Область техники, к которой относится изобретение
Предлагаемое изобретение может быть использовано в области реконструкции и анимации фотореалистичных 3D-моделей людей для приложений виртуальной и дополненной реальности. В частности, предлагаемое изобретение может быть использовано для создания полноразмерных 3D-моделей человека с использованием моделей глубокого обучения.
Описание предшествующего уровня техники
В последнее время наблюдается повышенный интерес к реконструкции и анимации фотореалистичных 3D-моделей людей для приложений виртуальной и дополненной реальности. Наиболее успешные из доступных в настоящее время способов обучаются в течение нескольких минут или нескольких часов.
Также наблюдается растущий интерес [31, 34, 2, 9, 37, 38, 13, 11] к цифровым реконструкциям статических и динамических сцен с приложениями в дополненной и виртуальной реальности, телеприсутствии, 3D-графике и мобильных устройствах [3]. Стандартный процесс получения персонализированных 3D-моделей является дорогостоящим и включает в себя видеосъемку с помощью многокамерных установок с точной калибровкой и ручную настройку 3D-моделей для анимации.
Чтобы снизить эти затраты, было предложено множество подходов, основанных на параметрических моделях, которые устраняют необходимость ручной настройки и анимации 3D-моделей. Некоторые из этих подходов требуют на входе только монокулярные видео [3, 14, 23, 5, 45, 14], что значительно снижает затраты. С другой стороны, эти подходы, хотя и упрощают этап получения данных, все же требуют значительных затрат времени на обучение. При рассмотрении практической применимости способа не менее важно учитывать время предварительной обработки данных, но оно часто не указывается.
Было предложено множество способов, основанных на нейронных представлениях, которые позволяют моделировать сложные статические и динамические сцены [29, 15, 25, 16, 6, 27, 33]. Некоторые из этих способов основаны на мощных нейронных полях излучения (NeRF) [25], которые требуют на входе многоракурсных или монокулярных видео. Несмотря на то, что эти подходы позволяют получать реалистичные реконструкции, большинство из них требуют многочасового обучения и часто страдают от артефактов рендеринга в сложных позах 3D-моделей людей.
Например, InstantAvatar [14] использует несколько инженерных приемов, таких как хэш-таблицы (Instant-NGP [26]) и модуль пропуска пустого пространства, которые значительно сокращают необходимое время обучения. Однако, будучи способом, основанным на точках, InstantAvatar очень чувствителен к точности оценки параметров SMPL [24] и использует отдельный этап оптимизации для этих параметров, что значительно увеличивает общее время вычислений, необходимое для создания 3D-модели человека.
В последнее время был достигнут прогресс в способах объемного сплющивания, которые используют 3D-гауссианы для моделирования сцены и позволяют быстро обучать модели и быстро выполнять рендеринг [20, 23, 22, 19, 22, 21, 47, 35, 48]. В оригинальной статье [17] было предложено использовать 3D-гауссианы для моделирования статических сцен, и этот подход был применен к динамическим сценам, таким как 3D-модели людей.
Animatable 3D Gaussian расширяет 3D-гауссианы на динамические сцены с людьми, моделируя 3D-модели людей в каноническом пространстве и деформируя их в пространство наблюдения с использованием параметров позы. Хотя этот подход обеспечивает высококачественный рендеринг и требует всего нескольких минут на обучение, он очень чувствителен к оценке параметров SMPL и часто не справляется с рендерингом 3D-моделей в сложных позах.
Отложенный нейронный рендеринг (BNR) [44] (https://arxiv.org/abs/1904.12356) использовался во многих работах, связанных с трехмерными моделями человека [43, 9, 3, 32, 39], и его главными преимуществами являются высокая скорость рендеринга и реалистичность. Кроме того, он требует в качестве входных данных только грубой трехмерной геометрии, что значительно повышает практичность этого подхода, поскольку получение высокоточной трехмерной геометрии является дорогостоящим. Нейронный рендерер часто реализуется в виде сверточной сети, что упрощает перенос системы на мобильные устройства. BINAR [43] - это однопроходная система, которая принимает в качестве входных данных одно изображение и способна анимировать трехмерные модели человека в новых ракурсах и позах. В ней используется сеть диффузионного закрашивания [12] для заполнения отсутствующих текстур, которые отсутствуют в исходном ракурсе. MoRF [3] предлагает модуль деформации нейронной текстуры, который направлен на компенсацию несоответствий при подгонке сетки и создает четкие текстуры.
Предлагаемый способ основан на подходе отложенного нейронного рендеринга (DNR), который обеспечивает быстрый рендеринг трехмерных моделей и способствует высокой реалистичности, и следует работам предыдущих способов [43, 3, 14, 5, 9, 30] по созданию трехмерных моделей человека и использует параметрическую модель тела SMPL-X [28] в качестве грубой трехмерной геометрии.
Сущность изобретения
Предлагается система для генерации видео реконструированной фотореалистичной трехмерной модели человека, содержащая функционально связанные между собой:
модуль предварительной обработки видео, сконфигурированный для:
a) выборки кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой, с указанием опорного кадра в выбранных кадрах;
для каждого выбранного кадра:
b) детектирования человека,
c) сегментации изображения человека;
d) определения на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела;
e) получения параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек;
f) прогнозирования 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры;
модуль извлечения текстуры, сконфигурированный для:
для каждого выбранного кадра:
а) растеризации 3D-сетки и соответствующих параметров камеры, получения UV-карты, выполнения с помощью UV-карты сопоставления точек на 3D-сетке с пикселями выбранного кадра путем обработки выбранного кадра, сегментированного изображения человека, 3D-сетки и параметров камеры,
для получения:
3D-изображения человека, в котором пиксели, видимые на данном выбранном кадре, имеют цвет на результирующем 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются интерполированными цветами,
первой двоичной маски, содержащей информацию о том, какие пиксели имеют цвет,
второй двоичной маски, содержащей информацию о том, какие пиксели не имели цвета, но имеют интерполированные цвета;
b) прогнозирования с помощью обученных нейронных сетей нейронной текстуры для сегментированного изображения человека на основе выбранного кадра и сегментированного изображения человека;
c) объединения 3D-изображения человека, первой двоичной маски, второй двоичной маски и предсказанной нейронной текстуры, в результате чего получается стек текстур;
модуль слияния текстур, сконфигурированный для: для каждого обработанного выбранного кадра:
a) назначения каждому пикселю каждого стека текстур его весового коэффициента в зависимости от направления нормали пикселя относительно оси объектива камеры;
b) выбора из всех стеков текстур тех двух стеков текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека; и
c) слияния выбранных двух стеков текстур с заполнением пробелов, образованных пикселями, не относящимися к выбранным двум стекам текстур, теми пикселями из невыбранных стеков текстур, которые имеют наибольшие весовые коэффициенты, для получения объединенной текстуры;
результирующий модуль, сконфигурированный для:
- при настройке системы:
a) растеризации объединенной текстуры и UV-карты опорного кадра;
b) рендеринга результата растеризации для получения реконструированного 3D-изображения;
c) сравнения с помощью дискриминаторной нейронной сети реконструированного 3D-изображения с изображением человека из опорного кадра;
d) обратного распространения ошибки для настройки нейронных сетей и рендерера,
при этом настройка системы повторяется до тех пор, пока разница между реконструированным 3D-изображением и изображением человека из выбранного опорного кадра не перестанет уменьшаться;
- при работе системы:
для каждого кадра из выбранных кадров:
a) растеризации произвольной желаемой UV-карты и объединенной текстуры,
b) рендеринга результата растеризации для получения реконструированного 3D-изображения;
c) отображения реконструированного 3D-изображения человека на экране компьютерного устройства пользователя;
при этом описанные выше действия повторяются для всех выбранных кадров для формирования видео с реконструированной фотореалистичной 3D-моделью человека на экране компьютерного устройства пользователя.
Также предлагается способ настройки предлагаемой системы, который включает в себя следующие этапы:
с помощью модуля предварительной обработки видео:
a) выборку кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой, с указанием опорного кадра в выбранных кадрах;
для каждого выбранного кадра:
b) детектирование человека,
c) сегментацию изображения человека;
d) определение на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела;
e) получение параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек;
f) прогнозирование 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры;
с помощью модуля извлечения текстуры: для каждого выбранного кадра:
а) растеризацию 3D-сетки и соответствующих параметров камеры, получение UV-карты, выполнение с помощью UV-карты сопоставления точек на 3D-сетке с пикселями выбранного кадра путем обработки выбранного кадра, сегментированного изображения человека, 3D-сетки и параметров камеры, для получения:
3D-изображения человека, в котором пиксели, видимые на данном выбранном кадре, имеют цвет на результирующем 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются интерполированными цветами,
первой двоичной маски, содержащей информацию о том, какие пиксели имеют цвет,
второй двоичной маски, содержащей информацию о том, какие пиксели не имели цвета, но имеют интерполированные цвета;
b) прогнозирование с помощью обученных нейронных сетей нейронной текстуры для сегментированного изображения человека на основе выбранного кадра и сегментированного изображения человека;
c) объединение 3D-изображения человека, первой двоичной маски, второй двоичной маски и предсказанной нейронной текстуры, в результате чего получается стек текстур;
для всех обработанных выбранных кадров с помощью модуля слияния текстур:
a) назначение каждому пикселю каждого стека текстур его весового коэффициента в зависимости от направления нормали пикселя относительно оси объектива камеры;
b) выбор из всех стеков текстур тех двух стеков текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека; и
c) слияние выбранных двух стеков текстур с заполнением пробелов, образованных пикселями, не относящимися к выбранным двум стекам текстур, теми пикселями из невыбранных стеков текстур, которые имеют наибольшие весовые коэффициенты, для получения объединенной текстуры;
с помощью результирующего модуля:
a) растеризацию объединенной текстуры и UV-карты опорного кадра;
b) рендеринг результата растеризации для получения реконструированного 3D-изображения;
c) сравнение с помощью дискриминаторной нейронной сети реконструированного 3D-изображения с изображением человека из опорного кадра;
d) обратное распространение ошибки для настройки нейронных сетей и рендерера,
при этом настройка системы повторяется до тех пор, пока разница между реконструированным 3D-изображением и изображением человека из выбранного опорного кадра не перестанет уменьшаться.
При этом этапы (а) и (b) в модуле извлечения текстуры выполняются параллельно.
Также предлагается способ генерации видео
реконструированной фотореалистичной 3D-модели человека с использованием системы по п. 1, включающий в себя следующие этапы:
с помощью модуля предварительной обработки видео:
a) выборку кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой;
для каждого выбранного кадра:
b) детектирование человека,
c) сегментацию изображения человека;
d) определение на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела;
e) получение параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек;
f) прогнозирование 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры;
с помощью модуля извлечения текстуры: для каждого выбранного кадра:
а) растеризацию 3D-сетки и соответствующих параметров камеры, получение UV-карты, выполнение с помощью UV-карты сопоставления точек на 3D-сетке с пикселями выбранного кадра путем обработки выбранного кадра, сегментированного изображения человека, 3D-сетки и параметров камеры,
для получения:
3D-изображения человека, в котором пиксели, видимые на данном выбранном кадре, имеют цвет на результирующем 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются интерполированными цветами,
первой двоичной маски, содержащей информацию о том, какие пиксели имеют цвет,
второй двоичной маски, содержащей информацию о том, какие пиксели не имели цвета, но имеют интерполированные цвета;
b) прогнозирование с помощью обученных нейронных сетей нейронной текстуры для сегментированного изображения человека на основе выбранного кадра и сегментированного изображения человека;
c) объединение 3D-изображения человека, первой двоичной маски, второй двоичной маски и предсказанной нейронной текстуры, в результате чего получается стек текстур;
для всех обработанных выбранных кадров с помощью модуля слияния текстур:
a) назначение каждому пикселю каждого стека текстур его весового коэффициента в зависимости от направления нормали пикселя относительно оси объектива камеры;
b) выбор из всех стеков текстур тех двух стеков текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека; и
c) слияние выбранных двух стеков текстур с заполнением пробелов, образованных пикселями, не относящимися к выбранным двум стекам текстур, теми пикселями из невыбранных стеков текстур, которые имеют наибольшие весовые коэффициенты, для получения объединенной текстуры;
с помощью результирующего модуля:
для каждого кадра из выбранных кадров:
a) растеризацию произвольной желаемой UV-карты и объединенной текстуры,
b) рендеринг результата растеризации для получения реконструированного 3D-изображения;
c) отображение реконструированного 3D-изображения человека на экране компьютерного устройства пользователя;
при этом описанные выше действия повторяются для всех выбранных кадров для формирования видео с реконструированной фотореалистичной 3D-моделью человека на экране компьютерного устройства пользователя.
При этом этапы (а) и (b) в модуле извлечения текстуры выполняются параллельно.
Этап (е) модуля предварительной обработки видео может быть реализован следующим образом:
получение приблизительного значения параметров позы тела человека, формы тела человека и параметров камеры с помощью способа, который оценивает параметры позы тела человека и формы тела человека по одному кадру;
получение уточненных параметров позы тела человека, формы тела человека и параметров камеры для каждого выбранного кадра путем обработки всех приблизительных значений параметров позы тела человека, формы тела человека и параметров камеры для всех выбранных кадров с помощью способа, который оценивает параметры позы и формы человека по нескольким изображениям.
Этап (f) модуля предварительной обработки видео может быть реализован с помощью параметрической модели тела SMPL-X.
В описании используются следующие термины:
"Монокулярное видео" означает видео, снятое на камеру смартфона.
"Параметрическая модель тела SMPL-X"
(https://arxiv.org/abs/1904.05866) - это способ, который принимает на вход параметры позы и формы (массивы вещественных чисел) и выводит 3D-сетку человеческого тела. Форма 3D-сетки тела задается параметрами формы. Поза тела задается параметрами позы.
"Тензор" - это массив вещественных чисел. Например, RGB-изображения высотой 512 и шириной 256 можно представить в виде тензора размерности 512×256×3 (высота × ширина × каналы). Каждый пиксель изображения задается 3 значениями, поэтому последнее измерение имеет 3 значения. Первые два измерения - это пространственные измерения - высота и ширина, последнее измерение - это измерение канала.
"Нейронная текстура" - это тензор, например, размерности 256×256×16.
"Дообучение" (Fine-Tuning) означает взятие весовых коэффициентов предобученной нейронной сети и использование их в качестве инициализации для новой модели. Новая модель обучается на новых данных. Дообучение используется для ускорения процесса обучения, и экспериментально установлено, что использование только 64 изображений оптимально для настройки и работы системы.
"Априор нейронной текстуры" - это набор нейронных сетей. Этот набор состоит из кодера, генератора, рендерера и дискриминатора. Эти сети были предобучены и известны, например, BINAR (https://arxiv.org/abs/2303.09375)). См. фиг. 3 настоящей заявки, "Кодер" - сеть кодера, "Генератор" - сеть генератора. См. фиг. 5 настоящей заявки, "Рендерер" - нейронная сеть рендеринга (например, нейронный рендерер может иметь архитектуру U-Net [36] с блоками ResNet [10]), "Дискриминатор" дискриминаторная нейронная сеть. Использование априора позволяет значительно сократить количество этапов обучения, необходимых для создания 3D-модели. Он также играет дополнительную роль, обеспечивая более широкие возможности обобщения 3D-моделей и способствуя высокой точности в более широком диапазоне поз и различных ракурсов камеры (спереди, сзади, сбоку и всего, что между ними), не представленных в обучающей последовательности.
"Параметры камеры" представлены 2 матрицами. Первая представляет собой положение и направление оптической оси камеры в трехмерном пространстве. Вторая матрица представляет собой фокусное расстояние и центр фокусировки камеры.
"Инициализация весовых коэффициентов" - это процедура установки весовых коэффициентов нейронной сети в малые случайные значения, которые определяют отправную точку для оптимизации (обучения) модели нейронной сети.
"Конкатенация" - это объединение двух тензоров. Например, тензор А размерности 10x10x5 объединяется с тензором В размерности 10×10×4. При объединении таких тензоров получается тензор размерности 10×10×(5+4)=10×10×9.
Предлагаемый способ требует на входе короткое монокулярное видео и создает анимированную полноразмерную 3D-модель человека в сжатые сроки.
Данное изобретение выполняет функции создания и анимации полноразмерных 3D-моделей человека, которые могут быть обучены на компьютере с графическими процессорами (GPU). Предлагаемый подход представляет собой значительный шаг к применимости полноразмерных 3D-моделей человека на периферийных устройствах, таких как мобильные телефоны и планшеты, за счет упрощения получения полноразмерных 3D-моделей человека и обеспечения возможности переноса на мобильные устройства и AR/VR-гарнитуры.
По меньшей мере один из множества модулей может быть реализован с помощью модели ИИ. Функция, связанная с ИИ, может выполняться с помощью энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или несколько процессоров. При этом один или несколько процессоров могут представлять собой процессор общего назначения, такой как центральный процессор (CPU), прикладной процессор (АР) или аналогичный, процессор, предназначенный только для обработки графики, такой как графический процессор (GPU), видеопроцессор (VPU), и/или процессор, выделенный для ИИ, такой как нейронный процессор (NPU).
Один или несколько процессоров управляют обработкой входных данных в соответствии с предварительно определенным правилом работы или моделью искусственного интеллекта (ИИ), хранящейся в энергонезависимой и энергозависимой памяти. Предварительно определенное правило работы или модель искусственного интеллекта создаются путем обучения или тренировки.
Здесь создание путем обучения означает, что путем применения алгоритма обучения к множеству обучающих данных создается предварительно определенное правило работы или модель ИИ с желаемыми характеристиками. Обучение может выполняться на самом устройстве, на котором выполняется ИИ в соответствии с вариантом осуществления, и/или может быть реализовано на отдельном сервере/системе.
Модель ИИ может состоять из нескольких слоев нейронной сети. Каждый слой имеет множество весовых коэффициентов и выполняет операцию слоя путем вычисления предыдущего слоя и операции с множеством весовых коэффициентов. Примеры нейронных сетей включают в себя, помимо прочего, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
Алгоритм обучения - это способ обучения заданного целевого устройства (например, робота) с использованием множества обучающих данных, чтобы инструктировать, разрешать или контролировать целевое устройство принимать решение или делать прогноз. Примеры алгоритмов обучения включают в себя, помимо прочего, обучение с учителем, обучение без учителя, частичное обучение с учителем или обучение с подкреплением.
Между тем, описанный выше способ, выполняемый электронным устройством, может быть реализован с использованием модели искусственного интеллекта.
Согласно описанию, в способе работы электронного устройства, способ может получать выходные данные, распознающие изображение, путем использования данных изображения в качестве входных данных для модели искусственного интеллекта. Модель искусственного интеллекта может быть получена путем обучения. Здесь "полученная путем обучения" означает, что предварительно определенное правило работы или модель искусственного интеллекта, сконфигурированные для выполнения желаемой функции (или цели), получаются путем обучения базовой модели искусственного интеллекта с использованием множества обучающих данных с помощью алгоритма обучения. Модель искусственного интеллекта может включать в себя несколько слоев нейронной сети. Каждый из множества слоев нейронной сети включает в себя множество весовых коэффициентов и выполняет вычисление нейронной сети путем вычисления между результатом вычисления предыдущего слоя и множеством весовых коэффициентов.
Визуальное понимание - это способ распознавания и обработки объектов, подобный человеческому зрению, и включает в себя, например, распознавание объектов, отслеживание объектов, поиск изображений, распознавание людей, распознавание сцен, трехмерную реконструкцию/локализацию или улучшение изображения.
Краткое описание чертежей
Вышеуказанные и/или другие аспекты станут более понятными из описания примерных вариантов осуществления со ссылками на прилагаемые чертежи, на которых:
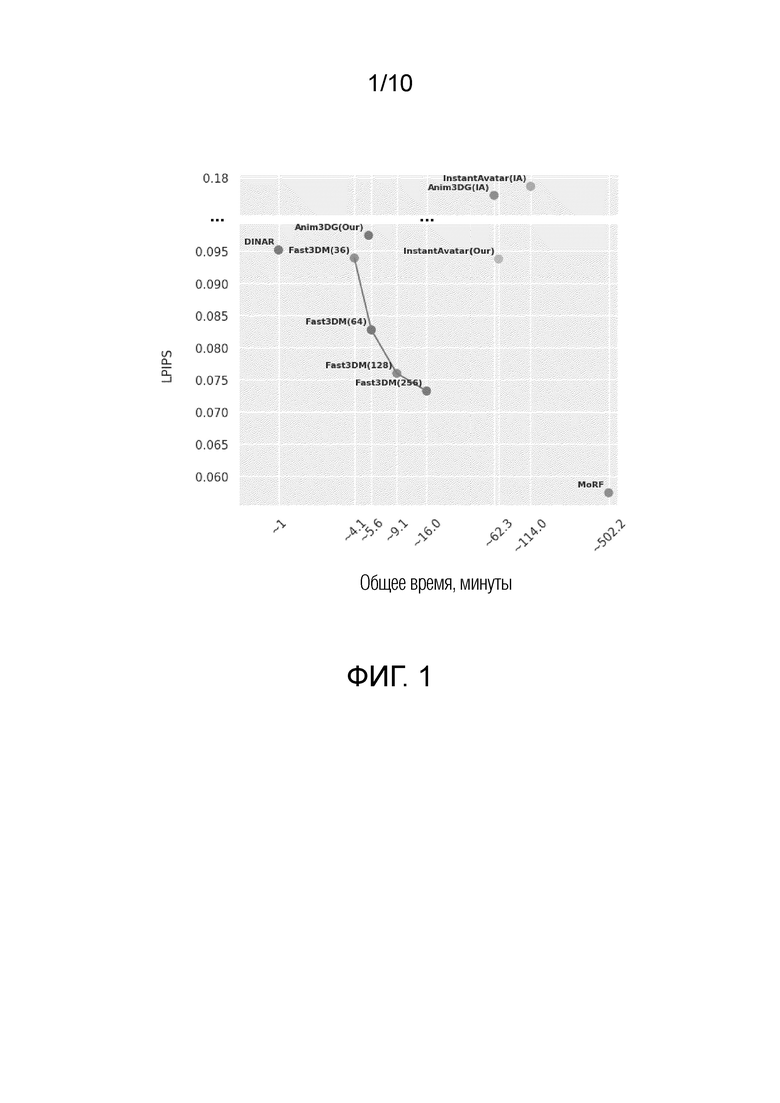
На фиг. 1 показано достижение лучшего соотношения скорость/качество предлагаемого изобретения по сравнению с другими базовыми показателями.
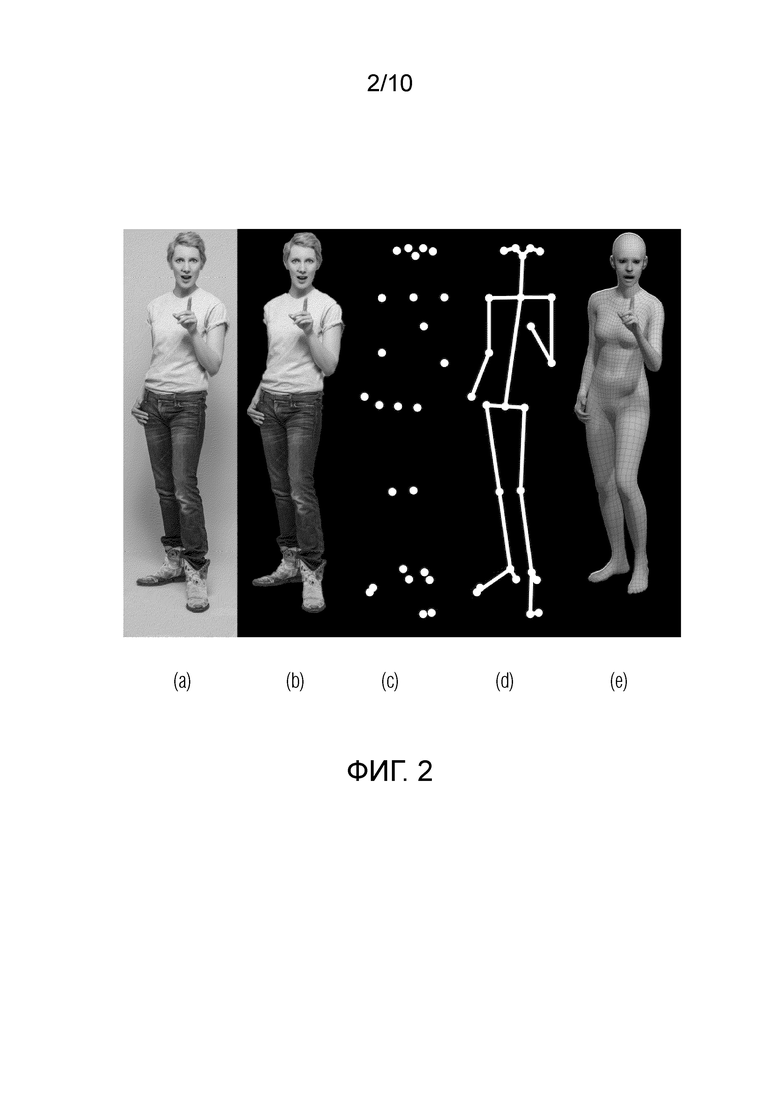
На фиг. 2 схематически показано построение 3D-сетки, где (а) - выбранный кадр, (b) - сегментированное изображение человека, (с) - местоположение опорных точек, (с!) - опорные точки, соединенные для наглядности, (е) - построенная 3D-сетка.
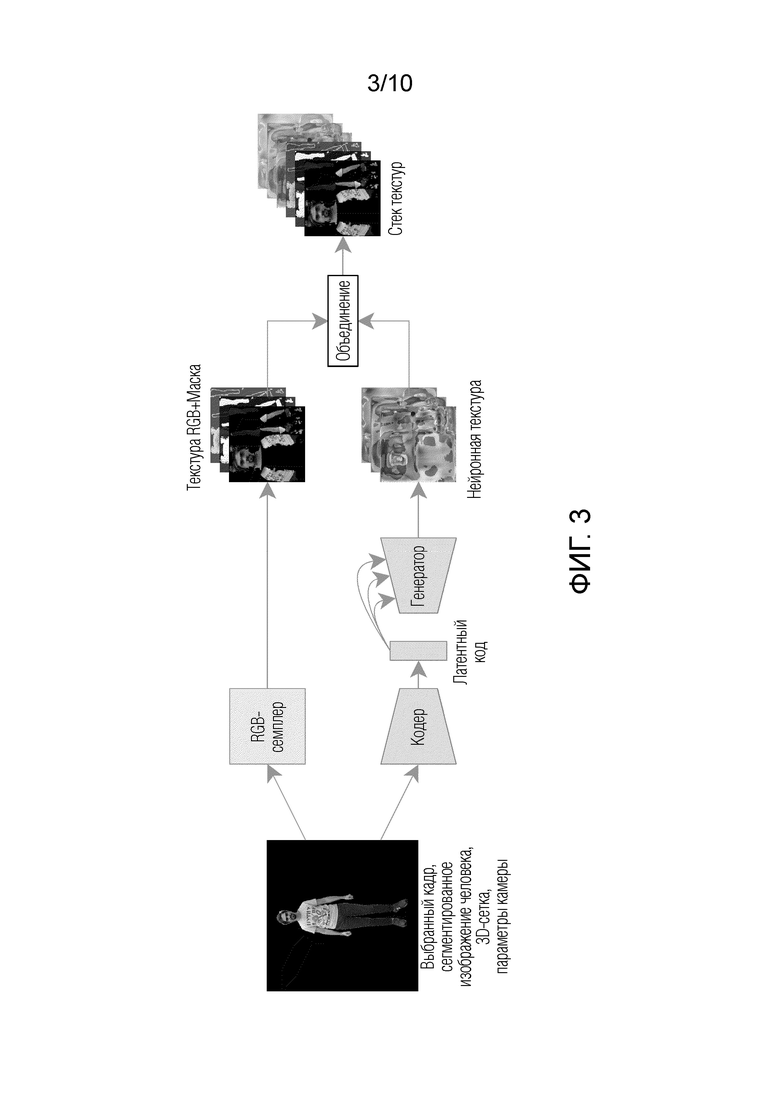
На фиг. 3 показано получение стека текстур для одного выбранного кадра.
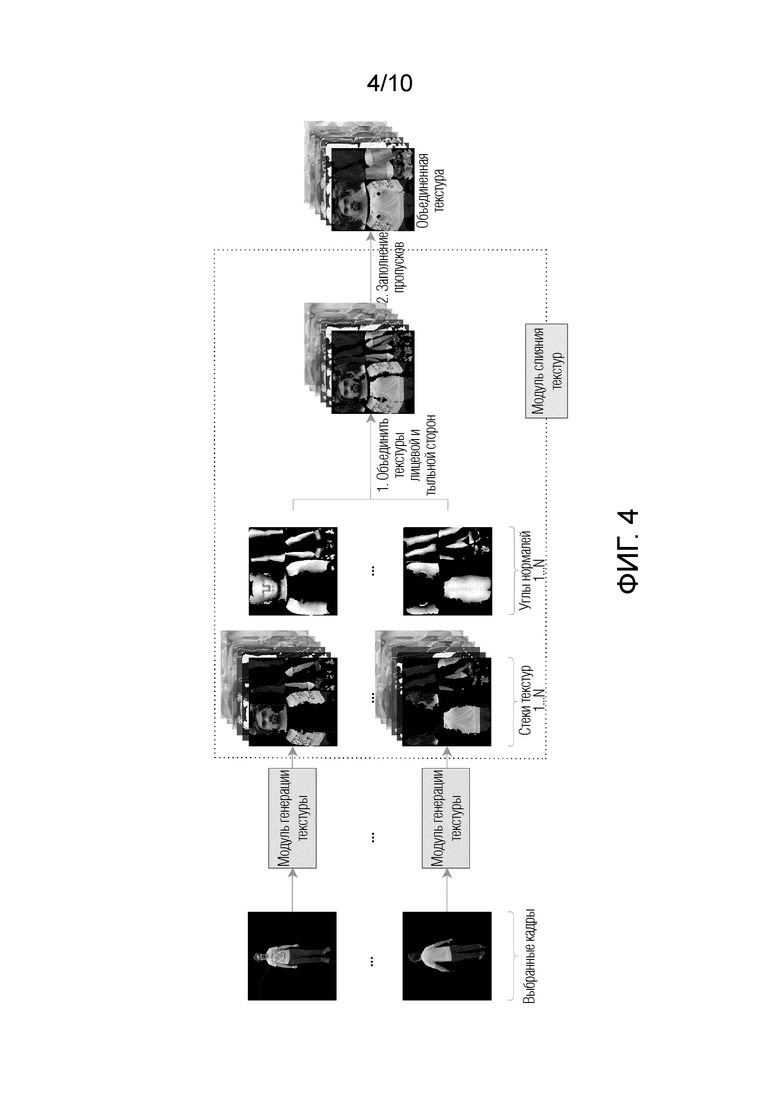
На фиг. 4 показан общий вид конвейера генерации объединенной текстуры.
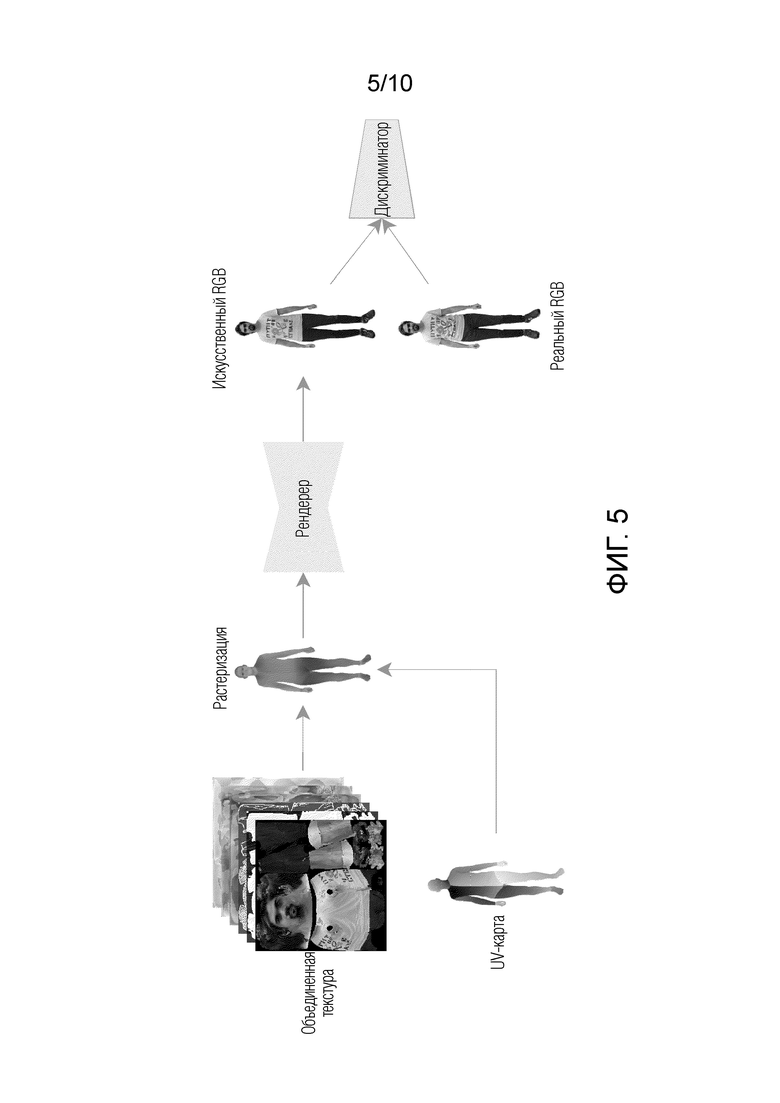
На фиг. 5 показан общий вид компонента нейронного рендеринга.
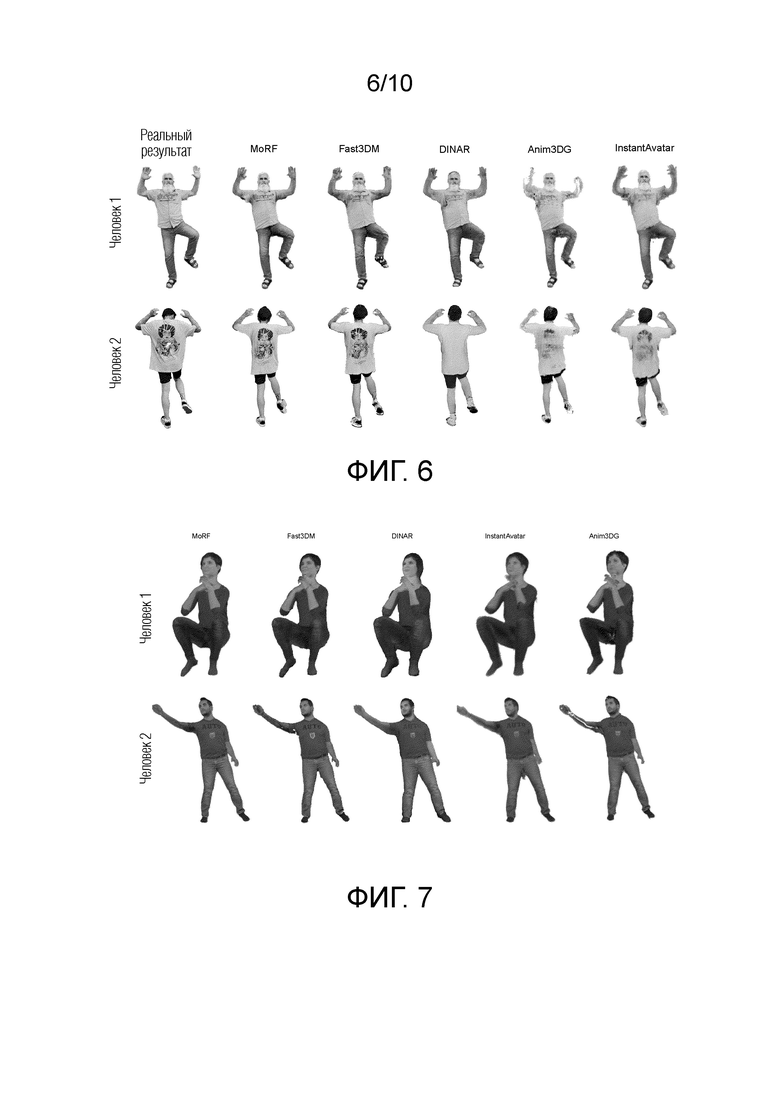
На фиг. 6 показано качественное сравнение всех способов на самостоятельно собранном наборе данных.
На фиг. 7 показано качественное сравнение всех способов на наборе данных PeopleSnapshot.
На фиг. 8 показано удаление априора нейронной текстуры.
На фиг. 9 показаны скриншоты из мобильного приложения.
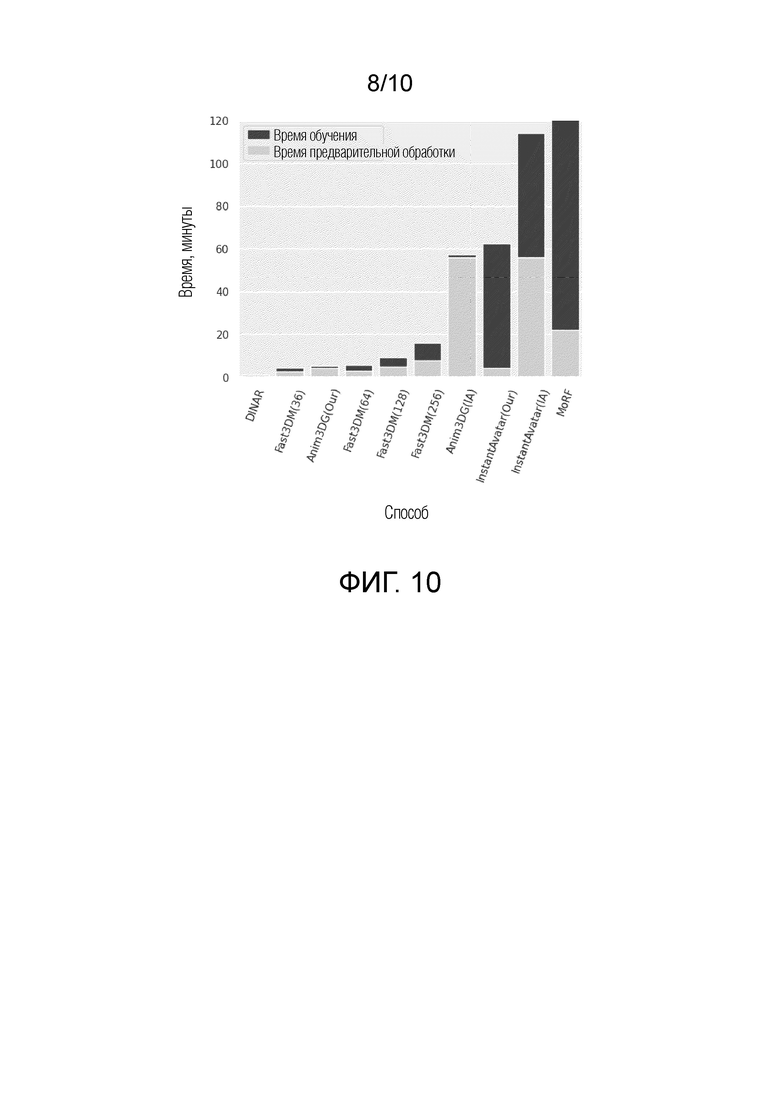
На фиг. 10 показано исследование общего времени вычислений.
На фиг. 11 показаны более качественные результаты для Fast3DM на самостоятельно собранном наборе данных.
На фиг. 12 показан образец изображений из самостоятельно собранного набора данных.
На фиг. 13 показаны более качественные результаты для Fast3DM на наборе данных PeopleSnapshot.
На фиг. 14 показаны примеры изображений из набора данных PeopleSnapshot.
Подробное описание изобретения
Предлагаемое изобретение выполняет создание и анимацию (видео) полноразмерной 3D-модели человека за короткий промежуток времени (около 5-10 минут) общего времени вычислений, включая предварительную обработку входных данных, например, на одном графическом процессоре NVIDIA GeForce RTX 4090 (GPU). В предлагаемом изобретении используется монокулярное (не 3D) видео, состоящее из последовательности кадров с человеком, эти типы видео являются наиболее распространенными и простыми в получении. Одним из преимуществ является то, что предлагаемый способ не требует других, более сложных, типов видео для реконструкции полноразмерной 3D-модели человека.
Предлагаемое изобретение используется на компьютере с графическим процессором для создания 3D-модели человека, после чего 3D-модель может быть отображена на мобильных устройствах, других компьютерах и AR/VR-гарнитурах. По сравнению с предыдущими разработками, предлагаемый способ обеспечивает лучшее соотношение между скоростью создания и визуальным качеством 3D-модели человека. Способ требует всего несколько минут, в то время как многие из существующих решений требуют часов.
На фиг. 1 показано достижение лучшего соотношения скорость/качество предлагаемого изобретения по сравнению с другими базовыми показателями, т.е. сравнение различных способов с измерением их скорости (ось X) и качества (ось Y). Предлагаемое изобретение на фиг. 1 обозначено как Fast3BM. Для сравнения также показаны подходы, известные из уровня техники:
Anim3BG (https://arxiv.org/abs/2311.164 82);
InstantAvatar (https://arxiv.org/abs/2212.10550);
DINAR (https://arxiv.orcf/abs/2303.09375);
MoRF (https://arxiv.orcf/abs/2303 10275).
На фиг. 1 по оси X отложен показатель LPIPS. LPIPS используется для количественной оценки степени сходства двух изображений. LPIPS - это метрика, которая принимает на вход два изображения и возвращает одно значение. Если это значение велико, значит, изображения отличаются друг от друга. Если значение равно 0, значит, эти два изображения идентичны. Ось X представляет собой общее время, необходимое для создания полноразмерной модели человека (знак "~" означает приблизительно). Левый нижний угол соответствует наилучшему значению, правый верхний угол - наихудшему. Из фиг. 1 видно, что предлагаемый способ наиболее близок к левому нижнему углу. Также показана производительность предлагаемого способа при изменении количества обучающих изображений (64, 128, 256 и т.д.). Большее количество изображений обеспечивает лучшее качество, но и требует больше времени. Таким образом, компромисс может быть достигнут путем изменения количества обучающих изображений. Все это позволяет сократить время, необходимое для создания 3D-модели, сохраняя при этом хорошее визуальное качество.
Предлагаемый способ (называемый Fast3DM) использует отложенный нейронный рендеринг в сочетании с параметрической моделью тела SMPL-X, что упрощает рендеринг 3D-моделей человека в новых позах и ракурсах. Для достижения короткого времени обучения и облегчения обобщения предлагается использовать априор нейронной текстуры, основанный на DINAR. В экспериментах предлагаемый подход обеспечивает лучшее качество реконструкции, чем большинство известных базовых способов, при этом требуя до 20 раз меньше общего времени вычислений. Кроме того, предлагаемый Fast3DM способствует применимости 30-моделей человека в реальном мире, поскольку создает 3D-модели, которые могут отображаться на мобильных устройствах как минимум со скоростью 30 кадров в секунду.
Для реализации предлагаемого способа реконструкции фотореалистичной 3D-модели человека можно использовать следующий набор компонентов: устройство хранения данных, процессор, графический процессор. Упомянутые компоненты образуют систему для реконструкции фотореалистичной 3D-модели человека, состоящую из следующих взаимосвязанных модулей:
1) модуль предварительной обработки видео;
2) модуль извлечения текстуры, включающий в себя RGB-семплер с первым растеризатором, нейронную сеть "Кодер", нейронную сеть "Генератор";
3) модуль слияния текстур;
4) результирующий модуль, содержащий блок выбора, второй растеризатор, нейронную сеть рендеринга, нейронную сеть дискриминатора;
Далее поэтапно раскрывается предлагаемый способ реконструкции фотореалистичной 3D-модели человека, реализуемый модулями предлагаемой системы.
Работа каждого модуля подробно описана со ссылками на фиг. 2, 4, 5.
Настоящее изобретение реализуется следующим образом:
Пользователь выбирает из устройства хранения данных или снимает на камеру входное видео с одним человеком, вращающимся перед камерой и возможно выполняющим различные движения частями тела. Входное видео представляет собой видеопоследовательность 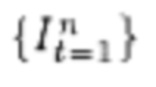 кадров, где n - количество кадров во входном видео, t - номер кадра, т.е.
кадров, где n - количество кадров во входном видео, t - номер кадра, т.е. 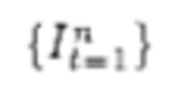 описывает набор кадров, начиная с 1 до n. Далее для каждого кадра видеопоследовательности
описывает набор кадров, начиная с 1 до n. Далее для каждого кадра видеопоследовательности 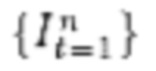 будет оценена 3D-сетка, полученная с помощью параметрической модели тела SMPL-X.
будет оценена 3D-сетка, полученная с помощью параметрической модели тела SMPL-X.
Работа модуля предварительной обработки видео описана со ссылкой на фиг. 2:
А) Предусмотрена выборка нескольких кадров из входного видео с использованием способов, известных из уровня техники. Кадры содержат изображения человека. В данном случае из входного видео выбираются кадры для дальнейшей обработки. Шаг, с которым производится выборка, зависит от длительности входного видео и является фиксированным и индивидуальным для каждого входного видео. Несмотря на то, что можно использовать любое количество кадров, экспериментально установлено, что для оптимальной скорости и качества необходимо выбирать 64 кадра. На фиг. 2(a) в качестве примера показан один выбранный кадр. Использование не всех кадров входного видео, а только выборочных кадров является одним из преимуществ предлагаемого изобретения.
B) С помощью способов, известных из уровня техники, производится детектирование человека в каждом из выбранных кадров и сегментация изображения человека из каждого из выбранных кадров. На фиг. 2(b) в качестве примера показано сегментированное изображение.
C) С помощью способов, известных из уровня техники, на сегментированном изображении человека производится нахождение местоположения опорных точек, в которых расположены суставы тела человека. На фиг. 2(c) в качестве примера показано местоположение опорных точек, соответствующих суставам человека сегментированного изображения. На фиг. 2(d) для наглядности соединены опорные точки, образующие основу силуэта человека.
D) На основе сегментированного изображения человека и местоположения опорных точек производят получение параметров позы тела человека и формы тела человека, а также параметров камеры для сегментированного изображения. Данный этап может быть выполнен любыми подходящими способами, известными из уровня техники.
Один из вариантов осуществления настоящего изобретения отличается от известных из уровня техники решений тем, что для получения уточненных параметров позы тела человека и формы тела человека, а также параметров камеры производится комбинирование известных способов следующим образом.
Используются способы, известные из уровня техники (например, ROMP (https://arxiv.orq/abs/2008.12272)), которые оценивают параметры позы тела человека, формы тела человека и параметры камеры по одному изображению на основе данных, включающих в себя сегментированное изображение человека и местоположения опорных точек человека на сегментированном изображении. Известные способы обеспечивают приближение параметров позы тела человека, формы тела человека и параметров камеры для всех выбранных кадров.
Однако полученные приближенные параметры не устраняют такого нежелательного явления, как "дрожание" (jitter), когда оцененные параметры позы сильно меняются для соседних изображений, что выглядит неестественно. Чтобы избежать дрожания и несоответствий оценок между соседними кадрами, параметры позы тела человека, формы тела человека и параметры камеры оцениваются для каждого изображения отдельно. Часто это приводит к тому, что параметры соседних изображений имеют очень разные значения. Это вызывает несоответствие, и его необходимо избегать. Для этого используется способ, который оценивает параметры позы тела человека, формы тела человека и параметры камеры по нескольким изображениям, например, используется способ пакетной подгонки сетки из MoRF (https: //arxiv. orcf/abs/2303.10275). Поскольку MoRF может обрабатывать несколько кадров одновременно, это устраняет дрожание.
Таким образом, для устранения дрожания все полученные приближения для всех выбранных кадров обрабатываются, например, с помощью способа пакетной подгонки сетки, предложенного в MoRF. Способ пакетной подгонки сетки выдает обновленные параметры позы тела человека, формы тела человека и параметры камеры для каждого выбранного кадра.
Итак, ROMP предсказывает приближение параметров позы тела человека, формы тела человека и параметров камеры, а затем дополнительный этап оптимизации с использованием MoRF дополнительно повышает их точность.
Е) Далее полученные параметры позы тела человека, формы тела человека и параметры камеры для одного выбранного кадра подаются на вход параметрической модели тела SMPL-X, которая предсказывает (строит) 3D-сетку человека. На фиг. 2 (е) в качестве примера показана предсказанная 3D-сетка человека.
Работа модуля извлечения текстуры описана со ссылкой на фиг. 3:
Модуль извлечения текстуры обеспечивает получение стека текстур для каждого выбранного кадра и содержит RGB-семплер с первым растеризатором, нейронные сети "Кодер" и "Генератор". Данный шаг отличает предлагаемое изобретение от подходов, известных из уровня техники, и позволяет улучшить визуальное качество 3D-модели человека за счет сохранения большого количества визуальной информации об объекте из входного видео.
Этап извлечения текстуры выполняется для каждого кадра следующим образом:
А) Выбранный кадр, сегментированное изображение человека, 3D-сетка и параметры камеры подаются на вход блока RGB-семплера.
Выходом блока RGB-семплера является RGB-текстура, состоящая из 3D-изображения человека, первой двоичной маски и второй двоичной маски. Описание двоичных масок приведено ниже.
Выбранный кадр состоит из пикселей, каждый пиксель содержит информацию о цвете RGB, блок RGB-семплера сопоставляет точки на 3D-сетке с пикселями выбранного кадра, т.е. определяет, какой точке на 3D-сетке соответствует какой пиксель выбранного кадра, результатом является 3D-сетка, раскрашенная в цвета RGB. Для получения такого соответствия используется UV-карта. Обработка с использованием UV-карты известна из уровня техники.
В предлагаемом изобретении UV-карта вычисляется с помощью первого растеризатора, расположенного в блоке RGB-семплера, который принимает на вход 3D-сетку и соответствующие параметры камеры и выводит UV-карту размерности Н × W × 2, где Н, W - пространственные размеры входного кадра. Имея UV-карту, значения пикселей входного изображения можно спроецировать в пространство текстур.
После обработки в блоке RGB-семплера с использованием UV-карты получаются:
- 3D-изображение человека, причем пиксели, видимые на данном выбранном кадре (и на соответствующем сегментированном изображении человека), имеют цвет, соответствующий цвету на исходном 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются (закрашиваются) цветами, полученными путем интерполяции цветов соседних пикселей на исходном изображении;
первая двоичная маска, которая несет информацию о том, какие пиксели имеют цвет (пом- ечены "1");
- вторая двоичная маска, которая несет информацию о том, какие пиксели не имеют цвета (помечены "0"), но имеют интерполированные цвета.
Интерполяция цветов соседних пикселей на исходном изображении осуществляется следующим образом. Значение пикселя -это 3 числа для красного, зеленого и синего цветов. Чтобы найти "среднее" значение, необходимо найти цвета соседних пикселей и найти для них средний цвет.
Если черный пиксель имеет соседние ячейки с цветами, отличными от черного, то находится средний цвет этих соседних ячеек и устанавливается в качестве цвета этого черного. Этот способ известен из уровня техники как inpating (заполнение пропусков).
В) На вход обученной нейронной сети, например, https://neerc.ifmo.ru/wiki/index.php?title=%DO%90%D0%B2%D1%82%D0 %BE%B0%BA%B0%BE%B0%B4%B0%B8%B1%80%B0%BE%B0%B2%B1%8 9%B0%B8%B0%BA, называемой "Кодер" (см. фиг. 3, нижняя схема), подается выбранный кадр, сегментированное изображение человека. На выходе получают латентный код, с помощью которого данные, полученные после "Кодера", передаются в нейронную сеть "Генератор" (см. фиг. 3, нижняя схема), на выходе которой получают "нейронную текстуру". "Нейронные текстуры" известны, например, из https://arxiv.orq/abs/1904.12356.
Этапы (А) и (В) могут выполняться параллельно.
С) Далее выполняется процесс объединения (конкатенации) данных, полученных на этапах (А) и (В) в модуле извлечения текстуры.
Результатом объединения является стек Т текстур, получаемый путем слияния нейронной текстуры Tneural, например, размерности 16 × 256 × 256, 3D-изображения человека (RGB-текстура) Trgb размерности 3 × 256 × 256 и двух двоичных карт Вsmp, В£ill размерности 1 × 256 × 256 каждая. Итоговые размерности - 21 × 256 × 256. Более конкретно:
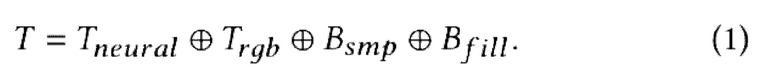
Tgen - это Тnеural,
знак ⊕ обозначает операцию конкатенации.
После получения стека текстур для каждого из выбранных кадров (см. фиг. 4 "выбранные кадры" и "модуль слияния текстур") выполняется этап "слияния текстур" в модуле слияния текстур, который описан со ссылкой на фиг. 4:
A) Стеки текстур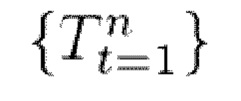 , полученные для всех выбранных кадров, подаются на вход модуля слияния текстур, а также соответствующие последовательности
, полученные для всех выбранных кадров, подаются на вход модуля слияния текстур, а также соответствующие последовательности 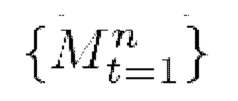 3D-сеток и параметры камеры
3D-сеток и параметры камеры 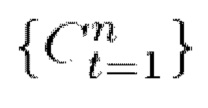 .
.
B) Поскольку 3D-сетка и соответствующие сегментированные изображения человека объединены на предыдущем этапе, то направления нормалей каждого пикселя стека текстур по отношению к оси объектива камеры известны или могут быть определены. При этом эти направления совпадают с направлениями нормалей к граням 3D-сетки по отношению к оси объектива камеры. Нормаль используется в трехмерной компьютерной графике для определения ориентации поверхности по отношению к источнику света. "Углы нормалей 1….N” для каждого выбранного кадра, указанные на фиг. 4, представляют собой маску, каждая точка которой будет белой (помечена как 1), если в результате вычислений выясняется, что нормаль совпадает с направлением оптической оси объектива камеры, т.е. перпендикулярна объективу камеры. Каждая точка маски будет черной (помечена как 0), если в результате вычислений выясняется, что нормаль расположена под углом к плоскости объектива камеры, при котором она не пересекает плоскость объектива камеры. Остальные точки будут иметь оттенки серого цвета в зависимости от угла падения нормали на плоскость объектива камеры. Т.е. каждому пикселю присваивается значение в диапазоне от 0 до 1, которое является весовым коэффициентом пикселя.
С) Из всех стеков текстур выбираются те два стека текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека, и объединяются. Такое объединение представляет собой хорошо известное суммирование непересекающихся областей спереди и сзади тела человека.
В этом случае на результирующем изображении образуются пробелы, в которых нет информации ни о цвете, ни о форме.
Поскольку местоположение пикселей, где расположены образовавшиеся пробелы, известно, то заполнение пробелов происходит на основе информации для пикселей, содержащихся в остальных стеках текстур. Причем, для заполнения пробелов выбираются те пиксели, значения весовых коэффициентов которых являются наибольшими. В результате получается объединенная текстура.
В решениях, известных из уровня техники, при объединении нейронных текстур, полученных с разных ракурсов камеры, возникают перекрывающиеся области, что приводит к появлению швов на текстуре при их наивном объединении. Эти изображения в некоторой степени смежные, т.е. имеют общие области. По сравнению с существующими решениями, предлагаемое слияние минимизирует швы на текстуре вблизи перекрывающихся областей, которые получаются из-за разности параметров камеры.
Работа результирующего модуля описана со ссылкой на фиг. 5.
Перед тем, как предлагаемая система приступит к реконструкции фотореалистичной 3D-модели человека для выбранного пользователем входного видео, система настраивается, причем настройка производится для каждого нового входного видео с изображением нового человека.
Этап настройки позволяет быстро перенастроить нейронную сеть рендеринга, нейронную сеть "Кодер", нейронную сеть "Генератор", дискриминаторную нейронную сеть, которые были обучены ранее на разнообразных обучающих наборах данных. Эта стратегия улучшает фотореалистичность создаваемых 3D-моделей человека.
Таким образом, вся система оптимизируется для генерации изображений, похожих на объект на входном видео.
В процессе оптимизации устанавливаются разные скорости обучения для нейронной сети рендеринга, нейронной сети "Кодер", нейронной сети "Генератор", дискриминаторной нейронной сети. Для каждого из этих компонентов используется отдельный планировщик скорости обучения с одним циклом и отдельная группа параметров в оптимизаторе Adam [18]. Выполняется дообучение (fine-tuning) за 200 шагов (если не указано иное).
Настройка системы производится следующим образом:
A) Блок выбора (не показан на фиг. 5) результирующего модуля случайным образом выбирает опорный кадр (Real RGB на фиг. 5) из выбранных кадров, т.е. опорный кадр уже был обработан на всех предыдущих этапах.
B) UV-карта опорного кадра и объединенная текстура растеризуются во втором растеризаторе. Затем производится рендеринг результата растеризации. В результате рендеринга получается реконструированное 3D-изображение (Fake RGB на фиг. 5).
C) С помощью дискриминаторной нейронной сети производится сравнение реконструированного 3D-изображения (Fake RGB на фиг. 5) с изображением человека из опорного кадра (Real RGB на фиг. 5).
D) Для достижения минимального различия между Fake RGB и Real RGB, известным способом производится обратное распространение ошибки по всей системе. Предусмотрена оптимизация следующей целевой функции:
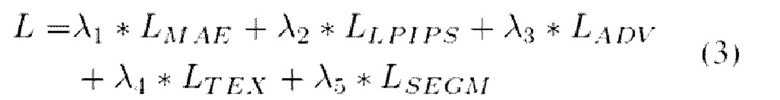
где LMAE, LLPIPS, LADV, LTEX, LSEGM - это функция потерь реконструкции, функция потерь восприятия, состязательная ненасыщающая функция потерь, регуляризация объединенной текстуры и функция потерь Дайса 41 соответственно. λlr λ2, λ3, λ4, λ5 - это вещественные числа, задающие весовые коэффициенты каждой функции потерь. Чем больше лямбда, тем важнее данная функция потерь. Например, если λ1 больше λ2, то это означает, что первая функция потерь важнее второй. В данном примере первая функция потерь -это МАЕ (LMAE), вторая функция потерь - LPIPS (LLPIPS).
В результате обратного распространения ошибки происходит корректировка весовых коэффициентов задействованных нейронных сетей: нейронной сети "Кодер", нейронной сети "Генератор", нейронной сети "Рендерер".
Шаг настройки повторяется до тех пор, пока разница между реконструированным 3D-изображением (Fake RGB на фиг. 5) и изображением человека из опорного кадра (Real RGB на фиг. 5) не перестанет уменьшаться.
После настройки системы блок выбора и дискриминаторная нейронная сеть не принимают участия в работе системы. При работе системы:
A) Для каждого кадра из выбранных кадров UV-карта, полученная в модуле извлечения текстуры (этап (А)), и объединенная текстура, полученная в модуле слияния текстур (этап (А)), растеризуются во втором растеризаторе.
B) Затем результат растеризации визуализируется в сконфигурированной нейронной сети рендеринга.
Таким образом, рендеринг (R) 3D-изображения человека в позе Ptarget и ракурсе Ctarget с соответствующим стеком Т текстур имеет следующий вид:
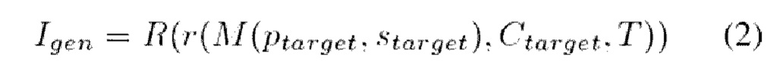
где Igen - реконструированное 3D-изображение человека (Fake RGB на фиг. 5),
r - операция растеризации,
М - 3D-сетка тела человека,
Ptarget - параметры позы тела человека,
starget - параметры формы тела человека,
Ctarget - параметры камеры, соответствующие новой позе,
Т - стек текстур.
В результате рендеринга получается реконструированное 3D-изображение человека в той позе, в которой человек был изображен на кадре, UV-карта которого была растеризована вместе с объединенной текстурой.
C) Реконструированное 3D-изображение человека отображается на экране компьютерного устройства пользователя.
При работе системы этапы А)-С) результирующего модуля повторяются для всех выбранных кадров. В результате пользователь видит на экране видео, состоящее из кадров, на каждом из которых отображается реконструированная фотореалистичная 3D-модель человека в той позе, в которой человек находится на выбранном кадре.
Для того, чтобы получить изображение человека в любой желаемой позе, а не только в той, которая отображена на выбранном кадре, необходимо использовать UV-карту, соответствующую произвольной желаемой позе, причем такая UV-карта может быть получена не обязательно на основе изображений того человека, изображение которого хочет получить пользователь. Существуют готовые последовательности UV-карт (или такие последовательности могут быть созданы перед работой системы), которые пользователь может выбрать перед запуском предлагаемой системы и использовать для получения изображения человека в новых позах, отличных от поз человека на входном видео.
Также, для реконструкции 3D-изображения человека в позах, отличных от тех, которые отображены на выбранном кадре, можно использовать упомянутую выше параметрическую модель тела SMPL-X. В этом случае на вход параметрической модели тела SMPL-X подаются данные произвольной позы тела человека и данные произвольной формы тела человека, а на выходе получается 3D-сетка человека в этой выбранной произвольной позе и форме тела. Далее вычисляется UV-карта с помощью первого растеризатора, который принимает на вход 3D-сетку и соответствующие параметры камеры и выводит UV-карту. Таким образом, как было сказано выше, для каждой новой позы и формы человека может использоваться новая UV-карта.
Предлагаемый способ оценивается на самостоятельно собранном наборе данных и на публичном бенчмарке PeopleSnapshot 1 и сравнивается с самыми современными способами, которые требуют только монокулярные видео или отдельные изображения для реконструкции 3D-модели человека. К таким способам относятся InstantAvatar [14], Animatable 3D Gaussian [23], BINAR [43] и MoRF [3]. При сравнении с этими способами предлагаемый подход обеспечивает лучшее соотношение между скоростью получения данных и качеством анимации. Представлено абляционное исследование, демонстрирующее влияние предлагаемых проектных решений. Ниже представлены результаты серии экспериментов, которые показывают влияние каждого из предложенных технических решений.
На фиг. 6 показано качественное сравнение всех способов на самостоятельно собранном наборе данных. Результат предлагаемого изобретения обозначен как Fast3DM. Предлагаемый способ сравнивается с классами способов создания полноразмерных 3D-моделей человека: способы на основе DNR (MoRF, DINAR), способ на основе NeRF (InstantAvatar) и способ на основе 3D-распыления гауссиан (Animatable 3D Gaussian). Для каждого способа показаны визуализации в двух новых позах. Из фиг. 6 видно, что изображения людей 1 и 2, полученные с помощью предлагаемого изобретения, хорошо сформированы и раскрашены и не имеют явных дефектов, как, например, у способа Anim3DG, при котором модель не смогла предсказать изображения кистей рук человека 1 или получила плохо сформированные руки и ноги человека 2.
На фиг. 7 показано качественное сравнение всех способов на самостоятельно собранном наборе данных и на публичном бенчмарке PeopleSnapshot [1]. Для каждого человека показаны визуализации в сложных, новых позах и ракурсах из готовых наборов новых поз, которые не использовались при обучении.
Ниже приведены эксперименты для сравнения предлагаемого изобретения с решениями, известными из уровня техники.
На этапах обучения и тестирования предлагаемые входные данные (с параметрами позы SMPL-X) передаются во все способы, чтобы исключить ненужную дисперсию в производительности. Кроме того, проведено абляционное исследование для изучения влияния каждого из предложенных технических решений.
Во многих системах для создания 3D-моделей человека в качестве грубой геометрии используются параметрические модели тела, такие как SMPL-X [28]. Качество системы ограничено точностью оценки этих параметров. Таким образом, для корректного сравнения крайне важно обеспечить использование одного и того же способа подгонки сетки и типов моделей тела. Если они разные - часто приходится прилагать много усилий, чтобы привести их к общему знаменателю.
Набор данных, собранный самостоятельно. Эксперименты проводились на самостоятельно собранном наборе данных, который содержит десять монокулярных видеороликов с людьми, вращающимися перед камерой и выполняющими различные движения частями тела. В выборку вошли люди с разными демографическими характеристиками, формами тела и топологией одежды.
Набор данных PeopleSnapshot. Кроме того, были проведены эксперименты на наборе данных PeopleSnapshot [1], который содержит монокулярные видеоролики с людьми, вращающимися перед камерой. Хотя InstantAvatar [14] и Animatable 3D Gaussian [23] используют общедоступные позы Anim-NeRF [5], было решено использовать вместо них предлагаемые позы. Таким образом, используются одни и те же входные данные и устраняется ненужная дисперсия производительности. Однако InstantAvatar при обучении с позами Anim-NeRF на наборе данных PeopleSnapshot демонстрирует немного более высокое качество.
Ниже приведена числовая оценка всех способов с использованием стандартных метрик: средняя абсолютная ошибка (МАЕ],) t структурное сходство (SS1M ↑), многомасштабное структурное сходство (MS-SSIM ↑ и изученное перцептивное сходство) фрагментов изображения [4 6] (LPIPS↓).
Для оценки способности к обобщению на новые ракурсы и позы приведена производительность всех способов на самостоятельно собранном наборе данных (Таблица 1). Тестовые последовательности содержат сложные, новые позы, не встречавшиеся в процессе обучения.
Таблица 1: Количественное сравнение на самостоятельно собранном наборе данных. МАЕ, SSIM, MS-SSIM, LPIPS. Приведены метрики качества, агрегированные по всем десяти субъектам из самостоятельно собранного набора данных. Согласно таблице 1, MoRF является лучшим, предлагаемый способ Fast3DM - вторым лучшим, а третий лучший… таблица 1

MoRF требует на входе монокулярное видео, тогда как DINAR -только одно изображение. Изучив таблицу 1 и прилагаемое абляционное исследование, можно сделать вывод, что предлагаемый способ Fast3DM естественным образом занимает промежуточное положение между этими способами. Варьируя количество обучающих изображений, можно добиться различных компромиссов между скоростью и качеством.
InstantAvatar и Animatable 3D Gaussian демонстрируют более низкое качество по сравнению с Fast3DM. Это можно объяснить тем фактом, что эти основанные на точках способы плохо работают на позах, которые слишком сильно отличаются от тех, которые наблюдались во время обучения (см. фиг. 6 и 7). Animatable 3D Gaussian подвержен переобучению на обучающих данных в большей степени, чем InstantAvatar.
Производительность этих способов оценивалась с использованием предложенного способа подгонки сетки и способа InstantAvatar. Обратите внимание на резкое падение производительности при использовании способа InstantAvatar.
Кроме того, было измерено среднее время предварительной обработки и обучения для всех способов, и эти данные представлены в Таблице 1. См. также дополнительные фиг. 1 и 8. Все измерения проводились на одном GPU NVIDIA GeForce RTX 4090 и CPU AMD Ryzen Threadripper PRO 3955WX с 16 ядрами. Под общим временем вычислений понимается суммарное время предварительной обработки и обучения.
Все способы требуют значительного времени на предварительную обработку, при этом Animatable 3D Gaussian и InstantAvatar требуют наибольшего количества времени.
У 3D Gaussian нет собственного общедоступного способа подгонки сетки, поэтому использовался способ InstantAvatar. DINAR - это однокадровый способ, который не требует дополнительного обучения или тонкой настройки, поэтому время обучения у него отсутствует. Предлагаемый способ Fast3DM занимает промежуточное положение между однокадровым DINAR и способами, основанными на видео, с умеренным увеличением общего времени вычислений при увеличении количества обучающих кадров. По сравнению с MoRF, Fast3DM (64) требует примерно в 186 раз меньше времени на обучение и примерно в 7 раз меньше времени на предварительную обработку.
Как показано на фиг. 6 и 7, предлагаемый способ позволяет создавать реалистичные 30-модели людей в сложных позах с сохранением высокочастотных деталей.
На фиг. 8 показано удаление априора нейронной текстуры. На фиг. 8 показано качество рендеринга предлагаемого способа при различной степени предварительного обучения. Как видно, полная версия (рендеринг + текстура) обеспечивает наилучшее качество.
Фиг. 9 демонстрирует скриншоты из мобильного приложения. На фиг. 9 показана визуализация предлагаемого способа на мобильном устройстве с процессором Qualcomm Snapdragon 888.
Фиг. 10 иллюстрирует исследование общего времени вычислений. Обратите внимание, что ось Y ограничена для наглядности.
По сравнению с DINAR [43] предлагаемый способ Fast3DM способен создавать 3D-модели людей с более высоким уровнем детализации. Причина в том, что по сравнению с DINAR, Fast3DM имеет тщательно продуманный этап тонкой настройки, который быстро улучшает 3D-модели людей, избегая при этом чрезмерной подгонки под обучающие данные. Кроме того, Fast3DM имеет алгоритм слияния текстур, который объединяет информацию из нескольких ракурсов и помогает сохранить индивидуальность объекта, в то время как DINAR использует диффузионную сеть для заполнения пропущенных текстур.
Благодаря тому, что в предлагаемом способе Fast3DM используется сильный априорный алгоритм нейронной текстуры, он способен визуализировать 3D-модели людей в сложных ракурсах и позах с высокой точностью и фотореалистичностью. В отличие от него, точечные способы, такие как Animatable 3D Gaussian [23] и InstantAvatar [14], не позволяют получить точные результаты в сложных позах, как видно на фиг. 5 и 6. Animatable 3D Gaussian восстанавливает достаточно точные лица, хотя и не без артефактов.
InstantAvatar также страдает от переобучения на обучающих позах. Артефакты могут быть видны в областях, которые не были видны во время обучения, таких как подмышки и область между ног. Также наблюдаются "плавающие" точки вокруг кистей рук и стоп. Однако следует отметить, что InstantAvatar восстанавливает лица с достаточно высоким уровнем детализации.
На фиг. 11 представлены дополнительные качественные результаты предлагаемого способа Fast3DM на предлагаемом самостоятельно собранном наборе данных. Для каждого человека показана визуализация в двух новых позах.
Фиг. 12 иллюстрирует примеры изображений из самостоятельно собранного набора данных. На фиг. 13 и 11 показаны дополнительные результаты визуализации предлагаемого способа на других объектах. Фиг. 13 иллюстрирует дополнительные качественные результаты Fast3DM на наборе данных PeopleSnapshot, показаны дополнительные результаты предлагаемого способа, для каждого человека показана визуализация в нескольких сложных, новых позах и ракурсах. Фиг. 14 иллюстрирует примеры изображений из набора данных PeopleSnapshot.
Таблица 2 иллюстрирует абляционное исследование с изменением ограничения по времени. Представлена производительность предлагаемого способа при фиксированном количестве эпох и различном количестве обучающих кадров.
Это предложение является описанием Таблицы 2. Пояснения к Таблице 2 приведены в абзаце выше под названием "Изменение ограничений по времени".

Изменение ограничений по времени (пояснения к Таблице 2). Проведено абляционное исследование по количеству обучающих изображений при отсутствии ограничений на количество шагов оптимизации, но с фиксированным количеством эпох, равным 12. Таким образом, можно проверить, получает ли предлагаемый способ преимущества от большего количества данных и вычислений; очевидно, что большее количество обучающих данных приводит к повышению качества, хотя и с умеренным увеличением времени предварительной обработки и обучения. Наилучшие значения связаны с последней строкой (количество изображений равно 256). Эта настройка является наилучшей из всех 4. Также видно, что метрики улучшаются с увеличением количества изображений. Таким образом, при наличии большего количества данных (количества изображений) и вычислительных ресурсов (времени предварительной обработки) предлагаемый способ может достичь лучшего качества. "Время предвар. обработки" - время предварительной обработки, т.е. время, затрачиваемое на выполнение первой части способа.
Изучено влияние использования модуля извлечения текстуры и результирующего модуля, особое внимание уделено следующим трем настройкам (см. фиг. 9). Первая - "с нуля", что означает, что не используются никакие предварительно обученные контрольные точки, а нейронные текстуры инициализируются случайным шумом. Вторая - "рендерер", где используются предварительно обученные контрольные точки для нейронного рендерера и дискриминаторной нейронной сети, а нейронная текстура инициализируется случайным шумом.
Последняя настройка - "рендерер + текстура", в которой используются контрольные точки для всех модулей, а нейронные текстуры инициализируются с помощью модуля слияния текстур. Как показано на фиг. 8, предлагаемая полная версия обеспечивает наилучшие результаты.
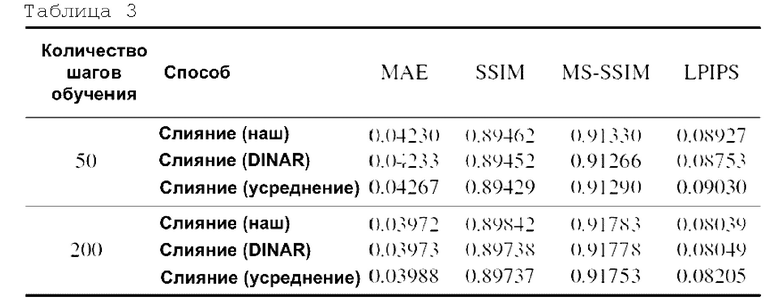
Способ слияния текстур. Проведена оценка эффективности предлагаемого нового способа слияния текстур и его сравнение со способом, представленным в DINAR [43]. Кроме того, рассмотрена простая эвристика, заключающаяся в усреднении всех текстур из обучающих ракурсов. Как показано в Таблице 3, простое усреднение приводит к наихудшему качеству. В обеих настройках с количеством шагов обучения, равным 50 и 200, способ усреднения имеет худшие метрики. Таким образом, он обеспечивает наихудшее качество. Предлагаемый способ слияния в обеих настройках имеет более высокие значения, что означает, что у него лучше метрики. Следовательно, качество лучше. Стоит отметить, что важность способа слияния текстур снижается по мере увеличения количества шагов оптимизации.
Таблица 3: Абляционное исследование способа слияния текстур. Значения метрик были усреднены по 5 субъектам из самостоятельно собранного набора данных.
Предлагаемый способ Fast3DM может визуализировать изображения с разрешением 512 × 512 со скоростью не менее 30 кадров в секунду (см. фиг. 10). Предложенные измерения проводились на Qualcomm Snapdragon 888.
Предлагаемый способ обучается на RGB-изображениях с разрешением 512. Используется априорный алгоритм нейронной текстуры, который состоит из нейронных сетей кодера, генератора, рендерера и дискриминатора. Во всех экспериментах использовалась одна и та же предварительно обученная контрольная точка для всех этик сетей.
Во время обучения использовались следующие функции потерь: функция потерь L2, функция потерь LPIPS [46], состязательная ненасыщающая функция потерь [В] и функция потерь Дайса [41]. Кроме того, большие отклонения объединенной текстуры ограничивались с помощью L2-peгyляpизaции.
Значения потерь агрегировались с помощью взвешенной суммы со следующими весовыми коэффициентами: для функции потерь L2 весовой коэффициент λ1=25.0, для функции потерь LPIPS весовой коэффициент λ2=20.0, для состязательной ненасыщающей функции потерь весовой коэффициент λ3=1.0, для L2 - регуляризации отклонений объединенной текстуры весовой коэффициент λ4=15.0 и для функции потерь Дайса весовой коэффициент λ0=25.0.
Для вычисления LPIPS использовалось случайное кадрирование размером 256 × 256 вокруг тела человека путем выбора случайной точки на 3D-сетке тела SMPL-X [28] с последующим кадрированием области.
Тонкая настройка всего способа производилась за 200 шагов. Использовался оптимизатор Adam с тремя отдельными группами параметров для объединенной текстуры, нейронной сети рендерера и дискриминаторной нейронной сети. Была установлена скорость обучения 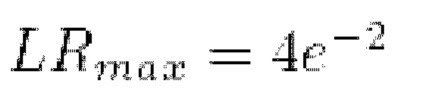 для объединенной текстуры, скорость обучения
для объединенной текстуры, скорость обучения 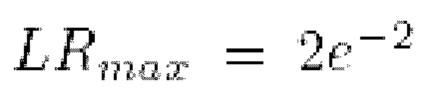 для нейронной сети рендерера и скорость обучения
для нейронной сети рендерера и скорость обучения 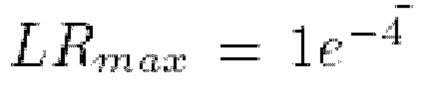 для дискриминаторной нейронной сети. Использовались три отдельный планировщика скорости обучения с одним циклом для каждой из этих групп со следующими параметрами планирования скорости обучения модели (планировщик необходим для изменения шага обучения модели в зависимости от времени оптимизации):
для дискриминаторной нейронной сети. Использовались три отдельный планировщика скорости обучения с одним циклом для каждой из этих групп со следующими параметрами планирования скорости обучения модели (планировщик необходим для изменения шага обучения модели в зависимости от времени оптимизации):
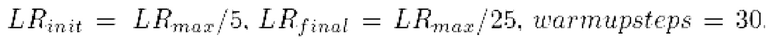
LR_init - начальное значение шага обучения,
LR_max - максимальное значение шага обучения,
LR_final - конечное значение шага обучения.
Warmupsteps - количество шагов для перекода от начального значения шага обучения к максимальному.
Эти параметры одинаковы для всех групп параметров. Размер пакета данных был установлен равным четырем.
Для предварительной обработки входных данных использовался подход, описанный в MoRF. Для определения 2D-ключевых точек на входных изображениях использовался OpenPose. Использовалась нейронная сеть сегментации человека. Затем оценивались параметры SMPL-X для каждого обучающего кадра.
Предлагаемый способ был протестирован в мобильном приложении для телеприсутствия на базе Qualcomm Snapdragon SoC, разработанном в [3]. Как и в [3], использовалась посттренировочная квантизация нейронной сети рендеринга и 8-битная квантизация нейронных текстур. Таким образом, Fast3DM -это готовая к применению система для создания полноразмерных 3D-моделей человека, требующая менее 5,5 минут общего времени вычислений. Это важный вклад в практическую применимость 3D-моделей людей.
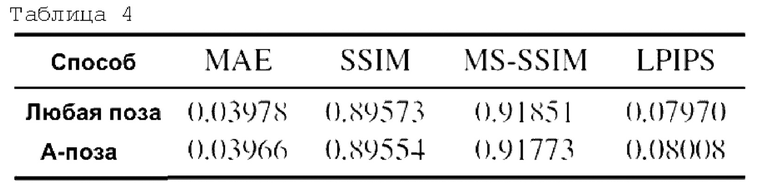
Разнообразие поз тела в обучающем видео может выступать в качестве регуляризатора и предотвращать переобучение априорного алгоритма. В Таблице 4 представлены две настройки. В первой использовались только те части входных видеороликов, которые содержали людей, вращающихся в приблизительной позе А-образной стойки. Эта настройка имеет ограниченное разнообразие поз. Во второй настройке использовались любые доступные позы. Как видно из Таблицы 4, использование более разнообразных видеороликов с точки зрения поз тела является полезным для предлагаемого способа. Из таблицы видно, что лучшие значения метрик (МАЕ, SSIM и т.д.) наблюдаются при настройке "Любая поза".
Таблица 4: Абляционное исследование разнообразия обучающих поз. Все значения являются средними по 5 субъектам из самостоятельно собранного набора данных. Дополнительное обсуждение результатов см. в тексте.
Фиксированные ограничения по времени. Представлены результаты для нескольких запусков предлагаемого способа, каждый из которых обозначен как Fast3DM (N), где N - количество обучающих кадров, причем N равно 236, 64, 128, 256.
Количество шагов оптимизации было зафиксировано и равно 200. Оптимальное количество обучающих кадров в этой настройке равно 64. При использовании 36 обучающих кадров наблюдается переобучение, что приводит к высоким значениям LPIPS. С другой стороны, при использовании большего количества кадров можно наблюдать недостаточное обучение - каждый обучающий кадр просматривается меньшее количество раз, и этого недостаточно для осмысленного обновления параметров и текстуры.
Заключение
Представлен новый способ генерации видео с реконструированной фотореалистичной 3D-моделью человека, требующий 5,5 минут общего времени вычислений. Для достижения этой цели используются нейронные текстуры, которые тщательно донастраиваются для каждого человека, что позволяет достичь лучшего компромисса между скоростью получения данных и качеством 3D-моделей людей, а также способностью к обобщению на новые ракурсы и позы. Также предложен способ, позволяющий агрегировать наиболее полезную информацию из заданных обучающих кадров. Таким образом, реализован вклад в практическую применимость 3D-моделей людей.
Вышеупомянутые примеры осуществления являются иллюстративными и не должны рассматриваться как ограничивающие. Кроме того, описание примеров реализации призвано проиллюстрировать изобретение, а не ограничивать объем притязаний, и специалистам в данной области техники будут очевидны многие альтернативные варианты, модификации и вариации.
Библиографический список
[1] Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Video based reconstruction of 3d people models. In CVPR, стр. 8387-8397, июнь 2018.
[2] Thiemo Alldieck, Mihai Zanfir, and Cristian Sminchisescu. Photorealistic monocular 3d reconstruction of humans wearing clothing. In CVPR, стр. 1506-1515, 2022.
[3] Renat Bashirov, Alexey Larionov, Evgeniya Ustinova, Mikhail Sidorenko, Bavid Svitov, Ilya Zakharkin, and Victor Lempitsky. Morf: Mobile realistic fullbody avatars from a monocular video, 2023.
[4] Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields, 2019.
[5] Jianchuan Chen, Ying Zhang, Di Kang, Xuefei Zhe, Linchao Bao, Xu Jia, and Huchuan Lu. Animatable neural radiance fields from monocular rgb videos, 2021.
[6] Guy Gafni, Justus Thies, Michael Zollh"ofer, and Matthias NieBner. Dynamic neural radiance fields for monocular 4d facial avatar reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), стр. 8649-8658, июнь 2021.
[7] Ke Gong, Yiming Gao, Xiaodan Liang, Xiaohui Shen, Meng Wang, and Liang Lin. Graphonomy: Universal human parsing via graph transfer learning. In CVPR, 2019.
[8] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014.
[9] Artur Grigorev, Karim Iskakov, Anastasia Ianina, Renat Bashirov, Ilya Zakharkin, Alexander Vakhitov, and Victor Lempitsky. Stylepeople: A generative model of fullbody human avatars. In CVPR, стр. 5151-5160, 2021.
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, стр. 770-778, 2016.
[11] Tong He, Yuanlu Xu, Shunsuke Saito, Stefano Soatto, and Tony Tung. Arch++: Animation-ready clothed human reconstruction revisited. In ICCV, стр. 11046-11056, 2021.
[12] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:684 0-6851, 2020.
[13] Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, and Tony Tung. Arch: Animatable reconstruction of clothed humans. In CVPR, стр. 3093-3102, 2020.
[14] Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. Instantavatar: Learning avatars from monocular video in 60 seconds, 2 022.
[15] Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. Neuman: Neural human radiance field from a single video. In ECCV, стр. 402-418. Springer, 2022.
[16] Yifan Jiang, Peter Hedman, Ben Mildenhall, Dejia Xu, Jonathan T. Barron, Zhangyang Wang, and Tianfan Xue. Alignerf: High-fidelity neural radiance fields via alignmentaware training, 2022.
[17] Bernhard Kerbl, Georgios Kopanas, Thomas Leimk"uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering, 2023.
[18] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2015.
[19] Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. Hugs: Human Gaussian splats, 2023.
[20] Jiahui Lei, Yufu Wang, Georgios Pavlakos, Lingjie Liu, and Kostas Daniilidis. Gart: Gaussian articulated template models, 2023.
[21] Mengtian Li, Shengxiang Yao, Zhifeng Xie, and Keyu Chen. Gaussianbody: Clothed human reconstruction via 3d Gaussian splatting, 2024.
[22] Zhe Li, Zerong Zheng, Lizhen Wang, and Yebin Liu. Animatable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling, 2023.
[23] Yang Liu, Xiang Huang, Minghan Qin, Qinwei Lin, and Haoqian Wang. Animatable 3d gaussian: Fast and highquality reconstruction of multiple human avatars, 2023.
[24] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multiperson linear model. ACM transactions on graphics (TOG), 34(6):1-16, 2015.
[25] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1): 99-106, 2021.
[26] Thomas M"uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics, 41(4):1-15, июль 2022.
[27] Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan В Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields, 2021.
[28] Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. In CVPR, 2019.
[29] Sida Peng, Junting Dong, Qianqian Wang, Shangzhan Zhang, Qing Shuai, Xiaowei Zhou, and Hujun Bao. Animatable neural radiance fields for modeling dynamic human bodies. In ICCV, стр. 14314-14323, 2021.
[30] Sida Peng, Yuanging Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans, 2021.
[31] Sergey Prokudin, Michael J Black, and Javier Romero. Smplpix: Neural avatars from 3d human models. In WACV, стр. 1810-1819, 2021.
[32] Amit Raj, Julian Tanke, James Hays, Minh Vo, Carsten Stoll, and Christoph Lassner. Anr: Articulated neural rendering for virtual avatars, 2020.
[33] Amit Raj, Michael Zollhoefer, Tomas Simon, Jason Saragih, Shunsuke Saito, James Hays, and Stephen Lombardi. Pva: Pixel-aligned volumetric avatars, 2021.
[34] Edoardo Remelli, Timur Bagautdinov, Shunsuke Saito, ChengleiWu, Tomas Simon, Shih-EnWei, Kaiwen Guo, Zhe Cao, Fabian Prada, Jason Saragih, et al. Drivable volumetric avatars using texel-aligned features. In ACM SIGGRAPH Conference Proceedings, стр. 1-9, 2022.
[35] Alfredo Rivero, ShahRukh Athar, Zhixin Shu, and Dimitris Samaras. Rig3dgs: Creating controllable portraits from casual monocular videos, 2024.
[36] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, стр. 234-241. Springer, 2015.
[37] Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In ICCV, стр. 2304-2314, 2019.
[38] Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In CVPR, стр. 84-93, 2020.
[39] Vanessa Sklyarova, Jenya Chelishev, Andreea Dogaru, Igor Medvedev, Victor Lempitsky, and Egor Zakharov. Neural haircut: Prior-guided strand-based hair reconstruction, 2023.
[40] Leslie N. Smith. Cyclical learning rates for training neural networks, 2017.
[41] Carole H Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M Jorge Cardoso. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep learning in medical image analysis and multimodal learning for clinical decision support, стр. 240-248. Springer, 2017.
[42] Yu Sun, Qian Bao, Wu Liu, Yili Fu, Michael J. Black, and Tao Mei. Monocular, one-step, regression of multiple 3d people, 2 021.
[43] David Svitov, Dmitrii Gudkov, Renat Bashirov, and Victor Lempitsky. Dinar: Diffusion inpainting of neural textures for one-shot human avatars, 2023.
[44] Justus Thies, Michael Zollh"ofer, and Matthias NieBner. Deferred neural rendering: Image synthesis using neural textures.
ACM Transactions on Graphics (TOG), 38(4):1-12, 2019.
[45] Chung-Yi Weng, Brian Curless, Pratul P Srinivasan, Jonathan T Barron, and Ira Kemelmacher-Shlizerman. Humannerf: Free-viewpoint rendering of moving people from monocular video. In CVPR, стр. 16210-16220, 2022.
[46] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.
[47] Zhongyuan Zhao, Zhenyu Bao, Qing Li, Guoping Qiu, and Kanglin Liu. Psavatar: A point-based morphable shape model for real-time head avatar animation with 3d Gaussian splatting, 2024.
[48] Zhenglin Zhou, Fan Ma, Hehe Fan, and Yi Yang. Headstudio: Text to animatable head avatars with 3d gaussian splatting, 2024.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| СПОСОБ РЕКОНСТРУКЦИИ 3D-МОДЕЛИ ОБЪЕКТА | 2020 |
|
RU2779271C2 |
| НЕЙРОСЕТЕВОЙ РЕНДЕРИНГ ТРЕХМЕРНЫХ ЧЕЛОВЕЧЕСКИХ АВАТАРОВ | 2021 |
|
RU2775825C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИСТАНЦИОННОГО ВЫБОРА ОДЕЖДЫ | 2020 |
|
RU2805003C2 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |



Изобретение относится к области информационных технологий, а именно к средствам создания 3D-модели человека. Технический результат - повышение качества и скорости создания фотореалистичной 3D-модели человека. Система для генерации видео с реконструированной фотореалистичной 3D-моделью человека содержит следующие функционально связанные между собой: модуль предварительной обработки видео, сконфигурированный для: a) выборки кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой, с указанием опорного кадра в выбранных кадрах; b) детектирования человека, c) сегментации изображения человека; d) определения на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела; e) получения параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек; f) прогнозирования 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры. 3 н. и 4 з.п. ф-лы, 14 ил., 4 табл.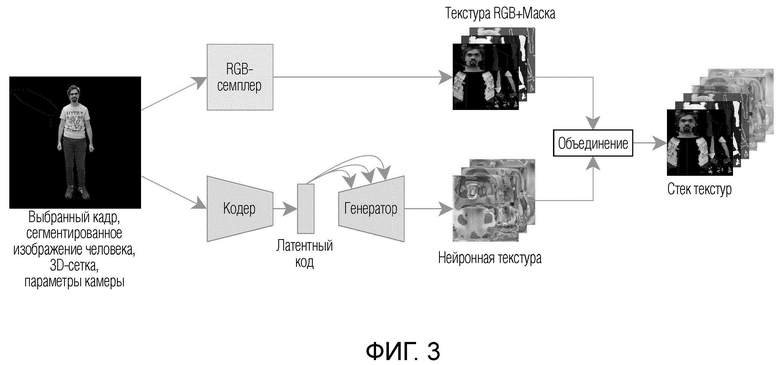
1. Система для генерации видео с реконструированной фотореалистичной 3D-моделью человека, содержащая следующие функционально связанные между собой:
модуль предварительной обработки видео, сконфигурированный для:
a) выборки кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой, с указанием опорного кадра в выбранных кадрах;
для каждого выбранного кадра:
b) детектирования человека,
c) сегментации изображения человека;
d) определения на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела;
e) получения параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек;
f) прогнозирования 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры;
модуль извлечения текстуры, сконфигурированный для:
для каждого выбранного кадра:
a) растеризации 3D-сетки и соответствующих параметров камеры, получения UV-карты, выполнения с помощью UV-карты сопоставления точек на 3D-сетке с пикселями выбранного кадра путем обработки выбранного кадра, сегментированного изображения человека, 3D-сетки и параметров камеры,
для получения:
3D-изображения человека, в котором пиксели, видимые на данном выбранном кадре, имеют цвет на результирующем 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются интерполированными цветами,
первой двоичной маски, содержащей информацию о том, какие пиксели имеют цвет,
второй двоичной маски, содержащей информацию о том, какие пиксели не имели цвета, но имеют интерполированные цвета;
b) прогнозирования с помощью обученных нейронных сетей нейронной текстуры для сегментированного изображения человека на основе выбранного кадра и сегментированного изображения человека;
с) объединения 3D-изображения человека, первой двоичной маски, второй двоичной маски и предсказанной нейронной текстуры, в результате чего получается стек текстур;
модуль слияния текстур, сконфигурированный для:
для каждого обработанного выбранного кадра:
a) назначения каждому пикселю каждого стека текстур его весового коэффициента в зависимости от направления нормали пикселя относительно оси объектива камеры;
b) выбора из всех стеков текстур тех двух стеков текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека; и
c) слияния выбранных двух стеков текстур с заполнением пробелов, образованных пикселями, не относящимися к выбранным двум стекам текстур, теми пикселями из невыбранных стеков текстур, которые имеют наибольшие весовые коэффициенты, для получения объединенной текстуры;
результирующий модуль, сконфигурированный для:
- при настройке системы:
a) растеризации объединенной текстуры и UV-карты опорного кадра;
b) рендеринга результата растеризации для получения реконструированного 3D-изображения;
c) сравнения с помощью дискриминаторной нейронной сети реконструированного 3D-изображения с изображением человека из опорного кадра;
d) обратного распространения ошибки для настройки нейронных сетей и рендерера,
при этом настройка системы повторяется до тех пор, пока разница между реконструированным 3D-изображением и изображением человека из выбранного опорного кадра не перестанет уменьшаться;
- при работе системы:
для каждого кадра из выбранных кадров:
a) растеризации произвольной желаемой UV-карты и объединенной текстуры,
b) рендеринга результата растеризации для получения реконструированного 3D-изображения;
c) отображения реконструированного 3D-изображения человека на экране компьютерного устройства пользователя;
при этом описанные выше действия повторяются для всех выбранных кадров для формирования видео с реконструированной фотореалистичной 3D-моделью человека на экране компьютерного устройства пользователя.
2. Способ настройки системы по п. 1, причем способ содержит следующие этапы:
с помощью модуля предварительной обработки видео:
a) выборка кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой, с указанием опорного кадра в выбранных кадрах;
для каждого выбранного кадра:
b) детектирование человека,
c) сегментация изображения человека;
d) определение на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела;
e) получение параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек;
f) прогнозирование 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры;
с помощью модуля извлечения текстуры:
для каждого выбранного кадра:
a) растеризация 3D-сетки и соответствующих параметров камеры, получение UV-карты, выполнение с помощью UV-карты сопоставления точек на 3D-сетке с пикселями выбранного кадра путем обработки выбранного кадра, сегментированного изображения человека, 3D-сетки и параметров камеры,
для получения:
3D-изображения человека, в котором пиксели, видимые на данном выбранном кадре, имеют цвет на результирующем 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются интерполированными цветами,
первой двоичной маски, содержащей информацию о том, какие пиксели имеют цвет,
второй двоичной маски, содержащей информацию о том, какие пиксели не имели цвета, но имеют интерполированные цвета;
b) прогнозирование с помощью обученных нейронных сетей нейронной текстуры для сегментированного изображения человека на основе выбранного кадра и сегментированного изображения человека;
с) объединение 3D-изображения человека, первой двоичной маски, второй двоичной маски и предсказанной нейронной текстуры, в результате чего получается стек текстур;
для всех обработанных выбранных кадров с помощью модуля слияния текстур:
a) назначение каждому пикселю каждого стека текстур его весового коэффициента в зависимости от направления нормали пикселя относительно оси объектива камеры;
b) выбор из всех стеков текстур тех двух стеков текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека; и
c) слияние выбранных двух стеков текстур с заполнением пробелов, образованных пикселями, не относящимися к выбранным двум стекам текстур, теми пикселями из невыбранных стеков текстур, которые имеют наибольшие весовые коэффициенты, для получения объединенной текстуры;
с помощью результирующего модуля:
a) растеризация объединенной текстуры и UV-карты опорного кадра;
b) рендеринг результата растеризации для получения реконструированного 3D-изображения;
c) сравнение с помощью дискриминаторной нейронной сети реконструированного 3D-изображения с изображением человека из опорного кадра;
d) обратное распространение ошибки для настройки нейронных сетей и рендерера,
при этом настройка системы повторяется до тех пор, пока разница между реконструированным 3D-изображением и изображением человека из выбранного опорного кадра не перестанет уменьшаться.
3. Способ по п. 2, отличающийся тем, что этапы (а) и (b) в модуле извлечения текстуры выполняются параллельно.
4. Способ генерации видео с реконструированной фотореалистичной 3D-моделью человека с помощью системы по п. 1, включающий в себя следующие этапы:
с помощью модуля предварительной обработки видео:
а) выборка кадров для дальнейшей обработки из входного видеоролика с человеком, вращающимся перед камерой;
для каждого выбранного кадра:
b) детектирование человека,
c) сегментация изображения человека;
d) определение на сегментированном изображении местоположения опорных точек, в которых находятся суставы тела человека с позой и формой тела;
e) получение параметров позы тела человека, формы тела человека и параметров камеры на основе данных, включающих в себя сегментированное изображение человека и найденные местоположения опорных точек;
f) прогнозирование 3D-сетки человека на основе параметров позы тела, формы тела и параметров камеры;
с помощью модуля извлечения текстуры:
для каждого выбранного кадра:
a) растеризация 3D-сетки и соответствующих параметров камеры, получение UV-карты, выполнение с помощью UV-карты сопоставления точек на 3D-сетке с пикселями выбранного кадра путем обработки выбранного кадра, сегментированного изображения человека, 3D-сетки и параметров камеры,
для получения:
3D-изображения человека, в котором пиксели, видимые на данном выбранном кадре, имеют цвет на результирующем 3D-изображении человека, а пиксели, которые не видны и, следовательно, не имеют цвета, заполняются интерполированными цветами,
первой двоичной маски, содержащей информацию о том, какие пиксели имеют цвет,
второй двоичной маски, содержащей информацию о том, какие пиксели не имели цвета, но имеют интерполированные цвета;
b) прогнозирование с помощью обученных нейронных сетей нейронной текстуры для сегментированного изображения человека на основе выбранного кадра и сегментированного изображения человека;
c) объединение 3D-изображения человека, первой двоичной маски, второй двоичной маски и предсказанной нейронной текстуры, в результате чего получается стек текстур;
для всех обработанных выбранных кадров с помощью модуля слияния текстур:
а) назначение каждому пикселю каждого стека текстур его весового коэффициента в зависимости от направления нормали пикселя относительно оси объектива камеры;
b) выбор из всех стеков текстур тех двух стеков текстур, которые отвечают за переднюю часть тела человека и заднюю часть тела человека; и
c) слияние выбранных двух стеков текстур с заполнением пробелов, образованных пикселями, не относящимися к выбранным двум стекам текстур, теми пикселями из невыбранных стеков текстур, которые имеют наибольшие весовые коэффициенты, для получения объединенной текстуры;
с помощью результирующего модуля:
для каждого кадра из выбранных кадров:
a) растеризация произвольной желаемой UV-карты и объединенной текстуры,
b) рендеринг результата растеризации для получения реконструированного 3D-изображения;
c) отображение реконструированного 3D-изображения человека на экране компьютерного устройства пользователя;
при этом описанные выше действия повторяются для всех выбранных кадров для формирования видео с реконструированной фотореалистичной 3D-моделью человека на экране компьютерного устройства пользователя.
5. Способ по п. 4, отличающийся тем, что этапы (а) и (b) в модуле извлечения текстуры выполняются параллельно.
6. Способ по п. 4, отличающийся тем, что этап е) модуля предварительной обработки видео реализуется следующим образом:
получение приблизительного значения параметров позы тела человека, формы тела человека и параметров камеры с помощью способа, который оценивает параметры позы тела человека и формы тела человека по одному кадру;
получение уточненных параметров позы тела человека, формы тела человека и параметров камеры для каждого выбранного кадра путем обработки всех приблизительных значений параметров позы тела человека, формы тела человека и параметров камеры для всех выбранных кадров с помощью способа, который оценивает параметры позы и формы человека по нескольким изображениям.
7. Способ по любому из пп. 4-6, отличающийся тем, что на этапе f) модуля предварительной обработки видео используется параметрическая модель тела SMPL-X.
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 9240067 B2, 19.01.2016 | |||
| US 11393163 B2, 19.07.2022 | |||
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |

