Область техники, к которой относится изобретение
Настоящее изобретение относится в общем к области компьютерного зрения и может найти применение в робототехнике, автономном вождении, реконструкции сцен, моделировании 3D объектов, в применениях AR/VR, в которых требуются метрические карты глубины и/или согласованные во времени карты глубины для видеопоследовательности, в 3D сканировании и т.д.
Уровень техники
Недавнее появление приложений понимания 3D привело к разработке методов оценки глубины. Они способствуют осуществлению навигации и взаимодействию роботов с окружением, пониманию окружения для планирования пути при автономном вождении или помощи водителю при вождении, корректному размещению объектов AR в окружении, 3D сканированию, постобработке видео, например, стабилизации видео, и т.п.
В уровне техники существует ряд подходов к оценке глубины на основе одного или множества видов в видеопоследовательности.
Решения для оценки глубины на основе одного вида не позволяют сохранять надежность измерений глубины на протяжении всей последовательности кадров, что ухудшает восприятие пользователя или даже делает такие алгоритмы практически неприменимыми.
Для выравнивания карт глубины для видео или набора позиционированных кадров предлагаются методы обучения во время тестирования (ТТТ). Известно, что в методах ТТТ данный процесс оптимизации выполняется независимо для каждого тестового ввода.
В оригинальном подходе ТТТ, представленном в [14] как CVD, оцениваются согласованные глубина и положения камеры на основе разреженной реконструкции COLMAP. В Deep3D [11] совместная оптимизация положения и глубины решается основанным на обучении подходом, однако из-за отсутствия априорных значений глубины этот метод выдает только неточные карты глубины.
Такая априорная информация используется в RobustCVD (Kopf, Rong и Huang 2021) для подгонки к модели деформирования, которая позволяет сохранять достаточную локальную согласованность глубины в коротких видеопоследовательностях. Однако RobustCVD практически не применим для более длинных видео из-за временнозатратной процедуры ТТТ, которая включает в себя маскирование динамических объектов посредством Mask-RCNN.
Контролируемая оценка глубины на основе одного вида является плохо обусловленной задачей [5], [12], [4], которую можно решить до масштаба только при наличии визуальных вводов. MiDaS [18] получает относительную глубину стереопар из крупномасштабных и разнообразных 3D фильмов и учится оценивать обратную глубину по смещению и масштабу. В GP2 [28] изучается смещение глубины, что позволяет прогнозировать карты глубины до масштаба. Однако масштаб глубины может значительно различаться во всей видеопоследовательности, поэтому оценочные карты глубины на основе одного вида не выровнены в 3D пространстве.
При известных положениях камеры многовидовые стерео методы, основанные на изучении, способны оценить плотную глубину в метрическом пространстве [7], [26], [8], [13], [25]. Положения камеры могут оцениваться, например, регрессионными сетями [22], [26], [24], [21], с применением эпиполярной геометрии [2], [20], [3], [23] или в соответствии с парадигмой «структура из движения» (COLMAP).
В методах многовидовой оценки глубины, таких как SimpleRecon [27], не учитываются другие прогнозы глубины при оценке глубины для целевого кадра. Это приводит к низкой корреляции ошибок глубины; следовательно, желательно дополнительно повысить согласованность. При разработке предложенного способа авторы настоящего изобретения рассматривали SimpleRecon как источник исходных оценок глубины.
В PseudoDepth ненадежные карты глубины отфильтровываются с помощью простой медианной стратегии и при оптимизации используется карта оценочной достоверности глубины. Все перечисленные выше модели оценивают оптический поток посредством предобученной сети и используют прогнозы для управления оценкой глубины. Наиболее близкими аналогами изобретения можно считать RobustCVD и GCVD, поскольку они также осуществляют оптимизацию на параметрической модель деформирования глубины. Однако ресурсоемкий метод RobustCVD обеспечивает только локальную согласованность с соседними кадрами и тестировался только на коротких видеопоследовательностях. GCVD является первым подходом, который обеспечивает глобальную согласованность для длинных видео за счет интеграции графа положений на основе ключевых кадров в процесс обучения, но он все же не способен обеспечить работу в реальном времени.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Данный раздел, в котором раскрыты различные аспекты заявленного изобретения, предназначен для краткого обзора заявленных объектов изобретения и вариантов их осуществления. Ниже приведены подробные характеристики технических средств и способов, которые реализуют комбинации признаков заявленного изобретения. Ни данное раскрытие изобретения, ни приведенное ниже подробное описание вместе с сопровождающими чертежами не следует рассматривать как определяющие объем заявленного изобретения. Объем правовой охраны заявленного изобретения определяется только нижеследующей формулой изобретения.
Техническая проблема, решаемая настоящим изобретением, состоит в последовательном выравнивании карт глубины для видео или набора позиционированных кадров.
Задача настоящего изобретения состоит в создании способа и системы, которые создают метрические карты глубины для позиционированных кадров видео.
Технический результат, достигаемый при применении заявленного изобретения, состоит в получении согласованных метрических карт глубины, основанных на абсолютных расстояниях до всех объектов в среде, изображенной в последовательности кадров видео.
В первом аспекте упомянутая выше задача решается способом коррекции данных глубины для множества видов в видеопоследовательности, содержащей один или более кадров, содержащим этапы, на которых: создают покадровые масштабные карты глубины в форме билинейных сплайнов для поднабора кадров из упомянутых одного или более кадров; для остальных кадров в одном или более кадрах инициализируют покадровые масштабные карты глубины путем репроецирования метрических карт глубины данного поднабора кадров; для всех кадров из одного или более кадров осуществляют итеративную оптимизацию покадровых масштабных карт глубины, причем все масштабные карты глубины инициализируют единицами перед коррекцией; и осуществляют итеративную оптимизацию масштабных карт глубины для данного поднабора кадров посредством алгоритма оптимизации на основе градиента.
Карты глубины до масштаба оценивают для каждого кадра видео, используя предобученную нейронную сеть. Согласно способу дополнительно получают метрические карты глубины путем поэлементного умножения исходной карты глубины на
соответствующую масштабную карту глубины. Способ может дополнительно содержать этап, на котором получают положения камеры для одного или более кадров с камеры, снявшей эти один или более кадров. Положения камеры можно получать с помощью гироскопа камеры или оценивать путем применения алгоритма оценки положения камеры к упомянутым одному или более кадрам.
В одном или более вариантах карты глубины могут быть сформированы в некотором масштабе, причем упомянутый масштаб может различаться между разными кадрами в упомянутых одном или более кадрах.
Во втором аспекте упомянутая выше задача решается устройством для коррекции данных глубины для множества видов, содержащим: модуль приема видеопоследовательности, выполненный с возможностью приема видеопоследовательности, содержащей один или более кадров; модуль формирования масштабной карты глубины, выполненный с возможностью формирования покадровых масштабных карт глубины в форме билинейных сплайнов для поднабора кадров, извлеченных из упомянутого одного или более кадров последовательности видеокадров, принятой модулем приема видеопоследовательности; модуль инициализации масштабной карты глубины, выполненный с возможностью инициализации покадровых масштабных карт глубины путем репроецирования метрических карт глубины данного поднабора кадров и инициализации всех масштабных карт глубины единицами перед коррекцией масштабных карт глубины; модуль коррекции масштабной карты глубины, выполненный с возможностью итеративной покадровой оптимизации масштабных карт глубины для всех кадров упомянутого одного или более кадров и итеративной оптимизации масштабных карт глубины для поднабора кадров посредством алгоритма оптимизации на основе градиента.
Устройство может дополнительно содержать камеру, выполненную с возможностью съемки видеопоследовательности, содержащей последовательность упомянутых одного или более кадров. Устройство может дополнительно содержать модуль формирования метрических карт глубины, выполненный с возможностью выполнения поэлементного умножения определенной исходной карты глубины для определенного кадра из упомянутых одного или более кадров на соответствующую масштабную карту глубины для получения метрических карт глубины.
Устройство может дополнительно содержать модуль получения положений камеры, выполненный с возможностью получения положений камеры для соответствующих кадров из упомянутого одного или более кадров видеопоследовательности.
Карты глубины могут быть сформированы в некотором (неизвестном) масштабе, причем этот масштаб различается между разными кадрами из упомянутого одного или более кадров.
В третьем аспекте упомянутая выше задача решается машиночитаемым носителем, на котором сохранены машиночитаемые инструкции, которые при выполнении по меньшей мере одним процессором предписывают по меньшей мере одному процессору осуществлять способ согласно первому аспекту.
Специалистам в данной области будет ясно, что изобретательский замысел не ограничен аспектами, изложенными выше, и изобретение может принимать форму других объектов, таких как система, компьютерная программа или компьютерный программный продукт. Дополнительные признаки, которые могут характеризовать конкретные варианты осуществления настоящего изобретения, будут очевидны специалистам в данной области техники из подробного описания вариантов осуществления, приведенного ниже.
Краткое описание чертежей
Чертежи приведены в данном документе для облегчения понимания сущности настоящего изобретения. Данные чертежи схематичны и не выполнены в масштабе. Чертежи служат только для иллюстрации и предназначены для определения объема настоящего изобретения.
Фиг. 1 схематично иллюстрирует предлагаемый подход;
Фиг. 2 - схематичное изображение устройства для коррекции данных глубины для множества видов в соответствии с вариантом осуществления;
Фиг. 3 иллюстрирует выборку из предложенного полученного самостоятельно набора данных;
Фиг. 4 иллюстрирует реконструкцию TSDF сцены из набора данных TUM RGB-D, полученную с использованием карт глубины MEDeA.
Осуществление изобретения
В настоящем изобретении предложен способ коррекции глубины для множества видов во время тестирования, подходящий для различных приложений компьютерного зрения и/или «визуального понимания». Визуальное понимание - это метод распознавания и обработки вещей аналогично человеческому зрению, и он включает, например, распознавание объектов, отслеживание объектов, поиск изображений, распознавание людей, распознавание сцен, трехмерную реконструкцию/локализацию или повышение качества изображения. Получив исходные карты глубины и соответствующие положения камеры, способ согласно изобретению выполняет покадровую коррекцию отдельных карт глубины, оптимизируя локальные коэффициенты масштабирования на регулярной сетке. Масштабные карты глубины инициализируются с использованием репроецированных карт глубины ключевых кадров, что обеспечивает многокадровую согласованность и ускоряет сходимость. В сочетании с обычным монокулярным методом оценки глубины, который прогнозирует глубину в соответствии с масштабом, например, используя предобученную нейронную сеть, способную оценивать глубину, настоящий подход позволяет получать согласованные метрические карты глубины.
В качестве ключевых кадров в различных реализациях настоящего изобретения можно выбрать любой один или более кадров видеопоследовательности. Например, не ограничивая изобретение, в качестве ключевого кадра можно использовать каждый i-й (например, восьмой) кадр видеопоследовательности.
Здесь следует отметить, что карты глубины до масштаба могут в общем различаться по масштабу между кадрами. Соответственно, для точки, видимой в двух кадрах, если последний спроецирован в 3D пространство с использованием оценочных карт глубины для двух таких кадров, эти проекции могут не совпадать из-за разных масштабов оценок глубины. Такой эффект называется временной несогласованностью. Он накладывает серьезные ограничения на практическое использование: 3D-реконструкция не будет работать или даст неадекватные результаты, так как карты глубины не будут выровнены в 3D-пространстве, а объекты дополненной реальности не будут стабилизированы в окружении. Настоящее изобретение направлено на устранение этого эффекта совместной коррекцией масштабов глубины отдельных карт глубины, чтобы выровнять их в трехмерном пространстве и обеспечить непротиворечивую пространственную информацию.
В отличие от известных моделей, упомянутых в приведенном выше описании известного уровня техники, которые оценивают оптический поток с помощью предобученной сети и используют прогнозы для управления оценкой глубины, способ согласно изобретению не требует сегментации, оценки нормалей или оценки оптического потока. При этом предложенный способ сохраняет согласованность в длинных видеопоследовательностях, являясь на порядок более быстрым, чем известные методы. Современные устройства оснащены системами слежения, и даже небольшие гироскопы смартфонов определяют положение камеры с достаточной точностью (см., например, [15]). Соответственно, настоящее изобретение сфокусировано только на коррекции глубины при наличии положений камеры. В экспериментах использовались эталонные положения, представленные в стандартных контрольных тестах, и положения ARCore для самостоятельно захваченных данных.
Изобретательский подход ТТТ увеличивает глубину видео посредством подгонки покадровых масштабных карт глубины. С этой целью применяется новая стратегия инициализации и обновления масштаба, которая обеспечивает согласованность множества кадров и ускоряет сходимость. Предлагаемый способ не требует вспомогательных модулей, а использует модель оценки глубины.
В предлагаемом способе в качестве ввода берутся положения камеры (полученные, например, гироскопом или оцененные с помощью алгоритма) и соответствующие карты глубины (измеренные датчиком или оцененные с помощью алгоритма) для отдельных кадров. Карты глубины могут быть как метрическими (представленными в абсолютных значениях), так и представленными в неизвестном масштабе; этот масштаб может различаться между разными кадрами (т.е. он может быть разным для каждого определенного кадра). Предлагаемый способ выдает метрические карты глубины, которые согласованы во времени, т.е. карты глубины из множества видов выровнены в 3D пространстве.
В кратком изложении предлагаемый способ содержит следующие этапы:
1. Для поднабора кадров, например, видеопоследовательности кадров, снятых камерой, создаются покадровые масштабные карты глубины в форме билинейных сплайнов. Перед коррекцией все эти масштабные карты глубины инициализируются единицами. Затем они итеративно оптимизируются с помощью алгоритма оптимизации на основе градиента. Метрические карты глубины можно получить путем поэлементного умножения исходной карты глубины на соответствующую масштабную карту глубины.
2. Для остальных кадров в видео покадровые масштабные карты глубины инициализируются путем репроецирования метрических карт глубины поднабора кадров, оптимизированных на этапе 1.
3. Для всех кадров в видео покадровые масштабные карты глубины оптимизируются итеративно как на этапе 1.
Карты глубины до масштаба можно оценивать для каждого кадра видео, используя предобученную нейронную сеть. В данном контексте термин «до масштаба» подразумевает следующее. Большинство современных методов оценки глубины, основанных на изображениях, оценивают только относительные, а не метрические значения глубины, т.е. оценивают, что некоторый определенный пиксель расположен, например, в n раз дальше, чем другой определенный пиксель. В таком случае говорят, что «карта глубины известна с точностью до масштаба».
Здесь следует отметить, что нейронным сетям обычно требуется большой объем данных для обучения. Чтобы научиться оценивать карту глубины при наличии изображению, нейронной сети следует показать ряд образцов некоторой формы {изображение, соответствующую карту глубин}. Однако собрать миллиардный набор данных с захваченной датчиками глубиной очень сложно: это дорого, а датчики имеют ограниченный диапазон. Поэтому изучались другие источники данных глубины.
Например, карты глубины можно получить из 3D реконструкции. В этом случае глубина может быть известна только в неизвестном масштабе («карты глубины до масштаба»); «реальную» метрическую глубину можно получить, умножив карту глубины до масштаба на один коэффициент, однако этот коэффициент неизвестен. Соответственно, модель, обученная на таких картах глубины, сможет только прогнозировать глубины в соответствии с масштабом.
В качестве альтернативы данные глубины можно получить от стереопары, поэтому любые видеопоследовательности, снятые стереокамерой, могут служить источником объемных и разнообразных обучающих данных. Но стерео глубину можно получить с неизвестным смещением и масштабом: «реальную» метрическую глубину Di можно получить из карты глубины до смещения и масштаба D0i, используя следующую формулу: 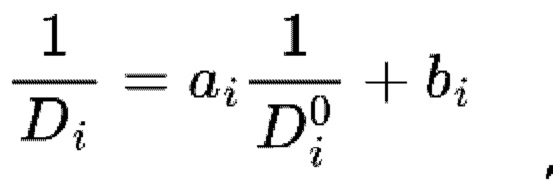 . где ai - коэффициент масштаба, bi - коэффициент смещения. Как и в случае с данными глубины до масштаба, модель, обученная на картах глубины до смещения и масштаба, может прогнозировать глубину только до смещения и масштаба.
. где ai - коэффициент масштаба, bi - коэффициент смещения. Как и в случае с данными глубины до масштаба, модель, обученная на картах глубины до смещения и масштаба, может прогнозировать глубину только до смещения и масштаба.
Предобученная нейронная сеть, используемая для оценки карт глубины до масштаба для каждого кадра видео в изобретении, может быть практически любой нейронной сетью, которая способна оценивать глубину. В качестве неограничивающего примера авторы настоящего изобретения использовали нейронные сети GP2 и SimpleRecon в различных вариантах осуществления изобретения.
Модель искусственного интеллекта, используемую в предобученной нейронной сети, можно получить путем обучения. В данном контексте «полученный путем обучения» означает, что заданное рабочее правило или модель искусственного интеллекта, выполненную с возможностью выполнения желаемой функции (или цели), получают путем обучения базовой модели искусственного интеллекта множеством элементов обучающих данных с помощью обучающего алгоритма. Модель искусственного интеллекта может включать в себя множество уровней нейронной сети. Каждый из множества уровней нейронной сети включает в себя множество значений сетевых параметров и выполняет нейросетевые вычисления, осуществляя вычисления между результатом вычисления предыдущего уровня и множеством значений параметров.
Обратное распространение, в общем, представляет собой алгоритм, выполняющий оценку градиентов функции потерь по отношению к переменным параметрам, задействованным в этом вычислении. Эти градиенты можно использовать в методах оптимизации на основе градиентов для минимизации значения функции потерь.
Алгоритм обратного распространения состоит из нескольких этапов:
1) Обход графа вычислений от ввода к выводу с выполнением операций в узлах графа вычислений. Граф вычислений выдает значение функции потерь, подлежащее минимизации.
2) Итерация в обратном направлении от вывода графа вычислений и вычисление градиента по одному узлу за раз в соответствии с цепным правилом. На этом этапе оцениваются градиенты функции потерь по отношению к вводу и переменным параметрам графа вычислений.
Механизм обратного распространения и методы оптимизации на основе градиента эффективно реализуются на всех платформах машинного обучения. Соответственно, при использовании стандартных нейронных уровней или базовых дифференцируемых алгебраических операций (таких как сложение, умножение, деление, применение логарифмических или экспоненциальных преобразований и т.д.) обычно нет необходимости в ручном обновлении параметров -эти обновления могут выполняться автоматически через оптимизацию на основе градиента.
Оптимизация на основе градиента обычно реализуется посредством вариантов градиентного спуска; в неограничивающих вариантах осуществления настоящего изобретения используется распространенный алгоритм оптимизации Адама как неограничивающий пример.
Оптимизация на основе градиента не может гарантировать достижение глобального оптимума. Однако она проявила себя как эффективный механизм стохастической оптимизации, когда получение решения алгебраически невозможно или требует недопустимого объема вычислений или памяти.
В настоящем способе используется функция потери при репроецировании, которая вычисляется в пространстве
представлений признаков изображения, полученных с помощью нейронной сети. Использование функции потери при репроецировании значительно улучшает окончательные результаты.
Другим существенным признаком заявляемого способа является инициализация карты глубины в масштабе путем репроецирования. Сначала оцениваются метрические карты глубины для поднабора кадров. Затем эти карты глубины репроецируются на остальные кадры. Репроецированные значения используются для инициализации масштабных карт глубины в этих кадрах.
Как видно на схематическом представлении предложенного способа на фиг.1, сначала оцениваются карты глубины для каждого кадра из одного или более кадров видеопоследовательности, независимо снятых камерой, с помощью предобученной модели оценки глубины, такой как модель для одного вида GP2 [28] или модель для множества видов (многовидовая модель) SimpleRecon [27]. Для кадра F с разрешением Н х W х 3 модель оценки глубины прогнозирует исходную глубину D0i, имеющую такое же разрешение Н х W. Затем оценочные карты глубины корректируются для повышения согласованности между указанными одним или более кадрами.
А. Модель деформирования глубины
Для кадра Fi масштабная карта Si оценивается посредством ТТТ, так что окончательный прогноз глубины рассчитывается как

В соответствии с настоящим изобретением коррекция глубины осуществляется с помощью параметрической пространетвенно - изменяющейся модели деформирования глубины, предложенной, например, в [RobustCVD], и Si формулируется как билинейный сплайн:
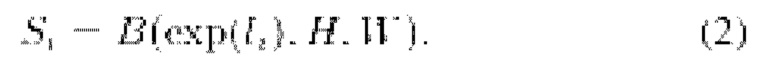
где li - обучаемый тензор размером h × w, а 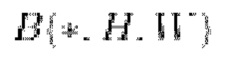 обозначает билинейную интерполяцию в Н х W. Соответственно, локальные коэффициенты масштабирования определяются на регулярной сетке по всему изображению. Для каждого пикселя в ячейке сетки билинейно интерполируются четыре значения в вершинах ячеек для получения коэффициента масштабирования.
обозначает билинейную интерполяцию в Н х W. Соответственно, локальные коэффициенты масштабирования определяются на регулярной сетке по всему изображению. Для каждого пикселя в ячейке сетки билинейно интерполируются четыре значения в вершинах ячеек для получения коэффициента масштабирования.
B. Обучение
Процедура обучения параметрической пространетвенно-изменяющейся модели деформирования глубины выполняется в две стадии: на стадии I оптимизируются масштабные карты глубины для ключевых кадров, а на стадии II рассматриваются все кадры. В контексте настоящего изобретения обратное распространение выполняется от значений функции потерь L к оптимизированным переменным, в данном конкретном случае к параметрам li сплайна. На стадии I оптимизация (и обратное распространение) выполняется на ключевых кадрах, а на стадии II - на всех остальных кадрах.
C. Деформирование
Процедура оптимизации руководствуется деформированием. В частности, цветное изображение Ij деформируется из положения камеры i-го кадра, при условии, что положения камеры и внутренние параметры камеры известны, и получается псевдоизображение  . Кроме того, такая же процедура деформирования применяется к признакам Fj изображения. Для GP2 [28] эти признаки извлекаются из блока 3 кодера. Для SimpleRecon использует вывод 2D сверточной части (следует отметить, что признаки можно извлекать без каких-либо дополнительных вычислений, так как обеспечивается прямой проход через сеть оценки глубины для получения оценок исходной глубины в любом случае), что приводит к получению карты
. Кроме того, такая же процедура деформирования применяется к признакам Fj изображения. Для GP2 [28] эти признаки извлекаются из блока 3 кодера. Для SimpleRecon использует вывод 2D сверточной части (следует отметить, что признаки можно извлекать без каких-либо дополнительных вычислений, так как обеспечивается прямой проход через сеть оценки глубины для получения оценок исходной глубины в любом случае), что приводит к получению карты  псевдопризнаков. Затем скорректированная по масштабу карта глубины Dj репроецируется в 3D пространство и проецируется на i-й кадр, что дает карту псевдоглубины
псевдопризнаков. Затем скорректированная по масштабу карта глубины Dj репроецируется в 3D пространство и проецируется на i-й кадр, что дает карту псевдоглубины 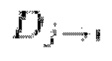
В идеале, карты псевдоцвета, псевдоглубины и псевдопризнаков должны совпадать с исходными, так как их расхождение приводит к потерям, каждая из которых относится к одной модальности. В данном контексте под модальностью следует понимать тип данных, в данном контексте карты цвета, глубины и признаков. Функции потерь (потери) вычисляются в данном случае на данных каждой из «модальностей»: потери цвета, 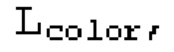 вычисляются на модальности «цвет», т.е. на RGB-изображениях. Потери глубины,
вычисляются на модальности «цвет», т.е. на RGB-изображениях. Потери глубины, 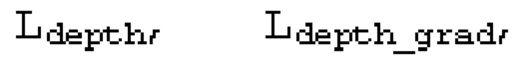 вычисляются на данных модальности «глубина», т.е. картах глубины. Потери признаков,
вычисляются на данных модальности «глубина», т.е. картах глубины. Потери признаков, 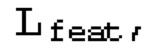 вычисляются на данных модальности «признаки», то есть на картах признаков, полученных моделью нейронной сети. Таким образом, в контексте настоящего изобретения существует три модальности:
вычисляются на данных модальности «признаки», то есть на картах признаков, полученных моделью нейронной сети. Таким образом, в контексте настоящего изобретения существует три модальности:
1. Цвет
2. Карта глубины
3. Нейросетевые признаки (карты признаков)
D. Потери
Во-первых, фотометрическая потеря 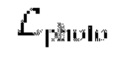 приводит к соответствию псевдоцвета
приводит к соответствию псевдоцвета 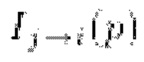 пикселя р цвету
пикселя р цвету 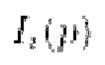 :
:
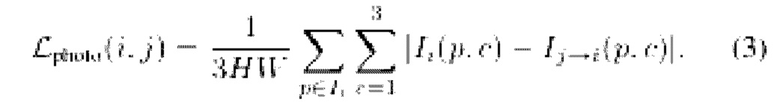
Затем потеря глубины 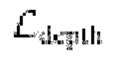 приближает псевдоглубину
приближает псевдоглубину 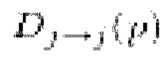 пикселя р к исходному значению
пикселя р к исходному значению 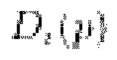 :
:
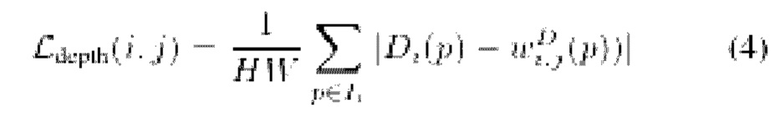
И наконец, потеря признаков 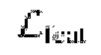 обеспечивает, что для пикселя р его вектор псевдопризнаков
обеспечивает, что для пикселя р его вектор псевдопризнаков  и вектор исходных признаков
и вектор исходных признаков 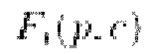 на карте признаков будут одинаковы:
на карте признаков будут одинаковы:
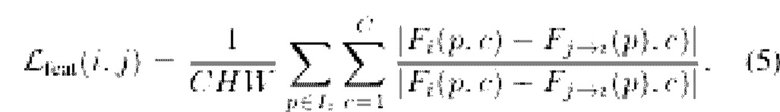
Кроме того, соблюдается GCVD [10], а потеря градиента глубины  используется для уменьшения размытия карт глубины и сохранения геометрической корректности исходных прогнозов глубины. Таким образом, общие потери формулируются как:
используется для уменьшения размытия карт глубины и сохранения геометрической корректности исходных прогнозов глубины. Таким образом, общие потери формулируются как:
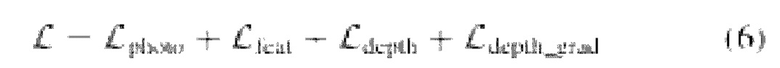
Е. Выборка пар кадров Вводится следующая запись:
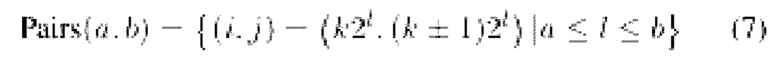
Для оптимизации используются два поднабора пар кадров: PI=Pairs(3, 6) и PII=Pairs (0, 2). Кадры в PI рассматриваются как ключевые кадры 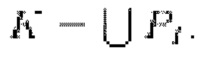 :
:
На стадии I из PI равномерно выбираются пары ключевых кадров (i, j). Для  выбирается li, минимизирующее
выбирается li, минимизирующее 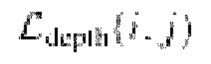 , где
, где - ближайший индекс к i. Точнее, li инициализируется следующим образом:
- ближайший индекс к i. Точнее, li инициализируется следующим образом:
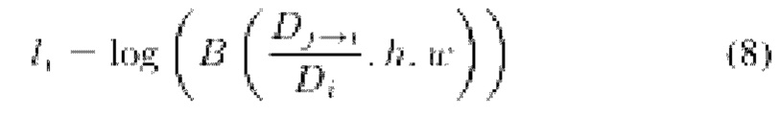
На стадии II обновляется  . Параметры
. Параметры 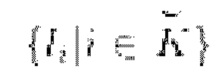 замораживаются (т.е. они не обновляются на данном этапе оптимизации).
замораживаются (т.е. они не обновляются на данном этапе оптимизации).
В одном из аспектов изобретения способ согласно изобретению реализуется с помощью устройства для коррекции данных глубины для множества видов. Это устройство содержит память и по меньшей мере один процессор и запрограммировано на выполнение этапов описанного выше способа. В качестве памяти может использоваться ROM, RAM, флэш-память, EEPROM и т.п., как будет понятно специалисту в данной области техники. Процессор может быть любым подходящим процессором, например, в качестве неограничивающего примера, компьютерным процессором общего назначения (CPU), графическим процессором (GPU), процессором цифровых сигналов (DSP) и т.п.
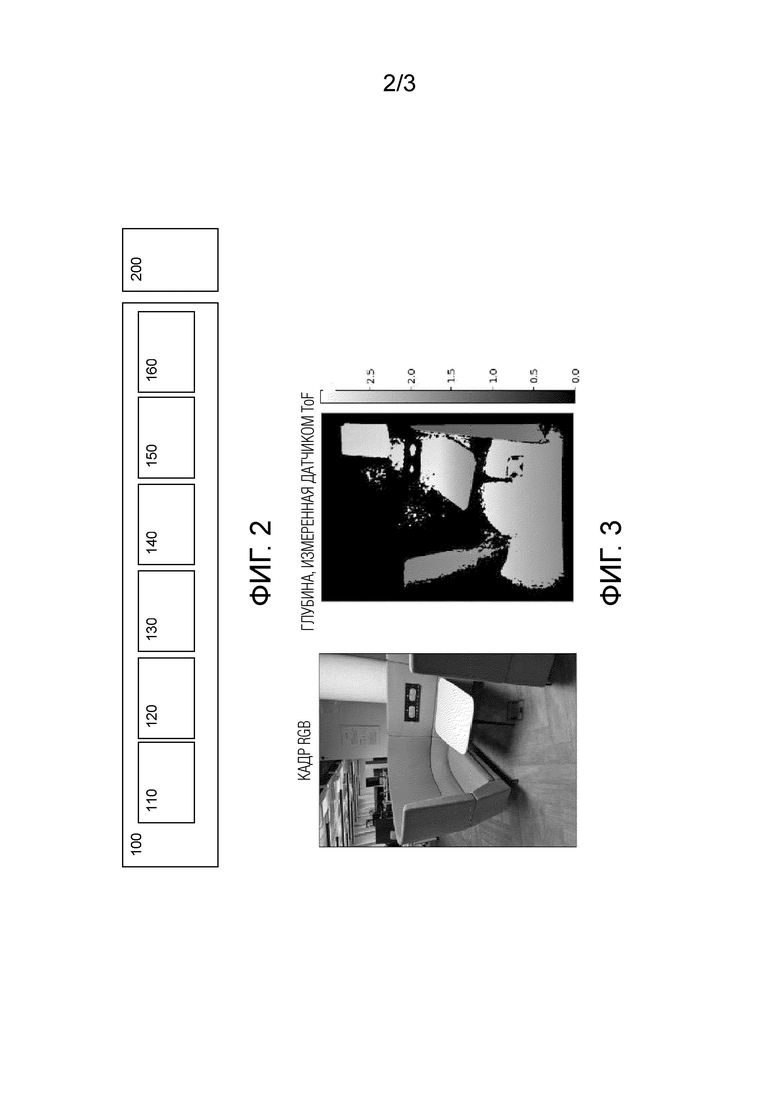
С помощью процессора можно реализовать следующие модули устройства. Как показано на фиг.2, устройство 100 для коррекции данных глубины для множества видов содержит модуль 110 приема видеопоследовательности, выполненный с возможностью приема видеопоследовательности, содержащей один или более кадров. Для этой цели устройство может также содержать (или быть связано) камеру 200, например, камеру RGB, способную захватывать видеопоследовательность, содержащую последовательность из одного или более кадров. В других вариантах осуществления видео может быть получено (или импортировано) из внешнего источника через один или более каналов передачи данных (которые могут быть беспроводными и/или проводными), как хорошо известно специалистам в данной области техники. Для этой цели модуль 110 приема видеопоследовательности может содержать интерфейс ввода/вывода (I/O) и, при необходимости, быть способен выполнять аналого-цифровое преобразование (АЦП), используя соответствующий преобразователь(и), если это необходимо.
Модуль 120 формирования масштабной карты частоты выполнен с возможностью формирования покадровых масштабных карт глубины в форме билинейных сплайнов для поднабора кадров, которые извлекаются из упомянутого одного или более кадров последовательности видеокадров, полученных модулем 110 приема видеопоследовательности. 110. Для каждого кадра результирующая карта глубины получается путем поэлементного умножения сплайна Si (определение сплайна можно найти, например, в работе "Two Dimensional Spline Interpolation Algorithms", Helmuth Spath (CRC Press, Wellesley, MA, USA, 1993)) на вывод нейронной сети оценки глубины (см. выражение 1). Каждая карта глубины имеет собственный, ассоциированный с нею билинейный сплайн. Эти сплайны оптимизируются, а затем модифицируются в процессе оптимизации так, чтобы полученные прогнозы глубины были согласованными. В одном или более неограничивающих вариантах осуществления настоящего изобретения согласованность результирующих прогнозов глубины является целью вышеупомянутого процесса оптимизации. Однако в других вариантах осуществления процесс оптимизации может выполняться за определенное максимальное количество итераций и/или до тех пор, пока значения функции потерь по существу не перестанут уменьшаться после определенного количества итераций. В различных реализациях настоящего изобретения один или более вышеупомянутых вариантов осуществления может быть более предпочтительным с точки зрения требуемой точности карты глубины и/или доступных вычислительных ресурсов или времени обработки.
Модуль 130 инициализации масштабной карты глубины выполнен с возможностью инициализации покадровых масштабных карт глубины путем репроецирования метрических карт глубины поднабора кадров, а также инициализации всех масштабных карт глубины единицами перед коррекцией масштабных карт глубины.
Модуль 140 коррекции масштабных карт глубины выполнен с возможностью итеративной оптимизации покадровых масштабных карт глубины для всех кадров упомянутого одного или более кадров, а также итеративной оптимизации масштабных карт глубины для поднабора кадров с помощью алгоритма оптимизации на основе градиента.
В одном или более неограничивающих вариантах осуществления устройство 100 для коррекции данных глубины для множества видов может дополнительно содержать модуль 150 формирования метрических карт глубины, который выполнен с возможностью выполнения поэлементного умножения определенной исходной карты глубины для определенного кадра из упомянутого одного или больше кадров на соответствующую масштабную карту глубины для получения метрических карт глубины. В других неограничивающих вариантах осуществления скорректированные масштабные карты глубины можно масштабировать до неизвестного масштаба для получения карт глубины в некотором масштабе, причем этот масштаб варьируется между различными кадрами в упомянутых одном или более кадрах.
В одном из неограничивающих вариантов осуществления устройство 100 для коррекции данных глубины для множества видов может содержать модуль 160 получения положения камеры, выполненный с возможностью получения положений камеры для соответствующих кадров из упомянутого одного или более кадров видеопоследовательности. Положения камеры можно получить от камеры 200, используя ее соответствующие собственные элементы, например, гироскоп, или можно оценить с помощью алгоритма оценки положения камеры. В качестве неограничивающего примера для оценки положения камеры в настоящем изобретении может использоваться любой алгоритм «структуры из движения» (семейство алгоритмов, оценивающих 3D структуру сцены по набору 2D изображений; например, COLMAP) или алгоритм одновременной локализации и отображения (SLAM) (семейство алгоритмов, оценивающих траекторию камеры с одновременным созданием карты окружения (например, ORB-SLAM)).
По меньшей мере один из вышеупомянутых модулей может быть реализован через модель AI. Функцию, связанную с AI, может выполнять энергонезависимая память, энергозависимая память и процессор. Процессор может включать в себя один или множество процессоров. В настоящее время один или более процессоров могут быть процессорами общего назначения, такими как центральный процессор (CPU), процессор приложений (АР), графический процессор (GPU), визуальный процессор (VPU), и/или специальный процессор для AI, такой как нейронный процессор (NPU) и т.п.Эти один или более процессоров управляют обработкой входных данных в соответствии с заданным рабочим правилом или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Заданное рабочее правило или модель искусственного интеллекта формируются посредством изучения или обучения. В данном контексте формирование посредством обучения означает, что при применении алгоритма обучения к множеству обучающих данных создается заданное рабочее правило или модель AI с требуемой характеристикой. Обучение может выполняться в самом устройстве, в котором выполняется AI согласно варианту осуществления, и/или может быть реализовано на отдельном сервере/системе. Модель AI может состоять из множества уровней нейронной сети. Каждый уровень имеет множество значений весов и выполняет операцию уровня посредством вычисления предыдущего уровня и операции множества весов. Примеры нейронных сетей включают, но не ограничиваются ими, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети. Кроме того, предлагаемый способ, выполняемый электронным устройством, может быть реализован с использованием модели искусственного интеллекта.
В различных неограничивающих вариантах осуществления изобретения способ изобретения может быть реализован в одном устройстве или в нескольких взаимодействующих устройствах, которые выполняют этапы предложенного способа и обмениваются результатами друг с другом. В последнем случае такие устройства могут быть соединены сетью(ями) передачи данных через линию(и) передачи данных, которая может быть беспроводной и/или проводной. Такая обработка также может распределяться между одним или более компьютерами, процессорами и т.п., связанными такой сетью (сетями) передачи (связи).
Реализация способа согласно изобретению приводит к получению метрических карт глубины для позиционированных видеокадров, которые позволяют получить абсолютные расстояния до всех окружающих объектов, отображаемых в последовательности видеокадров. Эти карты глубины согласованы во времени, т.е. карты глубины из нескольких видов выровнены в 3D пространстве. Примеры
Далее будут представлены результаты испытаний, полученные при реализации примеров вариантов осуществления настоящего изобретения, которые подтверждают возможность реализации предполагаемого применения настоящего изобретения и достижения указанного выше технического результата.
A. Наборы данных
Следуя процедуре, описанной в GCVD [10], изобретение было испытано на последовательностях видеокадров бенчмарка TUM RGB-D для помещений [19].
Кроме того, также были собраны видеоданные для помещений, чтобы оценить точность способа согласно изобретению в приложениях для смартфонов. Для сбора данных использовался смартфон Samsung S20+, оснащенный RGB-камерой и встроенным датчиком глубины ToF. Следует отметить, что в этом примере датчик глубины ToF использовался только как источник «эталонных» прогнозов глубины для оценки точности предложенного способа. Во всех других случаях датчик глубины не требуется для получения данных глубины в соответствии с настоящим изобретением. Положения камеры были получены с помощью отслеживающей программы ARCore. Пример полученного кадра показан на фиг.3.
B. Протокол оценки
В соответствии со стандартным протоколом оценки глубины [18], [17], [1], качество прогноза оценивалось на метриках abs rel δ. Поскольку изобретение выдает метрические карты глубины, оценочные карты глубины не выравниваются с эталонными картами до метрической оценки, как это делается при оценке глубины в масштабе или смещениях и масштабе [18], [17], [10].
Следует отметить, что качество работы алгоритма оценки глубины оценивалось путем сравнения его оценок глубины с «эталонными» значениями. В данном случае, если алгоритм оценки глубины прогнозирует карты глубины с точностью «до масштаба» или «до смещения и масштаба», то прямое сравнение спрогнозированных и «эталонных» значений глубины невозможно. Чтобы обеспечить возможность сравнения, необходимо сначала «выровнять» спрогнозированные карты глубины с «эталонными», т.е. привести спрогнозированные карты глубины к реальному масштабу данных. В упомянутых известных способах выбираются оптимальные коэффициенты масштаба (для карт глубины в масштабе) или оптимальные коэффициенты масштаба и смещения (для карт глубины в смещениях и масштабе). Кроме того, в упомянутых известных способах для каждой пары спрогнозированной карты глубины и эталонной карты глубины коэффициенты масштаба или смещения и масштаба выбираются независимо от других пар, и оптимальные значения коэффициентов вычисляются путем решения задачи оптимизации средней ошибки в зависимости от значений коэффициентов.
С. Детали реализации
Предложенный способ был реализован с применением Pytorch [16]. Обучение и оценка выполнялись на одном графическом процессоре Tesla р40.
Исходные карты глубины прогнозировались моделью оценки глубины. Перед коррекцией все тензоры инициализировались нулями. Затем они обновлялись с помощью оптимизатора Adam с размером пакета 8 пар кадров. Скорость обучения инициализировалась с 0,1 и снижалась в соответствии с экспоненциальным графиком: у=0,996 на стадии I и у=0,96 на стадии II. Этап I и этап II продолжались соответственно 600 и 60 эпох.
Следует отметить, что в данном контексте значения коэффициентов масштаба глубины (масштабов глубин) выбираются с использованием процесса оптимизации. Оптимизация включает в себя: 1) выбор исходного значения корректируемых параметров и 2) итеративную коррекцию значений набора параметров с применением определенного алгоритма оптимизации. Инициализация означает назначение определенного исходного значения каждому
оптимизируемому параметру (в данном контексте масштабам глубин), и это исходное значение в дальнейшем корректируется в ходе процесса оптимизации. Стратегия оптимизации, которая ускоряет процесс оптимизации за счет выбора исходных значений, наиболее близких к оптимальным, является одним из существенных признаков настоящего изобретения.

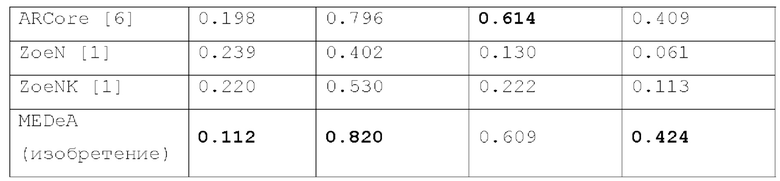
В таблице 1 представлены количественные результаты для видеоданных, полученных камерой смартфона, как упоминалось выше. Из таблицы 1 видно, что способ согласно изобретению (обозначенный в таблице 1 как MEDeA) дал наилучшие результаты среди испытанных способов. Предложенный способ проверялся на данных, полученных смартфоном с использованием положений камеры ARCore, чтобы доказать, что он может работать даже в сочетании с методами онлайн отслеживания, дающими зашумленные траектории камеры. В приведенной выше таблице 1 способ согласно изобретению, обозначенный как MEDeA, сравнивается с ZoeDepth [1], известным методом монокулярной метрической оценки глубины, а также представлены метрики для собственных карт глубины ARCore. Можно заметить, что предложенный способ превосходит известные способы на несовершенных реальных данных.
Следует отметить, что для различных неограничивающих вариантов осуществления изобретения разработаны «полная» версия (обозначенная здесь как "MEDeA-full") и «быстрая» версия (обозначенная здесь как "MEDeA-fast"). Основное различие между двумя версиями состоит в том, что оптимизация MEDeA-fast завершается, когда функция потерь L не уменьшается как минимум на 1% в течение 40 эпох на стадии I и 4 эпох на стадии II, тогда как в версии MEDeA-full не применяется никаких критериев раннего завершения. Кроме того, в MEDeA-fast используется разрешение изображения Н/4 х W/4 в течение всего процесса ТТТ, в то время как в MEDeA-full оптимизация производится с разрешением Н/4 х W/4 для первых 80% эпох, а затем переключается на полное разрешение Н х W для последних 20% эпох как на стадии I, так и на стадии II. (Н, W) составляют (480 640) для набора данных TUM RGB-D и (64 0 4 80) для данных, полученных с помощью смартфона, как описывалось выше. В MEDeA-fast признаки F извлекаются из блока кодировщика 3 модели GP2 [28]. В MEDeA-full используется вывод 2D сверточной части модели SimpleRecon [27].
Результаты экспериментальных испытаний
А. Сравнение с известным уровнем
В таблице 2 представлено количественное сравнение изобретательского подхода (обозначенного как MEDeA) с другими методами ТТТ на эталонном тесте TUM RGB-D.

В таблице 2 показаны результаты протестированных методов ТТТ, которые применялись к упомянутому выше набору данных TUM RGB-D. Представлены метрики абсолютной относительной ошибки глубины (abs rel) для предложенного способа, а также для известных способов. Один вариант осуществления изобретательского подхода, обозначенный как MEDeA-full в таблице 2 выше, продемонстрировал наилучший средний показатель и превзошел другие методы на 4 из 6 тестовых последовательностей. Другой вариант изобретательского подхода, обозначенный как MEDeA-fast, был лишь немного хуже, однако он был на порядок быстрее, чем сравниваемые известные подходы.
Очевидно, что изобретательский подход, обозначенный как MEDeA-full, превзошел известные способы в большинстве тестовых последовательностей, а также получил наивысший общий показатель. Быстрая модификация оказалась на втором месте, в среднем лишь немного уступая полной версии, но имела скорость логического вывода в 15 раз выше, чем у известного способа GCVD.
Метрические карты глубины, полученные предложенным способом, использовались для формирования трехмерной реконструкции с использованием интеграции TSDF (см. фиг.4). Как можно заметить, предлагаемый подход к коррекции глубины корректирует также ошибки масштаба отдельных карт глубины, так что полученная реконструкция выглядит хорошо выровненной. Таким образом, было показано, что предлагаемый способ обеспечивает приемлемое качество для применения в приложениях реконструкции сцен.
Результаты экспериментов показали, что предложенный способ превосходит известные способы обучения во время тестирования (ТТТ) для коррекции глубины видео. В отличие от известных способов ТТТ, выполняющих оценку нормалей, оценку оптического потока или сегментацию, в изобретении не задействованы никакие вспомогательные модели, а используется модель оценки глубины. В результате предложенный способ обеспечивает высокое качество на известном эталонном тесте TUM RGB-D для помещений, а также на зашумленных данных, полученных смартфоном, и работает в 15 раз быстрее, чем существующие методы. Было показано, что предложенная технология превосходит существующие способы коррекции глубины видео ТТТ и ее скорость выше почти в 15 раз.
Промышленная применимость
Оценку плотной глубины, выполняемую с использованием способа и устройства согласно изобретению, можно использовать для облегчения навигации и взаимодействия робота с окружением, обеспечения управления автономным вождением и помощи водителю при вождении, а также для создания иммерсивного опыта в AR. В других применениях изобретение обеспечивает понимание окружения при планировании пути для движущихся устройств и транспортных средств, корректное размещение объектов AR в виртуальной среде, 3D сканирование, постобработку видео, например, стабилизацию видео, и т.д.
Способ согласно изобретению может быть реализован в роботе, смартфоне, беспилотном транспортном средстве и, потенциально, в любом другом устройстве, которое 1) оснащено RGB-камерой, 2) способно получать или оценивать положения камеры, 3) способно получать или оценивать карты глубины. В качестве альтернативы, получение или оценка положений камеры и карт глубины, а также обработка оценки плотной глубины могут выполняться на удаленном вычислительном устройстве для управления таким устройством, как робот или беспилотное транспортное средство.
Специалистам в данной области будет понятно, что изобретение можно реализовать различными комбинациями аппаратных и программных средств, и никакие подобные конкретные комбинации не ограничивают объем настоящего изобретения. Описанные выше модули, образующие устройство согласно изобретению, можно реализовать в виде отдельных аппаратных средств, или же два или более модулей можно реализовать в виде одного аппаратного средства, или же систему согласно изобретению можно реализовать в виде одного или более компьютеров, процессоров (CPU), например, процессоров общего назначения или специализированных процессоров, например процессоров обработки цифровых сигналов (DSP), или одной или более ASIC, FPGA, логических элементов и т.д. В качестве альтернативы, один или более модулей можно реализовать как программное средство, например, программу или программы, элемент(ы) или модуль(и) компьютерной программы), которые управляют одним или более компьютерами, CPU и т.д. для реализации этапов способа и/или операций, подробно описанных выше. Это программное средство может быть реализовано на одном или более машиночитаемых носителей, которые хорошо известны специалистам в данной области, может храниться в одном или более блоках памяти, например, ROM, RAM, флеш-памяти, EEPROM и т.д., или поступать, например, от удаленных серверов через одно или более соединения проводной и/или беспроводной сети, интернет, соединение Ethernet, LAN или, при необходимости, другие локальные или глобальные компьютерные сети.
Специалистам будет понятно, что выше были описаны и показаны на чертежах только некоторые из возможных примеров способов и аппаратных средств, позволяющих реализовать варианты осуществления настоящего изобретения. Подробное описание вариантов осуществления изобретения, представленное выше, не предназначено для ограничения или определения объема правовой охраны настоящего изобретения.
Другие варианты осуществления, которые могут входить в объем настоящего изобретения, могут быть предложены специалистами в данной области техники по изучении вышеприведенного описания изобретения с обращением к сопровождающим чертежам, и все такие очевидные модификации, изменения и/или эквивалентные замены подлежат включению в объем настоящего изобретения. Все упомянутые и рассмотренные здесь источники из уровня техники настоящим включены в данное описание путем ссылки, когда это применимо.
Несмотря на то, что настоящее изобретение было описано и проиллюстрировано с обращением к различным вариантам осуществления, специалистам в данной области техники следует понимать, что могут быть выполнены различные изменения, касающиеся его формы и конкретных подробностей, не выходящие за рамки объема настоящего изобретения, который определяется только нижеприведенной формулой изобретения и ее эквивалентами.
Библиография
[1] Bhat, S. F., Birkl, R., Wofk, D., Wonka, P., and Muller, M. Zoedepth: Zero-shot transfer by combining relative and metric depth (2023)
[2] Bloesch, M., Czarnowski, J., Clark, R., Leutenegger, S., and Davison, A. Codeslam - learning a compact, optimisable representation for dense visual slam (2018)
[3] Czarnowski, J., Laidlow, Т., Clark, R., and Davison, A. Deepfactors: Real-time probabilistic dense monocular slam. IEEE Robotics and Automation Letters 5, 721-728 (2020)
[4] Eigen, D. and Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In 2015 IEEE International Conference on Computer Vision (ICCV), 2650-2658 (2015)
[5] Eigen, D., Puhrsch, C, and Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS'14, 2366-2374 (MIT Press, Cambridge, MA, USA, 2014)
[6] Google. Arcore. https://developers.google.com/ar
[7] Huang, P.-H., Matzen, K., Kopf, J., Ahuja, N., and Huang, J.-B. Deepmvs: Learning multi-view stereopsis. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
[8] Im, S., Jeon, H.-G., Lin, S., and Kweon, I. Dpsnet: End-to-end deep plane sweep stereo (2019)
[9] Kopf, J., Rong, x., and Huang, J.-B. Robust consistent video depth estimation (2021)
[10] Lee, Y.-C, Tseng, K.-W., Chen, G.-S., and Chen, C.-S. Globally consistent video depth and pose estimation with efficient test-time training (2022) [11] Lee, Y.-C, Tseng, K.-W., Chen, Y.-T., Chen, C.-C, Chen, C.-S., and Hung, Y.-P. 3d video stabilization with depth estimation by cnn-based optimization. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10616-10625 (2021)
[12] Liu, F., Shen, C, Lin, G., and Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans-actions on Pattern Analysis and Machine Intelligence 38 (2015)
[13] Long, x., Liu, L., Li, W., Theobalt, C, and Wang, W. Multi-view depth estimation using epipolar spatio-temporal networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8258-8267 (2021)
[14] Luo, X., Huang, J., Szeliski, R., Matzen, K., and Kopf, J. Consistent video depth estimation 39 (2020)
[15] Oufgir, Z., El Abderrahmani, A., and Satori, K. Arkit and arcore in serve to augmented reality. In 2020 International Conference on Intelligent Systems and Computer Vision (ISCV), 1-7 (2020)
[16] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, Т., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, В., Fang, L., Bai, J., and Chintala, S. Pytorch: An imperative style, high- performance deep learning library. In Advances in Neural Information Processing Systems 32, 8024-8035 (Curran Associates, Inc., 2019)
[17] Patakin, N., Vorontsova, A., Artemyev, M., and Konushin, A. Single- stage 3d geometry-preserving depth estimation model training on dataset mixtures with uncalibrated stereo data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1705^1714 (2022)
[18] Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., and Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero- shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence 44 (2022)
[19] Sturm, J., Engelhard, N., Endres, F., Burgard, W., and Cremers, D. A benchmark for the evaluation of rgb-d slam systems. In Proc. of the International Conference on Intelligent Robot Systems (IROS) (2012)
[20] Teed, Z. and Deng, J. Deepv2d: Video to depth with differentiable structure from motion. In International Conference on Learning Representations (2020)
[21] Teed, Z. and Deng, J. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. In Neural Information Processing Systems (2021)
[22] Ummenhofer, В., Zhou, H., Uhrig, J., Mayer, N., Ilg, E., Dosovitskiy, A., and Brox, T. Demon: Depth and motion network for learning monocular stereo. 5622-5631 (2017)
[23] Wang, J., Zhong, Y., Dai, Y., Birchfield, S., Zhang, K., Smolyanskiy, N., and Li, H. Deep two-view structure-from-motion revisited. CVPR (2021)
[24] Wei, X., Zhang, Y., Li, Z., Fu, Y., and Xue, X. Deepsfm: Structure from motion via deep bundle adjustment. In Vedaldi, A., Bischof, H., Brox, Т., and Frahm, J.-M., eds., Computer Vision - ECCV 2020, 230-247 (Springer International Publishing, Cham, 2020)
[25] Wimbauer, F., Yang, N., Stumberg, L., Zeller, N., and Cremers, D. Monorec: Semi-supervised dense reconstruction in dynamic environments from a single moving camera. 6108-6118 (2021)
[26] Yao, Y., Luo, Z., Li, S., Fang, Т., and Quan, L.
Mvsnet: Depth inference for unstructured multi-view stereo. European Conference on Computer Vision (ECCV) (2018)
[27] Sayed, M., Gibson, J., Watson, J., Prisacariu, V.A., Firman, M., and Godard, C. SimpleRecon: 3D Reconstruction Without 3D Convolutions. European Conference on Computer Vision (ECCV) (2022)
[28] Patakin, N., Vorontsova, A., Artemyev, M., Konushin, A. Single-stage 3D Geometry-Preserving Depth Estimation Model Training on Dataset Mixtures with Uncalibrated Stereo Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
| название | год | авторы | номер документа |
|---|---|---|---|
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| СПОСОБ И СИСТЕМА ДЛЯ УТОЧНЕНИЯ ПОЗЫ КАМЕРЫ С УЧЕТОМ ПЛАНА ПОМЕЩЕНИЯ | 2022 |
|
RU2794441C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| СПОСОБ УЧИТЫВАЮЩЕЙ ПОВТОРЯЮЩИЕСЯ СТРУКТУРЫ ИНТЕРПОЛЯЦИИ КАДРОВ ВИДЕО И РЕАЛИЗУЮЩИЕ ДАННЫЙ СПОСОБ УСТРОЙСТВО И НОСИТЕЛЬ | 2024 |
|
RU2836221C1 |
| СИСТЕМЫ И СПОСОБЫ ОЦЕНКИ ЖИЗНЕСПОСОБНОСТИ ЭМБРИОНОВ | 2018 |
|
RU2800079C2 |
| СПОСОБ ОЦЕНКИ ГЛУБИНЫ СЦЕНЫ ПО ИЗОБРАЖЕНИЮ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2761768C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ВРЕМЕННОГО ДОПОЛНЕНИЯ ВИДЕО | 2014 |
|
RU2560086C1 |
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| Способ создания многослойного представления сцены и вычислительное устройство для его реализации | 2021 |
|
RU2787928C1 |
| МЕТАДАННЫЕ ДЛЯ ФИЛЬТРАЦИИ ГЛУБИНЫ | 2013 |
|
RU2639686C2 |


Группа изобретений относится к области компьютерного зрения. Предложен способ коррекции данных глубины для множества видов в видеопоследовательности, содержащей один или более кадров, который содержит этап, на котором создают покадровые масштабные карты глубины в форме билинейных сплайнов для поднабора кадров из упомянутых одного или более кадров. Для остальных кадров в одном или более кадрах инициализируют покадровые масштабные карты глубины путем репроецирования метрических карт глубины данного поднабора кадров. Для всех кадров из одного или более кадров осуществляют итеративную оптимизацию покадровых масштабных карт глубины, причем все масштабные карты глубины инициализируют единицами перед коррекцией; и осуществляют итеративную оптимизацию масштабных карт глубины для данного поднабора кадров посредством алгоритма оптимизации на основе градиента. Также предусмотрены устройство и машиночитаемый носитель для реализации упомянутого способа. Технический результат состоит в получении согласованных метрических карт глубины, основанных на абсолютных расстояниях до всех объектов в среде, изображенной в последовательности кадров видео. 3 н. и 10 з.п. ф-лы, 4 ил., 2 табл.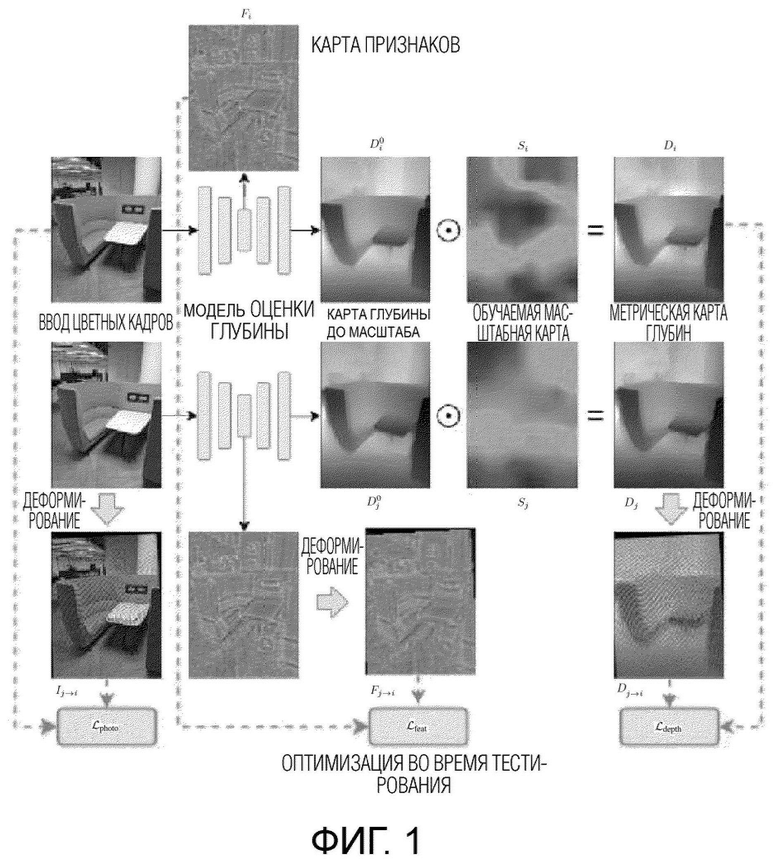
1. Способ коррекции данных глубины для множества видов в видеопоследовательности, содержащей один или более кадров, содержащий этапы, на которых: создают покадровые масштабные карты глубины в форме билинейных сплайнов для поднабора кадров из упомянутых одного или более кадров; получают метрические карты глубины путем поэлементного умножения исходной карты глубины на соответствующую масштабную карту глубины; для остальных кадров из одного или более кадров инициализируют покадровые масштабные карты глубины путем репроецирования упомянутых метрических карт глубины данного поднабора кадров; для всех кадров из одного или более кадров осуществляют итеративную оптимизацию покадровых масштабных карт глубины, причем все масштабные карты глубины инициализируют единицами перед коррекцией; и осуществляют итеративную оптимизацию масштабных карт глубины для данного поднабора кадров посредством алгоритма оптимизации на основе градиента.
2. Способ по п. 1, в котором карты глубины в масштабе оценивают для каждого кадра видео, используя предобученную нейронную сеть.
3. Способ по п. 1, в котором дополнительно получают положения камеры для одного или более кадров с камеры, снявшей эти один или более кадров.
4. Способ по п. 3, в котором положения камеры получают с помощью гироскопа камеры.
5. Способ по п. 3, в котором положения камеры оценивают путем применения алгоритма оценки положения камеры к упомянутым одному или более кадрам.
6. Способ по п. 1, в котором карты глубины формируются в некотором масштабе.
7. Способ по п. 6, в котором упомянутый масштаб различается между разными кадрами в упомянутых одном или более кадрах.
8. Электронное устройство для коррекции данных глубины для множества видов, содержащее: по меньшей мере один процессор, включающий в себя схему обработки; память, в которой сохранены инструкции, которые при выполнении по меньшей мере одним процессором по отдельности или вместе предписывают электронному устройству: принимать видеопоследовательность, содержащую один или более кадров; получать метрические карты глубины путем поэлементного умножения исходной карты глубины на соответствующую масштабную карту глубины; создавать покадровые масштабные карты глубины в форме билинейных сплайнов для поднабора кадров, извлеченных из упомянутого одного или более кадров видеопоследовательности; инициализировать покадровые масштабные карты глубины путем репроецирования метрических карт глубины данного поднабора кадров и инициализировать все масштабные карты глубины единицами перед коррекцией масштабных карт глубины; и итеративно оптимизировать покадровые масштабные карты глубины для всех кадров упомянутого одного или более кадров и итеративно оптимизировать масштабные карты глубины для поднабора кадров посредством алгоритма оптимизации на основе градиента.
9. Устройство по п. 8, дополнительно содержащее камеру, выполненную с возможностью съемки видеопоследовательности, содержащей последовательность упомянутых одного или более кадров.
10. Устройство по п. 8, в котором память сохраняет инструкции, которые при выполнении по меньшей мере одним процессором по отдельности или вместе предписывают электронному устройству: получать положения камеры для соответствующих кадров из упомянутого одного или более кадров видеопоследовательности.
11. Устройство по п. 8, в котором карты глубины формируются в некотором масштабе.
12. Устройство по п. 11, в котором упомянутый масштаб различается между разными кадрами из упомянутого одного или более кадров.
13. Машиночитаемый носитель, на котором сохранены машиночитаемые инструкции, которые при выполнении по меньшей мере одним процессором предписывают по меньшей мере одному процессору осуществлять способ по любому из пп. 1-7.
| Patakin, N., Vorontsova, A., Artemyev, M., Konushin, A., Single-stage 3D Geometry-Preserving Depth Estimation Model Training on Dataset Mixtures with Uncalibrated Stereo Data, In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, рр.1705-1714 | |||
| Sayed, M., Gibson, J., Watson, J., Prisacariu, V.A., |

