Изобретение относится к вычислительной технике, предназначено для решения задач обработки двумерных и трехмерных изображений. Может быть применено в стационарных и бортовых системах технического зрения, ориентации и навигации автономных роботов, в системах автоматизированного проектирования для анализа и синтеза объектов сложной геометрической формы. Отличительной особенностью устройства является высокое быстродействие и возможность применения такого способа программной обработки сцен, когда роль элементарных операндов выполняют не отдельные элементы описания геометрических объектов, а целые двумерные и трехмерные изображения, содержащие внутри себя обрабатываемые геометрические объекты. Наряду с упрощением процесса программирования такой способ позволяет создавать программы, инвариантные по отношению к геометрической форме обрабатываемых объектов и пространственному положению объектов внутри изображений. Высокое быстродействие, небольшие габариты и надежность позволят создавать роботы с принципиально новым уровнем автономности.
Известно устройство для параллельной обработки трехмерных сцен [1, 2], представляющее собой многопроцессорную SIMD-систему и состоящее из однородной процессорной матрицы формата А×А×А (где А - целое число), блока программного управления, узлов поворота, сжатия, памяти изображений. В устройстве высокая скорость обработки трехмерных сцен достигается за счет глубокого распараллеливания основных процедур обработки сцен (теоретико-множественных операций, анализа объектов на пересекаемость, процедур вычисления площадей и объемов, геометрических преобразований поворота, переноса, сжатия), осуществляемых над бинарными трехмерными изображениями формата А×А×А. Недостатком этого устройства является небольшая скорость обработки двумерных изображений высокого разрешения из-за низкой степени распараллеливания геометрических преобразований переноса, поворота, сжатия бинарных изображений формата 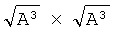 .
.
Наиболее близким к заявленному устройству является усовершенствованный вариант указанного устройства [3], содержащий в своем составе помимо средств высокопараллельной обработки бинарных изображений А×А×А также средства высокопараллельной обработки бинарных изображений . Кроме того, данное устройство позволяет выполнять ввод и вывод бинарных изображений формата А×А с высокой степенью параллелизации.
Недостатками прототипа являются: низкая точность и скорость решения задач обработки изображений. Недостатки вызваны: 1) низкой точностью и низкой скоростью вычисления объема (площади) одноцветного содержимого бинарного изображения; 2) низкой скоростью выполнения переноса и поворота составных изображений высокого и сверхвысокого разрешения; 3) низкой скоростью определения граничных координат одноцветного объекта на бинарном изображении; 4) низкой скоростью выполнения сжатия изображений; 5) нерациональным способом соединения памяти изображений с процессорной матрицей; 6) низкой скоростью ввода информации в процессорную матрицу; 7) низкой максимально допустимой частотой управления процессорной матрицей.
Первая причина обусловлена тем, что для подсчета числа процессорных элементов (ПЭ) матрицы А×А×А, имеющих на выходе сигнал логической «1», в прототипе использован аналоговый сумматор 43 и импульсный вольтметр 44 [3], каждый i-й вход которого соединен с выходом i-го процессорного элемента матрицы А×А×А; цифровой код суммы формируется путем аналого-цифрового преобразования сигнала-результата суммирования [1]. Если U1 - уровень логической «1», U0 - уровень логического «0», то, так как U1>0, U0>0, U1/U0<100 для А≈10 будет A3×U0>10×U1, т.е. аналого-цифровое вычисление общего числа пикселей трехмерного бинарного изображения А×А×А, имеющих состояние «1» (другими словами, вычисление объема единичного содержимого бинарного изображения А×А×А), не может быть осуществлено с точностью до одного пикселя. Точное определение объема требует дополнительных процедур обработки. Кроме того, время такого аналого-цифрового вычисления велико, при большом разрешении процессорной матрицы амплитуда сигнала с выхода аналогового сумматора может достигать нескольких десятков и сотен вольт, понятно, что время переходных процессов будет здесь чрезвычайно большим. Неудачным является и способ подключения входов сумматора к процессорной матрице. Непосредственная связь с выходами процессоров приведет к переключениям элементов сумматора (а значит, и к дополнительному энергопотреблению) при любом изменении состояния выходов процессоров, даже в том случае, когда отсутствует необходимость в измерении объема. Кроме того, вычисление объема в прототипе выполняется с помощью отдельной команды без распараллеливания процесса выполнения этой процедуры с другими операциями (например, поворотами и сдвигами).
Вторая причина является существенной по причине важности обработки составных изображений в прикладных задачах. В большинстве задач полное размещение объектов внутри изображений возможно только при разрешении S>100. В то же время разрешение процессорной матрицы А×А×А в настоящее время не может превышать А=100 (для бортовых устройств этот показатель еще значительно меньше) из-за причин, связанных с необходимостью обеспечения приемлемых габаритов, надежности, энергопотребления и стоимости устройства. В связи с этим обработка изображений высокого разрешения может быть осуществлена только путем их пофрагментной обработки. При этом наибольшая скорость обработки трехмерных изображений достигается, когда одновременно обрабатываемым фрагментом является фрагмент А×А×А; а наибольшая скорость обработки двумерных изображений достигается, если одновременно обрабатываемым фрагментом является фрагмент . Обработка составных изображений mA×mA×mA (где m>1 - целое) связана с обменом информацией между отдельными фрагментами А×А×А этих изображений, такой обмен сопровождается необходимостью организации временного хранения передаваемой информации. В прототипе обмен целыми фрагментами А×А×А (при поворотах на углы n×90° и при параллельном переносе на m×А шагов содержимого составных изображений, где n, m - целые числа) с наибольшей скоростью осуществляется внутри процессорной матрицы. В то же время конструкция прототипа и его система команд позволяют выполнять обмен целыми фрагментами А×А×А в матрице только с одновременным осуществлением поворота передаваемых фрагментов на углы, кратные 90°, а это замедляет скорость выполнения параллельных переносов (из-за необходимости восстановления углового положения сдвинутого изображения после процедуры переноса). Кроме того, в прототипе любое обращение к памяти изображений (и при записи - команда ВВЫВ [2], и при чтении - команда ЧПИ [3]) сопровождается сдвигом фрагмента А×А×А на шаг, что при организации одношагового переноса составного бинарного изображения mA×mA×mA (где m>2) становится излишним и приводит к необходимости осуществления временного хранения сдвигаемого фрагмента А×А×А в локальной памяти матрицы. Но такое хранение в матрице прототипа, как было сказано выше, связано с необходимостью последующего восстановления угловой пространственной ориентации сохраненного фрагмента. Все это отрицательным образом сказывается на скорости обработки составных изображений в прототипе.
Третья причина вызвана отсутствием в прототипе средств для высокоскоростного определения положения объекта на бинарном изображении и определения габаритных размеров объекта, это значительно увеличивает время решения задач обработки плоских и пространственных изображений. Так, вычисление крайней левой х-й координаты одноцветного объекта (образованного всеми пикселями изображения с яркостью 1) произвольной формы достигается в прототипе только путем многократного последовательного выполнения одношагового сдвига бинарного изображения, содержащего объект произвольной формы, вправо (в направлении 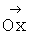 ) с одновременным анализом содержимого этого сдвинутого изображения на пустоту. В момент выхода объекта за пределы изображения определяется искомая х-я координата.
) с одновременным анализом содержимого этого сдвинутого изображения на пустоту. В момент выхода объекта за пределы изображения определяется искомая х-я координата.
Четвертая причина объясняется неправильным выбором оси сжатия для моделирования геометрических преобразований осевого сжатия над содержимым бинарных изображений А×А в узлах 4 [3] сжатия и отсутствием аппаратных средств для моделирования центрального сжатия изображений А×А с предельной степенью распараллеливания. В прототипе роль оси сжатия выполняет прямая PR [2], проходящая через центр квадрата А×А и параллельная стороне этого квадрата. Это сокращает общее число коэффициентов, сжатие изображения на которые могло бы быть реализовано с высокой степенью распараллеливания. Кроме того, решение некоторых прикладных задач обработки изображений (например, задачи построения трехмерных изображений по плоским стереоизображениям в реальном масштабе времени) требуют многократного выполнения центрального сжатия фрагментов А×А на фиксированный коэффициент. В прототипе такое преобразование может быть выполнено только путем последовательного выполнения нескольких осевых сжатий и поворотов, что снижает скорость решения задачи.
Пятая причина обусловлена тем, что в прототипе входы данных памяти изображений соединены непосредственно с выходами данных процессорной матрицы, а выходы данных памяти изображений соединены с входами матрицы только через блок коммутации. В результате стало невозможным совместить входы данных памяти изображений с ее выходами данных. Такой способ подключения делает невозможным обмен памяти изображений с узлами ввода-вывода изображений, минуя локальную память процессорной матрицы, это увеличивает время выполнения ввода-вывода, делает локальную память матрицы еще более дефицитным ресурсом. Кроме того, такое подключение удорожает дополнительное наращивание памяти изображений, снижает надежность устройства.
Шестая причина вызвана низкой скоростью ввода больших массивов данных в устройство. Так, при вводе оцифрованных фотоизображений в память прототипа значения разрядов кода яркости одного фотопикселя вводятся в матрицу процессоров через различные входы этой матрицы. Тем самым нарушается соответствие между введенной информацией об яркости пикселя и его у-ми и z-ми координатами в матрице А×А×А. Из-за особенностей процесса обработки изображений в рассматриваемых устройствах (который предполагает наличие такого соответствия между информацией об яркости пикселя и положением этой информации в матрице А×А×А) данный способ ввода требует выполнения дополнительных процедур для переноса введенной информации о каждом фотопикселе в свой процессор матрицы, координатно соответствующий этому фотопикселю. Кроме того, наличие в прототипе только одного узла ввода изображений не позволяет быстро вводить в устройство стереоизображения с целью построения на их основе трехмерных моделей объектов фотографируемых сцен. Отсутствуют также в прототипе и аппаратно-программные средства для параллельного ввода данных с выходов массивов датчиков (например, тактильных) в процессорную матрицу А×А×А устройства, в связи с чем ввод данных с выходов таких датчиков возможен только через внешний интерфейс блока управления прототипа. Перечисленное снижает скорость ввода изображений.
Седьмая причина объясняется тем, что в прототипе каждый k-й сигнал управления процессорной матрицей поступает из блока управления ко всем ПЭ-м матрицы по одной и той же проводной линии. Поскольку ПЭ-в много и они распределены в пространстве, паразитные емкости и сопротивления проводных линий высоки, что снижает максимально допустимую частоту управления матрицей. Простое умощнение управляющего выхода с целью увеличения скорости перезаряда паразитных емкостей неэффективно, т.к. с возрастанием тока увеличивается площадь печатных проводников (что приводит к росту паразитных емкостей) и возрастает уровень помех. Используемые элементная база и несуще-соединительная конструкция прототипа не позволяют уменьшить габариты устройства и повысить плотность монтажа. Все это снижает максимально-допустимую частоту управления процессорной матрицей, а значит, и уменьшают вычислительную производительность устройства в целом.
Целью изобретения является повышение скорости и точности обработки двумерных и трехмерных изображений.
Указанная цель достигается тем, что в коммутаторе входа локальной памяти каждого процессора матрицы введен дополнительный информационный вход, соединенный с информационным выходом регистра данного процессора, в каждый процессор матрицы введен дополнительный регистр, информационный вход которого соединен с информационным выходом локальной памяти этого процессора, управляющий вход соединен с дополнительно введенным управляющим выходом блока управления, а информационный выход соединен с соответствующим входом узла определения объема и с соответствующим входом формирователя кода заполнения, узел определения объема выполнен в виде цифрового комбинационного сумматора, формирователь кода заполнения выполнен в виде нескольких, не связанных между собой многовходовых схем ИЛИ, выходы которых соединены с дополнительно введенными информационными входами блока управления, введена матрица узлов буферной памяти, каждый узел которой состоит из двух одноразрядных регистров, информационный вход первого регистра соединен с соответствующим выходом матрицы процессоров, управляющий вход соединен с входом управления записью локальной памяти, информационный выход соединен с информационным входом второго одноразрядного регистра, управляющий вход которого соединен с управляющим входом регистра операнда процессора матрицы, а информационный выход соединен с соответствующими входами блока коммутации, введены дополнительные узлы сжатия, в которых введены дополнительные входы, соединенные с выходами матрицы процессоров, а выходы соединены с информационными входами блока коммутации, информационный вход и информационный выход каждого узла памяти соединен с соответствующим входом матрицы процессоров, являющимся одновременно информационным входом и информационными выходом устройства; введены дополнительные выходы блока управления, связанные с дополнительными входами блока коммутации, дополнительные выходы которого соединены с входами управления подключением информационных выходов датчиков к информационным входам процессорной матрицы, для каждого k-го сигнала управления матрицей множество элементов матрицы разбито на непересекаемые подмножества, для каждого подмножества введен усилитель первого каскада, выход которого соединен с k-м входом управления элемента данного подмножества, все множество усилителей m-го каскада разбито на непересекаемые подмножества, для каждого подмножества усилителей m-го каскада k-го сигнала управления матрицей введен усилитель m+1-го каскада, выход которого соединен с входом каждого усилителя m-го каскада своего подмножества, входы усилителей последнего каскада соединены с выходом блока управления, соответствующим k-му сигналу управления матрицей.
В отличие от прототипа в заявленном устройстве узел определения объема является полностью цифровой схемой, объем (площадь) объекта изображения вычисляется с точностью до одного пикселя, амплитуда сигналов внутри узла не превышает уровня логической «1». Переходные процессы внутри узла скоротечны, отпадает необходимость в цикле аналого-цифрового преобразования - все это увеличивает скорость обработки изображений. Входы сумматора не соединены непосредственно с выходами ПЭ, поэтому изменение состояния выходов данных ПЭ не приводит к обязательному переключению элементов сумматора и к дополнительному энергопотреблению. Вычисление объема выполняется параллельно с другими операциями (поворотами и сдвигами), что также увеличивает скорость обработки.
В отличие от прототипа в заявленном устройстве реализованы команды переноса (ПРН а1, а2; ПРН+; ПPHV а1, а2), позволяющие выполнить перенос содержимого бинарного фрагмента А×А×А без изменения углового положения этого содержимого и за единицы машинных тактов. Кроме того, реализованы безадресные команды (СДВ, СДВ+, СДВУ, ИНЕ+, П1Х, П1Х+, П1XV и др.), позволяющие увеличить скорость обработки двумерных и трехмерных изображений за счет сокращения времени на обновление информации об адресах используемых операндов-изображений. В каждом процессоре матрицы А×А×А аппаратно реализована функция «отрицание равнозначности», часто используемая при сравнении анализируемых изображений с изображением-эталоном.
Замена А3-входовой схемы ИЛИ прототипа формирователем кода заполнения бинарного изображения (КЗБИ) в заявленном устройстве позволяет за один цикл обращения к выходам всех процессоров матрицы получить существенно большую информацию о характере распределения содержимого бинарного изображения А×А×А, чем в прототипе, поскольку многоразрядный КЗБИ заявленного устройства гораздо информативней одноразрядного выхода схемы А3-входовой схемы ИЛИ прототипа. Так, в заявленном устройстве для определения граничных х-координат объекта внутри изображения А×А×А требуется всего один цикл обращения к формирователю КЗБИ, а в прототипе для этого необходима уже целая процедура обработки, состоящая из нескольких одношаговых сдвигов содержимого изображения А×А×А и нескольких циклов обращения к А3-входовой схеме ИЛИ.
В узлах сжатия заявленного устройства ось сжатия проходит не по центру квадрата А×А (как в прототипе), а по стороне этого квадрата, поэтому диапазон коэффициентов, осевое сжатие изображения А×А на которые может быть выполнено с предельной степенью распараллеливания, в заявленном устройстве в два раза шире, чем в прототипе. Кроме того, в узлах сжатия заявленного устройства аппаратно реализованы операции центрального сжатия изображения А×А, выполняемые с предельной степенью параллелизации. Все это повышает скорость обработки.
В отличие от прототипа в заявленном устройстве одноименные входы и выходы данных у памяти изображений совмещены и соединены только с одноименными входами процессорной матрицы, в результате число проводных связей и электрических соединений между электронными компонентами устройства стало меньше. Обмен информацией между памятью изображений и узлами ввода-вывода стал возможным без участия процессорной матрицы, что увеличило скорость обмена. Появилась возможность дополнительного наращивания памяти изображений.
В отличие от прототипа в заявленном устройстве ввод 2а-уровневых оцифрованных фрагментов А×А фотоизображений осуществляется путем последовательного ввода а бинарных изображений А×А с соблюдением соответствия между разрядным битом кода яркости пикселя и координатным положением этого пикселя на изображении, в результате по окончании ввода отпала необходимость в выполнении дополнительных процедур переноса информации об яркости пикселя из соседних процессоров матрицы в свой процессор матрицы. Кроме того, в состав заявленного устройства введен дополнительный узел ввода фотоизображений, что дало возможность ввода и обработки стереоизображений.
В отличие от прототипа в заявленном устройстве используется более совершенная специальная элементная база и другой тип несуще-соединительной конструкции, что позволяет уменьшить габариты устройства и паразитные емкости проводных связей. Кроме того, проводная сеть каждого k-го сигнала управления матрицей расчленена на несколько участков с паразитной емкостью, не превышающей допустимого значения Сдоп. Перезаряд каждого такого участка осуществляется при помощи дополнительно введенного усилителя, транслирующего k-й сигнал управления либо непосредственно от блока управления, либо через последовательную цепочку усилителей-ретрансляторов, площадь (и емкость) проводников при этом не возрастает. Поскольку время перезаряда паразитных емкостей уменьшается, максимально допустимая частота управления процессорной матрицей в заявленном устройстве будет выше, чем в прототипе.
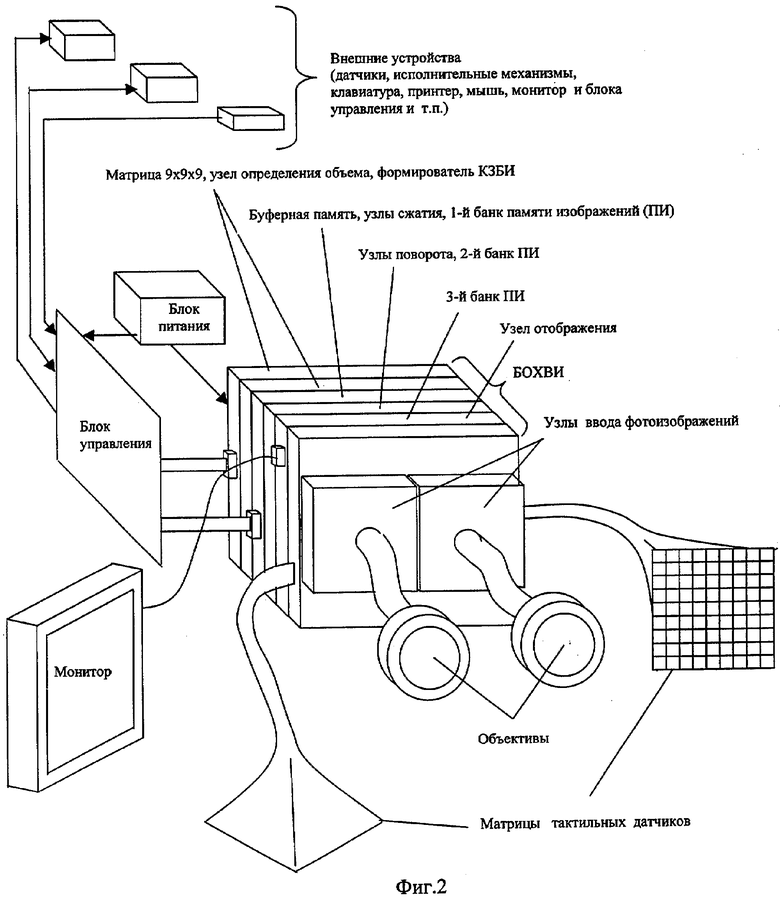
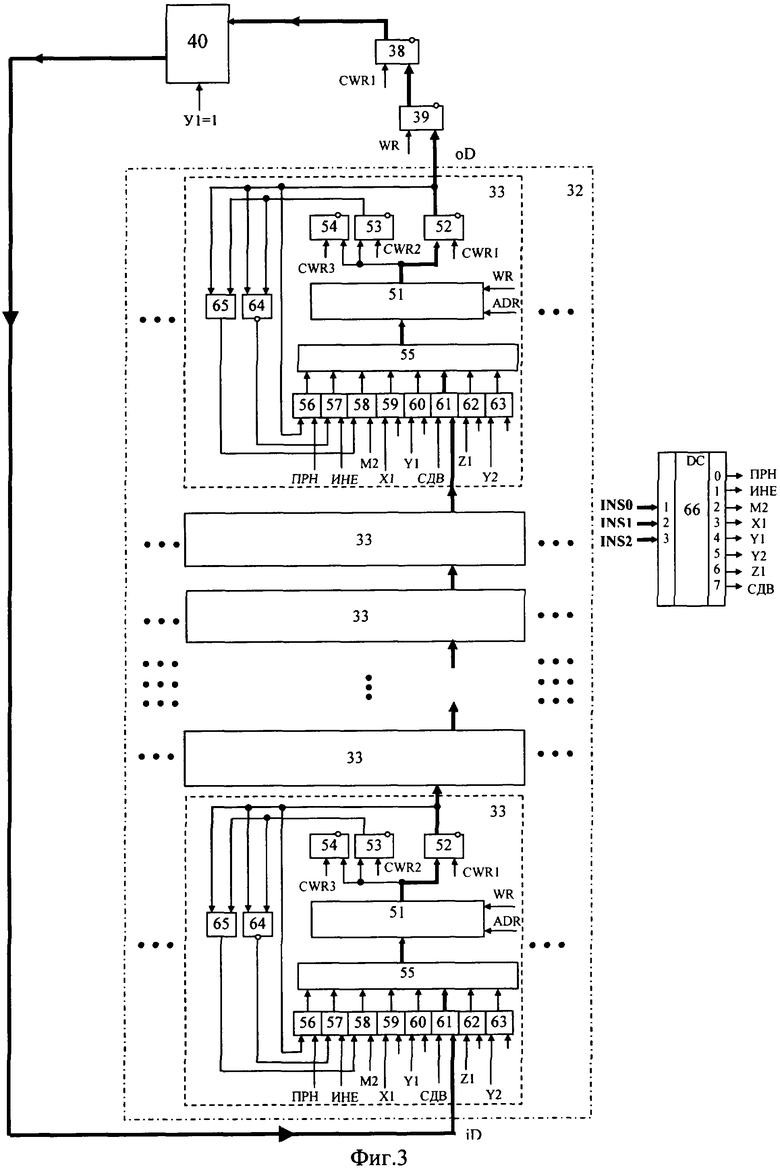
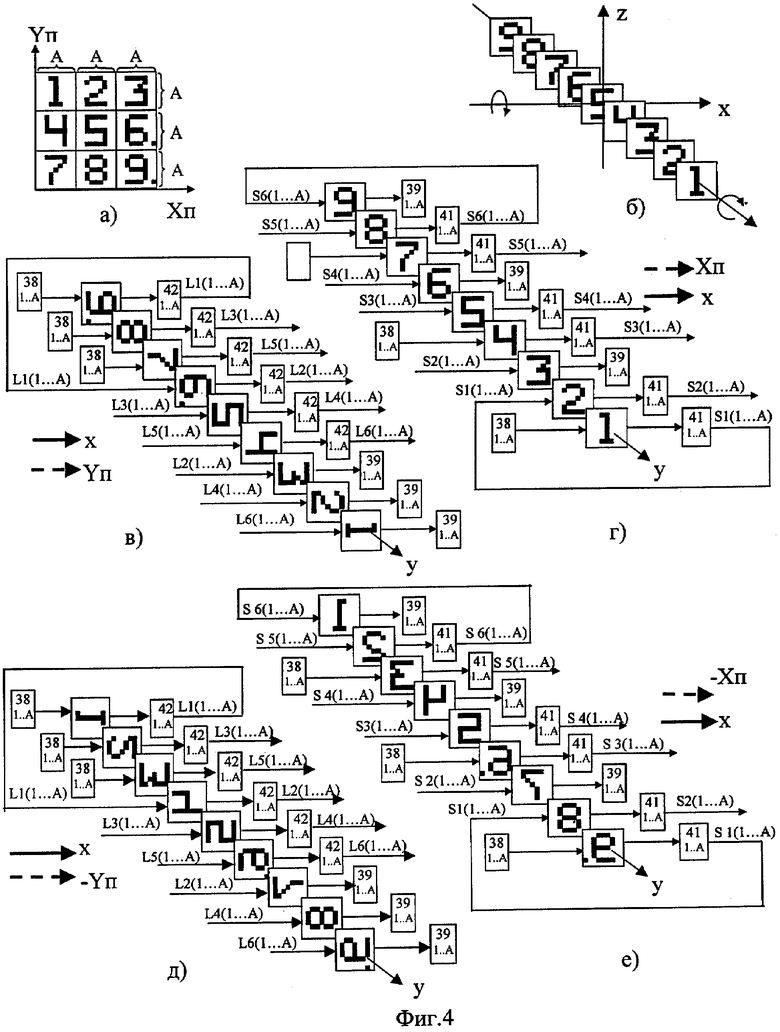
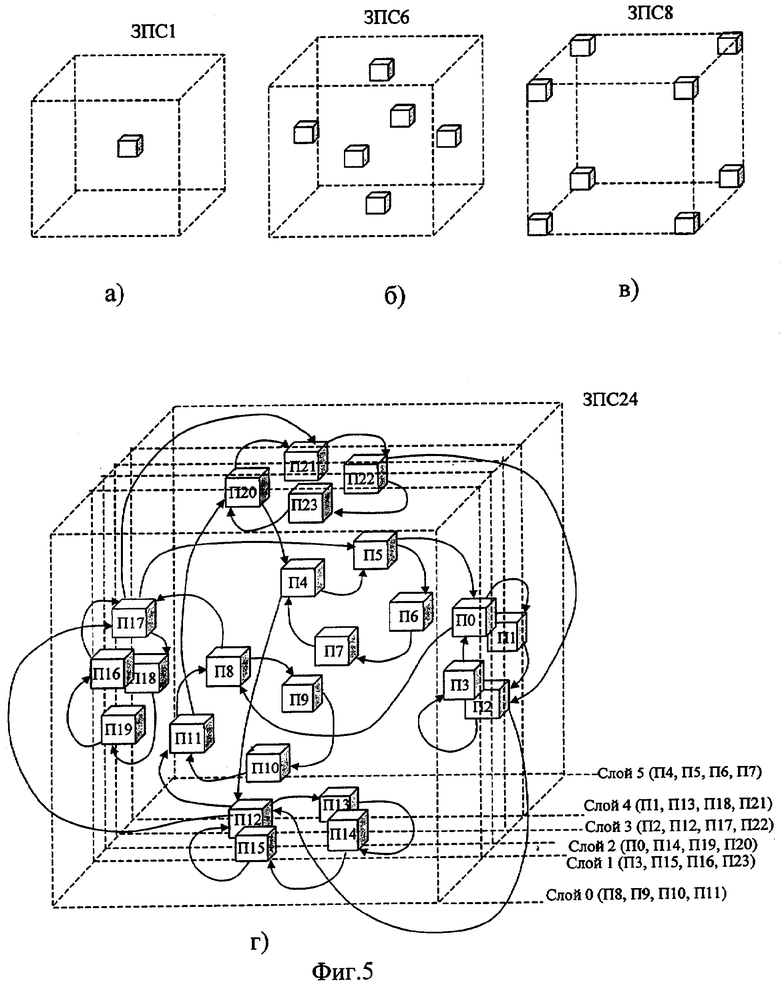
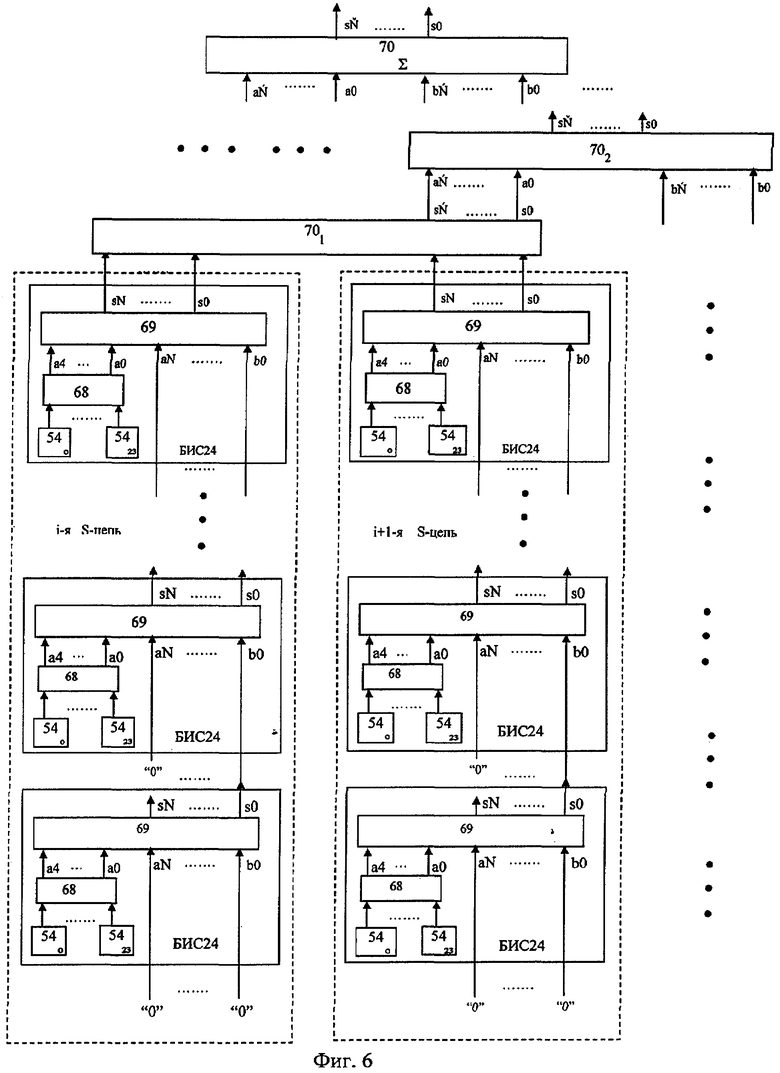
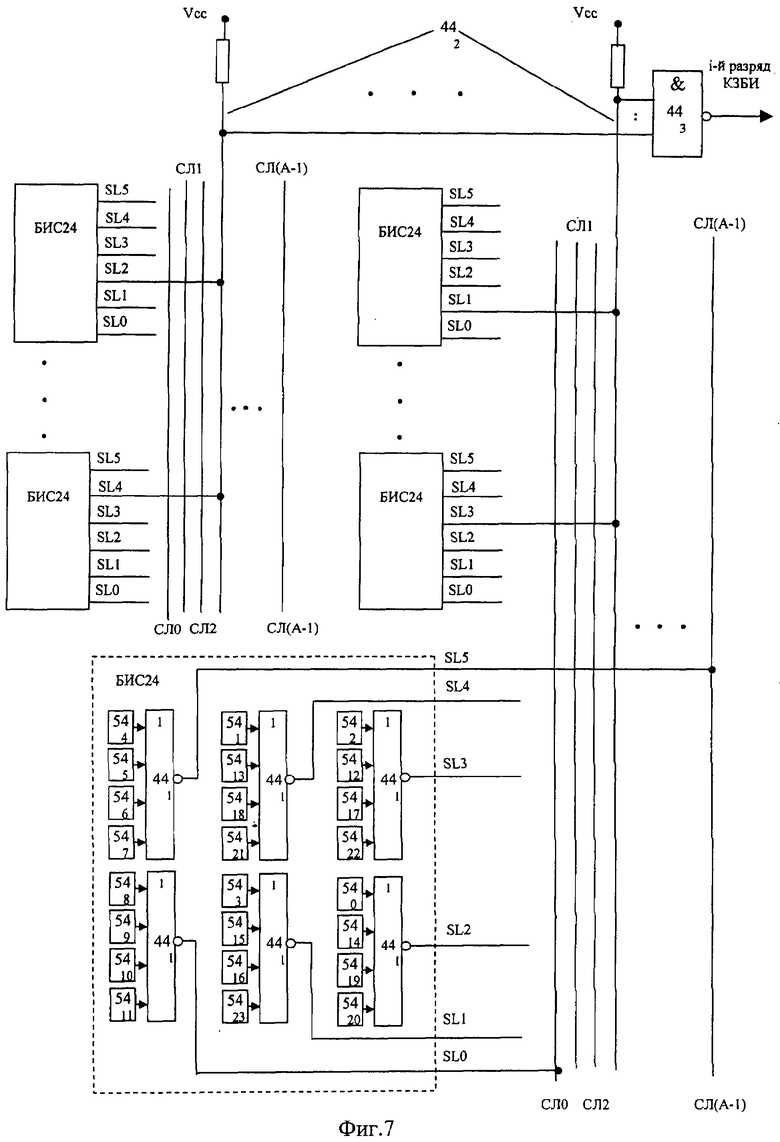
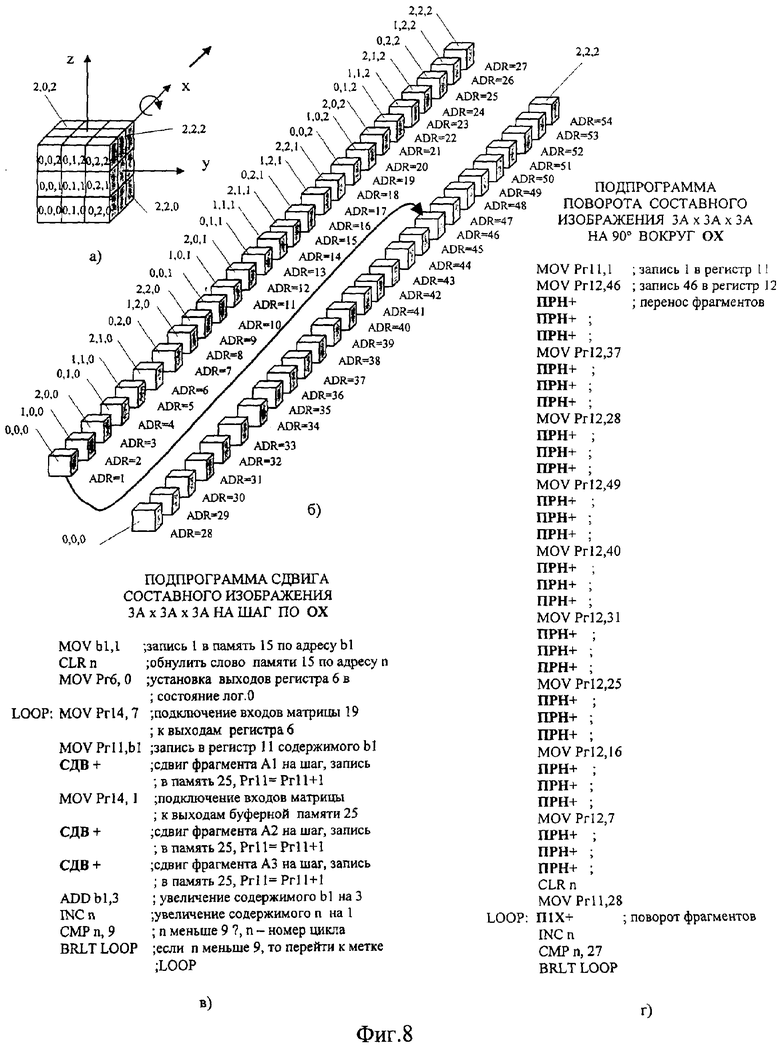
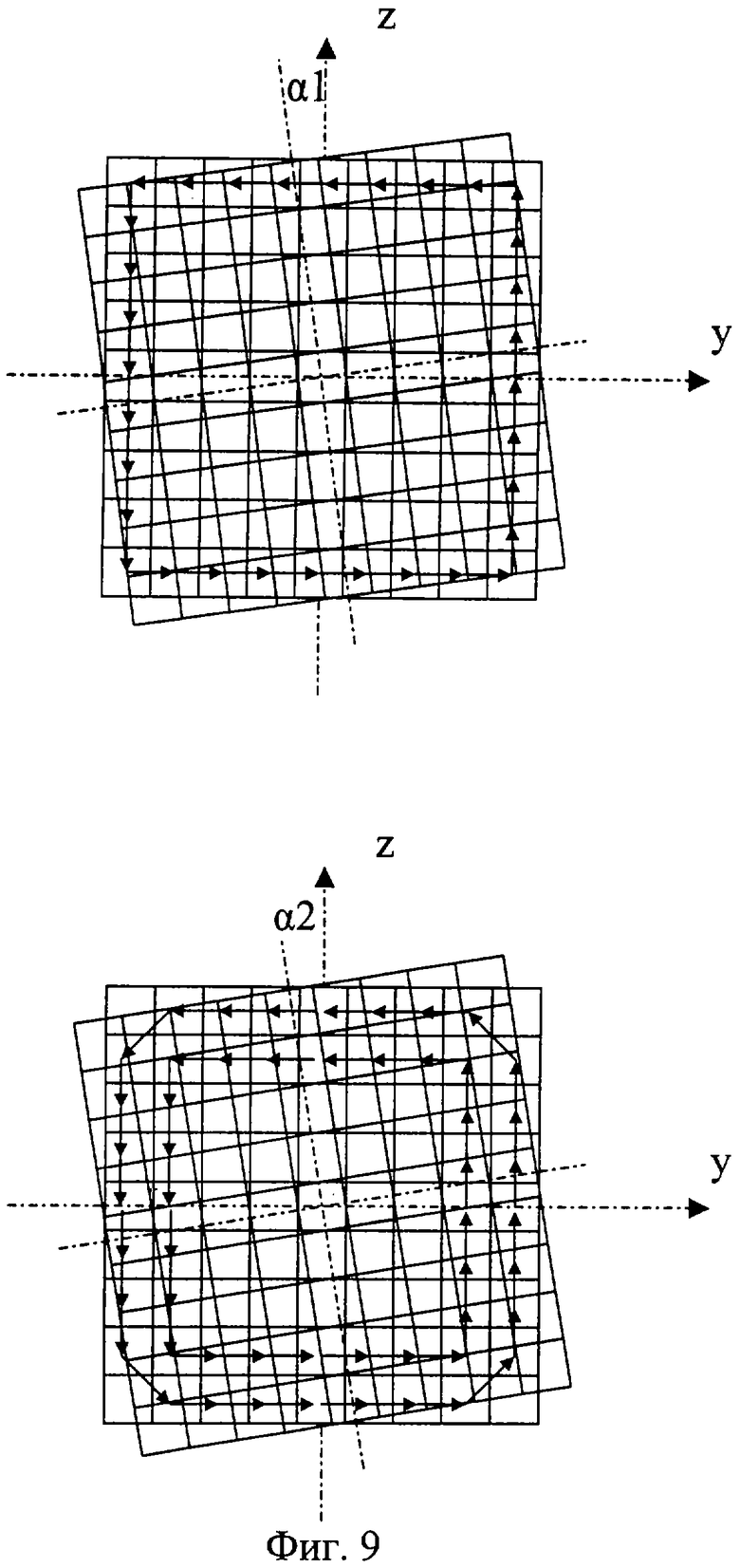
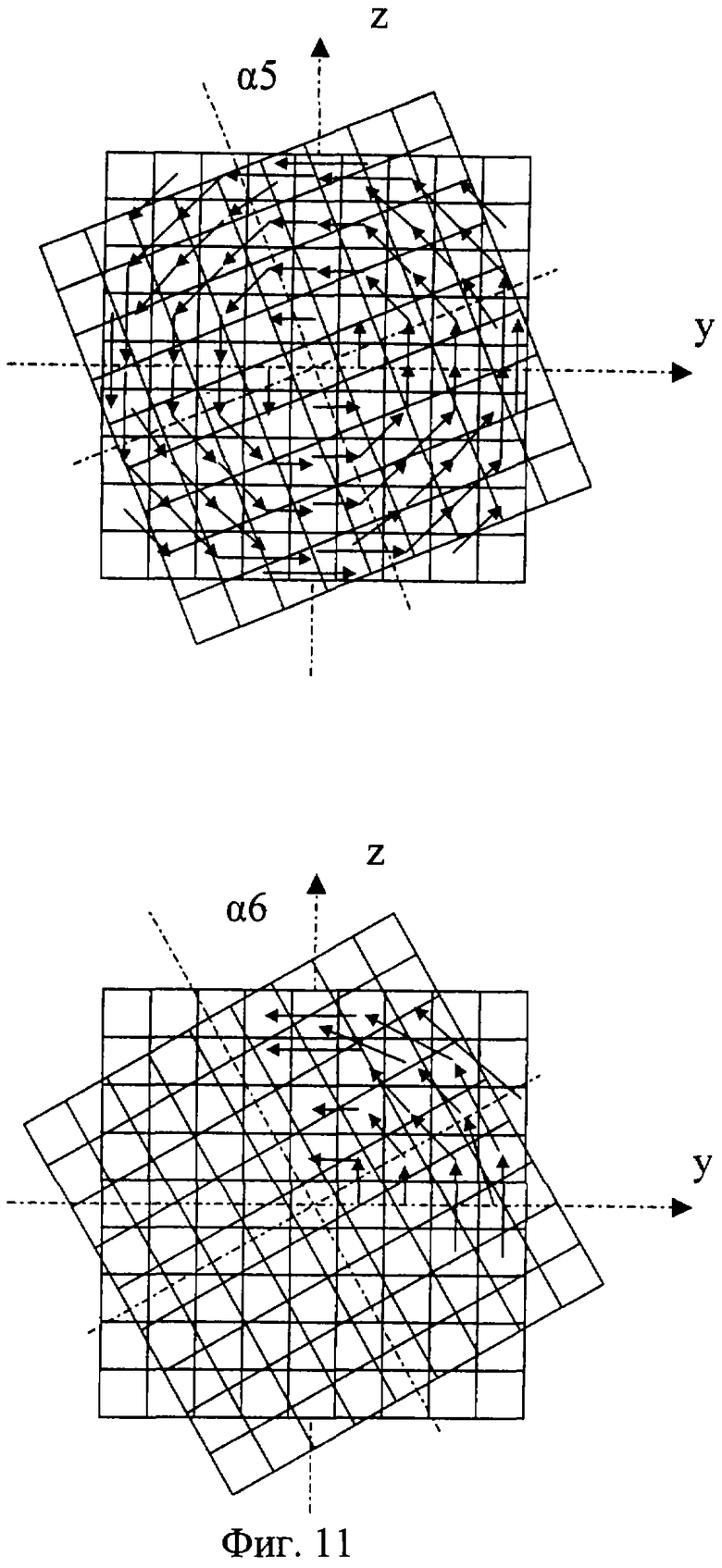
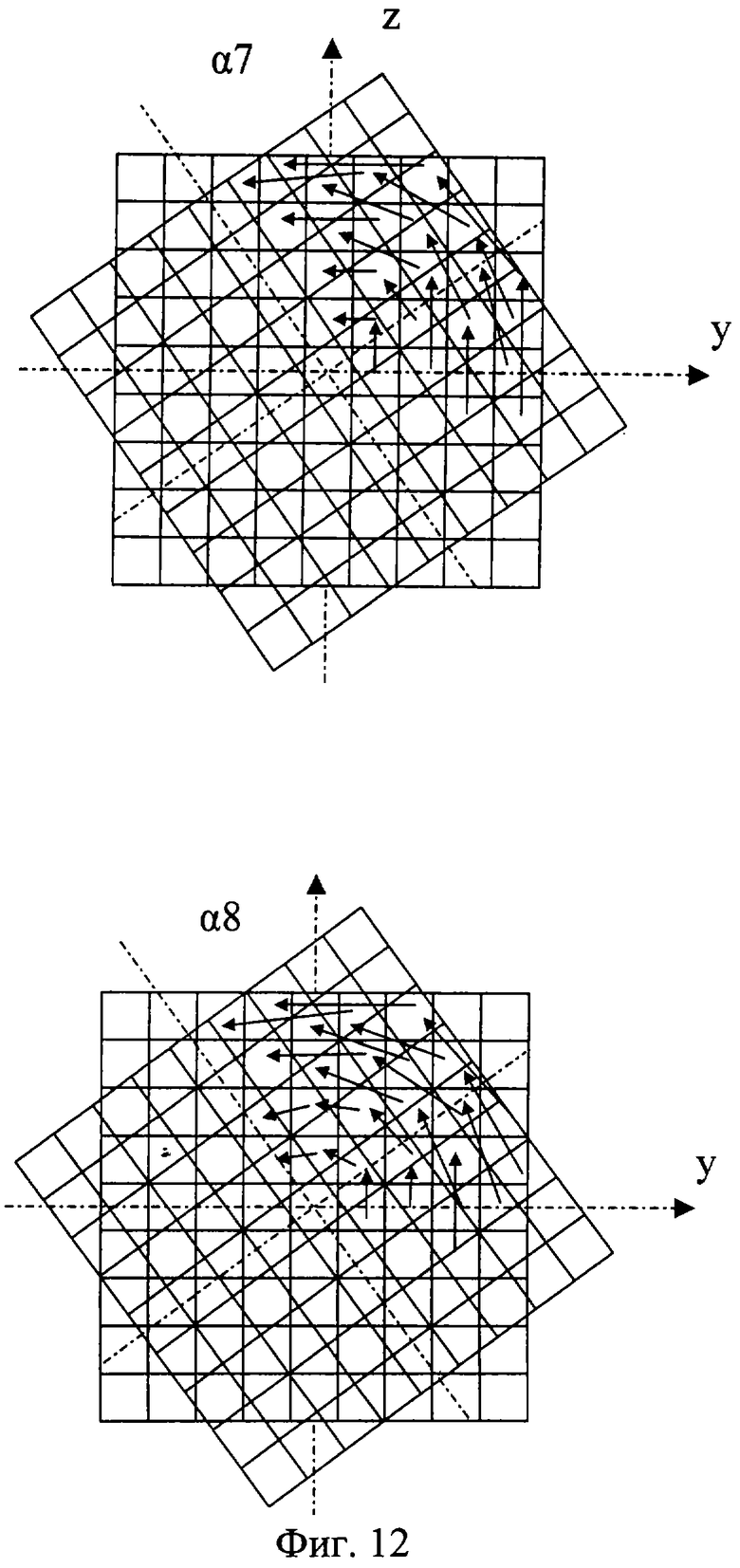
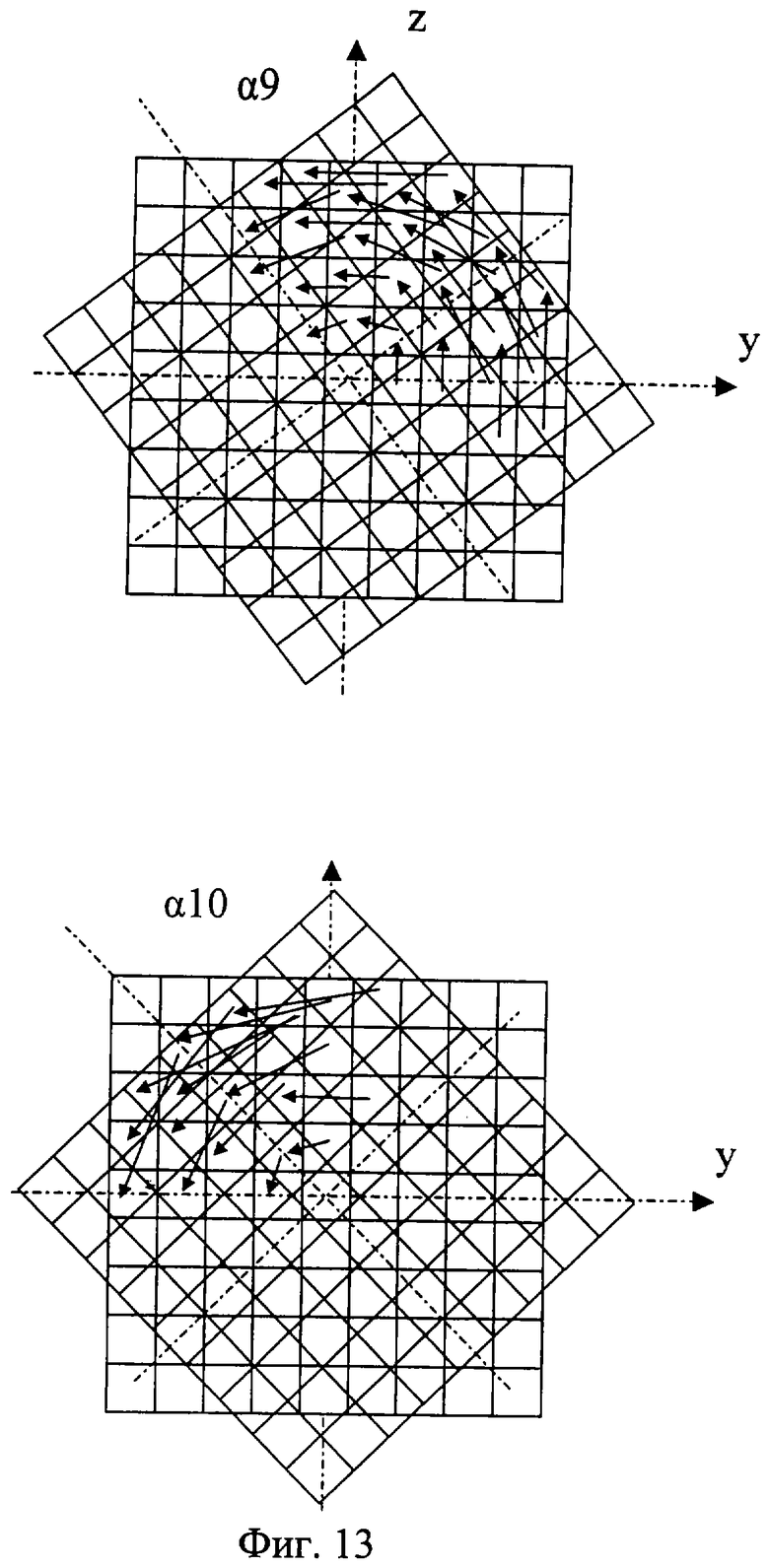
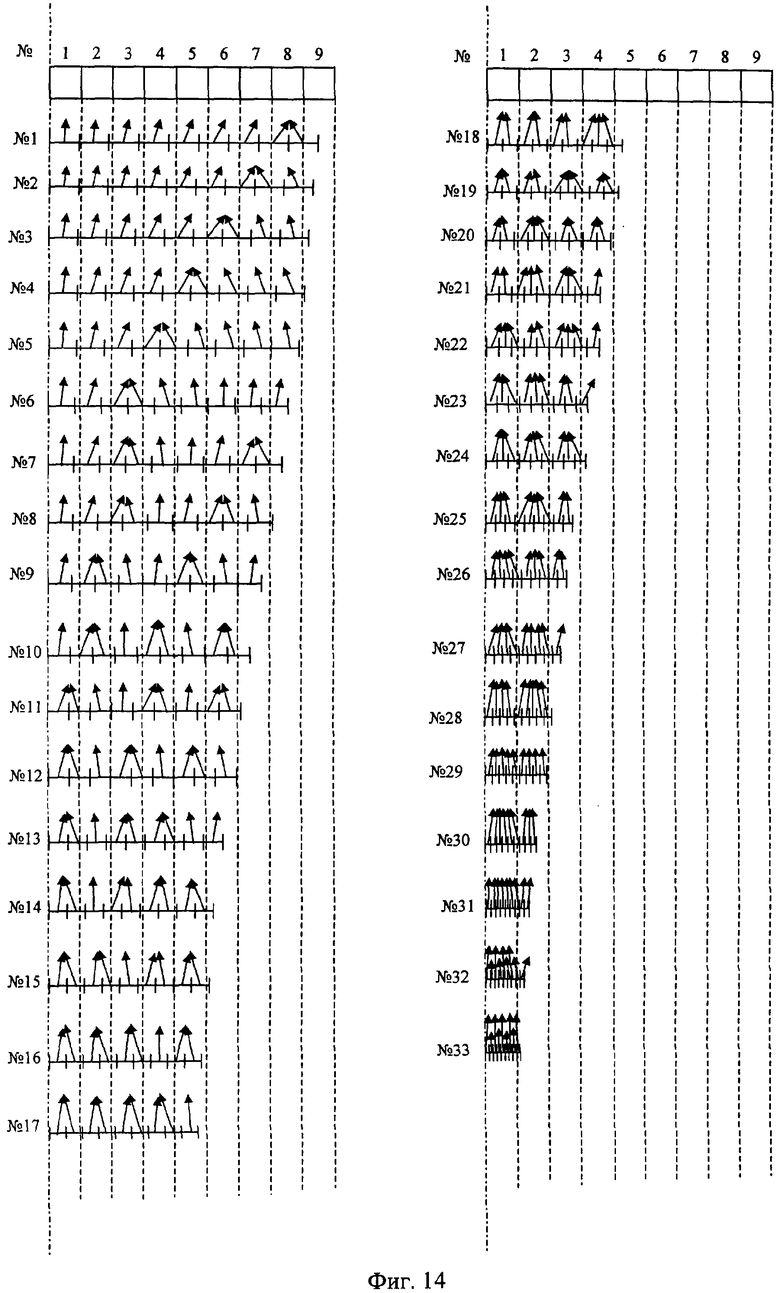
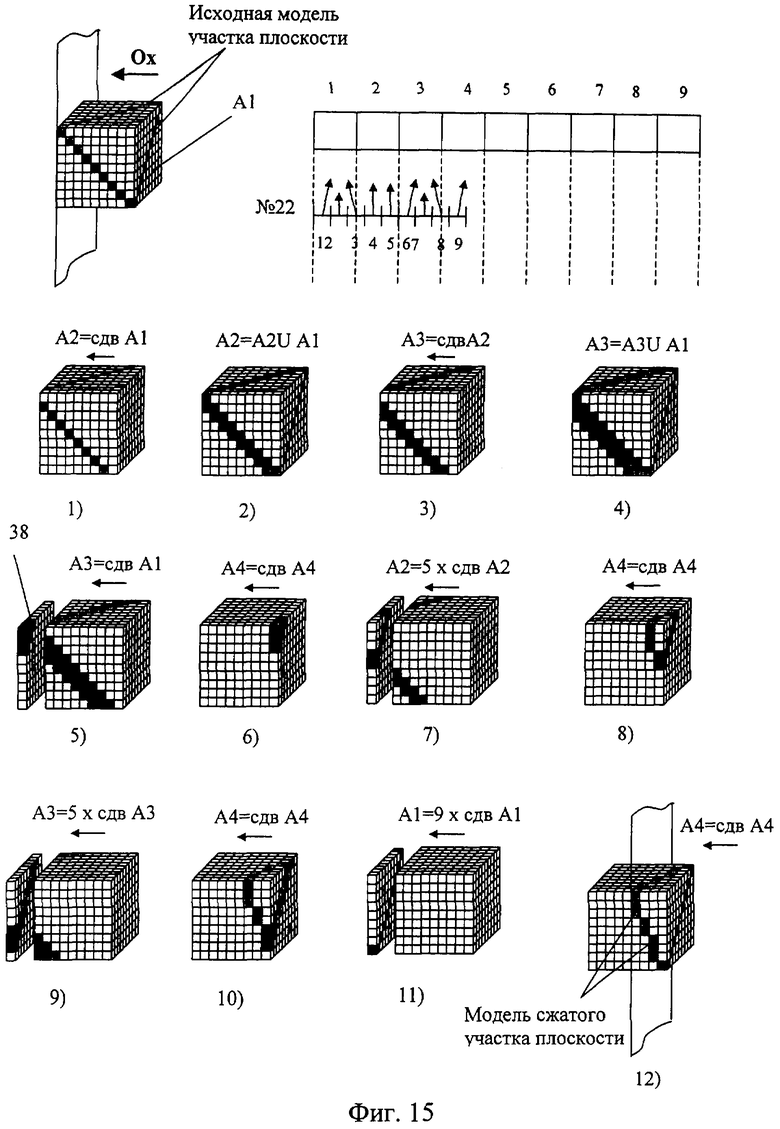
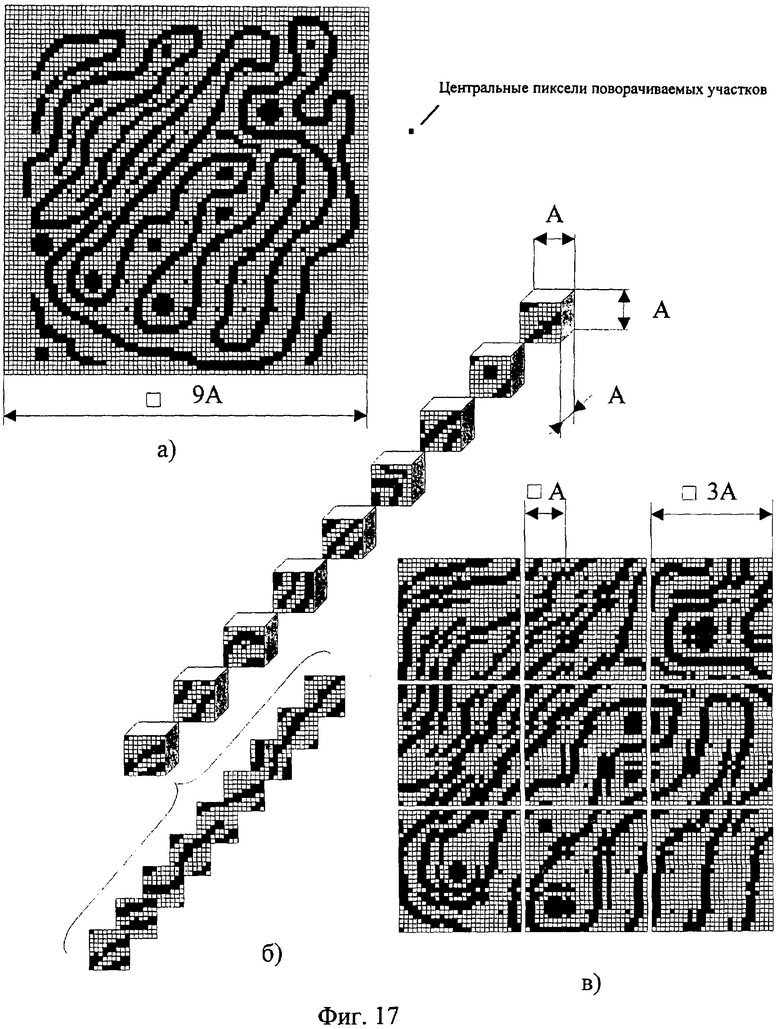
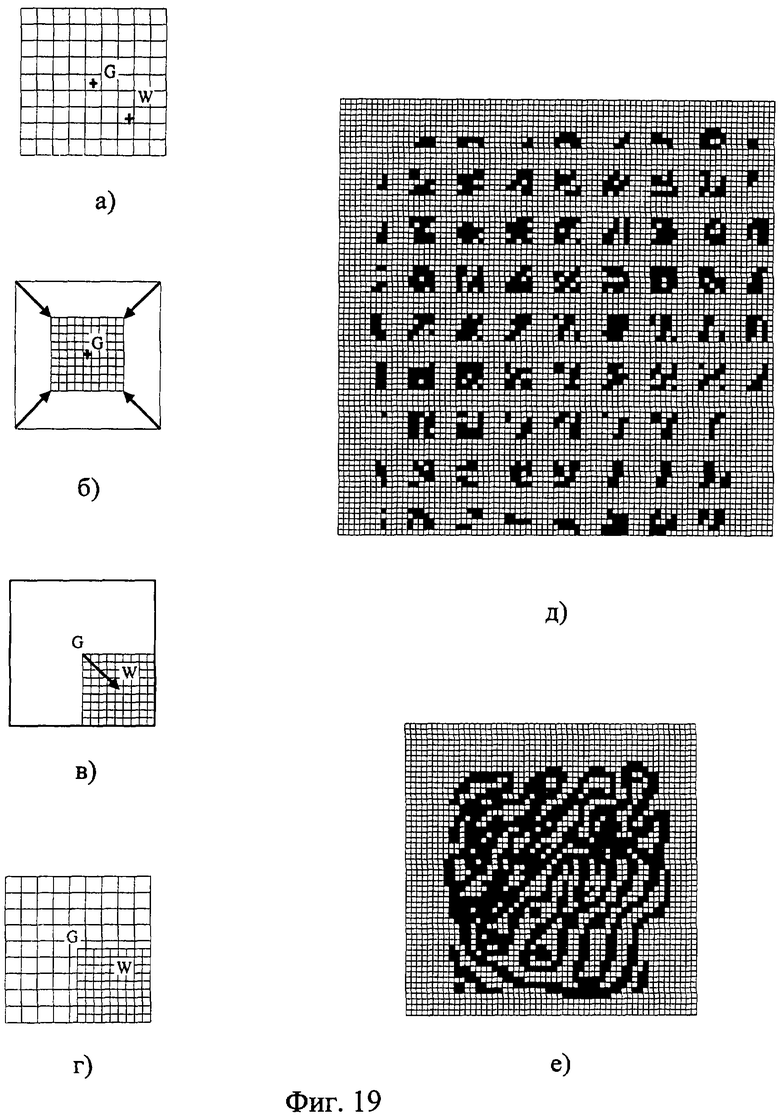
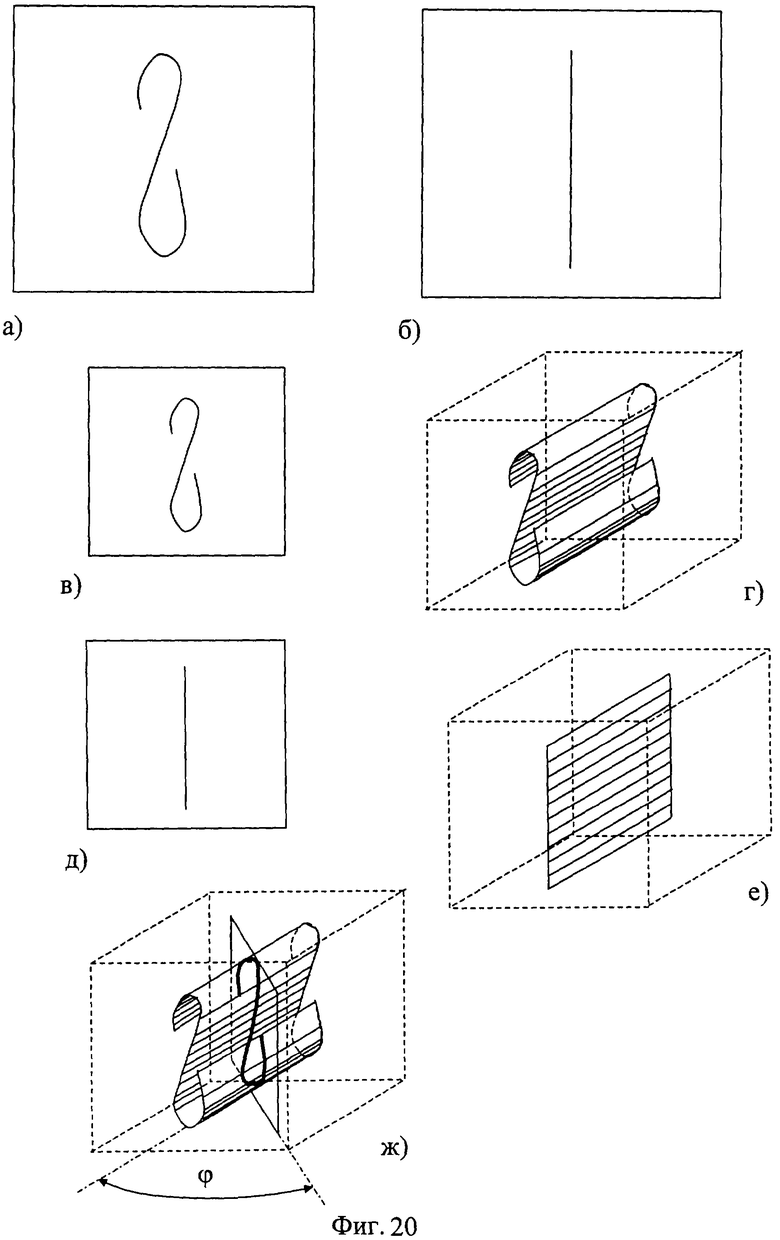
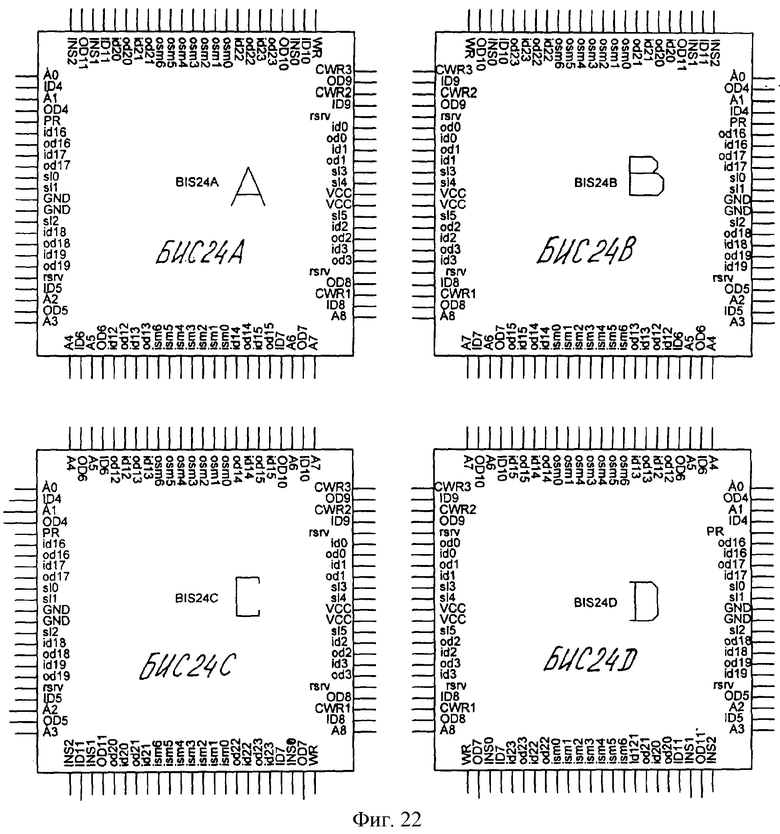
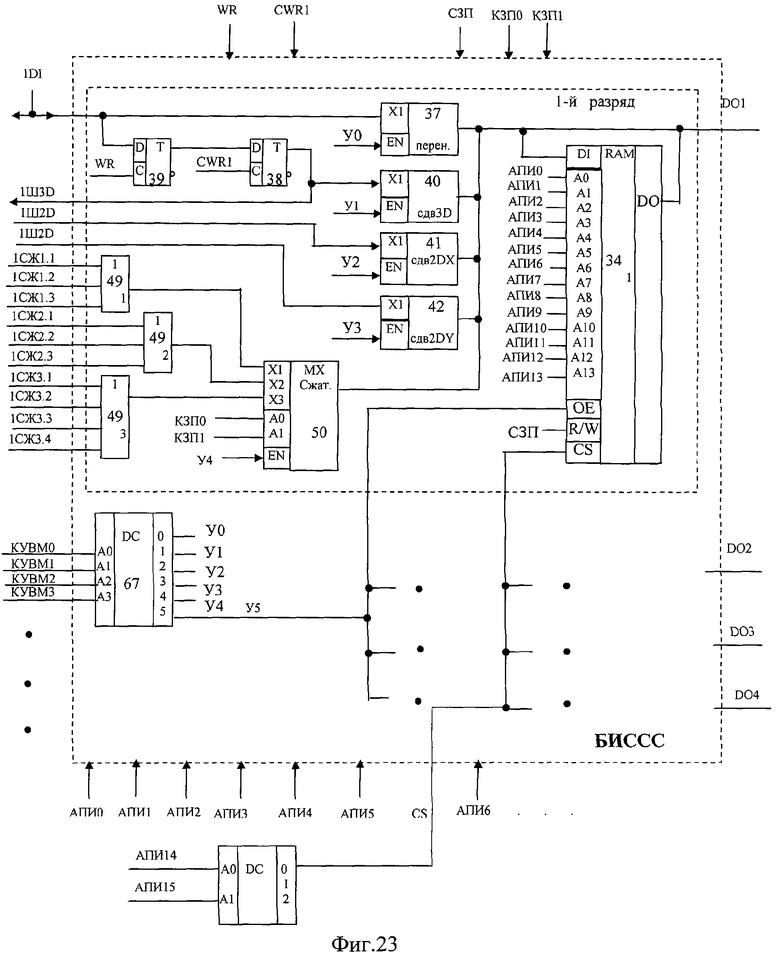
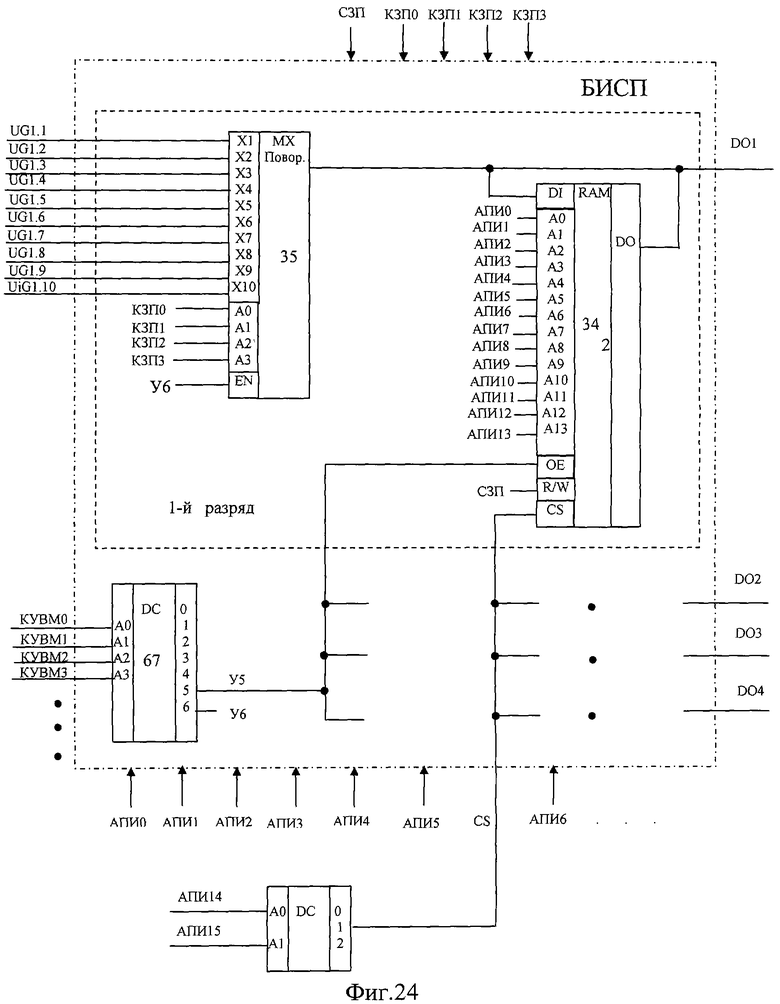
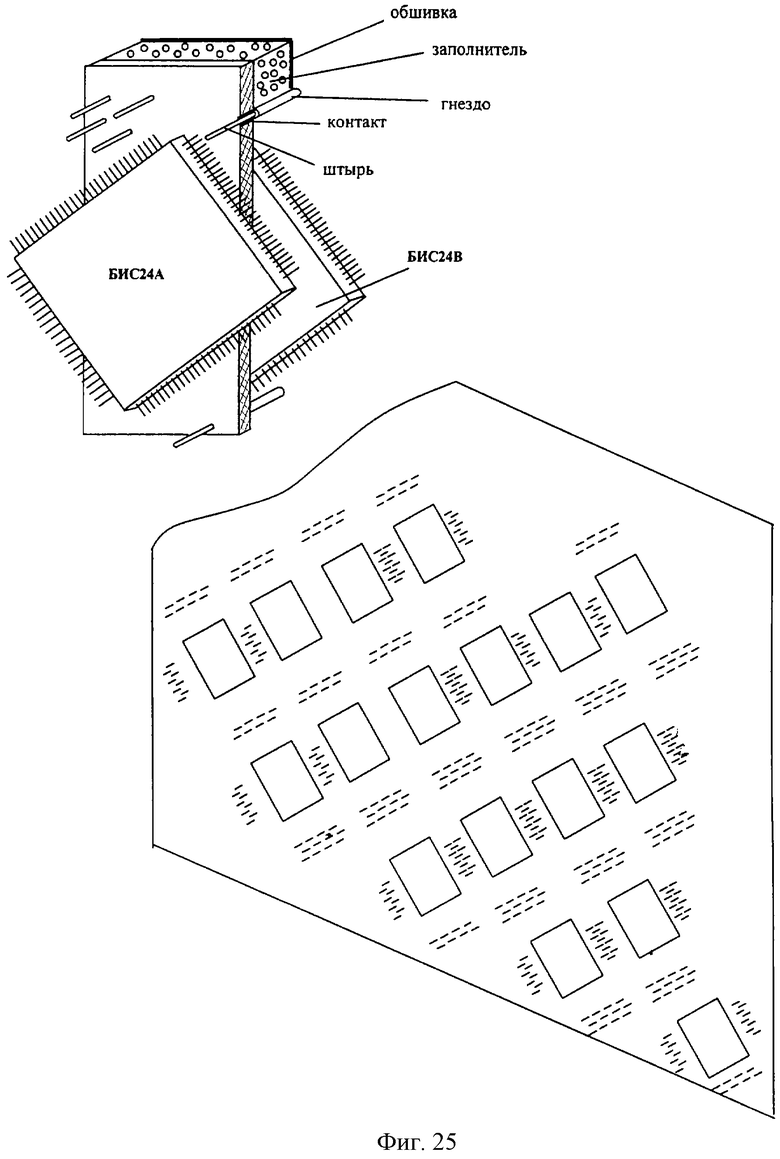
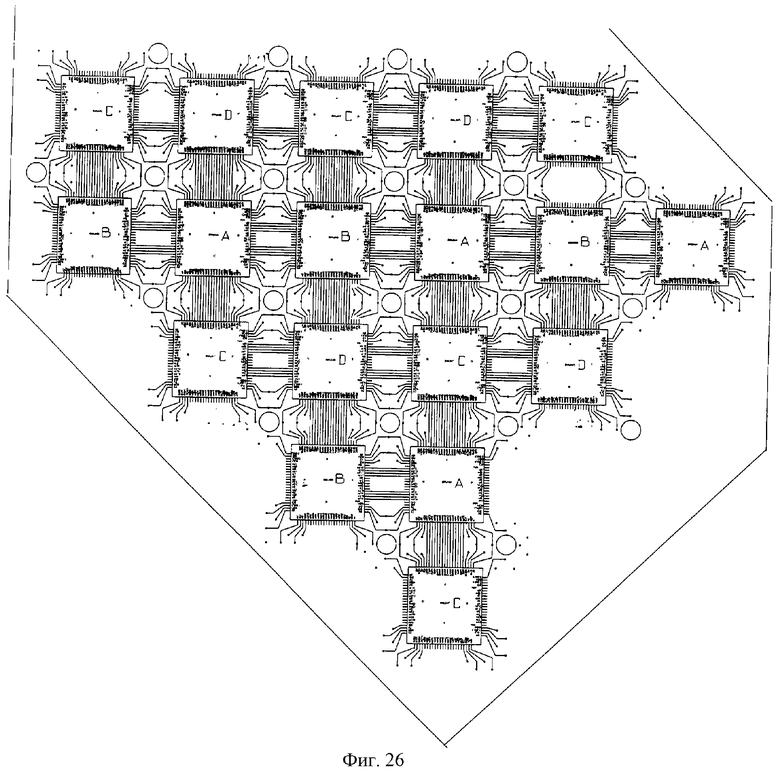
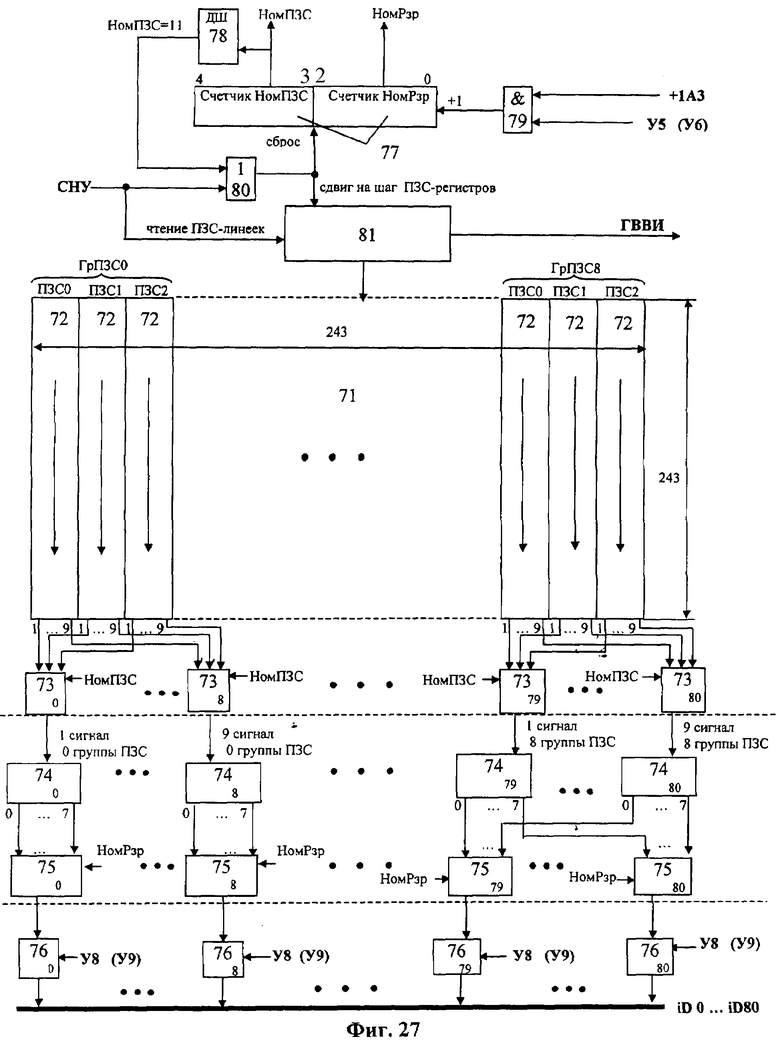
На фиг.1 изображена функциональная схема устройства. На фиг.2 показан общий вид варианта устройства. На фиг.3 изображена принципиальная схема процессорного элемента матрицы А×А×А и показаны основные пути передачи данных внутри и вне матрицы при выполнении операции одношагового переноса бинарного изображения А×А×А в направлении 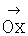 . Фиг.4 поясняет принцип реализации в устройстве одношагового переноса плоских изображений формата в направлениях ОпХп и ОпYп. На фиг.5 показаны системы процессоров матрицы А×А×А, являющиеся замкнутыми относительно своих ортогонально-кольцевых связей (ОКС) и реализуемые при помощи микросхемы БИС24. На фиг.6, 7 изображены вариант схемы узла определения объема и вариант схемы формирователя КЗБИ соответственно. Фиг.8 поясняет реализацию в устройстве операций переноса и поворота составных трехмерных изображений на углы, кратные 90°. На фиг.9, 10, 11, 12, 13 показан полный спектр р-дискретизирующих преобразований, моделирующих повороты бинарного изображения 9×9 на углы 0°<α≤45°. Полный спектр р-дискретизирующих преобразований, моделирующих геометрические преобразования сжатия бинарного изображения 9×9, показан на фиг.14. Фиг.15 иллюстрирует программное сжатие бинарного изображения А×А×А. Фиг.16 поясняет принцип моделирования поворота трехмерных бинарных составных изображений на угол, не кратный 90°. Фиг.17, 18 поясняют принцип моделирования поворота двумерных бинарных составных изображений на угол, не кратный 90°. Фиг.19 поясняет принцип моделирования центрального сжатия двумерных бинарных составных изображений. Фиг.20 поясняет принцип построения трехмерных моделей объектов по их плоским стереоизображениям. Принципиальная схема микросхем БИС24А, БИС24 В, БИС24С, БИС24D показана на фиг.21, их корпуса и расположение выводов показаны на фиг.22. На фиг.23, 24 изображены принципиальные схемы микросхем БИССС и БИСП соответственно. На фиг.25 показан вариант конструкции платы БОХВИ. На фиг.26 представлен чертеж печатных проводников одной из плат БОХВИ. На фиг.27 изображена функциональная схема узла ввода фотоизображений.
. Фиг.4 поясняет принцип реализации в устройстве одношагового переноса плоских изображений формата в направлениях ОпХп и ОпYп. На фиг.5 показаны системы процессоров матрицы А×А×А, являющиеся замкнутыми относительно своих ортогонально-кольцевых связей (ОКС) и реализуемые при помощи микросхемы БИС24. На фиг.6, 7 изображены вариант схемы узла определения объема и вариант схемы формирователя КЗБИ соответственно. Фиг.8 поясняет реализацию в устройстве операций переноса и поворота составных трехмерных изображений на углы, кратные 90°. На фиг.9, 10, 11, 12, 13 показан полный спектр р-дискретизирующих преобразований, моделирующих повороты бинарного изображения 9×9 на углы 0°<α≤45°. Полный спектр р-дискретизирующих преобразований, моделирующих геометрические преобразования сжатия бинарного изображения 9×9, показан на фиг.14. Фиг.15 иллюстрирует программное сжатие бинарного изображения А×А×А. Фиг.16 поясняет принцип моделирования поворота трехмерных бинарных составных изображений на угол, не кратный 90°. Фиг.17, 18 поясняют принцип моделирования поворота двумерных бинарных составных изображений на угол, не кратный 90°. Фиг.19 поясняет принцип моделирования центрального сжатия двумерных бинарных составных изображений. Фиг.20 поясняет принцип построения трехмерных моделей объектов по их плоским стереоизображениям. Принципиальная схема микросхем БИС24А, БИС24 В, БИС24С, БИС24D показана на фиг.21, их корпуса и расположение выводов показаны на фиг.22. На фиг.23, 24 изображены принципиальные схемы микросхем БИССС и БИСП соответственно. На фиг.25 показан вариант конструкции платы БОХВИ. На фиг.26 представлен чертеж печатных проводников одной из плат БОХВИ. На фиг.27 изображена функциональная схема узла ввода фотоизображений.
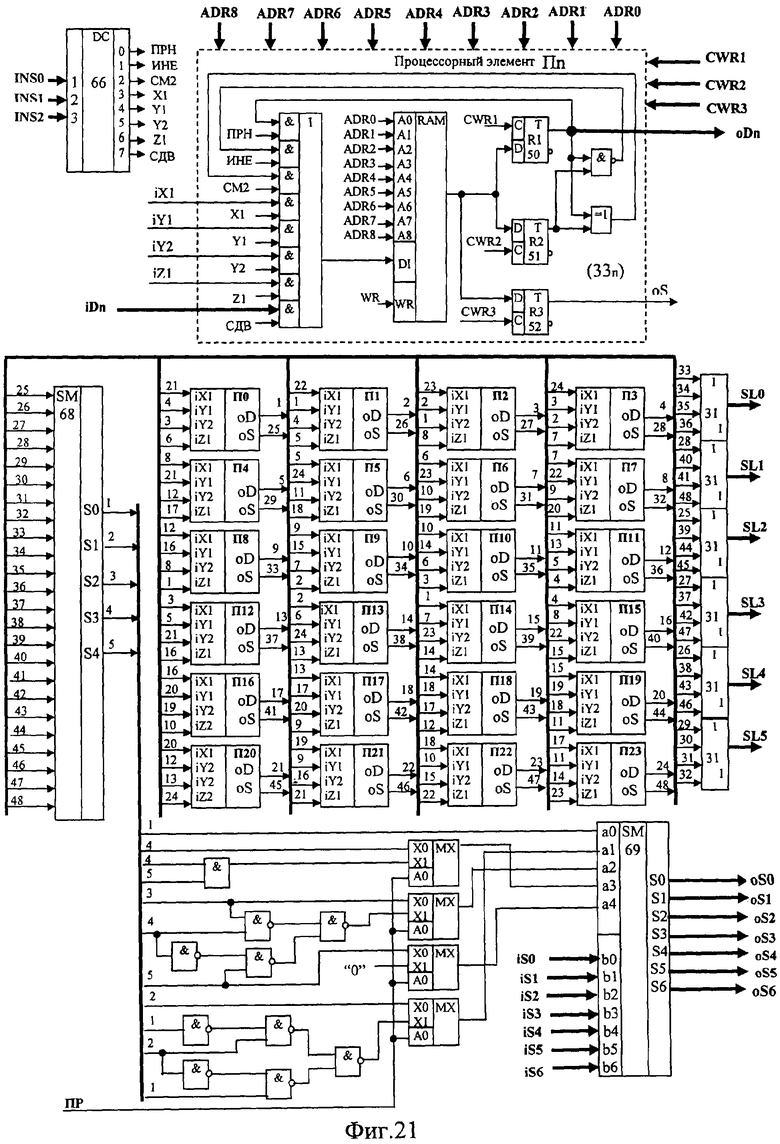
Устройство состоит из блока 1 управления (БУ) и блока 2 обработки, хранения, ввода и визуализации изображений (БОХВИ). Блок 1 включает в себя центральный управляющий процессор 3 с регистром 4 микрослова и программно-адресуемыми регистрами 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, память 15 программ и данных, контроллеры 16 внешних устройств 17, мультиплексор 18 адреса локальной памяти, элементы 19, 20, 21, 22, 23, 24, 25, 26, 27, 28 И, триггер 29, элемент задержки 30. Связь блока 1 с внешними устройствами осуществляется посредством интерфейса 31. Блок 2 состоит из матрицы 32 процессоров 33, памяти 34 изображений, коммутатора 35 поворотов, узла 36 сжатий, коммутатора 37 циклического переноса, буферной памяти 38, буферной памяти 39, коммутатора 40 3D-сдвигов, коммутатора 41 2DХ-сдвигов, коммутатора 42 2DY-сдвигов, узла 43 определения объема, формирователя 44 кода заполнения бинарного изображения (КЗБИ), узлов 45 ввода фотоизображения, матриц 46 тактильных датчиков, узла 47 отображения, коммутатора 48 слова. Узел 36 состоит из преобразователя 49 сжатий и коммутатора 50 сжатий. Каждый процессор 33 состоит из локальной памяти 51, одноразрядного регистра 52 первого операнда, одноразрядного регистра 53 второго операнда, одноразрядного регистра 54 объема, коммутатора входа локальной памяти, состоящей из схемы 55 ИЛИ, схем 56, 57, 58, 59, 60, 61, 62, 63 И, кроме того, в процессор 33 входит арифметико-логический узел, состоящий из схемы 64 И-НЕ и схемы 65 «отрицание равнозначности» (сложение по модулю 2). Код микрооперации дешифрируется в матрице 32 дешифраторами 66. Код управления входами матрицы 32 дешифрируется дешифратором 67. Узел 43 определения объема состоит из сумматоров 68, 69, 70. Каждый узел 45 ввода фотоизображений состоит из матрицы 71 ПЗС-приборов 72, коммутаторов 73, аналого-цифровых преобразователей 74, мультиплексоров 75, ключей 76, двоичного счетчика 77, дешифратора 78, схем 79 И, 80 ИЛИ, схемы 81 управления ПЗС.
Устройство работает следующим образом. В памяти 15 хранятся программы обработки. Каждая команда программы перед ее выполнением извлекается из памяти 15 и размещается в регистрах процессора 3, при этом адрес первого операнда размещается в регистре 11, адрес второго операнда - в регистре 12. Далее дешифрируется код операции извлеченной команды, после чего узлом микропрограммного управления процессора 3 вырабатываются сигналы микроопераций, необходимые для выполнения данной команды. Система команд заявленного устройства включает в себя арифметико-логические команды, команды условного и безусловного перехода, команды БОХВИ. Назначение и способ выполнения всех арифметико-логических команд, команд условного и безусловного перехода полностью определяются выбранной конструкцией процессора 3, памяти 15, интерфейса 31, которые выполняются по одной из известных схем (в частности, за их основу могут быть взяты центральный процессор, оперативная память и интерфейс ЭВМ «Электроника-100/25»). Содержимое одноразрядных слов, хранящихся по одному и тому же адресу в А3-узлах локальной памяти 51 процессоров 33 матрицы 32, в зависимости от выполняемой команды интерпретируется устройством либо как трехмерное бинарное изображение А×А×А, либо как двумерное фонарное изображение формата . На фиг.4 (а, б) показан способ представления содержимого трехмерного бинарного изображения 9×9×9 в виде двумерного бинарного изображения формата 27×27. В таблице 1 перечислены все команды БОХВИ и дано их описание. Каждой команде соответствует своя микропрограмма - набор микрокоманд, последовательное выполнение которых приводит к выполнению операции, заданной в команде. После дешифрации кода операции адрес начального микрослова команды записывается в регистр микроадреса процессора 3. По этому микроадресу из памяти микропрограмм процессора 3 извлекается управляющее микрослово и загружается в регистр 4. Это микрослово содержит управляющее поле, разряды которого используются для генерации сигналов требуемых микроопераций, а также поле следующего микроадреса и поле кода микроветвления. Поле следующего микроадреса содержит базовый микроадрес, который указывает на следующее микрослово при естественной последовательности выборки микрослов. Этот базовый микроадрес может быть модифицирован с целью микроветвления, поле кода микроветвления определяет, какие признаки необходимо проверить и использовать для модификации микроадреса. Часть управляющего поля микрослова образует поле управления БОХВИ, в это поле входят следующие группы двоичных разрядов:
разр
Все команды управления БОХВИ устройства перечислены в таблице 1.






Перечисленные команды управления БОХВИ выполняются следующим образом.
Микропрограмма команды П1Х состоит из микрокоманды, в управляющем поле БОХВИ микрослова которой установлены биты:
После расшифровки кода команды процессор 3 по тактовому импульсу С1 записывает микрослово команды П1Х в регистр 4 микрослова. После этого мультиплексор 18 адреса соединяет выходы регистра 11 адреса первого операнда с входами ADR процессорной матрицы, а мультиплексоры, образованные дешифраторами 66 и элементами 56, 57, 58, 59, 60, 61, 62, 63, соединяют входы данных локальной памяти 51 с выходами соответствующих процессоров 33 через входы iX1. По тактовому импульсу С2 посредством CWR1 происходит чтение содержимого локальной памяти 51 по адресу ADR в регистры 52, в результате на выходах oD всех процессоров 33 появляется исходное (поворачиваемое) трехмерное бинарное изображение А×А×А, а на входах данных локальной памяти формируется результирующее (повернутое) изображение А×А×А. Одновременно содержимое строки A×1×1 последнего (относительно Ох) слоя А×А×1 записывается в А разрядов программно-адресуемого регистра 13, это обеспечивает возможность передачи данных из БОХВИ в БУ. С приходом С3 сигнал WR запишет повернутое изображение в локальную память процессоров 33 по адресу ADR.
Микропрограмма команды П1Х+ состоит из микрокоманды, поле управления БОХВИ которой содержит биты:
Выполнение этой команды отличается от выполнения П1Х только тем, что после записи повернутого изображения в локальную память содержимое регистра 11 увеличивается на 1 по импульсу С4 посредством сигнала +1А1.
Микропрограмма команды П1ХУ состоит из одной микрокоманды, поле управления БОХВИ которой содержит биты:
Выполнение этой команды отличается от выполнения П1Х только тем, что чтение поворачиваемого изображения из локальной памяти производится одновременно и в регистр 52, и в регистр 54 каждого процессора 33. При этом сигнал CWR3 с выхода элемента 23 И устанавливает триггер-флаг 29 в лог.1 на время выполнения процедуры вычисления, объема и формирования кода КЗБИ. С окончанием чтения в регистры 54 начинается процесс вычисления объема прочитанного изображения А×А×А и формирование кода КЗБИ. Затем сигнал CWR3, пройдя через элемент 30 задержки, сбрасывает триггер-флаг 29 в лог.0, сообщая процессору 3 о завершении процедуры суммирования и процедуры формирования КЗБИ.
Микропрограмма команды П1Х2 а2, а1 состоит из нескольких микрокоманд, при этом выполнение первых микрокоманд связано с чтением из памяти 15 адреса а1 и адреса а2 с записью прочитанных значений в регистр 11 адреса первого операнда и в регистр 12 адреса второго операнда соответственно (способ организации такого чтения зависит от выбора одной из известных конструкций блока 1). После чтения адресов операндов выполняется микрослово, поле управления БОХВИ которого содержит биты:
Запись в локальную память осуществляется посредством следующего микрослова, поле управления БОХВИ которого содержит биты:
Микропрограмма команды П1Х2У а2, а1 отличается от микропрограммы команды П1Х2 а2, а1 тем, что предпоследнее микрослово имеет разряд ССМ=1.
Микропрограмма команды П1 Y состоит из микрокоманды:
Выполнение команды П1Y отличается от выполнения команды П1Х тем, что здесь выходы oD процессоров 33 соединены с входами локальной памяти через входы iY1.
Микропрограмма команды П1Y+ состоит из микрослова:
Выполнение команды П1Y+ отличается от выполнения команды П1Х+ тем, что здесь выходы oD процессоров 33 соединены с входами локальной памяти через входы iY1.
Микропрограмма команды П1Y2 а2, а1 начинается с чтения адресов а1, а2 (как и в команде П1Х2 а2, а1). По окончании чтения выполняется микрослово, поле управления БОХВИ которого содержит биты:
Запись в локальную память осуществляется посредством следующей микрокоманды, поле управления БОХВИ которого содержит биты:
Микропрограмма команды П1Y2V а2, а1 отличается от микропрограммы команды П1Y2 а1, а2 только тем, что имеет значение разряда ССМ=1 в предпоследнем микрослове команды.
Микропрограмма команды П2Y состоит из микрокоманды, поле управления БОХВИ которой содержит биты:
Выполнение команды П2Y отличается от выполнения команды П1Х тем, что здесь выходы oD процессоров 33 соединены с входами локальной памяти через входы iY2.
Микропрограмма команды П1Z состоит из микрослова, поле управления БОХВИ которого содержит биты:
Выполнение команды П1Z отличается от выполнения команды П1Х тем, что здесь выходы oD процессоров 33 соединены с входами локальной памяти через входы iZ1.
Микропрограмма команды П12+ состоит из микрослова, поле управления БОХВИ которого содержит биты:
Выполнение команды отличается от выполнения команды П1Х+ тем, что здесь выходы oD процессоров 33 соединены с входами локальной памяти через входы iZ1.
Микропрограмма команды П1ZV состоит из микрослова, управляющее поле БОХВИ которого содержит биты:
Выполнение команды отличается от выполнения команды П1ХУ тем, что здесь выходы oD процессоров 33 соединены с входами локальной памяти через входы iZ1.
Микропрограмма команды П1Z2 а2, а1 начинается с чтения адресов а1, а2 (как и в команде П1Х2 а1, а2). По окончании чтения выполняется микрослово, поле управления БОХВИ которого содержит биты:
Запись изображения-результата поворота в локальную память осуществляется посредством следующего микрослова, поле управления БОХВИ которого содержит биты:
Микропрограмма команды П1Z2V a2, а1 отличается от микропрограммы команды П1Z2 а1, а2 только тем, что предпоследняя микрокоманда имеет значение разряда ССМ=1.
Микропрограмма команды СДВ состоит из микрокоманды, поле управления БОХВИ микрослова которой содержит биты:
После расшифровки кода команды СДВ центральный процессор 3 по тактовому импульсу С1 записывает микрослово команды СДВ в регистр 4 микрослова. После этого мультиплексор 18 соединяет выходы регистра 11 адреса первого операнда с входами ADR процессорной матрицы, а мультиплексоры, образованные дешифраторами 66 и элементами 56, 57, 58, 59, 60, 61, 62 и 63, соединяют входы данных локальной памяти 51 с выходами oD соседних (в направлении - Ох) процессоров 33 через входы iD процессоров 33. Входы iD процессоров 33, относящихся к первому (по направлению Ох) слою A×A×1, являются входами процессорной матрицы 32. Выходы oD процессоров 33, относящихся к последнему (по направлению Ох) слою A×A×1 матрицы А×А×А, являются выходами процессорной матрицы 32. По тактовому импульсу С2 посредством сигнала CWR1 происходит чтение содержимого локальной памяти 51 с адресом ADR в регистры 52, данные буферной памяти 39 записываются в буферную память 38. В результате на выходах oD процессоров 33 формируется исходное (сдвигаемое) трехмерное бинарное изображение А×А×А, а на входах данных локальной памяти 51 формируется результирующее (сдвинутое) изображение А×А×А. С приходом С3 сигнал WR запишет сдвинутое изображение в локальную память 51 процессоров 33 по адресу ADR, последний слой A×A×1 исходного изображения запишется в буферную память 39 (фиг.3). В зависимости от значения поля КУВМ (код управления входами матрицы) программно-адресуемого регистра 14, указывающего на источник данных для входов матрицы, выполнение команды СДВ сопровождается:
а) КУВМ=0000 - записью содержимого последнего слоя A×A×1 исходного (не сдвинутого) изображения А×А×А в первый слой A×A×1 результирующего (сдвинутого) изображения А×А×А - циклический сдвиг;
б) КУВМ=0001 - записью состояния А2 выходов буферной памяти 38 в первый слой A×A×1 результирующего изображения А×А×А;
в) КУВМ=0010 - записью части содержимого последнего слоя А×А×1 исходного изображения А×А×А и части выходов буферной памяти 38 в первый слой А×А×1 результирующего изображения для моделирования операции сдвига плоского изображения на 1 шаг вдоль оси ОпХп (фиг.4 - г, е);
г) КУВМ=0011- записью части содержимого последнего слоя A×A×1 исходного изображения А×А×А и части выходов буферной памяти 38 в первый слой A×A×1 результирующего (сдвинутого) изображения для моделирования операции сдвига плоского изображения на 1 шаг вдоль оси ОпYп (фиг.4 - в, д);
д) КУВМ=0100 - записью содержимого последнего слоя A×A×1, сжатого на коэффициент k, исходного изображения А×А×А в первый слой A×A×1 результирующего изображения А×А×А, тип сжатия (осевое или центральное) и номер коэффициента k определяются кодом КЗП (код значения параметра) регистра 14;
е)КУВМ=0101-записью состояния А2 выходов памяти 34 изображений в первый слой A×A×1 результирующего изображения А×А×А;
ж) КУВМ=0110 - записью содержимого последнего слоя A×A×1, повернутого на угол α≤45, исходного изображения А×А×А в первый слой A×A×1 результирующего изображения А×А×А, номер угла α задан кодом КЗП регистра 14;
з) КУВМ=0111 - записью состояния А выходов программно-адресуемого регистра 6 в первый слой A×A×1 результирующего изображения А×А×А в виде А одинаковых строк A×1×1 этого слоя;
и) КУВМ=1000-записью состояния А2 выходов узла 451 ввода фотоизображения №1 в первый слой A×A×1 результирующего изображения А×А×А;
к) КУВМ=1001 - записью состояния А2 выходов узла 452 ввода фотоизображения №2 в первый слой A×A×1 результирующего изображения А×А×А;
л) КУВМ=1010 - записью состояния А2 выходов матрицы 461 тактильных датчиков в первый слой А×А×1 результирующего изображения А×А×А;
Микропрограмма команды СДВ+ состоит из микрокоманды, поле управления БОХВИ которой содержит биты:
Выполнение команды СДВ+ отличается от выполнения команды СДВ тем, что с окончанием сдвига сигналы +1А1, +1А2 увеличивают адреса операндов на 1.
Микропрограмма команды СДВУ состоит из одной микрокоманды, поле управления БОХВИ которой содержит биты:
Выполнение команды СДВУ отличается от выполнения СДВ только тем, что чтение сдвигаемого изображения из локальной памяти производится одновременно и в регистр 52, и в регистр 54 каждого процессора 33. По окончании чтения начинается процесс вычисления объема прочитанного изображения А×А×А.
Выполнение команды СДВ а2, а1 отличается от выполнения команды СДВ только тем, что перед выполнением сдвига из памяти 15 извлекаются адрес а1 (в регистр 11) и адрес а2 (в регистр 12).
Микропрограмма команды ПРН+ состоит из двух микрокоманд:
и
Первая микрокоманда читает исходное (копируемое) бинарное изображение А×А×А из локальной памяти 51 по адресу, хранящемуся в регистре 11, в регистры 52 процессоров 33. Вторая микрокоманда записывает прочитанное изображение в локальную память 51 по адресу, хранящемуся в регистре 12. После копирования содержимое регистров 11 и 12 увеличивается на 1.
Микропрограмма команды ПРН а2, а1 отличается от микропрограммы команды ПРН+ только тем, что перед выполнением двух последних микрокоманд происходит чтение адресов а1, а2 из памяти 15 в регистры 11 и 12 соответственно.
Микропрограмма команды ПРНV a1, а2 отличается от микропрограммы команды ПРН а1, а2 тем, что предпоследнее микрослово имеет бит ССМ=1. В результате сразу после чтения копируемого изображения начинается вычисление объема прочитанного изображения и формирование КЗБИ.
Микропрограмма команды ИНЕ+ состоит из двух микрокоманд:
и
При выполнении первой микрокоманды с приходом С2 читается первое изображение-операнд в регистры 52, а при выполнении второй микрокоманды по С2 читается второе изображение-операнд в регистры 53, затем С3 записывает изображение-результат выполненной теоретико-множественной операции (с выходов элементов 62 И-НЕ) в локальную память 51 по адресу второго операнда. После чего содержимое регистров 11 и 12 увеличивается на 1.
Микропрограмма команды ИНЕ а2,а1 отличается от микропрограммы команды ИНЕ+ тем, что перед выполнением двух последних микрослов происходит чтение адресов a1, а2 из памяти 15 в регистры 11 и 12 соответственно.
Микропрограмма команды СМ2+ отличается от команды ИНЕ+ кодом КМО=010. Кодом КМО=010 отличается и микропрограмма команды СМ2 а1, а2 от команды ИНЕ а1, а2.
Микропрограмма команды ЗПИ состоит из одной микрокоманды, поле управления БОХВИ которой содержит биты:
При выполнении команды ЗПИ с приходом СЗ состояние всех А2 входов iD матрицы 32 (источник информации определяется кодом КУВМ) импульсом СЗП записывается в память 34 изображений по адресу АПИ, значение которого расположено в программно-адресуемом регистре-счетчике 7. Одновременно сдвигается на шаг содержимое матрицы по адресу, значение которого хранится в регистре 11 (для обеспечения возможности оперативного контроля записываемой информации). После записи содержимое регистра 7 сигналом +1А3 увеличивается на 1.
Микропрограмма команды ЗУО состоит из одной микрокоманды, поле управления БОХВИ которой содержит биты:
При выполнении команды ЗУО с приходом С3 состояние всех А2 входов iD матрицы (источник информации определяется кодом КУВМ) импульсом СЗО записывается в память узла 47 отображения по адресу АЛО, значение которого расположено в регистре 5. Одновременно сдвигается на шаг содержимое матрицы 32 по адресу, значение которого хранится в регистре 11 (для обеспечения возможности оперативного контроля записываемой информации). После записи содержимое регистра 5 сигналом +1А3 увеличивается на 1. Конструкция и работа узла 47 не отличаются от конструкции и работы узла отображения прототипа.
Сумматор узла 43 определения объема в общем случае может быть выполнен по любой из известных схем двоичных сумматоров [5]. Выбор конкретной схемы сумматора 43 определяется выбором элементной базы процессорной матрицы 32 и способом компоновки электронных компонентов матрицы 32 на платах устройства. Для уменьшения габаритов матрицы А×А×А и повышения тактовой частоты ее управления необходимо размещать компоненты матрицы с максимально возможной плотностью. Поскольку всю процессорную матрицу 32 невозможно разместить на одном полупроводниковом кристалле, процессоры 33 и часть ее межпроцессорных связей реализуются внутри нескольких (от десятков до сотен) кристаллов, другая часть межпроцессорных связей выполняется в виде проводных связей между этими кристаллами. Надежность межкристальных связей определяется применяемым способом выполнения электрического соединения (неразъемные соединения надежнее разъемных).
Отсюда для повышения надежности устройства необходимо уменьшать число применяемых кристаллов, увеличивать долю внутрикристальных межпроцессорных связей, уменьшать долю разъемных межкристальных соединений. В то же время неоправданное уменьшение разъемных соединений может привести к недопустимому увеличению длины проводных связей или к резкому снижению ремонтнопригодности устройства. Наибольшую долю межпроцессорных связей прототипа составляют ортогонально-кольцевые связи (ОКС), реализующие повороты содержимого матрицы А×А×А на углы n×90° (где n - целое число) вокруг центральных ортогональных осей (Ox,Oy,Oz) куба А×А×А (фиг.5-г). Поэтому целесообразно размещать внутри одного кристалла все процессорные элементы 33 (с их ОКС), соответствующие кубики 1×1×1 которых при поворотах куба А×А×А на углы, кратные 90° градусов, переходят друг в друга. Процессорные элементы, удовлетворяющие этому условию, образуют замкнутую систему относительно своих ОКС. В матрице А×А×А можно выделить 4 типа таких замкнутых процессорных систем (ЗПС1, ЗПС6, ЗПС8, ЗПС24), содержащих 1, 6, 8 и 24 процессорных элементов 33 каждая соответственно (фиг.5). Наиболее многочисленной и универсальной является 24-процессорная замкнутая система (ЗПС24) - фиг.5 (г). В случае размещения ЗПС24 внутри одного кристалла (условно назовем такой кристалл БИС24) все ОКС процессоров 33 данной ЗПС24 тоже размещаются внутри этого кристалла. Возьмем за основу вышеописанный способ упаковки процессоров 33 в кристалле, тогда можно предложить следующую конструкцию узла 43 (фиг.6), допускающую возможность высокоплотной упаковки кристаллов матрицы А×А×А на плате. Узел 43 представляет собой многоступенчатый сумматор, каждая первая ступень 68 которого размещается внутри БИС24, выполняется по схеме параллельного комбинационного сумматора, и суммирует логические состояния с выходов регистров 52 24-х процессоров этого кристалла; вторая ступень 69 сумматора 43 размещается внутри этого же кристалла и суммирует код с выходов первой ступени сумматора 68 своего кристалла с выходным кодом второй ступени 69 соседнего кристалла БИС24.
Суммирование на этом этапе осуществляется последовательно от кристалла к кристаллу (фиг.6), образуя по схеме суммирования последовательную цепь связанных микросхем БИС24 (S-цепь). Из кристаллов БИС24, размещенных на одной стороне платы БОХВИ, формируется несколько таких S-цепей (независимых друг от друга по схеме суммирования). От числа кристаллов БИС24, входящих в самую длинную S-цепь, зависит время выполнения второго этапа суммирования (чем короче S-цепь, тем выше скорость суммирования). Коды частных сумм, снимаемые с выходов ступеней 69 кристаллов, находящихся в конце S-цепей, поступают на входы следующих ступеней-сумматоров 70, выполненных согласно одной из известных схем пирамидальных сумматоров [5] с использованием традиционной элементной базы. Микросхемы ступеней 70 расположены на плате за пределами участков платы, занятых микросхемами БИС24 (фиг.26).
А-разрядный формирователь 44 кода заполнения бинарного изображения (КЗБИ) состоит из А независимых одноразрядных формирователей КЗБИ. Каждый i-й одноразрядный формирователь КЗБИ представляет собой А2-входовую схему ИЛИ, входы которого соединены с выходами регистров 54 всех процессоров 33, принадлежащих i-му слою А×А×1 матрицы. Логическая 1 на выходе j-го одноразрядного формирователя КЗБИ означает, что j-й слой А×А×1 трехмерного бинарного изображения А×А×А, хранящегося в данный момент в регистрах 54 матрицы А×А×А, не пуст (т.е. содержит хотя бы один пиксель 1×1×1 в состоянии лог.1). Выбор конкретной схемы формирователя 44 зависит от выбора элементной базы процессорной матрицы и способа компоновки электронных компонентов матрицы на платах устройства. Если взять за основу вышеописанный способ упаковки процессоров 33 в кристалле БИС24, тогда можно предложить следующую конструкцию узла 44 (фиг.7), допускающую возможность высокоплотной упаковки кристаллов матрицы 32 на плате. В БИС24 вводятся шесть 4-входовых элементов 441 ИЛИ-НЕ, по одному элементу 441 на один слой ЗПС24. Процессоры 33 i-го слоя ЗПС24 (где 0≤i≤5) одновременно входят в состав j-го слоя А×А×1 (где 0≤i≤A-1) процессорной матрицы А×А×А. Каждый элемент 441 является первой ступенью одноразрядного формирователя КЗБИ, вторая ступень 442 выполнена по схеме «монтажное ИЛИ», третья ступень 443 выполнена по схеме И-НЕ и объединяет выходы всех ступеней 442 j-го одноразрядного формирователя КЗБИ.
Входы процессорной матрицы 32 одновременно являются информационными входами и выходами устройства и позволяют организовать высокоскоростной ввод-вывод больших массивов информации. В случае использования заявленного устройства для целей очувствления роботов эти входы могут быть использованы для ввода видеоинформации, а также информации, поступающей с выходов матриц 46 тактильных (или других типов) датчиков, моделирующих «рецепторы» робота. Простейший пример матрицы 46 - это массив несвязанных между собой пар контактов, работающих на замыкание и размыкание. Более сложно организованный массив датчиков встречается при вводе фотоизображений с выходов узлов 45.
Работу узлов 45 ввода фотоизображений рассмотрим на примере устройства с процессорной матрицей 9×9×9. Световой поток, модулированный по освещенности, через оптическую систему (объективы, оптико-волоконный кабель) поступает на матрицу 71 из 27 ПЗС-приборов 72 (фиг.27). На каждый ПЗС-прибор 72 фокусируется свой участок 9×243 вводимого изображения 243×243. Каждый ПЗС-прибор 72 содержит 9 линеек фоточувствительных элементов по 243 элементов в каждой линейке (фиг.27). Каждая линейка имеет собственный регистр сдвига, поэтому с одного прибора 72 одновременно снимается 9 аналоговых сигналов. С 27 приборов 72 одновременно снимается 243 аналоговых сигнала, соответствующих горизонтальной строке вводимого изображения. ПЗС-приборы 72 объединены в группы по 3 прибора 72 в каждой группе, каждой группе приборов 72 соответствует 9 аналого-цифровых 8-разрядных преобразователей 74. Подключение выходов ПЗС-приборов 72 к входам АЦП-преобразователей 74 осуществляется с помощью коммутаторов 73. Подключение выходов АЦП-преобразователей 74 к входам процессорной матрицы 9×9×9 осуществляется с помощью мультиплексоров 75 и ключей 76. Управляет коммутаторами счетчик 77, при этом младшая часть счетчика (0, 1, 2 разряды) управляет коммутаторами 75, старшая часть счетчика (3, 4 разряды) управляет коммутаторами 73. Кроме того, третьим состоянием выходов коммутаторов 76 управляет выход дешифратора 67 (У8 - для узла 451, У9 - для узла 452). Съем фотоизображения производится командой ЧТФ, состоящей из микрокоманды, поле управления БОХВИ микрослова которой содержит биты:
Сигнал СНУ осуществляет чтение ПЗС-линеек, после чего схема 81 сдвигает прочитанное содержимое на выход ПЗС-приборов 72. Если У8 (У9)=1, сигналы с выходов коммутаторов 74 поступают на входы матрицы 9×9×9. При выполнении команд типа СДВ (или ЗПИ) информация с входов матрицы 32 записывается в первый слой А×А×1 матрицы 32 по адресу, хранящемуся в регистре 11 (или в память 34 по адресу, хранящемуся в регистре 7). После записи сигнал +1А3 добавляет 1 в счетчик 77 и содержимое на входах матрицы 32 меняется. Одновременно изменяется содержимое адресных регистров-счетчиков 5, 7.
Рассмотрим использование вышеописанных команд управления БОХВИ для реализации простейших и наиболее часто используемых процедур обработки изображений высокого разрешения. Принцип обработки таких изображений с помощью заявленного устройства проиллюстрируем на примере трехмерного бинарного составного изображения 3А×3А×3А (фиг.8-а). Вариант размещения этого изображения в локальной памяти 49 матрицы 19 показан на фиг.8 (б) и состоит в размещении всех его 27 фрагментов F(i,j,k) формата А×А×А по 27 последовательным адресам (ADR1...ADR27) памяти 49. Установим взаимно-однозначное соответствие между фрагментами F(i,j,k) изображения 3А×3А×3А и адресом этого фрагмента в памяти 49, тогда параллельный перенос содержимого бинарного изображения 3А×3А×3А на вектор [qA,rA,sA] (где q,r,s - целые числа) сводится к последовательному обмену содержимым между фрагментами А×А×А с адресами ADR1...ADR27 (путем последовательного выполнения команд ПРН) и заполнению освободившихся фрагментов пустым содержимым (при помощи команд СМ2 а1, а1).
Сдвиг составного бинарного изображения 3А×3А×3А на один шаг в направлении Ох уже предполагает обмен слоями А×А×1 между фрагментами F(i,j,k). Программа, реализующая сдвиг изображения 3А×3А×3А на 1 шаг по Ох, приведена на фиг.8 (в).
Сжатия и повороты изображений А×А×А моделируются в устройстве при помощи т.н. р-дискретизирующих преобразований [2, 6]. При этом весь спектр р-дискретизирующих преобразований, моделирующих повороты бинарного изображения А×А на углы 0°<α≤45°, реализован в устройстве аппаратно (в узлах поворота), а из всего спектра р-дискретизирующих преобразований, моделирующих геометрические преобразования сжатия, часть преобразований (наиболее часто используемых) реализована в БОХВИ аппаратно (в узлах сжатия), другая часть этого спектра реализуется программно. Поясним сказанное на примере устройства с матрицей 9×9×9. Полный спектр р-дискретизирующих преобразований, моделирующих повороты бинарного изображения 9×9 на углы 0°<α≤45°, показан на фиг.9, 10, 11, 12, 13. Полный спектр р-дискретизирующих преобразований, моделирующих геометрические преобразования сжатия бинарного изображения 9×9 относительно стороны формата этого изображения, показан на фиг.14 (на примере сжатия одной строки 9×1). Способ реализации р-дискретизирующих преобразований в узлах поворота и сжатия заявленного устройства не отличается от способа реализации этих преобразований в узлах поворота и сжатия прототипа. Кроме того, устройство позволяет с достаточно высокой скоростью моделировать сжатия бинарных изображений программным способом. Фиг.15 иллюстрирует программное сжатие бинарного изображения А×А×А относительно плоскости грани куба А×А×А формата этого изображения.
Повороты составного бинарного изображения 3А×3А×3А на углы, кратные 90°, вокруг осей Ox, Oy, Oz выполняются последовательным выполнением команд П1Х, П1Y, П1Z, П2Y. Повороты на углы, не кратные 90°, выполняются в общем случае только над содержимым внутреннего куба (3/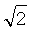 )A×(3/)A×(3/)A изображения 3А×3А×3А (фиг.16-а), при этом сначала выполняется расшивка внутреннего куба, затем выполняются повороты его отдельных фрагментов А/)×(А/)×(А/) (фиг.16-6), а затем повернутые фрагменты сшиваются в единое трехмерное изображение (фиг.16-в).
)A×(3/)A×(3/)A изображения 3А×3А×3А (фиг.16-а), при этом сначала выполняется расшивка внутреннего куба, затем выполняются повороты его отдельных фрагментов А/)×(А/)×(А/) (фиг.16-6), а затем повернутые фрагменты сшиваются в единое трехмерное изображение (фиг.16-в).
Поворот составного бинарного плоского изображения (3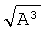 )×(3) включает в себя (фиг.17,18): 1) расшивку изображения (фиг.17-в); 2) поворот центрального содержимого фрагментов А×А расшитого изображения (фиг.18-а); 3) сшивание повернутых фрагментов в единое изображение (фиг.18-а). Принцип расшивки, поворота фрагментов расшитого изображения и последующего сшивания повернутых фрагментов в единое изображение дан в описании прототипа.
)×(3) включает в себя (фиг.17,18): 1) расшивку изображения (фиг.17-в); 2) поворот центрального содержимого фрагментов А×А расшитого изображения (фиг.18-а); 3) сшивание повернутых фрагментов в единое изображение (фиг.18-а). Принцип расшивки, поворота фрагментов расшитого изображения и последующего сшивания повернутых фрагментов в единое изображение дан в описании прототипа.
Сжатие составного бинарного плоского изображения (m)×(m) состоит из:
1) сжатия фрагментов (аппаратным или программным способом);
2) сшивания сжатых фрагментов в единое изображение (m)×(m). На фиг.19 (д) изображен результат центрального сжатия отдельных фрагментов А×А бинарного изображения, представленного на фиг.17(а). Здесь моделирование центрального сжатия каждого исходного фрагмента А×А (фиг.19-а) относительно центра G этого фрагмента (фиг.19-6) совмещено с моделированием параллельного переноса центра сжатого фрагмента из точки G в точку W (фиг.19 - в, г). На фиг.19 (е) показан окончательный результат сжатия составного изображения после сшивания отдельных сжатых фрагментов А×А в единое составное изображение.
Полутоновые составные изображения перед их обработкой в устройстве размещаются в памяти 51 матрицы 32. При этом двоичный код яркости одного пикселя размещается в памяти 51 того процессора 33, который в матрице А×А×А координатно соответствует данному пикселю так, что каждый разряд этого яркостного кода размещается по своему адресу, причем i-e разряды яркостных кодов всех пикселей фрагмента А×А×А расположены в памяти 51 по одному и тому же адресу. Числовая обработка яркостных кодов осуществляется одновременно во всех процессорах 33 последовательно разряд за разрядом (при помощи команд ИНЕ и СМ2, образующих функционально полный булевый базис). Передача яркостных кодов между пикселями-соседями внутри матрицы 19 для реализации числовых процедур, связанных с фильтрацией, сглаживанием изображений, оконтуриванием и выделением поверхностей на изображениях осуществляется при помощи описанных выше одношаговых сдвигов и поворотов на 90°.
Общий принцип построения с помощью заявленного устройства трехмерных моделей объектов по их плоским стереоизображениям поясним на примере построения трехмерной модели криволинейного черного отрезка по его двум плоским изображениям, полученных при фотографировании этого отрезка на белом фоне в двух направлениях, отличающихся на угол ϕ (фиг.20). Пусть плоское бинарное изображение на фиг.20 (а) - это отфильтрованное изображение криволинейного отрезка, полученное узлом 32, а плоское бинарное изображение на фиг.20 (б) - это отфильтрованное изображение того же криволинейного отрезка, но полученное узлом 31. Синтезируем из каждого указанного плоского изображения два трехмерных изображения следующим образом. Сожмем оба плоских изображения до разрешения mAx mA, разместим сжатое плоское изображение на грани mA×mA составного куба mA×mA×mA перпендикулярно Ох (фиг.20 - в, д). Затем последовательно выполняя mA раз одношаговый сдвиг в направлении Ох и склейку исходного и сдвинутого изображений, получим бинарную модель участка поверхности (фиг.20 - г, е). Для каждого фотоизображения будет своя поверхность. Повернем одну поверхность относительно другой на угол ϕ (фиг.20 - ж) и выполним над ними теоретико-множественную операцию «пересечение». Результатом операции и будет искомая трехмерная пиксельная модель криволинейного отрезка.
Вариант устройства, габариты которого позволяют использовать его в качестве бортового вычислителя в системе распознавания и ориентации автономного робота, показан на фиг.2. БОХВИ данного устройства включает: процессорную матрицу 9×9×9 (А=9); 729-входовой комбинационный сумматор, формирователь 9-разрядного кода КЗБИ, узлы поворота, узлы сжатия, буферную память, память изображений, узел отображения и узел ввода фотоизображений. БУ выполнен в виде одной платы. Емкость локальной памяти каждой ПЭ-матрицы - 512 бит. Вывод синтезированных изображений осуществляется на экран монитора, ввод фотоизображений осуществляется с помощью двух объективов, связанных с БОХВИ гибкими оптоволоконными кабелями.
Для уменьшения габаритов устройства и повышения его надежности в качестве основной элементной базы БОХВИ можно применить 6 типов цифровых специализированных микросхем (условно их обозначим: БИС24А, БИС24В, БИС24С, БИС24В, БИССС, БИСП).
Микросхемы БИС24А, БИС24 В, БИС24С, БИС240 предназначены для построения процессорной матрицы, первых ступеней узла определения объема и формирователя КЗБИ. Эти микросхемы являются аналогами кристалла БИС24, имеют одинаковое функциональное назначение и состав и отличаются только расположением внешних выводов. Использование нескольких типов кристаллов вместо одного типа кристалла БИС24 позволяет повысить тактовую частоту управления за счет высокой плотности монтажа. Каждая из этих микросхем содержит:
- 24 процессорных элемента 33, образующих вместе полную замкнутую систему ЗПС-24;
- комбинационный сумматор с 7-разрядным выходом;
- 6 формирователей кода заполнения слоя;
- преобразователь кода суммы.
Принципиальная схема микросхем БИС24А, БИС24В, БИС24С, БИС240 показана на фиг.21, их корпуса и расположение выводов показаны на фиг.22. Обозначение выводов и их функциональное назначение приведены в табл.2. Микросхемы БИС24А, БИС24 В, БИС24С, БИС240 позволяют реализовать все виды ЗПС процессорной матрицы.
Переключение БИС24 в режим ЗПС24 производится путем отключения ее преобразователя кода суммы (ПР=0).
Для переключения БИС24 в режим ЗПС6 необходимо установить ПР=0 и электрически соединить между собой внешние входы (iD) следующих ПЭ микросхемы:
1) П0, П1, П2, П3; 2) П4, П5, П6, П7; 3) П8, П9, П10, П11; 4) П12, П13, П14, П15;
5) П16, П17, П18, П19; 6) П20, П21, П22, П23.
На внешних входах iS0-iS6 сумматора устанавливается лог.0, код суммы снимается только с выходов oS1, oS2, oS3 сумматора микросхемы ((24/4)10=(110)2).
Для переключения БИС24 в режим ЗПС8 необходимо установить ПР=1 и электрически соединить внешние входы (iD) следующих ПЭ микросхемы:
1) П0, П9, П23; 2) П1, П5, П22; 3) П2, П6, П13; 4) П3, П10, П14; 5) П4, П17, П21;
6) П7, П12, П18; 7) П8, П16, П20; 8) П11, П15, П19.
На входах iS0-iS6 сумматора устанавливается лог.0, код суммы снимается с выходов oS0-iS3 сумматора микросхемы.
В режим ЗПС1 микросхема БИС24 переключается путем: 1) соединения всех ее 24 информационных входов iD; 2) на внешних входах сумматора устанавливается лог.0, код суммы снимается с 3-го или 4-го выхода сумматора микросхемы ((24)10=(1100)2).
Микросхема БИССС предназначена для построения узлов сдвига, узлов сжатия, буферной памяти, 1-го банка памяти изображений. Принципиальная схема микросхемы показана на фиг.23 и состоит из 4 одинаковых одноразрядных частей, с одним входом DI и с одним выходом DO каждая. В БОХВИ каждый i-й вход DI микросхемы БИССС соединен с одноименным выходом матрицы А×А×А, а каждый i-й выход DO соединен с противоположным (по направлению Ox) входом матрицы А×А×А.
БИСП предназначена для построения узла поворота и 2-го банка памяти изображений. Принципиальная схема микросхемы показана на фиг.24 и состоит из 4 одинаковых одноразрядных частей, с одним входом DI и с одним выходом DO каждая. В БОХВИ каждый i-й вход DI микросхемы БИССС соединен с одноименным выходом матрицы А×А×А, а каждый i-й выход DO соединен с противоположным (по направлению Ох) входом матрицы А×А×А.
Несущее-соединительная конструкция БОХВИ выполнена по схеме радиоэлектронного блока, описанного в [4], что значительно сокращает габариты устройства, уменьшает длину проводных связей, повышает тактовую частоту управления, обеспечивает ремонтопригодность устройства. Конструктивно БОХВИ состоит из набора плоских механически жестких плат, имеющих одинаковые габариты и связанных между собой специальными разъемными контактами-соединителями, равномерно расположенными по всей плоскости плат (фиг.2, 25-а). Ширина и высота БОХВИ определяются габаритными размерами самой большой платы, содержащей внутри себя ПЭ внешней оболочки матрицы 9×9×9. Наименьшие габариты БОХВИ достигаются в случае размещения микросхем с обеих сторон каждой платы. Вариант монтажной схемы 5-слойной платы, содержащей в себе ПЭ сразу 2 кубовых оболочек (9×9×9, 7×7×7) матрицы 9×9×9 (по кубовой оболочке с каждой стороны платы), показан на фиг.25 (б). На фиг.26 представлен чертеж печатных проводников верхнего слоя фрагмента этой платы (с микросхемами), содержащего тело кубовой оболочки 9×9×9 матрицы. Габаритные размеры всей платы БОХВИ не превышают 180 мм×220 мм. Длина БОХВИ определяется общим числом состыкованных плат (фиг.2). Вся процессорная матрица вместе с 729-входовым сумматором, полным 9-разрядным формирователем КЗБИ и комплектом усилителей управляющих сигналов матрицы, занимают от двух до трех плат. Буферная память, узлы поворота и сжатия, 2 банка памяти изображений занимают еще две платы. Таким образом, минимально необходимый комплект БОХВИ состоит из 4-5 плат. Состав БОХВИ может быть расширен за счет подключения дополнительных плат (например, плат 3-го, 4-го банка памяти изображений, плат высокоскоростного ввода-вывода изображений и др.) к 81-разрядной шине данных.
Таким образом, габариты БОХВИ позволяют использовать рассмотренный вариант заявленного устройства в качестве бортового вычислителя и оценить возможную тактовую частоту управления БОХВИ порядка 200-300 МГц. При такой частоте только формальная производительность обработки изображений достигает 150-200 млрд. операций в секунду. Если учесть, что устройство работает на всех этапах обработки изображений (от ввода исходных изображений, принятия решения до синтеза выводимых изображений) исключительно с пиксельными моделями объектов (т.е. здесь отпадает необходимость в смене метода геометрического моделирования - например, в переходе от пиксельного моделирования к моделированию многогранниками и обратно), алгоритмы решения задач более компактны и значительно короче алгоритмов традиционной числовой обработки, операции вычисления объема (площади), формирование КЗБИ выполняются одновременно с другими операциями обработки и имеют высокую степень распараллеливания, не зависящую от геометрической сложности обрабатываемых объектов, то выигрыш в скорости обработки изображений будет значительно выше названной формальной производительности. Устройство позволяет быстро выполнять предобработку исходных изображений, быстро синтезировать сложные трехмерные эталоны объектов и быстро осуществлять сравнение анализируемых объектов с этими эталонами.
Таким образом, по сравнению с прототипом заявленное устройство позволяет повысить скорость и точность обработки изображений. Быстродействие и небольшие габариты устройства дают возможность создать на его основе недорогие очувствленные роботы с чрезвычайно высокой степенью автономности, что, в свою очередь, позволит автоматизировать сферы человеческой деятельности, в настоящее время не подлежащие автоматизации.
ИСТОЧНИКИ ИНФОРМАЦИИ
1. Авт. свидетельство СССР №1456965.
2. Авт. свидетельство СССР №1612307.
3. Авт. свидетельство СССР №1817109.
4. Патент на изобретение №2192716.
5. Угрюмов Е.П. Цифровая схемотехника. БХВ-Петербург, 2001.
6. Авт. свидетельство СССР №1817108.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО УПРАВЛЕНИЯ АВТОНОМНЫМ РОБОТОМ | 2008 |
|
RU2424105C2 |
| Устройство для параллельной обработки трехмерных сцен | 1990 |
|
SU1817109A1 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1612307A2 |
| Устройство обработки изображений | 1989 |
|
SU1817108A1 |
| Устройство для параллельной обработки трехмерных сцен | 1986 |
|
SU1456965A1 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1689966A1 |
| УСТРОЙСТВО ОБРАБОТКИ ДВУХМЕРНЫХ И ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ | 2008 |
|
RU2376637C1 |
| УСТРОЙСТВО УПРАВЛЕНИЯ ВЫСОКОАДАПТИВНЫМ АВТОНОМНЫМ МОБИЛЬНЫМ РОБОТОМ | 2019 |
|
RU2705049C1 |
| Устройство для сопряжения оперативной памяти с внешними устройствами | 1981 |
|
SU993237A1 |
| Микропроцессорное вычислительное устройство | 1982 |
|
SU1269145A1 |



Изобретение относится к вычислительной технике и предназначено для решения задач обработки двумерных и трехмерных изображений. Изобретение направлено на повышение скорости и точности обработки двумерных и трехмерных изображений. В устройстве, содержащем матрицу процессоров, блок управления, матрицы узлов поворота, узлов сжатия, узлов памяти, блок коммутации, узел определения объема и формирователь кода заполнения, введены дополнительный информационный вход в коммутаторе входа локальной памяти каждого процессора матрицы, матрица узлов памяти, дополнительные входы узлов сжатия, соединенные с выходами матрицы процессоров, дополнительные выходы блока управления, соединенные с дополнительными входами блока коммутации. Для каждого k-го сигнала управления матрицей множество элементов матрицы разбито на непересекающиеся подмножества, для каждого подмножества введен усилитель первого каскада, все множество усилителей m-го каскада разбито на непересекающиеся подмножества, для каждого подмножества усилителей m-го каскада, кроме последнего, введен усилитель m+1 каскада, выход которого соединен с входом каждого усилителя m-го каскада; входы усилителей последнего каскада соединены с соответствующим выходом блока управления. 56 ил., 2 табл.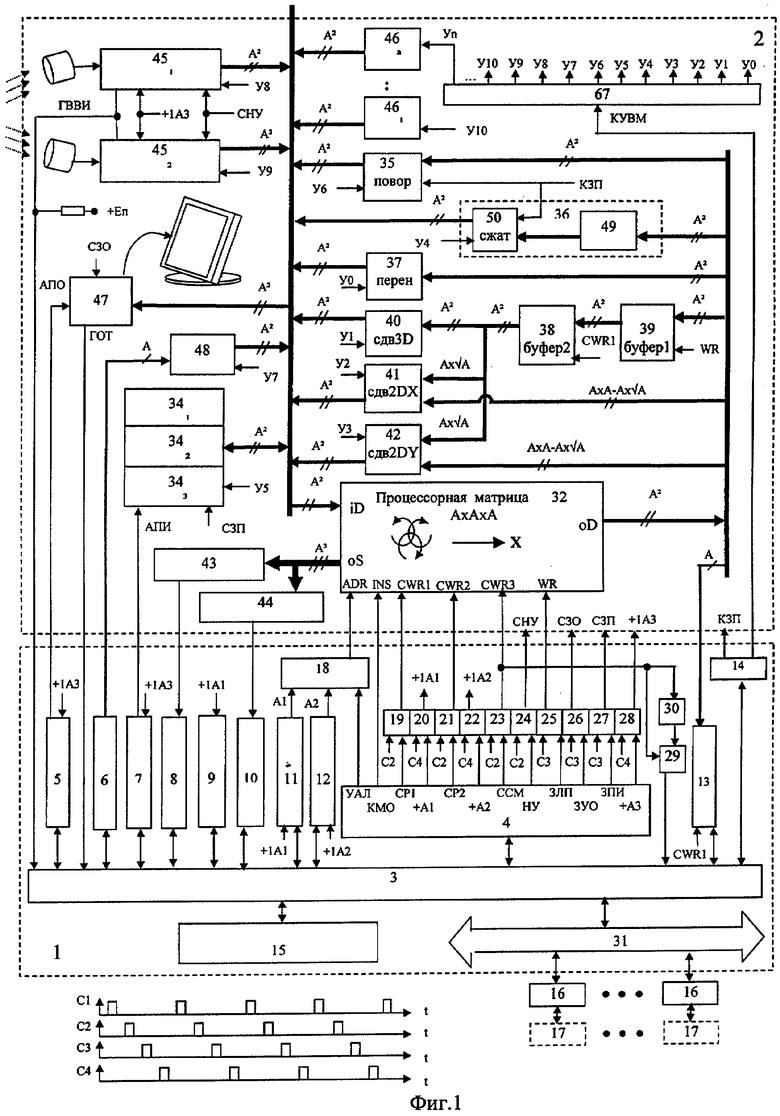
Устройство для параллельной обработки двумерных и трехмерных изображений, содержащее матрицу процессоров, блок управления, матрицу узлов поворота, матрицу узлов сжатия, матрицу узлов памяти, блок коммутации, узел определения объема и формирователь кода заполнения, каждый процессор матрицы содержит локальную память, коммутатор входа локальной памяти и регистры операндов, информационные выходы матрицы процессоров соединены с информационными входами матриц узлов поворота, узлов сжатия, узлов памяти и блока управления, информационные входы матрицы процессоров соединены через блок коммутации с информационными выходами матриц узлов поворота, узлов сжатия и блока управления, группы управляющих входов которого соединены с соответствующими управляющими входами матрицы процессоров, узлов поворота, сжатия, узлов памяти, информационные входы узла определения объема и формирователя кода заполнения соединены с соответствующими выходами процессоров матрицы, а их информационные выходы соединены с соответствующими информационными входами блока управления, отличающееся тем, что в коммутатор входа локальной памяти каждого процессора матрицы введен дополнительный информационный вход, соединенный с информационным выходом регистра данного процессора, в каждый процессор матрицы введен дополнительный регистр, информационный вход которого соединен с информационным выходом локальной памяти этого процессора, управляющий вход соединен с дополнительно введенным управляющим выходом блока управления, а информационный выход соединен с соответствующим входом узла определения объема и с соответствующим входом формирователя кода заполнения, узел определения объема выполнен в виде цифрового комбинационного сумматора, формирователь кода заполнения выполнен в виде нескольких не связанных между собой многовходовых схем ИЛИ, выходы которых соединены с дополнительно введенными информационными входами блока управления, введена матрица узлов буферной памяти, каждый узел которой состоит из двух одноразрядных регистров, информационный вход первого регистра соединен с соответствующим выходом матрицы процессоров, управляющий вход соединен с входом управления записью локальной памяти, информационный выход соединен с информационным входом второго одноразрядного регистра, управляющий вход которого соединен с управляющим входом регистра операнда процессора матрицы, а информационный выход соединен с соответствующими входами блока коммутации, информационный вход и информационный выход каждого узла памяти соединен с соответствующим входом матрицы процессоров, являющимся одновременно и информационным входом, и информационным выходом устройства; введены дополнительные выходы блока управления, соединенные с дополнительно введенными входами блока коммутации, дополнительные выходы которого соединены с входами управления подключением информационных выходов датчиков к информационным входам процессорной матрицы, для k-го сигнала управления матрицей множество элементов матрицы разбито на непересекающиеся подмножества, для каждого подмножества введен усилитель первого каскада, выход которого соединен с k-м входом управления каждого элемента данного подмножества, все множество усилителей m-го каскада разбито на непересекающиеся подмножества, для каждого подмножества усилителей m-го каскада k-го сигнала управления матрицей, кроме последнего каскада, введен усилитель (m+1)-го каскада, выход которого соединен с входом каждого усилителя m-го каскада своего подмножества, входы усилителей последнего каскада соединены с выходом блока управления, соответствующим k-му сигналу управления матрицей.
| Устройство для параллельной обработки трехмерных сцен | 1990 |
|
SU1817109A1 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1612307A2 |
| Устройство для параллельной обработки трехмерных сцен | 1986 |
|
SU1456965A1 |
| Устройство обработки изображений | 1989 |
|
SU1817108A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

