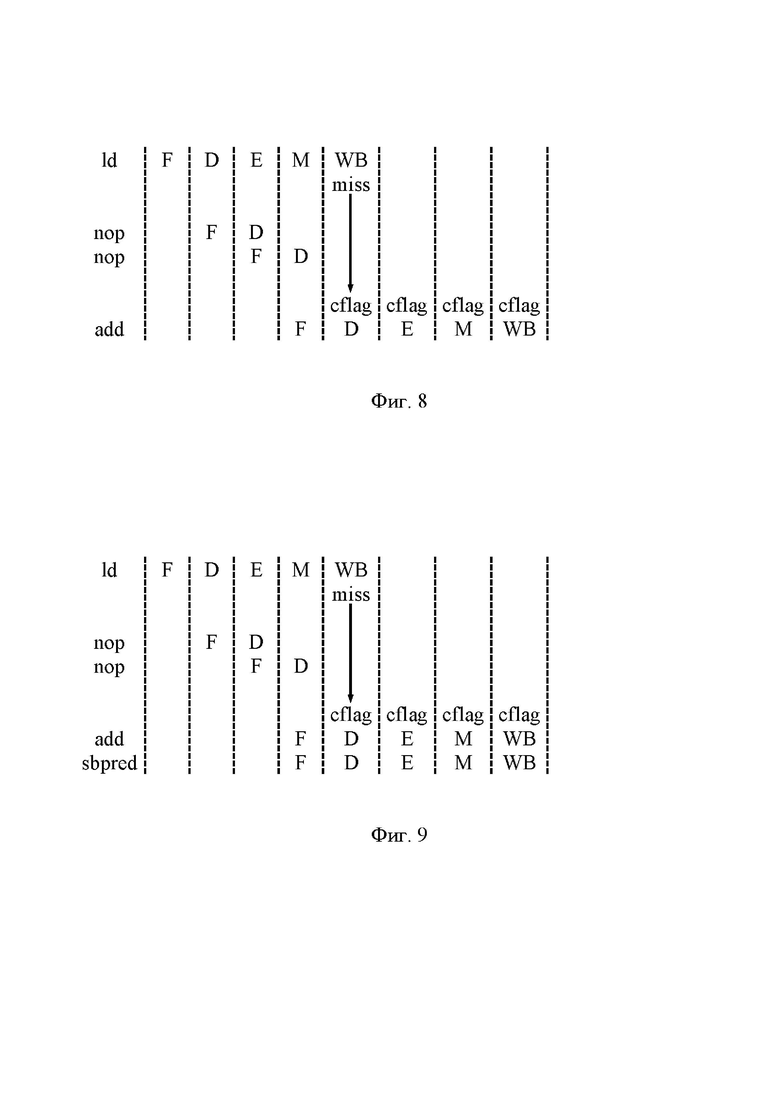
Фиг. 8 – схема конвейерного процесса обработки команд, отображенных во фрагменте программного кода с Фиг. 2, для VLIW-процессора с Фиг. 6 при возникновении задержки обновления операндов;
Фиг. 9 – схема конвейерного процесса обработки команд, отображенных во фрагменте программного кода с Фиг. 2, для VLIW-процессора с Фиг. 7 при возникновении задержки обновления операндов.
[22] Следует отметить, что форма и размеры отдельных элементов, отображенных на фигурах, являются условными и показаны так, чтобы наиболее наглядно проиллюстрировать взаимное расположение элементов VLIW-процессора, а также их причинно-следственную связь с техническим результатом. Кроме того, во избежание избыточного усложнения фигур некоторые взаимосвязи элементов, очевидные специалисту в данной области техники, могут быть не отображены. Фигуры также дополнены выполненными на английском языке буквенными и словесными обозначениями, которые являются общепринятыми в данной области техники, и которые способствуют более быстрому восприятию фигур специалистом в данной области техники.
Осуществление изобретения
[23] Осуществление изобретения будет показано на наилучших примерах его реализации, которые не являются ограничениями в отношении объема охраняемых прав.
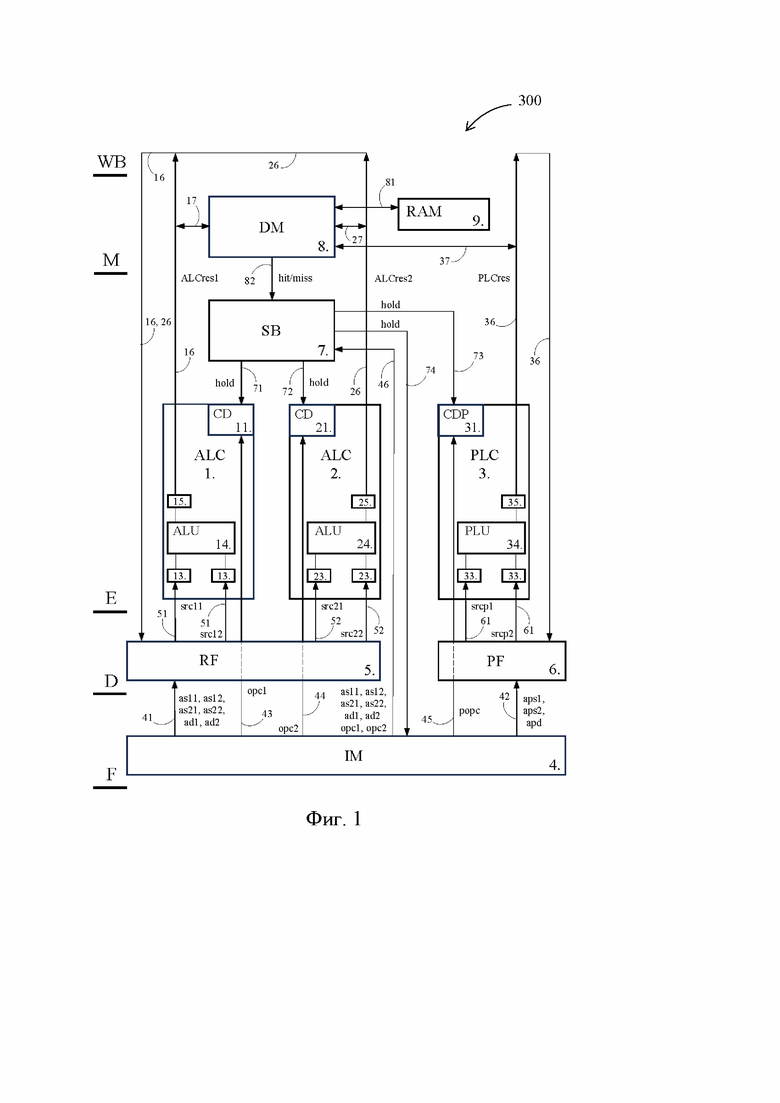
[24] На Фиг. 1 представлена блок-схема известного VLIW-процессора 300, в то время как на Фиг. 6 и 7 представлены соответственно блок-схемы первого VLIW-процессора 100 и второго VLIW-процессора 200, выполненных согласно первому и второму предпочтительным вариантам осуществления изобретения. В значительной степени блок-схемы на Фиг. 1, 6 и 7 повторяют друг друга, поэтому пока не указано иное, нижеследующее описание известного VLIW-процессора 300 относится также к первому и второму VLIW-процессорам 100 и 200. Идентичные элементы на Фиг. 1, 6 и 7 обозначены одними и теми же позициями.
[25] Известный VLIW-процессор 300 (Фиг. 1) содержит первый арифметико-логический функциональный блок 1 (ALC - arithmetic-logical channel), второй арифметико-логический функциональный блок 2, предикатно-логический функциональный блок 3 (PLC - predicate logical channel), память 4 команд (IM - instruction memory), регистровый файл 5 (RF - register file), предикатный файл 6 (PF - predicate file), блок 7 контроля готовности операндов (SB - scoreboarding), память 8 данных (DM – data memory), которая способна обмениваться данными с оперативной памятью 9 (RAM - random access memory). Первый арифметико-логический функциональный блок 1, второй арифметико-логический функциональный блок 2 и предикатно-логический функциональный блок 3 далее кратко именуются как функциональный блок 1, 2 или 3.
[26] Указанные элементы VLIW-процессора 300 представляют собой основные компоненты конвейера, задействованные в соответствующих стадиях конвейерного процесса, которые показаны в левой части Фиг. 1: выборка (F - fetch), дешифрация (D – decode), исполнение (E – execute), обращение к памяти (M – memory) и обратная запись результата (WB – write back). Обратим внимание, что наличие во VLIW-процессоре 300 одной единственной памяти 4 команд эквивалентно наличию во VLIW-процессоре 300 одного единственного подготовительного конвейера, способного в определенный момент времени обрабатывать на каждой из стадий F и D только по одной команде, которая представляет собой широкую команду. Тем временем наличие во VLIW-процессоре 300 трех функциональных блоков 1, 2 и 3 эквивалентно наличию во VLIW-процессоре 300 трех исполнительных конвейеров, способных в определенный момент времени обрабатывать на каждой из стадий E, M и WB сразу по три команды, которые представляют собой персонализированные команды, выделенные на стадии D из широкой команды.
[27] Что касается VLIW-процессоров 100 и 200, то описанная конфигурация VLIW-процессора 300 отражает лишь частный случай их исполнения, поскольку каждый из VLIW-процессоров 100 и 200 может содержать любое количество арифметико-логических и предикатно-логических функциональных блоков. Например, каждый из VLIW-процессоров 100 и 200 может содержать шесть арифметико-логических функциональных блоков и три предикатно-логических функциональных блока, а значит может обрабатывать широкую команду, включающую девять персонализированных команд.
[28] Далее, VLIW-процессор 300 содержит блок управления (не показан), обеспечивающий выработку и передачу управляющих сигналов на перечисленные выше элементы. В состав VLIW-процессора 300 входит также множество элементов, исполняющих тривиальные функции в конвейерном процессе и очевидных специалисту в данной области, таких как регистры, счетчики команд, шины передачи данных и т.п. Некоторые из таких элементов отображены на фигурах и будут раскрыты по ходу изложения.
[29] Память 4 команд представляет собой раздел кэш-памяти, в котором сохранен массив широких команд, подлежащих выполнению в ближайшее время. По сигналу, поступающему от счетчика команд, из указанного массива широких команд осуществляется выборка той широкой команды, которая должна быть выполнена следующей. Следует отметить, что каждая широкая команда компилируются из первой, второй и предикатной персонализированных команд за пределами VLIW-процессора 300.
[30] Под выборкой команды на стадии F понимается выдача из памяти 4 команд N-битового сигнала, который указывает адреса as11, as12 регистров для исходных операндов первой персонализированной команды, адреса as21, as22 регистров для исходных операндов второй персонализированной команды, адреса aps11, aps12 регистров для исходных операндов предикатной персонализированной команды, адреса ad1, ad2 и apd регистров для результирующих операндов соответственно первой, второй и предикатной персонализированных команд, а также коды opc1, opc2 и popc операций, осуществляемых первой, второй и предикатной персонализированными командами.
[31] Адреса as11, as12, as21, as22, ad1, ad2 регистров поступают из памяти 4 команд по шине 41 в регистровый файл 5, который представляет собой набор регистров, способных сохранять числовые данные целочисленного типа, с плавающей запятой и т.д. Тем временем адреса aps11, aps12, apd регистров поступают из памяти 4 команд по шине 42 в предикатный файл 6, который представляет собой набор регистров, способных сохранять булевые значения (1 или 0). В свою очередь, коды opc1, opc2 и popc операций поступают из памяти 4 команд по шинам 43, 44, 45 в первое, второе и предикатное управляющие устройства 11, 21 и 31 (CD, CDP – control device, control device predicate), входящие в состав функциональных блоков 1, 2 и 3.
[32] Регистровый файл 5 направляет исходные операнды src11 и src12, прочитанные в регистрах по адресам as11, as12, в функциональный блок 1 по шинам 51, и по шинам 52 направляет в функциональный блок 2 исходные операнды src21 и src22, прочитанные в регистрах по адресам as21, as22. Одновременно с этим предикатный файл 6 по шинам 61 направляет в функциональный блок 1 исходные операнды srcp1 и srcp2, прочитанные в регистрах по адресам aps1, aps2.
[33] Следует отметить, что в контексте настоящего изложения исходные операнды src11 и src12, являющиеся исходными операндами первой персонализированной команды, составляют первую группу операндов. Аналогично, исходные операнды src21 и src22, являющиеся операндами второй персонализированной команды, составляют вторую группу операндов, а исходные операнды srcp1 и srcp2 – предикатную группу операндов. Поступление в функциональные блоки 1, 2 и 3 соответственно первой, второй и предикатной групп операндов, а также кодов opc1, opc2 и popc операций завершает стадию D, а вместе с ней и работу подготовительного конвейера по выделению из широкой команды первой, второй и предикатной персонализированных команд.
[34] В состав функционального блока 1 помимо упомянутого управляющего устройства 11 включены входные регистры 13, арифметико-логическое устройство 14 (АЛУ, ALU - arithmetic-logical unit) и результирующий регистр 15. Исходные операнды src11 и src12 через входные регистры 13 поступают в АЛУ 14, в котором над ними выполняется операция, соответствующая коду opc1, после чего результат ALUres1 выполнения первой персонализированной команды через результирующий регистр 15 по шине 16 направляется в память 8 данных или в регистровый файл 5.
[35] Аналогично, исходные операнды src21 и src22 через входные регистры 23 поступают в АЛУ 24, в котором осуществляется операция, соответствующая коду opc2. Далее результат ALUres2 выполнения второй персонализированной команды через результирующий регистр 25 по шине 26 направляется в память 8 данных или в регистровый файл 5. И наконец, исходные операнды srcp1 и srcp2 через входные регистры 33 поступают в предикатное логическое устройство 34 (ПЛУ, PLU – predicate logical unit), в котором осуществляется операция, соответствующая коду popc. Результат PLUres выполнения предикатной персонализированной команды через результирующий регистр 35 по шине 36 направляется в память 8 данных или в предикатный файл 6. На этом стадия E конвейерного процесса, предусматривающая одновременное выполнение первой, второй и предикатной персонализированных команд при помощи первого, второго и третьего исполнительных конвейеров, завершается.
[36] Что касается управляющих устройств 11, 21, 31, то хотя на Фиг. 1, 6 и 7 они показаны в непосредственной близости с АЛУ 14, 24 и ПЛУ 34, это является лишь отражением их функциональной связи. В конструктивном исполнении VLIW-процессоров 100, 200 и 300 управляющие устройства 11, 21, 31 входят в состав упомянутого блока управления без физического выделения в отдельные модули. В настоящем изложении все функции, описанные для управляющих устройств 11, 21, 31, являются функциями блока управления.
[37] Далее, процесс конвейерной обработки некоторых персонализированных команд, таких как ld (load - загрузка (также – чтение) данных из памяти) или st (store – сохранение данных в память), включает обращение к памяти 8 данных, выполняемое с использованием шин 17, 27 и 37, соединяющими память 8 данных соответственно с шинами 16, 26 и 36. Память 8 данных представляет собой раздел кэш-памяти, сохраняющий массив данных, которые с большой вероятностью будут затребованы в ближайшее время. Передача данных по шинам 17, 27 и 37 в память 8 данных или из нее представляет собой суть того действия, которое выполняется конвейером на стадии M.
[38] При помощи шины 81 память 8 данных соединена также с оперативной памятью 9, а при помощи шины 82 – с блоком 7 контроля готовности операндов (далее – блок 7 готовности операндов). Функции блока 7 готовности операндов подробно описаны ниже, а здесь отметим, что блок 7 готовности операндов посредством шин 71, 72, 73 соединен соответственно с управляющими устройствами 11, 21, 31, а посредством шин 46 и 74 – с памятью 4 команд.
[39] На стадии WB данные, прочитанные в памяти 8 данных или являющиеся результатом выполненной АЛУ математической операции, передаются по шинам 16, 26, 36 для записи в регистры ad1, ad2 регистрового файла 5 и регистр apd предикатного файла 6. Вместе со стадией WB на этом завершается весь цикл конвейерного процесса обработки команд.
[40] Далее со ссылками на Фиг. 2, 3, 4 и 5 более подробно раскрывается техническая проблема, возникающая при функционировании VLIW-процессора 300 и решенная во VLIW-процессорах 100 и 200.
[41] На Фиг. 2 представлен фрагмент программного кода, написанного на используемом в микропроцессорах языке ассемблера. Данный фрагмент включает в себя последовательность персонализированных команд, поступающих на выполнение в функциональный блок 1 после их выделения из широких команд. Справа от символа // представлен комментарий по содержанию каждой команды. Обратим внимание, что команда nop не содержит выполняемой операции и используется, например, для синхронизации двух персонализированных команд, когда есть необходимость поместить их в одну широкую команду.
[42] Заметим, что регистр r1 в команде ld на Фиг. 2 имеет функцию регистра с адресом ad1 на Фиг. 1, а тот же регистр r1 в команде add на Фиг. 2 имеет функцию регистра с адресом as11 на Фиг. 1. Другими словами, операнд, подлежащий записи в регистр r1 (далее – целевой операнд), является результирующим операндом для команды ld и исходным операндом для команды add, а значит, выполнение команды add невозможно без завершения выполнения команды ld.
[43] На Фиг. 3 представлена схема конвейерного процесса обработки команд, отображенных во фрагменте программного кода на Фиг. 2. При прохождении командой ld стадии M, из памяти 8 данных должен быть прочитан целевой операнд для последующей записи в регистр r1. В случае, показанном на Фиг. 3, целевой операнд присутствует в памяти 8 данных, благодаря чему он извлекается из памяти 8 данных и передается по шине 17 на стадию WB за один такт. Затем целевой операнд посредством шины 16 пересылается на стадию D команды add, и команда add обрабатывается без задержки.
[44] Одновременно с выдачей целевого операнда память 8 данных по шине 82 передает на блок 7 готовности операндов сигнал hit (попадание в цель), свидетельствующий о нормальной работе и об отсутствии необходимости принятия каких-либо мер. Запись и чтение целевого операнда из регистрового файла 5 выполняется командами ld и add по входному и выходному фронту одного тактового импульса, что на Фиг. 3 схематично отражено стрелкой, поэтому стадии WB и D команд ld и add могут быть осуществлены за один такт.
[45] Блок 7 готовности операндов по шине 46 получает из памяти 4 команд информацию, какие операнды должны быть подготовлены для каждой из персонализированных команд, одновременно выполняемых функциональными блоками 1 и 2. Применительно к случаю на Фиг. 2, блок 7 готовности операндов по шине 46 получает из памяти 4 команд информацию, что для команды add требуется целевой операнд, который должен быть извлечен из памяти 8 данных в результате выполнения команды ld. Память 8 данных сообщает о готовности данного операнда посредством сигнала hit.
[46] На Фиг. 4 представлена схема того же самого конвейерного процесса для последовательности команд на Фиг. 2 с тем, однако, отличием, что команде ld не удается прочитать целевой операнд и направить его на стадию D команды add, поскольку целевой операнд отсутствует в памяти 8 данных. В этом случае память 8 данных обращается за целевым операндом к своим разделам нижнего уровня или даже к оперативной памяти 9 по шине 81, и одновременно направляет в блок 7 готовности операндов по шине 82 сигнал miss (промах). Поскольку выполнение команды add в этом случае не представляется возможным, блок 7 готовности операндов приостанавливает работу конвейера, направляя сигнал hold (остановка) на управляющие устройства 11, 21, 31 и память 4 команд по шинам 71, 72, 73, 74 соответственно.
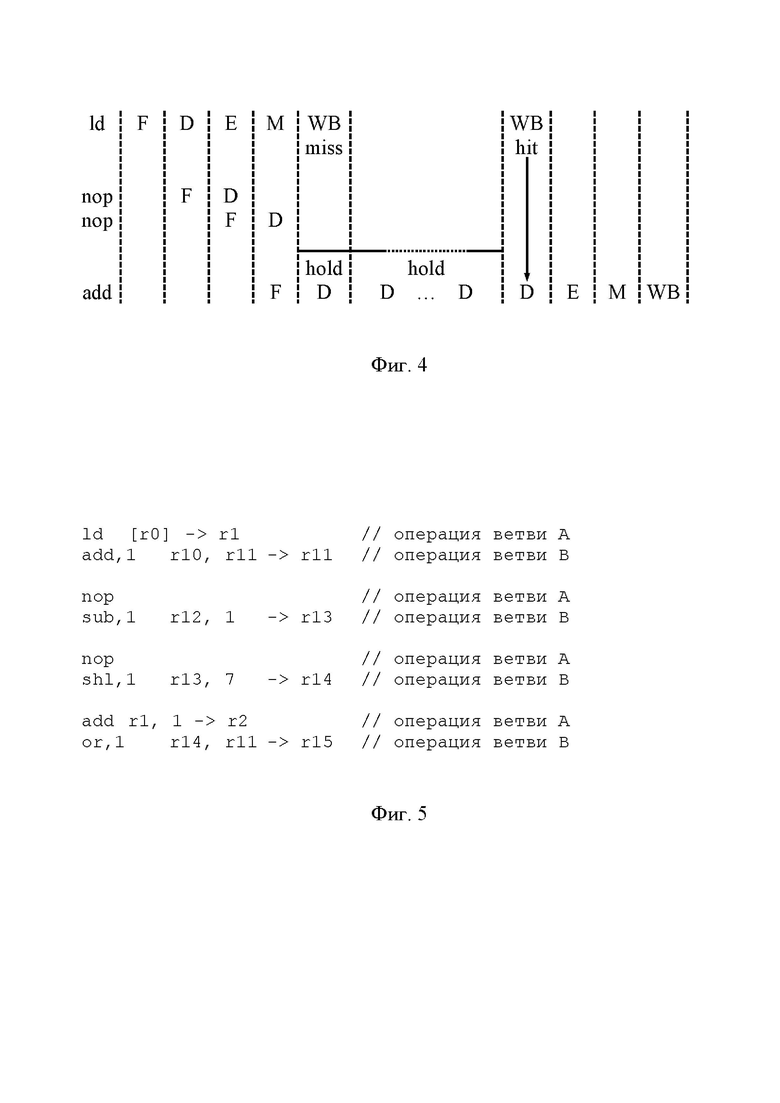
[47] Когда память 8 данных, наконец, предоставляет целевой операнд для чтения командой ld, память 8 данных направляет блоку 7 готовности операндов сигнал hit, и блок 7 готовности операндов сигнал снимает hold. В результате этого целевой операнд по шине 16 пересылается на стадию D команды add, и работа конвейера возобновляется. Как схематично показано на Фиг. 4, сигал hold может удерживаться длительное время, например на протяжении 100 тактов или больше.
[48] На Фиг. 5 показана последовательность широких команд, в каждой из которых соответствующая команда последовательности с Фиг. 2 выступает в качестве первой персонализированной команды, а сама последовательность команд с Фиг. 2 образует ветвь А. Соответственно, при остановке выполнения команды add ветви А, как это показано на Фиг. 4, останавливается и выполнение команды or, выступающей в качестве второй персонализированной команды и принадлежащей ветви B. Иначе говоря, блокировка ветви А вызывает блокировку ветви В.
[49] Предположим, что ветвь А является ветвью, переход на которую маловероятен, и которая включена в последовательность широких команд в качестве так называемой спекулятивной ветви, выполняемой «на всякий случай». Блокировка часто выполняемой ветви В из-за неготовности операндов у редко выполняемой ветви А является крайне нежелательным явлением, существенно замедляющим быстродействие VLIW-процессора 300. Более того, малое число выполненных переходов на ветвь А само по себе снижает вероятность нахождения целевого операнда в памяти 8 данных, что повышает вероятность и длительность остановки конвейера. Данная ситуация, являющаяся иллюстрацией стоящей перед изобретением технической проблемы, решена в предложенных VLIW-процессорах 100 и 200.
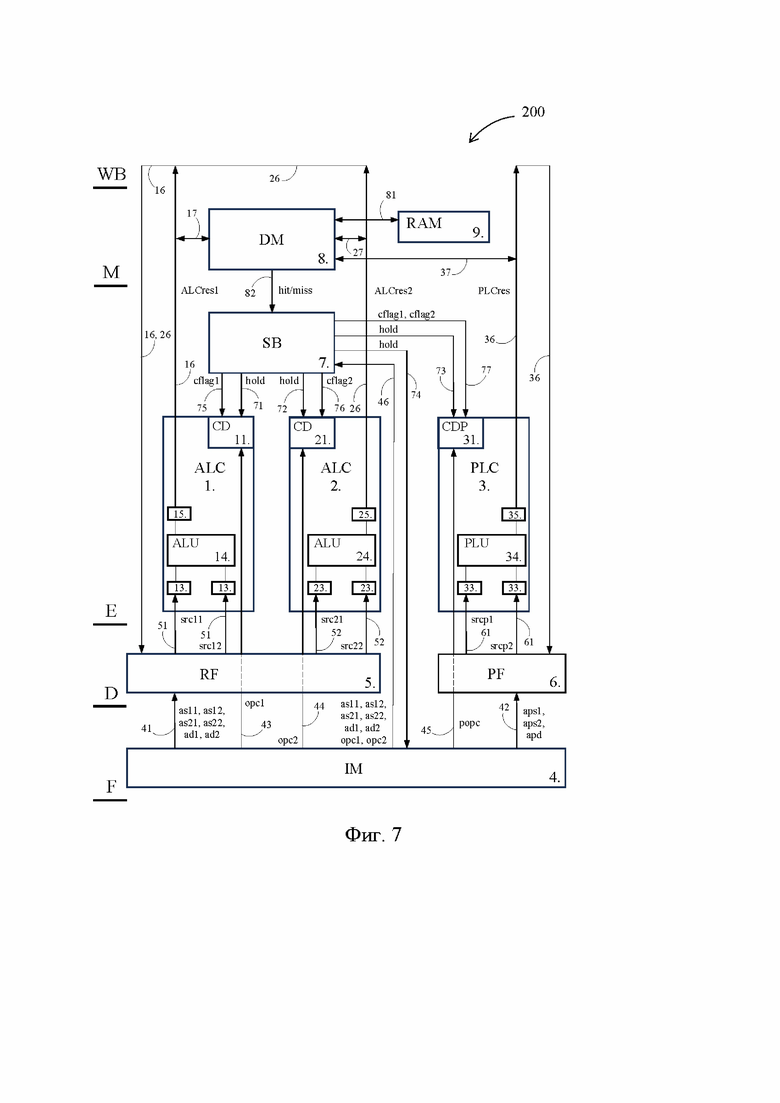
[50] На Фиг. 6 представлена блок-схема VLIW-процессора 100, выполненного согласно первому предпочтительному варианту осуществления изобретения. Описание элементов или взаимосвязей, которые во VLIW-процессоре 100 идентичны таковым во VLIW-процессоре 300, повторно приведено не будет, и далее будут раскрыты усовершенствования VLIW-процессора 100 относительно VLIW-процессора 300, которые позволяют решить техническую проблему путем достижения указанного выше технического результата.
[51] В дополнение к шинам 71, 72, 73, 74 или вместо них VLIW-процессор 100 снабжен шинами 75 и 76, соединяющими блок 7 готовности операндов с управляющими устройствами 11 и 21 соответственно. Кроме того, каждый из регистров регистрового файла 5, регистров 13, 15, 23, 25 и регистров памяти 8 данных (все вместе далее – регистры данных) снабжен дополнительным разрядом. В регистрах 13, 15, 23, 25 этот дополнительный разряд обозначен соответственно позициями 131, 151, 231, 251.
[52] Как и прежде, получая сигналы по шинам 46 и 82, блок 7 готовности операндов способен контролировать обновление первой группы операндов в регистровом файле 5. В условиях нормальной работы, например, показанной на Фиг. 3, функционирование VLIW-процессора 100 не отличается от описанного выше функционирования VLIW-процессора 300.
[53] Однако во VLIW-процессоре 100, когда какой-либо из операндов первой группы не обновлен до выполнения первой персонализированной команды, что эквивалентно тому, что не обновлена вся первая группа операндов, т.е. при получении сигнала miss по шине 82, блок 7 готовности операндов вместо передачи по шине 71 сигнала hold передает по шине 75 сигнал cflag1 (compromising flag – компрометирующий флаг). В другом исполнении сигнал cflag1 передается одновременно с сигналом hold, но имеет приоритет над ним, т.е. отменяет сигнал hold.
[54] Данная особенность VLIW-процессора 100 справедлива также и в отношении шин 73 и 74. При получении сигнала miss по шине 82, блок 7 готовности операндов либо не передает сигнал hold по шинам 73 и 74, либо предает по вновь введенным шинам (не показаны) на память 4 команд и функциональный блок 3 сигнал cflag1, отменяющий действие сигнала hold.
[55] Применительно к случаям с Фиг. 2 и 5, блок 7 готовности операндов предает по шине 75 сигнал cflag1, когда целевой операнд, т.е. операнд, подлежащий записи в регистр r1 по результату выполнения команды ld, не был записан в регистр r1 до выполнения команды add (как и прежде, предполагается, что ветвь А выполняется функциональным блоком 1). Тем не менее, как это показано на Фиг. 8, блок управления не приостанавливает конвейер, а продолжает выполнение команды add с прежним (не обновленным) операндом, сохраненным в регистре r1, одновременно с этим помещая компрометирующий флаг, т.е. битовое значение «1», в дополнительный разряд 131 соответствующего входного регистра 13.
[56] Далее компрометирующий флаг записывается в дополнительный разряд 151 результирующего регистра 15, а затем и в дополнительные разряды всех других регистров, которые сохраняют результат выполнения команды add, а именно в дополнительные разряды регистров памяти 8 данных и регистрового файла 5. Соответственно, любой из дополнительных разрядов 131, 151 и т.д. содержит информацию о готовности целевого операнда, т.е. может выступать в качестве регистра готовности операндов для команды add.
[57] Если результат выполнения команды add используется следующей командой ветви А, то из регистрового файла 5 в качестве входного операнда он записывается во входной регистр 13, а вместе с ним в дополнительный разряд 131 этого входного регистра 13 записывается компрометирующий флаг. Таким образом, результаты выполнения всех последующих команд ветви А, использующих операнды, помеченные компрометирующим флагом, также помечаются компрометирующим флагом.
[58] Блок управления при наличии компрометирующего флага в дополнительном разряде 151 распознает результат выполнения первой персонализированной команды как недостоверный результат. Поскольку компрометирующим флагом помечены и все последующие команды ветви А, то результаты их выполнения блок управления также признает недостоверными. Таким образом, при возникновении необходимости перехода на ветвь А все команды ветви А, начиная с команды ld, должны быть выполнены заново.
[59] Однако необходимость выполнения ветви А возникает не всегда, а по существу - довольно редко, поскольку задержка выдачи целевого операнда характерна именно для редко выполняемых команд. Таким образом, существует большая вероятность, что ветвь А не будет востребована, и в этом случае недостоверность ее результата не окажет влияния на результат выполнения программы, содержащей ветви А и В. В то же время, поскольку выполнение ветви А не вызвало задержку выполнения ветви В, то предложенный VLIW-процессор 100 выполнит программу, содержащую ветви А и В, за значительно меньшее время по сравнению с известным VLIW-процессором 300, который в обязательном порядке должен обеспечить получение достоверного результата ветви А.
[60] Если же переход на ветвь А все-таки будет реализован, то повторное выполнение команды ld и всех других, зависящих от ее результата, команд ветви А осуществляется посредством обращения к компенсирующему коду, по существу, являющегося идентичным основному коду ветви А. Все аспекты использования компенсирующего кода известны специалисту в данной области техники, а здесь отметим, что повторное обращение к памяти 8 данных за целевым операндом, поступающее со стороны команды ld, значительно ускоряет выдачу целевого операнда памятью 8 данных, поскольку данная ситуация соответствует задаче, решаемой алгоритмом работы кэш-памяти. Таким образом, и в этом случае предложенный VLIW-процессор 100 имеет преимущество в быстродействии по сравнению с известным VLIW-процессором 300.
[61] Обратим внимание, что хотя команда add была выполнена, не дожидаясь результата команды ld, выполнение самой команды ld будет завершено с достоверным результатом даже в этом случае. Поскольку результат выполнения команды ld после стадии WB сохраняется в регистровом файле 5, то строго говоря, повторное выполнение команды ld не является обязательным, а значит быстродействие VLIW-процессора 100 при переходе на ветвь А может быть еще выше.
[62] Тем не менее длительное сохранение результата команды ld в одном из регистров регистрового файла 5 в ожидании маловероятного повторного обращения к ветви А очевидным образом снижает число свободных регистров в регистровом файле 5. Ввиду того, что общее число регистров в регистровом файле 5 является сравнительно небольшим, выведение из оборота одного из регистров способно оказать отрицательное влияние на быстродействие VLIW-процессора 100, не компенсируемое сохраненным результатом выполнения команды ld. В рассматриваемом примере функционирования VLIW-процессора 100 при выполнении кода с Фиг. 5 предпочтение отдано в пользу повторного выполнения команды ld.
[63] Поскольку функциональный блок 2 полностью идентичен функциональному блоку 1, то в случае неготовности второй группы операндов до выполнения второй персонализированной команды, т.е. при получении управляющим устройством 21 по шине 72 от блока 7 готовности операндов сигнала cflag2, функциональный блок 2 осуществляет те же самые действия, что были описаны для функционального блока 1. Результат выполнения второй персонализированной команды при этом распознается блоком управления как недостоверный.
[64] Обратим внимание, что возможно наступление такой ситуации, когда одновременно не были обновлены и первая и вторая группы операндов. В этом случае конвейер также продолжает работу, а блок управления признает недостоверными результаты выполнения и первой и второй персонализированной команды. Целесообразность выполнения первой и второй персонализированной команд с получением заведомо недостоверных результатов объясняется выигрышем во времени, связанным с ускорением выдачи целевых операндов при повторном обращении к памяти 8 данных. Кроме того, в этом случае обеспечивается незамедлительная обработка следующей широкой команды, если входящие в нее персонализированные команды не связаны с текущей широкой командой.
[65] Тем временем, осуществление изобретения во VLIW-процессоре 100 связано с определенными техническими сложностями, поскольку используемые во VLIW-процессоре 100 регистры, снабженные дополнительным разрядом, выходят за рамки общепринятых стандартов, и должны быть изготовлены индивидуально. Кроме того, во VLIW-процессоре 100 все шины передачи данных должны быть снабжены дополнительной линией, соединяющей дополнительные разряды. В целом необходимо признать, что все эти моменты способны существенно ограничить область использования данного варианта осуществления изобретения.
[66] Однако указанные технические сложности не характерны для второго предпочтительного случая использования изобретения, а именно VLIW-процессора 200, блок-схема которого представлена на Фиг. 7. Регистры данных во VLIW-процессоре 200 идентичны таковым в известном VLIW-процессоре 300, однако, VLIW-процессор 200 снабжен шиной 77, способной передавать сигналы cflag1 и cflag2 на предикатно-логический функциональный блок 3. Применительно к ситуации задержки обновления целевого операнда в случаях с Фиг. 2 и 5, функционирование VLIW-процессора 200 проиллюстрировано на Фиг. 9.
[67] Если широкая команда содержит персонализированную команду, в отношении которой предполагается возможность задержки в подготовке исходных операндов (в случае с Фиг. 5 это команда add, выполняемая функциональным блоком 1), то в состав этой широкой команды включается предикатная персонализированная команда sbpred, выполнение которой предписывается функциональному блоку 3. При поступлении в функциональный блок 3 сигнала cflag1 по шине 77, компрометирующий флаг записывается во входной регистр 33, а после прохождения командой sbpred стадии WB сохраняется в регистре предикатного файла 6, который указан в команде sbpred, и который выполняет функцию регистра готовности операндов для данной персонализированной команды и содержащей ее ветви (в случае с Фиг. 5 это команда add и ветвь А).
[68] Если же широкая команда содержит, например, две персонализированные команды, в отношении которых предполагается возможность задержки в подготовке исходных операндов, то включенная в состав этой широкой команды предикатная персонализированная команда sbpred назначает два регистра предикатного файла 6, каждый из которых выполняет функцию регистра готовности операндов для своей персонализированной команды.
[69] При поступлении в функциональный блок 3 сигналов cflag1 и cflag2 первый из назначенных командой sbpred регистров предикатного файла 6 сохраняет первый компрометирующий флаг cflag1 для первой персонализированной команды, а второй из назначенных командой sbpred регистров предикатного файла 6 сохраняет второй компрометирующий флаг cflag2 для второй персонализированной команды. Как было указано выше, в функциональный блок 3 могут поступить сразу оба сигнала cflag1 и cflag2 или только один из них.
[70] Аналогично описанному выше VLIW-процессору 100, во VLIW-процессоре 200 сигналы cflag1, cflag2 имеют приоритет над сигналом hold, т.е. отменяют его действие. В предпочтительном случае персонализированные команды, которые не должны блокировать выполнение ширкой команды даже при неготовности используемых ими операндов, определяются заранее на этапе компиляции. Как правило, это первые команды той ветви, переход на которую является маловероятным. Следующие команды данной ветви получают компрометирующий флаг из предикатного файла 6.
[71] Сохранение компрометирующего флага в предикатном файле 6 предоставляет возможность использовать его в качестве обычного предиката, характеризующего состояние соответствующей персонализированной команды или ветви, которой принадлежит эта персонализированная команда. Например, компрометирующий флаг, сохраненный в предикатном файле 6, а точнее – в регистре, назначенном командой sbpred для выполнения функции регистра готовности операндов, может выступать в качестве условия перехода на другую ветвь или на компенсирующий код, а также в качестве самостоятельного операнда для логической операции.
[72] В остальном VLIW-процессор 200 имеет те же преимущества, что и описанный ранее VLIW-процессор 100.

Изобретение относится к области вычислительной техники, в частности к микропроцессорам с параллельным исполнением нескольких команд. Технический результат заключается в повышении производительности процессора с одновременным снижением энергопотребления и количества выделяемого тепла. Технический результат достигается за счет того, что процессор содержит подготовительный конвейер, регистровый файл, первый и второй исполнительные конвейеры, блок контроля готовности операндов, регистр готовности операндов и блок управления. Подготовительный конвейер способен выделять из широкой команды первую и вторую персонализированные команды. Первый и второй исполнительные конвейеры способны синхронно друг с другом выполнять соответственно первую и вторую персонализированные команды с использованием соответственно первой и второй групп операндов. Блок контроля готовности операндов способен контролировать обновление первой группы операндов в регистровом файле. Регистр готовности операндов способен сохранять компрометирующий флаг, когда первая группа операндов не была обновлена до выполнения первой персонализированной команды. Блок управления при наличии компрометирующего флага способен распознавать результат выполнения первой персонализированной команды как недостоверный результат. 8 з.п. ф-лы, 9 ил.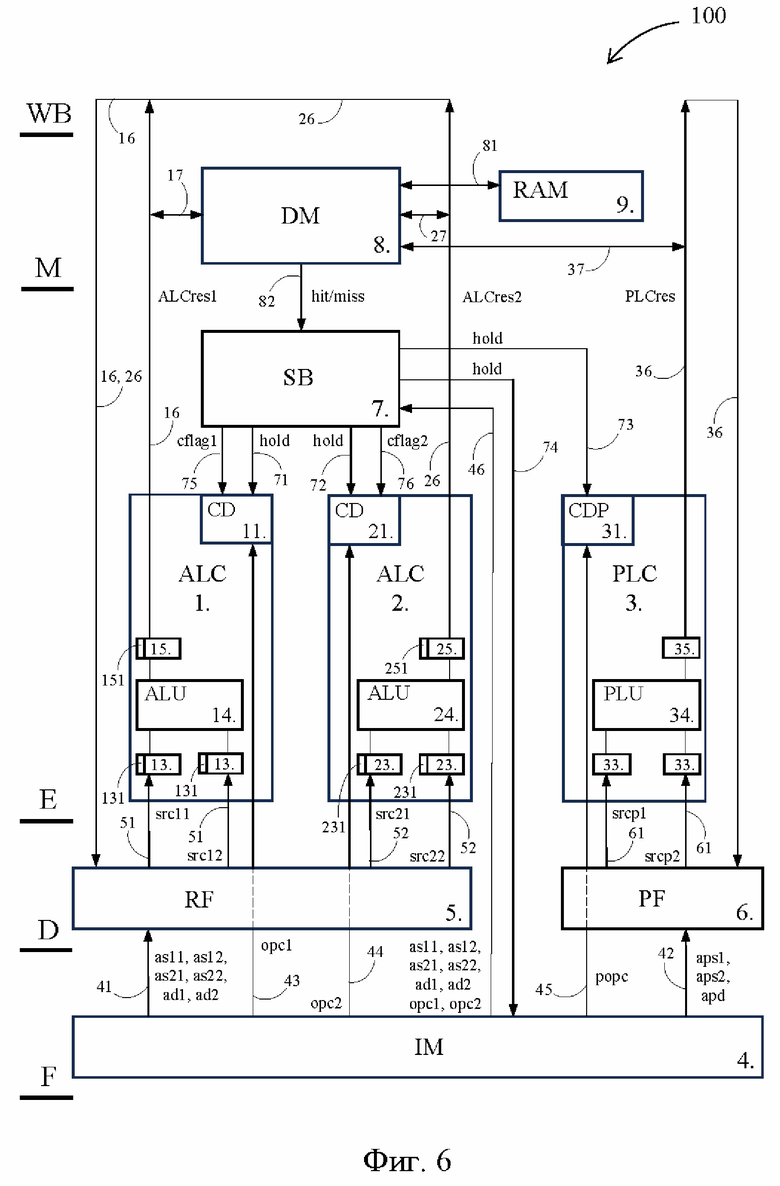
1. Процессор, содержащий подготовительный конвейер, регистровый файл, первый и второй исполнительные конвейеры, блок контроля готовности операндов, регистр готовности операндов и блок управления, при этом
подготовительный конвейер способен выделять из широкой команды первую и вторую персонализированные команды,
первый и второй исполнительные конвейеры способны синхронно друг с другом выполнять соответственно первую и вторую персонализированные команды с использованием соответственно первой и второй групп операндов,
блок контроля готовности операндов способен контролировать обновление первой группы операндов в регистровом файле,
регистр готовности операндов способен сохранять компрометирующий флаг, когда первая группа операндов не была обновлена до выполнения первой персонализированной команды, при этом
блок управления при наличии компрометирующего флага способен распознавать результат выполнения первой персонализированной команды как недостоверный результат.
2. Процессор по п. 1, в котором блок управления способен запускать повторное выполнение первой персонализированной команды посредством обращения к компенсирующему коду.
3. Процессор по п. 1, в котором блок управления способен не запускать повторное выполнение первой персонализированной команды, когда блок управления определил, что первая персонализированная команда является спекулятивной командой для неисполненного перехода.
4. Процессор по п. 1, в котором блок управления использует компрометирующий флаг для передачи управления или логической операции.
5. Процессор по п. 1, в котором регистр готовности операндов способен сохранять компрометирующий флаг для всей цепочки команд, следующих за первой персонализированной командой и являющихся зависимыми от нее, а блок управления способен признавать недостоверным результат выполнения всех команд из указанной цепочки.
6. Процессор по п. 1, в котором первый исполнительный конвейер содержит результирующий регистр, сохраняющий результат выполнения первой персонализированной команды, причем регистр готовности операндов включен в результирующий регистр в качестве отдельного разряда.
7. Процессор по п. 6, в котором регистры первого исполнительного конвейера, предназначенные для исходных операндов, а также регистры регистрового файла и кэш-памяти, предназначенные для операндов, снабжены отдельным разрядом, предназначенным для сохранения компрометирующего флага.
8. Процессор по п. 1, который содержит исполнительный конвейер для логических операций, а регистр готовности операндов входит в состав регистров исполнительного конвейера для логических операций.
9. Процессор по п. 1, в котором блок контроля готовности операндов способен контролировать обновление второй группы операндов в регистровом файле, причем
регистр готовности операндов является первым регистром готовности операндов, а компрометирующий флаг является первым компрометирующим флагом, при этом
процессор содержит второй регистр готовности операндов, который способен сохранять второй компрометирующий флаг, когда вторая группа операндов не была обновлена до выполнения второй персонализированной команды, при этом
блок управления при наличии второго компрометирующего флага способен распознавать результат выполнения второй персонализированной команды как недостоверный результат.
| US 20120151192 A1, 14.06.2012 | |||
| US 20140223142 A1, 07.08.2014 | |||
| US 20050138327 A1, 23.06.2005 | |||
| US 20180181400 A1, 28.06.2018 | |||
| ЦИФРО-СИГНАЛЬНЫЙ ПРОЦЕССОР С СИСТЕМОЙ КОМАНД VLIW | 2019 |
|
RU2694743C1 |

