ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение в общем относится к области вычислительной техники, а в частности к способу и системе для выполнения программного кода с помощью нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[0002] Современная вычислительная парадигма базируется на парадигме машины Тьюринга и архитектуре фон Неймана. Множество исследований показали, что широко используемая вычислительная парадигма достигла своих пределов совершенствования и обладает большим количеством недостатков, не позволяющих существенно увеличить производительность вычислений. В качестве таких ключевых недостатков можно упомянуть cache coherence problem (проблема консистентности состояния данных в основной памяти и кешах центрального процессора), memory wall problem (проблема опережения производительности вычислительного ядра процессора пропускной способности шины взаимодействия с памятью (DRAM)), data moving problem (проблема копирования или обмена данными между персистентной памятью, основной памятью (DRAM) системы и кешами процессора), power consumption problem (проблема избыточного потребления энергии), throughput bottleneck (проблема ограниченной пропускной способности интерфейсов взаимодействия), Big Data problem (или проблема обработки больших данных).
[0003] Современная вычислительная парадигма является алгоритмо-ориентированной и задействует несколько типов памяти (регистры CPU, DRAM, персистентная память). Исполнимый код и пользовательские данные хранятся в персистентной памяти, которая может быть представлена HDD/SSD или другими технологиями или устройствами персистентного хранения данных. Однако, ядро процессора не способно напрямую обращаться и работать с данными в персистентной памяти, поскольку этот тип памяти не является байт-адресуемым (за исключением некоторых типов памяти, например, NOR флеш или типов памяти, поддерживающих XiP (eXecute-in-Place) механизм). Поэтому любые данные (а также исполнительный код) прежде всего должны быть скопированы в DRAM, а в случае их модификации быть сохранены обратно в персистентную память.
[0004] Такой подход был достаточно эффективен в момент создания парадигмы, но в настоящее время такой подход вносит существенные накладные расходы (или понижение производительности вычислений) в окружении быстрой персистентной памяти и современных многоядерных процессоров. Более того, емкость (или объемы хранимых данных) современных HDD/SSD на порядки больше чем общий размер DRAM в одном экземпляре вычислительной системы, объемы обрабатываемых данных экспоненциально растут, что приводит к большим объемам обмена данными между персистентной памятью и DRAM, в результате это приводит к деградации производительности обработки данных в многопоточном окружении, исполняемом на многоядерных процессорах.
[0005] Более того, DRAM гораздо медленнее чем ядро процессора, поэтому исполнимый код и обрабатываемые данные приходится копировать в L1/L2/L3 кеш процессора для непосредственного исполнения и обработки. В условиях многопоточного окружения процессору приходится переключать контекст между задачами, что приводит к деградации производительности исполнения.
[0006] Современные процессоры являются многоядерными и у каждого ядра есть свой кеш, а также кеш, разделяемый несколькими ядрами процессора. Если какие-либо данные в кеше данных определенного ядра были модифицированы, то приходится использовать специальный cache coherence protocol с целью синхронизировать состояние данных в DRAM и кешах конкретных ядер процессора. Что в итоге приводит к существенной деградации производительности для большинства современных типов алгоритмов и вычислительных нагрузок на компьютерную систему.
[0007] Современная вычислительная парадигма результируется в существенном потреблении энергии в силу большого выделения энергии/тепла ядрами процессора, работающих на высоких частотах. Более того, данные и исполнимый код хранятся в DRAM памяти, которая расходует энергию на периодическую операцию обновления хранимых данных (чтение и немедленная запись без модификации данных), необходимую для хранения данных. Надо также заметить, что исполнение любого приложения представляет собой многократное повторение исполнения функций, из которых состоит приложение. То есть, приложения исполняются на миллионах процессоров и это означает что одна и та же логика функции исполняется многократно, расходуя энергию на исполнение этой функции. Можно сказать, что исключение расчетов одной и той же логики функции многократно способно существенно сократить расход энергии в компьютерных системах. А сокращение расхода энергии может существенно продлевать срок службы аккумулятора сотового телефона, к примеру.
[0008] Следовательно, недостатком известных решений в данной области техники является отсутствие возможности существенно снизить расход энергии в компьютерных системах.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0009] В заявленном техническом решении предлагается новый подход к выполнению программного кода с помощью нейронных сетей.
[0010] Таким образом, решается техническая проблема отсутствия возможности существенного снижения расхода энергии компьютерными системами.
[0011] Техническим результатом, достигающимся при решении данной проблемы, является снижение энергопотребления компьютерными вычислительными системами.
[0012] Указанный технический результат достигается благодаря осуществлению способа выполнения программного кода, с помощью по меньшей мере одного процессора, соединенного с по меньшей мере одной памятью, содержащего этапы, на которых:
получают программный код;
• осуществляют обработку программного кода, в результате которой: о определяют функции программного кода;
• определяют диапазон и шаг входных аргументов каждой функции программного кода;
• выполняют регистрацию выходных значений функции для каждого набора значений входных аргументов;
- получают в результате предыдущего этапа массив значений, содержащий выходные значения исполняемых функций и соответствующие им входные значения;
- обучают нейронные сети на основе данных в массиве значений, причем для каждой исполняемой функции обучается соответствующая нейронная сеть;
- исполняют функции программного кода с помощью соответствующих им нейронных сетей при обращении процессора к памяти.
[0013] В одном из частных вариантов реализации способа при осуществлении обработки программного кода, конвертируют каждую функцию программного кода в микроприложение.
[0014] Кроме того, заявленный технический результат достигается за счет вычислительной системы для выполнения программного кода, содержащей:
- по меньшей мере одну память содержащую:
• трехмерное пространство памяти, содержащее массив нейронных сетей каждая из которых соответствует исполняемой функции программного кода;
- по меньшей мере один процессор, выполненный с возможностью:
• получения входного значения для выполнения по меньшей мере одной функции;
• передачи входного значения массиву нейронных сетей;
• получения результата значения от массива нейронных сетей для выполнения функции программного кода.
[0015] В одном из частных вариантов реализации системы память содержит верхний слой памяти и нижний слой памяти, представляющие собой конвейер данных содержащий входные данные.
[0016] В другом частном варианте реализации системы память содержит верхний и нижний битовый массив.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0017] Фиг. 1 иллюстрирует причины избыточного потребления энергии в современной вычислительной парадигме.
[0018] Фиг. 2 иллюстрирует блок-схему заявленного способа.
[0019] Фиг. 3 иллюстрирует способ дедупликации исполнения программного кода.
[0020] Фиг. 4 иллюстрирует пример трансформации выходных значений в нейронную сеть.
[0021] Фиг. 5 иллюстрирует пример приложения как граф нейронных сетей.
[0022] Фиг. 6 иллюстрирует пример архитектуры вычислительной памяти.
[0023] Фиг. 7 иллюстрирует пример способа параллельных вычислений.
[0024] Фиг. 8 иллюстрирует пример взаимодействия центрального процессора с вычислительной памятью.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0025] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[0026] Cache coherence problem - Проблема согласованности кэша возникает, когда несколько кэшей хранят копии одних и тех же данных в основной памяти системы, и изменения, сделанные в одном кэше, необходимо распространить на состоянии данных в основной памяти системы и на другие кэши. Несоблюдение согласованности кэша может привести к повреждению данных и некорректному поведению программы.
[0027] Memory wall problem проблема опережения производительности процессора пропускной способности памяти.
[0028] Data moving problem - проблема копирования или обмена данными между персистентной памятью, основной памятью (DRAM) системы и кешами процессора.
[0029] Power consumption problem проблема роста энергопотребления при увеличении вычислительных мощностей.
[0030] Throughput bottleneck - проблема ограниченной пропускной способности интерфейсов взаимодействия.
[0031] Big Data problem проблема обработки больших данных в рамках современных баз данных и систем хранения данных.
[0032] Конечный автомат (КА) - математическая абстракция, модель дискретного устройства, имеющего один вход, один выход и в каждый момент времени находящегося в одном состоянии из множества возможных. Является частным случаем абстрактного дискретного автомата, число возможных внутренних состояний которого конечно.
[0033] При работе на вход КА последовательно поступают входные воздействия, а на выходе КА формирует выходные сигналы. Обычно под входными воздействиями принимают подачу на вход автомата символов одного алфавита, а на выход КА в процессе работы выдает символы в общем случае другого, возможно даже не пересекающегося со входным, алфавита.
[0034] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0035] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0036] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[0037] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
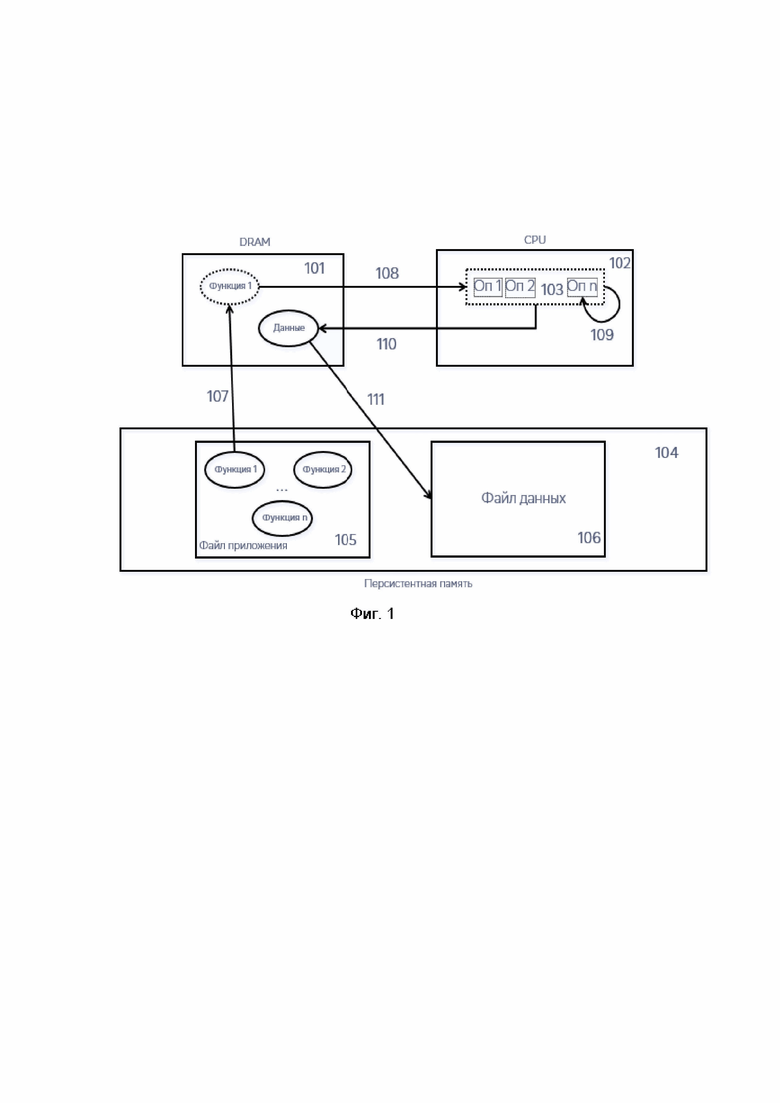
[0038] Как показано на Фиг. 1 современная вычислительная система включает в себя центральный процессор (102), оперативную память (101) и персистентную память (104). Персистентная память (104) предназначена для хранения файлов приложений (105) и файлов данных (106).
[0039] Любой вычислительный процесс начинается с того, что операционная система создает процесс, представленный специально определенной структурой в оперативной памяти (101). После этого происходит вычитывание кода логики приложения (107) из файла приложения (105) в персистентной памяти (104).
[0040] Когда процесс получает кванты времени на исполнение, то машинные коды операций переносятся (108) из оперативной памяти (101) в программный кэш (103) центрального процессора (102). После этого исполнительное ядро центрального процессора (102) выбирает машинные коды инструкций из программного кэша (103) и выполняет исполнение каждой инструкции (109).
[0041] Обычно, исполнение инструкций заключается в модификации или генерации некоторых данных, которые исходно сохраняются в кэше данных центрального процессора (102). Модифицированные линии кэша процессора нуждаются в сохранении (ПО) в оперативную память (101). В конечном итоге, модифицированные или «грязные» страницы оперативной памяти (101) файлов данных (106) нуждаются в сохранении (111) в персистентную память (104).
[0042] Как было указано выше, современная вычислительная парадигма результируется в существенном потреблении энергии в силу большого выделения энергии/тепла ядрами процессора, работающих на высоких частотах. Более того, данные и исполнимый код хранятся в DRAM памяти, которая расходует энергию на операцию обновления без модификации данных, необходимую для хранения данных.
[0043] Исполнение любого приложения представляет собой многократное повторение исполнения функций, из которых состоит приложение. То есть, приложения исполняются на миллионах процессоров и это означает, что одна и та же логика функции исполняется многократно, расходуя энергию на исполнение этой функции. Исключение расчетов одной и той же логики функции многократно способно существенно сократить расход энергии в компьютерных системах. А сокращение расхода энергии может существенно продлевать срок службы аккумулятора сотового телефона, к примеру.
[0044] Традиционно, компилятор трансформирует исходный код, написанный на языке высокого уровня, в бинарный машинный код, который может быть исполнен процессором. Это означает, что одна и та же функция, представленная бинарным кодом, многократно исполняется процессором, даже для случая одних и тех же входных данных. Однако, любая функция имеет набор входных аргументов и результатом ее работы является некоторое значение или объект данных. Технически, можно представить, что для каждого случая входных данных возможно сохранить результат расчета или выходное значение. Если иметь «полный набор» таких значений, то повторять расчет не нужно, поскольку его можно найти в таблице или массиве выходных значений. Фактически, это означает что можно не расходовать энергию на расчет результата функции и сам результат можно найти быстрее, поскольку расчет может требовать значительного времени на исполнение.
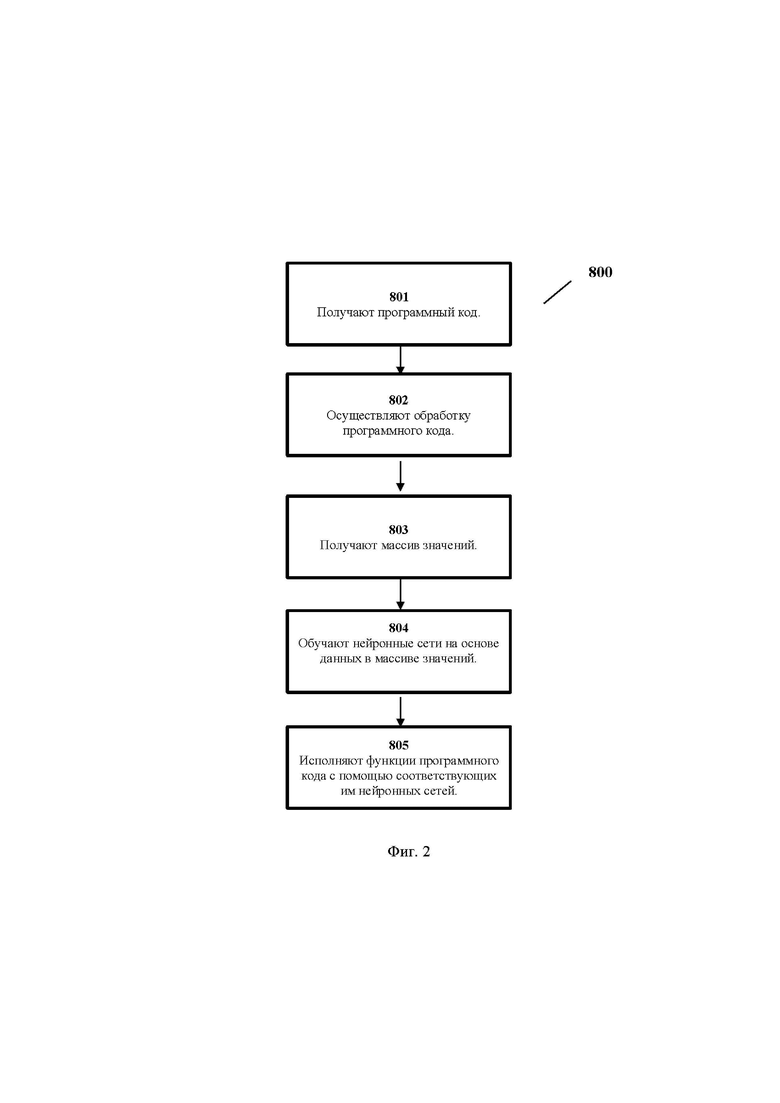
[0045] Как показано на Фиг. 2 способ выполнения программного кода (800) состоит из нескольких этапов.
[0046] На этапе (801) получают программный код.
[0047] Далее на этапе (802) осуществляют обработку программного кода.
[0048] На данном этапе определяют функции программного кода, определяют диапазон и шаг входных аргументов каждой функции программного кода, выполняют регистрацию выходных значений функции для каждого набора значений входных аргументов.
[0049] В одном из вариантов реализации изобретения при осуществлении обработки программного кода, конвертируют каждую функцию программного кода в микроприложение
[0050] Далее на этапе (803) получают в результате предыдущего этапа (802) массив значений, содержащий выходные значения исполняемых функций и соответствующие им входные значения.
[0051] Далее на этапе (804) обучают нейронные сети на основе данных в массиве значений, причем для каждой исполняемой функции обучается соответствующая нейронная сеть.
[0052] И на этапе (805) исполняют функции программного кода с помощью соответствующих им нейронных сетей при обращении процессора к памяти.
[0053] Рассмотрим подробно реализацию заявленного способа.
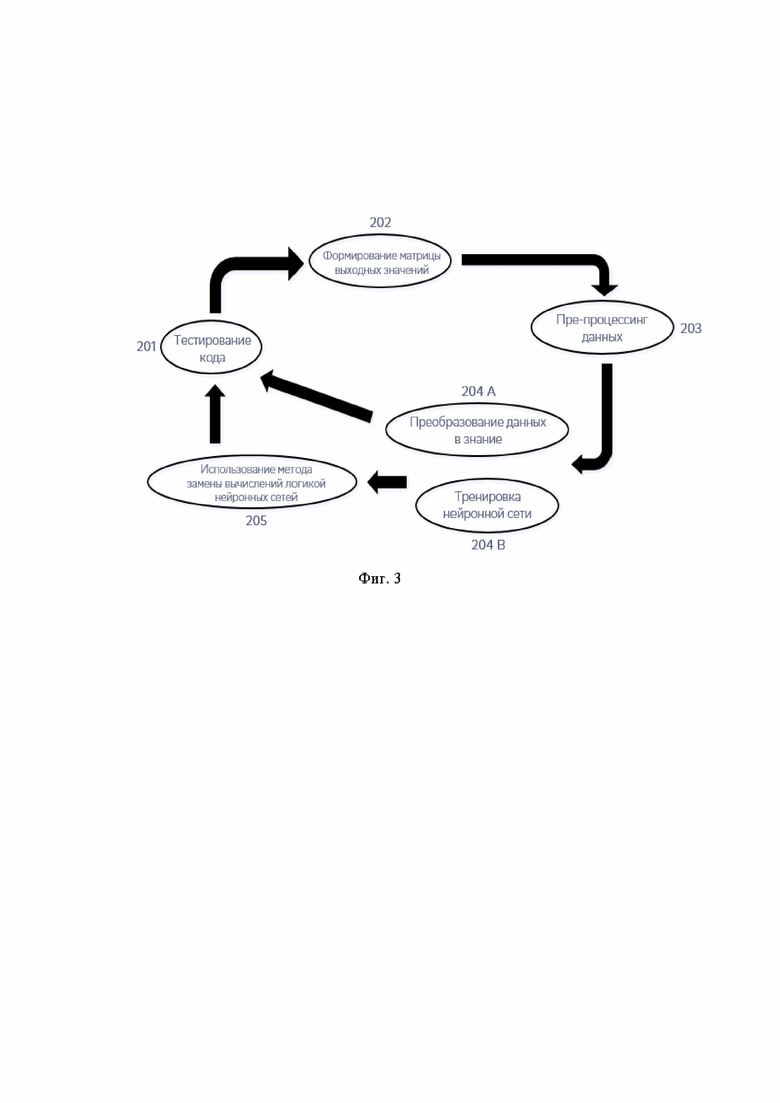
[0054] Как показано на Фиг. 3 процесс разработки любого программного обеспечения включает этап тестирования и исправления ошибок (201). Фактически, это первый этап, на котором исполнение одних и тех же участков кода (или функций) повторяется множество раз. То есть, на этапе тестирования формируется для каждой функции приложения массив значений, которые ставят в соответствие набору входных значений некоторое множество выходных или результирующих значений (202). Проводится проверка и коррекция (203) полученного массива данных (data pre-processing) с целью подготовки данных для тренировки нейронных сетей, к примеру, как следующий этап после тестирования программного обеспечения.
[0055] После этого полученный массив данных может быть преобразован либо в базу знаний (в виде массива значений в памяти, к примеру) (204А), либо в нейронную сеть (204В) (как более компактное представление) с целью использовать это знание для быстрой конвертации входных значений функции в результирующее значение без выполнения исполнения программного кода (205).
[0056] Технически, база знаний может быть неполной в силу ограниченного объема тестирования или намеренного сокращения объема входных значений. То есть, это может означать необходимость осуществления исполнения программного кода, если в базе данных нет значений для определенных экземпляров входных данных, либо с целью проверки вывода нейронной сети.
[0057] Технически, нейронная сеть способна делать прогноз для тех входных значений, которых не было в массиве данных, использованных для тренировки нейронной сети. Но вполне возможна ситуация, когда может потребоваться дополнительное тестирование программного кода (201) и новая тренировка нейронных сетей (204В) как результат неудовлетворительной работы подсистемы дедупликации исполнения программного кода.
[0058] Заявленный способ выполнения программного кода обладает рядом преимуществ:
1) Реализация заявленного способа уменьшает потребляемую энергию вычислительной системой за счет более энергоэффективного поиска в базе знаний или использования компактной нейронной сети вместо выполнения энергозатратного вычисления ядром процессора.
2) Реализация заявленного способа уменьшает потребляемую энергию вычислительной системой за счет использования персистентной памяти вместо DRAM, поскольку в отличии от DRAM персистентная память не нуждается в обновлении операции для хранения данных.
3) Реализация заявленного способа увеличивает производительность исполнения программного кода за счет более быстрого поиска в базе знаний или более быстрых операций нейронной сети.
4) Реализация заявленного способа предлагает глубоко параллельную модель исполнения за счет способности одновременно получать результаты разных функций для разных потоков исполнения, что может существенно улучшить общую производительность вычислительной системы.
5) Реализация заявленного способа предлагает осуществлять основные вычислительные операции в пространстве специально организованной вычислительной памяти, что способно разгрузить CPU от выполнения вычислений и существенно улучшить производительность вычислительной системы за счет массивно параллельных вычислительных операций в пространстве памяти.
[0059] Любое программное обеспечение представляет собой некоторый исполнимый модуль, состоящий из некоторого набора функций или методов, вызываемых одна за другой с целью реализации логики некоторого алгоритма. Одной из фундаментальных парадигм программирования является переиспользование реализованного функционала в виде функций или экземпляров классов, с целью уменьшения размера исполнимого модуля, сокращения объема тестирования и уменьшения количества ошибок в коде. Это означает что одна и та же функция может быть вызвана множество раз другими функциями или подсистемами приложения. То есть, другими словами исполнение одной и той же функции может повторяться многократно и даже с одними и теми же входными аргументами.
[0060] Фактически, любое приложение можно трансформировать в некоторый набор функций, каждая из которых может быть тестирована независимо. То есть, технически каждая функция может быть трансформирована в микроприложение, задачей которого является подача на вход функции некоторого набора входных значений и вычисление результата работы функции с целью формирования массива или тензора зависимости выходных значений функции от входных. В конечном итоге, весь набор микроприложений может исполняться множеством ядер или/и систем с целью провести тестирование в массивно параллельном режиме.
[0061] Однако, ситуация не столь проста, поскольку тело или логика конкретной функции может включать вызовы других функций, а также возвращать ошибки. Прежде всего, каждая функция обладает входными параметрами и результатом ее работы является некоторое значение или экземпляр выходного значения. Как входные параметры, так и выходное значение являются величинами определенного типа данных, который может принимать некоторое конкретное значение из некоторого множества значений соответствующего типа данных.
[0062] То есть, независимое тестирование каждой функции означает необходимость определить некоторый диапазон входных значений и шаг, с которым входные значения будут выбираться из полного множества значений и подаваться на вход функции для работы алгоритма. Таким образом, диапазон значений и шаг определяют конечное количество шагов для получения некоторого множества выходных значений функции.
[0063] Выходное значение функции тоже является определенным типом данных и это означает что если функция вызывает другие функции, то вместо их реального исполнения возможно результат их работы заменить на некоторый диапазон выходных значений, который может принимать значения с некоторым шагом. Потенциально, можно использовать готовые результаты тестирования функций, поскольку тестирование можно начинать снизу вверх.
[0064] Кроме того, можно в качестве результата работы функций также рассматривать возвращение некоторого набора кодов ошибок, с целью тестирования готовности функции корректно обрабатывать ошибки вызываемых функций.
[0065] Таким образом, возможно сформировать пространство тестирования функции в виде комбинации всех возможных путей исполнения, которые нужно проверить с целью получить выходное множество значений работы функции.
[0066] В итоге, задачей каждого микроприложения является проведение вычислений в рамках пространства тестирования посредством исполнения всего набора путей исполнения с целью формирования пространства зависимости выходного значения от значений входных параметров.
[0067] Таким образом, первым шагом способа является вычисление множества выходных значений функции для некоторого выбранного множества входных аргументов. То есть, логика функции изолируется в микроприложение, для каждого такого приложения определяется диапазон входных значений, которые должны быть поданы на вход функции. Этот диапазон входных значений может быть исходно сохранен в файл или микроприложение может быть способно генерировать входные значения на основании заданного диапазона и шага. Результатом работы микроприложения должен быть массив выходных значений функции, который может быть сохранен в файл или оставаться в памяти для выполнения следующего шага метода.
[0068] Если входные значения представляют собой непрерывный диапазон значений и объем выходных значений не столь велик, то выходные значения функции можно представить двумерным, трехмерным или, в общем случае, N-мерным массивом чисел. Входные значения аргументов могут выступать индексами в этом массиве и сохранять нужно только выходные значения функций.
[0069] Однако, если использовать некоторый достаточно большой диапазон значений, которые подаются на вход функции с некоторым шагом, то представление в виде массива не является оптимальным и не дает точное сопоставление входных значений с выходными значениями функции. В таком случае, можно рассматривать некоторый вариант дерева или другой структуры, которая способна сопоставить входные значения с выходными значениями и использоваться для поиска в массиве данных выходных значений функции.
[0070] Основной идеей способа является исключение повторного исполнения программного кода посредством замены процесса исполнения на операцию выбора значения в массиве, полученном на этапе тестирования. Если представить, что мы храним массив в быстрой персистентной памяти, то операция выбора значения из массива по индексу одновременно достаточно быстрая операция и не требует больших энергетических затрат, поскольку персистентная память не требует обновленной операции для хранения данных в отличии от DRAM.
[0071] Проблема заключена в том, что даже для одной функции массив выходных значений может быть достаточно большим, что в итоге может требовать огромных объемов памяти. Более того, приложение может содержать очень много функций, что в итоге приводит к невозможности поместить все данные в память. Однако, нейронная сеть может быть рассмотрена как решение этой проблемы. Поскольку, нейронная сеть может быть довольно компактным представлением некоторого знания. Фактически, полученная матрица выходных значений функции может быть использована для тренировки нейронной сети с целью получить набор весов, способных трансформировать входные значения функции в результат или выходное значение функции. Как результат, нейронная сеть может быть использована для конвертации набора входных аргументов в результирующее выходное значение функции вместо исполнения кода функции.
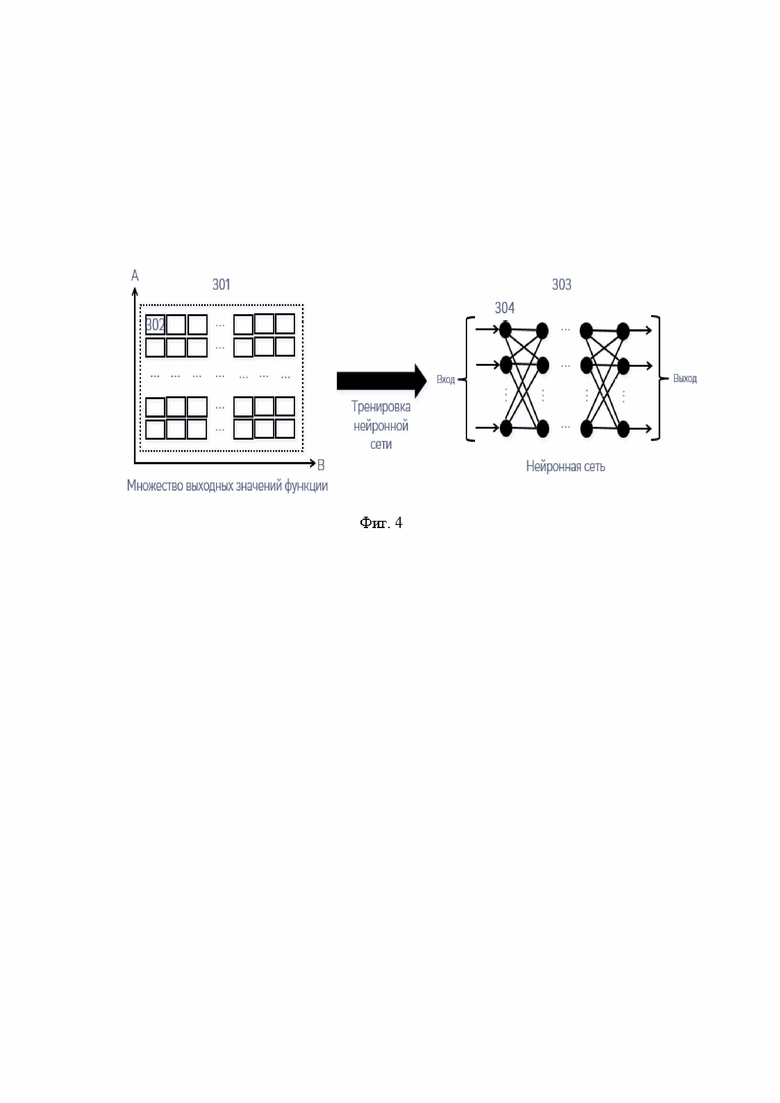
[0072] Как показано на Фиг. 4 тестирование кода отдельной функции формирует массив выходных значений (301). Если массив значений небольшой по размеру и представляет собой непрерывное множество значений, то, технически, этот массив можно использовать напрямую посредством использования входных значений в качестве индексов в этом массиве. Однако, если выходной массив (301) достаточно большой, то есть, включает большое количество страниц памяти (302), и не является непрерывным множеством значений, то нейронная сеть (303) может представлять более компактное представление знания о логике функции. То есть, посредством тренировки нейронной сети (303) нейроны (304) хранят знание о преобразовании входных значений в выходные значения. Более того, нейронная сеть может быть способна предсказывать те выходные значения, которые не были получены в рамках тестирования и тренировки нейронной сети.
[0073] В результате, каждая функция приложения может быть конвертирована в нейронную сеть, а само приложение может представлять граф нейронных сетей. То есть, вместо исполнения программного кода, поток исполнения приложения будет выглядеть как прохождение через некоторое множество нейронных сетей. И на каждом этапе нейронная сеть получает входные аргументы и выдает результат.
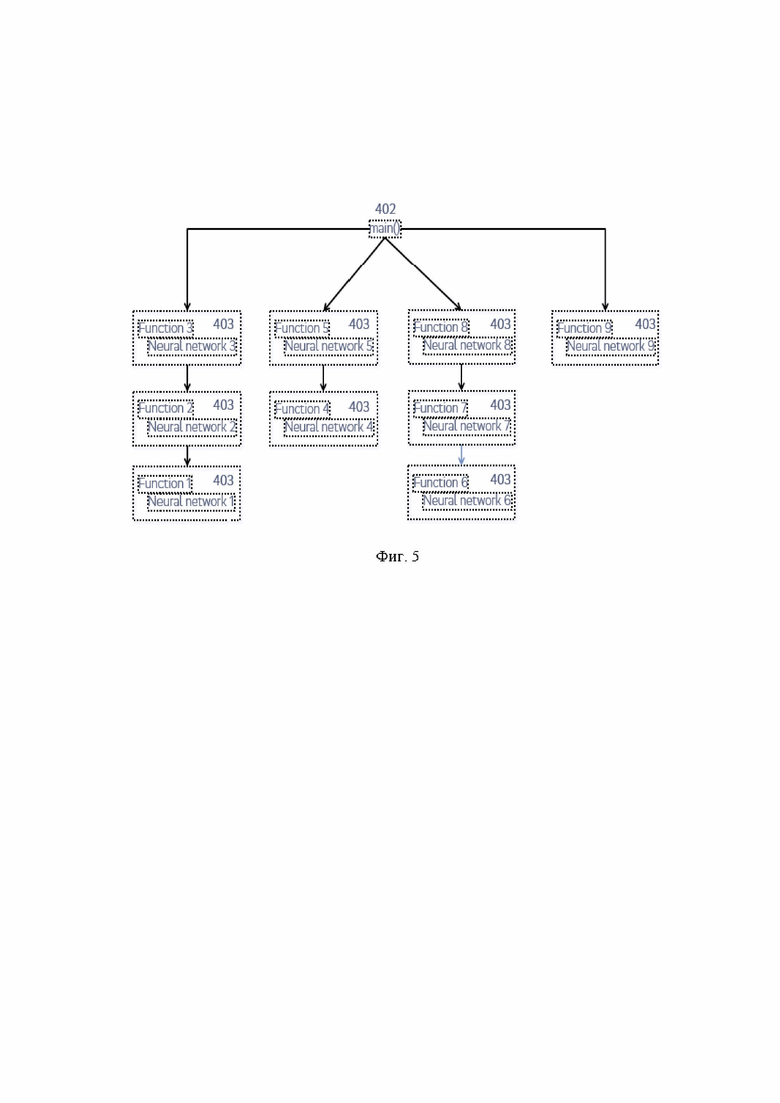
[0074] На Фиг. 5 показана структура приложения в результате конвертации функций в нейронные сети. Исполнение любого приложения начинается с вызова функции main() (402). Обычно, функция main() включает вызовы методов, которые представляют собой последовательность машинных инструкций, которые должны быть выполнены центральным процессором. Суть предложенного метода состоит в том, что логика каждой функции (403) заменяется нейронной сетью, которая на выходе должна давать некоторое результирующее значение на основании входных аргументов функции. Фактически, базовой абстракцией метода является быстрый поиск ответа, напоминающий обращение к массиву данных на основании индекса. Поскольку пространство поиска может быть достаточно большим, то простой массив значений заменяется на нейронную сеть, способную реализовать более компактное представление пространства поиска.
[0075] Любая нейронная сеть представляет собой набор слоев, каждый из которых содержит некоторое количество нейронов. Количество нейронов и слоев определяется архитектурой и функционалом конкретной нейронной сети. Нейронная сеть может быть реализована в рамках персистентной памяти, базовым элементом которой может быть нейрон или исполняющая ячейка памяти. В такой нейрон могут входить: (1) набор ячеек памяти или регистров для хранения анализируемой величины, (2) набор ячеек памяти или регистров для хранения веса, (3) функция активации. Таким образом, нейроны могут объединяться в слои, количество нейронов в слое и количество слоев определяется архитектурой конкретной нейронной сети.
[0076] Фактически, логика работы нейронной сети определяется матрицей или тензором весов, которая должна быть загружена в соответствующие ячейки памяти весов нейронов перед началом работы нейронной сети. Поскольку, планируется использовать персистентную память для реализации нейронной сети, то матрица весов может быть загружена один раз и использоваться многократно, даже в условиях холодной перезагрузки системы.
[0077] Первый слой нейронов получает входные значения, которые представляют входные аргументы функции, и производит первый этап обработки входных значений. Результат работы нейронов первого слоя подается в качестве входных значений для нейронов очередного слоя, и такая логика повторяется до тех пор, пока не будут пройдены все слои нейронной сети и будет получен финальный результат работы нейронной сети.
[0078] Между слоями нейронной сети может находиться interconnection network, задачей которой является реализация взаимодействия нейронов разных слоев посредством реализации схемы взаимодействия каждого с каждым.
[0079] Реализация конечного автомата функционирования нейронной сети может быть осуществлена специальной подсистемой управления (management unit). Поскольку любая функция приложения обычно реализует достаточно детерминистическую логику, то можно ожидать достаточно компактное представление нейронной сети, состоящую из небольшого количества нейронов и слоев. Поэтому нейронная сеть может быть более быстрым и более энерго эффективным решением, чем классическое исполнение процессором, особенно если исполнение программного кода требует циклов или рекурсивного исполнения логики функции.
[0080] Таким образом, можно представить трехмерную архитектуру вычислительной персистентной памяти, в которой в одном измерении находятся слои нейронной сети, а в другом измерении находятся разные нейронные сети. То есть, в таком трехмерном пространстве можно расположить множество функций приложения, каждая из которых реализуется индивидуальной нейронной сетью.
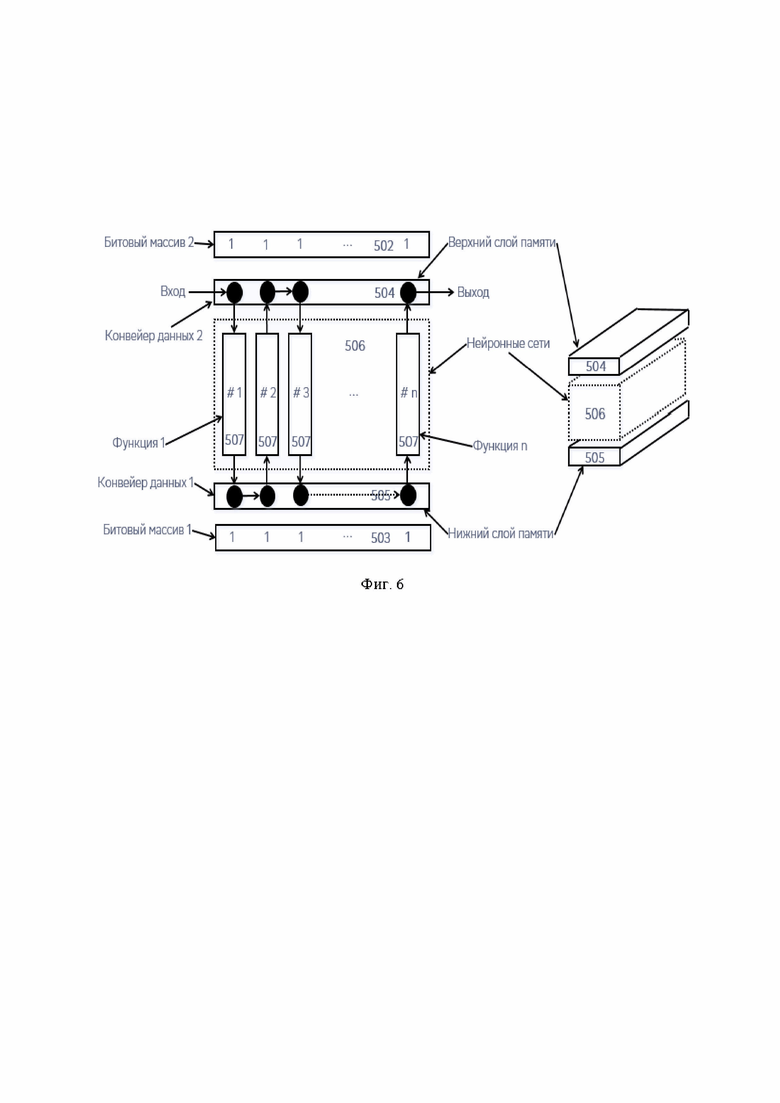
[0081] Трехмерное пространство нейронных сетей (или функций) можно дополнить сверху и снизу специальными слоями памяти, которые будут представлять собой конвейер, в котором могут перемещаться входные данные (или аргументы) функций и помещаться выходные данные или результаты работы функций. Фактически, конвейер представляет собой последовательность позиций, каждая из которых ассоциирована с соответствующей функцией или нейронной сетью. Помещая некоторые данные на первую позицию (например, на верхний конвейер), мы определяем входные аргументы первой функции или нейронной сети.
[0082] Нейронная сеть обрабатывает входные аргументы и помещает результат своей работы в нижний конвейер. После чего эти данные могут быть сдвинуты на вторую позицию в нижнем конвейере и быть поданы на вход второй нейронной сети, которая выдаст результат своей работы в верхний конвейер. Такая последовательность шагов может продолжаться до тех пор, пока не будут задействованы все функции, которые должны быть задействованы в этом алгоритме. В конечном итоге, результат работы алгоритма окажется в некоторых адресах памяти, к которым может обратиться CPU.
[0083] Исполнение конкретного алгоритма может не требовать вовлечения всех последовательно лежащих функций. Более того, физическое расположение функций может быть таково, что исполнение конкретного алгоритма может требовать исключить некоторую функцию из потока исполнения. Поэтому, предлагаемая архитектура может нуждаться в верхнем и нижнем bitmap'e, задачей которых является определить какая фукнция будет исполнена, а какая нет в текущем алгоритме.
[0084] Таким образом, если некоторая функция или функции не исполняются, то производится сдвиг данных до позиции той функции, которая должна быть исполнена на следующем этапе или шаге алгоритма.
[0085] Фиг. 6 представляет трехмерную архитектуру вычислительной памяти (501). Центральная часть вычислительной памяти представлена трехмерным массивом нейронов (506), способных реализовать нейронные сети. Фактически, массив нейронов (506) должен быть распределен между множеством нейронных сетей (507), каждая из которых представляет отдельную функцию. В итоге, вычислительная память (501) есть совокупность нейронных сетей (507), каждая из которых может получить набор значений на входе и выдать результат на выход.
[0086] Сверху массива нейронных сетей (506) находится верхний слой памяти (504) и нижний слой памяти (505). Верхний (504) и нижний (505) слои памяти представляют собой конвейер данных, на который могут помещаться входные данные (или аргументы) и выдаваться результаты работы нейронных сетей. Исходно данные помещаются в начало конвейера и могут сдвигаться с целью подачи на вход требуемой функции, представленной нейронной сетью (507). Предположим, что исходно порция данных помещается в верхний конвейер данных (504) и помещается на вход первой функции. После обработки данных первой функцией, результат попадает в нижний конвейер данных (505), после чего он сдвигается на вход функции, которая должна быть исполнена следующей в соответствии с логикой алгоритма.
[0087] Выбранная функция берет входные данные из нижнего конвейера (505), осуществляет их обработку и помещает результат в верхний конвейер (504). Такая последовательность шагов может повторяться несколько раз до полного исполнения алгоритма. Описанная логика может быть дополнена верхним (502) и нижним (503) битовыми массивами, которые могут определять должны ли данные обрабатываться функцией на определенной позиции. То есть, если соответствующий бит массива (502, 503) выставлен в единицу, то функция на этой позиции должна обработать входные данные. Если же бит выставлен в ноль, то данные должны быть смещены на одну позицию к следующей функции. На основании такой логики вычислительная память может реализовать логику обработки данных.
[0088] Предлагаемая архитектура вычислительной персистентной памяти способна обеспечить массово параллельную модель исполнения.
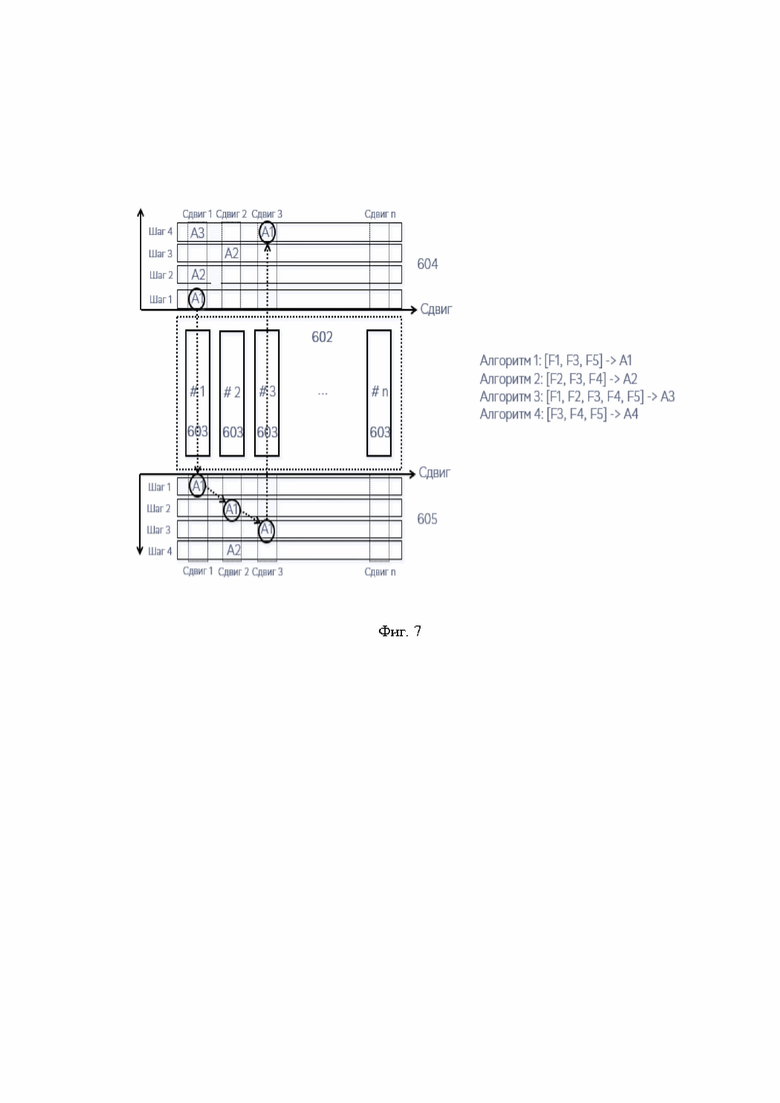
[0089] Фиг. 7 демонстрирует механизм физически параллельных вычислений в рамках архитектуры вычислительной памяти (602). Верхний (604) и нижний (605) конвейеры содержат позиции хранения входных (или выходных) данных для каждой нейронной сети (603). Соответственно, нейронные сети могут вести обработку данных физически параллельно при наличии входных данных. Массив входных данных может готовиться и подаваться на вход нейронных сетей одновременно, либо сдвиги данных в конвейере будут формировать входные данные на каждом шаге исполнения алгоритма. Имеется в виду, что начало исполнения каждого алгоритма может быть сдвинуто во времени, но физически несколько алгоритмов будут исполняться одновременно.
[0090] Если обратить внимание на конвейер, то можно заметить, что на каждом шаге каждой функции или нейронной сети могут быть поданы свои входные данные. То есть, вполне можно подготовить набор данных, который можно сдвигать последовательно слева направо. На каждом шаге несколько функций могут вести обработку данных параллельно. Это означает что архитектура вычислительной персистентной памяти способна выполнять несколько алгоритмов параллельно. Количество параллельно выполняемых алгоритмов определяется длиной конвейера или количеством функций, следующих друг за другом в трехмерном пространстве вычислительной памяти.
[0091] Заявленный способ реализуется с помощью вычислительной системы для выполнения программного кода содержащей:
- по меньшей мере одну память содержащую:
• трехмерное пространство памяти, содержащее массив нейронных сетей каждая из которых соответствует исполняемой функции программного кода;
- по меньшей мере один процессор, выполненный с возможностью:
• получения входного значения для выполнения по меньшей мере одной функции;
• передачи входного значения массиву нейронных сетей;
• получения результата значения от массива нейронных сетей для выполнения функции программного кода.
[0092] В одном из частных вариантов реализации системы память содержит верхний слой памяти и нижний слой памяти, представляющие собой конвейер данных содержащий входные данные.
[0093] В другом частном варианте реализации системы память содержит верхний и нижний битовый массив.
[0094] Фиг. 8 демонстрирует механизм взаимодействия центрального процессора (702) с вычислительной памятью (703). Каждое приложение (704) может быть представлено некоторой областью адресов в вычислительной памяти (703). Эта область адресов включает в себя некоторый набор нейронных сетей или функций, реализующих функционал приложения. Центральный процессор (702) должен на первом этапе (705) ассоциировать веса с позициями памяти приложения (704), с целью определить функциональную логику нейронных сетей. Технически, массив весов может быть определен в процессе тренинга нейронных сетей и сохранен персистентно в вычислительной памяти. С другой стороны, массив весов может подгружаться перед началом исполнения приложения, что может обеспечить большую гибкость в использовании пространства вычислительной памяти.
[0095] Следующим шагом (706) является подготовка входных данных центральным процессором (702) и подача на вход нейронных сетей приложений (704) в вычислительной памяти (703). Центральный процессор (702) может инициировать вычислительный процесс (707) одномоментно или подготавливать параллельные вычислительные процессы и последовательно инициировать в вычислительной памяти (703). По окончании исполнения алгоритма (или одного его шага) вычислительная память (703) уведомляет центральный процессор (702) об окончании вычислительного процесса в рамках приложения (704) и о готовности к исполнению следующего алгоритма (или его шага).
[0096] В предлагаемом методе функции приложения трансформируются в нейронные сети, которые непосредственно записываются в персистентную память. В память сохранены матрицы весов, которые определяют какие нейроны будут входить в конкретную сеть и как будет работать эта нейронная сеть. В дальнейшем процессору требуется только определить входные данные алгоритма (или алгоритмов) и запустить вычислительный процесс внутри вычислительной памяти.
[0097] После окончания вычислительных процессов, вычислительная память может известить процессор об окончании процесса вычислений посредством прерывания. Также, альтернативно, CPU может опрашивать вычислительную память с целью определения окончания вычислительных процессов.
[0098] Ключевой момент предлагаемого способа состоит в том, что алгоритмы могут исполняться непосредственно в памяти посредством нейронных сетей, не используя ресурсы центрального процессора. Задачей центрального процессора будет только подготовка исходных данных, запуск вычислений в памяти и обработка результатов вычислений в памяти. Предлагаемая модель параллельных вычислений в памяти может существенно улучшить производительность вычислений, понизить затраты энергии на вычисления и высвободить ресурсы центрального процессора на организацию и координацию параллельных вычислений в памяти.
[0099] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ВЫПОЛНЕНИЯ ПРОГРАММНОГО КОДА | 2024 |
|
RU2834855C1 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ДАННЫХ | 2024 |
|
RU2829301C1 |
| Способ выявления вредоносных файлов с использованием графа связей | 2023 |
|
RU2823749C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПИЛЯЦИИ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2835757C1 |
| Нейропроцессор (NPU) | 2024 |
|
RU2825124C1 |
| СПОСОБ ОБРАБОТКИ ДАННЫХ ПОСРЕДСТВОМ НЕЙРОННОЙ СЕТИ, ПОДВЕРГНУТОЙ ДЕКОМПОЗИЦИИ С УЧЕТОМ ОБЪЕМА ПАМЯТИ ВЫЧИСЛИТЕЛЬНОГО УСТРОЙСТВА (ВАРИАНТЫ), И КОМПЬЮТЕРНО-ЧИТАЕМЫЙ НОСИТЕЛЬ | 2023 |
|
RU2820172C1 |
| КОМАНДА И ЛОГИКА ДЛЯ ОБЕСПЕЧЕНИЯ ФУНКЦИОНАЛЬНЫХ ВОЗМОЖНОСТЕЙ ЦИКЛА ЗАЩИЩЕННОГО ХЕШИРОВАНИЯ С ШИФРОМ | 2014 |
|
RU2637463C2 |
| ПРОГРАММИРОВАНИЕ АВТОМАТИЗАЦИИ В 3D ГРАФИЧЕСКОМ РЕДАКТОРЕ С ТЕСНО СВЯЗАННОЙ ЛОГИКОЙ И ФИЗИЧЕСКИМ МОДЕЛИРОВАНИЕМ | 2014 |
|
RU2678356C2 |
| СПОСОБ РАЗДЕЛЕНИЯ ОПЕРАЦИИ СВЕРТКИ НА УСТРОЙСТВЕ С МАТРИЧНЫМИ УМНОЖИТЕЛЯМИ НА ОСНОВЕ СИСТОЛИЧЕСКИХ МАССИВОВ | 2024 |
|
RU2830039C1 |
| Архитектура параллельной вычислительной системы | 2016 |
|
RU2644535C2 |

Изобретение относится к области вычислительной техники, а в частности к способу и системе для выполнения программного кода с помощью нейронных сетей. Технический результат заключается в снижении энергопотребления компьютерными вычислительными системами. Технический результат достигается за счет способа выполнения программного кода, с помощью по меньшей мере одного процессора, соединенного с по меньшей мере одной памятью, содержащего этапы, на которых: получают программный код; осуществляют обработку программного кода, в результате которой: определяют функции программного кода; определяют диапазон и шаг входных аргументов каждой функции программного кода; выполняют регистрацию выходных значений функции для каждого набора значений входных аргументов; получают в результате предыдущего этапа массив значений, содержащий выходные значения исполняемых функций и соответствующие им входные значения; обучают нейронные сети на основе данных в массиве значений, причем для каждой исполняемой функции обучается соответствующая нейронная сеть; исполняют функции программного кода с помощью соответствующих им нейронных сетей при обращении процессора к памяти. 1 з.п. ф-лы, 8 ил.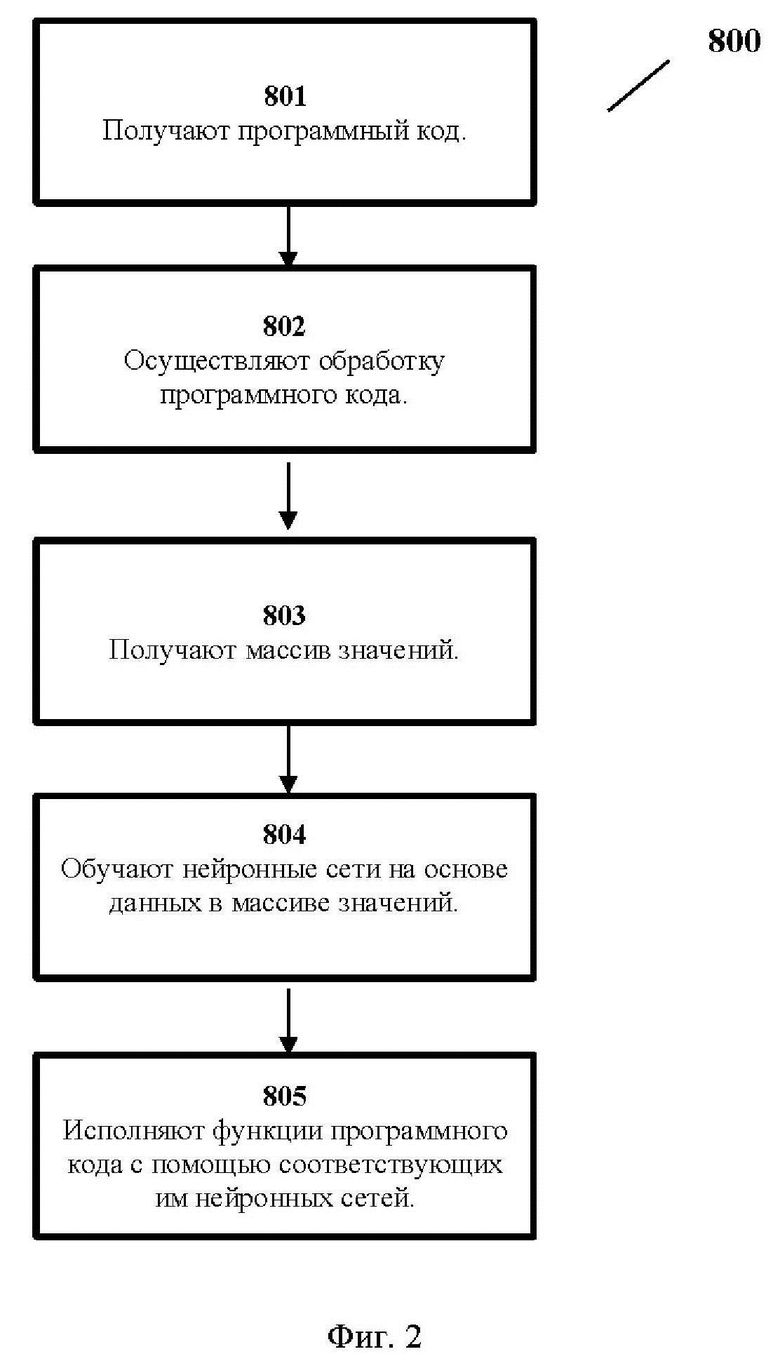
1. Способ выполнения программного кода, с помощью по меньшей мере одного процессора, соединенного с по меньшей мере одной памятью, содержащий этапы, на которых:
- получают программный код;
- осуществляют обработку программного кода, в результате которой:
 определяют функции программного кода;
определяют функции программного кода;
определяют диапазон и шаг входных аргументов каждой функции программного кода;
выполняют регистрацию выходных значений функции для каждого набора значений входных аргументов;
- получают в результате предыдущего этапа массив значений, содержащий выходные значения исполняемых функций и соответствующие им входные значения;
- обучают нейронные сети на основе данных в массиве значений, причем для каждой исполняемой функции обучается соответствующая нейронная сеть;
- исполняют функции программного кода с помощью соответствующих им нейронных сетей при обращении процессора к памяти.
2. Способ по п.1, характеризующийся тем, что при осуществлении обработки программного кода конвертируют каждую функцию программного кода в микроприложение.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| НЕЙРОННАЯ СЕТЬ С ПОРОГОВОЙ (k, t) СТРУКТУРОЙ ДЛЯ ПРЕОБРАЗОВАНИЯ ОСТАТОЧНОГО КОДА В ДВОИЧНЫЙ ПОЗИЦИОННЫЙ КОД | 2008 |
|
RU2380751C1 |
