Область техники
[1] Изобретение относится к микропроцессорной технике, в частности к микропроцессорам с конвейерной обработкой команд.
Предпосылки к созданию изобретения
[2] Традиционный процессор осуществляет обработку команд программы посредством конвейерного процесса, в котором каждая команда последовательно проходит через несколько стадий обработки, таких как выборка, дешифрация, исполнение, обращение к запоминающему устройству и обратная запись результата. В дальнейшем изложении комплекс технических средств, входящих в состав процессора и непосредственно связанных с осуществлением конвейерного процесса, именуется «конвейер». Классический конвейер позволяет осуществлять одновременную обработку нескольких команд, что существенно повышает производительность процессора, при этом каждая команда в определенный момент времени может находиться только на одной из стадий обработки, и на каждой стадии в определенный момент времени может обрабатываться только одна команда.
[3] Однако последовательная обработка команд может прерваться, когда программа содержит команду перехода (далее – вызывающая команда), результатом выполнения которой в зависимости от входного условия может стать как осуществление, так и неосуществление перехода. При осуществлении перехода вслед за вызывающей командой должна быть выполнена команда, сохраняемая в кэш-памяти по адресу, который не является следующим по счету адресом, или в оперативной памяти (далее – вызываемая команда), а при неосуществлении перехода вслед за вызывающей командой должна быть выполнена команда, имеющая в кэш-памяти следующий по счету адрес (далее – последующая команда).
[4] Тем временем решение о том, какая из вызываемой и последующей команд будет загружена в конвейер сразу за вызывающей командой, должно быть принято до выполнения вызывающей команды, а точнее, когда вызывающая команда находится на самой первой стадии конвейера. Ошибка в выборе между вызываемой и последующей командами приводит к тому, что обработка всей альтернативной ветви команд, определяемой выбранной командой, оказывается невостребованной, и конвейер должен приступить к обработке другой альтернативной ветви с самой первой стадии. Очевидно, что данный исход приводит к значительному снижению производительности процессора.
[5] В патентной публикации RU2602335C2, 20.11.2016 раскрыт процессор (далее – известный процессор), который снабжен предсказателем перехода, способным предсказывать результат выполнения вызывающей команды на основе статистики полученных ранее результатов. Предсказатель перехода содержит запоминающее устройство, именуемое как BTB (Branch Target Buffer – буфер целевых адресов), в котором для каждой вызывающей команды сохранен один или несколько вызываемых адресов, указывающих на ячейки памяти, сохраняющие соответствующие вызываемые команды. Соответственно, когда предсказатель перехода предсказывает, что результатом следующего выполнения вызывающей команды станет переход на вызываемую команду, то вслед за вызывающей командой в конвейер загружается вызываемая команда, сохраняемая по вызываемому адресу.
[6] Хотя одна и та же команда может служить вызываемой командой для нескольких вызывающих команд, соответствующий данной команде вызываемый адрес сохраняется в BTB для каждой вызывающей команды отдельно. Другими словами один и тот же вызываемый адрес может быть многократно сохранен в BTB с привязкой к разным вызывающим командам. Следует отметить, что BTB входит в состав предсказателя перехода на функциональном уровне, в то время как на конструктивном уровне он представляет собой раздел кэш-памяти процессора, в которой объем сохраняемой информации ограничен. Тем временем вызываемый адрес, как правило, являющийся адресом ячейки в оперативной памяти, имеет сравнительно большой битовый размер, а значит для его сохранения требуется сравнительно большой объем памяти. Многократное сохранение одного и того же вызываемого адреса в кэш-памяти выводит из оперативной работы значительную ее часть, что препятствует использованию кэш-памяти для сохранения других актуальных данных и команд, т.е. по существу является фактором, снижающим производительность известного процессора.
[7] Техническая проблема, на решение которой направлено изобретение, состоит в поиске решения, способного повысить производительность процессора через предоставление в его распоряжение дополнительного свободного объема кэш-памяти.
Сущность изобретения
[8] Для решения указанной технической проблемы в качестве изобретения предложен процессор (далее также – предложенный процессор), который содержит конвейер, кэш-память и предсказатель перехода. Кэш-память включает в себя хранилище вызываемых адресов и хранилище транзитных адресов. Предсказатель перехода способен для каждой вызывающей команды определять состояние, когда вслед за вызывающей командой в конвейер должна быть загружена вызываемая команда. Хранилище вызываемых адресов способно в своей единичной запоминающей структуре сохранять вызываемый адрес, идентифицирующий единичную запоминающей структуру, принадлежащую внешней памяти и сохраняющую вызываемую команду. Хранилище вызываемых адресов при этом способно сохранять каждый вызываемый адрес лишь в одной своей единичной запоминающей структуре. Хранилище транзитных адресов способно в своей единичной запоминающей структуре сохранять транзитный адрес, идентифицирующий единичную запоминающую структуру, принадлежащую хранилищу вызываемых адресов и сохраняющую вызываемый адрес. Тем временем хранилище транзитных адресов способно сохранять один и тот же транзитный адрес в более чем одной своей единичной запоминающей структуре. Для каждой вызывающей команды в хранилище транзитных адресов назначена своя единичная запоминающая структура.
[9] Технический результат изобретения состоит в уменьшении общего объема кэш-памяти, требуемого для сохранения вызываемых адресов в отношении одного и того же количества вызывающих команд.
[10] Причинно-следственная связь между признаками изобретения и техническим результатом заключается в следующем. Признак «для каждой вызывающей команды в хранилище транзитных адресов назначена своя единичная запоминающая структура» следует понимать так, что для каждой вызывающей команды в хранилище транзитных адресов назначена по меньшей мере одна единичная запоминающая структура, и каждая единичная запоминающая структура, принадлежащая хранилищу транзитных адресов, привязана только к одной вызывающей команде, для которой она является «своей». Кроме того, хранилище транзитных адресов способно сохранять один и тот же транзитный адрес в нескольких своих единичных запоминающих структурах. Из этого следует, что хранилище транзитных адресов способно сохранять транзитные адреса по меньшей мере в количестве, соответствующем количеству вызывающих команд, даже в том случае, если транзитные адреса повторяются.
[11] Каждый транзитный адрес при этом является адресом единичной запоминающей структуры, принадлежащей хранилищу вызываемых адресов и сохраняющей вызываемый адрес. В свою очередь, хранилище вызываемых адресов способно сохранять каждый вызываемый адрес лишь в одной своей единичной запоминающей структуре. Из этого следует, что хранилище вызываемых адресов способно сохранять только уникальные вызываемые адреса, а поскольку разным вызывающим командам часто соответствуют одни и те же вызываемые адреса, то хранилище вызываемых адресов сохраняет вызываемые адреса в количестве, значительно меньшем, чем количество вызывающих команд.
[12] Далее, вызываемый адрес идентифицирует единичную запоминающей структуру, принадлежащую внешней памяти, при этом признак «внешняя память» следует трактовать как запоминающее устройство, выполненное за пределами предложенного процессора, такое как оперативная память, накопительное запоминающее устройство и т.п. Тем временем транзитный адрес идентифицирует единичную запоминающую структуру, принадлежащую хранилищу вызываемых адресов, которое является разделом кэш-памяти предложенного процессора. Количество единичных запоминающих структур во внешней памяти, какую бы конструкцию она не имела, на много порядков превышает количество единичных запоминающих структур в кэш-памяти процессора, которая выполнена на кристалле заодно с процессором. Соответственно битовый размер транзитного адреса существенно меньше битового размера вызываемого адреса, а значит сохранение большого количества транзитных адресов и малого количества вызываемых адресов требует значительно меньшего объема кэш-памяти по сравнению с сохранением большого количества вызываемых адресов, как это реализовано в известном процессоре.
[13] В частном случае изобретения хранилище вызываемых адресов способно сохранять в качестве вызываемого адреса как целевой, так и перспективный адреса, что обуславливает следующее преимущество. Поскольку в предложенном процессоре общий объем кэш-памяти, занятый под сохранение целевых адресов, оказывается существенно меньше, чем таковой в известном процессоре, то появляется возможность для сохранения в кэш-памяти и перспективных адресов. Принимая во внимание, что в зависимости от входных условий программы каждый перспективный адрес в любой момент может стать целевым адресом и наоборот, данное исполнение уменьшает количество обращений к кэш-памяти и объем информации, записываемой в кэш-память, а значит способствует повышению производительности предложенного процессора.
[14] В другом частном случае изобретения для одной и той же вызывающей команды в хранилище транзитных адресов может быть назначена более чем одна своя единичная запоминающая структура. Данное исполнение позволяет сохранить в кэш-памяти предложенного процессора все вызываемые адреса вызывающей команды, если эта вызывающая команда имеет более чем один вызываемый адрес. Поскольку каждый из этих вызываемых адресов может стать целевым адресом, то при любом результате предсказания перехода кэш-память предложенного процессора располагает адресом команды, подлежащей загрузке в конвейер вслед за вызывающей командой. Соответственно, уменьшается количество обращений к кэш-памяти и объем информации, записываемой в кэш-память, что способствует повышению производительности предложенного процессора.
Краткое описание чертежей
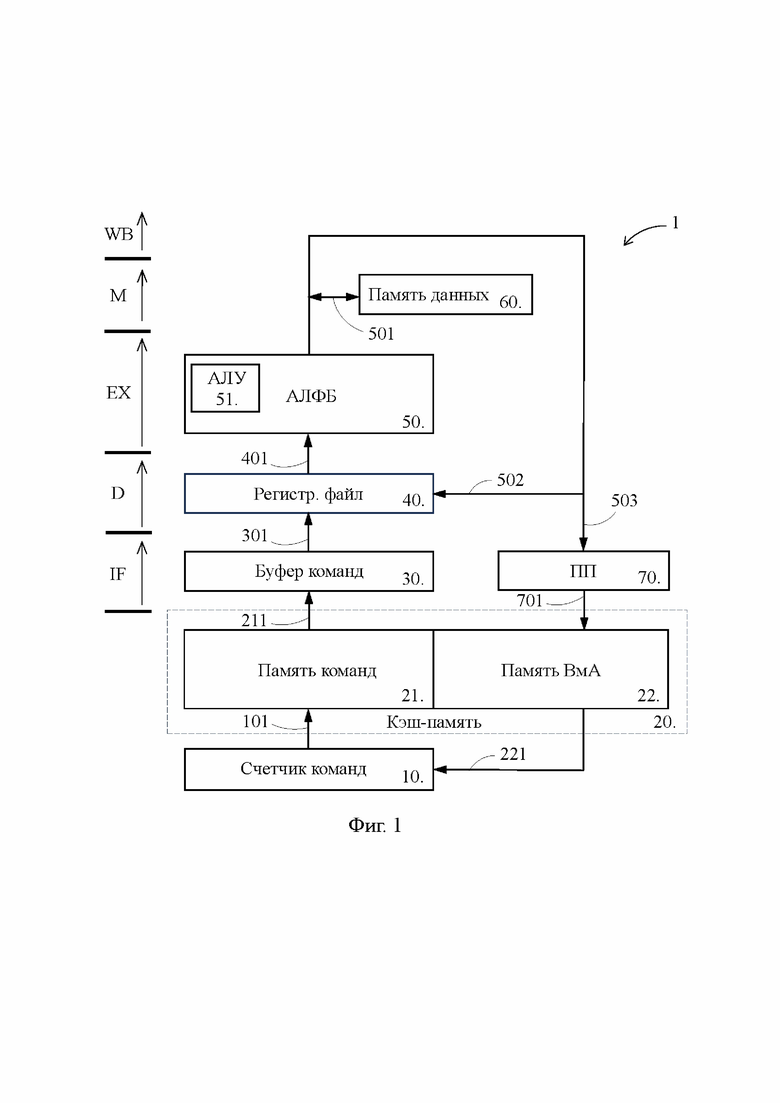
[15] Осуществление изобретения будет пояснено ссылками на фигуры:
Фиг. 1 - блок-схема традиционного процессора;
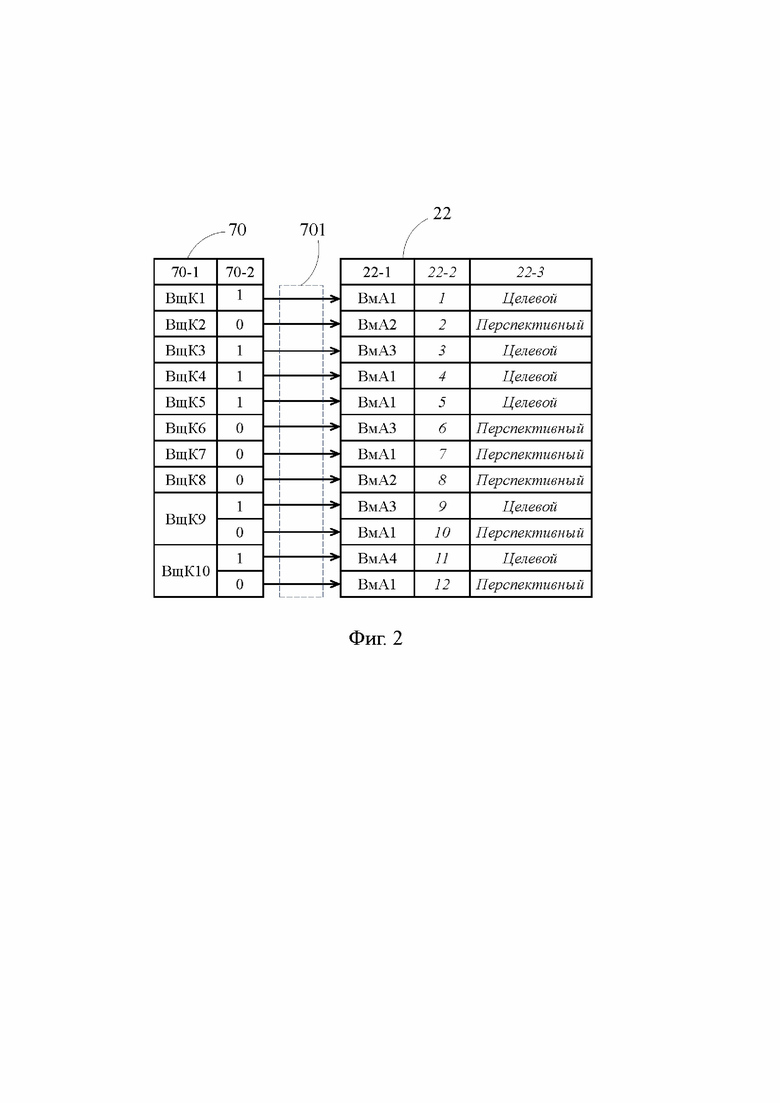
Фиг. 2 – блок-схема участка традиционного процессора, иллюстрирующая взаимосвязь предсказателя перехода и хранилища вызываемых адресов;
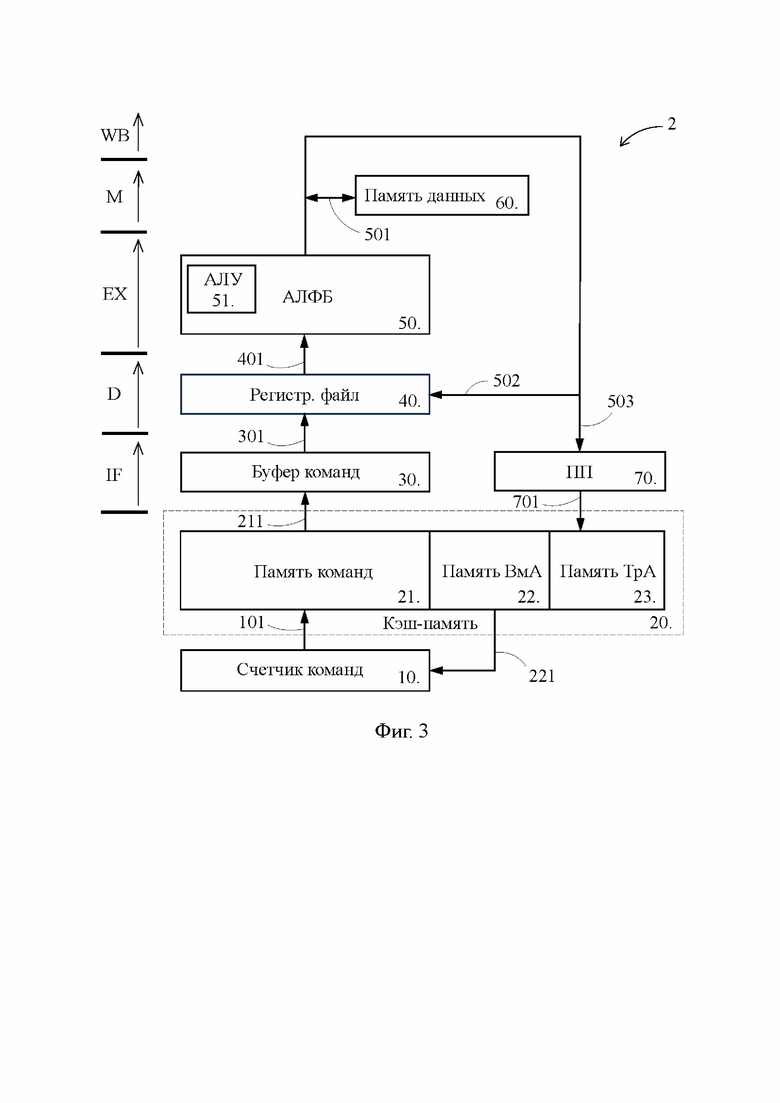
Фиг. 3 - блок-схема предложенного процессора;
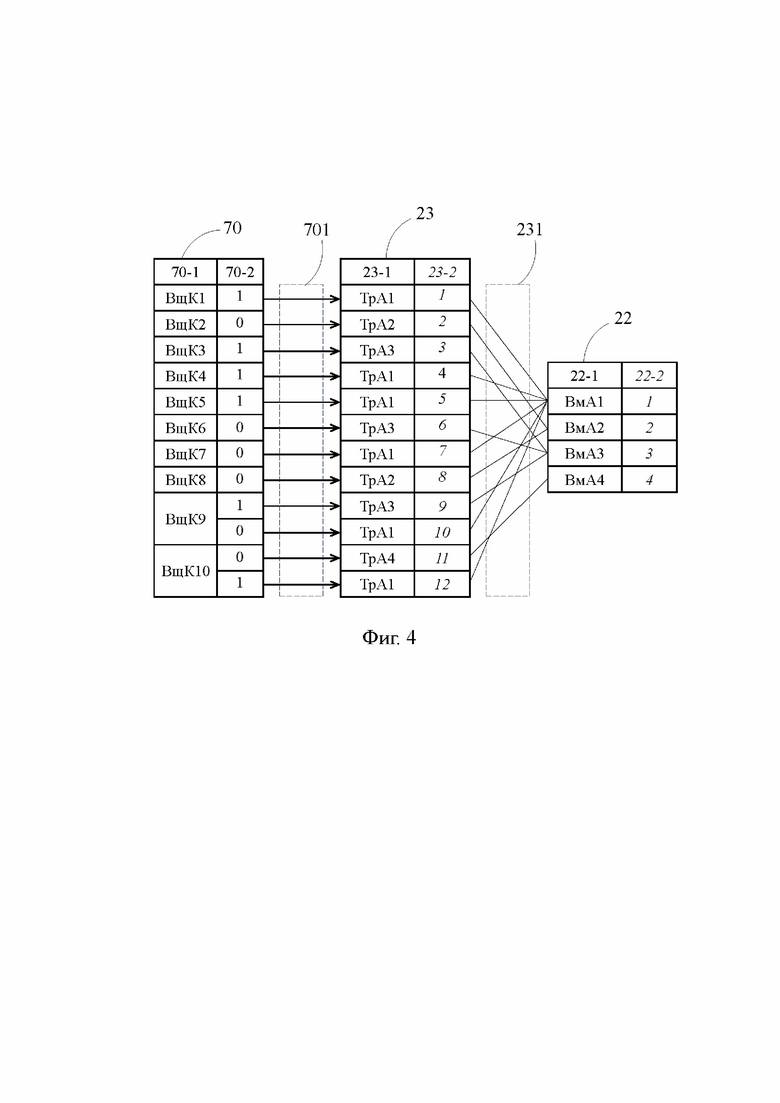
Фиг. 4 - блок-схема участка предложенного процессора, иллюстрирующая взаимосвязь предсказателя перехода, хранилища транзитных адресов и хранилища вызываемых адресов.
[16] Следует отметить, что форма и размеры отдельных элементов, отображенных на фигурах, являются условными и показаны так, чтобы наиболее наглядно проиллюстрировать взаимное расположение элементов предложенного процессора, а также их причинно-следственную связь с техническим результатом. Кроме того, во избежание избыточного усложнения фигур некоторые взаимосвязи элементов, очевидные специалисту в данной области техники, могут быть не отображены. Фигуры также содержат буквенные обозначения и словесные пояснения, которые способствуют более быстрому восприятию фигур специалистом в данной области техники.
Осуществление изобретения
[17] Осуществление изобретения будет показано на наилучших примерах его реализации, которые не являются ограничениями в отношении объема охраняемых прав.
[18] На Фиг. 1 представлена блок-схема традиционного процессора 1, который в концептуальном плане соответствует упомянутому выше известному процессору. В свою очередь, Фиг. 3 иллюстрирует блок-схему предложенного процессора 2, выполненного согласно изобретению. В значительной степени блок-схемы на Фиг. 1 и 3 повторяют друг друга, поэтому пока не указано иное, описанные ниже особенности предложенного процессора 2 свойственны также и традиционному процессору 1. Идентичные элементы на Фиг. 1 и Фиг. 3 обозначены одними и теми же позициями.
[19] Предложенный процессор 2 содержит счетчик 10 команд, кэш-память 20 управления, буфер 30 команд, регистровый файл 40, арифметико-логический функциональный блок 50 (АЛФБ) с включенным в его состав арифметико-логическим устройством 51 (АЛУ), кэш-память 60 данных, предсказатель 70 перехода (ПП). Кроме того, в состав предложенного процессора 2 входит блок управления (не показан), обеспечивающий выработку и передачу управляющих сигналов на перечисленные выше элементы, а также множество элементов, исполняющих тривиальные функции в конвейерном процессе и являющихся очевидными специалисту в данной области, таких как регистры, мультиплексоры, шины передачи данных и т.п. Некоторые из таких элементов отображены на Фиг. 3 и будут раскрыты по ходу изложения.
[20] Буфер 30 команд, регистровый файл 40, арифметико-логический функциональный блок 50, кэш-память 60 данных представляют собой основные компоненты конвейера, задействованные в соответствующих стадиях конвейерного процесса, которые показаны в левой части Фиг. 3: выборка команды (IF – instruction fetch), дешифрация (D – decode), исполнение (EX – execute), обращение к памяти (M – memory) и обратная запись результата (WB – write back). Вместе с тем конвейерный процесс, реализуемый предложенным процессором 2, может содержать гораздо больше стадий, чем указанные стадии IF, D, EX, M, WB. Принципы увеличения числа стадий конвейерного процесса, как правило, основанные на разделении указанных выше стадий на ряд более мелких стадий в целях уменьшения длительности такта, известны специалисту в данной области техники.
[21] Хотя на Фиг. 3 показан лишь один арифметико-логический функциональный блок 50, предложенный процессор 2 может иметь по существу любое количество арифметико-логических функциональных блоков 50, а также включать в себя предикатно-логические функциональные блоки, назначение и функционирование которых известны специалисту в данной области. Соответственно, предложенный процессор 2 может быть скалярным или суперскалярным процессором, осуществлять выполнение команд в порядке загрузки в конвейер (in-order execution) или в ином порядке (out-of-order execution). Притом что процессор 1 может быть выполнен по существу в любой архитектуре, предпочтительным является выполнение процессора 1 в архитектуре VLIW (Very Long Instruction Word). Следует также отметить, что предложенный процессор 2 может выступать как самостоятельный процессор или входить в состав более сложного процессора в качестве ядра.
[22] Каждая из кэш-памяти 20 управления и кэш-памяти 60 данных представляет собой кэш-память первого уровня, характеризующуюся наиболее быстрым доступом и известную как L1. Кэш-память 60 данных выполнена в виде отдельного устройства, однако, возможно исполнение, когда кэш-память 60 данных и кэш-память 20 управления объединены в одно устройство, в котором память 60 данных представлена в виде раздела.
[23] Кэш-память 20 управления предложенного процессора 2 включает в себя: кэш-память 21 команд, кэш-память 22 вызываемых адресов и кэш-память 23 транзитных адресов, каждая из которых может быть выполнена либо в виде отдельного устройства, либо в виде раздела единого устройства, как показано на Фиг. 3. Кэш-память 21 команд сохраняет команды программы, которые в ближайшее время подлежат загрузке в буфер 30 команд.
[24] Кэш-память 22 вызываемых адресов, выступающая в качестве хранилища вызываемых адресов, в своих единичных запоминающих структурах сохраняет адреса вызываемых команд (далее – вызываемые адреса или ВмА), каждый из которых идентифицирует единичную запоминающую структуру, принадлежащую внешней памяти и сохраняющую соответствующую вызываемую команду. Под внешней памятью в контексте настоящего изложения понимается запоминающее устройство, расположенное за пределами предложенного процессора 2 и способное сохранять существенно больший объем информации относительно способности кэш-памяти 20 управления, например такое, как оперативная память.
[25] Под единичной запоминающей структурой в контексте настоящего изложения понимается имеющая единую идентификацию совокупность первичных запоминающих элементов, которая включает в себя число разрядов, определенное архитектурой процессора для сохранения данного вида информации. Например, единичная запоминающая структура, сохраняющая вызываемый адрес, может включать в себя 40 разрядов, а единичная запоминающая структура, сохраняющая вызываемую команду может иметь переменный размер в зависимости от вида команды.
[26] В качестве вызываемого адреса кэш-память 22 вызываемых адресов способна сохранять целевой или перспективный адрес. Под целевым адресом в контексте настоящего изложения понимается адрес той вызываемой команды, переход на которую предсказан предсказателем 70 перехода для следующего выполнения соответствующей вызывающей команды, и которая подлежит загрузке в буфер 30 команд непосредственно вслед за этой вызывающей командой, когда эта вызывающая команда будет загружаться в буфер 30 команд в следующий раз. Под перспективным адресом в контексте настоящего изложения понимается адрес той вызываемой команды, переход на которую не предсказан предсказателем 70 перехода для следующего выполнения соответствующей вызывающей команды, но выполнялся ранее и с определенной вероятностью будет выполнен вновь. Таким образом, по итогу последнего предсказания перехода каждый целевой адрес может стать перспективным адресом и наоборот.
[27] Кэш-память 23 транзитных адресов, выступающая в качестве хранилища транзитных адресов, сохраняет транзитные адреса (ТрА), каждый из которых идентифицирует единичную запоминающую структуру, принадлежащую кэш-памяти 22 вызываемых адресов и сохраняющую соответствующий вызываемый адрес. Обратим внимание, что кэш-память 20 управления традиционного процессора 1 не содержит кэш-память 23 транзитных адресов, при этом как будет показано ниже, именно оснащение предложенного процессора 2 кэш-памятью 23 транзитных адресов определяет его преимущества перед традиционным процессором 1.
[28] Предсказатель 70 перехода способен для каждой вызывающей команды собирать статистику выполненных и невыполненных переходов, и способен трактовать собранную статистику в соответствии с заложенным в него алгоритмом предсказания перехода так, чтобы предсказать, будет ли при следующем выполнении вызывающей команды осуществлен переход на вызываемую команду. Специалисту в данной области техники известно множество алгоритмов предсказания перехода, и как таковые они не являются предметом настоящего изложения. Предсказатель 70 перехода может функционировать согласно любому из этих алгоритмов, например использовать алгоритм двухбитного насыщающегося счетчика. Когда предсказатель 70 перехода для какой-либо вызывающей команды предсказывает переход на вызываемую команду, он определяет состояние предложенного процессора 2, в котором при следующей загрузке данной вызывающей команды из кэш-памяти 21 команд в буфер 30 команд, вслед за ней в буфер 30 команд должна быть загружена данная вызываемая команда.
[29] На Фиг. 2 показана блок-схема участка традиционного процессора 1, иллюстрирующая взаимосвязь предсказателя 70 перехода и кэш-памяти 22 вызываемых адресов. Предсказатель 70 перехода для каждой выявленной вызывающей команды ВщК1 – ВщК10 сохраняет ее идентификатор (колонка 70-1) и результат предсказания перехода (колонка 70-2). Например, для вызывающих команд ВщК1 – ВщК8, результат предсказания перехода может быть выражен с использованием одного разряда, способного сохранять два состояния: «1» - осуществление перехода на вызываемую команду, и «0» - неосуществление перехода, т.е. выполнение последующей команды. В свою очередь, для вызывающих команд ВщК9 и ВщК10, результат предсказания выражается с использованием двух разрядов, способных сохранять три состояния: «10» - осуществление перехода на первую вызываемую команду, «01» - осуществление перехода на вторую вызываемую команду, и «00» - неосуществление перехода, т.е. выполнение последующей команды. В качестве идентификатора вызывающей команды (колонка 70-1) может быть использован ее адрес, например адрес в оперативной памяти, или часть адреса.
[30] Кэш-память 22 вызываемых адресов традиционного процессора 1, связанная с предсказателем 70 перехода шиной 701, в своих единичных запоминающих структурах для каждой из вызывающих команд ВщК1 – ВщК10 сохраняет соответствующий ей вызываемый адрес ВмА (колонка 22-1). Для целей наглядности Фиг. 2 в составе кэш-памяти 22 вызываемых адресов показаны колонки 22-2 и 22-3, первая из которых отображает порядковый номер, соответствующий каждому сохраненному вызываемому адресу, а вторая – статус вызываемого адреса. Когда для какой-либо вызывающей команды результат предсказания перехода на соответствующий ей вызываемый адрес равен «1», вызываемый адрес является целевым, в когда равен «0» – перспективным, что отражено в колонке 22-3.
[31] Как видно на Фиг. 2, хотя для 10-ти вызывающих команд ВщК1 – ВщК10 в колонке 22-1 сохранены 12 вызываемых адресов, только 4 из них, а именно ВмА1 – ВмА4, являются уникальными, остальные же совпадают с каким-либо из этих 4-х вызываемых адресов. Тем не менее при непосредственной связи предсказателя 70 перехода с кэш-памятью 22 целевых адресов, как это реализовано в традиционном процессоре 1, для каждого возможного перехода с вызывающих команд ВщК1 – ВщК10 должен быть сохранен свой вызываемый адрес. Из этого следует, что в традиционном процессоре 1 кэш-память 22 вызываемых адресов должна сохранить вызываемые адреса по числу возможных переходов, даже если вызываемые адреса повторяются. Другими словами, в традиционном процессоре 1 кэш-память 22 вызываемых адресов способна сохранять вызываемый адрес, например каждый из вызываемых адресов ВмА1 – ВмА3, в более чем одной своей единичной запоминающей структуре.
[32] Следует отметить, что вызываемые адреса ВмА1 – ВмА4 идентифицируют единичные запоминающие структуры, находящиеся во внешней по отношению к традиционному процессору 1 памяти, например в оперативной памяти, которая содержит очень большое число единичных запоминающих структур. Именно этим объясняется то обстоятельство, что вызываемые адреса ВмА1 – ВмА4 имеют значительный битовый размер, который как было отмечено выше, может составлять 40 бит. Ввиду весьма большого битового размера вызываемого адреса, многократное сохранение одного и того же вызываемого адреса в кэш-памяти 22 вызываемых адресов приводит к нерациональному использованию кэш-памяти 20 управления, что в конечном итоге снижает производительность традиционного процессора 1.
[33] В предложенном процессоре 2 кэш-память 20 управления содержит кэш-память 23 транзитных адресов (Фиг. 3 и Фиг. 4), которая с одной своей стороны соединена шиной 701 с предсказателем 70 перехода, а с другой своей стороны соединена шиной 231 с кэш-памятью 22 вызываемых адресов. Для каждой вызывающей команды ВщК1 – ВщК10 кэш-память 23 транзитных адресов сохраняет по меньшей мере один транзитный адрес (колонка 23-1), который идентифицирует единичную запоминающую структуру, принадлежащую кэш-памяти 22 вызываемых адресов и сохраняющую соответствующий вызываемый адрес. В иллюстративных целях на Фиг. 4 в составе кэш-памяти 23 транзитных адресов показана колонка 23-2, отображающая количество сохраненных транзитных адресов, равное 12.
[34] Тем временем в предложенном процессоре 2 кэш-память 22 вызываемых адресов способна сохранять каждый из вызываемых адресов ВмА1 – ВмА4 лишь в одной своей единичной запоминающей структуре, и поскольку количество сохраняемых вызываемых адресов равно 4-м, то кэш-память 22 вызываемых адресов содержит всего 4 единичных запоминающей структуры, подлежащих идентификации посредством транзитных адресов. Соответственно, количество уникальных транзитных адресов ТрА1 – ТрА4 также равно 4-м, а ввиду того, что число возможных переходов с вызывающих команд ВщК1 – ВщК10 равно 12-ти (колонка 23-2), то кэш-память 23 транзитных адресов способна сохранять один тот же транзитный адрес, в частности какой-либо адрес из группы транзитных адресов ТрА1 – ТрА3, в более чем одной своей единичной запоминающей структуре.
[35] Далее, поскольку идентификации посредством транзитных адресов ТрА1 – ТрА4 подлежат всего 4 единичные запоминающие структуры кэш-памяти 22 вызываемых адресов, то в противоположность вызываемым адресам ВмА1 – ВмА4, транзитные адреса ТрА1 – ТрА4 могут иметь весьма малый битовый размер, и даже многократное сохранение одних и тех же транзитных адресов в кэш-памяти 23 транзитных адресов не приводит к замораживанию такого большого объема кэш-памяти 20 управления, как это было в традиционном процессоре 1 при многократном сохранении одних и тех же вызываемых адресов ВмА1 – ВмА4.
[36] Следует отметить, что каждый транзитный адрес ТрА1 – ТрА12, сохраненный в кэш-памяти 23 транзитных адресов, находится в привязке к результату предсказания перехода для данной вызывающей команды (колонка 70-2), указывающему на статус идентифицируемого данным транзитным адресом вызываемого адреса в отношении данной вызывающей команды. Когда для какой-либо вызывающей команды результат предсказания перехода на соответствующий ей вызываемый адрес равен «1», этот вызываемый адрес является для нее целевым, в когда равен «0» – перспективным.
[37] Как видно на Фиг.4, например, вызываемый адрес ВмА1 для вызывающих команд ВщК1, ВщК4, ВщК5, ВщК10 является целевым адресом, а для вызывающих команд ВщК7, ВщК9 является перспективным адресом, что определяется по результату предсказания перехода для этих вызывающих команд, представленному в колонке 70-2 и равному «1» или «0». Однако кэш-память 22 вызываемых адресов сохраняет вызываемый адрес ВмА1 лишь в одной своей единичной запоминающей структуре, которая по существу является общей для всех вызывающих команд ВщК1, ВщК4, ВщК5, ВщК10, ВщК7 и ВщК9. Тем временем в кэш-памяти 23 транзитных адресов для каждой вызывающей команды ВщК1, ВщК4, ВщК5, ВщК10, ВщК7 и ВщК9 назначена своя, т.е. предназначенная исключительно для данной вызывающей команды, единичная запоминающая структура, сохраняющая один и тот же транзитный адрес ТрА1.
[38] Заметим, что например, для вызывающей команды ВщК9 в кэш-памяти 23 транзитных адресов назначены две своих единичных запоминающих структуры (Фиг. 4), сохраняющие транзитные адреса ТрА3 и ТрА1, что отражает возможность перехода с вызывающей команды ВщК9 на одну из двух вызываемых команд, сохраняемым по вызываемым адресам ВмА3 и ВмА1. В показанной на Фиг. 4 ситуации вызываемый адрес ВмА3 является целевым адресом, а вызываемый адрес ВмА1 – перспективным, однако, при другом результате предсказания перехода вызываемые адреса ВмА3 и ВмА1 могут изменить свой статус на противоположный, либо стать перспективными адресами одновременно. В последнем случае при следующей загрузке вызывающей команды ВщК9 в буфер 30 команд, вслед за ней в буфер 30 команд будет загружаться последующая команда.
[39] Возможно исполнение, когда кэш-память 23 транзитных адресов для каждого транзитного адреса ТрА1 – ТрА12 сохраняет предсказательное битовое значение, по существу дублирующее результат предсказания перехода для данной вызывающей команды, сохраненный в колонке 70-2. Предсказательное значение в этом случае может сохраняться в отдельной единичной запоминающей структуре кэш-памяти 23 транзитных адресов аналогично тому, как это было показано на примере кэш-памяти 22 вызываемых адресов традиционного процессора 1 (колонка 22-3).
[40] Количественный эффект от использования изобретения может быть проиллюстрирован на следующем типичном примере. Предположим, программа содержит 5000 вызывающих команд, при этом традиционный процессор 1 в кэш-памяти 22 вызываемых адресов способен сохранять 1000 вызываемых адресов, что обеспечивает возможность быстрой обработки переходов с 1000 вызывающих команд. Каждый из 1000 вызываемых адресов имеет битовый размер 40 бит, при этом уникальными являются 300 вызываемых адресов. Соответственно, для обеспечения возможных переходов с 1000 вызывающих команд в кэш-памяти 20 управления будет занято 1000*40=40000 бит.
[41] В предложенном процессоре 2 в кэш-памяти 23 транзитных адресов по-прежнему должны быть сохранены 1000 транзитных адресов, но только 300 уникальных вызываемых должны быть сохранены в кэш-памяти 22 вызываемых адресов. Для идентификации 300 единичных запоминающих структур, принадлежащих кэш-памяти 22 вызываемых адресов, транзитный адрес должен иметь битовый размер по меньшей мере 9 бит (29=512, что больше 300). Таким образом, для обеспечения возможных переходов с 1000 вызывающих команд в кэш-памяти 23 транзитных адресов будет занято 1000*9=9000 бит, в кэш-памяти 22 вызываемых адресов будет занято 300*40=12000 бит, а общий занятый объем кэш-памяти 20 управления составит 9000+12000=21000 бит.
[42] Таким образом, в отношении приведенного примера предложенный процессор 2 в сравнении с традиционным процессором 1 будет иметь 19000 бит свободного объема кэш-памяти 20 управления, что позволит сохранить в ней дополнительное количество вызываемых адресов и обеспечить быстрый переход с дополнительного количества вызывающих команд, а значит - увеличить производительность предложенного процессора 2.
[43] Предложенный процессор 2 работает следующим образом.
На стадии IF конвейерного процесса по сигналу, поступающему в кэш-память 21 команд по шине 101 от счетчика 10 команд и содержащему указание на адрес требуемой команды, кэш-память 21 команд передает требуемую команду (далее – отслеживаемая команда) в виде N-битовой последовательности по шине 211 в буфер 30 команд.
[44] На стадии D происходит расшифровка отслеживаемой команды, в ходе которой из указанной N-битовой последовательности выделяется по меньшей мере первая группа битов, указывающая на код операции, вторая и третья группы битов, указывающие на адреса исходных операндов в регистровом файле 40, и четвертая группа битов, указывающая на адрес для записи результирующего операнда в регистровом файле 40. Первая группа битов при этом передается из буфера 30 команд в блок управления, а вторая, третья и четвертая группы передаются из буфера 30 команд по шине 301 в регистровый файл 40.
[45] На стадии EX в арифметико-логический функциональный блок 50 по шине 401 поступают исходные операнды, прочитанные в регистровом файле 40. Одновременно с этим из блока управления в арифметико-логический функциональный блок 50 поступает сигнал, предписывающий выполнение операции, соответствующей упомянутому коду операции. После выполнения указанной операции над исходными операндами стадия EX завершается, а результат выполнения отслеживаемой команды из арифметико-логического функционального блока 50 по шине 501 направляется в кэш-память 60 данных (стадия M), а затем или вместо этого по шине 502 направляется в регистровый файл 40 (стадия WB), где записывается в качестве результирующего операнда отслеживаемой команды.
[46] Одновременно с направлением результата выполнения отслеживаемой команды по шине 502, результат выполнения отслеживаемой команды из арифметико-логического функционального блока 50 по шине 503 направляется в предсказатель 70 перехода, который игнорирует его, если отслеживаемая команда не является вызывающей командой. Если же предсказатель 70 перехода распознает отслеживаемую команду как вызывающую команду, с которой возможен переход на намеченную вызываемую команду, сохраняемую в оперативной памяти по намеченному вызываемому адресу, то он обрабатывает результат выполнения отслеживаемой команды в соответствии со свои алгоритмом, и сохраняет результат предсказания перехода для следующего выполнения отслеживаемой команды (далее – намеченный результат предсказания перехода).
[47] Кэш-память 22 вызываемых адресов сохраняет намеченный вызываемый адрес, а кэш-память 23 транзитных адресов сохраняет намеченный транзитный адрес в привязке к намеченному результату предсказания перехода, передаваемому в кэш-память 20 управления по шине 701. Когда кэш-память 20 управления в следующий раз получает от счетчика 10 команд сигнал о том, что планируется загрузка отслеживаемой команды, она действует в зависимости от намеченного результата предсказания перехода.
[48] Если намеченный результат предсказания перехода состоит в предсказанном осуществлении перехода, то кэш-память 23 транзитных адресов передает намеченный транзитный адрес в кэш-память 22 вызываемых адресов, которая в свою очередь, передает намеченный вызываемый адрес в оперативную память и передает на счетчик 10 команд сигнал о том, что после поступления намеченной вызывающей команды на стадию IF, счет команд надо вести с намеченной вызываемой команды. Далее кэш-память 21 команд получает от оперативной памяти намеченную вызываемую команду, которую загружает в буфер 30 команд непосредственно вслед за отслеживаемой командой.
[49] Если же намеченный результат предсказания перехода состоит в предсказанном неосуществлении перехода, то кэш-память 21 команд вслед за отслеживаемой командой загружает в буфер 30 команд последующую команду.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОЦЕССОР С ЗАГРУЗКОЙ КОМАНД В СОСТАВЕ КЭШЛАЙНА И ПРЕДСКАЗАНИЕМ ПЕРЕХОДА | 2024 |
|
RU2828600C1 |
| ПРОЦЕССОР С УСОВЕРШЕНСТВОВАННЫМ ПРЕДСКАЗАТЕЛЕМ ПЕРЕХОДА | 2024 |
|
RU2832441C1 |
| VLIW-ПРОЦЕССОР С ДОПОЛНИТЕЛЬНЫМ ПОДГОТОВИТЕЛЬНЫМ КОНВЕЙЕРОМ И ПРЕДСКАЗАТЕЛЕМ ПЕРЕХОДА | 2024 |
|
RU2816094C1 |
| СПОСОБ ХРАНЕНИЯ ДАННЫХ В КЭШ-ПАМЯТИ ПРОЦЕССОРА И ПРОЦЕССОР ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2024 |
|
RU2835778C1 |
| ЭНЕРГОЭФФЕКТИВНЫЙ МЕХАНИЗМ УПРЕЖДАЮЩЕЙ ВЫБОРКИ ИНСТРУКЦИЙ | 2006 |
|
RU2375745C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДСКАЗАНИЯ ВЕТВЛЕНИЙ | 2012 |
|
RU2602335C2 |
| СПОСОБ ОБЕСПЕЧЕНИЯ СВЯЗИ В КОММУНИКАЦИОННОЙ СРЕДЕ, КОМПЬЮТЕРНАЯ СИСТЕМА И ЭНЕРГОНЕЗАВИСИМЫЙ МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДАННЫХ | 2012 |
|
RU2574815C2 |
| ПРЕДСТАВЛЕНИЕ ПЕРЕХОДОВ ЦИКЛА В РЕГИСТРЕ ПРЕДЫСТОРИИ ПЕРЕХОДОВ С ПОМОЩЬЮ МНОЖЕСТВА БИТ | 2007 |
|
RU2447486C2 |
| УПРАВЛЕНИЕ В РЕЖИМЕ НИЗКИХ ПРИВИЛЕГИЙ РАБОТОЙ СРЕДСТВА СБОРА СВЕДЕНИЙ О ХОДЕ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2585969C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ МОДЕЛИРОВАНИЯ ПОВЕДЕНИЯ ПРЕДСКАЗАНИЯ ПЕРЕХОДОВ ЯВНОГО ВЫЗОВА ПОДПРОГРАММЫ | 2007 |
|
RU2417407C2 |
Изобретение относится к микропроцессорной технике, в частности к микропроцессорам с конвейерной обработкой команд. Технический результат заключается в уменьшении общего объема кэш-памяти, требуемого для сохранения вызываемых адресов в отношении одного и того же количества вызывающих команд. Предложенный процессор содержит конвейер, кэш-память и предсказатель перехода. Кэш-память включает в себя хранилище вызываемых адресов и хранилище транзитных адресов. Предсказатель перехода способен для каждой вызывающей команды определять состояние, когда вслед за вызывающей командой в конвейер должна быть загружена вызываемая команда. Хранилище вызываемых адресов способно в своей единичной запоминающей структуре сохранять вызываемый адрес, идентифицирующий единичную запоминающую структуру, принадлежащую внешней памяти и сохраняющую вызываемую команду. Хранилище вызываемых адресов при этом способно сохранять каждый вызываемый адрес лишь в одной своей единичной запоминающей структуре. 2 з.п. ф-лы, 4 ил.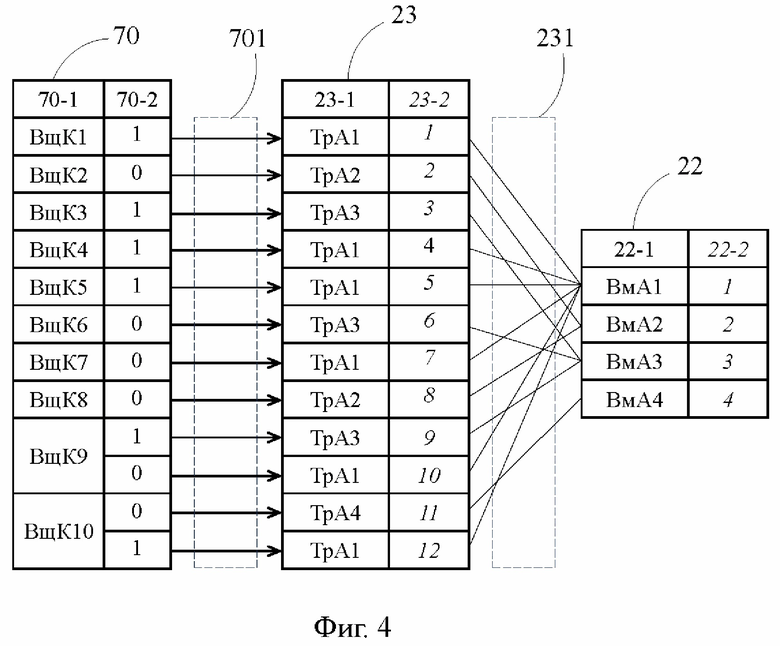
1. Процессор, который содержит конвейер, кэш-память и предсказатель перехода, при этом
кэш-память включает в себя хранилище вызываемых адресов и хранилище транзитных адресов, а предсказатель перехода способен для каждой вызывающей команды определять состояние, когда вслед за вызывающей командой в конвейер должна быть загружена вызываемая команда, при этом
хранилище вызываемых адресов способно в своей единичной запоминающей структуре сохранять вызываемый адрес, идентифицирующий единичную запоминающую структуру, принадлежащую внешней памяти и сохраняющую вызываемую команду, причем хранилище вызываемых адресов способно сохранять каждый вызываемый адрес лишь в одной своей единичной запоминающей структуре, при этом
хранилище транзитных адресов способно в своей единичной запоминающей структуре сохранять транзитный адрес, идентифицирующий единичную запоминающую структуру, принадлежащую хранилищу вызываемых адресов и сохраняющую вызываемый адрес, причем хранилище транзитных адресов способно сохранять один и тот же транзитный адрес в более чем одной своей единичной запоминающей структуре, при этом
для каждой вызывающей команды в хранилище транзитных адресов назначена своя единичная запоминающая структура.
2. Процессор по п. 1, в котором хранилище вызываемых адресов способно сохранять в качестве вызываемого адреса целевой или перспективный адрес.
3. Процессор по п. 1, в котором для одной и той же вызывающей команды в хранилище транзитных адресов может быть назначена более чем одна своя единичная запоминающая структура.
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДСКАЗАНИЯ ВЕТВЛЕНИЙ | 2012 |
|
RU2602335C2 |
| US 20020013894 A1, 31.01.2002 | |||
| Способ обнаружения неисправных элементов электрической схемы | 1988 |
|
SU1624369A1 |
| US 5530825 A1, 25.06.1996 | |||
| US 5606682 A1, 25.02.1997 | |||
| US 20140297919 A1, 02.10.2014 | |||
| US 20120079204 A1, 29.03.2012 | |||
| US 20090265514 A1, 22.10.2009. | |||

