Область техники
[1] Изобретение относится к микропроцессорной технике, в частности к микропроцессорам, снабженным кэш-памятью для хранения данных.
Предпосылки к созданию изобретения
[2] Современные процессоры характеризуются весьма высокой скоростью осуществления вычислительных команд, при этом самыми медленно исполняемыми командами, которые главным образом и ограничивают производительность процессора, являются команды, связанные с обращением к запоминающему устройству, а именно команды чтения и записи данных. Снабжение процессора собственным запоминающим устройством, выполненным заодно с иными компонентами процессора на полупроводниковом кристалле и далее именуемым как «кэш-память», позволяет снизить время исполнения команд чтения и записи данных и тем самым повысить производительность процессора. Однако данное преимущество реализуется при том лишь условии, что данные, подлежащие чтению, сохранены в кэш-памяти на момент исполнения команды чтения, т.е. при так называемом попадании в кэш. Другими словами, для заметного повышения производительности процессора его кэш-память должна быть способна сохранять значительный объем данных, притом что емкость кэш-памяти имеет очевидные конструктивные ограничения.
[3] Один из известных подходов к увеличению объема сохраненных данных в кэш-памяти заданной емкости состоит в сжатии данных (в другой формулировке - компрессия данных), когда для массива данных, содержащего множество элементов, определяют базовую величину, после чего с использованием заданного правила для каждого элемента массива определяют специфическую величину, характерную только для данного элемента массива и отличающую его от базовой величины. Сохранение базовой величины и множества специфических величин в кэш-памяти требует, как правило, существенно меньшей ее емкости по сравнению с сохранением всех элементов массива в исходном виде, при этом исходный вид каждого элемента массива может быть восстановлен из базовой величины и соответствующей специфической величины согласно заданному правилу. Таким образом кэш-память может вместить в себя гораздо больший объем данных, что увеличивает вероятность попадания в кэш, и в конечном счете - производительность процессора.
[4] В статье, представленной на конференции PACT'12 (International Conference on Parallel Architectures and Compilation Techniques), Minneapolis Minnesota USA September 19 - 23, 2012, (найдено в Интернет: https://users.ece.cmu.edu/~omutlu/pub/bdi-compression_pact12.pdf), раскрыт способ хранения данных в кэш-памяти процессора, применимый к массиву данных, подлежащих сохранению в одной строке кэш-памяти (далее - кэшлайн). Согласно данному известному способу, являющемуся прототипом изобретения, при сжатии данных для каждого элемента массива определяют его арифметическую разность с заранее установленной базовой величиной (в первоисточнике - база), и данная арифметическая разность подлежит сохранению в виде специфической величины (в первоисточнике - дельта). При необходимости восстановления исходного вида какого-либо элемента массива находят арифметическую сумму базовой величины и соответствующей специфической величины. Однако прототип изобретения имеет серьезный недостаток. Операции вычитания и сложения, выполняемые для каждого элемента массива соответственно при сжатии и восстановлении данных, требуют значительных аппаратных ресурсов, что приводит к неоправданному усложнению процессора и повышенному энергопотреблению.
[5] Техническая проблема, на решение которой направлено изобретение, состоит в упрощении конструкции процессора, кэш-память которого способна сохранять данные в сжатом виде.
Сущность изобретения
[6] Для решения указанной технической проблемы предложены два объекта изобретения. В качестве первого объекта изобретения предложен способ сохранения массива целевых значений в кэш-памяти процессора (далее - предложенный способ), включающий процедуру помещения массива в кэш-память и процедуру извлечения массива из кэш-памяти, причем каждое целевое значение массива представлено последовательностью разрядов двоичной системы счисления и имеет одно и то же число разрядов. Согласно способу в ходе процедуры помещения массива в кэш-память определяют первую группу целевых значений, которые имеют первую последовательность старших разрядов с одинаковыми битовыми значениями, и вторую группу целевых значений, которые имеют вторую последовательность старших разрядов с одинаковыми битовыми значениями, отличающуюся от первой последовательности старших разрядов. Первую и вторую последовательности старших разрядов помещают соответственно в первую и вторую общие единичные запоминающие структуры, в то время как последовательность младших разрядов каждого целевого значения первой и второй групп помещают в индивидуальную для данного целевого значения единичную запоминающую структуру. Создают при этом маску массива, которая сохраняет для каждого целевого значения характеристическое значение, определяющее принадлежность данного целевого значения к первой или второй группе. В ходе процедуры извлечения массива из кэш-памяти каждое целевое значение получают путем конкатенации первой или второй последовательности старших разрядов, извлеченной соответственно из первой или второй общей единичной запоминающей структуры, и последовательности младших разрядов, извлеченной из соответствующей данному целевому значению индивидуальной единичной запоминающей структуры. Выбор между первой и второй общими единичными запоминающими структурами для получения каждого целевого значения осуществляют на основе соответствующего характеристического значения маски массива.
[7] В качестве второго объекта изобретения предложен процессор (далее - предложенный процессор), содержащий кэш-память, способную сохранять массив целевых значений, первый и второй входные блоки, а также выходной блок. Кэш-память при этом содержит первую и вторую общие единичные запоминающие структуры, множество индивидуальных единичных запоминающих структур и масочную единичную запоминающую структуру. Первая и вторая общие единичные запоминающие структуры способны сохранять соответственно первую и вторую последовательности старших разрядов, а каждая из множества индивидуальных единичных запоминающих структур способна сохранять последовательность младших разрядов. Первый входной блок способен в отношении каждого из целевых значений определять, имеет ли данное целевое значение первую последовательность старших разрядов, и в случае положительного определения первый входной блок способен передавать последовательность младших разрядов данного целевого значения для сохранения в индивидуальной единичной запоминающей структуре, а масочная единичная запоминающая структура способна сохранять первое характеристическое значение в привязке к данному целевому значению. Второй входной блок способен в отношении каждого из целевых значений, не имеющих первой последовательности старших разрядов, определять, имеет ли данное целевое значение вторую последовательность старших разрядов, и в случае положительного определения второй входной блок способен передавать последовательность младших разрядов данного целевого значения для сохранения в индивидуальной единичной запоминающей структуре, а масочная единичная запоминающая структура способна сохранять второе характеристическое значение в привязке к данному целевому значению. Выходной блок способен восстанавливать целевое значение путем конкатенации первой последовательности старших разрядов, полученной из первой общей единичной запоминающей структуры, и последовательности младших разрядов, полученной из соответствующей данному целевому значению индивидуальной единичной запоминающей структуры, когда в привязке к данному целевому значению масочная единичная запоминающая структура сохраняет первое характеристическое значение. Выходной блок также способен восстанавливать целевое значение путем конкатенации второй последовательности старших разрядов, полученной из второй общей единичной запоминающей структуры, и последовательности младших разрядов, полученной из соответствующей данному целевому значению индивидуальной единичной запоминающей структуры, когда в привязке к данному целевому значению масочная единичная запоминающая структура сохраняет второе характеристическое значение.
[8] Технический результат, достигаемый при осуществлении первого и второго объектов изобретения, состоит в упрощении конструкции процессора, кэш-память которого способна сохранять данные в сжатом виде.
[9] Причинно-следственная связь между признаками первого и второго объектов изобретения и техническим результатом заключается в следующем. В предложенном способе и предложенном процессоре при сжатии массива целевых значений, осуществляемом в ходе процедуры помещения массива в кэш-память, старшие разряды каждого целевого значения сравнивают с первой и второй последовательностями старших разрядов, сохраненными в первой и второй общих единичных запоминающих структурах. На основании этого сравнения определяют принадлежность каждого целевого значения к первой или второй группе, при этом результат данного определения сохраняют в виде соответствующего характеристического значения в маске массива. Тем временем младшие разряды каждого целевого значения копируют в назначенную для данного целевого значения индивидуальную единичную запоминающую структуру. Другими словами, в предложенном способе и предложенном процессоре базовой величиной являются старшие разряды целевого значения, а специфической величиной, отличающей целевое значение от базовой величины, являются младшие разряды целевого значения.
[10] Таким образом, в отличие от прототипа, где при сжатии массива целевых значений специфическую величину рассчитывают путем нахождения разности между целевым значением и базовой величиной (т.е. операции вычитания), в предложенном способе и предложенном процессоре специфическую величину определяют по результату сравнения старших разрядов целевого значения с первой и второй последовательностями старших разрядов. Поскольку операция вычитания требует использования достаточно сложного и многокомпонентного устройства - сумматора, а операция сравнения осуществляется посредством гораздо более простого устройства - компаратора, то предложенный процессор, реализующий предложенный способ, имеет значительно упрощенную конструкцию относительно прототипа.
[11] Аналогичный эффект наблюдается и при восстановлении массива целевых значений, осуществляемом в ходе процедуры извлечения массива из кэш-памяти. В отличие от прототипа, где каждое целевое значение получают путем нахождения суммы базовой величины и соответствующей специфической величины (т.е. операции сложения), в предложенном способе и предложенном процессоре каждое целевое значение получают путем конкатенации (т.е. операции «склеивания», слияния) базовой величины и соответствующей специфической величины, для чего производят копирование старших разрядов из первой или второй общих единичных запоминающих структур и младших разрядов из соответствующей индивидуальной единичной запоминающей структуры в одну единичную запоминающую структуру. Следовательно, необходимость в использовании сумматоров, осуществляющих операции сложения при восстановлении целевых значений, в предложенном процессоре отсутствует, что позволяет упростить его конструкцию относительно прототипа.
[12] Благодаря более простой конструкции предложенный процессор, реализующий предложенный способ, может быть выполнен с использованием меньшего числа компонентов, иметь меньшие габариты и вес, а также потреблять меньшее количество энергии.
[13] Кроме того, в предложенном способе и предложенном процессоре предусмотрены две общие единичные запоминающие структуры, способные сохранять две последовательности старших разрядов, а значит, повышается вероятность того, что для каждого целевого значения массива будет найдена подходящая ему последовательность старших разрядов, или другими словами - вероятность того, что все целевые значения массива будут сжаты, даже если какие-то целевые значения существенным образом отличаются от других. Следует также отметить, что даже в том случае, когда все целевые значения имеют некоторое число совпадающих старших разрядов, сохранение двух последовательностей старших разрядов в качестве базовых величин позволяет сделать базовые величины более длинными, а специфические величины, т.е. индивидуально сохраняемые последовательности младших разрядов, сделать более короткими, благодаря чему эффективность сжатия массива целевых значений будет увеличена.
[14] В первом частном случае первого объекта изобретения массив целевых значений представляет собой совокупность целевых значений, входящих в один и тот же кэшлайн.
[15] В первом частном случае второго объекта изобретения массив целевых значений представляет собой совокупность целевых значений, входящих в один и тот же кэшлайн, при этом первая и вторая общие единичные запоминающие структуры, множество индивидуальных единичных запоминающих структур и масочная единичная запоминающая структура, способные обеспечить сохранение всех целевых значений массива, содержатся в строке кэш-памяти, предназначенной для сохранения кэшлайна.
[16] Технический результат, достигаемый при осуществлении первого и второго объектов изобретения в их первых частных случаях, состоит в более быстром доступе к требуемому целевому значению, сжатому в составе массива. Данное преимущество объясняется тем, что кэшлайн представляет собой минимальный извлекаемый из кэш-памяти фрагмент информации, а значит использование кэшлайна в качестве массива целевых значений позволяет минимизировать объем восстанавливаемых данных при необходимости извлечения требуемого целевого значения из кэш-памяти.
[17] Во втором частном случае первого объекта изобретения первая и вторая последовательности старших разрядов различаются по числу разрядов.
[18] Во втором частном случае второго объекта изобретения первая и вторая общие единичные запоминающие структуры способны сохранять первую и вторую последовательности старших разрядов, которые различаются по числу разрядов.
[19] Технический результат, достигаемый при осуществлении первого и второго объектов изобретения в их вторых частных случаях, состоит в еще большем повышении эффективности сжатия. Данное преимущество обусловлено тем, что удлинение даже одной из первой и второй последовательности старших разрядов приводит к укорочению соответствующих последовательностей младших разрядов, сохраняемых индивидуально для каждого целевого значения. Поскольку первая и вторая последовательности старших разрядов сохраняются лишь однократно для всего массива целевых значений в виде базовых величин, а последовательности младших разрядов сохраняются по числу целевых значений в виде специфических величин, то укорочение именно специфических величин способствует повышению эффективности сжатия массива целевых значений.
[20] В третьем частном случае первого объекта изобретения в ходе процедуры помещения массива в кэш-память определяют третью группу целевых значений, которые не имеют последовательности старших разрядов, совпадающей с первой или второй последовательностями старших разрядов. Помещают последовательность разрядов каждого целевого значения третьей группы в индивидуальную для данного целевого значения единичную запоминающую структуру, а в маске массива для каждого целевого значения третьей группы сохраняют характеристическое значение, определяющее принадлежность данного целевого значения к третьей группе. В ходе процедуры извлечения массива из кэш-памяти, когда характеристическое значение указывает на принадлежность целевого значения к третьей группе, целевое значение получают путем копирования последовательности разрядов из соответствующей единичной запоминающей структуры.
[21] В третьем частном случае второго объекта изобретения второй входной блок способен в отношении каждого из целевых значений, не имеющих первой и второй последовательностей старших разрядов, передавать последовательность всех разрядов данного целевого значения для сохранения в индивидуальной единичной запоминающей структуре, а масочная единичная запоминающая структура способна сохранять третье характеристическое значение в привязке к данному целевому значению. Кэш-память при этом способна выдавать последовательность разрядов, сохраненную в индивидуальной единичной запоминающей структуре, в качестве целевого значения, когда в привязке к данному целевому значению масочная единичная запоминающая структура сохраняет третье характеристическое значение.
[22] Технический результат, достигаемый при осуществлении первого и второго объектов изобретения в их третьих частных случаях, состоит в обеспечении сжатия массива целевых значений даже тогда, когда массив содержит отдельные целевые значения, которые не могут быть отнесены к какой-либо из первой и второй групп. Такие целевые значения, представляющие собой третью группу целевых значений, сохраняются в несжатом виде, что однако, не препятствует сжатию целевых значений из первой и второй групп.
Краткое описание чертежей
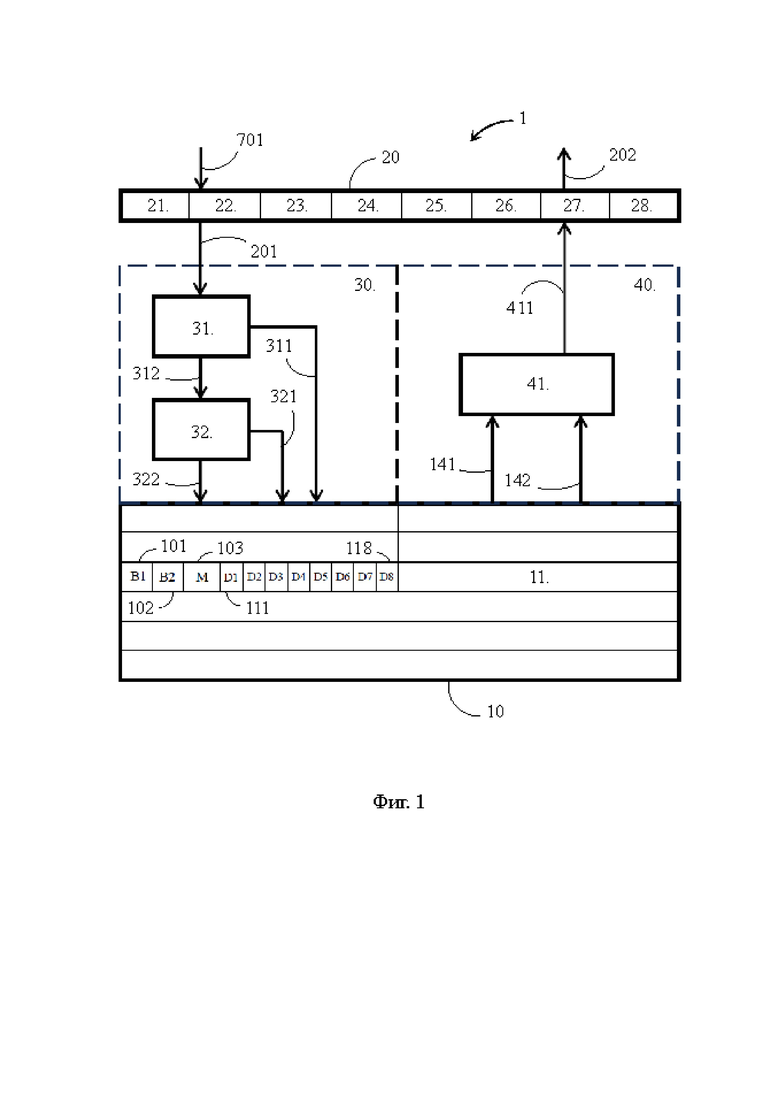
[23] Осуществление изобретения будет пояснено ссылками на фигуры:
Фиг. 1 - блок-схема фрагмента предложенного процессора в его предпочтительном случае, иллюстрирующая взаимодействие функциональных блоков при сжатии и восстановлении данных;
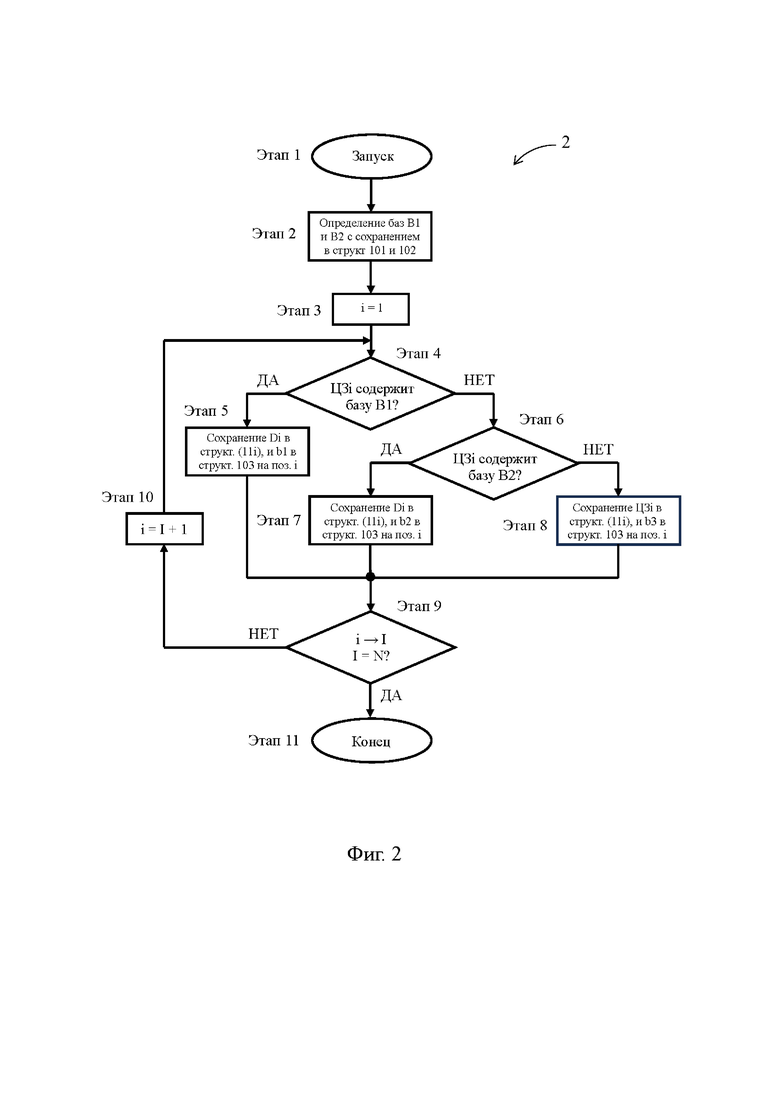
Фиг. 2 - блок-схема предложенного способа в его предпочтительном случае, иллюстрирующая процедуру сжатия данных;
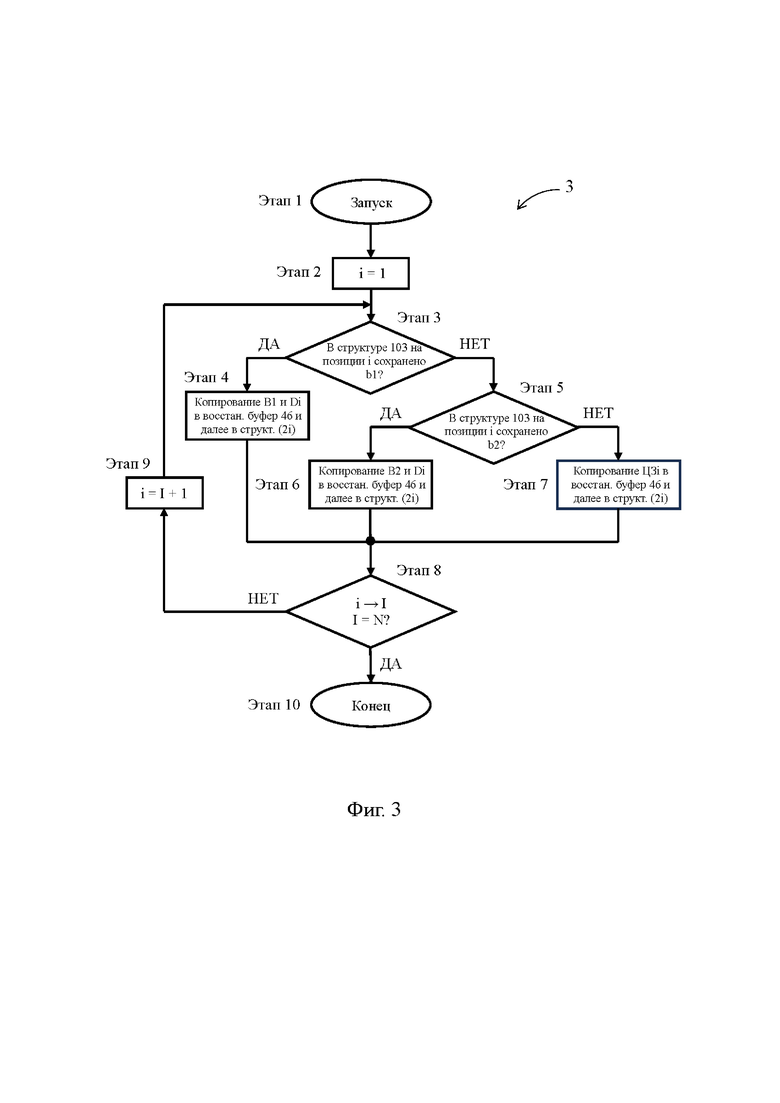
Фиг. 3 - блок-схема предложенного способа в его предпочтительном случае, иллюстрирующая процедуру восстановления данных;
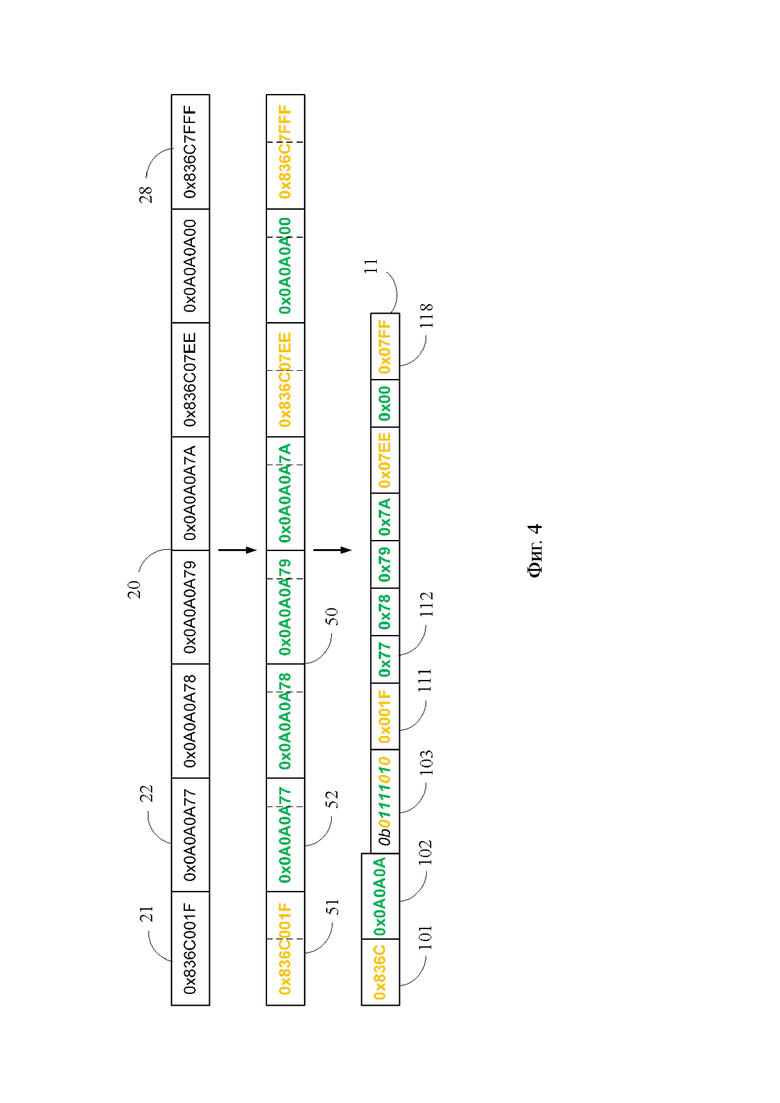
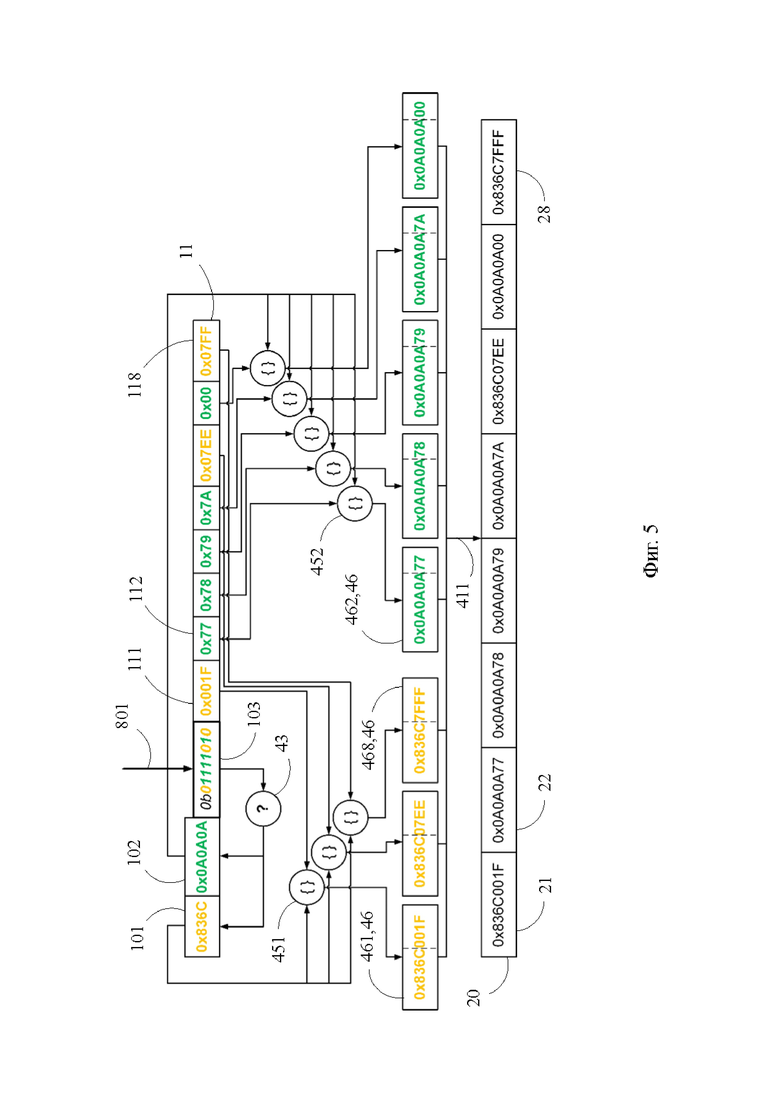
Фиг. 4 - пример осуществления предложенного способа в части, относящейся к процедуре сжатия данных;
Фиг. 5 - пример осуществления предложенного способа в части, относящейся к процедуре восстановления данных.
[24] Следует отметить, что форма и размеры отдельных элементов, отображенных на фигурах, являются условными и показаны так, чтобы наиболее наглядно проиллюстрировать взаимосвязи между элементами предложенного процессора, а также причинно-следственную связь между данными элементами и техническим результатом. Кроме того, во избежание избыточного усложнения фигур некоторые взаимосвязи элементов, очевидные специалисту в данной области техники, могут быть не отображены.
Осуществление изобретения
[25] Осуществление первого и второго объектов изобретения будет показано на наилучших примерах их реализации, которые не являются ограничениями в отношении объема охраняемых прав.
[26] На Фиг. 1 показан фрагмент предложенного процессора 1, выполненного согласно второму объекту изобретения. Предложенный процессор 1 может быть скалярным или суперскалярным процессором, может осуществлять выполнение команд в порядке загрузки (in-order execution) или в ином порядке (out-of-order execution), и может быть выполнен, по существу, в любой архитектуре, например в архитектуре VLIW (Very Long Instruction Word). Следует также отметить, что предложенный процессор 1 может входить в состав более сложного процессора в качестве ядра или выступать как самостоятельный процессор, содержащий одно или несколько ядер.
[27] Предложенный процессор 1 содержит кэш-память 10, которая способна сохранять данные, используемые в качестве операндов команд и представляющие собой числовые значения, адреса единичных запоминающих структур в других устройствах и т.д. Следует отметить, что наряду с кэш-памятью 10, по существу являющейся кэш-памятью данных, предложенный процессор 1 может содержать кэш-память иного назначения, например кэш-память команд, при этом каждая из разновидностей кэш-памяти может быть выполнена как в виде отдельного устройства, так и виде функционального раздела в одной интегрированной кэш-памяти.
[28] Кэш-память 10 сохраняет данные, именуемые в настоящем изложении как «целевые значения», в своих единичных запоминающих структурах. Под единичной запоминающей структурой в контексте настоящего изложения понимается имеющая единую идентификацию совокупность первичных запоминающих элементов, число которых задано архитектурой процессора для сохранения данного вида информации. Например, единичная запоминающая структура, сохраняющая адрес команды, может включать в себя строго 40 разрядов, а единичная запоминающая структура, сохраняющая числовое значение физической величины, может иметь, по существу, любой размер, установленный выполняемой программой.
[29] Тем временем, как было отмечено выше, минимальным извлекаемым из кэш-памяти 10 фрагментом информации является кэшлайн, представляющий собой массив целевых значений, который без применения сжатия данных, как правило, полностью занимает одну строку 11 кэш-памяти 10. На Фиг. 1 и 4 показан промежуточный буфер 20 предложенного процессора 1, сохраняющий типичный кэшлайн из 8 целевых значений, поступивший из оперативной памяти компьютера по шине 701 и подлежащий сохранению в кэш-памяти 10. Для сохранения данного кэшлайна (далее - тестовый кэшлайн) промежуточный буфер 20 задействует 8 единичных запоминающих структур 21-28, при этом точно такое же число единичных запоминающих структур такой же размерности для сохранения тестового кэшлайна должна была бы задействовать и кэш-память 10, если бы в ней не был использован предложенный способ. Обратная передача кэшлайна из промежуточного буфера 20 в оперативную память компьютера осуществляется по шине 202.
[30] Хотя в действительности целевые значения тестового кэшлайна сохранены в промежуточном буфере 20 в виде последовательности битов, для краткости записи на Фиг. 5 они представлены в 16-ричной системе счисления, в которой один знак может принимать 16 значений, а значит в двоичной системе счисления его отображение требует 4 бита. Поскольку каждое целевое значение содержит 8 знаков (первые два знака 0х являются указателем на 16-ричную систему счисления), то сохраняющая его единичная запоминающая структура 21-28 содержит 8*4=32 первичных запоминающих элемента, каждый из которых способен принимать два состояния 1 или 0, т.е. сохранять 1 бит. Таким образом, каждое целевое занимает 4 байта памяти, а весь тестовый кэшлайн - 32 байта, т.е. всю строку 11 кэш-памяти предложенного процессора 1. Исходя из этого, представляется весьма желательным сжать тестовый кэшлайн так, чтобы по меньшей мере часть строки 11, а в идеале - половина строки 11 осталась свободной и могла быть использована для сохранения других данных, увеличивая вероятность попадания в кэш.
[31] В этих целях предложенный процессор 1 снабжен сжимающим устройством 30, способным обеспечить сжатие тестового кэшлайна для сохранения в кэш-памяти 10, и восстанавливающим устройством 40, способным обеспечить восстановление тестового кэшлайна до исходного состояния для сохранения в промежуточном буфере 20, когда какое-либо целевое значение тестового кэшлайна затребовано выполняемой программой. Кэш-память 10, а именно строка 11, при этом содержит первую и вторую общие единичные запоминающие структуры 101 и 102, масочную единичную запоминающую структуру 103 и множество индивидуальных единичных запоминающих структур 111-118.
[32] Сжимающее устройство 30 содержит первый и второй входные блоки 31 и 32. Первый входной блок 31 соединен с промежуточным буфером 20 шиной 201, с кэш-памятью 10 - шиной 311 и со вторым входным блоком - шиной 312. Второй входной блок 32 соединен с кэш-памятью 10 шинами 321 и 322. Восстанавливающее устройство 40 содержит выходной блок 41, который соединен с кэш-памятью 10 шинами 141 и 142, и который соединен с промежуточным буфером 20 шиной 411. Кроме того, в состав сжимающего устройства 30 и восстанавливающего устройства 40 входят соответственно входной и выходной счетчики целевых значений, которые на Фиг. 1 не показаны. Следует также отметить, что шины 701, 201, 311, 312, 321, 322, 141, 142, 411 являются шинами передачи данных, при этом шины, предназначенные для передачи сигналов управления, на Фиг. 1 не показаны.
[33] Обратим внимание, что в контексте настоящего изложения понятия «сжимающее устройство 30», «первый входной блок 31», «второй входной блок 32», «восстанавливающее устройство 40», «выходной блок 41», «счетчик целевых значений» и т.п. отражают прежде всего описанное ниже функциональное содержание обозначаемых ими объектов, при этом техническая реализация этих объектов, обусловленная их функциональным содержанием, является очевидной для специалиста в данной области техники и может иметь различную конфигурацию. Кроме того, каждый из указанных объектов может быть выполнен в виде отдельного физически обособленного устройства или может быть выполнен без физического обособления в составе более сложного вычислительного устройства. Одновременно с этим возможно исполнение, когда компоненты какого-либо из указанных объектов могут быть распределены по разным устройствам.
[34] Предложенный способ осуществляется посредством осуществления двух взаимодополняющих процедур, а именно: процедуры помещения массива в кэш-память 10, которая по существу идентична показанной на Фиг. 2 процедуре 2 сжатия данных, и процедуры извлечения массива из кэш-памяти 10, которая по существу идентична показанной на Фиг. 3 процедуре 3 восстановления данных, при этом каждая из указанных процедур необходима для реализации назначения предложенного способа, т.е. для сохранения массива целевых значений в кэш-памяти 10 предложенного процессора 1. Функционирование предложенного процессора 1 при осуществлении процедуры 2 сжатия данных далее описано со ссылками на Фиг. 1, 2 и 4.
[35] Этап 1 процедуры 2 сжатия данных (Фиг. 2) заключается в запуске данной процедуры, что происходит, например, в момент копирования кэшлайна, подлежащего сохранению в кэш-памяти 10, из оперативной памяти компьютера в промежуточный буфер 20 по шине 701. В другом случае процедура 2 сжатия данных может быть запущена при выполнении команды store, когда кэшлайн подлежит сохранению в кэш-памяти 10 после включения в него целевого значения, скопированного из регистрового файла конвейера. Кэшлайн представляет собой массив целевых значений, в котором каждое целевое значение представлено последовательностью разрядов двоичной системы счисления и имеет одно и то же число разрядов. Например, все целевые значения тестового кэшлайна с Фиг. 4 имеют по 32 разряда, каждый из которых способен принимать значения двоичной системы счисления.
[36] На этапе 2 процедуры 2 сжатия данных, следующем за этапом 1, определяют первую последовательность старших разрядов с одинаковыми битовыми значениями и вторую последовательность старших разрядов с одинаковыми битовыми значениями, отличающуюся от первой последовательности старших разрядов. По существу первая и вторая последовательности старших разрядов с одинаковыми битовыми значениями представляют собой первую и вторую базовые величины (или кратко - первая и вторая базы В1 и В2), позволяющие отнести целевые значения кэшлайна, сохраненного в промежуточном буфере 20, к первой или второй группе. Например, в тестовом кэшлайне на Фиг. 4 первая и вторая базы В1 и В2 равны соответственно 0×8364С и 0×0А0А0А, а значит целевые значения со старшими разрядами 0×8364С составляют первую группу, а целевые значения со старшими разрядами 0×0А0А0А составляют вторую группу. Обратим внимание, что в тестовом кэшлайне первая и вторая базы В1 и В2 отличаются по числу разрядов. Возможность использования первой и второй баз В1 и В2 с различным числом разрядов позволяет максимизировать число разрядов в одной из первой и второй баз В1 и В2 (в тестовом кэшлайне - это вторая база В2), а значит повысить эффективность сжатия массива данных.
[37] Следует отметить, что этап 2 процедуры 2 сжатия данных может быть выполнен заранее, например, во время компиляции программы под архитектуру предложенного процессора 1. В этом случае первая и вторая базы В1 и В2 могут быть определены либо для каждого отдельного кэшлайна, либо сразу для множества кэшлайнов, в которых целевые значения имеют различия, главным образом, только в младших разрядах. При предварительном определении первой и второй баз В1 и В2 этап 2 процедуры 2 сжатия данных выражается в сохранении первой и второй баз В1 и В2 в первой и второй общих единичных запоминающих структурах 101 и 102 строки 11, как это показано на Фиг. 1 и 4.
[38] В другом случае выполнения этапа 2 процедуры 2 сжатия данных первую и вторую базы В1 и В2 определяют для каждого кэшлайна уже после его сохранения в промежуточном буфере 20. Например, в первом целевом значении фиксируют 4 старших разряда, которые принимают в качестве первой базы В1. Остальные целевые значения кэшлайна поочередно проверяют на совпадение их старших разрядов с первой базой В1, и в первом по счету целевом значении, у которого старшие разряды не совпали с первой базой, фиксируют 4 старших разряда, которые принимают в качестве второй базы В2. Если все целевые значения кэшлайна содержат первую или вторую базу В1 или В2, то для повышения эффективности сжатия кэшлайна в каждой из первой и второй баз В1 и В2 увеличивают число разрядов и производят повторную проверку. Если в кэшлайне выявлены целевые значения, которые не содержат первой или второй базы В1 или В2, то число разрядов в первой или второй базе В1 или В2 может быть уменьшено. Аналогично случаю предварительного определения, первая и вторая базы В1 и В2, определенные после сохранения кэшлайна в промежуточном буфере 20, подлежат сохранению в первой и второй общих единичных запоминающих структурах 101 и 102 строки 11, как это показано на Фиг. 1 и 4.
[39] На этапе 3 процедуры 2 сжатия данных, который следует за этапом 2, входному счетчику целевых значений присваивают значение i=1, после чего процедура 2 сжатия данных переходит на этап 4.
[40] На этапе 4 процедуры 2 сжатия данных определяют, содержит ли целевое значение под номером i (далее - ЦЗi) первую базу В1. Если результатом данного определения является ДА, то процедура 2 сжатия данных переходит на этап 5. В случае i=1, проверка первого по счету целевого значения ЦЗ1 тестового кэшлайна показала, что первое по счету целевое значение ЦЗ1 содержит первую базу В1, и эта ситуация отражена в ячейке 51 иллюстративной строки 50 (Фиг. 4). Этап 4 выполняется первым входным блоком 31, который получает целевое значение ЦЗi от промежуточного буфера 20 по шине 201 и сравнивает старшие разряды целевого значения ЦЗi с первой базой В1. Операция сравнения не требует сложной аппаратной реализации и может быть осуществлена с использованием компаратора, поэтому первый входной блок 31 имеет существенно более простую конструкцию по отношению к соответствующему устройству прототипа, где для выявления отличия целевого значения от базы используется более сложный сумматор.
[41] На этапе 5 процедуры 2 сжатия данных сохраняют специфическую величину целевого значения ЦЗi, представляющую собой последовательность младших разрядов данного целевого значения (далее кратко - дельта Di), в индивидуальной единичной запоминающей структуре (11i) строки 11. Обратим внимание, что в настоящем изложении числовое обозначение, содержащее изменяемый параметр i и заключенное в скобки, такое как (11i), указывает, что i является разрядом трехзначного числа. Одновременно с этим сохраняют характеристическое значение b1, указывающее на принадлежность целевого значения ЦЗi к первой группе с базой В1, на i-й позиции в масочной единичной запоминающей структуре 103 строки 11. Этап 5 выполняется кэш-памятью 10, которая получает дельту Di от первого входного блока 31 по шине 311 и формирует для данного целевого значения ЦЗi характеристическое значение b1.
[42] Как видно на Фиг. 4, для первого по счету целевого значения ЦЗ1 тестового кэшлайна (i=1), дельта D1 имеющая значение 0х001F, сохранена в индивидуальной единичной запоминающей структуре 111, а характеристическое значение b1, равное 0, сохранено на 1-й позиции в масочной единичной запоминающей структуре 103 строки 11 (первые два знака 0b в масочной единичной запоминающей структуре 103 являются указателем на двоичную систему счисления).
[43] После этапа 5 процедура 2 сжатия данных переходит на этап 9, где номер i целевого значения ЦЗi получает статус I, указывающий на завершение сжатия целевого значения ЦЗi. Одновременно с этим определяют, равен ли номер I целевого значения ЦЗi количеству N целевых значений в кэшлайне, и если результатом данного определения является НЕТ, то процедура 2 сжатия данных переходит на этап 10. Для первого по счету целевого значения ЦЗ1 I=1, а N=8, следовательно, в этом случае процедура 2 сжатия данных переходит на этап 10.
[44] На этапе 10 процедуры 2 сжатия данных входной счетчик целевых значений увеличивают на 1, и процедура 2 сжатия данных переходит на этап 4, который выполняют уже для целевого значения ЦЗ2. Однако в случае целевого значения ЦЗ2 результатом определения на этапе 4 становится НЕТ, поскольку как следует из Фиг.4, целевое значение ЦЗ2 не содержит первой базы В1, и процедура 2 сжатия данных переходит на этап 6.
[45] На этапе 6 процедуры 2 сжатия данных для целевого значения ЦЗi, в отношении которого на этапе 4 было установлено, что оно не содержит первой базы В1, определяют, содержит ли оно вторую базу В2. Если результатом данного определения является ДА, то процедура 2 сжатия данных переходит на этап 7. В отношении второго по счету целевого значения ЦЗ2 (i=2) тестового кэшлайна указанное определение показало, что второе по счету целевое значение ЦЗ2 содержит вторую базу В2, и эта ситуация отражена в ячейке 52 иллюстративной строки 50 (Фиг. 4). Этап 6 выполняется вторым входным блоком 32, который получает целевое значение ЦЗi от первого входным блока 31 по шине 312 и сравнивает старшие разряды целевого значения ЦЗi со второй базой В2. Преимущества от использования операции сравнения вторым входным блоком 32 аналогичны таковым, которые были описаны выше для первого входного блока 31.
[46] На этапе 7 процедуры 2 сжатия данных сохраняют дельту Di целевого значения ЦЗi в индивидуальной единичной запоминающей структуре (11i) строки 11, и одновременно с этим сохраняют характеристическое значение b2, указывающее на принадлежность целевого значения ЦЗi ко второй группе с базой В2, на i-й позиции в масочной единичной запоминающей структуре 103 строки 11. Как видно на Фиг. 4, для второго по счету целевого значения ЦЗ2 тестового кэшлайна (i=2), дельта D2, имеющая значение 0×77, сохранена в индивидуальной единичной запоминающей структуре 112, а характеристическое значение b2, равное 1, сохранено на 2-й позиции в масочной единичной запоминающей структуре 103 строки 11. Этап 7 выполняется кэш-памятью 10, которая получает дельту Di от второго входного блока 32 по шине 321 и формирует для данного целевого значения ЦЗi характеристическое значение b2.
[47] Как видно на Фиг. 4, каждое из целевых значений ЦЗi принадлежит либо к первой группе с базой В1, либо ко второй группе с базой В2. Данная ситуация является наиболее вероятной, поскольку кэшлайны, как правило, формируют из целевых значений, близких по величине, и в подавляющем числе случаев двух баз оказывается достаточно для охвата всех целевых значений кэшлайна. Таким образом, переход процедуры 2 сжатия данных с этапа 6 на этап 7 является наиболее вероятным. Однако существует возможность того, что кэшлайн содержит целевое значение, не относящееся к какой-либо из первой и второй групп, т.е. не содержащее ни одной из первой и второй баз В1 и В2. В этом случае на этапе 6 процедуры 2 сжатия данных делается определение НЕТ, и процедура 2 сжатия данных переходит на этап 8, выполняемый для целевых значений третьей группы.
[48] На этапе 8 процедуры 2 сжатия данных целевое значение ЦЗi сохраняют в индивидуальной единичной запоминающей структуре (11i) строки 11 полностью, и одновременно с этим сохраняют характеристическое значение b3, указывающее на принадлежность целевого значения ЦЗi к третьей группе, на i-й позиции в масочной единичной запоминающей структуре 103 строки 11. Поскольку характеристическое значение теперь должно быть способно отображать три значения, а именно b1, b2 и b3, то для его сохранения должны быть задействованы два разряда, а общее число разрядов масочной единичной запоминающей структуре 103 увеличивается с 8 до 16. Этап 8 выполняется кэш-памятью 10, которая получает целевое значение ЦЗi от второго входного блока 32 по шине 322 и формирует для данного целевого значения ЦЗi характеристическое значение b3.
[49] После каждого из этапов 5, 7 или 8 процедура 2 сжатия данных переходит на этап 9, и до тех пор, пока I не станет равным N, описанный цикл выполняют вновь для каждого следующего по счету целевого значения ЦЗi. Когда на этапе 9 входной счетчик целевых значений примет значение I=N, процедура 2 сжатия данных переходит на этап 11 и на этом завершается. Как видно на Фиг. 4, по завершении процедуры 2 сжатия данных тестовый кэшлайн, изначально занимающий 32 байта памяти в промежуточном буфере 20, сжимается до 17 байт в строке 11, в которой остаются свободными 15 байт.
[50] Следует отметить, что этап 8 процедуры 2 сжатия данных, как он был описан выше, является опциональным. Возможны варианты предложенного способа и предложенного процессора 1, когда на этапе 8 признают нецелесообразность сжатия данного кэшлайна, процедуру 2 сжатия данных останавливают, а кэшлайн сохраняют в строке 11 кэш-памяти 10 в несжатом виде.
[51] Функционирование предложенного процессора 1 при осуществлении процедуры 3 восстановления данных описано далее со ссылками на Фиг. 1, 3 и 5. Этап 1 процедуры 3 восстановления данных заключается в запуске данной процедуры, что происходит, например, при выполнении команды load, согласно которой одно из целевых значений кэшлайна должно быть скопировано из кэш-памяти 10 в регистровый файл конвейера. В другом случае процедура 3 восстановления данных может быть инициирована при переносе кэшлайна из кэш-памяти 10 в оперативную памяти компьютера, когда данный кэшлайн вытесняется другим кэшлайном, более релевантным исполняемой программе. Сигнал на выполнение этапа 1 процедуры 3 восстановления данных поступает в кэш-память 10 по шине 801 (Фиг. 5), после чего процедура 3 восстановления данных переходит на этап 2.
[52] На этапе 2 процедуры 3 восстановления данных выходному счетчику целевых значений присваивают значение i=1, после чего процедура 3 восстановления данных переходит на этап 3.
[53] На этапе 3 процедуры 3 восстановления данных определяют, сохранено ли в масочной единичной запоминающей структуре 103 на i-м месте, а при i=1 - на первом по счету месте, характеристическое значение b1. Если результатом данного определения является ДА, что справедливо для первого по счету характеристического значения тестового кэшлайна, которое равно 0 (Фиг. 5), то процедура 3 восстановления данных переходит на этап 4. В дополнение следует отметить, что этап 3 выполняется при помощи компаратора 43, входящего в состав восстанавливающего устройства 40 и имеющего известную специалисту в данной области конструкцию.
[54] На этапе 4 процедуры 3 восстановления данных осуществляют конкатенацию первой базы В1, сохраненной в первой общей единичной запоминающей структуре 101, и дельты Di, которая для i=1 представляет собой дельту D1, сохраненную в индивидуальной единичной запоминающей структуре 111. Операция конкатенации схематично обозначена в виде символического элемента 451, которого в действительности не существует, поскольку для выполнения конкатенации первую базу В1 (0×836С) и дельту D1 (0×001F) сохраняют в указанном порядке в восстанавливающем буфере 461, обеспечивая тем самым восстановление целевого значения ЦЗ1 до значения 0×836С001F. Из восстанавливающего буфера 461 целевое значение ЦЗ1 по шине 411 копируют в первую по счету единичную запоминающую структуру промежуточного буфера 20, т.е. в единичную запоминающую структуру 21, что становится началом восстановления кэшлайна.
[55] Хотя на Фиг. 5 показаны 8 восстанавливающих буферов 461-468, данное отображение носит иллюстративный характер в целях раскрытия взаимосвязи между общими 101, 102 и индивидуальными 111-118 единичными запоминающими структурами, задействованными для восстановления всех целевых значений ЦЗi тестового кэшлайна. В действительности восстановление каждого целевого значения ЦЗi выполняют поочередно, для чего используют лишь один единственный восстанавливающий буфер 46, который на Фиг. 5 в целях наглядности представлен в виде совокупности восстанавливающих буферов 461-468. По существу, восстанавливающий буфер 46 является примером исполнения выходного блока 41, при этом совокупность показанных на Фиг. 5 шин, соединяющих общие единичные запоминающие структуры 101 и 102 с восстанавливающими буферами 461-468, представлена на Фиг.1 в виде шины 141, а совокупность показанных на Фиг. 5 шин, соединяющих индивидуальные единичные запоминающие структуры 111-118 с восстанавливающими буферами 461-468, представлена на Фиг.1 в виде шины 142.
[56] Обратим внимание, что восстановление целевых значений кэшлайна посредством конкатенации практически не требует каких-либо специальных аппаратных средств, что выгодно отличает предложенный способ и предложенный процессор 1 от прототипа, где восстановление целевых значений кэшлайна осуществляется при помощи сумматора. Таким образом, конструкция предложенного процессора 1 существенно упрощается.
[57] После завершения этапа 4, на котором было восстановлено целевое значение ЦЗ1, процедура 3 восстановления данных переходит на этап 8, который является полностью идентичным этапу 9 процедуры 2 сжатия данных. Для I=1 результатом определения на этапе 8 становится НЕТ, и процедура 3 восстановления данных переходит на этап 9, который также является полностью идентичным этапу 10 процедуры 2 сжатия данных. После этапа 9, на котором счетчик целевых значений принял значение i=2, процедура 3 восстановления данных возвращается на этап 3.
[58] Как и на первой итерации, на этапе 3 процедуры 3 восстановления данных определяют, сохранено ли в масочной единичной запоминающей структуре 103 на i-м месте, а при i=2 - на втором по счету месте, характеристическое значение b1. Однако для тестового кэшлайна второе по счету характеристическое значение в масочной единичной запоминающей структуре имеет значение 1, т.е. b2, а значит результатом определения на этапе 3 в этом случае становится НЕТ, и процедура 3 восстановления данных переходит на этап 5.
[59] На этапе 5 процедуры 3 восстановления данных для характеристического значения, которое сохранено в масочной единичной запоминающей структуре 103 на i-м месте, и в отношении которого на этапе 3 установлено, что оно не является характеристическим значением b1, определяют, является ли оно характеристическим значением b2. Если результатом данного определения является ДА, то процедура 3 восстановления данных переходит на этап 6. Как видно на Фиг. 5, в случае тестового кэшлайна и при i=2, характеристическое значение, сохраненное в масочной единичной запоминающей структуре 103 на втором по счету месте является характеристическим значением b2, а значит результатом определения на этапе 5 является ДА, и процедура 3 восстановления данных переходит на этап 6.
[60] На этапе 6 процедуры 3 восстановления данных осуществляют конкатенацию второй базы В2, сохраненной во второй общей единичной запоминающей структуре 102, и дельты Di, которая для i=2 представляет собой дельту D2, сохраненную в индивидуальной единичной запоминающей структуре 112. Операцию конкатенации, которая на Фиг. 5 схематично обозначена в виде символического элемента 452, выполняют путем сохранения второй базы В2 (0×0А0А0А) и дельты D2 (0×77) в указанном порядке в восстанавливающем буфере 46 (на Фиг. 5 - также 462), аналогично тому, как было описано выше для этапа 4. Восстановленное данным образом целевое значение ЦЗ2 (0×0А0А0А77) по шине 411 копируют из восстанавливающего буфера 46 во вторую по счету единичную запоминающую структуру промежуточного буфера 20, т.е. в единичную запоминающую структуру 22.
[61] Если же на этапе 5 процедуры 3 восстановления данных результатом определения становится НЕТ, то процедура 3 восстановления данных переходит на этап 7, который предусмотрен для случая характеристического значения b3 и двухразрядного представления характеристических значений в масочной единичной запоминающей структуре 103. На этапе 7 в восстанавливающий буфер 46 копируют только значение, сохраненное в индивидуальной единичной запоминающей структуре (11i), которое и является целевым значением ЦЗi. Тем не менее, как видно на Фиг. 5, все целевые значения тестового кэшлайна восстановлены посредством выполнения этапов 4 и 6, а переход на этап 7 не осуществлялся. Соответственно, описанные выше этапы 5 и 7 процедуры 3 восстановления данных являются опциональными и подлежат выполнению только в том случае, когда в ходе процедуры 2 сжатия данных был выполнен этап 8.
[62] После каждого из этапов 4, 6 или 7 процедура 3 восстановления данных переходит на этап 8, и до тех пор, пока I не станет равным N, описанный цикл выполняют вновь для каждого следующего по счету характеристического значения, сохраненного в масочной единичной запоминающей структуре 103. Когда на этапе 9 входной счетчик целевых значений примет значение I=N, процедура 3 восстановления данных переходит на этап 10 и на этом завершается. Как видно на Фиг. 5, по завершении процедуры 3 восстановления данных промежуточный буфер 20 сохраняет полностью восстановленный тестовый кэшлайн, занимающий 32 байта памяти и готовый к использованию в конвейере или к передаче в оперативную память.
Изобретение относится к микропроцессорам, снабженным кэш-памятью для хранения данных. Технический результат заключается в упрощении конструкции процессора, кэш-память которого способна сохранять данные в сжатом виде. Технический результат достигается за счет выполнения этапов способа, на которых: определяют первую и вторую группы целевых значений, которые имеют последовательности старших разрядов с одинаковыми битовыми значениями, помещают первую и вторую последовательности старших разрядов соответственно в первую и вторую общие единичные запоминающие структуры, в то время как последовательность младших разрядов каждого целевого значения первой и второй групп помещают в индивидуальную для данного целевого значения единичную запоминающую структуру, создают маску массива, сохраняющую характеристическое значение, определяющее принадлежность целевого значения к первой или второй группе, в ходе процедуры извлечения массива из кэш-памяти каждое целевое значение получают путем конкатенации первой или второй последовательности старших разрядов и последовательности младших разрядов. 2 н. и 6 з.п. ф-лы, 5 ил.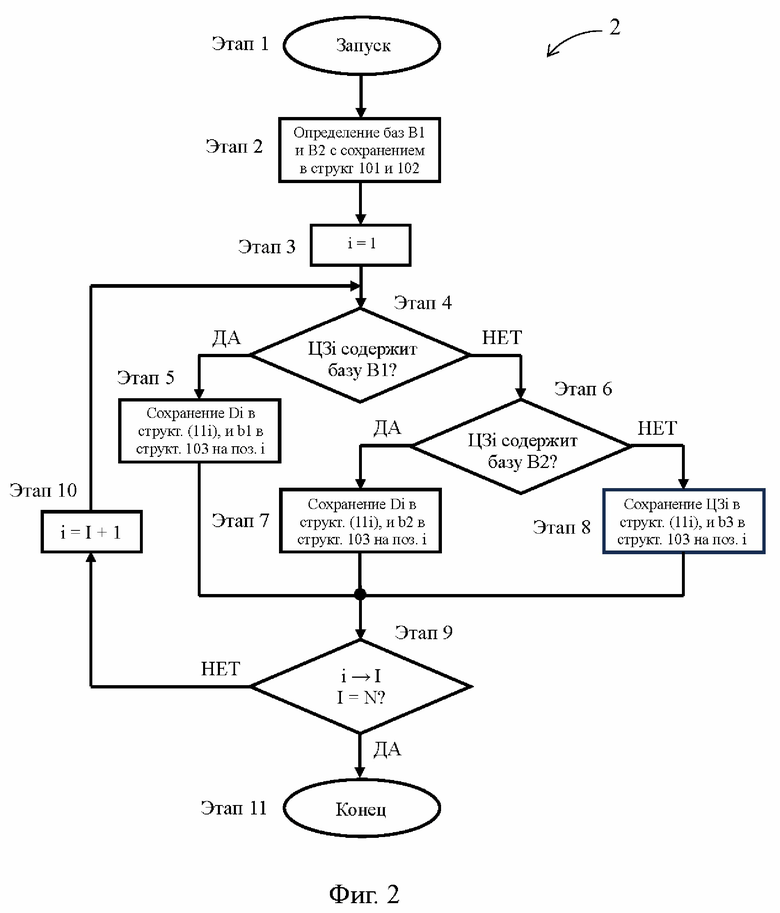
1. Способ сохранения массива целевых значений в кэш-памяти процессора, включающий процедуру помещения массива в кэш-память и процедуру извлечения массива из кэш-памяти, причем каждое целевое значение массива представлено последовательностью разрядов двоичной системы счисления и имеет одно и то же число разрядов, при этом согласно способу
в ходе процедуры помещения массива в кэш-память определяют первую группу целевых значений, которые имеют первую последовательность старших разрядов с одинаковыми битовыми значениями, и вторую группу целевых значений, которые имеют вторую последовательность старших разрядов с одинаковыми битовыми значениями, отличающуюся от первой последовательности старших разрядов, при этом
помещают первую и вторую последовательности старших разрядов соответственно в первую и вторую общие единичные запоминающие структуры, в то время как последовательность младших разрядов каждого целевого значения первой и второй групп помещают в индивидуальную для данного целевого значения единичную запоминающую структуру, и
создают маску массива, которая сохраняет для каждого целевого значения характеристическое значение, определяющее принадлежность данного целевого значения к первой или второй группе, а
в ходе процедуры извлечения массива из кэш-памяти каждое целевое значение получают путем конкатенации первой или второй последовательности старших разрядов, извлеченной соответственно из первой или второй общей единичной запоминающей структуры, и последовательности младших разрядов, извлеченной из соответствующей данному целевому значению индивидуальной единичной запоминающей структуры, при этом
выбор между первой и второй общими единичными запоминающими структурами для получения каждого целевого значения осуществляют на основе соответствующего характеристического значения маски массива.
2. Способ по п. 1, в котором массив целевых значений представляет собой совокупность целевых значений, входящих в один и тот же кэшлайн.
3. Способ по п. 1, в котором первая и вторая последовательности старших разрядов различаются по числу разрядов.
4. Способ по п. 1, в котором в ходе процедуры помещения массива в кэш-память определяют третью группу целевых значений, которые не имеют последовательности старших разрядов, совпадающей с первой или второй последовательностями старших разрядов, при этом
помещают последовательность разрядов каждого целевого значения третьей группы в индивидуальную для данного целевого значения единичную запоминающую структуру, а в маске массива для каждого целевого значения третьей группы сохраняют характеристическое значение, определяющее принадлежность данного целевого значения к третьей группе, а
в ходе процедуры извлечения массива из кэш-памяти, когда характеристическое значение указывает на принадлежность целевого значения к третьей группе, целевое значение получают путем копирования последовательности разрядов из соответствующей единичной запоминающей структуры.
5. Процессор, содержащий кэш-память, способную сохранять массив целевых значений, первый и второй входные блоки, а также выходной блок, при этом
кэш-память содержит первую и вторую общие единичные запоминающие структуры, множество индивидуальных единичных запоминающих структур и масочную единичную запоминающую структуру, причем первая и вторая общие единичные запоминающие структуры способны сохранять соответственно первую и вторую последовательности старших разрядов, а каждая из множества индивидуальных единичных запоминающих структур способна сохранять последовательность младших разрядов,
первый входной блок способен в отношении каждого из целевых значений определять, имеет ли данное целевое значение первую последовательность старших разрядов, и в случае положительного определения первый входной блок способен передавать последовательность младших разрядов данного целевого значения для сохранения в индивидуальной единичной запоминающей структуре, а масочная единичная запоминающая структура способна сохранять первое характеристическое значение в привязке к данному целевому значению,
второй входной блок способен в отношении каждого из целевых значений, не имеющих первой последовательности старших разрядов, определять, имеет ли данное целевое значение вторую последовательность старших разрядов, и в случае положительного определения второй входной блок способен передавать последовательность младших разрядов данного целевого значения для сохранения в индивидуальной единичной запоминающей структуре, а масочная единичная запоминающая структура способна сохранять второе характеристическое значение в привязке к данному целевому значению,
выходной блок способен восстанавливать целевое значение путем конкатенации первой последовательности старших разрядов, полученной из первой общей единичной запоминающей структуры, и последовательности младших разрядов, полученной из соответствующей данному целевому значению индивидуальной единичной запоминающей структуры, когда в привязке к данному целевому значению масочная единичная запоминающая структура сохраняет первое характеристическое значение, и
выходной блок способен восстанавливать целевое значение путем конкатенации второй последовательности старших разрядов, полученной из второй общей единичной запоминающей структуры, и последовательности младших разрядов, полученной из соответствующей данному целевому значению индивидуальной единичной запоминающей структуры, когда в привязке к данному целевому значению масочная единичная запоминающая структура сохраняет второе характеристическое значение.
6. Процессор по п. 5, в котором массив целевых значений представляет собой совокупность целевых значений, входящих в один и тот же кэшлайн, при этом первая и вторая общие единичные запоминающие структуры, множество индивидуальных единичных запоминающих структур и масочная единичная запоминающая структура, способные обеспечить сохранение всех целевых значений массива, содержатся в строке кэш-памяти, предназначенной для сохранения кэшлайна.
7. Процессор по п. 5, в котором первая и вторая общие единичные запоминающие структуры способны сохранять первую и вторую последовательности старших разрядов, которые различаются по числу разрядов.
8. Процессор по п. 5, в котором второй входной блок способен в отношении каждого из целевых значений, не имеющих первой и второй последовательностей старших разрядов, передавать последовательность всех разрядов данного целевого значения для сохранения в индивидуальной единичной запоминающей структуре, а масочная единичная запоминающая структура способна сохранять третье характеристическое значение в привязке к данному целевому значению, при этом
кэш-память способна выдавать последовательность разрядов, сохраненную в индивидуальной единичной запоминающей структуре, в качестве целевого значения, когда в привязке к данному целевому значению масочная единичная запоминающая структура сохраняет третье характеристическое значение.
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| ОПРЕДЕЛЕНИЕ ДЛИНЫ ГРУППЫ СИМВОЛЬНЫХ ДАННЫХ, СОДЕРЖАЩЕЙ СИМВОЛ ОКОНЧАНИЯ | 2013 |
|
RU2621000C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УСТАНОВКИ ПОЛИТИКИ КЭШИРОВАНИЯ В ПРОЦЕССОРЕ | 2008 |
|
RU2427892C2 |
| Оголовье для головных телефонов | 1930 |
|
SU20150A1 |

