Изобретение относится к устройству пересылки данных. В частности, оно относится к устройству, которое передает и принимает данные через шины данных, связывающие множество передатчиков данных. Здесь устройство передачи и приема данных определяется как схема, которая может выдавать и получать данные из шин данных. Следовательно, устройство памяти также можно считать устройством передачи и приема данных. Кроме того, настоящее изобретение относится к устройству пересылки данных, которое может непрерывно пересылать данные, считываемые из устройства памяти. Настоящее изобретение относится также к устройству пересылки данных для записи данных от границы байта в устройство памяти. Кроме того, изобретение относится к видеоигровому устройству, в котором используется упомянутое выше устройство пересылки.
Оборудование для обработки данных, например, видеоигровое устройство, то есть устройство для обработки информации, включает множество функциональных схем, каждая из которых предназначена для выполнения конкретной функции и имеет устройство передачи и приема данных, определенное выше.
Между множеством устройств передачи и приема данных, например, между CPU (центральный процессор ЦП) и устройством памяти необходимо осуществлять обмен данными с высокой скоростью.
Поэтому множество CPU, устройств памяти и тому подобных устройств передачи и приема данных подсоединяют к шине данных. Пересылка данных выполняется через шины данных, связывающие устройства передачи и приема данных. В известной системе для пересылки адресов по шинам все устройства передачи и приема данных, такие как CPU, RAM (оперативное запоминающее устройство ОЗУ) и VDP (процессор видеоизображений), подсоединены к одной шине данных.
Следовательно, в известной системе с описанной выше структурой данные, находящиеся в шине данных, должны присутствовать там лишь раз в некоторый момент времени для предотвращения конфликта между данными.
Таким образом возникает проблема, связанная с невозможностью параллельной пересылки различных видов данных, например, между CPU и RAM, и внешней памятью и VDP. Кроме того, если существует различие в размерах шин, через которые осуществляется сопряжение между устройствами передачи и приема данных, то каждое устройство передачи и приема данных должно иметь собственную схему интерфейса для сопряжения с общей CPU шиной.
С другой стороны, в видеоигровом устройстве, то есть в процессоре данных или устройстве для обработки информации, к консоли видеоигрового устройства подсоединяется съемное внешнее запоминающее устройство, то есть кассета, и данные, считываемые с кассеты, передаются в консоль по шине.
В последние годы увеличилось быстродействие CPU, и поэтому скорость пересылки данных в системе также стала выше.
Однако при этом следует иметь в виду, что высокая скорость передачи данных вызывает появление радиопомех, излучаемых в окружающее пространство. FCC (Федеральная Комиссия по Связи) или подобные ей организации установила стандарт, регламентирующий уровень излучения радиопомех.
Следовательно, в связи с таким стандартом FCC возникает проблема, заключающаяся в том, чтобы не допустить высокую скорость пересылки данных по шине в консоль от внешнего съемного устройства памяти, которое подсоединяется к консоли.
Между тем, как было сказано выше, в процессоре для обработки данных, например, в видеоигровом устройстве, требуется, чтобы данные между CPU и памятью, которые считаются функциональными схемами, можно было пересылать с высокой скоростью.
В этой связи для уменьшения функциональной нагрузки на CPU было предложено использовать устройство прямого доступа к памяти (DMA) для передачи или пересылки данных.
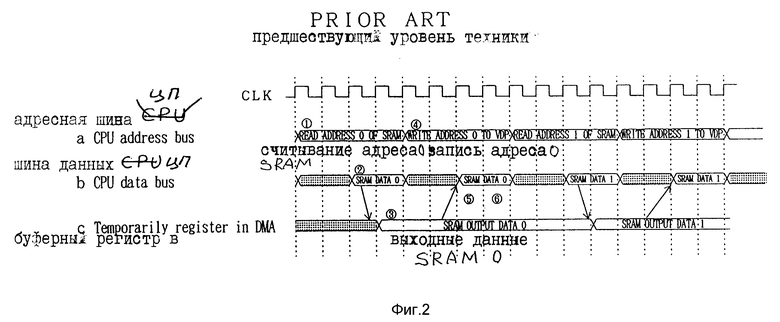
Фиг. 1 поясняет работу известной системы, в которой используется устройство прямого доступа к памяти. На фиг.2 показаны временные диаграммы, иллюстрирующие работу системы на фиг.1.
На фиг.1 показана примерная структура видеоигрового устройства, которая включает схему прямого доступа к памяти (DMA) 60, CPU 61 для выполнения и управления игровой программой, рабочую RAM 62 для хранения данных во время проведения игры и видеопроцессор (VDP) 63 для управления прокруткой изображений и отображаемых спрайтов (элементов динамического графического отображения), или шаблонов. Шина данных 64 соединена с каждой из указанных выше схем.
Процесс пересылки данных, посылаемых из RAM 62 в VDP 63, при такой структуре будет описан со ссылками на временные диаграммы, показанные на фиг.2. DMA 60 посылает адрес для считывания данных из RAM 62 синхронно с тактовым сигналом CLK и посылает считанные данные в адресную шину, которая на диаграмме не показана, но которая предусмотрена независимо от шины данных 64 (см. a  на фиг.2).
на фиг.2).
Данные считываются из RAM 62 по шине 64 согласно считанному адресу (b  на фиг.2). Данные, считанные из RAM 62 по шине 64, временно хранятся в буферном регистре в DMA 60, который на схеме не показан (c
на фиг.2). Данные, считанные из RAM 62 по шине 64, временно хранятся в буферном регистре в DMA 60, который на схеме не показан (c  на фиг.2).
на фиг.2).
Кроме того, из DMA 60 на вышеуказанную адресную шину (a  на фиг.2) выводится адрес записи. Одновременно с адресом записи (b
на фиг.2) выводится адрес записи. Одновременно с адресом записи (b  на фиг.2) на шину 64 выводится содержимое буферного регистра в DMA 60.
на фиг.2) на шину 64 выводится содержимое буферного регистра в DMA 60.
Далее данные, считанные из RAM 62 по шине 64, записываются в VDP 63 согласно адресу записи, который выводится в адресную шину (b  на фиг.2).
на фиг.2).
Таким образом, как для адресной шины, так и для шины данных необходимо использовать разделение времени в соответствии с фиг.2 для обеспечения доступа со стороны RAM 62 и VDP 63. Таким образом невозможно непрерывно считывать и записывать данные из RAM 62 и в VDP 63.
С другой стороны, в последние годы в качестве RAM 62 для передачи данных с высокой скоростью используется синхронное DRAM (динамическое оперативное запоминающее устройство), ввод и вывод из которого синхронизируется тактовыми сигналами. Однако в описанной выше известной структуре невозможно использовать способность непрерывного считывания данных из памяти, характерную для синхронного DRAM.
Одновременно невозможно непрерывно обрабатывать данные. Следовательно, также трудно обрабатывать данные в VDP 63 с высокой скоростью.
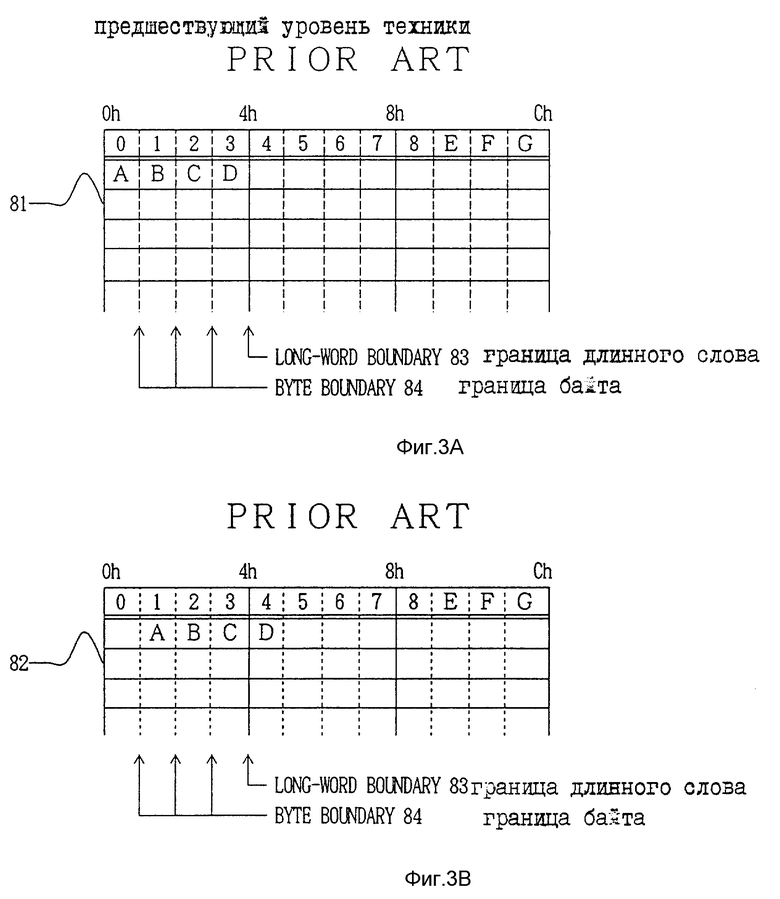
В описанном выше видеоигровом устройстве RAM должно содержать границу, которая определяется блоком из множества байт в зависимости от разрядности CPU, и, следовательно, необходимо считывать данные блоками, состоящими из нескольких байт (здесь и далее блок называется при необходимости "длинным словом"). Таким образом память поразрядной карты, которая используется для отображения видеоизображения в виде набора пикселей (элементов изображения), включает границу блока, состоящего из нескольких байт.
На фиг.3A представлен пример структуры данных 81 в известной RAM. Например, если взять RAM шириной 32 бита (четыре байта), то данные считываются из такой RAM блоками из четырех байт.
Следовательно, у каждого блока из четырех байт существует граница длинного слова 83. На фиг.3A данные "A", "B", "C" и "D" хранятся соответственно в 0-м байте, 1-м байте, 2-м байте и 3-м байте. Тогда данные "ABC " можно считывать сразу как длинное слово.
Напротив, в примере структуры данных 82 памяти поразрядной карты отображения, показанный на фиг.3B, также содержится граница длинного слова 83 на блок из множества байт, поскольку данные записываются поблочно по несколько байт.
Если один пиксель отображается с помощью 8 бит (1 байта), то 4 пикселя, расположенные горизонтально в поразрядной карте отображения, отображаются с помощью одного длинного слова (4 байта). Соответственно граница длинного слова 83 приходится на 4 пикселя в горизонтальном направлении.
При такой структуре памяти потребуется четырехкратный доступ, для того чтобы записать данные для 16 пикселей при записи данных от границы длинного слова 83. Однако в памяти поразрядной карты отображения для свободного конструирования изображений требуется запись по пикселю, то есть по байту. В этом случае, как показано на фиг.3B, для записи данных от границы байта 84 потребуется записывать данные по байту.
Следовательно, возникает проблема, заключающаяся в том, что для записи данных для 16 пикселей потребуется 16-кратная обработка доступа, из-за необходимости записи от границы байта 84 и записи по байту, что вызывает задержку при пересылке данных DMA.
Таким образом целью настоящего изобретения является создание устройства пересылки данных, которое может параллельно пересылать данные между несколькими устройствами передачи и приема данных.
Одной из частных целей настоящего изобретения является создание устройства пересылки данных, которое не нуждается в схеме интерфейса для сопряжения с CPU шиной на каждое устройство передачи и приема данных, даже если размеры шин отличаются у нескольких устройств передачи и приема данных.
В частности, одной из целей настоящего изобретения является создание видеоигровой аппаратуры, использующей устройство пересылки данных, в которой можно применить высокоскоростной CPU, и передавать через шину данные, считываемые из съемного внешнего устройства памяти, которые подсоединяется к консоли видеоигровой аппаратуры, в высокоскоростной CPU.
Другой целью настоящего изобретения является создание устройства пересылки данных, способное передавать данные, используя свойства синхронной DRAM, которая может непрерывно считывать данные.
Еще одной целью настоящего изобретения является создание устройства пересылки данных, использующего DMA, которое может уменьшить время доступа к памяти поразрядной карты отображения, даже если данные записываются в память поразрядной карты отображения от границы байта.
Кроме того, целью настоящего изобретения является создание устройства пересылки данных, использующее DMA, которое может уменьшить время передачи при записи данных от границы байта.
Еще одной целью настоящего изобретения является создание видеоигрового устройства, использующего устройство пересылки данных согласно настоящему изобретению, которое может осуществлять прокрутку и обработку спрайтов в видеопроцессоре с высокой скоростью.
Для реализации вышеуказанных целей устройство пересылки данных согласно настоящему изобретению соединяется со множеством устройств передачи и приема данных через соответствующие внешние шины для пересылки данных между множеством устройств передачи и приема данных, и включает множество схем шинного интерфейса, к которым подсоединяется каждая из соответствующих внешних шин, и схему прямого доступа к памяти, оперативно подключенную к множеству схем шинного интерфейса для пересылки данных между схемами из множества схем шинного интерфейса.
Кроме того, согласно настоящему изобретению в устройстве пересылки данных по меньшей мере две из множества схем шинного интерфейса подсоединены соответственно к внешним шинам, каждая из которых имеет отличный от других размер, и схеме обработки данных для разделения и объединения данных в соответствии с размером любой из внешних шин, по которой передаются данные, когда данные передаются между внешними шинами, имеющими каждая свой, отличный от других, размер.
Также в устройстве пересылки данных согласно настоящему изобретению множество схем шинного интерфейса и схема прямого доступа к памяти соединены внутренней шиной, размер которой соответствует максимальному размеру среди всех имеющихся размеров внешних мин.
В устройстве пересылки данных согласно настоящему изобретению схема обработки данных разделяет данные на первой внешней шине, имеющей первый шинный размер, и последовательно передает разделенные данные на вторую внешнюю шину, имеющую второй шинный размер, меньший, чем первый шинный размер, в соответствии с множеством тактовых импульсов.
С другой стороны, в устройстве пересылки данных согласно настоящему изобретению схема обработки данных объединяет данные в течение нескольких тактовых импульсов на второй внешней шине, имеющей второй шинный размер, и последовательно передает объединенные данные в первую внешнюю шину, имеющую первый шинный размер, больший второго шинного размера.
Кроме того, устройство обработки информации согласно настоящему изобретению включает устройство пересылки данных, множество устройств передачи и приема данных и множество внешних шин для подсоединения устройства пересылки данных к соответствующему устройству из множества устройств передачи и приема данных, причем устройство пересылки данных имеет множество схем шинного интерфейса, к которым подсоединены каждая из соответствующих внешних шин, и схему прямого доступа к памяти, оперативно подсоединенные к множеству схем шинного интерфейса, для пересылки данных между указанным множеством схем шинного интерфейса, а размер каждой внешней шины, подсоединенной к одному из устройств передачи и приема данных, является минимальным из всех размеров внешних шин, подсоединенных к устройству пересылки данных.
В настоящем изобретении, как было указано выше, устройство пересылки данных включает системный блок управления, подсоединенный к множеству устройств передачи и приема данных через соответствующие шины.
Устройство пересылки данных снабжено множеством схем шинного интерфейса, к которым подсоединены соответствующие шины, и схемой прямого доступа к памяти, которая пересылает данные, посланные в одну схему шинного интерфейса, в другую схему шинного интерфейса, а множество схем шинного интерфейса разделяет и объединяет данные в соответствии с размерами подключенных шин.
Это соответственно облегчает пересылку данных между устройствами передачи и приема данных, даже если размеры подключенных шин отличаются друг от друга. Кроме того, поскольку предусмотрено множество схем шинного интерфейса, к которым подсоединены соответствующие шины, то нет необходимости иметь схему интерфейса для каждого из устройств передачи и приема данных для соответствующего сопряжения с CPU.
Кроме того, устройство пересылки данных, пересылающее данные с использованием свойств синхронного DRAM, которое может считывать данные непрерывно, подсоединено к первой внешней шине и второй внешней шине, составляющую 1/n часть (где n - положительное целое число) размера первой внешней шины, и включает первую и вторую схемы шинного интерфейса, к которым подсоединены соответственно первая и вторая внешние шины, схему прямого доступа к памяти для пересылки данных на первую внешнюю шину, которые передаются на первую схему шинного интерфейса, на вторую схему шинного интерфейса, и внутреннюю шину, подсоединенную к первой и второй схемам шинного интерфейса и схеме прямого доступа к памяти, имеющую тот же самый размер, что и первая внешняя шина, причем первая схема шинного интерфейса преобразует данные, которые непрерывно передаются с заданным периодом синхронно с тактовыми сигналами на первую внешнюю шину, в данные с периодом 1/n заданного, и выводит преобразованные данные на внутреннюю шину, схема прямого доступа к памяти сдвигает данные на 1/n периода и вновь транслирует сдвинутые данные на внутреннюю шину, а вторая схема шинного интерфейса берет данные 1/n заданного периода, которые вновь передаются из схемы прямого доступа к памяти на внутреннюю шину, превращая полученные данные в непрерывную последовательность данных с периодом 1/n, и ретранслирует непрерывную последовательность данных с периодом 1/n на вторую внешнюю шину.
Как было указано выше, в настоящем изобретении схема шинного интерфейса синхронизируется тактовыми импульсами для вывода данных на первой шине на внутреннюю шину системного блока управления, а вторая схема шинного интерфейса пересылает данные с периодом 1/n заданного из схемы прямого доступа к памяти (DMA) на вторую шину в течение заданного периода.
Следовательно, согласно настоящему изобретению становится возможным непрерывно пересылать данные, имеющие заданный период на первой шине, на вторую шину с заданным периодом.
Кроме того, устройство пересылки данных также включает синхронное DRAM, входы и выходы которого синхронизируются тактовыми импульсами, подсоединенную к первой внешней шине для считывания данных, выводимых из синхронного DRAM, и пересылки данных в первую схему шинного интерфейса. Таким образом появляется возможность использования непрерывного считывания данных, характерного для синхронного DRAM.
В частности, если в качестве вышеуказанного положительного целого числа n использовать 2, то вторая схема интерфейса может посылать данные, к схеме прямого доступа к памяти (DMA) в виде верхних и нижних данных, составляющих 1/2 последовательности данных, на вторую шину.
Даже если данные в память поразрядной карты записываются от границы байта, устройство пересылки данных, использующее DMA, способное уменьшить время обработки доступа, согласно настоящему изобретению включает первую схему защелки для фиксации введенных n байт данных, вторую схему защелки, оперативно подсоединенную к первой схеме защелки, для фиксации (n-1) байт данных, выводимых из первой схемы защелки, и селектор, на который подается n байт данных, фиксируемых в первой схеме защелки, и скомбинированных n байт, которые образуются путем комбинирования зафиксированных n байт данных первой схемы защелки с зафиксированными (n-1) байт данных второй схемы защелки и последовательного сдвига на один байт, для составления необходимого набора n байт данных из поступивших n байт.
Следовательно, в DMA данные, считываемые по несколько байт из первой памяти, сдвигаются для пересылки во вторую память на несколько байт. Соответственно появляется возможность записи от границы байта при пересылке несколькими байтами во вторую память. Например, не более чем 5-разовая обработка доступа потребуется для пересылки данных для 16 пикселей, что резко уменьшает время передачи.
Кроме того, можно реализовать схему с простой структурой, например, две схемы защелки и селектор.
К тому же, так как селектор отбирает данные, можно уменьшить время задержки, связанной с операцией сдвига, что позволит передавать данные с более высокой скоростью.
Цели, признаки и преимущества настоящего изобретения станут очевидными из последующего подробного описания предпочтительного варианта настоящего изобретения со ссылками на чертежи.
На фиг. 1 представлена схема, раскрывающая принцип действия известного устройства согласно второму признаку настоящего изобретения.
На фиг. 2 показана временная диаграмма, иллюстрирующая работу схемы на фиг.1.
Фиг. 3A и 3B - схемы, поясняющие известную структуру согласно третьему признаку настоящего изобретения.
Фиг.4 - блок-схема варианта реализации настоящего изобретения.
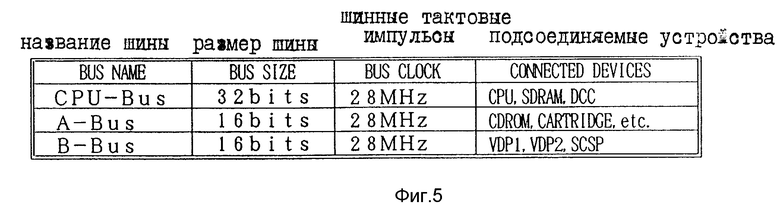
На фиг.5 показан пример структуры каждой шины на фиг.4.
Фиг. 6 - структурная схема системного блока управления, показанного на фиг.4.
На фиг. 7 показана временная диаграмма функционирования варианта реализации настоящего изобретения.
На фиг. 8 показана временная диаграмма функционирования варианта реализации настоящего изобретения.
На фиг. 9 показана примерная структурная схема прохождения сигналов в варианте реализации настоящего изобретения.
На фиг.10A представлено содержимое шины 6, показанной на фиг.9.
На фиг.10B представлена временная диаграмма шины 6, показанной на фиг.9.
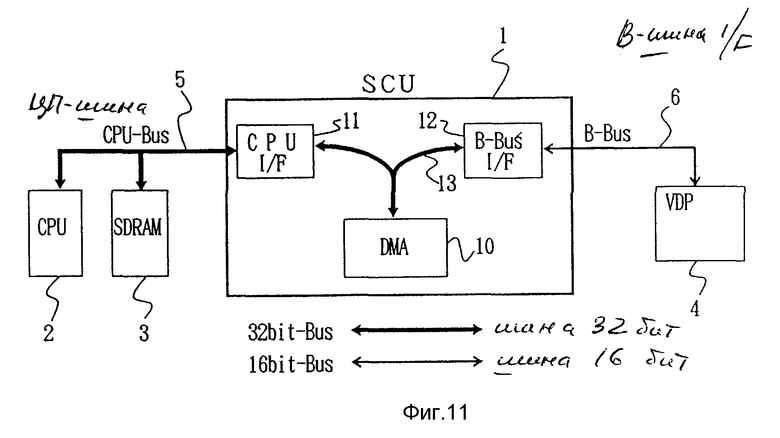
На фиг.11 - схема, раскрывающая вариант реализации согласно второму признаку настоящего изобретения.
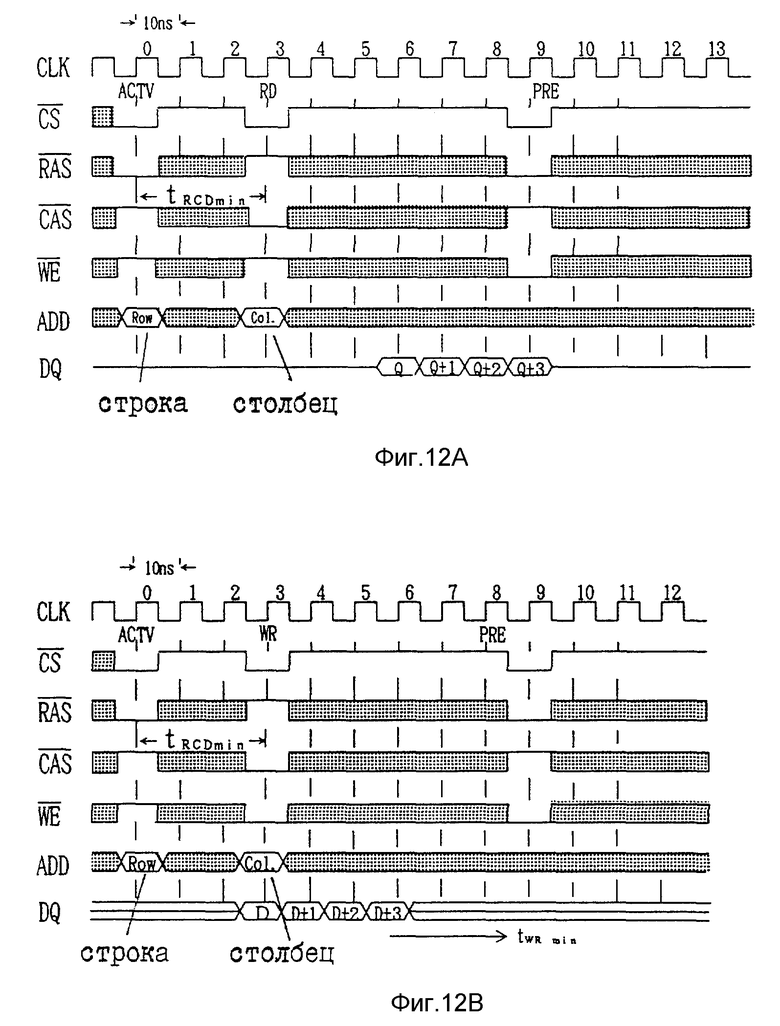
На фиг. 12A и 12B показан пример операций считывания и записи обычного синхронного DRAM.
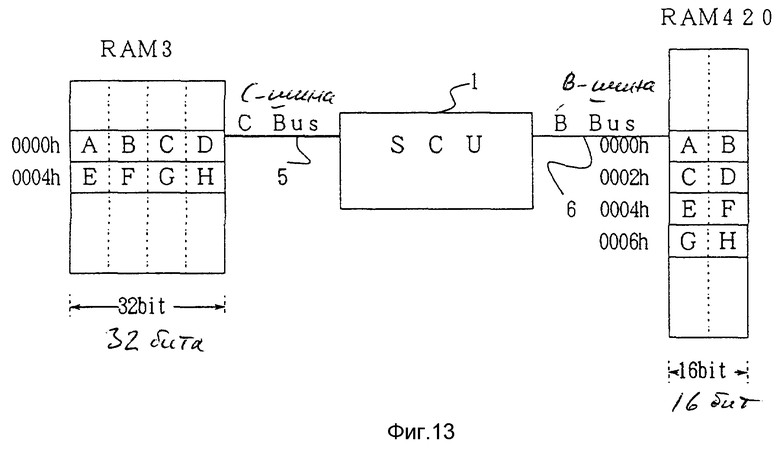
Фиг.13 - вариант реализации, соответствующий третьему признаку настоящего изобретения, где показана схема, объясняющая процесс пересылки посредством блока из множества байт.
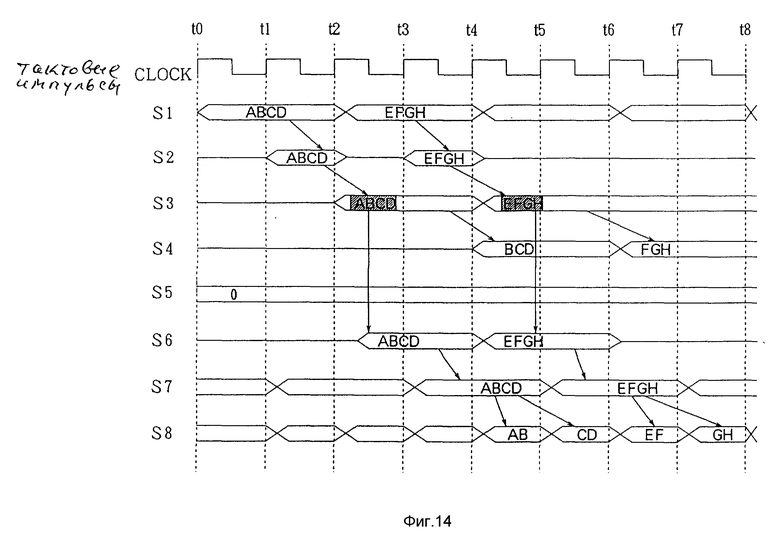
На фиг.14 показана временная диаграмма работы схемы согласно фиг.13.
На фиг.15 показана схема, поясняющая процесс пересылки границы байта.
На фиг.16 показана временная диаграмма работы схемы согласно фиг.15.
На фиг.17 показана схема, поясняющая процесс пересылки границы байта.
На фиг.18 показана временная диаграмма работы схемы согласно фиг.17.
На фиг. 19 показана другая схема, поясняющая процесс пересылки границы байта.
На фиг.20 показана временная диаграмма работы схемы согласно фиг.19.
На фиг.21 показана еще одна схема, поясняющая процесс пересылки границы байта.
На фиг.22 показана временная диаграмма работы схемы согласно фиг.21.
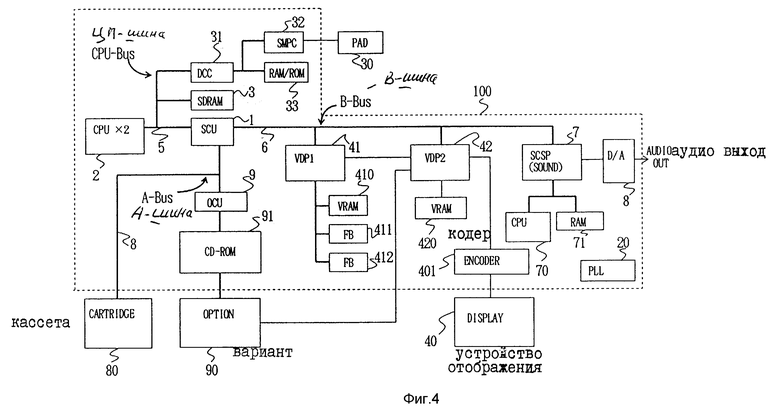
На фиг. 4 показан вариант реализации настоящего изобретения в виде блок-схемы, где используется устройство пересылки данных согласно настоящему изобретению в видеоигровой аппаратуре. Для обозначения соответствующих или идентичных элементов в последующем описании используются одинаковые цифровые ссылки.
На фиг. 4 зона 100, обведенная пунктирной линией, представляет собой консоль видеоигрового устройства.
Первая шина (CPU-BUS) 5, вторая шина (B-BUS) 6 и третья шина (A-BUS) 8 являются внешними шинами устройства пересылки данных, а CPU и память и т.п. подсоединены к каждой из внешних шин в качестве устройств передачи и приема данных. Устройство передачи и приема данных, как было указано выше, определяется как устройство, которое может передавать и получать данные через шину данных.
Кроме того, первая шина (CPU-BUS) 5, вторая шина (B-BUS) 6 и третья шина (A-BUS) 8 обычно подсоединены к системному блоку управления 1. Во всех описываемых далее вариантах системный блок управления 1 соответствует устройству пересылки данных, которое является предметом настоящего изобретения.
В примере, показанном на фиг.4, первая шина (CPU-BUS) 5 имеет шинный размер 32 бита, а каждая из вторых шин (B-BUS) 6 и третьих шин (A-BUS) 8 имеет шинный размер 16 бит.
На фиг.4 главный CPU 2 включает пару высокоскоростных CPU для управления всей аппаратурой. Синхронное DRAM 3 - это рабочее RAM, используемое главным CPU 2.
К функции системного блока управления 1 относится управление каждой из вышеописанных шин. Пример структуры системного блока управления 1 будет описан позднее вместе с фиг.6.
Цифровые ссылки 41 и 42 относятся к первому и второму видеопроцессорам (VDP).
Функцией первого VDP 41 является управление отображением спрайтов или шаблонов на экране. Видео RAM 410 подсоединено к первому VDP 41. Видео RAM 410 хранит команды управления для первого VDP 41 и символьные данные.
Кроме того, буферные памяти кадра (FB) 411 и 412 подсоединены к первому VDR 41. Каждая из FB 411 и 412 имеет деплексную буферную структуру, образованную из двух устройств памяти. Во время записи данных изображения для одного кадра в одно устройство памяти данные изображения для другого кадра могут считываться из другого устройства памяти.
Второй VDP 42 управляет прокруткой изображения на экране и определяет приоритетный порядок отображения изображений на экране. Видео RAM 420 подсоединено ко второму VDP 42. Второе видео PAM 420 хранит карту прокрутки, поразрядную карту изображения и данные о коэффициентах.
Главный CPU 2 и синхронное DRAM 3 подсоединены к системному блоку управления 1 через первую шину (CPU-BUS) 5. В то же время первый и второй VDP 41 и 42 подсоединены к системному блоку управления 1 через вторую шину (B-BUS) 6.
Кроме того, кассета 80, подсоединенная к третьей шине (A-BUS) 8, представляет собой съемное устройстве внешней памяти, которое подсоединяется к консоли 100 видеоигровой аппаратуры и имеет внутри устройство памяти для хранения игровой программы. Третья шина (A-BUS) 8 имеет тот же размер, что и вторая шина (B-BUS) 6.
Блок дисковода CD-ROM (постоянное запоминающее устройство на компакт-диске) 91 через блок управления оптического диска 9, а также функциональный блок, который генерирует внешний сигнал изображения, например, MPEG (Группа экспертов по движущимся изображениям), подсоединены к третьей шине (A-BUS) 8.
Часть третьей шины (A-BUS) 8 может быть выведена наружу из консоли 100 видеоигрового устройство. Если скорость пересылки данных будет высокой, не может быть соблюден стандарт FCC из-за такой проблемы, как излучение радиопомех. Одной из целей настоящего изобретения является решение этой проблемы.
CPU контроллер 31, подсоединенный к первой шине (CPU-BUS) 5, осуществляет арбитраж первой шины (CPU-BUS) 5, когда два высокоскоростных CPU 2 обращаются к синхронному DRAM 3 и системному блоку управления 1.
CPU контроллер 31 осуществляет диспетчерское управление, когда CPU 2 обращается к контроллеру 1/0 (ввода/вывода) (SMPC) 32 и RAM/ROM 33. Съемная клавиатура управления 30, которую можно подсоединять извне к консоли 100 видеоигрового устройства, приводится в действие играющим.
Кроме того, схема преобразователя 401 преобразует аналоговый RGB (красный-зеленый-синий) сигнал, который выводится из второго VDP 42, в видеосигнал. Видеосигнал, который выводится из схемы преобразования 401, отображается на устройстве отображения 40.
Процессор источника звука 7 (SCSP) подсоединен ко второй шине (B-BUS) 6 для управления процессом генерирования PCM/FM (импульсно-кодовая модуляция/частотная модуляция) звука. CPU 70 для звука и RAM 71, необходимое для работы CFU 70, подсоединены к процессору источника звука 7, a CPU управляет работой источника звука.
Кроме того, к процессору источника звука 7 подсоединен D/A (цифроаналоговый) преобразователь 8 для преобразования цифрового сигнала в аналоговый сигнал и затем его вывода на аудиовыход.
Схема PLL (фазовой синхронизации) 20 генерирует базовый синхросигнал, который подается во всю систему. Как было объяснено выше, в варианте реализации видеоигровой аппаратуры, представленном на фиг.4, системный блок управления 1 используется как центральная схема в соответствии с базовыми синхроимпульсами из схемы PLL 20 для согласования разных шинных размеров у первой шины (CPU-BUS) 5, к которой подсоединены главный CPU 2 и синхронное DRAM 3, второй шины (B-BUS) 6, к которой подсоединены первый и второй VDP 41 и 42, и третьей шины (A-BUS) 8, к которой подсоединена кассета памяти и которая выводится наружу из консоли 100 видеоигрового устройства.
Более подробно пример структуры первой шины (CPU-BAS) 5, втором шины (B-BUS) 6 и третьей шины (A-BUS) 8 будет разъяснен со ссылкой на фиг.5.
На фиг. 5 первая шина (CPU-BUS) 5 имеет шинный размер 32 бита, и CPU 2, синхронное DRAM 3 и контроллер CPU 31 подсоединены к первой шине 5. Третья шина (A-BUS) 8 имеет шинный размер 16 бит, к которой подсоединены дисковод CD-ROM 91 и кассета 80.
Кроме того, вторая шина (B-BUS) 6 имеет шинный размер 16 бит и к ней подсоединены первый и второй VDP 41 и 42 и процессор источника звука 7.
По первой, второй и третьей шинам 5, 6 и 8 данные передаются посредством шинных тактовых импульсов частотой 28 МГц, которые формируются на основе базовых тактовых импульсов, подаваемых в общем случае из схемы PLL 20.
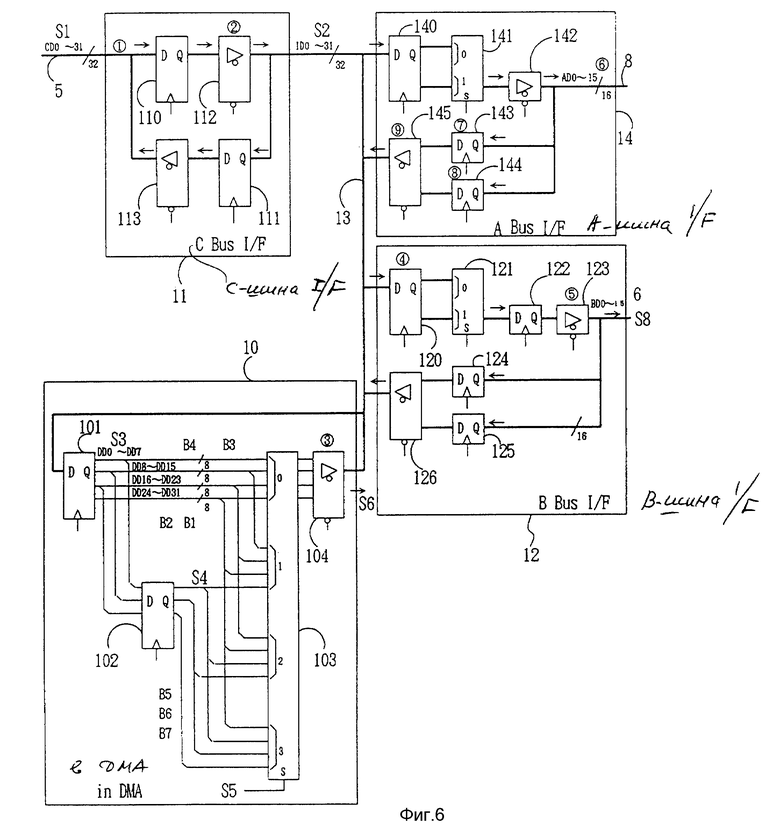
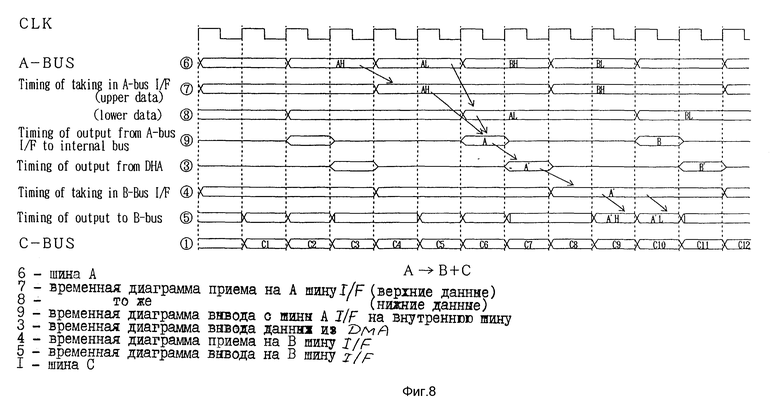
На фиг.6 подробно показан пример структуры системного блока управления 1 как устройства пересылки данных согласно настоящему изобретению. На фиг. 7 и 8 показаны временные диаграммы функционирования данного варианта настоящего изобретения. На фиг.7 показаны временные диаграммы при пересылке данных от первой шины (CPU-BUS) 5 на вторую шину (B-BUS) 6. На фиг.8 показаны временные диаграммы при пересылке данных от третьей шины (CPU-BUS) 8 на вторую шину (B-BUS) 6 и режим параллельной работы с первой шиной (CPU-ВUS).
На фиг. 7 и 8 номера в кружках обозначают временные диаграммы сигналов, относящихся к каждой части структуры, показанной на фиг.6.
На фиг.6 системный блок управления 1 включает первую схему шинного интерфейса 11, вторую схему шинного интерфейса 12, третью схему шинного интерфейса 14 и схему прямого доступа к памяти (DMA) 10.
Эти схемы соединены внутренней шиной 13, имеющей шинный размер 32 бита, тот же самый, что и у первой шины (GPU-BUS) 5. Кроме того, первая схема шинного интерфейса 11 подсоединена к первой шине (CDU-BUS) 5. Вторая схема шинного интерфейса 12 и третья схема шинного интерфейса 14 подсоединены ко второй шине (B-BUS) 6 и третьей шине (A-BUS) 8 соответственно.
Сначала со ссылками на фиг.7 будет пояснено, как происходит повторение данных с первой шины (CPU-BUS) 5 на вторую шину (B-BUS) 6.
Первая схема интерфейса 11 построена на триггерах FF 110 и 111 и буферах с тремя состояниями 112 и 113, имеющие каждый TTL (транзисторно-транзисторные) схемы с трехзначной логикой. Для управления работой этих схем на них из схемы PLL 20 (см. фиг.7) подаются базовые тактовые импульсы CLK.
Если вход триггера FF 110, то есть сигнал на первой шине (CPU-BUS) 5 представляет собой данные, считанные из синхронной DRAM 3, появляется непрерывный сигнал, показаный на фиг.7 под номером  Непрерывные данные зависят от характеристики синхронного DRAM 3, в котором входные и выходные сигналы синхронизируются тактовыми импульсами.
Непрерывные данные зависят от характеристики синхронного DRAM 3, в котором входные и выходные сигналы синхронизируются тактовыми импульсами.
В примере, показанном на фиг. 7, управление осуществляется так, что данные непрерывно выводятся по первой шине (CPU-BUS) 5 за два периода базового тактового импульса CLK ( фиг. 7). Соответственно буфер с тремя состояниями 112 преобразует выход на первой шине во временной сигнал под номером
фиг. 7). Соответственно буфер с тремя состояниями 112 преобразует выход на первой шине во временной сигнал под номером  на фиг. 7, и преобразованный временной сигнал выводится на внутреннюю шину 13.
на фиг. 7, и преобразованный временной сигнал выводится на внутреннюю шину 13.
В то же время DMA 10 построена на триггерах FF 101 и 102, селекторе 103 и буфере с тремя состояниями 104. Триггер FF 101 делит 32 бита данных, посылаемых от внутренней шины 13, на группы из 8 бит и подает группы из 8 бит в селектор 103 по шинам с B1 по B4.
Триггер FF 102 получает выделенные три верхние группы, посылаемые триггером FF 101, и выводит их ни селектор 103. Селектор 103 имеет четыре входа с 0 по 3. Данные из 32 бит, разделенные и затем сдвинутые на 8 бит, подаются на каждый из входов с 0 по 3.
Селектор 103 отбирает и выводит входные сигналы четырех входов с 0 по 3 в соответствии с сигналом выбора S5 и выводит их через буфер с тремя состояниями 104 на внутреннюю шину 13. На фиг.7 под номером  показана временная диаграмма выходного сигнала DMA 10.
показана временная диаграмма выходного сигнала DMA 10.
Как показано на фиг.7, выходной сигнал из DMA 10 ( на фиг.7) сдвинут на один тактовый период по отношению к временной диаграмме данных (
на фиг.7) сдвинут на один тактовый период по отношению к временной диаграмме данных ( на фиг. 7), выводимых из первой схемы шинного интерфейса 11. Таким образом появляется возможность предотвращения конфликта данных (
на фиг. 7), выводимых из первой схемы шинного интерфейса 11. Таким образом появляется возможность предотвращения конфликта данных ( и
и  на фиг.7) на внутренней шине 13.
на фиг.7) на внутренней шине 13.
Кроме того, вторая схема шинного интерфейса 12 получает данные, выводимые из DMA 10 на внутренним шину 13. Вторая схема шинного интерфейса 12 построена на триггерах FF 120, 122, 124 и 125, селекторе 121 и буферах с тремя состояниями 123 и 126.
Триггер FF 120 второй схемы шинного интерфейса 12 снимает данные с внутренней шины 13 в течение двух периодов базового тактового импульса CLK ( на фиг.7).
на фиг.7).
Кроме того, селектор 121 отбирает и выводит верхние 16 бит (A'H) и нижние 16 бит (B'H) и подает их через триггер 122 и буфер с тремя состояниями 123 на вторую шину (B-BUS) 6 ( на фиг.7).
на фиг.7).
Теперь будет описан случай, когда работа по первой шине (CPU-BUS) 5 может осуществляться параллельно с пересылкой данных по третьей шине (A-BUS) 8 на вторую шину (B-BUS) 6.
Данные на третьей шине (B-BUS) 8 генерируются путем синхронизации через за два периода базового тактового импульса CLK ( на фиг.8). Третья схема шинного интерфейса 14 выдает данные на третью шину (A-BUS) 8 в виде верхних и нижних данных (
на фиг.8). Третья схема шинного интерфейса 14 выдает данные на третью шину (A-BUS) 8 в виде верхних и нижних данных ( и
и  на фиг.8).
на фиг.8).
То есть третья схема шинного интерфейса 14 имеет такую же структуру, что и вторая схема шинного интерфейса 12. Данные на третьей шине (A-BUS) 8 поочередно вводятся в пару триггеров FF 143 и 144. Выходные сигналы триггеров 143 и 144 комбинируются в виде данных из 32 бит с помощью буферной схемы интерфейса с тремя состояниями 145 и выдаются на внутреннюю шину 13 ( на фиг.8).
на фиг.8).
DMA 10 получает и сдвигает на один базовый тактовый импульс данные из 32 бит, поданные на внутреннюю шину 13, и снова выводит сдвинутые данные из 32 бит во внутреннюю шину 13 ( на фиг.8). Вторая схема шинного интерфейса 12 воспринимает выходной сигнал за 4 периода базового тактового импульса (
на фиг.8). Вторая схема шинного интерфейса 12 воспринимает выходной сигнал за 4 периода базового тактового импульса ( на фиг.8).
на фиг.8).
Далее вторая схема шинного интерфейса 12 выдает соответственно верхние данные (A'H) и нижние данные (A'L) из 16 бит за 4 периода базового тактового импульса CLK ( на фиг.8).
на фиг.8).
Одновременно с вышеописанной операцией появляется возможность пересылать независимые данные (C1, C2 ...) из 32 бит за период базового тактового импульса CLK по первой шине (CPU-BUS) ( на фиг.8).
на фиг.8).
Как было объяснено выше, согласно настоящему изобретению становится возможным пересылать данные между устройствами передачи и приема данных, подсоединенными к шинам с разными размерами. Кроме того, нет необходимости иметь какую-либо схему шинного интерфейса, которая обеспечивает сопряжение с CPU шиной 5, в каждом устройстве передачи и приема данных, подсоединенном к соответствующей шине данных, поскольку системный блок управления 1 имеет внутренние схемы шинного интерфейса, каждая из которых обеспечивает каждое устройство передачи и приема данных.
На фиг. 9 показан подробный вариант, в котором данные, посылаемые через первую шину (CPU-BUS) 5, пересылаются через вторую шину (B-BUS) 6, имеющую ограниченный шинный размер, путем организации доступа к первому VDP 41 или второму VDP 42.
На фиг. 9 в качестве примера показан системный блок управления, пересылающий данные в первый VDP 41.
Для того чтобы выбрать и передать данные, посылаемые через первую шину (CPU-BUS) 5 из системного блока управления 1 в соответствующий первый VDP 41, необходимо передать адрес, данные и сигналы различения считывания/записи.
Сигнал адреса состоит из 20 бит с AO по 19 (требуется 20 сигнальных линий), данные содержат 16 бит с DO по 15 (требуется 16 сигнальных линии) и, кроме того, сигнал различения считывания/записи содержит R/W бит (требуется одна сигнальная линия). Таким образом всего потребуется 37 сигнальных линий.
Кроме того, учитывая, что пояснения к фиг. 4 и 6 были сокращены, необходимо иметь сигнал выбора кристалла (CS), который указывает, имеет ли системный блок управления 1 доступ к VDP 41 (0)/(1), и сигнал разрешения данных (DTEN), который указывает правильность данных на второй шине (B-BUS) 6 (0)/(1).
Соответственно описанные выше управляющие сигналы (CS и DTEN), указывающие на выбор кристалла и правильность данных, генерируются и посылаются на две сигнальные линии L1 и L2, как показано на фиг.9.
В то же время вторая шина (B-BUS) 6, которая соединяет системный блок управления 1 с первым VDP 41 и вторым VDP 42, имеет шинный размер 16 бит. Соответственно в варианте, показанном на фиг.9, вторая шина (B-BUS) 6, соединяющая системный блок управления 1 и первый VDP 41, имеет 16 сигнальных линий или шинный размер 16 бит и, кроме того, предусмотрены две сигнальные линии для управления (для сигналов управления CS и DTEN) между системным блоком управления 1 и первым VDP 41.
Когда системный блок управления 1 осуществляет доступ к первому VDP 41, системный блок управления 1 устанавливает сигнал выбора кристалла (CS) на LOW (0) (низкий уровень), и одновременно разделяет адреса на верхние и нижние для их передачи на вторую шину (B-BUS) 6.
После этого при записи на первый VDP 41 записываемые данные из 16 бит посылаются в виде данных 1 (DD1), данных 2 (DD2), данных 3 (DD3) ... . Причем каждое из данных передается на первую шину (B-BUS) 6 за один тактовый импульс CLK.
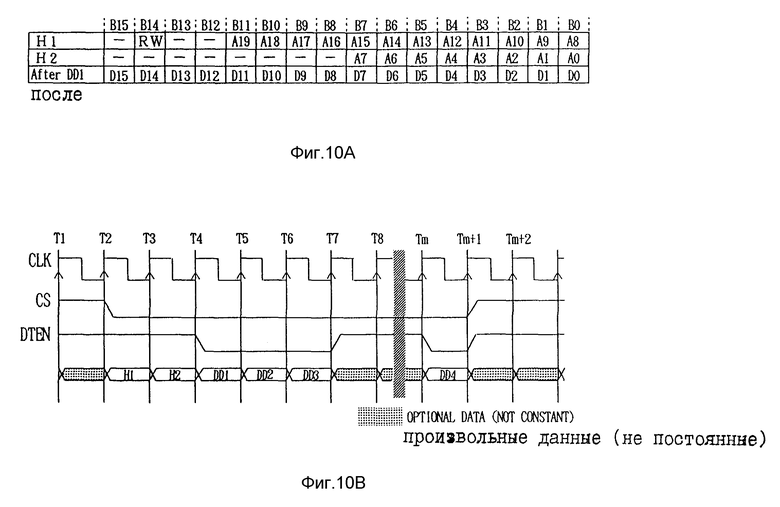
Содержимое описанной выше B-BUS 6 показано на фиг.10A. На фиг.10A с B15 по B0 - биты сигнальных линий (16 бит), а знак "-" означает неиспользуемый бит. Первая шина (B-BUS) 6 делится между H1, H2, DD1, DD2 ... в соответствии с ее содержимым.
Адрес делится на верхние 12 бит (H1) и нижние 8 бит (H2), и верхние 12 бит (H1) и пересылаются нижние 8 бит (H2). Кроме того, к оставшимся битам верхнего адреса H1 придается сигнал считывания/записи RW. Данные (c D 15 по D 0) из 16 бит располагаются после DD 1.
Первый VDP 41 подтверждает прием адресованных к нему данных посредством сигнала выбора кристалла CS, передаваемого от системного блока управления 1, а затем принимает переданные на него данные. При обработке считываемых данных от первого VDP 41 VDP 41 принимает адрес, разделенный на верхний и нижний адреса, и передает необходимые данные на вторую шину (B-BUS) 6.
Системный блок управления 1 принимает данные, переданные от VDP 41 через вторую шину (B-BUS) 6, и передает их на первую шину (CPU-BUS) 5 или третью шину (A-BUS) 8 через схемы шинного интерфейса 12, 11 и 14 DMA 10, описанные выше.
Есть возможность пересылать адреса и данные между системным блоком управления 1 и первым VDP 41 или подобным же образом вторым VDP 42 через описанную выше вторую шину (B-BUS) 6 размером 16 бит.
Теперь с использованием временных диаграмм будет пояснено образование сигналов управления на двух сигнальных линиях управления L1 и L2 соответственно для сигналов CS и DTEN и функционирование второй тины (B-BUS) 6. На фиг. 10B показаны временный диаграммы, иллюстрирующие работу второй шины (B-BUS) 6.
На фиг.10B моменты с T1 по T8 представляют фронты тактовых сигналов CLK на временною оси. H1 и H2 показывают соответственно верхним и нижний адреса на второй шине (B-BUS) 6. DD1-DD4 представляют данные на второй шине (B-BUS) 6.
На фиг. 10B, где показана временная диаграмма шины B-BUS 6, в начале сигнал выбора кристалла CS переключается на [LOW(0)] в момент T2 тактового импульса CLK. Одновременно за период с момента T2 по T3 системный блок управления 1 посылает верхний адрес H1 на вторую шину (B-BUS) 6. Вслед за этим в течение периода с момента T3 по момент T4 посылается нижний адрес H2.
При записи из системного блока управления 1 в первый VDP 41 данные DD1, DD2, DD3 и DD4 посылаются из системного блока управления 1 на вторую шину (B-BUS) 6 за один тактовый импульс CLK после момента T4. Одновременно сигнал DTEN, указывающий на правильность данных, переключается на [LOW (0)]. VDP 41 принимает H1, H2, DD1 ... в любое время. После DD1 данные можно записать только тогда, когда сигнал DTEN, указывающий на правильность данных, имеет уровень [LOW (0)].
Соответственно, если пересылка данных не может быть выполнена в течение некоторого периода, системный блок управления 1 устанавливает сигнал DTEN, указывающий на правильность данных, на уровень [HlGH (1)] (высокий уровень) и тогда операция записи для первого VDP 41 укорачивается.
В примере на фиг.10B данные DD4 можно вывести в момент Tm. Поэтому системный блок управления 1 снова устанавливает сигнал DTEN, указывающий на правильность данных, на уровень [LOW (0)] и одновременно выводит данные DD4 в течение периода с момента Tm до момента Tm + 1.
На фиг.10B показан пример записи четырех данных с DD1 по DD4. Сигнал выбора кристалла CS переходит на уровень [H1GH (1)] в момент Tm + 1 для окончания записи в VDP 41.
В то же время при считывании из первого VDP 41 данные DD1, DD2, DD3 и DD4 выводятся из VDP 1 за один тактовый импульс CLK вслед за моментом T4.
В этом случае сигнал DTEN, указывающий на правильность данных, который передается из системного блока управления 1, игнорируется, и непрерывные данные DD1, DD2, DD3 и DD4 принимаются в системный блок управления 1 в любое время.
Если завершено некоторое постоянное число считываний данных, системный блок управления 1 устанавливает сигнал выбора кристалла CS на уровень [H1GH (1)] для окончания доступа к считыванию данных.
Теперь будет рассмотрен случай, когда данные считываются из RAM, подсоединенного к первой шине (CPU-BUS) 5, на RAM, подсоединенный ко второй шине (B-BUS) 6. В этом случае, как было раскрыто в пояснениях к фиг.4, синхронное DRAM 3 используется в качестве RAM, подсоединенного к первой шине (CPU-BUS) 5. Это составляет второй признак настоящего изобретения, который дает возможность передавать данные, используя свойство синхронного DRAM 3, состоящее в том, что данные из нее можно считывать непрерывно.
На фиг.11 показана концептуальная структура видеоигрового устройства, в котором используется второй признак согласно настоящему изобретению и которое похоже на примеры, показанные на фиг. 4 и 6.
Для обозначения и идентификации соответствующих или одинаковых элементов, показанных на фиг. 4 и 6, используются те же самые цифровые ссылки.
Сравнение со структурой, показанной на фиг.4, показывает, что базовая структура согласно второму признаку настоящего изобретения, показанная на фиг. 1, ей соответствует и включает системный блок управления 1, CPU 2, синхронное DRAM 3, первый и второй VDP 41 и 42, процессор источника звука 7 и первую шину (CPU-BUS) 5 и вторую шину (B-BUS) 6, соединяющие вышеуказанные схемы.
Кроме того, первая схема шинного интерфейса 11, вторая схема шинного интерфейса 12 и схема прямого доступа к памяти (DMA) 10, которые образуют системный блок управления 1, показанный на фиг.1, соответствуют первой схеме шинного интерфейса 11, второй схеме шинного интерфейса 12 и схеме прямого доступа к памяти (DMA) 10, показанным на фиг.6.
Третья схема шинного интерфейса 14, подсоединенная к внутренней шине 13, раскрытой на фиг.6, на фиг.11 не показана. Это сделано потому, что структура третьей схемы шинного интерфейса 14 такая же, как и структура второй схемы шинного интерфейса 12, поскольку третья схема шинного интерфейса 14 подсоединена к внутренней шине 13 на 32 бита и внешней шине на 16 бит.
На фиг.6, когда данные, состоящие из 16 бит, передаются со второй и третьей шин 6 и 8, которые подсоединены соответственно ко второй и третьей схемам шинного интерфейса 12 и 14, на первую шину (CPU-BUS) 5, триггерные схемы FF 124 и 125 и буфер с тремя состояниями 126 во второй схеме шинного интерфейса 12 группируют два блока непрерывных данных из 16 бит в данные, состоящие из 32 бит, и выводят их на внутреннюю шину 13. Кроме того, триггерные схемы FF 143 и 144 и буфер с тремя состояниями 145 в третьей схеме шинного интерфейса 13 группируют и выводят данные на внутреннюю шину 13 таким же образом, как и во второй схеме шинного интерфейса 12.
Данные, состоящие из 32 бит, выводимые на внутреннюю шину 13, передаются на первую шину (CPU-BUS) 5 через DMA 10, триггерную схему FF 111 и буфер с тремя состояниями 113 в первой схеме шинного интерфейса 11, как было описано выше.
Синхронное DRAM 3 отличается тем, что его входные и выходные сигналы синхронизируются тактовыми импульсами, и непрерывным считыванием и записью данных вдобавок к свойствам известной DRAM. Один из примеров этого показан на фиг. 12A и 12B, где синхронное DRAM 3 синхронизирует работу известного DRAM посредством тактовых импульсов.
На фиг. 12A показана операция считывания обычного синхронного DRAM, включающего синхронное DRAM 3, на фиг.12B показаны временные диграммы, иллюстрирующие операцию записи. Операции считывания и записи выполняются в соответствии с сигналами управления /RAS/CAS и/WE.
Эти входные сигналы как сигналы управления принимаются синхронно с фронтами синхронизирующих тактовых импульсов CLK. Период тактового импульса CLK составляет 10 нс, а частота тактовых импульсов 100 МГц. Таким образом появляется возможность принимать входные сигналы синхронно с тактовыми импульсами.
Так как содержимое временной диаграммы непосредственно не относится к объяснению сути настоящего изобретения, подробное объяснение не приведено, но можно понять из фиг. 12A и 12B непрерывный вывод и запись данных посредством DQ, которые соответственно считывают и записывают данные.
Таким образом операция считывания и записи выполняется непрерывно, что является признаком синхронного DRAM. В настоящем изобретении синхронное DRAM используется в качестве RAM, как описано в связи с фиг.11. С помощью структуры DMA 10, показанного на фиг.6, можно создать устройство пересылки данных, использующее свойство синхронного DRAM.
Кроме того, хотя случай, когда данные из 32 бит на первой шине разделяются на два набора данных по 16 бит и посылаются на вторую шину, не ограничивает настоящего изобретения, суть второго признака также дает возможность разделения данных из 32 бит в отношении 1/n (где n - положительное целое число) и пересылки разделенных данных.
В известном устройстве была проблема возрастания времени доступа, то есть низкой скорости при операции пересылки DMA, когда запись данных начинается от границы байта и осуществляется байтами. Теперь будет объяснен третий признак настоящего изобретения, который должен разрешить вышеуказанную проблему.
Третий признак настоящего изобретения реализуется в DMA 10, предусмотренного в системном блоке управления 1 в вариантах, показанных на фиг.3 и 6.
Третий признак настоящего изобретения будет раскрыт вместе с рассмотрением структуры системного блока управления 1, показанной на фиг.6. Кроме того, поскольку третья схема интерфейса 14 имеет такую же структуру, что и вторая схема интерфейса 12, объясненная выше, повторные пояснения по поводу третьей схемы интерфейса 14 для упрощения опущены.
На фиг. 6 первая схема интерфейса 11 включает первую схему защелки (триггер) 110, которая фиксирует сигнал S1, состоящий из 32 бит, буферы с тремя состояниями 112, 113, которые выводят сигналы трехзначной логики, и вторую схему защелки 111, которая фиксирует сигнал, состоящий из 32 бит, на внутренней шине 13.
Вторая схема интерфейса 12 включает первую схему защелки 120, которая фиксирует данные 56, состоящие из 32 бит на внутренней шине 13, селектор 121, который получает и прообразует параллельные данные S6 из 32 бит, зафиксированные и выводимые из первой схемы защелки 120, в два блока данных по 16 бит, вторую схему защелки 122, которая фиксирует данные, состоящие из 16 бит, выводимые из селектора 121, и буфер с тремя состояниями 123, который принимает данные из 16 бит, зафиксированные второй схемой защелки 122, и выводит сигналы трехзначной логики на вторую шину (B-BUS) 6.
Поскольку вторая схема интерфейса 12 передает данные на второй шине (B-BUS) 6 на внутреннюю шину 13, вторая схема интерфейса 12 содержит две схемы защелки 124 и 125 для данных из 16 бит и буфер с тремя состояниями 126, который группирует данные из 16 бит, зафиксированные двумя схемами защелки 124 и 125, и выводит данные, состоящие из 32 бит, на внутреннюю шину 13.
DMA 10 включает первую схему защелки (триггер) 101, которая фиксирует данные из 32 бит на внутренней шине 13, вторую схему защелки (триггер) 102, которая фиксирует 3 нижних байта (24 бит) данных, селектор 103, который принимает комбинированные сигналы выходов от первой и второй схем защелки 101 и 102, отбирает и выводит выходные сигналы в соответствии с сигналом выбора S5, подаваемым на вход выбора S, и буфер с тремя состояниями 104, который принимает и выводит выходной сигнал из селектора 103 на внутреннюю шину 13.
Селектор 103 имеет четыре входа и один выход. То есть четырехбайтные выходные линии B1-B4 первой схемы защелки 101 подсоединены к первому входу 0 селектора 103. Три верхних байта выходных линий с B1 по B3 первой схемы защелки 101 и один нижний байт выходной линии B7 второй схемы защелки 102 подсоединены ко второму входу 1 селектора 103.
Два верхних байта выходных линий B1 и B2 первой схемы защелки 120 и два нижних байта выходных линий B6 и B7 второй схемы защелки 102 соединены с третьим входом 2 селектора 103.
Один верхний байт выходной линии B1 первой схемы защелки 101 и три нижних байта выходных линий с B5 по B7 второй схемы защелки 102 подаются к четвертому входу 3 селектора 103.
Соответственно данные из четырех байт, которые не были сдвинуты, вводятся в первый вход 0. Данные из четырех байт, которые сдвигаются на два байта, вводятся в третий вход 2. Данные из четырех байт, которые сдвигаются на три байта, вводятся в четвертый вход 3.
Таким образом, если сигнал выбора S5 выбирает первый вход 0, то будет выполняться передача от границы длинного слова (см. фиг.3A и 3B), как показано на фиг.13 и 14, которые будут описаны ниже. Кроме того, если сигнал выбора S5 выбирает второй вход 1, то передача будет выполняться к границе байта, которая сдвинута на один байт, как показано на фиг.15 и 16.
Кроме того, если сигнал выбора S5 выбирает третий вход 2, то будет выполняться передача к границе байта, которая сдвинута на два байта, как показано на фиг.17 и 18, которые будут объяснены ниже.
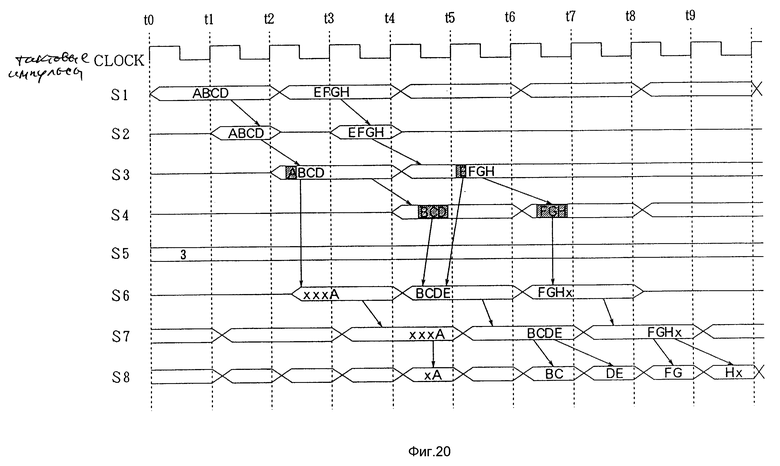
Если сигнал выбора S5 выбирает четвертый вход 3, то будет выполняться передача к границе байта, которая сдвинута на три байта, как показано на фиг.19 и 20.
Теперь со ссылками на фиг.13-22 будет объяснено, как выполняется DMA передача согласно третьему признаку настоящего изобретения.
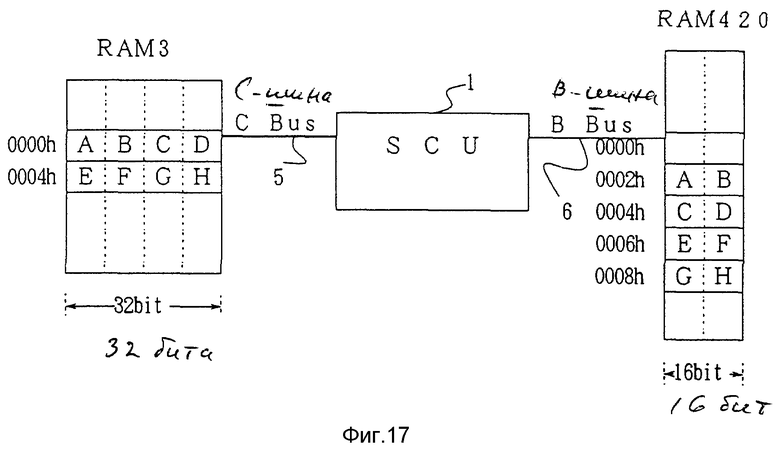
Сначала, со ссылкой на фиг.13, будет объяснена передача границы длинного слова, которая представляет собой передачу данных "ABCDEFGH" из восьми байт, то есть 32 бита с адресами (с 0000h по 007h) RAM 3, которая соответствует SDRAM 3, показанной на фиг.4, по первой шине (CPU-BUS) 5 на соответствующие адреса (с 0000h по 0007h) RAM 420, которая соответствует VRAM 420, подсоединенной к VDP 42 на фиг.2, по второй шине (B-BUS) 6 через системный блок управления 1.
Как показано на фиг.14, управление осуществляется так, что 4 байта данных S1 выводятся за два тактовых импульса по первой шине (CPU-BUS) 5. Данные S1 выводятся на внутреннюю шину 13 в момент времени t1 (сигнал S2). Затем параллельные данные S2 из четырех байт на внутренней шине 14 фиксируются первой схемой защелки 101 в DMA 10 в момент времени t2 (сигнал S3).
Выходной сигнал S3 первой схемы защелки 101 фиксируется второй схемой защелки 102 в момент времени t4 (сигнал 4). Затем сигнал выбора S5 для селектора 103 указывает на первый вход 0, чтобы осуществлять пересылку от границы длинного слова.
Соответственно селектор 103 выбирает данные "ABCD" из четырех байт, зафиксированные в первой схеме защелки 101, чтобы вывести данные как данные S6. Вторая схема интерфейса 12 отбирает данные S6 во вторую схему защелки 120 в момент времени t3.
Так как вторая шина (B-BUS) 6 содержит 16 бит, как показано в связи с сигналом S8, селектор 121 и схема защелки 122 преобразуют данные из 32 бит в два последовательных набора данных, каждый из которых имеет 16 бит. Данные выводятся на вторую шину (B-BUS) 6 через буфер с тремя состояниями 123.
Таким образом каждый блок данных, содержащий множество байт, записывается от границы длинного слова, как показано на фиг.14.
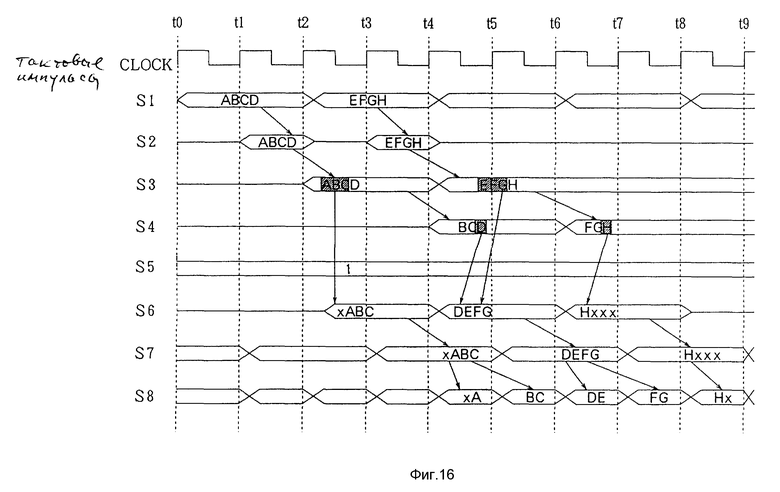
Теперь, как и в случае с фиг.13, когда данные с адресами с 0000h по 0007h RAM 3 по первой шине (CPU-BUS) 5 передаются на RAM 420 с адресами 0001h по 0008h по второй шине (B-BUS) 6, будет объяснена DMA передача, начиная от границы байта, которая в этом примере сдвинута на один байт, как показано на фиг.15.
Как показано на фиг.16, данные S1 из четырех байт выводятся за два тактовых импульса по первой шине (CPU-BUS) 5. Данные S1 выводятся на внутреннюю шину 13 в момент t1 (сигнал S2). Затем четыре байта параллельных данных S2 на внутренней шине 13 фиксируются в первой схеме защелки 101 DMA 10 в момент времени t2 (сигнал S3).
Три нижних байта выходных данных S3 из первой схемы защелки 101 фиксируются во второй схеме защелки 102 в момент времени t4 (сигнал S4). Благодаря передаче от границы байта, которая сдвигается на один байт, сигнал выбора S5 селектора 103 указывает на второй вход 1.
Соответственно селектор 103 выбирает данные "ABC" из верхних трех байтов (линии с B1 по B3) в первой схеме защелки 101 и данные из одного нижнего байта (линия B7) во второй схеме защелки 102 и выводит их как данные S6, представляющие собой "xABC". "x" означает, что данные не установлены.
Во второй схеме интерфейса 12 схема защелки 101 отбирает данные "xABC" в момент времени t3. Затем, так как вторая шина (B-BUS) 6 имеет шинный размер 16 бит, как показано в связи с сигналом S8, селектор 102 и схема защелки 122 преобразуют данные, состоящие из 32 бит, в два последовательных блока данных по 16 бит. Затем данные выводятся через буфер с тремя состояниями 123 на вторую шину (B-BUS) 6.
Одновременно в момент 14 первая схема защелки 101 DMA 10 фиксирует параллельные данные S2 "EFGH" из четырех байт на выходе.
Таким образом селектор 103 отбирает верхние данные "EFG" (линии с B1 по B3) из трех байт первой схемы защелки 101 и нижние данные "D" (линия B7) из одного байта и выводит их в виде данных S6. Соответственно получаются данные "DEFG".
Таким путем может быть начата запись по блокам, состоящим из множества байт, от границы байта, которая сдвинута на один байт, как показано на фиг. 15.
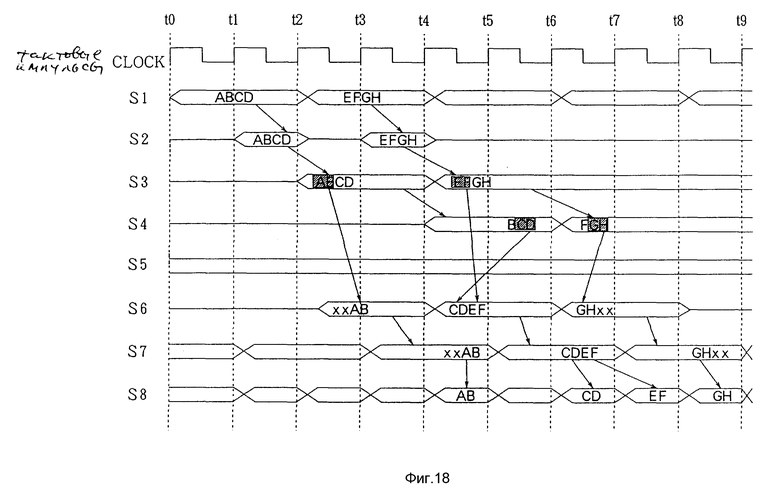
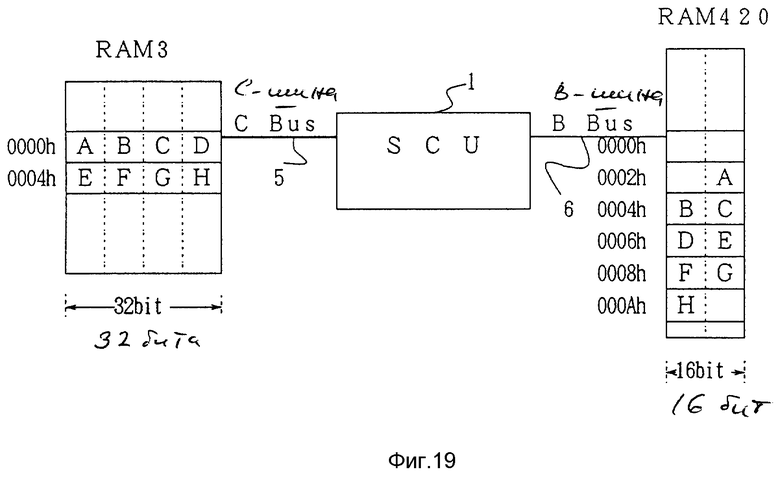
Далее со ссылкой на фиг.17 будет пояснена пересылка с DMA, начиная с границы байта, сдвинутой на два байта, что необходимо для передачи данных (с 0000h по 0007h) RAM 3 (с 0000h по 0007h) по первой шине (CPU-BUS) 5 на RAM 420 (с 0002h по 0009h) по второй шине (B-BUS).
Как показано на фиг. 18, данные S1 из четырех байт выводятся за два тактовых импульса по первой шине (CPU-BUS) 5. Данные S1 выводятся на внутреннюю шину 13 в момент t1 (сигнал S2). Затем первая схема защелки 101 (DMA 10) фиксирует параллельные данные S2 из четырех байт на внутренней шине 13 в момент t2 (сигнал S3).
Вторая схема защелки 121 фиксирует данные из трех нижних байт выходного сигнала S3 первой схемы защелки 101 в момент t4 (сигнал S4). Поскольку передача начинается с границы байта, сдвинутой на два байта, сигнал выбора S5 селектора 103 указывает на третий вход 2.
Соответственно селектор 103 отбирает верхние данные "AB" (линии B1 и B2) из двух байт, зафиксированные в первой схеме защелки 101, и два нижних байта (линии B6 и B7) во второй схеме защелки 102 и выводит их в виде данных S6. Это данные "xxAB". "x" означает, что данные не установлены, также как в вышеописанном примере.
Во втором схеме интерфейса 12 схема защелки 120 принимает данные в момент t3. Затем, поскольку вторая шина (B-BUS) 6 имеет шинный размер 16 бит, как показано в связи с сигналом S8, селектор 121 и схема защелки 122 преобразует данные из 32 бит в два блока последовательных данных по 16 бит. Данные выводятся на вторую шину (B-BUS) 6 через буфер с тремя состояниями 123.
Одновременно первая схема защелки 102 в DMA 10 фиксирует параллельные данные S2, то есть данные "EFGH" из четырех байт на внутренней шине 13 (сигнал S3) в момент t4.
Следовательно, селектор 103 отбирает данные "EF" (линии B1 и B2) из двух верхних байт в первой схеме защелки 101 и данные "CD" (линии B6 и B7) двух нижних байт во второй схеме защелки 102 и выводит их в виде данных 6. Это данные "CDEF".
Таким путем выполняется запись блоками, состоящими из нескольких байт, начиная с границы байта, которая сдвинута на два байта, как показано на фиг. 17.
Далее, со ссылкой на фиг. 19, будет пояснена передача DMA, начиная с границы байта, которая сдвинута на три байта. Посредством передачи DMA данные (с 0000h по 007h) RAM 3 по первой шине (CPU-BUS) 5 передаются на RAM 420 по шине B-BUS 6.
Как показано на фиг.20, данные S1 из четырех байт выводятся по первой шине (CPU-BUS) 5 за два тактовых импульса. Затем данные S1 выводятся на внутреннюю шину 14 в момент t1 (сигнал S2). После этого первая схема защелки 101 фиксирует четыре байта параллельных данных S2 из четырех байт на внутренней шине 13 в момент t2 (сигнал S3).
Вторая схема защелки 102 фиксирует нижние данные из трех байт выходного сигнала S3, зафиксированного первой схемой защелки 101 в момент t4 (сигнал S4). Поскольку передача начинается с границы байта, которая сдвинута на три байта, сигнал выбора S5 селектора 103 указывает на четвертый вход 3.
Следовательно, селектор 103 отбирает верхние данные (линия B1) из одного байта в первой схеме защелки 101 и нижние данные (линии с B5 по B7) из трех байт во второй схеме защелки 102 и выводит их в виде данных S6. Это данные "xxxA". "x" означает, что данные не установлены.
Во второй схеме интерфейса 12 схема защелки 120 принимает данные в момент S3. Тогда поскольку вторая шина (B-BUS) 6 имеет размер 16 бит, как показано с помощью сигнала S8, селектор 121 и схема защелки 122 преобразуют данные из 32 бит в два последовательных набора данных по 16 бит. Данные выводятся на вторую шину (B-BUS) 6 через буфер с тремя состояниями 123.
Одновременно первая схема защелки 101 DMA 10 фиксирует параллельные данные S2 из четырех бит на внутренней шине 13, то есть данные "EFGH", в момент t4 (сигнал S3).
Следовательно селектор 103 отбирает верхние данные "E" (линия B1) из одного байта в первой схеме защелки 101 и нижние данные "BCD" (линии с B5 по B7) из трех байт во второй схеме защелки 121 и выводит их в виде данных S6. Это данные "BCDE".
Таким путем запись по блокам из нескольких байт начинается с границы байта, которая сдвинута на три байта, как показано на фиг.19.
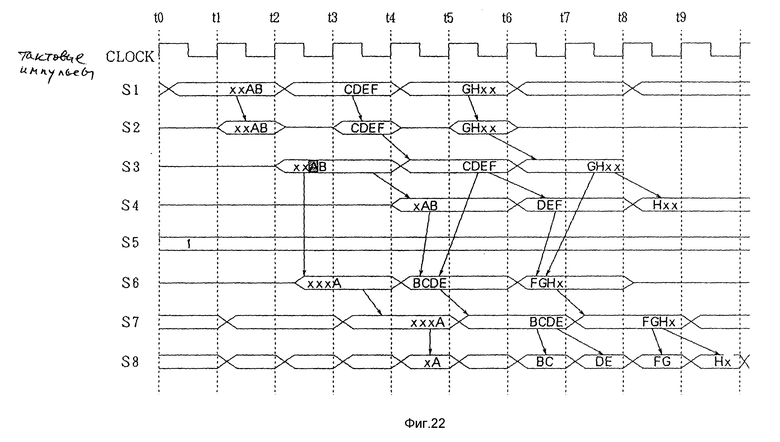
На фиг.21 показана примерная диаграмма пересылки DMA, которая начинается с границы байта, сдвинутой на 1 байт, что необходимо для передачи данных (с 0002h по 0009h) RAM 3 по первой шине (GPU-BUS) 5 на RAM 420 (с 0003h по 000Ah) по второй шине (B-BUS) 6.
Из фиг.22 очевидно, что работа системы в примере, показанном на фиг.21, в основном идентична примеру, показанному на фиг.16. Таким образом, даже если данные RAM1, то есть SDRAM 3, сдвинуты по отношению к границе длинного слова, данные можно пересылать блоками из нескольких байт к границе байта, сдвинутой относительно границы длинного слова.
Описанное выше RAM 2 соответствует VRAM 420 на фиг.2, то есть памяти поразрядной карты отображения, где один пиксель выражается одним байтом. В этом случае эффективно, к примеру, начинать запись с границы произвольного байта для последующего сдвига и отображения движущихся изображений. Тогда в случае использования настоящего изобретения это можно реализовать максимум 5-ю доступами для пересылки данных для 16 пикселей. В известном способе побайтной передачи потребуется 16 доступов. Следовательно, время пересылки уменьшается примерно до 1/3, так что пересылку можно будет выполнять с высокой скоростью для отображения видеоизображения.
Кроме того, в вышеописанный третий признак настоящего изобретения могут быть внесены некоторые изменения, изложенные ниже.
Хотя количество байт n в длинном слове принято равным 4, можно использовать и другое число.
Вторая память рассматривается как память поразрядной карты отображения. Однако можно использовать и другую память. Кроме того, вторая память имеет размер 16 бит, но можно использовать память размером 32 бит.
Хотя в данном варианте реализации настоящего изобретения B-BUS имеет размер 16 бит, можно использовать эту шину с размером 32 бит.
Согласно рассмотренным вариантам можно получить устройство пересылки данных, которое способно одновременно пересылать данные между несколькими устройствами передачи и приема данных.
Кроме того, можно получить устройство, которое не нуждается в схеме интерфейса для сопряжения с высокоскоростным CPU (через устройство передачи и приема данных, даже если размеры шин нескольких устройств передачи и приема данных различны.
Вдобавок согласно настоящему изобретению реализуется видеоигровое устройство, использующее устройство пересылки данных, в котором можно применить высокоскоростную CPU.
Кроме того, появляется возможность пересылки данных, используя свойства синхронного DRAM, которое может непрерывно считывать данные. Даже если устройство пересылки данных записывает данные от границы байта в память поразрядной карты отображения, устройство пересылки данных, использующее DMA, может уменьшить количество доступов согласно настоящему изобретению.
Может быть также реализовано устройство пересылки данных, использующее DMA, способное уменьшить время пересылки при записи данных от границы байта.
Хотя настоящее изобретение было описано со ссылкой на некоторые варианты, применение его в структуре видеоигрового устройства ими не ограничивается.
Должно быть совершенно очевидно, что варианты, подобные техническому замыслу изобретения, входят в объем, защищаемый настоящим изобретением.




Изобретение относится к устройствам пересылки данных, которое передает и принимает данные через шины данных, связывающие множество передатчиков данных. Технический результат достигается за счет обеспечения возможности параллельной пересылки данных между несколькими устройствами передачи и приема данных. Устройство пересылки данных используется в видеоигровом устройстве. Устройство пересылки данных имеет базовую структуру с множеством устройств передачи и приема данных, множеством схем шинного интерфейса, подсоединенных через шины соответственно к каждому из множества устройств передачи и приема данных, схему прямого доступа к памяти, которая пересылает данные, передаваемые на одну схему шинного интерфейса, к другой схеме шинного интерфейса, причем множество схем шинного интерфейса разделяет и объединяет данные в соответствии с размером подсоединенных шин для пересылки данных в другую схему шинного интерфейса. 5 с. и 9 з.п. ф-лы, 25 ил.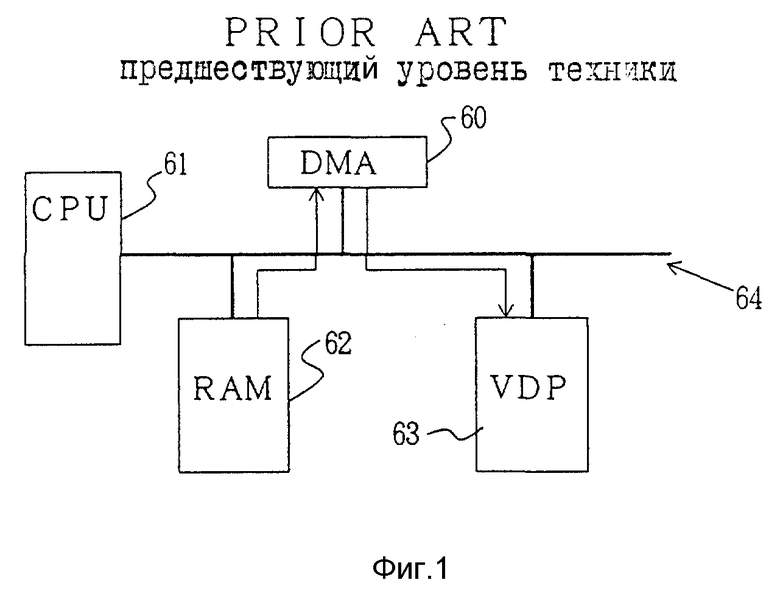
Приоритет по пунктам:
27.09.94 по пп.1 - 5, 10 и 11;
28.09.94 по пп.6 - 9;
30.09.94 по пп.12 - 14.
| US 5214775 A, 25.05.93 | |||
| " Перекладчик штучных грузов | 1972 |
|
SU479702A1 |
| Способ приготовления сернистого красителя защитного цвета | 1915 |
|
SU63A1 |
| Способ приготовления сернистого красителя защитного цвета | 1915 |
|
SU63A1 |
| Устройство для сортировки каменного угля | 1921 |
|
SU61A1 |
| Устройство для сопряжения ЭВМ | 1991 |
|
SU1837306A1 |
| Контроллер прямого доступа к памяти | 1991 |
|
SU1789987A1 |
