ОБЛАСТЬ ТЕХНИКИ
[1] Заявленное техническое решение в общем относится к области микропроцессоров, а в частности к устройству для матричных вычислений.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящий момент в современном мире выполняется большое количество операций с данными. С развитием и внедрением алгоритмов машинного обучения во все сферы жизнедеятельности, появилась необходимость в устройствах, способных эффективно работать с такими алгоритмами, и, в частности, с нейронными сетями. Одними из основных операций, совершаемых при инференсе (процесс получения вывода нейронной сети) и обучении и нейронных сетей являются операции манипуляции с матрицами, например, операции умножения матриц. Так, процессоры общего назначения, ввиду своей архитектуры, не приспособлены для выполнения процессов машинного обучения, таких как инференс и обучение нейронных сетей и т.д., с высокой скоростью, т.е. являются малоэффективными для таких операций. В связи с этим, в последние годы, особую важность получило направление развития специализированных устройств, таких как устройства матричных вычислений, векторные вычислители и т.д., специально предназначенных для параллельных вычислений.
[3] Устройства матричных вычислений предназначены для выполнения сложных матричных операций, например, в составе ускорителя инференса и обучения нейронных сетей. Так, матричные операции используются для реализации нейронных сетей, на основе которых построены алгоритмы машинного обучения, например, алгоритмы компьютерного зрения, алгоритмы распознавания речи и аудио, обработка естественного языка и т.д. Матричные операции (умножение матриц, операции свертки) используются для реализации фундаментальных операций нейронных сетей, например, обновление весов нейронной сети и т.д. В связи с этим, скорость выполнения процессов машинного обучения напрямую зависит от скорости выполнения матричных вычислений в таких устройствах. Поэтому в настоящее время, развитие аппаратных средств матричных вычислений является существенной задачей.
[4] Так, из уровня техники известно решение, раскрытое в патенте США US 10489479 B1 (HABANA LABS LTD [IL]), опубл. 26.11.2019. Указанное решение раскрывает устройство матричных вычислений на базе систолического массива, содержащее, в том числе систолический массив, выполненный с возможностью вычисления суммы произведений элементов матриц операндов, память, а также элементы, предназначенные для загрузки и преобразования входных данных в элементы обрабатываемого массива.
[5] Недостатком указанного решения является наличие в архитектуре блоков предварительной подготовки данных, осуществляющих транспонирование матриц перед загрузкой в систолический массив, что, как следствие увеличивает площадь устройства и повышает энергопотребление всего устройства. Кроме того, архитектура указанного решения не предполагает и не обеспечивает возможность многовходового суммирования результатов умножения.
[6] Общими недостатками известных из уровня техники решений является отсутствие аппаратного устройства матричных вычислений, обеспечивающего высокую производительность при выполнении вычислительных операций над элементами матриц и обладающего малой площадью и низким энергопотреблением.
[7] Соответственно, целью настоящего технического решения является создание устройства матричных вычислений, обладающего малой площадью и способного обеспечивать многовходовое суммирование элементов систолического массива. Кроме того, данное решение должно обеспечить снижение частоты доступа к блокам в устройстве и обеспечить выполнение вычислений без простоев при смене матриц. Также, заявленное решение должно обладать схемами исполнения умножения больших матриц, размеры которых превышают размеры кэша устройства матричных вычислений.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[8] В заявленном техническом решении предлагается новый подход к архитектуре устройства матричных вычислений, обеспечивающей уменьшение площади устройства, а также увеличение производительности устройства.
[9] Техническим результатом, достигающимся при решении данной проблемы, является уменьшение площади устройства (за счет использования многовходовых сумматоров).
[10] Дополнительным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является повышение производительности устройства матричных вычислений за счет снижения задержек при вычислении.
[11] Указанные технические результаты достигаются благодаря устройству матричных вычислений, размещенному на кристалле, содержащему:
• блок разделения конфигурационных пакетов, соединенный с внешним управляющим устройством, выполненный с возможностью получения, разделения и контроля исполнения конфигурационных пакетов;
• память, выполненную с возможностью получения от по меньшей мере внешней памяти и/или памяти векторного процессора матриц-операндов, их хранения, и передачи в блок матричного умножения на основе полученных конфигурационных пакетов;
• блок комбинирования, выполненный с возможностью получения множества скалярных элементов вектора из памяти векторного процессора, объединения указанных элементов в вектор, и передачи указанного вектора в память;
• блок матричного умножения, выполненный с возможностью умножения матриц-операндов на основе полученного конфигурационного пакета, включающий:
 систолический массив, выполненный с возможностью вычисления суммы произведений элементов матриц-операндов;
систолический массив, выполненный с возможностью вычисления суммы произведений элементов матриц-операндов;
блок задержек элементов матриц-операндов, выполненный с возможностью синхронизации вычислений внутри систолического массива;
буферную память, соединенную с внешним устройством, выполненную с возможностью накопления результатов вычислений из систолического массива и передачи накопленных результатов на внешнее устройство;
локальный блок управления, выполненный с возможностью управления очередностью передачи элементов матриц-операндов в систолический массив и управления передачей данных из систолического массива на внешнее устройство.
[12] В одном из частных вариантов реализации систолический массив состоит из множества вычислительных элементов.
[13] В другом частном варианте реализации множество вычислительных элементов объединены в блоки.
[14] В другом частном варианте реализации каждый вычислительный элемент представляет собой по меньшей мере умножитель-сумматор.
[15] В другом частном варианте реализации размер систолического массива равен 128×128 вычислительных элементов.
[16] В другом частном варианте реализации вычислительные элементы объединены в блоки размером по 8 вычислительных элементов.
[17] В другом частном варианте реализации матрицы-операнды представляют собой матрицы весов и матрицы признаков нейронной сети.
[18] В другом частном варианте реализации конфигурационные пакеты представляют собой инструкции для по меньшей мере: получения данных из внешней памяти, получения данных из памяти векторного процессора, операции вычисления матричного умножения.
[19] В другом частном варианте реализации блок разделения конфигурационных пакетов получает конфигурационные пакеты по общей мультиплексированной шине с идентификационными полями, которые соответствуют типу пакета.
[20] В другом частном варианте реализации блок матричного умножения дополнительно содержит контроллер входных данных, выполненный с возможностью приостановки и возобновления отправки данных в систолический массив в зависимости от состояния внешнего принимающего устройства.
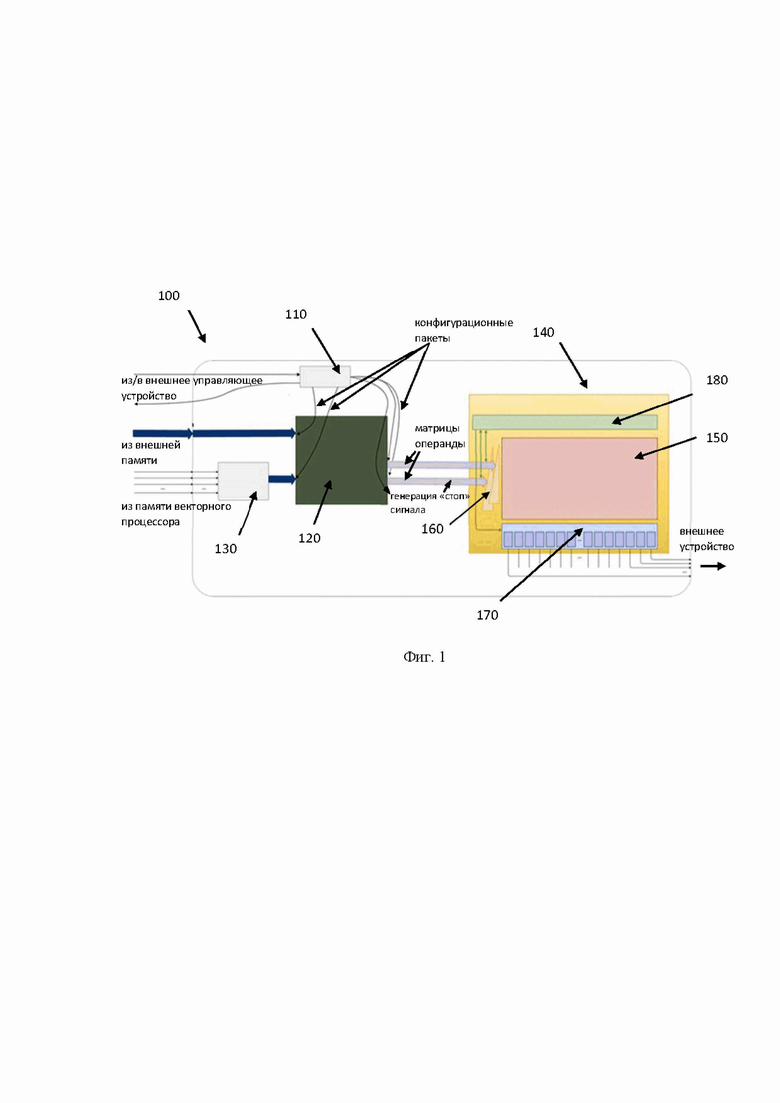
[21] В другом частном варианте реализации память представляет собой многопортовую многобанковую память.
[22] В другом частном варианте реализации вычислительные элементы систолического массива содержат активные и теневые регистры.
[23] В другом частном варианте реализации активные и теневые регистры выполнены с возможностью хранения элементов матриц-операндов.
[24] В другом частном варианте реализации загрузка элементов матриц-операндов в теневые регистры выполняется в процессе вычисления суммы произведений элементов матриц-операндов, которые находятся в активных регистрах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[25] Признаки заявленного технического решения и подробное описание приведено ниже в виде прилагаемых чертежей.
[26] Фиг. 1 иллюстрирует структурную схему устройства матричных вычислений.
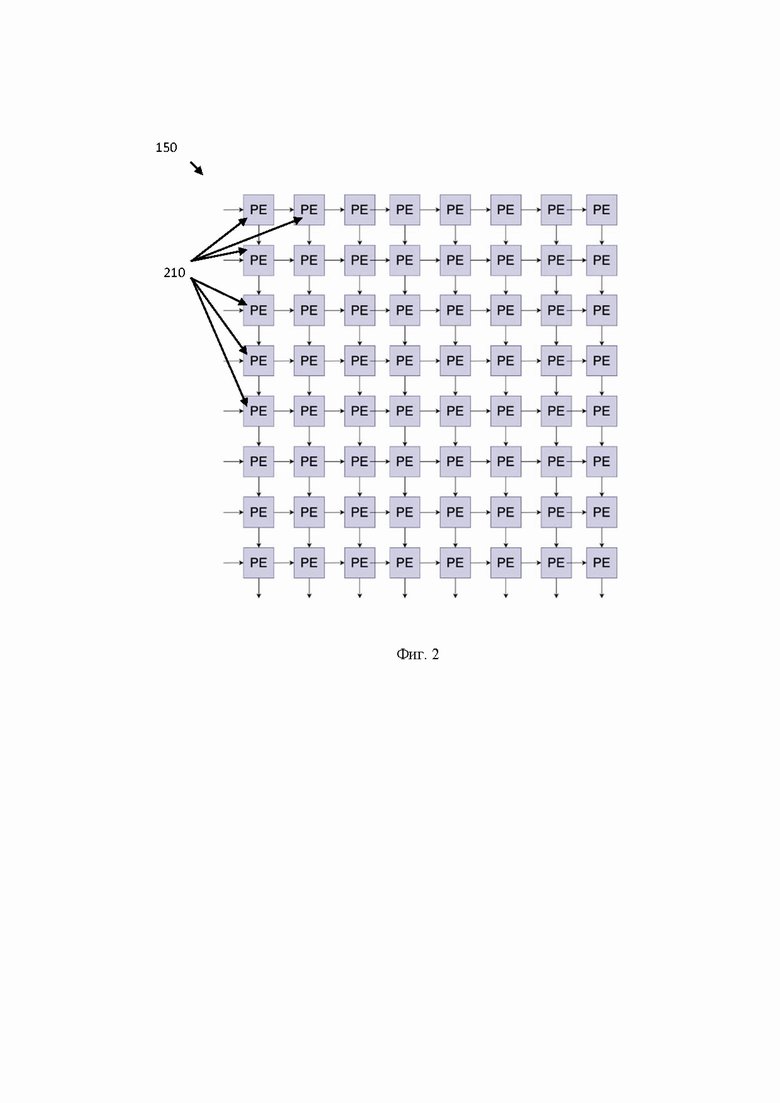
[27] Фиг. 2 иллюстрирует пример систолического массива, состоящего из вычислительных элементов.
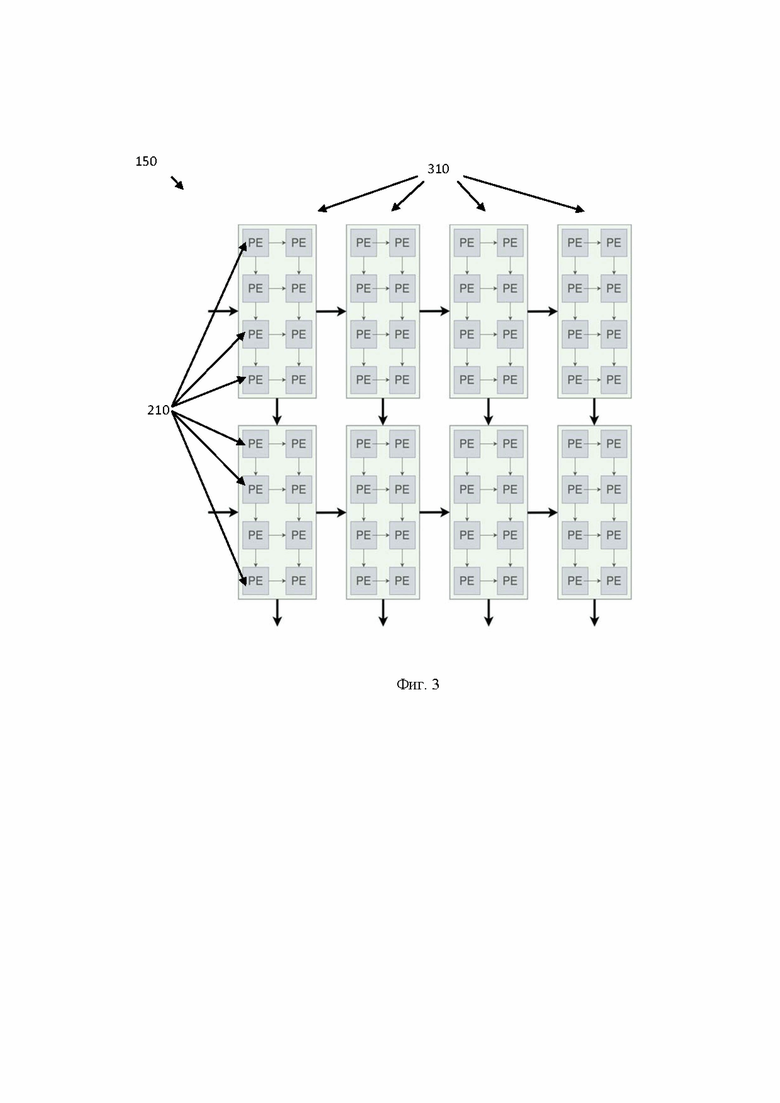
[28] Фиг. 3 иллюстрирует пример систолического массива, состоящего из вычислительных элементов, объединенных в блоки.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[29] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[30] Заявленное техническое решение предлагает новый подход в создании устройства матричных вычислений, предназначенного для выполнения операций матричного умножения и сопутствующей подготовке, и буферизации данных. Заявленное решение обеспечивает устройство матричных вычислений, которое обладает высокой производительностью (высокой скоростью вычисления операций) и малой площадью. Также, архитектура заявленного устройства обеспечивает снижение частоты доступа к блокам в устройстве и обеспечивает возможность выполнения вычислений без простоев при смене матриц. Кроме того, еще одним преимуществом, достигаемым при использовании заявленного решения, является возможность выполнения умножения больших матриц, размеры которых превышают размеры кэша устройства матричных вычислений.
[31] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, исполнения конфигурационных пакетов в устройстве матричных вычислений и т. п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, потоковую конфигурацию машинных команд, объектно-ориентированные методы и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться по проводным каналам от устройств управления, например, устройства управления ускорителем инференса и обучения нейронных сетей.
[32] На Фиг. 1 представлена блок схема устройства матричных вычислений 100. Указанное устройство 100 включает в себя блок разделения конфигурационных пакетов 110, память 120, блок комбинирования 130, блок матричного умножения 140, который включает систолический массив 150, блок задержек 160, буферную память 170, локальный блок управления 180.
[33] Заявленное техническое решение направлено на создание архитектуры нового аппаратного устройства матричных вычислений 100, которое обеспечивает высокую эффективность (производительность) при выполнении операций матричного умножения и обладает малой площадью. Заявленная архитектура основана на массиве обрабатывающих элементов, которые выполняют операции над элементами матриц операндов, например, над матрицами весов и матрицами признаков нейронной сети. Использование заявленного устройства 100 обеспечивает возможность выполнения операций матричного умножения с высокой скоростью (эффективностью, производительностью), за счет снижения задержек при выполнении операций и устранении задержек при смене матриц в устройстве 100. Преимущественно, устройство 100 используется, например, для ускорения вычислений глубокого обучения, выполнения операций свертки, обновления весов нейронной сети и т.д., в том числе, в составе ускорителей обучения и инференса нейронных сетей.
[34] Под термином инференс нейронной сети в данном решении следует понимать непрерывный процесс работы обученной нейронной сети с получением логического вывода.
[35] Как указывалось выше, устройство 100, преимущественно является частью ускорителей, и может управляться посредством потоков конфигураций, получаемых из устройства управления (внешнее по отношению к устройству 100) такого ускорителя. Однако, следует отметить, что аспекты применения указанного технического решения не ограничиваются указанным примером, и, устройство 100 может быть использовано в связке с другими элементами, обеспечивающими возможность взаимодействия с данными на уровне тензоров (матриц). Так, в одном частном варианте осуществления устройство матричных вычислений 100 имеет соединение с внешней памятью для получения данных из нее. Также устройство 100 имеет соединение с памятью векторного процессора, который также является внешним по отношению к указанному устройству 100. Результат вычислений, получаемых от устройства 100, также может быть передан во внешнее устройство, например, в векторный процессор для завершения вычислений нейронной сети и т.д., не ограничиваясь.
[36] Элементы устройства матричных вычислений 100 расположены на кристалле интегральной схемы (ИС). В одном частном варианте осуществления кристалл ИС может являться частью другого кристалла ИС, например, ускорителя нейросетей, который также содержит другие компоненты, связанные с устройством 100 (устройство управления векторный процессор и т.д.).
[37] Блок разделения конфигурационных пакетов 110 связан с внешним управляющим устройством и выполнен с возможностью получения, разделения и контроля исполнения конфигурационных пакетов. Указанный блок 110 предназначен для получения конфигурационного задания для всего устройства 100 и разделения указанного задания на подзадания для соответствующих элементов устройства 100. Стоит отметить, что за счет такого разделения обеспечивается возможность асинхронного выполнения операций, т.е. каждый конфигурационный пакет будет обрабатываться соответствующим этому пакету элементом устройства 100 независимо.
[38] Для управления устройством 100 внешнее управляющее устройство, например, внешнее управляющее устройство ускорителя инференса и обучения нейронной сети, отправляет конфигурационные пакеты в блок 110 для исполнения требуемых операций с данными. Под конфигурационными пакетами в данном решении следует понимать набор инструкций для определенного элемента устройства 100. Так, такими наборами инструкций могут являться по меньшей мере: инструкции для получения данных из внешней памяти, инструкции для получения данных из памяти векторного процессора, инструкции для выполнения операции вычисления матричного умножения.
[39] Так, в одном частном варианте осуществления конфигурационные пакеты могут содержать такие типы пакетов, как: пакеты, конфигурирующие загрузку данных из внешней памяти и из памяти векторного процессора, пакеты, конфигурируемые процесс матричного умножения. Так, в еще одном частном варианте осуществления блок 110 принимает конфигурационное задание от внешнего управляющего устройства, которое содержит, например, два конфигурационных пакета, которые направлены на выполнение загрузки данных из внешней памяти и памяти векторного процессора, и третий конфигурационный пакет на исполнение операции матричного умножения. Указанные пакеты распределяются в соответствующие элементы устройства 100, такие как память 120 - для двух конфигурационных пакетов, которые направлены на выполнение загрузки данных из внешней памяти и памяти векторного процессора, и блок 140 - для конфигурационного пакета на исполнение операции матричного умножения. Специалисту в данной области техники будет очевидно, что количество конфигурационных пакетов будет зависеть от источников получения данных (внешняя память, память векторного процессора и т.д.). Все конфигурационные пакеты подаются в устройство 100 по общей мультиплексированной шине с идентификационным полем, позволяющим различать виды передаваемых пакетов.
[40] Конфигурационные пакеты необходимы для упорядочивания процессов загрузки данных и обеспечивают, в том числе, возможность взаимодействия с данными, превышающими размер памяти 120 устройства 100. Так, данные, загружаемые в память 120 из внешней памяти или памяти векторного процессора за одну команду, могут не соответствовать одному заданию на умножение матриц. Так, например, можно осуществить загрузку весов для всей нейронной сети за одну команду, и потом вычитывать данные о весах постепенно, в соответствии с необходимостью таких данных в операции матричного умножения. И наоборот, операции умножения сверхбольших матриц, которые могут не вмещаться в память 120, могут быть разбиты на операции умножения матриц меньшего размера. Соответственно, конфигурационные пакеты необходимы для задания порядка считывания данных и порядка выполнения вычислительных операций с данными. Так, в еще одном частном примере реализации, операция чтения и весов и фичей из памяти 120 будет выполняться на основе одного конфигурационного пакета, который содержит в себе необходимый набор команд для управления всем процессом матричного умножения. Так, указанный пакет может содержать такие данные, как: частота смены весов в систолическом массиве 150 (через какой период времени необходимо подгрузить новые веса в вычислительные элементы систолического массива 150), порядок считывания элементов матриц-операндов из памяти 120 и т.д. Т.е. конфигурационные пакеты содержат данные, обеспечивающие возможность настройки параметров при вычислении и обеспечивающие возможность оптимально использовать память 120 в разных сценариях.
[41] Память 120 представляет собой многопортовую многобанковую память.
[42] Так, память 120 выполнена с возможностью хранения матриц операндов, получаемых от внешней памяти и/или памяти векторного процессора и выдачи в определенном порядке элементов матриц операндов. В качестве внешней памяти может использоваться память HBM. В качестве памяти векторного процессора может использоваться многопортовая разделяемая память. Матрицы-операнды представляют собой матрицы весов и матрицы признаков нейронной сети. Соответственно элементами матриц-операндов являются значения, расположенные в определенном месте матрицы
[43] После загрузки матриц-операндов (матрицы весов и признаков нейронной сети) указанные данные хранятся в памяти 120 до получения команды на исполнение операции матричного умножения. После получения такой команды, веса и признаки будут считываться из памяти 120 в определённом порядке и подаваться на систолический массив 150 для непосредственного вычисления.
[44] Размер матрицы признаков может быть N×128 (N - любое натуральное число, но важно, чтобы такая матрица помещалась память 120). Матрица весов всегда размером 128×128. Одной из особенностей заявленного решения является исключение необходимости транспонирования матрицы перед операцией умножения матриц, за счет того, что матрица весов подготавливается в транспонированном виде. Т.е. в умножитель 140 приходят строки матриц, а не строка и столбец, что обеспечивает неявное инвертирование второй матрицы. Указанная особенность также дополнительно снижает площадь устройства 100, т.к. матрицы загружаются одним набором соединительных элементов (провода), а также исключается необходимость в наличии устройства транспониатора в составе устройства 100.
[45] Блок комбинирования 130, выполненный с возможностью получения множества скалярных элементов вектора из памяти векторного процессора, объединения указанных элементов в вектор, и передачи указанного вектора в память.
[46] Так, указанный блок 130 предназначен для синхронизации скалярных элементов вектора, получаемых из памяти векторного процессора. Указанный блок может представлять собой память типа FIFO. Так, векторный процессор состоит из множества физически-размещенных скалярных элементов, предназначенных для выполнения вычислительных операций над элементами вектора (например, одной операции параллельно над 128 элементами вектора, которые выполняются 128 скалярными элементами), соответственно, в таком случае элементы вектора, приходящие в устройство 100 от скалярных элементов, будут иметь разную задержку. Указанный блок 130, осуществляет синхронизацию поступаемых элементов вектора от скалярных элементов векторного процессора, что, в свою очередь позволяет осуществить загрузку всего вектора в память 120.
[47] Блок матричного умножения 140 состоит из по меньшей мере следующих элементов: систолического массива 150, блока задержек 160, буферной памяти 170, локального блока управления 180.
[48] Рассмотрим более подробно указанные элементы.
[49] Систолический массив 150 предназначен для непосредственного вычисления суммы произведений элементов матриц-операндов. Более подробно пример систолического массива показан на Фиг. 2. Так, массив 150 состоит из множества вычислительных элементов 210 (PE, Processing Elements). В свою очередь, каждый вычислительный элемент 210 в составе систолического массива 150 может представлять, например, умножитель-сумматор и дополнительную вспомогательную логику. Размер систолического массива - 128×128 единичных (скалярных) умножителей-сумматоров. Так, устройство 100 выполнено с возможностью поочередной загрузки весов и признаков нейронной сети, т.е. перед операцией матричного умножения в систолический массив могут быть загружены веса (которые не меняются долгое время), а после этого уже будут подаваться элементы признаков нейронной сети, например, в виде вектора. Также стоит отметить, за счет того, что в систолическом массиве при вычислении суммы произведений переключение происходит от строки к строке вычислительных элементов 210, то при подаче одного вектора матрицы признаков, указанный вектор умножается на всю матрицу, что делает процесс матричного умножения более эффективным, по сравнению с другими специализированными устройствами, такими как векторный процессор.
[50] Так, в одном частном варианте осуществления вычислительные элементы 210 содержат активные и теневые регистры. Указанные регистры предназначены для хранения элементов матриц-операндов. Рассмотрим более подробно указанную особенность. Так, наличие теневых регистров обеспечивает возможность загрузки новых весов в указанные теневые регистры непосредственно в процессе умножения подаваемых элементов матрицы признаков на ранее загруженные элементы матрицы весов, находящиеся в активных регистрах. Соответственно, после окончания загрузки новых весов и после окончания потока элементов матрицы признаков, обеспечивается возможность бесшовного переключения на новые веса c минимальным простоем.
[51] В еще одном частном варианте, вычислительные элементы 210 систолического массива 150 могут быть объединены в блоки. Более подробно указанный пример показан на Фиг. 3. Так, вычислительные элементы 210 могут быть объединены в блочные вычислительные элементы 310, например, размером 4 (по высоте) на 2 (по ширине). Соответственно, в таком варианте исполнения размер систолического массива - 16×128 блочных элементов размером 4×2. Кроме того, в еще одном частном варианте осуществления блочные вычислительные элементы могут быть объединены, например, размером 8×1 элементов и т.д.
[52] Объединение элементарных вычислительных элементов 210 систолического массива 150 в блоки 310 позволяет дополнительно оптимизировать энергопотребление и снизить задержку вычислений. Так, объединение по вертикали позволяет использовать многовходовые сумматоры, которые экономят площадь на чипе, снижают энергопотребление и задержку вычислений. Объедение по горизонтали позволяет дополнительно уменьшить задержку вычислений.
[53] Также, для уменьшения энергопотребления элементарных математических блоков сложения и умножения в некоторых имплементациях допускается использовать нестандартные форматы представления чисел с плавающей точкой, например, форматы, отличающиеся от IEEE 754. Некоторые имплементации могут экономить площадь и потребление с помощью упрощения схем пред- и постнормализации при представлении чисел в ненормализованном формате (Exp8 + Int9), когда скрытый бит числа с плавающей точкой предварительно вычисляется, после чего мантисса, знак и этот скрытый бит конвертируются в знаковое целое.
[54] Рассмотрим процесс загрузки и смены весов в систолическом массиве 150.
[55] Кол-во тактов для загрузки весов (элементов матрицы весов) равно размеру систолического массива 150-128 тактов. Как указывалось ранее, загрузка весов для последующей операции умножения матриц может осуществляться во время исполнения предыдущей операции умножения. Если исполнение предыдущей задачи матричного умножения длится меньшее число тактов, чем требуется для предзагрузки весов, то появляется дополнительная пауза до тех пор, пока все веса не загрузятся в теневые регистры. Процесс чтения весов и признаков нейронной сети управляется конфигурационным пакетом, который управляет всем матричным умножением.
[56] Рассмотрим процесс приостановки вычислений в систолическом массиве 150.
[57] Т.к. систолический массив 150 является одним большим математическим блоком с фиксированной задержкой (latency), без глобального разрешающего сигнала (clock enable), то после приостановки подачи данных на вход массива 150, некоторое время данные будут продолжать выходить из массива 150. Соответственно, для накопления результатов, в блоке 140 предусмотрена буферная память 170.
[58] Так, указанная память 170 представляет собой кольцевой буфер типа FIFO со скалярными выходами. Указанная память 170 необходима для накопления данных, поступаемых с выхода массива 150. Например, если приостановка подачи данных на вход массива 150 вызвана неготовностью получателя результатов вычислений массива 150, например, неготовностью внешнего устройства, то соответственно, данные, которые поступают с выхода массива 150 будут сгружаться в указанную память 170 до тех пор, пока этот поток не остановится. Кроме того, указанная память 170 также необходима для нивелирования задержек, вызванных в процессе непосредственного вычисления суммы произведений элементов матриц-операндов систолическим массивом 150.
[59] В еще одном частном варианте осуществления, указанная приостановка может осуществляться с использованием кредитного счетчика. Прием валидных данных систолическим массивом 150 сопровождается декрементом кредитного счетчика. Если счетчик уменьшается до нуля, то схема выдает сигнал Stop, останавливающий отправку данных в систолический массив. Когда устройство-получатель опять готово принимать выход систолического массива, каждый выходящий валидный вектор сопровождается инкрементом кредитного счетчика. Если сигналы инкремента и декремента приходят в счетчик одновременно, то его значение не меняется.
[60] Блок задержек 160 представляет собой аппаратный блок, предназначенный для обеспечения корректной работы систолического массива, посредством задержек поступаемых на систолический массив 150 элементов для формирования данных в формате, который необходим систолическому массиву 150. Т.е. указанный блок 160 осуществляет упорядочивание входных элементов, поступающих в систолический массив, таким образом, чтобы последующие элементы поступали в массив с некоторой задержкой, необходимой для осуществления корректных вычислений внутри систолического массива 150.
[61] Так, рассмотрим процесс вычислений внутри систолического массива 150. Поскольку элементы матриц операндов будут поступать на вычислительные элементы 210 (Фиг. 2) последовательно, то и вычисления будут происходить не одновременно. Соответственно, выход первого левого вычислительного элемента 210 (Фиг. 2, первая строчка, первый столбец) будет происходить, например, за два такта. Т.е. в указанном элементе 210 произойдет операция A*B за два такта. Далее, результат этой операции отправиться в элемент 210 расположенный во второй строке, первого столба на Фиг. 2. Однако, указанный результат придет только спустя два такта. Для обеспечения корректной работы систолического массива 150, а, следовательно, и указанных вычислений, в блоке 140 размещен блок 160, который осуществляет задержки поступаемых элементов матриц на последующие вычислительные элементы 210. Указанный блок может выступать в качестве лесенки задержек с определенным шагом, например, два такта. Т.е. для каждого последующего элемента 210 в столбце задержка будет больше на определенный фиксированный параметр, 1 такт, 2 такта, 3 такта и т.д.
[62] Локальный блок управления 180 представляет собой программно-аппаратный блок, предназначенный для получения потоков данных и потоков управления от управляющего устройства 110 и преобразования указанных потоков в наборы низкоуровневых команд для управления систолическим массивом 150.
[63] Поскольку сам по себе систолический массив 150 представляет собой набор простейших вычислительных элементов 210, которые физически не предназначены для получения и обработки команд, то для осуществления управления указанными элементами 210, устройство 100 содержит блок 180. Так, указанный блок 180 выполнен с возможностью получения команд от других элементов устройства 100, например, команд о начале загрузки элементов матриц, о конце загрузки и т.д., и преобразования указанных команд в простейшие сигналы, такие как остановка вычислений, переключение теневых регистров и т.д. Соответственно на основе получаемых потоков данных и потоков управления, блок 180 управляет очередностью передачи элементов матриц-операндов в систолический массив, т.е. осуществляет управление блоком 160. Кроме того, в еще одном частном варианте осуществления локальный блок 180 осуществляет управление передачей данных из систолического массива на внешнее устройство, т.е. данные, полученные памятью 170, посредством блока 180 отправляются на внешнее устройство.
[64] Таким образом, в представленных материалах заявки были описаны различные варианты исполнения устройства матричных вычислений.
[65] Конкретный выбор элементов устройства 100 для реализации различных программно-аппаратных и/или архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[66] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО | 2024 |
|
RU2830044C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПИЛЯЦИИ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2835757C1 |
| СПОСОБ РАЗДЕЛЕНИЯ ОПЕРАЦИИ СВЕРТКИ НА УСТРОЙСТВЕ С МАТРИЧНЫМИ УМНОЖИТЕЛЯМИ НА ОСНОВЕ СИСТОЛИЧЕСКИХ МАССИВОВ | 2024 |
|
RU2830039C1 |
| УСТРОЙСТВО УПРАВЛЕНИЯ ВЫЧИСЛИТЕЛЬНЫМИ УСТРОЙСТВАМИ УСКОРИТЕЛЯ ВЫВОДА НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2832408C1 |
| Нейропроцессор (NPU) | 2024 |
|
RU2825124C1 |
| МАТРИЧНО-ВЕКТОРНЫЙ УМНОЖИТЕЛЬ С НАБОРОМ РЕГИСТРОВ ДЛЯ ХРАНЕНИЯ ВЕКТОРОВ, СОДЕРЖАЩИМ МНОГОПОРТОВУЮ ПАМЯТЬ | 2019 |
|
RU2795887C2 |
| Метод построения процессоров для вывода в сверточных нейронных сетях, основанный на потоковых вычислениях | 2020 |
|
RU2732201C1 |
| ПЕРЕПРОГРАММИРУЕМЫЙ ВЫЧИСЛИТЕЛЬ ДЛЯ СИСТЕМ ОБРАБОТКИ ИНФОРМАЦИИ | 1998 |
|
RU2146389C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ ЯДРО | 2023 |
|
RU2819403C1 |
| КОМАНДА УМНОЖЕНИЯ И СДВИГА ДЕСЯТИЧНОГО ЧИСЛА | 2017 |
|
RU2717965C1 |
Заявленное техническое решение в общем относится к области микропроцессоров, а в частности к устройству для матричных вычислений. Техническим результатом является уменьшение энергопотребления устройства матричных вычислений за счет уменьшения площади устройства. Технический результат достигается за счет реализации устройства матричных вычислений, размещенного на кристалле, содержащего: блок разделения конфигурационных пакетов, соединенный с внешним управляющим устройством, выполненный с возможностью получения, разделения и контроля исполнения конфигурационных пакетов; память, выполненную с возможностью получения от по меньшей мере внешней памяти и/или памяти векторного процессора матриц-операндов, их хранения и передачи в блок матричного умножения на основе полученных конфигурационных пакетов; блок комбинирования, выполненный с возможностью получения множества скалярных элементов вектора из памяти векторного процессора, объединения указанных элементов в вектор и передачи указанного вектора в память; блок матричного умножения, выполненный с возможностью умножения матриц-операндов на основе полученного конфигурационного пакета, включающий: систолический массив, выполненный с возможностью вычисления суммы произведений элементов матриц-операндов; блок задержек элементов матриц-операндов, выполненный с возможностью синхронизации вычислений внутри систолического массива; буферную память, соединенную с внешним устройством, выполненную с возможностью накопления результатов вычислений из систолического массива; локальный блок управления, выполненный с возможностью управления очередностью передачи элементов матриц-операндов в систолический массив и управления передачей данных из систолического массива на внешнее устройство. 13 з.п. ф-лы, 3 ил.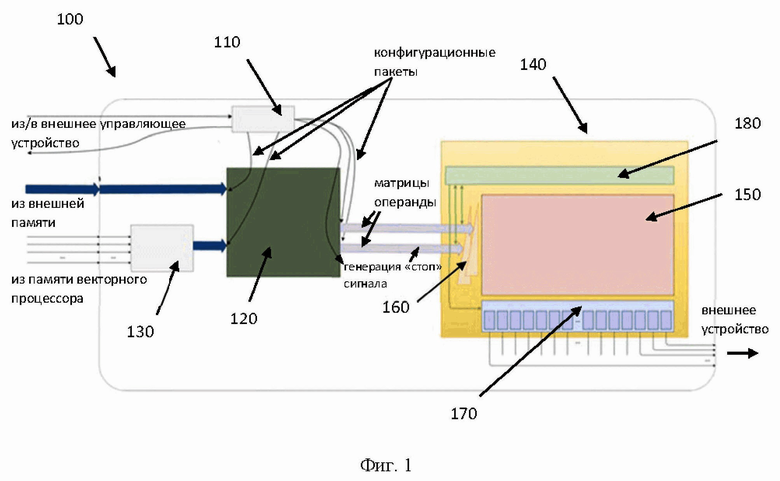
1. Устройство матричных вычислений, размещенное на кристалле, содержащее:
• блок разделения конфигурационных пакетов, соединенный с внешним управляющим устройством, выполненный с возможностью получения, разделения и контроля исполнения конфигурационных пакетов;
• память, выполненную с возможностью получения от по меньшей мере внешней памяти и/или памяти векторного процессора матриц-операндов, их хранения и передачи в блок матричного умножения на основе полученных конфигурационных пакетов;
• блок комбинирования, выполненный с возможностью получения множества скалярных элементов вектора из памяти векторного процессора, объединения указанных элементов в вектор и передачи указанного вектора в память;
• блок матричного умножения, выполненный с возможностью умножения матриц-операндов на основе полученного конфигурационного пакета, включающий:
 систолический массив, выполненный с возможностью вычисления суммы произведений элементов матриц-операндов;
систолический массив, выполненный с возможностью вычисления суммы произведений элементов матриц-операндов;
блок задержек элементов матриц-операндов, выполненный с возможностью синхронизации вычислений внутри систолического массива;
буферную память, соединенную с внешним устройством, выполненную с возможностью накопления результатов вычислений из систолического массива и передачи накопленных результатов на внешнее устройство;
локальный блок управления, выполненный с возможностью управления очередностью передачи элементов матриц-операндов в систолический массив и управления передачей данных из систолического массива на внешнее устройство.
2. Устройство по п. 1, характеризующееся тем, что систолический массив состоит из множества вычислительных элементов.
3. Устройство по п. 2, характеризующееся тем, что множество вычислительных элементов объединены в блоки.
4. Устройство по любому из пп. 2, 3, характеризующееся тем, что каждый вычислительный элемент представляет собой по меньшей мере умножитель-сумматор.
5. Устройство по п. 2, характеризующееся тем, что размер систолического массива равен 128×128 вычислительных элементов.
6. Устройство по п. 3, характеризующееся тем, что вычислительные элементы объединены в блоки, состоящие из вычислительных элементов.
7. Устройство по п. 1, характеризующееся тем, что матрицы-операнды представляют собой матрицы весов и матрицы признаков нейронной сети.
8. Устройство по п. 1, характеризующееся тем, что конфигурационные пакеты представляют собой инструкции для по меньшей мере: получения данных из внешней памяти, получения данных из памяти векторного процессора, операции вычисления матричного умножения.
9. Устройство по п. 1, характеризующееся тем, что блок разделения конфигурационных пакетов получает конфигурационные пакеты по общей мультиплексированной шине с идентификационными полями, которые соответствуют типу пакета.
10. Устройство по п. 1, характеризующееся тем, что блок матричного умножения дополнительно содержит контроллер входных данных, выполненный с возможностью приостановки и возобновления отправки данных в систолический массив в зависимости от состояния внешнего принимающего устройства.
11. Устройство по п. 1, характеризующееся тем, что память представляет собой многопортовую многобанковую память.
12. Устройство по п. 2, характеризующееся тем, что вычислительные элементы систолического массива содержат активные и теневые регистры.
13. Устройство по п. 12, характеризующееся тем, что активные и теневые регистры выполнены с возможностью хранения элементов матриц-операндов.
14. Устройство по пп. 12, 13, характеризующееся тем, что загрузка элементов матриц-операндов в теневые регистры выполняется в процессе вычисления суммы произведений элементов матриц-операндов, которые находятся в активных регистрах.
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоканальный систолический процессор для вычисления полиномиальных функций | 2020 |
|
RU2737236C1 |

