ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное решение относится к подходам по организации кэширования информации, в частности, к подходу по кэшированию блоков данных, который можно назвать, как "Кэш Сросшихся Очередей" (Coalesced Queues Cache, CQC).
УРОВЕНЬ ТЕХНИКИ
[0002] В вычислительной технике политики замены кэша (также известные, как алгоритмы замены кэша или алгоритмы кэша) представляют собой оптимизирующие инструкции или алгоритмы, которые компьютерная программа или структура, поддерживаемая аппаратным обеспечением, могут использовать для управления кэшем информации. Кэширование повышает производительность за счет хранения последних или часто используемых данных в ячейках памяти, доступ к которым осуществляется быстрее или с вычислительной точки зрения дешевле, чем к обычным хранилищам памяти. Когда кэш заполнен, алгоритм должен выбрать, какие элементы отбросить, чтобы освободить место для новых данных [1].
[0003] Из уровня техники известна реализация Адаптивного Замещающего Кэша (Adaptive Replacement Cache, ARC), раскрытого в патенте US 7469320 В2 (ORACLE AMERICA, INC., 23.12.2008). В известном решении алгоритм вытеснения реализован путем предварительного вычисления размера удаляемых блоков в кэше и последующей записи новых блоков в кэш, при условии, что размер удаляемых блоков равен или больше размера новых блоков. Несмотря на то что алгоритм вытеснения удаляемых блоков может быть совмещен с любой политикой вытеснения удаляемых блоков, проблема существующего способа заключается в том, что у данного решения гибкость адаптации ограничена кратно размеру нового блока, поступающего в кэш, его активация происходит только в этом случае.
[0004] Кроме того, в патенте US 7469320 В2 используется 2 разных очереди: одна отслеживает MRU (историчность доступа), а вторая MFU (частоту). Однако, элементы метаданных здесь не перетекают в пределах общего пространства кэша, так как есть явное разделение на разного рода очереди и четкий алгоритм регулирования длин очередей.
[0005] Таким образом, недостатком предшествующего уровня техники является недостаточная гибкость подхода за счет ограничения на количество потоков данных и очередей, как для данных, так и для индексов (элементов метаданных), а также невозможности сдвига границы между очередями без изменения размера всех очередей.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] Для достижения нового технического уровня необходимо было решить ряд технических проблем (задач):
• обеспечить возможность применения любой политики вытеснения кэширования или одновременного применения различных политик в пределах общего размера кэша,
• максимально сократить возможные накладные расходы (по памяти и времени исполнения) на обслуживание кэша, например, накопление счетчиков в элементах метаданных, индексов, историй и статистики манипулирования ими, путем реализации, в частном случае, структуры данных типа вероятностное множество,
• обеспечить адаптивную политику кэширования для многовариантных пользовательских сценариев нагрузки за счет тиринга блоков данных внутри кэша и использования множества очередей в нем.
[0007] В результате решения вышеуказанных проблем (задач) был разработан новый способ кэширования блоков данных, затрагивающий архитектуру самого кэширования, который можно назвать как "Кэш Сросшихся Очередей" (Coalesced Queues Cache, CQC), что позволило реализовать следующие преимущества:
• осуществление тиринга элементов блоков данных внутри очередей за счет сохранения элементов в одной или нескольких сросшихся очередях;
• одновременное применение любых политик вытеснения внутри каждой очереди в рамках общего кэша за счет использования, например, одной для всех или нескольких различных политик вытеснения для сросшихся очередей;
• поддержка высокого коэффициента успешных попаданий в кэш (hit ratio), адаптируясь к динамическим изменениям характера нагрузки на систему, и, в тоже время, обеспечение быстрого доступа к данным в кэше и низких накладных расходов по элементам метаданных за счет использования структуры типа вероятностное множество и путем периодического сдвига голов и/или хвостов сросшихся очередей (всех, одной или нескольких) вместо операций фактической перевставки самих элементов метаданных из одной очереди в другую и последующей потребности в произведении очищения статистики и/или истории блоков в кэше;
• многопоточная реализация очередей кэша за счет использования нескольких разных сросшихся очередей параллельно для разных потоков (источников) данных (multi-stream cache).
[0008] Частный случай реализации политики кэширования на базе заявленного способа CQC может иметь название, например, "Кэш перекрывающихся фильтров Блума" (Overlapping Bloom Filters Cache, OBFC).
[0009] Техническим результатом является повышение быстродействия кэша.
[0010] Дополнительным техническим результатом является обеспечение адаптивности кэша к высоким неравномерным нагрузкам.
[0011] Заявленный технический результат достигается за счет выполнения компьютерно-реализуемого способа кэширования блоков данных, выполняемого по меньшей мере одним процессором, и содержащего этапы, на которых:
• получают запрос на сохранение добавляемого блока данных в кэше,
• определяют необходимость вытеснения одного или более из имеющихся в кэше блоков данных,
• освобождают место для добавляемого блока данных путем
- вытеснения из одной или более сросшихся очередей, представляющих собой две или более очереди, организованные на базе одного списка или нескольких соединяющихся списков, и имеющие между собой общие элементы метаданных, - по меньшей мере, одного самого невостребованного элемента метаданных согласно установленной политике вытеснения и
- сохранения его в одну или более сросшихся очередей для вытесненных элементов метаданных или в одну или более структур данных типа вероятностное множество,
при этом, по меньшей мере, один блок данных, соответствующий, по меньшей мере, одному вытесненному элементу метаданных, удаляется из кэша,
• осуществляют вставку добавляемого блока данных в кэш и соответствующего ему элемента метаданных в одну или более сросшихся очередей,
причем добавляемый элемент метаданных, вне зависимости от его востребованности, вставляют в сросшуюся очередь с менее востребованными элементами метаданных,
• осуществляют периодический сдвиг начального и/или конечного элемента метаданных в одной или более сросшихся очередей для перемещения элементов метаданных в менее приоритетные очереди.
[0012] В одном из частных примеров реализации каждая из сросшихся очередей имеет собственную политику вытеснения.
[0013] В другом частном примере реализации используют несколько сросшихся очередей для различных потоков или источников данных, в зависимости от востребованности данных.
[0014] В другом частном примере реализации структура данных типа вероятностное множество реализована с помощью фильтра Блума или ленточного фильтра.
[0015] В другом частном примере реализации очереди ранжируются по степени востребованности элементов метаданных.
[0016] В другом частном примере реализации степень востребованности элементов метаданных определяется частотой обращений к соответствующим блокам данных.
[0017] В другом частном примере реализации способ дополнительно содержит этап, на котором выявляют неоптимально вытесненные блоки данных, манипулируя ими с использованием связанных элементов метаданных, при этом выявление неоптимально вытесненных блоков данных осуществляют с помощью структуры данных типа вероятностное множество, хранящей вытесненные элементы метаданных.
[0018] В другом частном примере реализации в случае получения запроса на сохранение блока данных, элемент метаданных которого признан неоптимально вытесненным, вставляют блок данных в кэш и соответствующий ему элемент метаданных в одну или более сросшихся очередей с более востребованными элементами метаданных.
[0019] В другом частном примере реализации период сдвига определяется на основе по меньшей мере одного из событий:
• срабатывание таймера,
• достижение заданного количества запросов,
• достижение порогового значения одного или нескольких параметров статистики обращений к кэшу.
[0020] В другом частном примере реализации используют дополнительный индекс прямой адресации для быстрого поиска элементов метаданных.
[0021] Заявленный технический результат достигается также за счет реализации устройства для кэширования блоков данных, содержащего по меньшей мере один процессор,
по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа кэширования блоков данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
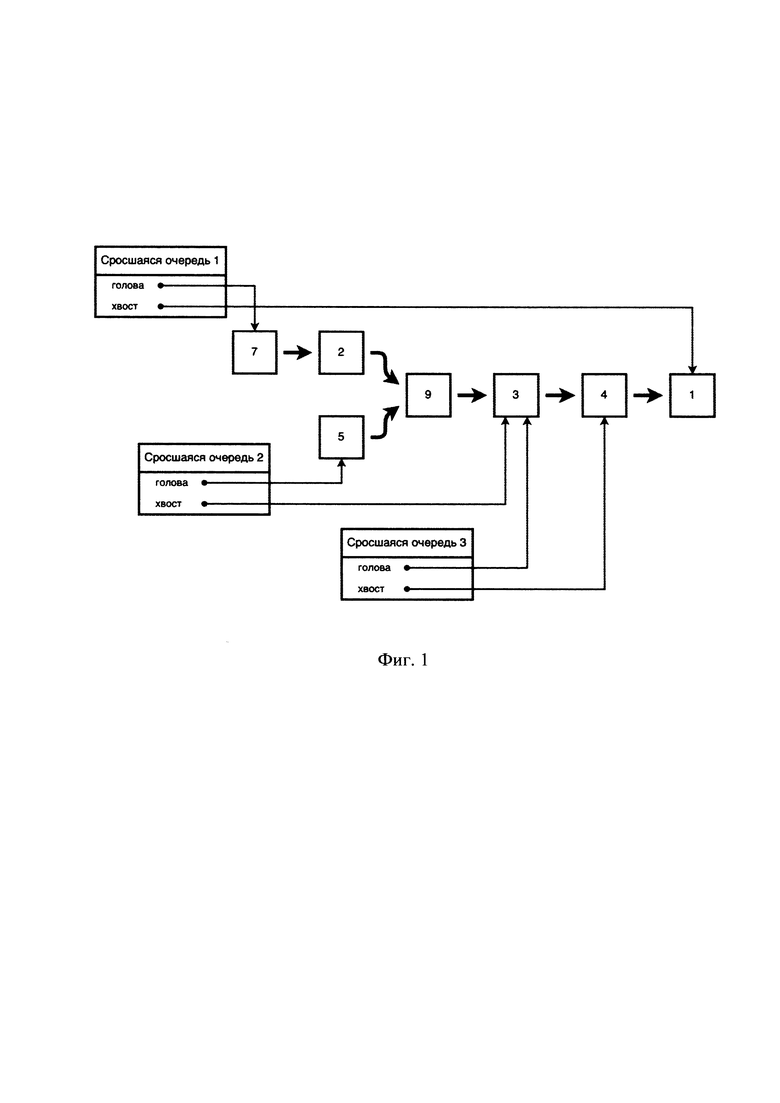
[0022] На Фиг. 1 представлена логическая схема (архитектура) кэширования на основе сросшихся очередей.
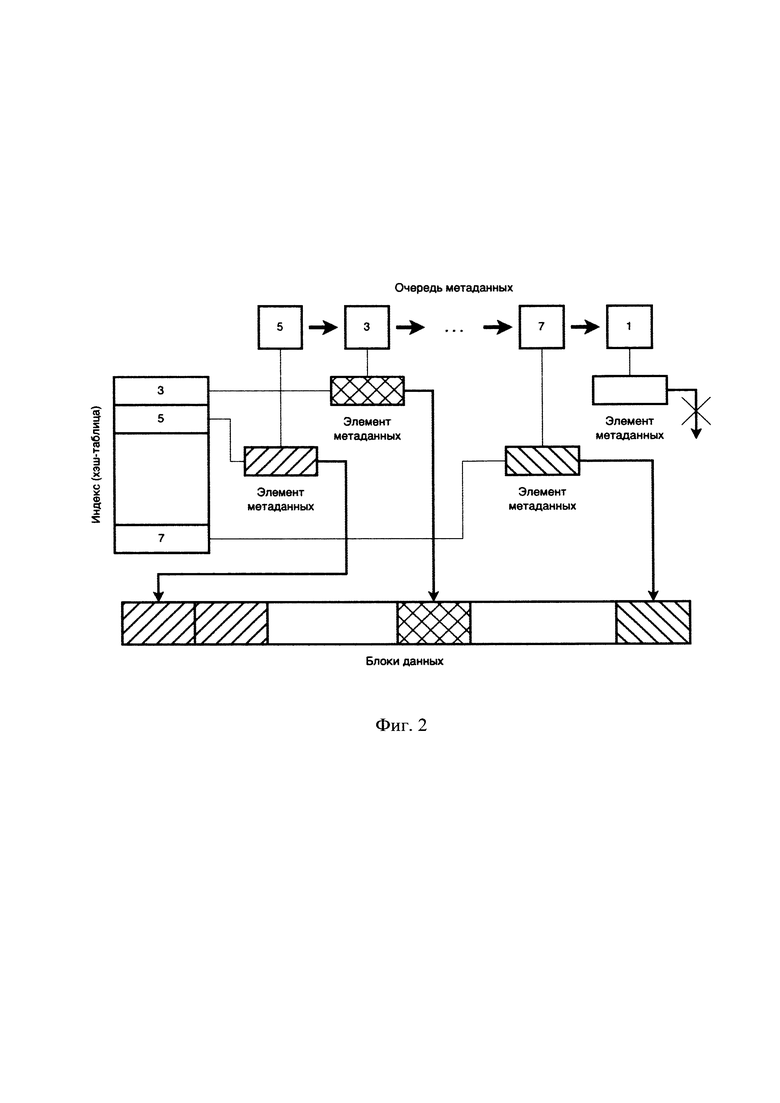
[0023] На Фиг. 2 представлена логическая взаимосвязь элементов кэша и блоков данных.
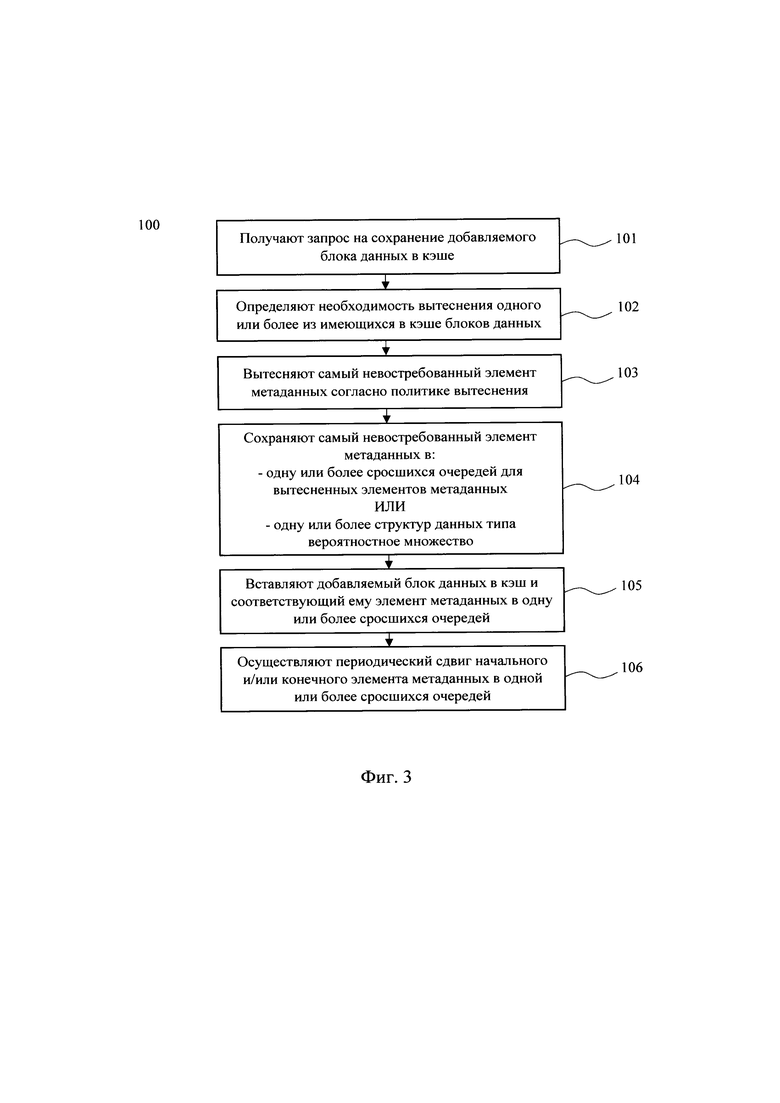
[0024] На Фиг. 3 представлена блок-схема компьютерно-реализуемого способа кэширования блоков данных.
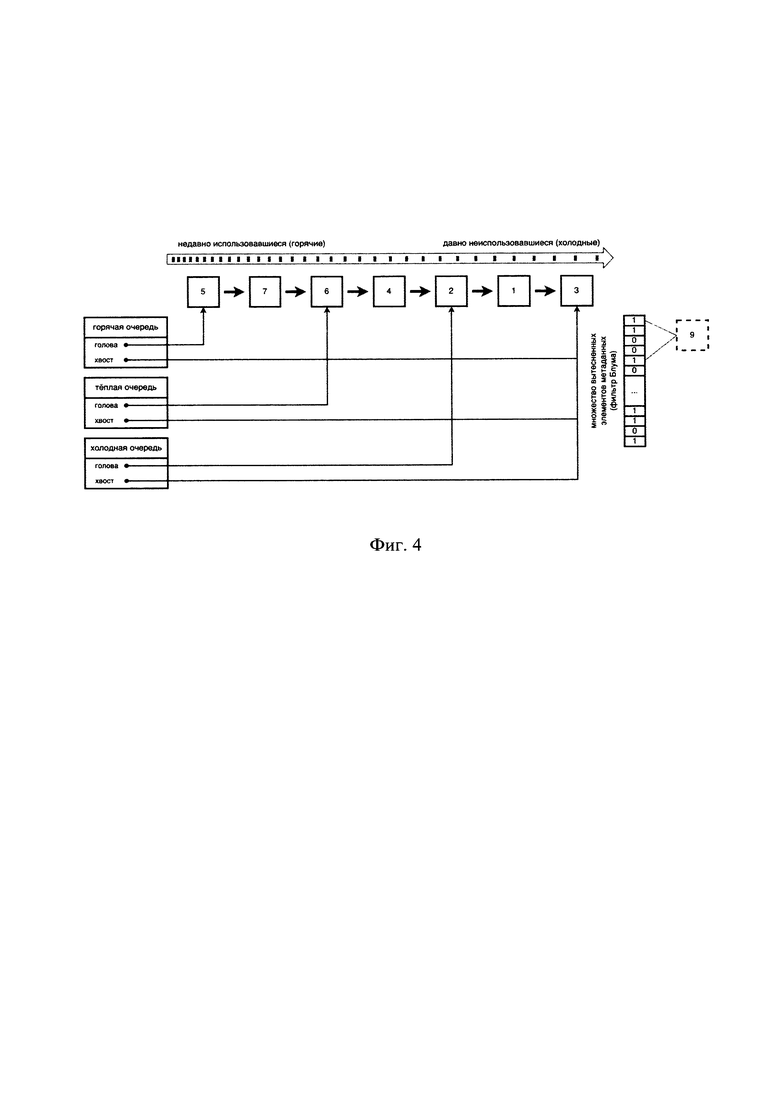
[0025] На Фиг. 4 представлен пример исходного состава кэша с уже вытесненным элементом.
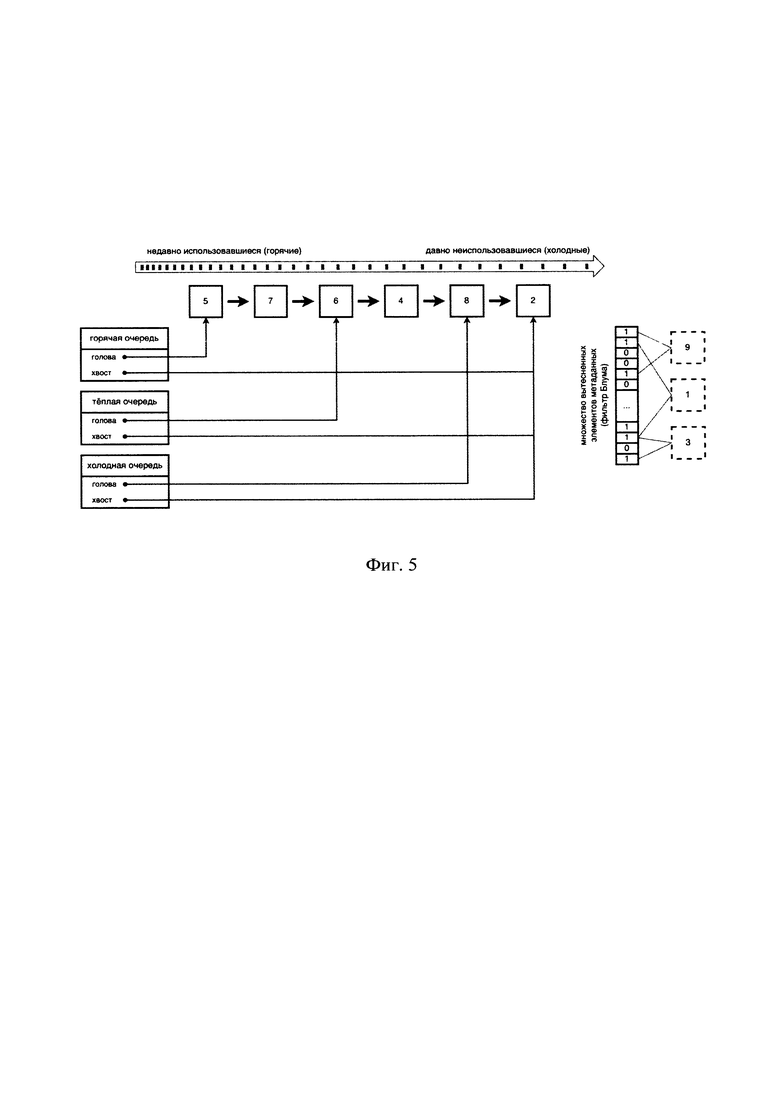
[0026] На Фиг. 5 представлен пример кэша с добавленным элементом.
[0027] На Фиг. 6 представлен пример механизма эйджинга (устаревания) элементов.
[0028] На Фиг. 7 представлен пример вставки ранее вытесненного элемента.
[0029] На Фиг. 8 представлен пример повышения степени востребованности элемента после повторного обращения.
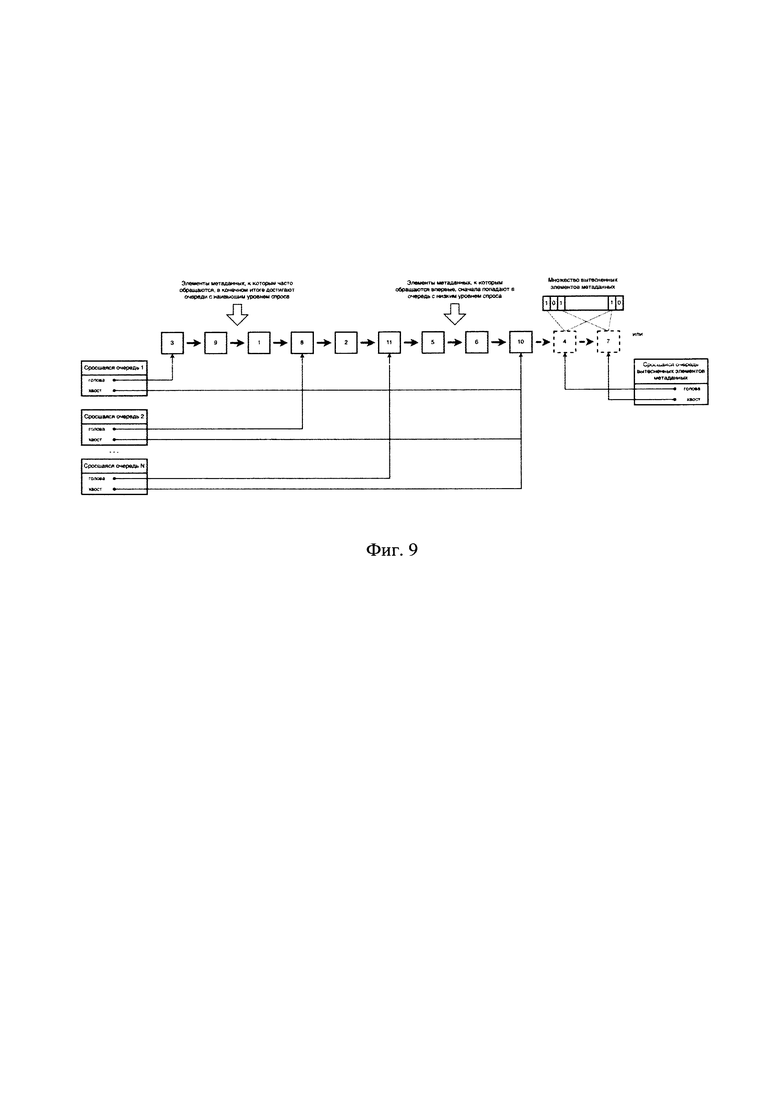
[0030] На Фиг. 9 представлена однопоточная реализации кэширования.
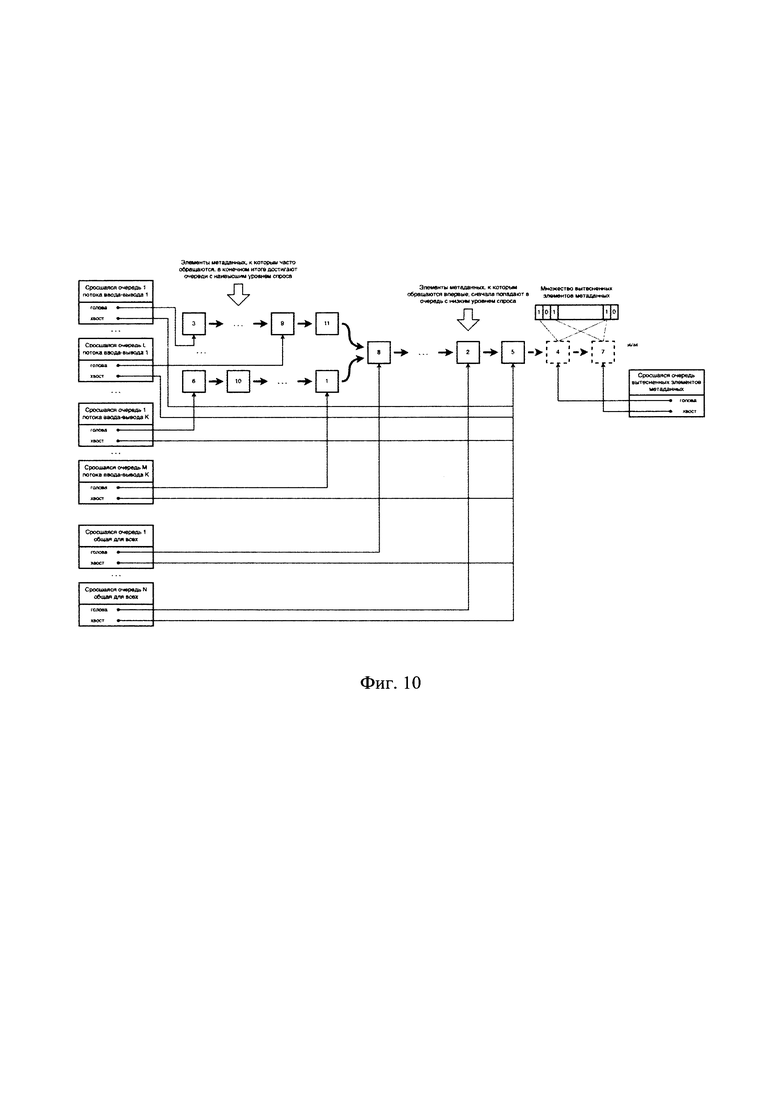
[0031] На Фиг. 10 представлена многопоточная реализации кэширования.
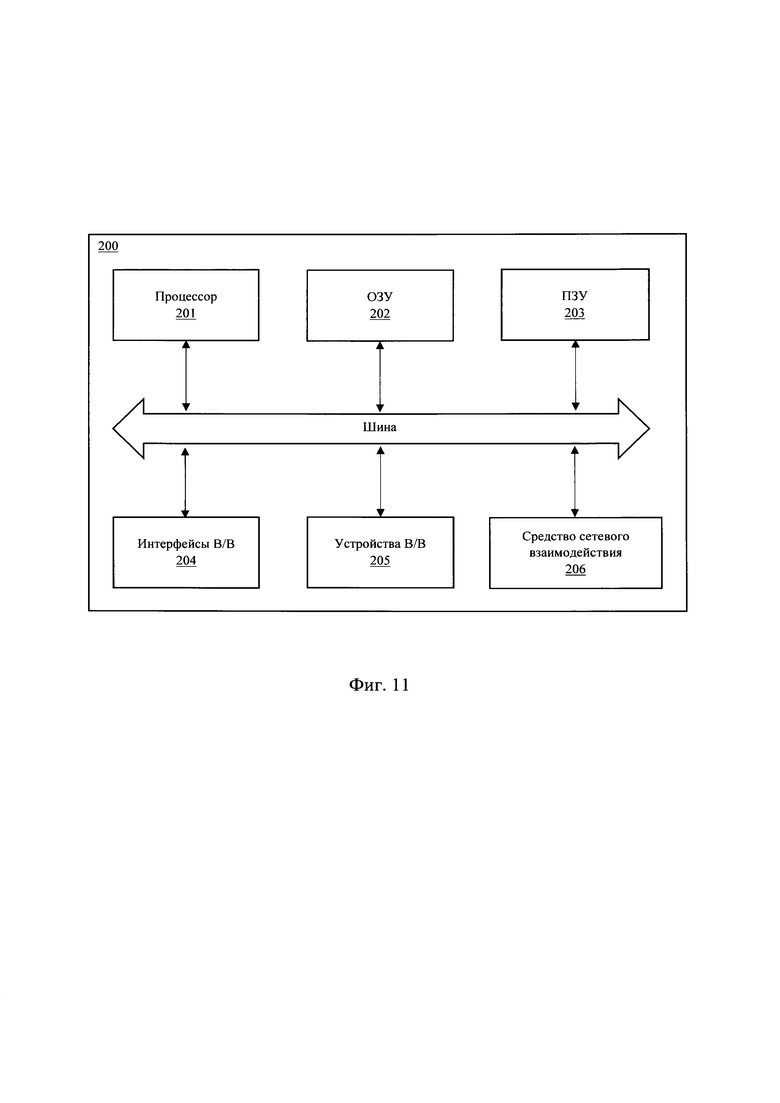
[0032] На Фиг. 11 представлена общая схема вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0033] Ниже будут описаны понятия и термины, необходимые для понимания настоящего изобретения.
[0034] Кэш - это промежуточный буфер памяти с быстрым доступом к нему, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удаленного источника, однако ее объем существенно ограничен по сравнению с хранилищем исходных данных.
[0035] Кэширование - это процесс использования более быстродействующей памяти, называемой кэшем, для хранения копий блоков информации из более медленной памяти, к которой вероятно будет обращение в ближайшее время. Кэширование обычно применяется центральными процессорами (CPU), оперативной памятью (RAM) и другими компонентами компьютерной системы для ускорения доступа к данным. Кэширование также может быть реализовано и использовано в программном обеспечении, например, в веб-серверах, браузерах, системах хранения данных, файловых системах, системах управления базами данных и многими другими приложениями для улучшения производительности. Различают кэши разных уровней (L1, L2, L3), которые отличаются размером и латентностью (временем доступа). Кэширование также включает алгоритмы вытеснения, которые определяют, какие данные будут удалены из кэша, чтобы освободить место для новых данных.
[0036] Тиринг (от англ. tiering) - это способ организации данных (или блоков данных, применительно к кэшу) в зависимости от степени их востребованности, т.е. их размещение и оперирование в виде структуры с различным уровнем/скоростью доступа или порядком обработки в зависимости от приоритета, задаваемого алгоритмом политики вытеснения. Например, редко используемые данные перемещаются на более медленные накопители, а часто используемые - на более быстрые. Применительно к кэшу, тиринг может быть реализован на базе ряда очередей из элементов, описывающих блоки данных с различной степенью «горячести».
[0037] Эйджинг (от англ. aging) - это периодический процесс охлаждения блоков данных в кэше, обеспечивающий их остывание и устаревание, с целью последующего вытеснения из кэша данных, которые перестали запрашиваться.
[0038] Очередь - это упорядоченная структура элементов в кэше, ссылающихся на блоки данных, используемая для отслеживания истории и/или частоты обращений к элементам в кэше.
[0039] Сросшиеся очереди - это две и более очередей, организованные на базе одного списка или нескольких соединяющихся списков, но каждая такая очередь включает в себя необязательно все элементы этого списка или этих соединяющихся списков. Другими словами, сросшиеся очереди имеют общие между собой элементы, а элементы, соответственно, могут входить в несколько очередей или во все очереди одновременно.
[0040] Список (в информатике) - это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза.
[0041] Связный список (в информатике) - это базовая динамическая структура данных, состоящая из узлов, содержащих данные и ссылки («связки») на следующий и/или предыдущий узел списка.
[0042] Блок данных - это блок размещенных данных, как правило, в блочном хранилище, файловой системе или базе данных.
[0043] Элемент метаданных (очереди и/или индекса прямой адресации) - это метаданные блока данных, как правило, содержащие указатель на блок данных, идентифицирующий данные (например, адрес блока на диске для дискового кэша) и дополнительную служебную информацию.
[0044] Политика вытеснения (от англ. eviction policy) - это правило, по которому выбирается один из элементов очереди для вытеснения из нее и освобождения места под вставку нового элемента.
[0045] Заявленный способ кэширования блоков данных в общем случае распространяется на информацию, которая читается с любых хранителей информации (блочные устройства, объектные хранилища, ленты, диски, облачные хранилища), и хранится, например, в системах типа: базы данных, вычислительные фреймворки, файловые системы, S3 хранилища, блочный уровень операционных систем (page cache). Необходимо отметить, что реализация заявленного решения не ограничивается конкретным источником происхождения блока, заявленное устройство просто умеет хранить некие блоки данных по запросу на сохранение.
[0046] На Фиг. 1 представлена логическая схема (архитектура) кэширования на основе сросшихся очередей.
[0047] Для тиринга блока данных внутри кэша, возможности реализации одновременно разных политик вытеснения элементов внутри кэша, возможности работы с кэшем в многопоточном режиме были разработаны архитектура и алгоритм кэширования CQC (Coalesced Queues Cache, "Кэш Сросшихся Очередей").
[0048] Сросшиеся очереди используются для отслеживания истории и степени горячести. Для тиринга блоков данных используются несколько сросшихся очередей и соответствующие блокам данных элементы метаданных в этих очередях, а история отслеживается самим принципом устройства очередей и политикой вытеснения.
[0049] Представленный на Фиг. 1 пример содержит вариант кэша на основе трех сросшихся очередей. Каждая сросшаяся очередь имеет начальный (голова) и конечный (хвост) элемент метаданных. Сросшаяся очередь 1 содержит элементы метаданных «7», «2», «9», «3», «4», «1», где элемент метаданных «7» - голова очереди, элемент метаданных «1» - хвост очереди. Сросшаяся очередь 2 содержит элементы метаданных «5», «9», «3», где элемент метаданных «5» - голова очереди, элемент метаданных «3» - хвост очереди. Сросшаяся очередь 3 содержит элементы метаданных «3», «4», где элемент метаданных «3» - голова очереди, элемент метаданных «4» - хвост очереди. Таким образом, например, все три сросшиеся очереди имеют общий между собой элемент, а именно элемент метаданных «3 ». При этом сросшиеся очереди могут иметь более одного общего элемента (например, сросшиеся очереди 1, 3 имеют общие между собой элементы «3», «4»), однако сросшиеся очереди не могут не иметь общего элемента на основании свойства сросшести.
[0050] Структура организации кэша в виде Кэша Сросшихся Очередей позволяет изменять размер конкретной очереди независимо от размера других очередей что в свою очередь позволяет достичь повышения быстродействии работы кэша, гибкой адаптации той или иной очереди к сложным многопользовательским сценариям нагрузки.
[0051] На Фиг. 2 представлена логическая взаимосвязь элементов кэша и блоков данных. Каждый элемент метаданных имеет указатель на данные. Для быстрого поиска и доступа к блокам данным в кэше, помимо очередей, чаще всего используют еще и индекс (хэш-таблицу). В альтернативном варианте воплощения заявленного решения можно использовать и дерево, но для кэша фиксированного размера предварительно выделенная хэш-таблица будет компактнее и работать за O(1).
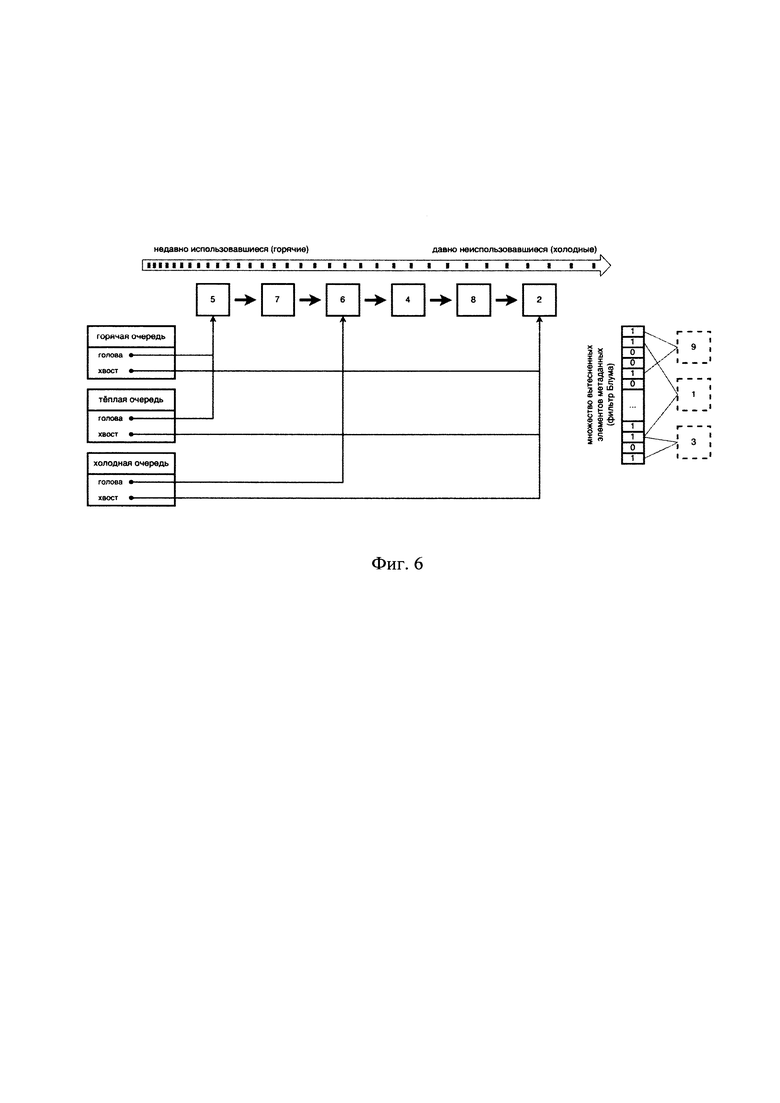
[0052] В частном примере реализации для быстрого поиска элементов метаданных используют дополнительный индекс прямой адресации. Каждый элемент метаданных вставляется одновременно в хэш-таблицу для прямой индексации и в очередь для управления вытеснением. Иными словами, кэш имеет индекс для прямого доступа к любому из его элементов метаданных.
[0053] На Фиг. 3 представлен компьютерно-реализуемый способ (100) кэширования блоков данных. Выполнение способа (100) осуществляется с помощью по меньшей мере одного процессора. В частном примере реализации выполнение способа (100) осуществляется с помощью устройства для кэширования блоков данных, которое может быть реализовано на базе вычислительного устройства, модифицированного в программно-аппаратной части таким образом, чтобы выполнять функции устройства для кэширования блоков данных. Более подробное описание вычислительного устройства раскрыто далее со ссылкой на Фиг. 11.
[0054] На первом этапе (101) получают запрос на сохранение добавляемого блока данных в кэше. Добавляемый блок данных может быть, как новым блоком данных, так и блоком данных, который был ранее ошибочно (неоптимально) вытеснен из кэша.
[0055] На Фиг. 4-8 проиллюстрирован предпочтительный вариант воплощения заявленного решения, раскрывающий тиринг блоков данных внутри кэша, содержащего сросшиеся очереди с горячими, теплыми и холодными блоками данных, а также вытесненными из кэша блоками данных (на примере Фиг. 4, вытесненному блоку данных соответствует элемент метаданных «9»). При этом вытесненные из кэша блоки данных хранятся в кэше в виде адресов без явных данных. В качестве альтернативы очередям с вытесненными элементами можно использовать структуры данных типа множество или вероятностное множество.
[0056] На примере Фиг. 4 рассмотрим появление запроса на добавление в кэш, ранее не присутствовавшего в кэше, блока данных с элементом метаданных «8». На этапе 102 определяют необходимость вытеснения одного или более из имеющихся в кэше блоков данных, чтобы освободить место для добавляемого блока данных, соответствующего элементу метаданных «8». Для освобождения, требуемого для добавляемого блока данных места, необходимо вытеснить блоки данных, соответствующие элементам метаданных «1» и «3», поскольку это самые холодные (невостребованные) данные.
[0057] В частном варианте реализации на этапе 102 может быть определено, что необходимость вытеснения одного или более из имеющихся в кэше блоков данных отсутствует. Это вариант возможен, когда кэш еще не заполнен (является пустым) или находится в процессе заполнения (частично заполнен), но еще имеется свободное место для добавляемого блока данных.
[0058] Самый(е) невостребованный(ые) элемент(ы) метаданных вытесняют согласно политике вытеснения (этап 103). В данном примере все очереди используют LRU-политику: вытесняется хвостовой элемент метаданных, а новый вставляется в голову. В данном конкретном случае (Фиг. 4), очереди имеют совпадающие хвосты (элемент метаданных «3»), т.е. более горячие очереди содержат менее горячие внутри себя. Востребованность элемента метаданных «3 » соответствует холодной очереди (т.е. очереди с наименее невостребованными элементами метаданных), в которой он находится, другие элементы метаданных («2», «1») из этой же очереди могут конкурировать с ним за место в кэше. К примеру, элемент метаданных «4» является теплым, потому что находится одновременно в горячей и теплой очередях, а элемент метаданных «9» является вытесненным и относящийся к нему блок данных отсутствует в кэше.
[0059] В предпочтительном варианте воплощения заявленного решения очереди ранжируются по степени востребованности элементов метаданных, где степень востребованности элементов метаданных определяется частотой обращений к соответствующим блокам данных.
[0060] Если некоторый элемент метаданных входит в несколько сросшихся очередей одновременно, то под степенью его горячести (востребованности) можно понимать горячесть (востребованность) наиболее холодной очереди, которая его содержит. Это обусловлено тем, что все элементы метаданных в этой наиболее холодной очереди могут конкурировать с ним за место в кэше.
[0061] Самая большая очередь может содержать в себе несколько маленьких и при перестановке элемента в списке, на базе которого они организованы, этот элемент может как одновременно удаляться из нескольких сросшихся очередей, так и одновременно вставляться в несколько сросшихся очередей, но при этом в реальности выполняется всего одна операция перемещения в списке.
[0062] Политика вытеснения элементов может быть единая для всех или же у каждой сросшейся очереди своя. Таким образом, для продвижения блока данных в кэше при повторных доступах могут использоваться разные подходы (политики вытеснения) в разных очередях.
[0063] В качестве политики вытеснения может выступать, но не ограничиваться указанными примерами:
• FIFO (англ. first in, first out «первым пришел - первым ушел»),
• LIFO (англ. last in, first out, «последним пришел - первым ушел»),
• FILO (англ. first in, last out, «первым пришел - последним ушел»),
• LRU (англ. least recently used, «вытеснение давно неиспользуемых»),
• MRU (англ. most recently used, «наиболее недавно использовавшийся»),
• LFU (англ. least-frequently used, «наименее часто используемый»).
[0064] В результате вытеснения получится состояние кэша, проиллюстрированное на Фиг. 5: элементы метаданных «1» и «3 » сохранятся во множестве вытесненных элементов метаданных, а их данные (блоки данных, соответствующие вытесненным элементам метаданных) будут удалены из кэша, чтобы записать добавляемый блок данных.
[0065] В предпочтительном варианте воплощения заявленного решения сохраняют самый невостребованный элемент метаданных в одну или более сросшихся очередей для вытесненных элементов метаданных или в одну, или более структур данных типа множество или вероятностное множество (этап 104). При этом структура данных типа вероятностное множество реализована с помощью фильтра Блума [2] или ленточного фильтра [3].
[0066] Здесь и далее под фильтром понимается вероятностная структура данных, позволяющая проверять принадлежность элемента к множеству. При этом существует возможность получить ложноположительное срабатывание (элемента в множестве нет, но структура данных сообщает, что он есть), но не ложноотрицательное. Реализует абстрактный тип данных «вероятностное множество».
[0067] Ленточный фильтр (от англ. Ribbon filter) является модификацией фильтра Блума и получил свое название ввиду того, что график распределения случайных битов в матрицах распределения Гаусса (статической функции) выглядит на графике буквально как лента [3].
[0068] Информацию о полностью вытесненных элементах метаданных из кэша можно хранить, например, в дополнительной сросшейся очереди, либо, в качестве альтернативы, использовать одну или несколько структур данных типа множество, которые можно реализовать в том числе вероятностным способом на основе фильтров Блума или ленточных фильтров. В структуре данных типа множество можно отслеживать все вставленные элементы метаданных или только вытесненные. В результате реализуется многовариантная архитектура кэша, имеющая максимальную вариативность размеров блоков данных при оперировании, не имеющая ограничений в части использования тех или иных вариантов реализации политик вытеснения и их используемого числа внутри кэша и возможность оптимального масштабирования без пересмотра архитектуры, например, по причине возрастания накладных расходов и на любых объемах данных, при выборе вероятностного варианта, например, OBFC.
[0069] Реализация заявленного алгоритма кэширования с политикой вытеснения кэширования на основе фильтров Блума был выбран для того, чтобы обеспечить и продемонстрировать максимальную эффективность работы вне зависимости от размеров блоков данных и размеров самого кэша, так как принцип работы фильтров Блума - это использование пространственно-эффективной структуры данных, предназначенной для быстрой проверки принадлежности элемента к множеству и работающей по вероятностному механизму. Фильтр Блума может сообщить, принадлежит ли элемент множеству или нет, но при этом может допускать ложноположительные ответы.
[0070] В контексте кэширования фильтры Блума могут использоваться для определения, находится ли определенный элемент метаданных в кэше или нет, без необходимости просматривать весь кэш. Это может значительно ускорить процесс поиска, снизить нагрузку на систему, и как следствие повысить скорости доступа к данным в кэше, что способствует повышению быстродействия кэша. Если фильтр Блума указывает, что некоторого элемента метаданных нет в кэше, то точно можно сказать, что его там нет. Если же фильтр Блума указывает, что этот элемент есть в кэше, то он может быть там, но есть небольшая вероятность, что это ложноположительный результат.
[0071] На этапе (105) осуществляют вставку добавляемого блока данных в кэш и соответствующего ему элемента метаданных в одну или более сросшихся очередей, представляющих собой две или более очереди, организованные на базе одного списка или нескольких соединяющихся списков, и имеющие между собой общие элементы метаданных (но не обязательно все).
[0072] Как видно на Фиг. 5, элемент метаданных «8» оказался в голове холодной очереди, как самый свежий (самый востребованный) из холодных элементов, к которому получали доступ недавно.
[0073] В предпочтительном варианте реализации заявленного изобретения добавляемый элемент метаданных, вне зависимости от его востребованности, вставляют в сросшуюся очередь с менее востребованными элементами метаданных. За счет того, что добавляемые (новые) блоки данных и соответствующие им элементы метаданных, которые встречаются впервые, могут быть вставлены только в холодную очередь - элементы более горячих очередей защищены от вымывающих кэш нагрузок, например, серии больших последовательных чтений без повторных обращений к считанным данным, что способствует повышению стабильности и быстродействия работы кэша.
[0074] На этапе (106) осуществляют периодический сдвиг начального и/или конечного элемента метаданных в одной или более сросшихся очередей для перемещения принадлежности элементов метаданных в менее приоритетные очереди в зависимости от степени востребованности элементов метаданных. Действия, осуществляемые на этапе (106), направлены на замену операциям фактической перевставки самих элементов метаданных из одной очереди в другую для очистки историй и статистики использования блоков данных в общем объеме кэша.
[0075] В целях борьбы с несвежими или застоявшимися в кэше элементами метаданных и соответствующими им блоками данных, с течением времени необходимо обновлять статистику и очищать историю. Сильная сторона сросшихся очередей заключается в возможности просто сдвигать или перемещать головы и хвосты сросшихся очередей по элементам списка(ов), на базе которого(ых) они созданы, избегая операций фактической перевставки самих элементов метаданных из одной очереди в другую. Например, просто сдвигать головы холодных очередей ближе к головам горячих для понижения степени горячести (востребованности) элементов метаданных, которые в результате этого действия тоже окажутся в холодных очередях, и увеличения размеров холодных очередей, при этом манипулируя лишь парой указателей. Со временем горячие элементы, при повторных запросах к ним, снова переместятся только в горячие очереди, уменьшив размер холодных очередей, обеспечивая цикличность процесса отсеивания застоявшихся элементов метаданных. Иногда при повторном обращении к элементу метаданных и соответствующему ему блоку данных мы можем принять решение о переносе этого элемента в более горячую очередь.
[0076] На Фиг. 6 представлен пример результата работы механизма эйджинга (устаревания) относительно предыдущего состояния (Фиг. 5), после вытеснения элементов метаданных «1» и «3». Голова самой горячей сросшейся очереди не изменяется, а головы более холодных сросшихся очередей сдвигаются на позицию соседней более горячей сросшейся очереди. Хвосты у всех сросшихся очередей смотрят в одно место, т.е. самый холодный элемент метаданных «2» - он самый холодный для всех. В результате осуществления операции эйджинга голова горячей сросшейся очереди «5» не изменилась, а голова теплой сросшейся очереди направлена туда же, куда и голова горячей («6» стала «5»). Таким образом, горячие элементы метаданных (такие как «5» и «7») горячей очереди стали теплыми, путем изменения лишь одного указателя. Аналогично, голова холодной сросшейся очереди «8» (см. Фиг. 5) сдвинется туда, где раньше была голова теплой сросшейся очереди (станет «6», см. Фиг 6), следовательно, ранее теплые элементы метаданных (такие как «6» и «4») станут холодными. Элементы метаданных «8» и «2» - как были холодными, так и остались холодными. Сразу после такого сдвига горячая и теплая очереди одинаковы по составу входящих элементов, из чего следует, что горячих элементов временно нет. В другом частном случае можно сдвигать головы менее холодных сросшихся очередей не в головы соседних более горячих сросшихся очередей, а, например, в середины, чтобы сохранить некоторое количество горячих элементов горячими.
[0077] В частном варианте реализации период сдвига начального (головы) и/или конечного (хвоста) элемента метаданных определяется на основе по меньшей мере одного из событий:
• срабатывание таймера, с заранее заданным временным интервалом, реализованный с помощью временных меток (timestamps),
• достижение заданного количества запросов,
• достижение порогового значения одного или нескольких параметров статистики обращений к кэшу, где в качестве параметров могут выступать, например, количество перемещений элементов метаданных между очередями; заданная дистанция, характеризующаяся общим количеством обращений к кэшу между последним и предпоследним обращениями к конкретному элементу.
[0078] В одном из вариантов реализации заявленного решения выявляют неоптимально вытесненные блоки данных, манипулируя ими с использованием связанных элементов метаданных, при этом выявление неоптимально вытесненных блоков данных осуществляют с помощью структуры данных типа вероятностное множество, хранящей вытесненные элементы метаданных.
[0079] Полученный, в результате работы структуры данных типа вероятностное множество (например, фильтра Блума), ложноположительный результат впоследствии отсекается путем непосредственного поиска в кэше. После того как элемент метаданных и соответствующий блок данных уже были вытеснены из кэша, структура данных типа вероятностное множество (например, фильтр Блума) позволяет узнать, был ли этот блок данных когда-то в прошлом уже вставлен в кэш, т.е. осуществляется детектирование ситуаций неоптимального (ошибочного) вытеснения.
[0080] При повторной вставке таких блоков данных, горячесть для соответствующих элементов метаданных может быть сразу повышена относительно других элементов метаданных, которые вставляются в кэш впервые. Структура данных типа вероятностное множество (например, фильтр Блума или ленточный фильтр) может использоваться либо для отслеживания только вытесненных элементов метаданных, либо для отслеживания вообще всех элементов метаданных, содержащихся в кэше. В конкретном варианте реализации фильтр Блума является частным случаем реализации абстрактного типа данных «множество».
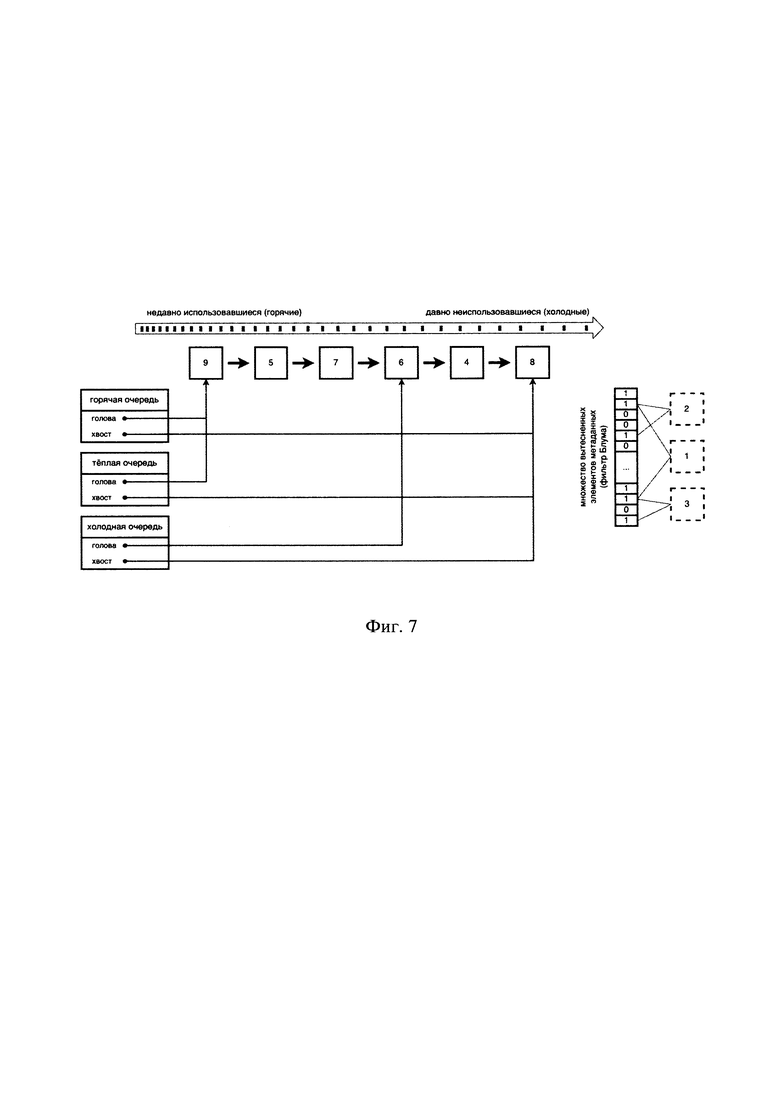
[0081] На Фиг. 7 представлен пример вставки блока данных, которому соответствует элемент метаданных «9», который был ранее отмечен как вытесненный. Поскольку известно, что к этому блоку данных в прошлом уже требовался доступ, и он находился в кэше, а затем был вытеснен, то его можно вставить с повышенным уровнем спроса. Элемент метаданных «9» будет вставлен сразу в голову теплой сросшейся очереди, как показано на Фиг. 7. В данном частном случае, чтобы сохранить принцип вложенности менее горячих сросшихся очередей в более горячие сросшиеся очереди - голова горячей очереди будет сдвинута на ту же позицию, куда и голова теплой очереди, пока они равны (т.е. ни один блок данных после процесса устаревания не стал вновь горячим). В результате этой вставки элемент метаданных «2» и его блок данных будут вытеснены, как самые холодные.
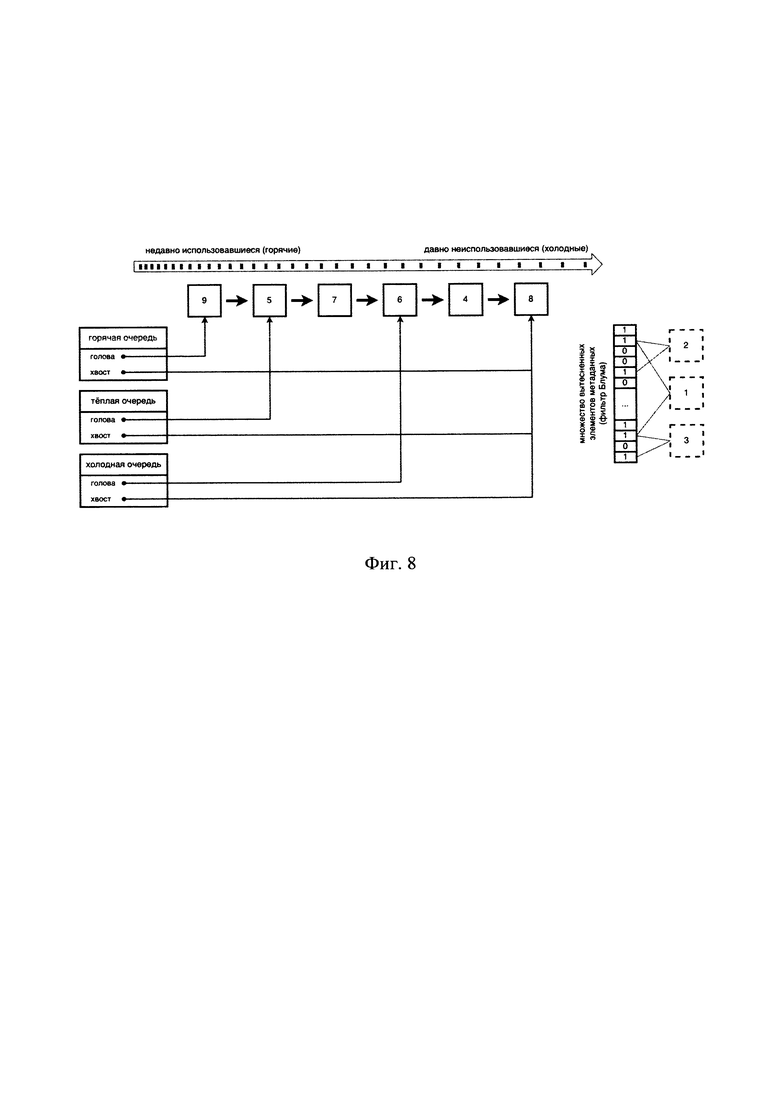
[0082] На Фиг. 8 представлен пример повышения степени востребованности (горячести) элемента метаданных «9» в кэше после повторного обращения к соответствующему блоку данных. Так, при последующих повторяющихся доступах к блоку данных с элементом метаданных «9», он переместится в горячую очередь, как показано на Фиг. 8, став самым востребованным (горячим) блоком данных и, соответственно, связанный с ним элемент метаданных «9» стал самым горячим элементом метаданных во всех сросшихся очередях.
[0083] На Фиг. 9 представлен пример реализации однопоточного кэша.
[0084] Благодаря тому, что все сросшиеся очереди на самом деле находятся в одном и том же списке элементов метаданных, такой кэш адаптируется к динамической нагрузке, за счет манипуляции длинами очередей, как описано выше, и не требует статического разделения на зоны фиксированного размера, что в свою очередь способствует повышению производительности и быстродействия работы кэша.
[0085] На Фиг. 10 представлен пример реализации многопоточного кэша.
[0086] Кэш для нескольких потоков данных тоже имеет общий индекс для прямого доступа к любому элементу из любой очереди. Принцип действия такой же, как и у единого для всех кэша, за исключением того, что горячие сросшиеся очереди у каждого потока данных (или только у некоторых, не у всех) имеют свой начальный (голова) и/или конечный (хвост) элемент метаданных, параллельные относительно других потоков данных. В общем случае, например, таких горячих сросшихся очередей может быть несколько, их задача - защищать часть элементов от вытеснения другими потоками данных за счет того, что часть элементов метаданных не находятся в едином списке, а находятся в нескольких разных списках, что исключает конкуренцию за место в кэше между ними. Например, в случае со сложным многопользовательским сценарием, в архитектуре кэша можно реализовать многопоточность охлажденных данных согласно заявленному решению, чтобы более эффективно работать в части разделения нагрузки, или же настроить для отдельных очередей тиринг, например, для горячей очереди попадание по политике FIFO для более быстрого вытеснения из горячей очереди случайных блоков, а для остальных очередей, например LRU для более справедливого разделения доступа при обработки записи.
[0087] В частном варианте реализации используют несколько сросшихся очередей для различных потоков или источников данных, в зависимости от востребованности данных. Таким образом, реализуют многопоточный режим доступа к блокам данных в кэше с помощью сросшихся очередей, используемых для распараллеливания потоков, тем самым защищая кэш от монопольного заполнения конкретным пользователем, что в свою очередь способствует повышению быстродействия работы кэша.
[0088] В одном из примеров реализации заявленного изобретения списки, на базе которых организованы очереди, входящие в состав сросшихся очередей, являются связными списками.
[0089] На Фиг. 11 представлен общий вид вычислительного устройства (200), на базе которого может быть реализовано устройство для кэширования блоков данных, обеспечивающее реализацию способа кэширования блоков данных.
[0090] В общем случае вычислительное устройство (200) содержит объединенные общей шиной информационного обмена один или несколько процессоров (201), средства памяти, такие как ОЗУ (202) и ПЗУ (203), интерфейсы ввода/вывода (204), устройства ввода/вывода (205), и средство для сетевого взаимодействия (206).
[0091] Процессор (201) (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. В качестве процессора (201) может также применяться графический процессор, например, Nvidia, AMD, Graphcore и пр. Процессор (201) имеет иерархию из нескольких уровней кэша (L1, L2, L3).
[0092] ОЗУ (202) представляет собой оперативную память и предназначено для хранения исполняемых процессором (201) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (202), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.).
[0093] ПЗУ (203) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, Blu-Ray Disc, MD) и др.
[0094] Для организации работы компонентов устройства (200) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (204). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SAT A, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0095] Для обеспечения взаимодействия пользователя с вычислительным устройством (700) применяются различные устройства (205) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0096] Средство сетевого взаимодействия (206) обеспечивает передачу данных устройством (200) посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (206) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0097] Дополнительно в составе устройства (200) могут также применяться средства спутниковой навигации, например, GPS, ГЛОНАСС, BeiDou, Galileo.
[0098] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
[0099] Источники информации:
[1] Cache replacement policies - Wikipedia. https://en.wikipedia.org/wiki/Cache_replacement_policies
[2] Bloom filter - Wikipedia. https://en.wikipedia.org/wiki/Bloom_filter
[3] Peter C. Dillinger et al. "Ribbon filter: practically smaller than Bloom and Xor", опубл. 08.03.2021. https://arxiv.org/pdf/2103.02515.pdf
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ДАННЫХ | 2024 |
|
RU2829301C1 |
| СПОСОБ УПРАВЛЕНИЯ СИСТЕМОЙ ХРАНЕНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2021 |
|
RU2805012C2 |
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |
| СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2824327C1 |
| УПРАВЛЕНИЕ ПАМЯТЬЮ ДЛЯ ВЫСОКОСКОРОСТНОГО УПРАВЛЕНИЯ ДОСТУПОМ К СРЕДЕ | 2007 |
|
RU2419226C2 |
| УПРАВЛЕНИЕ ПАМЯТЬЮ ДЛЯ ВЫСОКОСКОРОСТНОГО УПРАВЛЕНИЯ ДОСТУПОМ К СРЕДЕ | 2007 |
|
RU2491737C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СОЗДАНИЯ И АДМИНИСТРИРОВАНИЯ ВИРТУАЛЬНЫХ ЧАСТНЫХ ГРУПП В ОРИЕНТИРОВАННОЙ НА СОДЕРЖИМОЕ СЕТИ | 2011 |
|
RU2573771C2 |
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕННОГО ХРАНЕНИЯ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ С ОБЕСПЕЧЕНИЕМ ЦЕЛОСТНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ИНФОРМАЦИИ | 2021 |
|
RU2777270C1 |
| СПОСОБ ПОСТРОЕНИЯ РАСПРЕДЕЛЕННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ | 2018 |
|
RU2699683C1 |
| ИСПОЛЬЗОВАНИЕ ВНЕШНИХ УСТРОЙСТВ ПАМЯТИ ДЛЯ УЛУЧШЕНИЯ ПРОИЗВОДИТЕЛЬНОСТИ СИСТЕМЫ | 2005 |
|
RU2395115C2 |
Изобретение относится к способам кэширования данных. Технический результат заключается в повышении быстродействия кэша. Технический результата достигается за счет того, что способ содержит этапы, на которых:
получают запрос на сохранение данных в кэше; определяют необходимость вытеснения имеющихся в кэше блоков данных; освобождают место для добавляемого блока данных путем вытеснения из сросшейся очереди самого невостребованного элемента метаданных согласно политике вытеснения и сохранения его в сросшуюся очередь для вытесненных элементов метаданных или в структуру данных типа вероятностное множество, при этом блок данных, соответствующий вытесненному элементу метаданных, удаляется из кэша; осуществляют вставку добавляемого блока данных в кэш и элемента метаданных в сросшуюся очередь, причем добавляемый элемент метаданных вставляют в сросшуюся очередь с менее востребованными элементами метаданных; осуществляют периодический сдвиг начального или конечного элемента метаданных в сросшихся очередях для перемещения элементов метаданных в менее приоритетные очереди. 2 н. и 9 з.п. ф-лы, 11 ил.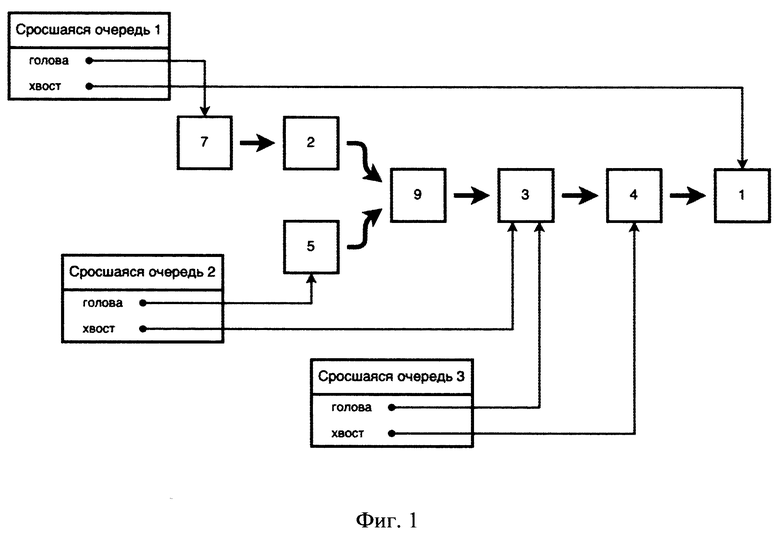
1. Компьютерно-реализуемый способ кэширования блоков данных, выполняемый по меньшей мере одним процессором, содержащий этапы, на которых:
• получают запрос на сохранение добавляемого блока данных в кэше,
• определяют необходимость вытеснения одного или более из имеющихся в кэше блоков данных,
• освобождают место для добавляемого блока данных путем
- вытеснения из одной или более сросшихся очередей, представляющих собой две или более очереди, организованные на базе одного списка или нескольких соединяющихся списков и имеющие между собой общие элементы метаданных, по меньшей мере одного самого невостребованного элемента метаданных согласно установленной политике вытеснения и
- сохранения его в одну или более сросшихся очередей для вытесненных элементов метаданных или в одну или более структур данных типа вероятностное множество,
при этом по меньшей мере один блок данных, соответствующий по меньшей мере одному вытесненному элементу метаданных, удаляется из кэша,
• осуществляют вставку добавляемого блока данных в кэш и соответствующего ему элемента метаданных в одну или более сросшихся очередей,
причем добавляемый элемент метаданных, вне зависимости от его востребованности, вставляют в сросшуюся очередь с менее востребованными элементами метаданных,
• осуществляют периодический сдвиг начального и/или конечного элемента(ов) метаданных в одной или более сросшихся очередей для перемещения элементов метаданных в менее приоритетные очереди.
2. Способ по п. 1, характеризующийся тем, что каждая из сросшихся очередей имеет собственную политику вытеснения.
3. Способ по п. 1, характеризующийся тем, что используют несколько сросшихся очередей для различных потоков или источников данных, в зависимости от востребованности данных.
4. Способ по п. 1, характеризующийся тем, что структура данных типа вероятностное множество реализована с помощью фильтра Блума или ленточного фильтра.
5. Способ по п. 1, характеризующийся тем, что очереди ранжируются по степени востребованности элементов метаданных.
6. Способ по п. 5, характеризующийся тем, что степень востребованности элементов метаданных определяется частотой обращений к соответствующим блокам данных.
7. Способ по п. 1, характеризующийся тем, что дополнительно содержит этап, на котором выявляют неоптимально вытесненные блоки данных, манипулируя ими с использованием связанных элементов метаданных, при этом выявление неоптимально вытесненных блоков данных осуществляют с помощью структуры данных типа вероятностное множество, хранящей вытесненные элементы метаданных.
8. Способ по п. 7, характеризующийся тем, что в случае получения запроса на сохранение блока данных, элемент метаданных которого признан неоптимально вытесненным, вставляют блок данных в кэш и соответствующий ему элемент метаданных в одну или более сросшихся очередей с более востребованными элементами метаданных.
9. Способ по п. 1, характеризующийся тем, что период сдвига определяется на основе по меньшей мере одного из событий:
• срабатывание таймера,
• достижение заданного количества запросов,
• достижение порогового значения одного или нескольких параметров статистики обращений к кэшу.
10. Способ по п. 1, характеризующийся тем, что используют дополнительный индекс прямой адресации для быстрого поиска элементов метаданных.
11. Устройство для кэширования блоков данных, содержащее
по меньшей мере один процессор,
по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из пп. 1-10.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| CN 114721722 A, 08.07.2022 | |||
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Программируемые устройства для обработки запросов передачи данных памяти | 2016 |
|
RU2690751C2 |

