Настоящее изобретение может быть использовано в сетях машинного обучения, компьютерного зрения и генеративно-состязательных сетях для создания синтетических наборов данных в целях повышения качества методов глубокого обучения.
Описание известного уровня техники
В последние годы резко повысилось качество нейронных генеративных моделей. Первые GAN [8] могли генерировать только цифры MNIST или изображения с низким разрешением. Самые современные модели [3, 16] способны генерировать изображения с настолько высокими качеством и разрешением, что люди часто с трудом могут отличить их от реальных.
С появлением современных методов, основанных на нейронных сетях, были также получены высококачественные решения задачи семантической сегментации изображения, которая имеет решающее значение для понимания сцен. В ряде работ описывается, что эти два подхода можно использовать вместе в одной обучающей схеме для создания реалистичного изображения с применением маски сегментации [13, 12] или для сегментации с частичным привлечением учителя.
Генеративно-состязательные сети (GAN) обычно состоят из сети генератора и сети дискриминатора. Генератор, обученный обманывать дискриминатор, генерирует изображение из случайного шума, а дискриминатор обучается дифференцировать реальные и сгенерированные изображения. Итеративное обучение обеих сетей делает генератор способным создавать изображения, неотличимые от реальных изображений. Основные проблемы, с которыми сталкивается сообщество машинного обучения, включают создание высококачественных изображений, создание изображений с большим разнообразием и стабильное обучение.
Архитектура первой GAN [8] была очень простой: дискриминатор и генератор состояли из только полносвязных слоев. Такая GAN была лишь способна генерировать цифры из набора данных MNIST или изображения с низким разрешением из CIFAR-10, и не работала на более сложных наборах данных. С появлением DCGAN [21] качество и разнообразие генерации изображений продолжили улучшаться благодаря использованию сверточных слоев и транспонированных сверточных слоев. Авторы упомянутой статьи [21] анализируют латентное пространство, демонстрируя интерполяцию между изображениями. Это была одна из первых работ, в которой было предложено использовать признаки дискриминатора для обучения классификатора. В [23] были предложены мини- дискриминация по мини-батчам (mini-batch discrimination), сопоставление признаков и сглаживание меток. Поскольку для сетей GAN не существует явной целевой функции, качество разных моделей трудно сравнивать. Авторы [23] предложили начальную оценку (Inception Score, IS) как объективную метрику для оценки качества сгенерированных изображений. Они показали, что IS хорошо коррелирует с субъективной оценкой человека. Одним из недостатков IS является то, что она может неверно интерпретировать качество, если GAN генерирует всего одно изображение на класс. В работе [11] была предложена новая целевая метрика для GAN, названная начальным расстоянием Фреше (Fr´echet Inception Distance, FID). Предполагается, что FID является усовершенствованием IS, поскольку вместо только оценки сгенерированных образцов она включает в себя действительное сравнение статистики сгенерированных образцов с реальными образцами. Обе эти оценки (FID и IS) обычно используются для измерения качества сгенерированных образцов. ProGAN [15] показала впечатляющие результаты на генерации высококачественных изображений с разрешением до 1024x1024. Предложенная прогрессивная стратегия обучения существенно стабилизировала обучение для обеих сетей. BigGAN [3] показала результаты самого высокого уровня на условной генерации с использованием ImageNet. В других работах были предложены новые потери [14, 18, 9], архитектуры и способы внедрения условной информации [19, 20].
В ряде работ были предложены методы изучения и манипулирования внутренними признаками GAN. Например, в GAN Dissection [2] авторы представили аналитическую структуру для визуализации и понимания свойств GAN на уровне элемента, объекта и сцены. В [4] авторы ввели редактор NeuralPhoto Editor как интерфейс для изучения обученного скрытого пространства порождающих моделей и внесения определенных семантических изменений в естественные изображения.
Семантическая сегментация решает задачу классификации каждого пикселя изображения по определенному набору категорий. С развитием моделей глубокого обучения качество семантической сегментации значительно повысилось по сравнению с методами, в основе которых лежат созданные вручную признаки.
Полносверточная сеть (Fully Convolution Network, FCN) [17] стала первой архитектурой, которая поддерживает сквозное обучение для задачи сегментации изображения. Основная сеть (AlexNet, VGG16) без полносвязных слоев была адаптирована для приема произвольных размеров изображений. Признаки, полученные основной сетью из изображений, затем увеличивают в размере через билинейную интерполяцию или через серию транспонированных сверток. Архитектура U-Net [22] является усовершенствованием относительно FCN: в ней часть кодера извлекает признаки из изображения, а часть декодера постепенно повышает дискретизацию карт признаков и формирует окончательный прогноз. Главным новшеством в U-Net являются пропускаемые соединения между соответствующими блоками частей декодера и кодера. Это оптимизирует градиентный поток, улучшая агрегацию информации разных масштабов. В сети Pyramid Scene Parsing Network (PSPNet) [26] был введен модуль пирамидального пулинга (Pyramid Pooling Module, PPM) для явного включения информации разных масштабов. Этот модуль выполняет операцию пулинга на картах признаков, используя параллельно различные размеры ядра. Затем выходы PPM увеличивают в размерах и объединяют для образования карт признаков, содержащих как глобальную, так и локальную контекстную информацию. Эта идея была изучена в DeepLabV3 [5], и в дальнейшем PPM заменили расширяющим пространственным пирамидным пулингом (Atrous Spatial Pyramid Pooling, ASPP).
В нем применяются расширенные (дилатационные) свертки с различной степенью дилатации. В DeepLabV3 последние слои свертки в основной сети кодера заменяются расширенной сверткой, чтобы предотвратить значительные потери в размере изображения. DeepLabV3+ [6] достигает отвечающих современным требованиям результатов на широко используемых тестовых программах. В ней DeepLabV3 была усовершенствована путем добавления простого, но эффективного модуля декодера для получения более четких масок сегментации. В настоящем изобретении в качестве базовой версии используется DeepLabV3+.
Сущность изобретения
Поскольку GAN могут создавать высококачественные изображения на основе некоторого случайного вектора, этот вектор и набор выводов промежуточных слоев содержат высокоуровневую информацию о построенном изображении. Поэтому возникает естественный вопрос, можно ли проецировать вектор и промежуточные признаки в маску семантической сегментации и генерировать изображения вместе с попиксельной аннотацией. Был проведен ряд экспериментов, которые показали, что на этот вопрос можно ответить утвердительно.
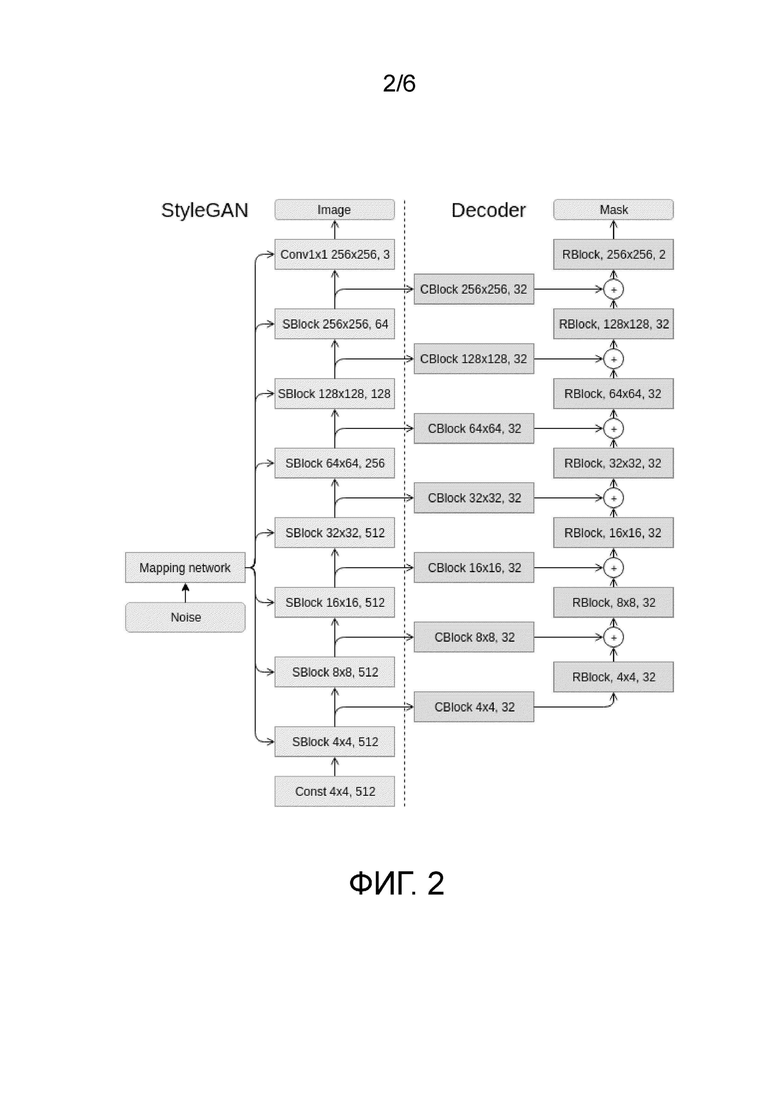
StyleGAN [16] - это современный метод генерации изображений без учителя с наилучшими оценками IS и FID на датасетах FFHQ, Celeba-HQ и LSUN. Применив ряд идей из исследований переноса стилей, авторы предложили новую архитектуру, в которой процесс синтеза изображений контролируется адаптивной нормализацией экземпляров (AdaIN). Генератор запускается с обученным постоянным тензором и корректирует стиль в каждом сверточном блоке на основе скрытого кода. На фиг. 2 показана архитектура генератора. Сеть отображения состоит из 8 полносвязных слоев, и каждый блок SBlock имеет слой повышающей дискретизации (upsampling), 2 свертки и 2 AdaIN.
Известен алгоритм генеративно-состязательных сетей, который взят за основу для генерации данных; используя его, можно генерировать данные из определенного распределения, однако известный метод не способен создать разметку для этих данных. Предложенный алгоритм одновременно генерирует данные и разметку для них. Предложен способ совместного синтеза изображений и попиксельных аннотаций.
Краткое описание чертежей
Представленные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления со ссылкой на прилагаемые чертежи, на которых:
фиг. 1 изображает пример изображения из StyleGAN-FFHQ и соответствующую созданную аннотацию для сегментации волос;
фиг. 2 - схематическое представление архитектуры сети;
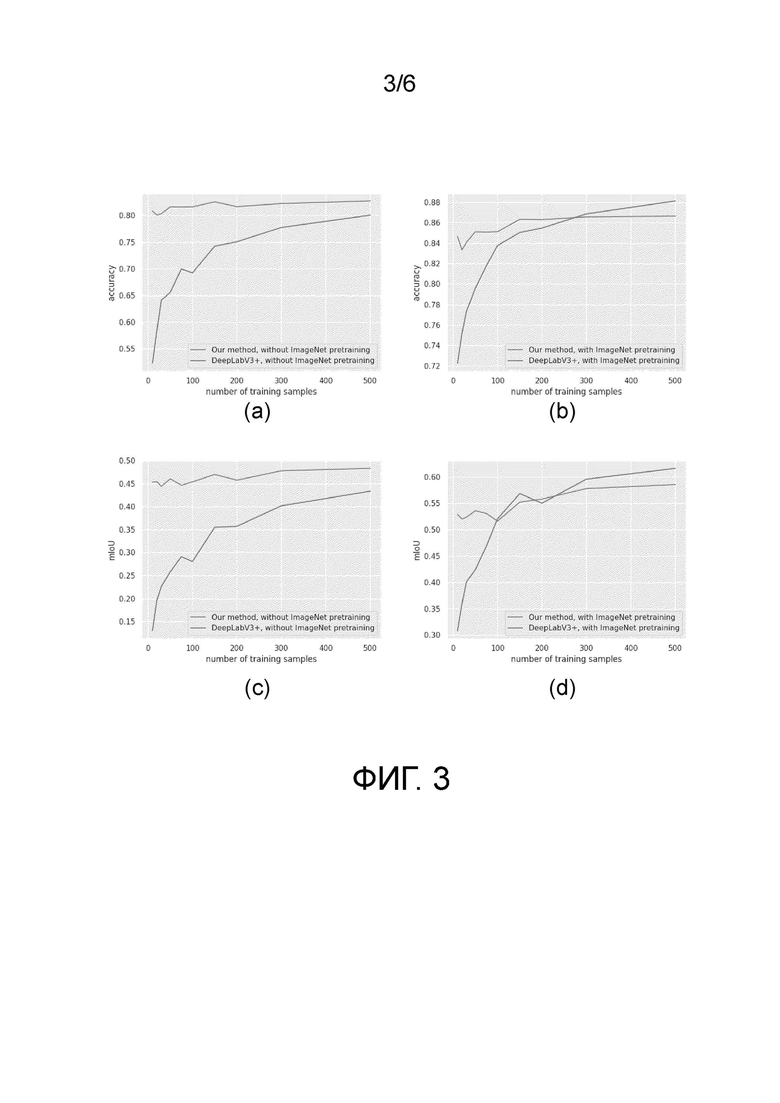
фиг. 3 - сравнение предлагаемого метода с базовой версией на интерьерах LSUN для различного количества обучающих образцов (верхняя кривая - предложенный метод без предобучения на ImageNet; нижняя кривая - DeepLabV3+ без предобучения на ImageNet);
фиг. 4 - маски сегментации для автомобилей из набора данных LSUN;
фиг. 5 - слева - произвольное изображение; в центре - результат последовательного применения моделей Image2StyleGAN и StyleGAN; справа - маска сегментации, созданная предлагаемым декодером, обученным на 20 аннотированных синтетических (без реальных или непомеченных) изображениях;
фиг. 6 - синтетические изображения из StyleGAN, обученной на датасетах FFHQ, и предложенные маски сегментации переднего правого зуба.
Подробное описание
Предложен способ совместного синтеза изображений и попиксельных аннотаций (масок сегментации) посредством GAN. GAN имеет хорошее высокоуровневое представление целевых данных, которые можно легко спроецировать в маски семантической сегментации. Этот метод можно использовать для создания обучающего набора данных для обучения отдельной сети семантической сегментации. Эксперименты показали, что такая сеть сегментация успешно обобщается на реальных данных. Кроме того, этот способ превосходит по производительности обучение с учителем при малом количестве обучающих образцов и работает на широком спектре различных сцен и классов. Изобретение может быть реализовано в программных и аппаратных средствах для получения изображений на экране.
Задача изобретения состоит в совместной генерации данных и соответствующей синтетической разметки с использованием генеративно-состязательных сетей, для которой требуется небольшое количество примеров разметки человеком. Предлагается использовать эту разметку для обучения подсети.
Предложенное изобретение позволяет достичь такого же качества алгоритмов глубокого обучения при меньшем количестве образцов, аннотированных человеком.
В настоящем описании продемонстрировано, что отдельная сеть семантической сегментации, обученная на синтетическом наборе данных, обобщается на реальных изображениях. Кроме того, в описании показано, что предлагаемый способ превосходит по производительности обычное обучение с учителем при малом количестве аннотированных изображений.
Предположим, что имеется модель GAN, которая обучена на некотором наборе данных. Модель GAN обучена создавать изображения с характеристиками, подобными характеристикам из целевого набора данных. Поскольку обучение GAN отнимает много времени и не представляет интереса для данного изобретения, во всех экспериментах использовались предварительно обученные модели, в частности, StyleGAN [17]. GAN берет случайный вектор в качестве ввода и выдает изображение. Основная идея предложенного способа состоит в добавлении облегченного декодера в эту GAN. Под облегченным подразумевается модель, имеющая гораздо меньшее количество параметров, чем GAN. Этот декодер обучается создавать попиксельную аннотацию для изображения, сгенерированного GAN. Для обучения декодера GAN создает несколько изображений, а человек-аннотатор аннотирует их вручную. На основании изображения, созданного GAN, человек рисует пиксельную маску представляющего интерес объекта. Аннотация именуется как маска сегментации или пиксельная карта. Декодер обучается на масках из предыдущего этапа с соответствующими промежуточными признаками GAN. Как и в большинстве исследовательских работ по семантической сегментации, минимизируется кросс-энтропия между предсказанной маской и эталоном. Чтобы уменьшить затраты на вычисления, во время обучения GAN остается фиксированной. Авторы продемонстрировали, что благодаря облегченному характеру декодера для его обучения требуется всего несколько изображений. Модифицированную сеть затем используют для создания большого набора данных изображений вместе с аннотацией.
Созданный синтетический набор данных состоит из пар изображений и предсказанных масок сегментации, которые можно рассматривать как эталонную разметку. Следовательно, этот набор данных можно использовать для обучения сети сегментации с учителем.
В настоящем изобретении в качестве базовой версии метода генерации изображения используется StyleGAN, а в качестве базовой версии метода сегментации изображения - DeepLabV3+.
В частности, предлагается аппаратное обеспечение, содержащее программные продукты, которые выполняют способ совместного синтеза изображений и попиксельных аннотаций посредством GAN, включающий следующие этапы. Предварительное обучение модели GAN на неразмеченном целевом наборе данных. Предполагается, что GAN является отображением из случайного вектора в изображение из распределения целевого набора данных (например, StyleGAN, DCGAN, BigGAN и т.п.). Расширение предобученной модели GAN путем добавления сети декодера. Эта сеть отображает признаки внутренних слоев модели GAN в маску семантической сегментации, соответствующую изображению, созданному GAN из тех же признаков. Аннотирование человеком нескольких образцов, созданных GAN, масками семантической сегментации. Обучение декодера на парах входных признаков и соответствующих аннотированных масок с учителем. Модель GAN остается фиксированной в процессе обучения. Создание большого синтетического набора данных из GAN и декодера путем применения этих моделей к случайным векторам. Обучение с учителем отдельной сети семантической сегментации на созданном синтетическом наборе данных.
В результате обеспечивается возможность создания синтетического набора данных, который можно использовать для обучения сети сегментации, используя всего несколько масок семантической сегментации, аннотированных человеком. Обычно требуются тысячи масок, аннотированных человеком.
Был описан алгоритм семантической сегментации, взятый за основу. Предлагаемый алгоритм сравнивался по точности с основным на различном количестве обучающих примеров.
В отличие от известного уровня настоящее изобретение обеспечивает:
- алгоритм для совместной генерации данных и связанной с ними аннотации разметки;
- возможность обучать модели глубокого обучения семантической сегментации с меньшим количеством аннотированных данных;
- возможность обучать на данных, сгенерированных GAN, и при этом данная модель успешно выполняет обобщение на реальных данных.
В общих чертах, настоящее изобретение заключается в следующем.
Примером реализации изобретения является его применение для ускорения интерактивного аннотирования для выполнения сегментации на пользовательском наборе данных. Это означает, что для обучения состязательной модели сегментации, хорошо работающей со случайными изображениями из Интернета, требуется меньше аннотированных масок семантической сегментации. Обычно для достижения такой же точности требуются сотни или тысячи аннотированных масок семантической сегментации.
Основная идея предлагаемого способа состоит в модификации уже обученной модели GAN путем добавления специальной облегченной сети семантической сегментации. Далее описывается архитектура этой сети и предлагаемый способ совместного синтеза изображений и попиксельных аннотаций.
Предварительное обучение GAN: Модель GAN предварительно обучают на наборе неразмеченных целевых данных (далее будут описаны эксперименты на нескольких наборах данных, включая FFHQ, интерьеры LSUN, автомобили LSUN). На первом этапе обучают модель GAN создавать изображения из имеющегося набора данных на основании случайных векторов. Обучение GAN - это длительный и ресурсоемкий процесс, который не рассматривается в данном документе. Во всех экспериментах предполагается наличие предобученной модели GAN, поэтому в данной работе используется StyleGAN, хотя идеи изобретения можно применить к любой другой архитектуре.
Построение декодера (назначение графов): На фиг. 2 показана архитектура предложенного декодера. Декодер отображает выходы промежуточных слоев GAN в маску семантической сегментации. Сеть отображения состоит из 8 полносвязных слоев, и каждый SBlock содержит слой повышающей дискретизации (upsampling), 2 свертки и 2 AdaIN. Каждый CBlock декодера принимает признаки из соответствующего SBlock StyleGAN в качестве ввода. CBlock состоит из dropout-слоя, свертки и слоя батч-нормализации. Этот блок отображает признаки из StyleGAN в декодер, уменьшая их размерность.
Вероятность выключения нейронов в dropout-слоях устанавливается на 50%, это значение было выбрано во время эксперимента. Каждый RBlock декодера имеет один остаточный блок с двумя сверточными слоями. Количество карт признаков для каждого сверточного слоя декодера установлено равным 32, поскольку первоначальные эксперименты показали, что увеличение количества карт признаков не приводит к улучшению качества.
Аннотирование нескольких синтетических изображений: Для дальнейшего обучения построенного декодера аннотируют вручную небольшой образец синтетических изображений; для каждой картинки из небольшого образца пользователь определяет маску интересующего объекта, рисуя ее с помощью компьютерной мыши. Изображения создаются путем отображения случайного вектора из нормального распределения посредством GAN, и промежуточные признаки сохраняются для дальнейшего обучения.
Обучение декодера: Декодер обучается с учителем (https://en.wikipedia.org/wiki/Supervised_learning), используя маски из предыдущего этапа с соответствующими промежуточными признаками GAN. Как и в большинстве исследований семантической сегментации, минимизируется кросс-энтропия между предсказанной маской и эталоном. Во время обучения GAN остается фиксированной, чтобы уменьшить затраты на вычисления.
Генерация большого синтетического набора данных: После обучения декодера генерируется произвольное количество синтетических изображений с соответствующими масками сегментации. Для этого выбирается случайный вектор из нормального распределения и подается на вход GAN, которая отображает его в синтетическое изображение. Выходы требуемых блоков генератора подаются в декодер, как было описано выше. И наконец, декодер создает маску сегментации, соответствующую предложенному синтетическому изображению.
Обучение сети сегментации: Созданный синтетический набор данных состоит из пар изображений и предсказанных масок сегментации, которые можно рассматривать в качестве эталона. Следовательно, этот набор данных можно использовать для обучения сети сегментации с учителем.
Рассмотрим этапы этого способа более подробно.
Обучение декодера
Как показано на фиг. 1, на этапе обучения декодер обучается совместному синтезу изображения 1 и маски 2 семантической сегментации. Как показано на фиг. 2, декодер принимает признаки из GAN и выдает маску сегментации.
Декодер обучается с учителем на парах входных признаков и соответствующих масок (см. фиг. 2). В частности, во время процедуры обучения кросс-энтропийная потеря минимизируется через обратное распространение, это стандартная процедура в обучении нейронных сетей. Такие пары можно собирать просто путем аннотирования созданных изображений и сохранения соответствующих промежуточных признаков из GAN. Следует отметить, что первоначальная GAN остается фиксированной (замороженной). Промежуточные признаки берутся после каждого блока Stylegan перед повышающей дискретизацией (upsampling-слой), как показано на фиг. 2.
Хорошо известно, что время обучения пропорционально количеству обучаемых параметров, поэтому веса GAN остаются фиксированными (замороженными) для уменьшения затрат на вычисления. Обучение занимает несколько минут, и декодер успешно обучается на небольшом количестве обучающих примеров. Обучающие примеры выбираются случайным образом из созданных изображений.
На фиг. 2 показана схема декодера с первоначальной StyleGAN. StyleGAN берет случайный вектор из нормального распределения (нормальное распределение - это вид непрерывного распределения вероятностей для вещественной случайной переменной (https://en.wikipedia.org/wiki/Normal_distribution)) в качестве ввода и выдает изображение. Декодер использует признаки из StyleGAN в качестве ввода и выдает маску. Признаки берутся после каждого блока StyleGAN.
Обучение сети сегментации на синтетических данных
Затем декодер обучают созданию большого набора данных из пар, сгенерированных GAN изображений и соответствующих масок, предсказанных декодером. Обучение производится с использованием DeepLabV3+ на этом синтетическом наборе данных. Эксперименты показали, что такая сеть успешно обобщается на реальных данных.
Нахождение маски сегментации без обучения сети сегментации
Для этой цели предложенный конвейер обучения модели сегментации включает в себя отдельную нейронную сеть на последнем этапе. Делается попытка проверить, можно ли удалить генерацию большого синтетического набора данных и обучение отдельной сети сегментации из предложенного конвейера, и ограничить его обученным декодером. Как декодер, так и модель сегментации выдают на выходе маску сегментации, но первый принимает в качестве ввода набор промежуточных функций GAN, а вторая берет само изображение. Последним этапом проведения эксперимента в такой формулировке является построение отображения из произвольного изображения в пространство промежуточных признаков GAN. Эта тема уже изучалась в литературе, в частности, в работе Image2StyleGAN [1] была предложена процедура оптимизации, которая отображает произвольное изображение в набор входных векторов для генератора StyleGAN. В результате ввода полученных векторов в этот генератор получается набор промежуточных признаков для соответствующего изображения, из которых с помощью предобученного предложенного декодера получается маска сегментации. Один из результатов показан на фиг. 5. На левом изображении показана произвольная фотография, на среднем - ее вид после последовательного применения генератора Image2StyleGAN и StyleGAN, и на правом - маска сегментации, созданная декодером, описанным в предыдущем эксперименте.
Способность настоящей модели обобщать можно использовать для очень специфической части лица. С этой целью авторы изобретения провели эксперимент с разметкой только правого верхнего переднего зуба. Хотя на фотографии лица человека видно более 10 зубов, предложенный способ продемонстрировал почти идеальные результаты при использовании всего 5 аннотированных синтетических изображений, как показано на фиг. 6 (только 5 синтетических изображений были аннотированы для обучения. Следует отметить, что предлагаемая модель ожидаемо сегментирует только один из нескольких одинаково текстурированных зубов).
Эксперименты
Автомобили LSUN. ("LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop". ссылка https://www.yf.io/p/lsun).
Авторы изобретения выбрали случайным образом подмножество из 100 изображений из валидационной части автомобилей LSUN и аннотировали их масками автомобилей. Затем набор данных был случайным образом разбит на обучающую и тестовую части, 20 образцов использовались для обучения и 80 образцов для тестирования. Для базовой версии авторы изобретения использовали эти 20 обучающих образцов для обучения DeepLabV3+ [7]. Для предложенного способа авторы изобретения также аннотировали 20 случайных изображений, сгенерированных StyleGAN, и использовали их для обучения декодера. Затем было сгенерировано 10000 синтетических образцов и на них обучена DeepLabV3+. Оба способа тестировались на 80 реальных образцах. Результаты оценки показаны в таблице 1. Примеры результатов представлены на фиг. 3. На фиг. 3 показано сравнение предлагаемого способа с базовой версией на интерьерах LSUN для различного количества обучающих образцов (верхняя кривая - предложенный способ без предобучения на ImageNet; нижняя кривая - DeepLabV3+ без предобучения на ImageNet): (a) - основная сеть без предобучения на ImageNet; точность; (b) - основная сеть, предобученная на ImageNet, точность; (c) - основная сеть без предобучения на ImageNet, среднее IoU; (d) - основная сеть, предобученная на ImageNet, среднее IoU. Точность и IoU используются в качестве оценочных метрик для сравнения базовой версии с предлагаемым методом. Оба метода оценивались на 80 тестовых изображениях. Результаты представлены в таблице 1. Предложенный метод дает увеличение точности более чем на 2% и увеличение IoU на 5% по сравнению с базовой версией. В таблице 1 также показано сравнение предлагаемого подхода с базовой версией в случае обучения нейронных сетей с нуля, то есть без использования основной сети, предобученной на ImageNet. В этом эксперименте в обучении использовали всего 20 аннотированных изображений в отличие от дополнительных миллионов изображений из ImageNet с многоклассовыми масками семантической сегментации в эксперименте с предобученной основной сетью. В этом случае повышение точности по сравнению с базовой версией становится еще больше (конкретно, более 10% по точности и 20% по IoU).
На фиг. 4 представлена визуализация результатов. Маски в верхнем ряду, полученные предлагаемым способом, более точны, чем маски в нижнем ряду, полученные базовой версией.
Таблица 1. Результаты оценки на наборе данных автомобилей LSUN с двумя классами (фон и автомобили)
основная сеть
Предложенный метод (изобретение)
-
0,9787
0,9408
Предложенный метод (изобретение)
ImageNet
0,9862
0,9609
Для задачи сегментации автомобилей использовался набор данных LSUN [24] с предобученной моделью StyleGAN. LSUN - это набор данных для классификации миллиона изображений, разбитых на 10 категорий сцен и 20 категорий объектов. Были выбраны только изображения, относящиеся к категории "автомобили". Было аннотировано вручную 100 изображений размером 512х384 пикселей с масками сегментации автомобилей. Из этих изображений 20 образцов использовались для обучения базовой модели DeepLabV3+, а остальные 80 - для оценки предложенного метода и базовой версии. Затем запускался весь обучающий конвейер, включающий генерацию 10000 синтетических изображений на этапе генерации набора данных и ручное аннотирование 20 из них. Оба метода оценивались на 80 тестовых изображениях. Результаты показаны в таблице 1. Предложенный метод обеспечил повышение точности более чем на 2% и повышение IoU на 5% по сравнению с базовой версией.
В таблице 1 также показано сравнение предлагаемого подхода с базовой версией в случае обучения нейронных сетей с нуля, то есть без использования основной сети, предобученной на ImageNet. В этом эксперименте в обучении использовалось всего 20 аннотированных изображений в отличие от дополнительных миллионов изображений из ImageNet с многоклассовыми масками семантической сегментации в эксперименте с предобученной основной сетью. В данном случае повышение точности по сравнению с базовой версией стало еще больше (конкретно, более 10% по точности и 20% по IoU). Дополнительное обсуждение приводится в подразделе с экспериментом на сценах с интерьерами.
Также на фиг. 4 продемонстрированы полученные маски сегментации для четырех изображений из тестового подмножества, чтобы подтвердить разницу в качестве между предлагаемым методом и базовой версией. На фиг. 4 показаны маски сегментации для автомобилей из набора данных LSUN. Верхний ряд - предлагаемый способ, нижний ряд - DeepLabV3+. Обучение проводилось на 20 аннотированных изображениях для обоих методов.
Протокол оценки.
Проводилось тестирование двух вариантов главной сети для DeepLabV3+ [7]: предобученной на ImageNet и без предобучения. Измерялись точность пикселей и пересечение по объединению, усредненное по классам (mIoU). DeepLabV3+, как и другие модели сегментации, использует предобученную на ImageNet основную сеть. ImageNet - это крупномасштабный датасет, содержащий 1 миллион аннотированных человеком изображений из 1000 классов. следовательно, такие методы подразумевают неявное использование классификационного аннотирования в дополнение к сегментационному. Авторы изобретения провели эксперименты для сравнения предлагаемого метода с базовой версией по двум протоколам: с основной сетью, предобученной на ImageNet, и без предобучения.
Авторы изобретения провели такие же эксперименты на наборе данных FFHQ. Flickr-Faces-HQ (FFHQ) - это высококачественный набор данных изображений человеческих лиц, изначально созданный в качестве бенчмарка для генеративно-состязательных сетей (GAN). Этот набор данных состоит из 70000 высококачественных изображений PNG с разрешением 1024×1024, значительно различающихся по возрасту, этнической принадлежности и фону изображения. Он также имеет хороший охват аксессуаров, таких как очки, солнцезащитные очки, шляпы и т.п. Для демонстрации предлагаемого метода на этом наборе данных в качестве целевой задачи использовалась сегментация волос. Авторы изобретения использовали 20 аннотированных человеком изображений для обучения и 80 аннотированных человеком изображений для тестирования.
Результаты представлены в таблице 2 (точность пикселей и пересечение по объединению, усредненное по классам (см. протокол оценки), они являются безразмерными величинами). Предлагаемый метод превосходит базовую модель DeepLabV3 на 7% по IoU и на 1% по точности.
Авторы изобретения также провели эксперименты с Image2StyleGAN для StyleGAN-FFHQ. На фиг. 5 показан пример вложения и маски. На левом изображении показан пример реального фото. Затем авторы изобретения применили алгоритм Image2StyleGAN, чтобы найти его представление в пространстве вложения. Реконструированное из этого вложения изображение изображено в центре. И наконец, авторы изобретения применили обученный декодер к признакам этого реконструированного изображения, чтобы получить маску сегментации волос. Эта маска показана на правом изображении.
Таблица 2. Результаты оценки на наборе данных FFHQ с двумя классами (фон и волосы)
основная сеть
Предложенный метод (изобретение)
ImageNet
0,8967
0,8243
Интерьеры LSUN - это подмножество из набора данных LSUN, которое содержит фотографии интерьеров помещений. В этом эксперименте предлагаемый метод сравнивался с базовой версией для различного количества обучающих образцов, чтобы увидеть динамику. Поскольку для интерьеров LSUN нет масок семантической сегментации, а аннотирование довольно утомительная процедура, авторы изобретения использовали для создания аннотации сеть сегментации из пакета GluonCV, предобученную на ADE20K. Из 150 классов в ADE20K было использовано всего 13, которые соответствовали сценам интерьеров. Результаты показаны на фиг. 3.
Сравнение предложенного метода с базовой версией при разных установках показано на четырех графиках. Авторы изобретения сравнили метрики IoU и точности для различного количества обучающих примеров. На графиках (а) и (b) сравнивается точность, а на графиках (c) и (d) - mIoU. Предобученная на ImageNet основная сеть использовалась для экспериментов (а) и (с). Сеть сегментации обучалась с нуля для экспериментов (b) и (d). Эксперименты показали, что предложенный метод хорошо работает с малым количеством обучающих образцов и в этом случае превосходит базовую версию с большим отрывом.
Подробности реализации
Для реализации предложенного алгоритма использовалась платформа MXNet Gluon [7]. Поскольку обучение StyleGAN отнимает много времени и не представляет интереса для данного изобретения, во всех экспериментах использовались модели, предобученные авторами первоначальной работы, которые были преобразованы в формат, принимаемый MXNet Gluon. Для обучения декодера использовался оптимизатор Adam с установкой его начальной скорости обучения на 1×10-4. При обучении первоначальной DeepLabV3+ использовались различные параметры обучения. В частности, использовался оптимизатор SGD с установкой момента на 0,9, начальной скорости обучения на 0,01 и коэффициент регуляризации весов сети на 1х10-4. Кроме того, ResNet-50 была взята в качестве основной сети для DeepLabV3+, и предполагалось, что она предобучена на ImageNet, если не указано иное. Во всех экспериментах для оценки качества использовались точность пикселей и пересечение по объединению, усредненное по классам (IoU).
Эксперименты показали, что предлагаемый метод хорошо работает при небольшом количестве обучающих примеров и в этом случае с большим отрывом превосходит обычное обучение под наблюдением. Однако с увеличением количества обучающих примеров разница в точности уменьшается (фиг. 3 (a), (c)). В случае использования основной сети, предобученной на ImageNet, предлагаемый метод с некоторого момента начинает работать хуже (фиг. 3 (b), (d)). Это может объяснить тем фактом, что сама GAN имеет ограниченные возможности: качество генерируемых изображений не является идеальным и GAN часто не способна генерировать некоторые редкие объекты. Следовательно, такие редкие объекты отсутствуют в синтетическом наборе данных. Кроме того, внутреннее представление GAN, из которого проецируются семантические маски, может немного отличаться от реального высокоуровневого представления. Например, для представления волос и бороды человека, вероятно, используются одни и те же признаки. В результате ухудшается качество сегментации волос.
Авторы изобретения предложили способ создания изображений вместе с масками семантической сегментации с использованием предобученной GAN. Его можно применять для обучения отдельной сети сегментации. Исследование показали, что такая сеть сегментации успешно обобщается на реальных данных.
Ограничения предлагаемого метода обусловлены двумя факторами. Первый - это недостаточное разнообразие сетей GAN. Второй - несовершенное внутреннее представление сетей GAN.
Описанные выше варианты осуществления являются примерными и не должны рассматриваться как ограничивающие. Кроме того, описание примерных вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и для специалистов в данной области техники будут очевидны многие альтернативы, модификации и варианты.
ЛИТЕРАТУРА
[1] Rameen Abdal, Yipeng Qin, and Peter Wonka. Image2stylegan: How to embed images into the stylegan latent space? arXiv preprint arXiv:1904.03189, 2019.
[2] David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B Tenenbaum, William T Freeman, and Antonio Torralba. Gan dissection: Visualizing and understanding generative adversarial networks. arXiv preprint arXiv:1811.10597, 2018.
[3] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
[4] Andrew Brock, Theodore Lim, James M Ritchie, and Nick Weston. Neural photo editing with introspective adversarial networks. arXiv preprint arXiv:1609.07093, 2016.
[5] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017.
[6] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018.
[7] Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv preprint arXiv:1512.01274, 2015.
[8] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672-2680, 2014.
[9] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems, pages 5767-5777, 2017.
[10] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. arXiv preprint arXiv:1812.01187, 2018.
[11] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, pages 6626-6637, 2017.
[12] Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-to-image translation. In ECCV, 2018.
[13] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. arxiv, 2016.
[14] Alexia Jolicoeur-Martineau. The relativistic discriminator: a key element missing from standard gan. arXiv preprint arXiv:1807.00734, 2018.
[15] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196, 2017.
[16] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. arXiv preprint arXiv:1812.04948, 2018.
[17] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431-3440, 2015.
[18] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? arXiv preprint arXiv:1801.04406, 2018.
[19] Takeru Miyato and Masanori Koyama. cgans with projection discriminator. arXiv preprint arXiv:1802.05637, 2018.
[20] Augustus Odena, Christopher Olah, and Jonathon Shlens. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 2642-2651. JMLR. org, 2017.
[21] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
[22] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234-241. Springer, 2015.
[23] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in neural information processing systems, pages 2234-2242, 2016.
[24] Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
[25] Zhi Zhang, Tong He, Hang Zhang, Zhongyuan Zhang, Junyuan Xie, and Mu Li. Bag of freebies for training object detection neural networks. arXiv preprint arXiv:1902.04103, 2019.
[26] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881-2890, 2017.
[27] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. arXiv preprint arXiv:1608.05442, 2016.
[28] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| ИНТЕРАКТИВНАЯ СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЙ | 2023 |
|
RU2833268C1 |
| Совместная неконтролируемая сегментация объектов и подрисовка | 2019 |
|
RU2710659C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| НЕЙРОСЕТЕВОЙ РЕНДЕРИНГ ТРЕХМЕРНЫХ ЧЕЛОВЕЧЕСКИХ АВАТАРОВ | 2021 |
|
RU2775825C1 |
| Система и способ для получения обработанного выходного изображения, имеющего выбираемый пользователем показатель качества | 2023 |
|
RU2823750C1 |
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |




Изобретение относится к способу и компьютерно-читаемому носителю для совместного синтеза изображений и попиксельных аннотаций для отображения. Технический результат заключается в повышении эффективности алгоритмов глубокого обучения. В способе предварительно обучают модель GAN на неразмеченном целевом наборе данных созданию изображений из имеющегося набора данных на основе случайных векторов, строят декодер путем отображения выводов промежуточных слоев GAN в маску семантической сегментации, аннотируют с привлечением человека несколько изображений, созданных GAN, масками семантической сегментации, обучают с учителем декодер на парах введенных признаков и соответствующих аннотированных масках для получения пар синтетических изображений с соответствующими попиксельными аннотациями, создают синтетический набор данных, причем синтетический набор данных состоит из пар изображений с соответствующими масками сегментации, путем выбора случайного вектора из нормального распределения и подачи случайного шума на вход GAN, которая отображает его в синтетическом изображении, обучают под наблюдением отдельную сеть семантической сегментации на созданном синтетическом наборе данных. 2 н. и 4 з.п. ф-лы, 2 табл., 6 ил.
1. Способ совместного синтеза изображений и попиксельных аннотаций для отображения, заключающийся в том, что
- предварительно обучают модель GAN на неразмеченном целевом наборе данных созданию изображений из имеющегося набора данных на основе случайных векторов;
- строят декодер путем отображения выводов промежуточных слоев GAN в маску семантической сегментации;
- аннотируют с привлечением человека несколько изображений, созданных GAN, масками семантической сегментации;
- обучают с учителем декодер на парах введенных признаков и соответствующих аннотированных масках для получения пар синтетических изображений с соответствующими попиксельными аннотациями;
- создают синтетический набор данных, причем синтетический набор данных состоит из пар изображений с соответствующими масками сегментации, путем выбора случайного вектора из нормального распределения и подачи случайного шума на вход GAN, которая отображает его в синтетическом изображении;
- обучают под наблюдением отдельную сеть семантической сегментации на созданном синтетическом наборе данных.
2. Способ по п. 1, в котором GAN является отображением из случайного вектора в изображение из распределения целевого набора данных.
3. Способ по п. 1, в котором модель GAN является моделью StyleGAN.
4. Способ по п. 1, в котором сеть декодера отображает признаки внутренних слоев модели GAN в маску семантической сегментации, соответствующую изображению, созданному GAN из тех же самых признаков.
5. Способ по п. 1, в котором модель GAN остается фиксированной во время обучения.
6. Компьютерно-читаемый носитель, на котором хранятся исполняемые компьютером инструкции для реализации способа по пп. 1-5.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| CN 107527318 A, 29.12.2017 | |||
| CN 107330444 A, 07.11.2017 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| СПОСОБ СВЕРХРАЗРЕШЕНИЯ ИЗОБРАЖЕНИЯ, ИМИТИРУЮЩЕГО ПОВЫШЕНИЕ ДЕТАЛИЗАЦИИ НА ОСНОВЕ ОПТИЧЕСКОЙ СИСТЕМЫ, ВЫПОЛНЯЕМЫЙ НА МОБИЛЬНОМ УСТРОЙСТВЕ, ОБЛАДАЮЩЕМ ОГРАНИЧЕННЫМИ РЕСУРСАМИ, И МОБИЛЬНОЕ УСТРОЙСТВО, ЕГО РЕАЛИЗУЮЩЕЕ | 2018 |
|
RU2697928C1 |

