Изобретение относится к вычислительной технике и предназначено для решения задач обработки изображений, задач размещения, распознавания образов, машинной графики.
Цель изобретения - увеличение скорости выполнения геометрических преобразований переноса, поворота, сжатия над плоскими изображениями высокого разрешения и увеличение скорости ввода-вывода изображений.
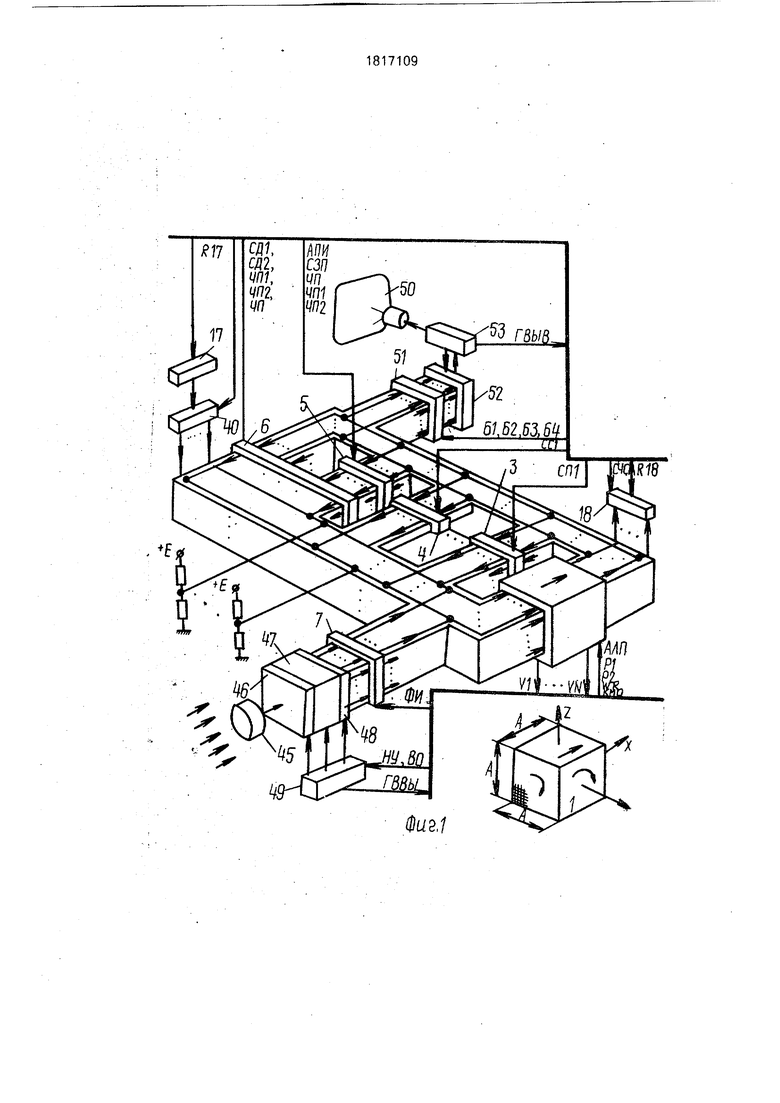
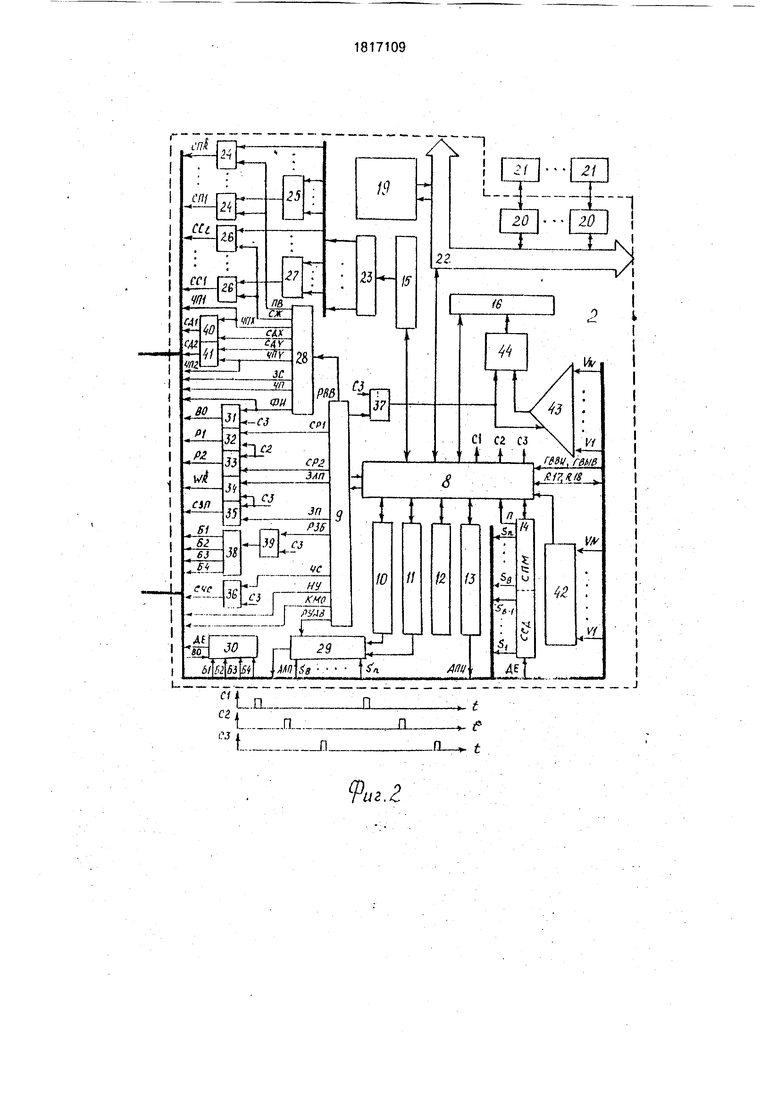
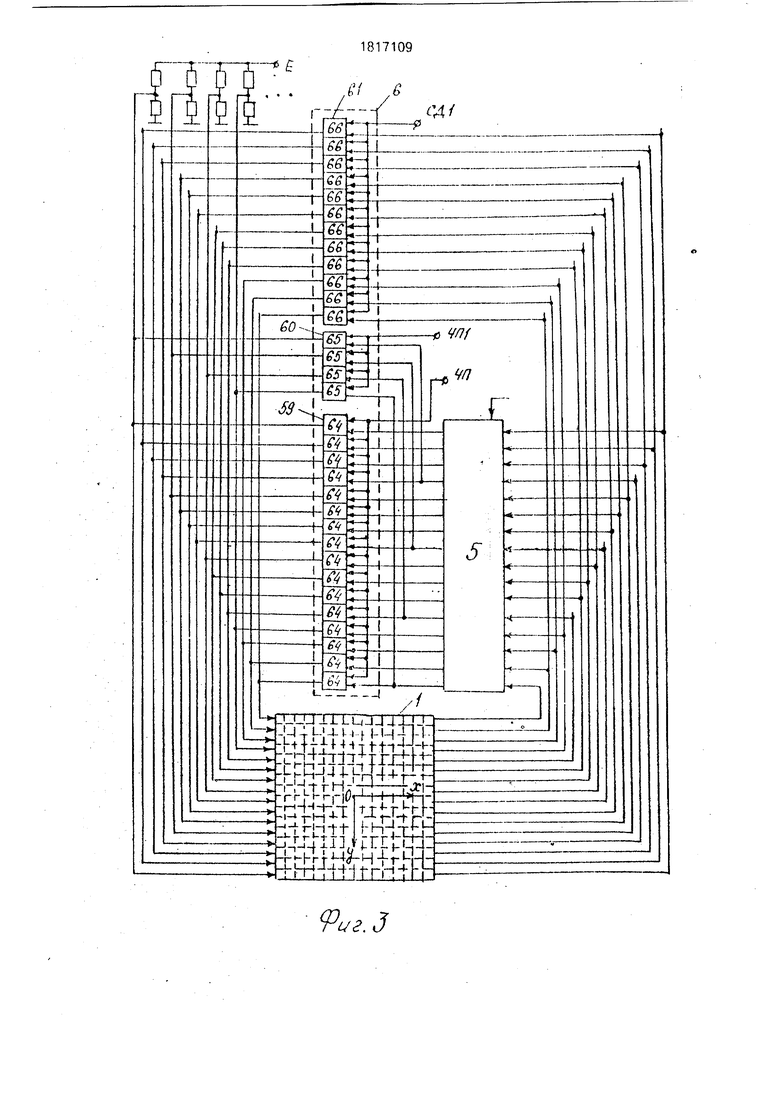
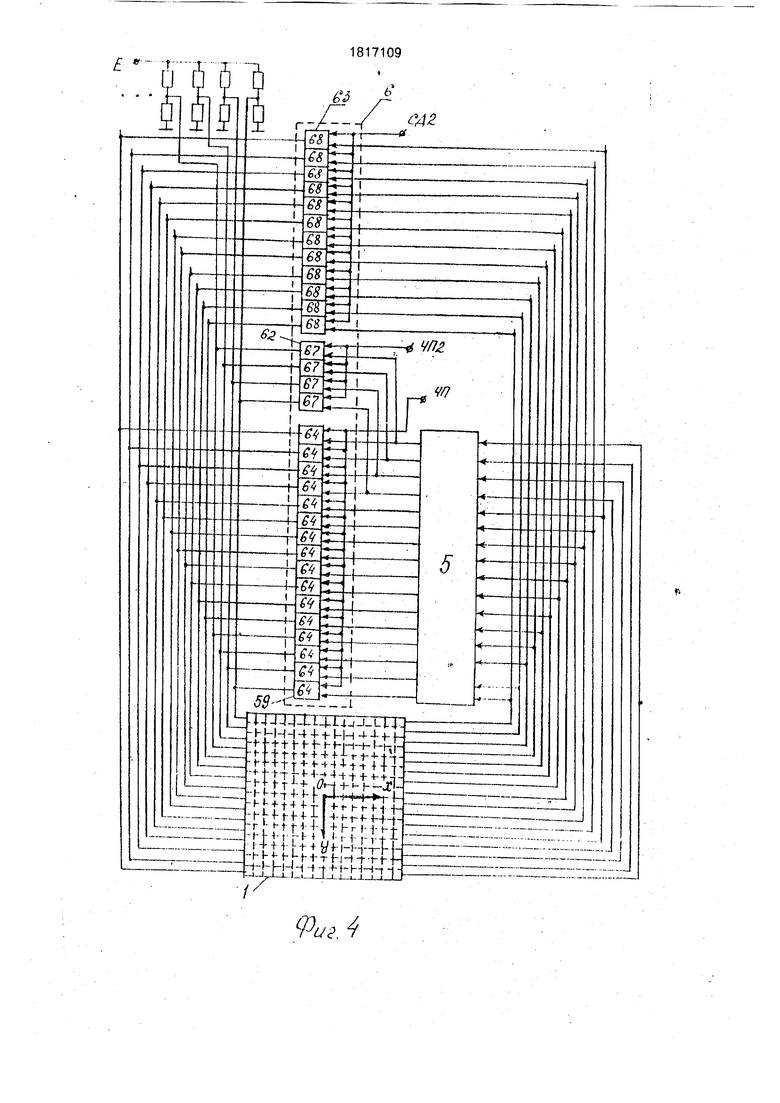
Нафиг.1и2 изображена функциональная схема устройства; на фиг.З и 4 - связи между блоком коммутации, памятью изображений и переноса плоских изображений; на фиг.6-9 - способы выполнения расшивки, поворотов, сжатий плоских изображений; на фиг.10 и 11 - вариант конструкции устройства ввода изображений; на фиг. 12 - вариант конструкции устройства вывода изображений.
Устройство состоит из матрицы 1 процессоров, блока 2 управления,узлов 3 поворота, узлов 4 сжатия, узлов 5 памяти, блока 6 коммутации, блока 7 сопряжения. Блок 2 включает в себя микропрограммный управляющий процессор 8 с регистром 9 микрослова и программно-адресуемыми регистрами 10, 11, 12, 13. 14, 15, 16, 17, 18, память 19 программ и данных, контроллеры 20 внешних устройств 21. Связь между отдельными узлами блока 2 осуществляется посредством интерфейса 22. Кроме того в блок 2 входят: дешифратор 23, элементы 24 И, 25 ИЛИ выбора узлов поворота, элементы 26 И, 27 ИЛИ выбора узлов сжатия, дешифратор 28 кода режима ввода-вывода, мультиплексор 29 адреса, элемент 30 ИЛИ, элементы 31, 32, 33,34, 35, 36, 37 И, дешифратор 38 кода буфера, блок 39 элементов И, двухвходовые элементы 40, 41 ИЛИ, узел определения объема-площади, состоящий из А -входовой схемы 42 ИЛИ, А3 -входово- го аналогового сумматора 43 и импульсного вольтметра 44. Матрица 1 посредством блока 7 связана с устройством ввода изображе00
о о
ний, состоящим из оптической системы 45, узла 46 фотодатчиков, распределительного узла 47, узла 48 аналогово-цифровых преобразователей, узла 49 управления, Выходы процессорной матрицы 1 соединены с устройством вывода изображений, включающим в себя узел 50 отображения, узел 51 памяти регенерации, узел 52 выборки пиксела, блок 53 формирования и управления, состоящий из узла 54 управления, памяти 55 цветов, цифроаналогового преобразователя 56. Узел 51 содержит в своем составе четыре буфера 57, состоящих из А2 элементов 58 памяти каждый. Блок 6 состоит из узлов 59, 60 и 61, 62, 63, состоящих в свою очередь, из двухвходовых элементов 64, 65, 66, 67, 68 И соответственно. Узел 52 включает четыре мультиплексора 69, мультиплексор 70, счетчик 71.
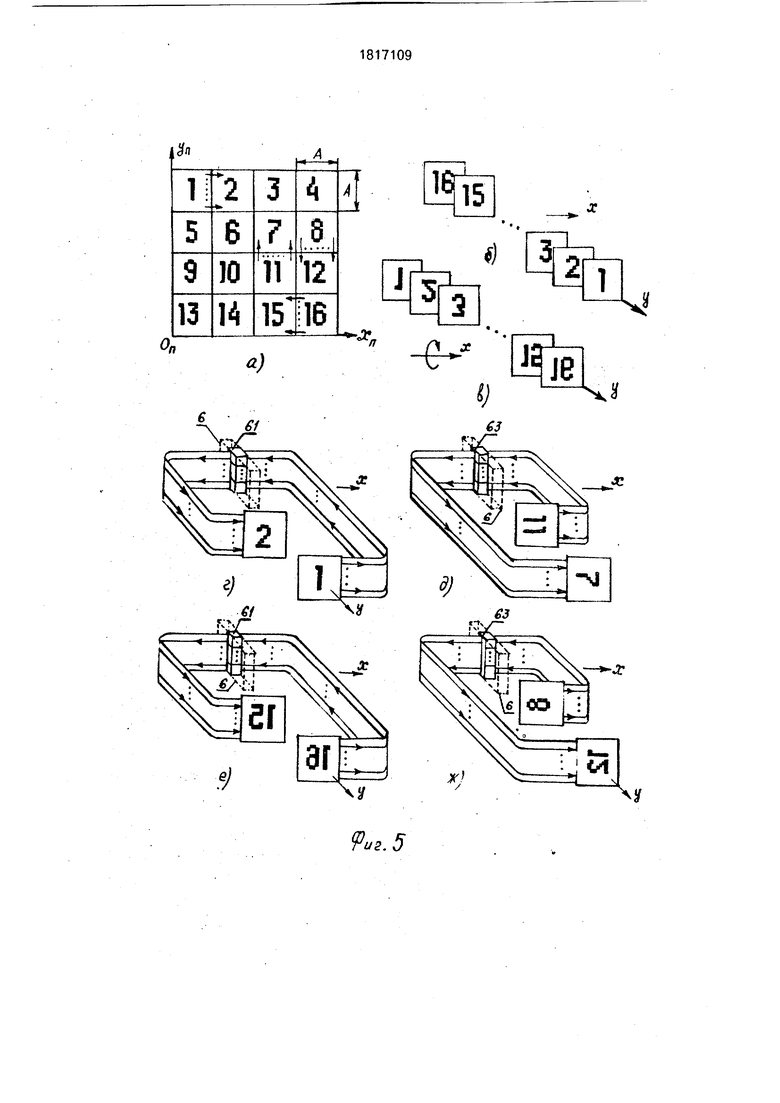
Устройство работает следующим образом. В памяти 19 хранятся программы обработки. Каждая команда программы перед ее выполнением извлекается из памяти 19 и разрешается в регистрах процессора 8, при этом адрес первого операнда размещается в регистре 10, адрес второго операнда - в регистре 11. Далее дешифрируется код операции извлеченной команды, после чего блоком микропрограммного управления процессора 8 вырабатываются сигналы микроопераций, необходимые для выполнения данной команды. Система команд заявленного устройства включает в себя арифметико-логические команды,команды условного и безуслоёного перехода, команды управления матрицей 1. Назначение и способ выполнения всех арифметико-логических команд, команд условного и безусловного перехода полностью определяются выбранной конструкцией процессора 8, памяти 19, интерфейса 22, которые выполняются по одной из известных схем (в частности, за их основу могут быть взяты центральный процессор, оперативная память и интерфейс ЭВМ Электроника-100/25 7. Содержимое одноразрядных слов, хранящихся по одному и тому же адресу в А узлах локальной памяти процессоров матрицы 1, в зависимости от выполняемой команды интерпретируется устройством либо как чрезмерное бинарное изображение А х А х А, либо как двухмерное бинарное изображение формата VA3 , На фиг.5 показан один из способов представления содержимого трехмерного бинарного изображения формата 16 х 16 х 16 (фиг. 15,б) в виде двухмерного бинарного изображения 64 х 64 (фиг.5,а). По сравнению с прототипом в систему команд заявленного устройства дополнительно введены следующие команды:
1) команда СДХ а1, а2 - бинарное изображение Vfi, хранящееся в матрице 1 по адресу а1, сдвинуть на шаг вдоль оси ОпХп (фиг.5,а), сдвинутое изображение за- писать в матрицу 1 по адресу а2.
2) команда СДУ а1, а2 - бинарное изображение vw X VA3, хранящееся в матрице 1 по адресу а 1, сдвинуть на шаг вдоль оси OnYn (фиг.5,а), сдвинутое изображение за- писать в матрицу 1 по адресу а2,
3) команда РСШ at, а2 - расшить изображение VA X VA, хранящееся в матрице 1 по адресу а1 вдоль осей 0ПХП и OnYn, расшитое изображение записать в матрицу 1 по адресу а2.
4) команда ПВП а1, а2 - повернуть содержимое бинарного изображения , предварительно расшитого вдоль осей ОпХп. OnYn и хранящегося в мат- рице 1 по адресу а1, вокруг центра изображения на угол, номер значения которого хранится в регистре 12, повернутое изображение записать в матрицу 1 по адресу а2,
5) команда СЖУ а1, а2 - бинарное изо- бражение i/A3, хранящееся в матрице 1 по адресу а1, сжать к оси OnYn на коэффициент, номер значения которого хранится в регистре 15, сжатое изображение записать в матрицу 1 по адресу а2, 6) команда СЖХ а1, а2 - бинарное изображение VA3, хранящееся в матрице 1 по адресу а1, сжать к оси ОпХп на коэффициент, номер значения которого хранится в регистре 15, сжатое изображение записать в матрицу 1 по адресу а2,
7) команда УУВВ - установить устройство ввода изображений в начальное состояние,
8) команда ВВИЗ - ввести фрагмент изображения в матрицу 1 с устройства ввоД3
9} команда ВЫВИ - вывести изображение из матрицы 1 на устройство вывода. Поскольку в заявленном устройстве (в
отличие от прототипа) выходы узла 5 соединены с входами матрицы 1 через блок 6 коммутации, чтение содержимого узла 5 осуществляется здесь иным, чем в прототипе, способом. В зависимости от устанавливаемого блоком 6 соответствия между выходами узла 5 и входами матрицы 1 команды чтения содержимого памяти 5 имеют следующие модификации:
а) команда ЧПЙ а1. Ь1 - записать бипарное изображение формата А х А, хранящееся в памяти 5 по адресу, х значение которого хранится в памяти 19 по адресу Ы, в первый (относительно ОХ) слой А х А х 1 трехмерного бинарного изображения А х А
х А, расположенного в матрице 1 по адресу а1, исходное содержимое этого изображе - ния сдвинуть на шаг в направлении ОХ (аналог команды ВВВ прототипа),
6) команда ЧПХ а1, Ы - записать би- нарное изображение формата 1, хранящееся в узле 5 по адресу, значение которого хранится в памяти 19 по адресу Ы, в первую (относительно ОпХп) строку 1 двухмерного бинарного изображения V/vT расположенного в матрице 1 по адресу а1, исходное содержимое этого изо- ажения сдвинуть на шаг в направлении ОпХп,
в) команда ЧПУ а1, Ы - записать би- нарное изображение формата 1, хранящееся в узле 5 по адресу, значение которого хранится в памяти 19 по адресуЬ 1, в первую (относительно ОпУп) строку 1 двухмерного бинарного изображения VA3 x VAi , расположенного в матрице 1 по адресу а1, исходное содержимое этого изображу ни я сдвинуть на шаг в направлении OnYn..
Каждой команде соответствует своя микропрограмма - набор микрокоманд, последовательное выполнение которых приводит к выполнению операции, заданной в команде. После дешифрации кода операции адрес начального микрослова команды за- писываетея в регистр микроадреса процессора 8. По этому микроадресу из памяти микропрограмм процессора 8 извлекается управляющее микрослово и загружается в регистр 9, Это микрослово содержит управ- ляющее поле, разряды которого используются для генерации сигналов требуемых микроопераций, а также поле следующего микроадреса и поле кода микроветвления. После следующего микроадреса содержит базовый микроадрес, который указывает на следующее микрослово при естественной последовательности выборки мйкрослов. Этот базовый микроадрес может быть модифицирован с целью микроветвления, поле кода микроветвления определяет, какие признаки необходимо проверить и использовать для модификации микроадреса. Часть управляющего поля микрослова образует поле управления матрицей 1. другая часть образует поле управления устройствами ввода-вывода. В поле управления матрицей Т входят разряды кода РВВ, разряд СР1, разряд СР2, разряд ЗЛП, разряды кода ШО, разряд ЗП, -разряд Ч С. разряды кода РУАВ. В поле управления устройствами ввода-вывода входят разряд НУ, разряды кода РЗБ.
Выполнение каждой из перечисленных команд проиллюстрируем на примере устройства, процессорная матрица 1 которого имеет формат 16 х 16 х 16, узлы 61 и 63 содержат по 192 двухвходовых элемента И каждый, образующих вместе прямоугольную матрицу 16 х 12, узел 59 содержит 256 (16х 16) двухвходовых элементов 64 И, узлы 60 и 62 содержат по 64 (16 х 4) двухвходовых элемента И каждый, высокоскоростной ввод изображений осуществляется с устройства ввода фотоизображений, построенного на базе приборов с зарядовой связью (ПЭС), высокоскоростной вывод изображений осуществляется на растровое электронно-лучевое устройство отображения.
Команда СДХ а1, а2 используется для выполнения высокоскоростного переноса изображения /А X VA на шаг в направлении ОпХп или в направлении -0ПХП. Для выполнения переноса в направлении 0ПХП исходное бинарное изображение VA X /А(фиг.5,а) размещается в матрице 1 по адресу а 1 таким образом, чтобы отдельные его плоские фрагменты А х А располагались параллельно плоскости ZOX согласно фиг.5(б,г). При выполнении сдвига изображения VA X Уд3 перенос внутреннего содержимого его плоских фрагментов А х А производится аналогично тому, как выполняется команда СДВ в прототипе. Обмен информацией между фрагментами А х А (фиг.5,г) осуществляется при помощи узла 61 (фиг.З). Начальное микрослово команды СДХ а 1,а2 содержит: РУАВ 00, СР1 1. По синхросигналу С1 (фиг.2), вырабатываемому генератором синхроимпульсов процессора 8, код адреса а1, снимаемый с выходов регистра 10, мультиплексором 29 подключается к входам АЛП матрицы 1. С приходом синхроимпульса С2 изображение VA xV/V3, снимаемое с выходов локальной памяти процессоров матрицы 1, записывается в регистры первого операнда матрицы 1. С приходом следующего синхроимпульса С1 извлекается второе микрослово, содержащее: РУАВ 01, СР1 О, КМО 0011 - код микрооперации Сдвиг на шаг по ОХ, РВВ 0011 - код режима СДХ, ЗЛП 1. Код а2, снимаемый с выходов регистра 11, подключается к входам АЛП матрицы 1. На управляющие входы элементов 66 поступает разрешающий сигнал с выхода СДХ дешифратора 28, в результате чего информация со 192 выходов матрицы 1 проходит на соответствующие 192 входа матрицы 1 (фиг.З, 5-г). Импульс СЗ записывает сдвинутое изображение х/А3 в матрицу 1 по адресу а2.Для выполнения переноса изображения шаг в направлении -ОпХ п изображение VA3 х /А(фиг.5,а,б)
необходимо повернуть на 180° вокруг оси ОХ (фиг.5,в) и на 180° вокруг оси OY (фиг.5,е, результирующее изображение записать в матрицу 1 по адресу а1, после чего выполнить команду СДХ а1, а2 вышеописанным способом.
Команда СДУ а1, а2, используется при выполнении высокоскоростного переноса изображения Vfi X шаг в направлении или в направлении -б /п-Дяя выполнения переноса в направлении UnVn исходное изображение .Б.а.б) поворачивается на 90° вокруг оси OY (фиг.5,д) и записывается по адресу а 1 в матрицу 1. При сдвиге обмен информацией между отдельными фрагментами А х А сдвигаемого изображения VA X VA осуществляется при помощи узла 63 (фиг.4). В отличие от микропрограммы команды СДХ at, а2 второе микрослово команды СДУ а1, а2 содержит код РВВ 0101 - код режима СДУ. Для выполнения переноса изображения У§Т (фиг.5,а,б) на шаг в направлении -OnYn исходное изображение Vfl X Vfi необходимо повернуть на 180° вокруг оси ОХ (фиг.5в) и на 90° вокруг оси OY (фиг.5ж), после чего выполнить команду СДУ а1, а2.
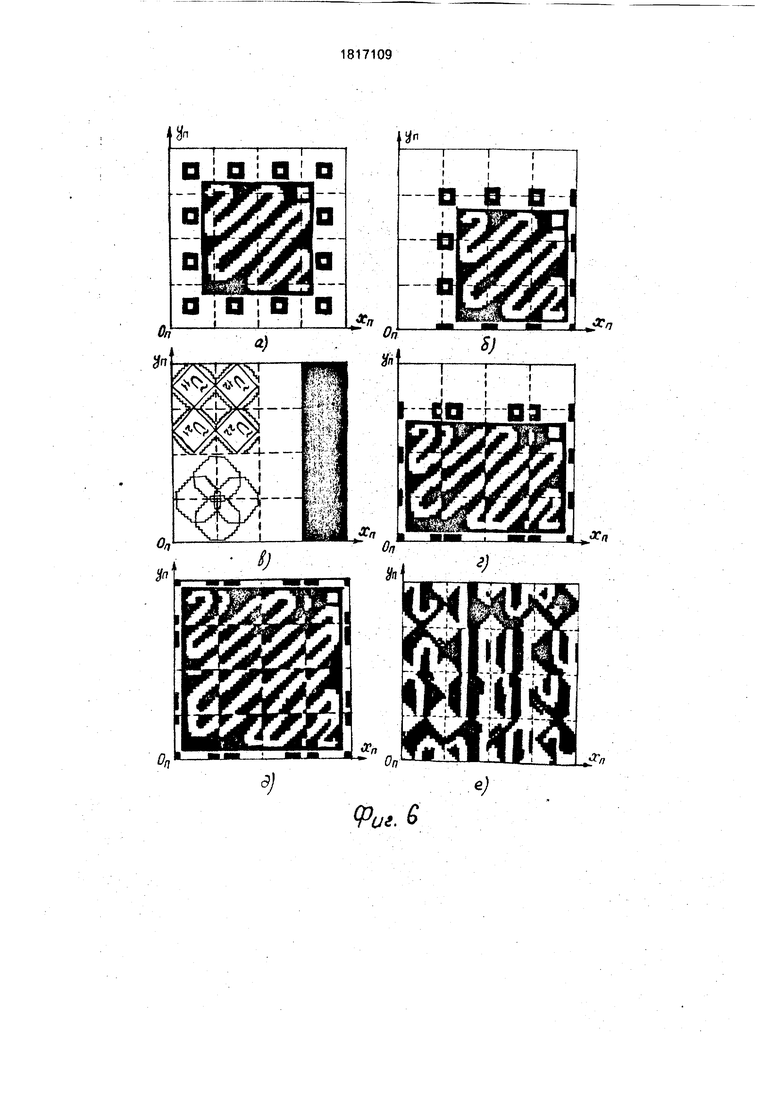
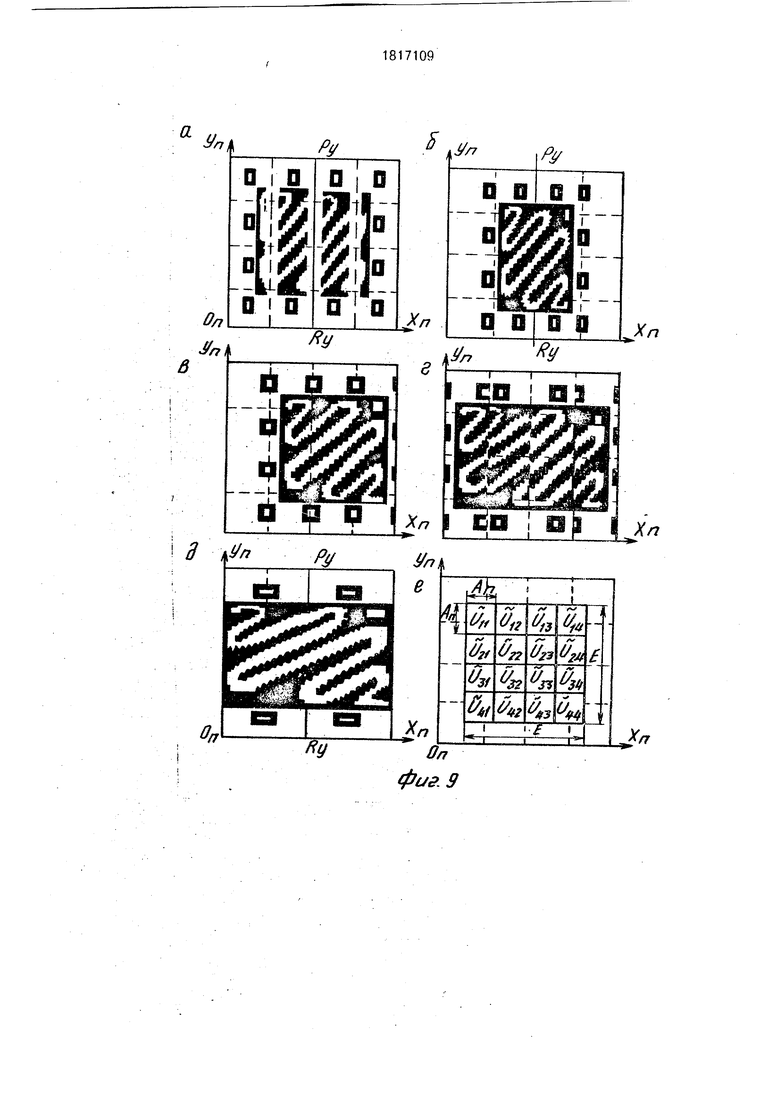
Команда РСШ а1, а2 вместе с командой ПВП at, a2 служат для моделирования поворота изображения VAr вокруг цент- ра изображения на угол, номер значения которого находится в регистре 12. При этом команда РСШ выполняет подготовительную операцию - расшивку исходного изображения (его поворачиваемую часть) на отдельные фрагменты Ап х Ап по слоям А х А х 1 матрицы 1. Выделим из квадрата А х А наибольший центральный квадрат Ап х Ап, вращение которого на любой произвольный угол у вокруг центра квадрата А х А (фиг.бв) не приводит к выходу точек квадрата Ап X А за пределы А х А. Очевидно, что Ап А/2 0,7А. Изображение Vfi состоит из А фрагментов А х А (на фиг.Тд эти фрагменты обозначены Uij, где I, j - {1,.... 4}. Поворачи- ваемый участок Е х Е изображения Vft х V/V COCTOMT из А фрагментов Ап х Ап (на фиг.Эе эти фрагменты обозначены Uij). Перед моделированием поворота поворачиваемое изображение V/ подверга- ется расшивке командой РСШ, в результате чего каждый фрагмент Cfij участка Е х Е этого изображения располагается в центре квадрата Uij {фиг.бд). Расшивка начинается с переноса исходного изображения VA X (с помощью псевдокоманд СДХ, СДУ) сначала по направлению ОпХп (фиг.9в), а затем по направлению -OnYn (фиг,66) до тех пор, пока центр U44 не совпадет с цент
0
5
0
5
0 0/ 5 0
5
5
ром U44. Из полученного таким образом изображения Т (фиг.6) выделяется его крайняя правая полоса А х при помощи изображения-маски М1 (фиг.бв): Р Т П М1, После этого изображения Т и сдвигаются на А шагов по направлению -ОпХп и вновь производится маскирование: Р PU/TnM1/. В результате трехкратного выполнения последней процедуры формируется изображение Р, показанное на фиг.бг. Аналогичным образом осуществляется расшивка полученного изображения Р вдоль оси OnYn (фиг.бд), в этом случае вместо маски М1 применяется изображение-маска М2, представляющее собой изображение М1 (фиг.бв), повернутое на 90° вокруг своего центра. Результат расшивки (фиг.бд) записывается в матрицу 1 по адресу а2.
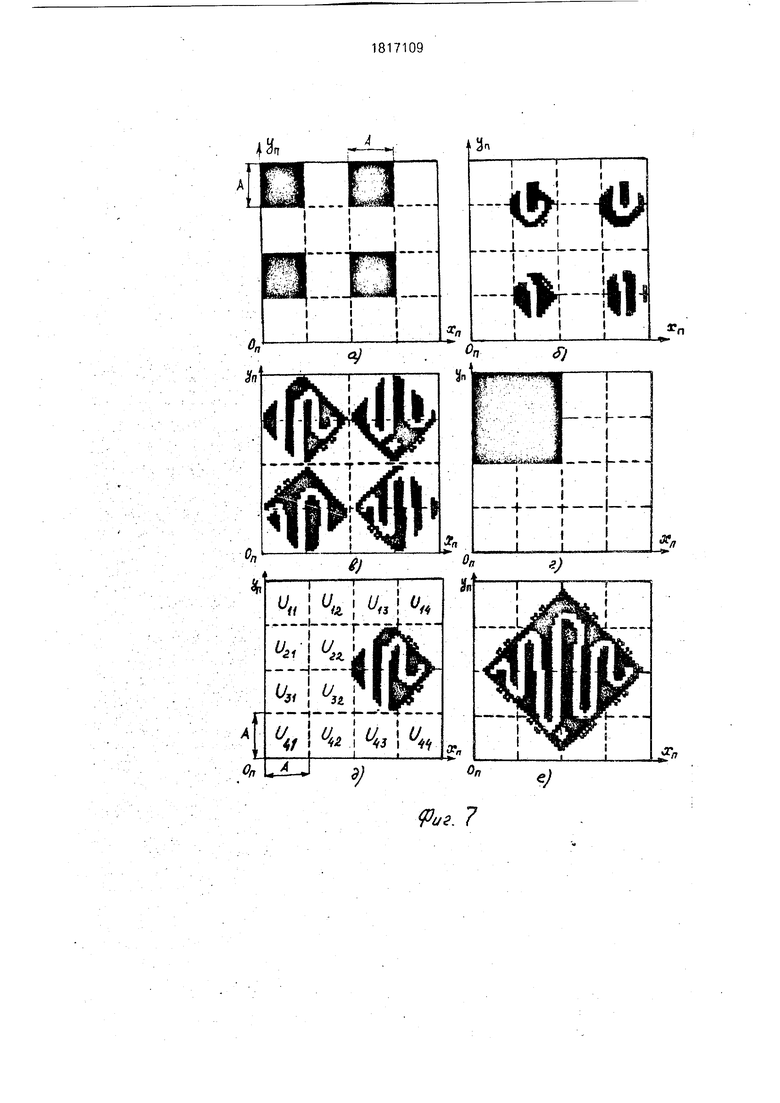
Команда ПВП а1, а2 использует расшитое командой РСШ изображение VA X VA(фиг.бд) и хранящееся в матрице 1 по адресу а1, в качестве своего исходного операнда. Выполнение команды начинается с поворота содержимого всех фрагментов Uij изображения (фиг.бд) вокруг центров фрагментов Uij на угол у , номер значения которого расположен в регистре 12 (фиг.бе). Реализация этой процедуры аналогична реализации в прототипе поворота трехмерного бинарного изображения А х А х А вокруг оси ОХ на произвольный угол у . Так как у-угол произвольный (из диапазона 0° у 360°), а высокоскоростной поворот, осуществляемый в узлах 3, производится только на углы из диапазона 0° а 45°, то поворот изображения А х А х А вокруг оси ОХ на- угол у в общем случае включает два этапа: 1) поворот изображения А х А, х А на угол 0° СЕ у : 45°, 2) дополнительный поворот повернутого изображения А х А х А на соответствующий угол кратный 90°. Таким образом каждому номеру значения у, хранящемуся в регистре 12, дается в соответствии свой номер значения «у. Этот номер хранится в виде константы в памяти 19 по жестко фиксированному адресу. В процессе выполнения команды ПВП этот адрес восстанавливается по коду, хранящемуся в регистре 12, и содержимое этой ячейки записывается в регистр 15. После выполнения поворота изображение (фиг.бе) сшивается в единый, повернутый на угол у квадрат Е х Е (фиг.7е). Сшивание осуществляется в несколько этапов. На первом этапе производится сшивание А повернутых фрагментов Ап х Ап (фиг.бе) в А/4 повернутых фрагмента 2Ап х 2АП - фиг,7в), на втором этапе производится сшивание А/4 повернутых фрагментов 2АП х 2Ап в А/16 повернутых
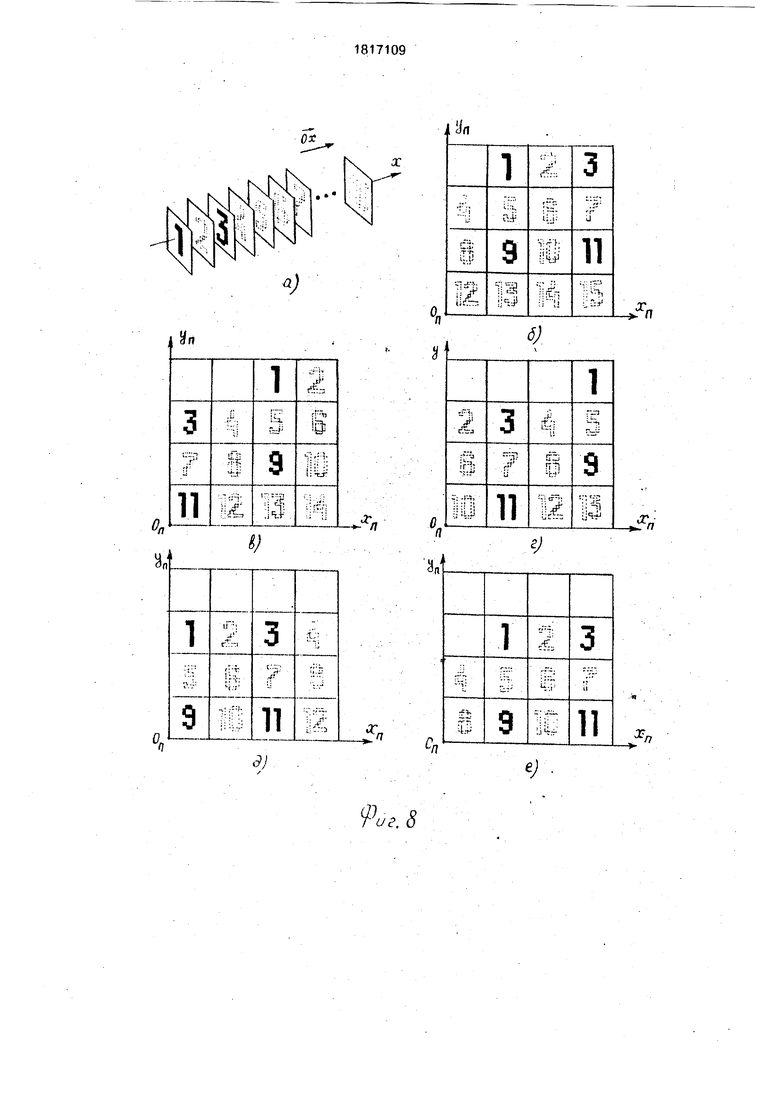
фрагмента 4АП х 4АП (фиг.7е) и т.д. Процедура сшивания заключается в переносе сшиваемых фрагментов в плоскости XnOnYn и выполнения над сдвинутыми фрагментами теоретико-множественной операции обье- динение. Каждый этап сшивания состоит из 4-х подэтапбв. Каждый подэтап включает в себя выделение из изображения , полученного на предыдущем этапе сшивания, группы фрагментов А х А, перенос которых в плоскости XnOnYn может быть осуществлен одновременно, и параллельный перенос содержимого этих фрагментов. Этап заканчивается объединением сдвинутого содержимого всех 4-х групп фрагментов А х А в одно общее изображение VA X V/vT На фиг.7б показан результат одновременного переноса 4-х фрагментов А х А изображения (фиг.бе), выделенных маской МЗ (фиг,7а). На фиг.7(д) показан результат переноса 4-х фрагментов А х А, выделенных маской М4 (фиг.7г) из изображения (фиг.7в) полученного в результате выполнения первого этапа сшивания. С целью повышения скорости переноса сшиваемых фрагментов на каждом l-м этапе сшивания используются 3 параметра переноса: 1) L I - число одношаговых сдвигов вдоль оси ОХ, 2) Ху-.число одношаговых сдвигов вдоль оси ОпХп, 3) Yy1 - число одношаговых сдвигов вдоль оси OnYn. Переносом изображенид А х А х А на LI шагов по направлению ОХ моделируется перенос изображения Vflr на N шагов (где N кратно А) в плоскости XnOnYn вдоль осей ОпХп и OnYn. Поясним это на следующем примере. Пусть необходимо одновременно перенести 4 фрагмента А х А, выделенных маской A3 (фиг.7а) из изображения (фиг.5а.б). на А 16 шагов в направлении ОпХп и на А 1 б шагов в направлении -QnYn. В заявленном устройстве данная процедура осуществляется путем последовательного выполнения едкого поворота на 9(У° вокруг OZ, пяти сдвигов по направлению Ох, одно- го поворота на 270° вокруг 02. Результат поворота изображения (фиг.5а,б) на 90° вокруг OZ показан на фиг.8(а). На фиг.8(б,в,г,д,е) показана двухмерная интерпретация переноса изображения VA, выделенно- го маской МЗ из изображения (фиг.ба), на 1, 2, 3, 4, 5 шагов по направлению вектора ОХ. Фиг.8(б) соответствует результату переноса выделенного изображения шагов по направлению , фиг.8(д) соот- ветствует результату переноса выделенного изображения на А шагов по направлению -OnYn, фиг.8(е} - результату переноса на А шагов по направлению -Оплп и на А шагов по направлению.. Параметры Ху, Yj
служат для точной установки перемещаемых фрагментов на плоскости XnOnYn. установка осуществляется при помощи микроподпрограмм аналогичных микропрограмм команд СДХ и СДУ (иначе псевдокоманд СДХ и СДУ). Параметры Lj1. X, Yf хранятся в памяти 19 в виде констант по жестко фиксированным адресам. Извлечение параметров Ly, XJ-, Y в процессе выполнения команды ПБП производится по коду, хранящемуся в регистре 12.
Команда СЖУ а 1, а2 предназначена для высокоскоростного сжатия (растяжения) содержимого изображения VA3 X уТ(от) прямой проходящей через центр этого изображения и параллельной оси OnYn. Микропрограммная реализация этой команды зависит от значения коэффициента К сжатия, номер которого хранится в регистре 15. При К 1 (собственно сжатие) исходное изображение VA X , хранящееся в матрице 1 по адресу а1, переписывается по адресу а2 с поворотом на 90° вокруг оси OZ (фиг.8а), Затем производится последовательное сжатие полученного изображения А х А х А (адрес а2) к плоскости ZOX (при помощи псевдокоманд СЖ - микроподпрограмм, аналогичных микропрограмме команды СЖ а1 прототипа). Двухмерная интерпретация результата сжатия изображения (фиг.ба) показана на фиг.Эа. Далее осуществляется сшивание отдельных полос /А/К/ х VA изображения (фиг.Эа) в единое сжатое изображение (V/VVK)x д/А3 (фиг.96). Сшивание заключается в последовательном выделении из изображения (фиг.Эа) содержимого каждой отдельной полосы А х (при помощи масок вида М1), переносе содержимого каждой Ј-й выделенной полосы А х к прямой PyRy на Х« шагов вдоль оси 0ПХП. По окончании переноса над сдвинутым содержимым полос выполняется теоретико-множественная операция объединение. Константы сшивания (X) хранятся в памяти 19 по жестко фиксированным адресам, извлечение их производится по коду, хранящемуся в регистре 15. При К 1 (растяжение) исходное изображение VA3, хранящееся по а 1, переписывается по адресу а2 и подвергается расшивке вдоль оси ОпХп (фиг.Эв.г), для чего по содержимому регистра 15 из памяти 19 извлекаются константы сшивания. Затем расшитое изображение растягивается от плоскости ZOX (при помощи псевдокоманд СЖ). Двухмерная интерпретация результата растяжения показана на фиг.Эд),
Команда СЖХа1, а2 предназначена для высокоскоростного сжатия (растяжения) содержимого изображения VA X vTr к (от) прямой PxRx, проходящей через центр этого изображения и параллельной оси ОпХп- Команда СЖХ выполняется аналогично команде СЖУ, однако расшивка (при К 1) и сшивание (при К 1) исходного изображения vfi здесь осуществляется вдоль оси 0ПУП.
Команда ЧПИ а1, Ы введена в систему команд устройства вместо команды ВВВ al прототипа. Выполнение команды ЧПИ а1, b 1 начинается с записи содержимого ячейки Ы памяти 19 в регистр 13. Далее выполняется микрокоманда, микрослово которой содержит: РУАВ 00, КМО 0011, СР+ 1, ЗЛП 1, РВВ 0110 - код режима ЧП. По импульсу С1 на адресных входах АЛП матрицы 1 установится код а1, сигнал с выхода ЧП дешифратора 28 установит на входах матрицы 1 информацию, извлеченную из памяти 5 по адресу, хранящемуся в регистре 13. С приходом С2 производится запись информации с выходов узлов локальной памяти матрицы 1 в регистры первого операнда матрицы 1. В момент прихода СЗ содержи- мое регистров первого операнда матрицы 1 со сдвигом на шаг записывается в узлы локальной памяти матрицы 1 по адресу а1, а в первый (по ОХ) слой А х А х 1 изображения А х А х А с адресом а1 записывается инфор- мация, извлеченная из памяти 5.
Команды ЧПХ а1, Ы и ЧПУ а 1, а2 предназначены для выполнения высокоскоростного переноса плоских изображений сверхвысокого разрешения F х F (где F ) на шаг в плоскости изображения. При выполнении этих команд производится обмен информацией между соседними фрагментами , образующими изображение F x F. Выполнение команды ЧПХ а1, Ы начинается с записи содержимого ячейки Ы памяти 19 в регистр 13. Далее выполняется микрокоманда, микрослово которой содержит: РУАВ 00, КМО 0011, РВВ 0111 - код режима ЧПХ, СР1 1, ЗЛП 1. По импульсу С1 сигнал с выхода ЧПХ дешифратора 28 открывает элементы И узлов 60, 61 и информация с-соответствующих выходов матрицы 1 и памяти 5 поступает на входы матрицы 1. В момент прихода С2 со- держимое локальной памяти с адресом а1 переписывается в регистры первого операнда матрицы 1, С приходом СЗ это содержимое со сдвигом на шаг записывается в локальную память матрицы 1 по адресу al.
Микропрограмма команды ЧПУ а1, Ы отличается от микропрограммы команды ЧПХ al, Ы только тем, что в последнем микрослове этой команды РВВ 1000 (код режима ЧПУ), поэтому с приходом импульса
С1 сигнал с выхода ЧПУ дешифратора 28 открывает элементы И узлов 62, 63.
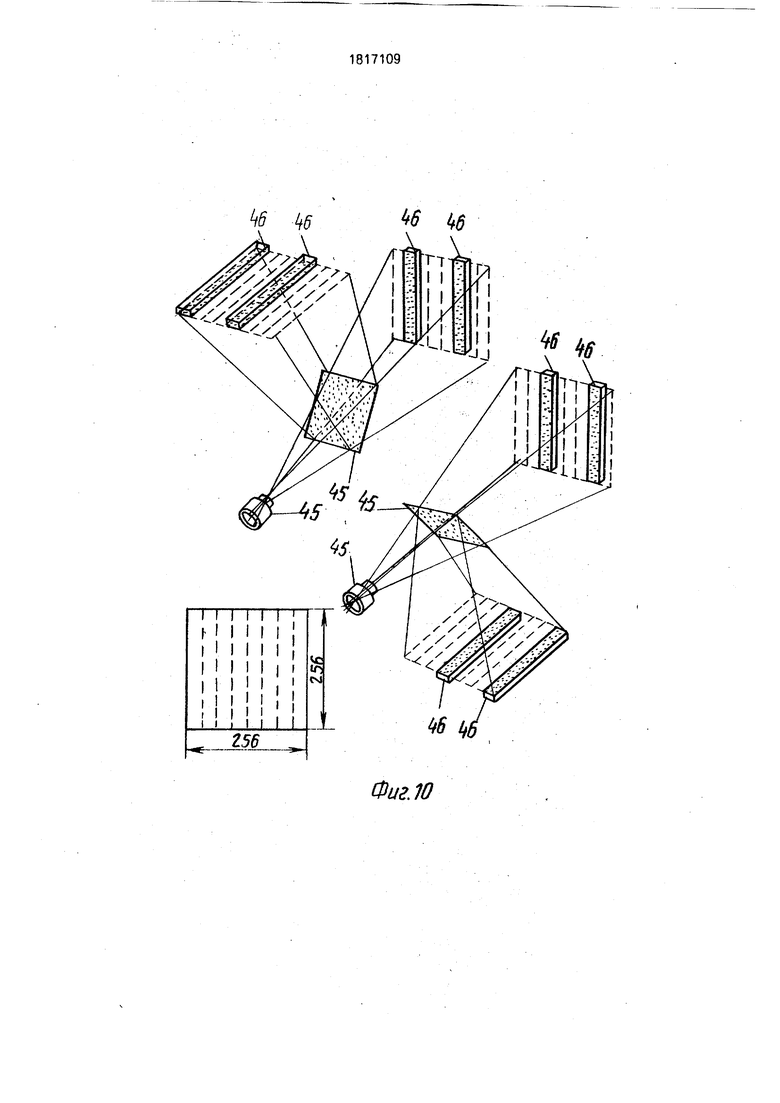
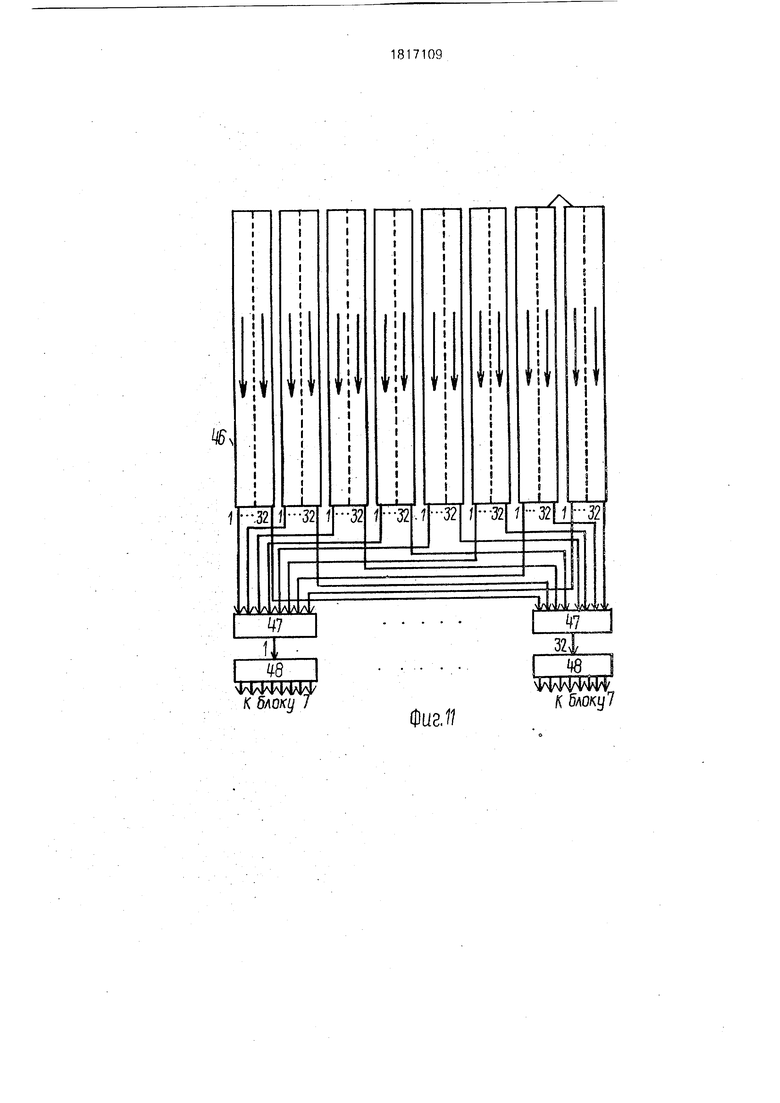
Команды УУВВ и ВВИЗ управляют работой устройства ввода изображений. Суть его работы состоит в преобразовании светового потока, модулированного по освещенности и поступающего в устройство ввода через оптическую систему 45, сначала в электрические аналоговые сигналы при помощи фотодатчиков 46, а затем в двоичный цифровой код при помощи аналого-цифро- вых преобразователей 48. Вариант устройства ввода, показанный на фиг. 10, 11 служит для высокоскоростного ввода 256 - уровне- вых фотоизображений формата 256 х 256, содержит в качестве своей оптической системы 45 два объектива и два полупрозрачных зеркала, функцию фотодатчиков 46 выполняют в нем 8 ПЗС-приборов. На каждый ПЗС-прибор системой 45 фокусируется свой участок 32 х 256 вводимого изображения. Объединение 8-ми таких участков образует полное изображение 256 х 256. Каждый ПЗС-прибор содержит 32 линейки фоточувствительных элементов по 256 фоточувстви- тельных элементов каждый (линейка соответствует вертикальной строке изображения 256 х 256). Каждая из линеек имеет собственный регистр сдвига, поэтому с одного ПЗС-прибора одновременно снимается 32 аналоговых сигнала, соответствующих 32 пикселеам вводимого изображения 256 х 256. С 8-ми ПЗС-приборов одновременно снимается 256 сигналов, соответствующих горизонтальной строке вводимого изображения. Узел 48 содержит 32 аналого-цифро- вых преобразователя, каждый из которых формирует на выходе параллельный восьмиразрядный код. В каждый момент времени распределительный узел 47 подключает к входам узла 48 только 32 аналоговых сигнала из 256 сигналов, снимаемых с 8 ПЗС- приборов.- В результате их аналого-цифрового преобразования на выходах узла 48 формируется 256-разрядный двоичный код, и узел 46 устанавливает признак ГВВИ 1. После приема указанного кода в матрицу 1 признак ГВВИ сбрасывается, к входам узла 48 подключаются следующие 32 сигналы считываемой 256-пиксельной строки, возобновляется процесс аналого-цифрового преобразования и т.д. Если строка введена в матрицу полностью, вместе с сбросом признака ГВВИ осуществляется сдвиг на шаг содержимого всех 256 регистров сдвига 8-ми ПЗС- приборов, после чего начинается цикл ввода следующей 256-пиксельной горизонтальной строки.
Команда УУВВ служит для установки устройства ввода в исходное состояние. Микрослово команды содержит НУ 1. С приходом С1 обнуляется регистр 14, узел 46 последовательно выполняет следующие операции: 1) информация из накопительных линеек передается в регистры сдвигов ПЗС- приборов, 2) на входах узла 48 устанавливаются первые 32 сигнала первой горизонтальной строки сформированного изображения 256 х 256, 3) выполняется цикл аналого-цифрового преобразования, 4) устанавливается признак ГВВИ 1.
Команда ВВИЗ служит для ввода в матрицу 1 256-разрядного кода, сформированного на выходах узла 48. Команда начинается с анализа признака ГВВИ. Если ГВВИ 0, анализ повторяется. Если ГВВИ 1, выполняется микрокоманда, микрослово которой содержит: РУАВ 10, РВВ 1001 - код режима ФИ, КМО 0011, СР1 1, ЗЛП 1. По импульсу С1 выходы разрядов регистра 14 мультиплексором 29 подключаются к входам АЛП матрицы 1, сигнал с выхода ФИ разрешает прохождение сигналов с выходов узла 48 на входы матрицы 1. С приходом С2 содержимое локальной памяти матрицы 1 по адресу, хранящемуся в разрядах , записывается в регистры первого операнда матрицы 1. По переднему фронту импульса СЗ информация с выходов узла48 записывается в первый (относительно (Ж) слой А х А х 1 матрицы 1, а информация, хранящаяся в регистрах первого операнда, снова со сдвигом на шаг переписывается в локальную память матрицы 1. По заднему фронту импульса ВО содержимое регистра 14 увеличивается на 1, на входах узла 48 устанавливаются следующие 32 сигнала с ПЗС-гфиборов, выполняется цикл аналого-цифрового преобразования, устанавливается признак ГВВИ 1 (был сброшен по переднему фронту импульса ВО). После заполнения всех 16 слоев 16x16x1 заполняемого текущего изображения 16 х 6х 16 счетчик ССД регистра 14 обнуляется, а содержимое счетчика СПМ увеличивается на 1 (смена адреса заполняемого изображения).
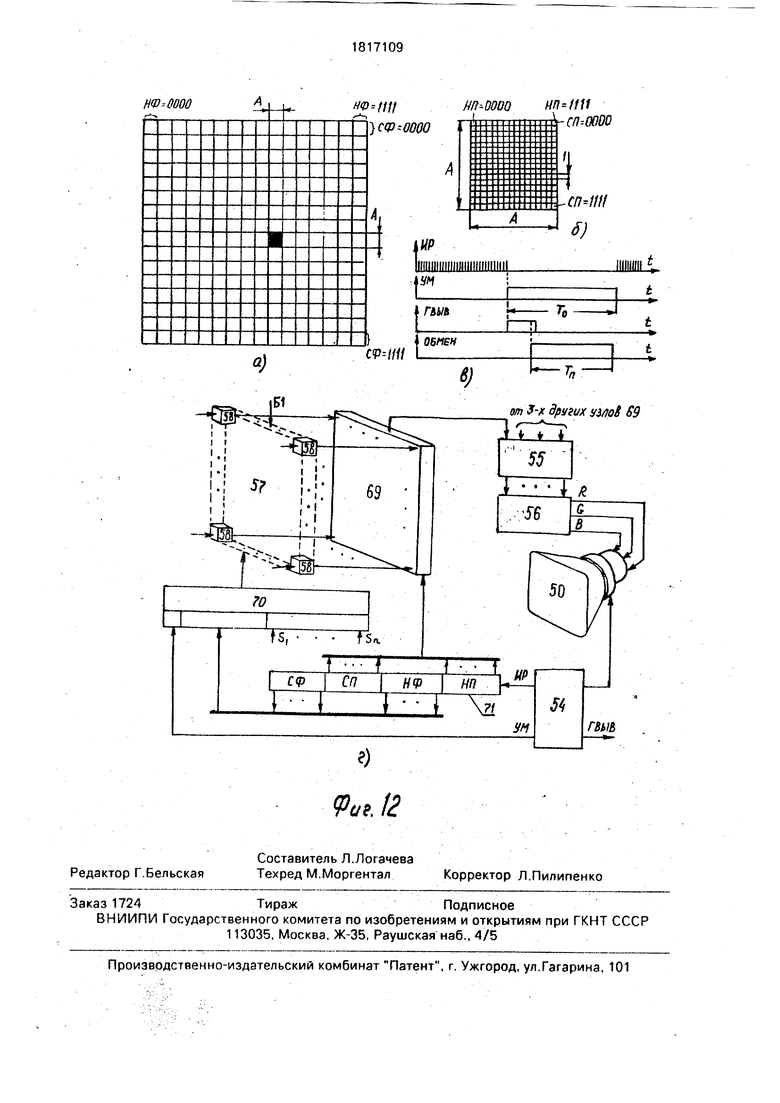
Команда ВЫВИ служит для передачи информации из матрицы 1 в устройство вывода изображений, функциональная схема которого показана на фиг.1, 12. Суть его работы заключается в сканировании содержимого памяти 5,1 и отображении полученного растрового изображения на экране электронно-лучевой трубки 50. В рассматриваемом варианте устройства память 51 служит для хранения 16-уровневого изображения 256 х 256 и состоит из 4-х буферов 57
с общей системой адресации. Каждый буфер 57 включает в себя А2 (256) запоминающих элементов 58 емкостью 256 бит каждый, А входов буфера 57 непосредственно соеди- нены с А выходами матрицы 1, обмен информацией между матрицей 1 и буферами 57 осуществляется бинарными изображениями А х А. При регенерации изображения с каждого из 4-х буферов 57 одновременно
считывается 1 бит информации. Этот считанный 4-разрядный код является индексом уровня яркости (цвета) одного пиксела отображаемого изображения А х А (фиг.12,а). Код индекса поступает в таблицу 55 цветов,
из которой по данному индексу извлекается 3 кода, соответствующие уровня м интенсивности красного, синего и зеленого цветов и относящиеся к данному пикселу. Извлеченные 3 кода поступают далее в узел 56 цифро-аналогового преобразования, где по ним формируются сигналы управления красным, синим и зеленым электронными прожекторами трубки 50. При А 16 отображаемое изображение 256 х 256 состоит из 256 фрагментов 16 х 16. Информация о каждом фрагменте 16x16 хранится в 256 х 4 элементах 58 по одному и тому же адресу. Выборка бита из элемента 58 производится с помощью кода адреса, состоящего из 4-разрядного поля СФ и 4-разрядного поля НФ. Выборка элемента 58 из буфера 57 производится с помощью кода, состоящего из 4-разрядного поля СП - 4-разрядного поля НП. Поле СФ хранит номер текущей строки
фрагментов 16x16 (фиг. 12 ,а) в изображении 256 х 256, поле НФ хранит номер текущего фрагмента 16 х 16 в текущей строке фрагментов, поле СП хранит номер текущей строки пикселов в текущем фрагменте 16 х
16, поле НП хранит номер текущего пиксела в текущей строке пикселов (фиг.126). Для А 16 счетчик 71 (фиг. 12г) состоит из 4-х 4-разрядных частей НП, НФ, СП, СФ. При регенерации изображения узел 54 вырабатывает синхроимпульсы ИР, которые поступают на счетный вход младшего разряда части НП счетчика 71, Сразу же после окончания периода регенерации узел 54 вырабатывает импульс УМ длительностью То и
импульс признака ГВЫВ 1 длительностью Тг То - Тп (фиг.12в), где То - время обратного хода луча (1,3 мсек, Тп - время, необходимое для передачи нового 16-уровневого изображения 256 х 256 из матрицы 1 в память 51. Адресные входы элементов 58 в зависимости от значения уровня УМ соединены либо с выходами Si-Sn регистра 14 (УМ 1), либо с выходами разрядов частей СФ и НФ счетчика 71 (УМ 0).
Выполнение команды ВЫВИ начинается с анализа признака ГВЫВ. Если ГВЫВ О, анализ повторяется. Если ГВВИ 1, выполняется микрокоманда, микрослово которой содержит: РУАВ 10. КМО 0011, СР1 1, ЗЛП 1, РЗБ 001 записи в первый буфер 57. По им,пульсу С1 выходы разрядов регистра 14 мультиплексором 29 подключаются к входам АЛП матрицы 1. С приходом С2 содержимое локальной памяти матрицы 1 с адресом, хранящимся в разрядах , записывается в регистры первого операнда матрицы 1. По переднему фронту импульса СЗ сигнал с выхода 61 дешифратора 38 записывает информацию с выходов матрицы 1 в первый буфер 57 по адресу, хранящемуся в регистре 14. По заднему фронту импульса СЗ сигнал с выхода элемента 30 увеличивает содержимое регистра-счетчика 14 на 1. Описанная микрокоманда выполняется 256 раз до полного заполнения первого буфера 57, после чего изменяется содержимое старших разрядов поля СПМ регистра 14. Аналогичным образом заполняются второй (РЗБ 010), третий (РЗБ 011) и четвертый (РЗБ 100) буферы 57.
Таким образом, скорость выполнения геометрических преобразований переноса, поворота, сжатия над плоскими изображениями высокого разрешения в заявленном устройстве выше скорости выполнения данных преобразований в прототипе. Скорость ввода изображений в заявленное устройство и скорость вывода изображений из него выше скорости выполнения операций ввода-вывода изображений в прототипе. Указанный положительный эффект достигнут
без снижения скорости обработки трехмерных изображений по сравнению с прототипом.
Ф о р м у л а и з о б р е т е н и я
Устройство для параллельной обработки трехмерных сцен, содержащее матрицу процессоров, блок управления, матрицу узлов поворота, матрицу узлов сжатия, матрицу узлов памяти, причем информационные
выходы матрицы процессоров соединены с информационными входами матриц узлов поворота, узлов сжатия, узлов памяти, блока управления и являются информационными выходами устройства, информационные
входы которого подключены к информационным входам матрицы процессоров и информационным выходам матриц узлов поворота, узлов сжатия и блока управления, группы управляющих выходов которого со- единены с соответствующими управляющими входами матриц процессоров, узлов поворота, узлов сжатия, узлов памяти, о т- личающееся тем, что, с целью увеличения скорости выполнения геометрических
преобразований переноса, поворота, сжатия над плоскими изображениями высокого разрешения и увеличения скорости ввода- вывода изображений, в устройство введен блок коммутации, выходы которого подключены к информационным входам матрицы процессоров, информационные выходы которой соединены с первой группой информационных входов блока коммутации, вторая группа информационных входов и
управляющие .входы которого соединены соответственно с выходами матрицы узлов памяти и соответствующей группой управляющих выходов блока управления.
60Ш81
фиг. 7
Фиг. 10
и
ад







| название | год | авторы | номер документа |
|---|---|---|---|
| Устройство обработки изображений | 1989 |
|
SU1817108A1 |
| УСТРОЙСТВО ОБРАБОТКИ ДВУХМЕРНЫХ И ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ | 2005 |
|
RU2289161C1 |
| УСТРОЙСТВО УПРАВЛЕНИЯ АВТОНОМНЫМ РОБОТОМ | 2008 |
|
RU2424105C2 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1689966A1 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1612307A2 |
| Устройство для параллельной обработки трехмерных сцен | 1986 |
|
SU1456965A1 |
| УСТРОЙСТВО ОБРАБОТКИ ДВУХМЕРНЫХ И ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ | 2008 |
|
RU2376637C1 |
| КРЕМНИЕВЫЙ МУЛЬТИПЛЕКСОР | 2015 |
|
RU2602373C1 |
| Многопроцессорная система | 1987 |
|
SU1464168A1 |
| Устройство для обработки цифровых изображений | 1988 |
|
SU1636848A1 |
Изобретение относится к вычислительной технике, предназначено для решения задач обработки изображений, задач размещения, распознавания образов, машинной графики. Целью изобретения является увеличение скорости выполнения геометрических преобразований переноса, поворота, сжатия над плоскими изображениями высокого разрешения и увеличение скорости ввода-вывода изображений. Для этого изобретение содержит матрицу процессоров, блок управления, матрицу узлов поворота, матрицу узлов сжатия, матрицу узлов памяти и блок коммутации. 12 ил.
vr&№№№
К блоку 7
Фиг. 77
К блоку/
| Устройство для параллельной обработки трехмерных сцен | 1986 |
|
SU1456965A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1612307A2 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
