Область техники
Предлагаемое изобретение относится к области интерактивной сегментации. Предлагаемое изобретение может быть использовано для технических ресурсов, таких как вычислительные системы для анализа данных, тестирования нейронных сетей. Решение можно использовать для улучшения сегментации изображений, выполняемой с помощью интерактивных нейронных сетей, которые принимают дополнительные пользовательские вводы.
Уровень техники
Недавний прогресс в области алгоритмов интерактивной сегментации был обусловлен появлением базовых нейронных сетей (то есть базовых нейронных сетей для сегментации). Мощные, но очень универсальные интерактивные базовые нейронные сети используются для решения задач на рынке конечного потребления, таких как обнаружение объектов, удаление объектов, сбор больших наборов данных, маркировка медицинских изображений, а также могут служить прочной основой в качестве нейронной сети интерактивной сегментации. В отличие от традиционной сегментации в режиме «офлайн», интерактивные методы используют дополнительные пользовательские вводы для управления процессом сегментации путем итеративного обновления маски сегментации. Нейронная сеть интерактивной сегментации предсказывает маску сегментации, которая накладывается на исходное изображение, чтобы выделить фрагмент для сегментации, выбранный пользователем. Маска сегментации - одноканальное изображение, которое включает в себя высокие значения (единицы), которые соответствуют пикселям фрагмента, который необходимо сегментировать на входном изображении, и низкие значения - фон (нули).
Сегментация осуществляется по кликам пользователей, размещаемым один за другим, образующим траекторию кликов. Каждый клик в этой траектории выбирается согласно определенной стратегии, учитывающей предыдущие взаимодействия (предыдущие клики). Клики пользователя могут быть положительными, то есть дополняющими необходимую маску, и отрицательными, которые исправляют исходную маску посредством удаления ненужной ее части, если необходимо. Для перевода кликов в пространственное представление клики пересчитываются в круги некоторого малого радиуса. Некоторые нейронные сети могут не требовать этапа отрисовки круга фиксированного радиуса и работать напрямую с численными координатами (например, Kirillov, A.; Mintun, Е.; Ravi, N.; Мао, Н.; Rolland, С.; Gustafson, L.; Xiao, Т.; Whitehead, S.; Berg, А.С.; Lo, W.-Y.; и др. 2023. Segment anything. arXiv preprint arXiv:2304.02643) поэтому для таких моделей блок отрисовки не используется, тогда в нейронную сеть подаются непосредственно сами координаты, которые называются необработанными.
Для обучения моделей интерактивной сегментации обычно используют следующие наборы данных (датасеты): Semantic Boundaries Dataset (SBD), COCO, LVIS, DAVIS, Pascal VOC, SA-1B a также их комбинации.
Все существующие методы используют простую стратегию оценки качества нейронной сети (используются метрики Отношение площади пересечения к площади объединения (Intersection over Union (IoU)) и Количество кликов (Number of clicks (NoC))), при которой последующий клик размещается в центре области выделенного объекта. Метрики качества являются математическим выражением качества масок, то есть показывают качество сегментации, выдаваемой моделью. При идеальном совпадении желаемой пользователем маски сегментации (эталонной маски сегментации) и маски, полученной нейронной сетью, IoU равна единице, что является максимально высоким значением. При полном несовпадении упомянутых масок IoU равно нулю, что является минимальным значением.
Обычно для определения центра области выделенного объекта выполняется преобразование расстояния к эталонной маске объекта. Эталонную маску объекта получают на этапе обучения и тестирования нейронной сети. Для этого используется маска сегментации, полученная профессиональными разметчиками.
Преобразование расстояния включает в себя карту преобразования расстояния, которая представляет собой одноканальное
изображение. Максимальное значение карты преобразования расстояния соответствует точке, максимально удаленной от границ объекта. Визуализация такого преобразования в качестве примера показана в https://static.packt-cdn.com/products/9781783283972/qraphics/3972QS_04_09.jpq, в данном случае в качестве центра области выделенного объекта выбрана грудь человека. Было проведено пользовательское исследование, в ходе которого выяснилось, что такой выбор центра объекта не всегда соответствует действиям пользователей. Кроме того, использование этой стратегии приводит к переподгонке показателя количества кликов (NoC), что наблюдалось в (Sofiiuk, Petrov и Konushin, 2021). Подавляющее большинство современных методов, основанных на кликах, основано на предположении, что пользователи склонны нажимать в центре области с наибольшей ошибкой (т.е. новый клик дает подсказку нейронной сети о месте, где она сильнее всего ошиблась). Однако исследование реальных пользователей показало, что это естественное предположение может вводить в заблуждение, особенно в случае длинных и тонких объектов или объектов сложной неправильной формы.
Большая часть сравнительных критериев интерактивной сегментации - либо помечены только границами (Hariharan и др., 2011), либо адаптированы (McGuinness и O'connor, 2010; Xu и др., 2016; Li, Chen и Koltun, 2018) на основе наборов данных семантической сегментации (Hariharan и др.). 2011; Perazzi и др. 2016а; Martin и др. 2001), или созданы специально для примера сегментации (Rother, Kolmogorov и Blake 2004), - содержат изображения со значительно меньшим разрешением, чем в предложенном изобретении. Сравнительный анализ данных с низким разрешением может не отражать относительное качество методов интерактивной сегментации, предназначенных для обработки изображений с высоким разрешением.
Сравнительный анализ интерактивной сегментации.
Grab-Cut (Rother, Kolmogorov и Blake, 2004) был первым набором данных интерактивной сегментации. Затем набор данных сегментации Berkeley (Martin и др., 2001) был адаптирован для интерактивной сегментации (McGuinness и O'Connor, 2010). Соответствующий протокол оценки подразумевал определение качества сегментации как объектов, так и границ по критерию IoU и требовал ручного взаимодействия с методом. Xu и др. (Xu и др. 2016) предложили автоматическую процедуру сравнительного анализа интерактивной сегментации на основе кликов на наборах данных сегментации PASCAL VOC 2012 (Everingham и др.) и COCO (Lin и др. 2014); в этой процедуре клики размещались строго по центру самой крупной ошибочной области, а качество определялось по стандартному критерию IoU. В последующей работе (Li, Chen и Koltun, 2018) были адаптированы наборы данных SBD (Hariharan и др., 2011) и DAVIS (Perazzi и др., 2016а) для интерактивной сегментации с использованием той же стратегии генерации кликов.
Различные пользовательские вводы.
Большинство методов интерактивной сегментации основаны на кликах, поэтому предлагаемое изобретение применяется только для подсказок, основанных на кликах. Подсказки дает пользователь, указывая (кликая) на объект, который хочет выделить. Однако были исследованы и другие типы взаимодействия, и предложенный подход к оценке может быть применен к ним путем изменения модуля дифференцируемой отрисовки. Ограничительные рамки использовались для выделения больших областей изображения (Xu и др., 2016; Rother, Kolmogorov и Blake, 2004), а также были адаптированы для сегментации тонких объектов (Liew и др., 2021). Gueziri и др. (Gueziri, McGuffin и Laporte, 2017) использовали вручную выполненные штрихи в качестве наведения. Также были предложены стратегии моделирования многократных штрихов: то есть использование случайных блужданий, которые не пересекают границы заднего и переднего плана (Batra и др. 2010), или выборку пикселей внутри «ошибочной зоны» между областями заднего и переднего плана (Bai и Wu 2014). В недавней работе (Agustsson, Uijlings и Ferrari, 2019) ограничительные рамки, полученные с помощью безграничного количества кликов (Papadopoulos и др., 2017), были объединены со смоделированными штрихами. В недавней работе по интерактивному матированию (Cheng и др. 2021b) предложена рандомизированная генерация равномерных кликов и штрихов на основе точек, случайно выбранных из маски.
Недавно представленная модель Segment Anything (SAM) (Кириллов и др., 2023) формулирует задачу как сегментацию с подсказками, где каждая подсказка может быть точкой, рамкой, маской или текстом. Специальный декодер подсказок позволяет выполнять эффективный амортизированный вывод всех
пользовательских вводов. Авторы SAM-HQ (Ke и др. 2023) показали, что добавление высококачественных масок к обучающим данным повышает производительность SAM на изображениях с высоким разрешением, а также улучшает качество сегментации границ. Авторы MobileSAM (Zhang и др., 2023а) представили облегченную версию SAM, которая значительно быстрее исходной нейронной сети.
Метрики Сегментации.
Одним из параметров качества, используемых в сегментации, является оценка границ объекта. Стандартное отношение площади пересечения к площади объединения (IoU) нечувствительно к границам, поэтому граничные метрики были сформулированы для специальной оценки. Метрика Trimap IoU (Kohli, Ladick'y и Torr, 2009; Chen и др., 2018) рассчитывается на расстоянии от границы эталонной маски, игнорируя отдаленные ошибочные пиксели. В случае с F-критерием, находящиеся на расстоянии пиксели прогнозируемых и эталонных границ сопоставляются посредством дорогостоящей в вычислительном отношении процедуры. Проблема производительности была решена с помощью аппроксимации F-критерия (Csurka, Larlus и Perronnin 2013; Perazzi et al. 2016b), которая все еще имеет высокую дисперсию. McGuinness и др. (McGuinness и O'connor, 2010) сформулировали критерий точности нечеткой границы, которая основана на заранее определенной степени неопределенности граничных пикселей. (Cheng и др., 2020) предложили усредненный критерий точности границ (mBA), который суммирует точность сегментации в пределах нескольких радиусов от эталонной границы. MQ (Yang и др., 2020) был унаследован из mBA, но включал в себя качество сегментации тела объекта для получения общего критерия качества. Поскольку основное внимание также уделяется задаче матирования изображений, качество границ оценивается по основанным на trimap критериям SAD, MSE (Xu и др., 2017) и MAD (Li, Zhang и Tao), а также ошибкам перцептивного градиента и связности (Xu и др., 2017). Новый критерий IoU границ (Cheng et al. 2021а) является простым и надежным в отношении размеров объекта, поэтому он используется в предлагаемом изобретении. Поскольку обычная метрика IoU не чувствительна к границам объекта, то для оценки качества границ маски сегментации, полученных нейронной сетью для интерактивной сегментации, используется BIoU. BIoU получается взятием 2% граничных пикселей на эталонной маске сегментации и подсчетом IoU только для граничных пикселей маски сегментации, полученной нейронной сетью.
Еще одним параметром, обычно используемым в интерактивной сегментации, является показатель метрики «Количество кликов» (NoC) (Jang и Kim, 2019; Sofiiuk и др., 2020), обозначающий количество кликов, необходимое для достижения заранее определенного порога IoU (улучшение и наблюдение целевых показателей - это увеличение и уменьшение IoU). Однако было замечено (Sofiiuk, Petrov и Konushin, 2021), что выбор центральных точек в протоколе оценки приводит к переподгонке этой метрики, демонстрируя при этом низкую производительность в реальных взаимодействиях.
Еще одним недостатком этой метрики является то, что она одинаково отбраковывает примеры, в которых желаемый порог был достигнут при последних взаимодействиях, и те, где он не был достигнут вообще. Таким образом, для сравнения интерактивных нейронных сетей предлагается использовать метрику «площадь под кривой IoU» (Jang и Kim 2019). Во всех экспериментах количество кликов ограничено десятью.
Для исследования устойчивости моделей к различным изменениям вводов (возмущениям), на нейронной сети машинного обучения применяют адверсативные атаки, например, https://hi-news.ru/science/sostyazatelnye-ataki-nejroset.html
Адверсативные атаки представляют из себя добавление небольших добавок к вводам нейронной сети, которые существенно меняют предсказания, полученные нейронной сетью. Адверсативные атаки обычно классифицируются как «черный ящик» или «белый ящик», в зависимости от того, доступна ли информация о подвергшейся атаке нейронной сети.
Адверсативная атака «черный ящик» не использует информацию об используемой нейронной сети, в то время как адверсативная атака «белый ящик» знает свойства нейронной сети, которая атакуется.
Обычно подходы с «черным ящиком» компенсируют недостаток информации о строении нейронной сети, из-за чего подходы с «черным ящиком» используют полнопереборные алгоритмы с обширными вычислениями. Например, Однопиксельная атака (Su, Vargas и Sakurai 2019) - это атака «черный ящик» на классификационные нейронные сети, основанная на дифференциальной эволюции: она создает большое количество возможных решений. В упомянутой статье выполняется поиск пикселя, такого, что изменение цвета в нем заставляет нейронную сеть сменить предсказываемый класс (например, с предсказания кошек на предсказание собак), соответственно решение - это найденный пиксель на каждой итерации на основе рандомизированной процедуры, независимой от нейронной сети.
Поскольку учитываются входные изображения с высоким разрешением и многочисленные клики, объем вычислений, необходимый для адверсативных атак «черный ящик», неосуществим в предлагаемом сценарии интерактивной сегментации. Соответственно, используются подходы «белый ящик».
В некоторых работах (Kamann и Rother, 2020) уже рассматривалась возможность сравнительного анализа устойчивости к различным искажениям традиционной сегментации, когда нет зависимости от пользовательского ввода. На данный момент опубликована серия работ, исследующих надежность высокоэффективных SAM (Kirillov и др., 2023): (Guan и др., 2023; Zhang и др., 2023b; Qiao и др., 2023; Wang, Zhao и Petzold). 2023). Однако все работы направлены на возмущение входного изображения, а не на подсказки пользователя.
Метод дифференцируемой отрисовки (Li и др., 2020) уже зарекомендовал себя для преобразования растровых изображений в векторные и позволил перенести алгоритмы компьютерного зрения в векторные изображения. Обычно параметры векторных геометрических примитивов оптимизируются напрямую посредством оптимизации градиента. В предлагаемых экспериментах по оптимизации кликов пользователей авторы следуют (Ма и др., 2022) и корректируют только координаты положения клика.
Сущность изобретения
Предлагается способ интерактивной сегментации изображения на основе последовательности кликов пользователя, осуществляемый нейронной сетью для интерактивной сегментации изображений, содержащий этапы, на которых:
a) обучают нейронную сеть для интерактивной сегментации изображений;
b) подают на вход обученной нейронной сети для интерактивной сегментации:
- изображение, на котором нужно выполнить сегментацию области изображения,
- координаты клика пользователя по изображению для сегментации упомянутой области изображения,
c) получают на выходе обученной нейронной сети предсказанную маску сегментации,
d) отображают предсказанную маску сегментации на дисплее пользователю,
повторяют этапы (b)-(d) для получения и отображения уточненной предсказанной маски сегментации, пока отображенная предсказанная маска сегментации не будет соответствовать желательной области для сегментации;
причем на этапе (а) обучения обучают упомянутую нейронную сеть посредством обучающих координат клика на обучающем изображении до тех пор, пока не перестанет уменьшаться ошибка между эталонной маской сегментации и предсказанной маской сегментации на отложенной выборке, причем осуществляют оптимизацию обучающих координат каждого клика на основе обратного распространения ошибки между эталонной маской сегментации и предсказанной маской сегментации при фиксированных весах нейронной сети, получая обучающие адверсативные координаты клика;
- на основе полученных обучающих адверсативных координат клика осуществляют обучение нейронной сети при отмененной фиксации ее весов путем обратного распространения ошибки через нейронную сеть для обновления ее весов.
Оптимизация обучающих координат клика осуществляется методом градиентного спуска. Клик пользователя включает в себя либо положительный клик, либо отрицательный клик на дисплее электронного устройства по изображению, в отношении которого нужно выполнить сегментацию области изображения, причем положительный клик маркирует желательную область для включения в сегментированное изображение, отрицательный клик маркирует не желательную область, которую необходимо исключить из сегментированного изображения. Причем нейронная сеть обучается посредством конвейера обучения для обучения нейронной сети для интерактивной сегментации изображений, содержащего: модуль дифференцируемой растеризации, осуществляющий дифференцируемую растеризацию обучающих координат клика, модуль суммирования карт кликов предыдущих и текущего обучающих раундов взаимодействия для вычисления поэлементной суммы растеризованных обучающих координат клика текущего обучающего раунда и обучающих адверсативных координат, полученных в предыдущем обучающем раунде взаимодействия, модуль функций потерь для вычисления функций потерь и градиентов функций потерь, использующихся для получения в текущем обучающем раунде взаимодействия обучающих адверсативных координат клика и обновления весов нейронной сети интерактивной сегментации, причем модуль дифференцируемой растеризации соединен с модулем суммирования карт кликов, а также с модулем функций потерь, нейронная сеть интерактивной сегментации соединена с модулем суммирования карт кликов, а также с модулем функций потерь. Обучающие данные для каждого обучающего раунда взаимодействия включают в себя набор обучающих данных текущего обучающего раунда взаимодействия, состоящий из: обучающего изображения, эталонной маски сегментации, соответствующей области для сегментации упомянутого обучающего изображения, причем обучающее изображение и эталонная маска сегментации остаются неизменными во всех обучающих раундах взаимодействия, обучающих координат клика на n-м обучающем раунде взаимодействия, на основании которых путем оптимизации методом градиентного спуска получают обучающие адверсативные координаты клика, причем обучающие координаты клика n-го обучающего раунда взаимодействия маркируют область для сегментации упомянутого обучающего изображения, причем обучающие координаты клика каждого раунда взаимодействия имеют отличные друг от друга значения, причем обучающие координаты клика в каждом обучающем раунде взаимодействия маркируют одну и ту же область для сегментации упомянутого обучающего изображения. Нейронная сеть обучается за заданное количество обучающих раундов взаимодействия.
При осуществлении обучения нейронной сети в 1-м обучающем раунде взаимодействия:
a) подают на вход конвейера для обучения нейронной сети набор обучающих данных;
b) осуществляют дифференцируемую растеризацию обучающих координат клика в модуле дифференцируемой растеризации, для получения растеризованных обучающих координат клика текущего обучающего раунда взаимодействия,
c) подают на вход нейронной сети:
обучающее изображение из упомянутого набора обучающих данных текущего обучающего раунда взаимодействия,
растеризованные обучающие координаты одного клика обучающего раунда взаимодействия, полученные на этапе (b);
при этом веса нейронной сети фиксируются;
d) получают на выходе нейронной сети предсказанную маску сегментации;
e) осуществляют сравнение предсказанной маски сегментации с эталонной маской сегментации из обучающих данных, поданных на этапе (а), посредством вычисления, в модуле функций потерь, функции потерь дифференцируемой аппроксимации целевой метрики качества IoU (Dice), а также функции потерь, регуляризирующей положение клика,
f) вычисляют в модуле функций потерь градиент функции потерь Dice по предсказанной маске сегментации,
j) вычисляют в модуле функций потерь градиент функции потерь, регуляризирующей положение клика, по растеризированным обучающим координатам клика;
h) используют полученные значения градиента функции потерь Dice для осуществления обратного распространения ошибки через:
- нейронную сеть от ее выхода до ее входов,
- модуль суммирования карт кликов предыдущего и текущего обучающих раундов взаимодействия, причем обратное распространение ошибки осуществляется только для растеризованных обучающих координат клика, используемых для обучения в текущем раунде,
- модуль дифференцируемой растеризации обучаемых координат клика;
используют полученные значения градиента функции потерь, регуляризирующей положение клика, для осуществления обратного распространения ошибки через модуль дифференцируемой
растеризации обучающих координат клика, при этом получают поправки обучающих координат клика методом градиентного спуска;
i) обновляют растеризованные обучающие координаты клика, используя полученные упомянутые поправки, получая при этом обучающие адверсативные координаты клика;
j) отменяют фиксацию весов нейронной сети, подают на вход нейронной сети обучающие адверсативные координаты клика и упомянутое обучающее изображение;
k) нейронная сеть вычисляет обновленную предсказанную маску сегментации, используют обновленную предсказанную маску сегментации для вычисления функции потерь Dice в модуле функций потерь;
осуществляют сравнение обновленной предсказанной маски сегментации с эталонной маской сегментации, посредством вычисления в модуле функций потерь функции потерь Dice, вычисляют в модуле функций потерь градиент функции потерь Dice по обновленной предсказанной маске сегментации,
l) используют полученные на этапе (k) значения градиента функции потерь Dice для осуществления обратного распространения ошибки через нейронную сеть и обновление ее весов;
переходят к следующему обучающему раунду взаимодействия, причем в каждом n-м обучающем раунде взаимодействия осуществляют следующие этапы:
m) подают на вход конвейера для обучения нейронной сети набор обучающих данных для текущего n-го обучающего раунда взаимодействия;
n) осуществляют дифференцируемую растеризацию обучающих координат одного клика п-го обучающего раунда взаимодействия, в модуле дифференцируемой растеризации, для получения растеризованных обучающих координат одного клика n-го обучающего раунда взаимодействия,
о) вычисляют поэлементную сумму растеризованных обучающих координат клика n-го обучающего раунда взаимодействия, и обновленных растеризованных обучающих координат клика, полученных в n-1 обучающем раунде взаимодействия на этапе (i);
р) подают на вход нейронной сети:
обучающее изображение из упомянутого набора обучающих данных текущего обучающего раунда взаимодействия, поэлементную сумму, полученную на этапе (о), при этом веса нейронной сети фиксируются;
q) осуществляют этапы (d)-(f);
r) вычисляют градиент функции потерь, регуляризирующей положение клика, по растеризированным обучающим координатам одного клика n-го обучающего раунда взаимодействия;
s) осуществляют этапы (h)-(l);
t) измеряют качество нейронной сети с обновленными весами на отложенной выборке, при этом этапы (m)-(t) осуществляют до тех пор, пока качество нейронной сети не перестанет увеличиваться.
Согласно изобретению, предлагаемый способ позволяет получить выходную маску сегментации, используя данные изображения и координаты клика в качестве вводов для нейронной сети искусственного интеллекта. Нейронную сеть искусственного интеллекта можно получить путем обучения. Здесь «полученное путем обучения» означает, что заранее определенное правило работы или нейронная сеть искусственного интеллекта, сконфигурированная для выполнения желаемой функции (или цели), получается путем обучения базовой нейронной сети искусственного интеллекта с помощью нескольких фрагментов обучающих данных с помощью алгоритма обучения. Нейронная сеть искусственного интеллекта может включать в себя множество слоев нейронной сети. Каждый из множества слоев нейронной сети включает в себя множество весовых значений и выполняет вычисления нейронной сети путем вычисления между результатом вычисления предыдущего слоя и множеством весовых значений.
Функция, связанная с AI, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или множество процессоров. При этом один или множество процессоров могут быть процессором общего назначения, таким как центральный процессор (ЦП), процессор приложений (АР) или т.п., блок обработки только графики, такой как графический процессор (GPU), блок визуальной обработки (VPU) и/или специальный процессор для искусственного интеллекта, такой как нейронный процессор (NPU). Таким образом, предлагаемое решение имеет аппаратную реализацию.
Один или множество процессоров управляют обработкой вводов в соответствии с заранее определенным рабочим правилом или нейронной сетью искусственного интеллекта (ИИ), хранящейся в энергонезависимой памяти и энергозависимой памяти. Заранее определенное рабочее правило или нейронная сеть искусственного интеллекта обеспечивается посредством тренировки или обучения.
Здесь обеспечение через обучение означает, что путем применения алгоритма обучения к множеству обучающих данных создается заранее определенное рабочее правило или нейронная сеть ИИ с желаемой характеристикой. Обучение может выполняться в самом устройстве, в котором выполняется ИИ согласно варианту осуществления, и/или может быть реализовано через отдельный сервер/систему.
Нейронная сеть ИИ может состоять из множества слоев нейронной сети. Каждый уровень имеет множество значений весов и выполняет операцию уровня посредством вычисления предыдущего уровня и операции множества весов. Примеры нейронных сетей включают, помимо прочего, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), сеть глубокого доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
Алгоритм обучения представляет собой способ обучения заранее определенного целевого устройства (например, робота) с использованием множества обучающих данных, чтобы заставить, разрешить или управлять целевым устройством для выполнения определения или прогнозирования. Примеры алгоритмов обучения включают, помимо прочего, обучение с учителем, обучение без учителя, полуконтролируемое обучение или обучение с подкреплением.
Краткое описание чертежей
Вышеупомянутые и/или другие аспекты будут более понятны из последующего описания примеров вариантов реализации со ссылкой на прилагаемые чертежи, на которых:
На фиг. 1 представлена схема предлагаемого способа.
На фиг. 2 показана визуализация масок сегментации, полученных известными нейронными сетями интерактивной сегментации RITM и SimpleClick на основании кликов пользователя по входному изображению в сравнении с эталонными масками сегментации.
На фиг. 3 показаны показатели метрики IoU в зависимости от вида сегментируемого изображения.
На фиг. 4 показаны: А) стандартная оценка интерактивной сегментации с вычислением площади под кривой IoU/BIoU; (В) предлагаемая метрика устойчивости IoU/BIoU-D как разница между площадями кривых для максимизации и минимизации траекторий адверсативных входов (траектория - объединение кликов всех раундов для одного изображения); (С) предложенная метрика устойчивости IoU/BIoU-OG, определяемая областью прироста оптимизации под кривой для каждого состязательного входа.
На фиг. 5 показаны траектории минимизации, базового уровня и максимизации метрик IoU в каждом раунде.
На фиг. 6 показано время аннотации на одно изображение.
На фиг. 7 показана статистика предлагаемого теста надежности с набором данных масок сегментации.
Подробное описание изобретения
Предлагается способ интерактивной сегментации изображений, при выполнении которого повышается качество и точность воспроизведения маски сегментации, причем пользователь может самостоятельно совершать взаимодействия с изображением посредством кликов при попытках сегментировать нужную ему область изображения. Например, пользователь может выделять как разные фрагменты для сегментации, так и семантически связанные фрагменты на изображении (например, выделить всех людей на фотографии). Задачей предлагаемого изобретения является интерактивное формирование маски сегментации для изображения с использованием нейронной сети для искусственного интеллекта (ИИ), которая правильно оконтуривает изображение или область изображения, выбранные пользователем при сегментации. Благодаря предлагаемому изобретению осуществляется повышение точности соответствия формируемой маски сегментации реальному оконтуриваемому фрагменту на изображении, снижение вычислительных затрат на создание маски сегментации хорошего качества, повышение качества маски сегментации, независимо от различий в расположениях пользовательских кликов при выборе области для сегментации. Благодаря предлагаемому изобретению улучшается точность предсказания маски сегментации любой известной нейронной сетью для интерактивной сегментации.
Благодаря предлагаемому изобретению более качественно осуществляться интерактивная сегментация изображения посредством любой известной дифференцируемой нейронной сети интерактивной сегментации, также повышается устойчивость работы дифференцируемой нейронной сети интерактивной сегментации к различиям в положениях пользовательских кликов при взаимодействии пользователя с изображением при выборе области для сегментации.
Предлагаемое изобретение может использоваться для таких технических ресурсов, как обучение нейронных сетей интерактивной сегментации для получения более точных фрагментов изображений для сегментации на основе кликов пользователей, вычислительных систем для анализа данных, тестирования нейронных сетей.
Для осуществления обучения дифференцируемая нейронная сеть интерактивной сегментации должна иметь дифференцируемый конвейер такой, который имеет возможность обратного распространения градиента функции потерь от выхода нейронной сети до ее входа при обучении. Градиент функции потерь считается в отношении функции потерь по правилу дифференцирования сложной функции обратного распространения ошибки. Для оптимизации
дифференцируемой нейронной сети в данном изобретении используется метод градиентного спуска (https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D0%B4%D0%B8%D0%B5%D0 %BD%D1%8 2%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D1%83%D1%81%D0%BA). Далее в настоящем описании под термином «нейронная сеть» понимается дифференцируемая нейронная сеть интерактивной сегментации.
Рассматриваемые в настоящей заявке аспекты предлагаемого изобретения также можно применять для оценки качества нейронных сетей интерактивной сегментации и для оценки устойчивости моделей к изменениям пользовательских вводов.
Интерактивная сегментация изображений направлена на сегментацию представляющих интерес областей с учетом изображения и некоторых последовательных пользовательских вводов (кликов, штрихов, контуров). Качество сегментации, проводимой нейронной сетью, измеряется по известным метрикам качества IoU/BIoU, устойчивость - по известным метрикам качества IoU-D/BIoU-D.
Предложенный способ может быть использован на этапе обучения на жесткой выборке (т.е. адверсативное обучение происходит на самых сложных примерах), майнинге и адверсативном обучении для повышения устойчивости нейронной сети и получения качественных масок сегментации независимо от положения клика пользователя.
В настоящей заявке используются следующие термины.
Изображение - это изображение, в отношении которого необходимо выполнить сегментацию.
Сегментация - процесс получения маски сегментации.
Маска сегментации - это получаемое нейронной сетью одноканальное изображение, маркирующее указанную пользователем область для целей сегментации. Маска сегментации имеет размер исходного изображения, причем максимальные значения (то есть - единицы) маркируют указанную пользователем область, а минимальные значения (то есть - нули) соответствуют заднему фону, то есть остальному изображению.
Эталонная маска сегментации - маска сегментации, заранее подготовленная профессиональными разметчиками для обучения и тестирования нейронных сетей, которая идеально соответствует желательной области для сегментации.
Положительный клик пользователя - клик на дисплее электронного устройства по изображению, в отношении которого нужно выполнить сегментацию, который маркирует желательную область для сегментации упомянутого изображения.
Отрицательный клик пользователя - клик на дисплее электронного устройства по изображению, который маркирует нежелательную область, которую необходимо исключить из сегментации упомянутого изображения.
Пользователь выполняет клик, например, курсором мыши, стилусом или пальцем на экране электронного устройства.
Область для сегментации - часть изображения, которую пользователь желает сегментировать.
Координаты клика - это координаты х, y клика пользователя по изображению, причем принимается, что система координат имеет начало координат в левом нижнем углу изображения, ось х направлена вправо, ось y направлена вверх относительно пользователя, сидящего за экраном дисплея.
Раунд взаимодействия при использовании обученной нейронной сети - это один клик пользователя, маркирующий желательную или нежелательную область для сегментации во время работы нейронной сети интерактивной сегментации.
Обучающий раунд взаимодействия на этапе обучения нейронной сети - эмуляция одного раунда взаимодействия в виде обучающих координат одного эмулированного клика, маркирующих область для сегментации обучающего изображения, причем обучающие координаты эмулированного клика (далее обучающие координаты клика) подвергаются дифференцируемой растеризации для получения растеризованных обучающих координат клика.
Обучающие адверсативные координаты клика - координаты, получаемые с помощью конвейера обучения из обучающих координат клика, причем обучающие адверсативные координаты клика максимизируют/минимизируют качество нейронной сети, измеренное метрикой качества (IoU).
Адверсативная атака - подача на вход обучаемой нейронной сети обучающих адверсативных координат клика.
Адверсативная атака белого ящика - это адверсативная атака с использованием знания о структуре атакуемой нейронной сети для и с возможностью вычисления градиентов для параметров дифференцируемого конвейера нейронной сети (этот термин используется в данной области техники см., например,
https://media.kaspersky.com/ru/business-security/attacks-on-artificial-intelligence-whitepaper.pdf;
https://cyberleninka.ru/article/n/shemy-atak-na-neuralnetworki-mashinnogo-obucheniya/viewer
https:/ /aisec.cs.msu. ru/sect ion_robust_ml/ robustness/)
Согласно настоящему изобретению при проведении интерактивной сегментации изображения на этапе использования обученной сети пользователь
- посредством по меньшей мере одного положительного клика на дисплее электронного устройства по изображению, в отношении которого нужно выполнить сегментацию, маркирует желательную область для сегментации упомянутого изображения,
- посредством по меньшей мере одного отрицательного клика на дисплее электронного устройства по упомянутому изображению маркирует не желательную область, которую необходимо исключить из сегментации упомянутого изображения.
При этом для каждого клика пользователя на вход обученной нейронной сети подают изображение и координаты клика пользователя по упомянутой области. После каждого раунда взаимодействия обученная нейронная сеть предсказывает новую маску сегментации, которая наиболее удовлетворяет текущим координатам клика пользователя. На выходе обученной нейронной сети получают маску сегментации, которую отображают на дисплее пользователю. Пользователь осуществляет клики до тех пор, пока не увидит на экране дисплея маску сегментации, соответствующую желательной области для сегментации.
На этапе обучения (переобучения) нейронную сеть обучают посредством обучающих координат клика на обучающем изображении до тех пор, пока ошибка на отложенной выборке не перестает уменьшаться https://cs.hse.ru/data/2017/11/21/1160780232/Slides-IntroToAI-HSE-2017-06-2-Panov.pdf
http://www.machinelearninq.ru/wiki/imaqes/a/af/Sem06_model_selec tion.pdf.
Осуществляют оптимизацию обучающих координат каждого клика на основе обратного распространения ошибки между эталонной маской сегментации и предсказанной маской сегментации при фиксированных весах нейронной сети, получая обучающие адверсативные координаты клика. На основе полученных обучающих адверсативных координат клика осуществляют обучение нейронной сети при отмененной фиксации ее весов путем обратного распространения ошибки через нейронную сеть для обновления ее весов. Более подробно этап обучения будет описан ниже.
Качественное обучение нейронной сети должно осуществляться с помощью очень большого количества обучающих кликов, например, более миллиона обучающих кликов, то есть обучать нейронную сеть только с помощью кликов реального пользователя нет возможности. Поэтому обучение происходит на эмулированных обучающих кликах по стратегии клика в области с наибольшей ошибкой. Стратегия клика в области с наибольшей ошибкой - это базовая стратегия выбора в качестве положения (координат) обучающего клика в области с наибольшей ошибкой между предсказанной маской прошлого раунда взаимодействия и эталонной маской сегментации. Такие стратегии известны и реализованы, например, в RITM (Sofiiuk, K., Petrov, I.A. и Konushin, А., 2022, Октябрь. Возобновление итеративного обучения с помощью маски для интерактивной сегментации. В 2022 году Международная конференция IEEE по обработке изображений (ICIP) (стр. 3141-3145). IEEE. https://arxiv.orq/pdf/2102.06583.pdf). Для подсчета ошибки осуществляется сопоставление эталонной и предсказанной маски сегментации, рассматриваются все области на этих двух масках и обнаруживаются области с ошибкой, то есть такие, где эти маски не совпали. Ошибки можно разбить на две категории. Первый тип ошибок - это Ложно Отрицательный, т.е. ошибка, где нейронная сеть при предсказании маски сегментации ошибочно не выделила часть объекта, например, при клике в человека не выделилась рука. Второй тип ошибок - это Ложно Положительный, когда, наоборот, нейронная сеть при предсказании маски сегментации выделила некую дополнительную область, например, при клике в человека выделился еще велосипед, на котором он сидит. Из всех ошибок выбирается область с наибольшей площадью, то есть область с наибольшей ошибкой. Затем используется известный из уровня техники алгоритм подсчета - для каждой из таких областей считается преобразование расстояния, и выбирается его максимум (преобразование расстояния - это одноканальное изображение, в котором каждый пиксель имеет значение, равное евклидову расстоянию до ближайшего пикселя обозначенной области. Преобразование расстояния - ресурсы по обучению анализу изображений (neubias.qithub.io)). Этот максимум соответствует центру области для сегментации, то есть точке, максимально удаленной от границ области для сегментации. Для этой области строится карта преобразования расстояния, то есть берут карту текущего клика (изображение круга) и суммируют значения всех пикселей этой карты, которые находятся внутри круга.
Для получения градиента обычно используются автоматические средства дифференцирования (например, библиотека PyTorch https://pytorch.org/. Математически такая библиотека выполняет вычисление для функции потерь L(Y_pred, Y_gt), ее градиент dL(Y_pred, Y_gt)/dY_pred). Для подсчета ошибки между предсказанием и эталоном (в сегментации это предсказанная моделью маска сегментации и эталонная маска сегментации, полученная разметчиками) используются функции потерь, которые выбираются эмпирически. Минимизация функции потерь выполняется для обучения нейронной сети на своих самых больших ошибках. Также минимизация функции потерь нужна для расчета предложенной метрики устойчивости, которая определяет, насколько сильно может измениться качество нейронной сети. В предлагаемом изобретении используется функция потерь (известная из Dice, L.R., 1945. Критерии степени экологической связи между видами. Экология, 26(3), стр. 297-302. https://ww.jstor.org/stable/1932409), которая является дифференцируемой аппроксимацией целевой метрики качества IoU. Также в предлагаемом изобретении используется функция потерь местоположения при взаимодействии, которая предоставляет значения градиента для координат (х, у) для их обновления соответственно с помощью градиентного спуска. Функция потерь местоположения при взаимодействии разработана в рамках предлагаемого изобретения специально для регуляризации функций потерь Dice, и нацелена на максимизацию/минимизацию качества сегментации.
Функция потерь местоположения при взаимодействии штрафует за выход положительного клика из области Ложно Отрицательный и выход отрицательного клика из области Ложно Положительный, то есть диапазон координат положительных и отрицательных кликов пользователя ограничивается. Другими словами, функция потерь местоположения при взаимодействии заставляет оптимизируемый клик текущего обучающего раунда удовлетворять здравому смыслу постановки задачи интерактивной сегментации. То есть, например, для выделения фрагмента нужно кликать именно на этот фрагмент, а не вне этого фрагмента, а для удаления лишнего элемента с изображения (например, выделилось два человека, а в эталонной маске один), нужно кликать на лишнего человека, а не вне этого элемента. То есть положительные клики будут находиться только внутри выделяемого фрагмента, а отрицательные - вне фрагмента.
Будет ли клик положительным или отрицательным, указывается пользователем непосредственно перед выполнением клика.
У нейронных сетей интерактивной сегментации, обученных по известной базовой стратегии, имеется проблема с устойчивостью, то есть, если координаты клика реального пользователя немного отличаются от центра области для сегментации, то получается сильная просадка качества сегментации. Если нейронная сеть в процессе обучения обучается только на кликах по базовой стратегии (то есть по кликам по центру области для сегментации), то нейронная сеть не ожидает реальные клики пользователя в другие части области сегментации, что приводит к падению качества синтезируемой маски сегментации. Согласно предлагаемому изобретению, в процесс обучения добавляется процедура улучшения устойчивости нейронной сети посредством получения обучающих адверсативных координат клика, как будет описано ниже. При обучении нейронной сети согласно предлагаемому изобретению, качество сегментации, которое получит пользователь при своем произвольном клике, будет выше, чем качество сегментации нейронной сети при том же клике, но обученной без применения предлагаемого в изобретении подхода.
В предлагаемом изобретении оптимизация пользовательских вводов реализуется посредством адверсативной атаки «белого ящика» на нейронную сеть интерактивной сегментации, реализованной с помощью полностью дифференцируемого конвейера.
На фигуре 1 показан пример конвейера обучения (модули, обозначенные темным цветом) для генерации адверсативных вводов. Путь обновления градиента отмечен темными стрелками, светлые стрелки показывают работу нейронной сети. Такой конвейер обучения используется как для переобучения и обучения нейронной сети, так и для оценки устойчивости и качества любой нейронной сети интерактивной сегментации.
Конвейер обучения для обучения нейронной сети 1 интерактивной сегментации изображений содержит следующие модули.
- Модуль 2 дифференцируемой растеризации, осуществляющий дифференцируемую растеризацию обучающих координат клика, а именно этап дифференцируемой отрисовки, широко используемый в уровне техники, поскольку исторически сложилось подавать на вход нейронной сети координаты клика в виде кругов. При дифференцируемой растеризации осуществляется дифференцируемый переход от обучающих координат (х,у) к одноканальному (монохромному) изображению, где в позиции этих обучающих координат нарисован круг (например, работа RITM (Sofiiuk, K., Petrov, I.A. и Konushin, А., 2022, Октябрь. Возобновление итеративного обучения с помощью маски для интерактивной сегментации. В 2022 году Международная конференция IEEE по обработке изображений (ICIP) (стр. 3141-3145). IEEE. https://arxiv.orq/pdf/2102.06583.pdf)), ранее дифференцируемый рендеринг не применялся к задаче оптимизации. Причем радиус круга является гиперпараметром каждой отдельной нейронной сети, например, для известной нейронной сети RITM (Sofiiuk, K., Petrov, I.A. и Konushin, А., 2022, Октябрь. Возобновление итеративного обучения с помощью маски для интерактивной сегментации. В 2022 году Международная конференция IEEE по обработке изображений (ICIP) (стр. 3141-3145). IEEE. https://arxiv.orq/pdf/2102.06583.pdf) радиус составляет 5 пикселей, причем положение центра круга совпадает с положением клика пользователя.
- Модуль 3 суммирования карт кликов предыдущих и текущего обучающих раундов взаимодействия для вычисления поэлементной суммы растеризованных обучающих координат клика текущего обучающего раунда и обучающих адверсативных координат, полученных в предыдущих обучающих раундах взаимодействия. Карта кликов представляет собой поэлементную сумму результата отрисовки круга клика текущего раунда взаимодействия с картой кликов предыдущих раундов. Суммирование осуществляется поэлементным сложением (конкатенацией), получается результирующий тензор, который используется далее.
- Модуль 4 функций потерь для вычисления функций потерь и градиентов функций потерь, использующихся для получения обучающих адверсативных координат клика и обновления весов нейронной сети интерактивной сегментации. Причем модуль 2 дифференцируемой растеризации соединен с модулем 3 суммирования карт кликов, а также с модулем 4 функций потерь. Нейронная сеть 1 интерактивной сегментации соединена с модулем 3 суммирования карт кликов, а также с модулем 4 функций потерь.
Как показано на фиг. 1, обучающие данные для каждого обучающего раунда взаимодействия включают в себя набор обучающих данных текущего обучающего раунда взаимодействия. Набор состоит из:
- обучающего изображения I (3-канальное RGB-изображение),
- эталонной маски PGT сегментации, соответствующей области для сегментации упомянутого обучающего изображения I,
- обучающих координат клика (X, Y) на n-м обучающем раунде взаимодействия, на основании которых путем оптимизации методом градиентного спуска получают обучающие адверсативные координаты клика.
Обучающее изображение I и эталонная маска PGT сегментации остаются неизменными во всех обучающих раундах взаимодействия. Обучающие координаты (X, Y) клика n-го обучающего раунда взаимодействия маркируют область для сегментации упомянутого обучающего изображения I, причем обучающие координаты (X, Y) клика каждого раунда взаимодействия имеют отличные друг от друга значения и маркируют одну и ту же область для сегментации упомянутого обучающего изображения.
Также в процессе обучения на вход обучаемой нейронной сети подаются:
- маска Pn-1 сегментации, полученная на предыдущем раунде взаимодействия, где n - номер раунда взаимодействия, такая маска подается на всех последующих раундах взаимодействия, кроме первого;
- поэлементная сумма Un-1 (получаемая в модуле 3) растеризованных обучающих координат клика n-го обучающего раунда взаимодействия, и обновленных растеризованных обучающих координат клика, полученных в n-1 обучающем раунде взаимодействия.
Рассмотрим более подробно (со ссылкой на фиг. 1) этап обучения нейронной сети интерактивной сегментации. Нейронная сеть обучается за заданное количество обучающих раундов взаимодействия до тех пор, пока измеренное качество нейронной сети с обновленными весами не перестанет увеличиваться. В 1-м обучающем раунде взаимодействия:
a) подают на вход конвейера для обучения нейронной сети 1 набор обучающих данных, то есть изображение I, эталонную маску PGT, обучающие координаты клика (X, Y);
b) осуществляют дифференцируемую растеризацию обучающих координат (X, Y) клика в модуле 2 дифференцируемой растеризации, для получения растеризованных обучающих координат клика текущего обучающего раунда взаимодействия,
c) подают на вход нейронной сети 1 обучающее изображение I из упомянутого набора обучающих данных текущего обучающего раунда взаимодействия, растеризованные обучающие координаты одного клика обучающего раунда взаимодействия, полученные на этапе (b) в модуле 2;
при этом веса нейронной сети 1 фиксируются;
d) получают на выходе нейронной сети 1 предсказанную маску РРМ сегментации;
e) осуществляют сравнение предсказанной маски РРМ сегментации с эталонной маской PGT сегментации, посредством вычисления, в модуле 4 функций потерь, функции потерь 4а дифференцируемой аппроксимации целевой метрики качества IoU (Dice), а также функции потерь 4b, регуляризирующей положение клика,
f) вычисляют в модуле 4 функций потерь градиент функции потерь 4а Dice по предсказанной маске РРМ сегментации,
j) вычисляют в модуле 4 функций потерь градиент функции потерь, регуляризирующей положение клика, по растеризированным обучающим координатам клика;
h) используют полученные значения градиента функции 4а потерь Dice для осуществления обратного распространения ошибки через:
- нейронную сеть 1 от ее выхода до ее входов,
- модуль 3 суммирования карт кликов предыдущего и текущего обучающих раундов взаимодействия, причем обратное распространение ошибки осуществляется только для растеризованных обучающих координат клика, используемых для обучения в текущем раунде,
- модуль 2 дифференцируемой растеризации обучаемых координат клика;
используют полученные значения градиента функции потерь 4b, регуляризирующей положение клика, для осуществления обратного распространения ошибки через модуль 2 дифференцируемой растеризации обучающих координат клика, при этом получают поправки Δх, Δу обучающих координат клика;
i) обновляют растеризованные обучающие координаты клика, используя полученные упомянутые поправки Δх, Δу, получая при этом обучающие адверсативные координаты клика;
j) отменяют фиксацию весов нейронной сети 1,
подают на вход нейронной сети 1 обучающие адверсативные координаты клика и упомянутое обучающее изображение I;
k) нейронная сеть вычисляет обновленную предсказанную маску PUM сегментации,
используют обновленную предсказанную маску PUM сегментации для вычисления функции потерь 4а Dice в модуле 4 функций потерь;
осуществляют сравнение обновленной предсказанной маски PUM сегментации с эталонной маской PGT сегментации, посредством вычисления в модуле 4 функций потерь функции 4а потерь Dice,
вычисляют в модуле 4 функций потерь градиент функции 4а потерь Dice по обновленной предсказанной маске PUM сегментации,
l) используют полученные на этапе (k) значения градиента функции 4а потерь Dice для осуществления обратного распространения ошибки через нейронную сеть 1 и обновление ее весов с помощью градиентного спуска.
Переходят к следующему обучающему раунду взаимодействия, причем в каждом n-м обучающем раунде взаимодействия осуществляют следующие этапы:
m) подают на вход конвейера для обучения нейронной сети 1 набор обучающих данных для текущего n-го обучающего раунда взаимодействия;
n) в модуле 2 дифференцируемой растеризации осуществляют дифференцируемую растеризацию обучающих координат одного клика п-го обучающего раунда взаимодействия для получения растеризованных обучающих координат одного клика n-го обучающего раунда взаимодействия,
о) в модуле 3 суммирования карт кликов предыдущего и текущего обучающих раундов взаимодействия вычисляют поэлементную сумму растеризованных обучающих координат клика п-го обучающего раунда взаимодействия, и обновленных растеризованных обучающих координат клика, полученных в n-1 обучающем раунде взаимодействия на этапе (i);
р) подают на вход нейронной сети 1:
обучающее изображение I из упомянутого набора обучающих данных текущего обучающего раунда взаимодействия,
поэлементную сумму Un-1, полученную на этапе (о), при этом веса нейронной сети 1 фиксируются; q) осуществляют этапы (d)-(f);
r) в модуле 4 функций потерь вычисляют градиент функции 4b потерь, регуляризирующей положение клика, по растеризированным обучающим координатам одного клика n-го обучающего раунда взаимодействия;
s) осуществляют этапы (h)-(l);
t) измеряют качество нейронной сети с обновленными весами на отложенной выборке (https://cs.hse.ru/data/2017/11/21/1160780232/Slides-IntroToAI-HSE-2017-06-2-Panov.pdf
http://www.machinelearning.ru/wiki/images/а/af/Sem06_model_selec tion.pdf)
при этом этапы (m)-(t) осуществляют до тех пор, пока качество нейронной сети 1 не перестанет увеличиваться, то есть, пока качество нейронной сети увеличивается, обучение продолжается, когда качество перестает увеличиваться, обучение прекращается.
Для первого обучающего раунда взаимодействия пользователя с фрагментом сегментации изображения одноканальное изображение первого раунда взаимодействия суммируется с нулевой картой кликов в модуле 3. На втором и последующих раундах взаимодействия одноканальное изображение клика текущего раунда взаимодействия суммируется в модуле 3 с картой кликов предыдущего(их) раунда(ов). Полученный тензор Un-1 подается на вход нейронной сети интерактивной сегментации изображений вместе с предсказанной маской предыдущего раунда.
В случае оценки устойчивости нейронной сети важно знать возможный диапазон качества работы нейронной сети (от худшего до лучшего), также для улучшения качества предсказания маски нейронной сетью и устойчивости нейронной сети необходимо генерировать именно худшие примеры для обучения нейронной сети на них, то есть нейронная сеть учится на своих самых сложных ошибках.
Таким образом, для улучшения качества и надежности нейронных сетей интерактивной сегментации во время процедуры обучения генерируют адверсативные вводы с минимизацией градиентного спуска целевой метрики IoU (например, максимизируя предполагаемые потери) для обучающих выборок в обучающем наборе данных (То есть вместо текущих раундов кликов). Интерактивная нейронная сеть получает этот сгенерированный клик в качестве вводов и прогнозирует маски сегментации. Все веса нейронной сети обновляются с использованием градиентного спуска и вычисляемой функции потерь. Происходят поочередные обновления - сначала при фиксированных весах нейронной сети обновляется положение клика с помощью градиентного спуска. Затем, при фиксированном положении клика, обновляются веса нейронной сети. Эта процедура позволяет нейронной сети учиться на своих ошибках, поскольку клики, обнаруженные с помощью изобретения, минимизируют качество сегментации нейронной сети, в то время как на этапе обновления нейронной сети она пытается исправить эти плохие маски сегментации.
При оценке устойчивости нейронной сети результатом генерации адверсативных пользовательских вводов являются две последовательности пользовательских вводов, которые минимизируют и максимизируют целевое качество (IoU) соответственно. Результатом оценки устойчивости нейронных сетей интерактивной сегментации изображений с использованием генерации адверсативных пользовательских вводов являются количественные показатели, характеризующие устойчивость нейронных сетей интерактивной сегментации изображений. Результатом генерации адверсативных пользовательских вводов для повышения устойчивости нейронной сети интерактивной сегментации является обученная нейронная сеть, которая имеет лучшее качество и надежные прогнозы относительно местоположений пользовательских вводов.
Для оценки надежности нейронных сетей интерактивной сегментации вводы объединяются в последовательности, на основе этих последовательностей рассчитываются предлагаемые метрики стабильности. Как было показано выше обучающие адверсативные координаты - это координаты, в которые теоретически пользователь должен совершить клик, чтобы получить маску, имеющую лучшее и худшее качество сегментации. Обучающие адверсативные координаты получают на этапе градиентного обновления координат (этап i), то есть для поиска лучшего положения клика функция потерь минимизируется, для поиска худшего положения клика максимизируется. Экстремальные положения ищутся, чтобы оценить устойчивость нейронной сети для интерактивной сегментации к изменению координат клика пользователя. Наиболее устойчивой будет модель, которая при кликах внутри фрагмента сегментации выдает стабильно хорошее качество маски сегментации без просадок, т.е. ее максимизирующая и минимизирующая траектории близки (траектории - последовательности из обучающих кликов разных раундов, но соответствующих одной эталонной маске сегментации, предсказанная же маска между раундами меняется). Показателем качества найденных координат кликов является разность метрик качества (IoU/BIoU), посчитанных для предсказанных масок при клике в каждую из найденных позиций независимо друг от друга. Если разность метрик качества сегментации (IoU/BIoU) близка к нулю, то нейронная сеть является устойчивой, т.к. независимо от положения ввода она справляется с выделением нужного объекта. Тестирование нейронной сети для интерактивной сегментации на одном вводе (как указано выше - при тестировании нейронной сети генерируются клики для симуляции кликов пользователя, поскольку нельзя посадить живого человека кликать на миллионы изображений) слишком не показательно, поскольку не дает понимания границ качества нейронной сети, то есть насколько плохие и хорошие значения качества нейронная сеть может получить на каждом изображении. Предлагаемый же подход генерирует траектории минимального и максимально качества нейронной сети, а мерой устойчивости является разность между этим траекториями. Например, для тестирования можно использовать 10 раундов, следовательно длина последовательности кликов равна 10-ти. Последовательность кликов состоит из найденных на каждом раунде взаимодействий пользовательских кликов (минимизирующих и максимизирующих метрики IoU/BioU). Такая последовательность кликов для каждого изображения уникальна и количество последовательностей совпадает с количеством входных изображений, которые нужно сегментировать. Для предложенного авторами набора данных (TETRIS (К ИЗУЧЕНИЮ НАДЕЖНОСТИ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ), то есть набора пар (изображения, эталонные маски) для обучения и тестирования моделей это 2000 изображений, соответственно имеется 2000 последовательностей из 20 кликов (10 минимизирующих и 10 максимизирующих метрики качества IoU/BioU).
Из уровня техники известно, что метрика IoU рассчитывается как отношение пересечения эталонной маски и предсказанной к их объединению. BioU считается также, но учитывает лишь 2% граничных пикселей выделяемого объекта https://www.baeldung.com/cs/object-detection-intersection-vs-union.
На Фиг. 2 показана визуализация масок сегментации, полученных известными нейронными сетями интерактивной сегментации RITM (третья строка сверху) и SimpleClick (четвертая строка сверху) на основании кликов пользователя по входному изображению в сравнении с эталонными масками сегментации (вторая строка сверху).
В строке «Image/clicks» - показаны сегментируемые изображения. Белые кружки обозначают клики пользователя, черные кружки - клики, соответствующие базовой стратегии (то есть заложенные в обычной нейронной сети). В строке «ground truth mask» - показаны эталонные маски сегментации, специально и заранее подготовленные для обучения и тестирования моделей (размечаются профессиональным разметчиком). Если пользователь не попадет в область клика, заложенную изначально в нейронной сети, то сегментация осуществиться плохо, значит выделится не та область для сегментации, которая требуется, то есть нейронная сеть предскажет маску сегментации, не совпадающую с эталонной маской, которая белым изображена во второй строке.
Строка «RITM» - показана тепловая карта (то есть аггрегированные значения качества всех масок во всех положениях кликов) метрики IoU переборным методом анализа для каждого возможного положения клика на сетке пикселей исходного изображения для нейронной сети RITM. Тепловая карта получается следующим образом: выполняется перебор всех целочисленных координат пользовательских вводов и считаются метрики качества IoU, затем полученное скалярное значение переводится в цвет в соответствии с цветовой палитрой тепловой карты (чем теплее цвет, тем выше IoU).
Строка «SimpleClick» - показана тепловая карта (то есть аггрегированные значения качества всех масок во всех положениях кликов) метрик IoU переборным методом анализа для каждого возможного положения клика на сетке пикселей исходного изображения для нейронной сети SimpleClick.
Фиг. 2 показывает, что клики пользователя не обязательно ставятся в центр фрагмента, который необходимо сегментировать, а также показывает, что качество предсказанных масок сегментации известных моделей RITM и SimpleClick могут существенно меняться в зависимости от положения кликов пользователя, то есть известные нейронной сети не вполне устойчивы и требуют переобучения для повышения точности предсказания масок сегментации.
Во время разработки предлагаемого изобретения было обнаружено и осуществлено следующее:
• Новое исследование шаблонов кликов реальных пользователей, которое показало, что пользователи не всегда кликают по центру объекта, как предполагается в большинстве существующих методов интерактивной сегментации. В известных моделях предположение, что ввод пользователя должен находиться в центре фрагмента, подлежащего сегментации, делалось для упрощения процесса генерации пользовательских вводов во время обучения.
• Разработана процедура генерации последовательностей взаимодействий посредством адверсативной атаки. Основываясь на дифференцируемом рендеринге пользовательских вводов, предлагаемая процедура остается полностью дифференцируемой и быстро сходящейся, так как задача поставлена к дифференцируемой оптимизации и не требуется выполнение полного перебора всех возможных положений вводов пользователя.
• Разработана процедура повышения качества и надежности нейронной сети интерактивной сегментации посредством процесса обучения, связанного с добавлением генерируемых адверсативных вводов во время обучения. Предлагаемое использование для улучшения качества и устойчивости с помощью изобретения.
• Представлен сравнительный анализ TETRIS (сравнительный анализ надежности), содержащий 2000 изображений высокого разрешения, тщательно отобранных и размеченных вручную с помощью тонких масок сегментации, то есть качественно размеченных эталонных масок сегментации для тестирования моделей интерактивной сегментации изображений. Половина предлагаемого набора данных (изображения, маски) содержит различные классы объектов. В TETRIS введено всего 2000 объектов, из них 1000 люди, и 1000 объектов из классов: транспорт, дикое животное, объект, домашнее животное, еда, архитектура, растение, статуя, а другая половина включает фотографии людей, которые, возможно, являются наиболее распространенным объектом редактирования в реальных сценариях.
• Сформулированы метрики надежности для задачи интерактивной сегментации и оценена надежность современных методов на основе предлагаемого TETRIS и известных стандартных сравнительных критериев (например, следующих известных наборов данных - GrabCut, Berkeley, DAVIS, COCO_Mval
https://arxiv.orq/pdf/2102.06583.pdf,
https://arxiv.org/pdf/2001.10331.pdf).
Предложенная методология позволяет создать более надежную и качественную нейронную сеть интерактивной сегментации изображений. Предлагаемое изобретение позволяет обучать как совсем новые нейронные сети, так и переобучать имеющиеся. При этом улучшая их показатели качества и устойчивости.
Ниже описаны этапы тестирования устойчивости известных моделей RITM и SAM. Здесь идет речь о сборе координат настоящих кликов профессиональных разметчиков для проверки гипотезы, что люди не всегда кликают в центр. Первый раунд взаимодействия предполагает кликать так, чтобы выделить объект, второй раунд - так чтобы исправить маску первого раунда. В каждом раунде взаимодействия каждый разметчик делает один клик.
Первый раунд взаимодействия.
Этап нужен для сбора кликов человека-разметчика, которые нужны для подтверждения, что проблема зависимости качества нейронной сети от положений вводов не выдумана, а действительно существует и более того, настоящие пользователи с ней сталкиваются. Для исследования с реальными пользователями предлагается следующая настройка. Сначала отбираются по 5 изображений из каждой категории предлагаемого подмножества объектов TETRIS. Отбор осуществляется из 2000 изображений, причем случайно выбираются 5 (изображений из каждой категории)*8 (категорий, описанных выше)=40 изображений. Отобранные изображений отображаются пользователю в веб-интерфейсе, который состоит из двух окон - слева окно с исходным изображением, справа окно с таким же изображением и с эталонной, качественно размеченной профессиональными разметчиками маской сегментации. На изображениях из тестового датасета имеется эталонная маска. Цель разметчика - кликнуть в объект, обозначенный этой маской. Задача для пользователя на первом раунде взаимодействия была сформулирована следующим образом - ваша задача совершить один клик по объекту в окне слева, обозначенному маской в правом окне. Всего в первом раунде приняли участие 600 отдельных людей, получивших по 15 взаимодействий на одно изображение. То есть, собираются 40*15=600 пользовательских вводов (сделанных профессиональными разметчиками) на которых проверяется гипотеза о влиянии положений вводов на качество сегментации. Фиг. 3 (подробное описание фигуры будет дано далее) иллюстрирует эти 600 вводов, по оси X показаны различные объекты, которые предлагались разметчику. Каждый столбец иллюстрирует качество маски сегментации для моделей RITM и SAM. Каждая точка внутри одного столбца представляет собой один клик на фрагмент изображения, который необходимо сегментировать. Если бы нейронной сети RITM и SAM были бы устойчивыми, то все пользователи и разметчики при клике на фрагмент сегментации получали бы одинаковую маску, но в реальности наблюдаются сильные различия в качестве получаемых масок. Второй раунд взаимодействия.
Для второго раунда тестируется только нейронная сеть HRNet18 RITM (Sofiiuk, Petrov и Konushin 2021) на всех взаимодействиях из первого раунда, то есть для тестирования нейронной сети RITM используются все изображения и маски сегментации, которые использовались в первом раунде. Нейронная сеть RITM запускается на 600 полученных в первом раунде взаимодействиях. Рассчитываются отношение площади пересечения к площади объединения (IoU) и два типа ошибок на каждом изображении - Ложно Положительный (нейронная сеть выбирает больше области, чем было в эталонной маске и Ложно Отрицательный (нейронная сеть пропустила некоторую область, которая была в эталонной маске). То есть, в RITM подают все изображения, которые использовались в первом раунде, и все координаты кликов разметчиков. Каждый из 600 кликов и соответствующих им изображений подаются по отдельности, чтобы получить маску для каждого из 600 кликов.
Маску второго раунда нужно исправлять т.к. разметчик видит, где она отличается от эталонной маски (например, что-то выделилось лишнее или наоборот нейронная сеть пропустила часть объекта).
Для отбора примеров масок сегментации, требующих исправления, после первого раунда взаимодействия производится тестирование нейронной сети RITM на всех собранных кликах первого раунда, то есть на координатах 600 кликов, и нейронная сеть RITM предсказывает свои маски.
Затем отбираются 40 лучших образцов масок, полученных при подаче в нейронную сеть RITM координат кликов первого раунда. Выбираются худшие по IoU маски с наибольшим количеством ошибок из каждой категории ошибок соответственно для того, чтобы разметчик сделал повторный клик для масок с ошибкой Ложно Положительный (FP), разметчика просят сделать отрицательный клик. Для этого, считая ошибку с эталонной маской выбирают наибольшую (то есть, смотря пересечения предсказанной и эталонной маски сравниваем площади ошибочных областей). Если наибольшая ошибка вне объекта (например, выделилось что-то лишнее, на фотографии два человека, а разметчику нужен только один, но выделились оба, т.е. ошибочный регион (со вторым человеком) вне целевого объекта (первого человека)), то нужен отрицательный клик, если внутри объекта, то положительный для коррекции маски. Для масок с ошибкой Ложно Отрицательный (FN) - сделать положительный клик соответственно. Изображение в левом окне соответственно отображалось с объектом, закрытым маской предыдущего раунда с прозрачностью (для обоих типов ошибок). На этом этапе участвовало еще 1200 отдельных разметчиков по 15 взаимодействий на каждое изображение каждого типа взаимодействия.
Анализ
Клик базовой стратегии, изначально заложенный в нейронной сети (клик по центру), согласуется с пользовательскими вводами только на простых круглых объектах (фрагмент для сегментации). В случае сложной геометрии фрагмента пользователи кликают по области с наибольшей площадью или выделяют части фрагмента для сегментации. Однако пользовательские вводы более сосредоточены вблизи геометрического центра, а не в области с максимальным преобразованием расстояния. Другими словами, базовая стратегия (клик по центру) работает только на простых фрагментах для сегментации, а на сложных пользователи кликают непредсказуемо. Таким образом, известные способы оценки качества моделей интерактивной сегментации не отражают настоящее качество этих моделей, которое увидят конечные пользователи при использовании нейронной сети для интерактивной сегментации изображений. То есть предсказание маски будет некачественным.
Особенно это заметно на длинных и тонких примерах, таких как змея (см. Фиг. 2 белые кружочки в верхней строке). По стандартной стратегии (заложенная в уже готовых нейронных сетях интерактивной сегментации) совершается клик по голове, где самая толстая часть объекта, однако пользователи кликают по логическому центру. Можно отметить, что качество нейронных сетей сильно различается в зависимости от положения реальных кликов пользователя.
Фигура 3 иллюстрирует значения показателей метрики IoU в зависимости от вида сегментируемого изображения. На фиг. 3 по оси X - название тестовых изображений (40 изображений), которые входят в обучающий набор данных TETRIS, цифры рядом с названиями тестовых изображений обозначают количество фрагментов данного изображения для сегментации. Например, еда-2 означает второе из 5 изображений в категории еда, то есть цифра - это номер изображения внутри категории, а индекс 0 - нулевое изображение внутри категории. По оси Y - метрика IoU. Прямоугольник - это среднее значение качества (IoU), рассчитанные 15 пользователями. То есть берутся 15 пользователей и известная модель, пользователь кликает, нейронная сеть предсказывает маску сегментации, далее по предсказанной маске сегментации считается IoU этой нейронной сети, и так для 15 пользователей, потом считается среднее значение. Каждая точка А отражает положение одного клика пользователя. Каждая точка В отражает клик по стандартной стратегии (то есть клик, заложенный в нейронной сети для интерактивной сегментации изображений). RITM и SAM две выбранные для исследования известные из уровня техники нейронной сети для интерактивной сегментации изображения. Стандартный клик осуществляется автоматически по базовой стратегии (клик в центр объекта), стандартный клик заложен в каждую известную нейронная сеть интерактивной сегментации изображения.
Видно, что более чем на половине тестовых выборок положение пользовательского клика сильно влияет на качество нейронной сети. Это также показывает, что пользователи легко попадают в эти сложные адверсативные моменты и получают крайне низкое качество сегментации. Сложные адверсативные точки - это точки, которые имеют значительно более низкое качество сегментации (IoU) при кликах в них. Поэтому такие положения кликов являются сложными адверсативными данными для нейронной сети при обучении.
Протокол оценки
Для начала давайте неформально определим надежность нейронной сети интерактивной сегментации - способность нейронной сети выводить стабильную, неизменную маску. При разных кликах на одну и ту же область для сегментации нейронная сеть выдает на выходе разные маски сегментации, для устойчивости же нужно, чтобы независимо от точности наведения пользователя своим кликом на нужный фрагмент маски не отличались друг от друга. Рассматриваются два вида взаимодействий - позитивные для добавления новых фрагментов сегментации изображения и негативные для удаления лишних фрагментов из фрагментов сегментации. Считаются действительными вводы, удовлетворяющие проверкам работоспособности - в первом раунде взаимодействий клик должен быть выполнен в маске объекта. В последующих раундах следующий положительный клик также размещается в маске, но только в той области, которая еще не выделена. Негативный клик размещается за пределами маски и только в уже выделенных областях.
Переборный метод анализа
Самый простой способ оценки устойчивости нейронной сети можно сформулировать как перебор всех возможных пользовательских вводов.
Однако даже для небольшого входного изображения с разрешением 400 пикселей полный поиск по 160000 вариантов (возможные варианты клика в один из пикселей изображения размером 400×400) требует нескольких часов на одно изображение и делает невозможным оценку нейронной сети на полном наборе данных (например, в TETRIS 2000 изображений) в разумные сроки. Приведены (см. фиг. 2) результаты перебора по всей целочисленной координатной сетке (координаты каждого пикселя входного изображения для полного перебора положений вводов) для нейронных сетей с кликами по 40 тестовым изображениям на основе исследования с участием пользователей.
Адверсативные вводы
Вследствие наличия недостатков в концепции перебора за разумное время предложен способ оптимизации, позволяющий сократить время обработки одного изображения с нескольких часов до нескольких секунд. Однако отметим, что данный подход позволяет искать только локальный экстремум функции потерь (градиентный спуск сходится к нему).
Определяется адверсативный клик пользователя как пара обучаемых (оптимизированных) 2d-координат (х,у) положения вводов пользователя. Используя технику дифференцируемого рендеринга, обучаемые координаты (х,у) отображаются в одноканальные изображения с кругами, центры которых имеют эти координаты, в одноканальные карты изображений с кругами, отрисованными в этих координатах. Круги отображаются по координатам оптимизируемых кликов. Радиус круга зависит от требований нейронной сети. Некоторые нейронные сети дополнительно принимают необработанные координаты без какой-либо обработки. Затем собираются все введенные пользователем данные с входным изображением и передаются в интерактивную нейронную сеть. Путем расчета потерь между выходными данными нейронной сети и эталонной маской выполняется обновление градиента для наилучшего и наихудшего местоположения точек, тем самым получая две траектории - максимизирующую и минимизирующую метрику IoU.
На фигуре 4 показаны: (А) стандартная оценка для интерактивной сегментации с вычислением площади под кривой IoU/BIoU (стрелки везде обозначают переходы между раундами взаимодействий); (В) предложенная метрика устойчивости IoU/BIoU-D как разница между площадями кривых для максимизации и минимизации траекторий адверсативных вводов; (С) предложенная метрика устойчивости IoU/BIoU-OG, определяемая областью прироста оптимизации под кривой для каждого адверсативного ввода. Все три графика показывают используемые метрики качества. График (А) - классический подсчет IoU как площади под кривой. График (В) - две траектории (IoU-Min и IoU-Max) и предлагаемая метрика устойчивости (IoU-D). График (С) - предлагаемая метрика устойчивости IoU-OG, расчет изменения метрики от оптимизации без учета изменения от добавления нового клика. Метрики устойчивости
Всего рассчитано 3 траектории симулированных адверсативных кликов (минимизации, максимизации IoU и базовая траектория кликов в центры объектов (такова базовая стратегия известных моделей интерактивной сегментации) - для нижней и верхней границ IoU (границ качества нейронной сети при изменении положения вводов - симулируются пользовательские вводы путем максимизации и минимизации потерь Dice во время оптимизации, например, поиск адверсативных вводов, которые максимизируют и минимизируют метрики IoU и BIoU (BIoU - версия IoU, учитывающая только границы). Третья траектория обозначает стандартную стратегию.
Первая предложенная метрика представляет собой простую разницу между площадями максимальной и минимизирующей кривых (IoU-D).
На фиг. 5 показана визуализация траекторий для 8-ми известных моделей на 5-ти датасетах (GrabCut, Berkeley, DAVIS, COCO-MVal, предлагаемый TETRIS) графики показывают визуализацию качества на траекториях из 10 кликов. По оси X в каждой клетке отражен номер раунда взаимодействий, по оси Y - метрика качества IoU. Верхняя строка - минимизирующая траектория, центральная - базовая, нижняя - максимизирующая. Как следует из фиг. 5, все три траектории сходятся с увеличением количества кликов. И разрыв соответственно уменьшается. Поэтому все эксперименты и расчеты проводятся за 10 кликов. Вторая предложенная метрика (то есть метрика IoU-OG) предназначена только для измерения выгоды от оптимизации. Как видно на кривой минимизации, с добавлением новых кликов качество все равно улучшается, поскольку даже плохой клик добавляет новую информацию. Таким образом, выгода IoU раскладывается на два слагаемых - выгода от нового клика и выгода от оптимизации (IoU-OG).
Технические детали реализации оценки устойчивости.
Для оценки принят дифференцируемый конвейер для методов интерактивной сегментации с доступной реализацией - RITM (Sofiiuk, Petrov и Konushin, 2021), CDNet (Chen и др., 2021), SimpleClick (Sofiiuk, Petrov и Konushin, 2021), CFR-ICL (Sun и др. 2023), GPCIS (Zhou и др. 2023). Мы также включаем нейронные сети сегментации с функцией подсказки - SAM (Kirillov и др. 2023), SAM-HQ (Ke и др. 2023), MobileSAM (Zhang и др. 2023). Всего проверено более 20 контрольных точек (то есть 20 различных моделей) на 4 известных наборах данных Grab-Cut, Berkeley, DAVIS, COCO-MVal и предлагаемом наборе данных высокого разрешения TETRIS.
Нормы градиентов по параметрам кликов исследовались при оптимизации 50 шагов нейронной сети RITM, и был сделан вывод, что большая часть изменений происходит на первых итерациях, поэтому количество шагов фиксируется на 10 обновлениях (Kingma и Ва 2014) с оптимизатором во всех экспериментах.
Чтобы уравнять нейронные сети с разным разрешением на входе, скорость обучения линейно масштабируется по коэффициенту размера вводов 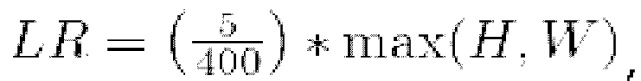 где 5/400 - нормирующий множитель, Н - высота изображения в пикселях, W - ширина изображения в пикселях. Клики размещаются плотно один за другим с инициализацией из стандартной стратегии - центры областей с наибольшей ошибкой.
где 5/400 - нормирующий множитель, Н - высота изображения в пикселях, W - ширина изображения в пикселях. Клики размещаются плотно один за другим с инициализацией из стандартной стратегии - центры областей с наибольшей ошибкой.
В ходе экспериментов было выявлено, что найти наихудшее положение клика гораздо проще, чем найти наилучшее. Однако такие обнаруженные вводы не прошли проверку работоспособности - например, положительные клики за пределами целевого объекта. Поэтому была добавлена регуляризация, позволяющая учитывать только действительные вводы во время оптимизации. Регуляризация заключается в построении карты расстояний от маски для всех областей ложноположительных (FP) и ложноотрицательных (FN) ошибок. При этом для положительного клика суммируется карта расстояний FN в положениях, охватываемых этим кликом, и FP для отрицательного клика. Суммарная потеря состоит из двух величин - Dice (1945) и величины регуляризации (потерь местоположения при взаимодействии) с коэффициентом 1000. На этапах оптимизации сохраняются только действительные положения входов в соответствии с двумя условиями:
1. Новый этап лучше с точки зрения показателей метрик IoU и BIoU в зависимости от текущего режима оптимизации (минимизация или максимизация).
2. Новое положение не ухудшает потерю маски с допуском 5%.
Иллюстрация одного этапа представлена на фиг. 1. Обратите внимание, что некоторые нейронные сети используют пользовательские вводы в необработанном формате. Для них пропускается этап дифференцируемого рендеринга и координаты оптимизируются напрямую. Также реализованы все использованные авторами приемы оценки, такие как ZoomIn (Sofiiuk и др., 2020), Cascade-Refinement (Sun и др., 2023), перевороты с приращением во время тестирования (Sofiiuk, Petrov и Konushin, 2021), выбор маски по прогнозируемым оценкам (Kirillov и др., 2023) и т.д., а также выполнена их совместимость с предлагаемой структурой.
TETRIS
5.1 Сбор Данных
Выбор классов объектов. В TETRIS классы объектов выбираются в соответствии с требованиями конкретной задачи. В частности, выбираются классы объектов, которые могут оказаться полезными для редактирования и маркировки изображений. Всего рассмотрено 9 метаклассов: транспорт, дикое животное, предмет, домашнее животное, еда, архитектура, растение, статуя, человек. Таким образом, включены классы, присутствующие в PASCAL VOC 2012 (Everingham и др.), и некоторые другие распространенные классы COCO (Lin и др. 2014) (за исключением людей по соображениям конфиденциальности).
Получение и аннотирование изображений - ручная разметка датасета для получения эталонных масок сегментации.
1000 изображений с фотосайта Unsplash отбираются вручную. Лицензия Unsplash (https://unsplash.com/license) позволяет бесплатно использовать изображения в любых целях. С помощью инструмента маркировки CVAT (cva 2018) собранные изображения сегментируются на полигональные области, классифицируемые как передний план, задний план или неопределенные. Затем к неопределенным областям применяется матирование, так что они становятся либо передним планом, либо задним планом.
Если на изображении показано несколько объектов, то соответствующие альфа-карты объединяются и для них устанавливаются пороговые значения для получения двоичной маски сегментации. Наконец, все маски проверяются профессиональным разметчиком.
Таблица 1: Таблица оценки различных нейронных сетей на трех наборах данных. Предусмотрены области минимизации, базовой линии и максимизации под кривыми IoU с предлагаемыми метриками устойчивости IoU-D и IoU-OG. Столбцы слева направо - название метода (Method), название архитектуры нейронной сети (Model), набор данных для обучения (Data) (SBD - (Hariharan и др., 2011), C+L - (Lin и др., 2014), SA-1В - (Kirillov и др., 2023)), три набора данных для тестирования (Berkeley (Martin и др. 2001), DAVIS (Perazzi и др. 2016а), TETRIS (предложен)) по 5 столбцов каждый - первые три столбца обозначают область под кривыми минимизации, базового уровня и максимизации IoU для 10 раундов взаимодействия. Последние два столбца обозначают предлагаемые метрики надежности IoU-D и IoU-OG.
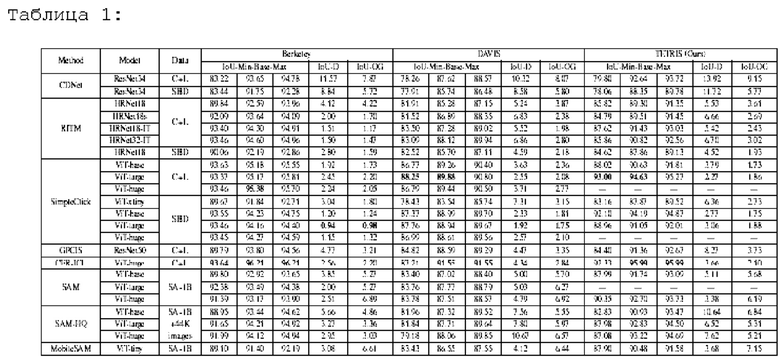
Таблица 2: Сравнение набора данных TETRIS с существующими сравнительными критериями интерактивной сегментации.
Предлагаемый сравнительный критерий содержит изображения со значительно большим разрешением (медиана 12 МП), чем существующие наборы данных (медиана от 0,2 МП до 0,4 МП), что делает его гораздо более подходящим для тестирования методов интерактивной сегментации в реальных сценариях. Столбцы слева направо - название набора данных (Dataset), количество изображений (Images), количество экземпляров (Instances) и медианное разрешение (median resolution).
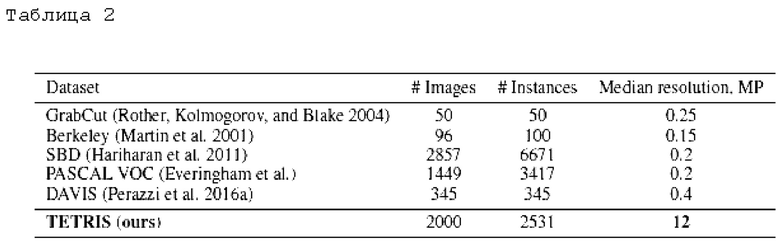
На фигуре 6 показано время аннотации на одно изображение (затраченное время у профессионального разметчика на получение эталонной маски сегментации). В среднем на маркировку одного изображения с высоким разрешением уходит всего 32 минуты; большинство изображений были помечены в течение 2 часов. На создание самого сложного изображения ушло около 5 часов.
Статистика набора данных
Анализ данных. На фигуре 7 показана статистика набора данных TETRIS.
7 (А) - гистограмма распределения классов объектов по категориям;
7 (B) распределение тендеров людей в датасете;
7 (С) распределение возрастов в датасете;
7 (D) географическое распределение фотографий в датасете;
7 (E) распределения размеров объектов в мегапикселях;
7 (F) распределение размеров изображений.
Общий вывод - предложенный датасет TETRIS - достаточно разнообразен и может быть использован для оценки качества моделей с точки зрения реального применения т.к. содержит разнообразные изображения.
Метрики, связанные с человеком, предусматривали подмножество предлагаемого набора данных, предназначенное только для людей. Количественное сравнение наборов данных интерактивной сегментации представлено в таблице 2. Помимо низкого разрешения, GrabCut (Rother, Kolmogorov и Blake, 2004) и Berkeley (Martin и др., 2001) имеют слишком мало примеров. 345 кадров DAVIS (Perazzi и др., 2016а) взяты всего из 50 видео, поэтому визуальное разнообразие сильно ограничено. PASCAL VOC 2012 (Everingham и др.) и SBD (Hariharan и др. 2011) используют один и тот же набор изображений только 20 классов, поэтому разнообразие классов в обоих сравнительных анализах незначительное. Кроме того, границы объектов в PASCAL VOC чрезвычайно грубы, что делает его не очень полезным для тестирования методов высокого разрешения.
Чтобы получить полную картину, предложенный набор данных сравнивается с недавно представленными наборами данных семантической сегментации и матирования. Помимо формальных, объективных, количественных характеристик, таких как количество изображений, количество экземпляров, разрешение изображения и т.д., важно удобство использования. Удобство использования является неотъемлемой характеристикой, подразумевающей правильное лицензирование (свободное использование, включая коммерческие приложения), отсутствие нарушения конфиденциальности (все изображенные люди должны дать четкое согласие) и любые другие вопросы, которые могут ограничить или запретить использование набора данных для любых академических или коммерческих целей.
В отличие от синтетического набора данных Compositions-1K (Xu и др., 2017), содержащего реальные объекты, вставленные в фоновые изображения из Pascal VOC и COCO, TETRIS включает в себя реальные данные, вручную помеченные разметчиками-людьми. Соответственно, доменный разрыв между TETRIS и реальными фотографиями меньше, а результаты, полученные для TETRIS, более адекватно отражают качество интерактивной сегментации.
Набор данных MOS-600 (Yang и др., 2020), который еще не опубликован, содержит изображения, изображающие объекты сложной структуры без аннотаций масок: позволяет только качественное сравнение, что является огромным недостатком для сравнительного анализа. BIG (Cheng и др., 2020) на самом деле небольшой: всего 50 проверочных и 100 тестовых изображений, по одному объекту на изображение. AIM500 (Li, Zhang и Тао) также меньше, чем TETRIS и содержит всего 500 образцов. Он также имеет нечеткую лицензию на изображение и, по всей видимости, содержит 100 фотографий людей, согласие на использование которых не было получено. Это делает AIM500 непригодным для коммерческого применения. АМ-2к (Li и др., 2022) содержит только изображения животных, a PM-10k (Li и др., 2022) состоит из портретов людей. Оба они относятся к более узкой области, тогда как TETRIS не ограничивается какой-то конкретной категорией, а стремится охватить широкий спектр сценариев. У АМ-2k те же проблемы с лицензированием, что и у AIM500. РМ-10k не является общедоступным из-за проблем с конфиденциальностью. Однако версия этого набора данных, подвергшаяся размытию лиц с целью сохранения конфиденциальности, опубликована как РЗМ-10k. Однако по-прежнему существует обеспокоенность по поводу конфиденциальности, поскольку человека можно идентифицировать, даже если его лицо размыто. В этом исследовании показана маска сегментации строгой зависимости, выводимая известными нейронными сетями интерактивной сегментации относительно местоположения вводимых пользователем данных. Приведены результаты исследования с реальными пользователями и анализа ответов 1800 участников. Предлагаются стратегия генерации адверсативных вводов для улучшения качества нейронных сетей интерактивной сегментации, повышения их устойчивости и оценки диапазона возможного качества в реальных приложениях, а также предложенная стратегия оценки множественных траекторий, которая позволяет формулировать метрики устойчивости (IoU-D и IoU-OD) для задачи интерактивной сегментации. Эти метрики проверены на десятках общедоступных нейронных сетей на известных наборах данных и предложенном сравнительном анализе TETRIS с 2000 изображениями с высоким разрешением, размеченными вручную.
Вышеизложенные примерные варианты осуществления являются примерами и не должны рассматриваться как ограничивающие. Кроме того, описание примерных вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и специалистам в данной области техники будут очевидны многие альтернативы, модификации и вариации.
Ссылки
2018. Computer Vision Annotation Tool (CVAT). https://github.com/openvinotoolkit/cvat.
Agustsson, E.; Uijlings, J.R.R.; and Ferrari, V. 2019. Interactive Full Image Segmentation by Considering All Regions Jointly. In CVPR.
Bai, J.; and Wu, X. 2014. Error-Tolerant Scribbles Based Interactive Image Segmentation. In CVPR. Batra, D.; Kowdle, A.; Parikh, D.; Luo, J.; and Chen, T. 2010. iCoseg: Interactive co-segmentation with intelligent scribble guidance.
Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; and Yuille, A.L. 2018. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. TPAMI.
Chen, X.; Zhao, Z.; Yu, F.; Zhang, Y.; and Duan, M. 2021.
Conditional diffusion for interactive segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 7345-7354.
Cheng, В.; Girshick, R.; Doll'ar, P.; Berg, A.C.; and Kirillov, A. 2021a. Boundary IoU: Improving object-centric image segmentation evaluation. In CVPR.
Cheng, H.; Xu, S.; Jiang, X.; and Wang, R. 2021b. Deep Image Matting with Flexible Guidance Input. In BMVC.
Cheng, H.K.; Chung, J.; Tai, Y.-W.; and Tang, C.-K. 2020. CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement. In CVPR.
Csurka, G.; Larlus, D.; and Perronnin, F. 2013. What is a good evaluation measure for semantic segmentation? In BMVC.
Dice, L.R. 1945. Measures of the amount of ecologic association between species. Ecology, 26(3): 297-302.
Everingham, M.; Van Gool, L.; Williams, С.K.I.; Winn, J.; and Zisserman, A. The PASCAL Visual Object Classes
Challenge 2012 (VOC2012) Results, http://www.pascalnetwork.org/challenges/VOC/voc2012/workshop/index.html.
Guan, Z.; Hu, M.; Zhou, Z.; Zhang, J.; Li, S.; and Liu, N. 2023. Badsam: Exploring security vulnerabilities of sam via backdoor attacks. arXiv preprint arXiv:2305.03289.
Gueziri, H.-E.; McGuffin, M.; and Laporte, C. 2017. Latency Management in Scribble-Based Interactive Segmentation of Medical Images. IEEE Transactions on Biomedical Engineering.
Hariharan, В.; Arbelaez, P.; Bourdev, L.; Maji, S.; and Malik, J. 2011. Semantic Contours from Inverse Detectors. In ICCV.
Jang, W.-D.; and Kim, C.-S. 2019. Interactive image segmentation via backpropagating refinement scheme. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5297-5306.
Kamann, C.; and Rother, C. 2020. Benchmarking the robustness of semantic segmentation neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8828-8838.
Ke, L.; Ye, M.; Danelljan, M.; Liu, Y.; Tai, Y.-W.; Tang, С.-K.; and Yu, F. 2023. Segment Anything in High Quality. arXiv preprint arXiv:2306.01567.
Kingma, D.P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, Т.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. 2023. Segment anything. arXiv preprint arXiv:2304.02643.
Kohli, P.; Ladick'y, L.; and Torr, P. 2009. Robust Higher Order Potentials for Enforcing Label Consistency. IJCV.
Li, J.; Zhang, J.; Maybank, S.J.; and Tao, D. 2022. Bridging Composite and Real: Towards End-to-End Deep Image Matting. In IJCV. Li, J.; Zhang, J.; and Tao, D. Deep Automatic Natural Image Matting. In IJCAI-21.
Li, T.-M.; luk'aˇc, M.; Micha¨el, G.; and Ragan-Kelley, J.
2020. Differentiable Vector Graphics Rasterization for Editing and Learning. ACM Trans. Graph. (Proc. SIGGRAPH Asia), 39(6): 193:1-193:15.
Li, Z.; Chen, Q.; and Koltun, V. 2018. Interactive image segmentation with latent diversity. In CVPR.
Liew, J. H.; Cohen, S.; Price, В.; Mai, L.; and Feng, J. 2021. Deep Interactive Thin Object Selection. In WACV.
Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll'ar, P.; and Zitnick, C.L. 2014. Microsoft coco: Common objects in context. In ECCV.
Ma, X.; Zhou, Y.; Xu, X.; Sun, В.; Filev, V.; Orlov, N.; Fu, Y.; and Shi, H. 2022. Towards Layer-wise Image Vectorization. In Proceedings of the IEEE conference on computer vision and pattern recognition.
Martin, D.; Fowlkes, C.; Tal, D.; and Malik, J. 2001. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring cological statistics. In ICCV.
McGuinness, K.; and O'connor, N.E. 2010. A comparative evaluation of interactive segmentation algorithms. Pattern Recognition, 43(2): 434-444.
Papadopoulos, D.P.; Uijlings, J.R.R.; Keller, F.; and Ferrari, V. 2017. Extreme Clicking for Efficient Object Annotation. ICCV.
Perazzi, F.; Pont-Tuset, J.; McWilliams, В.; Van Gool, L.;
Gross, M.; and Sorkine-Hornung, A. 2016a. A benchmark dataset and evaluation methodology for video object segmentation. In CVPR.
Perazzi, F.; Pont-Tuset, J.; McWilliams, В.; Van Gool, L.;
Gross, M.; and Sorkine-Hornung, A. 2016b. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. In CVPR.
Qiao, Y.; Zhang, C; Kang, Т.; Kim, D.; Tariq, S.; Zhang, C.; and Hong, C.S. 2023. Robustness of sam: Segment anything under corruptions and beyond. arXiv preprint arXiv:2306.07713.
Rother, C.; Kolmogorov, V.; and Blake, A. 2004. GrabCut - Interactive Foreground Extraction using Iterated Graph Cuts. ACM transactions on graphics (TOG), 23(3): 309-314.
Sofiiuk, K.; Petrov, I.; Barinova, O.; and Konushin, A. 2020. f-brs: Rethinking backpropagating refinement for interactive segmentation. In CVPR.
Sofiiuk, K.; Petrov, I.A.; and Konushin, A. 2021. Reviving Iterative Training with Mask Guidance for Interactive Segmentation. arXiv preprint arXiv:2102.06583.
Su, J.; Vargas, D.V.; and Sakurai, K. 2019. One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation, 23(5): 828-841.
Sun, S.; Xian, M.; Xu, F.; Yao, Т.; and Capriotti, L. 2023.
CFR-ICL: Cascade-Forward Refinement with Iterative Click Loss for Interactive Image Segmentation.
Wang, Y.; Zhao, Y.; and Petzold, L. 2023. An empirical study on the robustness of the segment anything neural network (sam). arXiv preprint arXiv:2305.06422.
Xu, N.; Price, В.; Cohen, S.; and Huang, T. 2017. Deep Image Matting. In CVPR.
Xu, N.; Price, В.; Cohen, S.; Yang, J.; and Huang, T.S. 2016. Deep interactive object selection. In CVPR.
Yang, C.; Wang, Y.; Zhang, J.; Zhang, H.; Lin, Z.; and Yuille, A. 2020. Meticulous Object Segmentation. arXiv preprint arXiv:2012.07181.
Zhang, C.; Han, D.; Qiao, Y.; Kim, J.U.; Bae, S.-H.; Lee, S.; and Hong, C.S. 2023a. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv preprint arXiv:2306.14289.
Zhang, C.; Zhang, C.; Kang, Т.; Kim, D.; Bae, S.-H.; and Kweon, I.S. 2023b. Attack-sam: Towards evaluating adversarial bustness of segment anything neural network. arXiv preprint arXiv:2305.00866.
Zhou, M.; Wang, H.; Zhao, Q.; Li, Y.; Huang, Y.; Meng, D.;
and Zheng, Y. 2023. Interactive Segmentation As Gaussion Process Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 19488-19497.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ДИСТАНЦИОННОГО ЗОНДИРОВАНИЯ ЗЕМЛИ С ПОМОЩЬЮ НЕЙРОННОЙ СЕТИ СО ШТРАФОМ НА ТОЧНОСТЬ ГРАНИЦЫ СЕГМЕНТАЦИИ | 2019 |
|
RU2740736C1 |
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| СПОСОБ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ОСУЩЕСТВЛЯТЬ РАЗМЕТКИ ТЕЛЕРЕНТГЕНОГРАММ В ПРЯМОЙ И БОКОВОЙ ПРОЕКЦИЯХ | 2019 |
|
RU2717911C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ДЕФЕКТОВ НА ИЗОБРАЖЕНИИ КОМПОЗИЦИОННЫХ ИЗДЕЛИЙ | 2022 |
|
RU2807288C1 |
| СИСТЕМА И СПОСОБ ДИАГНОСТИКИ ПАТОЛОГИЙ ЛЕГКИХ ПО РЕНТГЕНОВСКИМ ИЗОБРАЖЕНИЯМ | 2023 |
|
RU2840011C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ПАТОЛОГИЙ ЛЕГКИХ ПО РЕНТГЕНОВСКИМ ИЗОБРАЖЕНИЯМ | 2023 |
|
RU2840009C1 |
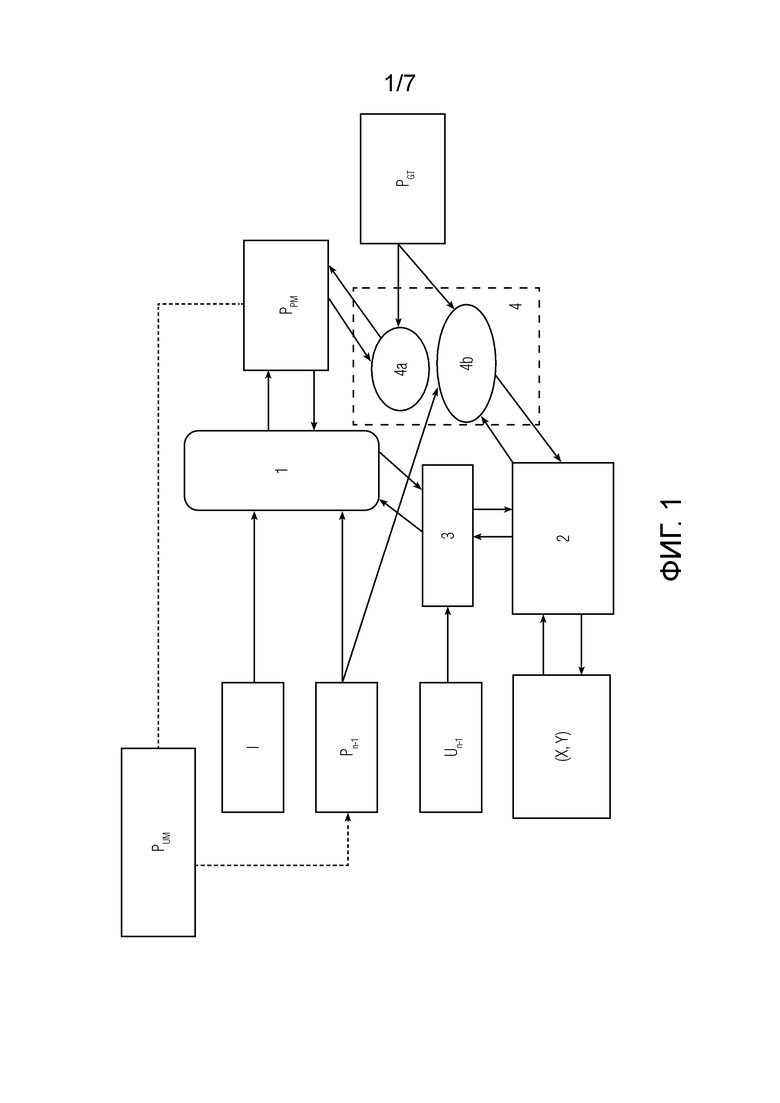
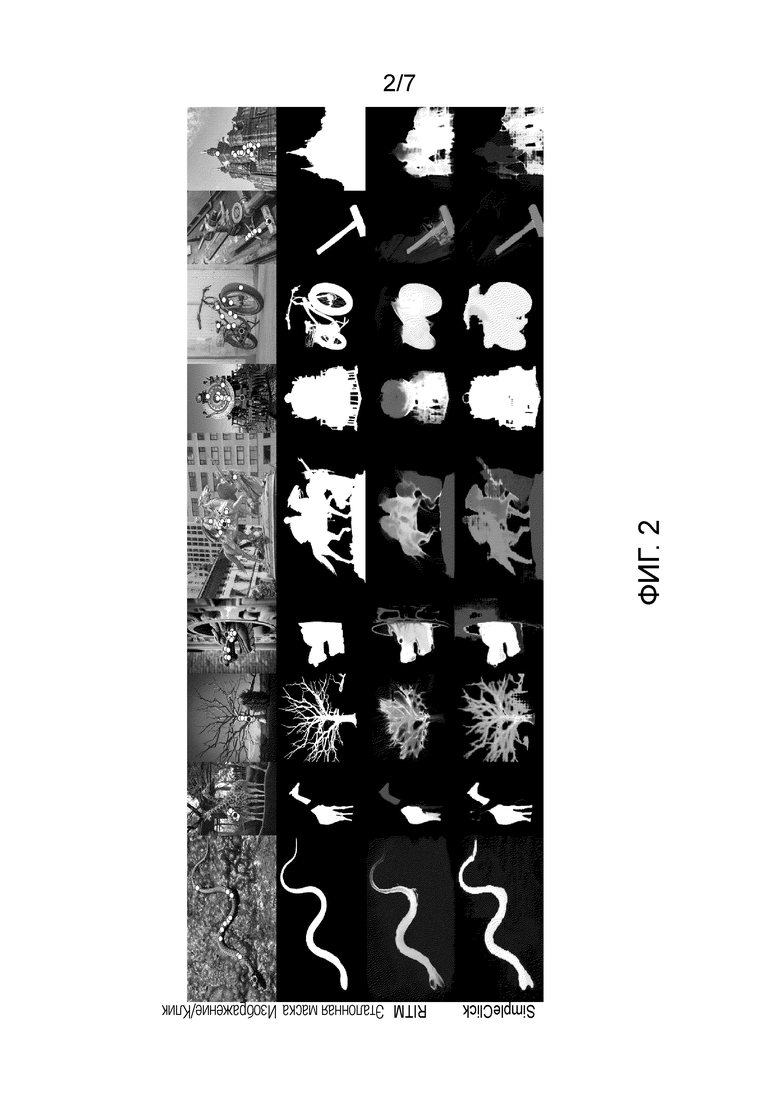
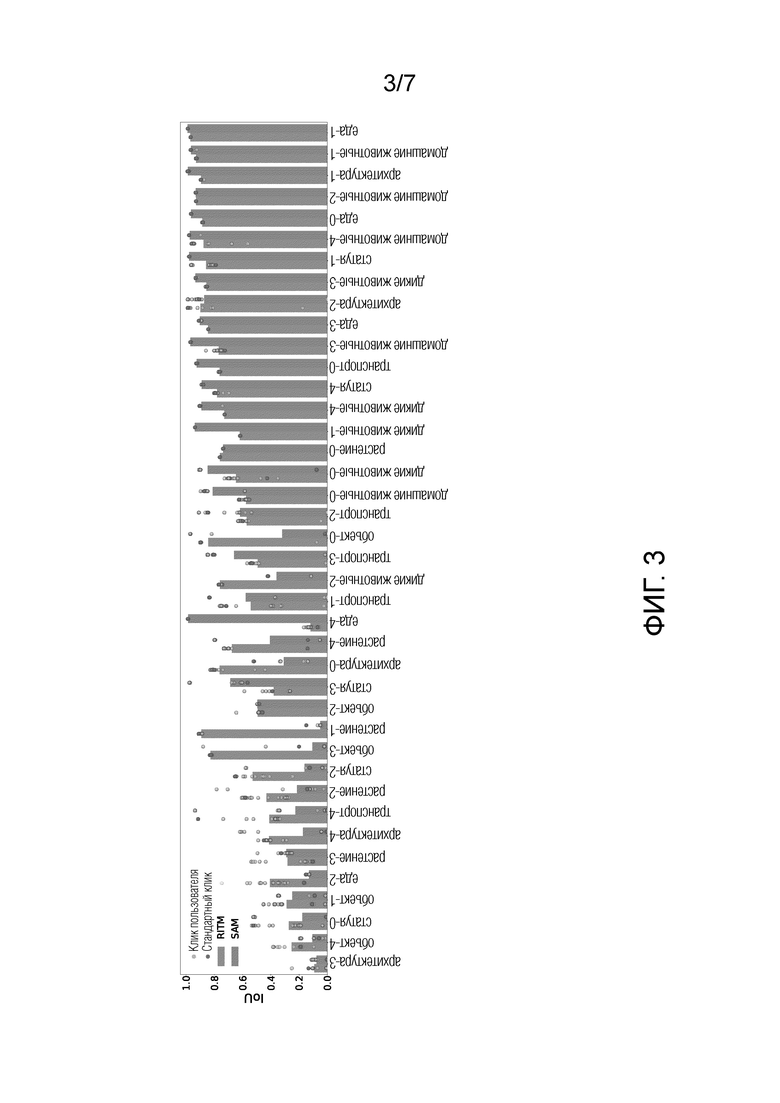
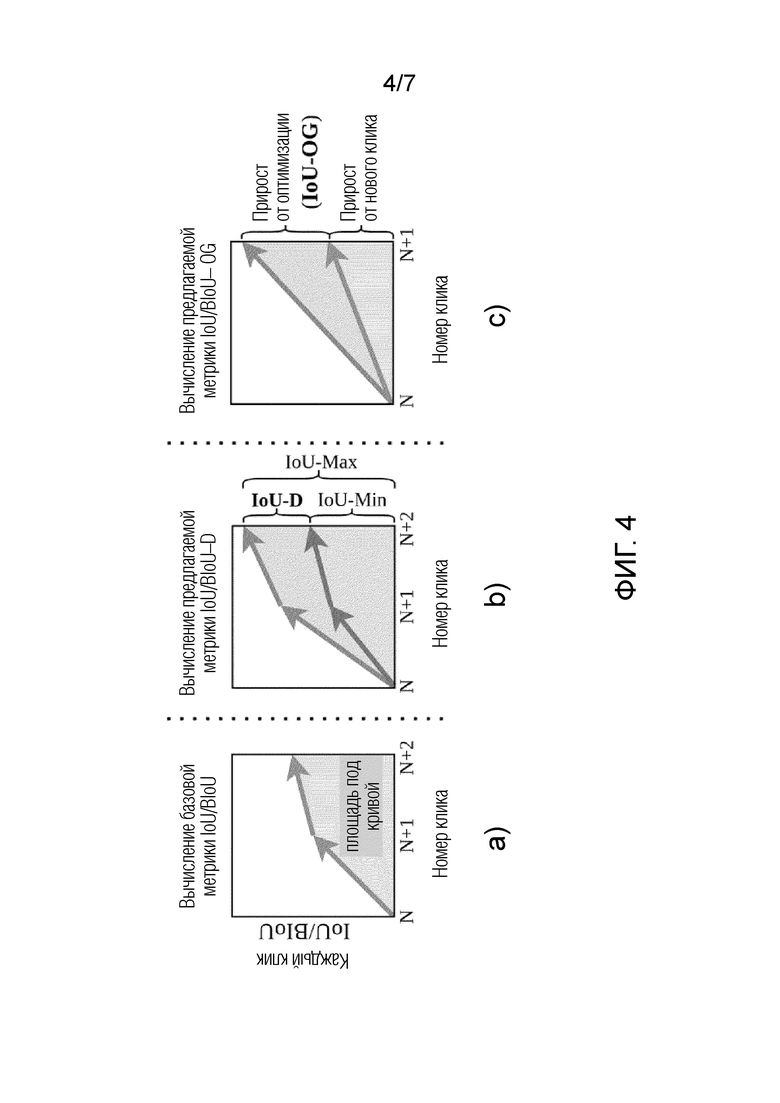

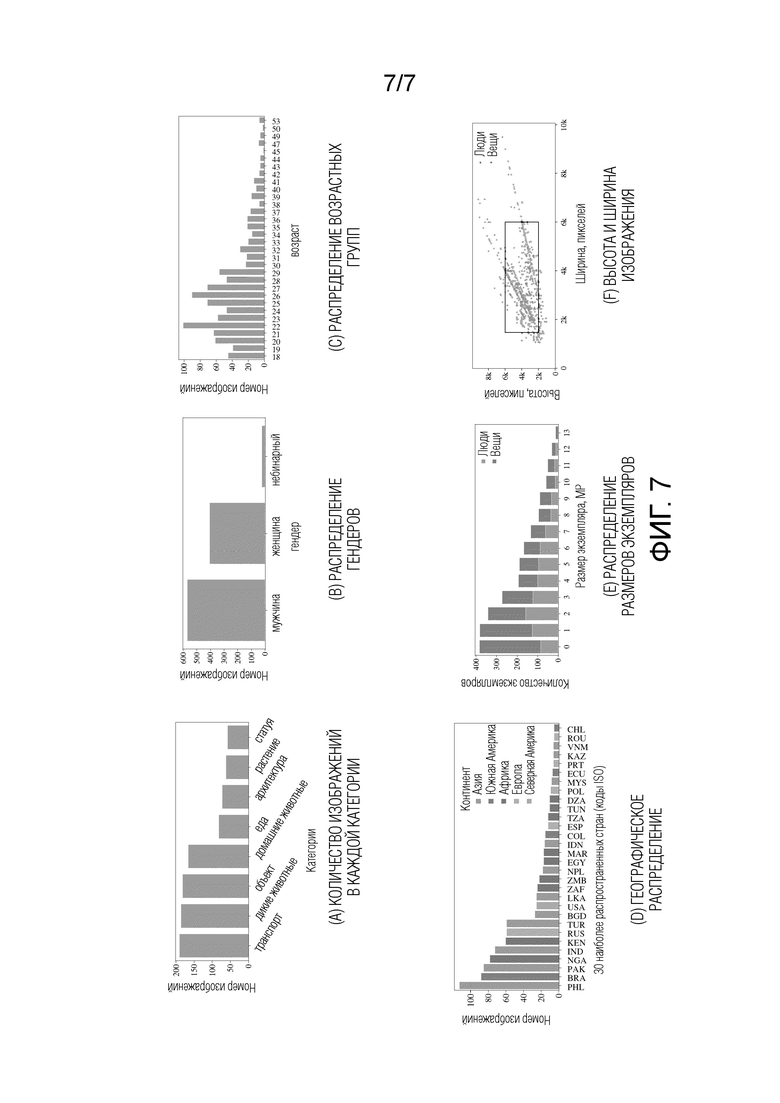
Изобретение относится к способу интерактивной сегментации изображения на основе последовательности кликов пользователя, осуществляемой обученной нейронной сетью для интерактивной сегментации изображений. Технический результат заключается в улучшении качества и повышении точности воспроизведения маски сегментации, предсказанной нейронной сетью. Способ содержит этапы, на которых: подают на вход нейронной сети изображение, координаты клика пользователя; получают на выходе обученной нейронной сети предсказанную маску сегментации, отображают предсказанную маску сегментации на дисплее пользователю. Причем на этапе обучения обучают упомянутую нейронную сеть посредством обучающих координат клика на обучающем изображении до тех пор, пока уменьшается ошибка между эталонной маской сегментации и предсказанной маской сегментации на отложенной выборке, причем осуществляют оптимизацию обучающих координат каждого клика на основе обратного распространения ошибки между эталонной маской сегментации и предсказанной маской сегментации при фиксированных весах нейронной сети, получая обучающие адверсативные координаты клика; на основе полученных обучающих адверсативных координат клика осуществляют обучение нейронной сети при отмененной фиксации ее весов путем обратного распространения ошибки через нейронную сеть для обновления ее весов. 6 з.п. ф-лы, 7 ил., 2 табл.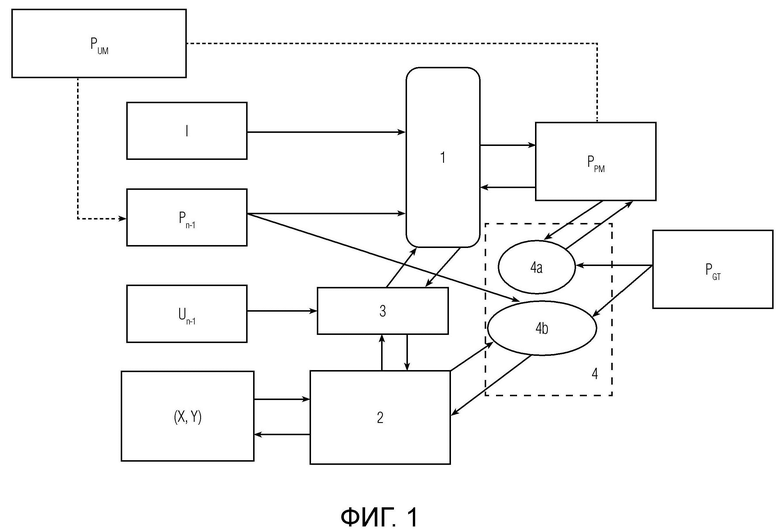
1. Способ интерактивной сегментации изображения на основе последовательности кликов пользователя, осуществляемый обученной нейронной сетью для интерактивной сегментации изображений, содержащий этапы, на которых:
a) подают на вход обученной нейронной сети для интерактивной сегментации:
указание пользователем, является ли клик пользователя положительным или отрицательным;
изображение, на котором нужно выполнить сегментацию области изображения,
координаты клика пользователя по изображению для сегментации упомянутой области изображения;
b) получают на выходе обученной нейронной сети предсказанную маску сегментации;
c) отображают предсказанную маску сегментации на дисплее пользователю;
повторяют этапы а) - с) для получения и отображения уточненной предсказанной маски сегментации, пока отображенная предсказанная маска сегментации не будет соответствовать желательной области для сегментации;
причем при обучении нейронной сети обучают упомянутую нейронную сеть посредством обучающих координат клика на обучающем изображении до тех пор, пока не перестанет уменьшаться ошибка между эталонной маской сегментации и предсказанной маской сегментации на отложенной выборке, причем осуществляют оптимизацию обучающих координат каждого клика на основе обратного распространения ошибки между эталонной маской сегментации и предсказанной маской сегментации при фиксированных весах нейронной сети, получая обучающие адверсативные координаты клика, в которые теоретически пользователь должен совершить клик, чтобы получить маску, имеющую лучшее и худшее качество сегментации;
на основе полученных обучающих адверсативных координат клика осуществляют обучение нейронной сети при отмененной фиксации ее весов путем обратного распространения ошибки через нейронную сеть для обновления ее весов.
2. Способ по п. 1, в котором оптимизация обучающих координат клика осуществляется методом градиентного спуска.
3. Способ по любому из пп. 1, 2, в котором клик пользователя включает в себя либо положительный клик либо отрицательный клик на дисплее электронного устройства по изображению, в отношении которого нужно выполнить сегментацию области изображения,
причем положительный клик маркирует желательную область для включения в сегментированное изображение,
отрицательный клик маркирует нежелательную область, которую необходимо исключить из сегментированного изображения.
4. Способ по любому из пп. 1-3, в котором нейронная сеть обучается посредством обучающего конвейера для обучения нейронной сети для интерактивной сегментации изображений, содержащего:
модуль дифференцируемой растеризации, осуществляющий дифференцируемую растеризацию обучающих координат клика,
модуль суммирования карт кликов предыдущих и текущего обучающих раундов взаимодействия для вычисления поэлементной суммы растеризованных обучающих координат клика текущего обучающего раунда и обучающих адверсативных координат, полученных в предыдущем обучающем раунде взаимодействия,
модуль функций потерь для вычисления функций потерь и градиентов функций потерь, использующихся для получения обучающих адверсативных координат клика и обновления весов нейронной сети интерактивной сегментации,
причем модуль дифференцируемой растеризации соединен с модулем суммирования карт кликов, а также с модулем функций потерь,
нейронная сеть интерактивной сегментации соединена с модулем суммирования карт кликов, а также с модулем функций потерь.
5. Способ по п. 4, причем обучающие данные для каждого обучающего раунда взаимодействия включают в себя набор обучающих данных текущего обучающего раунда взаимодействия, состоящий из:
обучающего изображения,
эталонной маски сегментации, соответствующей области для сегментации упомянутого обучающего изображения,
причем обучающее изображение и эталонная маска сегментации остаются неизменными во всех обучающих раундах взаимодействия,
обучающих координат клика на n-м обучающем раунде взаимодействия, на основании которых путем оптимизации методом градиентного спуска получают обучающие адверсативные координаты клика,
причем обучающие координаты клика n-го обучающего раунда взаимодействия маркируют область для сегментации упомянутого обучающего изображения, причем обучающие координаты клика каждого раунда взаимодействия имеют отличные друг от друга значения,
причем обучающие координаты клика в каждом обучающем раунде взаимодействия маркируют одну и ту же область для сегментации упомянутого обучающего изображения.
6. Способ по п. 5, причем нейронная сеть обучается за заданное количество обучающих раундов взаимодействия.
7. Способ по п. 6, причем при осуществлении обучения в 1-м обучающем раунде взаимодействия:
a) подают на вход конвейера для обучения нейронной сети набор обучающих данных;
b) осуществляют дифференцируемую растеризацию обучающих координат клика в модуле дифференцируемой растеризации для получения растеризованных обучающих координат клика текущего обучающего раунда взаимодействия;
c) подают на вход нейронной сети:
обучающее изображение из упомянутого набора обучающих данных текущего обучающего раунда взаимодействия,
растеризованные обучающие координаты одного клика обучающего раунда взаимодействия, полученные на этапе b),
при этом веса нейронной сети фиксируются;
d) получают на выходе нейронной сети предсказанную маску сегментации;
e) осуществляют сравнение предсказанной маски сегментации с эталонной маской сегментации из обучающих данных, поданных на этапе а), посредством вычисления, в модуле функций потерь, функции потерь дифференцируемой аппроксимации целевой метрики качества IoU (Dice), а также функции потерь, регуляризирующей положение клика;
f) вычисляют в модуле функций потерь градиент функции потерь Dice по предсказанной маске сегментации;
j) вычисляют в модуле функций потерь градиент функции потерь, регуляризирующей положение клика, по растеризированным обучающим координатам клика;
h) используют полученные значения градиента функции потерь Dice для осуществления обратного распространения ошибки через:
- нейронную сеть от ее выхода до ее входов,
- модуль суммирования карт кликов предыдущего и текущего обучающих раундов взаимодействия, причем обратное распространение ошибки осуществляется только для растеризованных обучающих координат клика, используемых для обучения в текущем раунде,
- модуль дифференцируемой растеризации обучаемых координат клика,
используют полученные значения градиента функции потерь, регуляризирующей положение клика, для осуществления обратного распространения ошибки через модуль дифференцируемой
растеризации обучающих координат клика, при этом получают поправки обучающих координат клика методом градиентного спуска;
i) обновляют растеризованные обучающие координаты клика, используя полученные упомянутые поправки, получая при этом обучающие адверсативные координаты клика;
j) отменяют фиксацию весов нейронной сети,
подают на вход нейронной сети обучающие адверсативные координаты клика и упомянутое обучающее изображение;
k) нейронная сеть вычисляет обновленную предсказанную маску сегментации,
используют обновленную предсказанную маску сегментации для вычисления функции потерь Dice в модуле функций потерь,
осуществляют сравнение обновленной предсказанной маски сегментации с эталонной маской сегментации посредством вычисления в модуле функций потерь функции потерь Dice,
вычисляют в модуле функций потерь градиент функции потерь Dice по обновленной предсказанной маске сегментации;
l) используют полученные на этапе k) значения градиента функции потерь Dice для осуществления обратного распространения ошибки через нейронную сеть и обновление ее весов;
переходят к следующему обучающему раунду взаимодействия,
причем в каждом n-м обучающем раунде взаимодействия осуществляют следующие этапы:
m) подают на вход конвейера для обучения нейронной сети набор обучающих данных для текущего n-го обучающего раунда взаимодействия;
n) осуществляют дифференцируемую растеризацию обучающих координат одного клика n-го обучающего раунда взаимодействия в модуле дифференцируемой растеризации для получения
растеризованных обучающих координат одного клика n-го обучающего раунда взаимодействия;
о) вычисляют поэлементную сумму растеризованных обучающих координат клика n-го обучающего раунда взаимодействия и обновленных растеризованных обучающих координат клика, полученных в n-1 обучающем раунде взаимодействия на этапе i);
р) подают на вход нейронной сети:
обучающее изображение из упомянутого набора обучающих данных текущего обучающего раунда взаимодействия, поэлементную сумму, полученную на этапе о), при этом веса нейронной сети фиксируются;
q) осуществляют этапы d) - f);
r) вычисляют градиент функции потерь, регуляризирующей положение клика, по растеризированным обучающим координатам одного клика n-го обучающего раунда взаимодействия;
s) осуществляют этапы h) - 1);
t) измеряют качество нейронной сети с обновленными весами на отложенной выборке, при этом этапы m) - t) осуществляют до тех пор, пока качество нейронной сети не перестанет увеличиваться.
| QIAOQIAO WEI et al | |||
| Focused and Collaborative Feedback Integration for Interactive Image Segmentation, 31.03.2023, https://arxiv.org/abs/2303.11880 | |||
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |
| JONATHAN PEREIRA, Многослойный перцептрон и алгоритм обратного распространения ошибки, 19.04.2021 | |||

