Область техники
Изобретение относится к области информационных технологий. Описываемый способ выявления персональных данных предназначен для выявления и очистки (замены) персональных данных, получаемых из контролируемых источников информации.
Уровень техники
Государственными органами, муниципальными органами, юридическими или физическими лицами, организующими или осуществляющими обработку персональных данных, и третьими лицами, получающими доступ к персональным данным, должна обеспечиваться конфиденциальность таких данных, которая предполагает недопустимость их публикации в открытых материалах без согласования с субъектом персональных данных.
Федеральный Закон от 27 июля 2006 г. №152-ФЗ «О персональных данных» определяет персональные данные как любую информацию, относящуюся к определенному или определяемому на основании такой информации физическому лицу (субъекту персональных данных). Примером таких данных о физическом лице могут служить: 1) фамилия, имя, отчество; 2) год, месяц, дата и место рождения; 3) адрес; 4) семейное, социальное, имущественное положение; 5) образование; 6) профессия; 7) доходы (за исключением лиц, чьи доходы подлежат общественному контролю, например, чиновников); 8) другая информация.
Применение процедур обезличивания персональных данных нормативно закреплено постановлением Правительства Российской Федерации от 21 марта 2012 г. №211 и является обязательным для операторов персональных данных.
Федеральный закон Российской Федерации от 27 июля 2006 г. N 152-ФЗ "О персональных данных" (№152-ФЗ) обязывает операторов персональных данных принять множество мер для построения системы защиты персональных данных как организационного, так и инженерно-технического характера.
Органам государственной власти, осуществляющим контрольно-надзорные функции по исполнению №152-ФЗ, операторам персональных данных (как они определены в данном законе) необходимы инструменты контроля за соблюдением законодательства. Такие инструменты должны обрабатывать большие объемы неструктурированной информации открытых источников для эффективного автоматического обнаружения персональных данных и очистки (замены) от них текстов с сохранением смысловой целостности. Также необходимо иметь гибкие механизмы настройки этих инструментов в соответствии с действующим законодательством.
Существует множество средств с различной функциональностью, предназначенных для поддержки подобных задач. Однако часто достаточно большой объем работы по очистке (замене) и преобразованию материалов, содержащих персональные данные, приходится выполнять вручную.
Известно решение RU №2096824 С1, МПК G06F 15/16, G06F 17/60, представляющее собой устройство автоматизированной обработки информационных материалов для персонализированного использования. Указанная система выявляет наличие в обрабатываемых информационных материалах сведений, описывает с точки зрения их содержания как элементы, определенные в составе характеристики информационной потребности пользователя, фиксирует факт наличия таких сведений и соответствующие им элементы характеристики информационной потребности пользователя и затем использует эти элементы и их сочетания при представлении пользователю содержания обрабатываемых материалов. Обработку выполняют в интерактивном режиме, при этом последовательно демонстрируют отдельные смысловые фрагменты, на которые подразделены обрабатываемые информационные материалы, в форме, соответствующей их виду. В случае выявления смысловой связи между содержанием данного фрагмента и теми или иными из элементов характеристики информационной потребности пользователя фиксируют наличие такой связи путем формирования индивидуального признака для каждого из упомянутых элементов, с которым выявлена связь данного смыслового фрагмента. При выявлении различной степени связи данного смыслового фрагмента с разными элементами характеристики информационной потребности пользователя формируют признаки принадлежности этих элементов разным уровням информационной потребности пользователя в соответствии с количеством выявленных градаций связи. Осуществляют формирование образа локальной структуры данного смыслового фрагмента, представляющей собой помеченный связный неориентированный граф, вершинам которого поставлены в соответствие те элементы характеристики информационной потребности пользователя, для которых сформированы признаки наличия связи с содержанием данного смыслового фрагмента, указанный граф является полносвязным. В указанном патенте результат обработки отображают в визуально воспринимаемом виде с заменой кратных ребер геометрическими образами, размеры или цвет которых соответствуют их кратности, и цифровой индикацией кратности ребер полученного интегрального графа.
Данное изобретение обеспечивает выявление смысловых элементов текста на основе предварительно установленных контекстных признаков, однако не дает возможности контролировать, выявлять и очищать (заменять) выявленные фрагменты персональных данных или персональные данные целиком.
Раскрытие изобретения
Описываемый патентуемый способ реализует функции контроля и очистки (замены) персональных данных на кодовые слова, в потоке текстовых материалов открытых источников информации и в текстах загружаемых материалов с сохранением смысловой целостности исходного текста электронного документа, сообщения или публикации. Предлагаемый способ позволяет обеспечить контроль соблюдения Федерального Закона от 27 июля 2006 г. №152-ФЗ «О персональных данных» в большом информационном пространстве открытых источников информации с применением передовых информационных технологий.
В одном из вариантов реализации способ предполагает выполнение 3 стадий: мониторинг, выявление и очистка (замена) персональных данных. Мониторинг персональных данных - это систематический сбор и обработка информации, - процедуры, которые могут быть использованы для улучшения процесса контроля персональных данных, его автоматизации, а также, косвенно, для информирования общественности о соблюдении требований Федерального Закона. Таким образом, раскрываемый патентуемый способ является инструментом осуществления оценки соблюдения требований №152-ФЗ. Патентуемый способ несет одну или более из трех обусловленных законом функций:
- выявляет открытые источники информации, публикующие персональные данные, в отношении которых контрольно-надзорным органам возможно оценить объем и систематичность нарушений и выбрать адекватные санкции, а самим владельцам источников устранить причины возможных нарушений закона;
- обеспечивает фактографическую базу для осуществления надзорных процедур в соответствии с №152-ФЗ;
- устанавливает соответствия предписаниям №152-ФЗ.
Патентуемый способ решает следующий комплекс задач:
1) мониторинг открытых источников информации (веб-сайты органов государственной власти, печатные средства массовой информации (СМИ), интернет-СМИ, блоги и форумы, далее - открытые источники);
2) семантический разбор текстов открытых источников и загружаемых текстовых файлов и выявление в русскоязычных текстах персональных данных;
3) лингвистическая обработка материалов открытых источников с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, измерения ущерба персоне, данные которой были опубликованы, такие как: кластеризация и рубрицирование текстов, ранжирование и жанровая классификация текстов, выделение в тексте объектов (персона, организация, бренд, географическое понятие), расчет индекса качества объекта и определение роли выявленного в тексте объекта, выявление в тексте прямой речи персоны;
4) удаление (замена) и очистка персональных данных с сохранением смысловой целостности, структуры исходного текста и формирование отчуждаемого словаря замен;
5) восстановление персональных данных в исходном тексте с помощью словаря замен.
Патентуемый способ реализуется системой устройств и программных модулей (далее Система), которая содержит следующие функциональные элементы: сервер сбора данных открытых источников информации; сервер лингвистической обработки, включающий лингвистический процессор; сервер приложений, обеспечивающий интерфейс Системы и пользователя.
При этом сервер сбора данных открытых источников информации, соединен с сетевым интерфейсом, что обеспечивает сетевой доступ к открытым источникам информации (Интернет) и передачу данных к сетевому интерфейсу сервера лингвистической обработки.
При этом сервер лингвистической обработки, содержит лингвистический процессор обработки текстов и базу данных.
Лингвистический процессор обработки текстов выполняет:
1. Выделение информационного объекта и ранжирование важности его упоминания в тексте сообщения (главная, второстепенная или эпизодическая роль). Извлекаемая в ходе данной процедуры информация используется как вспомогательная для оценки потенциального ущерба от публикации персональных данных при расчете индекса качества.
2. Категоризацию (рубрицирование) текстов, в ходе которой тексты относятся к одной из трех категорий (допускается их иерархическое расширение в ходе эксплуатации штатными средствами Системы): открытые, частные, закрытые. Рубрицирование необходимо для упрощения задания критериев поиска нарушений и упорядочения их отображения в интерфейсе Системы. Публикация сведений о должности, месте работы, образовании, за редким исключением, не несет никакой угрозы, как правило, такого рода данные открыты. Напротив, серия и номер паспорта, адрес проживания персоны, сведения о доходах и т.п. представляют собой закрытую информацию. Специалисты, ответственные за обнаружение персональных данных, могут, в частности, ограничивать размер результирующей выборки и повышать релевантность результатов поиска штатными средствами Системы (настройка рубрицирования с помощью введения дочерних подрубрик с последующей визуализацией в результатах поиска и отчетах Системы только интересующих или сгруппированных по категориям данных).
3. Жанровую классификацию текстов. Учет жанра текста требуется для ведения статистики по публикации персональных данных, для получения представления о том, какие тексты (новость; интервью; аналитика; аналитическая статья, TV; ток-шоу; законодательство; пресс-релиз; публицистика; отзывы; рейтинги; прочее) потенциально наиболее опасны. Особенно полезным представляется совместный учет статистических данных, полученных в результате жанровой классификации и рубрицирования (категоризации персональных данных).
4. Выявление групп лингвистически схожих текстов и кластеризацию поступающих информационных материалов. Кластеризация информационных материалов необходима, например, для выявления смещения фокуса риска от публикации персональных данных, определения новых категорий для рубрицирования персональных данных. Кроме того, наличие сведений о принадлежности текстов из одного источника к одному кластеру позволит исключить из результатов поиска лишние данные. Например, информация о доходах чиновников, в отличие от остальных категорий населения, является открытой, и декларации об их доходах, опубликованные на сайтах ведомств, будут формировать кластер. Учет этого обстоятельства позволит исключить декларации из результатов поиска документов с закрытыми персональными данными.
5. Выделение прямой речи информационных объектов. Извлекаемая в ходе данной процедуры информация используется как вспомогательная для оценки потенциального ущерба от публикации персональных данных при расчете индекса качества (см. п.7 данного раздела).
6. Определение количества эфирного времени с сюжетами, в которых освещается информационный объект. Извлекаемая в ходе данной процедуры информация используется как вспомогательная для оценки потенциального ущерба от публикации персональных данных при расчете индекса качества (см. п.7 данного раздела).
7. Расчет индекса качества для выявленных информационных объектов, отражающего качественную оценку отношения в тексте открытого источника к заданному объекту. Индекс качества рассчитывается с использованием следующих данных: влиятельность источника (рассчитанная на основе оперативно обновляемых данных о его цитируемости), номер полосы, размер текста, наличие иллюстрации, роль объекта в тексте, наличие цитат объекта в тексте, характер упоминания объекта в тексте (негатив или позитив). Индекс качества позволяет, в частности, оценить степень потенциального ущерба от публикации персональных данных в том или ином источнике.
Таким образом, серверы сбора данных осуществляют обход целевых открытых источников и передачу предварительно обработанных текстов серверу лингвистической обработки. После разбора текста и в зависимости от его результатов в базе данных сервера лингвистической обработки сохраняются разобранные тексты, информация об обходе и адреса ссылок источников. Доступ к проанализированным текстам, отчетам о результатах разбора, статистическим данным и т.п., хранящимся на сервере лингвистической обработки, обеспечивает сервер приложений через поддерживаемый на нем веб-интерфейс автоматизированного рабочего места (АРМ) аналитика. Также на этом сервере работает и веб-интерфейс АРМ администратора. Дополнительно веб-интерфейсы АРМ аналитика и АРМ администратора обеспечивают хранение пользовательских настроек.
Кроме того, в состав инфраструктурных средств Системы входит коммутационное оборудование, межсетевой экран.
Ключевыми (но не единственными) функциональными возможностями, обеспечиваемыми патентуемым способом, являются:
- сбор и сохранение в базе данных Системы текстовых данных открытых источников. Входные данные Системы (в зависимости от источника) следующие:
1. HTML- и XML-файлы - интернет-блоги и форумы, интернет-СМИ;
2. DOC-, DOCX-, RTF-, XLS-, XLSX-, CSV-, ТХТ-, HTML-, PDF-файлы - веб-сайты органов государственной власти (ОГВ);
3. PDF-файлы - официальные печатные СМИ;
4. PDF-, HTML- и XML-файлы интернет-СМИ;
5. мультимедийные файлы - ролики Федеральных телевизионных каналов.
- выявление в неструктурированных текстах персон и связанных с ними атрибутов (должность, место работы, номер служебного телефона, адрес электронной почты, сведения о доходах и образовании, дата рождения, место рождения, номер личного мобильного телефона, ИНН, родственные связи, паспортные данные, водительское удостоверение, атрибуты банковской карты, номер автомобиля, домашний телефон, адрес регистрации/проживания и т.д.).
- выявление в текстах других объектов (организаций, брендов, географических понятий и т.д.) с целью повышения эффективности анализа текстов, содержащих персональные данные.
- категоризация (рубрицирование) неструктурированных текстов с целью отнесения текстов, содержащих персональные данные к одной из категорий, с возможностью введения новых рубрик (подкатегорий) штатными средствами Системы и, соответственно, осуществление более тонкой настройки средств мониторинга, анализа и подготовки отчетности Системы. Предустановленные категории в Системе:
- Открытые данные, которые не позволяют установить местонахождение объекта (в нерабочее время), членов его семьи, связаться с ними, публикация которых не представляет угрозы для репутации либо обязательна в силу служебных обязанностей. К категории общедоступных не могут быть отнесены данные документов, позволяющих однозначно идентифицировать персону, а также сведения о расовой принадлежности и религиозных убеждениях: 1) ФИО; 2) Пол; 3) Должность; 4) Место работы; 5) Номер служебного телефона; 6) Адрес служебной почты; 7) Образование (за исключением данных документов об образовании); 8) Сведения о воинском учете (за исключением данных об учетных документах); 9) Профессия; 10) Сведения о доходах и имуществе (для госслужащих).
- Частные данные, доступные на сайтах поиска работы, объявлений, знакомств, телефонный справочник: 1) Дата рождения; 2) Место рождения; 3) Адрес личной почты; 4) Номер личного мобильного телефона; 5) Гражданство; 6) ИНН; 7) Родственные связи.
- Закрытые данные: 1) Все паспортные данные; 2) Водительское удостоверение; 3) Номер и прочие атрибуты пластиковой карты (CVV, дата окончания срока действия); 4) Доходы, имущество (не для госслужащих); 5) Номер автомобиля; 6) Домашний телефон; 7) Адрес регистрации, проживания.
- кластеризация информационных материалов с целью выявления групп поступающих в Систему текстов предназначена для уточнения (дополнения) процедур рубрицирования, группировки текстов с общими типами персональных данных. Осуществление кластеризации текстов с общими типами персональных данных приводит к образованию кластеров в пределах рубрики. Для недопущения образования слишком крупных и неинформативных кластеров в них включат тексты, содержащие не менее 3 типов персональных данных. Информация о доходах чиновников, в отличие от остальных категорий населения, является открытой, и декларации об их доходах, опубликованные на сайтах ведомств, будут формировать кластер открытой информации. Соответствующий справочник публичных персон содержит список чиновников, персональные данные которых относятся к разрешенной категории. Примером такой категории является категория «Доходы чиновника».
- ранжирование упоминания объекта в тексте (определение роли, в которой объект упомянут в тексте: главная, эпизодическая) с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, измерения ущерба персоне, данные которой были опубликованы.
- жанровая классификация текстов с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, в частности для сбора информации для различных исследований с целью уточнения целевой аудитории, а также как вспомогательная информация в случае необходимости расследования фактов выявления персональных данных.
- расчет индекса качества объекта, выявленного в тексте с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, измерения понесенного или потенциального ущерба персоне, данные которой были опубликованы, с учетом влиятельности (в т.ч. цитируемости) источника публикации текста с персональными данными, а также как вспомогательная информация в случае необходимости расследования фактов выявления персональных данных.
- выявление в тексте прямой речи персоны с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, выявления первоисточника информации, используемой в тексте по фокусу на авторе цитаты.
- построение рейтингов источников публикации персональных данных по количеству выявленных нарушений в этой части с возможностью группировки по типу открытого источника (СМИ, блог и т.д.).
- фильтрация источников, не представляющих по тем или иным причинам интереса для задач мониторинга, с целью повышения эффективности анализа текстов, содержащих персональные данные.
- фильтрация текстов, содержащих персональные данные о публичных персонах из соответствующего справочника, редактируемого штатными средствами Системы, с целью повышения эффективности анализа текстов, содержащих персональные данные.
- настройка чувствительности лингвистического процессора штатными средствами Системы (режимы повышенной точности выявления персональных данных и наибольшей полноты выявления персональных данных), с целью повышения эффективности анализа текстов, содержащих персональные данные.
- выбор глубины ретроспективы и различных аналитических разрезов для визуализации результатов лингвистической обработки в виде отчетов.
- преобразование неструктурированных текстов, поступающих на вход Системе, в структурированные (формата XML), содержащие информацию о выявленных персональных данных и объектах в тексте.
- экспорт результатов лингвистической обработки в один из распространенных форматов (doc, docx, rtf, xls, xlsx, csv, txt, xml, pdf).
- очистка (замена) персональных данных в тексте с сохранением смысловой целостности и структуры исходного текста с возможностью замены элементов персональных данных на кодовые слова, сохранения словаря замен в отдельном файле или базе данных.
- сохранение в базе данных Системы фактографических данных о публикации персональных данных: текста публикации в исходном формате, ссылки на источник, даты и времени публикации, текста документа с произведенными заменами персональных данных, записей действий серверов Системы в журнал операций (лог-файл).
Патентуемый способ поддерживает инструменты, позволяющие сократить объемы ручной работы и подключать для обработки дополнительные источники. Механизмы выявления и очистки (замены) данных определены декларативным образом и используются как при работе с новыми подключаемыми источниками данных, так и при работе с загружаемыми файлами распространенных текстовых форматов. Патентуемый способ обеспечивает эффективное и надежное выполнение всех этапов сбора, обработки, мониторинга, анализа и преобразования данных для множества источников и больших наборов данных.
Сущность изобретения
Техническим результатом, достигаемым данным изобретением, является высокая релевантность результатов выдачи при выявлении персональных данных в открытых информационных источниках и в текстовых файлах наиболее распространенных форматов и сами результаты обработки неструктурированной текстовой информации, в том числе:
1. получение фактографических данных, подтверждающих публикацию персональных данных в материальном виде (электронном или в виде бумажного отчета) по результатам выявления персональных данных;
2. формирование обезличенного текста, не содержащего персональных данных, и словаря замен персональных данных;
3. формирование набора аналитических отчетов.
Указанный технический результат достигается за счет сбора данных открытых источников, семантического разбора и анализа текстов, лингвистической обработки с целью выявления персональных данных, объектов и сопутствующих атрибутов обрабатываемых текстов на естественном (русском) языке. Синергетический эффект при использовании изобретения достигается за счет применения методов и результатов лингвистической обработки неструктурированных текстов для решения задач выявления в них персональных данных и очистки (замены) персональных данных с сохранением смысловой целостности и структуры текстов. Технический результат достигается, в частности, за счет сбора и сохранения в базе данных Системы текстовых данных открытых источников с последующим применением методов лингвистической обработки, что приводит к появлению как минимум следующих результатов:
- выявление в неструктурированных текстах персон и связанных с ними атрибутов (должность, место работы, номер служебного телефона, адрес электронной почты, сведения о доходах и образовании, дата рождения, место рождения, номер личного мобильного телефона, ИНН, родственные связи, паспортные данные, водительское удостоверение, атрибуты банковской карты, номер автомобиля, домашний телефон, адрес регистрации/проживания);
- выявление в текстах других объектов (организаций, брендов, географических понятий);
- кластеризация информационных материалов с целью выявления групп поступающих в Систему текстов предназначена для уточнения (дополнения) процедур рубрицирования, группировки текстов с общими типами персональных данных. Осуществление кластеризации текстов с общими типами персональных данных приводит к образованию кластеров в пределах рубрики. Для недопущения образования слишком крупных и неинформативных кластеров в них включат тексты, содержащие не менее 3 типов персональных данных. Информация о доходах чиновников, в отличие от остальных категорий населения, является открытой, и декларации об их доходах, опубликованные на сайтах ведомств, будут формировать кластер открытой информации. Соответствующий справочник публичных персон содержит список чиновников, персональные данные которых относятся к разрешенной категории. Примером такой категории является категория «Доходы чиновника»;
- ранжирование упоминания объекта в тексте (определение роли в которой объект упомянут в тексте: главная, эпизодическая) с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, измерения ущерба персоне, данные которой были опубликованы;
- жанровая классификация текстов с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, в частности для сбора информации для различных исследований с целью уточнения целевой аудитории, а также как вспомогательная информация в случае необходимости расследования фактов выявления персональных данных;
- расчет индекса качества объекта, выявленного в тексте с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, измерения понесенного или потенциального ущерба персоне, данные которой были опубликованы, с учетом влиятельности (в т.ч. цитируемости) источника публикации текста с персональными данными, а также как вспомогательная информация в случае необходимости расследования фактов выявления персональных данных;
- выявление в тексте прямой речи персоны с целью повышения точности и удобства анализа информации о фактах выявления персональных данных, выявления первоисточника информации, используемой в тексте по фокусу на авторе цитаты;
- настройка чувствительности лингвистического процессора штатными средствами Системы (режимы повышенной точности выявления персональных данных и режим наибольшей полноты выявления персональных данных), с целью повышения эффективности анализа текстов, содержащих персональные данные;
- преобразование неструктурированных текстов, поступающих на вход Системе, в структурированные (формата XML), содержащие информацию о выявленных персональных данных и объектах в тексте;
- очистка текста от персональных данных с сохранением смысловой целостности и структуры исходного текста с возможностью замены элементов персональных данных на кодовые слова, сохранения словаря замен в отдельном файле или базе данных;
- сохранение в базе данных Системы фактографических данных о публикации персональных данных: текста публикации в исходном формате, ссылки на источник, даты и времени публикации, текста документа с произведенными заменами персональных данных, записей действий серверов Системы в журнал операций (лог-файл).
Основной эффект раскрытого в изобретении способа состоит в применении перечисленных лингвистических технологий для получения статистической, аналитической и фактографической информации о фактах и источниках публикации персональных данных, гибкой и удобной настройке реализованных в изобретении функций и инструментов, решающих перечисленные основные задачи, а также вспомогательные, такие как количественная оценка принесенного (потенциального) ущерба персоне, публичные данные которой были опубликованы и возможность повышения уровня безопасности хранения и передачи персональных данных, благодаря функциям обезличивания.
В рамках данного изобретения предполагается наличие как минимум одного сервера, работающего под управлением Microsoft Windows Server, что позволяет ориентироваться на технические решения компании Microsoft для системного и прикладного программного обеспечения, используемого в Системе. АРМ аналитика и администратора являются платформонезависимыми (кросс-платформенными).
Патентуемый способ реализуют при помощи следующих элементов и средств Системы:
- Серверов сбора данных;
- Серверов лингвистической обработки;
- Серверов приложений.
Краткое описание чертежей
Фиг.1 - схема Системы, реализующей патентуемый способ.
Фиг.2 - блок-схема способа выявления персональных данных.
Фиг.3 - схема сбора и обработки данных.
Осуществление изобретения
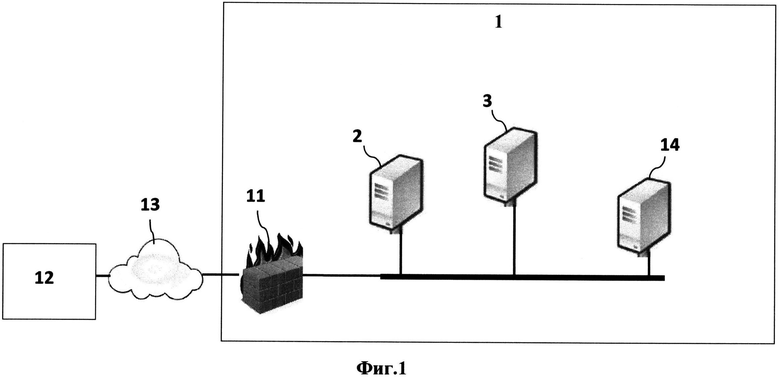
Согласно Фиг.1 Система, реализующая способ выявления персональных данных открытых источников неструктурированной информации включает в себя устройство очистки персональных данных 1, которое посредством межсетевого экрана 11, осуществляет доступ к общедоступным сетям открытых источников информации 12 через Интернет 13.
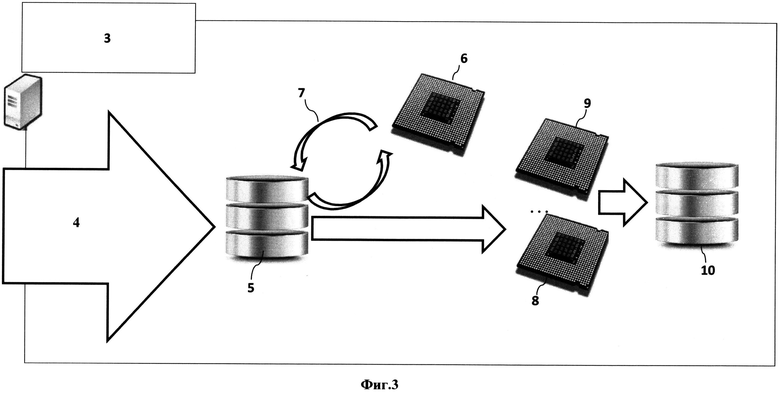
Система, реализующая патентуемый способ, содержит, по меньшей мере, один сервер сбора данных 2 открытых источников информации 12, соединенный с сетевым интерфейсом 4. При этом сервер сбора 2 осуществляет обход и сбор информации из открытых источников, перечисленных в расширяемом штатными средствами Системы списке обязательных к обработке источников. Кроме того, на сервере сбора 2 выполняется выделение ссылок и текста из загруженных документов. Собранная информация сохраняется в базе данных 10 на сервере лингвистической обработки 3.
Помимо выявления сущностей и фактов в поступающих текстах, сервер лингвистической обработки 3 осуществляет рубрицирование, жанровую классификацию, кластеризацию материалов, выявление в тексте и ранжирование объектов, выявление прямой речи персон, расчет индекса качества, выделение и очистку (замену) персональных данных. Результаты и информация, необходимая для решения этих задач, хранятся в базе данных на сервере лингвистической обработки 3.
Сервер приложений 14 поддерживает веб-интерфейсы АРМ аналитика и АРМ администратора и обеспечивает хранение пользовательских настроек и управление доступом.
Согласно Фиг.1 способ выявления персональных данных реализуется при помощи сервера сбора 2, содержащего в себе как минимум следующие модули: сбора персональных данных, синтаксического разбора, обработки и загрузки разобранных текстов, модуль выявления персональных данных.
В одном из вариантов реализации патентуемого способа сервер лингвистической обработки 3 содержит модуль очистки персональных данных 8.
Согласно Фиг.2 алгоритм реализации одного из вариантов применения изобретения: Создают задание через АРМ администратора по обходу открытых источников 12. Параметры сформированного задания передают на сервер сбора 2 (см. Фиг.1) в модуль сбора.
При этом с помощью модуля сбора персональных данных реализуют следующие этапы патентуемого способа:
а1. Загрузка текста. На данном этапе производятся обход сайтов открытых источников 12 и загрузка текстов, либо передача последних из внешней системы (например, системы мониторинга СМИ или файлового хранилища);
а2. Выделение ссылок. На данном этапе из загруженных текстов выделяются ссылки (URL) для их добавления к адресам дальнейшего обхода. В отсутствие ссылок обход прекращается.
При помощи модуля синтаксического разбора выполняют этапы способа:
б1. Получение текста. На данном этапе производится получение текстов от модуля сбора.
б2. Извлечение текста. На данном этапе из текста извлекается текст, бинарные файлы преобразуются к текстовому формату;
б3. Определение языка и кодовой страницы. На данном этапе определяются язык и кодировка текста.
При помощи модуля обработки и загрузки разобранных текстов открытых источников 12 в базу Системы выполняют следующие этапы патентуемого способа:
в1. Получение текста. На данном этапе текст, подготовленный к разбору, поступает от модуля синтаксического разбора.
в2. Отправка на выявление персональных данных и получение результата. На данном этапе текст отправляется в модуль выявления персональных данных и по окончании обработки загружается из него в модуль обработки и загрузки;
в3. Отправка на лингвистическую обработку и получение результата. На данном этапе производятся как отправка на обработку лингвистическому процессору 6, так и получение проанализированного им текста;
в4. Индексация текста. На данном этапе выполняется индексация текста для его дальнейшей загрузки в базу данных;
в5. Сохранение текста. Разобранный и проиндексированный текст сохраняется в БД Системы.
При помощи модуля выявления персональных данных реализуют следующие этапы патентуемого способа:
г1. Разбор текста и выявление сущностей. На данном этапе производится морфологический анализ и выделение в тексте сущностей (таких как именованные и неименованные сущности, специальные сущности);
г2. Построение семантической сети. На данном этапе производится формирование модулем сети, содержащей все сущности, упоминавшиеся в тексте: наименования предметов и лиц, действий и признаков, связанные различными типами синтактико-семантических связей;
г3. Выявление персональных данных. На данном этапе производится выделение в тексте на основе семантических шаблонов, хранящихся в Системе, фрагментов текста, в которых участвуют сущность-элемент персональных данных и персона, к которой эта сущность относится, т.е. связей между сущностями, выявленными на этапе (г1).
Модуль выявления персональных данных выполнен с возможностью выделения в тексте персональных данных, включая обнаружение фактов упоминаний персон в тексте и дополнительной персональной информации, связанной с выявленными персонами. В результате семантической обработки данных выявляются также связи между персонами. Модуль выявления персональных данных выполняет:
- Обработку базы данных 5 лингвистического процессора 6, содержащую тексты, статьи для выявления персональных данных.
- Выявление и выделение персональных данных в потоке информации из базы данных 5 лингвистического процессора 6.
- Выявления фактов с персональными данными на основе шаблонов.
Сохранения в БД смещения и длины персональных данных. В настройках модуля выявления персональных данных используются следующие словари и правила:
- морфологический словарь русского языка;
- морфологический словарь имен русского языка;
- семантический словарь русского языка;
- словарь географических наименований;
- словарь ключевых слов иностранных организаций;
- названия месяцев;
- названия месяцев в именительном падеже;
- названия месяцев в родительном падеже;
- правила разбиения текста на токены (фрагменты текста - предложения и лексемы, выделенные на основе знаков препинания и тегов HTML);
- словарь ключевых слов для обозначения индивидуального предпринимателя;
- словарь для нечеткого распознавания ключевых слов для обозначения индивидуального предпринимателя;
- правила для распознавания корректных ИНН;
- правила распознавания номеров;
- правила для распознавания номера и серии паспорта;
- правила для распознавания корректных счетов;
- правила распознавания дат;
- правила для распознавания некорректных счетов;
- правила для распознавания некорректно записанных ИНН;
- правила распознавания даты рождения;
- правила распознавания места рождения;
- правила для склеивания токенов в один;
- правило для выделения номеров автомобилей;
- правило для выделения адресов электронной почты;
- вспомогательное правило для выделения названий организаций;
- правило для выделения дат;
- правило для выделения дат;
- правило для выделения сложных дат;
- правило для выделения дат;
- правило для выделения географических названий;
- вспомогательное правило для выделения географических названий в составе адресов;
- вспомогательное правило для выделения имен персон (полных);
- правило для выделения составляющих частей адресов;
- правило для выделения полных адресов;
- правило для выделения иностранных адресов;
- правило для выделения паспортных данных;
- правило для выделения данных загранпаспорта;
- правило для выделения должностей;
- правило для выделения должностей;
- вспомогательное правило для выделения сложных географических имен;
- вспомогательное правило для выделения имен персон (отдельных);
- правило для выделения телефонных номеров;
- правила для замен.
В одном из примеров реализации в случае обнаружения упоминания персоны модуль выявления персональных данных выделяет в тексте следующие признаки:
1) Дата и место рождения персоны. Датой рождения персоны является полная дата рождения или частичное указание даты (год, месяц или определенный период в прошлом).
2) Адрес места жительства персоны. Адресом места жительства персоны является любое указание на регион проживания персоны, город проживания или более точный адрес.
3) Семейный статус. Семейным статусом персоны является указание на текущий статус, указание на наличие или отсутствие семейных отношений в прошлом.
4) Наличие детей. Под наличием детей понимается указание на наличие или отсутствие детей.
5) Профессия, место работы. Профессией, местом работы является любое указание на род деятельности персоны и места работы (в прошлом и настоящем).
6) Оценка имущественного положения. Оценкой имущественного положения является указание на наличия имущества любого вида.
7) Информация о доходах. Информацией о доходах является любая информация, указывающая на наличие доходов, источников доходов и размеров доходов персоны.
8) Информация об образовании. Информацией об образовании является любая информация, указывающая на место обучения, вид образования, наличие текстов, подтверждающих образование, дату обучения персоны.
При помощи модуля очистки персональных данных 8 выполняют следующие этапы патентуемого способа:
д1. Формирование замещающих фрагментов. На данном этапе на основании сведений о фактах персональных данных, полученных от модуля выявления персональных данных, формируются замещающие их фрагменты текста.
д2. Подстановка сформированных фрагментов. На данном этапе на основании сведений о положении персональных данных в тексте помечаются соответствующие участки на удаление и вставляются замещающие фрагменты.
д3. Удаление персональных данных. На данном этапе удаляются фрагменты текста в соответствии с разметкой.
Модуль очистки персональных данных 8 содержит в себе комплекс технических решений, обуславливающих возможность модуля очистки персональных данных выполнять:
1. Подбор кодового слова или словосочетания из соответствующего справочника замен в соответствии с замещаемым элементом персональных данных (например, фраза «Беляев А.Ф., проживающий по адресу: ул.Солянка, д.1/2, кв.47» будет заменена на фразу «[ПерсонаN], проживающая по адресу: [АдресN]», где N - натуральное число из множества положительных целых, рассчитываемое инкрементально для каждого случая выявления персональных данных в рамках одного текста).
2. Удаление из текста выявленных персональных данных.
3. Замену в тексте выявленных персональных данных на кодовые обозначения, как указано в примере п.1.
4. Запись в базу данных 5 лингвистического процессора 6 значений соответствующих атрибутов с сохранением связей 'исходное значение' - 'замена'.
5. Запись в базу данных результатов обработки текста, полученного после замен выявленных в тексте персональных данных, и запись в базу данных результатов обработки таблицы соответствия кодовых обозначений замененным персональным данным.
При помощи лингвистического процессора 6 выполняют этапы способа:
е1. Выделение и ранжирование информационных объектов. На данном этапе выполняется оценка роли объекта в тексте;
е2. Выделение прямой речи информационных объектов (персон). На данном этапе выполняется выделение прямой речи объектов в текстах.
е3. Жанровая классификация текстов. На данном этапе выполняется отнесение текста с персональными данными к одному из предопределенных в словаре Системы жанров.
е4. Определение количества эфирного времени. На данном этапе выполняется извлечение информации о количестве эфирного времени телевизионного ролика из текста, сопровождающего поставку ролика сюжета;
е5. Расчет индекса качества. На данном этапе выполняется оценка качества освещения в СМИ деятельности персоны на основании характеристик текста, влиятельности СМИ и некоторых других параметров;
е6. Определение принадлежности текста к рубрике. На данном этапе выполняется определение принадлежности текста к рубрике на основе встречающихся в нем персональных данных.
е7. Кластеризацию текстов. На данном этапе выполняется выявление в каждой рубрике групп текстов с общими и наиболее часто встречающимися вместе типами персональных данных.
В одном из вариантов реализации патентуемого способа сервер приложений 14 содержит процессор мониторинга персональных данных, который формирует базу данных результатов обработки, формирует аналитическую отчетность на базе лингвистически обработанной информации, фильтрации и выбора глубины ретроспективы и аналитических разрезов. Процессор мониторинга персональных данных также осуществляет экспорт результатов очистки персональных данных в базу данных результатов обработки в форме файлов, сохраняемых с использованием распространенных форматов хранения данных. Процессор мониторинга персональных данных на основании информации, хранящейся в базе данных лингвистического процессора 6, обеспечивает решение задачи создания конечных отчетов в одном из видов представления: рейтинги, динамика показателей, региональные показатели, кластеры. Так же процессор мониторинга персональных данных осуществляет построение рейтингов по количеству выявленных нарушений в части персональных данных; экспорт исходных и обработанных текстов, содержащих персональные данные, в один из форматов: doc, docx, rtf, xls, xlsx, txt, xml, pdf.
Лингвистический процессор 6 сервера лингвистической обработки 3 выполнен с возможностью подключения внешних модулей 9 (SOAP-архитектура). Подключаемые модули 9 расширяют возможности способа выявления персональных данных. Более детальное описание подключаемых модулей 9 рассмотрено далее.
В одном из вариантов реализации изобретения лингвистический процессор 6 содержит подключенный модуль классификации текстов, выполненный с возможностью категоризации текстов (рубрицирования) отнесения обработанных текстов к одной из категорий персональных данных (закрытые, частные, общедоступные). Модуль классификации текстов упрощает обнаружение наиболее потенциально опасных текстов. Модуль классификации текстов определяет принадлежность текста к рубрике на основе типов персональных данных,
Основополагающей процедурой в этом и большей части других модулей, выполняющих лингвистическую обработку текста, является выделение из текста сущностей и фактов, которое осуществляет лингвистический процессор 6.
Модуль рубрицирования текстов является инструментом обнаружения потенциально опасных (с точки зрения опубликования персональных данных) видов текстов. Особенно полезным представляется совместный учет статистических данных по модулю рубрицирования и модулю жанровой классификации. Классификация осуществляется путем записи в базу данных 5 лингвистического процессора 6 соответствующих атрибутов и отнесение обнаруженных персональных данных к группе закрытых, частных, общедоступных.
При этом к категории закрытых относятся тексты, содержащие: 1) Все паспортные данные; 2) Водительское удостоверение; 3) Номер и прочие атрибуты пластиковой карты (CVV, дата окончания срока действия); 4) Доходы, имущество (не для госслужащих); 5) Номер автомобиля; 6) Домашний телефон; 7) Адрес регистрации, проживания.
К категории частных относятся тексты, содержащие условно закрытые данные, доступные на сайтах поиска работы, объявлений, знакомств, опубликованные в телефонном справочнике: 1) Дата рождения; 2) Место рождения; 3) Адрес личной почты; 4) Номер личного мобильного телефона; 5) Гражданство; 6) ИНН; 7) Родственные связи. Сюда же относятся данные, публикация которых не представляет угрозы для репутации, либо обязательна в силу служебных обязанностей. Например: дата рождения; место рождения; реквизиты банковского счета; адрес личной почты; номер личного мобильного телефона; гражданство; ОГРНИП, ИНН; данные документов об образовании; данные, касающиеся расовой, национальной принадлежности, политических взглядов, религиозных или философских убеждений; данные о семейном положении, наличии детей.
К категории общедоступных относятся тексты, не позволяющие установить местонахождение объекта (в нерабочее время), членов его семьи, связаться с ними, а также данные, публикация которых не представляет угрозы для репутации объекта либо обязательна в силу служебных обязанностей, но при этом к данной категории не относятся данные текстов, позволяющих однозначно идентифицировать персону, а также сведения о ее расовой принадлежности и религиозных убеждениях. Например: 1) ФИО; 2) Пол; 3) Должность; 4) Место работы; 5) Номер служебного телефона; 6) Адрес служебной почты; 7) Образование (за исключением данных документов об образовании); 8) Сведения о воинском учете (за исключением данных об учетных документах); 9) Профессия; 10) Сведения о доходах и имуществе (для госслужащих).
В одном из вариантов реализации изобретения лингвистический процессор 6 содержит подключенный модуль жанровой классификации, который выполнен с возможностью отнесения текста к определенной группе по жанру, определяемому с помощью лингвистических технологий: новость; интервью; аналитика; аналитическая статья, TV; ток-шоу; законодательство; пресс-релиз; публицистика; отзывы; рейтинги; прочее.
В одном из вариантов реализации изобретения лингвистический процессор содержит подключенный модуль расчета индекса качества, который позволяет осуществлять комплексную оценку качества освещения объекта в тексте и записывает в базу данных 5 лингвистического процессора 6 соответствующие атрибуты. Реализованный расчет системы индексов позволяет оперативно оценивать степень потенциального ущерба для упоминаемой в тексте персоны от публикации ее персональных данных. Индекс качества рассчитывается с использованием следующих данных: влиятельность открытого источника (рассчитанная на основе оперативно обновляемых данных о его цитируемости); номер полосы (для текстов печатных СМИ); размер текста; наличие иллюстрации; роль объекта в статье; наличие цитат объекта в статье; характер упоминания объектов в тексте (позитив, негатив, нейтраль).
В одном из вариантов реализации изобретения лингвистический процессор содержит подключенный модуль поиска и фильтрации, который обеспечивает поиск и фильтрацию данных (текстов исходных и обработанных статей, публикаций записей блогов; нарушений в части персональных данных; объектов и т.д.) в базе данных лингвистического процессора. Модуль выполняет следующие задачи: осуществляет контекстный поиск по массиву исходных текстов, в том числе по указанной в качестве критерия части слова; выполняет расширенный поиск с возможностью выбора одного или нескольких параметров; фильтрует результаты поиска по одному или нескольким параметрам.
В одном из вариантов реализации изобретения сервер приложений 14 содержит подключенный модуль администрирования Системы, реализующей патентуемый способ. Модуль предоставляет пользователю, наделенному соответствующими полномочиями, инструментарий гибкой настройки и аудита, управления справочниками, словарями, журналами, учетными записями и правами пользователей, расписаниями работы служб и т.д.
Модуль администрирования решает следующие задачи: контролирует на основе расписания, заданного для каждого отрытого источника, своевременность поступления материалов в Систему; управляет расписанием поставки материалов, оповещениями о поступлениях, ошибках и других событиях в Системе; обеспечивает возможность настройки сервера сбора 2 и сервера лингвистической обработки 3. Предварительная обработка и загрузка текстов открытых источников предполагает настройку следующих параметров обработки: ведение списка источников; установка порога глубины обхода Интернет-источников; установка типов загружаемых и исключаемых файлов; установка адресов Интернет-страниц для проверки обновлений содержимого открытого источника; определение дисковой квоты для источников, управление справочниками и словарями Системы; просмотр журнала аудита с возможностью фильтрации записей по нескольким атрибутам, возможностью записи журнала Системы в лог-файл.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ И ФИЛЬТРАЦИИ ЗАПРЕЩЕННОГО КОНТЕНТА В СЕТИ | 2020 |
|
RU2738335C1 |
| Система автоматического обновления и формирования техник реализации компьютерных атак для системы обеспечения информационной безопасности | 2023 |
|
RU2809929C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| Гибридная автоматическая система управления доступом пользователей к информационным ресурсам в публичных компьютерных сетях | 2018 |
|
RU2697925C1 |
| СПОСОБ ПРОВЕРКИ НАУЧНЫХ РАБОТ ОГРАНИЧЕННОГО РАСПРОСТРАНЕНИЯ НА ПЛАГИАТ | 2021 |
|
RU2774100C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| Система автоматической деперсонализации отсканированных рукописных историй болезни | 2020 |
|
RU2744493C1 |
| Система и способ внешнего контроля поверхности кибератаки | 2021 |
|
RU2778635C1 |
| СИСТЕМА ПОИСКА ИНФОРМАЦИИ | 2020 |
|
RU2797036C1 |
| СИСТЕМА И СПОСОБ АДАПТИВНОГО УПРАВЛЕНИЯ И КОНТРОЛЯ ДЕЙСТВИЙ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ПОВЕДЕНИЯ ПОЛЬЗОВАТЕЛЯ | 2012 |
|
RU2534935C2 |
Изобретение относится к области информационных технологий. Техническим результатом является обеспечение высокой релевантности результатов выдачи при выявлении персональных данных в открытых информационных источниках и в текстовых файлах наиболее распространенных форматов. Выявление персональных данных достигается посредством лингвистических технологий, реализованных при помощи сервера сбора данных, сервера лингвистической обработки, сервера приложений. В предлагаемом способе создают задание на основе поступающих через АРМ администратора параметров по обходу открытых источников. Затем загружают текст, производят обход открытых источников и загрузку текстов либо передачу текстов из внешней системы. Выделяют ссылки из загруженных текстов для их добавления к адресам дальнейшего обхода. Извлекают текст, бинарные файлы преобразуются к текстовому формату. Подготовленный к разбору текст разбирают и выявляют сущности, производят выделение сущностей персональных данных в тексте. Выявляют персональные данные, выделяют факты (сущности, выявленные на предыдущем этапе, связанные с персонами) персональных данных в тексте. 6 з.п. ф-лы, 3 ил.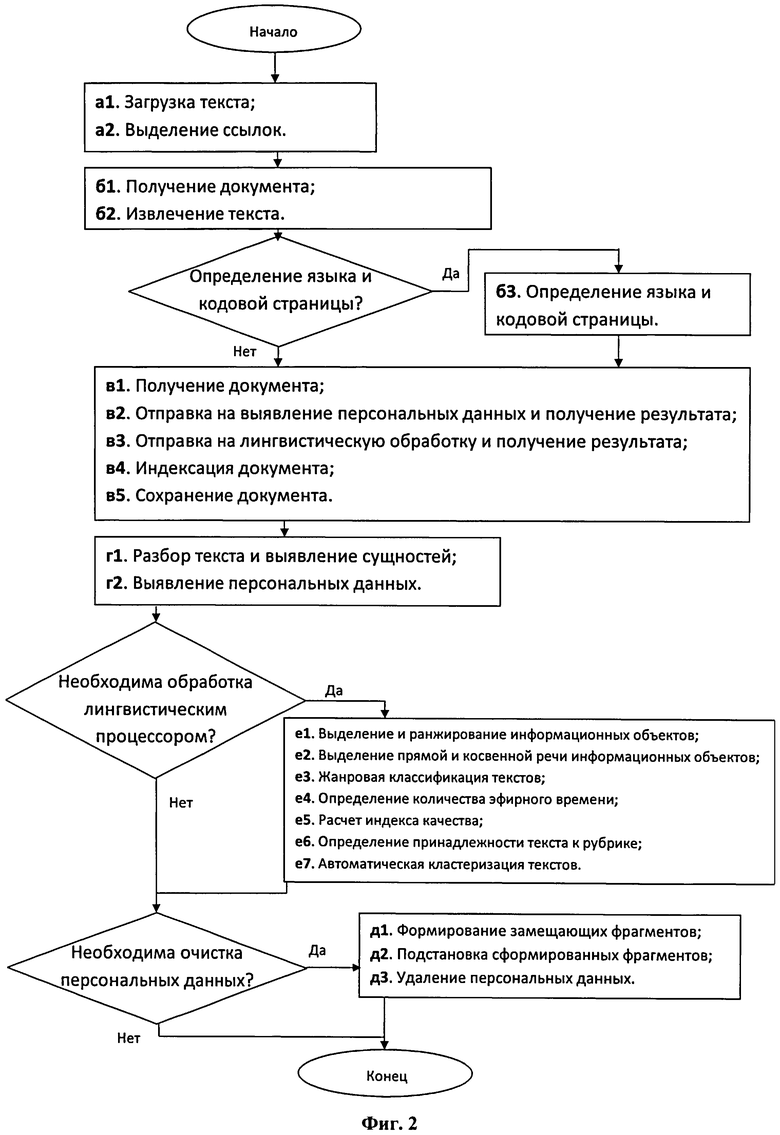
1. Способ выявления персональных данных содержит следующие элементы: один или несколько серверов сбора данных открытых источников информации, один или несколько серверов лингвистической обработки, один или несколько серверов приложений, при этом:
- при помощи сервера приложений создают задание на основе поступающих через АРМ администратора параметров по обходу открытых источников;
- сервер сбора данных содержит модуль сбора, при помощи которого выполняют следующие этапы патентуемого способа:
- загружают текст, производят обход открытых источников и загрузку текстов либо передачу текстов из внешней системы;
- выделяют ссылки из загруженных текстов для их добавления к адресам дальнейшего обхода, при отсутствии ссылок обход прекращается;
- сервер сбора данных содержит модуль синтаксического разбора, при помощи которого выполняют следующие этапы патентуемого способа:
- получают текст от модуля сбора;
- извлекают текст, бинарные файлы преобразуются к текстовому формату;
- сервер сбора данных содержит модуль обработки и загрузки разобранных текстов открытых источников в базу данных сервера лингвистической обработки, при помощи модуля обработки и загрузки выполняют следующие этапы патентуемого способа:
- получают текст, подготовленный к разбору от модуля синтаксического разбора;
- отправляют текст на выявление персональных данных в модуль выявления персональных данных и по окончании обработки загружают из модуля выявления персональных данных;
- сервер сбора данных содержит модуль выявления персональных данных, при помощи которого выполняют этапы способа:
- разбирают текст и выявляют сущности, производят выделение сущностей персональных данных в тексте;
- выявляют персональные данные, выделяют факты (сущности, выявленные на предыдущем этапе, связанные с персонами) персональных данных в тексте.
2. Способ по п.1, в котором с помощью модуля синтаксического разбора дополнительно определяют язык, кодовую страницу, кодировку текста.
3. Способ по п.1, в котором сервер лингвистической обработки дополнительно содержит модуль очистки персональных данных, при помощи которого выполняют дополнительные этапы патентуемого способа:
- формируют замещающие фрагменты на основании сведений о выявленных в тексте персональных данных, полученных от модуля выявления персональных данных;
- выполняют подстановку сформированных фрагментов на основании сведений о положении персональных данных в тексте, помечают соответствующие участки на удаление и вставляют замещающие фрагменты;
- удаляют персональные данные (фрагменты текста их содержащие) в соответствии с разметкой;
- формируют набор записей, содержащий информацию для обеспечения возможности отдельного хранения обнаруженных персональных данных от исходного текста, а также возвращения в текст замененных персональных данных.
4. Способ по п.1, в котором после выявления персональных данных и загрузки текста из модуля выявления персональных данных полученный текст отправляют на обработку лингвистическому процессору, при помощи которого выполняют дополнительные этапы способа:
- индексируют текст для дальнейшей загрузки в базу данных сервера лингвистической обработки;
- сохраняют в базу данных сервера лингвистической обработки разобранный и проиндексированный текст;
- выделяют и ранжируют информационные объекты, оценивают роли объекта в тексте;
- выделяют прямую речь информационных объектов в текстах;
- производят жанровую классификацию текстов, отнесение текста с персональными данными к одному из предопределенных жанров;
- определяют количество эфирного времени, извлекают информацию о количестве эфирного времени телевизионного ролика из текста, сопровождающего поставку ролика сюжета;
- рассчитывают индекс качества, оценивают качество освещения открытым источником деятельности персоны на основании характеристик текста, влиятельности источника;
- определяют принадлежность текста к рубрике (категории) на основе встречающихся в нем персональных данных;
- выполняют кластеризацию текстов, выявление в рубрике групп текстов с общими типами персональных данных.
5. Способ по п.1, в котором сервер приложений содержит подключенный модуль администрирования Системы, реализующей способ.
6. Способ по п.5, в котором модуль администрирования выполняет дополнительные этапы способа:
- контролирует на основе расписания, заданного для каждого отрытого источника, своевременность поступления материалов в Систему; управляет расписанием поставки материалов, оповещениями о поступлениях; обеспечивает возможность настройки сервера сбора и сервера лингвистической обработки.
7. Способ по п.2, в котором сервер приложений содержит процессор мониторинга персональных данных, при помощи которого выполняют, по крайней мере, один из дополнительных этапов способа:
- формируют базу данных результатов обработки;
- формируют аналитическую отчетность на базе лингвистически обработанных текстов;
- выполняют фильтрацию и выбор глубины ретроспективы и аналитических разрезов;
- осуществляют экспорт результатов очистки персональных данных в базу данных результатов обработки в форме отчетов, сохраняемых с использованием распространенных форматов хранения данных;
- создают отчеты по одной из категорий: рейтинги (в том числе рейтинги по количеству выявленных нарушений в части персональных данных), динамика показателей, региональные показатели, кластеры;
- выполняют экспорт исходных и обработанных текстов, содержащих персональные данные, в один из форматов: doc, docx, rtf, xls, xlsx, txt, xml, pdf.
| Узловяжущее устройство | 1958 |
|
SU119485A1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 2008 |
|
RU2386167C1 |
| СПОСОБЫ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИОННЫХ МАТЕРИАЛОВ ДЛЯ ПЕРСОНАЛИЗИРОВАННОГО ИСПОЛЬЗОВАНИЯ | 1996 |
|
RU2096824C1 |
| СПОСОБ И СИСТЕМА АНАЛИЗА РАСПЕЧАТАННОГО ДОКУМЕНТА НА НАЛИЧИЕ В НЕМ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2008 |
|
RU2395117C2 |
| US 5987440 A, 16.11.1999 | |||

