Область техники
[1] Изобретение относится к микропроцессорной технике, в частности к микропроцессорам с параллельным исполнением нескольких команд, а более точно к микропроцессорам, выполненным в архитектуре VLIW (Very Long Instruction Word, далее - VLIW-процессоры).
Предпосылки к созданию изобретения
[2] VLIW-процессор реализует общеизвестный конвейерный процесс обработки команд (далее также - конвейерный процесс), в котором каждая команда последовательно проходит через несколько стадий обработки, таких как выборка, дешифрация, исполнение, обращение к запоминающему устройству и обратная запись результата. В дальнейшем изложении комплекс технических средств, входящих в состав процессора и непосредственно связанных с осуществлением конвейерного процесса, именуется «конвейер». Упомянутое запоминающее устройство представляет собой кэш-память процессора, которая в дальнейшем изложении кратко именуется как «память», если не указано иное.
[3] Классический конвейер позволяет осуществлять одновременную обработку нескольких команд, причем каждая из команд в определенный момент времени находится на одной из стадий обработки, и на каждой стадии в определенный момент времени может обрабатываться только одна команда. Тем не менее VLIW-процессор снабжен несколькими функциональными блоками, позволяющими, начиная со стадии исполнения, обрабатывать несколько команд одновременно уже на каждой стадии. Другими словами, конвейер типичного VLIW-процессора включает в себя один подготовительный конвейер, выполняющий стадии выборки и дешифрации, и несколько исполнительных конвейеров, выполняющих стадии исполнения, обращения к памяти и обратной записи.
[4] Однако один подготовительный конвейер не может вывести на стадию исполнения несколько команд одновременно, поскольку на каждой своей стадии он может обрабатывать только одну команду. Во VLIW-процессоре данная проблема решается с помощью операции, выполняемой на этапе компиляции, а именно операции объединения нескольких команд (далее - персонализированная команда) в одну команду (далее - широкая команда).
[5] Соответственно, на стадиях выборки и дешифрации широкая команда проходит обработку как одна команда, а на стадии исполнения разделяется на несколько персонализированных команд, каждая из которых поступает на исполнение в предписанный ей функциональный блок. Одно из названий этой широкой команды на английском языке по существу и зашифровано в аббревиатуре VLIW. Описанная конфигурация VLIW-процессора известна специалисту в данной области, например, из патентной публикации US2012151192A1, 14.06.2012, и может рассматриваться в качестве прототипа изобретения.
[6] Следует отметить, что наиболее ярко преимущество VLIW-процессора проявляется при ветвлении программы, когда из нескольких альтернативных ветвей персонализированных команд должна быть выбрана одна целевая ветвь, подлежащая дальнейшей обработке. В этом случае посредством включения по одной персонализированной команде из каждой альтернативной ветви в одну широкую команду и обработки последовательности таких широких команд, VLIW-процессор обеспечивает обработку всех альтернативных ветвей до того, как из них будет выбрана целевая ветвь.
[7] Благодаря указанному свойству VLIW-процессора, при выполнении команды передачи управления VLIW-процессор уже располагает прошедшей через стадии выборки и дешифрации целевой ветвью персонализированных команд, независимо от того, какая из альтернативных ветвей персонализированных команд будет выбрана в качестве целевой ветви, что существенно увеличивает быстродействие VLIW-процессора при прохождении данного участка программы.
[8] Однако на более крупномасштабном участке программа может содержать несколько последовательных ветвлений, в которых уже сами широкие команды образуют свои альтернативные ветви. В этой ситуации, начиная, например со второго уровня ветвления, широкие команды не могут вместить в себя все альтернативные ветви персонализированных команд по той причине, что число персонализированных команд, включенных в широкую команду, ограничено числом функциональных блоков.
[9] При переходе программы на альтернативную ветвь, персонализированные команды которой не включались в широкие команды, конвейер должен быть загружен заново, и в связи с этим быстродействие VLIW-процессора естественным образом замедляется. Указанный недостаток известного VLIW-процессора более подробно проиллюстрирован ниже со ссылками на фигуры, а здесь отметим, что увеличенное время работы процессора также вызывает избыточное потребление электроэнергии и повышенное тепловыделение, требующее принятие дополнительных мер по организации охлаждения.
[10] Техническая проблема, на решение которой направлено изобретение, состоит в поиске решения, способного повысить производительность VLIW-процессора.
Сущность изобретения
[11] Для решения указанной технической проблемы в качестве изобретения предложен процессор (далее также - предложенный VLIW-процессор), содержащий первый подготовительный конвейер, действующий постоянно, и второй подготовительный конвейер, запускаемый временно, а также первый и второй исполнительные конвейеры. Первый и второй подготовительные конвейеры способны параллельно друг другу осуществлять обработку соответственно первой и второй последовательностей широких команд. Каждая широкая команда при этом включает в себя первую и вторую персонализированные команды, предназначенные к выполнению соответственно первым и вторым исполнительными конвейерами. Первый исполнительный конвейер способен выполнять персонализированную команду подготовки исходного перехода, запускающую второй подготовительный конвейер и предшествующую персонализированной команде осуществления исходного перехода. Первый и второй исполнительные конвейеры способны принимать к выполнению первую и вторую персонализированные команды, выделенные из широких команд той одной из первой и второй последовательностей широких команд, которая определена на основе результата выполнения первым или вторым исполнительным конвейером персонализированной команды осуществления исходного перехода.
[12] Технический результат изобретения состоит в уменьшении времени, затрачиваемого VLIW-процессором на выполнение программы, что повышает быстродействие и производительность VLIW-процессора, т.е. является решением поставленной перед изобретением технической проблемы. Следует отметить, что в контексте настоящего изложения понятие «выполнение программы» означает выполнение тех входящих в программу персонализированных команд, которые позволяют пройти путь от начальной персонализированной команды до конечной. Поскольку программа может содержать несколько таких путей, то понятие «выполнение программы» не подразумевает обязательное выполнение всех входящих в программу персонализированных команд.
[13] Причинно-следственная связь между признаками изобретения и техническим результатом заключается в следующем. В дополнение к первому подготовительному конвейеру предложенный VLIW-процессор снабжен вторым подготовительным конвейером, благодаря чему предложенный VLIW-процессор способен одновременно обрабатывать две последовательности широких команд. Соответственно, в предложенном VLIW-процессоре два подготовительных конвейера способны подготавливать к передаче на исполнительные конвейеры в два раза больше альтернативных ветвей персонализированных команд по сравнению с известным VLIW-процессором.
[14] Если в результате выполнения команды передачи управления должна быть продолжена обработка любой одной из этих последовательностей широких команд, то персонализированные команды обеих ее альтернативных ветвей, одна из которых в дальнейшем станет целевой ветвью, незамедлительно поступают в исполнительные конвейеры. Следовательно, число последовательных ветвлений, которое предложенный VLIW-процессор способен гарантированно проходить без задержки, увеличивается вдвое по сравнению с известным VLIW-процессором, что очевидным образом повышает быстродействие предложенного VLIW-процессора.
[15] Поскольку повышенное быстродействие обеспечивает предложенному VLIW-процессору возможность выполнения программы за меньшее время, то по сравнению с известным VLIW-процессором для выполнения одной и той же программы, характеризующейся развитым ветвлением, предложенный VLIW-процессор расходует меньше электроэнергии и выделяет меньше тепла. Экономному энергопотреблению способствует также непостоянный режим работы второго подготовительного конвейера, при котором запуск второго подготовительного конвейера осуществляется только в случае необходимости.
[16] Данный эффект усиливается ввиду того, что выполнение первым исполнительным конвейером персонализированной команды подготовки исходного перехода обеспечивает запуск второго подготовительного конвейера непосредственно перед тем, как в него начнет загружаться вторая последовательность широких команд, что еще больше сокращает время работы второго подготовительного конвейера и уменьшает расход электроэнергии.
[17] В первом частном случае изобретения первый и второй исполнительные конвейеры выполнены с возможностью принимать к выполнению первую и вторую персонализированные команды, выделенные из первой по счету широкой команды второй последовательности широких команд, от второго подготовительного конвейера. В дополнение к этому первый и второй исполнительные конвейеры выполнены с возможностью принимать к выполнению первую и вторую персонализированные команды, выделенные из следующих широких команд второй последовательности широких команд, от первого подготовительного конвейера. Первый и второй подготовительные конвейеры при этом выполнены с возможностью переноса широких команд второй последовательности широких команд с текущих стадий второго подготовительного конвейера на следующие стадии первого подготовительного конвейера.
[18] Данное исполнение изобретения предусматривает немедленное освобождение второго подготовительного конвейера, когда выполнена команда передачи управления на персонализированную команду, обработанную вторым подготовительным конвейером в составе широкой команды второй последовательности. Соответственно, второй подготовительный конвейер может быть либо использован для обработки новой последовательности широких команд, содержащей новые альтернативные ветви, что в конечном итоге играет в пользу увеличения быстродействия предложенного VLIW-процессора, либо незамедлительно выключен для экономии электроэнергии.
[19] Во втором частном случае изобретения блок управления предложенного процессора при помощи предсказателя перехода способен определять вероятную версию первой последовательности широких команд, когда первая последовательность широких команд содержит персонализированную команду осуществления собственного перехода. В качестве первой последовательности широких команд первый подготовительный конвейер использует упомянутую вероятную версию первой последовательности широких команд.
[20] В данном исполнении изобретения предложенный VLIW-процессор снабжен предсказателем перехода, благодаря которому при дальнейшем ветвлении программы загружаемая в первый подготовительный конвейер последовательность широких команд содержит наиболее вероятную альтернативную ветвь персонализированных команд. Соответственно снижается вероятность ошибочного выбора альтернативной ветви, а вместе с этим - и вероятность перезагрузки первого подготовительного конвейера. Таким образом, предсказатель перехода также способствует увеличению числа последовательных ветвлений, на которых предложенный VLIW-процессор способен выполнять программу без задержки, а значит, предсказатель перехода позволяет еще больше повысить быстродействие предложенного VLIW-процессора.
[21] В развитии второго частного случая изобретения блок управления предложенного процессора при помощи предсказателя перехода способен определять вероятную версию второй последовательности широких команд, когда вторая последовательность содержит персонализированную команду осуществления собственного перехода. В качестве второй последовательности широких команд второй подготовительный конвейер использует упомянутую вероятную версию второй последовательности широких команд.
[22] Технический результат данного исполнения изобретения состоит в дальнейшем увеличении быстродействия предложенного VLIW-процессора. Данное преимущество становится возможным благодаря тому, что последовательность широких команд, загружаемая во второй подготовительный конвейер, также содержит наиболее вероятную альтернативную ветвь персонализированных команд, определенную с помощью предсказателя перехода. Как было показано выше, такая мера увеличивает число альтернативных ветвлений программы, которые могут быть обработаны без остановки на перезагрузку второго подготовительного конвейера.
Краткое описание чертежей
[23] Осуществление изобретения будет пояснено ссылками на фигуры:
Фиг. 1 - блок-схема известного VLIW-процессора;
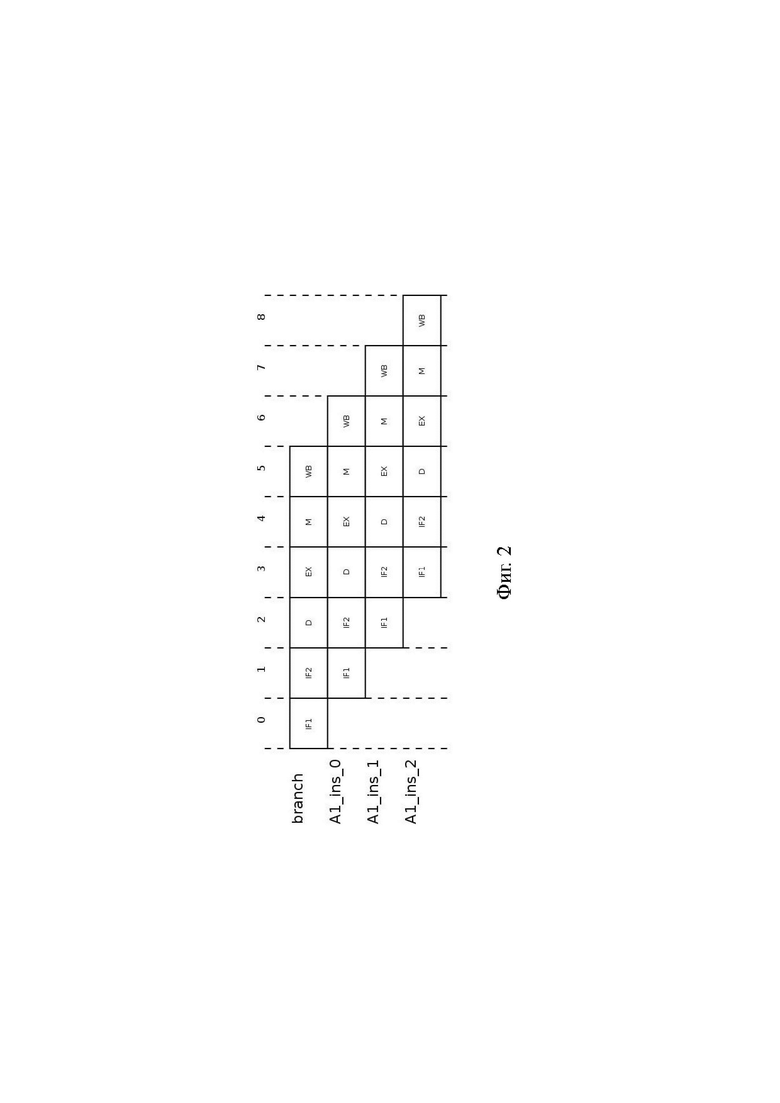
Фиг. 2 - схема конвейерного процесса, реализуемого известным VLIW-процессором при продолжении обработки подготовленной последовательности широких команд;
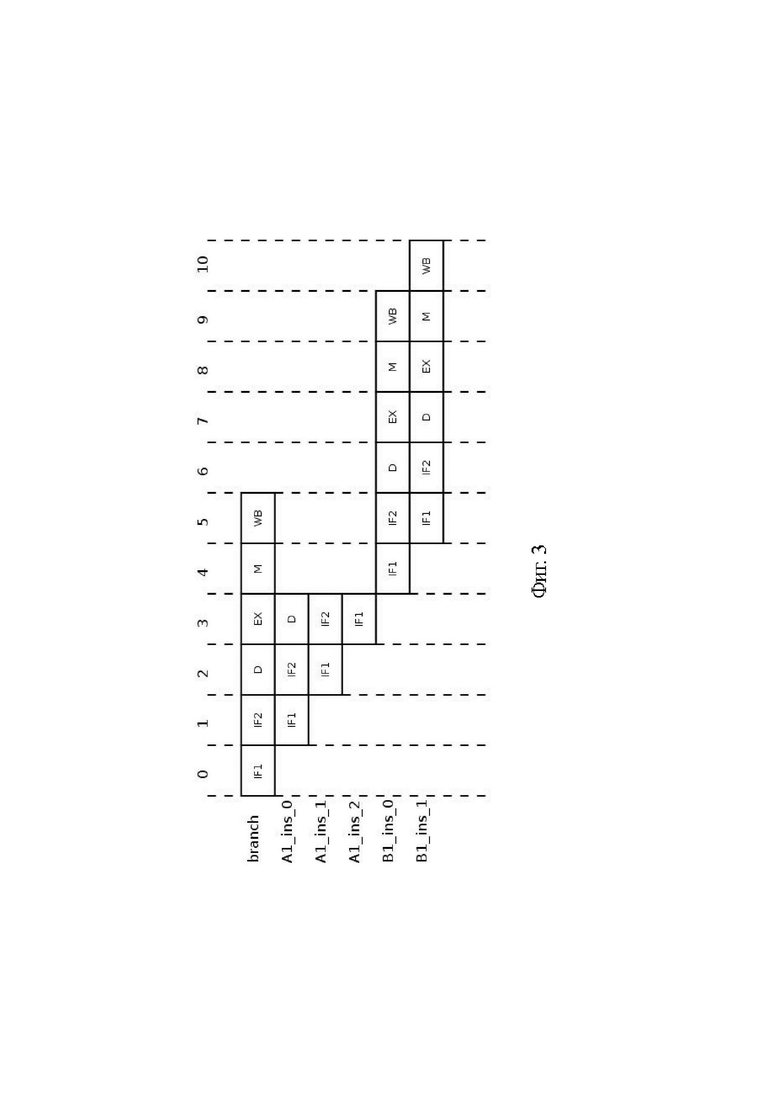
Фиг. 3 - схема конвейерного процесса, реализуемого известным VLIW-процессором при переходе на неподготовленную последовательность широких команд;
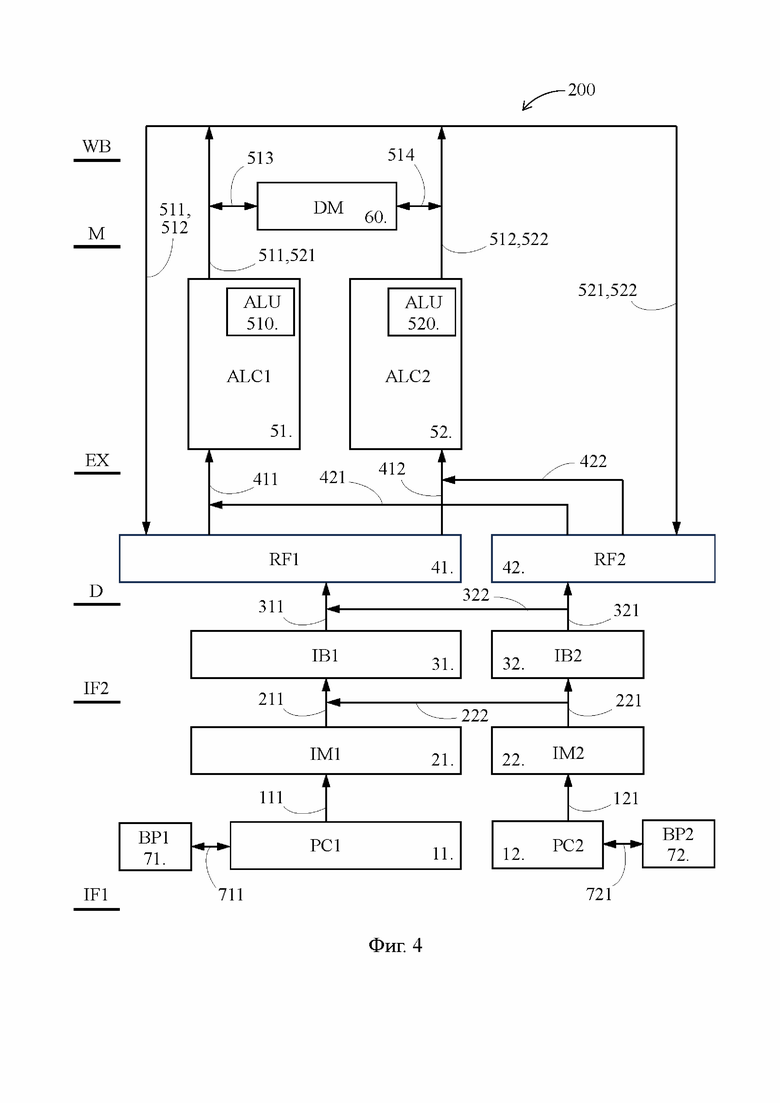
Фиг. 4 - блок-схема предложенного VLIW-процессора, выполненного согласно наиболее предпочтительному варианту осуществления изобретения;
Фиг. 5 - схема конвейерного процесса, реализуемого предложенным VLIW-процессором с задействованием второго подготовительного конвейера;
Фиг. 6 - схема выполняемой предложенным VLIW-процессором программы, иллюстрирующая преимущества предложенного VLIW-процессора.
[24] Следует отметить, что форма и размеры отдельных элементов, отображенных на фигурах, являются условными и показаны так, чтобы наиболее наглядно проиллюстрировать взаимное расположение элементов предложенного VLIW-процессора, а также их причинно-следственную связь с техническим результатом. Кроме того, во избежание избыточного усложнения фигур некоторые взаимосвязи элементов, очевидные специалисту в данной области техники, могут быть не отображены. Фигуры также дополнены выполненными на английском языке буквенными и словесными обозначениями, которые являются общепринятыми в данной области техники, и которые способствуют более быстрому восприятию фигур специалистом в данной области техники.
Осуществление изобретения
[25] Осуществление изобретения будет показано на наилучших примерах его реализации, которые не являются ограничениями в отношении объема охраняемых прав.
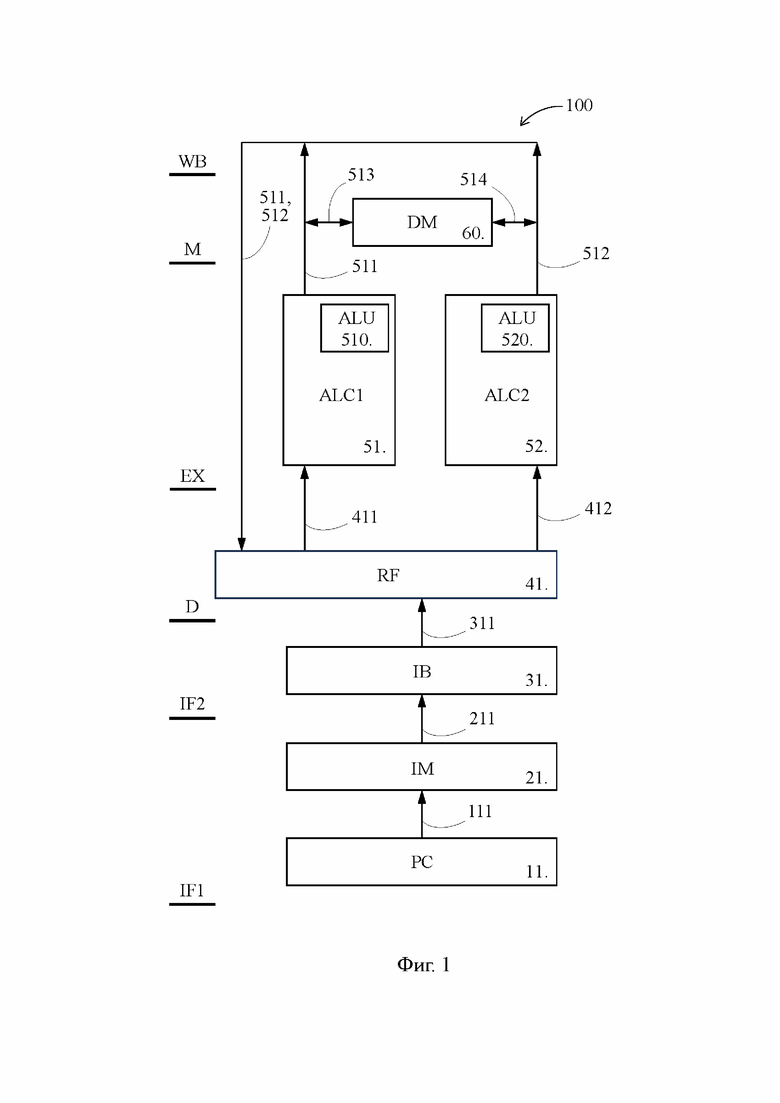
[26] На Фиг. 1 представлена блок-схема известного VLIW-процессора 100, в то время как на Фиг. 4 представлена блок-схема предложенного VLIW-процессора 200, выполненного согласно наиболее предпочтительному варианту осуществления изобретения. В значительной степени блок-схемы на Фиг. 1 и 4 повторяют друг друга, поэтому пока не указано иное, нижеследующее описание известного VLIW-процессора 100 относится также к предложенному VLIW-процессору 200. Идентичные элементы на Фиг. 1 и 4 обозначены одними и теми же позициями.
[27] Каждый из известного VLIW-процессора 100 (Фиг. 1) и предложенного VLIW-процессора 200 (Фиг. 4) содержит счетчик 11 команд (PC1 - program counter), память 21 команд (IM1 - instruction memory), буфер 31 команд (IB1 - instruction buffer), регистровый файл 41 (RF1 - register file), первый арифметико-логический функциональный блок 51 (ALC1 - arithmetic-logical channel), второй арифметико-логический функциональный блок 52 (ALC2), память 60 данных (DM - data memory). Первый и второй арифметико-логические функциональные блоки 51 и 52 далее кратко именуются как первый и второй функциональные блоки 51 и 52.
[28] Указанные элементы известного VLIW-процессора 100 и предложенного VLIW-процессора 200 представляют собой основные компоненты конвейера, задействованные в соответствующих стадиях конвейерного процесса, которые показаны в левой части Фиг. 1 и 4: выборка команды на подготовительном этапе (IF1 - instruction fetch), выборка команды на завершающем этапе (IF2), дешифрация (D - decode), исполнение (EX - execute), обращение к памяти (M - memory) и обратная запись результата (WB - write back).
[29] Обратим внимание, что наличие в известном VLIW-процессоре 100 по одному элементу из перечисленных выше элементов 11, 21, 31, 41 эквивалентно наличию в известном VLIW-процессоре 100 одного подготовительного конвейера, способного в каждый момент времени обрабатывать на каждой из стадий IF1-D только по одной команде, которая представляет собой широкую команду. Тем временем наличие в известном VLIW-процессоре 100 двух функциональных блоков 51 и 52 эквивалентно наличию в известном VLIW-процессоре 100 двух исполнительных конвейеров, способных в каждый момент времени обрабатывать на каждой из стадий E, M и WB сразу по две команды, которые представляют собой персонализированные команды, выделенные на стадии D из широкой команды.
[30] Что касается предложенного VLIW-процессора 200, то хотя на Фиг. 4 также показаны только два исполнительных конвейера, он может содержать, по существу, любое количество исполнительных конвейеров, при этом как правило, не все из этих исполнительных конвейеров содержат упомянутые выше арифметико-логические функциональные блоки. Некоторые исполнительные конвейеры предложенного VLIW-процессора 200 вместо арифметико-логических функциональных блоков могут содержать непоказанные на Фиг. 4 предикатно-логические функциональные блоки (PLC - predicate logical channel), назначение и функционирование которых известны специалисту в данной области. Например, предложенный VLIW-процессор 200 может содержать шесть арифметико-логических функциональных блоков и три предикатно-логических функциональных блока, а значит может выполнять широкую команду, включающую девять персонализированных команд.
[31] Следует также отметить, что часть конвейерного процесса, реализуемая подготовительным конвейером предложенного VLIW-процессора 200, может содержать гораздо больше стадий, чем указанные выше стадии IF1, IF2 и D. Аналогичное утверждение справедливо и для исполнительных конвейеров предложенного VLIW-процессора 200, которые помимо стадий EX, M и WB могут осуществлять иные стадии конвейерного процесса. Принципы увеличения числа стадий конвейерного процесса, как правило, основанные на разделении указанных выше стадий на ряд более мелких стадий в целях уменьшения длительности такта, известны специалисту в данной области техники.
[32] Далее, в состав каждого из известного и предложенного VLIW-процессоров 100 и 200 входит блок управления (не показан), обеспечивающий выработку и передачу управляющих сигналов на перечисленные выше элементы. Кроме того, каждый из известного и предложенного VLIW-процессоров 100 и 200 содержит множество элементов, исполняющих тривиальные функции в конвейерном процессе и являющихся очевидными специалисту в данной области, таких как регистры, мультиплексоры, шины передачи данных и т.п. Некоторые из таких элементов отображены на Фиг. 1 и 4 и будут раскрыты по ходу изложения.
[33] Память 21 команд представляет собой раздел кэш-памяти, в котором сохранены широкие команды, подлежащие выполнению в ближайшее время. Следует отметить, что каждая широкая команда компилируются из первой и второй персонализированных команд за пределами известного предложенного VLIW-процессоров 100 и 200. По сигналу, поступающему по шине 111 от счетчика 11 команд, из памяти 21 команд читается строка, здесь и далее именуемая «кэш-лайн» (cache line), содержащая ту широкую команду, которая должна быть обработана следующей (далее - требуемая широкая команда). Соответственно под «выборкой команды на подготовительном этапе», т.е. под стадией конвейерного процесса IF1, понимается нахождение в памяти 21 команд кэш-лайна, который содержит требуемую широкую команду, и передача этого кэш-лайна по шине 211 в буфер 31 команд.
[34] На стадии IF2 производится так называемая распаковка кэш-лайна с выделением из него требуемой широкой команды. Соответственно, под «выборкой команды на завершающем этапе», т.е. под стадией конвейерного процесса IF2, понимается выдача из буфера 31 команд N-битового сигнала, который указывает адреса as11, as12 регистров для исходных операндов первой персонализированной команды, адреса as21, as22 регистров для исходных операндов второй персонализированной команды, адреса ad1 и ad2 регистров для результирующих операндов первой и второй персонализированных команд, а также коды opc1 и opc2 операций, осуществляемых первой и второй персонализированными командами.
[35] Адреса as11, as12, as21, as22, ad1, ad2 регистров поступают из буфера 31 команд по шине 311 в регистровый файл 41, который представляет собой набор регистров, способных сохранять числовые данные целочисленного типа, с плавающей запятой и т.д. В свою очередь, коды opc1 и opc2 операций поступают из буфера 31 команд в упомянутый выше блок управления.
[36] Регистровый файл 41 направляет исходные операнды src11 и src12, прочитанные в регистрах по адресам as11, as12, в первый функциональный блок 51 по шине 411, и по шине 412 направляет во второй функциональный блок 52 исходные операнды src21 и src22, прочитанные в регистрах по адресам as21, as22. Поступление соответствующих исходных операндов в первый и второй функциональные блоки 51 и 52, а также поступление кодов операций opc1 и opc2 в блок управления завершает стадию D, а вместе с ней и работу подготовительного конвейера по обработке широкой команды и выделению из широкой команды первой и второй персонализированных команд.
[37] В состав первого функционального блока 51 включено арифметико-логическое устройство 510 (АЛУ, ALU - arithmetic-logical unit). Исходные операнды src11 и src12 поступают в АЛУ 510, в котором над ними выполняется операция, соответствующая коду opc1, после чего результат ALUres1 выполнения первой персонализированной команды по шине 511 направляется в память 60 данных или в регистровый файл 41, где записывается в регистр ad1 в качестве результирующего операнда первой персонализированной команды.
[38] Аналогично, исходные операнды src21 и src22 поступают в АЛУ 520, в котором над ними осуществляется операция, соответствующая коду opc2. Затем результат ALUres2 выполнения второй персонализированной команды по шине 512 направляется в память 60 данных или в регистровый файл 41 для записи в регистр ad2. На этом стадия EX конвейерного процесса, предусматривающая одновременное выполнение первой и второй персонализированных команд при помощи первого и второго исполнительных конвейеров, завершается.
[39] Далее, конвейерный процесс обработки некоторых персонализированных команд, таких как ld (load - загрузка (также - чтение) данных из памяти) или st (store - сохранение данных в память), включает обращение к памяти 60 данных, выполняемое с использованием шин 513 и 514, соединяющих память 60 данных соответственно с шинами 511 и 512. Память 60 данных представляет собой раздел кэш-памяти, сохраняющий массив данных, которые с большой вероятностью будут затребованы в ближайшее время. Передача данных по шинам 513 и 514 в память 60 данных или из нее представляет собой суть того действия, которое выполняется первым и вторым исполнительными конвейерами на стадии M.
[40] На стадии WB данные, прочитанные из памяти 60 данных или являющиеся результатом выполненной АЛУ математической операции, передаются по шинам 511 и 512 для записи в регистры ad1, ad2 регистрового файла 41. Вместе со стадией WB на этом завершается весь цикл конвейерного процесса обработки персонализированных команд.
[41] Следует обратить внимание, что в известном и предложенном VLIW-процессорах 100 и 200 под первым и вторым исполнительными конвейерами понимается совокупность элементов, являющихся необходимыми для осуществления стадий E, M, WB конвейерного процесса в отношении первой и второй персонализированных команд. В частности первый исполнительный конвейер включает в себя по меньшей мере первый функциональный блок 51, шины 511 и 513, а также входящие в блок управления устройства, управляющие первым функциональным блоком 51 и коммутирующими компонентами, которые реализуют функции обращения к памяти 60 данных и записи в регистровый файл 41. Аналогично второй исполнительный конвейер включает в себя по меньшей мере второй функциональный блок 52, шины 512 и 514, а также упомянутые управляющие устройства, входящие в блок управления, и коммутирующие компоненты.
[42] Кроме того, термины «первый» и «второй», используемые в отношении первого и второго исполнительных конвейеров предложенного VLIW-процессора 200, не имеют какого-либо иного смысла помимо указания на их различие, т.е. любой из двух исполнительных конвейеров может быть принят в качестве первого или второго исполнительного конвейера.
[43] Далее со ссылками на Фиг. 2 и 3 более подробно раскрывается техническая проблема, возникающая в известном VLIW-процессоре 100 при продолжении обработки только одной из двух последовательностей широких команд. В целях упрощения изложения принимается модель, в которой каждая из двух последовательностей широких команд содержит только одну альтернативную ветвь А1 или В1, образованную первыми персонализированными командами.
[44] Например, каждая широкая команда каждой последовательности образована первой персонализированной командой, содержащей операцию для выполнения первым функциональным блоком 51, и второй персонализированной командой в виде команды nop, которая не содержат выполняемой операции, в результате чего второй функциональный блок 52, по существу, простаивает. Таким образом, в рамках этой модели схемы на Фиг. 2 и 3 эквивалентны схемам конвейерного процесса обработки двух альтернативных ветвей А1 и В1 первых персонализированных команд, когда только одна из этих альтернативных ветвей А1 и В1 должна поступить на выполнение в первый функциональный блок 51.
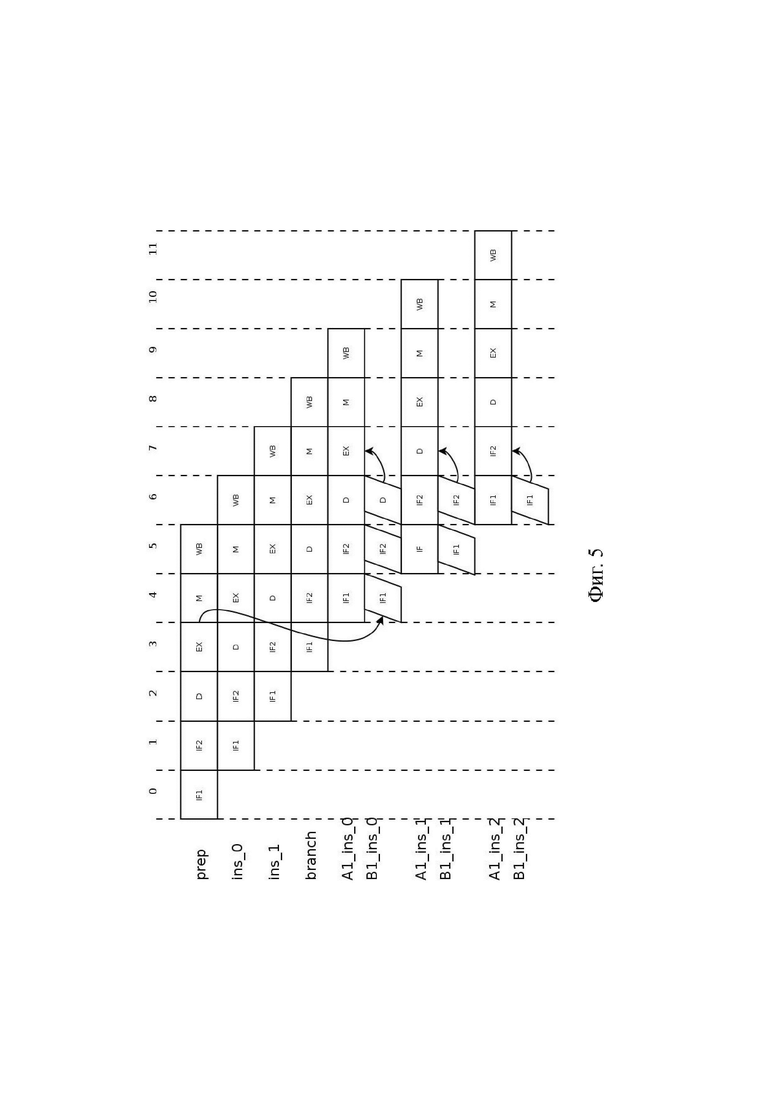
[45] Как видно на Фиг. 2, в момент нахождения команды branch на стадии EX, который приходится на такт 3, в подготовительный конвейер загружены три команды: А1_ins_0, А1_ins_1, А1_ins_2, которые принадлежат альтернативной ветви А1. После выполнения команды branch, которая показала результат NOT TAKEN (переход не выполнен), альтернативная ветвь А1 стала целевой ветвью, и загруженные в подготовительный конвейер команды А1_ins_0, А1_ins_1, А1_ins_2 продолжают обрабатываться подготовительным и исполнительным конвейерами без задержек. В ситуации на Фиг. 2 известный VLIW-процессор 100 показывает максимально возможное быстродействие.
[46] На Фиг. 3 изображен случай, когда после выполнения команды branch с результатом TAKEN (переход выполнен) определено, что загруженные в подготовительный конвейер команды А1_ins_0, А1_ins_1, А1_ins_2 не являются командами целевой ветви. Поскольку дальнейшая обработка указанных команд не имеет смысла, то она прерывается, а сами команды подлежат удалению, при этом подготовительный конвейер на такте 4 начинает обработку команд В1_ins_0, В1_ins_1 целевой ветви В1 с первой стадии. Обратим внимание, что обработка второй команды В1_ins_1 целевой ветви завершается на такте 10, в то время как в случае на Фиг. 2 обработка второй команды А1_ins_1 целевой ветви завершалась на такте 7. Таким образом, при ошибочном выборе целевой ветви задержка обработки команд составила 3 такта, или другими словами, быстродействие известного VLIW-процессора 100 ухудшилось на 43%.
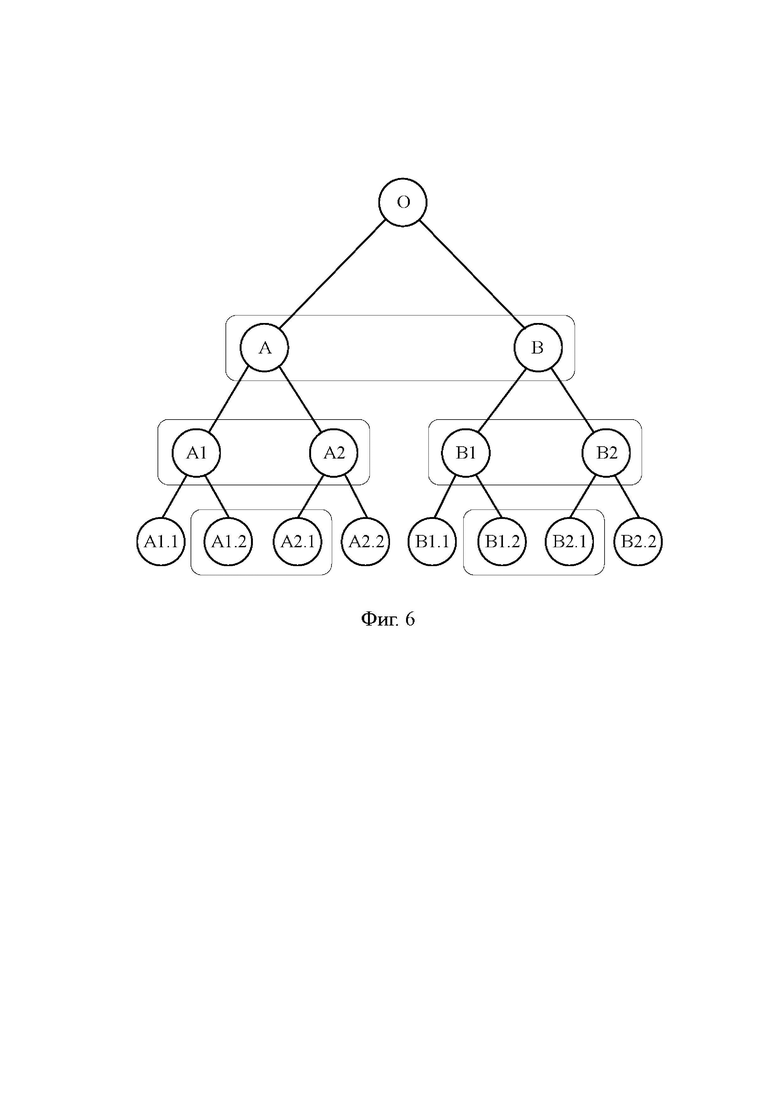
[47] Другая иллюстрация решаемой изобретением технической проблемы представлена на Фиг. 6. Элемент О символизирует ветвь персонализированных команд, содержащую персонализированную команду передачи управления на одну из альтернативных ветвей А и В. Более точно, альтернативная ветвь А непосредственно следует за ветвью О и выбирается, когда результатом команды передачи управления является NOT TAKEN. В свою очередь, альтернативная ветвь В определяется адресом перехода, указанным в команде передачи управления и выбирается, когда результатом команды передачи управления является TAKEN.
[48] Тем временем загруженная в подготовительный конвейер известного VLIW-процессора 100 последовательность широких команд А-В, показанная на Фиг. 6 в виде овала, включает в себя обе альтернативные ветви А и В. Именно поэтому независимо от того, которая из альтернативных ветвей А и В по результату выполнения персонализированной команды передачи управления ветви О будет выбрана в качестве целевой ветви, ее обработка будет продолжена без задержки.
[49] Однако каждая из альтернативных ветвей А и В содержит свою команду передачи управления, а значит образует свое ветвление соответственно на альтернативные ветви А1-А2 и В1-В2. Более точно, ветвь А1 непосредственно следует за ветвью А и выбирается по результату TAKEN, а ветвь А2 находится по адресу перехода и выбирается по результату NOT TAKEN. Аналогично, ветвь В1 непосредственно следует за ветвью В и выбирается по результату TAKEN, а ветвь В2 находится по адресу перехода и выбирается по результату NOT TAKEN.
[50] Последовательность широких команд А-В при этом может быть продолжена только одной из последовательностей широких команд А1-А2 и В1-В2, поскольку подготовительный конвейер известного VLIW-процессора 100 может обрабатывать только одну последовательность широких команд. Ошибочный выбор загружаемой в подготовительный конвейер последовательности широких команд из А1-А2 и В1-В2 приведет к повторной загрузке подготовительного конвейера и соответствующему увеличению времени выполнения программы. Таким образом, известный VLIW-процессор 100 способен гарантировать прохождение без потери времени лишь одного ветвления программы, которым на Фиг. 6 является ветвление из ветви О.
[51] В предложенном VLIW-процессоре 200 (Фиг. 4) подготовительный конвейер, образованный счетчиком 11 команд, памятью 21 команд, буфером 31 команд, регистровым файлом 41, и являющийся полностью идентичным подготовительному конвейеру известного VLIW-процессора 100, выступает в качестве первого подготовительного конвейера. Одновременно с этим предложенный VLIW-процессор 200 снабжен вторым подготовительным конвейером, который содержит счетчик 12 команд, память 22 команд, буфер 32 команд, регистровый файл 42, функции и конструктивное исполнение которых идентичны таковым у соответствующих элементов первого подготовительного конвейера.
[52] Подобно первому подготовительному конвейеру во втором подготовительном конвейере счетчик 12 команд соединен с памятью 22 команд шиной 121, буфер 32 команд соединен с памятью 22 команд и регистровым файлом 42 шинами 221 и 321, а регистровый файл 42 соединен с первым и вторым функциональными блоками 51 и 52 шинами 421 и 422. Помимо этого, память 22 команд соединена с буфером 31 команд шиной 222, а буфер 32 команд соединен с регистровым файлом 41 шиной 322. Выходы первого и второго функциональных блоков 51 и 52 соединены с регистровым файлом 42 шинами 521 и 522, назначение которых аналогично таковому у шин 511 и 512.
[53] Последовательность широких команд, обрабатываемая первым подготовительным конвейером в предложенном VLIW-процессоре 200 выступает в качестве первой последовательности широких команд, и соответственно, последовательность широких команд, обрабатываемая вторым подготовительным конвейером представляет собой вторую последовательность широких команд. Первый и второй подготовительные конвейеры способны осуществлять обработку своих последовательностей широких команд параллельно друг другу, а первый и второй функциональные блоки 51 и 52 способны принимать к выполнению соответственно первые и вторые персонализированные команды, выделенные из широких команд либо первой, либо второй последовательности.
[54] Далее, в состав предложенного VLIW-процессора 200 включены предсказатели 71 и 72 перехода (BP1, BP2 - branch predictor), соединенные соответственно со счетчиками 11 и 12 команд при помощи шин 711 и 721. Функции предсказателей 71 и 72 перехода раскрыты ниже, а здесь отметим, что несмотря на то, что на Фиг. 4 предсказатели 71 и 72 перехода показаны в виде отдельных разнесенных в пространстве блоков, в реальном исполнении они могут быть выполнены в составе единого устройства.
[55] Функционирование и преимущества предложенного VLIW-процессора 200, связанные с задействованием второго подготовительного конвейера, будут пояснены со ссылкой на Фиг. 5, на которой изображен реализуемый предложенным VLIW-процессором 200 конвейерный процесс. Модель команд конвейерного процесса на Фиг. 5 аналогична описанной выше модели команд, использованной для описания конвейерного процесса на Фиг. 2 и 3. Стадии первого подготовительного конвейера для каждой обрабатываемой им команды на Фиг. 5 обозначены прямоугольниками, в то время как стадии второго подготовительного конвейера на Фиг. 5 обозначены параллелограммами.
[56] Когда компилятор определяет, что через несколько тактов в широкую команду должна быть включена персонализированная команда branch передачи управления, он заблаговременно включает персонализированную команду prep, запускающую второй подготовительный конвейер, в широкую команду, предшествующую широкой команде с персонализированной командой branch. Выполнение команды branch сопровождается либо продолжением обработки альтернативной ветви А1 при результате NOT TAKEN, либо осуществлением перехода на альтернативную ветвь В1 при результате TAKEN, поэтому команда branch, следующая за командой prep, в контексте настоящего изложения именуется также командой осуществления исходного перехода, а команда prep - командой подготовки исходного перехода.
[57] Как видно на Фиг. 5, между командами prep и branch в первый подготовительный конвейер загружены две команды ins_0 и ins_1, не имеющие отношения к альтернативным ветвям А1 и В1. Данное обстоятельство не является случайным, поскольку из Фиг. 5 следует, что переход от команды branch на целевую ветвь, обработанную вторым подготовительным конвейером, выполняется без пропуска тактов тогда, когда прохождение командой prep стадии EX и прохождение командой branch стадии IF1 приходится на один и тот же такт. Соответственно для максимизации производительности предложенного VLIW-процессора 200 между командами prep и branch могут быть обработаны еще две команды ins_0 и ins_1. В то же время при других условиях команда prep может быть выполнена заранее.
[58] После прохождения командой prep стадии EX (такт 3), на следующем такте 4 происходит запуск второго подготовительного конвейера, который незамедлительно принимает первую команду В1_ins_0 альтернативной ветви В1 на свою стадию IF1, что на Фиг. 5 показано стрелкой. Одновременно с этим в первый подготовительный конвейер на такте 4 начинает загружаться первая команда А1_ins_0 альтернативной ветви А1. Когда команда branch проходит стадию EX, первые команды А1_ins_0 и В1_ins_0 альтернативных ветвей А1 и В1 уже находятся на стадии D, вторые команды А1_ins_1 и В1_ins_1 находятся на стадии IF1, а третьи команды А1_ins_2 и В1_ins_2 - на стадии IF2. Благодаря параллельной обработке обеих альтернативных ветвей А1 и В1, выполнение программы продолжится без задержки независимо от того, какая из этих альтернативных ветвей станет целевой ветвью по результату выполнения команды branch.
[59] Если бы на Фиг. 5 в качестве целевой ветви была выбрана альтернативная ветвь А1, то функционирование предложенного VLIW-процессора 200 не отличалось бы от функционирования известного VLIW-процессора 100, проиллюстрированного на Фиг. 2. Однако на Фиг. 5 целевой ветвью стала альтернативная ветвь В1, загруженная во второй подготовительный конвейер. В этом случае первая команда В1_ins_0 передается со стадии D второго подготовительного конвейера на стадию EX первого исполнительного конвейера, а следующие за ней команды В1_ins_1 и В1_ins_2 передаются со стадий IF2 и IF1 второго подготовительного конвейера соответственно на стадии D и IF2 первого подготовительного конвейера. Направления передачи команд В1_ins_0, В1_ins_1 и В1_ins_2 из второго подготовительного конвейера на Фиг. 5 показаны стрелками.
[60] Таким образом, второй подготовительный конвейер освобождается и может быть использован для обработки альтернативной ветви команд, возникающей на следующем ветвлении программы, поддерживая высокую производительность предложенного VLIW-процессора 200. Если же необходимость задействования второго подготовительного конвейера отсутствует, он выключается в целях экономии электроэнергии.
[61] Возвращаясь к Фиг. 4, если по результату выполнения первым или вторым функциональными блоками 51 и 52 персонализированной команды осуществления исходного перехода, установлено, что исходный переход должен быть осуществлен на вторую последовательность широких команд, то первый и второй функциональные блоки 51 и 52 принимают к выполнению первую и вторую персонализированные команды, выделенные из первой по счету широкой команды второй последовательности, от второго подготовительного конвейера. Более точно, первый и второй функциональные блоки 51 и 52 по шинам 421 и 422 принимают от регистрового файла 42 исходные операнды для указанных первой и второй персонализированных команд, а блок управления принимает от регистрового файла 42 код операций для указанных первой и второй персонализированных команд.
[62] Вторая по счету широкая команда второй последовательности передается от буфера 32 команд на регистровый файл 41 по шине 322, а третья по счету широкая команда второй последовательности передается от памяти 22 команд на буфер 31 команд по шине 222. Широкие команды первой последовательности, находящиеся на разных стадиях первого подготовительного конвейера при этом не сохраняются. Соответственно, первые и вторые персонализированные команды, выделенные из второй по счету и следующих за ней широких команд второй последовательности, поступают в первый и второй функциональные блоки 51 и 52 уже из первого подготовительного конвейера, а точнее - из регистрового файла 41.
[63] Возвращаясь к Фиг. 6, если подготовительный конвейер известного VLIW-процессора 100 способен обработать последовательность широких команд А-В и одну из последовательностей А1-А2 и В1-В2, то в предложенном VLIW-процессоре 200 первый подготовительный конвейер обрабатывает последовательности А-В и А1-А2, а второй подготовительный конвейер обрабатывает последовательность В1-В2.
[64] Таким образом, в противоположность способности известного VLIW-процессора 100 гарантировать безостановочное выполнение только последовательности широких команд А-В, предложенный VLIW-процессор 200 способен безостановочно выполнить последовательность А-В и любую из последовательностей А1-А2 и В1-В2, какая бы из них ни содержала целевую ветвь персонализированных команд. Другими словами, если известный VLIW-процессор 100 безостановочно проходит только один уровень ветвления О, то предложенный VLIW-процессор 200 безостановочно проходит два уровня ветвления, первым из которых является уровень О, а вторым - уровень АВ.
[65] Однако показанные на Фиг. 6 альтернативные ветви А1, А2, В1, В2 также разветвляются, поэтому представляется весьма желательным, чтобы предложенный VLIW-процессор 200 мог без задержки обработать и вновь образованные альтернативные ветви А1.1 - В2.2. Тем временем дальнейшее увеличение числа подготовительных конвейеров сопровождается как соответствующим увеличением числа элементов аппаратной части, так и соответствующим увеличением потребления электроэнергии, но при этом уже не дает прежнего эффекта по увеличению быстродействия. Данное противоречие обусловлено увеличением длины критических цепей, включающих в себя новые элементы и требующих увеличения длительности такта. В предложенном VLIW-процессоре 200 проблема увеличения числа последовательных альтернативных ветвей, которые могут быть обработаны без задержки, решена по-другому.
[66] Как было показано выше, предложенный VLIW-процессор 200 снабжен предсказателями 71 и 72 перехода, соединенными с блоком управления и со счетчиками команд 11 и 12. Принцип работы и конструктивное исполнение предсказателя перехода, который может быть использован в качестве предсказателей 71 и 72 перехода, известны специалисту в данной области техники и не являются предметом изобретения. Как правило, в основе алгоритма предсказания перехода лежит статистика выполненных переходов, собранная ранее на аналогичных случаях. Современные предсказатели перехода достаточно точны, и вероятность осуществления перехода в предсказанном ими направлении зачастую превышает 90%.
[67] Следует отметить, что в контексте настоящего изложения под персонализированной командой осуществления исходного перехода понимается персонализированная команда передачи управления, для осуществления которой (передачи управления) должен быть запущен второй подготовительный конвейер. Тем временем под персонализированной командой осуществления собственного перехода понимается персонализированная команда передачи управления, которая (передача управления) осуществляется без использования второго подготовительного конвейера, например в случае, когда второй подготовительный конвейер задействован для выполнения персонализированной команды осуществления исходного перехода.
[68] В предложенном VLIW-процессоре 200 блок управления при помощи предсказателя 71 перехода способен определять наиболее вероятную для перехода альтернативную ветвь персонализированных команд, а вместе с ней и вероятную версию первой последовательности широких команд, когда компилятор включил в одну из широких команд первой последовательности персонализированную команду осуществления собственного перехода.
[69] Под вероятной версией первой последовательности широких команд понимается совокупный набор широких команд, включающий в себя первый и второй наборы широких команд. Первый набор широких команд включает в себя широкие команды первой последовательности, предшествующие широкой команде с персонализированной командой осуществления собственного перехода, и саму эту широкую команду. Второй набор широких команд включает в себя широкие команды, которые следует за персонализированной командой осуществления собственного перехода согласно предсказанию перехода. Первый набор широких команд подлежит обязательному выполнению, при этом второй набор широких команд будет выполнен лишь с некоторой вероятностью.
[70] Блок управления управляет счетчиком 11 команд так, чтобы последовательно загружать в первый подготовительный конвейер широкие команды, входящие в вероятную версию первой последовательности. Другими словами, первый подготовительный конвейер использует вероятную версию первой последовательности широких команд в качестве первой последовательности широких команд.
[71] Аналогичным образом блок управления при помощи предсказателя 72 перехода способен определять вероятную версию второй последовательности широких команд, когда компилятор включил в одну из широких команд второй последовательности персонализированную команду осуществления собственного перехода. Подобно описанному выше, блок управления управляет счетчиком 12 команд так, чтобы последовательно загружать во второй подготовительный конвейер широкие команды, входящие в вероятную версию второй последовательности, которая фактически используется в качестве второй последовательности широких команд.
[72] Как видно на Фиг. 6, каждая из альтернативных ветвей А1 и А2, входящих в последовательность широких команд А1-А2, разветвляется еще на две альтернативные ветви, для гарантированной обработки которых без потери времени следовало бы составить из них еще две последовательности широких команд. Однако первый подготовительный конвейер может принять только одну последовательность широких команд, которая на основании предсказания переходов формируется из наиболее вероятных альтернативных ветвей, в данном случае - это альтернативные ветви А1.2 и А2.1.
[73] Аналогично, каждая из альтернативных ветвей В1 и В2, входящих в последовательность широких команд В1-В2, также разветвляется на две альтернативные ветви, при этом второй подготовительный конвейер принимает только одну последовательность широких команд, которая на основании предсказания переходов формируется из наиболее вероятных альтернативных ветвей В1.2 и В2.1.
[74] Таким образом, предложенный VLIW-процессор 200 с использованием предсказателей 71 и 72 перехода способен гарантированно выполнить без задержки последовательность широких команд А-В, следом за ней гарантированно выполнить без задержки любую из последовательностей А1-А2 и В1-В2, на какую бы из них ни был совершен исходный переход, и следом за ней с очень большой вероятностью выполнить без задержки одну из последовательностей А1.2-А2.1 или В1.2-В2.1.
[75] Другими словами, с использованием предсказателей 71 и 72 перехода предложенный VLIW-процессор 200 безостановочно проходит три уровня ветвления, первым из которых является уровень О, вторым - уровень АВ, а третьим - уровень А1В2. Обратим внимание, что на Фиг. 6 персонализированная команда подготовки исходного перехода и персонализированная команда осуществления исходного перехода принадлежит ветви О, а своя персонализированная команда осуществления собственного перехода принадлежит каждой из альтернативных ветвей А1, А2, В1 и В2.
[76] В заключение заметим, что дополнительно ко второму подготовительному конвейеру предложенный VLIW-процессор 200 может быть снабжен третьим, четвертым и т.д. подготовительными конвейерами, функционирование, конструктивное исполнение и достигаемые эффекты которых являются аналогичными таковым у второго подготовительного конвейера.
Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в уменьшении времени, затрачиваемого VLIW-процессором на выполнение программы для повышения быстродействия и производительности. Технический результат достигается за счёт того, что в VLIW-процессоре первый и второй подготовительные конвейеры способны параллельно друг другу осуществлять обработку соответственно первой и второй последовательностей широких команд, причем каждая широкая команда включает в себя первую и вторую персонализированные команды, предназначенные к выполнению первым и вторым исполнительными конвейерами, причем первый исполнительный конвейер способен выполнять персонализированную команду подготовки исходного перехода, запускающую второй подготовительный конвейер и предшествующую персонализированной команде осуществления исходного перехода, при этом первый и второй исполнительные конвейеры способны принимать к выполнению первую и вторую персонализированные команды, выделенные из широких команд той одной из первой и второй последовательностей широких команд, которая определена на основе результата выполнения первым или вторым исполнительным конвейером персонализированной команды осуществления исходного перехода. 3 з.п. ф-лы, 6 ил.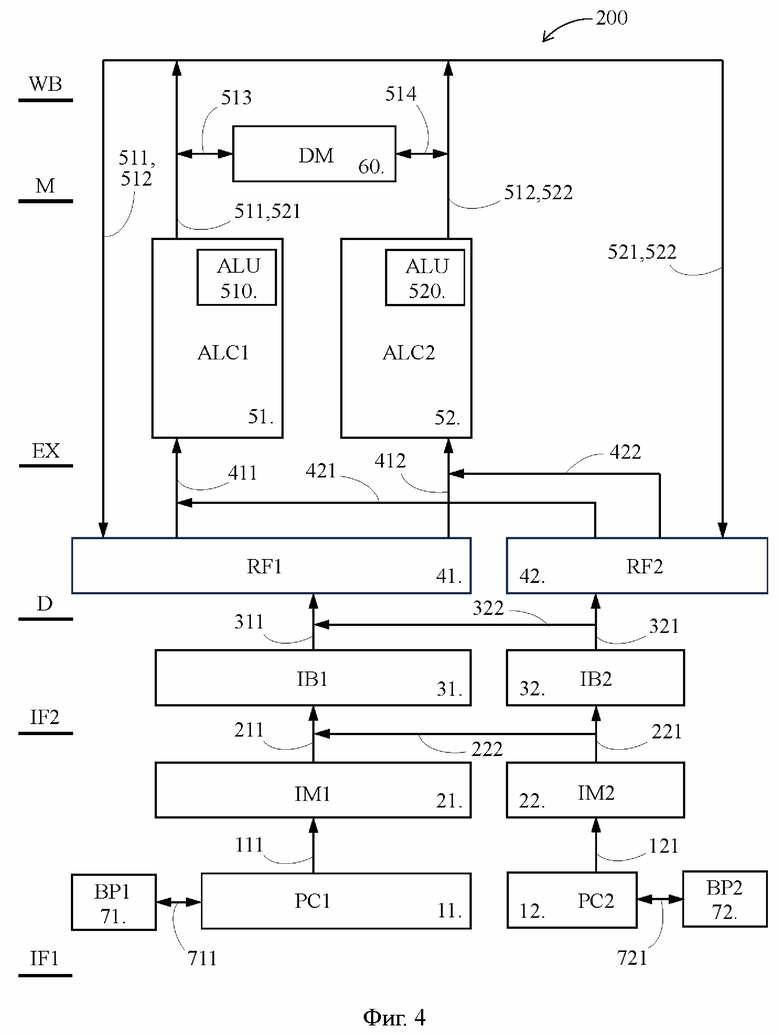
1. Процессор, содержащий первый подготовительный конвейер, действующий постоянно, и второй подготовительный конвейер, запускаемый временно, а также первый и второй исполнительные конвейеры, при этом
первый и второй подготовительные конвейеры способны параллельно друг другу осуществлять обработку соответственно первой и второй последовательностей широких команд, причем каждая широкая команда включает в себя первую и вторую персонализированные команды, предназначенные к выполнению первым и вторым исполнительными конвейерами, причем
первый исполнительный конвейер способен выполнять персонализированную команду подготовки исходного перехода, запускающую второй подготовительный конвейер и предшествующую персонализированной команде осуществления исходного перехода, при этом
первый и второй исполнительные конвейеры способны принимать к выполнению первую и вторую персонализированные команды, выделенные из широких команд той одной из первой и второй последовательностей широких команд, которая определена на основе результата выполнения первым или вторым исполнительным конвейером персонализированной команды осуществления исходного перехода.
2. Процессор по п. 1, в котором первый и второй исполнительные конвейеры выполнены с возможностью принимать к выполнению первую и вторую персонализированные команды, выделенные из первой по счету широкой команды второй последовательности широких команд, от второго подготовительного конвейера, и
выполнены с возможностью принимать к выполнению первую и вторую персонализированные команды, выделенные из следующих широких команд второй последовательности широких команд, от первого подготовительного конвейера, при этом
первый и второй подготовительные конвейеры выполнены с возможностью переноса широких команд второй последовательности широких команд с текущих стадий второго подготовительного конвейера на следующие стадии первого подготовительного конвейера.
3. Процессор по п. 1, блок управления которого при помощи предсказателя перехода способен определять вероятную версию первой последовательности широких команд, когда первая последовательность широких команд содержит персонализированную команду осуществления собственного перехода, причем в качестве первой последовательности широких команд первый подготовительный конвейер использует упомянутую вероятную версию первой последовательности широких команд.
4. Процессор по п. 3, блок управления которого при помощи предсказателя перехода способен определять вероятную версию второй последовательности широких команд, когда вторая последовательность широких команд содержит персонализированную команду осуществления собственного перехода, причем в качестве второй последовательности широких команд второй подготовительный конвейер использует упомянутую вероятную версию второй последовательности широких команд.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 9697004 B2, 04.07.2017 | |||
| Sensen Hu, Jing Huang | |||
| Exploring Adaptive Cache for Reconfigurable VLIW Processor, опубл | |||
| Способ очистки нефти и нефтяных продуктов и уничтожения их флюоресценции | 1921 |
|
SU31A1 |
| US | |||

