Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится, в общем, к области синтеза и обработки изображений на основе искусственного интеллекта (ИИ) и, в частности, к реализуемому компьютером способу создания анимируемого аватара человека в полный рост из одного изображения этого человека, а также к вычислительному устройству и машиночитаемому носителю для реализации этого способа.
Уровень техники
[0002] Одним из драйверов современного роста интереса к фотореалистичным аватарам в полный рост является использование аватаров в полный рост в приложениях виртуальной и дополненной реальности. Помимо реалистичности и точности аватаров, огромное значение имеет простота получения новых персонализированных аватаров. Для этого в ряде работ предлагаются методы восстановления текстурированной 3D модели человека из одного изображения, однако такие модели требуют дополнительных усилий на создание скелета (риггинга) для анимации. Использование дополнительных методов риггинга значительно усложняет процесс получения аватара и часто ограничивает позы, которые можно обрабатывать. В то же время в некоторых из последних методов используются текстурированные параметрические модели человеческого тела с применением дорисовки в текстурном пространстве. Однако существующим текстурным методам не хватает фотореализма и качества рендеринга.
[0003] Альтернативой прямому использованию классических RGB текстур является использование отложенного нейронного рендеринга. Такие подходы позволяют создавать аватары человека, определяемые параметрической моделью. Получаемые аватары более фотореалистичны, и их легче анимировать. Однако существующие методы требуют видеопоследовательность для создания аватара. Система StylePeople, также основанная на отложенном нейронном рендеринге и параметрической модели, позволяет создавать аватары из отдельных изображений, однако страдает от низкого качества рендеринга ненаблюдаемых на изображении частей тела.
[0004] В основе многих систем создания аватаров лежат параметрические модели человеческого тела, наиболее популярными из которых являются модель тела SMPL, а также модель SMPL-X, которая дополняет SMPL выражениями лица и артикуляцией рук. Такие модели представляют человеческое тело без одежды и волос. Для добавления одежды и выполнения фотореалистичного рендеринга можно использовать методы, основанные на отложенном нейронном рендеринге (DNR) или полях нейронного излучения (NeRF). В DNR используется многоканальная обучаемая нейронная текстура и сверточная сеть рендерера для реалистичного рендеринга полученных аватаров. Это упрощает анимацию полученного аватара. В NeRF для рендеринга используется выборка вдоль луча в неявном пространстве, что позволяет извлекать точную и согласованную геометрию.
[0005] В методах создания аватара из одного снимка аватары тела человека реконструируются из одного изображения. В ранних работах это достигалось дорисовкой частичных RGB текстур. Такие методы не позволяли реалистично моделировать аватары с одеждой. В более поздних работах по моделированию тела по одному снимку за основу берутся неявная геометрия и модели яркости, которые прогнозируют непрозрачность и цвет с помощью многослойного персептрона, обуславливаемого векторами признаков, извлекаемых из входного изображения. Хотя такое направление работы часто позволяет восстановить сложные геометрические детали, восстановленная текстура ненаблюдаемых на изображении частей обычно имеет ограниченную реалистичность.
[0006] В системе ARCH для создания подходящих для анимации аватаров используется каноническое пространство с построенным скелетом. ARCH++ улучшает качество получаемых аватаров путем пересмотра основных этапов ARCH. В них также решается проблема ненаблюдаемых на изображении поверхностей путем синтеза вида человека сзади по его виду спереди. PHORHUM улучшает моделирование геометрии путем добавления суждения об освещении сцены и альбедо поверхности. В ICON используются локальные признаки для исключения зависимости восстановленной геометрии от глобальной позы. В этом методе сначала оцениваются отдельные модели из каждого вида, а затем эти модели объединяются с помощью SCANimate. Данный метод использует RGB текстуры, применяемые к реконструированной геометрии, что ограничивает фотореализм рендеринга.
[0007] Альтернативный подход к получению аватаров из одного снимка заключается в использовании моделей генерации аватаров, как предложено в StylePeople. Авторы исключают необходимость реконструировать ненаблюдаемые на изображении части, используя взаимосопряженность в скрытом пространстве GAN. К сожалению, несовершенство лежащей в их основе генеративной модели часто приводит к неправдоподобному виду ненаблюдаемых частей.
[0008] Известной альтернативой генеративным моделям являются диффузионные модели. В области моделирования человека диффузионные модели показали высокую эффективность для решения задачи генерации движений человека. В RODIN диффузионная модель используется для создания аватаров головы без построенного скелета в виде полей нейронного излучения, представленных 2D картами признаков. В TEXTure используются текстовое руководство и предобученная диффузионная модель для создания согласованной с видом RGB текстуры заданной геометрии. Однако, насколько известно авторам изобретения, до настоящего времени диффузионные модели не использовались для создания нейронных текстур для трехмерных объектов.
Сущность изобретения
[0009] Настоящее изобретение позволяет преодолеть или, по меньшей мере, частично решить одну или более из обсуждавшихся выше проблем предшествующего уровня. Таким образом, предложен новый способ создания фотореалистичных анимируемых аватаров человека из одной фотографии. Чтобы сделать эти аватары пригодными для анимации, используется подход на основе нейронной текстуры вместе с параметрической моделью тела SMPL-X. Предложена новая архитектура для генерации нейронных текстур, в которой текстура содержит как RGB часть, явно выделенную выборкой пикселей из входного изображения, так и дополнительные нейронные каналы, получаемые путем отображения изображения в скрытое векторное пространство и декодирования результата в текстурное пространство. Обучение генерации текстуры с помощью сети рендеринга осуществляется сквозным методом. Для восстановления нейронной текстуры для ненаблюдаемых на изображении частей человеческого тела была разработана диффузионная модель. Такой подход позволяет получать фотореалистичные аватары человека из одиночных изображений. При наличии нескольких изображений нейронные текстуры, соответствующие разным изображениям, можно объединить, а все еще отсутствующие части можно восстановить путем диффузионной дорисовки. Отличие настоящего изобретения от известного уровня техники, включая модель StylePeople, основанную на генеративно-состязательной структуре, для дорисовки текстур человеческого тела, заключается, по меньшей мере, в применении диффузии для дорисовки. Было обнаружено, что использование диффузии уменьшает проблемы с коллапсом обучения и позволяет получать правдоподобные выборки из сложных мультимодальных распределений.
[0010] Таким образом, вклад настоящего изобретения в предшествующий уровень техники включает в себя:
• новый подход к моделированию аватаров людей на основе нейронных текстур, объединяющих компоненты RGB и скрытые компоненты; и
• диффузионную модель, адаптированную к нейронным текстурам, которая, как было продемонстрировано и подтверждено экспериментально, способна такие текстуры дорисовывать.
[0011] Способность предлагаемого способа создавать реалистичные анимируемые аватары из одного изображения или фотографии была продемонстрирована и экспериментально подтверждена. Экспериментальные данные приводятся в конце настоящего описания. Раскрытый способ позволяет получать фотореалистичный анимируемый аватар человека из одного изображения. Например, для иллюстрации, получив одно изображение или фотографию человека спереди, предложенный способ позволит фотореалистично и достоверно восстановить вид человека сзади. Эффективность и точность предложенного метода была продемонстрирована и экспериментально подтверждена на реальных изображениях, взятых из общедоступного набора данных Snapshot People, и на изображениях людей в естественных позах.
[0012] Исходя из вышеизложенного, в первом аспекте настоящего изобретения предложен реализуемый компьютером способ создания анимируемого аватара человека в полный рост из одного изображения человека. Способ включает себя этапы, на которых: получают изображение Irgb человека и расчетную параметрическую модель тела, определяемую значениями параметров позы р и параметров формы s тела человека на изображении, и значениями параметров камеры С, использованных при захвате изображения; на основе параметрической модели тела определяют функцию текстурирования FUV, задающую отображение между каждым наблюдаемым на изображении пикселем тела человека и соответствующими координатами текстуры в текстурном пространстве, причем для всех ненаблюдаемых на изображении пикселей тела человека функция текстурирования дополнительно задает соответствующие координаты текстуры в текстурном пространстве; осуществляют выборку RGB текстуры Trgb тела человека на основе отображения и получают карту Bsmp выбранных пикселей, причем RGB текстура Trgb содержит для каждого наблюдаемого на изображении пикселя тела человека соответствующее значение пикселя, а также содержит одну или несколько ненаблюдаемых текстурных областей, соответствующих координатам текстуры ненаблюдаемых на изображении пикселей тела человека; создают текстуру Tgen тела человека, наблюдаемого на изображении, путем пропускания изображения через обученную сеть кодировщика Е - генератора G; получают нейронную текстуру Т путем конкатенации RGB текстуры Trgb, карты Bsmp выбранных пикселей и созданной текстуры Tgen; осуществляют дорисовку ненаблюдаемых текстурных областей нейронной текстуры Т с помощью обученной диффузионной модели дорисовки; преобразуют растеризованное изображение R аватара человека в полный рост в новой позе с помощью обученного нейронного рендерера θ в рендерное изображение Irend аватара человека в полный рост в новой позе, причем растеризованное изображение R получают из дорисованной нейронной текстуры Tinpainted и отображения, заданного функцией текстурирования FUV, в котором параметрическая модель тела модифицирована на основе параметров целевой позы ptarget и/или параметры камеры модифицированы в параметры целевой камеры Ctarget, причем параметры целевой позы ptarget и/или параметры целевой камеры Ctarget соответствуют упомянутой новой позе аватара человека в полный рост.
[0013] В качестве развития первого аспекта изобретения в способе дополнительно осуществляют дорисовку в выбранной RGB текстуре промежутков, не превышающих заданный пороговый размер, путем усреднения соседних пикселей и получения карты Bfill дорисованных пикселей, причем карту Bfill дорисованных пикселей дополнительно используют при конкатенации на этапе получения нейронной текстуры Т.
[0014] В дополнительном развитии первого аспекта изобретения в способе этап дорисовки S125 ненаблюдаемых текстурных областей нейронной текстуры Т выполняют путем добавления гауссового шума к нейронной текстуре Т и последующего итеративного выполнения процедуры удаления шума на нейронной текстуре Т с гауссовым шумом Tnoise раз с помощью обученной диффузионной модели дорисовки до тех пор, пока вместо гауссового шума не появится дорисованная нейронная текстура Tinpainted.
[0015] В дополнительном развитии первого аспекта изобретения параметрическая модель тела основана на сетке М с фиксированной топологией, управляемой значениями параметров позы р и параметров формы s.
[0016] В дополнительном развитии первого аспекта изобретения кодировщик Е обученной сети кодировщика Е - генератора G основан на дискриминаторе StyleGAN2 и обучен сжимать изображение Irgb в вектор признаков  , и генератор G обученной сети кодировщика Е - генератора G основан на генераторе StyleGAN2 и обучен создавать текстуру Tgen из вектора признаков
, и генератор G обученной сети кодировщика Е - генератора G основан на генераторе StyleGAN2 и обучен создавать текстуру Tgen из вектора признаков  .
.
[0017] В дополнительном развитии первого аспекта изобретения отображение создают путем UV-развертки, выполняемой с передним разрезом представления тела человека на изображении.
[0018] В дополнительном развитии первого аспекта изобретения в способе дополнительно находят закрытую область тела человека на изображении Irgb и исключают эту закрытую область при осуществлении выборки RGB текстуры Trgb.
[0019] В дополнительном развитии первого аспекта изобретения обученная диффузионная модель дорисовки основана на вероятностной модели рассеяния шума (DDPM), имеющей удаляющую шум архитектуру U-Net, обученную дорисовке ненаблюдаемых текстурных областей нейронной текстуры Т для получения дорисованной нейронной текстуры Tinpainted, в которой удаляющая шум архитектура U-Net имеет остаточные блоки BigGAN для повышающей дискретизации и понижающей дискретизации и слои внимания на ряде уровней иерархии признаков удаляющей шум архитектуры U-Net.
[0020] В дополнительном развитии первого аспекта изобретения обученная диффузионная модель дорисовки дополнительно содержит основанный на векторной квантованной генеративно-состязательной сети (VQGAN) автокодировщик, включающий в себя кодировщик EVQ, обученный кодировать нейронную текстуру Т в скрытое представление нейронной текстуры Т меньшей размерности, вводимое в удаляющую шум архитектуру U-Net, и декодировщик DVQ, обученный декодировать вывод удаляющей шум архитектуры U-Net в дорисованную нейронную текстуру Tinpainted.
[0021] В дополнительном развитии первого аспекта изобретения обучение сети кодировщика Е - генератора G, диффузионной модели дорисовки и нейронного рендерера θ осуществляют на двух стадиях обучения:
на первой стадии обучения:
упомянутую сеть кодировщика Е - генератора G и упомянутый нейронный рендерер θ, основанный на рендеринговой архитектуре U-Net, имеющей блоки ResNet, которые образуют конвейер, обучают сквозным методом на основе наборов многоракурсных изображений, используемых в качестве обучающих данных,
на каждом этапе обучения из множества этапов обучения во время обучения на первой стадии обучения:
выбирают два различных изображения из одного и того же набора из наборов многоракурсных изображений: первое изображение, показывающее человека в позе, имеющей параметры входной позы pinput, используемое в качестве входного изображения, и второе изображение, показывающее человека в позе, имеющей другие параметры целевой позы ptarget, используемое в качестве эталонного изображения (IG),
пропускают первое изображение и параметры целевой позы ptarget через конвейер, обучаемый рендерингу рендерного изображения Irend, показывающего аватар человека в позе, имеющей параметры целевой позы ptarget.
вычисляют на основе, по меньшей мере, рендерного изображения Irend и эталонного изображения IGT значение потерь в соответствии с одной или несколькими из следующих функций потерь: потери L2 различия между рендерным изображением Irend и соответствующим эталонным изображением IGT, потери выученного перцептивного сходства между патчами изображения, LPIPS, между рендерным изображением Irend и соответствующим эталонным изображением IGT, ненасыщающей состязательной потери на основе дискриминатора StyleGAN2 с регуляризацией R1 и потери Dice между спрогнозированной маской сегментации spred и эталонной маской сегментации sGT,
вычисляют градиенты на основе значения потерь, и
обновляют параметры сети кодировщика Е - генератора G и нейронного рендерера θ на основе этих градиентов; и
после того, как значение потерь по одной или нескольким функциям потерь минимизируется, фиксируют выученные параметры сети кодировщика Е - генератора G и нейронного рендерера в и переходят ко второй стадии обучения;
на второй стадии обучения:
диффузионную модель дорисовки, содержащую, по меньшей мере, удаляющую шум архитектуру U-Net, добавляют в конвейер и обучают с использованием обуславливаемого обучения диффузии осуществлять дорисовку ненаблюдаемых текстурных областей нейронной текстуры T, при этом
на каждом этапе обучения из множества этапов обучения во время обучения на второй стадии обучения:
получают объединенную нейронную текстуру, используемую в качестве эталонной нейронной текстуры, причем объединенную нейронную текстуру получают путем объединения неполных нейронных текстур, полученных из двух или более изображений, охватывающих различные углы обзора и выбранных из одного и того же набора многоракурсных изображений из наборов многоракурсных изображений, используемых в качестве обучающих данных,
добавляют гауссов шум к объединенной нейронной текстуре в соответствии со случайным шагом t, где t=[0, Tnoise],
осуществляют конкатенацию к объединенной нейронной текстуре с добавленным гауссовым шумом неполной нейронной текстуры из неполных нейронных текстур, используемых для получения объединенной нейронной текстуры,
пропускают объединенную нейронную текстуру с добавленным гауссовым шумом и с конкатенированной неполной нейронной текстурой через диффузионную модель дорисовки, прогнозирующую для шага t шум, который следует удалить для получения дорисованной объединенной нейронной текстуры,
вычисляют, по меньшей мере, на основе спрогнозированного шума и добавленного гауссового шума значение потерь в соответствии с функцией потери L1,
вычисляют градиенты на основе значения потерь, и
обновляют параметры удаляющей шум архитектуры U-Net, используемой для диффузионной дорисовки на основе градиентов; и
после того, как значение потерь минимизируется, осуществляют точную настройку предобученного конвейера путем выполнения множества дополнительных этапов обучения.
[0022] В дополнительном развитии первого аспекта изобретения точная настройка включает в себя фиксацию весов и смещений нейронного рендерера θ и распространение градиентов из дифференцируемого нейронного рендерера θ в каналы RGB текстуры RGB Trgb причем упомянутые градиенты вычисляют на основе значения потерь, получаемого на первой стадии обучения. Например, нейронная текстура может содержать, как будет подробно описано ниже, 20 или 21 канал. Три из указанных каналов являются каналами RGB, а остальные каналы являются нейронными. В описанном процессе распространения каналы RGB представляются как один или несколько модифицируемых тензоров значений, цвета RGB корректируются путем изменения значений в указанных тензорах с использованием градиентов на основе функции потерь.
[0023] В дополнительном развитии первого аспекта изобретения, если в обучаемую диффузионную модель дорисовки дополнительно включен (необязательный) основанный на VQGAN автокодировщик, то основанный на VQGAN автокодировщик дополнительно обучают на первой стадии обучения кодировать нейронные текстуры Т в скрытые представления нейронных текстур Т меньшей размерности и декодировать скрытые представления нейронных текстур Т меньшей размерности путем минимизации значения потерь, вычисляемого по одной или нескольким функциям потерь, используемым на первой стадии обучения, а затем обучение на второй стадии обучения выполняют в скрытом пространстве предобученного основанного на VQGAN автокодировщика.
[0024] В дополнительном развитии первого аспекта изобретения на первой стадии обучения потерю L2 различия и потерю LPIPS вычисляют для всего изображения и дополнительно вычисляют с заданным весом для области изображения, содержащей лицо.
[0025] В дополнительном развитии первого аспекта изобретения объединение основано на взвешенном усреднении, пирамидальном смешивании или смешивании Пуассона нейронных текстур.
[0026] В дополнительном развитии первого аспекта изобретения на второй стадии обучения используют прореживание с заданной вероятностью в остаточных блоках удаляющей шум архитектуры U-Net.
[0027] В дополнительном развитии первого аспекта изобретения наборы многоракурсных изображений содержат изображения людей в различной одежде с различным телосложением, оттенком кожи, разного пола и во множестве различных поз, снятых с разных углов обзора.
[0028] В дополнительном развитии первого аспекта изобретения угол обзора определяют как угол между векторами нормалей соответствующей точки сетки М с фиксированной топологией и вектором направления камеры.
[0029] Во втором аспекте изобретения предложено вычислительное устройство, содержащее процессор и память, хранящую исполняемые процессором инструкции и параметры, содержащие, по меньшей мере, веса и смещения обученного конвейера сети кодировщика Е - генератора G, диффузионной модели дорисовки, и нейронного рендерера θ, отличающееся тем, что при выполнении процессором исполняемых процессором инструкций процессор побуждает вычислительное устройство выполнять способ создания анимируемого аватара человека в полный рост из одного изображения человека в соответствии с первым аспектом изобретения или любым его развитием.
[0030] В дополнительном развитии второго аспекта изобретения вычислительное устройство дополнительно содержит камеру, сконфигурированную для захвата изображения Irgb человека.
[0031] В третьем аспекте изобретения предложен энергонезависимый машиночитаемый носитель, хранящий машиноисполняемые инструкции и параметры, содержащие по меньшей мере веса и смещения обученного конвейера сети кодировщика Е - генератора G, диффузионной модели дорисовки и нейронного рендерера θ, отличающийся тем, что выполнение вычислительным устройством машиноисполняемых инструкций побуждает вычислительное устройство выполнять способ создания анимируемого аватара человека в полный рост из одного изображения человека в соответствии с первым аспектом изобретения или любым его развитием.
Краткое описание чертежей
[0032] Представленные выше и другие признаки настоящего изобретения будут подробно описаны в следующем разделе "Подробное описание изобретения" со ссылками на прилагаемые чертежи, на которых:
Фиг. 1 - блок-схема реализуемого компьютером способа создания анимируемого аватара человека в полный рост из одного изображения человека в соответствии с первым аспектом настоящего изобретения.
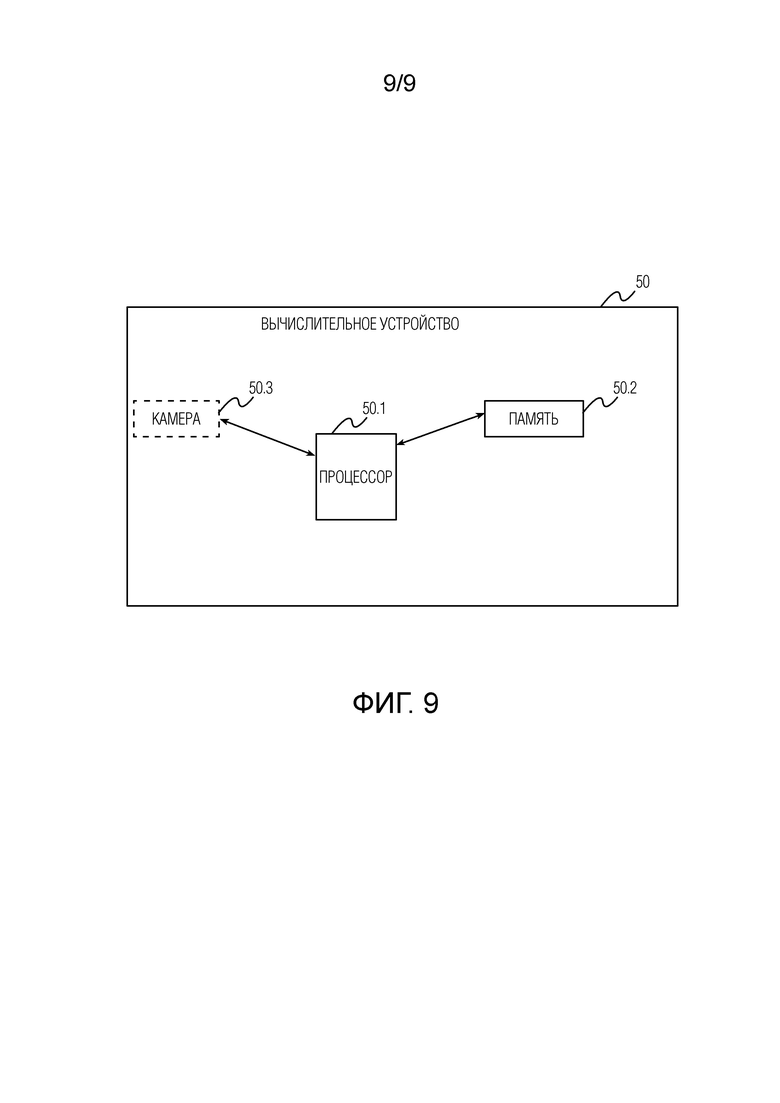
Фиг. 2 - неограничивающее схематичное изображение всего конвейера, предложенного для реализуемого компьютером способа создания анимируемого аватара человека в полный рост из одного изображения человека в соответствии с первым аспектом настоящего изобретения.
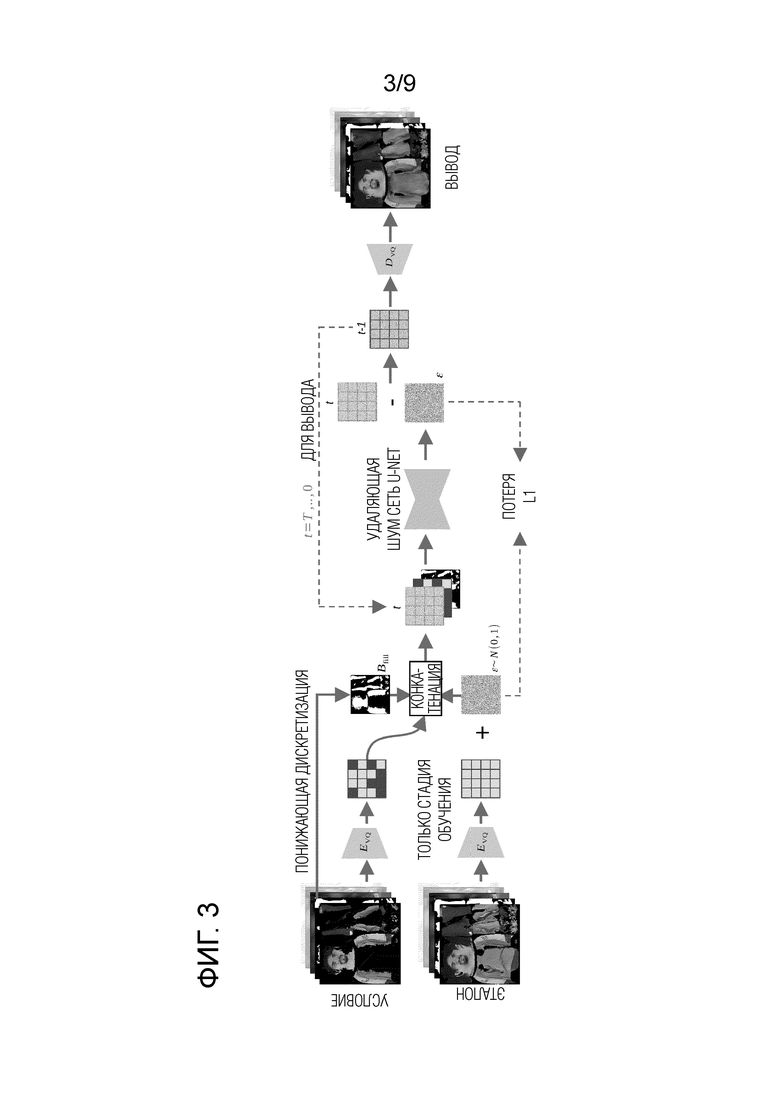
Фиг. 3 - неограничивающее схематичное изображение, иллюстрирующее работу и другие детали предлагаемой диффузионной модели дорисовки, содержащей (необязательный) основанный на VQGAN автокодировщик и удаляющую шум архитектуру U-Net, используемые в способе в соответствии с первым аспектом настоящего изобретения; на фигуре показаны детали блока "VQGAN", изображенного на фиг. 1, а также показаны в общем виде стадии обучения и использования удаляющей шум архитектуры U-Net.
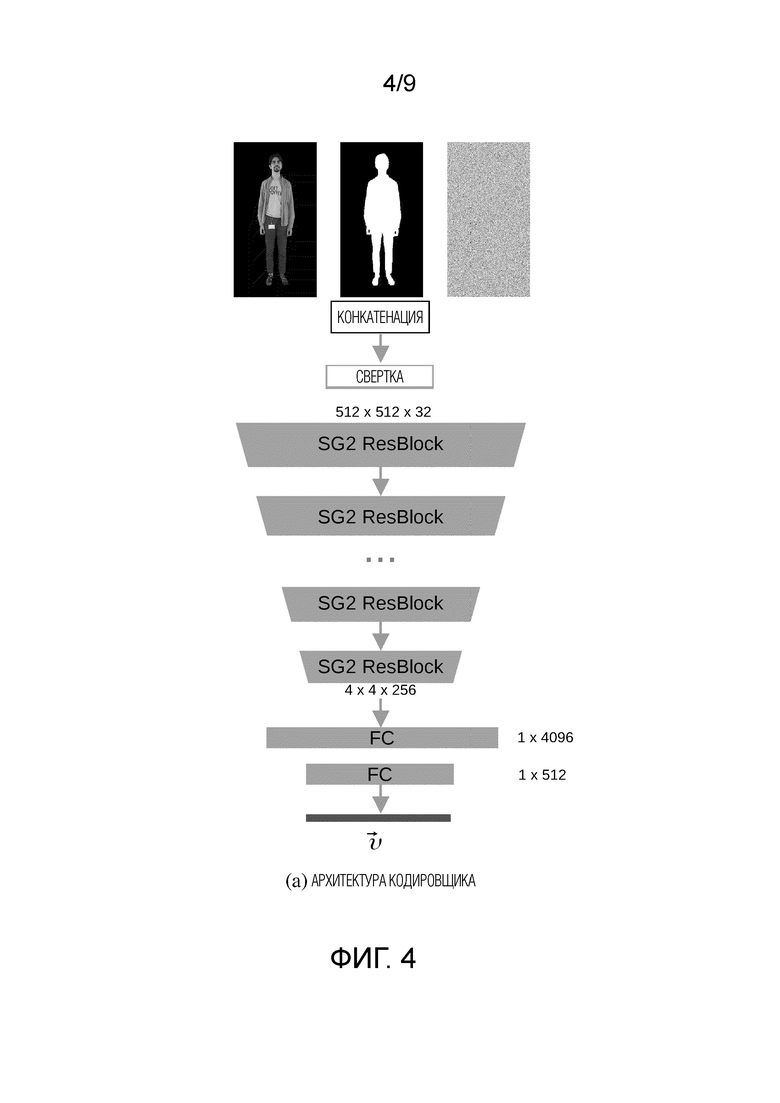
Фиг. 4 - схематичное изображение неограничивающей реализации архитектуры кодировщика Е из сети кодировщика Е - генератора G, используемой в способе согласно первому аспекту настоящего изобретения для генерации основной части Tgen нейронной текстуры.
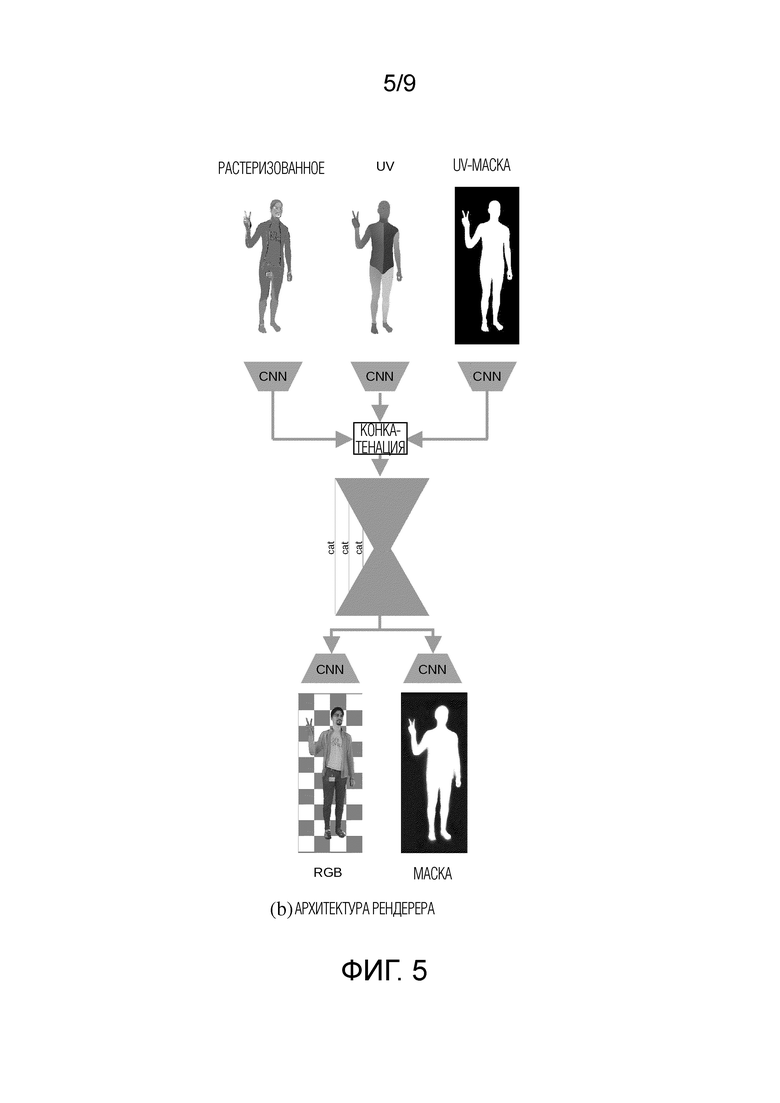
Фиг. 5 - схематичное изображение неограничивающей реализации нейронного рендерера θ, используемого в способе согласно первому аспекту настоящего изобретения для преобразования растеризованного изображения R аватара человека в полный рост в новой позе в рендерное изображение Irend.
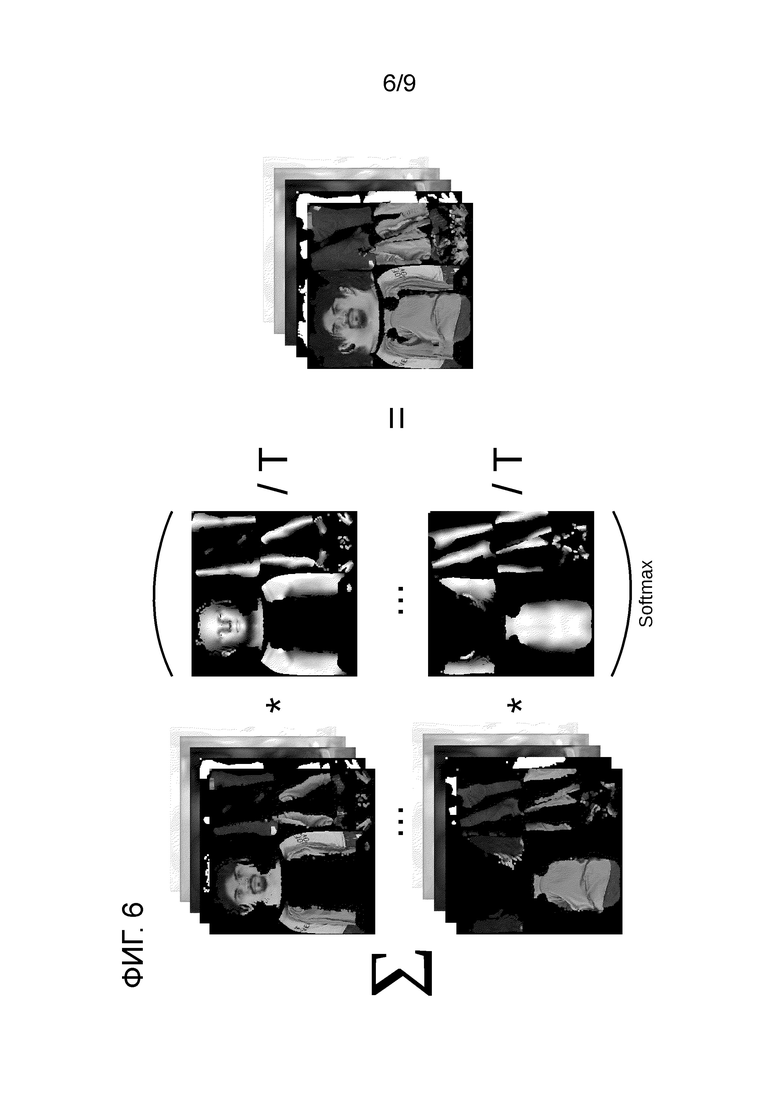
Фиг. 6 - упрощенное представление этапа объединения нейронных текстур для получения полной нейронной текстуры на основе различных изображений набора многоракурсных изображений, охватывающего различные углы обзора.
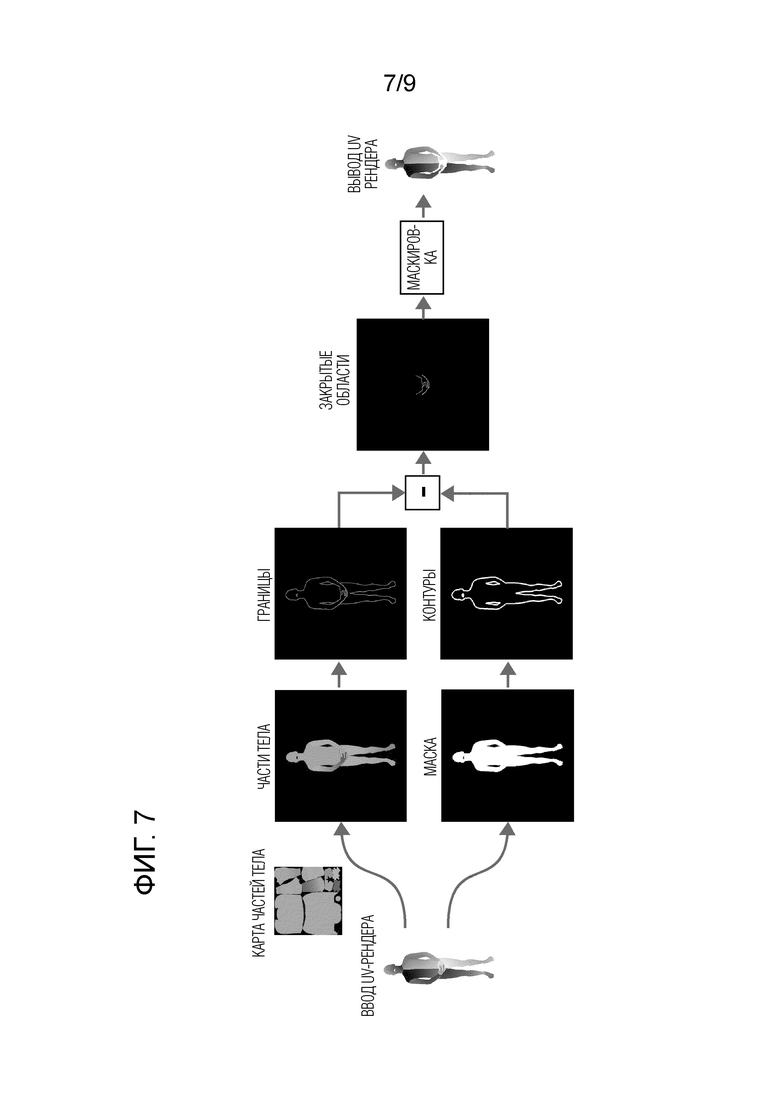
Фиг. 7 - схематичное изображение необязательного этапа обнаружения закрытой области тела человека на изображении Irgb.
Фиг. 8 - иллюстрация анимированных аватаров людей в полный рост в различных позах, созданных способом согласно первому аспекту настоящего изобретения на основе соответствующих одиночных изображений (показанных в левой части фигуры).
Фиг. 9 - неограничивающее схематичное изображение вычислительного устройства в соответствии со вторым аспектом настоящего изобретения.
Подробное описание изобретения
[0033] Диффузионные модели представляют собой вероятностные модели для обучения распределению р(х) путем постепенного удаления шума из нормально распределенной переменной. Такое удаление шума соответствует обучению обратному процессу для фиксированной цепи Маркова длиной Tnoise. В наиболее успешных моделях генерации изображений используется перевзвешенный вариант вариационной нижней границы р(х). Эти модели также можно интерпретировать как удаляющие шум автокодировщики ∈ω(xt,t); t=1,…, Tnoise с общими весами. Такие автокодировщики можно обучить прогнозированию xt-1 с пониженным уровнем шума по сравнению с xt. На данный момент известно, что эти модели удаления шума можно обучать с помощью упрощенной функции потерь:
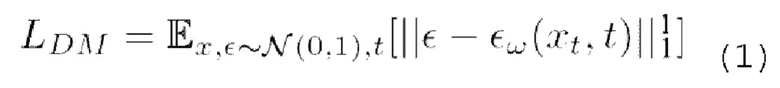
где Е (математическое ожидание) представляет операцию усреднения, t выбирается равномерно из {1,…, Tnoise}, ∈ - шум из нормального гауссового распределения N(0, 1) со средним значением 0 и дисперсией 1, ∈W - шум, прогнозируемый удаляющей шум U-Net с обучаемыми параметрами w. Обычно, на каждом этапе обучения удаляющая шум U-Net принимает на входе зашумленное изображение xt и количество шагов t, соответствующее количеству добавленного гауссового шума, и прогнозирует шум, который необходимо удалить для получения обесшумленного изображения. Затем вычисляется потеря L1 между добавленным гауссовым шумом и спрогнозированным шумом. Для дорисовки нейронной текстуры предлагаемый способ использует скрытую диффузию, которая, как было показано, эффективна при дорисовке RGB изображений. Используемый в данном описании термин "нейронная текстура" означает, в общем, текстуру, имеющую произвольное количество каналов, значения которых подбираются градиентными методами на основе вычисления функции потерь. Рендеринг такой текстуры в RGB выполняется нейронным рендерером, который преобразует растеризованную 3D модель (то есть сетку) с такой текстурой в RGB изображение.
[0034] Реализуемый компьютером способ создания анимируемого аватара человека в полный рост из одного изображения этого человека состоит из двух основных частей: компонентов создания аватара и диффузионной модели дорисовки. Такое деление не является обязательным, но используется в данном описании для простоты объяснения. На фиг. 1 показана блок-схема предлагаемого способа. На фиг. 2 показано неограничивающее схематичное изображение всего конвейера, используемого данным способом; в этом представлении диффузионная модель дорисовки схематически представлена блоком "VQGAN", а все остальное, показанное на фиг. 2, соответствует компонентам создания аватара. На фиг. 3 показано неограничивающее схематичное изображение, иллюстрирующее работу и другие детали предлагаемой диффузионной модели дорисовки.
[0035] В общем, предлагаемый способ реконструирует нейронную текстуру из входного изображения человека, используя два пути, а затем использует операцию текстурирования и нейронный рендеринг для синтеза правдоподобных изображений аватара, соответствующих человеку в различных позах, и, при необходимости, с разных углов обзора. Последовательность таких правдоподобных изображений может использоваться для анимации аватара. В данном описании модель дорисовки называется "диффузионной моделью дорисовки", так как она обучается на основе вероятностной модели рассеяния шума (DDPM) поверх предобученных компонентов создания аватара.
[0036] Способ в соответствии с первым аспектом настоящего изобретения генерирует 3D аватары с построенным скелетом одетых людей с помощью конвейера, включающего в себя, по меньшей мере, сеть кодировщика Е-генератора G, диффузионную модель дорисовки и нейронный рендерер, обучаемых вместе в сквозном режиме. На этапе S100 способ получает в качестве ввода RGB изображение Irgb и параметрическую модель тела. В предпочтительном варианте параметрическая модель тела представляет собой параметрическую модель тела SMPL-X. Однако можно использовать и другие известные параметрические модели тела. Во время обучения модели SMPL-X подгоняются к последовательным изображениям по принципу SMPLifyX с дополнительной потерей Dice сегментации между прогнозируемой маской сегментации и эталонной маской сегментации, что позволяет улучшить согласование силуэтов человека.
[0037] Более конкретно, в одном варианте осуществления настоящего изобретения используется сетка SMPL-X M(p; s) с фиксированной топологией, управляемая наборами параметров позы р и параметров формы s. На этапе S105 способа определяется функция UV-карты FUV (М (ptarget, s), Ctarget) Для отображения текстуры. Для SMPL-X можно опционально использовать специально созданную UV-развертку с передним разрезом, чтобы избежать сложных для дорисовки швов на виде сзади. Однако могут использоваться и другие типы разрезов. Процесс рендеринга принимает в качестве ввода сетку М и параметры желаемой камеры Ctarget. Для риггинга сетки могут использоваться параметры позы ptarget. Функция текстурирования FUV генерирует UV-карту размером Н × W × 2, где Н и W определяют размер выходного изображения, а для каждого (наблюдаемого или ненаблюдаемого) пикселя заданы текстурные координаты [i, j] на L-канальной текстуре Т. Иными словами, UV-карту можно рассматривать как двухканальную "текстуру", которая указывает, какой тексель (текстурный элемент) соответствует какой вершине модели тела. Следовательно, функция текстурирования FUV может использоваться в растеризаторе R (FUV, Т) для отображения пикселей выходного изображения в признаках текселей нейронной текстуры Т. Таким образом, растеризатор R создает изображение размером Н × W × L.
[0038] Параметры растеризатора R можно установить таким образом, чтобы H и W соответствовали высоте и ширине входного RGB изображения Irgb. В этом случае функцию UV-карты FUV можно использовать не только для отображения векторов признаков из нейронной текстуры Т, но и для выборки значений цвета из входного изображения Irgb в текстурное пространство: Trgb=ξ (FUV (М (pinput, s), Cinput), Irgb). Здесь количество каналов L=3, pinput соответствует позе человека в Irgb, a Cinput _ параметры камеры, восстановленные из Irgb. Отображение ξ переносит значение цвета из Irgb в точку текстуры Trgb, определенную посредством FUV, на этапе S110 способа. Эта RGB текстура позволяет явным образом сохранять информацию о высокочастотных деталях и исходных цветах (как будет обсуждаться ниже), которые сложно сохранить при отображении всего изображения в вектор ограниченной размерности. Кроме того, может потребоваться простое заполнение средним значением, чтобы удалить промежутки, появляющиеся на текстуре из-за дискретности сетки выборки. Следовательно, можно применить дорисовку небольших промежутков (например, промежутков, не превышающих заданный пороговый размер в n пикселей, где n равно, например, 20 пикселям или менее, 15 пикселям или менее, 10 пикселям или менее, 5 пикселям или менее, 2 пикселям или даже одному пикселю), например, путем усреднения соседних пикселей для заполнения промежутков в Trgb. Двоичную карту Bsmp выбранных пикселей и двоичную карту Bfill выбранных и дорисованных пикселей можно сохранить для последующего использования при генерации нейронной текстуры.
[0039] Для осуществления выборки RGB текстуры на этапе S110 способа можно использовать следующий неограничивающий алгоритм выборки RGB текстуры с усреднением пикселей, находящихся рядом с промежутком (промежутками):
Алгоритм 1. Алгоритм выборки RGB текстуры
Требует: RGB (размер × размер × 3)
Требует: UV (размер × размер × 2)
# Инициализация текстуры нулями
Т ← нули (размер текстуры × размер текстуры × 3)
С ← нули (размер текстуры × размер текстуры)
# Заполнение текселей средним значением соседей
для ∀x, y ∈ [0. размер] выполнить
(i, j) ← UV [х; у]
для ∀k, m ∈ [-1, 0, 1] выполнить
T [i+k, j+m]+=RGB[x; у]
С [i+k, j+m]+=1
закончить для
закончить для
Т=Т/С
# Заполнение точных значений в текселях, для которых дорисовка не требуется
для ∀x, у ∈ [0. размер] выполнить
(i, j) ← UV [х; у]
Т [i, j] ← RGB[x; у]
закончить для
[0040] Представленный выше Алгоритм 1 не следует интерпретировать как единственно возможный алгоритм для выборки RGB текстуры, поскольку специалист в данной области сможет предложить другой алгоритм для реализации таких же или аналогичных функций. Следовательно, приведенный выше Алгоритм 1 следует интерпретировать как неограничивающий пример.
[0041] Основной частью нейронной текстуры является Tgen. Она имеет количество каналов L=16 и создается на этапе S115 способа с использованием обученной сети кодировщика Е - генератора G. Следовательно, Tgen=G (Е (Irgb)). Кодировщик Е сжимает входное изображение Irgb в вектор признаков  . На фиг. 4 схематически показана неограничивающая реализация архитектуры кодировщика Е. В качестве архитектуры кодировщика Е авторы изобретения адаптировали архитектуру дискриминатора StyleGAN2 с некоторыми модификациями. В частности, на вход сети подаются три ввода: RGB изображение Irgb, маска сегментации S и дополнительный одноканальный шум. Дополнительный одноканальный шум вводится, чтобы обеспечить дополнительную свободу генеративной модели при обучении GAN. Эффективность использования шума в генеративных нейронных сетях была продемонстрирована авторами StyleGAN. Принятые на входе изображения конкатенируются каналами и пропускаются через извлекатель признаков с архитектурой, эквивалентной дискриминатору StyleGAN, состоящему из блоков ResNet. Головной блок модели был модифицирован для вывода вектора признаков размерности 512. Затем этот вектор используется в качестве ввода генератора
. На фиг. 4 схематически показана неограничивающая реализация архитектуры кодировщика Е. В качестве архитектуры кодировщика Е авторы изобретения адаптировали архитектуру дискриминатора StyleGAN2 с некоторыми модификациями. В частности, на вход сети подаются три ввода: RGB изображение Irgb, маска сегментации S и дополнительный одноканальный шум. Дополнительный одноканальный шум вводится, чтобы обеспечить дополнительную свободу генеративной модели при обучении GAN. Эффективность использования шума в генеративных нейронных сетях была продемонстрирована авторами StyleGAN. Принятые на входе изображения конкатенируются каналами и пропускаются через извлекатель признаков с архитектурой, эквивалентной дискриминатору StyleGAN, состоящему из блоков ResNet. Головной блок модели был модифицирован для вывода вектора признаков размерности 512. Затем этот вектор используется в качестве ввода генератора 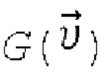 , и предлагаемый кодировщик обучается в сквозном режиме с помощью этого генератора и рендерера. Генератор
, и предлагаемый кодировщик обучается в сквозном режиме с помощью этого генератора и рендерера. Генератор 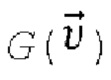 имеет архитектуру генератора StyleGAN2 и преобразует вектор признаков в основную часть Tgen нейронной текстуры. Tgen имеет количество каналов L=16, как и в StylePeople.
имеет архитектуру генератора StyleGAN2 и преобразует вектор признаков в основную часть Tgen нейронной текстуры. Tgen имеет количество каналов L=16, как и в StylePeople.
[0042] Окончательная (но без дорисованных ненаблюдаемых на изображении областей) нейронная текстура Т, используемая в данном способе, имеет размер 256 × 256 × 20 или 256 × 256 × 21. Окончательная нейронная текстура Т получается на этапе S120 способа путем конкатенации RGB текстуры Trgb (256 × 256 × 3), карты Bsmp выбранных пикселей, сгенерированной текстуры Tgen (256 × 256 × 16) и, при необходимости, карты Bfill дорисованных пикселей:
T=Tgen ⊕ Trgb ⊕ Bsmp (2а), или
T=Tgen ⊕ Trgb ⊕ Bsmp ⊕ Bfill (2b)
[0043] После получения окончательной нейронной текстуры способ переходит к этапу S125 дорисовки ненаблюдаемых текстурных областей нейронной текстуры Т с помощью обученной диффузионной модели дорисовки для получения Tinpainted. Затем нейронный рендерер θ (R(FUV, Tinpainted)) преобразует на этапе S130 способа растеризованное изображение R. (FUV, Tinpainted) с L каналами в выходное RGB изображение Irend. Нейронный рендерер θ имеет архитектуру U-Net с блоками ResNet. На фиг. 5 схематически представлена неограничивающая реализация нейронного рендерера θ. Нейронный рендерер θ принимает в качестве ввода три изображения: растеризованное изображение R. модели тела SMPL-X с дорисованной нейронной текстурой Tinpaintedf UV-рендер и UV-маску. UV-рендер представляет собой растеризованную 3D модель (т.е. сетку) в виде двухканального изображения, где каждый пиксель является координатой на текстуре, из которой берется соответствующее значение цвета. UV-маска определяет, в каких пикселях UV-рендера координаты текстуры заданы и в каких пикселях UV-рендера координаты текстуры не заданы. В последнем случае пиксели, не имеющие заданных текстурных координат, можно указать в UV-маске, например, значением "0". Каждое входное изображение пропускается через сверточную сеть, состоящую из двух сверток с активацией LeakyReLU и слоев BatchNorm. Выходные признаки конкатенируются и подаются в сеть U-Net, содержащую блоки ResNet. U-Net имеет 3 уровня, связанных конкатенацией признаков. Выход U-Net пропускается через две дополнительные сверточные сети для прогнозирования рендерного RGB изображения Irend аватара и его маски.
[0044] Таким образом, можно получить растеризованное изображение R из дорисованной нейронной текстуры Tinpainted и отображения, заданного функцией текстурирования FUV, в котором параметрическая модель тела модифицируется на основе параметров целевой позы, и/или параметры камеры модифицируются в параметры целевой камеры Ctarget. Параметры целевой позы ptarget и/или параметры целевой камеры Ctarget соответствуют упомянутой новой позе аватара человека в полный рост. Следует понимать, что во всех материалах настоящего изобретения понятие "новая поза аватара человека в полный рост" включает в себя любые позы аватара человека, которые можно получить, изменив по меньшей мере один параметр из параметров позы и/или по меньшей мере один параметр из параметров камеры. Следовательно, новая поза аватара человека в полный рост, получаемая путем изменения только параметра(ов) камеры, также считается новой позой аватара человека в полный рост, даже если поза человека на изображении осталась неизменной.
[0045] Нейронный рендерер обучается вместе с сетью кодировщика Е - генератора G. Следовательно, рендеринг аватара человека в полный рост в новой позе ptarget на основе одного входного RGB изображения Irgb, изображающего человека в позе pinput, может иметь следующую форму:
Tinpainted=G (Е (Irgb)) ⊕ ξ (FUV (М (pinput, s), Cinput), Irgb) ⊕ Bsmp (3a), или
Tinpainted=G (Е (Irgb)) ⊕ ξ (FUV (М (pinput, s), Cinput), Irgb) ⊕ Bsmp ⊕ Bfill (3b)
Irend=θ (R (FUV (M (ptarget, s), Ctarget) Tinpainted)) (4)
[0046] При обучении минимизируются одна или несколько из следующих потерь: потеря L2 различия между рендерным изображением Irend и соответствующим эталонным изображением IGT, потеря LPIPS (Learned Perceptual Image Patch Similarity) выученного (учитываемого) перцептивного сходства между патчами изображения между рендерным изображением Irend и соответствующим эталонным изображением IGT , ненасыщающая состязательная потеря на основе дискриминатора StyleGAN2 с R1-регуляризацией и потеря Dice между спрогнозированной маской сегментации Spred и эталонной маской сегментации SGT. В предпочтительном варианте минимизируется комбинация всех вышеупомянутых функций потерь (см. математическое выражение (5) ниже). Потеря L2 различия и потеря LPIPS вычисляются для всего изображения и могут быть вычислены дополнительно с весом для области с лицом, так как лицо имеет большое значение для человеческого восприятия. Этот вес в предпочтительном варианте равен 0,1, но в других вариантах он может быть больше (например, от 0,11 до 0,2) или меньше (например, от 0,09 до 0,01). Ненасыщающую состязательную потерю можно использовать для того, чтобы сделать Irend более правдоподобным и четким. Эту ненасыщающую состязательную потерю Adv можно использовать с дискриминатором D из StyleGAN2 с R1-регуляризацией. Таким образом, общие потери, используемые в предпочтительном варианте осуществления, могут иметь следующую форму:
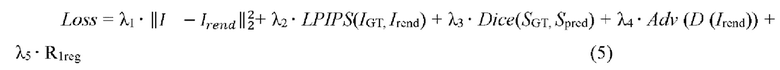
[0047] Выбор гиперпараметров λ1…5 будет описан ниже.
[0048] Для улучшения качества аватара на этапе вывода (inference) могут дополнительно применяться несколько методов. Чтобы улучшить детали текстуры в наблюдаемой на изображении части, можно выполнить несколько (конкретно 64) шагов оптимизации RGB каналов с градиентами из дифференцируемого рендерера для входного изображения. В частности, для этого можно использовать градиенты из нейронного рендерера в, полученные путем сравнения рендерного изображения Irend с входным RGB изображением Irgb. Такие градиенты можно применить к текселям с весами, соответствующими углам между векторами нормалей и направлением камеры, как будет подробно обсуждаться со ссылкой на фиг.5 ниже. Это гарантирует, что будут оптимизироваться только те тексели, которые видны на входном изображении Irgb с приоритетом наиболее фронтальных из них. Потеря L2 различия и потеря LPIPS могут использоваться для запуска согласования цвета, а состязательную потерю Adv с регуляризацией R1, аналогично потере, используемой в математическом выражении (5) общей потери, можно использовать для усиления детализации.
[0049] Также опционально можно применить линейную корректировку к RGB каналам выхода декодирования VQGAN (фиг. 3), чтобы улучшить согласование цвета между передним и задним видами после стадии дорисовки:
Trgb=Trgbα+β (8)
[0050] В этом случае все тексели имеют общие обучаемые параметры альфа и бета, которые можно оптимизировать с помощью градиентов нейронного рендерера, полученных пикселями, наблюдаемыми на входном изображении Irgb. В результате, RGB каналы нейронной текстуры на выходе VQGAN усиливают согласование цвета с выбранной RGB текстурой Trgb. Это позволяет минимизировать шов (швы) после объединения текстур.
[0051] Кроме того, ввиду несовершенства сеток SMPL-X существует проблема несовершенств подгонки SMPL-X, когда пиксели ошибочно выбираются из одной части тела в другую в областях, которые закрывают сами себя (например, руки, расположенные перед телом). Эти несовершенства подгонки SMPL-X могут привести к неправдоподобным рендерам. Для решения этой проблемы во входном изображении Irgb выявляют закрытые области тела человека, включая те области, которые человек сам закрывает на себе, и текстура внутри контура этого перекрытия не выбирается на этапе S110 способа. Невыбранная текстура, содержащаяся в контуре перекрытия, а также все другие ненаблюдаемые текстурные области затем подвергаются дорисовке на этапе S125 способа. Как показано на фиг. 7, в одной реализации может использоваться растеризация с помощью палитры в качестве текстуры для нахождения перекрывающихся областей. В частности, каждой конечности можно назначить отдельный цвет в палитре, а переход между этими конечностями можно сделать плавным с помощью цветового градиента. Это позволяет избежать швов при растеризации. Границы в растеризации палитры можно найти с помощью алгоритма Кэнни или любого другого алгоритма детектора границ, известного в данной области. Затем можно определить контуры человека путем бинарной растеризации SMPL-X. Выводя эти контуры из границ, получают карту закрытой области (закрытых областей) тела человека. Полученную карту затем используют для маскирования областей в UV-рендере. Это позволяет опираться на дорисовку на более поздних этапах конвейера, а не на выборку пикселей в перекрывающихся областях.
[0052] Обучение выполняется на наборах многоракурсных изображений, таких как наборы кадров видео (или наборы рендеров 3D моделей). В неограничивающей реализации обучения на первой стадии обучения на каждом этапе обучения берутся два разных кадра из одного и того же набора, один служит входным изображением Irgb с параметрами входной позы pinput а другой - целевым изображением с параметрами целевой позы ptarget и/или параметрами целевой камеры Ctarget. Таким образом, эти два изображения имеют различные параметры камеры, а также два различных параметра позы тела одного и того же человека. В одной реализации обучения два кадра можно выбрать из одного и того же набора многоракурсных изображений таким образом, чтобы различия в параметрах позы и/или параметрах камеры между двумя изображениями были больше или равны соответствующему заранее определенному минимальному порогу (порогам) различия, чтобы исключить выборку изображений, имеющих недостаточные различия в параметрах позы и/или параметрах камеры. Конвейеру это важно для обобщения на новые положения камеры С и позы р. Для этого нейронный рендерер θ и сеть кодировщика Е - генератора G обучаются дорисовывать текстурные области, не наблюдаемые в Irgb.
[0053] Хотя нейронный рендерер в и сеть кодировщика Е генератора G обучаются компенсировать небольшое количество ненаблюдаемых текстурных областей, которые могут присутствовать в целевом виде, было обнаружено, что эта возможность в основном ограничена небольшими изменениям в позе тела и/или параметрах камеры. Самый простой способ получить аватар, рендеринг которого можно осуществить под произвольными углами, - это создать его из нескольких изображений путем объединения соответствующих нейронных текстур. Для этого может быть использована простая схема смешивания, схематично показанная на фиг. 6. В частности, предположим, что дано N входных изображений 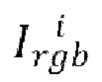 человека с различными параметрами камеры
человека с различными параметрами камеры 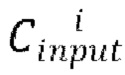 , что дает N нейронных текстур Ti. Эти текстуры естественным образом покрывают разные области тела человека, наблюдаемые на разных входных изображениях. Для объединения этих текстур можно использовать функцию F(T1… TN, λ1… λN), схематически показанную на фиг. 6. λ1 - это вспомогательная информация о текстурной области, наблюдаемой или видимой на соответствующем входном изображении
, что дает N нейронных текстур Ti. Эти текстуры естественным образом покрывают разные области тела человека, наблюдаемые на разных входных изображениях. Для объединения этих текстур можно использовать функцию F(T1… TN, λ1… λN), схематически показанную на фиг. 6. λ1 - это вспомогательная информация о текстурной области, наблюдаемой или видимой на соответствующем входном изображении 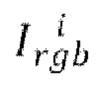 .
.
[0054] В качестве вспомогательной информации λ1 могут использоваться углы между векторами нормалей соответствующей точки сетки Mi и вектором направления камеры. Таким образом, λ1 определяет, насколько фронтальной является каждая точка текстуры по отношению к камере. Используя эту информацию, выполняется объединение текстур с выделением наиболее фронтальных пикселей для каждого Ti. Затем текстуры Ti агрегируются с использованием средневзвешенного значения с весами, вычисляемыми как 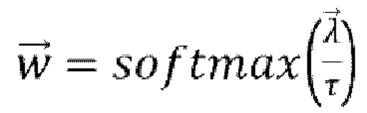 . Фактор τ определяет резкость границ на стыке объединяемых текстур. Следует отметить, что веса можно рассчитывать и другими способами. Таким образом, окончательную объединенную текстуру можно вычислить следующим образом:
. Фактор τ определяет резкость границ на стыке объединяемых текстур. Следует отметить, что веса можно рассчитывать и другими способами. Таким образом, окончательную объединенную текстуру можно вычислить следующим образом:
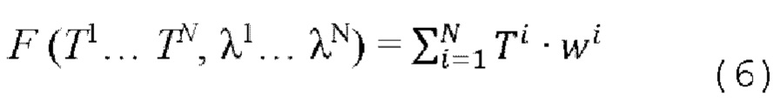
[0055] Этот метод позволяет получать аватары из нескольких снимков путем объединения аватаров из одиночных снимков для различных видов. Также могут использоваться более сложные схемы смешивания, такие как пирамидальное смешивание или смешивание Пуассона.
[0056] В качестве заключительной части предложенного способа используется диффузионная модель дорисовки, включающая удаляющую шум архитектуру U-Net и, необязательно, основанный на VQGAN автокодировщик. Диффузионную модель дорисовки можно обучить с учителем, где в качестве вводов используются неполные текстуры, основанные на отдельных фотографиях, а в качестве эталонных изображений используются объединенные текстуры, агрегированные из нескольких видов.
[0057] Важно отметить, что, поскольку распределение правдоподобных ("правильных") полных текстур при предоставленной входной частичной текстуре обычно очень сложное и мультимодальное, авторы настоящего изобретения предложили использовать рабочий подход вероятностной модели рассеяния шума, DDPM, и обучать архитектуру удаляющей шум U-Net вместо прямого преобразования ввода в вывод. Как было описано выше, в неограничивающей реализации нейронная текстура Т имеет разрешение 256×256×20 (без карты Bfill дорисованных пикселей) или 256×256×21 (с картой Bfill дорисованных пикселей). Это влечет высокие требования к памяти во время обучения диффузионной модели. Чтобы уменьшить потребление памяти и улучшить сходимость сети, во-первых, можно уменьшить размер нейронной текстуры с помощью основанного на VQGAN автокодировщика. Как показано на фиг. 2, основанный на VQGAN автокодировщик добавлен в качестве альтернативной ветви для входа нейронного рендерера θ. После предварительного обучения основанного на VQGAN автокодировщика можно точно настроить конвейер от начала до конца, чтобы адаптировать нейронный рендерер θ к артефактам декомпрессии основанного на VQGAN автокодировщика в дорисованной нейронной текстуре Tinpainted. Для обучения основанного на VQGAN автокодировщика более точному восстановлению нейронных текстур можно использовать несколько функций потерь. Для улучшения визуального качества аватара после декомпрессии текстуры можно использовать функции потерь в RGB пространстве. Во время обучения аватар подвергается рендерингу, как описано в представленном выше выражении (4), с дорисованной нейронной текстурой Tinpainted, а затем оптимизируется функция потерь (5). Для дополнительной регуляризации и сохранения свойств нейронной текстуры для всех видов можно использовать дополнительную потерю L2 в пространстве текстуры 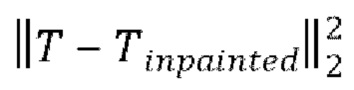 .
.
[0058] После добавления основанного на VQGAN автокодировщика в конвейер дорисовки нейронной текстуры, как показано на фиг.3 , удаляющая шум архитектура U-Net на основе модели DDPM обучается в скрытом пространстве предварительно обученного основанного на VQGAN автокодировщика. Следовательно, удаляющая шум архитектура U-Net, основанная на модели DDPM, применяется к T0c=V (T0) размером 64 × 64 × 3, полученному после сжатия нейронной текстуры на основе одного вида кодировщиком VQGAN EVQ. Удаляющую шум архитектуру U-Net, основанную на модели DDPM, можно обучать с механизмом внимания, например, с одним или несколькими слоями внимания. Удаляющую шум архитектуру U-Net обуславливают с помощью EVQ(T0) ⊕ b(B0fill), где b - билинейное изменение размера в пространственный размер T0c. Таким образом, конкатенация условия и текстуры Тс, искаженной нормально распределенным (гауссовым) шумом, соответствующим шагу t диффузии, подается в качестве ввода в удаляющую шум архитектуру U-Net. При этом удаляющая шум архитектура U-Net обучается удалять шум из ввода путем минимизации потери LDM (1). Как уже объяснялось выше, потеря LDM может быть основана на функции потери L1.
[0059] Как отмечалось выше, диффузионная модель дорисовки, проиллюстрированная на фиг. 3, обучается с использованием объединенных нейронных текстур (фиг. 6) в качестве эталонных нейронных текстур. В данном случае, объединенные нейронные текстуры могут быть сгенерированы из набора данных 3D-сканов человека. В качестве обучающих данных также можно использовать набор данных многоракурсных фотоснимков людей с хорошим угловым охватом. Как отмечалось выше, удаляющая шум архитектура U-Net восстанавливает текстуру Тс (а именно, ее скрытое представление) из шума на основе условия. Затем текстура Тс преобразуется в восстановленную полноразмерную нейронную текстуру T с помощью декодировщика VQGAN DVQ. Чтобы сохранить все детали входного изображения Irgb, восстановленная нейронная текстура T затем объединяется с входной текстурой T0 с использованием маски 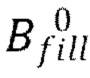 , чтобы получить дорисованную нейронную текстуру Tinpainted:
, чтобы получить дорисованную нейронную текстуру Tinpainted:
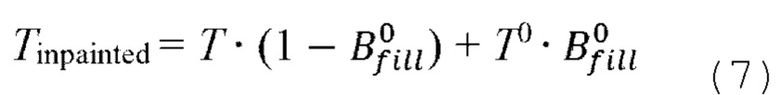
[0060] Полученная текстура имеет все детали, наблюдаемые на входном изображении 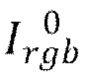 , а части человека, не наблюдаемые на входном изображении
, а части человека, не наблюдаемые на входном изображении  , восстанавливаются с помощью диффузионной модели дорисовки в скрытом пространстве основанного на VQGAN автокодировщика. На фиг. 8 показаны примеры анимированных аватаров людей в полный рост в различных позах, сгенерированные вышеописанным способом для соответствующих одиночных входных изображений Irgb, показанных в левой части фигуры.
, восстанавливаются с помощью диффузионной модели дорисовки в скрытом пространстве основанного на VQGAN автокодировщика. На фиг. 8 показаны примеры анимированных аватаров людей в полный рост в различных позах, сгенерированные вышеописанным способом для соответствующих одиночных входных изображений Irgb, показанных в левой части фигуры.
[0061] На фиг. 9 представлено неограничивающее схематичное изображение вычислительного устройства 50 согласно второму аспекту настоящего изобретения. Следует понимать, что вычислительное устройство 50 может быть сконфигурировано для выполнения вышеописанного способа в соответствии с первым аспектом или в соответствии с любым развитием первого аспекта. Вычислительное устройство 50 содержит процессор 50.1 и память 50.2, в которой хранятся исполняемые процессором инструкции и параметры, включающие, по меньшей мере, веса и смещения обученного конвейера сети кодировщика Е - генератора G, диффузионной модели дорисовки и нейронного рендерера θ. После выполнения исполняемых процессором инструкций процессором 50.1 процессор 50.1 побуждает вычислительное устройство 50 выполнять способ создания анимируемого аватара человека в полный рост из одного изображения этого человека согласно первому аспекту или согласно любому другому развитию первого аспекта.
[0062] Вычислительное устройство 50 может быть любого типа, например, оно может представлять собой, но без ограничения, компьютер общего назначения, специализированный компьютер, компьютерную сеть, ноутбук, смартфон, планшет, смарт-часы, умные очки, гарнитуру AR/VR или другое программируемое устройство. Процессор 50.1 может быть процессором любого типа. Процессор 50.1 может представлять собой, без ограничения, один или несколько из следующих процессоров: процессор общего назначения (например, ЦП), процессор цифровых сигналов (DSP), процессор приложений (АР), графический процессор (GPU), процессор машинного зрения (VPU), выделенный под ИИ процессор (например, нейронный процессор, NPU). Процессор может быть реализован в виде системы на кристалле (SOC), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства (PLD), дискретного логического элемента, транзисторной логики, дискретных аппаратных компонентов, или любой их комбинации. Процессор может быть разделен на блоки, каждый из которых выполняет один или несколько этапов вышеописанного способа.
[0063] Память 50.2 может представлять собой, но без ограничения, постоянное запоминающее устройство (ROM) и оперативное запоминающее устройство (RAM). Могут использоваться любые типы RAM и ROM. Вычислительное устройство 5 0 может дополнительно содержать камеру 50.3 любого типа, способную захватывать изображения. Вычислительное устройство 50 может работать на любой операционной системе и может содержать любые другие необходимые программные средства, аппаратно-программные средства и аппаратные средства (например, не показанные блок связи, интерфейс ввода/вывода, камеру, источник питания и т.д.).
[0064] Специалисту в данной области техники будет понятно, что для удобства и краткости подробного описания рабочего процесса упомянутого вычислительного устройства 50 следует обратиться к соответствующему процессу в описанных выше вариантах осуществления способа. Их детальное описание не повторяется.
[0065] Далее будут обсуждаться обучающие данные и обучающие данные сетей. Детали, обсуждаемые ниже, не следует рассматривать как ограничение. Вместо этого приведенное ниже описание и неограничивающие примеры можно считать подтверждающими достаточность раскрытия настоящего изобретения в соответствии с настоящей заявкой на патент. Сеть кодировщика Е - генератора G, диффузионная модель дорисовки, нейронный рендерер θ или любой аспект их обучения можно реализовать с использованием библиотек машинного обучения с открытым исходным кодом, например, TensorFlow, Keras, PyTorch и так далее. Обучение может осуществляться офлайн или онлайн. Обучение конвейера сети кодировщика Е - генератора сети G, диффузионной модели дорисовки и нейронного рендерера θ выполнялось на RGB изображениях с разрешением 512×512. Однако разрешение обучающих RGB изображений может быть больше или меньше упомянутого разрешения 512×512. Для каждого входного изображения размером 3 × 512 × 512 генерировалась нейронная текстура размером 21 × 256 × 256. В этой нейронной текстуре первые 16 каналов были сгенерированы генератором G обученной сети кодировщика Е - генератора G, следующие три канала были RGB каналами, а оставшиеся два канала были масками выборки и дорисовки. Генератор G имеет архитектуру StyleGAN2 и принимает в качестве ввода вектор признаков  , сгенерированный кодировщиком Е обученной сети кодировщика Е -генератора G. Кодировщик Е имеет архитектуру дискриминатора StyleGAN2 с модифицированной головной частью для вывода вектора длиной 512. Полученную текстуру применяли к модели SMPL-X и подвергали растеризации. Растеризованное изображение имело размер 21×512×512 и подавалось в нейронный рендерер в, имеющий архитектуру U-Net с блоками ResNet. На выходе нейронного рендерера в получали окончательное изображение с разрешением 3 × 512 × 512. Генератор G и нейронный рендерер θ обучали сквозным методом с размером пакета, равным четырем. Однако, размер пакета может быть больше или меньше четырех.
, сгенерированный кодировщиком Е обученной сети кодировщика Е -генератора G. Кодировщик Е имеет архитектуру дискриминатора StyleGAN2 с модифицированной головной частью для вывода вектора длиной 512. Полученную текстуру применяли к модели SMPL-X и подвергали растеризации. Растеризованное изображение имело размер 21×512×512 и подавалось в нейронный рендерер в, имеющий архитектуру U-Net с блоками ResNet. На выходе нейронного рендерера в получали окончательное изображение с разрешением 3 × 512 × 512. Генератор G и нейронный рендерер θ обучали сквозным методом с размером пакета, равным четырем. Однако, размер пакета может быть больше или меньше четырех.
[0066] Для обучения можно использовать комбинацию одной или нескольких функций потерь (в предпочтительном варианте использовались все следующие функции потерь): потерю L2 различия между реконструированным изображением Irend и соответствующим эталонным изображением IGT, потерю выученного перцептивного сходства между патчами изображения (LPIPS) между рендерным изображением Irend и соответствующим эталонным изображением IGT, ненасыщающую состязательную потерю на основе дискриминатора StyleGAN2 с R1-регуляризацией и потерю Dice между маской спрогнозированной сегментации Spred и маской эталонной сегментации SGT. В предпочтительном варианте использовалась взвешенная сумма вышеупомянутых потерь со следующими весами: потеря L2 различия с весом λ1=2,2; потеря LPIPS с весом λ2=1,0; потеря Dice с весом λ3=1,0; состязательная потеря с весом λ4=0,01. Следует отметить, что представленные выше значения весов не следует понимать в ограничительном смысле, так как данный способ вполне может обеспечить достижение технического результата(ов) с модифицированными весами. Такая модификация будет очевидной для специалиста в данной области после прочтения этого раскрытия. Для каждых 16 итераций применялась ленивая регуляризация R1 с весом λ5=0,1. Для вычисления потери LPIPS брали случайные кадры 256 × 256 из изображений размером 512 × 512. Конвейер сети кодировщика Е - генератора G, диффузионная модель дорисовки и нейронный рендерер θ обучались за 100000 шагов с использованием оптимизатора ADAM со скоростью обучения 2е-3
[0067] Основанный на VQGAN автокодировщик обучали сжимать нейронные текстуры до тензоров 6×64×64, состоящих из векторов длиной шесть из обучаемого словаря с 8192 элементами. Сначала основанный на VQGAN автокодировщик обучали за 300000 шагов. Затем конвейер (с добавленным предобученным основанным на VQGAN автокодировщиком) настраивали сквозным методом за дополнительных 20000 шагов, чтобы уменьшить артефакты нейронного рендерера в при обработке нейронных текстур, обработанных основанным на VQGAN автокодировщиком. После этого диффузионную модель дорисовки обучали восстанавливать отсутствующие части текстуры. В диффузионной модели дорисовки использовалась удаляющая шум архитектура U-Net с остаточными блоками BigGAN для повышающей и понижающей дискретизации и со слоями внимания на трех уровнях иерархии признаков. Чтобы дополнительно исключить переобучение, использовалось прореживание с вероятностью 0,5 в остаточных блоках удаляющей шум архитектуры U-Net. Диффузионную модель дорисовки обучали за 50000 итераций с помощью оптимизатора AdamW с размером пакета 128 и скоростью обучения 1,0е-6.
[0068] Для обучения конвейера использовались только 2D-изображения, полученные путем рендеринга набора данных Texel. Генератор G сети кодировщик Е - генератор G и нейронный рендерер θ предварительно обучались на 2D-изображениях 13000 человек в различных позах. Было замечено, что различные позы имеют решающее значение для обучения реалистично анимируемых аватаров. Для каждого изображения получали маску сегментации с использованием сегментации Graphonnomy, а параметрическую модель тела SMPL-X подгоняли с помощью SMPLify-X. Для улучшения формы тела подогнанной параметрической модели тела SMPL-X дополнительно использовали потерю Dice сегментации.
[0069] Для обучения автокодировщика VGQAN и диффузионной модели дорисовки использовались рендеры из набора данных Texel. Из набора данных Texel было получено 3333 скана человека. На них изображены люди в различной одежде, с различным телосложением, оттенком кожи и полом. Каждый скан подвергали рендерингу с 8 различных видов (или углов обзора камеры) для получения многоракурсного набора данных. Рендеры также дорабатывали путем изменения углов обзора камеры и изменения цвета. Таким образом, на каждого человека в наборе данных получали 72 скана. Следует отметить, что для обучения этой модели подходят любые изображения из различных видов, не обязательно полученные из 3D-сканов.
[0070] Сгенерированные аватары и их анимации оценивались качественно на наборе данных AzurePeople. Этот набор данных содержит людей в различной одежде, стоящих в естественных позах. Кроме того, обученный конвейер оценивался количественно на общедоступном бенчмарке SnapshotPeople. Он содержит 24 видео, на которых люди вращаются в позе А. Из каждого видео отбирались кадры с видом спереди и сзади, чтобы измерить точность реконструкции вида сзади. Для каждого изображения получали маску сегментации и подгонку SMPL-X, как было описано выше.
[0071] Количественные результаты. В следующей таблице 1 представлено количественное сравнение:
Таблица 1: Сравнение метрик на бенчмарке SnapshotPeople. Описанный способ сравнивается не только с другими подходами на основе параметрических моделей (StylePeople), но и с подходами, восстанавливающими геометрию и требующими использования дополнительных методов для риггинга (PIFu, Phorhum) или восстановления геометрии в канонической позе (ARCH, ARCH++). 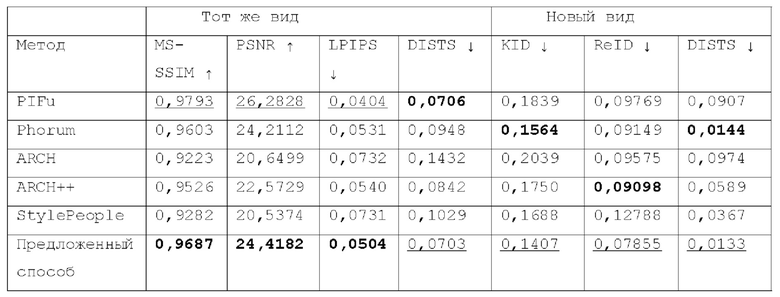
[0072] Авторы настоящего изобретения сравнили изобретение с различными способами создания аватара из одного изображения, в том числе требующими дополнительных этапов риггинга для анимации. Для ясности приведенная выше таблица 1 разделена на три части. PIFu и PHORHUM восстанавливают 3D-сетку человека в позе, показанной на входном изображении. Это накладывает строгие ограничения на позу человека на входном изображении при желании его анимировать. ARCH и ARCH++ восстанавливают 3D-сетку в каноническом пространстве, на которой легче осуществить риггинг и анимацию. StylePeople и настоящее изобретение основаны на параметрической модели человека, поэтому их легче всего анимировать, и на них не влияют несовершенства риггинга.
[0073] В публикациях сообщается о ряде метрик для численной оценки сгенерированных аватаров, а именно: многомасштабное структурное сходство (MS-SSIM ↑), пиковое отношение сигнал-шум (PSNR↑), потеря выученного перцептивного сходства между патчами изображения (LPIPS↓). Эти эталонные метрики измеряются на аватарах видов спереди для общедоступного бенчмарка SnapshotPeople. Согласно этим метрикам для вида спереди предлагаемый способ работает наравне с методами без риггинга. Для оценки качества вида сзади (и, следовательно, возможности обобщения в новые виды) сообщаются измерения образования ядра (KID↓). Эта метрика позволяет оценить качество сгенерированных изображений и больше подходит для небольших объемов данных, чем FID. Предложенный способ выдал самое высокое значение KID по сравнению с другими способами. Для оценки показателя реидентификации сохранения идентичности (ReID↓) использовалась мера на основе модели FlipReID для реидентификации человека. Предлагаемый способ дал наилучшие результаты в сохранении идентичности человека между видами спереди и сзади. Для дополнительной проверки качества текстур и измерения структурного сходства в случаях с невыровненными эталонными изображениями использовалась мера глубокого сходства структуры и текстуры изображения Deep Image Structure and Texture Similarity (DISTS↓). В таблице 1 приведены измерения для вида спереди и сзади. Предлагаемый способ выдал наиболее естественно выглядящие аватары для обоих видов.
[0074] При этом предлагаемый способ реалистично реконструирует текстуру ткани одежды на спине (например, складки на брюках), что повышает реалистичность рендеров. Использование всей информации из данного изображения позволяет не копировать ненужные узоры из вида спереди в вид сзади (как это обычно делается методами выравнивания по пикселям при восстановлении текстуры для вида сзади). Использование выбранной RGB текстуры в качестве дополнения к нейронной текстуре позволяет добиться фотореалистичных деталей лица и сохранить высокочастотные детали. Было замечено, что PIFu точно воспроизводит цвет аватара и хорошо восстанавливает геометрию. Однако этот метод не сохраняет высокочастотные детали, из-за чего аватарам не хватает фотореализма. PHORHUM создает очень фотореалистичные аватары, но часто страдает от цветовых сдвигов. Еще одним методологическим недостатком данного подхода является отсутствие априорной информации для тела человека. Поэтому модель может переобучаться на человеческих позах из обучающего набора данных, что может привести к некорректной работе с новыми позами. Аватары, сгенерированные ARCH, содержат сильные цветовые артефакты и подвержены ошибкам восстановления геометрии. ARCH++ значительно улучшает геометрию и качество цвета для вида спереди, но вид сзади по-прежнему страдает от смещения цвета и артефактов. Аватар по методу StylePeople основан на параметрической модели человека и может легко анимироваться без применения сторонних методов или дополнительного риггинга. Однако охват скрытого пространства их модели ограничен, что приводит к переобучению и плохому обобщению для новых людей при выполнении вывода на основе одного вида.
[0075] В настоящем документе раскрыт новый способ для моделирования человеческих аватаров на основе нейронных текстур, которые объединяют компоненты RGB и скрытые компоненты. Компоненты RGB используются для сохранения высокочастотных деталей, а нейронные компоненты добавляют волосы и одежду к базовой сетке SMPL-X. Использование параметрической модели SMPL-X в качестве основы позволяет легко анимировать полученный аватар. Предлагаемый способ восстанавливает отсутствующие части текстуры с помощью адаптированной диффузионной платформы для дорисовки таких текстур. Таким образом, данный метод позволяет создавать аватары с построенным скелетом, повышая также качество рендеринга ненаблюдаемых на изображении частей тела по сравнению с современными методами реконструкции человеческих моделей без построения скелета.
[0076] Специалисту будет также понятно, что различные иллюстративные логические блоки и этапы, представленные в вариантах осуществления изобретения, могут быть реализованы электронными аппаратными средствами, компьютерным программным обеспечением или их комбинацией. Выбор реализации этих функций с помощью аппаратных или программных средств зависит от конкретных применений и проектных требований ко всей системе. Специалист в данной области может использовать различные методы для реализации описанных функций для каждого конкретного применения, но не следует считать, что такая реализация выходит за пределы объема вариантов осуществления данного приложения.
[0077] В настоящем изобретении также предложен энергонезависимый машиночитаемый носитель данных. Машиночитаемый носитель хранит машиноисполняемые инструкции и параметры, включающие в себя, по меньшей мере, веса и смещения обученного конвейера сети кодировщика Е - генератора G, диффузионной модели дорисовки и нейронного рендерера θ, причем выполнение машиноисполняемых инструкций вычислительным устройством (например, описанным выше вычислительным устройством 50) побуждает это вычислительное устройство выполнять способ создания анимируемого аватара человека в полный рост из одного изображения этого человека в соответствии с первым аспектом настоящего изобретения или любым его развитием.
[0078] Все или некоторые из описанных вариантов осуществления могут быть реализованы с использованием программных средств, аппаратных средств, программно-аппаратных средств или любой их комбинации. При использовании программных средств для реализации вариантов осуществления, эти варианты осуществления могут быть реализованы полностью или частично в виде машиноисполняемых инструкций. При загрузке машинных инструкций и их исполнении на вычислительном устройстве полностью или частично генерируются процедура или функции в соответствии с вариантами осуществления. Машинные инструкции могут храниться на машиночитаемом носителе данных или могут передаваться с машиночитаемого носителя данных на другой машиночитаемый носитель данных. Например, машинные инструкции могут передаваться с веб-сайта, вычислительного устройства, сервера или дата-центра на другой веб-сайт, вычислительное устройство, сервер или дата-центр по проводной линии связи (например, коаксиальному кабелю, оптоволоконному кабелю или цифровой абонентской линии (DSL)) или беспроводной линии связи (например, инфракрасной, радио или СВЧ). Машиночитаемый носитель данных может быть любым подходящим носителем, к которому может осуществлять доступ вычислительное устройство, или устройством хранения данных, например, сервером или дата-центром с интегрированным одним или несколькими пригодными носителями. Подходящим носителем может быть магнитный носитель (например, гибкий диск, жесткий диск или магнитная лента), оптический носитель (например, цифровой видеодиск (DVD)), полупроводниковый носитель (например, твердотельный накопитель (SSD)) или тому подобное.
[0079] Также следует отметить, что порядок выполнения этапов раскрытого способа не является строгим, т.е. некоторые (один или несколько) этапы можно поменять местами и/или объединить. Во всех материалах настоящего описания ссылка на элемент в единственном числе не исключает наличия нескольких таких элементов при фактическом осуществлении изобретения, и, наоборот, ссылка на элемент во множественном числе не исключает наличие всего одного такого элемента при фактическом осуществлении изобретения. Любое значение упомянутых выше параметров не следует интерпретировать в ограничительном смысле, напротив, его следует рассматривать как представляющее среднюю точку определенного диапазона, определяемого как средняя точка ± приблизительно до 20%.
[0080] Приведенные выше описания представляют собой всего лишь конкретные реализации настоящего изобретения, но не предназначены для ограничения объема его защиты. Любое изменение или замена, которую сможет легко предусмотреть специалист в данной области техники в рамках объема, раскрытого в данной заявке, должны подпадать под объем охраны данного изобретения. Таким образом, объем защиты настоящего изобретения устанавливается в соответствии с объемом защиты формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| НЕЙРОСЕТЕВОЙ РЕНДЕРИНГ ТРЕХМЕРНЫХ ЧЕЛОВЕЧЕСКИХ АВАТАРОВ | 2021 |
|
RU2775825C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| СПОСОБ СИНТЕЗА ВИДЕО ИЗ ВХОДНОГО КАДРА АВТОРЕГРЕССИОННЫМ МЕТОДОМ, ПОЛЬЗОВАТЕЛЬСКОЕ ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЧИТЫВАЕМЫЙ КОМПЬЮТЕРОМ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2829010C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИСТАНЦИОННОГО ВЫБОРА ОДЕЖДЫ | 2020 |
|
RU2805003C2 |


Изобретение относится к области синтеза и обработки изображений на основе искусственного интеллекта. Техническим результатом является упрощение процесса получения аватара человека и расширение возможных к обработке поз. Технический результат достигается тем, что получают изображение человека и расчетную параметрическую модель тела; определяют функцию текстурирования; осуществляют выборку RGB текстуры тела человека и получают карту выбранных пикселей; нейронную текстуру путем конкатенации RGB текстуры, карты выбранных пикселей и созданной текстуры; осуществляют дорисовку ненаблюдаемых текстурных областей нейронной текстуры с помощью обученной диффузионной модели дорисовки; преобразуют растеризованное изображение аватара человека в полный рост в новой позе с помощью обученного нейронного рендерера в рендерное изображение аватара человека в полный рост в новой позе. 3 н. и 17 з.п. ф-лы, 9 ил., 1 табл.
1. Реализуемый компьютером способ создания анимируемого аватара человека в полный рост из одного изображения человека, включающий в себя этапы, на которых:
получают (S100) изображение (Irgb) человека и расчетную параметрическую модель тела, определяемую значениями параметров позы (р) и параметров формы (s) тела человека на изображении, и значениями параметров камеры (С), использованных при захвате изображения;
на основе параметрической модели тела определяют (S105) функцию текстурирования (FUV), задающую отображение между каждым наблюдаемым на изображении пикселем тела человека и соответствующими координатами текстуры в текстурном пространстве, причем для всех ненаблюдаемых на изображении пикселей тела человека функция текстурирования дополнительно задает соответствующие координаты текстуры в текстурном пространстве;
осуществляют выборку (S110) RGB текстуры (Trgb) тела человека на основе отображения и получают карту (Bsmp) выбранных пикселей, причем RGB текстура (Trgb) содержит для каждого наблюдаемого на изображении пикселя тела человека соответствующее значение пикселя, а также содержит одну или несколько ненаблюдаемых текстурных областей, соответствующих координатам текстуры ненаблюдаемых на изображении пикселей тела человека;
создают (S115) текстуру (Tgen) тела человека, наблюдаемого на изображении, путем пропускания изображения через обученную сеть кодировщика (Е) - генератора (G);
получают (S120) нейронную текстуру (Т) путем конкатенации RGB текстуры (Trgb), карты (Bsmp) выбранных пикселей и созданной текстуры (Tgen);
осуществляют дорисовку (S125) ненаблюдаемых текстурных областей нейронной текстуры (Т) с помощью обученной диффузионной модели дорисовки;
преобразуют (S130) растеризованное изображение (R) аватара человека в полный рост в новой позе с помощью обученного нейронного рендерера (θ) в рендерное изображение (Irend) аватара человека в полный рост в новой позе,
причем растеризованное изображение (R) получают из дорисованной нейронной текстуры (Tinpainted) и отображения, заданного функцией текстурирования (FUV), в котором параметрическая модель тела модифицирована на основе параметров целевой позы (ptarget) и/или параметры камеры модифицированы в параметры целевой камеры (Ctarget), причем параметры целевой позы (ptarget) и/или параметры целевой камеры (Ctarqet) соответствуют упомянутой новой позе аватара человека в полный рост.
2. Способ по п. 1, в котором дополнительно осуществляют дорисовку в выбранной RGB текстуре промежутков, не превышающих заданный пороговый размер, путем усреднения соседних пикселей и получения карты (Bfill) дорисованных пикселей, причем
карту (Bfill) дорисованных пикселей дополнительно используют при конкатенации на этапе получения нейронной текстуры (Т).
3. Способ по п. 1, в котором этап дорисовки (S125) ненаблюдаемых текстурных областей нейронной текстуры (Т) выполняют путем добавления гауссового шума к нейронной текстуре (Т) и последующего итеративного выполнения процедуры удаления шума на нейронной текстуре (Т) с гауссовым шумом Tnoise раз с помощью обученной диффузионной модели дорисовки до тех пор, пока вместо гауссового шума не появится дорисованная нейронная текстура (Tinpainted).
4. Способ по п. 1, в котором параметрическая модель тела основана на сетке М с фиксированной топологией, управляемой значениями параметров позы (р) и параметров формы (s).
5. Способ по п. 1, в котором
кодировщик (Е) обученной сети кодировщика (Е) - генератора (G) основан на дискриминаторе StyleGAN2 и обучен сжимать изображение (Irgb) в вектор признаков 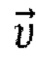 , и
, и
генератор (G) обученной сети кодировщика (Е) - генератора (G) основан на генераторе StyleGAN2 и обучен создавать текстуру (Tgen) из вектора признаков 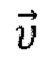 .
.
6. Способ по п. 1, в котором отображение создают с помощью UV-развертки, выполняемой с передним разрезом представления тела человека на изображении.
7. Способ по п. 1, в котором дополнительно находят закрытую область тела человека на изображении (Irgb) и исключают эту закрытую область при осуществлении выборки RGB текстуры (Trgb).
8. Способ по п. 1, в котором обученная диффузионная модель дорисовки основана на вероятностной модели рассеяния шума (DDPM), имеющей удаляющую шум архитектуру U-Net, обученную дорисовке ненаблюдаемых текстурных областей нейронной текстуры (Т) для получения дорисованной нейронной текстуры (Tinpainted), в которой удаляющая шум архитектура U-Net имеет остаточные блоки BigGAN для повышающей дискретизации и понижающей дискретизации и слои внимания на ряде уровней иерархии признаков удаляющей шум архитектуры U-Net.
9. Способ по п. 8, в котором обученная диффузионная модель дорисовки дополнительно содержит основанный на векторной квантованной генеративно-состязательной сети (VQGAN) автокодировщик, включающий в себя кодировщик (EVQ), обученный кодировать нейронную текстуру (Т) в скрытое представление нейронной текстуры (Т) меньшей размерности, вводимое в удаляющую шум архитектуру U-Net, и декодировщик (DVQ), обученный декодировать вывод удаляющей шум архитектуры U-Net в дорисованную нейронную текстуру (Tinpainted).
10. Способ по п. 1, в котором обучение сети кодировщика (Е) - генератора (G), диффузионной модели дорисовки и нейронного рендерера (θ) осуществляют на двух стадиях обучения:
на первой стадии обучения:
упомянутую сеть кодировщика (Е) - генератора (G) и упомянутый нейронный рендерер (θ), основанный на рендеринговой архитектуре U-Net, имеющей блоки ResNet, которые образуют конвейер, обучают сквозным методом на основе наборов многоракурсных изображений, используемых в качестве обучающих данных,
на каждом этапе обучения из множества этапов обучения во время обучения на первой стадии обучения:
выбирают два различных изображения из одного и того же набора из наборов многоракурсных изображений: первое изображение, показывающее человека в позе, имеющей параметры входной позы (pinput), используемое в качестве входного изображения, и второе изображение, показывающее человека в позе, имеющей другие параметры целевой позы (ptarget), используемое в качестве эталонного изображения (IGT),
пропускают первое изображение и параметры целевой позы (ptarget) через конвейер, обучаемый рендерингу рендерного изображения (Irend), показывающего аватар человека в позе, имеющей параметры целевой позы (ptarget),
вычисляют на основе, по меньшей мере, рендерного изображения (Irend) и эталонного изображения (IGT) значение потерь в соответствии с одной или несколькими из следующих функций потерь: потери L2 различия между рендерным изображением (Irend) и соответствующим эталонным изображением (IGT), потери выученного перцептивного сходства между патчами изображения (LPIPS) между рендерным изображением (Irend) и соответствующим эталонным изображением (IGT), ненасыщающей состязательной потери на основе дискриминатора StyleGAN2 с регуляризацией R1 и потери Dice между спрогнозированной маской сегментации (Spred) и эталонной маской сегментации (SGT),
вычисляют градиенты на основе значения потерь и обновляют параметры сети кодировщика (Е) - генератора (G) и нейронного рендерера (θ) на основе этих градиентов; и
после того, как значение потерь по одной или нескольким функциям потерь минимизируется, фиксируют выученные параметры сети кодировщика (Е) - генератора (G) и нейронного рендерера (θ) и переходят ко второй стадии обучения;
на второй стадии обучения:
диффузионную модель дорисовки, содержащую, по меньшей мере, удаляющую шум архитектуру U-Net, добавляют в конвейер и обучают с использованием обуславливаемого обучения диффузии осуществлять дорисовку ненаблюдаемых текстурных областей нейронной текстуры (Т), при этом
на каждом этапе обучения из множества этапов обучения во время обучения на второй стадии обучения:
получают объединенную нейронную текстуру, используемую в качестве эталонной нейронной текстуры, причем объединенную нейронную текстуру получают путем объединения неполных нейронных текстур, полученных из двух или более изображений, охватывающих различные углы обзора и выбранных из одного и того же набора многоракурсных изображений из наборов многоракурсных изображений, используемых в качестве обучающих данных,
добавляют гауссов шум к объединенной нейронной текстуре в соответствии со случайным шагом t, где t=[0, Tnoise],
осуществляют конкатенацию к объединенной нейронной текстуре с добавленным гауссовым шумом неполной нейронной текстуры из неполных нейронных текстур, используемых для получения объединенной нейронной текстуры,
пропускают объединенную нейронную текстуру с добавленным гауссовым шумом и с конкатенированной неполной нейронной текстурой через диффузионную модель дорисовки, прогнозирующую для шага t шум, который следует удалить для получения дорисованной объединенной нейронной текстуры,
вычисляют, по меньшей мере, на основе спрогнозированного шума и добавленного гауссового шума значение потерь в соответствии с функцией потери L1,
вычисляют градиенты на основе значения потерь, и
обновляют параметры удаляющей шум архитектуры U-Net, используемой для диффузионной дорисовки на основе градиентов; и
после того, как значение потерь минимизируется, осуществляют точную настройку предобученного конвейера путем выполнения множества дополнительных этапов обучения.
11. Способ по п. 10, в котором точная настройка включает в себя фиксацию весов и смещений нейронного рендерера (θ) и распространение градиентов из дифференцируемого нейронного рендерера (θ) в каналы RGB текстуры RGB (Trgb), причем упомянутые градиенты вычисляют на основе значения потерь, полученного на первой стадии обучения.
12. Способ по п. 10, в котором, если в обучаемую диффузионную модель дорисовки дополнительно включен основанный на VQGAN автокодировщик, то основанный на VQGAN автокодировщик дополнительно обучают на первой стадии обучения кодировать нейронные текстуры (Т) в скрытые представления нейронных текстур (Т) меньшей размерности и декодировать скрытые представления нейронных текстур (Т) меньшей размерности путем минимизации значения потерь, вычисляемого по одной или нескольким функциям потерь, используемым на первой стадии обучения, а затем обучение на второй стадии обучения выполняют в скрытом пространстве предобученного основанного на VQGAN автокодировщика.
13. Способ по п. 10, в котором на первой стадии обучения потерю L2 различия и потерю LPIPS вычисляют для всего изображения и дополнительно вычисляют с заданным весом для области изображения, содержащей лицо.
14. Способ по п. 10, в котором объединение основано на взвешенном усреднении, пирамидальном смешивании или смешивании Пуассона нейронных текстур.
15. Способ по п. 10, в котором на второй стадии обучения используют прореживание с заданной вероятностью в остаточных блоках удаляющей шум архитектуры U-Net.
16. Способ по п. 10, в котором наборы многоракурсных изображений содержат изображения людей в различной одежде с различным телосложением, оттенком кожи, разного пола и во множестве различных поз, снятых с разных углов обзора.
17. Способ по п. 10, в котором угол обзора определяют как угол между векторами нормалей соответствующей точки сетки М с фиксированной топологией и вектором направления камеры.
18. Вычислительное устройство (50), содержащее процессор (50.1) и память (50.2), хранящую исполняемые процессором инструкции и параметры, содержащие, по меньшей мере, веса и смещения обученного конвейера сети кодировщика (Е) - генератора (G), диффузионной модели дорисовки и нейронного рендерера (θ), отличающееся тем, что при выполнении процессором (50.1) исполняемых процессором инструкций процессор (50.1) побуждает вычислительное устройство (50) выполнять способ по любому из пп. 1-17 создания анимируемого аватара человека в полный рост из одного изображения человека.
19. Вычислительное устройство (50) по п. 18, дополнительно содержащее камеру (50.3), сконфигурированную для захвата изображения (Irgb) человека.
20. Машиночитаемый носитель, хранящий машиноисполняемые инструкции и параметры, содержащие по меньшей мере веса и смещения обученного конвейера сети кодировщика (Е) - генератора (G), диффузионной модели дорисовки и нейронного рендерера (θ), отличающийся тем, что выполнение вычислительным устройством машиноисполняемых инструкций побуждает вычислительное устройство выполнять способ по любому из пп. 1-17 создания анимируемого аватара человека в полный рост из одного изображения человека.
| KRIPASINDHU SARKAR et al.: "Style and Pose Control for Image Synthesis of Humans from a Single Monocular View", 22.02.2021, Найдено в: "https://arxiv.org/pdf/2102.11263.pdf" | |||
| AMIT RAJ et al.: "ANR: Articulated Neural Rendering for Virtual Avatars", 2021, Найдено в: |

