ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к кодированию видео. В частности, оно относится к способам и устройствам кодирования и декодирования иммерсивного видео.
УРОВЕНЬ ТЕХНИКИ
Иммерсивное видео, также известное как видео с шестью степенями свободы (6DoF), представляет собой видео трехмерной (3D) сцены, которое позволяет реконструировать виды сцены для точек обзора, которые отличаются по положению и ориентации. Оно представляет дальнейшее развитие видео с тремя степенями свободы (3DoF), которое позволяет реконструировать виды для точек обзора с произвольной ориентацией, но только в одной фиксированной точке в пространстве. В 3DoF степени свободы являются угловыми, а именно наклоном, вращением и отклонением. 3DoF-видео поддерживает повороты головы, другими словами, пользователь, просматривающий видеоконтент, может смотреть в сцене в любом направлении, но не может перемещаться в другое место в сцене. 6DoF-видео поддерживает повороты головы и дополнительно поддерживает выбор позиции в сцене, с которой просматривается сцена.
Для формирования 6DoF-видео для записи сцены требуется множество камер. Каждая камера формирует данные изображения (часто в данном контексте называемые данными текстуры) и соответствующие данные глубины. Для каждого пикселя данные глубины представляют глубину, на которой данной камерой наблюдаются пиксельные данные соответствующего изображения. Каждая из множества камер обеспечивает соответствующий вид сцены. Передача всех данных текстуры и данных глубины для всех видов может быть непрактичной или неэффективной во многих применениях.
Для уменьшения избыточности между видами было предложено обрезать виды и упаковывать их в «текстурный атлас» для каждого кадра потока видео. Этот подход призван уменьшить или устранить перекрывающиеся части между множественными видами и тем самым повысить эффективность. Неперекрывающиеся участки различных видов, которые остаются после обрезки, могут назваться «накладками». Пример данного подхода описан в работе Alvaro Collet и др., «High-quality streamable free-viewpoint video», ACM Trans. Graphics (SIGGRAPH), 34(4), 2015.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Было бы желательно повысить качество и эффективность кодирования иммерсивного видео. Подход с использованием обрезки (т.е. исключения избыточных текстурных накладок) для создания текстурных атласов, как описано выше, может помочь снизить скорость передачи пикселей. Однако обрезка видов часто требует детального анализа, который не позволяет избежать ошибок и может привести к снижению качества для конечного пользователя. Поэтому существует потребность в надежных и простых способах снижения скорости передачи пикселей.
Изобретение определено формулой изобретения.
Как показано на примерах, в соответствии с аспектом настоящего изобретения предложен способ кодирования видеоданных, содержащих один или более исходных видов, причем каждый исходный вид содержит текстурную карту и карту глубины, при этом способ включает:
прием видеоданных;
обработку карты глубины по меньшей мере одного исходного вида для формирования обработанной карты глубины, включающую:
нелинейную фильтрацию и
понижающую дискретизацию; и
кодирование обработанной карты глубины и текстурной карты по меньшей мере одного исходного вида для формирования двоичного видеопотока.
Предпочтительно по меньшей мере часть нелинейной фильтрации выполняют перед понижающей дискретизацией.
Авторы изобретения обнаружили, что нелинейная фильтрация карты глубины перед понижающей дискретизацией может помочь исключить, уменьшить или смягчить ошибки, вносимые понижающей дискретизацией. В частности, нелинейная фильтрация может помочь предотвратить частичное или полное исчезание с карты глубины мелких или тонких объектов переднего плана из-за понижающей дискретизации. Было обнаружено, что в этом отношении нелинейная фильтрация может быть предпочтительнее линейной фильтрации, поскольку линейная фильтрация может вводить промежуточные значения глубины на границах между объектами переднего плана и задним планом. Это затрудняет декодеру различение границ объекта и больших градиентов глубины.
Видеоданные могут содержать иммерсивное 6DoF-видео.
Нелинейная фильтрация может включать увеличение области по меньшей мере одного объекта переднего плана на карте глубины.
Увеличение объекта переднего плана перед повышающей дискретизацией может помочь обеспечить, чтобы объект переднего плана лучше выдерживал процесс понижающей дискретизации, другими словами, чтобы он лучше сохранялся на обработанной карте глубины.
Объект переднего плана может быть идентифицирован как локальная группа пикселей на относительной небольшой глубине. Задний план может быть идентифицирован как пиксели на относительно большой глубине. Периферийные пиксели объектов переднего плана можно локально отличить от заднего плана, например, применив пороговое значение к значениям глубины на карте глубины.
Нелинейная фильтрация может включать морфологическую фильтрацию, в частности, полутоновую морфологическую фильтрацию, например, фильтр «максимум», фильтр «минимум» или другой фильтр, основанный на порядковых статистиках. Когда карта глубины содержит уровни глубины с особым смыслом, например, нулевой уровень глубины указывает на недопустимую глубину, такие уровни глубины предпочтительно считать передним планом, несмотря на их фактическое значение. Соответственно, эти уровни предпочтительно сохраняются после субдискретизации. Следовательно, их область также может быть увеличена.
Нелинейная фильтрация может включать применение фильтра, разработанного с использованием алгоритма машинного обучения.
Алгоритм машинного обучения может быть натренирован на уменьшение или минимизацию ошибки реконструкции реконструированной карты глубины после того, как обработанная карта глубины была кодирована и декодирована.
Натренированный фильтр может точно также способствовать сохранению объектов переднего плана на обработанной (повергнутой понижающей дискретизации) карте глубины.
Способ может также включать разработку фильтра с использованием алгоритма машинного обучения, причем фильтр разрабатывают для уменьшения ошибки реконструкции реконструированной карты глубины после того, как обработанная карта была кодирована и декодирована, и при этом нелинейная фильтрация включает применение разработанного фильтра.
Нелинейная фильтрация может включать обработку нейронной сетью, а разработка фильтра может включать тренировку нейронной сети.
Нелинейная фильтрация может быть выполнена нейронной сетью, содержащей множество слоев, а понижающая дискретизация может быть выполнена между двумя из указанных слоев.
Понижающая дискретизация может быть выполнена слоем подвыборки по максимальному значению (или подвыборки по минимальному значению) нейронной сети.
Способ может включать обработку карты глубины в соответствии с множеством наборов параметров обработки для формирования соответствующего множества обработанных карт глубины, при этом способ включает: выбор набора параметров обработки, который уменьшает ошибку реконструкции реконструированной карты глубины после того, как соответствующая обработанная карта глубины была кодирована и декодирована; и формирование двоичного потока метаданных, идентифицирующего выбранный набор параметров.
Это может позволить оптимизировать параметры для данного применения или данной видеопоследовательности.
В число параметров обработки могут входить определение нелинейной фильтрации и/или определение выполненной понижающей дискретизации. В качестве альтернативы или дополнительно параметры обработки могут включать определение операций обработки, которые должны быть выполнены в декодере при реконструкции карты глубины.
Для каждого набора параметров обработки способ может включать: формирование соответствующей обработанной карты глубины в соответствии с набором параметров обработки; кодирование обработанной карты глубины для формирования кодированной карты глубины; декодирование кодированной карты глубины; реконструкцию карты глубины из декодированной карты глубины и сравнение реконструированной карты глубины с картой глубины по меньшей мере одного исходного вида для определения ошибки реконструкции.
В соответствии еще с одним аспектом предложен способ декодирования видеоданных, содержащих один или более исходных видов, включающий:
прием двоичного видеопотока, содержащего кодированную карту глубины и кодированную текстурную карту по меньшей мере для одного исходного вида;
декодирование кодированной карты глубины для получения декодированной карты глубины;
декодирование кодированной текстурной карты для получения декодированной текстурной карты и
обработку декодированной карты глубины для формирования реконструированной карты глубины, при этом обработка включает:
повышающую дискретизацию и
нелинейную фильтрацию.
Способ может также включать: перед этапом обработки декодированной карты глубины для формирования реконструированной карты глубины обнаружение того, что декодированная карта имеет меньшее разрешение, чем декодированная текстурная карта.
В некоторых схемах кодирования карта глубины может быть подвергнута понижающей дискретизации только в определенных случаях или только для определенных видов. Благодаря сравнению разрешения декодированной карты глубины с разрешением декодированной текстурной карты способ декодирования позволяет определять, применялась ли понижающая дискретизация в кодере. Это может позволить избежать необходимости использования метаданных в двоичном потоке метаданных для сигнализации о том, какие карты глубины были подвергнуты понижающей дискретизации, и в какой степени они были повергнуты понижающей дискретизации (в этом примере предполагается, что текстурная карта кодирована при полном разрешении).
Для формирования реконструированной карты глубины декодированная карта глубины может быть повергнута повышающей дискретизации до того же самого разрешения, что и у декодированной текстурной карты.
Предпочтительно нелинейная фильтрация в способе декодирования выполнена с возможностью компенсации эффекта нелинейной фильтрации, которую применяли в способе кодирования.
Нелинейная фильтрация может включать уменьшение области по меньшей мере одного объекта переднего плана на карте глубины. Это может быть уместно, когда нелинейная фильтрация во время кодирования включала увеличение области по меньшей мере одного объекта переднего плана.
Нелинейная фильтрация может включать морфологическую фильтрацию, в частности, полутоновую морфологическую фильтрацию, например, фильтр «максимум», фильтр «минимум» или другой фильтр, основанный на порядковых статистиках.
Нелинейная фильтрация во время декодирования предпочтительно компенсирует или обращает эффект нелинейной фильтрации во время кодирования. Например, если нелинейная фильтрация во время кодирования включает фильтр «максимум» (полутоновую дилатацию), то нелинейная фильтрация во время декодирования может включать фильтр «минимум» (полутоновую эрозию), и наоборот. Когда карта глубины содержит уровни глубины с особым смыслом, например, нулевой уровень глубины указывает на недопустимую глубину, такие уровни глубины предпочтительно считать передним планом, несмотря на их фактическое значение.
Предпочтительно по меньшей мере часть нелинейной фильтрации выполняют после повышающей дискретизации. Необязательно всю нелинейную фильтрацию выполняют после повышающей дискретизации.
Обработка декодированной карты глубины может быть основана по меньшей мере частично на декодированной текстурной карте. Авторы изобретения поняли, что текстурная карта содержит полезную информацию, помогающую реконструировать карту глубины. В частности, когда границы объектов переднего плана были изменены нелинейной фильтрацией во время кодирования, анализ текстурной карты может помочь компенсировать или обратить изменения.
Способ может включать: повышающую дискретизацию декодированной карты глубины; идентификацию периферийных пикселей по меньшей мере одного объекта переднего плана на подвергнутой повышающей дискретизации карте глубины; определение на основе декодированной текстурной карты, похожи ли периферийные пиксели больше на объект переднего плана или на задний план; и применение нелинейной фильтрации только к периферийным пикселям, которые определены как более похожие на задний план.
Таким образом, текстурную карту используют для помощи в идентификации пикселей, которые были преобразованы из заднего плана в передний план в результате нелинейной фильтрации во время кодирования. Нелинейная фильтрация во время декодирования может помочь вернуть эти идентифицированные пиксели в состав заднего плана.
Нелинейная фильтрация может включать сглаживание краев по меньшей мере одного объекта переднего плана.
Сглаживание может включать: идентификацию периферийных пикселей по меньшей мере одного объекта переднего плана на подвергнутой повышающей дискретизации карте глубины; для каждого периферийного пикселя анализ количества и/или расположения пикселей переднего плана и заднего плана в окрестности этого периферийного пикселя; на основе результата анализа идентификацию выпадающих периферийных пикселей, которые выступают из объекта в задний план; и применение нелинейной фильтрации только к идентифицированным периферийным пикселям.
Анализ может включать подсчет количества пикселей заднего плана в окрестности, причем периферийный пиксель идентифицируют как выпадающий из объекта, если количество пикселей заднего плана в окрестности выше заданного порогового значения.
В качестве альтернативы или дополнительно анализ может включать идентификацию пространственной структуры пикселей переднего плана и заднего плана в окрестности, причем периферийный пиксель идентифицируют как выброс, если пространственная структура в его окрестности соответствует одной или более заданным пространственным структурам.
Способ может также включать прием двоичного потока метаданных, связанного с двоичным видеопотоком, причем двоичный поток метаданных идентифицирует набор параметров, а способ необязательно также включает обработку декодированной карты глубины в соответствии с идентифицированным набором параметров.
Параметры обработки могут включать определение нелинейной фильтрации и/или определение повышающей дискретизации, которую нужно выполнить.
Нелинейная фильтрация может включать применение фильтра, разработанного с использованием алгоритма машинного обучения.
Алгоритм машинного обучения может быть натренирован на уменьшение или минимизацию ошибки реконструкции реконструированной карты глубины после того, как обработанная карта глубины была кодирована и декодирована.
Фильтр может быть определен в двоичном потоке метаданных, связанном с двоичным видеопотоком.
Предложена также компьютерная программа, содержащая компьютерный код для вызова осуществления системой обработки способа, описанного выше, при запуске указанной программы в системе обработки.
Компьютерная программа может храниться на компьютерочитаемом носителе данных. Это может быть некратковременный носитель данных.
В соответствии еще с одним аспектом предложен видеокодер, выполненный с возможностью кодирования видеоданных, содержащих один или более исходных видов, причем каждый исходный вид содержит текстурную карту и карту глубины, при этом видеокодер содержит:
вход, выполненный с возможностью приема видеоданных;
видеопроцессор, выполненный с возможностью обработки карты глубины по меньшей мере одного исходного вида для формирования обработанной карты глубины, включающей:
нелинейную фильтрацию и
понижающую дискретизацию;
кодер, выполненный с возможностью кодирования текстурной карты по меньшей мере одного исходного вида и обработанной карты глубины для формирования двоичного видеопотока; и
выход, выполненный с возможностью вывода двоичного видеопотока.
В соответствии еще с одним аспектом предложен видеодекодер, выполненный с возможностью декодирования видеоданных, содержащих один или более исходных видов, при этом видеодекодер содержит:
вход двоичного потока, выполненный с возможностью приема двоичного видеопотока, причем двоичный видеопоток содержит кодированную карту глубины и кодированную текстурную карту по меньшей мере для одного исходного вида;
первый декодер, выполненный с возможностью декодирования из двоичного видеопотока кодированной карты глубины для получения декодированной карты глубины;
второй декодер, выполненный с возможностью декодирования из двоичного видеопотока кодированной текстурной карты для получения декодированной текстурной карты;
процессор реконструкции, выполненный с возможностью обработки декодированной карты глубины для формирования реконструированной карты глубины, при этом обработка включает:
повышающую дискретизацию и
нелинейную фильтрацию,
и выход, выполненный с возможностью вывода реконструированной карты глубины.
Эти и другие аспекты изобретения будут очевидны и разъяснены со ссылкой на вариант (варианты) осуществления, описанный(-ые) ниже.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Для лучшего понимания изобретения и более ясной демонстрации способа его осуществления на практике далее только в качестве примера сделаны ссылки на сопроводительные чертежи, на которых:
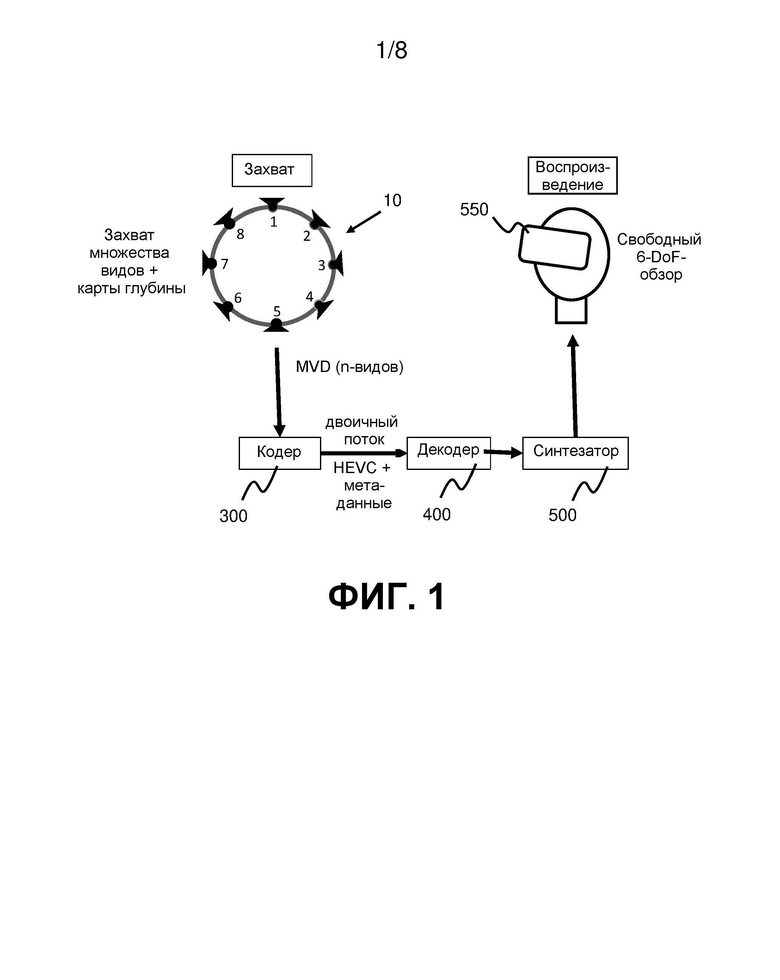
на фиг. 1 показан пример кодирования и декодирования иммерсивного видео с использованием существующих видеокодеков;
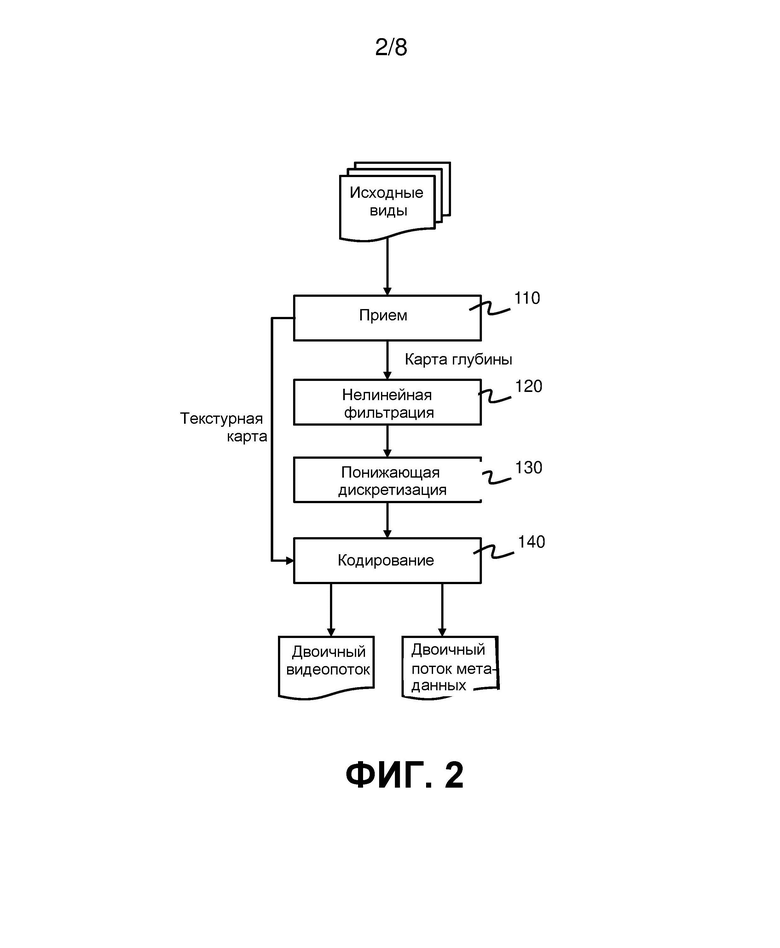
на фиг. 2 приведена блок-схема, показывающая способ кодирования видеоданных в соответствии с вариантом реализации;
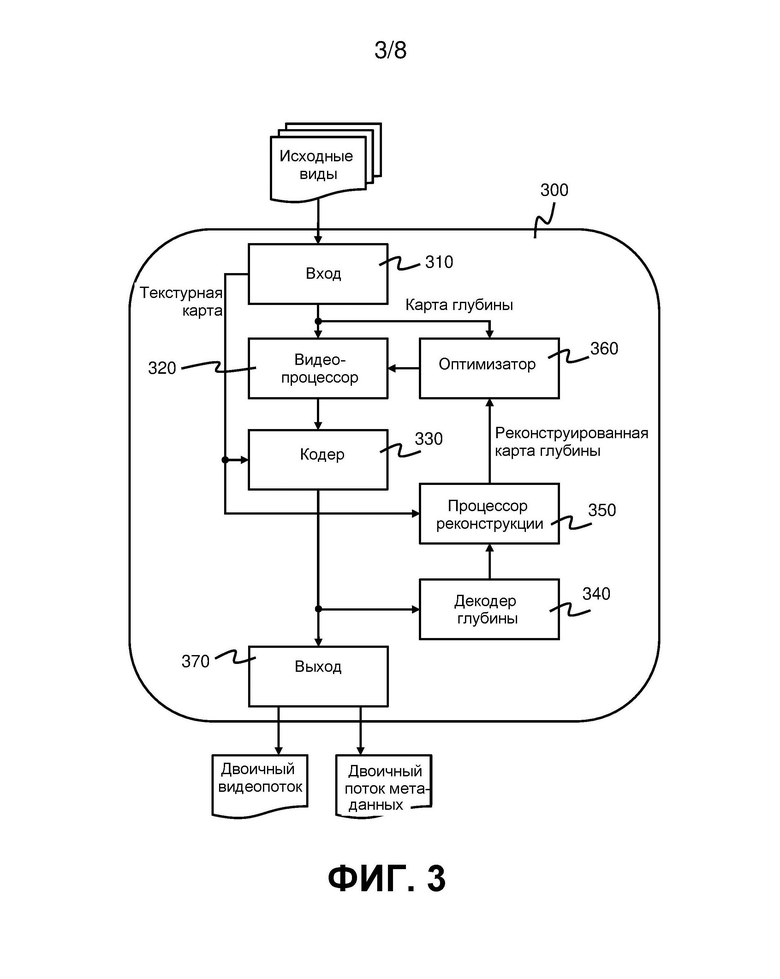
на фиг. 3 приведена блок-схема видеокодера в соответствии с вариантом реализации;
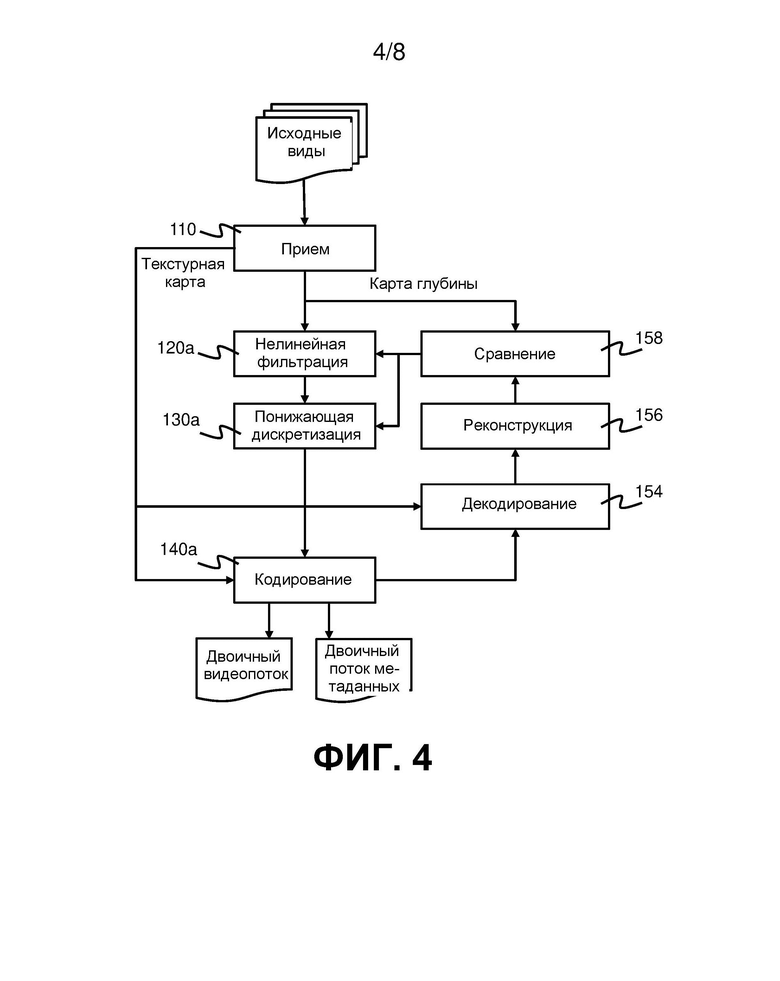
на фиг. 4 приведена блок-схема, иллюстрирующая способ кодирования видеоданных в соответствии еще с одним вариантом реализации;
на фиг. 5 приведена блок-схема, показывающая способ декодирования видеоданных в соответствии с вариантом реализации;
на фиг. 6 приведена блок-схема видеодекодера в соответствии с вариантом реализации;
на фиг. 7 показан способ выборочного применения нелинейной фильтрации к конкретным пикселям в способе декодирования в соответствии с вариантом реализации;
на фиг. 8 приведена блок-схема, иллюстрирующая способ декодирования видеоданных в соответствии еще с одним вариантом реализации; и
на фиг. 9 показано использование обработки нейронной сетью для кодирования и декодирования видеоданных в соответствии с вариантом реализации.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Далее описано изобретение со ссылками на фигуры чертежей.
Следует понимать, что подробное описание и конкретные примеры, показывая отдельные варианты реализации устройства, систем и способов, служат только в качестве иллюстрации и не предусматривают ограничения объема изобретения. Эти и другие признаки, аспекты и преимущества устройства, систем и способов настоящего изобретения станут более понятными из нижеследующего описания, прилагаемой формулы изобретения и сопроводительных чертежей. Следует понимать, что фигуры являются лишь схематическими и изображены не в масштабе. Кроме того, следует понимать, что одинаковые ссылочные позиции использованы на всех фигурах для обозначения одинаковых или аналогичных деталей.
Раскрыты способы кодирования и декодирования иммерсивного видео. В способе кодирования исходные видеоданные, содержащие один или более исходных видов, кодируют в двоичный видеопоток. Перед кодированием к данным о глубине по меньшей мере одного из исходных видов применяют нелинейную фильтрацию и понижающую дискретизацию. Понижающая дискретизация карты глубины помогает уменьшить объем данных, подлежащих передаче, и, следовательно, помогает уменьшить скорость передачи в битах. Однако авторы изобретения обнаружили, что просто понижающая дискретизация может привести к исчезанию тонких или небольших объектов переднего плана, таких как провода, с карты глубины, повергнутой понижающей дискретизации. Варианты реализации настоящего изобретения направлены на смягчение этого эффекта и сохранения небольших и тонких объектов на карте глубины.
Варианты реализации настоящего изобретения могут быть пригодны для реализации части технического стандарта, такого как ISO/IEC 23090-12 MPEG-I, часть 12, Иммерсивное видео. Там, где это возможно, терминология, используемая в настоящем документе, выбрана в соответствии с терминами, используемыми в MPEG-I, часть 12. Тем не менее, следует понимать, что объем настоящего изобретения не ограничен ни MPEG-I Part 12, ни каким-либо другим техническим стандартом.
Возможно, будет полезно изложить следующие определения/пояснения:
«3D-сцена» относится к визуальному контенту в глобальной эталонной системе координат.
«Атлас» представляет собой совокупность накладок из одного или более представлений вида после процесса упаковки в пару картинок, которая содержит картинку компонента текстуры и соответствующую картинку компонента глубины.
«Атласный компонент» представляет собой текстурный или глубинный компонент атласа.
«Параметры камеры» определяют проекцию, используемую для формирования представления вида из трехмерной сцены.
«Обрезка» представляет собой процесс идентификации и извлечения перекрытых областей в разных видах, что приводит к появлению накладок.
«Рендерер» представляет собой вариант осуществления процесса создания окна просмотра или всенаправленного вида из трехмерного вида сцены, соответствующего положению и ориентации просмотра.
«Исходный вид» представляет собой исходный видеоматериал перед кодированием, который соответствует формату представления вида, который может быть получен путем захвата трехмерной сцены реальной камерой или путем проецирования виртуальной камерой на поверхность с использованием параметров исходной камеры.
«Целевой вид» определяется либо как пространственное окно просмотра, либо как всенаправленный вид в требуемом положении и ориентации просмотра.
«Представление вида» содержит массивы двумерных образцов компонента текстуры и соответствующего компонента глубины, представляющие собой проекцию трехмерной сцены на поверхность с использованием параметров камеры.
Алгоритм машинного обучения представляет собой любой алгоритм самообучения, который обрабатывает входные данные с целью получения или прогнозирования выходных данных. В некоторых вариантах осуществления настоящего изобретения входные данные содержат один или более видов, декодированных из битового потока, а выходные данные содержат прогнозирование/реконструкцию целевого вида.
Специалисту в данной области очевидны подходящие алгоритмы машинного обучения для использования в настоящем изобретении. Примеры подходящих алгоритмов машинного обучения включают алгоритмы на основе дерева принятия решений и искусственных нейронных сетей. Другие алгоритмы машинного обучения, такие как логистическая регрессия, машины опорных векторов или наивная байесовская модель, являются подходящими альтернативами.
Структура искусственной нейронной сети (или просто нейронной сети) вдохновлена головным мозгом человека. Нейронные сети состоят из слоев, причем каждый слой содержит множество нейронов. Каждый нейрон содержит математическую операцию. В частности, каждый нейрон может содержать отличную от других взвешенную комбинацию преобразований одного типа (например, преобразований одного и того же типа, сигмоидального и т.д., но с разными весами). В ходе обработки входных данных математическую операцию каждого нейрона выполняют на входных данных для создания числовых выходных данных, и выходные данные каждого слоя в нейронной сети подают на один или более других слоев (например, последовательно). Конечный слой предоставляет выходные данные.
Способы обучения алгоритма машинного обучения хорошо известны. Как правило, такие способы включают получение обучающего набора данных, содержащего элементы обучающих входных данных и соответствующие элементы обучающих выходных данных. Инициализированный алгоритм машинного обучения применяют к каждому элементу входных данных для формирования элементов спрогнозированных выходных данных. Ошибку между элементами спрогнозированных выходных данных и соответствующими элементами обучающих выходных данных используют для изменения алгоритма машинного обучения. Этот процесс может повторяться до тех пор, пока ошибка не сойдется, и прогнозируемые элементы выходных данных будут достаточно похожи (например, ±1%) на элементы обучающих выходных данных. Это широко известно как метод обучения с учителем.
Например, когда последовательность операций для машинного обучения формируют из нейронной сети, математическую операцию (ее вес) могут изменять для каждого нейрона до тех пор, пока ошибка не сойдется. Известные способы модификации нейронной сети включают градиентный спуск, алгоритмы обратного распространения и т.д.
Сверточная нейронная сеть (convolutional neural network, CNN или ConvNet) представляет собой класс глубоких нейронных сетей, наиболее часто применяемых для анализа визуальных изображений. CNN являются регуляризованными вариантами многослойных перцептронов.
На фиг. 1 показана в упрощенном виде система для кодирования и декодирования иммерсивного видео. Для захвата множества видов сцены используют массив камер 10. Каждая камера захватывает обычные изображения (называемые в настоящем документе «текстурными картами») и карту глубины вида перед ней. Набор видов, содержащий данные о текстуре и глубине, подают в кодер 300. Кодер кодирует, как данные о текстуре, так и данные о глубине, в обычный двоичных видеопоток - в данном случае двоичный поток с высокоэффективным кодированием видео (high efficiency video coding, HEVC). Он сопровождается двоичным потоком метаданных для информирования декодера 400 о том, что означают различные части двоичного видеопотока. Например, метаданные указывают декодеру, какие части двоичного видеопотока соответствуют текстурным картам, а какие соответствуют картам глубины. В зависимости от сложности и гибкости схемы кодирования может потребоваться больше или меньше метаданных. Например, очень простая схема может весьма жестко определять структуру двоичного потока, так что для его распаковки на стороне декодера требуется мало метаданных или вообще не требуется метаданных. Чем больше количество дополнительных возможностей для двоичного потока, тем большее количество метаданных потребуется.
Декодер 400 декодирует кодированные виды (текстуру и глубину). Он передает декодированные виды синтезатору 500. Синтезатор 500 соединен с устройством отображения, таким как гарнитура 550 виртуальной реальности. Гарнитура 550 подает синтезатору 500 запрос на синтез и рендеринг конкретного вида 3D-сцены с использованием декодированных видов в соответствии с текущим положением и ориентацией гарнитуры 550.
Преимущество системы, показанной на фиг. 1, заключается в том, что она выполнена с возможностью использования обычных 2D-видеокодеков для кодирования и декодирования данных о текстуре и глубине. Однако недостатком является необходимость кодирования, передачи и декодирования большого количества данных. Поэтому было бы желательно уменьшить скорость передачи данных как можно с меньшим ущербом для качества реконструированных видов.
На фиг. 2 показан способ кодирования в соответствии с первым вариантом реализации. На фиг. 3 показан видеокодер, который может быть выполнен с возможностью осуществления способа, приведенного на фиг. 2. Видеокодер содержит вход 310, выполненный с возможностью приема видеоданных. С входом соединен видеопроцессор 320, который выполнен с возможностью приема карт глубины, принятых входом. Кодер 330 выполнен с возможностью приема обработанных карт глубины от видеопроцессора 320. Выход 370 выполнен с возможностью вывода двоичного видеопотока, сформированного кодером 330. Видеокодер 300 также содержит декодер 340 глубины, процессор 350 реконструкции и оптимизатор 360. Эти компоненты будут описаны подробнее в связи со вторым вариантом реализации способа кодирования, который описан ниже со ссылкой на фиг. 4.
Со ссылкой на фиг. 2 и 3, способ согласно первому варианту реализации начинается на этапе 110 с приема входом 310 видеоданных, содержащих текстурную карту и карту глубины. На этапах 120 и 130 видеопроцессор 320 обрабатывает карту глубины для формирования обработанной карты глубины. Обработка включает нелинейную фильтрацию карты глубины на этапе 120 и понижающую дискретизацию отфильтрованной карты глубины на этапе 130. На этапе 140 кодер 330 кодирует обработанную карту глубины и текстурную карту для формирования двоичного видеопотока. Затем сформированный двоичный видеопоток выводят через выход 370.
Исходные виды, принятые на входе 310, могут представлять собой виды, захваченные массивом камер 10. Однако это не существенно, и исходные виды необязательно должны быть идентичны видам, захваченным камерой. Некоторые из исходных видов, принимаемых на входе 310, могут быть синтезированными или иным образом обработанными исходными видами. Количество исходных видов, принимаемых на входе 310, может быть больше или меньше, чем количество видов, захваченных массивом камер 10.
В варианте реализации на фиг. 2 нелинейная фильтрация 120 и понижающая дискретизация 130 объединены в один этап. Используют уменьшающий размер фильтра «подвыборка по максимальному значению 2×2». Это означает, что каждый пиксель в обработанной карте глубины принимает максимальное значение пикселя в окрестности 2×2 из четырех пикселей на первоначальной входной карте глубины. Этот выбор нелинейной фильтрации и понижающей дискретизации вытекает из двух соображений:
1. Результат понижающей дискретизации не должен включать промежуточные, т.е. «переходные», уровни глубины. Такие промежуточные уровни глубины получались бы, например, при использовании линейного фильтра. Авторы изобретения поняли, что промежуточные уровни глубины часто дают неверные результаты после синтеза вида на стороне декодера.
2. Тонкие объекты переднего плана, представленные на картах глубины, должны быть сохранены. В противном случае, например, относительно тонкий объект исчезнет на заднем плане. Следует отметить, что при этом предполагается, что передний план, т.е. близкие объекты, кодируют как высокие (яркие) уровни, а задний план, т.е. далекие объекты, кодируют как низкие (темные) уровни (соглашение о диспаратности). В альтернативном варианте реализации понижающий дискретизатор «подвыборка по минимальному значению 2×2» будет иметь тот же эффект при условии использования соглашения о кодировании координаты z (координата z увеличивается с увеличением расстояния от объектива).
Эта операция обработки по сути увеличивает размер всех локальных объектов переднего плана и, следовательно, сохраняет небольшие и тонкие объекты. Однако декодер предпочтительно должен знать, какую операцию применяли, так как он предпочтительно должен отменить введенное смещение и сжать все объекты, чтобы снова выровнять карту глубины с текстурой.
В соответствии с настоящим вариантом реализации снижаются требования к памяти для видеодекодера. Первоначальная скорость передачи пикселей была следующей: 1Y + 0,5CrCb + 1D, где Y - канал яркости, CrCb - каналы цветности, D - канал глубины. Согласно настоящему примеру, в котором используют понижающую дискретизацию с коэффициентом четыре (2×2), скорость передачи пикселей принимает следующий вид: 1Y + 0,5CrCb + 0,25D. Следовательно, можно достичь уменьшения скорости передачи пикселей на 30%. Наиболее практичные видеодекодеры имеют соотношение 4:2:0 и не включают монохромные режимы. В этом случае достигается уменьшение пикселей на 37,5%.
На фиг. 4 приведена блок-схема, иллюстрирующая способ кодирования в соответствии со вторым вариантом реализации. Этот способ начинается аналогично способу, приведенному на фиг. 2, с приема входом 310 видеокодера исходных изображений на этапе 110. На этапах 120a и 130a видеопроцессор 320 обрабатывает карту глубины в соответствии с множеством наборов параметров обработки для формирования соответствующего множества обработанных карт глубины (каждая карта глубины соответствует набору параметров обработки). В этом варианте реализации система предназначена для опробования каждой из этих карт глубины, чтобы определить, какая из них даст наилучшее качество на стороне декодера. На этапе 140a каждая из обработанных карт глубины кодируется кодером 330. На этапе 154 декодер 340 глубины декодирует каждую кодированную карту глубины. Декодированные карты глубины передают процессору 350 реконструкции. На этапе 156 процессор 350 реконструкции реконструирует карты глубины из декодированных карт глубины. Затем на этапе 158 оптимизатор 360 сравнивает каждую реконструированную карту глубины с первоначальной картой глубины исходного вида, чтобы определить ошибку реконструкции. Ошибка реконструкции количественно определяет разницу между первоначальной картой глубины и реконструированной картой глубины. На основе результата сравнения оптимизатор 360 выбирает набор параметров, которые привели к реконструированной карте глубины, имеющий наименьшую ошибку реконструкции. Этот набор параметров выбирают для использования при формировании двоичного видеопотока. Выход 370 выводит двоичный видеопоток, соответствующий выбранному набору параметров.
Следует отметить, что работа декодера 340 глубины и процессора 350 реконструкции будет описана подробнее ниже со ссылкой на способ декодирования (см. фиг. 5-8).
По существу видеокодер 300 реализует декодер в цикле, чтобы он мог прогнозировать, как двоичный поток будет декодирован в декодере на дальнем конце. Видеокодер 300 выбирает набор параметров, который даст наилучшие рабочие характеристики в декодере на дальнем конце (с точки зрения минимизации ошибки реконструкции для данной целевой скорости передачи битов или скорости передачи пикселей). Оптимизация может быть выполнена итеративно, как предполагается блок-схемой на фиг. 4, причем параметры нелинейной фильтрации 120 и/или понижающей дискретизации 130 обновляются в каждой итерации после сравнения 158 оптимизатором 360. В альтернативном варианте реализации видеодекодер может опробовать фиксированное множество наборов параметров, причем это может быть сделано последовательно или параллельно. Например, в реализации с высокой степенью параллелизма в видеокодере 300 может быть N кодеров (и декодеров), каждый из которых выполнен с возможностью опробования набора параметров для кодирования карты глубины. Это может увеличить количество наборов параметров, которые могут быть опробованы в отведенное время, за счет увеличения сложности и/или размера кодера 300.
В число опробываемых параметров могут входить параметры нелинейной фильтрации 120a, параметры понижающей дискретизации 130a либо и те и другие. Например, система может экспериментировать с понижающей дискретизацией на различные коэффициенты в одном или обоих измерениях. Аналогичным образом система может экспериментировать с различными нелинейными фильтрами. Например, вместо фильтра «максимум» (который назначает каждому пикселю максимальное значение в локальной окрестности) может быть использован основанный на порядковых статистиках фильтр другого типа. Например, нелинейный фильтр может анализировать локальную окрестность вокруг данного пикселя и может назначать пикселю второе наивысшее значение в окрестности. Это может обеспечить эффект, подобный фильтру «максимум», в то же время помогая избежать чувствительности к отдельным выпадающим значениям. Размер ядра нелинейного фильтра является еще одним параметром, который может изменяться.
Следует отметить, что параметры обработки в видеодекодере также могут быть включены в набор параметров (как будет описано подробнее ниже). Таким образом, видеокодер может выбирать набор, параметров как для кодирования, так и для декодирования, который помогает оптимизировать качество в зависимости от скорости передачи битов/скорости передачи пикселей. Оптимизация может быть выполнена для данной сцены или для данной видеопоследовательности либо, в более общем случае, на тренировочном наборе различных сцен и видеопоследовательностей. Таким образом, лучший набор параметров может меняться для каждой последовательности, для каждой скорости передачи битов и/или для каждой допустимой скорости передачи пикселей.
Параметры, которые полезны или необходимы для правильного декодирования двоичного видеопотока видеодекодером, могут быт встроены в двоичных поток метаданных, связанный с двоичным видеопотоком. Двоичный поток метаданных может быть передан/транспортирован в видеодекодер вместе с двоичным видеопотоком или отдельно от него.
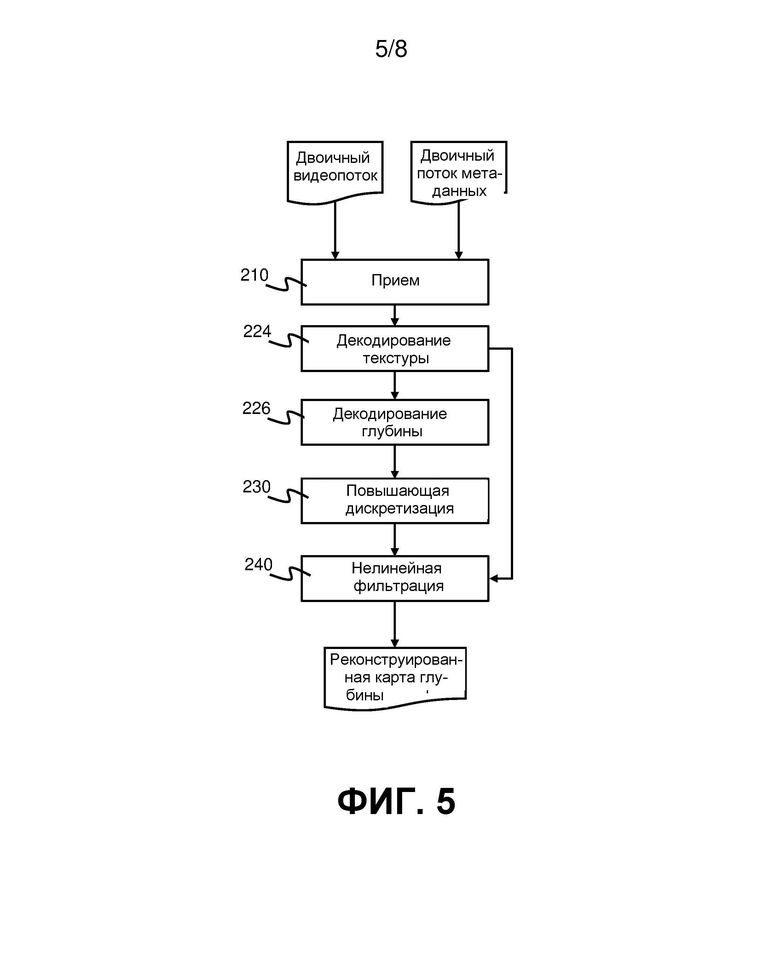
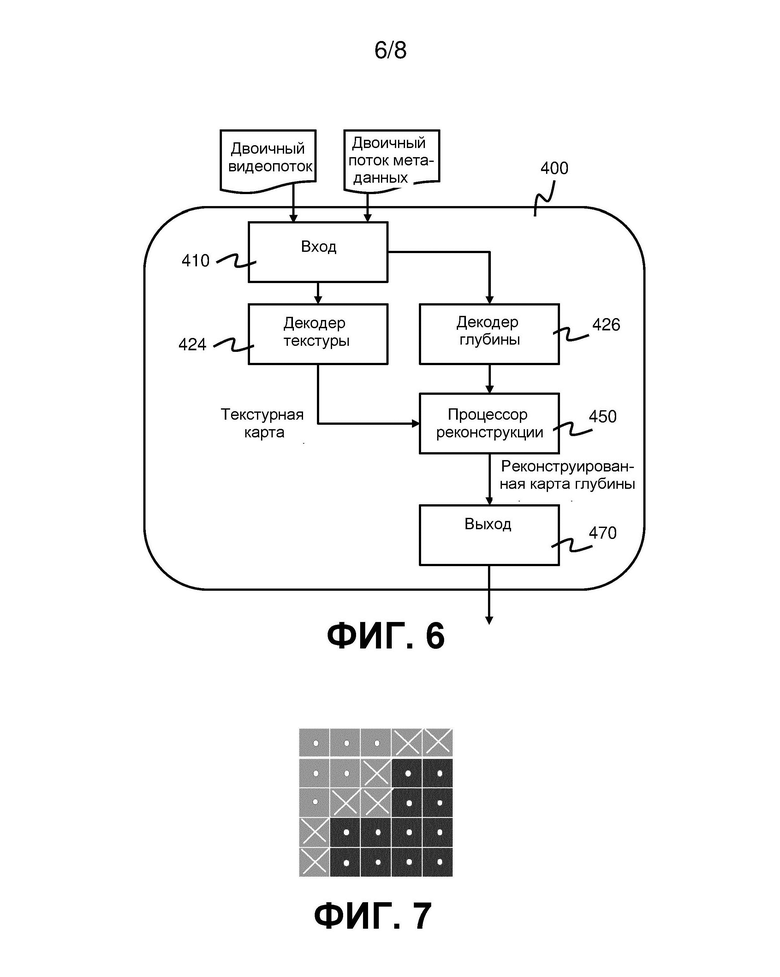
На фиг. 5 приведена блок-схема, показывающая способ декодирования видеоданных в соответствии с вариантом реализации. На Фиг. 6 приведена блок-схема соответствующего видеодекодера 400. Видеодекодер 400 содержит вход 410, декодер 424 текстуры, декодер 426 глубины, процессор 450 реконструкции и выход 470. Вход 410 соединен с декодером 424 текстуры и декодером 426 глубины. Процессор 450 реконструкции выполнен с возможностью приема декодированных текстурных карт от декодера 424 текстуры и приема декодированных карт глубины от декодера 426 глубины. Процессор 450 реконструкции выполнен с возможностью подачи реконструированных карт глубины на выход 470.
Способ на фиг. 5 начинается на этапе 210 с приема входом 410 двоичного видеопотока и необязательно двоичного потока метаданных. На этапе 224 декодер 424 текстуры декодирует текстурную карту из двоичного видеопотока. На этапе 226 декодер 426 глубины декодирует карту глубины из двоичного видеопотока. На этапах 230 и 240 видеопроцессор 450 обрабатывает декодированную карту глубины для формирования реконструированной карты глубины. Эта обработка включает повышающую дискретизацию 230 и нелинейную фильтрацию 240. Обработка, в частности, нелинейная фильтрация 240, может также зависеть от содержимого декодированной текстурной карты, как будет описано подробнее ниже.
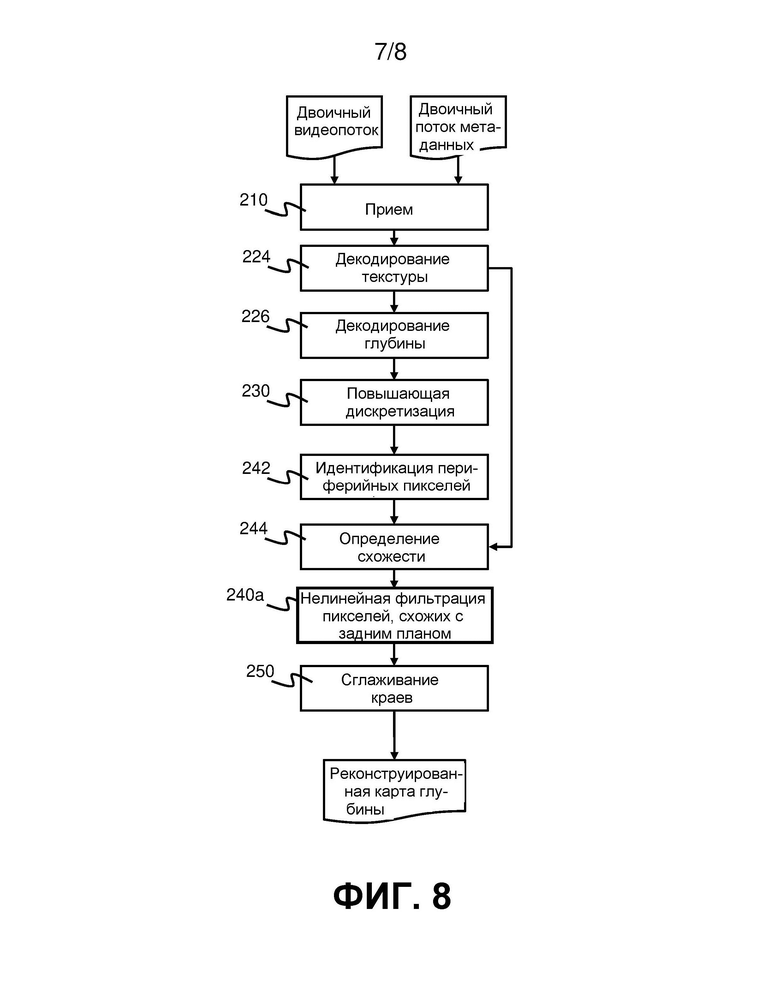
Далее со ссылкой на фиг. 8 будет более подробно описан один пример способа, приведенного на фиг. 5. В этом варианте реализации повышающая дискретизация 230 включает повышающую дискретизацию ближайшей окрестности, при которой каждому пикселю в блоке пикселей 2×2 на карте, подвергнутой повышающей дискретизации, назначают значение одного из пикселей с декодированной карты глубины. Этот повышающий дискретизатор «ближайшая окрестность 2×2» масштабирует карту глубины до ее первоначального размера. Подобно операции подвыборки по максимальному значению в кодере эта процедура в декодере исключает создание промежуточных уровней глубины. Характеристики подвергнутой повышающей дискретизации карты глубины по сравнению с первоначальной картой глубины в кодере могут быть спрогнозированы заранее: уменьшающий масштаб фильтр «подвыборка по максимальному значению» имеет тенденцию к увеличению области объектов переднего плана. Поэтому некоторые пиксели глубины на подвергнутой повышающей дискретизации карте глубины являются пикселями переднего плана, которые вместо этого должны быть задним планом; однако обычно нет пикселей глубины заднего плана, которые вместо этого должны быть передним планом. Другими словами, после повышающей дискретизации объекты иногда слишком большие, но, как правило, не слишком маленькие.
В настоящем изобретении, чтобы отменить смещение (объектов переднего плана, которые увеличились в размере), нелинейная фильтрация 240 подвергнутых повышающей дискретизации карт глубины включает цветовой адаптивный условный фильтр «эрозия» (этапы 242, 244 и 240a на фиг. 8). Относящаяся к эрозии часть (оператор минимума) обеспечивает уменьшение размера объекта, в то время как цветовая адаптация обеспечивает правильное пространственное положение края глубины, т.е., переходы на полномасштабной текстурной карте указывают, где должны быть края. Из-за нелинейности, с которой работает фильтр «эрозия» (т.е. пиксели либо эродированные, либо нет), получающиеся в результате края объекта могут быть зашумленными. Соседние с краем пиксели могут при минимально различающемся вводе давать разные результаты классификации «эрозия или не эрозия». Такой шум отрицательно влияет на гладкость края объекта. Авторы изобретения поняли, что такая гладкость является важным требованием для получения результатов синтеза вида с достаточным качеством восприятия. Поэтому нелинейная фильтрация 240 также включает фильтр гладкости контура (этап 250) для сглаживания краев на карте глубины.
Далее будет более подробно описана нелинейная фильтрация 240 в соответствии с настоящим вариантом реализации. На фиг. 7 показана небольшая увеличенная область подвергнутой повышающей дискретизации карты глубины, представляющая ядро фильтра перед линейной фильтрацией 240. Серые квадратики указывают пиксели переднего плана; черные квадратики указывают пиксели заднего плана. Периферийные пиксели объекта переднего плана помечены знаком X. Это пиксели, которые могут представлять расширенную/увеличенную область объекта переднего плана, вызванную нелинейной фильтрацией в кодере. Другими словами, существует неопределенность в отношении того, являются ли периферийные пиксели X в действительности пикселями переднего плана или заднего плана.
Этапы, предпринимаемые для выполнения адаптивной эрозии, следующие:
1. Поиск локальных краев переднего плана, т.е. периферийных пикселей объектов переднего плана (помеченных знаком X на фиг. 7). Это может быть сделано путем применения локального порогового значения, чтобы отличать пиксели переднего плана от пикселей заднего плана. Затем периферийные пиксели идентифицируют как те пиксели переднего плана, которые смежны с пикселями заднего плана (в данном примере в смысле 4-связности). Это делают с помощью процессора 450 реконструкции на этапе 242. Карта глубины может, для эффективности, содержать упакованные области из множества видов камеры. Края на границах таких областей игнорируют, поскольку они не указывают края объектов.
2. Для идентифицированных краевых пикселей (например, центральный пиксель в ядре 5×5 на фиг. 7) определение среднего цвета текстуры переднего плана и заднего плана в ядре 5×5. Это делают на основе только «доверенных» пикселей (помеченных точкой •), другими словами, из вычисления средней текстуры переднего плана и заднего плана исключают неопределенные краевые пиксели X. Исключают также пиксели из возможно соседних областей-накладок, которые применяют, например, другие виды камеры.
3. Определение сходства с передним планом, т.е. достоверности переднего плана: 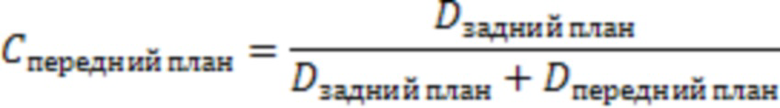 ,
,
где: D указывает (например, евклидово) цветовое расстояние между цветом центрального пикселя и средним цветом пикселей заднего плана или переднего плана. Эта метрика достоверности будет близка к 1, если центральный пиксель сравнительно больше схож со средним цветом переднего плана в окрестности. Она будет близка к нулю, если центральный пиксель сравнительно больше схож со средним цветом заднего плана в окрестности. На этапе 244 процессор 450 реконструкции определяет сходство идентифицированных периферийных пикселей с передним планом.
4. Отметка знаком X всех периферийных пикселей, для которых Спередний план<порогового значения (например, 0,5).
5. Эродирование всех отмеченных пикселей, т.е. взятие минимального значения в локальной (например, 3×3) окрестности. На этапе 240a процессор 450 реконструкции применяет эту нелинейную фильтрацию к отмеченным периферийным пикселям (которые более схожи с задним планом, чем с передним планом).
Как упомянуто выше, этот процесс может вносить шум и может привести к неровным краям на карте глубины. Этапы, предпринимаемые для сглаживания краев объекта, представленного на карте глубины, следующие:
1. Поиск локальных краев переднего плана, т.е. периферийных пикселей объектов переднего плана (вроде тех, которые помечены знаком X на фиг. 7).
2. Для этих краевых пикселей (например, центральный пиксель на фиг. 7) подсчет количества пикселей заднего плана в ядре 3×3 вокруг пикселя, представляющего интерес.
3. Отметка всех краевых пикселей, для которых подсчитанное количество > порогового значения.
4. Эродирование всех отмеченных пикселей, т.е. взятие минимального значения в локальной (например, 3×3) окрестности. Этот этап выполняют с помощью процессора 450 реконструкции на этапе 250.
Такое сглаживание имеет тенденцию к преобразованию выпадающих или выступающих пикселей переднего плана в пиксели заднего плана.
В вышеприведенном примере в способе для определения того, был ли выпадающий периферийный пиксель выступающим из объекта переднего плана, используют количество пикселей заднего плана в ядре 3×3. Могут быть использованы и другие способы. Например, в качестве альтернативы или дополнительно к подсчету количества пикселей могут быть проанализированы положения пикселей переднего плана и заднего плана в ядре. Если пиксели заднего плана все находятся по одну сторону от рассматриваемого пикселя, то с большей вероятностью это может быть пиксель переднего плана. С другой стороны, если пиксели заднего плана разбросаны повсюду вокруг рассматриваемого пикселя, то этот пиксель может быть выбросом или шумом, и, скорее всего, в действительности является пикселем заднего плана.
Пиксели в ядре могут быть классифицированы двоичным образом как передний план или задний план. Двоичный флаг кодирует это для каждого пикселя, причем логическая «1» указывает задний план, а логический «0» указывает передний план. Тогда окрестность (т.е. пиксели в ядре) может быть описана n-значным двоичным числом, где n является количеством пикселей в ядре, окружающем пиксель, представляющий интерес. Один пример способа построения двоичного числа приведен в следующей таблице:
В этом примере b = b7 b6 b5 b4 b3 b2 b1 b0 = 101001012 = 165 (следует отметить, что алгоритм, описанный выше со ссылкой на фиг. 5, соответствует подсчету количества ненулевых битов в b (= 4)).
Тренировка включает подсчет для каждого значения b, насколько часто представляющий интерес пиксель (центральный пиксель ядра) является передним планом или задним планом. В предположении одинаковой стоимости ложных распознаваний и пропусков, пиксель определяют как пиксель переднего плана, если он с большей вероятностью (в тренировочном наборе) является пикселем переднего плана, чем пикселем заднего плана, и наоборот.
Реализация декодера построит b и извлечет ответ (интересующий пиксель является пикселем переднего плана или интересующий пиксель является пикселем заднего плана) из таблицы подстановки (look up table, LUT).
Подход на основе нелинейно фильтрации карты глубины как в кодере, так и в декодере (например, дилатации и эрозии, соответственно, как описано выше), является парадоксальным, поскольку было бы естественно ожидать, что он удалит информацию из карты глубины. Однако авторы изобретения, к своему удивлению, обнаружили, что чем меньше карты глубины, которые создаются с использованием подхода на основе нелинейной понижающей дискретизации, тем с более высоким качеством они могут быть кодированы (с использованием обычного видеокодека) при данной скорости передачи битов. Этот выигрыш в качестве превышает потери в реконструкции; поэтому суммарный эффект заключается в повышении сквозного качества при снижении скорости передачи пикселей.
Как описано выше со ссылкой на фиг. 3 и 4, внутри видеокодера можно реализовать декодер, чтобы оптимизировать параметры нелинейной фильтрации и понижающей дискретизации и тем самым уменьшить ошибку реконструкции. В этом случае декодер 340 глубины в видеокодере 300 по существу идентичен кодеру 426 глубины в видеодекодере 400, а процессор 350 реконструкции в видеокодере 300 по существу идентичен процессору 450 реконструкции в видеодекодере 400. Эти соответствующие компоненты выполняют по существу идентичные процессы.
Если параметры нелинейной фильтрации и понижающей дискретизации в видеокодере были выбраны так, чтобы уменьшить ошибку реконструкции, как описано выше, выбранные параметры могут быть сообщены в двоичном потоке метаданных, который является входными данными для видеодекодера. Процессор 450 реконструкции может использовать параметры, сообщенные в двоичном потоке метаданных, в качестве помощи для правильной реконструкции карты глубины. Параметры обработки реконструкции могут включать, без ограничений: коэффициент повышающей дискретизации в одном или обоих измерениях; размер ядра для идентификации периферийных пикселей объектов переднего плана; размер ядра для эрозии; тип нелинейной фильтрации, подлежащей применению (например, использовать ли фильтр «минимум» или фильтр другого типа); размер ядра для идентификации пикселей переднего плана и размер ядра для сглаживания.
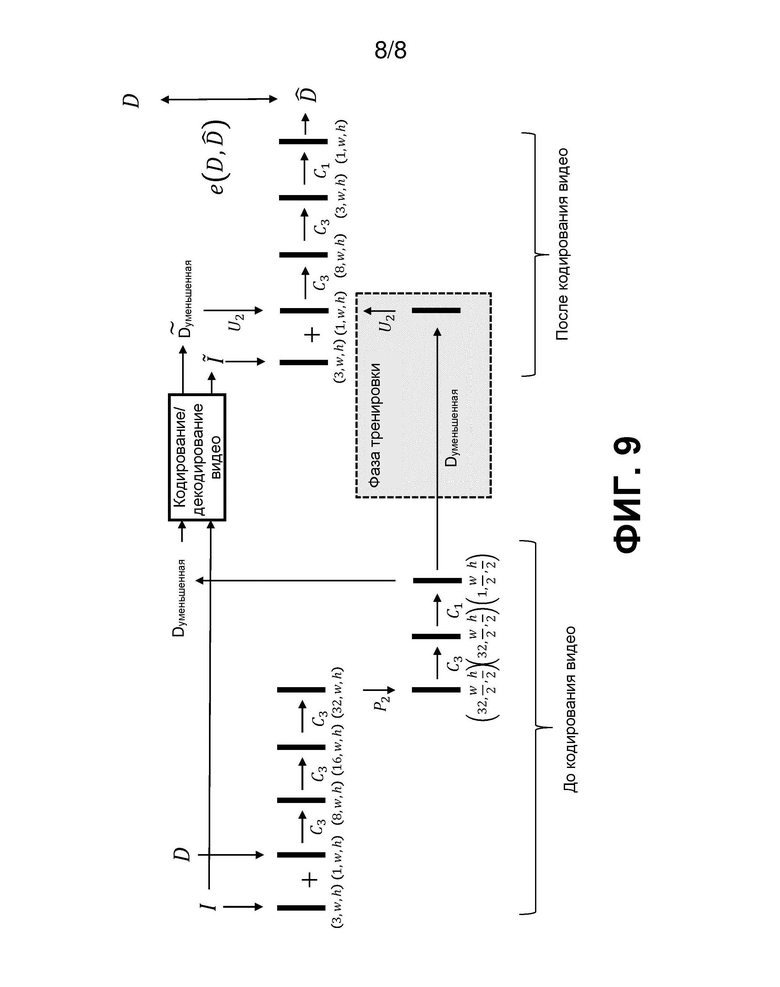
Далее со ссылкой на фиг. 9 будет описан альтернативный вариант реализации. В этом варианте реализации вместо нелинейных фильтров ручного кодирования для кодера и декодера используют архитектуру нейронной сети. Нейронная сеть разделена для моделирования операции уменьшения масштаба и увеличения масштаба глубины. Эта сеть проходит сквозную тренировку и учится как оптимальному уменьшению масштаба, так и оптимальному увеличению масштаба. Однако во время разработки (т.е. для кодирования и декодирования реальных последовательностей) первую часть используют до видеокодера, а вторую часть используют после видеодекодера. Таким образом, первая часть обеспечивает нелинейную фильтрацию 120 для способа кодирования, а вторая часть обеспечивает нелинейную фильтрацию 240 для способа декодирования.
Параметры (веса) сети второй части сети могут быть переданы в виде метаданных с помощью двоичного потока. Следует отметить, что могут быть созданы различные наборы сетевых параметров, соответствующих различным конфигурациям кодирования (разные коэффициенты уменьшения масштаба, разные целевые скорости передачи битов и т.д.). Это означает, что увеличивающий масштаб фильтр для карты глубины будет вести себя оптимально для данной скорости передачи битов текстурной карты. Это может повысить производительность, поскольку артефакты кодирования текстуры изменяют характеристики яркости и цветности, и, особенно на границах объекта, это изменение приведет к разным весам нейронной сети увеличения масштаба глубины.
На фиг. 9 показан пример архитектуры для данного варианта реализации, в котором нейронная сеть представляет собой сверточную нейронную сеть (CNN). Символы на схеме означают следующее:
 - входная 3-канальная текстурная карта полного разрешения;
- входная 3-канальная текстурная карта полного разрешения;
 - декодированная текстурная карта полного разрешения;
- декодированная текстурная карта полного разрешения;
D - входная 1-канальная карта глубины полного разрешения;
 - карта глубины уменьшенного масштаба;
- карта глубины уменьшенного масштаба;
 - декодированная карта глубины уменьшенного масштаба;
- декодированная карта глубины уменьшенного масштаба;
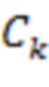 - свертка с ядром
- свертка с ядром 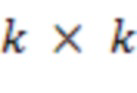 ;
;
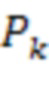 - коэффициент
- коэффициент 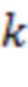 уменьшения масштаба;
уменьшения масштаба;
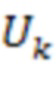 -коэффициент
-коэффициент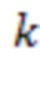 повышающей дискретизации.
повышающей дискретизации.
Каждая вертикальная черная полоса на схеме представляет тензор входных данных или промежуточных данных, другими словами, входные данные для слоя нейронной сети. Размеры каждого тензора описываются тройкой (p, w, h), где w и h - ширина и высота изображения, соответственно, а p - количество плоскостей или каналов данных. Соответственно, входная текстурная карта имеет размеры (3, w, h) - три плоскости, соответствующие трем цветовым каналам. Подвергнутая понижающей дискретизации карта глубины имеет размеры (1, w/2, h/2).
Уменьшение масштаба Pk может включать операцию усреднения уменьшения масштаба с коэффициентом k или подвыборки по максимальному значению (или подвыборки по минимальному значению) с размером ядра k. Операция усреднения уменьшения масштаба может вводить некоторые промежуточные значения, но последующие слои нейронной сети могут исправлять это (например, на основе информации о текстуре).
Следует отметить, что на фазе тренировки декодированную карту глубины, , не используют. Вместо этого используют несжатую карту глубины уменьшенного масштаба. Причина этого заключается в том, что на фазе тренировки нейронной сети требуется вычисление производных, что невозможно для нелинейной функции видеокодера. На практике это приближение, скорее всего, будет справедливо, особенно для более высокого качества (более высоких скоростей передачи битов). На фазе логического вывода (т.е. при обработке реальных видеоданных) несжатая карта глубины уменьшенного масштаба, очевидно, недоступна видеодекодеру. Поэтому используют декодированную карту глубины. Следует отметить также, что декодированную текстурную карту полного разрешения используют на фазе тренировки, как и на фазе логического вывода. Вычислять производные нет необходимости, поскольку это вспомогательная информация, а не данные, обрабатываемые нейронной сетью.
Вторая часть нейронной сети (после декодирования видео) будет, как правило, содержать только несколько сверточных слоев ввиду сложности ограничений, которые возможны на клиентском устройстве.
Для использования подхода на основе глубокого изучения важно наличие тренировочных данных. В этом случае их легко получить. Несжатое текстурное изображение и карту глубины полного разрешения используют на стороне ввода перед кодированием видео. Вторая часть сети использует декодированную текстуру и карту глубины уменьшенного масштаба (посредством первой половины сети в качестве входных данных для тренировки), и ошибка оценивается по соответствующей действительности карте глубины полного разрешения, которую также использовали в качестве входных данных. Поэтому, по сути, накладки из исходной карты глубины высокого разрешения служат для нейронной сети как входными данными, так и выходными данными. Следовательно, сеть имеет некоторые аспекты как архитектуры автоматического кодера, так и архитектуры UNet. Однако предлагаемая архитектура - это не просто комбинация этих подходов. Например, декодированная текстурная карта поступает во вторую часть сети в качестве вспомогательных данных для оптимальной реконструкции карты глубины высокого разрешения.
В примере, показанном на фиг. 9, входные данные нейронной сети в видеокодере 300 содержат текстурную карту и карту D глубины. Понижающую дискретизацию P2 выполняют между двумя слоями нейронной сети. Существуют три слоя нейронной сети до понижающей дискретизации и два слоя после нее. Выходные данные части нейронной сети в видеокодере 300 содержат карту глубины уменьшенного масштаба. Она кодируется кодером 320 на этапе 140.
Кодированную карту глубины передают в видеодекодер 400 в двоичном видеопотоке. Ее декодируют с помощью декодера 426 глубины на этапе 226. В результате получают декодированную карту глубины уменьшенного масштаба. К ней применяют повышающую дискретизацию (U2) для использования в части нейронной сети в видеодекодере 400. Другой частью входных данных для этой части нейронной сети является декодированная текстурная карта полного разрешения, которая сформирована декодером 424 текстуры. Вторая часть нейронной сети имеет три слоя. Она создает в качестве выходных данных реконструированную оценку 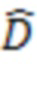 , которую сравнивают с первоначальной картой D глубины для получения итоговой ошибки e.
, которую сравнивают с первоначальной картой D глубины для получения итоговой ошибки e.
Из вышесказанного понятно, что обработка нейронной сетью может быть реализована в видеокодере 300 с помощью видеопроцессора 320 и в видеодекодере 400 с помощью процессора 450 реконструкции. В показанном примере нелинейную фильтрацию 120 и понижающую дискретизацию 130 выполняют интегрированным образом с помощью части нейронной сети в видеокодере 300. В видеодекодере 400 повышающую дискретизацию 230 выполняют отдельно перед нелинейной фильтрацией 240, которую выполняют с помощью нейронной сети.
Понятно, что расположение слоев нейронной сети, показанное на Фиг. 9, не имеет ограничительного характера и может быть изменено в других вариантах реализации. В этом примере сеть создает подвергнутые понижающей дискретизации карты глубины размером 2×Разумеется, могут быть использованы и другие коэффициенты масштабирования.
В нескольких вариантах реализации, описанных выше, упоминались фильтрация с выбором максимума, подвыборка по максимальному значению, дилатация или аналогичные операции в кодере. Понятно, что в этих вариантах реализации предполагается, что глубину кодируют как 1/d (или другую подобную обратную зависимость), где d является расстоянием от камеры. При таком предположении более высокие значения на карте глубины указывают объекты переднего плана, а низкие значения на карте глубины обозначают задний план. Таким образом, применяя операцию типа максимума или дилатации, способ стремится увеличить объекты переднего плана. Соответствующий обратный процесс в декодере может заключаться в применении операции типа минимума или эрозии.
Конечно, в других вариантах реализации глубина может быть кодирована как d или log d (или другая переменная, которая находится в прямой корреляционной зависимости с d). Это означает, что объекты переднего плана представлены низкими значениями d, а задний план высокими значениями d. В таких вариантах реализации в кодере может быть выполнена фильтрация с выбором минимума, подвыборка по минимальному значению, эрозия или подобная операция. Опять же, это будет иметь тенденцию к увеличению объектов переднего плана, что и является целью. Соответствующий обратный процесс в декодере может заключаться в применении операции типа максимума или дилатации.
Способы кодирования и декодирования на фиг. 2, 4, 5, 8 и 9, и кодер и декодер на фиг. 3 и 6 могут быть реализованы в аппаратных средствах или программном обеспечении или в сочетании того и другого (например, в виде прошивки, запущенной на аппаратном устройстве). В той степени, в которой вариант осуществления частично или полностью реализован в программном обеспечении, функциональные этапы, показанные в блок-схемах процесса, могут быть выполнены с помощью соответствующим образом запрограммированных физических вычислительных устройств, таких как один или более центральных процессоров (ЦП), графических процессоров (ГП) или ускорителей нейронных сетей (УНС). Каждый процесс и его отдельные составляющие этапы, как показано на блок-схемах, может быть выполнен одним и тем же или различными вычислительными устройствами. В соответствии с вариантами реализации, компьютерочитаемый носитель для хранения данных хранит компьютерную программу, содержащую компьютерный программный код, выполненный с возможностью вызова выполнения одними или более физическими вычислительными устройствами способа кодирования или декодирования, как описано выше, при выполнении программы на одном или более физических вычислительных устройств.
Носитель данных может содержать энергозависимую и энергонезависимую компьютерную память, такую как ОЗУ, ППЗУ, СППЗУ и ЭСППЗУ. Различные носители данных могут находиться в пределах вычислительного устройства или выполнены с возможностью перемещения, так что одна или более программ, хранящихся на носителях данных, могут быть загружены в процессор.
Метаданные согласно одному варианту осуществления могут храниться на носителе для хранения данных. Битовый поток согласно одному варианту осуществления может храниться на одном и том же носителе для хранения данных или другом носителе для хранения данных. Метаданные могут быть вложены в битовый поток, но это не существенно. Аналогично, метаданные и/или двоичные потоки (с метаданными в двоичном потоке или отдельно от него) могут быть переданы в виде сигнала, смодулированного на электромагнитной несущей волне. Сигнал может быть определен в соответствии со стандартом цифровой связи. Несущая волна может быть несущей оптического диапазона, волной радиочастоты, миллиметровой волной или волной связи ближнего поля. Она может передаваться проводным или беспроводным способом.
В той степени, в которой вариант осуществления частично или полностью реализован в аппаратных средствах, блоки, показанные на блок-схемах на Фиг. 3 и 6, могут быть отдельными физическими компонентами или логическими звеньями отдельных физических компонентов, либо все они могут быть реализованы интегрированным образом в одном физическом компоненте. Функции одного блока, показанного на чертежах, при реализации могут быть разделены между несколькими компонентами, либо функции нескольких блоков, показанных на чертежах, при реализации могут быть объединены в отдельные компоненты. Например, хотя на Фиг. 6 декодер 424 текстуры и декодер 426 глубины показаны как отдельные компоненты, их функции могут быть обеспечены одним унифицированным компонентом декодера.
В целом, примеры способов кодирования и декодирования данных, компьютерная программа, которая реализует эти способы, и видеокодеры и видеодекодеры указаны в нижеприведенных вариантах реализации.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
1. Способ кодирования видеоданных, содержащих один или более исходных видов, причем каждый исходный вид содержит текстурную карту и карту глубины, при этом способ включает:
прием (110) видеоданных;
обработку карты глубины по меньшей мере одного исходного вида для формирования обработанной карты глубины, включающую:
нелинейную фильтрацию (120) и
понижающую дискретизацию (130); и
кодирование (140) обработанной карты глубины и текстурной карты по меньшей мере одного исходного вида для формирования двоичного видеопотока.
2. Способ по варианту реализации 1, в котором нелинейная фильтрация включает увеличение области по меньшей мере одного объекта переднего плана на карте глубины.
3. Способ по варианту реализации 1 или 2, в котором нелинейная фильтрация включает применение фильтра, разработанного с использованием алгоритма машинного обучения.
4. Способ по любому из предыдущих вариантов реализации, в котором нелинейную фильтрацию выполняют с помощью нейронной сети, содержащей множество слоев, а понижающую дискретизацию выполняют между двумя из указанных слоев.
5. Способ по любому из предыдущих вариантов реализации, который включает обработку (120a, 130a) карты глубины в соответствии с множеством наборов параметров обработки для формирования соответствующего множества обработанных карт глубины,
при этом способ также включает:
выбор набора параметров обработки, который уменьшает ошибку реконструкции реконструированной карты глубины после того, как соответствующая обработанная карта глубины была кодирована и декодирована; и
формирование двоичного потока метаданных, идентифицирующего выбранный набор параметров.
6. Способ декодирования видеоданных, содержащих один или более исходных видов, включающий:
прием (210) двоичного видеопотока, содержащего кодированную карту глубины и кодированную текстурную карту по меньшей мере для одного исходного вида;
декодирование (226) кодированной карты глубины для получения декодированной карты глубины;
декодирование (224) кодированной текстурной карты для получения декодированной текстурной карты; и
обработку декодированной карты глубины для формирования реконструированной карты глубины, при этом обработка включает:
повышающую дискретизацию (230) и
нелинейную фильтрацию (240).
7. Способ по варианту реализации 6, также включающий перед этапом обработки декодированной карты глубины для формирования реконструированной карты глубины обнаружение того, что декодированная карта имеет меньшее разрешение, чем декодированная текстурная карта.
8. Способ по варианту реализации 6 или варианту реализации 7, в котором нелинейная фильтрация включает уменьшение области по меньшей мере одного объекта переднего плана на карте глубины.
9. Способ по любому из вариантов реализации 6-8, в котором обработка декодированной карты глубины основана по меньшей мере частично на декодированной текстурной карте.
10. Способ по любому из вариантов реализации 6-9, включающий:
повышающую дискретизацию (230) декодированной карты глубины;
идентификацию (242) периферийных пикселей по меньшей мере одного объекта переднего плана на подвергнутой повышающей дискретизации карте глубины;
определение (244) на основе декодированной текстурной карты, похожи ли периферийные пиксели больше на объект переднего плана или на задний план; и
применение (240a) нелинейной фильтрации только к периферийным пикселям, которые определены как более похожие на задний план.
11. Способ по любому из вариантов реализации, в котором нелинейная фильтрация включает сглаживание (250) краев по меньшей мере одного объекта переднего плана.
12. Способ по любому из вариантов реализации 6-11, также включающий прием двоичного потока метаданных, связанного с двоичным видеопотоком, причем двоичный поток метаданных идентифицирует набор параметров,
а способ также включает обработку декодированной карты глубины в соответствии с идентифицированным набором параметров.
13. Компьютерная программа, содержащая компьютерный код для вызова реализации системой обработки любого из вариантов реализации 1-12 при запуске указанной программы в системе обработки.
14. Видеокодер (300), выполненный с возможностью кодирования видеоданных, содержащих один или более исходных видов, причем каждый исходный вид содержит текстурную карту и карту глубины, при этом видеокодер содержит:
вход (310), выполненный с возможностью приема видеоданных;
видеопроцессор (320), выполненный с возможностью обработки карты глубины по меньшей мере одного исходного вида для формирования обработанной карты глубины, включающей:
нелинейную фильтрацию (120) и
понижающую дискретизацию (130);
кодер (330), выполненный с возможностью кодирования текстурной карты по меньшей мере одного исходного вида и обработанной карты глубины для формирования двоичного видеопотока; и
выход (360), выполненный с возможностью вывода двоичного видеопотока.
15. Видеодекодер (400), выполненный с возможностью декодирования видеоданных, содержащих один или более исходных видов, при этом видеодекодер содержит:
вход (410) двоичного потока, выполненный с возможностью приема двоичного видеопотока, причем двоичный видеопоток содержит кодированную карту глубины и кодированную текстурную карту по меньшей мере для одного исходного вида;
первый декодер (426), выполненный с возможностью декодирования из двоичного видеопотока кодированной карты глубины для получения декодированной карты глубины;
второй декодер (424), выполненный с возможностью декодирования из двоичного видеопотока кодированной текстурной карты для получения декодированной текстурной карты;
процессор (450) реконструкции, выполненный с возможностью обработки декодированной карты глубины для формирования реконструированной карты глубины, при этом обработка включает:
повышающую дискретизацию (230) и
нелинейную фильтрацию (240),
и выход (470), выполненный с возможностью вывода реконструированной карты глубины.
В число компонентов аппаратных средств для использования в вариантах реализации настоящего изобретения входят, без ограничений, обычные микропроцессоры, специализированные интегральные схемы (ASIC) и программируемые пользователем вентильные матрицы (FPGA). Один или более блоков могут быть реализованы в виде комбинации специализированных аппаратных средств для выполнения некоторых функций и одного или более запрограммированных микропроцессоров и связанных с ними схем для выполнения других функций.
Более конкретно, настоящее изобретение определено прилагаемой формулой изобретения.
Другие вариации описанных вариантов осуществления могут быть поняты и реализованы специалистом в данной области техники при осуществлении заявленного изобретения на практике после ознакомления с чертежами, описанием и прилагаемой формулой изобретения. В пунктах формулы изобретения слово "содержащий" не исключает другие элементы или этапы, а грамматические средства выражения единственного числа не исключают множества. Отдельный процессор или другой блок может выполнять функции нескольких изделий, указанных в формуле изобретения. Сам факт того, что некоторые меры перечислены во взаимно отличающихся зависимых пунктах формулы изобретения, не указывает на то, что комбинация этих мер не может быть использована для получения преимущества. В случае компьютерной программы, обсужденной выше, она может храниться/распространяться на подходящем носителе, таком как оптический носитель для хранения данных или твердотельный носитель, поставляемый вместе с другими аппаратными средствами или как их часть, но может также распространяться в других формах, например, через сеть Интернет или другие проводные или беспроводные телекоммуникационные системы. Если термин «выполнен таким образом, чтобы» используется в формуле изобретения или описании, следует отметить, что термин «выполнен таким образом, чтобы» следует считать эквивалентным термину «выполнен с возможностью». Никакие ссылочные позиции в формуле изобретения не следует рассматривать как ограничивающие ее объем.
Изобретение относится к кодированию видео. Техническим результатом является повышение качества и эффективности кодирования иммерсивного видео. Результат достигается тем, что исходные видеоданные, содержащие один или более исходных видов, кодируют в двоичный видеопоток. Перед кодированием к данным о глубине по меньшей мере одного из исходных видов применяют нелинейную фильтрацию и понижающую дискретизацию. После декодирования декодированные данные глубины подвергают повышающей дискретизации и нелинейной фильтрации. 5 н. и 8 з.п. ф-лы, 9 ил., 1 табл.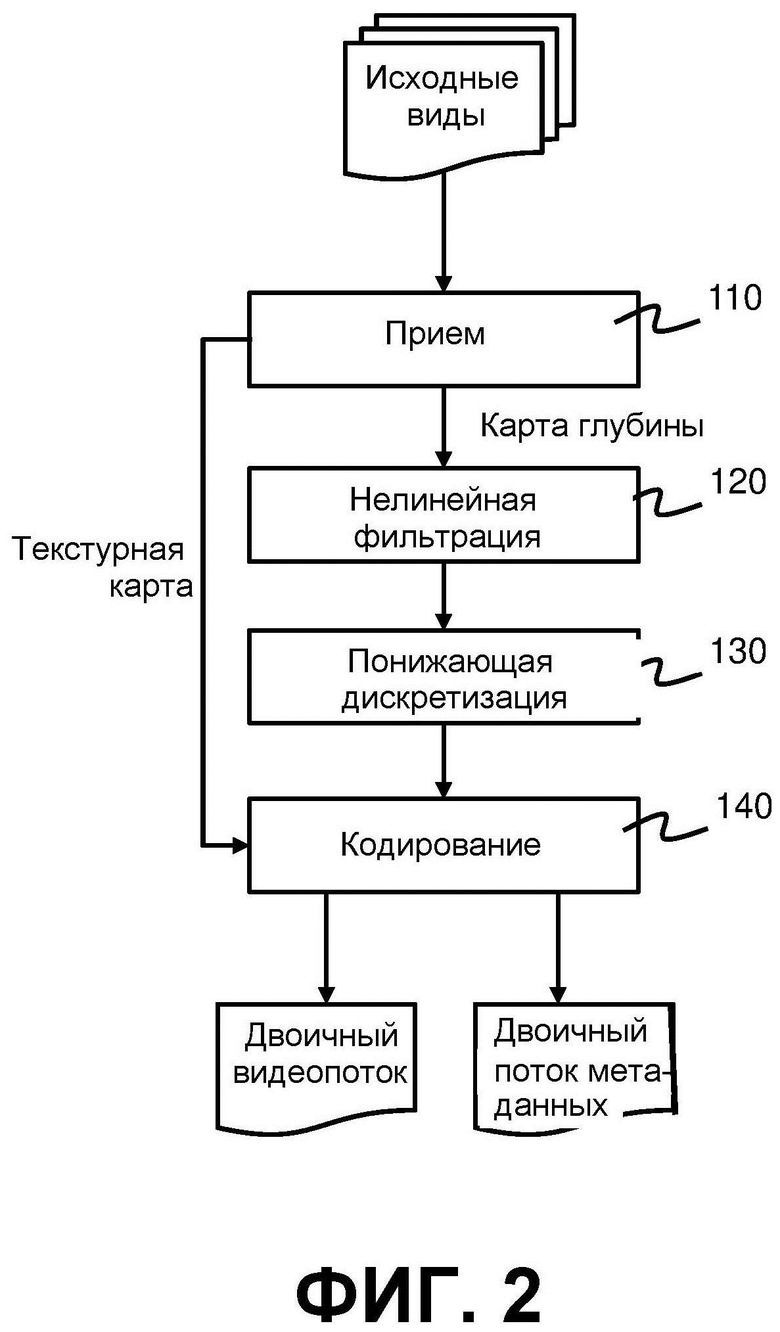
1. Способ кодирования видеоданных, содержащих один или более исходных видов, причем каждый исходный вид содержит текстурную карту и карту глубины, при этом способ включает:
прием (110) видеоданных;
обработку карты глубины по меньшей мере одного исходного вида для формирования обработанной карты глубины; и
кодирование (140) обработанной карты глубины и текстурной карты по меньшей мере одного исходного вида для формирования двоичного видеопотока,
отличающийся тем, что обработка включает:
нелинейную фильтрацию (120) карты глубины для формирования нелинейно отфильтрованной карты глубины и
понижающую дискретизацию (130) нелинейно отфильтрованной карты глубины для формирования обработанной карты глубины;
причем нелинейная фильтрация включает увеличение области по меньшей мере одного объекта переднего плана на карте глубины.
2. Способ по п. 1, в котором нелинейная фильтрация включает применение фильтра, разработанного с использованием алгоритма машинного обучения.
3. Способ по любому из предыдущих пунктов, в котором нелинейную фильтрацию выполняют с помощью нейронной сети, содержащей множество слоев, а понижающую дискретизацию выполняют между двумя из указанных слоев.
4. Способ по любому из предыдущих пунктов, который включает обработку (120а, 130а) карты глубины в соответствии с множеством наборов параметров обработки для формирования соответствующего множества обработанных карт глубины,
причем параметры обработки включают по меньшей мере одно из: определения выполненной нелинейной фильтрации, определения выполненной понижающей дискретизации и определения операций обработки, подлежащих выполнению в декодере при реконструкции карты глубины,
при этом способ также включает:
выбор набора параметров обработки, который уменьшает ошибку реконструкции реконструированной карты глубины после того, как соответствующая обработанная карта глубины была кодирована и декодирована; и
формирование двоичного потока метаданных, идентифицирующего выбранный набор параметров.
5. Способ декодирования видеоданных, содержащих один или более исходных видов, включающий:
прием (210) двоичного видеопотока, содержащего кодированную карту глубины и кодированную текстурную карту по меньшей мере для одного исходного вида;
декодирование (226) кодированной карты глубины для получения декодированной карты глубины;
декодирование (224) кодированной текстурной карты для получения декодированной текстурной карты и
обработку декодированной карты глубины для формирования реконструированной карты глубины, при этом обработка включает:
повышающую дискретизацию (230) декодированной карты глубины для формирования подвергнутой повышающей дискретизации карты глубины, и
при этом способ отличается тем, что обработка также включает
нелинейную фильтрацию (240) подвергнутой повышающей дискретизации карты глубины для формирования реконструированной карты глубины,
причем нелинейная фильтрация включает уменьшение области по меньшей мере одного объекта переднего плана на карте глубины.
6. Способ по п. 5, также включающий перед этапом обработки декодированной карты глубины для формирования реконструированной карты глубины обнаружение того, что декодированная карта глубины имеет меньшее разрешение, чем декодированная текстурная карта.
7. Способ по любому из пп. 5, 6, в котором обработка декодированной карты глубины основана по меньшей мере частично на декодированной текстурной карте.
8. Способ по любому из пп. 5-7, включающий:
повышающую дискретизацию (230) декодированной карты глубины;
идентификацию (242) периферийных пикселей по меньшей мере одного объекта переднего плана на подвергнутой повышающей дискретизации карте глубины;
определение (244) на основе декодированной текстурной карты, похожи ли периферийные пиксели больше на объект переднего плана или на задний план; и
применение (240а) нелинейной фильтрации только к периферийным пикселям, которые определены как более похожие на задний план.
9. Способ по любому из пп. 5-8, в котором нелинейная фильтрация включает сглаживание (250) краев по меньшей мере одного объекта переднего плана.
10. Способ по любому из пп. 5-9, также включающий прием двоичного потока метаданных, связанного с двоичным видеопотоком, причем двоичный поток метаданных идентифицирует набор параметров, включающий в себя определение нелинейной фильтрации и/или определение повышающей дискретизации, подлежащей выполнению,
а способ также включает обработку декодированной карты глубины в соответствии с идентифицированным набором параметров.
11. Компьютерочитаемый носитель данных, хранящий компьютерную программу, содержащую компьютерный код для вызова реализации системой обработки способа по любому из пп. 1-10 при запуске указанной программы в системе обработки.
12. Видеокодер (300), выполненный с возможностью кодирования видеоданных, содержащих один или более исходных видов, причем каждый исходный вид содержит текстурную карту и карту глубины, при этом видеокодер содержит:
вход (310), выполненный с возможностью приема видеоданных;
видеопроцессор (320), выполненный с возможностью обработки карты глубины по меньшей мере одного исходного вида для формирования обработанной карты глубины,
кодер (330), выполненный с возможностью кодирования текстурной карты по меньшей мере одного исходного вида и обработанной карты глубины для формирования двоичного видеопотока; и
выход (360), выполненный с возможностью вывода двоичного видеопотока,
отличающийся тем, что обработка включает:
нелинейную фильтрацию (120) карты глубины для формирования нелинейно отфильтрованной карты глубины и
понижающую дискретизацию (130) нелинейно отфильтрованной карты глубины для формирования обработанной карты глубины;
причем нелинейная фильтрация включает увеличение области по меньшей мере одного объекта переднего плана на карте глубины.
13. Видеодекодер (400), выполненный с возможностью декодирования видеоданных, содержащих один или более исходных видов, при этом видеодекодер содержит:
вход (410) двоичного потока, выполненный с возможностью приема двоичного видеопотока, причем двоичный видеопоток содержит кодированную карту глубины и кодированную текстурную карту по меньшей мере для одного исходного вида;
первый декодер (426), выполненный с возможностью декодирования из двоичного видеопотока кодированной карты глубины для получения декодированной карты глубины;
второй декодер (424), выполненный с возможностью декодирования из двоичного видеопотока кодированной текстурной карты для получения декодированной текстурной карты;
процессор (450) реконструкции, выполненный с возможностью обработки декодированной карты глубины для формирования реконструированной карты глубины, и
выход (470), выполненный с возможностью вывода реконструированной карты глубины,
отличающийся тем, что обработка включает:
повышающую дискретизацию (230) декодированной карты глубины для формирования подвергнутой повышающей дискретизации карты глубины и
нелинейную фильтрацию (240) подвергнутой повышающей дискретизации карты глубины для формирования реконструированной карты глубины,
причем нелинейная фильтрация включает уменьшение области по меньшей мере одного объекта переднего плана на карте глубины.
| US 2016012567 A1, 2016.01.14 | |||
| US 2012269458 A1, 2012.10.25 | |||
| US 2019110038 A1, 2019.04.11 | |||
| WO 2018218643 A1, 2018.12.06 | |||
| US 10417748 B2, 2019.09.17 | |||
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛОВ | 2012 |
|
RU2583040C2 |
| US 9117277 B2, 2015.08.25 | |||
| US 9398313 B2, 2016.07.19. | |||

