Заявленное изобретение относится к вычислительным системам, а более конкретно - к системам и способам распознавания рукописного текста с помощью нейронных сетей.
Рукописный текст сильно отличается от напечатанного. Основные отличия заключаются в большой вариативности почерков, сложной геометрии символов, наличием связок между символами. Дополнительно, изображения рукописного текста часто сняты при плохом освещении, и других помехах, что также затрудняет распознавание.
Текущие решения для распознавания рукописного текста имеют ряд ключевых ограничений:
- размер и скорость работы известных решений не позволяют использовать их на мобильных устройствах;
- текущие решения преобразуют входное изображение к заранее заданным постоянным размерам. Это приводит в невозможности корректного распознавания текста на узких и широких изображениях.
Из уровня техники известны различные способы распознавания рукописных текстовых данных на изображениях.
Например, в работах [1, 2, 3] предложены нейросетевые методы для распознавания рукописного текста. Но у перечисленных подходов есть заметные недостатки:
- невозможность применения методов к изображениям текстовых полей произвольного размера в силу выбранных архитектур нейросетей;
- высокие требования к вычислительной мощности.
Это проблемы частично решены в работе [4], но предложенное решение содержит в 6 раз меньше параметров, что кардинально влияет на скорость работы.
Задачей заявленного изобретения является устранение недостатков известного уровня техники. Технический результат заключается в обеспечении способа нейросетевого распознавания рукописных текстовых данных на изображениях, который позволяет обеспечить:
- легковесность и скорость: заявленное техническое решение может применяться в условиях ограниченных вычислительных мощностей;
- возможность обрабатывать входные изображения произвольной ширины;
- возможность распознавания, которая происходит с учетом языковой модели;
- возможность выполнять сегментацию строки, обозначая геометрические позиции символов.
Поставленная задача решается, а заявленный технический результат достигается посредством заявленного способа нейросетевого распознавания рукописных текстовых данных на изображениях. При этом способ может быть реализован на мобильных устройствах.
На фигурах представлены:
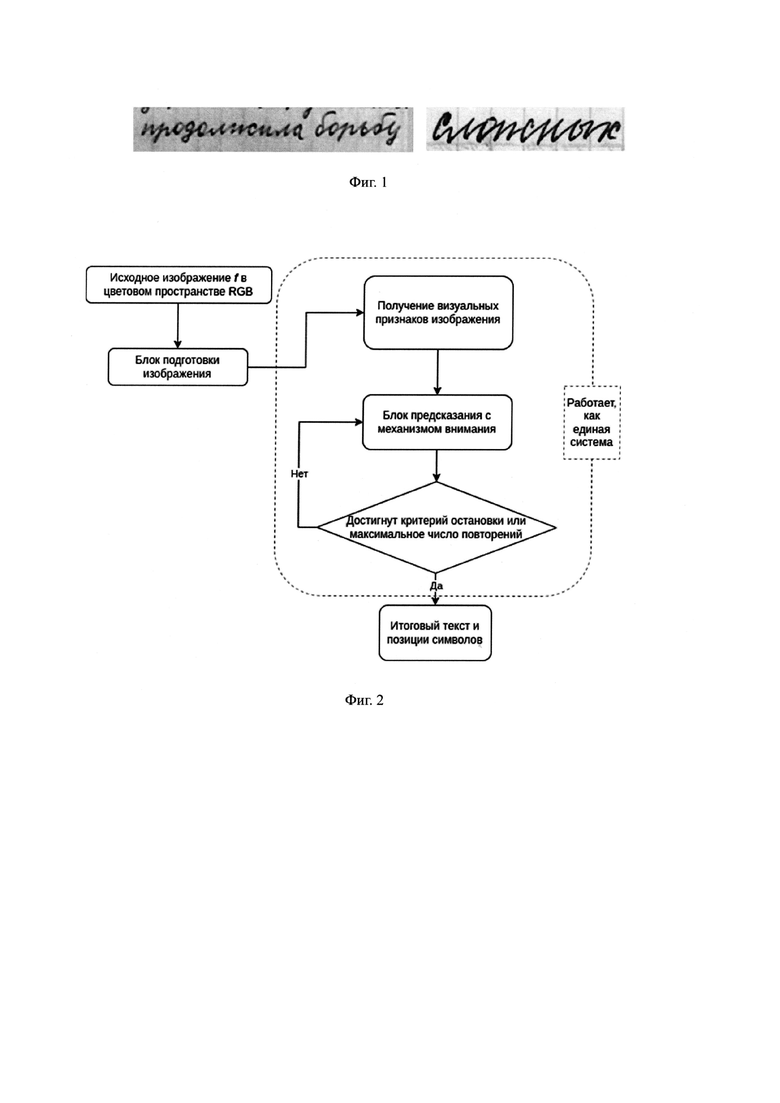
Фиг. 1: Примеры распознаваемых изображений
Фиг. 2: Блок-схема работы алгоритма
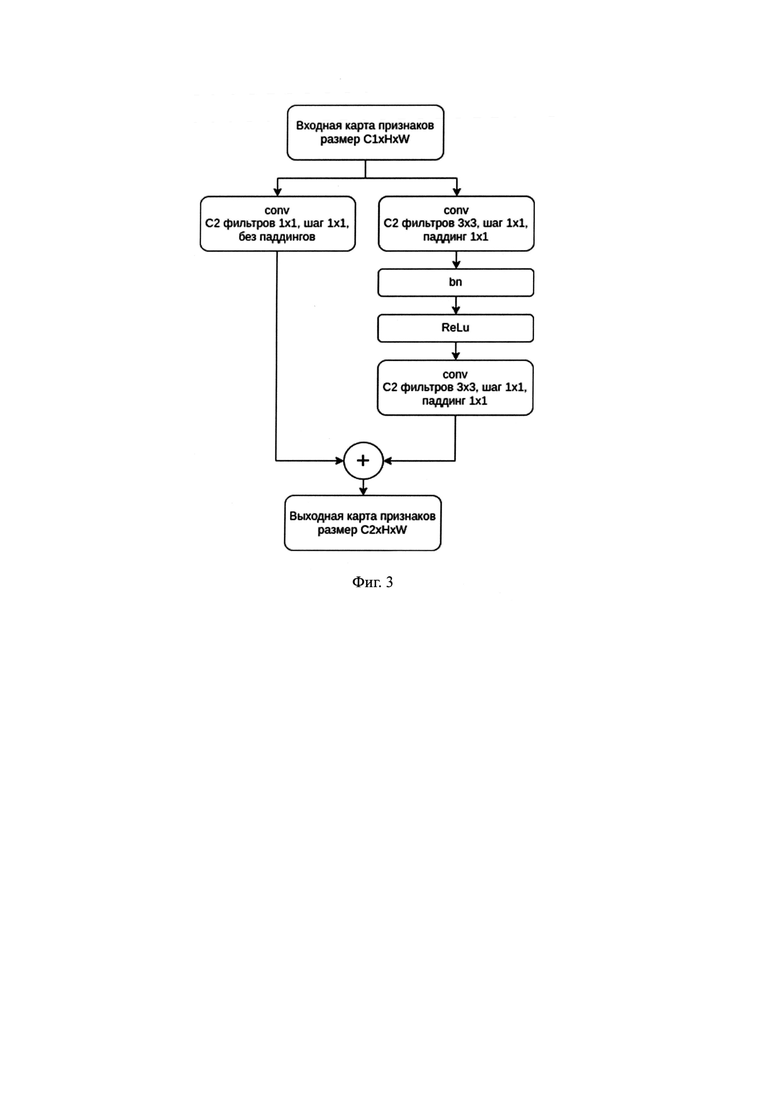
Фиг. 3: Блок-схема остаточного блока
Фиг. 4: Визуализация весов механизма внимания
Фиг. 5: Пример верно распознанных текстовых полей
Пусть на вход подается входное изображение f текстового поля (например, см. фиг. 1) документа. Также известны размеры изображения f текстового поля. Необходимо извлечь текстовую информацию из текстового поля f, а также получить координаты расположения символов.
Описание алгоритма работы нейросетевого детектора.
Параметры алгоритма следующие:
N - максимальная длина последовательности символов на изображении;
Hf - Высота входного изображения после предобработки
Схема патентуемого алгоритма представлена на фиг. 2. Рассматривается изображение/ в цветовом пространстве RGB, содержащее текстовое поле (фиг. 1) документа. На выходе ожидается ответ нейросетевого метода: текстовая строка и координаты символов на изображении.
Входное изображение f обрабатывается нейросетевым методом по следующему алгоритму:
1. Изображение f подается в блок подготовки изображения, где оно преобразуется в одноканальное, а также приводится к высоте Hf.
2. На втором этапе предварительно обученная нейронная сеть извлекает визуальные признаки из подготовленного изображения, формируя карту признаков Mf.
3. Блок предсказания с механизмом внимания итеративно декодирует карту признаков Mf, предсказывая символы по-одному с учетом ранее предсказанных. Если достигается критерий остановки или число итераций превысило N, то распознавание заканчивается.
Реализация нейросетевого метода распознавания.
Извлечение визуальных признаков и блок предсказания с механизмом внимания являются компонентами одной нейросетевой модели. Признаки извлекаются при помощи сверточной части, блок предсказания состоит из рекуррентной сети с механизмом внимания. Архитектура сверточной части состоит из остаточных блоков (фиг. 3) и представлена в Таблице 1. При обучении сети на вход подавались одноканальные изображения размера 400×64 пикселей, на выходе сети ожидаются распределения псевдовероятностей принадлежности Sa возможным классам по размеру алфавита.
Блок предсказания состоит из механизма внимания и рекуррентной части. Он итеративно обрабатывает извлеченную карту признаков, используя предсказания с предыдущего шага.
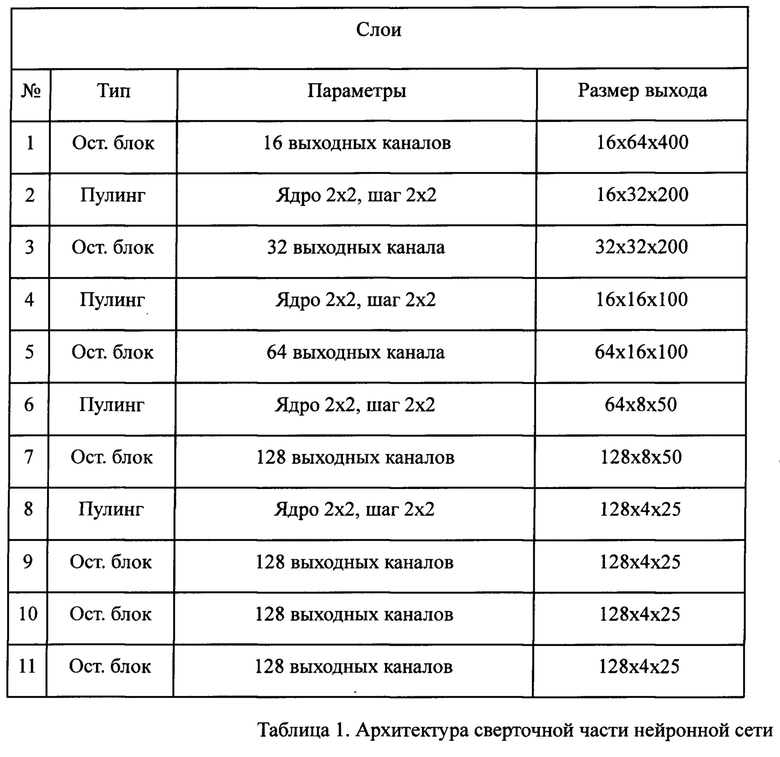
Механизм внимания принимает на вход карту признаков размера Mf 128×4×25 и вектор предыдущего ответа размера ht-1 128. Вычисление оценки внимания происходит по следующей формуле:
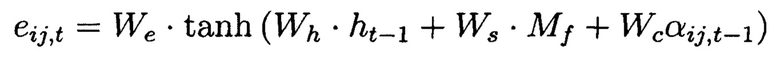
Здесь We, Wh, Ws и Wc - обучаемые весовые матрицы. Далее вычисляется оконная оценка внимания

Где Sw - размер окна.
Итоговые веса внимания рассчитываются по формуле:
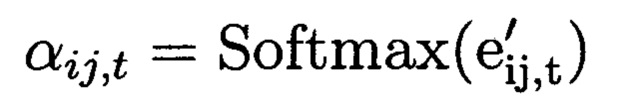
Итоговый взвешенный вход на шаге t получаем, выполнив:
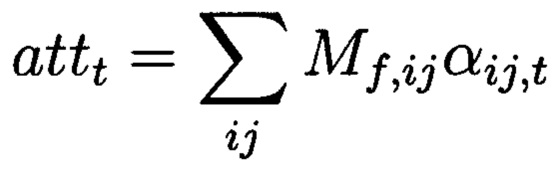
По полученному взвешенному входу и предыдущему ответу получаем ответ на текущем шаге
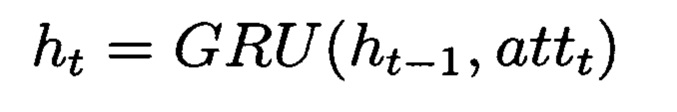
Для получения псевдовероятностей символов применяется полносвязный слой с выходом, равным размеру алфавита Sa.
Для обучения искусственной нейронной сети были использованы данные из открытых источников, а также синтетические данные. Для создания синтетического набора данных, были собраны шрифты, имитирующие рукописный текст. Синтетическое изображение было получено нанесением текста, написанного одним из шрифтов на задний фон. Набор данных из открытых источников состоит из вырезанных строк, написанных от руки.
Примеры работы предлагаемого алгоритма.
Для удобства визуального восприятия работы алгоритма для входного изображения на каждой итерации его работы отображаются веса механизма внимания (фиг. 4). При этом, чем светлее область, тем более значимой она является на данной итерации. Можно видеть, что во время работы алгоритм имитирует чтение, как бы фокусируясь на символах по порядку слева направо.
На фиг. 5 изображен результат распознавания двух текстовых полей, имитирующих реальные поля из документов. Можно видеть, что поля отличаются разной шириной и разной длиной текстовой последовательности на них. Также текст имеет разный стиль написания и визуальные искажения. В верхнем левом углу содержится строка -результат распознавания, далее ниже представлены уверенности алгоритма в каждом символе и его геометрическое положение.
Важно отдельно отметить, что предложенный метод для своей работы не требует дополнительного оборудования (например, графических процессоров) и может быть запущен на устройствах с архитектурой процессора х86_64, ARM, Эльбрус и др.
Список источников, предлагающих решение аналогичной задачи
1. Li, Minghao, et al. "Trocr: Transformer-based optical character recognition with pre-trained models." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 11.2023.
2. Fujitake, Masato. "Dtrocr: Decoder-only transformer for optical character recognition." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.
3. Diaz, Daniel Hernandez, et al. "Rethinking text line recognition models." arXiv preprint arXiv:2104.07787 (2021).
4. Chaudhary, Kartik, and Raghav Bali. "Easter2.0: Improving convolutional models for handwritten text recognition." arXiv preprint arXiv:2205.14879 (2022).
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| РАСПОЗНАВАНИЕ СОБЫТИЙ НА ФОТОГРАФИЯХ С АВТОМАТИЧЕСКИМ ВЫДЕЛЕНИЕМ АЛЬБОМОВ | 2020 |
|
RU2742602C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| РАСПРЕДЕЛЁННОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРСОНАЛИЗАЦИИ | 2018 |
|
RU2702980C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2020 |
|
RU2760637C1 |
| Способ нейросетевого контроля текстовых данных на изображениях документов | 2023 |
|
RU2806012C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ И ТАБЛИЦ В ДОКУМЕНТАХ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ГЛОБАЛЬНОГО КОНТЕКСТА ДОКУМЕНТА | 2019 |
|
RU2723293C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ОБУЧЕННЫМИ НЕЙРОННЫМИ СЕТЯМИ | 2021 |
|
RU2779281C1 |


Изобретение относится к области вычислительной техники, а именно к способам распознавания рукописного текста с помощью нейронных сетей. Технический результат заключается в повышении скорости обработки, а также в возможности обрабатывать входные изображения произвольной ширины. Способ нейросетевого распознавания рукописных текстовых данных на изображениях заключается в том, что на вход подается изображение f текстового поля документа, размеры которого известны, при этом далее рассматривают изображение f в цветовом пространстве RGB, содержащем текстовое поле документа, при этом входное изображение f обрабатывается нейросетевым методом по следующему алгоритму: изображение f подается в блок подготовки изображения, где оно преобразуется в одноканальное, а также приводится к высоте Hf; на втором этапе предварительно обученная нейронная сеть извлекает визуальные признаки из подготовленного изображения, формируя карту признаков Mf, блок предсказания с механизмом внимания итеративно декодирует карту признаков Mf, предсказывая символы по одному с учетом ранее предсказанных, при этом если достигается критерий остановки или число итераций превысило N, то распознавание заканчивается, при этом извлечение визуальных признаков и блок предсказания с механизмом внимания являются компонентами одной нейросетевой модели. 3 з.п. ф-лы, 5 ил., 1 табл.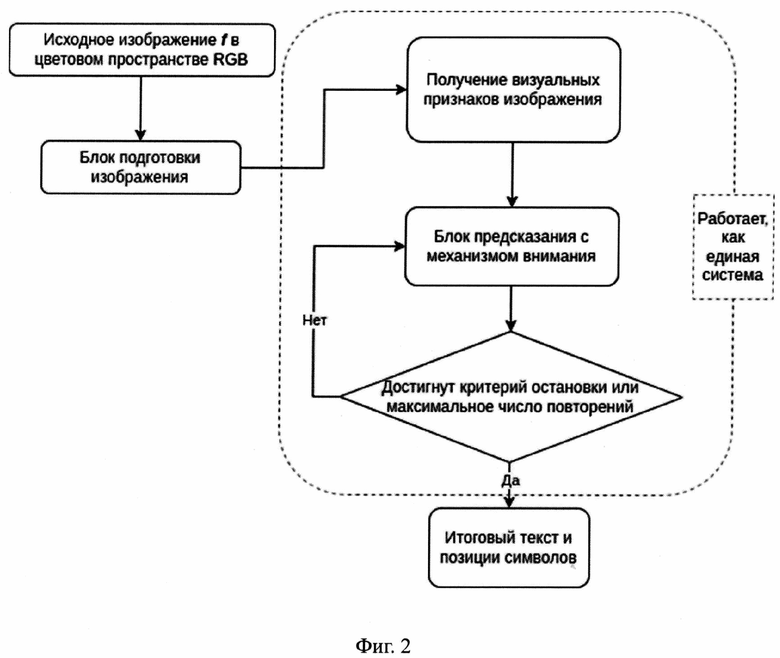
1. Способ нейросетевого распознавания рукописных текстовых данных на изображениях, заключающийся в том, что на вход подается входное изображение f текстового поля документа, размеры которого известны, отличающийся тем, что далее рассматривают изображение f в цветовом пространстве RGB, содержащем текстовое поле документа, при этом входное изображение f обрабатывается нейросетевым методом по следующему алгоритму:
изображение f подается в блок подготовки изображения, где оно преобразуется в одноканальное, а также приводится к высоте Hf;
на втором этапе предварительно обученная нейронная сеть извлекает визуальные признаки из подготовленного изображения, формируя карту признаков Mf; блок предсказания с механизмом внимания итеративно декодирует карту признаков Mf, предсказывая символы по одному с учетом ранее предсказанных, при этом если достигается критерий остановки или число итераций превысило N, то распознавание заканчивается, при этом извлечение визуальных признаков и блок предсказания с механизмом внимания являются компонентами одной нейросетевой модели.
2. Способ нейросетевого распознавания рукописных текстовых данных на изображениях по п. 1, отличающийся тем, что визуальные признаки извлекаются при помощи сверточной части, а блок предсказания состоит из рекуррентной сети с механизмом внимания.
3. Способ нейросетевого распознавания рукописных текстовых данных на изображениях по п. 1, отличающийся тем, что блок предсказания состоит из рекуррентной сети с механизмом внимания, при этом блок предсказания итеративно обрабатывает извлеченную карту признаков, используя предсказания с предыдущего шага.
4. Способ нейросетевого распознавания рукописных текстовых данных на изображениях по п. 1, отличающийся тем, что реализуется на мобильных устройствах.
| CN 113361666 B, 07.09.2021 | |||
| US 11922318 B2, 05.03.2024 | |||
| US 10936862 B2, 02.03.2021 | |||
| US 8009914 B2, 30.08.2011 | |||
| РАСПОЗНАВАНИЕ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2661750C1 |
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ПОМОЩЬЮ СИНТЕТИЧЕСКИХ ФОТОРЕАЛИСТИЧНЫХ СОДЕРЖАЩИХ ЗНАКИ ИЗОБРАЖЕНИЙ | 2018 |
|
RU2709661C1 |

