Область техники, к которой относится изобретение
Настоящее изобретение может найти применение в компьютерном зрении для создания реконструкции 3D-сцены и визуализации результатов этой реконструкции 3D-сцены, которые могут быть использованы для визуальной локализации, визуальной аналитики содержимого сцены, в частности, для обнаружения и сегментации сцены в 3D-пространстве, оценки плана помещения, а также для визуализации внутреннего пространства помещений по созданной 3D-модели, и для решения других задачи.
Описание известного уровня техники
3D-реконструкция является основной задачей компьютерного зрения, применяющейся в таких областях, как робототехника и AR/VR. Эти сценарии применения требуют тонко детализированных, правдоподобных и плотных реконструкций.
Однако получение таких реконструкций все еще представляет проблему для современных методов реконструкции из-за несовершенства входных данных: неполноты наблюдений в виде закрытых и невидимых областей, межкадровой несогласованности и неизбежных ошибок измерений. Поэтому возможно возникновение артефактов реконструкции. Глобальные артефакты включают в себя поврежденную структуру сцены и некорректное разделение; столь серьезные недостатки делают реконструированную сцену практически бесполезной.
Кроме того, может возникать множество локальных артефактов: например, дублированные поверхности, которые не удалось наложить друг на друга после замыкания цикла, дыры в закрытых и невидимых областях, неплоские стены и пол, покрытые углублениями и возвышениями. Хотя такие артефакты не столь драматичны, они все же накладывают ограничения, например, на сценарии навигации, в которых требуется точная оценка границ помещения.
Плотная 3D-реконструкция по изображениям RGB традиционно подразумевает оценку карт глубины для изображений RGB и их слияние, что является еще одним потенциальным источником ошибок. В недавних методах 3D-реконструкции делается попытка минимизировать этот нежелательный эффект с помощью прямого предсказания TSDF (Truncated Signed distance function, функции усеченного расстояния со знаком), с помощью которой удобно устанавливать сцену в трехмерном пространстве; использование этой функции с применением алгоритма марширующих кубов позволяет восстановить сетку или облако точек, соответствующее данной сцене, см., например, https://en.wikipedia.org/wiki/Signed_distance_function). Такие методы извлекают признаки изображения с помощью 2D CNN, проецируют их обратно в трехмерное пространство, агрегируют их и предсказывают окончательный TSDF объем с помощью 3D CNN. Хотя это и эффективный способ для совместного рассмотрения всех входных изображений, использование TSDF не решает проблем с глобальной структурой сцены и плоскими поверхностями.
В подавляющем большинстве помещений стены плоские и вертикальные, а пол плоский и горизонтальный. Эти базовые, неограничивающие знания о геометрии сцены в помещении могут быть использованы в процессе реконструкции.
Недавно были представлены методы, позволяющие реконструировать 3D сцену путем оценки TSDF объема непосредственно по изображениям. TSDF объем - это эффективный способ совместного рассмотрения всех входных изображений, однако объединение признаков с нескольких ракурсов остается сложной задачей. Соответственно, прогресс в этой области методов реконструкции TSDF в основном связан с разработкой стратегий агрегирования признаков.
Atlas [2] впервые реализовал модель 3D-реконструкции от начала до конца, в которой признаки изображения проецируются обратно и накапливаются в воксельном объеме, который затем передается в 3D CNN, прогнозирующую TSDF объем (функции усеченного расстояния со знаком). Функция расстояния со знаком (SDF) - это ортогональное расстояние данной точки х до границы множества Ω в метрическом пространстве, где знак определяется тем, находится ли х внутри Ω или нет. SDF является стандартным способом кодирования 3D-пространства (расстояния между точками пространства и рассматриваемым объектом). TSDF - это модификация SDF, в которой значения больших расстояний усекаются для ускорения преобразования алгоритма 3D-реконструкции. Функции расстояния со знаком обычно используются для 3D реконструкции и неоднократно появлялись в предшествующем уровне техники, например, в работе "A volumetric method for building complex models from range images", SIGGRAPH, 1996.
Благодаря своей простоте TSDF объем является широко используемым представлением для 3D-реконструкций, а также в современных подходах к реконструкции. Atlas использует явно недостаточно оптимальную стратегию усреднения для объединения признаков изображения, которая пересматривается в следующих подходах. NeuralRecon [3] использует стратегию иерархического объединения: в ней признаки соседних видов усредняются и объединяются по кластерам видов с использованием сети RNN.
NeuralRecon демонстрирует производительность в режиме реального времени на последовательных вводах. VoRTX [1] преодолевает ограничения последовательной обработки путем объединения всех видов вместе.
В этом методе введена модель трансформера для реконструкции TSDF (a transformer model for TSDF reconstruction) и включен механизм внимания на уровне 20-признаков для объединения множества видов. Другая модель на основе трансформеров, TransformerFusion [4], использует внимание на уровне вокселей, чтобы уделять внимание наиболее информативным признакам на изображениях с разных ракурсов.
Нормали поверхности представляют геометрию сцены таким образом, что они в некотором смысле дополняют карты глубины. Следовательно, их можно использовать для ограничения оценок глубины или рассматривать как отдельный источник пространственной информации. Поэтому использование нормалей для 3D-реконструкции активно изучалось в последние годы. VolSDF [6] и NeUS [7] минимизируют фотометрические потери и дополнительно ограничивают SDF с помощью эйкональной потери, побуждая нормали, оцениваемые как градиенты SDF, иметь норму, равную 1. NeuRIS [12] регуляризирует предсказанные нормали с помощью априорных нормалей, прогнозируемых обучаемым методом, и использует фотометрическую согласованность множества видов между нормалями и глубинами, чтобы отфильтровать недостоверные ограничения. NeuralRoom [18] также использует сеть оценки нормалей и применяет потери нормалей для бестекстурных областей, которые не могут быть эффективно ограничены потерей фотометрической согласованности из-за неоднозначности формы и яркости. В отличие от NeurlS и NeuralRoom, в предлагаемом изобретении нормали получают непосредственно из самой спрогнозированной TSDF.
Кроме того, были рассмотрены различные способы применения пространственной сегментации для 3D реконструкции.
SceneCode [19] получает представление сегментации с помощью VAE, обусловленное изображением RGB, и решает задачу объединения меток сегментации путем совместной оптимизации пространственно-ориентированных низкоразмерных кодов перекрывающихся изображений.
В ряде методов [13-17] применяется распознавание объектов и их замена моделями CAD. Хотя получаемые результаты являются визуально правдоподобными, они вряд ли способны восстановить реальную сцену, скорее создается 3D-модель, более или менее похожая на нее. Предлагаемое изобретение, напротив, направлено на реконструкцию реальной сцены.
Manhattan-SDF [5], который является ближайшим аналогом предложенной регуляризации сегментации нормалей, NSR (Normal-Segmentation Regularization), сфокусирован на улучшении реконструкции низкотекстурированных областей. Manhattan-SDF определяет области пола и стен с помощью предварительно обученной сети сегментации и побуждает нормали к поверхности полов и стен быть коллинеарными с тремя доминирующими направлениями, чтобы полученная реконструкция удовлетворяла предположению о манхэттенском мире. Однако бенчмарки для помещений, такие как ScanNet, содержат не манхэттенские сцены, имеющие более трех доминирующих направлений, для которых метод Manhattan-SDF неприменим.
В последних методах объемной 3D-реконструкции имеет место нежелательный компромисс, когда приходится полагаться на входные данные и восстанавливать правильную геометрию сцены. Даже незначительные ошибки или несоответствия во входных данных могут привести к нарушению реконструируемой сцены. Глобальные артефакты могут проявляться в виде искаженных форм комнат, а реконструированные поверхности могут содержать локальные артефакты, такие как углубления, дыры и возвышения. К счастью, некоторые из этих проблем можно решить, используя априорные знания о сцене, поскольку большинство комнат окружены плоскими вертикальными стенами и плоским горизонтальным полом.
Сущность изобретения
Предложен способ реконструкции 3D-сцены и ее визуализации с использованием нейронной сети, состоящей из базовой нейронной сети, включающей скелет и голову TSDF, и голову сегментации, содержащий этапы, на которых:
обучают базовую нейронную сеть получению TSDF объема для вокселей сцены, для чего выполняют следующие шаги:
- вводят обучающие данные, включающие обучающую последовательность кадров RGB с соответствующими данными положения камеры, в скелет;
- вычисляют потери TSDF между прогнозом TSDF, полученным головой TSDF из выходов данных из скелета, и эталонным сканом;
- получают с помощью головы сегментации из вывода данных из скелета прогноз сегментации, определяющий области "пола", "стен", "другого", для каждого вокселя;
- вычисляют потери сегментации между прогнозом сегментации и эталоном сегментации;
- вычисляют координаты нормалей как градиенты прогноза TSDF для значений TSDF в каждом вокселе по всем вокселям сцены;
- вычисляют обычные потери нормалей для нормалей для областей стен и областей пола на основе результатов эталона TSDF и градиентов прогноза TSDF;
- вычисляют общую функцию потерь как сумму потерь TSDF, потерь сегментации и обычных потерь нормалей;
- минимизируют общую функцию потерь;
используют обученную базовую нейронную сеть для получения TSDF объема входной последовательности RGB-кадров реальной сцены;
применяют к TSDF объему алгоритм, вычисляющий реконструкцию 3D-сцены;
осуществляют рендеринг реконструкции 3D-сцены для получения визуализации 3D-сцены.
При этом алгоритмом, вычисляющим реконструкцию 3D-сцены, является алгоритм марширующих кубов. Голову сегментации и голову TSDF используют параллельно во время обучения. Способ содержит дополнительные этапы, реализуемые после этапа вычисления координат нормалей, на которых:
выбирают нормаль в областях стен и вычисляют их вертикальные составляющие;
выбирают нормаль в областях пола и вычисляют их горизонтальные составляющие.
Этап вычисления потерь нормалей может заключаться в следующем:
в каждой точке в областях, в которых голова сегментации прогнозирует "стену", рассматривают вертикальные составляющие векторов нормали, и к обычным потерям нормалей прибавляют длину z-составляющей вектора нормали,
и в каждой точке в областях, в которых голова сегментации прогнозирует "пол", рассматривают горизонтальные составляющие векторов нормали, а также рассматривают х- и у-составляющие вектора нормали, и прибавляют норму двумерного вектора, состоящего из этих двух составляющих, к обычным потерям нормалей.
Общую функцию потерь можно вычислять как сумму потерь TSDF, потерь сегментации и потерь нормалей. Минимизацию общей функции потерь можно реализовать путем вычисления градиента общей функции потерь по всем параметрам базовой нейронной сети. Способ может дополнительно обеспечивать обратное распространение ошибки минимизированной общей функции потерь и обновление параметров базовой нейронной сети в соответствии с минимизированной функцией потерь, обновляя при этом параметры базовой нейронной сети. Этапы обучения повторяют до тех пор, пока общая функция потерь не перестанет уменьшаться. В другом варианте этапы обучения повторяют до тех пор, пока общая функция потерь не достигнет заданного порогового значения.
Также предложено вычислительное устройство, содержащее процессор и память, в которой хранятся инструкции для выполнения этапов предложенного способа.
По меньшей мере один из множества модулей может быть реализован в виде нейронной сети. Функция, связанная с нейронной сетью, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или несколько процессоров. При этом один или множество процессоров могут быть процессором общего назначения, таким как центральный процессор (CPU), процессор приложений (АР) или т.п., блок обработки только графики, такой как графический процессор (GPU), блок визуальной обработки (VPU) и/или специальный процессор для искусственного интеллекта, такой как нейронный процессор (NPU).
Эти один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным рабочим правилом или сетью искусственного интеллекта (AI), хранящимися в энергонезависимой памяти или энергозависимой памяти и реализуемыми аппаратными средствами. Аппаратное средство представляет собой машиночитаемый носитель, на котором хранится программное обеспечение.
В данном контексте предоставление посредством обучения означает, что путем применения алгоритма обучения к множеству обучающих данных создается предопределенное рабочее правило или нейронная сеть с требуемыми характеристиками. Обучение может осуществляться в самом устройстве, в котором выполняется обработка нейронной сети согласно варианту осуществления, и/или может быть реализовано на отдельном сервере/системе.
Нейронная сеть (базовая нейронная сеть) может состоять из множества слоев нейронной сети. Каждый слой имеет множество значений весов и выполняет операцию слоя посредством вычисления предыдущего слоя и операции со множеством весов. Примеры базовых нейронных сетей включают, без ограничения перечисленным, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
Алгоритм обучения представляет собой способ обучения заранее определенного целевого устройства (например, робота) с использованием множества обучающих данных, чтобы побудить, разрешить или контролировать целевое устройство для выполнения определения или прогнозирования. Примеры алгоритмов обучения включают, без ограничения перечисленным, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
Кроме того, предлагаемый способ, выполняемый электронным устройством, может быть реализован с использованием модели искусственного интеллекта.
Визуальное понимание - это метод распознавания и обработки вещей аналогично человеческому зрению, и оно включает в себя, например, распознавание объекта, отслеживание объекта, поиск изображений, распознавание людей, распознавание сцен, 3D-визуализацию сцен или улучшение изображений.
Краткое описание чертежей
Представленные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления со ссылкой на прилагаемые чертежи, на которых:
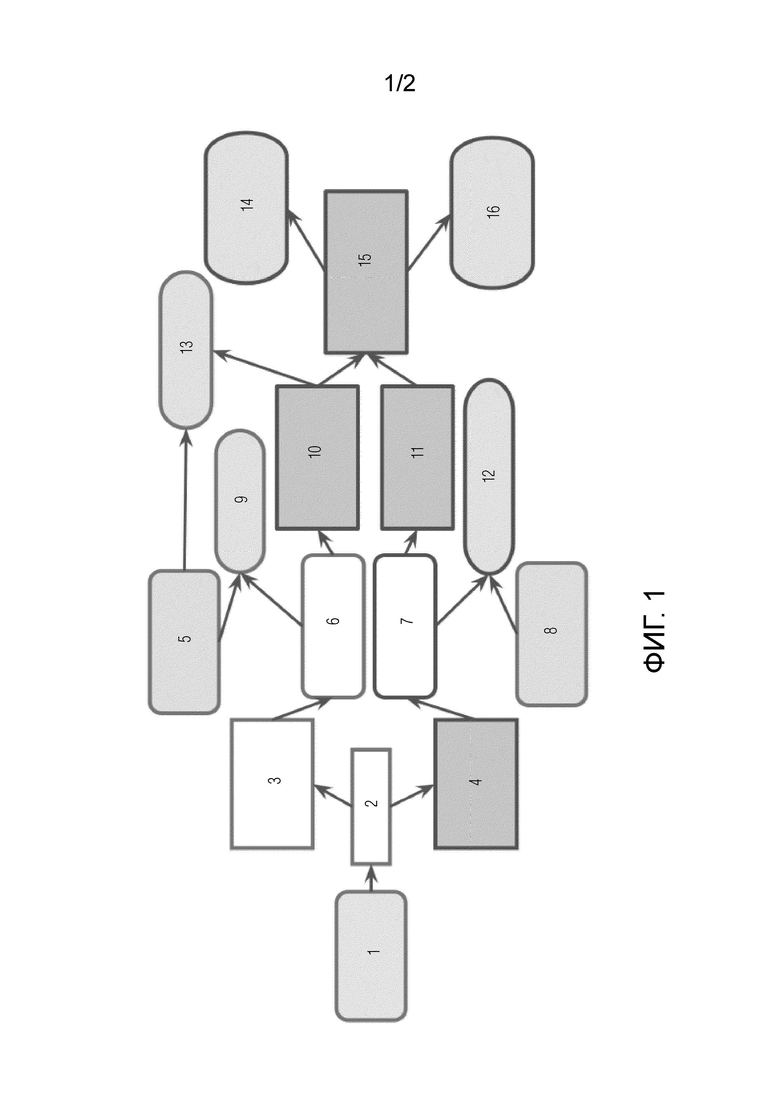
Фиг. 1 иллюстрирует предлагаемую процедуру обучения модифицированным методам 3D-реконструкции.
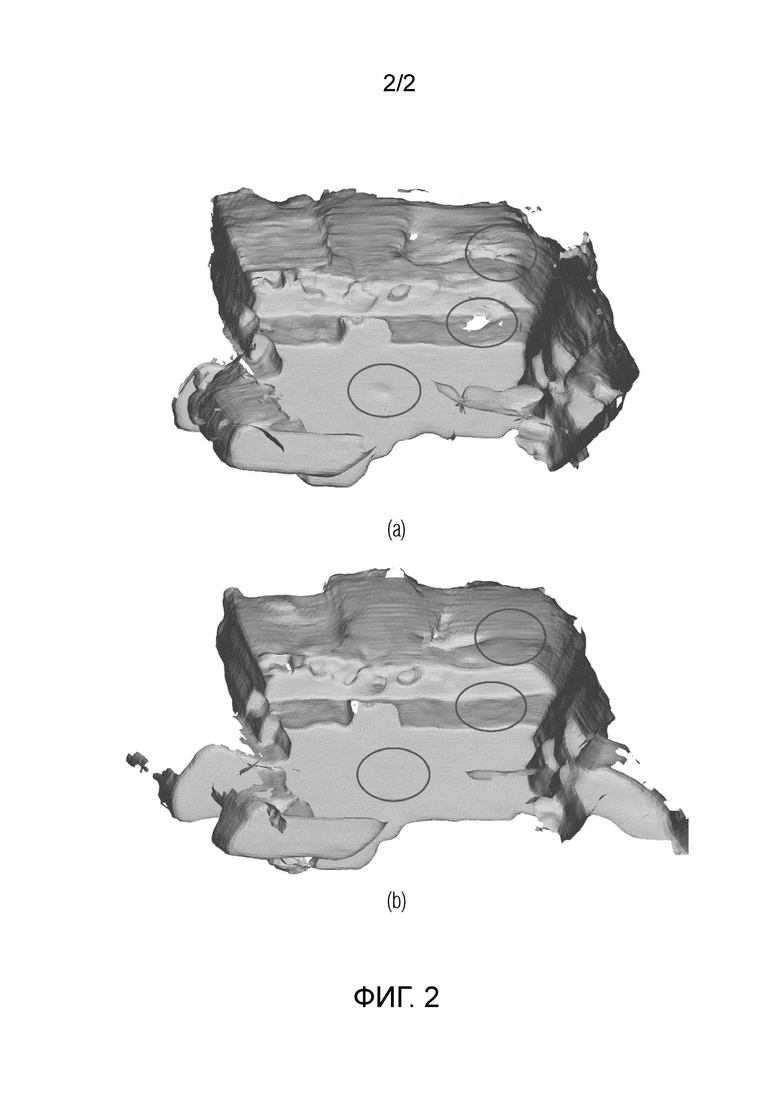
Фиг. 2 иллюстрирует визуализацию 3D-сцен, реконструированных с использованием исходного VoRTX и VoRTX+NSR, полученных с помощью исходного VoRTX (а) и предлагаемого VoRTX+NSR (b).
Подробное описание изобретения
Настоящее изобретение может найти применение в системах визуальной аналитики внутри помещений, мобильных и наземных системах 3D-сканирования для различных сцен внутри помещений, например, квартир, офисов, торговых помещений и т.п. Предлагаемое изобретение направлено на обнаружение и выравнивание структурных элементов, таких как вертикальные и горизонтальные поверхности (например, пол и стены) в помещениях и может использоваться при 3D-реконструкции и визуализации 3D-сцены.
В данном описании использованы следующие термины.
Реконструкция 3D-сцены представляет собой облако точек или сетку, т.е. математическое представление 3D-объекта, полученное путем применения известных алгоритмов (например, марширующих кубов), к TSBF объему.
Визуализация 3D-сцены представляет собой визуализацию, например, на устройстве отображения, упомянутой реконструкции 3D-сцены, то есть двухмерного изображения, которое показывает, как выглядит объект, представленный облаком точек сцены или сеткой сцены.
Рендеринг - способ получения упомянутой визуализации 3D-сцены из реконструкции 3D-сцены.
Базовая нейронная сеть - любая известная нейронная сеть, реализующая получение TSDF объема для вокселей сцены из последовательности RGB-кадров с положениями камеры. Базовая нейронная сеть включает в себя скелет и голову TSBF.
Предлагается NSR (регуляризация сегментации нормалей), автоматическая модификация методов, которые выполняют реконструкцию сцены путем прогнозирования функции усеченного расстояния со знаком (Truncated Signed Bistance Function, TSBF). Предложенную регуляризацию можно интегрировать в любой известный метод реконструкции (базовую нейронную сеть), прогнозирующий TSBF по последовательности кадров с положениями камеры. Согласно настоящему изобретению, NSR включает в себя работу нескольких компонентов, один из них представляет собой модуль 3D разреженной сверточной сегментации (голову сегментации), кроме того, NSR включает в себя вычисление нормалей, определение нормалей в областях стен и полов и вычисление их отклонений от горизонтали/вертикали, как будет описано ниже.
Предлагаемая модификация рассматривает в процессе обучения структуру сцены путем обнаружения стен и пола в сцене и штрафования соответствующих нормалей к поверхности за отклонение от горизонтального и вертикального направлений, соответственно (при этом учитывается отклонение нормалей от требуемых направлений), как будет описано ниже.
Предлагаемое изобретение позволяет устранить глобальные артефакты при реконструкции 3D-сцены; благодаря предлагаемому изобретению устраняются искажения формы помещения, кроме того, изобретение позволяет избавиться от некоторых локальных артефактов, таких как углубления, дыры и возвышения, в реконструкции 3D-сцены и ее визуализации.
В настоящее время предлагаемое изобретение можно применить к данным, полученным смартфонами с системами слежения (например, ARCore для смартфонов Android), или любым видеоданным с известной траекторией камеры (например, полученным с помощью RealSense Т265). Пользователь может снимать видео помещения, например, смартфоном, и с помощью предлагаемого изобретения получать реконструкцию 3D-сцены в виде сетки сцены или облака точек сцены, которая после рендеринга преобразуется в визуализацию 3D-сцены, которую пользователь может видеть на экране.
Можно осуществить рендеринг сетки или облака точек, тогда визуализация (изображение) сцены будет представлена в виде, необходимом пользователю. Его можно использовать, например, для приложений VR/AR (игр, дизайна интерьера, приложений для недвижимости или для навигации). Минимальный перечень компонентов: камера, модуль слежения, оценивающий положение и угол камеры, запоминающее устройство с процессором и возможностью применения нейронных сетей.
Основной технический результат, обеспечиваемый настоящим изобретением, заключается в следующем:
- Предложена NSR, являющаяся модификацией методов реконструкции 3D-сцены, которая включает в себя новый обучаемый модуль и связанную с ним процедуру обучения с потерями нормалей и сегментации базовой нейронной сети на наборе данных, для которого имеется видео с положениями и углами камеры, эталонные реконструкции и разметка сегментации полов и стен. В результате обучения получают базовую нейронную сеть, принимающую на входе видео с положениями и ракурсами камер и прогнозирующую TSBF и сегментацию по 3 классам (пол, стены, другое). Причем, когда базовая нейронная сеть уже обучена, прогноз сегментации больше не требуется для основной цели (определения стен, пола и др.), и используется только прогноз TSDF, по которому можно вычислить сетку. NSR можно внедрить в произвольную обучаемую модель (нейронную сеть), которая выдает TSDF и обучается сквозным образом на семантически аннотированных 3D-данных. Существуют общедоступные наборы таких данных для обучения (обучающие последовательности RGB-кадров с соответствующими данными положений камеры), например, ScanNet [ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes, CVPR, 2017] (который использовался для обучения базовой нейронной сети в изобретении). Реализована концепция "обучения с учителем", то есть для того, чтобы базовая нейронная сеть правильно прогнозировала TSDF и классы сегментации, ей необходимо получать примеры таких данных в процессе обучения.
- NSR применяется к ряду современных подходов к реконструкции и демонстрирует рост производительности и улучшение качества реконструкции по сравнению с современными методами реконструкции на нескольких наборах данных. Предлагаемая разработка представляет собой регуляризацию, которую можно применить к произвольному методу реконструкции сцены в комнате, который предсказывает TSDF на основе видео с положениями камеры.
Основным вкладом настоящего изобретения является новая регуляризация геометрической сегментации, состоящая во введении вспомогательных потерь нормалей, оптимизированных вместе с дополнительной головой сегментации. Предложенные в изобретении блоки обучения для базовой нейронной сети повышают качество реконструкции сцены: охват, точность, полноту, F1-меру, и позволяют получать более плавные и ровные реконструкции с меньшим количеством "углублений" и "возвышений".
Во время обучения не вычисляются результаты 3D-реконструкции. В процессе обучения вычисляются прогноз TSBF, сегментации и прогноз нормалей, вычисляются значения функции потерь, и они минимизируются. Однако если для сцены прогнозируется TSDF, то на ее основе можно вычислить саму 3D-реконструкцию (с помощью алгоритма марширующих кубов). Во время обучения в этом нет необходимости, но, когда сеть уже обучена, это делается для получения реконструкции.
Рассматриваемая в изобретении обученная базовая нейронная сеть характеризуется тем, что в результате ее работы (если также применяется алгоритм марширующих кубов) можно получить облако точек или треугольную сетку (сетку треугольников), соответствующую данной сцене. То есть, если это облако точек, то результатом является набор точек сцены (их координаты и цвета), а если это сетка, то результатом являются треугольные грани, соединяющие некоторые тройки этих точек (т.е. поверхность треугольников).
В кратком изложении, процедура получения визуализации 3D сцены состоит в следующем:
- используют базовую модель нейронной сети, обученной, как будет описано ниже, получению TSDF объема входной последовательности RGB-кадров реальной сцены.
- применяют к TSDF объему алгоритм, вычисляющий реконструкцию 3D сцены (представление в виде треугольной сетки);
- осуществляют рендеринг реконструкции 3D-сцены для получения визуализации 3D-сцены.
Реализованную в виде разреженного 3D сверточного модуля NSR можно внедрить в произвольную обучаемую модель, которая выдает на выходе TSDF, и ее можно обучать сквозным методом на облаках точек 3D сегментации.
В процессе логического вывода, при применении уже обученной базовой нейронной сети к новым (никогда ранее не встречавшимся) данным, модули, использовавшиеся при обучении базовой нейронной сети, не требуются, поэтому наличие NSR при обучении не накладывает никаких ограничений на сценарии применения.
Также предложено аппаратное средство, представляющее собой машиночитаемый носитель, на котором хранится программный продукт, реализующий способ реконструкции 3D-сцены с использованием регуляризации сегментации нормалей TSDF при обучении базовой нейронной сети, при этом предлагаемые этапы обучения, согласно способу, подходят для любых существующих базовых нейронных сетей для 3D реконструкции. Более конкретно, предлагаемые этапы обучения могут обучать любую базовую нейронную сеть, реализующую реконструкцию 3D-сцены с прогнозированием TSDF на основе RGB-видео с положениями камеры. При этом на вход обученной базовой нейронной сети подается цветное видео сцены и положения камер для каждого кадра этого видео, и результат в виде фиксированной 3D-реконструкции этой сцены получают после применения алгоритма к TSDF объему на выходе обученной базовой нейронной сети.
Настоящее изобретение можно использовать с любыми устройствами, выполненными с возможностью снимать видео и оценивать траекторию камеры (положения и углы камеры для каждого видеокадра). Это может быть камера слежения (например, RealSense Т265), смартфон (например, Android-смартфон с системой Google ArCore), робот-пылесос, оснащенный видеокамерой и системой слежения, или даже просто видеокамера, к данным которых применимы методы оценки траектории.
На фиг. 1 показана предлагаемая процедура обучения для модифицированных методов 3D-реконструкции. В кратком изложении, ключевая концепция предлагаемого изобретения заключается в способе обучения сети искусственного интеллекта (AI) (базовой нейронной сети) осуществлению 3D реконструкции сцены с помощью NSR (регуляризации сегментации нормалей), содержащем следующие этапы:
Этап 1: извлекают значение признаков изображения и прогнозируют представление 3D пространства с помощью нейронной сети. Следует отметить, что значения признака изображения - это элементы данных, представляющие максимальный интерес, которые будут передаваться и анализироваться нейронной сетью, т.е. значения признаков изображения являются внутренними (скрытыми, промежуточными) представлениями для нейронной сети. Этот этап выполняется блоками 2, 3, 5, 6, 9, показанными на фиг. 1. Как будет подробно описано ниже, блоки 2, 3, 5, 6, 9 осуществляют ввод обучающих данных в скелет; применяют голову TSDF для вычисления потерь TSDF.
Этап 2 используется только при обучении базовой нейронной сети: сегментируют пространство с помощью информации о сегментации (например, пол/стена). Этот этап выполняется блоками 4, 7, 8, 11, 12, показанными на фиг. 1. Как будет подробно описано ниже, блоки 4, 7, 8, 11, 12 осуществляют применение головы сегментации; вычисляют потери сегментации; определяют области пола и стен.
Этап 3 используется только при обучении базовой нейронной сети: обучают базовую нейронную сеть таким образом, чтобы определенные пол и стена были плоскими. Этот этап выполняется блоками 10, 11, 13, 14, 15, 16, показанными на фиг. 1. Как будет подробно описано ниже, блоки 10, 11, 13, 14, 15, 16 выполняют вычисление координат нормалей как градиентов TSDF; выбирают нормали в областях стен и вычисляют их вертикальные составляющие; выбирают нормали в областях пола и вычисляют их горизонтальные составляющие; вычисляют обычные потери нормалей; обеспечивают обратное распространение ошибки путем обновления параметров нейронной сети в соответствии с вычисленным градиентом для уменьшения общей функции потерь.
Описанные выше этапы осуществляют многократно в процессе обучения базовой нейронной сети. Однако при работе уже обученной базовой нейронной сети выполняется только первый этап. Введенные обучающие данные используются только для обучения, а при работе обученной базовой нейронной сети вводимыми данными являются RGB-кадры и положение камеры в пространстве. Таким образом, блоки 4, 7, 10, 11, 12, 13, 14, 15, 16 не используются в работе обученной базовой нейронной сети.
Следовательно, базовая нейронная сеть обучается новым способом. Когда базовая нейросеть уже обучена таким образом, можно получить 3D-реконструкцию сцены без артефактов в областях пола и стен в процессе работы базовой нейросети. При работе базовой нейронной сети после предложенного обучения вывод реконструкции 3D-сцены происходит обычным образом, как и в базовой версии базовой нейронной сети.
Таким образом, NSR - это регуляризация сегментации нормалей, которая применяется именно во время обучения. При выводе реконструкции 3D-сцены из уже обученной базовой нейронной сети используется базовая нейронная сеть, которая обучена лучше благодаря NSR. NSR - это модификация методов 3D-реконструкции сцены, работа которой построена на предположении традиционной структуры сцены.
В процессе работы обученная базовая нейронная сеть просто определяет значение TSBF во всех вокселях, однако благодаря обучению NSR результат на выходе 3D-реконструкции таков, что полы и стены в ней получаются ровными.
Стены и пол находятся в реконструируемой сцене, и при обучении NSR накладывает ограничения на их нормали на этапах 2 и 3. Эти ограничения заключаются в том, что:
- нормали (т.е. перпендикуляры) к поверхности стен должны быть максимально горизонтальными, чтобы стены были вертикальными, и
- нормали к поверхности пола должны быть максимально вертикальными, чтобы пол был горизонтальным.
Предположение "должны быть максимально горизонтальными/вертикальными" означает, что отклонение нормалей от требуемого направления штрафуется, то есть к минимизированной общей функции потерь добавляется член, соответствующий отклонению нормалей от требуемых направлений. Отклонение - это разность между текущим значением и идеальным значением. Эта разность может быть равна нулю, что соответствует отсутствию отклонения, но даже для качественной 3D-модели это будет ненулевое число, то есть с математической точки зрения оно является дополнительным членом. Минимизация общей функции потерь может осуществляться любым известным методом, однако в настоящем изобретении используются градиентные методы, например, метод адаптивного градиентного спуска, а именно метод Adam [Adam: А Method for Stochastic Optimization, https://arxiv.org/abs/1412.6980].
Отдельные функции потерь состоят из значений, соответствующих степени различия между спрогнозированным TSDF и эталоном (потеря TSDF), степени различия между спрогнозированными семантическими метками и семантикой эталона (семантическая потеря), степени различия между нормалями к поверхности и нормалями к эталонам (обычные потери нормалей), степени не вертикальности стен и не горизонтальности пола (добавленные отклонения нормалей). Из таких отдельных функций потерь (штрафов), соответствующих различным критериям качества 3D-модели, формируется общая функция потерь, которая минимизируется в процессе обучения базовой нейронной сети.
Общие функции потерь описывают некоторое отображение, которое принимает прогноз в качестве ввода и возвращает значение, при этом, чем лучше прогноз, тем меньше это значение. Другими словами, общая функция потерь - это математическая интерпретация того, насколько текущая базовая нейронная сеть отличается от "идеальной". Причем чем меньше значение общей функции потерь, тем лучше, поэтому оно минимизируется, то есть выбираются значения таких базовых параметров нейронной сети, как веса, для которых значение общей функции потерь будет как можно меньшим (например, чем ближе проекция нормали к 0, тем ближе нормаль к идеалу). Общая функция потерь используется только для обучения базовой нейронной сети. Общая функция потерь содержит все ограничения, накладываемые на 3D-модель. А именно, как будет подробно описано ниже: ограничения на TSDF (они берутся из базовой нейронной сети, это может быть степень различия между спрогнозированным TSDF и эталоном, степень различия между прогнозом, будет ли данный воксель содержать точку сцены или нет на основе эталона, и т.д.) Кроме того, в общей функции потерь представлены условия различия между спрогнозированными семантическими метками и эталоном, различия между спрогнозированными нормалями и эталоном, отличие длины нормалей от единицы, отклонение нормалей к стенам/полам от горизонтального/вертикального направлений.
Отклонение нормалей стен от горизонтального направления равно длине их вертикальной составляющей (т.е. проекции нормали стены на ось z), то есть если нормаль к стене имеет идеальное горизонтальное направление, то вертикальная составляющая равна 0. Отклонение нормалей пола от вертикального направления равно длине их горизонтальной составляющей (т.е. проекции нормали к полу на плоскость х-у), то есть если нормаль к полу имеет идеальное горизонтальное направление, то горизонтальная составляющая равна 0.
Вычисляют функцию TSDF в воксельном объеме для сцены, сохраняют расстояние от каждого вокселя до ближайшей поверхности как значение функции TSDF для каждого вокселя. Вычисляют нормали поверхностей в воксельном объеме сцены как градиенты функции TSDF (поскольку восстановленная поверхность является поверхностью уровня для TSDF, т.е. решение уравнения TSDF=0), которые также вычисляют и сохраняют для каждого вокселя.
Нормали перпендикулярны поверхности по определению, однако поверхность может быть не идеальной, например, пол может быть не горизонтальным, а наклонным или иметь углубления/возвышения, и стены могут быть не вертикальными. Следует отметить, что артефакты при реконструкции сцены возникают из-за многих факторов: неточной оценки траектории камеры, недостаточно обученной базовой нейронной сети или недостаточного покрытия сцены кадрами, из-за чего часть сцены может быть "невидимой". В данном изобретении используется естественное предположение, что в реальной сцене стены в комнатах вертикальные и не имеют артефактов, полы горизонтальные и не имеют артефактов, и обучение построено на этом предположении.
3D-модель сцены представляет собой облако точек или сетку. 3D-реконструкцию сцены осуществляют на основе последовательности кадров, представляющих изображения сцены, и соответствующих положений и ракурсов камеры для каждого кадра из последовательности на основе 3D-модели сцены. Кадры изображения захватываются камерой, а параметры камеры оцениваются системой слежения или одним из соответствующих методов локализации, применяемых к видео в данной области техники.
Базовая нейронная сеть, для которой может быть использовано предлагаемое изобретение, состоит из "скелета" - основной части, вычисляющей признаки, и "головы" TSDF. Две "головы" представляют собой вычисленные прогнозы на основе этих признаков, а именно прогнозирование TSDF вычисляется головой TSDF, а сегментации вычисляются головой сегментации. Другими словами, если взять произвольную базовую нейронную сеть для применения предложенного метода, то эта базовая нейронная сеть изначально имеет скелет и голову TSDF, а для обучения добавляется голова сегментации. Например, в Atlas [2] скелетом является 2D CNN, которая прогнозирует признаки в изображениях, проекцию в 3D и кодирующую часть 3D-сети, а оставшаяся декодирующая часть - это реконструкция. VoRTX [1] имеет аналогичную структуру, но также является промежуточной сетью-трансформером для слияния признаков.
Предлагаемое изобретение представляет собой способ визуализации 3D-сцены с использованием нейронной сети, состоящей из базовой нейронной сети, включающей скелет и голову TSDF, и головы сегментации, основанной на обучении с использованием регуляризации сегментации нормалей TSDF (т.е. с использованием определения семантических структурных элементов и их выравниванием), который содержит следующие этапы:
Обучение базовой нейронной сети (как следует из фиг. 1):
- В скелет (блок 2 на фиг. 1) вводят обучающие данные, представляющие собой обучающие RGB-кадры с соответствующими данными камеры в виде входных тензоров (блок 1 на фиг. 1). Скелет обрабатывает входные тензоры и вычисляет промежуточные признаки, которые в дальнейшем будут использоваться для прогнозирования и сегментации TSDF. Выводы скелета являются промежуточными представлениями ввода, которые можно рассматривать как внутренние признаки этой последовательности.
- Применяют голову TSDF (блок 3 на фиг. 1) для промежуточных признаков, выданных скелетом. Голова TSDF прогнозирует TSDF объем, чтобы получить прогноз TSDF значений TSDF в каждом вокселе соответствующей сцены, причем каждый воксель имеет соответствующее значение TSDF в этом месте. Для каждого вокселя в пространстве необходимо определить расстояние от этого вокселя до поверхности реконструируемого объекта. Прогноз знака TSDF характеризует, на какой стороне поверхности расположен данный воксель, если он находится внутри этого объекта, то расстояние принимается со знаком минус, в противном случае со знаком плюс. Блок 6 представляет результат блока 3, то есть прогноз TSDF для всего вексельного объема.
- Вычисляют потери TSDF между данными прогнозирования TSDF и данными эталонного скана (из блока 5 на фиг. 1). Вычисление выполняют после скелета в отдельном модуле "Потери TSDF" (блок 9 на фиг. 1). Этот модуль принимает TSDF и прогнозы эталонного скана в качестве ввода и вычисляет потери TSDF. Эталонный скан - это "корректный" скан, полученный с помощью лазерного сканера, датчика глубины или другим известным методом. Эталонный скан - это идеальная реконструкция, которую любая обучаемая базовая нейронная сеть стремится реконструировать при обучении. Потери являются показателем того, насколько текущая реконструкция отличается от идеальной (эталона). Базовую нейронную сеть обучают максимально точно реконструировать сцену, вычисляют потери и применяют метод градиентной оптимизации для минимизации общей функции потерь. Таким образом, параметры базовой нейронной сети итеративно обновляются, чтобы уменьшить потери, а прогнозы максимально приблизить к "идеалу".
Применяют голову сегментации (блок 4 на фиг. 1) к промежуточным признакам, выводимым из скелета, для получения прогноза сегментации (блок 7 на фиг. 1). Голова сегментации состоит из нескольких слоев, которые добавляются к базовой нейронной сети и прогнозируют метки сегментации в каждом вокселе. Метка сегментации - это метка класса, к которому принадлежит данный воксель, в данном случае метка класса "пол", "стены", "другое".
- Вычисляют потери сегментации (блок 12 на фиг. 1) между прогнозом сегментации (блок 7 на фиг. 1) и эталоном сегментации (блок 8 на фиг. 1). Эталон сегментации известен для обучающего набора.
Голова TSDF и голова сегментации могут работать параллельно. Потери TSDF вычисляются на основе прогноза TSDF (т.е. после него). Аналогично, потеря сегментации вычисляется на основе прогноза сегментации (т.е. после него).
Все вычисленные потери (потери TSDF, потери сегментации и зависимые от нормали потери (которые будут описаны ниже) прибавляются к общей функции потерь, которая оптимизируется в процессе обучения нейронной сети. Вычисленные потери используются для обратного распространения ошибки, т.е. обновления параметров базовой нейронной сети в соответствии с градиентом общей функции потерь по этим параметрам.
Определяют области пола и стен из прогноза сегментации (блок 11 на фиг. 1)
Это значит, что при сегментации определяют области пола и стен, то есть те воксели, для которых спрогнозирована метка "пол" или "стена". Для каждой точки пространства определяется, является ли она стеной, полом или чем-то еще. Таким образом, области стен и пола определяются за один проход.
Вычисляют координаты нормалей в виде градиентов TSDF (нормаль - это 3D вектор) (блок 10 на фиг. 1). Нормали вычисляются для всех вокселей в пространстве (сцене) как градиенты спрогнозированного TSDF. Если поверхность является изоповерхностью некоторой функции, то градиент этой функции будет перпендикулярен поверхности. Сначала вычисляют нормали для всех вокселей, то есть направление нормали к поверхности в каждом вокселе вычисляют как градиент от функции TSDF. Если поверхность является поверхностью уровня некоторой функции (если это поверхность уровня 0 для TSDF, то решение TSDF=0), то градиенты этой функции перпендикулярны этой поверхности, то есть являются нормалями.
Затем вычисляют все нормали, выбирают те, которые соответствуют вокселям стен (голова сегментации как раз прогнозирует, какие воксели являются стенами, какие полами, и какие - всем остальным). Для нормалей в вокселях стен вычисляют вертикальную составляющую. Аналогично для нормалей в вокселях пола вычисляют горизонтальную составляющую. А именно:
Выбирают нормали в областях стен (блок 15 на фиг. 1) и вычисляют их вертикальные составляющие, т.е. z-составляющие нормали (блок 14 на фиг. 1), на основе данных, полученных из блоков 10 и 11), т.е. проекции нормали на вертикальную плоскость, при этом выбирают нормали, соответствующие вокселям, сегментированным как "стена". Если стена идеально ровная, то нормали во всех точках стены будут одинаковыми, если нет, то они могут различаться. Выбирают нормаль в областях пола (блок 15 на фиг. 1) и вычисляют их горизонтальные составляющие (блок 16 на фиг. 1), т.е. проекцию нормали на горизонтальную плоскость Оху, при этом выбирают нормали, соответствующие вокселям, сегментированным "пол".
Вычисляют обычные потери нормалей (блок 13 на фиг. 1) (функции потерь для нормалей), которые традиционно используются для реконструкции, из блоков 10 (прогноз) и 5 (эталон).
К обычным потерям нормалей относятся:
1. Различие между спрогнозированными нормалями (градиентами спрогнозированного TSDF) и эталонными (градиентами TSDF для эталонного скана). Для вычисления этих потерь необходимы спрогнозированные и реальные нормали, спрогнозированные нормали вычисляются из базовой нейронной сети, а реальные нормали из сканов, имеющихся в обучающих данных.
2. Эйкональная потеря - это отличие длин векторов нормалей от единицы (поскольку TSDF соответствует расстоянию до поверхности, то градиент этой функции в идеале должен иметь единицу длины. И отличие длины от единицы тоже штрафуется). Для вычисления этих потерь необходимы только спрогнозированные нормали.
Обе эти обычные потери нормалей часто встречаются в предшествующем уровне техники, например, в [MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction, NeurlPS, 2022]).
- Вычисляют общую функцию потерь, которая равна сумме потерь TSBF, потерь сегментации и условных потерь нормалей;
- Вычисляют градиент общей функции потерь относительно параметров базовой нейронной сети. Параметры базовой нейронной сети обновляют в соответствии с этим градиентом для уменьшения (минимизации) общей функции потерь от эпохи к эпохе обучения. То есть, осуществляют обратное распространение ошибки, известное из уровня техники. Минимизацию выполняют для того, чтобы найти такие базовые параметры нейронной сети, при которых прогнозы будут наиболее точными (принципы оптимизации на основе градиентов, используемые в нейронных сетях, были описаны выше). Процесс обучения нейронной сети заключается в выборе таких параметров нейронной сети, при которых прогноз TSDF будет максимально приближен к идеалу. Параметры базовой нейронной сети выбирают (обучают) таким образом, чтобы не было нерегулярностей. И окончательно обученная базовая нейросеть тут же реконструирует сцену так, что полы и стены становятся ровными. Базовая нейронная сеть во время обучения учитывает все отклонения стен и полов от "идеальных" плоскостей (вертикальных/горизонтальных) и штрафует (прибавляет к общей функции потерь) их все, независимо от того, происходит ли это отклонение на большой площади или на маленькой. Каждая точка, сегментированная как стены или полы, вносит вклад в оптимизацию базовой нейронной сети. И этот вклад равен отклонению нормали в данной точке от горизонтального/вертикального направления. В процессе обучения имеются такие параметры базовой нейронной сети, для которых общая функция потерь минимальна, при нахождении этих параметров сама общая функция потерь больше не используется, а используются эти "оптимальные" параметры базовой нейронной сети.
- Обратное распространение ошибки обеспечивает обновление параметров базовой нейронной сети в соответствии с минимизированной функцией потерь. Общая функция потерь уменьшается после каждой эпохи обучения. Этапы обучения повторяются до тех пор, пока общая функция потерь не перестанет уменьшаться или пока общая функция потерь не достигнет заданного порогового значения, заданного разработчиком. Также процесс обучения может выполняться в течение фиксированного количества эпох, или же, как и в базовых версиях этой нейронной сети, могут также применяться и другие критерии остановки процесса обучения, например, до тех пор, пока не будет достигнуто значение общей функции потерь в следующей эпохе обучения ниже заданного порогового значения.
На этапе работы обученной базовой нейронной сети используются только блоки 1, 2, 3, 6. Работа обученной базовой нейронной сети содержит следующие этапы: последовательность RGB кадров сцены снимают камерой с разных ракурсов и положений камеры в пространстве. Данные камеры содержат положение камеры в пространстве в фиксированной системе координат, которая определяется трехмерным вектором, и угол камеры, представляющий собой матрицу поворота 3×3 (матрицу направляющего косинуса). Матрицу поворота 3×3 можно получить любым способом, например, SfM (например, COLMAP (Structure-from-Motion Revisited, CVPR, 2016) или каким-нибудь SLAM (например, ORB-SLAM: A Versatile and Accurate Monocular SLAM System, IEEE Transactions on Robotics, 2015). Входные RGB-кадры с соответствующими данными камеры берутся из камеры, с помощью которой они получены, или из памяти устройства, в котором реализован предлагаемый метод. Если камера выполнена с возможностью вычисления положения камеры (например, Android-смартфон с трекером ArCore), то эти данные могут быть сразу переданы на устройство, в котором будут выполняться вычисления. В противном случае сначала необходимо получить соответствующие данные камеры (возможно, на том же устройстве, которое будет вычислять все остальное) головы TSDF.
- Кадры RGB и данные камеры вводятся в скелет обученной базовой нейронной сети в виде входных тензоров. Обученная базовая нейронная сеть получает TSDF объем входной последовательности RGB-кадров реальной сцены. Трехмерная поверхность определяется как изоповерхность нулевого уровня TSDF. Это осуществляется с помощью известных алгоритмов, например, алгоритма марширующих кубов (представленного в работе "Marching cubes: A high resolution 3D surface construction algorithm", SIGGRAPH, 1987). Таким образом, для RGB-видео сцены с известной траекторией камеры 3D реконструкция сцены задается в виде облака точек или треугольной сетки, как описано выше. При этом пол и стены в полученной реконструкции 3D сцены не имеют локальных артефактов, таких как углубления, дыры и возвышения, и т.п. Пол и стены сегментируются, т.е. каждый воксель помечается меткой класса, которому соответствует данная точка. В настоящем изобретении этими классами являются "пол", "стена", "другое".
- Далее выполняется рендеринг реконструкции 3D-сцены для получения визуализации 3D-сцены. Полученная в результате визуализация 3D-сцены затем отображается пользователю.
Предлагаемая обученная базовая нейронная сеть формируется таким образом, чтобы области, соответствующие полу, были плоскими и горизонтальными, а области, соответствующие стенам, были плоскими и вертикальными.
В отличие от традиционных методов 3D-реконструкции, оптимизирующих геометрическую корректность сканов, в предлагаемом методе регуляризации структурные элементы сцены (пол и стены) дополнительно сегментируются, а базовая нейронная сеть оптимизируется так, чтобы эти элементы были плоскими, поверхность пола сцены была горизонтальной, а стены - вертикальными.
Вспомогательный модуль сегментации стен и пола (голова сегментации), а именно дополнительные слои, которые добавляются после скелета для прогнозирования меток сегментации, обучается вместе с базовой нейронной сетью, прогнозирующей функцию усеченного расстояния со знаком (TSDF) сцены, и в областях, соответствующих полу и стенам, оцениваются направления нормалей к поверхности сцены, то есть оцениваются все поверхности, находящиеся в сцене. В областях стен штрафуется вертикальная составляющая этой нормали, а в областях пола штрафуется горизонтальная составляющая, это означает, что:
в каждой точке областей, в которых голова сегментации прогнозирует класс «стена», рассматриваются вертикальные составляющие векторов нормалей, и длина этой вертикальной составляющей (то есть z-составляющая вектора нормали) прибавляется к функции потерь,
и в областях, в которых прогнозируется класс "пол", рассматривается горизонтальная составляющая (х- и у-составляющие векторов нормалей) и прибавляется функция потерь для этой составляющей (норма двумерного вектора, составленного из этих двух составляющих).
Если в функции потерь есть такие составляющие х, у, z, то параметры базовой нейронной сети обновляются таким образом, чтобы эти члены стали меньше. Меньшее значение этих членов приводит к большему выравниванию поверхности сцены в областях пола и стен. Если нормали пола становятся более вертикальными, то сами полы становятся более горизонтальными, и то же самое касается стен.
То есть оптимизация осуществляется методами градиентного спуска (а именно методом стохастической оптимизации [Adam: А Method for Stochastic Optimization, https://arxiv.org/abs/1412.6980], общепринятыми для обучения нейронных сетей. Оптимизация позволяет выравнивать области стен и полов, поскольку в результате этого процесса оптимизации уменьшаются значения общей функции потерь, включая члены, соответствующие нормалям к стенам и полу. Чем меньше упомянутые члены, тем меньше нормали отклоняются от "корректных" направлений и, соответственно, более выровненными становятся сами поверхности пола и стен. Такая оптимизация позволяет выровнять области стен и пола и предотвратить появление ошибок реконструкции, таких как закругления стен, углубления, дыры и возвышения на поверхностях.
A. Новая голова сегментации (блок 4 на фиг. 1).
Голова сегментации представляет собой разреженную 3D сверточную сеть, созданную на основе разреженной 3D сети U-Net. Поскольку архитектуры моделей прогнозирования TSDF также имеют архитектуру U-Net, голова сегментации ответвляется от своего энкодера и состоит из двух разреженных 3D сверточных модулей. Каждый модуль включает в себя разреженную 3D-свертку с последующей батч нормализацией и два остаточных 3D-сверточных блока. Предлагаемая голова сегментации выводит 3D-сегментацию в виде пространственной карты с тремя каналами, каждый из которых соответствует одной категории сегментации: стене, полу и другому.
B. Обучение
Обучается базовая нейронная сеть, которая прогнозирует TSDF объем сцены. Эта базовая нейронная сеть обучается таким образом, чтобы области пола и стены стремились стать горизонтальными и вертикальными, соответственно. Для этого базовую нейронную сеть обучают прогнозировать метку сегментации вместе с TSDF. Когда прогнозируются TSDF и метки сегментации, нормали поверхности вычисляются как градиенты TSDF. Рассматриваются области пола и стен. Для точек, сегментированных как пол, к функции потерь прибавляется отклонение соответствующих нормалей от вертикального направления. Аналогично, для точек, сегментированных как стены, к функции потерь прибавляется отклонение соответствующих нормалей от горизонтального направления. Эти члены потерь направлены на то, чтобы сделать поверхность пола более горизонтальной, а поверхности стен более вертикальными.
Предлагается обучение головы 3D-сегментации на датасете ScanNet с облаками точек, аннотированными метками сегментации для каждой точки, т.е. датасет содержит облака точек, в которых каждая точка аннотирована (помечена) меткой соответствующего класса сегментации. Исходные категории ScanNet пол и ковер преобразованы в категорию "пол", а стена, окно, дверь, картина вошли в категорию "стены". Все точки, считающиеся не принадлежащими ни к категории стен, ни к категории пола, подпадают под категорию "другое". Отдельная категория потолка не рассматривается, так как в сканах ScanNet слишком мало точек потолка из-за процесса съемки.
Обучение проводят в два этапа. На первом этапе обучают базовую нейронную сеть, которая прогнозирует TSDF, вместе с головой 3D-сегментации, которая учится разделять точки на три категории (пол, стены и другое), руководствуясь потерями сегментации. Геометрия сцены не подвергается штрафованию в течение первых эпох, чтобы не нарушить процедуру обучения ранними ошибочными оценками классов сегментации. Это значит, что на начальных этапах еще не обученная базовая нейронная сеть будет, вероятнее всего, некорректно предсказывать принадлежность к классам "пол", "стены" ", "другое".
В течение первых эпох обучения предлагаемый штраф не применяется к нормалям пола и стены. Это означает, что в этих первых эпохах члены, соответствующие вертикальным/горизонтальным составляющим нормалей стены/пола, не прибавляются к общей функции потерь. Нейронная сеть преимущественно обучается реконструировать полную сцену (используя голову TSDF) и определять стены, пол и другое (используя голову сегментации).
Когда базовая нейронная сеть уже способна определить, где находятся стены и пол, к общей функции потерь добавляются члены для нормалей и оптимизируется общая функция потерь. При этом потери TSDF и сегментации также продолжают участвовать в оптимизации.
В общем случае термин "штрафование" означает, что к общей функции потерь добавляется соответствующий член. Тот факт, что в начале обучения не добавляются члены для нормалей, продиктован здравым смыслом: пока базовая нейросеть еще не обучена, она скорее всего некорректно определит полы и стены, поэтому будут скорректированы неправильные нормали. С оштрафованными данными ничего не происходит. Различие между прогнозами и "идеалом" "штрафуется", и этот термин означает, что данное различие добавляется к минимизированной общей функции потерь. В последующие эпохи добавляются потери на нормалях поверхностей и процесс продолжается с объединенным прогнозированием геометрии и сегментаций сцены (блоки 6, 7 на фиг. 1). То есть члены, соответствующие вертикальным/горизонтальным составляющим нормалей стены/пола, добавляются к общей функции потерь. Процесс оптимизации продолжается. Из оценочного представления TSBF выводятся нормали к поверхностям: являясь производными первого порядка поверхностной функции, они легко вычисляются одной сверткой. Оценка нормалей реализуется как специальный необучаемый 3D сверточный слой, поэтому эту операцию можно легко включить в обучаемую модель.
С. Потери
Используются две группы потерь в зависимости от нормалей поверхности. Во-первых, эксплуатируются обычные потери нормалей. Извлекаются эталонные нормали из эталонного представления TSDF и штрафуется (разность между прогнозом и эталоном добавляется как член к функции потерь, которая минимизируется) расхождение между спрогнозированными и эталонными нормалями с использованием как косинусного расстояния (расстояния, обратного нормализованному скалярному произведению векторов), так и евклидова расстояния. Эти эталонные потери дополняются безэталонной эйкональной потерей, которая регуляризирует L2-норму нормали, вынуждая ее стремиться к 1. Эталонные данные используются только на этапе обучения. После обучения базовую нейронную сеть можно применять к данным, для которых нет эталона.
Кроме обычных потерь введена регуляризация сегментации нормалей, которая рассматривает как нормали поверхности, так и 3D-сегментацию (сегментационную разметку (аннотацию с метаклассом) каждой трехмерной точки). В общем, стимулом является, чтобы стены были вертикальными, а пол - горизонтальным. Для удобства обозначим набор 3D-точек, классифицированных как пол, символом F, а стены символом W.
W. Регуляризуются невертикальные составляющие нормали nx, ny в каждой точке 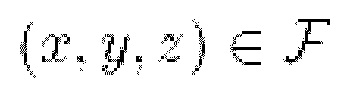 :
:
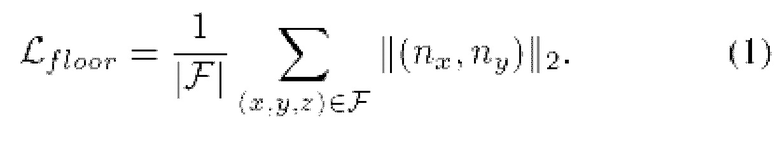
Для стен применяется L1-потеря для вертикальной составляющей ^:
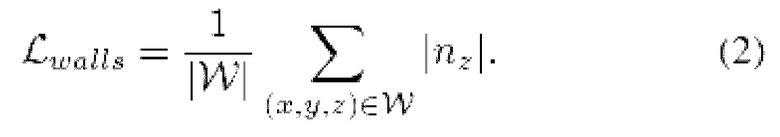
В абляционном исследовании изучалось, как каждая потеря влияет на качество реконструкции, и было доказано, что они дополняют друг друга, затрагивая различные аспекты реконструкции.
D. Вывод
Во время вывода 3D-сегментация не требуется. Следовательно, аннотация 3D сегментации служит только для целей обучения: руководствуясь дополнительной информацией о сегментации, метод обучается более точно прогнозировать TSDF.
Эксперименты
А. Базовые методы
В качестве базовых методов рассматривалось несколько современных методов реконструкции TSDF. Были выбраны методы, основанные на различных принципах работы, чтобы доказать применимость предлагаемой модификации к широкому спектру подходов к слиянию нескольких видов. То есть в данной области техники известно множество различных методов реконструкции TSDF для сцены, снятой с разных ракурсов. Предложенную в изобретении регуляризацию можно применить с любым из них, независимо от того, на каких принципах они основаны. Для подтверждения этого было рассмотрено несколько существующих методов, основанных на различных принципах (описаны ниже).
В частности, использовались основанный на преобразователе VoRTX [1] и основанный на усреднении Atlas [2] (блоки 2, 3 на фиг. 1 (скелет и голова TSDF).
Atlas [2] объединяет объекты в единый объем признаков. В нем отсутствует оценка глубины и выполняется трехмерная реконструкция с прямым прогнозом TSDF объема. Эта схема позволяет рассматривать входные изображения совместно и эффективно. Более того, Atlas оснащен механизмом, который позволяет реконструировать невидимые области сцены с помощью априорных 3D-изображений.
VoRTX [1] - это метод объемной 3D-реконструкции от начала до конца, осуществляющий объединение нескольких изображений с помощью преобразователей.
VoRTX сохраняет мелкие детали путем улучшения слияния в зависимости от положения камеры, и обрабатывает перекрытия, оценивая исходную геометрию сцены, чтобы исключить проецирование элементов изображения в закрытые области. Закрытые области возникают, если один объект перекрывает другой с ракурса съемки камеры, в этом случае некоторые области могут быть не видны (конкретно на видеокадрах). Сочетание этих приемов позволяет добиться самого высокого качества реконструкции.
B. Датасеты
Предложенный метод обучали на ScanNet [8], который содержит 1613 сцен в помещениях с эталонными положениями камеры, 3D-реконструкциями и метками сегментации. Всего содержится 2,5 млн кадров RGB-D в 707 различных пространствах. Были приняты стандартные разделения и результаты отчетов для тестового подмножества. Также оценивалось качество переноса базовых нейронных сетей, обученных на ScanNet, на другие датасеты: TUM RGB-D, давно принятый бенчмарк RGB-D SLAM; ICL-NUIM, небольшой бенчмарк реконструкции RGBD с восемью сценами, визуализированными в синтетической структуре, и 7-Scenes [9], небольшой, но сложный датасет RGB-D для помещений, содержащий 7 реальных пространств внутри помещений.
C. Протокол оценки
Для каждого кадра визуализировалась карта глубины эталона на основе сетки эталона по отношению к соответствующему положению камеры. Аналогичным образом, оценочная карта глубины визуализировалась из оценочной сетки и маскировалась в областях, где глубина эталона недействительна. Все оценочные маскированные карты глубины были интегрированы в один TSDF объем.
Во всех экспериментах качество реконструкции оценивалось с помощью стандартных эталонных метрик реконструкции: точность, полнота, прецизионность, отказ и F-показатель с порогом 5 см [2]; сетка, полученная из маскированных оценочных глубин, сравнивалась с сеткой эталонов.
Таблица I: Качество реконструкции, выполненной с помощью базовых версий и модифицированных методов на ScanNet. Лучшие показатели выделены жирным шрифтом.
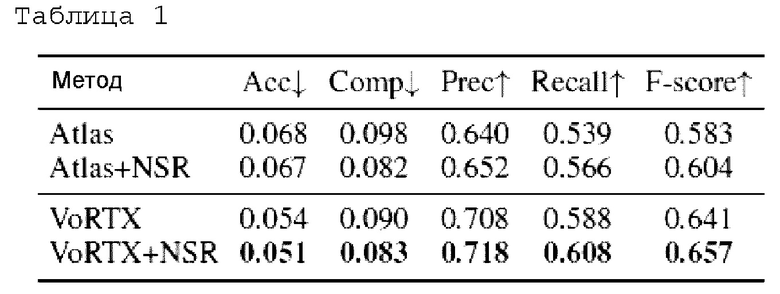
Acc - точность - среднее расстояние от точек спрогнозированной 3D-модели до ближайших точек эталонной модели.
Comp - полнота - среднее расстояние от основных точек эталона 3D-модели до ближайших точек спрогнозированной модели.
Prec - прецизионность - процент точек спрогнозированной 3D-модели, для которых расстояние до ближайшей точки из эталонной модели составляет менее 5 см.
Recall - отказ - процент точек эталонной модели, для которых расстояние до ближайшей точки от прогнозируемой 3D-модели составляет менее 5 см.
F-показатель - среднее гармоническое значение прецизионности и отказа.
Стрелки указывают, какое значение лучше (стрелка вниз - чем меньше, тем лучше, стрелка вверх - чем больше, тем лучше)
Выводы: Для обоих методов (Atlas, Vortx) добавление регуляризации NSR улучшает качество по всем метрикам.
Таблица II: Качество реконструкции, выполненной с помощью базовой версии VoRTX и модифицированного метода, обученного на ScanNet, на датасетах ICL-NUIM, TUM RGB-D и 7Scenes. Лучшие показатели для каждого датасета выделены жирным шрифтом.
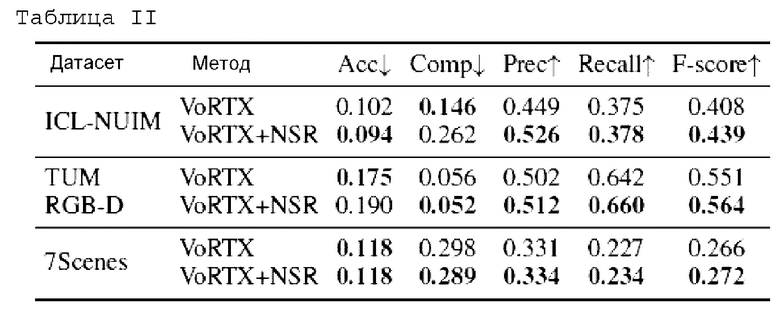
Выводы: При переносе базовой нейронной сети, обученной на одном датасете, на другие данные, добавление NSR регуляризации также повышает качество практически по всем метрикам (тесты проводились на 3 датасетах: ICL-NUIM, TUM RGB-B, 7Scenes)
D. Вывод
В процессе вывода выборки K=60 ключевых кадров брали произвольным образом, чтобы для каждой пары последовательных ключевых кадров относительный поворот составлял не менее 15°, а сдвиг - не менее 10 см. Эти выборочные ключевые кадры использовались для оценки TSDF всей сцены; результирующую сетку сцены получали из TSBF с помощью алгоритма марширующих кубов.
Выбор ключевых кадров производился на самом начальном этапе, еще до ввода данных в нейронную сеть. Целью этого является уменьшение затрат времени и памяти на алгоритм (обрабатываются не все кадры подряд, а только ключевые, поскольку если кадры расположены очень близко друг к другу (сняты с одинаковых положений камеры), то информация в них дублируется и избыточна).
Алгоритм марширующих кубов применялся на заключительном этапе к результатам базовой нейронной сети (базовая нейронная сеть возвращает TSDF для всей сцены, а алгоритм марширующих кубов строит из этого TSDF облако точек или сетку).
Е. Детали реализации
Предлагаемая голова сегментации (блок 4 на фиг. 1) обучалась с нуля в течение такого же количества эпох, как и базовая нейронная сеть. Использовался оптимизатор Adam со стандартной начальной скоростью обучения 0,001.
Предлагаемый метод был реализован на платформе PyTorch, а предлагаемая сеть обучалась на одном графическом процессоре NVIDIA Tesla Р40.
Использовались внутренние и внешние параметры, представленные в датасетах [8-11], которые корректировались вместе с масштабированием изображения. Согласно [5], положения камеры инициализировались единицами и представляли исходную SDF как единичную сферу с нормалями поверхности, направленными внутрь.
V. Результаты
А. Сравнение с известным уровнем
Метрики реконструкции в ScanNet собраны в Таблице I, а качество переноса 3D-модели в бенчмарки ICL-NUIM, TUM RGB-D и 7Scenes показано в Таблице II.
В таблице III проиллюстрировано качество реконструкции, полученное с использованием различных комбинаций потерь в ScanNet. "С" обозначает обычные потери, "N" - потери на нормалях, "NS" - потери на сегментации нормалей.
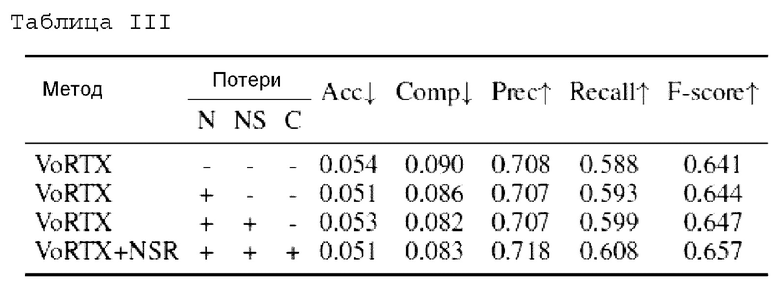
Выводы: добавление отдельных членов к общей функции потерь повышает качество 3D-модели, и наилучшие результаты можно получить, если добавить все предложенные в изобретении модификации (функции потерь как для нормалей, так и для сегментации, и классические потери нормалей).
На фиг. 2 представлена визуализация результатов 3D-реконструкции. Фиг. 2 изображает визуализацию 3D-реконструкций, полученных с помощью базовых версий VoRTX (а) и VoRTX+NSR (b). Из таблицы видно, что добавление NSR к базовому методу заметно повышает качество. Проблемные области увеличены, чтобы подчеркнуть преимущества использования NSR. Как видно, предложенная модификация позволила заполнить дыры в плоских поверхностях, тогда как базовые версии создали неполную реконструкцию с недостающими точками в этих областях. Более того, в отличие от базовых версий, NSR способствует тому, чтобы стены и пол были ровными и плоскими.
Анализировалось влияние применения каждой составляющей NSR на качество реконструкции. Все абляционные исследования проводились с использованием VoRTX [1] в качестве базовой версии и тех же протоколов обучения/оценки, которые были описаны выше, если не указано иное. Сначала исследовалось качество оценочной сегментации путем использования эталонных аннотаций сегментации вместо спрогнозированных.
Затем исследовались базовые нейронные сети, обученные с использованием различных комбинаций обычных потерь нормалей и потерь сегментации нормалей, чтобы убедиться, что качество реконструкции улучшилось при использовании предлагаемых потерь.
Таким образом, предлагается NSR, являющаяся модификацией методов реконструкции сцены, которая позволяет рассматривать типичную структуру сцены. В частности, предлагаемая модификация определяет стены и пол в облаке точек и штрафует соответствующие нормали поверхности за отклонение от горизонтального и вертикального направлений, соответственно. Реализованная в виде разреженного 3D сверточного модуля, NSR может быть включена в произвольную обучаемую модель, которая выдает на выходе TSBF, и подвергаться обучению от начала до конца на облаках точек 3D сегментации. В процессе вывода 3D-сегментация не требуется, поэтому использование NSR не накладывает никаких ограничений на пользовательские сценарии. Предлагаемую модификацию применяли в нескольких современных методах реконструкции TSDF, и был продемонстрирован значительный прирост производительности на стандартным датасетах: ScanNet, ICL-NUIM и TUM RGB-D.
Описанные выше иллюстративные варианты осуществления являются примерами и не должны рассматриваться как ограничивающие. Кроме того, описание этих вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и многие альтернативы, модификации и варианты будут очевидны для специалистов в данной области техники.
ЛИТЕРАТУРА
[1] N. Stier, A. Rich, P. Sen, and Т. H"ollerer, "VoRTX: Volumetric 3D Reconstruction With Transformers for Voxelwise View Selection and Fusion," in 3DV, 2021, pp.320-330.
[2] Z. Murez, T. van As, J. Bartolozzi, A. Sinha, V. Badrinarayanan, and A. Rabinovich, "Atlas: End-to-end 3D scene reconstruction from posed images," in ECCV, Glasgow, UK, 2020, pp.414-431.
[3] J. Sun, Y. Xie, L. Chen, X. Zhou, and H. Bao, "NeuralRecon: Real-time coherent 3D reconstruction from monocular video," in CVPR, 2021, pp.15598-15607.
[4] A. Bovzivc, P. Palafox, J. Thies, A. Dai, and Matthias Niesner, "TransformerFusion: Monocular RGB scene reconstruction using transformers," in NeurlPS, 2021.
[5] H. Guo, S. Peng, H. Lin, Q. Wang, G. Zhang, H. Bao, and X. Zhou, "Neural 3D Scene Reconstruction with the Manhattan-world Assumption," in CVPR, 2022.
[6] L. Yariv, J. Gu, Y. Kasten, and Y. Lipman, "Volume rendering of neural implicit surfaces," in NeurlPS, 2021.
[7] P. Wang, L. Liu, Y. Liu, Ch. Theobalt, T. Komura, and W. Wang, "NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction," in NeurlPS, 2021.
[8] A. Dai, A. X. Chang, M. Savva, M. Halber, Th. Funkhouser, and M. Niesner, "ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes," in CVPR, 2017.
[9] J. Shotton, B. Glocker, Ch. Zach, Sh. Izadi, A. Criminisi, and A. Fitzgibbon, "Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images," in CVPR, 2013.
[10] A. Handa, T. Whelan, J.B. McDonald, and A.J. Davison, "A Benchmark for RGB-B Visual Odometry, 3D Reconstruction and SLAM," in ICRA, Hong Kong, China, 2014.
[11] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and B. Cremers, "A Benchmark for the Evaluation of RGB-B SLAM Systems," in IROS, 2012.
[12] J. Wang, P. Wang, X. Long, C. Theobalt, T. Komura, L. Liu, W. Wang, "NeuRIS: Neural Reconstruction of Indoor Scenes Using Normal Priors," in ECCV, 2022.
[13] A. Avetisyan, M. Bahnert, A. Dai, M. Savva, A. X. Chang, and M. Niesner, "Scan2cad: Learning CAB Model Alignment in RGB-B Scans," in CVPR, 2019.
[14] A. Avetisyan, A. Dai, and M. Niesner, "End-To-End CAD Model Retrieval and 9dof Alignment in 3D Scans," in ICCV, 2019.
[15] M. Dahnert, A. Dai, L. Guibas, and M. Niesner, "Joint Embedding of 3D Scan and CAD Objects," in ICCV, 2019.
[16] Sh. Hampali, S. Stekovic, S. Deb Sarkar, Ch. S. Kumar, F. Fraundorfer, and V. Lepetit, "Monte Carlo Scene Search for 3D Scene Understanding," in CVPR, 2021.
[17] S. Ainetter, S. Stekovic, F. Fraundorfer, V. Lepetit, "Automatically Annotating Indoor Images With CAD Models via RGB-D Scans," in WACV, 2023, pp. 3156-3164.
[18] Y. Wang, Z. Li, Y. Jiang, K. Zhou, T. Cao, Y. Fu, C. Xiao, "Neural- Room: Geometry-Constrained Neural Implicit Surfaces for Indoor Scene Reconstruction,", in ACM Transactions on Graphics (TOG), 2022.
[19] Sh. Zhi, M. Bloesch, S. Leutenegger, and A. J. Davison, "SceneCode: Monocular Dense Segmentation Reconstruction Using Learned Encoded Scene Representations," in CVPR, 2019, pp. 11768-11777.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| Способ и устройство для коррекции карт глубины для множества видов | 2023 |
|
RU2827434C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИСТАНЦИОННОГО ВЫБОРА ОДЕЖДЫ | 2020 |
|
RU2805003C2 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СПОСОБ И СИСТЕМА ДЛЯ УТОЧНЕНИЯ ПОЗЫ КАМЕРЫ С УЧЕТОМ ПЛАНА ПОМЕЩЕНИЯ | 2022 |
|
RU2794441C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
Изобретение относится к обработке изображений. Технический результат направлен на повышение точности реконструкции 3D-сцены. Способ реконструкции 3D-сцены и ее визуализации с использованием нейронной сети, состоящей из базовой нейронной сети, включающей в себя скелет, являющийся основной частью базовой нейронной сети, вычисляющей признаки, голову TSDF, осуществляющую прогнозирование значений TSDF в каждом вокселе, и голову сегментации, представляющую собой модуль 3D разреженной сверточной сегментации, прогнозирующий метки сегментации в каждом вокселе, содержащий этапы, на которых: обучают базовую нейронную сеть получению TSDF объема для вокселей сцены следующим образом, вводят обучающие данные, вычисляют потери TSDF между прогнозом TSDF, вычисляют потери сегментации между прогнозом сегментации и эталоном сегментации, вычисляют координаты нормалей, вычисляют общую функцию потерь как сумму потерь TSDF, минимизируют общую функцию потерь, используют обученную базовую нейронную сеть для получения TSDF объема входной последовательности RGB-кадров реальной сцены, применяют к TSDF объему алгоритм, вычисляющий реконструкцию 3D-сцены, осуществляют рендеринг реконструкции 3D-сцены для получения визуализации 3D-сцены. 2 н. и 9 з.п. ф-лы, 2 ил., 3 табл. 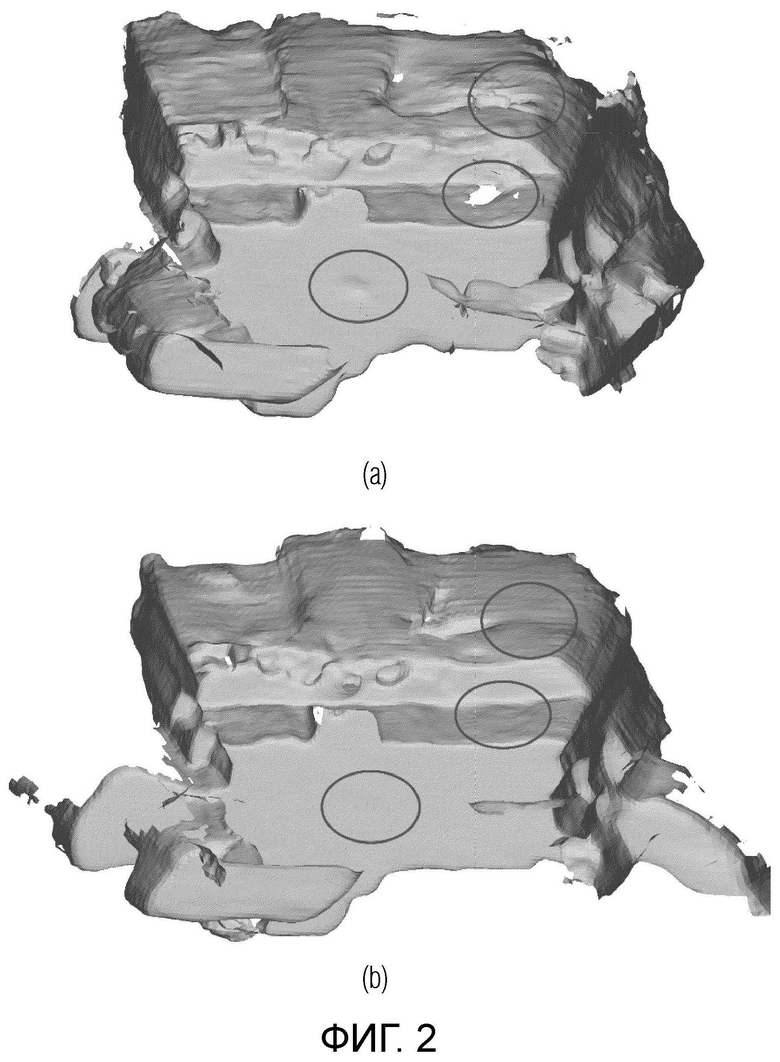
1. Способ реконструкции 3D-сцены и ее визуализации с использованием нейронной сети, состоящей из базовой нейронной сети, включающей в себя скелет, являющийся основной частью базовой нейронной сети, вычисляющей признаки, голову TSDF (Truncated Signed distance function, функции усеченного расстояния со знаком), осуществляющую прогнозирование значений TSDF в каждом вокселе, и голову сегментации, представляющую собой модуль 3D разреженной сверточной сегментации, прогнозирующий метки сегментации в каждом вокселе, содержащий этапы, на которых:
обучают базовую нейронную сеть получению TSDF объема для вокселей сцены следующим образом:
- вводят обучающие данные, включающие в себя обучающую последовательность кадров RGB с соответствующими данными положения камеры, в скелет;
- вычисляют потери TSDF между прогнозом TSDF, полученным головой TSDF из вывода данных из скелета, и эталонным сканом;
- получают с помощью головы сегментации из вывода данных из скелета прогноз сегментации, определяющий области "пола", "стен", "другого", для каждого вокселя;
- вычисляют потери сегментации между прогнозом сегментации и эталоном сегментации;
- вычисляют координаты нормалей как градиенты прогноза TSDF для значений TSDF в каждом вокселе по всем вокселям сцены;
- вычисляют потери нормалей для нормалей для областей стен и областей пола на основе результатов эталона TSDF и градиентов прогноза TSDF;
- вычисляют общую функцию потерь как сумму потерь TSDF, потерь сегментации и потерь нормалей;
- минимизируют общую функцию потерь;
используют обученную базовую нейронную сеть для получения TSDF объема входной последовательности RGB-кадров реальной сцены;
применяют к TSDF объему алгоритм, вычисляющий реконструкцию 3D-сцены;
осуществляют рендеринг реконструкции 3D-сцены для получения визуализации 3D-сцены.
2. Способ по п. 1, в котором алгоритмом, вычисляющим реконструкцию 3D-сцены, является алгоритм марширующих кубов.
3. Способ по любому из пп. 1, 2, в котором голову сегментации и голову TSDF используют параллельно во время обучения.
4. Способ по любому из пп. 1-3, содержащий дополнительные этапы, реализуемые после этапа вычисления координат нормалей, на которых:
выбирают нормаль в областях стен и вычисляют их вертикальные составляющие;
выбирают нормаль в областях пола и вычисляют их горизонтальные составляющие.
5. Способ по любому из пп. 1-4, в котором на этапе вычисления обычных потерь нормалей выполняют следующее:
в каждой точке в областях, в которых голова сегментации прогнозирует "стену", рассматривают вертикальные составляющие векторов нормали, и к обычным потерям нормалей прибавляют длину z-составляющей вектора нормали,
и в каждой точке в областях, в которых голова сегментации прогнозирует "пол", рассматривают горизонтальные составляющие векторов нормали, а также рассматривают х- и у-составляющие вектора нормали и прибавляют норму двумерного вектора, состоящего из этих двух составляющих, к обычным потерям нормалей.
6. Способ по любому из пп. 1-5, в котором общую функцию потерь вычисляют как сумму потерь TSDF, потерь сегментации и обычных потерь нормалей.
7. Способ по любому из пп. 1-6, в котором минимизацию общей функции потерь реализуют путем вычисления градиента общей функции потерь по всем параметрам базовой нейронной сети.
8. Способ по любому из пп. 1-7, в котором дополнительно обеспечивают обратное распространение ошибки минимизированной общей функции потерь и обновляют параметры базовой нейронной сети в соответствии с минимизированной функцией потерь, обновляя при этом параметры базовой нейронной сети.
9. Способ по любому из пп. 1-8, в котором этапы обучения повторяют до тех пор, пока общая функция потерь не перестанет уменьшаться.
10. Способ по любому из пп. 1-8, в котором этапы обучения повторяют до тех пор, пока общая функция потерь не достигнет заданного порогового значения.
11. Вычислительное устройство, содержащее процессор и память, в которой хранятся инструкции, которые при выполнении в процессоре реализуют способ по п. 1.
| N | |||
| STIER, et al | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| CN 108230337 A, 29.06.2018 | |||
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| Способ распознавания объектов на изображении | 2018 |
|
RU2693267C1 |

