Область техники
[0001] Настоящее изобретение относится к области искусственного интеллекта (ИИ) и, в частности, к способу оценки глубины сцены (с возможностью восстановления геометрии сцены) по изображению сцены и вычислительному устройству для реализации упомянутого способа, в которых применяется модель оценки глубины сцены, полученная посредством нейросетевых технологий.
Уровень техники
[0002] Монокулярная оценка глубины сцены по единственному изображению играет решающую роль в понимании геометрии 3D сцены для таких приложений, как, например, AR (дополненная реальность) и 3D-моделирование. В традиционных способах оценки глубины применяют различные эффективные и оригинальные способы использования данных изображения, в которых осуществляют поиск полезных ориентиров в визуальных данных посредством обнаружения краев, оценки плоскостей или сопоставления объектов. В последнее время подходы, основанные на глубоком обучении, начали конкурировать с классическими алгоритмами машинного зрения, в которых используются подбираемые вручную признаки. Основные достижения в этой области заключаются в обучении сверточных нейронных сетей оценке действительнозначной карты глубины по RGB изображению. Разнообразные обучающие данные необходимы для обучения модели, способной работать в различных реальных сценариях.
[0003] Источники данных о глубине многочисленны и имеют различные характеристики. Сканеры LiDAR (обнаружение и определение дальности с помощью света), которые обычно используются для сценариев автономного вождения, обеспечивают точные, но редкие измерения глубины. Таким образом, эти данные требуют тщательной фильтрации и ручной обработки. Дешевые и миниатюрные серийные датчики глубины на основе активного стерео со структурированным светом (например, Microsoft Kinect) или времяпролетные (Time-of-Flight) датчики (например, Microsoft Kinect Azure или датчики глубины во многих смартфонах) обеспечивают относительно плотные оценки, но при этом они являются менее точными и имеют ограниченный диапазон определяемых расстояний. Такие датчики в основном используются для сценариев внутри помещений. В некоторых наборах данных RGB-D (комбинация RGB изображения и изображения глубины), таких как RedWeb и DIML outdoor, стереопары служат в качестве данных о глубине. Тем не менее, стандартная процедура оценки глубины, основанная на оптическом потоке, не всегда дает точные карты глубины, особенно для объектов, расположенных на большом расстоянии (10м и более).
[0004] Недавно метод определения структуры по движению (SfM) был применен для оценки карт глубины посредством реконструкции сцены, см., например, Li, Z., Snavely, N.: Mega depth: Learning single-view depth prediction from internet photos. In: Computer Vision and Pattern Recognition (CVPR), 2018, по результатам этой работы был опубликован набор данных MegaDepth RGB-D, который был получен с использованием SfM с итеративным уточнением. Аналогичный подход был применен в работе Li, Z., Dekel, T., Cole, F., Tucker, R., Snavely, N., Liu, C., Freeman, W.T.: Learning the depths of moving people by watching frozen people, 2019 для набора данных неподвижных людей. Однако метод SfM работает в предположении, что сцена является статичной и не содержит движущихся объектов. Таким образом, метод SfM в основном применяется для воссоздания архитектурных элементов или силуэтов.
[0005] В то время как в некоторых наборах данных содержится абсолютная глубина (обычно измеряемая датчиками или оцениваемая по выровненным стереокамерам с известными внутренними и внешними параметрами), другие наборы данных содержат только глубину с точностью до масштаба (UTS, обычно восстанавливаемую методом SfM или оцениваемую по выровненным стереокамерам с неизвестными параметрами). Также имеется несколько наборов данных, содержащих обратную глубину с точностью до масштаба со сдвигом (UTSS, обычно оцениваемую по невыровненным стереокамерам с неизвестными параметрами).
[0006] В целом, ни один из существующих наборов данных, используемых отдельно, не является достаточным с точки зрения точности, разнообразия и количества изображений для обучения надежной модели оценки глубины сцены. Этот недостаток побуждает к использованию различных стратегий смешивания обучающих данных из разных источников во время обучения, см., например, Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer, 2019. Первая версия данного документа может быть рассмотрена в качестве ближайшего уровня техники.
[0007] Для обучения моделей, которые оценивают глубину в абсолютных значениях, могут быть использованы только обучающие данные с абсолютными значениями глубины. Модели UTS можно обучать как на абсолютных обучающих данных, так и на обучающих данных UTS. В решении ближайшего уровня техники, указанном в предыдущем абзаце данного описания, предлагалось обучать модель UTSS на абсолютных данных, данных UTS и данных UTSS из разных источников. Полученная в результате такого обучения модель продемонстрировала впечатляющую способность к обобщению. Однако у моделей UTSS есть серьезный недостаток, заключающийся в том, что они не могут восстановить геометрию сцены.
Сущность изобретения
[0008] В первом аспекте настоящего раскрытия обеспечен способ оценки глубины сцены по изображению, содержащий этапы, на которых: получают изображение; оценивают глубину сцены на изображении с использованием инвариантной масштабу модели, основанной на нейронной сети с облегченной архитектурой, которую обучают с использованием обучающих изображений, причем на каждой итерации обучения используется смесь изображений, выбираемых случайно из обучающих изображений с абсолютными данными, обучающих изображений с UTS (Up-to-Scale) данными и обучающих изображений с UTSS (Up-to-Shift-Scale) данными в случайных пропорциях.
[0009] Во втором аспекте настоящего изобретения обеспечено вычислительное устройство пользователя, содержащее процессор и память, хранящую обученную нейронную сеть и исполняемые процессором инструкции, которые при исполнении побуждают процессор к выполнению способа оценки глубины сцены по изображению сцены согласно первому аспекту настоящего изобретения.
[0010] Раскрытое изобретение решает по меньшей мере некоторые или все из вышеперечисленных проблем уровня техники, обеспечивая точную и надежную модель оценки глубины сцены по изображению за счет применения инвариантной масштабу модели, основанной на нейронной сети, на каждой итерации обучения которой в дополнение к обучающим изображениям попеременно используется либо комбинация абсолютных данных и данных UTS, соответствующая обучающим изображениям, либо комбинация данных UTSS и данных UTS, соответствующая обучающим изображениям. Кроме того, предложенное изобретение пригодно для применения на вычислительных устройствах, обладающих ограниченными ресурсами, поскольку архитектура нейронной сети в используемой инвариантной масштабу модели является облегченной. Наконец, использование предложенного изобретения не требует специального оборудования, такого как сканер LiDAR, времяпролетный (ToF-) датчик и т.д., для оценки глубины сцены (на основе которой может быть дополнительно построена геометрия сцены), поскольку для такой оценки предложенному изобретению достаточно лишь единственного изображения (например, RGB-изображения сцены), которое может быть получено обычной камерой.
Краткое описание чертежей
[0011] Конкретные варианты осуществления, реализации и другие подробности раскрытого изобретения проиллюстрированы на чертежах, на которых:
[ФИГ. 1] ФИГ. 1 иллюстрирует блок-схему последовательности операций способа оценки глубины сцены по изображению согласно варианту осуществления настоящего изобретения.
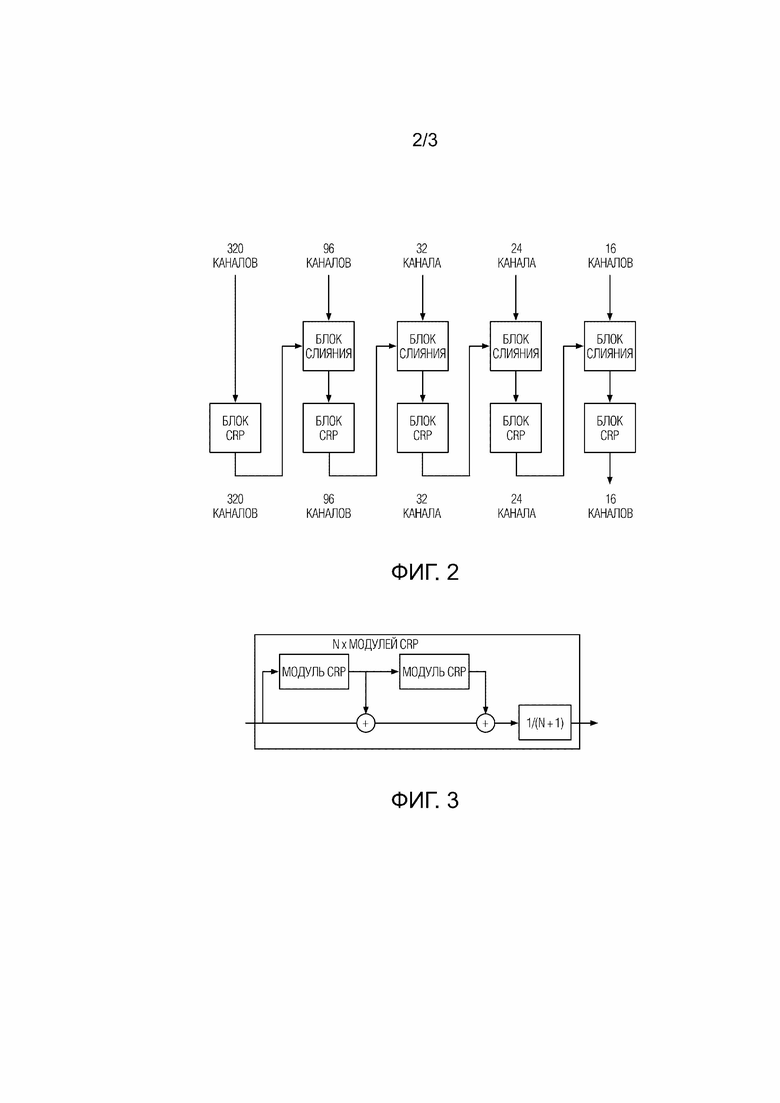
[ФИГ. 2] ФИГ. 2 иллюстрирует схему ветви уточнения нейронной сети в предложенной архитектуре согласно варианту осуществления настоящего изобретения.
[ФИГ. 3] ФИГ. 3 иллюстрирует пример структуры блока CRP (цепного разностного пулинга) нейронной сети в предложенной архитектуре согласно варианту осуществления настоящего изобретения.
[ФИГ. 4] ФИГ. 4 иллюстрирует блок-схему вычислительного устройства согласно варианту осуществления настоящего изобретения.
Подробное описание
[0012] Сначала будут описаны некоторые общие понятия и концепции применимых нейросетевых технологий, а затем данный раздел сконцентрируется на отличиях и модификациях этих концепций в настоящем изобретении. Специалист в данной области поймет, что ниже приведено не полное теоретическое описание всех известных нейросетевых технологий, а только та часть такого описания, которая граничит с и необходима для теоретического обоснования и практической реализации заявленного изобретения. Особый акцент будет сделан на различные модификации и отличия заявленного изобретения от известного уровня техники, а также на различные реализации и варианты осуществления заявленного изобретения.
[0013] Оценка глубины в настоящем изобретении решается как задача плотной разметки в непрерывном пространстве. Эффективное решение такой задачи может быть получено с помощью архитектур кодировщика-декодера с обходными (skip-) связями, первоначально разработанных для семантической сегментации. Такие архитектуры позволяют успешно комбинировать предварительно базовую (backbone-) нейронную сеть, которая служит модулем извлечения признаков, с различными архитектурами декодеров. В качестве примера, а не ограничения, типичным модулем извлечения признаков может быть мощная сеть для классификации, такая как ResNet или ResNeXt, предварительно обученная на большом и разнообразном наборе данных, например наборе данных ImageNet. Обобщающая способность этих моделей позволяет использовать их для различных задач визуального распознавания, в том числе для текущей задачи оценки глубины сцены по изображению сцены.
[0014] Наиболее известные и распространенные архитектуры нейронных сетей слишком дороги с вычислительной точки зрения для использования в режиме реального времени на обладающих ограниченными ресурсами вычислительных устройствах, таких как смартфоны, планшеты и т.д. В таком случае в качестве кодировщика, т.е. модуля извлечения признаков, может быть применена модель нейронной сети с легковесной архитектурой, например, MobileNetV2 или EfficientNet.
[0015] Для обнаружения объектов и семантической сегментации в архитектуре нейронных сетей может быть применен декодер. Для этой цели имеется ряд эффективных декодеров, например, Light-Weight Refine Net, EffcientDet и HRNet. Декодер Light-Weight Refine Net осуществляет итеративное слияние (fuse) карт глубоких признаков с картами неглубоких (shallow) признаков. Декодер EffcientDet работает аналогичным образом, но с добавлением обратной процедуры слияния. Декодер HRNet работает немного иначе: обрабатывая входные данные в нескольких параллельных ветвях с разными разрешениями, он извлекает высокоуровневые признаки и распространяет низкоуровневые признаки. В результате выходные данные содержат как структурную, так и семантическую информацию, поэтому входные данные используются эффективно.
[0016] Несмотря на то, что одни и те же легковесные кодировщики часто используются в разных эффективных архитектурах нейронных сетей для решения различных задач, конструкция декодеров имеет тенденцию быть более специфичной для определенной задачи. Поскольку вычислительная эффективность является одним из ключевых факторов при реализации настоящего изобретения, решающее значение имеет правильный выбор архитектуры декодера. Согласно одной из возможных методик можно осуществить поиск наиболее компактной, но эффективной архитектуры блока декодера для оценки глубины сцены, среди известных архитектур нейронной сети. Согласно другой методике можно выполнить балансировку производительности и точности за счет обучения легковесной архитектуры декодера с применением переноса обучения (transfer learning).
[0017] Оценка абсолютной глубины. Существует несколько подходов к решению проблемы оценки глубины. Большинство работ посвящено оценке абсолютной глубины в метрических единицах. Однако не всегда можно определить масштаб сцены по единственному изображению. Для получения обучающих данных об абсолютной глубине необходимо использовать датчик глубины или предоставить стереопары, полученные камерой/камерами с известными внешними параметрами, что значительно усложняет процесс сбора обучающих данных.
[0018] Оценка глубины, получаемая с точностью до масштаба (UTS). Глубина UTS - это глубина, которая определена с точностью до неизвестного коэффициента (причем для всей карты глубины). Иными словами, можно сказать, что единицы измерения неизвестны. Другими словами, в отношении UTS глубины не известно, в чем измеряется глубина, в метрах, километрах или миллиметрах. Другие подходы сосредоточены на оценке глубины с точностью до неизвестного коэффициента. Они нацелены на восстановление геометрии сцены, а не на предсказание расстояний до отдельных точек в сцене. Данные UTS для обучения моделей получить легче, чем абсолютные данные, но их предварительная обработка требует времени и вычислительных ресурсов.
[0019] Оценка обратной глубины, получаемая с точностью до масштаба со сдвигом (UTSS). Глубина UTSS (данные обратной глубины) - это глубина, которая определена с точностью до масштаба и сдвига. Иными словами, если известно значение обратной глубины d, то UTSS данные о такой обратной глубине могут быть определены как d* = a * d+b, где a и b - неизвестные коэффициенты. Оценка обратной глубины UTSS может использоваться для решения задачи SVDE (Single-View Depth Estimation, оценка глубины по одному кадру). Однако, у этого способа есть серьезный недостаток: геометрия сцены не может быть восстановлена должным образом, если сдвиг b обратной глубины неизвестен. Основное преимущество этого способа заключается в простоте сбора данных, поскольку глубина UTSS является доступной и легко обрабатываемой. В этой заявке будет показано, что обучение инвариантной масштабу UTS модели, основанной на нейронной сети с облегченной архитектурой, может быть выполнено на абсолютных, UTS и UTSS обучающих данных.
[0020] В настоящей заявке предложено практическое решение для оценки глубины (и опционально геометрии) сцены по изображению сцены, которое обеспечивает баланс между точностью оценки и вычислительной эффективностью. Такой баланс достигается за счет применения нейронной сети с облегченной архитектурой и определенной последовательности обучения нейронной сети на абсолютных, UTS и UTSS обучающих данных. ФИГ. 1 иллюстрирует блок-схему последовательности операций способа оценки обратной глубины сцены по изображению сцены согласно варианту осуществления настоящего изобретения. Способ содержит этап S100, на котором получают изображение, и этап S110, на котором оценивают глубины сцены на изображении с использованием инвариантной масштабу модели, основанной на нейронной сети с облегченной архитектурой, которую обучают с использованием обучающих изображений. На каждой итерации обучения используется смесь изображений, выбираемых случайно из обучающих изображений с абсолютными данными, обучающих изображений с UTS (Up-to-Scale) данными и обучающих изображений с UTSS (Up-to-Shift-Scale) данными в случайных пропорциях. Другими словами, в смесь обучающих изображений выбирается N любых изображений с любыми разметками случайно. В одном варианте осуществления настоящего изобретения глубину сцены на изображении оценивают с использованием инвариантной масштабу модели, основанной на нейронной сети с облегченной архитектурой, как обратный логарифм глубины сцены на изображении. Поскольку инвариантная масштабу модель, основанная на нейронной сети с облегченной архитектурой, оценивает глубину с точностью до коэффициента, на основе такой оценки глубины сцены может быть дополнительно построена геометрия сцены. Таким образом, в одном варианте осуществления настоящего изобретения способ может дополнительно содержащий этап, на котором строят геометрию сцены на основе полученной оценки глубины сцены.
[0021] Изображение на этапе S100 может быть любым изображением из изображения, захватываемого камерой вычислительного устройства, изображения, извлекаемого из памяти вычислительного устройства, или изображения, загружаемого по сети. Оценка, на этапе S110, может быть выполнена инвариантной масштабу моделью, основанной на нейронной сети с облегченной архитектурой, на центральном процессоре (CPU) или любом ином специализированном процессоре (ASIC, SoC, FPGA, GPU) вычислительного устройства.
[0022] Инвариантная масштабу модель, основанная на нейронной сети с облегченной архитектурой, содержит кодировщик и декодер. В качестве кодировщика могут быть использованы, но без ограничения упомянутым, кодировщик MobileNet, кодировщика MobileNetv2, или архитектуры кодировщика из EfficientNet (а именно EfficientNet-Lite0, EfficientNet-b0, b1, b2, b3, b4, b5), предварительно обученные задаче классификации на наборе обучающих данных ImageNet. Декодер, применяемый в предложенной инвариантной масштабу модели, основан на декодере vanilla Light-Weight Refine Net, в архитектуру которого внесены следующие модификации для удовлетворения требований вычислительной эффективности и для решения проблем со стабильностью. Первая модификация: слой, который отображает выходной сигал кодировщика на 256 каналов, был заменен на блок слияния, который число каналов не меняет (т.е. число выходных каналов блока слияния равно числу каналов на соответствующем уровне кодировщика). Число каналов в каждом последующем блоке слияния (fusion), выполненном с возможностью обеспечения слияния сигнала с выхода более глубокого уровня декодера и сигнала с соответствующего уровня кодировщика, в каскаде блоков слияния снижено относительно предыдущего блока слияния и равно числу каналов на выходе из кодировщика. Каскад блоков слияния в предпочтительном варианте осуществления содержит четыре блока слияния, но без ограничения конкретным числом, поскольку большее или меньшее число блоков слияния в каскаде может применяться для достижения баланса между точностью оценки и вычислительной эффективностью на различных аппаратных конфигурациях, на которых раскрытый способ исполняется. Каскад блоков CRP в предпочтительном варианте осуществления содержит пять блоков CRP, но без ограничения конкретным числом, поскольку большее или меньшее число блоков CRP в каскаде может применяться для достижения баланса между точностью оценки и вычислительной эффективностью на различных аппаратных конфигурациях, на которых раскрытый способ исполняется. Вышеописанные особенности проиллюстрированы со ссылкой на ФИГ. 2, на которой показана схема ветви уточнения (декодера) нейронной сети в предложенной архитектуре согласно варианту осуществления настоящего изобретения.
[0023] Вторая модификация: сложение в блоке CRP (цепного разностного пулинга) дополнено операцией усреднения для того, чтобы блоки CRP не препятствовали сходимости обучаемой инвариантной масштабу модели. Другими словами, в каждый блок CRP (цепного разностного пулинга), содержащий два модуля CRP, каждый из которых обеспечивает аддитивную модификацию входного сигнала при помощи операции пулинга (MaxPooling) и операции свертки с фильтром, добавлена операция деления сигнала на выходе блока CRP на число модулей CRP плюс один, содержащихся в данном блоке CRP. Каскад модулей CRP в блоке CRP в предпочтительном варианте осуществления содержит два модуля CRP, но без ограничения этим конкретным числом, поскольку большее или меньшее число модулей CRP в каскаде может применяться для достижения баланса между точностью оценки и вычислительной эффективностью на различных аппаратных конфигурациях, на которых раскрытый способ исполняется. Вышеописанные особенности проиллюстрированы со ссылкой на ФИГ. 3, на которой показан пример структуры блока CRP нейронной сети в предложенной архитектуре согласно варианту осуществления настоящего изобретения.
[0024] Инвариантная масштабу модель, основанная на нейронной сети с облегченной архитектурой, которая описана выше, выдает оценки логарифма обратной глубины (например, в форме карты логарифма обратной глубины), которые вдвое меньше целевой карты логарифма обратной глубины, поэтому масштаб выводимых оценок логарифмов обратной глубины изобретения увеличивают до целевого (исходного) разрешения с помощью, например, билинейной интерполяции или любого другого метода. Выходные оценки логарифмов обратной глубины изображения интерпретируются как значения в логарифмической шкале.
[0025] Перед началом обучения нейронной сети веса нейронной сети, которая подлежит обучению, могут быть инициализированы случайным образом. На каждой итерации обучения нейронной сети используют ограниченное число случайно выбираемых обучающих изображений. Кроме того, на стадии обучения нейронной сети может быть применена сумма функций потерь, которая подлежит минимизации.
[0026] Инвариантные масштабу попарные потери. При обучении нейронной сети в данной заявке предлагается использовать функцию попарных потерь L1, которая может быть вычислена следующим образом:
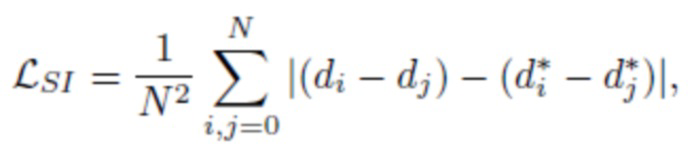 (1)
(1)
где d логарифм прогнозируемой обратной глубины, а  логарифм обратной истинной глубины. Предложенная попарная потеря L1 является инвариантной масштабу (SI), поэтому ее можно использовать для обучения как на картах абсолютной глубины, так и на картах глубины UTS. Для вычисления этой потери, выполняется суммирование по N2 членам.
логарифм обратной истинной глубины. Предложенная попарная потеря L1 является инвариантной масштабу (SI), поэтому ее можно использовать для обучения как на картах абсолютной глубины, так и на картах глубины UTS. Для вычисления этой потери, выполняется суммирование по N2 членам.
[0027] Однако вышеуказанная функция (1) попарных потерь L1 может быть вычислена более эффективно за время  . Пусть
. Пусть  представляет собой список упорядоченных по возрастанию разностных значений
представляет собой список упорядоченных по возрастанию разностных значений 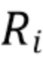 между значениями
между значениями 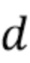 логарифма прогнозируемой обратной глубины и значениями логарифма истинной обратной глубины:
логарифма прогнозируемой обратной глубины и значениями логарифма истинной обратной глубины: 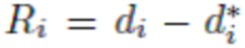 . После перестановки и группировки схожих членов функцию попарных потерь L1 можно записать следующим образом:
. После перестановки и группировки схожих членов функцию попарных потерь L1 можно записать следующим образом:
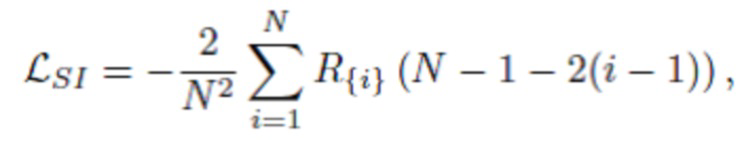 (2)
(2)
где представляет собой упорядоченный список 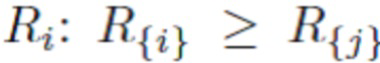 , если i > j. Чтобы упорядочить список требуется операций,
, если i > j. Чтобы упорядочить список требуется операций, 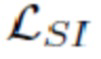 вычисляется за линейное время. В целом вычислительные затраты на вычисление попарных потерь
вычисляется за линейное время. В целом вычислительные затраты на вычисление попарных потерь 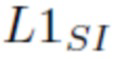 составляют .
составляют .
Таким образом, на каждой итерации обучения нейронной сети для обучающих изображений, сопровождаемых абсолютными или UTS данными, может быть применена функция потерь  инвариантных масштабу попарных потерь, указанная выше под номером (2).
инвариантных масштабу попарных потерь, указанная выше под номером (2).
[0028] Инвариантные масштабу со сдвигом (SSI) попарные потери. Попарные потери SI могут быть легко преобразованы в попарные потери SSI. Для этого логарифм глубины d заменяется нормализованной глубиной:
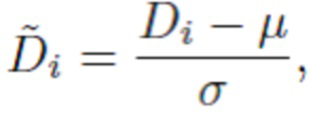 (3)
(3)
где μ и σ представляют собой, соответственно, среднее значение и среднеквадратичное отклонение, где 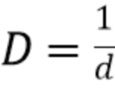 . Учитывая вышесказанное, функцию инвариантных масштабу со сдвигом попарных потерь можно записать следующим образом:
. Учитывая вышесказанное, функцию инвариантных масштабу со сдвигом попарных потерь можно записать следующим образом:
 (4)
(4)
Таким образом, на каждой итерации обучения нейронной сети, для обучающих изображений, сопровождаемых абсолютными, UTS или UTSS данными, может быть применена модифицированная функция 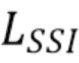 инвариантных масштабу со сдвигом попарных потерь, указанная выше под номером (4).
инвариантных масштабу со сдвигом попарных потерь, указанная выше под номером (4).
[0029] В дополнительном варианте осуществления настоящего изобретения совокупная функция потерь может быть вычислена следующим образом:  , где
, где  - соответствующая функция потерь,
- соответствующая функция потерь,  - соответствующий вес функции потерь, при этом веса подбираются таким образом, чтобы градиенты от различных функций потерь были равны по модулю:
- соответствующий вес функции потерь, при этом веса подбираются таким образом, чтобы градиенты от различных функций потерь были равны по модулю: 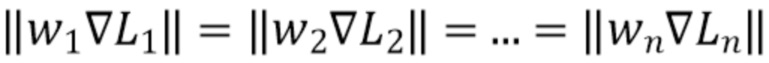 . Функции потерь считаются разными для разных наборов данных. Также разными считаются SI и SSI функции потерь. Градиенты могут быть вычислены при помощи усреднения экспоненциальным скользящим средним с предопределенным параметром сглаживания. Могут быть использованы другие типы скользящей средней, например, простая, взвешенная и т.д. Предопределенный параметр сглаживания, например, размер окна скользящей средней, может быть предопределен или подобран эмпирически. Сумма весов функций потерь равна 1 и каждый из весов неотрицателен. Таким образом, имея смесь истинных (ground-truth) данных UTS и UTSS, SI потери можно использовать для обучения на абсолютных и UTS данных, а потери SSI можно использовать для обучения как на абсолютных и UTS данных, так и на данных UTSS.
. Функции потерь считаются разными для разных наборов данных. Также разными считаются SI и SSI функции потерь. Градиенты могут быть вычислены при помощи усреднения экспоненциальным скользящим средним с предопределенным параметром сглаживания. Могут быть использованы другие типы скользящей средней, например, простая, взвешенная и т.д. Предопределенный параметр сглаживания, например, размер окна скользящей средней, может быть предопределен или подобран эмпирически. Сумма весов функций потерь равна 1 и каждый из весов неотрицателен. Таким образом, имея смесь истинных (ground-truth) данных UTS и UTSS, SI потери можно использовать для обучения на абсолютных и UTS данных, а потери SSI можно использовать для обучения как на абсолютных и UTS данных, так и на данных UTSS.
[0030] Абсолютные данные для обучения нейронной сети оценивать глубину сцены могут быть получены с помощью датчика движения. Данные UTS для обучения нейронной сети оценивать глубину сцены получают с точностью до масштаба с помощью алгоритма Structure From Motion из фильмов, которые доступны в Интернете. Данные UTSS для обучения нейронной сети оценивать глубину и геометрию сцены получают из откалиброванных стереоизображений с помощью алгоритма определения оптического потока (RAFT). На каждой итерации обучения нейронной сети обучающие изображения из смеси обучающих изображений демонстрируют обучаемой нейронной сети в случайном порядке.
[0031] ФИГ. 4 иллюстрирует блок-схему вычислительного устройства (200) согласно варианту осуществления настоящего изобретения. Вычислительное устройство (200) пользователя содержит по меньшей мере процессор (205) и память (210), которые соединены друг с другом с возможностью взаимодействия. Процессор (205) может выполнять, среди прочих операций, этапы S100 и S110 способа, проиллюстрированного на ФИГ. 1. Память (210) хранит обученную нейронную сеть (набор параметров/весовых коэффициентов) и исполняемые процессором инструкции, которые при исполнении побуждают процессор к выполнению способа оценки глубины сцены по изображению с использованием обученной нейронной сети. Память (210) способна хранить любые другие данные и информацию. Вычислительное устройство (200) может содержать другие непоказанные компоненты, например, экран, камеру, блок связи, воспринимающую касание панель, динамик, микрофон, Bluetooth-модуль, NFC-модуль, Wi-Fi-модуль, блок питания и соответствующие межсоединения. Раскрытый способ оценки глубины сцены по изображению может быть реализован на широком спектре вычислительных устройств (200), таких как ноутбуки, смартфоны, планшеты, мобильные роботы и навигационные системы. Реализация предложенного способа поддерживает все виды устройств, способных выполнять вычисления на CPU. Кроме того, если вычислительное устройство имеет дополнительное устройство для ускорения нейронной сети, такое как GPU (графический процессор), NPU (модуль нейронной обработки), TPU (модуль обработки тензорных данных), на таких устройствах возможна более быстрая реализация.
[0032] По меньшей мере один из множества модулей, блоков, компонентов, этапов, подэтапов может быть реализован с помощью модели ИИ. Функция, связанная с ИИ, может выполняться через энергонезависимую память, энергозависимую память и процессор. Процессор может включать в себя один или несколько процессоров. Один или несколько процессоров могут быть процессором общего назначения, таким как центральный процессор (CPU), прикладным процессором (AP) или тому подобным, графическим процессором, таким как графический процессор (GPU), процессором визуальной информации (VPU) и/или выделенным ИИ процессором, таким как нейронный процессор (NPU). Один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным операционным правилом или моделью искусственного интеллекта (ИИ), хранящейся в энергонезависимой памяти и энергозависимой памяти. Предопределенное операционное правило или модель ИИ обеспечивается посредством обучения. Должно быть понятно, что применение алгоритма обучения к множеству обучающих данных обеспечивает создание предопределенного операционного правила или модель ИИ с желаемой характеристикой(-ами). Обучение может быть выполнено в самом устройстве, в котором выполняется ИИ в соответствии с вариантом осуществления, и/или может быть реализовано через отдельный сервер/систему.
[0033] Модель ИИ может состоять из множества слоев нейронной сети. Каждый слой имеет множество весовых значений и выполняет операцию слоя через вычисление предыдущего слоя и операцию применения множества весовых коэффициентов. Примеры нейронных сетей включают, но без ограничения, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), сеть глубокого убеждения (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративные состязательные сети (GAN) и глубокие Q-сети. Алгоритм обучения представляет собой способ обучения целевого вычислительного устройства на множестве обучающих данных, чтобы вызывать, обеспечивать возможность или управлять целевым вычислительным устройством для осуществления определения, оценки прогнозирования. Примеры алгоритмов обучения включают в себя, но без ограничения, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
[0034] Следует четко понимать, что не все технические эффекты, упомянутые в настоящем документе, должны быть реализованы в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без достижения некоторых из этих технических эффектов, в то время как другие варианты осуществления могут быть реализованы с достижением других технических эффектов или вообще без них.
[0035] Модификации и усовершенствования вышеописанных реализаций настоящей технологии могут стать очевидными для специалистов в данной области техники. Приведенное выше описание должно быть скорее иллюстративным, но не ограничивающим. Таким образом, предполагается, что сфера применения настоящей технологии будет ограничен исключительно объемом прилагаемой формулы изобретения.
[0036] Хотя вышеописанные реализации были описаны и показаны со ссылкой на конкретные этапы, выполняемые в определенном порядке, следует понимать, что эти этапы могут быть объединены, подразделены или переупорядочены без отступления от данного раскрытия настоящей технологии. Соответственно, порядок и группировка этапов не является ограничением настоящей технологии. Использование единственного числа по отношению к любому раскрытому в данной заявке элементу не исключает того, что таких элементов может быть множество при фактической реализации.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ СОВМЕСТНОГО ВЫПОЛНЕНИЯ ДЕБАЙЕРИЗАЦИИ И УСТРАНЕНИЯ ШУМОВ ИЗОБРАЖЕНИЯ С ПОМОЩЬЮ НЕЙРОННОЙ СЕТИ | 2020 |
|
RU2764395C1 |
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| Способ создания многослойного представления сцены и вычислительное устройство для его реализации | 2021 |
|
RU2787928C1 |
| СПОСОБ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ПРАВДОПОДОБНОГО ОТОБРАЖЕНИЯ ТЕЧЕНИЯ ВРЕМЕНИ СУТОЧНОГО МАСШТАБА | 2020 |
|
RU2745209C1 |
| Способ управления бортовыми системами беспилотных транспортных средств при помощи нейронных сетей на основе архитектуры трансформеров | 2024 |
|
RU2841111C1 |
| СПОСОБ ПОСТРОЕНИЯ КАРТЫ ГЛУБИНЫ ПО ПАРЕ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2806009C2 |
| УСТРАНЕНИЕ РАЗМЫТИЯ ИЗОБРАЖЕНИЯ | 2020 |
|
RU2742346C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |


Настоящее изобретение относится к области вычислительной техники для оценки глубины сцены по изображению сцены. Технический результат заключается в повышении точности и надежности оценки глубины сцены по единственному изображению на вычислительном устройстве. Технический результат достигается за счет способа оценки глубины сцены по изображению, который содержит этапы, на которых: получают изображение; оценивают глубину сцены на изображении с использованием инвариантной масштабу модели, основанной на нейронной сети с облегченной архитектурой, которую обучают с использованием обучающих изображений, причем на каждой итерации обучения используется смесь изображений, выбираемых случайно из обучающих изображений с абсолютными данными, обучающих изображений с UTS (Up-to-Scale) данными и обучающих изображений с UTSS (Up-to-Shift-Scale) данными в случайных пропорциях. 2 н. и 12 з.п. ф-лы, 4 ил.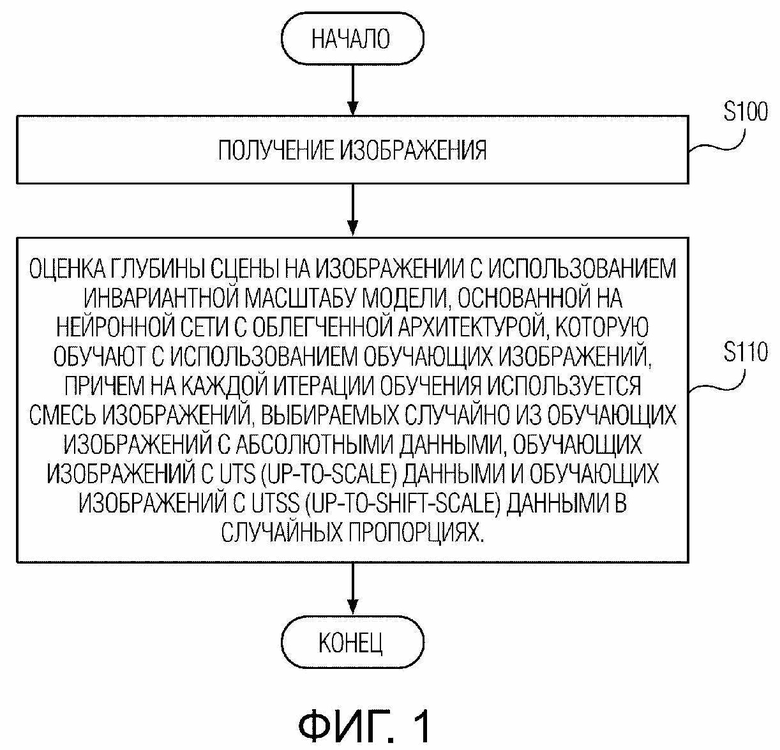
1. Способ оценки глубины сцены по изображению, содержащий этапы, на которых:
получают (S100) изображение;
оценивают (S110) глубину сцены на изображении с использованием модели, предсказывающей глубину с точностью до масштабирующего коэффициента, основанной на нейронной сети с облегченной архитектурой, которую обучают с использованием обучающих изображений, причем на каждой итерации обучения используется смесь изображений, выбираемых случайно из обучающих изображений с известными оценками абсолютной глубины, обучающих изображений с данными оценки глубины, полученными с точностью до масштабирующего коэффициента (UTS), и обучающих изображений с данными оценки обратной глубины, полученными с точностью до неизвестных коэффициентов сдвига и масштаба (UTSS), в случайных пропорциях,
в котором нейронная сеть состоит из кодировщика и модифицированного декодера, в котором:
число каналов в каждом последующем блоке слияния (fusion), выполненном с возможностью обеспечения слияния сигнала с выхода более глубокого уровня декодера и сигнала с соответствующего уровня кодировщика, в каскаде блоков слияния снижено относительно предыдущего блока слияния и равно числу каналов на выходе соответствующего уровня кодировщика, и
в процессе обучения, в каждый блок CRP (цепного разностного пулинга), содержащий два модуля CRP, каждый из которых обеспечивает аддитивную модификацию входного сигнала при помощи операции пулинга (MaxPooling) и операции свертки с фильтром, добавлена операция деления сигнала на выходе блока CRP на число модулей CRP плюс один.
2. Способ по п. 1, в котором глубину сцены на изображении оценивают с использованием модели, основанной на нейронной сети с облегченной архитектурой, которая выдает оценки логарифма обратной глубины сцены на изображении.
3. Способ по п. 1, дополнительно содержащий этап, на котором строят геометрию сцены на основе полученной оценки глубины сцены.
4. Способ по п. 1, в котором перед обучением нейронной сети веса нейронной сети, которая подлежит обучению, инициализируют случайным образом.
5. Способ по п. 1, в котором на стадии обучения нейронной сети применяют одну или более функций потерь, которые подлежат минимизации.
6. Способ по п. 5, в котором на каждой итерации обучения нейронной сети для изображений, сопровождаемых абсолютными или UTS данными, применяется функция потерь 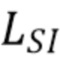 инвариантных масштабу попарных потерь:
инвариантных масштабу попарных потерь:

где 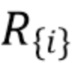 представляет собой список упорядоченных по возрастанию разностных значений
представляет собой список упорядоченных по возрастанию разностных значений  между значениями
между значениями 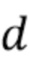 логарифма прогнозируемой обратной глубины и значениями
логарифма прогнозируемой обратной глубины и значениями 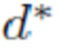 логарифма истинной обратной глубины.
логарифма истинной обратной глубины.
7. Способ по п. 5, в котором на каждой итерации обучения нейронной сети, для изображений, сопровождаемых абсолютными, UTS или UTSS данными применяют нижеследующую модифицированную функцию  инвариантных масштабу со сдвигом попарных потерь:
инвариантных масштабу со сдвигом попарных потерь:
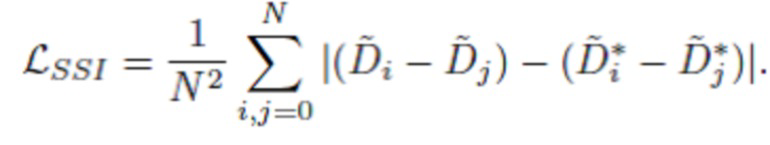 ,
,
при этом 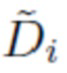 представляет собой нормализованное значение обратной прогнозируемой глубины, вычисляемое как
представляет собой нормализованное значение обратной прогнозируемой глубины, вычисляемое как 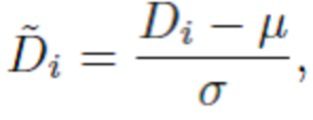 где μ и σ представляют собой, соответственно, среднее отклонение и среднеквадратичное отклонение, где
где μ и σ представляют собой, соответственно, среднее отклонение и среднеквадратичное отклонение, где  .
.
8. Способ по любому из пп. 6, 7, в котором дополнительно вычисляют совокупную функцию потерь:  ,
,
где  - соответствующая функция потерь,
- соответствующая функция потерь,  - соответствующий вес функции потерь,
- соответствующий вес функции потерь,
при этом веса подбираются таким образом, чтобы градиенты от различных функций потерь были равны по модулю: 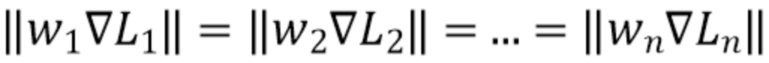 ,
,
при этом градиенты вычисляются при помощи усреднения экспоненциальным скользящим средним с предопределенным параметром сглаживания, и
сумма весов функций потерь равна 1 и каждый из весов неотрицателен.
9. Способ по п. 1, в котором кодировщик представляет собой кодировщик MobileNetV2 или EfficientNet, а модифицированный декодер представляет собой модифицированный декодер Light-Weight RefineNet,
при этом каскад блоков слияния в модифицированном декодере содержит четыре блока слияния, а каскад блоков CRP в модифицированном декодере содержит пять блоков CRP.
10. Способ по п. 1, в котором абсолютные данные для обучения нейронной сети оценивать глубину и геометрию сцены получают с помощью датчика движения.
11. Способ по п. 1, в котором данные UTS для обучения нейронной сети оценивать глубину и геометрию сцены получают с точностью до масштаба с помощью алгоритма Structure From Motion из фильмов, которые доступны в Интернете.
12. Способ по п. 1, в котором данные UTSS для обучения нейронной сети оценивать глубину и геометрию сцены получают из откалиброванных стереоизображений с помощью алгоритма определения оптического потока (RAFT).
13. Способ по любому из пп. 10-12, в котором на каждой итерации обучения нейронной сети обучающие изображения из смеси обучающих изображений демонстрируют обучаемой нейронной сети в случайном порядке.
14. Вычислительное устройство (200) пользователя, содержащее процессор (205) и память (210), хранящую обученную нейронную сеть и исполняемые процессором инструкции, которые при исполнении побуждают процессор к выполнению способа оценки глубины сцены по изображению сцены по любому из пп. 1-13 с использованием обученной нейронной сети.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| RU 2014106718 A, 27.08.2015. | |||

