Изобретение относится к вычислительной технике и предназначено для обработки трехмерных изображений.
Цель изобретения - повышение отказоустойчивости устройства.
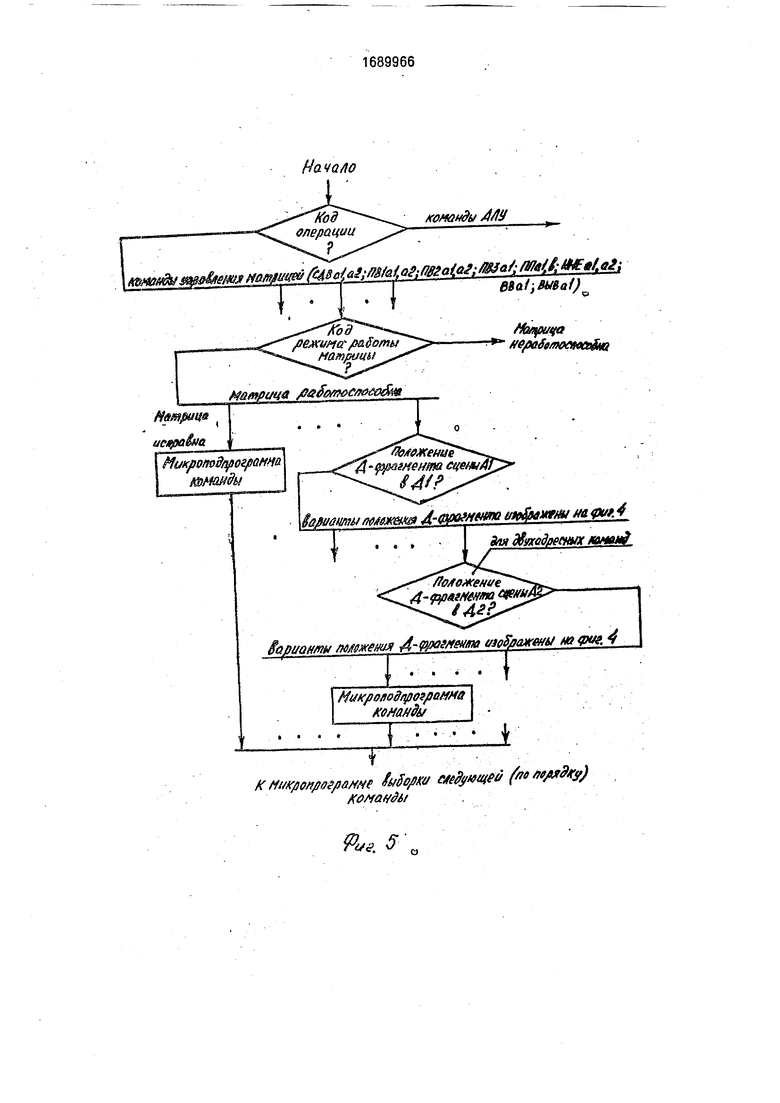
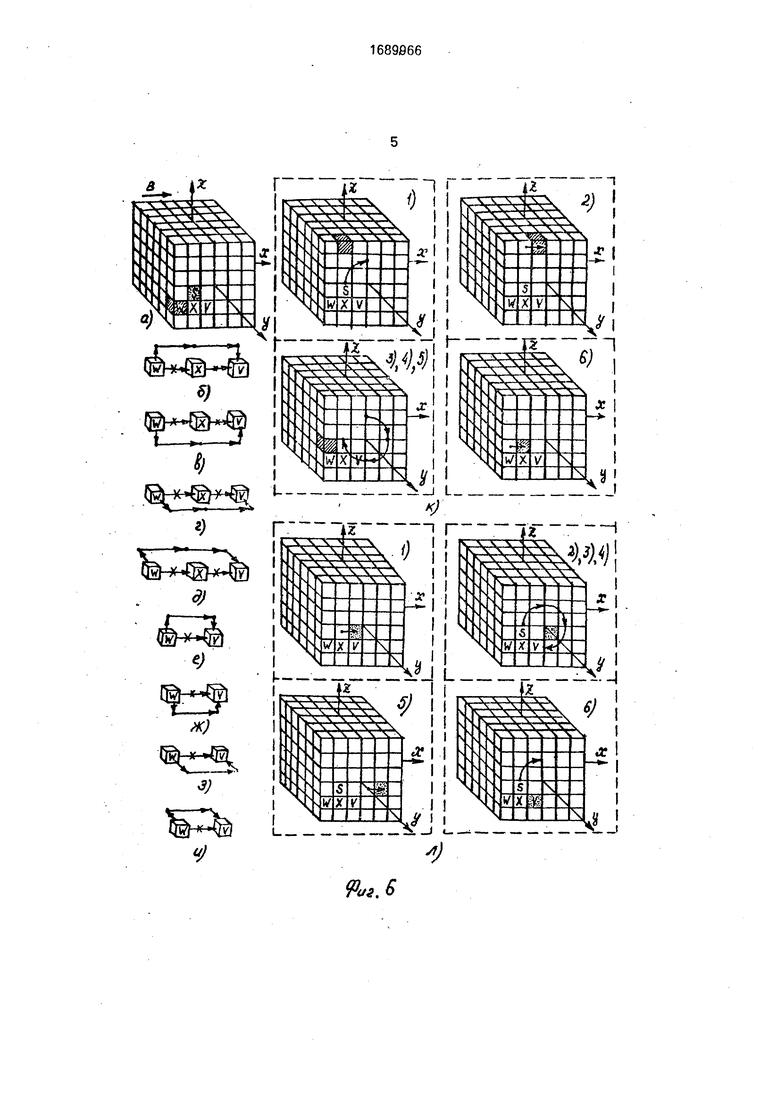
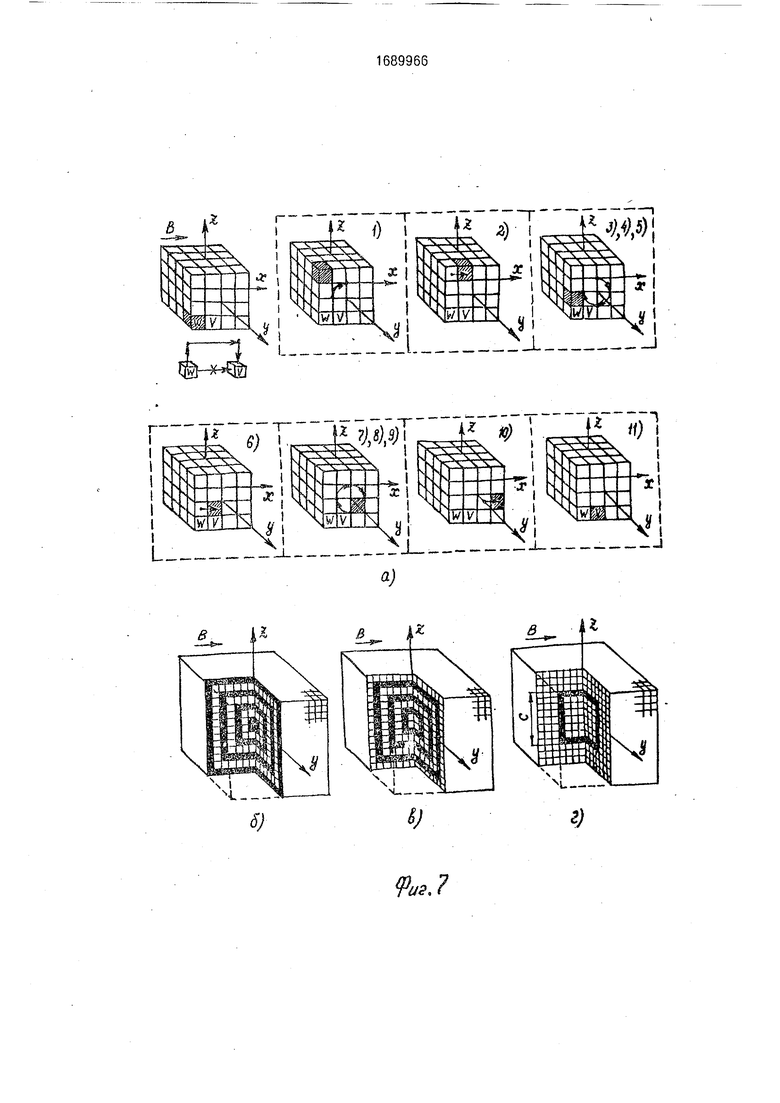
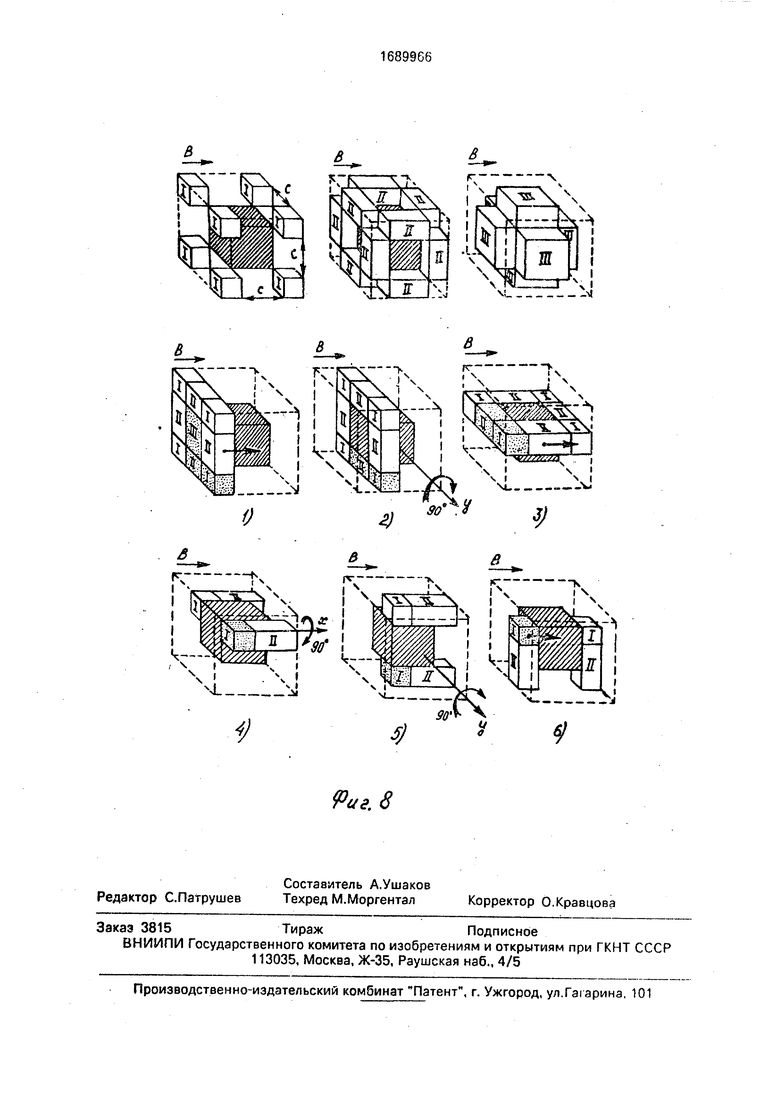
На фиг. 1 и 2 представлено устройство параллельной обработки трехмерных сцен; на фиг. 3 - общий принцип построения процессорной матрицы устройства с использованием универсальных 24-процессорных модулей; на фиг. 4 - варианты распределения памяти процессоров для различных режимов работы матрицы; на фиг. 5 - общая схема алгоритма микропрограммы, реализующей в устройстве команду управления матрицей; на фиг. 6 и 7 - способы обхода отказавших элементов матрицы; на фиг. 8 - способ прокачки содержимого двухуровневой сцены А х А х А через исправную кубовую оболочку С х С х С.
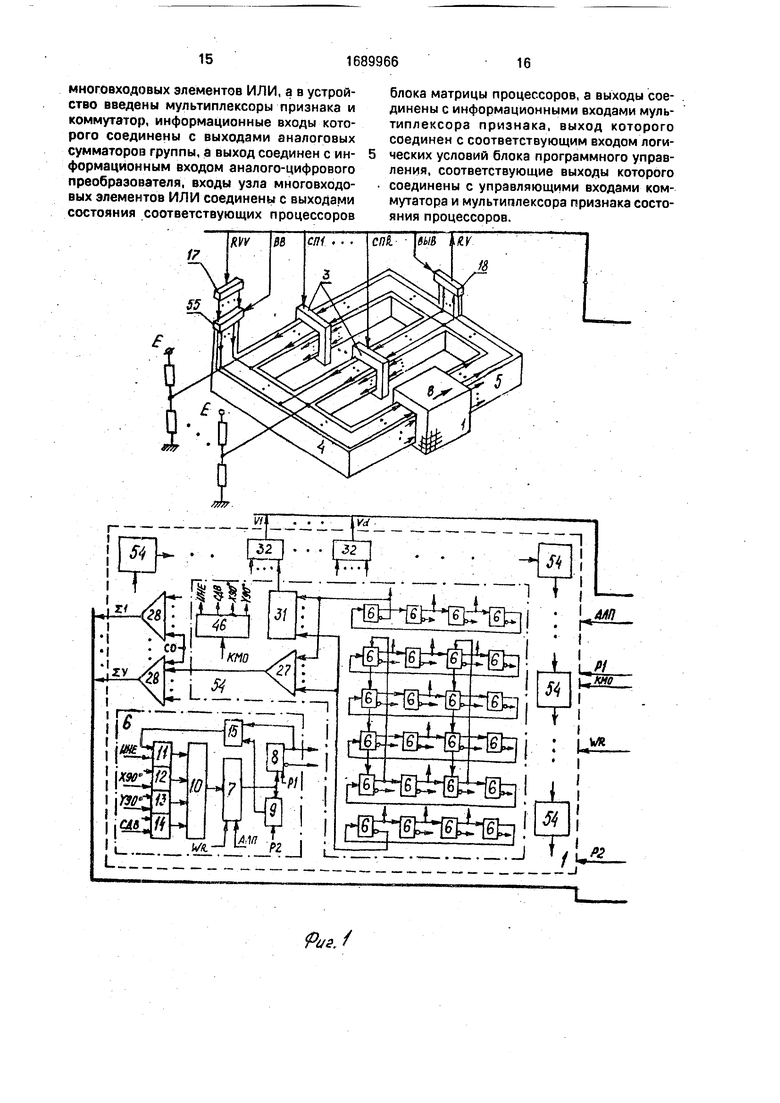
Устройство содержит блок матрицы процессоров, состоящий из трехмерной матрицы 1 А х А х А процессоров и блок 2
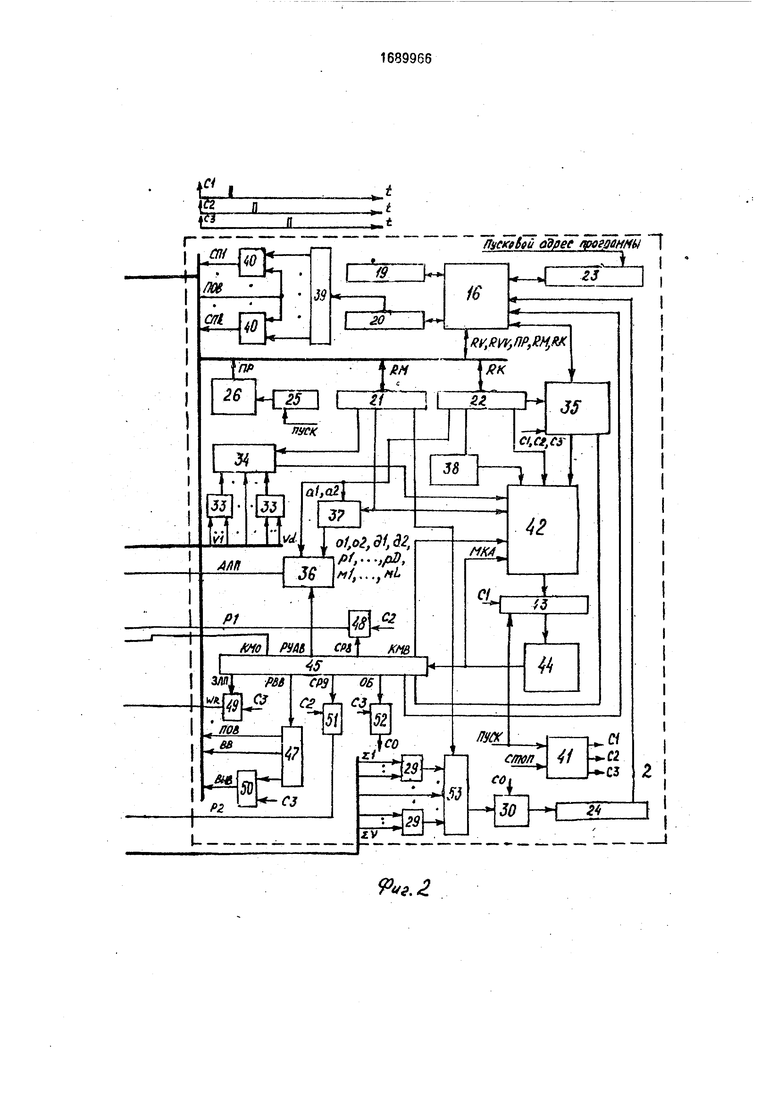
управления. К устройству могут быть подключены блоки 3 поворота через входы 4 и выходы 5 матрицы. Матрица 1 состоит из А3 процессоров 6. Каждый из которых включает в себя узел 7 памяти, первый регистр 8 операнда, второй реп-стр 9 операнда, элемент ИЛИ 10, блок элементов И, состоящий из элементов И 11-14; элемент ИЛИ-НЕ 15. Блок 2 управления содержит управляющий процессор, узел 16 памяти программ и данных, программноадресуемые регистры 17- 24; таймер 25, узел 26 прерывания. Устройство содержит также группу аналоговых сумматоров в виде ступеней 27-29 аналогового сумматора, аналого-цифровой преобразователь 30, узел многовходовых элементов ИЛИ в виде ступеней 31-33 многовходового элемента ИЛИ, мультиплексор 34 признака состояния процессоров. Управляющий процессор содержит арифметико-логической узел 35, мультиплексор 36 адреса, преобразователь 37 адреса, дешифратор 38 команды, дешифратор 39 выбора слоя поворота, элементы И
w
Ё
00
О Ю
с
о.
40, узел микропрограммного управления. Узел микропрограммного управления состоит из генератора 41 синхронизирующих импульсов, генератора 42 адреса микрослова, регистра 43 адреса микрослова, узла 44 памяти микрослов, регистра 45 микрослова, дешифраторов 46 кода микрооперации, дешифратора 47 кода режима ввода-вывода, элементов И 48-52. Ступени 28 и 29 соединены с преобразователем 30 посредством коммутатора 53. Процессоры 6, образующие относительно своих ортогонально-кольцевых связей замкнутую систему, и связанные с ними дешифратор 46, ступени 27,31 объединяются в конструктивный модуль 54. Регистр 17 связан с входами 4 матрицы 1 посредством блока 55 элементов И.
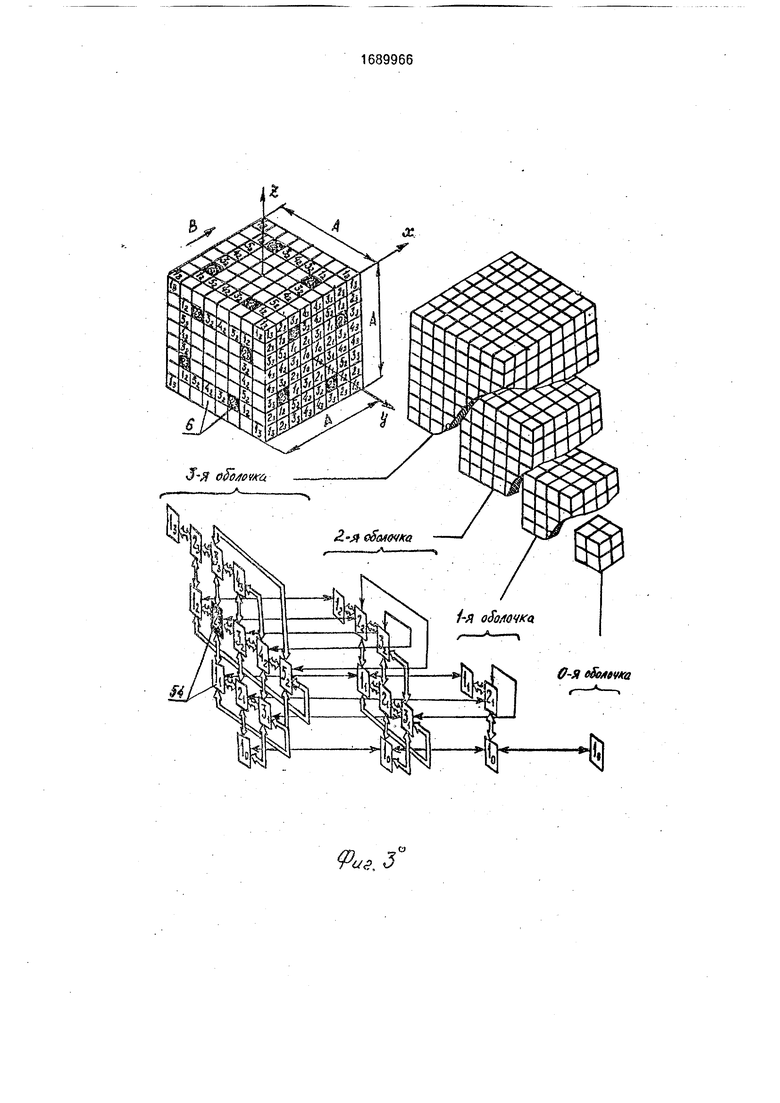
Структура межмодульных связей матрицы 1, построенной на универсальных 24- процессорных модулей, изображена на фиг. 3. Из фиг. 3 видно, что все межмодульные связи матрицы могут быть разбиты на две большие группы: группы связей, соединяющих модули, процессоры 6 которых образуют в кубе А х А х А кубовые оболочки с толщиной, равной 1 (вкладываемые друг в друга по принципу матрешки); и группы связей, сшивающих эти оболочки в единый куб Ах Ах А. При отказе межмодульной связи нарушение нормального функционирования прототипа происходит из-за отсутствия возможности выполнить операцию переноса сцены А х А х А на шаг по В без искажений. В случае отказа процессора 6 нарушение нормального функционирования прототипа происходит: из- за отсутствия возможности выполнить операцию переноса сцены А х А х А на шаг по В без искажений; из-за потери аппаратных средств для хранения и параллельной обработки информации об уровнях яркости куба I х I х I отказавшего процессора 6. В предлагаемом устройстве первые две из названных причин устраняются путем организации автоматического обхода отказавших модулей и межмодульных связей. Последняя из причин устраняется путем использования аппаратных средств исправных модулей для хранения и обработки информации об уровнях яркости кубиков I х I х I отказавших процессоров 6. Адресуемой информационной единицей матрицы 1 является двухуровневая сцена формата F. Формат F составлен из кубиков I х х I исправных процессоров 6. Уровень яркости каждого кубика I х I х I в двухуровневой сцене формата F принимает значение 1 или О. При наличии в матрице 1 А3 исправных процессоров 6 формат F совпадает с формой.куба
А х А х А. Выход из строя процессоров 6 равнозначен изменению формата F сцены, это изменение заключается в удалении из куба А х А х А кубиков I х I х отказавших
процессоров 6, Команды управления матрицей, хранящиеся в узле 16, оперируют двухуровневыми сценами формата А х А х А. Это объясняется тем, что текущий формат F в силу случайности отказа
0 процессоров 6 является непредсказуемым, формат А х А х А заранее известен и при абсолютно исправной матрице 1 обеспечивает максимальную скорость обработки информации в устройстве. В случае отказа
5 хотя бы одного процессора 6 становится невозможным размещение обрабатываемой двухуровневой сцены А х А х А внутри одной адресуемой сцены формата F, обмен информацией между процессорами 6 нару0 шается. Поэтому при отказе элементов матрицы выполнение команд, оперирующих полноформатными сценами Ах Ах А, осуществляется в устройстве с использованием метода эмуляции. В роли эмулируемой вы5 числительной системы выступает устройство с абсолютно исправной матрицей 1, а в роли эмулирующей - устройство с матрицей текущего состояния (имеющей неисправные модули или неисправные межмодуль0 ные связи).
Для предотвращения потери информации об уровнях яркости кубиков I х I х I отказавших процессоров 6 в сценах А х А х А функцию хранения содержимого узла 7 от5 казавших процессоров 6 берут на себя узлы 7 исправных модулей. В этом случае адресное поле узлов 7 разбивается на три части. Первая часть, содержащая NI адресов, предназначена для хранения информации об
0 уровнях яркости кубиков I х I х I исправных
процессоров 6 в NI двухуровневых сценах
формата А х А х А (другими словами - для
хранения 0-фрагментов сцен А х А х А).
Вторая часть, содержащая N2 адресов,
5 предназначена для хранения информации об уровнях яркости кубиков I х I х I отказавших процессоров 6 в NI двухуровневых сценах А х А х А (другими словами - для хранения D-фрагментов сцен А х А х А).
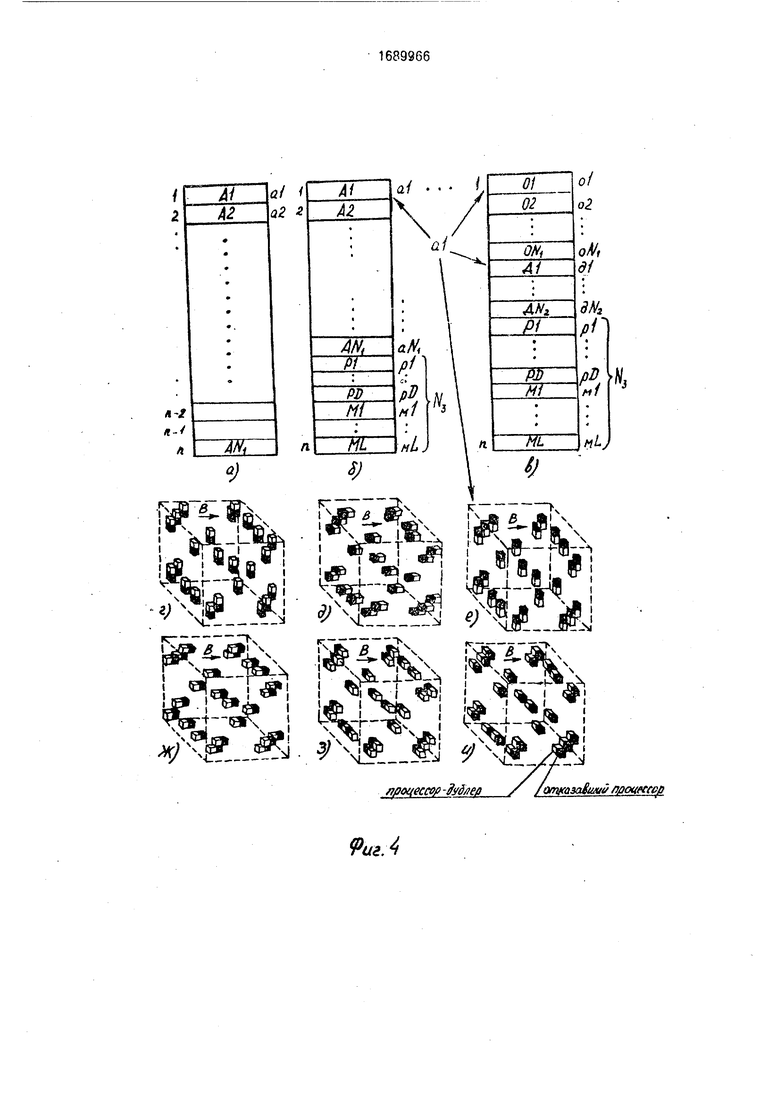
0 Третья часть, содержащая NS адресов, предназначена для хранения сцен-масок (двухуровневых сцен-констант)и рабочих сцен, имеющих формат F и используемых микропрограммами эмуляции для формиро5 вания и хранения промежуточных результатов, получаемых в ходе обработки полноформатных сцен. Из указанного распределения адресов узла 7 памяти становится очевидным, что отказоустойчивые программы, оперирующие полноформатными сценами А х А х А, должны использовать не всю область адресов узла 7 памяти, а только NI адресов. Процессор 6 исправного модуля, содержащий в своем узле 7 информацию об уровне яркости кубика I х I х I i-ro отказавшего процессора б в сцене А х А х А, назовем дублером 1-го отказавшего процессора. Поскольку в устройстве устойчивость к отказам процессоров 6 достигается, если число отказавших процессоров б не превышает А3/2, для представления одной полноформатной сцены А х А х А достаточно двух двухуровневых сцен формата F. Первая из этих сцен, называемая в дальнейшем 0- сценой (или 0-фрагментом сцены А х А х А), содержит информацию об уровнях яркости собственных кубичов I х I х исправных процессоров 6 в представляемой сцене А х А х А. Вторая сцена, называемая D-сценой, содержит информацию об уровнях яркости кубиков 1 х х 1 отказавших процессоров 6 в представляемой сцене А х А х А (другими словами - содержит D-фрзгмент представляемой сцены А х А х А). При Ni/N2 гл каждая D-сценз содержит m D-фрагмен- тов, дополняющих m 0-сцен до полноформатных двухуровневых сцен. Варианты положения D-фрагментов в D-сцене показаны на фиг. 4 (г - и). Каждому такому положению соответствует свой D-адрес. При m 1 адресное поле памяти в узле 7 распределяется более экономно, чем при m 1 (т.е. число NI здесь существенно выше), однако в этом случае возникает необходимость в процедуре установки сформированного D- фрагмента в D-сцену по заданному D-адре- су. Микропрограммы, реализующие команды управления матрицей, можно представить в виде последовательности более крупных, чем микрослова, структурных единиц- псевдокоманд, Псевдокоманды по выполняемой функции и способу микропрограммной реализации аналогичны командам ИНЕ А1, А2, СДВ А1, А2, ПВ1 А1, А2, но оперируют сценами текущего формата F. Для различия между мнемоническими обозначениями команд м псевдокоманд между мнемоническими обозначениями сцен и адресов сцен в дальнейшем сцены и коды операций команд условимся обозначать прописными буквами, а адреса сцен и коды операций псевдокоманд-строчными буквами (например: а1 - адрес сцены А1; пв1 d1, d2 - обозначение псевдокоманды, осуществляющей поворот содержимого сцены D1 формата F на угол 90° вокруг оси Ох и запись результатз поворота в сцену Д2; СДВ а1, а2 - обозначение команды, осуществляющей сдвиг содержимого полноформатной сцены А1 на таг по В и запись результата сдвига
в полноформатную сцену А2), Двухуровневые сцены формата А х А х А условимся обозначать AN (где N - номер сцены), а их адреса - aN. 0-сцену сцены AN условимся обозначать ON, а ее адрес - oN. D-сцену сцены AN будем обозначать DN, а ее адрес - dN. Сцены-маски (формата F) обозначим ML (где L - номер сцены-маски), а их адреса м. Рабочие сцены (формата F) условимся обозна0 чать PD (где D - номер рабочей сцены), а их адреса - pD, В момент включения устройства или в процессе работы устройства в результате прерывания по таймеру 25 (цикл запроса прерывания определяется исходя
5 из значения предельно допустимой вероятности наработки матрицы на отказ) производится запуск диагностирующей программы. По окончании работы диагностирующей программы делается вывод о ра0 ботослособности матрицы. Если матрица признана работоспособной, но имеет отдельные неисправные элементы, в регистре 21 устанавливается соответствующий код режима работы матрицы, в матрице синте5 зируются необходимые сцены-маски. Каждый из режимов работы матрицы характеризуется своим распределением адресов памяти в узле 7, своим способом выполнения команд управления матрицей. Возмож0 н-ые варианты распределения адресов памяти в узле 7 для различных режимов работы матрицы показаны на фиг. 4. Распределение, изображенное на фиг. 4 (а), соответствует режиму работы матрицы, когда
5 устройство абсолютно исправно. Распределение, изображенное на фиг. 4 (б), соответствует случаю, когда матрица имеет только отдельные неисправные межмодульные связи. Распределение, изображенное на
0 фиг. 4 (в - и), соответствует случаю, когда в матрице имеются отдельные неисправные модули и отдельные неисправные межмодульные связи. Код режима работы матрицы однозначно определяет: число, вид исполь5 зуемых сцен-масок, коды их адресов; число используемых рабочих сцен, коды их адресов. Код режима работы матрицы совместно с кодом адреса aN однозначно определяют: код адреса oN: код адреса dN; положение
0 D-фрагмента сцены AN в DN. Генерация всех перечисленных кодов по коду режима работы матрицы и KOflaM aN, хранящимся в адресной части регистра 22 команды, осуществляется в преобразователе 37 адреса.
5 В зависимости от кода, поступающего с многоразрядного поля РУАВ регистра 45 микрослова, на выходе преобразователя 37 формируется один из кодов ON, dN, ml. P1 и т.д. При неисправной, но работоспособной матрице 1 выполнение команд типа
СДВ,а1,а2; ПВЗ а1; ВВ а1; ВЫВа1 связано с обходом отказавшихся элементов матрицы. Во избежание значительного снижения скорости обработки полноформатных сцен Ах А х А и устройстве обход отказавших модулей и межмодульных связей при эмуляции команд СДВ, ПВЗ, ВВ, ВЫВ должен осуществляться с высокой степенью парал- лелизации, а путь обхода был коротким, дублеры отказавших процессоров 6 должны располагаться в непосредственной близости к модулю, содержащему эти отказавшие процессоры 6. Этому условию удовлетворяют варианты размещения процессоров- дублеров, изображенные на фиг. 4 (г - и). Здесь кубики I x i x I процессоров отказавшего модуля заштрихованы, кубики х -i x I их процессоров-дублеров незаштрихованы; кубик отказавшего процессора и кубик его дублера имеют общую грань. Возможные пути обхода отказавших элементов матрицы условно изображены на фиг. 6 (б - и). Обход отказавших процессоров 6 включает две основные процедуры; формирование фрагмента 02 результирующей сцены А2 из О- и D-фрагментов исходной сцены А1; формирование D-фрагмента сцены А2 из фрагмента 01 исходной сцены А1. Формирование 02 осуществляется путем использования двух сцен-масок: М1 и М2. Все кубики х I х сцены-маски М1 имеют уровень яркости О, кроме кубиков, являющихся ближайшими соседями кубиков I x i x I отказавших процессоров в направлении ЁЗ, Сцена-маска М2 является теоретико-множественным дополнением сцены М1. Вариант обхода отказавшего процессора 6 показан на фиг. 6 (к, л) и соответствует направлению обхода, условно изображенному на фиг. 6 (б). Здесь X - отказавший процессор 6; W - процессор 6, передающий в абсолютно исправной матрице 1 информацию в процессорX; Y-процессор 6, принимающий в абсолютно исправной матрице 1 информацию из процессора X; S - дублер пооцессора X; М2 М1. Уровень Г в сцене М1 имеет только кубик процессора V.
Микроподпрограмма обхода при выполнении команды СДВ А1, а2 (фиг. 6, к, л) в терминах псевдокоманд имеет вид:
1.пв2 о1, р1; поворот 01 на 90° вокруг Оу и запись результата поворота в сцену Р1 (на случай, если А2 А1) - фиг. G, к - 1.
2.сдв СИ, 02
3, ине о2, о2; маскирование 02 02пМ2
-02UM1.
4.ине м1. о2
5.сдв д1, р2; фиг. 6, л - 1.
6.пв2, р2,р2;фиг. 6, л-2, 3, 4.
0
7.пв2 р2, р2
8.пв2 р2, р2
9.сдв р2. р2; фиг. 6, л - 5.
10.пв2 р2, р2; фиг. 6, в - 6.
11.ине р2.р2 маскирование Р2 P2nM1 P2UM1 Р21Ш2.
12.инеМ2, р2
13. ине р2, о2; склеивание 02 P2U02
P2f02.
14.ине о2, 62; сцена 02 сформирована.
15.сдв р1, р1; фиг. 6, к -2.
16.пв2 р1,
17.пв2р1,
pi;
р1.
фиг. 6, к-3,4, 5.
18. пв2 р1, р1.
5 19. сдв р1, р1; фиг. 6, к - 6. D-фрагмент сцены А2 сформирован и находится в Р1.
20.ине d2, d2; начало размещения D- фрагмента сцены А2 в Д2 (положение D- фрагмента сцены А1 и Д1 и положение
0 D-фрагмента смены А2 в Д2 совпадают и соответствуют фиг. 4, г),
21. маскирование Д2 Д2пМ4 Д2 U МЗ..Уровень яркости 1 в сцене-маске МЗ имеет только кубик Iх
5 процессора S. M4 МЗ.
22.ине р1, р1; выделение -фрагмента сцены А2 из Р1:Р1 P1nM3 P1UM4.
23. ине р1. d2: склеивание D2 D2UP1
DTUP1.
0 Как видно из приведенного примера, способ обхода отказавшего процессора 6 (а значит и вид соответствующей микроподпрограммы обхода) зависит от положения дублера отказавшего процессора в матрице
5 1. Если Ј процессоров- дублеров расположены относительно своих дублируемых процессоров одинаковым образом, обход всех f отказавших процессоров осуществляется одновременно путем использования одной
0 общей микроподпрограммы обхода и общих
масок М1, М2, МЗ, М4. Например, обход 24
отказавших процессоров 6, изображенных
на фиг. 4 (г), осуществляется одновременно
в соответствии с ранее рассмотренным ал5 горитмом, но с применением собственных сцен-масок. Вариант обхода отказавшей межмодульной связи (соединяющей в абсолютно исправной матрице 1 выход процессора W с входом процессора V) показан на
0 фиг, 7 (а). Обход осуществляется по направлению, условно изображенному на фиг. 6 (е). Уровень яркости 1 в сцене-маске М5 имеет кубик процессора V, вход которого соединен с отказавшей межмодульной связью.
5 В терминах псевдокоманд микроподпрограмма обхода отказавшей межмодульной связи имеет вид:
1. пв2 а1, р1; поворот сцены А1 на угол 90° вокруг Оу и запись результата поворота
в сцену Р1 (на случай, если А2 (а-1).
2.сдва1,а2
3.ине а2, а2;21аскирование А2 - А2 V М5. Мб - М5.
4.ине м5, а2
5.сдв р1
6.по2 р1
7.по2 р1
А2пМ6
р1; фиг. 7 (а-2). р1;фиг. 7(а-3,4,5).
Р1
8.пв2 р1, р1
9.сдв р1, р1; фиг. 7 (а - 6).
10.пв2 р1, р1;фиг. 7 (а-7. 8. 9), 11.пв2 р1, р1
12.пв2 р1, р1
13.сдв р1.р1;фиг. 7(а- 10).
14.пв2 р1,р1.фиг. 7(а-11). Д5.иие р1, р1; маскирование Р1« Р1пМ5
P1UM6.
16. ине мб, р1
--JTi ине р1, а2; склеивание А2 А20 Р1 - A2UP1.
18. инеа2, а2 .
Если одновременный обход всех отказавших элементов матрицы невозможен (отсутствует общее направление обхода, процессоры-дублеры а D-фрагменте расположены относительно дублируемых процессоров не одинаковым образом), отказавшие процессоры и межмодульные связи делятся на m групп. Элементы, входящие в группу, обходятся одновременно с использованием общей микроподпрограммы и общих сцен- масок. Обход групп осуществляется последовательно - группа за группой. По результатам обхода всех групп формируется общий О- и общий D-фрагменты результирующей сцены А х А х А. Микроподпрограммы, реализующие команды ПВЗ а1; ВВ а1; ВЫВ а1. отличаются от рассмотренных микроподпрограмм, реализующих команду СДВ а1, а2,тем, что А2 А1, 02 01, Д2 Д1. В отличие от команд СДВ. ПВЗ. ВВ. ВЫВ выполнение команд ПВ1 и ПВ2 не требует обхода отказавших модулей и межмодульных связей, так как все ортогонально-кольцевые связи расположены внутри 24-процессорных модулей. Однако, если при отказе только межмодульных связей способ микропрограммной реализации команд ПВ1 и ПВ2 практически не отличается от способа реализации команд ПВ1 А1, А2и ПВ2 А1, А2 прототипа (за исключением кода РУАВ - а предлагаемом устройстве этот код многоразрядный), то выход из строя модулей изменяет способ микропрограммной реализации этих команд вследствие изменения способа внутреннего представления сцен А х А х А в устройстве. В последнем случае процесс выполнения команд ПВ1 а1,а2 и ПВ2 а1. а2 включает три основpi
,р1
р1
Р1
РШМ2
-Д2ПМ1
А1) - фиг. 7 ных этапа: 1) поворот 0-фрагмента сцены А1 на 90° вокруг оси Ох (для ПВ2 - вокруг оси Оу); 2) поворот копии D-фрагмента сцены А1 на 90° вокруг оси Ох (для ПВ2 - вокруг оси 5 Оу); 3) запись повернутой копии D-фрагмен- та по адресу D-фрагмента сцены А2. В терминах псевдокоманд микропрограмма, реализующая команду ПВ2 al, з2 имеет вид:
1. пв2 о1, о2; поворот 0-фрагмента. 10 2. пв2 д1, р1: попорот D-фрагмента.
3. еда р1. р2. размещение D-фрагмекта з Д2. В рассматриваемом примере положение D-фрагмента сцены А1 а Д1 соответствует положению, изображенному на фиг. 4 15 (ж); положение D-фрагмента сцены А2 в Д2 соответствует положению, изображенному на фиг. 4(д). А, пв2 pi, 5. пв2 р1, 20 б. пз2р1.
7.сдвр1.
8.пв2 р1,
9. ине р1, р1; максироаание Р1 -P1UM1. 25 10, инем1,р1
11.ине д2, д2. максирование д2 : °Д2иМ2.
12. ИН8М2, д2
13. ине р1. д2; склеивание Д2 Р1иД2
30 °1иД2.
14. инед2, д2.
В случае отказа процессоров 6 микропрограмма, реализующая команду ИНЕ а1, а2, производит следующие виды операций 35 теоретикомножественную операцию 02 02U ШТ над 0-фрагментами сцен А1 и А2; осуществляет привязку копии (D 1) сцены D1 к D-фрагменту сцены А2 (в результате выполненной привязки информация об уровнях 40 яркости кубика I х I х I одного и того же отказавшего процессора 6. относящаяся к двум различным сценам А1 и А2 располагается в одном процессоре-дублере): теооети- ческо-множественную операцию Р1 т ulv 45 Ш27; осуществляет выделение результирующего D-фрагмента из сцен Р1 и записывает его по D-адресу D-фрагмента сцены А2 данного вида отказа матрицы:
1.ине01,о2;021/01.
50 2. сдв д 1, р1. в рассматриваемом примере положение D-фрзгмента сцены А1 в 01 соответствует положению, изображенному на фиг. 4 (г); положение D-фрагмента сцены А2 в D2 соответствует положению, изобре- 55 женному на фиг. 4 (д). 3. пв2 р1, р1
4.пв2 р1,
5.по2 р1,
Р1 Р1
5. сдв р1, р1
7. пв2 р1, pi; привязка закончена
А2пМ6
фиг. 7
pi
,р1
р1
Р1
РШМ2
р2. размещение D-фрагмекта атриваемом примере положента сцены А1 а Д1 соответстию, изображенному на фиг. 4 е D-фрагмента сцены А2 в Д2 положению, изображенному
р1; максироаание Р1 1,р1
-Д2ПМ1
4.пв2 р1,
5.по2 р1,
Р1 Р1
5. сдв р1, р1
7. пв2 р1, pi; привязка закончена
8. мне д2, р1
Д.ине р1, р1; маскирование Р1 РШМ2 P1UM1
10. инем1, р1; маски М1 и М2 определены на стр. 8
1 . д2; маскирование D2 D2n М1 D2VM2
12. инем2, д2
13. инв р1, д2; склеивание D2 P1UD2
P1I/D2
14. инед2.д2 .
В систему команд устройства введена команда условного перехода: ПП aN, в - если содержимое полноформатной сцены AN пусто, передать управление команде, хранящейся в узле памяти 16 по адресу в: в противном случае - перейти к следующей по порядку команде. Под пустой двухуровневой сценой А х А х А здесь понимается полноформатная сцена, все кубики И которой имеют уровень яркости 1 (негативное представление). Анализ содержимого сцены AN осуществляется при помощи комбинационной схемы, состоящей в общем случае иа последовательно соединенных ступеней 31-33 (фиг, 1,2). Каждая ступень 31 входит в состав модуля 54 и представляет собой 24-зходовую схему ИЛИ, входы которой соединены с инверсными выходами одноразрядных регистров 8 этого модуля, Каждая ступень 32 является многовходовой схемой ИЛИ, входы J-й ступени 32 соединены с выходами ступеней 31 тех модулей, кубики I х I х процессоров 6 которых образуют в кубе А х А х А матрицы j-ю кубовую оболочку (фиг. 3). Каждая ступень 33 представляет собой многозходовую схему ИЛИ, входы которой соединены с выходами двух или более ступеней 32. В процессе выполнения командыЈin aN, в содержимое сцены AN (если в матрице 1 отсутствуют отказавшие процессоры 6) или ON (при наличии отказавших процессоров 6 в матрице 1) извлекается из узлов 7 и записывается в регистры 8. В зависимости от кода режима работы матрицы, хранящегося в регистре 21, мультиплексор 34 подключает вход генератора 42 адреса микрослова к выходу одной из ступеней 33 или 32. Например, npi абсолютно исправной матрице к входу генератора 42 подключается выход той ступени
33,входы которой соединены с выходами всех ступеней 32 устройства, при этом сигнал, снимаемый с выхода мультиплексора
34,характеризует сразу все содержимое сцены AN. Если в матрице 1 имеются отказавшие п роцессоры 6, к входу генератора 42 подключается ступень 33 (или 32) все первые ступени 31 которой соединены с «справными процессорами 6. Кубовы
оболочки ступеней 32, подключенных к входам указанной ступени 33, образуют фильт- рирующую зону куба А х А х А матрицы (фиг. 7, б, в, г). При наличии отказавших процессоров 6 анализ содержимого сцены AN состоит в последовательной прокачке всего содержимого копии сцены через данную фильтрующую зону. Элементарный шаг прокатки включает: перемещение анализи0 руемого участка копии сцены AN в фильтрующую зону; пересылку 0-фрагмента перемещенной сцены-копии из узлов 7 в регистры 8; 3) микроветвление по результатам анализа сигнала, снимаемого с выхода
5 ступени 33 (32), связанной с входом генератора 42, Если сигнал равен 1 (что означает содержимое фильтрующей зоны не пусто), осуществляется передача управления команде, следующей по порядку за выполняе0 мой командой ПП aN, в. Если сигнал равен О, производится установка следующего участка сцены-копии в фильтрующую зону и анализ содержимого этого участка. Процедура прокачки через фильтрующую зону
5 продолжается до тех пор, пока все содержимое анализируемой сцены AN не пройдет через фильтрующую зону, после чего осуществляется передача управления команде,расположенной в памяти 16
0 по адресу в. Процесс перемещения сцены- копии через фильтрующую зону осуществляется с обходом отказавших процессоров 6 (подобно тому, как это делается при выполнении команды СДВ). На фиг. 8 (1 - 6)
5 показаны способы прокачки различных областей сцены AN (, II, III) через фильтрующую зону, представляющую собой кубовую оболочку с габаритами С х С х С (С А/2). Прокачка через составной фильтр, содержа0 щий более одной кубовой оболочки (фиг. 7, б, в), является предпочтительней, поскольку отличается большей скоростью (поверхность фильтрующей зоны в этом случае больше). При использовании составного
5 фильтра анализу подвергается сигнал, снимаемый с выхода ступени 33, кубовые оболочки ступеней 32 которой входят в состав данного составного фильтра. В систему команд устройства входит-команда ОБ aN 0 Сформировать в регистре 19 код значения величины объема нулевого содержимого сцены AN. Команда ОБ выполняется в устройстве при помощи аналогового сумматора, состоящего из ступеней 27-29; коммутатора
5 53; аналого-цифровых преобразователей 30; программно-адресуемых регистров 19 и 24; арифметико-логического узла 35. Каждая ступень 27 расположена в модуле 54 и выполнена по параллельной схеме аналогового сумматора, входы ступени 27 соединены
с инверсными выходами регистров 8 модуля. Ступень 28 с целью уменьшения погреш- ности суммирования оыполнена по последовательной схеме сумматора, входы каждой ступени 23 соединены с выходами ступеней 27 тех модулей, кубики 1 х I x I процессоров 6 которых образуют одну из кубовых оболочек (фиг. 3). Ступень 29 выполнена также по последооательной схеме аналогового сумматора, входы ступени 29 соединены с выходами доух или более ступеней 28. О процессе выполнения команды ОБ аМ содержимое сцены AN (если в матрице 1 отсутствуют отказавшие процессоры б) или ON (в противном случае извлекается из узлов 7 и записывается в регистры 8. В за- ВИСИРИОСТИ от кода режима работы матрицы, хранящегося в регистре 21, коммутатор 53 подключает аход преобразователя 30 к выходу одной из ступеней 29 или 28. Например, при абсолютно исправной матрице 1 к входу преобразователя 30 подключается выход той ступени 29, входы которой соединены с выходами всех ступеней 28 устройства. С момента появления сигнала на выходе элемента И 52 через временную за- .держку. связанную с аналоговым суммированием, на входе преобразователя 30 появляется импульс, амплитуда которого пропорциональна числу кубиков I x I x I сцены AN, имеющих уровень яркости О. Для того, чтобы данная пропорциональность соблюдалось, ступени 27, 24 процессорных модулей 54, моделирующих замкнутые (относительно ортогонально-кольцевых связей) системы, содержащие Е 1, 6, 8, 12 процессоров 6, соединены с входами ступеней 28, с коэффициентом передачи по входу, равному 24/Е. В момент появления импульса на выходе аналогового сумматора начинается процесс измерения его амплитуды, по окончании которого в регистре 24 формируется код значения амплитуды импульса. Далее этот код из регистра 24 передается в регистр 19. При наличии отказавших процессоров 6 в матрице 1 вход преобразователя 30 посредством коммутатора 53 и в соответствии с кодом, хранящимся в регистре 21, соединяется с выходом той ступени 29 (или 28), все кубовые оболочки (оболочка) которой исправны и образуют в совокупности область измерения (фиг. 7, б, в, г). Выполнение команды ОБ aN в этом случае начинается с обнуления регистра 19. Код значения объема нулевого содержимого сцены aN формируется в результате последовательной прокачки содержимого копии сцены AN через облать измерения. Каждый элементарный шаг прокачки включает перемещение участка копии сцены AN, предназначенного для измерения его нулевого содержимого, в область измерения; из- влечение 0-фрагмента перемещенной сцены-копии из узлов 7 и запись извлеченного
фрагмента в регистры 8; собственно измерение (аналоговое суммирование кубиков I x x S, принадлежащих области измерения и имеющих уровень яркости О, аналого- цифровое преобразование амплитуды
импульса-результата суммирования); цифровое суммирование нового содержимого регистра 24 с содержимым регистпа 19. полученным на предыдущем шаге, и запись ре- суммирования Р регистр 19;
гашение измеренного участка (запись Г э узлы 7 процессоров 6. чьи кубики x I x I принадлежат ооласти измерения по адресу сцены-копии) с целью исключения из процесса суммирования нулевого содержимого
этого участка в случае попадания его в область измерения при последующих шагах прокачки. Как видно из всего изложенного, выполнение микропрограмм, реализующих команды управления матрицей, з зависимости от содержимого регистров 21,22 (фиг. 5), а также в зависимости от значений анализируемых признаков осуществляется по одному из альтернативных путей. Выбор пути происходит з результате микроветвлений,
производимых в генераторе 42 адреса мик- рослоаа. Для того, чтобы выработать надлежащую посгедовательность микрокоманд, каждое микрослово памяти 44 содержит поле микроадреса следующего микрослона
(базовый микроадрес}. Этот микроадрес при необходимости ветвления на другие микропрограммы может быть модифицирован в зависимости от состояния разрядов регистра 21, 22, от значения признаков, снимаемых с выходов мультиплексоров 34 и узла 35. С этой целью микрослово содержит поле кода микроветвления (КМВ).
Формула изобретения Устройство для параллельной обработки трехмерных сцен, содержащее блок матрицы процессоров и блок программного управления, соответствующие выходы которого соединены с входами адреса и кодов операций обмена и обработки блока
матрицы процессоров, группу аналоговых сумматоров и аналого-цифровой преоорэзователь, выход которого соединен с соответствующим входом логических условий блока программного управления, входы аналоговых сумматоров группы соединены с выходами состояния соответствующих процессоров блока матрицы процессоре, отличающееся тем, что, с целью повышения отказоустойчивости устройства, в блок матрицы процессоров введен узел
многовходовых элементов ИЛИ, а в устройство введены мультиплексоры признака и коммутатор, информационные входы которого соединены с выходами аналоговых сумматоров группы, а выход соединен с информационным входом аналого-цифрового преобразователя, входы узла многовходовых элементов ИЛИ соединены с выходами состояния соответствующих процессоров
блока матрицы процессоров, а выходы соединены с информационными входами мультиплексора признака, выход которого соединен с соответствующим входом логических условий блока программного управления, соответствующие выходы которого соединены с управляющими входами коммутатора и мультиплексора признака состояния процессоров.






| название | год | авторы | номер документа |
|---|---|---|---|
| Устройство обработки изображений | 1989 |
|
SU1817108A1 |
| Устройство для параллельной обработки трехмерных сцен | 1986 |
|
SU1456965A1 |
| Устройство для параллельной обработки трехмерных сцен | 1988 |
|
SU1612307A2 |
| УСТРОЙСТВО ОБРАБОТКИ ДВУХМЕРНЫХ И ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ | 2005 |
|
RU2289161C1 |
| УСТРОЙСТВО УПРАВЛЕНИЯ АВТОНОМНЫМ РОБОТОМ | 2008 |
|
RU2424105C2 |
| Устройство для параллельной обработки трехмерных сцен | 1990 |
|
SU1817109A1 |
| УСТРОЙСТВО УПРАВЛЕНИЯ ВЫСОКОАДАПТИВНЫМ АВТОНОМНЫМ МОБИЛЬНЫМ РОБОТОМ | 2019 |
|
RU2705049C1 |
| Многопроцессорная система | 1987 |
|
SU1464168A1 |
| УСТРОЙСТВО ОБРАБОТКИ ДВУХМЕРНЫХ И ТРЕХМЕРНЫХ ИЗОБРАЖЕНИЙ | 2008 |
|
RU2376637C1 |
| Устройство для оценки степени оптимальности размещения в многопроцессорных гиперкубических циклических системах | 2019 |
|
RU2718166C1 |
Изобретение относится к вычислительной технике и предназначено для обработки трехмерных изображений. Цель изобретения -повышение отказоустойчивости устройства. Отказавшие в устройстве связи обнаруживаются с помощью диагностирующей программы. Функции отказавших процессоров выполняют работающие процессоры за счет программного обеспечения блока программного управления. 8 ил.
W.
32
г.
Пк
Г77
2У
Г6
I fl г т.
lutf Uta / j
il if
tm
ч
X90
ЙУА/
Пуско&ей оЪрее фогрвммы 7
-J3U I
.Ј
0W J
о
с
. 1 . . . . c Jc :
J
ч- M
л
H /:
Г«БЬ I «109f
Й4-.
i
W 4. о .V-ttft
NT
Ul
/
pjxx
/r;
x
Xх 1
i
i / В leBx
I S
..jaB
На чало
К MutfflOfifloe/iaHMt ItiStyM Gfftyttyeo (тауяЯф) комацд&г
Ян. 5 „
in
L
«o
5
«S34
со
CD CD O
со
CO
ГХ.
5
«
в
В
6
IT;
ч
-
VI
4)
n
л 171
9f
.
4J
i ffVESr
v 4SZ22EZ3
iч i
41N I
41V
У
a
a
,-
,s
Й
-.
k-iriNli N
-
9Q1
4
it
0
| Устройство для параллельной обработки трехмерных сцен | 1986 |
|
SU1456965A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Пневматический водоподъемный аппарат-двигатель | 1917 |
|
SU1986A1 |
| Авторское свидетельство СССР по заявке Мг 4365371 /24, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
